Spaces:
Build error
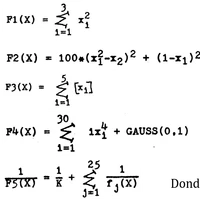
Build error
Update requirements.txt
Browse files- requirements.txt +45 -1
requirements.txt
CHANGED
|
@@ -1 +1,45 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Gradio para la interfaz
|
| 2 |
+
gradio
|
| 3 |
+
|
| 4 |
+
# Transformers para modelos de resumen abstractivo
|
| 5 |
+
transformers
|
| 6 |
+
|
| 7 |
+
# Doctr para OCR en documentos PDF
|
| 8 |
+
python-doctr[torch]
|
| 9 |
+
|
| 10 |
+
# Cleantext para limpieza de texto
|
| 11 |
+
clean-text
|
| 12 |
+
|
| 13 |
+
# SpellChecker para corrección de ortografía
|
| 14 |
+
pyspellchecker
|
| 15 |
+
|
| 16 |
+
# NLTK para tokenización y procesamiento de lenguaje
|
| 17 |
+
nltk
|
| 18 |
+
|
| 19 |
+
# Scikit-learn para resumen extractivo (TF-IDF, TextRank)
|
| 20 |
+
scikit-learn
|
| 21 |
+
|
| 22 |
+
# NetworkX para algoritmos de grafos (TextRank)
|
| 23 |
+
networkx
|
| 24 |
+
|
| 25 |
+
# PyMuPDF para extraer texto de PDFs
|
| 26 |
+
PyMuPDF
|
| 27 |
+
|
| 28 |
+
# Hugging Face para interacción con el hub
|
| 29 |
+
huggingface_hub
|
| 30 |
+
|
| 31 |
+
# TQDM para barras de progreso
|
| 32 |
+
tqdm
|
| 33 |
+
|
| 34 |
+
# Rouge Score para evaluar los resúmenes
|
| 35 |
+
rouge-score
|
| 36 |
+
|
| 37 |
+
# Natsort para ordenamiento natural
|
| 38 |
+
natsort
|
| 39 |
+
|
| 40 |
+
# Torch para soporte a modelos de aprendizaje profundo
|
| 41 |
+
torch
|
| 42 |
+
|
| 43 |
+
# Pandas para la manipulación de datos en evaluación de resúmenes
|
| 44 |
+
pandas
|
| 45 |
+
|