Spaces:
Sleeping

Sleeping
Upload 6 files
Browse files- Dockerfile +16 -0
- Pipfile +4 -0
- Pipfile.lock +0 -0
- README.md +84 -0
- app.py +44 -0
- requirements.txt +80 -0
Dockerfile
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.8-slim-buster
|
| 2 |
+
|
| 3 |
+
RUN apt update && apt install -y ffmpeg git
|
| 4 |
+
|
| 5 |
+
WORKDIR /app
|
| 6 |
+
|
| 7 |
+
COPY requirements.txt requirements.txt
|
| 8 |
+
RUN pip3 install -r requirements.txt
|
| 9 |
+
|
| 10 |
+
EXPOSE 8000 8000
|
| 11 |
+
|
| 12 |
+
ENV GRADIO_SERVER_PORT 8000
|
| 13 |
+
|
| 14 |
+
COPY . .
|
| 15 |
+
|
| 16 |
+
CMD [ "python3", "app.py"]
|
Pipfile
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[packages]
|
| 2 |
+
whisper = {git = "https://github.com/openai/whisper.git"}
|
| 3 |
+
gradio = "*"
|
| 4 |
+
ffmpeg-python = "*"
|
Pipfile.lock
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
README.md
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# Whisper OpenAi Tool Gradio Web implementation
|
| 3 |
+
Whisper is an automatic speech recognition (ASR) system Gradio Web UI Implementation
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
## Installation
|
| 8 |
+
|
| 9 |
+
Install ffmeg on Your Device
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
# on Ubuntu or Debian
|
| 13 |
+
sudo apt update
|
| 14 |
+
sudo apt install ffmpeg
|
| 15 |
+
|
| 16 |
+
# on MacOS using Homebrew (https://brew.sh/)
|
| 17 |
+
brew install ffmpeg
|
| 18 |
+
|
| 19 |
+
# on Windows using Chocolatey (https://chocolatey.org/)
|
| 20 |
+
choco install ffmpeg
|
| 21 |
+
|
| 22 |
+
# on Windows using Scoop (https://scoop.sh/)
|
| 23 |
+
scoop install ffmpeg
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
Download Program
|
| 27 |
+
|
| 28 |
+
```bash
|
| 29 |
+
mkdir whisper-sppech2txt
|
| 30 |
+
cd whisper-sppech2txt
|
| 31 |
+
git clone https://github.com/innovatorved/whisper-openai-gradio-implementation.git .
|
| 32 |
+
pip install -r requirements.txt
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
Run Program
|
| 37 |
+
|
| 38 |
+
```bash
|
| 39 |
+
python app.py
|
| 40 |
+
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
## Available models and languages ([Credit](https://github.com/innovatorved/whisper-openai-gradio-implementation/blob/main/README.md))
|
| 44 |
+
|
| 45 |
+
There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and relative speed.
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|
| 49 |
+
|:------:|:----------:|:------------------:|:------------------:|:-------------:|:--------------:|
|
| 50 |
+
| tiny | 39 M | `tiny.en` | `tiny` | ~1 GB | ~32x |
|
| 51 |
+
| base | 74 M | `base.en` | `base` | ~1 GB | ~16x |
|
| 52 |
+
| small | 244 M | `small.en` | `small` | ~2 GB | ~6x |
|
| 53 |
+
| medium | 769 M | `medium.en` | `medium` | ~5 GB | ~2x |
|
| 54 |
+
| large | 1550 M | N/A | `large` | ~10 GB | 1x |
|
| 55 |
+
|
| 56 |
+
For English-only applications, the `.en` models tend to perform better, especially for the `tiny.en` and `base.en` models. We observed that the difference becomes less significant for the `small.en` and `medium.en` models.
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## Screenshots
|
| 60 |
+
|
| 61 |
+
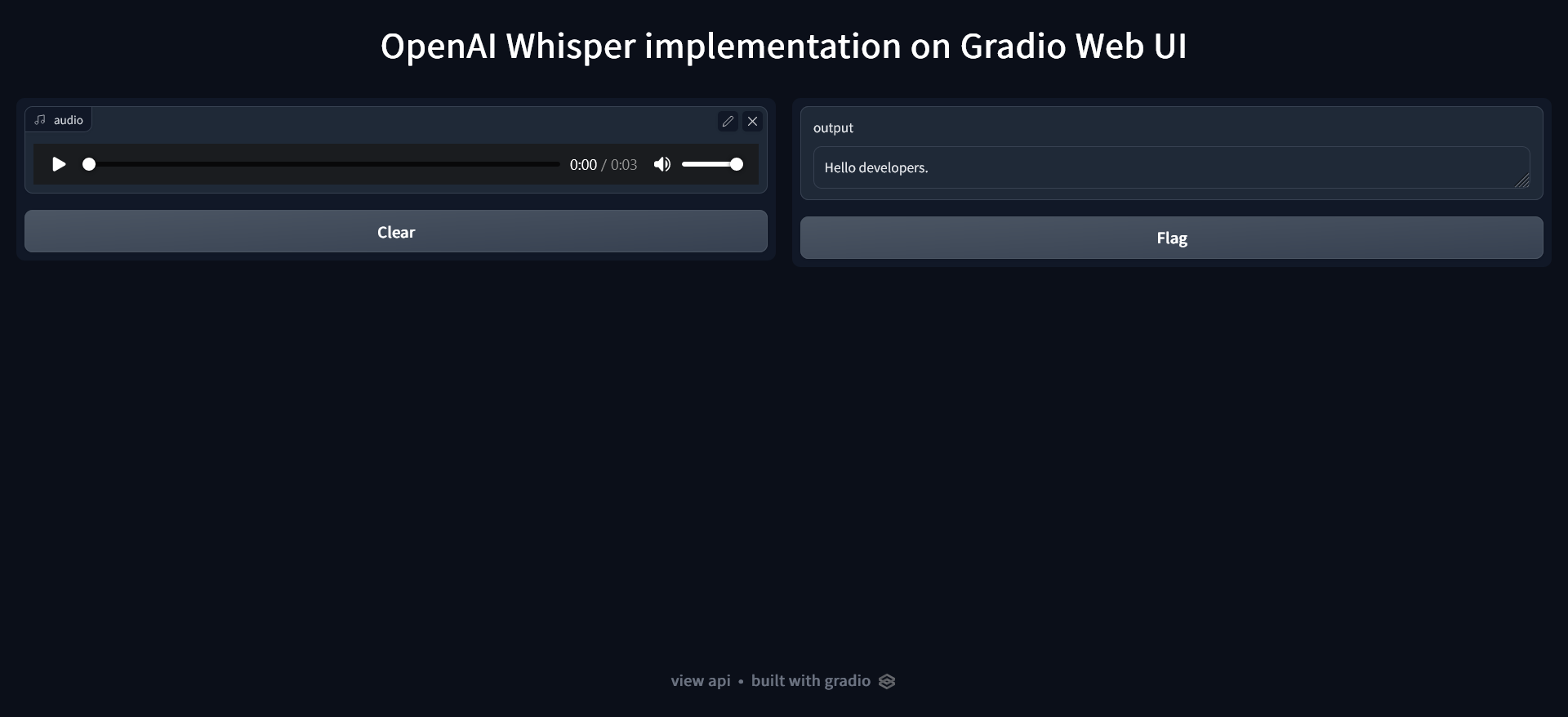
|
| 62 |
+
## License
|
| 63 |
+
|
| 64 |
+
[MIT](https://choosealicense.com/licenses/mit/)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
## Reference
|
| 68 |
+
|
| 69 |
+
- [https://github.com/openai/whisper](https://github.com/openai/whisper)
|
| 70 |
+
- [https://openai.com/blog/whisper/](https://openai.com/blog/whisper/)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
## Authors
|
| 74 |
+
|
| 75 |
+
- [Ved Gupta](https://www.github.com/innovatorved)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
## 🚀 About Me
|
| 79 |
+
I'm a Developer i will feel the code then write .
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
## Support
|
| 83 |
+
|
| 84 |
+
For support, email vedgupta@protonmail.com
|
app.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import whisper
|
| 2 |
+
|
| 3 |
+
# You can choose your model from - see it on readme file and update the modelname
|
| 4 |
+
modelname = "base"
|
| 5 |
+
model = whisper.load_model(modelname)
|
| 6 |
+
|
| 7 |
+
import gradio as gr
|
| 8 |
+
import time
|
| 9 |
+
|
| 10 |
+
def SpeechToText(audio):
|
| 11 |
+
if audio == None : return ""
|
| 12 |
+
time.sleep(1)
|
| 13 |
+
|
| 14 |
+
audio = whisper.load_audio(audio)
|
| 15 |
+
audio = whisper.pad_or_trim(audio)
|
| 16 |
+
|
| 17 |
+
# make log-Mel spectrogram and move to the same device as the model
|
| 18 |
+
mel = whisper.log_mel_spectrogram(audio).to(model.device)
|
| 19 |
+
|
| 20 |
+
# Detect the Max probability of language ?
|
| 21 |
+
_, probs = model.detect_language(mel)
|
| 22 |
+
language = max(probs, key=probs.get)
|
| 23 |
+
|
| 24 |
+
# Decode audio to Text
|
| 25 |
+
options = whisper.DecodingOptions(fp16 = False)
|
| 26 |
+
result = whisper.decode(model, mel, options)
|
| 27 |
+
return (language , result.text)
|
| 28 |
+
|
| 29 |
+
print("Starting the Gradio Web UI")
|
| 30 |
+
gr.Interface(
|
| 31 |
+
title = 'OpenAI Whisper implementation on Gradio Web UI',
|
| 32 |
+
fn=SpeechToText,
|
| 33 |
+
|
| 34 |
+
inputs=[
|
| 35 |
+
gr.Audio(source="microphone", type="filepath")
|
| 36 |
+
],
|
| 37 |
+
outputs=[
|
| 38 |
+
"label",
|
| 39 |
+
"textbox",
|
| 40 |
+
],
|
| 41 |
+
live=True
|
| 42 |
+
).launch(
|
| 43 |
+
debug=False,
|
| 44 |
+
)
|
requirements.txt
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
aiofiles==23.1.0
|
| 2 |
+
aiohttp==3.8.4
|
| 3 |
+
aiosignal==1.3.1
|
| 4 |
+
altair==5.0.1
|
| 5 |
+
anyio==3.7.0
|
| 6 |
+
async-timeout==4.0.2
|
| 7 |
+
attrs==23.1.0
|
| 8 |
+
bcrypt==4.0.0
|
| 9 |
+
certifi==2023.5.7
|
| 10 |
+
cffi==1.15.1
|
| 11 |
+
charset-normalizer==3.1.0
|
| 12 |
+
click==8.1.3
|
| 13 |
+
contourpy==1.0.7
|
| 14 |
+
cryptography==38.0.1
|
| 15 |
+
cycler==0.11.0
|
| 16 |
+
exceptiongroup==1.1.1
|
| 17 |
+
fastapi==0.95.2
|
| 18 |
+
ffmpeg-python==0.2.0
|
| 19 |
+
ffmpy==0.3.0
|
| 20 |
+
filelock==3.12.0
|
| 21 |
+
fonttools==4.39.4
|
| 22 |
+
frozenlist==1.3.3
|
| 23 |
+
fsspec==2023.5.0
|
| 24 |
+
future==0.18.2
|
| 25 |
+
gradio==3.32.0
|
| 26 |
+
gradio_client==0.2.5
|
| 27 |
+
h11==0.14.0
|
| 28 |
+
httpcore==0.17.2
|
| 29 |
+
httpx==0.24.1
|
| 30 |
+
huggingface-hub==0.14.1
|
| 31 |
+
idna==3.4
|
| 32 |
+
Jinja2==3.1.2
|
| 33 |
+
jsonschema==4.17.3
|
| 34 |
+
kiwisolver==1.4.4
|
| 35 |
+
linkify-it-py==2.0.2
|
| 36 |
+
markdown-it-py==2.2.0
|
| 37 |
+
MarkupSafe==2.1.2
|
| 38 |
+
matplotlib==3.7.1
|
| 39 |
+
mdit-py-plugins==0.3.3
|
| 40 |
+
mdurl==0.1.2
|
| 41 |
+
more-itertools==8.14.0
|
| 42 |
+
multidict==6.0.4
|
| 43 |
+
numpy==1.24.3
|
| 44 |
+
orjson==3.8.14
|
| 45 |
+
packaging==23.1
|
| 46 |
+
pandas==2.0.1
|
| 47 |
+
paramiko==2.11.0
|
| 48 |
+
Pillow==9.5.0
|
| 49 |
+
pycparser==2.21
|
| 50 |
+
pycryptodome==3.15.0
|
| 51 |
+
pydantic==1.10.8
|
| 52 |
+
pydub==0.25.1
|
| 53 |
+
Pygments==2.15.1
|
| 54 |
+
PyNaCl==1.5.0
|
| 55 |
+
pyparsing==3.0.9
|
| 56 |
+
pyrsistent==0.19.3
|
| 57 |
+
python-dateutil==2.8.2
|
| 58 |
+
python-multipart==0.0.6
|
| 59 |
+
pytz==2023.3
|
| 60 |
+
PyYAML==6.0
|
| 61 |
+
regex==2022.9.13
|
| 62 |
+
requests==2.31.0
|
| 63 |
+
rfc3986==1.5.0
|
| 64 |
+
semantic-version==2.10.0
|
| 65 |
+
six==1.16.0
|
| 66 |
+
sniffio==1.3.0
|
| 67 |
+
starlette==0.27.0
|
| 68 |
+
tokenizers==0.12.1
|
| 69 |
+
toolz==0.12.0
|
| 70 |
+
torch==1.12.1
|
| 71 |
+
tqdm==4.65.0
|
| 72 |
+
transformers==4.22.2
|
| 73 |
+
typing_extensions==4.6.2
|
| 74 |
+
tzdata==2023.3
|
| 75 |
+
uc-micro-py==1.0.2
|
| 76 |
+
urllib3==2.0.2
|
| 77 |
+
uvicorn==0.22.0
|
| 78 |
+
websockets==11.0.3
|
| 79 |
+
whisper @ git+https://github.com/openai/whisper.git@0b1ba3d46ebf7fe6f953acfd8cad62a4f851b49f
|
| 80 |
+
yarl==1.9.2
|