Spaces:
Build error

Build error
Update README_Ru.md
Browse files- README_Ru.md +27 -0
README_Ru.md
CHANGED
|
@@ -82,7 +82,34 @@
|
|
| 82 |

|
| 83 |
|
| 84 |
# Обучение
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 85 |
Для обучения модели передачи стиля Рейчел чатботу я использовал несколько моделей. Обучение моделей проходит в два этапа. На первом этапе модель пытается уловить личность Рейчел и изучает ее монологи. На втором этапе модель пытается узнать, как Рейчел ведет себя в диалогах, поэтому на этом этапе модель обучается на диалогах.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 86 |
1. Первый этап - GPT2. Для наборов данных я использовал TextDataset от PyTorch и библиотеку трансформаторов от huggingface.
|
| 87 |
Результаты показаны на изображении ниже
|
| 88 |

|
|
|
|
| 82 |

|
| 83 |
|
| 84 |
# Обучение
|
| 85 |
+
|
| 86 |
+
## Архитектура модели GPT2
|
| 87 |
+
Архитектура модели GPT-2 (Generative Pre-trained Transformer 2) основана на трансформерной архитектуре, предложенной в статье "Attention is All You Need" от Vaswani et al. (2017). Однако, GPT-2 представляет собой усовершенствование и расширение этой базовой архитектуры. Вот основные компоненты архитектуры GPT-2:
|
| 88 |
+
|
| 89 |
+
1. **Stacked Transformer Decoder Layers**: GPT-2 состоит из нескольких блоков трансформера, где каждый блок представляет собой "слой декодера". Каждый слой декодера включает в себя множество механизмов внимания и нормализацию LayerNorm.
|
| 90 |
+
|
| 91 |
+
2. **Multi-Head Self-Attention Mechanism**: Этот механизм позволяет модели сосредотачиваться на различных частях входных данных и извлекать их взаимосвязи. В GPT-2 используется множество "голов" внимания, которые позволяют модели фокусироваться на разных аспектах данных.
|
| 92 |
+
|
| 93 |
+
3. **Feed-Forward Neural Networks**: Каждый блок трансформера содержит также набор полносвязных слоев (feed-forward networks), которые применяются к выходу из слоев внимания.
|
| 94 |
+
|
| 95 |
+
4. **Positional Encoding**: Для того чтобы модель могла учитывать порядок слов в последовательности, в GPT-2 используется позиционное кодирование, которое добавляет информацию о позиции каждого слова в последовательности.
|
| 96 |
+
|
| 97 |
+
5. **Layer Normalization**: Нормализация слоев (LayerNorm) применяется после каждого слоя в трансформере для стабилизации обучения.
|
| 98 |
+
|
| 99 |
+
6. **Residual Connections**: В GPT-2 используются связи прямого распространения (residual connections), которые позволяют более эффективно передавать градиенты в глубоких нейронных сетях.
|
| 100 |
+
|
| 101 |
+
7. **Position-wise Feedforward Networks**: Полносвязные сети применяются к каждой позиции в последовательности независимо, что позволяет модели лучше захватывать локальные зависимости.
|
| 102 |
+
|
| 103 |
+
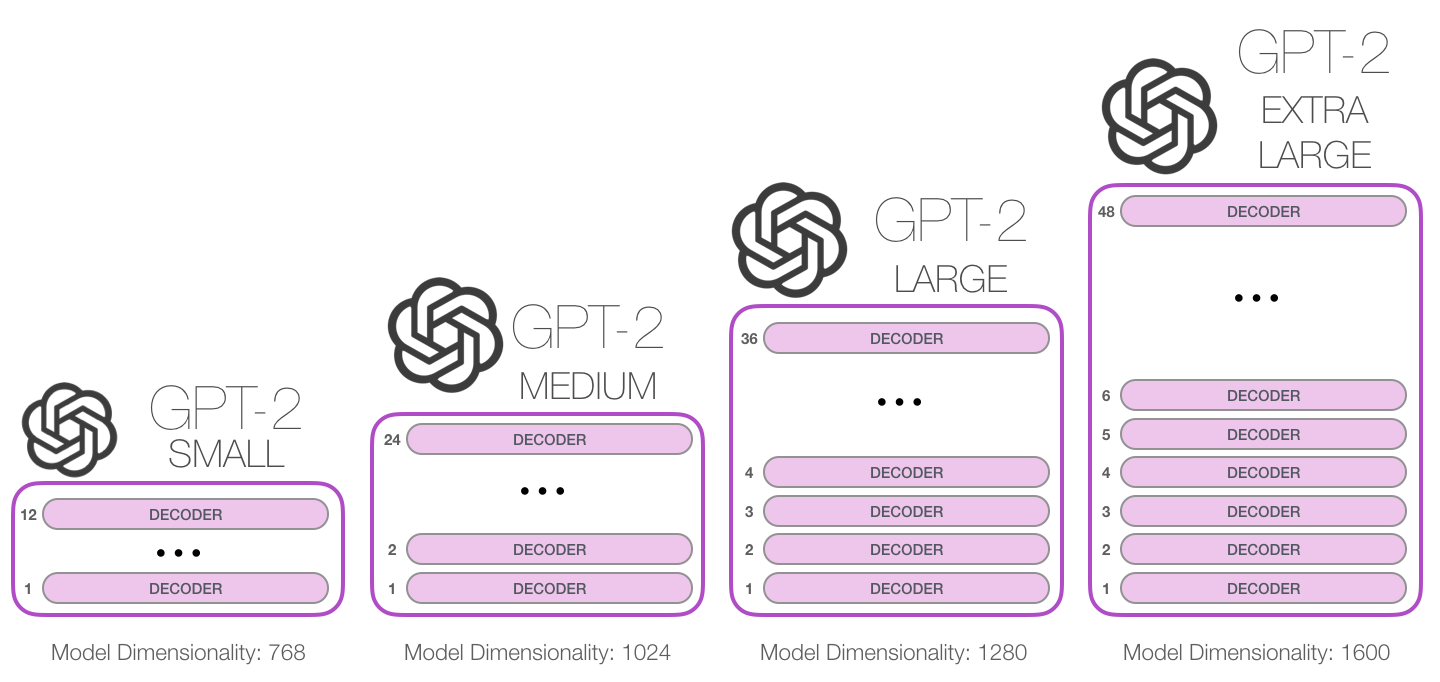
Архитектура GPT-2 представляет собой стек этих блоков, причем количество блоков и их размер могут варьироваться в зависимости от размера модели. Например, оригинальная модель GPT-2 имеет 12 слоев декодера для маленьких версий и до 48 слоев для самых крупных версий.
|
| 104 |
Для обучения модели передачи стиля Рейчел чатботу я использовал несколько моделей. Обучение моделей проходит в два этапа. На первом этапе модель пытается уловить личность Рейчел и изучает ее монологи. На втором этапе модель пытается узнать, как Рейчел ведет себя в диалогах, поэтому на этом этапе модель обучается на диалогах.
|
| 105 |
+
|
| 106 |
+
В данной работе было обучено 3 модели из четырёх: GPT-2-small, GPT-2-medium, GPT-2-large
|
| 107 |
+

|
| 108 |
+
|
| 109 |
+
Архитектура GPT-2 в зависимости от размера модели представленна на рисунке ниже:
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
1. Первый этап - GPT2. Для наборов данных я использовал TextDataset от PyTorch и библиотеку трансформаторов от huggingface.
|
| 114 |
Результаты показаны на изображении ниже
|
| 115 |

|