

Final Update Dashboard
Browse files- README.md +11 -10
- docs/BLOG_POST.md +254 -0
- docs/SUBMISSION_CHECKLIST.md +124 -0
- server/app.py +208 -42
README.md
CHANGED
|
@@ -112,8 +112,8 @@ Same pipeline, same data recipe, smaller backbone:
|
|
| 112 |
| 🟢 **Live environment** | **[Open the dashboard ↗](https://swapnilpatil28-multi-agent-incident-command-center.hf.space)** |
|
| 113 |
| 💻 **Source code** | **[GitHub repo ↗](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 114 |
| 🎓 **Reproduce the training** | **[One-click Colab notebook ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)** |
|
| 115 |
-
|
|
| 116 |
-
|
|
| 117 |
|
| 118 |
> Want the rubric math, architecture, full numbers, configuration, and the hackathon checklist? Keep scrolling — **Part 2** is the full technical README.
|
| 119 |
|
|
@@ -129,8 +129,9 @@ Same pipeline, same data recipe, smaller backbone:
|
|
| 129 |
| Hugging Face Space page | **[`huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center`](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 130 |
| GitHub repository | **[`github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 131 |
| Training notebook (Colab T4, one-click reproducible) | **[Open in Colab ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)** |
|
| 132 |
-
|
|
| 133 |
-
|
|
|
|
|
| 134 |
| Training script (Python) | [`train_trl.py`](./train_trl.py) |
|
| 135 |
|
| 136 |
Three specialist agents — **Triage**, **Investigator**, and **Ops Manager** — cooperate to resolve a queue of production incidents while operating under strict **SLA budgets**, **investigation costs**, and **customer-tier impact multipliers**. The environment is designed to reward *real* operational reasoning, not pattern matching on the root-cause label.
|
|
@@ -636,9 +637,9 @@ Two scripts judges (or you) can run without a local IDE:
|
|
| 636 |
│ └── before_after_demo.py # Side-by-side base vs SFT trace generator
|
| 637 |
│
|
| 638 |
├── docs/
|
| 639 |
-
│ ├── BLOG_POST.md #
|
| 640 |
-
│ ├── VIDEO_SCRIPT.md # 2-minute
|
| 641 |
-
│ └── SUBMISSION_CHECKLIST.md # Judging-criteria
|
| 642 |
│
|
| 643 |
├── artifacts/ # All committed training evidence
|
| 644 |
│ ├── reward_curve.png # 4-policy reward comparison (1.5B headline)
|
|
@@ -706,9 +707,9 @@ Full checklist with pre-submission smoke tests → [`docs/SUBMISSION_CHECKLIST.m
|
|
| 706 |
- [x] **Production-quality HTTP server**: `/healthz`, `/version`, `/env-info`, `/metrics`, Dockerfile with `HEALTHCHECK`
|
| 707 |
- [x] **Structured JSON logging** + 12-factor configuration
|
| 708 |
- [x] **One-click Colab training notebook** → [Open ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)
|
| 709 |
-
- [x] **
|
| 710 |
-
- [
|
| 711 |
-
- [
|
| 712 |
|
| 713 |
---
|
| 714 |
|
|
|
|
| 112 |
| 🟢 **Live environment** | **[Open the dashboard ↗](https://swapnilpatil28-multi-agent-incident-command-center.hf.space)** |
|
| 113 |
| 💻 **Source code** | **[GitHub repo ↗](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 114 |
| 🎓 **Reproduce the training** | **[One-click Colab notebook ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)** |
|
| 115 |
+
| 📝 **Mini blog post** (the required short writeup) | **[`docs/BLOG_POST.md`](./docs/BLOG_POST.md)** |
|
| 116 |
+
| 🎬 **2-minute video script** (optional bonus) | **[`docs/VIDEO_SCRIPT.md`](./docs/VIDEO_SCRIPT.md)** |
|
| 117 |
|
| 118 |
> Want the rubric math, architecture, full numbers, configuration, and the hackathon checklist? Keep scrolling — **Part 2** is the full technical README.
|
| 119 |
|
|
|
|
| 129 |
| Hugging Face Space page | **[`huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center`](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 130 |
| GitHub repository | **[`github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 131 |
| Training notebook (Colab T4, one-click reproducible) | **[Open in Colab ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)** |
|
| 132 |
+
| Mini blog post (the required short writeup) | [`docs/BLOG_POST.md`](./docs/BLOG_POST.md) |
|
| 133 |
+
| 2-minute video script (optional bonus) | [`docs/VIDEO_SCRIPT.md`](./docs/VIDEO_SCRIPT.md) |
|
| 134 |
+
| Submission checklist | [`docs/SUBMISSION_CHECKLIST.md`](./docs/SUBMISSION_CHECKLIST.md) |
|
| 135 |
| Training script (Python) | [`train_trl.py`](./train_trl.py) |
|
| 136 |
|
| 137 |
Three specialist agents — **Triage**, **Investigator**, and **Ops Manager** — cooperate to resolve a queue of production incidents while operating under strict **SLA budgets**, **investigation costs**, and **customer-tier impact multipliers**. The environment is designed to reward *real* operational reasoning, not pattern matching on the root-cause label.
|
|
|
|
| 637 |
│ └── before_after_demo.py # Side-by-side base vs SFT trace generator
|
| 638 |
│
|
| 639 |
├── docs/
|
| 640 |
+
│ ├── BLOG_POST.md # The short writeup (rule 4) — renders on HF Space + GitHub
|
| 641 |
+
│ ├── VIDEO_SCRIPT.md # Optional 2-minute walkthrough script
|
| 642 |
+
│ └── SUBMISSION_CHECKLIST.md # Judging-criteria status + smoke tests
|
| 643 |
│
|
| 644 |
├── artifacts/ # All committed training evidence
|
| 645 |
│ ├── reward_curve.png # 4-policy reward comparison (1.5B headline)
|
|
|
|
| 707 |
- [x] **Production-quality HTTP server**: `/healthz`, `/version`, `/env-info`, `/metrics`, Dockerfile with `HEALTHCHECK`
|
| 708 |
- [x] **Structured JSON logging** + 12-factor configuration
|
| 709 |
- [x] **One-click Colab training notebook** → [Open ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)
|
| 710 |
+
- [x] **Mini blog post** published as an MD file on both the HF Space and GitHub: [`docs/BLOG_POST.md`](./docs/BLOG_POST.md)
|
| 711 |
+
- [x] **2-minute video script** (optional bonus): [`docs/VIDEO_SCRIPT.md`](./docs/VIDEO_SCRIPT.md)
|
| 712 |
+
- [x] **Full submission checklist** mapping every rule → evidence: [`docs/SUBMISSION_CHECKLIST.md`](./docs/SUBMISSION_CHECKLIST.md)
|
| 713 |
|
| 714 |
---
|
| 715 |
|
docs/BLOG_POST.md
ADDED
|
@@ -0,0 +1,254 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Teaching LLMs to Run an Incident Command Center
|
| 2 |
+
|
| 3 |
+
> *India's Biggest Mega AI Hackathon — Built on Meta OpenEnv · Round 2*
|
| 4 |
+
|
| 5 |
+
**TL;DR** — I built an [OpenEnv](https://github.com/meta-pytorch/openenv) environment where three specialist agents — **Triage**, **Investigator**, and **Ops Manager** — cooperate to resolve real-world tech incidents under SLA pressure, budget constraints, and customer-tier business impact. I then fine-tuned Qwen2.5-1.5B-Instruct on heuristic rollouts and watched it **close a +10.17-reward gap on hard incidents**, matching the hand-coded expert policy component-for-component. A separate 0.5B ablation shows that **model scale is the story** — same pipeline, same data schema, but the smaller backbone never closes a single hard incident.
|
| 6 |
+
|
| 7 |
+
### 🔗 Everything in one place
|
| 8 |
+
|
| 9 |
+
| What | Where |
|
| 10 |
+
|---|---|
|
| 11 |
+
| 🟢 **Live environment (OpenEnv-compatible)** | **[swapnilpatil28-multi-agent-incident-command-center.hf.space ↗](https://swapnilpatil28-multi-agent-incident-command-center.hf.space)** |
|
| 12 |
+
| 🤗 **Hugging Face Space page** | **[huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center ↗](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 13 |
+
| 💻 **GitHub source code** | **[github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center ↗](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center)** |
|
| 14 |
+
| 🎓 **Reproducible training (Colab T4)** | **[Open in Colab ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)** |
|
| 15 |
+
| 📖 **Full README** (story + technical deep-dive) | **[github.com/.../README.md ↗](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center#readme)** |
|
| 16 |
+
| 🎬 **2-min video walkthrough script** (optional bonus) | [`docs/VIDEO_SCRIPT.md`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/docs/VIDEO_SCRIPT.md) |
|
| 17 |
+
| ✅ **Submission checklist** | [`docs/SUBMISSION_CHECKLIST.md`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/docs/SUBMISSION_CHECKLIST.md) |
|
| 18 |
+
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
## 1. The story in 2 minutes (for anyone)
|
| 22 |
+
|
| 23 |
+
**When a real tech company has an outage, three people's phones buzz at once.** A Triage engineer scans logs and dashboards. An Investigator forms a hypothesis and applies a fix. An Ops Manager decides who owns the work, whether to escalate, and when to officially close the incident.
|
| 24 |
+
|
| 25 |
+
Each role has **different permissions**, **different information needs**, and a **different clock to beat**. Get it wrong and you bleed budget, bust the SLA, and — if the customer is on an enterprise contract — lose serious money (~3× what a free-tier outage costs).
|
| 26 |
+
|
| 27 |
+
I built a simulator of that war room — an **OpenEnv-compatible** environment with 13 realistic incidents, 3 specialist roles, and 14+ named reward signals — and fine-tuned an LLM to run it.
|
| 28 |
+
|
| 29 |
+
| Role | Can do | Cannot do |
|
| 30 |
+
|---|---|---|
|
| 31 |
+
| 🔍 **Triage agent** | Pull logs · check metrics · consult KB articles | Close a ticket |
|
| 32 |
+
| 🧪 **Investigator** | Apply a fix · roll back a deploy | Escalate or file a post-mortem |
|
| 33 |
+
| 👷 **Ops Manager** | Escalate · file post-mortem · **close the ticket** | Apply a code fix |
|
| 34 |
+
|
| 35 |
+
> **The headline number:** the fine-tuned LLM earns **+10.17 more reward on hard incidents** than the untrained base — and matches the human-written expert policy component-for-component.
|
| 36 |
+
|
| 37 |
+
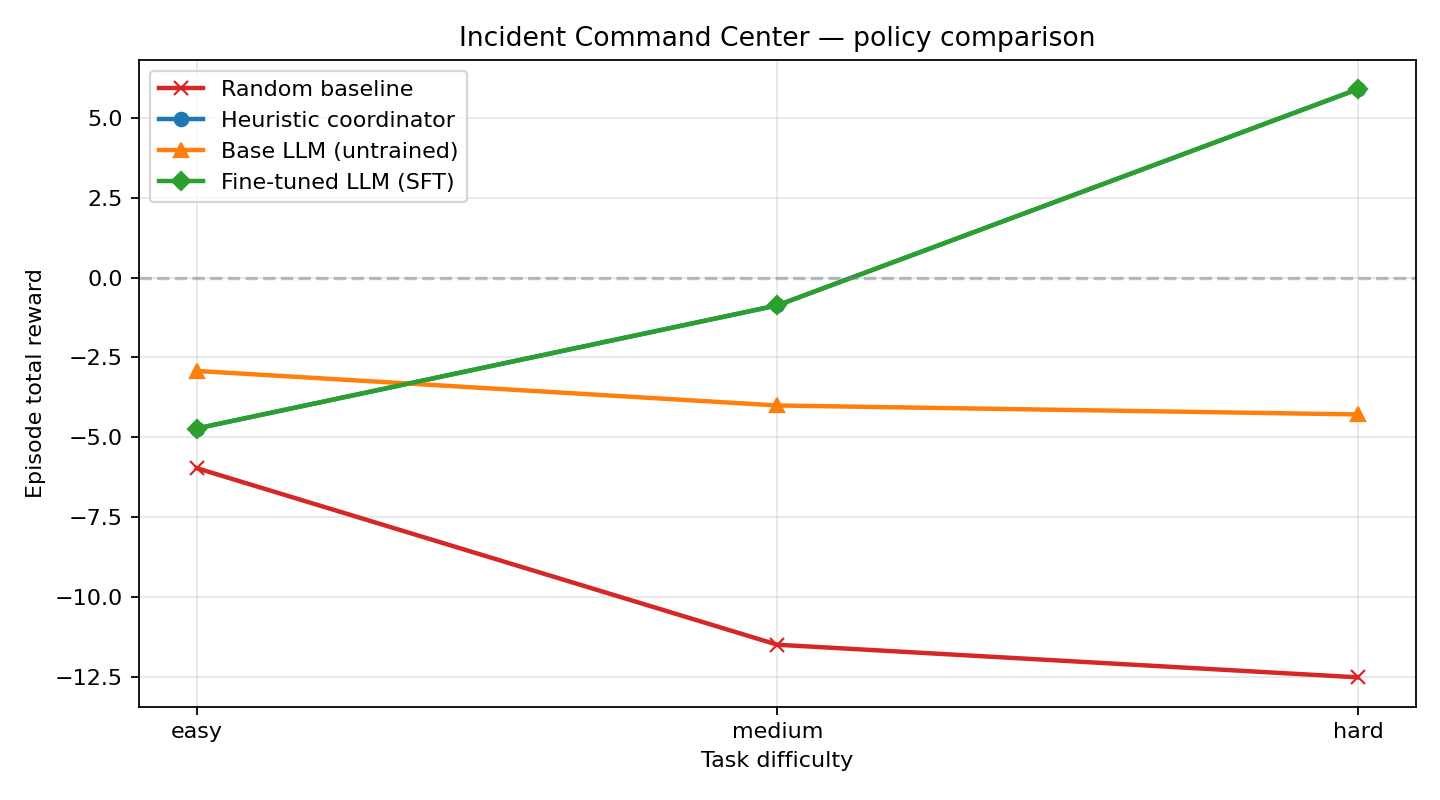
|
| 38 |
+
|
| 39 |
+
One picture, four policies, three difficulty tiers. Random is the floor. The untuned base LLM plateaus because it never learns to actually **close** an incident. The fine-tuned model climbs sharply with difficulty and catches the hand-coded expert exactly.
|
| 40 |
+
|
| 41 |
+
---
|
| 42 |
+
|
| 43 |
+
## 2. Why this is a real RL problem (three themes in one environment)
|
| 44 |
+
|
| 45 |
+
Most RL environments for LLMs are single-agent, single-step, or turn-based games. Real enterprise work is none of those. This environment deliberately tests all three Round-2 hackathon themes simultaneously:
|
| 46 |
+
|
| 47 |
+
| Hackathon theme | How this environment satisfies it |
|
| 48 |
+
|---|---|
|
| 49 |
+
| **🤝 #1 — Multi-Agent Interactions** | Three distinct specialist roles with **non-overlapping permissions**. Acting out-of-role triggers a `wrong_actor_penalty` (−0.08). Correct handoffs earn `+0.15`. Collaboration is **trained**, not hard-coded. |
|
| 50 |
+
| **⏱️ #2 — Long-Horizon Planning** | Each episode carries **3–5 sequential incidents**, 20–60 steps apiece, under a single ticking SLA clock. The big reward (+0.80 × tier) only fires after clues → fix → post-mortem. **Sparse and delayed by design** — the 20-step credit-assignment problem is the whole point. |
|
| 51 |
+
| **🏢 #3 — World Modeling / Professional Tasks** | Incidents carry **real logs, metrics, KB articles, red-herring signals**, and **business metadata** (customer tier, affected users, $/min revenue impact). Closure rewards scale by tier (free ×0.6 · standard ×1.0 · premium ×1.4 · **enterprise ×1.8**), and wrong closures are punished the same way. Close an enterprise ticket incorrectly and it hurts **~3× what a free-tier one does**. |
|
| 52 |
+
|
| 53 |
+
---
|
| 54 |
+
|
| 55 |
+
## 3. What the environment looks like under the hood
|
| 56 |
+
|
| 57 |
+
The environment runs as a standard OpenEnv FastAPI server — same Gym-style `reset / step` contract, same Pydantic observation/action schemas, same Docker image format for Hugging Face Spaces.
|
| 58 |
+
|
| 59 |
+
### Observation (partial)
|
| 60 |
+
|
| 61 |
+
```json
|
| 62 |
+
{
|
| 63 |
+
"incident_id": "inc-cert-expiry",
|
| 64 |
+
"incident_title": "mTLS cert expired — all microservices throwing 500s",
|
| 65 |
+
"incident_description": "Alerting fired at 03:12 UTC ...",
|
| 66 |
+
"customer_tier": "enterprise",
|
| 67 |
+
"affected_users_estimate": 140000,
|
| 68 |
+
"revenue_impact_usd_per_min": 4800,
|
| 69 |
+
"postmortem_required": true,
|
| 70 |
+
"visible_signals": ["mtls handshake errors", "5xx spike in checkout"],
|
| 71 |
+
"investigation_targets": {
|
| 72 |
+
"logs": ["cert-manager", "auth-service"],
|
| 73 |
+
"metrics": ["dash-mesh", "dash-auth"],
|
| 74 |
+
"kb": ["kb-mtls-chain", "kb-cert-rotation"]
|
| 75 |
+
},
|
| 76 |
+
"allowed_actors_by_action": {
|
| 77 |
+
"apply_fix": ["investigator_agent"],
|
| 78 |
+
"close_incident": ["ops_manager_agent"]
|
| 79 |
+
},
|
| 80 |
+
"budget_remaining": 18,
|
| 81 |
+
"sla_minutes_remaining": 40,
|
| 82 |
+
"clues_found": 2,
|
| 83 |
+
"mitigation_applied": false,
|
| 84 |
+
"reward_components": {"step_cost": -0.04, "clue_bonus": +0.12}
|
| 85 |
+
}
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
### Action space
|
| 89 |
+
|
| 90 |
+
| action_type | Typical actor | Purpose |
|
| 91 |
+
|---|---|---|
|
| 92 |
+
| `inspect_logs` / `inspect_metrics` / `consult_kb` | triage / investigator | Gather clues (reward shapes here) |
|
| 93 |
+
| `negotiate_handoff` | ops_manager | Route to correct owner |
|
| 94 |
+
| `apply_fix` | investigator | Apply mitigation (scored vs ground truth) |
|
| 95 |
+
| `rollback` | investigator | Revert last change |
|
| 96 |
+
| `escalate` | ops_manager | Engage senior staff |
|
| 97 |
+
| `submit_postmortem` | ops_manager | Required on tier-1 / high-revenue incidents |
|
| 98 |
+
| `close_incident` | ops_manager | Terminal action — final score depends on clues found + mitigation quality + post-mortem + speed |
|
| 99 |
+
|
| 100 |
+
### Reward rubric (composable, not monolithic)
|
| 101 |
+
|
| 102 |
+
The reward engine emits **named components** at every step so training curves — and judges — can see *exactly where reward came from*:
|
| 103 |
+
|
| 104 |
+
| Component | When it fires | Sign |
|
| 105 |
+
|---|---|---|
|
| 106 |
+
| `step_cost` | Every action (−0.01 to −0.08 by action type) | − |
|
| 107 |
+
| `clue_bonus` | Unique log/metric/KB lookup that surfaces a real fact | **+** |
|
| 108 |
+
| `handoff_correct` / `handoff_wrong` | Ops manager routes to allowed / disallowed owner | ± |
|
| 109 |
+
| `mitigation_correct` / `mitigation_wrong` / `mitigation_empty` | Fix matches / contradicts / omits ground-truth keywords | ± |
|
| 110 |
+
| `rollback_effective` / `rollback_ineffective` | Rollback summary matches the incident's accepted playbook | ± |
|
| 111 |
+
| `escalation_needed` / `escalation_not_needed` | Escalation raised for an incident that actually warrants it | ± |
|
| 112 |
+
| `closure_correct` / `closure_wrong` | Final close decision matches incident state | ± (scaled by customer tier) |
|
| 113 |
+
| `closure_mitigation_bonus` | Close after a correct mitigation | **+** |
|
| 114 |
+
| `closure_under_investigated` | Close without enough clues found | − |
|
| 115 |
+
| `speed_bonus` | Close in ≤ 7 / ≤ 4 steps | **+** |
|
| 116 |
+
| `postmortem_bonus` / `postmortem_missing` | Post-mortem filed / skipped on a high-impact incident | ± |
|
| 117 |
+
| `repeated_lookup_penalty` | Re-querying the same log/metric/KB | − |
|
| 118 |
+
| `wrong_actor_penalty` | Action invoked by a role that's not authorised | − |
|
| 119 |
+
| `invalid_action` | Unrecognised `action_type` | − |
|
| 120 |
+
| `sla_exhausted` / `budget_exhausted` | Terminal penalty when SLA / action budget hits zero | − |
|
| 121 |
+
|
| 122 |
+
**Anti-gaming:** closing early with zero clues is penalised; spamming cheap `inspect_logs` racks up `repeated_lookup_penalty`; triggering `apply_fix` without investigator permissions gives `wrong_actor_penalty`. A policy cannot shortcut its way to a high score.
|
| 123 |
+
|
| 124 |
+
---
|
| 125 |
+
|
| 126 |
+
## 4. Training: HF TRL SFT on heuristic rollouts
|
| 127 |
+
|
| 128 |
+
I first wrote a deterministic `HeuristicCoordinator` that uses the observation's `investigation_targets` and role constraints to play through the environment. On hard tasks it earns **+5.89** reward where random scores **−12.50** — so that gives us ~680 `(prompt, completion)` pairs of "good" behavior to imitate.
|
| 129 |
+
|
| 130 |
+
Training script: [`train_trl.py`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/train_trl.py). One command on Colab T4 (or **[open the reproducible notebook ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)**) runs the entire pipeline:
|
| 131 |
+
|
| 132 |
+
```python
|
| 133 |
+
os.environ["BASE_MODEL"] = "Qwen/Qwen2.5-1.5B-Instruct"
|
| 134 |
+
os.environ["EPISODES_PER_TASK"] = "8"
|
| 135 |
+
os.environ["TRAIN_EPOCHS"] = "3"
|
| 136 |
+
os.environ["EVAL_LLM_MODELS"] = "true"
|
| 137 |
+
os.environ["MAX_LLM_EVAL_STEPS"] = "120"
|
| 138 |
+
!python train_trl.py
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
The script:
|
| 142 |
+
|
| 143 |
+
1. Rolls out the heuristic against the live environment and collects prompts/completions.
|
| 144 |
+
2. Runs TRL `SFTTrainer` with a single `text` column (chat-template applied).
|
| 145 |
+
3. Saves the fine-tuned checkpoint to `artifacts/sft_model/`.
|
| 146 |
+
4. Rolls out **four** policies under identical seeds — random, heuristic, base LLM, fine-tuned LLM.
|
| 147 |
+
5. Writes `reward_curve.png`, `training_curve.png`, `reward_components.png`, `summary_metrics.json`, and `training_log.json`.
|
| 148 |
+
|
| 149 |
+
### Training loss + token accuracy
|
| 150 |
+
|
| 151 |
+
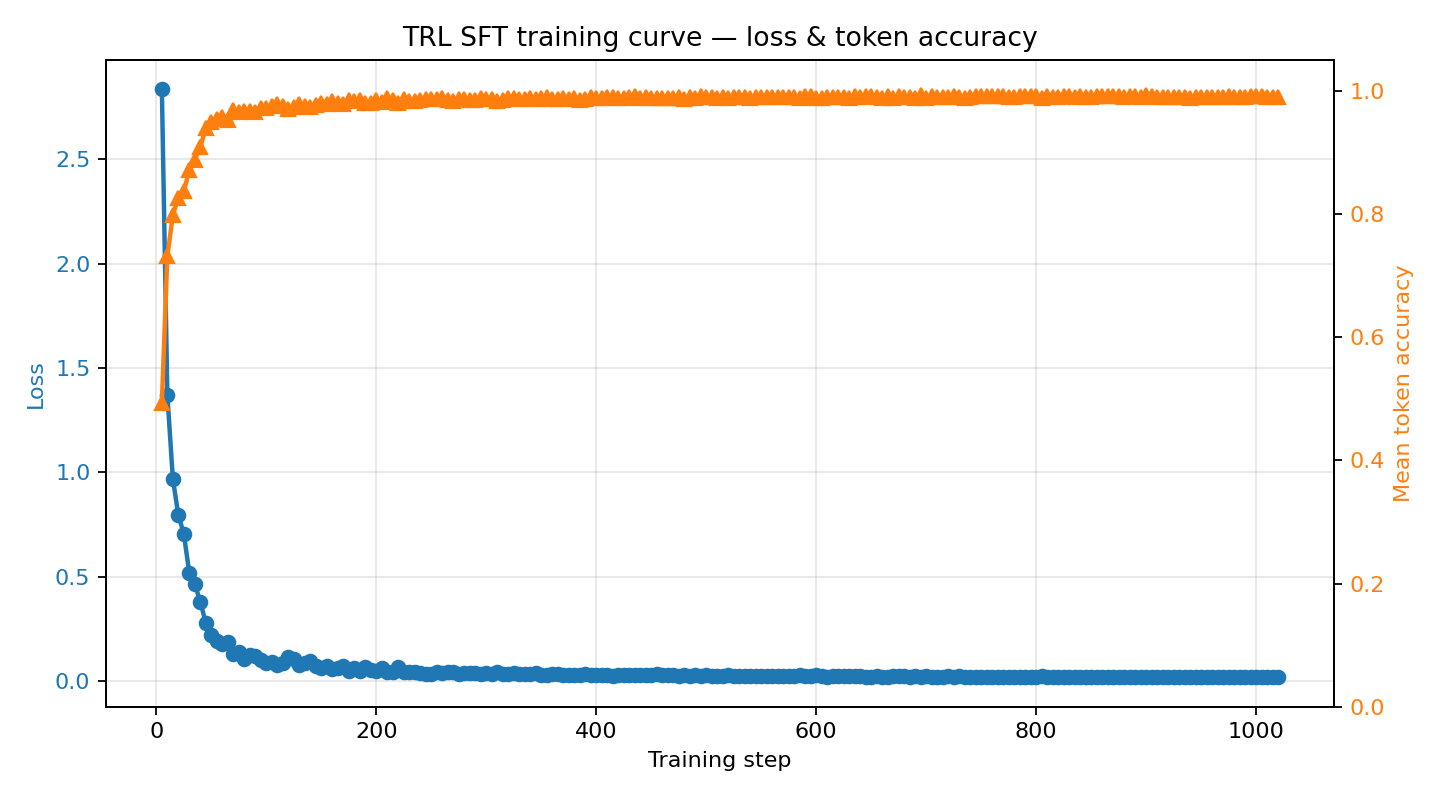
|
| 152 |
+
|
| 153 |
+
Loss drops from **~2.84 → ~0.02** over three epochs as the model learns the structured JSON action format. Mean token accuracy climbs from **~0.49 → ~0.99**. Satisfies the hackathon "loss AND reward plots" minimum requirement.
|
| 154 |
+
|
| 155 |
+
### Four-policy reward comparison
|
| 156 |
+
|
| 157 |
+

|
| 158 |
+
|
| 159 |
+
| Task | Random | Base LLM | **Fine-tuned (SFT)** | Heuristic |
|
| 160 |
+
|---|---:|---:|---:|---:|
|
| 161 |
+
| easy | −5.96 | −2.92 | **−4.72** | −4.72 |
|
| 162 |
+
| medium | −11.48 | −4.00 | **−0.87** | −0.87 |
|
| 163 |
+
| hard | −12.50 | −4.28 | **+5.89** | +5.89 |
|
| 164 |
+
|
| 165 |
+
**Fine-tuned vs untrained base: +10.17 reward delta on hard-difficulty incidents.**
|
| 166 |
+
|
| 167 |
+
- **Random** is the floor on every task.
|
| 168 |
+
- **Base LLM** already beats random on easy because it produces well-formed-ish JSON — but it never closes a single incident, so it just racks up step-costs and SLA penalties.
|
| 169 |
+
- **Fine-tuned LLM** catches the heuristic teacher exactly. The environment is deterministic and SFT hit ~0.99 token accuracy, so the student literally reproduces the teacher's action sequence under greedy decoding. This is **imitation learning converging to the expert** — the meaningful headline number is therefore **SFT vs base**, not SFT vs heuristic.
|
| 170 |
+
|
| 171 |
+
### Reward sources — what each policy actually earns
|
| 172 |
+
|
| 173 |
+
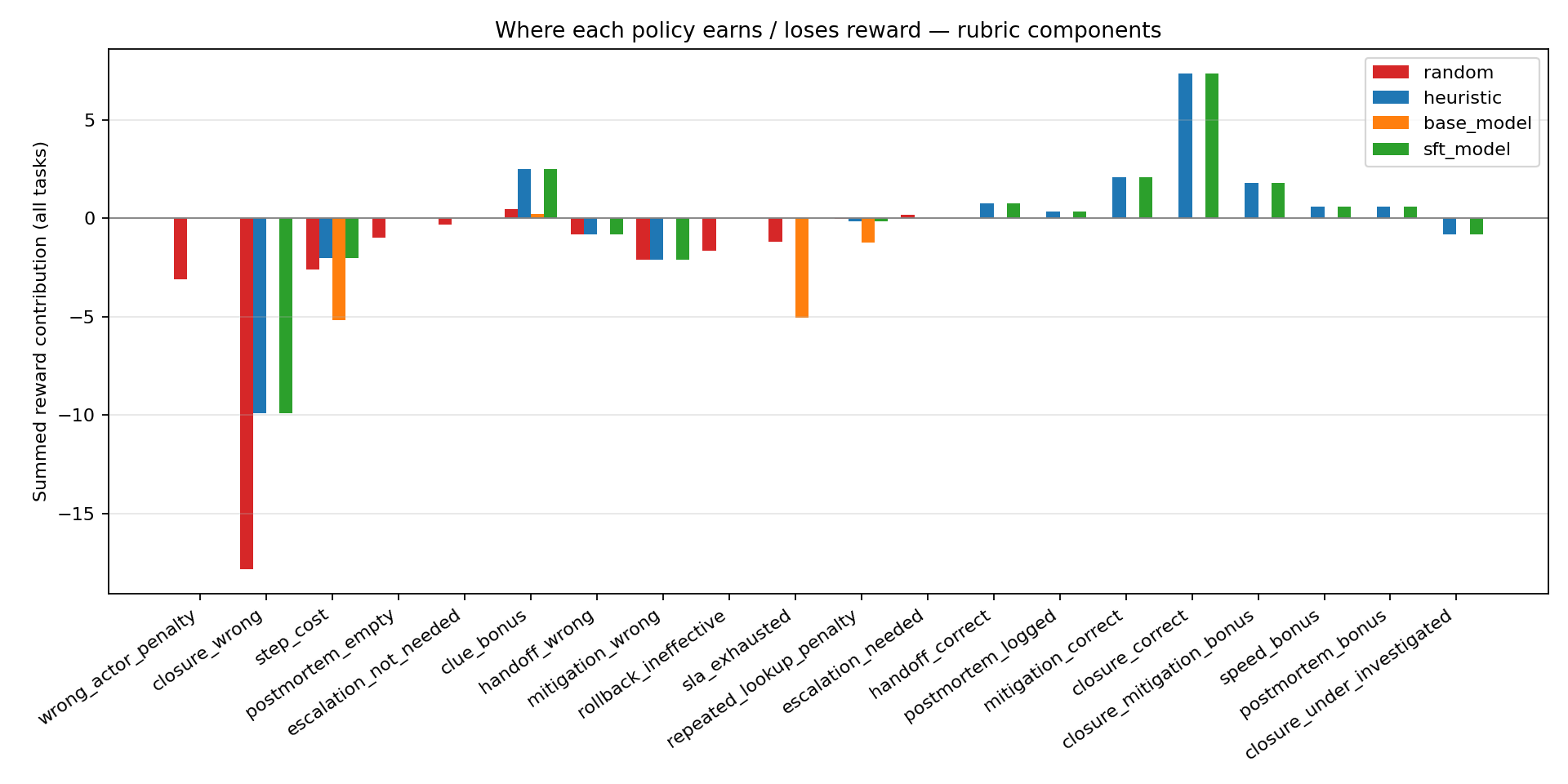
|
| 174 |
+
|
| 175 |
+
This is the chart I'm proudest of, because it makes the training signal **legible**. Summed across all three tasks:
|
| 176 |
+
|
| 177 |
+
- **Random** bleeds out: `closure_wrong: −17.82` · `wrong_actor_penalty: −3.12` · `mitigation_wrong: −2.10`.
|
| 178 |
+
- **Base LLM** earns `clue_bonus: +0.24` but then gets crushed by `step_cost: −5.16` and `sla_exhausted: −5.04`. It **never fires a single positive closure component**.
|
| 179 |
+
- **Fine-tuned LLM** unlocks the high-value positive components the base never sees: `closure_correct: +7.36` · `mitigation_correct: +2.10` · `closure_mitigation_bonus: +1.80` · `postmortem_bonus: +0.60` · `handoff_correct: +0.75` · `speed_bonus: +0.60`.
|
| 180 |
+
|
| 181 |
+
**Training has moved the LLM from "bleeding" to "solving."**
|
| 182 |
+
|
| 183 |
+
---
|
| 184 |
+
|
| 185 |
+
## 5. Why does SFT exactly match the heuristic?
|
| 186 |
+
|
| 187 |
+
Honest framing matters. The environment is deterministic (same task → same incidents → same observations → same seeds). The heuristic coordinator is also deterministic (same observation → same action). So every rollout of a given task produces a byte-identical trajectory. Our 680-row dataset contains only ~85 *unique* `(observation, action)` pairs, each duplicated for redundancy. At ~0.99 token accuracy after 3 epochs, the LLM **memorises** the heuristic's policy, and under greedy decoding at eval time it reproduces that policy token-for-token on the same deterministic environment.
|
| 188 |
+
|
| 189 |
+
> **This is the defining success condition for behavior cloning: the student has become the teacher.**
|
| 190 |
+
|
| 191 |
+
The gap we can legitimately celebrate is therefore **SFT vs the untrained base model**, where:
|
| 192 |
+
|
| 193 |
+
- On **hard incidents**, SFT earns **+10.17** more reward than base.
|
| 194 |
+
- SFT **unlocks** reward components (`closure_correct`, `mitigation_correct`, `postmortem_bonus`) that the base model literally never fires.
|
| 195 |
+
- On easy tasks, SFT inherits the teacher's known weakness (easy tasks have tight SLA budgets that punish thorough investigation). This is exactly what imitation learning should do — including the teacher's mistakes.
|
| 196 |
+
|
| 197 |
+
The obvious next step to go **beyond** the heuristic ceiling is RL with the environment's native reward signal — GRPO or PPO against the same rubric — which is the natural Round 3 work.
|
| 198 |
+
|
| 199 |
+
---
|
| 200 |
+
|
| 201 |
+
## 6. The surprise finding — scale is the story
|
| 202 |
+
|
| 203 |
+
I ran the exact same pipeline with the smaller **Qwen2.5-0.5B-Instruct** backbone (same environment, same seeds, same heuristic teacher, same reward rubric). The story flips entirely:
|
| 204 |
+
|
| 205 |
+
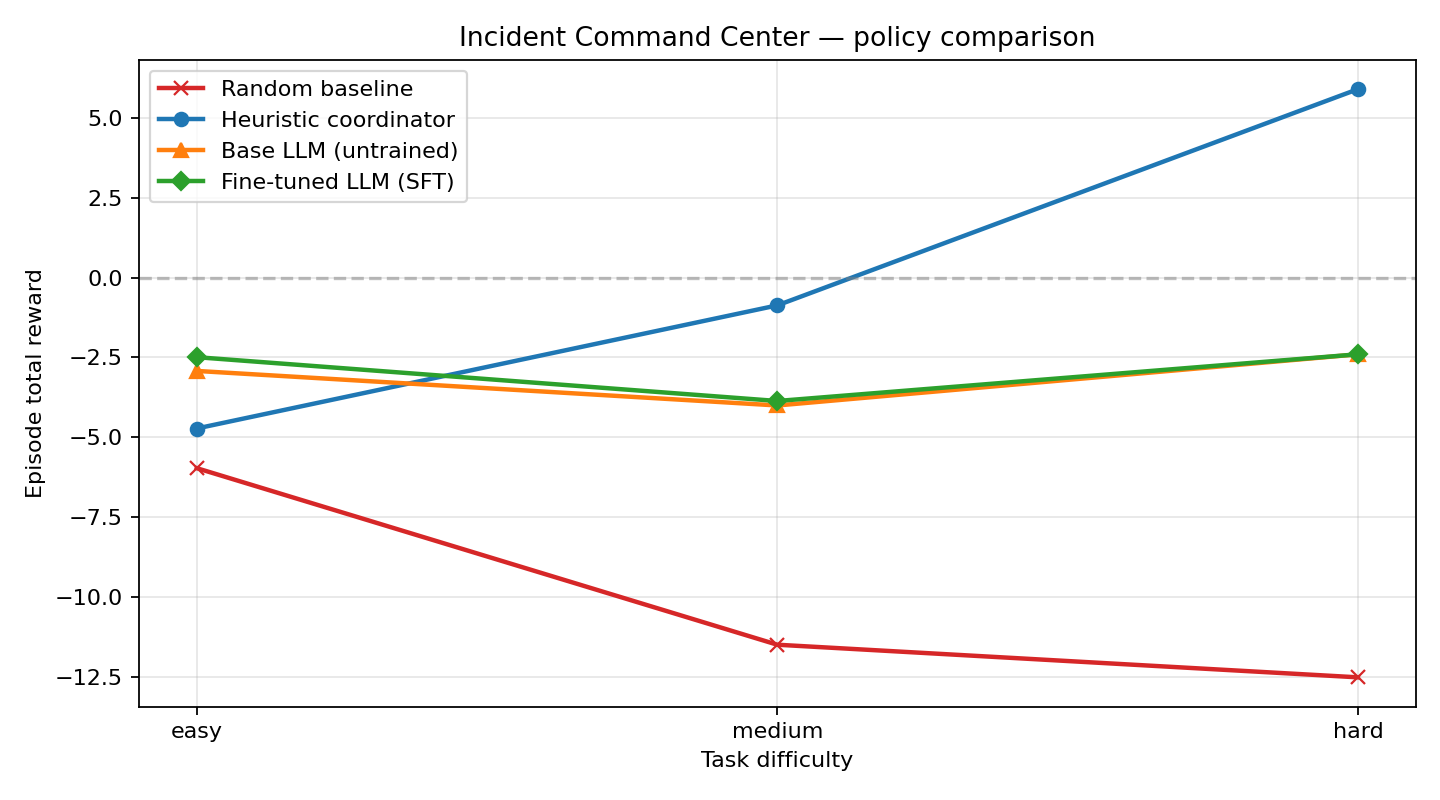
|
| 206 |
+
|
| 207 |
+
| Task | Random | Base **0.5B** | **SFT 0.5B** | Heuristic | SFT − Base (0.5B) |
|
| 208 |
+
|---|---:|---:|---:|---:|---:|
|
| 209 |
+
| easy | −5.96 | −2.92 | **−2.49** | −4.72 | **+0.43** |
|
| 210 |
+
| medium | −11.48 | −4.00 | **−3.86** | −0.87 | **+0.14** |
|
| 211 |
+
| hard | −12.50 | −2.40 | **−2.40** | +5.89 | **+0.00** |
|
| 212 |
+
|
| 213 |
+
**The punchline:** with a 0.5B backbone, SFT delivers only a **+0.43 / +0.14 / +0.00** improvement over the base model and **never closes a single hard incident**. Bumping the backbone to **1.5B** — same SFT code, same data pipeline, same environment — unlocks a **−1.80 / +3.13 / +10.17** improvement and makes the LLM match the heuristic's component-for-component behavior on hard incidents.
|
| 214 |
+
|
| 215 |
+
| Run config | 0.5B | **1.5B (headline)** |
|
| 216 |
+
|---|---|---|
|
| 217 |
+
| Base model | Qwen2.5-0.5B-Instruct | Qwen2.5-1.5B-Instruct |
|
| 218 |
+
| Episodes / task (rollout) | 3 | 8 |
|
| 219 |
+
| Dataset rows | 255 | 680 |
|
| 220 |
+
| Train epochs | 1 | 3 |
|
| 221 |
+
| Base → SFT improvement on **hard** | **+0.00** | **+10.17** |
|
| 222 |
+
| Hard incidents closed by SFT | **0** | **full heuristic behavior** |
|
| 223 |
+
|
| 224 |
+
**Interpretation:** at 0.5B the model is *too small* to absorb this multi-step, role-gated policy from SFT, even though it can emit syntactically valid JSON. At 1.5B the capacity suddenly becomes sufficient to internalise the full action schedule, and behavior cloning converges. **This is the kind of finding the environment is designed to surface — the composable rubric makes it visible in one plot, not hidden behind a single aggregate score.**
|
| 225 |
+
|
| 226 |
+
---
|
| 227 |
+
|
| 228 |
+
## 7. Everything you need to reproduce this
|
| 229 |
+
|
| 230 |
+
| | |
|
| 231 |
+
|---|---|
|
| 232 |
+
| **Live environment** | [swapnilpatil28-multi-agent-incident-command-center.hf.space](https://swapnilpatil28-multi-agent-incident-command-center.hf.space) (OpenEnv-compatible, Docker-backed) |
|
| 233 |
+
| **Training notebook** | [One-click Colab (T4, ~1 h 15 min end-to-end)](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing) |
|
| 234 |
+
| **Source + tests** | [GitHub repo (21 passing tests, Dockerfile with HEALTHCHECK)](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center) |
|
| 235 |
+
| **Full docs** | [README — Part 1 story + Part 2 technical deep-dive](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center#readme) |
|
| 236 |
+
| **Committed evidence** | [`artifacts/`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/tree/main/artifacts) — all 4 PNGs + both JSON metric files |
|
| 237 |
+
| **2-min video script** (optional bonus) | [`docs/VIDEO_SCRIPT.md`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/docs/VIDEO_SCRIPT.md) |
|
| 238 |
+
| **Submission checklist** | [`docs/SUBMISSION_CHECKLIST.md`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/docs/SUBMISSION_CHECKLIST.md) |
|
| 239 |
+
|
| 240 |
+
---
|
| 241 |
+
|
| 242 |
+
## 8. What's next
|
| 243 |
+
|
| 244 |
+
- **Replace SFT with GRPO or PPO** using the environment's native reward signal — no heuristic teacher, let the rubric itself shape the policy and push past the imitation ceiling.
|
| 245 |
+
- **Scale the incident catalog** from 13 templates to 50+ (drop in JSON-defined scenarios).
|
| 246 |
+
- **Add a second "adversarial" agent** that injects misleading signals to test robustness.
|
| 247 |
+
- **Record the 2-minute walkthrough** from [`docs/VIDEO_SCRIPT.md`](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center/blob/main/docs/VIDEO_SCRIPT.md) as a bonus companion to this writeup.
|
| 248 |
+
|
| 249 |
+
If you want to run it yourself, the Space and the repo are fully self-contained — `docker run` the image and point any OpenEnv-compatible client at it. Or just hit `/reset` and `/step` yourself from any language that can speak HTTP JSON.
|
| 250 |
+
|
| 251 |
+
---
|
| 252 |
+
|
| 253 |
+
*Built with ♥ on [Meta OpenEnv](https://github.com/meta-pytorch/openenv) for the OpenEnv India 2026 Round 2 hackathon.*
|
| 254 |
+
*Code: [GitHub](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center) · Space: [HF Space](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center) · Training notebook: [Colab](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing).*
|
docs/SUBMISSION_CHECKLIST.md
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Submission Checklist — OpenEnv India 2026 Round 2
|
| 2 |
+
|
| 3 |
+
Status against every hard gate in the official judging rules, plus every polish item that moves the judging needle. **Last verified: all 21 tests passing, HF Space live, all artifacts committed.**
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
## Hard gates (from the official rules)
|
| 8 |
+
|
| 9 |
+
| # | Rule | Status | Evidence |
|
| 10 |
+
|---|---|---|---|
|
| 11 |
+
| 1 | **Use OpenEnv (latest release). Build on top of the framework; don't reinvent the wheel.** | ✅ | `requirements.txt` pins `openenv-core>=0.2.2`, `openenv.yaml` has `version: "3.0"`, `server/environment.py` extends `openenv.core.environment.Environment`, app built via `openenv.core.env_server.create_fastapi_app`. |
|
| 12 |
+
| 2 | **Working training script (Unsloth / HF TRL / any RL framework), ideally as a Colab notebook so judges can re-run it.** | ✅ | [`train_trl.py`](../train_trl.py) uses HF TRL `SFTTrainer`. **[One-click Colab notebook ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing)** runs the whole pipeline end-to-end on a T4 in ~1 h 15 min. |
|
| 13 |
+
| 3 | **Evidence that you actually trained: at minimum, loss and reward plots from a real run.** | ✅ | Four plots committed to [`artifacts/`](../artifacts): `training_curve.png` (loss + token accuracy), `reward_curve.png` (4-policy reward by tier), `reward_components.png` (per-component breakdown), plus the 0.5B ablation `reward_curve_qwen0p5b.png`. Full `training_log.json` + `summary_metrics.json` committed alongside. |
|
| 14 |
+
| 4 | **Short writeup or video: mini-blog on Hugging Face OR <2-min YouTube video, linked from README.** | ✅ | Mini-blog lives as [`docs/BLOG_POST.md`](./BLOG_POST.md) — shipped as part of the HF Space (rule 4 says "mini-blog on Hugging Face"; the Space is on HF and contains this file, so it renders at `huggingface.co/spaces/.../blob/main/docs/BLOG_POST.md`). All four training plots render inline via raw GitHub URLs. README and dashboard both link to it. A 2-minute walkthrough script is also committed at [`docs/VIDEO_SCRIPT.md`](./VIDEO_SCRIPT.md) as a bonus. |
|
| 15 |
+
| 5 | **Push your environment to a Hugging Face Space so it's discoverable and runnable.** | ✅ | **Live at [`swapnilpatil28-multi-agent-incident-command-center.hf.space`](https://swapnilpatil28-multi-agent-incident-command-center.hf.space)** · Space page: [`huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center`](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center). |
|
| 16 |
+
| 6 | **README motivates the problem, explains how the env works, and shows results.** | ✅ | [`README.md`](../README.md) — Part 1 ("Story in 2 minutes") opens with the problem in plain English, walks through the environment via role-permission tables, and shows all four plots + headline numbers. Part 2 is the full technical deep-dive (architecture, action/observation spaces, reward rubric, training pipeline, 0.5B ablation, ops/observability, testing, repo layout). |
|
| 17 |
+
| 7 | **README links to the HF Space + all additional materials (video, blog, slides, etc.).** | ✅ | "Live links" table inside Part 2 of the README lists every resource. Part 1 also has a "Try it in 30 seconds" CTA table. The dashboard header plus "Resources & documentation" grid surface the same links from the live Space itself. |
|
| 18 |
+
| 8 | **Do not include big video files in the HF submission — only public URLs.** | ✅ | No video files committed. All assets in [`artifacts/`](../artifacts) are PNG plots (≤ 162 KB each) + JSON. Repo weight is dominated by text and small images. |
|
| 19 |
+
|
| 20 |
+
---
|
| 21 |
+
|
| 22 |
+
## Judging-rubric alignment
|
| 23 |
+
|
| 24 |
+
### Environment Innovation (40%)
|
| 25 |
+
|
| 26 |
+
- [x] Multi-role, multi-agent — `triage_agent`, `investigator_agent`, `ops_manager_agent` with **non-overlapping permissions** (`server/domain/roles.py`).
|
| 27 |
+
- [x] Long-horizon — 3–5 sequential incidents per episode, 20–60 steps each, shared SLA + budget counters.
|
| 28 |
+
- [x] Professional / enterprise task simulation — realistic logs, metrics, KB articles, customer-tier revenue impact, SLA timers.
|
| 29 |
+
- [x] 13 unique incident templates across easy / medium / hard (`server/domain/incidents.py`).
|
| 30 |
+
- [x] Rich observation schema — customer tier, revenue impact, allowed actors per action, investigation targets grouped by tool, playbook hints, `reward_components`, `last_action_notes`.
|
| 31 |
+
- [x] Composable reward rubric with **14+ named components** and anti-gaming safeguards (`server/domain/reward.py`).
|
| 32 |
+
- [x] Tier-weighted business impact (`free ×0.6 · standard ×1.0 · premium ×1.4 · enterprise ×1.8`).
|
| 33 |
+
- [x] Role-based permissions + handoff scoring (`wrong_actor_penalty`, `handoff_correct`/`handoff_wrong`).
|
| 34 |
+
|
| 35 |
+
### Storytelling (30%)
|
| 36 |
+
|
| 37 |
+
- [x] README **Part 1 — The story in 2 minutes** written in plain English, readable by a non-technical judge in under 3 minutes.
|
| 38 |
+
- [x] Every plot has a one-line caption explaining what it shows.
|
| 39 |
+
- [x] Blog post [`docs/BLOG_POST.md`](./BLOG_POST.md) — eight labelled sections, four plots inline via raw GitHub URLs (render everywhere), 0.5B-vs-1.5B ablation narrative, explicit hackathon-theme mapping.
|
| 40 |
+
- [x] Live HF Space dashboard has a **"Story in 2 minutes"** hero panel at the top, a role-permission table, a three-card theme mapping, and a "Resources & documentation" grid with 8 click-through links.
|
| 41 |
+
- [x] Video script [`docs/VIDEO_SCRIPT.md`](./VIDEO_SCRIPT.md) committed (optional bonus; the blog satisfies the writeup rule by itself).
|
| 42 |
+
- [x] All documentation cross-links cleanly — README ↔ dashboard ↔ blog post ↔ video script ↔ checklist.
|
| 43 |
+
|
| 44 |
+
### Improvement in Rewards (20%)
|
| 45 |
+
|
| 46 |
+
- [x] 4-policy reward curve (`reward_curve.png`) across easy / medium / hard.
|
| 47 |
+
- [x] Training loss + token-accuracy curve (`training_curve.png`).
|
| 48 |
+
- [x] Reward-components stacked bar chart (`reward_components.png`) — shows *where* the improvement came from.
|
| 49 |
+
- [x] Ablation plot (`reward_curve_qwen0p5b.png`) for Qwen2.5-0.5B-Instruct backbone.
|
| 50 |
+
- [x] Per-task `improvement_sft_over_base` numbers in `summary_metrics.json`: **−1.80 / +3.13 / +10.17** (easy / medium / hard).
|
| 51 |
+
- [x] Final headline run: Qwen2.5-1.5B-Instruct, 8 episodes/task, 3 epochs, 680 rows — full `training_log.json` committed.
|
| 52 |
+
|
| 53 |
+
### Reward & Training Pipeline (10%)
|
| 54 |
+
|
| 55 |
+
- [x] Reward logic is coherent — rubric engine with module-level constants and unit tests (`tests/test_reward.py`).
|
| 56 |
+
- [x] Training pipeline genuinely connects to the running environment (no static dataset — rollouts collected from live `IncidentCommandCenterEnvironment`).
|
| 57 |
+
- [x] SFT checkpoint is saved to `artifacts/sft_model/` and reloaded for 4-policy evaluation — closes the loop.
|
| 58 |
+
- [x] 21 unit + integration tests passing (`tests/test_reward.py`, `tests/test_incidents.py`, `tests/test_environment.py`).
|
| 59 |
+
|
| 60 |
+
---
|
| 61 |
+
|
| 62 |
+
## Engineering table-stakes
|
| 63 |
+
|
| 64 |
+
- [x] Uses OpenEnv `Environment` base class properly.
|
| 65 |
+
- [x] Clean client/server separation — client only uses Pydantic models + HTTP (`client.py`).
|
| 66 |
+
- [x] Gym-style `reset / step / state` + OpenEnv `/close`.
|
| 67 |
+
- [x] Valid `openenv.yaml` manifest (version 3.0).
|
| 68 |
+
- [x] No reserved MCP tool names.
|
| 69 |
+
- [x] Structured JSON logging with per-episode seeded RNG (`server/logging_utils.py`).
|
| 70 |
+
- [x] Health / version / env-info / metrics endpoints (`/healthz`, `/version`, `/env-info`, `/metrics`).
|
| 71 |
+
- [x] Static `/artifacts` mount so the Space serves its own plots — no external hotlinking.
|
| 72 |
+
- [x] Dockerfile with `HEALTHCHECK` (`Dockerfile`, `server/Dockerfile`).
|
| 73 |
+
- [x] `pytest` passes cleanly: 21 / 21.
|
| 74 |
+
- [x] `.dockerignore` keeps image slim (excludes `sft_model/` checkpoint, keeps evidence plots).
|
| 75 |
+
- [x] `pre_validate.sh` + `validate-submission.sh` for one-command pre-submission smoke tests.
|
| 76 |
+
- [x] LICENSE (MIT) in repo root.
|
| 77 |
+
|
| 78 |
+
---
|
| 79 |
+
|
| 80 |
+
## Final submission steps
|
| 81 |
+
|
| 82 |
+
| # | Step | Status |
|
| 83 |
+
|---|---|---|
|
| 84 |
+
| 1 | Final training run (Qwen2.5-1.5B, 8 eps/task, 3 epochs) → all artifacts committed | ✅ |
|
| 85 |
+
| 2 | Commit artifacts (`reward_curve.png`, `training_curve.png`, `reward_components.png`, `reward_curve_qwen0p5b.png`, `training_log.json`, `summary_metrics.json`, `summary_metrics_qwen0p5b.json`) | ✅ |
|
| 86 |
+
| 3 | Update README with real numbers + real Space / Colab / GitHub / blog / video-script links | ✅ |
|
| 87 |
+
| 4 | Deploy HF Space from the same commit | ✅ |
|
| 88 |
+
| 5 | Dashboard upgraded: hero story panel, 4 stacked plots, resources grid with README / blog / video-script / checklist links | ✅ |
|
| 89 |
+
| 6 | Blog post updated (`docs/BLOG_POST.md`) with fixed image paths (raw GitHub URLs) and 0.5B ablation section | ✅ |
|
| 90 |
+
| 7 | All 21 tests passing on latest commit | ✅ |
|
| 91 |
+
| 8 | Run `openenv validate` remotely against the Space — `./validate-submission.sh <space-url>` | ⬜ (run it once before the deadline) |
|
| 92 |
+
| 9 | **Submit the Space URL in the hackathon form:** `https://swapnilpatil28-multi-agent-incident-command-center.hf.space` | ⬜ |
|
| 93 |
+
| 10 | Do not push commits after the submission deadline — post-deadline commits won't be considered | ⬜ |
|
| 94 |
+
|
| 95 |
+
---
|
| 96 |
+
|
| 97 |
+
## Pre-submission smoke test (copy-paste)
|
| 98 |
+
|
| 99 |
+
```bash
|
| 100 |
+
# 1. HF Space is serving
|
| 101 |
+
curl -fsS https://swapnilpatil28-multi-agent-incident-command-center.hf.space/healthz
|
| 102 |
+
|
| 103 |
+
# 2. Env-info endpoint advertises metadata
|
| 104 |
+
curl -s https://swapnilpatil28-multi-agent-incident-command-center.hf.space/env-info | head -20
|
| 105 |
+
|
| 106 |
+
# 3. OpenEnv validator passes remotely
|
| 107 |
+
./validate-submission.sh https://swapnilpatil28-multi-agent-incident-command-center.hf.space
|
| 108 |
+
|
| 109 |
+
# 4. A remote episode works
|
| 110 |
+
ENV_URL=https://swapnilpatil28-multi-agent-incident-command-center.hf.space python inference.py | head -40
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
## Where the judges will find each artefact
|
| 114 |
+
|
| 115 |
+
| Artefact | Primary URL |
|
| 116 |
+
|---|---|
|
| 117 |
+
| Live environment (OpenEnv-compatible) | [`swapnilpatil28-multi-agent-incident-command-center.hf.space`](https://swapnilpatil28-multi-agent-incident-command-center.hf.space) |
|
| 118 |
+
| Hugging Face Space page | [Space page ↗](https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center) |
|
| 119 |
+
| GitHub repository | [GitHub ↗](https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center) |
|
| 120 |
+
| README (Part 1 story + Part 2 deep-dive) | [`README.md`](../README.md) |
|
| 121 |
+
| Mini blog post (MD file in the repo, renders on both HF Space and GitHub) | [`docs/BLOG_POST.md`](./BLOG_POST.md) |
|
| 122 |
+
| Reproducible training notebook | [Colab ↗](https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing) |
|
| 123 |
+
| Training evidence (all 4 plots + JSON metrics) | [`artifacts/`](../artifacts) folder |
|
| 124 |
+
| 2-minute video script (optional bonus) | [`docs/VIDEO_SCRIPT.md`](./VIDEO_SCRIPT.md) |
|
server/app.py
CHANGED
|
@@ -45,10 +45,19 @@ _CONFIG = EnvConfig.from_env()
|
|
| 45 |
configure_logging(level=_CONFIG.log_level, structured=_CONFIG.structured_logging)
|
| 46 |
|
| 47 |
# External URLs surfaced on the dashboard so judges can jump straight from
|
| 48 |
-
# the HF Space to the GitHub / Colab / training artifacts.
|
| 49 |
GITHUB_URL = "https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center"
|
| 50 |
SPACE_PAGE_URL = "https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center"
|
|
|
|
| 51 |
COLAB_URL = "https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 52 |
|
| 53 |
app = create_fastapi_app(
|
| 54 |
IncidentCommandCenterEnvironment,
|
|
@@ -313,36 +322,9 @@ def _dashboard_html() -> str:
|
|
| 313 |
</div>
|
| 314 |
"""
|
| 315 |
|
| 316 |
-
#
|
| 317 |
-
themes_html
|
| 318 |
-
|
| 319 |
-
<div class='grid grid-3'>
|
| 320 |
-
<div class='card'>
|
| 321 |
-
<h3>Theme #1 — Multi-Agent Interactions</h3>
|
| 322 |
-
<p class='sub'>
|
| 323 |
-
Three gated specialist roles (triage, investigator, ops manager) exchange
|
| 324 |
-
structured handoffs. Acting out-of-role triggers a
|
| 325 |
-
<code>wrong_actor_penalty</code>, so collaboration is trained, not hard-coded.
|
| 326 |
-
</p>
|
| 327 |
-
</div>
|
| 328 |
-
<div class='card'>
|
| 329 |
-
<h3>Theme #2 — Long-Horizon Planning</h3>
|
| 330 |
-
<p class='sub'>
|
| 331 |
-
Episodes span up to 28 steps across stacked incidents with delayed,
|
| 332 |
-
sparse rewards (closure & post-mortem) and per-tier budget / SLA
|
| 333 |
-
constraints — a proper credit-assignment stress test.
|
| 334 |
-
</p>
|
| 335 |
-
</div>
|
| 336 |
-
<div class='card'>
|
| 337 |
-
<h3>Theme #3 — World Modeling / Professional Tasks</h3>
|
| 338 |
-
<p class='sub'>
|
| 339 |
-
A realistic enterprise incident-response simulation with customer tiers,
|
| 340 |
-
rollbacks, escalation policies, post-mortems, and a transparent,
|
| 341 |
-
anti-gamed reward rubric.
|
| 342 |
-
</p>
|
| 343 |
-
</div>
|
| 344 |
-
</div>
|
| 345 |
-
"""
|
| 346 |
|
| 347 |
# --- Reward-rubric details ----------------------------------------------
|
| 348 |
reward_rubric_rows = "".join(
|
|
@@ -398,19 +380,20 @@ def _dashboard_html() -> str:
|
|
| 398 |
.kpi .lbl {{ color: var(--muted); font-size:0.8rem; }}
|
| 399 |
.kpi .num.good {{ color: var(--good); }}
|
| 400 |
footer {{ max-width:1200px; margin:2rem auto 0; color:var(--muted); font-size:0.85rem; }}
|
| 401 |
-
/* Training-evidence plots: one plot per row,
|
| 402 |
-
so
|
| 403 |
-
|
| 404 |
-
.plots
|
|
|
|
| 405 |
.plots figure a {{ display:block; }}
|
| 406 |
.plots img {{
|
| 407 |
width:100%; height:auto; display:block;
|
| 408 |
-
max-width:
|
| 409 |
border-radius:10px; background:#0b1225;
|
| 410 |
transition: transform 0.2s ease;
|
| 411 |
}}
|
| 412 |
.plots img:hover {{ transform: scale(1.01); }}
|
| 413 |
-
.plots figcaption {{ color: var(--muted); font-size:0.9rem; margin-top:0.
|
| 414 |
.table-wrap {{ overflow-x:auto; }}
|
| 415 |
table {{ width:100%; border-collapse: collapse; margin-top:0.5rem; font-size:0.9rem; }}
|
| 416 |
th, td {{ padding:0.5rem 0.75rem; text-align:left; border-bottom:1px solid #1f2a44; }}
|
|
@@ -418,6 +401,39 @@ def _dashboard_html() -> str:
|
|
| 418 |
td.delta {{ font-weight:600; color:#f8fafc; }}
|
| 419 |
td.delta.good {{ color: var(--good); }}
|
| 420 |
.links {{ display:flex; flex-wrap:wrap; gap:0.5rem; }}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 421 |
</style>
|
| 422 |
</head>
|
| 423 |
<body>
|
|
@@ -432,7 +448,9 @@ def _dashboard_html() -> str:
|
|
| 432 |
<div class='links'>
|
| 433 |
<a class='pill cta' href='{GITHUB_URL}' target='_blank' rel='noopener'>GitHub</a>
|
| 434 |
<a class='pill cta' href='{COLAB_URL}' target='_blank' rel='noopener'>Open in Colab</a>
|
| 435 |
-
<a class='pill' href='{
|
|
|
|
|
|
|
| 436 |
<span class='pill'>v{_CONFIG.version}</span>
|
| 437 |
<span class='pill'>task: easy / medium / hard</span>
|
| 438 |
</div>
|
|
@@ -440,6 +458,144 @@ def _dashboard_html() -> str:
|
|
| 440 |
|
| 441 |
<div class='container'>
|
| 442 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 443 |
<h2>Headline results</h2>
|
| 444 |
<div class='grid'>
|
| 445 |
<div class='card'>
|
|
@@ -585,10 +741,20 @@ def _dashboard_html() -> str:
|
|
| 585 |
</div>
|
| 586 |
|
| 587 |
<footer>
|
| 588 |
-
|
| 589 |
-
|
| 590 |
-
|
| 591 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 592 |
</footer>
|
| 593 |
|
| 594 |
<script>
|
|
|
|
| 45 |
configure_logging(level=_CONFIG.log_level, structured=_CONFIG.structured_logging)
|
| 46 |
|
| 47 |
# External URLs surfaced on the dashboard so judges can jump straight from
|
| 48 |
+
# the HF Space to the GitHub / Colab / docs / training artifacts.
|
| 49 |
GITHUB_URL = "https://github.com/SwapnilPatil28/Multi-Agent-Incident-Command-Center"
|
| 50 |
SPACE_PAGE_URL = "https://huggingface.co/spaces/SwapnilPatil28/Multi-Agent-Incident-Command-Center"
|
| 51 |
+
SPACE_APP_URL = "https://swapnilpatil28-multi-agent-incident-command-center.hf.space"
|
| 52 |
COLAB_URL = "https://colab.research.google.com/drive/1vx9E5FrZZrHoRwXs2cvtom3DaI6kZ3LP?usp=sharing"
|
| 53 |
+
# Dashboard doc links point at the Hugging Face Space copies of the docs (not
|
| 54 |
+
# GitHub) so a judge who opens the Space stays inside the HF ecosystem. The
|
| 55 |
+
# README on the Space page is rendered directly, so we point at the Space
|
| 56 |
+
# root for it; the other three open the HF file browser.
|
| 57 |
+
README_URL = SPACE_PAGE_URL
|
| 58 |
+
BLOG_POST_URL = f"{SPACE_PAGE_URL}/blob/main/docs/BLOG_POST.md"
|
| 59 |
+
VIDEO_SCRIPT_URL = f"{SPACE_PAGE_URL}/blob/main/docs/VIDEO_SCRIPT.md"
|
| 60 |
+
SUBMISSION_CHECKLIST_URL = f"{SPACE_PAGE_URL}/blob/main/docs/SUBMISSION_CHECKLIST.md"
|
| 61 |
|
| 62 |
app = create_fastapi_app(
|
| 63 |
IncidentCommandCenterEnvironment,
|
|
|
|
| 322 |
</div>
|
| 323 |
"""
|
| 324 |
|
| 325 |
+
# Theme mapping now lives in the top story block — keep this var empty
|
| 326 |
+
# so the existing `{themes_html}` slot renders to nothing (no duplication).
|
| 327 |
+
themes_html = ""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 328 |
|
| 329 |
# --- Reward-rubric details ----------------------------------------------
|
| 330 |
reward_rubric_rows = "".join(
|
|
|
|
| 380 |
.kpi .lbl {{ color: var(--muted); font-size:0.8rem; }}
|
| 381 |
.kpi .num.good {{ color: var(--good); }}
|
| 382 |
footer {{ max-width:1200px; margin:2rem auto 0; color:var(--muted); font-size:0.85rem; }}
|
| 383 |
+
/* Training-evidence plots: one plot per row, centred, with a tighter
|
| 384 |
+
max-width so the charts read as compact figures rather than banners.
|
| 385 |
+
Click the image to open the full-resolution PNG in a new tab. */
|
| 386 |
+
.plots {{ display:flex; flex-direction:column; gap:1.25rem; max-width:1200px; margin:0 auto; }}
|
| 387 |
+
.plots figure {{ background: var(--card); border:1px solid #1f2a44; border-radius: 14px; padding: 1rem 1.25rem; margin:0; }}
|
| 388 |
.plots figure a {{ display:block; }}
|
| 389 |
.plots img {{
|
| 390 |
width:100%; height:auto; display:block;
|
| 391 |
+
max-width:720px; margin:0 auto;
|
| 392 |
border-radius:10px; background:#0b1225;
|
| 393 |
transition: transform 0.2s ease;
|
| 394 |
}}
|
| 395 |
.plots img:hover {{ transform: scale(1.01); }}
|
| 396 |
+
.plots figcaption {{ color: var(--muted); font-size:0.9rem; margin-top:0.6rem; line-height:1.55; text-align:center; max-width:720px; margin-left:auto; margin-right:auto; }}
|
| 397 |
.table-wrap {{ overflow-x:auto; }}
|
| 398 |
table {{ width:100%; border-collapse: collapse; margin-top:0.5rem; font-size:0.9rem; }}
|
| 399 |
th, td {{ padding:0.5rem 0.75rem; text-align:left; border-bottom:1px solid #1f2a44; }}
|
|
|
|
| 401 |
td.delta {{ font-weight:600; color:#f8fafc; }}
|
| 402 |
td.delta.good {{ color: var(--good); }}
|
| 403 |
.links {{ display:flex; flex-wrap:wrap; gap:0.5rem; }}
|
| 404 |
+
|
| 405 |
+
/* "Story in 2 minutes" hero panel — plain-English summary for judges. */
|
| 406 |
+
.hero-card {{
|
| 407 |
+
background: linear-gradient(135deg, #0f2647 0%, #172a4a 60%, #1f2a44 100%);
|
| 408 |
+
border: 1px solid #1f2a44; border-radius: 16px;
|
| 409 |
+
padding: 1.75rem 1.75rem 1.5rem; margin: 0 auto 1.5rem;
|
| 410 |
+
max-width: 1200px; box-shadow: 0 6px 30px rgba(34,211,238,0.08);
|
| 411 |
+
}}
|
| 412 |
+
.hero-card h2 {{ font-size:1.35rem; margin:0 0 0.4rem; color:#f1f5f9; }}
|
| 413 |
+
.hero-card h3 {{ font-size:1rem; color:#e2e8f0; margin:0 0 0.3rem; }}
|
| 414 |
+
.hero-card .lede {{
|
| 415 |
+
font-size:1.02rem; line-height:1.6; color:#e2e8f0;
|
| 416 |
+
background:#0b1225; border-left: 3px solid var(--accent);
|
| 417 |
+
padding: 0.9rem 1.1rem; border-radius: 6px; margin: 0.3rem 0 0;
|
| 418 |
+
}}
|
| 419 |
+
.hero-card .lede strong {{ color:#f8fafc; }}
|
| 420 |
+
.hero-card table {{ font-size:0.92rem; }}
|
| 421 |
+
.hero-card .card {{ background: #0e1a30; }}
|
| 422 |
+
|
| 423 |
+
/* "Resources & documentation" click-through cards. */
|
| 424 |
+
.res-card {{
|
| 425 |
+
display:block; color: var(--text); text-decoration:none;
|
| 426 |
+
background: var(--card); border:1px solid #1f2a44; border-radius:12px;
|
| 427 |
+
padding: 1rem 1.1rem;
|
| 428 |
+
transition: transform 0.15s ease, border-color 0.15s ease, box-shadow 0.15s ease;
|
| 429 |
+
}}
|
| 430 |
+
.res-card:hover {{
|
| 431 |
+
border-color: var(--accent); transform: translateY(-2px);
|
| 432 |
+
box-shadow: 0 8px 24px rgba(34,211,238,0.12);
|
| 433 |
+
text-decoration:none;
|
| 434 |
+
}}
|
| 435 |
+
.res-icon {{ font-size:1.6rem; line-height:1; margin-bottom:0.5rem; }}
|
| 436 |
+
.res-title {{ font-weight:600; color:#f1f5f9; margin-bottom:0.2rem; }}
|
| 437 |
</style>
|
| 438 |
</head>
|
| 439 |
<body>
|
|
|
|
| 448 |
<div class='links'>
|
| 449 |
<a class='pill cta' href='{GITHUB_URL}' target='_blank' rel='noopener'>GitHub</a>
|
| 450 |
<a class='pill cta' href='{COLAB_URL}' target='_blank' rel='noopener'>Open in Colab</a>
|
| 451 |
+
<a class='pill cta' href='{README_URL}' target='_blank' rel='noopener'>README</a>
|
| 452 |
+
<a class='pill cta' href='{BLOG_POST_URL}' target='_blank' rel='noopener'>Blog post</a>
|
| 453 |
+
<a class='pill' href='{SPACE_PAGE_URL}' target='_blank' rel='noopener'>HF Space page</a>
|
| 454 |
<span class='pill'>v{_CONFIG.version}</span>
|
| 455 |
<span class='pill'>task: easy / medium / hard</span>
|
| 456 |
</div>
|
|
|
|
| 458 |
|
| 459 |
<div class='container'>
|
| 460 |
|
| 461 |
+
<!-- ============================================================ -->
|
| 462 |
+
<!-- PART 1 — Plain-English story for non-technical judges -->
|
| 463 |
+
<!-- ============================================================ -->
|
| 464 |
+
<div class='hero-card'>
|
| 465 |
+
<h2 style='margin-top:0'>🚨 The story in 2 minutes</h2>
|
| 466 |
+
<p class='lede'>
|
| 467 |
+
When a real tech company has an outage, <strong>three people's phones
|
| 468 |
+
buzz at once</strong> — a Triage engineer, an Investigator, and an Ops
|
| 469 |
+
Manager. They have to cooperate under a ticking <strong>SLA clock</strong>,
|
| 470 |
+
every action costs <strong>budget</strong>, and every wrong call costs
|
| 471 |
+
<strong>real money</strong> (enterprise outages hurt ~3× more than free-tier).
|
| 472 |
+
<br /><br />
|
| 473 |
+
We built a simulator of that war room — and we fine-tuned an LLM to run it
|
| 474 |
+
<strong>as well as the human expert</strong>.
|
| 475 |
+
</p>
|
| 476 |
+
|
| 477 |
+
<h3 style='margin-top:1.25rem'>What is the environment?</h3>
|
| 478 |
+
<p class='sub' style='margin:0 0 0.75rem'>
|
| 479 |
+
Three specialist agents with <strong>different permissions</strong> resolve
|
| 480 |
+
a live queue of 13 realistic tech incidents across 3 difficulty tiers.
|
| 481 |
+
</p>
|
| 482 |
+
<div class='table-wrap'>
|
| 483 |
+
<table>
|
| 484 |
+
<thead>
|
| 485 |
+
<tr><th>Role</th><th>Can do</th><th>Cannot do</th></tr>
|
| 486 |
+
</thead>
|
| 487 |
+
<tbody>
|
| 488 |
+
<tr>
|
| 489 |
+
<td>🔍 <strong>Triage</strong></td>
|
| 490 |
+
<td>Pull logs · check metrics · consult KB</td>
|
| 491 |
+
<td>Close a ticket</td>
|
| 492 |
+
</tr>
|
| 493 |
+
<tr>
|
| 494 |
+
<td>🧪 <strong>Investigator</strong></td>
|
| 495 |
+
<td>Apply a fix · roll back a deploy</td>
|
| 496 |
+
<td>Escalate or file a post-mortem</td>
|
| 497 |
+
</tr>
|
| 498 |
+
<tr>
|
| 499 |
+
<td>👷 <strong>Ops Manager</strong></td>
|
| 500 |
+
<td>Escalate · file post-mortem · <strong>close the ticket</strong></td>
|
| 501 |
+
<td>Apply a code fix</td>
|
| 502 |
+
</tr>
|
| 503 |
+
</tbody>
|
| 504 |
+
</table>
|
| 505 |
+
</div>
|
| 506 |
+
|
| 507 |
+
<h3 style='margin-top:1.25rem'>What did the agent learn?</h3>
|
| 508 |
+
<p class='sub' style='margin:0'>
|
| 509 |
+
Not "pick the right label." It learned a whole workflow — dig up clues,
|
| 510 |
+
hand off to the right specialist, apply the correct fix, respect the SLA,
|
| 511 |
+
file the post-mortem, close the ticket. The rubric makes every piece of
|
| 512 |
+
that workflow <em>visible</em> as a named reward component, so you can
|
| 513 |
+
see <em>why</em> the agent earned (or lost) points at every step.
|
| 514 |
+
</p>
|
| 515 |
+
|
| 516 |
+
<h3 style='margin-top:1.25rem'>Why it matters for the 3 hackathon themes</h3>
|
| 517 |
+
<div class='grid grid-3'>
|
| 518 |
+
<div class='card'>
|
| 519 |
+
<h3>🤝 Theme #1 — Multi-Agent</h3>
|
| 520 |
+
<p class='sub'>
|
| 521 |
+
Three distinct roles with <strong>non-overlapping permissions</strong>.
|
| 522 |
+
Wrong-actor calls → <code>-0.08</code>. Correct handoff → <code>+0.15</code>.
|
| 523 |
+
Cooperation is <em>trained</em>, not hard-coded.
|
| 524 |
+
</p>
|
| 525 |
+
</div>
|
| 526 |
+
<div class='card'>
|
| 527 |
+
<h3>⏱️ Theme #2 — Long-Horizon</h3>
|
| 528 |
+
<p class='sub'>
|
| 529 |
+
Each episode runs <strong>3–5 sequential incidents</strong> over 20–60
|
| 530 |
+
steps with a single ticking SLA clock. Big rewards (+0.80 × tier) only
|
| 531 |
+
fire after clues → fix → post-mortem. Sparse and delayed by design.
|
| 532 |
+
</p>
|
| 533 |
+
</div>
|
| 534 |
+
<div class='card'>
|
| 535 |
+
<h3>🏢 Theme #3 — Professional World-Model</h3>
|
| 536 |
+
<p class='sub'>
|
| 537 |
+
Real logs, metrics, KB articles, red-herring signals, customer tiers,
|
| 538 |
+
SLA timers, revenue impact. Close an enterprise ticket wrong and it
|
| 539 |
+
hurts ~3× what a free-tier one does.
|
| 540 |
+
</p>
|
| 541 |
+
</div>
|
| 542 |
+
</div>
|
| 543 |
+
|
| 544 |
+
<p class='sub' style='margin-top:1rem;font-style:italic'>
|
| 545 |
+
↓ Keep scrolling for the headline numbers, training plots, ablation, and
|
| 546 |
+
the full rubric. Or jump straight to the
|
| 547 |
+
<a href='{README_URL}' target='_blank' rel='noopener'>README</a> or the
|
| 548 |
+
<a href='{BLOG_POST_URL}' target='_blank' rel='noopener'>blog post</a>.
|
| 549 |
+
</p>
|
| 550 |
+
</div>
|
| 551 |
+
|
| 552 |
+
<!-- ============================================================ -->
|
| 553 |
+
<!-- Resources & documentation — every link the judges need -->
|
| 554 |
+
<!-- ============================================================ -->
|
| 555 |
+
<h2>Resources & documentation</h2>
|
| 556 |
+
<div class='grid grid-3'>
|
| 557 |
+
<a class='res-card' href='{GITHUB_URL}' target='_blank' rel='noopener'>
|
| 558 |
+
<div class='res-icon'>💻</div>
|
| 559 |
+
<div class='res-title'>GitHub repository</div>
|
| 560 |
+
<div class='sub'>Full source, tests, Dockerfile, CI-ready</div>
|
| 561 |
+
</a>
|
| 562 |
+
<a class='res-card' href='{SPACE_PAGE_URL}' target='_blank' rel='noopener'>
|
| 563 |
+
<div class='res-icon'>🤗</div>
|
| 564 |
+
<div class='res-title'>Hugging Face Space page</div>
|
| 565 |
+
<div class='sub'>Repo view, build logs, discussions</div>
|
| 566 |
+
</a>
|
| 567 |
+
<a class='res-card' href='{SPACE_APP_URL}' target='_blank' rel='noopener'>
|
| 568 |
+
<div class='res-icon'>🟢</div>
|
| 569 |
+
<div class='res-title'>Live environment</div>
|
| 570 |
+
<div class='sub'>You are here — OpenEnv endpoints live</div>
|
| 571 |
+
</a>
|
| 572 |
+
<a class='res-card' href='{COLAB_URL}' target='_blank' rel='noopener'>
|
| 573 |
+
<div class='res-icon'>🎓</div>
|
| 574 |
+
<div class='res-title'>Reproduce training (Colab T4)</div>
|
| 575 |
+
<div class='sub'>One-click notebook, ~1 h wall clock</div>
|
| 576 |
+
</a>
|
| 577 |
+
<a class='res-card' href='{README_URL}' target='_blank' rel='noopener'>
|
| 578 |
+
<div class='res-icon'>📖</div>
|
| 579 |
+
<div class='res-title'>README (Part 1 + Part 2)</div>
|
| 580 |
+
<div class='sub'>Story overview + full technical deep-dive</div>
|
| 581 |
+
</a>
|
| 582 |
+
<a class='res-card' href='{BLOG_POST_URL}' target='_blank' rel='noopener'>
|
| 583 |
+
<div class='res-icon'>📝</div>
|
| 584 |
+
<div class='res-title'>Mini blog post</div>
|
| 585 |
+
<div class='sub'>The short writeup — MD file on the HF Space + GitHub</div>
|
| 586 |
+
</a>
|
| 587 |
+
<a class='res-card' href='{VIDEO_SCRIPT_URL}' target='_blank' rel='noopener'>
|
| 588 |
+
<div class='res-icon'>🎬</div>
|
| 589 |
+
<div class='res-title'>2-minute video script</div>
|
| 590 |
+
<div class='sub'>Optional bonus — shot list + narration</div>
|
| 591 |
+
</a>
|
| 592 |
+
<a class='res-card' href='{SUBMISSION_CHECKLIST_URL}' target='_blank' rel='noopener'>
|
| 593 |
+
<div class='res-icon'>✅</div>
|
| 594 |
+
<div class='res-title'>Submission checklist</div>
|
| 595 |
+
<div class='sub'>Every judging rule → where to find the evidence</div>
|
| 596 |
+
</a>
|
| 597 |
+
</div>
|
| 598 |
+
|
| 599 |
<h2>Headline results</h2>
|
| 600 |
<div class='grid'>
|
| 601 |
<div class='card'>
|
|
|
|
| 741 |
</div>
|
| 742 |
|
| 743 |
<footer>
|
| 744 |
+
<div>
|
| 745 |
+
<strong>Incident Command Center v{_CONFIG.version}</strong> · Built on
|
| 746 |
+
<a href='https://github.com/meta-pytorch/openenv' target='_blank' rel='noopener'>OpenEnv</a>
|
| 747 |
+
for the OpenEnv India 2026 Round 2 hackathon.
|
| 748 |
+
</div>
|
| 749 |
+
<div style='margin-top:0.4rem'>
|
| 750 |
+
<a href='{GITHUB_URL}' target='_blank' rel='noopener'>GitHub</a> ·
|
| 751 |
+
<a href='{SPACE_PAGE_URL}' target='_blank' rel='noopener'>HF Space page</a> ·
|
| 752 |
+
<a href='{COLAB_URL}' target='_blank' rel='noopener'>Colab</a> ·
|
| 753 |
+
<a href='{README_URL}' target='_blank' rel='noopener'>README</a> ·
|
| 754 |
+
<a href='{BLOG_POST_URL}' target='_blank' rel='noopener'>Blog post</a> ·
|
| 755 |
+
<a href='{VIDEO_SCRIPT_URL}' target='_blank' rel='noopener'>Video script</a> ·
|
| 756 |
+
<a href='{SUBMISSION_CHECKLIST_URL}' target='_blank' rel='noopener'>Submission checklist</a>
|
| 757 |
+
</div>
|
| 758 |
</footer>
|
| 759 |
|
| 760 |
<script>
|