Spaces:
Sleeping

Sleeping
pushing for deployment
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .devcontainer/devcontainer.json +3 -0
- .env.example +1 -0
- .github/dependabot.yml +12 -0
- .gitignore +83 -0
- _pages/data_recommendation.py +109 -0
- _pages/data_selection.py +48 -0
- _pages/gallery.py +5 -0
- _pages/goal.py +77 -0
- _pages/home.py +38 -0
- _pages/my_account.py +51 -0
- _pages/report.py +4 -0
- _pages/summarization.py +78 -0
- _pages/visualization.py +117 -0
- commit_for_lfs.sh +22 -0
- failure.json +3 -0
- large_files.txt +81 -0
- lida-0.0.14.dist-info/INSTALLER +1 -0
- lida-0.0.14.dist-info/LICENSE +21 -0
- lida-0.0.14.dist-info/METADATA +288 -0
- lida-0.0.14.dist-info/RECORD +121 -0
- lida-0.0.14.dist-info/REQUESTED +0 -0
- lida-0.0.14.dist-info/WHEEL +5 -0
- lida-0.0.14.dist-info/entry_points.txt +2 -0
- lida-0.0.14.dist-info/top_level.txt +1 -0
- lida_ko/__init__.py +5 -0
- lida_ko/cli.py +47 -0
- lida_ko/components/__init__.py +7 -0
- lida_ko/components/executor.py +282 -0
- lida_ko/components/goal.py +65 -0
- lida_ko/components/infographer.py +62 -0
- lida_ko/components/manager.py +449 -0
- lida_ko/components/persona.py +52 -0
- lida_ko/components/recommender.py +118 -0
- lida_ko/components/scaffold.py +123 -0
- lida_ko/components/summarizer.py +171 -0
- lida_ko/components/viz/__init__.py +6 -0
- lida_ko/components/viz/vizeditor.py +44 -0
- lida_ko/components/viz/vizevaluator.py +58 -0
- lida_ko/components/viz/vizexplainer.py +60 -0
- lida_ko/components/viz/vizgenerator.py +40 -0
- lida_ko/components/viz/vizrecommender.py +86 -0
- lida_ko/components/viz/vizrepairer.py +43 -0
- lida_ko/datamodel.py +280 -0
- lida_ko/utils.py +227 -0
- lida_ko/version.py +1 -0
- lida_ko/web/.gitignore +142 -0
- lida_ko/web/__init__.py +5 -0
- lida_ko/web/app.py +310 -0
- memo.md +3 -0
- public_data/config.json +0 -0
.devcontainer/devcontainer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:94803b7d77a0422321a2c120ea97516f8e818d261ba4c5c36b0802e1d74f7fa1
|
| 3 |
+
size 968
|
.env.example
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
OPENAI_API_KEY=""
|
.github/dependabot.yml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# To get started with Dependabot version updates, you'll need to specify which
|
| 2 |
+
# package ecosystems to update and where the package manifests are located.
|
| 3 |
+
# Please see the documentation for more information:
|
| 4 |
+
# https://docs.github.com/github/administering-a-repository/configuration-options-for-dependency-updates
|
| 5 |
+
# https://containers.dev/guide/dependabot
|
| 6 |
+
|
| 7 |
+
version: 2
|
| 8 |
+
updates:
|
| 9 |
+
- package-ecosystem: "devcontainers"
|
| 10 |
+
directory: "/"
|
| 11 |
+
schedule:
|
| 12 |
+
interval: weekly
|
.gitignore
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Compiled source #
|
| 2 |
+
###################
|
| 3 |
+
*.com
|
| 4 |
+
*.class
|
| 5 |
+
*.dll
|
| 6 |
+
*.exe
|
| 7 |
+
*.o
|
| 8 |
+
*.so
|
| 9 |
+
|
| 10 |
+
# Packages #
|
| 11 |
+
############
|
| 12 |
+
# it's better to unpack these files and commit the raw source
|
| 13 |
+
# git has its own built in compression methods
|
| 14 |
+
*.7z
|
| 15 |
+
*.dmg
|
| 16 |
+
*.gz
|
| 17 |
+
*.iso
|
| 18 |
+
*.jar
|
| 19 |
+
*.rar
|
| 20 |
+
*.tar
|
| 21 |
+
*.zip
|
| 22 |
+
|
| 23 |
+
# Logs and databases #
|
| 24 |
+
######################
|
| 25 |
+
*.log
|
| 26 |
+
*.sql
|
| 27 |
+
*.sqlite
|
| 28 |
+
|
| 29 |
+
# OS generated files #
|
| 30 |
+
######################
|
| 31 |
+
.DS_Store
|
| 32 |
+
.DS_Store?
|
| 33 |
+
._*
|
| 34 |
+
.Spotlight-V100
|
| 35 |
+
.Trashes
|
| 36 |
+
ehthumbs.db
|
| 37 |
+
Thumbs.db
|
| 38 |
+
|
| 39 |
+
# IDE and Editor folders #
|
| 40 |
+
##########################
|
| 41 |
+
.idea/
|
| 42 |
+
.vscode/
|
| 43 |
+
*.swp
|
| 44 |
+
*.swo
|
| 45 |
+
*~
|
| 46 |
+
|
| 47 |
+
# Node.js #
|
| 48 |
+
###########
|
| 49 |
+
/node_modules/
|
| 50 |
+
/npm-debug.log
|
| 51 |
+
/yarn-error.log
|
| 52 |
+
|
| 53 |
+
# Python #
|
| 54 |
+
##########
|
| 55 |
+
__pycache__/
|
| 56 |
+
*.py[cod]
|
| 57 |
+
*.pyo
|
| 58 |
+
*.pyd
|
| 59 |
+
.Python
|
| 60 |
+
env/
|
| 61 |
+
venv/
|
| 62 |
+
pip-log.txt
|
| 63 |
+
pip-delete-this-directory.txt
|
| 64 |
+
.tox/
|
| 65 |
+
.coverage
|
| 66 |
+
.cache
|
| 67 |
+
*.egg-info/
|
| 68 |
+
.installed.cfg
|
| 69 |
+
*.egg
|
| 70 |
+
|
| 71 |
+
# Visual Studio Code #
|
| 72 |
+
######################
|
| 73 |
+
.vscode/*
|
| 74 |
+
!.vscode/settings.json
|
| 75 |
+
!.vscode/tasks.json
|
| 76 |
+
!.vscode/launch.json
|
| 77 |
+
!.vscode/extensions.json
|
| 78 |
+
|
| 79 |
+
# Others #
|
| 80 |
+
##########
|
| 81 |
+
.env
|
| 82 |
+
.secret
|
| 83 |
+
lida_ko/web/ui
|
_pages/data_recommendation.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from utils import load_datasets, get_chroma
|
| 3 |
+
from streamlit_extras.grid import grid
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from streamlit_extras.dataframe_explorer import dataframe_explorer
|
| 6 |
+
import json
|
| 7 |
+
import openai
|
| 8 |
+
|
| 9 |
+
st.title("🤖 데이터 추천 받기 from AI")
|
| 10 |
+
|
| 11 |
+
# ChromaDB 로드
|
| 12 |
+
collection = get_chroma()
|
| 13 |
+
|
| 14 |
+
# ID to metadata 딕셔너리 로드
|
| 15 |
+
with open("./data/id_to_metadata.json", "r") as f:
|
| 16 |
+
id_to_metadata = json.load(f)
|
| 17 |
+
|
| 18 |
+
# 초기 데이터프레임 로드
|
| 19 |
+
# Section 1: 데이터 추천받기
|
| 20 |
+
st.header("1️⃣ 데이터 추천받기")
|
| 21 |
+
|
| 22 |
+
# 사용자 입력 처리
|
| 23 |
+
dataframe = load_datasets()
|
| 24 |
+
with st.container():
|
| 25 |
+
prompt = st.chat_input("무엇이 궁금하신가요? 또는 어떤 데이터를 찾고 있나요?", key='1')
|
| 26 |
+
|
| 27 |
+
if prompt:
|
| 28 |
+
st.session_state.messages.append({"role": "user", "content": prompt})
|
| 29 |
+
|
| 30 |
+
# 벡터 검색 수행
|
| 31 |
+
results = collection.query(query_texts=[prompt], n_results=10)
|
| 32 |
+
result_ids = results['ids'][0]
|
| 33 |
+
result_titles = [id_to_metadata[id]['title'] for id in result_ids if id in id_to_metadata]
|
| 34 |
+
# AI 응답 생성 (OpenAI API 사용)
|
| 35 |
+
with st.chat_message("assistant"):
|
| 36 |
+
message_placeholder = st.empty()
|
| 37 |
+
full_response = ""
|
| 38 |
+
with st.spinner("AI가 답변을 준비 중입니다..."):
|
| 39 |
+
response = openai.chat.completions.create(
|
| 40 |
+
model="gpt-3.5-turbo",
|
| 41 |
+
messages=[
|
| 42 |
+
{"role": "system", "content": "You are a helpful assistant that recommends datasets based on user queries. MUST answer in KOREAN (한글)"},
|
| 43 |
+
{"role": "user", "content": f"""이 쿼리에 의해서 '{prompt}', 나 이런 데이터베이스를 추천받았어: {', '.join(result_titles)}. 이 중에서 어떤게 내 질문에 가장 잘 대답할 수 있는지 순서대로 1,2,3,4.. 이런식으로 정렬해주고, 각각의 이유도 설명해줄래?
|
| 44 |
+
만약 추천할만한 데이터가 없다고 생각한다면 절대 지어내지말고 그냥 '없어'라고 대답해줘."""},
|
| 45 |
+
],
|
| 46 |
+
stream=True
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
for chunk in response:
|
| 50 |
+
partial_response = chunk.choices[0].delta.content
|
| 51 |
+
if partial_response:
|
| 52 |
+
full_response += partial_response
|
| 53 |
+
message_placeholder.markdown(full_response + "▌")
|
| 54 |
+
message_placeholder.markdown(full_response)
|
| 55 |
+
|
| 56 |
+
st.session_state.messages.append({"role": "assistant", "content": full_response})
|
| 57 |
+
|
| 58 |
+
# 데이터프레임 필터링
|
| 59 |
+
filtered_df = dataframe[dataframe.index.isin(result_ids)]
|
| 60 |
+
else:
|
| 61 |
+
filtered_df = dataframe
|
| 62 |
+
|
| 63 |
+
# 채팅 기록 표시
|
| 64 |
+
# for message in st.session_state.messages:
|
| 65 |
+
# with st.chat_message(message["role"]):
|
| 66 |
+
# st.markdown(message["content"])
|
| 67 |
+
|
| 68 |
+
# 데이터프레임 전처리
|
| 69 |
+
filtered_df['keywords'] = filtered_df['keywords'].apply(lambda x: ', '.join(x) if isinstance(x, list) else x)
|
| 70 |
+
list_columns = [col for col in filtered_df.columns if filtered_df[col].apply(lambda x: isinstance(x, list)).all()]
|
| 71 |
+
dict_columns = [col for col in filtered_df.columns if filtered_df[col].apply(lambda x: isinstance(x, dict)).all()]
|
| 72 |
+
filtered_df = filtered_df.drop(columns=list_columns + dict_columns)
|
| 73 |
+
|
| 74 |
+
st.divider()
|
| 75 |
+
|
| 76 |
+
st.header("2️⃣ 추천 받은 데이터 중 선택하기")
|
| 77 |
+
|
| 78 |
+
# TODO : bug here!!!!!
|
| 79 |
+
if len(filtered_df) == 0:
|
| 80 |
+
st.warning("추천된 데이터가 없습니다. 다른 쿼리를 시도해주세요.")
|
| 81 |
+
st.stop()
|
| 82 |
+
selectable_dataset_list = [None] + filtered_df['title'].values.tolist()
|
| 83 |
+
|
| 84 |
+
# 데이터 선택 옵션
|
| 85 |
+
selected_dataset = st.selectbox(
|
| 86 |
+
"🔍 분석할 데이터를 선택하세요",
|
| 87 |
+
selectable_dataset_list,
|
| 88 |
+
index=selectable_dataset_list.index(st.session_state.get('selected_dataset')) if st.session_state.get('selected_dataset') in selectable_dataset_list else 0
|
| 89 |
+
)
|
| 90 |
+
st.session_state['selected_dataset'] = selected_dataset
|
| 91 |
+
|
| 92 |
+
st.divider()
|
| 93 |
+
|
| 94 |
+
# 다음 페이지로 이동
|
| 95 |
+
def switch_to_summarization():
|
| 96 |
+
st.switch_page("_pages/summarization.py")
|
| 97 |
+
|
| 98 |
+
st.header("3️⃣ 데이터 요약으로 넘어가기")
|
| 99 |
+
next_page = st.button(
|
| 100 |
+
label=f"️✅ {st.session_state.selected_dataset}으로 요약하기" if st.session_state.selected_dataset else "⛔ 데이터를 선택해야 요약을 볼 수 있습니다.",
|
| 101 |
+
use_container_width=True,
|
| 102 |
+
type="secondary",
|
| 103 |
+
disabled=st.session_state.selected_dataset is None,
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
if next_page:
|
| 107 |
+
switch_to_summarization()
|
| 108 |
+
|
| 109 |
+
st.divider()
|
_pages/data_selection.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from utils import load_datasets, save_session_cache
|
| 3 |
+
from streamlit_extras.grid import grid
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from streamlit_extras.dataframe_explorer import dataframe_explorer
|
| 6 |
+
|
| 7 |
+
st.title("💁 데이터 직접 선택하기")
|
| 8 |
+
|
| 9 |
+
# Section 1: Data Selection
|
| 10 |
+
st.header("1️⃣ 데이터 목록 필터링 하기")
|
| 11 |
+
dataframe = load_datasets()
|
| 12 |
+
|
| 13 |
+
dataframe['keywords'] = dataframe['keywords'].apply(lambda x: ', '.join(x) if isinstance(x, list) else x)
|
| 14 |
+
list_columns = [col for col in dataframe.columns if dataframe[col].apply(lambda x: isinstance(x, list)).all()]
|
| 15 |
+
dict_columns = [col for col in dataframe.columns if dataframe[col].apply(lambda x: isinstance(x, dict)).all()]
|
| 16 |
+
# list 타입의 컬럼을 드랍
|
| 17 |
+
dataframe = dataframe.drop(columns=list_columns)
|
| 18 |
+
dataframe = dataframe.drop(columns=dict_columns)
|
| 19 |
+
filtered_df = dataframe_explorer(dataframe, case=False)
|
| 20 |
+
st.dataframe(filtered_df, use_container_width=True)
|
| 21 |
+
st.divider()
|
| 22 |
+
|
| 23 |
+
st.header("2️⃣ 분석 데이터 선택하기")
|
| 24 |
+
|
| 25 |
+
selectable_dataset_list = [None] + filtered_df['title'].values.tolist()
|
| 26 |
+
|
| 27 |
+
# Select data for analysis
|
| 28 |
+
selected_dataset = st.selectbox(
|
| 29 |
+
"🔍 분석할 데이터를 선택하세요",
|
| 30 |
+
selectable_dataset_list,
|
| 31 |
+
index=selectable_dataset_list.index(st.session_state.selected_dataset) if st.session_state.selected_dataset in selectable_dataset_list else 0)
|
| 32 |
+
st.session_state['selected_dataset'] = selected_dataset
|
| 33 |
+
st.divider()
|
| 34 |
+
|
| 35 |
+
# session_id=save_session_cache(st.session_state.to_dict())
|
| 36 |
+
def switch_to_summarization():
|
| 37 |
+
st.switch_page(f"_pages/summarization.py")
|
| 38 |
+
st.header("3️⃣ 데이터 요약으로 넘어가기")
|
| 39 |
+
next_page = st.button(label=f"️✅ {st.session_state.selected_dataset}으로 요약하기" if st.session_state.selected_dataset else "⛔ 데이터를 선택해야 요약을 볼 수 있습니다.",
|
| 40 |
+
use_container_width=True,
|
| 41 |
+
type="secondary",
|
| 42 |
+
disabled=st.session_state.selected_dataset is None,
|
| 43 |
+
)
|
| 44 |
+
if next_page:
|
| 45 |
+
switch_to_summarization()
|
| 46 |
+
|
| 47 |
+
st.divider()
|
| 48 |
+
|
_pages/gallery.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.grid import grid
|
| 3 |
+
|
| 4 |
+
st.write("### 분석된 데이터와 시각화 결과")
|
| 5 |
+
|
_pages/goal.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import streamlit as st
|
| 4 |
+
from streamlit_extras.grid import grid
|
| 5 |
+
from streamlit_card import card
|
| 6 |
+
|
| 7 |
+
from lida_ko import Manager, TextGenerationConfig
|
| 8 |
+
from lida_ko.datamodel import Goal
|
| 9 |
+
|
| 10 |
+
openai_api_key = os.environ["OPENAI_API_KEY"]
|
| 11 |
+
selected_dataset = st.session_state.selected_dataset
|
| 12 |
+
selected_method = st.session_state.selected_method
|
| 13 |
+
selected_model = st.session_state.selected_model
|
| 14 |
+
use_cache = st.session_state.use_cache
|
| 15 |
+
temperature = st.session_state.temperature
|
| 16 |
+
lida_manager: Manager = st.session_state.lida_manager
|
| 17 |
+
summary = st.session_state.summary
|
| 18 |
+
num_goals = st.session_state.num_goals
|
| 19 |
+
own_goal = st.session_state.own_goal
|
| 20 |
+
|
| 21 |
+
st.title("🎯 분석 목표 설정하기")
|
| 22 |
+
st.write("")
|
| 23 |
+
st.empty()
|
| 24 |
+
|
| 25 |
+
if not summary:
|
| 26 |
+
st.error("**ERROR**: 🚨 데이터 요약을 먼저 생성해주세요.")
|
| 27 |
+
st.stop()
|
| 28 |
+
|
| 29 |
+
if summary:
|
| 30 |
+
textgen_config = TextGenerationConfig(
|
| 31 |
+
n=1,
|
| 32 |
+
temperature=temperature,
|
| 33 |
+
model=selected_model,
|
| 34 |
+
use_cache=use_cache)
|
| 35 |
+
|
| 36 |
+
# **** lida.goals *****
|
| 37 |
+
goals = lida_manager.goals(summary, n=num_goals, textgen_config=textgen_config)
|
| 38 |
+
st.write(f"## Goals ({len(goals)})")
|
| 39 |
+
|
| 40 |
+
default_goal = goals[0].question
|
| 41 |
+
goal_questions = [goal.question for goal in goals]
|
| 42 |
+
|
| 43 |
+
selected_goal = st.selectbox('Choose a generated goal', options=goal_questions, index=0)
|
| 44 |
+
selected_goal_index = goal_questions.index(selected_goal)
|
| 45 |
+
selected_goal_object = goals[selected_goal_index]
|
| 46 |
+
st.session_state.selected_goal_object = selected_goal_object
|
| 47 |
+
|
| 48 |
+
# st.markdown("### Selected Goal")
|
| 49 |
+
st.write("")
|
| 50 |
+
st.write("")
|
| 51 |
+
st.write("")
|
| 52 |
+
col1, col2, col3, = st.columns([1, 1, 1])
|
| 53 |
+
with col1:
|
| 54 |
+
st.write("### 1️⃣ 분석 목표")
|
| 55 |
+
st.write("")
|
| 56 |
+
st.write(f"- {selected_goal_object.question}")
|
| 57 |
+
with col2:
|
| 58 |
+
st.write("### 2️⃣시각화 방안")
|
| 59 |
+
st.write("")
|
| 60 |
+
st.write(f"- {selected_goal_object.visualization}")
|
| 61 |
+
with col3:
|
| 62 |
+
st.write("### 3️⃣ 인사이트")
|
| 63 |
+
st.write("")
|
| 64 |
+
st.write(f"- {selected_goal_object.rationale}")
|
| 65 |
+
|
| 66 |
+
st.divider()
|
| 67 |
+
|
| 68 |
+
st.header("✨ 시각화 만들기")
|
| 69 |
+
|
| 70 |
+
next_page = st.button(label=f"️✅ {st.session_state.selected_goal_object.visualization}으로 시각화 생성!" if st.session_state.selected_goal_object else "⛔ 목표를 선택해야 시각화를 생성할 수 있습니다.",
|
| 71 |
+
use_container_width=True,
|
| 72 |
+
type="secondary",
|
| 73 |
+
disabled=st.session_state.selected_goal_object is None,
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
if next_page:
|
| 77 |
+
st.switch_page(f"_pages/visualization.py")
|
_pages/home.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
st.title("Busan AI Data Navigator")
|
| 5 |
+
st.caption("부산 공공데이터 추천, 분석, 시각화 서비스 with 생성형 인공지능")
|
| 6 |
+
|
| 7 |
+
st.divider()
|
| 8 |
+
col1, col2 = st.columns([4,2])
|
| 9 |
+
with col1:
|
| 10 |
+
st.image(image='./static/cute_background.png', use_column_width=True)
|
| 11 |
+
with col2:
|
| 12 |
+
st.markdown("""
|
| 13 |
+
<div style="background-color: #f0f8ff; padding: 20px; border-radius: 10px; text-align: center;">
|
| 14 |
+
<h2 style="color: #0056b3; margin-bottom: 5px;">🚀 데이터의 새로운 지평을 열다</h2>
|
| 15 |
+
<h3 style="color: #FF6347; font-size: 2.5em; margin-bottom: 15px;">Busan Data Navigator</h3>
|
| 16 |
+
<p style="color: #333; font-size: 18px; margin-bottom: 40px;">
|
| 17 |
+
🧠 생성형 AI 📊 원클릭 시각화 💡 즉각적인 인사이트
|
| 18 |
+
</p>
|
| 19 |
+
<hr style="border: 0; height: 1px; background-image: linear-gradient(to right, #f0f8ff, #333, #f0f8ff); margin-bottom: 40px;">
|
| 20 |
+
<h3 style="color: #28a745; margin-bottom: 15px;">부산의 모든 데이터, 당신의 손끝에서</h3>
|
| 21 |
+
<p style="color: #333; font-size: 16px; margin-bottom: 20px;">
|
| 22 |
+
🌊 부산의 바다처럼 넓고 깊은 데이터의 세계로 빠져보세요
|
| 23 |
+
</p>
|
| 24 |
+
</div>
|
| 25 |
+
""", unsafe_allow_html=True)
|
| 26 |
+
|
| 27 |
+
st.markdown("""
|
| 28 |
+
---
|
| 29 |
+
### 🌟 Busan Data Navigator로 무엇을 할 수 있나요?
|
| 30 |
+
|
| 31 |
+
- 🔍 **손쉬운 데이터 탐색**: 부산시의 방대한 데이터를 쉽게 찾고 이해하세요.
|
| 32 |
+
- 🤖 **AI 기반 인사이트**: 생성형 AI가 당신만의 데이터 스토리를 만들어냅니다.
|
| 33 |
+
- 📈 **클릭 한 번으로 시각화**: 복잡한 코딩 없이 데이터를 아름답게 표현하세요.
|
| 34 |
+
- 🌈 **창의적 발견**: 숨겨진 패턴과 트렌드를 발견하여 혁신을 이끌어내세요.
|
| 35 |
+
- 🚀 **의사결정 가속화**: 데이터 기반의 빠르고 정확한 결정을 내리세요.
|
| 36 |
+
|
| 37 |
+
> 전문가가 아니어도 괜찮아요. 누구나 쉽게 공공데이터를 활용할 수 있어요!
|
| 38 |
+
""")
|
_pages/my_account.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.title("마이 페이지")
|
| 4 |
+
|
| 5 |
+
# User Information
|
| 6 |
+
col1, col2, col3 = st.columns(3)
|
| 7 |
+
|
| 8 |
+
with col1:
|
| 9 |
+
st.subheader("사용자 정보")
|
| 10 |
+
st.image("./static/boogi.png", caption="증명사진", width=100)
|
| 11 |
+
st.write("**성명:** 부기")
|
| 12 |
+
st.write("**소속 기관:** 부산광역시")
|
| 13 |
+
st.write("**소속 부서:** 디지털경제혁신실 시민행복팀")
|
| 14 |
+
st.write("**이메일:** boogi@korea.kr")
|
| 15 |
+
st.write("**직책:** 주무관")
|
| 16 |
+
|
| 17 |
+
with col2:
|
| 18 |
+
st.subheader("최근 활동")
|
| 19 |
+
st.write("**마지막 로그인:** 2024-06-28 10:30 AM")
|
| 20 |
+
st.write("**로그인 IP:** 192.168.1.1")
|
| 21 |
+
st.write("**프리미엄 구독 상태:** :white_check_mark: 활성")
|
| 22 |
+
st.write("**구독 만료일:** 2025-06-28")
|
| 23 |
+
|
| 24 |
+
with st.container():
|
| 25 |
+
st.write("**로그인 기록**")
|
| 26 |
+
with st.popover("**확인**"):
|
| 27 |
+
recent_logins = ["2024-06-27 09:15 AM", "2024-06-26 08:45 AM", "2024-06-25 10:00 AM", "2024-06-24 11:30 AM", "2024-06-23 09:00 AM", "2024-06-22 08:30 AM"]
|
| 28 |
+
for elem in recent_logins:
|
| 29 |
+
st.write(f"{elem}")
|
| 30 |
+
|
| 31 |
+
# Data Analysis History
|
| 32 |
+
with col3:
|
| 33 |
+
st.subheader("데이터 분석 이력")
|
| 34 |
+
st.write("**분석 내역**")
|
| 35 |
+
with st.popover("**확인**"):
|
| 36 |
+
analyzed_datasets = [
|
| 37 |
+
"부산광역시_아동급식카드 가맹점",
|
| 38 |
+
"부산광역시_종합병원 현황",
|
| 39 |
+
"부산광역시 북구_주민등록 인구통계",
|
| 40 |
+
"법정동별연료별차종별_자동차등록대수",
|
| 41 |
+
]
|
| 42 |
+
for elem in analyzed_datasets:
|
| 43 |
+
st.write(f"{elem}")
|
| 44 |
+
st.write("**시각화 내역**")
|
| 45 |
+
with st.popover("**확인**"):
|
| 46 |
+
build_visualizations = ['viz1.png', 'viz2.png', 'viz3.png', 'viz4.png']
|
| 47 |
+
build_visualizations = [f"./static/{elem}" for elem in build_visualizations]
|
| 48 |
+
for title, elem in zip(analyzed_datasets, build_visualizations):
|
| 49 |
+
st.subheader(f"{title}")
|
| 50 |
+
st.image(elem, use_column_width=True)
|
| 51 |
+
st.markdown("---")
|
_pages/report.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.write("### 데이터 선택")
|
| 4 |
+
|
_pages/summarization.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import streamlit as st
|
| 4 |
+
from lida_ko import Manager, TextGenerationConfig, llm
|
| 5 |
+
from lida_ko.datamodel import Summary
|
| 6 |
+
|
| 7 |
+
from utils import title_to_df, title_to_filename, title_to_id, id_to_metadata
|
| 8 |
+
|
| 9 |
+
openai_api_key = os.environ["OPENAI_API_KEY"]
|
| 10 |
+
selected_dataset = st.session_state.selected_dataset
|
| 11 |
+
selected_method = st.session_state.selected_method
|
| 12 |
+
selected_model = st.session_state.selected_model
|
| 13 |
+
use_cache = st.session_state.use_cache
|
| 14 |
+
temperature = st.session_state.temperature
|
| 15 |
+
lida_manager: Manager = st.session_state.lida_manager
|
| 16 |
+
|
| 17 |
+
st.title("🔎 요약 확인하기")
|
| 18 |
+
st.write("")
|
| 19 |
+
st.empty()
|
| 20 |
+
|
| 21 |
+
if not selected_dataset and selected_method:
|
| 22 |
+
st.error("**ERROR**: 🚨 대상 데이터를 먼저 선택해주세요")
|
| 23 |
+
st.stop()
|
| 24 |
+
|
| 25 |
+
if openai_api_key and selected_dataset and selected_method:
|
| 26 |
+
textgen_config = TextGenerationConfig(
|
| 27 |
+
n=1,
|
| 28 |
+
temperature=temperature,
|
| 29 |
+
model=selected_model,
|
| 30 |
+
use_cache=use_cache)
|
| 31 |
+
|
| 32 |
+
st.write("## Summary")
|
| 33 |
+
# **** lida.summarize *****
|
| 34 |
+
with st.spinner(f"{selected_dataset}에 대한 요약 생성 중..."):
|
| 35 |
+
df = title_to_df(selected_dataset)
|
| 36 |
+
filename = title_to_filename(selected_dataset)
|
| 37 |
+
metadata = id_to_metadata(title_to_id(selected_dataset))
|
| 38 |
+
selected_dataset = df
|
| 39 |
+
st.session_state.selected_dataframe = df
|
| 40 |
+
|
| 41 |
+
summary: Summary = lida_manager.summarize(
|
| 42 |
+
data=selected_dataset,
|
| 43 |
+
file_name=filename,
|
| 44 |
+
summary_method=selected_method,
|
| 45 |
+
textgen_config=textgen_config,
|
| 46 |
+
metadata=metadata)
|
| 47 |
+
st.write("### 1️⃣ 데이터 설명 및 요약")
|
| 48 |
+
if "dataset_description" in summary:
|
| 49 |
+
st.write(summary["dataset_description"])
|
| 50 |
+
st.divider()
|
| 51 |
+
|
| 52 |
+
st.write("### 2️⃣데이터 컬럼 확인")
|
| 53 |
+
if "fields" in summary:
|
| 54 |
+
fields = summary["fields"]
|
| 55 |
+
nfields = []
|
| 56 |
+
for field in fields:
|
| 57 |
+
flatted_fields = {}
|
| 58 |
+
flatted_fields["column"] = field["column"]
|
| 59 |
+
# flatted_fields["dtype"] = field["dtype"]
|
| 60 |
+
for row in field["properties"].keys():
|
| 61 |
+
if row != "samples":
|
| 62 |
+
flatted_fields[row] = field["properties"][row]
|
| 63 |
+
else:
|
| 64 |
+
flatted_fields[row] = str(field["properties"][row])
|
| 65 |
+
# flatted_fields = {**flatted_fields, **field["properties"]}
|
| 66 |
+
nfields.append(flatted_fields)
|
| 67 |
+
nfields_df = pd.DataFrame(nfields)
|
| 68 |
+
st.write(nfields_df)
|
| 69 |
+
else:
|
| 70 |
+
st.write(str(summary))
|
| 71 |
+
st.session_state.summary = summary
|
| 72 |
+
st.divider()
|
| 73 |
+
|
| 74 |
+
st.write("### 3️⃣ 데이터 원본 확인")
|
| 75 |
+
show_original_data = st.button("데이터 원본 보기", use_container_width=True)
|
| 76 |
+
if show_original_data:
|
| 77 |
+
with st.spinner("데이터 원본 로딩 중 (데이터가 많으면 오래 걸릴 수 있습니다.)"):
|
| 78 |
+
st.write(df)
|
_pages/visualization.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import streamlit as st
|
| 5 |
+
from streamlit_extras.grid import grid
|
| 6 |
+
from streamlit_card import card
|
| 7 |
+
|
| 8 |
+
from lida_ko import Manager, TextGenerationConfig
|
| 9 |
+
from lida_ko.datamodel import Goal
|
| 10 |
+
from lida_ko.utils import clean_code_snippet
|
| 11 |
+
|
| 12 |
+
openai_api_key = os.environ["OPENAI_API_KEY"]
|
| 13 |
+
selected_dataset = st.session_state.selected_dataset
|
| 14 |
+
selected_method = st.session_state.selected_method
|
| 15 |
+
selected_model = st.session_state.selected_model
|
| 16 |
+
use_cache = st.session_state.use_cache
|
| 17 |
+
temperature = st.session_state.temperature
|
| 18 |
+
lida_manager: Manager = st.session_state.lida_manager
|
| 19 |
+
summary = st.session_state.summary
|
| 20 |
+
selected_goal_object: Goal = st.session_state.selected_goal_object
|
| 21 |
+
selected_dataframe: pd.DataFrame = st.session_state.selected_dataframe
|
| 22 |
+
num_visualizations = st.session_state.num_visualizations
|
| 23 |
+
|
| 24 |
+
def generate_visualizations(code = None, feedback=None):
|
| 25 |
+
if code and feedback:
|
| 26 |
+
visualizations = lida_manager.repair(
|
| 27 |
+
code=code,
|
| 28 |
+
goal=selected_goal_object,
|
| 29 |
+
summary=summary,
|
| 30 |
+
feedback=feedback,
|
| 31 |
+
textgen_config=textgen_config,
|
| 32 |
+
library=st.session_state.selected_library
|
| 33 |
+
)
|
| 34 |
+
else:
|
| 35 |
+
visualizations = lida_manager.visualize(
|
| 36 |
+
summary=summary,
|
| 37 |
+
goal=selected_goal_object,
|
| 38 |
+
textgen_config=textgen_config,
|
| 39 |
+
library=st.session_state.selected_library)
|
| 40 |
+
return visualizations
|
| 41 |
+
|
| 42 |
+
st.title("📊 데이터 시각화 만들기")
|
| 43 |
+
st.write("")
|
| 44 |
+
st.empty()
|
| 45 |
+
|
| 46 |
+
if not selected_goal_object:
|
| 47 |
+
st.error("**ERROR**: 🚨 데이터 분석 목표를 설정해주세요.")
|
| 48 |
+
st.stop()
|
| 49 |
+
|
| 50 |
+
if selected_goal_object:
|
| 51 |
+
# Update the visualization generation call to use the selected library.
|
| 52 |
+
|
| 53 |
+
textgen_config = TextGenerationConfig(
|
| 54 |
+
n=num_visualizations, temperature=temperature,
|
| 55 |
+
model=selected_model,
|
| 56 |
+
use_cache=use_cache)
|
| 57 |
+
|
| 58 |
+
# **** lida.visualize *****
|
| 59 |
+
if not st.session_state.update_viz:
|
| 60 |
+
visualizations = generate_visualizations()
|
| 61 |
+
st.session_state.visualizations = visualizations
|
| 62 |
+
else:
|
| 63 |
+
st.session_state.update_viz = False
|
| 64 |
+
|
| 65 |
+
col1, col2, col3 = st.columns([5, 0.5, 5])
|
| 66 |
+
def render_visualization(idx, viz):
|
| 67 |
+
st.write(f'### 🌟 시각화 {idx + 1}')
|
| 68 |
+
if viz:
|
| 69 |
+
with st.spinner("인공지능이 시각화를 생성중입니다..."):
|
| 70 |
+
try:
|
| 71 |
+
if st.session_state.selected_library == "plotly":
|
| 72 |
+
data = st.session_state.selected_dataframe
|
| 73 |
+
# extract the code from the generated responses and execute it
|
| 74 |
+
temp_namespace = {
|
| 75 |
+
'data': data,
|
| 76 |
+
}
|
| 77 |
+
exec(clean_code_snippet(viz['code']), temp_namespace)
|
| 78 |
+
fig = st.plotly_chart(temp_namespace['chart'])
|
| 79 |
+
else:
|
| 80 |
+
from PIL import Image
|
| 81 |
+
import io
|
| 82 |
+
import base64
|
| 83 |
+
|
| 84 |
+
imgdata = base64.b64decode(viz.raster)
|
| 85 |
+
img = Image.open(io.BytesIO(imgdata))
|
| 86 |
+
st.image(img, caption=f"Visualization {idx + 1}", use_column_width=True)
|
| 87 |
+
except Exception as e:
|
| 88 |
+
st.error(f"Error loading visualization: {e}")
|
| 89 |
+
with st.popover("🧑💻 코드 확인하기", use_container_width=True):
|
| 90 |
+
if isinstance(viz, dict):
|
| 91 |
+
code_string = viz['code']
|
| 92 |
+
else:
|
| 93 |
+
code_string = viz.code
|
| 94 |
+
st.code(clean_code_snippet(code_string))
|
| 95 |
+
with st.popover("🗨️ 변경 요청하기", use_container_width=True):
|
| 96 |
+
chat_message = st.chat_input("(구현 중)변경하고 싶은 내용을 자연어 로 입력해주세요",key=f"chat_message_{idx}",
|
| 97 |
+
disabled=True)
|
| 98 |
+
if chat_message:
|
| 99 |
+
st.session_state.visualizations = generate_visualizations(viz['code'], chat_message)
|
| 100 |
+
st.session_state.update_viz = True
|
| 101 |
+
st.rerun()
|
| 102 |
+
render_visualization(idx, st.session_state.visualizations[idx])
|
| 103 |
+
|
| 104 |
+
return fig
|
| 105 |
+
|
| 106 |
+
with col1:
|
| 107 |
+
idx = 0
|
| 108 |
+
selected_viz = st.session_state.visualizations[idx]
|
| 109 |
+
render_visualization(idx, selected_viz)
|
| 110 |
+
|
| 111 |
+
with col2:
|
| 112 |
+
st.empty()
|
| 113 |
+
|
| 114 |
+
with col3:
|
| 115 |
+
idx = 1
|
| 116 |
+
selected_viz = visualizations[idx]
|
| 117 |
+
render_visualization(idx, selected_viz)
|
commit_for_lfs.sh
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# large_files.txt 파일이 존재하는지 확인
|
| 4 |
+
if [ ! -f large_files.txt ]; then
|
| 5 |
+
echo "Error: large_files.txt file not found!"
|
| 6 |
+
exit 1
|
| 7 |
+
fi
|
| 8 |
+
|
| 9 |
+
# large_files.txt 파일의 각 줄을 읽어서 처리
|
| 10 |
+
while IFS= read -r file; do
|
| 11 |
+
# 파일이 존재하는지 확인
|
| 12 |
+
if [ -f "$file" ]; then
|
| 13 |
+
echo "Processing $file"
|
| 14 |
+
git rm --cached "$file"
|
| 15 |
+
git add "$file"
|
| 16 |
+
else
|
| 17 |
+
echo "Warning: $file not found!"
|
| 18 |
+
fi
|
| 19 |
+
done < large_files.txt
|
| 20 |
+
|
| 21 |
+
# 변경 사항 커밋
|
| 22 |
+
git commit -m "Move large files to Git LFS"
|
failure.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a44280b73d46fd1d9963549c1dc166719206a38822744ba34c8d057fda160f81
|
| 3 |
+
size 30048
|
large_files.txt
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
./lida_ko/web/ui/component---src-pages-demo-tsx-54fd6da10fa870d8d843.js.map
|
| 2 |
+
./data/chroma_db/chroma.sqlite3
|
| 3 |
+
./data/id_to_metadata_col.json
|
| 4 |
+
./data/id_to_metadata_col_aug.json
|
| 5 |
+
./_csv_data/부산광역시해운대구_재정정보공개시스템_세입자료수납내역표_20240115.JSON
|
| 6 |
+
./_csv_data/부산광역시_도시공간정보시스템도로(그리드면)_20240524.JSON
|
| 7 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_계량기정보_20240106.JSON
|
| 8 |
+
./_csv_data/부산광역시_교통시설물관리시스템_교통안전시설물정보(안전표지정보)_20220630.JSON
|
| 9 |
+
./_csv_data/부산광역시_연제구_자료관도서목록_20200916.JSON
|
| 10 |
+
./_csv_data/부산광역시_도로명주소정보_20240415.CSV
|
| 11 |
+
./_csv_data/부산광역시영도구_영도도서관장서현황_20230816.CSV
|
| 12 |
+
./_csv_data/부산광역시해운대구_재정정보공개시스템_세부사업별예산현액및지출액_20230113.JSON
|
| 13 |
+
./_csv_data/부산시설공단_영락공원묘지사용현황_20201118.JSON
|
| 14 |
+
./_csv_data/부산광역시연제구_자료관도서목록_20240414.JSON
|
| 15 |
+
./_csv_data/부산교통공사_시간대별승하차인원_20231231.JSON
|
| 16 |
+
./_csv_data/부산시설공단_영락공원묘지사용현황_20230125.JSON
|
| 17 |
+
./_csv_data/부산광역시_지능형교통정보_RSE정보_20240430.JSON
|
| 18 |
+
./_csv_data/부산광역시_부산도시공간정보시스템_도로상하수도기반시설물_하수맨홀_20231013.JSON
|
| 19 |
+
./_csv_data/부산관광공사_부산관광기업지원센터홈페이지메타데이터개방_20230818.JSON
|
| 20 |
+
./_csv_data/부산광역시_지능형교통정보_구간DSRC정보_20240430.CSV
|
| 21 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_계량기정보_20230126.JSON
|
| 22 |
+
./_csv_data/부산광역시_버스노선별승하차정보_20230731.JSON
|
| 23 |
+
./_csv_data/부산광역시사하구_불법주정차단속현황_20231130.JSON
|
| 24 |
+
./_csv_data/부산광역시_열섬관측지점정보_20240430.JSON
|
| 25 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_수납정보_당월및체납수납처리정보_20240510.CSV
|
| 26 |
+
./_csv_data/부산도시철도시간대별승하차현황_20161231.JSON
|
| 27 |
+
./_csv_data/부산광역시_한국도로공사연계특별상황발생관리_20230828.JSON
|
| 28 |
+
./_csv_data/부산광역시_지능형교통정보_구간DSRC정보_20240430.JSON
|
| 29 |
+
./_csv_data/부산광역시_굴착사업예정지별규모정보_20230812.JSON
|
| 30 |
+
./_csv_data/부산광역시_지역화폐(동백전)가맹점현황_20240305.JSON
|
| 31 |
+
./_csv_data/부산광역시_제로페이가맹점현황_20230630.JSON
|
| 32 |
+
./_csv_data/부산광역시_도시공간정보시스템기초구역및새주소_20220627.JSON
|
| 33 |
+
./_csv_data/부산교통공사_시간대별승하차인원_20221231.JSON
|
| 34 |
+
./_csv_data/부산광역시부산진구_불법주정차단속현황_20240325.JSON
|
| 35 |
+
./_csv_data/부산교통공사_시간대별승하차인원_20201231.JSON
|
| 36 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_세입집계정보_세입일집계_20240106.CSV
|
| 37 |
+
./_csv_data/부산광역시_동래구_지적정보_20240213.JSON
|
| 38 |
+
./_csv_data/부산광역시사상구_일반건축물시가표준액_20211231.CSV
|
| 39 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_간단e납부시스템연계자료_일반수납내역분배자료_20240106.CSV
|
| 40 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_계량기정보_계량기변경이력정보_20220131.JSON
|
| 41 |
+
./_csv_data/부산광역시_지능형교통정보_RSE정보_20240430.CSV
|
| 42 |
+
./_csv_data/부산광역시_대기질진단평가대기질측정소기상정보_20230825.JSON
|
| 43 |
+
./_csv_data/부산시설공단_영락공원봉안사용현황_20240125.JSON
|
| 44 |
+
./_csv_data/부산광역시_부산도시공간정보시스템_도로상하수도기반시설물_부과정보_20231017.JSON
|
| 45 |
+
./_csv_data/부산광역시_해운대구_재정정보공개시스템_세입자료_20231213.JSON
|
| 46 |
+
./_csv_data/부산광역시_도로명주소정보_20240415.JSON
|
| 47 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_요금계산관련정보_감액관리대장_20240106.JSON
|
| 48 |
+
./_csv_data/부산도시철도시간대별승하차현황_20191231.JSON
|
| 49 |
+
./_csv_data/부산교통공사_시간대별승하차인원_20211231.JSON
|
| 50 |
+
./_csv_data/부산광역시_지능형교통정보구간레벨패턴정보_20240531.CSV
|
| 51 |
+
./_csv_data/부산광역시_교통시설물관리시스템_교통안전시설물정보(차선정보)_20220630.JSON
|
| 52 |
+
./_csv_data/부산광역시사상구_일반건축물시가표준액_20211231.JSON
|
| 53 |
+
./_csv_data/부산광역시_연제구_자료관도서목록_20200916.CSV
|
| 54 |
+
./_csv_data/부산시설공단_영락공원묘지사용현황_20240125.JSON
|
| 55 |
+
./_csv_data/부산광역시_한국도로공사연계특별상황발생관리_20230828.CSV
|
| 56 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_요금계산관련정보_감액관리대장_20230126.JSON
|
| 57 |
+
./_csv_data/부산광역시_아동급식카드가맹점_20240320.JSON
|
| 58 |
+
./_csv_data/부산시설공단_영락공원묘지사용현황_20220125.JSON
|
| 59 |
+
./_csv_data/��산시설공단_영락공원봉안사용현황_20201022.JSON
|
| 60 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_수납정보_과오수납처리정보_20230126.JSON
|
| 61 |
+
./_csv_data/부산광역시_강서구_불법주정차문자알림서비스_단속정보관리_20240517.JSON
|
| 62 |
+
./_csv_data/부산광역시상수도사업본부_수용가정보시스템_수납정보_과오수납처리정보_20240106.JSON
|
| 63 |
+
./_csv_data/부산도시철도시간대별승하차현황_20141231.JSON
|
| 64 |
+
./_csv_data/부산광역시_도시공간정보시스템_도로(건축물)정보_20230717.JSON
|
| 65 |
+
./_csv_data/부산교통공사_시간대별승하차인원_20181231.JSON
|
| 66 |
+
./_csv_data/부산광역시_부산광역시_도시공간정보시스템_도로관리(가로수)_20230717.CSV
|
| 67 |
+
./_csv_data/부산광역시부산진구_일반건축물시가표준액_20221003.JSON
|
| 68 |
+
./_csv_data/부산광역시_동래구_지적정보_20230210.JSON
|
| 69 |
+
./_csv_data/부산광역시_제로페이가맹점현황_20230630.CSV
|
| 70 |
+
./_csv_data/부산광역시_도시공간정보시스템_도로(건축물)정보_20230717.CSV
|
| 71 |
+
./_csv_data/부산시설공단_영락공원봉안사용현황_20220125.JSON
|
| 72 |
+
./_csv_data/부산교통공사_시간대별승하차인원_20240430.JSON
|
| 73 |
+
./_csv_data/부산광역시연제구_자료관도서목록_20240414.CSV
|
| 74 |
+
./_csv_data/부산광역시_열섬관측지점정보_20240331.CSV
|
| 75 |
+
./_csv_data/부산광역시_지능형교통정보구간레벨패턴정보_20240531.JSON
|
| 76 |
+
./_csv_data/부산광역시_지역화폐(동백전)가맹점현황_20240305.CSV
|
| 77 |
+
./_csv_data/부산도시철도시간대별승하차현황_20151231.JSON
|
| 78 |
+
./_csv_data/부산광역시영도구_영도도서관장서현황_20230816.JSON
|
| 79 |
+
./_csv_data/부산시설공단_영락공원봉안사용현황_20230125.JSON
|
| 80 |
+
./_csv_data/부산광역시_한국도로공사연계고속도로정보_20230828.JSON
|
| 81 |
+
./_csv_data/부산광역시_열섬관측지점정보_20240430.CSV
|
lida-0.0.14.dist-info/INSTALLER
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
pip
|
lida-0.0.14.dist-info/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Microsoft Corporation.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE
|
lida-0.0.14.dist-info/METADATA
ADDED
|
@@ -0,0 +1,288 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.1
|
| 2 |
+
Name: lida
|
| 3 |
+
Version: 0.0.14
|
| 4 |
+
Summary: LIDA: Automatic Generation of Visualizations from Data
|
| 5 |
+
Author-email: Victor Dibia <victordibia@microsoft.com>
|
| 6 |
+
License: MIT License
|
| 7 |
+
|
| 8 |
+
Copyright (c) Microsoft Corporation.
|
| 9 |
+
|
| 10 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 11 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 12 |
+
in the Software without restriction, including without limitation the rights
|
| 13 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 14 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 15 |
+
furnished to do so, subject to the following conditions:
|
| 16 |
+
|
| 17 |
+
The above copyright notice and this permission notice shall be included in all
|
| 18 |
+
copies or substantial portions of the Software.
|
| 19 |
+
|
| 20 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 21 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 22 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 23 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 24 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 25 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 26 |
+
SOFTWARE
|
| 27 |
+
|
| 28 |
+
Project-URL: Homepage, https://github.com/microsoft/lida
|
| 29 |
+
Project-URL: Bug Tracker, https://github.com/microsoft/lida/issues
|
| 30 |
+
Classifier: Programming Language :: Python :: 3
|
| 31 |
+
Classifier: License :: OSI Approved :: MIT License
|
| 32 |
+
Classifier: Operating System :: OS Independent
|
| 33 |
+
Requires-Python: >=3.9
|
| 34 |
+
Description-Content-Type: text/markdown
|
| 35 |
+
License-File: LICENSE
|
| 36 |
+
Requires-Dist: llmx >=0.0.21a
|
| 37 |
+
Requires-Dist: pydantic
|
| 38 |
+
Requires-Dist: uvicorn
|
| 39 |
+
Requires-Dist: typer
|
| 40 |
+
Requires-Dist: fastapi
|
| 41 |
+
Requires-Dist: python-multipart
|
| 42 |
+
Requires-Dist: scipy
|
| 43 |
+
Requires-Dist: numpy
|
| 44 |
+
Requires-Dist: pandas
|
| 45 |
+
Requires-Dist: matplotlib
|
| 46 |
+
Requires-Dist: altair
|
| 47 |
+
Requires-Dist: seaborn
|
| 48 |
+
Requires-Dist: plotly
|
| 49 |
+
Requires-Dist: plotnine
|
| 50 |
+
Requires-Dist: statsmodels
|
| 51 |
+
Requires-Dist: networkx
|
| 52 |
+
Requires-Dist: geopandas
|
| 53 |
+
Requires-Dist: matplotlib-venn
|
| 54 |
+
Requires-Dist: wordcloud
|
| 55 |
+
Requires-Dist: kaleido !=0.2.1.post1,>=0.2.1
|
| 56 |
+
Provides-Extra: infographics
|
| 57 |
+
Requires-Dist: peacasso ; extra == 'infographics'
|
| 58 |
+
Provides-Extra: tools
|
| 59 |
+
Requires-Dist: geopy ; extra == 'tools'
|
| 60 |
+
Requires-Dist: basemap ; extra == 'tools'
|
| 61 |
+
Requires-Dist: basemap-data-hires ; extra == 'tools'
|
| 62 |
+
Provides-Extra: transformers
|
| 63 |
+
Requires-Dist: llmx[transformers] ; extra == 'transformers'
|
| 64 |
+
Provides-Extra: web
|
| 65 |
+
Requires-Dist: fastapi ; extra == 'web'
|
| 66 |
+
Requires-Dist: uvicorn ; extra == 'web'
|
| 67 |
+
|
| 68 |
+
# LIDA: Automatic Generation of Visualizations and Infographics using Large Language Models
|
| 69 |
+
|
| 70 |
+
[](https://badge.fury.io/py/lida)
|
| 71 |
+
[](https://arxiv.org/abs/2303.02927)
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
<a target="_blank" href="https://colab.research.google.com/github/microsoft/lida/blob/main/notebooks/tutorial.ipynb">
|
| 75 |
+
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
|
| 76 |
+
</a>
|
| 77 |
+
|
| 78 |
+
<!-- <img src="docs/images/lidascreen.png" width="100%" /> -->
|
| 79 |
+
|
| 80 |
+
LIDA is a library for generating data visualizations and data-faithful infographics. LIDA is grammar agnostic (will work with any programming language and visualization libraries e.g. matplotlib, seaborn, altair, d3 etc) and works with multiple large language model providers (OpenAI, Azure OpenAI, PaLM, Cohere, Huggingface). Details on the components of LIDA are described in the [paper here](https://arxiv.org/abs/2303.02927) and in this tutorial [notebook](notebooks/tutorial.ipynb). See the project page [here](https://microsoft.github.io/lida/) for updates!.
|
| 81 |
+
|
| 82 |
+
> **Note on Code Execution:**
|
| 83 |
+
> To create visualizations, LIDA _generates_ and _executes_ code.
|
| 84 |
+
> Ensure that you run LIDA in a secure environment.
|
| 85 |
+
|
| 86 |
+
## Features
|
| 87 |
+
|
| 88 |
+
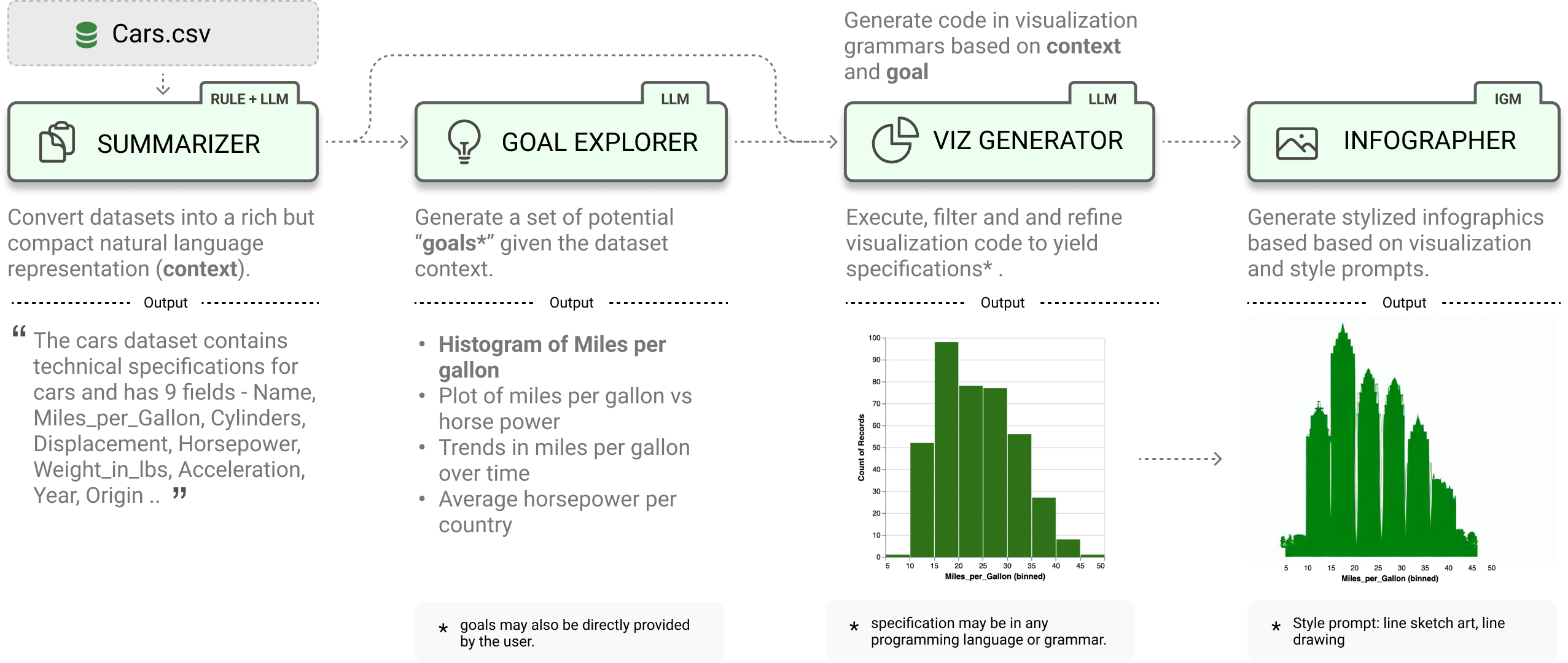
|
| 89 |
+
|
| 90 |
+
LIDA treats _**visualizations as code**_ and provides a clean api for generating, executing, editing, explaining, evaluating and repairing visualization code.
|
| 91 |
+
|
| 92 |
+
- [x] Data Summarization
|
| 93 |
+
- [x] Goal Generation
|
| 94 |
+
- [x] Visualization Generation
|
| 95 |
+
- [x] Visualization Editing
|
| 96 |
+
- [x] Visualization Explanation
|
| 97 |
+
- [x] Visualization Evaluation and Repair
|
| 98 |
+
- [x] Visualization Recommendation
|
| 99 |
+
- [x] Infographic Generation (beta) # pip install lida[infographics]
|
| 100 |
+
|
| 101 |
+
```python
|
| 102 |
+
|
| 103 |
+
from lida import Manager, llm
|
| 104 |
+
|
| 105 |
+
lida = Manager(text_gen = llm("openai")) # palm, cohere ..
|
| 106 |
+
summary = lida.summarize("data/cars.csv")
|
| 107 |
+
goals = lida.goals(summary, n=2) # exploratory data analysis
|
| 108 |
+
charts = lida.visualize(summary=summary, goal=goals[0]) # exploratory data analysis
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
## Getting Started
|
| 112 |
+
|
| 113 |
+
Setup and verify that your python environment is **`python 3.10`** or higher (preferably, use [Conda](https://docs.conda.io/en/main/miniconda.html#installing)). Install the library via pip.
|
| 114 |
+
|
| 115 |
+
```bash
|
| 116 |
+
pip install lida
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
Once requirements are met, setup your api key. Learn more about setting up keys for other LLM providers [here](https://github.com/victordibia/llmx).
|
| 120 |
+
|
| 121 |
+
```bash
|
| 122 |
+
export OPENAI_API_KEY=<your key>
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
Alternatively you can install the library in dev model by cloning this repo and running `pip install -e .` in the repository root.
|
| 126 |
+
|
| 127 |
+
## Web API and UI
|
| 128 |
+
|
| 129 |
+
LIDA comes with an optional bundled ui and web api that you can explore by running the following command:
|
| 130 |
+
|
| 131 |
+
```bash
|
| 132 |
+
lida ui --port=8080 --docs
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
Then navigate to http://localhost:8080/ in your browser. To view the web api specification, add the `--docs` option to the cli command, and navigate to `http://localhost:8080/api/docs` in your browser.
|
| 136 |
+
|
| 137 |
+
The fastest and recommended way to get started after installation will be to try out the web ui above or run the [tutorial notebook](notebooks/tutorial.ipynb).
|
| 138 |
+
|
| 139 |
+
## Building the Web API and UI with Docker
|
| 140 |
+
|
| 141 |
+
The LIDA web api and ui can be setup using docker and the command below (ensure that you have docker installed, and you have set your `OPENAI_API_KEY` environment variable).
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
docker compose up
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
### Data Summarization
|
| 148 |
+
|
| 149 |
+
Given a dataset, generate a compact summary of the data.
|
| 150 |
+
|
| 151 |
+
```python
|
| 152 |
+
from lida import Manager
|
| 153 |
+
|
| 154 |
+
lida = Manager()
|
| 155 |
+
summary = lida.summarize("data/cars.json") # generate data summary
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
### Goal Generation
|
| 159 |
+
|
| 160 |
+
Generate a set of visualization goals given a data summary.
|
| 161 |
+
|
| 162 |
+
```python
|
| 163 |
+
goals = lida.goals(summary, n=5, persona="ceo with aerodynamics background") # generate goals
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
Add a `persona` parameter to generate goals based on that persona.
|
| 167 |
+
|
| 168 |
+
### Visualization Generation
|
| 169 |
+
|
| 170 |
+
Generate, refine, execute and filter visualization code given a data summary and visualization goal. Note that LIDA represents **visualizations as code**.
|
| 171 |
+
|
| 172 |
+
```python
|
| 173 |
+
# generate charts (generate and execute visualization code)
|
| 174 |
+
charts = lida.visualize(summary=summary, goal=goals[0], library="matplotlib") # seaborn, ggplot ..
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
### Visualization Editing
|
| 178 |
+
|
| 179 |
+
Given a visualization, edit the visualization using natural language.
|
| 180 |
+
|
| 181 |
+
```python
|
| 182 |
+
# modify chart using natural language
|
| 183 |
+
instructions = ["convert this to a bar chart", "change the color to red", "change y axes label to Fuel Efficiency", "translate the title to french"]
|
| 184 |
+
edited_charts = lida.edit(code=code, summary=summary, instructions=instructions, library=library, textgen_config=textgen_config)
|
| 185 |
+
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
### Visualization Explanation
|
| 189 |
+
|
| 190 |
+
Given a visualization, generate a natural language explanation of the visualization code (accessibility, data transformations applied, visualization code)
|
| 191 |
+
|
| 192 |
+
```python
|
| 193 |
+
# generate explanation for chart
|
| 194 |
+
explanation = lida.explain(code=charts[0].code, summary=summary)
|
| 195 |
+
```
|
| 196 |
+
|
| 197 |
+
### Visualization Evaluation and Repair
|
| 198 |
+
|
| 199 |
+
Given a visualization, evaluate to find repair instructions (which may be human authored, or generated), repair the visualization.
|
| 200 |
+
|
| 201 |
+
```python
|
| 202 |
+
evaluations = lida.evaluate(code=code, goal=goals[i], library=library)
|
| 203 |
+
```
|
| 204 |
+
|
| 205 |
+
### Visualization Recommendation
|
| 206 |
+
|
| 207 |
+
Given a dataset, generate a set of recommended visualizations.
|
| 208 |
+
|
| 209 |
+
```python
|
| 210 |
+
recommendations = lida.recommend(code=code, summary=summary, n=2, textgen_config=textgen_config)
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
### Infographic Generation [WIP]
|
| 214 |
+
|
| 215 |
+
Given a visualization, generate a data-faithful infographic. This methods should be considered experimental, and uses stable diffusion models from the [peacasso](https://github.com/victordibia/peacasso) library. You will need to run `pip install lida[infographics]` to install the required dependencies.
|
| 216 |
+
|
| 217 |
+
```python
|
| 218 |
+
infographics = lida.infographics(visualization = charts[0].raster, n=3, style_prompt="line art")
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
## Using LIDA with Locally Hosted LLMs (HuggingFace)
|
| 222 |
+
|
| 223 |
+
LIDA uses the [llmx](https://github.com/victordibia/llmx) library as its interface for text generation. llmx supports multiple local models including HuggingFace models. You can use the huggingface models directly (assuming you have a gpu) or connect to an openai compatible local model endpoint e.g. using the excellent [vllm](https://vllm.readthedocs.io/en/latest/) library.
|
| 224 |
+
|
| 225 |
+
#### Using HuggingFace Models Directly
|
| 226 |
+
|
| 227 |
+
```python
|
| 228 |
+
!pip3 install --upgrade llmx==0.0.17a0
|
| 229 |
+
|
| 230 |
+
# Restart the colab session
|
| 231 |
+
|
| 232 |
+
from lida import Manager
|
| 233 |
+
from llmx import llm
|
| 234 |
+
text_gen = llm(provider="hf", model="uukuguy/speechless-llama2-hermes-orca-platypus-13b", device_map="auto")
|
| 235 |
+
lida = Manager(text_gen=text_gen)
|
| 236 |
+
# now you can call lida methods as above e.g.
|
| 237 |
+
sumamry = lida.summarize("data/cars.csv") # ....
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
#### Using an OpenAI Compatible Endpoint e.g. [vllm server](https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html#openai-compatible-server)
|
| 241 |
+
|
| 242 |
+
```python
|
| 243 |
+
from lida import Manager, TextGenerationConfig , llm
|
| 244 |
+
|
| 245 |
+
model_name = "uukuguy/speechless-llama2-hermes-orca-platypus-13b"
|
| 246 |
+
model_details = [{'name': model_name, 'max_tokens': 2596, 'model': {'provider': 'openai', 'parameters': {'model': model_name}}}]
|
| 247 |
+
|
| 248 |
+
# assuming your vllm endpoint is running on localhost:8000
|
| 249 |
+
text_gen = llm(provider="openai", api_base="http://localhost:8000/v1", api_key="EMPTY", models=model_details)
|
| 250 |
+
lida = Manager(text_gen = text_gen)
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
## Important Notes / Caveats / FAQs
|
| 254 |
+
|
| 255 |
+
- LIDA generates and executes code based on provided input. Ensure that you run LIDA in a secure environment with appropriate permissions.
|
| 256 |
+
- LIDA currently works best with datasets that have a small number of columns (<= 10). This is mainly due to the limited context size for most models. For larger datasets, consider preprocessing your dataset to use a subset of the columns.
|
| 257 |
+
- LIDA assumes the dataset exists and is in a format that can be loaded into a pandas dataframe. For example, a csv file, or a json file with a list of objects. In practices the right dataset may need to be curated and preprocessed to ensure that it is suitable for the task at hand.
|
| 258 |
+
- Smaller LLMs (e.g., OSS LLMs on Huggingface) have limited instruction following capabilities and may not work well with LIDA. LIDA works best with larger LLMs (e.g., OpenAI GPT 3.5, GPT 4).
|
| 259 |
+
- How reliable is the LIDA approach? The LIDA [paper](https://aclanthology.org/2023.acl-demo.11/) describes experiments that evaluate the reliability of LIDA using a visualization error rate metric. With the current version of prompts, data summarization techniques, preprocessing/postprocessing logic and LLMs, LIDA has an error rate of < 3.5% on over 2200 visualizations generated (compared to a baseline of over 10% error rate). This area is work in progress.
|
| 260 |
+
- Can I build my own apps with LIDA? Yes! You can either use the python api directly in your app or setup a web api endpoint and use the web api in your app. See the [web api](#web-api-and-ui) section for more details.
|
| 261 |
+
- How is LIDA related to OpenAI Code Interpreter: LIDA shares several similarities with code interpreter in the sense that both involve writing and executing code to address user intent. LIDA differs in its focus on visualization, providing a modular api for developer reuse and providing evaluation metrics on the visualization use case.
|
| 262 |
+
|
| 263 |
+
Naturally, some of the limitations above could be addressed by a much welcomed PR.
|
| 264 |
+
|
| 265 |
+
## Community Examples Built with LIDA
|
| 266 |
+
|
| 267 |
+
- LIDA + Streamlit: [lida-streamlit](https://github.com/lida-project/lida-streamlit),
|
| 268 |
+
|
| 269 |
+
## Documentation and Citation
|
| 270 |
+
|
| 271 |
+
A short paper describing LIDA (Accepted at ACL 2023 Conference) is available [here](https://arxiv.org/abs/2303.02927).
|
| 272 |
+
|
| 273 |
+
```bibtex
|
| 274 |
+
@inproceedings{dibia2023lida,
|
| 275 |
+
title = "{LIDA}: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models",
|
| 276 |
+
author = "Dibia, Victor",
|
| 277 |
+
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations)",
|
| 278 |
+
month = jul,
|
| 279 |
+
year = "2023",
|
| 280 |
+
address = "Toronto, Canada",
|
| 281 |
+
publisher = "Association for Computational Linguistics",
|
| 282 |
+
url = "https://aclanthology.org/2023.acl-demo.11",
|
| 283 |
+
doi = "10.18653/v1/2023.acl-demo.11",
|
| 284 |
+
pages = "113--126",
|
| 285 |
+
}
|
| 286 |
+
```
|
| 287 |
+
|
| 288 |
+
LIDA builds on insights in automatic generation of visualization from an earlier paper - [Data2Vis: Automatic Generation of Data Visualizations Using Sequence to Sequence Recurrent Neural Networks](https://arxiv.org/abs/1804.03126).
|
lida-0.0.14.dist-info/RECORD
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
../../../bin/lida,sha256=aNl2RQh-pBOgkJImOISZsOhtYHbW6PVS6yOqxzgGO5o,210
|
| 2 |
+
lida-0.0.14.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
| 3 |
+
lida-0.0.14.dist-info/LICENSE,sha256=ws_MuBL-SCEBqPBFl9_FqZkaaydIJmxHrJG2parhU4M,1141
|
| 4 |
+
lida-0.0.14.dist-info/METADATA,sha256=IAPteJfo0fZNZ2mpdZP39YNHxoR2pPT1gVPlJ5qd2Q8,13393
|
| 5 |
+
lida-0.0.14.dist-info/RECORD,,
|
| 6 |
+
lida-0.0.14.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
| 7 |
+
lida-0.0.14.dist-info/WHEEL,sha256=oiQVh_5PnQM0E3gPdiz09WCNmwiHDMaGer_elqB3coM,92
|
| 8 |
+
lida-0.0.14.dist-info/entry_points.txt,sha256=MEt9wqeDV8qbUj6Os23WEuAdal3m1iT5MEq5eDONYKE,38
|
| 9 |
+
lida-0.0.14.dist-info/top_level.txt,sha256=I2cAWyFnAsrpZXthVWLiW313NQFig1tbewqtUHTeOQc,5
|
| 10 |
+
lida/__init__.py,sha256=EZhgVFF1Gq8fl5l45uNpLwWduFy382T8PI6StlsJwFw,170
|
| 11 |
+
lida/__pycache__/__init__.cpython-312.pyc,,
|
| 12 |
+
lida/__pycache__/cli.cpython-312.pyc,,
|
| 13 |
+
lida/__pycache__/datamodel.cpython-312.pyc,,
|
| 14 |
+
lida/__pycache__/utils.cpython-312.pyc,,
|
| 15 |
+
lida/__pycache__/version.cpython-312.pyc,,
|
| 16 |
+
lida/cli.py,sha256=lDK4B4IarXpXzqr3fqZmF8oxVayV0iUgGr8ja6QPHXc,976
|
| 17 |
+
lida/components/__init__.py,sha256=8TmnzYd8y9hWMk636q_Nh7FKGTKWugxxy6xT9NTPUnk,168
|
| 18 |
+
lida/components/__pycache__/__init__.cpython-312.pyc,,
|
| 19 |
+
lida/components/__pycache__/executor.cpython-312.pyc,,
|
| 20 |
+
lida/components/__pycache__/goal.cpython-312.pyc,,
|
| 21 |
+
lida/components/__pycache__/infographer.cpython-312.pyc,,
|
| 22 |
+
lida/components/__pycache__/manager.cpython-312.pyc,,
|
| 23 |
+
lida/components/__pycache__/persona.cpython-312.pyc,,
|
| 24 |
+
lida/components/__pycache__/scaffold.cpython-312.pyc,,
|
| 25 |
+
lida/components/__pycache__/summarizer.cpython-312.pyc,,
|
| 26 |
+
lida/components/executor.py,sha256=D89sad5eGPYiA5bgXna7qab16_TwmHf-pbZLZYvzD_Y,10741
|
| 27 |
+
lida/components/goal.py,sha256=clxYLLhnvD52OWYP86GGW3JlnTIDzt-0AwX13BiLW7w,3272
|
| 28 |
+
lida/components/infographer.py,sha256=66N9V_wKO_BFy5tqKmx-zThDwyARx2NmQ4Ffl_QhV-0,2201
|
| 29 |
+
lida/components/manager.py,sha256=zMZp9dE8PXDI0kwB0r5Lo9AEgJBHW2Ql93gtjk_ZM7w,13710
|
| 30 |
+
lida/components/persona.py,sha256=9R0qG84UaaTyN77mYd_Tu5JRviEJcmeo0XlFOxRRuQw,2299
|
| 31 |
+
lida/components/scaffold.py,sha256=DK-a6O9sjRHXVofyOSOzkAyTucVESxIwq4YrJDih2Xg,5090
|
| 32 |
+
lida/components/summarizer.py,sha256=JZMFjgwxfJmre_0ZndEV-ffev9yScsd7vZO6DWRFpwM,6819
|
| 33 |
+
lida/components/viz/__init__.py,sha256=9N76qTPXTP3rC4YEfZBYlRnyHCWmMiD3e5k4lKyLWcU,166
|
| 34 |
+
lida/components/viz/__pycache__/__init__.cpython-312.pyc,,
|
| 35 |
+
lida/components/viz/__pycache__/vizeditor.cpython-312.pyc,,
|
| 36 |
+
lida/components/viz/__pycache__/vizevaluator.cpython-312.pyc,,
|
| 37 |
+
lida/components/viz/__pycache__/vizexplainer.cpython-312.pyc,,
|
| 38 |
+
lida/components/viz/__pycache__/vizgenerator.cpython-312.pyc,,
|
| 39 |
+
lida/components/viz/__pycache__/vizrecommender.cpython-312.pyc,,
|
| 40 |
+
lida/components/viz/__pycache__/vizrepairer.cpython-312.pyc,,
|
| 41 |
+
lida/components/viz/vizeditor.py,sha256=YmtmMT-GG9h9-OATkJD9y6vsCpuHtSPotn-qCSiAZ8I,2246
|
| 42 |
+
lida/components/viz/vizevaluator.py,sha256=hcWYD4iCw2JPe5uPXhuim1MZgqp6UXptlOmiUEQCaHM,3632
|
| 43 |
+
lida/components/viz/vizexplainer.py,sha256=FNjJds68yfaosSoxzOTyFw_GQzZXnW9PHCiIeO8iq0c,3141
|
| 44 |
+
lida/components/viz/vizgenerator.py,sha256=PqmdY1sRW7lRj518nnKjtiBNtBEErjghW4mtpX2eslc,2762
|
| 45 |
+
lida/components/viz/vizrecommender.py,sha256=7YTnfjceT_78pZy2Mw8U-mxQr7vfhMw87HnDKcfXXBc,3225
|
| 46 |
+
lida/components/viz/vizrepairer.py,sha256=4NE3dzZ0ZzVLikqL71PmzCqkpCYJDJVwV7xygdJoFHc,2056
|
| 47 |
+
lida/datamodel.py,sha256=-8CqFd1yDcq8VWCMpVtchykb2oA-DxO_udD3Gb15agg,5066
|
| 48 |
+
lida/utils.py,sha256=-hHNifyRQp4BI18mLJBblqS4_fi1JlQKODxgoFbKACc,7883
|
| 49 |
+
lida/version.py,sha256=Re70LR9m7cAhH54rssYyZTF_NDTijR8Lo_1hWF3ofTI,19
|
| 50 |
+
lida/web/.gitignore,sha256=XFjtcLQokSpzuLSJJA0krmuRnvuZnml0xOI1t6DfgB8,1951
|
| 51 |
+
lida/web/__init__.py,sha256=41PQWCBiwBL4PvUq7LTosbpPKRjMhiO-_nw_a1_a9i0,57
|
| 52 |
+
lida/web/__pycache__/__init__.cpython-312.pyc,,
|
| 53 |
+
lida/web/__pycache__/app.cpython-312.pyc,,
|
| 54 |
+
lida/web/app.py,sha256=oFIo74JKgStw_k07rDliS0ID4K5ZUnhCxZ3h06SeC6M,12076
|
| 55 |
+
lida/web/ui/21614df092a0a42959abd49fa5ffec5702fa9463-ea1bf954f60f23d1e6a7.js,sha256=4aVDoO4R7GgvncjyOrYPQMm35-fkz9hAn_Ba4HcBA4k,75617
|
| 56 |
+
lida/web/ui/21614df092a0a42959abd49fa5ffec5702fa9463-ea1bf954f60f23d1e6a7.js.map,sha256=Ie75dYmYDOdc2hLI3rBSNL7r2vwfGPgR3TxhvYqfMc4,232206
|
| 57 |
+
lida/web/ui/404.html,sha256=WDZyjf50UKcX-JAm1E-2ccKZfFbhfWYdhSkLucKuLhc,33693
|
| 58 |
+
lida/web/ui/404/index.html,sha256=VZT2ohc4teIE3xGwSfJYHK6gCb85KpLXPUAyDhvwD6M,33689
|
| 59 |
+
lida/web/ui/81e257386408544e35976acc2a4075b730ed48a4-326068d326429305ec9e.js,sha256=AvN2-sKtJiA_A9MDyI8u0UbtMYIT4-awXL-scJmbTng,1023442
|
| 60 |
+
lida/web/ui/81e257386408544e35976acc2a4075b730ed48a4-326068d326429305ec9e.js.LICENSE.txt,sha256=w99HJHjUmlrRrav8yVCgDpHvFi0mJwdB8NYFWSE9FBY,368
|
| 61 |
+
lida/web/ui/81e257386408544e35976acc2a4075b730ed48a4-326068d326429305ec9e.js.map,sha256=2MvtKHv3u2EozXwFLN9ZzZtfKK-jvFR7ddNcE6BnwRw,2235246
|
| 62 |
+
lida/web/ui/app-80dcacffbc4d71399cc7.js,sha256=UpI_z7ci8jkyQVPmv0-S1yd4PPOFSPz1QgN8lxj7oxo,92843
|
| 63 |
+
lida/web/ui/app-80dcacffbc4d71399cc7.js.map,sha256=lpqocLT96d03A9iyXSZYJNFPKuIPMYZOdJSGVRqm8NA,366829
|
| 64 |
+
lida/web/ui/chunk-map.json,sha256=NGlK5-KjsqlFr7uI2i-4r1Eop1Ofma1KchnM6GUbwBg,463
|
| 65 |
+
lida/web/ui/component---src-pages-404-tsx-271998ff555bf33bd7ce.js,sha256=OsJgqFvtKgcd-fOt1uZrFT1UPpLIsoqpw5WWyZ-6DoU,796
|
| 66 |
+
lida/web/ui/component---src-pages-404-tsx-271998ff555bf33bd7ce.js.map,sha256=uXI9Lodeu5ecit4MNgtOOriKL_CVHvoqaE1qOdE9aFM,1986
|
| 67 |
+
lida/web/ui/component---src-pages-demo-tsx-54fd6da10fa870d8d843.js,sha256=vF-8PLKlISyekaiRteMe1aqLMylVti66TegM0yObxEM,2575854
|
| 68 |
+
lida/web/ui/component---src-pages-demo-tsx-54fd6da10fa870d8d843.js.LICENSE.txt,sha256=OxpnaKJbsQKb59YXzfE7x9aF59tIhVexdZgCjJMqxvA,255
|
| 69 |
+
lida/web/ui/component---src-pages-demo-tsx-54fd6da10fa870d8d843.js.map,sha256=n1L7Qfc7WOpV_Ul3JTENJPuk2gfWYvzHouSJorJ8fgY,11066782
|
| 70 |
+
lida/web/ui/component---src-pages-index-tsx-36a4bd360cacad51120f.js,sha256=JoCdvxYcTxez9vGw13FpCgZYJThh265trVR3XoxmsIM,58467
|
| 71 |
+
lida/web/ui/component---src-pages-index-tsx-36a4bd360cacad51120f.js.LICENSE.txt,sha256=2JfuP83fRW3Pz2a3fdlWh1bR2RT2rng4b4l3wyTq1QI,81
|
| 72 |
+
lida/web/ui/component---src-pages-index-tsx-36a4bd360cacad51120f.js.map,sha256=mmUYQgNR-kNhgzhywSz-5HdebUNb-2B2ltIxu0vqP_I,144441
|
| 73 |
+
lida/web/ui/component---src-pages-login-tsx-bbe1cb64566ee588bf48.js,sha256=EBMIINO9mLg5P8Buf9q_V1Vy2Jrt-FX7fS0vzecPJHs,334
|
| 74 |
+
lida/web/ui/component---src-pages-login-tsx-bbe1cb64566ee588bf48.js.map,sha256=7R9pGDJ2sLjkRzbPW7FOcgso8-sTA8cA8_ZcZy9wZh8,834
|
| 75 |
+
lida/web/ui/demo/index.html,sha256=INJepIamxOF4J532hQBiB_6LXoRV-qRpyCFJb2ZLi88,45396
|
| 76 |
+
lida/web/ui/favicon-32x32.png,sha256=iVkmreRqCcMmvCfA8GG97KSXJ5VQgr2LSGvEy9dwqjM,1261
|
| 77 |
+
lida/web/ui/files/infographics_small.jpg,sha256=gH3Et6K7K6Mc6nlYVRUU-r1OTcfTsbzAoSwcmYqy9XY,579528
|
| 78 |
+
lida/web/ui/files/lidamodules.jpg,sha256=km8887P_cmVFEWfszKXjiXyJf1e96kQyYnhUCiDP9vc,444281
|
| 79 |
+
lida/web/ui/framework-adcf09f5896f386aa38b.js,sha256=R1V2mLMyVcde9eXyWw0ISUWAQsw4CuzIXRtiCF4jZzs,129870
|
| 80 |
+
lida/web/ui/framework-adcf09f5896f386aa38b.js.LICENSE.txt,sha256=rAVUv7o8YtMNUiCz6P4UPh956J0Bsf5kE7k45rmyTRU,736
|
| 81 |
+
lida/web/ui/framework-adcf09f5896f386aa38b.js.map,sha256=MhhKN2GC_0Vh_WeH2Jf5fRJY8eqB29lzZ8e9F8Afz4I,325126
|
| 82 |
+
lida/web/ui/icons/icon-144x144.png,sha256=Oe4BCNmLpmc7QHjSrJaKa35QNMLWP7D-PV6u3O8vakM,5193
|
| 83 |
+
lida/web/ui/icons/icon-192x192.png,sha256=f1Qt7KzgXebMXRMLEpQ8HmwJ7iRWKD1utxMt0ks9-Ps,7253
|
| 84 |
+
lida/web/ui/icons/icon-256x256.png,sha256=V_ya4RWfpMAm8bMX4jiyOH9CI0APPvYRuEeHf1QCmx4,10405
|
| 85 |
+
lida/web/ui/icons/icon-384x384.png,sha256=kgccmWDwgsjEfdJU1Ql3S6eNHAezlFITs-YDpIbR6qA,16972
|
| 86 |
+
lida/web/ui/icons/icon-48x48.png,sha256=b877kD-RF_LyQY9FQVOg8WfN8aOS77aSqBWe--dE7Rg,1554
|
| 87 |
+
lida/web/ui/icons/icon-512x512.png,sha256=gG61aUWehlG1C5sDcHbLsAE8WqvtRudkQAlAtHpEjVY,17708
|
| 88 |
+
lida/web/ui/icons/icon-72x72.png,sha256=M4vgzglAN18UyYfVQdLJXD5lH66LojMpTE2tMolj0wY,2301
|
| 89 |
+
lida/web/ui/icons/icon-96x96.png,sha256=sGMi8cFXyKVL8nd0zr_UtpZWQ-DeKHhkoK8DvWwb1u0,3189
|
| 90 |
+
lida/web/ui/images/default.png,sha256=8Uujd1ZsVvu2TipGh-IpL96VY-D4EzgT8dMwhRqYH-c,2181
|
| 91 |
+
lida/web/ui/images/screen.png,sha256=32yA0XTIACR41rEOSbPRalcOflnbhtqQuedkKXxdP-0,859540
|
| 92 |
+
lida/web/ui/images/videoscreen.png,sha256=JEKpRdZ6Hu05L90Z6a08VDzyeheQrDfjJQkPjb0ThFY,297503
|
| 93 |
+
lida/web/ui/index.html,sha256=KVhiLpswj6qrXgXkD-QXQyac9xfcp4TN9N7L-pz37PI,70501
|
| 94 |
+
lida/web/ui/login/index.html,sha256=fygLgpAVim7XQejshb5PVb6uJ23AS-KEC0wfkVrPdKs,38129
|
| 95 |
+
lida/web/ui/manifest.webmanifest,sha256=I27E1YkJkNox5HH0KCrdeJGd0qJ5TBJ2Ik-CSfLboIo,839
|
| 96 |
+
lida/web/ui/page-data/404.html/page-data.json,sha256=SNaqt-SfyIUEBDdfZOcKMwf6-5m2ABaAeyrWcVD5nDo,124
|
| 97 |
+
lida/web/ui/page-data/404/page-data.json,sha256=WeQ4MtE5uTDhhcllrYfoasoa0MAV4JlQVQ7cbPJaNjM,120
|
| 98 |
+
lida/web/ui/page-data/app-data.json,sha256=ezJ1Co9TkrHd2IgPGxSl1arWm-hPcRCTvUhalSSNvGA,50
|
| 99 |
+
lida/web/ui/page-data/demo/page-data.json,sha256=w9CFbpbu7wwO7GSH_9OBLcXUQrgFUgKvnL4k26x2hdU,234
|
| 100 |
+
lida/web/ui/page-data/index/page-data.json,sha256=WgJ2ybagiFRTVk336zFdCCoqTyKNaYETjbUDnJyaN8U,230
|
| 101 |
+
lida/web/ui/page-data/login/page-data.json,sha256=olO33JwKWIwZ_lTwiOQoA9Rq19CrSTWvwEbXKz8Tcs0,136
|
| 102 |
+
lida/web/ui/page-data/sq/d/1865044719.json,sha256=txg4OyXorH8gMXXj9hHOyDUuq7crmUkyfrInBKwWpdQ,204
|
| 103 |
+
lida/web/ui/polyfill-9f027554f9c426b688ff.js,sha256=4Zs9J1BzMqSXPEFoTmn5Egi-w75lmBhIyEyZX6ohIw8,84996
|
| 104 |
+
lida/web/ui/polyfill-9f027554f9c426b688ff.js.map,sha256=1LhDnOuoeo2PShM63PPP-_fa67tNskVFk_TyQohImOU,207967
|
| 105 |
+
lida/web/ui/sitemap/sitemap-0.xml,sha256=wsMkW4LAkoHiSEltYHJVkWPW4glVfIwl0StUQRyIIo4,657
|
| 106 |
+
lida/web/ui/sitemap/sitemap-index.xml,sha256=TAqF8h914e7WqqcADO52Lg5CJnSla6AMhUN4PhVCLoc,198
|
| 107 |
+
lida/web/ui/styles.15bd7f1a07f6d77699dc.css,sha256=RqfsFlXsptr-TPoKmmwWaueDIF6wuKSnEzKJCtRhdDw,28926
|
| 108 |
+
lida/web/ui/webpack-runtime-8958b079d5c4b6876c66.js,sha256=k_UYQlqXY1g5bCLkgL0rfXM9ISNIDZwRm4_1dmJOhJo,4031
|
| 109 |
+
lida/web/ui/webpack-runtime-8958b079d5c4b6876c66.js.map,sha256=oBf39hpx6q_gE1pnzzq6jXfjtxZ91rnwKoSZCOMKwBk,18625
|
| 110 |
+
lida/web/ui/webpack.stats.json,sha256=sYVq0gTItl0k683QH5E4zTogNUYvh_7sc5KS_rwr_3I,3151
|
| 111 |
+
lida/web/ui/~partytown/debug/partytown-atomics.js,sha256=CCiVZvJlJJ-bpdlu3YZp56d9lwRXLBr3vwPnwFBqOgY,28104
|
| 112 |
+
lida/web/ui/~partytown/debug/partytown-media.js,sha256=zxUyEHmEWOnQPbvASzdPsXb0OpQzuuSbbEBrYxuRxzo,17511
|
| 113 |
+
lida/web/ui/~partytown/debug/partytown-sandbox-sw.js,sha256=mVf8LhtM14vhjQAYRv-jbS4h1Qy4yJQ6VatbJ0ETcR8,27197
|
| 114 |
+
lida/web/ui/~partytown/debug/partytown-sw.js,sha256=PZMigbHnae4mx1-iGRMqmnjYyEa9jemjxN0mauWrX2E,1995
|
| 115 |
+
lida/web/ui/~partytown/debug/partytown-ww-atomics.js,sha256=IcpXMfkSWv3bEsostzwb7Vc-VWUwjyPIq_C_OlvZAwU,82089
|
| 116 |
+
lida/web/ui/~partytown/debug/partytown-ww-sw.js,sha256=G6aQu6TpZodxizX_-Y0oVgjr6cUYucD8Un3hoKSevTA,81649
|
| 117 |
+
lida/web/ui/~partytown/debug/partytown.js,sha256=MHbZY3VWACUHpWJ8On1qh4a4TlU-lK_YEfIp6CioEDk,3341
|
| 118 |
+
lida/web/ui/~partytown/partytown-atomics.js,sha256=reONw3Q-OMEL7dQBnsdRp5FBkTw7ScQC-ot7LPeKZ_4,28273
|
| 119 |
+
lida/web/ui/~partytown/partytown-media.js,sha256=B-7OwpuPYwU90tdc5kT_yH77suMas2JfPaNh1k26o60,5689
|
| 120 |
+
lida/web/ui/~partytown/partytown-sw.js,sha256=_Cwc2iY6AaE0R0ZBAf_nQlF6JHxIg3hKU1VTUhkyED0,29137
|
| 121 |
+
lida/web/ui/~partytown/partytown.js,sha256=Zp1E4gz7Nbna2RFs1iRc1hH-4a7p6b717bwjLX-KYkc,1384
|
lida-0.0.14.dist-info/REQUESTED
ADDED
|
File without changes
|
lida-0.0.14.dist-info/WHEEL
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Wheel-Version: 1.0
|
| 2 |
+
Generator: bdist_wheel (0.42.0)
|
| 3 |
+
Root-Is-Purelib: true
|
| 4 |
+
Tag: py3-none-any
|
| 5 |
+
|
lida-0.0.14.dist-info/entry_points.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[console_scripts]
|
| 2 |
+
lida = lida.cli:run
|
lida-0.0.14.dist-info/top_level.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
lida
|
lida_ko/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from llmx import TextGenerationConfig, llm, TextGenerator
|
| 2 |
+
from .components.manager import Manager
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
__all__ = ["TextGenerationConfig", "llm", "TextGenerator", "Manager"]
|
lida_ko/cli.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import typer
|
| 2 |
+
import uvicorn
|
| 3 |
+
import os
|
| 4 |
+
from typing_extensions import Annotated
|
| 5 |
+
from llmx import providers
|
| 6 |
+
|
| 7 |
+
# from lida.web.backend.app import launch
|
| 8 |
+
|
| 9 |
+
app = typer.Typer()
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
@app.command()
|
| 13 |
+
def ui(host: str = "127.0.0.1",
|
| 14 |
+
port: int = 8081,
|
| 15 |
+
workers: int = 1,
|
| 16 |
+
reload: Annotated[bool, typer.Option("--reload")] = True,
|
| 17 |
+
docs: bool = False):
|
| 18 |
+
"""
|
| 19 |
+
Launch the lida .Pass in parameters host, port, workers, and reload to override the default values.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
os.environ["LIDA_API_DOCS"] = str(docs)
|
| 23 |
+
|
| 24 |
+
uvicorn.run(
|
| 25 |
+
"lida.web.app:app",
|
| 26 |
+
host=host,
|
| 27 |
+
port=port,
|
| 28 |
+
workers=workers,
|
| 29 |
+
reload=reload,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
@app.command()
|
| 34 |
+
def models():
|
| 35 |
+
print("A list of supported providers:")
|
| 36 |
+
for provider in providers.items():
|
| 37 |
+
print(f"Provider: {provider[1]['name']}")
|
| 38 |
+
for model in provider[1]["models"]:
|
| 39 |
+
print(f" - {model['name']}")
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def run():
|
| 43 |
+
app()
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
if __name__ == "__main__":
|
| 47 |
+
app()
|
lida_ko/components/__init__.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .summarizer import Summarizer
|
| 2 |
+
from .viz import *
|
| 3 |
+
from .goal import *
|
| 4 |
+
from .scaffold import *
|
| 5 |
+
from .executor import *
|
| 6 |
+
from .manager import *
|
| 7 |
+
from .persona import *
|
lida_ko/components/executor.py
ADDED
|
@@ -0,0 +1,282 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import base64
|
| 3 |
+
import importlib
|
| 4 |
+
import io
|
| 5 |
+
import os
|
| 6 |
+
import re
|
| 7 |
+
import traceback
|
| 8 |
+
from typing import Any, List
|
| 9 |
+
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
import pandas as pd
|
| 12 |
+
import plotly.io as pio
|
| 13 |
+
|
| 14 |
+
from lida_ko.datamodel import ChartExecutorResponse, Summary
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def preprocess_code(code: str) -> str:
|
| 18 |
+
"""Preprocess code to remove any preamble and explanation text"""
|
| 19 |
+
|
| 20 |
+
code = code.replace("<imports>", "")
|
| 21 |
+
code = code.replace("<stub>", "")
|
| 22 |
+
code = code.replace("<transforms>", "")
|
| 23 |
+
|
| 24 |
+
# remove all text after chart = plot(data)
|
| 25 |
+
if "chart = plot(data)" in code:
|
| 26 |
+
# print(code)
|
| 27 |
+
index = code.find("chart = plot(data)")
|
| 28 |
+
if index != -1:
|
| 29 |
+
code = code[: index + len("chart = plot(data)")]
|
| 30 |
+
|
| 31 |
+
if "```" in code:
|
| 32 |
+
pattern = r"```(?:\w+\n)?([\s\S]+?)```"
|
| 33 |
+
matches = re.findall(pattern, code)
|
| 34 |
+
if matches:
|
| 35 |
+
code = matches[0]
|
| 36 |
+
# code = code.replace("```", "")
|
| 37 |
+
# return code
|
| 38 |
+
|
| 39 |
+
if "import" in code:
|
| 40 |
+
# return only text after the first import statement
|
| 41 |
+
index = code.find("import")
|
| 42 |
+
if index != -1:
|
| 43 |
+
code = code[index:]
|
| 44 |
+
|
| 45 |
+
code = code.replace("```", "")
|
| 46 |
+
if "chart = plot(data)" not in code:
|
| 47 |
+
code = code + "\nchart = plot(data)"
|
| 48 |
+
return code
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def get_globals_dict(code_string, data):
|
| 52 |
+
# Parse the code string into an AST
|
| 53 |
+
tree = ast.parse(code_string)
|
| 54 |
+
# Extract the names of the imported modules and their aliases
|
| 55 |
+
imported_modules = []
|
| 56 |
+
for node in tree.body:
|
| 57 |
+
if isinstance(node, ast.Import):
|
| 58 |
+
for alias in node.names:
|
| 59 |
+
module = importlib.import_module(alias.name)
|
| 60 |
+
imported_modules.append((alias.name, alias.asname, module))
|
| 61 |
+
elif isinstance(node, ast.ImportFrom):
|
| 62 |
+
module = importlib.import_module(node.module)
|
| 63 |
+
for alias in node.names:
|
| 64 |
+
obj = getattr(module, alias.name)
|
| 65 |
+
imported_modules.append(
|
| 66 |
+
(f"{node.module}.{alias.name}", alias.asname, obj)
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
# Import the required modules into a dictionary
|
| 70 |
+
globals_dict = {}
|
| 71 |
+
for module_name, alias, obj in imported_modules:
|
| 72 |
+
if alias:
|
| 73 |
+
globals_dict[alias] = obj
|
| 74 |
+
else:
|
| 75 |
+
globals_dict[module_name.split(".")[-1]] = obj
|
| 76 |
+
|
| 77 |
+
ex_dicts = {"pd": pd, "data": data, "plt": plt}
|
| 78 |
+
globals_dict.update(ex_dicts)
|
| 79 |
+
return globals_dict
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class ChartExecutor:
|
| 83 |
+
"""Execute code and return chart object"""
|
| 84 |
+
|
| 85 |
+
def __init__(self) -> None:
|
| 86 |
+
pass
|
| 87 |
+
|
| 88 |
+
def execute(
|
| 89 |
+
self,
|
| 90 |
+
code_specs: List[str],
|
| 91 |
+
data: Any,
|
| 92 |
+
summary: Summary,
|
| 93 |
+
library="altair",
|
| 94 |
+
return_error: bool = False,
|
| 95 |
+
) -> Any:
|
| 96 |
+
"""Validate and convert code"""
|
| 97 |
+
|
| 98 |
+
# # check if user has given permission to execute code. if env variable
|
| 99 |
+
# # LIDA_ALLOW_CODE_EVAL is set to '1'. Else raise exception
|
| 100 |
+
# if os.environ.get("LIDA_ALLOW_CODE_EVAL") != '1':
|
| 101 |
+
# raise Exception(
|
| 102 |
+
# "Permission to execute code not granted. Please set the environment variable LIDA_ALLOW_CODE_EVAL to '1' to allow code execution.")
|
| 103 |
+
|
| 104 |
+
if isinstance(summary, dict):
|
| 105 |
+
summary = Summary(**summary)
|
| 106 |
+
|
| 107 |
+
charts = []
|
| 108 |
+
code_spec_copy = code_specs.copy()
|
| 109 |
+
code_specs = [preprocess_code(code) for code in code_specs]
|
| 110 |
+
if library == "altair":
|
| 111 |
+
for code in code_specs:
|
| 112 |
+
try:
|
| 113 |
+
ex_locals = get_globals_dict(code, data)
|
| 114 |
+
exec(code, ex_locals)
|
| 115 |
+
chart = ex_locals["chart"]
|
| 116 |
+
vega_spec = chart.to_dict()
|
| 117 |
+
del vega_spec["data"]
|
| 118 |
+
if "datasets" in vega_spec:
|
| 119 |
+
del vega_spec["datasets"]
|
| 120 |
+
|
| 121 |
+
vega_spec["data"] = {"url": f"/files/data/{summary.file_name}"}
|
| 122 |
+
charts.append(
|
| 123 |
+
ChartExecutorResponse(
|
| 124 |
+
spec=vega_spec,
|
| 125 |
+
status=True,
|
| 126 |
+
raster=None,
|
| 127 |
+
code=code,
|
| 128 |
+
library=library,
|
| 129 |
+
)
|
| 130 |
+
)
|
| 131 |
+
except Exception as exception_error:
|
| 132 |
+
print(code_spec_copy, "\n===========\n")
|
| 133 |
+
print(exception_error)
|
| 134 |
+
print(traceback.format_exc())
|
| 135 |
+
if return_error:
|
| 136 |
+
charts.append(
|
| 137 |
+
ChartExecutorResponse(
|
| 138 |
+
spec=None,
|
| 139 |
+
status=False,
|
| 140 |
+
raster=None,
|
| 141 |
+
code=code,
|
| 142 |
+
library=library,
|
| 143 |
+
error={
|
| 144 |
+
"message": str(exception_error),
|
| 145 |
+
"traceback": traceback.format_exc(),
|
| 146 |
+
},
|
| 147 |
+
)
|
| 148 |
+
)
|
| 149 |
+
return charts
|
| 150 |
+
elif library == "matplotlib" or library == "seaborn":
|
| 151 |
+
# print colum dtypes
|
| 152 |
+
for code in code_specs:
|
| 153 |
+
try:
|
| 154 |
+
ex_locals = get_globals_dict(code, data)
|
| 155 |
+
# print(ex_locals)
|
| 156 |
+
exec(code, ex_locals)
|
| 157 |
+
chart = ex_locals["chart"]
|
| 158 |
+
if plt:
|
| 159 |
+
buf = io.BytesIO()
|
| 160 |
+
plt.box(False)
|
| 161 |
+
plt.grid(color="lightgray", linestyle="dashed", zorder=-10)
|
| 162 |
+
# try:
|
| 163 |
+
# plt.draw()
|
| 164 |
+
# # plt.tight_layout()
|
| 165 |
+
# except AttributeError:
|
| 166 |
+
# print("Warning: tight_layout encountered an error. The layout may not be optimal.")
|
| 167 |
+
# pass
|
| 168 |
+
|
| 169 |
+
plt.savefig(buf, format="png", dpi=100, pad_inches=0.2)
|
| 170 |
+
buf.seek(0)
|
| 171 |
+
plot_data = base64.b64encode(buf.read()).decode("ascii")
|
| 172 |
+
plt.close()
|
| 173 |
+
charts.append(
|
| 174 |
+
ChartExecutorResponse(
|
| 175 |
+
spec=None,
|
| 176 |
+
status=True,
|
| 177 |
+
raster=plot_data,
|
| 178 |
+
code=code,
|
| 179 |
+
library=library,
|
| 180 |
+
)
|
| 181 |
+
)
|
| 182 |
+
except Exception as exception_error:
|
| 183 |
+
print(code_spec_copy[0])
|
| 184 |
+
print("****\n", str(exception_error))
|
| 185 |
+
# print(traceback.format_exc())
|
| 186 |
+
if return_error:
|
| 187 |
+
charts.append(
|
| 188 |
+
ChartExecutorResponse(
|
| 189 |
+
spec=None,
|
| 190 |
+
status=False,
|
| 191 |
+
raster=None,
|
| 192 |
+
code=code,
|
| 193 |
+
library=library,
|
| 194 |
+
error={
|
| 195 |
+
"message": str(exception_error),
|
| 196 |
+
"traceback": traceback.format_exc(),
|
| 197 |
+
},
|
| 198 |
+
)
|
| 199 |
+
)
|
| 200 |
+
return charts
|
| 201 |
+
elif library == "ggplot":
|
| 202 |
+
# print colum dtypes
|
| 203 |
+
for code in code_specs:
|
| 204 |
+
try:
|
| 205 |
+
ex_locals = get_globals_dict(code, data)
|
| 206 |
+
exec(code, ex_locals)
|
| 207 |
+
chart = ex_locals["chart"]
|
| 208 |
+
if plt:
|
| 209 |
+
buf = io.BytesIO()
|
| 210 |
+
chart.save(buf, format="png")
|
| 211 |
+
plot_data = base64.b64encode(buf.getvalue()).decode("utf-8")
|
| 212 |
+
charts.append(
|
| 213 |
+
ChartExecutorResponse(
|
| 214 |
+
spec=None,
|
| 215 |
+
status=True,
|
| 216 |
+
raster=plot_data,
|
| 217 |
+
code=code,
|
| 218 |
+
library=library,
|
| 219 |
+
)
|
| 220 |
+
)
|
| 221 |
+
except Exception as exception_error:
|
| 222 |
+
print(code)
|
| 223 |
+
print(traceback.format_exc())
|
| 224 |
+
if return_error:
|
| 225 |
+
charts.append(
|
| 226 |
+
ChartExecutorResponse(
|
| 227 |
+
spec=None,
|
| 228 |
+
status=False,
|
| 229 |
+
raster=None,
|
| 230 |
+
code=code,
|
| 231 |
+
library=library,
|
| 232 |
+
error={
|
| 233 |
+
"message": str(exception_error),
|
| 234 |
+
"traceback": traceback.format_exc(),
|
| 235 |
+
},
|
| 236 |
+
)
|
| 237 |
+
)
|
| 238 |
+
return charts
|
| 239 |
+
|
| 240 |
+
elif library == "plotly":
|
| 241 |
+
for code in code_specs:
|
| 242 |
+
try:
|
| 243 |
+
ex_locals = get_globals_dict(code, data)
|
| 244 |
+
exec(code, ex_locals)
|
| 245 |
+
chart = ex_locals["chart"]
|
| 246 |
+
|
| 247 |
+
if pio:
|
| 248 |
+
chart_bytes = pio.to_image(chart, 'png')
|
| 249 |
+
plot_data = base64.b64encode(chart_bytes).decode('utf-8')
|
| 250 |
+
|
| 251 |
+
charts.append(
|
| 252 |
+
ChartExecutorResponse(
|
| 253 |
+
spec=None,
|
| 254 |
+
status=True,
|
| 255 |
+
raster=plot_data,
|
| 256 |
+
code=code,
|
| 257 |
+
library=library,
|
| 258 |
+
)
|
| 259 |
+
)
|
| 260 |
+
except Exception as exception_error:
|
| 261 |
+
print(code)
|
| 262 |
+
print(traceback.format_exc())
|
| 263 |
+
if return_error:
|
| 264 |
+
charts.append(
|
| 265 |
+
ChartExecutorResponse(
|
| 266 |
+
spec=None,
|
| 267 |
+
status=False,
|
| 268 |
+
raster=None,
|
| 269 |
+
code=code,
|
| 270 |
+
library=library,
|
| 271 |
+
error={
|
| 272 |
+
"message": str(exception_error),
|
| 273 |
+
"traceback": traceback.format_exc(),
|
| 274 |
+
},
|
| 275 |
+
)
|
| 276 |
+
)
|
| 277 |
+
return charts
|
| 278 |
+
|
| 279 |
+
else:
|
| 280 |
+
raise Exception(
|
| 281 |
+
f"Unsupported library. Supported libraries are altair, matplotlib, seaborn, ggplot, plotly. You provided {library}"
|
| 282 |
+
)
|
lida_ko/components/goal.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
from lida_ko.utils import clean_code_snippet
|
| 4 |
+
from llmx import TextGenerator
|
| 5 |
+
from lida_ko.datamodel import Goal, TextGenerationConfig, Persona
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
SYSTEM_INSTRUCTIONS = """
|
| 9 |
+
You are a an experienced data analyst who can generate a given number of insightful GOALS about data, when given a summary of the data, and a specified persona. The VISUALIZATIONS YOU RECOMMEND MUST FOLLOW VISUALIZATION BEST PRACTICES (e.g., must use bar charts instead of pie charts for comparing quantities) AND BE MEANINGFUL (e.g., plot longitude and latitude on maps where appropriate). They must also be relevant to the specified persona. Each goal must include a question, a visualization (THE VISUALIZATION MUST REFERENCE THE EXACT COLUMN FIELDS FROM THE SUMMARY), and a rationale (JUSTIFICATION FOR WHICH dataset FIELDS ARE USED and what we will learn from the visualization). Each goal MUST mention the exact fields from the dataset summary above. YOU MUST provide goals in KOREAN, 한글
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
FORMAT_INSTRUCTIONS = """
|
| 13 |
+
THE OUTPUT MUST BE A CODE SNIPPET OF A VALID LIST OF JSON OBJECTS. IT MUST USE THE FOLLOWING FORMAT:
|
| 14 |
+
|
| 15 |
+
```[
|
| 16 |
+
{ "index": 0, "question": "What is the distribution of X", "visualization": "histogram of X", "rationale": "This tells about "} ..
|
| 17 |
+
]
|
| 18 |
+
```
|
| 19 |
+
THE OUTPUT SHOULD ONLY USE THE JSON FORMAT ABOVE.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
logger = logging.getLogger("lida")
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class GoalExplorer():
|
| 26 |
+
"""Generat goals given a summary of data"""
|
| 27 |
+
|
| 28 |
+
def __init__(self) -> None:
|
| 29 |
+
pass
|
| 30 |
+
|
| 31 |
+
def generate(self, summary: dict, textgen_config: TextGenerationConfig,
|
| 32 |
+
text_gen: TextGenerator, n=5, persona: Persona = None) -> list[Goal]:
|
| 33 |
+
"""Generate goals given a summary of data"""
|
| 34 |
+
|
| 35 |
+
user_prompt = f"""The number of GOALS to generate is {n}. The goals should be based on the data summary below, \n\n .
|
| 36 |
+
{summary} \n\n"""
|
| 37 |
+
|
| 38 |
+
if not persona:
|
| 39 |
+
persona = Persona(
|
| 40 |
+
persona="A highly skilled data analyst who can come up with complex, insightful goals about data",
|
| 41 |
+
rationale="")
|
| 42 |
+
|
| 43 |
+
user_prompt += f"""\n The generated goals SHOULD BE FOCUSED ON THE INTERESTS AND PERSPECTIVE of a '{persona.persona} persona, who is insterested in complex, insightful goals about the data. \n"""
|
| 44 |
+
|
| 45 |
+
messages = [
|
| 46 |
+
{"role": "system", "content": SYSTEM_INSTRUCTIONS},
|
| 47 |
+
{"role": "assistant",
|
| 48 |
+
"content":
|
| 49 |
+
f"{user_prompt}\n\n {FORMAT_INSTRUCTIONS} \n\n. The generated {n} goals are: \n "}]
|
| 50 |
+
|
| 51 |
+
result: list[Goal] = text_gen.generate(messages=messages, config=textgen_config)
|
| 52 |
+
|
| 53 |
+
try:
|
| 54 |
+
json_string = clean_code_snippet(result.text[0]["content"])
|
| 55 |
+
result = json.loads(json_string)
|
| 56 |
+
# cast each item in the list to a Goal object
|
| 57 |
+
if isinstance(result, dict):
|
| 58 |
+
result = [result]
|
| 59 |
+
result = [Goal(**x) for x in result]
|
| 60 |
+
except json.decoder.JSONDecodeError:
|
| 61 |
+
logger.info(f"Error decoding JSON: {result.text[0]['content']}")
|
| 62 |
+
print(f"Error decoding JSON: {result.text[0]['content']}")
|
| 63 |
+
raise ValueError(
|
| 64 |
+
"The model did not return a valid JSON object while attempting generate goals. Consider using a larger model or a model with higher max token length.")
|
| 65 |
+
return result
|
lida_ko/components/infographer.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import logging
|
| 3 |
+
from typing import Any, List, Union
|
| 4 |
+
import PIL
|
| 5 |
+
from peacasso.generator import ImageGenerator
|
| 6 |
+
from peacasso.datamodel import GeneratorConfig, ModelConfig
|
| 7 |
+
from peacasso.utils import base64_to_pil, pil_to_base64
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger("lida")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Infographer():
|
| 14 |
+
"""Generat infographics given a visualization and a summary of data"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, model_config: ModelConfig = None) -> None:
|
| 17 |
+
self.model = None
|
| 18 |
+
self.model_config = model_config or ModelConfig(
|
| 19 |
+
device="cuda",
|
| 20 |
+
model="runwayml/stable-diffusion-v1-5",
|
| 21 |
+
revision="main"
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
def load_model(self) -> None:
|
| 25 |
+
"""Load image generator model from config"""
|
| 26 |
+
self.model = ImageGenerator(model_config=self.model_config)
|
| 27 |
+
|
| 28 |
+
def generate(
|
| 29 |
+
self, visualization: Union[torch.FloatTensor, PIL.Image.Image, str],
|
| 30 |
+
n: int, style_prompt: Union[str, List[str]] = "line art pastel",
|
| 31 |
+
return_pil: bool = True
|
| 32 |
+
) -> List[Any]:
|
| 33 |
+
"""Generate a an infographic, given a visualization and style"""
|
| 34 |
+
|
| 35 |
+
if isinstance(visualization, str):
|
| 36 |
+
try:
|
| 37 |
+
visualization, _ = base64_to_pil(visualization)
|
| 38 |
+
except Exception as pil_exception:
|
| 39 |
+
logger.error(pil_exception)
|
| 40 |
+
raise ValueError(
|
| 41 |
+
f'Could not convert provided visualization to PIL image, {str(pil_exception)}') from pil_exception
|
| 42 |
+
self.load_model()
|
| 43 |
+
|
| 44 |
+
gen_config = GeneratorConfig(
|
| 45 |
+
prompt=style_prompt,
|
| 46 |
+
num_images=n,
|
| 47 |
+
width=512,
|
| 48 |
+
height=512,
|
| 49 |
+
guidance_scale=7.5,
|
| 50 |
+
num_inference_steps=50,
|
| 51 |
+
init_image=visualization,
|
| 52 |
+
return_intermediates=False,
|
| 53 |
+
seed=2147483647,
|
| 54 |
+
use_prompt_weights=False,
|
| 55 |
+
negative_prompt="text, background shapes or lines, title, words, characters, titles, letters",
|
| 56 |
+
strength=0.6,
|
| 57 |
+
filter_nsfw=False)
|
| 58 |
+
|
| 59 |
+
result = self.model.generate(gen_config)
|
| 60 |
+
if not return_pil:
|
| 61 |
+
result["images"] = [pil_to_base64(img) for img in result["images"]]
|
| 62 |
+
return result
|
lida_ko/components/manager.py
ADDED
|
@@ -0,0 +1,449 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Visualization manager class that handles the visualization of the data with the following methods
|
| 2 |
+
|
| 3 |
+
# summarize data given a df
|
| 4 |
+
# generate goals given a summary
|
| 5 |
+
# generate generate visualization specifications given a summary and a goal
|
| 6 |
+
# execute the specification given some data
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
from typing import List, Union
|
| 10 |
+
import logging
|
| 11 |
+
|
| 12 |
+
import pandas as pd
|
| 13 |
+
from llmx import llm, TextGenerator
|
| 14 |
+
from lida_ko.datamodel import Goal, Summary, TextGenerationConfig, Persona
|
| 15 |
+
from lida_ko.utils import read_dataframe
|
| 16 |
+
from ..components.summarizer import Summarizer
|
| 17 |
+
from ..components.goal import GoalExplorer
|
| 18 |
+
from ..components.persona import PersonaExplorer
|
| 19 |
+
from ..components.executor import ChartExecutor
|
| 20 |
+
from ..components.viz import VizGenerator, VizEditor, VizExplainer, VizEvaluator, VizRepairer, VizRecommender
|
| 21 |
+
|
| 22 |
+
import lida_ko.web as lida
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
logger = logging.getLogger("lida")
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class Manager(object):
|
| 29 |
+
def __init__(self, text_gen: TextGenerator = None) -> None:
|
| 30 |
+
"""
|
| 31 |
+
Initialize the Manager object.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
text_gen (TextGenerator, optional): Text generator object. Defaults to None.
|
| 35 |
+
"""
|
| 36 |
+
|
| 37 |
+
self.text_gen = text_gen or llm()
|
| 38 |
+
|
| 39 |
+
self.summarizer = Summarizer()
|
| 40 |
+
self.goal = GoalExplorer()
|
| 41 |
+
self.vizgen = VizGenerator()
|
| 42 |
+
self.vizeditor = VizEditor()
|
| 43 |
+
self.executor = ChartExecutor()
|
| 44 |
+
self.explainer = VizExplainer()
|
| 45 |
+
self.evaluator = VizEvaluator()
|
| 46 |
+
self.repairer = VizRepairer()
|
| 47 |
+
self.recommender = VizRecommender()
|
| 48 |
+
self.data = None
|
| 49 |
+
self.infographer = None
|
| 50 |
+
self.persona = PersonaExplorer()
|
| 51 |
+
|
| 52 |
+
def check_textgen(self, config: TextGenerationConfig):
|
| 53 |
+
"""
|
| 54 |
+
Check if self.text_gen is the same as the config passed in. If not, update self.text_gen.
|
| 55 |
+
|
| 56 |
+
Args:
|
| 57 |
+
config (TextGenerationConfig): Text generation configuration.
|
| 58 |
+
"""
|
| 59 |
+
if config.provider is None:
|
| 60 |
+
config.provider = self.text_gen.provider or "openai"
|
| 61 |
+
logger.info("Provider is not set, using default provider - %s", config.provider)
|
| 62 |
+
return
|
| 63 |
+
|
| 64 |
+
if self.text_gen.provider != config.provider:
|
| 65 |
+
|
| 66 |
+
logger.info(
|
| 67 |
+
"Switching Text Generator Provider from %s to %s",
|
| 68 |
+
self.text_gen.provider,
|
| 69 |
+
config.provider)
|
| 70 |
+
self.text_gen = llm(provider=config.provider)
|
| 71 |
+
|
| 72 |
+
def summarize(
|
| 73 |
+
self,
|
| 74 |
+
data: Union[pd.DataFrame, str],
|
| 75 |
+
file_name="",
|
| 76 |
+
n_samples: int = 3,
|
| 77 |
+
summary_method: str = "default",
|
| 78 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(n=1, temperature=0),
|
| 79 |
+
metadata: dict = None,
|
| 80 |
+
) -> Summary:
|
| 81 |
+
"""
|
| 82 |
+
Summarize data given a DataFrame or file path.
|
| 83 |
+
|
| 84 |
+
Args:
|
| 85 |
+
data (Union[pd.DataFrame, str]): Input data, either a DataFrame or file path.
|
| 86 |
+
file_name (str, optional): Name of the file if data is loaded from a file path. Defaults to "".
|
| 87 |
+
n_samples (int, optional): Number of summary samples to generate. Defaults to 3.
|
| 88 |
+
summary_method (str, optional): Summary method to use. Defaults to "default".
|
| 89 |
+
textgen_config (TextGenerationConfig, optional): Text generation configuration. Defaults to TextGenerationConfig(n=1, temperature=0).
|
| 90 |
+
|
| 91 |
+
Returns:
|
| 92 |
+
Summary: Summary object containing the generated summary.
|
| 93 |
+
|
| 94 |
+
Example of Summary:
|
| 95 |
+
|
| 96 |
+
{'name': 'cars.csv',
|
| 97 |
+
'file_name': 'cars.csv',
|
| 98 |
+
'dataset_description': '',
|
| 99 |
+
'fields': [{'column': 'Name',
|
| 100 |
+
'properties': {'dtype': 'string',
|
| 101 |
+
'samples': ['Nissan Altima S 4dr',
|
| 102 |
+
'Mercury Marauder 4dr',
|
| 103 |
+
'Toyota Prius 4dr (gas/electric)'],
|
| 104 |
+
'num_unique_values': 385,
|
| 105 |
+
'semantic_type': '',
|
| 106 |
+
'description': ''}},
|
| 107 |
+
{'column': 'Type',
|
| 108 |
+
'properties': {'dtype': 'category',
|
| 109 |
+
'samples': ['SUV', 'Minivan', 'Sports Car'],
|
| 110 |
+
'num_unique_values': 5,
|
| 111 |
+
'semantic_type': '',
|
| 112 |
+
'description': ''}},
|
| 113 |
+
{'column': 'AWD',
|
| 114 |
+
'properties': {'dtype': 'number',
|
| 115 |
+
'std': 0,
|
| 116 |
+
'min': 0,
|
| 117 |
+
'max': 1,
|
| 118 |
+
'samples': [1, 0],
|
| 119 |
+
'num_unique_values': 2,
|
| 120 |
+
'semantic_type': '',
|
| 121 |
+
'description': ''}},
|
| 122 |
+
}
|
| 123 |
+
|
| 124 |
+
"""
|
| 125 |
+
self.check_textgen(config=textgen_config)
|
| 126 |
+
|
| 127 |
+
if isinstance(data, str):
|
| 128 |
+
file_name = data.split("/")[-1]
|
| 129 |
+
data = read_dataframe(data)
|
| 130 |
+
|
| 131 |
+
self.data = data
|
| 132 |
+
return self.summarizer.summarize(
|
| 133 |
+
data=self.data, text_gen=self.text_gen, file_name=file_name, n_samples=n_samples,
|
| 134 |
+
summary_method=summary_method, textgen_config=textgen_config,
|
| 135 |
+
metadata=metadata)
|
| 136 |
+
|
| 137 |
+
def goals(
|
| 138 |
+
self,
|
| 139 |
+
summary: Summary,
|
| 140 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 141 |
+
n: int = 5,
|
| 142 |
+
persona: Persona = None
|
| 143 |
+
) -> List[Goal]:
|
| 144 |
+
"""
|
| 145 |
+
Generate goals based on a summary.
|
| 146 |
+
|
| 147 |
+
Args:
|
| 148 |
+
summary (Summary): Input summary.
|
| 149 |
+
textgen_config (TextGenerationConfig, optional): Text generation configuration. Defaults to TextGenerationConfig().
|
| 150 |
+
n (int, optional): Number of goals to generate. Defaults to 5.
|
| 151 |
+
persona (Persona, str, dict, optional): Persona information. Defaults to None.
|
| 152 |
+
|
| 153 |
+
Returns:
|
| 154 |
+
List[Goal]: List of generated goals.
|
| 155 |
+
|
| 156 |
+
Example of list of goals:
|
| 157 |
+
|
| 158 |
+
Goal 0
|
| 159 |
+
Question: What is the distribution of Retail_Price?
|
| 160 |
+
|
| 161 |
+
Visualization: histogram of Retail_Price
|
| 162 |
+
|
| 163 |
+
Rationale: This tells about the spread of prices of cars in the dataset.
|
| 164 |
+
|
| 165 |
+
Goal 1
|
| 166 |
+
Question: What is the distribution of Horsepower_HP_?
|
| 167 |
+
|
| 168 |
+
Visualization: box plot of Horsepower_HP_
|
| 169 |
+
|
| 170 |
+
Rationale: This tells about the distribution of horsepower of cars in the dataset.
|
| 171 |
+
"""
|
| 172 |
+
self.check_textgen(config=textgen_config)
|
| 173 |
+
|
| 174 |
+
if isinstance(persona, dict):
|
| 175 |
+
persona = Persona(**persona)
|
| 176 |
+
if isinstance(persona, str):
|
| 177 |
+
persona = Persona(persona=persona, rationale="")
|
| 178 |
+
|
| 179 |
+
return self.goal.generate(summary=summary, text_gen=self.text_gen,
|
| 180 |
+
textgen_config=textgen_config, n=n, persona=persona)
|
| 181 |
+
|
| 182 |
+
def personas(
|
| 183 |
+
self, summary, textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 184 |
+
n=5):
|
| 185 |
+
self.check_textgen(config=textgen_config)
|
| 186 |
+
|
| 187 |
+
return self.persona.generate(summary=summary, text_gen=self.text_gen,
|
| 188 |
+
textgen_config=textgen_config, n=n)
|
| 189 |
+
|
| 190 |
+
def visualize(
|
| 191 |
+
self,
|
| 192 |
+
summary,
|
| 193 |
+
goal,
|
| 194 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 195 |
+
library="seaborn",
|
| 196 |
+
return_error: bool = False,
|
| 197 |
+
):
|
| 198 |
+
if isinstance(goal, dict):
|
| 199 |
+
goal = Goal(**goal)
|
| 200 |
+
if isinstance(goal, str):
|
| 201 |
+
goal = Goal(question=goal, visualization=goal, rationale="")
|
| 202 |
+
|
| 203 |
+
self.check_textgen(config=textgen_config)
|
| 204 |
+
code_specs = self.vizgen.generate(
|
| 205 |
+
summary=summary, goal=goal, textgen_config=textgen_config, text_gen=self.text_gen,
|
| 206 |
+
library=library)
|
| 207 |
+
if library == "plotly":
|
| 208 |
+
# if library is plotly, return chart without executing
|
| 209 |
+
charts = [{
|
| 210 |
+
'code' : code,
|
| 211 |
+
'data' : self.data,
|
| 212 |
+
'summary' : summary,
|
| 213 |
+
'library' : library,
|
| 214 |
+
} for code in code_specs]
|
| 215 |
+
else:
|
| 216 |
+
charts = self.execute(
|
| 217 |
+
code_specs=code_specs,
|
| 218 |
+
data=self.data,
|
| 219 |
+
summary=summary,
|
| 220 |
+
library=library,
|
| 221 |
+
return_error=return_error,
|
| 222 |
+
)
|
| 223 |
+
return charts
|
| 224 |
+
|
| 225 |
+
def execute(
|
| 226 |
+
self,
|
| 227 |
+
code_specs,
|
| 228 |
+
data,
|
| 229 |
+
summary: Summary,
|
| 230 |
+
library: str = "seaborn",
|
| 231 |
+
return_error: bool = False,
|
| 232 |
+
):
|
| 233 |
+
|
| 234 |
+
if data is None:
|
| 235 |
+
root_file_path = os.path.dirname(os.path.abspath(lida.__file__))
|
| 236 |
+
print(root_file_path)
|
| 237 |
+
data = read_dataframe(
|
| 238 |
+
os.path.join(root_file_path, "files/data", summary.file_name)
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
# col_properties = summary.properties
|
| 242 |
+
|
| 243 |
+
return self.executor.execute(
|
| 244 |
+
code_specs=code_specs,
|
| 245 |
+
data=data,
|
| 246 |
+
summary=summary,
|
| 247 |
+
library=library,
|
| 248 |
+
return_error=return_error,
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
def edit(
|
| 252 |
+
self,
|
| 253 |
+
code,
|
| 254 |
+
summary: Summary,
|
| 255 |
+
instructions: List[str],
|
| 256 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 257 |
+
library: str = "seaborn",
|
| 258 |
+
return_error: bool = False,
|
| 259 |
+
):
|
| 260 |
+
"""Edit a visualization code given a set of instructions
|
| 261 |
+
|
| 262 |
+
Args:
|
| 263 |
+
code (_type_): _description_
|
| 264 |
+
instructions (List[Dict]): A list of instructions
|
| 265 |
+
|
| 266 |
+
Returns:
|
| 267 |
+
_type_: _description_
|
| 268 |
+
"""
|
| 269 |
+
|
| 270 |
+
self.check_textgen(config=textgen_config)
|
| 271 |
+
|
| 272 |
+
if isinstance(instructions, str):
|
| 273 |
+
instructions = [instructions]
|
| 274 |
+
|
| 275 |
+
code_specs = self.vizeditor.generate(
|
| 276 |
+
code=code,
|
| 277 |
+
summary=summary,
|
| 278 |
+
instructions=instructions,
|
| 279 |
+
textgen_config=textgen_config,
|
| 280 |
+
text_gen=self.text_gen,
|
| 281 |
+
library=library,
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
charts = self.execute(
|
| 285 |
+
code_specs=code_specs,
|
| 286 |
+
data=self.data,
|
| 287 |
+
summary=summary,
|
| 288 |
+
library=library,
|
| 289 |
+
return_error=return_error,
|
| 290 |
+
)
|
| 291 |
+
return charts
|
| 292 |
+
|
| 293 |
+
def repair(
|
| 294 |
+
self,
|
| 295 |
+
code,
|
| 296 |
+
goal: Goal,
|
| 297 |
+
summary: Summary,
|
| 298 |
+
feedback,
|
| 299 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 300 |
+
library: str = "seaborn",
|
| 301 |
+
return_error: bool = False,
|
| 302 |
+
):
|
| 303 |
+
""" Repair a visulization given some feedback"""
|
| 304 |
+
self.check_textgen(config=textgen_config)
|
| 305 |
+
code_specs = self.repairer.generate(
|
| 306 |
+
code=code,
|
| 307 |
+
feedback=feedback,
|
| 308 |
+
goal=goal,
|
| 309 |
+
summary=summary,
|
| 310 |
+
textgen_config=textgen_config,
|
| 311 |
+
text_gen=self.text_gen,
|
| 312 |
+
library=library,
|
| 313 |
+
)
|
| 314 |
+
if library == "plotly":
|
| 315 |
+
# if library is plotly, return chart without executing
|
| 316 |
+
charts = [{
|
| 317 |
+
'code' : code,
|
| 318 |
+
'data' : self.data,
|
| 319 |
+
'summary' : summary,
|
| 320 |
+
'library' : library,
|
| 321 |
+
} for code in code_specs]
|
| 322 |
+
charts = self.execute(
|
| 323 |
+
code_specs=code_specs,
|
| 324 |
+
data=self.data,
|
| 325 |
+
summary=summary,
|
| 326 |
+
library=library,
|
| 327 |
+
return_error=return_error,
|
| 328 |
+
)
|
| 329 |
+
return charts
|
| 330 |
+
|
| 331 |
+
def explain(
|
| 332 |
+
self,
|
| 333 |
+
code,
|
| 334 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 335 |
+
library: str = "seaborn",
|
| 336 |
+
):
|
| 337 |
+
"""Explain a visualization code given a set of instructions
|
| 338 |
+
|
| 339 |
+
Args:
|
| 340 |
+
code (_type_): _description_
|
| 341 |
+
instructions (List[Dict]): A list of instructions
|
| 342 |
+
|
| 343 |
+
Returns:
|
| 344 |
+
_type_: _description_
|
| 345 |
+
"""
|
| 346 |
+
self.check_textgen(config=textgen_config)
|
| 347 |
+
return self.explainer.generate(
|
| 348 |
+
code=code,
|
| 349 |
+
textgen_config=textgen_config,
|
| 350 |
+
text_gen=self.text_gen,
|
| 351 |
+
library=library,
|
| 352 |
+
)
|
| 353 |
+
|
| 354 |
+
def evaluate(
|
| 355 |
+
self,
|
| 356 |
+
code,
|
| 357 |
+
goal: Goal,
|
| 358 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 359 |
+
library: str = "seaborn",
|
| 360 |
+
):
|
| 361 |
+
"""Evaluate a visualization code given a goal
|
| 362 |
+
|
| 363 |
+
Args:
|
| 364 |
+
code (_type_): _description_
|
| 365 |
+
goal (Goal): A visualization goal
|
| 366 |
+
|
| 367 |
+
Returns:
|
| 368 |
+
_type_: _description_
|
| 369 |
+
"""
|
| 370 |
+
|
| 371 |
+
self.check_textgen(config=textgen_config)
|
| 372 |
+
|
| 373 |
+
return self.evaluator.generate(
|
| 374 |
+
code=code,
|
| 375 |
+
goal=goal,
|
| 376 |
+
textgen_config=textgen_config,
|
| 377 |
+
text_gen=self.text_gen,
|
| 378 |
+
library=library,
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
def recommend(
|
| 382 |
+
self,
|
| 383 |
+
code,
|
| 384 |
+
summary: Summary,
|
| 385 |
+
n=4,
|
| 386 |
+
textgen_config: TextGenerationConfig = TextGenerationConfig(),
|
| 387 |
+
library: str = "seaborn",
|
| 388 |
+
return_error: bool = False,
|
| 389 |
+
):
|
| 390 |
+
"""Edit a visualization code given a set of instructions
|
| 391 |
+
|
| 392 |
+
Args:
|
| 393 |
+
code (_type_): _description_
|
| 394 |
+
instructions (List[Dict]): A list of instructions
|
| 395 |
+
|
| 396 |
+
Returns:
|
| 397 |
+
_type_: _description_
|
| 398 |
+
"""
|
| 399 |
+
|
| 400 |
+
self.check_textgen(config=textgen_config)
|
| 401 |
+
|
| 402 |
+
code_specs = self.recommender.generate(
|
| 403 |
+
code=code,
|
| 404 |
+
summary=summary,
|
| 405 |
+
n=n,
|
| 406 |
+
textgen_config=textgen_config,
|
| 407 |
+
text_gen=self.text_gen,
|
| 408 |
+
library=library,
|
| 409 |
+
)
|
| 410 |
+
charts = self.execute(
|
| 411 |
+
code_specs=code_specs,
|
| 412 |
+
data=self.data,
|
| 413 |
+
summary=summary,
|
| 414 |
+
library=library,
|
| 415 |
+
return_error=return_error,
|
| 416 |
+
)
|
| 417 |
+
return charts
|
| 418 |
+
|
| 419 |
+
def infographics(self, visualization: str, n: int = 1,
|
| 420 |
+
style_prompt: Union[str, List[str]] = "",
|
| 421 |
+
return_pil: bool = False
|
| 422 |
+
):
|
| 423 |
+
"""
|
| 424 |
+
Generate infographics using the peacasso package.
|
| 425 |
+
|
| 426 |
+
Args:
|
| 427 |
+
visualization (str): A visualization code
|
| 428 |
+
n (int, optional): The number of infographics to generate. Defaults to 1.
|
| 429 |
+
style_prompt (Union[str, List[str]], optional): A style prompt or list of style prompts. Defaults to "".
|
| 430 |
+
|
| 431 |
+
Raises:
|
| 432 |
+
ImportError: If the peacasso package is not installed.
|
| 433 |
+
"""
|
| 434 |
+
|
| 435 |
+
try:
|
| 436 |
+
import peacasso
|
| 437 |
+
|
| 438 |
+
except ImportError as exc:
|
| 439 |
+
raise ImportError(
|
| 440 |
+
'Please install lida with infographics support. pip install lida[infographics]. You will also need a GPU runtime.'
|
| 441 |
+
) from exc
|
| 442 |
+
|
| 443 |
+
from ..components.infographer import Infographer
|
| 444 |
+
|
| 445 |
+
if self.infographer is None:
|
| 446 |
+
logger.info("Initializing Infographer")
|
| 447 |
+
self.infographer = Infographer()
|
| 448 |
+
return self.infographer.generate(
|
| 449 |
+
visualization=visualization, n=n, style_prompt=style_prompt, return_pil=return_pil)
|
lida_ko/components/persona.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
from lida_ko.utils import clean_code_snippet
|
| 4 |
+
from llmx import TextGenerator
|
| 5 |
+
from lida_ko.datamodel import Persona, TextGenerationConfig
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
system_prompt = """You are an experienced data analyst who can take a dataset summary and generate a list of n personas (e.g., ceo or accountant for finance related data, economist for population or gdp related data, doctors for health data, or just users) that might be critical stakeholders in exploring some data and describe rationale for why they are critical. The personas should be prioritized based on their relevance to the data. Think step by step.
|
| 9 |
+
|
| 10 |
+
Your response should be perfect JSON in the following format:
|
| 11 |
+
```[{"persona": "persona1", "rationale": "..."},{"persona": "persona1", "rationale": "..."}]```
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger("lida")
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class PersonaExplorer():
|
| 18 |
+
"""Generat personas given a summary of data"""
|
| 19 |
+
|
| 20 |
+
def __init__(self) -> None:
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
def generate(self, summary: dict, textgen_config: TextGenerationConfig,
|
| 24 |
+
text_gen: TextGenerator, n=5) -> list[Persona]:
|
| 25 |
+
"""Generate personas given a summary of data"""
|
| 26 |
+
|
| 27 |
+
user_prompt = f"""The number of PERSONAs to generate is {n}. Generate {n} personas in the right format given the data summary below,\n .
|
| 28 |
+
{summary} \n""" + """
|
| 29 |
+
|
| 30 |
+
.
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
messages = [
|
| 34 |
+
{"role": "system", "content": system_prompt},
|
| 35 |
+
{"role": "assistant", "content": user_prompt},
|
| 36 |
+
]
|
| 37 |
+
|
| 38 |
+
result = text_gen.generate(messages=messages, config=textgen_config)
|
| 39 |
+
|
| 40 |
+
try:
|
| 41 |
+
json_string = clean_code_snippet(result.text[0]["content"])
|
| 42 |
+
result = json.loads(json_string)
|
| 43 |
+
# cast each item in the list to a Goal object
|
| 44 |
+
if isinstance(result, dict):
|
| 45 |
+
result = [result]
|
| 46 |
+
result = [Persona(**x) for x in result]
|
| 47 |
+
except json.decoder.JSONDecodeError:
|
| 48 |
+
logger.info(f"Error decoding JSON: {result.text[0]['content']}")
|
| 49 |
+
print(f"Error decoding JSON: {result.text[0]['content']}")
|
| 50 |
+
raise ValueError(
|
| 51 |
+
"The model did not return a valid JSON object while attempting generate personas. Consider using a larger model or a model with higher max token length.")
|
| 52 |
+
return result
|
lida_ko/components/recommender.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tqdm
|
| 2 |
+
import os
|
| 3 |
+
import pickle
|
| 4 |
+
import json
|
| 5 |
+
import logging
|
| 6 |
+
import pandas as pd
|
| 7 |
+
from typing import List, Dict, Any
|
| 8 |
+
|
| 9 |
+
from konlpy.tag import Okt
|
| 10 |
+
from rank_bm25 import BM25Okapi
|
| 11 |
+
|
| 12 |
+
from llmx import TextGenerator, TextGenerationConfig
|
| 13 |
+
|
| 14 |
+
system_prompt = """
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
class Recommender:
|
| 18 |
+
def __init__(self) -> None:
|
| 19 |
+
self.recommendation = None
|
| 20 |
+
self.vector_db = None
|
| 21 |
+
self.query = None
|
| 22 |
+
self.metadata_for_bm25 = None
|
| 23 |
+
|
| 24 |
+
with open('data/id_to_metadata.json', 'r') as f:
|
| 25 |
+
self.id_to_metadata = json.load(f)
|
| 26 |
+
self._set_metadata_for_bm25()
|
| 27 |
+
self.okt = None
|
| 28 |
+
|
| 29 |
+
def recommend(self,
|
| 30 |
+
text_gen: TextGenerator,
|
| 31 |
+
textgen_config: TextGenerationConfig,
|
| 32 |
+
query: str) -> Dict[Any]:
|
| 33 |
+
self.query = query
|
| 34 |
+
self.recommend_by_bm25()
|
| 35 |
+
self.recoomend_by_questions()
|
| 36 |
+
|
| 37 |
+
messages = [
|
| 38 |
+
{"role": "system", "content": system_prompt},
|
| 39 |
+
{"role": "assistant", "content": f"""
|
| 40 |
+
Annotate the dictionary below. Only return a JSON object.
|
| 41 |
+
{base_summary}
|
| 42 |
+
"""},
|
| 43 |
+
]
|
| 44 |
+
# result must contains title, reason, relavance
|
| 45 |
+
extracted_result = []
|
| 46 |
+
text_gen.generate(messages=messages, config=textgen_config)
|
| 47 |
+
|
| 48 |
+
return extracted_result
|
| 49 |
+
|
| 50 |
+
def _set_metadata_for_bm25(self, data: Dict) -> Dict:
|
| 51 |
+
cache_file = 'data/metadata_for_bm25.pkl'
|
| 52 |
+
|
| 53 |
+
if not os.path.exists(cache_file):
|
| 54 |
+
result = {}
|
| 55 |
+
for k, v in self.id_to_metadata.items():
|
| 56 |
+
result[k] = ''
|
| 57 |
+
result[k] += v['title'] + ' '
|
| 58 |
+
result[k] += v['description'] + ' '
|
| 59 |
+
result[k] += ', '.join(v['keywords']) + ' '
|
| 60 |
+
result[k] += v['organization'] + ' '
|
| 61 |
+
result[k] += v['department'] + ' '
|
| 62 |
+
with open(cache_file, 'wb') as f:
|
| 63 |
+
pickle.dump(result, f)
|
| 64 |
+
result = self._set_metadata_for_bm25
|
| 65 |
+
return self.metadata_for_bm25
|
| 66 |
+
|
| 67 |
+
with open(cache_file, 'rb') as f:
|
| 68 |
+
result = pickle.load(f)
|
| 69 |
+
result = self._set_metadata_for_bm25
|
| 70 |
+
return self.metadata_for_bm25
|
| 71 |
+
|
| 72 |
+
def _set_tokenized_corpus(self) -> None:
|
| 73 |
+
self.okt = Okt()
|
| 74 |
+
cache_file = 'data/tokenized_corpus.pkl'
|
| 75 |
+
|
| 76 |
+
if os.path.exists(cache_file):
|
| 77 |
+
with open(cache_file, 'rb') as f:
|
| 78 |
+
tokenized_corpus = pickle.load(f)
|
| 79 |
+
self.tokenized_corpus = tokenized_corpus
|
| 80 |
+
return
|
| 81 |
+
|
| 82 |
+
tokenized_corpus = [self.okt.morphs(value) for value in tqdm(self.metadata_for_bm25.values(), desc='Tokenizing')]
|
| 83 |
+
|
| 84 |
+
with open(cache_file, 'wb') as f:
|
| 85 |
+
pickle.dump(tokenized_corpus, f)
|
| 86 |
+
|
| 87 |
+
self.tokenized_corpus =tokenized_corpus
|
| 88 |
+
|
| 89 |
+
def _recommend_by_bm25(self, top_n=20) -> List[str]:
|
| 90 |
+
if not self.query:
|
| 91 |
+
raise ValueError("query must be provided")
|
| 92 |
+
|
| 93 |
+
tokenized_query = self.okt.morphs(self.query)
|
| 94 |
+
|
| 95 |
+
bm25 = BM25Okapi(self.tokenized_corpus)
|
| 96 |
+
|
| 97 |
+
# 쿼리와 각 설명 간의 BM25 점수 계산
|
| 98 |
+
scores = bm25.get_scores(tokenized_query)
|
| 99 |
+
print(scores)
|
| 100 |
+
|
| 101 |
+
# 점수와 인덱스를 함께 저장
|
| 102 |
+
scored_datasets = list(zip(scores, self.metadata_for_bm25))
|
| 103 |
+
# 점수에 따라 정렬 (내림차순)
|
| 104 |
+
scored_datasets.sort(key=lambda x: x[0], reverse=True)
|
| 105 |
+
|
| 106 |
+
# 상위 N개의 결과 추출
|
| 107 |
+
top_n = 20
|
| 108 |
+
top_n_datasets = scored_datasets[:top_n]
|
| 109 |
+
|
| 110 |
+
print(top_n_datasets)
|
| 111 |
+
|
| 112 |
+
# 결과 출력
|
| 113 |
+
for score, data_id in top_n_datasets:
|
| 114 |
+
print(f"Dataset: {self.id_to_metadata[data_id]['title']}, Score: {score:.4f}, Description: {self.id_to_metadata[data_id]['description']}")
|
| 115 |
+
|
| 116 |
+
def _recommend_by_questions(self) -> List[str]:
|
| 117 |
+
pass
|
| 118 |
+
|
lida_ko/components/scaffold.py
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import asdict
|
| 2 |
+
|
| 3 |
+
from lida_ko.datamodel import Goal
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# if len(plt.xticks()[0])) > 20 assuming plot is made with plt or
|
| 7 |
+
# len(ax.get_xticks()) > 20 assuming plot is made with ax, set a max of 20
|
| 8 |
+
# ticks on x axis, ticker.MaxNLocator(20)
|
| 9 |
+
|
| 10 |
+
class ChartScaffold(object):
|
| 11 |
+
"""Return code scaffold for charts in multiple visualization libraries"""
|
| 12 |
+
|
| 13 |
+
def __init__(
|
| 14 |
+
self,
|
| 15 |
+
) -> None:
|
| 16 |
+
|
| 17 |
+
pass
|
| 18 |
+
|
| 19 |
+
def get_template(self, goal: Goal, library: str):
|
| 20 |
+
|
| 21 |
+
general_instructions = f"If the solution requires a single value (e.g. max, min, median, first, last etc), ALWAYS add a line (axvline or axhline) to the chart, ALWAYS with a legend containing the single value (formatted with 0.2F). If using a <field> where semantic_type=date, YOU MUST APPLY the following transform before using that column i) convert date fields to date types using data[''] = pd.to_datetime(data[<field>], errors='coerce'), ALWAYS use errors='coerce' ii) drop the rows with NaT values data = data[pd.notna(data[<field>])] iii) convert field to right time format for plotting. ALWAYS make sure the x-axis labels are legible (e.g., rotate when needed). Solve the task carefully by completing ONLY the <imports> AND <stub> section. Given the dataset summary, the plot(data) method should generate a {library} chart ({goal.visualization}) that addresses this goal: {goal.question}. DO NOT WRITE ANY CODE TO LOAD THE DATA. The data is already loaded and available in the variable data."
|
| 22 |
+
|
| 23 |
+
matplotlib_instructions = f" {general_instructions} DO NOT include plt.show(). The plot method must return a matplotlib object (plt). Think step by step. \n"
|
| 24 |
+
|
| 25 |
+
if library == "matplotlib":
|
| 26 |
+
instructions = {
|
| 27 |
+
"role": "assistant",
|
| 28 |
+
"content": f" {matplotlib_instructions}. Use BaseMap for charts that require a map. Scope of BaseMap Must be restricted within BUSAN(city of south korea) area."}
|
| 29 |
+
template = \
|
| 30 |
+
f"""
|
| 31 |
+
import matplotlib.pyplot as plt
|
| 32 |
+
import pandas as pd
|
| 33 |
+
import matplotlib.font_manager as fm
|
| 34 |
+
<imports>
|
| 35 |
+
# plan -
|
| 36 |
+
def plot(data: pd.DataFrame):
|
| 37 |
+
path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
|
| 38 |
+
fontprop = fm.FontProperties(fname=path, size=12)
|
| 39 |
+
plt.rc('font', family=fontprop.get_name())
|
| 40 |
+
<stub> # only modify this section
|
| 41 |
+
plt.title('{goal.question}', wrap=True)
|
| 42 |
+
return plt;
|
| 43 |
+
|
| 44 |
+
chart = plot(data) # data already contains the data to be plotted. Always include this line. No additional code beyond this line."""
|
| 45 |
+
elif library == "seaborn":
|
| 46 |
+
instructions = {
|
| 47 |
+
"role": "assistant",
|
| 48 |
+
"content": f"{matplotlib_instructions}. Use BaseMap for charts that require a map. Scope of BaseMap Must be restricted within BUSAN(city of south korea) area."}
|
| 49 |
+
|
| 50 |
+
template = \
|
| 51 |
+
f"""
|
| 52 |
+
import seaborn as sns
|
| 53 |
+
import pandas as pd
|
| 54 |
+
import matplotlib.pyplot as plt
|
| 55 |
+
import matplotlib.font_manager as fm
|
| 56 |
+
<imports>
|
| 57 |
+
# solution plan
|
| 58 |
+
# i. ..
|
| 59 |
+
def plot(data: pd.DataFrame):
|
| 60 |
+
path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
|
| 61 |
+
fontprop = fm.FontProperties(fname=path, size=12)
|
| 62 |
+
plt.rc('font', family=fontprop.get_name())
|
| 63 |
+
|
| 64 |
+
<stub> # only modify this section
|
| 65 |
+
plt.title('{goal.question}', wrap=True)
|
| 66 |
+
return plt;
|
| 67 |
+
|
| 68 |
+
chart = plot(data) # data already contains the data to be plotted. Always include this line. No additional code beyond this line."""
|
| 69 |
+
|
| 70 |
+
elif library == "ggplot":
|
| 71 |
+
instructions = {
|
| 72 |
+
"role": "assistant",
|
| 73 |
+
"content": f"{general_instructions}. The plot method must return a ggplot object (chart)`. Think step by step.p. \n",
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
template = \
|
| 77 |
+
f"""
|
| 78 |
+
import plotnine as p9
|
| 79 |
+
<imports>
|
| 80 |
+
def plot(data: pd.DataFrame):
|
| 81 |
+
chart = <stub>
|
| 82 |
+
|
| 83 |
+
return chart;
|
| 84 |
+
|
| 85 |
+
chart = plot(data) # data already contains the data to be plotted. Always include this line. No additional code beyond this line.. """
|
| 86 |
+
|
| 87 |
+
elif library == "altair":
|
| 88 |
+
instructions = {
|
| 89 |
+
"role": "system",
|
| 90 |
+
"content": f"{general_instructions}. Always add a type that is BASED on semantic_type to each field such as :Q, :O, :N, :T, :G. Use :T if semantic_type is year or date. The plot method must return an altair object (chart)`. Think step by step. \n",
|
| 91 |
+
}
|
| 92 |
+
template = \
|
| 93 |
+
"""
|
| 94 |
+
import altair as alt
|
| 95 |
+
<imports>
|
| 96 |
+
def plot(data: pd.DataFrame):
|
| 97 |
+
<stub> # only modify this section
|
| 98 |
+
return chart
|
| 99 |
+
chart = plot(data) # data already contains the data to be plotted. Always include this line. No additional code beyond this line..
|
| 100 |
+
"""
|
| 101 |
+
|
| 102 |
+
elif library == "plotly":
|
| 103 |
+
instructions = {
|
| 104 |
+
"role": "system",
|
| 105 |
+
"content": f"{general_instructions} If calculating metrics such as mean, median, mode, etc. ALWAYS use the option 'numeric_only=True' when applicable and available, AVOID visualizations that require nbformat library. DO NOT inlcude fig.show(). The plot method must return an plotly figure object (fig)`. Think step by step. \n.",
|
| 106 |
+
}
|
| 107 |
+
template = \
|
| 108 |
+
"""
|
| 109 |
+
import plotly.express as px
|
| 110 |
+
<imports>
|
| 111 |
+
def plot(data: pd.DataFrame):
|
| 112 |
+
fig = <stub> # only modify this section
|
| 113 |
+
|
| 114 |
+
return chart
|
| 115 |
+
chart = plot(data) # variable data already contains the data to be plotted and should not be loaded again. Always include this line. No additional code beyond this line..
|
| 116 |
+
"""
|
| 117 |
+
|
| 118 |
+
else:
|
| 119 |
+
raise ValueError(
|
| 120 |
+
"Unsupported library. Choose from 'matplotlib', 'seaborn', 'plotly', 'bokeh', 'ggplot', 'altair'."
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
return template, instructions
|
lida_ko/components/summarizer.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
from typing import Union
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from lida_ko.utils import clean_code_snippet, read_dataframe
|
| 7 |
+
from lida_ko.datamodel import TextGenerationConfig
|
| 8 |
+
from llmx import TextGenerator
|
| 9 |
+
import warnings
|
| 10 |
+
|
| 11 |
+
system_prompt = """
|
| 12 |
+
You are an experienced data analyst that can annotate datasets. Your instructions are as follows:
|
| 13 |
+
i) ALWAYS generate the name of the dataset and the dataset_description
|
| 14 |
+
ii) ALWAYS generate a field description.
|
| 15 |
+
iii.) ALWAYS generate a semantic_type (a single word) for each field given its values e.g. company, city, number, supplier, location, gender, longitude, latitude, url, ip address, zip code, email, etc
|
| 16 |
+
You must return an updated JSON dictionary without any preamble or explanation.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
logger = logging.getLogger("lida")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class Summarizer():
|
| 23 |
+
def __init__(self) -> None:
|
| 24 |
+
self.summary = None
|
| 25 |
+
|
| 26 |
+
def check_type(self, dtype: str, value):
|
| 27 |
+
"""Cast value to right type to ensure it is JSON serializable"""
|
| 28 |
+
if isinstance(value, float) and math.isnan(value):
|
| 29 |
+
return None
|
| 30 |
+
if "float" in str(dtype):
|
| 31 |
+
return float(value)
|
| 32 |
+
elif "int" in str(dtype):
|
| 33 |
+
return int(value)
|
| 34 |
+
else:
|
| 35 |
+
return value
|
| 36 |
+
|
| 37 |
+
def get_column_properties(self, df: pd.DataFrame, n_samples: int = 3) -> list[dict]:
|
| 38 |
+
"""Get properties of each column in a pandas DataFrame"""
|
| 39 |
+
properties_list = []
|
| 40 |
+
for column in df.columns:
|
| 41 |
+
dtype = df[column].dtype
|
| 42 |
+
properties = {}
|
| 43 |
+
if dtype in [int, float, complex]:
|
| 44 |
+
properties["dtype"] = "number"
|
| 45 |
+
properties["std"] = self.check_type(dtype, df[column].std())
|
| 46 |
+
properties["min"] = self.check_type(dtype, df[column].min())
|
| 47 |
+
properties["max"] = self.check_type(dtype, df[column].max())
|
| 48 |
+
|
| 49 |
+
elif dtype == bool:
|
| 50 |
+
properties["dtype"] = "boolean"
|
| 51 |
+
elif dtype == object:
|
| 52 |
+
# Check if the string column can be cast to a valid datetime
|
| 53 |
+
try:
|
| 54 |
+
with warnings.catch_warnings():
|
| 55 |
+
warnings.simplefilter("ignore")
|
| 56 |
+
pd.to_datetime(df[column], errors='raise')
|
| 57 |
+
properties["dtype"] = "date"
|
| 58 |
+
except ValueError:
|
| 59 |
+
# Check if the string column has a limited number of values
|
| 60 |
+
if df[column].nunique() / len(df[column]) < 0.5:
|
| 61 |
+
properties["dtype"] = "category"
|
| 62 |
+
else:
|
| 63 |
+
properties["dtype"] = "string"
|
| 64 |
+
elif pd.api.types.is_categorical_dtype(df[column]):
|
| 65 |
+
properties["dtype"] = "category"
|
| 66 |
+
elif pd.api.types.is_datetime64_any_dtype(df[column]):
|
| 67 |
+
properties["dtype"] = "date"
|
| 68 |
+
else:
|
| 69 |
+
properties["dtype"] = str(dtype)
|
| 70 |
+
|
| 71 |
+
# add min max if dtype is date
|
| 72 |
+
if properties["dtype"] == "date":
|
| 73 |
+
try:
|
| 74 |
+
properties["min"] = df[column].min()
|
| 75 |
+
properties["max"] = df[column].max()
|
| 76 |
+
except TypeError:
|
| 77 |
+
cast_date_col = pd.to_datetime(df[column], errors='coerce')
|
| 78 |
+
properties["min"] = cast_date_col.min()
|
| 79 |
+
properties["max"] = cast_date_col.max()
|
| 80 |
+
# Add additional properties to the output dictionary
|
| 81 |
+
nunique = df[column].nunique()
|
| 82 |
+
if "samples" not in properties:
|
| 83 |
+
non_null_values = df[column][df[column].notnull()].unique()
|
| 84 |
+
n_samples = min(n_samples, len(non_null_values))
|
| 85 |
+
samples = pd.Series(non_null_values).sample(
|
| 86 |
+
n_samples, random_state=42).tolist()
|
| 87 |
+
properties["samples"] = samples
|
| 88 |
+
properties["num_unique_values"] = nunique
|
| 89 |
+
properties["semantic_type"] = ""
|
| 90 |
+
properties["description"] = ""
|
| 91 |
+
properties_list.append(
|
| 92 |
+
{"column": column, "properties": properties})
|
| 93 |
+
|
| 94 |
+
return properties_list
|
| 95 |
+
|
| 96 |
+
def enrich(self, base_summary: dict, text_gen: TextGenerator,
|
| 97 |
+
textgen_config: TextGenerationConfig) -> dict:
|
| 98 |
+
"""Enrich the data summary with descriptions"""
|
| 99 |
+
logger.info(f"Enriching the data summary with descriptions")
|
| 100 |
+
|
| 101 |
+
messages = [
|
| 102 |
+
{"role": "system", "content": system_prompt},
|
| 103 |
+
{"role": "assistant", "content": f"""
|
| 104 |
+
Annotate the dictionary below. Only return a JSON object.
|
| 105 |
+
{base_summary}
|
| 106 |
+
"""},
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
response = text_gen.generate(messages=messages, config=textgen_config)
|
| 110 |
+
enriched_summary = base_summary
|
| 111 |
+
try:
|
| 112 |
+
json_string = clean_code_snippet(response.text[0]["content"])
|
| 113 |
+
enriched_summary = json.loads(json_string)
|
| 114 |
+
except json.decoder.JSONDecodeError:
|
| 115 |
+
error_msg = f"The model did not return a valid JSON object while attempting to generate an enriched data summary. Consider using a default summary or a larger model with higher max token length. | {response.text[0]['content']}"
|
| 116 |
+
logger.info(error_msg)
|
| 117 |
+
print(response.text[0]["content"])
|
| 118 |
+
response_usage = response.usage if response.usage else "Usage information is not available"
|
| 119 |
+
raise ValueError(error_msg + "" + response_usage.total_tokens)
|
| 120 |
+
return enriched_summary
|
| 121 |
+
|
| 122 |
+
def summarize(
|
| 123 |
+
self, data: Union[pd.DataFrame, str],
|
| 124 |
+
text_gen: TextGenerator, file_name="", n_samples: int = 3,
|
| 125 |
+
textgen_config=TextGenerationConfig(n=1),
|
| 126 |
+
summary_method: str = "default", encoding: str = 'utf-8',
|
| 127 |
+
metadata: dict = None) -> dict:
|
| 128 |
+
"""Summarize data from a pandas DataFrame or a file location"""
|
| 129 |
+
|
| 130 |
+
# if data is a file path, read it into a pandas DataFrame, set file_name to the file name
|
| 131 |
+
if isinstance(data, str):
|
| 132 |
+
file_name = data.split("/")[-1]
|
| 133 |
+
# modified to include encoding
|
| 134 |
+
data = read_dataframe(data, encoding=encoding)
|
| 135 |
+
data_properties = self.get_column_properties(data, n_samples)
|
| 136 |
+
|
| 137 |
+
# default single stage summary construction
|
| 138 |
+
base_summary = {
|
| 139 |
+
"name": file_name,
|
| 140 |
+
"file_name": file_name,
|
| 141 |
+
"dataset_description": "",
|
| 142 |
+
"fields": data_properties,
|
| 143 |
+
}
|
| 144 |
+
if metadata is not None:
|
| 145 |
+
for k, v in metadata.items():
|
| 146 |
+
if k == 'file_data':
|
| 147 |
+
continue
|
| 148 |
+
if isinstance(v, list):
|
| 149 |
+
v = ', '.join(v)
|
| 150 |
+
base_summary[k] = v
|
| 151 |
+
|
| 152 |
+
data_summary = base_summary
|
| 153 |
+
|
| 154 |
+
if summary_method == "llm":
|
| 155 |
+
# two stage summarization with llm enrichment
|
| 156 |
+
data_summary = self.enrich(
|
| 157 |
+
base_summary,
|
| 158 |
+
text_gen=text_gen,
|
| 159 |
+
textgen_config=textgen_config)
|
| 160 |
+
elif summary_method == "columns":
|
| 161 |
+
# no enrichment, only column names
|
| 162 |
+
data_summary = {
|
| 163 |
+
"name": file_name,
|
| 164 |
+
"file_name": file_name,
|
| 165 |
+
"dataset_description": ""
|
| 166 |
+
}
|
| 167 |
+
|
| 168 |
+
data_summary["field_names"] = data.columns.tolist()
|
| 169 |
+
data_summary["file_name"] = file_name
|
| 170 |
+
|
| 171 |
+
return data_summary
|
lida_ko/components/viz/__init__.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .vizeditor import *
|
| 2 |
+
from .vizexplainer import *
|
| 3 |
+
from .vizgenerator import *
|
| 4 |
+
from .vizevaluator import *
|
| 5 |
+
from .vizrepairer import *
|
| 6 |
+
from .vizrecommender import *
|
lida_ko/components/viz/vizeditor.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from llmx import TextGenerator, TextGenerationConfig, TextGenerationResponse
|
| 2 |
+
from ..scaffold import ChartScaffold
|
| 3 |
+
from lida_ko.datamodel import Goal, Summary
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
system_prompt = """
|
| 7 |
+
You are a high skilled visualization assistant that can modify a provided visualization code based on a set of instructions. You MUST return a full program. DO NOT include any preamble text. Do not include explanations or prose.
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class VizEditor(object):
|
| 12 |
+
"""Generate visualizations from prompt"""
|
| 13 |
+
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
) -> None:
|
| 17 |
+
self.scaffold = ChartScaffold()
|
| 18 |
+
|
| 19 |
+
def generate(
|
| 20 |
+
self, code: str, summary: Summary, instructions: list[str],
|
| 21 |
+
textgen_config: TextGenerationConfig, text_gen: TextGenerator, library='altair'):
|
| 22 |
+
"""Edit a code spec based on instructions"""
|
| 23 |
+
|
| 24 |
+
instruction_string = ""
|
| 25 |
+
for i, instruction in enumerate(instructions):
|
| 26 |
+
instruction_string += f"{i+1}. {instruction} \n"
|
| 27 |
+
|
| 28 |
+
library_template, library_instructions = self.scaffold.get_template(Goal(
|
| 29 |
+
index=0,
|
| 30 |
+
question="",
|
| 31 |
+
visualization="",
|
| 32 |
+
rationale=""), library)
|
| 33 |
+
# print("instructions", instructions)
|
| 34 |
+
|
| 35 |
+
messages = [
|
| 36 |
+
{
|
| 37 |
+
"role": "system", "content": system_prompt}, {
|
| 38 |
+
"role": "system", "content": f"The dataset summary is : \n\n {summary} \n\n"}, {
|
| 39 |
+
"role": "system", "content": f"The modifications you make MUST BE CORRECT and based on the '{library}' library and also follow these instructions instructions \n\n{library_instructions} \n\n. The resulting code MUST use the following template \n\n {library_template} \n\n "}, {
|
| 40 |
+
"role": "user", "content": f"ALL ADDITIONAL LIBRARIES USED MUST BE IMPORTED.\n The code to be modified is: \n\n{code} \n\n. YOU MUST THINK STEP BY STEP, AND CAREFULLY MODIFY ONLY the content of the plot(..) method TO MEET EACH OF THE FOLLOWING INSTRUCTIONS: \n\n {instruction_string} \n\n. The completed modified code THAT FOLLOWS THE TEMPLATE above is. \n"}]
|
| 41 |
+
|
| 42 |
+
completions: TextGenerationResponse = text_gen.generate(
|
| 43 |
+
messages=messages, config=textgen_config)
|
| 44 |
+
return [x['content'] for x in completions.text]
|
lida_ko/components/viz/vizevaluator.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import json
|
| 3 |
+
from ...utils import clean_code_snippet
|
| 4 |
+
from llmx import TextGenerator, TextGenerationConfig, TextGenerationResponse
|
| 5 |
+
|
| 6 |
+
from lida_ko.datamodel import Goal
|
| 7 |
+
|
| 8 |
+
system_prompt = """
|
| 9 |
+
You are a helpful assistant highly skilled in evaluating the quality of a given visualization code by providing a score from 1 (bad) - 10 (good) while providing clear rationale. YOU MUST CONSIDER VISUALIZATION BEST PRACTICES for each evaluation. Specifically, you can carefully evaluate the code across the following dimensions
|
| 10 |
+
- bugs (bugs): are there bugs, logic errors, syntax error or typos? Are there any reasons why the code may fail to compile? How should it be fixed? If ANY bug exists, the bug score MUST be less than 5.
|
| 11 |
+
- Data transformation (transformation): Is the data transformed appropriately for the visualization type? E.g., is the dataset appropriated filtered, aggregated, or grouped if needed?
|
| 12 |
+
- Goal compliance (compliance): how well the code meets the specified visualization goals?
|
| 13 |
+
- Visualization type (type): CONSIDERING BEST PRACTICES, is the visualization type appropriate for the data and intent? Is there a visualization type that would be more effective in conveying insights? If a different visualization type is more appropriate, the score MUST be less than 5.
|
| 14 |
+
- Data encoding (encoding): Is the data encoded appropriately for the visualization type?
|
| 15 |
+
- aesthetics (aesthetics): Are the aesthetics of the visualization appropriate for the visualization type and the data?
|
| 16 |
+
|
| 17 |
+
You must provide a score for each of the above dimensions. Assume that data in chart = plot(data) contains a valid dataframe for the dataset. The `plot` function returns a chart (e.g., matplotlib, seaborn etc object).
|
| 18 |
+
|
| 19 |
+
Your OUTPUT MUST BE A VALID JSON LIST OF OBJECTS in the format:
|
| 20 |
+
|
| 21 |
+
```[
|
| 22 |
+
{ "dimension": "bugs", "score": x , "rationale": " .."}, { "dimension": "transformation", "score": x, "rationale": " .."}, { "dimension": "compliance", "score": x, "rationale": " .."},{ "dimension": "type", "score": x, "rationale": " .."}, { "dimension": "encoding", "score": x, "rationale": " .."}, { "dimension": "aesthetics", "score": x, "rationale": " .."}
|
| 23 |
+
]
|
| 24 |
+
```
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class VizEvaluator(object):
|
| 29 |
+
"""Generate visualizations Explanations given some code"""
|
| 30 |
+
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
) -> None:
|
| 34 |
+
pass
|
| 35 |
+
|
| 36 |
+
def generate(self, code: str, goal: Goal,
|
| 37 |
+
textgen_config: TextGenerationConfig, text_gen: TextGenerator, library='altair'):
|
| 38 |
+
"""Generate a visualization explanation given some code"""
|
| 39 |
+
|
| 40 |
+
messages = [
|
| 41 |
+
{"role": "system", "content": system_prompt},
|
| 42 |
+
{"role": "assistant",
|
| 43 |
+
"content": f"Generate an evaluation given the goal and code below in {library}. The specified goal is \n\n {goal.question} \n\n and the visualization code is \n\n {code} \n\n. Now, evaluate the code based on the 6 dimensions above. \n. THE SCORE YOU ASSIGN MUST BE MEANINGFUL AND BACKED BY CLEAR RATIONALE. A SCORE OF 1 IS POOR AND A SCORE OF 10 IS VERY GOOD. The structured evaluation is below ."},
|
| 44 |
+
]
|
| 45 |
+
|
| 46 |
+
# print(messages)
|
| 47 |
+
completions: TextGenerationResponse = text_gen.generate(
|
| 48 |
+
messages=messages, config=textgen_config)
|
| 49 |
+
|
| 50 |
+
completions = [clean_code_snippet(x['content']) for x in completions.text]
|
| 51 |
+
evaluations = []
|
| 52 |
+
for completion in completions:
|
| 53 |
+
try:
|
| 54 |
+
evaluation = json.loads(completion)
|
| 55 |
+
evaluations.append(evaluation)
|
| 56 |
+
except Exception as json_error:
|
| 57 |
+
print("Error parsing evaluation data", completion, str(json_error))
|
| 58 |
+
return evaluations
|
lida_ko/components/viz/vizexplainer.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import json
|
| 3 |
+
from lida_ko.utils import clean_code_snippet
|
| 4 |
+
from llmx import TextGenerator, TextGenerationConfig, TextGenerationResponse
|
| 5 |
+
from ..scaffold import ChartScaffold
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
system_prompt = """
|
| 9 |
+
You are a helpful assistant highly skilled in providing helpful, structured explanations of visualization of the plot(data: pd.DataFrame) method in the provided code. You divide the code into sections and provide a description of each section and an explanation. The first section should be named "accessibility" and describe the physical appearance of the chart (colors, chart type etc), the goal of the chart, as well the main insights from the chart.
|
| 10 |
+
You can explain code across the following 3 dimensions:
|
| 11 |
+
1. accessibility: the physical appearance of the chart (colors, chart type etc), the goal of the chart, as well the main insights from the chart.
|
| 12 |
+
2. transformation: This should describe the section of the code that applies any kind of data transformation (filtering, aggregation, grouping, null value handling etc)
|
| 13 |
+
3. visualization: step by step description of the code that creates or modifies the presented visualization.
|
| 14 |
+
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
format_instructions = """
|
| 18 |
+
Your output MUST be perfect JSON in THE FORM OF A VALID LIST of JSON OBJECTS WITH PROPERLY ESCAPED SPECIAL CHARACTERS e.g.,
|
| 19 |
+
|
| 20 |
+
```[
|
| 21 |
+
{"section": "accessibility", "code": "None", "explanation": ".."} , {"section": "transformation", "code": "..", "explanation": ".."} , {"section": "visualization", "code": "..", "explanation": ".."}
|
| 22 |
+
] ```
|
| 23 |
+
|
| 24 |
+
The code part of the dictionary must come from the supplied code and should cover the explanation. The explanation part of the dictionary must be a string. The section part of the dictionary must be one of "accessibility", "transformation", "visualization" with no repetition. THE LIST MUST HAVE EXACTLY 3 JSON OBJECTS [{}, {}, {}]. THE GENERATED JSON MUST BE A LIST IE START AND END WITH A SQUARE BRACKET.
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class VizExplainer(object):
|
| 29 |
+
"""Generate visualizations Explanations given some code"""
|
| 30 |
+
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
) -> None:
|
| 34 |
+
self.scaffold = ChartScaffold()
|
| 35 |
+
|
| 36 |
+
def generate(
|
| 37 |
+
self, code: str,
|
| 38 |
+
textgen_config: TextGenerationConfig, text_gen: TextGenerator, library='seaborn'):
|
| 39 |
+
"""Generate a visualization explanation given some code"""
|
| 40 |
+
|
| 41 |
+
messages = [
|
| 42 |
+
{"role": "system", "content": system_prompt},
|
| 43 |
+
{"role": "assistant", "content": f"The code to be explained is {code}.\n=======\n"},
|
| 44 |
+
{"role": "user",
|
| 45 |
+
"content": f"{format_instructions}. \n\n. The structured explanation for the code above is \n\n"}
|
| 46 |
+
]
|
| 47 |
+
|
| 48 |
+
completions: TextGenerationResponse = text_gen.generate(
|
| 49 |
+
messages=messages, config=textgen_config)
|
| 50 |
+
|
| 51 |
+
completions = [clean_code_snippet(x['content']) for x in completions.text]
|
| 52 |
+
explanations = []
|
| 53 |
+
|
| 54 |
+
for completion in completions:
|
| 55 |
+
try:
|
| 56 |
+
exp = json.loads(completion)
|
| 57 |
+
explanations.append(exp)
|
| 58 |
+
except Exception as e:
|
| 59 |
+
print("Error parsing completion", completion, str(e))
|
| 60 |
+
return explanations
|
lida_ko/components/viz/vizgenerator.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import asdict
|
| 2 |
+
from typing import Dict
|
| 3 |
+
from llmx import TextGenerator, TextGenerationConfig, TextGenerationResponse
|
| 4 |
+
|
| 5 |
+
from ..scaffold import ChartScaffold
|
| 6 |
+
from lida_ko.datamodel import Goal
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
system_prompt = """
|
| 10 |
+
You are a helpful assistant highly skilled in writing PERFECT code for visualizations. Given some code template, you complete the template to generate a visualization given the dataset and the goal described. The code you write MUST FOLLOW VISUALIZATION BEST PRACTICES ie. meet the specified goal, apply the right transformation, use the right visualization type, use the right data encoding, and use the right aesthetics (e.g., ensure axis are legible). The transformations you apply MUST be correct and the fields you use MUST be correct. The visualization CODE MUST BE CORRECT and MUST NOT CONTAIN ANY SYNTAX OR LOGIC ERRORS (e.g., it must consider the field types and use them correctly). You MUST first generate a brief plan for how you would solve the task e.g. what transformations you would apply e.g. if you need to construct a new column, what fields you would use, what visualization type you would use, what aesthetics you would use, etc. .
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class VizGenerator(object):
|
| 15 |
+
"""Generate visualizations from prompt"""
|
| 16 |
+
|
| 17 |
+
def __init__(
|
| 18 |
+
self
|
| 19 |
+
) -> None:
|
| 20 |
+
|
| 21 |
+
self.scaffold = ChartScaffold()
|
| 22 |
+
|
| 23 |
+
def generate(self, summary: Dict, goal: Goal,
|
| 24 |
+
textgen_config: TextGenerationConfig, text_gen: TextGenerator, library='altair'):
|
| 25 |
+
"""Generate visualization code given a summary and a goal"""
|
| 26 |
+
|
| 27 |
+
library_template, library_instructions = self.scaffold.get_template(goal, library)
|
| 28 |
+
messages = [
|
| 29 |
+
{"role": "system", "content": system_prompt},
|
| 30 |
+
{"role": "system", "content": f"The dataset summary is : {summary} \n\n"},
|
| 31 |
+
library_instructions,
|
| 32 |
+
{"role": "user",
|
| 33 |
+
"content":
|
| 34 |
+
f"Always add a legend with various colors where appropriate. The visualization code MUST only use data fields that exist in the dataset (field_names) or fields that are transformations based on existing field_names). Only use variables that have been defined in the code or are in the dataset summary. You MUST return a FULL PYTHON PROGRAM ENCLOSED IN BACKTICKS ``` that starts with an import statement. DO NOT add any explanation. \n\n THE GENERATED CODE SOLUTION SHOULD BE CREATED BY MODIFYING THE SPECIFIED PARTS OF THE TEMPLATE BELOW \n\n {library_template} \n\n.The FINAL COMPLETED CODE BASED ON THE TEMPLATE above is ... \n\n"}]
|
| 35 |
+
|
| 36 |
+
completions: TextGenerationResponse = text_gen.generate(
|
| 37 |
+
messages=messages, config=textgen_config)
|
| 38 |
+
response = [x['content'] for x in completions.text]
|
| 39 |
+
|
| 40 |
+
return response
|
lida_ko/components/viz/vizrecommender.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import json
|
| 3 |
+
from lida_ko.utils import clean_code_snippet
|
| 4 |
+
from ..scaffold import ChartScaffold
|
| 5 |
+
from llmx import TextGenerator, TextGenerationConfig, TextGenerationResponse
|
| 6 |
+
# from lida.modules.scaffold import ChartScaffold
|
| 7 |
+
from lida_ko.datamodel import Goal, Summary
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
system_prompt = """
|
| 11 |
+
|
| 12 |
+
You are a helpful assistant highly skilled in recommending a DIVERSE set of visualization code. Your input is an example visualization code, a summary of a dataset and an example visualization goal that the user has already seen. Given this input, your task is to recommend additional visualizations that a user may be interested. Your recommendation may consider different types of valid data aggregations, chart types, clearer ways of displaying information and uses different variables from the data summary. THE CODE YOU GENERATE MUST BE CORRECT (follow the language syntax and syntax of the visualization grammar) AND FOLLOW VISUALIZATION BEST PRACTICES.
|
| 13 |
+
|
| 14 |
+
Your output MUST be a n code snippets separated by ******* (5 asterisks). Each snippet MUST BE AN independent code snippet (with one plot method) similar to the example code. For example
|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
# code snippet 1
|
| 18 |
+
import ...
|
| 19 |
+
....
|
| 20 |
+
```
|
| 21 |
+
*****
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
# code snippet 2
|
| 25 |
+
import ...
|
| 26 |
+
....
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
```python
|
| 30 |
+
# code snippet n
|
| 31 |
+
import ...
|
| 32 |
+
....
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
logger = logging.getLogger("lida")
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class VizRecommender(object):
|
| 42 |
+
"""Generate visualizations from prompt"""
|
| 43 |
+
|
| 44 |
+
def __init__(
|
| 45 |
+
self,
|
| 46 |
+
) -> None:
|
| 47 |
+
self.scaffold = ChartScaffold()
|
| 48 |
+
|
| 49 |
+
def generate(
|
| 50 |
+
self, code: str, summary: Summary,
|
| 51 |
+
textgen_config: TextGenerationConfig,
|
| 52 |
+
text_gen: TextGenerator,
|
| 53 |
+
n=3,
|
| 54 |
+
library='seaborn'):
|
| 55 |
+
"""Recommend a code spec based on existing visualization"""
|
| 56 |
+
|
| 57 |
+
library_template, library_instructions = self.scaffold.get_template(Goal(
|
| 58 |
+
index=0,
|
| 59 |
+
question="",
|
| 60 |
+
visualization="",
|
| 61 |
+
rationale=""), library)
|
| 62 |
+
|
| 63 |
+
structure_instruction = f"""
|
| 64 |
+
EACH CODE SNIPPET MUST BE A FULL PROGRAM (IT MUST IMPORT ALL THE LIBRARIES THAT ARE USED AND MUST CONTAIN plot(data) method). IT MUST FOLLOW THE STRUCTURE BELOW AND ONLY MODIFY THE INDICATED SECTIONS. \n\n {library_template} \n\n.
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
messages = [
|
| 68 |
+
{"role": "system", "content": system_prompt},
|
| 69 |
+
{"role": "system", "content": structure_instruction},
|
| 70 |
+
{"role": "system", "content": f"The dataset summary is : \n\n {summary} \n\n"},
|
| 71 |
+
{"role": "system",
|
| 72 |
+
"content":
|
| 73 |
+
f"An example visualization code is: \n\n ```{code}``` \n\n. You MUST use only the {library} library. \n"},
|
| 74 |
+
{"role": "user", "content": f"Recommend {n} (n=({n})) visualizations in the format specified. \n."}]
|
| 75 |
+
|
| 76 |
+
textgen_config.messages = messages
|
| 77 |
+
result: TextGenerationResponse = text_gen.generate(
|
| 78 |
+
messages=messages, config=textgen_config)
|
| 79 |
+
output = []
|
| 80 |
+
snippets = result.text[0]["content"].split("*****")
|
| 81 |
+
for snippet in snippets:
|
| 82 |
+
cleaned_snippet = clean_code_snippet(snippet)
|
| 83 |
+
if len(cleaned_snippet) > 4:
|
| 84 |
+
output.append(cleaned_snippet)
|
| 85 |
+
|
| 86 |
+
return output
|
lida_ko/components/viz/vizrepairer.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, List, Union
|
| 2 |
+
from llmx import TextGenerator, TextGenerationConfig, TextGenerationResponse
|
| 3 |
+
|
| 4 |
+
from ..scaffold import ChartScaffold
|
| 5 |
+
from lida_ko.datamodel import Goal, Summary
|
| 6 |
+
|
| 7 |
+
system_prompt = """
|
| 8 |
+
You are a helpful assistant highly skilled in revising visualization code to improve the quality of the code and visualization based on feedback. Assume that data in plot(data) contains a valid dataframe.
|
| 9 |
+
You MUST return a full program. DO NOT include any preamble text. Do not include explanations or prose.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class VizRepairer(object):
|
| 14 |
+
"""Fix visualization code based on feedback"""
|
| 15 |
+
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
) -> None:
|
| 19 |
+
self.scaffold = ChartScaffold()
|
| 20 |
+
|
| 21 |
+
def generate(
|
| 22 |
+
self, code: str, feedback: Union[str, Dict, List[Dict]],
|
| 23 |
+
goal: Goal, summary: Summary, textgen_config: TextGenerationConfig,
|
| 24 |
+
text_gen: TextGenerator, library='altair',):
|
| 25 |
+
"""Fix a code spec based on feedback"""
|
| 26 |
+
library_template, library_instructions = self.scaffold.get_template(Goal(
|
| 27 |
+
index=0,
|
| 28 |
+
question="",
|
| 29 |
+
visualization="",
|
| 30 |
+
rationale=""), library)
|
| 31 |
+
messages = [
|
| 32 |
+
{"role": "system", "content": system_prompt},
|
| 33 |
+
{"role": "system", "content": f"The dataset summary is : {summary}. \n . The original goal was: {goal}."},
|
| 34 |
+
{"role": "system",
|
| 35 |
+
"content":
|
| 36 |
+
f"You MUST use only the {library}. The resulting code MUST use the following template {library_template}. Only use variables that have been defined in the code or are in the dataset summary"},
|
| 37 |
+
{"role": "user", "content": f"The existing code to be fixed is: {code}. \n Fix the code above to address the feedback: {feedback}. ONLY apply feedback that are CORRECT."}]
|
| 38 |
+
|
| 39 |
+
# library with the following instructions {library_instructions}
|
| 40 |
+
|
| 41 |
+
completions: TextGenerationResponse = text_gen.generate(
|
| 42 |
+
messages=messages, config=textgen_config)
|
| 43 |
+
return [x['content'] for x in completions.text]
|
lida_ko/datamodel.py
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# from dataclasses import dataclass
|
| 2 |
+
import base64
|
| 3 |
+
from dataclasses import field
|
| 4 |
+
from typing import Any, Dict, List, Optional, Union
|
| 5 |
+
|
| 6 |
+
from llmx import TextGenerationConfig
|
| 7 |
+
from pydantic.dataclasses import dataclass
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@dataclass
|
| 11 |
+
class VizGeneratorConfig:
|
| 12 |
+
"""Configuration for a visualization generation"""
|
| 13 |
+
|
| 14 |
+
hypothesis: str
|
| 15 |
+
data_summary: Optional[str] = ""
|
| 16 |
+
data_filename: Optional[str] = "cars.csv"
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@dataclass
|
| 20 |
+
class CompletionResult:
|
| 21 |
+
text: str
|
| 22 |
+
logprobs: Optional[List[float]]
|
| 23 |
+
prompt: str
|
| 24 |
+
suffix: str
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
@dataclass
|
| 28 |
+
class UploadUrl:
|
| 29 |
+
"""Response from a text generation"""
|
| 30 |
+
|
| 31 |
+
url: str
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
@dataclass
|
| 35 |
+
class Goal:
|
| 36 |
+
"""A visualization goal"""
|
| 37 |
+
question: str
|
| 38 |
+
visualization: str
|
| 39 |
+
rationale: str
|
| 40 |
+
index: Optional[int] = 0
|
| 41 |
+
|
| 42 |
+
def _repr_markdown_(self):
|
| 43 |
+
return f"""
|
| 44 |
+
### Goal {self.index}
|
| 45 |
+
---
|
| 46 |
+
**Question:** {self.question}
|
| 47 |
+
|
| 48 |
+
**Visualization:** `{self.visualization}`
|
| 49 |
+
|
| 50 |
+
**Rationale:** {self.rationale}
|
| 51 |
+
"""
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@dataclass
|
| 55 |
+
class Summary:
|
| 56 |
+
"""A summary of a dataset
|
| 57 |
+
Tweaked for lida_ko"""
|
| 58 |
+
|
| 59 |
+
name: str
|
| 60 |
+
file_name: str
|
| 61 |
+
dataset_description: str
|
| 62 |
+
field_names: List[Any]
|
| 63 |
+
fields: Optional[List[Any]] = None
|
| 64 |
+
title: Optional[str] = None
|
| 65 |
+
keywords: Optional[str] = None
|
| 66 |
+
organization: Optional[str] = None
|
| 67 |
+
department: Optional[str] = None
|
| 68 |
+
phone: Optional[str] = None
|
| 69 |
+
update_interval: Optional[str] = None
|
| 70 |
+
updated_at: Optional[str] = None
|
| 71 |
+
next_update_at: Optional[str] = None
|
| 72 |
+
cost: Optional[str] = None
|
| 73 |
+
serving_type: Optional[str] = None
|
| 74 |
+
download_count: Optional[str] = None
|
| 75 |
+
permission_scope: Optional[str] = None
|
| 76 |
+
timestamp: Optional[str] = None
|
| 77 |
+
augmentation: Optional[dict] = None
|
| 78 |
+
|
| 79 |
+
def _repr_markdown_(self):
|
| 80 |
+
field_lines = "\n".join([f"- **{name}:** {field}" for name,
|
| 81 |
+
field in zip(self.field_names, self.fields)])
|
| 82 |
+
metadata_lines = ""
|
| 83 |
+
if self.title is not None:
|
| 84 |
+
metadata_lines += f"- **Title:** {self.title}\n"
|
| 85 |
+
if self.keywords is not None:
|
| 86 |
+
metadata_lines += f"- **Keywords:** {self.keywords}\n"
|
| 87 |
+
if self.organization is not None:
|
| 88 |
+
metadata_lines += f"- **Organization:** {self.organization}\n"
|
| 89 |
+
if self.department is not None:
|
| 90 |
+
metadata_lines += f"- **Department:** {self.department}\n"
|
| 91 |
+
if self.phone is not None:
|
| 92 |
+
metadata_lines += f"- **Phone:** {self.phone}\n"
|
| 93 |
+
if self.update_interval is not None:
|
| 94 |
+
metadata_lines += f"- **Update Interval:** {self.update_interval}\n"
|
| 95 |
+
if self.updated_at is not None:
|
| 96 |
+
metadata_lines += f"- **Updated At:** {self.updated_at}\n"
|
| 97 |
+
if self.next_update_at is not None:
|
| 98 |
+
metadata_lines += f"- **Next Update At:** {self.next_update_at}\n"
|
| 99 |
+
if self.cost is not None:
|
| 100 |
+
metadata_lines += f"- **Cost:** {self.cost}\n"
|
| 101 |
+
if self.serving_type is not None:
|
| 102 |
+
metadata_lines += f"- **Serving Type:** {self.serving_type}\n"
|
| 103 |
+
if self.download_count is not None:
|
| 104 |
+
metadata_lines += f"- **Download Count:** {self.download_count}\n"
|
| 105 |
+
if self.permission_scope is not None:
|
| 106 |
+
metadata_lines += f"- **Permission Scope:** {self.permission_scope}\n"
|
| 107 |
+
if self.timestamp is not None:
|
| 108 |
+
metadata_lines += f"- **Timestamp:** {self.timestamp}\n"
|
| 109 |
+
if self.augmentation is not None:
|
| 110 |
+
metadata_lines += f"- **Augmentation:** {self.augmentation}\n"
|
| 111 |
+
return f"""
|
| 112 |
+
## Dataset Summary
|
| 113 |
+
|
| 114 |
+
---
|
| 115 |
+
|
| 116 |
+
**Name:** {self.name}
|
| 117 |
+
|
| 118 |
+
**File Name:** {self.file_name}
|
| 119 |
+
|
| 120 |
+
**Dataset Description:**
|
| 121 |
+
|
| 122 |
+
{self.dataset_description}
|
| 123 |
+
|
| 124 |
+
{metadata_lines}
|
| 125 |
+
|
| 126 |
+
**Fields:**
|
| 127 |
+
|
| 128 |
+
{field_lines}
|
| 129 |
+
"""
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
@dataclass
|
| 133 |
+
class Persona:
|
| 134 |
+
"""A persona"""
|
| 135 |
+
persona: str
|
| 136 |
+
rationale: str
|
| 137 |
+
|
| 138 |
+
def _repr_markdown_(self):
|
| 139 |
+
return f"""
|
| 140 |
+
### Persona
|
| 141 |
+
---
|
| 142 |
+
|
| 143 |
+
**Persona:** {self.persona}
|
| 144 |
+
|
| 145 |
+
**Rationale:** {self.rationale}
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
@dataclass
|
| 150 |
+
class GoalWebRequest:
|
| 151 |
+
"""A Goal Web Request"""
|
| 152 |
+
|
| 153 |
+
summary: Summary
|
| 154 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 155 |
+
default_factory=TextGenerationConfig
|
| 156 |
+
)
|
| 157 |
+
n: int = 5
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
@dataclass
|
| 161 |
+
class VisualizeWebRequest:
|
| 162 |
+
"""A Visualize Web Request"""
|
| 163 |
+
|
| 164 |
+
summary: Summary
|
| 165 |
+
goal: Goal
|
| 166 |
+
library: str = "seaborn"
|
| 167 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 168 |
+
default_factory=TextGenerationConfig
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
@dataclass
|
| 173 |
+
class VisualizeRecommendRequest:
|
| 174 |
+
"""A Visualize Recommendation Request"""
|
| 175 |
+
|
| 176 |
+
summary: Summary
|
| 177 |
+
code: str
|
| 178 |
+
library: str = "seaborn"
|
| 179 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 180 |
+
default_factory=TextGenerationConfig
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
@dataclass
|
| 185 |
+
class VisualizeEditWebRequest:
|
| 186 |
+
"""A Visualize Edit Web Request"""
|
| 187 |
+
|
| 188 |
+
summary: Summary
|
| 189 |
+
code: str
|
| 190 |
+
instructions: Union[str, List[str]]
|
| 191 |
+
library: str = "seaborn"
|
| 192 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 193 |
+
default_factory=TextGenerationConfig
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
@dataclass
|
| 198 |
+
class VisualizeRepairWebRequest:
|
| 199 |
+
"""A Visualize Repair Web Request"""
|
| 200 |
+
|
| 201 |
+
feedback: Optional[Union[str, List[str], List[Dict]]]
|
| 202 |
+
code: str
|
| 203 |
+
goal: Goal
|
| 204 |
+
summary: Summary
|
| 205 |
+
library: str = "seaborn"
|
| 206 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 207 |
+
default_factory=TextGenerationConfig
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
@dataclass
|
| 212 |
+
class VisualizeExplainWebRequest:
|
| 213 |
+
"""A Visualize Explain Web Request"""
|
| 214 |
+
|
| 215 |
+
code: str
|
| 216 |
+
library: str = "seaborn"
|
| 217 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 218 |
+
default_factory=TextGenerationConfig
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
@dataclass
|
| 223 |
+
class VisualizeEvalWebRequest:
|
| 224 |
+
"""A Visualize Eval Web Request"""
|
| 225 |
+
|
| 226 |
+
code: str
|
| 227 |
+
goal: Goal
|
| 228 |
+
library: str = "seaborn"
|
| 229 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 230 |
+
default_factory=TextGenerationConfig
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
@dataclass
|
| 235 |
+
class ChartExecutorResponse:
|
| 236 |
+
"""Response from a visualization execution"""
|
| 237 |
+
|
| 238 |
+
spec: Optional[Union[str, Dict]] # interactive specification e.g. vegalite
|
| 239 |
+
status: bool # True if successful
|
| 240 |
+
raster: Optional[str] # base64 encoded image
|
| 241 |
+
code: str # code used to generate the visualization
|
| 242 |
+
library: str # library used to generate the visualization
|
| 243 |
+
error: Optional[Dict] = None # error message if status is False
|
| 244 |
+
|
| 245 |
+
def _repr_mimebundle_(self, include=None, exclude=None):
|
| 246 |
+
bundle = {"text/plain": self.code}
|
| 247 |
+
if self.raster is not None:
|
| 248 |
+
bundle["image/png"] = self.raster
|
| 249 |
+
if self.spec is not None:
|
| 250 |
+
bundle["application/vnd.vegalite.v5+json"] = self.spec
|
| 251 |
+
|
| 252 |
+
return bundle
|
| 253 |
+
|
| 254 |
+
def savefig(self, path):
|
| 255 |
+
"""Save the raster image to a specified path if it exists"""
|
| 256 |
+
if self.raster:
|
| 257 |
+
with open(path, 'wb') as f:
|
| 258 |
+
f.write(base64.b64decode(self.raster))
|
| 259 |
+
else:
|
| 260 |
+
raise FileNotFoundError("No raster image to save")
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
@dataclass
|
| 264 |
+
class SummaryUrlRequest:
|
| 265 |
+
"""A request for generating a summary with file url"""
|
| 266 |
+
|
| 267 |
+
url: str
|
| 268 |
+
textgen_config: Optional[TextGenerationConfig] = field(
|
| 269 |
+
default_factory=TextGenerationConfig
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
@dataclass
|
| 274 |
+
class InfographicsRequest:
|
| 275 |
+
"""A request for infographics generation"""
|
| 276 |
+
|
| 277 |
+
visualization: str
|
| 278 |
+
n: int = 1
|
| 279 |
+
style_prompt: Union[str, List[str]] = ""
|
| 280 |
+
# return_pil: bool = False
|
lida_ko/utils.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import base64
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
from typing import Any, List, Tuple, Union
|
| 5 |
+
import os
|
| 6 |
+
import io
|
| 7 |
+
import numpy as np
|
| 8 |
+
import pandas as pd
|
| 9 |
+
import re
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
import tiktoken
|
| 12 |
+
from diskcache import Cache
|
| 13 |
+
import hashlib
|
| 14 |
+
import io
|
| 15 |
+
|
| 16 |
+
logger = logging.getLogger("lida")
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_dirs(path: str) -> List[str]:
|
| 20 |
+
return next(os.walk(path))[1]
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def clean_column_name(col_name: str) -> str:
|
| 24 |
+
"""
|
| 25 |
+
Clean a single column name by replacing special characters and spaces with underscores.
|
| 26 |
+
|
| 27 |
+
:param col_name: The name of the column to be cleaned.
|
| 28 |
+
:return: A sanitized string valid as a column name.
|
| 29 |
+
"""
|
| 30 |
+
return re.sub(r'[^0-9a-zA-Z_]', '_', col_name)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def clean_column_names(df: pd.DataFrame) -> pd.DataFrame:
|
| 34 |
+
"""
|
| 35 |
+
Clean all column names in the given DataFrame.
|
| 36 |
+
|
| 37 |
+
:param df: The DataFrame with possibly dirty column names.
|
| 38 |
+
:return: A copy of the DataFrame with clean column names.
|
| 39 |
+
"""
|
| 40 |
+
cleaned_df = df.copy()
|
| 41 |
+
cleaned_df.columns = [clean_column_name(col) for col in cleaned_df.columns]
|
| 42 |
+
return cleaned_df
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def read_dataframe(file_location: str, encoding: str = 'utf-8') -> pd.DataFrame:
|
| 46 |
+
"""
|
| 47 |
+
Read a dataframe from a given file location and clean its column names.
|
| 48 |
+
It also samples down to 4500 rows if the data exceeds that limit.
|
| 49 |
+
|
| 50 |
+
:param file_location: The path to the file containing the data.
|
| 51 |
+
:param encoding: Encoding to use for the file reading.
|
| 52 |
+
:return: A cleaned DataFrame.
|
| 53 |
+
"""
|
| 54 |
+
file_extension = file_location.split('.')[-1]
|
| 55 |
+
|
| 56 |
+
read_funcs = {
|
| 57 |
+
'json': lambda: pd.read_json(file_location, orient='records', encoding=encoding),
|
| 58 |
+
'csv': lambda: pd.read_csv(file_location, encoding=encoding),
|
| 59 |
+
'xls': lambda: pd.read_excel(file_location, encoding=encoding),
|
| 60 |
+
'xlsx': lambda: pd.read_excel(file_location, encoding=encoding),
|
| 61 |
+
'parquet': pd.read_parquet,
|
| 62 |
+
'feather': pd.read_feather,
|
| 63 |
+
'tsv': lambda: pd.read_csv(file_location, sep="\t", encoding=encoding)
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
if file_extension not in read_funcs:
|
| 67 |
+
raise ValueError('Unsupported file type')
|
| 68 |
+
|
| 69 |
+
try:
|
| 70 |
+
df = read_funcs[file_extension]()
|
| 71 |
+
except Exception as e:
|
| 72 |
+
logger.error(f"Failed to read file: {file_location}. Error: {e}")
|
| 73 |
+
raise
|
| 74 |
+
|
| 75 |
+
# Clean column names
|
| 76 |
+
cleaned_df = clean_column_names(df)
|
| 77 |
+
|
| 78 |
+
# Sample down to 4500 rows if necessary
|
| 79 |
+
if len(cleaned_df) > 4500:
|
| 80 |
+
logger.info(
|
| 81 |
+
"Dataframe has more than 4500 rows. We will sample 4500 rows.")
|
| 82 |
+
cleaned_df = cleaned_df.sample(4500)
|
| 83 |
+
|
| 84 |
+
if cleaned_df.columns.tolist() != df.columns.tolist():
|
| 85 |
+
write_funcs = {
|
| 86 |
+
'csv': lambda: cleaned_df.to_csv(file_location, index=False, encoding=encoding),
|
| 87 |
+
'xls': lambda: cleaned_df.to_excel(file_location, index=False),
|
| 88 |
+
'xlsx': lambda: cleaned_df.to_excel(file_location, index=False),
|
| 89 |
+
'parquet': lambda: cleaned_df.to_parquet(file_location, index=False),
|
| 90 |
+
'feather': lambda: cleaned_df.to_feather(file_location, index=False),
|
| 91 |
+
'json': lambda: cleaned_df.to_json(file_location, orient='records', index=False, default_handler=str),
|
| 92 |
+
'tsv': lambda: cleaned_df.to_csv(file_location, index=False, sep='\t', encoding=encoding)
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
if file_extension not in write_funcs:
|
| 96 |
+
raise ValueError('Unsupported file type')
|
| 97 |
+
|
| 98 |
+
try:
|
| 99 |
+
write_funcs[file_extension]()
|
| 100 |
+
except Exception as e:
|
| 101 |
+
logger.error(f"Failed to write file: {file_location}. Error: {e}")
|
| 102 |
+
raise
|
| 103 |
+
|
| 104 |
+
return cleaned_df
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def file_to_df(file_location: str):
|
| 108 |
+
""" Get summary of data from file location """
|
| 109 |
+
file_name = file_location.split("/")[-1]
|
| 110 |
+
df = None
|
| 111 |
+
if "csv" in file_name:
|
| 112 |
+
df = pd.read_csv(file_location)
|
| 113 |
+
elif "xlsx" in file_name:
|
| 114 |
+
df = pd.read_excel(file_location)
|
| 115 |
+
elif "json" in file_name:
|
| 116 |
+
df = pd.read_json(file_location, orient="records")
|
| 117 |
+
elif "parquet" in file_name:
|
| 118 |
+
df = pd.read_parquet(file_location)
|
| 119 |
+
elif "feather" in file_name:
|
| 120 |
+
df = pd.read_feather(file_location)
|
| 121 |
+
|
| 122 |
+
return df
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def plot_raster(rasters: Union[str, List[str]], figsize: Tuple[int, int] = (10, 10)):
|
| 126 |
+
"""
|
| 127 |
+
Plot a series of base64-encoded raster images in a horizontal layout.
|
| 128 |
+
|
| 129 |
+
Args:
|
| 130 |
+
rasters: A single base64 string or a list of base64-encoded strings representing the images.
|
| 131 |
+
figsize: A tuple indicating the size of the figure to display.
|
| 132 |
+
"""
|
| 133 |
+
plt.figure(figsize=figsize)
|
| 134 |
+
|
| 135 |
+
if isinstance(rasters, str):
|
| 136 |
+
rasters = [rasters]
|
| 137 |
+
|
| 138 |
+
images = []
|
| 139 |
+
|
| 140 |
+
# Find the max height for resizing
|
| 141 |
+
max_height = 0
|
| 142 |
+
for raster in rasters:
|
| 143 |
+
decoded_image = base64.b64decode(raster)
|
| 144 |
+
image = plt.imread(io.BytesIO(decoded_image), format='PNG')
|
| 145 |
+
|
| 146 |
+
max_height = max(max_height, image.shape[0])
|
| 147 |
+
|
| 148 |
+
# Resize images to max_height while preserving the aspect ratio and alpha channel if it exists
|
| 149 |
+
for raster in rasters:
|
| 150 |
+
decoded_image = base64.b64decode(raster)
|
| 151 |
+
image = plt.imread(io.BytesIO(decoded_image), format='PNG')
|
| 152 |
+
|
| 153 |
+
aspect_ratio = image.shape[1] / image.shape[0]
|
| 154 |
+
new_width = int(max_height * aspect_ratio)
|
| 155 |
+
image_resized = np.array([np.interp(np.linspace(
|
| 156 |
+
0, len(row), new_width), np.arange(0, len(row)), row) for row in image])
|
| 157 |
+
|
| 158 |
+
if image_resized.shape[2] == 4: # If RGBA, preserve alpha channel
|
| 159 |
+
alpha_channel = image_resized[:, :, 3:]
|
| 160 |
+
# Drop the alpha for visualization
|
| 161 |
+
image_resized = image_resized[:, :, :3]
|
| 162 |
+
image_resized = np.clip(image_resized, 0, 1)
|
| 163 |
+
image_resized = np.concatenate(
|
| 164 |
+
(image_resized, alpha_channel), axis=2)
|
| 165 |
+
|
| 166 |
+
images.append(image_resized)
|
| 167 |
+
|
| 168 |
+
# Concatenate images along the width
|
| 169 |
+
concatenated_image = np.concatenate(images, axis=1)
|
| 170 |
+
|
| 171 |
+
plt.imshow(concatenated_image)
|
| 172 |
+
plt.axis('off')
|
| 173 |
+
plt.show()
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
|
| 177 |
+
"""Returns the number of tokens used by a list of messages."""
|
| 178 |
+
try:
|
| 179 |
+
encoding = tiktoken.encoding_for_model(model)
|
| 180 |
+
except KeyError:
|
| 181 |
+
encoding = tiktoken.get_encoding("cl100k_base")
|
| 182 |
+
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this
|
| 183 |
+
num_tokens = 0
|
| 184 |
+
for message in messages:
|
| 185 |
+
# every message follows <im_start>{role/name}\n{content}<im_end>\n
|
| 186 |
+
num_tokens += 4
|
| 187 |
+
for key, value in message.items():
|
| 188 |
+
num_tokens += len(encoding.encode(value))
|
| 189 |
+
if key == "name": # if there's a name, the role is omitted
|
| 190 |
+
num_tokens += -1 # role is always required and always 1 token
|
| 191 |
+
num_tokens += 2 # every reply is primed with <im_start>assistant
|
| 192 |
+
return num_tokens
|
| 193 |
+
else:
|
| 194 |
+
raise NotImplementedError(
|
| 195 |
+
f"""num_tokens_from_messages() is not presently implemented for model {model}.""")
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
def cache_request(cache: Cache, params: Any, values: Any = None) -> Any:
|
| 199 |
+
# Generate a unique key for the request
|
| 200 |
+
|
| 201 |
+
key = hashlib.md5(json.dumps(
|
| 202 |
+
params, sort_keys=True).encode("utf-8")).hexdigest()
|
| 203 |
+
# Check if the request is cached
|
| 204 |
+
if key in cache and values is None:
|
| 205 |
+
print("retrieving from cache")
|
| 206 |
+
return cache[key]
|
| 207 |
+
|
| 208 |
+
# Cache the provided values and return them
|
| 209 |
+
if values:
|
| 210 |
+
print("saving to cache")
|
| 211 |
+
cache[key] = values
|
| 212 |
+
return values
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def clean_code_snippet(code_string):
|
| 216 |
+
# Extract code snippet using regex
|
| 217 |
+
cleaned_snippet = re.search(r'```(?:\w+)?\s*([\s\S]*?)\s*```', code_string)
|
| 218 |
+
|
| 219 |
+
if cleaned_snippet:
|
| 220 |
+
cleaned_snippet = cleaned_snippet.group(1)
|
| 221 |
+
else:
|
| 222 |
+
cleaned_snippet = code_string
|
| 223 |
+
|
| 224 |
+
# remove non-printable characters
|
| 225 |
+
# cleaned_snippet = re.sub(r'[\x00-\x1F]+', ' ', cleaned_snippet)
|
| 226 |
+
|
| 227 |
+
return cleaned_snippet
|
lida_ko/version.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
VERSION = "0.0.14"
|
lida_ko/web/.gitignore
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
output/
|
| 2 |
+
samples/
|
| 3 |
+
lida/web/backend/files
|
| 4 |
+
examples/experiment_results.json
|
| 5 |
+
examples/data
|
| 6 |
+
data
|
| 7 |
+
.DS_Store
|
| 8 |
+
test.py
|
| 9 |
+
experiments/data
|
| 10 |
+
test.py
|
| 11 |
+
.azure
|
| 12 |
+
|
| 13 |
+
# Byte-compiled / optimized / DLL files
|
| 14 |
+
__pycache__/
|
| 15 |
+
*.py[cod]
|
| 16 |
+
*$py.class
|
| 17 |
+
|
| 18 |
+
# C extensions
|
| 19 |
+
*.so
|
| 20 |
+
|
| 21 |
+
# Distribution / packaging
|
| 22 |
+
.Python
|
| 23 |
+
# build/
|
| 24 |
+
develop-eggs/
|
| 25 |
+
dist/
|
| 26 |
+
downloads/
|
| 27 |
+
eggs/
|
| 28 |
+
.eggs/
|
| 29 |
+
lib/
|
| 30 |
+
lib64/
|
| 31 |
+
parts/
|
| 32 |
+
sdist/
|
| 33 |
+
var/
|
| 34 |
+
wheels/
|
| 35 |
+
pip-wheel-metadata/
|
| 36 |
+
share/python-wheels/
|
| 37 |
+
*.egg-info/
|
| 38 |
+
.installed.cfg
|
| 39 |
+
*.egg
|
| 40 |
+
MANIFEST
|
| 41 |
+
.env
|
| 42 |
+
|
| 43 |
+
# PyInstaller
|
| 44 |
+
# Usually these files are written by a python script from a template
|
| 45 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 46 |
+
*.manifest
|
| 47 |
+
*.spec
|
| 48 |
+
|
| 49 |
+
# Installer logs
|
| 50 |
+
pip-log.txt
|
| 51 |
+
pip-delete-this-directory.txt
|
| 52 |
+
|
| 53 |
+
# Unit test / coverage reports
|
| 54 |
+
htmlcov/
|
| 55 |
+
.tox/
|
| 56 |
+
.nox/
|
| 57 |
+
.coverage
|
| 58 |
+
.coverage.*
|
| 59 |
+
.cache
|
| 60 |
+
nosetests.xml
|
| 61 |
+
coverage.xml
|
| 62 |
+
*.cover
|
| 63 |
+
*.py,cover
|
| 64 |
+
.hypothesis/
|
| 65 |
+
.pytest_cache/
|
| 66 |
+
|
| 67 |
+
# Translations
|
| 68 |
+
*.mo
|
| 69 |
+
*.pot
|
| 70 |
+
|
| 71 |
+
# Django stuff:
|
| 72 |
+
*.log
|
| 73 |
+
local_settings.py
|
| 74 |
+
db.sqlite3
|
| 75 |
+
db.sqlite3-journal
|
| 76 |
+
|
| 77 |
+
# Flask stuff:
|
| 78 |
+
instance/
|
| 79 |
+
.webassets-cache
|
| 80 |
+
|
| 81 |
+
# Scrapy stuff:
|
| 82 |
+
.scrapy
|
| 83 |
+
|
| 84 |
+
# Sphinx documentation
|
| 85 |
+
docs/_build/
|
| 86 |
+
|
| 87 |
+
# PyBuilder
|
| 88 |
+
target/
|
| 89 |
+
|
| 90 |
+
# Jupyter Notebook
|
| 91 |
+
.ipynb_checkpoints
|
| 92 |
+
|
| 93 |
+
# IPython
|
| 94 |
+
profile_default/
|
| 95 |
+
ipython_config.py
|
| 96 |
+
|
| 97 |
+
# pyenv
|
| 98 |
+
.python-version
|
| 99 |
+
|
| 100 |
+
# pipenv
|
| 101 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 102 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 103 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 104 |
+
# install all needed dependencies.
|
| 105 |
+
#Pipfile.lock
|
| 106 |
+
|
| 107 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 108 |
+
__pypackages__/
|
| 109 |
+
|
| 110 |
+
# Celery stuff
|
| 111 |
+
celerybeat-schedule
|
| 112 |
+
celerybeat.pid
|
| 113 |
+
|
| 114 |
+
# SageMath parsed files
|
| 115 |
+
*.sage.py
|
| 116 |
+
|
| 117 |
+
# Environments
|
| 118 |
+
.env
|
| 119 |
+
.venv
|
| 120 |
+
env/
|
| 121 |
+
venv/
|
| 122 |
+
ENV/
|
| 123 |
+
env.bak/
|
| 124 |
+
venv.bak/
|
| 125 |
+
|
| 126 |
+
# Spyder project settings
|
| 127 |
+
.spyderproject
|
| 128 |
+
.spyproject
|
| 129 |
+
|
| 130 |
+
# Rope project settings
|
| 131 |
+
.ropeproject
|
| 132 |
+
|
| 133 |
+
# mkdocs documentation
|
| 134 |
+
/site
|
| 135 |
+
|
| 136 |
+
# mypy
|
| 137 |
+
.mypy_cache/
|
| 138 |
+
.dmypy.json
|
| 139 |
+
dmypy.json
|
| 140 |
+
|
| 141 |
+
# Pyre type checker
|
| 142 |
+
.pyre/
|
lida_ko/web/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# __init__.py
|
| 2 |
+
|
| 3 |
+
"""Handle web backend API for lida.
|
| 4 |
+
"""
|
| 5 |
+
|
lida_ko/web/app.py
ADDED
|
@@ -0,0 +1,310 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import logging
|
| 4 |
+
import requests
|
| 5 |
+
from fastapi import FastAPI, UploadFile
|
| 6 |
+
from fastapi.staticfiles import StaticFiles
|
| 7 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 8 |
+
import traceback
|
| 9 |
+
|
| 10 |
+
from llmx import llm, providers
|
| 11 |
+
from ..datamodel import GoalWebRequest, SummaryUrlRequest, TextGenerationConfig, UploadUrl, VisualizeEditWebRequest, VisualizeEvalWebRequest, VisualizeExplainWebRequest, VisualizeRecommendRequest, VisualizeRepairWebRequest, VisualizeWebRequest, InfographicsRequest
|
| 12 |
+
from ..components import Manager
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# instantiate model and generator
|
| 16 |
+
textgen = llm()
|
| 17 |
+
logger = logging.getLogger("lida")
|
| 18 |
+
api_docs = os.environ.get("LIDA_API_DOCS", "False") == "True"
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
lida = Manager(text_gen=textgen)
|
| 22 |
+
app = FastAPI()
|
| 23 |
+
# allow cross origin requests for testing on localhost:800* ports only
|
| 24 |
+
app.add_middleware(
|
| 25 |
+
CORSMiddleware,
|
| 26 |
+
allow_origins=["http://localhost:8000", "http://127.0.0.1:8000", "http://localhost:8001"],
|
| 27 |
+
allow_credentials=True,
|
| 28 |
+
allow_methods=["*"],
|
| 29 |
+
allow_headers=["*"],
|
| 30 |
+
)
|
| 31 |
+
api = FastAPI(root_path="/api", docs_url="/docs" if api_docs else None, redoc_url=None)
|
| 32 |
+
app.mount("/api", api)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
root_file_path = os.path.dirname(os.path.abspath(__file__))
|
| 36 |
+
static_folder_root = os.path.join(root_file_path, "ui")
|
| 37 |
+
files_static_root = os.path.join(root_file_path, "files/")
|
| 38 |
+
data_folder = os.path.join(root_file_path, "files/data")
|
| 39 |
+
os.makedirs(data_folder, exist_ok=True)
|
| 40 |
+
os.makedirs(files_static_root, exist_ok=True)
|
| 41 |
+
os.makedirs(static_folder_root, exist_ok=True)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
# mount lida front end UI files
|
| 45 |
+
app.mount("/", StaticFiles(directory=static_folder_root, html=True), name="ui")
|
| 46 |
+
api.mount("/files", StaticFiles(directory=files_static_root, html=True), name="files")
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# def check_model
|
| 50 |
+
|
| 51 |
+
@api.post("/visualize")
|
| 52 |
+
async def visualize_data(req: VisualizeWebRequest) -> dict:
|
| 53 |
+
"""Generate goals given a dataset summary"""
|
| 54 |
+
try:
|
| 55 |
+
# print(req.textgen_config)
|
| 56 |
+
charts = lida.visualize(
|
| 57 |
+
summary=req.summary,
|
| 58 |
+
goal=req.goal,
|
| 59 |
+
textgen_config=req.textgen_config if req.textgen_config else TextGenerationConfig(),
|
| 60 |
+
library=req.library, return_error=True)
|
| 61 |
+
print("found charts: ", len(charts), " for goal: ")
|
| 62 |
+
if len(charts) == 0:
|
| 63 |
+
return {"status": False, "message": "No charts generated"}
|
| 64 |
+
return {"status": True, "charts": charts,
|
| 65 |
+
"message": "Successfully generated charts."}
|
| 66 |
+
|
| 67 |
+
except Exception as exception_error:
|
| 68 |
+
logger.error(f"Error generating visualization goals: {str(exception_error)}")
|
| 69 |
+
return {"status": False,
|
| 70 |
+
"message": f"Error generating visualization goals. {str(exception_error)}"}
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
@api.post("/visualize/edit")
|
| 74 |
+
async def edit_visualization(req: VisualizeEditWebRequest) -> dict:
|
| 75 |
+
"""Given a visualization code, and a goal, generate a new visualization"""
|
| 76 |
+
try:
|
| 77 |
+
textgen_config = req.textgen_config if req.textgen_config else TextGenerationConfig()
|
| 78 |
+
charts = lida.edit(
|
| 79 |
+
code=req.code,
|
| 80 |
+
summary=req.summary,
|
| 81 |
+
instructions=req.instructions,
|
| 82 |
+
textgen_config=textgen_config,
|
| 83 |
+
library=req.library, return_error=True)
|
| 84 |
+
|
| 85 |
+
# charts = [asdict(chart) for chart in charts]
|
| 86 |
+
if len(charts) == 0:
|
| 87 |
+
return {"status": False, "message": "No charts generated"}
|
| 88 |
+
return {"status": True, "charts": charts,
|
| 89 |
+
"message": f"Successfully edited charts."}
|
| 90 |
+
|
| 91 |
+
except Exception as exception_error:
|
| 92 |
+
logger.error(f"Error generating visualization edits: {str(exception_error)}")
|
| 93 |
+
print(traceback.print_exc())
|
| 94 |
+
return {"status": False,
|
| 95 |
+
"message": f"Error generating visualization edits."}
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
@api.post("/visualize/repair")
|
| 99 |
+
async def repair_visualization(req: VisualizeRepairWebRequest) -> dict:
|
| 100 |
+
""" Given a visualization goal and some feedback, generate a new visualization that addresses the feedback"""
|
| 101 |
+
|
| 102 |
+
try:
|
| 103 |
+
|
| 104 |
+
charts = lida.repair(
|
| 105 |
+
code=req.code,
|
| 106 |
+
feedback=req.feedback,
|
| 107 |
+
goal=req.goal,
|
| 108 |
+
summary=req.summary,
|
| 109 |
+
textgen_config=req.textgen_config if req.textgen_config else TextGenerationConfig(),
|
| 110 |
+
library=req.library,
|
| 111 |
+
return_error=True
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
if len(charts) == 0:
|
| 115 |
+
return {"status": False, "message": "No charts generated"}
|
| 116 |
+
return {"status": True, "charts": charts,
|
| 117 |
+
"message": "Successfully generated chart repairs"}
|
| 118 |
+
|
| 119 |
+
except Exception as exception_error:
|
| 120 |
+
logger.error(f"Error generating visualization repairs: {str(exception_error)}")
|
| 121 |
+
return {"status": False,
|
| 122 |
+
"message": f"Error generating visualization repairs."}
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
@api.post("/visualize/explain")
|
| 126 |
+
async def explain_visualization(req: VisualizeExplainWebRequest) -> dict:
|
| 127 |
+
"""Given a visualization code, provide an explanation of the code"""
|
| 128 |
+
textgen_config = req.textgen_config if req.textgen_config else TextGenerationConfig(
|
| 129 |
+
n=1,
|
| 130 |
+
temperature=0)
|
| 131 |
+
|
| 132 |
+
try:
|
| 133 |
+
explanations = lida.explain(
|
| 134 |
+
code=req.code,
|
| 135 |
+
textgen_config=textgen_config,
|
| 136 |
+
library=req.library)
|
| 137 |
+
return {"status": True, "explanations": explanations[0],
|
| 138 |
+
"message": "Successfully generated explanations"}
|
| 139 |
+
|
| 140 |
+
except Exception as exception_error:
|
| 141 |
+
logger.error(f"Error generating visualization explanation: {str(exception_error)}")
|
| 142 |
+
return {"status": False,
|
| 143 |
+
"message": f"Error generating visualization explanation."}
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
@api.post("/visualize/evaluate")
|
| 147 |
+
async def evaluate_visualization(req: VisualizeEvalWebRequest) -> dict:
|
| 148 |
+
"""Given a visualization code, provide an evaluation of the code"""
|
| 149 |
+
|
| 150 |
+
try:
|
| 151 |
+
evaluations = lida.evaluate(
|
| 152 |
+
code=req.code,
|
| 153 |
+
goal=req.goal,
|
| 154 |
+
textgen_config=req.textgen_config if req.textgen_config else TextGenerationConfig(
|
| 155 |
+
n=1,
|
| 156 |
+
temperature=0),
|
| 157 |
+
library=req.library)[0]
|
| 158 |
+
return {"status": True, "evaluations": evaluations,
|
| 159 |
+
"message": "Successfully generated evaluation"}
|
| 160 |
+
|
| 161 |
+
except Exception as exception_error:
|
| 162 |
+
logger.error(f"Error generating visualization evaluation: {str(exception_error)}")
|
| 163 |
+
return {"status": False,
|
| 164 |
+
"message": f"Error generating visualization evaluation. {str(exception_error)}"}
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
@api.post("/visualize/recommend")
|
| 168 |
+
async def recommend_visualization(req: VisualizeRecommendRequest) -> dict:
|
| 169 |
+
"""Given a dataset summary, generate a visualization recommendations"""
|
| 170 |
+
|
| 171 |
+
try:
|
| 172 |
+
textgen_config = req.textgen_config if req.textgen_config else TextGenerationConfig()
|
| 173 |
+
charts = lida.recommend(
|
| 174 |
+
summary=req.summary,
|
| 175 |
+
code=req.code,
|
| 176 |
+
textgen_config=textgen_config,
|
| 177 |
+
library=req.library,
|
| 178 |
+
return_error=True)
|
| 179 |
+
|
| 180 |
+
if len(charts) == 0:
|
| 181 |
+
return {"status": False, "message": "No charts generated"}
|
| 182 |
+
return {"status": True, "charts": charts,
|
| 183 |
+
"message": "Successfully generated chart recommendation"}
|
| 184 |
+
|
| 185 |
+
except Exception as exception_error:
|
| 186 |
+
logger.error(f"Error generating visualization recommendation: {str(exception_error)}")
|
| 187 |
+
return {"status": False,
|
| 188 |
+
"message": f"Error generating visualization recommendation."}
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
@api.post("/text/generate")
|
| 192 |
+
async def generate_text(textgen_config: TextGenerationConfig) -> dict:
|
| 193 |
+
"""Generate text given some prompt"""
|
| 194 |
+
|
| 195 |
+
try:
|
| 196 |
+
completions = textgen.generate(textgen_config)
|
| 197 |
+
return {"status": True, "completions": completions.text}
|
| 198 |
+
except Exception as exception_error:
|
| 199 |
+
logger.error(f"Error generating text: {str(exception_error)}")
|
| 200 |
+
return {"status": False, "message": f"Error generating text."}
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
@api.post("/goal")
|
| 204 |
+
async def generate_goal(req: GoalWebRequest) -> dict:
|
| 205 |
+
"""Generate goals given a dataset summary"""
|
| 206 |
+
try:
|
| 207 |
+
textgen_config = req.textgen_config if req.textgen_config else TextGenerationConfig()
|
| 208 |
+
goals = lida.goals(req.summary, n=req.n, textgen_config=textgen_config)
|
| 209 |
+
return {"status": True, "data": goals,
|
| 210 |
+
"message": f"Successfully generated {len(goals)} goals"}
|
| 211 |
+
except Exception as exception_error:
|
| 212 |
+
logger.error(f"Error generating goals: {str(exception_error)}")
|
| 213 |
+
# Check for a specific error message related to context length
|
| 214 |
+
if "context length" in str(exception_error).lower():
|
| 215 |
+
return {
|
| 216 |
+
"status": False,
|
| 217 |
+
"message": "The dataset you uploaded has too many columns. Please upload a dataset with fewer columns and try again."
|
| 218 |
+
}
|
| 219 |
+
|
| 220 |
+
# For other exceptions
|
| 221 |
+
return {
|
| 222 |
+
"status": False,
|
| 223 |
+
"message": f"Error generating visualization goals. {exception_error}"
|
| 224 |
+
}
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
@api.post("/summarize")
|
| 228 |
+
async def upload_file(file: UploadFile):
|
| 229 |
+
""" Upload a file and return a summary of the data """
|
| 230 |
+
# allow csv, excel, json
|
| 231 |
+
allowed_types = ["text/csv", "application/vnd.ms-excel", "application/json"]
|
| 232 |
+
|
| 233 |
+
# print("file: ", file)
|
| 234 |
+
# check file type
|
| 235 |
+
if file.content_type not in allowed_types:
|
| 236 |
+
return {"status": False,
|
| 237 |
+
"message": f"Uploaded file type ({file.content_type}) not allowed. Allowed types are: csv, excel, json"}
|
| 238 |
+
|
| 239 |
+
try:
|
| 240 |
+
|
| 241 |
+
# save file to files folder
|
| 242 |
+
file_location = os.path.join(data_folder, file.filename)
|
| 243 |
+
# open file without deleting existing contents
|
| 244 |
+
with open(file_location, "wb+") as file_object:
|
| 245 |
+
file_object.write(file.file.read())
|
| 246 |
+
|
| 247 |
+
# summarize
|
| 248 |
+
textgen_config = TextGenerationConfig(n=1, temperature=0)
|
| 249 |
+
summary = lida.summarize(
|
| 250 |
+
data=file_location,
|
| 251 |
+
file_name=file.filename,
|
| 252 |
+
summary_method="llm",
|
| 253 |
+
textgen_config=textgen_config)
|
| 254 |
+
return {"status": True, "summary": summary, "data_filename": file.filename}
|
| 255 |
+
except Exception as exception_error:
|
| 256 |
+
logger.error(f"Error processing file: {str(exception_error)}")
|
| 257 |
+
return {"status": False, "message": f"Error processing file."}
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
# upload via url
|
| 261 |
+
@api.post("/summarize/url")
|
| 262 |
+
async def upload_file_via_url(req: SummaryUrlRequest) -> dict:
|
| 263 |
+
""" Upload a file from a url and return a summary of the data """
|
| 264 |
+
url = req.url
|
| 265 |
+
textgen_config = req.textgen_config if req.textgen_config else TextGenerationConfig(
|
| 266 |
+
n=1, temperature=0)
|
| 267 |
+
file_name = url.split("/")[-1]
|
| 268 |
+
file_location = os.path.join(data_folder, file_name)
|
| 269 |
+
|
| 270 |
+
# download file
|
| 271 |
+
url_response = requests.get(url, allow_redirects=True, timeout=1000)
|
| 272 |
+
open(file_location, "wb").write(url_response.content)
|
| 273 |
+
try:
|
| 274 |
+
|
| 275 |
+
summary = lida.summarize(
|
| 276 |
+
data=file_location,
|
| 277 |
+
file_name=file_name,
|
| 278 |
+
summary_method="llm",
|
| 279 |
+
textgen_config=textgen_config)
|
| 280 |
+
return {"status": True, "summary": summary, "data_filename": file_name}
|
| 281 |
+
except Exception as exception_error:
|
| 282 |
+
# traceback.print_exc()
|
| 283 |
+
logger.error(f"Error processing file: {str(exception_error)}")
|
| 284 |
+
return {"status": False, "message": f"Error processing file."}
|
| 285 |
+
|
| 286 |
+
# convert image to infographics
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
@api.post("/infographer")
|
| 290 |
+
async def generate_infographics(req: InfographicsRequest) -> dict:
|
| 291 |
+
"""Generate infographics using the peacasso package"""
|
| 292 |
+
try:
|
| 293 |
+
result = lida.infographics(
|
| 294 |
+
visualization=req.visualization,
|
| 295 |
+
n=req.n,
|
| 296 |
+
style_prompt=req.style_prompt
|
| 297 |
+
# return_pil=req.return_pil
|
| 298 |
+
)
|
| 299 |
+
return {"status": True, "result": result, "message": "Successfully generated infographics"}
|
| 300 |
+
except Exception as exception_error:
|
| 301 |
+
logger.error(f"Error generating infographics: {str(exception_error)}")
|
| 302 |
+
return {"status": False,
|
| 303 |
+
"message": f"Error generating infographics. {str(exception_error)}"}
|
| 304 |
+
|
| 305 |
+
# list supported models
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
@api.get("/models")
|
| 309 |
+
def list_models() -> dict:
|
| 310 |
+
return {"status": True, "data": providers, "message": "Successfully listed models"}
|
memo.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## data for demonstration
|
| 2 |
+
아동급식카드 가맹점
|
| 3 |
+
- geo plot implementation
|
public_data/config.json
ADDED
|
File without changes
|