
File size: 1,290 Bytes
413cc55 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# MPT 30B inference code using CPU
Run inference on the latest MPT-30B model using your CPU. This inference code uses a [ggml](https://github.com/ggerganov/ggml) quantized model. To run the model we'll use a library called [ctransformers](https://github.com/marella/ctransformers) that has bindings to ggml in python.
Turn style with history on latest commit:
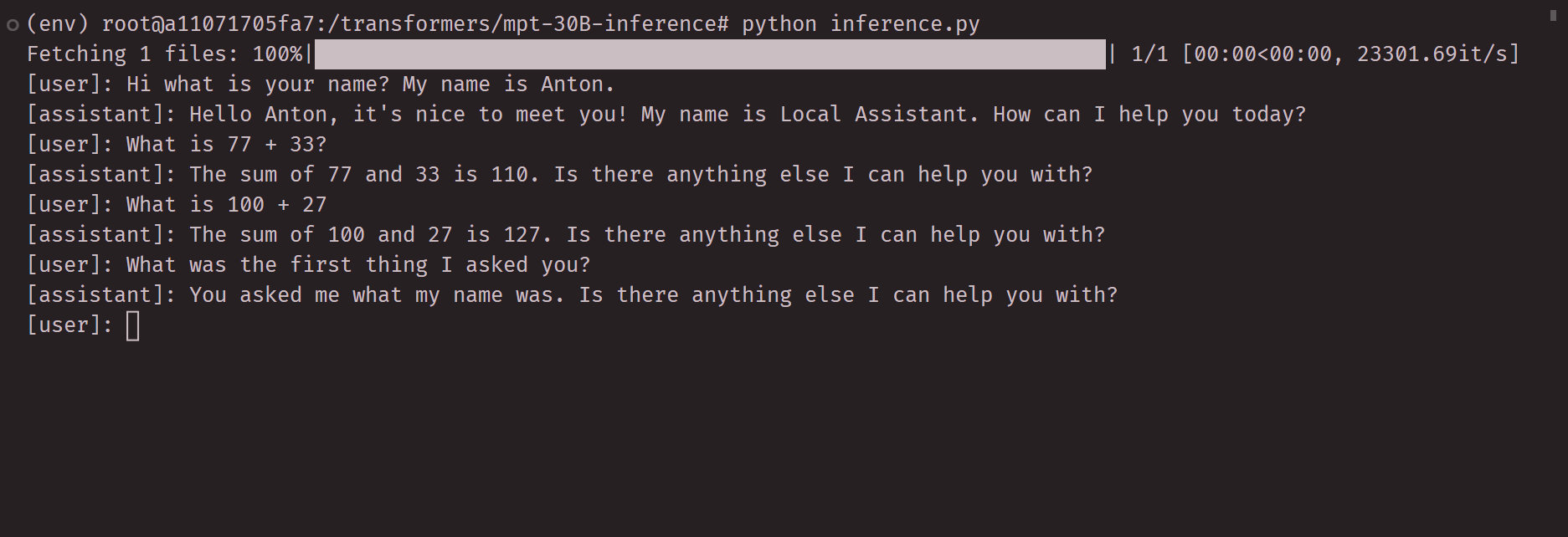
Video of initial demo:
[Inference Demo](https://github.com/abacaj/mpt-30B-inference/assets/7272343/486fc9b1-8216-43cc-93c3-781677235502)
## Requirements
I recommend you use docker for this model, it will make everything easier for you. Minimum specs system with 32GB of ram. Recommend to use `python 3.10`.
## Tested working on
Will post some numbers for these two later.
- AMD Epyc 7003 series CPU
- AMD Ryzen 5950x CPU
## Setup
First create a venv.
```sh
python -m venv env && source env/bin/activate
```
Next install dependencies.
```sh
pip install -r requirements.txt
```
Next download the quantized model weights (about 19GB).
```sh
python download_model.py
```
Ready to rock, run inference.
```sh
python inference.py
```
Next modify inference script prompt and generation parameters.
|