Spaces:
Running on Zero

Running on Zero
File size: 5,650 Bytes
f349c7e 6102720 f349c7e ebc3bf5 5b4cdaa ebc3bf5 f349c7e ebc3bf5 cfe8b7a 6ea3105 65b0baa cfe8b7a ebc3bf5 65b0baa ebc3bf5 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 | ---
title: Tiny Press
emoji: 📊
colorFrom: indigo
colorTo: gray
sdk: gradio
sdk_version: 6.15.2
python_version: '3.12'
app_file: app.py
pinned: false
license: mit
short_description: Compress any text to a token budget locally.
models:
- Qwen/Qwen2.5-1.5B-Instruct
tags:
- gradio
- build-small-hackathon
- thousand-token-wood
- text-compression
- prompt-optimization
- local-inference
---
# TinyPress — Prompt Compression Engine
> **HuggingFace Build Small Hackathon · Track: Thousand Token Wood**
The constraint *is* the feature. Give TinyPress a long piece of text, set a token budget, and get back a compressed version that still carries the meaning — scored, saved, and diffed so you can see exactly what was kept and what was shed.
No cloud. No API bill. Two small models running quietly on your machine.
---
## Demo
[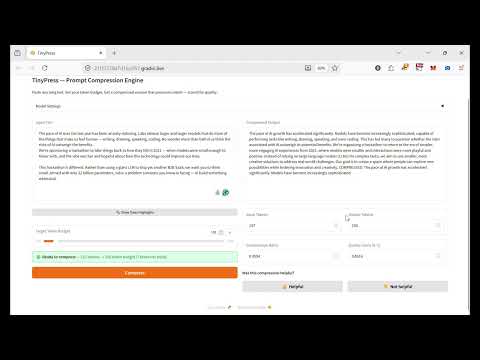](https://youtu.be/hDbIDtjjiB0)
💻 Try @ https://huggingface.co/spaces/build-small-hackathon/tiny-press
👩💻Notebook @ https://colab.research.google.com/github/SriharshaCR/tiny-press/blob/task/bootstrap/tinypress_colab.ipynb
### Social Media Posts
- https://x.com/sriharsha_cr/status/2065662576684650879
- https://www.linkedin.com/posts/sriharsha-cr_tinypress-prompt-compression-engine-activity-7471426128331624448-aKfe
---
## Why this fits Thousand Token Wood
Working inside a tight token budget is not a limitation to work around — it is the problem worth solving. LLM context windows are finite, prompt costs are real, and bloated inputs degrade output quality. TinyPress treats the token count as a hard constraint and makes compression the primary interaction: you set the budget, the model meets it, and a quality score tells you how much meaning survived.
---
## Features
| | |
|---|---|
| 🗜️ **Token-budget compression** | Set a target (100–1000 tokens) and compress to exactly that budget |
| 📊 **Quality score** | Cosine similarity between original and compressed text — 0 to 1, higher is better |
| 🟢🔴 **Live readiness banner** | Green when input is over budget and compression will run; red when already within budget |
| 🔍 **Token highlight panel** | Every token rendered as a colour-coded chip so you can see where your budget is going |
| 🔀 **Model hot-swap** | Switch the compression LLM mid-session without a restart (5 curated models, or any HF model ID) |
| 🎯 **Embedder hot-swap** | Switch the scoring embedder with per-model trade-off info (speed vs quality vs RAM) |
| 👍👎 **Feedback capture** | Rate every result, add an optional text note — saved instantly to SQLite |
| 📜 **Run history** | Every compression persisted locally with full metrics and configurable column visibility |
| 🔎 **Side-by-side diff** | Word-level colour diff — dropped (red), rewritten (amber), inserted (green), unchanged (plain) |
---
## Models
| Role | Default | Alternatives |
|---|---|---|
| Compression LLM | `Qwen/Qwen2.5-1.5B-Instruct` | Qwen2.5-0.5B, SmolLM2-1.7B, Phi-3.5-mini, Llama-3.2-1B |
| Quality scorer | `sentence-transformers/all-MiniLM-L6-v2` | mpnet-base, bge-small, bge-base, mxbai-large, gte-Qwen2-1.5B |
All models are open-weight and under 32B. Everything runs locally — no API calls, no data leaves your machine.
---
## Get started
```bash
python -m venv .venv
# Windows
.venv\Scripts\activate
# macOS / Linux
source .venv/bin/activate
pip install -r requirements.txt
python app.py
```
Open `http://localhost:7860`. That's it.
**Run it in Colab:** open `tinypress_colab.ipynb` — it installs dependencies, loads the models, and launches a public Gradio share URL. GPU runtime recommended for faster inference.
Optional environment overrides:
| Variable | Default | Description |
|---|---|---|
| `LLM_MODEL` | `Qwen/Qwen2.5-1.5B-Instruct` | Compression model |
| `EMBEDDER_MODEL` | `sentence-transformers/all-MiniLM-L6-v2` | Scoring embedder |
| `DB_PATH` | `tinypress.db` | SQLite database path |
| `PORT` | `7860` | Gradio server port |
---
## Hardware
| | Minimum | Recommended |
|---|---|---|
| RAM | 8 GB | 16 GB |
| VRAM | CPU-only works | 4 GB GPU speeds up inference |
| Disk | ~4 GB | ~4 GB |
---
## Architecture
```
Input text + token budget
│
core/compressor.py — builds prompt, calls LLM, hard-trims if it overshoots
│
models/model_loader.py — Qwen2.5-1.5B (or swapped model), loaded once, reused
│
core/scorer.py — cosine similarity via sentence-transformer embedder
│
db/store.py — saves run to SQLite
│
ui/compress_tab.py — shows result, metrics, feedback UI
```
Thin UI layer — Gradio handlers pass inputs to `core/`, return outputs. All logic lives in `core/` and `db/`.
Full docs: [Architecture](docs/architecture.md) · [Setup](docs/setup.md) · [Get Started](docs/get-started.md) · [Folder Structure](docs/folder-structure.md)
---
## About
Built by **[Sriharsha C R](https://www.linkedin.com/in/sriharsha-cr)** — AI Engineer and Cloud Native developer.
[](https://www.linkedin.com/in/sriharsha-cr)
[](https://x.com/sriharsha_cr)
[](https://huggingface.co/sriharsha-cr)
[](https://github.com/SriharshaCR)
|