

Commit
·
4eeefd1
0
Parent(s):
init
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- .gitignore +155 -0
- .gradio/certificate.pem +31 -0
- CODE_OF_CONDUCT.md +80 -0
- CONTRIBUTING.md +31 -0
- LICENSE.txt +399 -0
- MaskClustering +1 -0
- README.md +274 -0
- demo_colmap.py +330 -0
- demo_gradio.py +690 -0
- demo_viser.py +402 -0
- docs/package.md +45 -0
- exts/cropformer_runner.py +133 -0
- exts/maskclustering_runner.py +110 -0
- exts/ov_features.py +162 -0
- infer_arkit.py +319 -0
- logs/errors_20250618_110001.txt +1 -0
- logs/errors_20250619_002216.txt +8 -0
- logs/errors_20251113_191809.txt +1 -0
- logs/errors_20251116_181525.txt +1 -0
- logs/errors_20251116_181526.txt +2 -0
- mvp.py +1095 -0
- mvp_complete.py +1127 -0
- pyproject.toml +52 -0
- requirements.txt +7 -0
- requirements_demo.txt +16 -0
- run_arkit.py +172 -0
- vggt/dependency/__init__.py +3 -0
- vggt/dependency/distortion.py +182 -0
- vggt/dependency/np_to_pycolmap.py +318 -0
- vggt/dependency/projection.py +228 -0
- vggt/dependency/track_modules/__init__.py +0 -0
- vggt/dependency/track_modules/base_track_predictor.py +190 -0
- vggt/dependency/track_modules/blocks.py +329 -0
- vggt/dependency/track_modules/modules.py +202 -0
- vggt/dependency/track_modules/track_refine.py +419 -0
- vggt/dependency/track_modules/utils.py +216 -0
- vggt/dependency/track_predict.py +326 -0
- vggt/dependency/vggsfm_tracker.py +124 -0
- vggt/dependency/vggsfm_utils.py +305 -0
- vggt/heads/camera_head.py +149 -0
- vggt/heads/dpt_head.py +484 -0
- vggt/heads/head_act.py +125 -0
- vggt/heads/track_head.py +104 -0
- vggt/heads/track_modules/__init__.py +5 -0
- vggt/heads/track_modules/base_track_predictor.py +209 -0
- vggt/heads/track_modules/blocks.py +236 -0
- vggt/heads/track_modules/modules.py +204 -0
- vggt/heads/track_modules/utils.py +223 -0
- vggt/heads/utils.py +109 -0
.gitattributes
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SCM syntax highlighting & preventing 3-way merges
|
| 2 |
+
pixi.lock merge=binary linguist-language=YAML linguist-generated=true
|
.gitignore
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.hydra/
|
| 2 |
+
output/
|
| 3 |
+
ckpt/
|
| 4 |
+
# Byte-compiled / optimized / DLL files
|
| 5 |
+
__pycache__/
|
| 6 |
+
**/__pycache__/
|
| 7 |
+
*.py[cod]
|
| 8 |
+
*$py.class
|
| 9 |
+
|
| 10 |
+
# C extensions
|
| 11 |
+
*.so
|
| 12 |
+
|
| 13 |
+
# Distribution / packaging
|
| 14 |
+
.Python
|
| 15 |
+
build/
|
| 16 |
+
develop-eggs/
|
| 17 |
+
dist/
|
| 18 |
+
downloads/
|
| 19 |
+
eggs/
|
| 20 |
+
.eggs/
|
| 21 |
+
lib/
|
| 22 |
+
lib64/
|
| 23 |
+
parts/
|
| 24 |
+
sdist/
|
| 25 |
+
var/
|
| 26 |
+
wheels/
|
| 27 |
+
pip-wheel-metadata/
|
| 28 |
+
share/python-wheels/
|
| 29 |
+
*.egg-info/
|
| 30 |
+
.installed.cfg
|
| 31 |
+
*.egg
|
| 32 |
+
MANIFEST
|
| 33 |
+
|
| 34 |
+
# PyInstaller
|
| 35 |
+
# Usually these files are written by a python script from a template
|
| 36 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 37 |
+
*.manifest
|
| 38 |
+
*.spec
|
| 39 |
+
|
| 40 |
+
# Installer logs
|
| 41 |
+
pip-log.txt
|
| 42 |
+
pip-delete-this-directory.txt
|
| 43 |
+
|
| 44 |
+
# Unit test / coverage reports
|
| 45 |
+
htmlcov/
|
| 46 |
+
.tox/
|
| 47 |
+
.nox/
|
| 48 |
+
.coverage
|
| 49 |
+
.coverage.*
|
| 50 |
+
.cache
|
| 51 |
+
nosetests.xml
|
| 52 |
+
coverage.xml
|
| 53 |
+
*.cover
|
| 54 |
+
*.py,cover
|
| 55 |
+
.hypothesis/
|
| 56 |
+
.pytest_cache/
|
| 57 |
+
cover/
|
| 58 |
+
|
| 59 |
+
# Translations
|
| 60 |
+
*.mo
|
| 61 |
+
*.pot
|
| 62 |
+
|
| 63 |
+
# Django stuff:
|
| 64 |
+
*.log
|
| 65 |
+
local_settings.py
|
| 66 |
+
db.sqlite3
|
| 67 |
+
db.sqlite3-journal
|
| 68 |
+
|
| 69 |
+
# Flask stuff:
|
| 70 |
+
instance/
|
| 71 |
+
.webassets-cache
|
| 72 |
+
|
| 73 |
+
# Scrapy stuff:
|
| 74 |
+
.scrapy
|
| 75 |
+
|
| 76 |
+
# Sphinx documentation
|
| 77 |
+
docs/_build/
|
| 78 |
+
|
| 79 |
+
# PyBuilder
|
| 80 |
+
target/
|
| 81 |
+
|
| 82 |
+
# Jupyter Notebook
|
| 83 |
+
.ipynb_checkpoints
|
| 84 |
+
|
| 85 |
+
# IPython
|
| 86 |
+
profile_default/
|
| 87 |
+
ipython_config.py
|
| 88 |
+
|
| 89 |
+
# pyenv
|
| 90 |
+
.python-version
|
| 91 |
+
|
| 92 |
+
# pipenv
|
| 93 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 94 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 95 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 96 |
+
# install all needed dependencies.
|
| 97 |
+
#Pipfile.lock
|
| 98 |
+
|
| 99 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 100 |
+
__pypackages__/
|
| 101 |
+
|
| 102 |
+
# Celery stuff
|
| 103 |
+
celerybeat-schedule
|
| 104 |
+
celerybeat.pid
|
| 105 |
+
|
| 106 |
+
# SageMath parsed files
|
| 107 |
+
*.sage.py
|
| 108 |
+
|
| 109 |
+
# Environments
|
| 110 |
+
.env
|
| 111 |
+
.venv
|
| 112 |
+
env/
|
| 113 |
+
venv/
|
| 114 |
+
ENV/
|
| 115 |
+
env.bak/
|
| 116 |
+
venv.bak/
|
| 117 |
+
|
| 118 |
+
# Spyder project settings
|
| 119 |
+
.spyderproject
|
| 120 |
+
.spyproject
|
| 121 |
+
|
| 122 |
+
# Rope project settings
|
| 123 |
+
.ropeproject
|
| 124 |
+
|
| 125 |
+
# mkdocs documentation
|
| 126 |
+
/site
|
| 127 |
+
|
| 128 |
+
# mypy
|
| 129 |
+
.mypy_cache/
|
| 130 |
+
.dmypy.json
|
| 131 |
+
dmypy.json
|
| 132 |
+
|
| 133 |
+
# Pyre type checker
|
| 134 |
+
.pyre/
|
| 135 |
+
|
| 136 |
+
# pytype static type analyzer
|
| 137 |
+
.pytype/
|
| 138 |
+
|
| 139 |
+
# Profiling data
|
| 140 |
+
.prof
|
| 141 |
+
|
| 142 |
+
# Folder specific to your needs
|
| 143 |
+
**/tmp/
|
| 144 |
+
**/outputs/skyseg.onnx
|
| 145 |
+
skyseg.onnx
|
| 146 |
+
|
| 147 |
+
# pixi environments
|
| 148 |
+
.pixi
|
| 149 |
+
*.egg-info
|
| 150 |
+
temp/
|
| 151 |
+
**/*.pkl
|
| 152 |
+
**/*.ply
|
| 153 |
+
**/*.glb
|
| 154 |
+
**/*.bin
|
| 155 |
+
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 6 |
+
contributors and maintainers pledge to make participation in our project and
|
| 7 |
+
our community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
| 9 |
+
level of experience, education, socio-economic status, nationality, personal
|
| 10 |
+
appearance, race, religion, or sexual identity and orientation.
|
| 11 |
+
|
| 12 |
+
## Our Standards
|
| 13 |
+
|
| 14 |
+
Examples of behavior that contributes to creating a positive environment
|
| 15 |
+
include:
|
| 16 |
+
|
| 17 |
+
* Using welcoming and inclusive language
|
| 18 |
+
* Being respectful of differing viewpoints and experiences
|
| 19 |
+
* Gracefully accepting constructive criticism
|
| 20 |
+
* Focusing on what is best for the community
|
| 21 |
+
* Showing empathy towards other community members
|
| 22 |
+
|
| 23 |
+
Examples of unacceptable behavior by participants include:
|
| 24 |
+
|
| 25 |
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
| 26 |
+
advances
|
| 27 |
+
* Trolling, insulting/derogatory comments, and personal or political attacks
|
| 28 |
+
* Public or private harassment
|
| 29 |
+
* Publishing others' private information, such as a physical or electronic
|
| 30 |
+
address, without explicit permission
|
| 31 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 32 |
+
professional setting
|
| 33 |
+
|
| 34 |
+
## Our Responsibilities
|
| 35 |
+
|
| 36 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 37 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 38 |
+
response to any instances of unacceptable behavior.
|
| 39 |
+
|
| 40 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 41 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 42 |
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
| 43 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 44 |
+
threatening, offensive, or harmful.
|
| 45 |
+
|
| 46 |
+
## Scope
|
| 47 |
+
|
| 48 |
+
This Code of Conduct applies within all project spaces, and it also applies when
|
| 49 |
+
an individual is representing the project or its community in public spaces.
|
| 50 |
+
Examples of representing a project or community include using an official
|
| 51 |
+
project e-mail address, posting via an official social media account, or acting
|
| 52 |
+
as an appointed representative at an online or offline event. Representation of
|
| 53 |
+
a project may be further defined and clarified by project maintainers.
|
| 54 |
+
|
| 55 |
+
This Code of Conduct also applies outside the project spaces when there is a
|
| 56 |
+
reasonable belief that an individual's behavior may have a negative impact on
|
| 57 |
+
the project or its community.
|
| 58 |
+
|
| 59 |
+
## Enforcement
|
| 60 |
+
|
| 61 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 62 |
+
reported by contacting the project team at <opensource-conduct@meta.com>. All
|
| 63 |
+
complaints will be reviewed and investigated and will result in a response that
|
| 64 |
+
is deemed necessary and appropriate to the circumstances. The project team is
|
| 65 |
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
| 66 |
+
Further details of specific enforcement policies may be posted separately.
|
| 67 |
+
|
| 68 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 69 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 70 |
+
members of the project's leadership.
|
| 71 |
+
|
| 72 |
+
## Attribution
|
| 73 |
+
|
| 74 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
| 75 |
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
| 76 |
+
|
| 77 |
+
[homepage]: https://www.contributor-covenant.org
|
| 78 |
+
|
| 79 |
+
For answers to common questions about this code of conduct, see
|
| 80 |
+
https://www.contributor-covenant.org/faq
|
CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to vggt
|
| 2 |
+
We want to make contributing to this project as easy and transparent as
|
| 3 |
+
possible.
|
| 4 |
+
|
| 5 |
+
## Pull Requests
|
| 6 |
+
We actively welcome your pull requests.
|
| 7 |
+
|
| 8 |
+
1. Fork the repo and create your branch from `main`.
|
| 9 |
+
2. If you've added code that should be tested, add tests.
|
| 10 |
+
3. If you've changed APIs, update the documentation.
|
| 11 |
+
4. Ensure the test suite passes.
|
| 12 |
+
5. Make sure your code lints.
|
| 13 |
+
6. If you haven't already, complete the Contributor License Agreement ("CLA").
|
| 14 |
+
|
| 15 |
+
## Contributor License Agreement ("CLA")
|
| 16 |
+
In order to accept your pull request, we need you to submit a CLA. You only need
|
| 17 |
+
to do this once to work on any of Facebook's open source projects.
|
| 18 |
+
|
| 19 |
+
Complete your CLA here: <https://code.facebook.com/cla>
|
| 20 |
+
|
| 21 |
+
## Issues
|
| 22 |
+
We use GitHub issues to track public bugs. Please ensure your description is
|
| 23 |
+
clear and has sufficient instructions to be able to reproduce the issue.
|
| 24 |
+
|
| 25 |
+
Facebook has a [bounty program](https://www.facebook.com/whitehat/) for the safe
|
| 26 |
+
disclosure of security bugs. In those cases, please go through the process
|
| 27 |
+
outlined on that page and do not file a public issue.
|
| 28 |
+
|
| 29 |
+
## License
|
| 30 |
+
By contributing to vggt, you agree that your contributions will be licensed
|
| 31 |
+
under the LICENSE file in the root directory of this source tree.
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,399 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Attribution-NonCommercial 4.0 International
|
| 2 |
+
|
| 3 |
+
=======================================================================
|
| 4 |
+
|
| 5 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
| 6 |
+
does not provide legal services or legal advice. Distribution of
|
| 7 |
+
Creative Commons public licenses does not create a lawyer-client or
|
| 8 |
+
other relationship. Creative Commons makes its licenses and related
|
| 9 |
+
information available on an "as-is" basis. Creative Commons gives no
|
| 10 |
+
warranties regarding its licenses, any material licensed under their
|
| 11 |
+
terms and conditions, or any related information. Creative Commons
|
| 12 |
+
disclaims all liability for damages resulting from their use to the
|
| 13 |
+
fullest extent possible.
|
| 14 |
+
|
| 15 |
+
Using Creative Commons Public Licenses
|
| 16 |
+
|
| 17 |
+
Creative Commons public licenses provide a standard set of terms and
|
| 18 |
+
conditions that creators and other rights holders may use to share
|
| 19 |
+
original works of authorship and other material subject to copyright
|
| 20 |
+
and certain other rights specified in the public license below. The
|
| 21 |
+
following considerations are for informational purposes only, are not
|
| 22 |
+
exhaustive, and do not form part of our licenses.
|
| 23 |
+
|
| 24 |
+
Considerations for licensors: Our public licenses are
|
| 25 |
+
intended for use by those authorized to give the public
|
| 26 |
+
permission to use material in ways otherwise restricted by
|
| 27 |
+
copyright and certain other rights. Our licenses are
|
| 28 |
+
irrevocable. Licensors should read and understand the terms
|
| 29 |
+
and conditions of the license they choose before applying it.
|
| 30 |
+
Licensors should also secure all rights necessary before
|
| 31 |
+
applying our licenses so that the public can reuse the
|
| 32 |
+
material as expected. Licensors should clearly mark any
|
| 33 |
+
material not subject to the license. This includes other CC-
|
| 34 |
+
licensed material, or material used under an exception or
|
| 35 |
+
limitation to copyright. More considerations for licensors:
|
| 36 |
+
wiki.creativecommons.org/Considerations_for_licensors
|
| 37 |
+
|
| 38 |
+
Considerations for the public: By using one of our public
|
| 39 |
+
licenses, a licensor grants the public permission to use the
|
| 40 |
+
licensed material under specified terms and conditions. If
|
| 41 |
+
the licensor's permission is not necessary for any reason--for
|
| 42 |
+
example, because of any applicable exception or limitation to
|
| 43 |
+
copyright--then that use is not regulated by the license. Our
|
| 44 |
+
licenses grant only permissions under copyright and certain
|
| 45 |
+
other rights that a licensor has authority to grant. Use of
|
| 46 |
+
the licensed material may still be restricted for other
|
| 47 |
+
reasons, including because others have copyright or other
|
| 48 |
+
rights in the material. A licensor may make special requests,
|
| 49 |
+
such as asking that all changes be marked or described.
|
| 50 |
+
Although not required by our licenses, you are encouraged to
|
| 51 |
+
respect those requests where reasonable. More_considerations
|
| 52 |
+
for the public:
|
| 53 |
+
wiki.creativecommons.org/Considerations_for_licensees
|
| 54 |
+
|
| 55 |
+
=======================================================================
|
| 56 |
+
|
| 57 |
+
Creative Commons Attribution-NonCommercial 4.0 International Public
|
| 58 |
+
License
|
| 59 |
+
|
| 60 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 61 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 62 |
+
Attribution-NonCommercial 4.0 International Public License ("Public
|
| 63 |
+
License"). To the extent this Public License may be interpreted as a
|
| 64 |
+
contract, You are granted the Licensed Rights in consideration of Your
|
| 65 |
+
acceptance of these terms and conditions, and the Licensor grants You
|
| 66 |
+
such rights in consideration of benefits the Licensor receives from
|
| 67 |
+
making the Licensed Material available under these terms and
|
| 68 |
+
conditions.
|
| 69 |
+
|
| 70 |
+
Section 1 -- Definitions.
|
| 71 |
+
|
| 72 |
+
a. Adapted Material means material subject to Copyright and Similar
|
| 73 |
+
Rights that is derived from or based upon the Licensed Material
|
| 74 |
+
and in which the Licensed Material is translated, altered,
|
| 75 |
+
arranged, transformed, or otherwise modified in a manner requiring
|
| 76 |
+
permission under the Copyright and Similar Rights held by the
|
| 77 |
+
Licensor. For purposes of this Public License, where the Licensed
|
| 78 |
+
Material is a musical work, performance, or sound recording,
|
| 79 |
+
Adapted Material is always produced where the Licensed Material is
|
| 80 |
+
synched in timed relation with a moving image.
|
| 81 |
+
|
| 82 |
+
b. Adapter's License means the license You apply to Your Copyright
|
| 83 |
+
and Similar Rights in Your contributions to Adapted Material in
|
| 84 |
+
accordance with the terms and conditions of this Public License.
|
| 85 |
+
|
| 86 |
+
c. Copyright and Similar Rights means copyright and/or similar rights
|
| 87 |
+
closely related to copyright including, without limitation,
|
| 88 |
+
performance, broadcast, sound recording, and Sui Generis Database
|
| 89 |
+
Rights, without regard to how the rights are labeled or
|
| 90 |
+
categorized. For purposes of this Public License, the rights
|
| 91 |
+
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
| 92 |
+
Rights.
|
| 93 |
+
d. Effective Technological Measures means those measures that, in the
|
| 94 |
+
absence of proper authority, may not be circumvented under laws
|
| 95 |
+
fulfilling obligations under Article 11 of the WIPO Copyright
|
| 96 |
+
Treaty adopted on December 20, 1996, and/or similar international
|
| 97 |
+
agreements.
|
| 98 |
+
|
| 99 |
+
e. Exceptions and Limitations means fair use, fair dealing, and/or
|
| 100 |
+
any other exception or limitation to Copyright and Similar Rights
|
| 101 |
+
that applies to Your use of the Licensed Material.
|
| 102 |
+
|
| 103 |
+
f. Licensed Material means the artistic or literary work, database,
|
| 104 |
+
or other material to which the Licensor applied this Public
|
| 105 |
+
License.
|
| 106 |
+
|
| 107 |
+
g. Licensed Rights means the rights granted to You subject to the
|
| 108 |
+
terms and conditions of this Public License, which are limited to
|
| 109 |
+
all Copyright and Similar Rights that apply to Your use of the
|
| 110 |
+
Licensed Material and that the Licensor has authority to license.
|
| 111 |
+
|
| 112 |
+
h. Licensor means the individual(s) or entity(ies) granting rights
|
| 113 |
+
under this Public License.
|
| 114 |
+
|
| 115 |
+
i. NonCommercial means not primarily intended for or directed towards
|
| 116 |
+
commercial advantage or monetary compensation. For purposes of
|
| 117 |
+
this Public License, the exchange of the Licensed Material for
|
| 118 |
+
other material subject to Copyright and Similar Rights by digital
|
| 119 |
+
file-sharing or similar means is NonCommercial provided there is
|
| 120 |
+
no payment of monetary compensation in connection with the
|
| 121 |
+
exchange.
|
| 122 |
+
|
| 123 |
+
j. Share means to provide material to the public by any means or
|
| 124 |
+
process that requires permission under the Licensed Rights, such
|
| 125 |
+
as reproduction, public display, public performance, distribution,
|
| 126 |
+
dissemination, communication, or importation, and to make material
|
| 127 |
+
available to the public including in ways that members of the
|
| 128 |
+
public may access the material from a place and at a time
|
| 129 |
+
individually chosen by them.
|
| 130 |
+
|
| 131 |
+
k. Sui Generis Database Rights means rights other than copyright
|
| 132 |
+
resulting from Directive 96/9/EC of the European Parliament and of
|
| 133 |
+
the Council of 11 March 1996 on the legal protection of databases,
|
| 134 |
+
as amended and/or succeeded, as well as other essentially
|
| 135 |
+
equivalent rights anywhere in the world.
|
| 136 |
+
|
| 137 |
+
l. You means the individual or entity exercising the Licensed Rights
|
| 138 |
+
under this Public License. Your has a corresponding meaning.
|
| 139 |
+
|
| 140 |
+
Section 2 -- Scope.
|
| 141 |
+
|
| 142 |
+
a. License grant.
|
| 143 |
+
|
| 144 |
+
1. Subject to the terms and conditions of this Public License,
|
| 145 |
+
the Licensor hereby grants You a worldwide, royalty-free,
|
| 146 |
+
non-sublicensable, non-exclusive, irrevocable license to
|
| 147 |
+
exercise the Licensed Rights in the Licensed Material to:
|
| 148 |
+
|
| 149 |
+
a. reproduce and Share the Licensed Material, in whole or
|
| 150 |
+
in part, for NonCommercial purposes only; and
|
| 151 |
+
|
| 152 |
+
b. produce, reproduce, and Share Adapted Material for
|
| 153 |
+
NonCommercial purposes only.
|
| 154 |
+
|
| 155 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where
|
| 156 |
+
Exceptions and Limitations apply to Your use, this Public
|
| 157 |
+
License does not apply, and You do not need to comply with
|
| 158 |
+
its terms and conditions.
|
| 159 |
+
|
| 160 |
+
3. Term. The term of this Public License is specified in Section
|
| 161 |
+
6(a).
|
| 162 |
+
|
| 163 |
+
4. Media and formats; technical modifications allowed. The
|
| 164 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 165 |
+
all media and formats whether now known or hereafter created,
|
| 166 |
+
and to make technical modifications necessary to do so. The
|
| 167 |
+
Licensor waives and/or agrees not to assert any right or
|
| 168 |
+
authority to forbid You from making technical modifications
|
| 169 |
+
necessary to exercise the Licensed Rights, including
|
| 170 |
+
technical modifications necessary to circumvent Effective
|
| 171 |
+
Technological Measures. For purposes of this Public License,
|
| 172 |
+
simply making modifications authorized by this Section 2(a)
|
| 173 |
+
(4) never produces Adapted Material.
|
| 174 |
+
|
| 175 |
+
5. Downstream recipients.
|
| 176 |
+
|
| 177 |
+
a. Offer from the Licensor -- Licensed Material. Every
|
| 178 |
+
recipient of the Licensed Material automatically
|
| 179 |
+
receives an offer from the Licensor to exercise the
|
| 180 |
+
Licensed Rights under the terms and conditions of this
|
| 181 |
+
Public License.
|
| 182 |
+
|
| 183 |
+
b. No downstream restrictions. You may not offer or impose
|
| 184 |
+
any additional or different terms or conditions on, or
|
| 185 |
+
apply any Effective Technological Measures to, the
|
| 186 |
+
Licensed Material if doing so restricts exercise of the
|
| 187 |
+
Licensed Rights by any recipient of the Licensed
|
| 188 |
+
Material.
|
| 189 |
+
|
| 190 |
+
6. No endorsement. Nothing in this Public License constitutes or
|
| 191 |
+
may be construed as permission to assert or imply that You
|
| 192 |
+
are, or that Your use of the Licensed Material is, connected
|
| 193 |
+
with, or sponsored, endorsed, or granted official status by,
|
| 194 |
+
the Licensor or others designated to receive attribution as
|
| 195 |
+
provided in Section 3(a)(1)(A)(i).
|
| 196 |
+
|
| 197 |
+
b. Other rights.
|
| 198 |
+
|
| 199 |
+
1. Moral rights, such as the right of integrity, are not
|
| 200 |
+
licensed under this Public License, nor are publicity,
|
| 201 |
+
privacy, and/or other similar personality rights; however, to
|
| 202 |
+
the extent possible, the Licensor waives and/or agrees not to
|
| 203 |
+
assert any such rights held by the Licensor to the limited
|
| 204 |
+
extent necessary to allow You to exercise the Licensed
|
| 205 |
+
Rights, but not otherwise.
|
| 206 |
+
|
| 207 |
+
2. Patent and trademark rights are not licensed under this
|
| 208 |
+
Public License.
|
| 209 |
+
|
| 210 |
+
3. To the extent possible, the Licensor waives any right to
|
| 211 |
+
collect royalties from You for the exercise of the Licensed
|
| 212 |
+
Rights, whether directly or through a collecting society
|
| 213 |
+
under any voluntary or waivable statutory or compulsory
|
| 214 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 215 |
+
reserves any right to collect such royalties, including when
|
| 216 |
+
the Licensed Material is used other than for NonCommercial
|
| 217 |
+
purposes.
|
| 218 |
+
|
| 219 |
+
Section 3 -- License Conditions.
|
| 220 |
+
|
| 221 |
+
Your exercise of the Licensed Rights is expressly made subject to the
|
| 222 |
+
following conditions.
|
| 223 |
+
|
| 224 |
+
a. Attribution.
|
| 225 |
+
|
| 226 |
+
1. If You Share the Licensed Material (including in modified
|
| 227 |
+
form), You must:
|
| 228 |
+
|
| 229 |
+
a. retain the following if it is supplied by the Licensor
|
| 230 |
+
with the Licensed Material:
|
| 231 |
+
|
| 232 |
+
i. identification of the creator(s) of the Licensed
|
| 233 |
+
Material and any others designated to receive
|
| 234 |
+
attribution, in any reasonable manner requested by
|
| 235 |
+
the Licensor (including by pseudonym if
|
| 236 |
+
designated);
|
| 237 |
+
|
| 238 |
+
ii. a copyright notice;
|
| 239 |
+
|
| 240 |
+
iii. a notice that refers to this Public License;
|
| 241 |
+
|
| 242 |
+
iv. a notice that refers to the disclaimer of
|
| 243 |
+
warranties;
|
| 244 |
+
|
| 245 |
+
v. a URI or hyperlink to the Licensed Material to the
|
| 246 |
+
extent reasonably practicable;
|
| 247 |
+
|
| 248 |
+
b. indicate if You modified the Licensed Material and
|
| 249 |
+
retain an indication of any previous modifications; and
|
| 250 |
+
|
| 251 |
+
c. indicate the Licensed Material is licensed under this
|
| 252 |
+
Public License, and include the text of, or the URI or
|
| 253 |
+
hyperlink to, this Public License.
|
| 254 |
+
|
| 255 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 256 |
+
reasonable manner based on the medium, means, and context in
|
| 257 |
+
which You Share the Licensed Material. For example, it may be
|
| 258 |
+
reasonable to satisfy the conditions by providing a URI or
|
| 259 |
+
hyperlink to a resource that includes the required
|
| 260 |
+
information.
|
| 261 |
+
|
| 262 |
+
3. If requested by the Licensor, You must remove any of the
|
| 263 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 264 |
+
reasonably practicable.
|
| 265 |
+
|
| 266 |
+
4. If You Share Adapted Material You produce, the Adapter's
|
| 267 |
+
License You apply must not prevent recipients of the Adapted
|
| 268 |
+
Material from complying with this Public License.
|
| 269 |
+
|
| 270 |
+
Section 4 -- Sui Generis Database Rights.
|
| 271 |
+
|
| 272 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 273 |
+
apply to Your use of the Licensed Material:
|
| 274 |
+
|
| 275 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
| 276 |
+
to extract, reuse, reproduce, and Share all or a substantial
|
| 277 |
+
portion of the contents of the database for NonCommercial purposes
|
| 278 |
+
only;
|
| 279 |
+
|
| 280 |
+
b. if You include all or a substantial portion of the database
|
| 281 |
+
contents in a database in which You have Sui Generis Database
|
| 282 |
+
Rights, then the database in which You have Sui Generis Database
|
| 283 |
+
Rights (but not its individual contents) is Adapted Material; and
|
| 284 |
+
|
| 285 |
+
c. You must comply with the conditions in Section 3(a) if You Share
|
| 286 |
+
all or a substantial portion of the contents of the database.
|
| 287 |
+
|
| 288 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 289 |
+
replace Your obligations under this Public License where the Licensed
|
| 290 |
+
Rights include other Copyright and Similar Rights.
|
| 291 |
+
|
| 292 |
+
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
| 293 |
+
|
| 294 |
+
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
| 295 |
+
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
| 296 |
+
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
| 297 |
+
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
| 298 |
+
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
| 299 |
+
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
| 300 |
+
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
| 301 |
+
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
| 302 |
+
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
| 303 |
+
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
| 304 |
+
|
| 305 |
+
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
| 306 |
+
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
| 307 |
+
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
| 308 |
+
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
| 309 |
+
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
| 310 |
+
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
| 311 |
+
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
| 312 |
+
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
| 313 |
+
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
| 314 |
+
|
| 315 |
+
c. The disclaimer of warranties and limitation of liability provided
|
| 316 |
+
above shall be interpreted in a manner that, to the extent
|
| 317 |
+
possible, most closely approximates an absolute disclaimer and
|
| 318 |
+
waiver of all liability.
|
| 319 |
+
|
| 320 |
+
Section 6 -- Term and Termination.
|
| 321 |
+
|
| 322 |
+
a. This Public License applies for the term of the Copyright and
|
| 323 |
+
Similar Rights licensed here. However, if You fail to comply with
|
| 324 |
+
this Public License, then Your rights under this Public License
|
| 325 |
+
terminate automatically.
|
| 326 |
+
|
| 327 |
+
b. Where Your right to use the Licensed Material has terminated under
|
| 328 |
+
Section 6(a), it reinstates:
|
| 329 |
+
|
| 330 |
+
1. automatically as of the date the violation is cured, provided
|
| 331 |
+
it is cured within 30 days of Your discovery of the
|
| 332 |
+
violation; or
|
| 333 |
+
|
| 334 |
+
2. upon express reinstatement by the Licensor.
|
| 335 |
+
|
| 336 |
+
For the avoidance of doubt, this Section 6(b) does not affect any
|
| 337 |
+
right the Licensor may have to seek remedies for Your violations
|
| 338 |
+
of this Public License.
|
| 339 |
+
|
| 340 |
+
c. For the avoidance of doubt, the Licensor may also offer the
|
| 341 |
+
Licensed Material under separate terms or conditions or stop
|
| 342 |
+
distributing the Licensed Material at any time; however, doing so
|
| 343 |
+
will not terminate this Public License.
|
| 344 |
+
|
| 345 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 346 |
+
License.
|
| 347 |
+
|
| 348 |
+
Section 7 -- Other Terms and Conditions.
|
| 349 |
+
|
| 350 |
+
a. The Licensor shall not be bound by any additional or different
|
| 351 |
+
terms or conditions communicated by You unless expressly agreed.
|
| 352 |
+
|
| 353 |
+
b. Any arrangements, understandings, or agreements regarding the
|
| 354 |
+
Licensed Material not stated herein are separate from and
|
| 355 |
+
independent of the terms and conditions of this Public License.
|
| 356 |
+
|
| 357 |
+
Section 8 -- Interpretation.
|
| 358 |
+
|
| 359 |
+
a. For the avoidance of doubt, this Public License does not, and
|
| 360 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 361 |
+
conditions on any use of the Licensed Material that could lawfully
|
| 362 |
+
be made without permission under this Public License.
|
| 363 |
+
|
| 364 |
+
b. To the extent possible, if any provision of this Public License is
|
| 365 |
+
deemed unenforceable, it shall be automatically reformed to the
|
| 366 |
+
minimum extent necessary to make it enforceable. If the provision
|
| 367 |
+
cannot be reformed, it shall be severed from this Public License
|
| 368 |
+
without affecting the enforceability of the remaining terms and
|
| 369 |
+
conditions.
|
| 370 |
+
|
| 371 |
+
c. No term or condition of this Public License will be waived and no
|
| 372 |
+
failure to comply consented to unless expressly agreed to by the
|
| 373 |
+
Licensor.
|
| 374 |
+
|
| 375 |
+
d. Nothing in this Public License constitutes or may be interpreted
|
| 376 |
+
as a limitation upon, or waiver of, any privileges and immunities
|
| 377 |
+
that apply to the Licensor or You, including from the legal
|
| 378 |
+
processes of any jurisdiction or authority.
|
| 379 |
+
|
| 380 |
+
=======================================================================
|
| 381 |
+
|
| 382 |
+
Creative Commons is not a party to its public
|
| 383 |
+
licenses. Notwithstanding, Creative Commons may elect to apply one of
|
| 384 |
+
its public licenses to material it publishes and in those instances
|
| 385 |
+
will be considered the “Licensor.” The text of the Creative Commons
|
| 386 |
+
public licenses is dedicated to the public domain under the CC0 Public
|
| 387 |
+
Domain Dedication. Except for the limited purpose of indicating that
|
| 388 |
+
material is shared under a Creative Commons public license or as
|
| 389 |
+
otherwise permitted by the Creative Commons policies published at
|
| 390 |
+
creativecommons.org/policies, Creative Commons does not authorize the
|
| 391 |
+
use of the trademark "Creative Commons" or any other trademark or logo
|
| 392 |
+
of Creative Commons without its prior written consent including,
|
| 393 |
+
without limitation, in connection with any unauthorized modifications
|
| 394 |
+
to any of its public licenses or any other arrangements,
|
| 395 |
+
understandings, or agreements concerning use of licensed material. For
|
| 396 |
+
the avoidance of doubt, this paragraph does not form part of the
|
| 397 |
+
public licenses.
|
| 398 |
+
|
| 399 |
+
Creative Commons may be contacted at creativecommons.org.
|
MaskClustering
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
../Indoor/MaskClustering/
|
README.md
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>VGGT: Visual Geometry Grounded Transformer</h1>
|
| 3 |
+
|
| 4 |
+
<a href="https://jytime.github.io/data/VGGT_CVPR25.pdf" target="_blank" rel="noopener noreferrer">
|
| 5 |
+
<img src="https://img.shields.io/badge/Paper-VGGT" alt="Paper PDF">
|
| 6 |
+
</a>
|
| 7 |
+
<a href="https://arxiv.org/abs/2503.11651"><img src="https://img.shields.io/badge/arXiv-2503.11651-b31b1b" alt="arXiv"></a>
|
| 8 |
+
<a href="https://vgg-t.github.io/"><img src="https://img.shields.io/badge/Project_Page-green" alt="Project Page"></a>
|
| 9 |
+
<a href='https://huggingface.co/spaces/facebook/vggt'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a>
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
**[Visual Geometry Group, University of Oxford](https://www.robots.ox.ac.uk/~vgg/)**; **[Meta AI](https://ai.facebook.com/research/)**
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
[Jianyuan Wang](https://jytime.github.io/), [Minghao Chen](https://silent-chen.github.io/), [Nikita Karaev](https://nikitakaraevv.github.io/), [Andrea Vedaldi](https://www.robots.ox.ac.uk/~vedaldi/), [Christian Rupprecht](https://chrirupp.github.io/), [David Novotny](https://d-novotny.github.io/)
|
| 16 |
+
</div>
|
| 17 |
+
|
| 18 |
+
```bibtex
|
| 19 |
+
@inproceedings{wang2025vggt,
|
| 20 |
+
title={VGGT: Visual Geometry Grounded Transformer},
|
| 21 |
+
author={Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David},
|
| 22 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 23 |
+
year={2025}
|
| 24 |
+
}
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
## Updates
|
| 28 |
+
- [June 2, 2025] Added a script to run VGGT and save predictions in COLMAP format, with bundle adjustment support optional. The saved COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) or other NeRF/Gaussian splatting libraries.
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
- [May 3, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available in the [evaluation](https://github.com/facebookresearch/vggt/tree/evaluation) branch.
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
- [Apr 13, 2025] Training code is being gradually cleaned and uploaded to the [training](https://github.com/facebookresearch/vggt/tree/training) branch. It will be merged into the main branch once finalized.
|
| 35 |
+
|
| 36 |
+
## Overview
|
| 37 |
+
|
| 38 |
+
Visual Geometry Grounded Transformer (VGGT, CVPR 2025) is a feed-forward neural network that directly infers all key 3D attributes of a scene, including extrinsic and intrinsic camera parameters, point maps, depth maps, and 3D point tracks, **from one, a few, or hundreds of its views, within seconds**.
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## Quick Start
|
| 42 |
+
|
| 43 |
+
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
|
| 44 |
+
|
| 45 |
+
```bash
|
| 46 |
+
git clone git@github.com:facebookresearch/vggt.git
|
| 47 |
+
cd vggt
|
| 48 |
+
pip install -r requirements.txt
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
Alternatively, you can install VGGT as a package (<a href="docs/package.md">click here</a> for details).
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
Now, try the model with just a few lines of code:
|
| 55 |
+
|
| 56 |
+
```python
|
| 57 |
+
import torch
|
| 58 |
+
from vggt.models.vggt import VGGT
|
| 59 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 60 |
+
|
| 61 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 62 |
+
# bfloat16 is supported on Ampere GPUs (Compute Capability 8.0+)
|
| 63 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 64 |
+
|
| 65 |
+
# Initialize the model and load the pretrained weights.
|
| 66 |
+
# This will automatically download the model weights the first time it's run, which may take a while.
|
| 67 |
+
model = VGGT.from_pretrained("facebook/VGGT-1B").to(device)
|
| 68 |
+
|
| 69 |
+
# Load and preprocess example images (replace with your own image paths)
|
| 70 |
+
image_names = ["path/to/imageA.png", "path/to/imageB.png", "path/to/imageC.png"]
|
| 71 |
+
images = load_and_preprocess_images(image_names).to(device)
|
| 72 |
+
|
| 73 |
+
with torch.no_grad():
|
| 74 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 75 |
+
# Predict attributes including cameras, depth maps, and point maps.
|
| 76 |
+
predictions = model(images)
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
The model weights will be automatically downloaded from Hugging Face. If you encounter issues such as slow loading, you can manually download them [here](https://huggingface.co/facebook/VGGT-1B/blob/main/model.pt) and load, or:
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
model = VGGT()
|
| 83 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 84 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
## Detailed Usage
|
| 88 |
+
|
| 89 |
+
<details>
|
| 90 |
+
<summary>Click to expand</summary>
|
| 91 |
+
|
| 92 |
+
You can also optionally choose which attributes (branches) to predict, as shown below. This achieves the same result as the example above. This example uses a batch size of 1 (processing a single scene), but it naturally works for multiple scenes.
|
| 93 |
+
|
| 94 |
+
```python
|
| 95 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 96 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 97 |
+
|
| 98 |
+
with torch.no_grad():
|
| 99 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 100 |
+
images = images[None] # add batch dimension
|
| 101 |
+
aggregated_tokens_list, ps_idx = model.aggregator(images)
|
| 102 |
+
|
| 103 |
+
# Predict Cameras
|
| 104 |
+
pose_enc = model.camera_head(aggregated_tokens_list)[-1]
|
| 105 |
+
# Extrinsic and intrinsic matrices, following OpenCV convention (camera from world)
|
| 106 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(pose_enc, images.shape[-2:])
|
| 107 |
+
|
| 108 |
+
# Predict Depth Maps
|
| 109 |
+
depth_map, depth_conf = model.depth_head(aggregated_tokens_list, images, ps_idx)
|
| 110 |
+
|
| 111 |
+
# Predict Point Maps
|
| 112 |
+
point_map, point_conf = model.point_head(aggregated_tokens_list, images, ps_idx)
|
| 113 |
+
|
| 114 |
+
# Construct 3D Points from Depth Maps and Cameras
|
| 115 |
+
# which usually leads to more accurate 3D points than point map branch
|
| 116 |
+
point_map_by_unprojection = unproject_depth_map_to_point_map(depth_map.squeeze(0),
|
| 117 |
+
extrinsic.squeeze(0),
|
| 118 |
+
intrinsic.squeeze(0))
|
| 119 |
+
|
| 120 |
+
# Predict Tracks
|
| 121 |
+
# choose your own points to track, with shape (N, 2) for one scene
|
| 122 |
+
query_points = torch.FloatTensor([[100.0, 200.0],
|
| 123 |
+
[60.72, 259.94]]).to(device)
|
| 124 |
+
track_list, vis_score, conf_score = model.track_head(aggregated_tokens_list, images, ps_idx, query_points=query_points[None])
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
Furthermore, if certain pixels in the input frames are unwanted (e.g., reflective surfaces, sky, or water), you can simply mask them by setting the corresponding pixel values to 0 or 1. Precise segmentation masks aren't necessary - simple bounding box masks work effectively (check this [issue](https://github.com/facebookresearch/vggt/issues/47) for an example).
|
| 129 |
+
|
| 130 |
+
</details>
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
## Interactive Demo
|
| 134 |
+
|
| 135 |
+
We provide multiple ways to visualize your 3D reconstructions. Before using these visualization tools, install the required dependencies:
|
| 136 |
+
|
| 137 |
+
```bash
|
| 138 |
+
pip install -r requirements_demo.txt
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
### Interactive 3D Visualization
|
| 142 |
+
|
| 143 |
+
**Please note:** VGGT typically reconstructs a scene in less than 1 second. However, visualizing 3D points may take tens of seconds due to third-party rendering, independent of VGGT's processing time. The visualization is slow especially when the number of images is large.
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
#### Gradio Web Interface
|
| 147 |
+
|
| 148 |
+
Our Gradio-based interface allows you to upload images/videos, run reconstruction, and interactively explore the 3D scene in your browser. You can launch this in your local machine or try it on [Hugging Face](https://huggingface.co/spaces/facebook/vggt).
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
```bash
|
| 152 |
+
python demo_gradio.py
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
<details>
|
| 156 |
+
<summary>Click to preview the Gradio interactive interface</summary>
|
| 157 |
+
|
| 158 |
+
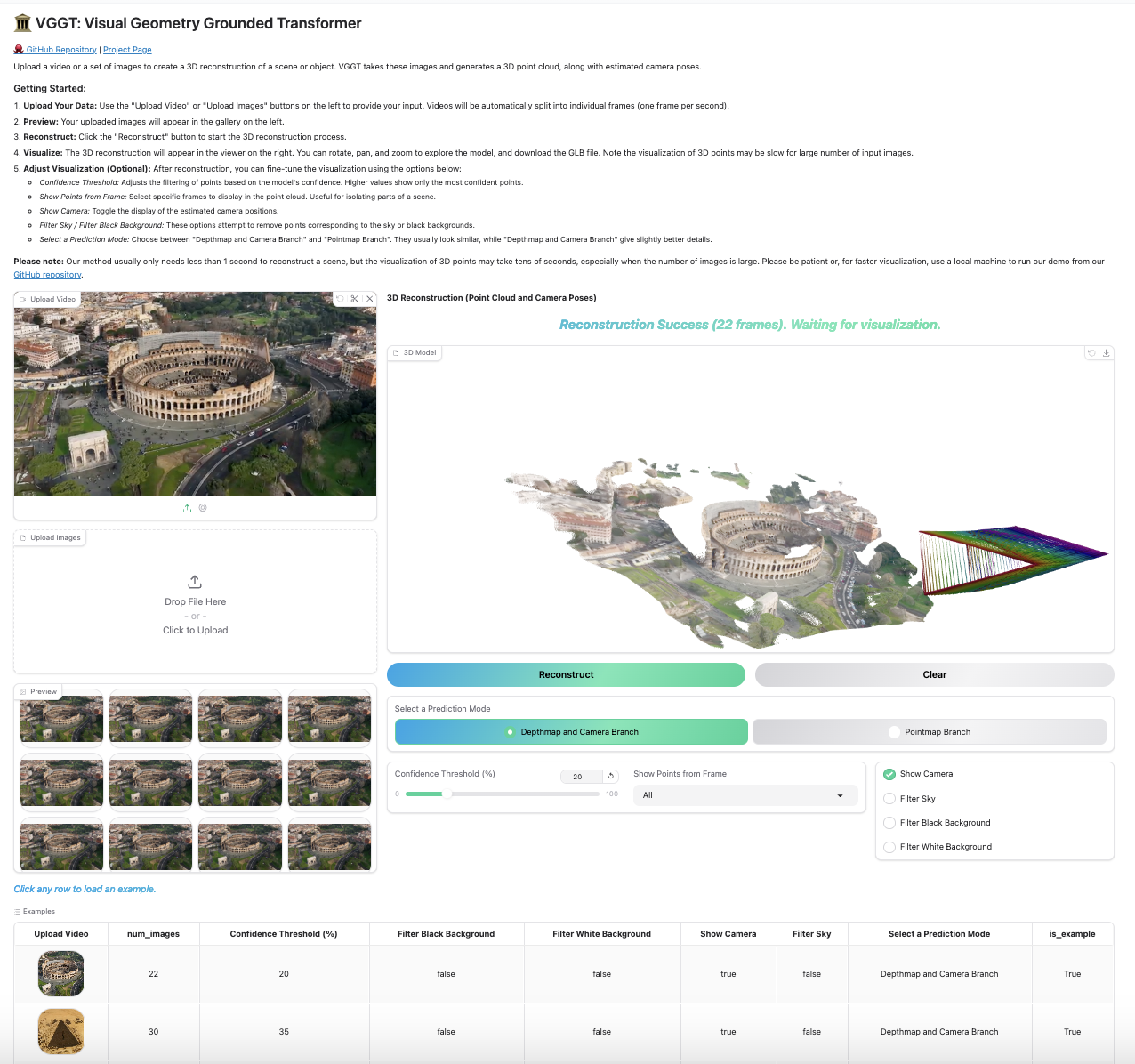
|
| 159 |
+
</details>
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
#### Viser 3D Viewer
|
| 163 |
+
|
| 164 |
+
Run the following command to run reconstruction and visualize the point clouds in viser. Note this script requires a path to a folder containing images. It assumes only image files under the folder. You can set `--use_point_map` to use the point cloud from the point map branch, instead of the depth-based point cloud.
|
| 165 |
+
|
| 166 |
+
```bash
|
| 167 |
+
python demo_viser.py --image_folder path/to/your/images/folder
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
## Exporting to COLMAP Format
|
| 171 |
+
|
| 172 |
+
We also support exporting VGGT's predictions directly to COLMAP format, by:
|
| 173 |
+
|
| 174 |
+
```bash
|
| 175 |
+
# Feedforward prediction only
|
| 176 |
+
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/
|
| 177 |
+
|
| 178 |
+
# With bundle adjustment
|
| 179 |
+
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --use_ba
|
| 180 |
+
# check the file for additional bundle adjustment configuration options
|
| 181 |
+
```
|
| 182 |
+
|
| 183 |
+
Please ensure that the images are stored in `/YOUR/SCENE_DIR/images/`. This folder should contain only the images. Check the examples folder for the desired data structure.
|
| 184 |
+
|
| 185 |
+
The reconstruction result (camera parameters and 3D points) will be automatically saved under `/YOUR/SCENE_DIR/sparse/` in the COLMAP format, such as:
|
| 186 |
+
|
| 187 |
+
```
|
| 188 |
+
SCENE_DIR/
|
| 189 |
+
├── images/
|
| 190 |
+
└── sparse/
|
| 191 |
+
├── cameras.bin
|
| 192 |
+
├── images.bin
|
| 193 |
+
└── points3D.bin
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
## Integration with Gaussian Splatting
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
The exported COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) for Gaussian Splatting training. Install `gsplat` following their official instructions (we recommend `gsplat==1.3.0`):
|
| 200 |
+
|
| 201 |
+
An example command to train the model is:
|
| 202 |
+
```
|
| 203 |
+
cd gsplat
|
| 204 |
+
python examples/simple_trainer.py default --data_factor 1 --data_dir /YOUR/SCENE_DIR/ --result_dir /YOUR/RESULT_DIR/
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
## Zero-shot Single-view Reconstruction
|
| 210 |
+
|
| 211 |
+
Our model shows surprisingly good performance on single-view reconstruction, although it was never trained for this task. The model does not need to duplicate the single-view image to a pair, instead, it can directly infer the 3D structure from the tokens of the single view image. Feel free to try it with our demos above, which naturally works for single-view reconstruction.
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
We did not quantitatively test monocular depth estimation performance ourselves, but [@kabouzeid](https://github.com/kabouzeid) generously provided a comparison of VGGT to recent methods [here](https://github.com/facebookresearch/vggt/issues/36). VGGT shows competitive or better results compared to state-of-the-art monocular approaches such as DepthAnything v2 or MoGe, despite never being explicitly trained for single-view tasks.
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
## Runtime and GPU Memory
|
| 219 |
+
|
| 220 |
+
We benchmark the runtime and GPU memory usage of VGGT's aggregator on a single NVIDIA H100 GPU across various input sizes.
|
| 221 |
+
|
| 222 |
+
| **Input Frames** | 1 | 2 | 4 | 8 | 10 | 20 | 50 | 100 | 200 |
|
| 223 |
+
|:----------------:|:-:|:-:|:-:|:-:|:--:|:--:|:--:|:---:|:---:|
|
| 224 |
+
| **Time (s)** | 0.04 | 0.05 | 0.07 | 0.11 | 0.14 | 0.31 | 1.04 | 3.12 | 8.75 |
|
| 225 |
+
| **Memory (GB)** | 1.88 | 2.07 | 2.45 | 3.23 | 3.63 | 5.58 | 11.41 | 21.15 | 40.63 |
|
| 226 |
+
|
| 227 |
+
Note that these results were obtained using Flash Attention 3, which is faster than the default Flash Attention 2 implementation while maintaining almost the same memory usage. Feel free to compile Flash Attention 3 from source to get better performance.
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
## Research Progression
|
| 231 |
+
|
| 232 |
+
Our work builds upon a series of previous research projects. If you're interested in understanding how our research evolved, check out our previous works:
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
<table border="0" cellspacing="0" cellpadding="0">
|
| 236 |
+
<tr>
|
| 237 |
+
<td align="left">
|
| 238 |
+
<a href="https://github.com/jytime/Deep-SfM-Revisited">Deep SfM Revisited</a>
|
| 239 |
+
</td>
|
| 240 |
+
<td style="white-space: pre;">──┐</td>
|
| 241 |
+
<td></td>
|
| 242 |
+
</tr>
|
| 243 |
+
<tr>
|
| 244 |
+
<td align="left">
|
| 245 |
+
<a href="https://github.com/facebookresearch/PoseDiffusion">PoseDiffusion</a>
|
| 246 |
+
</td>
|
| 247 |
+
<td style="white-space: pre;">─────►</td>
|
| 248 |
+
<td>
|
| 249 |
+
<a href="https://github.com/facebookresearch/vggsfm">VGGSfM</a> ──►
|
| 250 |
+
<a href="https://github.com/facebookresearch/vggt">VGGT</a>
|
| 251 |
+
</td>
|
| 252 |
+
</tr>
|
| 253 |
+
<tr>
|
| 254 |
+
<td align="left">
|
| 255 |
+
<a href="https://github.com/facebookresearch/co-tracker">CoTracker</a>
|
| 256 |
+
</td>
|
| 257 |
+
<td style="white-space: pre;">──┘</td>
|
| 258 |
+
<td></td>
|
| 259 |
+
</tr>
|
| 260 |
+
</table>
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
## Acknowledgements
|
| 264 |
+
|
| 265 |
+
Thanks to these great repositories: [PoseDiffusion](https://github.com/facebookresearch/PoseDiffusion), [VGGSfM](https://github.com/facebookresearch/vggsfm), [CoTracker](https://github.com/facebookresearch/co-tracker), [DINOv2](https://github.com/facebookresearch/dinov2), [Dust3r](https://github.com/naver/dust3r), [Moge](https://github.com/microsoft/moge), [PyTorch3D](https://github.com/facebookresearch/pytorch3d), [Sky Segmentation](https://github.com/xiongzhu666/Sky-Segmentation-and-Post-processing), [Depth Anything V2](https://github.com/DepthAnything/Depth-Anything-V2), [Metric3D](https://github.com/YvanYin/Metric3D) and many other inspiring works in the community.
|
| 266 |
+
|
| 267 |
+
## Checklist
|
| 268 |
+
|
| 269 |
+
- [ ] Release the training code
|
| 270 |
+
- [ ] Release VGGT-500M and VGGT-200M
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
## License
|
| 274 |
+
See the [LICENSE](./LICENSE.txt) file for details about the license under which this code is made available.
|
demo_colmap.py
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import random
|
| 8 |
+
import numpy as np
|
| 9 |
+
import glob
|
| 10 |
+
import os
|
| 11 |
+
import copy
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
# Configure CUDA settings
|
| 16 |
+
torch.backends.cudnn.enabled = True
|
| 17 |
+
torch.backends.cudnn.benchmark = True
|
| 18 |
+
torch.backends.cudnn.deterministic = False
|
| 19 |
+
|
| 20 |
+
import argparse
|
| 21 |
+
from pathlib import Path
|
| 22 |
+
import trimesh
|
| 23 |
+
import pycolmap
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
from vggt.models.vggt import VGGT
|
| 27 |
+
from vggt.utils.load_fn import load_and_preprocess_images_square
|
| 28 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 29 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 30 |
+
from vggt.utils.helper import create_pixel_coordinate_grid, randomly_limit_trues
|
| 31 |
+
from vggt.dependency.track_predict import predict_tracks
|
| 32 |
+
from vggt.dependency.np_to_pycolmap import batch_np_matrix_to_pycolmap, batch_np_matrix_to_pycolmap_wo_track
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# TODO: add support for masks
|
| 36 |
+
# TODO: add iterative BA
|
| 37 |
+
# TODO: add support for radial distortion, which needs extra_params
|
| 38 |
+
# TODO: test with more cases
|
| 39 |
+
# TODO: test different camera types
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def parse_args():
|
| 43 |
+
parser = argparse.ArgumentParser(description="VGGT Demo")
|
| 44 |
+
parser.add_argument("--scene_dir", type=str, required=True, help="Directory containing the scene images")
|
| 45 |
+
parser.add_argument("--seed", type=int, default=42, help="Random seed for reproducibility")
|
| 46 |
+
parser.add_argument("--use_ba", action="store_true", default=False, help="Use BA for reconstruction")
|
| 47 |
+
######### BA parameters #########
|
| 48 |
+
parser.add_argument(
|
| 49 |
+
"--max_reproj_error", type=float, default=8.0, help="Maximum reprojection error for reconstruction"
|
| 50 |
+
)
|
| 51 |
+
parser.add_argument("--shared_camera", action="store_true", default=False, help="Use shared camera for all images")
|
| 52 |
+
parser.add_argument("--camera_type", type=str, default="SIMPLE_PINHOLE", help="Camera type for reconstruction")
|
| 53 |
+
parser.add_argument("--vis_thresh", type=float, default=0.2, help="Visibility threshold for tracks")
|
| 54 |
+
parser.add_argument("--query_frame_num", type=int, default=5, help="Number of frames to query")
|
| 55 |
+
parser.add_argument("--max_query_pts", type=int, default=2048, help="Maximum number of query points")
|
| 56 |
+
parser.add_argument(
|
| 57 |
+
"--fine_tracking", action="store_true", default=True, help="Use fine tracking (slower but more accurate)"
|
| 58 |
+
)
|
| 59 |
+
parser.add_argument(
|
| 60 |
+
"--conf_thres_value", type=float, default=5.0, help="Confidence threshold value for depth filtering (wo BA)"
|
| 61 |
+
)
|
| 62 |
+
return parser.parse_args()
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def run_VGGT(model, images, dtype, resolution=518):
|
| 66 |
+
# images: [B, 3, H, W]
|
| 67 |
+
|
| 68 |
+
assert len(images.shape) == 4
|
| 69 |
+
assert images.shape[1] == 3
|
| 70 |
+
|
| 71 |
+
# hard-coded to use 518 for VGGT
|
| 72 |
+
images = F.interpolate(images, size=(resolution, resolution), mode="bilinear", align_corners=False)
|
| 73 |
+
|
| 74 |
+
with torch.no_grad():
|
| 75 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 76 |
+
images = images[None] # add batch dimension
|
| 77 |
+
aggregated_tokens_list, ps_idx = model.aggregator(images)
|
| 78 |
+
|
| 79 |
+
# Predict Cameras
|
| 80 |
+
pose_enc = model.camera_head(aggregated_tokens_list)[-1]
|
| 81 |
+
# Extrinsic and intrinsic matrices, following OpenCV convention (camera from world)
|
| 82 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(pose_enc, images.shape[-2:])
|
| 83 |
+
# Predict Depth Maps
|
| 84 |
+
depth_map, depth_conf = model.depth_head(aggregated_tokens_list, images, ps_idx)
|
| 85 |
+
|
| 86 |
+
extrinsic = extrinsic.squeeze(0).cpu().numpy()
|
| 87 |
+
intrinsic = intrinsic.squeeze(0).cpu().numpy()
|
| 88 |
+
depth_map = depth_map.squeeze(0).cpu().numpy()
|
| 89 |
+
depth_conf = depth_conf.squeeze(0).cpu().numpy()
|
| 90 |
+
return extrinsic, intrinsic, depth_map, depth_conf
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def demo_fn(args):
|
| 94 |
+
# Print configuration
|
| 95 |
+
print("Arguments:", vars(args))
|
| 96 |
+
|
| 97 |
+
# Set seed for reproducibility
|
| 98 |
+
np.random.seed(args.seed)
|
| 99 |
+
torch.manual_seed(args.seed)
|
| 100 |
+
random.seed(args.seed)
|
| 101 |
+
if torch.cuda.is_available():
|
| 102 |
+
torch.cuda.manual_seed(args.seed)
|
| 103 |
+
torch.cuda.manual_seed_all(args.seed) # for multi-GPU
|
| 104 |
+
print(f"Setting seed as: {args.seed}")
|
| 105 |
+
|
| 106 |
+
# Set device and dtype
|
| 107 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 108 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 109 |
+
print(f"Using device: {device}")
|
| 110 |
+
print(f"Using dtype: {dtype}")
|
| 111 |
+
|
| 112 |
+
# Run VGGT for camera and depth estimation
|
| 113 |
+
model = VGGT()
|
| 114 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 115 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 116 |
+
model.eval()
|
| 117 |
+
model = model.to(device)
|
| 118 |
+
print(f"Model loaded")
|
| 119 |
+
|
| 120 |
+
# Get image paths and preprocess them
|
| 121 |
+
image_dir = os.path.join(args.scene_dir, "images")
|
| 122 |
+
image_path_list = glob.glob(os.path.join(image_dir, "*"))
|
| 123 |
+
if len(image_path_list) == 0:
|
| 124 |
+
raise ValueError(f"No images found in {image_dir}")
|
| 125 |
+
base_image_path_list = [os.path.basename(path) for path in image_path_list]
|
| 126 |
+
|
| 127 |
+
# Load images and original coordinates
|
| 128 |
+
# Load Image in 1024, while running VGGT with 518
|
| 129 |
+
vggt_fixed_resolution = 518
|
| 130 |
+
img_load_resolution = 1024
|
| 131 |
+
|
| 132 |
+
images, original_coords = load_and_preprocess_images_square(image_path_list, img_load_resolution)
|
| 133 |
+
images = images.to(device)
|
| 134 |
+
original_coords = original_coords.to(device)
|
| 135 |
+
print(f"Loaded {len(images)} images from {image_dir}")
|
| 136 |
+
|
| 137 |
+
# Run VGGT to estimate camera and depth
|
| 138 |
+
# Run with 518x518 images
|
| 139 |
+
extrinsic, intrinsic, depth_map, depth_conf = run_VGGT(model, images, dtype, vggt_fixed_resolution)
|
| 140 |
+
points_3d = unproject_depth_map_to_point_map(depth_map, extrinsic, intrinsic)
|
| 141 |
+
|
| 142 |
+
if args.use_ba:
|
| 143 |
+
image_size = np.array(images.shape[-2:])
|
| 144 |
+
scale = img_load_resolution / vggt_fixed_resolution
|
| 145 |
+
shared_camera = args.shared_camera
|
| 146 |
+
|
| 147 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 148 |
+
# Predicting Tracks
|
| 149 |
+
# Using VGGSfM tracker instead of VGGT tracker for efficiency
|
| 150 |
+
# VGGT tracker requires multiple backbone runs to query different frames (this is a problem caused by the training process)
|
| 151 |
+
# Will be fixed in VGGT v2
|
| 152 |
+
|
| 153 |
+
# You can also change the pred_tracks to tracks from any other methods
|
| 154 |
+
# e.g., from COLMAP, from CoTracker, or by chaining 2D matches from Lightglue/LoFTR.
|
| 155 |
+
pred_tracks, pred_vis_scores, pred_confs, points_3d, points_rgb = predict_tracks(
|
| 156 |
+
images,
|
| 157 |
+
conf=depth_conf,
|
| 158 |
+
points_3d=points_3d,
|
| 159 |
+
masks=None,
|
| 160 |
+
max_query_pts=args.max_query_pts,
|
| 161 |
+
query_frame_num=args.query_frame_num,
|
| 162 |
+
keypoint_extractor="aliked+sp",
|
| 163 |
+
fine_tracking=args.fine_tracking,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
torch.cuda.empty_cache()
|
| 167 |
+
|
| 168 |
+
# rescale the intrinsic matrix from 518 to 1024
|
| 169 |
+
intrinsic[:, :2, :] *= scale
|
| 170 |
+
track_mask = pred_vis_scores > args.vis_thresh
|
| 171 |
+
|
| 172 |
+
# TODO: radial distortion, iterative BA, masks
|
| 173 |
+
reconstruction, valid_track_mask = batch_np_matrix_to_pycolmap(
|
| 174 |
+
points_3d,
|
| 175 |
+
extrinsic,
|
| 176 |
+
intrinsic,
|
| 177 |
+
pred_tracks,
|
| 178 |
+
image_size,
|
| 179 |
+
masks=track_mask,
|
| 180 |
+
max_reproj_error=args.max_reproj_error,
|
| 181 |
+
shared_camera=shared_camera,
|
| 182 |
+
camera_type=args.camera_type,
|
| 183 |
+
points_rgb=points_rgb,
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
if reconstruction is None:
|
| 187 |
+
raise ValueError("No reconstruction can be built with BA")
|
| 188 |
+
|
| 189 |
+
# Bundle Adjustment
|
| 190 |
+
ba_options = pycolmap.BundleAdjustmentOptions()
|
| 191 |
+
pycolmap.bundle_adjustment(reconstruction, ba_options)
|
| 192 |
+
|
| 193 |
+
reconstruction_resolution = img_load_resolution
|
| 194 |
+
else:
|
| 195 |
+
conf_thres_value = args.conf_thres_value
|
| 196 |
+
max_points_for_colmap = 100000 # randomly sample 3D points
|
| 197 |
+
shared_camera = False # in the feedforward manner, we do not support shared camera
|
| 198 |
+
camera_type = "PINHOLE" # in the feedforward manner, we only support PINHOLE camera
|
| 199 |
+
|
| 200 |
+
image_size = np.array([vggt_fixed_resolution, vggt_fixed_resolution])
|
| 201 |
+
num_frames, height, width, _ = points_3d.shape
|
| 202 |
+
|
| 203 |
+
points_rgb = F.interpolate(
|
| 204 |
+
images, size=(vggt_fixed_resolution, vggt_fixed_resolution), mode="bilinear", align_corners=False
|
| 205 |
+
)
|
| 206 |
+
points_rgb = (points_rgb.cpu().numpy() * 255).astype(np.uint8)
|
| 207 |
+
points_rgb = points_rgb.transpose(0, 2, 3, 1)
|
| 208 |
+
|
| 209 |
+
# (S, H, W, 3), with x, y coordinates and frame indices
|
| 210 |
+
points_xyf = create_pixel_coordinate_grid(num_frames, height, width)
|
| 211 |
+
|
| 212 |
+
conf_mask = depth_conf >= conf_thres_value
|
| 213 |
+
# at most writing 100000 3d points to colmap reconstruction object
|
| 214 |
+
conf_mask = randomly_limit_trues(conf_mask, max_points_for_colmap)
|
| 215 |
+
|
| 216 |
+
points_3d = points_3d[conf_mask]
|
| 217 |
+
points_xyf = points_xyf[conf_mask]
|
| 218 |
+
points_rgb = points_rgb[conf_mask]
|
| 219 |
+
|
| 220 |
+
print("Converting to COLMAP format")
|
| 221 |
+
reconstruction = batch_np_matrix_to_pycolmap_wo_track(
|
| 222 |
+
points_3d,
|
| 223 |
+
points_xyf,
|
| 224 |
+
points_rgb,
|
| 225 |
+
extrinsic,
|
| 226 |
+
intrinsic,
|
| 227 |
+
image_size,
|
| 228 |
+
shared_camera=shared_camera,
|
| 229 |
+
camera_type=camera_type,
|
| 230 |
+
)
|
| 231 |
+
|
| 232 |
+
reconstruction_resolution = vggt_fixed_resolution
|
| 233 |
+
|
| 234 |
+
reconstruction = rename_colmap_recons_and_rescale_camera(
|
| 235 |
+
reconstruction,
|
| 236 |
+
base_image_path_list,
|
| 237 |
+
original_coords.cpu().numpy(),
|
| 238 |
+
img_size=reconstruction_resolution,
|
| 239 |
+
shift_point2d_to_original_res=True,
|
| 240 |
+
shared_camera=shared_camera,
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
print(f"Saving reconstruction to {args.scene_dir}/sparse")
|
| 244 |
+
sparse_reconstruction_dir = os.path.join(args.scene_dir, "sparse")
|
| 245 |
+
os.makedirs(sparse_reconstruction_dir, exist_ok=True)
|
| 246 |
+
reconstruction.write(sparse_reconstruction_dir)
|
| 247 |
+
|
| 248 |
+
# Save point cloud for fast visualization
|
| 249 |
+
trimesh.PointCloud(points_3d, colors=points_rgb).export(os.path.join(args.scene_dir, "sparse/points.ply"))
|
| 250 |
+
|
| 251 |
+
return True
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
def rename_colmap_recons_and_rescale_camera(
|
| 255 |
+
reconstruction, image_paths, original_coords, img_size, shift_point2d_to_original_res=False, shared_camera=False
|
| 256 |
+
):
|
| 257 |
+
rescale_camera = True
|
| 258 |
+
|
| 259 |
+
for pyimageid in reconstruction.images:
|
| 260 |
+
# Reshaped the padded&resized image to the original size
|
| 261 |
+
# Rename the images to the original names
|
| 262 |
+
pyimage = reconstruction.images[pyimageid]
|
| 263 |
+
pycamera = reconstruction.cameras[pyimage.camera_id]
|
| 264 |
+
pyimage.name = image_paths[pyimageid - 1]
|
| 265 |
+
|
| 266 |
+
if rescale_camera:
|
| 267 |
+
# Rescale the camera parameters
|
| 268 |
+
pred_params = copy.deepcopy(pycamera.params)
|
| 269 |
+
|
| 270 |
+
real_image_size = original_coords[pyimageid - 1, -2:]
|
| 271 |
+
resize_ratio = max(real_image_size) / img_size
|
| 272 |
+
pred_params = pred_params * resize_ratio
|
| 273 |
+
real_pp = real_image_size / 2
|
| 274 |
+
pred_params[-2:] = real_pp # center of the image
|
| 275 |
+
|
| 276 |
+
pycamera.params = pred_params
|
| 277 |
+
pycamera.width = real_image_size[0]
|
| 278 |
+
pycamera.height = real_image_size[1]
|
| 279 |
+
|
| 280 |
+
if shift_point2d_to_original_res:
|
| 281 |
+
# Also shift the point2D to original resolution
|
| 282 |
+
top_left = original_coords[pyimageid - 1, :2]
|
| 283 |
+
|
| 284 |
+
for point2D in pyimage.points2D:
|
| 285 |
+
point2D.xy = (point2D.xy - top_left) * resize_ratio
|
| 286 |
+
|
| 287 |
+
if shared_camera:
|
| 288 |
+
# If shared_camera, all images share the same camera
|
| 289 |
+
# no need to rescale any more
|
| 290 |
+
rescale_camera = False
|
| 291 |
+
|
| 292 |
+
return reconstruction
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
if __name__ == "__main__":
|
| 296 |
+
args = parse_args()
|
| 297 |
+
with torch.no_grad():
|
| 298 |
+
demo_fn(args)
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
# Work in Progress (WIP)
|
| 302 |
+
|
| 303 |
+
"""
|
| 304 |
+
VGGT Runner Script
|
| 305 |
+
=================
|
| 306 |
+
|
| 307 |
+
A script to run the VGGT model for 3D reconstruction from image sequences.
|
| 308 |
+
|
| 309 |
+
Directory Structure
|
| 310 |
+
------------------
|
| 311 |
+
Input:
|
| 312 |
+
input_folder/
|
| 313 |
+
└── images/ # Source images for reconstruction
|
| 314 |
+
|
| 315 |
+
Output:
|
| 316 |
+
output_folder/
|
| 317 |
+
├── images/
|
| 318 |
+
├── sparse/ # Reconstruction results
|
| 319 |
+
│ ├── cameras.bin # Camera parameters (COLMAP format)
|
| 320 |
+
│ ├── images.bin # Pose for each image (COLMAP format)
|
| 321 |
+
│ ├── points3D.bin # 3D points (COLMAP format)
|
| 322 |
+
│ └── points.ply # Point cloud visualization file
|
| 323 |
+
└── visuals/ # Visualization outputs TODO
|
| 324 |
+
|
| 325 |
+
Key Features
|
| 326 |
+
-----------
|
| 327 |
+
• Dual-mode Support: Run reconstructions using either VGGT or VGGT+BA
|
| 328 |
+
• Resolution Preservation: Maintains original image resolution in camera parameters and tracks
|
| 329 |
+
• COLMAP Compatibility: Exports results in standard COLMAP sparse reconstruction format
|
| 330 |
+
"""
|
demo_gradio.py
ADDED
|
@@ -0,0 +1,690 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import cv2
|
| 9 |
+
import torch
|
| 10 |
+
import numpy as np
|
| 11 |
+
import gradio as gr
|
| 12 |
+
import sys
|
| 13 |
+
import shutil
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import glob
|
| 16 |
+
import gc
|
| 17 |
+
import time
|
| 18 |
+
|
| 19 |
+
sys.path.append("vggt/")
|
| 20 |
+
|
| 21 |
+
from visual_util import predictions_to_glb
|
| 22 |
+
from vggt.models.vggt import VGGT
|
| 23 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 24 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 25 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 26 |
+
|
| 27 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 28 |
+
|
| 29 |
+
print("Initializing and loading VGGT model...")
|
| 30 |
+
# model = VGGT.from_pretrained("facebook/VGGT-1B") # another way to load the model
|
| 31 |
+
|
| 32 |
+
model = VGGT()
|
| 33 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 34 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
model.eval()
|
| 38 |
+
model = model.to(device)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
# -------------------------------------------------------------------------
|
| 42 |
+
# 1) Core model inference
|
| 43 |
+
# -------------------------------------------------------------------------
|
| 44 |
+
def run_model(target_dir, model) -> dict:
|
| 45 |
+
"""
|
| 46 |
+
Run the VGGT model on images in the 'target_dir/images' folder and return predictions.
|
| 47 |
+
"""
|
| 48 |
+
print(f"Processing images from {target_dir}")
|
| 49 |
+
|
| 50 |
+
# Device check
|
| 51 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 52 |
+
if not torch.cuda.is_available():
|
| 53 |
+
raise ValueError("CUDA is not available. Check your environment.")
|
| 54 |
+
|
| 55 |
+
# Move model to device
|
| 56 |
+
model = model.to(device)
|
| 57 |
+
model.eval()
|
| 58 |
+
|
| 59 |
+
# Load and preprocess images
|
| 60 |
+
image_names = glob.glob(os.path.join(target_dir, "images", "*"))
|
| 61 |
+
image_names = sorted(image_names)
|
| 62 |
+
print(f"Found {len(image_names)} images")
|
| 63 |
+
if len(image_names) == 0:
|
| 64 |
+
raise ValueError("No images found. Check your upload.")
|
| 65 |
+
|
| 66 |
+
images = load_and_preprocess_images(image_names).to(device)
|
| 67 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 68 |
+
|
| 69 |
+
# Run inference
|
| 70 |
+
print("Running inference...")
|
| 71 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 72 |
+
|
| 73 |
+
with torch.no_grad():
|
| 74 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 75 |
+
predictions = model(images)
|
| 76 |
+
|
| 77 |
+
# Convert pose encoding to extrinsic and intrinsic matrices
|
| 78 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 79 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 80 |
+
predictions["extrinsic"] = extrinsic
|
| 81 |
+
predictions["intrinsic"] = intrinsic
|
| 82 |
+
|
| 83 |
+
# Convert tensors to numpy
|
| 84 |
+
for key in predictions.keys():
|
| 85 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 86 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension
|
| 87 |
+
|
| 88 |
+
# Generate world points from depth map
|
| 89 |
+
print("Computing world points from depth map...")
|
| 90 |
+
depth_map = predictions["depth"] # (S, H, W, 1)
|
| 91 |
+
world_points = unproject_depth_map_to_point_map(depth_map, predictions["extrinsic"], predictions["intrinsic"])
|
| 92 |
+
predictions["world_points_from_depth"] = world_points
|
| 93 |
+
|
| 94 |
+
# Clean up
|
| 95 |
+
torch.cuda.empty_cache()
|
| 96 |
+
return predictions
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
# -------------------------------------------------------------------------
|
| 100 |
+
# 2) Handle uploaded video/images --> produce target_dir + images
|
| 101 |
+
# -------------------------------------------------------------------------
|
| 102 |
+
def handle_uploads(input_video, input_images):
|
| 103 |
+
"""
|
| 104 |
+
Create a new 'target_dir' + 'images' subfolder, and place user-uploaded
|
| 105 |
+
images or extracted frames from video into it. Return (target_dir, image_paths).
|
| 106 |
+
"""
|
| 107 |
+
start_time = time.time()
|
| 108 |
+
gc.collect()
|
| 109 |
+
torch.cuda.empty_cache()
|
| 110 |
+
|
| 111 |
+
# Create a unique folder name
|
| 112 |
+
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
| 113 |
+
target_dir = f"input_images_{timestamp}"
|
| 114 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 115 |
+
|
| 116 |
+
# Clean up if somehow that folder already exists
|
| 117 |
+
if os.path.exists(target_dir):
|
| 118 |
+
shutil.rmtree(target_dir)
|
| 119 |
+
os.makedirs(target_dir)
|
| 120 |
+
os.makedirs(target_dir_images)
|
| 121 |
+
|
| 122 |
+
image_paths = []
|
| 123 |
+
|
| 124 |
+
# --- Handle images ---
|
| 125 |
+
if input_images is not None:
|
| 126 |
+
for file_data in input_images:
|
| 127 |
+
if isinstance(file_data, dict) and "name" in file_data:
|
| 128 |
+
file_path = file_data["name"]
|
| 129 |
+
else:
|
| 130 |
+
file_path = file_data
|
| 131 |
+
dst_path = os.path.join(target_dir_images, os.path.basename(file_path))
|
| 132 |
+
shutil.copy(file_path, dst_path)
|
| 133 |
+
image_paths.append(dst_path)
|
| 134 |
+
|
| 135 |
+
# --- Handle video ---
|
| 136 |
+
if input_video is not None:
|
| 137 |
+
if isinstance(input_video, dict) and "name" in input_video:
|
| 138 |
+
video_path = input_video["name"]
|
| 139 |
+
else:
|
| 140 |
+
video_path = input_video
|
| 141 |
+
|
| 142 |
+
vs = cv2.VideoCapture(video_path)
|
| 143 |
+
fps = vs.get(cv2.CAP_PROP_FPS)
|
| 144 |
+
frame_interval = int(fps * 1) # 1 frame/sec
|
| 145 |
+
|
| 146 |
+
count = 0
|
| 147 |
+
video_frame_num = 0
|
| 148 |
+
while True:
|
| 149 |
+
gotit, frame = vs.read()
|
| 150 |
+
if not gotit:
|
| 151 |
+
break
|
| 152 |
+
count += 1
|
| 153 |
+
if count % frame_interval == 0:
|
| 154 |
+
image_path = os.path.join(target_dir_images, f"{video_frame_num:06}.png")
|
| 155 |
+
cv2.imwrite(image_path, frame)
|
| 156 |
+
image_paths.append(image_path)
|
| 157 |
+
video_frame_num += 1
|
| 158 |
+
|
| 159 |
+
# Sort final images for gallery
|
| 160 |
+
image_paths = sorted(image_paths)
|
| 161 |
+
|
| 162 |
+
end_time = time.time()
|
| 163 |
+
print(f"Files copied to {target_dir_images}; took {end_time - start_time:.3f} seconds")
|
| 164 |
+
return target_dir, image_paths
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
# -------------------------------------------------------------------------
|
| 168 |
+
# 3) Update gallery on upload
|
| 169 |
+
# -------------------------------------------------------------------------
|
| 170 |
+
def update_gallery_on_upload(input_video, input_images):
|
| 171 |
+
"""
|
| 172 |
+
Whenever user uploads or changes files, immediately handle them
|
| 173 |
+
and show in the gallery. Return (target_dir, image_paths).
|
| 174 |
+
If nothing is uploaded, returns "None" and empty list.
|
| 175 |
+
"""
|
| 176 |
+
if not input_video and not input_images:
|
| 177 |
+
return None, None, None, None
|
| 178 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 179 |
+
return None, target_dir, image_paths, "Upload complete. Click 'Reconstruct' to begin 3D processing."
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
# -------------------------------------------------------------------------
|
| 183 |
+
# 4) Reconstruction: uses the target_dir plus any viz parameters
|
| 184 |
+
# -------------------------------------------------------------------------
|
| 185 |
+
def gradio_demo(
|
| 186 |
+
target_dir,
|
| 187 |
+
conf_thres=3.0,
|
| 188 |
+
frame_filter="All",
|
| 189 |
+
mask_black_bg=False,
|
| 190 |
+
mask_white_bg=False,
|
| 191 |
+
show_cam=True,
|
| 192 |
+
mask_sky=False,
|
| 193 |
+
prediction_mode="Pointmap Regression",
|
| 194 |
+
):
|
| 195 |
+
"""
|
| 196 |
+
Perform reconstruction using the already-created target_dir/images.
|
| 197 |
+
"""
|
| 198 |
+
if not os.path.isdir(target_dir) or target_dir == "None":
|
| 199 |
+
return None, "No valid target directory found. Please upload first.", None, None
|
| 200 |
+
|
| 201 |
+
start_time = time.time()
|
| 202 |
+
gc.collect()
|
| 203 |
+
torch.cuda.empty_cache()
|
| 204 |
+
|
| 205 |
+
# Prepare frame_filter dropdown
|
| 206 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 207 |
+
all_files = sorted(os.listdir(target_dir_images)) if os.path.isdir(target_dir_images) else []
|
| 208 |
+
all_files = [f"{i}: {filename}" for i, filename in enumerate(all_files)]
|
| 209 |
+
frame_filter_choices = ["All"] + all_files
|
| 210 |
+
|
| 211 |
+
print("Running run_model...")
|
| 212 |
+
with torch.no_grad():
|
| 213 |
+
predictions = run_model(target_dir, model)
|
| 214 |
+
|
| 215 |
+
# Save predictions
|
| 216 |
+
prediction_save_path = os.path.join(target_dir, "predictions.npz")
|
| 217 |
+
np.savez(prediction_save_path, **predictions)
|
| 218 |
+
|
| 219 |
+
# Handle None frame_filter
|
| 220 |
+
if frame_filter is None:
|
| 221 |
+
frame_filter = "All"
|
| 222 |
+
|
| 223 |
+
# Build a GLB file name
|
| 224 |
+
glbfile = os.path.join(
|
| 225 |
+
target_dir,
|
| 226 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 227 |
+
)
|
| 228 |
+
|
| 229 |
+
# Convert predictions to GLB
|
| 230 |
+
glbscene = predictions_to_glb(
|
| 231 |
+
predictions,
|
| 232 |
+
conf_thres=conf_thres,
|
| 233 |
+
filter_by_frames=frame_filter,
|
| 234 |
+
mask_black_bg=mask_black_bg,
|
| 235 |
+
mask_white_bg=mask_white_bg,
|
| 236 |
+
show_cam=show_cam,
|
| 237 |
+
mask_sky=mask_sky,
|
| 238 |
+
target_dir=target_dir,
|
| 239 |
+
prediction_mode=prediction_mode,
|
| 240 |
+
)
|
| 241 |
+
glbscene.export(file_obj=glbfile)
|
| 242 |
+
|
| 243 |
+
# Cleanup
|
| 244 |
+
del predictions
|
| 245 |
+
gc.collect()
|
| 246 |
+
torch.cuda.empty_cache()
|
| 247 |
+
|
| 248 |
+
end_time = time.time()
|
| 249 |
+
print(f"Total time: {end_time - start_time:.2f} seconds (including IO)")
|
| 250 |
+
log_msg = f"Reconstruction Success ({len(all_files)} frames). Waiting for visualization."
|
| 251 |
+
|
| 252 |
+
return glbfile, log_msg, gr.Dropdown(choices=frame_filter_choices, value=frame_filter, interactive=True)
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
# -------------------------------------------------------------------------
|
| 256 |
+
# 5) Helper functions for UI resets + re-visualization
|
| 257 |
+
# -------------------------------------------------------------------------
|
| 258 |
+
def clear_fields():
|
| 259 |
+
"""
|
| 260 |
+
Clears the 3D viewer, the stored target_dir, and empties the gallery.
|
| 261 |
+
"""
|
| 262 |
+
return None
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
def update_log():
|
| 266 |
+
"""
|
| 267 |
+
Display a quick log message while waiting.
|
| 268 |
+
"""
|
| 269 |
+
return "Loading and Reconstructing..."
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def update_visualization(
|
| 273 |
+
target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode, is_example
|
| 274 |
+
):
|
| 275 |
+
"""
|
| 276 |
+
Reload saved predictions from npz, create (or reuse) the GLB for new parameters,
|
| 277 |
+
and return it for the 3D viewer. If is_example == "True", skip.
|
| 278 |
+
"""
|
| 279 |
+
|
| 280 |
+
# If it's an example click, skip as requested
|
| 281 |
+
if is_example == "True":
|
| 282 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 283 |
+
|
| 284 |
+
if not target_dir or target_dir == "None" or not os.path.isdir(target_dir):
|
| 285 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 286 |
+
|
| 287 |
+
predictions_path = os.path.join(target_dir, "predictions.npz")
|
| 288 |
+
if not os.path.exists(predictions_path):
|
| 289 |
+
return None, f"No reconstruction available at {predictions_path}. Please run 'Reconstruct' first."
|
| 290 |
+
|
| 291 |
+
key_list = [
|
| 292 |
+
"pose_enc",
|
| 293 |
+
"depth",
|
| 294 |
+
"depth_conf",
|
| 295 |
+
"world_points",
|
| 296 |
+
"world_points_conf",
|
| 297 |
+
"images",
|
| 298 |
+
"extrinsic",
|
| 299 |
+
"intrinsic",
|
| 300 |
+
"world_points_from_depth",
|
| 301 |
+
]
|
| 302 |
+
|
| 303 |
+
loaded = np.load(predictions_path)
|
| 304 |
+
predictions = {key: np.array(loaded[key]) for key in key_list}
|
| 305 |
+
|
| 306 |
+
glbfile = os.path.join(
|
| 307 |
+
target_dir,
|
| 308 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
if not os.path.exists(glbfile):
|
| 312 |
+
glbscene = predictions_to_glb(
|
| 313 |
+
predictions,
|
| 314 |
+
conf_thres=conf_thres,
|
| 315 |
+
filter_by_frames=frame_filter,
|
| 316 |
+
mask_black_bg=mask_black_bg,
|
| 317 |
+
mask_white_bg=mask_white_bg,
|
| 318 |
+
show_cam=show_cam,
|
| 319 |
+
mask_sky=mask_sky,
|
| 320 |
+
target_dir=target_dir,
|
| 321 |
+
prediction_mode=prediction_mode,
|
| 322 |
+
)
|
| 323 |
+
glbscene.export(file_obj=glbfile)
|
| 324 |
+
|
| 325 |
+
return glbfile, "Updating Visualization"
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
# -------------------------------------------------------------------------
|
| 329 |
+
# Example images
|
| 330 |
+
# -------------------------------------------------------------------------
|
| 331 |
+
|
| 332 |
+
great_wall_video = "examples/videos/great_wall.mp4"
|
| 333 |
+
colosseum_video = "examples/videos/Colosseum.mp4"
|
| 334 |
+
room_video = "examples/videos/room.mp4"
|
| 335 |
+
kitchen_video = "examples/videos/kitchen.mp4"
|
| 336 |
+
fern_video = "examples/videos/fern.mp4"
|
| 337 |
+
single_cartoon_video = "examples/videos/single_cartoon.mp4"
|
| 338 |
+
single_oil_painting_video = "examples/videos/single_oil_painting.mp4"
|
| 339 |
+
pyramid_video = "examples/videos/pyramid.mp4"
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
# -------------------------------------------------------------------------
|
| 343 |
+
# 6) Build Gradio UI
|
| 344 |
+
# -------------------------------------------------------------------------
|
| 345 |
+
theme = gr.themes.Ocean()
|
| 346 |
+
theme.set(
|
| 347 |
+
checkbox_label_background_fill_selected="*button_primary_background_fill",
|
| 348 |
+
checkbox_label_text_color_selected="*button_primary_text_color",
|
| 349 |
+
)
|
| 350 |
+
|
| 351 |
+
with gr.Blocks(
|
| 352 |
+
theme=theme,
|
| 353 |
+
css="""
|
| 354 |
+
.custom-log * {
|
| 355 |
+
font-style: italic;
|
| 356 |
+
font-size: 22px !important;
|
| 357 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 358 |
+
-webkit-background-clip: text;
|
| 359 |
+
background-clip: text;
|
| 360 |
+
font-weight: bold !important;
|
| 361 |
+
color: transparent !important;
|
| 362 |
+
text-align: center !important;
|
| 363 |
+
}
|
| 364 |
+
|
| 365 |
+
.example-log * {
|
| 366 |
+
font-style: italic;
|
| 367 |
+
font-size: 16px !important;
|
| 368 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 369 |
+
-webkit-background-clip: text;
|
| 370 |
+
background-clip: text;
|
| 371 |
+
color: transparent !important;
|
| 372 |
+
}
|
| 373 |
+
|
| 374 |
+
#my_radio .wrap {
|
| 375 |
+
display: flex;
|
| 376 |
+
flex-wrap: nowrap;
|
| 377 |
+
justify-content: center;
|
| 378 |
+
align-items: center;
|
| 379 |
+
}
|
| 380 |
+
|
| 381 |
+
#my_radio .wrap label {
|
| 382 |
+
display: flex;
|
| 383 |
+
width: 50%;
|
| 384 |
+
justify-content: center;
|
| 385 |
+
align-items: center;
|
| 386 |
+
margin: 0;
|
| 387 |
+
padding: 10px 0;
|
| 388 |
+
box-sizing: border-box;
|
| 389 |
+
}
|
| 390 |
+
""",
|
| 391 |
+
) as demo:
|
| 392 |
+
# Instead of gr.State, we use a hidden Textbox:
|
| 393 |
+
is_example = gr.Textbox(label="is_example", visible=False, value="None")
|
| 394 |
+
num_images = gr.Textbox(label="num_images", visible=False, value="None")
|
| 395 |
+
|
| 396 |
+
gr.HTML(
|
| 397 |
+
"""
|
| 398 |
+
<h1>🏛️ VGGT: Visual Geometry Grounded Transformer</h1>
|
| 399 |
+
<p>
|
| 400 |
+
<a href="https://github.com/facebookresearch/vggt">🐙 GitHub Repository</a> |
|
| 401 |
+
<a href="#">Project Page</a>
|
| 402 |
+
</p>
|
| 403 |
+
|
| 404 |
+
<div style="font-size: 16px; line-height: 1.5;">
|
| 405 |
+
<p>Upload a video or a set of images to create a 3D reconstruction of a scene or object. VGGT takes these images and generates a 3D point cloud, along with estimated camera poses.</p>
|
| 406 |
+
|
| 407 |
+
<h3>Getting Started:</h3>
|
| 408 |
+
<ol>
|
| 409 |
+
<li><strong>Upload Your Data:</strong> Use the "Upload Video" or "Upload Images" buttons on the left to provide your input. Videos will be automatically split into individual frames (one frame per second).</li>
|
| 410 |
+
<li><strong>Preview:</strong> Your uploaded images will appear in the gallery on the left.</li>
|
| 411 |
+
<li><strong>Reconstruct:</strong> Click the "Reconstruct" button to start the 3D reconstruction process.</li>
|
| 412 |
+
<li><strong>Visualize:</strong> The 3D reconstruction will appear in the viewer on the right. You can rotate, pan, and zoom to explore the model, and download the GLB file. Note the visualization of 3D points may be slow for a large number of input images.</li>
|
| 413 |
+
<li>
|
| 414 |
+
<strong>Adjust Visualization (Optional):</strong>
|
| 415 |
+
After reconstruction, you can fine-tune the visualization using the options below
|
| 416 |
+
<details style="display:inline;">
|
| 417 |
+
<summary style="display:inline;">(<strong>click to expand</strong>):</summary>
|
| 418 |
+
<ul>
|
| 419 |
+
<li><em>Confidence Threshold:</em> Adjust the filtering of points based on confidence.</li>
|
| 420 |
+
<li><em>Show Points from Frame:</em> Select specific frames to display in the point cloud.</li>
|
| 421 |
+
<li><em>Show Camera:</em> Toggle the display of estimated camera positions.</li>
|
| 422 |
+
<li><em>Filter Sky / Filter Black Background:</em> Remove sky or black-background points.</li>
|
| 423 |
+
<li><em>Select a Prediction Mode:</em> Choose between "Depthmap and Camera Branch" or "Pointmap Branch."</li>
|
| 424 |
+
</ul>
|
| 425 |
+
</details>
|
| 426 |
+
</li>
|
| 427 |
+
</ol>
|
| 428 |
+
<p><strong style="color: #0ea5e9;">Please note:</strong> <span style="color: #0ea5e9; font-weight: bold;">VGGT typically reconstructs a scene in less than 1 second. However, visualizing 3D points may take tens of seconds due to third-party rendering, which are independent of VGGT's processing time. </span></p>
|
| 429 |
+
</div>
|
| 430 |
+
"""
|
| 431 |
+
)
|
| 432 |
+
|
| 433 |
+
target_dir_output = gr.Textbox(label="Target Dir", visible=False, value="None")
|
| 434 |
+
|
| 435 |
+
with gr.Row():
|
| 436 |
+
with gr.Column(scale=2):
|
| 437 |
+
input_video = gr.Video(label="Upload Video", interactive=True)
|
| 438 |
+
input_images = gr.File(file_count="multiple", label="Upload Images", interactive=True)
|
| 439 |
+
|
| 440 |
+
image_gallery = gr.Gallery(
|
| 441 |
+
label="Preview",
|
| 442 |
+
columns=4,
|
| 443 |
+
height="300px",
|
| 444 |
+
show_download_button=True,
|
| 445 |
+
object_fit="contain",
|
| 446 |
+
preview=True,
|
| 447 |
+
)
|
| 448 |
+
|
| 449 |
+
with gr.Column(scale=4):
|
| 450 |
+
with gr.Column():
|
| 451 |
+
gr.Markdown("**3D Reconstruction (Point Cloud and Camera Poses)**")
|
| 452 |
+
log_output = gr.Markdown(
|
| 453 |
+
"Please upload a video or images, then click Reconstruct.", elem_classes=["custom-log"]
|
| 454 |
+
)
|
| 455 |
+
reconstruction_output = gr.Model3D(height=520, zoom_speed=0.5, pan_speed=0.5)
|
| 456 |
+
|
| 457 |
+
with gr.Row():
|
| 458 |
+
submit_btn = gr.Button("Reconstruct", scale=1, variant="primary")
|
| 459 |
+
clear_btn = gr.ClearButton(
|
| 460 |
+
[input_video, input_images, reconstruction_output, log_output, target_dir_output, image_gallery],
|
| 461 |
+
scale=1,
|
| 462 |
+
)
|
| 463 |
+
|
| 464 |
+
with gr.Row():
|
| 465 |
+
prediction_mode = gr.Radio(
|
| 466 |
+
["Depthmap and Camera Branch", "Pointmap Branch"],
|
| 467 |
+
label="Select a Prediction Mode",
|
| 468 |
+
value="Depthmap and Camera Branch",
|
| 469 |
+
scale=1,
|
| 470 |
+
elem_id="my_radio",
|
| 471 |
+
)
|
| 472 |
+
|
| 473 |
+
with gr.Row():
|
| 474 |
+
conf_thres = gr.Slider(minimum=0, maximum=100, value=50, step=0.1, label="Confidence Threshold (%)")
|
| 475 |
+
frame_filter = gr.Dropdown(choices=["All"], value="All", label="Show Points from Frame")
|
| 476 |
+
with gr.Column():
|
| 477 |
+
show_cam = gr.Checkbox(label="Show Camera", value=True)
|
| 478 |
+
mask_sky = gr.Checkbox(label="Filter Sky", value=False)
|
| 479 |
+
mask_black_bg = gr.Checkbox(label="Filter Black Background", value=False)
|
| 480 |
+
mask_white_bg = gr.Checkbox(label="Filter White Background", value=False)
|
| 481 |
+
|
| 482 |
+
# ---------------------- Examples section ----------------------
|
| 483 |
+
examples = [
|
| 484 |
+
[colosseum_video, "22", None, 20.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 485 |
+
[pyramid_video, "30", None, 35.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 486 |
+
[single_cartoon_video, "1", None, 15.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 487 |
+
[single_oil_painting_video, "1", None, 20.0, False, False, True, True, "Depthmap and Camera Branch", "True"],
|
| 488 |
+
[room_video, "8", None, 5.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 489 |
+
[kitchen_video, "25", None, 50.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 490 |
+
[fern_video, "20", None, 45.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 491 |
+
]
|
| 492 |
+
|
| 493 |
+
def example_pipeline(
|
| 494 |
+
input_video,
|
| 495 |
+
num_images_str,
|
| 496 |
+
input_images,
|
| 497 |
+
conf_thres,
|
| 498 |
+
mask_black_bg,
|
| 499 |
+
mask_white_bg,
|
| 500 |
+
show_cam,
|
| 501 |
+
mask_sky,
|
| 502 |
+
prediction_mode,
|
| 503 |
+
is_example_str,
|
| 504 |
+
):
|
| 505 |
+
"""
|
| 506 |
+
1) Copy example images to new target_dir
|
| 507 |
+
2) Reconstruct
|
| 508 |
+
3) Return model3D + logs + new_dir + updated dropdown + gallery
|
| 509 |
+
We do NOT return is_example. It's just an input.
|
| 510 |
+
"""
|
| 511 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 512 |
+
# Always use "All" for frame_filter in examples
|
| 513 |
+
frame_filter = "All"
|
| 514 |
+
glbfile, log_msg, dropdown = gradio_demo(
|
| 515 |
+
target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode
|
| 516 |
+
)
|
| 517 |
+
return glbfile, log_msg, target_dir, dropdown, image_paths
|
| 518 |
+
|
| 519 |
+
gr.Markdown("Click any row to load an example.", elem_classes=["example-log"])
|
| 520 |
+
|
| 521 |
+
gr.Examples(
|
| 522 |
+
examples=examples,
|
| 523 |
+
inputs=[
|
| 524 |
+
input_video,
|
| 525 |
+
num_images,
|
| 526 |
+
input_images,
|
| 527 |
+
conf_thres,
|
| 528 |
+
mask_black_bg,
|
| 529 |
+
mask_white_bg,
|
| 530 |
+
show_cam,
|
| 531 |
+
mask_sky,
|
| 532 |
+
prediction_mode,
|
| 533 |
+
is_example,
|
| 534 |
+
],
|
| 535 |
+
outputs=[reconstruction_output, log_output, target_dir_output, frame_filter, image_gallery],
|
| 536 |
+
fn=example_pipeline,
|
| 537 |
+
cache_examples=False,
|
| 538 |
+
examples_per_page=50,
|
| 539 |
+
)
|
| 540 |
+
|
| 541 |
+
# -------------------------------------------------------------------------
|
| 542 |
+
# "Reconstruct" button logic:
|
| 543 |
+
# - Clear fields
|
| 544 |
+
# - Update log
|
| 545 |
+
# - gradio_demo(...) with the existing target_dir
|
| 546 |
+
# - Then set is_example = "False"
|
| 547 |
+
# -------------------------------------------------------------------------
|
| 548 |
+
submit_btn.click(fn=clear_fields, inputs=[], outputs=[reconstruction_output]).then(
|
| 549 |
+
fn=update_log, inputs=[], outputs=[log_output]
|
| 550 |
+
).then(
|
| 551 |
+
fn=gradio_demo,
|
| 552 |
+
inputs=[
|
| 553 |
+
target_dir_output,
|
| 554 |
+
conf_thres,
|
| 555 |
+
frame_filter,
|
| 556 |
+
mask_black_bg,
|
| 557 |
+
mask_white_bg,
|
| 558 |
+
show_cam,
|
| 559 |
+
mask_sky,
|
| 560 |
+
prediction_mode,
|
| 561 |
+
],
|
| 562 |
+
outputs=[reconstruction_output, log_output, frame_filter],
|
| 563 |
+
).then(
|
| 564 |
+
fn=lambda: "False", inputs=[], outputs=[is_example] # set is_example to "False"
|
| 565 |
+
)
|
| 566 |
+
|
| 567 |
+
# -------------------------------------------------------------------------
|
| 568 |
+
# Real-time Visualization Updates
|
| 569 |
+
# -------------------------------------------------------------------------
|
| 570 |
+
conf_thres.change(
|
| 571 |
+
update_visualization,
|
| 572 |
+
[
|
| 573 |
+
target_dir_output,
|
| 574 |
+
conf_thres,
|
| 575 |
+
frame_filter,
|
| 576 |
+
mask_black_bg,
|
| 577 |
+
mask_white_bg,
|
| 578 |
+
show_cam,
|
| 579 |
+
mask_sky,
|
| 580 |
+
prediction_mode,
|
| 581 |
+
is_example,
|
| 582 |
+
],
|
| 583 |
+
[reconstruction_output, log_output],
|
| 584 |
+
)
|
| 585 |
+
frame_filter.change(
|
| 586 |
+
update_visualization,
|
| 587 |
+
[
|
| 588 |
+
target_dir_output,
|
| 589 |
+
conf_thres,
|
| 590 |
+
frame_filter,
|
| 591 |
+
mask_black_bg,
|
| 592 |
+
mask_white_bg,
|
| 593 |
+
show_cam,
|
| 594 |
+
mask_sky,
|
| 595 |
+
prediction_mode,
|
| 596 |
+
is_example,
|
| 597 |
+
],
|
| 598 |
+
[reconstruction_output, log_output],
|
| 599 |
+
)
|
| 600 |
+
mask_black_bg.change(
|
| 601 |
+
update_visualization,
|
| 602 |
+
[
|
| 603 |
+
target_dir_output,
|
| 604 |
+
conf_thres,
|
| 605 |
+
frame_filter,
|
| 606 |
+
mask_black_bg,
|
| 607 |
+
mask_white_bg,
|
| 608 |
+
show_cam,
|
| 609 |
+
mask_sky,
|
| 610 |
+
prediction_mode,
|
| 611 |
+
is_example,
|
| 612 |
+
],
|
| 613 |
+
[reconstruction_output, log_output],
|
| 614 |
+
)
|
| 615 |
+
mask_white_bg.change(
|
| 616 |
+
update_visualization,
|
| 617 |
+
[
|
| 618 |
+
target_dir_output,
|
| 619 |
+
conf_thres,
|
| 620 |
+
frame_filter,
|
| 621 |
+
mask_black_bg,
|
| 622 |
+
mask_white_bg,
|
| 623 |
+
show_cam,
|
| 624 |
+
mask_sky,
|
| 625 |
+
prediction_mode,
|
| 626 |
+
is_example,
|
| 627 |
+
],
|
| 628 |
+
[reconstruction_output, log_output],
|
| 629 |
+
)
|
| 630 |
+
show_cam.change(
|
| 631 |
+
update_visualization,
|
| 632 |
+
[
|
| 633 |
+
target_dir_output,
|
| 634 |
+
conf_thres,
|
| 635 |
+
frame_filter,
|
| 636 |
+
mask_black_bg,
|
| 637 |
+
mask_white_bg,
|
| 638 |
+
show_cam,
|
| 639 |
+
mask_sky,
|
| 640 |
+
prediction_mode,
|
| 641 |
+
is_example,
|
| 642 |
+
],
|
| 643 |
+
[reconstruction_output, log_output],
|
| 644 |
+
)
|
| 645 |
+
mask_sky.change(
|
| 646 |
+
update_visualization,
|
| 647 |
+
[
|
| 648 |
+
target_dir_output,
|
| 649 |
+
conf_thres,
|
| 650 |
+
frame_filter,
|
| 651 |
+
mask_black_bg,
|
| 652 |
+
mask_white_bg,
|
| 653 |
+
show_cam,
|
| 654 |
+
mask_sky,
|
| 655 |
+
prediction_mode,
|
| 656 |
+
is_example,
|
| 657 |
+
],
|
| 658 |
+
[reconstruction_output, log_output],
|
| 659 |
+
)
|
| 660 |
+
prediction_mode.change(
|
| 661 |
+
update_visualization,
|
| 662 |
+
[
|
| 663 |
+
target_dir_output,
|
| 664 |
+
conf_thres,
|
| 665 |
+
frame_filter,
|
| 666 |
+
mask_black_bg,
|
| 667 |
+
mask_white_bg,
|
| 668 |
+
show_cam,
|
| 669 |
+
mask_sky,
|
| 670 |
+
prediction_mode,
|
| 671 |
+
is_example,
|
| 672 |
+
],
|
| 673 |
+
[reconstruction_output, log_output],
|
| 674 |
+
)
|
| 675 |
+
|
| 676 |
+
# -------------------------------------------------------------------------
|
| 677 |
+
# Auto-update gallery whenever user uploads or changes their files
|
| 678 |
+
# -------------------------------------------------------------------------
|
| 679 |
+
input_video.change(
|
| 680 |
+
fn=update_gallery_on_upload,
|
| 681 |
+
inputs=[input_video, input_images],
|
| 682 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 683 |
+
)
|
| 684 |
+
input_images.change(
|
| 685 |
+
fn=update_gallery_on_upload,
|
| 686 |
+
inputs=[input_video, input_images],
|
| 687 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 688 |
+
)
|
| 689 |
+
|
| 690 |
+
demo.queue(max_size=20).launch(show_error=True, share=True)
|
demo_viser.py
ADDED
|
@@ -0,0 +1,402 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import glob
|
| 9 |
+
import time
|
| 10 |
+
import threading
|
| 11 |
+
import argparse
|
| 12 |
+
from typing import List, Optional
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import torch
|
| 16 |
+
from tqdm.auto import tqdm
|
| 17 |
+
import viser
|
| 18 |
+
import viser.transforms as viser_tf
|
| 19 |
+
import cv2
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
try:
|
| 23 |
+
import onnxruntime
|
| 24 |
+
except ImportError:
|
| 25 |
+
print("onnxruntime not found. Sky segmentation may not work.")
|
| 26 |
+
|
| 27 |
+
from visual_util import segment_sky, download_file_from_url
|
| 28 |
+
from vggt.models.vggt import VGGT
|
| 29 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 30 |
+
from vggt.utils.geometry import closed_form_inverse_se3, unproject_depth_map_to_point_map
|
| 31 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def viser_wrapper(
|
| 35 |
+
pred_dict: dict,
|
| 36 |
+
port: int = 8080,
|
| 37 |
+
init_conf_threshold: float = 50.0, # represents percentage (e.g., 50 means filter lowest 50%)
|
| 38 |
+
use_point_map: bool = False,
|
| 39 |
+
background_mode: bool = False,
|
| 40 |
+
mask_sky: bool = False,
|
| 41 |
+
image_folder: str = None,
|
| 42 |
+
):
|
| 43 |
+
"""
|
| 44 |
+
Visualize predicted 3D points and camera poses with viser.
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
pred_dict (dict):
|
| 48 |
+
{
|
| 49 |
+
"images": (S, 3, H, W) - Input images,
|
| 50 |
+
"world_points": (S, H, W, 3),
|
| 51 |
+
"world_points_conf": (S, H, W),
|
| 52 |
+
"depth": (S, H, W, 1),
|
| 53 |
+
"depth_conf": (S, H, W),
|
| 54 |
+
"extrinsic": (S, 3, 4),
|
| 55 |
+
"intrinsic": (S, 3, 3),
|
| 56 |
+
}
|
| 57 |
+
port (int): Port number for the viser server.
|
| 58 |
+
init_conf_threshold (float): Initial percentage of low-confidence points to filter out.
|
| 59 |
+
use_point_map (bool): Whether to visualize world_points or use depth-based points.
|
| 60 |
+
background_mode (bool): Whether to run the server in background thread.
|
| 61 |
+
mask_sky (bool): Whether to apply sky segmentation to filter out sky points.
|
| 62 |
+
image_folder (str): Path to the folder containing input images.
|
| 63 |
+
"""
|
| 64 |
+
print(f"Starting viser server on port {port}")
|
| 65 |
+
|
| 66 |
+
server = viser.ViserServer(host="0.0.0.0", port=port)
|
| 67 |
+
server.gui.configure_theme(titlebar_content=None, control_layout="collapsible")
|
| 68 |
+
|
| 69 |
+
# Unpack prediction dict
|
| 70 |
+
images = pred_dict["images"] # (S, 3, H, W)
|
| 71 |
+
world_points_map = pred_dict["world_points"] # (S, H, W, 3)
|
| 72 |
+
conf_map = pred_dict["world_points_conf"] # (S, H, W)
|
| 73 |
+
|
| 74 |
+
depth_map = pred_dict["depth"] # (S, H, W, 1)
|
| 75 |
+
depth_conf = pred_dict["depth_conf"] # (S, H, W)
|
| 76 |
+
|
| 77 |
+
extrinsics_cam = pred_dict["extrinsic"] # (S, 3, 4)
|
| 78 |
+
intrinsics_cam = pred_dict["intrinsic"] # (S, 3, 3)
|
| 79 |
+
|
| 80 |
+
# Compute world points from depth if not using the precomputed point map
|
| 81 |
+
if not use_point_map:
|
| 82 |
+
world_points = unproject_depth_map_to_point_map(depth_map, extrinsics_cam, intrinsics_cam)
|
| 83 |
+
conf = depth_conf
|
| 84 |
+
else:
|
| 85 |
+
world_points = world_points_map
|
| 86 |
+
conf = conf_map
|
| 87 |
+
|
| 88 |
+
# Apply sky segmentation if enabled
|
| 89 |
+
if mask_sky and image_folder is not None:
|
| 90 |
+
conf = apply_sky_segmentation(conf, image_folder)
|
| 91 |
+
|
| 92 |
+
# Convert images from (S, 3, H, W) to (S, H, W, 3)
|
| 93 |
+
# Then flatten everything for the point cloud
|
| 94 |
+
colors = images.transpose(0, 2, 3, 1) # now (S, H, W, 3)
|
| 95 |
+
S, H, W, _ = world_points.shape
|
| 96 |
+
|
| 97 |
+
# Flatten
|
| 98 |
+
points = world_points.reshape(-1, 3)
|
| 99 |
+
colors_flat = (colors.reshape(-1, 3) * 255).astype(np.uint8)
|
| 100 |
+
conf_flat = conf.reshape(-1)
|
| 101 |
+
|
| 102 |
+
cam_to_world_mat = closed_form_inverse_se3(extrinsics_cam) # shape (S, 4, 4) typically
|
| 103 |
+
# For convenience, we store only (3,4) portion
|
| 104 |
+
cam_to_world = cam_to_world_mat[:, :3, :]
|
| 105 |
+
|
| 106 |
+
# Compute scene center and recenter
|
| 107 |
+
scene_center = np.mean(points, axis=0)
|
| 108 |
+
points_centered = points - scene_center
|
| 109 |
+
cam_to_world[..., -1] -= scene_center
|
| 110 |
+
|
| 111 |
+
# Store frame indices so we can filter by frame
|
| 112 |
+
frame_indices = np.repeat(np.arange(S), H * W)
|
| 113 |
+
|
| 114 |
+
# Build the viser GUI
|
| 115 |
+
gui_show_frames = server.gui.add_checkbox("Show Cameras", initial_value=True)
|
| 116 |
+
|
| 117 |
+
# Now the slider represents percentage of points to filter out
|
| 118 |
+
gui_points_conf = server.gui.add_slider(
|
| 119 |
+
"Confidence Percent", min=0, max=100, step=0.1, initial_value=init_conf_threshold
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
gui_frame_selector = server.gui.add_dropdown(
|
| 123 |
+
"Show Points from Frames", options=["All"] + [str(i) for i in range(S)], initial_value="All"
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
# Create the main point cloud handle
|
| 127 |
+
# Compute the threshold value as the given percentile
|
| 128 |
+
init_threshold_val = np.percentile(conf_flat, init_conf_threshold)
|
| 129 |
+
init_conf_mask = (conf_flat >= init_threshold_val) & (conf_flat > 0.1)
|
| 130 |
+
point_cloud = server.scene.add_point_cloud(
|
| 131 |
+
name="viser_pcd",
|
| 132 |
+
points=points_centered[init_conf_mask],
|
| 133 |
+
colors=colors_flat[init_conf_mask],
|
| 134 |
+
point_size=0.001,
|
| 135 |
+
point_shape="circle",
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
# We will store references to frames & frustums so we can toggle visibility
|
| 139 |
+
frames: List[viser.FrameHandle] = []
|
| 140 |
+
frustums: List[viser.CameraFrustumHandle] = []
|
| 141 |
+
|
| 142 |
+
def visualize_frames(extrinsics: np.ndarray, images_: np.ndarray) -> None:
|
| 143 |
+
"""
|
| 144 |
+
Add camera frames and frustums to the scene.
|
| 145 |
+
extrinsics: (S, 3, 4)
|
| 146 |
+
images_: (S, 3, H, W)
|
| 147 |
+
"""
|
| 148 |
+
# Clear any existing frames or frustums
|
| 149 |
+
for f in frames:
|
| 150 |
+
f.remove()
|
| 151 |
+
frames.clear()
|
| 152 |
+
for fr in frustums:
|
| 153 |
+
fr.remove()
|
| 154 |
+
frustums.clear()
|
| 155 |
+
|
| 156 |
+
# Optionally attach a callback that sets the viewpoint to the chosen camera
|
| 157 |
+
def attach_callback(frustum: viser.CameraFrustumHandle, frame: viser.FrameHandle) -> None:
|
| 158 |
+
@frustum.on_click
|
| 159 |
+
def _(_) -> None:
|
| 160 |
+
for client in server.get_clients().values():
|
| 161 |
+
client.camera.wxyz = frame.wxyz
|
| 162 |
+
client.camera.position = frame.position
|
| 163 |
+
|
| 164 |
+
img_ids = range(S)
|
| 165 |
+
for img_id in tqdm(img_ids):
|
| 166 |
+
cam2world_3x4 = extrinsics[img_id]
|
| 167 |
+
T_world_camera = viser_tf.SE3.from_matrix(cam2world_3x4)
|
| 168 |
+
|
| 169 |
+
# Add a small frame axis
|
| 170 |
+
frame_axis = server.scene.add_frame(
|
| 171 |
+
f"frame_{img_id}",
|
| 172 |
+
wxyz=T_world_camera.rotation().wxyz,
|
| 173 |
+
position=T_world_camera.translation(),
|
| 174 |
+
axes_length=0.05,
|
| 175 |
+
axes_radius=0.002,
|
| 176 |
+
origin_radius=0.002,
|
| 177 |
+
)
|
| 178 |
+
frames.append(frame_axis)
|
| 179 |
+
|
| 180 |
+
# Convert the image for the frustum
|
| 181 |
+
img = images_[img_id] # shape (3, H, W)
|
| 182 |
+
img = (img.transpose(1, 2, 0) * 255).astype(np.uint8)
|
| 183 |
+
h, w = img.shape[:2]
|
| 184 |
+
|
| 185 |
+
# If you want correct FOV from intrinsics, do something like:
|
| 186 |
+
# fx = intrinsics_cam[img_id, 0, 0]
|
| 187 |
+
# fov = 2 * np.arctan2(h/2, fx)
|
| 188 |
+
# For demonstration, we pick a simple approximate FOV:
|
| 189 |
+
fy = 1.1 * h
|
| 190 |
+
fov = 2 * np.arctan2(h / 2, fy)
|
| 191 |
+
|
| 192 |
+
# Add the frustum
|
| 193 |
+
frustum_cam = server.scene.add_camera_frustum(
|
| 194 |
+
f"frame_{img_id}/frustum", fov=fov, aspect=w / h, scale=0.05, image=img, line_width=1.0
|
| 195 |
+
)
|
| 196 |
+
frustums.append(frustum_cam)
|
| 197 |
+
attach_callback(frustum_cam, frame_axis)
|
| 198 |
+
|
| 199 |
+
def update_point_cloud() -> None:
|
| 200 |
+
"""Update the point cloud based on current GUI selections."""
|
| 201 |
+
# Here we compute the threshold value based on the current percentage
|
| 202 |
+
current_percentage = gui_points_conf.value
|
| 203 |
+
threshold_val = np.percentile(conf_flat, current_percentage)
|
| 204 |
+
|
| 205 |
+
print(f"Threshold absolute value: {threshold_val}, percentage: {current_percentage}%")
|
| 206 |
+
|
| 207 |
+
conf_mask = (conf_flat >= threshold_val) & (conf_flat > 1e-5)
|
| 208 |
+
|
| 209 |
+
if gui_frame_selector.value == "All":
|
| 210 |
+
frame_mask = np.ones_like(conf_mask, dtype=bool)
|
| 211 |
+
else:
|
| 212 |
+
selected_idx = int(gui_frame_selector.value)
|
| 213 |
+
frame_mask = frame_indices == selected_idx
|
| 214 |
+
|
| 215 |
+
combined_mask = conf_mask & frame_mask
|
| 216 |
+
point_cloud.points = points_centered[combined_mask]
|
| 217 |
+
point_cloud.colors = colors_flat[combined_mask]
|
| 218 |
+
|
| 219 |
+
@gui_points_conf.on_update
|
| 220 |
+
def _(_) -> None:
|
| 221 |
+
update_point_cloud()
|
| 222 |
+
|
| 223 |
+
@gui_frame_selector.on_update
|
| 224 |
+
def _(_) -> None:
|
| 225 |
+
update_point_cloud()
|
| 226 |
+
|
| 227 |
+
@gui_show_frames.on_update
|
| 228 |
+
def _(_) -> None:
|
| 229 |
+
"""Toggle visibility of camera frames and frustums."""
|
| 230 |
+
for f in frames:
|
| 231 |
+
f.visible = gui_show_frames.value
|
| 232 |
+
for fr in frustums:
|
| 233 |
+
fr.visible = gui_show_frames.value
|
| 234 |
+
|
| 235 |
+
# Add the camera frames to the scene
|
| 236 |
+
visualize_frames(cam_to_world, images)
|
| 237 |
+
|
| 238 |
+
print("Starting viser server...")
|
| 239 |
+
# If background_mode is True, spawn a daemon thread so the main thread can continue.
|
| 240 |
+
if background_mode:
|
| 241 |
+
|
| 242 |
+
def server_loop():
|
| 243 |
+
while True:
|
| 244 |
+
time.sleep(0.001)
|
| 245 |
+
|
| 246 |
+
thread = threading.Thread(target=server_loop, daemon=True)
|
| 247 |
+
thread.start()
|
| 248 |
+
else:
|
| 249 |
+
while True:
|
| 250 |
+
time.sleep(0.01)
|
| 251 |
+
|
| 252 |
+
return server
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
# Helper functions for sky segmentation
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def apply_sky_segmentation(conf: np.ndarray, image_folder: str) -> np.ndarray:
|
| 259 |
+
"""
|
| 260 |
+
Apply sky segmentation to confidence scores.
|
| 261 |
+
|
| 262 |
+
Args:
|
| 263 |
+
conf (np.ndarray): Confidence scores with shape (S, H, W)
|
| 264 |
+
image_folder (str): Path to the folder containing input images
|
| 265 |
+
|
| 266 |
+
Returns:
|
| 267 |
+
np.ndarray: Updated confidence scores with sky regions masked out
|
| 268 |
+
"""
|
| 269 |
+
S, H, W = conf.shape
|
| 270 |
+
sky_masks_dir = image_folder.rstrip("/") + "_sky_masks"
|
| 271 |
+
os.makedirs(sky_masks_dir, exist_ok=True)
|
| 272 |
+
|
| 273 |
+
# Download skyseg.onnx if it doesn't exist
|
| 274 |
+
if not os.path.exists("skyseg.onnx"):
|
| 275 |
+
print("Downloading skyseg.onnx...")
|
| 276 |
+
download_file_from_url("https://huggingface.co/JianyuanWang/skyseg/resolve/main/skyseg.onnx", "skyseg.onnx")
|
| 277 |
+
|
| 278 |
+
skyseg_session = onnxruntime.InferenceSession("skyseg.onnx")
|
| 279 |
+
image_files = sorted(glob.glob(os.path.join(image_folder, "*")))
|
| 280 |
+
sky_mask_list = []
|
| 281 |
+
|
| 282 |
+
print("Generating sky masks...")
|
| 283 |
+
for i, image_path in enumerate(tqdm(image_files[:S])): # Limit to the number of images in the batch
|
| 284 |
+
image_name = os.path.basename(image_path)
|
| 285 |
+
mask_filepath = os.path.join(sky_masks_dir, image_name)
|
| 286 |
+
|
| 287 |
+
if os.path.exists(mask_filepath):
|
| 288 |
+
sky_mask = cv2.imread(mask_filepath, cv2.IMREAD_GRAYSCALE)
|
| 289 |
+
else:
|
| 290 |
+
sky_mask = segment_sky(image_path, skyseg_session, mask_filepath)
|
| 291 |
+
|
| 292 |
+
# Resize mask to match H×W if needed
|
| 293 |
+
if sky_mask.shape[0] != H or sky_mask.shape[1] != W:
|
| 294 |
+
sky_mask = cv2.resize(sky_mask, (W, H))
|
| 295 |
+
|
| 296 |
+
sky_mask_list.append(sky_mask)
|
| 297 |
+
|
| 298 |
+
# Convert list to numpy array with shape S×H×W
|
| 299 |
+
sky_mask_array = np.array(sky_mask_list)
|
| 300 |
+
# Apply sky mask to confidence scores
|
| 301 |
+
sky_mask_binary = (sky_mask_array > 0.1).astype(np.float32)
|
| 302 |
+
conf = conf * sky_mask_binary
|
| 303 |
+
|
| 304 |
+
print("Sky segmentation applied successfully")
|
| 305 |
+
return conf
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
parser = argparse.ArgumentParser(description="VGGT demo with viser for 3D visualization")
|
| 309 |
+
parser.add_argument(
|
| 310 |
+
"--image_folder", type=str, default="examples/kitchen/images/", help="Path to folder containing images"
|
| 311 |
+
)
|
| 312 |
+
parser.add_argument("--use_point_map", action="store_true", help="Use point map instead of depth-based points")
|
| 313 |
+
parser.add_argument("--background_mode", action="store_true", help="Run the viser server in background mode")
|
| 314 |
+
parser.add_argument("--port", type=int, default=8080, help="Port number for the viser server")
|
| 315 |
+
parser.add_argument(
|
| 316 |
+
"--conf_threshold", type=float, default=25.0, help="Initial percentage of low-confidence points to filter out"
|
| 317 |
+
)
|
| 318 |
+
parser.add_argument("--mask_sky", action="store_true", help="Apply sky segmentation to filter out sky points")
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
def main():
|
| 322 |
+
"""
|
| 323 |
+
Main function for the VGGT demo with viser for 3D visualization.
|
| 324 |
+
|
| 325 |
+
This function:
|
| 326 |
+
1. Loads the VGGT model
|
| 327 |
+
2. Processes input images from the specified folder
|
| 328 |
+
3. Runs inference to generate 3D points and camera poses
|
| 329 |
+
4. Optionally applies sky segmentation to filter out sky points
|
| 330 |
+
5. Visualizes the results using viser
|
| 331 |
+
|
| 332 |
+
Command-line arguments:
|
| 333 |
+
--image_folder: Path to folder containing input images
|
| 334 |
+
--use_point_map: Use point map instead of depth-based points
|
| 335 |
+
--background_mode: Run the viser server in background mode
|
| 336 |
+
--port: Port number for the viser server
|
| 337 |
+
--conf_threshold: Initial percentage of low-confidence points to filter out
|
| 338 |
+
--mask_sky: Apply sky segmentation to filter out sky points
|
| 339 |
+
"""
|
| 340 |
+
args = parser.parse_args()
|
| 341 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 342 |
+
print(f"Using device: {device}")
|
| 343 |
+
|
| 344 |
+
print("Initializing and loading VGGT model...")
|
| 345 |
+
# model = VGGT.from_pretrained("facebook/VGGT-1B")
|
| 346 |
+
|
| 347 |
+
model = VGGT()
|
| 348 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 349 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 350 |
+
|
| 351 |
+
model.eval()
|
| 352 |
+
model = model.to(device)
|
| 353 |
+
|
| 354 |
+
# Use the provided image folder path
|
| 355 |
+
print(f"Loading images from {args.image_folder}...")
|
| 356 |
+
image_names = glob.glob(os.path.join(args.image_folder, "*"))
|
| 357 |
+
print(f"Found {len(image_names)} images")
|
| 358 |
+
|
| 359 |
+
images = load_and_preprocess_images(image_names).to(device)
|
| 360 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 361 |
+
|
| 362 |
+
print("Running inference...")
|
| 363 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 364 |
+
|
| 365 |
+
with torch.no_grad():
|
| 366 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 367 |
+
predictions = model(images)
|
| 368 |
+
|
| 369 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 370 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 371 |
+
predictions["extrinsic"] = extrinsic
|
| 372 |
+
predictions["intrinsic"] = intrinsic
|
| 373 |
+
|
| 374 |
+
print("Processing model outputs...")
|
| 375 |
+
for key in predictions.keys():
|
| 376 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 377 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension and convert to numpy
|
| 378 |
+
|
| 379 |
+
if args.use_point_map:
|
| 380 |
+
print("Visualizing 3D points from point map")
|
| 381 |
+
else:
|
| 382 |
+
print("Visualizing 3D points by unprojecting depth map by cameras")
|
| 383 |
+
|
| 384 |
+
if args.mask_sky:
|
| 385 |
+
print("Sky segmentation enabled - will filter out sky points")
|
| 386 |
+
|
| 387 |
+
print("Starting viser visualization...")
|
| 388 |
+
|
| 389 |
+
viser_server = viser_wrapper(
|
| 390 |
+
predictions,
|
| 391 |
+
port=args.port,
|
| 392 |
+
init_conf_threshold=args.conf_threshold,
|
| 393 |
+
use_point_map=args.use_point_map,
|
| 394 |
+
background_mode=args.background_mode,
|
| 395 |
+
mask_sky=args.mask_sky,
|
| 396 |
+
image_folder=args.image_folder,
|
| 397 |
+
)
|
| 398 |
+
print("Visualization complete")
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
if __name__ == "__main__":
|
| 402 |
+
main()
|
docs/package.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Alternative Installation Methods
|
| 2 |
+
|
| 3 |
+
This document explains how to install VGGT as a package using different package managers.
|
| 4 |
+
|
| 5 |
+
## Prerequisites
|
| 6 |
+
|
| 7 |
+
Before installing VGGT as a package, you need to install PyTorch and torchvision. We don't list these as dependencies to avoid CUDA version mismatches. Install them first, with an example as:
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
# install pytorch 2.3.1 with cuda 12.1
|
| 11 |
+
pip install torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu121
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
## Installation Options
|
| 15 |
+
|
| 16 |
+
### Install with pip
|
| 17 |
+
|
| 18 |
+
The simplest way to install VGGT is using pip:
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
pip install -e .
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
### Install and run with pixi
|
| 25 |
+
|
| 26 |
+
[Pixi](https://pixi.sh) is a package management tool for creating reproducible environments.
|
| 27 |
+
|
| 28 |
+
1. First, [download and install pixi](https://pixi.sh/latest/get_started/)
|
| 29 |
+
2. Then run:
|
| 30 |
+
|
| 31 |
+
```bash
|
| 32 |
+
pixi run -e python demo_gradio.py
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
### Install and run with uv
|
| 36 |
+
|
| 37 |
+
[uv](https://docs.astral.sh/uv/) is a fast Python package installer and resolver.
|
| 38 |
+
|
| 39 |
+
1. First, [install uv](https://docs.astral.sh/uv/getting-started/installation/)
|
| 40 |
+
2. Then run:
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
uv run --extra demo demo_gradio.py
|
| 44 |
+
```
|
| 45 |
+
|
exts/cropformer_runner.py
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import glob
|
| 4 |
+
import numpy as np
|
| 5 |
+
import cv2
|
| 6 |
+
from typing import List, Optional
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
Lightweight runner for CropFormer/Mask2Former inference without spawning a process.
|
| 10 |
+
Keeps a global singleton VisualizationDemo so the model is initialized only once.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
# Insert CropFormer project into sys.path only once
|
| 14 |
+
_CROPF_DIR = None
|
| 15 |
+
def make_cropformer_dir(MK_PATH: str) -> str:
|
| 16 |
+
global _CROPF_DIR
|
| 17 |
+
_CROPF_DIR = os.path.join(MK_PATH, "third_party/detectron2/projects/CropFormer")
|
| 18 |
+
if _CROPF_DIR not in sys.path:
|
| 19 |
+
sys.path.insert(0, _CROPF_DIR)
|
| 20 |
+
sys.path.insert(0, os.path.join(_CROPF_DIR, "demo_cropformer"))
|
| 21 |
+
|
| 22 |
+
# Globals (singleton)
|
| 23 |
+
_DEMO = None
|
| 24 |
+
_CFG_KEY = None # (config_file_abs, tuple(opts))
|
| 25 |
+
|
| 26 |
+
def _build_key(config_file: str, opts: Optional[List[str]]) -> tuple:
|
| 27 |
+
return (os.path.abspath(config_file), tuple(opts) if opts else ())
|
| 28 |
+
|
| 29 |
+
def preload_cropformer_model(config_file: str, opts: Optional[List[str]] = None) -> bool:
|
| 30 |
+
"""
|
| 31 |
+
Public helper to initialize the model once at script startup.
|
| 32 |
+
Returns True if initialized or already available.
|
| 33 |
+
"""
|
| 34 |
+
_ensure_demo(config_file, opts)
|
| 35 |
+
return True
|
| 36 |
+
|
| 37 |
+
def _ensure_demo(config_file: str, opts: Optional[List[str]]):
|
| 38 |
+
"""
|
| 39 |
+
Build or reuse a global VisualizationDemo for given config/options.
|
| 40 |
+
"""
|
| 41 |
+
global _DEMO, _CFG_KEY
|
| 42 |
+
key = _build_key(config_file, opts)
|
| 43 |
+
if _DEMO is not None and _CFG_KEY == key:
|
| 44 |
+
return _DEMO
|
| 45 |
+
|
| 46 |
+
# Lazy imports to avoid import cost at module import time
|
| 47 |
+
from detectron2.config import get_cfg
|
| 48 |
+
from detectron2.projects.deeplab import add_deeplab_config
|
| 49 |
+
from mask2former import add_maskformer2_config
|
| 50 |
+
from predictor import VisualizationDemo
|
| 51 |
+
|
| 52 |
+
cfg = get_cfg()
|
| 53 |
+
add_deeplab_config(cfg)
|
| 54 |
+
add_maskformer2_config(cfg)
|
| 55 |
+
cfg.merge_from_file(config_file)
|
| 56 |
+
if opts:
|
| 57 |
+
cfg.merge_from_list(opts)
|
| 58 |
+
cfg.freeze()
|
| 59 |
+
_DEMO = VisualizationDemo(cfg)
|
| 60 |
+
_CFG_KEY = key
|
| 61 |
+
return _DEMO
|
| 62 |
+
|
| 63 |
+
def run_cropformer_mask_predict(
|
| 64 |
+
config_file: str,
|
| 65 |
+
root: str,
|
| 66 |
+
image_path_pattern: str,
|
| 67 |
+
dataset: str,
|
| 68 |
+
seq_name_list: str,
|
| 69 |
+
confidence_threshold: float = 0.5,
|
| 70 |
+
opts: Optional[List[str]] = None,
|
| 71 |
+
) -> None:
|
| 72 |
+
"""
|
| 73 |
+
Run CropFormer/Mask2Former demo (mask_predict) logic directly from Python.
|
| 74 |
+
Writes mask PNGs into {root}/{seq}/output/mask (or special matterport3d path).
|
| 75 |
+
"""
|
| 76 |
+
from detectron2.data.detection_utils import read_image
|
| 77 |
+
import torch
|
| 78 |
+
|
| 79 |
+
demo = _ensure_demo(config_file, opts)
|
| 80 |
+
|
| 81 |
+
# Support multiple sequences joined by '+'
|
| 82 |
+
seq_names = seq_name_list.split("+")
|
| 83 |
+
for seq_name in seq_names:
|
| 84 |
+
seq_dir = os.path.join(root, seq_name)
|
| 85 |
+
image_list = sorted(glob.glob(os.path.join(seq_dir, image_path_pattern)))
|
| 86 |
+
if dataset == "matterport3d":
|
| 87 |
+
output_dir = os.path.join(seq_dir, seq_name, "output/mask")
|
| 88 |
+
else:
|
| 89 |
+
output_dir = os.path.join(seq_dir, "output/mask")
|
| 90 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 91 |
+
|
| 92 |
+
for path in image_list:
|
| 93 |
+
# Read BGR image as in original demo
|
| 94 |
+
img = read_image(path, format="BGR")
|
| 95 |
+
predictions = demo.run_on_image(img)
|
| 96 |
+
|
| 97 |
+
pred_masks = predictions["instances"].pred_masks
|
| 98 |
+
pred_scores = predictions["instances"].scores
|
| 99 |
+
|
| 100 |
+
# Select by threshold
|
| 101 |
+
selected_indexes = (pred_scores >= confidence_threshold)
|
| 102 |
+
selected_scores = pred_scores[selected_indexes]
|
| 103 |
+
selected_masks = pred_masks[selected_indexes]
|
| 104 |
+
|
| 105 |
+
if selected_masks.numel() == 0:
|
| 106 |
+
# Still write an empty mask to keep pipeline consistent
|
| 107 |
+
h, w = img.shape[:2]
|
| 108 |
+
cv2.imwrite(
|
| 109 |
+
os.path.join(output_dir, os.path.basename(path).split(".")[0] + ".png"),
|
| 110 |
+
np.zeros((h, w), dtype=np.uint8),
|
| 111 |
+
)
|
| 112 |
+
continue
|
| 113 |
+
|
| 114 |
+
_, m_H, m_W = selected_masks.shape
|
| 115 |
+
mask_image = np.zeros((m_H, m_W), dtype=np.uint8)
|
| 116 |
+
|
| 117 |
+
# Rank by score (ascending as in original script)
|
| 118 |
+
mask_id = 1
|
| 119 |
+
selected_scores, ranks = torch.sort(selected_scores)
|
| 120 |
+
for index in ranks:
|
| 121 |
+
num_pixels = torch.sum(selected_masks[index])
|
| 122 |
+
if num_pixels < 400:
|
| 123 |
+
# ignore small masks
|
| 124 |
+
continue
|
| 125 |
+
mask_image[(selected_masks[index] == 1).cpu().numpy()] = mask_id
|
| 126 |
+
mask_id += 1
|
| 127 |
+
|
| 128 |
+
cv2.imwrite(
|
| 129 |
+
os.path.join(output_dir, os.path.basename(path).split(".")[0] + ".png"),
|
| 130 |
+
mask_image,
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
|
exts/maskclustering_runner.py
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from typing import Optional
|
| 4 |
+
import argparse
|
| 5 |
+
import json
|
| 6 |
+
|
| 7 |
+
"""
|
| 8 |
+
Python runner for Indoor/MaskClustering main pipeline without spawning a process.
|
| 9 |
+
It reuses the project's own main(args) and get_args() utilities.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
_MK_PATH = None
|
| 13 |
+
_get_args = None
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def make_maskclustering_dir(MK_PATH: str) -> None:
|
| 17 |
+
"""
|
| 18 |
+
Ensure Indoor/MaskClustering repo is on sys.path so that
|
| 19 |
+
utils.*, graph.*, and main can be imported directly.
|
| 20 |
+
"""
|
| 21 |
+
global _MK_PATH
|
| 22 |
+
_MK_PATH = MK_PATH
|
| 23 |
+
if MK_PATH not in sys.path:
|
| 24 |
+
sys.path.insert(0, MK_PATH)
|
| 25 |
+
from dataset.scannet import WildDataset
|
| 26 |
+
def update_args(args):
|
| 27 |
+
config = args.config
|
| 28 |
+
config_file = config
|
| 29 |
+
if config in ['scannet', 'scannet18']:
|
| 30 |
+
config_file = 'scannet'
|
| 31 |
+
if config in ['scannetpp_v2_dust3r_posed', 'scannetpp_v2_dust3r_unposed']:
|
| 32 |
+
config_file = config
|
| 33 |
+
config_path = f'/home/jovyan/users/bulat/workspace/3drec/Indoor/MaskClustering/configs/{config_file}.json'
|
| 34 |
+
with open(config_path, 'r') as f:
|
| 35 |
+
config_data = json.load(f)
|
| 36 |
+
for key in config_data:
|
| 37 |
+
setattr(args, key, config_data[key])
|
| 38 |
+
return args
|
| 39 |
+
|
| 40 |
+
def get_args():
|
| 41 |
+
parser = argparse.ArgumentParser()
|
| 42 |
+
parser.add_argument('--seq_name', type=str)
|
| 43 |
+
parser.add_argument('--seq_name_list', type=str)
|
| 44 |
+
parser.add_argument('--config', type=str, default='scannet')
|
| 45 |
+
parser.add_argument('--debug', action="store_true")
|
| 46 |
+
parser.add_argument('--root', type=str)
|
| 47 |
+
parser.add_argument('-d', '--devices', type=int, nargs='+', default=[0, 1, 2, 3])
|
| 48 |
+
|
| 49 |
+
args = parser.parse_args()
|
| 50 |
+
args = update_args(args)
|
| 51 |
+
return args
|
| 52 |
+
|
| 53 |
+
def get_dataset(args):
|
| 54 |
+
|
| 55 |
+
if args.dataset == 'wild':
|
| 56 |
+
dataset = WildDataset(args.seq_name, root=args.root)
|
| 57 |
+
return dataset
|
| 58 |
+
|
| 59 |
+
global _get_args
|
| 60 |
+
_get_args = get_args
|
| 61 |
+
|
| 62 |
+
def run_mask_clustering(
|
| 63 |
+
config: str,
|
| 64 |
+
root: str,
|
| 65 |
+
seq_name_list: str,
|
| 66 |
+
step: Optional[int] = None,
|
| 67 |
+
view_consensus_threshold: Optional[float] = None,
|
| 68 |
+
debug: Optional[bool] = None,
|
| 69 |
+
) -> None:
|
| 70 |
+
"""
|
| 71 |
+
Execute the MaskClustering pipeline for one or multiple sequences.
|
| 72 |
+
Equivalent to:
|
| 73 |
+
python main.py --config {config} --root {root} --seq_name_list {seq_name_list}
|
| 74 |
+
with optional overrides for step, view_consensus_threshold, and debug.
|
| 75 |
+
"""
|
| 76 |
+
if _MK_PATH is None or _MK_PATH not in sys.path:
|
| 77 |
+
# Fallback: try to infer from environment variable or raise
|
| 78 |
+
env_mk = os.environ.get("MASKCLUSTERING_PATH")
|
| 79 |
+
if env_mk:
|
| 80 |
+
make_maskclustering_dir(env_mk)
|
| 81 |
+
else:
|
| 82 |
+
# Proceed; imports might still work if paths are globally set elsewhere
|
| 83 |
+
pass
|
| 84 |
+
|
| 85 |
+
# Lazy imports to avoid cost at module import time
|
| 86 |
+
from main import main as mk_main # type: ignore
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
# Build args from library defaults, then override what we need
|
| 93 |
+
args = _get_args()
|
| 94 |
+
args.config = config
|
| 95 |
+
args.root = root
|
| 96 |
+
args.seq_name_list = seq_name_list
|
| 97 |
+
if step is not None:
|
| 98 |
+
args.step = step
|
| 99 |
+
if view_consensus_threshold is not None:
|
| 100 |
+
args.view_consensus_threshold = view_consensus_threshold
|
| 101 |
+
if debug is not None:
|
| 102 |
+
args.debug = debug
|
| 103 |
+
|
| 104 |
+
# Emulate original __main__ loop over sequences
|
| 105 |
+
seqs = args.seq_name_list.split("+")
|
| 106 |
+
for seq_name in seqs:
|
| 107 |
+
args.seq_name = seq_name
|
| 108 |
+
mk_main(args)
|
| 109 |
+
|
| 110 |
+
|
exts/ov_features.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
This script extracts open-vocabulary visual features for each mask following OpenMask3D.
|
| 3 |
+
For each mask, we crop the image with CROP_SCALES=3 scales based on the mask.
|
| 4 |
+
Then we extract the visual features using CLIP model and average these features as the mask feature.
|
| 5 |
+
'''
|
| 6 |
+
|
| 7 |
+
import open_clip
|
| 8 |
+
import os
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from torch.utils.data import Dataset
|
| 13 |
+
from torch.utils.data import DataLoader
|
| 14 |
+
from tqdm import tqdm
|
| 15 |
+
import cv2
|
| 16 |
+
import argparse
|
| 17 |
+
import json
|
| 18 |
+
import sys
|
| 19 |
+
|
| 20 |
+
WD = None
|
| 21 |
+
_MK_PATH = None
|
| 22 |
+
def load(MK_PATH: str) -> None:
|
| 23 |
+
global _MK_PATH
|
| 24 |
+
_MK_PATH = MK_PATH
|
| 25 |
+
if MK_PATH not in sys.path:
|
| 26 |
+
sys.path.insert(0, MK_PATH)
|
| 27 |
+
|
| 28 |
+
from dataset.scannet import WildDataset
|
| 29 |
+
global WD
|
| 30 |
+
WD = WildDataset
|
| 31 |
+
|
| 32 |
+
def get_dataset(seq_name, root):
|
| 33 |
+
dataset = WD(seq_name, root=root)
|
| 34 |
+
return dataset
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
CROP_SCALES = 3 # follow OpenMask3D
|
| 39 |
+
|
| 40 |
+
class CroppedImageDataset(Dataset):
|
| 41 |
+
def __init__(self, seq_name_list, frame_id_list, mask_id_list, rgb_path_list, segmentation_path_list, preprocess):
|
| 42 |
+
'''
|
| 43 |
+
Given a list of masks, we calculate the open-vocabulary features for each mask.
|
| 44 |
+
|
| 45 |
+
Args:
|
| 46 |
+
seq_name_list: sequence name for each mask
|
| 47 |
+
frame_id_list: frame id for each mask
|
| 48 |
+
mask_id_list: mask id for each mask
|
| 49 |
+
rgb_path_list: rgb path for each mask
|
| 50 |
+
segmentation_path_list: segmentation path for each mask
|
| 51 |
+
preprocess: image preprocessing function
|
| 52 |
+
'''
|
| 53 |
+
self.seq_name_list = seq_name_list
|
| 54 |
+
self.frame_id_list = frame_id_list
|
| 55 |
+
self.mask_id_list = mask_id_list
|
| 56 |
+
self.preprocess = preprocess
|
| 57 |
+
self.rgb_path_list = rgb_path_list
|
| 58 |
+
self.segmentation_path_list = segmentation_path_list
|
| 59 |
+
|
| 60 |
+
def __len__(self):
|
| 61 |
+
return len(self.mask_id_list)
|
| 62 |
+
|
| 63 |
+
def __getitem__(self, idx):
|
| 64 |
+
def get_cropped_image(mask, rgb):
|
| 65 |
+
'''
|
| 66 |
+
Given a mask and an rgb image, we crop the image with CROP_SCALES scales based on the mask.
|
| 67 |
+
'''
|
| 68 |
+
def mask2box_multi_level(mask, level, expansion_ratio):
|
| 69 |
+
pos = np.where(mask)
|
| 70 |
+
top = np.min(pos[0])
|
| 71 |
+
bottom = np.max(pos[0])
|
| 72 |
+
left = np.min(pos[1])
|
| 73 |
+
right = np.max(pos[1])
|
| 74 |
+
|
| 75 |
+
if level == 0:
|
| 76 |
+
return left, top, right , bottom
|
| 77 |
+
shape = mask.shape
|
| 78 |
+
x_exp = int(abs(right - left)*expansion_ratio) * level
|
| 79 |
+
y_exp = int(abs(bottom - top)*expansion_ratio) * level
|
| 80 |
+
return max(0, left - x_exp), max(0, top - y_exp), min(shape[1], right + x_exp), min(shape[0], bottom + y_exp)
|
| 81 |
+
|
| 82 |
+
def crop_image(rgb, mask):
|
| 83 |
+
multiscale_cropped_images = []
|
| 84 |
+
for level in range(CROP_SCALES):
|
| 85 |
+
left, top, right, bottom = mask2box_multi_level(mask, level, 0.1)
|
| 86 |
+
cropped_image = rgb[top:bottom, left:right].copy()
|
| 87 |
+
multiscale_cropped_images.append(cropped_image)
|
| 88 |
+
return multiscale_cropped_images
|
| 89 |
+
|
| 90 |
+
mask = cv2.resize(mask.astype(np.uint8), (rgb.shape[1], rgb.shape[0]), interpolation=cv2.INTER_NEAREST)
|
| 91 |
+
multiscale_cropped_images = crop_image(rgb, mask)
|
| 92 |
+
return multiscale_cropped_images
|
| 93 |
+
|
| 94 |
+
def pad_into_square(image):
|
| 95 |
+
width, height = image.size
|
| 96 |
+
new_size = max(width, height)
|
| 97 |
+
new_image = Image.new("RGB", (new_size, new_size), (255,255,255))
|
| 98 |
+
left = (new_size - width) // 2
|
| 99 |
+
top = (new_size - height) // 2
|
| 100 |
+
new_image.paste(image, (left, top))
|
| 101 |
+
return new_image
|
| 102 |
+
|
| 103 |
+
seq_name = self.seq_name_list[idx]
|
| 104 |
+
frame_id = self.frame_id_list[idx]
|
| 105 |
+
mask_id = self.mask_id_list[idx]
|
| 106 |
+
rgb_path = self.rgb_path_list[idx]
|
| 107 |
+
segmentation_path = self.segmentation_path_list[idx]
|
| 108 |
+
|
| 109 |
+
rgb_image = cv2.imread(rgb_path)
|
| 110 |
+
rgb_image = cv2.cvtColor(rgb_image, cv2.COLOR_BGR2RGB)
|
| 111 |
+
|
| 112 |
+
segmentation_image = cv2.imread(segmentation_path, cv2.IMREAD_UNCHANGED)
|
| 113 |
+
mask = (segmentation_image == mask_id)
|
| 114 |
+
cropped_images = get_cropped_image(mask, np.array(rgb_image))
|
| 115 |
+
|
| 116 |
+
input_images = [self.preprocess(pad_into_square(Image.fromarray(cropped_image))) for cropped_image in cropped_images]
|
| 117 |
+
input_images = torch.stack(input_images)
|
| 118 |
+
return input_images, seq_name, frame_id, mask_id
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def main(model, preprocess, seq_name, root):
|
| 122 |
+
seq_name_list = [seq_name]
|
| 123 |
+
|
| 124 |
+
seq_name_list, frame_id_list, mask_id_list, rgb_path_list, segmentation_path_list = [], [], [], [], []
|
| 125 |
+
feature_dict = {}
|
| 126 |
+
for seq_name in seq_name_list:
|
| 127 |
+
dataset = get_dataset(seq_name, root)
|
| 128 |
+
if not os.path.exists(os.path.join(dataset.object_dict_dir, 'wild', f'object_dict.npy')):
|
| 129 |
+
continue
|
| 130 |
+
object_dict = np.load(f'{dataset.object_dict_dir}/wild/object_dict.npy', allow_pickle=True).item()
|
| 131 |
+
for key, value in object_dict.items():
|
| 132 |
+
mask_list = value['repre_mask_list']
|
| 133 |
+
if len(mask_list) == 0:
|
| 134 |
+
continue
|
| 135 |
+
for mask_info in mask_list:
|
| 136 |
+
seq_name_list.append(seq_name)
|
| 137 |
+
frame_id = mask_info[0]
|
| 138 |
+
frame_id_list.append(frame_id)
|
| 139 |
+
mask_id_list.append(mask_info[1])
|
| 140 |
+
rgb_path, segmentation_path = dataset.get_frame_path(frame_id)
|
| 141 |
+
rgb_path_list.append(rgb_path)
|
| 142 |
+
segmentation_path_list.append(segmentation_path)
|
| 143 |
+
feature_dict[seq_name] = {}
|
| 144 |
+
|
| 145 |
+
dataloader = DataLoader(CroppedImageDataset(seq_name_list, frame_id_list, mask_id_list, rgb_path_list, segmentation_path_list, preprocess), batch_size=64, shuffle=False, num_workers=16)
|
| 146 |
+
|
| 147 |
+
print('[INFO] extracting features')
|
| 148 |
+
for images, seq_names, frame_ids, mask_ids in tqdm(dataloader):
|
| 149 |
+
images = images.reshape(-1, 3, 224, 224)
|
| 150 |
+
image_input = images.cuda()
|
| 151 |
+
with torch.no_grad():
|
| 152 |
+
image_features = model.encode_image(image_input).float()
|
| 153 |
+
image_features /= image_features.norm(dim=-1, keepdim=True)
|
| 154 |
+
image_features = image_features.cpu().numpy()
|
| 155 |
+
for i in range(len(image_features) // CROP_SCALES):
|
| 156 |
+
feature_dict[seq_names[i]][f'{frame_ids[i]}_{mask_ids[i]}'] = image_features[CROP_SCALES*i:CROP_SCALES*(i+1)].mean(axis=0)
|
| 157 |
+
print('[INFO] finish extracting features')
|
| 158 |
+
|
| 159 |
+
for seq_name in seq_name_list:
|
| 160 |
+
dataset = get_dataset(seq_name, root)
|
| 161 |
+
if seq_name in feature_dict:
|
| 162 |
+
np.save(os.path.join(dataset.object_dict_dir, 'wild', f'open-vocabulary_features.npy'), feature_dict[seq_name])
|
infer_arkit.py
ADDED
|
@@ -0,0 +1,319 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import cv2
|
| 9 |
+
import torch
|
| 10 |
+
import numpy as np
|
| 11 |
+
import sys
|
| 12 |
+
import shutil
|
| 13 |
+
from datetime import datetime
|
| 14 |
+
import glob
|
| 15 |
+
import gc
|
| 16 |
+
import time
|
| 17 |
+
from pathlib import Path
|
| 18 |
+
from argparse import ArgumentParser
|
| 19 |
+
from tqdm import tqdm
|
| 20 |
+
from tqdm.contrib.concurrent import process_map
|
| 21 |
+
|
| 22 |
+
sys.path.append("vggt/")
|
| 23 |
+
|
| 24 |
+
from visual_util import predictions_to_glb
|
| 25 |
+
from vggt.models.vggt import VGGT
|
| 26 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 27 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 28 |
+
|
| 29 |
+
from rec_utils.datasets import ARKitDataset
|
| 30 |
+
from PIL import Image
|
| 31 |
+
from torchvision import transforms as TF
|
| 32 |
+
|
| 33 |
+
val_split = ['47334096', '47895367', '41125696', '41125756', '45662926', '47429925', '42898581', '48018972', '48018387', '44358455', '45261150', '42898538', '47430490', '47334109', '45663114', '42897508', '47430475', '47332901', '42899461', '45662942', '47331964', '47204552', '45261144', '41069021', '42899736', '42899737', '47430026', '48018566', '48458489', '42444955', '42446536', '47895341', '47430034', '45663154', '47430489', '42444950', '42898862', '44358451', '47331069', '41254405', '42445028', '44358448', '48458481', '47895771', '47204566', '42898508', '47331990', '47332911', '48018358', '44358498', '41159519', '45260905', '42898854', '42446533', '47115548', '45261581', '45260899', '48018346', '47333940', '47332908', '48018386', '42897559', '42445022', '42897696', '42897541', '42446529', '47333927', '47331061', '45261190', '47331063', '41159558', '47429995', '47334110', '47333934', '47332905', '48018356', '42444953', '47334241', '47332895', '47895740', '47331333', '42446038', '42446156', '48458663', '48458657', '48458660', '47333924', '45260928', '47895536', '41125760', '42899691', '41254246', '42445991', '42445441', '45662987', '47334234', '47334367', '47430424', '44358442', '47430045', '45663105', '42897550', '47430005', '41254412', '44358532', '47331311', '42898816', '47895736', '47895738', '48458667', '47332893', '42899612', '47204605', '41142278', '42446517', '42446079', '41159553', '42899726', '42898574', '47115469', '47331963', '42899700', '47334237', '47430048', '48018957', '47334117', '42446540', '44358536', '42444954', '41125722', '41159504', '47430047', '41159566', '42897651', '47333456', '47331068', '42446519', '47333923', '47895739', '47430483', '45261142', '47430470', '45662970', '47334105', '47429922', '48018962', '41142281', '47895745', '42446546', '42897678', '47204554', '47331334', '42897667', '42897629', '42899720', '41159557', '47895556', '42897521', '42898486', '45663113', '47334093', '42899714', '45662944', '48458465', '42446137', '48458473', '45260898', '42445429', '47430036', '48458430', '47204559', '42898544', '47895353', '42899685', '44358505', '47430051', '45260900', '42899698', '47331316', '45260914', '48018572', '47333918', '47334238', '42899723', '44358513', '42899620', '47115460', '45261619', '47429912', '41159571', '47334362', '48458654', '42446163', '41254269', '45662975', '47331644', '41159530', '44358499', '47204609', '47333431', '41159555', '47429987', '42899688', '45662921', '47332890', '47895374', '47430001', '45261587', '45260856', '47430038', '42897599', '47332885', '42899679', '44358435', '42445966', '47895348', '48018353', '47895357', '47204573', '47333452', '45663115', '48458424', '42444976', '42444968', '42897564', '47331336', '42445448', '45260854', '42898527', '47334379', '45260925', '47430023', '47331662', '45662983', '42898826', '42899694', '42899617', '45662924', '42446049', '42899717', '48458650', '41069046', '42899699', '41254435', '47331972', '47895750', '47331339', '42446165', '41159525', '47895547', '47332899', '47895541', '42445031', '47895365', '42446535', '42899739', '45261631', '47333925', '47895554', '47430485', '47115463', '42897695', '47430468', '47333916', '47895776', '42899471', '44358446', '47334360', '47334381', '42897552', '42898868', '47333436', '48018562', '42898519', '42899680', '41254402', '47334256', '42897692', '42899725', '47331653', '41254400', '42445026', '45261588', '42899734', '45662943', '47334120', '47331314', '48018737', '48458472', '47331971', '45261193', '42446016', '45260920', '48018571', '42446056', '47333443', '41069025', '42897549', '44358515', '47115526', '42897688', '48458417', '47115474', '47430024', '47332916', '42898554', '48018732', '48018375', '47331989', '47115452', '45261615', '47334103', '41159572', '41159508', '42446541', '47115529', '44358440', '47115550', '45663165', '47895779', '47334240', '47331646', '48018970', '47430002', '42446527', '47334102', '47332000', '47895783', '47895542', '48458747', '42898570', '47331337', '42899613', '48018345', '48458665', '42446083', '41254382', '41125731', '48458732', '44358518', '42899696', '42897504', '41069051', '48018368', '48018741', '47429971', '47331266', '42897528', '42445981', '45663107', '42897501', '47895534', '42445029', '47430471', '47333440', '42445988', '45260903', '41159540', '42897566', '48458456', '47331651', '47332910', '47333904', '42445021', '45261575', '47895355', '45261140', '47331654', '47333920', '47895743', '45261143', '42898822', '47430479', '42446167', '47334361', '47334380', '45662981', '48018966', '44358436', '47334252', '41254432', '48458647', '48018560', '47334107', '47895549', '45261632', '45261128', '47895350', '44358538', '41159534', '42899611', '42898521', '47331988', '42899729', '48458656', '47115525', '42897538', '42897545', '47331970', '42897647', '42897554', '47430003', '47332904', '41159541', '48018379', '42897526', '41069043', '47331319', '47895371', '42446104', '41159538', '42898818', '48018956', '42899619', '48018381', '41069042', '48458735', '45261182', '42446151', '42898869', '47334368', '47333899', '47430033', '41125718', '47331645', '44358584', '48018739', '45261179', '47333931', '47333898', '42898817', '47332918', '45261121', '42446522', '45261637', '48018559', '45663164', '47332005', '41254386', '47331265', '45663175', '42898497', '48018367', '47429904', '41254262', '47115543', '41254425', '48458652', '42445984', '41069050', '48018960', '42898811', '41069048', '47895364', '48018382', '42446103', '48458427', '45260857', '42899731', '47895782', '47430419', '42446093', '47429913', '47332915', '44358452', '47333457', '47334091', '45261133', '42446532', '47895735', '47204607', '47204556', '47334115', '41254441', '42897561', '48458484', '47429998', '42446116', '47331071', '45261594', '47333937', '47204575', '47333932', '47331661', '47895732', '47332004', '42445998', '47429914', '44358582', '48018361', '47204563', '41125700', '42899690', '41159529', '41125763', '47115473', '48458415', '47204578', '47331668', '45261185', '47430043', '42446114', '47430422', '47331324', '42444949', '47334372', '45663150', '42444966', '42444946', '41125709', '48018360', '47429975', '42898867', '45261129', '47333435', '42899712', '48018730', '47429992', '42897542', '48018372', '41254398', '47429906', '41159503', '47332886', '42897672', '47331064', '47334239', '47333441', '45261181', '48018347', '45662979', '47895777', '45663149', '47895552', '47331974', '47331322', '47334254', '48458428', '42898849', '41142280', '44358583', '45261620', '47429977', '47430007', '42899459', '42446100', '45663099', '47331262', '47331331']
|
| 34 |
+
|
| 35 |
+
def load_and_preprocess_images(image_list, mode="crop"):
|
| 36 |
+
"""
|
| 37 |
+
A quick start function to load and preprocess images for model input.
|
| 38 |
+
This assumes the images should have the same shape for easier batching, but our model can also work well with different shapes.
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
image_path_list (list): List of paths to image files
|
| 42 |
+
mode (str, optional): Preprocessing mode, either "crop" or "pad".
|
| 43 |
+
- "crop" (default): Sets width to 518px and center crops height if needed.
|
| 44 |
+
- "pad": Preserves all pixels by making the largest dimension 518px
|
| 45 |
+
and padding the smaller dimension to reach a square shape.
|
| 46 |
+
|
| 47 |
+
Returns:
|
| 48 |
+
torch.Tensor: Batched tensor of preprocessed images with shape (N, 3, H, W)
|
| 49 |
+
|
| 50 |
+
Raises:
|
| 51 |
+
ValueError: If the input list is empty or if mode is invalid
|
| 52 |
+
|
| 53 |
+
Notes:
|
| 54 |
+
- Images with different dimensions will be padded with white (value=1.0)
|
| 55 |
+
- A warning is printed when images have different shapes
|
| 56 |
+
- When mode="crop": The function ensures width=518px while maintaining aspect ratio
|
| 57 |
+
and height is center-cropped if larger than 518px
|
| 58 |
+
- When mode="pad": The function ensures the largest dimension is 518px while maintaining aspect ratio
|
| 59 |
+
and the smaller dimension is padded to reach a square shape (518x518)
|
| 60 |
+
- Dimensions are adjusted to be divisible by 14 for compatibility with model requirements
|
| 61 |
+
"""
|
| 62 |
+
# Check for empty list
|
| 63 |
+
if len(image_list) == 0:
|
| 64 |
+
raise ValueError("At least 1 image is required")
|
| 65 |
+
|
| 66 |
+
# Validate mode
|
| 67 |
+
if mode not in ["crop", "pad"]:
|
| 68 |
+
raise ValueError("Mode must be either 'crop' or 'pad'")
|
| 69 |
+
|
| 70 |
+
images = []
|
| 71 |
+
shapes = set()
|
| 72 |
+
to_tensor = TF.ToTensor()
|
| 73 |
+
target_size = 518
|
| 74 |
+
|
| 75 |
+
# First process all images and collect their shapes
|
| 76 |
+
for image in image_list:
|
| 77 |
+
# Open image
|
| 78 |
+
img = Image.fromarray(image)
|
| 79 |
+
|
| 80 |
+
# If there's an alpha channel, blend onto white background:
|
| 81 |
+
if img.mode == "RGBA":
|
| 82 |
+
# Create white background
|
| 83 |
+
background = Image.new("RGBA", img.size, (255, 255, 255, 255))
|
| 84 |
+
# Alpha composite onto the white background
|
| 85 |
+
img = Image.alpha_composite(background, img)
|
| 86 |
+
|
| 87 |
+
# Now convert to "RGB" (this step assigns white for transparent areas)
|
| 88 |
+
img = img.convert("RGB")
|
| 89 |
+
|
| 90 |
+
width, height = img.size
|
| 91 |
+
|
| 92 |
+
if mode == "pad":
|
| 93 |
+
# Make the largest dimension 518px while maintaining aspect ratio
|
| 94 |
+
if width >= height:
|
| 95 |
+
new_width = target_size
|
| 96 |
+
new_height = round(height * (new_width / width) / 14) * 14 # Make divisible by 14
|
| 97 |
+
else:
|
| 98 |
+
new_height = target_size
|
| 99 |
+
new_width = round(width * (new_height / height) / 14) * 14 # Make divisible by 14
|
| 100 |
+
else: # mode == "crop"
|
| 101 |
+
# Original behavior: set width to 518px
|
| 102 |
+
new_width = target_size
|
| 103 |
+
# Calculate height maintaining aspect ratio, divisible by 14
|
| 104 |
+
new_height = round(height * (new_width / width) / 14) * 14
|
| 105 |
+
|
| 106 |
+
# Resize with new dimensions (width, height)
|
| 107 |
+
img = img.resize((new_width, new_height), Image.Resampling.BICUBIC)
|
| 108 |
+
img = to_tensor(img) # Convert to tensor (0, 1)
|
| 109 |
+
|
| 110 |
+
# Center crop height if it's larger than 518 (only in crop mode)
|
| 111 |
+
# if mode == "crop" and new_height > target_size:
|
| 112 |
+
# start_y = (new_height - target_size) // 2
|
| 113 |
+
# img = img[:, start_y : start_y + target_size, :]
|
| 114 |
+
|
| 115 |
+
# For pad mode, pad to make a square of target_size x target_size
|
| 116 |
+
if mode == "pad":
|
| 117 |
+
h_padding = target_size - img.shape[1]
|
| 118 |
+
w_padding = target_size - img.shape[2]
|
| 119 |
+
|
| 120 |
+
if h_padding > 0 or w_padding > 0:
|
| 121 |
+
pad_top = h_padding // 2
|
| 122 |
+
pad_bottom = h_padding - pad_top
|
| 123 |
+
pad_left = w_padding // 2
|
| 124 |
+
pad_right = w_padding - pad_left
|
| 125 |
+
|
| 126 |
+
# Pad with white (value=1.0)
|
| 127 |
+
img = torch.nn.functional.pad(
|
| 128 |
+
img, (pad_left, pad_right, pad_top, pad_bottom), mode="constant", value=1.0
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
shapes.add((img.shape[1], img.shape[2]))
|
| 132 |
+
images.append(img)
|
| 133 |
+
|
| 134 |
+
# Check if we have different shapes
|
| 135 |
+
# In theory our model can also work well with different shapes
|
| 136 |
+
if len(shapes) > 1:
|
| 137 |
+
print(f"Warning: Found images with different shapes: {shapes}")
|
| 138 |
+
# Find maximum dimensions
|
| 139 |
+
max_height = max(shape[0] for shape in shapes)
|
| 140 |
+
max_width = max(shape[1] for shape in shapes)
|
| 141 |
+
|
| 142 |
+
# Pad images if necessary
|
| 143 |
+
padded_images = []
|
| 144 |
+
for img in images:
|
| 145 |
+
h_padding = max_height - img.shape[1]
|
| 146 |
+
w_padding = max_width - img.shape[2]
|
| 147 |
+
|
| 148 |
+
if h_padding > 0 or w_padding > 0:
|
| 149 |
+
pad_top = h_padding // 2
|
| 150 |
+
pad_bottom = h_padding - pad_top
|
| 151 |
+
pad_left = w_padding // 2
|
| 152 |
+
pad_right = w_padding - pad_left
|
| 153 |
+
|
| 154 |
+
img = torch.nn.functional.pad(
|
| 155 |
+
img, (pad_left, pad_right, pad_top, pad_bottom), mode="constant", value=1.0
|
| 156 |
+
)
|
| 157 |
+
padded_images.append(img)
|
| 158 |
+
images = padded_images
|
| 159 |
+
|
| 160 |
+
images = torch.stack(images) # concatenate images
|
| 161 |
+
|
| 162 |
+
# Ensure correct shape when single image
|
| 163 |
+
if len(image_list) == 1:
|
| 164 |
+
# Verify shape is (1, C, H, W)
|
| 165 |
+
if images.dim() == 3:
|
| 166 |
+
images = images.unsqueeze(0)
|
| 167 |
+
|
| 168 |
+
return images
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
# -------------------------------------------------------------------------
|
| 173 |
+
# 1) Core model inference
|
| 174 |
+
# -------------------------------------------------------------------------
|
| 175 |
+
def run_model(model, scene, device, max_images) -> dict:
|
| 176 |
+
"""
|
| 177 |
+
Run the VGGT model on images in the 'target_dir/images' folder and return predictions.
|
| 178 |
+
"""
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
if not torch.cuda.is_available():
|
| 182 |
+
raise ValueError("CUDA is not available. Check your environment.")
|
| 183 |
+
|
| 184 |
+
scene.filter_valid_poses()
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
print(f"Found {len(scene.images)} images")
|
| 188 |
+
frames = scene.frames
|
| 189 |
+
if len(scene.images) == 0:
|
| 190 |
+
raise ValueError(f"No images found at {scene.id}. Check your upload.")
|
| 191 |
+
if len(scene) > max_images:
|
| 192 |
+
print(f"Downsampling {len(scene)} images to {max_images} images")
|
| 193 |
+
frames = [scene.frames[i] for i in np.linspace(0, len(scene) - 1, max_images).round().astype(int)]
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
images = load_and_preprocess_images([frame.image for frame in frames]).to(device)
|
| 198 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 199 |
+
|
| 200 |
+
# Run inference
|
| 201 |
+
print("Running inference...")
|
| 202 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 203 |
+
|
| 204 |
+
with torch.no_grad():
|
| 205 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 206 |
+
predictions = model(images)
|
| 207 |
+
|
| 208 |
+
# Convert pose encoding to extrinsic and intrinsic matrices
|
| 209 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 210 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 211 |
+
predictions["poses"] = extrinsic
|
| 212 |
+
predictions["Ks"] = intrinsic
|
| 213 |
+
|
| 214 |
+
# Convert tensors to numpy
|
| 215 |
+
for key in predictions.keys():
|
| 216 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 217 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension
|
| 218 |
+
|
| 219 |
+
# Generate world points from depth map
|
| 220 |
+
# print("Computing world points from depth map...")
|
| 221 |
+
# depth_map = predictions["depth"] # (S, H, W, 1)
|
| 222 |
+
# world_points = unproject_depth_map_to_point_map(depth_map, predictions["poses"], predictions["Ks"])
|
| 223 |
+
# predictions["world_points_from_depth"] = world_points
|
| 224 |
+
|
| 225 |
+
# Clean up
|
| 226 |
+
torch.cuda.empty_cache()
|
| 227 |
+
predictions["image_names"] = [frame.image_path for frame in frames]
|
| 228 |
+
return predictions
|
| 229 |
+
|
| 230 |
+
def process_scene(
|
| 231 |
+
model,
|
| 232 |
+
scene_name,
|
| 233 |
+
scene,
|
| 234 |
+
output_dir,
|
| 235 |
+
device,
|
| 236 |
+
max_images=10000,
|
| 237 |
+
force=False
|
| 238 |
+
):
|
| 239 |
+
"""
|
| 240 |
+
Perform reconstruction using the already-created target_dir/images.
|
| 241 |
+
"""
|
| 242 |
+
|
| 243 |
+
if not force and (output_dir / "predictions.npz").exists():
|
| 244 |
+
print(f"Skipping scene {scene_name} because it already exists")
|
| 245 |
+
return
|
| 246 |
+
|
| 247 |
+
start_time = time.time()
|
| 248 |
+
gc.collect()
|
| 249 |
+
torch.cuda.empty_cache()
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
print("Running run_model...")
|
| 253 |
+
with torch.no_grad():
|
| 254 |
+
predictions = run_model(model, scene, device, max_images)
|
| 255 |
+
|
| 256 |
+
# Save predictions
|
| 257 |
+
|
| 258 |
+
del predictions["images"]
|
| 259 |
+
|
| 260 |
+
np.savez(output_dir / "predictions.npz", **predictions)
|
| 261 |
+
|
| 262 |
+
del predictions
|
| 263 |
+
gc.collect()
|
| 264 |
+
torch.cuda.empty_cache()
|
| 265 |
+
|
| 266 |
+
end_time = time.time()
|
| 267 |
+
|
| 268 |
+
import pickle
|
| 269 |
+
|
| 270 |
+
val_path = Path("../") / "Indoor/OKNO/data/arkitscenes/arkitscenes_offline_infos_train.pkl"
|
| 271 |
+
out_dir = Path("data/arkit_gt/processed")
|
| 272 |
+
with open(val_path, "rb") as f:
|
| 273 |
+
data = pickle.load(f)
|
| 274 |
+
|
| 275 |
+
data_list = data["data_list"]
|
| 276 |
+
val_split = [scene["lidar_points"]["lidar_path"] for scene in data_list][:2500]
|
| 277 |
+
val_split = [a.split("_")[0] for a in val_split]
|
| 278 |
+
print(val_split)
|
| 279 |
+
if __name__ == "__main__":
|
| 280 |
+
parser = ArgumentParser()
|
| 281 |
+
parser.add_argument("--scene_names", nargs="+", default=val_split)
|
| 282 |
+
parser.add_argument("--input_dir", type=str, default='/workspace-SR006.nfs2/datasets/arkitscenes/offline_prepared_data/posed_images/')
|
| 283 |
+
parser.add_argument("--output_dir", type=str, default='output/arkit_new')
|
| 284 |
+
parser.add_argument("--max_images", type=int, default=100)
|
| 285 |
+
parser.add_argument("--conf_thres", type=float, default=3.0)
|
| 286 |
+
parser.add_argument("--job_num", "-n", type=int, default=1)
|
| 287 |
+
parser.add_argument("--job_id", "-i", type=int, default=0)
|
| 288 |
+
parser.add_argument("--device", type=str, default="2")
|
| 289 |
+
parser.add_argument("--force", action="store_true")
|
| 290 |
+
args = parser.parse_args()
|
| 291 |
+
|
| 292 |
+
model = VGGT()
|
| 293 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 294 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 295 |
+
model.eval()
|
| 296 |
+
|
| 297 |
+
scene_names = args.scene_names[args.job_id::args.job_num]
|
| 298 |
+
# scene_names = ['47334096']
|
| 299 |
+
device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
|
| 300 |
+
|
| 301 |
+
model = model.to(device)
|
| 302 |
+
from datetime import datetime
|
| 303 |
+
errors_path = Path(f"logs/errors_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt")
|
| 304 |
+
|
| 305 |
+
dataset = ARKitDataset(args.input_dir)
|
| 306 |
+
for scene_name in tqdm(scene_names):
|
| 307 |
+
print(f"Processing scene {scene_name}")
|
| 308 |
+
try:
|
| 309 |
+
|
| 310 |
+
scene = dataset[scene_name]
|
| 311 |
+
output_dir = Path(args.output_dir) / scene_name
|
| 312 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 313 |
+
process_scene(model, scene_name, scene, output_dir,
|
| 314 |
+
device=device, max_images=args.max_images, force=args.force)
|
| 315 |
+
except Exception as e:
|
| 316 |
+
print(f"Error processing scene {scene_name}: {e}")
|
| 317 |
+
errors_path.parent.mkdir(parents=True, exist_ok=True)
|
| 318 |
+
with open(errors_path, "a") as f:
|
| 319 |
+
f.write(f"{scene_name}\n")
|
logs/errors_20250618_110001.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
41126383
|
logs/errors_20250619_002216.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
41126383
|
| 2 |
+
42897668
|
| 3 |
+
42897846
|
| 4 |
+
42897863
|
| 5 |
+
42897868
|
| 6 |
+
42897871
|
| 7 |
+
42898477
|
| 8 |
+
47204424
|
logs/errors_20251113_191809.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
47334096
|
logs/errors_20251116_181525.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
41126383
|
logs/errors_20251116_181526.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
42898477
|
| 2 |
+
42897668
|
mvp.py
ADDED
|
@@ -0,0 +1,1095 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import cv2
|
| 9 |
+
import torch
|
| 10 |
+
import numpy as np
|
| 11 |
+
import gradio as gr
|
| 12 |
+
import sys
|
| 13 |
+
import shutil
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import glob
|
| 16 |
+
import gc
|
| 17 |
+
import time
|
| 18 |
+
import open3d as o3d
|
| 19 |
+
import open_clip
|
| 20 |
+
from open_clip import tokenizer
|
| 21 |
+
import trimesh
|
| 22 |
+
import matplotlib.pyplot as plt
|
| 23 |
+
|
| 24 |
+
sys.path.append("vggt/")
|
| 25 |
+
MK_PATH = "MaskClustering"
|
| 26 |
+
from visual_util import predictions_to_glb
|
| 27 |
+
from vggt.models.vggt import VGGT
|
| 28 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 29 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 30 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 31 |
+
|
| 32 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 33 |
+
|
| 34 |
+
print(f"Using device: {device}")
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
print("Initializing and loading VGGT model...")
|
| 38 |
+
# model = VGGT.from_pretrained("facebook/VGGT-1B") # another way to load the model
|
| 39 |
+
|
| 40 |
+
model = VGGT()
|
| 41 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 42 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
model.eval()
|
| 46 |
+
model = model.to(device)
|
| 47 |
+
|
| 48 |
+
print("Initializing and loading Metric3D model...")
|
| 49 |
+
try:
|
| 50 |
+
metric3d_model = torch.hub.load('yvanyin/metric3d', 'metric3d_vit_small', pretrain=True, trust_repo=True)
|
| 51 |
+
except TypeError:
|
| 52 |
+
metric3d_model = torch.hub.load('yvanyin/metric3d', 'metric3d_vit_small', pretrain=True)
|
| 53 |
+
metric3d_model.to(device)
|
| 54 |
+
metric3d_model.eval()
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def load_clip():
|
| 59 |
+
print(f'[INFO] loading CLIP model...')
|
| 60 |
+
model, _, _ = open_clip.create_model_and_transforms("ViT-H-14", pretrained="laion2b_s32b_b79k")
|
| 61 |
+
model.cuda()
|
| 62 |
+
model.eval()
|
| 63 |
+
print(f'[INFO]', ' finish loading CLIP model...')
|
| 64 |
+
return model
|
| 65 |
+
|
| 66 |
+
def extract_text_feature(descriptions, clip_model, target_path):
|
| 67 |
+
text_tokens = tokenizer.tokenize(descriptions).cuda()
|
| 68 |
+
with torch.no_grad():
|
| 69 |
+
text_features = clip_model.encode_text(text_tokens).float()
|
| 70 |
+
text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 71 |
+
text_features = text_features.cpu().numpy()
|
| 72 |
+
|
| 73 |
+
text_features_dict = {}
|
| 74 |
+
for i, description in enumerate(descriptions):
|
| 75 |
+
text_features_dict[description] = text_features[i]
|
| 76 |
+
|
| 77 |
+
np.save(os.path.join(target_path, "text_features.npy"), text_features_dict)
|
| 78 |
+
return text_features_dict
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
clip_model = load_clip()
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
# -------------------------------------------------------------------------
|
| 85 |
+
# 1) Core model inference
|
| 86 |
+
# -------------------------------------------------------------------------
|
| 87 |
+
def run_model(target_dir, model, metric3d_model=None) -> dict:
|
| 88 |
+
"""
|
| 89 |
+
Run the VGGT model on images in the 'target_dir/images' folder and return predictions.
|
| 90 |
+
"""
|
| 91 |
+
print(f"Processing images from {target_dir}")
|
| 92 |
+
|
| 93 |
+
# Device check
|
| 94 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 95 |
+
if not torch.cuda.is_available():
|
| 96 |
+
raise ValueError("CUDA is not available. Check your environment.")
|
| 97 |
+
|
| 98 |
+
# Move model to device
|
| 99 |
+
model = model.to(device)
|
| 100 |
+
model.eval()
|
| 101 |
+
|
| 102 |
+
# Load and preprocess images
|
| 103 |
+
image_names = glob.glob(os.path.join(target_dir, "images", "*"))
|
| 104 |
+
image_names = sorted(image_names)
|
| 105 |
+
print(f"Found {len(image_names)} images")
|
| 106 |
+
if len(image_names) == 0:
|
| 107 |
+
raise ValueError("No images found. Check your upload.")
|
| 108 |
+
|
| 109 |
+
images = load_and_preprocess_images(image_names).to(device)
|
| 110 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 111 |
+
|
| 112 |
+
# Run inference
|
| 113 |
+
print("Running inference...")
|
| 114 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 115 |
+
|
| 116 |
+
with torch.no_grad():
|
| 117 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 118 |
+
predictions = model(images)
|
| 119 |
+
|
| 120 |
+
# Metric3D inference
|
| 121 |
+
if metric3d_model is not None:
|
| 122 |
+
print("Running Metric3D inference...")
|
| 123 |
+
# images is (B, 3, H, W) in [0, 1]
|
| 124 |
+
# Metric3D usually expects [0, 255] if input is tensor via inference dict
|
| 125 |
+
metric3d_input = images * 255.0
|
| 126 |
+
|
| 127 |
+
m_depths = []
|
| 128 |
+
# Process one by one to avoid potential batch issues if inference doesn't support batch
|
| 129 |
+
for i in range(metric3d_input.shape[0]):
|
| 130 |
+
img = metric3d_input[i:i+1] # (1, 3, H, W)
|
| 131 |
+
|
| 132 |
+
# Pad image to be divisible by 32 (standard for HourGlass/UNet architectures)
|
| 133 |
+
_, _, h, w = img.shape
|
| 134 |
+
ph = ((h - 1) // 32 + 1) * 32
|
| 135 |
+
pw = ((w - 1) // 32 + 1) * 32
|
| 136 |
+
|
| 137 |
+
padding = (0, pw - w, 0, ph - h) # left, right, top, bottom
|
| 138 |
+
if ph != h or pw != w:
|
| 139 |
+
img = torch.nn.functional.pad(img, padding, mode='constant', value=0)
|
| 140 |
+
|
| 141 |
+
with torch.no_grad():
|
| 142 |
+
pred_depth, confidence, _ = metric3d_model.inference({'input': img})
|
| 143 |
+
|
| 144 |
+
# Crop back to original size
|
| 145 |
+
if ph != h or pw != w:
|
| 146 |
+
pred_depth = pred_depth[:, :, :h, :w]
|
| 147 |
+
|
| 148 |
+
m_depths.append(pred_depth)
|
| 149 |
+
|
| 150 |
+
predictions["metric3d_depth"] = torch.cat(m_depths, dim=0)
|
| 151 |
+
|
| 152 |
+
# Scale alignment: scale = median(Depths_VGGT / Depths_Metric3D)
|
| 153 |
+
# We need to make sure we use valid depths (e.g. > 0) to avoid numerical issues
|
| 154 |
+
vggt_depth = predictions["depth"] # (B, H, W, 1) or similar
|
| 155 |
+
metric_depth = predictions["metric3d_depth"] # (B, 1, H, W) presumably
|
| 156 |
+
|
| 157 |
+
# Ensure shapes match for broadcasting or direct division
|
| 158 |
+
# VGGT depth usually (B, H, W, 1)
|
| 159 |
+
# Metric3D depth usually (B, 1, H, W) or (B, H, W) depending on model output.
|
| 160 |
+
# Let's check shapes and align.
|
| 161 |
+
|
| 162 |
+
# Adjust Metric3D depth shape to match VGGT if needed
|
| 163 |
+
# Assuming VGGT is (B, H, W, 1) and Metric3D is (B, 1, H, W)
|
| 164 |
+
if metric_depth.dim() == 4 and metric_depth.shape[1] == 1:
|
| 165 |
+
metric_depth = metric_depth.permute(0, 2, 3, 1) # -> (B, H, W, 1)
|
| 166 |
+
elif metric_depth.dim() == 3:
|
| 167 |
+
metric_depth = metric_depth.unsqueeze(-1) # -> (B, H, W, 1)
|
| 168 |
+
|
| 169 |
+
# Move to same device/dtype
|
| 170 |
+
vggt_depth = vggt_depth.to(metric_depth.device).float()[0]
|
| 171 |
+
metric_depth = metric_depth.float()
|
| 172 |
+
|
| 173 |
+
# Resize metric depth to match VGGT depth if they differ in spatial resolution
|
| 174 |
+
# vggt_depth: (B, H, W, 1) or (B, H, W)
|
| 175 |
+
# metric_depth: (B, H, W, 1) after permutation
|
| 176 |
+
|
| 177 |
+
target_h, target_w = vggt_depth.shape[1], vggt_depth.shape[2]
|
| 178 |
+
|
| 179 |
+
# Mask for valid values to compute median
|
| 180 |
+
print(f"Metric3D depth shape: {metric_depth.shape}")
|
| 181 |
+
print(f"VGGT depth shape: {vggt_depth.shape}")
|
| 182 |
+
valid_mask = (metric_depth > 1e-6) & (vggt_depth > 1e-6)
|
| 183 |
+
|
| 184 |
+
if valid_mask.sum() > 0:
|
| 185 |
+
ratio = metric_depth[valid_mask] / vggt_depth[valid_mask]
|
| 186 |
+
scale_factor = torch.median(ratio)
|
| 187 |
+
print(f"Computed scale factor (VGGT / Metric3D): {scale_factor.item():.4f}")
|
| 188 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 189 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 190 |
+
extrinsic = extrinsic[0]
|
| 191 |
+
add = torch.zeros_like(extrinsic[:, 2:])
|
| 192 |
+
add[..., -1] = 1
|
| 193 |
+
extrinsic = torch.cat([extrinsic, add], dim=-2)
|
| 194 |
+
zero_extrinsic = extrinsic[0]
|
| 195 |
+
for i, e in enumerate(extrinsic):
|
| 196 |
+
extrinsic[i] = zero_extrinsic @ torch.linalg.inv(e)
|
| 197 |
+
extrinsic[i, :3, 3] *= scale_factor
|
| 198 |
+
extrinsic_inv = torch.linalg.inv(extrinsic)
|
| 199 |
+
print(f"Extrinsic: {extrinsic.shape}")
|
| 200 |
+
extrinsic_inv = extrinsic_inv[None, ..., :3, :]
|
| 201 |
+
predictions["extrinsic"] = extrinsic_inv
|
| 202 |
+
predictions["pose"] = extrinsic[None]
|
| 203 |
+
print(f"Extrinsic: {extrinsic.shape} {extrinsic}")
|
| 204 |
+
predictions["intrinsic"] = intrinsic
|
| 205 |
+
|
| 206 |
+
# Convert tensors to numpy
|
| 207 |
+
for key in predictions.keys():
|
| 208 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 209 |
+
try:
|
| 210 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension
|
| 211 |
+
except ValueError:
|
| 212 |
+
pass
|
| 213 |
+
|
| 214 |
+
# Generate world points from depth map
|
| 215 |
+
print("Computing world points from depth map...")
|
| 216 |
+
predictions["depth"] = predictions["depth"] * scale_factor.item()
|
| 217 |
+
depth_map = predictions["depth"]
|
| 218 |
+
world_points = unproject_depth_map_to_point_map(depth_map, predictions["extrinsic"], predictions["intrinsic"])
|
| 219 |
+
predictions["world_points_from_depth"] = world_points
|
| 220 |
+
|
| 221 |
+
# Clean up
|
| 222 |
+
torch.cuda.empty_cache()
|
| 223 |
+
return predictions
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
# -------------------------------------------------------------------------
|
| 227 |
+
# 2) Handle uploaded video/images --> produce target_dir + images
|
| 228 |
+
# -------------------------------------------------------------------------
|
| 229 |
+
def handle_uploads(input_video, input_images):
|
| 230 |
+
"""
|
| 231 |
+
Create a new 'target_dir' + 'images' subfolder, and place user-uploaded
|
| 232 |
+
images or extracted frames from video into it. Return (target_dir, image_paths).
|
| 233 |
+
"""
|
| 234 |
+
start_time = time.time()
|
| 235 |
+
gc.collect()
|
| 236 |
+
torch.cuda.empty_cache()
|
| 237 |
+
|
| 238 |
+
# Create a unique folder name
|
| 239 |
+
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
| 240 |
+
target_dir = f"temp/input/{timestamp}"
|
| 241 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 242 |
+
|
| 243 |
+
# Clean up if somehow that folder already exists
|
| 244 |
+
if os.path.exists(target_dir):
|
| 245 |
+
shutil.rmtree(target_dir)
|
| 246 |
+
os.makedirs(target_dir)
|
| 247 |
+
os.makedirs(target_dir_images)
|
| 248 |
+
|
| 249 |
+
image_paths = []
|
| 250 |
+
|
| 251 |
+
# --- Handle images ---
|
| 252 |
+
if input_images is not None:
|
| 253 |
+
for file_data in input_images:
|
| 254 |
+
if isinstance(file_data, dict) and "name" in file_data:
|
| 255 |
+
file_path = file_data["name"]
|
| 256 |
+
else:
|
| 257 |
+
file_path = file_data
|
| 258 |
+
dst_path = os.path.join(target_dir_images, os.path.basename(file_path))
|
| 259 |
+
shutil.copy(file_path, dst_path)
|
| 260 |
+
image_paths.append(dst_path)
|
| 261 |
+
|
| 262 |
+
# --- Handle video ---
|
| 263 |
+
if input_video is not None:
|
| 264 |
+
if isinstance(input_video, dict) and "name" in input_video:
|
| 265 |
+
video_path = input_video["name"]
|
| 266 |
+
else:
|
| 267 |
+
video_path = input_video
|
| 268 |
+
|
| 269 |
+
vs = cv2.VideoCapture(video_path)
|
| 270 |
+
fps = vs.get(cv2.CAP_PROP_FPS)
|
| 271 |
+
frame_interval = int(fps * 1) # 1 frame/sec
|
| 272 |
+
|
| 273 |
+
count = 0
|
| 274 |
+
video_frame_num = 0
|
| 275 |
+
while True:
|
| 276 |
+
gotit, frame = vs.read()
|
| 277 |
+
if not gotit:
|
| 278 |
+
break
|
| 279 |
+
count += 1
|
| 280 |
+
if count % frame_interval == 0:
|
| 281 |
+
image_path = os.path.join(target_dir_images, f"{video_frame_num:06}.jpg")
|
| 282 |
+
cv2.imwrite(image_path, frame)
|
| 283 |
+
image_paths.append(image_path)
|
| 284 |
+
video_frame_num += 1
|
| 285 |
+
|
| 286 |
+
# Sort final images for gallery
|
| 287 |
+
image_paths = sorted(image_paths)
|
| 288 |
+
|
| 289 |
+
end_time = time.time()
|
| 290 |
+
print(f"Files copied to {target_dir_images}; took {end_time - start_time:.3f} seconds")
|
| 291 |
+
return target_dir, image_paths
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
# -------------------------------------------------------------------------
|
| 295 |
+
# 3) Update gallery on upload
|
| 296 |
+
# -------------------------------------------------------------------------
|
| 297 |
+
def update_gallery_on_upload(input_video, input_images):
|
| 298 |
+
"""
|
| 299 |
+
Whenever user uploads or changes files, immediately handle them
|
| 300 |
+
and show in the gallery. Return (target_dir, image_paths).
|
| 301 |
+
If nothing is uploaded, returns "None" and empty list.
|
| 302 |
+
"""
|
| 303 |
+
if not input_video and not input_images:
|
| 304 |
+
return None, None, None, None
|
| 305 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 306 |
+
return None, target_dir, image_paths, "Upload complete. Click 'Detect Objects' to begin 3D processing."
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
# -------------------------------------------------------------------------
|
| 310 |
+
# 4) Reconstruction: uses the target_dir plus any viz parameters
|
| 311 |
+
# -------------------------------------------------------------------------
|
| 312 |
+
def reconstruct(
|
| 313 |
+
target_dir,
|
| 314 |
+
conf_thres=50.0,
|
| 315 |
+
frame_filter="All",
|
| 316 |
+
mask_black_bg=False,
|
| 317 |
+
mask_white_bg=False,
|
| 318 |
+
show_cam=True,
|
| 319 |
+
mask_sky=False,
|
| 320 |
+
prediction_mode="Depthmap and Camera Branch",
|
| 321 |
+
text_labels="",
|
| 322 |
+
):
|
| 323 |
+
"""
|
| 324 |
+
Perform reconstruction using the already-created target_dir/images.
|
| 325 |
+
"""
|
| 326 |
+
prediction_mode = "Depthmap and Camera Branch" # Force prediction mode
|
| 327 |
+
if not os.path.isdir(target_dir) or target_dir == "None":
|
| 328 |
+
return None, "No valid target directory found. Please upload first.", None, None
|
| 329 |
+
|
| 330 |
+
start_time = time.time()
|
| 331 |
+
gc.collect()
|
| 332 |
+
torch.cuda.empty_cache()
|
| 333 |
+
|
| 334 |
+
# Prepare frame_filter dropdown
|
| 335 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 336 |
+
all_files = sorted(os.listdir(target_dir_images)) if os.path.isdir(target_dir_images) else []
|
| 337 |
+
image_names = [f.split(".")[0] for f in all_files]
|
| 338 |
+
all_files = [f"{i}: {filename}" for i, filename in enumerate(all_files)]
|
| 339 |
+
frame_filter_choices = ["All"] + all_files
|
| 340 |
+
|
| 341 |
+
print("Running run_model...")
|
| 342 |
+
with torch.no_grad():
|
| 343 |
+
predictions = run_model(target_dir, model, metric3d_model=metric3d_model)
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
# Save predictions
|
| 347 |
+
prediction_save_path = os.path.join(target_dir, "predictions.npz")
|
| 348 |
+
try:
|
| 349 |
+
np.savez(prediction_save_path, **predictions)
|
| 350 |
+
except Exception as e:
|
| 351 |
+
print(f"Warning: could not save predictions to npz: {e}")
|
| 352 |
+
|
| 353 |
+
depth_path = os.path.join(target_dir, "depth")
|
| 354 |
+
pose_path = os.path.join(target_dir, "pose")
|
| 355 |
+
intrinsic_path = os.path.join(target_dir, "intrinsic")
|
| 356 |
+
os.makedirs(depth_path, exist_ok=True)
|
| 357 |
+
os.makedirs(pose_path, exist_ok=True)
|
| 358 |
+
os.makedirs(intrinsic_path, exist_ok=True)
|
| 359 |
+
for i, d in enumerate(predictions["depth"]):
|
| 360 |
+
print(d.shape)
|
| 361 |
+
cv2.imwrite(os.path.join(depth_path, f"{image_names[i]}.png"), (d[..., 0] * 1000).astype(np.uint16))
|
| 362 |
+
intr = np.eye(4)
|
| 363 |
+
intr[:3, :3] = np.mean(predictions["intrinsic"], axis=0)
|
| 364 |
+
np.savetxt(os.path.join(intrinsic_path, "intrinsic_depth.txt"), intr)
|
| 365 |
+
|
| 366 |
+
for i, p in enumerate(predictions["pose"]):
|
| 367 |
+
np.savetxt(os.path.join(pose_path, f"{image_names[i]}.txt"), p)
|
| 368 |
+
|
| 369 |
+
# Handle None frame_filter
|
| 370 |
+
if frame_filter is None:
|
| 371 |
+
frame_filter = "All"
|
| 372 |
+
|
| 373 |
+
# Build a GLB file name
|
| 374 |
+
glbfile = os.path.join(
|
| 375 |
+
target_dir,
|
| 376 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 377 |
+
)
|
| 378 |
+
|
| 379 |
+
# Convert predictions to GLB
|
| 380 |
+
glbscene, point_cloud_data = predictions_to_glb(
|
| 381 |
+
predictions,
|
| 382 |
+
conf_thres=conf_thres,
|
| 383 |
+
filter_by_frames=frame_filter,
|
| 384 |
+
mask_black_bg=mask_black_bg,
|
| 385 |
+
mask_white_bg=mask_white_bg,
|
| 386 |
+
show_cam=show_cam,
|
| 387 |
+
mask_sky=mask_sky,
|
| 388 |
+
target_dir=target_dir,
|
| 389 |
+
prediction_mode=prediction_mode,
|
| 390 |
+
)
|
| 391 |
+
|
| 392 |
+
# Ensure colors are RGB (remove alpha if present) for Open3D
|
| 393 |
+
v = np.asarray(point_cloud_data.vertices)
|
| 394 |
+
c = np.asarray(point_cloud_data.colors) / 255.0
|
| 395 |
+
if c.shape[1] == 4:
|
| 396 |
+
c = c[:, :3]
|
| 397 |
+
|
| 398 |
+
glbscene.export(file_obj=glbfile)
|
| 399 |
+
pcd = o3d.geometry.PointCloud()
|
| 400 |
+
pcd.points = o3d.utility.Vector3dVector(v)
|
| 401 |
+
pcd.colors = o3d.utility.Vector3dVector(c)
|
| 402 |
+
|
| 403 |
+
pcd = pcd.voxel_down_sample(voxel_size=0.01)
|
| 404 |
+
o3d.io.write_point_cloud(os.path.join(target_dir, "point_cloud.ply"), pcd)
|
| 405 |
+
|
| 406 |
+
|
| 407 |
+
# Cleanup
|
| 408 |
+
del predictions
|
| 409 |
+
gc.collect()
|
| 410 |
+
torch.cuda.empty_cache()
|
| 411 |
+
|
| 412 |
+
end_time = time.time()
|
| 413 |
+
print(f"Total time: {end_time - start_time:.2f} seconds (including IO)")
|
| 414 |
+
log_msg = f"Reconstruction Success ({len(all_files)} frames). Waiting for visualization."
|
| 415 |
+
os.system(f"python {MK_PATH}/third_party/detectron2/projects/CropFormer/demo_cropformer/mask_predict.py \
|
| 416 |
+
--config-file {MK_PATH}/third_party/detectron2/projects/CropFormer/configs/entityv2/entity_segmentation/mask2former_hornet_3x.yaml \
|
| 417 |
+
--root /home/jovyan/users/bulat/workspace/3drec/vggt/temp/input/ --image_path_pattern images/*.jpg --dataset arkit_gt \
|
| 418 |
+
--seq_name_list {os.path.basename(target_dir)} --opts MODEL.WEIGHTS \
|
| 419 |
+
{MK_PATH}/Mask2Former_hornet_3x_576d0b.pth")
|
| 420 |
+
os.system(f"python {MK_PATH}/main.py --config wild --root /home/jovyan/users/bulat/workspace/3drec/vggt/temp/input --seq_name_list {os.path.basename(target_dir)}")
|
| 421 |
+
os.system(f"PYTHONPATH={MK_PATH} python {MK_PATH}/semantics/get_open-voc_features.py --config wild\
|
| 422 |
+
--root /home/jovyan/users/bulat/workspace/3drec/vggt/temp/input --seq_name_list {os.path.basename(target_dir)}")
|
| 423 |
+
|
| 424 |
+
return glbfile, log_msg, gr.Dropdown(choices=frame_filter_choices, value=frame_filter, interactive=True)
|
| 425 |
+
|
| 426 |
+
def visualize_detections(target_dir, conf_thres, frame_filter="All", mask_black_bg=False, mask_white_bg=False, show_cam=True, mask_sky=False, prediction_mode="Depthmap and Camera Branch"):
|
| 427 |
+
"""
|
| 428 |
+
Generate a GLB scene with bounding boxes for detected objects.
|
| 429 |
+
"""
|
| 430 |
+
if not target_dir or not os.path.exists(target_dir):
|
| 431 |
+
return None, "Target directory not found."
|
| 432 |
+
|
| 433 |
+
ply_path = os.path.join(target_dir, "point_cloud.ply")
|
| 434 |
+
npz_path = os.path.join(target_dir, "output", "object", "prediction.npz")
|
| 435 |
+
|
| 436 |
+
# 1. Загрузить point cloud как основу сцены
|
| 437 |
+
if not os.path.exists(ply_path):
|
| 438 |
+
return None, f"Point cloud not found at {ply_path}. Please run detection first."
|
| 439 |
+
|
| 440 |
+
pcd = o3d.io.read_point_cloud(ply_path)
|
| 441 |
+
points = np.asarray(pcd.points)
|
| 442 |
+
colors = np.asarray(pcd.colors)
|
| 443 |
+
|
| 444 |
+
if points.size == 0:
|
| 445 |
+
return None, "Point cloud is empty."
|
| 446 |
+
|
| 447 |
+
# Создаем базовую сцену из облака точек
|
| 448 |
+
scene = trimesh.Scene()
|
| 449 |
+
|
| 450 |
+
if colors.size == 0:
|
| 451 |
+
t_colors = np.ones((len(points), 4), dtype=np.uint8) * 255
|
| 452 |
+
else:
|
| 453 |
+
if colors.max() <= 1.0:
|
| 454 |
+
t_colors = (colors * 255).astype(np.uint8)
|
| 455 |
+
else:
|
| 456 |
+
t_colors = colors.astype(np.uint8)
|
| 457 |
+
if t_colors.shape[1] == 3:
|
| 458 |
+
t_colors = np.hstack([t_colors, np.ones((len(t_colors), 1), dtype=np.uint8) * 255])
|
| 459 |
+
|
| 460 |
+
base_pc = trimesh.PointCloud(vertices=points, colors=t_colors)
|
| 461 |
+
scene.add_geometry(base_pc)
|
| 462 |
+
|
| 463 |
+
# 2. Добавить боксы по результатам детекции, если они есть
|
| 464 |
+
legend_md = ""
|
| 465 |
+
if os.path.exists(npz_path):
|
| 466 |
+
try:
|
| 467 |
+
loaded = np.load(npz_path, allow_pickle=True)
|
| 468 |
+
# Check for detection keys
|
| 469 |
+
if 'pred_masks' in loaded:
|
| 470 |
+
masks = loaded['pred_masks'].T
|
| 471 |
+
labels = loaded['pred_classes']
|
| 472 |
+
confs = loaded['pred_score']
|
| 473 |
+
|
| 474 |
+
# Load text features to map labels to names
|
| 475 |
+
text_features_path = os.path.join(target_dir, "text_features.npy")
|
| 476 |
+
label_to_name = {}
|
| 477 |
+
if os.path.exists(text_features_path):
|
| 478 |
+
try:
|
| 479 |
+
text_features_dict = np.load(text_features_path, allow_pickle=True).item()
|
| 480 |
+
feature_keys = list(text_features_dict.keys())
|
| 481 |
+
for i, name in enumerate(feature_keys):
|
| 482 |
+
label_to_name[i] = name
|
| 483 |
+
except Exception as e:
|
| 484 |
+
print(f"Warning: Could not load text features for label mapping: {e}")
|
| 485 |
+
|
| 486 |
+
# Filter
|
| 487 |
+
if isinstance(confs, (list, tuple)):
|
| 488 |
+
confs = np.array(confs)
|
| 489 |
+
|
| 490 |
+
valid_indices = np.where(confs > conf_thres)[0]
|
| 491 |
+
|
| 492 |
+
if len(valid_indices) > 0:
|
| 493 |
+
legend_items = {}
|
| 494 |
+
cmap = plt.get_cmap("tab10")
|
| 495 |
+
|
| 496 |
+
detected_labels = np.unique(labels[valid_indices])
|
| 497 |
+
label_to_color = {label: cmap(i % 10) for i, label in enumerate(detected_labels)}
|
| 498 |
+
|
| 499 |
+
for idx in valid_indices:
|
| 500 |
+
mask = masks[idx]
|
| 501 |
+
if hasattr(mask, "toarray"):
|
| 502 |
+
mask = mask.toarray().flatten()
|
| 503 |
+
mask = mask.astype(bool)
|
| 504 |
+
|
| 505 |
+
# Verify mask size
|
| 506 |
+
if len(mask) != len(points):
|
| 507 |
+
# This is critical. If GLB points are filtered, masks might not match.
|
| 508 |
+
# If masks were generated on the FULL point cloud, we need the FULL point cloud to compute BBox.
|
| 509 |
+
# If we can't guarantee alignment, we skip or print warning.
|
| 510 |
+
# Ideally, detection pipeline should handle this alignment.
|
| 511 |
+
pass
|
| 512 |
+
# For now, let's assume they align or we skip.
|
| 513 |
+
# If alignment fails, we just don't add the box.
|
| 514 |
+
|
| 515 |
+
if len(mask) == len(points):
|
| 516 |
+
obj_points = points[mask]
|
| 517 |
+
if len(obj_points) >= 4:
|
| 518 |
+
obj_pcd = trimesh.PointCloud(obj_points)
|
| 519 |
+
try:
|
| 520 |
+
bbox = obj_pcd.bounding_box_oriented
|
| 521 |
+
except Exception:
|
| 522 |
+
bbox = obj_pcd.bounding_box
|
| 523 |
+
|
| 524 |
+
# Пропускаем нерелевантно большие боксы: если максимальная длина > 2.5 м
|
| 525 |
+
try:
|
| 526 |
+
ext = np.asarray(bbox.extents).astype(float)
|
| 527 |
+
if float(np.max(ext)) > 2.5:
|
| 528 |
+
continue
|
| 529 |
+
except Exception:
|
| 530 |
+
pass
|
| 531 |
+
|
| 532 |
+
# Строим только «каркас» бокса по 8 вершинам и трансформу:
|
| 533 |
+
# соединяем пары вершин, чьи локальные знаки отличаются ровно по одной оси
|
| 534 |
+
verts = np.asarray(bbox.vertices)
|
| 535 |
+
if verts.shape[0] != 8:
|
| 536 |
+
continue
|
| 537 |
+
T = np.asarray(bbox.transform)
|
| 538 |
+
center = T[:3, 3]
|
| 539 |
+
R = T[:3, :3]
|
| 540 |
+
# Локальные координаты (в осях бокса)
|
| 541 |
+
local = (verts - center) @ R
|
| 542 |
+
# Присваиваем каждой вершине тройку знаков (+/-1)
|
| 543 |
+
signs = np.where(local >= 0.0, 1, -1).astype(int)
|
| 544 |
+
sign_to_idx = {tuple(s): i for i, s in enumerate(signs)}
|
| 545 |
+
# Сгенерировать 12 рёбер: пары вершин, различающиеся знаком ровно по одной оси
|
| 546 |
+
edges_idx = set()
|
| 547 |
+
for sx in (-1, 1):
|
| 548 |
+
for sy in (-1, 1):
|
| 549 |
+
for sz in (-1, 1):
|
| 550 |
+
s = (sx, sy, sz)
|
| 551 |
+
if s not in sign_to_idx:
|
| 552 |
+
continue
|
| 553 |
+
for axis in range(3):
|
| 554 |
+
s2 = list(s)
|
| 555 |
+
s2[axis] *= -1
|
| 556 |
+
s2 = tuple(s2)
|
| 557 |
+
if s2 in sign_to_idx:
|
| 558 |
+
i0 = sign_to_idx[s]
|
| 559 |
+
i1 = sign_to_idx[s2]
|
| 560 |
+
if i0 != i1:
|
| 561 |
+
edges_idx.add(tuple(sorted((i0, i1))))
|
| 562 |
+
if not edges_idx:
|
| 563 |
+
continue
|
| 564 |
+
segments = np.array([[verts[i], verts[j]] for (i, j) in edges_idx], dtype=float)
|
| 565 |
+
|
| 566 |
+
lbl_idx = labels[idx]
|
| 567 |
+
lbl_name = label_to_name.get(lbl_idx, f"Class {lbl_idx}")
|
| 568 |
+
color = label_to_color.get(lbl_idx, (1, 0, 0, 1))
|
| 569 |
+
|
| 570 |
+
color_u8 = (np.array(color) * 255).astype(np.uint8)
|
| 571 |
+
# Постоянная толщина рамки: 3 см (0.03)
|
| 572 |
+
radius = 0.015
|
| 573 |
+
for seg in segments:
|
| 574 |
+
p1, p2 = seg[0], seg[1]
|
| 575 |
+
v = p2 - p1
|
| 576 |
+
length = float(np.linalg.norm(v))
|
| 577 |
+
if length <= 1e-8:
|
| 578 |
+
continue
|
| 579 |
+
direction = v / length
|
| 580 |
+
try:
|
| 581 |
+
cyl = trimesh.creation.cylinder(radius=radius, height=length, sections=12)
|
| 582 |
+
except Exception:
|
| 583 |
+
continue
|
| 584 |
+
# Повернуть ось Z к направлению ребра и перенести в середину
|
| 585 |
+
try:
|
| 586 |
+
align = trimesh.geometry.align_vectors([0, 0, 1], direction)
|
| 587 |
+
cyl.apply_transform(align)
|
| 588 |
+
except Exception:
|
| 589 |
+
pass
|
| 590 |
+
midpoint = (p1 + p2) / 2.0
|
| 591 |
+
cyl.apply_translation(midpoint)
|
| 592 |
+
# Материал без влияния освещения (эмуляция unlit через emissive)
|
| 593 |
+
try:
|
| 594 |
+
emissive = (color_u8[:3] / 255.0).tolist()
|
| 595 |
+
mat = trimesh.visual.material.PBRMaterial(
|
| 596 |
+
baseColorFactor=(0.0, 0.0, 0.0, 1.0),
|
| 597 |
+
metallicFactor=0.0,
|
| 598 |
+
roughnessFactor=1.0,
|
| 599 |
+
emissiveFactor=emissive,
|
| 600 |
+
doubleSided=True,
|
| 601 |
+
)
|
| 602 |
+
cyl.visual.material = mat
|
| 603 |
+
except Exception:
|
| 604 |
+
cyl.visual.face_colors = np.tile(color_u8[None, :], (len(cyl.faces), 1))
|
| 605 |
+
scene.add_geometry(cyl)
|
| 606 |
+
legend_items[lbl_name] = color
|
| 607 |
+
|
| 608 |
+
legend_md = "### Legend\n"
|
| 609 |
+
for lbl_name, color in legend_items.items():
|
| 610 |
+
c_u8 = (np.array(color) * 255).astype(np.uint8)
|
| 611 |
+
hex_c = "#{:02x}{:02x}{:02x}".format(c_u8[0], c_u8[1], c_u8[2])
|
| 612 |
+
legend_md += f"- <span style='color:{hex_c}'>■</span> {lbl_name}\n"
|
| 613 |
+
|
| 614 |
+
except Exception as e:
|
| 615 |
+
print(f"Error loading detections: {e}")
|
| 616 |
+
legend_md = f"Error loading detections: {e}"
|
| 617 |
+
|
| 618 |
+
# Export combined scene (облако + боксы)
|
| 619 |
+
out_path = os.path.join(target_dir, f"combined_viz_{conf_thres}.glb")
|
| 620 |
+
scene.export(file_obj=out_path)
|
| 621 |
+
|
| 622 |
+
return out_path, legend_md
|
| 623 |
+
|
| 624 |
+
def detect_objects(text_labels, target_dir, conf_thres, *viz_args):
|
| 625 |
+
"""
|
| 626 |
+
Detect objects from text labels and return the detected objects.
|
| 627 |
+
"""
|
| 628 |
+
# Require non-empty text labels
|
| 629 |
+
if not text_labels or not isinstance(text_labels, str) or len([l.strip() for l in text_labels.split(";") if l.strip()]) == 0:
|
| 630 |
+
return None, "Please enter at least one text label (separated by ';')."
|
| 631 |
+
|
| 632 |
+
# 1. Run reconstruction first if needed (checking if predictions exist)
|
| 633 |
+
predictions_path = os.path.join(target_dir, "predictions.npz")
|
| 634 |
+
if not os.path.exists(predictions_path):
|
| 635 |
+
# We need to run reconstruction. But reconstruction needs inputs we might not have in this function scope easily
|
| 636 |
+
# unless we pass them or assume they are in target_dir.
|
| 637 |
+
# reconstruct function takes target_dir. Let's call it.
|
| 638 |
+
# However, reconstruct is heavy and takes many args.
|
| 639 |
+
# Let's assume for now user clicked Reconstruct or we call it with defaults/passed args if we merged them.
|
| 640 |
+
|
| 641 |
+
# Actually, if we want one button to do both, we should probably call `reconstruct` logic here.
|
| 642 |
+
# But `reconstruct` returns GLB path.
|
| 643 |
+
# Let's call run_model directly if predictions don't exist?
|
| 644 |
+
# Better: Reuse reconstruct function logic or call it.
|
| 645 |
+
|
| 646 |
+
# Simplify: If predictions don't exist, run standard reconstruction first
|
| 647 |
+
print("Predictions not found, running reconstruction first...")
|
| 648 |
+
# We need arguments for reconstruction.
|
| 649 |
+
# viz_args contains [frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode]
|
| 650 |
+
# conf_thres is passed separately.
|
| 651 |
+
|
| 652 |
+
# reconstruct signature: target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode, text_labels
|
| 653 |
+
# viz_args order from click: frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode
|
| 654 |
+
|
| 655 |
+
reconstruct(target_dir, 50.0, *viz_args, text_labels=text_labels) # conf_thres 3.0 default for reconstruction points
|
| 656 |
+
|
| 657 |
+
|
| 658 |
+
# Extract text features if provided
|
| 659 |
+
if text_labels:
|
| 660 |
+
labels = [l.strip() for l in text_labels.split(";") if l.strip()]
|
| 661 |
+
if labels:
|
| 662 |
+
print(f"Extracting features for labels: {labels}")
|
| 663 |
+
text_features = extract_text_feature(labels, clip_model, target_dir)
|
| 664 |
+
print(f"Text features: {text_features}")
|
| 665 |
+
os.system(f"PYTHONPATH={MK_PATH} python {MK_PATH}/semantics/wopen-voc_query.py --config wild\
|
| 666 |
+
--root /home/jovyan/users/bulat/workspace/3drec/vggt/temp/input --seq_name {os.path.basename(target_dir)}")
|
| 667 |
+
|
| 668 |
+
return visualize_detections(target_dir, conf_thres, *viz_args)
|
| 669 |
+
|
| 670 |
+
|
| 671 |
+
# -------------------------------------------------------------------------
|
| 672 |
+
# 5) Helper functions for UI resets + re-visualization
|
| 673 |
+
# -------------------------------------------------------------------------
|
| 674 |
+
def clear_fields():
|
| 675 |
+
"""
|
| 676 |
+
Clears the 3D viewer, the stored target_dir, and empties the gallery.
|
| 677 |
+
"""
|
| 678 |
+
return None
|
| 679 |
+
|
| 680 |
+
|
| 681 |
+
def update_log():
|
| 682 |
+
"""
|
| 683 |
+
Display a quick log message while waiting.
|
| 684 |
+
"""
|
| 685 |
+
return "Loading and Reconstructing..."
|
| 686 |
+
|
| 687 |
+
|
| 688 |
+
def update_visualization(
|
| 689 |
+
target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode, is_example
|
| 690 |
+
):
|
| 691 |
+
"""
|
| 692 |
+
Reload saved predictions from npz, create (or reuse) the GLB for new parameters,
|
| 693 |
+
and return it for the 3D viewer. If is_example == "True", skip.
|
| 694 |
+
"""
|
| 695 |
+
|
| 696 |
+
# If it's an example click, skip as requested
|
| 697 |
+
if is_example == "True":
|
| 698 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 699 |
+
|
| 700 |
+
if not target_dir or target_dir == "None" or not os.path.isdir(target_dir):
|
| 701 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 702 |
+
|
| 703 |
+
predictions_path = os.path.join(target_dir, "predictions.npz")
|
| 704 |
+
if not os.path.exists(predictions_path):
|
| 705 |
+
return None, f"No reconstruction available at {predictions_path}. Please run 'Reconstruct' first."
|
| 706 |
+
|
| 707 |
+
key_list = [
|
| 708 |
+
"pose_enc",
|
| 709 |
+
"depth",
|
| 710 |
+
"depth_conf",
|
| 711 |
+
"world_points",
|
| 712 |
+
"world_points_conf",
|
| 713 |
+
"images",
|
| 714 |
+
"extrinsic",
|
| 715 |
+
"intrinsic",
|
| 716 |
+
"world_points_from_depth",
|
| 717 |
+
]
|
| 718 |
+
|
| 719 |
+
loaded = np.load(predictions_path, allow_pickle=True)
|
| 720 |
+
predictions = {key: np.array(loaded[key]) for key in key_list}
|
| 721 |
+
|
| 722 |
+
glbfile = os.path.join(
|
| 723 |
+
target_dir,
|
| 724 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 725 |
+
)
|
| 726 |
+
|
| 727 |
+
glbscene = predictions_to_glb(
|
| 728 |
+
predictions,
|
| 729 |
+
conf_thres=conf_thres,
|
| 730 |
+
filter_by_frames=frame_filter,
|
| 731 |
+
mask_black_bg=mask_black_bg,
|
| 732 |
+
mask_white_bg=mask_white_bg,
|
| 733 |
+
show_cam=show_cam,
|
| 734 |
+
mask_sky=mask_sky,
|
| 735 |
+
target_dir=target_dir,
|
| 736 |
+
prediction_mode=prediction_mode,
|
| 737 |
+
)
|
| 738 |
+
glbscene.export(file_obj=glbfile)
|
| 739 |
+
|
| 740 |
+
return glbfile, "Updating Visualization"
|
| 741 |
+
|
| 742 |
+
|
| 743 |
+
# -------------------------------------------------------------------------
|
| 744 |
+
# Example images
|
| 745 |
+
# -------------------------------------------------------------------------
|
| 746 |
+
|
| 747 |
+
great_wall_video = "examples/videos/great_wall.mp4"
|
| 748 |
+
colosseum_video = "examples/videos/Colosseum.mp4"
|
| 749 |
+
room_video = "examples/videos/room.mp4"
|
| 750 |
+
kitchen_video = "examples/videos/kitchen.mp4"
|
| 751 |
+
fern_video = "examples/videos/fern.mp4"
|
| 752 |
+
single_cartoon_video = "examples/videos/single_cartoon.mp4"
|
| 753 |
+
single_oil_painting_video = "examples/videos/single_oil_painting.mp4"
|
| 754 |
+
pyramid_video = "examples/videos/pyramid.mp4"
|
| 755 |
+
|
| 756 |
+
|
| 757 |
+
# -------------------------------------------------------------------------
|
| 758 |
+
# 6) Build Gradio UI
|
| 759 |
+
# -------------------------------------------------------------------------
|
| 760 |
+
theme = gr.themes.Ocean()
|
| 761 |
+
theme.set(
|
| 762 |
+
checkbox_label_background_fill_selected="*button_primary_background_fill",
|
| 763 |
+
checkbox_label_text_color_selected="*button_primary_text_color",
|
| 764 |
+
)
|
| 765 |
+
|
| 766 |
+
with gr.Blocks(
|
| 767 |
+
theme=theme,
|
| 768 |
+
css="""
|
| 769 |
+
.custom-log * {
|
| 770 |
+
font-style: italic;
|
| 771 |
+
font-size: 22px !important;
|
| 772 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 773 |
+
-webkit-background-clip: text;
|
| 774 |
+
background-clip: text;
|
| 775 |
+
font-weight: bold !important;
|
| 776 |
+
color: transparent !important;
|
| 777 |
+
text-align: center !important;
|
| 778 |
+
}
|
| 779 |
+
|
| 780 |
+
.example-log * {
|
| 781 |
+
font-style: italic;
|
| 782 |
+
font-size: 16px !important;
|
| 783 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 784 |
+
-webkit-background-clip: text;
|
| 785 |
+
background-clip: text;
|
| 786 |
+
color: transparent !important;
|
| 787 |
+
}
|
| 788 |
+
|
| 789 |
+
#my_radio .wrap {
|
| 790 |
+
display: flex;
|
| 791 |
+
flex-wrap: nowrap;
|
| 792 |
+
justify-content: center;
|
| 793 |
+
align-items: center;
|
| 794 |
+
}
|
| 795 |
+
|
| 796 |
+
#my_radio .wrap label {
|
| 797 |
+
display: flex;
|
| 798 |
+
width: 50%;
|
| 799 |
+
justify-content: center;
|
| 800 |
+
align-items: center;
|
| 801 |
+
margin: 0;
|
| 802 |
+
padding: 10px 0;
|
| 803 |
+
box-sizing: border-box;
|
| 804 |
+
}
|
| 805 |
+
""",
|
| 806 |
+
) as demo:
|
| 807 |
+
# Instead of gr.State, we use a hidden Textbox:
|
| 808 |
+
is_example = gr.Textbox(label="is_example", visible=False, value="None")
|
| 809 |
+
num_images = gr.Textbox(label="num_images", visible=False, value="None")
|
| 810 |
+
|
| 811 |
+
gr.HTML(
|
| 812 |
+
"""
|
| 813 |
+
<h1>🦁 Zoo3D: Zero-Shot 3D Object Detection at Scene Level 🐼</h1>
|
| 814 |
+
<p>
|
| 815 |
+
<a href="https://github.com/col14m/zoo3d">GitHub Repository</a>
|
| 816 |
+
</p>
|
| 817 |
+
|
| 818 |
+
<div style="font-size: 16px; line-height: 1.5;">
|
| 819 |
+
<p>Upload a video or a set of images to create a 3D reconstruction and run open‑vocabulary 3D object detection from your text labels. The app builds a point cloud and draws colored wireframe bounding boxes for the detected objects.</p>
|
| 820 |
+
|
| 821 |
+
<h3>Getting Started:</h3>
|
| 822 |
+
<ol>
|
| 823 |
+
<li><strong>Upload Your Data:</strong> Use "Upload Video" or "Upload Images". Videos are sampled at 1 frame/sec.</li>
|
| 824 |
+
<li><strong>Enter Text Labels (Required):</strong> Provide one or more labels separated by semicolons, e.g. <code>chair; table; plant</code>.</li>
|
| 825 |
+
<li><strong>Detect:</strong> Click <strong>"Detect Objects"</strong>. The app will reconstruct the scene (if needed) and then run detection.</li>
|
| 826 |
+
<li><strong>Threshold (Optional):</strong> Tune the <em>Detection Threshold</em> (0–1). Higher = fewer, more confident detections.</li>
|
| 827 |
+
<li><strong>Visualize & Download:</strong> A single 3D view shows the point cloud and colored wireframe boxes. A legend maps colors to labels. You can download the GLB.</li>
|
| 828 |
+
</ol>
|
| 829 |
+
<p><strong style="color: #0ea5e9;">Notes:</strong> <span style="color: #0ea5e9; font-weight: bold;">Reconstruction is triggered automatically on first run. If no labels are provided, you'll see an error: </span><code>Please enter at least one text label (separated by ';').</code></p>
|
| 830 |
+
</div>
|
| 831 |
+
"""
|
| 832 |
+
)
|
| 833 |
+
|
| 834 |
+
target_dir_output = gr.Textbox(label="Target Dir", visible=False, value="None")
|
| 835 |
+
|
| 836 |
+
with gr.Row():
|
| 837 |
+
with gr.Column(scale=2):
|
| 838 |
+
input_video = gr.Video(label="Upload Video", interactive=True)
|
| 839 |
+
input_images = gr.File(file_count="multiple", label="Upload Images", interactive=True)
|
| 840 |
+
|
| 841 |
+
image_gallery = gr.Gallery(
|
| 842 |
+
label="Preview",
|
| 843 |
+
columns=4,
|
| 844 |
+
height="300px",
|
| 845 |
+
show_download_button=True,
|
| 846 |
+
object_fit="contain",
|
| 847 |
+
preview=True,
|
| 848 |
+
)
|
| 849 |
+
|
| 850 |
+
with gr.Column(scale=4):
|
| 851 |
+
text_labels = gr.Textbox(label="Text Labels (separated by ;)", placeholder="cat; dog; car")
|
| 852 |
+
with gr.Column():
|
| 853 |
+
|
| 854 |
+
|
| 855 |
+
gr.Markdown("**3D Reconstruction & detection (Point Cloud and Bounding Boxes)**")
|
| 856 |
+
log_output = gr.Markdown(
|
| 857 |
+
"Please upload a video or images, then click Detect Objects.", elem_classes=["custom-log"]
|
| 858 |
+
)
|
| 859 |
+
reconstruction_output = gr.Model3D(height=520, zoom_speed=0.5, pan_speed=0.5)
|
| 860 |
+
|
| 861 |
+
with gr.Row():
|
| 862 |
+
detect_btn = gr.Button("Detect Objects", scale=1, variant="primary")
|
| 863 |
+
clear_btn = gr.ClearButton(
|
| 864 |
+
[input_video, input_images, reconstruction_output, log_output, target_dir_output, image_gallery, text_labels],
|
| 865 |
+
scale=1,
|
| 866 |
+
)
|
| 867 |
+
# with gr.Row():
|
| 868 |
+
# prediction_mode = gr.Textbox(
|
| 869 |
+
# value="Depthmap and Camera Branch",
|
| 870 |
+
# visible=False,
|
| 871 |
+
# label="Prediction Mode"
|
| 872 |
+
# )
|
| 873 |
+
|
| 874 |
+
# We'll create a hidden component so the event handlers don't break
|
| 875 |
+
prediction_mode = gr.Textbox(value="Depthmap and Camera Branch", visible=False)
|
| 876 |
+
|
| 877 |
+
# Основные параметры визуализации реконструкции
|
| 878 |
+
with gr.Row():
|
| 879 |
+
conf_thres = gr.Slider(
|
| 880 |
+
minimum=0,
|
| 881 |
+
maximum=100,
|
| 882 |
+
value=50,
|
| 883 |
+
step=0.1,
|
| 884 |
+
label="Confidence Threshold (%)",
|
| 885 |
+
visible=False,
|
| 886 |
+
)
|
| 887 |
+
frame_filter = gr.Dropdown(
|
| 888 |
+
choices=["All"],
|
| 889 |
+
value="All",
|
| 890 |
+
label="Show Points from Frame",
|
| 891 |
+
visible=False,
|
| 892 |
+
)
|
| 893 |
+
with gr.Column():
|
| 894 |
+
show_cam = gr.Checkbox(label="Show Camera", value=True, visible=False)
|
| 895 |
+
mask_sky = gr.Checkbox(label="Filter Sky", value=False, visible=False)
|
| 896 |
+
mask_black_bg = gr.Checkbox(label="Filter Black Background", value=False, visible=False)
|
| 897 |
+
mask_white_bg = gr.Checkbox(label="Filter White Background", value=False, visible=False)
|
| 898 |
+
|
| 899 |
+
# Порог для детекции и легенда цветов боксов
|
| 900 |
+
detection_conf_thres = gr.Slider(
|
| 901 |
+
minimum=0,
|
| 902 |
+
maximum=1,
|
| 903 |
+
value=0.6,
|
| 904 |
+
step=0.01,
|
| 905 |
+
label="Detection Threshold",
|
| 906 |
+
)
|
| 907 |
+
detection_legend = gr.Markdown("Legend will appear here")
|
| 908 |
+
|
| 909 |
+
# ---------------------- Examples section ----------------------
|
| 910 |
+
examples = [
|
| 911 |
+
]
|
| 912 |
+
|
| 913 |
+
def example_pipeline(
|
| 914 |
+
input_video,
|
| 915 |
+
num_images_str,
|
| 916 |
+
input_images,
|
| 917 |
+
conf_thres,
|
| 918 |
+
mask_black_bg,
|
| 919 |
+
mask_white_bg,
|
| 920 |
+
show_cam,
|
| 921 |
+
mask_sky,
|
| 922 |
+
prediction_mode,
|
| 923 |
+
is_example_str,
|
| 924 |
+
text_labels,
|
| 925 |
+
):
|
| 926 |
+
"""
|
| 927 |
+
1) Copy example images to new target_dir
|
| 928 |
+
2) Reconstruct (and Detect if labels present)
|
| 929 |
+
3) Return model3D + logs + new_dir + updated dropdown + gallery
|
| 930 |
+
We do NOT return is_example. It's just an input.
|
| 931 |
+
"""
|
| 932 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 933 |
+
# Always use "All" for frame_filter in examples
|
| 934 |
+
frame_filter = "All"
|
| 935 |
+
|
| 936 |
+
detection_conf = 0.85
|
| 937 |
+
|
| 938 |
+
glbfile, legend_md = detect_objects(
|
| 939 |
+
text_labels,
|
| 940 |
+
target_dir,
|
| 941 |
+
detection_conf,
|
| 942 |
+
frame_filter,
|
| 943 |
+
mask_black_bg,
|
| 944 |
+
mask_white_bg,
|
| 945 |
+
show_cam,
|
| 946 |
+
mask_sky,
|
| 947 |
+
prediction_mode
|
| 948 |
+
)
|
| 949 |
+
|
| 950 |
+
log_msg = "Example loaded and processed."
|
| 951 |
+
|
| 952 |
+
return glbfile, log_msg + "\n\n" + legend_md, target_dir, gr.Dropdown(choices=["All"], value="All", interactive=True), image_paths
|
| 953 |
+
|
| 954 |
+
detect_btn.click(fn=clear_fields, inputs=[], outputs=[]).then(
|
| 955 |
+
fn=detect_objects,
|
| 956 |
+
inputs=[
|
| 957 |
+
text_labels,
|
| 958 |
+
target_dir_output,
|
| 959 |
+
detection_conf_thres,
|
| 960 |
+
frame_filter,
|
| 961 |
+
mask_black_bg,
|
| 962 |
+
mask_white_bg,
|
| 963 |
+
show_cam,
|
| 964 |
+
mask_sky,
|
| 965 |
+
prediction_mode
|
| 966 |
+
],
|
| 967 |
+
outputs=[reconstruction_output, detection_legend]
|
| 968 |
+
).then(
|
| 969 |
+
fn=lambda: "False", inputs=[], outputs=[is_example] # set is_example to "False"
|
| 970 |
+
)
|
| 971 |
+
|
| 972 |
+
detection_conf_thres.change(
|
| 973 |
+
fn=visualize_detections,
|
| 974 |
+
inputs=[
|
| 975 |
+
target_dir_output,
|
| 976 |
+
detection_conf_thres,
|
| 977 |
+
frame_filter,
|
| 978 |
+
mask_black_bg,
|
| 979 |
+
mask_white_bg,
|
| 980 |
+
show_cam,
|
| 981 |
+
mask_sky,
|
| 982 |
+
prediction_mode
|
| 983 |
+
],
|
| 984 |
+
outputs=[reconstruction_output, detection_legend]
|
| 985 |
+
)
|
| 986 |
+
|
| 987 |
+
# -------------------------------------------------------------------------
|
| 988 |
+
# Real-time Visualization Updates
|
| 989 |
+
# -------------------------------------------------------------------------
|
| 990 |
+
conf_thres.change(
|
| 991 |
+
update_visualization,
|
| 992 |
+
[
|
| 993 |
+
target_dir_output,
|
| 994 |
+
conf_thres,
|
| 995 |
+
frame_filter,
|
| 996 |
+
mask_black_bg,
|
| 997 |
+
mask_white_bg,
|
| 998 |
+
show_cam,
|
| 999 |
+
mask_sky,
|
| 1000 |
+
prediction_mode,
|
| 1001 |
+
is_example,
|
| 1002 |
+
],
|
| 1003 |
+
[reconstruction_output, log_output],
|
| 1004 |
+
)
|
| 1005 |
+
frame_filter.change(
|
| 1006 |
+
update_visualization,
|
| 1007 |
+
[
|
| 1008 |
+
target_dir_output,
|
| 1009 |
+
conf_thres,
|
| 1010 |
+
frame_filter,
|
| 1011 |
+
mask_black_bg,
|
| 1012 |
+
mask_white_bg,
|
| 1013 |
+
show_cam,
|
| 1014 |
+
mask_sky,
|
| 1015 |
+
prediction_mode,
|
| 1016 |
+
is_example,
|
| 1017 |
+
],
|
| 1018 |
+
[reconstruction_output, log_output],
|
| 1019 |
+
)
|
| 1020 |
+
mask_black_bg.change(
|
| 1021 |
+
update_visualization,
|
| 1022 |
+
[
|
| 1023 |
+
target_dir_output,
|
| 1024 |
+
conf_thres,
|
| 1025 |
+
frame_filter,
|
| 1026 |
+
mask_black_bg,
|
| 1027 |
+
mask_white_bg,
|
| 1028 |
+
show_cam,
|
| 1029 |
+
mask_sky,
|
| 1030 |
+
prediction_mode,
|
| 1031 |
+
is_example,
|
| 1032 |
+
],
|
| 1033 |
+
[reconstruction_output, log_output],
|
| 1034 |
+
)
|
| 1035 |
+
mask_white_bg.change(
|
| 1036 |
+
update_visualization,
|
| 1037 |
+
[
|
| 1038 |
+
target_dir_output,
|
| 1039 |
+
conf_thres,
|
| 1040 |
+
frame_filter,
|
| 1041 |
+
mask_black_bg,
|
| 1042 |
+
mask_white_bg,
|
| 1043 |
+
show_cam,
|
| 1044 |
+
mask_sky,
|
| 1045 |
+
prediction_mode,
|
| 1046 |
+
is_example,
|
| 1047 |
+
],
|
| 1048 |
+
[reconstruction_output, log_output],
|
| 1049 |
+
)
|
| 1050 |
+
show_cam.change(
|
| 1051 |
+
update_visualization,
|
| 1052 |
+
[
|
| 1053 |
+
target_dir_output,
|
| 1054 |
+
conf_thres,
|
| 1055 |
+
frame_filter,
|
| 1056 |
+
mask_black_bg,
|
| 1057 |
+
mask_white_bg,
|
| 1058 |
+
show_cam,
|
| 1059 |
+
mask_sky,
|
| 1060 |
+
prediction_mode,
|
| 1061 |
+
is_example,
|
| 1062 |
+
],
|
| 1063 |
+
[reconstruction_output, log_output],
|
| 1064 |
+
)
|
| 1065 |
+
prediction_mode.change(
|
| 1066 |
+
update_visualization,
|
| 1067 |
+
[
|
| 1068 |
+
target_dir_output,
|
| 1069 |
+
conf_thres,
|
| 1070 |
+
frame_filter,
|
| 1071 |
+
mask_black_bg,
|
| 1072 |
+
mask_white_bg,
|
| 1073 |
+
show_cam,
|
| 1074 |
+
mask_sky,
|
| 1075 |
+
prediction_mode,
|
| 1076 |
+
is_example,
|
| 1077 |
+
],
|
| 1078 |
+
[reconstruction_output, log_output],
|
| 1079 |
+
)
|
| 1080 |
+
|
| 1081 |
+
# # -------------------------------------------------------------------------
|
| 1082 |
+
# # Auto-update gallery whenever user uploads or changes their files
|
| 1083 |
+
# # -------------------------------------------------------------------------
|
| 1084 |
+
input_video.change(
|
| 1085 |
+
fn=update_gallery_on_upload,
|
| 1086 |
+
inputs=[input_video, input_images],
|
| 1087 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 1088 |
+
)
|
| 1089 |
+
input_images.change(
|
| 1090 |
+
fn=update_gallery_on_upload,
|
| 1091 |
+
inputs=[input_video, input_images],
|
| 1092 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 1093 |
+
)
|
| 1094 |
+
|
| 1095 |
+
demo.queue(max_size=20).launch(show_error=True, share=True)
|
mvp_complete.py
ADDED
|
@@ -0,0 +1,1127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import cv2
|
| 9 |
+
import torch
|
| 10 |
+
import numpy as np
|
| 11 |
+
import gradio as gr
|
| 12 |
+
import sys
|
| 13 |
+
import shutil
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import glob
|
| 16 |
+
import gc
|
| 17 |
+
import time
|
| 18 |
+
import open3d as o3d
|
| 19 |
+
import open_clip
|
| 20 |
+
from open_clip import tokenizer
|
| 21 |
+
import trimesh
|
| 22 |
+
import matplotlib.pyplot as plt
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
MK_PATH = "/home/jovyan/users/bulat/workspace/3drec/Indoor/MaskClustering"
|
| 26 |
+
sys.path.append("vggt/")
|
| 27 |
+
sys.path.append(MK_PATH)
|
| 28 |
+
|
| 29 |
+
# Preload CropFormer model once on script import
|
| 30 |
+
try:
|
| 31 |
+
from exts.cropformer_runner import preload_cropformer_model, make_cropformer_dir
|
| 32 |
+
make_cropformer_dir(MK_PATH)
|
| 33 |
+
preload_cropformer_model(
|
| 34 |
+
config_file=os.path.join(MK_PATH, "third_party/detectron2/projects/CropFormer/configs/entityv2/entity_segmentation/mask2former_hornet_3x.yaml"),
|
| 35 |
+
opts=[
|
| 36 |
+
"MODEL.WEIGHTS",
|
| 37 |
+
os.path.join(MK_PATH, "Mask2Former_hornet_3x_576d0b.pth"),
|
| 38 |
+
],
|
| 39 |
+
)
|
| 40 |
+
except Exception as e:
|
| 41 |
+
print(f"[Warning] Could not preload CropFormer model: {e}")
|
| 42 |
+
|
| 43 |
+
from exts.ov_features import load as load_ov_features, main as main_ov_features
|
| 44 |
+
load_ov_features(MK_PATH)
|
| 45 |
+
|
| 46 |
+
from visual_util import predictions_to_glb
|
| 47 |
+
from vggt.models.vggt import VGGT
|
| 48 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 49 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 50 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 51 |
+
|
| 52 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 53 |
+
|
| 54 |
+
print("Initializing and loading VGGT model...")
|
| 55 |
+
# model = VGGT.from_pretrained("facebook/VGGT-1B") # another way to load the model
|
| 56 |
+
|
| 57 |
+
model = VGGT()
|
| 58 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 59 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
model.eval()
|
| 63 |
+
model = model.to(device)
|
| 64 |
+
|
| 65 |
+
print("Initializing and loading Metric3D model...")
|
| 66 |
+
try:
|
| 67 |
+
metric3d_model = torch.hub.load('yvanyin/metric3d', 'metric3d_vit_small', pretrain=True, trust_repo=True)
|
| 68 |
+
except TypeError:
|
| 69 |
+
metric3d_model = torch.hub.load('yvanyin/metric3d', 'metric3d_vit_small', pretrain=True)
|
| 70 |
+
metric3d_model.to(device)
|
| 71 |
+
metric3d_model.eval()
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def load_clip():
|
| 76 |
+
print(f'[INFO] loading CLIP model...')
|
| 77 |
+
model, _, preprocess = open_clip.create_model_and_transforms("ViT-H-14", pretrained="laion2b_s32b_b79k")
|
| 78 |
+
model.cuda()
|
| 79 |
+
model.eval()
|
| 80 |
+
print(f'[INFO]', ' finish loading CLIP model...')
|
| 81 |
+
return model, preprocess
|
| 82 |
+
|
| 83 |
+
def extract_text_feature(descriptions, clip_model, target_path):
|
| 84 |
+
text_tokens = tokenizer.tokenize(descriptions).cuda()
|
| 85 |
+
with torch.no_grad():
|
| 86 |
+
text_features = clip_model.encode_text(text_tokens).float()
|
| 87 |
+
text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 88 |
+
text_features = text_features.cpu().numpy()
|
| 89 |
+
|
| 90 |
+
text_features_dict = {}
|
| 91 |
+
for i, description in enumerate(descriptions):
|
| 92 |
+
text_features_dict[description] = text_features[i]
|
| 93 |
+
|
| 94 |
+
np.save(os.path.join(target_path, "text_features.npy"), text_features_dict)
|
| 95 |
+
return text_features_dict
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
clip_model, clip_preprocess = load_clip()
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
# -------------------------------------------------------------------------
|
| 102 |
+
# 1) Core model inference
|
| 103 |
+
# -------------------------------------------------------------------------
|
| 104 |
+
def run_model(target_dir, model, metric3d_model=None) -> dict:
|
| 105 |
+
"""
|
| 106 |
+
Run the VGGT model on images in the 'target_dir/images' folder and return predictions.
|
| 107 |
+
"""
|
| 108 |
+
print(f"Processing images from {target_dir}")
|
| 109 |
+
|
| 110 |
+
# Device check
|
| 111 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 112 |
+
if not torch.cuda.is_available():
|
| 113 |
+
raise ValueError("CUDA is not available. Check your environment.")
|
| 114 |
+
|
| 115 |
+
# Move model to device
|
| 116 |
+
model = model.to(device)
|
| 117 |
+
model.eval()
|
| 118 |
+
|
| 119 |
+
# Load and preprocess images
|
| 120 |
+
image_names = glob.glob(os.path.join(target_dir, "images", "*"))
|
| 121 |
+
image_names = sorted(image_names)
|
| 122 |
+
print(f"Found {len(image_names)} images")
|
| 123 |
+
if len(image_names) == 0:
|
| 124 |
+
raise ValueError("No images found. Check your upload.")
|
| 125 |
+
|
| 126 |
+
images = load_and_preprocess_images(image_names).to(device)
|
| 127 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 128 |
+
|
| 129 |
+
# Run inference
|
| 130 |
+
print("Running inference...")
|
| 131 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 132 |
+
|
| 133 |
+
with torch.no_grad():
|
| 134 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 135 |
+
predictions = model(images)
|
| 136 |
+
|
| 137 |
+
# Metric3D inference
|
| 138 |
+
if metric3d_model is not None:
|
| 139 |
+
print("Running Metric3D inference...")
|
| 140 |
+
# images is (B, 3, H, W) in [0, 1]
|
| 141 |
+
# Metric3D usually expects [0, 255] if input is tensor via inference dict
|
| 142 |
+
metric3d_input = images * 255.0
|
| 143 |
+
|
| 144 |
+
m_depths = []
|
| 145 |
+
# Process one by one to avoid potential batch issues if inference doesn't support batch
|
| 146 |
+
for i in range(metric3d_input.shape[0]):
|
| 147 |
+
img = metric3d_input[i:i+1] # (1, 3, H, W)
|
| 148 |
+
|
| 149 |
+
# Pad image to be divisible by 32 (standard for HourGlass/UNet architectures)
|
| 150 |
+
_, _, h, w = img.shape
|
| 151 |
+
ph = ((h - 1) // 32 + 1) * 32
|
| 152 |
+
pw = ((w - 1) // 32 + 1) * 32
|
| 153 |
+
|
| 154 |
+
padding = (0, pw - w, 0, ph - h) # left, right, top, bottom
|
| 155 |
+
if ph != h or pw != w:
|
| 156 |
+
img = torch.nn.functional.pad(img, padding, mode='constant', value=0)
|
| 157 |
+
|
| 158 |
+
with torch.no_grad():
|
| 159 |
+
pred_depth, confidence, _ = metric3d_model.inference({'input': img})
|
| 160 |
+
|
| 161 |
+
# Crop back to original size
|
| 162 |
+
if ph != h or pw != w:
|
| 163 |
+
pred_depth = pred_depth[:, :, :h, :w]
|
| 164 |
+
|
| 165 |
+
m_depths.append(pred_depth)
|
| 166 |
+
|
| 167 |
+
predictions["metric3d_depth"] = torch.cat(m_depths, dim=0)
|
| 168 |
+
|
| 169 |
+
# Scale alignment: scale = median(Depths_VGGT / Depths_Metric3D)
|
| 170 |
+
# We need to make sure we use valid depths (e.g. > 0) to avoid numerical issues
|
| 171 |
+
vggt_depth = predictions["depth"] # (B, H, W, 1) or similar
|
| 172 |
+
metric_depth = predictions["metric3d_depth"] # (B, 1, H, W) presumably
|
| 173 |
+
|
| 174 |
+
# Ensure shapes match for broadcasting or direct division
|
| 175 |
+
# VGGT depth usually (B, H, W, 1)
|
| 176 |
+
# Metric3D depth usually (B, 1, H, W) or (B, H, W) depending on model output.
|
| 177 |
+
# Let's check shapes and align.
|
| 178 |
+
|
| 179 |
+
# Adjust Metric3D depth shape to match VGGT if needed
|
| 180 |
+
# Assuming VGGT is (B, H, W, 1) and Metric3D is (B, 1, H, W)
|
| 181 |
+
if metric_depth.dim() == 4 and metric_depth.shape[1] == 1:
|
| 182 |
+
metric_depth = metric_depth.permute(0, 2, 3, 1) # -> (B, H, W, 1)
|
| 183 |
+
elif metric_depth.dim() == 3:
|
| 184 |
+
metric_depth = metric_depth.unsqueeze(-1) # -> (B, H, W, 1)
|
| 185 |
+
|
| 186 |
+
# Move to same device/dtype
|
| 187 |
+
vggt_depth = vggt_depth.to(metric_depth.device).float()[0]
|
| 188 |
+
metric_depth = metric_depth.float()
|
| 189 |
+
|
| 190 |
+
# Resize metric depth to match VGGT depth if they differ in spatial resolution
|
| 191 |
+
# vggt_depth: (B, H, W, 1) or (B, H, W)
|
| 192 |
+
# metric_depth: (B, H, W, 1) after permutation
|
| 193 |
+
|
| 194 |
+
target_h, target_w = vggt_depth.shape[1], vggt_depth.shape[2]
|
| 195 |
+
|
| 196 |
+
# Mask for valid values to compute median
|
| 197 |
+
print(f"Metric3D depth shape: {metric_depth.shape}")
|
| 198 |
+
print(f"VGGT depth shape: {vggt_depth.shape}")
|
| 199 |
+
valid_mask = (metric_depth > 1e-6) & (vggt_depth > 1e-6)
|
| 200 |
+
|
| 201 |
+
if valid_mask.sum() > 0:
|
| 202 |
+
ratio = metric_depth[valid_mask] / vggt_depth[valid_mask]
|
| 203 |
+
scale_factor = torch.median(ratio)
|
| 204 |
+
print(f"Computed scale factor (VGGT / Metric3D): {scale_factor.item():.4f}")
|
| 205 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 206 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 207 |
+
extrinsic = extrinsic[0]
|
| 208 |
+
add = torch.zeros_like(extrinsic[:, 2:])
|
| 209 |
+
add[..., -1] = 1
|
| 210 |
+
extrinsic = torch.cat([extrinsic, add], dim=-2)
|
| 211 |
+
zero_extrinsic = extrinsic[0]
|
| 212 |
+
for i, e in enumerate(extrinsic):
|
| 213 |
+
extrinsic[i] = zero_extrinsic @ torch.linalg.inv(e)
|
| 214 |
+
extrinsic[i, :3, 3] *= scale_factor
|
| 215 |
+
extrinsic_inv = torch.linalg.inv(extrinsic)
|
| 216 |
+
print(f"Extrinsic: {extrinsic.shape}")
|
| 217 |
+
extrinsic_inv = extrinsic_inv[None, ..., :3, :]
|
| 218 |
+
predictions["extrinsic"] = extrinsic_inv
|
| 219 |
+
predictions["pose"] = extrinsic[None]
|
| 220 |
+
print(f"Extrinsic: {extrinsic.shape} {extrinsic}")
|
| 221 |
+
predictions["intrinsic"] = intrinsic
|
| 222 |
+
|
| 223 |
+
# Convert tensors to numpy
|
| 224 |
+
for key in predictions.keys():
|
| 225 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 226 |
+
try:
|
| 227 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension
|
| 228 |
+
except ValueError:
|
| 229 |
+
pass
|
| 230 |
+
|
| 231 |
+
# Generate world points from depth map
|
| 232 |
+
print("Computing world points from depth map...")
|
| 233 |
+
predictions["depth"] = predictions["depth"] * scale_factor.item()
|
| 234 |
+
depth_map = predictions["depth"]
|
| 235 |
+
world_points = unproject_depth_map_to_point_map(depth_map, predictions["extrinsic"], predictions["intrinsic"])
|
| 236 |
+
predictions["world_points_from_depth"] = world_points
|
| 237 |
+
|
| 238 |
+
# Clean up
|
| 239 |
+
torch.cuda.empty_cache()
|
| 240 |
+
return predictions
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
# -------------------------------------------------------------------------
|
| 244 |
+
# 2) Handle uploaded video/images --> produce target_dir + images
|
| 245 |
+
# -------------------------------------------------------------------------
|
| 246 |
+
def handle_uploads(input_video, input_images):
|
| 247 |
+
"""
|
| 248 |
+
Create a new 'target_dir' + 'images' subfolder, and place user-uploaded
|
| 249 |
+
images or extracted frames from video into it. Return (target_dir, image_paths).
|
| 250 |
+
"""
|
| 251 |
+
start_time = time.time()
|
| 252 |
+
gc.collect()
|
| 253 |
+
torch.cuda.empty_cache()
|
| 254 |
+
|
| 255 |
+
# Create a unique folder name
|
| 256 |
+
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
| 257 |
+
target_dir = f"temp/input/{timestamp}"
|
| 258 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 259 |
+
|
| 260 |
+
# Clean up if somehow that folder already exists
|
| 261 |
+
if os.path.exists(target_dir):
|
| 262 |
+
shutil.rmtree(target_dir)
|
| 263 |
+
os.makedirs(target_dir)
|
| 264 |
+
os.makedirs(target_dir_images)
|
| 265 |
+
|
| 266 |
+
image_paths = []
|
| 267 |
+
|
| 268 |
+
# --- Handle images ---
|
| 269 |
+
if input_images is not None:
|
| 270 |
+
for file_data in input_images:
|
| 271 |
+
if isinstance(file_data, dict) and "name" in file_data:
|
| 272 |
+
file_path = file_data["name"]
|
| 273 |
+
else:
|
| 274 |
+
file_path = file_data
|
| 275 |
+
dst_path = os.path.join(target_dir_images, os.path.basename(file_path))
|
| 276 |
+
shutil.copy(file_path, dst_path)
|
| 277 |
+
image_paths.append(dst_path)
|
| 278 |
+
|
| 279 |
+
# --- Handle video ---
|
| 280 |
+
if input_video is not None:
|
| 281 |
+
if isinstance(input_video, dict) and "name" in input_video:
|
| 282 |
+
video_path = input_video["name"]
|
| 283 |
+
else:
|
| 284 |
+
video_path = input_video
|
| 285 |
+
|
| 286 |
+
vs = cv2.VideoCapture(video_path)
|
| 287 |
+
fps = vs.get(cv2.CAP_PROP_FPS)
|
| 288 |
+
frame_interval = int(fps * 1) # 1 frame/sec
|
| 289 |
+
|
| 290 |
+
count = 0
|
| 291 |
+
video_frame_num = 0
|
| 292 |
+
while True:
|
| 293 |
+
gotit, frame = vs.read()
|
| 294 |
+
if not gotit:
|
| 295 |
+
break
|
| 296 |
+
count += 1
|
| 297 |
+
if count % frame_interval == 0:
|
| 298 |
+
image_path = os.path.join(target_dir_images, f"{video_frame_num:06}.jpg")
|
| 299 |
+
cv2.imwrite(image_path, frame)
|
| 300 |
+
image_paths.append(image_path)
|
| 301 |
+
video_frame_num += 1
|
| 302 |
+
|
| 303 |
+
# Sort final images for gallery
|
| 304 |
+
image_paths = sorted(image_paths)
|
| 305 |
+
|
| 306 |
+
end_time = time.time()
|
| 307 |
+
print(f"Files copied to {target_dir_images}; took {end_time - start_time:.3f} seconds")
|
| 308 |
+
return target_dir, image_paths
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
# -------------------------------------------------------------------------
|
| 312 |
+
# 3) Update gallery on upload
|
| 313 |
+
# -------------------------------------------------------------------------
|
| 314 |
+
def update_gallery_on_upload(input_video, input_images):
|
| 315 |
+
"""
|
| 316 |
+
Whenever user uploads or changes files, immediately handle them
|
| 317 |
+
and show in the gallery. Return (target_dir, image_paths).
|
| 318 |
+
If nothing is uploaded, returns "None" and empty list.
|
| 319 |
+
"""
|
| 320 |
+
if not input_video and not input_images:
|
| 321 |
+
return None, None, None, None
|
| 322 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 323 |
+
return None, target_dir, image_paths, "Upload complete. Click 'Detect Objects' to begin 3D processing."
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
# -------------------------------------------------------------------------
|
| 327 |
+
# 4) Reconstruction: uses the target_dir plus any viz parameters
|
| 328 |
+
# -------------------------------------------------------------------------
|
| 329 |
+
def reconstruct(
|
| 330 |
+
target_dir,
|
| 331 |
+
conf_thres=50.0,
|
| 332 |
+
frame_filter="All",
|
| 333 |
+
mask_black_bg=False,
|
| 334 |
+
mask_white_bg=False,
|
| 335 |
+
show_cam=True,
|
| 336 |
+
mask_sky=False,
|
| 337 |
+
prediction_mode="Depthmap and Camera Branch",
|
| 338 |
+
text_labels="",
|
| 339 |
+
):
|
| 340 |
+
"""
|
| 341 |
+
Perform reconstruction using the already-created target_dir/images.
|
| 342 |
+
"""
|
| 343 |
+
prediction_mode = "Depthmap and Camera Branch" # Force prediction mode
|
| 344 |
+
if not os.path.isdir(target_dir) or target_dir == "None":
|
| 345 |
+
return None, "No valid target directory found. Please upload first.", None, None
|
| 346 |
+
|
| 347 |
+
start_time = time.time()
|
| 348 |
+
gc.collect()
|
| 349 |
+
torch.cuda.empty_cache()
|
| 350 |
+
|
| 351 |
+
# Prepare frame_filter dropdown
|
| 352 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 353 |
+
all_files = sorted(os.listdir(target_dir_images)) if os.path.isdir(target_dir_images) else []
|
| 354 |
+
image_names = [f.split(".")[0] for f in all_files]
|
| 355 |
+
all_files = [f"{i}: {filename}" for i, filename in enumerate(all_files)]
|
| 356 |
+
frame_filter_choices = ["All"] + all_files
|
| 357 |
+
|
| 358 |
+
print("Running run_model...")
|
| 359 |
+
with torch.no_grad():
|
| 360 |
+
predictions = run_model(target_dir, model, metric3d_model=metric3d_model)
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
# Save predictions
|
| 364 |
+
prediction_save_path = os.path.join(target_dir, "predictions.npz")
|
| 365 |
+
try:
|
| 366 |
+
np.savez(prediction_save_path, **predictions)
|
| 367 |
+
except Exception as e:
|
| 368 |
+
print(f"Warning: could not save predictions to npz: {e}")
|
| 369 |
+
|
| 370 |
+
depth_path = os.path.join(target_dir, "depth")
|
| 371 |
+
pose_path = os.path.join(target_dir, "pose")
|
| 372 |
+
intrinsic_path = os.path.join(target_dir, "intrinsic")
|
| 373 |
+
os.makedirs(depth_path, exist_ok=True)
|
| 374 |
+
os.makedirs(pose_path, exist_ok=True)
|
| 375 |
+
os.makedirs(intrinsic_path, exist_ok=True)
|
| 376 |
+
for i, d in enumerate(predictions["depth"]):
|
| 377 |
+
print(d.shape)
|
| 378 |
+
cv2.imwrite(os.path.join(depth_path, f"{image_names[i]}.png"), (d[..., 0] * 1000).astype(np.uint16))
|
| 379 |
+
intr = np.eye(4)
|
| 380 |
+
intr[:3, :3] = np.mean(predictions["intrinsic"], axis=0)
|
| 381 |
+
np.savetxt(os.path.join(intrinsic_path, "intrinsic_depth.txt"), intr)
|
| 382 |
+
|
| 383 |
+
for i, p in enumerate(predictions["pose"]):
|
| 384 |
+
np.savetxt(os.path.join(pose_path, f"{image_names[i]}.txt"), p)
|
| 385 |
+
|
| 386 |
+
# Handle None frame_filter
|
| 387 |
+
if frame_filter is None:
|
| 388 |
+
frame_filter = "All"
|
| 389 |
+
|
| 390 |
+
# Build a GLB file name
|
| 391 |
+
glbfile = os.path.join(
|
| 392 |
+
target_dir,
|
| 393 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 394 |
+
)
|
| 395 |
+
|
| 396 |
+
# Convert predictions to GLB
|
| 397 |
+
glbscene, point_cloud_data = predictions_to_glb(
|
| 398 |
+
predictions,
|
| 399 |
+
conf_thres=conf_thres,
|
| 400 |
+
filter_by_frames=frame_filter,
|
| 401 |
+
mask_black_bg=mask_black_bg,
|
| 402 |
+
mask_white_bg=mask_white_bg,
|
| 403 |
+
show_cam=show_cam,
|
| 404 |
+
mask_sky=mask_sky,
|
| 405 |
+
target_dir=target_dir,
|
| 406 |
+
prediction_mode=prediction_mode,
|
| 407 |
+
)
|
| 408 |
+
|
| 409 |
+
# Ensure colors are RGB (remove alpha if present) for Open3D
|
| 410 |
+
v = np.asarray(point_cloud_data.vertices)
|
| 411 |
+
c = np.asarray(point_cloud_data.colors) / 255.0
|
| 412 |
+
if c.shape[1] == 4:
|
| 413 |
+
c = c[:, :3]
|
| 414 |
+
|
| 415 |
+
glbscene.export(file_obj=glbfile)
|
| 416 |
+
pcd = o3d.geometry.PointCloud()
|
| 417 |
+
pcd.points = o3d.utility.Vector3dVector(v)
|
| 418 |
+
pcd.colors = o3d.utility.Vector3dVector(c)
|
| 419 |
+
|
| 420 |
+
pcd = pcd.voxel_down_sample(voxel_size=0.01)
|
| 421 |
+
o3d.io.write_point_cloud(os.path.join(target_dir, "point_cloud.ply"), pcd)
|
| 422 |
+
|
| 423 |
+
|
| 424 |
+
# Cleanup
|
| 425 |
+
del predictions
|
| 426 |
+
gc.collect()
|
| 427 |
+
torch.cuda.empty_cache()
|
| 428 |
+
|
| 429 |
+
end_time = time.time()
|
| 430 |
+
print(f"Total time: {end_time - start_time:.2f} seconds (including IO)")
|
| 431 |
+
log_msg = f"Reconstruction Success ({len(all_files)} frames). Waiting for visualization."
|
| 432 |
+
# Run CropFormer mask prediction via Python API (no system call)
|
| 433 |
+
try:
|
| 434 |
+
from exts.cropformer_runner import run_cropformer_mask_predict
|
| 435 |
+
except ImportError:
|
| 436 |
+
from .exts.cropformer_runner import run_cropformer_mask_predict # if used as a module
|
| 437 |
+
run_cropformer_mask_predict(
|
| 438 |
+
config_file=os.path.join(MK_PATH, "third_party/detectron2/projects/CropFormer/configs/entityv2/entity_segmentation/mask2former_hornet_3x.yaml"),
|
| 439 |
+
root="/home/jovyan/users/bulat/workspace/3drec/vggt/temp/input/",
|
| 440 |
+
image_path_pattern="images/*.jpg",
|
| 441 |
+
dataset="arkit_gt",
|
| 442 |
+
seq_name_list=os.path.basename(target_dir),
|
| 443 |
+
confidence_threshold=0.5,
|
| 444 |
+
opts=[
|
| 445 |
+
"MODEL.WEIGHTS",
|
| 446 |
+
os.path.join(MK_PATH, "Mask2Former_hornet_3x_576d0b.pth"),
|
| 447 |
+
],
|
| 448 |
+
)
|
| 449 |
+
os.system(f"python /home/jovyan/users/bulat/workspace/3drec/Indoor/MaskClustering/main.py --config wild --root /home/jovyan/users/bulat/workspace/3drec/vggt/temp/input --seq_name_list {os.path.basename(target_dir)}")
|
| 450 |
+
main_ov_features(clip_model, clip_preprocess, os.path.basename(target_dir), "/home/jovyan/users/bulat/workspace/3drec/vggt/temp/input")
|
| 451 |
+
|
| 452 |
+
return glbfile, log_msg, gr.Dropdown(choices=frame_filter_choices, value=frame_filter, interactive=True)
|
| 453 |
+
|
| 454 |
+
def visualize_detections(target_dir, conf_thres, frame_filter="All", mask_black_bg=False, mask_white_bg=False, show_cam=True, mask_sky=False, prediction_mode="Depthmap and Camera Branch"):
|
| 455 |
+
"""
|
| 456 |
+
Generate a GLB scene with bounding boxes for detected objects.
|
| 457 |
+
"""
|
| 458 |
+
if not target_dir or not os.path.exists(target_dir):
|
| 459 |
+
return None, "Target directory not found."
|
| 460 |
+
|
| 461 |
+
ply_path = os.path.join(target_dir, "point_cloud.ply")
|
| 462 |
+
npz_path = os.path.join(target_dir, "output", "object", "prediction.npz")
|
| 463 |
+
|
| 464 |
+
# 1. Загрузить point cloud как основу сцены
|
| 465 |
+
if not os.path.exists(ply_path):
|
| 466 |
+
return None, f"Point cloud not found at {ply_path}. Please run detection first."
|
| 467 |
+
|
| 468 |
+
pcd = o3d.io.read_point_cloud(ply_path)
|
| 469 |
+
points = np.asarray(pcd.points)
|
| 470 |
+
colors = np.asarray(pcd.colors)
|
| 471 |
+
|
| 472 |
+
if points.size == 0:
|
| 473 |
+
return None, "Point cloud is empty."
|
| 474 |
+
|
| 475 |
+
# Создаем базовую сцену из облака точек
|
| 476 |
+
scene = trimesh.Scene()
|
| 477 |
+
|
| 478 |
+
if colors.size == 0:
|
| 479 |
+
t_colors = np.ones((len(points), 4), dtype=np.uint8) * 255
|
| 480 |
+
else:
|
| 481 |
+
if colors.max() <= 1.0:
|
| 482 |
+
t_colors = (colors * 255).astype(np.uint8)
|
| 483 |
+
else:
|
| 484 |
+
t_colors = colors.astype(np.uint8)
|
| 485 |
+
if t_colors.shape[1] == 3:
|
| 486 |
+
t_colors = np.hstack([t_colors, np.ones((len(t_colors), 1), dtype=np.uint8) * 255])
|
| 487 |
+
|
| 488 |
+
base_pc = trimesh.PointCloud(vertices=points, colors=t_colors)
|
| 489 |
+
scene.add_geometry(base_pc)
|
| 490 |
+
|
| 491 |
+
# 2. Добавить боксы по результатам детекции, если они есть
|
| 492 |
+
legend_md = ""
|
| 493 |
+
if os.path.exists(npz_path):
|
| 494 |
+
try:
|
| 495 |
+
loaded = np.load(npz_path, allow_pickle=True)
|
| 496 |
+
# Check for detection keys
|
| 497 |
+
if 'pred_masks' in loaded:
|
| 498 |
+
masks = loaded['pred_masks'].T
|
| 499 |
+
labels = loaded['pred_classes']
|
| 500 |
+
confs = loaded['pred_score']
|
| 501 |
+
|
| 502 |
+
# Load text features to map labels to names
|
| 503 |
+
text_features_path = os.path.join(target_dir, "text_features.npy")
|
| 504 |
+
label_to_name = {}
|
| 505 |
+
if os.path.exists(text_features_path):
|
| 506 |
+
try:
|
| 507 |
+
text_features_dict = np.load(text_features_path, allow_pickle=True).item()
|
| 508 |
+
feature_keys = list(text_features_dict.keys())
|
| 509 |
+
for i, name in enumerate(feature_keys):
|
| 510 |
+
label_to_name[i] = name
|
| 511 |
+
except Exception as e:
|
| 512 |
+
print(f"Warning: Could not load text features for label mapping: {e}")
|
| 513 |
+
|
| 514 |
+
# Filter
|
| 515 |
+
if isinstance(confs, (list, tuple)):
|
| 516 |
+
confs = np.array(confs)
|
| 517 |
+
|
| 518 |
+
valid_indices = np.where(confs > conf_thres)[0]
|
| 519 |
+
|
| 520 |
+
if len(valid_indices) > 0:
|
| 521 |
+
legend_items = {}
|
| 522 |
+
cmap = plt.get_cmap("tab10")
|
| 523 |
+
|
| 524 |
+
detected_labels = np.unique(labels[valid_indices])
|
| 525 |
+
label_to_color = {label: cmap(i % 10) for i, label in enumerate(detected_labels)}
|
| 526 |
+
|
| 527 |
+
for idx in valid_indices:
|
| 528 |
+
mask = masks[idx]
|
| 529 |
+
if hasattr(mask, "toarray"):
|
| 530 |
+
mask = mask.toarray().flatten()
|
| 531 |
+
mask = mask.astype(bool)
|
| 532 |
+
|
| 533 |
+
# Verify mask size
|
| 534 |
+
if len(mask) != len(points):
|
| 535 |
+
# This is critical. If GLB points are filtered, masks might not match.
|
| 536 |
+
# If masks were generated on the FULL point cloud, we need the FULL point cloud to compute BBox.
|
| 537 |
+
# If we can't guarantee alignment, we skip or print warning.
|
| 538 |
+
# Ideally, detection pipeline should handle this alignment.
|
| 539 |
+
pass
|
| 540 |
+
# For now, let's assume they align or we skip.
|
| 541 |
+
# If alignment fails, we just don't add the box.
|
| 542 |
+
|
| 543 |
+
if len(mask) == len(points):
|
| 544 |
+
obj_points = points[mask]
|
| 545 |
+
if len(obj_points) >= 4:
|
| 546 |
+
obj_pcd = trimesh.PointCloud(obj_points)
|
| 547 |
+
try:
|
| 548 |
+
bbox = obj_pcd.bounding_box_oriented
|
| 549 |
+
except Exception:
|
| 550 |
+
bbox = obj_pcd.bounding_box
|
| 551 |
+
|
| 552 |
+
# Строим только «каркас» бокса по 8 вершинам и трансформу:
|
| 553 |
+
# соединяем пары вершин, чьи локальные знаки отличаются ровно по одной оси
|
| 554 |
+
verts = np.asarray(bbox.vertices)
|
| 555 |
+
if verts.shape[0] != 8:
|
| 556 |
+
continue
|
| 557 |
+
T = np.asarray(bbox.transform)
|
| 558 |
+
center = T[:3, 3]
|
| 559 |
+
R = T[:3, :3]
|
| 560 |
+
# Локальные координаты (в осях бокса)
|
| 561 |
+
local = (verts - center) @ R
|
| 562 |
+
# Присваиваем каждой вершине тройку знаков (+/-1)
|
| 563 |
+
signs = np.where(local >= 0.0, 1, -1).astype(int)
|
| 564 |
+
sign_to_idx = {tuple(s): i for i, s in enumerate(signs)}
|
| 565 |
+
# Сгенерировать 12 рёбер: пары вершин, различающиеся знаком ровно по одной оси
|
| 566 |
+
edges_idx = set()
|
| 567 |
+
for sx in (-1, 1):
|
| 568 |
+
for sy in (-1, 1):
|
| 569 |
+
for sz in (-1, 1):
|
| 570 |
+
s = (sx, sy, sz)
|
| 571 |
+
if s not in sign_to_idx:
|
| 572 |
+
continue
|
| 573 |
+
for axis in range(3):
|
| 574 |
+
s2 = list(s)
|
| 575 |
+
s2[axis] *= -1
|
| 576 |
+
s2 = tuple(s2)
|
| 577 |
+
if s2 in sign_to_idx:
|
| 578 |
+
i0 = sign_to_idx[s]
|
| 579 |
+
i1 = sign_to_idx[s2]
|
| 580 |
+
if i0 != i1:
|
| 581 |
+
edges_idx.add(tuple(sorted((i0, i1))))
|
| 582 |
+
if not edges_idx:
|
| 583 |
+
continue
|
| 584 |
+
segments = np.array([[verts[i], verts[j]] for (i, j) in edges_idx], dtype=float)
|
| 585 |
+
|
| 586 |
+
lbl_idx = labels[idx]
|
| 587 |
+
lbl_name = label_to_name.get(lbl_idx, f"Class {lbl_idx}")
|
| 588 |
+
color = label_to_color.get(lbl_idx, (1, 0, 0, 1))
|
| 589 |
+
|
| 590 |
+
color_u8 = (np.array(color) * 255).astype(np.uint8)
|
| 591 |
+
# Постоянная толщина рамки: 3 см (0.03)
|
| 592 |
+
radius = 0.015
|
| 593 |
+
for seg in segments:
|
| 594 |
+
p1, p2 = seg[0], seg[1]
|
| 595 |
+
v = p2 - p1
|
| 596 |
+
length = float(np.linalg.norm(v))
|
| 597 |
+
if length <= 1e-8:
|
| 598 |
+
continue
|
| 599 |
+
direction = v / length
|
| 600 |
+
try:
|
| 601 |
+
cyl = trimesh.creation.cylinder(radius=radius, height=length, sections=12)
|
| 602 |
+
except Exception:
|
| 603 |
+
continue
|
| 604 |
+
# Повернуть ось Z к направлению ребра и перенести в середину
|
| 605 |
+
try:
|
| 606 |
+
align = trimesh.geometry.align_vectors([0, 0, 1], direction)
|
| 607 |
+
cyl.apply_transform(align)
|
| 608 |
+
except Exception:
|
| 609 |
+
pass
|
| 610 |
+
midpoint = (p1 + p2) / 2.0
|
| 611 |
+
cyl.apply_translation(midpoint)
|
| 612 |
+
# Материал без влияния освещения (эмуляция unlit через emissive)
|
| 613 |
+
try:
|
| 614 |
+
emissive = (color_u8[:3] / 255.0).tolist()
|
| 615 |
+
mat = trimesh.visual.material.PBRMaterial(
|
| 616 |
+
baseColorFactor=(0.0, 0.0, 0.0, 1.0),
|
| 617 |
+
metallicFactor=0.0,
|
| 618 |
+
roughnessFactor=1.0,
|
| 619 |
+
emissiveFactor=emissive,
|
| 620 |
+
doubleSided=True,
|
| 621 |
+
)
|
| 622 |
+
cyl.visual.material = mat
|
| 623 |
+
except Exception:
|
| 624 |
+
cyl.visual.face_colors = np.tile(color_u8[None, :], (len(cyl.faces), 1))
|
| 625 |
+
scene.add_geometry(cyl)
|
| 626 |
+
legend_items[lbl_name] = color
|
| 627 |
+
|
| 628 |
+
legend_md = "### Legend\n"
|
| 629 |
+
for lbl_name, color in legend_items.items():
|
| 630 |
+
c_u8 = (np.array(color) * 255).astype(np.uint8)
|
| 631 |
+
hex_c = "#{:02x}{:02x}{:02x}".format(c_u8[0], c_u8[1], c_u8[2])
|
| 632 |
+
legend_md += f"- <span style='color:{hex_c}'>■</span> {lbl_name}\n"
|
| 633 |
+
|
| 634 |
+
except Exception as e:
|
| 635 |
+
print(f"Error loading detections: {e}")
|
| 636 |
+
legend_md = f"Error loading detections: {e}"
|
| 637 |
+
|
| 638 |
+
# Export combined scene (облако + боксы)
|
| 639 |
+
out_path = os.path.join(target_dir, f"combined_viz_{conf_thres}.glb")
|
| 640 |
+
scene.export(file_obj=out_path)
|
| 641 |
+
|
| 642 |
+
return out_path, legend_md
|
| 643 |
+
|
| 644 |
+
def detect_objects(text_labels, target_dir, conf_thres, *viz_args):
|
| 645 |
+
"""
|
| 646 |
+
Detect objects from text labels and return the detected objects.
|
| 647 |
+
"""
|
| 648 |
+
# Require non-empty text labels
|
| 649 |
+
if not text_labels or not isinstance(text_labels, str) or len([l.strip() for l in text_labels.split(";") if l.strip()]) == 0:
|
| 650 |
+
return None, "Please enter at least one text label (separated by ';')."
|
| 651 |
+
|
| 652 |
+
# 1. Run reconstruction first if needed (checking if predictions exist)
|
| 653 |
+
predictions_path = os.path.join(target_dir, "predictions.npz")
|
| 654 |
+
if not os.path.exists(predictions_path):
|
| 655 |
+
# We need to run reconstruction. But reconstruction needs inputs we might not have in this function scope easily
|
| 656 |
+
# unless we pass them or assume they are in target_dir.
|
| 657 |
+
# reconstruct function takes target_dir. Let's call it.
|
| 658 |
+
# However, reconstruct is heavy and takes many args.
|
| 659 |
+
# Let's assume for now user clicked Reconstruct or we call it with defaults/passed args if we merged them.
|
| 660 |
+
|
| 661 |
+
# Actually, if we want one button to do both, we should probably call `reconstruct` logic here.
|
| 662 |
+
# But `reconstruct` returns GLB path.
|
| 663 |
+
# Let's call run_model directly if predictions don't exist?
|
| 664 |
+
# Better: Reuse reconstruct function logic or call it.
|
| 665 |
+
|
| 666 |
+
# Simplify: If predictions don't exist, run standard reconstruction first
|
| 667 |
+
print("Predictions not found, running reconstruction first...")
|
| 668 |
+
# We need arguments for reconstruction.
|
| 669 |
+
# viz_args contains [frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode]
|
| 670 |
+
# conf_thres is passed separately.
|
| 671 |
+
|
| 672 |
+
# reconstruct signature: target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode, text_labels
|
| 673 |
+
# viz_args order from click: frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode
|
| 674 |
+
|
| 675 |
+
reconstruct(target_dir, 50.0, *viz_args, text_labels=text_labels) # conf_thres 3.0 default for reconstruction points
|
| 676 |
+
|
| 677 |
+
|
| 678 |
+
# Extract text features if provided
|
| 679 |
+
if text_labels:
|
| 680 |
+
labels = [l.strip() for l in text_labels.split(";") if l.strip()]
|
| 681 |
+
if labels:
|
| 682 |
+
print(f"Extracting features for labels: {labels}")
|
| 683 |
+
text_features = extract_text_feature(labels, clip_model, target_dir)
|
| 684 |
+
print(f"Text features: {text_features}")
|
| 685 |
+
os.system(f"PYTHONPATH=/home/jovyan/users/bulat/workspace/3drec/Indoor/MaskClustering python /home/jovyan/users/bulat/workspace/3drec/Indoor/MaskClustering/semantics/wopen-voc_query.py --config wild\
|
| 686 |
+
--root /home/jovyan/users/bulat/workspace/3drec/vggt/temp/input --seq_name {os.path.basename(target_dir)}")
|
| 687 |
+
|
| 688 |
+
return visualize_detections(target_dir, conf_thres, *viz_args)
|
| 689 |
+
|
| 690 |
+
|
| 691 |
+
# -------------------------------------------------------------------------
|
| 692 |
+
# 5) Helper functions for UI resets + re-visualization
|
| 693 |
+
# -------------------------------------------------------------------------
|
| 694 |
+
def clear_fields():
|
| 695 |
+
"""
|
| 696 |
+
Clears the 3D viewer, the stored target_dir, and empties the gallery.
|
| 697 |
+
"""
|
| 698 |
+
return None
|
| 699 |
+
|
| 700 |
+
|
| 701 |
+
def update_log():
|
| 702 |
+
"""
|
| 703 |
+
Display a quick log message while waiting.
|
| 704 |
+
"""
|
| 705 |
+
return "Loading and Reconstructing..."
|
| 706 |
+
|
| 707 |
+
|
| 708 |
+
def update_visualization(
|
| 709 |
+
target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode, is_example
|
| 710 |
+
):
|
| 711 |
+
"""
|
| 712 |
+
Reload saved predictions from npz, create (or reuse) the GLB for new parameters,
|
| 713 |
+
and return it for the 3D viewer. If is_example == "True", skip.
|
| 714 |
+
"""
|
| 715 |
+
|
| 716 |
+
# If it's an example click, skip as requested
|
| 717 |
+
if is_example == "True":
|
| 718 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 719 |
+
|
| 720 |
+
if not target_dir or target_dir == "None" or not os.path.isdir(target_dir):
|
| 721 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 722 |
+
|
| 723 |
+
predictions_path = os.path.join(target_dir, "predictions.npz")
|
| 724 |
+
if not os.path.exists(predictions_path):
|
| 725 |
+
return None, f"No reconstruction available at {predictions_path}. Please run 'Reconstruct' first."
|
| 726 |
+
|
| 727 |
+
key_list = [
|
| 728 |
+
"pose_enc",
|
| 729 |
+
"depth",
|
| 730 |
+
"depth_conf",
|
| 731 |
+
"world_points",
|
| 732 |
+
"world_points_conf",
|
| 733 |
+
"images",
|
| 734 |
+
"extrinsic",
|
| 735 |
+
"intrinsic",
|
| 736 |
+
"world_points_from_depth",
|
| 737 |
+
]
|
| 738 |
+
|
| 739 |
+
loaded = np.load(predictions_path, allow_pickle=True)
|
| 740 |
+
predictions = {key: np.array(loaded[key]) for key in key_list}
|
| 741 |
+
|
| 742 |
+
glbfile = os.path.join(
|
| 743 |
+
target_dir,
|
| 744 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 745 |
+
)
|
| 746 |
+
|
| 747 |
+
if not os.path.exists(glbfile):
|
| 748 |
+
glbscene = predictions_to_glb(
|
| 749 |
+
predictions,
|
| 750 |
+
conf_thres=conf_thres,
|
| 751 |
+
filter_by_frames=frame_filter,
|
| 752 |
+
mask_black_bg=mask_black_bg,
|
| 753 |
+
mask_white_bg=mask_white_bg,
|
| 754 |
+
show_cam=show_cam,
|
| 755 |
+
mask_sky=mask_sky,
|
| 756 |
+
target_dir=target_dir,
|
| 757 |
+
prediction_mode=prediction_mode,
|
| 758 |
+
)
|
| 759 |
+
glbscene.export(file_obj=glbfile)
|
| 760 |
+
|
| 761 |
+
return glbfile, "Updating Visualization"
|
| 762 |
+
|
| 763 |
+
|
| 764 |
+
# -------------------------------------------------------------------------
|
| 765 |
+
# Example images
|
| 766 |
+
# -------------------------------------------------------------------------
|
| 767 |
+
|
| 768 |
+
great_wall_video = "examples/videos/great_wall.mp4"
|
| 769 |
+
colosseum_video = "examples/videos/Colosseum.mp4"
|
| 770 |
+
room_video = "examples/videos/room.mp4"
|
| 771 |
+
kitchen_video = "examples/videos/kitchen.mp4"
|
| 772 |
+
fern_video = "examples/videos/fern.mp4"
|
| 773 |
+
single_cartoon_video = "examples/videos/single_cartoon.mp4"
|
| 774 |
+
single_oil_painting_video = "examples/videos/single_oil_painting.mp4"
|
| 775 |
+
pyramid_video = "examples/videos/pyramid.mp4"
|
| 776 |
+
|
| 777 |
+
|
| 778 |
+
# -------------------------------------------------------------------------
|
| 779 |
+
# 6) Build Gradio UI
|
| 780 |
+
# -------------------------------------------------------------------------
|
| 781 |
+
theme = gr.themes.Ocean()
|
| 782 |
+
theme.set(
|
| 783 |
+
checkbox_label_background_fill_selected="*button_primary_background_fill",
|
| 784 |
+
checkbox_label_text_color_selected="*button_primary_text_color",
|
| 785 |
+
)
|
| 786 |
+
|
| 787 |
+
with gr.Blocks(
|
| 788 |
+
theme=theme,
|
| 789 |
+
css="""
|
| 790 |
+
.custom-log * {
|
| 791 |
+
font-style: italic;
|
| 792 |
+
font-size: 22px !important;
|
| 793 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 794 |
+
-webkit-background-clip: text;
|
| 795 |
+
background-clip: text;
|
| 796 |
+
font-weight: bold !important;
|
| 797 |
+
color: transparent !important;
|
| 798 |
+
text-align: center !important;
|
| 799 |
+
}
|
| 800 |
+
|
| 801 |
+
.example-log * {
|
| 802 |
+
font-style: italic;
|
| 803 |
+
font-size: 16px !important;
|
| 804 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 805 |
+
-webkit-background-clip: text;
|
| 806 |
+
background-clip: text;
|
| 807 |
+
color: transparent !important;
|
| 808 |
+
}
|
| 809 |
+
|
| 810 |
+
#my_radio .wrap {
|
| 811 |
+
display: flex;
|
| 812 |
+
flex-wrap: nowrap;
|
| 813 |
+
justify-content: center;
|
| 814 |
+
align-items: center;
|
| 815 |
+
}
|
| 816 |
+
|
| 817 |
+
#my_radio .wrap label {
|
| 818 |
+
display: flex;
|
| 819 |
+
width: 50%;
|
| 820 |
+
justify-content: center;
|
| 821 |
+
align-items: center;
|
| 822 |
+
margin: 0;
|
| 823 |
+
padding: 10px 0;
|
| 824 |
+
box-sizing: border-box;
|
| 825 |
+
}
|
| 826 |
+
""",
|
| 827 |
+
) as demo:
|
| 828 |
+
# Instead of gr.State, we use a hidden Textbox:
|
| 829 |
+
is_example = gr.Textbox(label="is_example", visible=False, value="None")
|
| 830 |
+
num_images = gr.Textbox(label="num_images", visible=False, value="None")
|
| 831 |
+
|
| 832 |
+
gr.HTML(
|
| 833 |
+
"""
|
| 834 |
+
<h1>🦁 Zoo3D: Zero-Shot 3D Object Detection at Scene Level 🐼</h1>
|
| 835 |
+
<p>
|
| 836 |
+
<a href="https://github.com/col14m/zoo3d">GitHub Repository</a>
|
| 837 |
+
</p>
|
| 838 |
+
|
| 839 |
+
<div style="font-size: 16px; line-height: 1.5;">
|
| 840 |
+
<p>Upload a video or a set of images to create a 3D reconstruction and run open‑vocabulary 3D object detection from your text labels. The app builds a point cloud and draws colored wireframe bounding boxes for the detected objects.</p>
|
| 841 |
+
|
| 842 |
+
<h3>Getting Started:</h3>
|
| 843 |
+
<ol>
|
| 844 |
+
<li><strong>Upload Your Data:</strong> Use "Upload Video" or "Upload Images". Videos are sampled at 1 frame/sec.</li>
|
| 845 |
+
<li><strong>Enter Text Labels (Required):</strong> Provide one or more labels separated by semicolons, e.g. <code>chair; table; plant</code>.</li>
|
| 846 |
+
<li><strong>Detect:</strong> Click <strong>"Detect Objects"</strong>. The app will reconstruct the scene (if needed) and then run detection.</li>
|
| 847 |
+
<li><strong>Threshold (Optional):</strong> Tune the <em>Detection Cosine Similarity Threshold</em> (0–1). Higher = fewer, more confident detections.</li>
|
| 848 |
+
<li><strong>Visualize & Download:</strong> A single 3D view shows the point cloud and colored wireframe boxes. A legend maps colors to labels. You can download the GLB.</li>
|
| 849 |
+
</ol>
|
| 850 |
+
<p><strong style="color: #0ea5e9;">Notes:</strong> <span style="color: #0ea5e9; font-weight: bold;">Reconstruction is triggered automatically on first run. If no labels are provided, you'll see an error: </span><code>Please enter at least one text label (separated by ';').</code></p>
|
| 851 |
+
</div>
|
| 852 |
+
"""
|
| 853 |
+
)
|
| 854 |
+
|
| 855 |
+
target_dir_output = gr.Textbox(label="Target Dir", visible=False, value="None")
|
| 856 |
+
|
| 857 |
+
with gr.Row():
|
| 858 |
+
with gr.Column(scale=2):
|
| 859 |
+
input_video = gr.Video(label="Upload Video", interactive=True)
|
| 860 |
+
input_images = gr.File(file_count="multiple", label="Upload Images", interactive=True)
|
| 861 |
+
|
| 862 |
+
image_gallery = gr.Gallery(
|
| 863 |
+
label="Preview",
|
| 864 |
+
columns=4,
|
| 865 |
+
height="300px",
|
| 866 |
+
show_download_button=True,
|
| 867 |
+
object_fit="contain",
|
| 868 |
+
preview=True,
|
| 869 |
+
)
|
| 870 |
+
|
| 871 |
+
with gr.Column(scale=4):
|
| 872 |
+
text_labels = gr.Textbox(label="Text Labels (separated by ;)", placeholder="cat; dog; car")
|
| 873 |
+
with gr.Column():
|
| 874 |
+
|
| 875 |
+
|
| 876 |
+
gr.Markdown("**3D Reconstruction (Point Cloud and Camera Poses)**")
|
| 877 |
+
log_output = gr.Markdown(
|
| 878 |
+
"Please upload a video or images, then click Detect Objects.", elem_classes=["custom-log"]
|
| 879 |
+
)
|
| 880 |
+
reconstruction_output = gr.Model3D(height=520, zoom_speed=0.5, pan_speed=0.5)
|
| 881 |
+
|
| 882 |
+
with gr.Row():
|
| 883 |
+
detect_btn = gr.Button("Detect Objects", scale=1, variant="primary")
|
| 884 |
+
clear_btn = gr.ClearButton(
|
| 885 |
+
[input_video, input_images, reconstruction_output, log_output, target_dir_output, image_gallery, text_labels],
|
| 886 |
+
scale=1,
|
| 887 |
+
)
|
| 888 |
+
# with gr.Row():
|
| 889 |
+
# prediction_mode = gr.Textbox(
|
| 890 |
+
# value="Depthmap and Camera Branch",
|
| 891 |
+
# visible=False,
|
| 892 |
+
# label="Prediction Mode"
|
| 893 |
+
# )
|
| 894 |
+
|
| 895 |
+
# We'll create a hidden component so the event handlers don't break
|
| 896 |
+
prediction_mode = gr.Textbox(value="Depthmap and Camera Branch", visible=False)
|
| 897 |
+
|
| 898 |
+
# Основные параметры визуализации реконструкции
|
| 899 |
+
with gr.Row():
|
| 900 |
+
conf_thres = gr.Slider(
|
| 901 |
+
minimum=0,
|
| 902 |
+
maximum=100,
|
| 903 |
+
value=50,
|
| 904 |
+
step=0.1,
|
| 905 |
+
label="Confidence Threshold (%)",
|
| 906 |
+
visible=False,
|
| 907 |
+
)
|
| 908 |
+
frame_filter = gr.Dropdown(
|
| 909 |
+
choices=["All"],
|
| 910 |
+
value="All",
|
| 911 |
+
label="Show Points from Frame",
|
| 912 |
+
visible=False,
|
| 913 |
+
)
|
| 914 |
+
with gr.Column():
|
| 915 |
+
show_cam = gr.Checkbox(label="Show Camera", value=True, visible=False)
|
| 916 |
+
mask_sky = gr.Checkbox(label="Filter Sky", value=False, visible=False)
|
| 917 |
+
mask_black_bg = gr.Checkbox(label="Filter Black Background", value=False, visible=False)
|
| 918 |
+
mask_white_bg = gr.Checkbox(label="Filter White Background", value=False, visible=False)
|
| 919 |
+
|
| 920 |
+
# Порог для детекции и легенда цветов боксов
|
| 921 |
+
detection_conf_thres = gr.Slider(
|
| 922 |
+
minimum=0,
|
| 923 |
+
maximum=1,
|
| 924 |
+
value=0.6,
|
| 925 |
+
step=0.01,
|
| 926 |
+
label="Detection Cosine Similarity Threshold",
|
| 927 |
+
)
|
| 928 |
+
detection_legend = gr.Markdown("Legend will appear here")
|
| 929 |
+
|
| 930 |
+
# ---------------------- Examples section ----------------------
|
| 931 |
+
examples = [
|
| 932 |
+
]
|
| 933 |
+
|
| 934 |
+
def example_pipeline(
|
| 935 |
+
input_video,
|
| 936 |
+
num_images_str,
|
| 937 |
+
input_images,
|
| 938 |
+
conf_thres,
|
| 939 |
+
mask_black_bg,
|
| 940 |
+
mask_white_bg,
|
| 941 |
+
show_cam,
|
| 942 |
+
mask_sky,
|
| 943 |
+
prediction_mode,
|
| 944 |
+
is_example_str,
|
| 945 |
+
text_labels,
|
| 946 |
+
):
|
| 947 |
+
"""
|
| 948 |
+
1) Copy example images to new target_dir
|
| 949 |
+
2) Reconstruct (and Detect if labels present)
|
| 950 |
+
3) Return model3D + logs + new_dir + updated dropdown + gallery
|
| 951 |
+
We do NOT return is_example. It's just an input.
|
| 952 |
+
"""
|
| 953 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 954 |
+
# Always use "All" for frame_filter in examples
|
| 955 |
+
frame_filter = "All"
|
| 956 |
+
|
| 957 |
+
# We use detect_objects logic here to handle both reconstruction and detection if needed.
|
| 958 |
+
# But detect_objects signature is (text_labels, target_dir, conf_thres, *viz_args)
|
| 959 |
+
# where viz_args are frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode
|
| 960 |
+
# BUT wait, detect_objects calls reconstruct ONLY if predictions don't exist.
|
| 961 |
+
# Here we just uploaded new files, so predictions definitely don't exist.
|
| 962 |
+
# So we can call detect_objects directly.
|
| 963 |
+
# Note: detect_objects uses detection_conf_thres (default 0.85).
|
| 964 |
+
# But here we only have conf_thres input from examples (which is for reconstruction point cloud filtering).
|
| 965 |
+
# We should probably use a default for detection conf thres or add it to examples.
|
| 966 |
+
# Let's use a hardcoded default for detection in examples for now, e.g. 0.5 or 0.85
|
| 967 |
+
|
| 968 |
+
detection_conf = 0.85
|
| 969 |
+
|
| 970 |
+
glbfile, legend_md = detect_objects(
|
| 971 |
+
text_labels,
|
| 972 |
+
target_dir,
|
| 973 |
+
detection_conf,
|
| 974 |
+
frame_filter,
|
| 975 |
+
mask_black_bg,
|
| 976 |
+
mask_white_bg,
|
| 977 |
+
show_cam,
|
| 978 |
+
mask_sky,
|
| 979 |
+
prediction_mode
|
| 980 |
+
)
|
| 981 |
+
|
| 982 |
+
log_msg = "Example loaded and processed."
|
| 983 |
+
|
| 984 |
+
return glbfile, log_msg + "\n\n" + legend_md, target_dir, gr.Dropdown(choices=["All"], value="All", interactive=True), image_paths
|
| 985 |
+
|
| 986 |
+
detect_btn.click(fn=clear_fields, inputs=[], outputs=[]).then(
|
| 987 |
+
fn=detect_objects,
|
| 988 |
+
inputs=[
|
| 989 |
+
text_labels,
|
| 990 |
+
target_dir_output,
|
| 991 |
+
detection_conf_thres,
|
| 992 |
+
frame_filter,
|
| 993 |
+
mask_black_bg,
|
| 994 |
+
mask_white_bg,
|
| 995 |
+
show_cam,
|
| 996 |
+
mask_sky,
|
| 997 |
+
prediction_mode
|
| 998 |
+
],
|
| 999 |
+
outputs=[reconstruction_output, detection_legend]
|
| 1000 |
+
).then(
|
| 1001 |
+
fn=lambda: "False", inputs=[], outputs=[is_example] # set is_example to "False"
|
| 1002 |
+
)
|
| 1003 |
+
|
| 1004 |
+
detection_conf_thres.change(
|
| 1005 |
+
fn=visualize_detections,
|
| 1006 |
+
inputs=[
|
| 1007 |
+
target_dir_output,
|
| 1008 |
+
detection_conf_thres,
|
| 1009 |
+
frame_filter,
|
| 1010 |
+
mask_black_bg,
|
| 1011 |
+
mask_white_bg,
|
| 1012 |
+
show_cam,
|
| 1013 |
+
mask_sky,
|
| 1014 |
+
prediction_mode
|
| 1015 |
+
],
|
| 1016 |
+
outputs=[reconstruction_output, detection_legend]
|
| 1017 |
+
)
|
| 1018 |
+
|
| 1019 |
+
# -------------------------------------------------------------------------
|
| 1020 |
+
# Real-time Visualization Updates
|
| 1021 |
+
# -------------------------------------------------------------------------
|
| 1022 |
+
conf_thres.change(
|
| 1023 |
+
update_visualization,
|
| 1024 |
+
[
|
| 1025 |
+
target_dir_output,
|
| 1026 |
+
conf_thres,
|
| 1027 |
+
frame_filter,
|
| 1028 |
+
mask_black_bg,
|
| 1029 |
+
mask_white_bg,
|
| 1030 |
+
show_cam,
|
| 1031 |
+
mask_sky,
|
| 1032 |
+
prediction_mode,
|
| 1033 |
+
is_example,
|
| 1034 |
+
],
|
| 1035 |
+
[reconstruction_output, log_output],
|
| 1036 |
+
)
|
| 1037 |
+
frame_filter.change(
|
| 1038 |
+
update_visualization,
|
| 1039 |
+
[
|
| 1040 |
+
target_dir_output,
|
| 1041 |
+
conf_thres,
|
| 1042 |
+
frame_filter,
|
| 1043 |
+
mask_black_bg,
|
| 1044 |
+
mask_white_bg,
|
| 1045 |
+
show_cam,
|
| 1046 |
+
mask_sky,
|
| 1047 |
+
prediction_mode,
|
| 1048 |
+
is_example,
|
| 1049 |
+
],
|
| 1050 |
+
[reconstruction_output, log_output],
|
| 1051 |
+
)
|
| 1052 |
+
mask_black_bg.change(
|
| 1053 |
+
update_visualization,
|
| 1054 |
+
[
|
| 1055 |
+
target_dir_output,
|
| 1056 |
+
conf_thres,
|
| 1057 |
+
frame_filter,
|
| 1058 |
+
mask_black_bg,
|
| 1059 |
+
mask_white_bg,
|
| 1060 |
+
show_cam,
|
| 1061 |
+
mask_sky,
|
| 1062 |
+
prediction_mode,
|
| 1063 |
+
is_example,
|
| 1064 |
+
],
|
| 1065 |
+
[reconstruction_output, log_output],
|
| 1066 |
+
)
|
| 1067 |
+
mask_white_bg.change(
|
| 1068 |
+
update_visualization,
|
| 1069 |
+
[
|
| 1070 |
+
target_dir_output,
|
| 1071 |
+
conf_thres,
|
| 1072 |
+
frame_filter,
|
| 1073 |
+
mask_black_bg,
|
| 1074 |
+
mask_white_bg,
|
| 1075 |
+
show_cam,
|
| 1076 |
+
mask_sky,
|
| 1077 |
+
prediction_mode,
|
| 1078 |
+
is_example,
|
| 1079 |
+
],
|
| 1080 |
+
[reconstruction_output, log_output],
|
| 1081 |
+
)
|
| 1082 |
+
show_cam.change(
|
| 1083 |
+
update_visualization,
|
| 1084 |
+
[
|
| 1085 |
+
target_dir_output,
|
| 1086 |
+
conf_thres,
|
| 1087 |
+
frame_filter,
|
| 1088 |
+
mask_black_bg,
|
| 1089 |
+
mask_white_bg,
|
| 1090 |
+
show_cam,
|
| 1091 |
+
mask_sky,
|
| 1092 |
+
prediction_mode,
|
| 1093 |
+
is_example,
|
| 1094 |
+
],
|
| 1095 |
+
[reconstruction_output, log_output],
|
| 1096 |
+
)
|
| 1097 |
+
prediction_mode.change(
|
| 1098 |
+
update_visualization,
|
| 1099 |
+
[
|
| 1100 |
+
target_dir_output,
|
| 1101 |
+
conf_thres,
|
| 1102 |
+
frame_filter,
|
| 1103 |
+
mask_black_bg,
|
| 1104 |
+
mask_white_bg,
|
| 1105 |
+
show_cam,
|
| 1106 |
+
mask_sky,
|
| 1107 |
+
prediction_mode,
|
| 1108 |
+
is_example,
|
| 1109 |
+
],
|
| 1110 |
+
[reconstruction_output, log_output],
|
| 1111 |
+
)
|
| 1112 |
+
|
| 1113 |
+
# # -------------------------------------------------------------------------
|
| 1114 |
+
# # Auto-update gallery whenever user uploads or changes their files
|
| 1115 |
+
# # -------------------------------------------------------------------------
|
| 1116 |
+
input_video.change(
|
| 1117 |
+
fn=update_gallery_on_upload,
|
| 1118 |
+
inputs=[input_video, input_images],
|
| 1119 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 1120 |
+
)
|
| 1121 |
+
input_images.change(
|
| 1122 |
+
fn=update_gallery_on_upload,
|
| 1123 |
+
inputs=[input_video, input_images],
|
| 1124 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 1125 |
+
)
|
| 1126 |
+
|
| 1127 |
+
demo.queue(max_size=20).launch(show_error=True, share=True)
|
pyproject.toml
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
authors = [{name = "Jianyuan Wang", email = "jianyuan@robots.ox.ac.uk"}]
|
| 3 |
+
dependencies = [
|
| 4 |
+
"numpy<2",
|
| 5 |
+
"Pillow",
|
| 6 |
+
"huggingface_hub",
|
| 7 |
+
"einops",
|
| 8 |
+
"safetensors",
|
| 9 |
+
"opencv-python",
|
| 10 |
+
]
|
| 11 |
+
name = "vggt"
|
| 12 |
+
requires-python = ">= 3.10"
|
| 13 |
+
version = "0.0.1"
|
| 14 |
+
|
| 15 |
+
[project.optional-dependencies]
|
| 16 |
+
demo = [
|
| 17 |
+
"gradio==5.17.1",
|
| 18 |
+
"viser==0.2.23",
|
| 19 |
+
"tqdm",
|
| 20 |
+
"hydra-core",
|
| 21 |
+
"omegaconf",
|
| 22 |
+
"opencv-python",
|
| 23 |
+
"scipy",
|
| 24 |
+
"onnxruntime",
|
| 25 |
+
"requests",
|
| 26 |
+
"trimesh",
|
| 27 |
+
"matplotlib",
|
| 28 |
+
]
|
| 29 |
+
|
| 30 |
+
# Using setuptools as the build backend
|
| 31 |
+
[build-system]
|
| 32 |
+
requires = ["setuptools>=61.0", "wheel"]
|
| 33 |
+
build-backend = "setuptools.build_meta"
|
| 34 |
+
|
| 35 |
+
# setuptools configuration
|
| 36 |
+
[tool.setuptools.packages.find]
|
| 37 |
+
where = ["."]
|
| 38 |
+
include = ["vggt*"]
|
| 39 |
+
|
| 40 |
+
# Pixi configuration
|
| 41 |
+
[tool.pixi.workspace]
|
| 42 |
+
channels = ["conda-forge"]
|
| 43 |
+
platforms = ["linux-64"]
|
| 44 |
+
|
| 45 |
+
[tool.pixi.pypi-dependencies]
|
| 46 |
+
vggt = { path = ".", editable = true }
|
| 47 |
+
|
| 48 |
+
[tool.pixi.environments]
|
| 49 |
+
default = { solve-group = "default" }
|
| 50 |
+
demo = { features = ["demo"], solve-group = "default" }
|
| 51 |
+
|
| 52 |
+
[tool.pixi.tasks]
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.3.1
|
| 2 |
+
torchvision==0.18.1
|
| 3 |
+
numpy==1.26.1
|
| 4 |
+
Pillow
|
| 5 |
+
huggingface_hub
|
| 6 |
+
einops
|
| 7 |
+
safetensors
|
requirements_demo.txt
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio==5.17.1
|
| 2 |
+
viser==0.2.23
|
| 3 |
+
tqdm
|
| 4 |
+
hydra-core
|
| 5 |
+
omegaconf
|
| 6 |
+
opencv-python
|
| 7 |
+
scipy
|
| 8 |
+
onnxruntime
|
| 9 |
+
requests
|
| 10 |
+
trimesh
|
| 11 |
+
matplotlib
|
| 12 |
+
# feel free to skip the dependencies below if you do not need demo_colmap.py
|
| 13 |
+
pycolmap==3.10.0
|
| 14 |
+
pyceres==2.3
|
| 15 |
+
git+https://github.com/jytime/LightGlue.git#egg=lightglue
|
| 16 |
+
|
run_arkit.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import cv2
|
| 9 |
+
import torch
|
| 10 |
+
import numpy as np
|
| 11 |
+
import sys
|
| 12 |
+
import shutil
|
| 13 |
+
from datetime import datetime
|
| 14 |
+
import glob
|
| 15 |
+
import gc
|
| 16 |
+
import time
|
| 17 |
+
from pathlib import Path
|
| 18 |
+
from argparse import ArgumentParser
|
| 19 |
+
from tqdm import tqdm
|
| 20 |
+
from tqdm.contrib.concurrent import process_map
|
| 21 |
+
|
| 22 |
+
sys.path.append("vggt/")
|
| 23 |
+
|
| 24 |
+
from visual_util import predictions_to_glb
|
| 25 |
+
from vggt.models.vggt import VGGT
|
| 26 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 27 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 28 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 29 |
+
|
| 30 |
+
from rec_utils.datasets import ARKitDataset
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
# -------------------------------------------------------------------------
|
| 40 |
+
# 1) Core model inference
|
| 41 |
+
# -------------------------------------------------------------------------
|
| 42 |
+
def run_model(model, target_dir, device, max_images) -> dict:
|
| 43 |
+
"""
|
| 44 |
+
Run the VGGT model on images in the 'target_dir/images' folder and return predictions.
|
| 45 |
+
"""
|
| 46 |
+
print(f"Processing images from {target_dir}")
|
| 47 |
+
|
| 48 |
+
if not torch.cuda.is_available():
|
| 49 |
+
raise ValueError("CUDA is not available. Check your environment.")
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
# Load and preprocess images
|
| 53 |
+
image_names = [*target_dir.glob("*.jpg")]
|
| 54 |
+
image_names = sorted(image_names)
|
| 55 |
+
print(f"Found {len(image_names)} images")
|
| 56 |
+
if len(image_names) == 0:
|
| 57 |
+
raise ValueError(f"No images found at {target_dir}. Check your upload.")
|
| 58 |
+
if len(image_names) > max_images:
|
| 59 |
+
print(f"Downsampling {len(image_names)} images to {max_images} images")
|
| 60 |
+
image_names = [image_names[i] for i in np.linspace(0, len(image_names) - 1, max_images).round().astype(int)]
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
images = load_and_preprocess_images(image_names).to(device)
|
| 64 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 65 |
+
|
| 66 |
+
# Run inference
|
| 67 |
+
print("Running inference...")
|
| 68 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 69 |
+
|
| 70 |
+
with torch.no_grad():
|
| 71 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 72 |
+
predictions = model(images)
|
| 73 |
+
|
| 74 |
+
# Convert pose encoding to extrinsic and intrinsic matrices
|
| 75 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 76 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 77 |
+
predictions["poses"] = extrinsic
|
| 78 |
+
predictions["Ks"] = intrinsic
|
| 79 |
+
|
| 80 |
+
# Convert tensors to numpy
|
| 81 |
+
for key in predictions.keys():
|
| 82 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 83 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension
|
| 84 |
+
|
| 85 |
+
# Generate world points from depth map
|
| 86 |
+
# print("Computing world points from depth map...")
|
| 87 |
+
# depth_map = predictions["depth"] # (S, H, W, 1)
|
| 88 |
+
# world_points = unproject_depth_map_to_point_map(depth_map, predictions["poses"], predictions["Ks"])
|
| 89 |
+
# predictions["world_points_from_depth"] = world_points
|
| 90 |
+
|
| 91 |
+
# Clean up
|
| 92 |
+
torch.cuda.empty_cache()
|
| 93 |
+
predictions["image_names"] = [str(image_name) for image_name in image_names]
|
| 94 |
+
return predictions
|
| 95 |
+
|
| 96 |
+
def process_scene(
|
| 97 |
+
model,
|
| 98 |
+
scene_name,
|
| 99 |
+
input_dir,
|
| 100 |
+
output_dir,
|
| 101 |
+
device,
|
| 102 |
+
max_images=10000,
|
| 103 |
+
force=False
|
| 104 |
+
):
|
| 105 |
+
"""
|
| 106 |
+
Perform reconstruction using the already-created target_dir/images.
|
| 107 |
+
"""
|
| 108 |
+
|
| 109 |
+
if not force and (output_dir / "predictions.npz").exists():
|
| 110 |
+
print(f"Skipping scene {scene_name} because it already exists")
|
| 111 |
+
return
|
| 112 |
+
|
| 113 |
+
start_time = time.time()
|
| 114 |
+
gc.collect()
|
| 115 |
+
torch.cuda.empty_cache()
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
print("Running run_model...")
|
| 119 |
+
with torch.no_grad():
|
| 120 |
+
predictions = run_model(model, input_dir, device, max_images)
|
| 121 |
+
|
| 122 |
+
# Save predictions
|
| 123 |
+
|
| 124 |
+
del predictions["images"]
|
| 125 |
+
|
| 126 |
+
np.savez(output_dir / "predictions.npz", **predictions)
|
| 127 |
+
|
| 128 |
+
del predictions
|
| 129 |
+
gc.collect()
|
| 130 |
+
torch.cuda.empty_cache()
|
| 131 |
+
|
| 132 |
+
end_time = time.time()
|
| 133 |
+
|
| 134 |
+
if __name__ == "__main__":
|
| 135 |
+
parser = ArgumentParser()
|
| 136 |
+
parser.add_argument("--scene_names", nargs="+", default=os.listdir("/workspace-SR006.nfs2/datasets/arkitscenes/offline_prepared_data/posed_images/"))
|
| 137 |
+
parser.add_argument("--input_dir", type=str, default='/workspace-SR006.nfs2/datasets/arkitscenes/offline_prepared_data/posed_images/')
|
| 138 |
+
parser.add_argument("--output_dir", type=str, default='output/arkit_250')
|
| 139 |
+
parser.add_argument("--max_images", type=int, default=250)
|
| 140 |
+
parser.add_argument("--conf_thres", type=float, default=3.0)
|
| 141 |
+
parser.add_argument("--job_num", "-n", type=int, default=1)
|
| 142 |
+
parser.add_argument("--job_id", "-i", type=int, default=0)
|
| 143 |
+
parser.add_argument("--device", type=str, default="2")
|
| 144 |
+
parser.add_argument("--force", action="store_true")
|
| 145 |
+
args = parser.parse_args()
|
| 146 |
+
|
| 147 |
+
model = VGGT()
|
| 148 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 149 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 150 |
+
model.eval()
|
| 151 |
+
|
| 152 |
+
scene_names = args.scene_names[args.job_id::args.job_num]
|
| 153 |
+
scene_names = ['47334096']
|
| 154 |
+
device = f"cuda:{args.device}" if torch.cuda.is_available() else "cpu"
|
| 155 |
+
|
| 156 |
+
model = model.to(device)
|
| 157 |
+
from datetime import datetime
|
| 158 |
+
errors_path = Path(f"logs/errors_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt")
|
| 159 |
+
|
| 160 |
+
for scene_name in tqdm(scene_names):
|
| 161 |
+
print(f"Processing scene {scene_name}")
|
| 162 |
+
|
| 163 |
+
input_dir = Path(args.input_dir) / scene_name
|
| 164 |
+
output_dir = Path(args.output_dir) / scene_name
|
| 165 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 166 |
+
try:
|
| 167 |
+
process_scene(model, scene_name, input_dir, output_dir, device=device, max_images=args.max_images, force=args.force)
|
| 168 |
+
except Exception as e:
|
| 169 |
+
print(f"Error processing scene {scene_name}: {e}")
|
| 170 |
+
errors_path.parent.mkdir(parents=True, exist_ok=True)
|
| 171 |
+
with open(errors_path, "a") as f:
|
| 172 |
+
f.write(f"{scene_name}\n")
|
vggt/dependency/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .track_modules.track_refine import refine_track
|
| 2 |
+
from .track_modules.blocks import BasicEncoder, ShallowEncoder
|
| 3 |
+
from .track_modules.base_track_predictor import BaseTrackerPredictor
|
vggt/dependency/distortion.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
from typing import Union
|
| 10 |
+
|
| 11 |
+
ArrayLike = Union[np.ndarray, torch.Tensor]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def _is_numpy(x: ArrayLike) -> bool:
|
| 15 |
+
return isinstance(x, np.ndarray)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _is_torch(x: ArrayLike) -> bool:
|
| 19 |
+
return isinstance(x, torch.Tensor)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def _ensure_torch(x: ArrayLike) -> torch.Tensor:
|
| 23 |
+
"""Convert input to torch tensor if it's not already one."""
|
| 24 |
+
if _is_numpy(x):
|
| 25 |
+
return torch.from_numpy(x)
|
| 26 |
+
elif _is_torch(x):
|
| 27 |
+
return x
|
| 28 |
+
else:
|
| 29 |
+
return torch.tensor(x)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def single_undistortion(params, tracks_normalized):
|
| 33 |
+
"""
|
| 34 |
+
Apply undistortion to the normalized tracks using the given distortion parameters once.
|
| 35 |
+
|
| 36 |
+
Args:
|
| 37 |
+
params (torch.Tensor or numpy.ndarray): Distortion parameters of shape BxN.
|
| 38 |
+
tracks_normalized (torch.Tensor or numpy.ndarray): Normalized tracks tensor of shape [batch_size, num_tracks, 2].
|
| 39 |
+
|
| 40 |
+
Returns:
|
| 41 |
+
torch.Tensor: Undistorted normalized tracks tensor.
|
| 42 |
+
"""
|
| 43 |
+
params = _ensure_torch(params)
|
| 44 |
+
tracks_normalized = _ensure_torch(tracks_normalized)
|
| 45 |
+
|
| 46 |
+
u, v = tracks_normalized[..., 0].clone(), tracks_normalized[..., 1].clone()
|
| 47 |
+
u_undist, v_undist = apply_distortion(params, u, v)
|
| 48 |
+
return torch.stack([u_undist, v_undist], dim=-1)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def iterative_undistortion(params, tracks_normalized, max_iterations=100, max_step_norm=1e-10, rel_step_size=1e-6):
|
| 52 |
+
"""
|
| 53 |
+
Iteratively undistort the normalized tracks using the given distortion parameters.
|
| 54 |
+
|
| 55 |
+
Args:
|
| 56 |
+
params (torch.Tensor or numpy.ndarray): Distortion parameters of shape BxN.
|
| 57 |
+
tracks_normalized (torch.Tensor or numpy.ndarray): Normalized tracks tensor of shape [batch_size, num_tracks, 2].
|
| 58 |
+
max_iterations (int): Maximum number of iterations for the undistortion process.
|
| 59 |
+
max_step_norm (float): Maximum step norm for convergence.
|
| 60 |
+
rel_step_size (float): Relative step size for numerical differentiation.
|
| 61 |
+
|
| 62 |
+
Returns:
|
| 63 |
+
torch.Tensor: Undistorted normalized tracks tensor.
|
| 64 |
+
"""
|
| 65 |
+
params = _ensure_torch(params)
|
| 66 |
+
tracks_normalized = _ensure_torch(tracks_normalized)
|
| 67 |
+
|
| 68 |
+
B, N, _ = tracks_normalized.shape
|
| 69 |
+
u, v = tracks_normalized[..., 0].clone(), tracks_normalized[..., 1].clone()
|
| 70 |
+
original_u, original_v = u.clone(), v.clone()
|
| 71 |
+
|
| 72 |
+
eps = torch.finfo(u.dtype).eps
|
| 73 |
+
for idx in range(max_iterations):
|
| 74 |
+
u_undist, v_undist = apply_distortion(params, u, v)
|
| 75 |
+
dx = original_u - u_undist
|
| 76 |
+
dy = original_v - v_undist
|
| 77 |
+
|
| 78 |
+
step_u = torch.clamp(torch.abs(u) * rel_step_size, min=eps)
|
| 79 |
+
step_v = torch.clamp(torch.abs(v) * rel_step_size, min=eps)
|
| 80 |
+
|
| 81 |
+
J_00 = (apply_distortion(params, u + step_u, v)[0] - apply_distortion(params, u - step_u, v)[0]) / (2 * step_u)
|
| 82 |
+
J_01 = (apply_distortion(params, u, v + step_v)[0] - apply_distortion(params, u, v - step_v)[0]) / (2 * step_v)
|
| 83 |
+
J_10 = (apply_distortion(params, u + step_u, v)[1] - apply_distortion(params, u - step_u, v)[1]) / (2 * step_u)
|
| 84 |
+
J_11 = (apply_distortion(params, u, v + step_v)[1] - apply_distortion(params, u, v - step_v)[1]) / (2 * step_v)
|
| 85 |
+
|
| 86 |
+
J = torch.stack([torch.stack([J_00 + 1, J_01], dim=-1), torch.stack([J_10, J_11 + 1], dim=-1)], dim=-2)
|
| 87 |
+
|
| 88 |
+
delta = torch.linalg.solve(J, torch.stack([dx, dy], dim=-1))
|
| 89 |
+
|
| 90 |
+
u += delta[..., 0]
|
| 91 |
+
v += delta[..., 1]
|
| 92 |
+
|
| 93 |
+
if torch.max((delta**2).sum(dim=-1)) < max_step_norm:
|
| 94 |
+
break
|
| 95 |
+
|
| 96 |
+
return torch.stack([u, v], dim=-1)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def apply_distortion(extra_params, u, v):
|
| 100 |
+
"""
|
| 101 |
+
Applies radial or OpenCV distortion to the given 2D points.
|
| 102 |
+
|
| 103 |
+
Args:
|
| 104 |
+
extra_params (torch.Tensor or numpy.ndarray): Distortion parameters of shape BxN, where N can be 1, 2, or 4.
|
| 105 |
+
u (torch.Tensor or numpy.ndarray): Normalized x coordinates of shape Bxnum_tracks.
|
| 106 |
+
v (torch.Tensor or numpy.ndarray): Normalized y coordinates of shape Bxnum_tracks.
|
| 107 |
+
|
| 108 |
+
Returns:
|
| 109 |
+
points2D (torch.Tensor): Distorted 2D points of shape BxNx2.
|
| 110 |
+
"""
|
| 111 |
+
extra_params = _ensure_torch(extra_params)
|
| 112 |
+
u = _ensure_torch(u)
|
| 113 |
+
v = _ensure_torch(v)
|
| 114 |
+
|
| 115 |
+
num_params = extra_params.shape[1]
|
| 116 |
+
|
| 117 |
+
if num_params == 1:
|
| 118 |
+
# Simple radial distortion
|
| 119 |
+
k = extra_params[:, 0]
|
| 120 |
+
u2 = u * u
|
| 121 |
+
v2 = v * v
|
| 122 |
+
r2 = u2 + v2
|
| 123 |
+
radial = k[:, None] * r2
|
| 124 |
+
du = u * radial
|
| 125 |
+
dv = v * radial
|
| 126 |
+
|
| 127 |
+
elif num_params == 2:
|
| 128 |
+
# RadialCameraModel distortion
|
| 129 |
+
k1, k2 = extra_params[:, 0], extra_params[:, 1]
|
| 130 |
+
u2 = u * u
|
| 131 |
+
v2 = v * v
|
| 132 |
+
r2 = u2 + v2
|
| 133 |
+
radial = k1[:, None] * r2 + k2[:, None] * r2 * r2
|
| 134 |
+
du = u * radial
|
| 135 |
+
dv = v * radial
|
| 136 |
+
|
| 137 |
+
elif num_params == 4:
|
| 138 |
+
# OpenCVCameraModel distortion
|
| 139 |
+
k1, k2, p1, p2 = (extra_params[:, 0], extra_params[:, 1], extra_params[:, 2], extra_params[:, 3])
|
| 140 |
+
u2 = u * u
|
| 141 |
+
v2 = v * v
|
| 142 |
+
uv = u * v
|
| 143 |
+
r2 = u2 + v2
|
| 144 |
+
radial = k1[:, None] * r2 + k2[:, None] * r2 * r2
|
| 145 |
+
du = u * radial + 2 * p1[:, None] * uv + p2[:, None] * (r2 + 2 * u2)
|
| 146 |
+
dv = v * radial + 2 * p2[:, None] * uv + p1[:, None] * (r2 + 2 * v2)
|
| 147 |
+
else:
|
| 148 |
+
raise ValueError("Unsupported number of distortion parameters")
|
| 149 |
+
|
| 150 |
+
u = u.clone() + du
|
| 151 |
+
v = v.clone() + dv
|
| 152 |
+
|
| 153 |
+
return u, v
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
if __name__ == "__main__":
|
| 157 |
+
import random
|
| 158 |
+
import pycolmap
|
| 159 |
+
|
| 160 |
+
max_diff = 0
|
| 161 |
+
for i in range(1000):
|
| 162 |
+
# Define distortion parameters (assuming 1 parameter for simplicity)
|
| 163 |
+
B = random.randint(1, 500)
|
| 164 |
+
track_num = random.randint(100, 1000)
|
| 165 |
+
params = torch.rand((B, 1), dtype=torch.float32) # Batch size 1, 4 parameters
|
| 166 |
+
tracks_normalized = torch.rand((B, track_num, 2), dtype=torch.float32) # Batch size 1, 5 points
|
| 167 |
+
|
| 168 |
+
# Undistort the tracks
|
| 169 |
+
undistorted_tracks = iterative_undistortion(params, tracks_normalized)
|
| 170 |
+
|
| 171 |
+
for b in range(B):
|
| 172 |
+
pycolmap_intri = np.array([1, 0, 0, params[b].item()])
|
| 173 |
+
pycam = pycolmap.Camera(model="SIMPLE_RADIAL", width=1, height=1, params=pycolmap_intri, camera_id=0)
|
| 174 |
+
|
| 175 |
+
undistorted_tracks_pycolmap = pycam.cam_from_img(tracks_normalized[b].numpy())
|
| 176 |
+
diff = (undistorted_tracks[b] - undistorted_tracks_pycolmap).abs().median()
|
| 177 |
+
max_diff = max(max_diff, diff)
|
| 178 |
+
print(f"diff: {diff}, max_diff: {max_diff}")
|
| 179 |
+
|
| 180 |
+
import pdb
|
| 181 |
+
|
| 182 |
+
pdb.set_trace()
|
vggt/dependency/np_to_pycolmap.py
ADDED
|
@@ -0,0 +1,318 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import pycolmap
|
| 9 |
+
from .projection import project_3D_points_np
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def batch_np_matrix_to_pycolmap(
|
| 13 |
+
points3d,
|
| 14 |
+
extrinsics,
|
| 15 |
+
intrinsics,
|
| 16 |
+
tracks,
|
| 17 |
+
image_size,
|
| 18 |
+
masks=None,
|
| 19 |
+
max_reproj_error=None,
|
| 20 |
+
max_points3D_val=3000,
|
| 21 |
+
shared_camera=False,
|
| 22 |
+
camera_type="SIMPLE_PINHOLE",
|
| 23 |
+
extra_params=None,
|
| 24 |
+
min_inlier_per_frame=64,
|
| 25 |
+
points_rgb=None,
|
| 26 |
+
):
|
| 27 |
+
"""
|
| 28 |
+
Convert Batched NumPy Arrays to PyCOLMAP
|
| 29 |
+
|
| 30 |
+
Check https://github.com/colmap/pycolmap for more details about its format
|
| 31 |
+
|
| 32 |
+
NOTE that colmap expects images/cameras/points3D to be 1-indexed
|
| 33 |
+
so there is a +1 offset between colmap index and batch index
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
NOTE: different from VGGSfM, this function:
|
| 37 |
+
1. Use np instead of torch
|
| 38 |
+
2. Frame index and camera id starts from 1 rather than 0 (to fit the format of PyCOLMAP)
|
| 39 |
+
"""
|
| 40 |
+
# points3d: Px3
|
| 41 |
+
# extrinsics: Nx3x4
|
| 42 |
+
# intrinsics: Nx3x3
|
| 43 |
+
# tracks: NxPx2
|
| 44 |
+
# masks: NxP
|
| 45 |
+
# image_size: 2, assume all the frames have been padded to the same size
|
| 46 |
+
# where N is the number of frames and P is the number of tracks
|
| 47 |
+
|
| 48 |
+
N, P, _ = tracks.shape
|
| 49 |
+
assert len(extrinsics) == N
|
| 50 |
+
assert len(intrinsics) == N
|
| 51 |
+
assert len(points3d) == P
|
| 52 |
+
assert image_size.shape[0] == 2
|
| 53 |
+
|
| 54 |
+
if max_reproj_error is not None:
|
| 55 |
+
projected_points_2d, projected_points_cam = project_3D_points_np(points3d, extrinsics, intrinsics)
|
| 56 |
+
projected_diff = np.linalg.norm(projected_points_2d - tracks, axis=-1)
|
| 57 |
+
projected_points_2d[projected_points_cam[:, -1] <= 0] = 1e6
|
| 58 |
+
reproj_mask = projected_diff < max_reproj_error
|
| 59 |
+
|
| 60 |
+
if masks is not None and reproj_mask is not None:
|
| 61 |
+
masks = np.logical_and(masks, reproj_mask)
|
| 62 |
+
elif masks is not None:
|
| 63 |
+
masks = masks
|
| 64 |
+
else:
|
| 65 |
+
masks = reproj_mask
|
| 66 |
+
|
| 67 |
+
assert masks is not None
|
| 68 |
+
|
| 69 |
+
if masks.sum(1).min() < min_inlier_per_frame:
|
| 70 |
+
print(f"Not enough inliers per frame, skip BA.")
|
| 71 |
+
return None, None
|
| 72 |
+
|
| 73 |
+
# Reconstruction object, following the format of PyCOLMAP/COLMAP
|
| 74 |
+
reconstruction = pycolmap.Reconstruction()
|
| 75 |
+
|
| 76 |
+
inlier_num = masks.sum(0)
|
| 77 |
+
valid_mask = inlier_num >= 2 # a track is invalid if without two inliers
|
| 78 |
+
valid_idx = np.nonzero(valid_mask)[0]
|
| 79 |
+
|
| 80 |
+
# Only add 3D points that have sufficient 2D points
|
| 81 |
+
for vidx in valid_idx:
|
| 82 |
+
# Use RGB colors if provided, otherwise use zeros
|
| 83 |
+
rgb = points_rgb[vidx] if points_rgb is not None else np.zeros(3)
|
| 84 |
+
reconstruction.add_point3D(points3d[vidx], pycolmap.Track(), rgb)
|
| 85 |
+
|
| 86 |
+
num_points3D = len(valid_idx)
|
| 87 |
+
camera = None
|
| 88 |
+
# frame idx
|
| 89 |
+
for fidx in range(N):
|
| 90 |
+
# set camera
|
| 91 |
+
if camera is None or (not shared_camera):
|
| 92 |
+
pycolmap_intri = _build_pycolmap_intri(fidx, intrinsics, camera_type, extra_params)
|
| 93 |
+
|
| 94 |
+
camera = pycolmap.Camera(
|
| 95 |
+
model=camera_type, width=image_size[0], height=image_size[1], params=pycolmap_intri, camera_id=fidx + 1
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
# add camera
|
| 99 |
+
reconstruction.add_camera(camera)
|
| 100 |
+
|
| 101 |
+
# set image
|
| 102 |
+
cam_from_world = pycolmap.Rigid3d(
|
| 103 |
+
pycolmap.Rotation3d(extrinsics[fidx][:3, :3]), extrinsics[fidx][:3, 3]
|
| 104 |
+
) # Rot and Trans
|
| 105 |
+
|
| 106 |
+
image = pycolmap.Image(
|
| 107 |
+
id=fidx + 1, name=f"image_{fidx + 1}", camera_id=camera.camera_id, cam_from_world=cam_from_world
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
points2D_list = []
|
| 111 |
+
|
| 112 |
+
point2D_idx = 0
|
| 113 |
+
|
| 114 |
+
# NOTE point3D_id start by 1
|
| 115 |
+
for point3D_id in range(1, num_points3D + 1):
|
| 116 |
+
original_track_idx = valid_idx[point3D_id - 1]
|
| 117 |
+
|
| 118 |
+
if (reconstruction.points3D[point3D_id].xyz < max_points3D_val).all():
|
| 119 |
+
if masks[fidx][original_track_idx]:
|
| 120 |
+
# It seems we don't need +0.5 for BA
|
| 121 |
+
point2D_xy = tracks[fidx][original_track_idx]
|
| 122 |
+
# Please note when adding the Point2D object
|
| 123 |
+
# It not only requires the 2D xy location, but also the id to 3D point
|
| 124 |
+
points2D_list.append(pycolmap.Point2D(point2D_xy, point3D_id))
|
| 125 |
+
|
| 126 |
+
# add element
|
| 127 |
+
track = reconstruction.points3D[point3D_id].track
|
| 128 |
+
track.add_element(fidx + 1, point2D_idx)
|
| 129 |
+
point2D_idx += 1
|
| 130 |
+
|
| 131 |
+
assert point2D_idx == len(points2D_list)
|
| 132 |
+
|
| 133 |
+
try:
|
| 134 |
+
image.points2D = pycolmap.ListPoint2D(points2D_list)
|
| 135 |
+
image.registered = True
|
| 136 |
+
except:
|
| 137 |
+
print(f"frame {fidx + 1} is out of BA")
|
| 138 |
+
image.registered = False
|
| 139 |
+
|
| 140 |
+
# add image
|
| 141 |
+
reconstruction.add_image(image)
|
| 142 |
+
|
| 143 |
+
return reconstruction, valid_mask
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def pycolmap_to_batch_np_matrix(reconstruction, device="cpu", camera_type="SIMPLE_PINHOLE"):
|
| 147 |
+
"""
|
| 148 |
+
Convert a PyCOLMAP Reconstruction Object to batched NumPy arrays.
|
| 149 |
+
|
| 150 |
+
Args:
|
| 151 |
+
reconstruction (pycolmap.Reconstruction): The reconstruction object from PyCOLMAP.
|
| 152 |
+
device (str): Ignored in NumPy version (kept for API compatibility).
|
| 153 |
+
camera_type (str): The type of camera model used (default: "SIMPLE_PINHOLE").
|
| 154 |
+
|
| 155 |
+
Returns:
|
| 156 |
+
tuple: A tuple containing points3D, extrinsics, intrinsics, and optionally extra_params.
|
| 157 |
+
"""
|
| 158 |
+
|
| 159 |
+
num_images = len(reconstruction.images)
|
| 160 |
+
max_points3D_id = max(reconstruction.point3D_ids())
|
| 161 |
+
points3D = np.zeros((max_points3D_id, 3))
|
| 162 |
+
|
| 163 |
+
for point3D_id in reconstruction.points3D:
|
| 164 |
+
points3D[point3D_id - 1] = reconstruction.points3D[point3D_id].xyz
|
| 165 |
+
|
| 166 |
+
extrinsics = []
|
| 167 |
+
intrinsics = []
|
| 168 |
+
|
| 169 |
+
extra_params = [] if camera_type == "SIMPLE_RADIAL" else None
|
| 170 |
+
|
| 171 |
+
for i in range(num_images):
|
| 172 |
+
# Extract and append extrinsics
|
| 173 |
+
pyimg = reconstruction.images[i + 1]
|
| 174 |
+
pycam = reconstruction.cameras[pyimg.camera_id]
|
| 175 |
+
matrix = pyimg.cam_from_world.matrix()
|
| 176 |
+
extrinsics.append(matrix)
|
| 177 |
+
|
| 178 |
+
# Extract and append intrinsics
|
| 179 |
+
calibration_matrix = pycam.calibration_matrix()
|
| 180 |
+
intrinsics.append(calibration_matrix)
|
| 181 |
+
|
| 182 |
+
if camera_type == "SIMPLE_RADIAL":
|
| 183 |
+
extra_params.append(pycam.params[-1])
|
| 184 |
+
|
| 185 |
+
# Convert lists to NumPy arrays instead of torch tensors
|
| 186 |
+
extrinsics = np.stack(extrinsics)
|
| 187 |
+
intrinsics = np.stack(intrinsics)
|
| 188 |
+
|
| 189 |
+
if camera_type == "SIMPLE_RADIAL":
|
| 190 |
+
extra_params = np.stack(extra_params)
|
| 191 |
+
extra_params = extra_params[:, None]
|
| 192 |
+
|
| 193 |
+
return points3D, extrinsics, intrinsics, extra_params
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
########################################################
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def batch_np_matrix_to_pycolmap_wo_track(
|
| 200 |
+
points3d,
|
| 201 |
+
points_xyf,
|
| 202 |
+
points_rgb,
|
| 203 |
+
extrinsics,
|
| 204 |
+
intrinsics,
|
| 205 |
+
image_size,
|
| 206 |
+
shared_camera=False,
|
| 207 |
+
camera_type="SIMPLE_PINHOLE",
|
| 208 |
+
):
|
| 209 |
+
"""
|
| 210 |
+
Convert Batched NumPy Arrays to PyCOLMAP
|
| 211 |
+
|
| 212 |
+
Different from batch_np_matrix_to_pycolmap, this function does not use tracks.
|
| 213 |
+
|
| 214 |
+
It saves points3d to colmap reconstruction format only to serve as init for Gaussians or other nvs methods.
|
| 215 |
+
|
| 216 |
+
Do NOT use this for BA.
|
| 217 |
+
"""
|
| 218 |
+
# points3d: Px3
|
| 219 |
+
# points_xyf: Px3, with x, y coordinates and frame indices
|
| 220 |
+
# points_rgb: Px3, rgb colors
|
| 221 |
+
# extrinsics: Nx3x4
|
| 222 |
+
# intrinsics: Nx3x3
|
| 223 |
+
# image_size: 2, assume all the frames have been padded to the same size
|
| 224 |
+
# where N is the number of frames and P is the number of tracks
|
| 225 |
+
|
| 226 |
+
N = len(extrinsics)
|
| 227 |
+
P = len(points3d)
|
| 228 |
+
|
| 229 |
+
# Reconstruction object, following the format of PyCOLMAP/COLMAP
|
| 230 |
+
reconstruction = pycolmap.Reconstruction()
|
| 231 |
+
|
| 232 |
+
for vidx in range(P):
|
| 233 |
+
reconstruction.add_point3D(points3d[vidx], pycolmap.Track(), points_rgb[vidx])
|
| 234 |
+
|
| 235 |
+
camera = None
|
| 236 |
+
# frame idx
|
| 237 |
+
for fidx in range(N):
|
| 238 |
+
# set camera
|
| 239 |
+
if camera is None or (not shared_camera):
|
| 240 |
+
pycolmap_intri = _build_pycolmap_intri(fidx, intrinsics, camera_type)
|
| 241 |
+
|
| 242 |
+
camera = pycolmap.Camera(
|
| 243 |
+
model=camera_type, width=image_size[0], height=image_size[1], params=pycolmap_intri, camera_id=fidx + 1
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
# add camera
|
| 247 |
+
reconstruction.add_camera(camera)
|
| 248 |
+
|
| 249 |
+
# set image
|
| 250 |
+
cam_from_world = pycolmap.Rigid3d(
|
| 251 |
+
pycolmap.Rotation3d(extrinsics[fidx][:3, :3]), extrinsics[fidx][:3, 3]
|
| 252 |
+
) # Rot and Trans
|
| 253 |
+
|
| 254 |
+
image = pycolmap.Image(
|
| 255 |
+
id=fidx + 1, name=f"image_{fidx + 1}", camera_id=camera.camera_id, cam_from_world=cam_from_world
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
points2D_list = []
|
| 259 |
+
|
| 260 |
+
point2D_idx = 0
|
| 261 |
+
|
| 262 |
+
points_belong_to_fidx = points_xyf[:, 2].astype(np.int32) == fidx
|
| 263 |
+
points_belong_to_fidx = np.nonzero(points_belong_to_fidx)[0]
|
| 264 |
+
|
| 265 |
+
for point3D_batch_idx in points_belong_to_fidx:
|
| 266 |
+
point3D_id = point3D_batch_idx + 1
|
| 267 |
+
point2D_xyf = points_xyf[point3D_batch_idx]
|
| 268 |
+
point2D_xy = point2D_xyf[:2]
|
| 269 |
+
points2D_list.append(pycolmap.Point2D(point2D_xy, point3D_id))
|
| 270 |
+
|
| 271 |
+
# add element
|
| 272 |
+
track = reconstruction.points3D[point3D_id].track
|
| 273 |
+
track.add_element(fidx + 1, point2D_idx)
|
| 274 |
+
point2D_idx += 1
|
| 275 |
+
|
| 276 |
+
assert point2D_idx == len(points2D_list)
|
| 277 |
+
|
| 278 |
+
try:
|
| 279 |
+
image.points2D = pycolmap.ListPoint2D(points2D_list)
|
| 280 |
+
image.registered = True
|
| 281 |
+
except:
|
| 282 |
+
print(f"frame {fidx + 1} does not have any points")
|
| 283 |
+
image.registered = False
|
| 284 |
+
|
| 285 |
+
# add image
|
| 286 |
+
reconstruction.add_image(image)
|
| 287 |
+
|
| 288 |
+
return reconstruction
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
def _build_pycolmap_intri(fidx, intrinsics, camera_type, extra_params=None):
|
| 292 |
+
"""
|
| 293 |
+
Helper function to get camera parameters based on camera type.
|
| 294 |
+
|
| 295 |
+
Args:
|
| 296 |
+
fidx: Frame index
|
| 297 |
+
intrinsics: Camera intrinsic parameters
|
| 298 |
+
camera_type: Type of camera model
|
| 299 |
+
extra_params: Additional parameters for certain camera types
|
| 300 |
+
|
| 301 |
+
Returns:
|
| 302 |
+
pycolmap_intri: NumPy array of camera parameters
|
| 303 |
+
"""
|
| 304 |
+
if camera_type == "PINHOLE":
|
| 305 |
+
pycolmap_intri = np.array(
|
| 306 |
+
[intrinsics[fidx][0, 0], intrinsics[fidx][1, 1], intrinsics[fidx][0, 2], intrinsics[fidx][1, 2]]
|
| 307 |
+
)
|
| 308 |
+
elif camera_type == "SIMPLE_PINHOLE":
|
| 309 |
+
focal = (intrinsics[fidx][0, 0] + intrinsics[fidx][1, 1]) / 2
|
| 310 |
+
pycolmap_intri = np.array([focal, intrinsics[fidx][0, 2], intrinsics[fidx][1, 2]])
|
| 311 |
+
elif camera_type == "SIMPLE_RADIAL":
|
| 312 |
+
raise NotImplementedError("SIMPLE_RADIAL is not supported yet")
|
| 313 |
+
focal = (intrinsics[fidx][0, 0] + intrinsics[fidx][1, 1]) / 2
|
| 314 |
+
pycolmap_intri = np.array([focal, intrinsics[fidx][0, 2], intrinsics[fidx][1, 2], extra_params[fidx][0]])
|
| 315 |
+
else:
|
| 316 |
+
raise ValueError(f"Camera type {camera_type} is not supported yet")
|
| 317 |
+
|
| 318 |
+
return pycolmap_intri
|
vggt/dependency/projection.py
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
from .distortion import apply_distortion
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def img_from_cam_np(
|
| 13 |
+
intrinsics: np.ndarray, points_cam: np.ndarray, extra_params: np.ndarray | None = None, default: float = 0.0
|
| 14 |
+
) -> np.ndarray:
|
| 15 |
+
"""
|
| 16 |
+
Apply intrinsics (and optional radial distortion) to camera-space points.
|
| 17 |
+
|
| 18 |
+
Args
|
| 19 |
+
----
|
| 20 |
+
intrinsics : (B,3,3) camera matrix K.
|
| 21 |
+
points_cam : (B,3,N) homogeneous camera coords (x, y, z)ᵀ.
|
| 22 |
+
extra_params: (B, N) or (B, k) distortion params (k = 1,2,4) or None.
|
| 23 |
+
default : value used for np.nan replacement.
|
| 24 |
+
|
| 25 |
+
Returns
|
| 26 |
+
-------
|
| 27 |
+
points2D : (B,N,2) pixel coordinates.
|
| 28 |
+
"""
|
| 29 |
+
# 1. perspective divide ───────────────────────────────────────
|
| 30 |
+
z = points_cam[:, 2:3, :] # (B,1,N)
|
| 31 |
+
points_cam_norm = points_cam / z # (B,3,N)
|
| 32 |
+
uv = points_cam_norm[:, :2, :] # (B,2,N)
|
| 33 |
+
|
| 34 |
+
# 2. optional distortion ──────────────────────────────────────
|
| 35 |
+
if extra_params is not None:
|
| 36 |
+
uu, vv = apply_distortion(extra_params, uv[:, 0], uv[:, 1])
|
| 37 |
+
uv = np.stack([uu, vv], axis=1) # (B,2,N)
|
| 38 |
+
|
| 39 |
+
# 3. homogeneous coords then K multiplication ─────────────────
|
| 40 |
+
ones = np.ones_like(uv[:, :1, :]) # (B,1,N)
|
| 41 |
+
points_cam_h = np.concatenate([uv, ones], axis=1) # (B,3,N)
|
| 42 |
+
|
| 43 |
+
# batched mat-mul: K · [u v 1]ᵀ
|
| 44 |
+
points2D_h = np.einsum("bij,bjk->bik", intrinsics, points_cam_h) # (B,3,N)
|
| 45 |
+
points2D = np.nan_to_num(points2D_h[:, :2, :], nan=default) # (B,2,N)
|
| 46 |
+
|
| 47 |
+
return points2D.transpose(0, 2, 1) # (B,N,2)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def project_3D_points_np(
|
| 51 |
+
points3D: np.ndarray,
|
| 52 |
+
extrinsics: np.ndarray,
|
| 53 |
+
intrinsics: np.ndarray | None = None,
|
| 54 |
+
extra_params: np.ndarray | None = None,
|
| 55 |
+
*,
|
| 56 |
+
default: float = 0.0,
|
| 57 |
+
only_points_cam: bool = False,
|
| 58 |
+
):
|
| 59 |
+
"""
|
| 60 |
+
NumPy clone of ``project_3D_points``.
|
| 61 |
+
|
| 62 |
+
Parameters
|
| 63 |
+
----------
|
| 64 |
+
points3D : (N,3) world-space points.
|
| 65 |
+
extrinsics : (B,3,4) [R|t] matrix for each of B cameras.
|
| 66 |
+
intrinsics : (B,3,3) K matrix (optional if you only need cam-space).
|
| 67 |
+
extra_params : (B,k) or (B,N) distortion parameters (k ∈ {1,2,4}) or None.
|
| 68 |
+
default : value used to replace NaNs.
|
| 69 |
+
only_points_cam : if True, skip the projection and return points_cam with points2D as None.
|
| 70 |
+
|
| 71 |
+
Returns
|
| 72 |
+
-------
|
| 73 |
+
(points2D, points_cam) : A tuple where points2D is (B,N,2) pixel coords or None if only_points_cam=True,
|
| 74 |
+
and points_cam is (B,3,N) camera-space coordinates.
|
| 75 |
+
"""
|
| 76 |
+
# ----- 0. prep sizes -----------------------------------------------------
|
| 77 |
+
N = points3D.shape[0] # #points
|
| 78 |
+
B = extrinsics.shape[0] # #cameras
|
| 79 |
+
|
| 80 |
+
# ----- 1. world → homogeneous -------------------------------------------
|
| 81 |
+
w_h = np.ones((N, 1), dtype=points3D.dtype)
|
| 82 |
+
points3D_h = np.concatenate([points3D, w_h], axis=1) # (N,4)
|
| 83 |
+
|
| 84 |
+
# broadcast to every camera (no actual copying with np.broadcast_to) ------
|
| 85 |
+
points3D_h_B = np.broadcast_to(points3D_h, (B, N, 4)) # (B,N,4)
|
| 86 |
+
|
| 87 |
+
# ----- 2. apply extrinsics (camera frame) ------------------------------
|
| 88 |
+
# X_cam = E · X_hom
|
| 89 |
+
# einsum: E_(b i j) · X_(b n j) → (b n i)
|
| 90 |
+
points_cam = np.einsum("bij,bnj->bni", extrinsics, points3D_h_B) # (B,N,3)
|
| 91 |
+
points_cam = points_cam.transpose(0, 2, 1) # (B,3,N)
|
| 92 |
+
|
| 93 |
+
if only_points_cam:
|
| 94 |
+
return None, points_cam
|
| 95 |
+
|
| 96 |
+
# ----- 3. intrinsics + distortion ---------------------------------------
|
| 97 |
+
if intrinsics is None:
|
| 98 |
+
raise ValueError("`intrinsics` must be provided unless only_points_cam=True")
|
| 99 |
+
|
| 100 |
+
points2D = img_from_cam_np(intrinsics, points_cam, extra_params=extra_params, default=default)
|
| 101 |
+
|
| 102 |
+
return points2D, points_cam
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def project_3D_points(points3D, extrinsics, intrinsics=None, extra_params=None, default=0, only_points_cam=False):
|
| 106 |
+
"""
|
| 107 |
+
Transforms 3D points to 2D using extrinsic and intrinsic parameters.
|
| 108 |
+
Args:
|
| 109 |
+
points3D (torch.Tensor): 3D points of shape Px3.
|
| 110 |
+
extrinsics (torch.Tensor): Extrinsic parameters of shape Bx3x4.
|
| 111 |
+
intrinsics (torch.Tensor): Intrinsic parameters of shape Bx3x3.
|
| 112 |
+
extra_params (torch.Tensor): Extra parameters of shape BxN, used for radial distortion.
|
| 113 |
+
default (float): Default value to replace NaNs.
|
| 114 |
+
only_points_cam (bool): If True, skip the projection and return points2D as None.
|
| 115 |
+
|
| 116 |
+
Returns:
|
| 117 |
+
tuple: (points2D, points_cam) where points2D is of shape BxNx2 or None if only_points_cam=True,
|
| 118 |
+
and points_cam is of shape Bx3xN.
|
| 119 |
+
"""
|
| 120 |
+
with torch.cuda.amp.autocast(dtype=torch.double):
|
| 121 |
+
N = points3D.shape[0] # Number of points
|
| 122 |
+
B = extrinsics.shape[0] # Batch size, i.e., number of cameras
|
| 123 |
+
points3D_homogeneous = torch.cat([points3D, torch.ones_like(points3D[..., 0:1])], dim=1) # Nx4
|
| 124 |
+
# Reshape for batch processing
|
| 125 |
+
points3D_homogeneous = points3D_homogeneous.unsqueeze(0).expand(B, -1, -1) # BxNx4
|
| 126 |
+
|
| 127 |
+
# Step 1: Apply extrinsic parameters
|
| 128 |
+
# Transform 3D points to camera coordinate system for all cameras
|
| 129 |
+
points_cam = torch.bmm(extrinsics, points3D_homogeneous.transpose(-1, -2))
|
| 130 |
+
|
| 131 |
+
if only_points_cam:
|
| 132 |
+
return None, points_cam
|
| 133 |
+
|
| 134 |
+
# Step 2: Apply intrinsic parameters and (optional) distortion
|
| 135 |
+
points2D = img_from_cam(intrinsics, points_cam, extra_params, default)
|
| 136 |
+
|
| 137 |
+
return points2D, points_cam
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def img_from_cam(intrinsics, points_cam, extra_params=None, default=0.0):
|
| 141 |
+
"""
|
| 142 |
+
Applies intrinsic parameters and optional distortion to the given 3D points.
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
intrinsics (torch.Tensor): Intrinsic camera parameters of shape Bx3x3.
|
| 146 |
+
points_cam (torch.Tensor): 3D points in camera coordinates of shape Bx3xN.
|
| 147 |
+
extra_params (torch.Tensor, optional): Distortion parameters of shape BxN, where N can be 1, 2, or 4.
|
| 148 |
+
default (float, optional): Default value to replace NaNs in the output.
|
| 149 |
+
|
| 150 |
+
Returns:
|
| 151 |
+
points2D (torch.Tensor): 2D points in pixel coordinates of shape BxNx2.
|
| 152 |
+
"""
|
| 153 |
+
|
| 154 |
+
# Normalize by the third coordinate (homogeneous division)
|
| 155 |
+
points_cam = points_cam / points_cam[:, 2:3, :]
|
| 156 |
+
# Extract uv
|
| 157 |
+
uv = points_cam[:, :2, :]
|
| 158 |
+
|
| 159 |
+
# Apply distortion if extra_params are provided
|
| 160 |
+
if extra_params is not None:
|
| 161 |
+
uu, vv = apply_distortion(extra_params, uv[:, 0], uv[:, 1])
|
| 162 |
+
uv = torch.stack([uu, vv], dim=1)
|
| 163 |
+
|
| 164 |
+
# Prepare points_cam for batch matrix multiplication
|
| 165 |
+
points_cam_homo = torch.cat((uv, torch.ones_like(uv[:, :1, :])), dim=1) # Bx3xN
|
| 166 |
+
# Apply intrinsic parameters using batch matrix multiplication
|
| 167 |
+
points2D_homo = torch.bmm(intrinsics, points_cam_homo) # Bx3xN
|
| 168 |
+
|
| 169 |
+
# Extract x and y coordinates
|
| 170 |
+
points2D = points2D_homo[:, :2, :] # Bx2xN
|
| 171 |
+
|
| 172 |
+
# Replace NaNs with default value
|
| 173 |
+
points2D = torch.nan_to_num(points2D, nan=default)
|
| 174 |
+
|
| 175 |
+
return points2D.transpose(1, 2) # BxNx2
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
if __name__ == "__main__":
|
| 179 |
+
# Set up example input
|
| 180 |
+
B, N = 24, 10240
|
| 181 |
+
|
| 182 |
+
for _ in range(100):
|
| 183 |
+
points3D = np.random.rand(N, 3).astype(np.float64)
|
| 184 |
+
extrinsics = np.random.rand(B, 3, 4).astype(np.float64)
|
| 185 |
+
intrinsics = np.random.rand(B, 3, 3).astype(np.float64)
|
| 186 |
+
|
| 187 |
+
# Convert to torch tensors
|
| 188 |
+
points3D_torch = torch.tensor(points3D)
|
| 189 |
+
extrinsics_torch = torch.tensor(extrinsics)
|
| 190 |
+
intrinsics_torch = torch.tensor(intrinsics)
|
| 191 |
+
|
| 192 |
+
# Run NumPy implementation
|
| 193 |
+
points2D_np, points_cam_np = project_3D_points_np(points3D, extrinsics, intrinsics)
|
| 194 |
+
|
| 195 |
+
# Run torch implementation
|
| 196 |
+
points2D_torch, points_cam_torch = project_3D_points(points3D_torch, extrinsics_torch, intrinsics_torch)
|
| 197 |
+
|
| 198 |
+
# Convert torch output to numpy
|
| 199 |
+
points2D_torch_np = points2D_torch.detach().numpy()
|
| 200 |
+
points_cam_torch_np = points_cam_torch.detach().numpy()
|
| 201 |
+
|
| 202 |
+
# Compute difference
|
| 203 |
+
diff = np.abs(points2D_np - points2D_torch_np)
|
| 204 |
+
print("Difference between NumPy and PyTorch implementations:")
|
| 205 |
+
print(diff)
|
| 206 |
+
|
| 207 |
+
# Check max error
|
| 208 |
+
max_diff = np.max(diff)
|
| 209 |
+
print(f"Maximum difference: {max_diff}")
|
| 210 |
+
|
| 211 |
+
if np.allclose(points2D_np, points2D_torch_np, atol=1e-6):
|
| 212 |
+
print("Implementations match closely.")
|
| 213 |
+
else:
|
| 214 |
+
print("Significant differences detected.")
|
| 215 |
+
|
| 216 |
+
if points_cam_np is not None:
|
| 217 |
+
points_cam_diff = np.abs(points_cam_np - points_cam_torch_np)
|
| 218 |
+
print("Difference between NumPy and PyTorch camera-space coordinates:")
|
| 219 |
+
print(points_cam_diff)
|
| 220 |
+
|
| 221 |
+
# Check max error
|
| 222 |
+
max_cam_diff = np.max(points_cam_diff)
|
| 223 |
+
print(f"Maximum camera-space coordinate difference: {max_cam_diff}")
|
| 224 |
+
|
| 225 |
+
if np.allclose(points_cam_np, points_cam_torch_np, atol=1e-6):
|
| 226 |
+
print("Camera-space coordinates match closely.")
|
| 227 |
+
else:
|
| 228 |
+
print("Significant differences detected in camera-space coordinates.")
|
vggt/dependency/track_modules/__init__.py
ADDED
|
File without changes
|
vggt/dependency/track_modules/base_track_predictor.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
from einops import rearrange, repeat
|
| 10 |
+
|
| 11 |
+
from .blocks import EfficientUpdateFormer, CorrBlock
|
| 12 |
+
from .utils import sample_features4d, get_2d_embedding, get_2d_sincos_pos_embed
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class BaseTrackerPredictor(nn.Module):
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
stride=4,
|
| 19 |
+
corr_levels=5,
|
| 20 |
+
corr_radius=4,
|
| 21 |
+
latent_dim=128,
|
| 22 |
+
hidden_size=384,
|
| 23 |
+
use_spaceatt=True,
|
| 24 |
+
depth=6,
|
| 25 |
+
fine=False,
|
| 26 |
+
):
|
| 27 |
+
super(BaseTrackerPredictor, self).__init__()
|
| 28 |
+
"""
|
| 29 |
+
The base template to create a track predictor
|
| 30 |
+
|
| 31 |
+
Modified from https://github.com/facebookresearch/co-tracker/
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
self.stride = stride
|
| 35 |
+
self.latent_dim = latent_dim
|
| 36 |
+
self.corr_levels = corr_levels
|
| 37 |
+
self.corr_radius = corr_radius
|
| 38 |
+
self.hidden_size = hidden_size
|
| 39 |
+
self.fine = fine
|
| 40 |
+
|
| 41 |
+
self.flows_emb_dim = latent_dim // 2
|
| 42 |
+
self.transformer_dim = self.corr_levels * (self.corr_radius * 2 + 1) ** 2 + self.latent_dim * 2
|
| 43 |
+
|
| 44 |
+
if self.fine:
|
| 45 |
+
# TODO this is the old dummy code, will remove this when we train next model
|
| 46 |
+
self.transformer_dim += 4 if self.transformer_dim % 2 == 0 else 5
|
| 47 |
+
else:
|
| 48 |
+
self.transformer_dim += (4 - self.transformer_dim % 4) % 4
|
| 49 |
+
|
| 50 |
+
space_depth = depth if use_spaceatt else 0
|
| 51 |
+
time_depth = depth
|
| 52 |
+
|
| 53 |
+
self.updateformer = EfficientUpdateFormer(
|
| 54 |
+
space_depth=space_depth,
|
| 55 |
+
time_depth=time_depth,
|
| 56 |
+
input_dim=self.transformer_dim,
|
| 57 |
+
hidden_size=self.hidden_size,
|
| 58 |
+
output_dim=self.latent_dim + 2,
|
| 59 |
+
mlp_ratio=4.0,
|
| 60 |
+
add_space_attn=use_spaceatt,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
self.norm = nn.GroupNorm(1, self.latent_dim)
|
| 64 |
+
|
| 65 |
+
# A linear layer to update track feats at each iteration
|
| 66 |
+
self.ffeat_updater = nn.Sequential(nn.Linear(self.latent_dim, self.latent_dim), nn.GELU())
|
| 67 |
+
|
| 68 |
+
if not self.fine:
|
| 69 |
+
self.vis_predictor = nn.Sequential(nn.Linear(self.latent_dim, 1))
|
| 70 |
+
|
| 71 |
+
def forward(self, query_points, fmaps=None, iters=4, return_feat=False, down_ratio=1):
|
| 72 |
+
"""
|
| 73 |
+
query_points: B x N x 2, the number of batches, tracks, and xy
|
| 74 |
+
fmaps: B x S x C x HH x WW, the number of batches, frames, and feature dimension.
|
| 75 |
+
note HH and WW is the size of feature maps instead of original images
|
| 76 |
+
"""
|
| 77 |
+
B, N, D = query_points.shape
|
| 78 |
+
B, S, C, HH, WW = fmaps.shape
|
| 79 |
+
|
| 80 |
+
assert D == 2
|
| 81 |
+
|
| 82 |
+
# Scale the input query_points because we may downsample the images
|
| 83 |
+
# by down_ratio or self.stride
|
| 84 |
+
# e.g., if a 3x1024x1024 image is processed to a 128x256x256 feature map
|
| 85 |
+
# its query_points should be query_points/4
|
| 86 |
+
if down_ratio > 1:
|
| 87 |
+
query_points = query_points / float(down_ratio)
|
| 88 |
+
query_points = query_points / float(self.stride)
|
| 89 |
+
|
| 90 |
+
# Init with coords as the query points
|
| 91 |
+
# It means the search will start from the position of query points at the reference frames
|
| 92 |
+
coords = query_points.clone().reshape(B, 1, N, 2).repeat(1, S, 1, 1)
|
| 93 |
+
|
| 94 |
+
# Sample/extract the features of the query points in the query frame
|
| 95 |
+
query_track_feat = sample_features4d(fmaps[:, 0], coords[:, 0])
|
| 96 |
+
|
| 97 |
+
# init track feats by query feats
|
| 98 |
+
track_feats = query_track_feat.unsqueeze(1).repeat(1, S, 1, 1) # B, S, N, C
|
| 99 |
+
# back up the init coords
|
| 100 |
+
coords_backup = coords.clone()
|
| 101 |
+
|
| 102 |
+
# Construct the correlation block
|
| 103 |
+
|
| 104 |
+
fcorr_fn = CorrBlock(fmaps, num_levels=self.corr_levels, radius=self.corr_radius)
|
| 105 |
+
|
| 106 |
+
coord_preds = []
|
| 107 |
+
|
| 108 |
+
# Iterative Refinement
|
| 109 |
+
for itr in range(iters):
|
| 110 |
+
# Detach the gradients from the last iteration
|
| 111 |
+
# (in my experience, not very important for performance)
|
| 112 |
+
coords = coords.detach()
|
| 113 |
+
|
| 114 |
+
# Compute the correlation (check the implementation of CorrBlock)
|
| 115 |
+
|
| 116 |
+
fcorr_fn.corr(track_feats)
|
| 117 |
+
fcorrs = fcorr_fn.sample(coords) # B, S, N, corrdim
|
| 118 |
+
|
| 119 |
+
corrdim = fcorrs.shape[3]
|
| 120 |
+
|
| 121 |
+
fcorrs_ = fcorrs.permute(0, 2, 1, 3).reshape(B * N, S, corrdim)
|
| 122 |
+
|
| 123 |
+
# Movement of current coords relative to query points
|
| 124 |
+
flows = (coords - coords[:, 0:1]).permute(0, 2, 1, 3).reshape(B * N, S, 2)
|
| 125 |
+
|
| 126 |
+
flows_emb = get_2d_embedding(flows, self.flows_emb_dim, cat_coords=False)
|
| 127 |
+
|
| 128 |
+
# (In my trials, it is also okay to just add the flows_emb instead of concat)
|
| 129 |
+
flows_emb = torch.cat([flows_emb, flows], dim=-1)
|
| 130 |
+
|
| 131 |
+
track_feats_ = track_feats.permute(0, 2, 1, 3).reshape(B * N, S, self.latent_dim)
|
| 132 |
+
|
| 133 |
+
# Concatenate them as the input for the transformers
|
| 134 |
+
transformer_input = torch.cat([flows_emb, fcorrs_, track_feats_], dim=2)
|
| 135 |
+
|
| 136 |
+
if transformer_input.shape[2] < self.transformer_dim:
|
| 137 |
+
# pad the features to match the dimension
|
| 138 |
+
pad_dim = self.transformer_dim - transformer_input.shape[2]
|
| 139 |
+
pad = torch.zeros_like(flows_emb[..., 0:pad_dim])
|
| 140 |
+
transformer_input = torch.cat([transformer_input, pad], dim=2)
|
| 141 |
+
|
| 142 |
+
# 2D positional embed
|
| 143 |
+
# TODO: this can be much simplified
|
| 144 |
+
pos_embed = get_2d_sincos_pos_embed(self.transformer_dim, grid_size=(HH, WW)).to(query_points.device)
|
| 145 |
+
sampled_pos_emb = sample_features4d(pos_embed.expand(B, -1, -1, -1), coords[:, 0])
|
| 146 |
+
sampled_pos_emb = rearrange(sampled_pos_emb, "b n c -> (b n) c").unsqueeze(1)
|
| 147 |
+
|
| 148 |
+
x = transformer_input + sampled_pos_emb
|
| 149 |
+
|
| 150 |
+
# B, N, S, C
|
| 151 |
+
x = rearrange(x, "(b n) s d -> b n s d", b=B)
|
| 152 |
+
|
| 153 |
+
# Compute the delta coordinates and delta track features
|
| 154 |
+
delta = self.updateformer(x)
|
| 155 |
+
# BN, S, C
|
| 156 |
+
delta = rearrange(delta, " b n s d -> (b n) s d", b=B)
|
| 157 |
+
delta_coords_ = delta[:, :, :2]
|
| 158 |
+
delta_feats_ = delta[:, :, 2:]
|
| 159 |
+
|
| 160 |
+
track_feats_ = track_feats_.reshape(B * N * S, self.latent_dim)
|
| 161 |
+
delta_feats_ = delta_feats_.reshape(B * N * S, self.latent_dim)
|
| 162 |
+
|
| 163 |
+
# Update the track features
|
| 164 |
+
track_feats_ = self.ffeat_updater(self.norm(delta_feats_)) + track_feats_
|
| 165 |
+
track_feats = track_feats_.reshape(B, N, S, self.latent_dim).permute(0, 2, 1, 3) # BxSxNxC
|
| 166 |
+
|
| 167 |
+
# B x S x N x 2
|
| 168 |
+
coords = coords + delta_coords_.reshape(B, N, S, 2).permute(0, 2, 1, 3)
|
| 169 |
+
|
| 170 |
+
# Force coord0 as query
|
| 171 |
+
# because we assume the query points should not be changed
|
| 172 |
+
coords[:, 0] = coords_backup[:, 0]
|
| 173 |
+
|
| 174 |
+
# The predicted tracks are in the original image scale
|
| 175 |
+
if down_ratio > 1:
|
| 176 |
+
coord_preds.append(coords * self.stride * down_ratio)
|
| 177 |
+
else:
|
| 178 |
+
coord_preds.append(coords * self.stride)
|
| 179 |
+
|
| 180 |
+
# B, S, N
|
| 181 |
+
if not self.fine:
|
| 182 |
+
vis_e = self.vis_predictor(track_feats.reshape(B * S * N, self.latent_dim)).reshape(B, S, N)
|
| 183 |
+
vis_e = torch.sigmoid(vis_e)
|
| 184 |
+
else:
|
| 185 |
+
vis_e = None
|
| 186 |
+
|
| 187 |
+
if return_feat:
|
| 188 |
+
return coord_preds, vis_e, track_feats, query_track_feat
|
| 189 |
+
else:
|
| 190 |
+
return coord_preds, vis_e
|
vggt/dependency/track_modules/blocks.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Modified from https://github.com/facebookresearch/co-tracker/
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
from functools import partial
|
| 15 |
+
from typing import Callable
|
| 16 |
+
import collections
|
| 17 |
+
from torch import Tensor
|
| 18 |
+
from itertools import repeat
|
| 19 |
+
|
| 20 |
+
from .utils import bilinear_sampler
|
| 21 |
+
|
| 22 |
+
from .modules import Mlp, AttnBlock, CrossAttnBlock, ResidualBlock
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class BasicEncoder(nn.Module):
|
| 26 |
+
def __init__(self, input_dim=3, output_dim=128, stride=4):
|
| 27 |
+
super(BasicEncoder, self).__init__()
|
| 28 |
+
|
| 29 |
+
self.stride = stride
|
| 30 |
+
self.norm_fn = "instance"
|
| 31 |
+
self.in_planes = output_dim // 2
|
| 32 |
+
|
| 33 |
+
self.norm1 = nn.InstanceNorm2d(self.in_planes)
|
| 34 |
+
self.norm2 = nn.InstanceNorm2d(output_dim * 2)
|
| 35 |
+
|
| 36 |
+
self.conv1 = nn.Conv2d(input_dim, self.in_planes, kernel_size=7, stride=2, padding=3, padding_mode="zeros")
|
| 37 |
+
self.relu1 = nn.ReLU(inplace=True)
|
| 38 |
+
self.layer1 = self._make_layer(output_dim // 2, stride=1)
|
| 39 |
+
self.layer2 = self._make_layer(output_dim // 4 * 3, stride=2)
|
| 40 |
+
self.layer3 = self._make_layer(output_dim, stride=2)
|
| 41 |
+
self.layer4 = self._make_layer(output_dim, stride=2)
|
| 42 |
+
|
| 43 |
+
self.conv2 = nn.Conv2d(
|
| 44 |
+
output_dim * 3 + output_dim // 4, output_dim * 2, kernel_size=3, padding=1, padding_mode="zeros"
|
| 45 |
+
)
|
| 46 |
+
self.relu2 = nn.ReLU(inplace=True)
|
| 47 |
+
self.conv3 = nn.Conv2d(output_dim * 2, output_dim, kernel_size=1)
|
| 48 |
+
|
| 49 |
+
for m in self.modules():
|
| 50 |
+
if isinstance(m, nn.Conv2d):
|
| 51 |
+
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
|
| 52 |
+
elif isinstance(m, (nn.InstanceNorm2d)):
|
| 53 |
+
if m.weight is not None:
|
| 54 |
+
nn.init.constant_(m.weight, 1)
|
| 55 |
+
if m.bias is not None:
|
| 56 |
+
nn.init.constant_(m.bias, 0)
|
| 57 |
+
|
| 58 |
+
def _make_layer(self, dim, stride=1):
|
| 59 |
+
layer1 = ResidualBlock(self.in_planes, dim, self.norm_fn, stride=stride)
|
| 60 |
+
layer2 = ResidualBlock(dim, dim, self.norm_fn, stride=1)
|
| 61 |
+
layers = (layer1, layer2)
|
| 62 |
+
|
| 63 |
+
self.in_planes = dim
|
| 64 |
+
return nn.Sequential(*layers)
|
| 65 |
+
|
| 66 |
+
def forward(self, x):
|
| 67 |
+
_, _, H, W = x.shape
|
| 68 |
+
|
| 69 |
+
x = self.conv1(x)
|
| 70 |
+
x = self.norm1(x)
|
| 71 |
+
x = self.relu1(x)
|
| 72 |
+
|
| 73 |
+
a = self.layer1(x)
|
| 74 |
+
b = self.layer2(a)
|
| 75 |
+
c = self.layer3(b)
|
| 76 |
+
d = self.layer4(c)
|
| 77 |
+
|
| 78 |
+
a = _bilinear_intepolate(a, self.stride, H, W)
|
| 79 |
+
b = _bilinear_intepolate(b, self.stride, H, W)
|
| 80 |
+
c = _bilinear_intepolate(c, self.stride, H, W)
|
| 81 |
+
d = _bilinear_intepolate(d, self.stride, H, W)
|
| 82 |
+
|
| 83 |
+
x = self.conv2(torch.cat([a, b, c, d], dim=1))
|
| 84 |
+
x = self.norm2(x)
|
| 85 |
+
x = self.relu2(x)
|
| 86 |
+
x = self.conv3(x)
|
| 87 |
+
return x
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class ShallowEncoder(nn.Module):
|
| 91 |
+
def __init__(self, input_dim=3, output_dim=32, stride=1, norm_fn="instance"):
|
| 92 |
+
super(ShallowEncoder, self).__init__()
|
| 93 |
+
self.stride = stride
|
| 94 |
+
self.norm_fn = norm_fn
|
| 95 |
+
self.in_planes = output_dim
|
| 96 |
+
|
| 97 |
+
if self.norm_fn == "group":
|
| 98 |
+
self.norm1 = nn.GroupNorm(num_groups=8, num_channels=self.in_planes)
|
| 99 |
+
self.norm2 = nn.GroupNorm(num_groups=8, num_channels=output_dim * 2)
|
| 100 |
+
elif self.norm_fn == "batch":
|
| 101 |
+
self.norm1 = nn.BatchNorm2d(self.in_planes)
|
| 102 |
+
self.norm2 = nn.BatchNorm2d(output_dim * 2)
|
| 103 |
+
elif self.norm_fn == "instance":
|
| 104 |
+
self.norm1 = nn.InstanceNorm2d(self.in_planes)
|
| 105 |
+
self.norm2 = nn.InstanceNorm2d(output_dim * 2)
|
| 106 |
+
elif self.norm_fn == "none":
|
| 107 |
+
self.norm1 = nn.Sequential()
|
| 108 |
+
|
| 109 |
+
self.conv1 = nn.Conv2d(input_dim, self.in_planes, kernel_size=3, stride=2, padding=1, padding_mode="zeros")
|
| 110 |
+
self.relu1 = nn.ReLU(inplace=True)
|
| 111 |
+
|
| 112 |
+
self.layer1 = self._make_layer(output_dim, stride=2)
|
| 113 |
+
|
| 114 |
+
self.layer2 = self._make_layer(output_dim, stride=2)
|
| 115 |
+
self.conv2 = nn.Conv2d(output_dim, output_dim, kernel_size=1)
|
| 116 |
+
|
| 117 |
+
for m in self.modules():
|
| 118 |
+
if isinstance(m, nn.Conv2d):
|
| 119 |
+
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
|
| 120 |
+
elif isinstance(m, (nn.BatchNorm2d, nn.InstanceNorm2d, nn.GroupNorm)):
|
| 121 |
+
if m.weight is not None:
|
| 122 |
+
nn.init.constant_(m.weight, 1)
|
| 123 |
+
if m.bias is not None:
|
| 124 |
+
nn.init.constant_(m.bias, 0)
|
| 125 |
+
|
| 126 |
+
def _make_layer(self, dim, stride=1):
|
| 127 |
+
self.in_planes = dim
|
| 128 |
+
|
| 129 |
+
layer1 = ResidualBlock(self.in_planes, dim, self.norm_fn, stride=stride)
|
| 130 |
+
return layer1
|
| 131 |
+
|
| 132 |
+
def forward(self, x):
|
| 133 |
+
_, _, H, W = x.shape
|
| 134 |
+
|
| 135 |
+
x = self.conv1(x)
|
| 136 |
+
x = self.norm1(x)
|
| 137 |
+
x = self.relu1(x)
|
| 138 |
+
|
| 139 |
+
tmp = self.layer1(x)
|
| 140 |
+
x = x + F.interpolate(tmp, (x.shape[-2:]), mode="bilinear", align_corners=True)
|
| 141 |
+
tmp = self.layer2(tmp)
|
| 142 |
+
x = x + F.interpolate(tmp, (x.shape[-2:]), mode="bilinear", align_corners=True)
|
| 143 |
+
tmp = None
|
| 144 |
+
x = self.conv2(x) + x
|
| 145 |
+
|
| 146 |
+
x = F.interpolate(x, (H // self.stride, W // self.stride), mode="bilinear", align_corners=True)
|
| 147 |
+
|
| 148 |
+
return x
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def _bilinear_intepolate(x, stride, H, W):
|
| 152 |
+
return F.interpolate(x, (H // stride, W // stride), mode="bilinear", align_corners=True)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
class EfficientUpdateFormer(nn.Module):
|
| 156 |
+
"""
|
| 157 |
+
Transformer model that updates track estimates.
|
| 158 |
+
"""
|
| 159 |
+
|
| 160 |
+
def __init__(
|
| 161 |
+
self,
|
| 162 |
+
space_depth=6,
|
| 163 |
+
time_depth=6,
|
| 164 |
+
input_dim=320,
|
| 165 |
+
hidden_size=384,
|
| 166 |
+
num_heads=8,
|
| 167 |
+
output_dim=130,
|
| 168 |
+
mlp_ratio=4.0,
|
| 169 |
+
add_space_attn=True,
|
| 170 |
+
num_virtual_tracks=64,
|
| 171 |
+
):
|
| 172 |
+
super().__init__()
|
| 173 |
+
|
| 174 |
+
self.out_channels = 2
|
| 175 |
+
self.num_heads = num_heads
|
| 176 |
+
self.hidden_size = hidden_size
|
| 177 |
+
self.add_space_attn = add_space_attn
|
| 178 |
+
self.input_transform = torch.nn.Linear(input_dim, hidden_size, bias=True)
|
| 179 |
+
self.flow_head = torch.nn.Linear(hidden_size, output_dim, bias=True)
|
| 180 |
+
self.num_virtual_tracks = num_virtual_tracks
|
| 181 |
+
|
| 182 |
+
if self.add_space_attn:
|
| 183 |
+
self.virual_tracks = nn.Parameter(torch.randn(1, num_virtual_tracks, 1, hidden_size))
|
| 184 |
+
else:
|
| 185 |
+
self.virual_tracks = None
|
| 186 |
+
|
| 187 |
+
self.time_blocks = nn.ModuleList(
|
| 188 |
+
[
|
| 189 |
+
AttnBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio, attn_class=nn.MultiheadAttention)
|
| 190 |
+
for _ in range(time_depth)
|
| 191 |
+
]
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
if add_space_attn:
|
| 195 |
+
self.space_virtual_blocks = nn.ModuleList(
|
| 196 |
+
[
|
| 197 |
+
AttnBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio, attn_class=nn.MultiheadAttention)
|
| 198 |
+
for _ in range(space_depth)
|
| 199 |
+
]
|
| 200 |
+
)
|
| 201 |
+
self.space_point2virtual_blocks = nn.ModuleList(
|
| 202 |
+
[CrossAttnBlock(hidden_size, hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(space_depth)]
|
| 203 |
+
)
|
| 204 |
+
self.space_virtual2point_blocks = nn.ModuleList(
|
| 205 |
+
[CrossAttnBlock(hidden_size, hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(space_depth)]
|
| 206 |
+
)
|
| 207 |
+
assert len(self.time_blocks) >= len(self.space_virtual2point_blocks)
|
| 208 |
+
self.initialize_weights()
|
| 209 |
+
|
| 210 |
+
def initialize_weights(self):
|
| 211 |
+
def _basic_init(module):
|
| 212 |
+
if isinstance(module, nn.Linear):
|
| 213 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 214 |
+
if module.bias is not None:
|
| 215 |
+
nn.init.constant_(module.bias, 0)
|
| 216 |
+
|
| 217 |
+
def init_weights_vit_timm(module: nn.Module, name: str = ""):
|
| 218 |
+
"""ViT weight initialization, original timm impl (for reproducibility)"""
|
| 219 |
+
if isinstance(module, nn.Linear):
|
| 220 |
+
trunc_normal_(module.weight, std=0.02)
|
| 221 |
+
if module.bias is not None:
|
| 222 |
+
nn.init.zeros_(module.bias)
|
| 223 |
+
|
| 224 |
+
def forward(self, input_tensor, mask=None):
|
| 225 |
+
tokens = self.input_transform(input_tensor)
|
| 226 |
+
|
| 227 |
+
init_tokens = tokens
|
| 228 |
+
|
| 229 |
+
B, _, T, _ = tokens.shape
|
| 230 |
+
|
| 231 |
+
if self.add_space_attn:
|
| 232 |
+
virtual_tokens = self.virual_tracks.repeat(B, 1, T, 1)
|
| 233 |
+
tokens = torch.cat([tokens, virtual_tokens], dim=1)
|
| 234 |
+
|
| 235 |
+
_, N, _, _ = tokens.shape
|
| 236 |
+
|
| 237 |
+
j = 0
|
| 238 |
+
for i in range(len(self.time_blocks)):
|
| 239 |
+
time_tokens = tokens.contiguous().view(B * N, T, -1) # B N T C -> (B N) T C
|
| 240 |
+
time_tokens = self.time_blocks[i](time_tokens)
|
| 241 |
+
|
| 242 |
+
tokens = time_tokens.view(B, N, T, -1) # (B N) T C -> B N T C
|
| 243 |
+
if self.add_space_attn and (i % (len(self.time_blocks) // len(self.space_virtual_blocks)) == 0):
|
| 244 |
+
space_tokens = tokens.permute(0, 2, 1, 3).contiguous().view(B * T, N, -1) # B N T C -> (B T) N C
|
| 245 |
+
point_tokens = space_tokens[:, : N - self.num_virtual_tracks]
|
| 246 |
+
virtual_tokens = space_tokens[:, N - self.num_virtual_tracks :]
|
| 247 |
+
|
| 248 |
+
virtual_tokens = self.space_virtual2point_blocks[j](virtual_tokens, point_tokens, mask=mask)
|
| 249 |
+
virtual_tokens = self.space_virtual_blocks[j](virtual_tokens)
|
| 250 |
+
point_tokens = self.space_point2virtual_blocks[j](point_tokens, virtual_tokens, mask=mask)
|
| 251 |
+
space_tokens = torch.cat([point_tokens, virtual_tokens], dim=1)
|
| 252 |
+
tokens = space_tokens.view(B, T, N, -1).permute(0, 2, 1, 3) # (B T) N C -> B N T C
|
| 253 |
+
j += 1
|
| 254 |
+
|
| 255 |
+
if self.add_space_attn:
|
| 256 |
+
tokens = tokens[:, : N - self.num_virtual_tracks]
|
| 257 |
+
|
| 258 |
+
tokens = tokens + init_tokens
|
| 259 |
+
|
| 260 |
+
flow = self.flow_head(tokens)
|
| 261 |
+
return flow
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class CorrBlock:
|
| 265 |
+
def __init__(self, fmaps, num_levels=4, radius=4, multiple_track_feats=False, padding_mode="zeros"):
|
| 266 |
+
B, S, C, H, W = fmaps.shape
|
| 267 |
+
self.S, self.C, self.H, self.W = S, C, H, W
|
| 268 |
+
self.padding_mode = padding_mode
|
| 269 |
+
self.num_levels = num_levels
|
| 270 |
+
self.radius = radius
|
| 271 |
+
self.fmaps_pyramid = []
|
| 272 |
+
self.multiple_track_feats = multiple_track_feats
|
| 273 |
+
|
| 274 |
+
self.fmaps_pyramid.append(fmaps)
|
| 275 |
+
for i in range(self.num_levels - 1):
|
| 276 |
+
fmaps_ = fmaps.reshape(B * S, C, H, W)
|
| 277 |
+
fmaps_ = F.avg_pool2d(fmaps_, 2, stride=2)
|
| 278 |
+
_, _, H, W = fmaps_.shape
|
| 279 |
+
fmaps = fmaps_.reshape(B, S, C, H, W)
|
| 280 |
+
self.fmaps_pyramid.append(fmaps)
|
| 281 |
+
|
| 282 |
+
def sample(self, coords):
|
| 283 |
+
r = self.radius
|
| 284 |
+
B, S, N, D = coords.shape
|
| 285 |
+
assert D == 2
|
| 286 |
+
|
| 287 |
+
H, W = self.H, self.W
|
| 288 |
+
out_pyramid = []
|
| 289 |
+
for i in range(self.num_levels):
|
| 290 |
+
corrs = self.corrs_pyramid[i] # B, S, N, H, W
|
| 291 |
+
*_, H, W = corrs.shape
|
| 292 |
+
|
| 293 |
+
dx = torch.linspace(-r, r, 2 * r + 1)
|
| 294 |
+
dy = torch.linspace(-r, r, 2 * r + 1)
|
| 295 |
+
delta = torch.stack(torch.meshgrid(dy, dx, indexing="ij"), axis=-1).to(coords.device)
|
| 296 |
+
|
| 297 |
+
centroid_lvl = coords.reshape(B * S * N, 1, 1, 2) / 2**i
|
| 298 |
+
delta_lvl = delta.view(1, 2 * r + 1, 2 * r + 1, 2)
|
| 299 |
+
coords_lvl = centroid_lvl + delta_lvl
|
| 300 |
+
|
| 301 |
+
corrs = bilinear_sampler(corrs.reshape(B * S * N, 1, H, W), coords_lvl, padding_mode=self.padding_mode)
|
| 302 |
+
corrs = corrs.view(B, S, N, -1)
|
| 303 |
+
|
| 304 |
+
out_pyramid.append(corrs)
|
| 305 |
+
|
| 306 |
+
out = torch.cat(out_pyramid, dim=-1).contiguous() # B, S, N, LRR*2
|
| 307 |
+
return out
|
| 308 |
+
|
| 309 |
+
def corr(self, targets):
|
| 310 |
+
B, S, N, C = targets.shape
|
| 311 |
+
if self.multiple_track_feats:
|
| 312 |
+
targets_split = targets.split(C // self.num_levels, dim=-1)
|
| 313 |
+
B, S, N, C = targets_split[0].shape
|
| 314 |
+
|
| 315 |
+
assert C == self.C
|
| 316 |
+
assert S == self.S
|
| 317 |
+
|
| 318 |
+
fmap1 = targets
|
| 319 |
+
|
| 320 |
+
self.corrs_pyramid = []
|
| 321 |
+
for i, fmaps in enumerate(self.fmaps_pyramid):
|
| 322 |
+
*_, H, W = fmaps.shape
|
| 323 |
+
fmap2s = fmaps.view(B, S, C, H * W) # B S C H W -> B S C (H W)
|
| 324 |
+
if self.multiple_track_feats:
|
| 325 |
+
fmap1 = targets_split[i]
|
| 326 |
+
corrs = torch.matmul(fmap1, fmap2s)
|
| 327 |
+
corrs = corrs.view(B, S, N, H, W) # B S N (H W) -> B S N H W
|
| 328 |
+
corrs = corrs / torch.sqrt(torch.tensor(C).float())
|
| 329 |
+
self.corrs_pyramid.append(corrs)
|
vggt/dependency/track_modules/modules.py
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
from functools import partial
|
| 12 |
+
from typing import Callable
|
| 13 |
+
import collections
|
| 14 |
+
from torch import Tensor
|
| 15 |
+
from itertools import repeat
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# From PyTorch internals
|
| 19 |
+
def _ntuple(n):
|
| 20 |
+
def parse(x):
|
| 21 |
+
if isinstance(x, collections.abc.Iterable) and not isinstance(x, str):
|
| 22 |
+
return tuple(x)
|
| 23 |
+
return tuple(repeat(x, n))
|
| 24 |
+
|
| 25 |
+
return parse
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def exists(val):
|
| 29 |
+
return val is not None
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def default(val, d):
|
| 33 |
+
return val if exists(val) else d
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
to_2tuple = _ntuple(2)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class ResidualBlock(nn.Module):
|
| 40 |
+
"""
|
| 41 |
+
ResidualBlock: construct a block of two conv layers with residual connections
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
def __init__(self, in_planes, planes, norm_fn="group", stride=1, kernel_size=3):
|
| 45 |
+
super(ResidualBlock, self).__init__()
|
| 46 |
+
|
| 47 |
+
self.conv1 = nn.Conv2d(
|
| 48 |
+
in_planes, planes, kernel_size=kernel_size, padding=1, stride=stride, padding_mode="zeros"
|
| 49 |
+
)
|
| 50 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=kernel_size, padding=1, padding_mode="zeros")
|
| 51 |
+
self.relu = nn.ReLU(inplace=True)
|
| 52 |
+
|
| 53 |
+
num_groups = planes // 8
|
| 54 |
+
|
| 55 |
+
if norm_fn == "group":
|
| 56 |
+
self.norm1 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 57 |
+
self.norm2 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 58 |
+
if not stride == 1:
|
| 59 |
+
self.norm3 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 60 |
+
|
| 61 |
+
elif norm_fn == "batch":
|
| 62 |
+
self.norm1 = nn.BatchNorm2d(planes)
|
| 63 |
+
self.norm2 = nn.BatchNorm2d(planes)
|
| 64 |
+
if not stride == 1:
|
| 65 |
+
self.norm3 = nn.BatchNorm2d(planes)
|
| 66 |
+
|
| 67 |
+
elif norm_fn == "instance":
|
| 68 |
+
self.norm1 = nn.InstanceNorm2d(planes)
|
| 69 |
+
self.norm2 = nn.InstanceNorm2d(planes)
|
| 70 |
+
if not stride == 1:
|
| 71 |
+
self.norm3 = nn.InstanceNorm2d(planes)
|
| 72 |
+
|
| 73 |
+
elif norm_fn == "none":
|
| 74 |
+
self.norm1 = nn.Sequential()
|
| 75 |
+
self.norm2 = nn.Sequential()
|
| 76 |
+
if not stride == 1:
|
| 77 |
+
self.norm3 = nn.Sequential()
|
| 78 |
+
else:
|
| 79 |
+
raise NotImplementedError
|
| 80 |
+
|
| 81 |
+
if stride == 1:
|
| 82 |
+
self.downsample = None
|
| 83 |
+
else:
|
| 84 |
+
self.downsample = nn.Sequential(nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride), self.norm3)
|
| 85 |
+
|
| 86 |
+
def forward(self, x):
|
| 87 |
+
y = x
|
| 88 |
+
y = self.relu(self.norm1(self.conv1(y)))
|
| 89 |
+
y = self.relu(self.norm2(self.conv2(y)))
|
| 90 |
+
|
| 91 |
+
if self.downsample is not None:
|
| 92 |
+
x = self.downsample(x)
|
| 93 |
+
|
| 94 |
+
return self.relu(x + y)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class Mlp(nn.Module):
|
| 98 |
+
"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""
|
| 99 |
+
|
| 100 |
+
def __init__(
|
| 101 |
+
self,
|
| 102 |
+
in_features,
|
| 103 |
+
hidden_features=None,
|
| 104 |
+
out_features=None,
|
| 105 |
+
act_layer=nn.GELU,
|
| 106 |
+
norm_layer=None,
|
| 107 |
+
bias=True,
|
| 108 |
+
drop=0.0,
|
| 109 |
+
use_conv=False,
|
| 110 |
+
):
|
| 111 |
+
super().__init__()
|
| 112 |
+
out_features = out_features or in_features
|
| 113 |
+
hidden_features = hidden_features or in_features
|
| 114 |
+
bias = to_2tuple(bias)
|
| 115 |
+
drop_probs = to_2tuple(drop)
|
| 116 |
+
linear_layer = partial(nn.Conv2d, kernel_size=1) if use_conv else nn.Linear
|
| 117 |
+
|
| 118 |
+
self.fc1 = linear_layer(in_features, hidden_features, bias=bias[0])
|
| 119 |
+
self.act = act_layer()
|
| 120 |
+
self.drop1 = nn.Dropout(drop_probs[0])
|
| 121 |
+
self.fc2 = linear_layer(hidden_features, out_features, bias=bias[1])
|
| 122 |
+
self.drop2 = nn.Dropout(drop_probs[1])
|
| 123 |
+
|
| 124 |
+
def forward(self, x):
|
| 125 |
+
x = self.fc1(x)
|
| 126 |
+
x = self.act(x)
|
| 127 |
+
x = self.drop1(x)
|
| 128 |
+
x = self.fc2(x)
|
| 129 |
+
x = self.drop2(x)
|
| 130 |
+
return x
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class AttnBlock(nn.Module):
|
| 134 |
+
def __init__(
|
| 135 |
+
self,
|
| 136 |
+
hidden_size,
|
| 137 |
+
num_heads,
|
| 138 |
+
attn_class: Callable[..., nn.Module] = nn.MultiheadAttention,
|
| 139 |
+
mlp_ratio=4.0,
|
| 140 |
+
**block_kwargs,
|
| 141 |
+
):
|
| 142 |
+
"""
|
| 143 |
+
Self attention block
|
| 144 |
+
"""
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 147 |
+
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 148 |
+
|
| 149 |
+
self.attn = attn_class(embed_dim=hidden_size, num_heads=num_heads, batch_first=True, **block_kwargs)
|
| 150 |
+
|
| 151 |
+
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
| 152 |
+
|
| 153 |
+
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, drop=0)
|
| 154 |
+
|
| 155 |
+
def forward(self, x, mask=None):
|
| 156 |
+
# Prepare the mask for PyTorch's attention (it expects a different format)
|
| 157 |
+
# attn_mask = mask if mask is not None else None
|
| 158 |
+
# Normalize before attention
|
| 159 |
+
x = self.norm1(x)
|
| 160 |
+
|
| 161 |
+
# PyTorch's MultiheadAttention returns attn_output, attn_output_weights
|
| 162 |
+
# attn_output, _ = self.attn(x, x, x, attn_mask=attn_mask)
|
| 163 |
+
|
| 164 |
+
attn_output, _ = self.attn(x, x, x)
|
| 165 |
+
|
| 166 |
+
# Add & Norm
|
| 167 |
+
x = x + attn_output
|
| 168 |
+
x = x + self.mlp(self.norm2(x))
|
| 169 |
+
return x
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
class CrossAttnBlock(nn.Module):
|
| 173 |
+
def __init__(self, hidden_size, context_dim, num_heads=1, mlp_ratio=4.0, **block_kwargs):
|
| 174 |
+
"""
|
| 175 |
+
Cross attention block
|
| 176 |
+
"""
|
| 177 |
+
super().__init__()
|
| 178 |
+
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 179 |
+
self.norm_context = nn.LayerNorm(hidden_size)
|
| 180 |
+
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 181 |
+
|
| 182 |
+
self.cross_attn = nn.MultiheadAttention(
|
| 183 |
+
embed_dim=hidden_size, num_heads=num_heads, batch_first=True, **block_kwargs
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
| 187 |
+
|
| 188 |
+
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, drop=0)
|
| 189 |
+
|
| 190 |
+
def forward(self, x, context, mask=None):
|
| 191 |
+
# Normalize inputs
|
| 192 |
+
x = self.norm1(x)
|
| 193 |
+
context = self.norm_context(context)
|
| 194 |
+
|
| 195 |
+
# Apply cross attention
|
| 196 |
+
# Note: nn.MultiheadAttention returns attn_output, attn_output_weights
|
| 197 |
+
attn_output, _ = self.cross_attn(x, context, context, attn_mask=mask)
|
| 198 |
+
|
| 199 |
+
# Add & Norm
|
| 200 |
+
x = x + attn_output
|
| 201 |
+
x = x + self.mlp(self.norm2(x))
|
| 202 |
+
return x
|
vggt/dependency/track_modules/track_refine.py
ADDED
|
@@ -0,0 +1,419 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from functools import partial
|
| 13 |
+
from torch import nn, einsum
|
| 14 |
+
from einops import rearrange, repeat
|
| 15 |
+
from einops.layers.torch import Rearrange, Reduce
|
| 16 |
+
|
| 17 |
+
from PIL import Image
|
| 18 |
+
import os
|
| 19 |
+
from typing import Union, Tuple
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def refine_track(
|
| 23 |
+
images, fine_fnet, fine_tracker, coarse_pred, compute_score=False, pradius=15, sradius=2, fine_iters=6, chunk=40960
|
| 24 |
+
):
|
| 25 |
+
"""
|
| 26 |
+
Refines the tracking of images using a fine track predictor and a fine feature network.
|
| 27 |
+
Check https://arxiv.org/abs/2312.04563 for more details.
|
| 28 |
+
|
| 29 |
+
Args:
|
| 30 |
+
images (torch.Tensor): The images to be tracked.
|
| 31 |
+
fine_fnet (nn.Module): The fine feature network.
|
| 32 |
+
fine_tracker (nn.Module): The fine track predictor.
|
| 33 |
+
coarse_pred (torch.Tensor): The coarse predictions of tracks.
|
| 34 |
+
compute_score (bool, optional): Whether to compute the score. Defaults to False.
|
| 35 |
+
pradius (int, optional): The radius of a patch. Defaults to 15.
|
| 36 |
+
sradius (int, optional): The search radius. Defaults to 2.
|
| 37 |
+
|
| 38 |
+
Returns:
|
| 39 |
+
torch.Tensor: The refined tracks.
|
| 40 |
+
torch.Tensor, optional: The score.
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
# coarse_pred shape: BxSxNx2,
|
| 44 |
+
# where B is the batch, S is the video/images length, and N is the number of tracks
|
| 45 |
+
# now we are going to extract patches with the center at coarse_pred
|
| 46 |
+
# Please note that the last dimension indicates x and y, and hence has a dim number of 2
|
| 47 |
+
B, S, N, _ = coarse_pred.shape
|
| 48 |
+
_, _, _, H, W = images.shape
|
| 49 |
+
|
| 50 |
+
# Given the raidus of a patch, compute the patch size
|
| 51 |
+
psize = pradius * 2 + 1
|
| 52 |
+
|
| 53 |
+
# Note that we assume the first frame is the query frame
|
| 54 |
+
# so the 2D locations of the first frame are the query points
|
| 55 |
+
query_points = coarse_pred[:, 0]
|
| 56 |
+
|
| 57 |
+
# Given 2D positions, we can use grid_sample to extract patches
|
| 58 |
+
# but it takes too much memory.
|
| 59 |
+
# Instead, we use the floored track xy to sample patches.
|
| 60 |
+
|
| 61 |
+
# For example, if the query point xy is (128.16, 252.78),
|
| 62 |
+
# and the patch size is (31, 31),
|
| 63 |
+
# our goal is to extract the content of a rectangle
|
| 64 |
+
# with left top: (113.16, 237.78)
|
| 65 |
+
# and right bottom: (143.16, 267.78).
|
| 66 |
+
# However, we record the floored left top: (113, 237)
|
| 67 |
+
# and the offset (0.16, 0.78)
|
| 68 |
+
# Then what we need is just unfolding the images like in CNN,
|
| 69 |
+
# picking the content at [(113, 237), (143, 267)].
|
| 70 |
+
# Such operations are highly optimized at pytorch
|
| 71 |
+
# (well if you really want to use interpolation, check the function extract_glimpse() below)
|
| 72 |
+
|
| 73 |
+
with torch.no_grad():
|
| 74 |
+
content_to_extract = images.reshape(B * S, 3, H, W)
|
| 75 |
+
C_in = content_to_extract.shape[1]
|
| 76 |
+
|
| 77 |
+
# Please refer to https://pytorch.org/docs/stable/generated/torch.nn.Unfold.html
|
| 78 |
+
# for the detailed explanation of unfold()
|
| 79 |
+
# Here it runs sliding windows (psize x psize) to build patches
|
| 80 |
+
# The shape changes from
|
| 81 |
+
# (B*S)x C_in x H x W to (B*S)x C_in x H_new x W_new x Psize x Psize
|
| 82 |
+
# where Psize is the size of patch
|
| 83 |
+
content_to_extract = content_to_extract.unfold(2, psize, 1).unfold(3, psize, 1)
|
| 84 |
+
|
| 85 |
+
# Floor the coarse predictions to get integers and save the fractional/decimal
|
| 86 |
+
track_int = coarse_pred.floor().int()
|
| 87 |
+
track_frac = coarse_pred - track_int
|
| 88 |
+
|
| 89 |
+
# Note the points represent the center of patches
|
| 90 |
+
# now we get the location of the top left corner of patches
|
| 91 |
+
# because the ouput of pytorch unfold are indexed by top left corner
|
| 92 |
+
topleft = track_int - pradius
|
| 93 |
+
topleft_BSN = topleft.clone()
|
| 94 |
+
|
| 95 |
+
# clamp the values so that we will not go out of indexes
|
| 96 |
+
# NOTE: (VERY IMPORTANT: This operation ASSUMES H=W).
|
| 97 |
+
# You need to seperately clamp x and y if H!=W
|
| 98 |
+
topleft = topleft.clamp(0, H - psize)
|
| 99 |
+
|
| 100 |
+
# Reshape from BxSxNx2 -> (B*S)xNx2
|
| 101 |
+
topleft = topleft.reshape(B * S, N, 2)
|
| 102 |
+
|
| 103 |
+
# Prepare batches for indexing, shape: (B*S)xN
|
| 104 |
+
batch_indices = torch.arange(B * S)[:, None].expand(-1, N).to(content_to_extract.device)
|
| 105 |
+
|
| 106 |
+
# extracted_patches: (B*S) x N x C_in x Psize x Psize
|
| 107 |
+
extracted_patches = content_to_extract[batch_indices, :, topleft[..., 1], topleft[..., 0]]
|
| 108 |
+
|
| 109 |
+
if chunk < 0:
|
| 110 |
+
# Extract image patches based on top left corners
|
| 111 |
+
# Feed patches to fine fent for features
|
| 112 |
+
patch_feat = fine_fnet(extracted_patches.reshape(B * S * N, C_in, psize, psize))
|
| 113 |
+
else:
|
| 114 |
+
patches = extracted_patches.reshape(B * S * N, C_in, psize, psize)
|
| 115 |
+
|
| 116 |
+
patch_feat_list = []
|
| 117 |
+
for p in torch.split(patches, chunk):
|
| 118 |
+
patch_feat_list += [fine_fnet(p)]
|
| 119 |
+
patch_feat = torch.cat(patch_feat_list, 0)
|
| 120 |
+
|
| 121 |
+
C_out = patch_feat.shape[1]
|
| 122 |
+
|
| 123 |
+
# Refine the coarse tracks by fine_tracker
|
| 124 |
+
# reshape back to B x S x N x C_out x Psize x Psize
|
| 125 |
+
patch_feat = patch_feat.reshape(B, S, N, C_out, psize, psize)
|
| 126 |
+
patch_feat = rearrange(patch_feat, "b s n c p q -> (b n) s c p q")
|
| 127 |
+
|
| 128 |
+
# Prepare for the query points for fine tracker
|
| 129 |
+
# They are relative to the patch left top corner,
|
| 130 |
+
# instead of the image top left corner now
|
| 131 |
+
# patch_query_points: N x 1 x 2
|
| 132 |
+
# only 1 here because for each patch we only have 1 query point
|
| 133 |
+
patch_query_points = track_frac[:, 0] + pradius
|
| 134 |
+
patch_query_points = patch_query_points.reshape(B * N, 2).unsqueeze(1)
|
| 135 |
+
|
| 136 |
+
# Feed the PATCH query points and tracks into fine tracker
|
| 137 |
+
fine_pred_track_lists, _, _, query_point_feat = fine_tracker(
|
| 138 |
+
query_points=patch_query_points, fmaps=patch_feat, iters=fine_iters, return_feat=True
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
# relative the patch top left
|
| 142 |
+
fine_pred_track = fine_pred_track_lists[-1].clone()
|
| 143 |
+
|
| 144 |
+
# From (relative to the patch top left) to (relative to the image top left)
|
| 145 |
+
for idx in range(len(fine_pred_track_lists)):
|
| 146 |
+
fine_level = rearrange(fine_pred_track_lists[idx], "(b n) s u v -> b s n u v", b=B, n=N)
|
| 147 |
+
fine_level = fine_level.squeeze(-2)
|
| 148 |
+
fine_level = fine_level + topleft_BSN
|
| 149 |
+
fine_pred_track_lists[idx] = fine_level
|
| 150 |
+
|
| 151 |
+
# relative to the image top left
|
| 152 |
+
refined_tracks = fine_pred_track_lists[-1].clone()
|
| 153 |
+
refined_tracks[:, 0] = query_points
|
| 154 |
+
|
| 155 |
+
score = None
|
| 156 |
+
|
| 157 |
+
if compute_score:
|
| 158 |
+
score = compute_score_fn(query_point_feat, patch_feat, fine_pred_track, sradius, psize, B, N, S, C_out)
|
| 159 |
+
|
| 160 |
+
return refined_tracks, score
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def refine_track_v0(
|
| 164 |
+
images, fine_fnet, fine_tracker, coarse_pred, compute_score=False, pradius=15, sradius=2, fine_iters=6
|
| 165 |
+
):
|
| 166 |
+
"""
|
| 167 |
+
COPIED FROM VGGSfM
|
| 168 |
+
|
| 169 |
+
Refines the tracking of images using a fine track predictor and a fine feature network.
|
| 170 |
+
Check https://arxiv.org/abs/2312.04563 for more details.
|
| 171 |
+
|
| 172 |
+
Args:
|
| 173 |
+
images (torch.Tensor): The images to be tracked.
|
| 174 |
+
fine_fnet (nn.Module): The fine feature network.
|
| 175 |
+
fine_tracker (nn.Module): The fine track predictor.
|
| 176 |
+
coarse_pred (torch.Tensor): The coarse predictions of tracks.
|
| 177 |
+
compute_score (bool, optional): Whether to compute the score. Defaults to False.
|
| 178 |
+
pradius (int, optional): The radius of a patch. Defaults to 15.
|
| 179 |
+
sradius (int, optional): The search radius. Defaults to 2.
|
| 180 |
+
|
| 181 |
+
Returns:
|
| 182 |
+
torch.Tensor: The refined tracks.
|
| 183 |
+
torch.Tensor, optional: The score.
|
| 184 |
+
"""
|
| 185 |
+
|
| 186 |
+
# coarse_pred shape: BxSxNx2,
|
| 187 |
+
# where B is the batch, S is the video/images length, and N is the number of tracks
|
| 188 |
+
# now we are going to extract patches with the center at coarse_pred
|
| 189 |
+
# Please note that the last dimension indicates x and y, and hence has a dim number of 2
|
| 190 |
+
B, S, N, _ = coarse_pred.shape
|
| 191 |
+
_, _, _, H, W = images.shape
|
| 192 |
+
|
| 193 |
+
# Given the raidus of a patch, compute the patch size
|
| 194 |
+
psize = pradius * 2 + 1
|
| 195 |
+
|
| 196 |
+
# Note that we assume the first frame is the query frame
|
| 197 |
+
# so the 2D locations of the first frame are the query points
|
| 198 |
+
query_points = coarse_pred[:, 0]
|
| 199 |
+
|
| 200 |
+
# Given 2D positions, we can use grid_sample to extract patches
|
| 201 |
+
# but it takes too much memory.
|
| 202 |
+
# Instead, we use the floored track xy to sample patches.
|
| 203 |
+
|
| 204 |
+
# For example, if the query point xy is (128.16, 252.78),
|
| 205 |
+
# and the patch size is (31, 31),
|
| 206 |
+
# our goal is to extract the content of a rectangle
|
| 207 |
+
# with left top: (113.16, 237.78)
|
| 208 |
+
# and right bottom: (143.16, 267.78).
|
| 209 |
+
# However, we record the floored left top: (113, 237)
|
| 210 |
+
# and the offset (0.16, 0.78)
|
| 211 |
+
# Then what we need is just unfolding the images like in CNN,
|
| 212 |
+
# picking the content at [(113, 237), (143, 267)].
|
| 213 |
+
# Such operations are highly optimized at pytorch
|
| 214 |
+
# (well if you really want to use interpolation, check the function extract_glimpse() below)
|
| 215 |
+
|
| 216 |
+
with torch.no_grad():
|
| 217 |
+
content_to_extract = images.reshape(B * S, 3, H, W)
|
| 218 |
+
C_in = content_to_extract.shape[1]
|
| 219 |
+
|
| 220 |
+
# Please refer to https://pytorch.org/docs/stable/generated/torch.nn.Unfold.html
|
| 221 |
+
# for the detailed explanation of unfold()
|
| 222 |
+
# Here it runs sliding windows (psize x psize) to build patches
|
| 223 |
+
# The shape changes from
|
| 224 |
+
# (B*S)x C_in x H x W to (B*S)x C_in x H_new x W_new x Psize x Psize
|
| 225 |
+
# where Psize is the size of patch
|
| 226 |
+
content_to_extract = content_to_extract.unfold(2, psize, 1).unfold(3, psize, 1)
|
| 227 |
+
|
| 228 |
+
# Floor the coarse predictions to get integers and save the fractional/decimal
|
| 229 |
+
track_int = coarse_pred.floor().int()
|
| 230 |
+
track_frac = coarse_pred - track_int
|
| 231 |
+
|
| 232 |
+
# Note the points represent the center of patches
|
| 233 |
+
# now we get the location of the top left corner of patches
|
| 234 |
+
# because the ouput of pytorch unfold are indexed by top left corner
|
| 235 |
+
topleft = track_int - pradius
|
| 236 |
+
topleft_BSN = topleft.clone()
|
| 237 |
+
|
| 238 |
+
# clamp the values so that we will not go out of indexes
|
| 239 |
+
# NOTE: (VERY IMPORTANT: This operation ASSUMES H=W).
|
| 240 |
+
# You need to seperately clamp x and y if H!=W
|
| 241 |
+
topleft = topleft.clamp(0, H - psize)
|
| 242 |
+
|
| 243 |
+
# Reshape from BxSxNx2 -> (B*S)xNx2
|
| 244 |
+
topleft = topleft.reshape(B * S, N, 2)
|
| 245 |
+
|
| 246 |
+
# Prepare batches for indexing, shape: (B*S)xN
|
| 247 |
+
batch_indices = torch.arange(B * S)[:, None].expand(-1, N).to(content_to_extract.device)
|
| 248 |
+
|
| 249 |
+
# Extract image patches based on top left corners
|
| 250 |
+
# extracted_patches: (B*S) x N x C_in x Psize x Psize
|
| 251 |
+
extracted_patches = content_to_extract[batch_indices, :, topleft[..., 1], topleft[..., 0]]
|
| 252 |
+
|
| 253 |
+
# Feed patches to fine fent for features
|
| 254 |
+
patch_feat = fine_fnet(extracted_patches.reshape(B * S * N, C_in, psize, psize))
|
| 255 |
+
|
| 256 |
+
C_out = patch_feat.shape[1]
|
| 257 |
+
|
| 258 |
+
# Refine the coarse tracks by fine_tracker
|
| 259 |
+
|
| 260 |
+
# reshape back to B x S x N x C_out x Psize x Psize
|
| 261 |
+
patch_feat = patch_feat.reshape(B, S, N, C_out, psize, psize)
|
| 262 |
+
patch_feat = rearrange(patch_feat, "b s n c p q -> (b n) s c p q")
|
| 263 |
+
|
| 264 |
+
# Prepare for the query points for fine tracker
|
| 265 |
+
# They are relative to the patch left top corner,
|
| 266 |
+
# instead of the image top left corner now
|
| 267 |
+
# patch_query_points: N x 1 x 2
|
| 268 |
+
# only 1 here because for each patch we only have 1 query point
|
| 269 |
+
patch_query_points = track_frac[:, 0] + pradius
|
| 270 |
+
patch_query_points = patch_query_points.reshape(B * N, 2).unsqueeze(1)
|
| 271 |
+
|
| 272 |
+
# Feed the PATCH query points and tracks into fine tracker
|
| 273 |
+
fine_pred_track_lists, _, _, query_point_feat = fine_tracker(
|
| 274 |
+
query_points=patch_query_points, fmaps=patch_feat, iters=fine_iters, return_feat=True
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
# relative the patch top left
|
| 278 |
+
fine_pred_track = fine_pred_track_lists[-1].clone()
|
| 279 |
+
|
| 280 |
+
# From (relative to the patch top left) to (relative to the image top left)
|
| 281 |
+
for idx in range(len(fine_pred_track_lists)):
|
| 282 |
+
fine_level = rearrange(fine_pred_track_lists[idx], "(b n) s u v -> b s n u v", b=B, n=N)
|
| 283 |
+
fine_level = fine_level.squeeze(-2)
|
| 284 |
+
fine_level = fine_level + topleft_BSN
|
| 285 |
+
fine_pred_track_lists[idx] = fine_level
|
| 286 |
+
|
| 287 |
+
# relative to the image top left
|
| 288 |
+
refined_tracks = fine_pred_track_lists[-1].clone()
|
| 289 |
+
refined_tracks[:, 0] = query_points
|
| 290 |
+
|
| 291 |
+
score = None
|
| 292 |
+
|
| 293 |
+
if compute_score:
|
| 294 |
+
score = compute_score_fn(query_point_feat, patch_feat, fine_pred_track, sradius, psize, B, N, S, C_out)
|
| 295 |
+
|
| 296 |
+
return refined_tracks, score
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
################################## NOTE: NOT USED ##################################
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
def compute_score_fn(query_point_feat, patch_feat, fine_pred_track, sradius, psize, B, N, S, C_out):
|
| 303 |
+
"""
|
| 304 |
+
Compute the scores, i.e., the standard deviation of the 2D similarity heatmaps,
|
| 305 |
+
given the query point features and reference frame feature maps
|
| 306 |
+
"""
|
| 307 |
+
|
| 308 |
+
from kornia.utils.grid import create_meshgrid
|
| 309 |
+
from kornia.geometry.subpix import dsnt
|
| 310 |
+
|
| 311 |
+
# query_point_feat initial shape: B x N x C_out,
|
| 312 |
+
# query_point_feat indicates the feat at the coorponsing query points
|
| 313 |
+
# Therefore we don't have S dimension here
|
| 314 |
+
query_point_feat = query_point_feat.reshape(B, N, C_out)
|
| 315 |
+
# reshape and expand to B x (S-1) x N x C_out
|
| 316 |
+
query_point_feat = query_point_feat.unsqueeze(1).expand(-1, S - 1, -1, -1)
|
| 317 |
+
# and reshape to (B*(S-1)*N) x C_out
|
| 318 |
+
query_point_feat = query_point_feat.reshape(B * (S - 1) * N, C_out)
|
| 319 |
+
|
| 320 |
+
# Radius and size for computing the score
|
| 321 |
+
ssize = sradius * 2 + 1
|
| 322 |
+
|
| 323 |
+
# Reshape, you know it, so many reshaping operations
|
| 324 |
+
patch_feat = rearrange(patch_feat, "(b n) s c p q -> b s n c p q", b=B, n=N)
|
| 325 |
+
|
| 326 |
+
# Again, we unfold the patches to smaller patches
|
| 327 |
+
# so that we can then focus on smaller patches
|
| 328 |
+
# patch_feat_unfold shape:
|
| 329 |
+
# B x S x N x C_out x (psize - 2*sradius) x (psize - 2*sradius) x ssize x ssize
|
| 330 |
+
# well a bit scary, but actually not
|
| 331 |
+
patch_feat_unfold = patch_feat.unfold(4, ssize, 1).unfold(5, ssize, 1)
|
| 332 |
+
|
| 333 |
+
# Do the same stuffs above, i.e., the same as extracting patches
|
| 334 |
+
fine_prediction_floor = fine_pred_track.floor().int()
|
| 335 |
+
fine_level_floor_topleft = fine_prediction_floor - sradius
|
| 336 |
+
|
| 337 |
+
# Clamp to ensure the smaller patch is valid
|
| 338 |
+
fine_level_floor_topleft = fine_level_floor_topleft.clamp(0, psize - ssize)
|
| 339 |
+
fine_level_floor_topleft = fine_level_floor_topleft.squeeze(2)
|
| 340 |
+
|
| 341 |
+
# Prepare the batch indices and xy locations
|
| 342 |
+
|
| 343 |
+
batch_indices_score = torch.arange(B)[:, None, None].expand(-1, S, N) # BxSxN
|
| 344 |
+
batch_indices_score = batch_indices_score.reshape(-1).to(patch_feat_unfold.device) # B*S*N
|
| 345 |
+
y_indices = fine_level_floor_topleft[..., 0].flatten() # Flatten H indices
|
| 346 |
+
x_indices = fine_level_floor_topleft[..., 1].flatten() # Flatten W indices
|
| 347 |
+
|
| 348 |
+
reference_frame_feat = patch_feat_unfold.reshape(
|
| 349 |
+
B * S * N, C_out, psize - sradius * 2, psize - sradius * 2, ssize, ssize
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
# Note again, according to pytorch convention
|
| 353 |
+
# x_indices cooresponds to [..., 1] and y_indices cooresponds to [..., 0]
|
| 354 |
+
reference_frame_feat = reference_frame_feat[batch_indices_score, :, x_indices, y_indices]
|
| 355 |
+
reference_frame_feat = reference_frame_feat.reshape(B, S, N, C_out, ssize, ssize)
|
| 356 |
+
# pick the frames other than the first one, so we have S-1 frames here
|
| 357 |
+
reference_frame_feat = reference_frame_feat[:, 1:].reshape(B * (S - 1) * N, C_out, ssize * ssize)
|
| 358 |
+
|
| 359 |
+
# Compute similarity
|
| 360 |
+
sim_matrix = torch.einsum("mc,mcr->mr", query_point_feat, reference_frame_feat)
|
| 361 |
+
softmax_temp = 1.0 / C_out**0.5
|
| 362 |
+
heatmap = torch.softmax(softmax_temp * sim_matrix, dim=1)
|
| 363 |
+
# 2D heatmaps
|
| 364 |
+
heatmap = heatmap.reshape(B * (S - 1) * N, ssize, ssize) # * x ssize x ssize
|
| 365 |
+
|
| 366 |
+
coords_normalized = dsnt.spatial_expectation2d(heatmap[None], True)[0]
|
| 367 |
+
grid_normalized = create_meshgrid(ssize, ssize, normalized_coordinates=True, device=heatmap.device).reshape(
|
| 368 |
+
1, -1, 2
|
| 369 |
+
)
|
| 370 |
+
|
| 371 |
+
var = torch.sum(grid_normalized**2 * heatmap.view(-1, ssize * ssize, 1), dim=1) - coords_normalized**2
|
| 372 |
+
std = torch.sum(torch.sqrt(torch.clamp(var, min=1e-10)), -1) # clamp needed for numerical stability
|
| 373 |
+
|
| 374 |
+
score = std.reshape(B, S - 1, N)
|
| 375 |
+
# set score as 1 for the query frame
|
| 376 |
+
score = torch.cat([torch.ones_like(score[:, 0:1]), score], dim=1)
|
| 377 |
+
|
| 378 |
+
return score
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
def extract_glimpse(
|
| 382 |
+
tensor: torch.Tensor, size: Tuple[int, int], offsets, mode="bilinear", padding_mode="zeros", debug=False, orib=None
|
| 383 |
+
):
|
| 384 |
+
B, C, W, H = tensor.shape
|
| 385 |
+
|
| 386 |
+
h, w = size
|
| 387 |
+
xs = torch.arange(0, w, dtype=tensor.dtype, device=tensor.device) - (w - 1) / 2.0
|
| 388 |
+
ys = torch.arange(0, h, dtype=tensor.dtype, device=tensor.device) - (h - 1) / 2.0
|
| 389 |
+
|
| 390 |
+
vy, vx = torch.meshgrid(ys, xs)
|
| 391 |
+
grid = torch.stack([vx, vy], dim=-1) # h, w, 2
|
| 392 |
+
grid = grid[None]
|
| 393 |
+
|
| 394 |
+
B, N, _ = offsets.shape
|
| 395 |
+
|
| 396 |
+
offsets = offsets.reshape((B * N), 1, 1, 2)
|
| 397 |
+
offsets_grid = offsets + grid
|
| 398 |
+
|
| 399 |
+
# normalised grid to [-1, 1]
|
| 400 |
+
offsets_grid = (offsets_grid - offsets_grid.new_tensor([W / 2, H / 2])) / offsets_grid.new_tensor([W / 2, H / 2])
|
| 401 |
+
|
| 402 |
+
# BxCxHxW -> Bx1xCxHxW
|
| 403 |
+
tensor = tensor[:, None]
|
| 404 |
+
|
| 405 |
+
# Bx1xCxHxW -> BxNxCxHxW
|
| 406 |
+
tensor = tensor.expand(-1, N, -1, -1, -1)
|
| 407 |
+
|
| 408 |
+
# BxNxCxHxW -> (B*N)xCxHxW
|
| 409 |
+
tensor = tensor.reshape((B * N), C, W, H)
|
| 410 |
+
|
| 411 |
+
sampled = torch.nn.functional.grid_sample(
|
| 412 |
+
tensor, offsets_grid, mode=mode, align_corners=False, padding_mode=padding_mode
|
| 413 |
+
)
|
| 414 |
+
|
| 415 |
+
# NOTE: I am not sure it should be h, w or w, h here
|
| 416 |
+
# but okay for sqaures
|
| 417 |
+
sampled = sampled.reshape(B, N, C, h, w)
|
| 418 |
+
|
| 419 |
+
return sampled
|
vggt/dependency/track_modules/utils.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
# Modified from https://github.com/facebookresearch/PoseDiffusion
|
| 8 |
+
# and https://github.com/facebookresearch/co-tracker/tree/main
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
from typing import Optional, Tuple, Union
|
| 16 |
+
from einops import rearrange, repeat
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_2d_sincos_pos_embed(embed_dim: int, grid_size: Union[int, Tuple[int, int]], return_grid=False) -> torch.Tensor:
|
| 20 |
+
"""
|
| 21 |
+
This function initializes a grid and generates a 2D positional embedding using sine and cosine functions.
|
| 22 |
+
It is a wrapper of get_2d_sincos_pos_embed_from_grid.
|
| 23 |
+
Args:
|
| 24 |
+
- embed_dim: The embedding dimension.
|
| 25 |
+
- grid_size: The grid size.
|
| 26 |
+
Returns:
|
| 27 |
+
- pos_embed: The generated 2D positional embedding.
|
| 28 |
+
"""
|
| 29 |
+
if isinstance(grid_size, tuple):
|
| 30 |
+
grid_size_h, grid_size_w = grid_size
|
| 31 |
+
else:
|
| 32 |
+
grid_size_h = grid_size_w = grid_size
|
| 33 |
+
grid_h = torch.arange(grid_size_h, dtype=torch.float)
|
| 34 |
+
grid_w = torch.arange(grid_size_w, dtype=torch.float)
|
| 35 |
+
grid = torch.meshgrid(grid_w, grid_h, indexing="xy")
|
| 36 |
+
grid = torch.stack(grid, dim=0)
|
| 37 |
+
grid = grid.reshape([2, 1, grid_size_h, grid_size_w])
|
| 38 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 39 |
+
if return_grid:
|
| 40 |
+
return (pos_embed.reshape(1, grid_size_h, grid_size_w, -1).permute(0, 3, 1, 2), grid)
|
| 41 |
+
return pos_embed.reshape(1, grid_size_h, grid_size_w, -1).permute(0, 3, 1, 2)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim: int, grid: torch.Tensor) -> torch.Tensor:
|
| 45 |
+
"""
|
| 46 |
+
This function generates a 2D positional embedding from a given grid using sine and cosine functions.
|
| 47 |
+
|
| 48 |
+
Args:
|
| 49 |
+
- embed_dim: The embedding dimension.
|
| 50 |
+
- grid: The grid to generate the embedding from.
|
| 51 |
+
|
| 52 |
+
Returns:
|
| 53 |
+
- emb: The generated 2D positional embedding.
|
| 54 |
+
"""
|
| 55 |
+
assert embed_dim % 2 == 0
|
| 56 |
+
|
| 57 |
+
# use half of dimensions to encode grid_h
|
| 58 |
+
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
|
| 59 |
+
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
|
| 60 |
+
|
| 61 |
+
emb = torch.cat([emb_h, emb_w], dim=2) # (H*W, D)
|
| 62 |
+
return emb
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def get_1d_sincos_pos_embed_from_grid(embed_dim: int, pos: torch.Tensor) -> torch.Tensor:
|
| 66 |
+
"""
|
| 67 |
+
This function generates a 1D positional embedding from a given grid using sine and cosine functions.
|
| 68 |
+
|
| 69 |
+
Args:
|
| 70 |
+
- embed_dim: The embedding dimension.
|
| 71 |
+
- pos: The position to generate the embedding from.
|
| 72 |
+
|
| 73 |
+
Returns:
|
| 74 |
+
- emb: The generated 1D positional embedding.
|
| 75 |
+
"""
|
| 76 |
+
assert embed_dim % 2 == 0
|
| 77 |
+
omega = torch.arange(embed_dim // 2, dtype=torch.double)
|
| 78 |
+
omega /= embed_dim / 2.0
|
| 79 |
+
omega = 1.0 / 10000**omega # (D/2,)
|
| 80 |
+
|
| 81 |
+
pos = pos.reshape(-1) # (M,)
|
| 82 |
+
out = torch.einsum("m,d->md", pos, omega) # (M, D/2), outer product
|
| 83 |
+
|
| 84 |
+
emb_sin = torch.sin(out) # (M, D/2)
|
| 85 |
+
emb_cos = torch.cos(out) # (M, D/2)
|
| 86 |
+
|
| 87 |
+
emb = torch.cat([emb_sin, emb_cos], dim=1) # (M, D)
|
| 88 |
+
return emb[None].float()
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def get_2d_embedding(xy: torch.Tensor, C: int, cat_coords: bool = True) -> torch.Tensor:
|
| 92 |
+
"""
|
| 93 |
+
This function generates a 2D positional embedding from given coordinates using sine and cosine functions.
|
| 94 |
+
|
| 95 |
+
Args:
|
| 96 |
+
- xy: The coordinates to generate the embedding from.
|
| 97 |
+
- C: The size of the embedding.
|
| 98 |
+
- cat_coords: A flag to indicate whether to concatenate the original coordinates to the embedding.
|
| 99 |
+
|
| 100 |
+
Returns:
|
| 101 |
+
- pe: The generated 2D positional embedding.
|
| 102 |
+
"""
|
| 103 |
+
B, N, D = xy.shape
|
| 104 |
+
assert D == 2
|
| 105 |
+
|
| 106 |
+
x = xy[:, :, 0:1]
|
| 107 |
+
y = xy[:, :, 1:2]
|
| 108 |
+
div_term = (torch.arange(0, C, 2, device=xy.device, dtype=torch.float32) * (1000.0 / C)).reshape(1, 1, int(C / 2))
|
| 109 |
+
|
| 110 |
+
pe_x = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
|
| 111 |
+
pe_y = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
|
| 112 |
+
|
| 113 |
+
pe_x[:, :, 0::2] = torch.sin(x * div_term)
|
| 114 |
+
pe_x[:, :, 1::2] = torch.cos(x * div_term)
|
| 115 |
+
|
| 116 |
+
pe_y[:, :, 0::2] = torch.sin(y * div_term)
|
| 117 |
+
pe_y[:, :, 1::2] = torch.cos(y * div_term)
|
| 118 |
+
|
| 119 |
+
pe = torch.cat([pe_x, pe_y], dim=2) # (B, N, C*3)
|
| 120 |
+
if cat_coords:
|
| 121 |
+
pe = torch.cat([xy, pe], dim=2) # (B, N, C*3+3)
|
| 122 |
+
return pe
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def bilinear_sampler(input, coords, align_corners=True, padding_mode="border"):
|
| 126 |
+
r"""Sample a tensor using bilinear interpolation
|
| 127 |
+
|
| 128 |
+
`bilinear_sampler(input, coords)` samples a tensor :attr:`input` at
|
| 129 |
+
coordinates :attr:`coords` using bilinear interpolation. It is the same
|
| 130 |
+
as `torch.nn.functional.grid_sample()` but with a different coordinate
|
| 131 |
+
convention.
|
| 132 |
+
|
| 133 |
+
The input tensor is assumed to be of shape :math:`(B, C, H, W)`, where
|
| 134 |
+
:math:`B` is the batch size, :math:`C` is the number of channels,
|
| 135 |
+
:math:`H` is the height of the image, and :math:`W` is the width of the
|
| 136 |
+
image. The tensor :attr:`coords` of shape :math:`(B, H_o, W_o, 2)` is
|
| 137 |
+
interpreted as an array of 2D point coordinates :math:`(x_i,y_i)`.
|
| 138 |
+
|
| 139 |
+
Alternatively, the input tensor can be of size :math:`(B, C, T, H, W)`,
|
| 140 |
+
in which case sample points are triplets :math:`(t_i,x_i,y_i)`. Note
|
| 141 |
+
that in this case the order of the components is slightly different
|
| 142 |
+
from `grid_sample()`, which would expect :math:`(x_i,y_i,t_i)`.
|
| 143 |
+
|
| 144 |
+
If `align_corners` is `True`, the coordinate :math:`x` is assumed to be
|
| 145 |
+
in the range :math:`[0,W-1]`, with 0 corresponding to the center of the
|
| 146 |
+
left-most image pixel :math:`W-1` to the center of the right-most
|
| 147 |
+
pixel.
|
| 148 |
+
|
| 149 |
+
If `align_corners` is `False`, the coordinate :math:`x` is assumed to
|
| 150 |
+
be in the range :math:`[0,W]`, with 0 corresponding to the left edge of
|
| 151 |
+
the left-most pixel :math:`W` to the right edge of the right-most
|
| 152 |
+
pixel.
|
| 153 |
+
|
| 154 |
+
Similar conventions apply to the :math:`y` for the range
|
| 155 |
+
:math:`[0,H-1]` and :math:`[0,H]` and to :math:`t` for the range
|
| 156 |
+
:math:`[0,T-1]` and :math:`[0,T]`.
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
input (Tensor): batch of input images.
|
| 160 |
+
coords (Tensor): batch of coordinates.
|
| 161 |
+
align_corners (bool, optional): Coordinate convention. Defaults to `True`.
|
| 162 |
+
padding_mode (str, optional): Padding mode. Defaults to `"border"`.
|
| 163 |
+
|
| 164 |
+
Returns:
|
| 165 |
+
Tensor: sampled points.
|
| 166 |
+
"""
|
| 167 |
+
|
| 168 |
+
sizes = input.shape[2:]
|
| 169 |
+
|
| 170 |
+
assert len(sizes) in [2, 3]
|
| 171 |
+
|
| 172 |
+
if len(sizes) == 3:
|
| 173 |
+
# t x y -> x y t to match dimensions T H W in grid_sample
|
| 174 |
+
coords = coords[..., [1, 2, 0]]
|
| 175 |
+
|
| 176 |
+
if align_corners:
|
| 177 |
+
coords = coords * torch.tensor([2 / max(size - 1, 1) for size in reversed(sizes)], device=coords.device)
|
| 178 |
+
else:
|
| 179 |
+
coords = coords * torch.tensor([2 / size for size in reversed(sizes)], device=coords.device)
|
| 180 |
+
|
| 181 |
+
coords -= 1
|
| 182 |
+
|
| 183 |
+
return F.grid_sample(input, coords, align_corners=align_corners, padding_mode=padding_mode)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def sample_features4d(input, coords):
|
| 187 |
+
r"""Sample spatial features
|
| 188 |
+
|
| 189 |
+
`sample_features4d(input, coords)` samples the spatial features
|
| 190 |
+
:attr:`input` represented by a 4D tensor :math:`(B, C, H, W)`.
|
| 191 |
+
|
| 192 |
+
The field is sampled at coordinates :attr:`coords` using bilinear
|
| 193 |
+
interpolation. :attr:`coords` is assumed to be of shape :math:`(B, R,
|
| 194 |
+
2)`, where each sample has the format :math:`(x_i, y_i)`. This uses the
|
| 195 |
+
same convention as :func:`bilinear_sampler` with `align_corners=True`.
|
| 196 |
+
|
| 197 |
+
The output tensor has one feature per point, and has shape :math:`(B,
|
| 198 |
+
R, C)`.
|
| 199 |
+
|
| 200 |
+
Args:
|
| 201 |
+
input (Tensor): spatial features.
|
| 202 |
+
coords (Tensor): points.
|
| 203 |
+
|
| 204 |
+
Returns:
|
| 205 |
+
Tensor: sampled features.
|
| 206 |
+
"""
|
| 207 |
+
|
| 208 |
+
B, _, _, _ = input.shape
|
| 209 |
+
|
| 210 |
+
# B R 2 -> B R 1 2
|
| 211 |
+
coords = coords.unsqueeze(2)
|
| 212 |
+
|
| 213 |
+
# B C R 1
|
| 214 |
+
feats = bilinear_sampler(input, coords)
|
| 215 |
+
|
| 216 |
+
return feats.permute(0, 2, 1, 3).view(B, -1, feats.shape[1] * feats.shape[3]) # B C R 1 -> B R C
|
vggt/dependency/track_predict.py
ADDED
|
@@ -0,0 +1,326 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
from .vggsfm_utils import *
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def predict_tracks(
|
| 13 |
+
images,
|
| 14 |
+
conf=None,
|
| 15 |
+
points_3d=None,
|
| 16 |
+
masks=None,
|
| 17 |
+
max_query_pts=2048,
|
| 18 |
+
query_frame_num=5,
|
| 19 |
+
keypoint_extractor="aliked+sp",
|
| 20 |
+
max_points_num=163840,
|
| 21 |
+
fine_tracking=True,
|
| 22 |
+
complete_non_vis=True,
|
| 23 |
+
):
|
| 24 |
+
"""
|
| 25 |
+
Predict tracks for the given images and masks.
|
| 26 |
+
|
| 27 |
+
TODO: support non-square images
|
| 28 |
+
TODO: support masks
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
This function predicts the tracks for the given images and masks using the specified query method
|
| 32 |
+
and track predictor. It finds query points, and predicts the tracks, visibility, and scores for the query frames.
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
images: Tensor of shape [S, 3, H, W] containing the input images.
|
| 36 |
+
conf: Tensor of shape [S, 1, H, W] containing the confidence scores. Default is None.
|
| 37 |
+
points_3d: Tensor containing 3D points. Default is None.
|
| 38 |
+
masks: Optional tensor of shape [S, 1, H, W] containing masks. Default is None.
|
| 39 |
+
max_query_pts: Maximum number of query points. Default is 2048.
|
| 40 |
+
query_frame_num: Number of query frames to use. Default is 5.
|
| 41 |
+
keypoint_extractor: Method for keypoint extraction. Default is "aliked+sp".
|
| 42 |
+
max_points_num: Maximum number of points to process at once. Default is 163840.
|
| 43 |
+
fine_tracking: Whether to use fine tracking. Default is True.
|
| 44 |
+
complete_non_vis: Whether to augment non-visible frames. Default is True.
|
| 45 |
+
|
| 46 |
+
Returns:
|
| 47 |
+
pred_tracks: Numpy array containing the predicted tracks.
|
| 48 |
+
pred_vis_scores: Numpy array containing the visibility scores for the tracks.
|
| 49 |
+
pred_confs: Numpy array containing the confidence scores for the tracks.
|
| 50 |
+
pred_points_3d: Numpy array containing the 3D points for the tracks.
|
| 51 |
+
pred_colors: Numpy array containing the point colors for the tracks. (0, 255)
|
| 52 |
+
"""
|
| 53 |
+
|
| 54 |
+
device = images.device
|
| 55 |
+
dtype = images.dtype
|
| 56 |
+
tracker = build_vggsfm_tracker().to(device, dtype)
|
| 57 |
+
|
| 58 |
+
# Find query frames
|
| 59 |
+
query_frame_indexes = generate_rank_by_dino(images, query_frame_num=query_frame_num, device=device)
|
| 60 |
+
|
| 61 |
+
# Add the first image to the front if not already present
|
| 62 |
+
if 0 in query_frame_indexes:
|
| 63 |
+
query_frame_indexes.remove(0)
|
| 64 |
+
query_frame_indexes = [0, *query_frame_indexes]
|
| 65 |
+
|
| 66 |
+
# TODO: add the functionality to handle the masks
|
| 67 |
+
keypoint_extractors = initialize_feature_extractors(
|
| 68 |
+
max_query_pts, extractor_method=keypoint_extractor, device=device
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
pred_tracks = []
|
| 72 |
+
pred_vis_scores = []
|
| 73 |
+
pred_confs = []
|
| 74 |
+
pred_points_3d = []
|
| 75 |
+
pred_colors = []
|
| 76 |
+
|
| 77 |
+
fmaps_for_tracker = tracker.process_images_to_fmaps(images)
|
| 78 |
+
|
| 79 |
+
if fine_tracking:
|
| 80 |
+
print("For faster inference, consider disabling fine_tracking")
|
| 81 |
+
|
| 82 |
+
for query_index in query_frame_indexes:
|
| 83 |
+
print(f"Predicting tracks for query frame {query_index}")
|
| 84 |
+
pred_track, pred_vis, pred_conf, pred_point_3d, pred_color = _forward_on_query(
|
| 85 |
+
query_index,
|
| 86 |
+
images,
|
| 87 |
+
conf,
|
| 88 |
+
points_3d,
|
| 89 |
+
fmaps_for_tracker,
|
| 90 |
+
keypoint_extractors,
|
| 91 |
+
tracker,
|
| 92 |
+
max_points_num,
|
| 93 |
+
fine_tracking,
|
| 94 |
+
device,
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
pred_tracks.append(pred_track)
|
| 98 |
+
pred_vis_scores.append(pred_vis)
|
| 99 |
+
pred_confs.append(pred_conf)
|
| 100 |
+
pred_points_3d.append(pred_point_3d)
|
| 101 |
+
pred_colors.append(pred_color)
|
| 102 |
+
|
| 103 |
+
if complete_non_vis:
|
| 104 |
+
pred_tracks, pred_vis_scores, pred_confs, pred_points_3d, pred_colors = _augment_non_visible_frames(
|
| 105 |
+
pred_tracks,
|
| 106 |
+
pred_vis_scores,
|
| 107 |
+
pred_confs,
|
| 108 |
+
pred_points_3d,
|
| 109 |
+
pred_colors,
|
| 110 |
+
images,
|
| 111 |
+
conf,
|
| 112 |
+
points_3d,
|
| 113 |
+
fmaps_for_tracker,
|
| 114 |
+
keypoint_extractors,
|
| 115 |
+
tracker,
|
| 116 |
+
max_points_num,
|
| 117 |
+
fine_tracking,
|
| 118 |
+
min_vis=500,
|
| 119 |
+
non_vis_thresh=0.1,
|
| 120 |
+
device=device,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
pred_tracks = np.concatenate(pred_tracks, axis=1)
|
| 124 |
+
pred_vis_scores = np.concatenate(pred_vis_scores, axis=1)
|
| 125 |
+
pred_confs = np.concatenate(pred_confs, axis=0) if pred_confs else None
|
| 126 |
+
pred_points_3d = np.concatenate(pred_points_3d, axis=0) if pred_points_3d else None
|
| 127 |
+
pred_colors = np.concatenate(pred_colors, axis=0) if pred_colors else None
|
| 128 |
+
|
| 129 |
+
# from vggt.utils.visual_track import visualize_tracks_on_images
|
| 130 |
+
# visualize_tracks_on_images(images[None], torch.from_numpy(pred_tracks[None]), torch.from_numpy(pred_vis_scores[None])>0.2, out_dir="track_visuals")
|
| 131 |
+
|
| 132 |
+
return pred_tracks, pred_vis_scores, pred_confs, pred_points_3d, pred_colors
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def _forward_on_query(
|
| 136 |
+
query_index,
|
| 137 |
+
images,
|
| 138 |
+
conf,
|
| 139 |
+
points_3d,
|
| 140 |
+
fmaps_for_tracker,
|
| 141 |
+
keypoint_extractors,
|
| 142 |
+
tracker,
|
| 143 |
+
max_points_num,
|
| 144 |
+
fine_tracking,
|
| 145 |
+
device,
|
| 146 |
+
):
|
| 147 |
+
"""
|
| 148 |
+
Process a single query frame for track prediction.
|
| 149 |
+
|
| 150 |
+
Args:
|
| 151 |
+
query_index: Index of the query frame
|
| 152 |
+
images: Tensor of shape [S, 3, H, W] containing the input images
|
| 153 |
+
conf: Confidence tensor
|
| 154 |
+
points_3d: 3D points tensor
|
| 155 |
+
fmaps_for_tracker: Feature maps for the tracker
|
| 156 |
+
keypoint_extractors: Initialized feature extractors
|
| 157 |
+
tracker: VGG-SFM tracker
|
| 158 |
+
max_points_num: Maximum number of points to process at once
|
| 159 |
+
fine_tracking: Whether to use fine tracking
|
| 160 |
+
device: Device to use for computation
|
| 161 |
+
|
| 162 |
+
Returns:
|
| 163 |
+
pred_track: Predicted tracks
|
| 164 |
+
pred_vis: Visibility scores for the tracks
|
| 165 |
+
pred_conf: Confidence scores for the tracks
|
| 166 |
+
pred_point_3d: 3D points for the tracks
|
| 167 |
+
pred_color: Point colors for the tracks (0, 255)
|
| 168 |
+
"""
|
| 169 |
+
frame_num, _, height, width = images.shape
|
| 170 |
+
|
| 171 |
+
query_image = images[query_index]
|
| 172 |
+
query_points = extract_keypoints(query_image, keypoint_extractors, round_keypoints=False)
|
| 173 |
+
query_points = query_points[:, torch.randperm(query_points.shape[1], device=device)]
|
| 174 |
+
|
| 175 |
+
# Extract the color at the keypoint locations
|
| 176 |
+
query_points_long = query_points.squeeze(0).round().long()
|
| 177 |
+
pred_color = images[query_index][:, query_points_long[:, 1], query_points_long[:, 0]]
|
| 178 |
+
pred_color = (pred_color.permute(1, 0).cpu().numpy() * 255).astype(np.uint8)
|
| 179 |
+
|
| 180 |
+
# Query the confidence and points_3d at the keypoint locations
|
| 181 |
+
if (conf is not None) and (points_3d is not None):
|
| 182 |
+
assert height == width
|
| 183 |
+
assert conf.shape[-2] == conf.shape[-1]
|
| 184 |
+
assert conf.shape[:3] == points_3d.shape[:3]
|
| 185 |
+
scale = conf.shape[-1] / width
|
| 186 |
+
|
| 187 |
+
query_points_scaled = (query_points.squeeze(0) * scale).round().long()
|
| 188 |
+
query_points_scaled = query_points_scaled.cpu().numpy()
|
| 189 |
+
|
| 190 |
+
pred_conf = conf[query_index][query_points_scaled[:, 1], query_points_scaled[:, 0]]
|
| 191 |
+
pred_point_3d = points_3d[query_index][query_points_scaled[:, 1], query_points_scaled[:, 0]]
|
| 192 |
+
|
| 193 |
+
# heuristic to remove low confidence points
|
| 194 |
+
# should I export this as an input parameter?
|
| 195 |
+
valid_mask = pred_conf > 1.2
|
| 196 |
+
if valid_mask.sum() > 512:
|
| 197 |
+
query_points = query_points[:, valid_mask] # Make sure shape is compatible
|
| 198 |
+
pred_conf = pred_conf[valid_mask]
|
| 199 |
+
pred_point_3d = pred_point_3d[valid_mask]
|
| 200 |
+
pred_color = pred_color[valid_mask]
|
| 201 |
+
else:
|
| 202 |
+
pred_conf = None
|
| 203 |
+
pred_point_3d = None
|
| 204 |
+
|
| 205 |
+
reorder_index = calculate_index_mappings(query_index, frame_num, device=device)
|
| 206 |
+
|
| 207 |
+
images_feed, fmaps_feed = switch_tensor_order([images, fmaps_for_tracker], reorder_index, dim=0)
|
| 208 |
+
images_feed = images_feed[None] # add batch dimension
|
| 209 |
+
fmaps_feed = fmaps_feed[None] # add batch dimension
|
| 210 |
+
|
| 211 |
+
all_points_num = images_feed.shape[1] * query_points.shape[1]
|
| 212 |
+
|
| 213 |
+
# Don't need to be scared, this is just chunking to make GPU happy
|
| 214 |
+
if all_points_num > max_points_num:
|
| 215 |
+
num_splits = (all_points_num + max_points_num - 1) // max_points_num
|
| 216 |
+
query_points = torch.chunk(query_points, num_splits, dim=1)
|
| 217 |
+
else:
|
| 218 |
+
query_points = [query_points]
|
| 219 |
+
|
| 220 |
+
pred_track, pred_vis, _ = predict_tracks_in_chunks(
|
| 221 |
+
tracker, images_feed, query_points, fmaps_feed, fine_tracking=fine_tracking
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
pred_track, pred_vis = switch_tensor_order([pred_track, pred_vis], reorder_index, dim=1)
|
| 225 |
+
|
| 226 |
+
pred_track = pred_track.squeeze(0).float().cpu().numpy()
|
| 227 |
+
pred_vis = pred_vis.squeeze(0).float().cpu().numpy()
|
| 228 |
+
|
| 229 |
+
return pred_track, pred_vis, pred_conf, pred_point_3d, pred_color
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
def _augment_non_visible_frames(
|
| 233 |
+
pred_tracks: list, # ← running list of np.ndarrays
|
| 234 |
+
pred_vis_scores: list, # ← running list of np.ndarrays
|
| 235 |
+
pred_confs: list, # ← running list of np.ndarrays for confidence scores
|
| 236 |
+
pred_points_3d: list, # ← running list of np.ndarrays for 3D points
|
| 237 |
+
pred_colors: list, # ← running list of np.ndarrays for colors
|
| 238 |
+
images: torch.Tensor,
|
| 239 |
+
conf,
|
| 240 |
+
points_3d,
|
| 241 |
+
fmaps_for_tracker,
|
| 242 |
+
keypoint_extractors,
|
| 243 |
+
tracker,
|
| 244 |
+
max_points_num: int,
|
| 245 |
+
fine_tracking: bool,
|
| 246 |
+
*,
|
| 247 |
+
min_vis: int = 500,
|
| 248 |
+
non_vis_thresh: float = 0.1,
|
| 249 |
+
device: torch.device = None,
|
| 250 |
+
):
|
| 251 |
+
"""
|
| 252 |
+
Augment tracking for frames with insufficient visibility.
|
| 253 |
+
|
| 254 |
+
Args:
|
| 255 |
+
pred_tracks: List of numpy arrays containing predicted tracks.
|
| 256 |
+
pred_vis_scores: List of numpy arrays containing visibility scores.
|
| 257 |
+
pred_confs: List of numpy arrays containing confidence scores.
|
| 258 |
+
pred_points_3d: List of numpy arrays containing 3D points.
|
| 259 |
+
pred_colors: List of numpy arrays containing point colors.
|
| 260 |
+
images: Tensor of shape [S, 3, H, W] containing the input images.
|
| 261 |
+
conf: Tensor of shape [S, 1, H, W] containing confidence scores
|
| 262 |
+
points_3d: Tensor containing 3D points
|
| 263 |
+
fmaps_for_tracker: Feature maps for the tracker
|
| 264 |
+
keypoint_extractors: Initialized feature extractors
|
| 265 |
+
tracker: VGG-SFM tracker
|
| 266 |
+
max_points_num: Maximum number of points to process at once
|
| 267 |
+
fine_tracking: Whether to use fine tracking
|
| 268 |
+
min_vis: Minimum visibility threshold
|
| 269 |
+
non_vis_thresh: Non-visibility threshold
|
| 270 |
+
device: Device to use for computation
|
| 271 |
+
|
| 272 |
+
Returns:
|
| 273 |
+
Updated pred_tracks, pred_vis_scores, pred_confs, pred_points_3d, and pred_colors lists.
|
| 274 |
+
"""
|
| 275 |
+
last_query = -1
|
| 276 |
+
final_trial = False
|
| 277 |
+
cur_extractors = keypoint_extractors # may be replaced on the final trial
|
| 278 |
+
|
| 279 |
+
while True:
|
| 280 |
+
# Visibility per frame
|
| 281 |
+
vis_array = np.concatenate(pred_vis_scores, axis=1)
|
| 282 |
+
|
| 283 |
+
# Count frames with sufficient visibility using numpy
|
| 284 |
+
sufficient_vis_count = (vis_array > non_vis_thresh).sum(axis=-1)
|
| 285 |
+
non_vis_frames = np.where(sufficient_vis_count < min_vis)[0].tolist()
|
| 286 |
+
|
| 287 |
+
if len(non_vis_frames) == 0:
|
| 288 |
+
break
|
| 289 |
+
|
| 290 |
+
print("Processing non visible frames:", non_vis_frames)
|
| 291 |
+
|
| 292 |
+
# Decide the frames & extractor for this round
|
| 293 |
+
if non_vis_frames[0] == last_query:
|
| 294 |
+
# Same frame failed twice - final "all-in" attempt
|
| 295 |
+
final_trial = True
|
| 296 |
+
cur_extractors = initialize_feature_extractors(2048, extractor_method="sp+sift+aliked", device=device)
|
| 297 |
+
query_frame_list = non_vis_frames # blast them all at once
|
| 298 |
+
else:
|
| 299 |
+
query_frame_list = [non_vis_frames[0]] # Process one at a time
|
| 300 |
+
|
| 301 |
+
last_query = non_vis_frames[0]
|
| 302 |
+
|
| 303 |
+
# Run the tracker for every selected frame
|
| 304 |
+
for query_index in query_frame_list:
|
| 305 |
+
new_track, new_vis, new_conf, new_point_3d, new_color = _forward_on_query(
|
| 306 |
+
query_index,
|
| 307 |
+
images,
|
| 308 |
+
conf,
|
| 309 |
+
points_3d,
|
| 310 |
+
fmaps_for_tracker,
|
| 311 |
+
cur_extractors,
|
| 312 |
+
tracker,
|
| 313 |
+
max_points_num,
|
| 314 |
+
fine_tracking,
|
| 315 |
+
device,
|
| 316 |
+
)
|
| 317 |
+
pred_tracks.append(new_track)
|
| 318 |
+
pred_vis_scores.append(new_vis)
|
| 319 |
+
pred_confs.append(new_conf)
|
| 320 |
+
pred_points_3d.append(new_point_3d)
|
| 321 |
+
pred_colors.append(new_color)
|
| 322 |
+
|
| 323 |
+
if final_trial:
|
| 324 |
+
break # Stop after final attempt
|
| 325 |
+
|
| 326 |
+
return pred_tracks, pred_vis_scores, pred_confs, pred_points_3d, pred_colors
|
vggt/dependency/vggsfm_tracker.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from functools import partial
|
| 13 |
+
from torch import nn, einsum
|
| 14 |
+
from einops import rearrange, repeat
|
| 15 |
+
from einops.layers.torch import Rearrange, Reduce
|
| 16 |
+
|
| 17 |
+
from hydra.utils import instantiate
|
| 18 |
+
from omegaconf import OmegaConf
|
| 19 |
+
|
| 20 |
+
from .track_modules.track_refine import refine_track
|
| 21 |
+
from .track_modules.blocks import BasicEncoder, ShallowEncoder
|
| 22 |
+
from .track_modules.base_track_predictor import BaseTrackerPredictor
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class TrackerPredictor(nn.Module):
|
| 26 |
+
def __init__(self, **extra_args):
|
| 27 |
+
super(TrackerPredictor, self).__init__()
|
| 28 |
+
"""
|
| 29 |
+
Initializes the tracker predictor.
|
| 30 |
+
|
| 31 |
+
Both coarse_predictor and fine_predictor are constructed as a BaseTrackerPredictor,
|
| 32 |
+
check track_modules/base_track_predictor.py
|
| 33 |
+
|
| 34 |
+
Both coarse_fnet and fine_fnet are constructed as a 2D CNN network
|
| 35 |
+
check track_modules/blocks.py for BasicEncoder and ShallowEncoder
|
| 36 |
+
"""
|
| 37 |
+
# Define coarse predictor configuration
|
| 38 |
+
coarse_stride = 4
|
| 39 |
+
self.coarse_down_ratio = 2
|
| 40 |
+
|
| 41 |
+
# Create networks directly instead of using instantiate
|
| 42 |
+
self.coarse_fnet = BasicEncoder(stride=coarse_stride)
|
| 43 |
+
self.coarse_predictor = BaseTrackerPredictor(stride=coarse_stride)
|
| 44 |
+
|
| 45 |
+
# Create fine predictor with stride = 1
|
| 46 |
+
self.fine_fnet = ShallowEncoder(stride=1)
|
| 47 |
+
self.fine_predictor = BaseTrackerPredictor(
|
| 48 |
+
stride=1,
|
| 49 |
+
depth=4,
|
| 50 |
+
corr_levels=3,
|
| 51 |
+
corr_radius=3,
|
| 52 |
+
latent_dim=32,
|
| 53 |
+
hidden_size=256,
|
| 54 |
+
fine=True,
|
| 55 |
+
use_spaceatt=False,
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
def forward(
|
| 59 |
+
self, images, query_points, fmaps=None, coarse_iters=6, inference=True, fine_tracking=True, fine_chunk=40960
|
| 60 |
+
):
|
| 61 |
+
"""
|
| 62 |
+
Args:
|
| 63 |
+
images (torch.Tensor): Images as RGB, in the range of [0, 1], with a shape of B x S x 3 x H x W.
|
| 64 |
+
query_points (torch.Tensor): 2D xy of query points, relative to top left, with a shape of B x N x 2.
|
| 65 |
+
fmaps (torch.Tensor, optional): Precomputed feature maps. Defaults to None.
|
| 66 |
+
coarse_iters (int, optional): Number of iterations for coarse prediction. Defaults to 6.
|
| 67 |
+
inference (bool, optional): Whether to perform inference. Defaults to True.
|
| 68 |
+
fine_tracking (bool, optional): Whether to perform fine tracking. Defaults to True.
|
| 69 |
+
|
| 70 |
+
Returns:
|
| 71 |
+
tuple: A tuple containing fine_pred_track, coarse_pred_track, pred_vis, and pred_score.
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
if fmaps is None:
|
| 75 |
+
batch_num, frame_num, image_dim, height, width = images.shape
|
| 76 |
+
reshaped_image = images.reshape(batch_num * frame_num, image_dim, height, width)
|
| 77 |
+
fmaps = self.process_images_to_fmaps(reshaped_image)
|
| 78 |
+
fmaps = fmaps.reshape(batch_num, frame_num, -1, fmaps.shape[-2], fmaps.shape[-1])
|
| 79 |
+
|
| 80 |
+
if inference:
|
| 81 |
+
torch.cuda.empty_cache()
|
| 82 |
+
|
| 83 |
+
# Coarse prediction
|
| 84 |
+
coarse_pred_track_lists, pred_vis = self.coarse_predictor(
|
| 85 |
+
query_points=query_points, fmaps=fmaps, iters=coarse_iters, down_ratio=self.coarse_down_ratio
|
| 86 |
+
)
|
| 87 |
+
coarse_pred_track = coarse_pred_track_lists[-1]
|
| 88 |
+
|
| 89 |
+
if inference:
|
| 90 |
+
torch.cuda.empty_cache()
|
| 91 |
+
|
| 92 |
+
if fine_tracking:
|
| 93 |
+
# Refine the coarse prediction
|
| 94 |
+
fine_pred_track, pred_score = refine_track(
|
| 95 |
+
images, self.fine_fnet, self.fine_predictor, coarse_pred_track, compute_score=False, chunk=fine_chunk
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
if inference:
|
| 99 |
+
torch.cuda.empty_cache()
|
| 100 |
+
else:
|
| 101 |
+
fine_pred_track = coarse_pred_track
|
| 102 |
+
pred_score = torch.ones_like(pred_vis)
|
| 103 |
+
|
| 104 |
+
return fine_pred_track, coarse_pred_track, pred_vis, pred_score
|
| 105 |
+
|
| 106 |
+
def process_images_to_fmaps(self, images):
|
| 107 |
+
"""
|
| 108 |
+
This function processes images for inference.
|
| 109 |
+
|
| 110 |
+
Args:
|
| 111 |
+
images (torch.Tensor): The images to be processed with shape S x 3 x H x W.
|
| 112 |
+
|
| 113 |
+
Returns:
|
| 114 |
+
torch.Tensor: The processed feature maps.
|
| 115 |
+
"""
|
| 116 |
+
if self.coarse_down_ratio > 1:
|
| 117 |
+
# whether or not scale down the input images to save memory
|
| 118 |
+
fmaps = self.coarse_fnet(
|
| 119 |
+
F.interpolate(images, scale_factor=1 / self.coarse_down_ratio, mode="bilinear", align_corners=True)
|
| 120 |
+
)
|
| 121 |
+
else:
|
| 122 |
+
fmaps = self.coarse_fnet(images)
|
| 123 |
+
|
| 124 |
+
return fmaps
|
vggt/dependency/vggsfm_utils.py
ADDED
|
@@ -0,0 +1,305 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
import warnings
|
| 9 |
+
from typing import Dict, List, Optional, Tuple, Union
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import pycolmap
|
| 13 |
+
import torch
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
from lightglue import ALIKED, SIFT, SuperPoint
|
| 16 |
+
|
| 17 |
+
from .vggsfm_tracker import TrackerPredictor
|
| 18 |
+
|
| 19 |
+
# Suppress verbose logging from dependencies
|
| 20 |
+
logging.getLogger("dinov2").setLevel(logging.WARNING)
|
| 21 |
+
warnings.filterwarnings("ignore", message="xFormers is available")
|
| 22 |
+
warnings.filterwarnings("ignore", message="dinov2")
|
| 23 |
+
|
| 24 |
+
# Constants
|
| 25 |
+
_RESNET_MEAN = [0.485, 0.456, 0.406]
|
| 26 |
+
_RESNET_STD = [0.229, 0.224, 0.225]
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def build_vggsfm_tracker(model_path=None):
|
| 30 |
+
"""
|
| 31 |
+
Build and initialize the VGGSfM tracker.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
model_path: Path to the model weights file. If None, weights are downloaded from HuggingFace.
|
| 35 |
+
|
| 36 |
+
Returns:
|
| 37 |
+
Initialized tracker model in eval mode.
|
| 38 |
+
"""
|
| 39 |
+
tracker = TrackerPredictor()
|
| 40 |
+
|
| 41 |
+
if model_path is None:
|
| 42 |
+
default_url = "https://huggingface.co/facebook/VGGSfM/resolve/main/vggsfm_v2_tracker.pt"
|
| 43 |
+
tracker.load_state_dict(torch.hub.load_state_dict_from_url(default_url))
|
| 44 |
+
else:
|
| 45 |
+
tracker.load_state_dict(torch.load(model_path))
|
| 46 |
+
|
| 47 |
+
tracker.eval()
|
| 48 |
+
return tracker
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def generate_rank_by_dino(
|
| 52 |
+
images, query_frame_num, image_size=336, model_name="dinov2_vitb14_reg", device="cuda", spatial_similarity=False
|
| 53 |
+
):
|
| 54 |
+
"""
|
| 55 |
+
Generate a ranking of frames using DINO ViT features.
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
images: Tensor of shape (S, 3, H, W) with values in range [0, 1]
|
| 59 |
+
query_frame_num: Number of frames to select
|
| 60 |
+
image_size: Size to resize images to before processing
|
| 61 |
+
model_name: Name of the DINO model to use
|
| 62 |
+
device: Device to run the model on
|
| 63 |
+
spatial_similarity: Whether to use spatial token similarity or CLS token similarity
|
| 64 |
+
|
| 65 |
+
Returns:
|
| 66 |
+
List of frame indices ranked by their representativeness
|
| 67 |
+
"""
|
| 68 |
+
# Resize images to the target size
|
| 69 |
+
images = F.interpolate(images, (image_size, image_size), mode="bilinear", align_corners=False)
|
| 70 |
+
|
| 71 |
+
# Load DINO model
|
| 72 |
+
dino_v2_model = torch.hub.load("facebookresearch/dinov2", model_name)
|
| 73 |
+
dino_v2_model.eval()
|
| 74 |
+
dino_v2_model = dino_v2_model.to(device)
|
| 75 |
+
|
| 76 |
+
# Normalize images using ResNet normalization
|
| 77 |
+
resnet_mean = torch.tensor(_RESNET_MEAN, device=device).view(1, 3, 1, 1)
|
| 78 |
+
resnet_std = torch.tensor(_RESNET_STD, device=device).view(1, 3, 1, 1)
|
| 79 |
+
images_resnet_norm = (images - resnet_mean) / resnet_std
|
| 80 |
+
|
| 81 |
+
with torch.no_grad():
|
| 82 |
+
frame_feat = dino_v2_model(images_resnet_norm, is_training=True)
|
| 83 |
+
|
| 84 |
+
# Process features based on similarity type
|
| 85 |
+
if spatial_similarity:
|
| 86 |
+
frame_feat = frame_feat["x_norm_patchtokens"]
|
| 87 |
+
frame_feat_norm = F.normalize(frame_feat, p=2, dim=1)
|
| 88 |
+
|
| 89 |
+
# Compute the similarity matrix
|
| 90 |
+
frame_feat_norm = frame_feat_norm.permute(1, 0, 2)
|
| 91 |
+
similarity_matrix = torch.bmm(frame_feat_norm, frame_feat_norm.transpose(-1, -2))
|
| 92 |
+
similarity_matrix = similarity_matrix.mean(dim=0)
|
| 93 |
+
else:
|
| 94 |
+
frame_feat = frame_feat["x_norm_clstoken"]
|
| 95 |
+
frame_feat_norm = F.normalize(frame_feat, p=2, dim=1)
|
| 96 |
+
similarity_matrix = torch.mm(frame_feat_norm, frame_feat_norm.transpose(-1, -2))
|
| 97 |
+
|
| 98 |
+
distance_matrix = 100 - similarity_matrix.clone()
|
| 99 |
+
|
| 100 |
+
# Ignore self-pairing
|
| 101 |
+
similarity_matrix.fill_diagonal_(-100)
|
| 102 |
+
similarity_sum = similarity_matrix.sum(dim=1)
|
| 103 |
+
|
| 104 |
+
# Find the most common frame
|
| 105 |
+
most_common_frame_index = torch.argmax(similarity_sum).item()
|
| 106 |
+
|
| 107 |
+
# Conduct FPS sampling starting from the most common frame
|
| 108 |
+
fps_idx = farthest_point_sampling(distance_matrix, query_frame_num, most_common_frame_index)
|
| 109 |
+
|
| 110 |
+
# Clean up all tensors and models to free memory
|
| 111 |
+
del frame_feat, frame_feat_norm, similarity_matrix, distance_matrix
|
| 112 |
+
del dino_v2_model
|
| 113 |
+
torch.cuda.empty_cache()
|
| 114 |
+
|
| 115 |
+
return fps_idx
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def farthest_point_sampling(distance_matrix, num_samples, most_common_frame_index=0):
|
| 119 |
+
"""
|
| 120 |
+
Farthest point sampling algorithm to select diverse frames.
|
| 121 |
+
|
| 122 |
+
Args:
|
| 123 |
+
distance_matrix: Matrix of distances between frames
|
| 124 |
+
num_samples: Number of frames to select
|
| 125 |
+
most_common_frame_index: Index of the first frame to select
|
| 126 |
+
|
| 127 |
+
Returns:
|
| 128 |
+
List of selected frame indices
|
| 129 |
+
"""
|
| 130 |
+
distance_matrix = distance_matrix.clamp(min=0)
|
| 131 |
+
N = distance_matrix.size(0)
|
| 132 |
+
|
| 133 |
+
# Initialize with the most common frame
|
| 134 |
+
selected_indices = [most_common_frame_index]
|
| 135 |
+
check_distances = distance_matrix[selected_indices]
|
| 136 |
+
|
| 137 |
+
while len(selected_indices) < num_samples:
|
| 138 |
+
# Find the farthest point from the current set of selected points
|
| 139 |
+
farthest_point = torch.argmax(check_distances)
|
| 140 |
+
selected_indices.append(farthest_point.item())
|
| 141 |
+
|
| 142 |
+
check_distances = distance_matrix[farthest_point]
|
| 143 |
+
# Mark already selected points to avoid selecting them again
|
| 144 |
+
check_distances[selected_indices] = 0
|
| 145 |
+
|
| 146 |
+
# Break if all points have been selected
|
| 147 |
+
if len(selected_indices) == N:
|
| 148 |
+
break
|
| 149 |
+
|
| 150 |
+
return selected_indices
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def calculate_index_mappings(query_index, S, device=None):
|
| 154 |
+
"""
|
| 155 |
+
Construct an order that switches [query_index] and [0]
|
| 156 |
+
so that the content of query_index would be placed at [0].
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
query_index: Index to swap with 0
|
| 160 |
+
S: Total number of elements
|
| 161 |
+
device: Device to place the tensor on
|
| 162 |
+
|
| 163 |
+
Returns:
|
| 164 |
+
Tensor of indices with the swapped order
|
| 165 |
+
"""
|
| 166 |
+
new_order = torch.arange(S)
|
| 167 |
+
new_order[0] = query_index
|
| 168 |
+
new_order[query_index] = 0
|
| 169 |
+
if device is not None:
|
| 170 |
+
new_order = new_order.to(device)
|
| 171 |
+
return new_order
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def switch_tensor_order(tensors, order, dim=1):
|
| 175 |
+
"""
|
| 176 |
+
Reorder tensors along a specific dimension according to the given order.
|
| 177 |
+
|
| 178 |
+
Args:
|
| 179 |
+
tensors: List of tensors to reorder
|
| 180 |
+
order: Tensor of indices specifying the new order
|
| 181 |
+
dim: Dimension along which to reorder
|
| 182 |
+
|
| 183 |
+
Returns:
|
| 184 |
+
List of reordered tensors
|
| 185 |
+
"""
|
| 186 |
+
return [torch.index_select(tensor, dim, order) if tensor is not None else None for tensor in tensors]
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def initialize_feature_extractors(max_query_num, det_thres=0.005, extractor_method="aliked", device="cuda"):
|
| 190 |
+
"""
|
| 191 |
+
Initialize feature extractors that can be reused based on a method string.
|
| 192 |
+
|
| 193 |
+
Args:
|
| 194 |
+
max_query_num: Maximum number of keypoints to extract
|
| 195 |
+
det_thres: Detection threshold for keypoint extraction
|
| 196 |
+
extractor_method: String specifying which extractors to use (e.g., "aliked", "sp+sift", "aliked+sp+sift")
|
| 197 |
+
device: Device to run extraction on
|
| 198 |
+
|
| 199 |
+
Returns:
|
| 200 |
+
Dictionary of initialized extractors
|
| 201 |
+
"""
|
| 202 |
+
extractors = {}
|
| 203 |
+
methods = extractor_method.lower().split("+")
|
| 204 |
+
|
| 205 |
+
for method in methods:
|
| 206 |
+
method = method.strip()
|
| 207 |
+
if method == "aliked":
|
| 208 |
+
aliked_extractor = ALIKED(max_num_keypoints=max_query_num, detection_threshold=det_thres)
|
| 209 |
+
extractors["aliked"] = aliked_extractor.to(device).eval()
|
| 210 |
+
elif method == "sp":
|
| 211 |
+
sp_extractor = SuperPoint(max_num_keypoints=max_query_num, detection_threshold=det_thres)
|
| 212 |
+
extractors["sp"] = sp_extractor.to(device).eval()
|
| 213 |
+
elif method == "sift":
|
| 214 |
+
sift_extractor = SIFT(max_num_keypoints=max_query_num)
|
| 215 |
+
extractors["sift"] = sift_extractor.to(device).eval()
|
| 216 |
+
else:
|
| 217 |
+
print(f"Warning: Unknown feature extractor '{method}', ignoring.")
|
| 218 |
+
|
| 219 |
+
if not extractors:
|
| 220 |
+
print(f"Warning: No valid extractors found in '{extractor_method}'. Using ALIKED by default.")
|
| 221 |
+
aliked_extractor = ALIKED(max_num_keypoints=max_query_num, detection_threshold=det_thres)
|
| 222 |
+
extractors["aliked"] = aliked_extractor.to(device).eval()
|
| 223 |
+
|
| 224 |
+
return extractors
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
def extract_keypoints(query_image, extractors, round_keypoints=True):
|
| 228 |
+
"""
|
| 229 |
+
Extract keypoints using pre-initialized feature extractors.
|
| 230 |
+
|
| 231 |
+
Args:
|
| 232 |
+
query_image: Input image tensor (3xHxW, range [0, 1])
|
| 233 |
+
extractors: Dictionary of initialized extractors
|
| 234 |
+
|
| 235 |
+
Returns:
|
| 236 |
+
Tensor of keypoint coordinates (1xNx2)
|
| 237 |
+
"""
|
| 238 |
+
query_points = None
|
| 239 |
+
|
| 240 |
+
with torch.no_grad():
|
| 241 |
+
for extractor_name, extractor in extractors.items():
|
| 242 |
+
query_points_data = extractor.extract(query_image, invalid_mask=None)
|
| 243 |
+
extractor_points = query_points_data["keypoints"]
|
| 244 |
+
if round_keypoints:
|
| 245 |
+
extractor_points = extractor_points.round()
|
| 246 |
+
|
| 247 |
+
if query_points is not None:
|
| 248 |
+
query_points = torch.cat([query_points, extractor_points], dim=1)
|
| 249 |
+
else:
|
| 250 |
+
query_points = extractor_points
|
| 251 |
+
|
| 252 |
+
return query_points
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def predict_tracks_in_chunks(
|
| 256 |
+
track_predictor, images_feed, query_points_list, fmaps_feed, fine_tracking, num_splits=None, fine_chunk=40960
|
| 257 |
+
):
|
| 258 |
+
"""
|
| 259 |
+
Process a list of query points to avoid memory issues.
|
| 260 |
+
|
| 261 |
+
Args:
|
| 262 |
+
track_predictor (object): The track predictor object used for predicting tracks.
|
| 263 |
+
images_feed (torch.Tensor): A tensor of shape (B, T, C, H, W) representing a batch of images.
|
| 264 |
+
query_points_list (list or tuple): A list/tuple of tensors, each of shape (B, Ni, 2) representing chunks of query points.
|
| 265 |
+
fmaps_feed (torch.Tensor): A tensor of feature maps for the tracker.
|
| 266 |
+
fine_tracking (bool): Whether to perform fine tracking.
|
| 267 |
+
num_splits (int, optional): Ignored when query_points_list is provided. Kept for backward compatibility.
|
| 268 |
+
|
| 269 |
+
Returns:
|
| 270 |
+
tuple: A tuple containing the concatenated predicted tracks, visibility, and scores.
|
| 271 |
+
"""
|
| 272 |
+
# If query_points_list is not a list or tuple but a single tensor, handle it like the old version for backward compatibility
|
| 273 |
+
if not isinstance(query_points_list, (list, tuple)):
|
| 274 |
+
query_points = query_points_list
|
| 275 |
+
if num_splits is None:
|
| 276 |
+
num_splits = 1
|
| 277 |
+
query_points_list = torch.chunk(query_points, num_splits, dim=1)
|
| 278 |
+
|
| 279 |
+
# Ensure query_points_list is a list for iteration (as torch.chunk returns a tuple)
|
| 280 |
+
if isinstance(query_points_list, tuple):
|
| 281 |
+
query_points_list = list(query_points_list)
|
| 282 |
+
|
| 283 |
+
fine_pred_track_list = []
|
| 284 |
+
pred_vis_list = []
|
| 285 |
+
pred_score_list = []
|
| 286 |
+
|
| 287 |
+
for split_points in query_points_list:
|
| 288 |
+
# Feed into track predictor for each split
|
| 289 |
+
fine_pred_track, _, pred_vis, pred_score = track_predictor(
|
| 290 |
+
images_feed, split_points, fmaps=fmaps_feed, fine_tracking=fine_tracking, fine_chunk=fine_chunk
|
| 291 |
+
)
|
| 292 |
+
fine_pred_track_list.append(fine_pred_track)
|
| 293 |
+
pred_vis_list.append(pred_vis)
|
| 294 |
+
pred_score_list.append(pred_score)
|
| 295 |
+
|
| 296 |
+
# Concatenate the results from all splits
|
| 297 |
+
fine_pred_track = torch.cat(fine_pred_track_list, dim=2)
|
| 298 |
+
pred_vis = torch.cat(pred_vis_list, dim=2)
|
| 299 |
+
|
| 300 |
+
if pred_score is not None:
|
| 301 |
+
pred_score = torch.cat(pred_score_list, dim=2)
|
| 302 |
+
else:
|
| 303 |
+
pred_score = None
|
| 304 |
+
|
| 305 |
+
return fine_pred_track, pred_vis, pred_score
|
vggt/heads/camera_head.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
from vggt.layers import Mlp
|
| 15 |
+
from vggt.layers.block import Block
|
| 16 |
+
from vggt.heads.head_act import activate_pose
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class CameraHead(nn.Module):
|
| 20 |
+
"""
|
| 21 |
+
CameraHead predicts camera parameters from token representations using iterative refinement.
|
| 22 |
+
|
| 23 |
+
It applies a series of transformer blocks (the "trunk") to dedicated camera tokens.
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
def __init__(
|
| 27 |
+
self,
|
| 28 |
+
dim_in: int = 2048,
|
| 29 |
+
trunk_depth: int = 4,
|
| 30 |
+
pose_encoding_type: str = "absT_quaR_FoV",
|
| 31 |
+
num_heads: int = 16,
|
| 32 |
+
mlp_ratio: int = 4,
|
| 33 |
+
init_values: float = 0.01,
|
| 34 |
+
trans_act: str = "linear",
|
| 35 |
+
quat_act: str = "linear",
|
| 36 |
+
fl_act: str = "relu", # Field of view activations: ensures FOV values are positive.
|
| 37 |
+
):
|
| 38 |
+
super().__init__()
|
| 39 |
+
|
| 40 |
+
if pose_encoding_type == "absT_quaR_FoV":
|
| 41 |
+
self.target_dim = 9
|
| 42 |
+
else:
|
| 43 |
+
raise ValueError(f"Unsupported camera encoding type: {pose_encoding_type}")
|
| 44 |
+
|
| 45 |
+
self.trans_act = trans_act
|
| 46 |
+
self.quat_act = quat_act
|
| 47 |
+
self.fl_act = fl_act
|
| 48 |
+
self.trunk_depth = trunk_depth
|
| 49 |
+
|
| 50 |
+
# Build the trunk using a sequence of transformer blocks.
|
| 51 |
+
self.trunk = nn.Sequential(
|
| 52 |
+
*[
|
| 53 |
+
Block(dim=dim_in, num_heads=num_heads, mlp_ratio=mlp_ratio, init_values=init_values)
|
| 54 |
+
for _ in range(trunk_depth)
|
| 55 |
+
]
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
# Normalizations for camera token and trunk output.
|
| 59 |
+
self.token_norm = nn.LayerNorm(dim_in)
|
| 60 |
+
self.trunk_norm = nn.LayerNorm(dim_in)
|
| 61 |
+
|
| 62 |
+
# Learnable empty camera pose token.
|
| 63 |
+
self.empty_pose_tokens = nn.Parameter(torch.zeros(1, 1, self.target_dim))
|
| 64 |
+
self.embed_pose = nn.Linear(self.target_dim, dim_in)
|
| 65 |
+
|
| 66 |
+
# Module for producing modulation parameters: shift, scale, and a gate.
|
| 67 |
+
self.poseLN_modulation = nn.Sequential(nn.SiLU(), nn.Linear(dim_in, 3 * dim_in, bias=True))
|
| 68 |
+
|
| 69 |
+
# Adaptive layer normalization without affine parameters.
|
| 70 |
+
self.adaln_norm = nn.LayerNorm(dim_in, elementwise_affine=False, eps=1e-6)
|
| 71 |
+
self.pose_branch = Mlp(in_features=dim_in, hidden_features=dim_in // 2, out_features=self.target_dim, drop=0)
|
| 72 |
+
|
| 73 |
+
def forward(self, aggregated_tokens_list: list, num_iterations: int = 4) -> list:
|
| 74 |
+
"""
|
| 75 |
+
Forward pass to predict camera parameters.
|
| 76 |
+
|
| 77 |
+
Args:
|
| 78 |
+
aggregated_tokens_list (list): List of token tensors from the network;
|
| 79 |
+
the last tensor is used for prediction.
|
| 80 |
+
num_iterations (int, optional): Number of iterative refinement steps. Defaults to 4.
|
| 81 |
+
|
| 82 |
+
Returns:
|
| 83 |
+
list: A list of predicted camera encodings (post-activation) from each iteration.
|
| 84 |
+
"""
|
| 85 |
+
# Use tokens from the last block for camera prediction.
|
| 86 |
+
tokens = aggregated_tokens_list[-1]
|
| 87 |
+
|
| 88 |
+
# Extract the camera tokens
|
| 89 |
+
pose_tokens = tokens[:, :, 0]
|
| 90 |
+
pose_tokens = self.token_norm(pose_tokens)
|
| 91 |
+
|
| 92 |
+
pred_pose_enc_list = self.trunk_fn(pose_tokens, num_iterations)
|
| 93 |
+
return pred_pose_enc_list
|
| 94 |
+
|
| 95 |
+
def trunk_fn(self, pose_tokens: torch.Tensor, num_iterations: int) -> list:
|
| 96 |
+
"""
|
| 97 |
+
Iteratively refine camera pose predictions.
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
pose_tokens (torch.Tensor): Normalized camera tokens with shape [B, 1, C].
|
| 101 |
+
num_iterations (int): Number of refinement iterations.
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
list: List of activated camera encodings from each iteration.
|
| 105 |
+
"""
|
| 106 |
+
B, S, C = pose_tokens.shape # S is expected to be 1.
|
| 107 |
+
pred_pose_enc = None
|
| 108 |
+
pred_pose_enc_list = []
|
| 109 |
+
|
| 110 |
+
for _ in range(num_iterations):
|
| 111 |
+
# Use a learned empty pose for the first iteration.
|
| 112 |
+
if pred_pose_enc is None:
|
| 113 |
+
module_input = self.embed_pose(self.empty_pose_tokens.expand(B, S, -1))
|
| 114 |
+
else:
|
| 115 |
+
# Detach the previous prediction to avoid backprop through time.
|
| 116 |
+
pred_pose_enc = pred_pose_enc.detach()
|
| 117 |
+
module_input = self.embed_pose(pred_pose_enc)
|
| 118 |
+
|
| 119 |
+
# Generate modulation parameters and split them into shift, scale, and gate components.
|
| 120 |
+
shift_msa, scale_msa, gate_msa = self.poseLN_modulation(module_input).chunk(3, dim=-1)
|
| 121 |
+
|
| 122 |
+
# Adaptive layer normalization and modulation.
|
| 123 |
+
pose_tokens_modulated = gate_msa * modulate(self.adaln_norm(pose_tokens), shift_msa, scale_msa)
|
| 124 |
+
pose_tokens_modulated = pose_tokens_modulated + pose_tokens
|
| 125 |
+
|
| 126 |
+
pose_tokens_modulated = self.trunk(pose_tokens_modulated)
|
| 127 |
+
# Compute the delta update for the pose encoding.
|
| 128 |
+
pred_pose_enc_delta = self.pose_branch(self.trunk_norm(pose_tokens_modulated))
|
| 129 |
+
|
| 130 |
+
if pred_pose_enc is None:
|
| 131 |
+
pred_pose_enc = pred_pose_enc_delta
|
| 132 |
+
else:
|
| 133 |
+
pred_pose_enc = pred_pose_enc + pred_pose_enc_delta
|
| 134 |
+
|
| 135 |
+
# Apply final activation functions for translation, quaternion, and field-of-view.
|
| 136 |
+
activated_pose = activate_pose(
|
| 137 |
+
pred_pose_enc, trans_act=self.trans_act, quat_act=self.quat_act, fl_act=self.fl_act
|
| 138 |
+
)
|
| 139 |
+
pred_pose_enc_list.append(activated_pose)
|
| 140 |
+
|
| 141 |
+
return pred_pose_enc_list
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def modulate(x: torch.Tensor, shift: torch.Tensor, scale: torch.Tensor) -> torch.Tensor:
|
| 145 |
+
"""
|
| 146 |
+
Modulate the input tensor using scaling and shifting parameters.
|
| 147 |
+
"""
|
| 148 |
+
# modified from https://github.com/facebookresearch/DiT/blob/796c29e532f47bba17c5b9c5eb39b9354b8b7c64/models.py#L19
|
| 149 |
+
return x * (1 + scale) + shift
|
vggt/heads/dpt_head.py
ADDED
|
@@ -0,0 +1,484 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Inspired by https://github.com/DepthAnything/Depth-Anything-V2
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
from typing import List, Dict, Tuple, Union
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
import torch.nn.functional as F
|
| 17 |
+
from .head_act import activate_head
|
| 18 |
+
from .utils import create_uv_grid, position_grid_to_embed
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class DPTHead(nn.Module):
|
| 22 |
+
"""
|
| 23 |
+
DPT Head for dense prediction tasks.
|
| 24 |
+
|
| 25 |
+
This implementation follows the architecture described in "Vision Transformers for Dense Prediction"
|
| 26 |
+
(https://arxiv.org/abs/2103.13413). The DPT head processes features from a vision transformer
|
| 27 |
+
backbone and produces dense predictions by fusing multi-scale features.
|
| 28 |
+
|
| 29 |
+
Args:
|
| 30 |
+
dim_in (int): Input dimension (channels).
|
| 31 |
+
patch_size (int, optional): Patch size. Default is 14.
|
| 32 |
+
output_dim (int, optional): Number of output channels. Default is 4.
|
| 33 |
+
activation (str, optional): Activation type. Default is "inv_log".
|
| 34 |
+
conf_activation (str, optional): Confidence activation type. Default is "expp1".
|
| 35 |
+
features (int, optional): Feature channels for intermediate representations. Default is 256.
|
| 36 |
+
out_channels (List[int], optional): Output channels for each intermediate layer.
|
| 37 |
+
intermediate_layer_idx (List[int], optional): Indices of layers from aggregated tokens used for DPT.
|
| 38 |
+
pos_embed (bool, optional): Whether to use positional embedding. Default is True.
|
| 39 |
+
feature_only (bool, optional): If True, return features only without the last several layers and activation head. Default is False.
|
| 40 |
+
down_ratio (int, optional): Downscaling factor for the output resolution. Default is 1.
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
def __init__(
|
| 44 |
+
self,
|
| 45 |
+
dim_in: int,
|
| 46 |
+
patch_size: int = 14,
|
| 47 |
+
output_dim: int = 4,
|
| 48 |
+
activation: str = "inv_log",
|
| 49 |
+
conf_activation: str = "expp1",
|
| 50 |
+
features: int = 256,
|
| 51 |
+
out_channels: List[int] = [256, 512, 1024, 1024],
|
| 52 |
+
intermediate_layer_idx: List[int] = [4, 11, 17, 23],
|
| 53 |
+
pos_embed: bool = True,
|
| 54 |
+
feature_only: bool = False,
|
| 55 |
+
down_ratio: int = 1,
|
| 56 |
+
) -> None:
|
| 57 |
+
super(DPTHead, self).__init__()
|
| 58 |
+
self.patch_size = patch_size
|
| 59 |
+
self.activation = activation
|
| 60 |
+
self.conf_activation = conf_activation
|
| 61 |
+
self.pos_embed = pos_embed
|
| 62 |
+
self.feature_only = feature_only
|
| 63 |
+
self.down_ratio = down_ratio
|
| 64 |
+
self.intermediate_layer_idx = intermediate_layer_idx
|
| 65 |
+
|
| 66 |
+
self.norm = nn.LayerNorm(dim_in)
|
| 67 |
+
|
| 68 |
+
# Projection layers for each output channel from tokens.
|
| 69 |
+
self.projects = nn.ModuleList(
|
| 70 |
+
[nn.Conv2d(in_channels=dim_in, out_channels=oc, kernel_size=1, stride=1, padding=0) for oc in out_channels]
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
# Resize layers for upsampling feature maps.
|
| 74 |
+
self.resize_layers = nn.ModuleList(
|
| 75 |
+
[
|
| 76 |
+
nn.ConvTranspose2d(
|
| 77 |
+
in_channels=out_channels[0], out_channels=out_channels[0], kernel_size=4, stride=4, padding=0
|
| 78 |
+
),
|
| 79 |
+
nn.ConvTranspose2d(
|
| 80 |
+
in_channels=out_channels[1], out_channels=out_channels[1], kernel_size=2, stride=2, padding=0
|
| 81 |
+
),
|
| 82 |
+
nn.Identity(),
|
| 83 |
+
nn.Conv2d(
|
| 84 |
+
in_channels=out_channels[3], out_channels=out_channels[3], kernel_size=3, stride=2, padding=1
|
| 85 |
+
),
|
| 86 |
+
]
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
self.scratch = _make_scratch(out_channels, features, expand=False)
|
| 90 |
+
|
| 91 |
+
# Attach additional modules to scratch.
|
| 92 |
+
self.scratch.stem_transpose = None
|
| 93 |
+
self.scratch.refinenet1 = _make_fusion_block(features)
|
| 94 |
+
self.scratch.refinenet2 = _make_fusion_block(features)
|
| 95 |
+
self.scratch.refinenet3 = _make_fusion_block(features)
|
| 96 |
+
self.scratch.refinenet4 = _make_fusion_block(features, has_residual=False)
|
| 97 |
+
|
| 98 |
+
head_features_1 = features
|
| 99 |
+
head_features_2 = 32
|
| 100 |
+
|
| 101 |
+
if feature_only:
|
| 102 |
+
self.scratch.output_conv1 = nn.Conv2d(head_features_1, head_features_1, kernel_size=3, stride=1, padding=1)
|
| 103 |
+
else:
|
| 104 |
+
self.scratch.output_conv1 = nn.Conv2d(
|
| 105 |
+
head_features_1, head_features_1 // 2, kernel_size=3, stride=1, padding=1
|
| 106 |
+
)
|
| 107 |
+
conv2_in_channels = head_features_1 // 2
|
| 108 |
+
|
| 109 |
+
self.scratch.output_conv2 = nn.Sequential(
|
| 110 |
+
nn.Conv2d(conv2_in_channels, head_features_2, kernel_size=3, stride=1, padding=1),
|
| 111 |
+
nn.ReLU(inplace=True),
|
| 112 |
+
nn.Conv2d(head_features_2, output_dim, kernel_size=1, stride=1, padding=0),
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
def forward(
|
| 116 |
+
self,
|
| 117 |
+
aggregated_tokens_list: List[torch.Tensor],
|
| 118 |
+
images: torch.Tensor,
|
| 119 |
+
patch_start_idx: int,
|
| 120 |
+
frames_chunk_size: int = 8,
|
| 121 |
+
) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:
|
| 122 |
+
"""
|
| 123 |
+
Forward pass through the DPT head, supports processing by chunking frames.
|
| 124 |
+
Args:
|
| 125 |
+
aggregated_tokens_list (List[Tensor]): List of token tensors from different transformer layers.
|
| 126 |
+
images (Tensor): Input images with shape [B, S, 3, H, W], in range [0, 1].
|
| 127 |
+
patch_start_idx (int): Starting index for patch tokens in the token sequence.
|
| 128 |
+
Used to separate patch tokens from other tokens (e.g., camera or register tokens).
|
| 129 |
+
frames_chunk_size (int, optional): Number of frames to process in each chunk.
|
| 130 |
+
If None or larger than S, all frames are processed at once. Default: 8.
|
| 131 |
+
|
| 132 |
+
Returns:
|
| 133 |
+
Tensor or Tuple[Tensor, Tensor]:
|
| 134 |
+
- If feature_only=True: Feature maps with shape [B, S, C, H, W]
|
| 135 |
+
- Otherwise: Tuple of (predictions, confidence) both with shape [B, S, 1, H, W]
|
| 136 |
+
"""
|
| 137 |
+
B, S, _, H, W = images.shape
|
| 138 |
+
|
| 139 |
+
# If frames_chunk_size is not specified or greater than S, process all frames at once
|
| 140 |
+
if frames_chunk_size is None or frames_chunk_size >= S:
|
| 141 |
+
return self._forward_impl(aggregated_tokens_list, images, patch_start_idx)
|
| 142 |
+
|
| 143 |
+
# Otherwise, process frames in chunks to manage memory usage
|
| 144 |
+
assert frames_chunk_size > 0
|
| 145 |
+
|
| 146 |
+
# Process frames in batches
|
| 147 |
+
all_preds = []
|
| 148 |
+
all_conf = []
|
| 149 |
+
|
| 150 |
+
for frames_start_idx in range(0, S, frames_chunk_size):
|
| 151 |
+
frames_end_idx = min(frames_start_idx + frames_chunk_size, S)
|
| 152 |
+
|
| 153 |
+
# Process batch of frames
|
| 154 |
+
if self.feature_only:
|
| 155 |
+
chunk_output = self._forward_impl(
|
| 156 |
+
aggregated_tokens_list, images, patch_start_idx, frames_start_idx, frames_end_idx
|
| 157 |
+
)
|
| 158 |
+
all_preds.append(chunk_output)
|
| 159 |
+
else:
|
| 160 |
+
chunk_preds, chunk_conf = self._forward_impl(
|
| 161 |
+
aggregated_tokens_list, images, patch_start_idx, frames_start_idx, frames_end_idx
|
| 162 |
+
)
|
| 163 |
+
all_preds.append(chunk_preds)
|
| 164 |
+
all_conf.append(chunk_conf)
|
| 165 |
+
|
| 166 |
+
# Concatenate results along the sequence dimension
|
| 167 |
+
if self.feature_only:
|
| 168 |
+
return torch.cat(all_preds, dim=1)
|
| 169 |
+
else:
|
| 170 |
+
return torch.cat(all_preds, dim=1), torch.cat(all_conf, dim=1)
|
| 171 |
+
|
| 172 |
+
def _forward_impl(
|
| 173 |
+
self,
|
| 174 |
+
aggregated_tokens_list: List[torch.Tensor],
|
| 175 |
+
images: torch.Tensor,
|
| 176 |
+
patch_start_idx: int,
|
| 177 |
+
frames_start_idx: int = None,
|
| 178 |
+
frames_end_idx: int = None,
|
| 179 |
+
) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:
|
| 180 |
+
"""
|
| 181 |
+
Implementation of the forward pass through the DPT head.
|
| 182 |
+
|
| 183 |
+
This method processes a specific chunk of frames from the sequence.
|
| 184 |
+
|
| 185 |
+
Args:
|
| 186 |
+
aggregated_tokens_list (List[Tensor]): List of token tensors from different transformer layers.
|
| 187 |
+
images (Tensor): Input images with shape [B, S, 3, H, W].
|
| 188 |
+
patch_start_idx (int): Starting index for patch tokens.
|
| 189 |
+
frames_start_idx (int, optional): Starting index for frames to process.
|
| 190 |
+
frames_end_idx (int, optional): Ending index for frames to process.
|
| 191 |
+
|
| 192 |
+
Returns:
|
| 193 |
+
Tensor or Tuple[Tensor, Tensor]: Feature maps or (predictions, confidence).
|
| 194 |
+
"""
|
| 195 |
+
if frames_start_idx is not None and frames_end_idx is not None:
|
| 196 |
+
images = images[:, frames_start_idx:frames_end_idx].contiguous()
|
| 197 |
+
|
| 198 |
+
B, S, _, H, W = images.shape
|
| 199 |
+
|
| 200 |
+
patch_h, patch_w = H // self.patch_size, W // self.patch_size
|
| 201 |
+
|
| 202 |
+
out = []
|
| 203 |
+
dpt_idx = 0
|
| 204 |
+
|
| 205 |
+
for layer_idx in self.intermediate_layer_idx:
|
| 206 |
+
x = aggregated_tokens_list[layer_idx][:, :, patch_start_idx:]
|
| 207 |
+
|
| 208 |
+
# Select frames if processing a chunk
|
| 209 |
+
if frames_start_idx is not None and frames_end_idx is not None:
|
| 210 |
+
x = x[:, frames_start_idx:frames_end_idx]
|
| 211 |
+
|
| 212 |
+
x = x.view(B * S, -1, x.shape[-1])
|
| 213 |
+
|
| 214 |
+
x = self.norm(x)
|
| 215 |
+
|
| 216 |
+
x = x.permute(0, 2, 1).reshape((x.shape[0], x.shape[-1], patch_h, patch_w))
|
| 217 |
+
|
| 218 |
+
x = self.projects[dpt_idx](x)
|
| 219 |
+
if self.pos_embed:
|
| 220 |
+
x = self._apply_pos_embed(x, W, H)
|
| 221 |
+
x = self.resize_layers[dpt_idx](x)
|
| 222 |
+
|
| 223 |
+
out.append(x)
|
| 224 |
+
dpt_idx += 1
|
| 225 |
+
|
| 226 |
+
# Fuse features from multiple layers.
|
| 227 |
+
out = self.scratch_forward(out)
|
| 228 |
+
# Interpolate fused output to match target image resolution.
|
| 229 |
+
out = custom_interpolate(
|
| 230 |
+
out,
|
| 231 |
+
(int(patch_h * self.patch_size / self.down_ratio), int(patch_w * self.patch_size / self.down_ratio)),
|
| 232 |
+
mode="bilinear",
|
| 233 |
+
align_corners=True,
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
if self.pos_embed:
|
| 237 |
+
out = self._apply_pos_embed(out, W, H)
|
| 238 |
+
|
| 239 |
+
if self.feature_only:
|
| 240 |
+
return out.view(B, S, *out.shape[1:])
|
| 241 |
+
|
| 242 |
+
out = self.scratch.output_conv2(out)
|
| 243 |
+
preds, conf = activate_head(out, activation=self.activation, conf_activation=self.conf_activation)
|
| 244 |
+
|
| 245 |
+
preds = preds.view(B, S, *preds.shape[1:])
|
| 246 |
+
conf = conf.view(B, S, *conf.shape[1:])
|
| 247 |
+
return preds, conf
|
| 248 |
+
|
| 249 |
+
def _apply_pos_embed(self, x: torch.Tensor, W: int, H: int, ratio: float = 0.1) -> torch.Tensor:
|
| 250 |
+
"""
|
| 251 |
+
Apply positional embedding to tensor x.
|
| 252 |
+
"""
|
| 253 |
+
patch_w = x.shape[-1]
|
| 254 |
+
patch_h = x.shape[-2]
|
| 255 |
+
pos_embed = create_uv_grid(patch_w, patch_h, aspect_ratio=W / H, dtype=x.dtype, device=x.device)
|
| 256 |
+
pos_embed = position_grid_to_embed(pos_embed, x.shape[1])
|
| 257 |
+
pos_embed = pos_embed * ratio
|
| 258 |
+
pos_embed = pos_embed.permute(2, 0, 1)[None].expand(x.shape[0], -1, -1, -1)
|
| 259 |
+
return x + pos_embed
|
| 260 |
+
|
| 261 |
+
def scratch_forward(self, features: List[torch.Tensor]) -> torch.Tensor:
|
| 262 |
+
"""
|
| 263 |
+
Forward pass through the fusion blocks.
|
| 264 |
+
|
| 265 |
+
Args:
|
| 266 |
+
features (List[Tensor]): List of feature maps from different layers.
|
| 267 |
+
|
| 268 |
+
Returns:
|
| 269 |
+
Tensor: Fused feature map.
|
| 270 |
+
"""
|
| 271 |
+
layer_1, layer_2, layer_3, layer_4 = features
|
| 272 |
+
|
| 273 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 274 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 275 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 276 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 277 |
+
|
| 278 |
+
out = self.scratch.refinenet4(layer_4_rn, size=layer_3_rn.shape[2:])
|
| 279 |
+
del layer_4_rn, layer_4
|
| 280 |
+
|
| 281 |
+
out = self.scratch.refinenet3(out, layer_3_rn, size=layer_2_rn.shape[2:])
|
| 282 |
+
del layer_3_rn, layer_3
|
| 283 |
+
|
| 284 |
+
out = self.scratch.refinenet2(out, layer_2_rn, size=layer_1_rn.shape[2:])
|
| 285 |
+
del layer_2_rn, layer_2
|
| 286 |
+
|
| 287 |
+
out = self.scratch.refinenet1(out, layer_1_rn)
|
| 288 |
+
del layer_1_rn, layer_1
|
| 289 |
+
|
| 290 |
+
out = self.scratch.output_conv1(out)
|
| 291 |
+
return out
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
################################################################################
|
| 295 |
+
# Modules
|
| 296 |
+
################################################################################
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
def _make_fusion_block(features: int, size: int = None, has_residual: bool = True, groups: int = 1) -> nn.Module:
|
| 300 |
+
return FeatureFusionBlock(
|
| 301 |
+
features,
|
| 302 |
+
nn.ReLU(inplace=True),
|
| 303 |
+
deconv=False,
|
| 304 |
+
bn=False,
|
| 305 |
+
expand=False,
|
| 306 |
+
align_corners=True,
|
| 307 |
+
size=size,
|
| 308 |
+
has_residual=has_residual,
|
| 309 |
+
groups=groups,
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
def _make_scratch(in_shape: List[int], out_shape: int, groups: int = 1, expand: bool = False) -> nn.Module:
|
| 314 |
+
scratch = nn.Module()
|
| 315 |
+
out_shape1 = out_shape
|
| 316 |
+
out_shape2 = out_shape
|
| 317 |
+
out_shape3 = out_shape
|
| 318 |
+
if len(in_shape) >= 4:
|
| 319 |
+
out_shape4 = out_shape
|
| 320 |
+
|
| 321 |
+
if expand:
|
| 322 |
+
out_shape1 = out_shape
|
| 323 |
+
out_shape2 = out_shape * 2
|
| 324 |
+
out_shape3 = out_shape * 4
|
| 325 |
+
if len(in_shape) >= 4:
|
| 326 |
+
out_shape4 = out_shape * 8
|
| 327 |
+
|
| 328 |
+
scratch.layer1_rn = nn.Conv2d(
|
| 329 |
+
in_shape[0], out_shape1, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 330 |
+
)
|
| 331 |
+
scratch.layer2_rn = nn.Conv2d(
|
| 332 |
+
in_shape[1], out_shape2, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 333 |
+
)
|
| 334 |
+
scratch.layer3_rn = nn.Conv2d(
|
| 335 |
+
in_shape[2], out_shape3, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 336 |
+
)
|
| 337 |
+
if len(in_shape) >= 4:
|
| 338 |
+
scratch.layer4_rn = nn.Conv2d(
|
| 339 |
+
in_shape[3], out_shape4, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 340 |
+
)
|
| 341 |
+
return scratch
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
class ResidualConvUnit(nn.Module):
|
| 345 |
+
"""Residual convolution module."""
|
| 346 |
+
|
| 347 |
+
def __init__(self, features, activation, bn, groups=1):
|
| 348 |
+
"""Init.
|
| 349 |
+
|
| 350 |
+
Args:
|
| 351 |
+
features (int): number of features
|
| 352 |
+
"""
|
| 353 |
+
super().__init__()
|
| 354 |
+
|
| 355 |
+
self.bn = bn
|
| 356 |
+
self.groups = groups
|
| 357 |
+
self.conv1 = nn.Conv2d(features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups)
|
| 358 |
+
self.conv2 = nn.Conv2d(features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups)
|
| 359 |
+
|
| 360 |
+
self.norm1 = None
|
| 361 |
+
self.norm2 = None
|
| 362 |
+
|
| 363 |
+
self.activation = activation
|
| 364 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 365 |
+
|
| 366 |
+
def forward(self, x):
|
| 367 |
+
"""Forward pass.
|
| 368 |
+
|
| 369 |
+
Args:
|
| 370 |
+
x (tensor): input
|
| 371 |
+
|
| 372 |
+
Returns:
|
| 373 |
+
tensor: output
|
| 374 |
+
"""
|
| 375 |
+
|
| 376 |
+
out = self.activation(x)
|
| 377 |
+
out = self.conv1(out)
|
| 378 |
+
if self.norm1 is not None:
|
| 379 |
+
out = self.norm1(out)
|
| 380 |
+
|
| 381 |
+
out = self.activation(out)
|
| 382 |
+
out = self.conv2(out)
|
| 383 |
+
if self.norm2 is not None:
|
| 384 |
+
out = self.norm2(out)
|
| 385 |
+
|
| 386 |
+
return self.skip_add.add(out, x)
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
class FeatureFusionBlock(nn.Module):
|
| 390 |
+
"""Feature fusion block."""
|
| 391 |
+
|
| 392 |
+
def __init__(
|
| 393 |
+
self,
|
| 394 |
+
features,
|
| 395 |
+
activation,
|
| 396 |
+
deconv=False,
|
| 397 |
+
bn=False,
|
| 398 |
+
expand=False,
|
| 399 |
+
align_corners=True,
|
| 400 |
+
size=None,
|
| 401 |
+
has_residual=True,
|
| 402 |
+
groups=1,
|
| 403 |
+
):
|
| 404 |
+
"""Init.
|
| 405 |
+
|
| 406 |
+
Args:
|
| 407 |
+
features (int): number of features
|
| 408 |
+
"""
|
| 409 |
+
super(FeatureFusionBlock, self).__init__()
|
| 410 |
+
|
| 411 |
+
self.deconv = deconv
|
| 412 |
+
self.align_corners = align_corners
|
| 413 |
+
self.groups = groups
|
| 414 |
+
self.expand = expand
|
| 415 |
+
out_features = features
|
| 416 |
+
if self.expand == True:
|
| 417 |
+
out_features = features // 2
|
| 418 |
+
|
| 419 |
+
self.out_conv = nn.Conv2d(
|
| 420 |
+
features, out_features, kernel_size=1, stride=1, padding=0, bias=True, groups=self.groups
|
| 421 |
+
)
|
| 422 |
+
|
| 423 |
+
if has_residual:
|
| 424 |
+
self.resConfUnit1 = ResidualConvUnit(features, activation, bn, groups=self.groups)
|
| 425 |
+
|
| 426 |
+
self.has_residual = has_residual
|
| 427 |
+
self.resConfUnit2 = ResidualConvUnit(features, activation, bn, groups=self.groups)
|
| 428 |
+
|
| 429 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 430 |
+
self.size = size
|
| 431 |
+
|
| 432 |
+
def forward(self, *xs, size=None):
|
| 433 |
+
"""Forward pass.
|
| 434 |
+
|
| 435 |
+
Returns:
|
| 436 |
+
tensor: output
|
| 437 |
+
"""
|
| 438 |
+
output = xs[0]
|
| 439 |
+
|
| 440 |
+
if self.has_residual:
|
| 441 |
+
res = self.resConfUnit1(xs[1])
|
| 442 |
+
output = self.skip_add.add(output, res)
|
| 443 |
+
|
| 444 |
+
output = self.resConfUnit2(output)
|
| 445 |
+
|
| 446 |
+
if (size is None) and (self.size is None):
|
| 447 |
+
modifier = {"scale_factor": 2}
|
| 448 |
+
elif size is None:
|
| 449 |
+
modifier = {"size": self.size}
|
| 450 |
+
else:
|
| 451 |
+
modifier = {"size": size}
|
| 452 |
+
|
| 453 |
+
output = custom_interpolate(output, **modifier, mode="bilinear", align_corners=self.align_corners)
|
| 454 |
+
output = self.out_conv(output)
|
| 455 |
+
|
| 456 |
+
return output
|
| 457 |
+
|
| 458 |
+
|
| 459 |
+
def custom_interpolate(
|
| 460 |
+
x: torch.Tensor,
|
| 461 |
+
size: Tuple[int, int] = None,
|
| 462 |
+
scale_factor: float = None,
|
| 463 |
+
mode: str = "bilinear",
|
| 464 |
+
align_corners: bool = True,
|
| 465 |
+
) -> torch.Tensor:
|
| 466 |
+
"""
|
| 467 |
+
Custom interpolate to avoid INT_MAX issues in nn.functional.interpolate.
|
| 468 |
+
"""
|
| 469 |
+
if size is None:
|
| 470 |
+
size = (int(x.shape[-2] * scale_factor), int(x.shape[-1] * scale_factor))
|
| 471 |
+
|
| 472 |
+
INT_MAX = 1610612736
|
| 473 |
+
|
| 474 |
+
input_elements = size[0] * size[1] * x.shape[0] * x.shape[1]
|
| 475 |
+
|
| 476 |
+
if input_elements > INT_MAX:
|
| 477 |
+
chunks = torch.chunk(x, chunks=(input_elements // INT_MAX) + 1, dim=0)
|
| 478 |
+
interpolated_chunks = [
|
| 479 |
+
nn.functional.interpolate(chunk, size=size, mode=mode, align_corners=align_corners) for chunk in chunks
|
| 480 |
+
]
|
| 481 |
+
x = torch.cat(interpolated_chunks, dim=0)
|
| 482 |
+
return x.contiguous()
|
| 483 |
+
else:
|
| 484 |
+
return nn.functional.interpolate(x, size=size, mode=mode, align_corners=align_corners)
|
vggt/heads/head_act.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def activate_pose(pred_pose_enc, trans_act="linear", quat_act="linear", fl_act="linear"):
|
| 13 |
+
"""
|
| 14 |
+
Activate pose parameters with specified activation functions.
|
| 15 |
+
|
| 16 |
+
Args:
|
| 17 |
+
pred_pose_enc: Tensor containing encoded pose parameters [translation, quaternion, focal length]
|
| 18 |
+
trans_act: Activation type for translation component
|
| 19 |
+
quat_act: Activation type for quaternion component
|
| 20 |
+
fl_act: Activation type for focal length component
|
| 21 |
+
|
| 22 |
+
Returns:
|
| 23 |
+
Activated pose parameters tensor
|
| 24 |
+
"""
|
| 25 |
+
T = pred_pose_enc[..., :3]
|
| 26 |
+
quat = pred_pose_enc[..., 3:7]
|
| 27 |
+
fl = pred_pose_enc[..., 7:] # or fov
|
| 28 |
+
|
| 29 |
+
T = base_pose_act(T, trans_act)
|
| 30 |
+
quat = base_pose_act(quat, quat_act)
|
| 31 |
+
fl = base_pose_act(fl, fl_act) # or fov
|
| 32 |
+
|
| 33 |
+
pred_pose_enc = torch.cat([T, quat, fl], dim=-1)
|
| 34 |
+
|
| 35 |
+
return pred_pose_enc
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def base_pose_act(pose_enc, act_type="linear"):
|
| 39 |
+
"""
|
| 40 |
+
Apply basic activation function to pose parameters.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
pose_enc: Tensor containing encoded pose parameters
|
| 44 |
+
act_type: Activation type ("linear", "inv_log", "exp", "relu")
|
| 45 |
+
|
| 46 |
+
Returns:
|
| 47 |
+
Activated pose parameters
|
| 48 |
+
"""
|
| 49 |
+
if act_type == "linear":
|
| 50 |
+
return pose_enc
|
| 51 |
+
elif act_type == "inv_log":
|
| 52 |
+
return inverse_log_transform(pose_enc)
|
| 53 |
+
elif act_type == "exp":
|
| 54 |
+
return torch.exp(pose_enc)
|
| 55 |
+
elif act_type == "relu":
|
| 56 |
+
return F.relu(pose_enc)
|
| 57 |
+
else:
|
| 58 |
+
raise ValueError(f"Unknown act_type: {act_type}")
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def activate_head(out, activation="norm_exp", conf_activation="expp1"):
|
| 62 |
+
"""
|
| 63 |
+
Process network output to extract 3D points and confidence values.
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
out: Network output tensor (B, C, H, W)
|
| 67 |
+
activation: Activation type for 3D points
|
| 68 |
+
conf_activation: Activation type for confidence values
|
| 69 |
+
|
| 70 |
+
Returns:
|
| 71 |
+
Tuple of (3D points tensor, confidence tensor)
|
| 72 |
+
"""
|
| 73 |
+
# Move channels from last dim to the 4th dimension => (B, H, W, C)
|
| 74 |
+
fmap = out.permute(0, 2, 3, 1) # B,H,W,C expected
|
| 75 |
+
|
| 76 |
+
# Split into xyz (first C-1 channels) and confidence (last channel)
|
| 77 |
+
xyz = fmap[:, :, :, :-1]
|
| 78 |
+
conf = fmap[:, :, :, -1]
|
| 79 |
+
|
| 80 |
+
if activation == "norm_exp":
|
| 81 |
+
d = xyz.norm(dim=-1, keepdim=True).clamp(min=1e-8)
|
| 82 |
+
xyz_normed = xyz / d
|
| 83 |
+
pts3d = xyz_normed * torch.expm1(d)
|
| 84 |
+
elif activation == "norm":
|
| 85 |
+
pts3d = xyz / xyz.norm(dim=-1, keepdim=True)
|
| 86 |
+
elif activation == "exp":
|
| 87 |
+
pts3d = torch.exp(xyz)
|
| 88 |
+
elif activation == "relu":
|
| 89 |
+
pts3d = F.relu(xyz)
|
| 90 |
+
elif activation == "inv_log":
|
| 91 |
+
pts3d = inverse_log_transform(xyz)
|
| 92 |
+
elif activation == "xy_inv_log":
|
| 93 |
+
xy, z = xyz.split([2, 1], dim=-1)
|
| 94 |
+
z = inverse_log_transform(z)
|
| 95 |
+
pts3d = torch.cat([xy * z, z], dim=-1)
|
| 96 |
+
elif activation == "sigmoid":
|
| 97 |
+
pts3d = torch.sigmoid(xyz)
|
| 98 |
+
elif activation == "linear":
|
| 99 |
+
pts3d = xyz
|
| 100 |
+
else:
|
| 101 |
+
raise ValueError(f"Unknown activation: {activation}")
|
| 102 |
+
|
| 103 |
+
if conf_activation == "expp1":
|
| 104 |
+
conf_out = 1 + conf.exp()
|
| 105 |
+
elif conf_activation == "expp0":
|
| 106 |
+
conf_out = conf.exp()
|
| 107 |
+
elif conf_activation == "sigmoid":
|
| 108 |
+
conf_out = torch.sigmoid(conf)
|
| 109 |
+
else:
|
| 110 |
+
raise ValueError(f"Unknown conf_activation: {conf_activation}")
|
| 111 |
+
|
| 112 |
+
return pts3d, conf_out
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def inverse_log_transform(y):
|
| 116 |
+
"""
|
| 117 |
+
Apply inverse log transform: sign(y) * (exp(|y|) - 1)
|
| 118 |
+
|
| 119 |
+
Args:
|
| 120 |
+
y: Input tensor
|
| 121 |
+
|
| 122 |
+
Returns:
|
| 123 |
+
Transformed tensor
|
| 124 |
+
"""
|
| 125 |
+
return torch.sign(y) * (torch.expm1(torch.abs(y)))
|
vggt/heads/track_head.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from .dpt_head import DPTHead
|
| 9 |
+
from .track_modules.base_track_predictor import BaseTrackerPredictor
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class TrackHead(nn.Module):
|
| 13 |
+
"""
|
| 14 |
+
Track head that uses DPT head to process tokens and BaseTrackerPredictor for tracking.
|
| 15 |
+
The tracking is performed iteratively, refining predictions over multiple iterations.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
dim_in,
|
| 21 |
+
patch_size=14,
|
| 22 |
+
features=128,
|
| 23 |
+
iters=4,
|
| 24 |
+
predict_conf=True,
|
| 25 |
+
stride=2,
|
| 26 |
+
corr_levels=7,
|
| 27 |
+
corr_radius=4,
|
| 28 |
+
hidden_size=384,
|
| 29 |
+
):
|
| 30 |
+
"""
|
| 31 |
+
Initialize the TrackHead module.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
dim_in (int): Input dimension of tokens from the backbone.
|
| 35 |
+
patch_size (int): Size of image patches used in the vision transformer.
|
| 36 |
+
features (int): Number of feature channels in the feature extractor output.
|
| 37 |
+
iters (int): Number of refinement iterations for tracking predictions.
|
| 38 |
+
predict_conf (bool): Whether to predict confidence scores for tracked points.
|
| 39 |
+
stride (int): Stride value for the tracker predictor.
|
| 40 |
+
corr_levels (int): Number of correlation pyramid levels
|
| 41 |
+
corr_radius (int): Radius for correlation computation, controlling the search area.
|
| 42 |
+
hidden_size (int): Size of hidden layers in the tracker network.
|
| 43 |
+
"""
|
| 44 |
+
super().__init__()
|
| 45 |
+
|
| 46 |
+
self.patch_size = patch_size
|
| 47 |
+
|
| 48 |
+
# Feature extractor based on DPT architecture
|
| 49 |
+
# Processes tokens into feature maps for tracking
|
| 50 |
+
self.feature_extractor = DPTHead(
|
| 51 |
+
dim_in=dim_in,
|
| 52 |
+
patch_size=patch_size,
|
| 53 |
+
features=features,
|
| 54 |
+
feature_only=True, # Only output features, no activation
|
| 55 |
+
down_ratio=2, # Reduces spatial dimensions by factor of 2
|
| 56 |
+
pos_embed=False,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
# Tracker module that predicts point trajectories
|
| 60 |
+
# Takes feature maps and predicts coordinates and visibility
|
| 61 |
+
self.tracker = BaseTrackerPredictor(
|
| 62 |
+
latent_dim=features, # Match the output_dim of feature extractor
|
| 63 |
+
predict_conf=predict_conf,
|
| 64 |
+
stride=stride,
|
| 65 |
+
corr_levels=corr_levels,
|
| 66 |
+
corr_radius=corr_radius,
|
| 67 |
+
hidden_size=hidden_size,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
self.iters = iters
|
| 71 |
+
|
| 72 |
+
def forward(self, aggregated_tokens_list, images, patch_start_idx, query_points=None, iters=None):
|
| 73 |
+
"""
|
| 74 |
+
Forward pass of the TrackHead.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
aggregated_tokens_list (list): List of aggregated tokens from the backbone.
|
| 78 |
+
images (torch.Tensor): Input images of shape (B, S, C, H, W) where:
|
| 79 |
+
B = batch size, S = sequence length.
|
| 80 |
+
patch_start_idx (int): Starting index for patch tokens.
|
| 81 |
+
query_points (torch.Tensor, optional): Initial query points to track.
|
| 82 |
+
If None, points are initialized by the tracker.
|
| 83 |
+
iters (int, optional): Number of refinement iterations. If None, uses self.iters.
|
| 84 |
+
|
| 85 |
+
Returns:
|
| 86 |
+
tuple:
|
| 87 |
+
- coord_preds (torch.Tensor): Predicted coordinates for tracked points.
|
| 88 |
+
- vis_scores (torch.Tensor): Visibility scores for tracked points.
|
| 89 |
+
- conf_scores (torch.Tensor): Confidence scores for tracked points (if predict_conf=True).
|
| 90 |
+
"""
|
| 91 |
+
B, S, _, H, W = images.shape
|
| 92 |
+
|
| 93 |
+
# Extract features from tokens
|
| 94 |
+
# feature_maps has shape (B, S, C, H//2, W//2) due to down_ratio=2
|
| 95 |
+
feature_maps = self.feature_extractor(aggregated_tokens_list, images, patch_start_idx)
|
| 96 |
+
|
| 97 |
+
# Use default iterations if not specified
|
| 98 |
+
if iters is None:
|
| 99 |
+
iters = self.iters
|
| 100 |
+
|
| 101 |
+
# Perform tracking using the extracted features
|
| 102 |
+
coord_preds, vis_scores, conf_scores = self.tracker(query_points=query_points, fmaps=feature_maps, iters=iters)
|
| 103 |
+
|
| 104 |
+
return coord_preds, vis_scores, conf_scores
|
vggt/heads/track_modules/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
vggt/heads/track_modules/base_track_predictor.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
from einops import rearrange, repeat
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
from .blocks import EfficientUpdateFormer, CorrBlock
|
| 13 |
+
from .utils import sample_features4d, get_2d_embedding, get_2d_sincos_pos_embed
|
| 14 |
+
from .modules import Mlp
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class BaseTrackerPredictor(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
stride=1,
|
| 21 |
+
corr_levels=5,
|
| 22 |
+
corr_radius=4,
|
| 23 |
+
latent_dim=128,
|
| 24 |
+
hidden_size=384,
|
| 25 |
+
use_spaceatt=True,
|
| 26 |
+
depth=6,
|
| 27 |
+
max_scale=518,
|
| 28 |
+
predict_conf=True,
|
| 29 |
+
):
|
| 30 |
+
super(BaseTrackerPredictor, self).__init__()
|
| 31 |
+
"""
|
| 32 |
+
The base template to create a track predictor
|
| 33 |
+
|
| 34 |
+
Modified from https://github.com/facebookresearch/co-tracker/
|
| 35 |
+
and https://github.com/facebookresearch/vggsfm
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
self.stride = stride
|
| 39 |
+
self.latent_dim = latent_dim
|
| 40 |
+
self.corr_levels = corr_levels
|
| 41 |
+
self.corr_radius = corr_radius
|
| 42 |
+
self.hidden_size = hidden_size
|
| 43 |
+
self.max_scale = max_scale
|
| 44 |
+
self.predict_conf = predict_conf
|
| 45 |
+
|
| 46 |
+
self.flows_emb_dim = latent_dim // 2
|
| 47 |
+
|
| 48 |
+
self.corr_mlp = Mlp(
|
| 49 |
+
in_features=self.corr_levels * (self.corr_radius * 2 + 1) ** 2,
|
| 50 |
+
hidden_features=self.hidden_size,
|
| 51 |
+
out_features=self.latent_dim,
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
self.transformer_dim = self.latent_dim + self.latent_dim + self.latent_dim + 4
|
| 55 |
+
|
| 56 |
+
self.query_ref_token = nn.Parameter(torch.randn(1, 2, self.transformer_dim))
|
| 57 |
+
|
| 58 |
+
space_depth = depth if use_spaceatt else 0
|
| 59 |
+
time_depth = depth
|
| 60 |
+
|
| 61 |
+
self.updateformer = EfficientUpdateFormer(
|
| 62 |
+
space_depth=space_depth,
|
| 63 |
+
time_depth=time_depth,
|
| 64 |
+
input_dim=self.transformer_dim,
|
| 65 |
+
hidden_size=self.hidden_size,
|
| 66 |
+
output_dim=self.latent_dim + 2,
|
| 67 |
+
mlp_ratio=4.0,
|
| 68 |
+
add_space_attn=use_spaceatt,
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
self.fmap_norm = nn.LayerNorm(self.latent_dim)
|
| 72 |
+
self.ffeat_norm = nn.GroupNorm(1, self.latent_dim)
|
| 73 |
+
|
| 74 |
+
# A linear layer to update track feats at each iteration
|
| 75 |
+
self.ffeat_updater = nn.Sequential(nn.Linear(self.latent_dim, self.latent_dim), nn.GELU())
|
| 76 |
+
|
| 77 |
+
self.vis_predictor = nn.Sequential(nn.Linear(self.latent_dim, 1))
|
| 78 |
+
|
| 79 |
+
if predict_conf:
|
| 80 |
+
self.conf_predictor = nn.Sequential(nn.Linear(self.latent_dim, 1))
|
| 81 |
+
|
| 82 |
+
def forward(self, query_points, fmaps=None, iters=6, return_feat=False, down_ratio=1, apply_sigmoid=True):
|
| 83 |
+
"""
|
| 84 |
+
query_points: B x N x 2, the number of batches, tracks, and xy
|
| 85 |
+
fmaps: B x S x C x HH x WW, the number of batches, frames, and feature dimension.
|
| 86 |
+
note HH and WW is the size of feature maps instead of original images
|
| 87 |
+
"""
|
| 88 |
+
B, N, D = query_points.shape
|
| 89 |
+
B, S, C, HH, WW = fmaps.shape
|
| 90 |
+
|
| 91 |
+
assert D == 2, "Input points must be 2D coordinates"
|
| 92 |
+
|
| 93 |
+
# apply a layernorm to fmaps here
|
| 94 |
+
fmaps = self.fmap_norm(fmaps.permute(0, 1, 3, 4, 2))
|
| 95 |
+
fmaps = fmaps.permute(0, 1, 4, 2, 3)
|
| 96 |
+
|
| 97 |
+
# Scale the input query_points because we may downsample the images
|
| 98 |
+
# by down_ratio or self.stride
|
| 99 |
+
# e.g., if a 3x1024x1024 image is processed to a 128x256x256 feature map
|
| 100 |
+
# its query_points should be query_points/4
|
| 101 |
+
if down_ratio > 1:
|
| 102 |
+
query_points = query_points / float(down_ratio)
|
| 103 |
+
|
| 104 |
+
query_points = query_points / float(self.stride)
|
| 105 |
+
|
| 106 |
+
# Init with coords as the query points
|
| 107 |
+
# It means the search will start from the position of query points at the reference frames
|
| 108 |
+
coords = query_points.clone().reshape(B, 1, N, 2).repeat(1, S, 1, 1)
|
| 109 |
+
|
| 110 |
+
# Sample/extract the features of the query points in the query frame
|
| 111 |
+
query_track_feat = sample_features4d(fmaps[:, 0], coords[:, 0])
|
| 112 |
+
|
| 113 |
+
# init track feats by query feats
|
| 114 |
+
track_feats = query_track_feat.unsqueeze(1).repeat(1, S, 1, 1) # B, S, N, C
|
| 115 |
+
# back up the init coords
|
| 116 |
+
coords_backup = coords.clone()
|
| 117 |
+
|
| 118 |
+
fcorr_fn = CorrBlock(fmaps, num_levels=self.corr_levels, radius=self.corr_radius)
|
| 119 |
+
|
| 120 |
+
coord_preds = []
|
| 121 |
+
|
| 122 |
+
# Iterative Refinement
|
| 123 |
+
for _ in range(iters):
|
| 124 |
+
# Detach the gradients from the last iteration
|
| 125 |
+
# (in my experience, not very important for performance)
|
| 126 |
+
coords = coords.detach()
|
| 127 |
+
|
| 128 |
+
fcorrs = fcorr_fn.corr_sample(track_feats, coords)
|
| 129 |
+
|
| 130 |
+
corr_dim = fcorrs.shape[3]
|
| 131 |
+
fcorrs_ = fcorrs.permute(0, 2, 1, 3).reshape(B * N, S, corr_dim)
|
| 132 |
+
fcorrs_ = self.corr_mlp(fcorrs_)
|
| 133 |
+
|
| 134 |
+
# Movement of current coords relative to query points
|
| 135 |
+
flows = (coords - coords[:, 0:1]).permute(0, 2, 1, 3).reshape(B * N, S, 2)
|
| 136 |
+
|
| 137 |
+
flows_emb = get_2d_embedding(flows, self.flows_emb_dim, cat_coords=False)
|
| 138 |
+
|
| 139 |
+
# (In my trials, it is also okay to just add the flows_emb instead of concat)
|
| 140 |
+
flows_emb = torch.cat([flows_emb, flows / self.max_scale, flows / self.max_scale], dim=-1)
|
| 141 |
+
|
| 142 |
+
track_feats_ = track_feats.permute(0, 2, 1, 3).reshape(B * N, S, self.latent_dim)
|
| 143 |
+
|
| 144 |
+
# Concatenate them as the input for the transformers
|
| 145 |
+
transformer_input = torch.cat([flows_emb, fcorrs_, track_feats_], dim=2)
|
| 146 |
+
|
| 147 |
+
# 2D positional embed
|
| 148 |
+
# TODO: this can be much simplified
|
| 149 |
+
pos_embed = get_2d_sincos_pos_embed(self.transformer_dim, grid_size=(HH, WW)).to(query_points.device)
|
| 150 |
+
sampled_pos_emb = sample_features4d(pos_embed.expand(B, -1, -1, -1), coords[:, 0])
|
| 151 |
+
|
| 152 |
+
sampled_pos_emb = rearrange(sampled_pos_emb, "b n c -> (b n) c").unsqueeze(1)
|
| 153 |
+
|
| 154 |
+
x = transformer_input + sampled_pos_emb
|
| 155 |
+
|
| 156 |
+
# Add the query ref token to the track feats
|
| 157 |
+
query_ref_token = torch.cat(
|
| 158 |
+
[self.query_ref_token[:, 0:1], self.query_ref_token[:, 1:2].expand(-1, S - 1, -1)], dim=1
|
| 159 |
+
)
|
| 160 |
+
x = x + query_ref_token.to(x.device).to(x.dtype)
|
| 161 |
+
|
| 162 |
+
# B, N, S, C
|
| 163 |
+
x = rearrange(x, "(b n) s d -> b n s d", b=B)
|
| 164 |
+
|
| 165 |
+
# Compute the delta coordinates and delta track features
|
| 166 |
+
delta, _ = self.updateformer(x)
|
| 167 |
+
|
| 168 |
+
# BN, S, C
|
| 169 |
+
delta = rearrange(delta, " b n s d -> (b n) s d", b=B)
|
| 170 |
+
delta_coords_ = delta[:, :, :2]
|
| 171 |
+
delta_feats_ = delta[:, :, 2:]
|
| 172 |
+
|
| 173 |
+
track_feats_ = track_feats_.reshape(B * N * S, self.latent_dim)
|
| 174 |
+
delta_feats_ = delta_feats_.reshape(B * N * S, self.latent_dim)
|
| 175 |
+
|
| 176 |
+
# Update the track features
|
| 177 |
+
track_feats_ = self.ffeat_updater(self.ffeat_norm(delta_feats_)) + track_feats_
|
| 178 |
+
|
| 179 |
+
track_feats = track_feats_.reshape(B, N, S, self.latent_dim).permute(0, 2, 1, 3) # BxSxNxC
|
| 180 |
+
|
| 181 |
+
# B x S x N x 2
|
| 182 |
+
coords = coords + delta_coords_.reshape(B, N, S, 2).permute(0, 2, 1, 3)
|
| 183 |
+
|
| 184 |
+
# Force coord0 as query
|
| 185 |
+
# because we assume the query points should not be changed
|
| 186 |
+
coords[:, 0] = coords_backup[:, 0]
|
| 187 |
+
|
| 188 |
+
# The predicted tracks are in the original image scale
|
| 189 |
+
if down_ratio > 1:
|
| 190 |
+
coord_preds.append(coords * self.stride * down_ratio)
|
| 191 |
+
else:
|
| 192 |
+
coord_preds.append(coords * self.stride)
|
| 193 |
+
|
| 194 |
+
# B, S, N
|
| 195 |
+
vis_e = self.vis_predictor(track_feats.reshape(B * S * N, self.latent_dim)).reshape(B, S, N)
|
| 196 |
+
if apply_sigmoid:
|
| 197 |
+
vis_e = torch.sigmoid(vis_e)
|
| 198 |
+
|
| 199 |
+
if self.predict_conf:
|
| 200 |
+
conf_e = self.conf_predictor(track_feats.reshape(B * S * N, self.latent_dim)).reshape(B, S, N)
|
| 201 |
+
if apply_sigmoid:
|
| 202 |
+
conf_e = torch.sigmoid(conf_e)
|
| 203 |
+
else:
|
| 204 |
+
conf_e = None
|
| 205 |
+
|
| 206 |
+
if return_feat:
|
| 207 |
+
return coord_preds, vis_e, track_feats, query_track_feat, conf_e
|
| 208 |
+
else:
|
| 209 |
+
return coord_preds, vis_e, conf_e
|
vggt/heads/track_modules/blocks.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Modified from https://github.com/facebookresearch/co-tracker/
|
| 9 |
+
|
| 10 |
+
import math
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
from .utils import bilinear_sampler
|
| 16 |
+
from .modules import Mlp, AttnBlock, CrossAttnBlock, ResidualBlock
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class EfficientUpdateFormer(nn.Module):
|
| 20 |
+
"""
|
| 21 |
+
Transformer model that updates track estimates.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(
|
| 25 |
+
self,
|
| 26 |
+
space_depth=6,
|
| 27 |
+
time_depth=6,
|
| 28 |
+
input_dim=320,
|
| 29 |
+
hidden_size=384,
|
| 30 |
+
num_heads=8,
|
| 31 |
+
output_dim=130,
|
| 32 |
+
mlp_ratio=4.0,
|
| 33 |
+
add_space_attn=True,
|
| 34 |
+
num_virtual_tracks=64,
|
| 35 |
+
):
|
| 36 |
+
super().__init__()
|
| 37 |
+
|
| 38 |
+
self.out_channels = 2
|
| 39 |
+
self.num_heads = num_heads
|
| 40 |
+
self.hidden_size = hidden_size
|
| 41 |
+
self.add_space_attn = add_space_attn
|
| 42 |
+
|
| 43 |
+
# Add input LayerNorm before linear projection
|
| 44 |
+
self.input_norm = nn.LayerNorm(input_dim)
|
| 45 |
+
self.input_transform = torch.nn.Linear(input_dim, hidden_size, bias=True)
|
| 46 |
+
|
| 47 |
+
# Add output LayerNorm before final projection
|
| 48 |
+
self.output_norm = nn.LayerNorm(hidden_size)
|
| 49 |
+
self.flow_head = torch.nn.Linear(hidden_size, output_dim, bias=True)
|
| 50 |
+
self.num_virtual_tracks = num_virtual_tracks
|
| 51 |
+
|
| 52 |
+
if self.add_space_attn:
|
| 53 |
+
self.virual_tracks = nn.Parameter(torch.randn(1, num_virtual_tracks, 1, hidden_size))
|
| 54 |
+
else:
|
| 55 |
+
self.virual_tracks = None
|
| 56 |
+
|
| 57 |
+
self.time_blocks = nn.ModuleList(
|
| 58 |
+
[
|
| 59 |
+
AttnBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio, attn_class=nn.MultiheadAttention)
|
| 60 |
+
for _ in range(time_depth)
|
| 61 |
+
]
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
if add_space_attn:
|
| 65 |
+
self.space_virtual_blocks = nn.ModuleList(
|
| 66 |
+
[
|
| 67 |
+
AttnBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio, attn_class=nn.MultiheadAttention)
|
| 68 |
+
for _ in range(space_depth)
|
| 69 |
+
]
|
| 70 |
+
)
|
| 71 |
+
self.space_point2virtual_blocks = nn.ModuleList(
|
| 72 |
+
[CrossAttnBlock(hidden_size, hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(space_depth)]
|
| 73 |
+
)
|
| 74 |
+
self.space_virtual2point_blocks = nn.ModuleList(
|
| 75 |
+
[CrossAttnBlock(hidden_size, hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(space_depth)]
|
| 76 |
+
)
|
| 77 |
+
assert len(self.time_blocks) >= len(self.space_virtual2point_blocks)
|
| 78 |
+
self.initialize_weights()
|
| 79 |
+
|
| 80 |
+
def initialize_weights(self):
|
| 81 |
+
def _basic_init(module):
|
| 82 |
+
if isinstance(module, nn.Linear):
|
| 83 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 84 |
+
if module.bias is not None:
|
| 85 |
+
nn.init.constant_(module.bias, 0)
|
| 86 |
+
torch.nn.init.trunc_normal_(self.flow_head.weight, std=0.001)
|
| 87 |
+
|
| 88 |
+
self.apply(_basic_init)
|
| 89 |
+
|
| 90 |
+
def forward(self, input_tensor, mask=None):
|
| 91 |
+
# Apply input LayerNorm
|
| 92 |
+
input_tensor = self.input_norm(input_tensor)
|
| 93 |
+
tokens = self.input_transform(input_tensor)
|
| 94 |
+
|
| 95 |
+
init_tokens = tokens
|
| 96 |
+
|
| 97 |
+
B, _, T, _ = tokens.shape
|
| 98 |
+
|
| 99 |
+
if self.add_space_attn:
|
| 100 |
+
virtual_tokens = self.virual_tracks.repeat(B, 1, T, 1)
|
| 101 |
+
tokens = torch.cat([tokens, virtual_tokens], dim=1)
|
| 102 |
+
|
| 103 |
+
_, N, _, _ = tokens.shape
|
| 104 |
+
|
| 105 |
+
j = 0
|
| 106 |
+
for i in range(len(self.time_blocks)):
|
| 107 |
+
time_tokens = tokens.contiguous().view(B * N, T, -1) # B N T C -> (B N) T C
|
| 108 |
+
|
| 109 |
+
time_tokens = self.time_blocks[i](time_tokens)
|
| 110 |
+
|
| 111 |
+
tokens = time_tokens.view(B, N, T, -1) # (B N) T C -> B N T C
|
| 112 |
+
if self.add_space_attn and (i % (len(self.time_blocks) // len(self.space_virtual_blocks)) == 0):
|
| 113 |
+
space_tokens = tokens.permute(0, 2, 1, 3).contiguous().view(B * T, N, -1) # B N T C -> (B T) N C
|
| 114 |
+
point_tokens = space_tokens[:, : N - self.num_virtual_tracks]
|
| 115 |
+
virtual_tokens = space_tokens[:, N - self.num_virtual_tracks :]
|
| 116 |
+
|
| 117 |
+
virtual_tokens = self.space_virtual2point_blocks[j](virtual_tokens, point_tokens, mask=mask)
|
| 118 |
+
virtual_tokens = self.space_virtual_blocks[j](virtual_tokens)
|
| 119 |
+
point_tokens = self.space_point2virtual_blocks[j](point_tokens, virtual_tokens, mask=mask)
|
| 120 |
+
|
| 121 |
+
space_tokens = torch.cat([point_tokens, virtual_tokens], dim=1)
|
| 122 |
+
tokens = space_tokens.view(B, T, N, -1).permute(0, 2, 1, 3) # (B T) N C -> B N T C
|
| 123 |
+
j += 1
|
| 124 |
+
|
| 125 |
+
if self.add_space_attn:
|
| 126 |
+
tokens = tokens[:, : N - self.num_virtual_tracks]
|
| 127 |
+
|
| 128 |
+
tokens = tokens + init_tokens
|
| 129 |
+
|
| 130 |
+
# Apply output LayerNorm before final projection
|
| 131 |
+
tokens = self.output_norm(tokens)
|
| 132 |
+
flow = self.flow_head(tokens)
|
| 133 |
+
|
| 134 |
+
return flow, None
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class CorrBlock:
|
| 138 |
+
def __init__(self, fmaps, num_levels=4, radius=4, multiple_track_feats=False, padding_mode="zeros"):
|
| 139 |
+
"""
|
| 140 |
+
Build a pyramid of feature maps from the input.
|
| 141 |
+
|
| 142 |
+
fmaps: Tensor (B, S, C, H, W)
|
| 143 |
+
num_levels: number of pyramid levels (each downsampled by factor 2)
|
| 144 |
+
radius: search radius for sampling correlation
|
| 145 |
+
multiple_track_feats: if True, split the target features per pyramid level
|
| 146 |
+
padding_mode: passed to grid_sample / bilinear_sampler
|
| 147 |
+
"""
|
| 148 |
+
B, S, C, H, W = fmaps.shape
|
| 149 |
+
self.S, self.C, self.H, self.W = S, C, H, W
|
| 150 |
+
self.num_levels = num_levels
|
| 151 |
+
self.radius = radius
|
| 152 |
+
self.padding_mode = padding_mode
|
| 153 |
+
self.multiple_track_feats = multiple_track_feats
|
| 154 |
+
|
| 155 |
+
# Build pyramid: each level is half the spatial resolution of the previous
|
| 156 |
+
self.fmaps_pyramid = [fmaps] # level 0 is full resolution
|
| 157 |
+
current_fmaps = fmaps
|
| 158 |
+
for i in range(num_levels - 1):
|
| 159 |
+
B, S, C, H, W = current_fmaps.shape
|
| 160 |
+
# Merge batch & sequence dimensions
|
| 161 |
+
current_fmaps = current_fmaps.reshape(B * S, C, H, W)
|
| 162 |
+
# Avg pool down by factor 2
|
| 163 |
+
current_fmaps = F.avg_pool2d(current_fmaps, kernel_size=2, stride=2)
|
| 164 |
+
_, _, H_new, W_new = current_fmaps.shape
|
| 165 |
+
current_fmaps = current_fmaps.reshape(B, S, C, H_new, W_new)
|
| 166 |
+
self.fmaps_pyramid.append(current_fmaps)
|
| 167 |
+
|
| 168 |
+
# Precompute a delta grid (of shape (2r+1, 2r+1, 2)) for sampling.
|
| 169 |
+
# This grid is added to the (scaled) coordinate centroids.
|
| 170 |
+
r = self.radius
|
| 171 |
+
dx = torch.linspace(-r, r, 2 * r + 1, device=fmaps.device, dtype=fmaps.dtype)
|
| 172 |
+
dy = torch.linspace(-r, r, 2 * r + 1, device=fmaps.device, dtype=fmaps.dtype)
|
| 173 |
+
# delta: for every (dy,dx) displacement (i.e. Δx, Δy)
|
| 174 |
+
self.delta = torch.stack(torch.meshgrid(dy, dx, indexing="ij"), dim=-1) # shape: (2r+1, 2r+1, 2)
|
| 175 |
+
|
| 176 |
+
def corr_sample(self, targets, coords):
|
| 177 |
+
"""
|
| 178 |
+
Instead of storing the entire correlation pyramid, we compute each level's correlation
|
| 179 |
+
volume, sample it immediately, then discard it. This saves GPU memory.
|
| 180 |
+
|
| 181 |
+
Args:
|
| 182 |
+
targets: Tensor (B, S, N, C) — features for the current targets.
|
| 183 |
+
coords: Tensor (B, S, N, 2) — coordinates at full resolution.
|
| 184 |
+
|
| 185 |
+
Returns:
|
| 186 |
+
Tensor (B, S, N, L) where L = num_levels * (2*radius+1)**2 (concatenated sampled correlations)
|
| 187 |
+
"""
|
| 188 |
+
B, S, N, C = targets.shape
|
| 189 |
+
|
| 190 |
+
# If you have multiple track features, split them per level.
|
| 191 |
+
if self.multiple_track_feats:
|
| 192 |
+
targets_split = torch.split(targets, C // self.num_levels, dim=-1)
|
| 193 |
+
|
| 194 |
+
out_pyramid = []
|
| 195 |
+
for i, fmaps in enumerate(self.fmaps_pyramid):
|
| 196 |
+
# Get current spatial resolution H, W for this pyramid level.
|
| 197 |
+
B, S, C, H, W = fmaps.shape
|
| 198 |
+
# Reshape feature maps for correlation computation:
|
| 199 |
+
# fmap2s: (B, S, C, H*W)
|
| 200 |
+
fmap2s = fmaps.view(B, S, C, H * W)
|
| 201 |
+
# Choose appropriate target features.
|
| 202 |
+
fmap1 = targets_split[i] if self.multiple_track_feats else targets # shape: (B, S, N, C)
|
| 203 |
+
|
| 204 |
+
# Compute correlation directly
|
| 205 |
+
corrs = compute_corr_level(fmap1, fmap2s, C)
|
| 206 |
+
corrs = corrs.view(B, S, N, H, W)
|
| 207 |
+
|
| 208 |
+
# Prepare sampling grid:
|
| 209 |
+
# Scale down the coordinates for the current level.
|
| 210 |
+
centroid_lvl = coords.reshape(B * S * N, 1, 1, 2) / (2**i)
|
| 211 |
+
# Make sure our precomputed delta grid is on the same device/dtype.
|
| 212 |
+
delta_lvl = self.delta.to(coords.device).to(coords.dtype)
|
| 213 |
+
# Now the grid for grid_sample is:
|
| 214 |
+
# coords_lvl = centroid_lvl + delta_lvl (broadcasted over grid)
|
| 215 |
+
coords_lvl = centroid_lvl + delta_lvl.view(1, 2 * self.radius + 1, 2 * self.radius + 1, 2)
|
| 216 |
+
|
| 217 |
+
# Sample from the correlation volume using bilinear interpolation.
|
| 218 |
+
# We reshape corrs to (B * S * N, 1, H, W) so grid_sample acts over each target.
|
| 219 |
+
corrs_sampled = bilinear_sampler(
|
| 220 |
+
corrs.reshape(B * S * N, 1, H, W), coords_lvl, padding_mode=self.padding_mode
|
| 221 |
+
)
|
| 222 |
+
# The sampled output is (B * S * N, 1, 2r+1, 2r+1). Flatten the last two dims.
|
| 223 |
+
corrs_sampled = corrs_sampled.view(B, S, N, -1) # Now shape: (B, S, N, (2r+1)^2)
|
| 224 |
+
out_pyramid.append(corrs_sampled)
|
| 225 |
+
|
| 226 |
+
# Concatenate all levels along the last dimension.
|
| 227 |
+
out = torch.cat(out_pyramid, dim=-1).contiguous()
|
| 228 |
+
return out
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
def compute_corr_level(fmap1, fmap2s, C):
|
| 232 |
+
# fmap1: (B, S, N, C)
|
| 233 |
+
# fmap2s: (B, S, C, H*W)
|
| 234 |
+
corrs = torch.matmul(fmap1, fmap2s) # (B, S, N, H*W)
|
| 235 |
+
corrs = corrs.view(fmap1.shape[0], fmap1.shape[1], fmap1.shape[2], -1) # (B, S, N, H*W)
|
| 236 |
+
return corrs / math.sqrt(C)
|
vggt/heads/track_modules/modules.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
from functools import partial
|
| 12 |
+
from typing import Callable
|
| 13 |
+
import collections
|
| 14 |
+
from torch import Tensor
|
| 15 |
+
from itertools import repeat
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# From PyTorch internals
|
| 19 |
+
def _ntuple(n):
|
| 20 |
+
def parse(x):
|
| 21 |
+
if isinstance(x, collections.abc.Iterable) and not isinstance(x, str):
|
| 22 |
+
return tuple(x)
|
| 23 |
+
return tuple(repeat(x, n))
|
| 24 |
+
|
| 25 |
+
return parse
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def exists(val):
|
| 29 |
+
return val is not None
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def default(val, d):
|
| 33 |
+
return val if exists(val) else d
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
to_2tuple = _ntuple(2)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class ResidualBlock(nn.Module):
|
| 40 |
+
"""
|
| 41 |
+
ResidualBlock: construct a block of two conv layers with residual connections
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
def __init__(self, in_planes, planes, norm_fn="group", stride=1, kernel_size=3):
|
| 45 |
+
super(ResidualBlock, self).__init__()
|
| 46 |
+
|
| 47 |
+
self.conv1 = nn.Conv2d(
|
| 48 |
+
in_planes, planes, kernel_size=kernel_size, padding=1, stride=stride, padding_mode="zeros"
|
| 49 |
+
)
|
| 50 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=kernel_size, padding=1, padding_mode="zeros")
|
| 51 |
+
self.relu = nn.ReLU(inplace=True)
|
| 52 |
+
|
| 53 |
+
num_groups = planes // 8
|
| 54 |
+
|
| 55 |
+
if norm_fn == "group":
|
| 56 |
+
self.norm1 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 57 |
+
self.norm2 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 58 |
+
if not stride == 1:
|
| 59 |
+
self.norm3 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 60 |
+
|
| 61 |
+
elif norm_fn == "batch":
|
| 62 |
+
self.norm1 = nn.BatchNorm2d(planes)
|
| 63 |
+
self.norm2 = nn.BatchNorm2d(planes)
|
| 64 |
+
if not stride == 1:
|
| 65 |
+
self.norm3 = nn.BatchNorm2d(planes)
|
| 66 |
+
|
| 67 |
+
elif norm_fn == "instance":
|
| 68 |
+
self.norm1 = nn.InstanceNorm2d(planes)
|
| 69 |
+
self.norm2 = nn.InstanceNorm2d(planes)
|
| 70 |
+
if not stride == 1:
|
| 71 |
+
self.norm3 = nn.InstanceNorm2d(planes)
|
| 72 |
+
|
| 73 |
+
elif norm_fn == "none":
|
| 74 |
+
self.norm1 = nn.Sequential()
|
| 75 |
+
self.norm2 = nn.Sequential()
|
| 76 |
+
if not stride == 1:
|
| 77 |
+
self.norm3 = nn.Sequential()
|
| 78 |
+
else:
|
| 79 |
+
raise NotImplementedError
|
| 80 |
+
|
| 81 |
+
if stride == 1:
|
| 82 |
+
self.downsample = None
|
| 83 |
+
else:
|
| 84 |
+
self.downsample = nn.Sequential(nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride), self.norm3)
|
| 85 |
+
|
| 86 |
+
def forward(self, x):
|
| 87 |
+
y = x
|
| 88 |
+
y = self.relu(self.norm1(self.conv1(y)))
|
| 89 |
+
y = self.relu(self.norm2(self.conv2(y)))
|
| 90 |
+
|
| 91 |
+
if self.downsample is not None:
|
| 92 |
+
x = self.downsample(x)
|
| 93 |
+
|
| 94 |
+
return self.relu(x + y)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class Mlp(nn.Module):
|
| 98 |
+
"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""
|
| 99 |
+
|
| 100 |
+
def __init__(
|
| 101 |
+
self,
|
| 102 |
+
in_features,
|
| 103 |
+
hidden_features=None,
|
| 104 |
+
out_features=None,
|
| 105 |
+
act_layer=nn.GELU,
|
| 106 |
+
norm_layer=None,
|
| 107 |
+
bias=True,
|
| 108 |
+
drop=0.0,
|
| 109 |
+
use_conv=False,
|
| 110 |
+
):
|
| 111 |
+
super().__init__()
|
| 112 |
+
out_features = out_features or in_features
|
| 113 |
+
hidden_features = hidden_features or in_features
|
| 114 |
+
bias = to_2tuple(bias)
|
| 115 |
+
drop_probs = to_2tuple(drop)
|
| 116 |
+
linear_layer = partial(nn.Conv2d, kernel_size=1) if use_conv else nn.Linear
|
| 117 |
+
|
| 118 |
+
self.fc1 = linear_layer(in_features, hidden_features, bias=bias[0])
|
| 119 |
+
self.act = act_layer()
|
| 120 |
+
self.drop1 = nn.Dropout(drop_probs[0])
|
| 121 |
+
self.fc2 = linear_layer(hidden_features, out_features, bias=bias[1])
|
| 122 |
+
self.drop2 = nn.Dropout(drop_probs[1])
|
| 123 |
+
|
| 124 |
+
def forward(self, x):
|
| 125 |
+
x = self.fc1(x)
|
| 126 |
+
x = self.act(x)
|
| 127 |
+
x = self.drop1(x)
|
| 128 |
+
x = self.fc2(x)
|
| 129 |
+
x = self.drop2(x)
|
| 130 |
+
return x
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class AttnBlock(nn.Module):
|
| 134 |
+
def __init__(
|
| 135 |
+
self,
|
| 136 |
+
hidden_size,
|
| 137 |
+
num_heads,
|
| 138 |
+
attn_class: Callable[..., nn.Module] = nn.MultiheadAttention,
|
| 139 |
+
mlp_ratio=4.0,
|
| 140 |
+
**block_kwargs,
|
| 141 |
+
):
|
| 142 |
+
"""
|
| 143 |
+
Self attention block
|
| 144 |
+
"""
|
| 145 |
+
super().__init__()
|
| 146 |
+
|
| 147 |
+
self.norm1 = nn.LayerNorm(hidden_size)
|
| 148 |
+
self.norm2 = nn.LayerNorm(hidden_size)
|
| 149 |
+
|
| 150 |
+
self.attn = attn_class(embed_dim=hidden_size, num_heads=num_heads, batch_first=True, **block_kwargs)
|
| 151 |
+
|
| 152 |
+
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
| 153 |
+
|
| 154 |
+
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, drop=0)
|
| 155 |
+
|
| 156 |
+
def forward(self, x, mask=None):
|
| 157 |
+
# Prepare the mask for PyTorch's attention (it expects a different format)
|
| 158 |
+
# attn_mask = mask if mask is not None else None
|
| 159 |
+
# Normalize before attention
|
| 160 |
+
x = self.norm1(x)
|
| 161 |
+
|
| 162 |
+
# PyTorch's MultiheadAttention returns attn_output, attn_output_weights
|
| 163 |
+
# attn_output, _ = self.attn(x, x, x, attn_mask=attn_mask)
|
| 164 |
+
|
| 165 |
+
attn_output, _ = self.attn(x, x, x)
|
| 166 |
+
|
| 167 |
+
# Add & Norm
|
| 168 |
+
x = x + attn_output
|
| 169 |
+
x = x + self.mlp(self.norm2(x))
|
| 170 |
+
return x
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class CrossAttnBlock(nn.Module):
|
| 174 |
+
def __init__(self, hidden_size, context_dim, num_heads=1, mlp_ratio=4.0, **block_kwargs):
|
| 175 |
+
"""
|
| 176 |
+
Cross attention block
|
| 177 |
+
"""
|
| 178 |
+
super().__init__()
|
| 179 |
+
|
| 180 |
+
self.norm1 = nn.LayerNorm(hidden_size)
|
| 181 |
+
self.norm_context = nn.LayerNorm(hidden_size)
|
| 182 |
+
self.norm2 = nn.LayerNorm(hidden_size)
|
| 183 |
+
|
| 184 |
+
self.cross_attn = nn.MultiheadAttention(
|
| 185 |
+
embed_dim=hidden_size, num_heads=num_heads, batch_first=True, **block_kwargs
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
| 189 |
+
|
| 190 |
+
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, drop=0)
|
| 191 |
+
|
| 192 |
+
def forward(self, x, context, mask=None):
|
| 193 |
+
# Normalize inputs
|
| 194 |
+
x = self.norm1(x)
|
| 195 |
+
context = self.norm_context(context)
|
| 196 |
+
|
| 197 |
+
# Apply cross attention
|
| 198 |
+
# Note: nn.MultiheadAttention returns attn_output, attn_output_weights
|
| 199 |
+
attn_output, _ = self.cross_attn(x, context, context, attn_mask=mask)
|
| 200 |
+
|
| 201 |
+
# Add & Norm
|
| 202 |
+
x = x + attn_output
|
| 203 |
+
x = x + self.mlp(self.norm2(x))
|
| 204 |
+
return x
|
vggt/heads/track_modules/utils.py
ADDED
|
@@ -0,0 +1,223 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
# Modified from https://github.com/facebookresearch/vggsfm
|
| 8 |
+
# and https://github.com/facebookresearch/co-tracker/tree/main
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
from typing import Optional, Tuple, Union
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def get_2d_sincos_pos_embed(embed_dim: int, grid_size: Union[int, Tuple[int, int]], return_grid=False) -> torch.Tensor:
|
| 19 |
+
"""
|
| 20 |
+
This function initializes a grid and generates a 2D positional embedding using sine and cosine functions.
|
| 21 |
+
It is a wrapper of get_2d_sincos_pos_embed_from_grid.
|
| 22 |
+
Args:
|
| 23 |
+
- embed_dim: The embedding dimension.
|
| 24 |
+
- grid_size: The grid size.
|
| 25 |
+
Returns:
|
| 26 |
+
- pos_embed: The generated 2D positional embedding.
|
| 27 |
+
"""
|
| 28 |
+
if isinstance(grid_size, tuple):
|
| 29 |
+
grid_size_h, grid_size_w = grid_size
|
| 30 |
+
else:
|
| 31 |
+
grid_size_h = grid_size_w = grid_size
|
| 32 |
+
grid_h = torch.arange(grid_size_h, dtype=torch.float)
|
| 33 |
+
grid_w = torch.arange(grid_size_w, dtype=torch.float)
|
| 34 |
+
grid = torch.meshgrid(grid_w, grid_h, indexing="xy")
|
| 35 |
+
grid = torch.stack(grid, dim=0)
|
| 36 |
+
grid = grid.reshape([2, 1, grid_size_h, grid_size_w])
|
| 37 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 38 |
+
if return_grid:
|
| 39 |
+
return (pos_embed.reshape(1, grid_size_h, grid_size_w, -1).permute(0, 3, 1, 2), grid)
|
| 40 |
+
return pos_embed.reshape(1, grid_size_h, grid_size_w, -1).permute(0, 3, 1, 2)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim: int, grid: torch.Tensor) -> torch.Tensor:
|
| 44 |
+
"""
|
| 45 |
+
This function generates a 2D positional embedding from a given grid using sine and cosine functions.
|
| 46 |
+
|
| 47 |
+
Args:
|
| 48 |
+
- embed_dim: The embedding dimension.
|
| 49 |
+
- grid: The grid to generate the embedding from.
|
| 50 |
+
|
| 51 |
+
Returns:
|
| 52 |
+
- emb: The generated 2D positional embedding.
|
| 53 |
+
"""
|
| 54 |
+
assert embed_dim % 2 == 0
|
| 55 |
+
|
| 56 |
+
# use half of dimensions to encode grid_h
|
| 57 |
+
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
|
| 58 |
+
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
|
| 59 |
+
|
| 60 |
+
emb = torch.cat([emb_h, emb_w], dim=2) # (H*W, D)
|
| 61 |
+
return emb
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def get_1d_sincos_pos_embed_from_grid(embed_dim: int, pos: torch.Tensor) -> torch.Tensor:
|
| 65 |
+
"""
|
| 66 |
+
This function generates a 1D positional embedding from a given grid using sine and cosine functions.
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
- embed_dim: The embedding dimension.
|
| 70 |
+
- pos: The position to generate the embedding from.
|
| 71 |
+
|
| 72 |
+
Returns:
|
| 73 |
+
- emb: The generated 1D positional embedding.
|
| 74 |
+
"""
|
| 75 |
+
assert embed_dim % 2 == 0
|
| 76 |
+
omega = torch.arange(embed_dim // 2, dtype=torch.double)
|
| 77 |
+
omega /= embed_dim / 2.0
|
| 78 |
+
omega = 1.0 / 10000**omega # (D/2,)
|
| 79 |
+
|
| 80 |
+
pos = pos.reshape(-1) # (M,)
|
| 81 |
+
out = torch.einsum("m,d->md", pos, omega) # (M, D/2), outer product
|
| 82 |
+
|
| 83 |
+
emb_sin = torch.sin(out) # (M, D/2)
|
| 84 |
+
emb_cos = torch.cos(out) # (M, D/2)
|
| 85 |
+
|
| 86 |
+
emb = torch.cat([emb_sin, emb_cos], dim=1) # (M, D)
|
| 87 |
+
return emb[None].float()
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def get_2d_embedding(xy: torch.Tensor, C: int, cat_coords: bool = True) -> torch.Tensor:
|
| 91 |
+
"""
|
| 92 |
+
This function generates a 2D positional embedding from given coordinates using sine and cosine functions.
|
| 93 |
+
|
| 94 |
+
Args:
|
| 95 |
+
- xy: The coordinates to generate the embedding from.
|
| 96 |
+
- C: The size of the embedding.
|
| 97 |
+
- cat_coords: A flag to indicate whether to concatenate the original coordinates to the embedding.
|
| 98 |
+
|
| 99 |
+
Returns:
|
| 100 |
+
- pe: The generated 2D positional embedding.
|
| 101 |
+
"""
|
| 102 |
+
B, N, D = xy.shape
|
| 103 |
+
assert D == 2
|
| 104 |
+
|
| 105 |
+
x = xy[:, :, 0:1]
|
| 106 |
+
y = xy[:, :, 1:2]
|
| 107 |
+
div_term = (torch.arange(0, C, 2, device=xy.device, dtype=torch.float32) * (1000.0 / C)).reshape(1, 1, int(C / 2))
|
| 108 |
+
|
| 109 |
+
pe_x = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
|
| 110 |
+
pe_y = torch.zeros(B, N, C, device=xy.device, dtype=torch.float32)
|
| 111 |
+
|
| 112 |
+
pe_x[:, :, 0::2] = torch.sin(x * div_term)
|
| 113 |
+
pe_x[:, :, 1::2] = torch.cos(x * div_term)
|
| 114 |
+
|
| 115 |
+
pe_y[:, :, 0::2] = torch.sin(y * div_term)
|
| 116 |
+
pe_y[:, :, 1::2] = torch.cos(y * div_term)
|
| 117 |
+
|
| 118 |
+
pe = torch.cat([pe_x, pe_y], dim=2) # (B, N, C*3)
|
| 119 |
+
if cat_coords:
|
| 120 |
+
pe = torch.cat([xy, pe], dim=2) # (B, N, C*3+3)
|
| 121 |
+
return pe
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def bilinear_sampler(input, coords, align_corners=True, padding_mode="border"):
|
| 125 |
+
r"""Sample a tensor using bilinear interpolation
|
| 126 |
+
|
| 127 |
+
`bilinear_sampler(input, coords)` samples a tensor :attr:`input` at
|
| 128 |
+
coordinates :attr:`coords` using bilinear interpolation. It is the same
|
| 129 |
+
as `torch.nn.functional.grid_sample()` but with a different coordinate
|
| 130 |
+
convention.
|
| 131 |
+
|
| 132 |
+
The input tensor is assumed to be of shape :math:`(B, C, H, W)`, where
|
| 133 |
+
:math:`B` is the batch size, :math:`C` is the number of channels,
|
| 134 |
+
:math:`H` is the height of the image, and :math:`W` is the width of the
|
| 135 |
+
image. The tensor :attr:`coords` of shape :math:`(B, H_o, W_o, 2)` is
|
| 136 |
+
interpreted as an array of 2D point coordinates :math:`(x_i,y_i)`.
|
| 137 |
+
|
| 138 |
+
Alternatively, the input tensor can be of size :math:`(B, C, T, H, W)`,
|
| 139 |
+
in which case sample points are triplets :math:`(t_i,x_i,y_i)`. Note
|
| 140 |
+
that in this case the order of the components is slightly different
|
| 141 |
+
from `grid_sample()`, which would expect :math:`(x_i,y_i,t_i)`.
|
| 142 |
+
|
| 143 |
+
If `align_corners` is `True`, the coordinate :math:`x` is assumed to be
|
| 144 |
+
in the range :math:`[0,W-1]`, with 0 corresponding to the center of the
|
| 145 |
+
left-most image pixel :math:`W-1` to the center of the right-most
|
| 146 |
+
pixel.
|
| 147 |
+
|
| 148 |
+
If `align_corners` is `False`, the coordinate :math:`x` is assumed to
|
| 149 |
+
be in the range :math:`[0,W]`, with 0 corresponding to the left edge of
|
| 150 |
+
the left-most pixel :math:`W` to the right edge of the right-most
|
| 151 |
+
pixel.
|
| 152 |
+
|
| 153 |
+
Similar conventions apply to the :math:`y` for the range
|
| 154 |
+
:math:`[0,H-1]` and :math:`[0,H]` and to :math:`t` for the range
|
| 155 |
+
:math:`[0,T-1]` and :math:`[0,T]`.
|
| 156 |
+
|
| 157 |
+
Args:
|
| 158 |
+
input (Tensor): batch of input images.
|
| 159 |
+
coords (Tensor): batch of coordinates.
|
| 160 |
+
align_corners (bool, optional): Coordinate convention. Defaults to `True`.
|
| 161 |
+
padding_mode (str, optional): Padding mode. Defaults to `"border"`.
|
| 162 |
+
|
| 163 |
+
Returns:
|
| 164 |
+
Tensor: sampled points.
|
| 165 |
+
"""
|
| 166 |
+
coords = coords.detach().clone()
|
| 167 |
+
############################################################
|
| 168 |
+
# IMPORTANT:
|
| 169 |
+
coords = coords.to(input.device).to(input.dtype)
|
| 170 |
+
############################################################
|
| 171 |
+
|
| 172 |
+
sizes = input.shape[2:]
|
| 173 |
+
|
| 174 |
+
assert len(sizes) in [2, 3]
|
| 175 |
+
|
| 176 |
+
if len(sizes) == 3:
|
| 177 |
+
# t x y -> x y t to match dimensions T H W in grid_sample
|
| 178 |
+
coords = coords[..., [1, 2, 0]]
|
| 179 |
+
|
| 180 |
+
if align_corners:
|
| 181 |
+
scale = torch.tensor(
|
| 182 |
+
[2 / max(size - 1, 1) for size in reversed(sizes)], device=coords.device, dtype=coords.dtype
|
| 183 |
+
)
|
| 184 |
+
else:
|
| 185 |
+
scale = torch.tensor([2 / size for size in reversed(sizes)], device=coords.device, dtype=coords.dtype)
|
| 186 |
+
|
| 187 |
+
coords.mul_(scale) # coords = coords * scale
|
| 188 |
+
coords.sub_(1) # coords = coords - 1
|
| 189 |
+
|
| 190 |
+
return F.grid_sample(input, coords, align_corners=align_corners, padding_mode=padding_mode)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def sample_features4d(input, coords):
|
| 194 |
+
r"""Sample spatial features
|
| 195 |
+
|
| 196 |
+
`sample_features4d(input, coords)` samples the spatial features
|
| 197 |
+
:attr:`input` represented by a 4D tensor :math:`(B, C, H, W)`.
|
| 198 |
+
|
| 199 |
+
The field is sampled at coordinates :attr:`coords` using bilinear
|
| 200 |
+
interpolation. :attr:`coords` is assumed to be of shape :math:`(B, R,
|
| 201 |
+
2)`, where each sample has the format :math:`(x_i, y_i)`. This uses the
|
| 202 |
+
same convention as :func:`bilinear_sampler` with `align_corners=True`.
|
| 203 |
+
|
| 204 |
+
The output tensor has one feature per point, and has shape :math:`(B,
|
| 205 |
+
R, C)`.
|
| 206 |
+
|
| 207 |
+
Args:
|
| 208 |
+
input (Tensor): spatial features.
|
| 209 |
+
coords (Tensor): points.
|
| 210 |
+
|
| 211 |
+
Returns:
|
| 212 |
+
Tensor: sampled features.
|
| 213 |
+
"""
|
| 214 |
+
|
| 215 |
+
B, _, _, _ = input.shape
|
| 216 |
+
|
| 217 |
+
# B R 2 -> B R 1 2
|
| 218 |
+
coords = coords.unsqueeze(2)
|
| 219 |
+
|
| 220 |
+
# B C R 1
|
| 221 |
+
feats = bilinear_sampler(input, coords)
|
| 222 |
+
|
| 223 |
+
return feats.permute(0, 2, 1, 3).view(B, -1, feats.shape[1] * feats.shape[3]) # B C R 1 -> B R C
|
vggt/heads/utils.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def position_grid_to_embed(pos_grid: torch.Tensor, embed_dim: int, omega_0: float = 100) -> torch.Tensor:
|
| 12 |
+
"""
|
| 13 |
+
Convert 2D position grid (HxWx2) to sinusoidal embeddings (HxWxC)
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
pos_grid: Tensor of shape (H, W, 2) containing 2D coordinates
|
| 17 |
+
embed_dim: Output channel dimension for embeddings
|
| 18 |
+
|
| 19 |
+
Returns:
|
| 20 |
+
Tensor of shape (H, W, embed_dim) with positional embeddings
|
| 21 |
+
"""
|
| 22 |
+
H, W, grid_dim = pos_grid.shape
|
| 23 |
+
assert grid_dim == 2
|
| 24 |
+
pos_flat = pos_grid.reshape(-1, grid_dim) # Flatten to (H*W, 2)
|
| 25 |
+
|
| 26 |
+
# Process x and y coordinates separately
|
| 27 |
+
emb_x = make_sincos_pos_embed(embed_dim // 2, pos_flat[:, 0], omega_0=omega_0) # [1, H*W, D/2]
|
| 28 |
+
emb_y = make_sincos_pos_embed(embed_dim // 2, pos_flat[:, 1], omega_0=omega_0) # [1, H*W, D/2]
|
| 29 |
+
|
| 30 |
+
# Combine and reshape
|
| 31 |
+
emb = torch.cat([emb_x, emb_y], dim=-1) # [1, H*W, D]
|
| 32 |
+
|
| 33 |
+
return emb.view(H, W, embed_dim) # [H, W, D]
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def make_sincos_pos_embed(embed_dim: int, pos: torch.Tensor, omega_0: float = 100) -> torch.Tensor:
|
| 37 |
+
"""
|
| 38 |
+
This function generates a 1D positional embedding from a given grid using sine and cosine functions.
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
- embed_dim: The embedding dimension.
|
| 42 |
+
- pos: The position to generate the embedding from.
|
| 43 |
+
|
| 44 |
+
Returns:
|
| 45 |
+
- emb: The generated 1D positional embedding.
|
| 46 |
+
"""
|
| 47 |
+
assert embed_dim % 2 == 0
|
| 48 |
+
device = pos.device
|
| 49 |
+
omega = torch.arange(embed_dim // 2, dtype=torch.float32 if device.type == "mps" else torch.double, device=device)
|
| 50 |
+
omega /= embed_dim / 2.0
|
| 51 |
+
omega = 1.0 / omega_0**omega # (D/2,)
|
| 52 |
+
|
| 53 |
+
pos = pos.reshape(-1) # (M,)
|
| 54 |
+
out = torch.einsum("m,d->md", pos, omega) # (M, D/2), outer product
|
| 55 |
+
|
| 56 |
+
emb_sin = torch.sin(out) # (M, D/2)
|
| 57 |
+
emb_cos = torch.cos(out) # (M, D/2)
|
| 58 |
+
|
| 59 |
+
emb = torch.cat([emb_sin, emb_cos], dim=1) # (M, D)
|
| 60 |
+
return emb.float()
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# Inspired by https://github.com/microsoft/moge
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def create_uv_grid(
|
| 67 |
+
width: int, height: int, aspect_ratio: float = None, dtype: torch.dtype = None, device: torch.device = None
|
| 68 |
+
) -> torch.Tensor:
|
| 69 |
+
"""
|
| 70 |
+
Create a normalized UV grid of shape (width, height, 2).
|
| 71 |
+
|
| 72 |
+
The grid spans horizontally and vertically according to an aspect ratio,
|
| 73 |
+
ensuring the top-left corner is at (-x_span, -y_span) and the bottom-right
|
| 74 |
+
corner is at (x_span, y_span), normalized by the diagonal of the plane.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
width (int): Number of points horizontally.
|
| 78 |
+
height (int): Number of points vertically.
|
| 79 |
+
aspect_ratio (float, optional): Width-to-height ratio. Defaults to width/height.
|
| 80 |
+
dtype (torch.dtype, optional): Data type of the resulting tensor.
|
| 81 |
+
device (torch.device, optional): Device on which the tensor is created.
|
| 82 |
+
|
| 83 |
+
Returns:
|
| 84 |
+
torch.Tensor: A (width, height, 2) tensor of UV coordinates.
|
| 85 |
+
"""
|
| 86 |
+
# Derive aspect ratio if not explicitly provided
|
| 87 |
+
if aspect_ratio is None:
|
| 88 |
+
aspect_ratio = float(width) / float(height)
|
| 89 |
+
|
| 90 |
+
# Compute normalized spans for X and Y
|
| 91 |
+
diag_factor = (aspect_ratio**2 + 1.0) ** 0.5
|
| 92 |
+
span_x = aspect_ratio / diag_factor
|
| 93 |
+
span_y = 1.0 / diag_factor
|
| 94 |
+
|
| 95 |
+
# Establish the linspace boundaries
|
| 96 |
+
left_x = -span_x * (width - 1) / width
|
| 97 |
+
right_x = span_x * (width - 1) / width
|
| 98 |
+
top_y = -span_y * (height - 1) / height
|
| 99 |
+
bottom_y = span_y * (height - 1) / height
|
| 100 |
+
|
| 101 |
+
# Generate 1D coordinates
|
| 102 |
+
x_coords = torch.linspace(left_x, right_x, steps=width, dtype=dtype, device=device)
|
| 103 |
+
y_coords = torch.linspace(top_y, bottom_y, steps=height, dtype=dtype, device=device)
|
| 104 |
+
|
| 105 |
+
# Create 2D meshgrid (width x height) and stack into UV
|
| 106 |
+
uu, vv = torch.meshgrid(x_coords, y_coords, indexing="xy")
|
| 107 |
+
uv_grid = torch.stack((uu, vv), dim=-1)
|
| 108 |
+
|
| 109 |
+
return uv_grid
|