+
+
+
+
+
+
+
+
+-
+
- LLM/LVM is Data-hungry +
+
+-
+
- Streaming Data Flow +
+
+-
+
- Scaling Exact Attention +
You
+请问“我今天去国家大剧院看了一场精彩的演出”表达了怎样的情绪?
+积极
+You
+请抽取以下文本中出现的时间、地点、任务和发生的时间:“我今天去国家大剧院看了一场精彩的演出”。
+在您提供的文本中:
+You
+将“我今天去国家大剧院看了一场精彩的演出”翻译成英文。
+“I went to the National Grand Theater today and watched a wonderful performance.”
+

数据集难以获取, 大小受限
+任何文章都可以作为数据进行训练
+不同模型之间不能共享知识
+只需要一个模型
+无标注的数据很多, 但是很难利用起来.
+数据无需标注, 可以自然直接对文档进行训练.
+训练GPT-3使用了大约0.75TB的文本数据
+这样的训练量在如今看来并不算多
+

这种范式下ETL与模型训练完全串行,是一种简单明了的方式。
++

多模态大模型的ETL流程正变得越来越复杂
+处理流程复杂耗时,甚至超过训练开销
+
An aerial video sweeps over a majestic ocean cliff with striatedrock formations in rich hues of red, green, and orange.The sun’srays enhance the colorful palette of the landscape, while the sea’sazure watersgently crash aqainst the clif’s base. Visible are thetextured detais ofthe clif face and the contrast of the areeralaae and seaqrasscoating parts of the rock.Seabirds can beseen flying close to the water around the rocky outcrop. Thevideo conveys a serene yet dynamic coastal scenery, highlightingthe natural beauty and geological diversity of a rugged coastline
+🌋 LLaVA-1.6-Yi-34B (3s/it)
+A breathtakina aerial view of a rocky cliff iutting out into theocean.The cliff. adorned with vibrant qreen moss and patches ofyellow and red lichen, is bathed in the warm glow of the sun. Theocean, a deep blue, is dotted with small white waves that crashagainst the cliff’s base. The perspective of the video is fromabove, providing a bird’s eye view of the cliff and the surroundingocean.The sun’s rays illuminate the scene, casting a beautifullight on the cliff and the ocean. The video is a stunningrepresentation of the raw beauty of nature.
+
+ +
+


流式传输数据可以解决这些问题
但流式数据传输只是一个开始,我们需要构建完全基于流式数据的训练框架

+ +
+
+
+
引入DPU集群,允许将数据直接传输到GPU, 消除内存数据库的开销
+
+ +
+
+ +
+
+
+
+ +
+
Thanks
+

![]()
+ # ![]() >
+ #
>
+ #
+ + + +
+ +::: + +::: {.column width="40%"} + +多模态大模型的ETL流程正变得越来越复杂 + +- E: 数据模态多,来源复杂,拉取时间长 +- T: 数据处理流程复杂 +- L: 存储占用高 + + +::: + +:::: + +## What's the Problem? {auto-animate=true} + +多模态数据由于版权和存储原因,大多以下载链接的形式分发,获取速率受到限制 + +```{=html} +{{< include components/webvid.qmd >}} +``` + +::: {style="text-align:center; font-size: 0.4em;"} + +webvid以url形式提供, 共包括10730233条数据 + +::: + + + +::: {.notes} + + +- 这意味着国内需要使用昂贵的国际带宽来获取数据,对于一个小型数据中心, 下载相当于Sora训练量的数据集可能需要花费数年的时间。 + +- 即便只下载webvid这样中等规模的数据,下载和处理的时间可能也是训练的瓶颈. + +::: + + +## What's the Problem? {auto-animate=true} + +处理流程复杂耗时,甚至超过训练开销 + +:::: columns + +::: {.column width="60%"} + +::: {style="margin-top: 50px;"} + + + +::: + + + +::: + +::: {.column width="40%"} + + ++ +
+ +::: + +::: {.column width="50%"} + +::: {.incremental} + +- 数据来源复杂 +- 数据源不能立即被拉取 +- 数据处理流程复杂 +- 数据处理和模型训练耦合 +- 数据量过大,无法一次性处理 +- ... + +::: + + + +::: + +:::: + + +## What's the Problem? {auto-animate=true} + + +:::: columns + +::: {.column width="50%"} + +- 数据流离模型训练越来越远 +- 仍然使用传统的方式处理数据,+{width=80%} +
+ +## Streaming to the rescue {auto-animate=true .smaller} + +:::: columns + +::: {.column width="60%"} -1. **Clone the space locally** -2. **Install Quarto**: In order to render your Quarto site without Docker, we recommend installing Quarto by following the instructions on the [official Quarto website](https://quarto.org/docs/get-started/). -3. **Install Quarto VS Code extension**: The [Quarto VS Code Extension](https://quarto.org/docs/tools/vscode.html) includes a number of productivity tools including YAML Autocomplete, a preview button, and a visual editor. Quarto works great with VS Code, but the extension does make it easier to get the most out of Quarto. -4. **Edit the site**: The website files are contained in the `src` directory, and the site navigation is defined in `src/_quarto.yml`. Try editing these files and either clicking the "Preview" button in VS Code, or calling `quarto preview src` from the command line. -5. **Learn more about Quarto**: You can do a lot of things with Quarto, and they are all documented on the [Quarto Website](https://quarto.org/guide/). In particular, you may be interested in: - - All about building [websites](https://quarto.org/docs/websites/) - - Building Static [Dashboards](https://quarto.org/docs/dashboards/) - - How to write [books](https://quarto.org/docs/books/index.html) and [manuscripts](https://quarto.org/docs/manuscripts/) - - Reproducible [presentations](https://quarto.org/docs/presentations/) - - Including [Observable](https://quarto.org/docs/interactive/ojs/) or [Shiny](https://quarto.org/docs/interactive/shiny/) applications in your Quarto site + + + -::: {.callout-warning} -It can take a couple of minutes for the Space to deploy to Hugging Face after the Docker build process completes. Two see your changes you will need to do two things: -1) Wait for your space's status to go from 'Building' to 'Running'(this is visible in the status bar above the Space) -2) Force-reload the web page by holding Shift and hitting the reload button in your browser. ++{width=80%} +
+ +::: + +::: {.column width="40%"} + + + +::: {.incremental} + +- [x] 零启动开销 + +- [x] 数据处理进程和模型训练进程完全分离 + +- [x] 节点内通过`SharedMemory`通信, 节点间通过内存数据库通信 + +- [x] 数据处理集群拓扑与GPU拓扑无关, 可以动态调整 + +- [x] 定时sink数据库,允许回溯数据流 + +- [x] 确定性的数据切分和洗牌算法,确保回溯的一致性 + +::: + + + +::: + + + +:::: + + +## {auto-animate=true background="./figures/mosaicml-streaming-dataset-img-1.gif"} + +::: {.notes} + +每个云上shard内的样本具备确定性的切分和洗牌算法,确保回溯的一致性, 并与训练拓扑无关 + +::: + +## Training on the internet {auto-animate=true .smaller background="./figures/mosaicml-streaming-dataset-img-1.gif" background-opacity=0.25} + +使用S3作为数据和权重的存储后端, 无缝进行不同规模的云迁移 + +```{=html} +{{< include components/cloud-switch.qmd >}} +``` + +## Training on the internet {auto-animate=true .smaller} + +引入DPU集群,允许将数据直接传输到GPU, 消除内存数据库的开销 + + ++{width=100%} +
+ + + + + + + Powered by ++{width=80%} +
+ +## Training on the internet {auto-animate=true .smaller} + +:::: columns + +::: {.column width="50%"} + ++{width=60%} +
+ +::: + +::: {.column width="50%"} + +- 进一步分离了数据处理和模型训练 +- 使ETL与模型训练完全并行 + +::: + +:::: + +::: {.fragment} + +```{=html} +{{< include components/profile-stream.qmd >}} +``` + +::: + + + + +# {.theme-section} + +::: {.title} + +Scaling Exact Attention + +::: + + + +## Efficient distributed training infra {auto-animate="true"} + +| | Flash-Attn-2 | FP8 (H100) | 3D Parallel + Zero | Padding Free | Fused Kernel | Static Graph | TGS[^l] | +|------------:|:------------:|:----------:|:------------------:|:------------:|:------------:|:------------:|:---:| +| Platformers | ✔️ | ✔️ | ✔️ | ✔️ | [100%]{style="color:red;"} | ✔️ | [3743]{style="color:red;"} | +| Megatron-LM | ✖️ | ✔️ | ✔️ | ✖️ | 80% | ✖️ | 3581 | +| Deepspeed | ✔️ | ✖️ | ✔️ | ✖️ | 60% | ✖️ |✖️ | +| Colossal-ai | ✖️ | ✖️ | ✔️ | ✖️ | 40% | ✖️ | 2610 | + + + +[^l]: Training LLaMA2 7b on DGX (8*A100 40GB) with 4096 sequence Length + +## Scaling exact attention to ultra long sequence {auto-animate="true"} + + + + + +## Scaling exact attention to ultra long sequence {auto-animate="true"} + ++{width=80%} +
+ + + +## Scaling exact attention to ultra long sequence {auto-animate="true"} + +:::: columns + +::: {.column width="50%"} + + + +```{=html} +{{< include ./components/seq-time.qmd >}} +``` + +::: + +::: {.column width="50%"} + + + +```{=html} +{{< include ./components/seq-tflops.qmd >}} +``` + ::: -## Code Execution +:::: -One of the main virtues of Quarto is that it lets you combine code and text in a single document. -By default, if you include a code chunk in your document, Quarto will execute that code and include the output in the rendered document. -This is great for reproducibility and for creating documents that are always up-to-date. -For example you can include code which generates a plot like this: + + + + + + -```{python} -import seaborn as sns -import matplotlib.pyplot as plt +## Scaling exact attention to ultra long sequence {auto-animate="true"} -# Sample data -tips = sns.load_dataset("tips") -# Create a seaborn plot -sns.set_style("whitegrid") -g = sns.lmplot(x="total_bill", y="tip", data=tips, aspect=2) -g = g.set_axis_labels("Total bill (USD)", "Tip").set(xlim=(0, 60), ylim=(0, 12)) -plt.title("Tip by Total Bill") -plt.show() +```{=html} +{{< include mocha.qmd >}} ``` -When the website is built the Python code will run and the output will be included in the document. +# {.theme-end} + +::: columns + +::: {.column width="50%"} + +::: {.r-fit-text} + +Thanks + +::: + +::: + +::: {.column width="25%"} + +::: {style="text-align:center;"} + + + +::: + + + + +::: + +::: {.column width="25%"} + +::: {style="text-align:center;"} + + + +::: + + + + +::: -You can also include [inline code](https://quarto.org/docs/computations/inline-code.html) to insert computed values into text. -For example we can include the maximum tip value in the `tips` data frame like this: ``{python} tips['tip'].max()``. -You can control [code execution](https://quarto.org/docs/computations/execution-options.html), or [freeze code output](https://quarto.org/docs/projects/code-execution.html#freeze) to capture the output of long running computations. -## About the Open Source AI Cookbook -To provide a realistic example of how Quarto can help you organize long-form documentation, -we've implemented the Hugging Face [Open-Source AI Cookbook](https://github.com/huggingface/cookbook) in Quarto. -The Open-Source AI Cookbook is a collection of notebooks illustrating practical aspects of building AI applications and solving various machine learning tasks using open-source tools and models. -You can read more about it, or contribute your own Notebook on the [Github Repo](https://github.com/huggingface/cookbook) + + + +::: diff --git a/src/lwm.qmd b/src/lwm.qmd new file mode 100644 index 0000000000000000000000000000000000000000..6e3e4695b838178e411dff6900d96439660b3ba9 --- /dev/null +++ b/src/lwm.qmd @@ -0,0 +1,93 @@ +Text to Video. LWM generates videos based on text prompts, autoregressively.
+Text to Video. Our model generates videos based on text prompts, autoregressively.
+ -
-::: callout-note
-💡 As you can see, there are many steps to tune in this architecture: tuning the system properly will yield significant performance gains.
-:::
-
-In this notebook, we will take a look into many of these blue notes to see how to tune your RAG system and get the best performance.
-
-__Let's dig into the model building!__ First, we install the required model dependancies.
-
-```{python}
-!pip install -q torch transformers transformers accelerate bitsandbytes langchain sentence-transformers faiss-gpu openpyxl pacmap
-```
-
-```{python}
-%reload_ext dotenv
-%dotenv
-```
-
-```{python}
-from tqdm.notebook import tqdm
-import pandas as pd
-from typing import Optional, List, Tuple
-from datasets import Dataset
-import matplotlib.pyplot as plt
-
-pd.set_option(
- "display.max_colwidth", None # <1>
-)
-```
-1. This will be helpful when visualizing retriever outputs
-
-### Load your knowledge base
-
-```{python}
-import datasets
-
-ds = datasets.load_dataset("m-ric/huggingface_doc", split="train")
-```
-
-```{python}
-from langchain.docstore.document import Document as LangchainDocument
-
-RAW_KNOWLEDGE_BASE = [
- LangchainDocument(page_content=doc["text"], metadata={"source": doc["source"]})
- for doc in tqdm(ds)
-]
-```
-
-# 1. Retriever - embeddings 🗂️
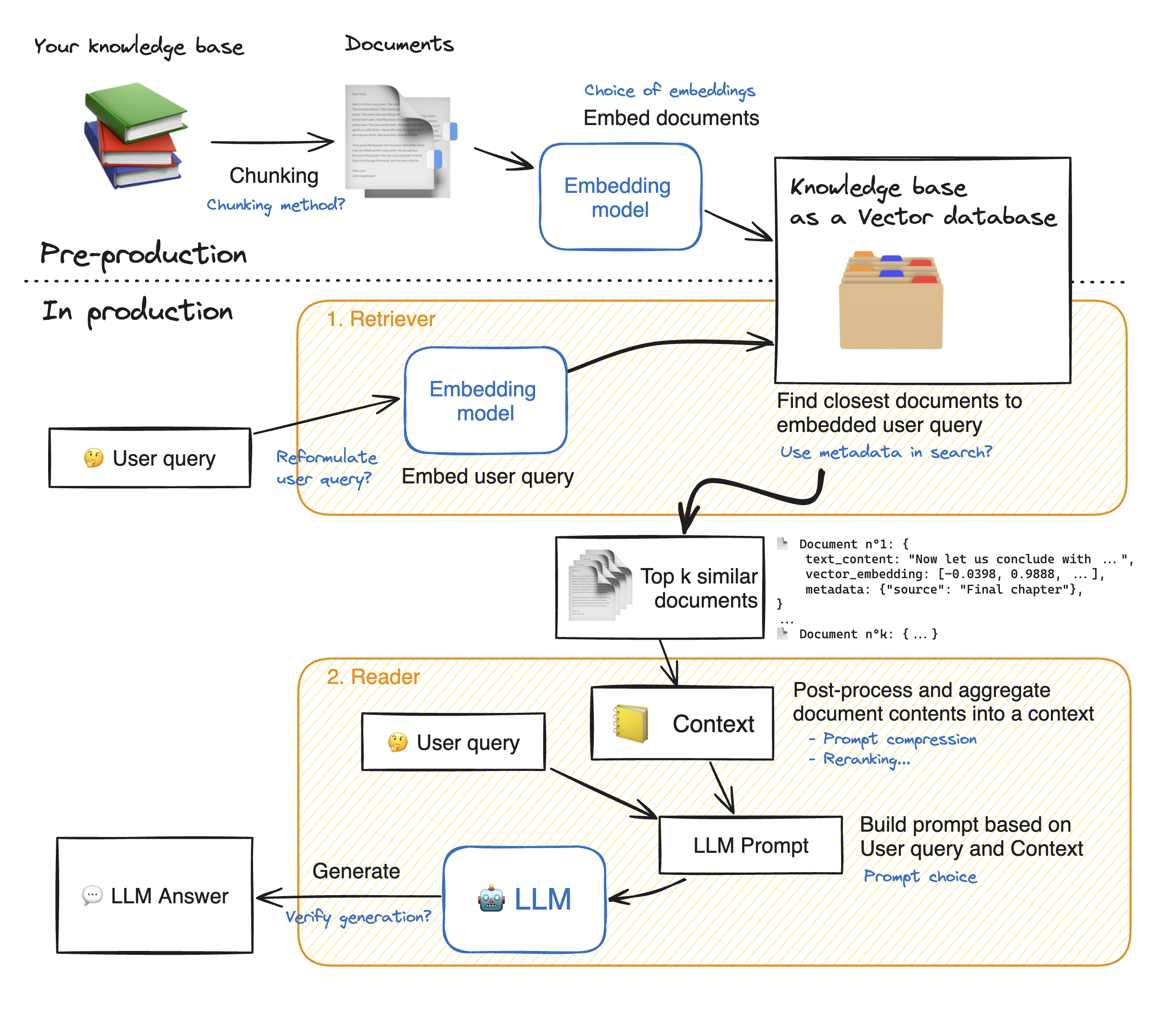
-The __retriever acts like an internal search engine__: given the user query, it returns a few relevant snippets from your knowledge base.
-
-These snippets will then be fed to the Reader Model to help it generate its answer.
-
-So __our objective here is, given a user question, to find the most snippets from our knowledge base to answer that question.__
-
-This is a wide objective, it leaves open some questions. How many snippets should we retrieve? This parameter will be named `top_k`.
-
-How long should these snippets be? This is called the `chunk size`. There's no one-size-fits-all answers, but here are a few elements:
-- 🔀 Your `chunk size` is allowed to vary from one snippet to the other.
-- Since there will always be some noise in your retrieval, increasing the `top_k` increases the chance to get relevant elements in your retrieved snippets. 🎯 Shooting more arrows increases your probability to hit your target.
-- Meanwhile, the summed length of your retrieved documents should not be too high: for instance, for most current models 16k tokens will probably drown your Reader model in information due to [Lost-in-the-middle phenomenon](https://huggingface.co/papers/2307.03172). 🎯 Give your reader model only the most relevant insights, not a huge pile of books!
-
-::: callout-note
-In this notebook, we use Langchain library since __it offers a huge variety of options for vector databases and allows us to keep document metadata throughout the processing__.
-:::
-
-### 1.1 Split the documents into chunks
-
-- In this part, __we split the documents from our knowledge base into smaller chunks__ which will be the snippets on which the reader LLM will base its answer.
-- The goal is to prepare a collection of **semantically relevant snippets**. So their size should be adapted to precise ideas: too small will truncate ideas, too large will dilute them.
-
-::: callout-tip
-💡 Many options exist for text splitting: splitting on words, on sentence boundaries, recursive chunking that processes documents in a tree-like way to preserve structure information... To learn more about chunking, I recommend you read [this great notebook](https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb) by Greg Kamradt.
-:::
-
-
-- **Recursive chunking** breaks down the text into smaller parts step by step using a given list of separators sorted from the most important to the least important separator. If the first split doesn't give the right size or shape chunks, the method repeats itself on the new chunks using a different separator. For instance with the list of separators `["\n\n", "\n", ".", ""]`:
- - The method will first break down the document wherever there is a double line break `"\n\n"`.
- - Resulting documents will be split again on simple line breaks `"\n"`, then on sentence ends `"."`.
- - And finally, if some chunks are still too big, they will be split whenever they overflow the maximum size.
-
-- With this method, the global structure is well preserved, at the expense of getting slight variations in chunk size.
-
-> [This space](https://huggingface.co/spaces/A-Roucher/chunk_visualizer) lets you visualize how different splitting options affect the chunks you get.
-
-🔬 Let's experiment a bit with chunk sizes, beginning with an arbitrary size, and see how splits work. We use Langchain's implementation of recursive chunking with `RecursiveCharacterTextSplitter`.
-- Parameter `chunk_size` controls the length of individual chunks: this length is counted by default as the number of characters in the chunk.
-- Parameter `chunk_overlap` lets adjacent chunks get a bit of overlap on each other. This reduces the probability that an idea could be cut in half by the split between two adjacent chunks. We ~arbitrarily set this to 1/10th of the chunk size, you could try different values!
-
-```{python}
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-
-# We use a hierarchical list of separators specifically tailored for splitting Markdown documents
-# This list is taken from LangChain's MarkdownTextSplitter class.
-MARKDOWN_SEPARATORS = [
- "\n#{1,6} ",
- "```\n",
- "\n\\*\\*\\*+\n",
- "\n---+\n",
- "\n___+\n",
- "\n\n",
- "\n",
- " ",
- "",
-]
-
-text_splitter = RecursiveCharacterTextSplitter(
- chunk_size=1000, # <1>
- chunk_overlap=100, # <2>
- add_start_index=True, # <3>
- strip_whitespace=True, # <4>
- separators=MARKDOWN_SEPARATORS,
-)
-
-docs_processed = []
-for doc in RAW_KNOWLEDGE_BASE:
- docs_processed += text_splitter.split_documents([doc])
-```
-1. The maximum number of characters in a chunk: we selected this value arbitrally
-2. The number of characters to overlap between chunks
-3. If `True`, includes chunk's start index in metadata
-4. If `True`, strips whitespace from the start and end of every document
-
-
-We also have to keep in mind that when embedding documents, we will use an embedding model that has accepts a certain maximum sequence length `max_seq_length`.
-
-So we should make sure that our chunk sizes are below this limit, because any longer chunk will be truncated before processing, thus losing relevancy.
-
-```{python}
-#| colab: {referenced_widgets: [ae043feeb0914c879e2a9008b413d952]}
-from sentence_transformers import SentenceTransformer
-
-# To get the value of the max sequence_length, we will query the underlying `SentenceTransformer` object used in the RecursiveCharacterTextSplitter.
-print(
- f"Model's maximum sequence length: {SentenceTransformer('thenlper/gte-small').max_seq_length}"
-)
-
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-small")
-lengths = [len(tokenizer.encode(doc.page_content)) for doc in tqdm(docs_processed)]
-
-# Plot the distrubution of document lengths, counted as the number of tokens
-fig = pd.Series(lengths).hist()
-plt.title("Distribution of document lengths in the knowledge base (in count of tokens)")
-plt.show()
-```
-
-👀 As you can see, __the chunk lengths are not aligned with our limit of 512 tokens__, and some documents are above the limit, thus some part of them will be lost in truncation!
- - So we should change the `RecursiveCharacterTextSplitter` class to count length in number of tokens instead of number of characters.
- - Then we can choose a specific chunk size, here we would choose a lower threshold than 512:
- - smaller documents could allow the split to focus more on specific ideas.
- - But too small chunks would split sentences in half, thus losing meaning again: the proper tuning is a matter of balance.
-
-```{python}
-#| colab: {referenced_widgets: [f900cf4ab3a94f45bfa7298f433566ed]}
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-from transformers import AutoTokenizer
-
-EMBEDDING_MODEL_NAME = "thenlper/gte-small"
-
-
-def split_documents(
- chunk_size: int,
- knowledge_base: List[LangchainDocument],
- tokenizer_name: Optional[str] = EMBEDDING_MODEL_NAME,
-) -> List[LangchainDocument]:
- """
- Split documents into chunks of maximum size `chunk_size` tokens and return a list of documents.
- """
- text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
- AutoTokenizer.from_pretrained(tokenizer_name),
- chunk_size=chunk_size,
- chunk_overlap=int(chunk_size / 10),
- add_start_index=True,
- strip_whitespace=True,
- separators=MARKDOWN_SEPARATORS,
- )
-
- docs_processed = []
- for doc in knowledge_base:
- docs_processed += text_splitter.split_documents([doc])
-
- # Remove duplicates
- unique_texts = {}
- docs_processed_unique = []
- for doc in docs_processed:
- if doc.page_content not in unique_texts:
- unique_texts[doc.page_content] = True
- docs_processed_unique.append(doc)
-
- return docs_processed_unique
-
-
-docs_processed = split_documents(
- 512, # We choose a chunk size adapted to our model
- RAW_KNOWLEDGE_BASE,
- tokenizer_name=EMBEDDING_MODEL_NAME,
-)
-
-# Let's visualize the chunk sizes we would have in tokens from a common model
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained(EMBEDDING_MODEL_NAME)
-lengths = [len(tokenizer.encode(doc.page_content)) for doc in tqdm(docs_processed)]
-fig = pd.Series(lengths).hist()
-plt.title("Distribution of document lengths in the knowledge base (in count of tokens)")
-plt.show()
-```
-
-➡️ Now the chunk length distribution looks better!
-
-### 1.2 Building the vector database
-
-We want to compute the embeddings for all the chunks of our knowledge base: to learn more on sentence embeddings, we recommend reading [this guide](https://osanseviero.github.io/hackerllama/blog/posts/sentence_embeddings/).
-
-#### How does retrieval work ?
-
-Once the chunks are all embedded, we store them into a vector database. When the user types in a query, it gets embedded by the same model previously used, and a similarity search returns the closest documents from the vector database.
-
-The technical challenge is thus, given a query vector, to quickly find the nearest neighbours of this vector in the vector database. To do this, we need to choose two things: a distance, and a search algorithm to find the nearest neighbors quickly within a database of thousands of records.
-
-##### Nearest Neighbor search algorithm
-
-There are plentiful choices for the nearest neighbor search algorithm: we go with Facebook's [FAISS](https://github.com/facebookresearch/faiss), since FAISS is performant enough for most use cases, and it is well known thus widely implemented.
-
-##### Distances
-
-Regarding distances, you can find a good guide [here](https://osanseviero.github.io/hackerllama/blog/posts/sentence_embeddings/#distance-between-embeddings). In short:
-
-- **Cosine similarity** computes similarity between two vectors as the cosinus of their relative angle: it allows us to compare vector directions are regardless of their magnitude. Using it requires to normalize all vectors, to rescale them into unit norm.
-- **Dot product** takes into account magnitude, with the sometimes undesirable effect that increasing a vector's length will make it more similar to all others.
-- **Euclidean distance** is the distance between the ends of vectors.
-
-You can try [this small exercise](https://developers.google.com/machine-learning/clustering/similarity/check-your-understanding) to check your understanding of these concepts. But once vectors are normalized, [the choice of a specific distance does not matter much](https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-use).
-
-Our particular model works well with cosine similarity, so choose this distance, and we set it up both in the Embedding model, and in the `distance_strategy` argument of our FAISS index. With cosine similarity, we have to normalize our embeddings.
-
-::: {.callout-warning}
-🚨👇 The cell below takes a few minutes to run on A10G!
-:::
-
-```{python}
-from langchain.vectorstores import FAISS
-from langchain_community.embeddings import HuggingFaceEmbeddings
-from langchain_community.vectorstores.utils import DistanceStrategy
-
-embedding_model = HuggingFaceEmbeddings(
- model_name=EMBEDDING_MODEL_NAME,
- multi_process=True,
- model_kwargs={"device": "cuda"},
- encode_kwargs={"normalize_embeddings": True}, # set True for cosine similarity
-)
-
-KNOWLEDGE_VECTOR_DATABASE = FAISS.from_documents(
- docs_processed, embedding_model, distance_strategy=DistanceStrategy.COSINE
-)
-```
-
-👀 To visualize the search for the closest documents, let's project our embeddings from 384 dimensions down to 2 dimensions using PaCMAP.
-
-::: {.callout-note}
-💡 We chose PaCMAP rather than other techniques such as t-SNE or UMAP, since [it is efficient (preserves local and global structure), robust to initialization parameters and fast](https://www.nature.com/articles/s42003-022-03628-x#Abs1).
-:::
-
-
-```{python}
-# embed a user query in the same space
-user_query = "How to create a pipeline object?"
-query_vector = embedding_model.embed_query(user_query)
-```
-
-```{python}
-import pacmap
-import numpy as np
-import plotly.express as px
-
-embedding_projector = pacmap.PaCMAP(
- n_components=2, n_neighbors=None, MN_ratio=0.5, FP_ratio=2.0, random_state=1
-)
-
-embeddings_2d = [
- list(KNOWLEDGE_VECTOR_DATABASE.index.reconstruct_n(idx, 1)[0])
- for idx in range(len(docs_processed))
-] + [query_vector]
-
-# fit the data (The index of transformed data corresponds to the index of the original data)
-documents_projected = embedding_projector.fit_transform(np.array(embeddings_2d), init="pca")
-```
-
-```{python}
-df = pd.DataFrame.from_dict(
- [
- {
- "x": documents_projected[i, 0],
- "y": documents_projected[i, 1],
- "source": docs_processed[i].metadata["source"].split("/")[1],
- "extract": docs_processed[i].page_content[:100] + "...",
- "symbol": "circle",
- "size_col": 4,
- }
- for i in range(len(docs_processed))
- ]
- + [
- {
- "x": documents_projected[-1, 0],
- "y": documents_projected[-1, 1],
- "source": "User query",
- "extract": user_query,
- "size_col": 100,
- "symbol": "star",
- }
- ]
-)
-
-# visualize the embedding
-fig = px.scatter(
- df,
- x="x",
- y="y",
- color="source",
- hover_data="extract",
- size="size_col",
- symbol="symbol",
- color_discrete_map={"User query": "black"},
- width=1000,
- height=700,
-)
-fig.update_traces(
- marker=dict(opacity=1, line=dict(width=0, color="DarkSlateGrey")), selector=dict(mode="markers")
-)
-fig.update_layout(
- legend_title_text="Chunk source",
- title="2D Projection of Chunk Embeddings via PaCMAP",
-)
-fig.show()
-```
-
-
-
-::: callout-note
-💡 As you can see, there are many steps to tune in this architecture: tuning the system properly will yield significant performance gains.
-:::
-
-In this notebook, we will take a look into many of these blue notes to see how to tune your RAG system and get the best performance.
-
-__Let's dig into the model building!__ First, we install the required model dependancies.
-
-```{python}
-!pip install -q torch transformers transformers accelerate bitsandbytes langchain sentence-transformers faiss-gpu openpyxl pacmap
-```
-
-```{python}
-%reload_ext dotenv
-%dotenv
-```
-
-```{python}
-from tqdm.notebook import tqdm
-import pandas as pd
-from typing import Optional, List, Tuple
-from datasets import Dataset
-import matplotlib.pyplot as plt
-
-pd.set_option(
- "display.max_colwidth", None # <1>
-)
-```
-1. This will be helpful when visualizing retriever outputs
-
-### Load your knowledge base
-
-```{python}
-import datasets
-
-ds = datasets.load_dataset("m-ric/huggingface_doc", split="train")
-```
-
-```{python}
-from langchain.docstore.document import Document as LangchainDocument
-
-RAW_KNOWLEDGE_BASE = [
- LangchainDocument(page_content=doc["text"], metadata={"source": doc["source"]})
- for doc in tqdm(ds)
-]
-```
-
-# 1. Retriever - embeddings 🗂️
-The __retriever acts like an internal search engine__: given the user query, it returns a few relevant snippets from your knowledge base.
-
-These snippets will then be fed to the Reader Model to help it generate its answer.
-
-So __our objective here is, given a user question, to find the most snippets from our knowledge base to answer that question.__
-
-This is a wide objective, it leaves open some questions. How many snippets should we retrieve? This parameter will be named `top_k`.
-
-How long should these snippets be? This is called the `chunk size`. There's no one-size-fits-all answers, but here are a few elements:
-- 🔀 Your `chunk size` is allowed to vary from one snippet to the other.
-- Since there will always be some noise in your retrieval, increasing the `top_k` increases the chance to get relevant elements in your retrieved snippets. 🎯 Shooting more arrows increases your probability to hit your target.
-- Meanwhile, the summed length of your retrieved documents should not be too high: for instance, for most current models 16k tokens will probably drown your Reader model in information due to [Lost-in-the-middle phenomenon](https://huggingface.co/papers/2307.03172). 🎯 Give your reader model only the most relevant insights, not a huge pile of books!
-
-::: callout-note
-In this notebook, we use Langchain library since __it offers a huge variety of options for vector databases and allows us to keep document metadata throughout the processing__.
-:::
-
-### 1.1 Split the documents into chunks
-
-- In this part, __we split the documents from our knowledge base into smaller chunks__ which will be the snippets on which the reader LLM will base its answer.
-- The goal is to prepare a collection of **semantically relevant snippets**. So their size should be adapted to precise ideas: too small will truncate ideas, too large will dilute them.
-
-::: callout-tip
-💡 Many options exist for text splitting: splitting on words, on sentence boundaries, recursive chunking that processes documents in a tree-like way to preserve structure information... To learn more about chunking, I recommend you read [this great notebook](https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb) by Greg Kamradt.
-:::
-
-
-- **Recursive chunking** breaks down the text into smaller parts step by step using a given list of separators sorted from the most important to the least important separator. If the first split doesn't give the right size or shape chunks, the method repeats itself on the new chunks using a different separator. For instance with the list of separators `["\n\n", "\n", ".", ""]`:
- - The method will first break down the document wherever there is a double line break `"\n\n"`.
- - Resulting documents will be split again on simple line breaks `"\n"`, then on sentence ends `"."`.
- - And finally, if some chunks are still too big, they will be split whenever they overflow the maximum size.
-
-- With this method, the global structure is well preserved, at the expense of getting slight variations in chunk size.
-
-> [This space](https://huggingface.co/spaces/A-Roucher/chunk_visualizer) lets you visualize how different splitting options affect the chunks you get.
-
-🔬 Let's experiment a bit with chunk sizes, beginning with an arbitrary size, and see how splits work. We use Langchain's implementation of recursive chunking with `RecursiveCharacterTextSplitter`.
-- Parameter `chunk_size` controls the length of individual chunks: this length is counted by default as the number of characters in the chunk.
-- Parameter `chunk_overlap` lets adjacent chunks get a bit of overlap on each other. This reduces the probability that an idea could be cut in half by the split between two adjacent chunks. We ~arbitrarily set this to 1/10th of the chunk size, you could try different values!
-
-```{python}
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-
-# We use a hierarchical list of separators specifically tailored for splitting Markdown documents
-# This list is taken from LangChain's MarkdownTextSplitter class.
-MARKDOWN_SEPARATORS = [
- "\n#{1,6} ",
- "```\n",
- "\n\\*\\*\\*+\n",
- "\n---+\n",
- "\n___+\n",
- "\n\n",
- "\n",
- " ",
- "",
-]
-
-text_splitter = RecursiveCharacterTextSplitter(
- chunk_size=1000, # <1>
- chunk_overlap=100, # <2>
- add_start_index=True, # <3>
- strip_whitespace=True, # <4>
- separators=MARKDOWN_SEPARATORS,
-)
-
-docs_processed = []
-for doc in RAW_KNOWLEDGE_BASE:
- docs_processed += text_splitter.split_documents([doc])
-```
-1. The maximum number of characters in a chunk: we selected this value arbitrally
-2. The number of characters to overlap between chunks
-3. If `True`, includes chunk's start index in metadata
-4. If `True`, strips whitespace from the start and end of every document
-
-
-We also have to keep in mind that when embedding documents, we will use an embedding model that has accepts a certain maximum sequence length `max_seq_length`.
-
-So we should make sure that our chunk sizes are below this limit, because any longer chunk will be truncated before processing, thus losing relevancy.
-
-```{python}
-#| colab: {referenced_widgets: [ae043feeb0914c879e2a9008b413d952]}
-from sentence_transformers import SentenceTransformer
-
-# To get the value of the max sequence_length, we will query the underlying `SentenceTransformer` object used in the RecursiveCharacterTextSplitter.
-print(
- f"Model's maximum sequence length: {SentenceTransformer('thenlper/gte-small').max_seq_length}"
-)
-
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-small")
-lengths = [len(tokenizer.encode(doc.page_content)) for doc in tqdm(docs_processed)]
-
-# Plot the distrubution of document lengths, counted as the number of tokens
-fig = pd.Series(lengths).hist()
-plt.title("Distribution of document lengths in the knowledge base (in count of tokens)")
-plt.show()
-```
-
-👀 As you can see, __the chunk lengths are not aligned with our limit of 512 tokens__, and some documents are above the limit, thus some part of them will be lost in truncation!
- - So we should change the `RecursiveCharacterTextSplitter` class to count length in number of tokens instead of number of characters.
- - Then we can choose a specific chunk size, here we would choose a lower threshold than 512:
- - smaller documents could allow the split to focus more on specific ideas.
- - But too small chunks would split sentences in half, thus losing meaning again: the proper tuning is a matter of balance.
-
-```{python}
-#| colab: {referenced_widgets: [f900cf4ab3a94f45bfa7298f433566ed]}
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-from transformers import AutoTokenizer
-
-EMBEDDING_MODEL_NAME = "thenlper/gte-small"
-
-
-def split_documents(
- chunk_size: int,
- knowledge_base: List[LangchainDocument],
- tokenizer_name: Optional[str] = EMBEDDING_MODEL_NAME,
-) -> List[LangchainDocument]:
- """
- Split documents into chunks of maximum size `chunk_size` tokens and return a list of documents.
- """
- text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
- AutoTokenizer.from_pretrained(tokenizer_name),
- chunk_size=chunk_size,
- chunk_overlap=int(chunk_size / 10),
- add_start_index=True,
- strip_whitespace=True,
- separators=MARKDOWN_SEPARATORS,
- )
-
- docs_processed = []
- for doc in knowledge_base:
- docs_processed += text_splitter.split_documents([doc])
-
- # Remove duplicates
- unique_texts = {}
- docs_processed_unique = []
- for doc in docs_processed:
- if doc.page_content not in unique_texts:
- unique_texts[doc.page_content] = True
- docs_processed_unique.append(doc)
-
- return docs_processed_unique
-
-
-docs_processed = split_documents(
- 512, # We choose a chunk size adapted to our model
- RAW_KNOWLEDGE_BASE,
- tokenizer_name=EMBEDDING_MODEL_NAME,
-)
-
-# Let's visualize the chunk sizes we would have in tokens from a common model
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained(EMBEDDING_MODEL_NAME)
-lengths = [len(tokenizer.encode(doc.page_content)) for doc in tqdm(docs_processed)]
-fig = pd.Series(lengths).hist()
-plt.title("Distribution of document lengths in the knowledge base (in count of tokens)")
-plt.show()
-```
-
-➡️ Now the chunk length distribution looks better!
-
-### 1.2 Building the vector database
-
-We want to compute the embeddings for all the chunks of our knowledge base: to learn more on sentence embeddings, we recommend reading [this guide](https://osanseviero.github.io/hackerllama/blog/posts/sentence_embeddings/).
-
-#### How does retrieval work ?
-
-Once the chunks are all embedded, we store them into a vector database. When the user types in a query, it gets embedded by the same model previously used, and a similarity search returns the closest documents from the vector database.
-
-The technical challenge is thus, given a query vector, to quickly find the nearest neighbours of this vector in the vector database. To do this, we need to choose two things: a distance, and a search algorithm to find the nearest neighbors quickly within a database of thousands of records.
-
-##### Nearest Neighbor search algorithm
-
-There are plentiful choices for the nearest neighbor search algorithm: we go with Facebook's [FAISS](https://github.com/facebookresearch/faiss), since FAISS is performant enough for most use cases, and it is well known thus widely implemented.
-
-##### Distances
-
-Regarding distances, you can find a good guide [here](https://osanseviero.github.io/hackerllama/blog/posts/sentence_embeddings/#distance-between-embeddings). In short:
-
-- **Cosine similarity** computes similarity between two vectors as the cosinus of their relative angle: it allows us to compare vector directions are regardless of their magnitude. Using it requires to normalize all vectors, to rescale them into unit norm.
-- **Dot product** takes into account magnitude, with the sometimes undesirable effect that increasing a vector's length will make it more similar to all others.
-- **Euclidean distance** is the distance between the ends of vectors.
-
-You can try [this small exercise](https://developers.google.com/machine-learning/clustering/similarity/check-your-understanding) to check your understanding of these concepts. But once vectors are normalized, [the choice of a specific distance does not matter much](https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-use).
-
-Our particular model works well with cosine similarity, so choose this distance, and we set it up both in the Embedding model, and in the `distance_strategy` argument of our FAISS index. With cosine similarity, we have to normalize our embeddings.
-
-::: {.callout-warning}
-🚨👇 The cell below takes a few minutes to run on A10G!
-:::
-
-```{python}
-from langchain.vectorstores import FAISS
-from langchain_community.embeddings import HuggingFaceEmbeddings
-from langchain_community.vectorstores.utils import DistanceStrategy
-
-embedding_model = HuggingFaceEmbeddings(
- model_name=EMBEDDING_MODEL_NAME,
- multi_process=True,
- model_kwargs={"device": "cuda"},
- encode_kwargs={"normalize_embeddings": True}, # set True for cosine similarity
-)
-
-KNOWLEDGE_VECTOR_DATABASE = FAISS.from_documents(
- docs_processed, embedding_model, distance_strategy=DistanceStrategy.COSINE
-)
-```
-
-👀 To visualize the search for the closest documents, let's project our embeddings from 384 dimensions down to 2 dimensions using PaCMAP.
-
-::: {.callout-note}
-💡 We chose PaCMAP rather than other techniques such as t-SNE or UMAP, since [it is efficient (preserves local and global structure), robust to initialization parameters and fast](https://www.nature.com/articles/s42003-022-03628-x#Abs1).
-:::
-
-
-```{python}
-# embed a user query in the same space
-user_query = "How to create a pipeline object?"
-query_vector = embedding_model.embed_query(user_query)
-```
-
-```{python}
-import pacmap
-import numpy as np
-import plotly.express as px
-
-embedding_projector = pacmap.PaCMAP(
- n_components=2, n_neighbors=None, MN_ratio=0.5, FP_ratio=2.0, random_state=1
-)
-
-embeddings_2d = [
- list(KNOWLEDGE_VECTOR_DATABASE.index.reconstruct_n(idx, 1)[0])
- for idx in range(len(docs_processed))
-] + [query_vector]
-
-# fit the data (The index of transformed data corresponds to the index of the original data)
-documents_projected = embedding_projector.fit_transform(np.array(embeddings_2d), init="pca")
-```
-
-```{python}
-df = pd.DataFrame.from_dict(
- [
- {
- "x": documents_projected[i, 0],
- "y": documents_projected[i, 1],
- "source": docs_processed[i].metadata["source"].split("/")[1],
- "extract": docs_processed[i].page_content[:100] + "...",
- "symbol": "circle",
- "size_col": 4,
- }
- for i in range(len(docs_processed))
- ]
- + [
- {
- "x": documents_projected[-1, 0],
- "y": documents_projected[-1, 1],
- "source": "User query",
- "extract": user_query,
- "size_col": 100,
- "symbol": "star",
- }
- ]
-)
-
-# visualize the embedding
-fig = px.scatter(
- df,
- x="x",
- y="y",
- color="source",
- hover_data="extract",
- size="size_col",
- symbol="symbol",
- color_discrete_map={"User query": "black"},
- width=1000,
- height=700,
-)
-fig.update_traces(
- marker=dict(opacity=1, line=dict(width=0, color="DarkSlateGrey")), selector=dict(mode="markers")
-)
-fig.update_layout(
- legend_title_text="Chunk source",
- title="2D Projection of Chunk Embeddings via PaCMAP",
-)
-fig.show()
-```
-
- -
-
-➡️ On the graph above, you can see a spatial representation of the kowledge base documents. As the vector embeddings represent the document's meaning, their closeness in meaning should be reflected in their embedding's closeness.
-
-The user query's embedding is also shown : we want to find the `k` document that have the closest meaning, thus we pick the `k` closest vectors.
-
-In the LangChain vector database implementation, this search operation is performed by the method `vector_database.similarity_search(query)`.
-
-Here is the result:
-
-```{python}
-print(f"\nStarting retrieval for {user_query=}...")
-retrieved_docs = KNOWLEDGE_VECTOR_DATABASE.similarity_search(query=user_query, k=5)
-print("\n==================================Top document==================================")
-print(retrieved_docs[0].page_content)
-print("==================================Metadata==================================")
-print(retrieved_docs[0].metadata)
-```
-
-# 2. Reader - LLM 💬
-
-In this part, the __LLM Reader reads the retrieved context to formulate its answer.__
-
-There are actually substeps that can all be tuned:
-1. The content of the retrieved documents is aggregated together into the "context", with many processing options like _prompt compression_.
-2. The context and the user query are aggregated into a prompt then given to the LLM to generate its answer.
-
-### 2.1. Reader model
-
-The choice of a reader model is important on a few aspects:
-- the reader model's `max_seq_length` must accomodate our prompt, which includes the context output by the retriever call: the context consists in 5 documents of 512 tokens each, so we aim for a context length of 4k tokens at least.
-- the reader model
-
-For this example, we chose [`HuggingFaceH4/zephyr-7b-beta`](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), a small but powerful model.
-
-::: callout-note
-With many models being released every week, you may want to substitute this model to the latest and greatest. The best way to keep track of open source LLMs is to check the [Open-source LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
-:::
-
-To make inference faster, we will load the quantized version of the model:
-
-```{python}
-#| colab: {referenced_widgets: [db31fd28d3604e78aead26af87b0384f]}
-from transformers import pipeline
-import torch
-from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
-
-READER_MODEL_NAME = "HuggingFaceH4/zephyr-7b-beta"
-
-bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_use_double_quant=True,
- bnb_4bit_quant_type="nf4",
- bnb_4bit_compute_dtype=torch.bfloat16,
-)
-model = AutoModelForCausalLM.from_pretrained(READER_MODEL_NAME, quantization_config=bnb_config)
-tokenizer = AutoTokenizer.from_pretrained(READER_MODEL_NAME)
-
-READER_LLM = pipeline(
- model=model,
- tokenizer=tokenizer,
- task="text-generation",
- do_sample=True,
- temperature=0.2,
- repetition_penalty=1.1,
- return_full_text=False,
- max_new_tokens=500,
-)
-```
-
-```{python}
-READER_LLM("What is 4+4? Answer:")
-```
-
-### 2.2. Prompt
-
-The RAG prompt template below is what we will feed to the Reader LLM: it is important to have it formatted in the Reader LLM's chat template.
-
-We give it our context and the user's question.
-
-```{python}
-prompt_in_chat_format = [
- {
- "role": "system",
- "content": """Using the information contained in the context,
-give a comprehensive answer to the question.
-Respond only to the question asked, response should be concise and relevant to the question.
-Provide the number of the source document when relevant.
-If the answer cannot be deduced from the context, do not give an answer.""",
- },
- {
- "role": "user",
- "content": """Context:
-{context}
----
-Now here is the question you need to answer.
-
-Question: {question}""",
- },
-]
-RAG_PROMPT_TEMPLATE = tokenizer.apply_chat_template(
- prompt_in_chat_format, tokenize=False, add_generation_prompt=True
-)
-print(RAG_PROMPT_TEMPLATE)
-```
-
-Let's test our Reader on our previously retrieved documents!
-
-```{python}
-retrieved_docs_text = [
- doc.page_content for doc in retrieved_docs
-] # we only need the text of the documents
-context = "\nExtracted documents:\n"
-context += "".join([f"Document {str(i)}:::\n" + doc for i, doc in enumerate(retrieved_docs_text)])
-
-final_prompt = RAG_PROMPT_TEMPLATE.format(
- question="How to create a pipeline object?", context=context
-)
-
-# Redact an answer
-answer = READER_LLM(final_prompt)[0]["generated_text"]
-print(answer)
-```
-
-### 2.3. Reranking
-
-A good option for RAG is to retrieve more documents than you want in the end, then rerank the results with a more powerful retrieval model before keeping only the `top_k`.
-
-For this, [Colbertv2](https://arxiv.org/abs/2112.01488) is a great choice: instead of a bi-encoder like our classical embedding models, it is a cross-encoder that computes more fine-grained interactions between the query tokens and each document's tokens.
-
-It is easily usable thanks to [the RAGatouille library](https://github.com/bclavie/RAGatouille).
-
-```{python}
-from ragatouille import RAGPretrainedModel
-
-RERANKER = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
-```
-
-# 3. Assembling it all!
-
-```{python}
-from transformers import Pipeline
-
-
-def answer_with_rag(
- question: str,
- llm: Pipeline,
- knowledge_index: FAISS,
- reranker: Optional[RAGPretrainedModel] = None,
- num_retrieved_docs: int = 30,
- num_docs_final: int = 5,
-) -> Tuple[str, List[LangchainDocument]]:
- # Gather documents with retriever
- print("=> Retrieving documents...")
- relevant_docs = knowledge_index.similarity_search(query=question, k=num_retrieved_docs)
- relevant_docs = [doc.page_content for doc in relevant_docs] # keep only the text
-
- # Optionally rerank results
- if reranker:
- print("=> Reranking documents...")
- relevant_docs = reranker.rerank(question, relevant_docs, k=num_docs_final)
- relevant_docs = [doc["content"] for doc in relevant_docs]
-
- relevant_docs = relevant_docs[:num_docs_final]
-
- # Build the final prompt
- context = "\nExtracted documents:\n"
- context += "".join([f"Document {str(i)}:::\n" + doc for i, doc in enumerate(relevant_docs)])
-
- final_prompt = RAG_PROMPT_TEMPLATE.format(question=question, context=context)
-
- # Redact an answer
- print("=> Generating answer...")
- answer = llm(final_prompt)[0]["generated_text"]
-
- return answer, relevant_docs
-```
-
-Let's see how our RAG pipeline answers a user query.
-
-```{python}
-question = "how to create a pipeline object?"
-
-answer, relevant_docs = answer_with_rag(
- question, READER_LLM, KNOWLEDGE_VECTOR_DATABASE, reranker=RERANKER
-)
-```
-
-```{python}
-print("==================================Answer==================================")
-print(f"{answer}")
-print("==================================Source docs==================================")
-for i, doc in enumerate(relevant_docs):
- print(f"Document {i}------------------------------------------------------------")
- print(doc)
-```
-
-✅ We now have a fully functional, performant RAG sytem. That's it for today! Congratulations for making it to the end 🥳
-
-
-# To go further 🗺️
-
-This is not the end of the journey! You can try many steps to improve your RAG system. We recommend doing so in an iterative way: bring small changes to the system and see what improves performance.
-
-### Setting up an evaluation pipeline
-
-- 💬 "You cannot improve the model performance that you do not measure", said Gandhi... or at least Llama2 told me he said it. Anyway, you should absolutely start by measuring performance: this means building a small evaluation dataset, then monitor the performance of your RAG system on this evaluation dataset.
-
-### Improving the retriever
-
-🛠️ __You can use these options to tune the results:__
-
-- Tune the chunking method:
- - Size of the chunks
- - Method: split on different separators, use [semantic chunking](https://python.langchain.com/docs/modules/data_connection/document_transformers/semantic-chunker)...
-- Change the embedding model
-
-👷♀️ __More could be considered:__
-- Try another chunking method, like semantic chunking
-- Change the index used (here, FAISS)
-- Query expansion: reformulate the user query in slightly different ways to retrieve more documents.
-
-### Improving the reader
-
-🛠️ __Here you can try the following options to improve results:__
-- Tune the prompt
-- Switch reranking on/off
-- Choose a more powerful reader model
-
-💡 __Many options could be considered here to further improve the results:__
-- Compress the retrieved context to keep only the most relevant parts to answer the query.
-- Extend the RAG system to make it more user-friendly:
- - cite source
- - make conversational
-
diff --git a/src/notebooks/automatic_embedding.ipynb b/src/notebooks/automatic_embedding.ipynb
deleted file mode 100644
index 176b26789df38b7be056a14bbbad729e02e85be2..0000000000000000000000000000000000000000
--- a/src/notebooks/automatic_embedding.ipynb
+++ /dev/null
@@ -1,825 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "id": "5d9aca72-957a-4ee2-862f-e011b9cd3a62",
- "metadata": {},
- "source": [
- "---\n",
- "title: \"Inference Endpoints\"\n",
- "---\n",
- "\n",
- "# How to use Inference Endpoints to Embed Documents\n",
- "\n",
- "_Authored by: [Derek Thomas](https://huggingface.co/derek-thomas)_\n",
- "\n",
- "## Goal\n",
- "I have a dataset I want to embed for semantic search (or QA, or RAG), I want the easiest way to do embed this and put it in a new dataset.\n",
- "\n",
- "## Approach\n",
- "I'm using a dataset from my favorite subreddit [r/bestofredditorupdates](https://www.reddit.com/r/bestofredditorupdates/). Because it has long entries, I will use the new [jinaai/jina-embeddings-v2-base-en](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) since it has an 8k context length. I will deploy this using [Inference Endpoint](https://huggingface.co/inference-endpoints) to save time and money. To follow this tutorial, you will need to **have already added a payment method**. If you haven't, you can add one here in [billing](https://huggingface.co/docs/hub/billing#billing). To make it even easier, I'll make this fully API based.\n",
- "\n",
- "To make this MUCH faster I will use the [Text Embeddings Inference](https://github.com/huggingface/text-embeddings-inference) image. This has many benefits like:\n",
- "- No model graph compilation step\n",
- "- Small docker images and fast boot times. Get ready for true serverless!\n",
- "- Token based dynamic batching\n",
- "- Optimized transformers code for inference using Flash Attention, Candle and cuBLASLt\n",
- "- Safetensors weight loading\n",
- "- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "3c830114-dd88-45a9-81b9-78b0e3da7384",
- "metadata": {},
- "source": [
- "## Requirements"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "35386f72-32cb-49fa-a108-3aa504e20429",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "!pip install -q aiohttp==3.8.3 datasets==2.14.6 pandas==1.5.3 requests==2.31.0 tqdm==4.66.1 huggingface-hub>=0.20"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b6f72042-173d-4a72-ade1-9304b43b528d",
- "metadata": {},
- "source": [
- "## Imports"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "id": "e2beecdd-d033-4736-bd45-6754ec53b4ac",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "import asyncio\n",
- "from getpass import getpass\n",
- "import json\n",
- "from pathlib import Path\n",
- "import time\n",
- "from typing import Optional\n",
- "\n",
- "from aiohttp import ClientSession, ClientTimeout\n",
- "from datasets import load_dataset, Dataset, DatasetDict\n",
- "from huggingface_hub import notebook_login, create_inference_endpoint, list_inference_endpoints, whoami\n",
- "import numpy as np\n",
- "import pandas as pd\n",
- "import requests\n",
- "from tqdm.auto import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "5eece903-64ce-435d-a2fd-096c0ff650bf",
- "metadata": {},
- "source": [
- "## Config\n",
- "`DATASET_IN` is where your text data is\n",
- "`DATASET_OUT` is where your embeddings will be stored\n",
- "\n",
- "Note I used 5 for the `MAX_WORKERS` since `jina-embeddings-v2` are quite memory hungry. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "id": "df2f79f0-9f28-46e6-9fc7-27e9537ff5be",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "DATASET_IN = 'derek-thomas/dataset-creator-reddit-bestofredditorupdates'\n",
- "DATASET_OUT = \"processed-subset-bestofredditorupdates\"\n",
- "ENDPOINT_NAME = \"boru-jina-embeddings-demo-ie\"\n",
- "\n",
- "MAX_WORKERS = 5 # This is for how many async workers you want. Choose based on the model and hardware \n",
- "ROW_COUNT = 100 # Choose None to use all rows, Im using 100 just for a demo"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "1e680f3d-4900-46cc-8b49-bb6ba3e27e2b",
- "metadata": {},
- "source": [
- "Hugging Face offers a number of GPUs that you can choose from a number of GPUs that you can choose in Inference Endpoints. Here they are in table form:\n",
- "\n",
- "| GPU | instanceType | instanceSize | vRAM |\n",
- "|---------------------|----------------|--------------|-------|\n",
- "| 1x Nvidia Tesla T4 | g4dn.xlarge | small | 16GB |\n",
- "| 4x Nvidia Tesla T4 | g4dn.12xlarge | large | 64GB |\n",
- "| 1x Nvidia A10G | g5.2xlarge | medium | 24GB |\n",
- "| 4x Nvidia A10G | g5.12xlarge | xxlarge | 96GB |\n",
- "| 1x Nvidia A100* | p4de | xlarge | 80GB |\n",
- "| 2x Nvidia A100* | p4de | 2xlarge | 160GB |\n",
- "\n",
- "\\*Note that for A100s you might get a note to email us to get access."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "id": "3c2106c1-2e5a-443a-9ea8-a3cd0e9c5a94",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "# GPU Choice\n",
- "VENDOR=\"aws\"\n",
- "REGION=\"us-east-1\"\n",
- "INSTANCE_SIZE=\"medium\"\n",
- "INSTANCE_TYPE=\"g5.2xlarge\""
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 5,
- "id": "0ca1140c-3fcc-4b99-9210-6da1505a27b7",
- "metadata": {
- "tags": []
- },
- "outputs": [
- {
- "data": {
- "application/vnd.jupyter.widget-view+json": {
- "model_id": "ee80821056e147fa9cabf30f64dc85a8",
- "version_major": 2,
- "version_minor": 0
- },
- "text/plain": [
- "VBox(children=(HTML(value='
-
-
-➡️ On the graph above, you can see a spatial representation of the kowledge base documents. As the vector embeddings represent the document's meaning, their closeness in meaning should be reflected in their embedding's closeness.
-
-The user query's embedding is also shown : we want to find the `k` document that have the closest meaning, thus we pick the `k` closest vectors.
-
-In the LangChain vector database implementation, this search operation is performed by the method `vector_database.similarity_search(query)`.
-
-Here is the result:
-
-```{python}
-print(f"\nStarting retrieval for {user_query=}...")
-retrieved_docs = KNOWLEDGE_VECTOR_DATABASE.similarity_search(query=user_query, k=5)
-print("\n==================================Top document==================================")
-print(retrieved_docs[0].page_content)
-print("==================================Metadata==================================")
-print(retrieved_docs[0].metadata)
-```
-
-# 2. Reader - LLM 💬
-
-In this part, the __LLM Reader reads the retrieved context to formulate its answer.__
-
-There are actually substeps that can all be tuned:
-1. The content of the retrieved documents is aggregated together into the "context", with many processing options like _prompt compression_.
-2. The context and the user query are aggregated into a prompt then given to the LLM to generate its answer.
-
-### 2.1. Reader model
-
-The choice of a reader model is important on a few aspects:
-- the reader model's `max_seq_length` must accomodate our prompt, which includes the context output by the retriever call: the context consists in 5 documents of 512 tokens each, so we aim for a context length of 4k tokens at least.
-- the reader model
-
-For this example, we chose [`HuggingFaceH4/zephyr-7b-beta`](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), a small but powerful model.
-
-::: callout-note
-With many models being released every week, you may want to substitute this model to the latest and greatest. The best way to keep track of open source LLMs is to check the [Open-source LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
-:::
-
-To make inference faster, we will load the quantized version of the model:
-
-```{python}
-#| colab: {referenced_widgets: [db31fd28d3604e78aead26af87b0384f]}
-from transformers import pipeline
-import torch
-from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
-
-READER_MODEL_NAME = "HuggingFaceH4/zephyr-7b-beta"
-
-bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_use_double_quant=True,
- bnb_4bit_quant_type="nf4",
- bnb_4bit_compute_dtype=torch.bfloat16,
-)
-model = AutoModelForCausalLM.from_pretrained(READER_MODEL_NAME, quantization_config=bnb_config)
-tokenizer = AutoTokenizer.from_pretrained(READER_MODEL_NAME)
-
-READER_LLM = pipeline(
- model=model,
- tokenizer=tokenizer,
- task="text-generation",
- do_sample=True,
- temperature=0.2,
- repetition_penalty=1.1,
- return_full_text=False,
- max_new_tokens=500,
-)
-```
-
-```{python}
-READER_LLM("What is 4+4? Answer:")
-```
-
-### 2.2. Prompt
-
-The RAG prompt template below is what we will feed to the Reader LLM: it is important to have it formatted in the Reader LLM's chat template.
-
-We give it our context and the user's question.
-
-```{python}
-prompt_in_chat_format = [
- {
- "role": "system",
- "content": """Using the information contained in the context,
-give a comprehensive answer to the question.
-Respond only to the question asked, response should be concise and relevant to the question.
-Provide the number of the source document when relevant.
-If the answer cannot be deduced from the context, do not give an answer.""",
- },
- {
- "role": "user",
- "content": """Context:
-{context}
----
-Now here is the question you need to answer.
-
-Question: {question}""",
- },
-]
-RAG_PROMPT_TEMPLATE = tokenizer.apply_chat_template(
- prompt_in_chat_format, tokenize=False, add_generation_prompt=True
-)
-print(RAG_PROMPT_TEMPLATE)
-```
-
-Let's test our Reader on our previously retrieved documents!
-
-```{python}
-retrieved_docs_text = [
- doc.page_content for doc in retrieved_docs
-] # we only need the text of the documents
-context = "\nExtracted documents:\n"
-context += "".join([f"Document {str(i)}:::\n" + doc for i, doc in enumerate(retrieved_docs_text)])
-
-final_prompt = RAG_PROMPT_TEMPLATE.format(
- question="How to create a pipeline object?", context=context
-)
-
-# Redact an answer
-answer = READER_LLM(final_prompt)[0]["generated_text"]
-print(answer)
-```
-
-### 2.3. Reranking
-
-A good option for RAG is to retrieve more documents than you want in the end, then rerank the results with a more powerful retrieval model before keeping only the `top_k`.
-
-For this, [Colbertv2](https://arxiv.org/abs/2112.01488) is a great choice: instead of a bi-encoder like our classical embedding models, it is a cross-encoder that computes more fine-grained interactions between the query tokens and each document's tokens.
-
-It is easily usable thanks to [the RAGatouille library](https://github.com/bclavie/RAGatouille).
-
-```{python}
-from ragatouille import RAGPretrainedModel
-
-RERANKER = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
-```
-
-# 3. Assembling it all!
-
-```{python}
-from transformers import Pipeline
-
-
-def answer_with_rag(
- question: str,
- llm: Pipeline,
- knowledge_index: FAISS,
- reranker: Optional[RAGPretrainedModel] = None,
- num_retrieved_docs: int = 30,
- num_docs_final: int = 5,
-) -> Tuple[str, List[LangchainDocument]]:
- # Gather documents with retriever
- print("=> Retrieving documents...")
- relevant_docs = knowledge_index.similarity_search(query=question, k=num_retrieved_docs)
- relevant_docs = [doc.page_content for doc in relevant_docs] # keep only the text
-
- # Optionally rerank results
- if reranker:
- print("=> Reranking documents...")
- relevant_docs = reranker.rerank(question, relevant_docs, k=num_docs_final)
- relevant_docs = [doc["content"] for doc in relevant_docs]
-
- relevant_docs = relevant_docs[:num_docs_final]
-
- # Build the final prompt
- context = "\nExtracted documents:\n"
- context += "".join([f"Document {str(i)}:::\n" + doc for i, doc in enumerate(relevant_docs)])
-
- final_prompt = RAG_PROMPT_TEMPLATE.format(question=question, context=context)
-
- # Redact an answer
- print("=> Generating answer...")
- answer = llm(final_prompt)[0]["generated_text"]
-
- return answer, relevant_docs
-```
-
-Let's see how our RAG pipeline answers a user query.
-
-```{python}
-question = "how to create a pipeline object?"
-
-answer, relevant_docs = answer_with_rag(
- question, READER_LLM, KNOWLEDGE_VECTOR_DATABASE, reranker=RERANKER
-)
-```
-
-```{python}
-print("==================================Answer==================================")
-print(f"{answer}")
-print("==================================Source docs==================================")
-for i, doc in enumerate(relevant_docs):
- print(f"Document {i}------------------------------------------------------------")
- print(doc)
-```
-
-✅ We now have a fully functional, performant RAG sytem. That's it for today! Congratulations for making it to the end 🥳
-
-
-# To go further 🗺️
-
-This is not the end of the journey! You can try many steps to improve your RAG system. We recommend doing so in an iterative way: bring small changes to the system and see what improves performance.
-
-### Setting up an evaluation pipeline
-
-- 💬 "You cannot improve the model performance that you do not measure", said Gandhi... or at least Llama2 told me he said it. Anyway, you should absolutely start by measuring performance: this means building a small evaluation dataset, then monitor the performance of your RAG system on this evaluation dataset.
-
-### Improving the retriever
-
-🛠️ __You can use these options to tune the results:__
-
-- Tune the chunking method:
- - Size of the chunks
- - Method: split on different separators, use [semantic chunking](https://python.langchain.com/docs/modules/data_connection/document_transformers/semantic-chunker)...
-- Change the embedding model
-
-👷♀️ __More could be considered:__
-- Try another chunking method, like semantic chunking
-- Change the index used (here, FAISS)
-- Query expansion: reformulate the user query in slightly different ways to retrieve more documents.
-
-### Improving the reader
-
-🛠️ __Here you can try the following options to improve results:__
-- Tune the prompt
-- Switch reranking on/off
-- Choose a more powerful reader model
-
-💡 __Many options could be considered here to further improve the results:__
-- Compress the retrieved context to keep only the most relevant parts to answer the query.
-- Extend the RAG system to make it more user-friendly:
- - cite source
- - make conversational
-
diff --git a/src/notebooks/automatic_embedding.ipynb b/src/notebooks/automatic_embedding.ipynb
deleted file mode 100644
index 176b26789df38b7be056a14bbbad729e02e85be2..0000000000000000000000000000000000000000
--- a/src/notebooks/automatic_embedding.ipynb
+++ /dev/null
@@ -1,825 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "id": "5d9aca72-957a-4ee2-862f-e011b9cd3a62",
- "metadata": {},
- "source": [
- "---\n",
- "title: \"Inference Endpoints\"\n",
- "---\n",
- "\n",
- "# How to use Inference Endpoints to Embed Documents\n",
- "\n",
- "_Authored by: [Derek Thomas](https://huggingface.co/derek-thomas)_\n",
- "\n",
- "## Goal\n",
- "I have a dataset I want to embed for semantic search (or QA, or RAG), I want the easiest way to do embed this and put it in a new dataset.\n",
- "\n",
- "## Approach\n",
- "I'm using a dataset from my favorite subreddit [r/bestofredditorupdates](https://www.reddit.com/r/bestofredditorupdates/). Because it has long entries, I will use the new [jinaai/jina-embeddings-v2-base-en](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) since it has an 8k context length. I will deploy this using [Inference Endpoint](https://huggingface.co/inference-endpoints) to save time and money. To follow this tutorial, you will need to **have already added a payment method**. If you haven't, you can add one here in [billing](https://huggingface.co/docs/hub/billing#billing). To make it even easier, I'll make this fully API based.\n",
- "\n",
- "To make this MUCH faster I will use the [Text Embeddings Inference](https://github.com/huggingface/text-embeddings-inference) image. This has many benefits like:\n",
- "- No model graph compilation step\n",
- "- Small docker images and fast boot times. Get ready for true serverless!\n",
- "- Token based dynamic batching\n",
- "- Optimized transformers code for inference using Flash Attention, Candle and cuBLASLt\n",
- "- Safetensors weight loading\n",
- "- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)\n",
- "\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "id": "3c830114-dd88-45a9-81b9-78b0e3da7384",
- "metadata": {},
- "source": [
- "## Requirements"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "35386f72-32cb-49fa-a108-3aa504e20429",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "!pip install -q aiohttp==3.8.3 datasets==2.14.6 pandas==1.5.3 requests==2.31.0 tqdm==4.66.1 huggingface-hub>=0.20"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "b6f72042-173d-4a72-ade1-9304b43b528d",
- "metadata": {},
- "source": [
- "## Imports"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "id": "e2beecdd-d033-4736-bd45-6754ec53b4ac",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "import asyncio\n",
- "from getpass import getpass\n",
- "import json\n",
- "from pathlib import Path\n",
- "import time\n",
- "from typing import Optional\n",
- "\n",
- "from aiohttp import ClientSession, ClientTimeout\n",
- "from datasets import load_dataset, Dataset, DatasetDict\n",
- "from huggingface_hub import notebook_login, create_inference_endpoint, list_inference_endpoints, whoami\n",
- "import numpy as np\n",
- "import pandas as pd\n",
- "import requests\n",
- "from tqdm.auto import tqdm"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "5eece903-64ce-435d-a2fd-096c0ff650bf",
- "metadata": {},
- "source": [
- "## Config\n",
- "`DATASET_IN` is where your text data is\n",
- "`DATASET_OUT` is where your embeddings will be stored\n",
- "\n",
- "Note I used 5 for the `MAX_WORKERS` since `jina-embeddings-v2` are quite memory hungry. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "id": "df2f79f0-9f28-46e6-9fc7-27e9537ff5be",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "DATASET_IN = 'derek-thomas/dataset-creator-reddit-bestofredditorupdates'\n",
- "DATASET_OUT = \"processed-subset-bestofredditorupdates\"\n",
- "ENDPOINT_NAME = \"boru-jina-embeddings-demo-ie\"\n",
- "\n",
- "MAX_WORKERS = 5 # This is for how many async workers you want. Choose based on the model and hardware \n",
- "ROW_COUNT = 100 # Choose None to use all rows, Im using 100 just for a demo"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "1e680f3d-4900-46cc-8b49-bb6ba3e27e2b",
- "metadata": {},
- "source": [
- "Hugging Face offers a number of GPUs that you can choose from a number of GPUs that you can choose in Inference Endpoints. Here they are in table form:\n",
- "\n",
- "| GPU | instanceType | instanceSize | vRAM |\n",
- "|---------------------|----------------|--------------|-------|\n",
- "| 1x Nvidia Tesla T4 | g4dn.xlarge | small | 16GB |\n",
- "| 4x Nvidia Tesla T4 | g4dn.12xlarge | large | 64GB |\n",
- "| 1x Nvidia A10G | g5.2xlarge | medium | 24GB |\n",
- "| 4x Nvidia A10G | g5.12xlarge | xxlarge | 96GB |\n",
- "| 1x Nvidia A100* | p4de | xlarge | 80GB |\n",
- "| 2x Nvidia A100* | p4de | 2xlarge | 160GB |\n",
- "\n",
- "\\*Note that for A100s you might get a note to email us to get access."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "id": "3c2106c1-2e5a-443a-9ea8-a3cd0e9c5a94",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "# GPU Choice\n",
- "VENDOR=\"aws\"\n",
- "REGION=\"us-east-1\"\n",
- "INSTANCE_SIZE=\"medium\"\n",
- "INSTANCE_TYPE=\"g5.2xlarge\""
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 5,
- "id": "0ca1140c-3fcc-4b99-9210-6da1505a27b7",
- "metadata": {
- "tags": []
- },
- "outputs": [
- {
- "data": {
- "application/vnd.jupyter.widget-view+json": {
- "model_id": "ee80821056e147fa9cabf30f64dc85a8",
- "version_major": 2,
- "version_minor": 0
- },
- "text/plain": [
- "VBox(children=(HTML(value='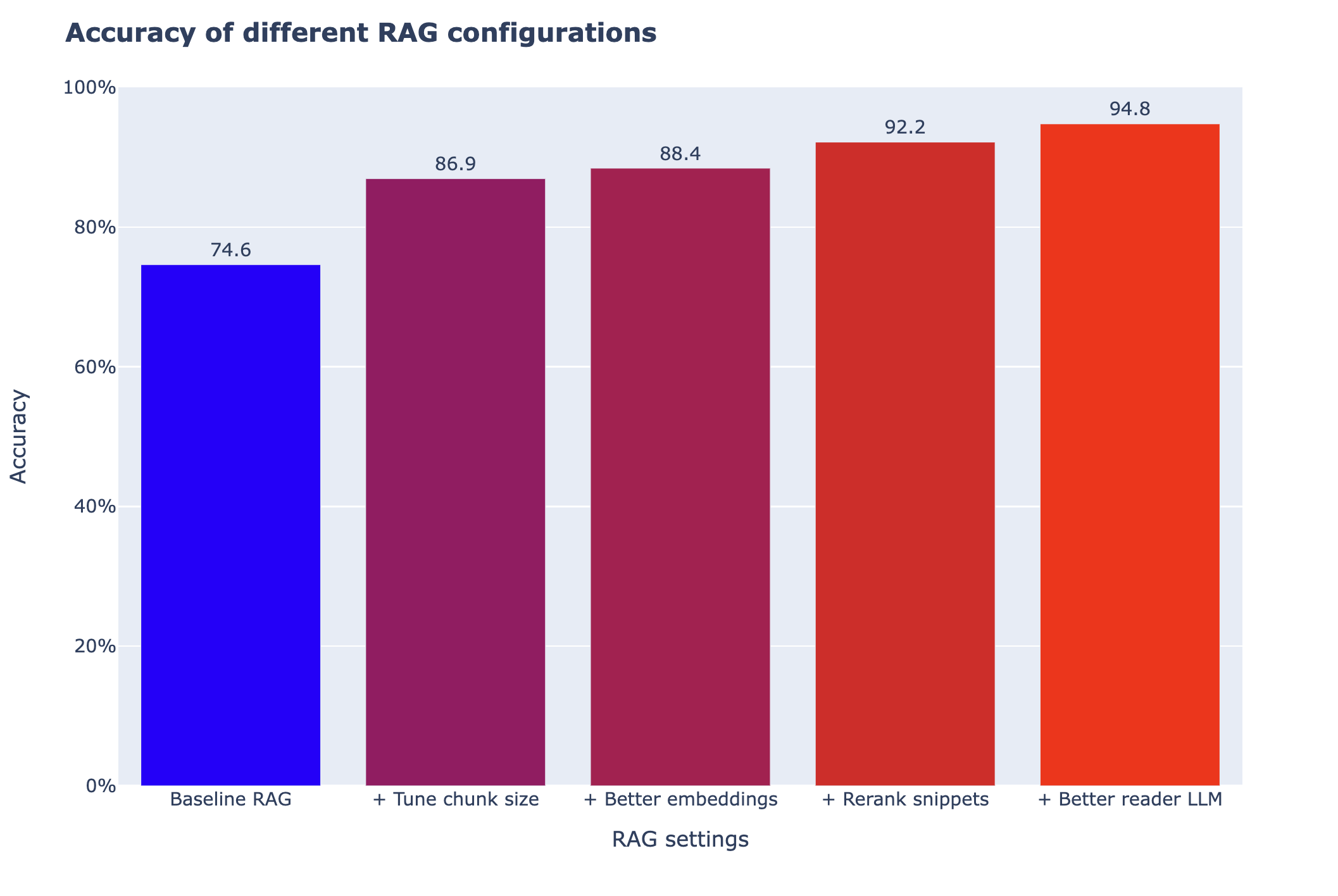 -
-As you can see, these had varying impact on performance. In particular, tuning the chunk size is both easy and very impactful.
-
-But this is our case: your results could be very different: now that you have a robust evaluation pipeline, you can set on to explore other options! 🗺️
-
diff --git a/src/notebooks/rag_zephyr_langchain.qmd b/src/notebooks/rag_zephyr_langchain.qmd
deleted file mode 100644
index 8db9bf70750043f834b3a9c18391ed1189889c27..0000000000000000000000000000000000000000
--- a/src/notebooks/rag_zephyr_langchain.qmd
+++ /dev/null
@@ -1,232 +0,0 @@
----
-title: Simple RAG
-jupyter: python3
-eval: false
-code-annotations: hover
-
----
-
-```{python}
-!pip install -q torch transformers accelerate bitsandbytes transformers sentence-transformers faiss-gpu
-```
-
-```{python}
-!pip install -q langchain
-```
-
-::: callout-note
-If running in Google Colab, you may need to run this cell to make sure you're using UTF-8 locale to install LangChain
-```{python}
-import locale
-locale.getpreferredencoding = lambda: "UTF-8"
-```
-:::
-
-
-## Prepare the data
-
-In this example, we'll load all of the issues (both open and closed) from [PEFT library's repo](https://github.com/huggingface/peft).
-
-First, you need to acquire a [GitHub personal access token](https://github.com/settings/tokens?type=beta) to access the GitHub API.
-
-```{python}
-from getpass import getpass
-
-ACCESS_TOKEN = getpass("YOUR_GITHUB_PERSONAL_TOKEN") # <1>
-```
-1. You can also use an environment variable to store your token.
-
-Next, we'll load all of the issues in the [huggingface/peft](https://github.com/huggingface/peft) repo:
-- By default, pull requests are considered issues as well, here we chose to exclude them from data with by setting `include_prs=False`
-- Setting `state = "all"` means we will load both open and closed issues.
-
-```{python}
-from langchain.document_loaders import GitHubIssuesLoader
-
-loader = GitHubIssuesLoader(
- repo="huggingface/peft",
- access_token=ACCESS_TOKEN,
- include_prs=False,
- state="all"
-)
-
-docs = loader.load()
-```
-
-The content of individual GitHub issues may be longer than what an embedding model can take as input. If we want to embed all of the available content, we need to chunk the documents into appropriately sized pieces.
-
-The most common and straightforward approach to chunking is to define a fixed size of chunks and whether there should be any overlap between them. Keeping some overlap between chunks allows us to preserve some semantic context between the chunks.
-
-Other approaches are typically more involved and take into account the documents' structure and context. For example, one may want to split a document based on sentences or paragraphs, or create chunks based on the
-
-The fixed-size chunking, however, works well for most common cases, so that is what we'll do here.
-
-```{python}
-from langchain.text_splitter import CharacterTextSplitter
-
-splitter = CharacterTextSplitter(chunk_size=512, chunk_overlap=30)
-
-chunked_docs = splitter.split_documents(docs)
-```
-
-## Create the embeddings + retriever
-
-Now that the docs are all of the appropriate size, we can create a database with their embeddings.
-
-To create document chunk embeddings we'll use the `HuggingFaceEmbeddings` and the [`BAAI/bge-base-en-v1.5`](https://huggingface.co/BAAI/bge-base-en-v1.5) embeddings model. To create the vector database, we'll use `FAISS`, a library developed by Facebook AI. This library offers efficient similarity search and clustering of dense vectors, which is what we need here. FAISS is currently one of the most used libraries for NN search in massive datasets.
-
-::: callout-tip
-There are many other embeddings models available on the Hub, and you can keep an eye on the best performing ones by checking the [Massive Text Embedding Benchmark (MTEB) Leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
-:::
-
-We'll access both the embeddings model and FAISS via LangChain API.
-
-```{python}
-from langchain.vectorstores import FAISS
-from langchain.embeddings import HuggingFaceEmbeddings
-
-db = FAISS.from_documents(chunked_docs,
- HuggingFaceEmbeddings(model_name='BAAI/bge-base-en-v1.5'))
-```
-
-We need a way to return(retrieve) the documents given an unstructured query. For that, we'll use the `as_retriever` method using the `db` as a backbone:
-- `search_type="similarity"` means we want to perform similarity search between the query and documents
-- `search_kwargs={'k': 4}` instructs the retriever to return top 4 results.
-
-```{python}
-retriever = db.as_retriever(
- search_type="similarity", # <1>
- search_kwargs={'k': 4} # <1>
-)
-```
-1. The ideal search type is context dependent, and you should experiment to find the best one for your data.
-
-The vector database and retriever are now set up, next we need to set up the next piece of the chain - the model.
-
-## Load quantized model
-
-For this example, we chose [`HuggingFaceH4/zephyr-7b-beta`](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), a small but powerful model.
-To make inference faster, we will load the quantized version of the model:
-
-:::::: {.callout-tip}
-With many models being released every week, you may want to substitute this model to the latest and greatest. The best way to keep track of open source LLMs is to check the [Open-source LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
-:::
-
-```{python}
-import torch
-from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
-
-model_name = 'HuggingFaceH4/zephyr-7b-beta'
-
-bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_use_double_quant=True,
- bnb_4bit_quant_type="nf4",
- bnb_4bit_compute_dtype=torch.bfloat16
-)
-
-model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=bnb_config)
-tokenizer = AutoTokenizer.from_pretrained(model_name)
-```
-
-## Setup the LLM chain
-
-Finally, we have all the pieces we need to set up the LLM chain.
-
-First, create a text_generation pipeline using the loaded model and its tokenizer.
-
-Next, create a prompt template - this should follow the format of the model, so if you substitute the model checkpoint, make sure to use the appropriate formatting.
-
-```{python}
-from langchain.llms import HuggingFacePipeline
-from langchain.prompts import PromptTemplate
-from transformers import pipeline
-from langchain_core.output_parsers import StrOutputParser
-
-text_generation_pipeline = pipeline(
- model=model, # <1>
- tokenizer=tokenizer, # <2>
- task="text-generation", # <3>
- temperature=0.2, # <4>
- do_sample=True, # <5>
- repetition_penalty=1.1, # <6>
- return_full_text=True, # <7>
- max_new_tokens=400, # <8>
-)
-
-llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
-
-prompt_template = """
-<|system|>
-Answer the question based on your knowledge. Use the following context to help:
-
-{context}
-
-
-<|user|>
-{question}
-
-<|assistant|>
-
- """
-
-prompt = PromptTemplate(
- input_variables=["context", "question"],
- template=prompt_template,
-)
-
-llm_chain = prompt | llm | StrOutputParser()
-```
-
-1. The pre-trained model for text generation.
-2. Tokenizer to preprocess input text and postprocess generated output.
-3. Specifies the task as text generation.
-4. Controls the randomness in the output generation. Lower values make the output more deterministic.
-5. Enables sampling to introduce randomness in the output generation.
-6. Penalizes repetition in the output to encourage diversity.
-7. Returns the full generated text including the input prompt.
-8. Limits the maximum number of new tokens generated.
-
-Note: _You can also use `tokenizer.apply_chat_template` to convert a list of messages (as dicts: `{'role': 'user', 'content': '(...)'}`) into a string with the appropriate chat format._
-
-
-Finally, we need to combine the `llm_chain` with the retriever to create a RAG chain. We pass the original question through to the final generation step, as well as the retrieved context docs:
-
-```{python}
-from langchain_core.runnables import RunnablePassthrough
-
-retriever = db.as_retriever()
-
-rag_chain = (
- {"context": retriever, "question": RunnablePassthrough()}
- | llm_chain
-)
-```
-
-## Compare the results
-
-Let's see the difference RAG makes in generating answers to the library-specific questions.
-
-```{python}
-question = "How do you combine multiple adapters?"
-```
-
-First, let's see what kind of answer we can get with just the model itself, no context added:
-
-```{python}
-#| colab: {base_uri: 'https://localhost:8080/', height: 125}
-llm_chain.invoke({"context":"", "question": question})
-```
-
-As you can see, the model interpreted the question as one about physical computer adapters, while in the context of PEFT, "adapters" refer to LoRA adapters.
-Let's see if adding context from GitHub issues helps the model give a more relevant answer:
-
-```{python}
-#| colab: {base_uri: 'https://localhost:8080/', height: 125}
-rag_chain.invoke(question)
-```
-
-As we can see, the added context, really helps the exact same model, provide a much more relevant and informed answer to the library-specific question.
-
-Notably, combining multiple adapters for inference has been added to the library, and one can find this information in the documentation, so for the next iteration of this RAG it may be worth including documentation embeddings.
-
diff --git a/src/notebooks/single_gpu.ipynb b/src/notebooks/single_gpu.ipynb
deleted file mode 100644
index f59a9ad16e3388b316c89121ab19a4126a02e35a..0000000000000000000000000000000000000000
--- a/src/notebooks/single_gpu.ipynb
+++ /dev/null
@@ -1,1129 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "FNdZ-kD0l78P"
- },
- "source": [
- "---\n",
- "title: Single GPU Fine-tuning\n",
- "---\n",
- "\n",
- "# Fine-tuning a Code LLM on Custom Code on a single GPU\n",
- "\n",
- "_Authored by: [Maria Khalusova](https://github.com/MKhalusova)_\n",
- "\n",
- "Publicly available code LLMs such as Codex, StarCoder, and Code Llama are great at generating code that adheres to general programming principles and syntax, but they may not align with an organization's internal conventions, or be aware of proprietary libraries.\n",
- "\n",
- "In this notebook, we'll see show how you can fine-tune a code LLM on private code bases to enhance its contextual awareness and improve a model's usefulness to your organization's needs. Since the code LLMs are quite large, fine-tuning them in a traditional manner can be resource-draining. Worry not! We will show how you can optimize fine-tuning to fit on a single GPU.\n",
- "\n",
- "\n",
- "## Dataset\n",
- "\n",
- "For this example, we picked the top 10 Hugging Face public repositories on GitHub. We have excluded non-code files from the data, such as images, audio files, presentations, and so on. For Jupyter notebooks, we've kept only cells containing code. The resulting code is stored as a dataset that you can find on the Hugging Face Hub under [`smangrul/hf-stack-v1`](https://huggingface.co/datasets/smangrul/hf-stack-v1). It contains repo id, file path, and file content.\n",
- "\n",
- "\n",
- "## Model\n",
- "\n",
- "We'll finetune [`bigcode/starcoderbase-1b`](https://huggingface.co/bigcode/starcoderbase-1b), which is a 1B parameter model trained on 80+ programming languages. This is a gated model, so if you plan to run this notebook with this exact model, you'll need to gain access to it on the model's page. Log in to your Hugging Face account to do so:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bPlCJYDK6vrF"
- },
- "outputs": [],
- "source": [
- "from huggingface_hub import notebook_login\n",
- "\n",
- "notebook_login()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "WMVe_c8q43Qo"
- },
- "source": [
- "To get started, let's install all the necessary libraries. As you can see, in addition to `transformers` and `datasets`, we'll be using `peft`, `bitsandbytes`, and `flash-attn` to optimize the training.\n",
- "\n",
- "By employing parameter-efficient training techniques, we can run this notebook on a single A100 High-RAM GPU."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Fp7i8WMCjKJG"
- },
- "outputs": [],
- "source": [
- "!pip install -q transformers datasets peft bitsandbytes flash-attn"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "16EdABzt3_Ig"
- },
- "source": [
- "Let's define some variables now. Feel free to play with these."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hru3G-CLmqis"
- },
- "outputs": [],
- "source": [
- "MODEL=\"bigcode/starcoderbase-1b\" # Model checkpoint on the Hugging Face Hub\n",
- "DATASET=\"smangrul/hf-stack-v1\" # Dataset on the Hugging Face Hub\n",
- "DATA_COLUMN=\"content\" # Column name containing the code content\n",
- "\n",
- "SEQ_LENGTH=2048 # Sequence length\n",
- "\n",
- "# Training arguments\n",
- "MAX_STEPS=2000 # max_steps\n",
- "BATCH_SIZE=16 # batch_size\n",
- "GR_ACC_STEPS=1 # gradient_accumulation_steps\n",
- "LR=5e-4 # learning_rate\n",
- "LR_SCHEDULER_TYPE=\"cosine\" # lr_scheduler_type\n",
- "WEIGHT_DECAY=0.01 # weight_decay\n",
- "NUM_WARMUP_STEPS=30 # num_warmup_steps\n",
- "EVAL_FREQ=100 # eval_freq\n",
- "SAVE_FREQ=100 # save_freq\n",
- "LOG_FREQ=25 # log_freq\n",
- "OUTPUT_DIR=\"peft-starcoder-lora-a100\" # output_dir\n",
- "BF16=True # bf16\n",
- "FP16=False # no_fp16\n",
- "\n",
- "# FIM trasformations arguments\n",
- "FIM_RATE=0.5 # fim_rate\n",
- "FIM_SPM_RATE=0.5 # fim_spm_rate\n",
- "\n",
- "# LORA\n",
- "LORA_R=8 # lora_r\n",
- "LORA_ALPHA=32 # lora_alpha\n",
- "LORA_DROPOUT=0.0 # lora_dropout\n",
- "LORA_TARGET_MODULES=\"c_proj,c_attn,q_attn,c_fc,c_proj\" # lora_target_modules\n",
- "\n",
- "# bitsandbytes config\n",
- "USE_NESTED_QUANT=True # use_nested_quant\n",
- "BNB_4BIT_COMPUTE_DTYPE=\"bfloat16\"# bnb_4bit_compute_dtype\n",
- "\n",
- "SEED=0"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FyZSXTbJrcnC"
- },
- "outputs": [],
- "source": [
- "from transformers import (\n",
- " AutoModelForCausalLM,\n",
- " AutoTokenizer,\n",
- " Trainer,\n",
- " TrainingArguments,\n",
- " logging,\n",
- " set_seed,\n",
- " BitsAndBytesConfig,\n",
- ")\n",
- "\n",
- "set_seed(SEED)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pO7F5L5AtKo1"
- },
- "source": [
- "## Prepare the data"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "1LmrIZqP0oUE"
- },
- "source": [
- "Begin by loading the data. As the dataset is likely to be quite large, make sure to enable the streaming mode. Streaming allows us to load the data progressively as we iterate over the dataset instead of downloading the whole dataset at once.\n",
- "\n",
- "We'll reserve the first 4000 examples as the validation set, and everything else will be the training data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4oJZvZb-1J88"
- },
- "outputs": [],
- "source": [
- "from datasets import load_dataset\n",
- "import torch\n",
- "from tqdm import tqdm\n",
- "\n",
- "\n",
- "dataset = load_dataset(\n",
- " DATASET,\n",
- " data_dir=\"data\",\n",
- " split=\"train\",\n",
- " streaming=True,\n",
- ")\n",
- "\n",
- "valid_data = dataset.take(4000)\n",
- "train_data = dataset.skip(4000)\n",
- "train_data = train_data.shuffle(buffer_size=5000, seed=SEED)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sLQ8t0LM2GR6"
- },
- "source": [
- "At this step, the dataset still contains raw data with code of arbitraty length. For training, we need inputs of fixed length. Let's create an Iterable dataset that would return constant-length chunks of tokens from a stream of text files.\n",
- "\n",
- "First, let's estimate the average number of characters per token in the dataset, which will help us later estimate the number of tokens in the text buffer later. By default, we'll only take 400 examples (`nb_examples`) from the dataset. Using only a subset of the entire dataset will reduce computational cost while still providing a reasonable estimate of the overall character-to-token ratio."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "KCiAvydztNsu",
- "outputId": "cabf7fd0-a922-4371-cbc6-60ee99ef7469"
- },
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "100%|██████████| 400/400 [00:10<00:00, 39.87it/s] "
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "The character to token ratio of the dataset is: 2.43\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- }
- ],
- "source": [
- "tokenizer = AutoTokenizer.from_pretrained(MODEL, trust_remote_code=True)\n",
- "\n",
- "def chars_token_ratio(dataset, tokenizer, data_column, nb_examples=400):\n",
- " \"\"\"\n",
- " Estimate the average number of characters per token in the dataset.\n",
- " \"\"\"\n",
- "\n",
- " total_characters, total_tokens = 0, 0\n",
- " for _, example in tqdm(zip(range(nb_examples), iter(dataset)), total=nb_examples):\n",
- " total_characters += len(example[data_column])\n",
- " total_tokens += len(tokenizer(example[data_column]).tokens())\n",
- "\n",
- " return total_characters / total_tokens\n",
- "\n",
- "\n",
- "chars_per_token = chars_token_ratio(train_data, tokenizer, DATA_COLUMN)\n",
- "print(f\"The character to token ratio of the dataset is: {chars_per_token:.2f}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6F13VGobB3Ma"
- },
- "source": [
- "The character-to-token ratio can also be used as an indicator of the quality of text tokenization. For instance, a character-to-token ratio of 1.0 would mean that each character is represented with a token, which is not very meaningful. This would indicate poor tokenization. In standard English text, one token is typically equivalent to approximately four characters, meaning the character-to-token ratio is around 4.0. We can expect a lower ratio in the code dataset, but generally speaking, a number between 2.0 and 3.5 can be considered good enough."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rcwYFRPpwxea"
- },
- "source": [
- "**Optional FIM transformations**\n",
- "\n",
- "\n",
- "Autoregressive language models typically generate sequences from left to right. By applying the FIM transformations, the model can also learn to infill text. Check out [\"Efficient Training of Language Models to Fill in the Middle\" paper](https://arxiv.org/pdf/2207.14255.pdf) to learn more about the technique.\n",
- "We'll define the FIM transformations here and will use them when creating the Iterable Dataset. However, if you want to omit transformations, feel free to set `fim_rate` to 0."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zmejYvEKw1E-"
- },
- "outputs": [],
- "source": [
- "import functools\n",
- "import numpy as np\n",
- "\n",
- "\n",
- "# Helper function to get token ids of the special tokens for prefix, suffix and middle for FIM transformations.\n",
- "@functools.lru_cache(maxsize=None)\n",
- "def get_fim_token_ids(tokenizer):\n",
- " try:\n",
- " FIM_PREFIX, FIM_MIDDLE, FIM_SUFFIX, FIM_PAD = tokenizer.special_tokens_map[\"additional_special_tokens\"][1:5]\n",
- " suffix_tok_id, prefix_tok_id, middle_tok_id, pad_tok_id = (\n",
- " tokenizer.vocab[tok] for tok in [FIM_SUFFIX, FIM_PREFIX, FIM_MIDDLE, FIM_PAD]\n",
- " )\n",
- " except KeyError:\n",
- " suffix_tok_id, prefix_tok_id, middle_tok_id, pad_tok_id = None, None, None, None\n",
- " return suffix_tok_id, prefix_tok_id, middle_tok_id, pad_tok_id\n",
- "\n",
- "\n",
- "## Adapted from https://github.com/bigcode-project/Megatron-LM/blob/6c4bf908df8fd86b4977f54bf5b8bd4b521003d1/megatron/data/gpt_dataset.py\n",
- "def permute(\n",
- " sample,\n",
- " np_rng,\n",
- " suffix_tok_id,\n",
- " prefix_tok_id,\n",
- " middle_tok_id,\n",
- " pad_tok_id,\n",
- " fim_rate=0.5,\n",
- " fim_spm_rate=0.5,\n",
- " truncate_or_pad=False,\n",
- "):\n",
- " \"\"\"\n",
- " Take in a sample (list of tokens) and perform a FIM transformation on it with a probability of fim_rate, using two FIM modes:\n",
- " PSM and SPM (with a probability of fim_spm_rate).\n",
- " \"\"\"\n",
- "\n",
- " # The if condition will trigger with the probability of fim_rate\n",
- " # This means FIM transformations will apply to samples with a probability of fim_rate\n",
- " if np_rng.binomial(1, fim_rate):\n",
- "\n",
- " # Split the sample into prefix, middle, and suffix, based on randomly generated indices stored in the boundaries list.\n",
- " boundaries = list(np_rng.randint(low=0, high=len(sample) + 1, size=2))\n",
- " boundaries.sort()\n",
- "\n",
- " prefix = np.array(sample[: boundaries[0]], dtype=np.int64)\n",
- " middle = np.array(sample[boundaries[0] : boundaries[1]], dtype=np.int64)\n",
- " suffix = np.array(sample[boundaries[1] :], dtype=np.int64)\n",
- "\n",
- " if truncate_or_pad:\n",
- " # calculate the new total length of the sample, taking into account tokens indicating prefix, middle, and suffix\n",
- " new_length = suffix.shape[0] + prefix.shape[0] + middle.shape[0] + 3\n",
- " diff = new_length - len(sample)\n",
- "\n",
- " # trancate or pad if there's a difference in length between the new length and the original\n",
- " if diff > 0:\n",
- " if suffix.shape[0] <= diff:\n",
- " return sample, np_rng\n",
- " suffix = suffix[: suffix.shape[0] - diff]\n",
- " elif diff < 0:\n",
- " suffix = np.concatenate([suffix, np.full((-1 * diff), pad_tok_id)])\n",
- "\n",
- " # With the probability of fim_spm_rateapply SPM variant of FIM transformations\n",
- " # SPM: suffix, prefix, middle\n",
- " if np_rng.binomial(1, fim_spm_rate):\n",
- " new_sample = np.concatenate(\n",
- " [\n",
- " [prefix_tok_id, suffix_tok_id],\n",
- " suffix,\n",
- " [middle_tok_id],\n",
- " prefix,\n",
- " middle,\n",
- " ]\n",
- " )\n",
- " # Otherwise, apply the PSM variant of FIM transformations\n",
- " # PSM: prefix, suffix, middle\n",
- " else:\n",
- "\n",
- " new_sample = np.concatenate(\n",
- " [\n",
- " [prefix_tok_id],\n",
- " prefix,\n",
- " [suffix_tok_id],\n",
- " suffix,\n",
- " [middle_tok_id],\n",
- " middle,\n",
- " ]\n",
- " )\n",
- " else:\n",
- " # don't apply FIM transformations\n",
- " new_sample = sample\n",
- "\n",
- " return list(new_sample), np_rng\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AwW5FviD9xBH"
- },
- "source": [
- "Let's define the `ConstantLengthDataset`, an Iterable dataset that will return constant-length chunks of tokens. To do so, we'll read a buffer of text from the original dataset until we hit the size limits and then apply tokenizer to convert the raw text into tokenized inputs. Optionally, we'll perform FIM transformations on some sequences (the proportion of sequences affected is controlled by `fim_rate`).\n",
- "\n",
- "Once defined, we can create instances of the `ConstantLengthDataset` from both training and validation data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "AgDW-692wzOl"
- },
- "outputs": [],
- "source": [
- "from torch.utils.data import IterableDataset\n",
- "from torch.utils.data.dataloader import DataLoader\n",
- "import random\n",
- "\n",
- "# Create an Iterable dataset that returns constant-length chunks of tokens from a stream of text files.\n",
- "\n",
- "class ConstantLengthDataset(IterableDataset):\n",
- " \"\"\"\n",
- " Iterable dataset that returns constant length chunks of tokens from stream of text files.\n",
- " Args:\n",
- " tokenizer (Tokenizer): The processor used for proccessing the data.\n",
- " dataset (dataset.Dataset): Dataset with text files.\n",
- " infinite (bool): If True the iterator is reset after dataset reaches end else stops.\n",
- " seq_length (int): Length of token sequences to return.\n",
- " num_of_sequences (int): Number of token sequences to keep in buffer.\n",
- " chars_per_token (int): Number of characters per token used to estimate number of tokens in text buffer.\n",
- " fim_rate (float): Rate (0.0 to 1.0) that sample will be permuted with FIM.\n",
- " fim_spm_rate (float): Rate (0.0 to 1.0) of FIM permuations that will use SPM.\n",
- " seed (int): Seed for random number generator.\n",
- " \"\"\"\n",
- "\n",
- " def __init__(\n",
- " self,\n",
- " tokenizer,\n",
- " dataset,\n",
- " infinite=False,\n",
- " seq_length=1024,\n",
- " num_of_sequences=1024,\n",
- " chars_per_token=3.6,\n",
- " content_field=\"content\",\n",
- " fim_rate=0.5,\n",
- " fim_spm_rate=0.5,\n",
- " seed=0,\n",
- " ):\n",
- " self.tokenizer = tokenizer\n",
- " self.concat_token_id = tokenizer.eos_token_id\n",
- " self.dataset = dataset\n",
- " self.seq_length = seq_length\n",
- " self.infinite = infinite\n",
- " self.current_size = 0\n",
- " self.max_buffer_size = seq_length * chars_per_token * num_of_sequences\n",
- " self.content_field = content_field\n",
- " self.fim_rate = fim_rate\n",
- " self.fim_spm_rate = fim_spm_rate\n",
- " self.seed = seed\n",
- "\n",
- " (\n",
- " self.suffix_tok_id,\n",
- " self.prefix_tok_id,\n",
- " self.middle_tok_id,\n",
- " self.pad_tok_id,\n",
- " ) = get_fim_token_ids(self.tokenizer)\n",
- " if not self.suffix_tok_id and self.fim_rate > 0:\n",
- " print(\"FIM is not supported by tokenizer, disabling FIM\")\n",
- " self.fim_rate = 0\n",
- "\n",
- " def __iter__(self):\n",
- " iterator = iter(self.dataset)\n",
- " more_examples = True\n",
- " np_rng = np.random.RandomState(seed=self.seed)\n",
- " while more_examples:\n",
- " buffer, buffer_len = [], 0\n",
- " while True:\n",
- " if buffer_len >= self.max_buffer_size:\n",
- " break\n",
- " try:\n",
- " buffer.append(next(iterator)[self.content_field])\n",
- " buffer_len += len(buffer[-1])\n",
- " except StopIteration:\n",
- " if self.infinite:\n",
- " iterator = iter(self.dataset)\n",
- " else:\n",
- " more_examples = False\n",
- " break\n",
- " tokenized_inputs = self.tokenizer(buffer, truncation=False)[\"input_ids\"]\n",
- " all_token_ids = []\n",
- "\n",
- " for tokenized_input in tokenized_inputs:\n",
- " # optionally do FIM permutations\n",
- " if self.fim_rate > 0:\n",
- " tokenized_input, np_rng = permute(\n",
- " tokenized_input,\n",
- " np_rng,\n",
- " self.suffix_tok_id,\n",
- " self.prefix_tok_id,\n",
- " self.middle_tok_id,\n",
- " self.pad_tok_id,\n",
- " fim_rate=self.fim_rate,\n",
- " fim_spm_rate=self.fim_spm_rate,\n",
- " truncate_or_pad=False,\n",
- " )\n",
- "\n",
- " all_token_ids.extend(tokenized_input + [self.concat_token_id])\n",
- " examples = []\n",
- " for i in range(0, len(all_token_ids), self.seq_length):\n",
- " input_ids = all_token_ids[i : i + self.seq_length]\n",
- " if len(input_ids) == self.seq_length:\n",
- " examples.append(input_ids)\n",
- " random.shuffle(examples)\n",
- " for example in examples:\n",
- " self.current_size += 1\n",
- " yield {\n",
- " \"input_ids\": torch.LongTensor(example),\n",
- " \"labels\": torch.LongTensor(example),\n",
- " }\n",
- "\n",
- "\n",
- "train_dataset = ConstantLengthDataset(\n",
- " tokenizer,\n",
- " train_data,\n",
- " infinite=True,\n",
- " seq_length=SEQ_LENGTH,\n",
- " chars_per_token=chars_per_token,\n",
- " content_field=DATA_COLUMN,\n",
- " fim_rate=FIM_RATE,\n",
- " fim_spm_rate=FIM_SPM_RATE,\n",
- " seed=SEED,\n",
- ")\n",
- "eval_dataset = ConstantLengthDataset(\n",
- " tokenizer,\n",
- " valid_data,\n",
- " infinite=False,\n",
- " seq_length=SEQ_LENGTH,\n",
- " chars_per_token=chars_per_token,\n",
- " content_field=DATA_COLUMN,\n",
- " fim_rate=FIM_RATE,\n",
- " fim_spm_rate=FIM_SPM_RATE,\n",
- " seed=SEED,\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rxev1sk6tRW9"
- },
- "source": [
- "## Prepare the model"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "UCtWV-U42Eq_"
- },
- "source": [
- "Now that the data is prepared, it's time to load the model! We're going to load the quantized version of the model.\n",
- "\n",
- "This will allow us to reduce memory usage, as quantization represents data with fewer bits. We'll use the `bitsandbytes` library to quantize the model, as it has a nice integration with `transformers`. All we need to do is define a `bitsandbytes` config, and then use it when loading the model.\n",
- "\n",
- "There are different variants of 4bit quantization, but generally, we recommend using NF4 quantization for better performance (`bnb_4bit_quant_type=\"nf4\"`).\n",
- "\n",
- "The `bnb_4bit_use_double_quant` option adds a second quantization after the first one to save an additional 0.4 bits per parameter.\n",
- "\n",
- "To learn more about quantization, check out the [\"Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA\" blog post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).\n",
- "\n",
- "Once defined, pass the config to the `from_pretrained` method to load the quantized version of the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "XuwoX6U2DUvK"
- },
- "outputs": [],
- "source": [
- "from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training\n",
- "from peft.tuners.lora import LoraLayer\n",
- "\n",
- "load_in_8bit = False\n",
- "\n",
- "# 4-bit quantization\n",
- "compute_dtype = getattr(torch, BNB_4BIT_COMPUTE_DTYPE)\n",
- "\n",
- "bnb_config = BitsAndBytesConfig(\n",
- " load_in_4bit=True,\n",
- " bnb_4bit_quant_type=\"nf4\",\n",
- " bnb_4bit_compute_dtype=compute_dtype,\n",
- " bnb_4bit_use_double_quant=USE_NESTED_QUANT,\n",
- ")\n",
- "\n",
- "device_map = {\"\": 0}\n",
- "\n",
- "model = AutoModelForCausalLM.from_pretrained(\n",
- " MODEL,\n",
- " load_in_8bit=load_in_8bit,\n",
- " quantization_config=bnb_config,\n",
- " device_map=device_map,\n",
- " use_cache=False, # We will be using gradient checkpointing\n",
- " trust_remote_code=True,\n",
- " use_flash_attention_2=True,\n",
- ")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "bO9e2FV8D8ZF"
- },
- "source": [
- "When using a quantized model for training, you need to call the `prepare_model_for_kbit_training()` function to preprocess the quantized model for training."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Qb_eB4xzEDBk"
- },
- "outputs": [],
- "source": [
- "model = prepare_model_for_kbit_training(model)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "lmnLjPZpDVtg"
- },
- "source": [
- "Now that the quantized model is ready, we can set up a LoRA configuration. LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.\n",
- "\n",
- "To train a model using LoRA technique, we need to wrap the base model as a `PeftModel`. This involves definign LoRA configuration with `LoraConfig`, and wrapping the original model with `get_peft_model()` using the `LoraConfig`.\n",
- "\n",
- "To learn more about LoRA and its parameters, refer to [PEFT documentation](https://huggingface.co/docs/peft/conceptual_guides/lora)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "_pAUU2FR2Gey",
- "outputId": "63328c2b-e693-49b1-ce0a-3ca8722f852a"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "trainable params: 5,554,176 || all params: 1,142,761,472 || trainable%: 0.4860310866343243\n"
- ]
- }
- ],
- "source": [
- "# Set up lora\n",
- "peft_config = LoraConfig(\n",
- " lora_alpha=LORA_ALPHA,\n",
- " lora_dropout=LORA_DROPOUT,\n",
- " r=LORA_R,\n",
- " bias=\"none\",\n",
- " task_type=\"CAUSAL_LM\",\n",
- " target_modules=LORA_TARGET_MODULES.split(\",\"),\n",
- ")\n",
- "\n",
- "model = get_peft_model(model, peft_config)\n",
- "model.print_trainable_parameters()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tHe7AElXzXVV"
- },
- "source": [
- "As you can see, by applying LoRA technique we will now need to train less than 1% of the parameters."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "T_CqVydc40IM"
- },
- "source": [
- "## Train the model"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Q_iN2khjrbD3"
- },
- "source": [
- "Now that we have prepared the data, and optimized the model, we are ready to bring everything together to start the training.\n",
- "\n",
- "To instantiate a `Trainer`, you need to define the training configuration. The most important is the `TrainingArguments`, which is a class that contains all the attributes to configure the training.\n",
- "\n",
- "These are similar to any other kind of model training you may run, so we won't go into detail here."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "65QHS8l1tKQe"
- },
- "outputs": [],
- "source": [
- "train_data.start_iteration = 0\n",
- "\n",
- "\n",
- "training_args = TrainingArguments(\n",
- " output_dir=f\"Your_HF_username/{OUTPUT_DIR}\",\n",
- " dataloader_drop_last=True,\n",
- " evaluation_strategy=\"steps\",\n",
- " save_strategy=\"steps\",\n",
- " max_steps=MAX_STEPS,\n",
- " eval_steps=EVAL_FREQ,\n",
- " save_steps=SAVE_FREQ,\n",
- " logging_steps=LOG_FREQ,\n",
- " per_device_train_batch_size=BATCH_SIZE,\n",
- " per_device_eval_batch_size=BATCH_SIZE,\n",
- " learning_rate=LR,\n",
- " lr_scheduler_type=LR_SCHEDULER_TYPE,\n",
- " warmup_steps=NUM_WARMUP_STEPS,\n",
- " gradient_accumulation_steps=GR_ACC_STEPS,\n",
- " gradient_checkpointing=True,\n",
- " fp16=FP16,\n",
- " bf16=BF16,\n",
- " weight_decay=WEIGHT_DECAY,\n",
- " push_to_hub=True,\n",
- " include_tokens_per_second=True,\n",
- ")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kB_fLRex09ut"
- },
- "source": [
- "As a final step, instantiate the `Trainer` and call the `train` method. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000
- },
- "id": "rS3nVwhUC69O",
- "outputId": "61a5bdb2-b7d0-4aed-8290-4bf20c2ccd38"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Training...\n"
- ]
- },
- {
- "data": {
- "text/html": [
- "\n",
- "
-
-As you can see, these had varying impact on performance. In particular, tuning the chunk size is both easy and very impactful.
-
-But this is our case: your results could be very different: now that you have a robust evaluation pipeline, you can set on to explore other options! 🗺️
-
diff --git a/src/notebooks/rag_zephyr_langchain.qmd b/src/notebooks/rag_zephyr_langchain.qmd
deleted file mode 100644
index 8db9bf70750043f834b3a9c18391ed1189889c27..0000000000000000000000000000000000000000
--- a/src/notebooks/rag_zephyr_langchain.qmd
+++ /dev/null
@@ -1,232 +0,0 @@
----
-title: Simple RAG
-jupyter: python3
-eval: false
-code-annotations: hover
-
----
-
-```{python}
-!pip install -q torch transformers accelerate bitsandbytes transformers sentence-transformers faiss-gpu
-```
-
-```{python}
-!pip install -q langchain
-```
-
-::: callout-note
-If running in Google Colab, you may need to run this cell to make sure you're using UTF-8 locale to install LangChain
-```{python}
-import locale
-locale.getpreferredencoding = lambda: "UTF-8"
-```
-:::
-
-
-## Prepare the data
-
-In this example, we'll load all of the issues (both open and closed) from [PEFT library's repo](https://github.com/huggingface/peft).
-
-First, you need to acquire a [GitHub personal access token](https://github.com/settings/tokens?type=beta) to access the GitHub API.
-
-```{python}
-from getpass import getpass
-
-ACCESS_TOKEN = getpass("YOUR_GITHUB_PERSONAL_TOKEN") # <1>
-```
-1. You can also use an environment variable to store your token.
-
-Next, we'll load all of the issues in the [huggingface/peft](https://github.com/huggingface/peft) repo:
-- By default, pull requests are considered issues as well, here we chose to exclude them from data with by setting `include_prs=False`
-- Setting `state = "all"` means we will load both open and closed issues.
-
-```{python}
-from langchain.document_loaders import GitHubIssuesLoader
-
-loader = GitHubIssuesLoader(
- repo="huggingface/peft",
- access_token=ACCESS_TOKEN,
- include_prs=False,
- state="all"
-)
-
-docs = loader.load()
-```
-
-The content of individual GitHub issues may be longer than what an embedding model can take as input. If we want to embed all of the available content, we need to chunk the documents into appropriately sized pieces.
-
-The most common and straightforward approach to chunking is to define a fixed size of chunks and whether there should be any overlap between them. Keeping some overlap between chunks allows us to preserve some semantic context between the chunks.
-
-Other approaches are typically more involved and take into account the documents' structure and context. For example, one may want to split a document based on sentences or paragraphs, or create chunks based on the
-
-The fixed-size chunking, however, works well for most common cases, so that is what we'll do here.
-
-```{python}
-from langchain.text_splitter import CharacterTextSplitter
-
-splitter = CharacterTextSplitter(chunk_size=512, chunk_overlap=30)
-
-chunked_docs = splitter.split_documents(docs)
-```
-
-## Create the embeddings + retriever
-
-Now that the docs are all of the appropriate size, we can create a database with their embeddings.
-
-To create document chunk embeddings we'll use the `HuggingFaceEmbeddings` and the [`BAAI/bge-base-en-v1.5`](https://huggingface.co/BAAI/bge-base-en-v1.5) embeddings model. To create the vector database, we'll use `FAISS`, a library developed by Facebook AI. This library offers efficient similarity search and clustering of dense vectors, which is what we need here. FAISS is currently one of the most used libraries for NN search in massive datasets.
-
-::: callout-tip
-There are many other embeddings models available on the Hub, and you can keep an eye on the best performing ones by checking the [Massive Text Embedding Benchmark (MTEB) Leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
-:::
-
-We'll access both the embeddings model and FAISS via LangChain API.
-
-```{python}
-from langchain.vectorstores import FAISS
-from langchain.embeddings import HuggingFaceEmbeddings
-
-db = FAISS.from_documents(chunked_docs,
- HuggingFaceEmbeddings(model_name='BAAI/bge-base-en-v1.5'))
-```
-
-We need a way to return(retrieve) the documents given an unstructured query. For that, we'll use the `as_retriever` method using the `db` as a backbone:
-- `search_type="similarity"` means we want to perform similarity search between the query and documents
-- `search_kwargs={'k': 4}` instructs the retriever to return top 4 results.
-
-```{python}
-retriever = db.as_retriever(
- search_type="similarity", # <1>
- search_kwargs={'k': 4} # <1>
-)
-```
-1. The ideal search type is context dependent, and you should experiment to find the best one for your data.
-
-The vector database and retriever are now set up, next we need to set up the next piece of the chain - the model.
-
-## Load quantized model
-
-For this example, we chose [`HuggingFaceH4/zephyr-7b-beta`](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), a small but powerful model.
-To make inference faster, we will load the quantized version of the model:
-
-:::::: {.callout-tip}
-With many models being released every week, you may want to substitute this model to the latest and greatest. The best way to keep track of open source LLMs is to check the [Open-source LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
-:::
-
-```{python}
-import torch
-from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
-
-model_name = 'HuggingFaceH4/zephyr-7b-beta'
-
-bnb_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_use_double_quant=True,
- bnb_4bit_quant_type="nf4",
- bnb_4bit_compute_dtype=torch.bfloat16
-)
-
-model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=bnb_config)
-tokenizer = AutoTokenizer.from_pretrained(model_name)
-```
-
-## Setup the LLM chain
-
-Finally, we have all the pieces we need to set up the LLM chain.
-
-First, create a text_generation pipeline using the loaded model and its tokenizer.
-
-Next, create a prompt template - this should follow the format of the model, so if you substitute the model checkpoint, make sure to use the appropriate formatting.
-
-```{python}
-from langchain.llms import HuggingFacePipeline
-from langchain.prompts import PromptTemplate
-from transformers import pipeline
-from langchain_core.output_parsers import StrOutputParser
-
-text_generation_pipeline = pipeline(
- model=model, # <1>
- tokenizer=tokenizer, # <2>
- task="text-generation", # <3>
- temperature=0.2, # <4>
- do_sample=True, # <5>
- repetition_penalty=1.1, # <6>
- return_full_text=True, # <7>
- max_new_tokens=400, # <8>
-)
-
-llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
-
-prompt_template = """
-<|system|>
-Answer the question based on your knowledge. Use the following context to help:
-
-{context}
-
-
-<|user|>
-{question}
-
-<|assistant|>
-
- """
-
-prompt = PromptTemplate(
- input_variables=["context", "question"],
- template=prompt_template,
-)
-
-llm_chain = prompt | llm | StrOutputParser()
-```
-
-1. The pre-trained model for text generation.
-2. Tokenizer to preprocess input text and postprocess generated output.
-3. Specifies the task as text generation.
-4. Controls the randomness in the output generation. Lower values make the output more deterministic.
-5. Enables sampling to introduce randomness in the output generation.
-6. Penalizes repetition in the output to encourage diversity.
-7. Returns the full generated text including the input prompt.
-8. Limits the maximum number of new tokens generated.
-
-Note: _You can also use `tokenizer.apply_chat_template` to convert a list of messages (as dicts: `{'role': 'user', 'content': '(...)'}`) into a string with the appropriate chat format._
-
-
-Finally, we need to combine the `llm_chain` with the retriever to create a RAG chain. We pass the original question through to the final generation step, as well as the retrieved context docs:
-
-```{python}
-from langchain_core.runnables import RunnablePassthrough
-
-retriever = db.as_retriever()
-
-rag_chain = (
- {"context": retriever, "question": RunnablePassthrough()}
- | llm_chain
-)
-```
-
-## Compare the results
-
-Let's see the difference RAG makes in generating answers to the library-specific questions.
-
-```{python}
-question = "How do you combine multiple adapters?"
-```
-
-First, let's see what kind of answer we can get with just the model itself, no context added:
-
-```{python}
-#| colab: {base_uri: 'https://localhost:8080/', height: 125}
-llm_chain.invoke({"context":"", "question": question})
-```
-
-As you can see, the model interpreted the question as one about physical computer adapters, while in the context of PEFT, "adapters" refer to LoRA adapters.
-Let's see if adding context from GitHub issues helps the model give a more relevant answer:
-
-```{python}
-#| colab: {base_uri: 'https://localhost:8080/', height: 125}
-rag_chain.invoke(question)
-```
-
-As we can see, the added context, really helps the exact same model, provide a much more relevant and informed answer to the library-specific question.
-
-Notably, combining multiple adapters for inference has been added to the library, and one can find this information in the documentation, so for the next iteration of this RAG it may be worth including documentation embeddings.
-
diff --git a/src/notebooks/single_gpu.ipynb b/src/notebooks/single_gpu.ipynb
deleted file mode 100644
index f59a9ad16e3388b316c89121ab19a4126a02e35a..0000000000000000000000000000000000000000
--- a/src/notebooks/single_gpu.ipynb
+++ /dev/null
@@ -1,1129 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "FNdZ-kD0l78P"
- },
- "source": [
- "---\n",
- "title: Single GPU Fine-tuning\n",
- "---\n",
- "\n",
- "# Fine-tuning a Code LLM on Custom Code on a single GPU\n",
- "\n",
- "_Authored by: [Maria Khalusova](https://github.com/MKhalusova)_\n",
- "\n",
- "Publicly available code LLMs such as Codex, StarCoder, and Code Llama are great at generating code that adheres to general programming principles and syntax, but they may not align with an organization's internal conventions, or be aware of proprietary libraries.\n",
- "\n",
- "In this notebook, we'll see show how you can fine-tune a code LLM on private code bases to enhance its contextual awareness and improve a model's usefulness to your organization's needs. Since the code LLMs are quite large, fine-tuning them in a traditional manner can be resource-draining. Worry not! We will show how you can optimize fine-tuning to fit on a single GPU.\n",
- "\n",
- "\n",
- "## Dataset\n",
- "\n",
- "For this example, we picked the top 10 Hugging Face public repositories on GitHub. We have excluded non-code files from the data, such as images, audio files, presentations, and so on. For Jupyter notebooks, we've kept only cells containing code. The resulting code is stored as a dataset that you can find on the Hugging Face Hub under [`smangrul/hf-stack-v1`](https://huggingface.co/datasets/smangrul/hf-stack-v1). It contains repo id, file path, and file content.\n",
- "\n",
- "\n",
- "## Model\n",
- "\n",
- "We'll finetune [`bigcode/starcoderbase-1b`](https://huggingface.co/bigcode/starcoderbase-1b), which is a 1B parameter model trained on 80+ programming languages. This is a gated model, so if you plan to run this notebook with this exact model, you'll need to gain access to it on the model's page. Log in to your Hugging Face account to do so:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "bPlCJYDK6vrF"
- },
- "outputs": [],
- "source": [
- "from huggingface_hub import notebook_login\n",
- "\n",
- "notebook_login()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "WMVe_c8q43Qo"
- },
- "source": [
- "To get started, let's install all the necessary libraries. As you can see, in addition to `transformers` and `datasets`, we'll be using `peft`, `bitsandbytes`, and `flash-attn` to optimize the training.\n",
- "\n",
- "By employing parameter-efficient training techniques, we can run this notebook on a single A100 High-RAM GPU."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Fp7i8WMCjKJG"
- },
- "outputs": [],
- "source": [
- "!pip install -q transformers datasets peft bitsandbytes flash-attn"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "16EdABzt3_Ig"
- },
- "source": [
- "Let's define some variables now. Feel free to play with these."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "hru3G-CLmqis"
- },
- "outputs": [],
- "source": [
- "MODEL=\"bigcode/starcoderbase-1b\" # Model checkpoint on the Hugging Face Hub\n",
- "DATASET=\"smangrul/hf-stack-v1\" # Dataset on the Hugging Face Hub\n",
- "DATA_COLUMN=\"content\" # Column name containing the code content\n",
- "\n",
- "SEQ_LENGTH=2048 # Sequence length\n",
- "\n",
- "# Training arguments\n",
- "MAX_STEPS=2000 # max_steps\n",
- "BATCH_SIZE=16 # batch_size\n",
- "GR_ACC_STEPS=1 # gradient_accumulation_steps\n",
- "LR=5e-4 # learning_rate\n",
- "LR_SCHEDULER_TYPE=\"cosine\" # lr_scheduler_type\n",
- "WEIGHT_DECAY=0.01 # weight_decay\n",
- "NUM_WARMUP_STEPS=30 # num_warmup_steps\n",
- "EVAL_FREQ=100 # eval_freq\n",
- "SAVE_FREQ=100 # save_freq\n",
- "LOG_FREQ=25 # log_freq\n",
- "OUTPUT_DIR=\"peft-starcoder-lora-a100\" # output_dir\n",
- "BF16=True # bf16\n",
- "FP16=False # no_fp16\n",
- "\n",
- "# FIM trasformations arguments\n",
- "FIM_RATE=0.5 # fim_rate\n",
- "FIM_SPM_RATE=0.5 # fim_spm_rate\n",
- "\n",
- "# LORA\n",
- "LORA_R=8 # lora_r\n",
- "LORA_ALPHA=32 # lora_alpha\n",
- "LORA_DROPOUT=0.0 # lora_dropout\n",
- "LORA_TARGET_MODULES=\"c_proj,c_attn,q_attn,c_fc,c_proj\" # lora_target_modules\n",
- "\n",
- "# bitsandbytes config\n",
- "USE_NESTED_QUANT=True # use_nested_quant\n",
- "BNB_4BIT_COMPUTE_DTYPE=\"bfloat16\"# bnb_4bit_compute_dtype\n",
- "\n",
- "SEED=0"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "FyZSXTbJrcnC"
- },
- "outputs": [],
- "source": [
- "from transformers import (\n",
- " AutoModelForCausalLM,\n",
- " AutoTokenizer,\n",
- " Trainer,\n",
- " TrainingArguments,\n",
- " logging,\n",
- " set_seed,\n",
- " BitsAndBytesConfig,\n",
- ")\n",
- "\n",
- "set_seed(SEED)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "pO7F5L5AtKo1"
- },
- "source": [
- "## Prepare the data"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "1LmrIZqP0oUE"
- },
- "source": [
- "Begin by loading the data. As the dataset is likely to be quite large, make sure to enable the streaming mode. Streaming allows us to load the data progressively as we iterate over the dataset instead of downloading the whole dataset at once.\n",
- "\n",
- "We'll reserve the first 4000 examples as the validation set, and everything else will be the training data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "4oJZvZb-1J88"
- },
- "outputs": [],
- "source": [
- "from datasets import load_dataset\n",
- "import torch\n",
- "from tqdm import tqdm\n",
- "\n",
- "\n",
- "dataset = load_dataset(\n",
- " DATASET,\n",
- " data_dir=\"data\",\n",
- " split=\"train\",\n",
- " streaming=True,\n",
- ")\n",
- "\n",
- "valid_data = dataset.take(4000)\n",
- "train_data = dataset.skip(4000)\n",
- "train_data = train_data.shuffle(buffer_size=5000, seed=SEED)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "sLQ8t0LM2GR6"
- },
- "source": [
- "At this step, the dataset still contains raw data with code of arbitraty length. For training, we need inputs of fixed length. Let's create an Iterable dataset that would return constant-length chunks of tokens from a stream of text files.\n",
- "\n",
- "First, let's estimate the average number of characters per token in the dataset, which will help us later estimate the number of tokens in the text buffer later. By default, we'll only take 400 examples (`nb_examples`) from the dataset. Using only a subset of the entire dataset will reduce computational cost while still providing a reasonable estimate of the overall character-to-token ratio."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "KCiAvydztNsu",
- "outputId": "cabf7fd0-a922-4371-cbc6-60ee99ef7469"
- },
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "100%|██████████| 400/400 [00:10<00:00, 39.87it/s] "
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "The character to token ratio of the dataset is: 2.43\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- }
- ],
- "source": [
- "tokenizer = AutoTokenizer.from_pretrained(MODEL, trust_remote_code=True)\n",
- "\n",
- "def chars_token_ratio(dataset, tokenizer, data_column, nb_examples=400):\n",
- " \"\"\"\n",
- " Estimate the average number of characters per token in the dataset.\n",
- " \"\"\"\n",
- "\n",
- " total_characters, total_tokens = 0, 0\n",
- " for _, example in tqdm(zip(range(nb_examples), iter(dataset)), total=nb_examples):\n",
- " total_characters += len(example[data_column])\n",
- " total_tokens += len(tokenizer(example[data_column]).tokens())\n",
- "\n",
- " return total_characters / total_tokens\n",
- "\n",
- "\n",
- "chars_per_token = chars_token_ratio(train_data, tokenizer, DATA_COLUMN)\n",
- "print(f\"The character to token ratio of the dataset is: {chars_per_token:.2f}\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "6F13VGobB3Ma"
- },
- "source": [
- "The character-to-token ratio can also be used as an indicator of the quality of text tokenization. For instance, a character-to-token ratio of 1.0 would mean that each character is represented with a token, which is not very meaningful. This would indicate poor tokenization. In standard English text, one token is typically equivalent to approximately four characters, meaning the character-to-token ratio is around 4.0. We can expect a lower ratio in the code dataset, but generally speaking, a number between 2.0 and 3.5 can be considered good enough."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rcwYFRPpwxea"
- },
- "source": [
- "**Optional FIM transformations**\n",
- "\n",
- "\n",
- "Autoregressive language models typically generate sequences from left to right. By applying the FIM transformations, the model can also learn to infill text. Check out [\"Efficient Training of Language Models to Fill in the Middle\" paper](https://arxiv.org/pdf/2207.14255.pdf) to learn more about the technique.\n",
- "We'll define the FIM transformations here and will use them when creating the Iterable Dataset. However, if you want to omit transformations, feel free to set `fim_rate` to 0."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "zmejYvEKw1E-"
- },
- "outputs": [],
- "source": [
- "import functools\n",
- "import numpy as np\n",
- "\n",
- "\n",
- "# Helper function to get token ids of the special tokens for prefix, suffix and middle for FIM transformations.\n",
- "@functools.lru_cache(maxsize=None)\n",
- "def get_fim_token_ids(tokenizer):\n",
- " try:\n",
- " FIM_PREFIX, FIM_MIDDLE, FIM_SUFFIX, FIM_PAD = tokenizer.special_tokens_map[\"additional_special_tokens\"][1:5]\n",
- " suffix_tok_id, prefix_tok_id, middle_tok_id, pad_tok_id = (\n",
- " tokenizer.vocab[tok] for tok in [FIM_SUFFIX, FIM_PREFIX, FIM_MIDDLE, FIM_PAD]\n",
- " )\n",
- " except KeyError:\n",
- " suffix_tok_id, prefix_tok_id, middle_tok_id, pad_tok_id = None, None, None, None\n",
- " return suffix_tok_id, prefix_tok_id, middle_tok_id, pad_tok_id\n",
- "\n",
- "\n",
- "## Adapted from https://github.com/bigcode-project/Megatron-LM/blob/6c4bf908df8fd86b4977f54bf5b8bd4b521003d1/megatron/data/gpt_dataset.py\n",
- "def permute(\n",
- " sample,\n",
- " np_rng,\n",
- " suffix_tok_id,\n",
- " prefix_tok_id,\n",
- " middle_tok_id,\n",
- " pad_tok_id,\n",
- " fim_rate=0.5,\n",
- " fim_spm_rate=0.5,\n",
- " truncate_or_pad=False,\n",
- "):\n",
- " \"\"\"\n",
- " Take in a sample (list of tokens) and perform a FIM transformation on it with a probability of fim_rate, using two FIM modes:\n",
- " PSM and SPM (with a probability of fim_spm_rate).\n",
- " \"\"\"\n",
- "\n",
- " # The if condition will trigger with the probability of fim_rate\n",
- " # This means FIM transformations will apply to samples with a probability of fim_rate\n",
- " if np_rng.binomial(1, fim_rate):\n",
- "\n",
- " # Split the sample into prefix, middle, and suffix, based on randomly generated indices stored in the boundaries list.\n",
- " boundaries = list(np_rng.randint(low=0, high=len(sample) + 1, size=2))\n",
- " boundaries.sort()\n",
- "\n",
- " prefix = np.array(sample[: boundaries[0]], dtype=np.int64)\n",
- " middle = np.array(sample[boundaries[0] : boundaries[1]], dtype=np.int64)\n",
- " suffix = np.array(sample[boundaries[1] :], dtype=np.int64)\n",
- "\n",
- " if truncate_or_pad:\n",
- " # calculate the new total length of the sample, taking into account tokens indicating prefix, middle, and suffix\n",
- " new_length = suffix.shape[0] + prefix.shape[0] + middle.shape[0] + 3\n",
- " diff = new_length - len(sample)\n",
- "\n",
- " # trancate or pad if there's a difference in length between the new length and the original\n",
- " if diff > 0:\n",
- " if suffix.shape[0] <= diff:\n",
- " return sample, np_rng\n",
- " suffix = suffix[: suffix.shape[0] - diff]\n",
- " elif diff < 0:\n",
- " suffix = np.concatenate([suffix, np.full((-1 * diff), pad_tok_id)])\n",
- "\n",
- " # With the probability of fim_spm_rateapply SPM variant of FIM transformations\n",
- " # SPM: suffix, prefix, middle\n",
- " if np_rng.binomial(1, fim_spm_rate):\n",
- " new_sample = np.concatenate(\n",
- " [\n",
- " [prefix_tok_id, suffix_tok_id],\n",
- " suffix,\n",
- " [middle_tok_id],\n",
- " prefix,\n",
- " middle,\n",
- " ]\n",
- " )\n",
- " # Otherwise, apply the PSM variant of FIM transformations\n",
- " # PSM: prefix, suffix, middle\n",
- " else:\n",
- "\n",
- " new_sample = np.concatenate(\n",
- " [\n",
- " [prefix_tok_id],\n",
- " prefix,\n",
- " [suffix_tok_id],\n",
- " suffix,\n",
- " [middle_tok_id],\n",
- " middle,\n",
- " ]\n",
- " )\n",
- " else:\n",
- " # don't apply FIM transformations\n",
- " new_sample = sample\n",
- "\n",
- " return list(new_sample), np_rng\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "AwW5FviD9xBH"
- },
- "source": [
- "Let's define the `ConstantLengthDataset`, an Iterable dataset that will return constant-length chunks of tokens. To do so, we'll read a buffer of text from the original dataset until we hit the size limits and then apply tokenizer to convert the raw text into tokenized inputs. Optionally, we'll perform FIM transformations on some sequences (the proportion of sequences affected is controlled by `fim_rate`).\n",
- "\n",
- "Once defined, we can create instances of the `ConstantLengthDataset` from both training and validation data."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "AgDW-692wzOl"
- },
- "outputs": [],
- "source": [
- "from torch.utils.data import IterableDataset\n",
- "from torch.utils.data.dataloader import DataLoader\n",
- "import random\n",
- "\n",
- "# Create an Iterable dataset that returns constant-length chunks of tokens from a stream of text files.\n",
- "\n",
- "class ConstantLengthDataset(IterableDataset):\n",
- " \"\"\"\n",
- " Iterable dataset that returns constant length chunks of tokens from stream of text files.\n",
- " Args:\n",
- " tokenizer (Tokenizer): The processor used for proccessing the data.\n",
- " dataset (dataset.Dataset): Dataset with text files.\n",
- " infinite (bool): If True the iterator is reset after dataset reaches end else stops.\n",
- " seq_length (int): Length of token sequences to return.\n",
- " num_of_sequences (int): Number of token sequences to keep in buffer.\n",
- " chars_per_token (int): Number of characters per token used to estimate number of tokens in text buffer.\n",
- " fim_rate (float): Rate (0.0 to 1.0) that sample will be permuted with FIM.\n",
- " fim_spm_rate (float): Rate (0.0 to 1.0) of FIM permuations that will use SPM.\n",
- " seed (int): Seed for random number generator.\n",
- " \"\"\"\n",
- "\n",
- " def __init__(\n",
- " self,\n",
- " tokenizer,\n",
- " dataset,\n",
- " infinite=False,\n",
- " seq_length=1024,\n",
- " num_of_sequences=1024,\n",
- " chars_per_token=3.6,\n",
- " content_field=\"content\",\n",
- " fim_rate=0.5,\n",
- " fim_spm_rate=0.5,\n",
- " seed=0,\n",
- " ):\n",
- " self.tokenizer = tokenizer\n",
- " self.concat_token_id = tokenizer.eos_token_id\n",
- " self.dataset = dataset\n",
- " self.seq_length = seq_length\n",
- " self.infinite = infinite\n",
- " self.current_size = 0\n",
- " self.max_buffer_size = seq_length * chars_per_token * num_of_sequences\n",
- " self.content_field = content_field\n",
- " self.fim_rate = fim_rate\n",
- " self.fim_spm_rate = fim_spm_rate\n",
- " self.seed = seed\n",
- "\n",
- " (\n",
- " self.suffix_tok_id,\n",
- " self.prefix_tok_id,\n",
- " self.middle_tok_id,\n",
- " self.pad_tok_id,\n",
- " ) = get_fim_token_ids(self.tokenizer)\n",
- " if not self.suffix_tok_id and self.fim_rate > 0:\n",
- " print(\"FIM is not supported by tokenizer, disabling FIM\")\n",
- " self.fim_rate = 0\n",
- "\n",
- " def __iter__(self):\n",
- " iterator = iter(self.dataset)\n",
- " more_examples = True\n",
- " np_rng = np.random.RandomState(seed=self.seed)\n",
- " while more_examples:\n",
- " buffer, buffer_len = [], 0\n",
- " while True:\n",
- " if buffer_len >= self.max_buffer_size:\n",
- " break\n",
- " try:\n",
- " buffer.append(next(iterator)[self.content_field])\n",
- " buffer_len += len(buffer[-1])\n",
- " except StopIteration:\n",
- " if self.infinite:\n",
- " iterator = iter(self.dataset)\n",
- " else:\n",
- " more_examples = False\n",
- " break\n",
- " tokenized_inputs = self.tokenizer(buffer, truncation=False)[\"input_ids\"]\n",
- " all_token_ids = []\n",
- "\n",
- " for tokenized_input in tokenized_inputs:\n",
- " # optionally do FIM permutations\n",
- " if self.fim_rate > 0:\n",
- " tokenized_input, np_rng = permute(\n",
- " tokenized_input,\n",
- " np_rng,\n",
- " self.suffix_tok_id,\n",
- " self.prefix_tok_id,\n",
- " self.middle_tok_id,\n",
- " self.pad_tok_id,\n",
- " fim_rate=self.fim_rate,\n",
- " fim_spm_rate=self.fim_spm_rate,\n",
- " truncate_or_pad=False,\n",
- " )\n",
- "\n",
- " all_token_ids.extend(tokenized_input + [self.concat_token_id])\n",
- " examples = []\n",
- " for i in range(0, len(all_token_ids), self.seq_length):\n",
- " input_ids = all_token_ids[i : i + self.seq_length]\n",
- " if len(input_ids) == self.seq_length:\n",
- " examples.append(input_ids)\n",
- " random.shuffle(examples)\n",
- " for example in examples:\n",
- " self.current_size += 1\n",
- " yield {\n",
- " \"input_ids\": torch.LongTensor(example),\n",
- " \"labels\": torch.LongTensor(example),\n",
- " }\n",
- "\n",
- "\n",
- "train_dataset = ConstantLengthDataset(\n",
- " tokenizer,\n",
- " train_data,\n",
- " infinite=True,\n",
- " seq_length=SEQ_LENGTH,\n",
- " chars_per_token=chars_per_token,\n",
- " content_field=DATA_COLUMN,\n",
- " fim_rate=FIM_RATE,\n",
- " fim_spm_rate=FIM_SPM_RATE,\n",
- " seed=SEED,\n",
- ")\n",
- "eval_dataset = ConstantLengthDataset(\n",
- " tokenizer,\n",
- " valid_data,\n",
- " infinite=False,\n",
- " seq_length=SEQ_LENGTH,\n",
- " chars_per_token=chars_per_token,\n",
- " content_field=DATA_COLUMN,\n",
- " fim_rate=FIM_RATE,\n",
- " fim_spm_rate=FIM_SPM_RATE,\n",
- " seed=SEED,\n",
- ")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "rxev1sk6tRW9"
- },
- "source": [
- "## Prepare the model"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "UCtWV-U42Eq_"
- },
- "source": [
- "Now that the data is prepared, it's time to load the model! We're going to load the quantized version of the model.\n",
- "\n",
- "This will allow us to reduce memory usage, as quantization represents data with fewer bits. We'll use the `bitsandbytes` library to quantize the model, as it has a nice integration with `transformers`. All we need to do is define a `bitsandbytes` config, and then use it when loading the model.\n",
- "\n",
- "There are different variants of 4bit quantization, but generally, we recommend using NF4 quantization for better performance (`bnb_4bit_quant_type=\"nf4\"`).\n",
- "\n",
- "The `bnb_4bit_use_double_quant` option adds a second quantization after the first one to save an additional 0.4 bits per parameter.\n",
- "\n",
- "To learn more about quantization, check out the [\"Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA\" blog post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).\n",
- "\n",
- "Once defined, pass the config to the `from_pretrained` method to load the quantized version of the model."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "XuwoX6U2DUvK"
- },
- "outputs": [],
- "source": [
- "from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training\n",
- "from peft.tuners.lora import LoraLayer\n",
- "\n",
- "load_in_8bit = False\n",
- "\n",
- "# 4-bit quantization\n",
- "compute_dtype = getattr(torch, BNB_4BIT_COMPUTE_DTYPE)\n",
- "\n",
- "bnb_config = BitsAndBytesConfig(\n",
- " load_in_4bit=True,\n",
- " bnb_4bit_quant_type=\"nf4\",\n",
- " bnb_4bit_compute_dtype=compute_dtype,\n",
- " bnb_4bit_use_double_quant=USE_NESTED_QUANT,\n",
- ")\n",
- "\n",
- "device_map = {\"\": 0}\n",
- "\n",
- "model = AutoModelForCausalLM.from_pretrained(\n",
- " MODEL,\n",
- " load_in_8bit=load_in_8bit,\n",
- " quantization_config=bnb_config,\n",
- " device_map=device_map,\n",
- " use_cache=False, # We will be using gradient checkpointing\n",
- " trust_remote_code=True,\n",
- " use_flash_attention_2=True,\n",
- ")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "bO9e2FV8D8ZF"
- },
- "source": [
- "When using a quantized model for training, you need to call the `prepare_model_for_kbit_training()` function to preprocess the quantized model for training."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "Qb_eB4xzEDBk"
- },
- "outputs": [],
- "source": [
- "model = prepare_model_for_kbit_training(model)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "lmnLjPZpDVtg"
- },
- "source": [
- "Now that the quantized model is ready, we can set up a LoRA configuration. LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.\n",
- "\n",
- "To train a model using LoRA technique, we need to wrap the base model as a `PeftModel`. This involves definign LoRA configuration with `LoraConfig`, and wrapping the original model with `get_peft_model()` using the `LoraConfig`.\n",
- "\n",
- "To learn more about LoRA and its parameters, refer to [PEFT documentation](https://huggingface.co/docs/peft/conceptual_guides/lora)."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "id": "_pAUU2FR2Gey",
- "outputId": "63328c2b-e693-49b1-ce0a-3ca8722f852a"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "trainable params: 5,554,176 || all params: 1,142,761,472 || trainable%: 0.4860310866343243\n"
- ]
- }
- ],
- "source": [
- "# Set up lora\n",
- "peft_config = LoraConfig(\n",
- " lora_alpha=LORA_ALPHA,\n",
- " lora_dropout=LORA_DROPOUT,\n",
- " r=LORA_R,\n",
- " bias=\"none\",\n",
- " task_type=\"CAUSAL_LM\",\n",
- " target_modules=LORA_TARGET_MODULES.split(\",\"),\n",
- ")\n",
- "\n",
- "model = get_peft_model(model, peft_config)\n",
- "model.print_trainable_parameters()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "tHe7AElXzXVV"
- },
- "source": [
- "As you can see, by applying LoRA technique we will now need to train less than 1% of the parameters."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "T_CqVydc40IM"
- },
- "source": [
- "## Train the model"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "Q_iN2khjrbD3"
- },
- "source": [
- "Now that we have prepared the data, and optimized the model, we are ready to bring everything together to start the training.\n",
- "\n",
- "To instantiate a `Trainer`, you need to define the training configuration. The most important is the `TrainingArguments`, which is a class that contains all the attributes to configure the training.\n",
- "\n",
- "These are similar to any other kind of model training you may run, so we won't go into detail here."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "65QHS8l1tKQe"
- },
- "outputs": [],
- "source": [
- "train_data.start_iteration = 0\n",
- "\n",
- "\n",
- "training_args = TrainingArguments(\n",
- " output_dir=f\"Your_HF_username/{OUTPUT_DIR}\",\n",
- " dataloader_drop_last=True,\n",
- " evaluation_strategy=\"steps\",\n",
- " save_strategy=\"steps\",\n",
- " max_steps=MAX_STEPS,\n",
- " eval_steps=EVAL_FREQ,\n",
- " save_steps=SAVE_FREQ,\n",
- " logging_steps=LOG_FREQ,\n",
- " per_device_train_batch_size=BATCH_SIZE,\n",
- " per_device_eval_batch_size=BATCH_SIZE,\n",
- " learning_rate=LR,\n",
- " lr_scheduler_type=LR_SCHEDULER_TYPE,\n",
- " warmup_steps=NUM_WARMUP_STEPS,\n",
- " gradient_accumulation_steps=GR_ACC_STEPS,\n",
- " gradient_checkpointing=True,\n",
- " fp16=FP16,\n",
- " bf16=BF16,\n",
- " weight_decay=WEIGHT_DECAY,\n",
- " push_to_hub=True,\n",
- " include_tokens_per_second=True,\n",
- ")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "kB_fLRex09ut"
- },
- "source": [
- "As a final step, instantiate the `Trainer` and call the `train` method. "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000
- },
- "id": "rS3nVwhUC69O",
- "outputId": "61a5bdb2-b7d0-4aed-8290-4bf20c2ccd38"
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Training...\n"
- ]
- },
- {
- "data": {
- "text/html": [
- "\n",
- " | Step | \n", - "Training Loss | \n", - "Validation Loss | \n", - "
|---|---|---|
| 100 | \n", - "5.524600 | \n", - "7.456872 | \n", - "
| 200 | \n", - "5.617800 | \n", - "7.262190 | \n", - "
| 300 | \n", - "5.129100 | \n", - "6.410039 | \n", - "
| 400 | \n", - "5.052200 | \n", - "6.306774 | \n", - "
| 500 | \n", - "5.202900 | \n", - "6.117062 | \n", - "
| 600 | \n", - "4.654100 | \n", - "6.018349 | \n", - "
| 700 | \n", - "5.100200 | \n", - "6.000355 | \n", - "
| 800 | \n", - "5.049800 | \n", - "5.889457 | \n", - "
| 900 | \n", - "4.541200 | \n", - "5.813823 | \n", - "
| 1000 | \n", - "5.000700 | \n", - "5.834208 | \n", - "
| 1100 | \n", - "5.026500 | \n", - "5.781939 | \n", - "
| 1200 | \n", - "4.411800 | \n", - "5.720596 | \n", - "
| 1300 | \n", - "4.782500 | \n", - "5.736376 | \n", - "
| 1400 | \n", - "4.980200 | \n", - "5.712276 | \n", - "
| 1500 | \n", - "4.368700 | \n", - "5.689637 | \n", - "
| 1600 | \n", - "4.884700 | \n", - "5.675920 | \n", - "
| 1700 | \n", - "4.914400 | \n", - "5.662421 | \n", - "
| 1800 | \n", - "4.248700 | \n", - "5.660122 | \n", - "
| 1900 | \n", - "4.798400 | \n", - "5.664026 | \n", - "
| 2000 | \n", - "4.704200 | \n", - "5.655665 | \n", - "
"
- ],
- "text/plain": [
- "
