
dosyalar yüklendi
Browse files- .gitattributes +2 -0
- src/app.py +147 -0
- src/cross_encoder_model.py +42 -0
- src/encoder_algorithm.png +0 -0
- src/mixed_cross_encoder_model.py +54 -0
- src/v2_cross_encoder.keras +3 -0
- src/v2_mixed_data_cross_encoder.keras +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
src/v2_cross_encoder.keras filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
src/v2_mixed_data_cross_encoder.keras filter=lfs diff=lfs merge=lfs -text
|
src/app.py
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import tensorflow as tf
|
| 3 |
+
import numpy as np
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from transformers import AutoTokenizer
|
| 6 |
+
from cross_encoder_model import CrossEncoderTF
|
| 7 |
+
from mixed_cross_encoder_model import MixedDataCrossEncoderTF
|
| 8 |
+
|
| 9 |
+
MODEL_NAME = "dbmdz/bert-base-turkish-cased"
|
| 10 |
+
SAVED_CROSS_ENCODER_MODEL_PATH = "src/v2_cross_encoder.keras"
|
| 11 |
+
SAVED_MIXED_CROSS_ENCODER_MODEL_PATH = "src/v2_mixed_data_cross_encoder.keras"
|
| 12 |
+
MAX_TOKEN_LEN = 32
|
| 13 |
+
DATA_FILE_PATH = "model_0_data.csv"
|
| 14 |
+
TEXT_COLS = ['STRA', 'STRB']
|
| 15 |
+
LABEL_COL = 'DISTANCE'
|
| 16 |
+
EXCLUDE_COLS = TEXT_COLS + [LABEL_COL, 'FILLER']
|
| 17 |
+
NUMERICAL_FEATURE_DIM = 5132
|
| 18 |
+
|
| 19 |
+
@st.cache_data
|
| 20 |
+
def load_data():
|
| 21 |
+
try:
|
| 22 |
+
df = pd.read_csv(DATA_FILE_PATH, decimal=',', low_memory=False)
|
| 23 |
+
except FileNotFoundError:
|
| 24 |
+
st.error(f"Veri dosyası bulunamadı: {DATA_FILE_PATH}. Lütfen dosyanın uygulamanın çalıştığı dizinde olduğundan emin olun.")
|
| 25 |
+
st.stop()
|
| 26 |
+
return df
|
| 27 |
+
|
| 28 |
+
@st.cache_resource
|
| 29 |
+
def load_models_and_tokenizer():
|
| 30 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
|
| 31 |
+
|
| 32 |
+
cross_encoder_model = tf.keras.models.load_model(
|
| 33 |
+
SAVED_CROSS_ENCODER_MODEL_PATH,
|
| 34 |
+
custom_objects={'CrossEncoderTF': CrossEncoderTF}
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
mixed_cross_encoder_model = tf.keras.models.load_model(
|
| 38 |
+
SAVED_MIXED_CROSS_ENCODER_MODEL_PATH,
|
| 39 |
+
custom_objects={'MixedDataCrossEncoderTF': MixedDataCrossEncoderTF,
|
| 40 |
+
'numerical_feature_dim': NUMERICAL_FEATURE_DIM}
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
return tokenizer, cross_encoder_model, mixed_cross_encoder_model
|
| 44 |
+
|
| 45 |
+
try:
|
| 46 |
+
df_data = load_data()
|
| 47 |
+
numerical_feature_cols = df_data.columns.drop(EXCLUDE_COLS).tolist()
|
| 48 |
+
NUMERICAL_FEATURE_DIM = len(numerical_feature_cols)
|
| 49 |
+
tokenizer, cross_encoder_model, mixed_cross_encoder_model = load_models_and_tokenizer()
|
| 50 |
+
except Exception as e:
|
| 51 |
+
st.error(f"Yüklenirken bir hata oluştu: {e}")
|
| 52 |
+
st.stop()
|
| 53 |
+
|
| 54 |
+
def predict(model, tokenizer, str_a, str_b, numerical_features=None):
|
| 55 |
+
tokenized = tokenizer(
|
| 56 |
+
str_a, str_b,
|
| 57 |
+
max_length=MAX_TOKEN_LEN,
|
| 58 |
+
padding='max_length',
|
| 59 |
+
truncation=True,
|
| 60 |
+
return_tensors='np'
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
model_input = {
|
| 64 |
+
'input_ids': tokenized['input_ids'],
|
| 65 |
+
'attention_mask': tokenized['attention_mask'],
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
if numerical_features is not None:
|
| 69 |
+
model_input['numerical_features'] = numerical_features.reshape(1, -1).astype('float32')
|
| 70 |
+
|
| 71 |
+
prediction = model.predict(model_input)
|
| 72 |
+
score = prediction[0][0]
|
| 73 |
+
|
| 74 |
+
return float(score)
|
| 75 |
+
|
| 76 |
+
st.set_page_config(page_title="Varlık Benzerlik Testi", layout="centered")
|
| 77 |
+
st.title("İki Model Karşılaştırmalı Varlık Benzerlik Test Arayüzü")
|
| 78 |
+
|
| 79 |
+
st.info(
|
| 80 |
+
"Bu uygulama, metinsel verileri kullanarak iki varlığın "
|
| 81 |
+
"benzerlik olasılığını tahmin eder ve iki farklı modelin sonuçlarını karşılaştırır."
|
| 82 |
+
"(henüz bi-encoder mimarisi eklenmemiştir, sadece cross-encoder modeli kullanılıyor)"
|
| 83 |
+
"\n\n**Cross-encoder mimarisi:** yalnızca metin1, metin2 ve distance özellikleri ile eğitilmiştir."
|
| 84 |
+
"\n\n**Mixed-cross-encoder mimarisi:** metin1, metin2, distance ve numerik özellikler ile eğitilmiştir."
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
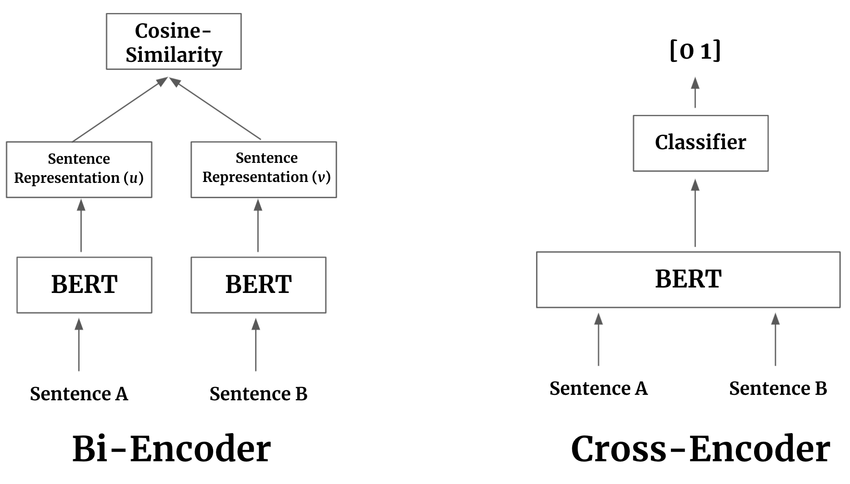
st.image("src/encoder_algorithm.png", caption="Encoder Algoritma Akışı", use_container_width=True)
|
| 88 |
+
|
| 89 |
+
st.header("Girdi String'leri")
|
| 90 |
+
|
| 91 |
+
stra_options = df_data['STRA'].unique()
|
| 92 |
+
str_a_input = st.selectbox("String A (STRA)", stra_options)
|
| 93 |
+
|
| 94 |
+
filtered_strb_options = df_data[df_data['STRA'] == str_a_input]['STRB'].unique()
|
| 95 |
+
str_b_input = st.selectbox("String B (STRB)", filtered_strb_options)
|
| 96 |
+
|
| 97 |
+
if st.button("Benzerliği Hesapla", type="primary"):
|
| 98 |
+
if not str_a_input or not str_b_input:
|
| 99 |
+
st.error("Lütfen her iki string alanını da seçin.")
|
| 100 |
+
else:
|
| 101 |
+
with st.spinner("Tahminler yapılıyor..."):
|
| 102 |
+
selected_row = df_data[(df_data['STRA'] == str_a_input) & (df_data['STRB'] == str_b_input)]
|
| 103 |
+
if not selected_row.empty:
|
| 104 |
+
numerical_features_for_prediction = selected_row[numerical_feature_cols].iloc[0].values
|
| 105 |
+
else:
|
| 106 |
+
st.error("Seçilen string'lere ait veri bulunamadı. Lütfen farklı seçimler yapın.")
|
| 107 |
+
st.stop()
|
| 108 |
+
|
| 109 |
+
cross_encoder_distance_score = predict(cross_encoder_model, tokenizer, str_a_input, str_b_input)
|
| 110 |
+
cross_encoder_similarity_score = 1 - cross_encoder_distance_score
|
| 111 |
+
|
| 112 |
+
mixed_cross_encoder_distance_score = predict(mixed_cross_encoder_model, tokenizer, str_a_input, str_b_input, numerical_features_for_prediction)
|
| 113 |
+
mixed_cross_encoder_similarity_score = 1 - mixed_cross_encoder_distance_score
|
| 114 |
+
|
| 115 |
+
actual_row = df_data[(df_data['STRA'] == str_a_input) & (df_data['STRB'] == str_b_input)]
|
| 116 |
+
if not actual_row.empty:
|
| 117 |
+
actual_distance = actual_row[LABEL_COL].iloc[0]
|
| 118 |
+
actual_similarity = 1 - actual_distance
|
| 119 |
+
else:
|
| 120 |
+
actual_distance = np.nan
|
| 121 |
+
actual_similarity = np.nan
|
| 122 |
+
|
| 123 |
+
st.subheader("Karşılaştırmalı Sonuçlar")
|
| 124 |
+
|
| 125 |
+
results_data = {
|
| 126 |
+
"Özellik": ["Tahmin Edilen Benzerlik", "Gerçek Benzerlik", "Tahmin Edilen Mesafe", "Gerçek Mesafe", "Karar"],
|
| 127 |
+
"Cross-Encoder Model": [
|
| 128 |
+
f"{cross_encoder_similarity_score:.4f}",
|
| 129 |
+
f"{actual_similarity:.4f}" if not np.isnan(actual_similarity) else "N/A",
|
| 130 |
+
f"{cross_encoder_distance_score:.4f}",
|
| 131 |
+
f"{actual_distance:.4f}" if not np.isnan(actual_distance) else "N/A",
|
| 132 |
+
"BENZER" if cross_encoder_similarity_score > 0.5 else "BENZER DEĞİL"
|
| 133 |
+
],
|
| 134 |
+
"Mixed Cross-Encoder Model": [
|
| 135 |
+
f"{mixed_cross_encoder_similarity_score:.4f}",
|
| 136 |
+
f"{actual_similarity:.4f}" if not np.isnan(actual_similarity) else "N/A",
|
| 137 |
+
f"{mixed_cross_encoder_distance_score:.4f}",
|
| 138 |
+
f"{actual_distance:.4f}" if not np.isnan(actual_distance) else "N/A",
|
| 139 |
+
"BENZER" if mixed_cross_encoder_similarity_score > 0.5 else "BENZER DEĞİL"
|
| 140 |
+
]
|
| 141 |
+
}
|
| 142 |
+
results_df = pd.DataFrame(results_data).set_index("Özellik")
|
| 143 |
+
st.dataframe(results_df)
|
| 144 |
+
|
| 145 |
+
st.markdown("---")
|
| 146 |
+
st.markdown(f"**Cross-Encoder Model Kararı:** `{str_a_input}` ve `{str_b_input}` kelimeleri **:{'blue' if cross_encoder_similarity_score > 0.5 else 'red'}[{'BENZER' if cross_encoder_similarity_score > 0.5 else 'BENZER DEĞİL'}]**.")
|
| 147 |
+
st.markdown(f"**Mixed Cross-Encoder Model Kararı:** `{str_a_input}` ve `{str_b_input}` kelimeleri **:{'blue' if mixed_cross_encoder_similarity_score > 0.5 else 'red'}[{'BENZER' if mixed_cross_encoder_similarity_score > 0.5 else 'BENZER DEĞİL'}]**.")
|
src/cross_encoder_model.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# src/model.py
|
| 2 |
+
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
from tensorflow.keras import layers, Model
|
| 5 |
+
from transformers import TFAutoModel
|
| 6 |
+
|
| 7 |
+
class CrossEncoderTF(Model):
|
| 8 |
+
def __init__(self, model_name="dbmdz/bert-base-turkish-cased", max_token_len=32, **kwargs):
|
| 9 |
+
super().__init__(**kwargs)
|
| 10 |
+
self.model_name = model_name
|
| 11 |
+
self.max_token_len = max_token_len
|
| 12 |
+
|
| 13 |
+
# 1. Metin Hattı (Transformer)
|
| 14 |
+
self.bert = TFAutoModel.from_pretrained(model_name)
|
| 15 |
+
|
| 16 |
+
# 2. Sadece çıktı katmanı
|
| 17 |
+
self.classifier = tf.keras.Sequential([
|
| 18 |
+
layers.Dense(256, activation='relu'),
|
| 19 |
+
layers.BatchNormalization(),
|
| 20 |
+
layers.Dropout(0.3),
|
| 21 |
+
layers.Dense(128, activation='relu'),
|
| 22 |
+
layers.BatchNormalization(),
|
| 23 |
+
layers.Dense(64, activation='relu'),
|
| 24 |
+
layers.BatchNormalization(),
|
| 25 |
+
layers.Dense(1, activation='sigmoid')
|
| 26 |
+
], name="classifier")
|
| 27 |
+
|
| 28 |
+
def call(self, inputs):
|
| 29 |
+
bert_output = self.bert(input_ids=inputs['input_ids'], attention_mask=inputs['attention_mask'])
|
| 30 |
+
text_features = bert_output.pooler_output
|
| 31 |
+
|
| 32 |
+
prediction_score = self.classifier(text_features)
|
| 33 |
+
return prediction_score
|
| 34 |
+
|
| 35 |
+
def get_config(self):
|
| 36 |
+
config = super().get_config()
|
| 37 |
+
config.update({
|
| 38 |
+
"model_name": self.model_name,
|
| 39 |
+
"max_token_len": self.max_token_len,
|
| 40 |
+
})
|
| 41 |
+
return config
|
| 42 |
+
|
src/encoder_algorithm.png
ADDED
|
src/mixed_cross_encoder_model.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# src/model.py
|
| 2 |
+
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
from tensorflow.keras import layers, Model
|
| 5 |
+
from transformers import TFAutoModel
|
| 6 |
+
|
| 7 |
+
class MixedDataCrossEncoderTF(Model):
|
| 8 |
+
def __init__(self, model_name="dbmdz/bert-base-turkish-cased", numerical_feature_dim=5132, max_token_len=32, **kwargs):
|
| 9 |
+
super().__init__(**kwargs)
|
| 10 |
+
self.model_name = model_name
|
| 11 |
+
self.numerical_feature_dim = numerical_feature_dim
|
| 12 |
+
self.max_token_len = max_token_len
|
| 13 |
+
|
| 14 |
+
self.bert = TFAutoModel.from_pretrained(model_name)
|
| 15 |
+
|
| 16 |
+
self.numerical_mlp = tf.keras.Sequential([
|
| 17 |
+
layers.Input(shape=(numerical_feature_dim,)),
|
| 18 |
+
layers.Dense(512, activation='relu'),
|
| 19 |
+
layers.Dropout(0.3),
|
| 20 |
+
layers.Dense(128, activation='relu')
|
| 21 |
+
], name="numerical_mlp")
|
| 22 |
+
|
| 23 |
+
self.concatenation = layers.Concatenate()
|
| 24 |
+
self.classifier = tf.keras.Sequential([
|
| 25 |
+
layers.Dense(256, activation='relu'),
|
| 26 |
+
layers.BatchNormalization(),
|
| 27 |
+
layers.Dropout(0.3),
|
| 28 |
+
layers.Dense(128, activation='relu'),
|
| 29 |
+
layers.BatchNormalization(),
|
| 30 |
+
layers.Dense(64, activation='relu'),
|
| 31 |
+
layers.BatchNormalization(),
|
| 32 |
+
layers.Dense(1, activation='sigmoid')
|
| 33 |
+
], name="classifier")
|
| 34 |
+
|
| 35 |
+
def call(self, inputs):
|
| 36 |
+
bert_output = self.bert(input_ids=inputs['input_ids'], attention_mask=inputs['attention_mask'])
|
| 37 |
+
text_features = bert_output.pooler_output
|
| 38 |
+
|
| 39 |
+
numerical_processed_features = self.numerical_mlp(inputs['numerical_features'])
|
| 40 |
+
|
| 41 |
+
combined_features = self.concatenation([text_features, numerical_processed_features])
|
| 42 |
+
|
| 43 |
+
prediction_score = self.classifier(combined_features)
|
| 44 |
+
return prediction_score
|
| 45 |
+
|
| 46 |
+
def get_config(self):
|
| 47 |
+
config = super().get_config()
|
| 48 |
+
config.update({
|
| 49 |
+
"model_name": self.model_name,
|
| 50 |
+
"numerical_feature_dim": self.numerical_feature_dim,
|
| 51 |
+
"max_token_len": self.max_token_len, # max_token_len'i de ekliyoruz
|
| 52 |
+
})
|
| 53 |
+
return config
|
| 54 |
+
|
src/v2_cross_encoder.keras
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:279deaf2759bce8a936ae23d4486e3e97f6c8c9c12e560e66662e81799aa7bc7
|
| 3 |
+
size 2916631
|
src/v2_mixed_data_cross_encoder.keras
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7d9f8f22a50b2c990c49ce98915547012f8a82e8192c1a8e3a4a82e59b432b66
|
| 3 |
+
size 35650863
|