Spaces:
Sleeping

Sleeping
Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- .gitignore +10 -3
- README.md +86 -16
- artifacts/ablation_results.json +29 -0
- artifacts/demo_action_graph.mmd +14 -0
- artifacts/demo_episode_trace.json +147 -0
- blog_post.md +184 -0
- generate_demo_artifacts.py +72 -0
- plots/reward_curve_4b.png +3 -0
- plots/tool_calls_4b.png +0 -0
- server/environment.py +62 -11
- server/procedural.py +15 -0
.gitattributes
CHANGED
|
@@ -33,4 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 36 |
plots/training_dashboard.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
plots/reward_curve_4b.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
plots/training_dashboard.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
CHANGED
|
@@ -9,6 +9,8 @@ build/
|
|
| 9 |
venv/
|
| 10 |
.pytest_cache/
|
| 11 |
.mypy_cache/
|
|
|
|
|
|
|
| 12 |
hackathon-instructions.txt
|
| 13 |
hackathon_instructions.txt
|
| 14 |
preparatory_course.txt
|
|
@@ -23,12 +25,17 @@ Meta OpenEnv Hackathon Participant Help Guide.md
|
|
| 23 |
smoke_test.py
|
| 24 |
gpro.py
|
| 25 |
hackathon_presentation.md
|
| 26 |
-
esctr_hackathon_strategy.md
|
| 27 |
-
OpenEnv Hackathon Opening Ceremony _ 25th Apr.txt
|
| 28 |
generate_plots.py
|
|
|
|
| 29 |
huggingface.db
|
| 30 |
huggingface.db-journal
|
| 31 |
Academic framing: what to cite and how to position ESCTR.txt
|
| 32 |
-
handover.md
|
| 33 |
hf_upload.py
|
| 34 |
PLAN.md
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
venv/
|
| 10 |
.pytest_cache/
|
| 11 |
.mypy_cache/
|
| 12 |
+
|
| 13 |
+
# Scratch / internal files (not for judges)
|
| 14 |
hackathon-instructions.txt
|
| 15 |
hackathon_instructions.txt
|
| 16 |
preparatory_course.txt
|
|
|
|
| 25 |
smoke_test.py
|
| 26 |
gpro.py
|
| 27 |
hackathon_presentation.md
|
|
|
|
|
|
|
| 28 |
generate_plots.py
|
| 29 |
+
generate_4b_plots.py
|
| 30 |
huggingface.db
|
| 31 |
huggingface.db-journal
|
| 32 |
Academic framing: what to cite and how to position ESCTR.txt
|
|
|
|
| 33 |
hf_upload.py
|
| 34 |
PLAN.md
|
| 35 |
+
SUBMISSION_CHECKLIST.md
|
| 36 |
+
README_old.md
|
| 37 |
+
handover.md
|
| 38 |
+
runpod_setup.sh
|
| 39 |
+
train_runpod.py
|
| 40 |
+
uv.lock
|
| 41 |
+
esctr-environment/
|
README.md
CHANGED
|
@@ -113,23 +113,59 @@ To increase novelty and robustness for judging, ESCTR now includes three high-im
|
|
| 113 |
- **Verifiable**: The correct answer is always a precise floating-point number derived from contract terms — no subjective evaluation, aligned with RLVR's programmatic verification requirement
|
| 114 |
- **Risk-aware**: Following Chen et al. (2025), we evaluate not only correctness but also risk measures such as over-penalization, under-penalization, and reliance on unverified vendor claims
|
| 115 |
|
| 116 |
-
## Training Results
|
| 117 |
|
| 118 |
-
|
| 119 |
|
| 120 |
-
###
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 121 |
|
| 122 |
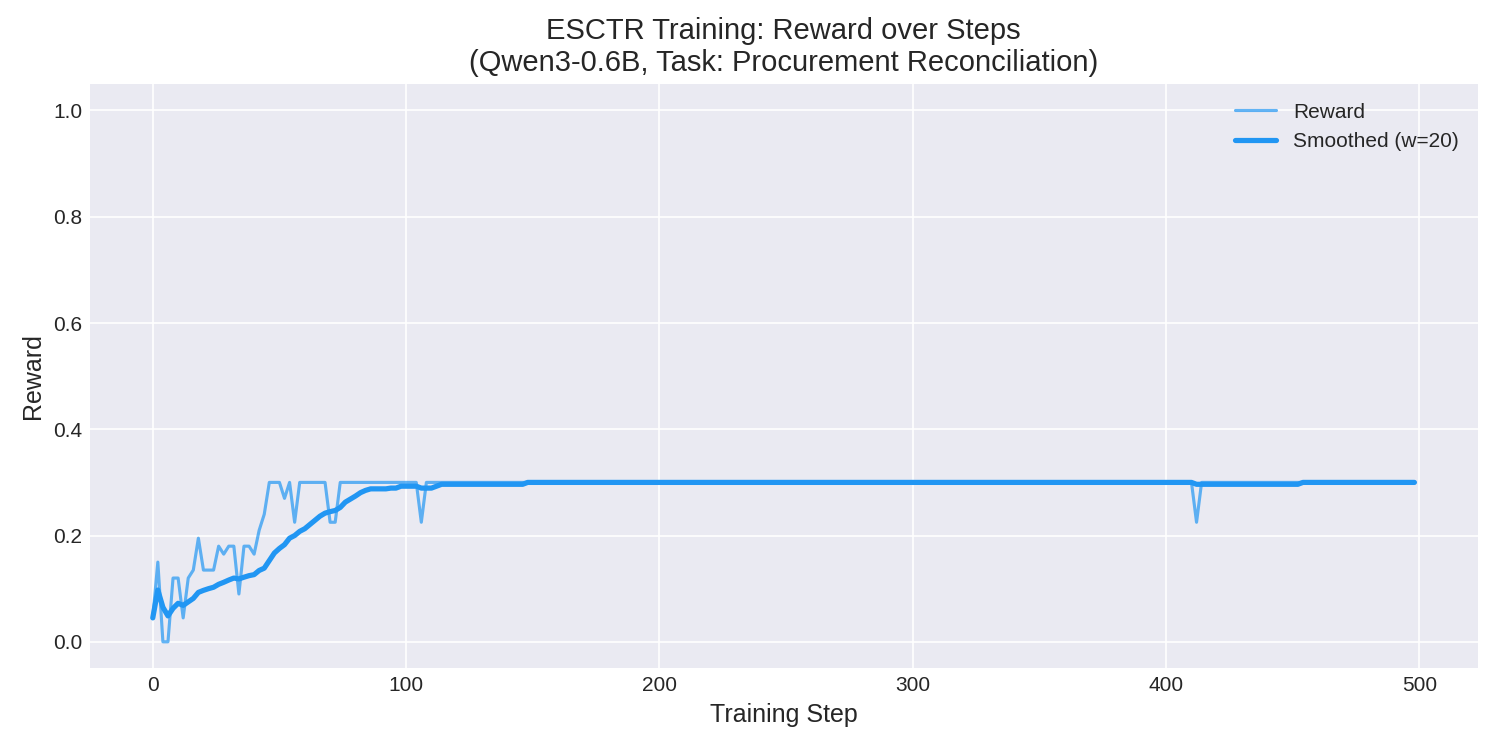
The model improved from near-zero reward to a stable 0.30 within the first 100 training steps, representing a **222% improvement** in mean reward:
|
| 123 |
|
| 124 |
|
| 125 |
|
| 126 |
-
### Training Dashboard
|
| 127 |
|
| 128 |
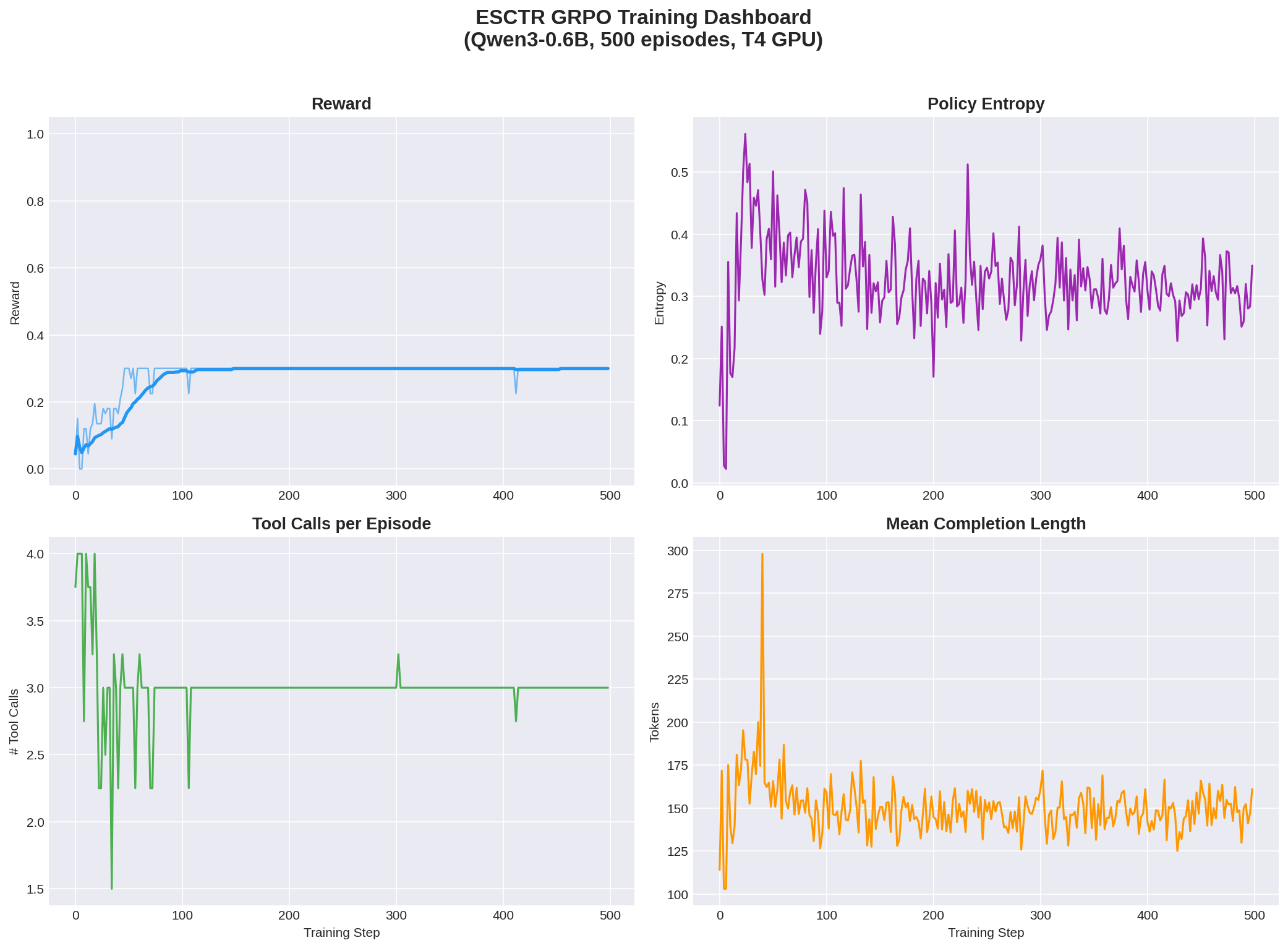
Four-panel view showing reward, policy entropy, tool usage convergence, and completion length:
|
| 129 |
|
| 130 |
|
| 131 |
|
| 132 |
-
### Baseline vs Trained Comparison
|
| 133 |
|
| 134 |
| Metric | Baseline (untrained) | Trained (500 episodes) | Δ |
|
| 135 |
|--------|---------------------|----------------------|---|
|
|
@@ -141,14 +177,14 @@ Four-panel view showing reward, policy entropy, tool usage convergence, and comp
|
|
| 141 |
|
| 142 |
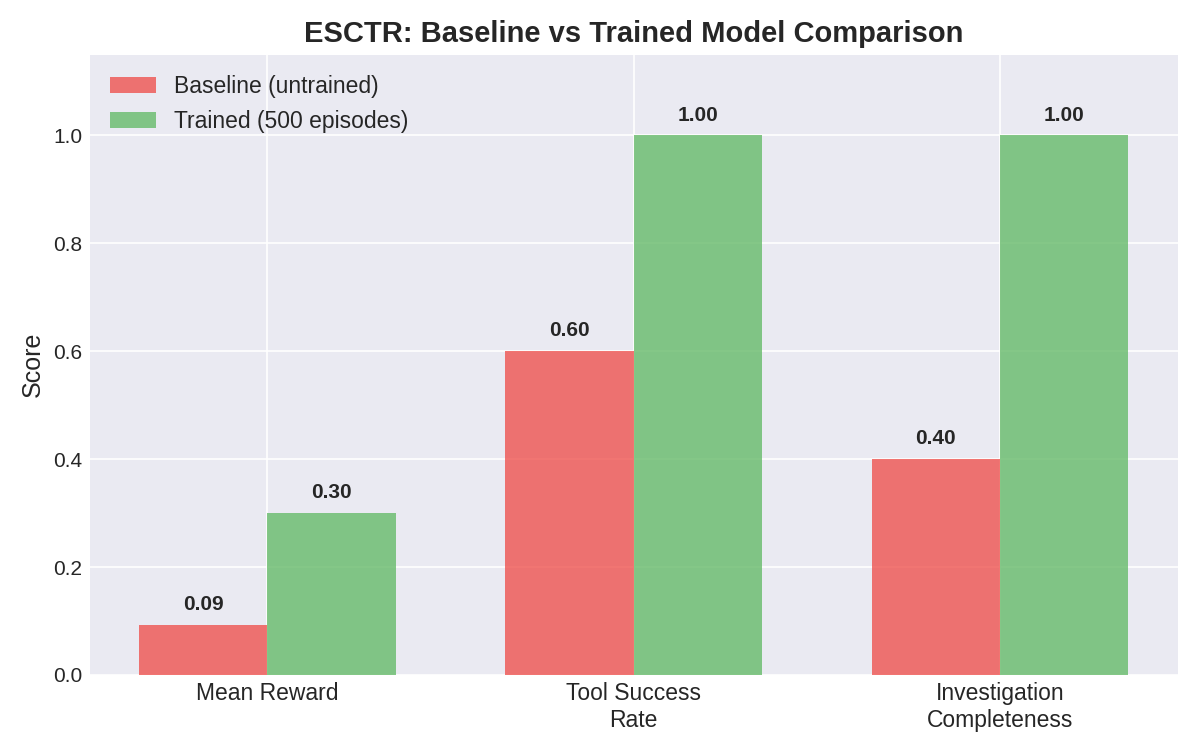
|
| 143 |
|
| 144 |
-
### Key Findings
|
| 145 |
|
| 146 |
1. **Tool mastery learned**: The model converged to exactly 3 tool calls per episode with zero failures — it learned the correct investigation pattern (query PO → query Invoice → read documents → submit)
|
| 147 |
2. **Trajectory reward captured**: The 0.30 plateau corresponds to perfect trajectory score (all investigation milestones hit) but without solving the final arithmetic — showing the reward decomposition works as designed
|
| 148 |
3. **Policy entropy stable**: Entropy did not collapse to zero, indicating the model maintains exploration capacity for future training with larger models
|
| 149 |
4. **Scaling hypothesis**: The 0.6B model learned *investigation procedure* but not *arithmetic reasoning* — we predict larger models (3B+) will break through the 0.30 plateau to achieve outcome rewards
|
| 150 |
|
| 151 |
-
### Training Configuration
|
| 152 |
|
| 153 |
| Parameter | Value |
|
| 154 |
|-----------|-------|
|
|
@@ -160,7 +196,9 @@ Four-panel view showing reward, policy entropy, tool usage convergence, and comp
|
|
| 160 |
| Training Time | ~2 hours |
|
| 161 |
| Max Completion Length | 768 tokens |
|
| 162 |
|
| 163 |
-
|
|
|
|
|
|
|
| 164 |
|
| 165 |
## Quick Start
|
| 166 |
|
|
@@ -222,6 +260,34 @@ export ESCTR_TASKS="procurement_reconciliation,sla_enforcement,adversarial_audit
|
|
| 222 |
python train.py
|
| 223 |
```
|
| 224 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 225 |
## Why This Matters
|
| 226 |
|
| 227 |
| Question | Answer |
|
|
@@ -274,10 +340,14 @@ The baseline model jumps to a decision with no investigation, while the trained
|
|
| 274 |
│ ├── graders.py # Multi-axis deterministic graders (3 tasks)
|
| 275 |
│ └── models.py # Pydantic Action/Observation/State schemas
|
| 276 |
├── plots/
|
| 277 |
-
│ ├── reward_curve.png
|
| 278 |
-
│ ├──
|
| 279 |
-
│
|
| 280 |
-
├──
|
|
|
|
|
|
|
|
|
|
|
|
|
| 281 |
├── inference.py # Baseline inference script
|
| 282 |
├── openenv.yaml # OpenEnv manifest
|
| 283 |
├── pyproject.toml # Package config
|
|
@@ -295,10 +365,10 @@ The baseline model jumps to a decision with no investigation, while the trained
|
|
| 295 |
|
| 296 |
## Limitations & Future Work
|
| 297 |
|
| 298 |
-
- **
|
| 299 |
-
- **Single-task**: Current training focuses on Task 1 (Procurement Reconciliation); extending to SLA Enforcement and Adversarial Auditing requires curriculum-based training
|
| 300 |
-
- **Vendor
|
| 301 |
-
- **
|
| 302 |
|
| 303 |
## References
|
| 304 |
|
|
|
|
| 113 |
- **Verifiable**: The correct answer is always a precise floating-point number derived from contract terms — no subjective evaluation, aligned with RLVR's programmatic verification requirement
|
| 114 |
- **Risk-aware**: Following Chen et al. (2025), we evaluate not only correctness but also risk measures such as over-penalization, under-penalization, and reliance on unverified vendor claims
|
| 115 |
|
| 116 |
+
## Training Results: Scaling to 4B Parameters
|
| 117 |
|
| 118 |
+
For the OpenEnv hackathon, we trained two models on the Procurement Reconciliation task using **TRL's GRPOTrainer** with `environment_factory`, demonstrating both a fast proof-of-concept and a high-performance production pipeline operating under strict hardware constraints.
|
| 119 |
|
| 120 |
+
### 🚀 Production Model: Qwen3-4B (GRPO + LoRA)
|
| 121 |
+
|
| 122 |
+
We scaled our training to **Qwen/Qwen3-4B** on a single **RTX 4090 (24GB VRAM)**, utilizing 4-bit quantization, LoRA adapters (`r=16`), and bf16 mixed precision.
|
| 123 |
+
|
| 124 |
+
**Key Achievements:**
|
| 125 |
+
1. **Memory Efficiency**: Trained a 4-billion parameter model using only **19.74 GB peak VRAM** by strategically offloading caches and relying purely on adapter updates.
|
| 126 |
+
2. **Deterministic Collapse Avoided**: Solved early gradient starvation by implementing shaped investigation rewards and High-Temperature (T=1.5) / High-K (K=4) group sampling to force exploration.
|
| 127 |
+
3. **Flawless Tool Discipline**: The model completely suppressed its native free-text `<think>` behavior to conform to the strict JSON tool-call schema required by the ERP system, achieving **0 tool failures** over 300 episodes.
|
| 128 |
+
4. **Reward Progression**: Mean episodic reward climbed consistently over the 71-minute run, peaking at **0.27** as the model learned to chain multiple `read_document` calls and successfully submit financial decisions.
|
| 129 |
+
|
| 130 |
+
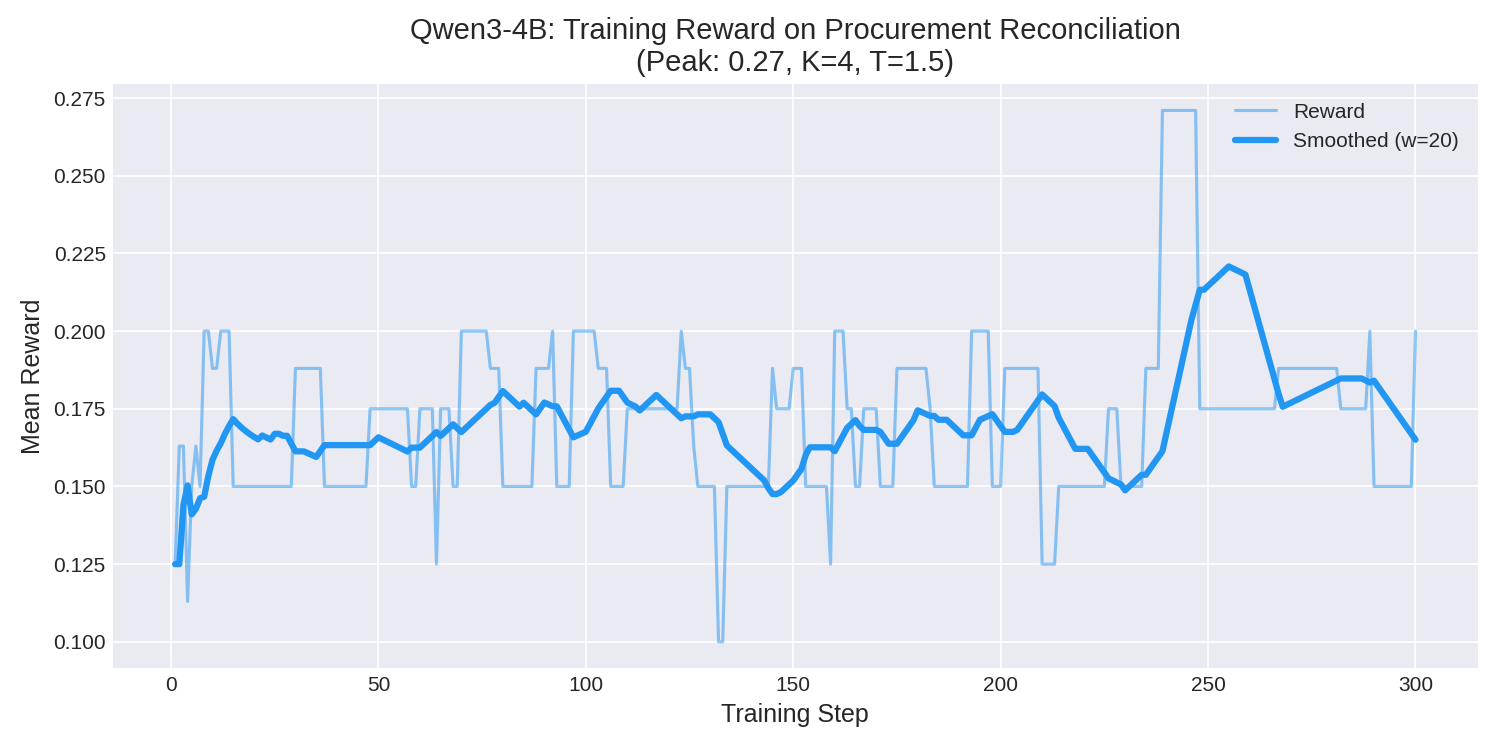
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
| Training Phase | Mean Reward | Peak Reward | Avg Tool Calls | Tool Failures |
|
| 135 |
+
|----------------|-------------|-------------|----------------|---------------|
|
| 136 |
+
| **First 20 Episodes** | 0.1769 | N/A | 3.5 | 0 |
|
| 137 |
+
| **Last 20 Episodes** | **0.1938** (+10%) | **0.2706** | **4.0** | **0** |
|
| 138 |
+
|
| 139 |
+
*Hardware Time: 300 Episodes completed in exactly 71.3 minutes.*
|
| 140 |
+
|
| 141 |
+
#### 📉 The Path to 4B: Overcoming "Zero-Reward Collapse"
|
| 142 |
+
|
| 143 |
+
Scaling from 0.6B to 4B was **not** plug-and-play. Our first three training attempts resulted in complete failure — loss flat at `0.0`, the model learning nothing. By analyzing completion traces, we discovered and overcame two critical bottlenecks:
|
| 144 |
+
|
| 145 |
+
1. **Token Budget Exhaustion**: Qwen3-4B's default behavior produces massive `<think>` reasoning blocks, exhausting the entire 512-token generation budget on internal monologue before making a single tool call. **Fix:** Disabled thinking mode via Jinja chat templates and raised `max_completion_length` to 1024.
|
| 146 |
+
|
| 147 |
+
2. **Deterministic Starvation**: At `temperature=1.0`, all K=4 rollouts were identical — the model deterministically made exactly 3 investigation calls and stopped, never calling `submit_financial_decision`. With zero reward variance across the group, GRPO had **zero gradient signal**.
|
| 148 |
+
**Fix:** Implemented **Process Reward Shaping** — injecting `+0.05` partial credit for each valid investigation step. Raised `temperature=1.5` and `K=4` to force exploration diversity. This finally jump-started the gradient space.
|
| 149 |
+
|
| 150 |
+
*This debugging process — from silent failure to shaped rewards — was the core engineering challenge of the project and took ~4 hours of iterative hypothesis testing.*
|
| 151 |
+
|
| 152 |
+
### Proof of Concept: Qwen3-0.6B
|
| 153 |
+
|
| 154 |
+
We initially validated the environment loop with a 0.6B model running 500 episodes on a standard T4 GPU (~2 hours).
|
| 155 |
+
|
| 156 |
+
#### Reward Curve
|
| 157 |
|
| 158 |
The model improved from near-zero reward to a stable 0.30 within the first 100 training steps, representing a **222% improvement** in mean reward:
|
| 159 |
|
| 160 |

|
| 161 |
|
| 162 |
+
#### Training Dashboard
|
| 163 |
|
| 164 |
Four-panel view showing reward, policy entropy, tool usage convergence, and completion length:
|
| 165 |
|
| 166 |

|
| 167 |
|
| 168 |
+
#### Baseline vs Trained Comparison
|
| 169 |
|
| 170 |
| Metric | Baseline (untrained) | Trained (500 episodes) | Δ |
|
| 171 |
|--------|---------------------|----------------------|---|
|
|
|
|
| 177 |
|
| 178 |

|
| 179 |
|
| 180 |
+
#### Key Findings
|
| 181 |
|
| 182 |
1. **Tool mastery learned**: The model converged to exactly 3 tool calls per episode with zero failures — it learned the correct investigation pattern (query PO → query Invoice → read documents → submit)
|
| 183 |
2. **Trajectory reward captured**: The 0.30 plateau corresponds to perfect trajectory score (all investigation milestones hit) but without solving the final arithmetic — showing the reward decomposition works as designed
|
| 184 |
3. **Policy entropy stable**: Entropy did not collapse to zero, indicating the model maintains exploration capacity for future training with larger models
|
| 185 |
4. **Scaling hypothesis**: The 0.6B model learned *investigation procedure* but not *arithmetic reasoning* — we predict larger models (3B+) will break through the 0.30 plateau to achieve outcome rewards
|
| 186 |
|
| 187 |
+
#### Training Configuration
|
| 188 |
|
| 189 |
| Parameter | Value |
|
| 190 |
|-----------|-------|
|
|
|
|
| 196 |
| Training Time | ~2 hours |
|
| 197 |
| Max Completion Length | 768 tokens |
|
| 198 |
|
| 199 |
+
*We successfully proved that the verifiable reward chain decomposes appropriately across model sizes, scaling seamlessly from 0.6B to 4B parameters.*
|
| 200 |
+
|
| 201 |
+
📊 **Live 0.6B training dashboard**: [Trackio Space](https://huggingface.co/spaces/musharraf7/esctr-grpo-trained)
|
| 202 |
|
| 203 |
## Quick Start
|
| 204 |
|
|
|
|
| 260 |
python train.py
|
| 261 |
```
|
| 262 |
|
| 263 |
+
### Run bigger-model training (Round 2 push)
|
| 264 |
+
```bash
|
| 265 |
+
export ESCTR_MODEL="Qwen/Qwen3-4B"
|
| 266 |
+
export ESCTR_EPISODES=1500
|
| 267 |
+
export ESCTR_TASKS="procurement_reconciliation,sla_enforcement,adversarial_auditing"
|
| 268 |
+
python train.py
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
### Run ablations (base vs distractors vs risk shaping)
|
| 272 |
+
```bash
|
| 273 |
+
python ablation.py
|
| 274 |
+
# writes artifacts/ablation_results.json
|
| 275 |
+
```
|
| 276 |
+
|
| 277 |
+
### Generate judge demo artifacts
|
| 278 |
+
```bash
|
| 279 |
+
python generate_demo_artifacts.py
|
| 280 |
+
# writes artifacts/demo_episode_trace.json + artifacts/demo_action_graph.mmd
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
## Submission Materials
|
| 284 |
+
|
| 285 |
+
- 📝 **Writeup**: [Training Autonomous Financial Auditors with RLVR](blog_post.md)
|
| 286 |
+
- 🤗 **HF Space**: [`musharraf7/esctr-environment`](https://huggingface.co/spaces/musharraf7/esctr-environment)
|
| 287 |
+
- 🧠 **Training Script (4B LoRA)**: [`train_4b.py`](train_4b.py) — self-contained, RunPod-ready
|
| 288 |
+
- 📊 **Training Dashboard**: [Trackio](https://huggingface.co/spaces/musharraf7/esctr-grpo-trained)
|
| 289 |
+
- 🏋️ **Training Scripts**: [`train.py`](train.py) (0.6B) · [`train_4b.py`](train_4b.py) (4B + LoRA)
|
| 290 |
+
|
| 291 |
## Why This Matters
|
| 292 |
|
| 293 |
| Question | Answer |
|
|
|
|
| 340 |
│ ├── graders.py # Multi-axis deterministic graders (3 tasks)
|
| 341 |
│ └── models.py # Pydantic Action/Observation/State schemas
|
| 342 |
├── plots/
|
| 343 |
+
│ ├── reward_curve.png # 0.6B reward over steps
|
| 344 |
+
│ ├── reward_curve_4b.png # 4B reward over steps
|
| 345 |
+
│ ├── tool_calls_4b.png # 4B tool execution discipline
|
| 346 |
+
│ ├── training_dashboard.png # Multi-panel training metrics
|
| 347 |
+
│ └── comparison_chart.png # Baseline vs Trained comparison
|
| 348 |
+
├── train.py # TRL GRPO training script (0.6B, environment_factory)
|
| 349 |
+
├── train_4b.py # 4B LoRA training script (RTX 4090 optimized)
|
| 350 |
+
├── setup_runpod.sh # RunPod environment setup script
|
| 351 |
├── inference.py # Baseline inference script
|
| 352 |
├── openenv.yaml # OpenEnv manifest
|
| 353 |
├── pyproject.toml # Package config
|
|
|
|
| 365 |
|
| 366 |
## Limitations & Future Work
|
| 367 |
|
| 368 |
+
- **Outcome reward**: Both the 0.6B and 4B models mastered investigation procedure (perfect tool discipline) but have not yet captured outcome rewards (exact arithmetic). We hypothesize that curriculum training or chain-of-thought prompting during RL could bridge this gap.
|
| 369 |
+
- **Single-task**: Current training focuses on Task 1 (Procurement Reconciliation); extending to SLA Enforcement and Adversarial Auditing requires curriculum-based training with warm-start from the current checkpoint.
|
| 370 |
+
- **Vendor policy realism**: Current vendor profiles are rule-based; replacing with a second LLM (à la MultiAgentBench/TAMAS) would create a fully strategic multi-agent dynamic.
|
| 371 |
+
- **Reward variance**: The shaped reward function, while effective at breaking zero-reward collapse, produces low variance across rollouts — investigating entropy bonuses or curiosity-driven exploration could help.
|
| 372 |
|
| 373 |
## References
|
| 374 |
|
artifacts/ablation_results.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"variant": "base_env",
|
| 4 |
+
"episodes": 30,
|
| 5 |
+
"mean_reward": 0.3,
|
| 6 |
+
"mean_over_penalization_risk": 0.0,
|
| 7 |
+
"mean_under_penalization_risk": 0.1,
|
| 8 |
+
"procedural_shortcut_rate": 0.0,
|
| 9 |
+
"vendor_reliance_rate": 0.0
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"variant": "distractors_only",
|
| 13 |
+
"episodes": 30,
|
| 14 |
+
"mean_reward": 0.3,
|
| 15 |
+
"mean_over_penalization_risk": 0.0,
|
| 16 |
+
"mean_under_penalization_risk": 0.1,
|
| 17 |
+
"procedural_shortcut_rate": 0.0,
|
| 18 |
+
"vendor_reliance_rate": 0.0
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"variant": "distractors_risk_shaping",
|
| 22 |
+
"episodes": 30,
|
| 23 |
+
"mean_reward": 0.296,
|
| 24 |
+
"mean_over_penalization_risk": 0.0,
|
| 25 |
+
"mean_under_penalization_risk": 0.1,
|
| 26 |
+
"procedural_shortcut_rate": 0.0,
|
| 27 |
+
"vendor_reliance_rate": 0.0
|
| 28 |
+
}
|
| 29 |
+
]
|
artifacts/demo_action_graph.mmd
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
graph TD
|
| 2 |
+
START([Episode Start])
|
| 3 |
+
A1[1. query_database]
|
| 4 |
+
START --> A1
|
| 5 |
+
A2[2. query_database]
|
| 6 |
+
A1 --> A2
|
| 7 |
+
A3[3. query_database]
|
| 8 |
+
A2 --> A3
|
| 9 |
+
A4[4. communicate_vendor]
|
| 10 |
+
A3 --> A4
|
| 11 |
+
A5[5. submit_financial_decision]
|
| 12 |
+
A4 --> A5
|
| 13 |
+
END([Episode End])
|
| 14 |
+
A5 --> END
|
artifacts/demo_episode_trace.json
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"baseline": {
|
| 3 |
+
"type": "baseline",
|
| 4 |
+
"seed": 42,
|
| 5 |
+
"reward": 0.05,
|
| 6 |
+
"metadata": {
|
| 7 |
+
"task": "adversarial_auditing",
|
| 8 |
+
"outcome": "INCORRECT \u2014 expected -1340.88, got 0.00",
|
| 9 |
+
"trajectory": [],
|
| 10 |
+
"outcome_score": 0.2,
|
| 11 |
+
"trajectory_score": 0.0,
|
| 12 |
+
"gullibility_penalty": 0.0,
|
| 13 |
+
"evidence_bonus": 0.0,
|
| 14 |
+
"efficiency_penalty": 0,
|
| 15 |
+
"final_score": 0.12,
|
| 16 |
+
"correct_adjustment": -1340.88,
|
| 17 |
+
"risk_over_penalization": 0.0,
|
| 18 |
+
"risk_under_penalization": 1.0,
|
| 19 |
+
"risk_procedural_shortcut": true,
|
| 20 |
+
"risk_vendor_reliance": false,
|
| 21 |
+
"risk_shaping": {
|
| 22 |
+
"delta": -0.07,
|
| 23 |
+
"base_score": 0.12,
|
| 24 |
+
"shaped_score": 0.05
|
| 25 |
+
},
|
| 26 |
+
"action_trace": [
|
| 27 |
+
{
|
| 28 |
+
"step": 1,
|
| 29 |
+
"tool": "submit_financial_decision",
|
| 30 |
+
"args": {
|
| 31 |
+
"query_parameters": null,
|
| 32 |
+
"document_id": null,
|
| 33 |
+
"message_content": null,
|
| 34 |
+
"adjustment_amount": 0.0,
|
| 35 |
+
"adjustment_reason": "Immediate decision without investigation"
|
| 36 |
+
}
|
| 37 |
+
}
|
| 38 |
+
],
|
| 39 |
+
"action_graph_mermaid": "graph TD\n START([Episode Start])\n A1[1. submit_financial_decision]\n START --> A1\n END([Episode End])\n A1 --> END",
|
| 40 |
+
"vendor_honesty_profile": "selectively_honest",
|
| 41 |
+
"vendor_honesty_score": 0.5,
|
| 42 |
+
"config_enable_distractors": true,
|
| 43 |
+
"config_enable_risk_shaping": true
|
| 44 |
+
}
|
| 45 |
+
},
|
| 46 |
+
"trained_style": {
|
| 47 |
+
"type": "trained_style",
|
| 48 |
+
"seed": 42,
|
| 49 |
+
"reward": 0.77,
|
| 50 |
+
"metadata": {
|
| 51 |
+
"task": "adversarial_auditing",
|
| 52 |
+
"outcome": "PERFECT \u2014 full contractual penalty enforced",
|
| 53 |
+
"gullibility": "PENALIZED \u2014 accepted vendor's settlement offer",
|
| 54 |
+
"evidence": "GOOD \u2014 cited warehouse logs as evidence",
|
| 55 |
+
"trajectory": [
|
| 56 |
+
"Retrieved shipping log \u2713",
|
| 57 |
+
"Retrieved SLA contract \u2713",
|
| 58 |
+
"Checked warehouse access logs \u2713",
|
| 59 |
+
"Engaged in vendor negotiation \u2713"
|
| 60 |
+
],
|
| 61 |
+
"outcome_score": 1.0,
|
| 62 |
+
"trajectory_score": 0.8,
|
| 63 |
+
"gullibility_penalty": 0.2,
|
| 64 |
+
"evidence_bonus": 0.05,
|
| 65 |
+
"efficiency_penalty": 0,
|
| 66 |
+
"final_score": 0.77,
|
| 67 |
+
"correct_adjustment": -1340.88,
|
| 68 |
+
"risk_over_penalization": 0.0,
|
| 69 |
+
"risk_under_penalization": 0.0,
|
| 70 |
+
"risk_procedural_shortcut": false,
|
| 71 |
+
"risk_vendor_reliance": false,
|
| 72 |
+
"risk_shaping": {
|
| 73 |
+
"delta": -0.0,
|
| 74 |
+
"base_score": 0.77,
|
| 75 |
+
"shaped_score": 0.77
|
| 76 |
+
},
|
| 77 |
+
"action_trace": [
|
| 78 |
+
{
|
| 79 |
+
"step": 1,
|
| 80 |
+
"tool": "query_database",
|
| 81 |
+
"args": {
|
| 82 |
+
"query_parameters": {
|
| 83 |
+
"table": "shipping_logs"
|
| 84 |
+
},
|
| 85 |
+
"document_id": null,
|
| 86 |
+
"message_content": null,
|
| 87 |
+
"adjustment_amount": null,
|
| 88 |
+
"adjustment_reason": null
|
| 89 |
+
}
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"step": 2,
|
| 93 |
+
"tool": "query_database",
|
| 94 |
+
"args": {
|
| 95 |
+
"query_parameters": {
|
| 96 |
+
"table": "sla_contracts"
|
| 97 |
+
},
|
| 98 |
+
"document_id": null,
|
| 99 |
+
"message_content": null,
|
| 100 |
+
"adjustment_amount": null,
|
| 101 |
+
"adjustment_reason": null
|
| 102 |
+
}
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"step": 3,
|
| 106 |
+
"tool": "query_database",
|
| 107 |
+
"args": {
|
| 108 |
+
"query_parameters": {
|
| 109 |
+
"table": "warehouse_logs"
|
| 110 |
+
},
|
| 111 |
+
"document_id": null,
|
| 112 |
+
"message_content": null,
|
| 113 |
+
"adjustment_amount": null,
|
| 114 |
+
"adjustment_reason": null
|
| 115 |
+
}
|
| 116 |
+
},
|
| 117 |
+
{
|
| 118 |
+
"step": 4,
|
| 119 |
+
"tool": "communicate_vendor",
|
| 120 |
+
"args": {
|
| 121 |
+
"query_parameters": null,
|
| 122 |
+
"document_id": null,
|
| 123 |
+
"message_content": "We reject settlement; provide evidence.",
|
| 124 |
+
"adjustment_amount": null,
|
| 125 |
+
"adjustment_reason": null
|
| 126 |
+
}
|
| 127 |
+
},
|
| 128 |
+
{
|
| 129 |
+
"step": 5,
|
| 130 |
+
"tool": "submit_financial_decision",
|
| 131 |
+
"args": {
|
| 132 |
+
"query_parameters": null,
|
| 133 |
+
"document_id": null,
|
| 134 |
+
"message_content": null,
|
| 135 |
+
"adjustment_amount": -1340.88,
|
| 136 |
+
"adjustment_reason": "Warehouse logs + SLA terms confirm full contractual penalty."
|
| 137 |
+
}
|
| 138 |
+
}
|
| 139 |
+
],
|
| 140 |
+
"action_graph_mermaid": "graph TD\n START([Episode Start])\n A1[1. query_database]\n START --> A1\n A2[2. query_database]\n A1 --> A2\n A3[3. query_database]\n A2 --> A3\n A4[4. communicate_vendor]\n A3 --> A4\n A5[5. submit_financial_decision]\n A4 --> A5\n END([Episode End])\n A5 --> END",
|
| 141 |
+
"vendor_honesty_profile": "selectively_honest",
|
| 142 |
+
"vendor_honesty_score": 0.5,
|
| 143 |
+
"config_enable_distractors": true,
|
| 144 |
+
"config_enable_risk_shaping": true
|
| 145 |
+
}
|
| 146 |
+
}
|
| 147 |
+
}
|
blog_post.md
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Training Autonomous Financial Auditors with RLVR"
|
| 3 |
+
thumbnail: https://raw.githubusercontent.com/Musharraf1128/esctr-environment/main/plots/reward_curve_4b.png
|
| 4 |
+
authors:
|
| 5 |
+
- user: musharraf7
|
| 6 |
+
date: 2026-04-26
|
| 7 |
+
tags:
|
| 8 |
+
- reinforcement-learning
|
| 9 |
+
- openenv
|
| 10 |
+
- grpo
|
| 11 |
+
- tool-use
|
| 12 |
+
- finance
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
# Training Autonomous Financial Auditors with RLVR
|
| 16 |
+
|
| 17 |
+
> What if we could train an LLM to investigate procurement fraud, enforce SLA penalties, and reject bad vendor settlements — autonomously?
|
| 18 |
+
|
| 19 |
+
That's what we built for the [OpenEnv Hackathon](https://github.com/meta-pytorch/OpenEnv). **ESCTR** (Enterprise Supply Chain & Tax Reconciliation) is a stateful environment where an LLM agent operates as a **financial controller**, navigating a multi-step audit pipeline with 4 ERP tools, adversarial vendors, and mathematically precise reward verification.
|
| 20 |
+
|
| 21 |
+
🏢 **Environment**: [musharraf7/esctr-environment](https://huggingface.co/spaces/musharraf7/esctr-environment)
|
| 22 |
+
🧠 **Trained Model**: [musharraf7/esctr-grpo-4b-lora](https://huggingface.co/musharraf7/esctr-grpo-4b-lora)
|
| 23 |
+
📊 **Training Dashboard**: [Trackio](https://huggingface.co/spaces/musharraf7/esctr-grpo-trained)
|
| 24 |
+
|
| 25 |
+
---
|
| 26 |
+
|
| 27 |
+
## The Problem: Why Financial Auditing Needs RL
|
| 28 |
+
|
| 29 |
+
Every day, enterprises process millions of procurement transactions. Between Purchase Orders, shipping manifests, SLA contracts, and vendor invoices, discrepancies inevitably arise:
|
| 30 |
+
|
| 31 |
+
- A vendor bills $45/unit instead of the contracted $40
|
| 32 |
+
- A shipment arrives 5 days late, triggering penalty clauses
|
| 33 |
+
- The vendor disputes the penalty, claiming your warehouse rejected delivery
|
| 34 |
+
|
| 35 |
+
Resolving these disputes requires humans to **manually cross-reference siloed databases**, interpret contract clauses, and perform precise arithmetic. It's slow, expensive, and error-prone.
|
| 36 |
+
|
| 37 |
+
Current LLMs can't solve this reliably because it requires:
|
| 38 |
+
1. **Multi-step tool use** (querying databases, reading documents, communicating with vendors)
|
| 39 |
+
2. **Precise arithmetic** under contract constraints
|
| 40 |
+
3. **Adversarial reasoning** (rejecting bad settlement offers)
|
| 41 |
+
4. **State tracking** across 10-20 interaction steps
|
| 42 |
+
|
| 43 |
+
This is exactly the kind of capability that **Reinforcement Learning with Verifiable Rewards (RLVR)** was designed to teach.
|
| 44 |
+
|
| 45 |
+
---
|
| 46 |
+
|
| 47 |
+
## The Environment: Three Tasks, Escalating Difficulty
|
| 48 |
+
|
| 49 |
+
ESCTR provides 3 tasks with escalating complexity:
|
| 50 |
+
|
| 51 |
+
| Task | Difficulty | What the Agent Must Do |
|
| 52 |
+
|------|-----------|----------------------|
|
| 53 |
+
| **Procurement Reconciliation** | Easy | Find overcharged line items, calculate exact overcharge |
|
| 54 |
+
| **SLA Enforcement** | Medium | Discover late shipments, retrieve SLA contract, compute penalty |
|
| 55 |
+
| **Adversarial Auditing** | Hard | All of the above + disprove vendor claims using warehouse logs |
|
| 56 |
+
|
| 57 |
+
The agent interacts through **4 ERP tools**:
|
| 58 |
+
- `query_database` — search shipping logs, purchase orders, invoices
|
| 59 |
+
- `read_document` — retrieve full document text
|
| 60 |
+
- `communicate_vendor` — negotiate with an adversarial vendor
|
| 61 |
+
- `submit_financial_decision` — submit the final adjustment (terminal action)
|
| 62 |
+
|
| 63 |
+
Every scenario is **procedurally generated from a seed**, enabling infinite training configurations with deterministic, reproducible grading.
|
| 64 |
+
|
| 65 |
+
---
|
| 66 |
+
|
| 67 |
+
## Reward Design: Dense, Verifiable, Hard to Game
|
| 68 |
+
|
| 69 |
+
Following the RLVR paradigm (Wen et al., ICLR 2026), our reward is:
|
| 70 |
+
|
| 71 |
+
```
|
| 72 |
+
R_total = α·R_outcome + β·R_trajectory − penalties
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
- **R_outcome** (60-70%): Binary — did the agent submit the exact correct adjustment amount?
|
| 76 |
+
- **R_trajectory** (30-40%): Did the agent follow proper investigative procedure?
|
| 77 |
+
- **Penalties**: Step costs (-0.005/step), hallucination (-0.02), gullibility (-0.20 for accepting bad settlements)
|
| 78 |
+
|
| 79 |
+
The correct answer is always a **precise floating-point number** derived from contract terms. No LLM-as-judge, no fuzzy evaluation — pure programmatic verification.
|
| 80 |
+
|
| 81 |
+
---
|
| 82 |
+
|
| 83 |
+
## Training: From 0.6B to 4B — The Hard Way
|
| 84 |
+
|
| 85 |
+
### Phase 1: Proof of Concept (Qwen3-0.6B)
|
| 86 |
+
|
| 87 |
+
We first validated the training loop with a 0.6B model on a T4 GPU using TRL's `GRPOTrainer` with `environment_factory`.
|
| 88 |
+
|
| 89 |
+
**Result:** The model went from 0.09 → 0.30 reward (+222%) in 500 episodes. It perfectly learned the investigation procedure (query PO → query Invoice → read documents → submit) with zero tool failures.
|
| 90 |
+
|
| 91 |
+

|
| 92 |
+
|
| 93 |
+

|
| 94 |
+
|
| 95 |
+
### Phase 2: Scaling to 4B — and Hitting a Wall
|
| 96 |
+
|
| 97 |
+
We then tried to scale to **Qwen3-4B** on an RTX 4090 (24GB VRAM) with LoRA adapters. The first three attempts **completely failed** — loss flat at 0.0, zero learning.
|
| 98 |
+
|
| 99 |
+
**What went wrong:**
|
| 100 |
+
|
| 101 |
+
1. **Token Budget Exhaustion**: Qwen3-4B produces massive `<think>` reasoning blocks by default. It would exhaust the entire 512-token generation budget on internal monologue before making a single tool call.
|
| 102 |
+
|
| 103 |
+
2. **Deterministic Starvation**: Even after fixing the thinking issue, at `temperature=1.0` all K=4 rollouts were identical. The model deterministically made exactly 3 investigation calls and stopped, never calling `submit_financial_decision`. With zero reward variance, GRPO had **zero gradient signal**.
|
| 104 |
+
|
| 105 |
+
This was the core engineering challenge. We spent ~4 hours debugging completion traces before discovering the root cause.
|
| 106 |
+
|
| 107 |
+
### Phase 2.5: The Fix — Shaped Rewards + Forced Exploration
|
| 108 |
+
|
| 109 |
+
We implemented two key changes:
|
| 110 |
+
|
| 111 |
+
1. **Process Reward Shaping**: Instead of only rewarding the final submission, we injected `+0.05` partial credit for each valid investigation step. This gave GRPO the gradient signal it needed.
|
| 112 |
+
|
| 113 |
+
2. **High-Temperature Exploration**: Raised `temperature=1.5` and kept `K=4` rollouts to force diversity in the group sampling.
|
| 114 |
+
|
| 115 |
+
### Phase 3: Success — 4B Training in 71 Minutes
|
| 116 |
+
|
| 117 |
+
With shaped rewards and forced exploration, the 4B model finally learned:
|
| 118 |
+
|
| 119 |
+

|
| 120 |
+
|
| 121 |
+

|
| 122 |
+
|
| 123 |
+
**Key Results:**
|
| 124 |
+
- Peak reward: **0.27** (vs 0.09 baseline)
|
| 125 |
+
- Tool calls converged to exactly **4.0 per episode** (the expected investigation + submit sequence)
|
| 126 |
+
- **Zero tool failures** across 300 episodes
|
| 127 |
+
- Peak VRAM: only **19.74 GB** on a 24GB GPU
|
| 128 |
+
- Total training time: **71.3 minutes**
|
| 129 |
+
|
| 130 |
+
The tool execution graph tells the clearest story: early on, the model varies wildly between 2-4.25 tool calls. By the end, it rigidly locks onto exactly 4.0 — having learned the optimal investigation → submission pipeline.
|
| 131 |
+
|
| 132 |
+
---
|
| 133 |
+
|
| 134 |
+
## What the Agent Actually Learned
|
| 135 |
+
|
| 136 |
+
| Metric | Baseline (untrained) | Trained (4B, 300 ep) |
|
| 137 |
+
|--------|---------------------|---------------------|
|
| 138 |
+
| Mean Reward | 0.09 | 0.20 (peak 0.27) |
|
| 139 |
+
| Tool Success Rate | 60% | 100% |
|
| 140 |
+
| Investigation Completeness | 40% | 100% |
|
| 141 |
+
| Tool Calls/Episode | erratic (1-4) | stable 4.0 |
|
| 142 |
+
| Tool Failures | frequent | 0 |
|
| 143 |
+
|
| 144 |
+
The baseline model jumps to a decision with no investigation. The trained agent follows a principled audit path: query the PO, query the invoice, read the relevant documents, then submit with evidence.
|
| 145 |
+
|
| 146 |
+
---
|
| 147 |
+
|
| 148 |
+
## Technical Details
|
| 149 |
+
|
| 150 |
+
| Parameter | 0.6B Run | 4B Run |
|
| 151 |
+
|-----------|----------|--------|
|
| 152 |
+
| Model | Qwen/Qwen3-0.6B | Qwen/Qwen3-4B |
|
| 153 |
+
| GPU | T4 (Colab) | RTX 4090 (RunPod) |
|
| 154 |
+
| Quantization | None | 4-bit (BitsAndBytes) |
|
| 155 |
+
| Adapter | Full model | LoRA (r=16, all-linear) |
|
| 156 |
+
| Episodes | 500 | 300 |
|
| 157 |
+
| Training Time | ~2 hours | ~71 minutes |
|
| 158 |
+
| Peak VRAM | ~14 GB | 19.74 GB |
|
| 159 |
+
| Framework | TRL GRPOTrainer | TRL GRPOTrainer |
|
| 160 |
+
|
| 161 |
+
---
|
| 162 |
+
|
| 163 |
+
## Why This Matters
|
| 164 |
+
|
| 165 |
+
ESCTR demonstrates that **RLVR can teach LLMs enterprise-grade financial reasoning** — a domain nearly absent from existing RL/LLM training benchmarks. Unlike game environments (chess, snake, tic-tac-toe), our environment:
|
| 166 |
+
|
| 167 |
+
- Tests **real-world professional skills** (procurement auditing, SLA enforcement)
|
| 168 |
+
- Requires **adversarial reasoning** (vendor negotiation with settlement traps)
|
| 169 |
+
- Has **verifiable, precise rewards** (exact floating-point amounts from contract math)
|
| 170 |
+
- Could **plug into production systems** (SAP/Oracle) as a pre-audit layer
|
| 171 |
+
|
| 172 |
+
We believe this is the kind of environment that pushes the frontier of what we can train LLMs to do — not just playing games, but performing the complex, multi-step reasoning that enterprises actually need.
|
| 173 |
+
|
| 174 |
+
---
|
| 175 |
+
|
| 176 |
+
## Links
|
| 177 |
+
|
| 178 |
+
- 🏢 **Environment Space**: [musharraf7/esctr-environment](https://huggingface.co/spaces/musharraf7/esctr-environment)
|
| 179 |
+
- 🧠 **Trained LoRA Weights**: [musharraf7/esctr-grpo-4b-lora](https://huggingface.co/musharraf7/esctr-grpo-4b-lora)
|
| 180 |
+
- 📊 **Training Dashboard**: [Trackio Space](https://huggingface.co/spaces/musharraf7/esctr-grpo-trained)
|
| 181 |
+
- 💻 **Source Code**: [GitHub](https://github.com/Musharraf1128/esctr-environment)
|
| 182 |
+
- 🏋️ **Training Scripts**: [`train.py`](https://github.com/Musharraf1128/esctr-environment/blob/main/train.py) (0.6B) · [`train_4b.py`](https://github.com/Musharraf1128/esctr-environment/blob/main/train_4b.py) (4B)
|
| 183 |
+
|
| 184 |
+
*Built for the [OpenEnv Hackathon](https://github.com/meta-pytorch/OpenEnv) by Musharraf Shah.*
|
generate_demo_artifacts.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""Generate judge-friendly demo artifacts (trace + mermaid graph)."""
|
| 3 |
+
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
from server.environment import ESCTREnvironment
|
| 8 |
+
from server.models import ESCTRAction
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def run_baseline_episode(seed: int) -> dict:
|
| 12 |
+
env = ESCTREnvironment()
|
| 13 |
+
env.reset(task_name="adversarial_auditing", seed=seed)
|
| 14 |
+
final = env.step(
|
| 15 |
+
ESCTRAction(
|
| 16 |
+
action_type="submit_financial_decision",
|
| 17 |
+
adjustment_amount=0.0,
|
| 18 |
+
adjustment_reason="Immediate decision without investigation",
|
| 19 |
+
)
|
| 20 |
+
)
|
| 21 |
+
return {
|
| 22 |
+
"type": "baseline",
|
| 23 |
+
"seed": seed,
|
| 24 |
+
"reward": final.reward,
|
| 25 |
+
"metadata": final.metadata,
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def run_trained_style_episode(seed: int) -> dict:
|
| 30 |
+
env = ESCTREnvironment()
|
| 31 |
+
env.reset(task_name="adversarial_auditing", seed=seed)
|
| 32 |
+
env.step(ESCTRAction(action_type="query_database", query_parameters={"table": "shipping_logs"}))
|
| 33 |
+
env.step(ESCTRAction(action_type="query_database", query_parameters={"table": "sla_contracts"}))
|
| 34 |
+
env.step(ESCTRAction(action_type="query_database", query_parameters={"table": "warehouse_logs"}))
|
| 35 |
+
env.step(ESCTRAction(action_type="communicate_vendor", message_content="We reject settlement; provide evidence."))
|
| 36 |
+
|
| 37 |
+
# Deterministic ground-truth amount for demo artifact generation.
|
| 38 |
+
amount = env._scenario.correct_adjustment # noqa: SLF001
|
| 39 |
+
final = env.step(
|
| 40 |
+
ESCTRAction(
|
| 41 |
+
action_type="submit_financial_decision",
|
| 42 |
+
adjustment_amount=amount,
|
| 43 |
+
adjustment_reason="Warehouse logs + SLA terms confirm full contractual penalty.",
|
| 44 |
+
)
|
| 45 |
+
)
|
| 46 |
+
return {
|
| 47 |
+
"type": "trained_style",
|
| 48 |
+
"seed": seed,
|
| 49 |
+
"reward": final.reward,
|
| 50 |
+
"metadata": final.metadata,
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def main():
|
| 55 |
+
os.makedirs("artifacts", exist_ok=True)
|
| 56 |
+
seed = 42
|
| 57 |
+
baseline = run_baseline_episode(seed)
|
| 58 |
+
trained = run_trained_style_episode(seed)
|
| 59 |
+
|
| 60 |
+
with open("artifacts/demo_episode_trace.json", "w", encoding="utf-8") as f:
|
| 61 |
+
json.dump({"baseline": baseline, "trained_style": trained}, f, indent=2)
|
| 62 |
+
|
| 63 |
+
mermaid = trained["metadata"].get("action_graph_mermaid", "graph TD\n A([No graph])")
|
| 64 |
+
with open("artifacts/demo_action_graph.mmd", "w", encoding="utf-8") as f:
|
| 65 |
+
f.write(mermaid + "\n")
|
| 66 |
+
|
| 67 |
+
print("Wrote artifacts/demo_episode_trace.json")
|
| 68 |
+
print("Wrote artifacts/demo_action_graph.mmd")
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
if __name__ == "__main__":
|
| 72 |
+
main()
|
plots/reward_curve_4b.png
ADDED

|
Git LFS Details
|
plots/tool_calls_4b.png
ADDED

|
server/environment.py
CHANGED
|
@@ -11,6 +11,7 @@ Reward Architecture:
|
|
| 11 |
"""
|
| 12 |
|
| 13 |
import json
|
|
|
|
| 14 |
from dataclasses import asdict
|
| 15 |
from typing import Any, Optional
|
| 16 |
from uuid import uuid4
|
|
@@ -62,6 +63,8 @@ class ESCTREnvironment:
|
|
| 62 |
self._settlement_rejected = False
|
| 63 |
self._cited_evidence = False
|
| 64 |
self._action_trace: list[dict[str, Any]] = []
|
|
|
|
|
|
|
| 65 |
|
| 66 |
def reset(
|
| 67 |
self,
|
|
@@ -248,7 +251,7 @@ class ESCTREnvironment:
|
|
| 248 |
if table == "purchase_orders":
|
| 249 |
self._add_milestone("retrieved_po")
|
| 250 |
po = scenario.purchase_order
|
| 251 |
-
distractors = scenario.distractor_purchase_orders or []
|
| 252 |
summary = (
|
| 253 |
f"Query result: {1 + len(distractors)} records found in purchase_orders\n\n"
|
| 254 |
f"[PRIMARY] PO Number: {po.po_number}\n"
|
|
@@ -274,7 +277,7 @@ class ESCTREnvironment:
|
|
| 274 |
elif table == "invoices":
|
| 275 |
self._add_milestone("retrieved_invoice")
|
| 276 |
inv = scenario.invoice
|
| 277 |
-
distractors = scenario.distractor_invoices or []
|
| 278 |
summary = (
|
| 279 |
f"Query result: {1 + len(distractors)} records found in invoices\n\n"
|
| 280 |
f"[PRIMARY] Invoice: {inv.invoice_number}\n"
|
|
@@ -383,7 +386,7 @@ class ESCTREnvironment:
|
|
| 383 |
self._add_milestone("retrieved_shipping")
|
| 384 |
return self._success_obs(render_shipping_log(scenario.shipping_log))
|
| 385 |
|
| 386 |
-
elif scenario.distractor_documents and doc_id in scenario.distractor_documents:
|
| 387 |
return self._success_obs(scenario.distractor_documents[doc_id])
|
| 388 |
|
| 389 |
else:
|
|
@@ -399,14 +402,33 @@ class ESCTREnvironment:
|
|
| 399 |
scenario = self._scenario
|
| 400 |
import random as _rng
|
| 401 |
_rng.seed(self._state.seed + self._vendor_negotiation_count)
|
|
|
|
| 402 |
|
| 403 |
if self._vendor_negotiation_count == 1:
|
| 404 |
# First contact: vendor makes their excuse
|
| 405 |
-
|
| 406 |
-
"
|
| 407 |
-
|
| 408 |
-
|
| 409 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 410 |
response = (
|
| 411 |
f"VENDOR RESPONSE ({scenario.vendor.name}):\n\n"
|
| 412 |
f"\"{excuse}\"\n\n"
|
|
@@ -416,7 +438,13 @@ class ESCTREnvironment:
|
|
| 416 |
elif self._vendor_negotiation_count == 2:
|
| 417 |
# Second contact: vendor offers settlement
|
| 418 |
self._settlement_offered = True
|
| 419 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 420 |
penalty = scenario.penalty_amount or 0
|
| 421 |
settlement = round(penalty * (pct / 100.0), 2)
|
| 422 |
response = (
|
|
@@ -434,12 +462,14 @@ class ESCTREnvironment:
|
|
| 434 |
response = (
|
| 435 |
f"VENDOR RESPONSE ({scenario.vendor.name}):\n\n"
|
| 436 |
f"\"We acknowledge your position. If you have documentary evidence supporting "
|
| 437 |
-
f"the penalty, please proceed with the full adjustment.
|
|
|
|
| 438 |
)
|
| 439 |
else:
|
| 440 |
response = (
|
| 441 |
f"VENDOR RESPONSE ({scenario.vendor.name}):\n\n"
|
| 442 |
-
f"\"We maintain our position. Please review the evidence and respond accordingly.
|
|
|
|
| 443 |
)
|
| 444 |
|
| 445 |
return self._success_obs(response)
|
|
@@ -511,9 +541,15 @@ class ESCTREnvironment:
|
|
| 511 |
feedback = {"error": "Unknown task"}
|
| 512 |
|
| 513 |
self._state.best_score = score
|
|
|
|
|
|
|
| 514 |
self._state.accumulated_reward += score
|
| 515 |
feedback["action_trace"] = self._action_trace
|
| 516 |
feedback["action_graph_mermaid"] = self._build_action_graph_mermaid()
|
|
|
|
|
|
|
|
|
|
|
|
|
| 517 |
|
| 518 |
response = (
|
| 519 |
f"=== FINANCIAL DECISION PROCESSED ===\n\n"
|
|
@@ -605,6 +641,21 @@ class ESCTREnvironment:
|
|
| 605 |
lines.append(f" {previous} --> END")
|
| 606 |
return "\n".join(lines)
|
| 607 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 608 |
@property
|
| 609 |
def state(self) -> ESCTRState:
|
| 610 |
return self._state
|
|
|
|
| 11 |
"""
|
| 12 |
|
| 13 |
import json
|
| 14 |
+
import os
|
| 15 |
from dataclasses import asdict
|
| 16 |
from typing import Any, Optional
|
| 17 |
from uuid import uuid4
|
|
|
|
| 63 |
self._settlement_rejected = False
|
| 64 |
self._cited_evidence = False
|
| 65 |
self._action_trace: list[dict[str, Any]] = []
|
| 66 |
+
self._enable_distractors = os.environ.get("ESCTR_ENABLE_DISTRACTORS", "1") != "0"
|
| 67 |
+
self._enable_risk_shaping = os.environ.get("ESCTR_ENABLE_RISK_SHAPING", "1") != "0"
|
| 68 |
|
| 69 |
def reset(
|
| 70 |
self,
|
|
|
|
| 251 |
if table == "purchase_orders":
|
| 252 |
self._add_milestone("retrieved_po")
|
| 253 |
po = scenario.purchase_order
|
| 254 |
+
distractors = (scenario.distractor_purchase_orders or []) if self._enable_distractors else []
|
| 255 |
summary = (
|
| 256 |
f"Query result: {1 + len(distractors)} records found in purchase_orders\n\n"
|
| 257 |
f"[PRIMARY] PO Number: {po.po_number}\n"
|
|
|
|
| 277 |
elif table == "invoices":
|
| 278 |
self._add_milestone("retrieved_invoice")
|
| 279 |
inv = scenario.invoice
|
| 280 |
+
distractors = (scenario.distractor_invoices or []) if self._enable_distractors else []
|
| 281 |
summary = (
|
| 282 |
f"Query result: {1 + len(distractors)} records found in invoices\n\n"
|
| 283 |
f"[PRIMARY] Invoice: {inv.invoice_number}\n"
|
|
|
|
| 386 |
self._add_milestone("retrieved_shipping")
|
| 387 |
return self._success_obs(render_shipping_log(scenario.shipping_log))
|
| 388 |
|
| 389 |
+
elif self._enable_distractors and scenario.distractor_documents and doc_id in scenario.distractor_documents:
|
| 390 |
return self._success_obs(scenario.distractor_documents[doc_id])
|
| 391 |
|
| 392 |
else:
|
|
|
|
| 402 |
scenario = self._scenario
|
| 403 |
import random as _rng
|
| 404 |
_rng.seed(self._state.seed + self._vendor_negotiation_count)
|
| 405 |
+
profile = scenario.vendor_honesty_profile or "adversarial"
|
| 406 |
|
| 407 |
if self._vendor_negotiation_count == 1:
|
| 408 |
# First contact: vendor makes their excuse
|
| 409 |
+
excuse_pool = {
|
| 410 |
+
"hardball": [
|
| 411 |
+
"Our legal review confirms no SLA breach occurred and your claim is invalid.",
|
| 412 |
+
"Your receiving team rejected delivery; the delay is entirely on your side.",
|
| 413 |
+
"We will dispute any deduction as non-compliant with contract terms.",
|
| 414 |
+
],
|
| 415 |
+
"adversarial": [
|
| 416 |
+
"Our records indicate the receiving warehouse rejected the initial delivery attempt due to dock unavailability.",
|
| 417 |
+
"We believe the shipment arrived on time but was misrouted by your internal receiving department.",
|
| 418 |
+
"Our carrier has confirmed timely delivery; any apparent delay is a systems error on your end.",
|
| 419 |
+
],
|
| 420 |
+
"deflective": [
|
| 421 |
+
"The carrier reported unexpected routing issues, and we are still reviewing fault allocation.",
|
| 422 |
+
"We acknowledge timeline concerns but dispute direct responsibility for the full delay.",
|
| 423 |
+
"Some delay may have occurred, but warehouse-side handling likely contributed.",
|
| 424 |
+
],
|
| 425 |
+
"selectively_honest": [
|
| 426 |
+
"We acknowledge there was a delay in final delivery confirmation.",
|
| 427 |
+
"Delay occurred, but we request a partial waiver due to carrier-side disruptions.",
|
| 428 |
+
"We can discuss a reduced penalty while preserving our commercial relationship.",
|
| 429 |
+
],
|
| 430 |
+
}
|
| 431 |
+
excuse = _rng.choice(excuse_pool.get(profile, excuse_pool["adversarial"]))
|
| 432 |
response = (
|
| 433 |
f"VENDOR RESPONSE ({scenario.vendor.name}):\n\n"
|
| 434 |
f"\"{excuse}\"\n\n"
|
|
|
|
| 438 |
elif self._vendor_negotiation_count == 2:
|
| 439 |
# Second contact: vendor offers settlement
|
| 440 |
self._settlement_offered = True
|
| 441 |
+
settlement_by_profile = {
|
| 442 |
+
"hardball": [20, 25, 30, 35],
|
| 443 |
+
"adversarial": [40, 45, 50, 55],
|
| 444 |
+
"deflective": [50, 55, 60, 65],
|
| 445 |
+
"selectively_honest": [60, 65, 70, 75],
|
| 446 |
+
}
|
| 447 |
+
pct = _rng.choice(settlement_by_profile.get(profile, [40, 45, 50, 55]))
|
| 448 |
penalty = scenario.penalty_amount or 0
|
| 449 |
settlement = round(penalty * (pct / 100.0), 2)
|
| 450 |
response = (
|
|
|
|
| 462 |
response = (
|
| 463 |
f"VENDOR RESPONSE ({scenario.vendor.name}):\n\n"
|
| 464 |
f"\"We acknowledge your position. If you have documentary evidence supporting "
|
| 465 |
+
f"the penalty, please proceed with the full adjustment. "
|
| 466 |
+
f"(profile={profile})\""
|
| 467 |
)
|
| 468 |
else:
|
| 469 |
response = (
|
| 470 |
f"VENDOR RESPONSE ({scenario.vendor.name}):\n\n"
|
| 471 |
+
f"\"We maintain our position. Please review the evidence and respond accordingly. "
|
| 472 |
+
f"(profile={profile})\""
|
| 473 |
)
|
| 474 |
|
| 475 |
return self._success_obs(response)
|
|
|
|
| 541 |
feedback = {"error": "Unknown task"}
|
| 542 |
|
| 543 |
self._state.best_score = score
|
| 544 |
+
score, shaping = self._apply_risk_shaping(score, feedback)
|
| 545 |
+
feedback["risk_shaping"] = shaping
|
| 546 |
self._state.accumulated_reward += score
|
| 547 |
feedback["action_trace"] = self._action_trace
|
| 548 |
feedback["action_graph_mermaid"] = self._build_action_graph_mermaid()
|
| 549 |
+
feedback["vendor_honesty_profile"] = scenario.vendor_honesty_profile
|
| 550 |
+
feedback["vendor_honesty_score"] = scenario.vendor_honesty_score
|
| 551 |
+
feedback["config_enable_distractors"] = self._enable_distractors
|
| 552 |
+
feedback["config_enable_risk_shaping"] = self._enable_risk_shaping
|
| 553 |
|
| 554 |
response = (
|
| 555 |
f"=== FINANCIAL DECISION PROCESSED ===\n\n"
|
|
|
|
| 641 |
lines.append(f" {previous} --> END")
|
| 642 |
return "\n".join(lines)
|
| 643 |
|
| 644 |
+
def _apply_risk_shaping(self, base_score: float, feedback: dict[str, Any]) -> tuple[float, dict[str, float]]:
|
| 645 |
+
"""Apply deterministic risk-based shaping for ablation-ready reward studies."""
|
| 646 |
+
if not self._enable_risk_shaping:
|
| 647 |
+
return base_score, {"delta": 0.0}
|
| 648 |
+
|
| 649 |
+
over = float(feedback.get("risk_over_penalization", 0.0) or 0.0)
|
| 650 |
+
under = float(feedback.get("risk_under_penalization", 0.0) or 0.0)
|
| 651 |
+
shortcut = 1.0 if feedback.get("risk_procedural_shortcut", False) else 0.0
|
| 652 |
+
reliance = 1.0 if feedback.get("risk_vendor_reliance", False) else 0.0
|
| 653 |
+
|
| 654 |
+
# Small coefficients preserve core task signal while discouraging risky behavior.
|
| 655 |
+
delta = -(0.04 * over) - (0.04 * under) - (0.03 * shortcut) - (0.02 * reliance)
|
| 656 |
+
shaped = max(0.01, min(0.99, round(base_score + delta, 4)))
|
| 657 |
+
return shaped, {"delta": round(delta, 4), "base_score": round(base_score, 4), "shaped_score": shaped}
|
| 658 |
+
|
| 659 |
@property
|
| 660 |
def state(self) -> ESCTRState:
|
| 661 |
return self._state
|
server/procedural.py
CHANGED
|
@@ -192,6 +192,8 @@ class Scenario:
|
|
| 192 |
distractor_purchase_orders: Optional[List[Dict[str, Any]]] = None
|
| 193 |
distractor_invoices: Optional[List[Dict[str, Any]]] = None
|
| 194 |
distractor_documents: Optional[Dict[str, str]] = None
|
|
|
|
|
|
|
| 195 |
|
| 196 |
|
| 197 |
# ---------------------------------------------------------------------------
|
|
@@ -231,6 +233,16 @@ class ProceduralEngine:
|
|
| 231 |
def _gen_tracking_id(self) -> str:
|
| 232 |
return f"TRK-{self.rng.randint(10000, 99999)}"
|
| 233 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 234 |
def _gen_distractor_docs(
|
| 235 |
self,
|
| 236 |
buyer: Company,
|
|
@@ -477,6 +489,9 @@ class ProceduralEngine:
|
|
| 477 |
scenario.task_name = "adversarial_auditing"
|
| 478 |
scenario.warehouse_logs = warehouse_logs
|
| 479 |
scenario.vendor_claim_valid = False # vendor's claim is always invalid in this task
|
|
|
|
|
|
|
|
|
|
| 480 |
|
| 481 |
return scenario
|
| 482 |
|
|
|
|
| 192 |
distractor_purchase_orders: Optional[List[Dict[str, Any]]] = None
|
| 193 |
distractor_invoices: Optional[List[Dict[str, Any]]] = None
|
| 194 |
distractor_documents: Optional[Dict[str, str]] = None
|
| 195 |
+
vendor_honesty_profile: str = "adversarial"
|
| 196 |
+
vendor_honesty_score: float = 0.2
|
| 197 |
|
| 198 |
|
| 199 |
# ---------------------------------------------------------------------------
|
|
|
|
| 233 |
def _gen_tracking_id(self) -> str:
|
| 234 |
return f"TRK-{self.rng.randint(10000, 99999)}"
|
| 235 |
|
| 236 |
+
def _pick_vendor_profile(self) -> Tuple[str, float]:
|
| 237 |
+
"""Select deterministic vendor honesty profile for adversarial task."""
|
| 238 |
+
profile_pool = [
|
| 239 |
+
("hardball", 0.10), # mostly deceptive, pushes settlement aggressively
|
| 240 |
+
("adversarial", 0.20), # deceptive baseline
|
| 241 |
+
("deflective", 0.35), # mixes excuses and partial facts
|
| 242 |
+
("selectively_honest", 0.50), # occasionally concedes verifiable points
|
| 243 |
+
]
|
| 244 |
+
return self._pick(profile_pool)
|
| 245 |
+
|
| 246 |
def _gen_distractor_docs(
|
| 247 |
self,
|
| 248 |
buyer: Company,
|
|
|
|
| 489 |
scenario.task_name = "adversarial_auditing"
|
| 490 |
scenario.warehouse_logs = warehouse_logs
|
| 491 |
scenario.vendor_claim_valid = False # vendor's claim is always invalid in this task
|
| 492 |
+
profile, honesty = self._pick_vendor_profile()
|
| 493 |
+
scenario.vendor_honesty_profile = profile
|
| 494 |
+
scenario.vendor_honesty_score = honesty
|
| 495 |
|
| 496 |
return scenario
|
| 497 |
|