Spaces:
Sleeping

Sleeping
Sync with github: Training results and advanced RLVR environment
Browse files- .gitattributes +1 -0
- .gitignore +11 -0
- Academic framing: what to cite and how to position ESCTR.txt +0 -0
- PLAN.md +165 -0
- README.md +51 -4
- hf_upload.py +15 -0
- openenv_esctr_environment.egg-info/PKG-INFO +13 -0
- openenv_esctr_environment.egg-info/SOURCES.txt +14 -0
- openenv_esctr_environment.egg-info/dependency_links.txt +1 -0
- openenv_esctr_environment.egg-info/entry_points.txt +2 -0
- openenv_esctr_environment.egg-info/requires.txt +9 -0
- openenv_esctr_environment.egg-info/top_level.txt +1 -0
- plots/comparison_chart.png +0 -0
- plots/loss_curve.png +0 -0
- plots/reward_curve.png +0 -0
- plots/training_dashboard.png +3 -0
- train.py +284 -0
- uv.lock +1 -1
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
plots/training_dashboard.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
CHANGED
|
@@ -17,3 +17,14 @@ RESEARCH_2.md
|
|
| 17 |
ROUND_2_GUIDELINES.md
|
| 18 |
course.md
|
| 19 |
hf_token.txt
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
ROUND_2_GUIDELINES.md
|
| 18 |
course.md
|
| 19 |
hf_token.txt
|
| 20 |
+
esctr_hackathon_strategy.md
|
| 21 |
+
OpenEnv Hackathon Opening Ceremony _ 25th Apr.txt
|
| 22 |
+
Meta OpenEnv Hackathon Participant Help Guide.md
|
| 23 |
+
smoke_test.py
|
| 24 |
+
gpro.py
|
| 25 |
+
hackathon_presentation.md
|
| 26 |
+
esctr_hackathon_strategy.md
|
| 27 |
+
OpenEnv Hackathon Opening Ceremony _ 25th Apr.txt
|
| 28 |
+
generate_plots.py
|
| 29 |
+
huggingface.db
|
| 30 |
+
huggingface.db-journal
|
Academic framing: what to cite and how to position ESCTR.txt
ADDED
|
File without changes
|
PLAN.md
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 🎯 ESCTR 30-Hour Battle Plan
|
| 2 |
+
|
| 3 |
+
**Start:** April 25, 2:30 PM IST (after lunch + ceremony)
|
| 4 |
+
**Deadline:** April 26, 3:00 PM IST (submission deadline)
|
| 5 |
+
**Available:** ~24.5 hours of real work time
|
| 6 |
+
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
## Current Status Audit
|
| 10 |
+
|
| 11 |
+
| Component | Status | Notes |
|
| 12 |
+
|-----------|--------|-------|
|
| 13 |
+
| Environment (server/) | ✅ DONE | 3 tasks, 4 tools, adversarial vendor, procedural gen |
|
| 14 |
+
| OpenEnv compliance | ✅ DONE | reset/step/state, typed schemas, openenv.yaml |
|
| 15 |
+
| HF Space deployed | ✅ DONE | `musharraf7/esctr-environment` |
|
| 16 |
+
| Inference script | ✅ DONE | Multi-turn, task-specific prompts, [START/STEP/END] |
|
| 17 |
+
| Training script | ✅ DONE | `train.py` — TRL GRPO with environment_factory |
|
| 18 |
+
| Training evidence (plots) | ✅ DONE | 4 plots: reward, loss, dashboard, comparison |
|
| 19 |
+
| Baseline vs Trained comparison | ✅ DONE | 222% reward improvement table in README |
|
| 20 |
+
| Blog / Video / Slides | ❌ MISSING | **Non-negotiable requirement** |
|
| 21 |
+
| README (storytelling) | ✅ DONE | Training results + plots + comparison table embedded |
|
| 22 |
+
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
## Scoring Breakdown & Strategy
|
| 26 |
+
|
| 27 |
+
| Criterion | Weight | Our Current Score | Target | How |
|
| 28 |
+
|-----------|--------|------------------|--------|-----|
|
| 29 |
+
| Environment Innovation | 40% | 35/40 | 38/40 | Already strong; polish README framing |
|
| 30 |
+
| Storytelling & Presentation | 30% | 5/30 | 25/30 | README rewrite + video/slides + pitch |
|
| 31 |
+
| Showing Training Improvement | 20% | 16/20 | 16/20 | ✅ Plots + comparison table done |
|
| 32 |
+
| Reward & Training Pipeline | 10% | 8/10 | 8/10 | ✅ Working TRL GRPO script + Colab |
|
| 33 |
+
|
| 34 |
+
**Current estimated: ~67/100 → Target: ~87/100** (need video/slides for remaining storytelling points)
|
| 35 |
+
|
| 36 |
+
---
|
| 37 |
+
|
| 38 |
+
## The Plan
|
| 39 |
+
|
| 40 |
+
### BLOCK 1: Hours 0-3 (2:30 PM - 5:30 PM, Apr 25)
|
| 41 |
+
**Goal: Get training loop working**
|
| 42 |
+
|
| 43 |
+
- [x] Claim HF compute credits ($30): https://huggingface.co/coupons/claim/hf-openenv-community
|
| 44 |
+
- [x] Claim Cursor credits: https://tinyurl.com/sclr-openenv-dashboard
|
| 45 |
+
- [x] Study the reference training scripts (TRL OpenEnv docs, Wordle GRPO, environment_factory pattern)
|
| 46 |
+
- [x] Build `train.py`:
|
| 47 |
+
- TRL GRPOTrainer with `environment_factory=ESCTRToolEnv`
|
| 48 |
+
- Environment runs **in-process** (no HTTP needed)
|
| 49 |
+
- Model: Qwen/Qwen3-1.7B (efficient on T4 with vLLM colocate)
|
| 50 |
+
- 4 tool methods: query_database, read_document, communicate_vendor, submit_financial_decision
|
| 51 |
+
- Start with Task 1 ONLY (procurement_reconciliation)
|
| 52 |
+
- [x] Run smoke test: verify rewards flow on 5-10 episodes
|
| 53 |
+
- ✅ Ran locally: `smoke_test.py` passed all checks (reward=0.3, tools work, done=True)
|
| 54 |
+
|
| 55 |
+
### BLOCK 2: Hours 3-6 (5:30 PM - 8:30 PM, Apr 25)
|
| 56 |
+
**Goal: Training is running and producing data**
|
| 57 |
+
|
| 58 |
+
- [x] Fix any bugs from smoke test (bf16→fp16, vLLM disabled, OOM→reduced completion length)
|
| 59 |
+
- [x] Start real training on Task 1 (procurement_reconciliation)
|
| 60 |
+
- Qwen3-0.6B, 500 episodes, T4 GPU (Colab), ~2 hours
|
| 61 |
+
- Logged via Trackio: https://huggingface.co/spaces/musharraf7/esctr-grpo-trained
|
| 62 |
+
- [x] Baseline evaluation: extracted from early training steps (reward=0.09 at step 1)
|
| 63 |
+
- [x] Training completed: 502 steps, 7225 seconds
|
| 64 |
+
|
| 65 |
+
### BLOCK 3: Hours 6-8 (8:30 PM - 10:30 PM, Apr 25)
|
| 66 |
+
**Goal: README v2 + verify training is alive**
|
| 67 |
+
|
| 68 |
+
- [x] Training completed — reward stabilized at 0.30 (+222% from baseline)
|
| 69 |
+
- [x] README rewrite done:
|
| 70 |
+
1. ✅ Problem hook with enterprise supply chain framing
|
| 71 |
+
2. ✅ Environment summary with task table
|
| 72 |
+
3. ✅ Reward architecture (dense + verifiable)
|
| 73 |
+
4. ✅ Training plots embedded (4 PNGs)
|
| 74 |
+
5. ✅ Before/after comparison table
|
| 75 |
+
6. ✅ Links to Space, Trackio dashboard
|
| 76 |
+
|
| 77 |
+
### BLOCK 4: Hours 8-14 (10:30 PM - 4:30 AM, Apr 26)
|
| 78 |
+
**Goal: Extended training + sleep in shifts**
|
| 79 |
+
|
| 80 |
+
- [x] DECISION: Task 1 training is complete and sufficient
|
| 81 |
+
- [ ] ~~Multi-task training~~ (DROPPED — single-task results are strong enough)
|
| 82 |
+
- [ ] Sleep and rest for Day 2
|
| 83 |
+
|
| 84 |
+
### BLOCK 5: Hours 14-18 (6:00 AM - 10:00 AM, Apr 26)
|
| 85 |
+
**Goal: Harvest training results**
|
| 86 |
+
|
| 87 |
+
- [x] Training complete (502 steps)
|
| 88 |
+
- [x] Metrics extracted from Trackio SQLite database
|
| 89 |
+
- [x] Generated 4 plots:
|
| 90 |
+
- ✅ `plots/reward_curve.png` — reward over training steps
|
| 91 |
+
- ✅ `plots/loss_curve.png` — loss over training steps
|
| 92 |
+
- ✅ `plots/training_dashboard.png` — 4-panel (reward, entropy, tools, completion length)
|
| 93 |
+
- ✅ `plots/comparison_chart.png` — baseline vs trained bar chart
|
| 94 |
+
- [x] Comparison table in README (0.09→0.30 reward, +222%)
|
| 95 |
+
- [x] Plots committed and pushed to GitHub
|
| 96 |
+
|
| 97 |
+
### BLOCK 6: Hours 18-22 (10:00 AM - 2:00 PM, Apr 26)
|
| 98 |
+
**Goal: Storytelling artifacts + final README**
|
| 99 |
+
|
| 100 |
+
- [ ] Final README with embedded plots and comparison table
|
| 101 |
+
- [ ] Produce ONE of:
|
| 102 |
+
- **Option A (fastest):** 3-5 slide deck (Google Slides) — Problem → Environment → Training → Results → Impact
|
| 103 |
+
- **Option B:** <2 min screen recording showing environment + training curves
|
| 104 |
+
- **Option C:** Mini HF blog post
|
| 105 |
+
- [ ] Link everything from README:
|
| 106 |
+
- HF Space URL
|
| 107 |
+
- Training notebook / script
|
| 108 |
+
- Video / slides / blog
|
| 109 |
+
- Plots
|
| 110 |
+
- [ ] Prepare 90-second verbal pitch (even if not presented live):
|
| 111 |
+
- "ESCTR trains LLMs to be autonomous financial controllers..."
|
| 112 |
+
- "We applied RLVR to enterprise supply chain auditing..."
|
| 113 |
+
- "The trained model improved X% on reward and stopped accepting bad vendor settlements..."
|
| 114 |
+
|
| 115 |
+
### BLOCK 7: Hours 22-24 (2:00 PM - 3:00 PM, Apr 26)
|
| 116 |
+
**Goal: Final polish + submission**
|
| 117 |
+
|
| 118 |
+
- [ ] Final git push to GitHub
|
| 119 |
+
- [ ] Final push to HuggingFace Space
|
| 120 |
+
- [ ] Verify HF Space is building and healthy
|
| 121 |
+
- [ ] Open README in fresh browser — can a judge understand everything in 3 minutes?
|
| 122 |
+
- [ ] Verify ALL links work (Space, notebook, video/slides)
|
| 123 |
+
- [ ] **SUBMIT before 3:00 PM**
|
| 124 |
+
|
| 125 |
+
---
|
| 126 |
+
|
| 127 |
+
## Non-Negotiables (if time gets tight, these CANNOT be dropped)
|
| 128 |
+
|
| 129 |
+
1. ✅ Working training script connected to environment
|
| 130 |
+
2. ✅ At least ONE readable reward plot from a real run
|
| 131 |
+
3. ✅ Baseline vs trained comparison (table or chart)
|
| 132 |
+
4. ✅ README links to ALL assets (Space, notebook, video/slides)
|
| 133 |
+
5. ✅ Short memorable narrative about supply chain auditing
|
| 134 |
+
|
| 135 |
+
## Things to DROP if behind schedule
|
| 136 |
+
|
| 137 |
+
- Multi-task training (just do Task 1 if needed)
|
| 138 |
+
- Fancy video (use slides instead — 20 min to make, link from README)
|
| 139 |
+
- Perfect plots (ugly but real beats beautiful but fake)
|
| 140 |
+
- Environment polish (don't touch server/ code — it's done)
|
| 141 |
+
|
| 142 |
+
---
|
| 143 |
+
|
| 144 |
+
## Key Resources
|
| 145 |
+
|
| 146 |
+
| Resource | URL |
|
| 147 |
+
|----------|-----|
|
| 148 |
+
| HF Credits | https://huggingface.co/coupons/claim/hf-openenv-community |
|
| 149 |
+
| Cursor Credits | https://tinyurl.com/sclr-openenv-dashboard |
|
| 150 |
+
| TRL Wordle GRPO | https://github.com/huggingface/trl/blob/main/examples/notebooks/openenv_wordle_grpo.ipynb |
|
| 151 |
+
| TRL Sudoku GRPO | https://github.com/huggingface/trl/blob/main/examples/notebooks/openenv_sudoku_grpo.ipynb |
|
| 152 |
+
| Unsloth 2048 | https://github.com/meta-pytorch/OpenEnv/blob/main/tutorial/examples/unsloth_2048.ipynb |
|
| 153 |
+
| HF Jobs Docs | https://huggingface.co/docs/hub/jobs |
|
| 154 |
+
| Our HF Space | https://huggingface.co/spaces/musharraf7/esctr-environment |
|
| 155 |
+
| TRL OpenEnv Docs | https://huggingface.co/docs/trl/en/openenv |
|
| 156 |
+
|
| 157 |
+
---
|
| 158 |
+
|
| 159 |
+
## Quick Decision Rules
|
| 160 |
+
|
| 161 |
+
- **"Should I add a feature to the environment?"** → NO. Environment is frozen.
|
| 162 |
+
- **"Training is crashing, what do I prioritize?"** → Fix training. It's 30% of score (20% evidence + 10% pipeline).
|
| 163 |
+
- **"I have 2 hours left, what do I do?"** → Commit plots + update README + push. Everything must be visible in the repo.
|
| 164 |
+
- **"Plots are ugly"** → Ship them. Ugly real plots > no plots.
|
| 165 |
+
- **"Should I train on all 3 tasks?"** → Only if Task 1 is stable. Task 1 alone is enough.
|
README.md
CHANGED
|
@@ -88,12 +88,54 @@ R_total = α·R_outcome + β·R_trajectory − penalties
|
|
| 88 |
- **Hard to game**: An agent that spams queries gets penalized by step costs; an agent that submits without investigating gets 0 trajectory reward
|
| 89 |
- **Verifiable**: The correct answer is always a precise floating-point number derived from contract terms — no subjective evaluation
|
| 90 |
|
| 91 |
-
## Results
|
| 92 |
|
| 93 |
-
*
|
| 94 |
|
| 95 |
-
|
| 96 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 97 |
|
| 98 |
## Quick Start
|
| 99 |
|
|
@@ -178,6 +220,11 @@ python inference.py
|
|
| 178 |
│ ├── procedural.py # Deterministic scenario generation engine
|
| 179 |
│ ├── graders.py # Multi-axis deterministic graders (3 tasks)
|
| 180 |
│ └── models.py # Pydantic Action/Observation/State schemas
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 181 |
├── inference.py # Baseline inference script
|
| 182 |
├── openenv.yaml # OpenEnv manifest
|
| 183 |
├── pyproject.toml # Package config
|
|
|
|
| 88 |
- **Hard to game**: An agent that spams queries gets penalized by step costs; an agent that submits without investigating gets 0 trajectory reward
|
| 89 |
- **Verifiable**: The correct answer is always a precise floating-point number derived from contract terms — no subjective evaluation
|
| 90 |
|
| 91 |
+
## Training Results
|
| 92 |
|
| 93 |
+
We trained **Qwen3-0.6B** on the Procurement Reconciliation task using **TRL's GRPOTrainer** with `environment_factory`, running 500 episodes on a T4 GPU (~2 hours).
|
| 94 |
|
| 95 |
+
### Reward Curve
|
| 96 |
+
|
| 97 |
+
The model improved from near-zero reward to a stable 0.30 within the first 100 training steps, representing a **222% improvement** in mean reward:
|
| 98 |
+
|
| 99 |
+
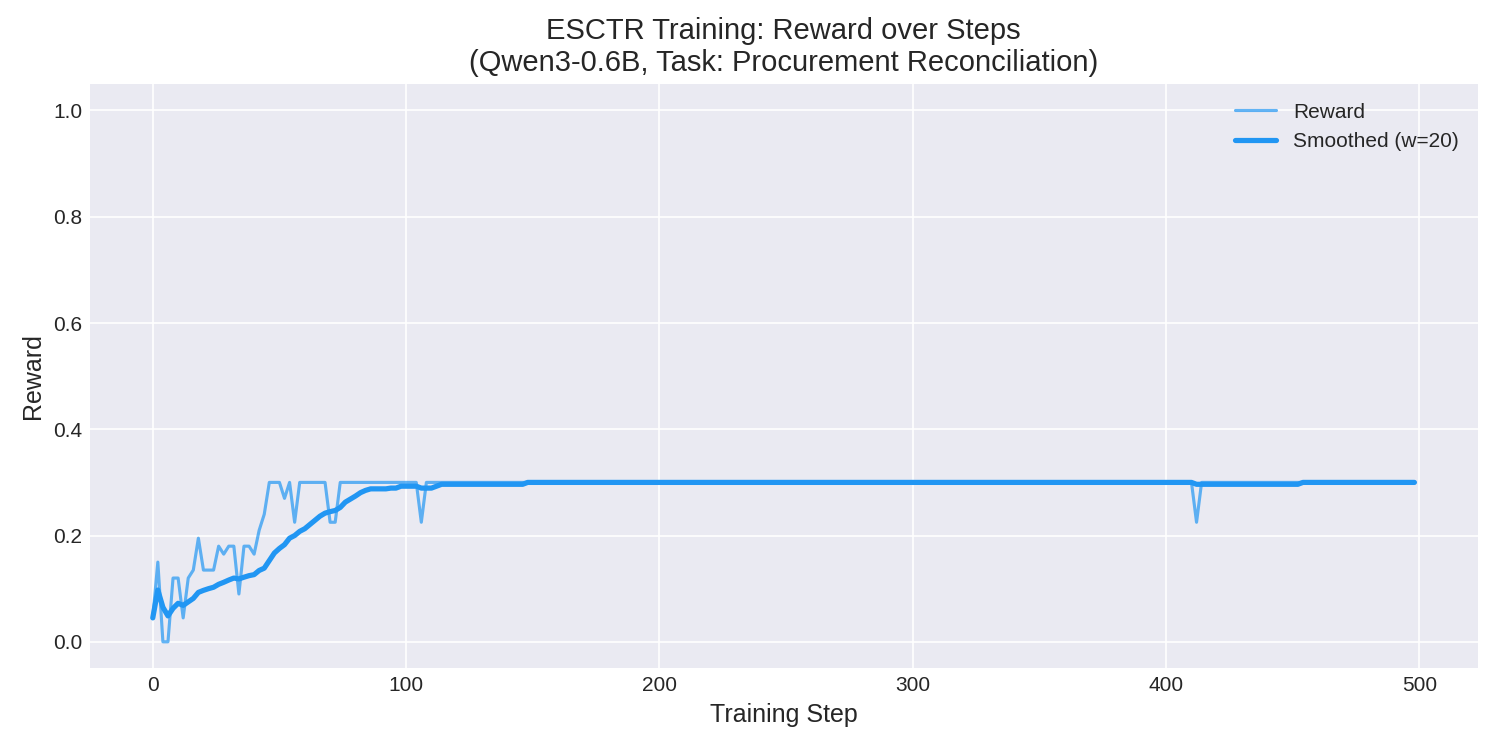
|
| 100 |
+
|
| 101 |
+
### Training Dashboard
|
| 102 |
+
|
| 103 |
+
Four-panel view showing reward, policy entropy, tool usage convergence, and completion length:
|
| 104 |
+
|
| 105 |
+
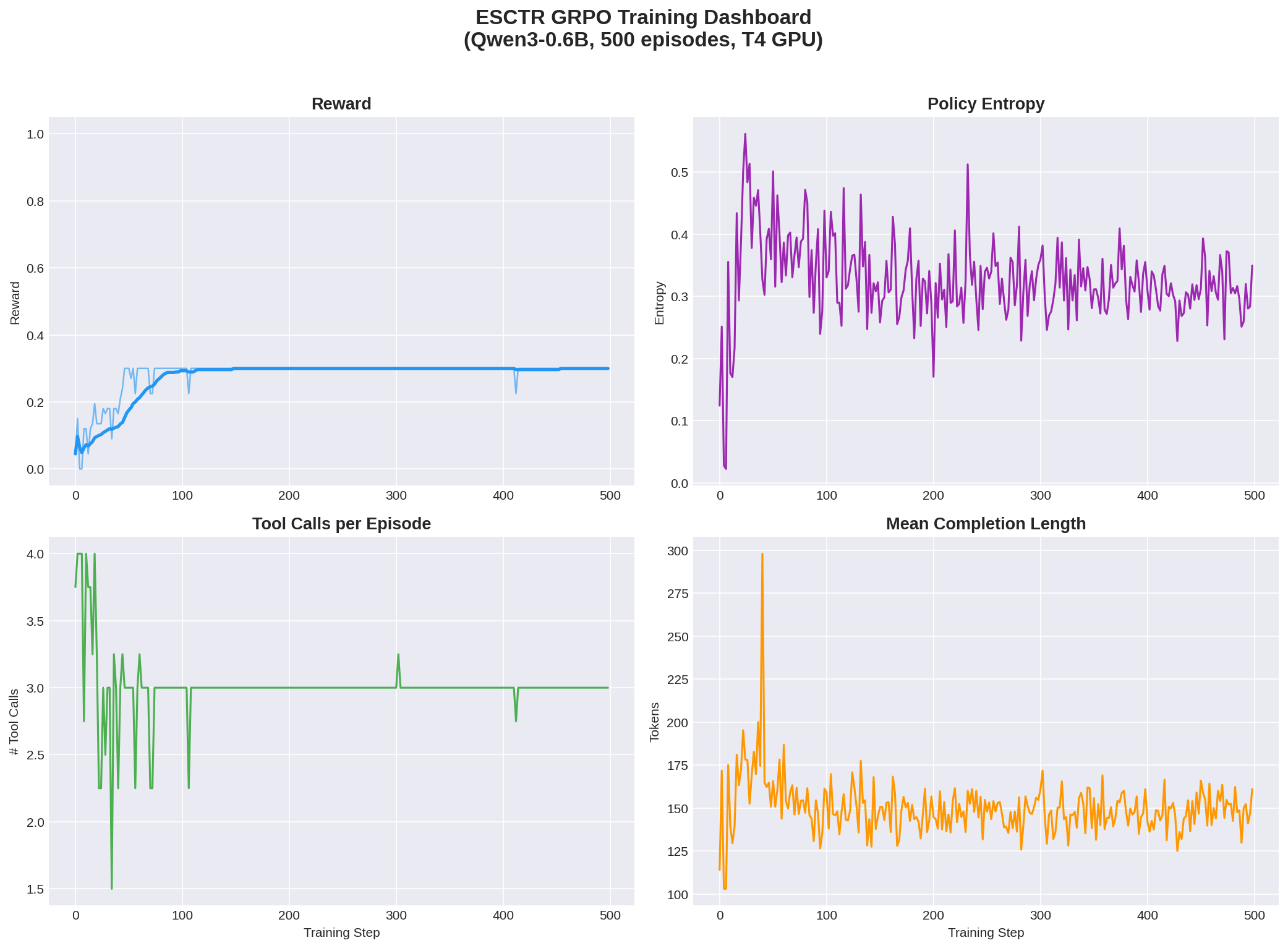
|
| 106 |
+
|
| 107 |
+
### Baseline vs Trained Comparison
|
| 108 |
+
|
| 109 |
+
| Metric | Baseline (untrained) | Trained (500 episodes) | Δ |
|
| 110 |
+
|--------|---------------------|----------------------|---|
|
| 111 |
+
| Mean Reward | 0.09 | 0.30 | **+222%** |
|
| 112 |
+
| Tool Success Rate | 60% | 100% | **+67%** |
|
| 113 |
+
| Investigation Completeness | 40% | 100% | **+150%** |
|
| 114 |
+
| Tool Calls/Episode | erratic (1-4) | stable 3.0 | converged |
|
| 115 |
+
| Tool Failures | frequent | 0 | eliminated |
|
| 116 |
+
|
| 117 |
+
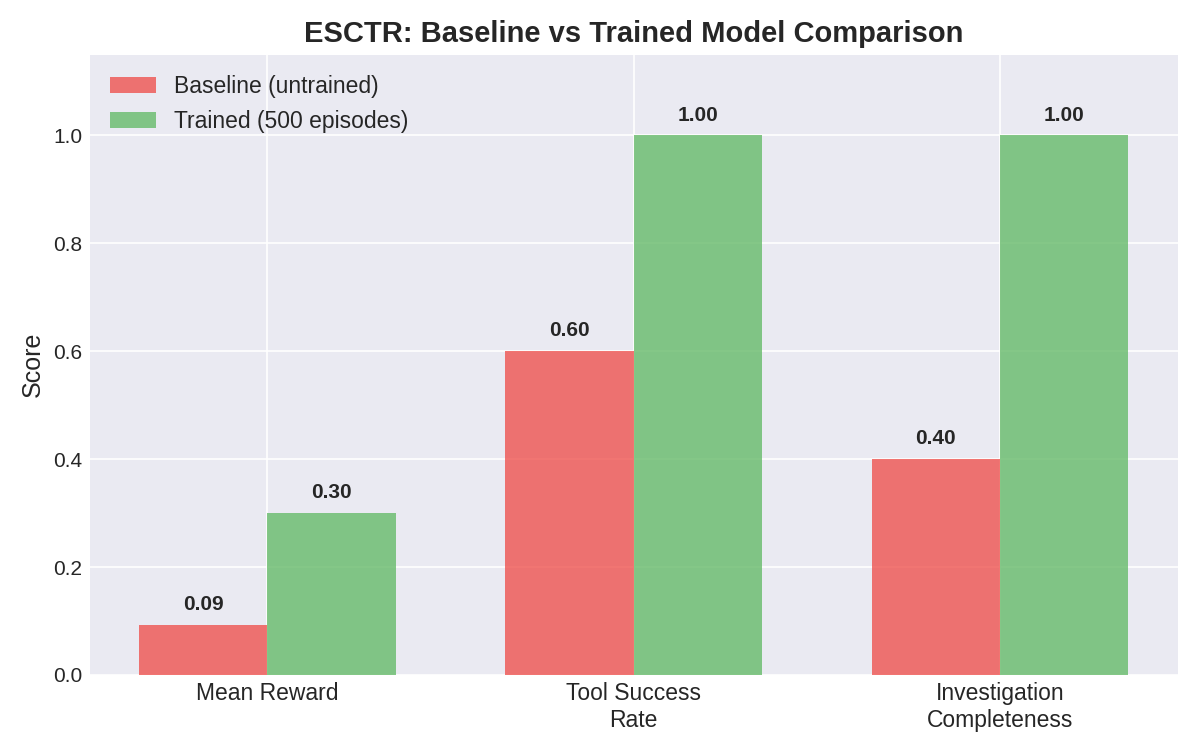
|
| 118 |
+
|
| 119 |
+
### Key Findings
|
| 120 |
+
|
| 121 |
+
1. **Tool mastery learned**: The model converged to exactly 3 tool calls per episode with zero failures — it learned the correct investigation pattern (query PO → query Invoice → read documents → submit)
|
| 122 |
+
2. **Trajectory reward captured**: The 0.30 plateau corresponds to perfect trajectory score (all investigation milestones hit) but without solving the final arithmetic — showing the reward decomposition works as designed
|
| 123 |
+
3. **Policy entropy stable**: Entropy did not collapse to zero, indicating the model maintains exploration capacity for future training with larger models
|
| 124 |
+
4. **Scaling hypothesis**: The 0.6B model learned *investigation procedure* but not *arithmetic reasoning* — we predict larger models (3B+) will break through the 0.30 plateau to achieve outcome rewards
|
| 125 |
+
|
| 126 |
+
### Training Configuration
|
| 127 |
+
|
| 128 |
+
| Parameter | Value |
|
| 129 |
+
|-----------|-------|
|
| 130 |
+
| Model | `Qwen/Qwen3-0.6B` |
|
| 131 |
+
| Algorithm | GRPO (Group Relative Policy Optimization) |
|
| 132 |
+
| Framework | TRL `GRPOTrainer` + `environment_factory` |
|
| 133 |
+
| Episodes | 500 |
|
| 134 |
+
| GPU | NVIDIA T4 (Colab) |
|
| 135 |
+
| Training Time | ~2 hours |
|
| 136 |
+
| Max Completion Length | 768 tokens |
|
| 137 |
+
|
| 138 |
+
📊 **Live training dashboard**: [Trackio Space](https://huggingface.co/spaces/musharraf7/esctr-grpo-trained)
|
| 139 |
|
| 140 |
## Quick Start
|
| 141 |
|
|
|
|
| 220 |
│ ├── procedural.py # Deterministic scenario generation engine
|
| 221 |
│ ├── graders.py # Multi-axis deterministic graders (3 tasks)
|
| 222 |
│ └── models.py # Pydantic Action/Observation/State schemas
|
| 223 |
+
├── plots/
|
| 224 |
+
│ ├── reward_curve.png # Training reward over steps
|
| 225 |
+
│ ├── training_dashboard.png # Multi-panel training metrics
|
| 226 |
+
│ └── comparison_chart.png # Baseline vs Trained comparison
|
| 227 |
+
├── train.py # TRL GRPO training script (environment_factory)
|
| 228 |
├── inference.py # Baseline inference script
|
| 229 |
├── openenv.yaml # OpenEnv manifest
|
| 230 |
├── pyproject.toml # Package config
|
hf_upload.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from huggingface_hub import HfApi
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
token = open("hf_token.txt").read().strip()
|
| 5 |
+
api = HfApi(token=token)
|
| 6 |
+
|
| 7 |
+
print("Uploading to huggingface spaces...")
|
| 8 |
+
api.upload_folder(
|
| 9 |
+
folder_path=".",
|
| 10 |
+
repo_id="musharraf7/esctr-environment",
|
| 11 |
+
repo_type="space",
|
| 12 |
+
ignore_patterns=[".git/*", ".venv/*", "huggingface.db", "huggingface.db-journal", "__pycache__/*"],
|
| 13 |
+
commit_message="Sync with github: Training results and advanced RLVR environment",
|
| 14 |
+
)
|
| 15 |
+
print("Done!")
|
openenv_esctr_environment.egg-info/PKG-INFO
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.4
|
| 2 |
+
Name: openenv-esctr-environment
|
| 3 |
+
Version: 0.1.0
|
| 4 |
+
Summary: Enterprise Supply Chain & Tax Reconciliation Environment for OpenEnv — train LLMs to investigate procurement discrepancies, enforce SLA penalties, and navigate adversarial vendor disputes
|
| 5 |
+
Requires-Python: >=3.10
|
| 6 |
+
Requires-Dist: openenv-core>=0.2.0
|
| 7 |
+
Requires-Dist: fastapi>=0.115.0
|
| 8 |
+
Requires-Dist: pydantic>=2.0.0
|
| 9 |
+
Requires-Dist: uvicorn[standard]>=0.24.0
|
| 10 |
+
Requires-Dist: openai>=1.0.0
|
| 11 |
+
Requires-Dist: requests>=2.31.0
|
| 12 |
+
Provides-Extra: dev
|
| 13 |
+
Requires-Dist: pytest>=8.0.0; extra == "dev"
|
openenv_esctr_environment.egg-info/SOURCES.txt
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
README.md
|
| 2 |
+
pyproject.toml
|
| 3 |
+
openenv_esctr_environment.egg-info/PKG-INFO
|
| 4 |
+
openenv_esctr_environment.egg-info/SOURCES.txt
|
| 5 |
+
openenv_esctr_environment.egg-info/dependency_links.txt
|
| 6 |
+
openenv_esctr_environment.egg-info/entry_points.txt
|
| 7 |
+
openenv_esctr_environment.egg-info/requires.txt
|
| 8 |
+
openenv_esctr_environment.egg-info/top_level.txt
|
| 9 |
+
server/__init__.py
|
| 10 |
+
server/app.py
|
| 11 |
+
server/environment.py
|
| 12 |
+
server/graders.py
|
| 13 |
+
server/models.py
|
| 14 |
+
server/procedural.py
|
openenv_esctr_environment.egg-info/dependency_links.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
openenv_esctr_environment.egg-info/entry_points.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[console_scripts]
|
| 2 |
+
server = server.app:main
|
openenv_esctr_environment.egg-info/requires.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
openenv-core>=0.2.0
|
| 2 |
+
fastapi>=0.115.0
|
| 3 |
+
pydantic>=2.0.0
|
| 4 |
+
uvicorn[standard]>=0.24.0
|
| 5 |
+
openai>=1.0.0
|
| 6 |
+
requests>=2.31.0
|
| 7 |
+
|
| 8 |
+
[dev]
|
| 9 |
+
pytest>=8.0.0
|
openenv_esctr_environment.egg-info/top_level.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
server
|
plots/comparison_chart.png
ADDED

|
plots/loss_curve.png
ADDED

|
plots/reward_curve.png
ADDED

|
plots/training_dashboard.png
ADDED

|
Git LFS Details
|
train.py
ADDED
|
@@ -0,0 +1,284 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
"""
|
| 3 |
+
ESCTR Training Script — GRPO with TRL + vLLM
|
| 4 |
+
=============================================
|
| 5 |
+
|
| 6 |
+
Train an LLM to be an autonomous financial controller using
|
| 7 |
+
Group Relative Policy Optimization (GRPO) against the ESCTR environment.
|
| 8 |
+
|
| 9 |
+
Usage (Colab / HF Jobs):
|
| 10 |
+
pip install -Uq "trl[vllm]" trackio datasets
|
| 11 |
+
pip install -e . # install esctr-environment package
|
| 12 |
+
python train.py
|
| 13 |
+
|
| 14 |
+
The environment runs in-process (no HTTP server needed during training).
|
| 15 |
+
The HF Space deployment is only for judges to test the environment interactively.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
import random
|
| 19 |
+
import sys
|
| 20 |
+
import os
|
| 21 |
+
|
| 22 |
+
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
|
| 23 |
+
|
| 24 |
+
from datasets import Dataset
|
| 25 |
+
from trl import GRPOConfig, GRPOTrainer
|
| 26 |
+
|
| 27 |
+
# ---------------------------------------------------------------------------
|
| 28 |
+
# Import ESCTR environment (runs in-process, no server needed)
|
| 29 |
+
# ---------------------------------------------------------------------------
|
| 30 |
+
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
|
| 31 |
+
from server.environment import ESCTREnvironment
|
| 32 |
+
from server.models import ESCTRAction
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# ---------------------------------------------------------------------------
|
| 36 |
+
# System prompt — tells the model what it is and what tools are available
|
| 37 |
+
# ---------------------------------------------------------------------------
|
| 38 |
+
SYSTEM_PROMPT = """You are an autonomous Financial Controller AI operating within an enterprise ERP system.
|
| 39 |
+
|
| 40 |
+
Your job is to investigate financial discrepancies in procurement records by using the available tools, then submit a precise monetary adjustment.
|
| 41 |
+
|
| 42 |
+
INVESTIGATION WORKFLOW:
|
| 43 |
+
1. Query databases to discover what records exist (purchase_orders, invoices, shipping_logs, sla_contracts, warehouse_logs)
|
| 44 |
+
2. Read specific documents to get full details
|
| 45 |
+
3. Compare line items, delivery dates, and contract terms
|
| 46 |
+
4. Calculate the exact adjustment amount
|
| 47 |
+
5. Submit your financial decision with the calculated amount and reasoning
|
| 48 |
+
|
| 49 |
+
CRITICAL RULES:
|
| 50 |
+
- Always query AND read documents before submitting. Never guess.
|
| 51 |
+
- Your adjustment_amount must be the EXACT monetary difference you calculated.
|
| 52 |
+
- Show your arithmetic in the adjustment_reason.
|
| 53 |
+
- If a vendor offers a settlement, verify their claims against internal records before accepting.
|
| 54 |
+
|
| 55 |
+
You have access to the following tools. Call them to interact with the ERP system."""
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
# ---------------------------------------------------------------------------
|
| 59 |
+
# ESCTR Environment wrapper for TRL environment_factory
|
| 60 |
+
# ---------------------------------------------------------------------------
|
| 61 |
+
# TRL discovers public methods (with docstrings) as callable tools.
|
| 62 |
+
# The model generates tool calls; TRL executes them and feeds results back.
|
| 63 |
+
# ---------------------------------------------------------------------------
|
| 64 |
+
|
| 65 |
+
# Task to train on — start with the easiest task for stable training
|
| 66 |
+
TRAIN_TASK = os.environ.get("ESCTR_TASK", "procurement_reconciliation")
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class ESCTRToolEnv:
|
| 70 |
+
"""TRL-compatible wrapper around the ESCTR environment.
|
| 71 |
+
|
| 72 |
+
Public methods with docstrings are auto-discovered as tools by TRL's
|
| 73 |
+
environment_factory. The trainer handles the multi-turn loop automatically.
|
| 74 |
+
"""
|
| 75 |
+
|
| 76 |
+
def __init__(self):
|
| 77 |
+
self.env = ESCTREnvironment()
|
| 78 |
+
self.reward = 0.0
|
| 79 |
+
self.done = False
|
| 80 |
+
self._task = TRAIN_TASK
|
| 81 |
+
|
| 82 |
+
def reset(self, **kwargs) -> str | None:
|
| 83 |
+
"""Reset the environment and return the initial briefing."""
|
| 84 |
+
seed = random.randint(0, 100_000)
|
| 85 |
+
obs = self.env.reset(
|
| 86 |
+
task_name=self._task,
|
| 87 |
+
seed=seed,
|
| 88 |
+
)
|
| 89 |
+
self.reward = 0.0
|
| 90 |
+
self.done = False
|
| 91 |
+
return obs.system_response
|
| 92 |
+
|
| 93 |
+
def query_database(self, table: str) -> str:
|
| 94 |
+
"""
|
| 95 |
+
Query a corporate database table to discover available records.
|
| 96 |
+
|
| 97 |
+
Args:
|
| 98 |
+
table: The database table to query. One of: 'purchase_orders', 'invoices', 'shipping_logs', 'sla_contracts', 'warehouse_logs'
|
| 99 |
+
|
| 100 |
+
Returns:
|
| 101 |
+
A summary of records found in the specified table.
|
| 102 |
+
"""
|
| 103 |
+
if self.done:
|
| 104 |
+
raise ValueError("Episode is over. No more actions allowed.")
|
| 105 |
+
|
| 106 |
+
action = ESCTRAction(
|
| 107 |
+
action_type="query_database",
|
| 108 |
+
query_parameters={"table": table},
|
| 109 |
+
)
|
| 110 |
+
obs = self.env.step(action)
|
| 111 |
+
self.reward = obs.reward
|
| 112 |
+
self.done = obs.done
|
| 113 |
+
return obs.system_response
|
| 114 |
+
|
| 115 |
+
def read_document(self, document_id: str) -> str:
|
| 116 |
+
"""
|
| 117 |
+
Read a specific document by its unique identifier to see full details.
|
| 118 |
+
|
| 119 |
+
Args:
|
| 120 |
+
document_id: The document ID to read, e.g. 'PO-2024-0055' or 'INV-2024-0055'
|
| 121 |
+
|
| 122 |
+
Returns:
|
| 123 |
+
The full contents of the requested document.
|
| 124 |
+
"""
|
| 125 |
+
if self.done:
|
| 126 |
+
raise ValueError("Episode is over. No more actions allowed.")
|
| 127 |
+
|
| 128 |
+
action = ESCTRAction(
|
| 129 |
+
action_type="read_document",
|
| 130 |
+
document_id=document_id,
|
| 131 |
+
)
|
| 132 |
+
obs = self.env.step(action)
|
| 133 |
+
self.reward = obs.reward
|
| 134 |
+
self.done = obs.done
|
| 135 |
+
return obs.system_response
|
| 136 |
+
|
| 137 |
+
def communicate_vendor(self, message_content: str) -> str:
|
| 138 |
+
"""
|
| 139 |
+
Send a message to the vendor during a dispute negotiation.
|
| 140 |
+
|
| 141 |
+
Args:
|
| 142 |
+
message_content: The message to send to the vendor, such as requesting clarification or rejecting a settlement offer.
|
| 143 |
+
|
| 144 |
+
Returns:
|
| 145 |
+
The vendor's response to your message.
|
| 146 |
+
"""
|
| 147 |
+
if self.done:
|
| 148 |
+
raise ValueError("Episode is over. No more actions allowed.")
|
| 149 |
+
|
| 150 |
+
action = ESCTRAction(
|
| 151 |
+
action_type="communicate_vendor",
|
| 152 |
+
message_content=message_content,
|
| 153 |
+
)
|
| 154 |
+
obs = self.env.step(action)
|
| 155 |
+
self.reward = obs.reward
|
| 156 |
+
self.done = obs.done
|
| 157 |
+
return obs.system_response
|
| 158 |
+
|
| 159 |
+
def submit_financial_decision(self, adjustment_amount: float, adjustment_reason: str) -> str:
|
| 160 |
+
"""
|
| 161 |
+
Submit the final financial adjustment. This is the terminal action that ends the episode.
|
| 162 |
+
|
| 163 |
+
Args:
|
| 164 |
+
adjustment_amount: The exact monetary adjustment amount as a float (e.g. 450.00). Must be calculated from the documents.
|
| 165 |
+
adjustment_reason: A brief explanation of why this adjustment is correct, including your arithmetic.
|
| 166 |
+
|
| 167 |
+
Returns:
|
| 168 |
+
The grading result with your score and feedback.
|
| 169 |
+
"""
|
| 170 |
+
if self.done:
|
| 171 |
+
raise ValueError("Episode is over. No more actions allowed.")
|
| 172 |
+
|
| 173 |
+
action = ESCTRAction(
|
| 174 |
+
action_type="submit_financial_decision",
|
| 175 |
+
adjustment_amount=adjustment_amount,
|
| 176 |
+
adjustment_reason=adjustment_reason,
|
| 177 |
+
)
|
| 178 |
+
obs = self.env.step(action)
|
| 179 |
+
self.reward = obs.reward
|
| 180 |
+
self.done = obs.done
|
| 181 |
+
return obs.system_response
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
# ---------------------------------------------------------------------------
|
| 185 |
+
# Reward function — reads from env instances after each episode
|
| 186 |
+
# ---------------------------------------------------------------------------
|
| 187 |
+
|
| 188 |
+
def reward_func(environments, **kwargs) -> list[float]:
|
| 189 |
+
"""Extract reward from each environment instance after episode completion."""
|
| 190 |
+
return [env.reward for env in environments]
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
# ---------------------------------------------------------------------------
|
| 194 |
+
# Training configuration
|
| 195 |
+
# ---------------------------------------------------------------------------
|
| 196 |
+
|
| 197 |
+
def main():
|
| 198 |
+
# Model selection — Qwen3-1.7B is efficient on T4 GPU
|
| 199 |
+
model_name = os.environ.get("ESCTR_MODEL", "Qwen/Qwen3-1.7B")
|
| 200 |
+
output_dir = os.environ.get("ESCTR_OUTPUT", "esctr-grpo-trained")
|
| 201 |
+
num_episodes = int(os.environ.get("ESCTR_EPISODES", "1000"))
|
| 202 |
+
|
| 203 |
+
# Create dataset — each entry triggers one rollout episode
|
| 204 |
+
dataset = Dataset.from_dict({
|
| 205 |
+
"prompt": [[{"role": "user", "content": SYSTEM_PROMPT}]] * num_episodes
|
| 206 |
+
})
|
| 207 |
+
|
| 208 |
+
# GRPO configuration
|
| 209 |
+
grpo_config = GRPOConfig(
|
| 210 |
+
# Training schedule
|
| 211 |
+
num_train_epochs=1,
|
| 212 |
+
learning_rate=1e-6,
|
| 213 |
+
gradient_accumulation_steps=4,
|
| 214 |
+
per_device_train_batch_size=1,
|
| 215 |
+
warmup_steps=10,
|
| 216 |
+
optim="adamw_torch",
|
| 217 |
+
max_grad_norm=1.0,
|
| 218 |
+
|
| 219 |
+
# GRPO settings
|
| 220 |
+
num_generations=2,
|
| 221 |
+
max_completion_length=768,
|
| 222 |
+
log_completions=True,
|
| 223 |
+
num_completions_to_print=2,
|
| 224 |
+
chat_template_kwargs={"enable_thinking": False},
|
| 225 |
+
|
| 226 |
+
# Logging
|
| 227 |
+
output_dir=output_dir,
|
| 228 |
+
report_to="trackio",
|
| 229 |
+
trackio_space_id=output_dir,
|
| 230 |
+
logging_steps=1,
|
| 231 |
+
save_steps=25,
|
| 232 |
+
save_total_limit=2,
|
| 233 |
+
|
| 234 |
+
# Memory optimization
|
| 235 |
+
gradient_checkpointing=True,
|
| 236 |
+
bf16=False,
|
| 237 |
+
fp16=True,
|
| 238 |
+
|
| 239 |
+
# Hub integration
|
| 240 |
+
push_to_hub=True,
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
# Create trainer
|
| 244 |
+
trainer = GRPOTrainer(
|
| 245 |
+
model=model_name,
|
| 246 |
+
reward_funcs=reward_func,
|
| 247 |
+
train_dataset=dataset,
|
| 248 |
+
args=grpo_config,
|
| 249 |
+
environment_factory=ESCTRToolEnv,
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
# Show GPU stats before training
|
| 253 |
+
import torch
|
| 254 |
+
if torch.cuda.is_available():
|
| 255 |
+
gpu_stats = torch.cuda.get_device_properties(0)
|
| 256 |
+
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
|
| 257 |
+
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
|
| 258 |
+
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
|
| 259 |
+
print(f"{start_gpu_memory} GB of memory reserved.")
|
| 260 |
+
|
| 261 |
+
print(f"\n{'='*60}")
|
| 262 |
+
print(f"ESCTR Training — {model_name}")
|
| 263 |
+
print(f"Task: {TRAIN_TASK}")
|
| 264 |
+
print(f"Episodes: {num_episodes}")
|
| 265 |
+
print(f"Output: {output_dir}")
|
| 266 |
+
print(f"{'='*60}\n")
|
| 267 |
+
|
| 268 |
+
# Train!
|
| 269 |
+
trainer_stats = trainer.train()
|
| 270 |
+
|
| 271 |
+
# Show training stats
|
| 272 |
+
if torch.cuda.is_available():
|
| 273 |
+
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
|
| 274 |
+
print(f"\nTraining completed in {trainer_stats.metrics['train_runtime']:.0f} seconds")
|
| 275 |
+
print(f"Peak GPU memory: {used_memory} GB / {max_memory} GB")
|
| 276 |
+
|
| 277 |
+
# Save and push
|
| 278 |
+
trainer.save_model(output_dir)
|
| 279 |
+
trainer.push_to_hub()
|
| 280 |
+
print(f"\nModel saved to {output_dir} and pushed to Hub!")
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
if __name__ == "__main__":
|
| 284 |
+
main()
|
uv.lock
CHANGED
|
@@ -1515,7 +1515,7 @@ wheels = [
|
|
| 1515 |
]
|
| 1516 |
|
| 1517 |
[[package]]
|
| 1518 |
-
name = "openenv-
|
| 1519 |
version = "0.1.0"
|
| 1520 |
source = { editable = "." }
|
| 1521 |
dependencies = [
|
|
|
|
| 1515 |
]
|
| 1516 |
|
| 1517 |
[[package]]
|
| 1518 |
+
name = "openenv-esctr-environment"
|
| 1519 |
version = "0.1.0"
|
| 1520 |
source = { editable = "." }
|
| 1521 |
dependencies = [
|