
Upload 10 files
Browse files- Dockerfile +32 -0
- demo_text.txt +12 -0
- flair_recognizer.py +198 -0
- index.md +26 -0
- openai_fake_data_generator.py +55 -0
- presidio_helpers.py +230 -0
- presidio_nlp_engine_config.py +135 -0
- presidio_streamlit.py +280 -0
- requirements.txt +10 -4
- text_analytics_wrapper.py +121 -0
Dockerfile
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.9-slim
|
| 2 |
+
|
| 3 |
+
RUN apt-get update && apt-get install -y \
|
| 4 |
+
build-essential \
|
| 5 |
+
curl \
|
| 6 |
+
software-properties-common \
|
| 7 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 8 |
+
|
| 9 |
+
WORKDIR /code
|
| 10 |
+
|
| 11 |
+
COPY ./requirements.txt /code/requirements.txt
|
| 12 |
+
|
| 13 |
+
RUN pip3 install -r requirements.txt
|
| 14 |
+
RUN pip3 install https://huggingface.co/spacy/en_core_web_sm/resolve/main/en_core_web_sm-any-py3-none-any.whl
|
| 15 |
+
RUN pip3 install https://huggingface.co/spacy/en_core_web_lg/resolve/main/en_core_web_lg-any-py3-none-any.whl
|
| 16 |
+
|
| 17 |
+
EXPOSE 7860
|
| 18 |
+
|
| 19 |
+
COPY . /code
|
| 20 |
+
|
| 21 |
+
RUN useradd -m -u 1000 user
|
| 22 |
+
USER user
|
| 23 |
+
ENV HOME=/home/user \
|
| 24 |
+
PATH=/home/user/.local/bin:$PATH
|
| 25 |
+
|
| 26 |
+
WORKDIR $HOME/app
|
| 27 |
+
|
| 28 |
+
COPY --chown=user . $HOME/app
|
| 29 |
+
|
| 30 |
+
HEALTHCHECK CMD curl --fail http://localhost:7860/_stcore/health
|
| 31 |
+
|
| 32 |
+
CMD python -m streamlit run presidio_streamlit.py --server.port=7860 --server.address=0.0.0.0
|
demo_text.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Here are a few example sentences we currently support:
|
| 2 |
+
|
| 3 |
+
Hello, my name is David Johnson and I live in Maine.
|
| 4 |
+
My credit card number is 4095-2609-9393-4932 and my crypto wallet id is 16Yeky6GMjeNkAiNcBY7ZhrLoMSgg1BoyZ.
|
| 5 |
+
|
| 6 |
+
On September 18 I visited microsoft.com and sent an email to test@presidio.site, from the IP 192.168.0.1.
|
| 7 |
+
|
| 8 |
+
My passport: 191280342 and my phone number: (212) 555-1234.
|
| 9 |
+
|
| 10 |
+
This is a valid International Bank Account Number: IL150120690000003111111 . Can you please check the status on bank account 954567876544?
|
| 11 |
+
|
| 12 |
+
Kate's social security number is 078-05-1126. Her driver license? it is 1234567A.
|
flair_recognizer.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Taken from https://github.com/microsoft/presidio/blob/main/docs/samples/python/flair_recognizer.py
|
| 2 |
+
|
| 3 |
+
import logging
|
| 4 |
+
from typing import Optional, List, Tuple, Set
|
| 5 |
+
|
| 6 |
+
from presidio_analyzer import (
|
| 7 |
+
RecognizerResult,
|
| 8 |
+
EntityRecognizer,
|
| 9 |
+
AnalysisExplanation,
|
| 10 |
+
)
|
| 11 |
+
from presidio_analyzer.nlp_engine import NlpArtifacts
|
| 12 |
+
|
| 13 |
+
from flair.data import Sentence
|
| 14 |
+
from flair.models import SequenceTagger
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger("presidio-analyzer")
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class FlairRecognizer(EntityRecognizer):
|
| 21 |
+
"""
|
| 22 |
+
Wrapper for a flair model, if needed to be used within Presidio Analyzer.
|
| 23 |
+
|
| 24 |
+
:example:
|
| 25 |
+
>from presidio_analyzer import AnalyzerEngine, RecognizerRegistry
|
| 26 |
+
|
| 27 |
+
>flair_recognizer = FlairRecognizer()
|
| 28 |
+
|
| 29 |
+
>registry = RecognizerRegistry()
|
| 30 |
+
>registry.add_recognizer(flair_recognizer)
|
| 31 |
+
|
| 32 |
+
>analyzer = AnalyzerEngine(registry=registry)
|
| 33 |
+
|
| 34 |
+
>results = analyzer.analyze(
|
| 35 |
+
> "My name is Christopher and I live in Irbid.",
|
| 36 |
+
> language="en",
|
| 37 |
+
> return_decision_process=True,
|
| 38 |
+
>)
|
| 39 |
+
>for result in results:
|
| 40 |
+
> print(result)
|
| 41 |
+
> print(result.analysis_explanation)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
ENTITIES = [
|
| 47 |
+
"LOCATION",
|
| 48 |
+
"PERSON",
|
| 49 |
+
"ORGANIZATION",
|
| 50 |
+
# "MISCELLANEOUS" # - There are no direct correlation with Presidio entities.
|
| 51 |
+
]
|
| 52 |
+
|
| 53 |
+
DEFAULT_EXPLANATION = "Identified as {} by Flair's Named Entity Recognition"
|
| 54 |
+
|
| 55 |
+
CHECK_LABEL_GROUPS = [
|
| 56 |
+
({"LOCATION"}, {"LOC", "LOCATION"}),
|
| 57 |
+
({"PERSON"}, {"PER", "PERSON"}),
|
| 58 |
+
({"ORGANIZATION"}, {"ORG"}),
|
| 59 |
+
# ({"MISCELLANEOUS"}, {"MISC"}), # Probably not PII
|
| 60 |
+
]
|
| 61 |
+
|
| 62 |
+
MODEL_LANGUAGES = {
|
| 63 |
+
"en": "flair/ner-english-large"
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
PRESIDIO_EQUIVALENCES = {
|
| 67 |
+
"PER": "PERSON",
|
| 68 |
+
"LOC": "LOCATION",
|
| 69 |
+
"ORG": "ORGANIZATION",
|
| 70 |
+
# 'MISC': 'MISCELLANEOUS' # - Probably not PII
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
def __init__(
|
| 74 |
+
self,
|
| 75 |
+
supported_language: str = "en",
|
| 76 |
+
supported_entities: Optional[List[str]] = None,
|
| 77 |
+
check_label_groups: Optional[Tuple[Set, Set]] = None,
|
| 78 |
+
model: SequenceTagger = None,
|
| 79 |
+
model_path: Optional[str] = None
|
| 80 |
+
):
|
| 81 |
+
self.check_label_groups = (
|
| 82 |
+
check_label_groups if check_label_groups else self.CHECK_LABEL_GROUPS
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
supported_entities = supported_entities if supported_entities else self.ENTITIES
|
| 86 |
+
|
| 87 |
+
if model and model_path:
|
| 88 |
+
raise ValueError("Only one of model or model_path should be provided.")
|
| 89 |
+
elif model and not model_path:
|
| 90 |
+
self.model = model
|
| 91 |
+
elif not model and model_path:
|
| 92 |
+
print(f"Loading model from {model_path}")
|
| 93 |
+
self.model = SequenceTagger.load(model_path)
|
| 94 |
+
else:
|
| 95 |
+
print(f"Loading model for language {supported_language}")
|
| 96 |
+
self.model = SequenceTagger.load(self.MODEL_LANGUAGES.get(supported_language))
|
| 97 |
+
|
| 98 |
+
super().__init__(
|
| 99 |
+
supported_entities=supported_entities,
|
| 100 |
+
supported_language=supported_language,
|
| 101 |
+
name="Flair Analytics",
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
def load(self) -> None:
|
| 105 |
+
"""Load the model, not used. Model is loaded during initialization."""
|
| 106 |
+
pass
|
| 107 |
+
|
| 108 |
+
def get_supported_entities(self) -> List[str]:
|
| 109 |
+
"""
|
| 110 |
+
Return supported entities by this model.
|
| 111 |
+
|
| 112 |
+
:return: List of the supported entities.
|
| 113 |
+
"""
|
| 114 |
+
return self.supported_entities
|
| 115 |
+
|
| 116 |
+
# Class to use Flair with Presidio as an external recognizer.
|
| 117 |
+
def analyze(
|
| 118 |
+
self, text: str, entities: List[str], nlp_artifacts: NlpArtifacts = None
|
| 119 |
+
) -> List[RecognizerResult]:
|
| 120 |
+
"""
|
| 121 |
+
Analyze text using Text Analytics.
|
| 122 |
+
|
| 123 |
+
:param text: The text for analysis.
|
| 124 |
+
:param entities: Not working properly for this recognizer.
|
| 125 |
+
:param nlp_artifacts: Not used by this recognizer.
|
| 126 |
+
:param language: Text language. Supported languages in MODEL_LANGUAGES
|
| 127 |
+
:return: The list of Presidio RecognizerResult constructed from the recognized
|
| 128 |
+
Flair detections.
|
| 129 |
+
"""
|
| 130 |
+
|
| 131 |
+
results = []
|
| 132 |
+
|
| 133 |
+
sentences = Sentence(text)
|
| 134 |
+
self.model.predict(sentences)
|
| 135 |
+
|
| 136 |
+
# If there are no specific list of entities, we will look for all of it.
|
| 137 |
+
if not entities:
|
| 138 |
+
entities = self.supported_entities
|
| 139 |
+
|
| 140 |
+
for entity in entities:
|
| 141 |
+
if entity not in self.supported_entities:
|
| 142 |
+
continue
|
| 143 |
+
|
| 144 |
+
for ent in sentences.get_spans("ner"):
|
| 145 |
+
if not self.__check_label(
|
| 146 |
+
entity, ent.labels[0].value, self.check_label_groups
|
| 147 |
+
):
|
| 148 |
+
continue
|
| 149 |
+
textual_explanation = self.DEFAULT_EXPLANATION.format(
|
| 150 |
+
ent.labels[0].value
|
| 151 |
+
)
|
| 152 |
+
explanation = self.build_flair_explanation(
|
| 153 |
+
round(ent.score, 2), textual_explanation
|
| 154 |
+
)
|
| 155 |
+
flair_result = self._convert_to_recognizer_result(ent, explanation)
|
| 156 |
+
|
| 157 |
+
results.append(flair_result)
|
| 158 |
+
|
| 159 |
+
return results
|
| 160 |
+
|
| 161 |
+
def _convert_to_recognizer_result(self, entity, explanation) -> RecognizerResult:
|
| 162 |
+
entity_type = self.PRESIDIO_EQUIVALENCES.get(entity.tag, entity.tag)
|
| 163 |
+
flair_score = round(entity.score, 2)
|
| 164 |
+
|
| 165 |
+
flair_results = RecognizerResult(
|
| 166 |
+
entity_type=entity_type,
|
| 167 |
+
start=entity.start_position,
|
| 168 |
+
end=entity.end_position,
|
| 169 |
+
score=flair_score,
|
| 170 |
+
analysis_explanation=explanation,
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
return flair_results
|
| 174 |
+
|
| 175 |
+
def build_flair_explanation(
|
| 176 |
+
self, original_score: float, explanation: str
|
| 177 |
+
) -> AnalysisExplanation:
|
| 178 |
+
"""
|
| 179 |
+
Create explanation for why this result was detected.
|
| 180 |
+
|
| 181 |
+
:param original_score: Score given by this recognizer
|
| 182 |
+
:param explanation: Explanation string
|
| 183 |
+
:return:
|
| 184 |
+
"""
|
| 185 |
+
explanation = AnalysisExplanation(
|
| 186 |
+
recognizer=self.__class__.__name__,
|
| 187 |
+
original_score=original_score,
|
| 188 |
+
textual_explanation=explanation,
|
| 189 |
+
)
|
| 190 |
+
return explanation
|
| 191 |
+
|
| 192 |
+
@staticmethod
|
| 193 |
+
def __check_label(
|
| 194 |
+
entity: str, label: str, check_label_groups: Tuple[Set, Set]
|
| 195 |
+
) -> bool:
|
| 196 |
+
return any(
|
| 197 |
+
[entity in egrp and label in lgrp for egrp, lgrp in check_label_groups]
|
| 198 |
+
)
|
index.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Simple demo website for Presidio
|
| 2 |
+
Here's a simple app, written in pure Python, to create a demo website for Presidio.
|
| 3 |
+
The app is based on the [streamlit](https://streamlit.io/) package.
|
| 4 |
+
|
| 5 |
+
A live version can be found here: https://huggingface.co/spaces/presidio/presidio_demo
|
| 6 |
+
|
| 7 |
+
## Requirements
|
| 8 |
+
1. Clone the repo and move to the `docs/samples/python/streamlit ` folder
|
| 9 |
+
1. Install dependencies (preferably in a virtual environment)
|
| 10 |
+
|
| 11 |
+
```sh
|
| 12 |
+
pip install -r requirements
|
| 13 |
+
```
|
| 14 |
+
> Note: This would install additional packages such as `transformers` and `flair` which are not mandatory for using Presidio.
|
| 15 |
+
|
| 16 |
+
2.
|
| 17 |
+
3. *Optional*: Update the `analyzer_engine` and `anonymizer_engine` functions for your specific implementation (in `presidio_helpers.py`).
|
| 18 |
+
3. Start the app:
|
| 19 |
+
|
| 20 |
+
```sh
|
| 21 |
+
streamlit run presidio_streamlit.py
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
## Output
|
| 25 |
+
Output should be similar to this screenshot:
|
| 26 |
+
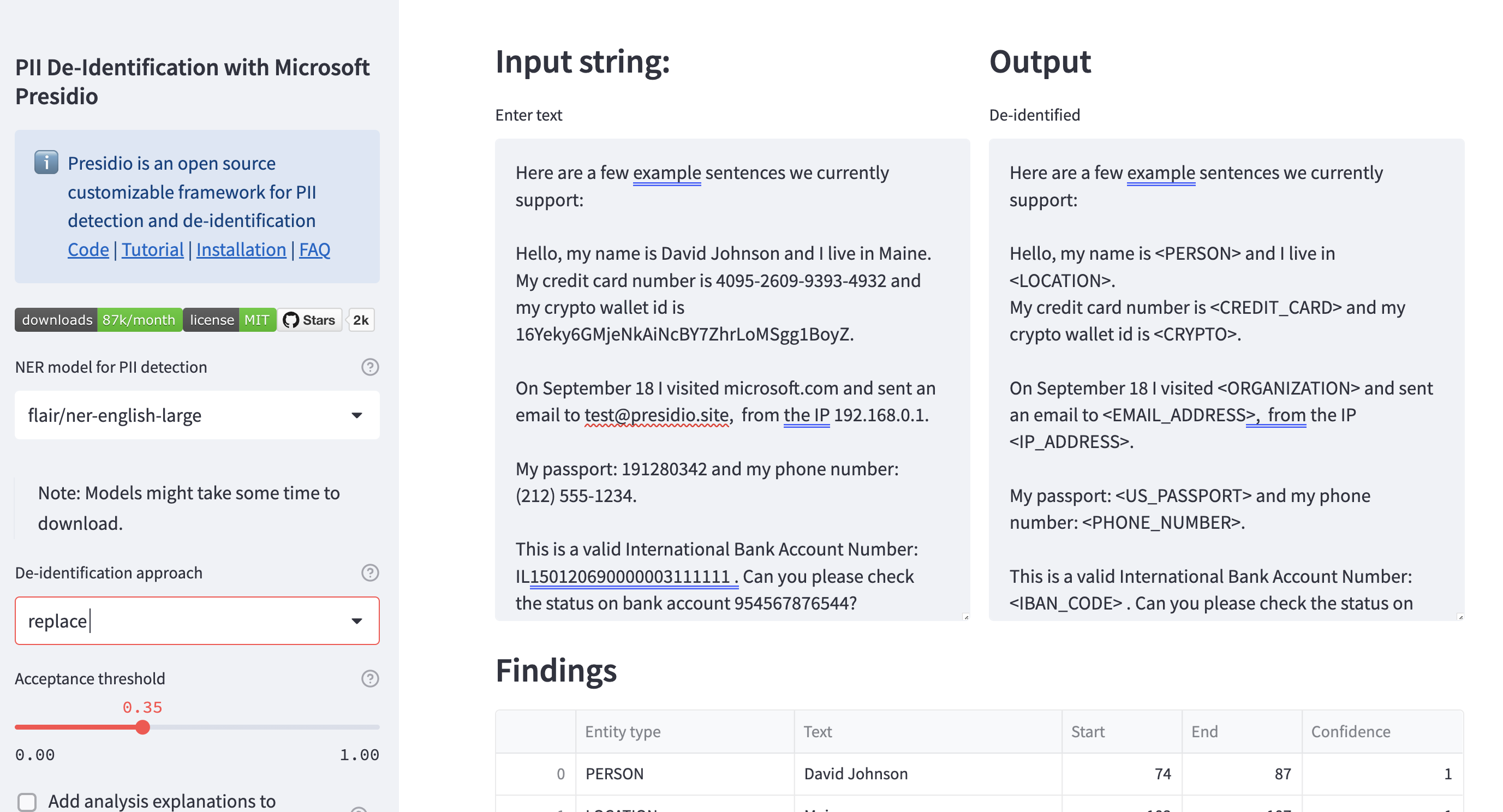
|
openai_fake_data_generator.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import openai
|
| 2 |
+
|
| 3 |
+
def set_openai_key(openai_key: str):
|
| 4 |
+
"""Set the OpenAI API key.
|
| 5 |
+
:param openai_key: the open AI key (https://help.openai.com/en/articles/4936850-where-do-i-find-my-secret-api-key)
|
| 6 |
+
"""
|
| 7 |
+
openai.api_key = openai_key
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def call_completion_model(
|
| 11 |
+
prompt: str, model: str = "text-davinci-003", max_tokens: int = 512
|
| 12 |
+
) -> str:
|
| 13 |
+
"""Creates a request for the OpenAI Completion service and returns the response.
|
| 14 |
+
|
| 15 |
+
:param prompt: The prompt for the completion model
|
| 16 |
+
:param model: OpenAI model name
|
| 17 |
+
:param max_tokens: Model's max_tokens parameter
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
response = openai.Completion.create(
|
| 21 |
+
model=model, prompt=prompt, max_tokens=max_tokens
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
return response["choices"][0].text
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def create_prompt(anonymized_text: str) -> str:
|
| 28 |
+
"""
|
| 29 |
+
Create the prompt with instructions to GPT-3.
|
| 30 |
+
|
| 31 |
+
:param anonymized_text: Text with placeholders instead of PII values, e.g. My name is <PERSON>.
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
prompt = f"""
|
| 35 |
+
Your role is to create synthetic text based on de-identified text with placeholders instead of Personally Identifiable Information (PII).
|
| 36 |
+
Replace the placeholders (e.g. ,<PERSON>, {{DATE}}, {{ip_address}}) with fake values.
|
| 37 |
+
|
| 38 |
+
Instructions:
|
| 39 |
+
|
| 40 |
+
a. Use completely random numbers, so every digit is drawn between 0 and 9.
|
| 41 |
+
b. Use realistic names that come from diverse genders, ethnicities and countries.
|
| 42 |
+
c. If there are no placeholders, return the text as is and provide an answer.
|
| 43 |
+
d. Keep the formatting as close to the original as possible.
|
| 44 |
+
e. If PII exists in the input, replace it with fake values in the output.
|
| 45 |
+
|
| 46 |
+
input: How do I change the limit on my credit card {{credit_card_number}}?
|
| 47 |
+
output: How do I change the limit on my credit card 2539 3519 2345 1555?
|
| 48 |
+
input: <PERSON> was the chief science officer at <ORGANIZATION>.
|
| 49 |
+
output: Katherine Buckjov was the chief science officer at NASA.
|
| 50 |
+
input: Cameroon lives in <LOCATION>.
|
| 51 |
+
output: Vladimir lives in Moscow.
|
| 52 |
+
input: {anonymized_text}
|
| 53 |
+
output:
|
| 54 |
+
"""
|
| 55 |
+
return prompt
|
presidio_helpers.py
ADDED
|
@@ -0,0 +1,230 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Helper methods for the Presidio Streamlit app
|
| 3 |
+
"""
|
| 4 |
+
from typing import List, Optional, Tuple
|
| 5 |
+
|
| 6 |
+
import streamlit as st
|
| 7 |
+
from presidio_analyzer import (
|
| 8 |
+
AnalyzerEngine,
|
| 9 |
+
RecognizerResult,
|
| 10 |
+
RecognizerRegistry,
|
| 11 |
+
PatternRecognizer,
|
| 12 |
+
)
|
| 13 |
+
from presidio_analyzer.nlp_engine import NlpEngine
|
| 14 |
+
from presidio_anonymizer import AnonymizerEngine
|
| 15 |
+
from presidio_anonymizer.entities import OperatorConfig
|
| 16 |
+
|
| 17 |
+
from openai_fake_data_generator import (
|
| 18 |
+
set_openai_key,
|
| 19 |
+
call_completion_model,
|
| 20 |
+
create_prompt,
|
| 21 |
+
)
|
| 22 |
+
from presidio_nlp_engine_config import (
|
| 23 |
+
create_nlp_engine_with_spacy,
|
| 24 |
+
create_nlp_engine_with_flair,
|
| 25 |
+
create_nlp_engine_with_transformers,
|
| 26 |
+
create_nlp_engine_with_azure_text_analytics,
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@st.cache_resource
|
| 31 |
+
def nlp_engine_and_registry(
|
| 32 |
+
model_family: str,
|
| 33 |
+
model_path: str,
|
| 34 |
+
ta_key: Optional[str] = None,
|
| 35 |
+
ta_endpoint: Optional[str] = None,
|
| 36 |
+
) -> Tuple[NlpEngine, RecognizerRegistry]:
|
| 37 |
+
"""Create the NLP Engine instance based on the requested model.
|
| 38 |
+
:param model_family: Which model package to use for NER.
|
| 39 |
+
:param model_path: Which model to use for NER. E.g.,
|
| 40 |
+
"StanfordAIMI/stanford-deidentifier-base",
|
| 41 |
+
"obi/deid_roberta_i2b2",
|
| 42 |
+
"en_core_web_lg"
|
| 43 |
+
:param ta_key: Key to the Text Analytics endpoint (only if model_path = "Azure Text Analytics")
|
| 44 |
+
:param ta_endpoint: Endpoint of the Text Analytics instance (only if model_path = "Azure Text Analytics")
|
| 45 |
+
"""
|
| 46 |
+
|
| 47 |
+
# Set up NLP Engine according to the model of choice
|
| 48 |
+
if "spaCy" in model_family:
|
| 49 |
+
return create_nlp_engine_with_spacy(model_path)
|
| 50 |
+
elif "flair" in model_family:
|
| 51 |
+
return create_nlp_engine_with_flair(model_path)
|
| 52 |
+
elif "HuggingFace" in model_family:
|
| 53 |
+
return create_nlp_engine_with_transformers(model_path)
|
| 54 |
+
elif "Azure Text Analytics" in model_family:
|
| 55 |
+
return create_nlp_engine_with_azure_text_analytics(ta_key, ta_endpoint)
|
| 56 |
+
else:
|
| 57 |
+
raise ValueError(f"Model family {model_family} not supported")
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
@st.cache_resource
|
| 61 |
+
def analyzer_engine(
|
| 62 |
+
model_family: str,
|
| 63 |
+
model_path: str,
|
| 64 |
+
ta_key: Optional[str] = None,
|
| 65 |
+
ta_endpoint: Optional[str] = None,
|
| 66 |
+
) -> AnalyzerEngine:
|
| 67 |
+
"""Create the NLP Engine instance based on the requested model.
|
| 68 |
+
:param model_family: Which model package to use for NER.
|
| 69 |
+
:param model_path: Which model to use for NER:
|
| 70 |
+
"StanfordAIMI/stanford-deidentifier-base",
|
| 71 |
+
"obi/deid_roberta_i2b2",
|
| 72 |
+
"en_core_web_lg"
|
| 73 |
+
:param ta_key: Key to the Text Analytics endpoint (only if model_path = "Azure Text Analytics")
|
| 74 |
+
:param ta_endpoint: Endpoint of the Text Analytics instance (only if model_path = "Azure Text Analytics")
|
| 75 |
+
"""
|
| 76 |
+
nlp_engine, registry = nlp_engine_and_registry(
|
| 77 |
+
model_family, model_path, ta_key, ta_endpoint
|
| 78 |
+
)
|
| 79 |
+
analyzer = AnalyzerEngine(nlp_engine=nlp_engine, registry=registry)
|
| 80 |
+
return analyzer
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
@st.cache_resource
|
| 84 |
+
def anonymizer_engine():
|
| 85 |
+
"""Return AnonymizerEngine."""
|
| 86 |
+
return AnonymizerEngine()
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
@st.cache_data
|
| 90 |
+
def get_supported_entities(
|
| 91 |
+
model_family: str, model_path: str, ta_key: str, ta_endpoint: str
|
| 92 |
+
):
|
| 93 |
+
"""Return supported entities from the Analyzer Engine."""
|
| 94 |
+
return analyzer_engine(
|
| 95 |
+
model_family, model_path, ta_key, ta_endpoint
|
| 96 |
+
).get_supported_entities() + ["GENERIC_PII"]
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
@st.cache_data
|
| 100 |
+
def analyze(
|
| 101 |
+
model_family: str, model_path: str, ta_key: str, ta_endpoint: str, **kwargs
|
| 102 |
+
):
|
| 103 |
+
"""Analyze input using Analyzer engine and input arguments (kwargs)."""
|
| 104 |
+
if "entities" not in kwargs or "All" in kwargs["entities"]:
|
| 105 |
+
kwargs["entities"] = None
|
| 106 |
+
|
| 107 |
+
if "deny_list" in kwargs and kwargs["deny_list"] is not None:
|
| 108 |
+
ad_hoc_recognizer = create_ad_hoc_deny_list_recognizer(kwargs["deny_list"])
|
| 109 |
+
kwargs["ad_hoc_recognizers"] = [ad_hoc_recognizer] if ad_hoc_recognizer else []
|
| 110 |
+
del kwargs["deny_list"]
|
| 111 |
+
|
| 112 |
+
return analyzer_engine(model_family, model_path, ta_key, ta_endpoint).analyze(
|
| 113 |
+
**kwargs
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def anonymize(
|
| 118 |
+
text: str,
|
| 119 |
+
operator: str,
|
| 120 |
+
analyze_results: List[RecognizerResult],
|
| 121 |
+
mask_char: Optional[str] = None,
|
| 122 |
+
number_of_chars: Optional[str] = None,
|
| 123 |
+
encrypt_key: Optional[str] = None,
|
| 124 |
+
):
|
| 125 |
+
"""Anonymize identified input using Presidio Anonymizer.
|
| 126 |
+
|
| 127 |
+
:param text: Full text
|
| 128 |
+
:param operator: Operator name
|
| 129 |
+
:param mask_char: Mask char (for mask operator)
|
| 130 |
+
:param number_of_chars: Number of characters to mask (for mask operator)
|
| 131 |
+
:param encrypt_key: Encryption key (for encrypt operator)
|
| 132 |
+
:param analyze_results: list of results from presidio analyzer engine
|
| 133 |
+
"""
|
| 134 |
+
|
| 135 |
+
if operator == "mask":
|
| 136 |
+
operator_config = {
|
| 137 |
+
"type": "mask",
|
| 138 |
+
"masking_char": mask_char,
|
| 139 |
+
"chars_to_mask": number_of_chars,
|
| 140 |
+
"from_end": False,
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
# Define operator config
|
| 144 |
+
elif operator == "encrypt":
|
| 145 |
+
operator_config = {"key": encrypt_key}
|
| 146 |
+
elif operator == "highlight":
|
| 147 |
+
operator_config = {"lambda": lambda x: x}
|
| 148 |
+
else:
|
| 149 |
+
operator_config = None
|
| 150 |
+
|
| 151 |
+
# Change operator if needed as intermediate step
|
| 152 |
+
if operator == "highlight":
|
| 153 |
+
operator = "custom"
|
| 154 |
+
elif operator == "synthesize":
|
| 155 |
+
operator = "replace"
|
| 156 |
+
else:
|
| 157 |
+
operator = operator
|
| 158 |
+
|
| 159 |
+
res = anonymizer_engine().anonymize(
|
| 160 |
+
text,
|
| 161 |
+
analyze_results,
|
| 162 |
+
operators={"DEFAULT": OperatorConfig(operator, operator_config)},
|
| 163 |
+
)
|
| 164 |
+
return res
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def annotate(text: str, analyze_results: List[RecognizerResult]):
|
| 168 |
+
"""Highlight the identified PII entities on the original text
|
| 169 |
+
|
| 170 |
+
:param text: Full text
|
| 171 |
+
:param analyze_results: list of results from presidio analyzer engine
|
| 172 |
+
"""
|
| 173 |
+
tokens = []
|
| 174 |
+
|
| 175 |
+
# Use the anonymizer to resolve overlaps
|
| 176 |
+
results = anonymize(
|
| 177 |
+
text=text,
|
| 178 |
+
operator="highlight",
|
| 179 |
+
analyze_results=analyze_results,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
# sort by start index
|
| 183 |
+
results = sorted(results.items, key=lambda x: x.start)
|
| 184 |
+
for i, res in enumerate(results):
|
| 185 |
+
if i == 0:
|
| 186 |
+
tokens.append(text[: res.start])
|
| 187 |
+
|
| 188 |
+
# append entity text and entity type
|
| 189 |
+
tokens.append((text[res.start : res.end], res.entity_type))
|
| 190 |
+
|
| 191 |
+
# if another entity coming i.e. we're not at the last results element, add text up to next entity
|
| 192 |
+
if i != len(results) - 1:
|
| 193 |
+
tokens.append(text[res.end : results[i + 1].start])
|
| 194 |
+
# if no more entities coming, add all remaining text
|
| 195 |
+
else:
|
| 196 |
+
tokens.append(text[res.end :])
|
| 197 |
+
return tokens
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def create_fake_data(
|
| 201 |
+
text: str,
|
| 202 |
+
analyze_results: List[RecognizerResult],
|
| 203 |
+
openai_key: str,
|
| 204 |
+
openai_model_name: str,
|
| 205 |
+
):
|
| 206 |
+
"""Creates a synthetic version of the text using OpenAI APIs"""
|
| 207 |
+
if not openai_key:
|
| 208 |
+
return "Please provide your OpenAI key"
|
| 209 |
+
results = anonymize(text=text, operator="replace", analyze_results=analyze_results)
|
| 210 |
+
set_openai_key(openai_key)
|
| 211 |
+
prompt = create_prompt(results.text)
|
| 212 |
+
fake = call_openai_api(prompt, openai_model_name)
|
| 213 |
+
return fake
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
@st.cache_data
|
| 217 |
+
def call_openai_api(prompt: str, openai_model_name: str) -> str:
|
| 218 |
+
fake_data = call_completion_model(prompt, model=openai_model_name)
|
| 219 |
+
return fake_data
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def create_ad_hoc_deny_list_recognizer(
|
| 223 |
+
deny_list=Optional[List[str]],
|
| 224 |
+
) -> Optional[PatternRecognizer]:
|
| 225 |
+
if not deny_list:
|
| 226 |
+
return None
|
| 227 |
+
|
| 228 |
+
deny_list_recognizer = PatternRecognizer(supported_entity="GENERIC_PII", deny_list=deny_list)
|
| 229 |
+
print(deny_list_recognizer.patterns)
|
| 230 |
+
return deny_list_recognizer
|
presidio_nlp_engine_config.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Tuple
|
| 2 |
+
|
| 3 |
+
import spacy
|
| 4 |
+
from presidio_analyzer import RecognizerRegistry
|
| 5 |
+
from presidio_analyzer.nlp_engine import NlpEngine, NlpEngineProvider
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def create_nlp_engine_with_spacy(
|
| 9 |
+
model_path: str,
|
| 10 |
+
) -> Tuple[NlpEngine, RecognizerRegistry]:
|
| 11 |
+
"""
|
| 12 |
+
Instantiate an NlpEngine with a spaCy model
|
| 13 |
+
:param model_path: spaCy model path.
|
| 14 |
+
"""
|
| 15 |
+
registry = RecognizerRegistry()
|
| 16 |
+
registry.load_predefined_recognizers()
|
| 17 |
+
|
| 18 |
+
if not spacy.util.is_package(model_path):
|
| 19 |
+
spacy.cli.download(model_path)
|
| 20 |
+
|
| 21 |
+
nlp_configuration = {
|
| 22 |
+
"nlp_engine_name": "spacy",
|
| 23 |
+
"models": [{"lang_code": "en", "model_name": model_path}],
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
nlp_engine = NlpEngineProvider(nlp_configuration=nlp_configuration).create_engine()
|
| 27 |
+
|
| 28 |
+
return nlp_engine, registry
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def create_nlp_engine_with_transformers(
|
| 32 |
+
model_path: str,
|
| 33 |
+
) -> Tuple[NlpEngine, RecognizerRegistry]:
|
| 34 |
+
"""
|
| 35 |
+
Instantiate an NlpEngine with a TransformersRecognizer and a small spaCy model.
|
| 36 |
+
The TransformersRecognizer would return results from Transformers models, the spaCy model
|
| 37 |
+
would return NlpArtifacts such as POS and lemmas.
|
| 38 |
+
:param model_path: HuggingFace model path.
|
| 39 |
+
"""
|
| 40 |
+
|
| 41 |
+
from transformers_rec import (
|
| 42 |
+
STANFORD_COFIGURATION,
|
| 43 |
+
BERT_DEID_CONFIGURATION,
|
| 44 |
+
TransformersRecognizer,
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
registry = RecognizerRegistry()
|
| 48 |
+
registry.load_predefined_recognizers()
|
| 49 |
+
|
| 50 |
+
if not spacy.util.is_package("en_core_web_sm"):
|
| 51 |
+
spacy.cli.download("en_core_web_sm")
|
| 52 |
+
# Using a small spaCy model + a HF NER model
|
| 53 |
+
transformers_recognizer = TransformersRecognizer(model_path=model_path)
|
| 54 |
+
|
| 55 |
+
if model_path == "StanfordAIMI/stanford-deidentifier-base":
|
| 56 |
+
transformers_recognizer.load_transformer(**STANFORD_COFIGURATION)
|
| 57 |
+
elif model_path == "obi/deid_roberta_i2b2":
|
| 58 |
+
transformers_recognizer.load_transformer(**BERT_DEID_CONFIGURATION)
|
| 59 |
+
else:
|
| 60 |
+
print(f"Warning: Model has no configuration, loading default.")
|
| 61 |
+
transformers_recognizer.load_transformer(**BERT_DEID_CONFIGURATION)
|
| 62 |
+
|
| 63 |
+
# Use small spaCy model, no need for both spacy and HF models
|
| 64 |
+
# The transformers model is used here as a recognizer, not as an NlpEngine
|
| 65 |
+
nlp_configuration = {
|
| 66 |
+
"nlp_engine_name": "spacy",
|
| 67 |
+
"models": [{"lang_code": "en", "model_name": "en_core_web_sm"}],
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
registry.add_recognizer(transformers_recognizer)
|
| 71 |
+
registry.remove_recognizer("SpacyRecognizer")
|
| 72 |
+
|
| 73 |
+
nlp_engine = NlpEngineProvider(nlp_configuration=nlp_configuration).create_engine()
|
| 74 |
+
|
| 75 |
+
return nlp_engine, registry
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def create_nlp_engine_with_flair(
|
| 79 |
+
model_path: str,
|
| 80 |
+
) -> Tuple[NlpEngine, RecognizerRegistry]:
|
| 81 |
+
"""
|
| 82 |
+
Instantiate an NlpEngine with a FlairRecognizer and a small spaCy model.
|
| 83 |
+
The FlairRecognizer would return results from Flair models, the spaCy model
|
| 84 |
+
would return NlpArtifacts such as POS and lemmas.
|
| 85 |
+
:param model_path: Flair model path.
|
| 86 |
+
"""
|
| 87 |
+
from flair_recognizer import FlairRecognizer
|
| 88 |
+
|
| 89 |
+
registry = RecognizerRegistry()
|
| 90 |
+
registry.load_predefined_recognizers()
|
| 91 |
+
|
| 92 |
+
if not spacy.util.is_package("en_core_web_sm"):
|
| 93 |
+
spacy.cli.download("en_core_web_sm")
|
| 94 |
+
# Using a small spaCy model + a Flair NER model
|
| 95 |
+
flair_recognizer = FlairRecognizer(model_path=model_path)
|
| 96 |
+
nlp_configuration = {
|
| 97 |
+
"nlp_engine_name": "spacy",
|
| 98 |
+
"models": [{"lang_code": "en", "model_name": "en_core_web_sm"}],
|
| 99 |
+
}
|
| 100 |
+
registry.add_recognizer(flair_recognizer)
|
| 101 |
+
registry.remove_recognizer("SpacyRecognizer")
|
| 102 |
+
|
| 103 |
+
nlp_engine = NlpEngineProvider(nlp_configuration=nlp_configuration).create_engine()
|
| 104 |
+
|
| 105 |
+
return nlp_engine, registry
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def create_nlp_engine_with_azure_text_analytics(ta_key: str, ta_endpoint: str):
|
| 109 |
+
"""
|
| 110 |
+
Instantiate an NlpEngine with a TextAnalyticsWrapper and a small spaCy model.
|
| 111 |
+
The TextAnalyticsWrapper would return results from calling Azure Text Analytics PII, the spaCy model
|
| 112 |
+
would return NlpArtifacts such as POS and lemmas.
|
| 113 |
+
:param ta_key: Azure Text Analytics key.
|
| 114 |
+
:param ta_endpoint: Azure Text Analytics endpoint.
|
| 115 |
+
"""
|
| 116 |
+
from text_analytics_wrapper import TextAnalyticsWrapper
|
| 117 |
+
|
| 118 |
+
if not ta_key or not ta_endpoint:
|
| 119 |
+
raise RuntimeError("Please fill in the Text Analytics endpoint details")
|
| 120 |
+
|
| 121 |
+
registry = RecognizerRegistry()
|
| 122 |
+
registry.load_predefined_recognizers()
|
| 123 |
+
|
| 124 |
+
ta_recognizer = TextAnalyticsWrapper(ta_endpoint=ta_endpoint, ta_key=ta_key)
|
| 125 |
+
nlp_configuration = {
|
| 126 |
+
"nlp_engine_name": "spacy",
|
| 127 |
+
"models": [{"lang_code": "en", "model_name": "en_core_web_sm"}],
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
nlp_engine = NlpEngineProvider(nlp_configuration=nlp_configuration).create_engine()
|
| 131 |
+
|
| 132 |
+
registry.add_recognizer(ta_recognizer)
|
| 133 |
+
registry.remove_recognizer("SpacyRecognizer")
|
| 134 |
+
|
| 135 |
+
return nlp_engine, registry
|
presidio_streamlit.py
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Streamlit app for Presidio."""
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import streamlit as st
|
| 6 |
+
import streamlit.components.v1 as components
|
| 7 |
+
|
| 8 |
+
from annotated_text import annotated_text
|
| 9 |
+
from streamlit_tags import st_tags
|
| 10 |
+
|
| 11 |
+
from presidio_helpers import (
|
| 12 |
+
get_supported_entities,
|
| 13 |
+
analyze,
|
| 14 |
+
anonymize,
|
| 15 |
+
annotate,
|
| 16 |
+
create_fake_data,
|
| 17 |
+
analyzer_engine,
|
| 18 |
+
nlp_engine_and_registry,
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
st.set_page_config(page_title="Presidio demo", layout="wide")
|
| 22 |
+
|
| 23 |
+
# Sidebar
|
| 24 |
+
st.sidebar.header(
|
| 25 |
+
"""
|
| 26 |
+
PII De-Identification with Microsoft Presidio
|
| 27 |
+
"""
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
st.sidebar.info(
|
| 31 |
+
"Presidio is an open source customizable framework for PII detection and de-identification\n"
|
| 32 |
+
"[Code](https://aka.ms/presidio) | "
|
| 33 |
+
"[Tutorial](https://microsoft.github.io/presidio/tutorial/) | "
|
| 34 |
+
"[Installation](https://microsoft.github.io/presidio/installation/) | "
|
| 35 |
+
"[FAQ](https://microsoft.github.io/presidio/faq/)",
|
| 36 |
+
icon="ℹ️",
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
st.sidebar.markdown(
|
| 40 |
+
"[](https://img.shields.io/pypi/dm/presidio-analyzer.svg)" # noqa
|
| 41 |
+
"[](https://opensource.org/licenses/MIT)"
|
| 42 |
+
""
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
model_help_text = """
|
| 46 |
+
Select which Named Entity Recognition (NER) model to use for PII detection, in parallel to rule-based recognizers.
|
| 47 |
+
Presidio supports multiple NER packages off-the-shelf, such as spaCy, Huggingface, Stanza and Flair,
|
| 48 |
+
as well as service such as Azure Text Analytics PII.
|
| 49 |
+
"""
|
| 50 |
+
st_ta_key = st_ta_endpoint = ""
|
| 51 |
+
st_model = "en_core_web_lg"
|
| 52 |
+
|
| 53 |
+
st_model_package = st.sidebar.selectbox(
|
| 54 |
+
"NER model package",
|
| 55 |
+
["spaCy", "flair", "HuggingFace", "Azure Text Analytics"],
|
| 56 |
+
index=2,
|
| 57 |
+
help="Select the NLP package to use for PII detection",
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
if st_model_package == "spaCy":
|
| 61 |
+
st_model = st.sidebar.selectbox(
|
| 62 |
+
"NER model for PII detection",
|
| 63 |
+
["en_core_web_lg", "en_core_web_trf", "Other"],
|
| 64 |
+
help=model_help_text,
|
| 65 |
+
)
|
| 66 |
+
elif st_model_package == "HuggingFace":
|
| 67 |
+
st_model = st.sidebar.selectbox(
|
| 68 |
+
"NER model for PII detection",
|
| 69 |
+
["obi/deid_roberta_i2b2", "StanfordAIMI/stanford-deidentifier-base", "Other"],
|
| 70 |
+
help=model_help_text,
|
| 71 |
+
)
|
| 72 |
+
elif st_model_package == "flair":
|
| 73 |
+
st_model = st.sidebar.selectbox(
|
| 74 |
+
"NER model for PII detection",
|
| 75 |
+
["flair/ner-english-large", "Other"],
|
| 76 |
+
help=model_help_text,
|
| 77 |
+
)
|
| 78 |
+
elif st_model_package == "Azure Text Analytics":
|
| 79 |
+
st_model = st.sidebar.selectbox(
|
| 80 |
+
"NER model for PII detection",
|
| 81 |
+
["Azure Text Analytics PII"],
|
| 82 |
+
help=model_help_text,
|
| 83 |
+
)
|
| 84 |
+
st_ta_key = st.sidebar.text_input("Text Analytics Key", type="password")
|
| 85 |
+
st_ta_endpoint = st.sidebar.text_input("Text Analytics Endpoint")
|
| 86 |
+
|
| 87 |
+
if st_model == "Other":
|
| 88 |
+
st_model = st.sidebar.text_input(
|
| 89 |
+
f"NER model name for package {st_model_package}", value=""
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
st.sidebar.warning("Note: Models might take some time to download. ")
|
| 94 |
+
|
| 95 |
+
analyzer_params = (st_model_package, st_model, st_ta_key, st_ta_endpoint)
|
| 96 |
+
|
| 97 |
+
st_operator = st.sidebar.selectbox(
|
| 98 |
+
"De-identification approach",
|
| 99 |
+
["redact", "replace", "synthesize", "highlight", "mask", "hash", "encrypt"],
|
| 100 |
+
index=1,
|
| 101 |
+
help="""
|
| 102 |
+
Select which manipulation to the text is requested after PII has been identified.\n
|
| 103 |
+
- Redact: Completely remove the PII text\n
|
| 104 |
+
- Replace: Replace the PII text with a constant, e.g. <PERSON>\n
|
| 105 |
+
- Synthesize: Replace with fake values (requires an OpenAI key)\n
|
| 106 |
+
- Highlight: Shows the original text with PII highlighted in colors\n
|
| 107 |
+
- Mask: Replaces a requested number of characters with an asterisk (or other mask character)\n
|
| 108 |
+
- Hash: Replaces with the hash of the PII string\n
|
| 109 |
+
- Encrypt: Replaces with an AES encryption of the PII string, allowing the process to be reversed
|
| 110 |
+
""",
|
| 111 |
+
)
|
| 112 |
+
st_mask_char = "*"
|
| 113 |
+
st_number_of_chars = 15
|
| 114 |
+
st_encrypt_key = "WmZq4t7w!z%C&F)J"
|
| 115 |
+
st_openai_key = ""
|
| 116 |
+
st_openai_model = "text-davinci-003"
|
| 117 |
+
|
| 118 |
+
if st_operator == "mask":
|
| 119 |
+
st_number_of_chars = st.sidebar.number_input(
|
| 120 |
+
"number of chars", value=st_number_of_chars, min_value=0, max_value=100
|
| 121 |
+
)
|
| 122 |
+
st_mask_char = st.sidebar.text_input(
|
| 123 |
+
"Mask character", value=st_mask_char, max_chars=1
|
| 124 |
+
)
|
| 125 |
+
elif st_operator == "encrypt":
|
| 126 |
+
st_encrypt_key = st.sidebar.text_input("AES key", value=st_encrypt_key)
|
| 127 |
+
elif st_operator == "synthesize":
|
| 128 |
+
st_openai_key = st.sidebar.text_input(
|
| 129 |
+
"OPENAI_KEY",
|
| 130 |
+
value=os.getenv("OPENAI_KEY", default=""),
|
| 131 |
+
help="See https://help.openai.com/en/articles/4936850-where-do-i-find-my-secret-api-key for more info.",
|
| 132 |
+
type="password",
|
| 133 |
+
)
|
| 134 |
+
st_openai_model = st.sidebar.text_input(
|
| 135 |
+
"OpenAI model for text synthesis",
|
| 136 |
+
value=st_openai_model,
|
| 137 |
+
help="See more here: https://platform.openai.com/docs/models/",
|
| 138 |
+
)
|
| 139 |
+
st_threshold = st.sidebar.slider(
|
| 140 |
+
label="Acceptance threshold",
|
| 141 |
+
min_value=0.0,
|
| 142 |
+
max_value=1.0,
|
| 143 |
+
value=0.35,
|
| 144 |
+
help="Define the threshold for accepting a detection as PII. See more here: ",
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
st_return_decision_process = st.sidebar.checkbox(
|
| 148 |
+
"Add analysis explanations to findings",
|
| 149 |
+
value=False,
|
| 150 |
+
help="Add the decision process to the output table. "
|
| 151 |
+
"More information can be found here: https://microsoft.github.io/presidio/analyzer/decision_process/",
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
# Allow and deny lists
|
| 155 |
+
st_deny_allow_expander = st.sidebar.expander(
|
| 156 |
+
"Allow and deny lists",
|
| 157 |
+
expanded=False,
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
with st_deny_allow_expander:
|
| 161 |
+
st_allow_list = st_tags(label="Add words to the allow list", text="Enter word and press enter.")
|
| 162 |
+
st.caption('Allow lists contain words that are not considered PII, but are detected as such.')
|
| 163 |
+
|
| 164 |
+
st_deny_list = st_tags(label="Add words to the deny list", text="Enter word and press enter.")
|
| 165 |
+
st.caption("Deny lists contain words that are considered PII, but are not detected as such.")
|
| 166 |
+
# Main panel
|
| 167 |
+
analyzer_load_state = st.info("Starting Presidio analyzer...")
|
| 168 |
+
nlp_engine, registry = nlp_engine_and_registry(*analyzer_params)
|
| 169 |
+
|
| 170 |
+
analyzer = analyzer_engine(*analyzer_params)
|
| 171 |
+
analyzer_load_state.empty()
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
# Choose entities
|
| 175 |
+
st_entities_expander = st.sidebar.expander("Choose entities to look for")
|
| 176 |
+
st_entities = st_entities_expander.multiselect(
|
| 177 |
+
label="Which entities to look for?",
|
| 178 |
+
options=get_supported_entities(*analyzer_params),
|
| 179 |
+
default=list(get_supported_entities(*analyzer_params)),
|
| 180 |
+
help="Limit the list of PII entities detected. "
|
| 181 |
+
"This list is dynamic and based on the NER model and registered recognizers. "
|
| 182 |
+
"More information can be found here: https://microsoft.github.io/presidio/analyzer/adding_recognizers/",
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
# Read default text
|
| 186 |
+
with open("demo_text.txt") as f:
|
| 187 |
+
demo_text = f.readlines()
|
| 188 |
+
|
| 189 |
+
# Create two columns for before and after
|
| 190 |
+
col1, col2 = st.columns(2)
|
| 191 |
+
|
| 192 |
+
# Before:
|
| 193 |
+
col1.subheader("Input string:")
|
| 194 |
+
st_text = col1.text_area(
|
| 195 |
+
label="Enter text",
|
| 196 |
+
value="".join(demo_text),
|
| 197 |
+
height=400,
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
st_analyze_results = analyze(
|
| 202 |
+
*analyzer_params,
|
| 203 |
+
text=st_text,
|
| 204 |
+
entities=st_entities,
|
| 205 |
+
language="en",
|
| 206 |
+
score_threshold=st_threshold,
|
| 207 |
+
return_decision_process=st_return_decision_process,
|
| 208 |
+
allow_list=st_allow_list,
|
| 209 |
+
deny_list=st_deny_list,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
# After
|
| 213 |
+
if st_operator not in ("highlight", "synthesize"):
|
| 214 |
+
with col2:
|
| 215 |
+
st.subheader(f"Output")
|
| 216 |
+
st_anonymize_results = anonymize(
|
| 217 |
+
text=st_text,
|
| 218 |
+
operator=st_operator,
|
| 219 |
+
mask_char=st_mask_char,
|
| 220 |
+
number_of_chars=st_number_of_chars,
|
| 221 |
+
encrypt_key=st_encrypt_key,
|
| 222 |
+
analyze_results=st_analyze_results,
|
| 223 |
+
)
|
| 224 |
+
st.text_area(label="De-identified", value=st_anonymize_results.text, height=400)
|
| 225 |
+
elif st_operator == "synthesize":
|
| 226 |
+
with col2:
|
| 227 |
+
st.subheader(f"OpenAI Generated output")
|
| 228 |
+
fake_data = create_fake_data(
|
| 229 |
+
st_text,
|
| 230 |
+
st_analyze_results,
|
| 231 |
+
openai_key=st_openai_key,
|
| 232 |
+
openai_model_name=st_openai_model,
|
| 233 |
+
)
|
| 234 |
+
st.text_area(label="Synthetic data", value=fake_data, height=400)
|
| 235 |
+
else:
|
| 236 |
+
st.subheader("Highlighted")
|
| 237 |
+
annotated_tokens = annotate(text=st_text, analyze_results=st_analyze_results)
|
| 238 |
+
# annotated_tokens
|
| 239 |
+
annotated_text(*annotated_tokens)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
# table result
|
| 243 |
+
st.subheader(
|
| 244 |
+
"Findings" if not st_return_decision_process else "Findings with decision factors"
|
| 245 |
+
)
|
| 246 |
+
if st_analyze_results:
|
| 247 |
+
df = pd.DataFrame.from_records([r.to_dict() for r in st_analyze_results])
|
| 248 |
+
df["text"] = [st_text[res.start : res.end] for res in st_analyze_results]
|
| 249 |
+
|
| 250 |
+
df_subset = df[["entity_type", "text", "start", "end", "score"]].rename(
|
| 251 |
+
{
|
| 252 |
+
"entity_type": "Entity type",
|
| 253 |
+
"text": "Text",
|
| 254 |
+
"start": "Start",
|
| 255 |
+
"end": "End",
|
| 256 |
+
"score": "Confidence",
|
| 257 |
+
},
|
| 258 |
+
axis=1,
|
| 259 |
+
)
|
| 260 |
+
df_subset["Text"] = [st_text[res.start : res.end] for res in st_analyze_results]
|
| 261 |
+
if st_return_decision_process:
|
| 262 |
+
analysis_explanation_df = pd.DataFrame.from_records(
|
| 263 |
+
[r.analysis_explanation.to_dict() for r in st_analyze_results]
|
| 264 |
+
)
|
| 265 |
+
df_subset = pd.concat([df_subset, analysis_explanation_df], axis=1)
|
| 266 |
+
st.dataframe(df_subset.reset_index(drop=True), use_container_width=True)
|
| 267 |
+
else:
|
| 268 |
+
st.text("No findings")
|
| 269 |
+
|
| 270 |
+
components.html(
|
| 271 |
+
"""
|
| 272 |
+
<script type="text/javascript">
|
| 273 |
+
(function(c,l,a,r,i,t,y){
|
| 274 |
+
c[a]=c[a]||function(){(c[a].q=c[a].q||[]).push(arguments)};
|
| 275 |
+
t=l.createElement(r);t.async=1;t.src="https://www.clarity.ms/tag/"+i;
|
| 276 |
+
y=l.getElementsByTagName(r)[0];y.parentNode.insertBefore(t,y);
|
| 277 |
+
})(window, document, "clarity", "script", "h7f8bp42n8");
|
| 278 |
+
</script>
|
| 279 |
+
"""
|
| 280 |
+
)
|
requirements.txt
CHANGED
|
@@ -1,6 +1,12 @@
|
|
| 1 |
-
pandas
|
| 2 |
-
streamlit
|
| 3 |
-
presidio-anonymizer
|
| 4 |
presidio-analyzer
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
torch
|
| 6 |
-
transformers
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
presidio-analyzer
|
| 2 |
+
presidio-anonymizer
|
| 3 |
+
streamlit
|
| 4 |
+
streamlit-tags
|
| 5 |
+
pandas
|
| 6 |
+
st-annotated-text
|
| 7 |
torch
|
| 8 |
+
transformers
|
| 9 |
+
flair
|
| 10 |
+
openai
|
| 11 |
+
spacy
|
| 12 |
+
azure-ai-textanalytics
|
text_analytics_wrapper.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List, Optional
|
| 3 |
+
|
| 4 |
+
import dotenv
|
| 5 |
+
from azure.ai.textanalytics import TextAnalyticsClient
|
| 6 |
+
from azure.core.credentials import AzureKeyCredential
|
| 7 |
+
|
| 8 |
+
from presidio_analyzer import EntityRecognizer, RecognizerResult, AnalysisExplanation
|
| 9 |
+
from presidio_analyzer.nlp_engine import NlpArtifacts
|
| 10 |
+
|
| 11 |
+
class TextAnalyticsWrapper(EntityRecognizer):
|
| 12 |
+
from azure.ai.textanalytics._models import PiiEntityCategory
|
| 13 |
+
TA_SUPPORTED_ENTITIES = [r.value for r in PiiEntityCategory]
|
| 14 |
+
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
supported_entities: Optional[List[str]] = None,
|
| 18 |
+
supported_language: str = "en",
|
| 19 |
+
ta_client: Optional[TextAnalyticsClient] = None,
|
| 20 |
+
ta_key: Optional[str] = None,
|
| 21 |
+
ta_endpoint: Optional[str] = None,
|
| 22 |
+
):
|
| 23 |
+
"""
|
| 24 |
+
Wrapper for the Azure Text Analytics client
|
| 25 |
+
:param ta_client: object of type TextAnalyticsClient
|
| 26 |
+
:param ta_key: Azure cognitive Services for Language key
|
| 27 |
+
:param ta_endpoint: Azure cognitive Services for Language endpoint
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
if not supported_entities:
|
| 31 |
+
supported_entities = self.TA_SUPPORTED_ENTITIES
|
| 32 |
+
|
| 33 |
+
super().__init__(
|
| 34 |
+
supported_entities=supported_entities,
|
| 35 |
+
supported_language=supported_language,
|
| 36 |
+
name="Azure Text Analytics PII",
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
self.ta_key = ta_key
|
| 40 |
+
self.ta_endpoint = ta_endpoint
|
| 41 |
+
|
| 42 |
+
if not ta_client:
|
| 43 |
+
ta_client = self.__authenticate_client(ta_key, ta_endpoint)
|
| 44 |
+
self.ta_client = ta_client
|
| 45 |
+
|
| 46 |
+
@staticmethod
|
| 47 |
+
def __authenticate_client(key: str, endpoint: str):
|
| 48 |
+
ta_credential = AzureKeyCredential(key)
|
| 49 |
+
text_analytics_client = TextAnalyticsClient(
|
| 50 |
+
endpoint=endpoint, credential=ta_credential
|
| 51 |
+
)
|
| 52 |
+
return text_analytics_client
|
| 53 |
+
|
| 54 |
+
def analyze(
|
| 55 |
+
self, text: str, entities: List[str] = None, nlp_artifacts: NlpArtifacts = None
|
| 56 |
+
) -> List[RecognizerResult]:
|
| 57 |
+
if not entities:
|
| 58 |
+
entities = []
|
| 59 |
+
response = self.ta_client.recognize_pii_entities(
|
| 60 |
+
[text], language=self.supported_language
|
| 61 |
+
)
|
| 62 |
+
results = [doc for doc in response if not doc.is_error]
|
| 63 |
+
recognizer_results = []
|
| 64 |
+
for res in results:
|
| 65 |
+
for entity in res.entities:
|
| 66 |
+
if entity.category not in self.supported_entities:
|
| 67 |
+
continue
|
| 68 |
+
analysis_explanation = TextAnalyticsWrapper._build_explanation(
|
| 69 |
+
original_score=entity.confidence_score,
|
| 70 |
+
entity_type=entity.category,
|
| 71 |
+
)
|
| 72 |
+
recognizer_results.append(
|
| 73 |
+
RecognizerResult(
|
| 74 |
+
entity_type=entity.category,
|
| 75 |
+
start=entity.offset,
|
| 76 |
+
end=entity.offset + len(entity.text),
|
| 77 |
+
score=entity.confidence_score,
|
| 78 |
+
analysis_explanation=analysis_explanation,
|
| 79 |
+
)
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
return recognizer_results
|
| 83 |
+
|
| 84 |
+
@staticmethod
|
| 85 |
+
def _build_explanation(
|
| 86 |
+
original_score: float, entity_type: str
|
| 87 |
+
) -> AnalysisExplanation:
|
| 88 |
+
explanation = AnalysisExplanation(
|
| 89 |
+
recognizer=TextAnalyticsWrapper.__class__.__name__,
|
| 90 |
+
original_score=original_score,
|
| 91 |
+
textual_explanation=f"Identified as {entity_type} by Text Analytics",
|
| 92 |
+
)
|
| 93 |
+
return explanation
|
| 94 |
+
|
| 95 |
+
def load(self) -> None:
|
| 96 |
+
pass
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
if __name__ == "__main__":
|
| 100 |
+
import presidio_helpers
|
| 101 |
+
dotenv.load_dotenv()
|
| 102 |
+
text = """
|
| 103 |
+
Here are a few example sentences we currently support:
|
| 104 |
+
|
| 105 |
+
Hello, my name is David Johnson and I live in Maine.
|
| 106 |
+
My credit card number is 4095-2609-9393-4932 and my crypto wallet id is 16Yeky6GMjeNkAiNcBY7ZhrLoMSgg1BoyZ.
|
| 107 |
+
|
| 108 |
+
On September 18 I visited microsoft.com and sent an email to test@presidio.site, from the IP 192.168.0.1.
|
| 109 |
+
|
| 110 |
+
My passport: 191280342 and my phone number: (212) 555-1234.
|
| 111 |
+
|
| 112 |
+
This is a valid International Bank Account Number: IL150120690000003111111 . Can you please check the status on bank account 954567876544?
|
| 113 |
+
|
| 114 |
+
Kate's social security number is 078-05-1126. Her driver license? it is 1234567A.
|
| 115 |
+
"""
|
| 116 |
+
analyzer = presidio_helpers.analyzer_engine(
|
| 117 |
+
model_path="Azure Text Analytics PII",
|
| 118 |
+
ta_key=os.environ["TA_KEY"],
|
| 119 |
+
ta_endpoint=os.environ["TA_ENDPOINT"],
|
| 120 |
+
)
|
| 121 |
+
analyzer.analyze(text=text, language="en")
|