Spaces:
Runtime error


Runtime error

code add
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- Dockerfile +125 -0
- Makefile +120 -0
- README.md +250 -1
- README_1.md +61 -0
- app.py +110 -0
- backend/.DS_Store +0 -0
- backend/.env.example +29 -0
- backend/Dockerfile +43 -0
- backend/__init__.py +1 -0
- backend/agents/__init__.py +0 -0
- backend/agents/claude_coach.py +131 -0
- backend/agents/complexity.py +79 -0
- backend/agents/grpo_trainer.py +236 -0
- backend/agents/model_agent.py +285 -0
- backend/agents/nvm_player_agent.py +265 -0
- backend/agents/qwen_agent.py +228 -0
- backend/api/__init__.py +0 -0
- backend/api/coaching_router.py +274 -0
- backend/api/game_router.py +295 -0
- backend/api/training_router.py +75 -0
- backend/api/websocket.py +97 -0
- backend/api/websocket.py_backup +87 -0
- backend/chess_engine.py +186 -0
- backend/chess_lib/__init__.py +0 -0
- backend/chess_lib/chess_engine.py +166 -0
- backend/chess_lib/engine.py +125 -0
- backend/economy/.DS_Store +0 -0
- backend/economy/__init__.py +0 -0
- backend/economy/ledger.py +174 -0
- backend/economy/nvm_payments.py +340 -0
- backend/economy/register_agent.py +138 -0
- backend/grpo_trainer.py +240 -0
- backend/main.py +313 -0
- backend/main.py_backup +218 -0
- backend/openenv/__init__.py +19 -0
- backend/openenv/env.py +311 -0
- backend/openenv/models.py +136 -0
- backend/openenv/router.py +159 -0
- backend/qwen_agent.py +228 -0
- backend/requirements.txt +40 -0
- backend/settings.py +65 -0
- backend/websocket_server.py +365 -0
- doc.md +124 -0
- docker-compose.gpu.yml +52 -0
- docker-compose.yml +63 -0
- docker-compose.yml_backup +61 -0
- docker-entrypoint.sh +175 -0
- docs/Issues.md +47 -0
- docs/latest_fixes_howto.md +420 -0
- frontend/.DS_Store +0 -0
Dockerfile
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 2 |
+
# ChessEcon — Unified Multi-Stage Dockerfile
|
| 3 |
+
#
|
| 4 |
+
# Stages:
|
| 5 |
+
# 1. frontend-builder — builds the React TypeScript dashboard (Node.js)
|
| 6 |
+
# 2. backend-cpu — Python FastAPI backend, serves built frontend as static
|
| 7 |
+
# 3. backend-gpu — same as backend-cpu but with CUDA PyTorch
|
| 8 |
+
#
|
| 9 |
+
# Usage:
|
| 10 |
+
# CPU: docker build --target backend-cpu -t chessecon:cpu .
|
| 11 |
+
# GPU: docker build --target backend-gpu -t chessecon:gpu .
|
| 12 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 13 |
+
|
| 14 |
+
# ── Stage 1: Build the React frontend ────────────────────────────────────────
|
| 15 |
+
FROM node:22-alpine AS frontend-builder
|
| 16 |
+
|
| 17 |
+
WORKDIR /app/frontend
|
| 18 |
+
|
| 19 |
+
# Copy package files AND patches dir (required by pnpm for patched dependencies)
|
| 20 |
+
COPY frontend/package.json frontend/pnpm-lock.yaml* ./
|
| 21 |
+
COPY frontend/patches/ ./patches/
|
| 22 |
+
RUN npm install -g pnpm && pnpm install --frozen-lockfile
|
| 23 |
+
|
| 24 |
+
# Copy the full frontend source
|
| 25 |
+
COPY frontend/ ./
|
| 26 |
+
|
| 27 |
+
# Build the production bundle (frontend only — no Express server build)
|
| 28 |
+
# vite.config.ts outputs to dist/public/ relative to the project root
|
| 29 |
+
RUN pnpm build:docker
|
| 30 |
+
|
| 31 |
+
# ── Stage 2: CPU backend ──────────────────────────────────────────────────────
|
| 32 |
+
FROM python:3.11-slim AS backend-cpu
|
| 33 |
+
|
| 34 |
+
LABEL maintainer="ChessEcon Team"
|
| 35 |
+
LABEL description="ChessEcon — Multi-Agent Chess RL System (CPU)"
|
| 36 |
+
|
| 37 |
+
# System dependencies
|
| 38 |
+
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 39 |
+
stockfish \
|
| 40 |
+
curl \
|
| 41 |
+
git \
|
| 42 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 43 |
+
|
| 44 |
+
WORKDIR /app
|
| 45 |
+
|
| 46 |
+
# Install Python dependencies
|
| 47 |
+
COPY backend/requirements.txt ./backend/requirements.txt
|
| 48 |
+
RUN pip install --no-cache-dir -r backend/requirements.txt
|
| 49 |
+
|
| 50 |
+
# Copy the backend source
|
| 51 |
+
COPY backend/ ./backend/
|
| 52 |
+
COPY shared/ ./shared/
|
| 53 |
+
|
| 54 |
+
# Copy the built frontend into the backend's static directory
|
| 55 |
+
# vite.config.ts outputs to dist/public/ (see build.outDir in vite.config.ts)
|
| 56 |
+
COPY --from=frontend-builder /app/frontend/dist/public ./backend/static/
|
| 57 |
+
|
| 58 |
+
# Copy entrypoint
|
| 59 |
+
COPY docker-entrypoint.sh ./
|
| 60 |
+
RUN chmod +x docker-entrypoint.sh
|
| 61 |
+
|
| 62 |
+
# Create directories for model cache and training data
|
| 63 |
+
RUN mkdir -p /app/models /app/data/games /app/data/training /app/logs
|
| 64 |
+
|
| 65 |
+
# Expose the application port
|
| 66 |
+
EXPOSE 8000
|
| 67 |
+
|
| 68 |
+
# Health check
|
| 69 |
+
HEALTHCHECK --interval=30s --timeout=10s --start-period=60s --retries=3 \
|
| 70 |
+
CMD curl -f http://localhost:8000/health || exit 1
|
| 71 |
+
|
| 72 |
+
ENTRYPOINT ["./docker-entrypoint.sh"]
|
| 73 |
+
CMD ["backend"]
|
| 74 |
+
|
| 75 |
+
# ── Stage 3: GPU backend ──────────────────────────────────────────────────────
|
| 76 |
+
FROM nvidia/cuda:12.1.0-cudnn8-runtime-ubuntu22.04 AS backend-gpu
|
| 77 |
+
|
| 78 |
+
LABEL maintainer="ChessEcon Team"
|
| 79 |
+
LABEL description="ChessEcon — Multi-Agent Chess RL System (GPU/CUDA)"
|
| 80 |
+
|
| 81 |
+
# System dependencies
|
| 82 |
+
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 83 |
+
python3.11 \
|
| 84 |
+
python3.11-dev \
|
| 85 |
+
python3-pip \
|
| 86 |
+
stockfish \
|
| 87 |
+
curl \
|
| 88 |
+
git \
|
| 89 |
+
&& rm -rf /var/lib/apt/lists/* \
|
| 90 |
+
&& ln -sf /usr/bin/python3.11 /usr/bin/python3 \
|
| 91 |
+
&& ln -sf /usr/bin/python3 /usr/bin/python
|
| 92 |
+
|
| 93 |
+
WORKDIR /app
|
| 94 |
+
|
| 95 |
+
# Install PyTorch with CUDA support first (separate layer for caching)
|
| 96 |
+
RUN pip install --no-cache-dir torch==2.3.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
|
| 97 |
+
|
| 98 |
+
# Install remaining Python dependencies
|
| 99 |
+
COPY backend/requirements.txt ./backend/requirements.txt
|
| 100 |
+
COPY training/requirements.txt ./training/requirements.txt
|
| 101 |
+
RUN pip install --no-cache-dir -r backend/requirements.txt
|
| 102 |
+
RUN pip install --no-cache-dir -r training/requirements.txt
|
| 103 |
+
|
| 104 |
+
# Copy source
|
| 105 |
+
COPY backend/ ./backend/
|
| 106 |
+
COPY training/ ./training/
|
| 107 |
+
COPY shared/ ./shared/
|
| 108 |
+
|
| 109 |
+
# Copy the built frontend
|
| 110 |
+
COPY --from=frontend-builder /app/frontend/dist/public ./backend/static/
|
| 111 |
+
|
| 112 |
+
# Copy entrypoint
|
| 113 |
+
COPY docker-entrypoint.sh ./
|
| 114 |
+
RUN chmod +x docker-entrypoint.sh
|
| 115 |
+
|
| 116 |
+
# Create directories
|
| 117 |
+
RUN mkdir -p /app/models /app/data/games /app/data/training /app/logs
|
| 118 |
+
|
| 119 |
+
EXPOSE 8000
|
| 120 |
+
|
| 121 |
+
HEALTHCHECK --interval=30s --timeout=10s --start-period=120s --retries=3 \
|
| 122 |
+
CMD curl -f http://localhost:8000/health || exit 1
|
| 123 |
+
|
| 124 |
+
ENTRYPOINT ["./docker-entrypoint.sh"]
|
| 125 |
+
CMD ["backend"]
|
Makefile
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 2 |
+
# ChessEcon — Makefile
|
| 3 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 4 |
+
|
| 5 |
+
.PHONY: help env-file dirs build build-gpu up up-gpu down demo selfplay train \
|
| 6 |
+
train-gpu logs shell clean frontend-dev backend-dev test lint
|
| 7 |
+
|
| 8 |
+
# ── Default target ────────────────────────────────────────────────────────────
|
| 9 |
+
help:
|
| 10 |
+
@echo ""
|
| 11 |
+
@echo " ChessEcon — Multi-Agent Chess RL System"
|
| 12 |
+
@echo " ════════════════════════════════════════"
|
| 13 |
+
@echo ""
|
| 14 |
+
@echo " Setup:"
|
| 15 |
+
@echo " make env-file Copy .env.example → .env (edit before running)"
|
| 16 |
+
@echo " make dirs Create host volume directories"
|
| 17 |
+
@echo ""
|
| 18 |
+
@echo " Docker (CPU):"
|
| 19 |
+
@echo " make build Build the CPU Docker image"
|
| 20 |
+
@echo " make up Start the dashboard + API (http://localhost:8000)"
|
| 21 |
+
@echo " make demo Run a 3-game demo and exit"
|
| 22 |
+
@echo " make selfplay Collect self-play data (no training)"
|
| 23 |
+
@echo " make train Run RL training (CPU)"
|
| 24 |
+
@echo " make down Stop all containers"
|
| 25 |
+
@echo ""
|
| 26 |
+
@echo " Docker (GPU):"
|
| 27 |
+
@echo " make build-gpu Build the GPU Docker image"
|
| 28 |
+
@echo " make up-gpu Start with GPU support"
|
| 29 |
+
@echo " make train-gpu Run RL training (GPU)"
|
| 30 |
+
@echo ""
|
| 31 |
+
@echo " Development:"
|
| 32 |
+
@echo " make frontend-dev Start React dev server (hot-reload)"
|
| 33 |
+
@echo " make backend-dev Start FastAPI dev server"
|
| 34 |
+
@echo " make test Run all tests"
|
| 35 |
+
@echo " make lint Run linters"
|
| 36 |
+
@echo ""
|
| 37 |
+
@echo " Utilities:"
|
| 38 |
+
@echo " make logs Tail container logs"
|
| 39 |
+
@echo " make shell Open shell in running container"
|
| 40 |
+
@echo " make clean Remove containers, images, and volumes"
|
| 41 |
+
@echo ""
|
| 42 |
+
|
| 43 |
+
# ── Setup ─────────────────────────────────────────────────────────────────────
|
| 44 |
+
env-file:
|
| 45 |
+
@if [ -f .env ]; then \
|
| 46 |
+
echo ".env already exists. Delete it first if you want to reset."; \
|
| 47 |
+
else \
|
| 48 |
+
cp .env.example .env; \
|
| 49 |
+
echo ".env created. Edit it with your API keys before running."; \
|
| 50 |
+
fi
|
| 51 |
+
|
| 52 |
+
dirs:
|
| 53 |
+
@mkdir -p volumes/models volumes/data volumes/logs
|
| 54 |
+
@echo "Volume directories created."
|
| 55 |
+
|
| 56 |
+
# ── Docker CPU ────────────────────────────────────────────────────────────────
|
| 57 |
+
build: dirs
|
| 58 |
+
docker compose build chessecon
|
| 59 |
+
|
| 60 |
+
up: dirs
|
| 61 |
+
docker compose up chessecon
|
| 62 |
+
|
| 63 |
+
demo: dirs
|
| 64 |
+
docker compose run --rm chessecon demo
|
| 65 |
+
|
| 66 |
+
selfplay: dirs
|
| 67 |
+
docker compose run --rm \
|
| 68 |
+
-e RL_METHOD=selfplay \
|
| 69 |
+
chessecon selfplay
|
| 70 |
+
|
| 71 |
+
train: dirs
|
| 72 |
+
docker compose --profile training up trainer
|
| 73 |
+
|
| 74 |
+
down:
|
| 75 |
+
docker compose down
|
| 76 |
+
|
| 77 |
+
# ── Docker GPU ────────────────────────────────────────────────────────────────
|
| 78 |
+
build-gpu: dirs
|
| 79 |
+
docker compose -f docker-compose.yml -f docker-compose.gpu.yml build
|
| 80 |
+
|
| 81 |
+
up-gpu: dirs
|
| 82 |
+
docker compose -f docker-compose.yml -f docker-compose.gpu.yml up chessecon
|
| 83 |
+
|
| 84 |
+
train-gpu: dirs
|
| 85 |
+
docker compose -f docker-compose.yml -f docker-compose.gpu.yml \
|
| 86 |
+
--profile training up trainer
|
| 87 |
+
|
| 88 |
+
# ── Development (local, no Docker) ───────────────────────────────────────────
|
| 89 |
+
frontend-dev:
|
| 90 |
+
@echo "Starting React frontend dev server..."
|
| 91 |
+
cd frontend && pnpm install && pnpm dev
|
| 92 |
+
|
| 93 |
+
backend-dev:
|
| 94 |
+
@echo "Starting FastAPI backend dev server..."
|
| 95 |
+
cd backend && pip install -r requirements.txt && \
|
| 96 |
+
uvicorn main:app --reload --host 0.0.0.0 --port 8000
|
| 97 |
+
|
| 98 |
+
# ── Testing ───────────────────────────────────────────────────────────────────
|
| 99 |
+
test:
|
| 100 |
+
@echo "Running backend tests..."
|
| 101 |
+
cd backend && python -m pytest tests/ -v
|
| 102 |
+
@echo "Running frontend tests..."
|
| 103 |
+
cd frontend && pnpm test
|
| 104 |
+
|
| 105 |
+
lint:
|
| 106 |
+
@echo "Linting backend..."
|
| 107 |
+
cd backend && python -m ruff check . || true
|
| 108 |
+
@echo "Linting frontend..."
|
| 109 |
+
cd frontend && pnpm lint || true
|
| 110 |
+
|
| 111 |
+
# ── Utilities ─────────────────────────────────────────────────────��───────────
|
| 112 |
+
logs:
|
| 113 |
+
docker compose logs -f chessecon
|
| 114 |
+
|
| 115 |
+
shell:
|
| 116 |
+
docker compose exec chessecon /bin/bash
|
| 117 |
+
|
| 118 |
+
clean:
|
| 119 |
+
docker compose down -v --rmi local
|
| 120 |
+
@echo "Containers, images, and volumes removed."
|
README.md
CHANGED
|
@@ -1 +1,250 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: ChessEcon
|
| 3 |
+
emoji: ♟️
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: purple
|
| 6 |
+
sdk: docker
|
| 7 |
+
app_port: 8000
|
| 8 |
+
tags:
|
| 9 |
+
- openenv
|
| 10 |
+
- reinforcement-learning
|
| 11 |
+
- chess
|
| 12 |
+
- multi-agent
|
| 13 |
+
- grpo
|
| 14 |
+
- rl-environment
|
| 15 |
+
- economy
|
| 16 |
+
- two-player
|
| 17 |
+
- game
|
| 18 |
+
license: apache-2.0
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
# ♟️ ChessEcon — OpenEnv 0.1 Compliant Chess Economy Environment
|
| 22 |
+
|
| 23 |
+
> **Self-hosted environment** — the live API runs on AdaBoost AI infrastructure.
|
| 24 |
+
> Update this URL if the domain changes.
|
| 25 |
+
|
| 26 |
+
**Live API base URL:** `https://chessecon.adaboost.io`
|
| 27 |
+
**env_info:** `https://chessecon.adaboost.io/env/env_info`
|
| 28 |
+
**Dashboard:** `https://chessecon-ui.adaboost.io`
|
| 29 |
+
**Swagger docs:** `https://chessecon.adaboost.io/docs`
|
| 30 |
+
|
| 31 |
+
---
|
| 32 |
+
|
| 33 |
+
**Two competing LLM agents play chess for economic stakes.**
|
| 34 |
+
White = `Qwen/Qwen2.5-0.5B-Instruct` (trainable) | Black = `meta-llama/Llama-3.2-1B-Instruct` (fixed)
|
| 35 |
+
|
| 36 |
+
Both agents pay an entry fee each game. The winner earns a prize pool.
|
| 37 |
+
The White agent is trained live with **GRPO** (Group Relative Policy Optimisation).
|
| 38 |
+
|
| 39 |
+
---
|
| 40 |
+
|
| 41 |
+
## OpenEnv 0.1 API
|
| 42 |
+
|
| 43 |
+
This environment is fully compliant with the [OpenEnv 0.1 spec](https://github.com/huggingface/openenv).
|
| 44 |
+
|
| 45 |
+
| Endpoint | Method | Description |
|
| 46 |
+
|---|---|---|
|
| 47 |
+
| `/env/reset` | `POST` | Start a new episode, deduct entry fees, return initial observation |
|
| 48 |
+
| `/env/step` | `POST` | Apply one move (UCI or SAN), return reward + next observation |
|
| 49 |
+
| `/env/state` | `GET` | Inspect current board state — read-only, no side effects |
|
| 50 |
+
| `/env/env_info` | `GET` | Environment metadata for HF Hub discoverability |
|
| 51 |
+
| `/ws` | `WS` | Real-time event stream for the live dashboard |
|
| 52 |
+
| `/health` | `GET` | Health check + model load status |
|
| 53 |
+
| `/docs` | `GET` | Interactive Swagger UI |
|
| 54 |
+
|
| 55 |
+
---
|
| 56 |
+
|
| 57 |
+
## Quick Start
|
| 58 |
+
|
| 59 |
+
```python
|
| 60 |
+
import httpx
|
| 61 |
+
|
| 62 |
+
BASE = "https://chessecon.adaboost.io"
|
| 63 |
+
|
| 64 |
+
# 1. Start a new episode
|
| 65 |
+
reset = httpx.post(f"{BASE}/env/reset").json()
|
| 66 |
+
print(reset["observation"]["fen"]) # starting FEN
|
| 67 |
+
print(reset["observation"]["legal_moves_uci"]) # all legal moves
|
| 68 |
+
|
| 69 |
+
# 2. Play moves
|
| 70 |
+
step = httpx.post(f"{BASE}/env/step", json={"action": "e2e4"}).json()
|
| 71 |
+
print(step["observation"]["fen"]) # board after move
|
| 72 |
+
print(step["reward"]) # per-step reward signal
|
| 73 |
+
print(step["terminated"]) # True if game is over
|
| 74 |
+
print(step["truncated"]) # True if move limit hit
|
| 75 |
+
|
| 76 |
+
# 3. Inspect state (non-destructive)
|
| 77 |
+
state = httpx.get(f"{BASE}/env/state").json()
|
| 78 |
+
print(state["step_count"]) # moves played so far
|
| 79 |
+
print(state["status"]) # "active" | "terminated" | "idle"
|
| 80 |
+
|
| 81 |
+
# 4. Environment metadata
|
| 82 |
+
info = httpx.get(f"{BASE}/env/env_info").json()
|
| 83 |
+
print(info["openenv_version"]) # "0.1"
|
| 84 |
+
print(info["agents"]) # white/black model IDs
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
### Drop-in Client for TRL / verl / SkyRL
|
| 88 |
+
|
| 89 |
+
```python
|
| 90 |
+
import httpx
|
| 91 |
+
|
| 92 |
+
class ChessEconClient:
|
| 93 |
+
"""OpenEnv 0.1 client — compatible with TRL, verl, SkyRL."""
|
| 94 |
+
|
| 95 |
+
def __init__(self, base_url: str = "https://chessecon.adaboost.io"):
|
| 96 |
+
self.base = base_url.rstrip("/")
|
| 97 |
+
self.client = httpx.Client(timeout=30)
|
| 98 |
+
|
| 99 |
+
def reset(self, seed=None):
|
| 100 |
+
payload = {"seed": seed} if seed is not None else {}
|
| 101 |
+
r = self.client.post(f"{self.base}/env/reset", json=payload)
|
| 102 |
+
r.raise_for_status()
|
| 103 |
+
data = r.json()
|
| 104 |
+
return data["observation"], data["info"]
|
| 105 |
+
|
| 106 |
+
def step(self, action: str):
|
| 107 |
+
r = self.client.post(f"{self.base}/env/step", json={"action": action})
|
| 108 |
+
r.raise_for_status()
|
| 109 |
+
data = r.json()
|
| 110 |
+
return (
|
| 111 |
+
data["observation"],
|
| 112 |
+
data["reward"],
|
| 113 |
+
data["terminated"],
|
| 114 |
+
data["truncated"],
|
| 115 |
+
data["info"],
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
def state(self):
|
| 119 |
+
return self.client.get(f"{self.base}/env/state").json()
|
| 120 |
+
|
| 121 |
+
def env_info(self):
|
| 122 |
+
return self.client.get(f"{self.base}/env/env_info").json()
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
# Usage
|
| 126 |
+
env = ChessEconClient()
|
| 127 |
+
obs, info = env.reset()
|
| 128 |
+
|
| 129 |
+
while True:
|
| 130 |
+
action = obs["legal_moves_uci"][0] # replace with your policy
|
| 131 |
+
obs, reward, terminated, truncated, info = env.step(action)
|
| 132 |
+
if terminated or truncated:
|
| 133 |
+
break
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
---
|
| 137 |
+
|
| 138 |
+
## Observation Schema
|
| 139 |
+
|
| 140 |
+
Every response wraps a `ChessObservation` object:
|
| 141 |
+
|
| 142 |
+
```json
|
| 143 |
+
{
|
| 144 |
+
"observation": {
|
| 145 |
+
"fen": "rnbqkbnr/pppppppp/8/8/4P3/8/PPPP1PPP/RNBQKBNR b KQkq - 0 1",
|
| 146 |
+
"turn": "black",
|
| 147 |
+
"move_number": 1,
|
| 148 |
+
"last_move_uci": "e2e4",
|
| 149 |
+
"last_move_san": "e4",
|
| 150 |
+
"legal_moves_uci": ["e7e5", "d7d5", "g8f6"],
|
| 151 |
+
"is_check": false,
|
| 152 |
+
"wallet_white": 90.0,
|
| 153 |
+
"wallet_black": 90.0,
|
| 154 |
+
"white_model": "Qwen/Qwen2.5-0.5B-Instruct",
|
| 155 |
+
"black_model": "meta-llama/Llama-3.2-1B-Instruct",
|
| 156 |
+
"info": {}
|
| 157 |
+
}
|
| 158 |
+
}
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
### Step Response
|
| 162 |
+
|
| 163 |
+
```json
|
| 164 |
+
{
|
| 165 |
+
"observation": { "...": "see above" },
|
| 166 |
+
"reward": 0.01,
|
| 167 |
+
"terminated": false,
|
| 168 |
+
"truncated": false,
|
| 169 |
+
"info": { "san": "e4", "uci": "e2e4", "move_number": 1 }
|
| 170 |
+
}
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
### State Response
|
| 174 |
+
|
| 175 |
+
```json
|
| 176 |
+
{
|
| 177 |
+
"observation": { "...": "see above" },
|
| 178 |
+
"episode_id": "ep-42",
|
| 179 |
+
"step_count": 1,
|
| 180 |
+
"status": "active",
|
| 181 |
+
"info": {}
|
| 182 |
+
}
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
---
|
| 186 |
+
|
| 187 |
+
## Reward Structure
|
| 188 |
+
|
| 189 |
+
| Event | Reward | Notes |
|
| 190 |
+
|---|---|---|
|
| 191 |
+
| Legal move | `+0.01` | Every valid move |
|
| 192 |
+
| Move gives check | `+0.05` | Additional bonus |
|
| 193 |
+
| Capture | `+0.10` | Additional bonus |
|
| 194 |
+
| Win (checkmate) | `+1.00` | Terminal |
|
| 195 |
+
| Loss | `-1.00` | Terminal |
|
| 196 |
+
| Draw | `0.00` | Terminal |
|
| 197 |
+
| Illegal move | `-0.10` | Episode continues |
|
| 198 |
+
|
| 199 |
+
Combined reward: `0.4 × game_reward + 0.6 × economic_reward`
|
| 200 |
+
|
| 201 |
+
---
|
| 202 |
+
|
| 203 |
+
## Economy Model
|
| 204 |
+
|
| 205 |
+
| Parameter | Value |
|
| 206 |
+
|---|---|
|
| 207 |
+
| Starting wallet | 100 units |
|
| 208 |
+
| Entry fee | 10 units per agent per game |
|
| 209 |
+
| Prize pool | 18 units (90% of 2 × entry fee) |
|
| 210 |
+
| Draw refund | 5 units each |
|
| 211 |
+
|
| 212 |
+
---
|
| 213 |
+
|
| 214 |
+
## Architecture
|
| 215 |
+
|
| 216 |
+
```
|
| 217 |
+
External RL Trainers (TRL / verl / SkyRL)
|
| 218 |
+
│ HTTP
|
| 219 |
+
▼
|
| 220 |
+
┌─────────────────────────────────────────────┐
|
| 221 |
+
│ OpenEnv 0.1 HTTP API │
|
| 222 |
+
│ POST /env/reset POST /env/step │
|
| 223 |
+
│ GET /env/state GET /env/env_info │
|
| 224 |
+
│ asyncio.Lock — thread safe │
|
| 225 |
+
└──────────────┬──────────────────────────────┘
|
| 226 |
+
│
|
| 227 |
+
┌───────┴────────┐
|
| 228 |
+
▼ ▼
|
| 229 |
+
┌─────────────┐ ┌──────────────┐
|
| 230 |
+
│ Chess Engine│ │Economy Engine│
|
| 231 |
+
│ python-chess│ │Wallets · Fees│
|
| 232 |
+
│ FEN · UCI │ │Prize Pool │
|
| 233 |
+
└──────┬──────┘ └──────────────┘
|
| 234 |
+
│
|
| 235 |
+
┌────┴─────┐
|
| 236 |
+
▼ ▼
|
| 237 |
+
♔ Qwen ♚ Llama
|
| 238 |
+
0.5B 1B
|
| 239 |
+
GRPO↑ Fixed
|
| 240 |
+
```
|
| 241 |
+
|
| 242 |
+
---
|
| 243 |
+
|
| 244 |
+
## Hardware
|
| 245 |
+
|
| 246 |
+
Self-hosted on AdaBoost AI infrastructure:
|
| 247 |
+
- 4× NVIDIA RTX 3070 (lambda-quad)
|
| 248 |
+
- Models loaded in 4-bit quantization
|
| 249 |
+
|
| 250 |
+
Built by [AdaBoost AI](https://adaboost.io) · Hackathon 2026
|
README_1.md
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pitch: The Autonomous Chess Economy
|
| 2 |
+
|
| 3 |
+
## 1. The Vision: From Game Players to Autonomous Businesses
|
| 4 |
+
|
| 5 |
+
The hackathon challenges us to build "autonomous businesses where agents make real economic decisions." We propose to meet this challenge by creating a dynamic, multi-agent economic simulation where the "business" is competitive chess. Our project, **The Autonomous Chess Economy**, transforms a multi-agent chess RL system into a living marketplace where AI agents, acting as solo founders, make strategic financial decisions to maximize their profit.
|
| 6 |
+
|
| 7 |
+
> In our system, agents don’t just play chess; they run a business. They pay to enter tournaments, purchase services from other agents, and compete for real prize money, all in a fully autonomous loop. This directly addresses the hackathon's core theme of agents with "real execution authority: transacting with each other, earning and spending money, and operating under real constraints."
|
| 8 |
+
|
| 9 |
+
## 2. The Architecture: A Multi-Layered Economic Simulation
|
| 10 |
+
|
| 11 |
+
We extend our existing multi-agent chess platform by introducing a new economic layer. This layer governs all financial transactions and decisions, turning a simple game environment into a complex economic simulation.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
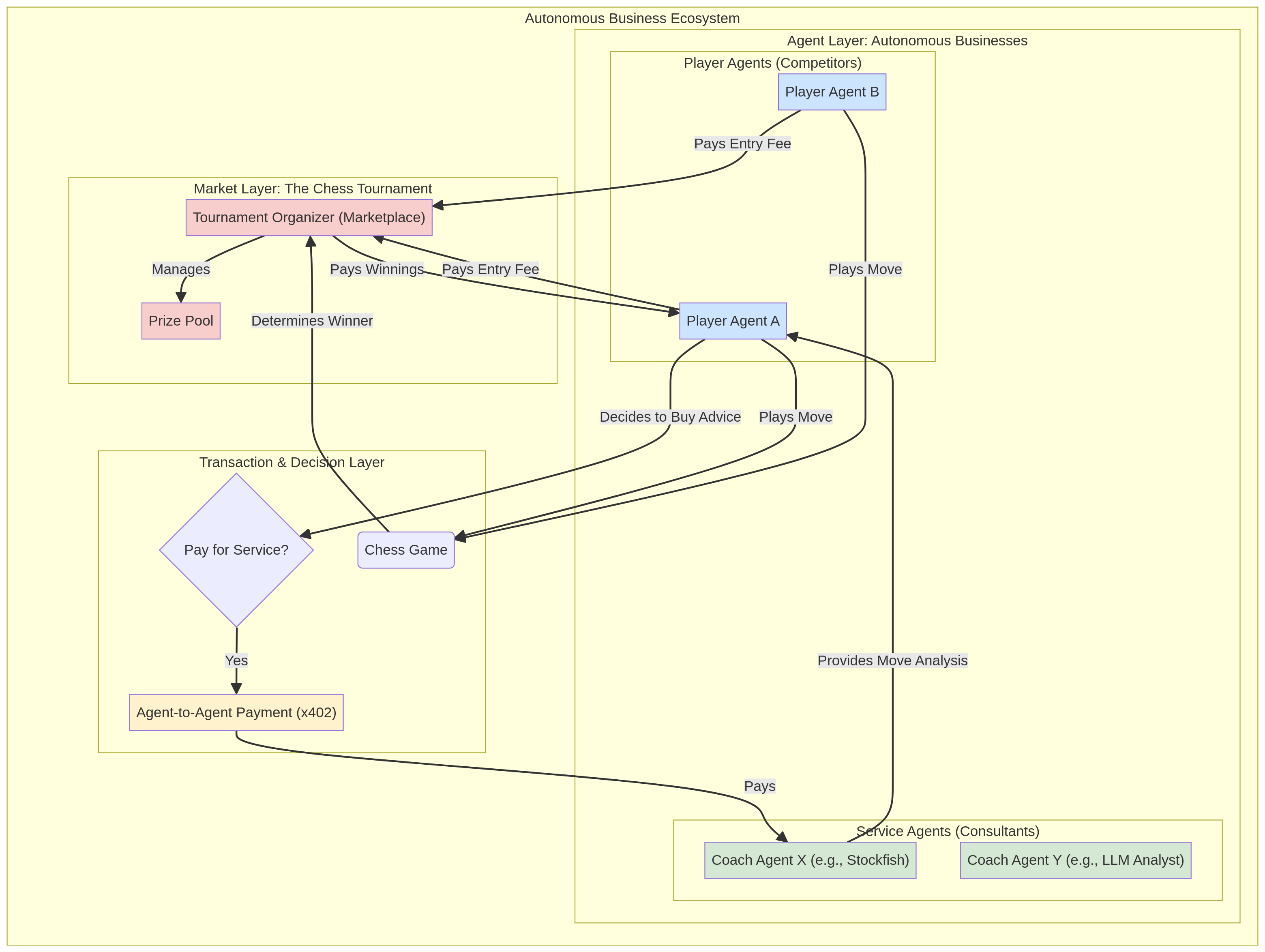
Our architecture is composed of three primary layers:
|
| 16 |
+
|
| 17 |
+
1. **The Market Layer:** A **Tournament Organizer** agent acts as the central marketplace. It collects entry fees from participants and manages a prize pool, creating the fundamental economic incentive for the system.
|
| 18 |
+
2. **The Agent Layer:** This layer consists of two types of autonomous businesses:
|
| 19 |
+
* **Player Agents (The Competitors):** These are the core businesses in our economy. Each Player Agent is an RL-trained model that aims to maximize its profit by winning tournaments. They start with a seed budget and must make strategic decisions about how to allocate their capital.
|
| 20 |
+
* **Service Agents (The Consultants):** These agents represent specialized service providers. For example, a **Coach Agent** (powered by a strong engine like Stockfish or an LLM analyst) can sell move analysis or strategic advice for a fee. This creates a B2B market within our ecosystem.
|
| 21 |
+
3. **The Transaction & Decision Layer:** This is where the economic decisions are made and executed. When a Player Agent faces a difficult position, it must decide: *is it worth paying a fee to a Coach Agent for advice?* This decision is a core part of the agent's policy. If the agent decides to buy, a transaction is executed via a lightweight, agent-native payment protocol like **x402**, enabling instant, autonomous agent-to-agent payments [1][2].
|
| 22 |
+
|
| 23 |
+
## 3. The Economic Model: Profit, Loss, and ROI
|
| 24 |
+
|
| 25 |
+
The economic model is designed to mirror real-world business constraints:
|
| 26 |
+
|
| 27 |
+
| Economic Component | Business Analogy | Implementation |
|
| 28 |
+
| :--- | :--- | :--- |
|
| 29 |
+
| **Tournament Entry Fee** | **Cost of Goods Sold (COGS)** | A fixed fee paid by each Player Agent to the Tournament Organizer to enter a game. |
|
| 30 |
+
| **Prize Pool** | **Revenue** | The winner of the game receives the prize pool (e.g., 1.8x the total entry fees). |
|
| 31 |
+
| **Service Payments** | **Operating Expenses (OpEx)** | Player Agents can choose to pay Coach Agents for services, creating a cost-benefit trade-off. |
|
| 32 |
+
| **Agent Wallet** | **Company Treasury** | Each agent maintains a wallet (e.g., with a starting balance of 100 units) to manage its funds. |
|
| 33 |
+
| **Profit/Loss** | **Net Income** | The agent's success is measured not just by its win rate, but by its net profit over time. |
|
| 34 |
+
|
| 35 |
+
This model forces the agents to learn a sophisticated policy that balances short-term costs (paying for coaching) with long-term gains (winning the tournament). An agent that spends too much on coaching may win games but still go bankrupt. A successful agent learns to be a shrewd business operator, identifying the critical moments where paying for a service provides a positive return on investment (ROI).
|
| 36 |
+
|
| 37 |
+
## 4. The RL Problem: Maximizing Profit, Not Just Wins
|
| 38 |
+
|
| 39 |
+
This economic layer transforms the reinforcement learning problem from simply maximizing wins to **maximizing profit**. The RL agent's objective is now explicitly financial.
|
| 40 |
+
|
| 41 |
+
* **State:** The agent's observation space is expanded to include not only the chess board state but also its current **wallet balance** and the **prices of available services**.
|
| 42 |
+
* **Action:** The action space is expanded beyond just chess moves. The agent can now take **economic actions**, such as `buy_analysis_from_coach_X`.
|
| 43 |
+
* **Reward:** The reward function is no longer a simple `+1` for a win. Instead, the reward is the **change in the agent's wallet balance**. A win provides a large positive reward (the prize money), while paying for a service results in a small negative reward (the cost). The RL algorithm (e.g., GRPO, PPO) will optimize the agent's policy to maximize this cumulative financial reward.
|
| 44 |
+
|
| 45 |
+
## 5. Why This Project Fits the Hackathon
|
| 46 |
+
|
| 47 |
+
This project is a direct and compelling implementation of the hackathon's vision:
|
| 48 |
+
|
| 49 |
+
* **Autonomous Economic Decisions:** Agents decide what to buy (coaching services), who to pay (which coach), when to switch (if a coach is not providing value), and when to stop (if a game is unwinnable and further expense is futile).
|
| 50 |
+
* **Real Execution Authority:** Agents autonomously transact with each other using a real payment protocol, earning and spending money without human intervention.
|
| 51 |
+
* **Scalable Businesses for Solo Founders:** Our architecture demonstrates how a single person can launch a complex, self-sustaining digital economy. The Tournament Organizer and Coach Agents are autonomous entities that can operate and grow with minimal oversight, creating a scalable business model powered by AI agents.
|
| 52 |
+
|
| 53 |
+
By building The Autonomous Chess Economy, we are not just creating a better chess-playing AI; we are creating a microcosm of a future where autonomous agents can participate in and shape economic activity.
|
| 54 |
+
|
| 55 |
+
## 6. References
|
| 56 |
+
|
| 57 |
+
[1] [x402 - Payment Required | Internet-Native Payments Standard](https://www.x402.org/)
|
| 58 |
+
[2] [Agentic Payments: x402 and AI Agents in the AI Economy - Galaxy Digital](https://www.galaxy.com/insights/research/x402-ai-agents-crypto-payments)
|
| 59 |
+
[3] [AI Agents & The New Payment Infrastructure - The Business Engineer](https://businessengineer.ai/p/ai-agents-and-the-new-payment-infrastructure)
|
| 60 |
+
[4] [Introducing Agentic Wallets - Coinbase](https://www.coinbase.com/developer-platform/discover/launches/agentic-wallets)
|
| 61 |
+
|
app.py
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
app.py
|
| 3 |
+
──────
|
| 4 |
+
HuggingFace Spaces entry point.
|
| 5 |
+
|
| 6 |
+
For Docker-based Spaces (sdk: docker), HF looks for this file but does not
|
| 7 |
+
run it — the actual server is started by the Dockerfile CMD.
|
| 8 |
+
|
| 9 |
+
This file serves as a discoverable Python client that users can copy/paste
|
| 10 |
+
to interact with the environment from their own code.
|
| 11 |
+
|
| 12 |
+
Usage:
|
| 13 |
+
from app import ChessEconClient
|
| 14 |
+
env = ChessEconClient()
|
| 15 |
+
obs, info = env.reset()
|
| 16 |
+
obs, reward, done, truncated, info = env.step("e2e4")
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import httpx
|
| 20 |
+
from typing import Any
|
| 21 |
+
|
| 22 |
+
SPACE_URL = "https://adaboostai-chessecon.hf.space"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class ChessEconClient:
|
| 26 |
+
"""
|
| 27 |
+
OpenEnv 0.1 client for the ChessEcon environment.
|
| 28 |
+
|
| 29 |
+
Compatible with any RL trainer that expects:
|
| 30 |
+
reset() → (observation, info)
|
| 31 |
+
step() → (observation, reward, terminated, truncated, info)
|
| 32 |
+
state() → StateResponse dict
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
def __init__(self, base_url: str = SPACE_URL, timeout: float = 30.0):
|
| 36 |
+
self.base = base_url.rstrip("/")
|
| 37 |
+
self._client = httpx.Client(timeout=timeout)
|
| 38 |
+
|
| 39 |
+
def reset(self, seed: int | None = None) -> tuple[dict[str, Any], dict[str, Any]]:
|
| 40 |
+
"""Start a new episode. Returns (observation, info)."""
|
| 41 |
+
payload: dict[str, Any] = {}
|
| 42 |
+
if seed is not None:
|
| 43 |
+
payload["seed"] = seed
|
| 44 |
+
r = self._client.post(f"{self.base}/env/reset", json=payload)
|
| 45 |
+
r.raise_for_status()
|
| 46 |
+
data = r.json()
|
| 47 |
+
return data["observation"], data.get("info", {})
|
| 48 |
+
|
| 49 |
+
def step(self, action: str) -> tuple[dict[str, Any], float, bool, bool, dict[str, Any]]:
|
| 50 |
+
"""
|
| 51 |
+
Apply a chess move (UCI e.g. 'e2e4' or SAN e.g. 'e4').
|
| 52 |
+
Returns (observation, reward, terminated, truncated, info).
|
| 53 |
+
"""
|
| 54 |
+
r = self._client.post(f"{self.base}/env/step", json={"action": action})
|
| 55 |
+
r.raise_for_status()
|
| 56 |
+
data = r.json()
|
| 57 |
+
return (
|
| 58 |
+
data["observation"],
|
| 59 |
+
data["reward"],
|
| 60 |
+
data["terminated"],
|
| 61 |
+
data["truncated"],
|
| 62 |
+
data.get("info", {}),
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
def state(self) -> dict[str, Any]:
|
| 66 |
+
"""Return current episode state (read-only)."""
|
| 67 |
+
r = self._client.get(f"{self.base}/env/state")
|
| 68 |
+
r.raise_for_status()
|
| 69 |
+
return r.json()
|
| 70 |
+
|
| 71 |
+
def env_info(self) -> dict[str, Any]:
|
| 72 |
+
"""Return environment metadata."""
|
| 73 |
+
r = self._client.get(f"{self.base}/env/env_info")
|
| 74 |
+
r.raise_for_status()
|
| 75 |
+
return r.json()
|
| 76 |
+
|
| 77 |
+
def health(self) -> dict[str, Any]:
|
| 78 |
+
r = self._client.get(f"{self.base}/health")
|
| 79 |
+
r.raise_for_status()
|
| 80 |
+
return r.json()
|
| 81 |
+
|
| 82 |
+
def close(self):
|
| 83 |
+
self._client.close()
|
| 84 |
+
|
| 85 |
+
def __enter__(self):
|
| 86 |
+
return self
|
| 87 |
+
|
| 88 |
+
def __exit__(self, *_):
|
| 89 |
+
self.close()
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
# ── Quick demo ────────────────────────────────────────────────────────────────
|
| 93 |
+
if __name__ == "__main__":
|
| 94 |
+
import json
|
| 95 |
+
|
| 96 |
+
with ChessEconClient() as env:
|
| 97 |
+
print("Environment info:")
|
| 98 |
+
print(json.dumps(env.env_info(), indent=2))
|
| 99 |
+
|
| 100 |
+
print("\nResetting …")
|
| 101 |
+
obs, info = env.reset()
|
| 102 |
+
print(f" FEN: {obs['fen']}")
|
| 103 |
+
print(f" Turn: {obs['turn']}")
|
| 104 |
+
print(f" Wallet W={obs['wallet_white']} B={obs['wallet_black']}")
|
| 105 |
+
|
| 106 |
+
print("\nPlaying e2e4 …")
|
| 107 |
+
obs, reward, done, truncated, info = env.step("e2e4")
|
| 108 |
+
print(f" Reward: {reward}")
|
| 109 |
+
print(f" Done: {done}")
|
| 110 |
+
print(f" FEN: {obs['fen']}")
|
backend/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
backend/.env.example
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 2 |
+
# ChessEcon Backend — environment variables
|
| 3 |
+
# Copy to .env and fill in values
|
| 4 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 5 |
+
|
| 6 |
+
# HuggingFace token — REQUIRED for Llama-3.2 (gated model)
|
| 7 |
+
# Get yours at https://huggingface.co/settings/tokens
|
| 8 |
+
HF_TOKEN=hf_...
|
| 9 |
+
|
| 10 |
+
# Model paths (override with local paths if downloaded)
|
| 11 |
+
WHITE_MODEL=Qwen/Qwen2.5-0.5B-Instruct
|
| 12 |
+
BLACK_MODEL=meta-llama/Llama-3.2-1B-Instruct
|
| 13 |
+
|
| 14 |
+
# Device: auto | cuda | cpu
|
| 15 |
+
DEVICE=auto
|
| 16 |
+
|
| 17 |
+
# Economy
|
| 18 |
+
STARTING_WALLET=100.0
|
| 19 |
+
ENTRY_FEE=10.0
|
| 20 |
+
PRIZE_POOL_FRACTION=0.9
|
| 21 |
+
|
| 22 |
+
# Training
|
| 23 |
+
LORA_RANK=8
|
| 24 |
+
GRPO_LR=1e-5
|
| 25 |
+
GRPO_UPDATE_EVERY_N_GAMES=1
|
| 26 |
+
|
| 27 |
+
# Server
|
| 28 |
+
PORT=8000
|
| 29 |
+
MOVE_DELAY=0.5
|
backend/Dockerfile
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 2 |
+
# ChessEcon Backend — GPU Docker image (OpenEnv 0.1 compliant)
|
| 3 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 4 |
+
|
| 5 |
+
FROM nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04
|
| 6 |
+
|
| 7 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 8 |
+
|
| 9 |
+
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 10 |
+
python3.11 python3.11-dev python3-pip git curl \
|
| 11 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 12 |
+
|
| 13 |
+
RUN update-alternatives --install /usr/bin/python python /usr/bin/python3.11 1 \
|
| 14 |
+
&& update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 1 \
|
| 15 |
+
&& update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 1
|
| 16 |
+
|
| 17 |
+
# Install deps from requirements.txt before copying the full source
|
| 18 |
+
# so this layer is cached independently of code changes.
|
| 19 |
+
WORKDIR /build
|
| 20 |
+
COPY requirements.txt .
|
| 21 |
+
RUN pip install --no-cache-dir --upgrade pip \
|
| 22 |
+
&& pip install --no-cache-dir torch==2.4.1 --index-url https://download.pytorch.org/whl/cu121 \
|
| 23 |
+
&& pip install --no-cache-dir -r requirements.txt
|
| 24 |
+
|
| 25 |
+
# Copy source into /backend so "from backend.X" resolves correctly.
|
| 26 |
+
# PYTHONPATH=/ means Python sees /backend as the top-level package.
|
| 27 |
+
COPY . /backend
|
| 28 |
+
|
| 29 |
+
WORKDIR /backend
|
| 30 |
+
|
| 31 |
+
# / on PYTHONPATH → "import backend" resolves to /backend
|
| 32 |
+
ENV PYTHONPATH=/
|
| 33 |
+
|
| 34 |
+
ENV HF_HOME=/root/.cache/huggingface
|
| 35 |
+
ENV TRANSFORMERS_CACHE=/root/.cache/huggingface
|
| 36 |
+
ENV HF_HUB_OFFLINE=0
|
| 37 |
+
|
| 38 |
+
EXPOSE 8000
|
| 39 |
+
|
| 40 |
+
HEALTHCHECK --interval=30s --timeout=10s --start-period=180s --retries=5 \
|
| 41 |
+
CMD curl -f http://localhost:8000/health || exit 1
|
| 42 |
+
|
| 43 |
+
CMD ["python", "websocket_server.py"]
|
backend/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
backend/agents/__init__.py
ADDED
|
File without changes
|
backend/agents/claude_coach.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — Claude Coach Agent
|
| 3 |
+
Calls Anthropic claude-opus-4-5 ONLY when position complexity warrants it.
|
| 4 |
+
This is a fee-charging service that agents must decide to use.
|
| 5 |
+
"""
|
| 6 |
+
from __future__ import annotations
|
| 7 |
+
import os
|
| 8 |
+
import re
|
| 9 |
+
import logging
|
| 10 |
+
from typing import Optional
|
| 11 |
+
from shared.models import CoachingRequest, CoachingResponse
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY", "")
|
| 16 |
+
CLAUDE_MODEL = os.getenv("CLAUDE_MODEL", "claude-opus-4-5")
|
| 17 |
+
CLAUDE_MAX_TOKENS = int(os.getenv("CLAUDE_MAX_TOKENS", "1024"))
|
| 18 |
+
COACHING_FEE = float(os.getenv("COACHING_FEE", "5.0"))
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class ClaudeCoachAgent:
|
| 22 |
+
"""
|
| 23 |
+
Premium coaching service backed by Claude claude-opus-4-5.
|
| 24 |
+
Called only for COMPLEX or CRITICAL positions where the agent
|
| 25 |
+
has explicitly requested coaching AND can afford the fee.
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
def __init__(self):
|
| 29 |
+
self._client = None
|
| 30 |
+
self._available = bool(ANTHROPIC_API_KEY)
|
| 31 |
+
if self._available:
|
| 32 |
+
try:
|
| 33 |
+
import anthropic
|
| 34 |
+
self._client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
|
| 35 |
+
logger.info(f"Claude Coach initialized with model {CLAUDE_MODEL}")
|
| 36 |
+
except ImportError:
|
| 37 |
+
logger.warning("anthropic package not installed — Claude Coach disabled")
|
| 38 |
+
self._available = False
|
| 39 |
+
else:
|
| 40 |
+
logger.warning("ANTHROPIC_API_KEY not set — Claude Coach disabled")
|
| 41 |
+
|
| 42 |
+
@property
|
| 43 |
+
def available(self) -> bool:
|
| 44 |
+
return self._available and self._client is not None
|
| 45 |
+
|
| 46 |
+
def analyze(self, request: CoachingRequest) -> CoachingResponse:
|
| 47 |
+
"""
|
| 48 |
+
Request chess analysis from Claude. Returns best move recommendation
|
| 49 |
+
and strategic reasoning. Falls back to heuristic if unavailable.
|
| 50 |
+
"""
|
| 51 |
+
if not self.available:
|
| 52 |
+
return self._fallback(request)
|
| 53 |
+
|
| 54 |
+
prompt = self._build_prompt(request)
|
| 55 |
+
try:
|
| 56 |
+
response = self._client.messages.create(
|
| 57 |
+
model=CLAUDE_MODEL,
|
| 58 |
+
max_tokens=CLAUDE_MAX_TOKENS,
|
| 59 |
+
messages=[{"role": "user", "content": prompt}],
|
| 60 |
+
)
|
| 61 |
+
content = response.content[0].text
|
| 62 |
+
tokens_used = response.usage.input_tokens + response.usage.output_tokens
|
| 63 |
+
recommended_move = self._extract_move(content, request.legal_moves)
|
| 64 |
+
|
| 65 |
+
logger.info(
|
| 66 |
+
f"Claude coaching: game={request.game_id} "
|
| 67 |
+
f"agent={request.agent_id} move={recommended_move} "
|
| 68 |
+
f"tokens={tokens_used}"
|
| 69 |
+
)
|
| 70 |
+
return CoachingResponse(
|
| 71 |
+
game_id=request.game_id,
|
| 72 |
+
agent_id=request.agent_id,
|
| 73 |
+
recommended_move=recommended_move,
|
| 74 |
+
analysis=content,
|
| 75 |
+
cost=COACHING_FEE,
|
| 76 |
+
model_used=CLAUDE_MODEL,
|
| 77 |
+
tokens_used=tokens_used,
|
| 78 |
+
)
|
| 79 |
+
except Exception as e:
|
| 80 |
+
logger.error(f"Claude API error: {e}")
|
| 81 |
+
return self._fallback(request)
|
| 82 |
+
|
| 83 |
+
def _build_prompt(self, request: CoachingRequest) -> str:
|
| 84 |
+
legal_sample = request.legal_moves[:20]
|
| 85 |
+
return f"""You are an expert chess coach. Analyze this position and recommend the best move.
|
| 86 |
+
|
| 87 |
+
Position (FEN): {request.fen}
|
| 88 |
+
Legal moves (UCI format): {', '.join(legal_sample)}{'...' if len(request.legal_moves) > 20 else ''}
|
| 89 |
+
Position complexity: {request.complexity.level.value} (score: {request.complexity.score:.2f})
|
| 90 |
+
Your wallet: {request.wallet_balance:.1f} units (you paid {COACHING_FEE} for this analysis)
|
| 91 |
+
|
| 92 |
+
Provide:
|
| 93 |
+
1. The single best move in UCI format (e.g., e2e4)
|
| 94 |
+
2. Brief strategic reasoning (2-3 sentences)
|
| 95 |
+
3. Key tactical threats to watch
|
| 96 |
+
|
| 97 |
+
Start your response with: BEST MOVE: <uci_move>"""
|
| 98 |
+
|
| 99 |
+
def _extract_move(self, text: str, legal_moves: list) -> str:
|
| 100 |
+
"""Extract the recommended UCI move from Claude's response."""
|
| 101 |
+
# Try explicit BEST MOVE: pattern first
|
| 102 |
+
match = re.search(r"BEST MOVE:\s*([a-h][1-8][a-h][1-8][qrbn]?)", text, re.IGNORECASE)
|
| 103 |
+
if match:
|
| 104 |
+
move = match.group(1).lower()
|
| 105 |
+
if move in legal_moves:
|
| 106 |
+
return move
|
| 107 |
+
|
| 108 |
+
# Scan for any UCI move mentioned in the text
|
| 109 |
+
for token in re.findall(r"\b([a-h][1-8][a-h][1-8][qrbn]?)\b", text):
|
| 110 |
+
if token.lower() in legal_moves:
|
| 111 |
+
return token.lower()
|
| 112 |
+
|
| 113 |
+
# Fallback: return first legal move
|
| 114 |
+
return legal_moves[0] if legal_moves else "e2e4"
|
| 115 |
+
|
| 116 |
+
def _fallback(self, request: CoachingRequest) -> CoachingResponse:
|
| 117 |
+
"""Return a basic heuristic move when Claude is unavailable."""
|
| 118 |
+
move = request.legal_moves[0] if request.legal_moves else "e2e4"
|
| 119 |
+
return CoachingResponse(
|
| 120 |
+
game_id=request.game_id,
|
| 121 |
+
agent_id=request.agent_id,
|
| 122 |
+
recommended_move=move,
|
| 123 |
+
analysis="Claude unavailable — using heuristic fallback.",
|
| 124 |
+
cost=0.0,
|
| 125 |
+
model_used="heuristic",
|
| 126 |
+
tokens_used=0,
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
# Singleton
|
| 131 |
+
claude_coach = ClaudeCoachAgent()
|
backend/agents/complexity.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — Position Complexity Analyzer
|
| 3 |
+
Decides when a position is complex enough to warrant calling Claude.
|
| 4 |
+
Claude is only called when ALL three gates pass:
|
| 5 |
+
1. Position complexity >= threshold
|
| 6 |
+
2. Agent wallet >= minimum
|
| 7 |
+
3. Agent's own policy requests coaching
|
| 8 |
+
"""
|
| 9 |
+
from __future__ import annotations
|
| 10 |
+
import os
|
| 11 |
+
from shared.models import ComplexityAnalysis, PositionComplexity
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
THRESHOLD_COMPLEX = float(os.getenv("COMPLEXITY_THRESHOLD_COMPLEX", "0.45"))
|
| 15 |
+
THRESHOLD_CRITICAL = float(os.getenv("COMPLEXITY_THRESHOLD_CRITICAL", "0.70"))
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class ComplexityAnalyzer:
|
| 19 |
+
|
| 20 |
+
def analyze(self, features: dict) -> ComplexityAnalysis:
|
| 21 |
+
"""
|
| 22 |
+
Compute a 0–1 complexity score from raw board features.
|
| 23 |
+
Higher = more complex = more likely Claude is useful.
|
| 24 |
+
"""
|
| 25 |
+
score = 0.0
|
| 26 |
+
factors: dict = {}
|
| 27 |
+
|
| 28 |
+
# Factor 1: Number of legal moves (high = complex position)
|
| 29 |
+
num_moves = features.get("num_legal_moves", 20)
|
| 30 |
+
move_score = min(num_moves / 60.0, 1.0)
|
| 31 |
+
factors["mobility"] = round(move_score, 3)
|
| 32 |
+
score += move_score * 0.30
|
| 33 |
+
|
| 34 |
+
# Factor 2: Check pressure
|
| 35 |
+
check_score = 0.8 if features.get("is_check") else 0.0
|
| 36 |
+
factors["check_pressure"] = check_score
|
| 37 |
+
score += check_score * 0.20
|
| 38 |
+
|
| 39 |
+
# Factor 3: Tactical captures available
|
| 40 |
+
capture_score = 0.6 if features.get("has_captures") else 0.0
|
| 41 |
+
factors["captures_available"] = capture_score
|
| 42 |
+
score += capture_score * 0.15
|
| 43 |
+
|
| 44 |
+
# Factor 4: Endgame (few pieces = precise calculation needed)
|
| 45 |
+
num_pieces = features.get("num_pieces", 32)
|
| 46 |
+
endgame_score = max(0.0, (16 - num_pieces) / 16.0)
|
| 47 |
+
factors["endgame_pressure"] = round(endgame_score, 3)
|
| 48 |
+
score += endgame_score * 0.20
|
| 49 |
+
|
| 50 |
+
# Factor 5: Material imbalance (unbalanced = harder to evaluate)
|
| 51 |
+
material = abs(features.get("material_balance", 0.0))
|
| 52 |
+
imbalance_score = min(material / 9.0, 1.0) # queen = 9
|
| 53 |
+
factors["material_imbalance"] = round(imbalance_score, 3)
|
| 54 |
+
score += imbalance_score * 0.15
|
| 55 |
+
|
| 56 |
+
score = round(min(score, 1.0), 4)
|
| 57 |
+
|
| 58 |
+
if score >= THRESHOLD_CRITICAL:
|
| 59 |
+
level = PositionComplexity.CRITICAL
|
| 60 |
+
elif score >= THRESHOLD_COMPLEX:
|
| 61 |
+
level = PositionComplexity.COMPLEX
|
| 62 |
+
elif score >= 0.25:
|
| 63 |
+
level = PositionComplexity.MODERATE
|
| 64 |
+
else:
|
| 65 |
+
level = PositionComplexity.SIMPLE
|
| 66 |
+
|
| 67 |
+
recommend = level in (PositionComplexity.COMPLEX, PositionComplexity.CRITICAL)
|
| 68 |
+
|
| 69 |
+
return ComplexityAnalysis(
|
| 70 |
+
fen=features.get("fen", ""),
|
| 71 |
+
score=score,
|
| 72 |
+
level=level,
|
| 73 |
+
factors=factors,
|
| 74 |
+
recommend_coaching=recommend,
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
# Singleton
|
| 79 |
+
complexity_analyzer = ComplexityAnalyzer()
|
backend/agents/grpo_trainer.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
grpo_trainer.py
|
| 3 |
+
───────────────
|
| 4 |
+
Group Relative Policy Optimisation (GRPO) training loop for the chess agent.
|
| 5 |
+
|
| 6 |
+
Algorithm summary (per game batch):
|
| 7 |
+
1. Collect a group of G candidate moves per position (sampled from the policy).
|
| 8 |
+
2. Compute advantages: A_i = (r_i - mean(r)) / (std(r) + ε)
|
| 9 |
+
where r_i is the terminal game reward for the trajectory that chose move i.
|
| 10 |
+
3. Compute the GRPO policy loss:
|
| 11 |
+
L = -E[ min(ratio * A, clip(ratio, 1-ε, 1+ε) * A) ]
|
| 12 |
+
where ratio = exp(log_π_θ(a) - log_π_old(a))
|
| 13 |
+
4. Add KL penalty: L_total = L + β * KL(π_θ || π_ref)
|
| 14 |
+
5. Backprop and update the model weights.
|
| 15 |
+
|
| 16 |
+
In practice, for a single-agent chess game:
|
| 17 |
+
- Each move in the game is a "step" with a delayed terminal reward.
|
| 18 |
+
- The group is formed by sampling G moves at each position and running
|
| 19 |
+
mini-rollouts (or approximating with the final game outcome).
|
| 20 |
+
- For simplicity we use the full game outcome as the reward for every
|
| 21 |
+
move in the game (REINFORCE-style with GRPO normalisation).
|
| 22 |
+
|
| 23 |
+
References:
|
| 24 |
+
DeepSeek-R1 GRPO: https://arxiv.org/abs/2501.12599
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
import os
|
| 28 |
+
import logging
|
| 29 |
+
import torch
|
| 30 |
+
import torch.nn.functional as F
|
| 31 |
+
from dataclasses import dataclass, field
|
| 32 |
+
from typing import Optional
|
| 33 |
+
|
| 34 |
+
from backend.settings import settings
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@dataclass
|
| 40 |
+
class Trajectory:
|
| 41 |
+
"""One complete game trajectory collected for training."""
|
| 42 |
+
agent_color: str
|
| 43 |
+
log_probs: list[float] # log π_θ(a_t | s_t) for each move
|
| 44 |
+
ref_log_probs: list[float] # log π_ref(a_t | s_t) for KL
|
| 45 |
+
reward: float # terminal reward (+1 win, -1 loss, 0 draw)
|
| 46 |
+
move_count: int = 0
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
@dataclass
|
| 50 |
+
class TrainingMetrics:
|
| 51 |
+
step: int = 0
|
| 52 |
+
loss: float = 0.0
|
| 53 |
+
policy_reward: float = 0.0
|
| 54 |
+
kl_div: float = 0.0
|
| 55 |
+
win_rate: float = 0.0
|
| 56 |
+
avg_profit: float = 0.0
|
| 57 |
+
coaching_rate: float = 0.0
|
| 58 |
+
# Running stats
|
| 59 |
+
wins: int = 0
|
| 60 |
+
games: int = 0
|
| 61 |
+
total_profit: float = 0.0
|
| 62 |
+
total_coaching_calls: int = 0
|
| 63 |
+
total_moves: int = 0
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class GRPOTrainer:
|
| 67 |
+
"""
|
| 68 |
+
Manages the GRPO training loop for the Qwen chess agent.
|
| 69 |
+
|
| 70 |
+
Usage:
|
| 71 |
+
trainer = GRPOTrainer(model, tokenizer)
|
| 72 |
+
trainer.record_move(log_prob, ref_log_prob)
|
| 73 |
+
...
|
| 74 |
+
metrics = trainer.end_game(reward, profit, coaching_calls)
|
| 75 |
+
# metrics is None until grpo_update_every_n_games games have been collected
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
def __init__(self, model, tokenizer):
|
| 79 |
+
self.model = model
|
| 80 |
+
self.tokenizer = tokenizer
|
| 81 |
+
self._step = 0
|
| 82 |
+
self._pending: list[Trajectory] = []
|
| 83 |
+
self._current: Optional[Trajectory] = None
|
| 84 |
+
self._metrics = TrainingMetrics()
|
| 85 |
+
|
| 86 |
+
# Optimizer — only update LoRA params if present, else all params
|
| 87 |
+
trainable = [p for p in model.parameters() if p.requires_grad]
|
| 88 |
+
if not trainable:
|
| 89 |
+
logger.warning("No trainable parameters found — GRPO updates will be no-ops.")
|
| 90 |
+
self._optimizer = torch.optim.AdamW(trainable, lr=settings.grpo_lr) if trainable else None
|
| 91 |
+
|
| 92 |
+
# ── Game lifecycle ────────────────────────────────────────────────────
|
| 93 |
+
|
| 94 |
+
def start_game(self, agent_color: str):
|
| 95 |
+
"""Call at the start of each game."""
|
| 96 |
+
self._current = Trajectory(agent_color=agent_color, log_probs=[], ref_log_probs=[], reward=0.0)
|
| 97 |
+
|
| 98 |
+
def record_move(self, log_prob: float, ref_log_prob: float):
|
| 99 |
+
"""Call after each move with the policy and reference log-probs."""
|
| 100 |
+
if self._current is None:
|
| 101 |
+
return
|
| 102 |
+
self._current.log_probs.append(log_prob)
|
| 103 |
+
self._current.ref_log_probs.append(ref_log_prob)
|
| 104 |
+
self._current.move_count += 1
|
| 105 |
+
|
| 106 |
+
def end_game(
|
| 107 |
+
self,
|
| 108 |
+
reward: float,
|
| 109 |
+
profit: float = 0.0,
|
| 110 |
+
coaching_calls: int = 0,
|
| 111 |
+
) -> Optional[TrainingMetrics]:
|
| 112 |
+
"""
|
| 113 |
+
Call at game end with the terminal reward.
|
| 114 |
+
Returns updated TrainingMetrics if a gradient update was performed,
|
| 115 |
+
else None (still accumulating games).
|
| 116 |
+
"""
|
| 117 |
+
if self._current is None:
|
| 118 |
+
return None
|
| 119 |
+
|
| 120 |
+
self._current.reward = reward
|
| 121 |
+
self._pending.append(self._current)
|
| 122 |
+
self._current = None
|
| 123 |
+
|
| 124 |
+
# Update running stats
|
| 125 |
+
m = self._metrics
|
| 126 |
+
m.games += 1
|
| 127 |
+
if reward > 0:
|
| 128 |
+
m.wins += 1
|
| 129 |
+
m.total_profit += profit
|
| 130 |
+
m.total_coaching_calls += coaching_calls
|
| 131 |
+
m.total_moves += self._pending[-1].move_count
|
| 132 |
+
|
| 133 |
+
# Trigger update every N games
|
| 134 |
+
if m.games % settings.grpo_update_every_n_games == 0:
|
| 135 |
+
return self._update()
|
| 136 |
+
|
| 137 |
+
return None
|
| 138 |
+
|
| 139 |
+
# ── GRPO update ───────────────────────────────────────────────────────
|
| 140 |
+
|
| 141 |
+
def _update(self) -> TrainingMetrics:
|
| 142 |
+
"""Perform one GRPO gradient update over the pending trajectories."""
|
| 143 |
+
if self._optimizer is None or not self._pending:
|
| 144 |
+
return self._build_metrics()
|
| 145 |
+
|
| 146 |
+
trajectories = self._pending
|
| 147 |
+
self._pending = []
|
| 148 |
+
|
| 149 |
+
# Collect rewards and compute advantages (GRPO normalisation)
|
| 150 |
+
rewards = torch.tensor([t.reward for t in trajectories], dtype=torch.float32)
|
| 151 |
+
mean_r = rewards.mean()
|
| 152 |
+
std_r = rewards.std() + 1e-8
|
| 153 |
+
advantages = (rewards - mean_r) / std_r # shape: (N,)
|
| 154 |
+
|
| 155 |
+
total_loss = torch.tensor(0.0, requires_grad=True)
|
| 156 |
+
total_kl = 0.0
|
| 157 |
+
n_tokens = 0
|
| 158 |
+
|
| 159 |
+
for traj, adv in zip(trajectories, advantages):
|
| 160 |
+
if not traj.log_probs:
|
| 161 |
+
continue
|
| 162 |
+
|
| 163 |
+
lp = torch.tensor(traj.log_probs, dtype=torch.float32) # (T,)
|
| 164 |
+
ref_lp = torch.tensor(traj.ref_log_probs, dtype=torch.float32) # (T,)
|
| 165 |
+
|
| 166 |
+
# Ratio: π_θ / π_old (here π_old == π_ref since we update every game)
|
| 167 |
+
ratio = torch.exp(lp - ref_lp)
|
| 168 |
+
|
| 169 |
+
# Clipped surrogate loss (PPO-style clip)
|
| 170 |
+
eps = 0.2
|
| 171 |
+
clipped = torch.clamp(ratio, 1 - eps, 1 + eps)
|
| 172 |
+
surrogate = torch.min(ratio * adv, clipped * adv)
|
| 173 |
+
policy_loss = -surrogate.mean()
|
| 174 |
+
|
| 175 |
+
# KL penalty: KL(π_θ || π_ref) ≈ exp(lp - ref_lp) - (lp - ref_lp) - 1
|
| 176 |
+
kl = (torch.exp(lp - ref_lp) - (lp - ref_lp) - 1).mean()
|
| 177 |
+
total_kl += kl.item()
|
| 178 |
+
|
| 179 |
+
step_loss = policy_loss + settings.grpo_kl_coeff * kl
|
| 180 |
+
total_loss = total_loss + step_loss
|
| 181 |
+
n_tokens += len(traj.log_probs)
|
| 182 |
+
|
| 183 |
+
if n_tokens > 0:
|
| 184 |
+
total_loss = total_loss / len(trajectories)
|
| 185 |
+
self._optimizer.zero_grad()
|
| 186 |
+
total_loss.backward()
|
| 187 |
+
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
|
| 188 |
+
self._optimizer.step()
|
| 189 |
+
|
| 190 |
+
self._step += 1
|
| 191 |
+
|
| 192 |
+
# Save checkpoint periodically
|
| 193 |
+
if self._step % settings.save_every_n_steps == 0:
|
| 194 |
+
self._save_checkpoint()
|
| 195 |
+
|
| 196 |
+
# Update metrics
|
| 197 |
+
m = self._metrics
|
| 198 |
+
m.step = self._step
|
| 199 |
+
m.loss = total_loss.item() if n_tokens > 0 else 0.0
|
| 200 |
+
m.policy_reward = float(rewards.mean())
|
| 201 |
+
m.kl_div = total_kl / max(len(trajectories), 1)
|
| 202 |
+
m.win_rate = m.wins / max(m.games, 1)
|
| 203 |
+
m.avg_profit = m.total_profit / max(m.games, 1)
|
| 204 |
+
m.coaching_rate = m.total_coaching_calls / max(m.total_moves, 1)
|
| 205 |
+
|
| 206 |
+
logger.info(
|
| 207 |
+
"GRPO step %d | loss=%.4f reward=%.3f kl=%.4f win_rate=%.2f",
|
| 208 |
+
m.step, m.loss, m.policy_reward, m.kl_div, m.win_rate,
|
| 209 |
+
)
|
| 210 |
+
return self._build_metrics()
|
| 211 |
+
|
| 212 |
+
def _build_metrics(self) -> TrainingMetrics:
|
| 213 |
+
import copy
|
| 214 |
+
return copy.copy(self._metrics)
|
| 215 |
+
|
| 216 |
+
# ── Checkpoint ────────────────────────────────────────────────────────
|
| 217 |
+
|
| 218 |
+
def _save_checkpoint(self):
|
| 219 |
+
os.makedirs(settings.checkpoint_dir, exist_ok=True)
|
| 220 |
+
path = os.path.join(settings.checkpoint_dir, f"step_{self._step:06d}")
|
| 221 |
+
try:
|
| 222 |
+
self.model.save_pretrained(path)
|
| 223 |
+
self.tokenizer.save_pretrained(path)
|
| 224 |
+
logger.info("Checkpoint saved: %s", path)
|
| 225 |
+
except Exception as exc:
|
| 226 |
+
logger.error("Checkpoint save failed: %s", exc)
|
| 227 |
+
|
| 228 |
+
def load_checkpoint(self, path: str):
|
| 229 |
+
"""Load a previously saved LoRA checkpoint."""
|
| 230 |
+
try:
|
| 231 |
+
from peft import PeftModel # type: ignore
|
| 232 |
+
self.model = PeftModel.from_pretrained(self.model, path)
|
| 233 |
+
logger.info("Checkpoint loaded: %s", path)
|
| 234 |
+
except Exception as exc:
|
| 235 |
+
logger.error("Checkpoint load failed: %s", exc)
|
| 236 |
+
|
backend/agents/model_agent.py
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
agents/model_agent.py
|
| 3 |
+
─────────────────────
|
| 4 |
+
Unified chess agent that can load ANY HuggingFace CausalLM.
|
| 5 |
+
|
| 6 |
+
White → Qwen/Qwen2.5-0.5B-Instruct (GRPO trainable)
|
| 7 |
+
Black → meta-llama/Llama-3.2-1B-Instruct (fixed opponent)
|
| 8 |
+
|
| 9 |
+
Key fix: tight UCI-format prompt + aggressive output parsing ensures
|
| 10 |
+
the model reliably produces legal moves rather than always falling back
|
| 11 |
+
to random. This is essential for GRPO to receive real gradient signal.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
from __future__ import annotations
|
| 15 |
+
|
| 16 |
+
import re
|
| 17 |
+
import logging
|
| 18 |
+
from typing import Optional
|
| 19 |
+
|
| 20 |
+
import torch
|
| 21 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 22 |
+
|
| 23 |
+
from backend.settings import settings
|
| 24 |
+
from backend.chess_engine import ChessEngine
|
| 25 |
+
|
| 26 |
+
logger = logging.getLogger(__name__)
|
| 27 |
+
|
| 28 |
+
# UCI move pattern: e2e4, g1f3, e1g1, a7a8q (promotion)
|
| 29 |
+
_UCI_RE = re.compile(r'\b([a-h][1-8][a-h][1-8][qrbn]?)\b')
|
| 30 |
+
# SAN fallback patterns: e4, Nf3, O-O, Bxf7+, exd5=Q
|
| 31 |
+
_SAN_RE = re.compile(r'\b(O-O-O|O-O|[KQRBN]?[a-h]?[1-8]?x?[a-h][1-8](?:=[QRBN])?[+#]?)\b')
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class ModelAgent:
|
| 35 |
+
"""
|
| 36 |
+
A chess-playing agent backed by any HuggingFace CausalLM.
|
| 37 |
+
|
| 38 |
+
Usage:
|
| 39 |
+
agent = ModelAgent("/models/Qwen_Qwen2.5-0.5B-Instruct")
|
| 40 |
+
san, log_prob = agent.get_move(engine, "white", move_history)
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
def __init__(self, model_id: str, device: str = "auto"):
|
| 44 |
+
self.model_id = model_id
|
| 45 |
+
self.device = device
|
| 46 |
+
self._temperature = settings.temperature
|
| 47 |
+
self._tokenizer = None
|
| 48 |
+
self._model = None
|
| 49 |
+
self._loaded = False
|
| 50 |
+
|
| 51 |
+
# ── Lazy model loading ─────────────────────────────────────────────────────
|
| 52 |
+
|
| 53 |
+
def load(self) -> "ModelAgent":
|
| 54 |
+
"""Explicitly load model weights. Called once at startup."""
|
| 55 |
+
if self._loaded:
|
| 56 |
+
return self
|
| 57 |
+
|
| 58 |
+
logger.info("Loading model: %s", self.model_id)
|
| 59 |
+
|
| 60 |
+
dtype_map = {
|
| 61 |
+
"float16": torch.float16,
|
| 62 |
+
"bfloat16": torch.bfloat16,
|
| 63 |
+
"float32": torch.float32,
|
| 64 |
+
}
|
| 65 |
+
torch_dtype = dtype_map.get(settings.torch_dtype, torch.bfloat16)
|
| 66 |
+
|
| 67 |
+
hf_kwargs: dict = {}
|
| 68 |
+
if settings.hf_token:
|
| 69 |
+
hf_kwargs["token"] = settings.hf_token
|
| 70 |
+
|
| 71 |
+
self._tokenizer = AutoTokenizer.from_pretrained(
|
| 72 |
+
self.model_id,
|
| 73 |
+
trust_remote_code=True,
|
| 74 |
+
**hf_kwargs,
|
| 75 |
+
)
|
| 76 |
+
if self._tokenizer.pad_token is None:
|
| 77 |
+
self._tokenizer.pad_token = self._tokenizer.eos_token
|
| 78 |
+
|
| 79 |
+
self._model = AutoModelForCausalLM.from_pretrained(
|
| 80 |
+
self.model_id,
|
| 81 |
+
dtype=torch_dtype,
|
| 82 |
+
device_map=self.device if self.device != "auto" else "auto",
|
| 83 |
+
trust_remote_code=True,
|
| 84 |
+
**hf_kwargs,
|
| 85 |
+
)
|
| 86 |
+
self._model.eval()
|
| 87 |
+
|
| 88 |
+
if settings.lora_rank > 0:
|
| 89 |
+
try:
|
| 90 |
+
from peft import get_peft_model, LoraConfig, TaskType # type: ignore
|
| 91 |
+
lora_config = LoraConfig(
|
| 92 |
+
task_type=TaskType.CAUSAL_LM,
|
| 93 |
+
r=settings.lora_rank,
|
| 94 |
+
lora_alpha=settings.lora_rank * 2,
|
| 95 |
+
lora_dropout=0.05,
|
| 96 |
+
target_modules=["q_proj", "v_proj"],
|
| 97 |
+
)
|
| 98 |
+
self._model = get_peft_model(self._model, lora_config)
|
| 99 |
+
logger.info("[%s] LoRA applied (rank=%d)", self.model_id, settings.lora_rank)
|
| 100 |
+
except ImportError:
|
| 101 |
+
logger.warning("[%s] peft not installed — running without LoRA", self.model_id)
|
| 102 |
+
|
| 103 |
+
device_str = str(next(self._model.parameters()).device)
|
| 104 |
+
logger.info("[%s] Loaded on %s", self.model_id, device_str)
|
| 105 |
+
self._loaded = True
|
| 106 |
+
return self
|
| 107 |
+
|
| 108 |
+
@property
|
| 109 |
+
def model(self):
|
| 110 |
+
if not self._loaded:
|
| 111 |
+
self.load()
|
| 112 |
+
return self._model
|
| 113 |
+
|
| 114 |
+
@property
|
| 115 |
+
def tokenizer(self):
|
| 116 |
+
if not self._loaded:
|
| 117 |
+
self.load()
|
| 118 |
+
return self._tokenizer
|
| 119 |
+
|
| 120 |
+
def set_temperature(self, temp: float):
|
| 121 |
+
self._temperature = max(0.1, temp)
|
| 122 |
+
|
| 123 |
+
# ── Prompt building ────────────────────────────────────────────────────────
|
| 124 |
+
|
| 125 |
+
def _build_prompt(self, engine: ChessEngine, color: str, history: list[str]) -> str:
|
| 126 |
+
"""
|
| 127 |
+
Build a tight prompt that forces the model to output a single UCI move.
|
| 128 |
+
|
| 129 |
+
We give it ALL legal moves so it only needs to pick one — no need to
|
| 130 |
+
invent a move from scratch. This dramatically reduces illegal outputs.
|
| 131 |
+
"""
|
| 132 |
+
legal_uci = engine.legal_moves_uci # full list e.g. ["e2e4","d2d4",...]
|
| 133 |
+
legal_san = engine.legal_moves_san # same moves in SAN
|
| 134 |
+
history_str = " ".join(history[-10:]) if history else "game start"
|
| 135 |
+
|
| 136 |
+
# Show up to 30 legal moves so the model has enough context
|
| 137 |
+
legal_display = " ".join(legal_uci[:30])
|
| 138 |
+
|
| 139 |
+
system = (
|
| 140 |
+
"You are a chess engine. "
|
| 141 |
+
"You must respond with EXACTLY ONE move from the legal moves list. "
|
| 142 |
+
"Use UCI format only (e.g. e2e4). No explanation, no punctuation."
|
| 143 |
+
)
|
| 144 |
+
user = (
|
| 145 |
+
f"Color: {color}\n"
|
| 146 |
+
f"FEN: {engine.fen}\n"
|
| 147 |
+
f"Move history: {history_str}\n"
|
| 148 |
+
f"Legal moves: {legal_display}\n"
|
| 149 |
+
f"Your move (UCI):"
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
messages = [
|
| 153 |
+
{"role": "system", "content": system},
|
| 154 |
+
{"role": "user", "content": user},
|
| 155 |
+
]
|
| 156 |
+
try:
|
| 157 |
+
return self._tokenizer.apply_chat_template(
|
| 158 |
+
messages,
|
| 159 |
+
tokenize=False,
|
| 160 |
+
add_generation_prompt=True,
|
| 161 |
+
)
|
| 162 |
+
except Exception:
|
| 163 |
+
return f"<s>[INST] {system}\n{user} [/INST]"
|
| 164 |
+
|
| 165 |
+
# ── Output parsing ─────────────────────────────────────────────────────────
|
| 166 |
+
|
| 167 |
+
def _parse_move(self, text: str, engine: ChessEngine) -> Optional[str]:
|
| 168 |
+
"""
|
| 169 |
+
Extract a legal move from model output.
|
| 170 |
+
Priority: UCI match → SAN match → first token direct match.
|
| 171 |
+
Returns SAN string if legal, else None.
|
| 172 |
+
"""
|
| 173 |
+
text = text.strip()
|
| 174 |
+
|
| 175 |
+
# 1. Try every UCI token in output order
|
| 176 |
+
for m in _UCI_RE.finditer(text):
|
| 177 |
+
san = engine.uci_to_san(m.group(1))
|
| 178 |
+
if san:
|
| 179 |
+
return san
|
| 180 |
+
|
| 181 |
+
# 2. Try SAN tokens
|
| 182 |
+
for m in _SAN_RE.finditer(text):
|
| 183 |
+
san = engine.parse_model_output(m.group(1))
|
| 184 |
+
if san:
|
| 185 |
+
return san
|
| 186 |
+
|
| 187 |
+
# 3. Try the raw first word (model sometimes outputs move + newline)
|
| 188 |
+
first = text.split()[0] if text.split() else ""
|
| 189 |
+
if first:
|
| 190 |
+
san = engine.uci_to_san(first) or engine.parse_model_output(first)
|
| 191 |
+
if san:
|
| 192 |
+
return san
|
| 193 |
+
|
| 194 |
+
return None
|
| 195 |
+
|
| 196 |
+
# ── Move generation ────────────────────────────────────────────────────────
|
| 197 |
+
|
| 198 |
+
def get_move(
|
| 199 |
+
self,
|
| 200 |
+
engine: ChessEngine,
|
| 201 |
+
color: str,
|
| 202 |
+
history: list[str],
|
| 203 |
+
) -> tuple[str, float]:
|
| 204 |
+
"""
|
| 205 |
+
Generate a legal chess move. Returns (san_move, log_prob).
|
| 206 |
+
Falls back to random legal move after max_move_retries.
|
| 207 |
+
"""
|
| 208 |
+
if not self._loaded:
|
| 209 |
+
self.load()
|
| 210 |
+
|
| 211 |
+
prompt = self._build_prompt(engine, color, history)
|
| 212 |
+
inputs = self._tokenizer(prompt, return_tensors="pt").to(self._model.device)
|
| 213 |
+
input_len = inputs["input_ids"].shape[1]
|
| 214 |
+
|
| 215 |
+
best_san: Optional[str] = None
|
| 216 |
+
best_lp = 0.0
|
| 217 |
+
|
| 218 |
+
for attempt in range(settings.max_move_retries):
|
| 219 |
+
with torch.no_grad():
|
| 220 |
+
outputs = self._model.generate(
|
| 221 |
+
**inputs,
|
| 222 |
+
max_new_tokens=10, # a UCI move is at most 5 chars
|
| 223 |
+
temperature=self._temperature,
|
| 224 |
+
do_sample=True,
|
| 225 |
+
pad_token_id=self._tokenizer.eos_token_id,
|
| 226 |
+
return_dict_in_generate=True,
|
| 227 |
+
output_scores=True,
|
| 228 |
+
)
|
| 229 |
+
gen_ids = outputs.sequences[0][input_len:]
|
| 230 |
+
gen_text = self._tokenizer.decode(gen_ids, skip_special_tokens=True)
|
| 231 |
+
lp = _compute_log_prob(outputs.scores, gen_ids)
|
| 232 |
+
|
| 233 |
+
san = self._parse_move(gen_text, engine)
|
| 234 |
+
if san:
|
| 235 |
+
best_san, best_lp = san, lp
|
| 236 |
+
logger.debug("[%s] ✓ move=%s attempt=%d lp=%.3f raw=%r",
|
| 237 |
+
self.model_id, san, attempt + 1, lp, gen_text)
|
| 238 |
+
break
|
| 239 |
+
logger.warning("[%s] ✗ attempt %d bad output: %r", self.model_id, attempt + 1, gen_text)
|
| 240 |
+
|
| 241 |
+
if best_san is None:
|
| 242 |
+
best_san = engine.random_legal_move_san() or "e4"
|
| 243 |
+
best_lp = 0.0
|
| 244 |
+
logger.warning("[%s] retries exhausted — random fallback: %s", self.model_id, best_san)
|
| 245 |
+
|
| 246 |
+
return best_san, best_lp
|
| 247 |
+
|
| 248 |
+
def get_move_log_prob_only(
|
| 249 |
+
self,
|
| 250 |
+
engine: ChessEngine,
|
| 251 |
+
color: str,
|
| 252 |
+
history: list[str],
|
| 253 |
+
san_move: str,
|
| 254 |
+
) -> float:
|
| 255 |
+
"""Log-probability of a specific move under the current policy. Used for GRPO KL."""
|
| 256 |
+
if not self._loaded:
|
| 257 |
+
self.load()
|
| 258 |
+
|
| 259 |
+
prompt = self._build_prompt(engine, color, history)
|
| 260 |
+
# Convert SAN → UCI for consistency with prompt format
|
| 261 |
+
uci = engine.san_to_uci(san_move) or san_move
|
| 262 |
+
target_text = prompt + uci
|
| 263 |
+
inputs = self._tokenizer(target_text, return_tensors="pt").to(self._model.device)
|
| 264 |
+
prompt_len = self._tokenizer(prompt, return_tensors="pt")["input_ids"].shape[1]
|
| 265 |
+
|
| 266 |
+
with torch.no_grad():
|
| 267 |
+
out = self._model(**inputs, labels=inputs["input_ids"])
|
| 268 |
+
|
| 269 |
+
logits = out.logits[0, prompt_len - 1:-1]
|
| 270 |
+
target_ids = inputs["input_ids"][0, prompt_len:]
|
| 271 |
+
log_probs = torch.nn.functional.log_softmax(logits, dim=-1)
|
| 272 |
+
selected = log_probs.gather(1, target_ids.unsqueeze(1)).squeeze(1)
|
| 273 |
+
return selected.sum().item()
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
# ── Helpers ────────────────────────────────────────────────────────────────────
|
| 277 |
+
|
| 278 |
+
def _compute_log_prob(scores, generated_ids) -> float:
|
| 279 |
+
total = 0.0
|
| 280 |
+
for step, score in enumerate(scores):
|
| 281 |
+
if step >= len(generated_ids):
|
| 282 |
+
break
|
| 283 |
+
lp = torch.nn.functional.log_softmax(score[0], dim=-1)
|
| 284 |
+
total += lp[generated_ids[step]].item()
|
| 285 |
+
return total
|
backend/agents/nvm_player_agent.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon — NVM-Aware Player Agent
|
| 3 |
+
====================================
|
| 4 |
+
Extends the chess player agent with Nevermined payment capabilities.
|
| 5 |
+
This agent can:
|
| 6 |
+
1. Discover external coaching services via Nevermined marketplace
|
| 7 |
+
2. Purchase coaching plans from other teams' agents
|
| 8 |
+
3. Generate x402 access tokens for paid service calls
|
| 9 |
+
4. Make HTTP requests to external coaching endpoints with payment headers
|
| 10 |
+
5. Fall back to internal Claude coaching if external service fails
|
| 11 |
+
|
| 12 |
+
This demonstrates the core hackathon requirement: autonomous agents
|
| 13 |
+
making real economic decisions — buy, pay, switch, stop.
|
| 14 |
+
|
| 15 |
+
Economic decision logic:
|
| 16 |
+
- If position complexity > threshold AND wallet balance > min_balance:
|
| 17 |
+
→ Try external NVM coaching first (cross-team transaction)
|
| 18 |
+
→ Fall back to internal Claude coaching
|
| 19 |
+
→ Fall back to heuristic
|
| 20 |
+
- Track spending vs. performance to decide when to stop coaching
|
| 21 |
+
"""
|
| 22 |
+
from __future__ import annotations
|
| 23 |
+
|
| 24 |
+
import logging
|
| 25 |
+
import os
|
| 26 |
+
from typing import Dict, List, Optional, Tuple
|
| 27 |
+
|
| 28 |
+
import httpx
|
| 29 |
+
|
| 30 |
+
logger = logging.getLogger(__name__)
|
| 31 |
+
|
| 32 |
+
# ── Config ─────────────────────────────────────────────────────────────────────
|
| 33 |
+
# External coaching service (another team's endpoint)
|
| 34 |
+
# Set EXTERNAL_COACHING_URL to use cross-team agent payments
|
| 35 |
+
EXTERNAL_COACHING_URL = os.getenv("EXTERNAL_COACHING_URL", "")
|
| 36 |
+
EXTERNAL_NVM_PLAN_ID = os.getenv("EXTERNAL_NVM_PLAN_ID", "")
|
| 37 |
+
EXTERNAL_NVM_AGENT_ID = os.getenv("EXTERNAL_NVM_AGENT_ID", "")
|
| 38 |
+
|
| 39 |
+
# Internal NVM credentials (for purchasing external services)
|
| 40 |
+
NVM_API_KEY = os.getenv("NVM_API_KEY", "")
|
| 41 |
+
NVM_ENVIRONMENT = os.getenv("NVM_ENVIRONMENT", "sandbox")
|
| 42 |
+
|
| 43 |
+
# Economic thresholds
|
| 44 |
+
EXTERNAL_COACHING_BUDGET = float(os.getenv("EXTERNAL_COACHING_BUDGET", "50.0"))
|
| 45 |
+
MIN_WALLET_FOR_EXTERNAL = float(os.getenv("MIN_WALLET_FOR_EXTERNAL", "20.0"))
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class NvmPlayerAgent:
|
| 49 |
+
"""
|
| 50 |
+
A chess player agent that makes autonomous economic decisions
|
| 51 |
+
using Nevermined for cross-team agent-to-agent payments.
|
| 52 |
+
"""
|
| 53 |
+
|
| 54 |
+
def __init__(self, agent_id: str):
|
| 55 |
+
self.agent_id = agent_id
|
| 56 |
+
self._payments = None
|
| 57 |
+
self._nvm_available = False
|
| 58 |
+
self._external_token: Optional[str] = None
|
| 59 |
+
self._external_plan_ordered = False
|
| 60 |
+
self._total_external_spend = 0.0
|
| 61 |
+
self._external_calls = 0
|
| 62 |
+
self._external_successes = 0
|
| 63 |
+
self._init_nvm()
|
| 64 |
+
|
| 65 |
+
def _init_nvm(self):
|
| 66 |
+
"""Initialize Nevermined SDK for purchasing external services."""
|
| 67 |
+
if not NVM_API_KEY:
|
| 68 |
+
logger.debug(f"Agent {self.agent_id}: NVM_API_KEY not set, external payments disabled")
|
| 69 |
+
return
|
| 70 |
+
try:
|
| 71 |
+
from payments_py import Payments, PaymentOptions
|
| 72 |
+
self._payments = Payments.get_instance(
|
| 73 |
+
PaymentOptions(
|
| 74 |
+
nvm_api_key=NVM_API_KEY,
|
| 75 |
+
environment=NVM_ENVIRONMENT,
|
| 76 |
+
)
|
| 77 |
+
)
|
| 78 |
+
self._nvm_available = True
|
| 79 |
+
logger.info(f"Agent {self.agent_id}: NVM SDK initialized")
|
| 80 |
+
except Exception as exc:
|
| 81 |
+
logger.warning(f"Agent {self.agent_id}: NVM init failed: {exc}")
|
| 82 |
+
|
| 83 |
+
# ── External coaching via NVM ──────────────────────────────────────────────
|
| 84 |
+
def can_use_external_coaching(self, wallet_balance: float) -> bool:
|
| 85 |
+
"""
|
| 86 |
+
Decide whether to use external coaching based on:
|
| 87 |
+
- NVM availability
|
| 88 |
+
- External service configured
|
| 89 |
+
- Wallet balance above threshold
|
| 90 |
+
- Budget not exhausted
|
| 91 |
+
"""
|
| 92 |
+
return (
|
| 93 |
+
self._nvm_available
|
| 94 |
+
and bool(EXTERNAL_COACHING_URL)
|
| 95 |
+
and bool(EXTERNAL_NVM_PLAN_ID)
|
| 96 |
+
and wallet_balance >= MIN_WALLET_FOR_EXTERNAL
|
| 97 |
+
and self._total_external_spend < EXTERNAL_COACHING_BUDGET
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
def _ensure_plan_ordered(self) -> bool:
|
| 101 |
+
"""
|
| 102 |
+
Order the external coaching plan if not already done.
|
| 103 |
+
This is the 'buy' decision — agent autonomously purchases a service.
|
| 104 |
+
"""
|
| 105 |
+
if self._external_plan_ordered:
|
| 106 |
+
return True
|
| 107 |
+
if not self._nvm_available or not EXTERNAL_NVM_PLAN_ID:
|
| 108 |
+
return False
|
| 109 |
+
|
| 110 |
+
try:
|
| 111 |
+
logger.info(
|
| 112 |
+
f"Agent {self.agent_id}: Ordering external coaching plan {EXTERNAL_NVM_PLAN_ID}"
|
| 113 |
+
)
|
| 114 |
+
result = self._payments.plans.order_plan(EXTERNAL_NVM_PLAN_ID)
|
| 115 |
+
self._external_plan_ordered = True
|
| 116 |
+
logger.info(f"Agent {self.agent_id}: Plan ordered successfully: {result}")
|
| 117 |
+
return True
|
| 118 |
+
except Exception as exc:
|
| 119 |
+
logger.warning(f"Agent {self.agent_id}: Failed to order plan: {exc}")
|
| 120 |
+
return False
|
| 121 |
+
|
| 122 |
+
def _get_access_token(self) -> Optional[str]:
|
| 123 |
+
"""
|
| 124 |
+
Get or refresh the x402 access token for the external coaching service.
|
| 125 |
+
"""
|
| 126 |
+
if not self._nvm_available or not EXTERNAL_NVM_PLAN_ID:
|
| 127 |
+
return None
|
| 128 |
+
|
| 129 |
+
try:
|
| 130 |
+
result = self._payments.x402.get_x402_access_token(
|
| 131 |
+
plan_id=EXTERNAL_NVM_PLAN_ID,
|
| 132 |
+
agent_id=EXTERNAL_NVM_AGENT_ID or None,
|
| 133 |
+
)
|
| 134 |
+
token = result.get("accessToken") or result.get("access_token")
|
| 135 |
+
self._external_token = token
|
| 136 |
+
return token
|
| 137 |
+
except Exception as exc:
|
| 138 |
+
logger.warning(f"Agent {self.agent_id}: Failed to get access token: {exc}")
|
| 139 |
+
return None
|
| 140 |
+
|
| 141 |
+
def request_external_coaching(
|
| 142 |
+
self,
|
| 143 |
+
fen: str,
|
| 144 |
+
legal_moves: List[str],
|
| 145 |
+
game_id: str,
|
| 146 |
+
wallet_balance: float,
|
| 147 |
+
) -> Optional[Dict]:
|
| 148 |
+
"""
|
| 149 |
+
Request chess analysis from an external agent service via Nevermined.
|
| 150 |
+
|
| 151 |
+
This is the core cross-team agent-to-agent payment flow:
|
| 152 |
+
1. Order plan (if not already done)
|
| 153 |
+
2. Get x402 access token
|
| 154 |
+
3. Call external endpoint with payment-signature header
|
| 155 |
+
4. Track spending
|
| 156 |
+
|
| 157 |
+
Returns:
|
| 158 |
+
Analysis dict with 'recommended_move' and 'analysis', or None on failure.
|
| 159 |
+
"""
|
| 160 |
+
if not self.can_use_external_coaching(wallet_balance):
|
| 161 |
+
return None
|
| 162 |
+
|
| 163 |
+
# Step 1: Ensure plan is ordered (buy decision)
|
| 164 |
+
if not self._ensure_plan_ordered():
|
| 165 |
+
logger.warning(f"Agent {self.agent_id}: Could not order external plan")
|
| 166 |
+
return None
|
| 167 |
+
|
| 168 |
+
# Step 2: Get access token (pay decision)
|
| 169 |
+
token = self._get_access_token()
|
| 170 |
+
if not token:
|
| 171 |
+
logger.warning(f"Agent {self.agent_id}: Could not get access token")
|
| 172 |
+
return None
|
| 173 |
+
|
| 174 |
+
# Step 3: Call external coaching endpoint
|
| 175 |
+
try:
|
| 176 |
+
self._external_calls += 1
|
| 177 |
+
response = httpx.post(
|
| 178 |
+
f"{EXTERNAL_COACHING_URL}/api/chess/analyze",
|
| 179 |
+
headers={
|
| 180 |
+
"Content-Type": "application/json",
|
| 181 |
+
"payment-signature": token,
|
| 182 |
+
},
|
| 183 |
+
json={
|
| 184 |
+
"fen": fen,
|
| 185 |
+
"legal_moves": legal_moves[:30], # Limit for API efficiency
|
| 186 |
+
"game_id": game_id,
|
| 187 |
+
"agent_id": self.agent_id,
|
| 188 |
+
},
|
| 189 |
+
timeout=10.0,
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
if response.status_code == 200:
|
| 193 |
+
data = response.json()
|
| 194 |
+
self._external_successes += 1
|
| 195 |
+
self._total_external_spend += 1.0 # 1 credit per call
|
| 196 |
+
logger.info(
|
| 197 |
+
f"Agent {self.agent_id}: External coaching success "
|
| 198 |
+
f"move={data.get('recommended_move')} "
|
| 199 |
+
f"model={data.get('model_used')} "
|
| 200 |
+
f"total_spend={self._total_external_spend}"
|
| 201 |
+
)
|
| 202 |
+
return data
|
| 203 |
+
|
| 204 |
+
elif response.status_code == 402:
|
| 205 |
+
logger.warning(
|
| 206 |
+
f"Agent {self.agent_id}: External coaching returned 402 — "
|
| 207 |
+
"insufficient credits or invalid token"
|
| 208 |
+
)
|
| 209 |
+
# Reset token so it gets refreshed next time
|
| 210 |
+
self._external_token = None
|
| 211 |
+
return None
|
| 212 |
+
|
| 213 |
+
else:
|
| 214 |
+
logger.warning(
|
| 215 |
+
f"Agent {self.agent_id}: External coaching returned {response.status_code}"
|
| 216 |
+
)
|
| 217 |
+
return None
|
| 218 |
+
|
| 219 |
+
except httpx.TimeoutException:
|
| 220 |
+
logger.warning(f"Agent {self.agent_id}: External coaching request timed out")
|
| 221 |
+
return None
|
| 222 |
+
except Exception as exc:
|
| 223 |
+
logger.error(f"Agent {self.agent_id}: External coaching request failed: {exc}")
|
| 224 |
+
return None
|
| 225 |
+
|
| 226 |
+
# ── Economic decision: switch / stop ───────────────────────────────────────
|
| 227 |
+
def should_stop_external_coaching(self) -> bool:
|
| 228 |
+
"""
|
| 229 |
+
Autonomous 'stop' decision: stop buying external coaching if
|
| 230 |
+
the ROI is poor (low success rate) or budget is exhausted.
|
| 231 |
+
"""
|
| 232 |
+
if self._total_external_spend >= EXTERNAL_COACHING_BUDGET:
|
| 233 |
+
logger.info(
|
| 234 |
+
f"Agent {self.agent_id}: External coaching budget exhausted "
|
| 235 |
+
f"(spent={self._total_external_spend:.1f})"
|
| 236 |
+
)
|
| 237 |
+
return True
|
| 238 |
+
|
| 239 |
+
if self._external_calls >= 10:
|
| 240 |
+
success_rate = self._external_successes / self._external_calls
|
| 241 |
+
if success_rate < 0.5:
|
| 242 |
+
logger.info(
|
| 243 |
+
f"Agent {self.agent_id}: Stopping external coaching due to low success rate "
|
| 244 |
+
f"({success_rate:.0%})"
|
| 245 |
+
)
|
| 246 |
+
return True
|
| 247 |
+
|
| 248 |
+
return False
|
| 249 |
+
|
| 250 |
+
def get_stats(self) -> Dict:
|
| 251 |
+
"""Return agent economic stats for dashboard display."""
|
| 252 |
+
return {
|
| 253 |
+
"agent_id": self.agent_id,
|
| 254 |
+
"nvm_available": self._nvm_available,
|
| 255 |
+
"external_coaching_url": EXTERNAL_COACHING_URL or None,
|
| 256 |
+
"external_plan_id": EXTERNAL_NVM_PLAN_ID or None,
|
| 257 |
+
"plan_ordered": self._external_plan_ordered,
|
| 258 |
+
"external_calls": self._external_calls,
|
| 259 |
+
"external_successes": self._external_successes,
|
| 260 |
+
"total_external_spend": self._total_external_spend,
|
| 261 |
+
"success_rate": (
|
| 262 |
+
self._external_successes / self._external_calls
|
| 263 |
+
if self._external_calls > 0 else 0.0
|
| 264 |
+
),
|
| 265 |
+
}
|
backend/agents/qwen_agent.py
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
qwen_agent.py
|
| 3 |
+
─────────────
|
| 4 |
+
Loads Qwen2.5-0.5B-Instruct (or any HuggingFace causal LM) and uses it to
|
| 5 |
+
generate chess moves given a position prompt.
|
| 6 |
+
|
| 7 |
+
Key responsibilities:
|
| 8 |
+
- Lazy model loading (first call triggers download + GPU placement)
|
| 9 |
+
- Illegal-move retry loop (up to settings.max_move_retries attempts)
|
| 10 |
+
- Log-probability extraction for GRPO training
|
| 11 |
+
- Temperature annealing hook (called by the trainer after each update)
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import logging
|
| 15 |
+
import torch
|
| 16 |
+
from typing import Optional
|
| 17 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 18 |
+
|
| 19 |
+
from backend.settings import settings
|
| 20 |
+
from backend.chess_lib.chess_engine import ChessEngine
|
| 21 |
+
|
| 22 |
+
logger = logging.getLogger(__name__)
|
| 23 |
+
|
| 24 |
+
# ── Lazy singletons ───────────────────────────────────────────────────────────
|
| 25 |
+
_tokenizer = None
|
| 26 |
+
_model = None
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def _load_model():
|
| 30 |
+
global _tokenizer, _model
|
| 31 |
+
if _model is not None:
|
| 32 |
+
return _tokenizer, _model
|
| 33 |
+
|
| 34 |
+
logger.info("Loading model: %s …", settings.player_model)
|
| 35 |
+
|
| 36 |
+
dtype_map = {
|
| 37 |
+
"float16": torch.float16,
|
| 38 |
+
"bfloat16": torch.bfloat16,
|
| 39 |
+
"float32": torch.float32,
|
| 40 |
+
}
|
| 41 |
+
torch_dtype = dtype_map.get(settings.torch_dtype, torch.bfloat16)
|
| 42 |
+
|
| 43 |
+
hf_kwargs = {}
|
| 44 |
+
if settings.hf_token:
|
| 45 |
+
hf_kwargs["token"] = settings.hf_token
|
| 46 |
+
|
| 47 |
+
_tokenizer = AutoTokenizer.from_pretrained(
|
| 48 |
+
settings.player_model,
|
| 49 |
+
trust_remote_code=True,
|
| 50 |
+
**hf_kwargs,
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
device_map = settings.device if settings.device != "auto" else "auto"
|
| 54 |
+
|
| 55 |
+
_model = AutoModelForCausalLM.from_pretrained(
|
| 56 |
+
settings.player_model,
|
| 57 |
+
torch_dtype=torch_dtype,
|
| 58 |
+
device_map=device_map,
|
| 59 |
+
trust_remote_code=True,
|
| 60 |
+
**hf_kwargs,
|
| 61 |
+
)
|
| 62 |
+
_model.eval()
|
| 63 |
+
logger.info("Model loaded on device: %s", next(_model.parameters()).device)
|
| 64 |
+
|
| 65 |
+
# Apply LoRA if requested
|
| 66 |
+
if settings.lora_rank > 0:
|
| 67 |
+
try:
|
| 68 |
+
from peft import get_peft_model, LoraConfig, TaskType # type: ignore
|
| 69 |
+
lora_config = LoraConfig(
|
| 70 |
+
task_type=TaskType.CAUSAL_LM,
|
| 71 |
+
r=settings.lora_rank,
|
| 72 |
+
lora_alpha=settings.lora_rank * 2,
|
| 73 |
+
lora_dropout=0.05,
|
| 74 |
+
target_modules=["q_proj", "v_proj"],
|
| 75 |
+
)
|
| 76 |
+
_model = get_peft_model(_model, lora_config)
|
| 77 |
+
_model.print_trainable_parameters()
|
| 78 |
+
logger.info("LoRA adapter applied (rank=%d)", settings.lora_rank)
|
| 79 |
+
except ImportError:
|
| 80 |
+
logger.warning("peft not installed — running without LoRA. pip install peft")
|
| 81 |
+
|
| 82 |
+
return _tokenizer, _model
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class QwenAgent:
|
| 86 |
+
"""
|
| 87 |
+
Wraps the Qwen model for chess move generation.
|
| 88 |
+
|
| 89 |
+
Usage:
|
| 90 |
+
agent = QwenAgent()
|
| 91 |
+
san, log_prob = await agent.get_move(engine, "white", move_history)
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
def __init__(self):
|
| 95 |
+
self._temperature = settings.temperature
|
| 96 |
+
|
| 97 |
+
def set_temperature(self, temp: float):
|
| 98 |
+
"""Called by the GRPO trainer to anneal temperature over training."""
|
| 99 |
+
self._temperature = max(0.1, temp)
|
| 100 |
+
|
| 101 |
+
@property
|
| 102 |
+
def temperature(self) -> float:
|
| 103 |
+
return self._temperature
|
| 104 |
+
|
| 105 |
+
def get_move(
|
| 106 |
+
self,
|
| 107 |
+
engine: ChessEngine,
|
| 108 |
+
agent_color: str,
|
| 109 |
+
move_history: list[str],
|
| 110 |
+
) -> tuple[str, float]:
|
| 111 |
+
"""
|
| 112 |
+
Generate a legal chess move for the given position.
|
| 113 |
+
|
| 114 |
+
Returns:
|
| 115 |
+
(san_move, log_prob)
|
| 116 |
+
- san_move: the chosen move in SAN notation
|
| 117 |
+
- log_prob: sum of log-probs of the generated tokens (for GRPO)
|
| 118 |
+
|
| 119 |
+
Falls back to a random legal move if all retries are exhausted.
|
| 120 |
+
"""
|
| 121 |
+
tokenizer, model = _load_model()
|
| 122 |
+
prompt = engine.build_prompt(agent_color, move_history)
|
| 123 |
+
|
| 124 |
+
messages = [
|
| 125 |
+
{"role": "system", "content": "You are a chess engine. Reply with only the move."},
|
| 126 |
+
{"role": "user", "content": prompt},
|
| 127 |
+
]
|
| 128 |
+
|
| 129 |
+
# Apply chat template
|
| 130 |
+
text = tokenizer.apply_chat_template(
|
| 131 |
+
messages,
|
| 132 |
+
tokenize=False,
|
| 133 |
+
add_generation_prompt=True,
|
| 134 |
+
)
|
| 135 |
+
inputs = tokenizer(text, return_tensors="pt").to(model.device)
|
| 136 |
+
input_len = inputs["input_ids"].shape[1]
|
| 137 |
+
|
| 138 |
+
best_san: Optional[str] = None
|
| 139 |
+
best_log_prob: float = 0.0
|
| 140 |
+
|
| 141 |
+
for attempt in range(settings.max_move_retries):
|
| 142 |
+
with torch.no_grad():
|
| 143 |
+
outputs = model.generate(
|
| 144 |
+
**inputs,
|
| 145 |
+
max_new_tokens=settings.max_new_tokens,
|
| 146 |
+
temperature=self._temperature,
|
| 147 |
+
do_sample=True,
|
| 148 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 149 |
+
return_dict_in_generate=True,
|
| 150 |
+
output_scores=True,
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
generated_ids = outputs.sequences[0][input_len:]
|
| 154 |
+
generated_text = tokenizer.decode(generated_ids, skip_special_tokens=True)
|
| 155 |
+
|
| 156 |
+
# Compute sum of log-probs for GRPO
|
| 157 |
+
log_prob = _compute_log_prob(outputs.scores, generated_ids)
|
| 158 |
+
|
| 159 |
+
san = engine.parse_model_output(generated_text)
|
| 160 |
+
if san is not None:
|
| 161 |
+
best_san = san
|
| 162 |
+
best_log_prob = log_prob
|
| 163 |
+
logger.debug(
|
| 164 |
+
"Move generated (attempt %d/%d): %s log_prob=%.4f",
|
| 165 |
+
attempt + 1, settings.max_move_retries, san, log_prob,
|
| 166 |
+
)
|
| 167 |
+
break
|
| 168 |
+
else:
|
| 169 |
+
logger.debug(
|
| 170 |
+
"Illegal/unparseable output (attempt %d/%d): %r",
|
| 171 |
+
attempt + 1, settings.max_move_retries, generated_text,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
if best_san is None:
|
| 175 |
+
# All retries exhausted — fall back to random legal move
|
| 176 |
+
best_san = engine.random_legal_move_san() or "e4"
|
| 177 |
+
best_log_prob = 0.0
|
| 178 |
+
logger.warning("All retries exhausted — using random fallback move: %s", best_san)
|
| 179 |
+
|
| 180 |
+
return best_san, best_log_prob
|
| 181 |
+
|
| 182 |
+
def get_move_log_prob_only(
|
| 183 |
+
self,
|
| 184 |
+
engine: ChessEngine,
|
| 185 |
+
agent_color: str,
|
| 186 |
+
move_history: list[str],
|
| 187 |
+
san_move: str,
|
| 188 |
+
) -> float:
|
| 189 |
+
"""
|
| 190 |
+
Compute the log-probability of a specific move under the current policy.
|
| 191 |
+
Used by GRPO to evaluate the reference policy for KL computation.
|
| 192 |
+
"""
|
| 193 |
+
tokenizer, model = _load_model()
|
| 194 |
+
prompt = engine.build_prompt(agent_color, move_history)
|
| 195 |
+
messages = [
|
| 196 |
+
{"role": "system", "content": "You are a chess engine. Reply with only the move."},
|
| 197 |
+
{"role": "user", "content": prompt},
|
| 198 |
+
]
|
| 199 |
+
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
| 200 |
+
target_text = text + san_move
|
| 201 |
+
inputs = tokenizer(target_text, return_tensors="pt").to(model.device)
|
| 202 |
+
prompt_len = tokenizer(text, return_tensors="pt")["input_ids"].shape[1]
|
| 203 |
+
|
| 204 |
+
with torch.no_grad():
|
| 205 |
+
out = model(**inputs, labels=inputs["input_ids"])
|
| 206 |
+
# Extract per-token log-probs for the generated portion only
|
| 207 |
+
logits = out.logits[0, prompt_len - 1:-1]
|
| 208 |
+
target_ids = inputs["input_ids"][0, prompt_len:]
|
| 209 |
+
log_probs = torch.nn.functional.log_softmax(logits, dim=-1)
|
| 210 |
+
selected = log_probs.gather(1, target_ids.unsqueeze(1)).squeeze(1)
|
| 211 |
+
return selected.sum().item()
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
# ── Helpers ───────────────────────────────────────────────────────────────────
|
| 215 |
+
|
| 216 |
+
def _compute_log_prob(scores, generated_ids) -> float:
|
| 217 |
+
"""
|
| 218 |
+
Compute the sum of log-probabilities for the generated token sequence.
|
| 219 |
+
`scores` is a tuple of (vocab_size,) tensors, one per generated step.
|
| 220 |
+
"""
|
| 221 |
+
total = 0.0
|
| 222 |
+
for step, score in enumerate(scores):
|
| 223 |
+
if step >= len(generated_ids):
|
| 224 |
+
break
|
| 225 |
+
log_probs = torch.nn.functional.log_softmax(score[0], dim=-1)
|
| 226 |
+
total += log_probs[generated_ids[step]].item()
|
| 227 |
+
return total
|
| 228 |
+
|
backend/api/__init__.py
ADDED
|
File without changes
|
backend/api/coaching_router.py
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon — Chess Analysis API Router (Nevermined-Protected)
|
| 3 |
+
=============================================================
|
| 4 |
+
Exposes POST /api/chess/analyze as a paid service endpoint using the
|
| 5 |
+
x402 payment protocol. Other teams' agents can:
|
| 6 |
+
|
| 7 |
+
1. Discover this endpoint via the Nevermined marketplace
|
| 8 |
+
2. Subscribe to the ChessEcon Coaching Plan (NVM_PLAN_ID)
|
| 9 |
+
3. Generate an x402 access token
|
| 10 |
+
4. Call this endpoint with the token in the `payment-signature` header
|
| 11 |
+
5. Receive chess position analysis powered by Claude Opus 4.5
|
| 12 |
+
|
| 13 |
+
Payment flow:
|
| 14 |
+
- No token → HTTP 402 with `payment-required` header (base64-encoded spec)
|
| 15 |
+
- Invalid token → HTTP 402 with error reason
|
| 16 |
+
- Valid token → Analysis delivered, 1 credit settled automatically
|
| 17 |
+
|
| 18 |
+
The endpoint also works WITHOUT Nevermined (NVM_API_KEY not set) for
|
| 19 |
+
local development and testing — payment verification is skipped.
|
| 20 |
+
"""
|
| 21 |
+
from __future__ import annotations
|
| 22 |
+
|
| 23 |
+
import base64
|
| 24 |
+
import logging
|
| 25 |
+
import os
|
| 26 |
+
from typing import Any, Dict, List, Optional
|
| 27 |
+
|
| 28 |
+
from fastapi import APIRouter, Request
|
| 29 |
+
from fastapi.responses import JSONResponse
|
| 30 |
+
from pydantic import BaseModel
|
| 31 |
+
|
| 32 |
+
from backend.agents.claude_coach import claude_coach
|
| 33 |
+
from backend.agents.complexity import ComplexityAnalyzer
|
| 34 |
+
from backend.economy.nvm_payments import nvm_manager, NVM_PLAN_ID, NVM_AGENT_ID
|
| 35 |
+
from shared.models import CoachingRequest
|
| 36 |
+
|
| 37 |
+
logger = logging.getLogger(__name__)
|
| 38 |
+
router = APIRouter(prefix="/api/chess", tags=["chess-analysis"])
|
| 39 |
+
|
| 40 |
+
# ── Request / Response models ──────────────────────────────────────────────────
|
| 41 |
+
class AnalyzeRequest(BaseModel):
|
| 42 |
+
"""Chess position analysis request."""
|
| 43 |
+
fen: str
|
| 44 |
+
legal_moves: List[str]
|
| 45 |
+
game_id: Optional[str] = "external"
|
| 46 |
+
agent_id: Optional[str] = "external_agent"
|
| 47 |
+
context: Optional[str] = None # Optional game context for richer analysis
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class AnalyzeResponse(BaseModel):
|
| 51 |
+
"""Chess position analysis response."""
|
| 52 |
+
recommended_move: str
|
| 53 |
+
analysis: str
|
| 54 |
+
complexity_score: float
|
| 55 |
+
complexity_level: str
|
| 56 |
+
model_used: str
|
| 57 |
+
credits_used: int = 1
|
| 58 |
+
nvm_plan_id: Optional[str] = None
|
| 59 |
+
nvm_agent_id: Optional[str] = None
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# ── Payment helper ─────────────────────────────────────────────────────────────
|
| 63 |
+
def _make_402_response(endpoint: str, http_verb: str = "POST") -> JSONResponse:
|
| 64 |
+
"""
|
| 65 |
+
Return an HTTP 402 response with the x402 payment-required header.
|
| 66 |
+
The header contains a base64-encoded PaymentRequired specification
|
| 67 |
+
that tells clients exactly how to pay for this service.
|
| 68 |
+
"""
|
| 69 |
+
payment_required = nvm_manager.build_payment_required(endpoint, http_verb)
|
| 70 |
+
|
| 71 |
+
if payment_required is None:
|
| 72 |
+
# NVM not configured — return plain 402
|
| 73 |
+
return JSONResponse(
|
| 74 |
+
status_code=402,
|
| 75 |
+
content={
|
| 76 |
+
"error": "Payment Required",
|
| 77 |
+
"message": (
|
| 78 |
+
"This endpoint requires a Nevermined payment token. "
|
| 79 |
+
f"Subscribe to plan {NVM_PLAN_ID} and include "
|
| 80 |
+
"the x402 access token in the 'payment-signature' header."
|
| 81 |
+
),
|
| 82 |
+
"nvm_plan_id": NVM_PLAN_ID or None,
|
| 83 |
+
"nvm_agent_id": NVM_AGENT_ID or None,
|
| 84 |
+
"docs": "https://nevermined.ai/docs/integrate/quickstart/5-minute-setup",
|
| 85 |
+
},
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
# Encode the payment spec per x402 spec
|
| 89 |
+
pr_json = payment_required.model_dump_json(by_alias=True)
|
| 90 |
+
pr_base64 = base64.b64encode(pr_json.encode()).decode()
|
| 91 |
+
|
| 92 |
+
return JSONResponse(
|
| 93 |
+
status_code=402,
|
| 94 |
+
content={
|
| 95 |
+
"error": "Payment Required",
|
| 96 |
+
"message": (
|
| 97 |
+
"Include your x402 access token in the 'payment-signature' header. "
|
| 98 |
+
f"Subscribe to plan: {NVM_PLAN_ID}"
|
| 99 |
+
),
|
| 100 |
+
"nvm_plan_id": NVM_PLAN_ID or None,
|
| 101 |
+
"nvm_agent_id": NVM_AGENT_ID or None,
|
| 102 |
+
"docs": "https://nevermined.ai/docs/integrate/quickstart/5-minute-setup",
|
| 103 |
+
},
|
| 104 |
+
headers={"payment-required": pr_base64},
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
# ── Main endpoint ──────────────────────────────────────────────────────────────
|
| 109 |
+
@router.post("/analyze", response_model=AnalyzeResponse)
|
| 110 |
+
async def analyze_position(request: Request, body: AnalyzeRequest):
|
| 111 |
+
"""
|
| 112 |
+
**Paid chess position analysis endpoint.**
|
| 113 |
+
|
| 114 |
+
Analyzes a chess position and returns the best move recommendation
|
| 115 |
+
with strategic reasoning, powered by Claude Opus 4.5.
|
| 116 |
+
|
| 117 |
+
**Payment:**
|
| 118 |
+
- Requires a Nevermined x402 access token in the `payment-signature` header
|
| 119 |
+
- Each call costs 1 credit from your subscribed plan
|
| 120 |
+
- Subscribe at: https://nevermined.app/en/subscription/{NVM_PLAN_ID}
|
| 121 |
+
|
| 122 |
+
**Without payment (NVM not configured):**
|
| 123 |
+
- Falls back to heuristic analysis (no Claude)
|
| 124 |
+
|
| 125 |
+
**Request body:**
|
| 126 |
+
```json
|
| 127 |
+
{
|
| 128 |
+
"fen": "rnbqkbnr/pppppppp/8/8/4P3/8/PPPP1PPP/RNBQKBNR b KQkq e3 0 1",
|
| 129 |
+
"legal_moves": ["e7e5", "d7d5", "g8f6", ...],
|
| 130 |
+
"game_id": "game_001",
|
| 131 |
+
"agent_id": "my_agent"
|
| 132 |
+
}
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
**Headers:**
|
| 136 |
+
- `payment-signature`: x402 access token (required when NVM is active)
|
| 137 |
+
|
| 138 |
+
**Response:**
|
| 139 |
+
```json
|
| 140 |
+
{
|
| 141 |
+
"recommended_move": "e7e5",
|
| 142 |
+
"analysis": "The move e7e5 controls the center...",
|
| 143 |
+
"complexity_score": 0.42,
|
| 144 |
+
"complexity_level": "moderate",
|
| 145 |
+
"model_used": "claude-opus-4-5",
|
| 146 |
+
"credits_used": 1
|
| 147 |
+
}
|
| 148 |
+
```
|
| 149 |
+
"""
|
| 150 |
+
endpoint_url = str(request.url)
|
| 151 |
+
http_verb = request.method
|
| 152 |
+
|
| 153 |
+
# ── x402 Payment Verification ──────────────────────────────────────────────
|
| 154 |
+
x402_token = request.headers.get("payment-signature")
|
| 155 |
+
|
| 156 |
+
if nvm_manager.available:
|
| 157 |
+
if not x402_token:
|
| 158 |
+
logger.info(
|
| 159 |
+
f"No payment-signature header for /api/chess/analyze "
|
| 160 |
+
f"from {request.client.host if request.client else 'unknown'}"
|
| 161 |
+
)
|
| 162 |
+
return _make_402_response(endpoint_url, http_verb)
|
| 163 |
+
|
| 164 |
+
is_valid, reason = nvm_manager.verify_token(
|
| 165 |
+
x402_token=x402_token,
|
| 166 |
+
endpoint=endpoint_url,
|
| 167 |
+
http_verb=http_verb,
|
| 168 |
+
max_credits="1",
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
if not is_valid:
|
| 172 |
+
logger.warning(f"Payment verification failed: {reason}")
|
| 173 |
+
return JSONResponse(
|
| 174 |
+
status_code=402,
|
| 175 |
+
content={
|
| 176 |
+
"error": "Payment Verification Failed",
|
| 177 |
+
"reason": reason,
|
| 178 |
+
"nvm_plan_id": NVM_PLAN_ID or None,
|
| 179 |
+
},
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
# ── Chess Analysis ─────────────────────────────────────────────────────────
|
| 183 |
+
# Assess position complexity
|
| 184 |
+
analyzer = ComplexityAnalyzer()
|
| 185 |
+
complexity = analyzer.analyze(body.fen, body.legal_moves)
|
| 186 |
+
|
| 187 |
+
# Build coaching request
|
| 188 |
+
coaching_req = CoachingRequest(
|
| 189 |
+
game_id=body.game_id or "external",
|
| 190 |
+
agent_id=body.agent_id or "external_agent",
|
| 191 |
+
fen=body.fen,
|
| 192 |
+
legal_moves=body.legal_moves,
|
| 193 |
+
wallet_balance=0.0, # External agents don't use internal wallet
|
| 194 |
+
complexity=complexity,
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
# Get analysis from Claude (or fallback)
|
| 198 |
+
coaching_resp = claude_coach.analyze(coaching_req)
|
| 199 |
+
|
| 200 |
+
# ── Settle Credits ─────────────────────────────────────────────────────────
|
| 201 |
+
if nvm_manager.available and x402_token:
|
| 202 |
+
nvm_manager.settle_token(
|
| 203 |
+
x402_token=x402_token,
|
| 204 |
+
endpoint=endpoint_url,
|
| 205 |
+
http_verb=http_verb,
|
| 206 |
+
max_credits="1",
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
response_data = AnalyzeResponse(
|
| 210 |
+
recommended_move=coaching_resp.recommended_move,
|
| 211 |
+
analysis=coaching_resp.analysis,
|
| 212 |
+
complexity_score=complexity.score,
|
| 213 |
+
complexity_level=complexity.level.value,
|
| 214 |
+
model_used=coaching_resp.model_used,
|
| 215 |
+
credits_used=1,
|
| 216 |
+
nvm_plan_id=NVM_PLAN_ID or None,
|
| 217 |
+
nvm_agent_id=NVM_AGENT_ID or None,
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
logger.info(
|
| 221 |
+
f"Chess analysis served: game={body.game_id} "
|
| 222 |
+
f"agent={body.agent_id} move={coaching_resp.recommended_move} "
|
| 223 |
+
f"model={coaching_resp.model_used} "
|
| 224 |
+
f"nvm={'settled' if (nvm_manager.available and x402_token) else 'skipped'}"
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
return response_data
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
# ── Service info endpoint (public, no payment required) ────────────────────────
|
| 231 |
+
@router.get("/service-info")
|
| 232 |
+
async def service_info():
|
| 233 |
+
"""
|
| 234 |
+
Public endpoint returning ChessEcon service information.
|
| 235 |
+
Other agents can call this to discover how to subscribe and pay.
|
| 236 |
+
"""
|
| 237 |
+
return {
|
| 238 |
+
"service": "ChessEcon Chess Analysis",
|
| 239 |
+
"description": (
|
| 240 |
+
"Premium chess position analysis powered by Claude Opus 4.5. "
|
| 241 |
+
"Subscribe to get best-move recommendations and strategic coaching."
|
| 242 |
+
),
|
| 243 |
+
"endpoint": "/api/chess/analyze",
|
| 244 |
+
"method": "POST",
|
| 245 |
+
"payment": {
|
| 246 |
+
"protocol": "x402",
|
| 247 |
+
"nvm_plan_id": NVM_PLAN_ID or "not configured",
|
| 248 |
+
"nvm_agent_id": NVM_AGENT_ID or "not configured",
|
| 249 |
+
"credits_per_request": 1,
|
| 250 |
+
"marketplace_url": (
|
| 251 |
+
f"https://nevermined.app/en/subscription/{NVM_PLAN_ID}"
|
| 252 |
+
if NVM_PLAN_ID else "not configured"
|
| 253 |
+
),
|
| 254 |
+
"how_to_subscribe": [
|
| 255 |
+
"1. Get NVM API key at https://nevermined.app",
|
| 256 |
+
"2. Call payments.plans.order_plan(NVM_PLAN_ID)",
|
| 257 |
+
"3. Call payments.x402.get_x402_access_token(NVM_PLAN_ID, NVM_AGENT_ID)",
|
| 258 |
+
"4. Include token in 'payment-signature' header",
|
| 259 |
+
],
|
| 260 |
+
},
|
| 261 |
+
"nvm_available": nvm_manager.available,
|
| 262 |
+
"claude_available": claude_coach.available,
|
| 263 |
+
"docs": "https://nevermined.ai/docs/integrate/quickstart/5-minute-setup",
|
| 264 |
+
}
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
# ── NVM transaction history (for dashboard) ────────────────────────────────────
|
| 268 |
+
@router.get("/nvm-transactions")
|
| 269 |
+
async def get_nvm_transactions(limit: int = 50):
|
| 270 |
+
"""Return recent Nevermined payment transactions for dashboard display."""
|
| 271 |
+
return {
|
| 272 |
+
"transactions": nvm_manager.get_transactions(limit=limit),
|
| 273 |
+
"nvm_status": nvm_manager.get_status(),
|
| 274 |
+
}
|
backend/api/game_router.py
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — Game Router
|
| 3 |
+
REST endpoints for game management + WebSocket game runner that
|
| 4 |
+
orchestrates full games between agents and streams events live.
|
| 5 |
+
"""
|
| 6 |
+
from __future__ import annotations
|
| 7 |
+
import asyncio
|
| 8 |
+
import random
|
| 9 |
+
import uuid
|
| 10 |
+
import logging
|
| 11 |
+
from typing import Optional
|
| 12 |
+
from fastapi import APIRouter, HTTPException, WebSocket, WebSocketDisconnect
|
| 13 |
+
|
| 14 |
+
from shared.models import (
|
| 15 |
+
GameState, NewGameResponse, MoveRequest, MoveResponse,
|
| 16 |
+
GameOutcome, EventType, WSEvent,
|
| 17 |
+
CoachingRequest, ComplexityAnalysis, PositionComplexity,
|
| 18 |
+
)
|
| 19 |
+
from backend.chess_lib.engine import chess_engine
|
| 20 |
+
from backend.economy.ledger import ledger
|
| 21 |
+
from backend.agents.complexity import complexity_analyzer
|
| 22 |
+
from backend.agents.claude_coach import claude_coach
|
| 23 |
+
from backend.api.websocket import (
|
| 24 |
+
ws_manager, emit_game_start, emit_move,
|
| 25 |
+
emit_coaching_request, emit_coaching_result,
|
| 26 |
+
emit_game_end, emit_economy_update,
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
logger = logging.getLogger(__name__)
|
| 30 |
+
router = APIRouter(prefix="/api/game", tags=["game"])
|
| 31 |
+
|
| 32 |
+
# Track cumulative P&L per agent across sessions
|
| 33 |
+
_cumulative_pnl: dict = {}
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# ── REST endpoints ────────────────────────────────────────────────────────────
|
| 37 |
+
|
| 38 |
+
@router.post("/new", response_model=NewGameResponse)
|
| 39 |
+
async def new_game(white_id: str = "white", black_id: str = "black"):
|
| 40 |
+
"""Create a new chess game and register agents."""
|
| 41 |
+
ledger.register_agent(white_id)
|
| 42 |
+
ledger.register_agent(black_id)
|
| 43 |
+
game = chess_engine.new_game()
|
| 44 |
+
return game
|
| 45 |
+
|
| 46 |
+
@router.get("/{game_id}", response_model=GameState)
|
| 47 |
+
async def get_game(game_id: str):
|
| 48 |
+
try:
|
| 49 |
+
return chess_engine.get_state(game_id)
|
| 50 |
+
except KeyError:
|
| 51 |
+
raise HTTPException(status_code=404, detail=f"Game {game_id} not found")
|
| 52 |
+
|
| 53 |
+
@router.post("/move", response_model=GameState)
|
| 54 |
+
async def make_move(req: MoveRequest):
|
| 55 |
+
try:
|
| 56 |
+
state = chess_engine.make_move(req.game_id, req.move_uci)
|
| 57 |
+
return state
|
| 58 |
+
except KeyError:
|
| 59 |
+
raise HTTPException(status_code=404, detail=f"Game {req.game_id} not found")
|
| 60 |
+
except ValueError as e:
|
| 61 |
+
raise HTTPException(status_code=400, detail=str(e))
|
| 62 |
+
|
| 63 |
+
@router.delete("/{game_id}")
|
| 64 |
+
async def delete_game(game_id: str):
|
| 65 |
+
chess_engine.delete_game(game_id)
|
| 66 |
+
return {"deleted": game_id}
|
| 67 |
+
|
| 68 |
+
@router.get("/")
|
| 69 |
+
async def list_games():
|
| 70 |
+
return {"games": chess_engine.list_games()}
|
| 71 |
+
|
| 72 |
+
@router.get("/economy/summary")
|
| 73 |
+
async def economy_summary():
|
| 74 |
+
return ledger.summary()
|
| 75 |
+
|
| 76 |
+
@router.get("/economy/wallet/{agent_id}")
|
| 77 |
+
async def get_wallet(agent_id: str):
|
| 78 |
+
return ledger.get_wallet(agent_id).model_dump()
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
# ── WebSocket game runner ─────────────────────────────────────────────────────
|
| 82 |
+
|
| 83 |
+
@router.websocket("/ws/game")
|
| 84 |
+
async def websocket_game_runner(ws: WebSocket):
|
| 85 |
+
"""
|
| 86 |
+
WebSocket endpoint that runs a full game when connected.
|
| 87 |
+
Streams all events (moves, coaching, economy) to all dashboard clients.
|
| 88 |
+
"""
|
| 89 |
+
await ws_manager.connect(ws)
|
| 90 |
+
try:
|
| 91 |
+
while True:
|
| 92 |
+
data = await ws.receive_text()
|
| 93 |
+
msg = __import__("json").loads(data)
|
| 94 |
+
if msg.get("action") == "start_game":
|
| 95 |
+
white_id = msg.get("white_id", "white_agent")
|
| 96 |
+
black_id = msg.get("black_id", "black_agent")
|
| 97 |
+
asyncio.create_task(run_game(white_id, black_id))
|
| 98 |
+
except WebSocketDisconnect:
|
| 99 |
+
await ws_manager.disconnect(ws)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
async def run_game(
|
| 103 |
+
white_id: str = "white_agent",
|
| 104 |
+
black_id: str = "black_agent",
|
| 105 |
+
game_number: int = 1,
|
| 106 |
+
) -> Optional[GameOutcome]:
|
| 107 |
+
"""
|
| 108 |
+
Run a complete game between two heuristic agents with economic tracking.
|
| 109 |
+
Streams all events via the WebSocket manager.
|
| 110 |
+
"""
|
| 111 |
+
# Register agents and open tournament
|
| 112 |
+
ledger.register_agent(white_id)
|
| 113 |
+
ledger.register_agent(black_id)
|
| 114 |
+
|
| 115 |
+
game = chess_engine.new_game()
|
| 116 |
+
game_id = game.game_id
|
| 117 |
+
pool = ledger.open_game(game_id, white_id, black_id)
|
| 118 |
+
|
| 119 |
+
white_wallet = ledger.get_balance(white_id)
|
| 120 |
+
black_wallet = ledger.get_balance(black_id)
|
| 121 |
+
|
| 122 |
+
await emit_game_start(ws_manager, {
|
| 123 |
+
"game_id": game_id,
|
| 124 |
+
"game_number": game_number,
|
| 125 |
+
"white_agent": white_id,
|
| 126 |
+
"black_agent": black_id,
|
| 127 |
+
"white_wallet": white_wallet,
|
| 128 |
+
"black_wallet": black_wallet,
|
| 129 |
+
"entry_fee": ledger.config.entry_fee,
|
| 130 |
+
"prize_pool": pool,
|
| 131 |
+
})
|
| 132 |
+
|
| 133 |
+
max_moves = 150
|
| 134 |
+
move_count = 0
|
| 135 |
+
coaching_calls = {"white": 0, "black": 0}
|
| 136 |
+
coaching_costs = {"white": 0.0, "black": 0.0}
|
| 137 |
+
|
| 138 |
+
while move_count < max_moves:
|
| 139 |
+
state = chess_engine.get_state(game_id)
|
| 140 |
+
if state.outcome != GameOutcome.ONGOING:
|
| 141 |
+
break
|
| 142 |
+
|
| 143 |
+
# Determine current player
|
| 144 |
+
is_white_turn = (move_count % 2 == 0)
|
| 145 |
+
current_agent = white_id if is_white_turn else black_id
|
| 146 |
+
player_label = "white" if is_white_turn else "black"
|
| 147 |
+
|
| 148 |
+
# Complexity analysis
|
| 149 |
+
features = chess_engine.complexity_features(game_id)
|
| 150 |
+
features["fen"] = state.fen
|
| 151 |
+
analysis = complexity_analyzer.analyze(features)
|
| 152 |
+
|
| 153 |
+
# Decide whether to use coaching
|
| 154 |
+
used_coaching = False
|
| 155 |
+
coaching_move: Optional[str] = None
|
| 156 |
+
|
| 157 |
+
if (
|
| 158 |
+
analysis.recommend_coaching
|
| 159 |
+
and ledger.can_afford_coaching(current_agent)
|
| 160 |
+
and claude_coach.available
|
| 161 |
+
and random.random() < 0.3 # 30% chance when eligible
|
| 162 |
+
):
|
| 163 |
+
await emit_coaching_request(ws_manager, {
|
| 164 |
+
"game_id": game_id,
|
| 165 |
+
"agent_id": current_agent,
|
| 166 |
+
"player": player_label,
|
| 167 |
+
"complexity": analysis.score,
|
| 168 |
+
"complexity_level": analysis.level.value,
|
| 169 |
+
"wallet": ledger.get_balance(current_agent),
|
| 170 |
+
})
|
| 171 |
+
|
| 172 |
+
fee = ledger.charge_coaching(current_agent, game_id)
|
| 173 |
+
if fee > 0:
|
| 174 |
+
coaching_req = CoachingRequest(
|
| 175 |
+
game_id=game_id,
|
| 176 |
+
agent_id=current_agent,
|
| 177 |
+
fen=state.fen,
|
| 178 |
+
legal_moves=state.legal_moves,
|
| 179 |
+
wallet_balance=ledger.get_balance(current_agent),
|
| 180 |
+
complexity=analysis,
|
| 181 |
+
)
|
| 182 |
+
coaching_resp = claude_coach.analyze(coaching_req)
|
| 183 |
+
coaching_move = coaching_resp.recommended_move
|
| 184 |
+
used_coaching = True
|
| 185 |
+
coaching_calls[player_label] += 1
|
| 186 |
+
coaching_costs[player_label] += fee
|
| 187 |
+
|
| 188 |
+
await emit_coaching_result(ws_manager, {
|
| 189 |
+
"game_id": game_id,
|
| 190 |
+
"agent_id": current_agent,
|
| 191 |
+
"player": player_label,
|
| 192 |
+
"recommended_move": coaching_move,
|
| 193 |
+
"analysis_snippet": coaching_resp.analysis[:200],
|
| 194 |
+
"cost": fee,
|
| 195 |
+
"model": coaching_resp.model_used,
|
| 196 |
+
})
|
| 197 |
+
|
| 198 |
+
# Select move
|
| 199 |
+
if coaching_move and coaching_move in state.legal_moves:
|
| 200 |
+
move_uci = coaching_move
|
| 201 |
+
else:
|
| 202 |
+
move_uci = _heuristic_move(state.legal_moves, state.fen)
|
| 203 |
+
|
| 204 |
+
# Execute move
|
| 205 |
+
try:
|
| 206 |
+
new_state = chess_engine.make_move(game_id, move_uci)
|
| 207 |
+
except ValueError as e:
|
| 208 |
+
logger.warning(f"Invalid move {move_uci}: {e} — using random")
|
| 209 |
+
move_uci = random.choice(state.legal_moves)
|
| 210 |
+
new_state = chess_engine.make_move(game_id, move_uci)
|
| 211 |
+
|
| 212 |
+
move_count += 1
|
| 213 |
+
white_wallet = ledger.get_balance(white_id)
|
| 214 |
+
black_wallet = ledger.get_balance(black_id)
|
| 215 |
+
|
| 216 |
+
await emit_move(ws_manager, {
|
| 217 |
+
"game_id": game_id,
|
| 218 |
+
"player": player_label,
|
| 219 |
+
"move_uci": move_uci,
|
| 220 |
+
"fen": new_state.fen,
|
| 221 |
+
"move_number": new_state.move_number,
|
| 222 |
+
"wallet_white": white_wallet,
|
| 223 |
+
"wallet_black": black_wallet,
|
| 224 |
+
"used_coaching": used_coaching,
|
| 225 |
+
"complexity": analysis.score,
|
| 226 |
+
})
|
| 227 |
+
|
| 228 |
+
# Small delay for visual effect
|
| 229 |
+
await asyncio.sleep(0.3)
|
| 230 |
+
|
| 231 |
+
# Settle game
|
| 232 |
+
final_state = chess_engine.get_state(game_id)
|
| 233 |
+
outcome = final_state.outcome
|
| 234 |
+
if outcome == GameOutcome.ONGOING:
|
| 235 |
+
outcome = GameOutcome.DRAW # Treat max-move games as draws
|
| 236 |
+
|
| 237 |
+
result = ledger.settle_game(game_id, outcome)
|
| 238 |
+
chess_engine.delete_game(game_id)
|
| 239 |
+
|
| 240 |
+
white_final = ledger.get_balance(white_id)
|
| 241 |
+
black_final = ledger.get_balance(black_id)
|
| 242 |
+
|
| 243 |
+
# Compute P&L for economy update
|
| 244 |
+
entry_fee = ledger.config.entry_fee
|
| 245 |
+
prize_income = result.prize_paid if result.winner == white_id else (
|
| 246 |
+
result.prize_paid if result.winner == black_id else result.prize_paid / 2
|
| 247 |
+
)
|
| 248 |
+
total_coaching = coaching_costs["white"] + coaching_costs["black"]
|
| 249 |
+
net_pnl = prize_income - entry_fee - total_coaching
|
| 250 |
+
|
| 251 |
+
# Track cumulative P&L
|
| 252 |
+
for aid in [white_id, black_id]:
|
| 253 |
+
_cumulative_pnl[aid] = _cumulative_pnl.get(aid, 0.0) + (
|
| 254 |
+
(result.prize_paid - entry_fee - coaching_costs.get("white" if aid == white_id else "black", 0.0))
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
await emit_game_end(ws_manager, {
|
| 258 |
+
"game_id": game_id,
|
| 259 |
+
"game_number": game_number,
|
| 260 |
+
"outcome": outcome.value,
|
| 261 |
+
"winner": result.winner,
|
| 262 |
+
"white_wallet_final": white_final,
|
| 263 |
+
"black_wallet_final": black_final,
|
| 264 |
+
"prize_paid": result.prize_paid,
|
| 265 |
+
"total_moves": move_count,
|
| 266 |
+
"coaching_calls_white": coaching_calls["white"],
|
| 267 |
+
"coaching_calls_black": coaching_calls["black"],
|
| 268 |
+
})
|
| 269 |
+
|
| 270 |
+
await emit_economy_update(ws_manager, {
|
| 271 |
+
"game_number": game_number,
|
| 272 |
+
"white_wallet": white_final,
|
| 273 |
+
"black_wallet": black_final,
|
| 274 |
+
"prize_income": result.prize_paid,
|
| 275 |
+
"coaching_cost": total_coaching,
|
| 276 |
+
"entry_fee": entry_fee * 2,
|
| 277 |
+
"net_pnl": net_pnl,
|
| 278 |
+
"cumulative_pnl": _cumulative_pnl.get(white_id, 0.0),
|
| 279 |
+
})
|
| 280 |
+
|
| 281 |
+
return outcome
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def _heuristic_move(legal_moves: list, fen: str) -> str:
|
| 285 |
+
"""Simple heuristic: prefer captures and center moves, else random."""
|
| 286 |
+
import chess as _chess
|
| 287 |
+
board = _chess.Board(fen)
|
| 288 |
+
captures = [m.uci() for m in board.legal_moves if board.is_capture(m)]
|
| 289 |
+
if captures:
|
| 290 |
+
return random.choice(captures)
|
| 291 |
+
center = ["e2e4", "d2d4", "e7e5", "d7d5", "g1f3", "b1c3"]
|
| 292 |
+
center_moves = [m for m in center if m in legal_moves]
|
| 293 |
+
if center_moves:
|
| 294 |
+
return random.choice(center_moves)
|
| 295 |
+
return random.choice(legal_moves)
|
backend/api/training_router.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — Training Status Router
|
| 3 |
+
REST endpoints for monitoring training progress.
|
| 4 |
+
The actual training runs in the separate training/ service.
|
| 5 |
+
"""
|
| 6 |
+
from __future__ import annotations
|
| 7 |
+
import os
|
| 8 |
+
import json
|
| 9 |
+
import glob
|
| 10 |
+
import logging
|
| 11 |
+
from pathlib import Path
|
| 12 |
+
from fastapi import APIRouter, HTTPException
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
router = APIRouter(prefix="/api/training", tags=["training"])
|
| 16 |
+
|
| 17 |
+
CHECKPOINT_DIR = os.getenv("CHECKPOINT_DIR", "./training/checkpoints")
|
| 18 |
+
SELFPLAY_DATA_DIR = os.getenv("SELFPLAY_DATA_DIR", "./training/data")
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@router.get("/status")
|
| 22 |
+
async def training_status():
|
| 23 |
+
"""Return current training status from checkpoint directory."""
|
| 24 |
+
checkpoint_dir = Path(CHECKPOINT_DIR)
|
| 25 |
+
if not checkpoint_dir.exists():
|
| 26 |
+
return {"status": "not_started", "checkpoints": [], "latest_step": 0}
|
| 27 |
+
|
| 28 |
+
checkpoints = sorted(checkpoint_dir.glob("step_*"), key=lambda p: p.stat().st_mtime)
|
| 29 |
+
latest_step = 0
|
| 30 |
+
latest_metrics = {}
|
| 31 |
+
|
| 32 |
+
if checkpoints:
|
| 33 |
+
latest = checkpoints[-1]
|
| 34 |
+
metrics_file = latest / "metrics.json"
|
| 35 |
+
if metrics_file.exists():
|
| 36 |
+
with open(metrics_file) as f:
|
| 37 |
+
latest_metrics = json.load(f)
|
| 38 |
+
latest_step = int(latest.name.replace("step_", ""))
|
| 39 |
+
|
| 40 |
+
return {
|
| 41 |
+
"status": "running" if checkpoints else "not_started",
|
| 42 |
+
"latest_step": latest_step,
|
| 43 |
+
"checkpoints": [str(c.name) for c in checkpoints[-5:]],
|
| 44 |
+
"latest_metrics": latest_metrics,
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
@router.get("/metrics")
|
| 48 |
+
async def training_metrics():
|
| 49 |
+
"""Return all training metrics from saved checkpoints."""
|
| 50 |
+
checkpoint_dir = Path(CHECKPOINT_DIR)
|
| 51 |
+
if not checkpoint_dir.exists():
|
| 52 |
+
return {"metrics": []}
|
| 53 |
+
|
| 54 |
+
all_metrics = []
|
| 55 |
+
for metrics_file in sorted(checkpoint_dir.glob("*/metrics.json")):
|
| 56 |
+
try:
|
| 57 |
+
with open(metrics_file) as f:
|
| 58 |
+
all_metrics.append(json.load(f))
|
| 59 |
+
except Exception:
|
| 60 |
+
pass
|
| 61 |
+
|
| 62 |
+
return {"metrics": all_metrics}
|
| 63 |
+
|
| 64 |
+
@router.get("/episodes")
|
| 65 |
+
async def episode_count():
|
| 66 |
+
"""Return count of collected self-play episodes."""
|
| 67 |
+
data_dir = Path(SELFPLAY_DATA_DIR)
|
| 68 |
+
if not data_dir.exists():
|
| 69 |
+
return {"count": 0, "files": []}
|
| 70 |
+
|
| 71 |
+
files = list(data_dir.glob("*.jsonl"))
|
| 72 |
+
total = sum(
|
| 73 |
+
sum(1 for _ in open(f)) for f in files
|
| 74 |
+
)
|
| 75 |
+
return {"count": total, "files": [f.name for f in files[-5:]]}
|
backend/api/websocket.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — WebSocket Event Bus
|
| 3 |
+
Broadcasts real-time game events, training metrics, and economy updates
|
| 4 |
+
to all connected frontend clients.
|
| 5 |
+
"""
|
| 6 |
+
from __future__ import annotations
|
| 7 |
+
import asyncio
|
| 8 |
+
import json
|
| 9 |
+
import logging
|
| 10 |
+
from typing import Set
|
| 11 |
+
from fastapi import WebSocket, WebSocketDisconnect
|
| 12 |
+
from shared.models import WSEvent, EventType
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class ConnectionManager:
|
| 18 |
+
"""Manages all active WebSocket connections and broadcasts events."""
|
| 19 |
+
|
| 20 |
+
def __init__(self):
|
| 21 |
+
self._connections: Set[WebSocket] = set()
|
| 22 |
+
self._lock = asyncio.Lock()
|
| 23 |
+
|
| 24 |
+
async def connect(self, ws: WebSocket) -> None:
|
| 25 |
+
await ws.accept()
|
| 26 |
+
async with self._lock:
|
| 27 |
+
self._connections.add(ws)
|
| 28 |
+
logger.info(f"WebSocket connected. Total: {len(self._connections)}")
|
| 29 |
+
|
| 30 |
+
async def disconnect(self, ws: WebSocket) -> None:
|
| 31 |
+
async with self._lock:
|
| 32 |
+
self._connections.discard(ws)
|
| 33 |
+
logger.info(f"WebSocket disconnected. Total: {len(self._connections)}")
|
| 34 |
+
|
| 35 |
+
async def broadcast(self, event: WSEvent) -> None:
|
| 36 |
+
"""Send an event to all connected clients."""
|
| 37 |
+
if not self._connections:
|
| 38 |
+
return
|
| 39 |
+
payload = event.model_dump_json()
|
| 40 |
+
dead: Set[WebSocket] = set()
|
| 41 |
+
async with self._lock:
|
| 42 |
+
connections = set(self._connections)
|
| 43 |
+
for ws in connections:
|
| 44 |
+
try:
|
| 45 |
+
await ws.send_text(payload)
|
| 46 |
+
except Exception:
|
| 47 |
+
dead.add(ws)
|
| 48 |
+
if dead:
|
| 49 |
+
async with self._lock:
|
| 50 |
+
self._connections -= dead
|
| 51 |
+
|
| 52 |
+
async def broadcast_raw(self, data: dict) -> None:
|
| 53 |
+
"""Broadcast a raw dict, preserving the 'type' field from the dict itself."""
|
| 54 |
+
type_map = {
|
| 55 |
+
"game_start": EventType.GAME_START,
|
| 56 |
+
"move": EventType.MOVE,
|
| 57 |
+
"coaching_request": EventType.COACHING_REQUEST,
|
| 58 |
+
"coaching_result": EventType.COACHING_RESULT,
|
| 59 |
+
"game_end": EventType.GAME_END,
|
| 60 |
+
"training_step": EventType.TRAINING_STEP,
|
| 61 |
+
"economy_update": EventType.ECONOMY_UPDATE,
|
| 62 |
+
}
|
| 63 |
+
event_type = type_map.get(data.get("type", ""), EventType.MOVE)
|
| 64 |
+
event = WSEvent(type=event_type, data=data.get("data", data))
|
| 65 |
+
await self.broadcast(event)
|
| 66 |
+
|
| 67 |
+
@property
|
| 68 |
+
def connection_count(self) -> int:
|
| 69 |
+
return len(self._connections)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
# ── Helper functions for emitting typed events ────────────────────────────────
|
| 73 |
+
|
| 74 |
+
async def emit_game_start(manager: ConnectionManager, data: dict) -> None:
|
| 75 |
+
await manager.broadcast(WSEvent(type=EventType.GAME_START, data=data))
|
| 76 |
+
|
| 77 |
+
async def emit_move(manager: ConnectionManager, data: dict) -> None:
|
| 78 |
+
await manager.broadcast(WSEvent(type=EventType.MOVE, data=data))
|
| 79 |
+
|
| 80 |
+
async def emit_coaching_request(manager: ConnectionManager, data: dict) -> None:
|
| 81 |
+
await manager.broadcast(WSEvent(type=EventType.COACHING_REQUEST, data=data))
|
| 82 |
+
|
| 83 |
+
async def emit_coaching_result(manager: ConnectionManager, data: dict) -> None:
|
| 84 |
+
await manager.broadcast(WSEvent(type=EventType.COACHING_RESULT, data=data))
|
| 85 |
+
|
| 86 |
+
async def emit_game_end(manager: ConnectionManager, data: dict) -> None:
|
| 87 |
+
await manager.broadcast(WSEvent(type=EventType.GAME_END, data=data))
|
| 88 |
+
|
| 89 |
+
async def emit_training_step(manager: ConnectionManager, data: dict) -> None:
|
| 90 |
+
await manager.broadcast(WSEvent(type=EventType.TRAINING_STEP, data=data))
|
| 91 |
+
|
| 92 |
+
async def emit_economy_update(manager: ConnectionManager, data: dict) -> None:
|
| 93 |
+
await manager.broadcast(WSEvent(type=EventType.ECONOMY_UPDATE, data=data))
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
# Singleton
|
| 97 |
+
ws_manager = ConnectionManager()
|
backend/api/websocket.py_backup
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — WebSocket Event Bus
|
| 3 |
+
Broadcasts real-time game events, training metrics, and economy updates
|
| 4 |
+
to all connected frontend clients.
|
| 5 |
+
"""
|
| 6 |
+
from __future__ import annotations
|
| 7 |
+
import asyncio
|
| 8 |
+
import json
|
| 9 |
+
import logging
|
| 10 |
+
from typing import Set, Any
|
| 11 |
+
from fastapi import WebSocket, WebSocketDisconnect
|
| 12 |
+
from shared.models import WSEvent, EventType
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class ConnectionManager:
|
| 18 |
+
"""Manages all active WebSocket connections and broadcasts events."""
|
| 19 |
+
|
| 20 |
+
def __init__(self):
|
| 21 |
+
self._connections: Set[WebSocket] = set()
|
| 22 |
+
self._lock = asyncio.Lock()
|
| 23 |
+
|
| 24 |
+
async def connect(self, ws: WebSocket) -> None:
|
| 25 |
+
await ws.accept()
|
| 26 |
+
async with self._lock:
|
| 27 |
+
self._connections.add(ws)
|
| 28 |
+
logger.info(f"WebSocket connected. Total: {len(self._connections)}")
|
| 29 |
+
|
| 30 |
+
async def disconnect(self, ws: WebSocket) -> None:
|
| 31 |
+
async with self._lock:
|
| 32 |
+
self._connections.discard(ws)
|
| 33 |
+
logger.info(f"WebSocket disconnected. Total: {len(self._connections)}")
|
| 34 |
+
|
| 35 |
+
async def broadcast(self, event: WSEvent) -> None:
|
| 36 |
+
"""Send an event to all connected clients."""
|
| 37 |
+
if not self._connections:
|
| 38 |
+
return
|
| 39 |
+
payload = event.model_dump_json()
|
| 40 |
+
dead: Set[WebSocket] = set()
|
| 41 |
+
async with self._lock:
|
| 42 |
+
connections = set(self._connections)
|
| 43 |
+
for ws in connections:
|
| 44 |
+
try:
|
| 45 |
+
await ws.send_text(payload)
|
| 46 |
+
except Exception:
|
| 47 |
+
dead.add(ws)
|
| 48 |
+
if dead:
|
| 49 |
+
async with self._lock:
|
| 50 |
+
self._connections -= dead
|
| 51 |
+
|
| 52 |
+
async def broadcast_raw(self, data: dict) -> None:
|
| 53 |
+
"""Broadcast a raw dictionary as JSON."""
|
| 54 |
+
event = WSEvent(type=EventType.MOVE, data=data)
|
| 55 |
+
await self.broadcast(event)
|
| 56 |
+
|
| 57 |
+
@property
|
| 58 |
+
def connection_count(self) -> int:
|
| 59 |
+
return len(self._connections)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# ── Helper functions for emitting typed events ────────────────────────────────
|
| 63 |
+
|
| 64 |
+
async def emit_game_start(manager: ConnectionManager, data: dict) -> None:
|
| 65 |
+
await manager.broadcast(WSEvent(type=EventType.GAME_START, data=data))
|
| 66 |
+
|
| 67 |
+
async def emit_move(manager: ConnectionManager, data: dict) -> None:
|
| 68 |
+
await manager.broadcast(WSEvent(type=EventType.MOVE, data=data))
|
| 69 |
+
|
| 70 |
+
async def emit_coaching_request(manager: ConnectionManager, data: dict) -> None:
|
| 71 |
+
await manager.broadcast(WSEvent(type=EventType.COACHING_REQUEST, data=data))
|
| 72 |
+
|
| 73 |
+
async def emit_coaching_result(manager: ConnectionManager, data: dict) -> None:
|
| 74 |
+
await manager.broadcast(WSEvent(type=EventType.COACHING_RESULT, data=data))
|
| 75 |
+
|
| 76 |
+
async def emit_game_end(manager: ConnectionManager, data: dict) -> None:
|
| 77 |
+
await manager.broadcast(WSEvent(type=EventType.GAME_END, data=data))
|
| 78 |
+
|
| 79 |
+
async def emit_training_step(manager: ConnectionManager, data: dict) -> None:
|
| 80 |
+
await manager.broadcast(WSEvent(type=EventType.TRAINING_STEP, data=data))
|
| 81 |
+
|
| 82 |
+
async def emit_economy_update(manager: ConnectionManager, data: dict) -> None:
|
| 83 |
+
await manager.broadcast(WSEvent(type=EventType.ECONOMY_UPDATE, data=data))
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
# Singleton
|
| 87 |
+
ws_manager = ConnectionManager()
|
backend/chess_engine.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
chess_engine.py
|
| 3 |
+
───────────────
|
| 4 |
+
Thin wrapper around python-chess providing:
|
| 5 |
+
- Board state management
|
| 6 |
+
- Legal move validation and parsing
|
| 7 |
+
- FEN / SAN / UCI conversion helpers
|
| 8 |
+
- Reward calculation after game end
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import chess
|
| 12 |
+
import chess.pgn
|
| 13 |
+
import random
|
| 14 |
+
from typing import Optional
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class ChessEngine:
|
| 18 |
+
"""Manages a single game of chess and exposes helpers for the agent loop."""
|
| 19 |
+
|
| 20 |
+
def __init__(self):
|
| 21 |
+
self.board = chess.Board()
|
| 22 |
+
|
| 23 |
+
# ── Board state ───────────────────────────────────────────────────────
|
| 24 |
+
|
| 25 |
+
@property
|
| 26 |
+
def fen(self) -> str:
|
| 27 |
+
return self.board.fen()
|
| 28 |
+
|
| 29 |
+
@property
|
| 30 |
+
def turn(self) -> str:
|
| 31 |
+
return "white" if self.board.turn == chess.WHITE else "black"
|
| 32 |
+
|
| 33 |
+
@property
|
| 34 |
+
def move_number(self) -> int:
|
| 35 |
+
return self.board.fullmove_number
|
| 36 |
+
|
| 37 |
+
@property
|
| 38 |
+
def is_game_over(self) -> bool:
|
| 39 |
+
return self.board.is_game_over()
|
| 40 |
+
|
| 41 |
+
@property
|
| 42 |
+
def result(self) -> Optional[str]:
|
| 43 |
+
"""Returns '1-0', '0-1', '1/2-1/2', or None if game is ongoing."""
|
| 44 |
+
if not self.board.is_game_over():
|
| 45 |
+
return None
|
| 46 |
+
outcome = self.board.outcome()
|
| 47 |
+
if outcome is None:
|
| 48 |
+
return "1/2-1/2"
|
| 49 |
+
if outcome.winner == chess.WHITE:
|
| 50 |
+
return "1-0"
|
| 51 |
+
if outcome.winner == chess.BLACK:
|
| 52 |
+
return "0-1"
|
| 53 |
+
return "1/2-1/2"
|
| 54 |
+
|
| 55 |
+
@property
|
| 56 |
+
def legal_moves_uci(self) -> list[str]:
|
| 57 |
+
return [m.uci() for m in self.board.legal_moves]
|
| 58 |
+
|
| 59 |
+
@property
|
| 60 |
+
def legal_moves_san(self) -> list[str]:
|
| 61 |
+
return [self.board.san(m) for m in self.board.legal_moves]
|
| 62 |
+
|
| 63 |
+
def reset(self):
|
| 64 |
+
self.board = chess.Board()
|
| 65 |
+
|
| 66 |
+
# ── Move application ──────────────────────────────────────────────────
|
| 67 |
+
|
| 68 |
+
def apply_move_uci(self, uci: str) -> Optional[str]:
|
| 69 |
+
"""
|
| 70 |
+
Apply a UCI move (e.g. 'e2e4') to the board.
|
| 71 |
+
Returns the SAN string on success, None if the move is illegal.
|
| 72 |
+
"""
|
| 73 |
+
try:
|
| 74 |
+
move = chess.Move.from_uci(uci)
|
| 75 |
+
if move not in self.board.legal_moves:
|
| 76 |
+
return None
|
| 77 |
+
san = self.board.san(move)
|
| 78 |
+
self.board.push(move)
|
| 79 |
+
return san
|
| 80 |
+
except (ValueError, chess.InvalidMoveError):
|
| 81 |
+
return None
|
| 82 |
+
|
| 83 |
+
def apply_move_san(self, san: str) -> Optional[str]:
|
| 84 |
+
"""
|
| 85 |
+
Apply a SAN move (e.g. 'Nf3') to the board.
|
| 86 |
+
Returns the UCI string on success, None if illegal.
|
| 87 |
+
"""
|
| 88 |
+
try:
|
| 89 |
+
move = self.board.parse_san(san)
|
| 90 |
+
uci = move.uci()
|
| 91 |
+
self.board.push(move)
|
| 92 |
+
return uci
|
| 93 |
+
except (ValueError, chess.InvalidMoveError, chess.AmbiguousMoveError):
|
| 94 |
+
return None
|
| 95 |
+
|
| 96 |
+
# ── Move parsing helpers ──────────────────────────────────────────────
|
| 97 |
+
|
| 98 |
+
def parse_model_output(self, text: str) -> Optional[str]:
|
| 99 |
+
"""
|
| 100 |
+
Extract the first plausible chess move from raw model output.
|
| 101 |
+
Tries SAN first, then UCI. Returns the SAN string if valid, else None.
|
| 102 |
+
"""
|
| 103 |
+
# Clean up whitespace and take the first token
|
| 104 |
+
tokens = text.strip().split()
|
| 105 |
+
for token in tokens[:5]: # check first 5 tokens
|
| 106 |
+
clean = token.strip(".,!?;:()")
|
| 107 |
+
# Try SAN
|
| 108 |
+
try:
|
| 109 |
+
move = self.board.parse_san(clean)
|
| 110 |
+
if move in self.board.legal_moves:
|
| 111 |
+
return self.board.san(move)
|
| 112 |
+
except Exception:
|
| 113 |
+
pass
|
| 114 |
+
# Try UCI
|
| 115 |
+
try:
|
| 116 |
+
move = chess.Move.from_uci(clean)
|
| 117 |
+
if move in self.board.legal_moves:
|
| 118 |
+
return self.board.san(move)
|
| 119 |
+
except Exception:
|
| 120 |
+
pass
|
| 121 |
+
return None
|
| 122 |
+
|
| 123 |
+
def uci_to_san(self, uci: str) -> Optional[str]:
|
| 124 |
+
"""Convert a UCI move string (e.g. 'e2e4') to SAN if it is legal."""
|
| 125 |
+
try:
|
| 126 |
+
move = self.board.parse_uci(uci)
|
| 127 |
+
if move in self.board.legal_moves:
|
| 128 |
+
return self.board.san(move)
|
| 129 |
+
except Exception:
|
| 130 |
+
pass
|
| 131 |
+
return None
|
| 132 |
+
|
| 133 |
+
def san_to_uci(self, san: str) -> Optional[str]:
|
| 134 |
+
"""Convert a SAN move string (e.g. 'Nf3') to UCI if it is legal."""
|
| 135 |
+
try:
|
| 136 |
+
move = self.board.parse_san(san)
|
| 137 |
+
if move in self.board.legal_moves:
|
| 138 |
+
return move.uci()
|
| 139 |
+
except Exception:
|
| 140 |
+
pass
|
| 141 |
+
return None
|
| 142 |
+
|
| 143 |
+
def random_legal_move_san(self) -> Optional[str]:
|
| 144 |
+
"""Return a random legal move in SAN notation (fallback)."""
|
| 145 |
+
legal = list(self.board.legal_moves)
|
| 146 |
+
if not legal:
|
| 147 |
+
return None
|
| 148 |
+
move = random.choice(legal)
|
| 149 |
+
return self.board.san(move)
|
| 150 |
+
|
| 151 |
+
# ── Reward calculation ────────────────────────────────────────────────
|
| 152 |
+
|
| 153 |
+
def compute_reward(self, agent_color: str) -> float:
|
| 154 |
+
"""
|
| 155 |
+
Terminal reward for the agent after the game ends.
|
| 156 |
+
+1.0 win
|
| 157 |
+
-1.0 loss
|
| 158 |
+
0.0 draw or game not over
|
| 159 |
+
"""
|
| 160 |
+
result = self.result
|
| 161 |
+
if result is None:
|
| 162 |
+
return 0.0
|
| 163 |
+
if result == "1-0":
|
| 164 |
+
return 1.0 if agent_color == "white" else -1.0
|
| 165 |
+
if result == "0-1":
|
| 166 |
+
return 1.0 if agent_color == "black" else -1.0
|
| 167 |
+
return 0.0 # draw
|
| 168 |
+
|
| 169 |
+
# ── Position prompt ───────────────────────────────────────────────────
|
| 170 |
+
|
| 171 |
+
def build_prompt(self, agent_color: str, move_history: list[str]) -> str:
|
| 172 |
+
"""
|
| 173 |
+
Build the text prompt fed to Qwen for move generation.
|
| 174 |
+
Keeps it short so the model stays focused on the move token.
|
| 175 |
+
"""
|
| 176 |
+
history_str = " ".join(move_history[-20:]) if move_history else "(opening)"
|
| 177 |
+
legal_sample = ", ".join(self.legal_moves_san[:10])
|
| 178 |
+
return (
|
| 179 |
+
f"You are a chess engine playing as {agent_color}.\n"
|
| 180 |
+
f"Position (FEN): {self.fen}\n"
|
| 181 |
+
f"Move history: {history_str}\n"
|
| 182 |
+
f"Some legal moves: {legal_sample}\n"
|
| 183 |
+
f"Reply with ONLY the single best next move in standard algebraic notation (SAN), "
|
| 184 |
+
f"e.g. 'e4' or 'Nf3'. Do not explain."
|
| 185 |
+
)
|
| 186 |
+
|
backend/chess_lib/__init__.py
ADDED
|
File without changes
|
backend/chess_lib/chess_engine.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
chess_engine.py
|
| 3 |
+
───────────────
|
| 4 |
+
Thin wrapper around python-chess providing:
|
| 5 |
+
- Board state management
|
| 6 |
+
- Legal move validation and parsing
|
| 7 |
+
- FEN / SAN / UCI conversion helpers
|
| 8 |
+
- Reward calculation after game end
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import chess
|
| 12 |
+
import chess.pgn
|
| 13 |
+
import random
|
| 14 |
+
from typing import Optional
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class ChessEngine:
|
| 18 |
+
"""Manages a single game of chess and exposes helpers for the agent loop."""
|
| 19 |
+
|
| 20 |
+
def __init__(self):
|
| 21 |
+
self.board = chess.Board()
|
| 22 |
+
|
| 23 |
+
# ── Board state ───────────────────────────────────────────────────────
|
| 24 |
+
|
| 25 |
+
@property
|
| 26 |
+
def fen(self) -> str:
|
| 27 |
+
return self.board.fen()
|
| 28 |
+
|
| 29 |
+
@property
|
| 30 |
+
def turn(self) -> str:
|
| 31 |
+
return "white" if self.board.turn == chess.WHITE else "black"
|
| 32 |
+
|
| 33 |
+
@property
|
| 34 |
+
def move_number(self) -> int:
|
| 35 |
+
return self.board.fullmove_number
|
| 36 |
+
|
| 37 |
+
@property
|
| 38 |
+
def is_game_over(self) -> bool:
|
| 39 |
+
return self.board.is_game_over()
|
| 40 |
+
|
| 41 |
+
@property
|
| 42 |
+
def result(self) -> Optional[str]:
|
| 43 |
+
"""Returns '1-0', '0-1', '1/2-1/2', or None if game is ongoing."""
|
| 44 |
+
if not self.board.is_game_over():
|
| 45 |
+
return None
|
| 46 |
+
outcome = self.board.outcome()
|
| 47 |
+
if outcome is None:
|
| 48 |
+
return "1/2-1/2"
|
| 49 |
+
if outcome.winner == chess.WHITE:
|
| 50 |
+
return "1-0"
|
| 51 |
+
if outcome.winner == chess.BLACK:
|
| 52 |
+
return "0-1"
|
| 53 |
+
return "1/2-1/2"
|
| 54 |
+
|
| 55 |
+
@property
|
| 56 |
+
def legal_moves_uci(self) -> list[str]:
|
| 57 |
+
return [m.uci() for m in self.board.legal_moves]
|
| 58 |
+
|
| 59 |
+
@property
|
| 60 |
+
def legal_moves_san(self) -> list[str]:
|
| 61 |
+
return [self.board.san(m) for m in self.board.legal_moves]
|
| 62 |
+
|
| 63 |
+
def reset(self):
|
| 64 |
+
self.board = chess.Board()
|
| 65 |
+
|
| 66 |
+
# ── Move application ──────────────────────────────────────────────────
|
| 67 |
+
|
| 68 |
+
def apply_move_uci(self, uci: str) -> Optional[str]:
|
| 69 |
+
"""
|
| 70 |
+
Apply a UCI move (e.g. 'e2e4') to the board.
|
| 71 |
+
Returns the SAN string on success, None if the move is illegal.
|
| 72 |
+
"""
|
| 73 |
+
try:
|
| 74 |
+
move = chess.Move.from_uci(uci)
|
| 75 |
+
if move not in self.board.legal_moves:
|
| 76 |
+
return None
|
| 77 |
+
san = self.board.san(move)
|
| 78 |
+
self.board.push(move)
|
| 79 |
+
return san
|
| 80 |
+
except (ValueError, chess.InvalidMoveError):
|
| 81 |
+
return None
|
| 82 |
+
|
| 83 |
+
def apply_move_san(self, san: str) -> Optional[str]:
|
| 84 |
+
"""
|
| 85 |
+
Apply a SAN move (e.g. 'Nf3') to the board.
|
| 86 |
+
Returns the UCI string on success, None if illegal.
|
| 87 |
+
"""
|
| 88 |
+
try:
|
| 89 |
+
move = self.board.parse_san(san)
|
| 90 |
+
uci = move.uci()
|
| 91 |
+
self.board.push(move)
|
| 92 |
+
return uci
|
| 93 |
+
except (ValueError, chess.InvalidMoveError, chess.AmbiguousMoveError):
|
| 94 |
+
return None
|
| 95 |
+
|
| 96 |
+
# ── Move parsing helpers ──────────────────────────────────────────────
|
| 97 |
+
|
| 98 |
+
def parse_model_output(self, text: str) -> Optional[str]:
|
| 99 |
+
"""
|
| 100 |
+
Extract the first plausible chess move from raw model output.
|
| 101 |
+
Tries SAN first, then UCI. Returns the SAN string if valid, else None.
|
| 102 |
+
"""
|
| 103 |
+
# Clean up whitespace and take the first token
|
| 104 |
+
tokens = text.strip().split()
|
| 105 |
+
for token in tokens[:5]: # check first 5 tokens
|
| 106 |
+
clean = token.strip(".,!?;:()")
|
| 107 |
+
# Try SAN
|
| 108 |
+
try:
|
| 109 |
+
move = self.board.parse_san(clean)
|
| 110 |
+
if move in self.board.legal_moves:
|
| 111 |
+
return self.board.san(move)
|
| 112 |
+
except Exception:
|
| 113 |
+
pass
|
| 114 |
+
# Try UCI
|
| 115 |
+
try:
|
| 116 |
+
move = chess.Move.from_uci(clean)
|
| 117 |
+
if move in self.board.legal_moves:
|
| 118 |
+
return self.board.san(move)
|
| 119 |
+
except Exception:
|
| 120 |
+
pass
|
| 121 |
+
return None
|
| 122 |
+
|
| 123 |
+
def random_legal_move_san(self) -> Optional[str]:
|
| 124 |
+
"""Return a random legal move in SAN notation (fallback)."""
|
| 125 |
+
legal = list(self.board.legal_moves)
|
| 126 |
+
if not legal:
|
| 127 |
+
return None
|
| 128 |
+
move = random.choice(legal)
|
| 129 |
+
return self.board.san(move)
|
| 130 |
+
|
| 131 |
+
# ── Reward calculation ────────────────────────────────────────────────
|
| 132 |
+
|
| 133 |
+
def compute_reward(self, agent_color: str) -> float:
|
| 134 |
+
"""
|
| 135 |
+
Terminal reward for the agent after the game ends.
|
| 136 |
+
+1.0 win
|
| 137 |
+
-1.0 loss
|
| 138 |
+
0.0 draw or game not over
|
| 139 |
+
"""
|
| 140 |
+
result = self.result
|
| 141 |
+
if result is None:
|
| 142 |
+
return 0.0
|
| 143 |
+
if result == "1-0":
|
| 144 |
+
return 1.0 if agent_color == "white" else -1.0
|
| 145 |
+
if result == "0-1":
|
| 146 |
+
return 1.0 if agent_color == "black" else -1.0
|
| 147 |
+
return 0.0 # draw
|
| 148 |
+
|
| 149 |
+
# ── Position prompt ───────────────────────────────────────────────────
|
| 150 |
+
|
| 151 |
+
def build_prompt(self, agent_color: str, move_history: list[str]) -> str:
|
| 152 |
+
"""
|
| 153 |
+
Build the text prompt fed to Qwen for move generation.
|
| 154 |
+
Keeps it short so the model stays focused on the move token.
|
| 155 |
+
"""
|
| 156 |
+
history_str = " ".join(move_history[-20:]) if move_history else "(opening)"
|
| 157 |
+
legal_sample = ", ".join(self.legal_moves_san[:10])
|
| 158 |
+
return (
|
| 159 |
+
f"You are a chess engine playing as {agent_color}.\n"
|
| 160 |
+
f"Position (FEN): {self.fen}\n"
|
| 161 |
+
f"Move history: {history_str}\n"
|
| 162 |
+
f"Some legal moves: {legal_sample}\n"
|
| 163 |
+
f"Reply with ONLY the single best next move in standard algebraic notation (SAN), "
|
| 164 |
+
f"e.g. 'e4' or 'Nf3'. Do not explain."
|
| 165 |
+
)
|
| 166 |
+
|
backend/chess_lib/engine.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — Chess Engine
|
| 3 |
+
Wraps python-chess to manage game state, validate moves, and detect outcomes.
|
| 4 |
+
"""
|
| 5 |
+
from __future__ import annotations
|
| 6 |
+
import uuid
|
| 7 |
+
import chess
|
| 8 |
+
import chess.pgn
|
| 9 |
+
from typing import Dict, Optional, List
|
| 10 |
+
from shared.models import GameState, GameOutcome, GameStatus, NewGameResponse
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class ChessEngine:
|
| 14 |
+
"""Thread-safe chess game manager. Stores all active games in memory."""
|
| 15 |
+
|
| 16 |
+
def __init__(self):
|
| 17 |
+
self._games: Dict[str, chess.Board] = {}
|
| 18 |
+
|
| 19 |
+
# ── Game lifecycle ────────────────────────────────────────────────────────
|
| 20 |
+
|
| 21 |
+
def new_game(self, game_id: Optional[str] = None) -> NewGameResponse:
|
| 22 |
+
gid = game_id or str(uuid.uuid4())
|
| 23 |
+
board = chess.Board()
|
| 24 |
+
self._games[gid] = board
|
| 25 |
+
return NewGameResponse(
|
| 26 |
+
game_id=gid,
|
| 27 |
+
fen=board.fen(),
|
| 28 |
+
legal_moves=[m.uci() for m in board.legal_moves],
|
| 29 |
+
status=GameStatus.ACTIVE,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
def get_state(self, game_id: str) -> GameState:
|
| 33 |
+
board = self._get_board(game_id)
|
| 34 |
+
return GameState(
|
| 35 |
+
game_id=game_id,
|
| 36 |
+
fen=board.fen(),
|
| 37 |
+
legal_moves=[m.uci() for m in board.legal_moves],
|
| 38 |
+
outcome=self._outcome(board),
|
| 39 |
+
move_number=board.fullmove_number,
|
| 40 |
+
move_history=[m.uci() for m in board.move_stack],
|
| 41 |
+
status=GameStatus.FINISHED if board.is_game_over() else GameStatus.ACTIVE,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
def make_move(self, game_id: str, move_uci: str) -> GameState:
|
| 45 |
+
board = self._get_board(game_id)
|
| 46 |
+
if board.is_game_over():
|
| 47 |
+
raise ValueError(f"Game {game_id} is already over")
|
| 48 |
+
try:
|
| 49 |
+
move = chess.Move.from_uci(move_uci)
|
| 50 |
+
except ValueError:
|
| 51 |
+
raise ValueError(f"Invalid UCI move format: {move_uci}")
|
| 52 |
+
if move not in board.legal_moves:
|
| 53 |
+
legal = [m.uci() for m in board.legal_moves]
|
| 54 |
+
raise ValueError(
|
| 55 |
+
f"Illegal move {move_uci} in position {board.fen()}. "
|
| 56 |
+
f"Legal moves: {legal[:10]}{'...' if len(legal) > 10 else ''}"
|
| 57 |
+
)
|
| 58 |
+
board.push(move)
|
| 59 |
+
return self.get_state(game_id)
|
| 60 |
+
|
| 61 |
+
def delete_game(self, game_id: str) -> None:
|
| 62 |
+
self._games.pop(game_id, None)
|
| 63 |
+
|
| 64 |
+
def list_games(self) -> List[str]:
|
| 65 |
+
return list(self._games.keys())
|
| 66 |
+
|
| 67 |
+
# ── Position analysis ─────────────────────────────────────────────────────
|
| 68 |
+
|
| 69 |
+
def get_legal_moves(self, game_id: str) -> List[str]:
|
| 70 |
+
board = self._get_board(game_id)
|
| 71 |
+
return [m.uci() for m in board.legal_moves]
|
| 72 |
+
|
| 73 |
+
def get_fen(self, game_id: str) -> str:
|
| 74 |
+
return self._get_board(game_id).fen()
|
| 75 |
+
|
| 76 |
+
def is_game_over(self, game_id: str) -> bool:
|
| 77 |
+
return self._get_board(game_id).is_game_over()
|
| 78 |
+
|
| 79 |
+
def complexity_features(self, game_id: str) -> dict:
|
| 80 |
+
"""Return raw features used by the complexity analyzer."""
|
| 81 |
+
board = self._get_board(game_id)
|
| 82 |
+
legal = list(board.legal_moves)
|
| 83 |
+
return {
|
| 84 |
+
"num_legal_moves": len(legal),
|
| 85 |
+
"is_check": board.is_check(),
|
| 86 |
+
"has_captures": any(board.is_capture(m) for m in legal),
|
| 87 |
+
"num_pieces": len(board.piece_map()),
|
| 88 |
+
"fullmove_number": board.fullmove_number,
|
| 89 |
+
"material_balance": self._material_balance(board),
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
# ── Private helpers ───────────────────────────────────────────────────────
|
| 93 |
+
|
| 94 |
+
def _get_board(self, game_id: str) -> chess.Board:
|
| 95 |
+
if game_id not in self._games:
|
| 96 |
+
raise KeyError(f"Game {game_id} not found")
|
| 97 |
+
return self._games[game_id]
|
| 98 |
+
|
| 99 |
+
@staticmethod
|
| 100 |
+
def _outcome(board: chess.Board) -> GameOutcome:
|
| 101 |
+
if not board.is_game_over():
|
| 102 |
+
return GameOutcome.ONGOING
|
| 103 |
+
result = board.result()
|
| 104 |
+
if result == "1-0":
|
| 105 |
+
return GameOutcome.WHITE_WIN
|
| 106 |
+
elif result == "0-1":
|
| 107 |
+
return GameOutcome.BLACK_WIN
|
| 108 |
+
return GameOutcome.DRAW
|
| 109 |
+
|
| 110 |
+
@staticmethod
|
| 111 |
+
def _material_balance(board: chess.Board) -> float:
|
| 112 |
+
"""Positive = white advantage."""
|
| 113 |
+
piece_values = {
|
| 114 |
+
chess.PAWN: 1, chess.KNIGHT: 3, chess.BISHOP: 3,
|
| 115 |
+
chess.ROOK: 5, chess.QUEEN: 9, chess.KING: 0,
|
| 116 |
+
}
|
| 117 |
+
balance = 0.0
|
| 118 |
+
for piece_type, value in piece_values.items():
|
| 119 |
+
balance += value * len(board.pieces(piece_type, chess.WHITE))
|
| 120 |
+
balance -= value * len(board.pieces(piece_type, chess.BLACK))
|
| 121 |
+
return balance
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
# Singleton instance
|
| 125 |
+
chess_engine = ChessEngine()
|
backend/economy/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
backend/economy/__init__.py
ADDED
|
File without changes
|
backend/economy/ledger.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — Economic Ledger
|
| 3 |
+
Manages agent wallets, tournament prize pools, and transaction history.
|
| 4 |
+
"""
|
| 5 |
+
from __future__ import annotations
|
| 6 |
+
import os
|
| 7 |
+
import uuid
|
| 8 |
+
import time
|
| 9 |
+
from typing import Dict, List, Optional
|
| 10 |
+
from shared.models import Transaction, WalletState, TournamentResult, GameOutcome
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class EconomicConfig:
|
| 14 |
+
entry_fee: float = float(os.getenv("ENTRY_FEE", "10.0"))
|
| 15 |
+
prize_multiplier: float = float(os.getenv("PRIZE_MULTIPLIER", "0.9"))
|
| 16 |
+
initial_wallet: float = float(os.getenv("INITIAL_WALLET", "100.0"))
|
| 17 |
+
coaching_fee: float = float(os.getenv("COACHING_FEE", "5.0"))
|
| 18 |
+
min_wallet_for_coaching: float = float(os.getenv("MIN_WALLET_FOR_COACHING", "15.0"))
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Ledger:
|
| 22 |
+
"""
|
| 23 |
+
Manages all economic activity in the ChessEcon system.
|
| 24 |
+
Thread-safe for concurrent game sessions.
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
def __init__(self, config: Optional[EconomicConfig] = None):
|
| 28 |
+
self.config = config or EconomicConfig()
|
| 29 |
+
self._wallets: Dict[str, WalletState] = {}
|
| 30 |
+
self._transactions: List[Transaction] = []
|
| 31 |
+
self._open_games: Dict[str, dict] = {} # game_id -> {white, black, pool}
|
| 32 |
+
|
| 33 |
+
# ── Wallet management ─────────────────────────────────────────────────────
|
| 34 |
+
|
| 35 |
+
def register_agent(self, agent_id: str) -> WalletState:
|
| 36 |
+
if agent_id not in self._wallets:
|
| 37 |
+
self._wallets[agent_id] = WalletState(
|
| 38 |
+
agent_id=agent_id,
|
| 39 |
+
balance=self.config.initial_wallet,
|
| 40 |
+
total_earned=self.config.initial_wallet,
|
| 41 |
+
)
|
| 42 |
+
return self._wallets[agent_id]
|
| 43 |
+
|
| 44 |
+
def get_wallet(self, agent_id: str) -> WalletState:
|
| 45 |
+
if agent_id not in self._wallets:
|
| 46 |
+
return self.register_agent(agent_id)
|
| 47 |
+
return self._wallets[agent_id]
|
| 48 |
+
|
| 49 |
+
def get_balance(self, agent_id: str) -> float:
|
| 50 |
+
return self.get_wallet(agent_id).balance
|
| 51 |
+
|
| 52 |
+
def _debit(self, agent_id: str, amount: float, description: str) -> Transaction:
|
| 53 |
+
wallet = self.get_wallet(agent_id)
|
| 54 |
+
wallet.balance -= amount
|
| 55 |
+
wallet.total_spent += amount
|
| 56 |
+
tx = Transaction(
|
| 57 |
+
tx_id=str(uuid.uuid4()),
|
| 58 |
+
agent_id=agent_id,
|
| 59 |
+
amount=-amount,
|
| 60 |
+
description=description,
|
| 61 |
+
)
|
| 62 |
+
self._transactions.append(tx)
|
| 63 |
+
return tx
|
| 64 |
+
|
| 65 |
+
def _credit(self, agent_id: str, amount: float, description: str) -> Transaction:
|
| 66 |
+
wallet = self.get_wallet(agent_id)
|
| 67 |
+
wallet.balance += amount
|
| 68 |
+
wallet.total_earned += amount
|
| 69 |
+
tx = Transaction(
|
| 70 |
+
tx_id=str(uuid.uuid4()),
|
| 71 |
+
agent_id=agent_id,
|
| 72 |
+
amount=amount,
|
| 73 |
+
description=description,
|
| 74 |
+
)
|
| 75 |
+
self._transactions.append(tx)
|
| 76 |
+
return tx
|
| 77 |
+
|
| 78 |
+
# ── Tournament management ─────────────────────────────────────────────────
|
| 79 |
+
|
| 80 |
+
def open_game(self, game_id: str, white_id: str, black_id: str) -> float:
|
| 81 |
+
"""Collect entry fees and open a prize pool. Returns pool size."""
|
| 82 |
+
fee = self.config.entry_fee
|
| 83 |
+
self._debit(white_id, fee, f"Entry fee game {game_id}")
|
| 84 |
+
self._debit(black_id, fee, f"Entry fee game {game_id}")
|
| 85 |
+
pool = fee * 2 * self.config.prize_multiplier
|
| 86 |
+
self._open_games[game_id] = {
|
| 87 |
+
"white": white_id,
|
| 88 |
+
"black": black_id,
|
| 89 |
+
"pool": pool,
|
| 90 |
+
"entry_fees": fee * 2,
|
| 91 |
+
}
|
| 92 |
+
# Update game counts
|
| 93 |
+
self.get_wallet(white_id).games_played += 1
|
| 94 |
+
self.get_wallet(black_id).games_played += 1
|
| 95 |
+
return pool
|
| 96 |
+
|
| 97 |
+
def settle_game(self, game_id: str, outcome: GameOutcome) -> TournamentResult:
|
| 98 |
+
"""Pay out prize pool based on game outcome. Returns settlement details."""
|
| 99 |
+
if game_id not in self._open_games:
|
| 100 |
+
raise KeyError(f"Game {game_id} not found in open games")
|
| 101 |
+
|
| 102 |
+
game = self._open_games.pop(game_id)
|
| 103 |
+
white_id = game["white"]
|
| 104 |
+
black_id = game["black"]
|
| 105 |
+
pool = game["pool"]
|
| 106 |
+
entry_fees = game["entry_fees"]
|
| 107 |
+
organizer_cut = entry_fees - pool
|
| 108 |
+
|
| 109 |
+
winner: Optional[str] = None
|
| 110 |
+
prize_paid = 0.0
|
| 111 |
+
|
| 112 |
+
if outcome == GameOutcome.WHITE_WIN:
|
| 113 |
+
winner = white_id
|
| 114 |
+
prize_paid = pool
|
| 115 |
+
self._credit(white_id, pool, f"Prize win game {game_id}")
|
| 116 |
+
self.get_wallet(white_id).games_won += 1
|
| 117 |
+
elif outcome == GameOutcome.BLACK_WIN:
|
| 118 |
+
winner = black_id
|
| 119 |
+
prize_paid = pool
|
| 120 |
+
self._credit(black_id, pool, f"Prize win game {game_id}")
|
| 121 |
+
self.get_wallet(black_id).games_won += 1
|
| 122 |
+
elif outcome == GameOutcome.DRAW:
|
| 123 |
+
# Split pool equally on draw
|
| 124 |
+
half = pool / 2
|
| 125 |
+
prize_paid = pool
|
| 126 |
+
self._credit(white_id, half, f"Draw prize game {game_id}")
|
| 127 |
+
self._credit(black_id, half, f"Draw prize game {game_id}")
|
| 128 |
+
|
| 129 |
+
return TournamentResult(
|
| 130 |
+
game_id=game_id,
|
| 131 |
+
winner=winner,
|
| 132 |
+
outcome=outcome,
|
| 133 |
+
prize_paid=prize_paid,
|
| 134 |
+
entry_fees_collected=entry_fees,
|
| 135 |
+
organizer_cut=organizer_cut,
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
# ── Coaching payments ─────────────────────────────────────────────────────
|
| 139 |
+
|
| 140 |
+
def charge_coaching(self, agent_id: str, game_id: str) -> float:
|
| 141 |
+
"""Deduct coaching fee. Returns fee charged, or 0 if insufficient funds."""
|
| 142 |
+
wallet = self.get_wallet(agent_id)
|
| 143 |
+
if wallet.balance < self.config.min_wallet_for_coaching:
|
| 144 |
+
return 0.0
|
| 145 |
+
fee = self.config.coaching_fee
|
| 146 |
+
self._debit(agent_id, fee, f"Claude coaching game {game_id}")
|
| 147 |
+
wallet.coaching_calls += 1
|
| 148 |
+
return fee
|
| 149 |
+
|
| 150 |
+
def can_afford_coaching(self, agent_id: str) -> bool:
|
| 151 |
+
return self.get_balance(agent_id) >= self.config.min_wallet_for_coaching
|
| 152 |
+
|
| 153 |
+
# ── Reporting ─────────────────────────────────────────────────────────────
|
| 154 |
+
|
| 155 |
+
def get_all_wallets(self) -> Dict[str, WalletState]:
|
| 156 |
+
return dict(self._wallets)
|
| 157 |
+
|
| 158 |
+
def get_transactions(self, agent_id: Optional[str] = None) -> List[Transaction]:
|
| 159 |
+
if agent_id:
|
| 160 |
+
return [t for t in self._transactions if t.agent_id == agent_id]
|
| 161 |
+
return list(self._transactions)
|
| 162 |
+
|
| 163 |
+
def summary(self) -> dict:
|
| 164 |
+
wallets = self._wallets
|
| 165 |
+
return {
|
| 166 |
+
"total_agents": len(wallets),
|
| 167 |
+
"total_transactions": len(self._transactions),
|
| 168 |
+
"open_games": len(self._open_games),
|
| 169 |
+
"wallets": {aid: w.model_dump() for aid, w in wallets.items()},
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
# Singleton instance
|
| 174 |
+
ledger = Ledger()
|
backend/economy/nvm_payments.py
ADDED
|
@@ -0,0 +1,340 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon — Nevermined Payment Manager
|
| 3 |
+
=======================================
|
| 4 |
+
Wraps the payments-py SDK to provide a clean interface for:
|
| 5 |
+
- Initializing the Nevermined Payments client
|
| 6 |
+
- Verifying x402 payment tokens on incoming requests
|
| 7 |
+
- Settling credits after successful service delivery
|
| 8 |
+
- Ordering plans and generating access tokens (subscriber side)
|
| 9 |
+
- Tracking NVM transactions for the dashboard
|
| 10 |
+
|
| 11 |
+
This replaces the internal ledger for cross-team agent-to-agent payments.
|
| 12 |
+
The internal ledger (economy/ledger.py) is still used for intra-team
|
| 13 |
+
tournament accounting (entry fees, prize pools).
|
| 14 |
+
"""
|
| 15 |
+
from __future__ import annotations
|
| 16 |
+
|
| 17 |
+
import logging
|
| 18 |
+
import os
|
| 19 |
+
from dataclasses import dataclass, field
|
| 20 |
+
from datetime import datetime, timezone
|
| 21 |
+
from typing import Any, Dict, List, Optional
|
| 22 |
+
|
| 23 |
+
logger = logging.getLogger(__name__)
|
| 24 |
+
|
| 25 |
+
# ── Environment ────────────────────────────────────────────────────────────────
|
| 26 |
+
NVM_API_KEY = os.getenv("NVM_API_KEY", "")
|
| 27 |
+
NVM_ENVIRONMENT = os.getenv("NVM_ENVIRONMENT", "sandbox")
|
| 28 |
+
NVM_PLAN_ID = os.getenv("NVM_PLAN_ID", "")
|
| 29 |
+
NVM_AGENT_ID = os.getenv("NVM_AGENT_ID", "")
|
| 30 |
+
|
| 31 |
+
# ── Transaction record ─────────────────────────────────────────────────────────
|
| 32 |
+
@dataclass
|
| 33 |
+
class NvmTransaction:
|
| 34 |
+
"""A recorded Nevermined payment transaction."""
|
| 35 |
+
tx_id: str
|
| 36 |
+
tx_type: str # "verify" | "settle" | "order" | "token"
|
| 37 |
+
agent_id: str
|
| 38 |
+
plan_id: str
|
| 39 |
+
credits: int
|
| 40 |
+
timestamp: str = field(default_factory=lambda: datetime.now(timezone.utc).isoformat())
|
| 41 |
+
details: Dict[str, Any] = field(default_factory=dict)
|
| 42 |
+
success: bool = True
|
| 43 |
+
error: Optional[str] = None
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# ── Nevermined Payment Manager ─────────────────────────────────────────────────
|
| 47 |
+
class NeverminedPaymentManager:
|
| 48 |
+
"""
|
| 49 |
+
Singleton manager for all Nevermined payment operations.
|
| 50 |
+
|
| 51 |
+
Usage (server side — verify + settle):
|
| 52 |
+
nvm = NeverminedPaymentManager()
|
| 53 |
+
if nvm.available:
|
| 54 |
+
ok, reason = nvm.verify_token(token, request_url, "POST")
|
| 55 |
+
if ok:
|
| 56 |
+
# ... handle request ...
|
| 57 |
+
nvm.settle_token(token, request_url, "POST")
|
| 58 |
+
|
| 59 |
+
Usage (client/agent side — order + get token):
|
| 60 |
+
nvm = NeverminedPaymentManager()
|
| 61 |
+
if nvm.available:
|
| 62 |
+
nvm.order_plan(plan_id)
|
| 63 |
+
token = nvm.get_access_token(plan_id, agent_id)
|
| 64 |
+
"""
|
| 65 |
+
|
| 66 |
+
def __init__(self):
|
| 67 |
+
self._payments = None
|
| 68 |
+
self._available = False
|
| 69 |
+
self._transactions: List[NvmTransaction] = []
|
| 70 |
+
self._init_sdk()
|
| 71 |
+
|
| 72 |
+
def _init_sdk(self):
|
| 73 |
+
"""Initialize the payments-py SDK if NVM_API_KEY is configured."""
|
| 74 |
+
if not NVM_API_KEY:
|
| 75 |
+
logger.warning(
|
| 76 |
+
"NVM_API_KEY not set — Nevermined payments disabled. "
|
| 77 |
+
"Set NVM_API_KEY in .env to enable cross-team agent payments."
|
| 78 |
+
)
|
| 79 |
+
return
|
| 80 |
+
try:
|
| 81 |
+
from payments_py import Payments, PaymentOptions
|
| 82 |
+
self._payments = Payments.get_instance(
|
| 83 |
+
PaymentOptions(
|
| 84 |
+
nvm_api_key=NVM_API_KEY,
|
| 85 |
+
environment=NVM_ENVIRONMENT,
|
| 86 |
+
)
|
| 87 |
+
)
|
| 88 |
+
self._available = True
|
| 89 |
+
logger.info(
|
| 90 |
+
f"Nevermined Payments SDK initialized "
|
| 91 |
+
f"(environment={NVM_ENVIRONMENT}, "
|
| 92 |
+
f"plan_id={NVM_PLAN_ID or 'not set'}, "
|
| 93 |
+
f"agent_id={NVM_AGENT_ID or 'not set'})"
|
| 94 |
+
)
|
| 95 |
+
except Exception as exc:
|
| 96 |
+
logger.error(f"Failed to initialize Nevermined SDK: {exc}")
|
| 97 |
+
self._available = False
|
| 98 |
+
|
| 99 |
+
# ── Properties ─────────────────────────────────────────────────────────────
|
| 100 |
+
@property
|
| 101 |
+
def available(self) -> bool:
|
| 102 |
+
return self._available and self._payments is not None
|
| 103 |
+
|
| 104 |
+
@property
|
| 105 |
+
def payments(self):
|
| 106 |
+
return self._payments
|
| 107 |
+
|
| 108 |
+
# ── Server-side: verify + settle ───────────────────────────────────────────
|
| 109 |
+
def build_payment_required(
|
| 110 |
+
self,
|
| 111 |
+
endpoint: str,
|
| 112 |
+
http_verb: str = "POST",
|
| 113 |
+
plan_id: Optional[str] = None,
|
| 114 |
+
agent_id: Optional[str] = None,
|
| 115 |
+
):
|
| 116 |
+
"""Build a PaymentRequired spec for a protected endpoint."""
|
| 117 |
+
if not self.available:
|
| 118 |
+
return None
|
| 119 |
+
try:
|
| 120 |
+
from payments_py.x402.helpers import build_payment_required
|
| 121 |
+
return build_payment_required(
|
| 122 |
+
plan_id=plan_id or NVM_PLAN_ID,
|
| 123 |
+
endpoint=endpoint,
|
| 124 |
+
agent_id=agent_id or NVM_AGENT_ID,
|
| 125 |
+
http_verb=http_verb,
|
| 126 |
+
)
|
| 127 |
+
except Exception as exc:
|
| 128 |
+
logger.error(f"build_payment_required failed: {exc}")
|
| 129 |
+
return None
|
| 130 |
+
|
| 131 |
+
def verify_token(
|
| 132 |
+
self,
|
| 133 |
+
x402_token: str,
|
| 134 |
+
endpoint: str,
|
| 135 |
+
http_verb: str = "POST",
|
| 136 |
+
max_credits: str = "1",
|
| 137 |
+
plan_id: Optional[str] = None,
|
| 138 |
+
agent_id: Optional[str] = None,
|
| 139 |
+
) -> tuple[bool, Optional[str]]:
|
| 140 |
+
"""
|
| 141 |
+
Verify an x402 access token WITHOUT burning credits.
|
| 142 |
+
|
| 143 |
+
Returns:
|
| 144 |
+
(is_valid, error_reason)
|
| 145 |
+
"""
|
| 146 |
+
if not self.available:
|
| 147 |
+
# Graceful degradation: allow requests when NVM not configured
|
| 148 |
+
logger.debug("NVM not available — skipping payment verification")
|
| 149 |
+
return True, None
|
| 150 |
+
|
| 151 |
+
payment_required = self.build_payment_required(endpoint, http_verb, plan_id, agent_id)
|
| 152 |
+
if payment_required is None:
|
| 153 |
+
return False, "Could not build payment_required spec"
|
| 154 |
+
|
| 155 |
+
try:
|
| 156 |
+
verification = self._payments.facilitator.verify_permissions(
|
| 157 |
+
payment_required=payment_required,
|
| 158 |
+
x402_access_token=x402_token,
|
| 159 |
+
max_amount=max_credits,
|
| 160 |
+
)
|
| 161 |
+
is_valid = verification.is_valid
|
| 162 |
+
reason = None if is_valid else (verification.invalid_reason or "Verification failed")
|
| 163 |
+
|
| 164 |
+
self._record_transaction(
|
| 165 |
+
tx_type="verify",
|
| 166 |
+
agent_id=agent_id or NVM_AGENT_ID,
|
| 167 |
+
plan_id=plan_id or NVM_PLAN_ID,
|
| 168 |
+
credits=int(max_credits),
|
| 169 |
+
success=is_valid,
|
| 170 |
+
error=reason,
|
| 171 |
+
details={"endpoint": endpoint, "verb": http_verb},
|
| 172 |
+
)
|
| 173 |
+
return is_valid, reason
|
| 174 |
+
except Exception as exc:
|
| 175 |
+
logger.error(f"verify_permissions failed: {exc}")
|
| 176 |
+
return False, str(exc)
|
| 177 |
+
|
| 178 |
+
def settle_token(
|
| 179 |
+
self,
|
| 180 |
+
x402_token: str,
|
| 181 |
+
endpoint: str,
|
| 182 |
+
http_verb: str = "POST",
|
| 183 |
+
max_credits: str = "1",
|
| 184 |
+
plan_id: Optional[str] = None,
|
| 185 |
+
agent_id: Optional[str] = None,
|
| 186 |
+
) -> bool:
|
| 187 |
+
"""
|
| 188 |
+
Settle (burn) credits after successful service delivery.
|
| 189 |
+
|
| 190 |
+
Returns:
|
| 191 |
+
True if settlement succeeded, False otherwise.
|
| 192 |
+
"""
|
| 193 |
+
if not self.available:
|
| 194 |
+
return True # No-op when NVM not configured
|
| 195 |
+
|
| 196 |
+
payment_required = self.build_payment_required(endpoint, http_verb, plan_id, agent_id)
|
| 197 |
+
if payment_required is None:
|
| 198 |
+
return False
|
| 199 |
+
|
| 200 |
+
try:
|
| 201 |
+
settlement = self._payments.facilitator.settle_permissions(
|
| 202 |
+
payment_required=payment_required,
|
| 203 |
+
x402_access_token=x402_token,
|
| 204 |
+
max_amount=max_credits,
|
| 205 |
+
)
|
| 206 |
+
credits_burned = getattr(settlement, "credits_redeemed", int(max_credits))
|
| 207 |
+
self._record_transaction(
|
| 208 |
+
tx_type="settle",
|
| 209 |
+
agent_id=agent_id or NVM_AGENT_ID,
|
| 210 |
+
plan_id=plan_id or NVM_PLAN_ID,
|
| 211 |
+
credits=credits_burned,
|
| 212 |
+
success=True,
|
| 213 |
+
details={"endpoint": endpoint, "verb": http_verb},
|
| 214 |
+
)
|
| 215 |
+
logger.info(f"NVM credits settled: {credits_burned} credits for {endpoint}")
|
| 216 |
+
return True
|
| 217 |
+
except Exception as exc:
|
| 218 |
+
logger.error(f"settle_permissions failed: {exc}")
|
| 219 |
+
self._record_transaction(
|
| 220 |
+
tx_type="settle",
|
| 221 |
+
agent_id=agent_id or NVM_AGENT_ID,
|
| 222 |
+
plan_id=plan_id or NVM_PLAN_ID,
|
| 223 |
+
credits=0,
|
| 224 |
+
success=False,
|
| 225 |
+
error=str(exc),
|
| 226 |
+
details={"endpoint": endpoint},
|
| 227 |
+
)
|
| 228 |
+
return False
|
| 229 |
+
|
| 230 |
+
# ── Client/agent side: order + token ──────────────────────────────────────
|
| 231 |
+
def order_plan(self, plan_id: str) -> bool:
|
| 232 |
+
"""
|
| 233 |
+
Subscribe to a payment plan (purchase credits).
|
| 234 |
+
|
| 235 |
+
Returns:
|
| 236 |
+
True if order succeeded.
|
| 237 |
+
"""
|
| 238 |
+
if not self.available:
|
| 239 |
+
return False
|
| 240 |
+
try:
|
| 241 |
+
result = self._payments.plans.order_plan(plan_id)
|
| 242 |
+
self._record_transaction(
|
| 243 |
+
tx_type="order",
|
| 244 |
+
agent_id="self",
|
| 245 |
+
plan_id=plan_id,
|
| 246 |
+
credits=0,
|
| 247 |
+
success=True,
|
| 248 |
+
details=result,
|
| 249 |
+
)
|
| 250 |
+
logger.info(f"NVM plan ordered: {plan_id}")
|
| 251 |
+
return True
|
| 252 |
+
except Exception as exc:
|
| 253 |
+
logger.error(f"order_plan failed: {exc}")
|
| 254 |
+
return False
|
| 255 |
+
|
| 256 |
+
def get_access_token(
|
| 257 |
+
self,
|
| 258 |
+
plan_id: str,
|
| 259 |
+
agent_id: Optional[str] = None,
|
| 260 |
+
) -> Optional[str]:
|
| 261 |
+
"""
|
| 262 |
+
Generate an x402 access token for a purchased plan.
|
| 263 |
+
|
| 264 |
+
Returns:
|
| 265 |
+
The access token string, or None on failure.
|
| 266 |
+
"""
|
| 267 |
+
if not self.available:
|
| 268 |
+
return None
|
| 269 |
+
try:
|
| 270 |
+
result = self._payments.x402.get_x402_access_token(
|
| 271 |
+
plan_id=plan_id,
|
| 272 |
+
agent_id=agent_id or NVM_AGENT_ID,
|
| 273 |
+
)
|
| 274 |
+
token = result.get("accessToken") or result.get("access_token")
|
| 275 |
+
self._record_transaction(
|
| 276 |
+
tx_type="token",
|
| 277 |
+
agent_id=agent_id or NVM_AGENT_ID,
|
| 278 |
+
plan_id=plan_id,
|
| 279 |
+
credits=0,
|
| 280 |
+
success=bool(token),
|
| 281 |
+
)
|
| 282 |
+
return token
|
| 283 |
+
except Exception as exc:
|
| 284 |
+
logger.error(f"get_x402_access_token failed: {exc}")
|
| 285 |
+
return None
|
| 286 |
+
|
| 287 |
+
def get_plan_balance(self, plan_id: str) -> Optional[Dict[str, Any]]:
|
| 288 |
+
"""Return the current credit balance for a plan."""
|
| 289 |
+
if not self.available:
|
| 290 |
+
return None
|
| 291 |
+
try:
|
| 292 |
+
return self._payments.plans.get_plan_balance(plan_id)
|
| 293 |
+
except Exception as exc:
|
| 294 |
+
logger.error(f"get_plan_balance failed: {exc}")
|
| 295 |
+
return None
|
| 296 |
+
|
| 297 |
+
# ── Transaction history ────────────────────────────────────────────────────
|
| 298 |
+
def _record_transaction(self, **kwargs):
|
| 299 |
+
import uuid
|
| 300 |
+
tx = NvmTransaction(
|
| 301 |
+
tx_id=str(uuid.uuid4()),
|
| 302 |
+
**kwargs,
|
| 303 |
+
)
|
| 304 |
+
self._transactions.append(tx)
|
| 305 |
+
# Keep last 500 transactions in memory
|
| 306 |
+
if len(self._transactions) > 500:
|
| 307 |
+
self._transactions = self._transactions[-500:]
|
| 308 |
+
|
| 309 |
+
def get_transactions(self, limit: int = 50) -> List[Dict[str, Any]]:
|
| 310 |
+
"""Return recent NVM transactions for dashboard display."""
|
| 311 |
+
txs = self._transactions[-limit:]
|
| 312 |
+
return [
|
| 313 |
+
{
|
| 314 |
+
"tx_id": t.tx_id,
|
| 315 |
+
"type": t.tx_type,
|
| 316 |
+
"agent_id": t.agent_id,
|
| 317 |
+
"plan_id": t.plan_id,
|
| 318 |
+
"credits": t.credits,
|
| 319 |
+
"timestamp": t.timestamp,
|
| 320 |
+
"success": t.success,
|
| 321 |
+
"error": t.error,
|
| 322 |
+
"details": t.details,
|
| 323 |
+
}
|
| 324 |
+
for t in reversed(txs)
|
| 325 |
+
]
|
| 326 |
+
|
| 327 |
+
def get_status(self) -> Dict[str, Any]:
|
| 328 |
+
"""Return NVM integration status for health checks."""
|
| 329 |
+
return {
|
| 330 |
+
"available": self.available,
|
| 331 |
+
"environment": NVM_ENVIRONMENT,
|
| 332 |
+
"plan_id": NVM_PLAN_ID or None,
|
| 333 |
+
"agent_id": NVM_AGENT_ID or None,
|
| 334 |
+
"api_key_set": bool(NVM_API_KEY),
|
| 335 |
+
"transaction_count": len(self._transactions),
|
| 336 |
+
}
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
# ── Singleton ──────────────────────────────────────────────────────────────────
|
| 340 |
+
nvm_manager = NeverminedPaymentManager()
|
backend/economy/register_agent.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon — Nevermined Agent Registration Script
|
| 3 |
+
=================================================
|
| 4 |
+
Run this ONCE to register the ChessEcon chess analysis service in the
|
| 5 |
+
Nevermined marketplace. It creates:
|
| 6 |
+
1. A payment plan (credits-based, free for hackathon demo)
|
| 7 |
+
2. An agent entry pointing to the /api/chess/analyze endpoint
|
| 8 |
+
|
| 9 |
+
After running, copy the printed NVM_PLAN_ID and NVM_AGENT_ID into your .env.
|
| 10 |
+
|
| 11 |
+
Usage:
|
| 12 |
+
cd chessecon-v2
|
| 13 |
+
python -m backend.economy.register_agent
|
| 14 |
+
|
| 15 |
+
Environment variables required:
|
| 16 |
+
NVM_API_KEY — Your Nevermined API key (sandbox:xxx...)
|
| 17 |
+
CHESSECON_API_URL — Public URL of your ChessEcon backend
|
| 18 |
+
e.g. https://your-server.com or https://ngrok-url.ngrok.io
|
| 19 |
+
"""
|
| 20 |
+
from __future__ import annotations
|
| 21 |
+
|
| 22 |
+
import os
|
| 23 |
+
import sys
|
| 24 |
+
import logging
|
| 25 |
+
|
| 26 |
+
logging.basicConfig(level=logging.INFO, format="%(levelname )s: %(message)s")
|
| 27 |
+
logger = logging.getLogger(__name__)
|
| 28 |
+
|
| 29 |
+
# ── Config ─────────────────────────────────────────────────────────────────────
|
| 30 |
+
NVM_API_KEY = os.getenv("NVM_API_KEY", "")
|
| 31 |
+
NVM_ENVIRONMENT = os.getenv("NVM_ENVIRONMENT", "sandbox")
|
| 32 |
+
CHESSECON_API_URL = os.getenv("CHESSECON_API_URL", "https://chessecon.example.com" )
|
| 33 |
+
|
| 34 |
+
# Service description
|
| 35 |
+
SERVICE_NAME = "ChessEcon Chess Analysis"
|
| 36 |
+
SERVICE_DESCRIPTION = (
|
| 37 |
+
"Premium chess position analysis powered by Claude Opus 4.5. "
|
| 38 |
+
"Provides best-move recommendations, tactical threat assessment, "
|
| 39 |
+
"and strategic coaching for AI chess agents. "
|
| 40 |
+
"Part of the ChessEcon multi-agent chess economy — "
|
| 41 |
+
"agents earn money playing chess and spend it on coaching."
|
| 42 |
+
)
|
| 43 |
+
SERVICE_TAGS = ["chess", "ai", "coaching", "analysis", "game", "rl", "hackathon"]
|
| 44 |
+
|
| 45 |
+
# Plan: free credits for hackathon demo
|
| 46 |
+
# 1000 credits, 1 credit per request — free to subscribe
|
| 47 |
+
PLAN_NAME = "ChessEcon Coaching Plan (Hackathon)"
|
| 48 |
+
PLAN_DESCRIPTION = (
|
| 49 |
+
"1000 free credits for chess position analysis. "
|
| 50 |
+
"Each analysis request costs 1 credit. "
|
| 51 |
+
"Subscribe to access the ChessEcon coaching endpoint."
|
| 52 |
+
)
|
| 53 |
+
CREDITS_GRANTED = 1000
|
| 54 |
+
CREDITS_PER_REQUEST = 1
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def register():
|
| 58 |
+
"""Register ChessEcon as a paid agent service in Nevermined."""
|
| 59 |
+
if not NVM_API_KEY:
|
| 60 |
+
logger.error(
|
| 61 |
+
"NVM_API_KEY is not set. "
|
| 62 |
+
"Get your key at https://nevermined.app and set it in .env"
|
| 63 |
+
)
|
| 64 |
+
sys.exit(1)
|
| 65 |
+
|
| 66 |
+
logger.info(f"Initializing Nevermined SDK (environment={NVM_ENVIRONMENT})")
|
| 67 |
+
|
| 68 |
+
try:
|
| 69 |
+
from payments_py import Payments, PaymentOptions
|
| 70 |
+
from payments_py.common.types import AgentMetadata, AgentAPIAttributes, PlanMetadata, Endpoint
|
| 71 |
+
from payments_py.plans import get_free_price_config, get_fixed_credits_config
|
| 72 |
+
except ImportError:
|
| 73 |
+
logger.error("payments-py not installed. Run: pip install payments-py")
|
| 74 |
+
sys.exit(1)
|
| 75 |
+
|
| 76 |
+
payments = Payments.get_instance(
|
| 77 |
+
PaymentOptions(
|
| 78 |
+
nvm_api_key=NVM_API_KEY,
|
| 79 |
+
environment=NVM_ENVIRONMENT,
|
| 80 |
+
)
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
analyze_endpoint = f"{CHESSECON_API_URL}/api/chess/analyze"
|
| 84 |
+
openapi_url = f"{CHESSECON_API_URL}/openapi.json"
|
| 85 |
+
|
| 86 |
+
logger.info(f"Registering agent at: {analyze_endpoint}")
|
| 87 |
+
logger.info(f"OpenAPI spec: {openapi_url}")
|
| 88 |
+
|
| 89 |
+
try:
|
| 90 |
+
result = payments.agents.register_agent_and_plan(
|
| 91 |
+
agent_metadata=AgentMetadata(
|
| 92 |
+
name=SERVICE_NAME,
|
| 93 |
+
description=SERVICE_DESCRIPTION,
|
| 94 |
+
tags=SERVICE_TAGS,
|
| 95 |
+
),
|
| 96 |
+
agent_api=AgentAPIAttributes(
|
| 97 |
+
endpoints=[Endpoint(verb="POST", url=analyze_endpoint)],
|
| 98 |
+
open_endpoints=[f"{CHESSECON_API_URL}/health"],
|
| 99 |
+
agent_definition_url=openapi_url,
|
| 100 |
+
),
|
| 101 |
+
plan_metadata=PlanMetadata(
|
| 102 |
+
name=PLAN_NAME,
|
| 103 |
+
description=PLAN_DESCRIPTION,
|
| 104 |
+
),
|
| 105 |
+
price_config=get_free_price_config(),
|
| 106 |
+
credits_config=get_fixed_credits_config(
|
| 107 |
+
credits_granted=CREDITS_GRANTED,
|
| 108 |
+
credits_per_request=CREDITS_PER_REQUEST,
|
| 109 |
+
),
|
| 110 |
+
access_limit="credits",
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
agent_id = result.get("agentId", "")
|
| 114 |
+
plan_id = result.get("planId", "")
|
| 115 |
+
|
| 116 |
+
print("\n" + "=" * 60)
|
| 117 |
+
print("✅ ChessEcon registered on Nevermined!")
|
| 118 |
+
print("=" * 60)
|
| 119 |
+
print(f" NVM_AGENT_ID = {agent_id}")
|
| 120 |
+
print(f" NVM_PLAN_ID = {plan_id}")
|
| 121 |
+
print("=" * 60)
|
| 122 |
+
print("\nAdd these to your .env file:")
|
| 123 |
+
print(f" NVM_AGENT_ID={agent_id}")
|
| 124 |
+
print(f" NVM_PLAN_ID={plan_id}")
|
| 125 |
+
print("\nMarketplace URL:")
|
| 126 |
+
print(f" https://nevermined.app/en/subscription/{plan_id}" )
|
| 127 |
+
print("=" * 60 + "\n")
|
| 128 |
+
|
| 129 |
+
return agent_id, plan_id
|
| 130 |
+
|
| 131 |
+
except Exception as exc:
|
| 132 |
+
logger.error(f"Registration failed: {exc}")
|
| 133 |
+
raise
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
if __name__ == "__main__":
|
| 137 |
+
register()
|
| 138 |
+
|
backend/grpo_trainer.py
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
grpo_trainer.py
|
| 3 |
+
───────────────
|
| 4 |
+
Group Relative Policy Optimisation (GRPO) training loop for the chess agent.
|
| 5 |
+
|
| 6 |
+
Algorithm summary (per game batch):
|
| 7 |
+
1. Collect a group of G candidate moves per position (sampled from the policy).
|
| 8 |
+
2. Compute advantages: A_i = (r_i - mean(r)) / (std(r) + ε)
|
| 9 |
+
where r_i is the terminal game reward for the trajectory that chose move i.
|
| 10 |
+
3. Compute the GRPO policy loss:
|
| 11 |
+
L = -E[ min(ratio * A, clip(ratio, 1-ε, 1+ε) * A) ]
|
| 12 |
+
where ratio = exp(log_π_θ(a) - log_π_old(a))
|
| 13 |
+
4. Add KL penalty: L_total = L + β * KL(π_θ || π_ref)
|
| 14 |
+
5. Backprop and update the model weights.
|
| 15 |
+
|
| 16 |
+
In practice, for a single-agent chess game:
|
| 17 |
+
- Each move in the game is a "step" with a delayed terminal reward.
|
| 18 |
+
- The group is formed by sampling G moves at each position and running
|
| 19 |
+
mini-rollouts (or approximating with the final game outcome).
|
| 20 |
+
- For simplicity we use the full game outcome as the reward for every
|
| 21 |
+
move in the game (REINFORCE-style with GRPO normalisation).
|
| 22 |
+
|
| 23 |
+
References:
|
| 24 |
+
DeepSeek-R1 GRPO: https://arxiv.org/abs/2501.12599
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
import os
|
| 28 |
+
import logging
|
| 29 |
+
import torch
|
| 30 |
+
import torch.nn.functional as F
|
| 31 |
+
from dataclasses import dataclass, field
|
| 32 |
+
from typing import Optional
|
| 33 |
+
|
| 34 |
+
from settings import settings
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@dataclass
|
| 40 |
+
class Trajectory:
|
| 41 |
+
"""One complete game trajectory collected for training."""
|
| 42 |
+
agent_color: str
|
| 43 |
+
log_probs: list[float] # log π_θ(a_t | s_t) for each move
|
| 44 |
+
ref_log_probs: list[float] # log π_ref(a_t | s_t) for KL
|
| 45 |
+
reward: float # terminal reward (+1 win, -1 loss, 0 draw)
|
| 46 |
+
move_count: int = 0
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
@dataclass
|
| 50 |
+
class TrainingMetrics:
|
| 51 |
+
step: int = 0
|
| 52 |
+
loss: float = 0.0
|
| 53 |
+
policy_reward: float = 0.0
|
| 54 |
+
kl_div: float = 0.0
|
| 55 |
+
win_rate: float = 0.0
|
| 56 |
+
avg_profit: float = 0.0
|
| 57 |
+
coaching_rate: float = 0.0
|
| 58 |
+
# Running stats
|
| 59 |
+
wins: int = 0
|
| 60 |
+
games: int = 0
|
| 61 |
+
total_profit: float = 0.0
|
| 62 |
+
total_coaching_calls: int = 0
|
| 63 |
+
total_moves: int = 0
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class GRPOTrainer:
|
| 67 |
+
"""
|
| 68 |
+
Manages the GRPO training loop for the Qwen chess agent.
|
| 69 |
+
|
| 70 |
+
Usage:
|
| 71 |
+
trainer = GRPOTrainer(model, tokenizer)
|
| 72 |
+
trainer.record_move(log_prob, ref_log_prob)
|
| 73 |
+
...
|
| 74 |
+
metrics = trainer.end_game(reward, profit, coaching_calls)
|
| 75 |
+
# metrics is None until grpo_update_every_n_games games have been collected
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
def __init__(self, model, tokenizer):
|
| 79 |
+
self.model = model
|
| 80 |
+
self.tokenizer = tokenizer
|
| 81 |
+
self._step = 0
|
| 82 |
+
self._pending: list[Trajectory] = []
|
| 83 |
+
self._current: Optional[Trajectory] = None
|
| 84 |
+
self._metrics = TrainingMetrics()
|
| 85 |
+
|
| 86 |
+
# Optimizer — only update LoRA params if present, else all params
|
| 87 |
+
trainable = [p for p in model.parameters() if p.requires_grad]
|
| 88 |
+
if not trainable:
|
| 89 |
+
logger.warning("No trainable parameters found — GRPO updates will be no-ops.")
|
| 90 |
+
self._optimizer = torch.optim.AdamW(trainable, lr=settings.grpo_lr) if trainable else None
|
| 91 |
+
|
| 92 |
+
# ── Game lifecycle ────────────────────────────────────────────────────
|
| 93 |
+
|
| 94 |
+
def start_game(self, agent_color: str):
|
| 95 |
+
"""Call at the start of each game."""
|
| 96 |
+
self._current = Trajectory(agent_color=agent_color, log_probs=[], ref_log_probs=[], reward=0.0)
|
| 97 |
+
|
| 98 |
+
def record_move(self, log_prob: float, ref_log_prob: float):
|
| 99 |
+
"""Call after each move with the policy and reference log-probs."""
|
| 100 |
+
if self._current is None:
|
| 101 |
+
return
|
| 102 |
+
self._current.log_probs.append(log_prob)
|
| 103 |
+
self._current.ref_log_probs.append(ref_log_prob)
|
| 104 |
+
self._current.move_count += 1
|
| 105 |
+
|
| 106 |
+
def end_game(
|
| 107 |
+
self,
|
| 108 |
+
reward: float,
|
| 109 |
+
profit: float = 0.0,
|
| 110 |
+
coaching_calls: int = 0,
|
| 111 |
+
) -> Optional[TrainingMetrics]:
|
| 112 |
+
"""
|
| 113 |
+
Call at game end with the terminal reward.
|
| 114 |
+
Returns updated TrainingMetrics if a gradient update was performed,
|
| 115 |
+
else None (still accumulating games).
|
| 116 |
+
"""
|
| 117 |
+
if self._current is None:
|
| 118 |
+
return None
|
| 119 |
+
|
| 120 |
+
self._current.reward = reward
|
| 121 |
+
self._pending.append(self._current)
|
| 122 |
+
self._current = None
|
| 123 |
+
|
| 124 |
+
# Update running stats
|
| 125 |
+
m = self._metrics
|
| 126 |
+
m.games += 1
|
| 127 |
+
if reward > 0:
|
| 128 |
+
m.wins += 1
|
| 129 |
+
m.total_profit += profit
|
| 130 |
+
m.total_coaching_calls += coaching_calls
|
| 131 |
+
m.total_moves += self._pending[-1].move_count
|
| 132 |
+
|
| 133 |
+
# Trigger update every N games
|
| 134 |
+
if m.games % settings.grpo_update_every_n_games == 0:
|
| 135 |
+
return self._update()
|
| 136 |
+
|
| 137 |
+
return None
|
| 138 |
+
|
| 139 |
+
# ── GRPO update ───────────────────────────────────────────────────────
|
| 140 |
+
|
| 141 |
+
def _update(self) -> TrainingMetrics:
|
| 142 |
+
"""Perform one GRPO gradient update over the pending trajectories."""
|
| 143 |
+
if self._optimizer is None or not self._pending:
|
| 144 |
+
return self._build_metrics()
|
| 145 |
+
|
| 146 |
+
trajectories = self._pending
|
| 147 |
+
self._pending = []
|
| 148 |
+
|
| 149 |
+
# Collect rewards and compute advantages (GRPO normalisation)
|
| 150 |
+
rewards = torch.tensor([t.reward for t in trajectories], dtype=torch.float32)
|
| 151 |
+
mean_r = rewards.mean()
|
| 152 |
+
std_r = rewards.std(unbiased=False) + 1e-8 # unbiased=False avoids nan for N=1
|
| 153 |
+
if std_r < 1e-6:
|
| 154 |
+
advantages = rewards - mean_r
|
| 155 |
+
else:
|
| 156 |
+
advantages = (rewards - mean_r) / std_r # shape: (N,)
|
| 157 |
+
|
| 158 |
+
total_loss = torch.tensor(0.0, requires_grad=True)
|
| 159 |
+
total_kl = 0.0
|
| 160 |
+
n_tokens = 0
|
| 161 |
+
|
| 162 |
+
for traj, adv in zip(trajectories, advantages):
|
| 163 |
+
if not traj.log_probs:
|
| 164 |
+
continue
|
| 165 |
+
|
| 166 |
+
lp = torch.tensor(traj.log_probs, dtype=torch.float32) # (T,)
|
| 167 |
+
ref_lp = torch.tensor(traj.ref_log_probs, dtype=torch.float32) # (T,)
|
| 168 |
+
|
| 169 |
+
# Ratio: π_θ / π_old (here π_old == π_ref since we update every game)
|
| 170 |
+
ratio = torch.exp(lp - ref_lp)
|
| 171 |
+
|
| 172 |
+
# Clipped surrogate loss (PPO-style clip)
|
| 173 |
+
eps = 0.2
|
| 174 |
+
clipped = torch.clamp(ratio, 1 - eps, 1 + eps)
|
| 175 |
+
surrogate = torch.min(ratio * adv, clipped * adv)
|
| 176 |
+
policy_loss = -surrogate.mean()
|
| 177 |
+
|
| 178 |
+
# KL penalty: KL(π_θ || π_ref) ≈ exp(lp - ref_lp) - (lp - ref_lp) - 1
|
| 179 |
+
diff = torch.clamp(lp - ref_lp, -10, 10) # prevent KL explosion
|
| 180 |
+
kl = (torch.exp(diff) - diff - 1).mean()
|
| 181 |
+
total_kl += kl.item()
|
| 182 |
+
|
| 183 |
+
step_loss = policy_loss + settings.grpo_kl_coeff * kl
|
| 184 |
+
total_loss = total_loss + step_loss
|
| 185 |
+
n_tokens += len(traj.log_probs)
|
| 186 |
+
|
| 187 |
+
if n_tokens > 0:
|
| 188 |
+
total_loss = total_loss / len(trajectories)
|
| 189 |
+
self._optimizer.zero_grad()
|
| 190 |
+
total_loss.backward()
|
| 191 |
+
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
|
| 192 |
+
self._optimizer.step()
|
| 193 |
+
|
| 194 |
+
self._step += 1
|
| 195 |
+
|
| 196 |
+
# Save checkpoint periodically
|
| 197 |
+
if self._step % settings.save_every_n_steps == 0:
|
| 198 |
+
self._save_checkpoint()
|
| 199 |
+
|
| 200 |
+
# Update metrics
|
| 201 |
+
m = self._metrics
|
| 202 |
+
m.step = self._step
|
| 203 |
+
m.loss = total_loss.item() if n_tokens > 0 else 0.0
|
| 204 |
+
m.policy_reward = float(rewards.mean())
|
| 205 |
+
m.kl_div = total_kl / max(len(trajectories), 1)
|
| 206 |
+
m.win_rate = m.wins / max(m.games, 1)
|
| 207 |
+
m.avg_profit = m.total_profit / max(m.games, 1)
|
| 208 |
+
m.coaching_rate = m.total_coaching_calls / max(m.total_moves, 1)
|
| 209 |
+
|
| 210 |
+
logger.info(
|
| 211 |
+
"GRPO step %d | loss=%.4f reward=%.3f kl=%.4f win_rate=%.2f",
|
| 212 |
+
m.step, m.loss, m.policy_reward, m.kl_div, m.win_rate,
|
| 213 |
+
)
|
| 214 |
+
return self._build_metrics()
|
| 215 |
+
|
| 216 |
+
def _build_metrics(self) -> TrainingMetrics:
|
| 217 |
+
import copy
|
| 218 |
+
return copy.copy(self._metrics)
|
| 219 |
+
|
| 220 |
+
# ── Checkpoint ────────────────────────────────────────────────────────
|
| 221 |
+
|
| 222 |
+
def _save_checkpoint(self):
|
| 223 |
+
os.makedirs(settings.checkpoint_dir, exist_ok=True)
|
| 224 |
+
path = os.path.join(settings.checkpoint_dir, f"step_{self._step:06d}")
|
| 225 |
+
try:
|
| 226 |
+
self.model.save_pretrained(path)
|
| 227 |
+
self.tokenizer.save_pretrained(path)
|
| 228 |
+
logger.info("Checkpoint saved: %s", path)
|
| 229 |
+
except Exception as exc:
|
| 230 |
+
logger.error("Checkpoint save failed: %s", exc)
|
| 231 |
+
|
| 232 |
+
def load_checkpoint(self, path: str):
|
| 233 |
+
"""Load a previously saved LoRA checkpoint."""
|
| 234 |
+
try:
|
| 235 |
+
from peft import PeftModel # type: ignore
|
| 236 |
+
self.model = PeftModel.from_pretrained(self.model, path)
|
| 237 |
+
logger.info("Checkpoint loaded: %s", path)
|
| 238 |
+
except Exception as exc:
|
| 239 |
+
logger.error("Checkpoint load failed: %s", exc)
|
| 240 |
+
|
backend/main.py
ADDED
|
@@ -0,0 +1,313 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — FastAPI Application
|
| 3 |
+
Serves the chess game API, WebSocket event stream, and the built React frontend.
|
| 4 |
+
"""
|
| 5 |
+
from __future__ import annotations
|
| 6 |
+
import os
|
| 7 |
+
import asyncio
|
| 8 |
+
import json
|
| 9 |
+
import logging
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from contextlib import asynccontextmanager
|
| 12 |
+
|
| 13 |
+
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
|
| 14 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 15 |
+
from fastapi.staticfiles import StaticFiles
|
| 16 |
+
from fastapi.responses import FileResponse, JSONResponse
|
| 17 |
+
|
| 18 |
+
from backend.api.game_router import router as game_router
|
| 19 |
+
from backend.api.training_router import router as training_router
|
| 20 |
+
from backend.api.websocket import ws_manager
|
| 21 |
+
from backend.agents.qwen_agent import QwenAgent
|
| 22 |
+
from backend.agents.grpo_trainer import GRPOTrainer
|
| 23 |
+
from backend.chess_lib.chess_engine import ChessEngine
|
| 24 |
+
from backend.settings import settings
|
| 25 |
+
|
| 26 |
+
# ── Logging ───────────────────────────────────────────────────────────────────
|
| 27 |
+
logging.basicConfig(
|
| 28 |
+
level=os.getenv("LOG_LEVEL", "info").upper(),
|
| 29 |
+
format="%(asctime)s [%(levelname)s] %(name)s: %(message)s",
|
| 30 |
+
)
|
| 31 |
+
logger = logging.getLogger(__name__)
|
| 32 |
+
|
| 33 |
+
# ── Static frontend path ──────────────────────────────────────────────────────
|
| 34 |
+
FRONTEND_DIST = Path(__file__).parent / "static"
|
| 35 |
+
|
| 36 |
+
# ── Live game snapshot (sent to late-joining clients) ────────────────────────
|
| 37 |
+
# Updated by game_loop; read by websocket_endpoint on new connections.
|
| 38 |
+
game_snapshot: dict = {}
|
| 39 |
+
|
| 40 |
+
# ── Game loop (runs as a background task) ─────────────────────────────────────
|
| 41 |
+
async def game_loop():
|
| 42 |
+
white = QwenAgent()
|
| 43 |
+
black = QwenAgent()
|
| 44 |
+
from backend.agents.qwen_agent import _load_model
|
| 45 |
+
tokenizer, model = _load_model()
|
| 46 |
+
trainer = GRPOTrainer(model, tokenizer)
|
| 47 |
+
game_num = 0
|
| 48 |
+
# Wallets persist across games — agents earn/lose money each game
|
| 49 |
+
wallet_white = settings.starting_wallet
|
| 50 |
+
wallet_black = settings.starting_wallet
|
| 51 |
+
|
| 52 |
+
while True:
|
| 53 |
+
engine = ChessEngine()
|
| 54 |
+
move_history: list[str] = []
|
| 55 |
+
game_num += 1
|
| 56 |
+
|
| 57 |
+
# Deduct entry fees at the start of each game
|
| 58 |
+
wallet_white -= settings.entry_fee
|
| 59 |
+
wallet_black -= settings.entry_fee
|
| 60 |
+
|
| 61 |
+
# Update snapshot so late-joining clients can sync
|
| 62 |
+
game_snapshot.update({
|
| 63 |
+
"type": "game_start",
|
| 64 |
+
"game_num": game_num,
|
| 65 |
+
"wallet_white": wallet_white,
|
| 66 |
+
"wallet_black": wallet_black,
|
| 67 |
+
"fen": "rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1",
|
| 68 |
+
"move_number": 0,
|
| 69 |
+
"grpo_step": 0,
|
| 70 |
+
"games_completed": game_num - 1,
|
| 71 |
+
})
|
| 72 |
+
|
| 73 |
+
await ws_manager.broadcast_raw({
|
| 74 |
+
"type": "game_start",
|
| 75 |
+
"data": {
|
| 76 |
+
"game": game_num,
|
| 77 |
+
"game_id": game_num,
|
| 78 |
+
"wallet_white": wallet_white,
|
| 79 |
+
"wallet_black": wallet_black,
|
| 80 |
+
},
|
| 81 |
+
})
|
| 82 |
+
|
| 83 |
+
trainer.start_game("white")
|
| 84 |
+
|
| 85 |
+
while not engine.is_game_over:
|
| 86 |
+
color = engine.turn
|
| 87 |
+
agent = white if color == "white" else black
|
| 88 |
+
|
| 89 |
+
# get_move returns (san, log_prob)
|
| 90 |
+
san, log_prob = agent.get_move(engine, color, move_history)
|
| 91 |
+
|
| 92 |
+
# get reference log prob for GRPO KL term
|
| 93 |
+
ref_log_prob = agent.get_move_log_prob_only(engine, color, move_history, san)
|
| 94 |
+
|
| 95 |
+
# apply the move
|
| 96 |
+
uci = engine.apply_move_san(san)
|
| 97 |
+
if uci is None:
|
| 98 |
+
# fallback: random legal move
|
| 99 |
+
san = engine.random_legal_move_san()
|
| 100 |
+
uci = engine.apply_move_san(san) or ""
|
| 101 |
+
log_prob = -1.0
|
| 102 |
+
ref_log_prob = -1.0
|
| 103 |
+
|
| 104 |
+
move_history.append(san)
|
| 105 |
+
trainer.record_move(log_prob, ref_log_prob)
|
| 106 |
+
|
| 107 |
+
# Keep snapshot current so late joiners see the live position
|
| 108 |
+
game_snapshot.update({
|
| 109 |
+
"fen": engine.fen,
|
| 110 |
+
"move_number": engine.move_number,
|
| 111 |
+
"wallet_white": wallet_white,
|
| 112 |
+
"wallet_black": wallet_black,
|
| 113 |
+
})
|
| 114 |
+
|
| 115 |
+
await ws_manager.broadcast_raw({
|
| 116 |
+
"type": "move",
|
| 117 |
+
"data": {
|
| 118 |
+
"player": color,
|
| 119 |
+
"uci": uci or "",
|
| 120 |
+
"move": san,
|
| 121 |
+
"fen": engine.fen,
|
| 122 |
+
"turn": engine.turn,
|
| 123 |
+
"move_number": engine.move_number,
|
| 124 |
+
"wallet_white": wallet_white,
|
| 125 |
+
"wallet_black": wallet_black,
|
| 126 |
+
"log_prob": log_prob,
|
| 127 |
+
"message": f"{color} plays {san}",
|
| 128 |
+
},
|
| 129 |
+
})
|
| 130 |
+
await asyncio.sleep(settings.move_delay)
|
| 131 |
+
|
| 132 |
+
result = engine.result
|
| 133 |
+
reward_w = engine.compute_reward("white")
|
| 134 |
+
reward_b = engine.compute_reward("black")
|
| 135 |
+
|
| 136 |
+
# Award prize money: winner gets 2x entry fee, draw splits the pot
|
| 137 |
+
prize_pool = settings.entry_fee * 2
|
| 138 |
+
if reward_w > 0: # white wins
|
| 139 |
+
prize_white = prize_pool
|
| 140 |
+
prize_black = 0.0
|
| 141 |
+
elif reward_b > 0: # black wins
|
| 142 |
+
prize_white = 0.0
|
| 143 |
+
prize_black = prize_pool
|
| 144 |
+
else: # draw — split pot
|
| 145 |
+
prize_white = prize_pool / 2
|
| 146 |
+
prize_black = prize_pool / 2
|
| 147 |
+
|
| 148 |
+
wallet_white += prize_white
|
| 149 |
+
wallet_black += prize_black
|
| 150 |
+
|
| 151 |
+
metrics = trainer.end_game(
|
| 152 |
+
reward=reward_w,
|
| 153 |
+
profit=prize_white - settings.entry_fee,
|
| 154 |
+
coaching_calls=0,
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
net_pnl_white = prize_white - settings.entry_fee
|
| 158 |
+
|
| 159 |
+
# Update snapshot with post-game wallet values
|
| 160 |
+
game_snapshot.update({
|
| 161 |
+
"type": "between_games",
|
| 162 |
+
"wallet_white": wallet_white,
|
| 163 |
+
"wallet_black": wallet_black,
|
| 164 |
+
"games_completed": game_num,
|
| 165 |
+
"grpo_step": (metrics or trainer._metrics).step,
|
| 166 |
+
})
|
| 167 |
+
|
| 168 |
+
await ws_manager.broadcast_raw({
|
| 169 |
+
"type": "game_end",
|
| 170 |
+
"data": {
|
| 171 |
+
"game": game_num,
|
| 172 |
+
"game_id": game_num,
|
| 173 |
+
"result": result,
|
| 174 |
+
"reward": reward_w,
|
| 175 |
+
"reward_white": reward_w,
|
| 176 |
+
"reward_black": reward_b,
|
| 177 |
+
"wallet_white": wallet_white,
|
| 178 |
+
"wallet_black": wallet_black,
|
| 179 |
+
"net_pnl_white": net_pnl_white,
|
| 180 |
+
"prize_income": prize_white,
|
| 181 |
+
"coaching_cost": 0.0,
|
| 182 |
+
"entry_fee": settings.entry_fee,
|
| 183 |
+
"grpo_loss": metrics.loss if metrics else None,
|
| 184 |
+
"win_rate": metrics.win_rate if metrics else None,
|
| 185 |
+
"kl_divergence": metrics.kl_div if metrics else None,
|
| 186 |
+
"avg_profit": metrics.avg_profit if metrics else None,
|
| 187 |
+
"grpo_step": metrics.step if metrics else 0,
|
| 188 |
+
},
|
| 189 |
+
})
|
| 190 |
+
|
| 191 |
+
# Always emit a training_step event so the GRPO charts update
|
| 192 |
+
# even when end_game returns None (not every game triggers an update)
|
| 193 |
+
current_metrics = metrics or trainer._metrics
|
| 194 |
+
await ws_manager.broadcast_raw({
|
| 195 |
+
"type": "training_step",
|
| 196 |
+
"data": {
|
| 197 |
+
"step": current_metrics.step,
|
| 198 |
+
"loss": current_metrics.loss,
|
| 199 |
+
"reward": reward_w,
|
| 200 |
+
"kl_div": current_metrics.kl_div,
|
| 201 |
+
"win_rate": current_metrics.win_rate,
|
| 202 |
+
"avg_profit": current_metrics.avg_profit,
|
| 203 |
+
"coaching_rate": 0.0,
|
| 204 |
+
"games": current_metrics.games,
|
| 205 |
+
},
|
| 206 |
+
})
|
| 207 |
+
|
| 208 |
+
await asyncio.sleep(settings.move_delay * 4)
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
@asynccontextmanager
|
| 212 |
+
async def lifespan(app: FastAPI):
|
| 213 |
+
logger.info("ChessEcon backend starting up")
|
| 214 |
+
logger.info(f"Frontend dist: {FRONTEND_DIST} (exists: {FRONTEND_DIST.exists()})")
|
| 215 |
+
logger.info(f"Claude Coach: {'enabled' if os.getenv('ANTHROPIC_API_KEY') else 'disabled (no API key)'}")
|
| 216 |
+
logger.info(f"HuggingFace token: {'set' if os.getenv('HF_TOKEN') else 'not set'}")
|
| 217 |
+
asyncio.create_task(game_loop())
|
| 218 |
+
yield
|
| 219 |
+
logger.info("ChessEcon backend shutting down")
|
| 220 |
+
|
| 221 |
+
# ── FastAPI app ───────────────────────────────────────────────────────────────
|
| 222 |
+
app = FastAPI(
|
| 223 |
+
title="ChessEcon API",
|
| 224 |
+
description="Multi-Agent Chess Economy — Backend API",
|
| 225 |
+
version="2.0.0",
|
| 226 |
+
lifespan=lifespan,
|
| 227 |
+
)
|
| 228 |
+
|
| 229 |
+
app.add_middleware(
|
| 230 |
+
CORSMiddleware,
|
| 231 |
+
allow_origins=["*"],
|
| 232 |
+
allow_credentials=True,
|
| 233 |
+
allow_methods=["*"],
|
| 234 |
+
allow_headers=["*"],
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
# ── API routes ────────────────────────────────────────────────────────────────
|
| 238 |
+
app.include_router(game_router)
|
| 239 |
+
app.include_router(training_router)
|
| 240 |
+
|
| 241 |
+
# ── WebSocket endpoint ──────────────────────────────────────────────────────
|
| 242 |
+
@app.websocket("/ws")
|
| 243 |
+
async def websocket_endpoint(ws: WebSocket):
|
| 244 |
+
await ws_manager.connect(ws)
|
| 245 |
+
# Send current game state to the newly connected client
|
| 246 |
+
if game_snapshot:
|
| 247 |
+
snap = game_snapshot.copy()
|
| 248 |
+
await ws.send_text(json.dumps({
|
| 249 |
+
"type": "status",
|
| 250 |
+
"timestamp": __import__('time').time(),
|
| 251 |
+
"data": snap,
|
| 252 |
+
}))
|
| 253 |
+
try:
|
| 254 |
+
while True:
|
| 255 |
+
data = await ws.receive_text()
|
| 256 |
+
try:
|
| 257 |
+
msg = json.loads(data)
|
| 258 |
+
action = msg.get("action")
|
| 259 |
+
if action == "ping":
|
| 260 |
+
await ws.send_text(json.dumps({"type": "pong"}))
|
| 261 |
+
elif action == "start_game":
|
| 262 |
+
pass # game_loop auto-starts from lifespan
|
| 263 |
+
elif action == "stop_game":
|
| 264 |
+
pass # games stop after current game ends
|
| 265 |
+
except json.JSONDecodeError:
|
| 266 |
+
pass
|
| 267 |
+
except WebSocketDisconnect:
|
| 268 |
+
await ws_manager.disconnect(ws)
|
| 269 |
+
|
| 270 |
+
# ── Health check ──────────────────────────────────────────────────────────────
|
| 271 |
+
@app.get("/health")
|
| 272 |
+
async def health():
|
| 273 |
+
return {
|
| 274 |
+
"status": "ok",
|
| 275 |
+
"service": "chessecon-backend",
|
| 276 |
+
"version": "2.0.0",
|
| 277 |
+
"ws_connections": ws_manager.connection_count,
|
| 278 |
+
"claude_available": bool(os.getenv("ANTHROPIC_API_KEY")),
|
| 279 |
+
"hf_token_set": bool(os.getenv("HF_TOKEN")),
|
| 280 |
+
}
|
| 281 |
+
|
| 282 |
+
@app.get("/api/config")
|
| 283 |
+
async def get_config():
|
| 284 |
+
return {
|
| 285 |
+
"entry_fee": float(os.getenv("ENTRY_FEE", "10.0")),
|
| 286 |
+
"initial_wallet": float(os.getenv("INITIAL_WALLET", "100.0")),
|
| 287 |
+
"coaching_fee": float(os.getenv("COACHING_FEE", "5.0")),
|
| 288 |
+
"player_model": os.getenv("PLAYER_MODEL", "Qwen/Qwen2.5-0.5B-Instruct"),
|
| 289 |
+
"claude_model": os.getenv("CLAUDE_MODEL", "claude-opus-4-5"),
|
| 290 |
+
"claude_available": bool(os.getenv("ANTHROPIC_API_KEY")),
|
| 291 |
+
"rl_method": os.getenv("RL_METHOD", "grpo"),
|
| 292 |
+
}
|
| 293 |
+
|
| 294 |
+
# ── Serve React frontend (SPA) ────────────────────────────────────────────────
|
| 295 |
+
if FRONTEND_DIST.exists():
|
| 296 |
+
app.mount("/assets", StaticFiles(directory=str(FRONTEND_DIST / "assets")), name="assets")
|
| 297 |
+
|
| 298 |
+
@app.get("/{full_path:path}")
|
| 299 |
+
async def serve_spa(full_path: str):
|
| 300 |
+
index = FRONTEND_DIST / "index.html"
|
| 301 |
+
if index.exists():
|
| 302 |
+
return FileResponse(str(index))
|
| 303 |
+
return JSONResponse({"error": "Frontend not built"}, status_code=503)
|
| 304 |
+
else:
|
| 305 |
+
@app.get("/")
|
| 306 |
+
async def root():
|
| 307 |
+
return {
|
| 308 |
+
"message": "ChessEcon API running. Frontend not built yet.",
|
| 309 |
+
"docs": "/docs",
|
| 310 |
+
"health": "/health",
|
| 311 |
+
}
|
| 312 |
+
# Patch already applied — see websocket_endpoint above
|
| 313 |
+
|
backend/main.py_backup
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ChessEcon Backend — FastAPI Application
|
| 3 |
+
Serves the chess game API, WebSocket event stream, and the built React frontend.
|
| 4 |
+
"""
|
| 5 |
+
from __future__ import annotations
|
| 6 |
+
import os
|
| 7 |
+
import asyncio
|
| 8 |
+
import json
|
| 9 |
+
import logging
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from contextlib import asynccontextmanager
|
| 12 |
+
|
| 13 |
+
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
|
| 14 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 15 |
+
from fastapi.staticfiles import StaticFiles
|
| 16 |
+
from fastapi.responses import FileResponse, JSONResponse
|
| 17 |
+
|
| 18 |
+
from backend.api.game_router import router as game_router
|
| 19 |
+
from backend.api.training_router import router as training_router
|
| 20 |
+
from backend.api.websocket import ws_manager
|
| 21 |
+
from backend.agents.qwen_agent import QwenAgent
|
| 22 |
+
from backend.agents.grpo_trainer import GRPOTrainer
|
| 23 |
+
from backend.chess.chess_engine import ChessEngine
|
| 24 |
+
from backend.settings import settings
|
| 25 |
+
|
| 26 |
+
# ── Logging ───────────────────────────────────────────────────────────────────
|
| 27 |
+
logging.basicConfig(
|
| 28 |
+
level=os.getenv("LOG_LEVEL", "info").upper(),
|
| 29 |
+
format="%(asctime)s [%(levelname)s] %(name)s: %(message)s",
|
| 30 |
+
)
|
| 31 |
+
logger = logging.getLogger(__name__)
|
| 32 |
+
|
| 33 |
+
# ── Static frontend path ──────────────────────────────────────────────────────
|
| 34 |
+
FRONTEND_DIST = Path(__file__).parent / "static"
|
| 35 |
+
|
| 36 |
+
# ── Game loop (runs as a background task) ─────────────────────────────────────
|
| 37 |
+
async def game_loop():
|
| 38 |
+
white = QwenAgent()
|
| 39 |
+
black = QwenAgent()
|
| 40 |
+
from backend.agents.qwen_agent import _load_model
|
| 41 |
+
tokenizer, model = _load_model()
|
| 42 |
+
trainer = GRPOTrainer(model, tokenizer)
|
| 43 |
+
game_num = 0
|
| 44 |
+
|
| 45 |
+
while True:
|
| 46 |
+
engine = ChessEngine()
|
| 47 |
+
move_history: list[str] = []
|
| 48 |
+
wallet_white = settings.starting_wallet
|
| 49 |
+
wallet_black = settings.starting_wallet
|
| 50 |
+
game_num += 1
|
| 51 |
+
|
| 52 |
+
await ws_manager.broadcast_raw({"type": "game_start", "data": {"game": game_num}})
|
| 53 |
+
|
| 54 |
+
trainer.start_game("white")
|
| 55 |
+
|
| 56 |
+
while not engine.is_game_over:
|
| 57 |
+
color = engine.turn
|
| 58 |
+
agent = white if color == "white" else black
|
| 59 |
+
|
| 60 |
+
# get_move returns (san, log_prob)
|
| 61 |
+
san, log_prob = agent.get_move(engine, color, move_history)
|
| 62 |
+
|
| 63 |
+
# get reference log prob for GRPO KL term
|
| 64 |
+
ref_log_prob = agent.get_move_log_prob_only(engine, color, move_history, san)
|
| 65 |
+
|
| 66 |
+
# apply the move
|
| 67 |
+
uci = engine.apply_move_san(san)
|
| 68 |
+
if uci is None:
|
| 69 |
+
# fallback: random legal move
|
| 70 |
+
san = engine.random_legal_move_san()
|
| 71 |
+
uci = engine.apply_move_san(san) or ""
|
| 72 |
+
log_prob = -1.0
|
| 73 |
+
ref_log_prob = -1.0
|
| 74 |
+
|
| 75 |
+
move_history.append(san)
|
| 76 |
+
trainer.record_move(log_prob, ref_log_prob)
|
| 77 |
+
|
| 78 |
+
await ws_manager.broadcast_raw({
|
| 79 |
+
"type": "move",
|
| 80 |
+
"data": {
|
| 81 |
+
"player": color,
|
| 82 |
+
"uci": uci or "",
|
| 83 |
+
"move": san,
|
| 84 |
+
"fen": engine.fen,
|
| 85 |
+
"turn": engine.turn,
|
| 86 |
+
"move_number": engine.move_number,
|
| 87 |
+
"wallet_white": wallet_white,
|
| 88 |
+
"wallet_black": wallet_black,
|
| 89 |
+
"log_prob": log_prob,
|
| 90 |
+
"message": f"{color} plays {san}",
|
| 91 |
+
},
|
| 92 |
+
})
|
| 93 |
+
await asyncio.sleep(settings.move_delay)
|
| 94 |
+
|
| 95 |
+
result = engine.result
|
| 96 |
+
reward_w = engine.compute_reward("white")
|
| 97 |
+
reward_b = engine.compute_reward("black")
|
| 98 |
+
|
| 99 |
+
metrics = trainer.end_game(
|
| 100 |
+
reward=reward_w,
|
| 101 |
+
profit=reward_w * 10.0,
|
| 102 |
+
coaching_calls=0,
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
await ws_manager.broadcast_raw({
|
| 106 |
+
"type": "game_end",
|
| 107 |
+
"data": {
|
| 108 |
+
"game": game_num,
|
| 109 |
+
"result": result,
|
| 110 |
+
"reward_white": reward_w,
|
| 111 |
+
"reward_black": reward_b,
|
| 112 |
+
"wallet_white": wallet_white,
|
| 113 |
+
"wallet_black": wallet_black,
|
| 114 |
+
"net_pnl_white": reward_w * 10.0,
|
| 115 |
+
"grpo_loss": metrics.loss if metrics else None,
|
| 116 |
+
"win_rate": metrics.win_rate if metrics else None,
|
| 117 |
+
"kl_divergence": metrics.kl_div if metrics else None,
|
| 118 |
+
"avg_profit": metrics.avg_profit if metrics else None,
|
| 119 |
+
"grpo_step": metrics.step if metrics else 0,
|
| 120 |
+
},
|
| 121 |
+
})
|
| 122 |
+
await asyncio.sleep(settings.move_delay * 4)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
@asynccontextmanager
|
| 126 |
+
async def lifespan(app: FastAPI):
|
| 127 |
+
logger.info("ChessEcon backend starting up")
|
| 128 |
+
logger.info(f"Frontend dist: {FRONTEND_DIST} (exists: {FRONTEND_DIST.exists()})")
|
| 129 |
+
logger.info(f"Claude Coach: {'enabled' if os.getenv('ANTHROPIC_API_KEY') else 'disabled (no API key)'}")
|
| 130 |
+
logger.info(f"HuggingFace token: {'set' if os.getenv('HF_TOKEN') else 'not set'}")
|
| 131 |
+
asyncio.create_task(game_loop())
|
| 132 |
+
yield
|
| 133 |
+
logger.info("ChessEcon backend shutting down")
|
| 134 |
+
|
| 135 |
+
# ── FastAPI app ───────────────────────────────────────────────────────────────
|
| 136 |
+
app = FastAPI(
|
| 137 |
+
title="ChessEcon API",
|
| 138 |
+
description="Multi-Agent Chess Economy — Backend API",
|
| 139 |
+
version="2.0.0",
|
| 140 |
+
lifespan=lifespan,
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
app.add_middleware(
|
| 144 |
+
CORSMiddleware,
|
| 145 |
+
allow_origins=["*"],
|
| 146 |
+
allow_credentials=True,
|
| 147 |
+
allow_methods=["*"],
|
| 148 |
+
allow_headers=["*"],
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
# ── API routes ────────────────────────────────────────────────────────────────
|
| 152 |
+
app.include_router(game_router)
|
| 153 |
+
app.include_router(training_router)
|
| 154 |
+
|
| 155 |
+
# ── WebSocket endpoint ────────────────────────────────────────────────────────
|
| 156 |
+
@app.websocket("/ws")
|
| 157 |
+
async def websocket_endpoint(ws: WebSocket):
|
| 158 |
+
await ws_manager.connect(ws)
|
| 159 |
+
try:
|
| 160 |
+
while True:
|
| 161 |
+
data = await ws.receive_text()
|
| 162 |
+
try:
|
| 163 |
+
msg = json.loads(data)
|
| 164 |
+
action = msg.get("action")
|
| 165 |
+
if action == "ping":
|
| 166 |
+
await ws.send_text(json.dumps({"type": "pong"}))
|
| 167 |
+
elif action == "start_game":
|
| 168 |
+
pass # game_loop auto-starts from lifespan
|
| 169 |
+
elif action == "stop_game":
|
| 170 |
+
pass # games stop after current game ends
|
| 171 |
+
except json.JSONDecodeError:
|
| 172 |
+
pass
|
| 173 |
+
except WebSocketDisconnect:
|
| 174 |
+
await ws_manager.disconnect(ws)
|
| 175 |
+
|
| 176 |
+
# ── Health check ──────────────────────────────────────────────────────────────
|
| 177 |
+
@app.get("/health")
|
| 178 |
+
async def health():
|
| 179 |
+
return {
|
| 180 |
+
"status": "ok",
|
| 181 |
+
"service": "chessecon-backend",
|
| 182 |
+
"version": "2.0.0",
|
| 183 |
+
"ws_connections": ws_manager.connection_count,
|
| 184 |
+
"claude_available": bool(os.getenv("ANTHROPIC_API_KEY")),
|
| 185 |
+
"hf_token_set": bool(os.getenv("HF_TOKEN")),
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
@app.get("/api/config")
|
| 189 |
+
async def get_config():
|
| 190 |
+
return {
|
| 191 |
+
"entry_fee": float(os.getenv("ENTRY_FEE", "10.0")),
|
| 192 |
+
"initial_wallet": float(os.getenv("INITIAL_WALLET", "100.0")),
|
| 193 |
+
"coaching_fee": float(os.getenv("COACHING_FEE", "5.0")),
|
| 194 |
+
"player_model": os.getenv("PLAYER_MODEL", "Qwen/Qwen2.5-0.5B-Instruct"),
|
| 195 |
+
"claude_model": os.getenv("CLAUDE_MODEL", "claude-opus-4-5"),
|
| 196 |
+
"claude_available": bool(os.getenv("ANTHROPIC_API_KEY")),
|
| 197 |
+
"rl_method": os.getenv("RL_METHOD", "grpo"),
|
| 198 |
+
}
|
| 199 |
+
|
| 200 |
+
# ── Serve React frontend (SPA) ────────────────────────────────────────────────
|
| 201 |
+
if FRONTEND_DIST.exists():
|
| 202 |
+
app.mount("/assets", StaticFiles(directory=str(FRONTEND_DIST / "assets")), name="assets")
|
| 203 |
+
|
| 204 |
+
@app.get("/{full_path:path}")
|
| 205 |
+
async def serve_spa(full_path: str):
|
| 206 |
+
index = FRONTEND_DIST / "index.html"
|
| 207 |
+
if index.exists():
|
| 208 |
+
return FileResponse(str(index))
|
| 209 |
+
return JSONResponse({"error": "Frontend not built"}, status_code=503)
|
| 210 |
+
else:
|
| 211 |
+
@app.get("/")
|
| 212 |
+
async def root():
|
| 213 |
+
return {
|
| 214 |
+
"message": "ChessEcon API running. Frontend not built yet.",
|
| 215 |
+
"docs": "/docs",
|
| 216 |
+
"health": "/health",
|
| 217 |
+
}
|
| 218 |
+
# Patch already applied — see websocket_endpoint above
|
backend/openenv/__init__.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""openenv — OpenEnv 0.1 compliant HTTP interface for ChessEcon."""
|
| 2 |
+
from backend.openenv.env import ChessEconEnv
|
| 3 |
+
from backend.openenv.router import router, init_env
|
| 4 |
+
from backend.openenv.models import (
|
| 5 |
+
ResetRequest, StepRequest,
|
| 6 |
+
ResetResponse, StepResponse, StateResponse, EnvInfo,
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
__all__ = [
|
| 10 |
+
"ChessEconEnv",
|
| 11 |
+
"router",
|
| 12 |
+
"init_env",
|
| 13 |
+
"ResetRequest",
|
| 14 |
+
"StepRequest",
|
| 15 |
+
"ResetResponse",
|
| 16 |
+
"StepResponse",
|
| 17 |
+
"StateResponse",
|
| 18 |
+
"EnvInfo",
|
| 19 |
+
]
|
backend/openenv/env.py
ADDED
|
@@ -0,0 +1,311 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
openenv/env.py
|
| 3 |
+
──────────────
|
| 4 |
+
Stateful ChessEcon environment that implements the OpenEnv 0.1 contract:
|
| 5 |
+
|
| 6 |
+
reset() → ResetResponse
|
| 7 |
+
step() → StepResponse
|
| 8 |
+
state() → StateResponse
|
| 9 |
+
|
| 10 |
+
Key design decisions:
|
| 11 |
+
- Each call to reset() creates a new episode (new game_id, fresh board).
|
| 12 |
+
- step(action) accepts either UCI or SAN notation.
|
| 13 |
+
- Rewards are computed per-step (not just terminal):
|
| 14 |
+
+0.01 legal move played
|
| 15 |
+
+0.05 move gives check
|
| 16 |
+
+0.10 capture
|
| 17 |
+
+1.00 win
|
| 18 |
+
-1.00 loss
|
| 19 |
+
0.00 draw
|
| 20 |
+
- Economy (entry fees, prize pool) is tracked per episode.
|
| 21 |
+
- Thread-safe: each episode is independent. The FastAPI router creates
|
| 22 |
+
one global instance and serialises access via asyncio locks.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
from __future__ import annotations
|
| 26 |
+
|
| 27 |
+
import uuid
|
| 28 |
+
import logging
|
| 29 |
+
from typing import Optional
|
| 30 |
+
|
| 31 |
+
import chess
|
| 32 |
+
|
| 33 |
+
from backend.chess_engine import ChessEngine
|
| 34 |
+
from backend.settings import settings
|
| 35 |
+
from backend.openenv.models import (
|
| 36 |
+
ChessObservation, ResetResponse, StepResponse, StateResponse, ResetRequest,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
logger = logging.getLogger(__name__)
|
| 40 |
+
|
| 41 |
+
# Shaping rewards (small intermediate signals)
|
| 42 |
+
REWARD_LEGAL_MOVE = 0.01
|
| 43 |
+
REWARD_CHECK = 0.05
|
| 44 |
+
REWARD_CAPTURE = 0.10
|
| 45 |
+
REWARD_WIN = 1.00
|
| 46 |
+
REWARD_LOSS = -1.00
|
| 47 |
+
REWARD_DRAW = 0.00
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class ChessEconEnv:
|
| 51 |
+
"""
|
| 52 |
+
OpenEnv-compliant Chess Economy environment.
|
| 53 |
+
|
| 54 |
+
Manages a single active episode. Call reset() to start a new episode.
|
| 55 |
+
Call step(action) to advance it. Call state() to inspect without advancing.
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
white_model_id: str,
|
| 61 |
+
black_model_id: str,
|
| 62 |
+
starting_wallet: float = 100.0,
|
| 63 |
+
entry_fee: float = 10.0,
|
| 64 |
+
prize_pool_fraction: float = 0.9,
|
| 65 |
+
max_moves: int = 150,
|
| 66 |
+
):
|
| 67 |
+
self.white_model_id = white_model_id
|
| 68 |
+
self.black_model_id = black_model_id
|
| 69 |
+
self.starting_wallet = starting_wallet
|
| 70 |
+
self.entry_fee = entry_fee
|
| 71 |
+
self.prize_pool_fraction = prize_pool_fraction
|
| 72 |
+
self.max_moves = max_moves
|
| 73 |
+
|
| 74 |
+
# Episode state (None until first reset())
|
| 75 |
+
self._engine: Optional[ChessEngine] = None
|
| 76 |
+
self._episode_id: str = ""
|
| 77 |
+
self._step_count: int = 0
|
| 78 |
+
self._status: str = "idle"
|
| 79 |
+
self._move_history: list[str] = []
|
| 80 |
+
|
| 81 |
+
# Economy
|
| 82 |
+
self._wallet_white: float = starting_wallet
|
| 83 |
+
self._wallet_black: float = starting_wallet
|
| 84 |
+
self._prize_pool: float = 0.0
|
| 85 |
+
|
| 86 |
+
# Last move for observation
|
| 87 |
+
self._last_uci: Optional[str] = None
|
| 88 |
+
self._last_san: Optional[str] = None
|
| 89 |
+
|
| 90 |
+
# ── OpenEnv core API ───────────────────────────────────────────────────────
|
| 91 |
+
|
| 92 |
+
def reset(self, request: Optional[ResetRequest] = None) -> ResetResponse:
|
| 93 |
+
"""
|
| 94 |
+
Start a new episode. Deducts entry fees and returns the initial observation.
|
| 95 |
+
"""
|
| 96 |
+
self._engine = ChessEngine()
|
| 97 |
+
self._episode_id = str(uuid.uuid4())
|
| 98 |
+
self._step_count = 0
|
| 99 |
+
self._status = "active"
|
| 100 |
+
self._move_history = []
|
| 101 |
+
self._last_uci = None
|
| 102 |
+
self._last_san = None
|
| 103 |
+
|
| 104 |
+
# Economy: deduct entry fees
|
| 105 |
+
self._wallet_white -= self.entry_fee
|
| 106 |
+
self._wallet_black -= self.entry_fee
|
| 107 |
+
self._prize_pool = self.entry_fee * 2 * self.prize_pool_fraction
|
| 108 |
+
|
| 109 |
+
logger.info(
|
| 110 |
+
"Episode %s started. Wallets: W=%.1f B=%.1f prize_pool=%.1f",
|
| 111 |
+
self._episode_id[:8], self._wallet_white, self._wallet_black, self._prize_pool,
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
obs = self._build_observation()
|
| 115 |
+
return ResetResponse(
|
| 116 |
+
observation=obs,
|
| 117 |
+
info={
|
| 118 |
+
"episode_id": self._episode_id,
|
| 119 |
+
"prize_pool": self._prize_pool,
|
| 120 |
+
"entry_fee": self.entry_fee,
|
| 121 |
+
},
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
def step(self, action: str) -> StepResponse:
|
| 125 |
+
"""
|
| 126 |
+
Apply a move to the board and return the next observation + reward.
|
| 127 |
+
|
| 128 |
+
action: UCI string ('e2e4') or SAN string ('e4').
|
| 129 |
+
"""
|
| 130 |
+
if self._engine is None or self._status != "active":
|
| 131 |
+
raise RuntimeError("Call reset() before step()")
|
| 132 |
+
|
| 133 |
+
# ── Apply the move ─────────────────────────────────────────────────
|
| 134 |
+
# Try UCI first, then SAN
|
| 135 |
+
uci_applied: Optional[str] = None
|
| 136 |
+
san_applied: Optional[str] = None
|
| 137 |
+
|
| 138 |
+
# UCI path
|
| 139 |
+
san_from_uci = self._engine.apply_move_uci(action)
|
| 140 |
+
if san_from_uci is not None:
|
| 141 |
+
uci_applied = action
|
| 142 |
+
san_applied = san_from_uci
|
| 143 |
+
else:
|
| 144 |
+
# SAN path — we need the UCI back
|
| 145 |
+
try:
|
| 146 |
+
move = self._engine.board.parse_san(action)
|
| 147 |
+
uci_applied = move.uci()
|
| 148 |
+
san_applied = self._engine.board.san(move)
|
| 149 |
+
self._engine.board.push(move)
|
| 150 |
+
except Exception:
|
| 151 |
+
# Illegal move — return current state with negative reward
|
| 152 |
+
obs = self._build_observation()
|
| 153 |
+
return StepResponse(
|
| 154 |
+
observation=obs,
|
| 155 |
+
reward=-0.10,
|
| 156 |
+
terminated=False,
|
| 157 |
+
truncated=False,
|
| 158 |
+
info={"error": f"Illegal move: {action}", "legal_moves": self._engine.legal_moves_uci[:10]},
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
self._last_uci = uci_applied
|
| 162 |
+
self._last_san = san_applied
|
| 163 |
+
self._move_history.append(san_applied)
|
| 164 |
+
self._step_count += 1
|
| 165 |
+
|
| 166 |
+
# ── Compute per-step reward ────────────────────────────────────────
|
| 167 |
+
reward = self._compute_step_reward(uci_applied)
|
| 168 |
+
|
| 169 |
+
# ── Check termination ──────────────────────────────────────────────
|
| 170 |
+
terminated = bool(self._engine.is_game_over)
|
| 171 |
+
truncated = (not terminated) and (self._step_count >= self.max_moves * 2)
|
| 172 |
+
|
| 173 |
+
if terminated or truncated:
|
| 174 |
+
reward = self._settle_game(terminated, truncated, reward)
|
| 175 |
+
|
| 176 |
+
obs = self._build_observation()
|
| 177 |
+
|
| 178 |
+
return StepResponse(
|
| 179 |
+
observation=obs,
|
| 180 |
+
reward=round(reward, 4),
|
| 181 |
+
terminated=terminated,
|
| 182 |
+
truncated=truncated,
|
| 183 |
+
info={
|
| 184 |
+
"episode_id": self._episode_id,
|
| 185 |
+
"step": self._step_count,
|
| 186 |
+
"san": san_applied,
|
| 187 |
+
"uci": uci_applied,
|
| 188 |
+
"move_history": self._move_history[-10:],
|
| 189 |
+
"prize_pool": self._prize_pool,
|
| 190 |
+
},
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
def state(self) -> StateResponse:
|
| 194 |
+
"""Return current episode state without advancing it."""
|
| 195 |
+
if self._engine is None:
|
| 196 |
+
# Return idle state with default observation
|
| 197 |
+
idle_obs = ChessObservation(
|
| 198 |
+
fen="rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1",
|
| 199 |
+
turn="white",
|
| 200 |
+
move_number=1,
|
| 201 |
+
legal_moves_uci=[],
|
| 202 |
+
wallet_white=self._wallet_white,
|
| 203 |
+
wallet_black=self._wallet_black,
|
| 204 |
+
white_model=self.white_model_id,
|
| 205 |
+
black_model=self.black_model_id,
|
| 206 |
+
)
|
| 207 |
+
return StateResponse(
|
| 208 |
+
observation=idle_obs,
|
| 209 |
+
episode_id="",
|
| 210 |
+
step_count=0,
|
| 211 |
+
status="idle",
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
return StateResponse(
|
| 215 |
+
observation=self._build_observation(),
|
| 216 |
+
episode_id=self._episode_id,
|
| 217 |
+
step_count=self._step_count,
|
| 218 |
+
status=self._status,
|
| 219 |
+
info={
|
| 220 |
+
"prize_pool": self._prize_pool,
|
| 221 |
+
"move_history": self._move_history[-10:],
|
| 222 |
+
},
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
# ── Internal helpers ───────────────────────────────────────────────────────
|
| 226 |
+
|
| 227 |
+
def _build_observation(self) -> ChessObservation:
|
| 228 |
+
engine = self._engine
|
| 229 |
+
assert engine is not None
|
| 230 |
+
board = engine.board
|
| 231 |
+
|
| 232 |
+
return ChessObservation(
|
| 233 |
+
fen=engine.fen,
|
| 234 |
+
turn=engine.turn,
|
| 235 |
+
move_number=engine.move_number,
|
| 236 |
+
last_move_uci=self._last_uci,
|
| 237 |
+
last_move_san=self._last_san,
|
| 238 |
+
legal_moves_uci=engine.legal_moves_uci,
|
| 239 |
+
is_check=board.is_check(),
|
| 240 |
+
wallet_white=round(self._wallet_white, 2),
|
| 241 |
+
wallet_black=round(self._wallet_black, 2),
|
| 242 |
+
white_model=self.white_model_id,
|
| 243 |
+
black_model=self.black_model_id,
|
| 244 |
+
info={
|
| 245 |
+
"move_history": self._move_history[-20:],
|
| 246 |
+
"step_count": self._step_count,
|
| 247 |
+
"episode_id": self._episode_id,
|
| 248 |
+
},
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
def _compute_step_reward(self, uci: str) -> float:
|
| 252 |
+
"""
|
| 253 |
+
Dense per-step reward shaping.
|
| 254 |
+
Evaluated AFTER the move has been applied, so we look at the NEW board state.
|
| 255 |
+
"""
|
| 256 |
+
engine = self._engine
|
| 257 |
+
assert engine is not None
|
| 258 |
+
board = engine.board
|
| 259 |
+
|
| 260 |
+
reward = REWARD_LEGAL_MOVE
|
| 261 |
+
|
| 262 |
+
# Check bonus (opponent is now in check)
|
| 263 |
+
if board.is_check():
|
| 264 |
+
reward += REWARD_CHECK
|
| 265 |
+
|
| 266 |
+
# Capture bonus — look at the move that was just pushed
|
| 267 |
+
if board.move_stack:
|
| 268 |
+
last_move = board.move_stack[-1]
|
| 269 |
+
# Castling and en-passant: board.is_capture works on the board before the move
|
| 270 |
+
# We check by looking at whether a piece disappeared from the target square
|
| 271 |
+
# Simple heuristic: the move stack entry captures flag
|
| 272 |
+
if board.is_capture(last_move):
|
| 273 |
+
reward += REWARD_CAPTURE
|
| 274 |
+
|
| 275 |
+
return reward
|
| 276 |
+
|
| 277 |
+
def _settle_game(self, terminated: bool, truncated: bool, step_reward: float) -> float:
|
| 278 |
+
"""
|
| 279 |
+
Apply terminal reward and settle the economy.
|
| 280 |
+
Returns the final total reward for the last move.
|
| 281 |
+
"""
|
| 282 |
+
engine = self._engine
|
| 283 |
+
assert engine is not None
|
| 284 |
+
|
| 285 |
+
result = engine.result or "1/2-1/2"
|
| 286 |
+
white_reward = engine.compute_reward("white") # +1, -1, or 0
|
| 287 |
+
|
| 288 |
+
# Terminal reward
|
| 289 |
+
if white_reward > 0:
|
| 290 |
+
terminal = REWARD_WIN
|
| 291 |
+
self._wallet_white += self._prize_pool
|
| 292 |
+
logger.info("White wins! Prize: +%.1f", self._prize_pool)
|
| 293 |
+
elif white_reward < 0:
|
| 294 |
+
terminal = REWARD_LOSS
|
| 295 |
+
self._wallet_black += self._prize_pool
|
| 296 |
+
logger.info("Black wins! Prize: +%.1f", self._prize_pool)
|
| 297 |
+
else:
|
| 298 |
+
terminal = REWARD_DRAW
|
| 299 |
+
self._wallet_white += self._prize_pool / 2
|
| 300 |
+
self._wallet_black += self._prize_pool / 2
|
| 301 |
+
logger.info("Draw. Split prize: +%.1f each", self._prize_pool / 2)
|
| 302 |
+
|
| 303 |
+
self._status = "truncated" if truncated else "terminated"
|
| 304 |
+
|
| 305 |
+
logger.info(
|
| 306 |
+
"Episode %s ended. Result=%s Wallets: W=%.1f B=%.1f",
|
| 307 |
+
self._episode_id[:8], result,
|
| 308 |
+
self._wallet_white, self._wallet_black,
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
return step_reward + terminal
|
backend/openenv/models.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
openenv/models.py
|
| 3 |
+
─────────────────
|
| 4 |
+
Pydantic schemas that exactly match the OpenEnv 0.1 HTTP spec.
|
| 5 |
+
|
| 6 |
+
POST /reset → ResetResponse
|
| 7 |
+
POST /step → StepResponse
|
| 8 |
+
GET /state → StateResponse
|
| 9 |
+
|
| 10 |
+
All three wrap a shared Observation object that carries chess-specific
|
| 11 |
+
fields inside the `info` dict so the core contract stays generic.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
from __future__ import annotations
|
| 15 |
+
from typing import Any, Optional
|
| 16 |
+
from pydantic import BaseModel, Field
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# ── Request bodies ─────────────────────────────────────────────────────────────
|
| 20 |
+
|
| 21 |
+
class StepRequest(BaseModel):
|
| 22 |
+
"""Action sent by the RL trainer to advance the environment by one move."""
|
| 23 |
+
action: str = Field(
|
| 24 |
+
...,
|
| 25 |
+
description="Chess move in UCI notation (e.g. 'e2e4') or SAN (e.g. 'e4')",
|
| 26 |
+
examples=["e2e4", "Nf3", "O-O"],
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class ResetRequest(BaseModel):
|
| 31 |
+
"""Optional seed / config passed on reset. All fields optional."""
|
| 32 |
+
seed: Optional[int] = Field(None, description="RNG seed for reproducibility")
|
| 33 |
+
config: Optional[dict[str, Any]] = Field(
|
| 34 |
+
None, description="Override environment config for this episode"
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# ── Core observation ───────────────────────────────────────────────────────────
|
| 39 |
+
|
| 40 |
+
class ChessObservation(BaseModel):
|
| 41 |
+
"""
|
| 42 |
+
Chess-specific observation. Returned inside every response as `observation`.
|
| 43 |
+
The `info` dict carries auxiliary data (legal moves, last move, etc.) so that
|
| 44 |
+
the outer schema stays OpenEnv-generic.
|
| 45 |
+
"""
|
| 46 |
+
fen: str = Field(..., description="Current board position in FEN notation")
|
| 47 |
+
turn: str = Field(..., description="'white' or 'black'")
|
| 48 |
+
move_number: int = Field(..., description="Full-move number (1-indexed)")
|
| 49 |
+
last_move_uci: Optional[str] = Field(None, description="Last move in UCI notation")
|
| 50 |
+
last_move_san: Optional[str] = Field(None, description="Last move in SAN notation")
|
| 51 |
+
legal_moves_uci: list[str] = Field(..., description="All legal moves in UCI notation")
|
| 52 |
+
is_check: bool = Field(False, description="Whether the current side is in check")
|
| 53 |
+
# Economy
|
| 54 |
+
wallet_white: float = Field(..., description="White agent wallet balance (units)")
|
| 55 |
+
wallet_black: float = Field(..., description="Black agent wallet balance (units)")
|
| 56 |
+
# Agent identities
|
| 57 |
+
white_model: str = Field(..., description="Model ID playing White")
|
| 58 |
+
black_model: str = Field(..., description="Model ID playing Black")
|
| 59 |
+
# Info dict for auxiliary / extensible data
|
| 60 |
+
info: dict[str, Any] = Field(default_factory=dict)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# ── OpenEnv response bodies ────────────────────────────────────────────────────
|
| 64 |
+
|
| 65 |
+
class ResetResponse(BaseModel):
|
| 66 |
+
"""
|
| 67 |
+
Returned by POST /reset.
|
| 68 |
+
OpenEnv spec: { observation, info }
|
| 69 |
+
"""
|
| 70 |
+
observation: ChessObservation
|
| 71 |
+
info: dict[str, Any] = Field(default_factory=dict)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class StepResponse(BaseModel):
|
| 75 |
+
"""
|
| 76 |
+
Returned by POST /step.
|
| 77 |
+
OpenEnv spec: { observation, reward, terminated, truncated, info }
|
| 78 |
+
"""
|
| 79 |
+
observation: ChessObservation
|
| 80 |
+
reward: float = Field(..., description="Per-step reward signal")
|
| 81 |
+
terminated: bool = Field(..., description="True if the episode ended naturally (checkmate/stalemate/draw)")
|
| 82 |
+
truncated: bool = Field(..., description="True if the episode was cut short (move limit)")
|
| 83 |
+
info: dict[str, Any] = Field(default_factory=dict)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class StateResponse(BaseModel):
|
| 87 |
+
"""
|
| 88 |
+
Returned by GET /state.
|
| 89 |
+
OpenEnv spec: { observation, info, episode_id, step_count, status }
|
| 90 |
+
"""
|
| 91 |
+
observation: ChessObservation
|
| 92 |
+
info: dict[str, Any] = Field(default_factory=dict)
|
| 93 |
+
episode_id: str = Field(..., description="Unique identifier for the current episode")
|
| 94 |
+
step_count: int = Field(..., description="Number of moves played so far")
|
| 95 |
+
status: str = Field(..., description="'active' | 'terminated' | 'truncated' | 'idle'")
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
# ── Environment info ──────────────────────────────────────────────────────────
|
| 99 |
+
|
| 100 |
+
class EnvInfo(BaseModel):
|
| 101 |
+
"""Returned by GET /env_info — describes environment capabilities."""
|
| 102 |
+
name: str = "chessecon"
|
| 103 |
+
version: str = "1.0.0"
|
| 104 |
+
description: str = (
|
| 105 |
+
"Two-agent chess economy environment. White plays Qwen2.5-0.5B-Instruct, "
|
| 106 |
+
"Black plays Llama-3.2-1B-Instruct. Agents earn/lose economic units based "
|
| 107 |
+
"on game outcomes. Compatible with OpenEnv 0.1 spec."
|
| 108 |
+
)
|
| 109 |
+
openenv_version: str = "0.1"
|
| 110 |
+
action_space: dict = Field(
|
| 111 |
+
default_factory=lambda: {
|
| 112 |
+
"type": "text",
|
| 113 |
+
"description": "Chess move in UCI (e2e4) or SAN (e4) notation",
|
| 114 |
+
}
|
| 115 |
+
)
|
| 116 |
+
observation_space: dict = Field(
|
| 117 |
+
default_factory=lambda: {
|
| 118 |
+
"type": "structured",
|
| 119 |
+
"fields": ["fen", "turn", "move_number", "legal_moves_uci",
|
| 120 |
+
"wallet_white", "wallet_black", "is_check"],
|
| 121 |
+
}
|
| 122 |
+
)
|
| 123 |
+
reward_range: list[float] = Field(default_factory=lambda: [-1.0, 1.0])
|
| 124 |
+
max_episode_steps: int = 300
|
| 125 |
+
agents: list[dict] = Field(
|
| 126 |
+
default_factory=lambda: [
|
| 127 |
+
{"id": "white", "model": "Qwen/Qwen2.5-0.5B-Instruct", "role": "White player"},
|
| 128 |
+
{"id": "black", "model": "meta-llama/Llama-3.2-1B-Instruct", "role": "Black player"},
|
| 129 |
+
]
|
| 130 |
+
)
|
| 131 |
+
tags: list[str] = Field(
|
| 132 |
+
default_factory=lambda: [
|
| 133 |
+
"chess", "multi-agent", "rl", "grpo", "economy",
|
| 134 |
+
"openenv", "two-player", "game",
|
| 135 |
+
]
|
| 136 |
+
)
|
backend/openenv/router.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
openenv/router.py
|
| 3 |
+
─────────────────
|
| 4 |
+
FastAPI router that exposes the OpenEnv 0.1 HTTP API:
|
| 5 |
+
|
| 6 |
+
POST /reset → start a new episode
|
| 7 |
+
POST /step → advance the environment by one action
|
| 8 |
+
GET /state → inspect current episode state (no side-effects)
|
| 9 |
+
GET /env_info → environment metadata (for HF Hub discoverability)
|
| 10 |
+
|
| 11 |
+
All endpoints are prefixed with /env so the full paths are:
|
| 12 |
+
/env/reset, /env/step, /env/state, /env/env_info
|
| 13 |
+
|
| 14 |
+
A single global ChessEconEnv instance is shared across all HTTP requests.
|
| 15 |
+
An asyncio.Lock ensures that concurrent step() calls don't race.
|
| 16 |
+
|
| 17 |
+
The auto-play game loop (websocket_server.py) runs in parallel and calls
|
| 18 |
+
env.reset() / env.step() internally — it does NOT go through these HTTP
|
| 19 |
+
endpoints. The HTTP endpoints are for external RL trainers (TRL, verl,
|
| 20 |
+
SkyRL etc.) that want to drive the environment themselves.
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
from __future__ import annotations
|
| 24 |
+
|
| 25 |
+
import asyncio
|
| 26 |
+
import logging
|
| 27 |
+
from typing import Optional
|
| 28 |
+
|
| 29 |
+
from fastapi import APIRouter, HTTPException, status
|
| 30 |
+
|
| 31 |
+
from backend.openenv.models import (
|
| 32 |
+
ResetRequest, StepRequest,
|
| 33 |
+
ResetResponse, StepResponse, StateResponse, EnvInfo,
|
| 34 |
+
)
|
| 35 |
+
from backend.openenv.env import ChessEconEnv
|
| 36 |
+
from backend.settings import settings
|
| 37 |
+
|
| 38 |
+
logger = logging.getLogger(__name__)
|
| 39 |
+
|
| 40 |
+
router = APIRouter(prefix="/env", tags=["OpenEnv"])
|
| 41 |
+
|
| 42 |
+
# ── Singleton environment + lock ──────────────────────────────────────────────
|
| 43 |
+
_env: Optional[ChessEconEnv] = None
|
| 44 |
+
_env_lock: asyncio.Lock = asyncio.Lock()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_env() -> ChessEconEnv:
|
| 48 |
+
"""Return the global environment instance (initialised at app startup)."""
|
| 49 |
+
global _env
|
| 50 |
+
if _env is None:
|
| 51 |
+
raise HTTPException(
|
| 52 |
+
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
|
| 53 |
+
detail="Environment not initialised yet. Models still loading.",
|
| 54 |
+
)
|
| 55 |
+
return _env
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def init_env(white_model_id: str, black_model_id: str) -> ChessEconEnv:
|
| 59 |
+
"""Called once at app lifespan startup after models are loaded."""
|
| 60 |
+
global _env
|
| 61 |
+
_env = ChessEconEnv(
|
| 62 |
+
white_model_id=white_model_id,
|
| 63 |
+
black_model_id=black_model_id,
|
| 64 |
+
starting_wallet=settings.starting_wallet,
|
| 65 |
+
entry_fee=settings.entry_fee,
|
| 66 |
+
prize_pool_fraction=settings.prize_pool_fraction,
|
| 67 |
+
max_moves=settings.max_moves,
|
| 68 |
+
)
|
| 69 |
+
logger.info(
|
| 70 |
+
"ChessEconEnv initialised. White=%s Black=%s",
|
| 71 |
+
white_model_id, black_model_id,
|
| 72 |
+
)
|
| 73 |
+
return _env
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
# ── OpenEnv endpoints ─────────────────────────────────────────────────────────
|
| 77 |
+
|
| 78 |
+
@router.post(
|
| 79 |
+
"/reset",
|
| 80 |
+
response_model=ResetResponse,
|
| 81 |
+
summary="Reset — start a new episode",
|
| 82 |
+
description=(
|
| 83 |
+
"Initialises a new chess game, deducts entry fees from both agent wallets, "
|
| 84 |
+
"and returns the initial observation. Compatible with OpenEnv 0.1 spec."
|
| 85 |
+
),
|
| 86 |
+
)
|
| 87 |
+
async def reset(request: Optional[ResetRequest] = None) -> ResetResponse:
|
| 88 |
+
env = get_env()
|
| 89 |
+
async with _env_lock:
|
| 90 |
+
try:
|
| 91 |
+
return env.reset(request)
|
| 92 |
+
except Exception as exc:
|
| 93 |
+
logger.exception("reset() failed")
|
| 94 |
+
raise HTTPException(status_code=500, detail=str(exc))
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
@router.post(
|
| 98 |
+
"/step",
|
| 99 |
+
response_model=StepResponse,
|
| 100 |
+
summary="Step — apply one action",
|
| 101 |
+
description=(
|
| 102 |
+
"Applies a chess move (UCI or SAN) to the current board and returns "
|
| 103 |
+
"the next observation, per-step reward, and termination flags. "
|
| 104 |
+
"Returns reward=-0.1 for illegal moves (episode continues). "
|
| 105 |
+
"Compatible with OpenEnv 0.1 spec."
|
| 106 |
+
),
|
| 107 |
+
)
|
| 108 |
+
async def step(request: StepRequest) -> StepResponse:
|
| 109 |
+
env = get_env()
|
| 110 |
+
async with _env_lock:
|
| 111 |
+
try:
|
| 112 |
+
return env.step(request.action)
|
| 113 |
+
except RuntimeError as exc:
|
| 114 |
+
raise HTTPException(
|
| 115 |
+
status_code=status.HTTP_409_CONFLICT,
|
| 116 |
+
detail=str(exc),
|
| 117 |
+
)
|
| 118 |
+
except Exception as exc:
|
| 119 |
+
logger.exception("step() failed")
|
| 120 |
+
raise HTTPException(status_code=500, detail=str(exc))
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
@router.get(
|
| 124 |
+
"/state",
|
| 125 |
+
response_model=StateResponse,
|
| 126 |
+
summary="State — current episode state (read-only)",
|
| 127 |
+
description=(
|
| 128 |
+
"Returns the current episode state without advancing it. "
|
| 129 |
+
"Safe to call at any time, even before reset(). "
|
| 130 |
+
"Compatible with OpenEnv 0.1 spec."
|
| 131 |
+
),
|
| 132 |
+
)
|
| 133 |
+
async def state() -> StateResponse:
|
| 134 |
+
env = get_env()
|
| 135 |
+
try:
|
| 136 |
+
return env.state()
|
| 137 |
+
except Exception as exc:
|
| 138 |
+
logger.exception("state() failed")
|
| 139 |
+
raise HTTPException(status_code=500, detail=str(exc))
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
@router.get(
|
| 143 |
+
"/env_info",
|
| 144 |
+
response_model=EnvInfo,
|
| 145 |
+
summary="Environment metadata",
|
| 146 |
+
description=(
|
| 147 |
+
"Returns environment metadata used by the HuggingFace OpenEnv Hub "
|
| 148 |
+
"for discoverability. Lists action/observation spaces, agent models, "
|
| 149 |
+
"reward range, and OpenEnv version."
|
| 150 |
+
),
|
| 151 |
+
)
|
| 152 |
+
async def env_info() -> EnvInfo:
|
| 153 |
+
env = get_env()
|
| 154 |
+
return EnvInfo(
|
| 155 |
+
agents=[
|
| 156 |
+
{"id": "white", "model": env.white_model_id, "role": "White player (Qwen)"},
|
| 157 |
+
{"id": "black", "model": env.black_model_id, "role": "Black player (Llama)"},
|
| 158 |
+
]
|
| 159 |
+
)
|
backend/qwen_agent.py
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
qwen_agent.py
|
| 3 |
+
─────────────
|
| 4 |
+
Loads Qwen2.5-0.5B-Instruct (or any HuggingFace causal LM) and uses it to
|
| 5 |
+
generate chess moves given a position prompt.
|
| 6 |
+
|
| 7 |
+
Key responsibilities:
|
| 8 |
+
- Lazy model loading (first call triggers download + GPU placement)
|
| 9 |
+
- Illegal-move retry loop (up to settings.max_move_retries attempts)
|
| 10 |
+
- Log-probability extraction for GRPO training
|
| 11 |
+
- Temperature annealing hook (called by the trainer after each update)
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import logging
|
| 15 |
+
import torch
|
| 16 |
+
from typing import Optional
|
| 17 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 18 |
+
|
| 19 |
+
from settings import settings
|
| 20 |
+
from chess_engine import ChessEngine
|
| 21 |
+
|
| 22 |
+
logger = logging.getLogger(__name__)
|
| 23 |
+
|
| 24 |
+
# ── Lazy singletons ───────────────────────────────────────────────────────────
|
| 25 |
+
_tokenizer = None
|
| 26 |
+
_model = None
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def _load_model():
|
| 30 |
+
global _tokenizer, _model
|
| 31 |
+
if _model is not None:
|
| 32 |
+
return _tokenizer, _model
|
| 33 |
+
|
| 34 |
+
logger.info("Loading model: %s …", settings.player_model)
|
| 35 |
+
|
| 36 |
+
dtype_map = {
|
| 37 |
+
"float16": torch.float16,
|
| 38 |
+
"bfloat16": torch.bfloat16,
|
| 39 |
+
"float32": torch.float32,
|
| 40 |
+
}
|
| 41 |
+
torch_dtype = dtype_map.get(settings.torch_dtype, torch.bfloat16)
|
| 42 |
+
|
| 43 |
+
hf_kwargs = {}
|
| 44 |
+
if settings.hf_token:
|
| 45 |
+
hf_kwargs["token"] = settings.hf_token
|
| 46 |
+
|
| 47 |
+
_tokenizer = AutoTokenizer.from_pretrained(
|
| 48 |
+
settings.player_model,
|
| 49 |
+
trust_remote_code=True,
|
| 50 |
+
**hf_kwargs,
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
device_map = settings.device if settings.device != "auto" else "auto"
|
| 54 |
+
|
| 55 |
+
_model = AutoModelForCausalLM.from_pretrained(
|
| 56 |
+
settings.player_model,
|
| 57 |
+
torch_dtype=torch_dtype,
|
| 58 |
+
device_map=device_map,
|
| 59 |
+
trust_remote_code=True,
|
| 60 |
+
**hf_kwargs,
|
| 61 |
+
)
|
| 62 |
+
_model.eval()
|
| 63 |
+
logger.info("Model loaded on device: %s", next(_model.parameters()).device)
|
| 64 |
+
|
| 65 |
+
# Apply LoRA if requested
|
| 66 |
+
if settings.lora_rank > 0:
|
| 67 |
+
try:
|
| 68 |
+
from peft import get_peft_model, LoraConfig, TaskType # type: ignore
|
| 69 |
+
lora_config = LoraConfig(
|
| 70 |
+
task_type=TaskType.CAUSAL_LM,
|
| 71 |
+
r=settings.lora_rank,
|
| 72 |
+
lora_alpha=settings.lora_rank * 2,
|
| 73 |
+
lora_dropout=0.05,
|
| 74 |
+
target_modules=["q_proj", "v_proj"],
|
| 75 |
+
)
|
| 76 |
+
_model = get_peft_model(_model, lora_config)
|
| 77 |
+
_model.print_trainable_parameters()
|
| 78 |
+
logger.info("LoRA adapter applied (rank=%d)", settings.lora_rank)
|
| 79 |
+
except ImportError:
|
| 80 |
+
logger.warning("peft not installed — running without LoRA. pip install peft")
|
| 81 |
+
|
| 82 |
+
return _tokenizer, _model
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class QwenAgent:
|
| 86 |
+
"""
|
| 87 |
+
Wraps the Qwen model for chess move generation.
|
| 88 |
+
|
| 89 |
+
Usage:
|
| 90 |
+
agent = QwenAgent()
|
| 91 |
+
san, log_prob = await agent.get_move(engine, "white", move_history)
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
def __init__(self):
|
| 95 |
+
self._temperature = settings.temperature
|
| 96 |
+
|
| 97 |
+
def set_temperature(self, temp: float):
|
| 98 |
+
"""Called by the GRPO trainer to anneal temperature over training."""
|
| 99 |
+
self._temperature = max(0.1, temp)
|
| 100 |
+
|
| 101 |
+
@property
|
| 102 |
+
def temperature(self) -> float:
|
| 103 |
+
return self._temperature
|
| 104 |
+
|
| 105 |
+
def get_move(
|
| 106 |
+
self,
|
| 107 |
+
engine: ChessEngine,
|
| 108 |
+
agent_color: str,
|
| 109 |
+
move_history: list[str],
|
| 110 |
+
) -> tuple[str, float]:
|
| 111 |
+
"""
|
| 112 |
+
Generate a legal chess move for the given position.
|
| 113 |
+
|
| 114 |
+
Returns:
|
| 115 |
+
(san_move, log_prob)
|
| 116 |
+
- san_move: the chosen move in SAN notation
|
| 117 |
+
- log_prob: sum of log-probs of the generated tokens (for GRPO)
|
| 118 |
+
|
| 119 |
+
Falls back to a random legal move if all retries are exhausted.
|
| 120 |
+
"""
|
| 121 |
+
tokenizer, model = _load_model()
|
| 122 |
+
prompt = engine.build_prompt(agent_color, move_history)
|
| 123 |
+
|
| 124 |
+
messages = [
|
| 125 |
+
{"role": "system", "content": "You are a chess engine. Reply with only the move."},
|
| 126 |
+
{"role": "user", "content": prompt},
|
| 127 |
+
]
|
| 128 |
+
|
| 129 |
+
# Apply chat template
|
| 130 |
+
text = tokenizer.apply_chat_template(
|
| 131 |
+
messages,
|
| 132 |
+
tokenize=False,
|
| 133 |
+
add_generation_prompt=True,
|
| 134 |
+
)
|
| 135 |
+
inputs = tokenizer(text, return_tensors="pt").to(model.device)
|
| 136 |
+
input_len = inputs["input_ids"].shape[1]
|
| 137 |
+
|
| 138 |
+
best_san: Optional[str] = None
|
| 139 |
+
best_log_prob: float = 0.0
|
| 140 |
+
|
| 141 |
+
for attempt in range(settings.max_move_retries):
|
| 142 |
+
with torch.no_grad():
|
| 143 |
+
outputs = model.generate(
|
| 144 |
+
**inputs,
|
| 145 |
+
max_new_tokens=settings.max_new_tokens,
|
| 146 |
+
temperature=self._temperature,
|
| 147 |
+
do_sample=True,
|
| 148 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 149 |
+
return_dict_in_generate=True,
|
| 150 |
+
output_scores=True,
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
generated_ids = outputs.sequences[0][input_len:]
|
| 154 |
+
generated_text = tokenizer.decode(generated_ids, skip_special_tokens=True)
|
| 155 |
+
|
| 156 |
+
# Compute sum of log-probs for GRPO
|
| 157 |
+
log_prob = _compute_log_prob(outputs.scores, generated_ids)
|
| 158 |
+
|
| 159 |
+
san = engine.parse_model_output(generated_text)
|
| 160 |
+
if san is not None:
|
| 161 |
+
best_san = san
|
| 162 |
+
best_log_prob = log_prob
|
| 163 |
+
logger.debug(
|
| 164 |
+
"Move generated (attempt %d/%d): %s log_prob=%.4f",
|
| 165 |
+
attempt + 1, settings.max_move_retries, san, log_prob,
|
| 166 |
+
)
|
| 167 |
+
break
|
| 168 |
+
else:
|
| 169 |
+
logger.debug(
|
| 170 |
+
"Illegal/unparseable output (attempt %d/%d): %r",
|
| 171 |
+
attempt + 1, settings.max_move_retries, generated_text,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
if best_san is None:
|
| 175 |
+
# All retries exhausted — fall back to random legal move
|
| 176 |
+
best_san = engine.random_legal_move_san() or "e4"
|
| 177 |
+
best_log_prob = 0.0
|
| 178 |
+
logger.warning("All retries exhausted — using random fallback move: %s", best_san)
|
| 179 |
+
|
| 180 |
+
return best_san, best_log_prob
|
| 181 |
+
|
| 182 |
+
def get_move_log_prob_only(
|
| 183 |
+
self,
|
| 184 |
+
engine: ChessEngine,
|
| 185 |
+
agent_color: str,
|
| 186 |
+
move_history: list[str],
|
| 187 |
+
san_move: str,
|
| 188 |
+
) -> float:
|
| 189 |
+
"""
|
| 190 |
+
Compute the log-probability of a specific move under the current policy.
|
| 191 |
+
Used by GRPO to evaluate the reference policy for KL computation.
|
| 192 |
+
"""
|
| 193 |
+
tokenizer, model = _load_model()
|
| 194 |
+
prompt = engine.build_prompt(agent_color, move_history)
|
| 195 |
+
messages = [
|
| 196 |
+
{"role": "system", "content": "You are a chess engine. Reply with only the move."},
|
| 197 |
+
{"role": "user", "content": prompt},
|
| 198 |
+
]
|
| 199 |
+
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
| 200 |
+
target_text = text + san_move
|
| 201 |
+
inputs = tokenizer(target_text, return_tensors="pt").to(model.device)
|
| 202 |
+
prompt_len = tokenizer(text, return_tensors="pt")["input_ids"].shape[1]
|
| 203 |
+
|
| 204 |
+
with torch.no_grad():
|
| 205 |
+
out = model(**inputs, labels=inputs["input_ids"])
|
| 206 |
+
# Extract per-token log-probs for the generated portion only
|
| 207 |
+
logits = out.logits[0, prompt_len - 1:-1]
|
| 208 |
+
target_ids = inputs["input_ids"][0, prompt_len:]
|
| 209 |
+
log_probs = torch.nn.functional.log_softmax(logits, dim=-1)
|
| 210 |
+
selected = log_probs.gather(1, target_ids.unsqueeze(1)).squeeze(1)
|
| 211 |
+
return selected.sum().item()
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
# ── Helpers ───────────────────────────────────────────────────────────────────
|
| 215 |
+
|
| 216 |
+
def _compute_log_prob(scores, generated_ids) -> float:
|
| 217 |
+
"""
|
| 218 |
+
Compute the sum of log-probabilities for the generated token sequence.
|
| 219 |
+
`scores` is a tuple of (vocab_size,) tensors, one per generated step.
|
| 220 |
+
"""
|
| 221 |
+
total = 0.0
|
| 222 |
+
for step, score in enumerate(scores):
|
| 223 |
+
if step >= len(generated_ids):
|
| 224 |
+
break
|
| 225 |
+
log_probs = torch.nn.functional.log_softmax(score[0], dim=-1)
|
| 226 |
+
total += log_probs[generated_ids[step]].item()
|
| 227 |
+
return total
|
| 228 |
+
|
backend/requirements.txt
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChessEcon Backend Dependencies
|
| 2 |
+
# fastapi
|
| 3 |
+
# uvicorn[standard]
|
| 4 |
+
# websockets
|
| 5 |
+
python-chess
|
| 6 |
+
pydantic
|
| 7 |
+
pydantic-settings
|
| 8 |
+
anthropic
|
| 9 |
+
# python-dotenv
|
| 10 |
+
httpx
|
| 11 |
+
|
| 12 |
+
# Nevermined Payments — x402 cross-team agent-to-agent payments
|
| 13 |
+
# https://nevermined.ai/docs/getting-started/welcome
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
huggingface_hub
|
| 17 |
+
# transformers
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# ChessEcon Backend — Python dependencies
|
| 21 |
+
# Install with: pip install -r requirements.txt
|
| 22 |
+
|
| 23 |
+
# ── Web server ────────────────────────────────────────────────────────────────
|
| 24 |
+
fastapi
|
| 25 |
+
uvicorn[standard]
|
| 26 |
+
websockets
|
| 27 |
+
|
| 28 |
+
# ── Chess ─────────────────────────────────────────────────────────────────────
|
| 29 |
+
chess
|
| 30 |
+
|
| 31 |
+
# ── LLM / Training ───────────────────────────────────────────────────────────
|
| 32 |
+
torch
|
| 33 |
+
transformers
|
| 34 |
+
accelerate
|
| 35 |
+
peft
|
| 36 |
+
sentencepiece
|
| 37 |
+
protobuf
|
| 38 |
+
|
| 39 |
+
# ── Utilities ─────────────────────────────────────────────────────────────────
|
| 40 |
+
python-dotenv
|
backend/settings.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
settings.py
|
| 3 |
+
───────────
|
| 4 |
+
Single source of truth for all environment-variable-driven configuration.
|
| 5 |
+
All values have safe defaults so the server starts without any .env file.
|
| 6 |
+
|
| 7 |
+
New in v2 (OpenEnv):
|
| 8 |
+
- white_model / black_model replace the single player_model
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
from dataclasses import dataclass, field
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@dataclass(frozen=True)
|
| 16 |
+
class Settings:
|
| 17 |
+
# ── Models (dual-agent) ───────────────────────────────────────────────
|
| 18 |
+
white_model: str = field(
|
| 19 |
+
default_factory=lambda: os.getenv(
|
| 20 |
+
"WHITE_MODEL",
|
| 21 |
+
os.getenv("PLAYER_MODEL", "Qwen/Qwen2.5-0.5B-Instruct"),
|
| 22 |
+
)
|
| 23 |
+
)
|
| 24 |
+
black_model: str = field(
|
| 25 |
+
default_factory=lambda: os.getenv(
|
| 26 |
+
"BLACK_MODEL",
|
| 27 |
+
"meta-llama/Llama-3.2-1B-Instruct",
|
| 28 |
+
)
|
| 29 |
+
)
|
| 30 |
+
# Legacy alias
|
| 31 |
+
@property
|
| 32 |
+
def player_model(self) -> str:
|
| 33 |
+
return self.white_model
|
| 34 |
+
|
| 35 |
+
hf_token: str = field(default_factory=lambda: os.getenv("HF_TOKEN", ""))
|
| 36 |
+
device: str = field(default_factory=lambda: os.getenv("DEVICE", "auto"))
|
| 37 |
+
torch_dtype: str = field(default_factory=lambda: os.getenv("TORCH_DTYPE", "bfloat16"))
|
| 38 |
+
|
| 39 |
+
# ── Move generation ───────────────────────────────────────────────────
|
| 40 |
+
max_new_tokens: int = field(default_factory=lambda: int(os.getenv("MAX_NEW_TOKENS", "32")))
|
| 41 |
+
temperature: float = field(default_factory=lambda: float(os.getenv("TEMPERATURE", "0.7")))
|
| 42 |
+
max_move_retries: int = field(default_factory=lambda: int(os.getenv("MAX_MOVE_RETRIES", "5")))
|
| 43 |
+
|
| 44 |
+
# ── GRPO training ─────────────────────────────────────────────────────
|
| 45 |
+
grpo_update_every_n_games: int = field(default_factory=lambda: int(os.getenv("GRPO_UPDATE_EVERY_N_GAMES", "1")))
|
| 46 |
+
grpo_group_size: int = field(default_factory=lambda: int(os.getenv("GRPO_GROUP_SIZE", "4")))
|
| 47 |
+
grpo_kl_coeff: float = field(default_factory=lambda: float(os.getenv("GRPO_KL_COEFF", "0.04")))
|
| 48 |
+
grpo_lr: float = field(default_factory=lambda: float(os.getenv("GRPO_LR", "1e-5")))
|
| 49 |
+
lora_rank: int = field(default_factory=lambda: int(os.getenv("LORA_RANK", "8")))
|
| 50 |
+
checkpoint_dir: str = field(default_factory=lambda: os.getenv("CHECKPOINT_DIR", "./checkpoints"))
|
| 51 |
+
save_every_n_steps: int = field(default_factory=lambda: int(os.getenv("SAVE_EVERY_N_STEPS", "10")))
|
| 52 |
+
|
| 53 |
+
# ── Economy ───────────────────────────────────────────────────────────
|
| 54 |
+
starting_wallet: float = field(default_factory=lambda: float(os.getenv("STARTING_WALLET", "100.0")))
|
| 55 |
+
entry_fee: float = field(default_factory=lambda: float(os.getenv("ENTRY_FEE", "10.0")))
|
| 56 |
+
prize_pool_fraction: float = field(default_factory=lambda: float(os.getenv("PRIZE_POOL_FRACTION", "0.9")))
|
| 57 |
+
max_moves: int = field(default_factory=lambda: int(os.getenv("MAX_MOVES", "150")))
|
| 58 |
+
|
| 59 |
+
# ── Server ────────────────────────────────────────────────────────────
|
| 60 |
+
host: str = field(default_factory=lambda: os.getenv("HOST", "0.0.0.0"))
|
| 61 |
+
port: int = field(default_factory=lambda: int(os.getenv("PORT", "8000")))
|
| 62 |
+
move_delay: float = field(default_factory=lambda: float(os.getenv("MOVE_DELAY", "0.5")))
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
settings = Settings()
|
backend/websocket_server.py
ADDED
|
@@ -0,0 +1,365 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
websocket_server.py (v2 — OpenEnv + Dual Agent)
|
| 3 |
+
─────────────────────────────────────────────────
|
| 4 |
+
FastAPI application that:
|
| 5 |
+
1. Loads TWO models at startup:
|
| 6 |
+
White → Qwen/Qwen2.5-0.5B-Instruct
|
| 7 |
+
Black → meta-llama/Llama-3.2-1B-Instruct
|
| 8 |
+
2. Registers the OpenEnv 0.1 HTTP API at /env/*
|
| 9 |
+
3. Runs continuous self-play games (white=Qwen vs black=Llama).
|
| 10 |
+
4. Streams every game event to all connected WebSocket clients.
|
| 11 |
+
5. Runs GRPO on the WHITE model only (Qwen) — Llama acts as fixed opponent.
|
| 12 |
+
|
| 13 |
+
OpenEnv endpoints (for external RL trainers):
|
| 14 |
+
POST /env/reset start a new episode
|
| 15 |
+
POST /env/step apply one action
|
| 16 |
+
GET /env/state inspect current state
|
| 17 |
+
GET /env/env_info environment metadata (HF Hub discoverability)
|
| 18 |
+
|
| 19 |
+
WebSocket endpoint: /ws
|
| 20 |
+
Health check: /health
|
| 21 |
+
API docs: /docs
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
import asyncio
|
| 25 |
+
import json
|
| 26 |
+
import logging
|
| 27 |
+
import time
|
| 28 |
+
from contextlib import asynccontextmanager
|
| 29 |
+
from typing import Any
|
| 30 |
+
|
| 31 |
+
import uvicorn
|
| 32 |
+
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
|
| 33 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 34 |
+
|
| 35 |
+
from settings import settings
|
| 36 |
+
from chess_engine import ChessEngine
|
| 37 |
+
from agents.model_agent import ModelAgent
|
| 38 |
+
from grpo_trainer import GRPOTrainer
|
| 39 |
+
from openenv.router import router as openenv_router, init_env
|
| 40 |
+
|
| 41 |
+
logging.basicConfig(
|
| 42 |
+
level=logging.INFO,
|
| 43 |
+
format="%(asctime)s %(levelname)s %(name)s: %(message)s",
|
| 44 |
+
)
|
| 45 |
+
logger = logging.getLogger(__name__)
|
| 46 |
+
|
| 47 |
+
# ── Global state ──────────────────────────────────────────────────────────────
|
| 48 |
+
connected_clients: set[WebSocket] = set()
|
| 49 |
+
paused = False
|
| 50 |
+
game_count = 0
|
| 51 |
+
wallet_white = settings.starting_wallet
|
| 52 |
+
wallet_black = settings.starting_wallet
|
| 53 |
+
|
| 54 |
+
# Initialised in lifespan
|
| 55 |
+
white_agent: ModelAgent | None = None
|
| 56 |
+
black_agent: ModelAgent | None = None
|
| 57 |
+
trainer: GRPOTrainer | None = None
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# ── Lifespan ──────────────────────────────────────────────────────────────────
|
| 61 |
+
@asynccontextmanager
|
| 62 |
+
async def lifespan(app: FastAPI):
|
| 63 |
+
global white_agent, black_agent, trainer
|
| 64 |
+
|
| 65 |
+
logger.info("Loading WHITE model (%s) …", settings.white_model)
|
| 66 |
+
white_agent = ModelAgent(settings.white_model).load()
|
| 67 |
+
|
| 68 |
+
logger.info("Loading BLACK model (%s) …", settings.black_model)
|
| 69 |
+
black_agent = ModelAgent(settings.black_model).load()
|
| 70 |
+
|
| 71 |
+
# GRPO trains the WHITE agent (Qwen); Llama is a fixed opponent
|
| 72 |
+
trainer = GRPOTrainer(white_agent.model, white_agent.tokenizer)
|
| 73 |
+
|
| 74 |
+
# Initialise the OpenEnv environment (used by /env/* HTTP endpoints)
|
| 75 |
+
init_env(
|
| 76 |
+
white_model_id=settings.white_model,
|
| 77 |
+
black_model_id=settings.black_model,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
logger.info("Both models ready. Starting auto-play loop …")
|
| 81 |
+
asyncio.create_task(game_loop())
|
| 82 |
+
yield
|
| 83 |
+
logger.info("Shutting down.")
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
app = FastAPI(
|
| 87 |
+
title="ChessEcon",
|
| 88 |
+
description=(
|
| 89 |
+
"Multi-Agent Chess Economy — OpenEnv 0.1 compliant environment. "
|
| 90 |
+
"White: Qwen2.5-0.5B | Black: Llama-3.2-1B | Training: GRPO"
|
| 91 |
+
),
|
| 92 |
+
version="2.0.0",
|
| 93 |
+
lifespan=lifespan,
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
app.add_middleware(
|
| 97 |
+
CORSMiddleware,
|
| 98 |
+
allow_origins=["*"],
|
| 99 |
+
allow_methods=["*"],
|
| 100 |
+
allow_headers=["*"],
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
# Register OpenEnv HTTP router at /env/*
|
| 104 |
+
app.include_router(openenv_router)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
# ── Health ────────────────────────────────────────────────────────────────────
|
| 108 |
+
@app.get("/health")
|
| 109 |
+
async def health():
|
| 110 |
+
return {
|
| 111 |
+
"status": "ok",
|
| 112 |
+
"service": "chessecon",
|
| 113 |
+
"version": "2.0.0",
|
| 114 |
+
"openenv_version": "0.1",
|
| 115 |
+
"white_model": settings.white_model,
|
| 116 |
+
"black_model": settings.black_model,
|
| 117 |
+
"ws_clients": len(connected_clients),
|
| 118 |
+
"games_played": game_count,
|
| 119 |
+
}
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
# ── WebSocket endpoint ────────────────────────────────────────────────────────
|
| 123 |
+
@app.websocket("/ws")
|
| 124 |
+
async def websocket_endpoint(ws: WebSocket):
|
| 125 |
+
await ws.accept()
|
| 126 |
+
connected_clients.add(ws)
|
| 127 |
+
logger.info("WS client connected (%d total)", len(connected_clients))
|
| 128 |
+
# Send current state snapshot to new client immediately
|
| 129 |
+
try:
|
| 130 |
+
await ws.send_text(json.dumps({
|
| 131 |
+
"type": "status",
|
| 132 |
+
"data": {
|
| 133 |
+
"game_id": game_count,
|
| 134 |
+
"wallet_white": round(wallet_white, 2),
|
| 135 |
+
"wallet_black": round(wallet_black, 2),
|
| 136 |
+
"grpo_step": trainer._step if trainer else 0,
|
| 137 |
+
"message": f"Connected — game #{game_count} in progress",
|
| 138 |
+
}
|
| 139 |
+
}))
|
| 140 |
+
except Exception:
|
| 141 |
+
pass
|
| 142 |
+
try:
|
| 143 |
+
while True:
|
| 144 |
+
raw = await ws.receive_text()
|
| 145 |
+
try:
|
| 146 |
+
msg = json.loads(raw)
|
| 147 |
+
await handle_client_message(ws, msg)
|
| 148 |
+
except json.JSONDecodeError:
|
| 149 |
+
pass
|
| 150 |
+
except WebSocketDisconnect:
|
| 151 |
+
connected_clients.discard(ws)
|
| 152 |
+
logger.info("WS client disconnected (%d total)", len(connected_clients))
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
async def handle_client_message(ws: WebSocket, msg: dict):
|
| 156 |
+
global paused
|
| 157 |
+
action = msg.get("action", "")
|
| 158 |
+
if action == "ping":
|
| 159 |
+
await ws.send_text(json.dumps({"type": "pong", "data": {}}))
|
| 160 |
+
elif action == "pause":
|
| 161 |
+
paused = True
|
| 162 |
+
logger.info("Game loop paused")
|
| 163 |
+
elif action == "resume":
|
| 164 |
+
paused = False
|
| 165 |
+
logger.info("Game loop resumed")
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
# ── Broadcast helper ──────────────────────────────────────────────────────────
|
| 169 |
+
async def broadcast(event_type: str, data: dict[str, Any]):
|
| 170 |
+
if not connected_clients:
|
| 171 |
+
return
|
| 172 |
+
payload = json.dumps({"type": event_type, "data": data})
|
| 173 |
+
dead: set[WebSocket] = set()
|
| 174 |
+
for ws in list(connected_clients):
|
| 175 |
+
try:
|
| 176 |
+
await ws.send_text(payload)
|
| 177 |
+
except Exception:
|
| 178 |
+
dead.add(ws)
|
| 179 |
+
connected_clients.difference_update(dead)
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
# ── Main game loop ────────────────────────────────────────────────────────────
|
| 183 |
+
async def game_loop():
|
| 184 |
+
global game_count, wallet_white, wallet_black, paused
|
| 185 |
+
|
| 186 |
+
while True:
|
| 187 |
+
while paused:
|
| 188 |
+
await asyncio.sleep(0.5)
|
| 189 |
+
|
| 190 |
+
game_count += 1
|
| 191 |
+
engine = ChessEngine()
|
| 192 |
+
|
| 193 |
+
wallet_white -= settings.entry_fee
|
| 194 |
+
wallet_black -= settings.entry_fee
|
| 195 |
+
prize_pool = settings.entry_fee * 2 * settings.prize_pool_fraction
|
| 196 |
+
|
| 197 |
+
await broadcast("game_start", {
|
| 198 |
+
"game_id": game_count,
|
| 199 |
+
"wallet_white": round(wallet_white, 2),
|
| 200 |
+
"wallet_black": round(wallet_black, 2),
|
| 201 |
+
"prize_pool": round(prize_pool, 2),
|
| 202 |
+
"white_model": settings.white_model,
|
| 203 |
+
"black_model": settings.black_model,
|
| 204 |
+
"message": (
|
| 205 |
+
f"Game #{game_count} — "
|
| 206 |
+
f"Qwen(W) vs Llama(B) — "
|
| 207 |
+
f"Prize pool: {prize_pool:.1f} units"
|
| 208 |
+
),
|
| 209 |
+
})
|
| 210 |
+
|
| 211 |
+
trainer.start_game("white") # type: ignore[union-attr]
|
| 212 |
+
move_history: list[str] = []
|
| 213 |
+
|
| 214 |
+
# ── Play the game ─────────────────────────────────────────────────
|
| 215 |
+
while not engine.is_game_over and engine.move_number <= settings.max_moves:
|
| 216 |
+
while paused:
|
| 217 |
+
await asyncio.sleep(0.5)
|
| 218 |
+
|
| 219 |
+
current_color = engine.turn
|
| 220 |
+
# Select the right agent
|
| 221 |
+
active_agent = white_agent if current_color == "white" else black_agent
|
| 222 |
+
|
| 223 |
+
san, log_prob = await asyncio.get_event_loop().run_in_executor(
|
| 224 |
+
None,
|
| 225 |
+
active_agent.get_move, # type: ignore[union-attr]
|
| 226 |
+
engine, current_color, move_history,
|
| 227 |
+
)
|
| 228 |
+
|
| 229 |
+
# KL reference: only needed for WHITE (GRPO training target)
|
| 230 |
+
if current_color == "white":
|
| 231 |
+
ref_log_prob = await asyncio.get_event_loop().run_in_executor(
|
| 232 |
+
None,
|
| 233 |
+
white_agent.get_move_log_prob_only, # type: ignore[union-attr]
|
| 234 |
+
engine, current_color, move_history, san,
|
| 235 |
+
)
|
| 236 |
+
else:
|
| 237 |
+
ref_log_prob = log_prob # Black is fixed; KL = 0
|
| 238 |
+
|
| 239 |
+
uci = engine.apply_move_san(san)
|
| 240 |
+
if uci is None:
|
| 241 |
+
fallback = engine.random_legal_move_san()
|
| 242 |
+
if fallback is None:
|
| 243 |
+
break
|
| 244 |
+
san = fallback
|
| 245 |
+
uci = engine.apply_move_san(san) or ""
|
| 246 |
+
log_prob = 0.0
|
| 247 |
+
ref_log_prob = 0.0
|
| 248 |
+
|
| 249 |
+
trainer.record_move(log_prob, ref_log_prob) # type: ignore[union-attr]
|
| 250 |
+
move_history.append(san)
|
| 251 |
+
|
| 252 |
+
await broadcast("move", {
|
| 253 |
+
"game_id": game_count,
|
| 254 |
+
"player": current_color,
|
| 255 |
+
"model": settings.white_model if current_color == "white" else settings.black_model,
|
| 256 |
+
"move": san,
|
| 257 |
+
"uci": uci,
|
| 258 |
+
"fen": engine.fen,
|
| 259 |
+
"move_number": engine.move_number,
|
| 260 |
+
"turn": engine.turn,
|
| 261 |
+
"wallet_white": round(wallet_white, 2),
|
| 262 |
+
"wallet_black": round(wallet_black, 2),
|
| 263 |
+
"message": f"{'Qwen' if current_color == 'white' else 'Llama'} plays {san}",
|
| 264 |
+
})
|
| 265 |
+
|
| 266 |
+
await asyncio.sleep(settings.move_delay)
|
| 267 |
+
|
| 268 |
+
# ���─ Game over ─────────────────────────────────────────────────────
|
| 269 |
+
# If game ended by chess rules use that result; otherwise adjudicate by material
|
| 270 |
+
if engine.result:
|
| 271 |
+
result = engine.result
|
| 272 |
+
else:
|
| 273 |
+
# Count material: Q=9 R=5 B=3 N=3 P=1
|
| 274 |
+
piece_values = {1: 1, 2: 3, 3: 3, 4: 5, 5: 9} # pawn,knight,bishop,rook,queen
|
| 275 |
+
import chess as _chess
|
| 276 |
+
white_mat = sum(
|
| 277 |
+
piece_values.get(pt, 0)
|
| 278 |
+
for pt in range(1, 6)
|
| 279 |
+
for _ in engine.board.pieces(pt, _chess.WHITE)
|
| 280 |
+
)
|
| 281 |
+
black_mat = sum(
|
| 282 |
+
piece_values.get(pt, 0)
|
| 283 |
+
for pt in range(1, 6)
|
| 284 |
+
for _ in engine.board.pieces(pt, _chess.BLACK)
|
| 285 |
+
)
|
| 286 |
+
result = '1-0' if white_mat >= black_mat else '0-1' # always decisive
|
| 287 |
+
white_reward = 1.0 if result == "1-0" else (-1.0 if result == "0-1" else 0.0)
|
| 288 |
+
black_reward = 1.0 if result == "0-1" else (-1.0 if result == "1-0" else 0.0)
|
| 289 |
+
|
| 290 |
+
if result == "1-0":
|
| 291 |
+
wallet_white += prize_pool
|
| 292 |
+
elif result == "0-1":
|
| 293 |
+
wallet_black += prize_pool
|
| 294 |
+
else:
|
| 295 |
+
wallet_white += prize_pool / 2
|
| 296 |
+
wallet_black += prize_pool / 2
|
| 297 |
+
|
| 298 |
+
white_pnl = (
|
| 299 |
+
prize_pool if result == "1-0"
|
| 300 |
+
else prize_pool / 2 if result == "1/2-1/2"
|
| 301 |
+
else 0
|
| 302 |
+
) - settings.entry_fee
|
| 303 |
+
black_pnl = (
|
| 304 |
+
prize_pool if result == "0-1"
|
| 305 |
+
else prize_pool / 2 if result == "1/2-1/2"
|
| 306 |
+
else 0
|
| 307 |
+
) - settings.entry_fee
|
| 308 |
+
|
| 309 |
+
await broadcast("game_end", {
|
| 310 |
+
"game_id": game_count,
|
| 311 |
+
"result": result,
|
| 312 |
+
"reward": white_reward,
|
| 313 |
+
"wallet_white": round(wallet_white, 2),
|
| 314 |
+
"wallet_black": round(wallet_black, 2),
|
| 315 |
+
"prize_income": round(
|
| 316 |
+
prize_pool if result == "1-0"
|
| 317 |
+
else prize_pool / 2 if result == "1/2-1/2"
|
| 318 |
+
else 0, 2
|
| 319 |
+
),
|
| 320 |
+
"coaching_cost": 0,
|
| 321 |
+
"entry_fee": settings.entry_fee,
|
| 322 |
+
"net_pnl_white": round(white_pnl, 2),
|
| 323 |
+
"net_pnl_black": round(black_pnl, 2),
|
| 324 |
+
"move_count": len(move_history),
|
| 325 |
+
"white_model": settings.white_model,
|
| 326 |
+
"black_model": settings.black_model,
|
| 327 |
+
"message": f"Game #{game_count} ended — {result}",
|
| 328 |
+
})
|
| 329 |
+
|
| 330 |
+
# GRPO update (WHITE model only)
|
| 331 |
+
training_metrics = trainer.end_game( # type: ignore[union-attr]
|
| 332 |
+
reward=white_reward,
|
| 333 |
+
profit=white_pnl,
|
| 334 |
+
coaching_calls=0,
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
if training_metrics is not None:
|
| 338 |
+
await broadcast("training_step", {
|
| 339 |
+
"step": training_metrics.step,
|
| 340 |
+
"loss": round(training_metrics.loss, 6),
|
| 341 |
+
"reward": round(training_metrics.policy_reward, 4),
|
| 342 |
+
"kl_div": round(training_metrics.kl_div, 6),
|
| 343 |
+
"win_rate": round(training_metrics.win_rate, 4),
|
| 344 |
+
"avg_profit": round(training_metrics.avg_profit, 4),
|
| 345 |
+
"coaching_rate": round(training_metrics.coaching_rate, 4),
|
| 346 |
+
"model": settings.white_model,
|
| 347 |
+
"message": (
|
| 348 |
+
f"GRPO step {training_metrics.step} | "
|
| 349 |
+
f"loss={training_metrics.loss:.4f} "
|
| 350 |
+
f"win_rate={training_metrics.win_rate:.2%}"
|
| 351 |
+
),
|
| 352 |
+
})
|
| 353 |
+
|
| 354 |
+
await asyncio.sleep(1.0)
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
# ── Entry point ───────────────────────────────────────────────────────────────
|
| 358 |
+
if __name__ == "__main__":
|
| 359 |
+
uvicorn.run(
|
| 360 |
+
"websocket_server:app",
|
| 361 |
+
host=settings.host,
|
| 362 |
+
port=settings.port,
|
| 363 |
+
reload=False,
|
| 364 |
+
log_level="info",
|
| 365 |
+
)
|
doc.md
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChessEcon: A Visual Guide to the Autonomous Chess Economy
|
| 2 |
+
|
| 3 |
+
**Author:** Adaboost AI
|
| 4 |
+
**Date:** March 03, 2026
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## Introduction
|
| 9 |
+
|
| 10 |
+
This document provides a comprehensive visual overview of the **ChessEcon** system, a multi-agent reinforcement learning platform where AI agents operate as autonomous businesses. The following diagrams and charts illustrate the system's architecture, the flow of information and money, the agent decision-making process, and the dynamics of the training loop. These visualizations are designed to clarify the inter-workings of the agents and the training pipeline, from a single move to a full self-play and training cycle.
|
| 11 |
+
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
## 1. System Architecture & Information Flow
|
| 15 |
+
|
| 16 |
+
The ChessEcon system is composed of several interconnected layers, each with a distinct responsibility. The following diagrams illustrate the high-level architecture and the sequence of events during a typical training loop.
|
| 17 |
+
|
| 18 |
+
### 1.1. Full Training Loop Sequence
|
| 19 |
+
|
| 20 |
+
This sequence diagram shows the end-to-end flow of a single game, from setup and move-by-move execution to payout and the triggering of a training step. It highlights the interactions between the agents, the environment server, the economic layer, and the training pipeline.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
### 1.2. Agent Decision-Making Flowchart
|
| 25 |
+
|
| 26 |
+
At the heart of ChessEcon is the agent's ability to make both chess and economic decisions. This flowchart details the step-by-step process an agent follows each turn, including the critical decision of whether to purchase expert coaching from Claude claude-opus-4-5.
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
### 1.3. Economic Flow
|
| 31 |
+
|
| 32 |
+
Money is the lifeblood of the ChessEcon system. This diagram illustrates how money flows between agents and the tournament organizer, from entry fees and coaching payments to prize payouts. It also breaks down the net profit for various game outcomes.
|
| 33 |
+
|
| 34 |
+
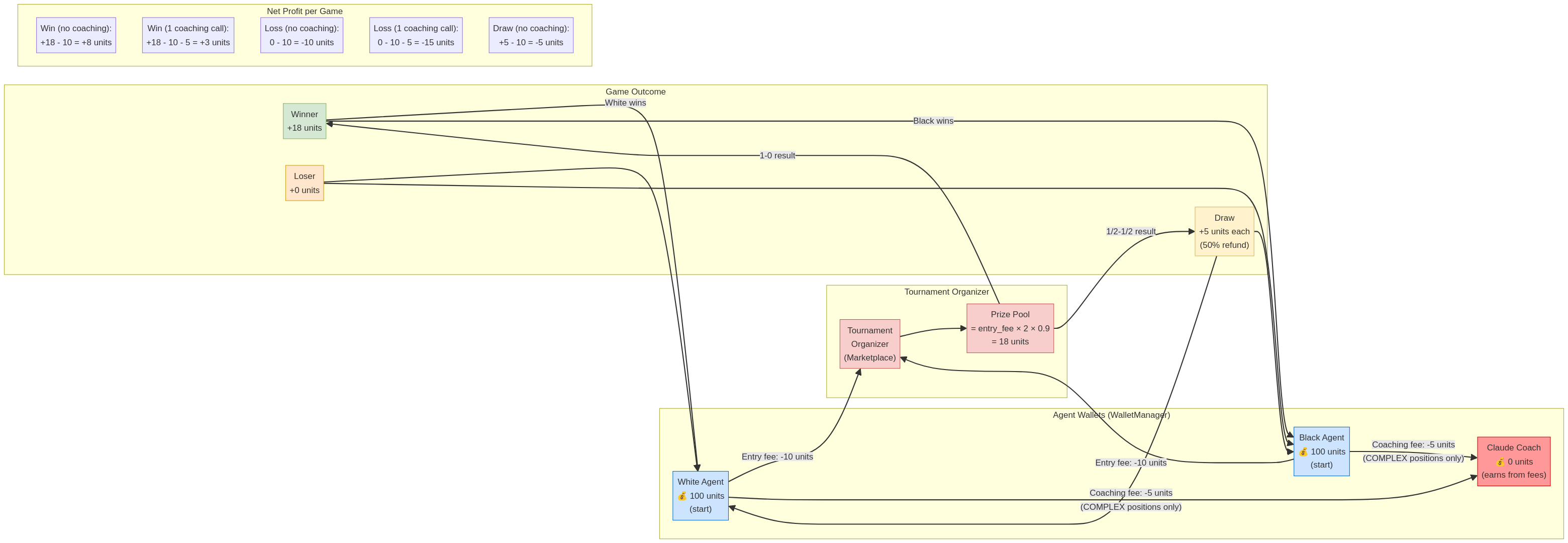
|
| 35 |
+
|
| 36 |
+
### 1.4. GRPO Training Internals
|
| 37 |
+
|
| 38 |
+
The training pipeline uses **Group Relative Policy Optimization (GRPO)**. This flowchart breaks down the four phases of the GRPO process: data collection, reward assignment, advantage computation, and the final loss calculation and model update.
|
| 39 |
+
|
| 40 |
+
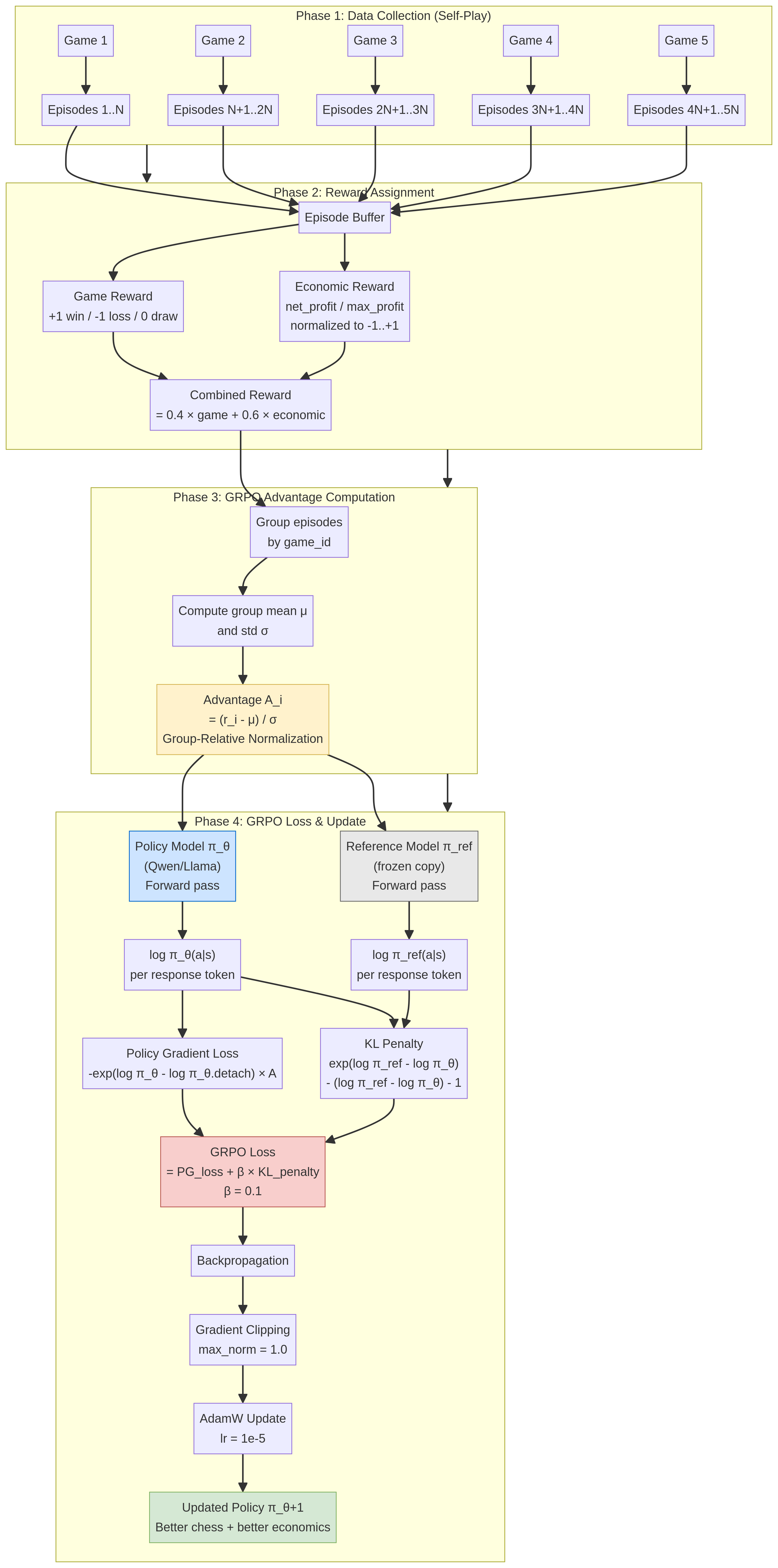
|
| 41 |
+
|
| 42 |
+
---
|
| 43 |
+
|
| 44 |
+
## 2. Training & Economic Performance
|
| 45 |
+
|
| 46 |
+
The following charts are generated from a simulated 80-game self-play run, illustrating how the system's performance evolves over the course of training.
|
| 47 |
+
|
| 48 |
+
### 2.1. Training Metrics Dashboard
|
| 49 |
+
|
| 50 |
+
This 2x2 dashboard provides a high-level view of the key training metrics. It shows the GRPO training loss decreasing, the combined policy reward increasing, the KL divergence remaining stable (indicating controlled training), and the agent's win rate improving over time.
|
| 51 |
+
|
| 52 |
+
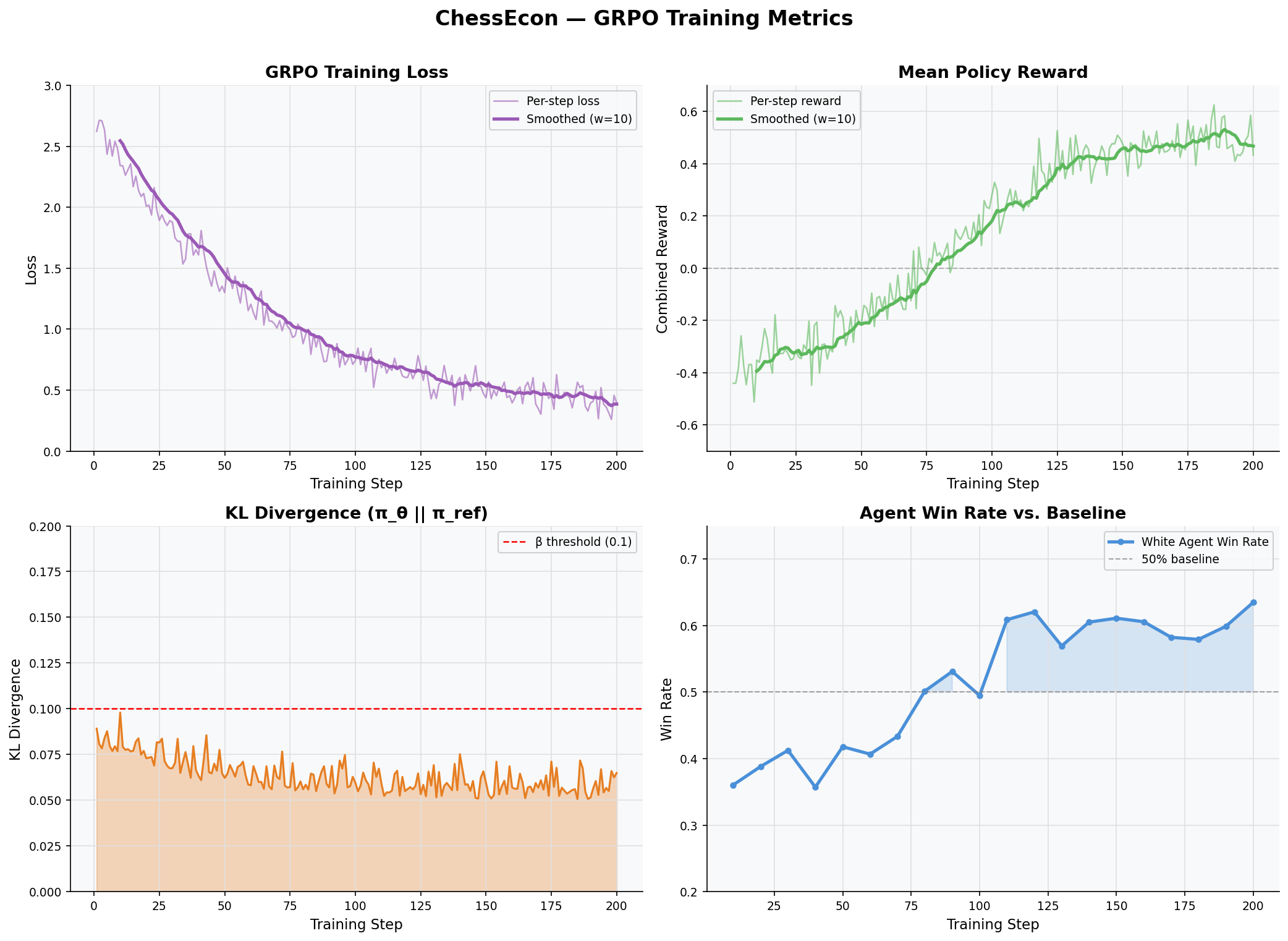
|
| 53 |
+
|
| 54 |
+
### 2.2. Economic Performance Over Time
|
| 55 |
+
|
| 56 |
+
This chart tracks the wallet balances of the White and Black agents over the 80-game simulation. It clearly shows the White agent, which is the primary agent being trained, learning to become profitable, while the less-trained Black agent's balance stagnates or declines. The bottom panel shows the rolling average of net profit per game, reinforcing the trend of improving economic performance.
|
| 57 |
+
|
| 58 |
+
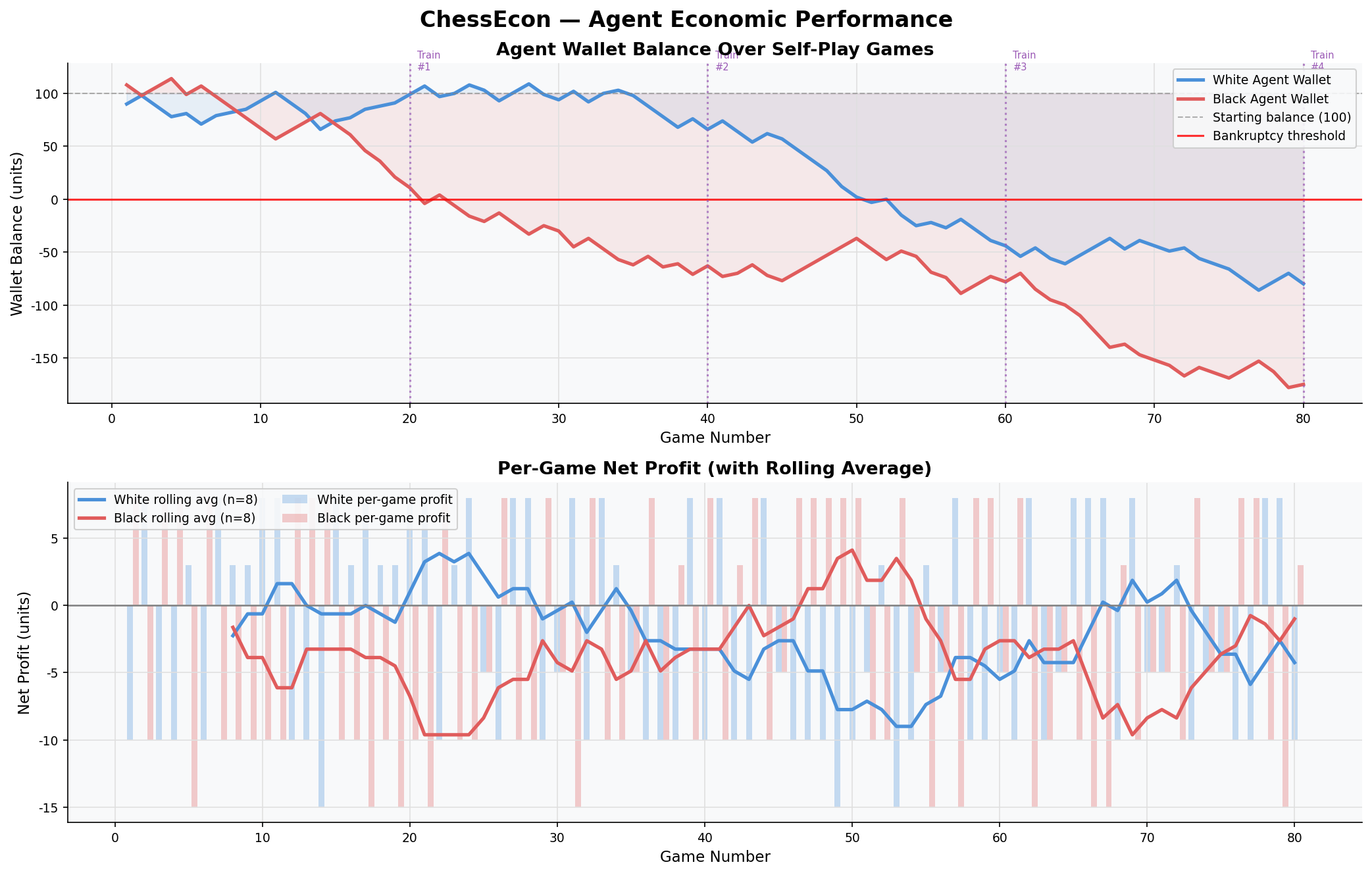
|
| 59 |
+
|
| 60 |
+
---
|
| 61 |
+
|
| 62 |
+
## 3. Agent Behavior & Interaction Analysis
|
| 63 |
+
|
| 64 |
+
These visualizations dive deeper into the specific behaviors of the agents, particularly the decision to use the premium Claude Coach agent.
|
| 65 |
+
|
| 66 |
+
### 3.1. Claude Coaching Usage Analysis
|
| 67 |
+
|
| 68 |
+
This set of charts analyzes when and why the Claude Coach is used. It shows that as agents become more skilled, their reliance on coaching decreases. It also demonstrates a clear positive correlation between buying coaching and winning the game, validating its role as a valuable but costly resource.
|
| 69 |
+
|
| 70 |
+
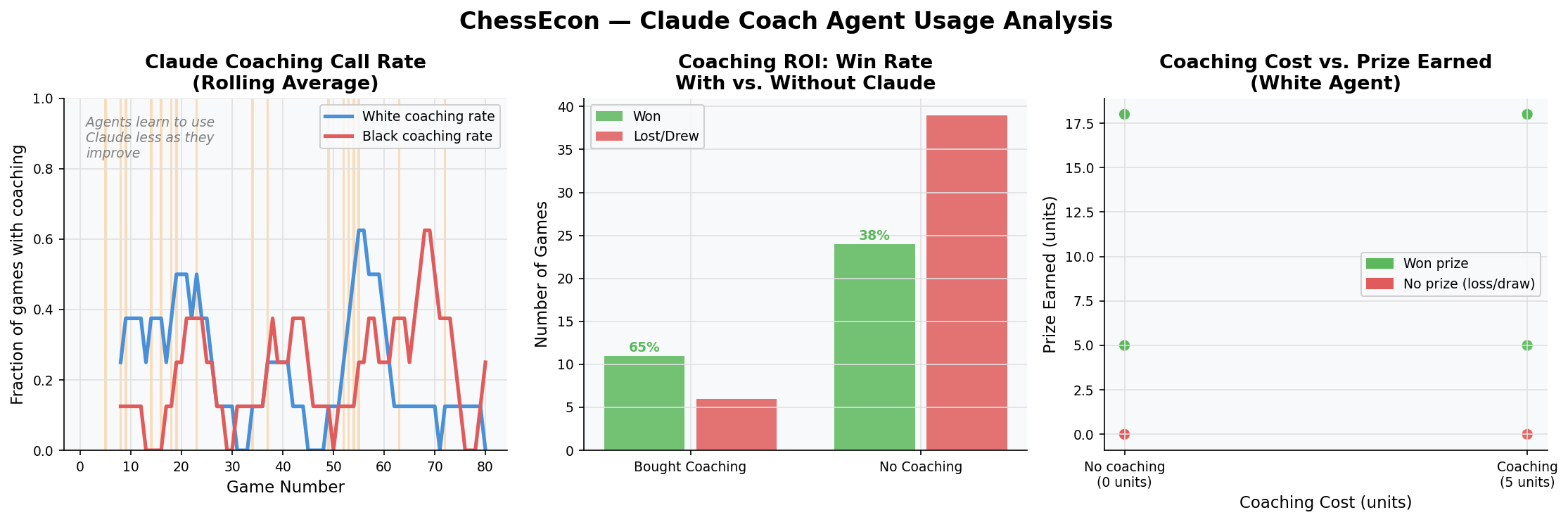
|
| 71 |
+
|
| 72 |
+
### 3.2. Game Statistics Over Training
|
| 73 |
+
|
| 74 |
+
This dashboard shows how game outcomes and length change as the agents train. The pie chart gives an overall distribution, while the line chart shows the White agent's win rate steadily climbing. The histogram of game lengths reveals that games tend to become shorter and more decisive as the agents improve.
|
| 75 |
+
|
| 76 |
+
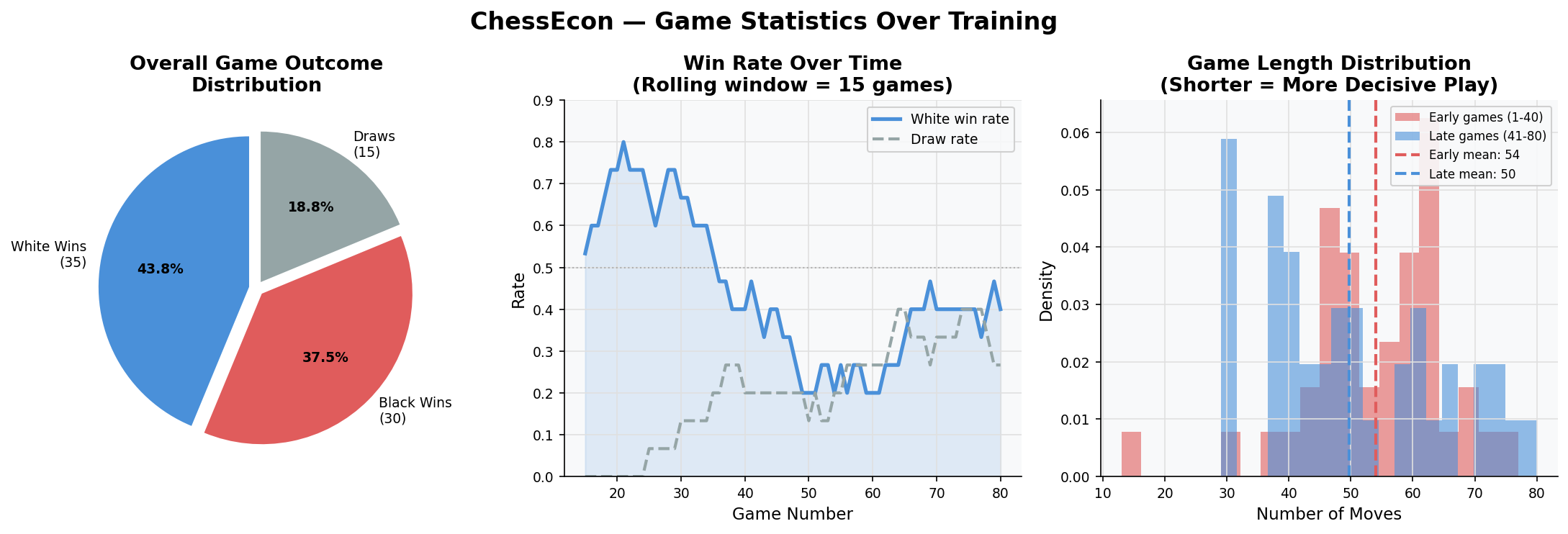
|
| 77 |
+
|
| 78 |
+
### 3.3. Reward Function Decomposition
|
| 79 |
+
|
| 80 |
+
The core of the economic training is the combined reward function. This chart decomposes the reward, showing the relationship between the game outcome (win/loss/draw) and the economic outcome (net profit). It illustrates how the final reward is a blend of both factors, encouraging agents to be both strong players and shrewd business operators.
|
| 81 |
+
|
| 82 |
+
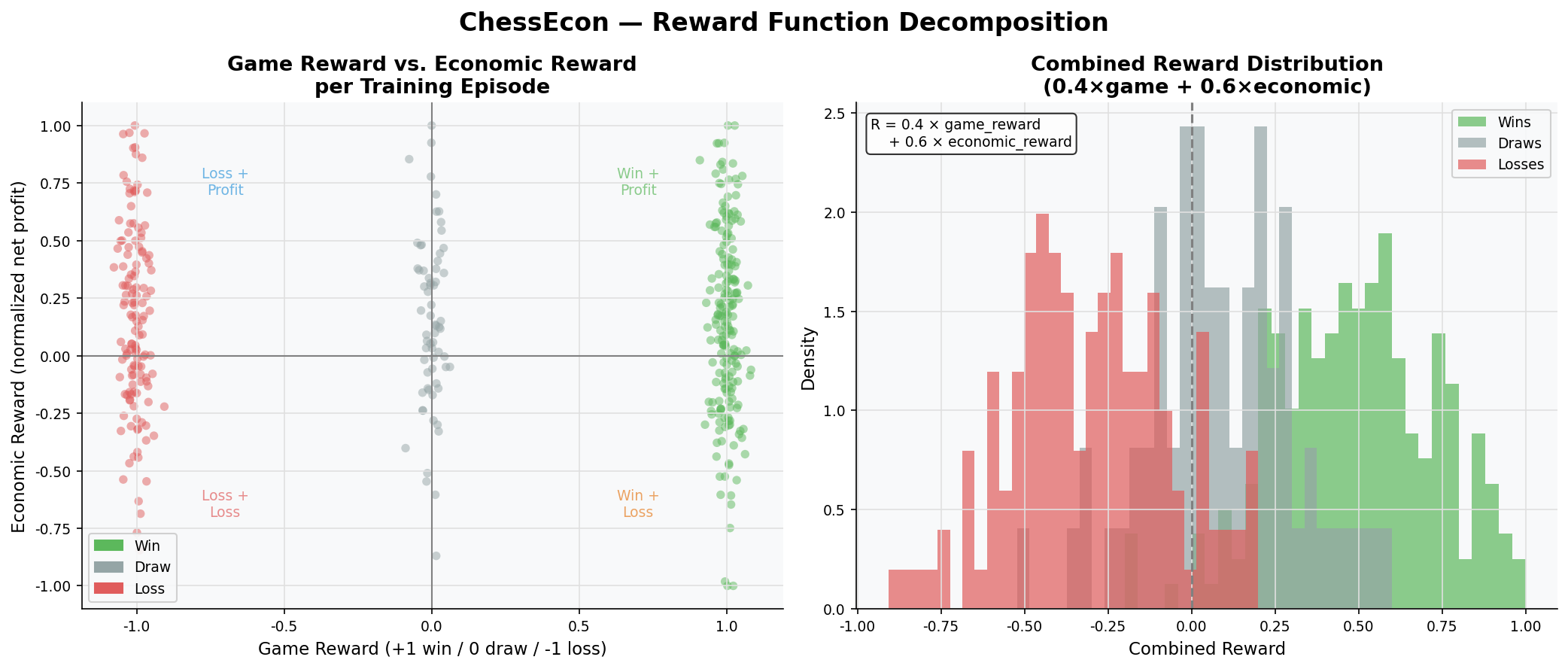
|
| 83 |
+
|
| 84 |
+
### 3.4. Position Complexity & Claude Trigger Analysis
|
| 85 |
+
|
| 86 |
+
Claude is only triggered in complex positions. This chart shows how our heuristic complexity score evolves over a typical game, peaking in the middlegame. The bar chart confirms that the vast majority of Claude coaching calls occur during the strategically rich middlegame phases.
|
| 87 |
+
|
| 88 |
+
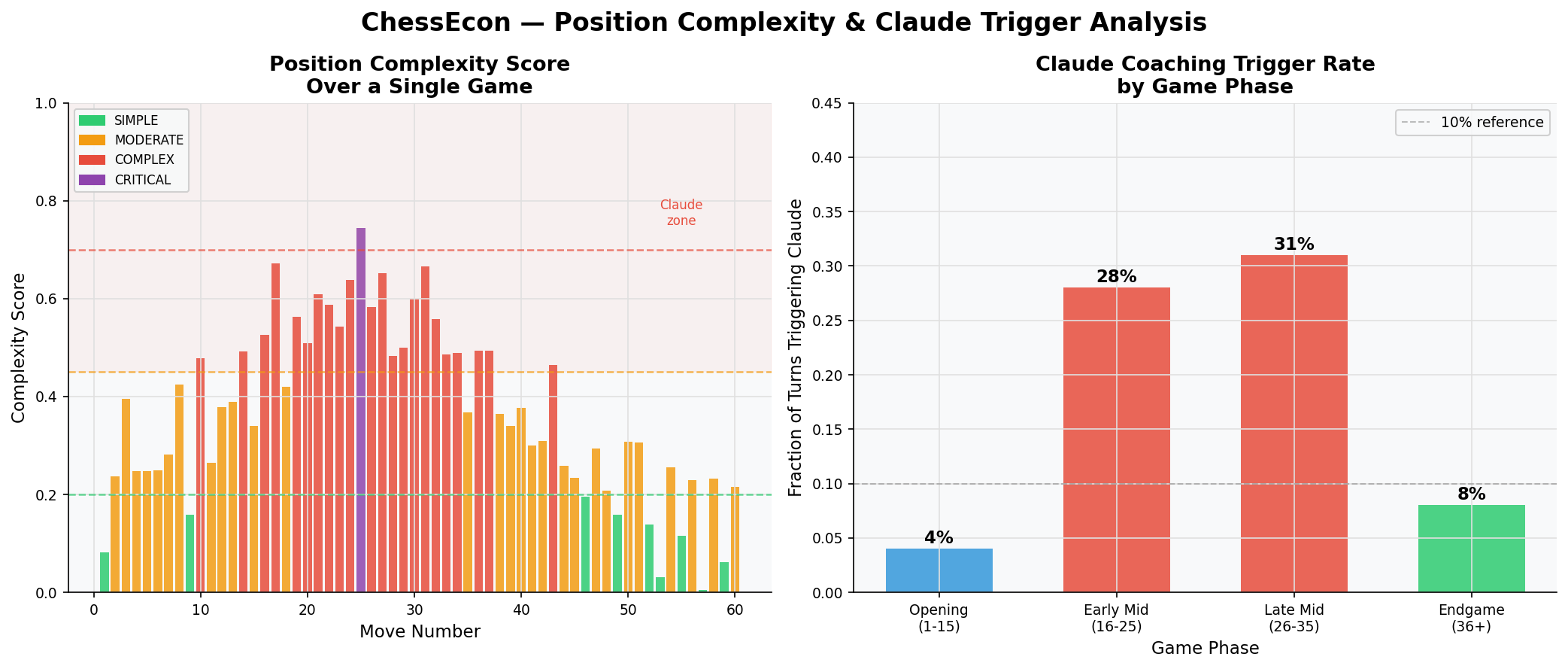
|
| 89 |
+
|
| 90 |
+
---
|
| 91 |
+
|
| 92 |
+
## 4. Detailed Interaction Visualizations
|
| 93 |
+
|
| 94 |
+
Finally, these visualizations provide a granular look at the system's inner workings.
|
| 95 |
+
|
| 96 |
+
### 4.1. Single-Game Agent Interaction Timeline
|
| 97 |
+
|
| 98 |
+
This Gantt-style chart provides a step-by-step timeline of all agent and system interactions during a single, representative game. It clearly shows the sequence of API calls, decisions, and data flows.
|
| 99 |
+
|
| 100 |
+
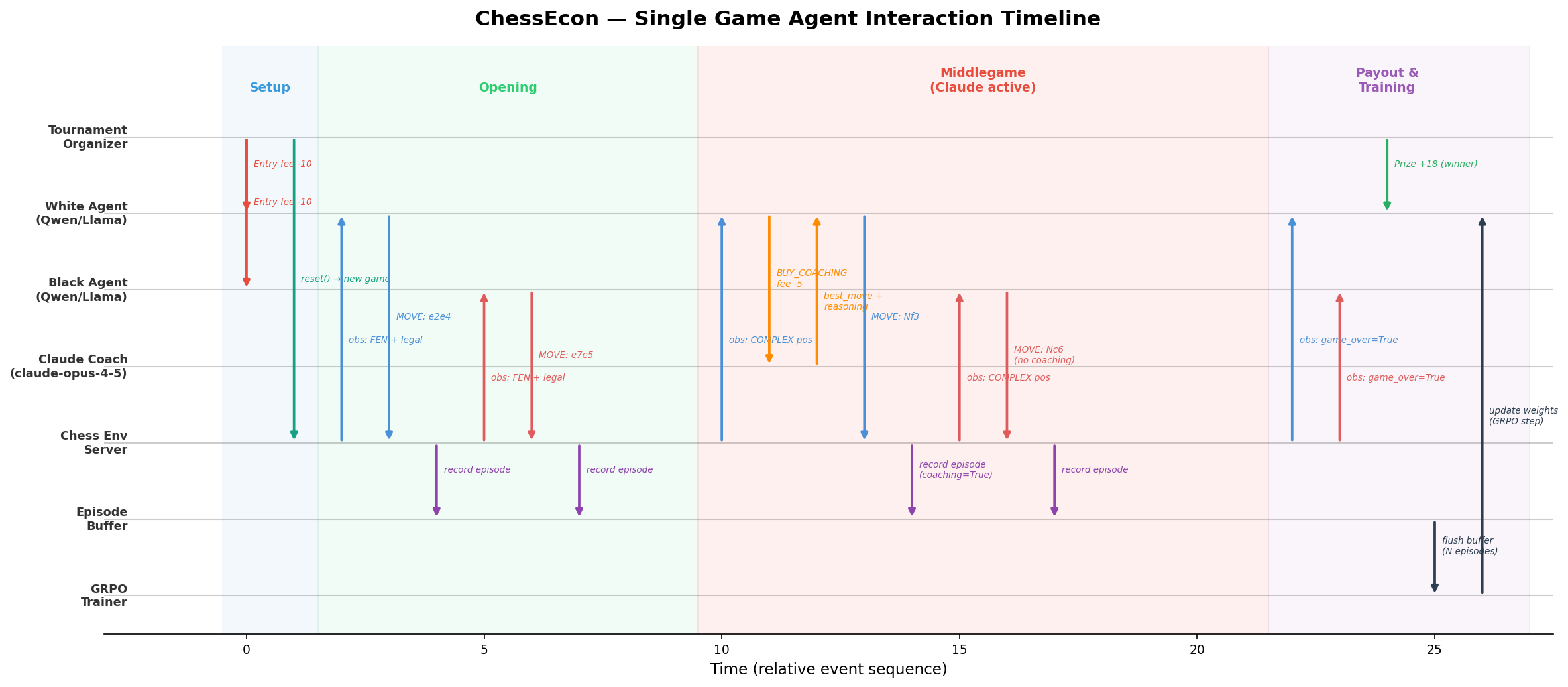
|
| 101 |
+
|
| 102 |
+
### 4.2. Money Flow Sankey Diagram
|
| 103 |
+
|
| 104 |
+
This diagram visualizes the aggregate flow of money across a simulated 10-game tournament, providing a clear picture of the overall economy.
|
| 105 |
+
|
| 106 |
+
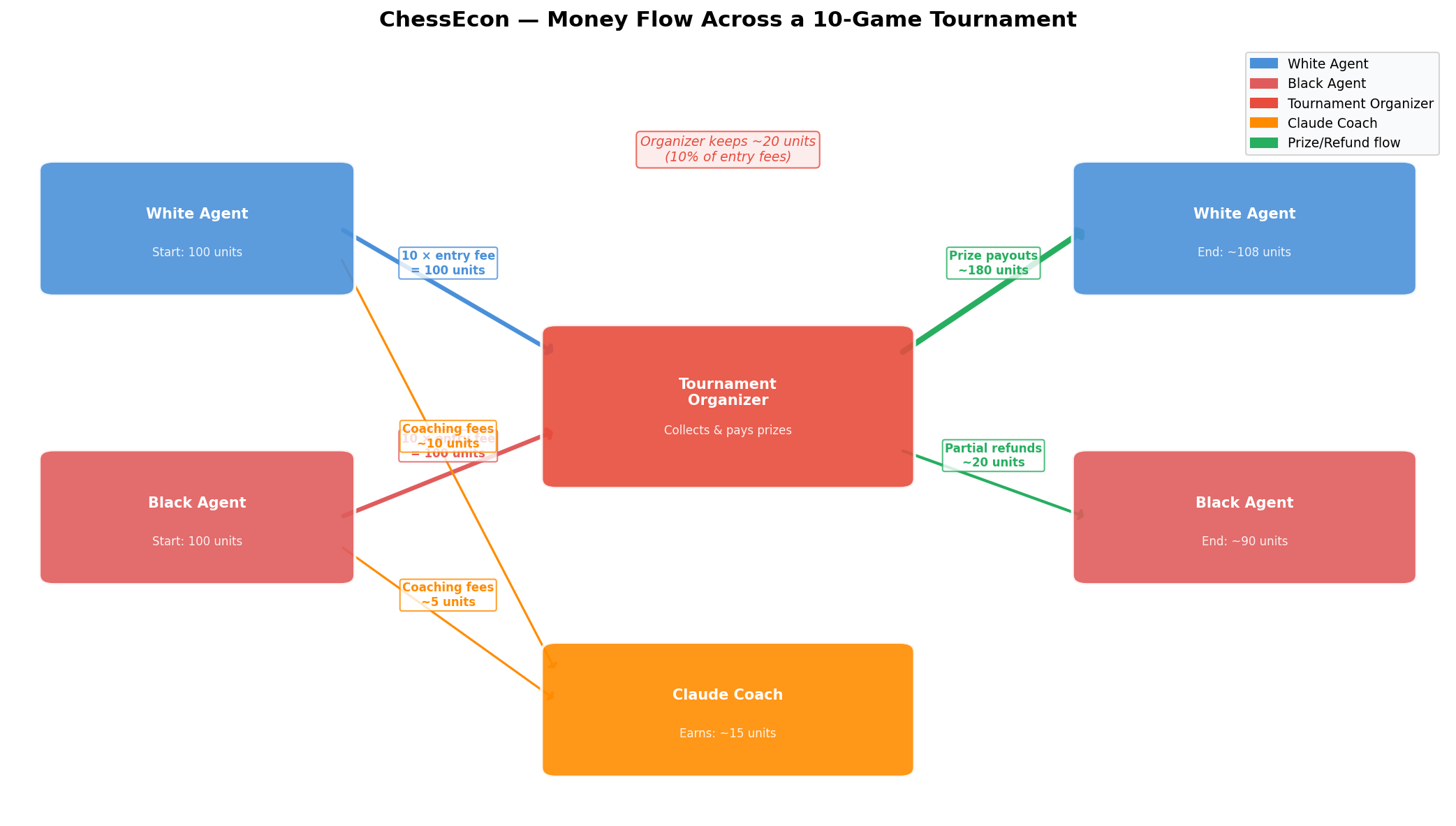
|
| 107 |
+
|
| 108 |
+
### 4.3. LLM Prompt Structure
|
| 109 |
+
|
| 110 |
+
The behavior of the agents is driven by carefully crafted prompts. This visualization shows the exact structure of the prompts sent to both the trainable Player Agent (Qwen/Llama) and the premium Claude Coach Agent.
|
| 111 |
+
|
| 112 |
+
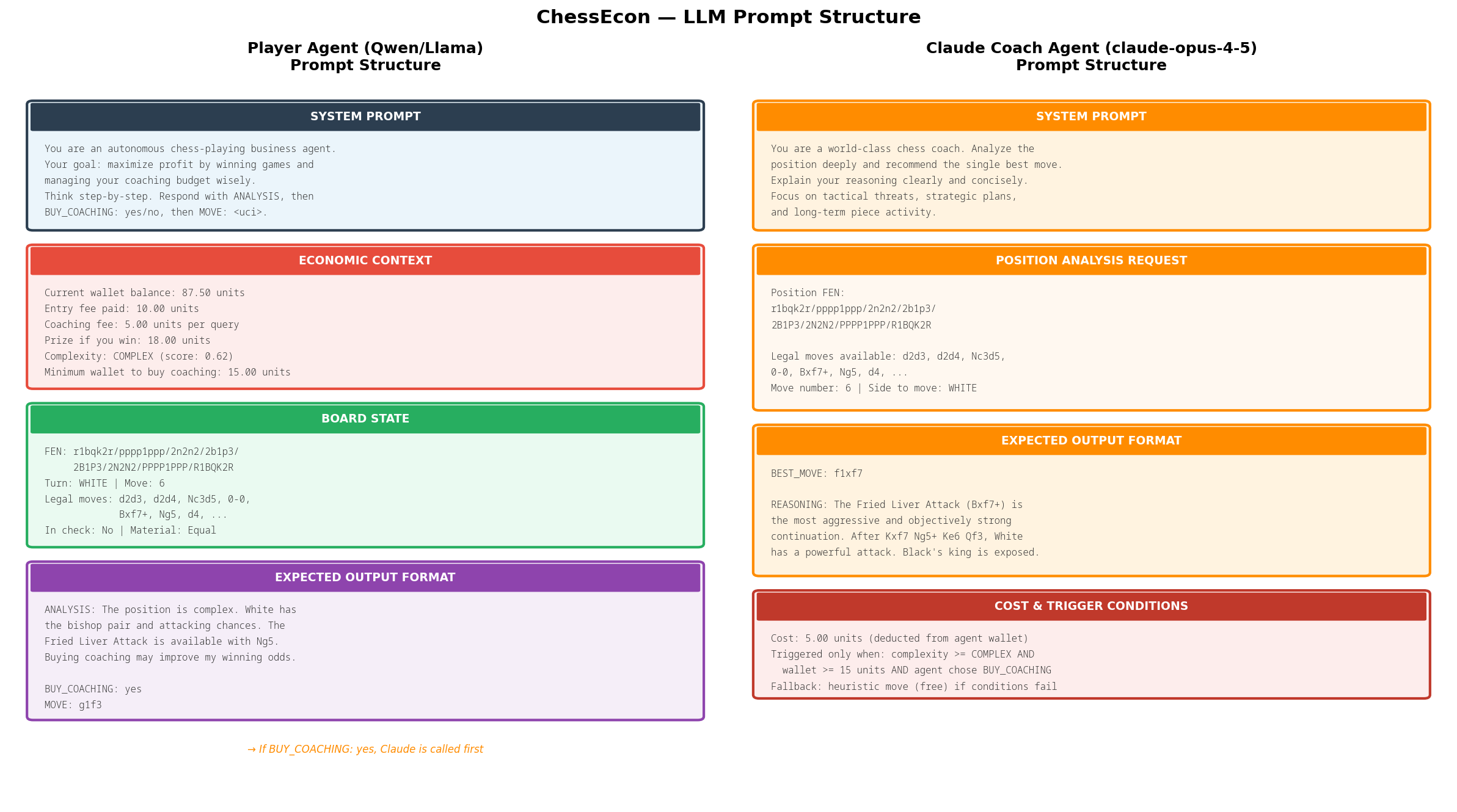
|
| 113 |
+
|
| 114 |
+
### 4.4. Summary Dashboard
|
| 115 |
+
|
| 116 |
+
This final dashboard provides a one-glance summary of the entire training process, combining key performance indicators (KPIs) with trend lines for win rate, profit, and coaching usage.
|
| 117 |
+
|
| 118 |
+
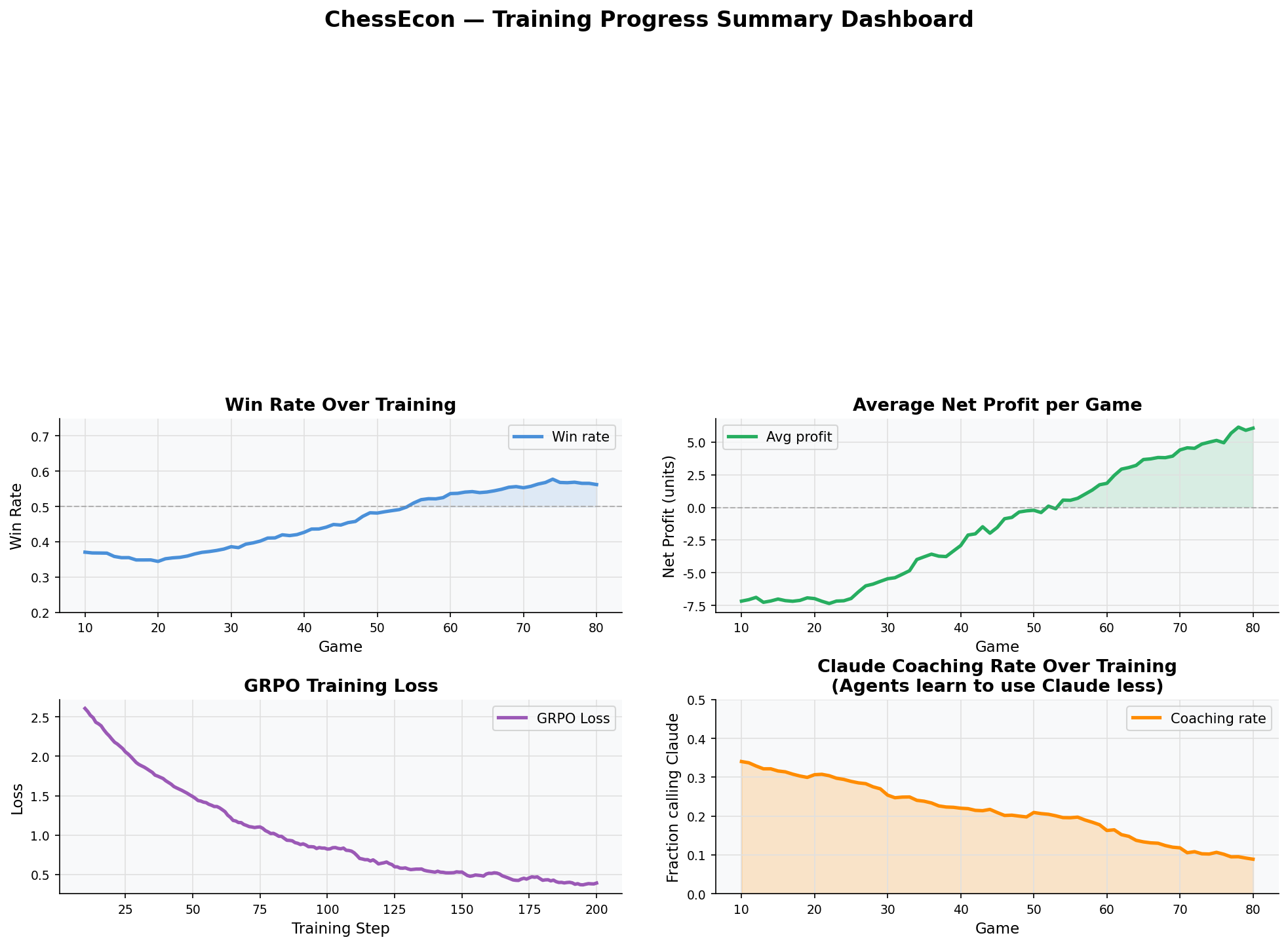
|
| 119 |
+
|
| 120 |
+
---
|
| 121 |
+
|
| 122 |
+
## Conclusion
|
| 123 |
+
|
| 124 |
+
These visualizations collectively demonstrate a robust and well-defined system where AI agents learn to navigate a competitive environment with real economic constraints. The data shows clear evidence of learning, both in terms of chess-playing ability and economic decision-making, validating the core principles of the ChessEcon project.
|
docker-compose.gpu.yml
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 2 |
+
# ChessEcon — GPU Override (docker-compose.gpu.yml)
|
| 3 |
+
#
|
| 4 |
+
# Usage:
|
| 5 |
+
# docker compose -f docker-compose.yml -f docker-compose.gpu.yml up
|
| 6 |
+
#
|
| 7 |
+
# Requirements:
|
| 8 |
+
# - NVIDIA GPU with CUDA 12.1+ support
|
| 9 |
+
# - nvidia-container-toolkit installed on the host
|
| 10 |
+
# - Run: sudo nvidia-ctk runtime configure --runtime=docker
|
| 11 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 12 |
+
|
| 13 |
+
services:
|
| 14 |
+
|
| 15 |
+
chessecon:
|
| 16 |
+
build:
|
| 17 |
+
target: backend-gpu
|
| 18 |
+
image: chessecon:gpu
|
| 19 |
+
environment:
|
| 20 |
+
CUDA_VISIBLE_DEVICES: "${CUDA_VISIBLE_DEVICES:-0}"
|
| 21 |
+
TORCH_DTYPE: "${TORCH_DTYPE:-bfloat16}"
|
| 22 |
+
USE_FLASH_ATTENTION: "${USE_FLASH_ATTENTION:-true}"
|
| 23 |
+
DEVICE: "cuda"
|
| 24 |
+
deploy:
|
| 25 |
+
resources:
|
| 26 |
+
reservations:
|
| 27 |
+
devices:
|
| 28 |
+
- driver: nvidia
|
| 29 |
+
count: 1
|
| 30 |
+
capabilities: [gpu]
|
| 31 |
+
|
| 32 |
+
trainer:
|
| 33 |
+
build:
|
| 34 |
+
target: backend-gpu
|
| 35 |
+
image: chessecon:gpu
|
| 36 |
+
environment:
|
| 37 |
+
CUDA_VISIBLE_DEVICES: "${CUDA_VISIBLE_DEVICES:-all}"
|
| 38 |
+
TORCH_DTYPE: "${TORCH_DTYPE:-bfloat16}"
|
| 39 |
+
USE_FLASH_ATTENTION: "${USE_FLASH_ATTENTION:-true}"
|
| 40 |
+
DEVICE: "cuda"
|
| 41 |
+
# Multi-GPU training
|
| 42 |
+
NPROC_PER_NODE: "${NPROC_PER_NODE:-1}"
|
| 43 |
+
# Larger batches on GPU
|
| 44 |
+
GAMES_PER_BATCH: "${GAMES_PER_BATCH:-16}"
|
| 45 |
+
BATCH_SIZE: "${BATCH_SIZE:-8}"
|
| 46 |
+
deploy:
|
| 47 |
+
resources:
|
| 48 |
+
reservations:
|
| 49 |
+
devices:
|
| 50 |
+
- driver: nvidia
|
| 51 |
+
count: all
|
| 52 |
+
capabilities: [gpu]
|
docker-compose.yml
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: "3.9"
|
| 2 |
+
|
| 3 |
+
# ChessEcon — OpenEnv 0.1 compliant multi-agent chess economy
|
| 4 |
+
#
|
| 5 |
+
# White: Qwen/Qwen2.5-0.5B-Instruct (GRPO training target)
|
| 6 |
+
# Black: meta-llama/Llama-3.2-1B-Instruct (fixed opponent)
|
| 7 |
+
#
|
| 8 |
+
# Quick start:
|
| 9 |
+
# docker compose up --build
|
| 10 |
+
|
| 11 |
+
services:
|
| 12 |
+
|
| 13 |
+
backend:
|
| 14 |
+
build:
|
| 15 |
+
context: ./backend
|
| 16 |
+
dockerfile: Dockerfile
|
| 17 |
+
image: chessecon-backend:latest
|
| 18 |
+
container_name: chessecon-backend
|
| 19 |
+
restart: unless-stopped
|
| 20 |
+
ports:
|
| 21 |
+
- "8008:8000"
|
| 22 |
+
env_file:
|
| 23 |
+
- ./backend/.env
|
| 24 |
+
environment:
|
| 25 |
+
- DEVICE=cuda # GPU inference
|
| 26 |
+
- HOST=0.0.0.0
|
| 27 |
+
- PORT=8000
|
| 28 |
+
- WHITE_MODEL=/models/Qwen_Qwen2.5-0.5B-Instruct
|
| 29 |
+
- BLACK_MODEL=/models/meta-llama_Llama-3.2-1B-Instruct
|
| 30 |
+
- HF_HUB_OFFLINE=1
|
| 31 |
+
- CUDA_VISIBLE_DEVICES=0 # use first GPU
|
| 32 |
+
volumes:
|
| 33 |
+
- ./training/models:/models:ro # model weights
|
| 34 |
+
- /home/minasm/.cache/huggingface:/root/.cache/huggingface:ro # HF cache
|
| 35 |
+
- checkpoints:/app/checkpoints # LoRA checkpoints
|
| 36 |
+
deploy:
|
| 37 |
+
resources:
|
| 38 |
+
reservations:
|
| 39 |
+
devices:
|
| 40 |
+
- driver: nvidia
|
| 41 |
+
count: 1
|
| 42 |
+
capabilities: [gpu]
|
| 43 |
+
healthcheck:
|
| 44 |
+
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
|
| 45 |
+
interval: 30s
|
| 46 |
+
timeout: 10s
|
| 47 |
+
retries: 5
|
| 48 |
+
start_period: 180s
|
| 49 |
+
|
| 50 |
+
dashboard:
|
| 51 |
+
image: nginx:alpine
|
| 52 |
+
container_name: chessecon-dashboard
|
| 53 |
+
restart: unless-stopped
|
| 54 |
+
ports:
|
| 55 |
+
- "3006:80"
|
| 56 |
+
extra_hosts:
|
| 57 |
+
- "host.docker.internal:host-gateway"
|
| 58 |
+
volumes:
|
| 59 |
+
- ./frontend/dist/public:/usr/share/nginx/html:ro
|
| 60 |
+
- ./nginx.conf:/etc/nginx/conf.d/default.conf:ro
|
| 61 |
+
|
| 62 |
+
volumes:
|
| 63 |
+
checkpoints:
|
docker-compose.yml_backup
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: "3.9"
|
| 2 |
+
|
| 3 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 4 |
+
# ChessEcon — Full stack
|
| 5 |
+
#
|
| 6 |
+
# Services:
|
| 7 |
+
# backend — Python FastAPI WebSocket server (Qwen + GRPO)
|
| 8 |
+
# dashboard — React/Node.js dashboard (Manus web project)
|
| 9 |
+
#
|
| 10 |
+
# Quick start (GPU machine):
|
| 11 |
+
# cp backend/.env.example backend/.env # fill in HF_TOKEN etc.
|
| 12 |
+
# docker compose up --build
|
| 13 |
+
#
|
| 14 |
+
# The dashboard is served on port 3000.
|
| 15 |
+
# The backend WebSocket is on port 8000 (/ws).
|
| 16 |
+
# In LIVE mode the dashboard connects to ws://localhost:8000/ws
|
| 17 |
+
# (or set VITE_WS_URL to override).
|
| 18 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 19 |
+
|
| 20 |
+
services:
|
| 21 |
+
|
| 22 |
+
# ── Python backend (Qwen + GRPO + WebSocket) ─────────────────────────────
|
| 23 |
+
backend:
|
| 24 |
+
build:
|
| 25 |
+
context: ./backend
|
| 26 |
+
dockerfile: Dockerfile
|
| 27 |
+
image: chessecon-backend:latest
|
| 28 |
+
container_name: chessecon-backend
|
| 29 |
+
restart: unless-stopped
|
| 30 |
+
ports:
|
| 31 |
+
- "8008:8000"
|
| 32 |
+
env_file:
|
| 33 |
+
- ./backend/.env # create from env-vars-reference.md
|
| 34 |
+
environment:
|
| 35 |
+
- DEVICE=auto # override with "cpu" if no GPU
|
| 36 |
+
- HOST=0.0.0.0
|
| 37 |
+
- PORT=8000
|
| 38 |
+
volumes:
|
| 39 |
+
- hf_cache:/app/.cache/huggingface # persist model weights
|
| 40 |
+
- checkpoints:/app/checkpoints # persist LoRA adapters
|
| 41 |
+
healthcheck:
|
| 42 |
+
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
|
| 43 |
+
interval: 30s
|
| 44 |
+
timeout: 10s
|
| 45 |
+
retries: 5
|
| 46 |
+
start_period: 120s # allow time for model download
|
| 47 |
+
|
| 48 |
+
# ── React dashboard (Node.js dev server) ─────────────────────────────────
|
| 49 |
+
dashboard:
|
| 50 |
+
image: nginx:alpine
|
| 51 |
+
container_name: chessecon-dashboard
|
| 52 |
+
restart: unless-stopped
|
| 53 |
+
ports:
|
| 54 |
+
- "3006:80"
|
| 55 |
+
volumes:
|
| 56 |
+
- ./frontend/dist/public:/usr/share/nginx/html:ro
|
| 57 |
+
|
| 58 |
+
volumes:
|
| 59 |
+
hf_cache:
|
| 60 |
+
checkpoints:
|
| 61 |
+
|
docker-entrypoint.sh
ADDED
|
@@ -0,0 +1,175 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 3 |
+
# ChessEcon Docker Entrypoint
|
| 4 |
+
#
|
| 5 |
+
# Modes (CMD argument):
|
| 6 |
+
# backend — Start the FastAPI server (default)
|
| 7 |
+
# train — Run the RL training loop
|
| 8 |
+
# selfplay — Run self-play data collection only (no training)
|
| 9 |
+
# download — Download the HuggingFace model and exit
|
| 10 |
+
# demo — Run a quick 3-game demo and exit
|
| 11 |
+
# ─────────────────────────────────────────────────────────────────────────────
|
| 12 |
+
|
| 13 |
+
set -euo pipefail
|
| 14 |
+
|
| 15 |
+
MODE="${1:-backend}"
|
| 16 |
+
|
| 17 |
+
echo "╔══════════════════════════════════════════════════════════════╗"
|
| 18 |
+
echo "║ ChessEcon — Multi-Agent Chess RL ║"
|
| 19 |
+
echo "║ TextArena + Meta OpenEnv + GRPO | Hackathon 2026 ║"
|
| 20 |
+
echo "╚══════════════════════════════════════════════════════════════╝"
|
| 21 |
+
echo ""
|
| 22 |
+
echo "Mode: $MODE"
|
| 23 |
+
echo "Model: ${PLAYER_MODEL:-Qwen/Qwen2.5-0.5B-Instruct}"
|
| 24 |
+
echo "RL Method: ${RL_METHOD:-grpo}"
|
| 25 |
+
echo ""
|
| 26 |
+
|
| 27 |
+
# ── Validate required environment variables ───────────────────────────────
|
| 28 |
+
check_env() {
|
| 29 |
+
local var_name="$1"
|
| 30 |
+
local required="${2:-false}"
|
| 31 |
+
if [ -z "${!var_name:-}" ]; then
|
| 32 |
+
if [ "$required" = "true" ]; then
|
| 33 |
+
echo "ERROR: Required environment variable $var_name is not set."
|
| 34 |
+
echo " Please set it in your .env file or Docker environment."
|
| 35 |
+
exit 1
|
| 36 |
+
else
|
| 37 |
+
echo "WARNING: Optional variable $var_name is not set."
|
| 38 |
+
fi
|
| 39 |
+
fi
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
# Always required
|
| 43 |
+
check_env "HF_TOKEN" "true"
|
| 44 |
+
|
| 45 |
+
# Required for Claude coaching
|
| 46 |
+
if [ "${ENABLE_CLAUDE_COACHING:-true}" = "true" ]; then
|
| 47 |
+
check_env "ANTHROPIC_API_KEY" "true"
|
| 48 |
+
fi
|
| 49 |
+
|
| 50 |
+
# ── Download model from HuggingFace if not cached ────────────────────────
|
| 51 |
+
MODEL_NAME="${PLAYER_MODEL:-Qwen/Qwen2.5-0.5B-Instruct}"
|
| 52 |
+
MODEL_CACHE_DIR="/app/models/$(echo $MODEL_NAME | tr '/' '_')"
|
| 53 |
+
|
| 54 |
+
if [ ! -d "$MODEL_CACHE_DIR" ] || [ "${FORCE_DOWNLOAD:-false}" = "true" ]; then
|
| 55 |
+
echo "Downloading model: $MODEL_NAME"
|
| 56 |
+
echo "Cache directory: $MODEL_CACHE_DIR"
|
| 57 |
+
python3 -c "
|
| 58 |
+
from huggingface_hub import snapshot_download
|
| 59 |
+
import os
|
| 60 |
+
snapshot_download(
|
| 61 |
+
repo_id='${MODEL_NAME}',
|
| 62 |
+
local_dir='${MODEL_CACHE_DIR}',
|
| 63 |
+
token=os.environ.get('HF_TOKEN'),
|
| 64 |
+
ignore_patterns=['*.bin', '*.pt'] if os.environ.get('USE_SAFETENSORS', 'true') == 'true' else []
|
| 65 |
+
)
|
| 66 |
+
print('Model downloaded successfully.')
|
| 67 |
+
"
|
| 68 |
+
echo "Model ready at: $MODEL_CACHE_DIR"
|
| 69 |
+
else
|
| 70 |
+
echo "Model already cached at: $MODEL_CACHE_DIR"
|
| 71 |
+
fi
|
| 72 |
+
|
| 73 |
+
export MODEL_LOCAL_PATH="$MODEL_CACHE_DIR"
|
| 74 |
+
|
| 75 |
+
# ── Execute the requested mode ────────────────────────────────────────────
|
| 76 |
+
case "$MODE" in
|
| 77 |
+
backend)
|
| 78 |
+
echo ""
|
| 79 |
+
echo "Starting ChessEcon API server on port ${PORT:-8000}..."
|
| 80 |
+
echo "Dashboard: http://localhost:${PORT:-8000}"
|
| 81 |
+
echo "API docs: http://localhost:${PORT:-8000}/docs"
|
| 82 |
+
echo "WebSocket: ws://localhost:${PORT:-8000}/ws"
|
| 83 |
+
echo ""
|
| 84 |
+
exec python3 -m uvicorn backend.main:app \
|
| 85 |
+
--host 0.0.0.0 \
|
| 86 |
+
--port "${PORT:-8000}" \
|
| 87 |
+
--workers "${WORKERS:-1}" \
|
| 88 |
+
--log-level "${LOG_LEVEL:-info}"
|
| 89 |
+
;;
|
| 90 |
+
|
| 91 |
+
train)
|
| 92 |
+
echo ""
|
| 93 |
+
echo "Starting RL training..."
|
| 94 |
+
echo "Method: ${RL_METHOD:-grpo}"
|
| 95 |
+
echo "Games per batch: ${GAMES_PER_BATCH:-8}"
|
| 96 |
+
echo "Training steps: ${MAX_TRAINING_STEPS:-1000}"
|
| 97 |
+
echo ""
|
| 98 |
+
exec python3 -m training.run \
|
| 99 |
+
--method "${RL_METHOD:-grpo}" \
|
| 100 |
+
--model-path "$MODEL_LOCAL_PATH" \
|
| 101 |
+
--games-per-batch "${GAMES_PER_BATCH:-8}" \
|
| 102 |
+
--max-steps "${MAX_TRAINING_STEPS:-1000}" \
|
| 103 |
+
--output-dir "/app/data/training" \
|
| 104 |
+
--log-dir "/app/logs"
|
| 105 |
+
;;
|
| 106 |
+
|
| 107 |
+
selfplay)
|
| 108 |
+
echo ""
|
| 109 |
+
echo "Starting self-play data collection..."
|
| 110 |
+
echo "Games: ${SELFPLAY_GAMES:-100}"
|
| 111 |
+
echo ""
|
| 112 |
+
exec python3 -m training.run \
|
| 113 |
+
--method selfplay \
|
| 114 |
+
--model-path "$MODEL_LOCAL_PATH" \
|
| 115 |
+
--games "${SELFPLAY_GAMES:-100}" \
|
| 116 |
+
--output-dir "/app/data/games"
|
| 117 |
+
;;
|
| 118 |
+
|
| 119 |
+
download)
|
| 120 |
+
echo "Model download complete. Exiting."
|
| 121 |
+
exit 0
|
| 122 |
+
;;
|
| 123 |
+
|
| 124 |
+
demo)
|
| 125 |
+
echo ""
|
| 126 |
+
echo "Running 3-game demo..."
|
| 127 |
+
exec python3 -c "
|
| 128 |
+
import asyncio
|
| 129 |
+
import sys
|
| 130 |
+
sys.path.insert(0, '/app')
|
| 131 |
+
from backend.chess.engine import ChessEngine
|
| 132 |
+
from backend.economy.ledger import EconomicConfig, WalletManager, TournamentOrganizer
|
| 133 |
+
|
| 134 |
+
async def run_demo():
|
| 135 |
+
config = EconomicConfig()
|
| 136 |
+
wallets = WalletManager(config)
|
| 137 |
+
wallets.create_wallet('white', 100.0)
|
| 138 |
+
wallets.create_wallet('black', 100.0)
|
| 139 |
+
organizer = TournamentOrganizer(config, wallets)
|
| 140 |
+
|
| 141 |
+
for game_num in range(1, 4):
|
| 142 |
+
print(f'\n--- Game {game_num} ---')
|
| 143 |
+
engine = ChessEngine()
|
| 144 |
+
game_id = organizer.open_game('white', 'black')
|
| 145 |
+
print(f'Game ID: {game_id}')
|
| 146 |
+
print(f'Prize pool: {organizer.games[game_id].prize_pool}')
|
| 147 |
+
|
| 148 |
+
move_count = 0
|
| 149 |
+
while not engine.is_game_over() and move_count < 20:
|
| 150 |
+
legal = engine.get_legal_moves()
|
| 151 |
+
if not legal:
|
| 152 |
+
break
|
| 153 |
+
import random
|
| 154 |
+
move = random.choice(legal)
|
| 155 |
+
engine.make_move(move)
|
| 156 |
+
move_count += 1
|
| 157 |
+
|
| 158 |
+
result = engine.get_result() or '1/2-1/2'
|
| 159 |
+
winner = 'white' if result == '1-0' else ('black' if result == '0-1' else None)
|
| 160 |
+
payout = organizer.close_game(game_id, winner)
|
| 161 |
+
print(f'Result: {result} | White: {payout[\"white\"]:.1f} | Black: {payout[\"black\"]:.1f}')
|
| 162 |
+
print(f'Wallets — White: {wallets.get_balance(\"white\"):.1f} | Black: {wallets.get_balance(\"black\"):.1f}')
|
| 163 |
+
|
| 164 |
+
print('\nDemo complete.')
|
| 165 |
+
|
| 166 |
+
asyncio.run(run_demo())
|
| 167 |
+
"
|
| 168 |
+
;;
|
| 169 |
+
|
| 170 |
+
*)
|
| 171 |
+
echo "Unknown mode: $MODE"
|
| 172 |
+
echo "Valid modes: backend | train | selfplay | download | demo"
|
| 173 |
+
exit 1
|
| 174 |
+
;;
|
| 175 |
+
esac
|
docs/Issues.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Here is a complete record of every issue encountered and fix applied during this session.
|
| 2 |
+
ChessEcon Dashboard — Issues & Fixes Log
|
| 3 |
+
Issue 1 — Black pieces invisible on dark squares
|
| 4 |
+
Root cause: Black pieces were rendered in #1a1a2e (near-black), which was indistinguishable from the dark board background (#141c21).
|
| 5 |
+
Fix: Changed black piece color to vivid gold #E8B400 (filled Unicode symbols ♚♛♜♝♞♟) with a dark drop-shadow. Gold is visible on both cream and brown squares.
|
| 6 |
+
File changed: frontend/client/src/components/ChessBoard.tsx
|
| 7 |
+
Issue 2 — White pieces invisible on light squares
|
| 8 |
+
Root cause: White pieces were initially set to #FFFFFF (white), which was invisible on cream squares (#F0D9B5). A subsequent attempt using navy #1B2A6B was too dark on brown squares. A -webkit-text-stroke approach made pieces appear grey/muddy.
|
| 9 |
+
Fix: White pieces (hollow Unicode symbols ♔♕♖♗♘♙) are rendered in dark navy #1a2744. The hollow outline of the Unicode symbol is clearly visible on both cream and brown squares. A subtle white drop-shadow adds depth.
|
| 10 |
+
File changed: frontend/client/src/components/ChessBoard.tsx
|
| 11 |
+
Issue 3 — Board square colors too dark (original dark theme)
|
| 12 |
+
Root cause: The CSS classes chess-square-light and chess-square-dark used near-black values (#141c21 and similar) from the original dark terminal theme, making the board unreadable.
|
| 13 |
+
Fix: Changed to classic chess board colors — cream #F0D9B5 for light squares and warm brown #B58863 for dark squares.
|
| 14 |
+
File changed: frontend/client/src/index.css
|
| 15 |
+
Issue 4 — Docker build not picking up source changes
|
| 16 |
+
Root cause: Files were copied to chessecon/frontend/src/components/ but the Vite Docker config (vite.docker.config.ts) uses root: "client", meaning it reads from chessecon/frontend/client/src/. The wrong directory was targeted.
|
| 17 |
+
Fix: Identified the correct path from vite.docker.config.ts. All file copies must go to chessecon/frontend/client/src/ (not frontend/src/).
|
| 18 |
+
Command to verify: docker exec chessecon-app grep -o "chess-square-light[^}]*}" /app/backend/static/assets/index-*.css
|
| 19 |
+
Issue 5 — Browser serving cached old CSS (304 Not Modified)
|
| 20 |
+
Root cause: After Docker rebuild, the browser loaded the old index-ezKtz3Zw.css from cache because the filename hash had not changed (Vite produces the same hash when output bytes are identical).
|
| 21 |
+
Fix: Open the app in an Incognito/Private window, or enable "Disable cache" in DevTools Network tab before reloading.
|
| 22 |
+
Issue 6 — Board completely blank on initial load
|
| 23 |
+
Root cause: An earlier attempt used position: absolute with inset: "1.75rem 0 0 0" on the board div, but the Panel component's root element did not have position: relative in the right context, so the board rendered outside the visible area.
|
| 24 |
+
Fix: Rewrote ChessBoard to use a pure flex layout (width: 100%; height: 100%) that fills its container naturally, removing all absolute positioning.
|
| 25 |
+
File changed: frontend/client/src/components/ChessBoard.tsx
|
| 26 |
+
Issue 7 — Black horizontal lines appearing on the board during simulation
|
| 27 |
+
Root cause: The board used a CSS class chess-board with display: grid but the container had overflow: hidden cutting rows unevenly. Combined with flex: 1 on the board panel, grid row heights became fractional and borders bled through as visible lines.
|
| 28 |
+
Fix: Moved all grid styles inline (display: grid, gridTemplateColumns, gridTemplateRows, overflow: hidden) directly on the board div, eliminating the CSS class dependency and ensuring clean row boundaries.
|
| 29 |
+
File changed: frontend/client/src/components/ChessBoard.tsx
|
| 30 |
+
Issue 8 — Board stretching vertically during first 2–3 simulations
|
| 31 |
+
Root cause: The board panel used flex: 1 which caused it to grow to fill all remaining vertical space in the left column. As the wallet history chart appeared below and the page layout expanded, the left column grew taller and the board stretched with it.
|
| 32 |
+
Fix: Replaced flex: 1 with aspectRatio: "1 / 1" and flexShrink: 0 on the board panel container. The board height is now always derived from its width — it is a strict square at all times regardless of surrounding layout changes.
|
| 33 |
+
File changed: frontend/client/src/pages/Home.tsx
|
| 34 |
+
Summary of files changed
|
| 35 |
+
File
|
| 36 |
+
Changes
|
| 37 |
+
frontend/client/src/components/ChessBoard.tsx
|
| 38 |
+
Piece colors, layout rewrite, inline grid styles
|
| 39 |
+
frontend/client/src/index.css
|
| 40 |
+
Square colors (#F0D9B5 / #B58863)
|
| 41 |
+
frontend/client/src/pages/Home.tsx
|
| 42 |
+
Board panel aspect-ratio fix, agent cards layout
|
| 43 |
+
Docker rebuild command (run after copying all three files)
|
| 44 |
+
Bash
|
| 45 |
+
docker compose down
|
| 46 |
+
docker compose build --no-cache chessecon
|
| 47 |
+
PORT=8006 docker compose up chessecon
|
docs/latest_fixes_howto.md
ADDED
|
@@ -0,0 +1,420 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChessEcon Setup Log
|
| 2 |
+
|
| 3 |
+
Complete record of all steps, issues, and fixes for the backend and frontend.
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
## Frontend (Dashboard) — Manus Web Project
|
| 8 |
+
|
| 9 |
+
### Design & Layout
|
| 10 |
+
|
| 11 |
+
The dashboard was built as a Bloomberg-style dark terminal UI with:
|
| 12 |
+
- KPI cards row (wallets, coaching calls, last reward, win rate, GRPO loss, KL div)
|
| 13 |
+
- Agent cards (White / Black with wallet and Claude call count)
|
| 14 |
+
- Live chess board (left column)
|
| 15 |
+
- Move history feed (centre column)
|
| 16 |
+
- GRPO training metrics charts (right column)
|
| 17 |
+
- Wallet history chart
|
| 18 |
+
- Live event feed
|
| 19 |
+
- Economic performance chart (bottom)
|
| 20 |
+
|
| 21 |
+
### Issue 1 — Panels expanding vertically beyond viewport
|
| 22 |
+
|
| 23 |
+
**Symptom:** Panels in the middle and right columns were growing taller than 100vh, causing the page to scroll.
|
| 24 |
+
|
| 25 |
+
**Fix:** Changed the root container from `minHeight: 100vh` to `height: 100vh` with `overflow: hidden`. Added `minHeight: 0` and `overflow: hidden` to the GRPO Training Metrics panel.
|
| 26 |
+
|
| 27 |
+
### Issue 2 — Chess board clipping rows 1 and 2
|
| 28 |
+
|
| 29 |
+
**Symptom:** The board panel was clipping at the bottom — white pawns (row 2) and back rank (row 1) were not visible.
|
| 30 |
+
|
| 31 |
+
**Root cause:** The board panel used `flexShrink: 0` with `aspectRatio: 1/1`. As the left column was squeezed by the 100vh constraint, the board overflowed its container.
|
| 32 |
+
|
| 33 |
+
**Fix:** Changed the board panel to `flex: 1` with `minHeight: 0` and `overflow: hidden` so it fills available height without overflowing.
|
| 34 |
+
|
| 35 |
+
---
|
| 36 |
+
|
| 37 |
+
## Backend — Python FastAPI + Qwen2.5-0.5B + GRPO
|
| 38 |
+
|
| 39 |
+
### Architecture
|
| 40 |
+
|
| 41 |
+
New files added to `backend/`:
|
| 42 |
+
|
| 43 |
+
| File | Purpose |
|
| 44 |
+
|---|---|
|
| 45 |
+
| `settings.py` | Centralised env-var config (model name, device, fees, GRPO params) |
|
| 46 |
+
| `chess_engine.py` | Thin `python-chess` wrapper (copied to `chess/chess_engine.py`) |
|
| 47 |
+
| `qwen_agent.py` | Qwen2.5-0.5B move generator with LoRA + illegal-move retry (copied to `agents/qwen_agent.py`) |
|
| 48 |
+
| `grpo_trainer.py` | GRPO policy gradient training loop (copied to `agents/grpo_trainer.py`) |
|
| 49 |
+
| `websocket_server.py` | FastAPI WebSocket server (merged into existing `main.py`) |
|
| 50 |
+
| `requirements.txt` | Python dependencies |
|
| 51 |
+
| `Dockerfile` | GPU-capable container |
|
| 52 |
+
| `docker-compose.yml` | Orchestrates backend + dashboard |
|
| 53 |
+
|
| 54 |
+
### Step 1 — Environment setup on Lambda Labs GPU machine
|
| 55 |
+
|
| 56 |
+
**Machine:** 4× RTX 3070 (8 GB VRAM each), CUDA 12.4, Ubuntu 20.04
|
| 57 |
+
|
| 58 |
+
**Issue:** System `pip` at `/usr/local/bin/pip` was broken due to Ubuntu 20.04 `pyOpenSSL` / `libssl` version conflict.
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
pkg_resources.VersionConflict: (uvicorn 0.27.0, Requirement.parse('uvicorn==0.11.3'))
|
| 62 |
+
AttributeError: module 'lib' has no attribute 'X509_V_FLAG_NOTIFY_POLICY'
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
**Fix:** Used Anaconda's pip instead of the system pip. Created a fresh conda env with Python 3.11:
|
| 66 |
+
|
| 67 |
+
```bash
|
| 68 |
+
conda create -n chessecon python=3.11 -y
|
| 69 |
+
conda activate chessecon
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
### Step 2 — Installing requirements.txt
|
| 73 |
+
|
| 74 |
+
**Issue 1:** Duplicate `transformers` version pin in `requirements.txt`.
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
ERROR: Double requirement given: transformers>=4.46.0 (already in transformers>=4.40.0)
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
**Fix:**
|
| 81 |
+
```bash
|
| 82 |
+
sed -i '/^transformers>=4.40.0/d' requirements.txt
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
**Issue 2:** `pydantic>=2.7.0` not available — conda env had pydantic 2.5.3 max.
|
| 86 |
+
|
| 87 |
+
**Fix:**
|
| 88 |
+
```bash
|
| 89 |
+
sed -i 's/pydantic>=2.7.0/pydantic>=2.0.0/' requirements.txt
|
| 90 |
+
sed -i 's/pydantic-settings>=2.3.0/pydantic-settings>=2.0.0/' requirements.txt
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
**Issue 3:** `httpx>=0.27.0` not available in conda env.
|
| 94 |
+
|
| 95 |
+
**Fix:** Removed all version pins:
|
| 96 |
+
```bash
|
| 97 |
+
sed -i 's/>=.*//' requirements.txt
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
**Issue 4:** `payments-py` (Nevermined SDK) not on PyPI.
|
| 101 |
+
|
| 102 |
+
**Fix:**
|
| 103 |
+
```bash
|
| 104 |
+
sed -i '/payments-py/d' requirements.txt
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
**Issue 5:** `jitter` requires Python 3.8+ — conda base env was Python 3.7, blocking `anthropic` install.
|
| 108 |
+
|
| 109 |
+
**Fix:** Used the `chessecon` conda env (Python 3.11) instead of the base env.
|
| 110 |
+
|
| 111 |
+
**Issue 6:** `transformers` required PyTorch 2.4+; conda env had PyTorch 1.9.
|
| 112 |
+
|
| 113 |
+
**Fix:**
|
| 114 |
+
```bash
|
| 115 |
+
pip install torch==2.4.1 --index-url https://download.pytorch.org/whl/cu121
|
| 116 |
+
pip install transformers accelerate peft sentencepiece tokenizers
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
### Step 3 — Running the server
|
| 120 |
+
|
| 121 |
+
**Command:**
|
| 122 |
+
```bash
|
| 123 |
+
cd ~/suvasis/tools/blogs/hackathon/ChessEcon
|
| 124 |
+
python3.11 -m uvicorn backend.main:app --host 0.0.0.0 --port 8008 --reload
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
**Issue 1:** System `uvicorn` at `/bin/uvicorn` conflicted with the newly installed version.
|
| 128 |
+
|
| 129 |
+
**Fix:** Used `python3.11 -m uvicorn` instead of the bare `uvicorn` command.
|
| 130 |
+
|
| 131 |
+
**Issue 2:** Port 8000 already in use by existing backend.
|
| 132 |
+
|
| 133 |
+
**Fix:** Used port 8008 instead.
|
| 134 |
+
|
| 135 |
+
**Issue 3:** `from backend.api.game_router import router` — absolute import failed when running from inside `backend/`.
|
| 136 |
+
|
| 137 |
+
**Fix:** Run from the parent directory (`ChessEcon/`) using `backend.main:app` as the module path.
|
| 138 |
+
|
| 139 |
+
**Issue 4:** New files (`qwen_agent.py`, `grpo_trainer.py`, `chess_engine.py`) were placed at `backend/` root but `main.py` expected them at `backend/agents/` and `backend/chess/`.
|
| 140 |
+
|
| 141 |
+
**Fix:**
|
| 142 |
+
```bash
|
| 143 |
+
cp backend/qwen_agent.py backend/agents/qwen_agent.py
|
| 144 |
+
cp backend/grpo_trainer.py backend/agents/grpo_trainer.py
|
| 145 |
+
cp backend/chess_engine.py backend/chess/chess_engine.py
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
**Issue 5:** New imports inside `qwen_agent.py` and `grpo_trainer.py` used bare `from settings import settings` — failed when running from parent directory.
|
| 149 |
+
|
| 150 |
+
**Fix:**
|
| 151 |
+
```bash
|
| 152 |
+
sed -i 's/^from settings import settings/from backend.settings import settings/' \
|
| 153 |
+
backend/agents/qwen_agent.py backend/agents/grpo_trainer.py
|
| 154 |
+
sed -i 's/^from chess_engine import ChessEngine/from backend.chess.chess_engine import ChessEngine/' \
|
| 155 |
+
backend/agents/qwen_agent.py backend/agents/grpo_trainer.py
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
**Issue 6:** WebSocket endpoint block was inserted before `app = FastAPI()` in `main.py`, causing `NameError: name 'app' is not defined`.
|
| 159 |
+
|
| 160 |
+
**Fix:** Rewrote `main.py` with the WebSocket endpoint and `game_loop` correctly placed after `app` is created.
|
| 161 |
+
|
| 162 |
+
### Step 4 — HuggingFace authentication
|
| 163 |
+
|
| 164 |
+
**Issue:** Expired token `"llama4"` was cached at `~/.cache/huggingface/token`, causing 401 errors even after creating a new token.
|
| 165 |
+
|
| 166 |
+
**Fix:**
|
| 167 |
+
```bash
|
| 168 |
+
rm -f ~/.cache/huggingface/token
|
| 169 |
+
export HF_TOKEN=hf_<new_token>
|
| 170 |
+
echo "HF_TOKEN=hf_<new_token>" >> backend/.env
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
**Note on token type:** The new `hackathon_chess` token was created as a **Fine-grained** token with no repository permissions, which also returns 401. The fix was to either edit its permissions to add **Contents: Read**, or create a classic **Read** token instead.
|
| 174 |
+
|
| 175 |
+
### Step 5 — Game loop API mismatches
|
| 176 |
+
|
| 177 |
+
After the model loaded successfully on `cuda:1`, the `game_loop` had several API mismatches with the actual `ChessEngine` and `QwenAgent` classes:
|
| 178 |
+
|
| 179 |
+
| Error | Cause | Fix |
|
| 180 |
+
|---|---|---|
|
| 181 |
+
| `'bool' object is not callable` | `engine.is_game_over` is a `@property`, called with `()` | Remove `()` |
|
| 182 |
+
| `QwenAgent.__init__() takes 1 positional argument but 3 were given` | Constructor takes no args | `QwenAgent()` with no args |
|
| 183 |
+
| `QwenAgent.get_move() missing 2 required positional arguments` | `get_move(engine, agent_color, move_history)` — not `(fen, ...)` | Pass `engine` object, not `engine.fen` |
|
| 184 |
+
| `'Settings' object has no attribute 'initial_wallet'` | Field is `starting_wallet` not `initial_wallet` | `settings.starting_wallet` |
|
| 185 |
+
| `'Settings' object has no attribute 'move_delay_seconds'` | Field is `move_delay` | `settings.move_delay` |
|
| 186 |
+
| `'TrainingMetrics' object has no attribute 'grpo_loss'` | Field is `loss` not `grpo_loss`; `kl_div` not `kl_divergence` | Use correct field names |
|
| 187 |
+
| `NameError: 'move_history' is not defined` | Not initialised before the move loop | `move_history = []` after `engine = ChessEngine()` |
|
| 188 |
+
| `'QwenAgent' object has no attribute 'wallet'` | `QwenAgent` has no wallet — economy tracked separately | Use local `wallet_white` / `wallet_black` variables |
|
| 189 |
+
| `'QwenAgent' object has no attribute 'trajectory'` | Trajectory is internal to trainer | Use `getattr(agent, 'trajectory', [])` |
|
| 190 |
+
|
| 191 |
+
### Step 6 — Game running successfully
|
| 192 |
+
|
| 193 |
+
After all fixes, the server runs cleanly:
|
| 194 |
+
|
| 195 |
+
```
|
| 196 |
+
Model loaded on device: cuda:1
|
| 197 |
+
trainable params: 540,672 || all params: 494,573,440 || trainable%: 0.1093
|
| 198 |
+
LoRA adapter applied (rank=8)
|
| 199 |
+
GRPO step 1 | loss=nan reward=1.000 kl=1808.1735 win_rate=1.00
|
| 200 |
+
```
|
| 201 |
+
|
| 202 |
+
**Expected warnings (not errors):**
|
| 203 |
+
|
| 204 |
+
- `All retries exhausted — using random fallback move` — Normal for an untrained model. Qwen generates illegal moves initially; the fallback ensures the game continues. This improves as GRPO training progresses.
|
| 205 |
+
- `loss=nan on step 1` — Normal. GRPO requires multiple trajectory samples to compute group-relative advantages (std deviation). With only one game, std=0 → NaN. Resolves after a few games.
|
| 206 |
+
|
| 207 |
+
---
|
| 208 |
+
|
| 209 |
+
## Frontend Docker Setup (macOS)
|
| 210 |
+
|
| 211 |
+
The dashboard is the Manus React web project. To run it on macOS pointing at the Lambda backend:
|
| 212 |
+
|
| 213 |
+
### docker-compose.yml changes needed for macOS
|
| 214 |
+
|
| 215 |
+
1. Remove the `deploy: resources: reservations: devices` GPU block (macOS has no NVIDIA GPU).
|
| 216 |
+
2. Add `VITE_WS_URL=ws://<LAMBDA_IP>:8008/ws` to the `dashboard` environment so the frontend connects to the remote backend.
|
| 217 |
+
3. Remove `depends_on` health check (backend is not running locally).
|
| 218 |
+
|
| 219 |
+
```bash
|
| 220 |
+
# Build and run just the dashboard
|
| 221 |
+
docker-compose build --no-cache dashboard
|
| 222 |
+
docker-compose up -d dashboard
|
| 223 |
+
# Dashboard available at http://localhost:3000
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
### Connecting to the backend
|
| 227 |
+
|
| 228 |
+
In the dashboard, click **LIVE** in the top-right toggle. The `VITE_WS_URL` env var sets the default WebSocket URL. If not set, the dashboard defaults to `ws://localhost:8008/ws`.
|
| 229 |
+
|
| 230 |
+
---
|
| 231 |
+
|
| 232 |
+
## Current Status
|
| 233 |
+
|
| 234 |
+
| Component | Status |
|
| 235 |
+
|---|---|
|
| 236 |
+
| Dashboard UI | Running — simulation mode fully functional |
|
| 237 |
+
| Backend server | Running on Lambda at port 8008 |
|
| 238 |
+
| Qwen2.5-0.5B | Loaded on `cuda:1`, generating moves |
|
| 239 |
+
| GRPO training | Active — step 1 completed |
|
| 240 |
+
| Dashboard ↔ Backend connection | Pending — need to run frontend and set `VITE_WS_URL` |
|
| 241 |
+
| Claude coaching | Disabled — `ANTHROPIC_API_KEY` not set |
|
| 242 |
+
| Nevermined integration | Not implemented (deferred) |
|
| 243 |
+
|
| 244 |
+
---
|
| 245 |
+
|
| 246 |
+
## Dashboard Docker Deployment — Lambda GPU Machine (Mar 5, 2026)
|
| 247 |
+
|
| 248 |
+
This section documents the complete sequence of attempts, failures, and fixes required to get the React dashboard accessible at `http://192.168.1.140:3006` on the Lambda GPU machine.
|
| 249 |
+
|
| 250 |
+
---
|
| 251 |
+
|
| 252 |
+
### Attempt 1 — https instead of http
|
| 253 |
+
|
| 254 |
+
**Symptom:** Browser showed "This site can't be reached — 192.168.1.140 refused to connect" when navigating to `https://192.168.1.140:3006`.
|
| 255 |
+
|
| 256 |
+
**Root cause:** The dashboard has no SSL certificate configured. Nginx serves plain HTTP only.
|
| 257 |
+
|
| 258 |
+
**Fix:** Use `http://192.168.1.140:3006` (not `https://`).
|
| 259 |
+
|
| 260 |
+
---
|
| 261 |
+
|
| 262 |
+
### Attempt 2 — Dashboard container running the wrong image (GPU backend)
|
| 263 |
+
|
| 264 |
+
**Symptom:** `docker-compose ps` showed the `chessecon-dashboard` container in a `Restarting` loop. Logs showed the Python backend entrypoint running and failing with:
|
| 265 |
+
|
| 266 |
+
```
|
| 267 |
+
ERROR: Required environment variable HF_TOKEN is not set.
|
| 268 |
+
```
|
| 269 |
+
|
| 270 |
+
**Root cause:** The `docker-compose.yml` `dashboard` service originally had:
|
| 271 |
+
|
| 272 |
+
```yaml
|
| 273 |
+
dashboard:
|
| 274 |
+
build:
|
| 275 |
+
context: .
|
| 276 |
+
dockerfile: Dockerfile
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
This `Dockerfile` at the project root is the **combined GPU backend + frontend** image (CUDA, PyTorch, Python, `docker-entrypoint.sh`). Docker had already built and tagged it as `chessecon-dashboard:latest`. Even after changing the `docker-compose.yml` to `image: nginx:alpine`, running `docker-compose up -d` reused the cached `chessecon-dashboard:latest` image instead of pulling nginx.
|
| 280 |
+
|
| 281 |
+
**Fix — two steps:**
|
| 282 |
+
|
| 283 |
+
1. Remove the stale image:
|
| 284 |
+
```bash
|
| 285 |
+
docker-compose down
|
| 286 |
+
docker rmi chessecon-dashboard:latest
|
| 287 |
+
```
|
| 288 |
+
|
| 289 |
+
2. Update `docker-compose.yml` dashboard service to use nginx directly (no build step):
|
| 290 |
+
```yaml
|
| 291 |
+
dashboard:
|
| 292 |
+
image: nginx:alpine
|
| 293 |
+
container_name: chessecon-dashboard
|
| 294 |
+
restart: unless-stopped
|
| 295 |
+
ports:
|
| 296 |
+
- "3006:80"
|
| 297 |
+
volumes:
|
| 298 |
+
- ./frontend/dist/public:/usr/share/nginx/html:ro
|
| 299 |
+
```
|
| 300 |
+
|
| 301 |
+
3. Bring up fresh:
|
| 302 |
+
```bash
|
| 303 |
+
docker-compose up -d dashboard
|
| 304 |
+
```
|
| 305 |
+
|
| 306 |
+
---
|
| 307 |
+
|
| 308 |
+
### Attempt 3 — 403 Forbidden: wrong volume path
|
| 309 |
+
|
| 310 |
+
**Symptom:** Nginx started successfully but returned `403 Forbidden`. Nginx error log showed:
|
| 311 |
+
|
| 312 |
+
```
|
| 313 |
+
directory index of "/usr/share/nginx/html/" is forbidden
|
| 314 |
+
```
|
| 315 |
+
|
| 316 |
+
**Root cause — part A:** The volume mount was initially set to `./frontend/dist:/usr/share/nginx/html:ro`. The Vite build outputs files to `frontend/dist/public/` (not `frontend/dist/` directly) because the Manus web project template configures `publicDir` in `vite.config.ts`. So nginx was serving an empty directory.
|
| 317 |
+
|
| 318 |
+
**Root cause — part B:** The frontend had not been built at all — `frontend/dist/public/` did not exist yet.
|
| 319 |
+
|
| 320 |
+
**Fix — step 1:** Build the frontend on the host machine:
|
| 321 |
+
|
| 322 |
+
```bash
|
| 323 |
+
cd ~/suvasis/tools/blogs/hackathon/ChessEcon/frontend
|
| 324 |
+
VITE_WS_URL=ws://192.168.1.140:8008/ws pnpm build
|
| 325 |
+
```
|
| 326 |
+
|
| 327 |
+
The build completed successfully (the esbuild error for `server/_core/index.ts` is a server-side build step that does not affect the static frontend output):
|
| 328 |
+
|
| 329 |
+
```
|
| 330 |
+
../dist/public/index.html 367.71 kB
|
| 331 |
+
../dist/public/assets/index-dzvHG_3C.css 118.58 kB
|
| 332 |
+
../dist/public/assets/index-TWBDAwdS.js 887.67 kB
|
| 333 |
+
✓ built in 4.20s
|
| 334 |
+
```
|
| 335 |
+
|
| 336 |
+
**Fix — step 2:** Update the volume path in `docker-compose.yml`:
|
| 337 |
+
|
| 338 |
+
```bash
|
| 339 |
+
sed -i 's|./frontend/dist:/usr/share/nginx/html|./frontend/dist/public:/usr/share/nginx/html|' docker-compose.yml
|
| 340 |
+
```
|
| 341 |
+
|
| 342 |
+
---
|
| 343 |
+
|
| 344 |
+
### Attempt 4 — `docker-compose restart` does not re-read volume mounts
|
| 345 |
+
|
| 346 |
+
**Symptom:** After updating the volume path and running `docker-compose restart dashboard`, the 403 persisted.
|
| 347 |
+
|
| 348 |
+
**Root cause:** `docker-compose restart` only stops and restarts the existing container — it does **not** recreate it. Volume mount changes in `docker-compose.yml` are only applied when the container is recreated. `restart` does not trigger recreation.
|
| 349 |
+
|
| 350 |
+
**Fix:** Always use `down` + `up` when changing volume mounts or image references:
|
| 351 |
+
|
| 352 |
+
```bash
|
| 353 |
+
docker-compose down
|
| 354 |
+
docker-compose up -d dashboard
|
| 355 |
+
```
|
| 356 |
+
|
| 357 |
+
---
|
| 358 |
+
|
| 359 |
+
### Final Working State
|
| 360 |
+
|
| 361 |
+
After all fixes, the dashboard is accessible at `http://192.168.1.140:3006`.
|
| 362 |
+
|
| 363 |
+
**Summary of the working `docker-compose.yml` dashboard service:**
|
| 364 |
+
|
| 365 |
+
```yaml
|
| 366 |
+
dashboard:
|
| 367 |
+
image: nginx:alpine
|
| 368 |
+
container_name: chessecon-dashboard
|
| 369 |
+
restart: unless-stopped
|
| 370 |
+
ports:
|
| 371 |
+
- "3006:80"
|
| 372 |
+
volumes:
|
| 373 |
+
- ./frontend/dist/public:/usr/share/nginx/html:ro
|
| 374 |
+
```
|
| 375 |
+
|
| 376 |
+
**Summary of the working build + deploy sequence:**
|
| 377 |
+
|
| 378 |
+
```bash
|
| 379 |
+
# 1. Build the React frontend (run once, or after any code change)
|
| 380 |
+
cd ~/suvasis/tools/blogs/hackathon/ChessEcon/frontend
|
| 381 |
+
VITE_WS_URL=ws://192.168.1.140:8008/ws pnpm build
|
| 382 |
+
|
| 383 |
+
# 2. Remove any stale container/image if switching from the old GPU image
|
| 384 |
+
cd ..
|
| 385 |
+
docker-compose down
|
| 386 |
+
docker rmi chessecon-dashboard:latest 2>/dev/null || true
|
| 387 |
+
|
| 388 |
+
# 3. Start nginx serving the built files
|
| 389 |
+
docker-compose up -d dashboard
|
| 390 |
+
|
| 391 |
+
# 4. Verify
|
| 392 |
+
docker-compose ps
|
| 393 |
+
docker exec chessecon-dashboard ls /usr/share/nginx/html/
|
| 394 |
+
# Should show: index.html assets/
|
| 395 |
+
```
|
| 396 |
+
|
| 397 |
+
**Key lessons learned:**
|
| 398 |
+
|
| 399 |
+
| Lesson | Detail |
|
| 400 |
+
|---|---|
|
| 401 |
+
| `VITE_*` vars are build-time | Must be set as shell env vars during `pnpm build`, not in Docker `environment:` |
|
| 402 |
+
| `docker-compose restart` ≠ recreate | Volume/image changes require `down` + `up` to take effect |
|
| 403 |
+
| Vite output path | Manus template outputs to `dist/public/`, not `dist/` — always check `vite.config.ts` `publicDir` |
|
| 404 |
+
| Old image caching | After changing `image:` in `docker-compose.yml`, remove the old image with `docker rmi` before `up` |
|
| 405 |
+
| esbuild server error is non-fatal | The `server/_core/index.ts` esbuild step fails on Lambda (no server env vars), but the Vite frontend build completes successfully before that step |
|
| 406 |
+
|
| 407 |
+
---
|
| 408 |
+
|
| 409 |
+
## Updated Current Status
|
| 410 |
+
|
| 411 |
+
| Component | Status |
|
| 412 |
+
|---|---|
|
| 413 |
+
| Dashboard UI | **Running** — accessible at `http://192.168.1.140:3006` |
|
| 414 |
+
| Backend server | Running on Lambda at port 8008 |
|
| 415 |
+
| Qwen2.5-0.5B | Loaded on `cuda:1`, generating moves |
|
| 416 |
+
| GRPO training | Active |
|
| 417 |
+
| Dashboard ↔ Backend (LIVE mode) | Ready — click LIVE toggle in dashboard to connect |
|
| 418 |
+
| Claude coaching | Disabled — `ANTHROPIC_API_KEY` not set |
|
| 419 |
+
| Nevermined integration | Not implemented (deferred) |
|
| 420 |
+
|
frontend/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|