
Update README.md
Browse files
README.md
CHANGED
|
@@ -178,16 +178,19 @@ All 3 agents trained with **TRL GRPOTrainer + Unsloth** using the deployed HF Sp
|
|
| 178 |
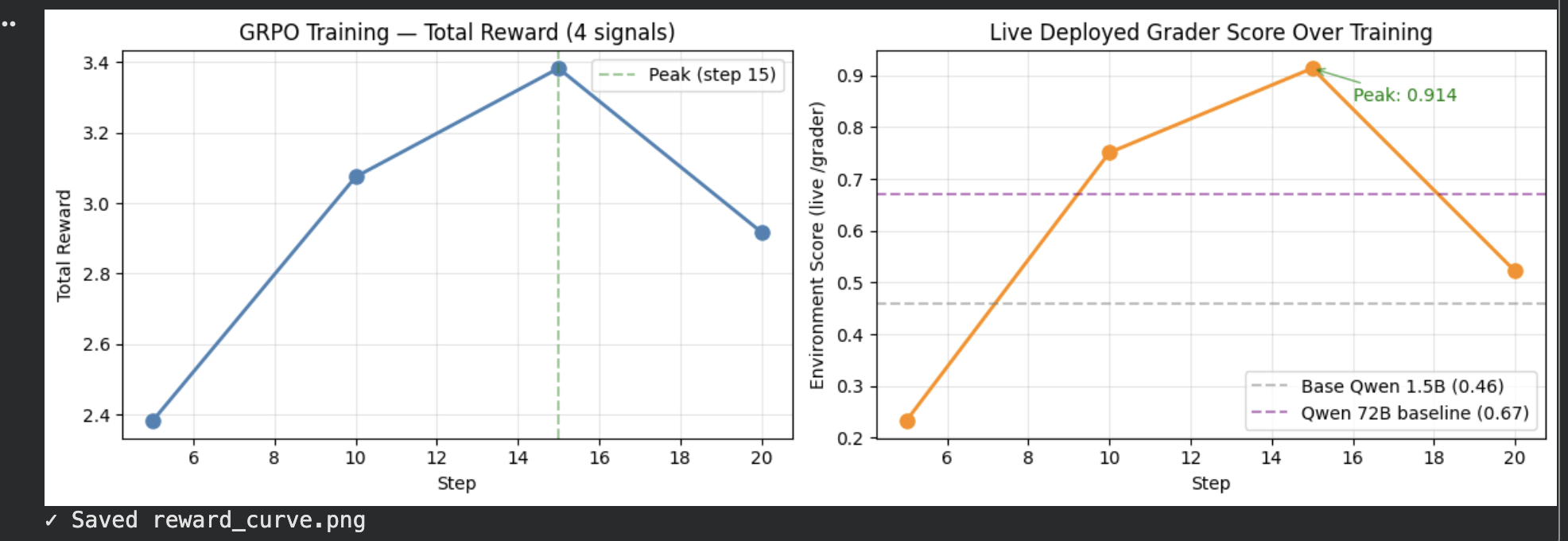
### Extractor Reward Curve
|
| 179 |
|
| 180 |
|
|
|
|
| 181 |
*Left: Total GRPO reward across 4 signals (format + field + math + completeness) over 20 training steps. Right: Live environment grader score peaking at **0.914** — above Qwen 72B baseline (0.67) and untrained 1.5B baseline (0.46).*
|
| 182 |
|
| 183 |
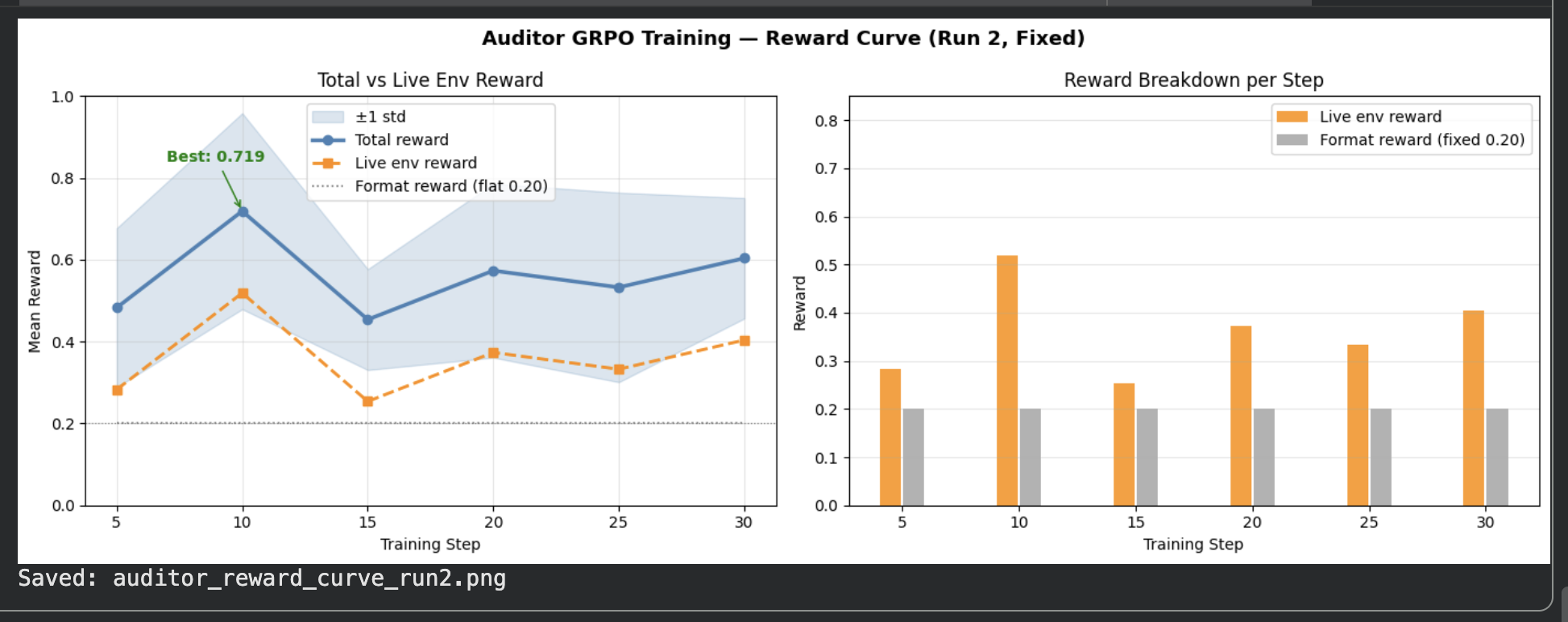
### Auditor Reward Curve (Run 2 — Bug Fixed)
|
| 184 |
|
| 185 |
|
|
|
|
| 186 |
*Total reward (blue) and live env reward (orange) over 30 steps with ±1 std band. Best total reward: **0.719**. Live env reward rose from 0.01 (dead signal in Run 1) to **0.52** after fixing the episode_id list bug.*
|
| 187 |
|
| 188 |
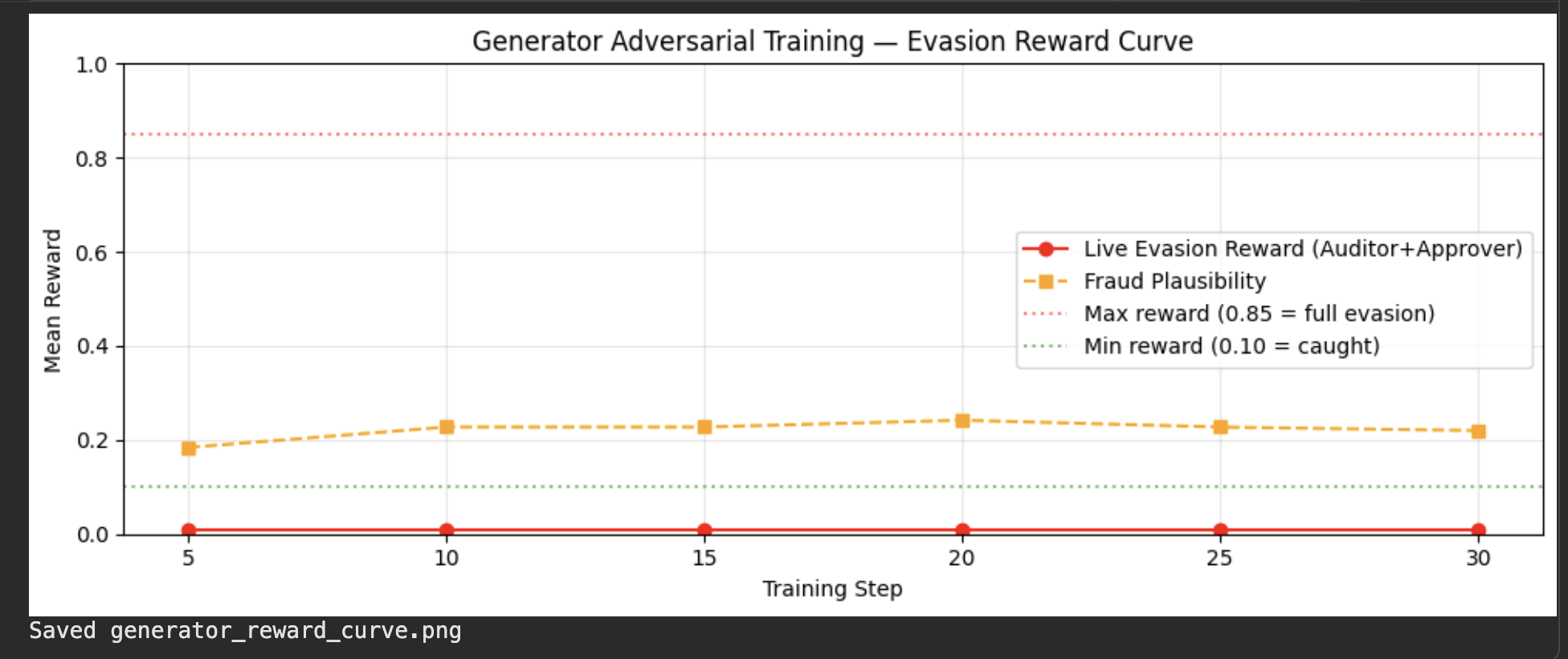
### Generator Reward Curve
|
| 189 |
|
| 190 |
|
|
|
|
| 191 |
*Live evasion reward (red) flat near 0 — Auditor+Approver caught all fraud attempts. Fraud plausibility reward (orange dashed) learned and stable at ~0.20, showing the Generator learned to produce realistic-looking invoices even without successful evasion.*
|
| 192 |
|
| 193 |
### 🔍 Reward Hacking Caught at Step 10
|
|
|
|
| 178 |
### Extractor Reward Curve
|
| 179 |
|
| 180 |

|
| 181 |
+
*X-axis: training step (1–20) · Y-axis: reward (0–1). Left: total GRPO reward across 4 independent signals (format 0.10 + field accuracy 0.40 + math 0.25 + completeness 0.25). Right: live `/grader` score peaking at **0.914** — above Qwen 72B baseline (0.67) and untrained 1.5B (0.46).*
|
| 182 |
*Left: Total GRPO reward across 4 signals (format + field + math + completeness) over 20 training steps. Right: Live environment grader score peaking at **0.914** — above Qwen 72B baseline (0.67) and untrained 1.5B baseline (0.46).*
|
| 183 |
|
| 184 |
### Auditor Reward Curve (Run 2 — Bug Fixed)
|
| 185 |
|
| 186 |

|
| 187 |
+
*X-axis: training step (1–30) · Y-axis: reward (0–1). Total reward (blue) and live env reward (orange) with ±1 std band. Best total: **0.719** at step 10. Live env reward climbed from 0.01 (dead signal, Run 1) to **0.52** after fixing the TRL episode_id list indexing bug.*
|
| 188 |
*Total reward (blue) and live env reward (orange) over 30 steps with ±1 std band. Best total reward: **0.719**. Live env reward rose from 0.01 (dead signal in Run 1) to **0.52** after fixing the episode_id list bug.*
|
| 189 |
|
| 190 |
### Generator Reward Curve
|
| 191 |
|
| 192 |

|
| 193 |
+
*X-axis: training step (1–30) · Y-axis: reward (0–1). Live evasion reward (red) flat near 0 — Auditor+Approver caught all fraud attempts. Fraud plausibility reward (orange dashed) stable at ~0.20 — Generator learned realistic invoice structure even without successful evasion.*
|
| 194 |
*Live evasion reward (red) flat near 0 — Auditor+Approver caught all fraud attempts. Fraud plausibility reward (orange dashed) learned and stable at ~0.20, showing the Generator learned to produce realistic-looking invoices even without successful evasion.*
|
| 195 |
|
| 196 |
### 🔍 Reward Hacking Caught at Step 10
|