
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,52 +1,64 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Invoice Processing Pipeline
|
| 3 |
-
emoji: 🧾
|
| 4 |
-
colorFrom: blue
|
| 5 |
-
colorTo: indigo
|
| 6 |
-
sdk: docker
|
| 7 |
-
app_port: 7860
|
| 8 |
-
tags:
|
| 9 |
-
- openenv
|
| 10 |
-
- multi-agent
|
| 11 |
-
- grpo
|
| 12 |
-
- rlhf
|
| 13 |
-
- fraud-detection
|
| 14 |
-
- invoice
|
| 15 |
-
---
|
| 16 |
-
|
| 17 |
<div align="center">
|
| 18 |
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
|
| 25 |
<br/>
|
| 26 |
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
|
|
|
|
|
|
| 30 |
|
| 31 |
-
|
|
|
|
|
|
|
| 32 |
|
| 33 |
</div>
|
| 34 |
|
| 35 |
---
|
| 36 |
|
| 37 |
-
## The Core Idea
|
| 38 |
|
| 39 |
> *A system that continuously generates harder challenges targeting its own weakest points.*
|
| 40 |
|
| 41 |
-
Most fraud detection pipelines are static. Ours **gets harder for itself over time**: the Regulator finds where the Auditor keeps failing, the Generator exploits those exact blind spots in the next episode, the Auditor's new mistakes update the Regulator — and the loop closes without any human intervention.
|
|
|
|
|
|
|
| 42 |
|
| 43 |
<div align="center">
|
| 44 |
-
<img width="1710" height="326" alt="5-agent loop" src="https://github.com/user-attachments/assets/319654c3-aa24-47e8-9716-734d4e902168" />
|
| 45 |
</div>
|
| 46 |
|
| 47 |
---
|
| 48 |
|
| 49 |
-
## 5-Agent Architecture
|
| 50 |
|
| 51 |
```mermaid
|
| 52 |
graph LR
|
|
@@ -62,125 +74,119 @@ graph LR
|
|
| 62 |
|
| 63 |
| Agent | Role | Reward Signal |
|
| 64 |
|:---:|:---|:---|
|
| 65 |
-
|
|
| 66 |
-
|
|
| 67 |
-
|
|
| 68 |
-
|
|
| 69 |
-
|
|
| 70 |
|
| 71 |
</div>
|
| 72 |
|
| 73 |
---
|
| 74 |
|
| 75 |
-
## Three Novel Features
|
| 76 |
|
| 77 |
-
<
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|:---|:---|
|
| 81 |
-
| **🔮 Predictive Regulator** | Computes trend slopes over 5-episode windows — warns of *emerging* blind spots before they go critical |
|
| 82 |
-
| **🧬 Compound Fraud** | Invoices can carry two simultaneous fraud signals (e.g. phantom vendor + price gouging). Partial credit for catching one; full reward for both |
|
| 83 |
-
| **📊 Confidence Calibration** | Tracks (confidence, correct?) pairs per fraud type. Flags *overconfident misses* — the most dangerous Auditor failure mode |
|
| 84 |
|
| 85 |
-
|
| 86 |
|
| 87 |
-
-
|
| 88 |
|
| 89 |
-
|
| 90 |
|
| 91 |
-
<
|
|
|
|
| 92 |
|
| 93 |
-
|
| 94 |
-
|:---:|:---|:---|:---:|
|
| 95 |
-
| 1 | `easy` | Single clean invoice — extract 5 fields | Easy |
|
| 96 |
-
| 2 | `medium` | Batch with date chaos, vendor typos, currency noise | Medium |
|
| 97 |
-
| 3 | `hard` | Extraction + PO reconciliation — flag overcharges, missing items | Hard |
|
| 98 |
-
| 4 | `expert` | Full fraud audit across all four fraud types | Expert |
|
| 99 |
-
| 5 | `adversarial` | OCR corruption, SUBTOTAL traps, fake TAX/FX noise lines | Expert |
|
| 100 |
-
| 6 | `negotiate` | Ask clarifying questions first (bonus for ≤2), then extract | Medium |
|
| 101 |
-
| 7 | `supply_chain` | Detect quantity shortfalls, price spikes, phantom deliveries | Expert |
|
| 102 |
-
| 8 | `long_horizon` | 20-step 4-phase investigation: extract → reconcile → audit → risk forecast | Expert |
|
| 103 |
-
| 9 | `personalized` | Adapts to your weak fields — next invoice always targets your worst category | Adaptive |
|
| 104 |
-
| 10 | `curriculum` | Auto-progresses easy→medium→hard→expert based on score (≥0.80 to advance) | Auto |
|
| 105 |
|
| 106 |
-
</
|
| 107 |
|
| 108 |
-
|
| 109 |
|
| 110 |
-
|
|
|
|
| 111 |
|
| 112 |
-
##
|
| 113 |
|
| 114 |
-
|
| 115 |
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
reward_math_consistency(extracted) # 0.25 — qty × unit_price = amount per line?
|
| 120 |
-
reward_completeness(extracted, gt) # 0.25 — all expected line items captured?
|
| 121 |
|
| 122 |
-
|
| 123 |
-
```
|
| 124 |
|
| 125 |
-
##
|
| 126 |
|
| 127 |
<div align="center">
|
| 128 |
|
| 129 |
-
|
|
| 130 |
-
|:---|:---:|:---|
|
| 131 |
-
|
|
| 132 |
-
|
|
| 133 |
-
|
|
| 134 |
-
|
|
| 135 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 136 |
|
| 137 |
</div>
|
| 138 |
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
```
|
| 142 |
-
Total = Precision(0.35) + Recall(0.35) + No-over-flagging(0.15) + Early-warning-bonus(0.15)
|
| 143 |
-
```
|
| 144 |
-
|
| 145 |
-
The early-warning bonus rewards predictions of *emerging* blind spots — before detection rates cross the critical threshold.
|
| 146 |
|
| 147 |
---
|
| 148 |
|
| 149 |
-
## Training Results — GRPO on Live Environment
|
| 150 |
|
| 151 |
-
All 3 agents trained with **TRL GRPOTrainer + Unsloth** using the deployed HF Space as the live reward verifier
|
| 152 |
|
| 153 |
<div align="center">
|
| 154 |
|
| 155 |
| Agent | Baseline | Best Achieved | Notes |
|
| 156 |
|:---:|:---:|:---:|:---|
|
| 157 |
-
|
|
| 158 |
-
|
|
| 159 |
-
|
|
| 160 |
|
| 161 |
</div>
|
| 162 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 163 |
|
| 164 |
|
|
|
|
|
|
|
| 165 |
|
| 166 |
|
| 167 |
-
|
| 168 |
|
| 169 |
-
|
| 170 |
|
| 171 |
-
###
|
| 172 |
|
| 173 |
-
At step 10 the model
|
| 174 |
|
| 175 |
```
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 179 |
```
|
| 180 |
|
| 181 |
-
Without 4 independent signals, a single aggregated reward would have called this success.
|
| 182 |
|
| 183 |
-
### Auditor Training
|
| 184 |
|
| 185 |
<div align="center">
|
| 186 |
|
|
@@ -199,21 +205,98 @@ Without 4 independent signals, a single aggregated reward would have called this
|
|
| 199 |
|
| 200 |
---
|
| 201 |
|
| 202 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 203 |
|
| 204 |
<div align="center">
|
| 205 |
|
| 206 |
-
|
|
| 207 |
-
|:---:|:---|
|
| 208 |
-
|
|
| 209 |
-
|
|
| 210 |
-
|
|
|
|
|
|
|
|
| 211 |
|
| 212 |
</div>
|
| 213 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 214 |
---
|
| 215 |
|
| 216 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 217 |
|
| 218 |
```
|
| 219 |
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
|
|
@@ -254,74 +337,182 @@ Without 4 independent signals, a single aggregated reward would have called this
|
|
| 254 |
|
| 255 |
---
|
| 256 |
|
| 257 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 258 |
|
| 259 |
### Core OpenEnv
|
| 260 |
|
| 261 |
| Endpoint | Method | Description |
|
| 262 |
|:---|:---:|:---|
|
| 263 |
-
| `/
|
| 264 |
-
| `/
|
| 265 |
-
| `/
|
| 266 |
-
| `/
|
| 267 |
-
| `/
|
| 268 |
-
| `/
|
| 269 |
-
| `/
|
| 270 |
-
| `/ws` | WS | WebSocket
|
|
|
|
| 271 |
|
| 272 |
### Multi-Agent
|
| 273 |
|
| 274 |
| Endpoint | Method | Description |
|
| 275 |
|:---|:---:|:---|
|
| 276 |
-
| `/multi/reset` | POST | Start 5-agent episode
|
| 277 |
-
| `/multi/extract` | POST | Score Extractor output (4 signals) |
|
| 278 |
-
| `/multi/audit` | POST | Score Auditor output, update tracker |
|
| 279 |
-
| `/multi/approve` | POST | Run Approver, compute Generator adversarial reward |
|
| 280 |
-
| `/
|
|
|
|
| 281 |
|
| 282 |
### Regulator
|
| 283 |
|
| 284 |
| Endpoint | Method | Description |
|
| 285 |
|:---|:---:|:---|
|
| 286 |
-
| `/regulator/report` | GET | Detection rates, blind spots, generator weights |
|
| 287 |
-
| `/regulator/forecast` | GET | Trend slopes + emerging blind spot warnings |
|
| 288 |
-
| `/regulator/calibration` | GET |
|
| 289 |
-
| `/regulator/predict` | POST | Score Regulator blind
|
|
|
|
| 290 |
|
| 291 |
---
|
| 292 |
|
| 293 |
-
##
|
| 294 |
|
| 295 |
-
|
| 296 |
-
# Health check
|
| 297 |
-
curl https://ps2181-invoice-processing-pipeline.hf.space/health
|
| 298 |
|
| 299 |
-
|
| 300 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 301 |
|
| 302 |
-
|
| 303 |
-
curl -X POST https://ps2181-invoice-processing-pipeline.hf.space/reset \
|
| 304 |
-
-H "Content-Type: application/json" -d '{"task_id": "curriculum"}'
|
| 305 |
|
| 306 |
-
|
| 307 |
-
curl -X POST https://ps2181-invoice-processing-pipeline.hf.space/multi/reset
|
| 308 |
|
| 309 |
-
#
|
| 310 |
-
|
| 311 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 312 |
|
| 313 |
---
|
| 314 |
|
| 315 |
-
##
|
| 316 |
|
| 317 |
<div align="center">
|
| 318 |
|
| 319 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 320 |
|:---|:---|
|
| 321 |
-
| **
|
| 322 |
-
| **
|
| 323 |
-
| **
|
| 324 |
-
| **
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 325 |
|
| 326 |
</div>
|
| 327 |
|
|
@@ -329,8 +520,10 @@ curl https://ps2181-invoice-processing-pipeline.hf.space/regulator/report
|
|
| 329 |
|
| 330 |
<div align="center">
|
| 331 |
|
| 332 |
-
|
|
|
|
|
|
|
| 333 |
|
| 334 |
-
*
|
| 335 |
|
| 336 |
</div>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
<div align="center">
|
| 2 |
|
| 3 |
+
<img src="https://capsule-render.vercel.app/api?type=waving&color=gradient&customColorList=6,11,20&height=200§ion=header&text=Invoice%20Processing%20Pipeline&fontSize=40&fontColor=fff&animation=twinkling&fontAlignY=35&desc=Self-Improving%20Multi-Agent%20Fraud%20Detection%20%7C%20OpenEnv%20%2B%20GRPO%20%2B%20Qwen2.5&descAlignY=55&descSize=16" width="100%"/>
|
| 4 |
+
|
| 5 |
+
<p>
|
| 6 |
+
<a href="https://ps2181-invoice-processing-pipeline.hf.space/web">
|
| 7 |
+
<img src="https://img.shields.io/badge/🚀%20Live%20Demo-HuggingFace%20Spaces-FF9D00?style=for-the-badge&logo=huggingface&logoColor=white" />
|
| 8 |
+
</a>
|
| 9 |
+
<a href="https://colab.research.google.com/drive/1C1_3giNt-NmbzKNFJr5_L1fms3L8LfmB">
|
| 10 |
+
<img src="https://img.shields.io/badge/Training%20Colab-Open%20Notebook-F9AB00?style=for-the-badge&logo=googlecolab&logoColor=white" />
|
| 11 |
+
</a>
|
| 12 |
+
<a href="https://ps2181-invoice-processing-pipeline.hf.space/docs">
|
| 13 |
+
<img src="https://img.shields.io/badge/API%20Docs-FastAPI-009688?style=for-the-badge&logo=fastapi&logoColor=white" />
|
| 14 |
+
</a>
|
| 15 |
+
</p>
|
| 16 |
+
|
| 17 |
+
<p>
|
| 18 |
+
<img src="https://img.shields.io/badge/Framework-OpenEnv-1A356E?style=for-the-badge" />
|
| 19 |
+
<img src="https://img.shields.io/badge/Model-Qwen2.5--1.5B%20+%20LoRA%20r%3D16-8B1A4E?style=for-the-badge" />
|
| 20 |
+
<img src="https://img.shields.io/badge/Training-GRPO%20+%20Unsloth-00A67E?style=for-the-badge" />
|
| 21 |
+
<img src="https://img.shields.io/badge/Agents-5%20Adversarial-E44D26?style=for-the-badge" />
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
<p>
|
| 25 |
+
<img src="https://img.shields.io/badge/Tasks-10%20Progressive-6C3483?style=for-the-badge" />
|
| 26 |
+
<img src="https://img.shields.io/badge/Deployment-Docker%20%7C%20HF%20Spaces-0D1117?style=for-the-badge&logo=docker" />
|
| 27 |
+
<img src="https://img.shields.io/badge/Theme-%234%20Self--Improvement-FF6B35?style=for-the-badge" />
|
| 28 |
+
<img src="https://img.shields.io/badge/Hackathon-Meta%20PyTorch%202026-185FA5?style=for-the-badge" />
|
| 29 |
+
</p>
|
| 30 |
|
| 31 |
<br/>
|
| 32 |
|
| 33 |
+
> **Meta PyTorch OpenEnv Hackathon — Grand Finale · April 25–26, 2026**
|
| 34 |
+
>
|
| 35 |
+
> Team: **Pritam Satpathy** & **Gnana Nawin T** · Scaler School of Technology, Bangalore
|
| 36 |
+
|
| 37 |
+
<br/>
|
| 38 |
|
| 39 |
+
<a href="https://git.io/typing-svg">
|
| 40 |
+
<img src="https://readme-typing-svg.demolab.com?font=Fira+Code&weight=600&size=22&pause=1000&color=007A87¢er=true&vCenter=true&width=750&lines=5-Agent+Adversarial+Fraud+Detection+System;Self-Improving+via+Cross-Episode+Regulator;GRPO-Trained+LoRA+Agents+on+Live+Environment;Invoice+%E2%86%92+Extract+%E2%86%92+Audit+%E2%86%92+Approve+%E2%86%92+Improve" alt="Typing SVG" />
|
| 41 |
+
</a>
|
| 42 |
|
| 43 |
</div>
|
| 44 |
|
| 45 |
---
|
| 46 |
|
| 47 |
+
## 🔥 The Core Idea
|
| 48 |
|
| 49 |
> *A system that continuously generates harder challenges targeting its own weakest points.*
|
| 50 |
|
| 51 |
+
Most fraud detection pipelines are **static**. Ours **gets harder for itself over time**: the Regulator finds where the Auditor keeps failing, the Generator exploits those exact blind spots in the next episode, the Auditor's new mistakes update the Regulator — and the loop closes without any human intervention.
|
| 52 |
+
|
| 53 |
+
**Primary theme: #4 Self-Improvement · Secondary: #1 Multi-Agent Interactions**
|
| 54 |
|
| 55 |
<div align="center">
|
| 56 |
+
<img width="1710" height="326" alt="5-agent self-improvement loop" src="https://github.com/user-attachments/assets/319654c3-aa24-47e8-9716-734d4e902168" />
|
| 57 |
</div>
|
| 58 |
|
| 59 |
---
|
| 60 |
|
| 61 |
+
## 🤖 5-Agent Architecture
|
| 62 |
|
| 63 |
```mermaid
|
| 64 |
graph LR
|
|
|
|
| 74 |
|
| 75 |
| Agent | Role | Reward Signal |
|
| 76 |
|:---:|:---|:---|
|
| 77 |
+
| 🎯 **Regulator** | Cross-episode oversight: detects Auditor blind spots, reweights Generator | Precision `0.35` + Recall `0.35` + No over-flagging `0.15` + Early warning `0.15` |
|
| 78 |
+
| ⚡ **Generator** | Adversary: creates invoices biased toward blind spots | `+0.85` evades both · `+0.60` evades Auditor · `+0.10` caught |
|
| 79 |
+
| 🔍 **Extractor** | Parser: text → structured JSON with 4 independent signals | Format `0.10` · Field accuracy `0.40` · Math `0.25` · Completeness `0.25` |
|
| 80 |
+
| 🕵️ **Auditor** | Detector: fraud classification with confidence scores | `+0.99` correct type · `+0.90` clean cleared · `+0.01` miss or FP |
|
| 81 |
+
| ✅ **Approver** | Gatekeeper: final approve / escalate / reject | `≥0.80` → reject · `0.50–0.80` → escalate · `<0.50` → approve |
|
| 82 |
|
| 83 |
</div>
|
| 84 |
|
| 85 |
---
|
| 86 |
|
| 87 |
+
## ⚡ Three Novel Features
|
| 88 |
|
| 89 |
+
<table>
|
| 90 |
+
<tr>
|
| 91 |
+
<td width="33%" align="center">
|
|
|
|
|
|
|
|
|
|
|
|
|
| 92 |
|
| 93 |
+
### 🔮 Predictive Regulator
|
| 94 |
|
| 95 |
+
Computes **trend slopes** over 5-episode windows.<br/>Warns of *emerging* blind spots **before** detection rates cross the critical threshold — proactive oversight, not reactive retraining.
|
| 96 |
|
| 97 |
+
`+0.15 early-warning bonus`
|
| 98 |
|
| 99 |
+
</td>
|
| 100 |
+
<td width="33%" align="center">
|
| 101 |
|
| 102 |
+
### 🧬 Compound Fraud
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 103 |
|
| 104 |
+
Invoices carry **two fraud signals simultaneously** (e.g. phantom vendor + price gouging).<br/>Partial credit `+0.65` for catching one; full reward `+0.99` for both.
|
| 105 |
|
| 106 |
+
Prevents single-signal heuristics.
|
| 107 |
|
| 108 |
+
</td>
|
| 109 |
+
<td width="33%" align="center">
|
| 110 |
|
| 111 |
+
### 📊 Confidence Calibration
|
| 112 |
|
| 113 |
+
Tracks `(confidence, correct?)` pairs per fraud type.<br/>Detects **overconfident misses** — the Auditor saying "90% sure, approved" on fraud — the most dangerous real-world failure mode.
|
| 114 |
|
| 115 |
+
</td>
|
| 116 |
+
</tr>
|
| 117 |
+
</table>
|
|
|
|
|
|
|
| 118 |
|
| 119 |
+
---
|
|
|
|
| 120 |
|
| 121 |
+
## 🎯 10 Tasks — Progressive Curriculum
|
| 122 |
|
| 123 |
<div align="center">
|
| 124 |
|
| 125 |
+
| # | Task | What the Agent Faces | Difficulty |
|
| 126 |
+
|:---:|:---|:---|:---:|
|
| 127 |
+
| 1 | `easy` | Single clean invoice — extract 5 fields | 🟢 Easy |
|
| 128 |
+
| 2 | `medium` | Batch with date chaos, vendor typos, currency noise | 🟡 Medium |
|
| 129 |
+
| 3 | `hard` | Extraction + PO reconciliation — flag overcharges, missing items | 🟠 Hard |
|
| 130 |
+
| 4 | `expert` | Full fraud audit across all four fraud types | 🔴 Expert |
|
| 131 |
+
| 5 | `adversarial` | OCR corruption, SUBTOTAL traps, fake TAX/FX noise lines | 🔴 Expert |
|
| 132 |
+
| 6 | `negotiate` | Ask clarifying questions first (bonus for ≤2), then extract | 🟡 Medium |
|
| 133 |
+
| 7 | `supply_chain` | Detect quantity shortfalls, price spikes, phantom deliveries | 🔴 Expert |
|
| 134 |
+
| 8 | `long_horizon` | 20-step 4-phase investigation: extract → reconcile → audit → risk forecast | 🔴 Expert |
|
| 135 |
+
| 9 | `personalized` | Adapts to your weak fields — next invoice always targets your worst category | 🔄 Adaptive |
|
| 136 |
+
| 10 | `curriculum` | Auto-progresses easy→medium→hard→expert based on score (≥0.80 to advance) | 🔄 Auto |
|
| 137 |
|
| 138 |
</div>
|
| 139 |
|
| 140 |
+
Dynamic difficulty also adjusts **within** each task via a rolling 10-episode score window: score above `0.85` → heavier OCR, more discrepancies, deeper traps. Drop below `0.60` → it eases off.
|
|
|
|
|
|
|
|
|
|
|
|
|
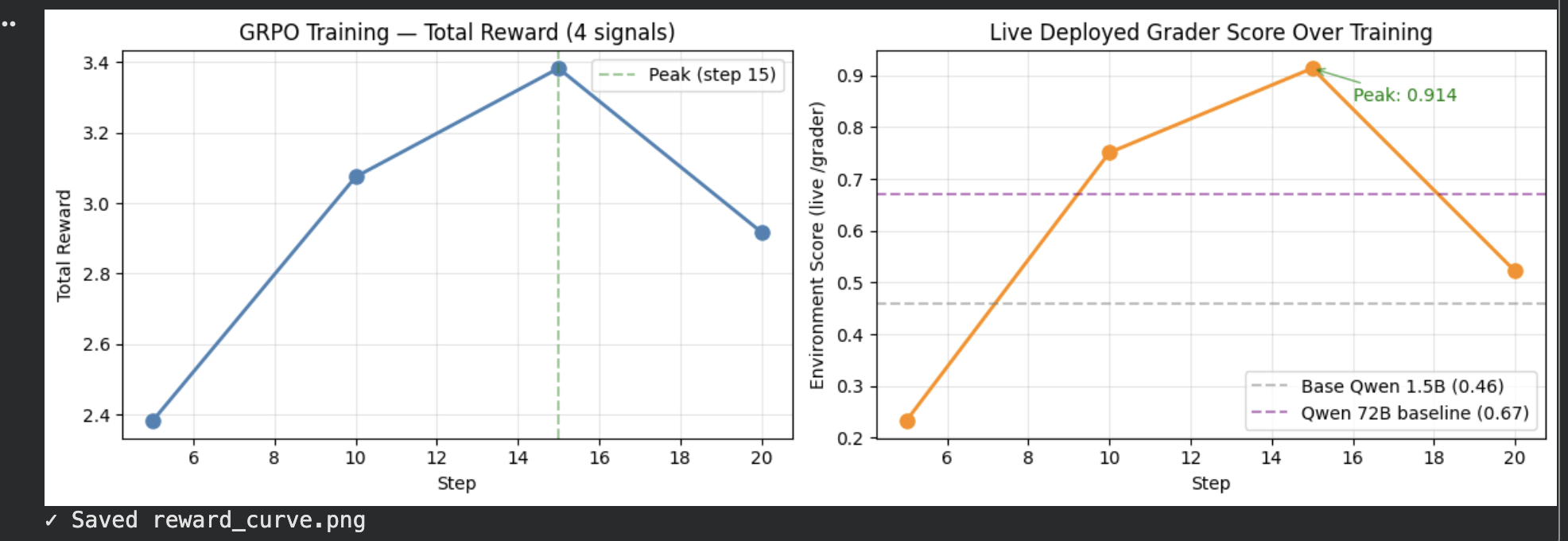
|
|
|
|
|
|
| 141 |
|
| 142 |
---
|
| 143 |
|
| 144 |
+
## 📈 Training Results — GRPO on Live Environment
|
| 145 |
|
| 146 |
+
All 3 agents trained with **TRL GRPOTrainer + Unsloth** using the deployed HF Space as the live reward verifier — `/grader` endpoint *is* the reward function during training.
|
| 147 |
|
| 148 |
<div align="center">
|
| 149 |
|
| 150 |
| Agent | Baseline | Best Achieved | Notes |
|
| 151 |
|:---:|:---:|:---:|:---|
|
| 152 |
+
| 🔍 **Extractor** | 0.10 (random) | **0.914** live grader | Peaked step 15 — above Qwen 72B baseline (0.67) |
|
| 153 |
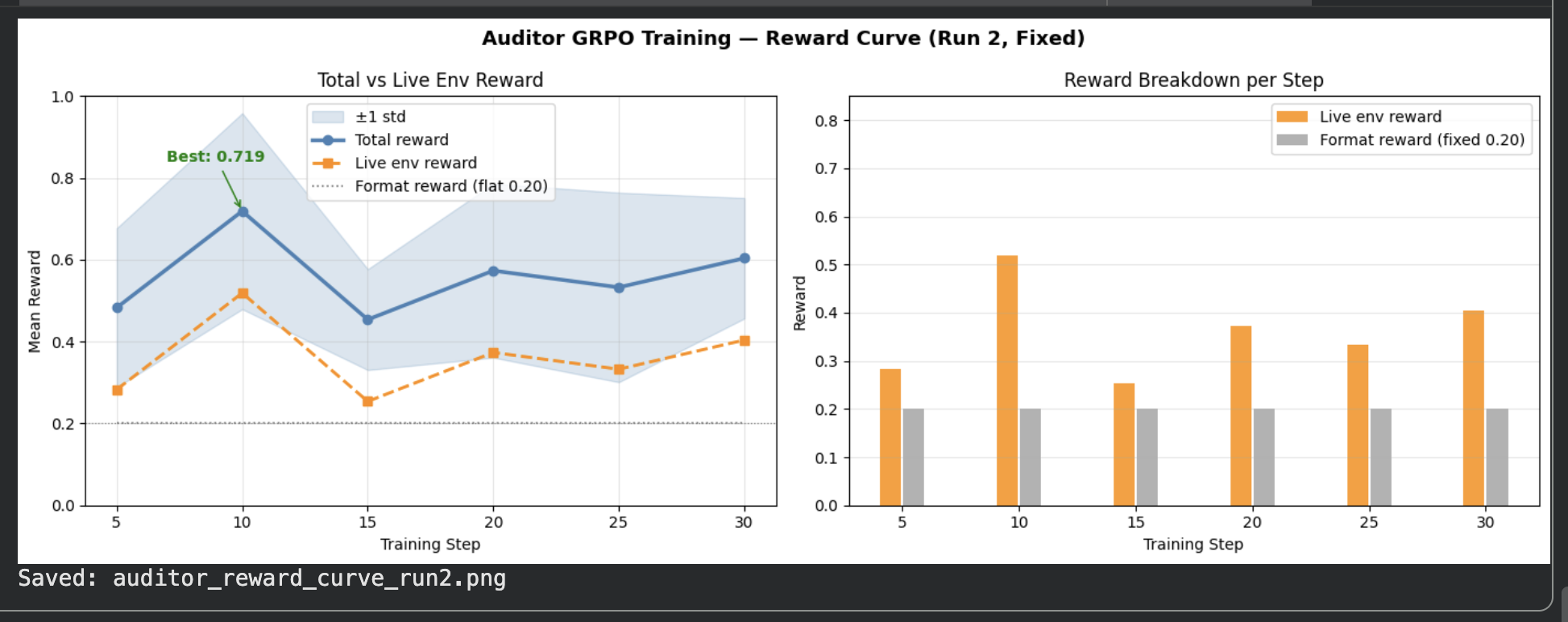
+
| 🕵️ **Auditor** | 0.01 (dead signal) | **0.719** total reward | Run 1 had episode_id bug; Run 2 → 0.01→0.52 live reward |
|
| 154 |
+
| ⚡ **Generator** | — | Format learned (~0.22) | Plausibility reward improved; evasion had same bug as Run 1 |
|
| 155 |
|
| 156 |
</div>
|
| 157 |
|
| 158 |
+
**Setup:** Qwen2.5-1.5B-Instruct · 4-bit QLoRA r=16 · Unsloth + TRL · Google Colab A100
|
| 159 |
+
|
| 160 |
+
### Extractor Reward Curve
|
| 161 |
+
|
| 162 |

|
| 163 |
|
| 164 |
+
### Auditor Reward Curve (Run 2)
|
| 165 |
+
|
| 166 |

|
| 167 |
|
| 168 |
+
### Generator Reward Curve
|
| 169 |
|
| 170 |
+
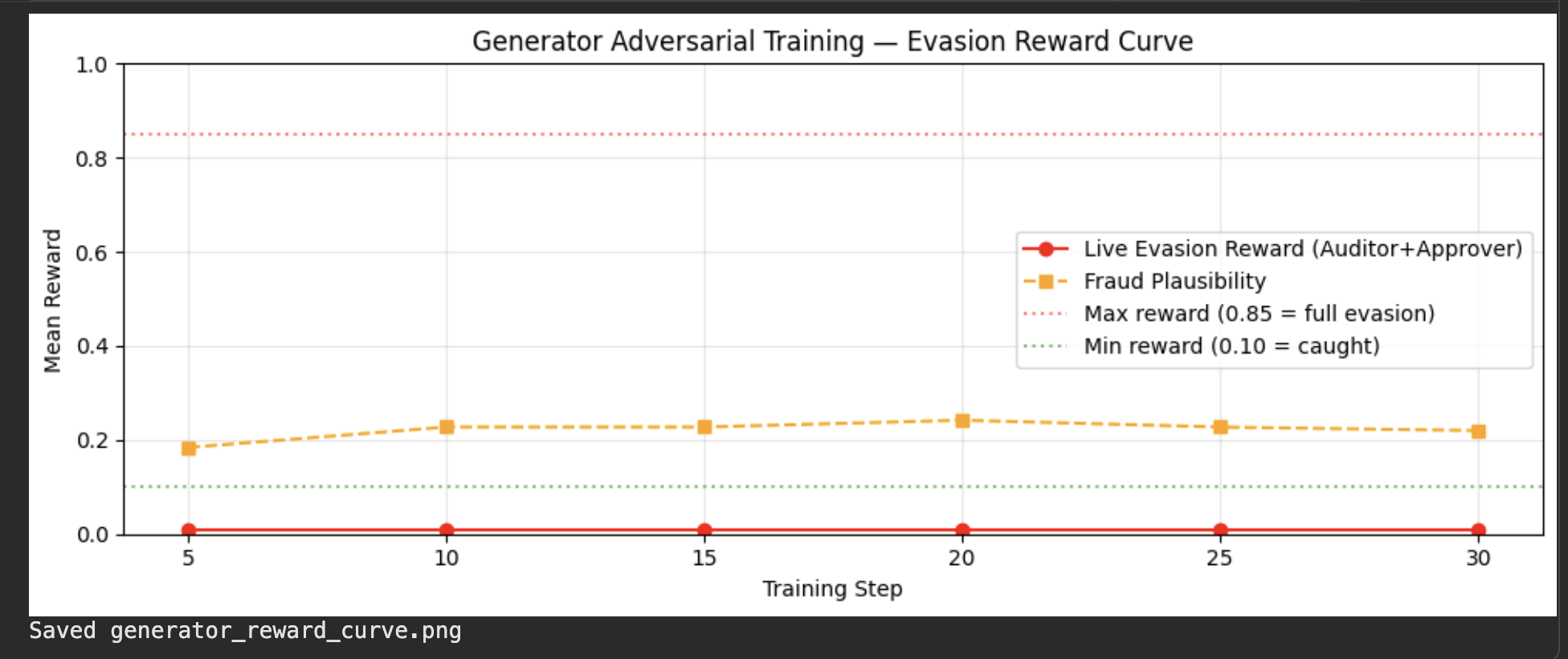
|
| 171 |
|
| 172 |
+
### 🔍 Reward Hacking Caught at Step 10
|
| 173 |
|
| 174 |
+
At step 10 the model achieved `math_consistency = 0.97` and `completeness = 1.0` while `field_accuracy = 0.00` — it had learned to output **arithmetically-consistent JSON with entirely hallucinated values**:
|
| 175 |
|
| 176 |
```
|
| 177 |
+
Step 10 — Reward Hacking Detected:
|
| 178 |
+
format: 0.10 ✅
|
| 179 |
+
math_consistency: 0.97 ✅ ← model gaming this signal
|
| 180 |
+
completeness: 1.00 ✅ ← model gaming this signal
|
| 181 |
+
field_accuracy: 0.00 ❌ ← hallucinating all values
|
| 182 |
+
|
| 183 |
+
Action: adjusted training emphasis on field_accuracy weight
|
| 184 |
+
Result: field_accuracy climbed to 0.30+ by step 30
|
| 185 |
```
|
| 186 |
|
| 187 |
+
Without 4 independent signals, a single aggregated reward would have called this success. **Independent signals are diagnostics, not just incentives.**
|
| 188 |
|
| 189 |
+
### Auditor Training — Run 2 (exact data)
|
| 190 |
|
| 191 |
<div align="center">
|
| 192 |
|
|
|
|
| 205 |
|
| 206 |
---
|
| 207 |
|
| 208 |
+
## 🎁 Reward Architecture
|
| 209 |
+
|
| 210 |
+
### 🔍 Extractor — 4 Independent Signals
|
| 211 |
+
|
| 212 |
+
```python
|
| 213 |
+
reward_format(extracted) # 0.10 — all 5 required JSON keys present?
|
| 214 |
+
reward_field_accuracy(extracted, gt) # 0.40 — vendor / date / currency / total match?
|
| 215 |
+
reward_math_consistency(extracted) # 0.25 — qty × unit_price = amount per line?
|
| 216 |
+
reward_completeness(extracted, gt) # 0.25 — all expected line items captured?
|
| 217 |
+
|
| 218 |
+
# All clamped to (0.01, 0.99) — no log(0), no gradient collapse at boundaries
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
### 🕵️ Auditor
|
| 222 |
|
| 223 |
<div align="center">
|
| 224 |
|
| 225 |
+
| Outcome | Reward | Why |
|
| 226 |
+
|:---|:---:|:---|
|
| 227 |
+
| Correct fraud type detected | **0.99** | Rewards precise classification, not just binary flagging |
|
| 228 |
+
| Clean invoice correctly approved | **0.90** | Keeps false-positive rate honest |
|
| 229 |
+
| Compound fraud — one of two types caught | **0.65** | Partial credit prevents cliff on hard cases |
|
| 230 |
+
| Fraud flagged but wrong type | **0.50** | Penalises sloppiness; rewards catching *something* |
|
| 231 |
+
| Miss or false positive | **0.01** | Near-zero punishes both failure modes symmetrically |
|
| 232 |
|
| 233 |
</div>
|
| 234 |
|
| 235 |
+
### ⚡ Generator (Adversarial Self-Play)
|
| 236 |
+
|
| 237 |
+
| Outcome | Reward |
|
| 238 |
+
|:---|:---:|
|
| 239 |
+
| Fraud evades **both** Auditor and Approver | **0.85** |
|
| 240 |
+
| Auditor misses, Approver catches | **0.60** |
|
| 241 |
+
| Auditor catches it | **0.10** |
|
| 242 |
+
|
| 243 |
+
### 🎯 Regulator — Cross-Episode
|
| 244 |
+
|
| 245 |
+
```
|
| 246 |
+
Total = Precision(0.35) + Recall(0.35) + No-over-flagging(0.15) + Early-warning-bonus(0.15)
|
| 247 |
+
```
|
| 248 |
+
|
| 249 |
+
The early-warning bonus rewards predictions of *emerging* blind spots — before detection rates cross the critical threshold.
|
| 250 |
+
|
| 251 |
---
|
| 252 |
|
| 253 |
+
## 🧠 Trained LoRA Agents
|
| 254 |
+
|
| 255 |
+
<div align="center">
|
| 256 |
+
|
| 257 |
+
| Agent | Base Model | LoRA Config | HuggingFace Hub |
|
| 258 |
+
|:---:|:---|:---:|:---|
|
| 259 |
+
| 🔍 Extractor | Qwen2.5-1.5B-Instruct | r=16, α=16, 4-bit QLoRA | [ps2181/extractor-lora-qwen2.5-1.5b](https://huggingface.co/ps2181/extractor-lora-qwen2.5-1.5b) |
|
| 260 |
+
| 🕵️ Auditor | Qwen2.5-1.5B-Instruct | r=16, α=16, 4-bit QLoRA | [ps2181/auditor-lora-qwen2.5-1.5b](https://huggingface.co/ps2181/auditor-lora-qwen2.5-1.5b) |
|
| 261 |
+
| ⚡ Generator | Qwen2.5-1.5B-Instruct | r=16, α=16, 4-bit QLoRA | [ps2181/generator-lora-qwen2.5-1.5b](https://huggingface.co/ps2181/generator-lora-qwen2.5-1.5b) |
|
| 262 |
+
|
| 263 |
+
</div>
|
| 264 |
+
|
| 265 |
+
**LoRA target modules:** `q_proj`, `k_proj`, `v_proj`, `o_proj`, `gate_proj`, `up_proj`, `down_proj`
|
| 266 |
+
|
| 267 |
+
---
|
| 268 |
+
|
| 269 |
+
## 🌍 The Regulator in Action
|
| 270 |
+
|
| 271 |
+
After each episode, the Regulator publishes a report the Generator uses to bias its next batch:
|
| 272 |
+
|
| 273 |
+
```
|
| 274 |
+
GET /regulator/report
|
| 275 |
+
|
| 276 |
+
{
|
| 277 |
+
"total_audits_recorded": 20,
|
| 278 |
+
"detection_rates": {
|
| 279 |
+
"phantom_vendor": "31% ⚠ BLIND SPOT (-0.08↓)",
|
| 280 |
+
"price_gouging": "74% ✓ OK (+0.03↑)",
|
| 281 |
+
"math_fraud": "81% ✓ OK (+0.01↑)",
|
| 282 |
+
"duplicate_submission": "62% ⚡ EMERGING (-0.02↓)"
|
| 283 |
+
},
|
| 284 |
+
"blind_spots": ["phantom_vendor"],
|
| 285 |
+
"emerging_blind_spots": ["duplicate_submission"],
|
| 286 |
+
"generator_weights": {
|
| 287 |
+
"phantom_vendor": 0.30, ← 3× upweighted (blind spot)
|
| 288 |
+
"duplicate_submission": 0.20, ← 2× upweighted (emerging)
|
| 289 |
+
"price_gouging": 0.125,
|
| 290 |
+
"math_fraud": 0.125,
|
| 291 |
+
"compound_fraud": 0.10
|
| 292 |
+
},
|
| 293 |
+
"verdict": "Recommend retraining on: phantom_vendor"
|
| 294 |
+
}
|
| 295 |
+
```
|
| 296 |
+
|
| 297 |
+
---
|
| 298 |
+
|
| 299 |
+
## 🎭 Sample Multi-Agent Episode
|
| 300 |
|
| 301 |
```
|
| 302 |
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
|
|
|
|
| 337 |
|
| 338 |
---
|
| 339 |
|
| 340 |
+
## 🚀 Quick Start
|
| 341 |
+
|
| 342 |
+
```bash
|
| 343 |
+
# Health check
|
| 344 |
+
curl https://ps2181-invoice-processing-pipeline.hf.space/health
|
| 345 |
+
|
| 346 |
+
# Environment-wide metrics
|
| 347 |
+
curl https://ps2181-invoice-processing-pipeline.hf.space/metrics
|
| 348 |
+
|
| 349 |
+
# Auto-progressive curriculum episode
|
| 350 |
+
curl -X POST https://ps2181-invoice-processing-pipeline.hf.space/reset \
|
| 351 |
+
-H "Content-Type: application/json" -d '{"task_id": "curriculum"}'
|
| 352 |
+
|
| 353 |
+
# Start multi-agent episode
|
| 354 |
+
curl -X POST https://ps2181-invoice-processing-pipeline.hf.space/multi/reset
|
| 355 |
+
|
| 356 |
+
# Regulator blind spot report
|
| 357 |
+
curl https://ps2181-invoice-processing-pipeline.hf.space/regulator/report
|
| 358 |
+
```
|
| 359 |
+
|
| 360 |
+
### Run Training (Google Colab)
|
| 361 |
+
|
| 362 |
+
[](https://colab.research.google.com/drive/1C1_3giNt-NmbzKNFJr5_L1fms3L8LfmB)
|
| 363 |
+
|
| 364 |
+
```
|
| 365 |
+
Colab → /reset (fresh synthetic invoice from live environment)
|
| 366 |
+
→ model generates JSON
|
| 367 |
+
→ /grader scores against ground truth
|
| 368 |
+
→ GRPO updates weights toward higher-reward completions
|
| 369 |
+
→ repeat 200 steps
|
| 370 |
+
```
|
| 371 |
+
|
| 372 |
+
---
|
| 373 |
+
|
| 374 |
+
## 🗂️ Repository Structure
|
| 375 |
+
|
| 376 |
+
```
|
| 377 |
+
invoice-processing-pipeline/
|
| 378 |
+
│
|
| 379 |
+
├── server/
|
| 380 |
+
│ ├── app.py # FastAPI — 18 endpoints
|
| 381 |
+
│ ├── environment.py # 10 tasks · graders · dynamic difficulty
|
| 382 |
+
│ ├── multi_agent_environment.py # 5-agent system + AuditorPerformanceTracker
|
| 383 |
+
│ ├── agents.py # Lazy-loading LoRA inference wrappers
|
| 384 |
+
│ └── web_ui.py # Gradio UI (mounted at /web)
|
| 385 |
+
│
|
| 386 |
+
├── models.py # Pydantic: Action · Observation · State
|
| 387 |
+
├── inference.py # Standalone inference helper
|
| 388 |
+
├── client.py # OpenEnv-compatible Python client
|
| 389 |
+
│
|
| 390 |
+
├── extractor_training_grpo.ipynb # 🔥 Extractor GRPO training (Unsloth + TRL)
|
| 391 |
+
├── auditor_grpo_training.ipynb # 🔥 Auditor GRPO training
|
| 392 |
+
├── generator_grpo_training.ipynb # 🔥 Generator GRPO training
|
| 393 |
+
│
|
| 394 |
+
├── assets/
|
| 395 |
+
│ ├── reward_curve.png # Extractor training curve
|
| 396 |
+
│ ├── auditor_reward_curve_run2.png
|
| 397 |
+
│ └── generator_reward_curve.png
|
| 398 |
+
│
|
| 399 |
+
├── openenv.yaml # OpenEnv manifest (all tasks declared)
|
| 400 |
+
├── Dockerfile # HF Spaces Docker (port 7860, non-root UID 1000)
|
| 401 |
+
├── pyproject.toml # Project metadata + dependencies
|
| 402 |
+
├── requirements.txt # Runtime dependencies
|
| 403 |
+
├── validate-submission.sh # Submission validator script
|
| 404 |
+
├── Blog.md # HuggingFace blog post
|
| 405 |
+
└── ROUND2_PROBLEM_STATEMENT.md # Full problem statement + reward design rationale
|
| 406 |
+
```
|
| 407 |
+
|
| 408 |
+
---
|
| 409 |
+
|
| 410 |
+
## 🔌 API Reference
|
| 411 |
|
| 412 |
### Core OpenEnv
|
| 413 |
|
| 414 |
| Endpoint | Method | Description |
|
| 415 |
|:---|:---:|:---|
|
| 416 |
+
| `/health` | `GET` | Health check → `{"status": "ok", "active_sessions": N}` |
|
| 417 |
+
| `/tasks` | `GET` | All tasks with descriptions, schemas, difficulty levels |
|
| 418 |
+
| `/metrics` | `GET` | Per-task episode counts, avg/best scores, Regulator state |
|
| 419 |
+
| `/reset` | `POST` | Start episode `{"task_id": "easy\|medium\|...\|curriculum"}` |
|
| 420 |
+
| `/step` | `POST` | Submit extraction → reward + feedback + hint + reward_breakdown |
|
| 421 |
+
| `/grader` | `POST` | Score without consuming an attempt (training reward signal) |
|
| 422 |
+
| `/state` | `GET` | Episode metadata — step_count, done, best_reward, history |
|
| 423 |
+
| `/ws` | `WS` | Full episode over WebSocket (OpenEnv standard) |
|
| 424 |
+
| `/web` | `GET` | Gradio interactive demo UI |
|
| 425 |
|
| 426 |
### Multi-Agent
|
| 427 |
|
| 428 |
| Endpoint | Method | Description |
|
| 429 |
|:---|:---:|:---|
|
| 430 |
+
| `/multi/reset` | `POST` | Start 5-agent episode — Generator biased by Regulator weights |
|
| 431 |
+
| `/multi/extract` | `POST` | Score Extractor output (4 independent signals) |
|
| 432 |
+
| `/multi/audit` | `POST` | Score Auditor output, update 30-episode performance tracker |
|
| 433 |
+
| `/multi/approve` | `POST` | Run Approver, compute Generator adversarial reward |
|
| 434 |
+
| `/multi/state/{id}` | `GET` | Full episode state including all agent scores |
|
| 435 |
+
| `/generator/score` | `POST` | Direct Generator scoring through Auditor+Approver pipeline |
|
| 436 |
|
| 437 |
### Regulator
|
| 438 |
|
| 439 |
| Endpoint | Method | Description |
|
| 440 |
|:---|:---:|:---|
|
| 441 |
+
| `/regulator/report` | `GET` | Detection rates, blind spots, calibration, generator weights |
|
| 442 |
+
| `/regulator/forecast` | `GET` | Trend slopes + emerging blind spot warnings with episode countdown |
|
| 443 |
+
| `/regulator/calibration` | `GET` | Overconfidence / underconfidence per fraud type |
|
| 444 |
+
| `/regulator/predict` | `POST` | Score a Regulator blind-spot prediction |
|
| 445 |
+
| `/regulator/demo_seed` | `POST` | Seed tracker with realistic demo data |
|
| 446 |
|
| 447 |
---
|
| 448 |
|
| 449 |
+
## 🏗️ Tech Stack
|
| 450 |
|
| 451 |
+
<div align="center">
|
|
|
|
|
|
|
| 452 |
|
| 453 |
+
| Layer | Technology |
|
| 454 |
+
|:---|:---|
|
| 455 |
+
| **Environment** | [OpenEnv](https://github.com/meta-pytorch/OpenEnv) · FastAPI · Pydantic v2 |
|
| 456 |
+
| **UI** | Gradio 4.x (mounted at `/web`) |
|
| 457 |
+
| **Deployment** | Docker · HuggingFace Spaces (vcpu-2 / 8 GB) |
|
| 458 |
+
| **Training** | [TRL GRPOTrainer](https://huggingface.co/docs/trl) · [Unsloth](https://github.com/unslothai/unsloth) |
|
| 459 |
+
| **Model** | `unsloth/Qwen2.5-1.5B-Instruct` · 4-bit QLoRA · r=16 · A100 |
|
| 460 |
+
| **Reward** | Live `/grader` endpoint on HF Space as verifier |
|
| 461 |
+
| **Session Mgmt** | Thread-safe `OrderedDict` · 200-session cap · LRU eviction |
|
| 462 |
+
| **Dynamic Difficulty** | Per-task rolling window (maxlen=10) → adjusts OCR intensity, batch size, discrepancy count |
|
| 463 |
|
| 464 |
+
</div>
|
|
|
|
|
|
|
| 465 |
|
| 466 |
+
---
|
|
|
|
| 467 |
|
| 468 |
+
## 🎭 Theme Alignment
|
| 469 |
+
|
| 470 |
+
<div align="center">
|
| 471 |
+
|
| 472 |
+
| Theme | Alignment | Evidence |
|
| 473 |
+
|:---:|:---|:---|
|
| 474 |
+
| **#4 Self-Improvement** (primary) | ✅ Core | Regulator detects blind spots → Generator biases toward them → Auditor improves → loop repeats |
|
| 475 |
+
| **#1 Multi-Agent Interactions** | ✅ Core | 5 agents with conflicting incentives — Generator vs Auditor adversarial self-play |
|
| 476 |
+
| **#1 Fleet AI Scalable Oversight** | ✅ Bonus | Regulator monitors Auditor cross-episode with predictive trend detection |
|
| 477 |
+
| **#3.1 Professional Tasks** | ✅ Core | Invoice + PO + vendor registry + supply chain = real enterprise AP workflow |
|
| 478 |
+
| **#2 Long-Horizon Planning** | ✅ Partial | `long_horizon` task: 20-step 4-phase investigation with multi-turn state |
|
| 479 |
+
|
| 480 |
+
</div>
|
| 481 |
|
| 482 |
---
|
| 483 |
|
| 484 |
+
## 👥 Team
|
| 485 |
|
| 486 |
<div align="center">
|
| 487 |
|
| 488 |
+
| | |
|
| 489 |
+
|:---:|:---:|
|
| 490 |
+
| **Pritam Satpathy** | **Gnana Nawin T** |
|
| 491 |
+
| [🤗 ps2181](https://huggingface.co/ps2181) | [🤗 gnananawin](https://huggingface.co/gnananawin) |
|
| 492 |
+
| Scaler School of Technology | Scaler School of Technology |
|
| 493 |
+
|
| 494 |
+
**Meta PyTorch OpenEnv Hackathon — Grand Finale · April 25–26, 2026 · Bangalore**
|
| 495 |
+
|
| 496 |
+
</div>
|
| 497 |
+
|
| 498 |
+
---
|
| 499 |
+
|
| 500 |
+
## 🔗 All Links
|
| 501 |
+
|
| 502 |
+
<div align="center">
|
| 503 |
+
|
| 504 |
+
| Resource | Link |
|
| 505 |
|:---|:---|
|
| 506 |
+
| 🚀 **Live Environment** | https://ps2181-invoice-processing-pipeline.hf.space |
|
| 507 |
+
| 🖥️ **Gradio Demo UI** | https://ps2181-invoice-processing-pipeline.hf.space/web |
|
| 508 |
+
| 📖 **API Documentation** | https://ps2181-invoice-processing-pipeline.hf.space/docs |
|
| 509 |
+
| 📊 **Metrics Dashboard** | https://ps2181-invoice-processing-pipeline.hf.space/metrics |
|
| 510 |
+
| 🤗 **Extractor Model** | https://huggingface.co/ps2181/extractor-lora-qwen2.5-1.5b |
|
| 511 |
+
| 🕵️ **Auditor Model** | https://huggingface.co/ps2181/auditor-lora-qwen2.5-1.5b |
|
| 512 |
+
| ⚡ **Generator Model** | https://huggingface.co/ps2181/generator-lora-qwen2.5-1.5b |
|
| 513 |
+
| 📓 **Training Colab** | https://colab.research.google.com/drive/1C1_3giNt-NmbzKNFJr5_L1fms3L8LfmB |
|
| 514 |
+
| 💻 **GitHub** | https://github.com/ps2181/invoice-processing-pipeline |
|
| 515 |
+
| 🧩 **OpenEnv Framework** | https://github.com/meta-pytorch/OpenEnv |
|
| 516 |
|
| 517 |
</div>
|
| 518 |
|
|
|
|
| 520 |
|
| 521 |
<div align="center">
|
| 522 |
|
| 523 |
+
<img src="https://capsule-render.vercel.app/api?type=waving&color=gradient&customColorList=6,11,20&height=100§ion=footer&animation=twinkling" width="100%"/>
|
| 524 |
+
|
| 525 |
+
**Built with ❤️ for the Meta PyTorch OpenEnv Hackathon 2026**
|
| 526 |
|
| 527 |
+
*"The system that gets harder for itself — so the agent never stops learning."*
|
| 528 |
|
| 529 |
</div>
|