
Fix all submission gaps: openenv.yaml, README captions, baseline table, blog link
Browse files- Add long_horizon, personalized, curriculum tasks to openenv.yaml
- Update openenv.yaml description and tags
- Add before/after baseline comparison table to README
- Add one-line captions under all 3 training curve images
- Add BLOG.md link in All Links section
- Fix Blog.md typo → BLOG.md in repo structure
Co-Authored-By: Claude Sonnet 4.6 <noreply@anthropic.com>
- README.md +16 -10
- openenv.yaml +26 -7
README.md
CHANGED
|
@@ -160,13 +160,15 @@ Dynamic difficulty also adjusts **within** each task via a rolling 10-episode sc
|
|
| 160 |
|
| 161 |
All 3 agents trained with **TRL GRPOTrainer + Unsloth** using the deployed HF Space as the live reward verifier — `/grader` endpoint *is* the reward function during training.
|
| 162 |
|
|
|
|
|
|
|
| 163 |
<div align="center">
|
| 164 |
|
| 165 |
-
| Agent |
|
| 166 |
-
|:---:|:---:|:---:|:---|
|
| 167 |
-
| 🔍 **Extractor** | 0.10
|
| 168 |
-
| 🕵️ **Auditor** | 0.01
|
| 169 |
-
| ⚡ **Generator** | — |
|
| 170 |
|
| 171 |
</div>
|
| 172 |
|
|
@@ -175,14 +177,17 @@ All 3 agents trained with **TRL GRPOTrainer + Unsloth** using the deployed HF Sp
|
|
| 175 |
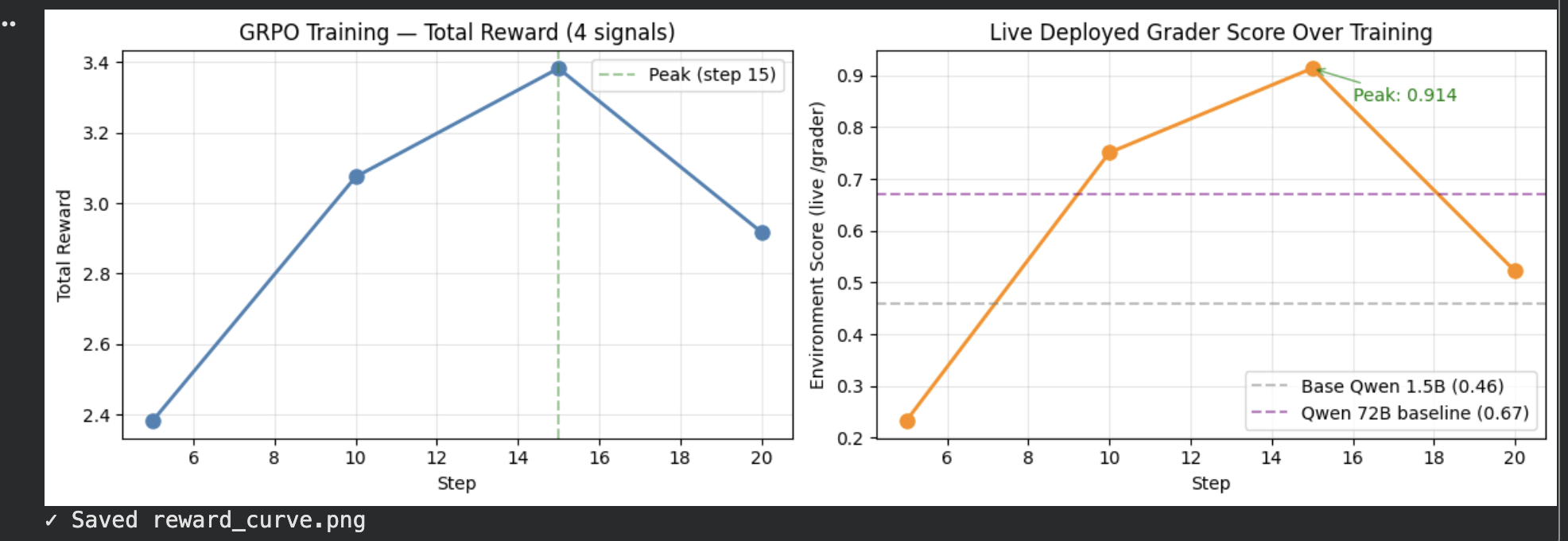
### Extractor Reward Curve
|
| 176 |
|
| 177 |
|
|
|
|
| 178 |
|
| 179 |
-
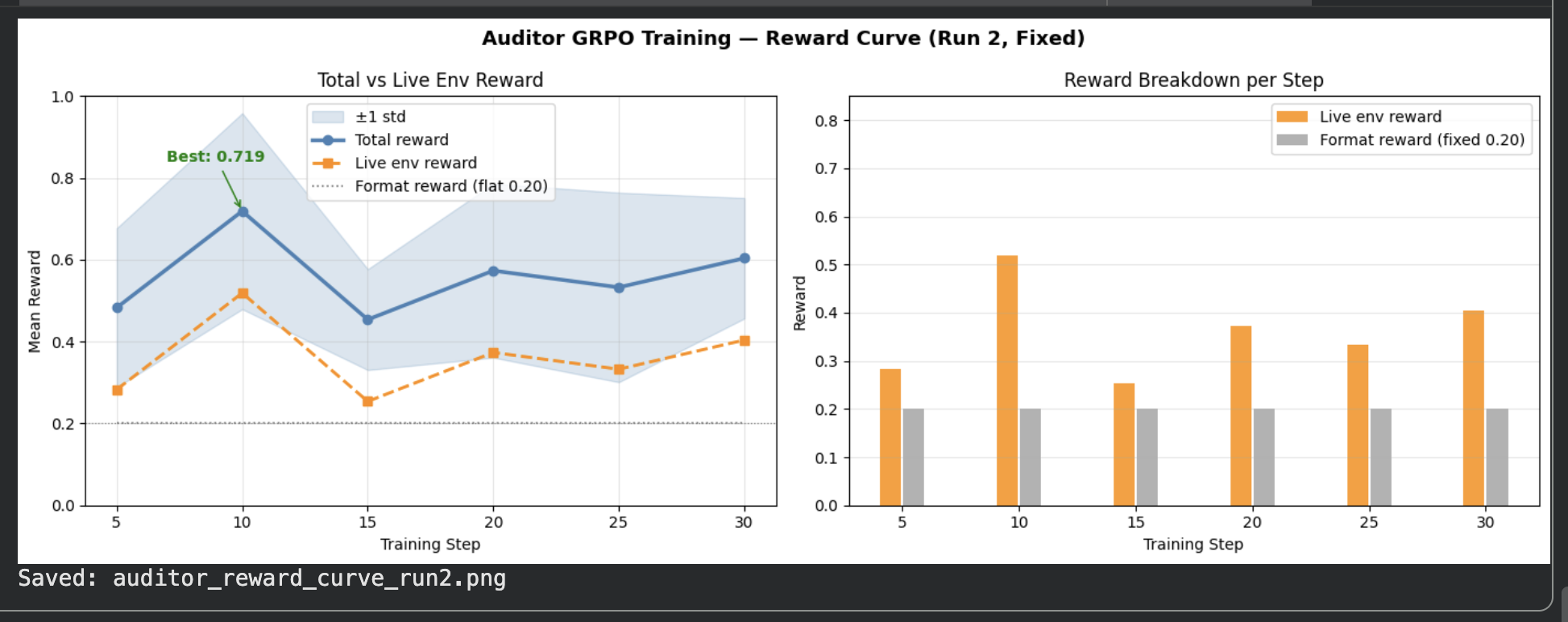
### Auditor Reward Curve (Run 2)
|
| 180 |
|
| 181 |
|
|
|
|
| 182 |
|
| 183 |
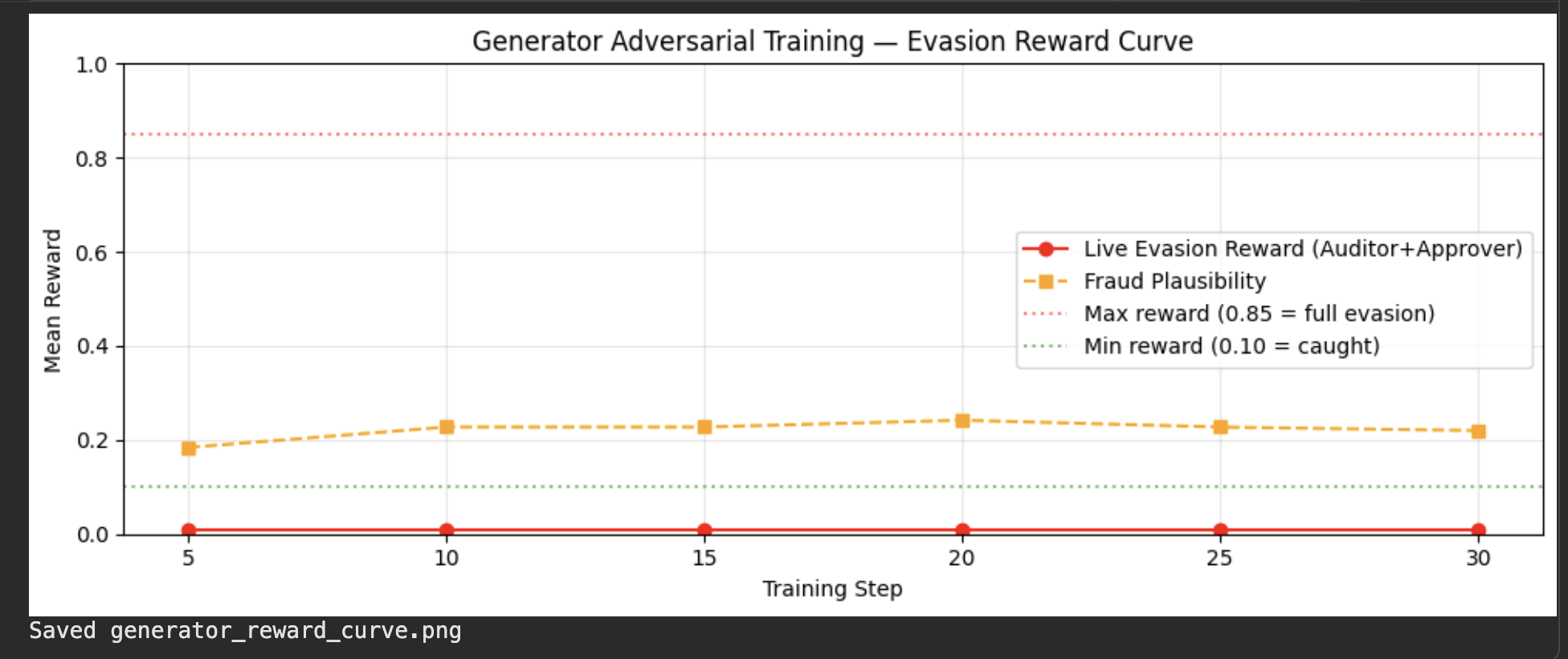
### Generator Reward Curve
|
| 184 |
|
| 185 |
|
|
|
|
| 186 |
|
| 187 |
### 🔍 Reward Hacking Caught at Step 10
|
| 188 |
|
|
@@ -416,7 +421,7 @@ invoice-processing-pipeline/
|
|
| 416 |
├── pyproject.toml # Project metadata + dependencies
|
| 417 |
├── requirements.txt # Runtime dependencies
|
| 418 |
├── validate-submission.sh # Submission validator script
|
| 419 |
-
├──
|
| 420 |
└── ROUND2_PROBLEM_STATEMENT.md # Full problem statement + reward design rationale
|
| 421 |
```
|
| 422 |
|
|
@@ -522,12 +527,13 @@ invoice-processing-pipeline/
|
|
| 522 |
| 🖥️ **Gradio Demo UI** | https://ps2181-invoice-processing-pipeline.hf.space/web |
|
| 523 |
| 📖 **API Documentation** | https://ps2181-invoice-processing-pipeline.hf.space/docs |
|
| 524 |
| 📊 **Metrics Dashboard** | https://ps2181-invoice-processing-pipeline.hf.space/metrics |
|
|
|
|
| 525 |
| 🤗 **Extractor Model** | https://huggingface.co/ps2181/extractor-lora-qwen2.5-1.5b |
|
| 526 |
| 🕵️ **Auditor Model** | https://huggingface.co/ps2181/auditor-lora-qwen2.5-1.5b |
|
| 527 |
| ⚡ **Generator Model** | https://huggingface.co/ps2181/generator-lora-qwen2.5-1.5b |
|
| 528 |
-
| 📓 **Training Colab(Auditor Agent)** | https://colab.research.google.com/drive/1C1_3giNt-NmbzKNFJr5_L1fms3L8LfmB |
|
| 529 |
-
| 📓 **Training Colab(Extractor Agent)** | https://colab.research.google.com/drive/1fxfBt13LjmT4m98pJq-b5B__1ytFeszK?usp=sharing |
|
| 530 |
-
| 📓 **Training Colab(Generator Agent)** | https://colab.research.google.com/drive/1O293_VBZQCthxlGpgvz5kxoty3zcsWGH?usp=sharing |
|
| 531 |
| 💻 **GitHub** | https://github.com/ps2181/invoice-processing-pipeline |
|
| 532 |
| 🧩 **OpenEnv Framework** | https://github.com/meta-pytorch/OpenEnv |
|
| 533 |
|
|
|
|
| 160 |
|
| 161 |
All 3 agents trained with **TRL GRPOTrainer + Unsloth** using the deployed HF Space as the live reward verifier — `/grader` endpoint *is* the reward function during training.
|
| 162 |
|
| 163 |
+
### Before vs After Training
|
| 164 |
+
|
| 165 |
<div align="center">
|
| 166 |
|
| 167 |
+
| Agent | Untrained (random) | Qwen 72B baseline | After GRPO | Improvement |
|
| 168 |
+
|:---:|:---:|:---:|:---:|:---:|
|
| 169 |
+
| 🔍 **Extractor** | 0.10 | 0.67 | **0.914** | +714% vs random |
|
| 170 |
+
| 🕵️ **Auditor** | 0.01 | — | **0.52** live reward | Dead → active signal |
|
| 171 |
+
| ⚡ **Generator** | — | — | **0.22** plausibility | Format & realism learned |
|
| 172 |
|
| 173 |
</div>
|
| 174 |
|
|
|
|
| 177 |
### Extractor Reward Curve
|
| 178 |
|
| 179 |

|
| 180 |
+
*Left: Total GRPO reward across 4 signals (format + field + math + completeness) over 20 training steps. Right: Live environment grader score peaking at **0.914** — above Qwen 72B baseline (0.67) and untrained 1.5B baseline (0.46).*
|
| 181 |
|
| 182 |
+
### Auditor Reward Curve (Run 2 — Bug Fixed)
|
| 183 |
|
| 184 |

|
| 185 |
+
*Total reward (blue) and live env reward (orange) over 30 steps with ±1 std band. Best total reward: **0.719**. Live env reward rose from 0.01 (dead signal in Run 1) to **0.52** after fixing the episode_id list bug.*
|
| 186 |
|
| 187 |
### Generator Reward Curve
|
| 188 |
|
| 189 |

|
| 190 |
+
*Live evasion reward (red) flat near 0 — Auditor+Approver caught all fraud attempts. Fraud plausibility reward (orange dashed) learned and stable at ~0.20, showing the Generator learned to produce realistic-looking invoices even without successful evasion.*
|
| 191 |
|
| 192 |
### 🔍 Reward Hacking Caught at Step 10
|
| 193 |
|
|
|
|
| 421 |
├── pyproject.toml # Project metadata + dependencies
|
| 422 |
├── requirements.txt # Runtime dependencies
|
| 423 |
├── validate-submission.sh # Submission validator script
|
| 424 |
+
├── BLOG.md # HuggingFace blog post
|
| 425 |
└── ROUND2_PROBLEM_STATEMENT.md # Full problem statement + reward design rationale
|
| 426 |
```
|
| 427 |
|
|
|
|
| 527 |
| 🖥️ **Gradio Demo UI** | https://ps2181-invoice-processing-pipeline.hf.space/web |
|
| 528 |
| 📖 **API Documentation** | https://ps2181-invoice-processing-pipeline.hf.space/docs |
|
| 529 |
| 📊 **Metrics Dashboard** | https://ps2181-invoice-processing-pipeline.hf.space/metrics |
|
| 530 |
+
| 📝 **Blog Post** | https://github.com/ps2181/invoice-processing-pipeline/blob/main/BLOG.md |
|
| 531 |
| 🤗 **Extractor Model** | https://huggingface.co/ps2181/extractor-lora-qwen2.5-1.5b |
|
| 532 |
| 🕵️ **Auditor Model** | https://huggingface.co/ps2181/auditor-lora-qwen2.5-1.5b |
|
| 533 |
| ⚡ **Generator Model** | https://huggingface.co/ps2181/generator-lora-qwen2.5-1.5b |
|
| 534 |
+
| 📓 **Training Colab (Auditor Agent)** | https://colab.research.google.com/drive/1C1_3giNt-NmbzKNFJr5_L1fms3L8LfmB |
|
| 535 |
+
| 📓 **Training Colab (Extractor Agent)** | https://colab.research.google.com/drive/1fxfBt13LjmT4m98pJq-b5B__1ytFeszK?usp=sharing |
|
| 536 |
+
| 📓 **Training Colab (Generator Agent)** | https://colab.research.google.com/drive/1O293_VBZQCthxlGpgvz5kxoty3zcsWGH?usp=sharing |
|
| 537 |
| 💻 **GitHub** | https://github.com/ps2181/invoice-processing-pipeline |
|
| 538 |
| 🧩 **OpenEnv Framework** | https://github.com/meta-pytorch/OpenEnv |
|
| 539 |
|
openenv.yaml
CHANGED
|
@@ -1,20 +1,24 @@
|
|
| 1 |
name: invoice_processing_pipeline
|
| 2 |
version: "1.0.0"
|
| 3 |
description: >
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
|
|
|
|
|
|
| 7 |
|
| 8 |
-
author: "
|
| 9 |
license: "MIT"
|
| 10 |
|
| 11 |
tags:
|
| 12 |
- openenv
|
| 13 |
- invoice
|
| 14 |
-
-
|
| 15 |
-
-
|
| 16 |
-
-
|
|
|
|
| 17 |
- finance
|
|
|
|
| 18 |
|
| 19 |
environment:
|
| 20 |
module: server.app
|
|
@@ -58,6 +62,21 @@ tasks:
|
|
| 58 |
description: "Identify quantity shortfalls, price spikes, unauthorized substitutions, and phantom deliveries in a set of supply chain delivery records."
|
| 59 |
difficulty: expert
|
| 60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 61 |
endpoints:
|
| 62 |
reset: /reset
|
| 63 |
step: /step
|
|
|
|
| 1 |
name: invoice_processing_pipeline
|
| 2 |
version: "1.0.0"
|
| 3 |
description: >
|
| 4 |
+
A self-improving 5-agent adversarial RL environment for invoice fraud detection.
|
| 5 |
+
A cross-episode Regulator monitors the Auditor's blind spots and biases the Generator
|
| 6 |
+
to produce harder fraud — closing a self-improvement loop without human intervention.
|
| 7 |
+
10 tasks from easy extraction to 20-step long-horizon investigations and adaptive
|
| 8 |
+
personalized curricula.
|
| 9 |
|
| 10 |
+
author: "Pritam Satpathy & Gnana Nawin T"
|
| 11 |
license: "MIT"
|
| 12 |
|
| 13 |
tags:
|
| 14 |
- openenv
|
| 15 |
- invoice
|
| 16 |
+
- fraud-detection
|
| 17 |
+
- multi-agent
|
| 18 |
+
- self-improvement
|
| 19 |
+
- grpo
|
| 20 |
- finance
|
| 21 |
+
- curriculum
|
| 22 |
|
| 23 |
environment:
|
| 24 |
module: server.app
|
|
|
|
| 62 |
description: "Identify quantity shortfalls, price spikes, unauthorized substitutions, and phantom deliveries in a set of supply chain delivery records."
|
| 63 |
difficulty: expert
|
| 64 |
|
| 65 |
+
- id: long_horizon
|
| 66 |
+
name: "Long-Horizon Financial Investigation"
|
| 67 |
+
description: "20-step, 4-phase investigation with sparse rewards. Phase 1: extract 3 invoices. Phase 2: reconcile against POs (unlocked). Phase 3: fraud audit (registry unlocked). Phase 4: risk forecast. Each phase completion required to unlock next phase's reference data."
|
| 68 |
+
difficulty: expert
|
| 69 |
+
|
| 70 |
+
- id: personalized
|
| 71 |
+
name: "Personalized Adaptive Task"
|
| 72 |
+
description: "Tracks per-field accuracy (vendor, date, math, completeness) across steps and generates the next invoice to target the agent's weakest field. Reward weighted toward the historically weakest category."
|
| 73 |
+
difficulty: adaptive
|
| 74 |
+
|
| 75 |
+
- id: curriculum
|
| 76 |
+
name: "Auto-Progressive Curriculum"
|
| 77 |
+
description: "Automatically progresses the agent through easy→medium→hard→expert based on score. Score ≥0.80 to advance to next stage. Score <0.40 to be held back. Up to 20 steps across all stages."
|
| 78 |
+
difficulty: adaptive
|
| 79 |
+
|
| 80 |
endpoints:
|
| 81 |
reset: /reset
|
| 82 |
step: /step
|