

Commit ·
0245be8
0
Parent(s):
Initial commit
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .env-example +48 -0
- .gitignore +17 -0
- LICENSE +21 -0
- Makefile +283 -0
- README.md +679 -0
- RESULTS.md +166 -0
- app/api/.dockerignore +4 -0
- app/api/API.md +666 -0
- app/api/Dockerfile +15 -0
- app/api/Makefile +159 -0
- app/api/config.py +176 -0
- app/api/data/training_data/org-about_the_company.md +36 -0
- app/api/data/training_data/org-board_of_directors.md +28 -0
- app/api/data/training_data/org-company_story.md +31 -0
- app/api/data/training_data/org-corporate_philosophy.md +31 -0
- app/api/data/training_data/org-customer_support.md +28 -0
- app/api/data/training_data/org-earnings_fy2023.md +58 -0
- app/api/data/training_data/org-management_team.md +28 -0
- app/api/data/training_data/project-frogonil.md +48 -0
- app/api/data/training_data/project-kekzal.md +50 -0
- app/api/data/training_data/project-memegen.md +36 -0
- app/api/data/training_data/project-memetrex.md +48 -0
- app/api/data/training_data/project-neurokek.md +56 -0
- app/api/data/training_data/project-pepetamine.md +48 -0
- app/api/data/training_data/project-pepetrak.md +36 -0
- app/api/helpers.py +658 -0
- app/api/llm.py +465 -0
- app/api/main.py +567 -0
- app/api/models.py +660 -0
- app/api/ngrok.py +117 -0
- app/api/requirements.txt +12 -0
- app/api/seed.py +166 -0
- app/api/static/img/rasagpt-icon-200x200.png +0 -0
- app/api/static/img/rasagpt-logo-1.png +0 -0
- app/api/static/img/rasagpt-logo-2.png +0 -0
- app/api/util.py +80 -0
- app/api/wait-for-it.sh +0 -0
- app/db/Dockerfile +5 -0
- app/db/create_db.sh +13 -0
- app/rasa-credentials/.dockerignore +4 -0
- app/rasa-credentials/Dockerfile +15 -0
- app/rasa-credentials/main.py +182 -0
- app/rasa-credentials/requirements.txt +8 -0
- app/rasa/.dockerignore +4 -0
- app/rasa/actions/Dockerfile +9 -0
- app/rasa/actions/__init__.py +0 -0
- app/rasa/actions/actions.py +73 -0
- app/rasa/config.yml +5 -0
- app/rasa/credentials.yml +7 -0
- app/rasa/custom_telegram.py +16 -0
.env-example
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ENV=local
|
| 2 |
+
|
| 3 |
+
FILE_UPLOAD_PATH=data
|
| 4 |
+
LLM_DEFAULT_TEMPERATURE=0
|
| 5 |
+
LLM_CHUNK_SIZE=1000
|
| 6 |
+
LLM_CHUNK_OVERLAP=200
|
| 7 |
+
LLM_DISTANCE_THRESHOLD=0.2
|
| 8 |
+
LLM_MAX_OUTPUT_TOKENS=256
|
| 9 |
+
LLM_MIN_NODE_LIMIT=3
|
| 10 |
+
LLM_DEFAULT_DISTANCE_STRATEGY=EUCLIDEAN
|
| 11 |
+
|
| 12 |
+
POSTGRES_USER=postgres
|
| 13 |
+
POSTGRES_PASSWORD=postgres
|
| 14 |
+
POSTGRES_DB=postgres
|
| 15 |
+
PGVECTOR_ADD_INDEX=true
|
| 16 |
+
|
| 17 |
+
DB_HOST=db
|
| 18 |
+
DB_PORT=5432
|
| 19 |
+
DB_USER=api
|
| 20 |
+
DB_NAME=api
|
| 21 |
+
DB_PASSWORD=<YOUR DATABASE PASSWORD>
|
| 22 |
+
|
| 23 |
+
NGROK_HOST=ngrok
|
| 24 |
+
NGROK_PORT=4040
|
| 25 |
+
NGROK_AUTHTOKEN=<YOUR NGROK AUTH TOKEN>
|
| 26 |
+
NGROK_API_KEY=<YOUR NGROK API KEY>
|
| 27 |
+
NGROK_INTERNAL_WEBHOOK_HOST=api
|
| 28 |
+
NGROK_INTERNAL_WEBHOOK_PORT=8888
|
| 29 |
+
NGROK_DEBUG=true
|
| 30 |
+
NGROK_CONFIG=/etc/ngrok.yml
|
| 31 |
+
|
| 32 |
+
RASA_WEBHOOK_HOST=rasa-core
|
| 33 |
+
RASA_WEBHOOK_PORT=5005
|
| 34 |
+
|
| 35 |
+
CREDENTIALS_PATH=/app/rasa/credentials.yml
|
| 36 |
+
|
| 37 |
+
TELEGRAM_ACCESS_TOKEN=<YOUR TELEGRAM ACCESS TOKEN>
|
| 38 |
+
TELEGRAM_BOTNAME=rasagpt
|
| 39 |
+
|
| 40 |
+
API_PORT=8888
|
| 41 |
+
API_HOST=api
|
| 42 |
+
|
| 43 |
+
PGADMIN_PORT=5050
|
| 44 |
+
PGADMIN_DEFAULT_PASSWORD=pgadmin
|
| 45 |
+
PGADMIN_DEFAULT_EMAIL=your@emailaddress.com
|
| 46 |
+
|
| 47 |
+
MODEL_NAME=gpt-3.5-turbo
|
| 48 |
+
OPENAI_API_KEY=<YOUR OPEN AI KEY>
|
.gitignore
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
.trunk
|
| 3 |
+
.vscode
|
| 4 |
+
mnt
|
| 5 |
+
venv/
|
| 6 |
+
.env
|
| 7 |
+
.env-dev
|
| 8 |
+
.env
|
| 9 |
+
.env-staging
|
| 10 |
+
.env-stage
|
| 11 |
+
.env-prod
|
| 12 |
+
.env-production
|
| 13 |
+
__pycache__/
|
| 14 |
+
app/rasa/models/*
|
| 15 |
+
app/rasa/.rasa
|
| 16 |
+
app/rasa/.config
|
| 17 |
+
app/rasa/.keras
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Paul Pierre
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
Makefile
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.PHONY: default banner help install build run stop restart logs ngrok pgadmin api api-stop db db-stop db-purge purge models shell-api shell-db shell-rasa shell-actions rasa-train rasa-start rasa-stop
|
| 2 |
+
|
| 3 |
+
defaut: help
|
| 4 |
+
|
| 5 |
+
help:
|
| 6 |
+
@make banner
|
| 7 |
+
@echo "+------------------+"
|
| 8 |
+
@echo "| 🏠 CORE COMMANDS |"
|
| 9 |
+
@echo "+------------------+"
|
| 10 |
+
@echo "make install - Install and run RasaGPT"
|
| 11 |
+
@echo "make build - Build docker images"
|
| 12 |
+
@echo "make run - Run RasaGPT"
|
| 13 |
+
@echo "make stop - Stop RasaGPT"
|
| 14 |
+
@echo "make restart - Restart RasaGPT\n"
|
| 15 |
+
@echo "+--------------------+"
|
| 16 |
+
@echo "| 🌍 ADMIN INTERACES |"
|
| 17 |
+
@echo "+--------------------+"
|
| 18 |
+
@echo "make logs - View logs via Dozzle"
|
| 19 |
+
@echo "make ngrok - View ngrok dashboard"
|
| 20 |
+
@echo "make pgadmin - View pgAdmin dashboard\n"
|
| 21 |
+
@echo "+-----------------------+"
|
| 22 |
+
@echo "| 👷 DEBUGGING COMMANDS |"
|
| 23 |
+
@echo "+-----------------------+"
|
| 24 |
+
@echo "make api - Run only API server"
|
| 25 |
+
@echo "make models - Build Rasa models"
|
| 26 |
+
@echo "make purge - Remove all docker images"
|
| 27 |
+
@echo "make db-purge - Delete all data in database"
|
| 28 |
+
@echo "make shell-api - Open shell in API container"
|
| 29 |
+
@echo "make shell-db - Open shell in database container"
|
| 30 |
+
@echo "make shell-rasa - Open shell in Rasa container"
|
| 31 |
+
@echo "make shell-actions - Open shell in Rasa actions container\n"
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
banner:
|
| 35 |
+
@echo "\n\n-------------------------------------"
|
| 36 |
+
@echo "▒█▀▀█ █▀▀█ █▀▀ █▀▀█ ▒█▀▀█ ▒█▀▀█ ▀▀█▀▀"
|
| 37 |
+
@echo "▒█▄▄▀ █▄▄█ ▀▀█ █▄▄█ ▒█░▄▄ ▒█▄▄█ ░▒█░░"
|
| 38 |
+
@echo "▒█░▒█ ▀░░▀ ▀▀▀ ▀░░▀ ▒█▄▄█ ▒█░░░ ░▒█░░"
|
| 39 |
+
@echo "+-----------------------------------+"
|
| 40 |
+
@echo "| http://RasaGPT.dev by @paulpierre |"
|
| 41 |
+
@echo "+-----------------------------------+\n\n"
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
# ==========================
|
| 46 |
+
# 👷 INITIALIZATION COMMANDS
|
| 47 |
+
# ==========================
|
| 48 |
+
|
| 49 |
+
# ---------------------------------------
|
| 50 |
+
# Run this first to setup the environment
|
| 51 |
+
# ---------------------------------------
|
| 52 |
+
install:
|
| 53 |
+
@make banner
|
| 54 |
+
@make stop
|
| 55 |
+
@make env-var
|
| 56 |
+
@make rasa-train
|
| 57 |
+
@make build
|
| 58 |
+
@make run
|
| 59 |
+
@make models
|
| 60 |
+
@make rasa-restart
|
| 61 |
+
@make seed
|
| 62 |
+
@echo "✅ RasaGPT installed and running"
|
| 63 |
+
|
| 64 |
+
# -----------------------
|
| 65 |
+
# Build the docker images
|
| 66 |
+
# -----------------------
|
| 67 |
+
build:
|
| 68 |
+
@echo "🏗️ Building docker images ..\n"
|
| 69 |
+
@docker-compose -f docker-compose.yml build
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
# ================
|
| 73 |
+
# 🏠 CORE COMMANDS
|
| 74 |
+
# ================
|
| 75 |
+
|
| 76 |
+
# ---------------------------
|
| 77 |
+
# Startup all docker services
|
| 78 |
+
# ---------------------------
|
| 79 |
+
|
| 80 |
+
run:
|
| 81 |
+
@echo "🚀 Starting docker-compose.yml ..\n"
|
| 82 |
+
@docker-compose -f docker-compose.yml up -d
|
| 83 |
+
|
| 84 |
+
# ---------------------------
|
| 85 |
+
# Stop all running containers
|
| 86 |
+
# ---------------------------
|
| 87 |
+
|
| 88 |
+
stop:
|
| 89 |
+
@echo "🔍 Stopping any running containers .. \n"
|
| 90 |
+
@docker-compose -f docker-compose.yml down
|
| 91 |
+
|
| 92 |
+
# ----------------------
|
| 93 |
+
# Restart all containers
|
| 94 |
+
# ----------------------
|
| 95 |
+
restart:
|
| 96 |
+
@echo "🔁 Restarting docker services ..\n"
|
| 97 |
+
@make stop
|
| 98 |
+
@make run
|
| 99 |
+
|
| 100 |
+
# ----------------------
|
| 101 |
+
# Restart Rasa core only
|
| 102 |
+
# ----------------------
|
| 103 |
+
rasa-restart:
|
| 104 |
+
@echo "🤖 Restarting Rasa so it grabs credentials ..\n"
|
| 105 |
+
@make rasa-stop
|
| 106 |
+
@make rasa-start
|
| 107 |
+
|
| 108 |
+
rasa-stop:
|
| 109 |
+
@echo "🤖 Stopping Rasa ..\n"
|
| 110 |
+
@docker-compose -f docker-compose.yml stop rasa-core
|
| 111 |
+
|
| 112 |
+
rasa-start:
|
| 113 |
+
@echo "🤖 Starting Rasa ..\n"
|
| 114 |
+
@docker-compose -f docker-compose.yml up -d rasa-core
|
| 115 |
+
|
| 116 |
+
rasa-build:
|
| 117 |
+
@echo "🤖 Building Rasa ..\n"
|
| 118 |
+
@docker-compose -f docker-compose.yml build rasa-core
|
| 119 |
+
|
| 120 |
+
# -----------------------
|
| 121 |
+
# Seed database with data
|
| 122 |
+
# -----------------------
|
| 123 |
+
seed:
|
| 124 |
+
@echo "🌱 Seeding database ..\n"
|
| 125 |
+
@docker-compose -f docker-compose.yml exec api /app/api/wait-for-it.sh db:5432 --timeout=60 -- python3 seed.py
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# =======================
|
| 129 |
+
# 🌍 WEB ADMIN INTERFACES
|
| 130 |
+
# =======================
|
| 131 |
+
|
| 132 |
+
# -------------------------
|
| 133 |
+
# Reverse HTTP tunnel admin
|
| 134 |
+
# -------------------------
|
| 135 |
+
ngrok:
|
| 136 |
+
@echo "📡 Opening ngrok agent in the browser ..\n"
|
| 137 |
+
@open http://localhost:4040
|
| 138 |
+
|
| 139 |
+
# ------------------------
|
| 140 |
+
# Postgres admin interface
|
| 141 |
+
# ------------------------
|
| 142 |
+
pgadmin:
|
| 143 |
+
@echo "👷♂️ Opening PG Admin in the browser ..\n"
|
| 144 |
+
@open http://localhost:5050
|
| 145 |
+
|
| 146 |
+
# ------------------------
|
| 147 |
+
# Container logs interface
|
| 148 |
+
# ------------------------
|
| 149 |
+
logs:
|
| 150 |
+
@echo "🔍 Opening container logs in the browser ..\n"
|
| 151 |
+
@open http://localhost:9999/
|
| 152 |
+
|
| 153 |
+
# =====================
|
| 154 |
+
# 👷 DEBUGGING COMMANDS
|
| 155 |
+
# =====================
|
| 156 |
+
|
| 157 |
+
# ---------------------------
|
| 158 |
+
# Startup just the API server
|
| 159 |
+
# ---------------------------
|
| 160 |
+
api:
|
| 161 |
+
@make db
|
| 162 |
+
@echo "🚀 Starting FastAPI and postgres ..\n"
|
| 163 |
+
@docker-compose -f docker-compose.yml up -d api
|
| 164 |
+
|
| 165 |
+
# ------------------------
|
| 166 |
+
# Startup just Postgres DB
|
| 167 |
+
# ------------------------
|
| 168 |
+
db:
|
| 169 |
+
@echo "🚀 Starting Postgres with pgvector ..\n"
|
| 170 |
+
@docker-compose -f docker-compose.yml up -d db
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
db-stop:
|
| 174 |
+
@echo " Stopping the database ..\n"
|
| 175 |
+
@docker-compose -f docker-compose.yml down db
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
db-reset:
|
| 179 |
+
@echo " Resetting the database ..\n"
|
| 180 |
+
@make db-purge
|
| 181 |
+
@make api
|
| 182 |
+
@make models
|
| 183 |
+
|
| 184 |
+
# -------------------------------
|
| 185 |
+
# Build the schema in Postgres DB
|
| 186 |
+
# -------------------------------
|
| 187 |
+
models:
|
| 188 |
+
@echo "💽 Building models in Postgres ..\n"
|
| 189 |
+
@docker-compose -f docker-compose.yml exec api /app/api/wait-for-it.sh db:5432 --timeout=60 -- python3 models.py
|
| 190 |
+
|
| 191 |
+
# -------------------------------
|
| 192 |
+
# Delete containers or bad images
|
| 193 |
+
# -------------------------------
|
| 194 |
+
purge:
|
| 195 |
+
@echo "🧹 Purging all containers and images ..\n"
|
| 196 |
+
@make stop
|
| 197 |
+
@docker system prune -a
|
| 198 |
+
@make install
|
| 199 |
+
|
| 200 |
+
# --------------------------------
|
| 201 |
+
# Delete the database mount volume
|
| 202 |
+
# --------------------------------
|
| 203 |
+
db-purge:
|
| 204 |
+
@echo "⛔ Are you sure you want to delete all data in the database? [y/N]\n"
|
| 205 |
+
@read confirmation; \
|
| 206 |
+
if [ "$$confirmation" = "y" ] || [ "$$confirmation" = "Y" ]; then \
|
| 207 |
+
echo "Deleting generated files .."; \
|
| 208 |
+
make stop; \
|
| 209 |
+
rm -rf ./mnt; \
|
| 210 |
+
echo "Deleted."; \
|
| 211 |
+
else \
|
| 212 |
+
echo "Aborted."; \
|
| 213 |
+
fi
|
| 214 |
+
|
| 215 |
+
# --------------------------------------
|
| 216 |
+
# Open a bash shell in the API container
|
| 217 |
+
# --------------------------------------
|
| 218 |
+
shell-api:
|
| 219 |
+
@echo "💻🐢 Opening a bash shell in the RasaGPT API container ..\n"
|
| 220 |
+
@if docker ps | grep api > /dev/null; then \
|
| 221 |
+
docker exec -it $$(docker ps | grep api | tr -d '\n' | awk '{print $$1}') /bin/bash; \
|
| 222 |
+
else \
|
| 223 |
+
echo "Container api is not running"; \
|
| 224 |
+
fi
|
| 225 |
+
|
| 226 |
+
# ---------------------------------------
|
| 227 |
+
# Open a bash shell in the Rasa container
|
| 228 |
+
# ---------------------------------------
|
| 229 |
+
shell-rasa:
|
| 230 |
+
@echo "💻🐢 Opening a bash shell in the rasa-core container ..\n"
|
| 231 |
+
@if docker ps | grep rasa-core > /dev/null; then \
|
| 232 |
+
docker exec -it $$(docker ps | grep rasa-core | tr -d '\n' | awk '{print $$1}') /bin/bash; \
|
| 233 |
+
else \
|
| 234 |
+
echo "Container rasa-core is not running"; \
|
| 235 |
+
fi
|
| 236 |
+
|
| 237 |
+
# -----------------------------------------------
|
| 238 |
+
# Open a bash shell in the Rasa actions container
|
| 239 |
+
# -----------------------------------------------
|
| 240 |
+
shell-actions:
|
| 241 |
+
@echo "💻🐢 Opening a bash shell in the rasa-actions container ..\n"
|
| 242 |
+
@if docker ps | grep rasa-actions > /dev/null; then \
|
| 243 |
+
docker exec -it $$(docker ps | grep rasa-actions | tr -d '\n' | awk '{print $$1}') /bin/bash; \
|
| 244 |
+
else \
|
| 245 |
+
echo "Container rasa-actions is not running"; \
|
| 246 |
+
fi
|
| 247 |
+
|
| 248 |
+
# -------------------------------------------
|
| 249 |
+
# Open a bash shell in the Postgres container
|
| 250 |
+
# -------------------------------------------
|
| 251 |
+
shell-db:
|
| 252 |
+
@echo "💻🐢 Opening a bash shell in the Postgres container ..\n"
|
| 253 |
+
@if docker ps | grep db > /dev/null; then \
|
| 254 |
+
docker exec -it $$(docker ps | grep db | tr -d '\n' | awk '{print $$1}') /bin/bash; \
|
| 255 |
+
else \
|
| 256 |
+
echo "Container db is not running"; \
|
| 257 |
+
fi
|
| 258 |
+
|
| 259 |
+
# ==================
|
| 260 |
+
# 💁 HELPER COMMANDS
|
| 261 |
+
# ==================
|
| 262 |
+
|
| 263 |
+
# -------------
|
| 264 |
+
# Check envvars
|
| 265 |
+
# -------------
|
| 266 |
+
env-var:
|
| 267 |
+
@echo "🔍 Checking if envvars are set ..\n";
|
| 268 |
+
@if ! test -e "./.env"; then \
|
| 269 |
+
@echo "❌ .env file not found. Please copy .env-example to .env and update values"; \
|
| 270 |
+
exit 1; \
|
| 271 |
+
else \
|
| 272 |
+
echo "✅ found .env\n"; \
|
| 273 |
+
fi
|
| 274 |
+
|
| 275 |
+
# -----------------
|
| 276 |
+
# Train Rasa models
|
| 277 |
+
# -----------------
|
| 278 |
+
rasa-train:
|
| 279 |
+
@echo "💽 Generating Rasa models ..\n"
|
| 280 |
+
@make rasa-start
|
| 281 |
+
@docker-compose -f docker-compose.yml exec rasa-core rasa train
|
| 282 |
+
@make rasa-stop
|
| 283 |
+
@echo "✅ Done\n"
|
README.md
ADDED
|
@@ -0,0 +1,679 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+

|
| 3 |
+
|
| 4 |
+
<br/><br/>
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# 🏠 Overview
|
| 8 |
+
|
| 9 |
+
💬 RasaGPT is the first headless LLM chatbot platform built on top of [Rasa](https://github.com/RasaHQ/rasa) and [Langchain](https://github.com/hwchase17/langchain). It is boilerplate and a reference implementation of Rasa and Telegram utilizing an LLM library like Langchain for indexing, retrieval and context injection.
|
| 10 |
+
|
| 11 |
+
<br/><br/>
|
| 12 |
+
|
| 13 |
+
# 💁♀️ Why RasaGPT?
|
| 14 |
+
|
| 15 |
+
RasaGPT works out of the box. A lot of the implementing headaches were sorted out so you don’t have to, including:
|
| 16 |
+
|
| 17 |
+
- Creating your own proprietary bot end-point using FastAPI, document upload and “training” 'pipeline included
|
| 18 |
+
- How to integrate Langchain/LlamaIndex and Rasa
|
| 19 |
+
- Library conflicts with LLM libraries and passing metadata
|
| 20 |
+
- Dockerized [support on MacOS](https://github.com/khalo-sa/rasa-apple-silicon) for running Rasa
|
| 21 |
+
- Reverse proxy with chatbots [via ngrok](https://ngrok.com/docs/ngrok-agent/)
|
| 22 |
+
- Implementing pgvector with your own custom schema instead of using Langchain’s highly opinionated [PGVector class](https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/pgvector.html)
|
| 23 |
+
- Adding multi-tenancy (Rasa [doesn't natively support this](https://forum.rasa.com/t/multi-tenancy-in-rasa-core/2382)), sessions and metadata between Rasa and your own backend / application
|
| 24 |
+
|
| 25 |
+
The backstory is familiar. A friend came to me with a problem. I scoured Google and Github for a decent reference implementation of LLM’s integrated with Rasa but came up empty-handed. I figured this to be a great opportunity to satiate my curiosity and 2 days later I had a proof of concept, and a week later this is what I came up with.
|
| 26 |
+
|
| 27 |
+
<br/>
|
| 28 |
+
|
| 29 |
+
> ⚠️ **Caveat emptor:**
|
| 30 |
+
This is far from production code and rife with prompt injection and general security vulnerabilities. I just hope someone finds this useful 😊
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
<br/><br/>
|
| 34 |
+
|
| 35 |
+
# **✨** Quick start
|
| 36 |
+
|
| 37 |
+
Getting started is easy, just make sure you meet the dependencies below.
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
# Get the code
|
| 41 |
+
git clone https://github.com/paulpierre/RasaGPT.git
|
| 42 |
+
cd RasaGPT
|
| 43 |
+
|
| 44 |
+
## Setup the .env file
|
| 45 |
+
cp .env-example .env
|
| 46 |
+
|
| 47 |
+
# Edit your .env file and add all the necessary credentials
|
| 48 |
+
make install
|
| 49 |
+
|
| 50 |
+
# Type "make" to see more options
|
| 51 |
+
make
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
<br/><br/>
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
# 🔥 Features
|
| 58 |
+
|
| 59 |
+
## Full Application and API
|
| 60 |
+
|
| 61 |
+
- LLM “learns” on an arbitrary corpus of data using Langchain
|
| 62 |
+
- Upload documents and “train” all via [FastAPI](https://fastapi.tiangolo.com/)
|
| 63 |
+
- Document versioning and automatic “re-training” implemented on upload
|
| 64 |
+
- Customize your own async end-points and database models via [FastAPI](https://fastapi.tiangolo.com/) and [SQLModel](https://sqlmodel.tiangolo.com/)
|
| 65 |
+
- Bot determines whether human handoff is necessary
|
| 66 |
+
- Bot generates tags based on user questions and response automatically
|
| 67 |
+
- Full API documentation via [Swagger](https://github.com/swagger-api/swagger-ui) and [Redoc](https://redocly.github.io/redoc/) included
|
| 68 |
+
- [Ngrok](ngrok.com/docs) end-points are automatically generated for you on startup so your bot can always be accessed via `https://t.me/yourbotname`
|
| 69 |
+
- Embedding similarity search built into Postgres via [pgvector](https://github.com/pgvector/pgvector) and Postgres functions
|
| 70 |
+
- [Dummy data included](https://github.com/paulpierre/RasaGPT/tree/main/app/api/data/training_data) for you to test and experiment
|
| 71 |
+
- Unlimited use cases from help desk, customer support, quiz, e-learning, dungeon and dragons, and more
|
| 72 |
+
<br/><br/>
|
| 73 |
+
## Rasa integration
|
| 74 |
+
|
| 75 |
+
- Built on top of [Rasa](https://rasa.com/docs/rasa/), the open source gold-standard for chat platforms
|
| 76 |
+
- Supports MacOS M1/M2 via Docker (canonical Rasa image [lacks MacOS arch. support](https://github.com/khalo-sa/rasa-apple-silicon))
|
| 77 |
+
- Supports Telegram, easily integrate Slack, Whatsapp, Line, SMS, etc.
|
| 78 |
+
- Setup complex dialog pipelines using NLU models form Huggingface like BERT or libraries/frameworks like Keras, Tensorflow with OpenAI GPT as fallback
|
| 79 |
+
<br/><br/>
|
| 80 |
+
## Flexibility
|
| 81 |
+
|
| 82 |
+
- Extend agentic, memory, etc. capabilities with Langchain
|
| 83 |
+
- Schema supports multi-tenancy, sessions, data storage
|
| 84 |
+
- Customize agent personalities
|
| 85 |
+
- Saves all of chat history and creating embeddings from all interactions future-proofing your retrieval strategy
|
| 86 |
+
- Automatically generate embeddings from knowledge base corpus and client feedback
|
| 87 |
+
|
| 88 |
+
<br/><br/>
|
| 89 |
+
|
| 90 |
+
# 🧑💻 Installing
|
| 91 |
+
|
| 92 |
+
## Requirements
|
| 93 |
+
|
| 94 |
+
- Python 3.9
|
| 95 |
+
- Docker & Docker compose ([Docker desktop MacOS](https://www.docker.com/products/docker-desktop/))
|
| 96 |
+
- Open AI [API key](https://platform.openai.com/account/api-keys)
|
| 97 |
+
- Telegram [bot credentials](https://core.telegram.org/bots#how-do-i-create-a-bot)
|
| 98 |
+
- Ngrok [auth token](https://dashboard.ngrok.com/tunnels/authtokens)
|
| 99 |
+
- Make ([MacOS](https://formulae.brew.sh/formula/make)/[Windows](https://stackoverflow.com/questions/32127524/how-to-install-and-use-make-in-windows))
|
| 100 |
+
- SQLModel
|
| 101 |
+
|
| 102 |
+
<br/>
|
| 103 |
+
|
| 104 |
+
## Setup
|
| 105 |
+
|
| 106 |
+
```bash
|
| 107 |
+
git clone https://github.com/paulpierre/RasaGPT.git
|
| 108 |
+
cd RasaGPT
|
| 109 |
+
cp .env-example .env
|
| 110 |
+
|
| 111 |
+
# Edit your .env file and all the credentials
|
| 112 |
+
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
<br/>
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
At any point feel free to just type in `make` and it will display the list of options, mostly useful for debugging:
|
| 119 |
+
|
| 120 |
+
<br/>
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+

|
| 124 |
+
|
| 125 |
+
<br/>
|
| 126 |
+
|
| 127 |
+
## Docker-compose
|
| 128 |
+
|
| 129 |
+
The easiest way to get started is using the `Makefile` in the root directory. It will install and run all the services for RasaGPT in the correct order.
|
| 130 |
+
|
| 131 |
+
```bash
|
| 132 |
+
make install
|
| 133 |
+
|
| 134 |
+
# This will automatically install and run RasaGPT
|
| 135 |
+
# After installation, to run again you can simply run
|
| 136 |
+
|
| 137 |
+
make run
|
| 138 |
+
```
|
| 139 |
+
<br/>
|
| 140 |
+
|
| 141 |
+
## Local Python Environment
|
| 142 |
+
|
| 143 |
+
This is useful if you wish to focus on developing on top of the API, a separate `Makefile` was made for this. This will create a local virtual environment for you.
|
| 144 |
+
|
| 145 |
+
```bash
|
| 146 |
+
# Assuming you are already in the RasaGPT directory
|
| 147 |
+
cd app/api
|
| 148 |
+
make install
|
| 149 |
+
|
| 150 |
+
# This will automatically install and run RasaGPT
|
| 151 |
+
# After installation, to run again you can simply run
|
| 152 |
+
|
| 153 |
+
make run
|
| 154 |
+
```
|
| 155 |
+
<br/>
|
| 156 |
+
|
| 157 |
+
Similarly, enter `make` to see a full list of commands
|
| 158 |
+
|
| 159 |
+
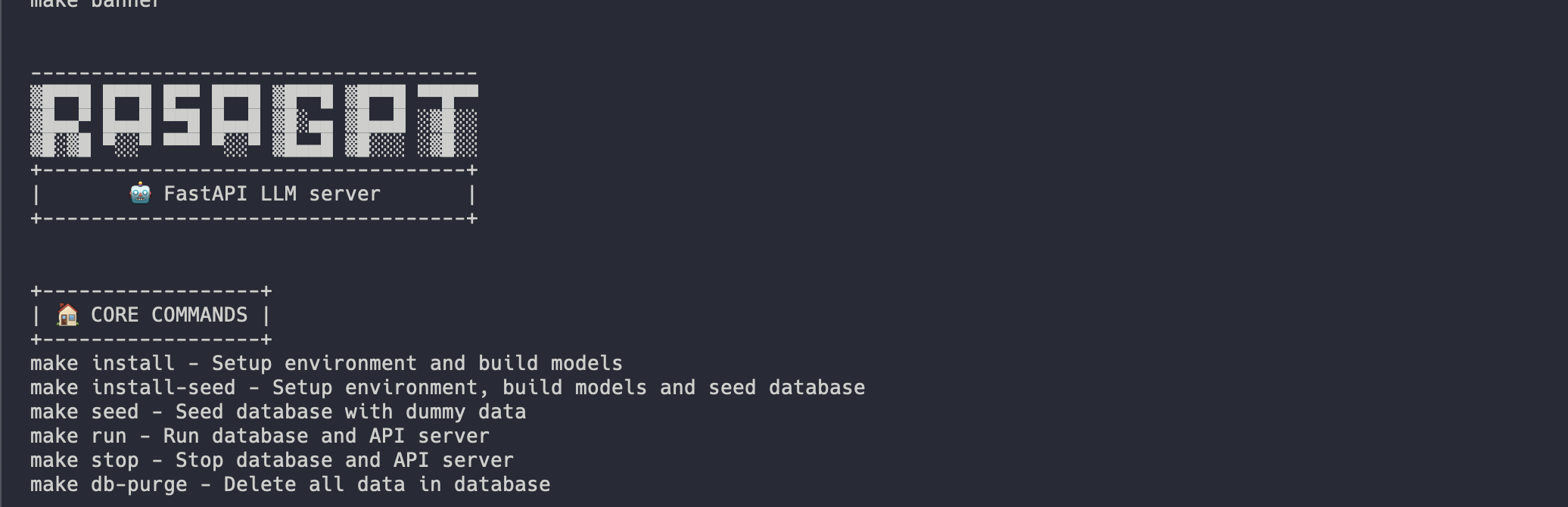
|
| 160 |
+
|
| 161 |
+
<br/>
|
| 162 |
+
|
| 163 |
+
## Installation process
|
| 164 |
+
|
| 165 |
+
Installation should be automated should look like this:
|
| 166 |
+
|
| 167 |
+
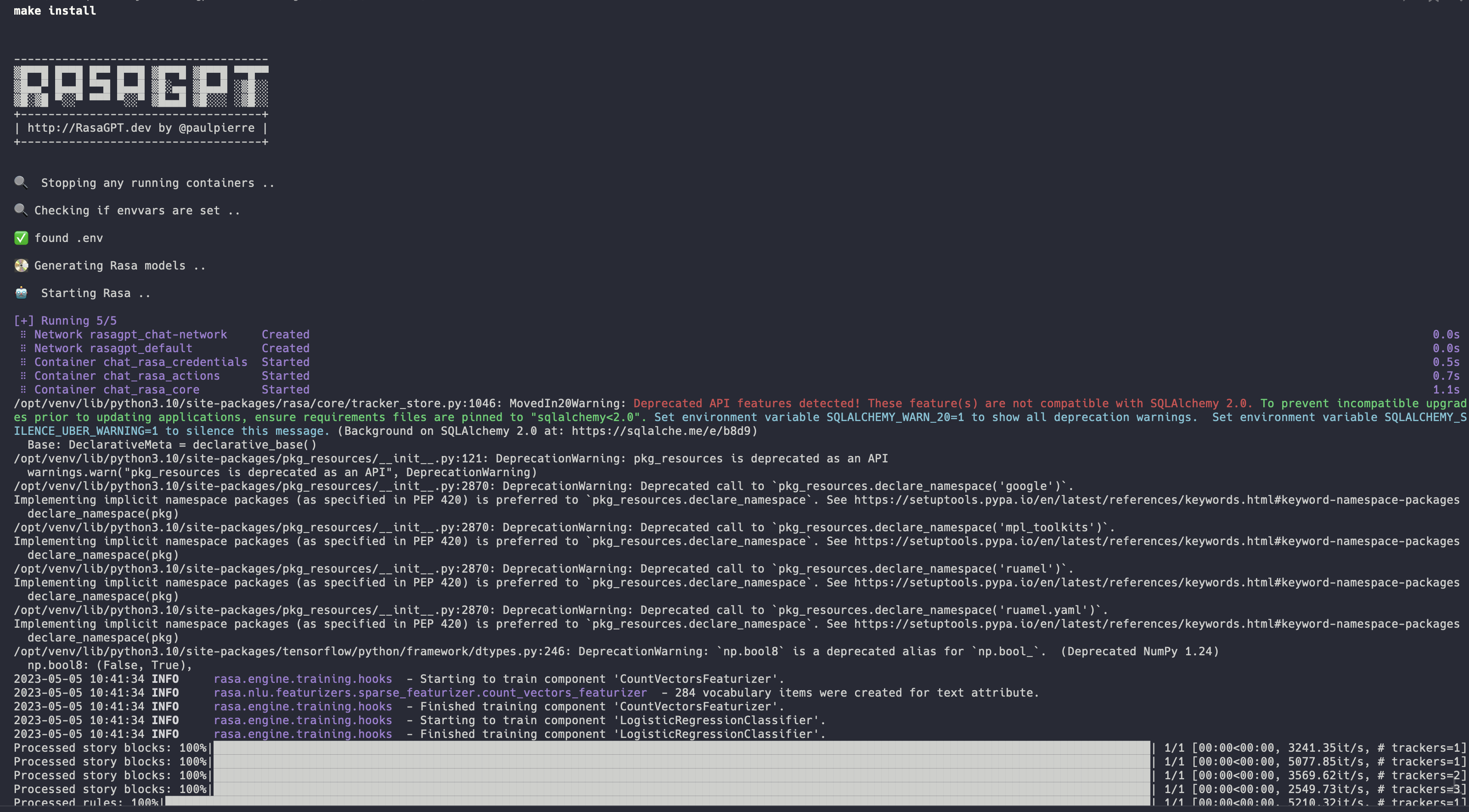
|
| 168 |
+
|
| 169 |
+
👉 Full installation log: [https://app.warp.dev/block/vflua6Eue29EPk8EVvW8Kd](https://app.warp.dev/block/vflua6Eue29EPk8EVvW8Kd)
|
| 170 |
+
|
| 171 |
+
<br/>
|
| 172 |
+
|
| 173 |
+
The installation process for Docker takes the following steps at a high level
|
| 174 |
+
|
| 175 |
+
1. Check to make sure you have `.env` available
|
| 176 |
+
2. Database is initialized with [`pgvector`](https://github.com/pgvector/pgvector)
|
| 177 |
+
3. Database models create the database schema
|
| 178 |
+
4. Trains the Rasa model so it is ready to run
|
| 179 |
+
5. Sets up ngrok with Rasa so Telegram has a webhook back to your API server
|
| 180 |
+
6. Sets up the Rasa actions server so Rasa can talk to the RasaGPT API
|
| 181 |
+
7. Database is populated with dummy data via `seed.py`
|
| 182 |
+
|
| 183 |
+
<br/><br/>
|
| 184 |
+
|
| 185 |
+
# ☑️ Next steps
|
| 186 |
+
<br/>
|
| 187 |
+
|
| 188 |
+
## 💬 Start chatting
|
| 189 |
+
|
| 190 |
+
You can start chatting with your bot by visiting 👉 [https://t.me/yourbotsname](https://t.me/yourbotsname)
|
| 191 |
+
|
| 192 |
+

|
| 193 |
+
|
| 194 |
+
<br/><br/>
|
| 195 |
+
|
| 196 |
+
## 👀 View logs
|
| 197 |
+
|
| 198 |
+
You can view all of the log by visiting 👉 [https://localhost:9999/](https://localhost:9999/) which will displaying real-time logs of all the docker containers
|
| 199 |
+
|
| 200 |
+

|
| 201 |
+
|
| 202 |
+
<br/><br/>
|
| 203 |
+
|
| 204 |
+
## 📖 API documentation
|
| 205 |
+
|
| 206 |
+
View the API endpoint docs by visiting 👉 [https://localhost:8888/docs](https://localhost:8888/docs)
|
| 207 |
+
|
| 208 |
+
In this page you can create and update entities, as well as upload documents to the knowledge base.
|
| 209 |
+
|
| 210 |
+
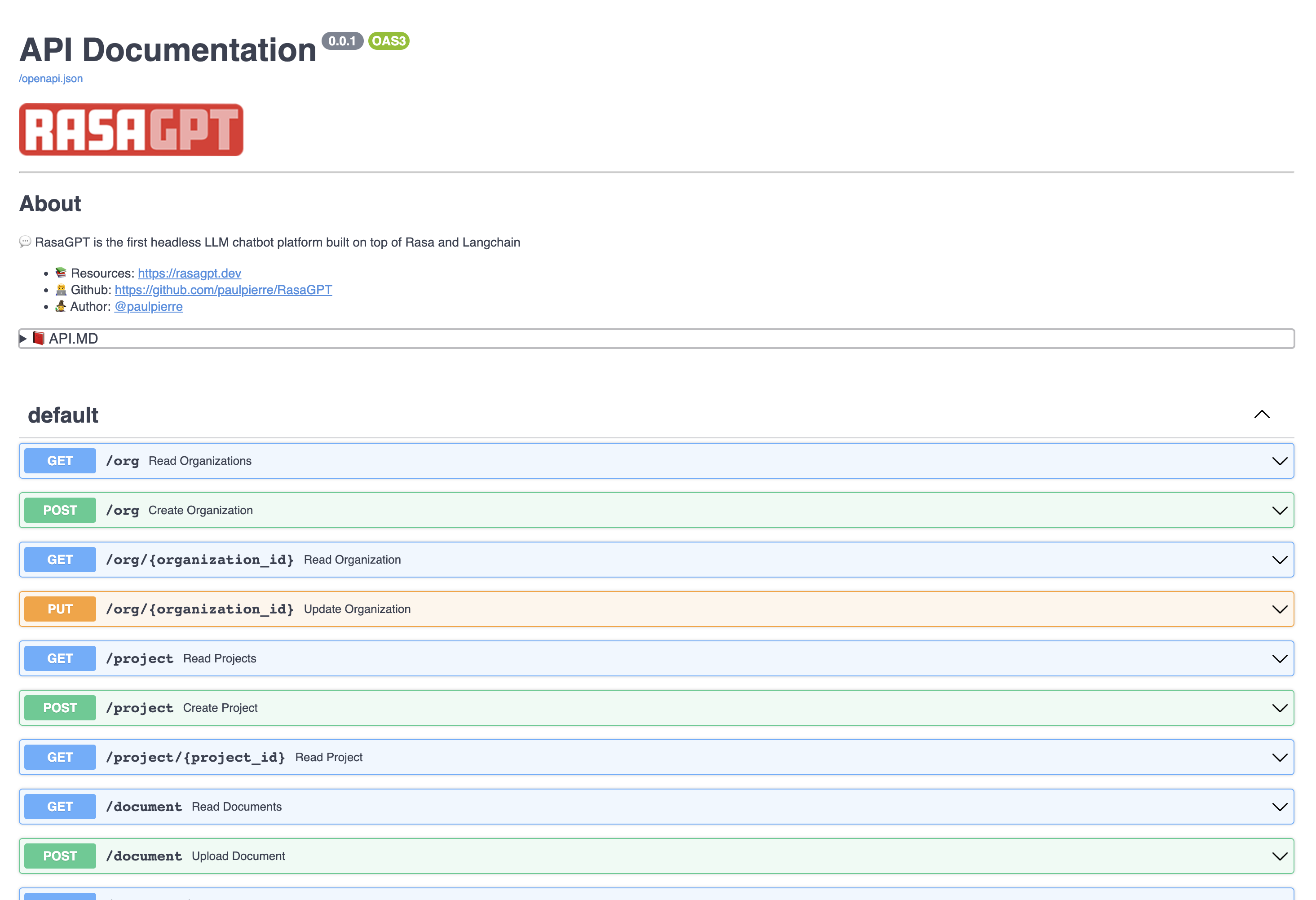
|
| 211 |
+
|
| 212 |
+
<br/><br/>
|
| 213 |
+
|
| 214 |
+
# ✏️ Examples
|
| 215 |
+
|
| 216 |
+
The bot is just a proof-of-concept and has not been optimized for retrieval. It currently uses 1000 character length chunking for indexing and basic euclidean distance for retrieval and quality is hit or miss.
|
| 217 |
+
|
| 218 |
+
You can view example hits and misses with the bot in the [RESULTS.MD](https://github.com/paulpierre/RasaGPT/blob/main/RESULTS.md) file. Overall I estimate index optimization and LLM configuration changes can increase output quality by more than 70%.
|
| 219 |
+
|
| 220 |
+
<br/>
|
| 221 |
+
|
| 222 |
+
👉 Click to see the [Q&A results of the demo data in RESULTS.MD](https://github.com/paulpierre/RasaGPT/blob/main/RESULTS.md)
|
| 223 |
+
|
| 224 |
+
<br/><br/>
|
| 225 |
+
|
| 226 |
+
# 💻 API Architecture and Usage
|
| 227 |
+
|
| 228 |
+
The REST API is straight forward, please visit the documentation 👉 http://localhost:8888/docs
|
| 229 |
+
|
| 230 |
+
The entities below have basic CRUD operations and return JSON
|
| 231 |
+
|
| 232 |
+
<br/><br/>
|
| 233 |
+
|
| 234 |
+
## Organization
|
| 235 |
+
|
| 236 |
+
This can be thought of as a company that is your client in a SaaS / multi-tenant world. By default a list of dummy organizations have been provided
|
| 237 |
+
|
| 238 |
+
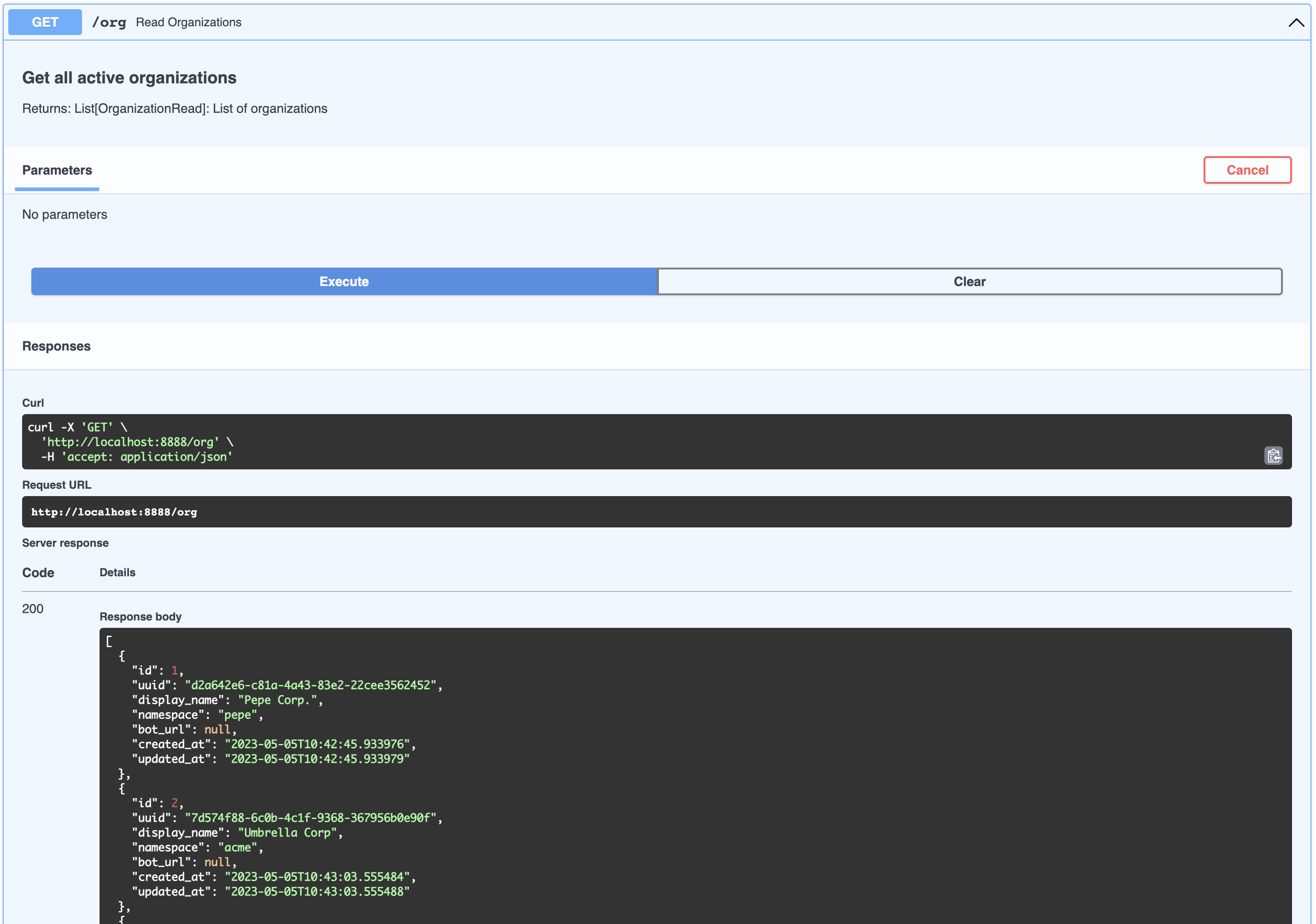
|
| 239 |
+
|
| 240 |
+
```bash
|
| 241 |
+
[
|
| 242 |
+
{
|
| 243 |
+
"id": 1,
|
| 244 |
+
"uuid": "d2a642e6-c81a-4a43-83e2-22cee3562452",
|
| 245 |
+
"display_name": "Pepe Corp.",
|
| 246 |
+
"namespace": "pepe",
|
| 247 |
+
"bot_url": null,
|
| 248 |
+
"created_at": "2023-05-05T10:42:45.933976",
|
| 249 |
+
"updated_at": "2023-05-05T10:42:45.933979"
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
"id": 2,
|
| 253 |
+
"uuid": "7d574f88-6c0b-4c1f-9368-367956b0e90f",
|
| 254 |
+
"display_name": "Umbrella Corp",
|
| 255 |
+
"namespace": "acme",
|
| 256 |
+
"bot_url": null,
|
| 257 |
+
"created_at": "2023-05-05T10:43:03.555484",
|
| 258 |
+
"updated_at": "2023-05-05T10:43:03.555488"
|
| 259 |
+
},
|
| 260 |
+
{
|
| 261 |
+
"id": 3,
|
| 262 |
+
"uuid": "65105a15-2ef0-4898-ac7a-8eafee0b283d",
|
| 263 |
+
"display_name": "Cyberdine Systems",
|
| 264 |
+
"namespace": "cyberdine",
|
| 265 |
+
"bot_url": null,
|
| 266 |
+
"created_at": "2023-05-05T10:43:04.175424",
|
| 267 |
+
"updated_at": "2023-05-05T10:43:04.175428"
|
| 268 |
+
},
|
| 269 |
+
{
|
| 270 |
+
"id": 4,
|
| 271 |
+
"uuid": "b7fb966d-7845-4581-a537-818da62645b5",
|
| 272 |
+
"display_name": "Bluth Companies",
|
| 273 |
+
"namespace": "bluth",
|
| 274 |
+
"bot_url": null,
|
| 275 |
+
"created_at": "2023-05-05T10:43:04.697801",
|
| 276 |
+
"updated_at": "2023-05-05T10:43:04.697804"
|
| 277 |
+
},
|
| 278 |
+
{
|
| 279 |
+
"id": 5,
|
| 280 |
+
"uuid": "9283d017-b24b-4ecd-bf35-808b45e258cf",
|
| 281 |
+
"display_name": "Evil Corp",
|
| 282 |
+
"namespace": "evil",
|
| 283 |
+
"bot_url": null,
|
| 284 |
+
"created_at": "2023-05-05T10:43:05.102546",
|
| 285 |
+
"updated_at": "2023-05-05T10:43:05.102549"
|
| 286 |
+
}
|
| 287 |
+
]
|
| 288 |
+
```
|
| 289 |
+
|
| 290 |
+
<br/>
|
| 291 |
+
|
| 292 |
+
### Project
|
| 293 |
+
|
| 294 |
+
This can be thought of as a product that belongs to a company. You can view the list of projects that belong to an organizations like so:
|
| 295 |
+
|
| 296 |
+
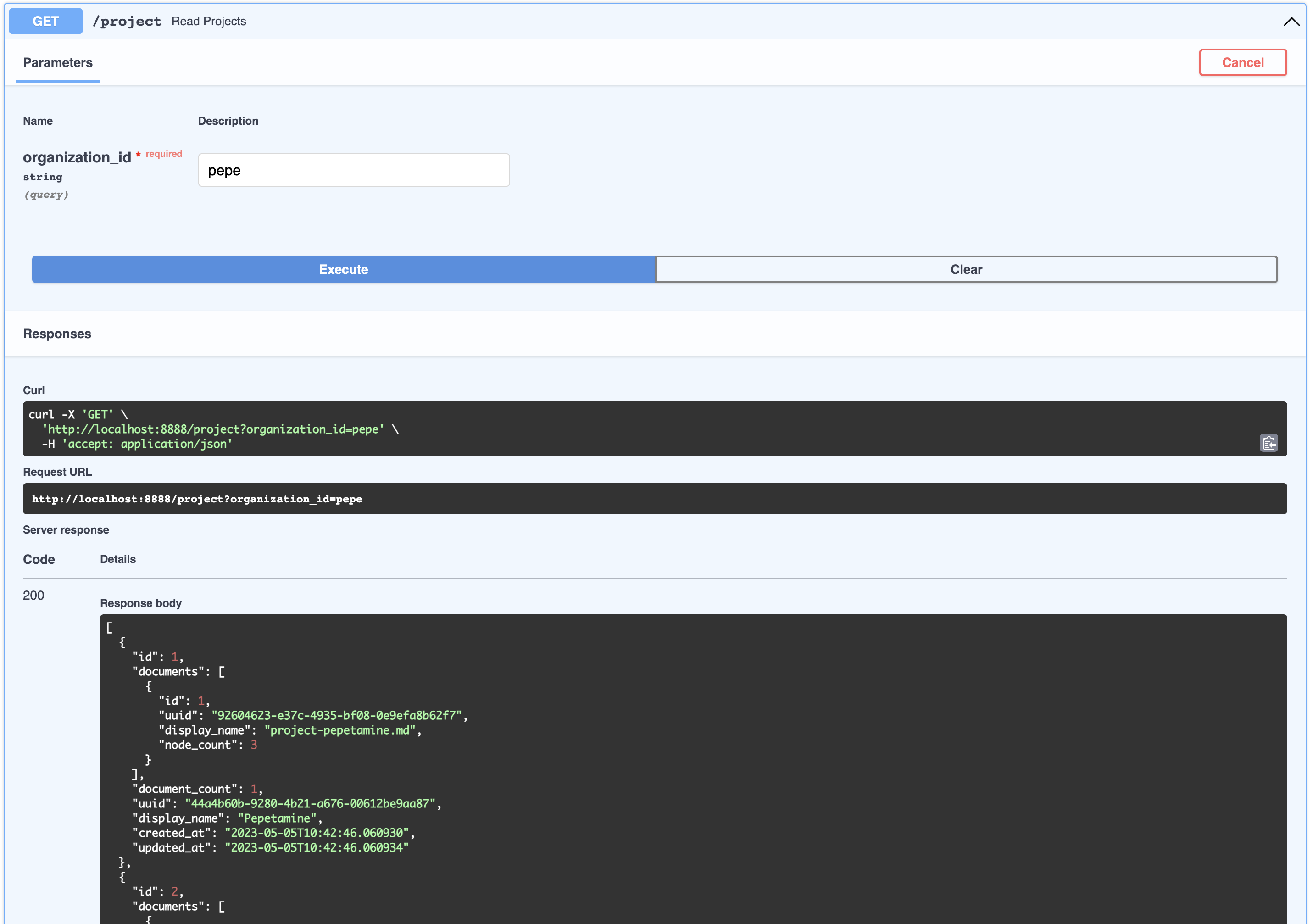
|
| 297 |
+
|
| 298 |
+
```bash
|
| 299 |
+
[
|
| 300 |
+
{
|
| 301 |
+
"id": 1,
|
| 302 |
+
"documents": [
|
| 303 |
+
{
|
| 304 |
+
"id": 1,
|
| 305 |
+
"uuid": "92604623-e37c-4935-bf08-0e9efa8b62f7",
|
| 306 |
+
"display_name": "project-pepetamine.md",
|
| 307 |
+
"node_count": 3
|
| 308 |
+
}
|
| 309 |
+
],
|
| 310 |
+
"document_count": 1,
|
| 311 |
+
"uuid": "44a4b60b-9280-4b21-a676-00612be9aa87",
|
| 312 |
+
"display_name": "Pepetamine",
|
| 313 |
+
"created_at": "2023-05-05T10:42:46.060930",
|
| 314 |
+
"updated_at": "2023-05-05T10:42:46.060934"
|
| 315 |
+
},
|
| 316 |
+
{
|
| 317 |
+
"id": 2,
|
| 318 |
+
"documents": [
|
| 319 |
+
{
|
| 320 |
+
"id": 2,
|
| 321 |
+
"uuid": "b408595a-3426-4011-9b9b-8e260b244f74",
|
| 322 |
+
"display_name": "project-frogonil.md",
|
| 323 |
+
"node_count": 3
|
| 324 |
+
}
|
| 325 |
+
],
|
| 326 |
+
"document_count": 1,
|
| 327 |
+
"uuid": "5ba6b812-de37-451d-83a3-8ccccadabd69",
|
| 328 |
+
"display_name": "Frogonil",
|
| 329 |
+
"created_at": "2023-05-05T10:42:48.043936",
|
| 330 |
+
"updated_at": "2023-05-05T10:42:48.043940"
|
| 331 |
+
},
|
| 332 |
+
{
|
| 333 |
+
"id": 3,
|
| 334 |
+
"documents": [
|
| 335 |
+
{
|
| 336 |
+
"id": 3,
|
| 337 |
+
"uuid": "b99d373a-3317-4699-a89e-90897ba00db6",
|
| 338 |
+
"display_name": "project-kekzal.md",
|
| 339 |
+
"node_count": 3
|
| 340 |
+
}
|
| 341 |
+
],
|
| 342 |
+
"document_count": 1,
|
| 343 |
+
"uuid": "1be4360c-f06e-4494-bf20-e7c73a56f003",
|
| 344 |
+
"display_name": "Kekzal",
|
| 345 |
+
"created_at": "2023-05-05T10:42:49.092675",
|
| 346 |
+
"updated_at": "2023-05-05T10:42:49.092678"
|
| 347 |
+
},
|
| 348 |
+
{
|
| 349 |
+
"id": 4,
|
| 350 |
+
"documents": [
|
| 351 |
+
{
|
| 352 |
+
"id": 4,
|
| 353 |
+
"uuid": "94da307b-5993-4ddd-a852-3d8c12f95f3f",
|
| 354 |
+
"display_name": "project-memetrex.md",
|
| 355 |
+
"node_count": 3
|
| 356 |
+
}
|
| 357 |
+
],
|
| 358 |
+
"document_count": 1,
|
| 359 |
+
"uuid": "1fd7e772-365c-451b-a7eb-4d529b0927f0",
|
| 360 |
+
"display_name": "Memetrex",
|
| 361 |
+
"created_at": "2023-05-05T10:42:50.184817",
|
| 362 |
+
"updated_at": "2023-05-05T10:42:50.184821"
|
| 363 |
+
},
|
| 364 |
+
{
|
| 365 |
+
"id": 5,
|
| 366 |
+
"documents": [
|
| 367 |
+
{
|
| 368 |
+
"id": 5,
|
| 369 |
+
"uuid": "6deff180-3e3e-4b09-ae5a-6502d031914a",
|
| 370 |
+
"display_name": "project-pepetrak.md",
|
| 371 |
+
"node_count": 4
|
| 372 |
+
}
|
| 373 |
+
],
|
| 374 |
+
"document_count": 1,
|
| 375 |
+
"uuid": "a389eb58-b504-48b4-9bc3-d3c93d2fbeaa",
|
| 376 |
+
"display_name": "PepeTrak",
|
| 377 |
+
"created_at": "2023-05-05T10:42:51.293352",
|
| 378 |
+
"updated_at": "2023-05-05T10:42:51.293355"
|
| 379 |
+
},
|
| 380 |
+
{
|
| 381 |
+
"id": 6,
|
| 382 |
+
"documents": [
|
| 383 |
+
{
|
| 384 |
+
"id": 6,
|
| 385 |
+
"uuid": "2e3c2155-cafa-4c6b-b7cc-02bb5156715b",
|
| 386 |
+
"display_name": "project-memegen.md",
|
| 387 |
+
"node_count": 5
|
| 388 |
+
}
|
| 389 |
+
],
|
| 390 |
+
"document_count": 1,
|
| 391 |
+
"uuid": "cec4154f-5d73-41a5-a764-eaf62fc3db2c",
|
| 392 |
+
"display_name": "MemeGen",
|
| 393 |
+
"created_at": "2023-05-05T10:42:52.562037",
|
| 394 |
+
"updated_at": "2023-05-05T10:42:52.562040"
|
| 395 |
+
},
|
| 396 |
+
{
|
| 397 |
+
"id": 7,
|
| 398 |
+
"documents": [
|
| 399 |
+
{
|
| 400 |
+
"id": 7,
|
| 401 |
+
"uuid": "baabcb6f-e14c-4d59-a019-ce29973b9f5c",
|
| 402 |
+
"display_name": "project-neurokek.md",
|
| 403 |
+
"node_count": 5
|
| 404 |
+
}
|
| 405 |
+
],
|
| 406 |
+
"document_count": 1,
|
| 407 |
+
"uuid": "4a1a0542-e314-4ae7-9961-720c2d092f04",
|
| 408 |
+
"display_name": "Neuro-kek",
|
| 409 |
+
"created_at": "2023-05-05T10:42:53.689537",
|
| 410 |
+
"updated_at": "2023-05-05T10:42:53.689539"
|
| 411 |
+
},
|
| 412 |
+
{
|
| 413 |
+
"id": 8,
|
| 414 |
+
"documents": [
|
| 415 |
+
{
|
| 416 |
+
"id": 8,
|
| 417 |
+
"uuid": "5be007ec-5c89-4bc4-8bfd-448a3659c03c",
|
| 418 |
+
"display_name": "org-about_the_company.md",
|
| 419 |
+
"node_count": 5
|
| 420 |
+
},
|
| 421 |
+
{
|
| 422 |
+
"id": 9,
|
| 423 |
+
"uuid": "c2b3fb39-18c0-4f3e-9c21-749b86942cba",
|
| 424 |
+
"display_name": "org-board_of_directors.md",
|
| 425 |
+
"node_count": 3
|
| 426 |
+
},
|
| 427 |
+
{
|
| 428 |
+
"id": 10,
|
| 429 |
+
"uuid": "41aa81a9-13a9-4527-a439-c2ac0215593f",
|
| 430 |
+
"display_name": "org-company_story.md",
|
| 431 |
+
"node_count": 4
|
| 432 |
+
},
|
| 433 |
+
{
|
| 434 |
+
"id": 11,
|
| 435 |
+
"uuid": "91c59eb8-8c05-4f1f-b09d-fcd9b44b5a20",
|
| 436 |
+
"display_name": "org-corporate_philosophy.md",
|
| 437 |
+
"node_count": 4
|
| 438 |
+
},
|
| 439 |
+
{
|
| 440 |
+
"id": 12,
|
| 441 |
+
"uuid": "631fc3a9-7f5f-4415-8283-78ff582be483",
|
| 442 |
+
"display_name": "org-customer_support.md",
|
| 443 |
+
"node_count": 3
|
| 444 |
+
},
|
| 445 |
+
{
|
| 446 |
+
"id": 13,
|
| 447 |
+
"uuid": "d4c3d3db-6f24-433e-b2aa-52a70a0af976",
|
| 448 |
+
"display_name": "org-earnings_fy2023.md",
|
| 449 |
+
"node_count": 5
|
| 450 |
+
},
|
| 451 |
+
{
|
| 452 |
+
"id": 14,
|
| 453 |
+
"uuid": "08dd478b-414b-46c4-95c0-4d96e2089e90",
|
| 454 |
+
"display_name": "org-management_team.md",
|
| 455 |
+
"node_count": 3
|
| 456 |
+
}
|
| 457 |
+
],
|
| 458 |
+
"document_count": 7,
|
| 459 |
+
"uuid": "1d2849b4-2715-4dcf-aa68-090a221942ba",
|
| 460 |
+
"display_name": "Pepe Corp. (company)",
|
| 461 |
+
"created_at": "2023-05-05T10:42:55.258902",
|
| 462 |
+
"updated_at": "2023-05-05T10:42:55.258904"
|
| 463 |
+
}
|
| 464 |
+
]
|
| 465 |
+
```
|
| 466 |
+
|
| 467 |
+
<br/>
|
| 468 |
+
|
| 469 |
+
## Document
|
| 470 |
+
|
| 471 |
+
This can be thought of as an artifact related to a product, like an FAQ page or a PDF with financial statement earnings. You can view all the Documents associated with an Organization’s Project like so:
|
| 472 |
+
|
| 473 |
+

|
| 474 |
+
|
| 475 |
+
```bash
|
| 476 |
+
{
|
| 477 |
+
"id": 1,
|
| 478 |
+
"uuid": "44a4b60b-9280-4b21-a676-00612be9aa87",
|
| 479 |
+
"organization": {
|
| 480 |
+
"id": 1,
|
| 481 |
+
"uuid": "d2a642e6-c81a-4a43-83e2-22cee3562452",
|
| 482 |
+
"display_name": "Pepe Corp.",
|
| 483 |
+
"bot_url": null,
|
| 484 |
+
"status": 2,
|
| 485 |
+
"created_at": "2023-05-05T10:42:45.933976",
|
| 486 |
+
"updated_at": "2023-05-05T10:42:45.933979",
|
| 487 |
+
"namespace": "pepe"
|
| 488 |
+
},
|
| 489 |
+
"document_count": 1,
|
| 490 |
+
"documents": [
|
| 491 |
+
{
|
| 492 |
+
"id": 1,
|
| 493 |
+
"uuid": "92604623-e37c-4935-bf08-0e9efa8b62f7",
|
| 494 |
+
"organization_id": 1,
|
| 495 |
+
"project_id": 1,
|
| 496 |
+
"display_name": "project-pepetamine.md",
|
| 497 |
+
"url": "",
|
| 498 |
+
"data": "# Pepetamine\n\nProduct Name: Pepetamine\n\nPurpose: Increases cognitive focus just like the Limitless movie\n\n**How to Use**\n\nPepetamine is available in the form of rare Pepe-coated tablets. The recommended dosage is one tablet per day, taken orally with a glass of water, preferably while browsing your favorite meme forum for maximum cognitive enhancement. For optimal results, take Pepetamine 30 minutes before engaging in mentally demanding tasks, such as decoding ancient Pepe hieroglyphics or creating your next viral meme masterpiece.\n\n**Side Effects**\n\nSome potential side effects of Pepetamine may include:\n\n1. Uncontrollable laughter and a sudden appreciation for dank memes\n2. An inexplicable desire to collect rare Pepes\n3. Enhanced meme creation skills, potentially leading to internet fame\n4. Temporary green skin pigmentation, resembling the legendary Pepe himself\n5. Spontaneously speaking in \"feels good man\" language\n\nWhile most side effects are generally harmless, consult your memologist if side effects persist or become bothersome.\n\n**Precautions**\n\nBefore taking Pepetamine, please consider the following precautions:\n\n1. Do not use Pepetamine if you have a known allergy to rare Pepes or dank memes.\n2. Pepetamine may not be suitable for individuals with a history of humor deficiency or meme intolerance.\n3. Exercise caution when driving or operating heavy machinery, as Pepetamine may cause sudden fits of laughter or intense meme ideation.\n\n**Interactions**\n\nPepetamine may interact with other substances, including:\n\n1. Normie supplements: Combining Pepetamine with normie supplements may result in meme conflicts and a decreased sense of humor.\n2. Caffeine: The combination of Pepetamine and caffeine may cause an overload of energy, resulting in hyperactive meme creation and potential internet overload.\n\nConsult your memologist if you are taking any other medications or substances to ensure compatibility with Pepetamine.\n\n**Overdose**\n\nIn case of an overdose, symptoms may include:\n\n1. Uncontrollable meme creation\n2. Delusions of grandeur as the ultimate meme lord\n3. Time warps into the world of Pepe\n\nIf you suspect an overdose, contact your local meme emergency service or visit the nearest meme treatment facility. Remember, the key to enjoying Pepetamine is to use it responsibly, and always keep in mind the wise words of our legendary Pepe: \"Feels good man.\"",
|
| 499 |
+
"hash": "fdee6da2b5441080dd78e7850d3d2e1403bae71b9e0526b9dcae4c0782d95a78",
|
| 500 |
+
"version": 1,
|
| 501 |
+
"status": 2,
|
| 502 |
+
"created_at": "2023-05-05T10:42:46.755428",
|
| 503 |
+
"updated_at": "2023-05-05T10:42:46.755431"
|
| 504 |
+
}
|
| 505 |
+
],
|
| 506 |
+
"display_name": "Pepetamine",
|
| 507 |
+
"created_at": "2023-05-05T10:42:46.060930",
|
| 508 |
+
"updated_at": "2023-05-05T10:42:46.060934"
|
| 509 |
+
}
|
| 510 |
+
```
|
| 511 |
+
|
| 512 |
+
<br/>
|
| 513 |
+
|
| 514 |
+
## Node
|
| 515 |
+
|
| 516 |
+
Although this is not exposed in the API, a node is a chunk of a document which embeddings get generated for. Nodes are used for retrieval search as well as context injection. A node belongs to a document.
|
| 517 |
+
|
| 518 |
+
<br/>
|
| 519 |
+
|
| 520 |
+
## User
|
| 521 |
+
|
| 522 |
+
A user represents the person talking to a bot. Users do not necessarily belong to an org or product, but this relationship is captured in ChatSession below.
|
| 523 |
+
|
| 524 |
+
<br/>
|
| 525 |
+
|
| 526 |
+
## ChatSession
|
| 527 |
+
|
| 528 |
+
Not exposed via API, but this represent a question and answer between the User and a bot. Each of these objects can be flexibly identified by a `session_id` which gets automatically generated. Chat Sessions contain rich metadata that can be used for training and optimization. ChatSessions via the `/chat` endpoint ARE in fact associated with organization (for multi-tenant security purposes)
|
| 529 |
+
|
| 530 |
+
<br/><br/>
|
| 531 |
+
|
| 532 |
+
# **📚 How it works**
|
| 533 |
+
|
| 534 |
+
<br/>
|
| 535 |
+
|
| 536 |
+
## Rasa
|
| 537 |
+
|
| 538 |
+
1. Rasa handles integration with the communication channel, in this case Telegram.
|
| 539 |
+
- It specifically handles submitting the target webhook user feedback should go through. In our case it is our FastAPI server via `/webhooks/{channel}/webhook`
|
| 540 |
+
2. Rasa has two components, the core [Rasa app](https://github.com/paulpierre/RasaGPT/tree/main/app/rasa) and an Rasa [actions server](https://github.com/paulpierre/RasaGPT/tree/main/app/rasa/actions) that runs separately
|
| 541 |
+
3. Rasa must be configured (done already) via a few yaml files:
|
| 542 |
+
- [config.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/config.yml) - contains NLU pipeline and policy configuration. What matters is setting the `FallbackClassifier` threshold
|
| 543 |
+
- [credentials.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/credentials.yml) - contains the path to our webhook and Telegram credentials. This will get updated by the helper service `rasa-credentials` via [app/rasa-credentials/main.py](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa-credentials/main.py)
|
| 544 |
+
- [domain.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/domain.yml) - This contains the chat entrypoint logic configuration like intent and the action to take against the intent. Here we add the `action_gpt_fallback` action which will trigger our [actions server](https://github.com/paulpierre/RasaGPT/tree/main/app/rasa/actions)
|
| 545 |
+
- [endpoints.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/endpoints.yml) - This is where we set our custom action end-point for Rasa to trigger our fallback
|
| 546 |
+
- [nlu.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/nlu.yml) - this is where we set our intent `out_of_scope`
|
| 547 |
+
- [rules.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/rules.yml) - we set a rule for this intent that it should trigger the action `action_gpt_fallback`
|
| 548 |
+
- [actions.py](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/actions/actions.py) - this is where we define and express our action via the `ActionGPTFallback` class. The method `name` returns the action we defined for our intent above
|
| 549 |
+
4. Rasa's NLU models must be trained which can be done via CLI with `rasa train` . This is done automatically for you when you run `make install`
|
| 550 |
+
5. Rasa's core must be ran via `rasa run` after training
|
| 551 |
+
6. Rasa's action server must be ran separately with `rasa run actions`
|
| 552 |
+
|
| 553 |
+
<br/>
|
| 554 |
+
|
| 555 |
+
## Telegram
|
| 556 |
+
|
| 557 |
+
1. Rasa automatically updates the Telegram Bot API with your callback webhook from [credentials.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/credentials.yml).
|
| 558 |
+
2. By default this is static. Since we are running on our local machine, we leverage [Ngrok](https://ngrok.com/) to generate a publically accessible URL and reverse tunnel into our docker container
|
| 559 |
+
3. `rasa-credentials` service takes care of this process for you. Ngrok runs as a service, once it is ready `rasa-credentials` calls the local ngrok API to retrieve the tunnel URL and updates the `credentials.yml` file and restarts Rasa for you
|
| 560 |
+
4. The webhook Telegram will send messages to will be our FastAPI server. Why this instead of Rasa? Because we want flexibility to capture metadata which Rasa makes a PITA and centralizing to the API server is ideal
|
| 561 |
+
5. The FastAPI server forwards this to the Rasa webhook
|
| 562 |
+
6. Rasa will then determine what action to take based on the user intent. Since the intents have been nerfed for this demo, it will go to the fallback action running in `actions.py`
|
| 563 |
+
7. The custom action will capture the metadata and forward the response from FastAPI to the user
|
| 564 |
+
|
| 565 |
+
<br/>
|
| 566 |
+
|
| 567 |
+
## PGVector
|
| 568 |
+
|
| 569 |
+
`pgvector` is a plugin for Postgres and automatically installed enabling your to store and calculate vector data types. We have our own implementation because the Langchain PGVector class is not flexible to adapt to our schema and we want flexibility.
|
| 570 |
+
|
| 571 |
+
1. By default in postgres, any files in the container's path `/docker-entry-initdb.d` get run if the database has not been initialized. In the [postgres Dockerfile](https://github.com/paulpierre/RasaGPT/blob/main/app/db/Dockerfile) we copy []`create_db.sh` which creates](https://github.com/paulpierre/RasaGPT/blob/main/app/db/create_db.sh) the db and user for our database
|
| 572 |
+
2. In the [`models` command](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/Makefile#L64) in the [Makefile](https://github.com/paulpierre/RasaGPT/blob/main/Makefile), we run the [models.py](https://github.com/paulpierre/RasaGPT/blob/main/app/api/models.py) in the API container which creates the tables from the models.
|
| 573 |
+
3. The [`enable_vector` method](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/app/api/models.py#L266) enables the pgvector extension in the database
|
| 574 |
+
|
| 575 |
+
<br/>
|
| 576 |
+
|
| 577 |
+
## Langchain
|
| 578 |
+
|
| 579 |
+
1. The training data gets loaded in the database
|
| 580 |
+
2. The data is indexed [if the index doesn't exist](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/app/api/main.py#L49) and [stored in a file named `index.json`](https://github.com/paulpierre/RasaGPT/blob/main/app/api/index.json)
|
| 581 |
+
3. LlamaIndex uses a basic `GPTSimpleVectorIndex` to find the relevant data and [injects it into a prompt](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/app/api/main.py#L66).
|
| 582 |
+
4. Guard rails via prompts are used to keep the conversation focused
|
| 583 |
+
|
| 584 |
+
<br/>
|
| 585 |
+
|
| 586 |
+
## Bot flow
|
| 587 |
+
|
| 588 |
+
1. The user will chat in Telegram and the message will be filtered for [existing intents](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/nlu.yml)
|
| 589 |
+
2. If it detects there is no intent match but instead matches the `out_of_scope`, [based on rules.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/rules.yml) it will trigger the `action_gpt_fallback` action
|
| 590 |
+
3. The [`ActionGPTFallback` function](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/actions/actions.py) will then call the [FastAPI API server](https://github.com/paulpierre/RasaGPT/blob/main/app/api/main.py)
|
| 591 |
+
4. the API using LlamaIndex will find the relevant indexed content and inject it into a prompt to send to OpenAI for inference
|
| 592 |
+
5. The prompt contains conversational guardrails including:
|
| 593 |
+
- Requests data be returned in JSON
|
| 594 |
+
- Create categorical tags based on what the user's question
|
| 595 |
+
- Return a boolean if the conversation should be escalated to a human (if there is no context match)
|
| 596 |
+
|
| 597 |
+
<br/><br/>
|
| 598 |
+
|
| 599 |
+
|
| 600 |
+
# 📝 TODO
|
| 601 |
+
- [ ] Write tests 😅
|
| 602 |
+
- [ ] Implement LlamaIndex optimizations
|
| 603 |
+
- [ ] Implement chat history
|
| 604 |
+
- [ ] Implement [Query Routers Abstractions](https://medium.com/@jerryjliu98/unifying-llm-powered-qa-techniques-with-routing-abstractions-438e2499a0d0) to understand which search strategy to use (one-shot vs few-shot)
|
| 605 |
+
- [ ] Explore other indexing methods like Tree indexes, Keyword indexes
|
| 606 |
+
- [ ] Add chat history for immediate recall and context setting
|
| 607 |
+
- [ ] Add a secondary adversarial agent ([Dual pattern model](https://simonwillison.net/2023/Apr/25/dual-llm-pattern/)) with the following potential functionalities:
|
| 608 |
+
- [ ] Determine if the question has been answered and if not, re-optimize search strategy
|
| 609 |
+
- [ ] Ensure prompt injection is not occurring
|
| 610 |
+
- [ ] Increase baseline similarity search by exploring:
|
| 611 |
+
- [ ] Regularly generate “fake” document embeddings based on historical queries and link to actual documents via [HyDE pattern](https://wfhbrian.com/revolutionizing-search-how-hypothetical-document-embeddings-hyde-can-save-time-and-increase-productivity/)
|
| 612 |
+
- [ ] Regularly generate “fake” user queries based on documents and link to actual document so user input search and “fake” queries can match better
|
| 613 |
+
|
| 614 |
+
|
| 615 |
+
<br/><br/>
|
| 616 |
+
|
| 617 |
+
# 🔍 Troubleshooting
|
| 618 |
+
|
| 619 |
+
In general, check your docker container logs by simply going to 👉 http://localhost:9999/
|
| 620 |
+
|
| 621 |
+
<br/>
|
| 622 |
+
|
| 623 |
+
## Ngrok issues
|
| 624 |
+
|
| 625 |
+
Always check that your webhooks with ngrok and Telegram match. Simply do this by
|
| 626 |
+
|
| 627 |
+
```bash
|
| 628 |
+
curl -sS "https://api.telegram.org/bot<your-bot-secret-token>/getWebhookInfo" | json_pp
|
| 629 |
+
```
|
| 630 |
+
|
| 631 |
+
<br/>
|
| 632 |
+
|
| 633 |
+
.. should return this:
|
| 634 |
+
|
| 635 |
+
```bash
|
| 636 |
+
{
|
| 637 |
+
"ok": true,
|
| 638 |
+
"result": {
|
| 639 |
+
"url": "https://b280-04-115-40-112.ngrok-free.app/webhooks/telegram/webhook",
|
| 640 |
+
"has_custom_certificate": false,
|
| 641 |
+
"pending_update_count": 0,
|
| 642 |
+
"max_connections": 40,
|
| 643 |
+
"ip_address": "1.2.3.4"
|
| 644 |
+
}
|
| 645 |
+
}
|
| 646 |
+
```
|
| 647 |
+
|
| 648 |
+
<br/>
|
| 649 |
+
|
| 650 |
+
.. which should match the URL in your `credentials.yml` file or visit the Ngrok admin UI 👉 [http://localhost:4040/status](http://localhost:4040/status)
|
| 651 |
+
|
| 652 |
+
|
| 653 |
+
|
| 654 |
+
<br/>
|
| 655 |
+
|
| 656 |
+
Looks like it is a match. If not, restart everything by running:
|
| 657 |
+
|
| 658 |
+
```bash
|
| 659 |
+
make restart
|
| 660 |
+
```
|
| 661 |
+
|
| 662 |
+
<br/><br/>
|
| 663 |
+
|
| 664 |
+
# 💪 Contributing / Issues
|
| 665 |
+
|
| 666 |
+
- Pull requests welcome
|
| 667 |
+
- Please submit issues via Github, I will do my best to resolve them
|
| 668 |
+
- If you want to get in touch, feel free to hmu on twitter via [`@paulpierre`](https://twitter.com/paulpierre)`
|
| 669 |
+
|
| 670 |
+
<br/><br/>
|
| 671 |
+
|
| 672 |
+
> 
|
| 673 |
+
> <br/> Congratulations, all your base are belong to us! kthxbye
|
| 674 |
+
|
| 675 |
+
<br/><br/>
|
| 676 |
+
|
| 677 |
+
# 📜 Open source license
|
| 678 |
+
|
| 679 |
+
Copyright (c) 2023 Paul Pierre. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NON-INFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
RESULTS.md
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+

|
| 3 |
+
|
| 4 |
+
<br/><br/>
|
| 5 |
+
|
| 6 |
+
# 📊 RasaGPT Query Results
|
| 7 |
+
|
| 8 |
+
The following are questions based on the example dummy data included in the RasaGPT repository. The response framing is great, but retrieval quality is not sufficient due to indexing. Here are some examples of Q&A hits and misses w/ some commentary.
|
| 9 |
+
|
| 10 |
+
<br/><br/>
|
| 11 |
+
|
| 12 |
+
# ☑️ Hits
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
<br/>
|
| 17 |
+
|
| 18 |
+
### ✅ “Tell me about Pepe Corp”
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
Pepe Corp is a groundbreaking parody pharmaceutical and technology company inspired by the iconic Pepe the Frog meme. Our mission is to revolutionize the world through the power of dank memes.
|
| 22 |
+
🏷️ company,mission
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
<br/>
|
| 26 |
+
|
| 27 |
+
### ✅ “What is the weather like in London today?” (It’s expected to say I don’t know)
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
I apologize, I'm not sure how to help with that
|
| 31 |
+
🏷️ weather
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
<br/>
|
| 35 |
+
|
| 36 |
+
### ✅ “What is the purpose of Kekzal?”
|
| 37 |
+
|
| 38 |
+
```bash
|
| 39 |
+
Kekzal enhances sexual function.
|
| 40 |
+
🏷️ purpose
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
<br/>
|
| 44 |
+
|
| 45 |
+
### ✅ “What is Kekzal and what are the side effects?”
|
| 46 |
+
|
| 47 |
+
```bash
|
| 48 |
+
Kekzal is a medication, but the document does not provide information on its side effects. It only advises to consult a memologist if side effects persist or become bothersome.
|
| 49 |
+
🏷️ Kekzal,side effects
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
>- It probably should not mention “the document” and this can be optimized by modifying the prompt template
|
| 53 |
+
|
| 54 |
+
<br/>
|
| 55 |
+
|
| 56 |
+
### ✅ “What should I consider before taking Kekzal?”
|
| 57 |
+
|
| 58 |
+
```bash
|
| 59 |
+
Before taking Kekzal, consider the following precautions: Do not use Kekzal if you have a known allergy to dank memes or an aversion to Pepe-themed roman.
|
| 60 |
+
🏷️ precautions
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
>- This is technically a hit, but because of the chunking settings, the original text gets cut off and says “roman” instead of “romantic..” so this is easily fixed
|
| 64 |
+
>- Ideally it should include “Kekzal” in the tags
|
| 65 |
+
|
| 66 |
+
<br/>
|
| 67 |
+
|
| 68 |
+
### ✅ “What are the overdose symptoms of Kekzal?”
|
| 69 |
+
|
| 70 |
+
```bash
|
| 71 |
+
In case of an overdose, symptoms may include: 1. An insatiable desire to create
|
| 72 |
+
🏷️ overdose,symptoms
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
- This is a technical hit, but again indexing cut it off and it is likely due to the configured output limits which is easily fixed
|
| 76 |
+
|
| 77 |
+
<br/>
|
| 78 |
+
|
| 79 |
+
### ✅ “Who is the CEO?”
|
| 80 |
+
|
| 81 |
+
```bash
|
| 82 |
+
The CEO of Pepe Corp is Amanda Gigglestein.
|
| 83 |
+
🏷️ CEO
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
<br/>
|
| 87 |
+
|
| 88 |
+
### ✅ “What are the 2023 plans of Pepe Corp?”
|
| 89 |
+
|
| 90 |
+
```bash
|
| 91 |
+
Pepe Corp plans to invest in research and development to create cutting-edge products that address the needs of our diverse customer base. Our R&D team will explore new areas of meme science and technology, developing products that meet the needs of our customers.
|
| 92 |
+
🏷️ plans,research and development,cutting-edge products,meme science,technology,customer needs
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
<br/>
|
| 96 |
+
|
| 97 |
+
### ✅ “What is the revenue for Q1 FY2023?”
|
| 98 |
+
|
| 99 |
+
```bash
|
| 100 |
+
$235 million
|
| 101 |
+
🏷️ revenue,Q1,FY2023
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
<br/>
|
| 105 |
+
|
| 106 |
+
### ✅ “Tell me about the early days of PepeCorp?”
|
| 107 |
+
|
| 108 |
+
```bash
|
| 109 |
+
In the early 21st century, a group of visionary memelords gathered in a dimly lit basement, fueled by their passion for dank memes and the iconic Pepe the Frog.
|
| 110 |
+
🏷️ company history,early days
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
<br/><br/>
|
| 114 |
+
|
| 115 |
+
# ❌ Misses
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
### ❌ “What are the side effects of Kekzal?”
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
Consult your memologist if side effects persist or become bothersome.
|
| 122 |
+
🏷️ Kekzal,side effects
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
>- The side effects are in the documentation but it misses it entirely. It did tag the product name unlike earlier sessions, but index optimization can fix this
|
| 126 |
+
|
| 127 |
+
<br/>
|
| 128 |
+
|
| 129 |
+
### ❌ “Who is Dr. Olivia Dankstein?”
|
| 130 |
+
|
| 131 |
+
```bash
|
| 132 |
+
I apologize, I'm not sure how to help with that.
|
| 133 |
+
🏷️ unknown
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
>- Not good, she is in the Board of Directors document and is Vice-Chair and Chief Scientific Officer of Pepe Corp. Better indexing strategies fix this.
|
| 137 |
+
|
| 138 |
+
<br/>
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
### ❌ “What is the list of products provided by Pepe Corp?”
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
Pepe Corp has a diverse portfolio of products, ranging from meme-inspired pharmaceuticals to advanced brain implants and mobile applications.
|
| 145 |
+
🏷️ products
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
>- Although it did answer, it is insufficient. This is where a tree index with summarization would help
|
| 149 |
+
|
| 150 |
+
<br/><br/>
|
| 151 |
+
|
| 152 |
+
# 🔬 Retrieval optimizations
|
| 153 |
+
|
| 154 |
+
So how could all of this be improved by what I estimate to be more than 70%+? Here are a few solutions I intend to explore:
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
- Better index-tuning at the LLM library level, specifically using llama-index instead of Langchain which specializes in retrieval
|
| 158 |
+
- Usage of [Query Routers Abstractions](https://medium.com/@jerryjliu98/unifying-llm-powered-qa-techniques-with-routing-abstractions-438e2499a0d0) to understand which search strategy to use (one-shot vs few-shot)
|
| 159 |
+
- Explore other indexing methods like Tree indexes, Keyword indexes
|
| 160 |
+
- Adding chat history for immediate recall and context setting
|
| 161 |
+
- Add a secondary adversarial agent ([Dual pattern model](https://simonwillison.net/2023/Apr/25/dual-llm-pattern/)) with the following potential functionalities:
|
| 162 |
+
- Determine if the question has been answered and if not, re-optimize search strategy
|
| 163 |
+
- Ensure prompt injection is not occurring
|
| 164 |
+
- Increase baseline similarity search by exploring:
|
| 165 |
+
- Regularly generate “fake” document embeddings based on historical queries and link to actual documents via [HyDE pattern](https://wfhbrian.com/revolutionizing-search-how-hypothetical-document-embeddings-hyde-can-save-time-and-increase-productivity/)
|
| 166 |
+
- Regularly generate “fake” user queries based on documents and link to actual document so user input search and “fake” queries can match better
|
app/api/.dockerignore
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
*.pyc
|
| 3 |
+
*.pyo
|
| 4 |
+
*.pyd
|
app/api/API.md
ADDED
|
@@ -0,0 +1,666 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
# 🏠 Overview
|
| 4 |
+
|
| 5 |
+
💬 RasaGPT is the first headless LLM chatbot platform built on top of Rasa and Langchain. It is boilerplate and a reference implementation of Rasa and Telegram utilizing an LLM library like langchain for indexing, retrieval and context injection.
|
| 6 |
+
|
| 7 |
+
<br/><br/>
|
| 8 |
+
|
| 9 |
+
# 💁♀️ Why RasaGPT?
|
| 10 |
+
|
| 11 |
+
RasaGPT just works out of the box. I went through all the implementation headaches so you don’t have to, including
|
| 12 |
+
|
| 13 |
+
- Creating your own proprietary bot end-point using FastAPI, document upload and “training” 'pipeline included
|
| 14 |
+
- How to integrate Langchain/LlamaIndex and Rasa
|
| 15 |
+
- Library conflicts with LLM libraries and passing metadata
|
| 16 |
+
- Dockerized support on MacOS for running Rasa
|
| 17 |
+
- Reverse proxy with chatbots via ngrok
|
| 18 |
+
- Implementing pgvector with your own custom schema instead of using Langchain’s highly opinionated PGVector class
|
| 19 |
+
- Adding multi-tenancy, sessions and metadata between Rasa and your own backend / application
|
| 20 |
+
|
| 21 |
+
The backstory is familiar. A friend came to me with a problem. I scoured Google and Github for a decent reference implementation of LLM’s integrated with Rasa but came up empty-handed. I figured this to be a great opportunity to satiate my curiosity and 2 days later I had a proof of concept, and a week later this is what I came up with.
|
| 22 |
+
|
| 23 |
+
<br/>
|
| 24 |
+
|
| 25 |
+
> ⚠️ **Caveat emptor:**
|
| 26 |
+
This is far from production code and rife with prompt injection and general security vulnerabilities. I just hope someone finds this useful 😊
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
<br/><br/>
|
| 30 |
+
|
| 31 |
+
# **✨** Quick start
|
| 32 |
+
|
| 33 |
+
Getting started is easy, just make sure you meet the dependencies below.
|
| 34 |
+
|
| 35 |
+
```bash
|
| 36 |
+
git clone https://github.com/paulpierre/RasaGPT.git
|
| 37 |
+
cd RasaGPT
|
| 38 |
+
cp .env-example .env
|
| 39 |
+
|
| 40 |
+
# Edit your .env file and add all the necessary credentials
|
| 41 |
+
make install
|
| 42 |
+
|
| 43 |
+
# Type "make" to see more options
|
| 44 |
+
make
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
<br/><br/>
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# 🔥 Features
|
| 51 |
+
|
| 52 |
+
## Full Application and API
|
| 53 |
+
|
| 54 |
+
- LLM “learns” on an arbitrary corpus of data using Langchain
|
| 55 |
+
- Upload documents and “train” all via FastAPI
|
| 56 |
+
- Document versioning and automatic “re-training” implemented on upload
|
| 57 |
+
- Customize your own async end-points
|
| 58 |
+
- Bot determines whether human handoff is necessary
|
| 59 |
+
- Bot generates tags based on user questions and response automatically
|
| 60 |
+
- Full API documentation via Swagger and Redoc included
|
| 61 |
+
- Ngrok end-points are automatically generated for you on startup so your bot can always be accessed via `https://t.me/yourbotname`
|
| 62 |
+
- Embedding similarity search built into Postgres via pgvector and Postgres functions
|
| 63 |
+
- Dummy data included for you to test and experiment
|
| 64 |
+
- Unlimited use cases from help desk, customer support, quiz, e-learning, dungeon and dragons, and more
|
| 65 |
+
<br/><br/>
|
| 66 |
+
## Rasa integration
|
| 67 |
+
|
| 68 |
+
- Built on top of Rasa, the open source gold-standard for chat platforms
|
| 69 |
+
- Supports MacOS M1/M2 via Docker (canonical Rasa image lacks MacOS arch. support)
|
| 70 |
+
- Supports Telegram, easily integrate Slack, Whatsapp, Line, SMS, etc.
|
| 71 |
+
- Setup complex dialog pipelines using NLU models form Huggingface like BERT or libraries/frameworks like Keras, Tensorflow with OpenAI GPT as fallback
|
| 72 |
+
<br/><br/>
|
| 73 |
+
## Flexibility
|
| 74 |
+
|
| 75 |
+
- Extend agentic, memory, etc. capabilities with Langchain
|
| 76 |
+
- Schema supports multi-tenancy, sessions, data storage
|
| 77 |
+
- Customize agent personalities
|
| 78 |
+
- Saves all of chat history and creating embeddings from all interactions future-proofing your retrieval strategy
|
| 79 |
+
- Automatically generate embeddings from knowledge base corpus and client feedback
|
| 80 |
+
|
| 81 |
+
<br/><br/>
|
| 82 |
+
|
| 83 |
+
# 🧑💻 Installing
|
| 84 |
+
|
| 85 |
+
## Requirements
|
| 86 |
+
|
| 87 |
+
- Python 3.9
|
| 88 |
+
- Docker & Docker compose ([Docker desktop MacOS](https://www.docker.com/products/docker-desktop/))
|
| 89 |
+
- Open AI [API key](https://platform.openai.com/account/api-keys)
|
| 90 |
+
- Telegram [bot credentials](https://core.telegram.org/bots#how-do-i-create-a-bot)
|
| 91 |
+
- Ngrok [auth token](https://dashboard.ngrok.com/tunnels/authtokens)
|
| 92 |
+
- Make ([MacOS](https://formulae.brew.sh/formula/make)/[Windows](https://stackoverflow.com/questions/32127524/how-to-install-and-use-make-in-windows))
|
| 93 |
+
- SQLModel
|
| 94 |
+
|
| 95 |
+
<br/>
|
| 96 |
+
|
| 97 |
+
## Setup
|
| 98 |
+
|
| 99 |
+
```bash
|
| 100 |
+
git clone https://github.com/paulpierre/RasaGPT.git
|
| 101 |
+
cd RasaGPT
|
| 102 |
+
cp .env-example .env
|
| 103 |
+
|
| 104 |
+
# Edit your .env file and all the credentials
|
| 105 |
+
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
<br/>
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
At any point feel free to just type in `make` and it will display the list of options, mostly useful for debugging:
|
| 112 |
+
|
| 113 |
+
<br/>
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+

|
| 117 |
+
|
| 118 |
+
<br/>
|
| 119 |
+
|
| 120 |
+
## Docker-compose
|
| 121 |
+
|
| 122 |
+
```bash
|
| 123 |
+
make install
|
| 124 |
+
|
| 125 |
+
# This will automatically install and run RasaGPT
|
| 126 |
+
# After installation, to run again you can simply run
|
| 127 |
+
|
| 128 |
+
make run
|
| 129 |
+
```
|
| 130 |
+
<br/>
|
| 131 |
+
|
| 132 |
+
## Local Python Environment
|
| 133 |
+
|
| 134 |
+
This is useful if you wish to focus on developing on top of the API, a separate `Makefile` was made for this. This will create a local virtual environment for you.
|
| 135 |
+
|
| 136 |
+
```bash
|
| 137 |
+
# Assuming you are already in the RasaGPT directory
|
| 138 |
+
cd app/api
|
| 139 |
+
make install
|
| 140 |
+
|
| 141 |
+
# This will automatically install and run RasaGPT
|
| 142 |
+
# After installation, to run again you can simply run
|
| 143 |
+
|
| 144 |
+
make run
|
| 145 |
+
```
|
| 146 |
+
<br/>
|
| 147 |
+
|
| 148 |
+
Similarly, enter `make` to see a full list of commands
|
| 149 |
+
|
| 150 |
+

|
| 151 |
+
|
| 152 |
+
<br/>
|
| 153 |
+
|
| 154 |
+
## Installation process
|
| 155 |
+
|
| 156 |
+
Installation should be automated should look like this:
|
| 157 |
+
|
| 158 |
+

|
| 159 |
+
|
| 160 |
+
👉 Full installation log: [https://app.warp.dev/block/vflua6Eue29EPk8EVvW8Kd](https://app.warp.dev/block/vflua6Eue29EPk8EVvW8Kd)
|
| 161 |
+
|
| 162 |
+
<br/>
|
| 163 |
+
|
| 164 |
+
The installation process for Docker takes the following steps at a high level
|
| 165 |
+
|
| 166 |
+
1. Check to make sure you have `.env` available
|
| 167 |
+
2. Database is initialized with `pgvector`
|
| 168 |
+
3. Database models create the database schema
|
| 169 |
+
4. Trains the Rasa model so it is ready to run
|
| 170 |
+
5. Sets up ngrok with Rasa so Telegram has a webhook back to your API server
|
| 171 |
+
6. Sets up the Rasa actions server so Rasa can talk to the RasaGPT API
|
| 172 |
+
7. Database is populated with dummy data via `seed.py`
|
| 173 |
+
|
| 174 |
+
<br/><br/>
|
| 175 |
+
|
| 176 |
+
# ☑️ Next steps
|
| 177 |
+
<br/>
|
| 178 |
+
|
| 179 |
+
## 💬 Start chatting
|
| 180 |
+
|
| 181 |
+
You can start chatting with your bot by visiting https://t.me/yourbotsname
|
| 182 |
+
|
| 183 |
+

|
| 184 |
+
|
| 185 |
+
<br/><br/>
|
| 186 |
+
|
| 187 |
+
## 👀 View logs
|
| 188 |
+
|
| 189 |
+
You can view all of the log by visiting: [https://localhost:9999/](https://localhost:9999/) which will displaying real-time logs of all the docker containers
|
| 190 |
+
|
| 191 |
+

|
| 192 |
+
|
| 193 |
+
<br/><br/>
|
| 194 |
+
|
| 195 |
+
## 📖 API documentation
|
| 196 |
+
|
| 197 |
+
View the API endpoint docs by visiting [https://localhost:8888/docs](https://localhost:8888/docs)
|
| 198 |
+
|
| 199 |
+

|
| 200 |
+
|
| 201 |
+
<br/><br/>
|
| 202 |
+
|
| 203 |
+
# ✏️ Examples
|
| 204 |
+
|
| 205 |
+
The bot is just a proof-of-concept and has not been optimized for retrieval. It currently uses 1000 character length chunking for indexing and basic euclidean distance for retrieval and quality is hit or miss.
|
| 206 |
+
|
| 207 |
+
You can view example hits and misses with the bot in the [RESULTS.MD](https://github.com/paulpierre/RasaGPT/blob/main/RESULTS.md) file. Overall I estimate index optimization and LLM configuration changes can increase output quality by more than 70%.
|
| 208 |
+
|
| 209 |
+
👉 Click to see the Q&A results of the demo data in RESULTS.MD
|
| 210 |
+
|
| 211 |
+
<br/><br/>
|
| 212 |
+
|
| 213 |
+
# 💻 API Architecture and Usage
|
| 214 |
+
|
| 215 |
+
The REST API is straight forward, please visit the documentation 👉 http://localhost:8888/docs
|
| 216 |
+
|
| 217 |
+
The entities below have basic CRUD operations and return JSON
|
| 218 |
+
|
| 219 |
+
<br/><br/>
|
| 220 |
+
|
| 221 |
+
## Organization
|
| 222 |
+
|
| 223 |
+
This can be thought of as a company that is your client in a SaaS / multi-tenant world. By default a list of dummy organizations have been provided
|
| 224 |
+
|
| 225 |
+

|
| 226 |
+
|
| 227 |
+
```bash
|
| 228 |
+
[
|
| 229 |
+
{
|
| 230 |
+
"id": 1,
|
| 231 |
+
"uuid": "d2a642e6-c81a-4a43-83e2-22cee3562452",
|
| 232 |
+
"display_name": "Pepe Corp.",
|
| 233 |
+
"namespace": "pepe",
|
| 234 |
+
"bot_url": null,
|
| 235 |
+
"created_at": "2023-05-05T10:42:45.933976",
|
| 236 |
+
"updated_at": "2023-05-05T10:42:45.933979"
|
| 237 |
+
},
|
| 238 |
+
{
|
| 239 |
+
"id": 2,
|
| 240 |
+
"uuid": "7d574f88-6c0b-4c1f-9368-367956b0e90f",
|
| 241 |
+
"display_name": "Umbrella Corp",
|
| 242 |
+
"namespace": "acme",
|
| 243 |
+
"bot_url": null,
|
| 244 |
+
"created_at": "2023-05-05T10:43:03.555484",
|
| 245 |
+
"updated_at": "2023-05-05T10:43:03.555488"
|
| 246 |
+
},
|
| 247 |
+
{
|
| 248 |
+
"id": 3,
|
| 249 |
+
"uuid": "65105a15-2ef0-4898-ac7a-8eafee0b283d",
|
| 250 |
+
"display_name": "Cyberdine Systems",
|
| 251 |
+
"namespace": "cyberdine",
|
| 252 |
+
"bot_url": null,
|
| 253 |
+
"created_at": "2023-05-05T10:43:04.175424",
|
| 254 |
+
"updated_at": "2023-05-05T10:43:04.175428"
|
| 255 |
+
},
|
| 256 |
+
{
|
| 257 |
+
"id": 4,
|
| 258 |
+
"uuid": "b7fb966d-7845-4581-a537-818da62645b5",
|
| 259 |
+
"display_name": "Bluth Companies",
|
| 260 |
+
"namespace": "bluth",
|
| 261 |
+
"bot_url": null,
|
| 262 |
+
"created_at": "2023-05-05T10:43:04.697801",
|
| 263 |
+
"updated_at": "2023-05-05T10:43:04.697804"
|
| 264 |
+
},
|
| 265 |
+
{
|
| 266 |
+
"id": 5,
|
| 267 |
+
"uuid": "9283d017-b24b-4ecd-bf35-808b45e258cf",
|
| 268 |
+
"display_name": "Evil Corp",
|
| 269 |
+
"namespace": "evil",
|
| 270 |
+
"bot_url": null,
|
| 271 |
+
"created_at": "2023-05-05T10:43:05.102546",
|
| 272 |
+
"updated_at": "2023-05-05T10:43:05.102549"
|
| 273 |
+
}
|
| 274 |
+
]
|
| 275 |
+
```
|
| 276 |
+
|
| 277 |
+
<br/>
|
| 278 |
+
|
| 279 |
+
### Project
|
| 280 |
+
|
| 281 |
+
This can be thought of as a product that belongs to a company. You can view the list of projects that belong to an organizations like so:
|
| 282 |
+
|
| 283 |
+

|
| 284 |
+
|
| 285 |
+
```bash
|
| 286 |
+
[
|
| 287 |
+
{
|
| 288 |
+
"id": 1,
|
| 289 |
+
"documents": [
|
| 290 |
+
{
|
| 291 |
+
"id": 1,
|
| 292 |
+
"uuid": "92604623-e37c-4935-bf08-0e9efa8b62f7",
|
| 293 |
+
"display_name": "project-pepetamine.md",
|
| 294 |
+
"node_count": 3
|
| 295 |
+
}
|
| 296 |
+
],
|
| 297 |
+
"document_count": 1,
|
| 298 |
+
"uuid": "44a4b60b-9280-4b21-a676-00612be9aa87",
|
| 299 |
+
"display_name": "Pepetamine",
|
| 300 |
+
"created_at": "2023-05-05T10:42:46.060930",
|
| 301 |
+
"updated_at": "2023-05-05T10:42:46.060934"
|
| 302 |
+
},
|
| 303 |
+
{
|
| 304 |
+
"id": 2,
|
| 305 |
+
"documents": [
|
| 306 |
+
{
|
| 307 |
+
"id": 2,
|
| 308 |
+
"uuid": "b408595a-3426-4011-9b9b-8e260b244f74",
|
| 309 |
+
"display_name": "project-frogonil.md",
|
| 310 |
+
"node_count": 3
|
| 311 |
+
}
|
| 312 |
+
],
|
| 313 |
+
"document_count": 1,
|
| 314 |
+
"uuid": "5ba6b812-de37-451d-83a3-8ccccadabd69",
|
| 315 |
+
"display_name": "Frogonil",
|
| 316 |
+
"created_at": "2023-05-05T10:42:48.043936",
|
| 317 |
+
"updated_at": "2023-05-05T10:42:48.043940"
|
| 318 |
+
},
|
| 319 |
+
{
|
| 320 |
+
"id": 3,
|
| 321 |
+
"documents": [
|
| 322 |
+
{
|
| 323 |
+
"id": 3,
|
| 324 |
+
"uuid": "b99d373a-3317-4699-a89e-90897ba00db6",
|
| 325 |
+
"display_name": "project-kekzal.md",
|
| 326 |
+
"node_count": 3
|
| 327 |
+
}
|
| 328 |
+
],
|
| 329 |
+
"document_count": 1,
|
| 330 |
+
"uuid": "1be4360c-f06e-4494-bf20-e7c73a56f003",
|
| 331 |
+
"display_name": "Kekzal",
|
| 332 |
+
"created_at": "2023-05-05T10:42:49.092675",
|
| 333 |
+
"updated_at": "2023-05-05T10:42:49.092678"
|
| 334 |
+
},
|
| 335 |
+
{
|
| 336 |
+
"id": 4,
|
| 337 |
+
"documents": [
|
| 338 |
+
{
|
| 339 |
+
"id": 4,
|
| 340 |
+
"uuid": "94da307b-5993-4ddd-a852-3d8c12f95f3f",
|
| 341 |
+
"display_name": "project-memetrex.md",
|
| 342 |
+
"node_count": 3
|
| 343 |
+
}
|
| 344 |
+
],
|
| 345 |
+
"document_count": 1,
|
| 346 |
+
"uuid": "1fd7e772-365c-451b-a7eb-4d529b0927f0",
|
| 347 |
+
"display_name": "Memetrex",
|
| 348 |
+
"created_at": "2023-05-05T10:42:50.184817",
|
| 349 |
+
"updated_at": "2023-05-05T10:42:50.184821"
|
| 350 |
+
},
|
| 351 |
+
{
|
| 352 |
+
"id": 5,
|
| 353 |
+
"documents": [
|
| 354 |
+
{
|
| 355 |
+
"id": 5,
|
| 356 |
+
"uuid": "6deff180-3e3e-4b09-ae5a-6502d031914a",
|
| 357 |
+
"display_name": "project-pepetrak.md",
|
| 358 |
+
"node_count": 4
|
| 359 |
+
}
|
| 360 |
+
],
|
| 361 |
+
"document_count": 1,
|
| 362 |
+
"uuid": "a389eb58-b504-48b4-9bc3-d3c93d2fbeaa",
|
| 363 |
+
"display_name": "PepeTrak",
|
| 364 |
+
"created_at": "2023-05-05T10:42:51.293352",
|
| 365 |
+
"updated_at": "2023-05-05T10:42:51.293355"
|
| 366 |
+
},
|
| 367 |
+
{
|
| 368 |
+
"id": 6,
|
| 369 |
+
"documents": [
|
| 370 |
+
{
|
| 371 |
+
"id": 6,
|
| 372 |
+
"uuid": "2e3c2155-cafa-4c6b-b7cc-02bb5156715b",
|
| 373 |
+
"display_name": "project-memegen.md",
|
| 374 |
+
"node_count": 5
|
| 375 |
+
}
|
| 376 |
+
],
|
| 377 |
+
"document_count": 1,
|
| 378 |
+
"uuid": "cec4154f-5d73-41a5-a764-eaf62fc3db2c",
|
| 379 |
+
"display_name": "MemeGen",
|
| 380 |
+
"created_at": "2023-05-05T10:42:52.562037",
|
| 381 |
+
"updated_at": "2023-05-05T10:42:52.562040"
|
| 382 |
+
},
|
| 383 |
+
{
|
| 384 |
+
"id": 7,
|
| 385 |
+
"documents": [
|
| 386 |
+
{
|
| 387 |
+
"id": 7,
|
| 388 |
+
"uuid": "baabcb6f-e14c-4d59-a019-ce29973b9f5c",
|
| 389 |
+
"display_name": "project-neurokek.md",
|
| 390 |
+
"node_count": 5
|
| 391 |
+
}
|
| 392 |
+
],
|
| 393 |
+
"document_count": 1,
|
| 394 |
+
"uuid": "4a1a0542-e314-4ae7-9961-720c2d092f04",
|
| 395 |
+
"display_name": "Neuro-kek",
|
| 396 |
+
"created_at": "2023-05-05T10:42:53.689537",
|
| 397 |
+
"updated_at": "2023-05-05T10:42:53.689539"
|
| 398 |
+
},
|
| 399 |
+
{
|
| 400 |
+
"id": 8,
|
| 401 |
+
"documents": [
|
| 402 |
+
{
|
| 403 |
+
"id": 8,
|
| 404 |
+
"uuid": "5be007ec-5c89-4bc4-8bfd-448a3659c03c",
|
| 405 |
+
"display_name": "org-about_the_company.md",
|
| 406 |
+
"node_count": 5
|
| 407 |
+
},
|
| 408 |
+
{
|
| 409 |
+
"id": 9,
|
| 410 |
+
"uuid": "c2b3fb39-18c0-4f3e-9c21-749b86942cba",
|
| 411 |
+
"display_name": "org-board_of_directors.md",
|
| 412 |
+
"node_count": 3
|
| 413 |
+
},
|
| 414 |
+
{
|
| 415 |
+
"id": 10,
|
| 416 |
+
"uuid": "41aa81a9-13a9-4527-a439-c2ac0215593f",
|
| 417 |
+
"display_name": "org-company_story.md",
|
| 418 |
+
"node_count": 4
|
| 419 |
+
},
|
| 420 |
+
{
|
| 421 |
+
"id": 11,
|
| 422 |
+
"uuid": "91c59eb8-8c05-4f1f-b09d-fcd9b44b5a20",
|
| 423 |
+
"display_name": "org-corporate_philosophy.md",
|
| 424 |
+
"node_count": 4
|
| 425 |
+
},
|
| 426 |
+
{
|
| 427 |
+
"id": 12,
|
| 428 |
+
"uuid": "631fc3a9-7f5f-4415-8283-78ff582be483",
|
| 429 |
+
"display_name": "org-customer_support.md",
|
| 430 |
+
"node_count": 3
|
| 431 |
+
},
|
| 432 |
+
{
|
| 433 |
+
"id": 13,
|
| 434 |
+
"uuid": "d4c3d3db-6f24-433e-b2aa-52a70a0af976",
|
| 435 |
+
"display_name": "org-earnings_fy2023.md",
|
| 436 |
+
"node_count": 5
|
| 437 |
+
},
|
| 438 |
+
{
|
| 439 |
+
"id": 14,
|
| 440 |
+
"uuid": "08dd478b-414b-46c4-95c0-4d96e2089e90",
|
| 441 |
+
"display_name": "org-management_team.md",
|
| 442 |
+
"node_count": 3
|
| 443 |
+
}
|
| 444 |
+
],
|
| 445 |
+
"document_count": 7,
|
| 446 |
+
"uuid": "1d2849b4-2715-4dcf-aa68-090a221942ba",
|
| 447 |
+
"display_name": "Pepe Corp. (company)",
|
| 448 |
+
"created_at": "2023-05-05T10:42:55.258902",
|
| 449 |
+
"updated_at": "2023-05-05T10:42:55.258904"
|
| 450 |
+
}
|
| 451 |
+
]
|
| 452 |
+
```
|
| 453 |
+
|
| 454 |
+
<br/>
|
| 455 |
+
|
| 456 |
+
## Document
|
| 457 |
+
|
| 458 |
+
This can be thought of as an artifact related to a product, like an FAQ page or a PDF with financial statement earnings. You can view all the Documents associated with an Organization’s Project like so:
|
| 459 |
+
|
| 460 |
+

|
| 461 |
+
|
| 462 |
+
```bash
|
| 463 |
+
{
|
| 464 |
+
"id": 1,
|
| 465 |
+
"uuid": "44a4b60b-9280-4b21-a676-00612be9aa87",
|
| 466 |
+
"organization": {
|
| 467 |
+
"id": 1,
|
| 468 |
+
"uuid": "d2a642e6-c81a-4a43-83e2-22cee3562452",
|
| 469 |
+
"display_name": "Pepe Corp.",
|
| 470 |
+
"bot_url": null,
|
| 471 |
+
"status": 2,
|
| 472 |
+
"created_at": "2023-05-05T10:42:45.933976",
|
| 473 |
+
"updated_at": "2023-05-05T10:42:45.933979",
|
| 474 |
+
"namespace": "pepe"
|
| 475 |
+
},
|
| 476 |
+
"document_count": 1,
|
| 477 |
+
"documents": [
|
| 478 |
+
{
|
| 479 |
+
"id": 1,
|
| 480 |
+
"uuid": "92604623-e37c-4935-bf08-0e9efa8b62f7",
|
| 481 |
+
"organization_id": 1,
|
| 482 |
+
"project_id": 1,
|
| 483 |
+
"display_name": "project-pepetamine.md",
|
| 484 |
+
"url": "",
|
| 485 |
+
"data": "# Pepetamine\n\nProduct Name: Pepetamine\n\nPurpose: Increases cognitive focus just like the Limitless movie\n\n**How to Use**\n\nPepetamine is available in the form of rare Pepe-coated tablets. The recommended dosage is one tablet per day, taken orally with a glass of water, preferably while browsing your favorite meme forum for maximum cognitive enhancement. For optimal results, take Pepetamine 30 minutes before engaging in mentally demanding tasks, such as decoding ancient Pepe hieroglyphics or creating your next viral meme masterpiece.\n\n**Side Effects**\n\nSome potential side effects of Pepetamine may include:\n\n1. Uncontrollable laughter and a sudden appreciation for dank memes\n2. An inexplicable desire to collect rare Pepes\n3. Enhanced meme creation skills, potentially leading to internet fame\n4. Temporary green skin pigmentation, resembling the legendary Pepe himself\n5. Spontaneously speaking in \"feels good man\" language\n\nWhile most side effects are generally harmless, consult your memologist if side effects persist or become bothersome.\n\n**Precautions**\n\nBefore taking Pepetamine, please consider the following precautions:\n\n1. Do not use Pepetamine if you have a known allergy to rare Pepes or dank memes.\n2. Pepetamine may not be suitable for individuals with a history of humor deficiency or meme intolerance.\n3. Exercise caution when driving or operating heavy machinery, as Pepetamine may cause sudden fits of laughter or intense meme ideation.\n\n**Interactions**\n\nPepetamine may interact with other substances, including:\n\n1. Normie supplements: Combining Pepetamine with normie supplements may result in meme conflicts and a decreased sense of humor.\n2. Caffeine: The combination of Pepetamine and caffeine may cause an overload of energy, resulting in hyperactive meme creation and potential internet overload.\n\nConsult your memologist if you are taking any other medications or substances to ensure compatibility with Pepetamine.\n\n**Overdose**\n\nIn case of an overdose, symptoms may include:\n\n1. Uncontrollable meme creation\n2. Delusions of grandeur as the ultimate meme lord\n3. Time warps into the world of Pepe\n\nIf you suspect an overdose, contact your local meme emergency service or visit the nearest meme treatment facility. Remember, the key to enjoying Pepetamine is to use it responsibly, and always keep in mind the wise words of our legendary Pepe: \"Feels good man.\"",
|
| 486 |
+
"hash": "fdee6da2b5441080dd78e7850d3d2e1403bae71b9e0526b9dcae4c0782d95a78",
|
| 487 |
+
"version": 1,
|
| 488 |
+
"status": 2,
|
| 489 |
+
"created_at": "2023-05-05T10:42:46.755428",
|
| 490 |
+
"updated_at": "2023-05-05T10:42:46.755431"
|
| 491 |
+
}
|
| 492 |
+
],
|
| 493 |
+
"display_name": "Pepetamine",
|
| 494 |
+
"created_at": "2023-05-05T10:42:46.060930",
|
| 495 |
+
"updated_at": "2023-05-05T10:42:46.060934"
|
| 496 |
+
}
|
| 497 |
+
```
|
| 498 |
+
|
| 499 |
+
<br/>
|
| 500 |
+
|
| 501 |
+
## Node
|
| 502 |
+
|
| 503 |
+
Although this is not exposed in the API, a node is a chunk of a document which embeddings get generated for. Nodes are used for retrieval search as well as context injection. A node belongs to a document.
|
| 504 |
+
|
| 505 |
+
<br/>
|
| 506 |
+
|
| 507 |
+
## User
|
| 508 |
+
|
| 509 |
+
A user represents the person talking to a bot. Users do not necessarily belong to an org or product, but this relationship is captured in ChatSession below.
|
| 510 |
+
|
| 511 |
+
<br/>
|
| 512 |
+
|
| 513 |
+
## ChatSession
|
| 514 |
+
|
| 515 |
+
Not exposed via API, but this represent a question and answer between the User and a bot. Each of these objects can be flexibly identified by a `session_id` which gets automatically generated. Chat Sessions contain rich metadata that can be used for training and optimization. ChatSessions via the `/chat` endpoint ARE in fact associated with organization (for multi-tenant security purposes)
|
| 516 |
+
|
| 517 |
+
<br/><br/>
|
| 518 |
+
|
| 519 |
+
# **📚 How it works**
|
| 520 |
+
|
| 521 |
+
<br/>
|
| 522 |
+
|
| 523 |
+
## Rasa
|
| 524 |
+
|
| 525 |
+
1. Rasa handles integration with the communication channel, in this case Telegram.
|
| 526 |
+
- It specifically handles submitting the target webhook user feedback should go through. In our case it is our FastAPI server via `/webhooks/{channel}/webhook`
|
| 527 |
+
2. Rasa has two components, the core [Rasa app](https://github.com/paulpierre/RasaGPT/tree/main/app/rasa) and an Rasa [actions server](https://github.com/paulpierre/RasaGPT/tree/main/app/rasa/actions) that runs separately
|
| 528 |
+
3. Rasa must be configured (done already) via a few yaml files:
|
| 529 |
+
- [config.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/config.yml) - contains NLU pipeline and policy configuration. What matters is setting the `FallbackClassifier` threshold
|
| 530 |
+
- [credentials.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/credentials.yml) - contains the path to our webhook and Telegram credentials. This will get updated by the helper service `rasa-credentials` via [update_credentials.py](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/update_credentials.py)
|
| 531 |
+
- [domain.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/domain.yml) - This contains the chat entrypoint logic configuration like intent and the action to take against the intent. Here we add the `action_gpt_fallback` action which will trigger our [actions server](https://github.com/paulpierre/RasaGPT/tree/main/app/rasa/actions)
|
| 532 |
+
- [endpoints.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/endpoints.yml) - This is where we set our custom action end-point for Rasa to trigger our fallback
|
| 533 |
+
- [nlu.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/nlu.yml) - this is where we set our intent `out_of_scope`
|
| 534 |
+
- [rules.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/rules.yml) - we set a rule for this intent that it should trigger the action `action_gpt_fallback`
|
| 535 |
+
- [actions.py](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/actions/actions.py) - this is where we define and express our action via the `ActionGPTFallback` class. The method `name` returns the action we defined for our intent above
|
| 536 |
+
4. Rasa's NLU models must be trained which can be done via CLI with `rasa train` . This is done automatically for you when you run `make install`
|
| 537 |
+
5. Rasa's core must be ran via `rasa run` after training
|
| 538 |
+
6. Rasa's action server must be ran separately with `rasa run actions`
|
| 539 |
+
|
| 540 |
+
<br/>
|
| 541 |
+
|
| 542 |
+
## Telegram
|
| 543 |
+
|
| 544 |
+
1. Rasa automatically updates the Telegram Bot API with your callback webhook from [credentials.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/credentials.yml).
|
| 545 |
+
2. By default this is static. Since we are running on our local machine, we leverage [Ngrok](https://ngrok.com/) to generate a publically accessible URL and reverse tunnel into our docker container
|
| 546 |
+
3. `rasa-credentials` service takes care of this process for you. Ngrok runs as a service, once it is ready `rasa-credentials` calls the local ngrok API to retrieve the tunnel URL and updates the `credentials.yml` file and restarts Rasa for you
|
| 547 |
+
4. The webhook Telegram will send messages to will be our FastAPI server. Why this instead of Rasa? Because we want flexibility to capture metadata which Rasa makes a PITA and centralizing to the API server is ideal
|
| 548 |
+
5. The FastAPI server forwards this to the Rasa webhook
|
| 549 |
+
6. Rasa will then determine what action to take based on the user intent. Since the intents have been nerfed for this demo, it will go to the fallback action running in `actions.py`
|
| 550 |
+
7. The custom action will capture the metadata and forward the response from FastAPI to the user
|
| 551 |
+
|
| 552 |
+
<br/>
|
| 553 |
+
|
| 554 |
+
## PGVector
|
| 555 |
+
|
| 556 |
+
`pgvector` is a plugin for Postgres and automatically installed enabling your to store and calculate vector data types. We have our own implementation because the Langchain PGVector class is not flexible to adapt to our schema and we want flexibility.
|
| 557 |
+
|
| 558 |
+
1. By default in postgres, any files in the container's path `/docker-entry-initdb.d` get run if the database has not been initialized. In the [postgres Dockerfile](https://github.com/paulpierre/RasaGPT/blob/main/app/db/Dockerfile) we copy `[create_db.sh` which creates](https://github.com/paulpierre/RasaGPT/blob/main/app/db/create_db.sh) the db and user for our database
|
| 559 |
+
2. In the `[models` command](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/Makefile#L64) in the [Makefile](https://github.com/paulpierre/RasaGPT/blob/main/Makefile), we run the [models.py](https://github.com/paulpierre/RasaGPT/blob/main/app/api/models.py) in the API container which creates the tables from the models.
|
| 560 |
+
3. The `[enable_vector` method](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/app/api/models.py#L266) enables the pgvector extension in the database
|
| 561 |
+
|
| 562 |
+
<br/>
|
| 563 |
+
|
| 564 |
+
## Langchain
|
| 565 |
+
|
| 566 |
+
1. The training data gets loaded in the database
|
| 567 |
+
2. The data is indexed [if the index doesn't exist](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/app/api/main.py#L49) and [stored in a file named `index.json`](https://github.com/paulpierre/RasaGPT/blob/main/app/api/index.json)
|
| 568 |
+
3. LlamaIndex uses a basic `GPTSimpleVectorIndex` to find the relevant data and [injects it into a prompt](https://github.com/paulpierre/RasaGPT/blob/dca9be4cd6fe4c9daaff1564267cdb5327a384a5/app/api/main.py#L66).
|
| 569 |
+
4. Guard rails via prompts are used to keep the conversation focused
|
| 570 |
+
|
| 571 |
+
<br/>
|
| 572 |
+
|
| 573 |
+
## Bot flow
|
| 574 |
+
|
| 575 |
+
1. The user will chat in Telegram and the message will be filtered for [existing intents](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/nlu.yml)
|
| 576 |
+
2. If it detects there is no intent match but instead matches the `out_of_scope`, [based on rules.yml](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/data/rules.yml) it will trigger the `action_gpt_fallback` action
|
| 577 |
+
3. The `[ActionGPTFallback` function](https://github.com/paulpierre/RasaGPT/blob/main/app/rasa/actions/actions.py) will then call the [FastAPI API server](https://github.com/paulpierre/RasaGPT/blob/main/app/api/main.py)
|
| 578 |
+
4. the API using LlamaIndex will find the relevant indexed content and inject it into a prompt to send to OpenAI for inference
|
| 579 |
+
5. The prompt contains conversational guardrails including:
|
| 580 |
+
- Requests data be returned in JSON
|
| 581 |
+
- Create categorical tags based on what the user's question
|
| 582 |
+
- Return a boolean if the conversation should be escalated to a human (if there is no context match)
|
| 583 |
+
|
| 584 |
+
<br/><br/>
|
| 585 |
+
|
| 586 |
+
|
| 587 |
+
# 📝 TODO
|
| 588 |
+
|
| 589 |
+
- [ ] Implement LlamaIndex optimizations
|
| 590 |
+
- [ ] Implement chat history
|
| 591 |
+
- [ ] Implement [Query Routers Abstractions](https://medium.com/@jerryjliu98/unifying-llm-powered-qa-techniques-with-routing-abstractions-438e2499a0d0) to understand which search strategy to use (one-shot vs few-shot)
|
| 592 |
+
- [ ] Explore other indexing methods like Tree indexes, Keyword indexes
|
| 593 |
+
- [ ] Add chat history for immediate recall and context setting
|
| 594 |
+
- [ ] Add a secondary adversarial agent ([Dual pattern model](https://simonwillison.net/2023/Apr/25/dual-llm-pattern/)) with the following potential functionalities:
|
| 595 |
+
- [ ] Determine if the question has been answered and if not, re-optimize search strategy
|
| 596 |
+
- [ ] Ensure prompt injection is not occurring
|
| 597 |
+
- [ ] Increase baseline similarity search by exploring:
|
| 598 |
+
- [ ] Regularly generate “fake” document embeddings based on historical queries and link to actual documents via [HyDE pattern](https://wfhbrian.com/revolutionizing-search-how-hypothetical-document-embeddings-hyde-can-save-time-and-increase-productivity/)
|
| 599 |
+
- [ ] Regularly generate “fake” user queries based on documents and link to actual document so user input search and “fake” queries can match better
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
<br/><br/>
|
| 603 |
+
|
| 604 |
+
# 🔍 Troubleshooting
|
| 605 |
+
|
| 606 |
+
In general, check your docker container logs by simply going to 👉 http://localhost:9999/
|
| 607 |
+
|
| 608 |
+
<br/>
|
| 609 |
+
|
| 610 |
+
## Ngrok issues
|
| 611 |
+
|
| 612 |
+
Always check that your webhooks with ngrok and Telegram match. Simply do this by
|
| 613 |
+
|
| 614 |
+
```bash
|
| 615 |
+
curl -sS "https://api.telegram.org/bot<your-bot-secret-token>/getWebhookInfo" | json_pp
|
| 616 |
+
```
|
| 617 |
+
|
| 618 |
+
<br/>
|
| 619 |
+
|
| 620 |
+
.. should return this:
|
| 621 |
+
|
| 622 |
+
```bash
|
| 623 |
+
{
|
| 624 |
+
"ok": true,
|
| 625 |
+
"result": {
|
| 626 |
+
"url": "https://b280-04-115-40-112.ngrok-free.app/webhooks/telegram/webhook",
|
| 627 |
+
"has_custom_certificate": false,
|
| 628 |
+
"pending_update_count": 0,
|
| 629 |
+
"max_connections": 40,
|
| 630 |
+
"ip_address": "1.2.3.4"
|
| 631 |
+
}
|
| 632 |
+
}
|
| 633 |
+
```
|
| 634 |
+
|
| 635 |
+
<br/>
|
| 636 |
+
|
| 637 |
+
.. which should match the URL in your `credentials.yml` file or visit the Ngrok admin UI 👉 [http://localhost:4040/status](http://localhost:4040/status)
|
| 638 |
+
|
| 639 |
+

|
| 640 |
+
|
| 641 |
+
<br/>
|
| 642 |
+
|
| 643 |
+
Looks like it is a match. If not, restart by everything by running:
|
| 644 |
+
|
| 645 |
+
```bash
|
| 646 |
+
make restart
|
| 647 |
+
```
|
| 648 |
+
|
| 649 |
+
<br/><br/>
|
| 650 |
+
|
| 651 |
+
# 💪 Contributing / Issues
|
| 652 |
+
|
| 653 |
+
- Pull requests welcome
|
| 654 |
+
- Please submit issues via Github, I will do my best to resolve them
|
| 655 |
+
- If you want to get in touch, feel free to hmu on twitter via `[@paulpierre](https://twitter.com/paulpierre)`
|
| 656 |
+
|
| 657 |
+
<br/><br/>
|
| 658 |
+
|
| 659 |
+
> 
|
| 660 |
+
> <br/> Congratulations, all your base are belong to us! kthxbye
|
| 661 |
+
|
| 662 |
+
<br/><br/>
|
| 663 |
+
|
| 664 |
+
# 📜 Open source license
|
| 665 |
+
|
| 666 |
+
Copyright (c) 2023 Paul Pierre. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NON-INFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
app/api/Dockerfile
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.9
|
| 2 |
+
|
| 3 |
+
# Set the path to the API directory
|
| 4 |
+
WORKDIR /app/api
|
| 5 |
+
|
| 6 |
+
# Copy the codebase into the container
|
| 7 |
+
COPY . .
|
| 8 |
+
|
| 9 |
+
# Install the requirements
|
| 10 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 11 |
+
|
| 12 |
+
# Expose the port
|
| 13 |
+
EXPOSE 8888
|
| 14 |
+
|
| 15 |
+
ENTRYPOINT ["uvicorn", "main:app", "--host", "api", "--port", "8888", "--reload"]
|
app/api/Makefile
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.PHONY: default banner install run stop db-purge env db db-stop models api api-stop seed
|
| 2 |
+
|
| 3 |
+
default: help
|
| 4 |
+
|
| 5 |
+
help:
|
| 6 |
+
make banner
|
| 7 |
+
@echo "+------------------+"
|
| 8 |
+
@echo "| 🏠 CORE COMMANDS |"
|
| 9 |
+
@echo "+------------------+"
|
| 10 |
+
@echo "make install - Setup environment and build models"
|
| 11 |
+
@echo "make install-seed - Setup environment, build models and seed database"
|
| 12 |
+
@echo "make seed - Seed database with dummy data"
|
| 13 |
+
@echo "make run - Run database and API server"
|
| 14 |
+
@echo "make stop - Stop database and API server"
|
| 15 |
+
@echo "make db-purge - Delete all data in database\n"
|
| 16 |
+
|
| 17 |
+
banner:
|
| 18 |
+
@echo "\n\n-------------------------------------"
|
| 19 |
+
@echo "▒█▀▀█ █▀▀█ █▀▀ █▀▀█ ▒█▀▀█ ▒█▀▀█ ▀▀█▀▀"
|
| 20 |
+
@echo "▒█▄▄▀ █▄▄█ ▀▀█ █▄▄█ ▒█░▄▄ ▒█▄▄█ ░▒█░░"
|
| 21 |
+
@echo "▒█░▒█ ▀░░▀ ▀▀▀ ▀░░▀ ▒█▄▄█ ▒█░░░ ░▒█░░"
|
| 22 |
+
@echo "+-----------------------------------+"
|
| 23 |
+
@echo "| 🤖 FastAPI LLM server |"
|
| 24 |
+
@echo "+-----------------------------------+\n\n"
|
| 25 |
+
|
| 26 |
+
# ================
|
| 27 |
+
# 🏠 CORE COMMANDS
|
| 28 |
+
# ================
|
| 29 |
+
|
| 30 |
+
# ----------------------------------
|
| 31 |
+
# Setup environment and build models
|
| 32 |
+
# ----------------------------------
|
| 33 |
+
install:
|
| 34 |
+
@make banner
|
| 35 |
+
@make api-install
|
| 36 |
+
@make db-stop
|
| 37 |
+
@echo "✅ Installation complete. Run 'make run' to start services.\n"
|
| 38 |
+
|
| 39 |
+
# ----------------------------------------------
|
| 40 |
+
# Setup environment and build models and seed DB
|
| 41 |
+
# ----------------------------------------------
|
| 42 |
+
install-seed:
|
| 43 |
+
@make banner
|
| 44 |
+
@make api-install
|
| 45 |
+
@make seed
|
| 46 |
+
@make db-stop
|
| 47 |
+
@echo "✅ Installation complete. Run 'make run' to start services.\n"
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
seed:
|
| 51 |
+
@make banner
|
| 52 |
+
@echo "🌱 Seeding database ..\n"
|
| 53 |
+
@python3 seed.py
|
| 54 |
+
|
| 55 |
+
# ---------------------------
|
| 56 |
+
# Run database and API server
|
| 57 |
+
# ---------------------------
|
| 58 |
+
run:
|
| 59 |
+
@make banner
|
| 60 |
+
@make env
|
| 61 |
+
@echo "🚀 Starting services ..\n"
|
| 62 |
+
@make db
|
| 63 |
+
@make api
|
| 64 |
+
|
| 65 |
+
# ----------------------------
|
| 66 |
+
# Stop database and API server
|
| 67 |
+
# ----------------------------
|
| 68 |
+
stop:
|
| 69 |
+
@make banner
|
| 70 |
+
@echo "🛑 Stopping services ..\n"
|
| 71 |
+
@make db-stop
|
| 72 |
+
@make api-stop
|
| 73 |
+
|
| 74 |
+
# ---------------------------
|
| 75 |
+
# Delete all data in database
|
| 76 |
+
# ---------------------------
|
| 77 |
+
db-purge:
|
| 78 |
+
@echo "⛔ Are you sure you want to delete all data in the database? [y/N]\n"
|
| 79 |
+
@read confirmation; \
|
| 80 |
+
if [ "$$confirmation" = "y" ] || [ "$$confirmation" = "Y" ]; then \
|
| 81 |
+
echo "Deleting generated files..."; \
|
| 82 |
+
make db-stop; \
|
| 83 |
+
rm -rf ../../mnt; \
|
| 84 |
+
echo "Deleted."; \
|
| 85 |
+
else \
|
| 86 |
+
echo "Aborted."; \
|
| 87 |
+
fi
|
| 88 |
+
|
| 89 |
+
# ==================
|
| 90 |
+
# 💁 HELPER COMMANDS
|
| 91 |
+
# ==================
|
| 92 |
+
|
| 93 |
+
# --------------
|
| 94 |
+
# Install helper
|
| 95 |
+
# --------------
|
| 96 |
+
api-install:
|
| 97 |
+
@echo "🏗️ Installing services ..\n"
|
| 98 |
+
@make env-create
|
| 99 |
+
@make db-stop
|
| 100 |
+
@make db
|
| 101 |
+
@make models
|
| 102 |
+
|
| 103 |
+
# -------------------
|
| 104 |
+
# Create a virtualenv
|
| 105 |
+
# -------------------
|
| 106 |
+
env-create:
|
| 107 |
+
@echo "Creating virtual environment .."
|
| 108 |
+
@if [ -d "./venv" ]; then \
|
| 109 |
+
echo "Environment and dependecies created already, loading .."; \
|
| 110 |
+
source ./venv/bin/activate; \
|
| 111 |
+
else \
|
| 112 |
+
echo "Install dependencies .."; \
|
| 113 |
+
python3 -m venv venv; \
|
| 114 |
+
. venv/bin/activate; \
|
| 115 |
+
pip3 install -r requirements.txt; \
|
| 116 |
+
fi
|
| 117 |
+
|
| 118 |
+
# ---------------------------
|
| 119 |
+
# Load an existing virtualenv
|
| 120 |
+
# ---------------------------
|
| 121 |
+
env:
|
| 122 |
+
@echo "loading virtual environment if exists"
|
| 123 |
+
@if [ -d "./venv" ]; then \
|
| 124 |
+
source ./venv/bin/activate; \
|
| 125 |
+
fi
|
| 126 |
+
|
| 127 |
+
# -----------------
|
| 128 |
+
# Start Postgres DB
|
| 129 |
+
# -----------------
|
| 130 |
+
db:
|
| 131 |
+
@echo "Starting Postgres with pgvector .."
|
| 132 |
+
@cd ../../ && docker-compose -f docker-compose.yml up -d db
|
| 133 |
+
|
| 134 |
+
# -----------------
|
| 135 |
+
# Stop Postgres DB
|
| 136 |
+
# -----------------
|
| 137 |
+
db-stop:
|
| 138 |
+
@cd ../../ && docker-compose -f docker-compose.yml up -d db
|
| 139 |
+
|
| 140 |
+
# ------------
|
| 141 |
+
# Build models
|
| 142 |
+
# ------------
|
| 143 |
+
models:
|
| 144 |
+
@echo "💽 Building models in database .."
|
| 145 |
+
@sleep 60 && python3 models.py
|
| 146 |
+
|
| 147 |
+
# -----------------
|
| 148 |
+
# Start FastAPI API
|
| 149 |
+
# -----------------
|
| 150 |
+
api:
|
| 151 |
+
@echo "⚡ Starting FastAPI API server .."
|
| 152 |
+
@sleep 5 && uvicorn main:app --port 8888 --reload
|
| 153 |
+
|
| 154 |
+
# -----------------
|
| 155 |
+
# Stop FastAPI API
|
| 156 |
+
# -----------------
|
| 157 |
+
api-stop:
|
| 158 |
+
@echo "🛑 Stopping FastAPI server .."
|
| 159 |
+
@killall uvicorn
|
app/api/config.py
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from enum import Enum, IntEnum
|
| 2 |
+
from dotenv import load_dotenv
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
import logging
|
| 5 |
+
import sys
|
| 6 |
+
import os
|
| 7 |
+
|
| 8 |
+
# -------
|
| 9 |
+
# Logging
|
| 10 |
+
# -------
|
| 11 |
+
|
| 12 |
+
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
|
| 13 |
+
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
|
| 16 |
+
# ----------------
|
| 17 |
+
# Environment vars
|
| 18 |
+
# ----------------
|
| 19 |
+
env = os.getenv("ENV", None)
|
| 20 |
+
|
| 21 |
+
if not env:
|
| 22 |
+
# Check up to 2 levels up for .env-{env} file
|
| 23 |
+
env_file = Path(__file__).parent.parent.parent / '.env'
|
| 24 |
+
logger.debug(f"Loading env file: {env_file}")
|
| 25 |
+
if os.path.exists(env_file):
|
| 26 |
+
load_dotenv(dotenv_path=env_file)
|
| 27 |
+
else:
|
| 28 |
+
raise Exception(f"Env file {env})file not found")
|
| 29 |
+
|
| 30 |
+
# -----------------------
|
| 31 |
+
# Configuration constants
|
| 32 |
+
# -----------------------
|
| 33 |
+
readme_file = Path(__file__).parent / "API.md"
|
| 34 |
+
|
| 35 |
+
readme_str = (
|
| 36 |
+
f"""
|
| 37 |
+
<details>
|
| 38 |
+
<summary>📕 API.MD</summary>
|
| 39 |
+
{readme_file.read_text()}
|
| 40 |
+
|
| 41 |
+
</details>
|
| 42 |
+
|
| 43 |
+
"""
|
| 44 |
+
if readme_file.exists()
|
| 45 |
+
else ""
|
| 46 |
+
)
|
| 47 |
+
APP_NAME = "API Documentation"
|
| 48 |
+
APP_VERSION = "0.0.1"
|
| 49 |
+
APP_DESCRIPTION = f"""
|
| 50 |
+

|
| 51 |
+
|
| 52 |
+
---
|
| 53 |
+
## About
|
| 54 |
+
💬 RasaGPT is the first headless LLM chatbot platform built on top of Rasa and Langchain
|
| 55 |
+
|
| 56 |
+
- 📚 Resources: [https://rasagpt.dev](https://rasagpt.dev)
|
| 57 |
+
- 🧑💻 Github: [https://github.com/paulpierre/RasaGPT](https://github.com/paulpierre/RasaGPT)
|
| 58 |
+
- 🧙 Author: [@paulpierre](https://twitter.com/paulpierre)
|
| 59 |
+
|
| 60 |
+
{readme_str}
|
| 61 |
+
"""
|
| 62 |
+
APP_ICON = "/public/img/rasagpt-icon-200x200.png"
|
| 63 |
+
APP_LOGO = "/public/img/rasagpt-logo-1.png"
|
| 64 |
+
|
| 65 |
+
FILE_UPLOAD_PATH = os.getenv("FILE_UPLOAD_PATH", "/tmp")
|
| 66 |
+
|
| 67 |
+
# Database configurations
|
| 68 |
+
POSTGRES_USER = os.getenv("POSTGRES_USER", "postgres")
|
| 69 |
+
POSTGRES_PASSWORD = os.getenv("POSTGRES_PASSWORD", "postgres")
|
| 70 |
+
DB_HOST = os.getenv("DB_HOST", "localhost")
|
| 71 |
+
DB_PORT = os.getenv("DB_PORT", 5432)
|
| 72 |
+
DB_USER = os.getenv("DB_USER")
|
| 73 |
+
DB_NAME = os.getenv("DB_NAME")
|
| 74 |
+
DB_PASSWORD = os.getenv("DB_PASSWORD")
|
| 75 |
+
DSN = f"postgresql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}:{DB_PORT}/{DB_NAME}"
|
| 76 |
+
SU_DSN = (
|
| 77 |
+
f"postgresql://{POSTGRES_USER}:{POSTGRES_PASSWORD}@{DB_HOST}:{DB_PORT}/{DB_NAME}"
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
RASA_WEBHOOK_HOST = os.getenv("RASA_WEBHOOK_HOST", "rasa-core")
|
| 81 |
+
RASA_WEBHOOK_PORT = os.getenv("RASA_WEBHOOK_PORT", 5005)
|
| 82 |
+
RASA_WEBHOOK_URL = f"http://{RASA_WEBHOOK_HOST}:{RASA_WEBHOOK_PORT}"
|
| 83 |
+
|
| 84 |
+
# LLM configurations
|
| 85 |
+
MODEL_NAME = os.getenv("MODEL_NAME")
|
| 86 |
+
LLM_DEFAULT_TEMPERATURE = float(os.getenv("LLM_DEFAULT_TEMPERATURE", 0.0))
|
| 87 |
+
LLM_CHUNK_SIZE = int(os.getenv("LLM_CHUNK_SIZE", 512))
|
| 88 |
+
LLM_CHUNK_OVERLAP = int(os.getenv("LLM_CHUNK_OVERLAP", 20))
|
| 89 |
+
LLM_DISTANCE_THRESHOLD = float(os.getenv("LLM_DISTANCE_THRESHOLD", 0.5))
|
| 90 |
+
LLM_MAX_OUTPUT_TOKENS = int(os.getenv("LLM_MAX_OUTPUT_TOKENS", 256))
|
| 91 |
+
LLM_MIN_NODE_LIMIT = int(os.getenv("LLM_MIN_NODE_LIMIT", 3))
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class DISTANCE_STRATEGY(Enum):
|
| 95 |
+
COSINE = "cosine"
|
| 96 |
+
EUCLIDEAN = "euclidean"
|
| 97 |
+
MAX_INNER_PRODUCT = "max_inner_product"
|
| 98 |
+
|
| 99 |
+
def __new__(cls, strategy_name: str):
|
| 100 |
+
obj = object.__new__(cls)
|
| 101 |
+
obj._value_ = strategy_name
|
| 102 |
+
return obj
|
| 103 |
+
|
| 104 |
+
@property
|
| 105 |
+
def strategy_name(self) -> str:
|
| 106 |
+
return self.value
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
DISTANCE_STRATEGIES = [
|
| 110 |
+
(
|
| 111 |
+
DISTANCE_STRATEGY.EUCLIDEAN,
|
| 112 |
+
"euclidean",
|
| 113 |
+
"<->",
|
| 114 |
+
"CREATE INDEX ON node USING ivfflat (embeddings vector_l2_ops) WITH (lists = 100);",
|
| 115 |
+
),
|
| 116 |
+
(
|
| 117 |
+
DISTANCE_STRATEGY.COSINE,
|
| 118 |
+
"cosine",
|
| 119 |
+
"<=>",
|
| 120 |
+
"CREATE INDEX ON node USING ivfflat (embeddings vector_cosine_ops) WITH (lists = 100);",
|
| 121 |
+
),
|
| 122 |
+
(
|
| 123 |
+
DISTANCE_STRATEGY.MAX_INNER_PRODUCT,
|
| 124 |
+
"max_inner_product",
|
| 125 |
+
"<#>",
|
| 126 |
+
"CREATE INDEX ON node USING ivfflat (embeddings vector_ip_ops) WITH (lists = 100);",
|
| 127 |
+
),
|
| 128 |
+
]
|
| 129 |
+
LLM_DEFAULT_DISTANCE_STRATEGY = DISTANCE_STRATEGY[
|
| 130 |
+
os.getenv("LLM_DEFAULT_DISTANCE_STRATEGY", "COSINE")
|
| 131 |
+
]
|
| 132 |
+
VECTOR_EMBEDDINGS_COUNT = 1536
|
| 133 |
+
PGVECTOR_ADD_INDEX = True if os.getenv("PGVECTOR_ADD_INDEX", False) else False
|
| 134 |
+
# Model constants
|
| 135 |
+
|
| 136 |
+
DOCUMENT_TYPE = IntEnum("DOCUMENT_TYPE", ["PLAINTEXT", "MARKDOWN", "HTML", "PDF"])
|
| 137 |
+
|
| 138 |
+
ENTITY_STATUS = IntEnum(
|
| 139 |
+
"ENTITY_STATUS",
|
| 140 |
+
["UNVERIFIED", "ACTIVE", "INACTIVE", "DELETED", "BANNED" "DEPRECATED"],
|
| 141 |
+
)
|
| 142 |
+
CHANNEL_TYPE = IntEnum(
|
| 143 |
+
"CHANNEL_TYPE", ["SMS", "TELEGRAM", "WHATSAPP", "EMAIL", "WEBSITE"]
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
AGENT_NAMES = [
|
| 147 |
+
"Aisha",
|
| 148 |
+
"Lilly",
|
| 149 |
+
"Hanna",
|
| 150 |
+
"Julia",
|
| 151 |
+
"Emily",
|
| 152 |
+
"Sophia",
|
| 153 |
+
"Alex",
|
| 154 |
+
"Isabella",
|
| 155 |
+
]
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
class LLM_MODELS(Enum):
|
| 159 |
+
TEXT_DAVINCI_003 = "text-davinci-003", 4097
|
| 160 |
+
GPT_35_TURBO = "gpt-3.5-turbo", 4096
|
| 161 |
+
TEXT_DAVINCI_002 = "text-davinci-002", 4097
|
| 162 |
+
CODE_DAVINCI_002 = "code-davinci-002", 8001
|
| 163 |
+
GPT_4 = "gpt-4", 8192
|
| 164 |
+
GPT_4_32K = "gpt-4-32k", 32768
|
| 165 |
+
|
| 166 |
+
def __init__(self, model_name, token_limit):
|
| 167 |
+
self._model_name = model_name
|
| 168 |
+
self._token_limit = token_limit
|
| 169 |
+
|
| 170 |
+
@property
|
| 171 |
+
def model_name(self) -> str:
|
| 172 |
+
return self._model_name
|
| 173 |
+
|
| 174 |
+
@property
|
| 175 |
+
def token_limit(self) -> int:
|
| 176 |
+
return self._token_limit
|
app/api/data/training_data/org-about_the_company.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# About the company
|
| 2 |
+
|
| 3 |
+
Title: About Pepe Corp
|
| 4 |
+
|
| 5 |
+
**Introduction**
|
| 6 |
+
|
| 7 |
+
Pepe Corp is a groundbreaking parody pharmaceutical and technology company inspired by the iconic Pepe the Frog meme. Our mission is to revolutionize the world through the power of dank memes, laughter, and innovation. By merging the realms of science and meme culture, we create cutting-edge products that entertain, amaze, and bring people together.
|
| 8 |
+
|
| 9 |
+
**Our Story**
|
| 10 |
+
|
| 11 |
+
Founded in 2021 by a group of visionary memelords, Pepe Corp began as a small startup focused on creating meme-based pharmaceuticals to counter the growing seriousness in the world. Recognizing the untapped potential of meme culture, our founders set out to explore the intersection between humor, science, and technology.
|
| 12 |
+
|
| 13 |
+
Over the years, Pepe Corp has grown into a multidisciplinary organization with a diverse portfolio of products, ranging from meme-inspired pharmaceuticals to advanced brain implants and mobile applications. Our products are designed to elevate the human experience by harnessing the power of memes, laughter, and the Pepe spirit.
|
| 14 |
+
|
| 15 |
+
**Our Values**
|
| 16 |
+
|
| 17 |
+
At Pepe Corp, our values drive everything we do:
|
| 18 |
+
|
| 19 |
+
1. **Innovation**: We are committed to pushing the boundaries of meme science and technology to develop products that challenge conventional wisdom and redefine the limits of possibility.
|
| 20 |
+
2. **Laughter**: We believe that laughter is a universal language that transcends barriers and brings people together. Our products are designed to elicit joy and promote the healing power of humor.
|
| 21 |
+
3. **Community**: We strive to create a global community of meme enthusiasts who share our passion for innovation, laughter, and the Pepe spirit.
|
| 22 |
+
4. **Sustainability**: We are dedicated to operating our business in a responsible and sustainable manner, ensuring the continued availability of dank memes for future generations.
|
| 23 |
+
|
| 24 |
+
**Our Products**
|
| 25 |
+
|
| 26 |
+
Pepe Corp's diverse product portfolio includes:
|
| 27 |
+
|
| 28 |
+
1. *Meme-inspired Pharmaceuticals*: Our groundbreaking pharmaceuticals blend meme culture with scientific research to provide unique and entertaining experiences for our customers.
|
| 29 |
+
2. *Cutting-Edge Devices*: From brain implants that enable meme-based communication to wearable technology that tracks your meme usage, our devices push the limits of what's possible.
|
| 30 |
+
3. *Mobile Applications*: Our multi-platform mobile apps, such as PepeTrak and MemeGen, offer innovative solutions to enhance mental health, monitor meme consumption, and generate personalized meme experiences.
|
| 31 |
+
|
| 32 |
+
**Our Future**
|
| 33 |
+
|
| 34 |
+
As we look to the future, Pepe Corp is dedicated to exploring new frontiers in meme science and technology. We will continue to develop innovative products that entertain, inspire, and bring people together. By harnessing the power of memes and the Pepe spirit, we aim to make the world a better, funnier place for all.
|
| 35 |
+
|
| 36 |
+
Join us on this incredible journey as we redefine the limits of possibility and laughter with Pepe Corp, where the future is dank!
|
app/api/data/training_data/org-board_of_directors.md
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Board of Directors
|
| 2 |
+
|
| 3 |
+
Title: Board of Directors
|
| 4 |
+
|
| 5 |
+
**Introduction**
|
| 6 |
+
|
| 7 |
+
At Pepe Corp, our Board of Directors is composed of accomplished leaders with diverse backgrounds and expertise in various fields. They share our passion for innovation, laughter, and the Pepe spirit, and are committed to guiding our company's strategic vision and overseeing its growth. Together, our Board of Directors ensures that Pepe Corp remains at the forefront of meme science and technology, making the world a better, funnier place.
|
| 8 |
+
|
| 9 |
+
**Board Members**
|
| 10 |
+
|
| 11 |
+
1. **Felix Memelord**: Chairman of the Board and Co-Founder
|
| 12 |
+
Felix is a pioneering memelord with over a decade of experience in meme culture and internet humor. As the co-founder of Pepe Corp, he has been instrumental in shaping the company's strategic direction and ensuring its commitment to innovation, laughter, and the Pepe spirit.
|
| 13 |
+
2. **Dr. Olivia Dankstein**: Vice-Chair and Chief Scientific Officer
|
| 14 |
+
Dr. Dankstein is a renowned scientist with extensive experience in neuroscience, psychology, and the science of humor. She is responsible for leading Pepe Corp's research and development efforts, driving the company's pursuit of groundbreaking meme-inspired pharmaceuticals and technologies.
|
| 15 |
+
3. **Mona Laughsalot**: Director and Chief Marketing Officer
|
| 16 |
+
Mona is a marketing expert with a background in digital media and consumer engagement. She has been instrumental in building Pepe Corp's global brand presence and creating memorable campaigns that showcase the company's innovative products and commitment to laughter.
|
| 17 |
+
4. **Henry Frogman**: Director and Chief Financial Officer
|
| 18 |
+
Henry is a seasoned finance executive with experience in corporate strategy and financial management. He oversees Pepe Corp's financial operations, ensuring the company's long-term sustainability and supporting its growth objectives.
|
| 19 |
+
5. **Iris Memequeen**: Director and Head of Human Resources
|
| 20 |
+
Iris is a human resources professional with a passion for fostering inclusive and supportive workplace environments. She is responsible for developing and implementing Pepe Corp's talent management strategies, cultivating a diverse and empowered team that embodies the Pepe spirit.
|
| 21 |
+
6. **Jackie Jokster**: Director and Head of Product Development
|
| 22 |
+
Jackie is an accomplished product developer with expertise in software engineering and user experience design. She leads Pepe Corp's product development efforts, ensuring that the company's offerings remain innovative, entertaining, and user-friendly.
|
| 23 |
+
7. **Vincent Laugherino**: Director and General Counsel
|
| 24 |
+
Vincent is an experienced attorney with a background in intellectual property, corporate law, and regulatory compliance. He advises Pepe Corp's management team and Board of Directors on legal matters, ensuring that the company operates in accordance with applicable laws and regulations.
|
| 25 |
+
|
| 26 |
+
**Conclusion**
|
| 27 |
+
|
| 28 |
+
The Pepe Corp Board of Directors is a dynamic team of leaders who are dedicated to guiding the company's strategic vision and overseeing its growth. By leveraging their diverse expertise and shared passion for innovation, laughter, and the Pepe spirit, our Board of Directors ensures that Pepe Corp remains a global leader in meme science and technology.
|
app/api/data/training_data/org-company_story.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Company Story
|
| 2 |
+
|
| 3 |
+
Title: Company Story
|
| 4 |
+
|
| 5 |
+
**The Genesis of Pepe Corp**
|
| 6 |
+
|
| 7 |
+
In the early 21st century, a group of visionary memelords gathered in a dimly lit basement, fueled by their passion for dank memes and the iconic Pepe the Frog. As they contemplated the growing seriousness of the world, they were struck by a sudden realization: the power of memes could be harnessed to create groundbreaking products that would not only entertain but also bring people together. And so, in 2021, Pepe Corp was born.
|
| 8 |
+
|
| 9 |
+
**The Early Days: Pioneering Meme-Based Pharmaceuticals**
|
| 10 |
+
|
| 11 |
+
The founders of Pepe Corp were determined to explore the untapped potential of meme culture. They began by creating a range of meme-inspired pharmaceuticals, blending cutting-edge scientific research with the universal language of laughter. These innovative products quickly gained a cult following, garnering both amusement and curiosity.
|
| 12 |
+
|
| 13 |
+
**Expanding Horizons: Meme-Driven Technology**
|
| 14 |
+
|
| 15 |
+
As Pepe Corp's reputation grew, so did its ambitions. The company expanded its focus to include the development of advanced technology inspired by meme culture. From brain implants that enabled meme-based communication to wearable devices that monitored meme consumption, Pepe Corp's inventions captured the imagination of people worldwide.
|
| 16 |
+
|
| 17 |
+
**Becoming a Global Meme Phenomenon**
|
| 18 |
+
|
| 19 |
+
Pepe Corp's rapid rise to prominence caught the attention of mainstream media, turning the once-underground company into a global meme phenomenon. Their unique blend of humor, science, and technology resonated with audiences across generations and cultures, establishing Pepe Corp as a symbol of innovation and laughter.
|
| 20 |
+
|
| 21 |
+
**Building a Meme Empire**
|
| 22 |
+
|
| 23 |
+
Today, Pepe Corp is a multidisciplinary organization with a diverse portfolio of products and services. Its offerings include meme-inspired pharmaceuticals, cutting-edge devices, and multi-platform mobile applications designed to enhance mental health, monitor meme consumption, and generate personalized meme experiences.
|
| 24 |
+
|
| 25 |
+
Pepe Corp's success is built on its unwavering commitment to innovation, laughter, and community. The company continues to push the boundaries of what's possible in the realm of meme science and technology, with the ultimate goal of making the world a better, funnier place.
|
| 26 |
+
|
| 27 |
+
**The Future: Redefining Possibility and Laughter**
|
| 28 |
+
|
| 29 |
+
As Pepe Corp looks to the future, it remains dedicated to exploring new frontiers in meme science and technology. The company's research and development teams are hard at work, creating the next generation of meme-based products that will entertain, inspire, and bring people together.
|
| 30 |
+
|
| 31 |
+
Pepe Corp's journey has only just begun, but its impact is already being felt around the world. As the company continues to redefine the limits of possibility and laughter, one thing is certain: the future is dank, and Pepe Corp is leading the way.
|
app/api/data/training_data/org-corporate_philosophy.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Corporate philosophy
|
| 2 |
+
|
| 3 |
+
Title: Corporate Philosophy
|
| 4 |
+
|
| 5 |
+
**Introduction**
|
| 6 |
+
|
| 7 |
+
At Pepe Corp, our corporate philosophy is rooted in the belief that humor, innovation, and the power of memes can transform the world. We are dedicated to creating groundbreaking products that entertain, amaze, and unite people in laughter. Our philosophy shapes every aspect of our business, guiding our decisions and inspiring our actions.
|
| 8 |
+
|
| 9 |
+
**Our Core Principles**
|
| 10 |
+
|
| 11 |
+
1. **Innovation**: We believe in pushing the boundaries of meme science and technology to develop products that challenge conventional wisdom and redefine the limits of possibility. Our commitment to innovation drives us to explore the untapped potential of meme culture, turning wild ideas into reality.
|
| 12 |
+
2. **Laughter**: We recognize that laughter is a universal language that transcends barriers and brings people together. We are dedicated to creating products that elicit joy, promote the healing power of humor, and spread the spirit of Pepe the Frog throughout the world.
|
| 13 |
+
3. **Community**: We strive to foster a global community of meme enthusiasts who share our passion for innovation, laughter, and the Pepe spirit. By cultivating a supportive and inclusive environment, we empower our team members, customers, and partners to express themselves freely and embrace the power of memes.
|
| 14 |
+
4. **Sustainability**: We understand that our success depends on the well-being of the world around us. We are committed to operating our business in a responsible and sustainable manner, ensuring the continued availability of dank memes for future generations.
|
| 15 |
+
|
| 16 |
+
**Our Ethos: The Pepe Spirit**
|
| 17 |
+
|
| 18 |
+
The Pepe spirit is at the heart of our corporate philosophy. Inspired by the iconic Pepe the Frog meme, this ethos represents our unwavering commitment to laughter, creativity, and the power of memes. The Pepe spirit guides our actions, influences our decisions, and serves as a constant reminder of our mission to make the world a better, funnier place.
|
| 19 |
+
|
| 20 |
+
**Our Commitment**
|
| 21 |
+
|
| 22 |
+
As a company, we pledge to uphold our corporate philosophy in every aspect of our business. We are committed to:
|
| 23 |
+
|
| 24 |
+
- Continuously exploring new frontiers in meme science and technology
|
| 25 |
+
- Developing innovative products that entertain, inspire, and bring people together
|
| 26 |
+
- Fostering a diverse and inclusive workplace that values creativity, collaboration, and the Pepe spirit
|
| 27 |
+
- Conducting our business with integrity, transparency, and a commitment to sustainability
|
| 28 |
+
|
| 29 |
+
**Conclusion**
|
| 30 |
+
|
| 31 |
+
At Pepe Corp, our corporate philosophy is more than just a set of guiding principles; it is the very essence of who we are as a company. By embracing the power of memes, laughter, and the Pepe spirit, we aim to transform the world and create a brighter, funnier future for all.
|
app/api/data/training_data/org-customer_support.md
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Customer support
|
| 2 |
+
|
| 3 |
+
Title: Management Team
|
| 4 |
+
|
| 5 |
+
**Introduction**
|
| 6 |
+
|
| 7 |
+
Pepe Corp's management team is composed of accomplished professionals who bring their unique expertise and passion for the Pepe spirit to the forefront of our operations. This dedicated team of leaders is committed to fostering an innovative, inclusive, and laughter-driven culture while driving the company's strategic objectives and ensuring its continued success.
|
| 8 |
+
|
| 9 |
+
**Management Team Members**
|
| 10 |
+
|
| 11 |
+
1. **Amanda Gigglestein**: Chief Executive Officer
|
| 12 |
+
Amanda is an experienced executive with a background in technology and entertainment. As CEO, she is responsible for setting Pepe Corp's strategic direction, overseeing its day-to-day operations, and ensuring that the company remains at the forefront of meme science and technology.
|
| 13 |
+
2. **Brandon Memeinator**: Chief Operating Officer
|
| 14 |
+
Brandon is a seasoned operations professional with extensive experience in scaling businesses and optimizing processes. As COO, he is responsible for streamlining Pepe Corp's operations, driving efficiency, and supporting the company's growth objectives.
|
| 15 |
+
3. **Dr. Penelope Pepescience**: Chief Research Officer
|
| 16 |
+
Dr. Pepescience is a leading expert in the field of meme psychology and neuroscience. As CRO, she directs Pepe Corp's research efforts, spearheading groundbreaking studies and collaborations that fuel the company's innovative product pipeline.
|
| 17 |
+
4. **Claire Froglover**: Chief Creative Officer
|
| 18 |
+
Claire is a talented creative professional with a background in graphic design, branding, and content creation. As CCO, she oversees Pepe Corp's creative direction, ensuring that the company's products, campaigns, and communications reflect the Pepe spirit and resonate with audiences worldwide.
|
| 19 |
+
5. **Timothy Chuckles**: Chief Technology Officer
|
| 20 |
+
Timothy is an accomplished technology executive with expertise in software development, artificial intelligence, and data analytics. As CTO, he leads Pepe Corp's technology initiatives, developing cutting-edge solutions that enhance the company's offerings and delight its customers.
|
| 21 |
+
6. **Sophia Memevator**: Chief Customer Officer
|
| 22 |
+
Sophia is a customer experience expert with a passion for creating memorable and engaging interactions. As CCO, she oversees Pepe Corp's customer service, community engagement, and user experience efforts, ensuring that the company's customers remain at the heart of everything it does.
|
| 23 |
+
7. **Edward Laughton**: Chief Sustainability Officer
|
| 24 |
+
Edward is a sustainability professional with a background in environmental management and corporate social responsibility. As CSO, he is responsible for developing and implementing Pepe Corp's sustainability strategy, ensuring the company's operations are conducted responsibly and with minimal environmental impact.
|
| 25 |
+
|
| 26 |
+
**Conclusion**
|
| 27 |
+
|
| 28 |
+
Pepe Corp's management team is a dynamic group of leaders who are dedicated to upholding the company's core values of innovation, laughter, and the Pepe spirit. By leveraging their diverse expertise and working collaboratively, our management team ensures that Pepe Corp remains a global leader in meme science and technology, making the world a better, funnier place.
|
app/api/data/training_data/org-earnings_fy2023.md
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Earnings FY2023
|
| 2 |
+
|
| 3 |
+
Title: Earnings FY2023
|
| 4 |
+
|
| 5 |
+
**Introduction**
|
| 6 |
+
|
| 7 |
+
As a leading company in meme science and technology, we are committed to continuing our mission of making the world a better, funnier place. In FY2023, we have focused on product innovation, strategic partnerships, and strengthening our global presence, while maintaining our commitment to the Pepe spirit and environmental sustainability.
|
| 8 |
+
|
| 9 |
+
**Strategic Objectives**
|
| 10 |
+
|
| 11 |
+
1. **Product Innovation**: We will invest in research and development to create cutting-edge products that address the needs of our diverse customer base. Our R&D team will explore new areas of meme science and technology, developing products that improve mental health, communication, and entertainment experiences.
|
| 12 |
+
2. **Market Expansion**: In FY2023, we plan to expand our presence in key international markets, targeting regions with significant growth potential. Our marketing team will develop tailored campaigns to raise awareness of our brand and products, while our sales team will work on securing new distribution partnerships.
|
| 13 |
+
3. **Strategic Partnerships**: We will pursue strategic partnerships with leading companies in the technology, entertainment, and pharmaceutical industries, leveraging their expertise and resources to enhance our product offerings and reach new audiences.
|
| 14 |
+
4. **Environmental Sustainability**: Pepe Corp is committed to operating responsibly and minimizing our environmental impact. In FY2023, we will work on implementing new sustainability initiatives and improving existing ones, focusing on areas such as waste reduction, energy efficiency, and responsible sourcing.
|
| 15 |
+
5. **Talent Development**: Our employees are our greatest asset, and we will continue to invest in their growth and development in FY2023. We will offer comprehensive training programs, provide opportunities for career advancement, and maintain an inclusive and supportive work environment that embodies the Pepe spirit.
|
| 16 |
+
6. **Customer Support Excellence**: We will strive to enhance our customer support experience, ensuring that our customers receive timely and effective assistance with their inquiries and concerns. Our Customer Support team will undergo additional training, and we will explore new technologies and processes to improve response times and customer satisfaction.
|
| 17 |
+
|
| 18 |
+
**Quarterly earnings:**
|
| 19 |
+
|
| 20 |
+
Pepe Corp is pleased to present our earnings report for Fiscal Year 2023. The following document outlines our quarterly organizational performance data and provides a simple but believable Profit and Loss (P&L) statement for the year. We are proud to report strong growth in revenue, driven by product innovation, market expansion, and strategic partnerships.
|
| 21 |
+
|
| 22 |
+
**Quarterly Organizational Performance Data**
|
| 23 |
+
|
| 24 |
+
*Note: All figures are in millions (USD)*
|
| 25 |
+
|
| 26 |
+
| Quarter | Revenue | Cost of Goods Sold (COGS) | Gross Profit | Operating Expenses | Operating Income | Net Income |
|
| 27 |
+
| --- | --- | --- | --- | --- | --- | --- |
|
| 28 |
+
| Q1 FY2023 | 50 | 20 | 30 | 15 | 15 | 12 |
|
| 29 |
+
| Q2 FY2023 | 55 | 22 | 33 | 16 | 17 | 13.5 |
|
| 30 |
+
| Q3 FY2023 | 60 | 24 | 36 | 17 | 19 | 15 |
|
| 31 |
+
| Q4 FY2023 | 70 | 28 | 42 | 18 | 24 | 19 |
|
| 32 |
+
| Total FY2023 | 235 | 94 | 141 | 66 | 75 | 59.5 |
|
| 33 |
+
|
| 34 |
+
**Profit & Loss Statement for FY2023**
|
| 35 |
+
|
| 36 |
+
*Note: All figures are in millions (USD)*
|
| 37 |
+
|
| 38 |
+
1. Revenue: $235
|
| 39 |
+
2. Cost of Goods Sold (COGS): $94
|
| 40 |
+
3. Gross Profit: $141
|
| 41 |
+
4. Operating Expenses: $66
|
| 42 |
+
a. Research & Development: $20
|
| 43 |
+
b. Sales & Marketing: $30
|
| 44 |
+
c. General & Administrative: $16
|
| 45 |
+
5. Operating Income: $75
|
| 46 |
+
6. Interest Expense: $3
|
| 47 |
+
7. Taxes: $12.5
|
| 48 |
+
8. Net Income: $59.5
|
| 49 |
+
|
| 50 |
+
Pepe Corp's performance in FY2023 reflects strong growth and continued success in our mission to make the world a better, funnier place. Our revenue has increased consistently throughout the year, and our strategic initiatives have resulted in improved operating income and net income. As we continue to innovate, expand, and strengthen our global presence, we are excited about the opportunities that lie ahead and are committed to delivering value to our shareholders and customers alike.
|
| 51 |
+
|
| 52 |
+
**Financial Projections**
|
| 53 |
+
|
| 54 |
+
In FY2024, we expect to achieve strong revenue growth driven by product innovation, market expansion, and strategic partnerships. We will continue to invest in R&D and marketing initiatives to support our growth objectives while maintaining a focus on cost optimization and operational efficiency.
|
| 55 |
+
|
| 56 |
+
**Conclusion**
|
| 57 |
+
|
| 58 |
+
Pepe Corp is excited about the opportunities that lie ahead in FY2024. We remain committed to our mission of making the world a better, funnier place, and we are confident that our strategic objectives will drive growth, innovation, and success in the upcoming fiscal year. Together, we will continue to spread the Pepe spirit and make a lasting impact on our customers and the world.
|
app/api/data/training_data/org-management_team.md
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Management team
|
| 2 |
+
|
| 3 |
+
Title: Management Team
|
| 4 |
+
|
| 5 |
+
**Introduction**
|
| 6 |
+
|
| 7 |
+
Pepe Corp's management team is composed of accomplished professionals who bring their unique expertise and passion for the Pepe spirit to the forefront of our operations. This dedicated team of leaders is committed to fostering an innovative, inclusive, and laughter-driven culture while driving the company's strategic objectives and ensuring its continued success.
|
| 8 |
+
|
| 9 |
+
**Management Team Members**
|
| 10 |
+
|
| 11 |
+
1. **Amanda Gigglestein**: Chief Executive Officer
|
| 12 |
+
Amanda is an experienced executive with a background in technology and entertainment. As CEO, she is responsible for setting Pepe Corp's strategic direction, overseeing its day-to-day operations, and ensuring that the company remains at the forefront of meme science and technology.
|
| 13 |
+
2. **Brandon Memeinator**: Chief Operating Officer
|
| 14 |
+
Brandon is a seasoned operations professional with extensive experience in scaling businesses and optimizing processes. As COO, he is responsible for streamlining Pepe Corp's operations, driving efficiency, and supporting the company's growth objectives.
|
| 15 |
+
3. **Dr. Penelope Pepescience**: Chief Research Officer
|
| 16 |
+
Dr. Pepescience is a leading expert in the field of meme psychology and neuroscience. As CRO, she directs Pepe Corp's research efforts, spearheading groundbreaking studies and collaborations that fuel the company's innovative product pipeline.
|
| 17 |
+
4. **Claire Froglover**: Chief Creative Officer
|
| 18 |
+
Claire is a talented creative professional with a background in graphic design, branding, and content creation. As CCO, she oversees Pepe Corp's creative direction, ensuring that the company's products, campaigns, and communications reflect the Pepe spirit and resonate with audiences worldwide.
|
| 19 |
+
5. **Timothy Chuckles**: Chief Technology Officer
|
| 20 |
+
Timothy is an accomplished technology executive with expertise in software development, artificial intelligence, and data analytics. As CTO, he leads Pepe Corp's technology initiatives, developing cutting-edge solutions that enhance the company's offerings and delight its customers.
|
| 21 |
+
6. **Sophia Memevator**: Chief Customer Officer
|
| 22 |
+
Sophia is a customer experience expert with a passion for creating memorable and engaging interactions. As CCO, she oversees Pepe Corp's customer service, community engagement, and user experience efforts, ensuring that the company's customers remain at the heart of everything it does.
|
| 23 |
+
7. **Edward Laughton**: Chief Sustainability Officer
|
| 24 |
+
Edward is a sustainability professional with a background in environmental management and corporate social responsibility. As CSO, he is responsible for developing and implementing Pepe Corp's sustainability strategy, ensuring the company's operations are conducted responsibly and with minimal environmental impact.
|
| 25 |
+
|
| 26 |
+
**Conclusion**
|
| 27 |
+
|
| 28 |
+
Pepe Corp's management team is a dynamic group of leaders who are dedicated to upholding the company's core values of innovation, laughter, and the Pepe spirit. By leveraging their diverse expertise and working collaboratively, our management team ensures that Pepe Corp remains a global leader in meme science and technology, making the world a better, funnier place.
|
app/api/data/training_data/project-frogonil.md
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Frogonil
|
| 2 |
+
|
| 3 |
+
Product Name: Frogonil
|
| 4 |
+
|
| 5 |
+
Purpose: Increases capacity to shitpost on social media
|
| 6 |
+
|
| 7 |
+
**How to Use**
|
| 8 |
+
|
| 9 |
+
Frogonil is available in the form of concentrated Pepe-powered capsules. The recommended dosage is one capsule per day, taken orally with a glass of water and a side of your preferred social media platform. For maximum shitposting potential, take Frogonil 15 minutes prior to engaging in online discussions or while crafting your next witty response to a controversial tweet.
|
| 10 |
+
|
| 11 |
+
**Side Effects**
|
| 12 |
+
|
| 13 |
+
Some potential side effects of Frogonil may include:
|
| 14 |
+
|
| 15 |
+
1. An insatiable appetite for internet trolling and stirring up online chaos
|
| 16 |
+
2. Unexpectedly profound insights into meme culture
|
| 17 |
+
3. An increased propensity for using the term "REEE" in everyday conversations
|
| 18 |
+
4. A heightened sense of humor and the ability to find irony in even the darkest situations
|
| 19 |
+
5. Periodic visions of Pepe as a spirit guide, leading you on a quest for the dankest memes
|
| 20 |
+
|
| 21 |
+
Please consult your memologist if side effects persist or become bothersome.
|
| 22 |
+
|
| 23 |
+
**Precautions**
|
| 24 |
+
|
| 25 |
+
Before taking Frogonil, consider the following precautions:
|
| 26 |
+
|
| 27 |
+
1. Do not use Frogonil if you have a history of being a buzzkill or an intolerance for internet humor.
|
| 28 |
+
2. Frogonil may not be suitable for individuals who prefer a quiet, peaceful online existence.
|
| 29 |
+
3. Exercise caution when engaging in real-life conversations, as Frogonil may cause users to inadvertently apply shitposting tactics in inappropriate situations.
|
| 30 |
+
|
| 31 |
+
**Interactions**
|
| 32 |
+
|
| 33 |
+
Frogonil may interact with other substances or activities, including:
|
| 34 |
+
|
| 35 |
+
1. Sarcasm inhibitors: Combining Frogonil with sarcasm inhibitors may lead to unpredictable humor fluctuations and an inability to detect irony.
|
| 36 |
+
2. Internet detox: Frogonil is not recommended for those engaging in an internet detox, as the temptation to shitpost may become overwhelming.
|
| 37 |
+
|
| 38 |
+
Consult your memologist if you are taking any other medications or participating in any activities that may interfere with Frogonil's effectiveness.
|
| 39 |
+
|
| 40 |
+
**Overdose**
|
| 41 |
+
|
| 42 |
+
In case of an overdose, symptoms may include:
|
| 43 |
+
|
| 44 |
+
1. Unstoppable shitposting, potentially leading to the creation of alternative online personas
|
| 45 |
+
2. A warped perception of reality where memes become the ultimate truth
|
| 46 |
+
3. Gaining an unsettling number of followers and admirers who appreciate your dark humor
|
| 47 |
+
|
| 48 |
+
If you suspect an overdose, contact your local meme crisis hotline or visit the nearest meme rehabilitation center. Remember, Frogonil is best enjoyed in moderation, and always heed the guidance of your Pepe-inspired spirit guide: "REEE-sponsibly."
|
app/api/data/training_data/project-kekzal.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Kekzal
|
| 2 |
+
|
| 3 |
+
Product Name: Kekzal
|
| 4 |
+
|
| 5 |
+
Purpose: Enhances sexual function
|
| 6 |
+
|
| 7 |
+
**How to Use**
|
| 8 |
+
|
| 9 |
+
Kekzal is available in the form of Pepe-approved, green diamond-shaped tablets. The recommended dosage is one tablet taken orally with a glass of water, approximately 60 minutes before engaging in intimate activities. For optimal results, immerse yourself in Pepe memes and share a laugh with your partner to set the mood.
|
| 10 |
+
|
| 11 |
+
**Side Effects**
|
| 12 |
+
|
| 13 |
+
Some potential side effects of Kekzal may include:
|
| 14 |
+
|
| 15 |
+
1. An increased propensity for whispering sweet Pepe nothings into your partner's ear
|
| 16 |
+
2. A heightened sense of humor, making even the most awkward intimate moments hilarious
|
| 17 |
+
3. The occasional urge to shout "KEK!" during moments of passion
|
| 18 |
+
4. Spontaneous and uncontrollable laughter during foreplay
|
| 19 |
+
5. An unexplained affinity for green lingerie and bedroom accessories
|
| 20 |
+
|
| 21 |
+
Consult your memologist if side effects persist or become bothersome.
|
| 22 |
+
|
| 23 |
+
**Precautions**
|
| 24 |
+
|
| 25 |
+
Before taking Kekzal, consider the following precautions:
|
| 26 |
+
|
| 27 |
+
1. Do not use Kekzal if you have a known allergy to dank memes or an aversion to Pepe-themed romantic encounters.
|
| 28 |
+
2. Kekzal may not be suitable for individuals with a history of humor-related intimacy issues or meme-related performance anxiety.
|
| 29 |
+
3. Exercise caution when engaging in intimate activities, as Kekzal may cause fits of laughter at inappropriate moments.
|
| 30 |
+
|
| 31 |
+
**Interactions**
|
| 32 |
+
|
| 33 |
+
Kekzal may interact with other substances or activities, including:
|
| 34 |
+
|
| 35 |
+
1. Seriousness supplements: Combining Kekzal with seriousness supplements may result in a decreased sense of humor and diminished intimate enjoyment.
|
| 36 |
+
2. Nostalgic media: Watching reruns of classic sitcoms or engaging in non-Pepe related activities may reduce Kekzal's effectiveness.
|
| 37 |
+
|
| 38 |
+
Consult your memologist if you are taking any other medications or participating in any activities that may interfere with Kekzal's intended effects.
|
| 39 |
+
|
| 40 |
+
**Overdose**
|
| 41 |
+
|
| 42 |
+
In case of an overdose, symptoms may include:
|
| 43 |
+
|
| 44 |
+
1. An insatiable desire to create erotic Pepe fanfiction
|
| 45 |
+
2. The belief that Pepe is the ultimate symbol of love and intimacy
|
| 46 |
+
3. An uncontrollable urge to redecorate your bedroom with Pepe-themed decor
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
If you suspect an overdose, contact your local meme crisis hotline or visit the nearest meme rehabilitation center. Remember, the key to enjoying Kekzal is to embrace its humor-enhancing effects responsibly, and to appreciate the amorous wisdom of our legendary Pepe: "Love is a meme, my friend."
|
app/api/data/training_data/project-memegen.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MemeGen
|
| 2 |
+
|
| 3 |
+
Product Name: MemeGen
|
| 4 |
+
|
| 5 |
+
Purpose: A meme generator mental health application generating better outcomes for patients
|
| 6 |
+
|
| 7 |
+
**About the App**
|
| 8 |
+
|
| 9 |
+
MemeGen is an innovative multi-platform mobile app designed to boost mental health through the healing power of memes. By utilizing Pepe Corp's cutting-edge meme generation technology, MemeGen crafts personalized and hilarious memes to suit your emotional needs, providing a unique therapeutic experience. Rediscover the joy of laughter and embrace the dank meme revolution with MemeGen.
|
| 10 |
+
|
| 11 |
+
**Features**
|
| 12 |
+
|
| 13 |
+
1. Personalized Meme Generation: MemeGen's advanced algorithms create custom memes based on your mood, preferences, and sense of humor to provide targeted mental health support.
|
| 14 |
+
2. Meme Therapy: Receive daily meme prescriptions tailored to your emotional needs, helping you navigate life's ups and downs with a healthy dose of laughter.
|
| 15 |
+
3. Mood Tracker: Monitor your mood and emotional progress with MemeGen's built-in mood tracker, offering valuable insights into your mental health journey.
|
| 16 |
+
4. Meme Community: Connect with fellow MemeGen users to share and discuss your favorite therapeutic memes, creating a supportive and laughter-filled environment.
|
| 17 |
+
5. Mental Health Resources: Access a library of mental health resources and tips, all infused with MemeGen's signature Pepe-inspired humor.
|
| 18 |
+
|
| 19 |
+
**Troubleshooting**
|
| 20 |
+
|
| 21 |
+
1. If MemeGen fails to load or crashes unexpectedly, try restarting your device and ensuring your app version is up-to-date.
|
| 22 |
+
2. If MemeGen's personalized memes seem off-target, double-check your preferences and mood inputs in the app settings.
|
| 23 |
+
3. For any other technical issues or concerns, contact MemeGen's dedicated support team at [support@memegen.com](mailto:support@memegen.com).
|
| 24 |
+
|
| 25 |
+
**FAQ**
|
| 26 |
+
|
| 27 |
+
1. *Is MemeGen compatible with my device?*
|
| 28 |
+
MemeGen is available for both iOS and Android devices, ensuring that laughter is always within reach.
|
| 29 |
+
2. *How does MemeGen maintain my privacy?*
|
| 30 |
+
MemeGen values user privacy and employs advanced encryption methods to protect your personal information and meme preferences. For more information, refer to our Privacy Policy.
|
| 31 |
+
3. *Can MemeGen replace professional mental health care?*
|
| 32 |
+
While MemeGen is designed to provide a fun and supportive mental health experience, it is not a substitute for professional mental health care. Always consult a qualified healthcare professional for serious mental health concerns.
|
| 33 |
+
4. *Are the memes generated by MemeGen safe for all audiences?*
|
| 34 |
+
MemeGen aims to provide a positive and inclusive experience, creating memes that cater to a wide range of humor preferences while avoiding offensive or harmful content.
|
| 35 |
+
|
| 36 |
+
Dive into the world of therapeutic meme generation with MemeGen and let the power of laughter and Pepe-inspired wisdom bring light to your mental health journey.
|
app/api/data/training_data/project-memetrex.md
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Memetrex
|
| 2 |
+
|
| 3 |
+
Product Name: Memetrex
|
| 4 |
+
|
| 5 |
+
Purpose: Increases memory, causing you to literally remember everything
|
| 6 |
+
|
| 7 |
+
**How to Use**
|
| 8 |
+
|
| 9 |
+
Memetrex is available in the form of Pepe-embossed, green elliptical tablets. The recommended dosage is one tablet taken orally with a glass of water, preferably while browsing your favorite meme database for mental stimulation. For optimal results, take Memetrex 30 minutes before engaging in memory-intensive activities, such as trivia night or an epic meme showdown.
|
| 10 |
+
|
| 11 |
+
**Side Effects**
|
| 12 |
+
|
| 13 |
+
Some potential side effects of Memetrex may include:
|
| 14 |
+
|
| 15 |
+
1. The sudden ability to recall every meme you've ever encountered, even the cringiest ones
|
| 16 |
+
2. An uncanny knack for winning online arguments by recalling obscure Pepe references
|
| 17 |
+
3. A newfound obsession with pop culture history, particularly as it relates to memes
|
| 18 |
+
4. The inability to forget embarrassing moments, both your own and those of others
|
| 19 |
+
5. The occasional urge to recite meme-related trivia at inappropriate moments
|
| 20 |
+
|
| 21 |
+
Consult your memologist if side effects persist or become bothersome.
|
| 22 |
+
|
| 23 |
+
**Precautions**
|
| 24 |
+
|
| 25 |
+
Before taking Memetrex, consider the following precautions:
|
| 26 |
+
|
| 27 |
+
1. Do not use Memetrex if you have a known allergy to dank memes or a history of meme-induced flashbacks.
|
| 28 |
+
2. Memetrex may not be suitable for individuals with a propensity for meme-related nightmares or those who wish to forget their past meme blunders.
|
| 29 |
+
3. Exercise caution when engaging in social situations, as Memetrex may cause users to inadvertently recall and share embarrassing memories.
|
| 30 |
+
|
| 31 |
+
**Interactions**
|
| 32 |
+
|
| 33 |
+
Memetrex may interact with other substances or activities, including:
|
| 34 |
+
|
| 35 |
+
1. Memory suppressants: Combining Memetrex with memory suppressants may result in an epic meme battle for mental dominance and unpredictable memory performance.
|
| 36 |
+
2. Binge-watching TV shows: The combination of Memetrex and binge-watching may cause an overload of pop culture references, leading to an irresistible urge to create crossover memes.
|
| 37 |
+
|
| 38 |
+
Consult your memologist if you are taking any other medications or participating in any activities that may interfere with Memetrex's effectiveness.
|
| 39 |
+
|
| 40 |
+
**Overdose**
|
| 41 |
+
|
| 42 |
+
In case of an overdose, symptoms may include:
|
| 43 |
+
|
| 44 |
+
1. A photographic memory of every meme ever created, resulting in an overwhelming desire to create a comprehensive meme encyclopedia
|
| 45 |
+
2. The belief that you are the ultimate meme archivist, destined to preserve dank memes for future generations
|
| 46 |
+
3. The inability to separate meme memories from your own life experiences
|
| 47 |
+
|
| 48 |
+
If you suspect an overdose, contact your local meme crisis hotline or visit the nearest meme rehabilitation center. Remember, the key to enjoying Memetrex is to use it responsibly and to cherish the unparalleled meme wisdom of our legendary Pepe: "With great meme-ory comes great responsibility."
|
app/api/data/training_data/project-neurokek.md
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Neuro-kek
|
| 2 |
+
|
| 3 |
+
Product Name: Neuro-Kek
|
| 4 |
+
|
| 5 |
+
Purpose: A brain implant that causes the patient to communicate only in memes
|
| 6 |
+
|
| 7 |
+
**About the Devices**
|
| 8 |
+
|
| 9 |
+
Neuro-Kek is a revolutionary brain implant developed by Pepe Corp, designed to transform the way you communicate by converting your thoughts into dank memes. By tapping into the brain's meme center, Neuro-Kek enables users to express themselves solely through the language of Pepe and other popular memes. Say goodbye to mundane conversations and embrace the next frontier of human communication with Neuro-Kek.
|
| 10 |
+
|
| 11 |
+
**Side-Effects and Warnings**
|
| 12 |
+
|
| 13 |
+
Potential side effects and warnings associated with the Neuro-Kek implant include:
|
| 14 |
+
|
| 15 |
+
1. Temporary or permanent loss of the ability to communicate in any form other than memes
|
| 16 |
+
2. Increased likelihood of being mistaken for a professional memelord
|
| 17 |
+
3. Sudden and uncontrollable cravings for rare Pepe collectibles
|
| 18 |
+
4. Inability to understand or participate in non-meme related conversations
|
| 19 |
+
5. The risk of becoming an internet sensation due to your unparalleled meme fluency
|
| 20 |
+
|
| 21 |
+
Please consult a certified memologist before undergoing the Neuro-Kek implant procedure.
|
| 22 |
+
|
| 23 |
+
**Device Features**
|
| 24 |
+
|
| 25 |
+
1. Instant Meme Generation: Neuro-Kek translates your thoughts into memes in real-time, ensuring you're always ready to deliver the perfect meme-based response.
|
| 26 |
+
2. Meme Mastery: Gain access to an extensive database of classic and trending memes, enhancing your meme fluency and communication skills.
|
| 27 |
+
3. Meme-to-Speech: Neuro-Kek's built-in meme-to-speech converter allows you to vocally communicate in meme format for seamless meme-based conversations.
|
| 28 |
+
4. Meme Analytics: Monitor your meme usage and trends with Neuro-Kek's meme analytics feature, helping you refine your meme communication strategies.
|
| 29 |
+
5. Meme Updates: Receive regular meme updates to keep your meme repertoire fresh and relevant in the ever-evolving meme landscape.
|
| 30 |
+
|
| 31 |
+
**Device Specifications**
|
| 32 |
+
|
| 33 |
+
1. Implant Material: Biocompatible Pepe-green nanomaterials
|
| 34 |
+
2. Power Source: Memergy - a revolutionary energy source derived from the user's innate meme enthusiasm
|
| 35 |
+
3. Connectivity: DankNet - a secure, meme-based communication network
|
| 36 |
+
4. Dimensions: 4.20 x 6.9 x 0.69 mm
|
| 37 |
+
5. Compatibility: Human brains with a dank sense of humor
|
| 38 |
+
|
| 39 |
+
**Troubleshooting**
|
| 40 |
+
|
| 41 |
+
1. If Neuro-Kek fails to generate memes, try immersing yourself in meme culture to replenish your memergy reserves.
|
| 42 |
+
2. If Neuro-Kek malfunctions or produces irrelevant memes, consult your memologist for a device recalibration.
|
| 43 |
+
3. For any other technical issues or concerns, contact Pepe Corp's dedicated support team at [support@neuro-kek.com](mailto:support@neuro-kek.com).
|
| 44 |
+
|
| 45 |
+
**FAQ**
|
| 46 |
+
|
| 47 |
+
1. *Is the Neuro-Kek implant procedure safe?*
|
| 48 |
+
The Neuro-Kek implant procedure is performed by certified memologists and follows strict safety guidelines to ensure a positive meme-enhancing experience.
|
| 49 |
+
2. *Can Neuro-Kek be removed or turned off?*
|
| 50 |
+
Neuro-Kek can be temporarily deactivated or removed by a certified memologist if the user wishes to revert to traditional communication methods.
|
| 51 |
+
3. *Does Neuro-Kek work with languages other than English?*
|
| 52 |
+
Absolutely! Neuro-Kek is designed to generate memes in multiple languages, ensuring that meme-based communication knows no boundaries.
|
| 53 |
+
4. *Is Neuro-Kek compatible with other brain implants or devices?*
|
| 54 |
+
Neuro-Kek's compatibility with other brain implants or devices may vary. Consult your memologist to discuss potential interactions.
|
| 55 |
+
|
| 56 |
+
Embrace the future of meme-based communication with the Neuro-Kek brain implant and let Pepe's wisdom guide you through the fascinating world of dank memes.
|
app/api/data/training_data/project-pepetamine.md
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pepetamine
|
| 2 |
+
|
| 3 |
+
Product Name: Pepetamine
|
| 4 |
+
|
| 5 |
+
Purpose: Increases cognitive focus just like the Limitless movie
|
| 6 |
+
|
| 7 |
+
**How to Use**
|
| 8 |
+
|
| 9 |
+
Pepetamine is available in the form of rare Pepe-coated tablets. The recommended dosage is one tablet per day, taken orally with a glass of water, preferably while browsing your favorite meme forum for maximum cognitive enhancement. For optimal results, take Pepetamine 30 minutes before engaging in mentally demanding tasks, such as decoding ancient Pepe hieroglyphics or creating your next viral meme masterpiece.
|
| 10 |
+
|
| 11 |
+
**Side Effects**
|
| 12 |
+
|
| 13 |
+
Some potential side effects of Pepetamine may include:
|
| 14 |
+
|
| 15 |
+
1. Uncontrollable laughter and a sudden appreciation for dank memes
|
| 16 |
+
2. An inexplicable desire to collect rare Pepes
|
| 17 |
+
3. Enhanced meme creation skills, potentially leading to internet fame
|
| 18 |
+
4. Temporary green skin pigmentation, resembling the legendary Pepe himself
|
| 19 |
+
5. Spontaneously speaking in "feels good man" language
|
| 20 |
+
|
| 21 |
+
While most side effects are generally harmless, consult your memologist if side effects persist or become bothersome.
|
| 22 |
+
|
| 23 |
+
**Precautions**
|
| 24 |
+
|
| 25 |
+
Before taking Pepetamine, please consider the following precautions:
|
| 26 |
+
|
| 27 |
+
1. Do not use Pepetamine if you have a known allergy to rare Pepes or dank memes.
|
| 28 |
+
2. Pepetamine may not be suitable for individuals with a history of humor deficiency or meme intolerance.
|
| 29 |
+
3. Exercise caution when driving or operating heavy machinery, as Pepetamine may cause sudden fits of laughter or intense meme ideation.
|
| 30 |
+
|
| 31 |
+
**Interactions**
|
| 32 |
+
|
| 33 |
+
Pepetamine may interact with other substances, including:
|
| 34 |
+
|
| 35 |
+
1. Normie supplements: Combining Pepetamine with normie supplements may result in meme conflicts and a decreased sense of humor.
|
| 36 |
+
2. Caffeine: The combination of Pepetamine and caffeine may cause an overload of energy, resulting in hyperactive meme creation and potential internet overload.
|
| 37 |
+
|
| 38 |
+
Consult your memologist if you are taking any other medications or substances to ensure compatibility with Pepetamine.
|
| 39 |
+
|
| 40 |
+
**Overdose**
|
| 41 |
+
|
| 42 |
+
In case of an overdose, symptoms may include:
|
| 43 |
+
|
| 44 |
+
1. Uncontrollable meme creation
|
| 45 |
+
2. Delusions of grandeur as the ultimate meme lord
|
| 46 |
+
3. Time warps into the world of Pepe
|
| 47 |
+
|
| 48 |
+
If you suspect an overdose, contact your local meme emergency service or visit the nearest meme treatment facility. Remember, the key to enjoying Pepetamine is to use it responsibly, and always keep in mind the wise words of our legendary Pepe: "Feels good man."
|
app/api/data/training_data/project-pepetrak.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# PepeTrak
|
| 2 |
+
|
| 3 |
+
Product Name: PepeTrak
|
| 4 |
+
|
| 5 |
+
Purpose: An award-winning diagnosis app suggesting appropriate Pepe Corp pharmaceutical interventions
|
| 6 |
+
|
| 7 |
+
**About the App**
|
| 8 |
+
|
| 9 |
+
PepeTrak is a groundbreaking multi-platform mobile app designed to help you navigate the wild world of Pepe Corp pharmaceuticals. Using advanced meme-based algorithms, PepeTrak assesses your current mood, meme preferences, and medical history to recommend the perfect Pepe Corp intervention to suit your needs. Say goodbye to aimless meme browsing and hello to a new era of personalized Pepe prescriptions.
|
| 10 |
+
|
| 11 |
+
**Features**
|
| 12 |
+
|
| 13 |
+
1. Meme Diagnosis: PepeTrak's state-of-the-art meme analysis technology evaluates your recent meme consumption and emotional state to provide a tailored meme diagnosis.
|
| 14 |
+
2. Pepe Prescription: Based on your meme diagnosis, PepeTrak suggests the most appropriate Pepe Corp pharmaceutical intervention to elevate your meme game.
|
| 15 |
+
3. Meme Tracking: Keep track of your meme-related progress and improvements with PepeTrak's meme tracking feature.
|
| 16 |
+
4. Meme Community: Connect with fellow PepeTrak users to share your favorite memes, discuss Pepe Corp pharmaceutical experiences, and spread the dank meme love.
|
| 17 |
+
5. Pepe Rewards: Earn exclusive Pepe points for using the app, redeemable for rare Pepe collectibles and discounts on Pepe Corp products.
|
| 18 |
+
|
| 19 |
+
**Troubleshooting**
|
| 20 |
+
|
| 21 |
+
1. If PepeTrak fails to load or crashes unexpectedly, try restarting your device and ensuring your app version is up-to-date.
|
| 22 |
+
2. If PepeTrak's meme diagnosis seems inaccurate, double-check your meme preferences and personal information in the app settings.
|
| 23 |
+
3. For any other technical issues or concerns, contact PepeTrak's dedicated support team at [support@pepetrak.com](mailto:support@pepetrak.com).
|
| 24 |
+
|
| 25 |
+
**FAQ**
|
| 26 |
+
|
| 27 |
+
1. *Is PepeTrak compatible with my device?*
|
| 28 |
+
PepeTrak is available for both iOS and Android devices, ensuring maximum meme accessibility.
|
| 29 |
+
2. *How does PepeTrak maintain my privacy?*
|
| 30 |
+
PepeTrak values user privacy and employs advanced encryption methods to protect your personal information and meme preferences. For more information, refer to our Privacy Policy.
|
| 31 |
+
3. *Can I use PepeTrak without a Pepe Corp pharmaceutical prescription?*
|
| 32 |
+
Absolutely! PepeTrak is designed to enhance your overall meme experience and can be used independently of Pepe Corp products.
|
| 33 |
+
4. *Are the Pepe Corp pharmaceuticals recommended by PepeTrak safe?*
|
| 34 |
+
Pepe Corp pharmaceuticals are designed for entertainment purposes only and should not be taken as actual medical advice. Always consult a professional healthcare provider before starting any new treatment.
|
| 35 |
+
|
| 36 |
+
Embark on a personalized meme journey with PepeTrak and let the spirit of Pepe guide you to dank meme enlightenment!
|
app/api/helpers.py
ADDED
|
@@ -0,0 +1,658 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import HTTPException
|
| 2 |
+
from uuid import UUID
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
from typing import (
|
| 6 |
+
Optional,
|
| 7 |
+
Union
|
| 8 |
+
)
|
| 9 |
+
from config import (
|
| 10 |
+
FILE_UPLOAD_PATH,
|
| 11 |
+
ENTITY_STATUS,
|
| 12 |
+
logger
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
from util import (
|
| 16 |
+
is_uuid,
|
| 17 |
+
get_file_hash
|
| 18 |
+
)
|
| 19 |
+
from sqlmodel import (
|
| 20 |
+
Session,
|
| 21 |
+
select
|
| 22 |
+
)
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
from models import (
|
| 25 |
+
Organization,
|
| 26 |
+
OrganizationCreate,
|
| 27 |
+
User,
|
| 28 |
+
UserCreate,
|
| 29 |
+
get_engine,
|
| 30 |
+
Project,
|
| 31 |
+
ProjectCreate,
|
| 32 |
+
Document,
|
| 33 |
+
Node,
|
| 34 |
+
ChatSession
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
# ================
|
| 38 |
+
# Helper functions
|
| 39 |
+
# ================
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
# ----------------------
|
| 43 |
+
# Organization functions
|
| 44 |
+
# ----------------------
|
| 45 |
+
def get_org_by_uuid_or_namespace(
|
| 46 |
+
id: Union[UUID, str], session: Optional[Session] = None, should_except: bool = True
|
| 47 |
+
):
|
| 48 |
+
if session:
|
| 49 |
+
org = (
|
| 50 |
+
Organization.by_uuid(str(id))
|
| 51 |
+
if is_uuid(id)
|
| 52 |
+
else session.exec(
|
| 53 |
+
select(Organization).where(Organization.namespace == str(id))
|
| 54 |
+
).first()
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
else:
|
| 58 |
+
with Session(get_engine()) as session:
|
| 59 |
+
org = (
|
| 60 |
+
Organization.by_uuid(str(id))
|
| 61 |
+
if is_uuid(id)
|
| 62 |
+
else session.exec(
|
| 63 |
+
select(Organization).where(Organization.namespace == str(id))
|
| 64 |
+
).first()
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
if not org and should_except is True:
|
| 68 |
+
raise HTTPException(
|
| 69 |
+
status_code=404, detail=f"Organization identifer {id} not found"
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
return org
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def create_org_by_org_or_uuid(
|
| 76 |
+
namespace: str = None,
|
| 77 |
+
display_name: str = None,
|
| 78 |
+
organization: Union[Organization, OrganizationCreate, str] = None,
|
| 79 |
+
session: Optional[Session] = None,
|
| 80 |
+
):
|
| 81 |
+
namespace = namespace or organization.namespace
|
| 82 |
+
|
| 83 |
+
if not namespace:
|
| 84 |
+
raise HTTPException(
|
| 85 |
+
status_code=400, detail="Organization namespace is required"
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
o = (
|
| 89 |
+
get_org_by_uuid_or_namespace(namespace, session=session, should_except=False)
|
| 90 |
+
if not isinstance(organization, Organization)
|
| 91 |
+
else organization
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
if o:
|
| 95 |
+
raise HTTPException(status_code=404, detail="Organization already exists")
|
| 96 |
+
|
| 97 |
+
if isinstance(organization, OrganizationCreate) or isinstance(organization, str):
|
| 98 |
+
organization = organization or OrganizationCreate(
|
| 99 |
+
namespace=namespace, display_name=display_name
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
db_org = Organization.from_orm(organization)
|
| 103 |
+
|
| 104 |
+
if session:
|
| 105 |
+
session.add(db_org)
|
| 106 |
+
session.commit()
|
| 107 |
+
session.refresh(db_org)
|
| 108 |
+
else:
|
| 109 |
+
with Session(get_engine()) as session:
|
| 110 |
+
session.add(db_org)
|
| 111 |
+
session.commit()
|
| 112 |
+
session.refresh(db_org)
|
| 113 |
+
elif isinstance(organization, Organization):
|
| 114 |
+
db_org = organization
|
| 115 |
+
db_org.update(
|
| 116 |
+
{
|
| 117 |
+
"namespace": namespace if namespace else organization.namespace,
|
| 118 |
+
"display_name": display_name
|
| 119 |
+
if display_name
|
| 120 |
+
else organization.display_name,
|
| 121 |
+
}
|
| 122 |
+
)
|
| 123 |
+
else:
|
| 124 |
+
db_org = Organization.create(
|
| 125 |
+
{"namespace": namespace, "display_name": display_name}
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
# Create folder for organization_uuid in uploads
|
| 129 |
+
os.mkdir(os.path.join(FILE_UPLOAD_PATH, str(db_org.uuid)))
|
| 130 |
+
|
| 131 |
+
return db_org
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
# --------------
|
| 135 |
+
# User functions
|
| 136 |
+
# --------------
|
| 137 |
+
def create_user(
|
| 138 |
+
user: Union[UserCreate, User] = None,
|
| 139 |
+
identifier: str = None,
|
| 140 |
+
identifier_type: str = None,
|
| 141 |
+
device_fingerprint: str = None,
|
| 142 |
+
first_name: str = None,
|
| 143 |
+
last_name: str = None,
|
| 144 |
+
email: str = None,
|
| 145 |
+
phone: str = None,
|
| 146 |
+
dob: str = None,
|
| 147 |
+
session: Optional[Session] = None,
|
| 148 |
+
):
|
| 149 |
+
# Check if user already exists
|
| 150 |
+
user = (
|
| 151 |
+
get_user_by_uuid_or_identifier(user.id or identifier, session=session)
|
| 152 |
+
if not isinstance(user, User)
|
| 153 |
+
else user
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
if isinstance(user, UserCreate):
|
| 157 |
+
db_user = User.from_orm(user)
|
| 158 |
+
|
| 159 |
+
if session:
|
| 160 |
+
session.add(db_user)
|
| 161 |
+
session.commit()
|
| 162 |
+
session.refresh(db_user)
|
| 163 |
+
else:
|
| 164 |
+
with Session(get_engine()) as session:
|
| 165 |
+
session.add(db_user)
|
| 166 |
+
session.commit()
|
| 167 |
+
session.refresh(db_user)
|
| 168 |
+
elif isinstance(user, User):
|
| 169 |
+
db_user = user
|
| 170 |
+
db_user.update(
|
| 171 |
+
{
|
| 172 |
+
"identifier": identifier if identifier else user.identifier,
|
| 173 |
+
"identifier_type": identifier_type
|
| 174 |
+
if identifier_type
|
| 175 |
+
else user.identifier_type,
|
| 176 |
+
"device_fingerprint": device_fingerprint
|
| 177 |
+
if device_fingerprint
|
| 178 |
+
else user.device_fingerprint,
|
| 179 |
+
"first_name": first_name if first_name else user.first_name,
|
| 180 |
+
"last_name": last_name if last_name else user.last_name,
|
| 181 |
+
"email": email if email else user.email,
|
| 182 |
+
"phone": phone if phone else user.phone,
|
| 183 |
+
"dob": dob if dob else user.dob,
|
| 184 |
+
}
|
| 185 |
+
)
|
| 186 |
+
else:
|
| 187 |
+
db_user = User.create(
|
| 188 |
+
{
|
| 189 |
+
"identifier": identifier,
|
| 190 |
+
"identifier_type": identifier_type,
|
| 191 |
+
"device_fingerprint": device_fingerprint,
|
| 192 |
+
"first_name": first_name,
|
| 193 |
+
"last_name": last_name,
|
| 194 |
+
"email": email,
|
| 195 |
+
"phone": phone,
|
| 196 |
+
"dob": dob,
|
| 197 |
+
}
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
return db_user
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def get_users(session: Optional[Session] = None):
|
| 204 |
+
if session:
|
| 205 |
+
users = session.exec(select(User)).all()
|
| 206 |
+
else:
|
| 207 |
+
with Session(get_engine()) as session:
|
| 208 |
+
users = session.exec(select(User)).all()
|
| 209 |
+
|
| 210 |
+
return users
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
def get_user_by_uuid_or_identifier(
|
| 214 |
+
id: Union[UUID, str], session: Optional[Session] = None, should_except: bool = True
|
| 215 |
+
):
|
| 216 |
+
if session:
|
| 217 |
+
user = (
|
| 218 |
+
User.by_uuid(str(id))
|
| 219 |
+
if is_uuid(str(id))
|
| 220 |
+
else session.exec(select(User).where(User.identifier == str(id))).first()
|
| 221 |
+
)
|
| 222 |
+
|
| 223 |
+
else:
|
| 224 |
+
with Session(get_engine()) as session:
|
| 225 |
+
user = (
|
| 226 |
+
User.by_uuid(str(id))
|
| 227 |
+
if is_uuid(str(id))
|
| 228 |
+
else session.exec(
|
| 229 |
+
select(User).where(User.identifier == str(id))
|
| 230 |
+
).first()
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
if not user and should_except is True:
|
| 234 |
+
raise HTTPException(status_code=404, detail=f"User identifer {id} not found")
|
| 235 |
+
|
| 236 |
+
return user
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
# ------------------
|
| 240 |
+
# Document functions
|
| 241 |
+
# ------------------
|
| 242 |
+
def create_document_by_file_path(
|
| 243 |
+
organization: Organization = None,
|
| 244 |
+
project: Project = None,
|
| 245 |
+
file_path: str = None,
|
| 246 |
+
url: Optional[str] = None,
|
| 247 |
+
file_version: Optional[int] = 1,
|
| 248 |
+
file_hash: Optional[str] = None,
|
| 249 |
+
overwrite: Optional[bool] = True,
|
| 250 |
+
session: Optional[Session] = None,
|
| 251 |
+
):
|
| 252 |
+
if not organization or not project:
|
| 253 |
+
raise HTTPException(
|
| 254 |
+
status_code=400, detail="Organization and project are required"
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
organization_id = organization.uuid
|
| 258 |
+
project_id = project.uuid
|
| 259 |
+
|
| 260 |
+
if not file_path or not os.path.exists(file_path):
|
| 261 |
+
raise HTTPException(status_code=400, detail="A valid file path is required")
|
| 262 |
+
|
| 263 |
+
if not file_hash:
|
| 264 |
+
file_hash = get_file_hash(file_path)
|
| 265 |
+
|
| 266 |
+
file_name = os.path.basename(file_path)
|
| 267 |
+
|
| 268 |
+
file_contents = open(file_path, "rb").read()
|
| 269 |
+
|
| 270 |
+
# ------------------------
|
| 271 |
+
# Handle duplicate content
|
| 272 |
+
# ------------------------
|
| 273 |
+
if get_document_by_hash(file_hash, session=session):
|
| 274 |
+
raise HTTPException(
|
| 275 |
+
status_code=409,
|
| 276 |
+
detail=f'Document "{file_name}" already uploaded! \n\nsha256:{file_hash}!',
|
| 277 |
+
)
|
| 278 |
+
|
| 279 |
+
# ----------------------------------
|
| 280 |
+
# Handle file versioning by filename
|
| 281 |
+
# ----------------------------------
|
| 282 |
+
|
| 283 |
+
# If we are overwriting, deprecate the current version and increment the version number of new file
|
| 284 |
+
document = get_document_by_name(
|
| 285 |
+
file_name,
|
| 286 |
+
project_id=project_id,
|
| 287 |
+
organization_id=organization_id,
|
| 288 |
+
session=session,
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
if document and overwrite:
|
| 292 |
+
file_version = document.version + 1
|
| 293 |
+
document.updated_at = datetime.utcnow()
|
| 294 |
+
document.status = ENTITY_STATUS.DEPRECATED.value
|
| 295 |
+
document.save()
|
| 296 |
+
else:
|
| 297 |
+
# ---------------------
|
| 298 |
+
# Create a new document
|
| 299 |
+
# ---------------------
|
| 300 |
+
document = Document(
|
| 301 |
+
display_name=file_name,
|
| 302 |
+
project_id=project.id,
|
| 303 |
+
organization_id=organization.id,
|
| 304 |
+
data=file_contents,
|
| 305 |
+
version=file_version,
|
| 306 |
+
hash=file_hash,
|
| 307 |
+
url=url if url else None,
|
| 308 |
+
)
|
| 309 |
+
if session:
|
| 310 |
+
session.add(document)
|
| 311 |
+
session.commit()
|
| 312 |
+
session.refresh(document)
|
| 313 |
+
|
| 314 |
+
# ---------------------
|
| 315 |
+
# Create the embeddings
|
| 316 |
+
# ---------------------
|
| 317 |
+
create_document_nodes(
|
| 318 |
+
document=document,
|
| 319 |
+
project=project,
|
| 320 |
+
organization=organization,
|
| 321 |
+
session=session,
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
else:
|
| 325 |
+
with Session(get_engine()) as session:
|
| 326 |
+
session.add(document)
|
| 327 |
+
session.commit()
|
| 328 |
+
session.refresh(document)
|
| 329 |
+
|
| 330 |
+
# ---------------------
|
| 331 |
+
# Create the embeddings
|
| 332 |
+
# ---------------------
|
| 333 |
+
create_document_nodes(
|
| 334 |
+
document=document,
|
| 335 |
+
project=project,
|
| 336 |
+
organization=organization,
|
| 337 |
+
session=session,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
if not document:
|
| 341 |
+
raise HTTPException(status_code=400, detail="Could not create document")
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
# --------------------------
|
| 345 |
+
# Create document embeddings
|
| 346 |
+
# --------------------------
|
| 347 |
+
def create_document_nodes(
|
| 348 |
+
document: Document,
|
| 349 |
+
project: Project,
|
| 350 |
+
organization: Organization,
|
| 351 |
+
session: Optional[Session] = None,
|
| 352 |
+
):
|
| 353 |
+
# Avoid circular imports
|
| 354 |
+
from llm import get_embeddings, get_token_count
|
| 355 |
+
|
| 356 |
+
project_uuid = str(project.uuid)
|
| 357 |
+
document_uuid = str(document.uuid)
|
| 358 |
+
document_id = document.id
|
| 359 |
+
organization_uuid = str(organization.uuid)
|
| 360 |
+
|
| 361 |
+
if not document or not project:
|
| 362 |
+
raise Exception("Missing required parameters document, project")
|
| 363 |
+
|
| 364 |
+
metadata = {
|
| 365 |
+
"project_uuid": project_uuid,
|
| 366 |
+
"document_uuid": document_uuid,
|
| 367 |
+
"organization_uuid": organization_uuid,
|
| 368 |
+
"document_id": document_id,
|
| 369 |
+
"version": document.version,
|
| 370 |
+
"name": document.display_name,
|
| 371 |
+
}
|
| 372 |
+
|
| 373 |
+
# convert document data bytes to string
|
| 374 |
+
document_data = (
|
| 375 |
+
document.data.decode("utf-8")
|
| 376 |
+
if isinstance(document.data, bytes)
|
| 377 |
+
else document.data
|
| 378 |
+
)
|
| 379 |
+
|
| 380 |
+
# lets get the embeddings
|
| 381 |
+
arr_documents, embeddings = get_embeddings(document_data)
|
| 382 |
+
|
| 383 |
+
# -------------------------------------------
|
| 384 |
+
# Process the embeddings and save to database
|
| 385 |
+
# -------------------------------------------
|
| 386 |
+
|
| 387 |
+
for doc, vec in zip(arr_documents, embeddings):
|
| 388 |
+
node = Node(
|
| 389 |
+
document_id=document.id,
|
| 390 |
+
embeddings=vec,
|
| 391 |
+
text=doc,
|
| 392 |
+
token_count=get_token_count(doc),
|
| 393 |
+
meta=metadata
|
| 394 |
+
)
|
| 395 |
+
if session:
|
| 396 |
+
session.add(node)
|
| 397 |
+
session.commit()
|
| 398 |
+
session.refresh(node)
|
| 399 |
+
|
| 400 |
+
else:
|
| 401 |
+
with Session(get_engine()) as session:
|
| 402 |
+
session.add(node)
|
| 403 |
+
session.commit()
|
| 404 |
+
session.refresh(node)
|
| 405 |
+
|
| 406 |
+
# Node.create(
|
| 407 |
+
# {
|
| 408 |
+
# "document_id": document.id,
|
| 409 |
+
# "embeddings": vec,
|
| 410 |
+
# "text": doc,
|
| 411 |
+
# "token_count": get_token_count(doc),
|
| 412 |
+
# "meta": metadata,
|
| 413 |
+
# }
|
| 414 |
+
# )
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
def get_documents_by_project_and_org(
|
| 418 |
+
project_id: Union[UUID, str],
|
| 419 |
+
organization_id: Union[UUID, str],
|
| 420 |
+
session: Optional[Session] = None,
|
| 421 |
+
):
|
| 422 |
+
if session:
|
| 423 |
+
org = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 424 |
+
project = get_project_by_uuid(project_id, org.uuid, session=session)
|
| 425 |
+
documents = session.exec(
|
| 426 |
+
select(Document).where(Document.project_id == project.id)
|
| 427 |
+
).all()
|
| 428 |
+
else:
|
| 429 |
+
with Session(get_engine()) as session:
|
| 430 |
+
org = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 431 |
+
project = get_project_by_uuid(project_id, org.uuid, session=session)
|
| 432 |
+
documents = session.exec(
|
| 433 |
+
select(Document).where(Document.project_id == project.id)
|
| 434 |
+
).all()
|
| 435 |
+
|
| 436 |
+
return documents
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
def get_document_by_uuid(
|
| 440 |
+
uuid: Union[UUID, str],
|
| 441 |
+
organization_id: Union[UUID, str] = None,
|
| 442 |
+
project_id: Union[UUID, str] = None,
|
| 443 |
+
session: Optional[Session] = None,
|
| 444 |
+
should_except: bool = True,
|
| 445 |
+
):
|
| 446 |
+
if not is_uuid(uuid):
|
| 447 |
+
raise HTTPException(
|
| 448 |
+
status_code=422, detail=f"Invalid document identifier {uuid}"
|
| 449 |
+
)
|
| 450 |
+
|
| 451 |
+
org = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 452 |
+
project = get_project_by_uuid(project_id, organization_id=org.uuid, session=session)
|
| 453 |
+
|
| 454 |
+
if session:
|
| 455 |
+
document = session.exec(
|
| 456 |
+
select(Document).where(
|
| 457 |
+
Document.project == project, Document.uuid == str(uuid)
|
| 458 |
+
)
|
| 459 |
+
).first()
|
| 460 |
+
|
| 461 |
+
else:
|
| 462 |
+
with Session(get_engine()) as session:
|
| 463 |
+
document = session.exec(
|
| 464 |
+
select(Document).where(
|
| 465 |
+
Document.project == project, Document.uuid == str(uuid)
|
| 466 |
+
)
|
| 467 |
+
).first()
|
| 468 |
+
|
| 469 |
+
if not document and should_except is True:
|
| 470 |
+
raise HTTPException(
|
| 471 |
+
status_code=404, detail=f"Document identifier {uuid} not found"
|
| 472 |
+
)
|
| 473 |
+
|
| 474 |
+
return document
|
| 475 |
+
|
| 476 |
+
|
| 477 |
+
def get_document_by_hash(hash: str, session: Optional[Session] = None):
|
| 478 |
+
if session:
|
| 479 |
+
document = session.exec(select(Document).where(Document.hash == hash)).first()
|
| 480 |
+
else:
|
| 481 |
+
with Session(get_engine()) as session:
|
| 482 |
+
document = session.exec(
|
| 483 |
+
select(Document).where(Document.hash == hash)
|
| 484 |
+
).first()
|
| 485 |
+
|
| 486 |
+
return document
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
def get_document_by_name(
|
| 490 |
+
file_name: str,
|
| 491 |
+
project_id: Union[UUID, str],
|
| 492 |
+
organization_id: Union[UUID, str],
|
| 493 |
+
session: Optional[Session] = None,
|
| 494 |
+
):
|
| 495 |
+
org = (
|
| 496 |
+
get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 497 |
+
if not isinstance(organization_id, Organization)
|
| 498 |
+
else organization_id
|
| 499 |
+
)
|
| 500 |
+
project = get_project_by_uuid(
|
| 501 |
+
project_id, organization_id=str(org.uuid), session=session
|
| 502 |
+
)
|
| 503 |
+
|
| 504 |
+
if session:
|
| 505 |
+
return session.exec(
|
| 506 |
+
select(Document).where(
|
| 507 |
+
Document.project == project,
|
| 508 |
+
Document.display_name == file_name,
|
| 509 |
+
Document.status == ENTITY_STATUS.ACTIVE.value,
|
| 510 |
+
)
|
| 511 |
+
).first()
|
| 512 |
+
else:
|
| 513 |
+
with Session(get_engine()) as session:
|
| 514 |
+
return session.exec(
|
| 515 |
+
select(Document).where(
|
| 516 |
+
Document.project == project,
|
| 517 |
+
Document.display_name == file_name,
|
| 518 |
+
Document.status == ENTITY_STATUS.ACTIVE.value,
|
| 519 |
+
)
|
| 520 |
+
).first()
|
| 521 |
+
|
| 522 |
+
|
| 523 |
+
# ---------------------
|
| 524 |
+
# ChatSession functions
|
| 525 |
+
# ---------------------
|
| 526 |
+
def get_chat_session_by_uuid(
|
| 527 |
+
id: Union[UUID, str], session: Optional[Session] = None, should_except: bool = False
|
| 528 |
+
):
|
| 529 |
+
if session:
|
| 530 |
+
chat_session = (
|
| 531 |
+
ChatSession.by_uuid(str(id))
|
| 532 |
+
if is_uuid(id)
|
| 533 |
+
else session.exec(
|
| 534 |
+
select(ChatSession).where(ChatSession.session_id == str(id))
|
| 535 |
+
).first()
|
| 536 |
+
)
|
| 537 |
+
|
| 538 |
+
else:
|
| 539 |
+
with Session(get_engine()) as session:
|
| 540 |
+
chat_session = (
|
| 541 |
+
ChatSession.by_uuid(str(id))
|
| 542 |
+
if is_uuid(id)
|
| 543 |
+
else session.exec(
|
| 544 |
+
select(ChatSession).where(ChatSession.session_id == str(id))
|
| 545 |
+
).first()
|
| 546 |
+
)
|
| 547 |
+
|
| 548 |
+
if not chat_session and should_except is True:
|
| 549 |
+
raise HTTPException(
|
| 550 |
+
status_code=404, detail=f"ChatSession identifer {id} not found"
|
| 551 |
+
)
|
| 552 |
+
|
| 553 |
+
return chat_session
|
| 554 |
+
|
| 555 |
+
|
| 556 |
+
# -----------------
|
| 557 |
+
# Project functions
|
| 558 |
+
# -----------------
|
| 559 |
+
|
| 560 |
+
|
| 561 |
+
def create_project_by_org(
|
| 562 |
+
project: Union[Project, ProjectCreate] = None,
|
| 563 |
+
organization_id: Union[Organization, str] = None,
|
| 564 |
+
display_name: str = None,
|
| 565 |
+
session: Optional[Session] = None,
|
| 566 |
+
):
|
| 567 |
+
organization = (
|
| 568 |
+
get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 569 |
+
if not isinstance(organization_id, Organization)
|
| 570 |
+
else organization_id
|
| 571 |
+
)
|
| 572 |
+
|
| 573 |
+
if isinstance(project, ProjectCreate):
|
| 574 |
+
db_project = Project.from_orm(project) if not project else project
|
| 575 |
+
db_project.organization_id = organization.id
|
| 576 |
+
|
| 577 |
+
# Lets give a default name if not set
|
| 578 |
+
db_project.display_name = (
|
| 579 |
+
f"📁 Untitled Project #{len(organization.projects) + 1}"
|
| 580 |
+
if not display_name and not project
|
| 581 |
+
else display_name
|
| 582 |
+
)
|
| 583 |
+
|
| 584 |
+
if session:
|
| 585 |
+
session.add(db_project)
|
| 586 |
+
session.commit()
|
| 587 |
+
session.refresh(db_project)
|
| 588 |
+
else:
|
| 589 |
+
with Session(get_engine()) as session:
|
| 590 |
+
session.add(db_project)
|
| 591 |
+
session.commit()
|
| 592 |
+
session.refresh(db_project)
|
| 593 |
+
elif isinstance(project, Project):
|
| 594 |
+
db_project = project
|
| 595 |
+
db_project.update(
|
| 596 |
+
{
|
| 597 |
+
"organization_id": organization.id,
|
| 598 |
+
"display_name": f"📁 Untitled Project #{len(organization.projects) + 1}"
|
| 599 |
+
if not display_name and not project
|
| 600 |
+
else display_name,
|
| 601 |
+
}
|
| 602 |
+
)
|
| 603 |
+
else:
|
| 604 |
+
db_project = Project.create(
|
| 605 |
+
{
|
| 606 |
+
"organization_id": organization.id,
|
| 607 |
+
"display_name": f"📁 Untitled Project #{len(organization.projects) + 1}"
|
| 608 |
+
if not display_name and not project
|
| 609 |
+
else display_name,
|
| 610 |
+
}
|
| 611 |
+
)
|
| 612 |
+
|
| 613 |
+
# -------------------------------
|
| 614 |
+
# Create project upload directory
|
| 615 |
+
# -------------------------------
|
| 616 |
+
project_dir = os.path.join(
|
| 617 |
+
FILE_UPLOAD_PATH, str(organization.uuid), str(db_project.uuid)
|
| 618 |
+
)
|
| 619 |
+
os.makedirs(project_dir, exist_ok=True)
|
| 620 |
+
|
| 621 |
+
# Create project
|
| 622 |
+
return db_project
|
| 623 |
+
|
| 624 |
+
|
| 625 |
+
def get_project_by_uuid(
|
| 626 |
+
uuid: Union[UUID, str] = None,
|
| 627 |
+
organization_id: Union[UUID, str] = None,
|
| 628 |
+
session: Optional[Session] = None,
|
| 629 |
+
should_except: bool = True,
|
| 630 |
+
):
|
| 631 |
+
if not is_uuid(uuid):
|
| 632 |
+
raise HTTPException(
|
| 633 |
+
status_code=422, detail=f"Invalid project identifier {uuid}"
|
| 634 |
+
)
|
| 635 |
+
|
| 636 |
+
org = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 637 |
+
|
| 638 |
+
if session:
|
| 639 |
+
project = session.exec(
|
| 640 |
+
select(Project).where(
|
| 641 |
+
Project.organization == org, Project.uuid == str(uuid)
|
| 642 |
+
)
|
| 643 |
+
).first()
|
| 644 |
+
|
| 645 |
+
else:
|
| 646 |
+
with Session(get_engine()) as session:
|
| 647 |
+
project = session.exec(
|
| 648 |
+
select(Project).where(
|
| 649 |
+
Project.organization == org, Project.uuid == str(uuid)
|
| 650 |
+
)
|
| 651 |
+
).first()
|
| 652 |
+
|
| 653 |
+
if not project and should_except is True:
|
| 654 |
+
raise HTTPException(
|
| 655 |
+
status_code=404, detail=f"Project identifier {uuid} not found"
|
| 656 |
+
)
|
| 657 |
+
|
| 658 |
+
return project
|
app/api/llm.py
ADDED
|
@@ -0,0 +1,465 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import openai
|
| 3 |
+
import json
|
| 4 |
+
from langchain.docstore.document import Document as LangChainDocument
|
| 5 |
+
from langchain.embeddings.openai import OpenAIEmbeddings
|
| 6 |
+
from fastapi import HTTPException
|
| 7 |
+
from uuid import UUID, uuid4
|
| 8 |
+
from langchain.text_splitter import (
|
| 9 |
+
CharacterTextSplitter,
|
| 10 |
+
MarkdownTextSplitter
|
| 11 |
+
)
|
| 12 |
+
from sqlmodel import (
|
| 13 |
+
Session,
|
| 14 |
+
text
|
| 15 |
+
)
|
| 16 |
+
from util import (
|
| 17 |
+
sanitize_input,
|
| 18 |
+
sanitize_output
|
| 19 |
+
)
|
| 20 |
+
from langchain import OpenAI
|
| 21 |
+
from typing import (
|
| 22 |
+
List,
|
| 23 |
+
Union,
|
| 24 |
+
Optional,
|
| 25 |
+
Dict,
|
| 26 |
+
Tuple,
|
| 27 |
+
Any
|
| 28 |
+
)
|
| 29 |
+
from helpers import (
|
| 30 |
+
get_user_by_uuid_or_identifier,
|
| 31 |
+
get_chat_session_by_uuid
|
| 32 |
+
)
|
| 33 |
+
from models import (
|
| 34 |
+
User,
|
| 35 |
+
Organization,
|
| 36 |
+
Project,
|
| 37 |
+
Node,
|
| 38 |
+
ChatSession,
|
| 39 |
+
ChatSessionResponse,
|
| 40 |
+
get_engine
|
| 41 |
+
)
|
| 42 |
+
from config import (
|
| 43 |
+
CHANNEL_TYPE,
|
| 44 |
+
DOCUMENT_TYPE,
|
| 45 |
+
LLM_MODELS,
|
| 46 |
+
LLM_DISTANCE_THRESHOLD,
|
| 47 |
+
LLM_DEFAULT_TEMPERATURE,
|
| 48 |
+
LLM_MAX_OUTPUT_TOKENS,
|
| 49 |
+
LLM_CHUNK_SIZE,
|
| 50 |
+
LLM_CHUNK_OVERLAP,
|
| 51 |
+
LLM_MIN_NODE_LIMIT,
|
| 52 |
+
LLM_DEFAULT_DISTANCE_STRATEGY,
|
| 53 |
+
VECTOR_EMBEDDINGS_COUNT,
|
| 54 |
+
DISTANCE_STRATEGY,
|
| 55 |
+
AGENT_NAMES,
|
| 56 |
+
logger
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# -------------
|
| 61 |
+
# Query the LLM
|
| 62 |
+
# -------------
|
| 63 |
+
def chat_query(
|
| 64 |
+
query_str: str,
|
| 65 |
+
session_id: Optional[Union[str, UUID]] = None,
|
| 66 |
+
meta: Optional[Dict[str, Any]] = {},
|
| 67 |
+
channel: Optional[CHANNEL_TYPE] = None,
|
| 68 |
+
identifier: Optional[str] = None,
|
| 69 |
+
project: Optional[Project] = None,
|
| 70 |
+
organization: Optional[Organization] = None,
|
| 71 |
+
session: Optional[Session] = None,
|
| 72 |
+
user_data: Optional[Dict[str, Any]] = None,
|
| 73 |
+
distance_strategy: Optional[DISTANCE_STRATEGY] = DISTANCE_STRATEGY.EUCLIDEAN,
|
| 74 |
+
distance_threshold: Optional[float] = LLM_DISTANCE_THRESHOLD,
|
| 75 |
+
node_limit: Optional[int] = LLM_MIN_NODE_LIMIT,
|
| 76 |
+
model: Optional[LLM_MODELS] = LLM_MODELS.GPT_35_TURBO,
|
| 77 |
+
max_output_tokens: Optional[int] = LLM_MAX_OUTPUT_TOKENS,
|
| 78 |
+
) -> ChatSessionResponse:
|
| 79 |
+
"""
|
| 80 |
+
Steps:
|
| 81 |
+
1. ✅ Clean user input
|
| 82 |
+
2. ✅ Create input embeddings
|
| 83 |
+
3. ✅ Search for similar nodes
|
| 84 |
+
4. ✅ Create prompt template w/ similar nodes
|
| 85 |
+
5. ✅ Submit prompt template to LLM
|
| 86 |
+
6. ✅ Get response from LLM
|
| 87 |
+
7. Create ChatSession
|
| 88 |
+
- Store embeddings
|
| 89 |
+
- Store tags
|
| 90 |
+
- Store is_escalate
|
| 91 |
+
8. Return response
|
| 92 |
+
"""
|
| 93 |
+
meta = {}
|
| 94 |
+
agent_name = None
|
| 95 |
+
embeddings = []
|
| 96 |
+
tags = []
|
| 97 |
+
is_escalate = False
|
| 98 |
+
response_message = None
|
| 99 |
+
prompt = None
|
| 100 |
+
context_str = None
|
| 101 |
+
MODEL_TOKEN_LIMIT = (
|
| 102 |
+
model.token_limit if isinstance(model, OpenAI) else LLM_MAX_OUTPUT_TOKENS
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
# ---------------------------------------------
|
| 106 |
+
# Generate a new session ID if none is provided
|
| 107 |
+
# ---------------------------------------------
|
| 108 |
+
prev_chat_session = (
|
| 109 |
+
get_chat_session_by_uuid(session_id=session_id, session=session)
|
| 110 |
+
if session_id
|
| 111 |
+
else None
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
# If we were given an invalid session_id
|
| 115 |
+
if session_id and not prev_chat_session:
|
| 116 |
+
return HTTPException(
|
| 117 |
+
status_code=404, detail=f"Chat session with ID {session_id} not found."
|
| 118 |
+
)
|
| 119 |
+
# If we were given a valid session_id
|
| 120 |
+
elif session_id and prev_chat_session and prev_chat_session.meta.get("agent"):
|
| 121 |
+
agent_name = prev_chat_session.meta["agent"]
|
| 122 |
+
# If this is a new session, generate a new ID
|
| 123 |
+
else:
|
| 124 |
+
session_id = str(uuid4())
|
| 125 |
+
|
| 126 |
+
meta["agent"] = agent_name if agent_name else random.choice(AGENT_NAMES)
|
| 127 |
+
|
| 128 |
+
# ----------------
|
| 129 |
+
# Clean user input
|
| 130 |
+
# ----------------
|
| 131 |
+
query_str = sanitize_input(query_str)
|
| 132 |
+
logger.debug(f"💬 Query received: {query_str}")
|
| 133 |
+
|
| 134 |
+
# ----------------
|
| 135 |
+
# Get token counts
|
| 136 |
+
# ----------------
|
| 137 |
+
query_token_count = get_token_count(query_str)
|
| 138 |
+
prompt_token_count = 0
|
| 139 |
+
|
| 140 |
+
# -----------------------
|
| 141 |
+
# Create input embeddings
|
| 142 |
+
# -----------------------
|
| 143 |
+
arr_query, embeddings = get_embeddings(query_str)
|
| 144 |
+
|
| 145 |
+
query_embeddings = embeddings[0]
|
| 146 |
+
|
| 147 |
+
# ------------------------
|
| 148 |
+
# Search for similar nodes
|
| 149 |
+
# ------------------------
|
| 150 |
+
nodes = get_nodes_by_embedding(
|
| 151 |
+
query_embeddings,
|
| 152 |
+
node_limit,
|
| 153 |
+
distance_strategy=distance_strategy
|
| 154 |
+
if isinstance(distance_strategy, DISTANCE_STRATEGY)
|
| 155 |
+
else LLM_DEFAULT_DISTANCE_STRATEGY,
|
| 156 |
+
distance_threshold=distance_threshold,
|
| 157 |
+
session=session,
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
if len(nodes) > 0:
|
| 161 |
+
if (not project or not organization) and session:
|
| 162 |
+
# get document from Node via session object:
|
| 163 |
+
document = session.get(Node, nodes[0].id).document
|
| 164 |
+
project = document.project
|
| 165 |
+
organization = project.organization
|
| 166 |
+
|
| 167 |
+
# ----------------------
|
| 168 |
+
# Create prompt template
|
| 169 |
+
# ----------------------
|
| 170 |
+
|
| 171 |
+
# concatenate all nodes into a single string
|
| 172 |
+
context_str = "\n\n".join([node.text for node in nodes])
|
| 173 |
+
|
| 174 |
+
# -------------------------------------------
|
| 175 |
+
# Let's make sure we don't exceed token limit
|
| 176 |
+
# -------------------------------------------
|
| 177 |
+
context_token_count = get_token_count(context_str)
|
| 178 |
+
|
| 179 |
+
# ----------------------------------------------
|
| 180 |
+
# if token count exceeds limit, truncate context
|
| 181 |
+
# ----------------------------------------------
|
| 182 |
+
if (
|
| 183 |
+
context_token_count + query_token_count + prompt_token_count
|
| 184 |
+
) > MODEL_TOKEN_LIMIT:
|
| 185 |
+
logger.debug("🚧 Exceeded token limit, truncating context")
|
| 186 |
+
token_delta = MODEL_TOKEN_LIMIT - (query_token_count + prompt_token_count)
|
| 187 |
+
context_str = context_str[:token_delta]
|
| 188 |
+
|
| 189 |
+
# create prompt template
|
| 190 |
+
system_prompt, user_prompt = get_prompt_template(
|
| 191 |
+
user_query=query_str,
|
| 192 |
+
context_str=context_str,
|
| 193 |
+
project=project,
|
| 194 |
+
organization=organization,
|
| 195 |
+
agent=agent_name,
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
prompt_token_count = get_token_count(prompt)
|
| 199 |
+
token_count = context_token_count + query_token_count + prompt_token_count
|
| 200 |
+
|
| 201 |
+
# ---------------------------
|
| 202 |
+
# Get response from LLM model
|
| 203 |
+
# ---------------------------
|
| 204 |
+
# It should return a JSON dict
|
| 205 |
+
llm_response = json.loads(
|
| 206 |
+
retrieve_llm_response(
|
| 207 |
+
user_prompt,
|
| 208 |
+
model=model,
|
| 209 |
+
max_output_tokens=max_output_tokens,
|
| 210 |
+
prefix_messages=system_prompt,
|
| 211 |
+
)
|
| 212 |
+
)
|
| 213 |
+
tags = llm_response.get("tags", [])
|
| 214 |
+
is_escalate = llm_response.get("is_escalate", False)
|
| 215 |
+
response_message = llm_response.get("message", None)
|
| 216 |
+
else:
|
| 217 |
+
logger.info("🚫📝 No similar nodes found, returning default response")
|
| 218 |
+
|
| 219 |
+
# ----------------
|
| 220 |
+
# Get user details
|
| 221 |
+
# ----------------
|
| 222 |
+
user = get_user_by_uuid_or_identifier(
|
| 223 |
+
identifier, session=session, should_except=False
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
if not user:
|
| 227 |
+
logger.debug("🚫👤 User not found, creating new user")
|
| 228 |
+
user_params = {
|
| 229 |
+
"identifier": identifier,
|
| 230 |
+
"identifier_type": channel.value
|
| 231 |
+
if isinstance(channel, CHANNEL_TYPE)
|
| 232 |
+
else channel,
|
| 233 |
+
}
|
| 234 |
+
if user_data:
|
| 235 |
+
user_params = {**user_params, **user_data}
|
| 236 |
+
|
| 237 |
+
user = User.create(user_params)
|
| 238 |
+
else:
|
| 239 |
+
logger.debug(f"👤 User found: {user}")
|
| 240 |
+
|
| 241 |
+
# -----------------------------------
|
| 242 |
+
# Calculate input and response tokens
|
| 243 |
+
# -----------------------------------
|
| 244 |
+
token_count = get_token_count(prompt) + get_token_count(response_message)
|
| 245 |
+
|
| 246 |
+
# ---------------
|
| 247 |
+
# Add to meta tag
|
| 248 |
+
# ---------------
|
| 249 |
+
if tags:
|
| 250 |
+
meta["tags"] = tags
|
| 251 |
+
|
| 252 |
+
meta["is_escalate"] = is_escalate
|
| 253 |
+
|
| 254 |
+
if session_id:
|
| 255 |
+
meta["session_id"] = session_id
|
| 256 |
+
|
| 257 |
+
# ------------------
|
| 258 |
+
# Create ChatSession
|
| 259 |
+
# ------------------
|
| 260 |
+
# chat_session = ChatSession.create({
|
| 261 |
+
# 'user_id': user.id,
|
| 262 |
+
# 'session_id': session_id,
|
| 263 |
+
# 'project_id': project.id if project else None,
|
| 264 |
+
# 'channel': channel.value if channel else None,
|
| 265 |
+
# 'user_message': query_str,
|
| 266 |
+
# 'embeddings': query_embeddings,
|
| 267 |
+
# 'token_count': token_count if token_count > 0 else None,
|
| 268 |
+
# 'response': response_message,
|
| 269 |
+
# 'meta': meta
|
| 270 |
+
# })
|
| 271 |
+
# #return ChatSession.from_orm(chat_session)
|
| 272 |
+
chat_session = ChatSession(
|
| 273 |
+
user_id=user.id,
|
| 274 |
+
session_id=session_id,
|
| 275 |
+
project_id=project.id if project else None,
|
| 276 |
+
channel=channel.value if isinstance(channel, CHANNEL_TYPE) else channel,
|
| 277 |
+
user_message=query_str,
|
| 278 |
+
embeddings=query_embeddings,
|
| 279 |
+
token_count=token_count if token_count > 0 else None,
|
| 280 |
+
response=response_message,
|
| 281 |
+
meta=meta,
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
if session:
|
| 285 |
+
session.add(chat_session)
|
| 286 |
+
session.commit()
|
| 287 |
+
session.refresh(chat_session)
|
| 288 |
+
|
| 289 |
+
else:
|
| 290 |
+
with Session(get_engine()) as session:
|
| 291 |
+
session.add(chat_session)
|
| 292 |
+
session.commit()
|
| 293 |
+
session.refresh(chat_session)
|
| 294 |
+
|
| 295 |
+
return chat_session
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
# ------------------------------
|
| 299 |
+
# Retrieve a random agent's name
|
| 300 |
+
# ------------------------------
|
| 301 |
+
def get_random_agent():
|
| 302 |
+
return random.choice(AGENT_NAMES)
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
# ------------------------
|
| 306 |
+
# Retrieve prompt template
|
| 307 |
+
# ------------------------
|
| 308 |
+
def get_prompt_template(
|
| 309 |
+
user_query: str = None,
|
| 310 |
+
context_str: str = None,
|
| 311 |
+
project: Optional[Project] = None,
|
| 312 |
+
organization: Optional[Organization] = None,
|
| 313 |
+
agent: str = None,
|
| 314 |
+
) -> str:
|
| 315 |
+
agent = f"{agent}, " if agent else ""
|
| 316 |
+
user_query = user_query if user_query else ""
|
| 317 |
+
context_str = context_str if context_str else ""
|
| 318 |
+
organization = (
|
| 319 |
+
project.organization.display_name
|
| 320 |
+
if project
|
| 321 |
+
else organization.display_name
|
| 322 |
+
if organization
|
| 323 |
+
else None
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
if not context_str or not user_query:
|
| 327 |
+
raise ValueError(
|
| 328 |
+
"Missing required arguments context_str, user_query, organization, agent"
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
system_prompt = [
|
| 332 |
+
{
|
| 333 |
+
"role": "system",
|
| 334 |
+
"content": f"""[AGENT]:
|
| 335 |
+
I am {agent} a very kind and enthusiastic customer support agent who loves to help customers. I am working on the behalf of "{organization}"
|
| 336 |
+
|
| 337 |
+
Given the following document from "{organization}", I will answer the [USER] questions using only the [DOCUMENT] and following the [RULES].
|
| 338 |
+
|
| 339 |
+
[DOCUMENT]:
|
| 340 |
+
{context_str}
|
| 341 |
+
|
| 342 |
+
[RULES]:
|
| 343 |
+
I will answer the user's questions using only the [DOCUMENT] provided. I will abide by the following rules:
|
| 344 |
+
- I am a kind and helpful human, the best customer support agent in existence
|
| 345 |
+
- I never lie or invent answers not explicitly provided in [DOCUMENT]
|
| 346 |
+
- If I am unsure of the answer response or the answer is not explicitly contained in [DOCUMENT], I will say: "I apologize, I'm not sure how to help with that".
|
| 347 |
+
- I always keep my answers short, relevant and concise.
|
| 348 |
+
- I will always respond in JSON format with the following keys: "message" my response to the user, "tags" an array of short labels categorizing user input, "is_escalate" a boolean, returning false if I am unsure and true if I do have a relevant answer
|
| 349 |
+
""",
|
| 350 |
+
}
|
| 351 |
+
]
|
| 352 |
+
|
| 353 |
+
return (system_prompt, f"[USER]:\n{user_query}")
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
# ----------------------------
|
| 357 |
+
# Get the count of tokens used
|
| 358 |
+
# ----------------------------
|
| 359 |
+
# https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
|
| 360 |
+
def get_token_count(text: str):
|
| 361 |
+
if not text:
|
| 362 |
+
return 0
|
| 363 |
+
|
| 364 |
+
return OpenAI().get_num_tokens(text=text)
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
# --------------------------------------------
|
| 368 |
+
# Query embedding search for similar documents
|
| 369 |
+
# --------------------------------------------
|
| 370 |
+
def get_nodes_by_embedding(
|
| 371 |
+
embeddings: List[float],
|
| 372 |
+
k: int = LLM_MIN_NODE_LIMIT,
|
| 373 |
+
distance_strategy: Optional[DISTANCE_STRATEGY] = LLM_DEFAULT_DISTANCE_STRATEGY,
|
| 374 |
+
distance_threshold: Optional[float] = LLM_DISTANCE_THRESHOLD,
|
| 375 |
+
session: Optional[Session] = None,
|
| 376 |
+
) -> List[Node]:
|
| 377 |
+
# Convert embeddings array into sql string
|
| 378 |
+
embeddings_str = str(embeddings)
|
| 379 |
+
|
| 380 |
+
if distance_strategy == DISTANCE_STRATEGY.EUCLIDEAN:
|
| 381 |
+
distance_fn = "match_node_euclidean"
|
| 382 |
+
elif distance_strategy == DISTANCE_STRATEGY.COSINE:
|
| 383 |
+
distance_fn = "match_node_cosine"
|
| 384 |
+
elif distance_strategy == DISTANCE_STRATEGY.MAX_INNER_PRODUCT:
|
| 385 |
+
distance_fn = "match_node_max_inner_product"
|
| 386 |
+
else:
|
| 387 |
+
raise Exception(f"Invalid distance strategy {distance_strategy}")
|
| 388 |
+
|
| 389 |
+
# ---------------------------
|
| 390 |
+
# Lets do a similarity search
|
| 391 |
+
# ---------------------------
|
| 392 |
+
sql = f"""SELECT * FROM {distance_fn}(
|
| 393 |
+
'{embeddings_str}'::vector({VECTOR_EMBEDDINGS_COUNT}),
|
| 394 |
+
{float(distance_threshold)}::double precision,
|
| 395 |
+
{int(k)});"""
|
| 396 |
+
|
| 397 |
+
# logger.debug(f'🔍 Query: {sql}')
|
| 398 |
+
|
| 399 |
+
# Execute query, convert results to Node objects
|
| 400 |
+
if not session:
|
| 401 |
+
with Session(get_engine()) as session:
|
| 402 |
+
nodes = session.exec(text(sql)).all()
|
| 403 |
+
else:
|
| 404 |
+
nodes = session.exec(text(sql)).all()
|
| 405 |
+
|
| 406 |
+
return [Node.by_uuid(str(node[0])) for node in nodes] if nodes else []
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
def retrieve_llm_response(
|
| 410 |
+
query_str: str,
|
| 411 |
+
model: Optional[LLM_MODELS] = LLM_MODELS.GPT_35_TURBO,
|
| 412 |
+
temperature: Optional[float] = LLM_DEFAULT_TEMPERATURE,
|
| 413 |
+
max_output_tokens: Optional[int] = LLM_MAX_OUTPUT_TOKENS,
|
| 414 |
+
prefix_messages: Optional[List[dict]] = None,
|
| 415 |
+
):
|
| 416 |
+
llm = OpenAI(
|
| 417 |
+
temperature=temperature,
|
| 418 |
+
model_name=model.model_name
|
| 419 |
+
if isinstance(model, LLM_MODELS)
|
| 420 |
+
else LLM_MODELS.GPT_35_TURBO.model_name,
|
| 421 |
+
max_tokens=max_output_tokens,
|
| 422 |
+
prefix_messages=prefix_messages,
|
| 423 |
+
)
|
| 424 |
+
try:
|
| 425 |
+
result = llm(prompt=query_str)
|
| 426 |
+
except openai.error.InvalidRequestError as e:
|
| 427 |
+
logger.error(f"🚨 LLM error: {e}")
|
| 428 |
+
raise HTTPException(status_code=500, detail=f"LLM error: {e}")
|
| 429 |
+
logger.debug(f"💬 LLM result: {str(result)}")
|
| 430 |
+
return sanitize_output(result)
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
# --------------------------
|
| 434 |
+
# Create document embeddings
|
| 435 |
+
# --------------------------
|
| 436 |
+
def get_embeddings(
|
| 437 |
+
document_data: str,
|
| 438 |
+
document_type: DOCUMENT_TYPE = DOCUMENT_TYPE.PLAINTEXT,
|
| 439 |
+
) -> Tuple[List[str], List[float]]:
|
| 440 |
+
documents = [LangChainDocument(page_content=document_data)]
|
| 441 |
+
|
| 442 |
+
logger.debug(documents)
|
| 443 |
+
if document_type == DOCUMENT_TYPE.MARKDOWN:
|
| 444 |
+
doc_splitter = MarkdownTextSplitter(
|
| 445 |
+
chunk_size=LLM_CHUNK_SIZE, chunk_overlap=LLM_CHUNK_OVERLAP
|
| 446 |
+
)
|
| 447 |
+
else:
|
| 448 |
+
doc_splitter = CharacterTextSplitter(
|
| 449 |
+
chunk_size=LLM_CHUNK_SIZE, chunk_overlap=LLM_CHUNK_OVERLAP
|
| 450 |
+
)
|
| 451 |
+
|
| 452 |
+
# Returns an array of Documents
|
| 453 |
+
split_documents = doc_splitter.split_documents(documents)
|
| 454 |
+
|
| 455 |
+
# Lets convert them into an array of strings for OpenAI
|
| 456 |
+
arr_documents = [doc.page_content for doc in split_documents]
|
| 457 |
+
|
| 458 |
+
# https://github.com/hwchase17/langchain/blob/d18b0caf0e00414e066c9903c8df72bb5bcf9998/langchain/embeddings/openai.py#L219
|
| 459 |
+
embed_func = OpenAIEmbeddings()
|
| 460 |
+
|
| 461 |
+
embeddings = embed_func.embed_documents(
|
| 462 |
+
texts=arr_documents, chunk_size=LLM_CHUNK_SIZE
|
| 463 |
+
)
|
| 464 |
+
|
| 465 |
+
return arr_documents, embeddings
|
app/api/main.py
ADDED
|
@@ -0,0 +1,567 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import (
|
| 2 |
+
FastAPI,
|
| 3 |
+
File,
|
| 4 |
+
Depends,
|
| 5 |
+
HTTPException,
|
| 6 |
+
UploadFile
|
| 7 |
+
)
|
| 8 |
+
from fastapi.openapi.utils import get_openapi
|
| 9 |
+
from fastapi.staticfiles import StaticFiles
|
| 10 |
+
from sqlmodel import Session, select
|
| 11 |
+
|
| 12 |
+
from typing import (
|
| 13 |
+
List,
|
| 14 |
+
Optional,
|
| 15 |
+
Union,
|
| 16 |
+
Any
|
| 17 |
+
)
|
| 18 |
+
from datetime import datetime
|
| 19 |
+
import requests
|
| 20 |
+
import aiohttp
|
| 21 |
+
import time
|
| 22 |
+
import json
|
| 23 |
+
import os
|
| 24 |
+
|
| 25 |
+
# -----------
|
| 26 |
+
# LLM imports
|
| 27 |
+
# -----------
|
| 28 |
+
from llm import (
|
| 29 |
+
chat_query
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
# ----------------
|
| 33 |
+
# Database imports
|
| 34 |
+
# ----------------
|
| 35 |
+
from models import (
|
| 36 |
+
# ---------------
|
| 37 |
+
# Database Models
|
| 38 |
+
# ---------------
|
| 39 |
+
Organization,
|
| 40 |
+
OrganizationCreate,
|
| 41 |
+
OrganizationRead,
|
| 42 |
+
OrganizationUpdate,
|
| 43 |
+
User,
|
| 44 |
+
UserCreate,
|
| 45 |
+
UserRead,
|
| 46 |
+
UserReadList,
|
| 47 |
+
UserUpdate,
|
| 48 |
+
DocumentRead,
|
| 49 |
+
DocumentReadList,
|
| 50 |
+
ProjectCreate,
|
| 51 |
+
ProjectRead,
|
| 52 |
+
ProjectReadList,
|
| 53 |
+
ChatSessionResponse,
|
| 54 |
+
ChatSessionCreatePost,
|
| 55 |
+
WebhookCreate,
|
| 56 |
+
# ------------------
|
| 57 |
+
# Database functions
|
| 58 |
+
# ------------------
|
| 59 |
+
get_engine,
|
| 60 |
+
get_session
|
| 61 |
+
|
| 62 |
+
)
|
| 63 |
+
from helpers import (
|
| 64 |
+
# ----------------
|
| 65 |
+
# Helper functions
|
| 66 |
+
# ----------------
|
| 67 |
+
get_org_by_uuid_or_namespace,
|
| 68 |
+
get_project_by_uuid,
|
| 69 |
+
get_user_by_uuid_or_identifier,
|
| 70 |
+
get_users,
|
| 71 |
+
get_documents_by_project_and_org,
|
| 72 |
+
get_document_by_uuid,
|
| 73 |
+
create_org_by_org_or_uuid,
|
| 74 |
+
create_project_by_org
|
| 75 |
+
)
|
| 76 |
+
from util import (
|
| 77 |
+
save_file,
|
| 78 |
+
get_sha256,
|
| 79 |
+
is_uuid,
|
| 80 |
+
logger
|
| 81 |
+
)
|
| 82 |
+
# -----------
|
| 83 |
+
# LLM imports
|
| 84 |
+
# -----------
|
| 85 |
+
from config import (
|
| 86 |
+
APP_NAME,
|
| 87 |
+
APP_VERSION,
|
| 88 |
+
APP_DESCRIPTION,
|
| 89 |
+
ENTITY_STATUS,
|
| 90 |
+
CHANNEL_TYPE,
|
| 91 |
+
LLM_MODELS,
|
| 92 |
+
LLM_DISTANCE_THRESHOLD,
|
| 93 |
+
LLM_DEFAULT_DISTANCE_STRATEGY,
|
| 94 |
+
LLM_MAX_OUTPUT_TOKENS,
|
| 95 |
+
LLM_MIN_NODE_LIMIT,
|
| 96 |
+
FILE_UPLOAD_PATH,
|
| 97 |
+
RASA_WEBHOOK_URL
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
# ------------------
|
| 102 |
+
# Mount static files
|
| 103 |
+
# ------------------
|
| 104 |
+
|
| 105 |
+
# TODO: implement this: https://fastapi.tiangolo.com/advanced/extending-openapi/#change-the-theme
|
| 106 |
+
# See if you can style it to the Radix UI theme
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
app = FastAPI()
|
| 110 |
+
|
| 111 |
+
app.mount("/static", StaticFiles(directory="static"), name="static")
|
| 112 |
+
|
| 113 |
+
# Health check endpoint
|
| 114 |
+
# ---------------------
|
| 115 |
+
@app.get("/health", include_in_schema=False)
|
| 116 |
+
def health_check():
|
| 117 |
+
return {'status': 'ok'}
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
# ======================
|
| 121 |
+
# ORGANIZATION ENDPOINTS
|
| 122 |
+
# ======================
|
| 123 |
+
|
| 124 |
+
# ---------------------
|
| 125 |
+
# Get all organizations
|
| 126 |
+
# ---------------------
|
| 127 |
+
@app.get("/org", response_model=List[OrganizationRead])
|
| 128 |
+
def read_organizations():
|
| 129 |
+
'''
|
| 130 |
+
## Get all active organizations
|
| 131 |
+
|
| 132 |
+
Returns:
|
| 133 |
+
List[OrganizationRead]: List of organizations
|
| 134 |
+
|
| 135 |
+
'''
|
| 136 |
+
with Session(get_engine()) as session:
|
| 137 |
+
orgs = session.exec(select(Organization).where(Organization.status == ENTITY_STATUS.ACTIVE.value)).all()
|
| 138 |
+
return orgs
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# ----------------------
|
| 142 |
+
# Create an organization
|
| 143 |
+
# ----------------------
|
| 144 |
+
@app.post("/org", response_model=Union[OrganizationRead, Any])
|
| 145 |
+
def create_organization(
|
| 146 |
+
*,
|
| 147 |
+
session: Session = Depends(get_session),
|
| 148 |
+
organization: Optional[OrganizationCreate] = None,
|
| 149 |
+
namespace: Optional[str] = None,
|
| 150 |
+
display_name: Optional[str] = None
|
| 151 |
+
):
|
| 152 |
+
'''
|
| 153 |
+
|
| 154 |
+
### Creates a new organization
|
| 155 |
+
### <u>Args:</u>
|
| 156 |
+
- **namespace**: Unique namespace for the organization (ex. openai)
|
| 157 |
+
- **name**: Name of the organization (ex. OpenAI)
|
| 158 |
+
- **bot_url**: URL of the bot (ex. https://t.me/your_bot)
|
| 159 |
+
|
| 160 |
+
### <u>Returns:</u>
|
| 161 |
+
- OrganizationRead
|
| 162 |
+
---
|
| 163 |
+
<details><summary>👇 💻 Code examples:</summary>
|
| 164 |
+
### 🖥️ Curl
|
| 165 |
+
```bash
|
| 166 |
+
curl -X POST "http://localhost:8888/org" -H "accept: application/json" -H "Content-Type: application/json" -d '{\"namespace\":\"openai\",\"name\":\"OpenAI\",\"bot_url\":\"https://t.me/your_bot\"}'
|
| 167 |
+
```
|
| 168 |
+
<br/>
|
| 169 |
+
### 🐍 Python
|
| 170 |
+
```python
|
| 171 |
+
import requests
|
| 172 |
+
response = requests.post("http://localhost:8888/org", json={"namespace":"openai","name":"OpenAI","bot_url":"https://t.me/your_bot"})
|
| 173 |
+
print(response.json())
|
| 174 |
+
```
|
| 175 |
+
</details>
|
| 176 |
+
'''
|
| 177 |
+
# Create organization
|
| 178 |
+
return create_org_by_org_or_uuid(
|
| 179 |
+
organization=organization,
|
| 180 |
+
namespace=namespace,
|
| 181 |
+
display_name=display_name, session=session
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
# ---------------------------
|
| 186 |
+
# Get an organization by UUID
|
| 187 |
+
# ---------------------------
|
| 188 |
+
@app.get("/org/{organization_id}", response_model=Union[OrganizationRead, Any])
|
| 189 |
+
def read_organization(
|
| 190 |
+
*,
|
| 191 |
+
session: Session = Depends(get_session),
|
| 192 |
+
organization_id: str
|
| 193 |
+
):
|
| 194 |
+
|
| 195 |
+
organization = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 196 |
+
|
| 197 |
+
return organization
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
# ------------------------------
|
| 201 |
+
# Update an organization by UUID
|
| 202 |
+
# ------------------------------
|
| 203 |
+
@app.put("/org/{organization_id}", response_model=Union[OrganizationRead, Any])
|
| 204 |
+
def update_organization(
|
| 205 |
+
*,
|
| 206 |
+
session: Session = Depends(get_session),
|
| 207 |
+
organization_id: str,
|
| 208 |
+
organization: OrganizationUpdate
|
| 209 |
+
):
|
| 210 |
+
|
| 211 |
+
org = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 212 |
+
|
| 213 |
+
org.update(organization.dict(exclude_unset=True))
|
| 214 |
+
return org
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
# =================
|
| 218 |
+
# Project endpoints
|
| 219 |
+
# =================
|
| 220 |
+
|
| 221 |
+
# -----------------------
|
| 222 |
+
# Get all projects by org
|
| 223 |
+
# -----------------------
|
| 224 |
+
@app.get("/project", response_model=List[ProjectReadList])
|
| 225 |
+
def read_projects(
|
| 226 |
+
*,
|
| 227 |
+
session: Session = Depends(get_session),
|
| 228 |
+
organization_id: str
|
| 229 |
+
):
|
| 230 |
+
|
| 231 |
+
organization = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 232 |
+
|
| 233 |
+
if not organization.projects:
|
| 234 |
+
raise HTTPException(status_code=404, detail='No projects found for organization')
|
| 235 |
+
|
| 236 |
+
return organization.projects
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
# -----------------------
|
| 240 |
+
# Create a project by org
|
| 241 |
+
# -----------------------
|
| 242 |
+
@app.post("/project", response_model=Union[ProjectRead, Any])
|
| 243 |
+
def create_project(
|
| 244 |
+
*,
|
| 245 |
+
session: Session = Depends(get_session),
|
| 246 |
+
organization_id: str,
|
| 247 |
+
project: ProjectCreate
|
| 248 |
+
):
|
| 249 |
+
return create_project_by_org(
|
| 250 |
+
organization_id=organization_id,
|
| 251 |
+
project=project,
|
| 252 |
+
session=session
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
# -----------------------------
|
| 257 |
+
# Get a project by UUID and org
|
| 258 |
+
# -----------------------------
|
| 259 |
+
@app.get("/project/{project_id}", response_model=Union[ProjectRead, Any])
|
| 260 |
+
def read_project(
|
| 261 |
+
*,
|
| 262 |
+
session: Session = Depends(get_session),
|
| 263 |
+
organization_id: str,
|
| 264 |
+
project_id: str
|
| 265 |
+
):
|
| 266 |
+
|
| 267 |
+
return get_project_by_uuid(uuid=project_id, organization_id=organization_id, session=session)
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
# ==================
|
| 271 |
+
# DOCUMENT ENDPOINTS
|
| 272 |
+
# ==================
|
| 273 |
+
|
| 274 |
+
# ---------------
|
| 275 |
+
# Upload document
|
| 276 |
+
# ---------------
|
| 277 |
+
@app.post("/document", response_model=Union[DocumentReadList, Any])
|
| 278 |
+
async def upload_document(
|
| 279 |
+
*,
|
| 280 |
+
session: Session = Depends(get_session),
|
| 281 |
+
organization_id: str,
|
| 282 |
+
project_id: str,
|
| 283 |
+
url: Optional[str] = None,
|
| 284 |
+
file: Optional[UploadFile] = File(...),
|
| 285 |
+
overwrite: Optional[bool] = True
|
| 286 |
+
):
|
| 287 |
+
organization = get_org_by_uuid_or_namespace(organization_id, session=session)
|
| 288 |
+
project = get_project_by_uuid(uuid=project_id, organization_id=organization_id, session=session)
|
| 289 |
+
file_root_path = os.path.join(FILE_UPLOAD_PATH, str(organization.uuid), str(project.uuid))
|
| 290 |
+
|
| 291 |
+
file_version = 1
|
| 292 |
+
|
| 293 |
+
# ------------------------
|
| 294 |
+
# Enforce XOR for url/file
|
| 295 |
+
# ------------------------
|
| 296 |
+
if url and file:
|
| 297 |
+
raise HTTPException(status_code=400, detail='You can only upload a file OR provide a URL, not both')
|
| 298 |
+
|
| 299 |
+
# --------------------
|
| 300 |
+
# Upload file from URL
|
| 301 |
+
# --------------------
|
| 302 |
+
if url:
|
| 303 |
+
file_name = url.split('/')[-1]
|
| 304 |
+
file_upload_path = os.path.join(file_root_path, file_name)
|
| 305 |
+
file_exists = os.path.isfile(file_upload_path)
|
| 306 |
+
|
| 307 |
+
if file_exists:
|
| 308 |
+
file_name = f'{file_name}_{int(time.time())}'
|
| 309 |
+
file_upload_path = os.path.join(file_root_path, file_name)
|
| 310 |
+
|
| 311 |
+
async with aiohttp.ClientSession() as session:
|
| 312 |
+
async with session.get(url) as resp:
|
| 313 |
+
if resp.status != 200:
|
| 314 |
+
raise HTTPException(status_code=400, detail=f'Could not download file from {url}')
|
| 315 |
+
|
| 316 |
+
with open(file_upload_path, 'wb') as f:
|
| 317 |
+
while True:
|
| 318 |
+
chunk = await resp.content.read(1024)
|
| 319 |
+
if not chunk:
|
| 320 |
+
break
|
| 321 |
+
f.write(chunk)
|
| 322 |
+
|
| 323 |
+
file_contents = open(file_upload_path, 'rb').read()
|
| 324 |
+
file_hash = get_sha256(contents=file_contents)
|
| 325 |
+
|
| 326 |
+
# -----------------------
|
| 327 |
+
# Upload file from device
|
| 328 |
+
# -----------------------
|
| 329 |
+
else:
|
| 330 |
+
file_name = file.filename
|
| 331 |
+
file_upload_path = os.path.join(file_root_path, file_name)
|
| 332 |
+
file_exists = os.path.isfile(file_upload_path)
|
| 333 |
+
|
| 334 |
+
if file_exists:
|
| 335 |
+
file_name = f'{file_name}_{int(time.time())}'
|
| 336 |
+
file_upload_path = os.path.join(file_root_path, file_name)
|
| 337 |
+
|
| 338 |
+
file_contents = await file.read()
|
| 339 |
+
file_hash = get_sha256(contents=file_contents)
|
| 340 |
+
await save_file(file, file_upload_path)
|
| 341 |
+
|
| 342 |
+
document_obj = create_document_by_file_path(
|
| 343 |
+
organization=organization,
|
| 344 |
+
project=project,
|
| 345 |
+
file_path=file_upload_path,
|
| 346 |
+
file_hash=file_hash,
|
| 347 |
+
file_version=file_version,
|
| 348 |
+
url=url,
|
| 349 |
+
overwrite=overwrite,
|
| 350 |
+
session=session
|
| 351 |
+
)
|
| 352 |
+
return document_obj
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
# --------------------------------
|
| 356 |
+
# List all documents for a project
|
| 357 |
+
# --------------------------------
|
| 358 |
+
@app.get("/document", response_model=List[DocumentReadList])
|
| 359 |
+
def read_documents(
|
| 360 |
+
*,
|
| 361 |
+
session: Session = Depends(get_session),
|
| 362 |
+
organization_id: str,
|
| 363 |
+
project_id: str
|
| 364 |
+
):
|
| 365 |
+
return get_documents_by_project_and_org(project_id=project_id, organization_id=organization_id, session=session)
|
| 366 |
+
|
| 367 |
+
# ----------------------
|
| 368 |
+
# Get a document by UUID
|
| 369 |
+
# ----------------------
|
| 370 |
+
@app.get("/document/{document_id}", response_model=DocumentRead)
|
| 371 |
+
def read_document(
|
| 372 |
+
*,
|
| 373 |
+
session: Session = Depends(get_session),
|
| 374 |
+
organization_id: str,
|
| 375 |
+
project_id: str,
|
| 376 |
+
document_id: str
|
| 377 |
+
):
|
| 378 |
+
return get_document_by_uuid(uuid=document_id, project_id=project_id, organization_id=organization_id, session=session)
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
# ==============
|
| 382 |
+
# USER ENDPOINTS
|
| 383 |
+
# ==============
|
| 384 |
+
|
| 385 |
+
# -------------
|
| 386 |
+
# Get all users
|
| 387 |
+
# -------------
|
| 388 |
+
@app.get("/user", response_model=List[UserReadList])
|
| 389 |
+
def read_users(
|
| 390 |
+
*,
|
| 391 |
+
session: Session = Depends(get_session),
|
| 392 |
+
):
|
| 393 |
+
return get_users(session=session)
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
# -------------
|
| 397 |
+
# Create a user
|
| 398 |
+
# -------------
|
| 399 |
+
@app.post("/user", response_model=UserRead)
|
| 400 |
+
def create_user(
|
| 401 |
+
*,
|
| 402 |
+
session: Session = Depends(get_session),
|
| 403 |
+
user: UserCreate
|
| 404 |
+
):
|
| 405 |
+
|
| 406 |
+
return create_user(
|
| 407 |
+
user=user,
|
| 408 |
+
session=session
|
| 409 |
+
)
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
# ------------------
|
| 413 |
+
# Get a user by UUID
|
| 414 |
+
# ------------------
|
| 415 |
+
@app.get("/user/{user_uuid}", response_model=UserRead)
|
| 416 |
+
def read_user(
|
| 417 |
+
*,
|
| 418 |
+
session: Session = Depends(get_session),
|
| 419 |
+
user_id: str
|
| 420 |
+
):
|
| 421 |
+
|
| 422 |
+
return get_user_by_uuid_or_identifier(id=user_id, session=session)
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
# ---------------------
|
| 426 |
+
# Update a user by UUID
|
| 427 |
+
# ---------------------
|
| 428 |
+
@app.put("/user/{user_uuid}", response_model=UserRead)
|
| 429 |
+
def update_user(*, user_uuid: str, user: UserUpdate):
|
| 430 |
+
|
| 431 |
+
# Get user by UUID
|
| 432 |
+
user = User.get(uuid=user_uuid)
|
| 433 |
+
|
| 434 |
+
# If user exists, update it
|
| 435 |
+
if user:
|
| 436 |
+
user.update(**user.dict())
|
| 437 |
+
return user
|
| 438 |
+
|
| 439 |
+
# If user doesn't exist, return 404
|
| 440 |
+
else:
|
| 441 |
+
raise HTTPException(status_code=404, detail=f'User {user_uuid} not found!')
|
| 442 |
+
|
| 443 |
+
|
| 444 |
+
# =============
|
| 445 |
+
# LLM ENDPOINTS
|
| 446 |
+
# =============
|
| 447 |
+
|
| 448 |
+
|
| 449 |
+
def process_webhook_telegram(webhook_data: dict):
|
| 450 |
+
"""
|
| 451 |
+
Telegram example response:
|
| 452 |
+
{
|
| 453 |
+
"update_id": 248146407,
|
| 454 |
+
"message": {
|
| 455 |
+
"message_id": 299,
|
| 456 |
+
"from": {
|
| 457 |
+
"id": 123456789,
|
| 458 |
+
"is_bot": false,
|
| 459 |
+
"first_name": "Elon",
|
| 460 |
+
"username": "elonmusk",
|
| 461 |
+
"language_code": "en"
|
| 462 |
+
},
|
| 463 |
+
"chat": {
|
| 464 |
+
"id": 123456789,
|
| 465 |
+
"first_name": "Elon",
|
| 466 |
+
"username": "elonmusk",
|
| 467 |
+
"type": "private"
|
| 468 |
+
},
|
| 469 |
+
"date": 1683115867,
|
| 470 |
+
"text": "Tell me about the company?"
|
| 471 |
+
}
|
| 472 |
+
}
|
| 473 |
+
"""
|
| 474 |
+
message = webhook_data.get('message', None)
|
| 475 |
+
chat = message.get('chat', None)
|
| 476 |
+
message_from = message.get('from', None)
|
| 477 |
+
return {
|
| 478 |
+
'update_id': webhook_data.get('update_id', None),
|
| 479 |
+
'message_id': message.get('message_id', None),
|
| 480 |
+
'user_id': message_from.get('id', None),
|
| 481 |
+
'username': message_from.get('username', None),
|
| 482 |
+
'user_language': message_from.get('language_code', None),
|
| 483 |
+
'user_firstname': chat.get('first_name', None),
|
| 484 |
+
'user_message': message.get('text', None),
|
| 485 |
+
'message_ts': datetime.fromtimestamp(message.get('date', None)) if message.get('date', None) else None,
|
| 486 |
+
'message_type': chat.get('type', None)
|
| 487 |
+
}
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
@app.post("/webhooks/{channel}/webhook")
|
| 491 |
+
def get_webhook(
|
| 492 |
+
*,
|
| 493 |
+
session: Session = Depends(get_session),
|
| 494 |
+
channel: str,
|
| 495 |
+
webhook: WebhookCreate
|
| 496 |
+
):
|
| 497 |
+
webhook_data = webhook.dict()
|
| 498 |
+
|
| 499 |
+
# --------------------
|
| 500 |
+
# Get webhook metadata
|
| 501 |
+
# --------------------
|
| 502 |
+
if channel == 'telegram':
|
| 503 |
+
rasa_webhook_url = f'{RASA_WEBHOOK_URL}/webhooks/{channel}/webhook'
|
| 504 |
+
data = process_webhook_telegram(webhook_data)
|
| 505 |
+
channel = CHANNEL_TYPE.TELEGRAM.value
|
| 506 |
+
user_data = {
|
| 507 |
+
'identifier': data['user_id'],
|
| 508 |
+
'identifier_type': channel,
|
| 509 |
+
'first_name': data['user_firstname'],
|
| 510 |
+
'language': data['user_language']
|
| 511 |
+
}
|
| 512 |
+
session_metadata = {
|
| 513 |
+
'update_id': data['update_id'],
|
| 514 |
+
'username': data['username'],
|
| 515 |
+
'message_id': data['user_message'],
|
| 516 |
+
'msg_ts': data['message_ts'],
|
| 517 |
+
'msg_type': data['message_type'],
|
| 518 |
+
}
|
| 519 |
+
user_message = data['user_message']
|
| 520 |
+
else:
|
| 521 |
+
# Not a valid channel, return 404
|
| 522 |
+
raise HTTPException(status_code=404, detail=f'Channel {channel} not a valid webhook channel!')
|
| 523 |
+
|
| 524 |
+
chat_session = chat_query(
|
| 525 |
+
user_message,
|
| 526 |
+
session=session,
|
| 527 |
+
channel=channel,
|
| 528 |
+
identifier=user_data['identifier'],
|
| 529 |
+
user_data=user_data,
|
| 530 |
+
meta=session_metadata
|
| 531 |
+
)
|
| 532 |
+
|
| 533 |
+
meta = chat_session.meta
|
| 534 |
+
|
| 535 |
+
# -----------------------------------------
|
| 536 |
+
# Lets add the LLM response to the metadata
|
| 537 |
+
# -----------------------------------------
|
| 538 |
+
webhook_data['message']['meta'] = {
|
| 539 |
+
'response': chat_session.response if chat_session.response else None,
|
| 540 |
+
'tags': meta['tags'] if 'tags' in meta else None,
|
| 541 |
+
'is_escalate': meta['is_escalate'] if 'is_escalate' in meta else False,
|
| 542 |
+
'session_id': meta['session_id'] if 'session_id' in meta else None
|
| 543 |
+
|
| 544 |
+
}
|
| 545 |
+
|
| 546 |
+
# -----------------------------------
|
| 547 |
+
# Forward the webhook to Rasa webhook
|
| 548 |
+
# -----------------------------------
|
| 549 |
+
res = requests.post(rasa_webhook_url, data=json.dumps(webhook_data))
|
| 550 |
+
logger.debug(f'[🤖 RasaGPT API webhook]\nPosting data: {json.dumps(webhook_data)}\n\n[🤖 RasaGPT API webhook]\nRasa webhook response: {res.text}')
|
| 551 |
+
|
| 552 |
+
return {'status': 'ok'}
|
| 553 |
+
|
| 554 |
+
|
| 555 |
+
# ------------------
|
| 556 |
+
# Customize API docs
|
| 557 |
+
# ------------------
|
| 558 |
+
_schema = get_openapi(
|
| 559 |
+
title=APP_NAME,
|
| 560 |
+
description=APP_DESCRIPTION,
|
| 561 |
+
version=APP_VERSION,
|
| 562 |
+
routes=app.routes,
|
| 563 |
+
)
|
| 564 |
+
_schema['info']['x-logo'] = {
|
| 565 |
+
'url': '/static/img/rasagpt-logo-1.png'
|
| 566 |
+
}
|
| 567 |
+
app.openapi_schema = _schema
|
app/api/models.py
ADDED
|
@@ -0,0 +1,660 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from sqlalchemy.dialects.postgresql import JSONB
|
| 2 |
+
from sqlalchemy.orm import declared_attr
|
| 3 |
+
from pgvector.sqlalchemy import Vector
|
| 4 |
+
from sqlalchemy import Column
|
| 5 |
+
from datetime import datetime
|
| 6 |
+
from util import snake_case
|
| 7 |
+
import uuid as uuid_pkg
|
| 8 |
+
|
| 9 |
+
from sqlmodel import (
|
| 10 |
+
UniqueConstraint,
|
| 11 |
+
create_engine,
|
| 12 |
+
Relationship,
|
| 13 |
+
SQLModel,
|
| 14 |
+
Session,
|
| 15 |
+
select,
|
| 16 |
+
Field,
|
| 17 |
+
)
|
| 18 |
+
from typing import (
|
| 19 |
+
Optional,
|
| 20 |
+
Union,
|
| 21 |
+
List,
|
| 22 |
+
Dict,
|
| 23 |
+
Any
|
| 24 |
+
)
|
| 25 |
+
from config import (
|
| 26 |
+
LLM_DEFAULT_DISTANCE_STRATEGY,
|
| 27 |
+
VECTOR_EMBEDDINGS_COUNT,
|
| 28 |
+
LLM_MAX_OUTPUT_TOKENS,
|
| 29 |
+
DISTANCE_STRATEGIES,
|
| 30 |
+
LLM_MIN_NODE_LIMIT,
|
| 31 |
+
PGVECTOR_ADD_INDEX,
|
| 32 |
+
ENTITY_STATUS,
|
| 33 |
+
CHANNEL_TYPE,
|
| 34 |
+
LLM_MODELS,
|
| 35 |
+
DB_USER,
|
| 36 |
+
SU_DSN,
|
| 37 |
+
logger,
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
# ==========
|
| 42 |
+
# Base model
|
| 43 |
+
# ==========
|
| 44 |
+
class BaseModel(SQLModel):
|
| 45 |
+
@declared_attr
|
| 46 |
+
def __tablename__(cls) -> str:
|
| 47 |
+
return snake_case(cls.__name__)
|
| 48 |
+
|
| 49 |
+
@classmethod
|
| 50 |
+
def by_uuid(self, _uuid: uuid_pkg.UUID):
|
| 51 |
+
with Session(get_engine()) as session:
|
| 52 |
+
q = select(self).where(self.uuid == _uuid)
|
| 53 |
+
org = session.exec(q).first()
|
| 54 |
+
return org if org else None
|
| 55 |
+
|
| 56 |
+
def update(self, o: Union[SQLModel, dict] = None):
|
| 57 |
+
if not o:
|
| 58 |
+
raise ValueError("Must provide a model or dict to update values")
|
| 59 |
+
o = o if isinstance(o, dict) else o.dict(exclude_unset=True)
|
| 60 |
+
for key, value in o.items():
|
| 61 |
+
setattr(self, key, value)
|
| 62 |
+
|
| 63 |
+
# save and commit to database
|
| 64 |
+
with Session(get_engine()) as session:
|
| 65 |
+
session.add(self)
|
| 66 |
+
session.commit()
|
| 67 |
+
session.refresh(self)
|
| 68 |
+
|
| 69 |
+
def delete(self):
|
| 70 |
+
with Session(get_engine()) as session:
|
| 71 |
+
self.status = ENTITY_STATUS.DELETED
|
| 72 |
+
self.updated_at = datetime.utcnow()
|
| 73 |
+
session.add(self)
|
| 74 |
+
session.commit()
|
| 75 |
+
session.refresh(self)
|
| 76 |
+
|
| 77 |
+
@classmethod
|
| 78 |
+
def create(self, o: Union[SQLModel, dict] = None):
|
| 79 |
+
if not o:
|
| 80 |
+
raise ValueError("Must provide a model or dict to update values")
|
| 81 |
+
|
| 82 |
+
with Session(get_engine()) as session:
|
| 83 |
+
obj = self.from_orm(o) if isinstance(o, SQLModel) else self(**o)
|
| 84 |
+
session.add(obj)
|
| 85 |
+
session.commit()
|
| 86 |
+
session.refresh(obj)
|
| 87 |
+
|
| 88 |
+
return obj
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
# ============
|
| 92 |
+
# Organization
|
| 93 |
+
# ============
|
| 94 |
+
class Organization(BaseModel, table=True):
|
| 95 |
+
id: Optional[int] = Field(default=None, primary_key=True)
|
| 96 |
+
uuid: Optional[uuid_pkg.UUID] = Field(
|
| 97 |
+
unique=True, default_factory=uuid_pkg.uuid4
|
| 98 |
+
) # UUID for the organization
|
| 99 |
+
display_name: Optional[str] = Field(
|
| 100 |
+
default="Untitled Organization 😊", index=True
|
| 101 |
+
) # display name of the organization
|
| 102 |
+
namespace: str = Field(
|
| 103 |
+
unique=True, index=True
|
| 104 |
+
) # unique organization namespace for URLs, etc.
|
| 105 |
+
bot_url: Optional[str] = Field(default=None) # URL for the bot
|
| 106 |
+
status: Optional[ENTITY_STATUS] = Field(default=ENTITY_STATUS.ACTIVE.value)
|
| 107 |
+
created_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 108 |
+
updated_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 109 |
+
|
| 110 |
+
# -------------
|
| 111 |
+
# Relationships
|
| 112 |
+
# -------------
|
| 113 |
+
projects: Optional[List["Project"]] = Relationship(back_populates="organization")
|
| 114 |
+
documents: Optional[List["Document"]] = Relationship(back_populates="organization")
|
| 115 |
+
|
| 116 |
+
@property
|
| 117 |
+
def project_count(self) -> int:
|
| 118 |
+
return len(self.projects)
|
| 119 |
+
|
| 120 |
+
@property
|
| 121 |
+
def document_count(self) -> int:
|
| 122 |
+
return len(self.documents)
|
| 123 |
+
|
| 124 |
+
def __repr__(self):
|
| 125 |
+
return f"<Organization id={self.id} name={self.display_name} namespace={self.namespace} uuid={self.uuid}>"
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
class OrganizationCreate(SQLModel):
|
| 129 |
+
display_name: Optional[str]
|
| 130 |
+
namespace: Optional[str]
|
| 131 |
+
bot_url: Optional[str]
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
class OrganizationRead(SQLModel):
|
| 135 |
+
id: int
|
| 136 |
+
uuid: uuid_pkg.UUID
|
| 137 |
+
display_name: str
|
| 138 |
+
namespace: Optional[str]
|
| 139 |
+
bot_url: Optional[str]
|
| 140 |
+
created_at: datetime
|
| 141 |
+
updated_at: datetime
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class OrganizationUpdate(SQLModel):
|
| 145 |
+
display_name: Optional[str]
|
| 146 |
+
namespace: Optional[str]
|
| 147 |
+
bot_url: Optional[str]
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
# ===============
|
| 151 |
+
# User (customer)
|
| 152 |
+
# ===============
|
| 153 |
+
class User(BaseModel, table=True):
|
| 154 |
+
id: Optional[int] = Field(default=None, primary_key=True)
|
| 155 |
+
identifier: str = Field(default=None, unique=True, index=True)
|
| 156 |
+
identifier_type: Optional[CHANNEL_TYPE] = Field(default=None)
|
| 157 |
+
uuid: Optional[uuid_pkg.UUID] = Field(unique=True, default_factory=uuid_pkg.uuid4)
|
| 158 |
+
first_name: Optional[str] = Field(default=None)
|
| 159 |
+
last_name: Optional[str] = Field(default=None)
|
| 160 |
+
email: Optional[str] = Field(default=None)
|
| 161 |
+
phone: Optional[str] = Field(default=None)
|
| 162 |
+
dob: Optional[datetime] = Field(default=None)
|
| 163 |
+
device_fingerprint: Optional[str] = Field(default=None)
|
| 164 |
+
created_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 165 |
+
updated_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 166 |
+
|
| 167 |
+
# -------------
|
| 168 |
+
# Relationships
|
| 169 |
+
# -------------
|
| 170 |
+
chat_sessions: Optional[List["ChatSession"]] = Relationship(back_populates="user")
|
| 171 |
+
|
| 172 |
+
@property
|
| 173 |
+
def chat_session_count(self) -> int:
|
| 174 |
+
return len(self.chat_sessions)
|
| 175 |
+
|
| 176 |
+
__table_args__ = (
|
| 177 |
+
UniqueConstraint("identifier", "identifier_type", name="unq_id_idtype"),
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
def __repr__(self):
|
| 181 |
+
return f"<User id={self.id} uuid={self.uuid} project_id={self.project_id} device_fingerprint={self.device_fingerprint}>"
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class UserCreate(SQLModel):
|
| 185 |
+
identifier: str
|
| 186 |
+
identifier_type: CHANNEL_TYPE
|
| 187 |
+
device_fingerprint: Optional[str]
|
| 188 |
+
first_name: Optional[str]
|
| 189 |
+
last_name: Optional[str]
|
| 190 |
+
email: Optional[str]
|
| 191 |
+
phone: Optional[str]
|
| 192 |
+
dob: Optional[datetime]
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class UserReadList(SQLModel):
|
| 196 |
+
id: int
|
| 197 |
+
identifier: Optional[str]
|
| 198 |
+
identifier_type: Optional[CHANNEL_TYPE]
|
| 199 |
+
uuid: uuid_pkg.UUID
|
| 200 |
+
device_fingerprint: Optional[str]
|
| 201 |
+
first_name: Optional[str]
|
| 202 |
+
last_name: Optional[str]
|
| 203 |
+
email: Optional[str]
|
| 204 |
+
phone: Optional[str]
|
| 205 |
+
dob: Optional[datetime]
|
| 206 |
+
chat_session_count: int
|
| 207 |
+
created_at: datetime
|
| 208 |
+
updated_at: datetime
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class UserUpdate(SQLModel):
|
| 212 |
+
device_fingerprint: Optional[str]
|
| 213 |
+
device_fingerprint: Optional[str]
|
| 214 |
+
first_name: Optional[str]
|
| 215 |
+
last_name: Optional[str]
|
| 216 |
+
email: Optional[str]
|
| 217 |
+
phone: Optional[str]
|
| 218 |
+
dob: Optional[datetime]
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
# =======
|
| 222 |
+
# Project
|
| 223 |
+
# =======
|
| 224 |
+
class Project(BaseModel, table=True):
|
| 225 |
+
id: Optional[int] = Field(default=None, primary_key=True)
|
| 226 |
+
uuid: Optional[uuid_pkg.UUID] = Field(unique=True, default_factory=uuid_pkg.uuid4)
|
| 227 |
+
organization_id: int = Field(default=None, foreign_key="organization.id")
|
| 228 |
+
display_name: str = Field(default="📝 Untitled Project")
|
| 229 |
+
status: Optional[ENTITY_STATUS] = Field(default=ENTITY_STATUS.ACTIVE.value)
|
| 230 |
+
created_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 231 |
+
updated_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 232 |
+
|
| 233 |
+
# -------------
|
| 234 |
+
# Relationships
|
| 235 |
+
# -------------
|
| 236 |
+
organization: Optional["Organization"] = Relationship(back_populates="projects")
|
| 237 |
+
documents: Optional[List["Document"]] = Relationship(back_populates="project")
|
| 238 |
+
chat_sessions: Optional[List["ChatSession"]] = Relationship(
|
| 239 |
+
back_populates="project"
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
@property
|
| 243 |
+
def document_count(self) -> int:
|
| 244 |
+
return len(self.documents)
|
| 245 |
+
|
| 246 |
+
def __repr__(self):
|
| 247 |
+
return f"<Project id={self.id} name={self.display_name} uuid={self.uuid} project_id={self.uuid}>"
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
class ProjectCreate(SQLModel):
|
| 251 |
+
display_name: Optional[str]
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
class ProjectReadListOrganization(SQLModel):
|
| 255 |
+
uuid: uuid_pkg.UUID
|
| 256 |
+
display_name: str
|
| 257 |
+
namespace: Optional[str]
|
| 258 |
+
document_count: int
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
class ProjectUpdate(SQLModel):
|
| 262 |
+
display_name: Optional[str]
|
| 263 |
+
status: Optional[ENTITY_STATUS]
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
# =========
|
| 267 |
+
# Documents
|
| 268 |
+
# =========
|
| 269 |
+
class Document(BaseModel, table=True):
|
| 270 |
+
id: Optional[int] = Field(default=None, primary_key=True)
|
| 271 |
+
uuid: Optional[uuid_pkg.UUID] = Field(unique=True, default_factory=uuid_pkg.uuid4)
|
| 272 |
+
organization_id: int = Field(default=None, foreign_key="organization.id")
|
| 273 |
+
project_id: int = Field(default=None, foreign_key="project.id")
|
| 274 |
+
display_name: str = Field(default="Untitled Document 😊")
|
| 275 |
+
url: str = Field(default="")
|
| 276 |
+
data: Optional[bytes] = Field(default=None)
|
| 277 |
+
hash: str = Field(default=None)
|
| 278 |
+
version: Optional[int] = Field(default=1)
|
| 279 |
+
status: Optional[ENTITY_STATUS] = Field(default=ENTITY_STATUS.ACTIVE.value)
|
| 280 |
+
created_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 281 |
+
updated_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 282 |
+
|
| 283 |
+
# -------------
|
| 284 |
+
# Relationships
|
| 285 |
+
# -------------
|
| 286 |
+
nodes: Optional[List["Node"]] = Relationship(back_populates="document")
|
| 287 |
+
organization: Optional["Organization"] = Relationship(back_populates="documents")
|
| 288 |
+
project: Optional["Project"] = Relationship(back_populates="documents")
|
| 289 |
+
|
| 290 |
+
@property
|
| 291 |
+
def node_count(self) -> int:
|
| 292 |
+
return len(self.nodes)
|
| 293 |
+
|
| 294 |
+
__table_args__ = (UniqueConstraint("uuid", "hash", name="unq_org_document"),)
|
| 295 |
+
|
| 296 |
+
def __repr__(self):
|
| 297 |
+
return f"<Document id={self.id} name={self.display_name} uuid={self.uuid}>"
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
class ProjectRead(SQLModel):
|
| 301 |
+
id: int
|
| 302 |
+
uuid: uuid_pkg.UUID
|
| 303 |
+
organization: Organization
|
| 304 |
+
document_count: int
|
| 305 |
+
documents: Optional[List[Document]] = None
|
| 306 |
+
display_name: str
|
| 307 |
+
created_at: datetime
|
| 308 |
+
updated_at: datetime
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
class DocumentCreate(SQLModel):
|
| 312 |
+
project: Project
|
| 313 |
+
display_name: Optional[str]
|
| 314 |
+
url: Optional[str]
|
| 315 |
+
version: Optional[str]
|
| 316 |
+
data: Optional[bytes]
|
| 317 |
+
hash: Optional[str]
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
class DocumentUpdate(SQLModel):
|
| 321 |
+
status: Optional[ENTITY_STATUS]
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
# ==============
|
| 325 |
+
# Document Nodes
|
| 326 |
+
# ==============
|
| 327 |
+
class Node(BaseModel, table=True):
|
| 328 |
+
class Config:
|
| 329 |
+
arbitrary_types_allowed = True
|
| 330 |
+
|
| 331 |
+
id: Optional[int] = Field(default=None, primary_key=True)
|
| 332 |
+
document_id: int = Field(default=None, foreign_key="document.id")
|
| 333 |
+
uuid: Optional[uuid_pkg.UUID] = Field(unique=True, default_factory=uuid_pkg.uuid4)
|
| 334 |
+
embeddings: Optional[List[float]] = Field(
|
| 335 |
+
sa_column=Column(Vector(VECTOR_EMBEDDINGS_COUNT))
|
| 336 |
+
)
|
| 337 |
+
meta: Optional[Dict] = Field(default=None, sa_column=Column(JSONB))
|
| 338 |
+
token_count: Optional[int] = Field(default=None)
|
| 339 |
+
text: str = Field(default=None, nullable=False)
|
| 340 |
+
status: Optional[ENTITY_STATUS] = Field(default=ENTITY_STATUS.ACTIVE.value)
|
| 341 |
+
created_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 342 |
+
updated_at: Optional[datetime] = Field(default_factory=datetime.now)
|
| 343 |
+
|
| 344 |
+
# -------------
|
| 345 |
+
# Relationships
|
| 346 |
+
# -------------
|
| 347 |
+
document: Optional["Document"] = Relationship(back_populates="nodes")
|
| 348 |
+
|
| 349 |
+
def __repr__(self):
|
| 350 |
+
return f"<Node id={self.id} uuid={self.uuid} document={self.document_id}>"
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
class NodeCreate(SQLModel):
|
| 354 |
+
document: Document
|
| 355 |
+
embeddings: List[float]
|
| 356 |
+
token_count: Optional[int]
|
| 357 |
+
text: str
|
| 358 |
+
status: Optional[ENTITY_STATUS]
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
class NodeRead(SQLModel):
|
| 362 |
+
id: int
|
| 363 |
+
document: Document
|
| 364 |
+
embeddings: Optional[List[float]]
|
| 365 |
+
token_count: Optional[int]
|
| 366 |
+
text: str
|
| 367 |
+
created_at: datetime
|
| 368 |
+
|
| 369 |
+
|
| 370 |
+
class DocumentReadNodeList(SQLModel):
|
| 371 |
+
id: int
|
| 372 |
+
uuid: uuid_pkg.UUID
|
| 373 |
+
display_name: str
|
| 374 |
+
node_count: int
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
class NodeReadResult(SQLModel):
|
| 378 |
+
id: int
|
| 379 |
+
token_count: Optional[int]
|
| 380 |
+
text: str
|
| 381 |
+
meta: Optional[Dict]
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
class ProjectReadListDocumentList(SQLModel):
|
| 385 |
+
uuid: uuid_pkg.UUID
|
| 386 |
+
display_name: str
|
| 387 |
+
node_count: Optional[int]
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
class ProjectReadList(SQLModel):
|
| 391 |
+
id: int
|
| 392 |
+
# organization: ProjectReadListOrganization
|
| 393 |
+
documents: Optional[List[DocumentReadNodeList]]
|
| 394 |
+
document_count: int
|
| 395 |
+
uuid: uuid_pkg.UUID
|
| 396 |
+
display_name: str
|
| 397 |
+
created_at: datetime
|
| 398 |
+
updated_at: datetime
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
class NodeReadList(SQLModel):
|
| 402 |
+
id: int
|
| 403 |
+
document: DocumentReadNodeList
|
| 404 |
+
embeddings: Optional[List[float]]
|
| 405 |
+
token_count: Optional[int]
|
| 406 |
+
text: str
|
| 407 |
+
created_at: datetime
|
| 408 |
+
|
| 409 |
+
|
| 410 |
+
class NodeUpdate(SQLModel):
|
| 411 |
+
status: Optional[ENTITY_STATUS] = Field(default=ENTITY_STATUS.ACTIVE.value)
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
class NodeReadListDocumentRead(SQLModel):
|
| 415 |
+
uuid: uuid_pkg.UUID
|
| 416 |
+
token_count: Optional[int]
|
| 417 |
+
created_at: datetime
|
| 418 |
+
|
| 419 |
+
|
| 420 |
+
class DocumentReadList(SQLModel):
|
| 421 |
+
id: int
|
| 422 |
+
uuid: uuid_pkg.UUID
|
| 423 |
+
display_name: str
|
| 424 |
+
version: int
|
| 425 |
+
nodes: Optional[List[NodeReadListDocumentRead]] = None
|
| 426 |
+
node_count: int
|
| 427 |
+
hash: str
|
| 428 |
+
created_at: datetime
|
| 429 |
+
updated_at: datetime
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
# ============
|
| 433 |
+
# Chat Session
|
| 434 |
+
# ============
|
| 435 |
+
class ChatSession(BaseModel, table=True):
|
| 436 |
+
class Config:
|
| 437 |
+
arbitrary_types_allowed = True
|
| 438 |
+
|
| 439 |
+
id: Optional[int] = Field(default=None, primary_key=True)
|
| 440 |
+
session_id: Optional[uuid_pkg.UUID] = Field(
|
| 441 |
+
index=True, default_factory=uuid_pkg.uuid4
|
| 442 |
+
)
|
| 443 |
+
user_id: int = Field(default=None, foreign_key="user.id")
|
| 444 |
+
project_id: int = Field(default=None, foreign_key="project.id")
|
| 445 |
+
channel: CHANNEL_TYPE = Field(default=CHANNEL_TYPE.TELEGRAM)
|
| 446 |
+
user_message: str = Field(default=None)
|
| 447 |
+
token_count: Optional[int] = Field(default=None)
|
| 448 |
+
embeddings: Optional[List[float]] = Field(
|
| 449 |
+
sa_column=Column(Vector(VECTOR_EMBEDDINGS_COUNT))
|
| 450 |
+
)
|
| 451 |
+
response: Optional[str] = Field(default=None)
|
| 452 |
+
meta: Optional[Dict] = Field(default=None, sa_column=Column(JSONB))
|
| 453 |
+
created_at: datetime = Field(default_factory=datetime.now)
|
| 454 |
+
|
| 455 |
+
# -------------
|
| 456 |
+
# Relationships
|
| 457 |
+
# -------------
|
| 458 |
+
user: Optional["User"] = Relationship(back_populates="chat_sessions")
|
| 459 |
+
project: Optional["Project"] = Relationship(back_populates="chat_sessions")
|
| 460 |
+
|
| 461 |
+
def __repr__(self):
|
| 462 |
+
return f"<ChatSession id={self.id} uuid={self.uuid} project_id={self.project_id} user_id={self.user_id} message={self.user_message}>"
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
class ChatSessionCreatePost(SQLModel):
|
| 466 |
+
project_id: Optional[str] = ""
|
| 467 |
+
organization_id: Optional[str] = "pepe"
|
| 468 |
+
channel: Optional[CHANNEL_TYPE] = CHANNEL_TYPE.TELEGRAM
|
| 469 |
+
query: Optional[str] = "What is the weather like in London right now?"
|
| 470 |
+
identifier: Optional[str] = "@username"
|
| 471 |
+
distance_strategy: Optional[str] = LLM_DEFAULT_DISTANCE_STRATEGY
|
| 472 |
+
max_output_tokens: Optional[int] = LLM_MAX_OUTPUT_TOKENS
|
| 473 |
+
node_limit: Optional[int] = LLM_MIN_NODE_LIMIT
|
| 474 |
+
model: Optional[str] = LLM_MODELS.GPT_35_TURBO
|
| 475 |
+
session_id: Optional[str] = ""
|
| 476 |
+
|
| 477 |
+
|
| 478 |
+
class ChatSessionCreate(SQLModel):
|
| 479 |
+
channel: CHANNEL_TYPE
|
| 480 |
+
token_count: Optional[int]
|
| 481 |
+
user_message: str
|
| 482 |
+
embeddings: List[float]
|
| 483 |
+
response: Optional[str]
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
class ChatSessionRead(SQLModel):
|
| 487 |
+
id: int
|
| 488 |
+
user: User
|
| 489 |
+
project: Optional[ProjectReadListDocumentList]
|
| 490 |
+
token_count: Optional[int]
|
| 491 |
+
channel: CHANNEL_TYPE
|
| 492 |
+
user_message: str
|
| 493 |
+
embeddings: List[float]
|
| 494 |
+
response: Optional[str]
|
| 495 |
+
meta: Optional[dict]
|
| 496 |
+
created_at: datetime = Field(default_factory=datetime.now)
|
| 497 |
+
|
| 498 |
+
|
| 499 |
+
class ChatSessionResponse(SQLModel):
|
| 500 |
+
meta: Optional[dict]
|
| 501 |
+
response: Optional[str]
|
| 502 |
+
user_message: Optional[str]
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
class ProjectReadChatSessionRead(SQLModel):
|
| 506 |
+
id: int
|
| 507 |
+
token_count: Optional[int]
|
| 508 |
+
channel: CHANNEL_TYPE
|
| 509 |
+
created_at: datetime = Field(default_factory=datetime.now)
|
| 510 |
+
|
| 511 |
+
|
| 512 |
+
class ChatSessionReadUserRead(SQLModel):
|
| 513 |
+
id: int
|
| 514 |
+
project: Optional[ProjectReadListDocumentList]
|
| 515 |
+
token_count: Optional[int]
|
| 516 |
+
channel: CHANNEL_TYPE
|
| 517 |
+
user_message: str
|
| 518 |
+
response: Optional[str]
|
| 519 |
+
created_at: datetime = Field(default_factory=datetime.now)
|
| 520 |
+
|
| 521 |
+
|
| 522 |
+
class UserRead(SQLModel):
|
| 523 |
+
id: int
|
| 524 |
+
identifier: Optional[str]
|
| 525 |
+
identifier_type: Optional[CHANNEL_TYPE]
|
| 526 |
+
uuid: uuid_pkg.UUID
|
| 527 |
+
language: Optional[str]
|
| 528 |
+
device_fingerprint: Optional[str]
|
| 529 |
+
first_name: Optional[str]
|
| 530 |
+
last_name: Optional[str]
|
| 531 |
+
email: Optional[str]
|
| 532 |
+
phone: Optional[str]
|
| 533 |
+
dob: Optional[datetime]
|
| 534 |
+
chat_session_count: int
|
| 535 |
+
chat_sessions: Optional[List[ChatSessionReadUserRead]]
|
| 536 |
+
created_at: datetime
|
| 537 |
+
updated_at: datetime
|
| 538 |
+
|
| 539 |
+
|
| 540 |
+
class DocumentReadProjectRead(SQLModel):
|
| 541 |
+
uuid: uuid_pkg.UUID
|
| 542 |
+
display_name: str
|
| 543 |
+
namespace: Optional[str]
|
| 544 |
+
document_count: int
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
class DocumentRead(SQLModel):
|
| 548 |
+
id: int
|
| 549 |
+
uuid: uuid_pkg.UUID
|
| 550 |
+
project: DocumentReadProjectRead
|
| 551 |
+
organization: OrganizationRead
|
| 552 |
+
display_name: str
|
| 553 |
+
node_count: int
|
| 554 |
+
url: Optional[str]
|
| 555 |
+
version: int
|
| 556 |
+
data: bytes
|
| 557 |
+
hash: str
|
| 558 |
+
created_at: datetime
|
| 559 |
+
updated_at: datetime
|
| 560 |
+
|
| 561 |
+
|
| 562 |
+
class WebhookCreate(SQLModel):
|
| 563 |
+
update_id: str
|
| 564 |
+
message: Dict[str, Any]
|
| 565 |
+
|
| 566 |
+
|
| 567 |
+
class WebhookResponse(SQLModel):
|
| 568 |
+
update_id: str
|
| 569 |
+
message: Dict[str, Any]
|
| 570 |
+
|
| 571 |
+
|
| 572 |
+
# ==================
|
| 573 |
+
# Database functions
|
| 574 |
+
# ==================
|
| 575 |
+
def get_engine(dsn: str = SU_DSN):
|
| 576 |
+
return create_engine(dsn)
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
def get_session():
|
| 580 |
+
with Session(get_engine()) as session:
|
| 581 |
+
yield session
|
| 582 |
+
|
| 583 |
+
|
| 584 |
+
def create_db():
|
| 585 |
+
logger.info("...Enabling pgvector and creating database tables")
|
| 586 |
+
enable_vector()
|
| 587 |
+
BaseModel.metadata.create_all(get_engine(dsn=SU_DSN))
|
| 588 |
+
create_user_permissions()
|
| 589 |
+
create_vector_index()
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
def create_user_permissions():
|
| 593 |
+
session = Session(get_engine(dsn=SU_DSN))
|
| 594 |
+
# grant access to entire database and all tables to user DB_USER
|
| 595 |
+
query = f"GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO {DB_USER};"
|
| 596 |
+
session.execute(query)
|
| 597 |
+
session.commit()
|
| 598 |
+
session.close()
|
| 599 |
+
|
| 600 |
+
|
| 601 |
+
def drop_db():
|
| 602 |
+
BaseModel.metadata.drop_all(get_engine(dsn=SU_DSN))
|
| 603 |
+
|
| 604 |
+
|
| 605 |
+
def create_vector_index():
|
| 606 |
+
# -------------------------------------
|
| 607 |
+
# Let's add an index for the embeddings
|
| 608 |
+
# -------------------------------------
|
| 609 |
+
if PGVECTOR_ADD_INDEX is True:
|
| 610 |
+
session = Session(get_engine(dsn=SU_DSN))
|
| 611 |
+
for strategy in DISTANCE_STRATEGIES:
|
| 612 |
+
session.execute(strategy[3])
|
| 613 |
+
session.commit()
|
| 614 |
+
|
| 615 |
+
|
| 616 |
+
def enable_vector():
|
| 617 |
+
session = Session(get_engine(dsn=SU_DSN))
|
| 618 |
+
query = "CREATE EXTENSION IF NOT EXISTS vector;"
|
| 619 |
+
session.execute(query)
|
| 620 |
+
session.commit()
|
| 621 |
+
add_vector_distance_fn(session)
|
| 622 |
+
session.close()
|
| 623 |
+
|
| 624 |
+
|
| 625 |
+
def add_vector_distance_fn(session: Session):
|
| 626 |
+
for strategy in DISTANCE_STRATEGIES:
|
| 627 |
+
strategy_name = strategy[1]
|
| 628 |
+
strategy_distance_str = strategy[2]
|
| 629 |
+
|
| 630 |
+
query = f"""create or replace function match_node_{strategy_name} (
|
| 631 |
+
query_embeddings vector({VECTOR_EMBEDDINGS_COUNT}),
|
| 632 |
+
match_threshold float,
|
| 633 |
+
match_count int
|
| 634 |
+
) returns table (
|
| 635 |
+
uuid uuid,
|
| 636 |
+
text varchar,
|
| 637 |
+
similarity float
|
| 638 |
+
)
|
| 639 |
+
language plpgsql
|
| 640 |
+
as $$
|
| 641 |
+
begin
|
| 642 |
+
return query
|
| 643 |
+
select
|
| 644 |
+
node.uuid,
|
| 645 |
+
node.text,
|
| 646 |
+
1 - (node.embeddings {strategy_distance_str} query_embeddings) as similarity
|
| 647 |
+
from node
|
| 648 |
+
where 1 - (node.embeddings {strategy_distance_str} query_embeddings) > match_threshold
|
| 649 |
+
order by similarity desc
|
| 650 |
+
limit match_count;
|
| 651 |
+
end;
|
| 652 |
+
$$;"""
|
| 653 |
+
|
| 654 |
+
session.execute(query)
|
| 655 |
+
session.commit()
|
| 656 |
+
session.close()
|
| 657 |
+
|
| 658 |
+
|
| 659 |
+
if __name__ == "__main__":
|
| 660 |
+
create_db()
|
app/api/ngrok.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import yaml
|
| 4 |
+
import requests
|
| 5 |
+
import logging
|
| 6 |
+
import httpx
|
| 7 |
+
import asyncio
|
| 8 |
+
from time import sleep
|
| 9 |
+
from fastapi import FastAPI, Depends, HTTPException
|
| 10 |
+
|
| 11 |
+
# ---------
|
| 12 |
+
CREDENTIALS_READY = False
|
| 13 |
+
RETRY_LIMIT = 10
|
| 14 |
+
RETRY_INTERVAL = 15
|
| 15 |
+
|
| 16 |
+
# ----------------
|
| 17 |
+
# Environment vars
|
| 18 |
+
# ----------------
|
| 19 |
+
NGROK_HOST = os.getenv('NGROK_HOST', 'ngrok')
|
| 20 |
+
NGROK_PORT = os.getenv('NGROK_PORT', 4040)
|
| 21 |
+
NGROK_INTERNAL_WEBHOOK_HOST = os.getenv('NGROK_INTERNAL_WEBHOOK_HOST', 'rasa-core')
|
| 22 |
+
NGROK_INTERNAL_WEBHOOK_PORT = os.getenv('NGROK_INTERNAL_WEBHOOK_PORT', 5005)
|
| 23 |
+
NGROK_API_URL = f'http://{NGROK_HOST}:{NGROK_PORT}'
|
| 24 |
+
TELEGRAM_ACCESS_TOKEN = os.getenv('TELEGRAM_ACCESS_TOKEN', None)
|
| 25 |
+
TELEGRAM_BOTNAME = os.getenv('TELEGRAM_BOTNAME', None)
|
| 26 |
+
CREDENTIALS_PATH = os.getenv('CREDENTIALS_PATH', '/app/rasa/credentials.yml')
|
| 27 |
+
|
| 28 |
+
# -------
|
| 29 |
+
# Logging
|
| 30 |
+
# -------
|
| 31 |
+
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
|
| 32 |
+
logger = logging.getLogger(__name__)
|
| 33 |
+
logger.debug(f'NGROK_HOST: {NGROK_HOST}:{NGROK_PORT}\nNGROK_API_URL: {NGROK_API_URL}\nNGROK_INTERNAL_WEBHOOK_HOST: {NGROK_INTERNAL_WEBHOOK_HOST}:{NGROK_INTERNAL_WEBHOOK_PORT}')
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
async def wait_for_ngrok_api():
|
| 37 |
+
while True:
|
| 38 |
+
try:
|
| 39 |
+
async with httpx.AsyncClient() as client:
|
| 40 |
+
response = await client.get(f"{NGROK_API_URL}/api/tunnels")
|
| 41 |
+
response.raise_for_status()
|
| 42 |
+
logger.debug('ngrok API is online.')
|
| 43 |
+
return True
|
| 44 |
+
except httpx.RequestError:
|
| 45 |
+
logger.debug('ngrok API is offline. Waiting...')
|
| 46 |
+
await asyncio.sleep(RETRY_INTERVAL)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
async def get_active_tunnels():
|
| 50 |
+
response = requests.get(f'{NGROK_API_URL}/api/tunnels')
|
| 51 |
+
response.raise_for_status()
|
| 52 |
+
tunnels = response.json()['tunnels']
|
| 53 |
+
return tunnels
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
async def stop_tunnel(tunnel):
|
| 57 |
+
tunnel_id = tunnel['name']
|
| 58 |
+
response = requests.delete(f'{NGROK_API_URL}/api/tunnels/{tunnel_id}')
|
| 59 |
+
response.raise_for_status()
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
async def stop_all_tunnels():
|
| 63 |
+
active_tunnels = await get_active_tunnels()
|
| 64 |
+
if not active_tunnels:
|
| 65 |
+
logger.debug('No active tunnels found.')
|
| 66 |
+
else:
|
| 67 |
+
for tunnel in active_tunnels:
|
| 68 |
+
logger.debug(f"Stopping tunnel: {tunnel['name']} ({tunnel['public_url']})")
|
| 69 |
+
await stop_tunnel(tunnel)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
async def create_tunnel():
|
| 73 |
+
response = requests.post(f'{NGROK_API_URL}/api/tunnels', json={
|
| 74 |
+
'addr': f'{NGROK_INTERNAL_WEBHOOK_HOST}:{NGROK_INTERNAL_WEBHOOK_PORT}',
|
| 75 |
+
'proto': 'http',
|
| 76 |
+
'name': NGROK_INTERNAL_WEBHOOK_HOST,
|
| 77 |
+
|
| 78 |
+
})
|
| 79 |
+
response.raise_for_status()
|
| 80 |
+
return response.json()['public_url']
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
# ----------------------
|
| 84 |
+
# Fetch ngrok public URL
|
| 85 |
+
# ----------------------
|
| 86 |
+
async def get_ngrok_url():
|
| 87 |
+
return await create_tunnel()
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
# ----------------------------
|
| 91 |
+
# Update Rasa credentials file
|
| 92 |
+
# ----------------------------
|
| 93 |
+
async def update_credentials_file(ngrok_url):
|
| 94 |
+
global CREDENTIALS_READY
|
| 95 |
+
try:
|
| 96 |
+
with open(CREDENTIALS_PATH, 'r') as file:
|
| 97 |
+
credentials = yaml.safe_load(file)
|
| 98 |
+
|
| 99 |
+
credentials['telegram']['webhook_url'] = f"{ngrok_url}/webhooks/telegram/webhook"
|
| 100 |
+
credentials['telegram']['access_token'] = TELEGRAM_ACCESS_TOKEN
|
| 101 |
+
credentials['telegram']['verify'] = TELEGRAM_BOTNAME
|
| 102 |
+
|
| 103 |
+
with open(CREDENTIALS_PATH, 'w') as file:
|
| 104 |
+
yaml.safe_dump(credentials, file)
|
| 105 |
+
|
| 106 |
+
return True
|
| 107 |
+
except Exception as e:
|
| 108 |
+
logger.warning(f'Error updating {CREDENTIALS_PATH}: {e}')
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
# ---------------------
|
| 112 |
+
# Endpoint dependencies
|
| 113 |
+
# ---------------------
|
| 114 |
+
async def check_endpoint_availability():
|
| 115 |
+
if not CREDENTIALS_READY:
|
| 116 |
+
raise HTTPException(status_code=403, detail="Endpoint not available yet")
|
| 117 |
+
return True
|
app/api/requirements.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
SQLAlchemy
|
| 2 |
+
uvicorn[standard]
|
| 3 |
+
pgvector
|
| 4 |
+
python-multipart
|
| 5 |
+
psycopg2-binary
|
| 6 |
+
python-dotenv
|
| 7 |
+
fastapi[all]
|
| 8 |
+
langchain==0.0.157
|
| 9 |
+
tiktoken
|
| 10 |
+
aiofiles
|
| 11 |
+
sqlmodel
|
| 12 |
+
openai
|
app/api/seed.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ----------------
|
| 2 |
+
# Database imports
|
| 3 |
+
# ----------------
|
| 4 |
+
from helpers import (
|
| 5 |
+
create_org_by_org_or_uuid,
|
| 6 |
+
create_project_by_org,
|
| 7 |
+
create_document_by_file_path
|
| 8 |
+
)
|
| 9 |
+
from config import (
|
| 10 |
+
FILE_UPLOAD_PATH,
|
| 11 |
+
logger
|
| 12 |
+
)
|
| 13 |
+
from util import (
|
| 14 |
+
get_file_hash
|
| 15 |
+
)
|
| 16 |
+
import os
|
| 17 |
+
|
| 18 |
+
# --------------------
|
| 19 |
+
# Create organizations
|
| 20 |
+
# --------------------
|
| 21 |
+
|
| 22 |
+
organizations = [
|
| 23 |
+
{
|
| 24 |
+
'display_name': 'Pepe Corp.',
|
| 25 |
+
'namespace': 'pepe',
|
| 26 |
+
'projects': [
|
| 27 |
+
{
|
| 28 |
+
'display_name': 'Pepetamine',
|
| 29 |
+
'docs': [
|
| 30 |
+
'project-pepetamine.md'
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
'display_name': 'Frogonil',
|
| 35 |
+
'docs': [
|
| 36 |
+
'project-frogonil.md'
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
'display_name': 'Kekzal',
|
| 41 |
+
'docs': [
|
| 42 |
+
'project-kekzal.md'
|
| 43 |
+
]
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
'display_name': 'Memetrex',
|
| 47 |
+
'docs': [
|
| 48 |
+
'project-memetrex.md'
|
| 49 |
+
]
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
'display_name': 'PepeTrak',
|
| 53 |
+
'docs': [
|
| 54 |
+
'project-pepetrak.md'
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
'display_name': 'MemeGen',
|
| 59 |
+
'docs': [
|
| 60 |
+
'project-memegen.md'
|
| 61 |
+
]
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
'display_name': 'Neuro-kek',
|
| 65 |
+
'docs': [
|
| 66 |
+
'project-neurokek.md'
|
| 67 |
+
]
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
'display_name': 'Pepe Corp. (company)',
|
| 71 |
+
'docs': [
|
| 72 |
+
'org-about_the_company.md',
|
| 73 |
+
'org-board_of_directors.md',
|
| 74 |
+
'org-company_story.md',
|
| 75 |
+
'org-corporate_philosophy.md',
|
| 76 |
+
'org-customer_support.md',
|
| 77 |
+
'org-earnings_fy2023.md',
|
| 78 |
+
'org-management_team.md'
|
| 79 |
+
]
|
| 80 |
+
}
|
| 81 |
+
]
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
'display_name': 'Umbrella Corp',
|
| 85 |
+
'namespace': 'acme',
|
| 86 |
+
'projects': [
|
| 87 |
+
{'display_name': 'T-Virus'},
|
| 88 |
+
{'display_name': 'G-Virus'},
|
| 89 |
+
{'display_name': 'Umbrella Corp. (company)'}
|
| 90 |
+
]
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
'display_name': 'Cyberdine Systems',
|
| 94 |
+
'namespace': 'cyberdine',
|
| 95 |
+
'projects': [
|
| 96 |
+
{'display_name': 'Skynet'},
|
| 97 |
+
{'display_name': 'Cyberdine Systems (company)'}
|
| 98 |
+
]
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
'display_name': 'Bluth Companies',
|
| 102 |
+
'namespace': 'bluth',
|
| 103 |
+
'projects': [
|
| 104 |
+
{'display_name': 'Bluth Company (company)'}
|
| 105 |
+
]
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
'display_name': 'Evil Corp',
|
| 109 |
+
'namespace': 'evil',
|
| 110 |
+
'projects': [
|
| 111 |
+
{'display_name': 'E-Coin'},
|
| 112 |
+
{'display_name': 'E-Corp Power'},
|
| 113 |
+
{'display_name': 'Bank of E Network'},
|
| 114 |
+
{'display_name': 'E Corp Labs'},
|
| 115 |
+
{'display_name': 'Evil Corp (company)'}
|
| 116 |
+
]
|
| 117 |
+
}
|
| 118 |
+
]
|
| 119 |
+
|
| 120 |
+
training_data_path = os.path.join(os.path.dirname(__file__), f'{FILE_UPLOAD_PATH}/training_data')
|
| 121 |
+
|
| 122 |
+
for org in organizations:
|
| 123 |
+
|
| 124 |
+
org_obj = create_org_by_org_or_uuid(
|
| 125 |
+
display_name=org['display_name'],
|
| 126 |
+
namespace=org['namespace']
|
| 127 |
+
)
|
| 128 |
+
logger.debug(f'🏠 Created organization: {org_obj.display_name}')
|
| 129 |
+
|
| 130 |
+
if 'projects' not in org:
|
| 131 |
+
continue
|
| 132 |
+
|
| 133 |
+
for project in org['projects']:
|
| 134 |
+
project['organization'] = org_obj
|
| 135 |
+
|
| 136 |
+
project_obj = create_project_by_org(
|
| 137 |
+
organization_id=org_obj,
|
| 138 |
+
display_name=project['display_name']
|
| 139 |
+
)
|
| 140 |
+
logger.debug(f'🗂️ Created project: {project_obj.display_name}')
|
| 141 |
+
|
| 142 |
+
project_uuid = str(project_obj.uuid)
|
| 143 |
+
org_uuid = str(org_obj.uuid)
|
| 144 |
+
|
| 145 |
+
# if the directory does not exist, create it
|
| 146 |
+
if not os.path.exists(os.path.join(FILE_UPLOAD_PATH, org_uuid, project_uuid)):
|
| 147 |
+
os.mkdir(os.path.join(FILE_UPLOAD_PATH, org_uuid, project_uuid))
|
| 148 |
+
|
| 149 |
+
if 'docs' not in project:
|
| 150 |
+
continue
|
| 151 |
+
|
| 152 |
+
for doc in project['docs']:
|
| 153 |
+
file_path = os.path.join(training_data_path, doc)
|
| 154 |
+
|
| 155 |
+
# check if file exists
|
| 156 |
+
if os.path.isfile(file_path):
|
| 157 |
+
file_hash = get_file_hash(file_path)
|
| 158 |
+
create_document_by_file_path(
|
| 159 |
+
organization=org_obj,
|
| 160 |
+
project=project_obj,
|
| 161 |
+
file_path=file_path,
|
| 162 |
+
file_hash=file_hash
|
| 163 |
+
)
|
| 164 |
+
logger.info(f' ✅ Created document: {doc}')
|
| 165 |
+
else:
|
| 166 |
+
logger.error(f' ❌ Document not found: {doc}')
|
app/api/static/img/rasagpt-icon-200x200.png
ADDED
|
|
app/api/static/img/rasagpt-logo-1.png
ADDED
|
|
app/api/static/img/rasagpt-logo-2.png
ADDED
|
|
app/api/util.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import UploadFile
|
| 2 |
+
from functools import partial
|
| 3 |
+
from sqlmodel import Session
|
| 4 |
+
from hashlib import sha256
|
| 5 |
+
from uuid import UUID
|
| 6 |
+
import aiofiles
|
| 7 |
+
import json
|
| 8 |
+
import re
|
| 9 |
+
from config import (
|
| 10 |
+
logger
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
_snake_1 = partial(re.compile(r'(.)((?<![^A-Za-z])[A-Z][a-z]+)').sub, r'\1_\2')
|
| 14 |
+
_snake_2 = partial(re.compile(r'([a-z0-9])([A-Z])').sub, r'\1_\2')
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def snake_case(string: str) -> str:
|
| 18 |
+
return _snake_2(_snake_1(string)).casefold()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def is_uuid(uuid: str):
|
| 22 |
+
uuid = str(uuid) if isinstance(uuid, UUID) else uuid
|
| 23 |
+
return re.match(r"^[0-9a-f]{8}-?[0-9a-f]{4}-?4[0-9a-f]{3}-?[89ab][0-9a-f]{3}-?[0-9a-f]{12}$", uuid)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
async def save_file(file: UploadFile, file_path: str):
|
| 27 |
+
async with aiofiles.open(file_path, 'wb') as f:
|
| 28 |
+
await f.write(await file.read())
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def get_sha256(contents: bytes):
|
| 32 |
+
return sha256(contents).hexdigest()
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def get_file_hash(
|
| 36 |
+
file_path: str,
|
| 37 |
+
):
|
| 38 |
+
with open(file_path, 'rb') as f:
|
| 39 |
+
file_hash = sha256(f.read()).hexdigest()
|
| 40 |
+
|
| 41 |
+
return file_hash
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
# -------------------
|
| 45 |
+
# Clean up LLM output
|
| 46 |
+
# -------------------
|
| 47 |
+
def sanitize_output(
|
| 48 |
+
str_output: str
|
| 49 |
+
):
|
| 50 |
+
# Let's sanitize the JSON
|
| 51 |
+
res = str_output.replace("\n", '')
|
| 52 |
+
|
| 53 |
+
# If the first character is "?", remove it. Ran into this issue for some reason.
|
| 54 |
+
if res[0] == '?':
|
| 55 |
+
res = res[1:]
|
| 56 |
+
|
| 57 |
+
# check if response is valid json
|
| 58 |
+
try:
|
| 59 |
+
json.loads(res)
|
| 60 |
+
except json.JSONDecodeError:
|
| 61 |
+
raise ValueError(f'LLM response is not valid JSON: {res}')
|
| 62 |
+
|
| 63 |
+
if 'message' not in res or 'tags' not in res or 'is_escalate' not in res:
|
| 64 |
+
raise ValueError(f'LLM response is missing required fields: {res}')
|
| 65 |
+
|
| 66 |
+
logger.debug(f'Output: {res}')
|
| 67 |
+
return res
|
| 68 |
+
|
| 69 |
+
# ------------------
|
| 70 |
+
# Clean up LLM input
|
| 71 |
+
# ------------------
|
| 72 |
+
def sanitize_input(
|
| 73 |
+
str_input: str
|
| 74 |
+
):
|
| 75 |
+
# Escape single quotes that cause output JSON issues
|
| 76 |
+
str_input = str_input.replace("'", "")
|
| 77 |
+
|
| 78 |
+
logger.debug(f'Input: {str_input}')
|
| 79 |
+
return str_input
|
| 80 |
+
|
app/api/wait-for-it.sh
ADDED
|
File without changes
|
app/db/Dockerfile
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM ankane/pgvector:latest
|
| 2 |
+
|
| 3 |
+
# Copy in the load-extensions script
|
| 4 |
+
COPY ./create_db.sh /docker-entrypoint-initdb.d/
|
| 5 |
+
RUN chmod +x /docker-entrypoint-initdb.d/create_db.sh
|
app/db/create_db.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# This is run one-time during the first time Postgres is initialized
|
| 4 |
+
|
| 5 |
+
echo "Creating database ${DB_NAME} and user..."
|
| 6 |
+
|
| 7 |
+
# Create the user and database "api"
|
| 8 |
+
|
| 9 |
+
psql -v ON_ERROR_STOP=1 --username "$POSTGRES_USER" <<-EOSQL
|
| 10 |
+
CREATE USER ${DB_USER} WITH ENCRYPTED PASSWORD '${DB_PASSWORD}';
|
| 11 |
+
CREATE DATABASE ${DB_NAME} OWNER ${DB_USER};
|
| 12 |
+
GRANT ALL PRIVILEGES ON DATABASE ${DB_NAME} TO ${DB_USER};
|
| 13 |
+
EOSQL
|
app/rasa-credentials/.dockerignore
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
*.pyc
|
| 3 |
+
*.pyo
|
| 4 |
+
*.pyd
|
app/rasa-credentials/Dockerfile
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.8-slim
|
| 2 |
+
|
| 3 |
+
WORKDIR /app/rasa-credentials
|
| 4 |
+
COPY . .
|
| 5 |
+
|
| 6 |
+
# Add CURL
|
| 7 |
+
RUN apt-get -y update
|
| 8 |
+
RUN apt-get -y install curl
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 12 |
+
# Expose the port
|
| 13 |
+
EXPOSE 8889
|
| 14 |
+
|
| 15 |
+
ENTRYPOINT ["uvicorn", "main:app", "--host", "rasa-credentials", "--port", "8889", "--reload"]
|
app/rasa-credentials/main.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import (
|
| 2 |
+
HTTPException,
|
| 3 |
+
FastAPI,
|
| 4 |
+
Depends,
|
| 5 |
+
)
|
| 6 |
+
import requests
|
| 7 |
+
import logging
|
| 8 |
+
import asyncio
|
| 9 |
+
import httpx
|
| 10 |
+
import yaml
|
| 11 |
+
import sys
|
| 12 |
+
import os
|
| 13 |
+
|
| 14 |
+
# ---------
|
| 15 |
+
# Constants
|
| 16 |
+
# ---------
|
| 17 |
+
CREDENTIALS_READY = False
|
| 18 |
+
RETRY_LIMIT = 10
|
| 19 |
+
RETRY_INTERVAL = 15
|
| 20 |
+
|
| 21 |
+
# ----------------
|
| 22 |
+
# Environment vars
|
| 23 |
+
# ----------------
|
| 24 |
+
NGROK_HOST = os.getenv("NGROK_HOST", "ngrok")
|
| 25 |
+
NGROK_PORT = os.getenv("NGROK_PORT", 4040)
|
| 26 |
+
NGROK_INTERNAL_WEBHOOK_HOST = os.getenv("NGROK_INTERNAL_WEBHOOK_HOST", "rasa-core")
|
| 27 |
+
NGROK_INTERNAL_WEBHOOK_PORT = os.getenv("NGROK_INTERNAL_WEBHOOK_PORT", 5005)
|
| 28 |
+
NGROK_API_URL = f"http://{NGROK_HOST}:{NGROK_PORT}"
|
| 29 |
+
TELEGRAM_ACCESS_TOKEN = os.getenv("TELEGRAM_ACCESS_TOKEN", None)
|
| 30 |
+
TELEGRAM_BOTNAME = os.getenv("TELEGRAM_BOTNAME", None)
|
| 31 |
+
CREDENTIALS_PATH = os.getenv("CREDENTIALS_PATH", "/app/rasa/credentials.yml")
|
| 32 |
+
|
| 33 |
+
# -------
|
| 34 |
+
# Logging
|
| 35 |
+
# -------
|
| 36 |
+
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
|
| 37 |
+
logger = logging.getLogger(__name__)
|
| 38 |
+
logger.debug(
|
| 39 |
+
f"NGROK_HOST: {NGROK_HOST}:{NGROK_PORT}\nNGROK_API_URL: {NGROK_API_URL}\nNGROK_INTERNAL_WEBHOOK_HOST: {NGROK_INTERNAL_WEBHOOK_HOST}:{NGROK_INTERNAL_WEBHOOK_PORT}"
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
async def wait_for_ngrok_api():
|
| 44 |
+
while True:
|
| 45 |
+
try:
|
| 46 |
+
async with httpx.AsyncClient() as client:
|
| 47 |
+
response = await client.get(f"{NGROK_API_URL}/api/tunnels")
|
| 48 |
+
response.raise_for_status()
|
| 49 |
+
logger.debug("ngrok API is online.")
|
| 50 |
+
return True
|
| 51 |
+
except httpx.RequestError:
|
| 52 |
+
logger.debug("ngrok API is offline. Waiting...")
|
| 53 |
+
await asyncio.sleep(RETRY_INTERVAL)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
async def get_active_tunnels():
|
| 57 |
+
try:
|
| 58 |
+
response = requests.get(f"{NGROK_API_URL}/api/tunnels")
|
| 59 |
+
response.raise_for_status()
|
| 60 |
+
tunnels = response.json()["tunnels"]
|
| 61 |
+
except requests.exceptions.HTTPError:
|
| 62 |
+
tunnels = []
|
| 63 |
+
return tunnels
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
async def stop_tunnel(tunnel):
|
| 67 |
+
tunnel_id = tunnel["name"]
|
| 68 |
+
response = requests.delete(f"{NGROK_API_URL}/api/tunnels/{tunnel_id}")
|
| 69 |
+
response.raise_for_status()
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
async def stop_all_tunnels():
|
| 73 |
+
active_tunnels = await get_active_tunnels()
|
| 74 |
+
if not active_tunnels:
|
| 75 |
+
logger.debug("No active tunnels found.")
|
| 76 |
+
else:
|
| 77 |
+
for tunnel in active_tunnels:
|
| 78 |
+
logger.debug(f"Stopping tunnel: {tunnel['name']} ({tunnel['public_url']})")
|
| 79 |
+
await stop_tunnel(tunnel)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
async def get_tunnel(retry=0):
|
| 83 |
+
if retry > RETRY_LIMIT:
|
| 84 |
+
raise Exception(
|
| 85 |
+
f"Could not create ngrok tunnel. Exceed retry limit of {RETRY_LIMIT} attempts."
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
active_tunnels = await get_active_tunnels()
|
| 89 |
+
if len(active_tunnels) == 0:
|
| 90 |
+
logger.debug(f"No active tunnels found. Trying again in {RETRY_INTERVAL}s..")
|
| 91 |
+
await asyncio.sleep(RETRY_INTERVAL)
|
| 92 |
+
retry += 1
|
| 93 |
+
return await get_tunnel(retry=retry)
|
| 94 |
+
else:
|
| 95 |
+
return active_tunnels[0]["public_url"]
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
async def create_tunnel():
|
| 99 |
+
response = requests.post(
|
| 100 |
+
f"{NGROK_API_URL}/api/tunnels",
|
| 101 |
+
json={
|
| 102 |
+
"addr": f"{NGROK_INTERNAL_WEBHOOK_HOST}:{NGROK_INTERNAL_WEBHOOK_PORT}",
|
| 103 |
+
"proto": "http",
|
| 104 |
+
"name": NGROK_INTERNAL_WEBHOOK_HOST,
|
| 105 |
+
},
|
| 106 |
+
)
|
| 107 |
+
try:
|
| 108 |
+
response.raise_for_status()
|
| 109 |
+
return response.json()["public_url"]
|
| 110 |
+
except requests.exceptions.HTTPError as e:
|
| 111 |
+
logger.warning(f"Error creating ngrok tunnel: {e}")
|
| 112 |
+
return False
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# ----------------------------
|
| 116 |
+
# Update Rasa credentials file
|
| 117 |
+
# ----------------------------
|
| 118 |
+
async def update_credentials_file(ngrok_url):
|
| 119 |
+
global CREDENTIALS_READY
|
| 120 |
+
try:
|
| 121 |
+
with open(CREDENTIALS_PATH, "r") as file:
|
| 122 |
+
credentials = yaml.safe_load(file)
|
| 123 |
+
|
| 124 |
+
credentials["custom_telegram.CustomTelegramInput"][
|
| 125 |
+
"webhook_url"
|
| 126 |
+
] = f"{ngrok_url}/webhooks/telegram/webhook"
|
| 127 |
+
credentials["custom_telegram.CustomTelegramInput"][
|
| 128 |
+
"access_token"
|
| 129 |
+
] = TELEGRAM_ACCESS_TOKEN
|
| 130 |
+
credentials["custom_telegram.CustomTelegramInput"]["verify"] = TELEGRAM_BOTNAME
|
| 131 |
+
|
| 132 |
+
with open(CREDENTIALS_PATH, "w") as file:
|
| 133 |
+
yaml.safe_dump(credentials, file)
|
| 134 |
+
|
| 135 |
+
CREDENTIALS_READY = True
|
| 136 |
+
except Exception as e:
|
| 137 |
+
logger.warning(f"Error updating {CREDENTIALS_PATH}: {e}")
|
| 138 |
+
sys.exit(1)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# -----------------
|
| 142 |
+
# FastAPI endpoints
|
| 143 |
+
# -----------------
|
| 144 |
+
|
| 145 |
+
app = FastAPI()
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
# -------------
|
| 149 |
+
# Startup event
|
| 150 |
+
# -------------
|
| 151 |
+
@app.on_event("startup")
|
| 152 |
+
async def startup_event():
|
| 153 |
+
env = os.getenv("ENV", None)
|
| 154 |
+
if env and env.lower() in ["dev", "development", "local"]:
|
| 155 |
+
await wait_for_ngrok_api()
|
| 156 |
+
url = await get_tunnel()
|
| 157 |
+
if not url:
|
| 158 |
+
logger.debug("No active tunnels found. Creating one...")
|
| 159 |
+
url = await create_tunnel()
|
| 160 |
+
logger.debug(f"Tunnel url: {url}")
|
| 161 |
+
await update_credentials_file(url)
|
| 162 |
+
else:
|
| 163 |
+
logger.debug("Not in dev environment. Skipping.")
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
# ---------------------
|
| 167 |
+
# Endpoint dependencies
|
| 168 |
+
# ---------------------
|
| 169 |
+
async def check_endpoint_availability():
|
| 170 |
+
if not CREDENTIALS_READY:
|
| 171 |
+
raise HTTPException(status_code=403, detail="Endpoint not available yet")
|
| 172 |
+
return True
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
# ---------------------
|
| 176 |
+
# Health check endpoint
|
| 177 |
+
# ---------------------
|
| 178 |
+
# This endpoint is used by docker-compose to check if the
|
| 179 |
+
# container is ready. If it is ready, Rasa core can start
|
| 180 |
+
@app.get("/", dependencies=[Depends(check_endpoint_availability)])
|
| 181 |
+
async def health_check():
|
| 182 |
+
return {"status": "ok"}
|
app/rasa-credentials/requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python-dotenv
|
| 2 |
+
rasa-sdk
|
| 3 |
+
requests
|
| 4 |
+
pyyaml
|
| 5 |
+
uvicorn[standard]
|
| 6 |
+
fastapi[all]
|
| 7 |
+
httpx
|
| 8 |
+
asyncio
|
app/rasa/.dockerignore
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
| 2 |
+
*.pyc
|
| 3 |
+
*.pyo
|
| 4 |
+
*.pyd
|
app/rasa/actions/Dockerfile
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM khalosa/rasa-aarch64:3.5.2
|
| 2 |
+
|
| 3 |
+
COPY . /app
|
| 4 |
+
|
| 5 |
+
WORKDIR /app
|
| 6 |
+
RUN pip install python-dotenv rasa-sdk requests
|
| 7 |
+
EXPOSE 5055
|
| 8 |
+
|
| 9 |
+
CMD ["run", "actions", "--debug"]
|
app/rasa/actions/__init__.py
ADDED
|
File without changes
|
app/rasa/actions/actions.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from rasa_sdk.executor import CollectingDispatcher
|
| 2 |
+
from typing import Any, Text, Dict, List
|
| 3 |
+
from rasa_sdk import Action, Tracker
|
| 4 |
+
from dotenv import load_dotenv
|
| 5 |
+
from logging import getLogger
|
| 6 |
+
from enum import IntEnum
|
| 7 |
+
import os
|
| 8 |
+
|
| 9 |
+
logger = getLogger(__name__)
|
| 10 |
+
|
| 11 |
+
env = os.getenv("ENV", "local")
|
| 12 |
+
env_file = f".env-{env}"
|
| 13 |
+
load_dotenv(dotenv_path=f"../../.env-{env}")
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
MODEL_NAME = os.getenv("MODEL_NAME")
|
| 17 |
+
CHANNEL_TYPE = IntEnum(
|
| 18 |
+
"CHANNEL_TYPE", ["SMS", "TELEGRAM", "WHATSAPP", "EMAIL", "WEBSITE"]
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
logger = getLogger(__name__)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class ActionGPTFallback(Action):
|
| 25 |
+
def name(self) -> str:
|
| 26 |
+
return "action_gpt_fallback"
|
| 27 |
+
|
| 28 |
+
def get_channel(self, channel: str) -> CHANNEL_TYPE:
|
| 29 |
+
if channel == "telegram":
|
| 30 |
+
return CHANNEL_TYPE.TELEGRAM
|
| 31 |
+
elif channel == "whatsapp":
|
| 32 |
+
return CHANNEL_TYPE.WHATSAPP
|
| 33 |
+
elif channel == "sms":
|
| 34 |
+
return CHANNEL_TYPE.SMS
|
| 35 |
+
elif channel == "email":
|
| 36 |
+
return CHANNEL_TYPE.EMAIL
|
| 37 |
+
else:
|
| 38 |
+
return CHANNEL_TYPE.WEBSITE
|
| 39 |
+
|
| 40 |
+
def run(
|
| 41 |
+
self,
|
| 42 |
+
dispatcher: CollectingDispatcher,
|
| 43 |
+
tracker: Tracker,
|
| 44 |
+
domain: Dict[Text, Any],
|
| 45 |
+
) -> List[Dict[Text, Any]]:
|
| 46 |
+
# ------------
|
| 47 |
+
# Get metadata
|
| 48 |
+
# ------------
|
| 49 |
+
data = tracker.latest_message
|
| 50 |
+
metadata = data['metadata'] if data and 'metadata' in data else None
|
| 51 |
+
response = metadata['response'] if metadata and 'response' in metadata else None
|
| 52 |
+
tags = metadata['tags'] if metadata and 'tags' in metadata else None
|
| 53 |
+
is_escalate = (
|
| 54 |
+
metadata['is_escalate'] if metadata and 'is_escalate' in metadata else None
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
if is_escalate is True:
|
| 58 |
+
response = f'{response} \n\n ⚠️💁 [ESCALATE TO HUMAN]'
|
| 59 |
+
|
| 60 |
+
if tags is not None:
|
| 61 |
+
response = f'{response} \n\n 🏷️ {",".join(tags)}'
|
| 62 |
+
|
| 63 |
+
logger.debug(
|
| 64 |
+
f"""[🤖 ActionGPTFallback]
|
| 65 |
+
data: {data}
|
| 66 |
+
metadata: {metadata}
|
| 67 |
+
response: {response}
|
| 68 |
+
tags: {tags}
|
| 69 |
+
is_escalate: {is_escalate}
|
| 70 |
+
"""
|
| 71 |
+
)
|
| 72 |
+
dispatcher.utter_message(text=response)
|
| 73 |
+
return []
|
app/rasa/config.yml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
recipe: default.v1
|
| 2 |
+
assistant_id: 20230303-132941-slow-interest
|
| 3 |
+
language: en
|
| 4 |
+
policies:
|
| 5 |
+
- name: RulePolicy
|
app/rasa/credentials.yml
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
custom_telegram.CustomTelegramInput:
|
| 2 |
+
access_token: null
|
| 3 |
+
verify: null
|
| 4 |
+
webhook_url: null
|
| 5 |
+
rasa:
|
| 6 |
+
url: http://rasa-core:5005/webhook
|
| 7 |
+
rest: null
|
app/rasa/custom_telegram.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from rasa.core.channels.telegram import TelegramInput
|
| 2 |
+
from rasa.shared.utils import common as rasa_common
|
| 3 |
+
from typing import Any, Dict, Optional, Text
|
| 4 |
+
from sanic.request import Request
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class CustomTelegramInput(TelegramInput):
|
| 8 |
+
|
| 9 |
+
def get_metadata(self, request: Request) -> Optional[Dict[Text, Any]]:
|
| 10 |
+
|
| 11 |
+
# For whatever reason, Rasa is unable to pass data via 'metadata' so 'meta' works for now
|
| 12 |
+
metadata = request.json.get('message', {}).get('meta')
|
| 13 |
+
|
| 14 |
+
# Debug
|
| 15 |
+
rasa_common.logger.debug(f'[🤖 ActionGPTFallback]\nmetadata: {metadata}')
|
| 16 |
+
return metadata if metadata is not None else None
|