Spaces:
Running


Running
Commit ·
0247228
0
Parent(s):
Initial Clean State
Browse files- .gitattributes +35 -0
- .gitignore +3 -0
- Dockerfile +11 -0
- README.md +112 -0
- danbooru_vectors_multiview_cpu_fp16.pkl +3 -0
- main.py +701 -0
- requirements.txt +5 -0
- tags_enhanced.csv +0 -0
.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*cuda*
|
| 2 |
+
my_model_bge_m3/
|
| 3 |
+
*.ignore
|
Dockerfile
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.12
|
| 2 |
+
WORKDIR /app
|
| 3 |
+
COPY requirements.txt .
|
| 4 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 5 |
+
RUN useradd -m -u 1000 user
|
| 6 |
+
USER user
|
| 7 |
+
ENV HOME=/home/user \
|
| 8 |
+
PATH=/home/user/.local/bin:$PATH
|
| 9 |
+
COPY --chown=user . /app
|
| 10 |
+
EXPOSE 7860
|
| 11 |
+
CMD ["python", "main.py"]
|
README.md
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: DanbooruSearch
|
| 3 |
+
emoji: 👁
|
| 4 |
+
colorFrom: red
|
| 5 |
+
colorTo: indigo
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: false
|
| 8 |
+
license: mit
|
| 9 |
+
short_description: 使用模糊搜索查找danbooru标签
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
## Danbooru模糊查找
|
| 13 |
+
|
| 14 |
+
本项目提供一种模糊查找Danbooru标签的方法。用户可以凭借模糊的语言描述,查找Danbooru数据集中对应的标签。
|
| 15 |
+
|
| 16 |
+
目前,仅支持使用汉语和英语进行查找。
|
| 17 |
+
|
| 18 |
+
⚠查找结果中可能包含NSFW内容。
|
| 19 |
+
|
| 20 |
+
### 使用说明
|
| 21 |
+
|
| 22 |
+
本程序有三个查找参数:
|
| 23 |
+
|
| 24 |
+
- `top_k`:每个词取前`top_k`个相关的标签。
|
| 25 |
+
|
| 26 |
+
- `结果上限`:对于整个查找,展示综合得分的前N名
|
| 27 |
+
|
| 28 |
+
- `热度权重`:0~1,这个数值越高,标签频数在综合得分中的权重越大。推荐设为0.15
|
| 29 |
+
|
| 30 |
+
设置完查找参数后,用户可以在「画面描述」中输入汉语或英语的词语或自然语言,点击「开始搜索」后,程序将进行查找。
|
| 31 |
+
|
| 32 |
+
### 工作模式
|
| 33 |
+
|
| 34 |
+
#### 完整画面查找
|
| 35 |
+
|
| 36 |
+
你可以输入对画面的完整描述,程序将生成匹配的danbooru标签集。
|
| 37 |
+
|
| 38 |
+
**示例输入**
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
一个穿着白色水手服、蓝色短裙的少女,在下着大雨的城市街道奔跑,她的标签是不甘、愤怒、流泪,她的衣服湿透。
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
**建议参数**
|
| 45 |
+
|
| 46 |
+
- `top_k`:较小,例如5
|
| 47 |
+
|
| 48 |
+
- `结果上限`:一般的SDXL系生图模型支持70-80个标签,设为80
|
| 49 |
+
|
| 50 |
+
- `热度权重`:0.15
|
| 51 |
+
|
| 52 |
+
**示例输出**
|
| 53 |
+
|
| 54 |
+
```
|
| 55 |
+
short_dress, city, streaming_tears, street, white_serafuku, tag, hashtag, clothes, furious, fume, label, rain, blue_background, tears, miniskirt, white_sailor_collar, shorts_under_skirt, dressing, serafuku, costume, shorts_under_dress, dress, crying, blue_skin, undressing, microskirt, object_in_clothes, tearing_up, blue_theme, black_serafuku, running, blue_shoes, >:(, shared_clothes, clothes_on_and_off, blue_liquid, jogging, clothes_in_front, wiping_tears, grey_serafuku, urban, angry, shorts, fleeing, town, wet_clothes, la_grondement_du_haine, wet_face, slug_girl, price_tag, changing_clothes, clothes_on_floor, angry_sex, wet_shirt, training_bra, wet_hair, sword_girls, cityscape, annoyed, running_on_liquid, outdoors, short_sleeves, supergirl, teardrop, girly_running, after_rain, short_shorts, blue_eyes, taking_shelter, city_lights, |_|, running_towards_viewer, nipple_tag, wet_floor, showering, mourning, ^^^, wet_jacket, w, chasing
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
同时,程序输出一份详细的查询结果表格,用户也可以在表格中选择合适的标签
|
| 59 |
+
|
| 60 |
+
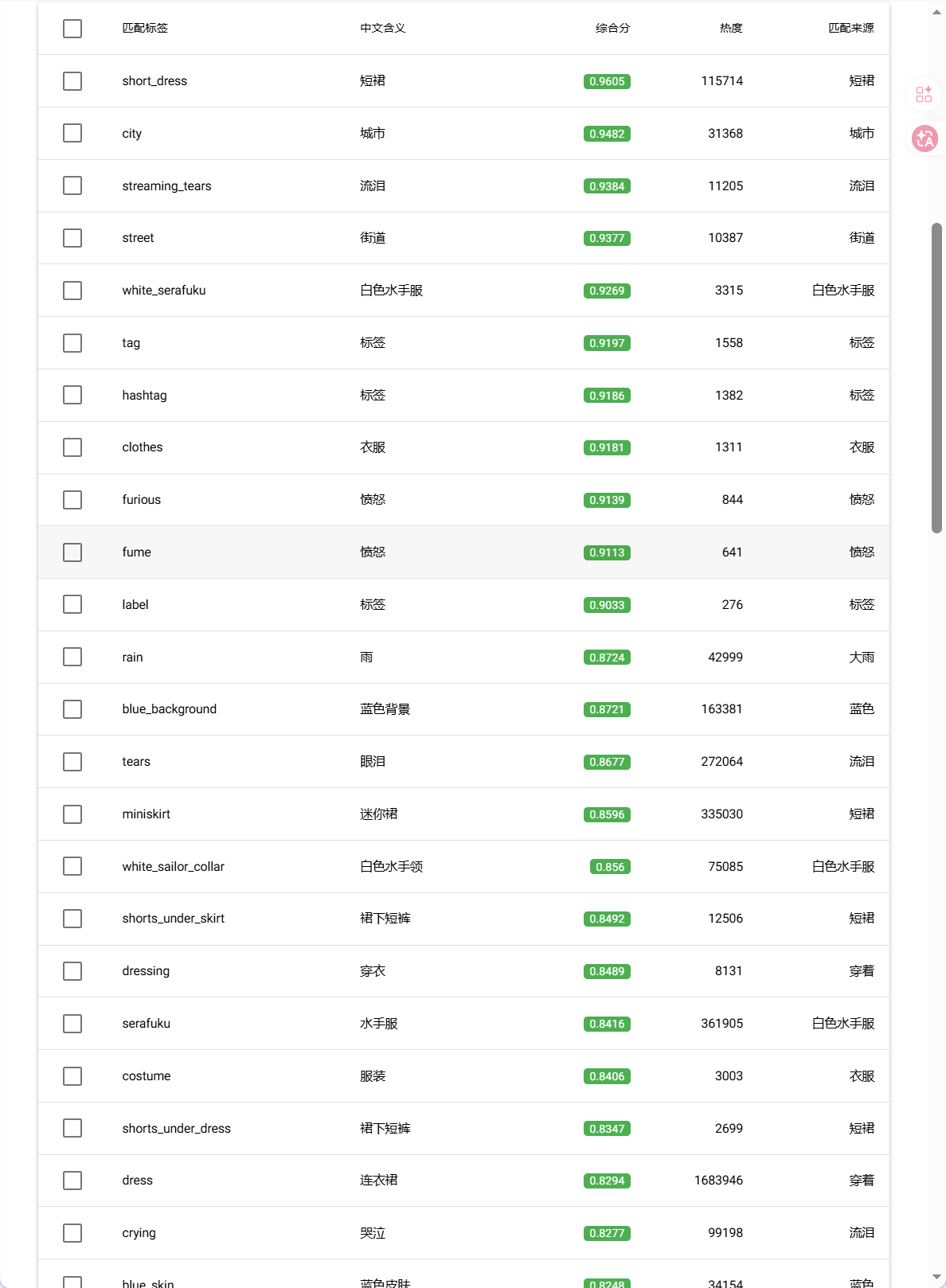
|
| 61 |
+
|
| 62 |
+
#### 关键词精准查找
|
| 63 |
+
|
| 64 |
+
你或许对某个词有模糊的印象,但不知道它对应的danbooru标签具体是什么。此时,你可以使用此程序精确查找。
|
| 65 |
+
|
| 66 |
+
**示例输入**
|
| 67 |
+
|
| 68 |
+
```
|
| 69 |
+
假肢
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
**建议参数**
|
| 73 |
+
|
| 74 |
+
- `top_k`:较小,例如5
|
| 75 |
+
|
| 76 |
+
- `结果上限`:较小,例如10
|
| 77 |
+
|
| 78 |
+
- `热度权重`:0.15
|
| 79 |
+
|
| 80 |
+
**示例输出**
|
| 81 |
+
|
| 82 |
+
```
|
| 83 |
+
running_blades, prosthetic_leg, peg_leg, severed_limb, fake_claws, fake_nails, detached_legs, multiple_legs, separated_legs, alternate_footwear
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
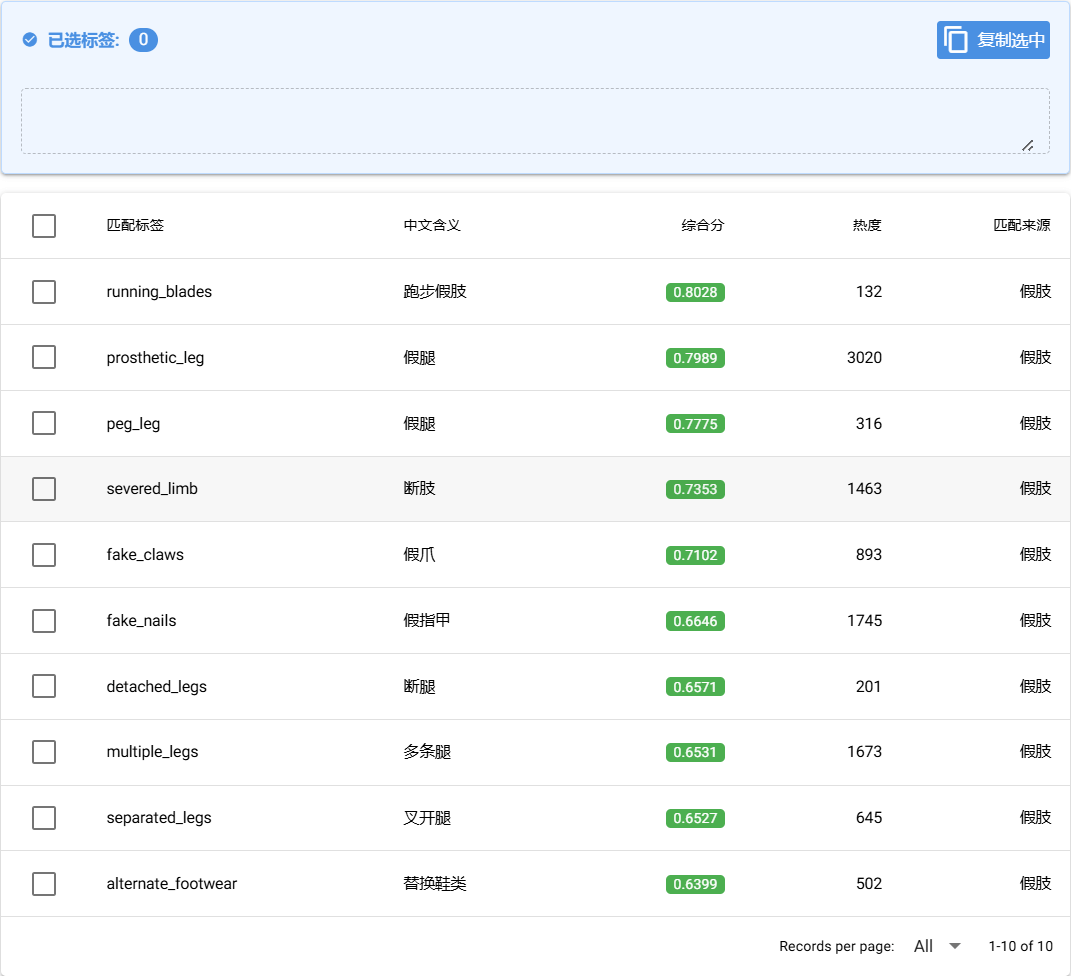
|
| 87 |
+
|
| 88 |
+
#### 概念模糊查找
|
| 89 |
+
|
| 90 |
+
你可能像搜索关于某一个概念的关键词。此时,你可以使用此程序进行概念模糊查找。
|
| 91 |
+
|
| 92 |
+
**示例输入**
|
| 93 |
+
|
| 94 |
+
```
|
| 95 |
+
裙子
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
**建议参数**
|
| 99 |
+
|
| 100 |
+
- `top_k`:较大,例如40
|
| 101 |
+
|
| 102 |
+
- `结果上限`:较大,例如80
|
| 103 |
+
|
| 104 |
+
- `热度权重`:0.15
|
| 105 |
+
|
| 106 |
+
**示例输出**
|
| 107 |
+
|
| 108 |
+
```
|
| 109 |
+
skirt, dress, one_piece, white_skirt, black_skirt, upskirt, skirt_set, long_skirt, long_dress, pink_skirt, skirt_hold, skirt_lift, sweater_dress, skirt_suit, multicolored_skirt, skirt_pull, under_skirt, gown, dress_lift, unworn_skirt, skirt_tug, print_skirt, dress_tug, dress_flower, orange_skirt, flower_skirt, flower_dress, wet_dress, skirt_under_dress, wet_skirt, dress_ribbon, taut_skirt, armored_skirt, culottes, swimsuit_skirt, skort, skirt_rolled_up, dress_flip, skousers, dress_over_shirt, striped_clothes, dress_shirt, sleeveless_dress, undressing, clothes, lingerie, striped_dress, layered_dress, adjusting_clothes, multicolored_dress, clothes_between_thighs, hooded_dress, dressing, layered_clothes, clothes_on_floor, evening_gown, dress_shoes, hand_under_clothes, tearing_clothes, multicolored_clothes, clothed_female_nude_female, clothes_down, ballerina, holding_cloth, changing_clothes, shorts_under_dress, cloth, shirt_under_dress, clothes_on_and_off, folded_clothes, hand_under_dress, clothes_on_shoulders, dress_suit, reflective_clothes, night_clothes
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
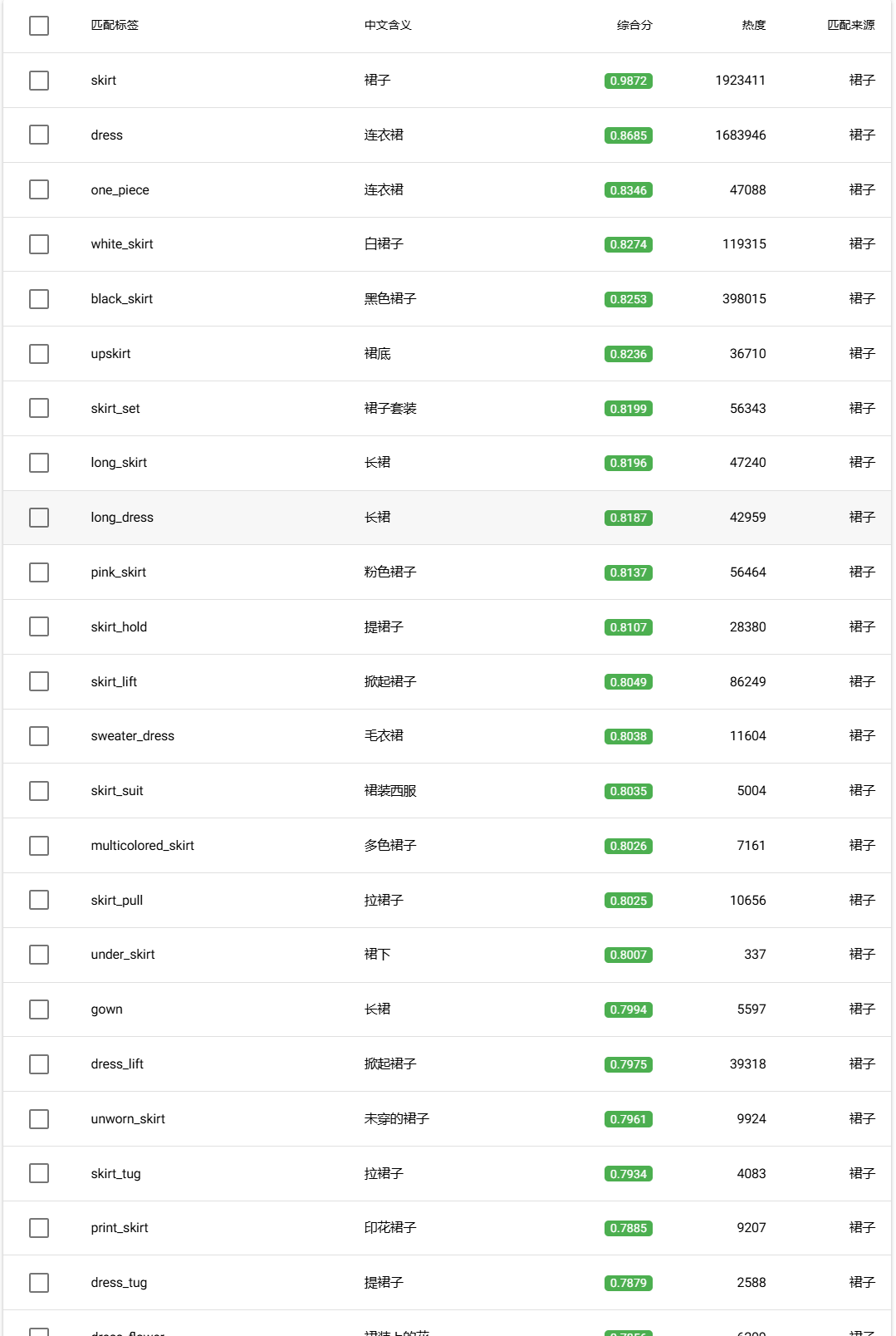
|
danbooru_vectors_multiview_cpu_fp16.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f6e8c5a1bbdf44b6883927d6ab8c9c51f362eec806f84f5ac2686df49febf3d
|
| 3 |
+
size 395689916
|
main.py
ADDED
|
@@ -0,0 +1,701 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
from sentence_transformers import SentenceTransformer, util
|
| 3 |
+
import os
|
| 4 |
+
import pickle
|
| 5 |
+
import jieba
|
| 6 |
+
import numpy as np
|
| 7 |
+
from nicegui import ui, app, run
|
| 8 |
+
import asyncio
|
| 9 |
+
import torch
|
| 10 |
+
import re
|
| 11 |
+
import time
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def is_running_on_huggingface_space():
|
| 15 |
+
return os.environ.get("SPACE_ID") is not None
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# 核心逻辑类 (单例模式)
|
| 19 |
+
class DanbooruTagger:
|
| 20 |
+
_instance = None
|
| 21 |
+
_lock = asyncio.Lock()
|
| 22 |
+
|
| 23 |
+
@classmethod
|
| 24 |
+
async def get_instance(cls):
|
| 25 |
+
"""获取单例,如果未初始化则等待初始化"""
|
| 26 |
+
async with cls._lock:
|
| 27 |
+
if cls._instance is None:
|
| 28 |
+
cls._instance = cls()
|
| 29 |
+
await run.io_bound(cls._instance.load)
|
| 30 |
+
return cls._instance
|
| 31 |
+
|
| 32 |
+
def __init__(self, model_path=None, csv_file='tags_enhanced.csv',
|
| 33 |
+
cache_file='danbooru_vectors_multiview_'):
|
| 34 |
+
|
| 35 |
+
local_model_path = 'my_model_bge_m3'
|
| 36 |
+
hf_model_id = 'BAAI/bge-m3'
|
| 37 |
+
|
| 38 |
+
if model_path:
|
| 39 |
+
self.model_path = model_path
|
| 40 |
+
elif os.path.exists(local_model_path):
|
| 41 |
+
print(f"DTOOL: 检测到本地模型文件夹 '{local_model_path}',将使用本地模型。")
|
| 42 |
+
self.model_path = local_model_path
|
| 43 |
+
else:
|
| 44 |
+
print(f"DTOOL: 未找到本地模型,将使用 HuggingFace ID '{hf_model_id}'。")
|
| 45 |
+
self.model_path = hf_model_id
|
| 46 |
+
|
| 47 |
+
self.csv_path = csv_file
|
| 48 |
+
self.device = 'cpu' if torch.cuda.is_available() else 'cpu'
|
| 49 |
+
# [修改] 更改缓存文件名后缀,避免读取旧缓存报错,触发重新构建
|
| 50 |
+
self.cache_path = cache_file + self.device + '_fp16.pkl'
|
| 51 |
+
|
| 52 |
+
self.model = None
|
| 53 |
+
self.df = None
|
| 54 |
+
self.emb_en = None
|
| 55 |
+
self.emb_cn = None
|
| 56 |
+
self.emb_wiki = None
|
| 57 |
+
self.emb_cn_core = None # [新增] 核心词向量
|
| 58 |
+
|
| 59 |
+
self.max_log_count = 15.0
|
| 60 |
+
self.is_loaded = False
|
| 61 |
+
|
| 62 |
+
# 停用词表
|
| 63 |
+
self.stop_words = {
|
| 64 |
+
',', '.', ':', ';', '?', '!', '"', "'", '`',
|
| 65 |
+
'(', ')', '[', ']', '{', '}', '<', '>',
|
| 66 |
+
'-', '_', '=', '+', '/', '\\', '|', '@', '#', '$', '%', '^', '&', '*', '~',
|
| 67 |
+
',', '。', ':', ';', '?', '!', '“', '”', '‘', '’',
|
| 68 |
+
'(', ')', '【', '】', '《', '》', '、', '…', '—', '·',
|
| 69 |
+
' ', '\t', '\n', '\r',
|
| 70 |
+
'的', '地', '得', '了', '着', '过',
|
| 71 |
+
'是', '为', '被', '给', '把', '让', '由',
|
| 72 |
+
'在', '从', '自', '向', '往', '对', '于',
|
| 73 |
+
'和', '与', '及', '或', '且', '而', '但', '并', '即', '又', '也',
|
| 74 |
+
'啊', '吗', '吧', '呢', '噢', '哦', '哈', '呀', '哇',
|
| 75 |
+
'我', '你', '他', '她', '它', '我们', '你们', '他们',
|
| 76 |
+
'这', '那', '此', '其', '谁', '啥', '某', '每',
|
| 77 |
+
'这个', '那个', '这些', '那些', '这里', '那里',
|
| 78 |
+
'个', '位', '只', '条', '张', '幅', '件', '套', '双', '对', '副',
|
| 79 |
+
'种', '类', '群', '些', '点', '份', '部', '名',
|
| 80 |
+
'很', '太', '更', '最', '挺', '特', '好', '真',
|
| 81 |
+
'一', '一个', '一种', '一下', '一点', '一些',
|
| 82 |
+
'有', '无', '非', '没', '不'
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
# 类型映射表
|
| 86 |
+
self.cat_map = {
|
| 87 |
+
'0': 'General', '1': 'Artist', '3': 'Copyright', '4': 'Character', '5': 'Meta'
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
def load(self):
|
| 91 |
+
if self.is_loaded: return
|
| 92 |
+
t0 = time.time()
|
| 93 |
+
|
| 94 |
+
# 加载缓存
|
| 95 |
+
if not os.path.exists(self.cache_path):
|
| 96 |
+
print("\n" + "=" * 50)
|
| 97 |
+
print("DTOOL: 未找到四视图索引缓存,开始首次构建(这可能需要 1~3 分钟)...")
|
| 98 |
+
print("=" * 50 + "\n")
|
| 99 |
+
self._build_from_csv()
|
| 100 |
+
else:
|
| 101 |
+
print(f"DTOOL: 正在加载缓存索引 ({self.cache_path})...")
|
| 102 |
+
self._load_from_cache()
|
| 103 |
+
|
| 104 |
+
if os.path.exists(self.csv_path):
|
| 105 |
+
self._smart_update()
|
| 106 |
+
|
| 107 |
+
# 模型加载
|
| 108 |
+
if self.model is None:
|
| 109 |
+
self._load_model()
|
| 110 |
+
|
| 111 |
+
self._setup_jieba_from_memory()
|
| 112 |
+
self.is_loaded = True
|
| 113 |
+
print(f"DTOOL: 系统初始化完成,耗时 {time.time() - t0:.2f} 秒")
|
| 114 |
+
|
| 115 |
+
def _load_model(self):
|
| 116 |
+
print(f"DTOOL: 正在加载模型 (路径: {self.model_path}, Device: {self.device})...")
|
| 117 |
+
try:
|
| 118 |
+
self.model = SentenceTransformer(self.model_path, device=self.device)
|
| 119 |
+
except Exception as e:
|
| 120 |
+
print(f"DTOOL: 本地模型加载失败,尝试从 HF 拉取: {e}")
|
| 121 |
+
self.model = SentenceTransformer('BAAI/bge-m3', device=self.device)
|
| 122 |
+
|
| 123 |
+
def _read_csv_robust(self, path):
|
| 124 |
+
for enc in ['utf-8', 'gbk', 'gb18030']:
|
| 125 |
+
try:
|
| 126 |
+
return pd.read_csv(path, dtype=str, encoding=enc).fillna("")
|
| 127 |
+
except UnicodeDecodeError:
|
| 128 |
+
continue
|
| 129 |
+
raise ValueError("CSV 读取失败,请检查编码")
|
| 130 |
+
|
| 131 |
+
def _preprocess_raw_df(self, df):
|
| 132 |
+
df.dropna(subset=['name'], inplace=True)
|
| 133 |
+
df = df[df['name'].str.strip() != '']
|
| 134 |
+
|
| 135 |
+
for col in ['cn_name', 'category', 'wiki', 'nsfw']:
|
| 136 |
+
if col not in df.columns: df[col] = ''
|
| 137 |
+
|
| 138 |
+
df['category'] = df['category'].fillna('0')
|
| 139 |
+
df['nsfw'] = df['nsfw'].fillna('0')
|
| 140 |
+
|
| 141 |
+
for char in [',', '|', '、']:
|
| 142 |
+
df['cn_name'] = df['cn_name'].str.replace(char, ',', regex=False)
|
| 143 |
+
|
| 144 |
+
if 'post_count' not in df.columns: df['post_count'] = 0
|
| 145 |
+
df['post_count'] = pd.to_numeric(df['post_count'], errors='coerce').fillna(0)
|
| 146 |
+
|
| 147 |
+
df['cn_name'] = df['cn_name'].fillna("")
|
| 148 |
+
df['wiki'] = df['wiki'].fillna("")
|
| 149 |
+
|
| 150 |
+
# [新增] 提取 cn_name 的第一个词作为核心词
|
| 151 |
+
# 逻辑:按逗号分割,取第一个,去除首尾空格
|
| 152 |
+
df['cn_core'] = df['cn_name'].str.split(',', n=1).str[0].str.strip()
|
| 153 |
+
df['cn_core'] = df['cn_core'].fillna("")
|
| 154 |
+
|
| 155 |
+
df.drop_duplicates(subset=['name'], inplace=True)
|
| 156 |
+
df.reset_index(drop=True, inplace=True)
|
| 157 |
+
return df
|
| 158 |
+
|
| 159 |
+
def _build_from_csv(self):
|
| 160 |
+
print(f"DTOOL: 正在全量读取 {self.csv_path} ...")
|
| 161 |
+
raw_df = self._read_csv_robust(self.csv_path)
|
| 162 |
+
print("DTOOL: 正在预处理数据...")
|
| 163 |
+
self.df = self._preprocess_raw_df(raw_df)
|
| 164 |
+
self.max_log_count = np.log1p(self.df['post_count'].max())
|
| 165 |
+
self._load_model()
|
| 166 |
+
self._encode_and_save()
|
| 167 |
+
|
| 168 |
+
def _encode_and_save(self):
|
| 169 |
+
print("DTOOL: 正在生成向量索引...")
|
| 170 |
+
|
| 171 |
+
print("DTOOL: 正在生成英文索引...")
|
| 172 |
+
self.emb_en = self.model.encode(self.df['name'].tolist(), batch_size=64, show_progress_bar=True,
|
| 173 |
+
convert_to_tensor=True)
|
| 174 |
+
|
| 175 |
+
print("DTOOL: 正在生成中文扩展索引...")
|
| 176 |
+
self.emb_cn = self.model.encode(self.df['cn_name'].tolist(), batch_size=64, show_progress_bar=True,
|
| 177 |
+
convert_to_tensor=True)
|
| 178 |
+
|
| 179 |
+
print("DTOOL: 正在生成释义索引...")
|
| 180 |
+
self.emb_wiki = self.model.encode(self.df['wiki'].tolist(), batch_size=64, show_progress_bar=True,
|
| 181 |
+
convert_to_tensor=True)
|
| 182 |
+
|
| 183 |
+
print("DTOOL: 正在生成中文核心词索引...")
|
| 184 |
+
self.emb_cn_core = self.model.encode(self.df['cn_core'].tolist(), batch_size=64, show_progress_bar=True,
|
| 185 |
+
convert_to_tensor=True)
|
| 186 |
+
|
| 187 |
+
print("DTOOL: 正在保存 (FP16)...")
|
| 188 |
+
cache_data = {
|
| 189 |
+
'df': self.df,
|
| 190 |
+
'embeddings_en': self.emb_en.half(),
|
| 191 |
+
'embeddings_cn': self.emb_cn.half(),
|
| 192 |
+
'embeddings_wiki': self.emb_wiki.half(),
|
| 193 |
+
'embeddings_cn_core': self.emb_cn_core.half(), # [新增]
|
| 194 |
+
'max_log_count': self.max_log_count
|
| 195 |
+
}
|
| 196 |
+
with open(self.cache_path, 'wb') as f:
|
| 197 |
+
pickle.dump(cache_data, f)
|
| 198 |
+
print("DTOOL: 缓存保存成功!")
|
| 199 |
+
|
| 200 |
+
def _load_from_cache(self):
|
| 201 |
+
with open(self.cache_path, 'rb') as f:
|
| 202 |
+
data = pickle.load(f)
|
| 203 |
+
self.df = data['df']
|
| 204 |
+
self.emb_en = data['embeddings_en'].float()
|
| 205 |
+
self.emb_cn = data['embeddings_cn'].float()
|
| 206 |
+
self.emb_wiki = data.get('embeddings_wiki', torch.zeros_like(self.emb_en)).float()
|
| 207 |
+
self.emb_cn_core = data.get('embeddings_cn_core', torch.zeros_like(self.emb_en)).float()
|
| 208 |
+
self.max_log_count = data.get('max_log_count', 15.0)
|
| 209 |
+
|
| 210 |
+
def _smart_update(self):
|
| 211 |
+
print("DTOOL: 正在检查数据变更...")
|
| 212 |
+
raw_df = self._read_csv_robust(self.csv_path)
|
| 213 |
+
compare_df = raw_df.copy()
|
| 214 |
+
|
| 215 |
+
for col in ['cn_name', 'wiki', 'nsfw']:
|
| 216 |
+
if col not in compare_df.columns: compare_df[col] = ""
|
| 217 |
+
compare_df[col] = compare_df[col].fillna("")
|
| 218 |
+
|
| 219 |
+
for char in [',', '|', '、']:
|
| 220 |
+
compare_df['cn_name'] = compare_df['cn_name'].str.replace(char, ',', regex=False)
|
| 221 |
+
|
| 222 |
+
current_map = {}
|
| 223 |
+
for _, row in compare_df.iterrows():
|
| 224 |
+
current_map[row['name']] = (row['cn_name'], row['wiki'], row['nsfw'])
|
| 225 |
+
|
| 226 |
+
cached_df = self.df
|
| 227 |
+
cached_map = {}
|
| 228 |
+
has_wiki = 'wiki' in cached_df.columns
|
| 229 |
+
has_nsfw = 'nsfw' in cached_df.columns
|
| 230 |
+
for _, row in cached_df.iterrows():
|
| 231 |
+
w = row['wiki'] if has_wiki else ""
|
| 232 |
+
n = row['nsfw'] if has_nsfw else "0"
|
| 233 |
+
cached_map[row['name']] = (row['cn_name'], w, n)
|
| 234 |
+
|
| 235 |
+
new_tags = []
|
| 236 |
+
changed_tags = []
|
| 237 |
+
|
| 238 |
+
for name, new_tuple in current_map.items():
|
| 239 |
+
if name not in cached_map:
|
| 240 |
+
new_tags.append(name)
|
| 241 |
+
else:
|
| 242 |
+
if new_tuple != cached_map[name]:
|
| 243 |
+
changed_tags.append(name)
|
| 244 |
+
|
| 245 |
+
if not new_tags and not changed_tags:
|
| 246 |
+
print("DTOOL: 数据已是最新。")
|
| 247 |
+
return
|
| 248 |
+
|
| 249 |
+
print(f"DTOOL: 检测到变更 -> 新增: {len(new_tags)}, 修改: {len(changed_tags)}")
|
| 250 |
+
print("DTOOL: 检测到数据变���,触发重建索引...")
|
| 251 |
+
self._build_from_csv()
|
| 252 |
+
|
| 253 |
+
def _setup_jieba_from_memory(self):
|
| 254 |
+
print("DTOOL: 正在从内存构建 Jieba 词典...")
|
| 255 |
+
if self.df is not None:
|
| 256 |
+
target_col = 'cn_name'
|
| 257 |
+
texts = self.df[target_col].dropna().astype(str).tolist()
|
| 258 |
+
unique_words = set()
|
| 259 |
+
for text in texts:
|
| 260 |
+
parts = text.replace(',', ' ').split()
|
| 261 |
+
for part in parts:
|
| 262 |
+
part = part.strip()
|
| 263 |
+
if len(part) > 1: unique_words.add(part)
|
| 264 |
+
for word in unique_words:
|
| 265 |
+
jieba.add_word(word, 2000)
|
| 266 |
+
|
| 267 |
+
def _smart_split(self, text):
|
| 268 |
+
tokens = []
|
| 269 |
+
chunks = re.split(r'([\u4e00-\u9fa5]+)', text)
|
| 270 |
+
for chunk in chunks:
|
| 271 |
+
if not chunk.strip(): continue
|
| 272 |
+
if re.match(r'[\u4e00-\u9fa5]+', chunk):
|
| 273 |
+
tokens.extend(jieba.cut(chunk))
|
| 274 |
+
else:
|
| 275 |
+
cleaned = re.sub(r'[,()\[\]{}:]', ' ', chunk)
|
| 276 |
+
parts = cleaned.split()
|
| 277 |
+
for part in parts:
|
| 278 |
+
try:
|
| 279 |
+
float(part)
|
| 280 |
+
except ValueError:
|
| 281 |
+
tokens.append(part)
|
| 282 |
+
return tokens
|
| 283 |
+
|
| 284 |
+
def search(self, user_query, top_k=5, limit=80, popularity_weight=0.15, show_nsfw=False,
|
| 285 |
+
use_segmentation=True, target_layers=None, target_categories=None):
|
| 286 |
+
if not self.is_loaded: self.load()
|
| 287 |
+
|
| 288 |
+
if target_layers is None: target_layers = ['英文', '中文扩展词', '释义', '中文核心词']
|
| 289 |
+
if target_categories is None: target_categories = ['General', 'Character', 'Copyright']
|
| 290 |
+
|
| 291 |
+
if use_segmentation:
|
| 292 |
+
raw_keywords = self._smart_split(user_query)
|
| 293 |
+
keywords = [w.strip() for w in raw_keywords if w.strip() and w.strip() not in self.stop_words]
|
| 294 |
+
search_queries = [user_query] + keywords
|
| 295 |
+
else:
|
| 296 |
+
keywords = []
|
| 297 |
+
search_queries = [user_query]
|
| 298 |
+
|
| 299 |
+
query_embeddings = self.model.encode(search_queries, convert_to_tensor=True).float()
|
| 300 |
+
|
| 301 |
+
empty_hits = [[] for _ in search_queries]
|
| 302 |
+
hits_en = util.semantic_search(query_embeddings, self.emb_en,
|
| 303 |
+
top_k=top_k) if '英文' in target_layers else empty_hits
|
| 304 |
+
hits_cn = util.semantic_search(query_embeddings, self.emb_cn,
|
| 305 |
+
top_k=top_k) if '中文扩展词' in target_layers else empty_hits
|
| 306 |
+
hits_wiki = util.semantic_search(query_embeddings, self.emb_wiki,
|
| 307 |
+
top_k=top_k) if '释义' in target_layers else empty_hits
|
| 308 |
+
hits_cn_core = util.semantic_search(query_embeddings, self.emb_cn_core,
|
| 309 |
+
top_k=top_k) if '中文核心词' in target_layers else empty_hits
|
| 310 |
+
|
| 311 |
+
final_results = {}
|
| 312 |
+
|
| 313 |
+
for i, _ in enumerate(search_queries):
|
| 314 |
+
source_word = search_queries[i]
|
| 315 |
+
combined = []
|
| 316 |
+
for h in hits_en[i]: combined.append((h, '英文'))
|
| 317 |
+
for h in hits_cn[i]: combined.append((h, '中文扩展词'))
|
| 318 |
+
for h in hits_wiki[i]: combined.append((h, '释义'))
|
| 319 |
+
for h in hits_cn_core[i]: combined.append((h, '中文核心词'))
|
| 320 |
+
|
| 321 |
+
for hit, layer in combined:
|
| 322 |
+
score = hit['score']
|
| 323 |
+
if score < 0.35: continue
|
| 324 |
+
|
| 325 |
+
idx = hit['corpus_id']
|
| 326 |
+
row = self.df.iloc[idx]
|
| 327 |
+
|
| 328 |
+
nsfw_flag = str(row.get('nsfw', '0'))
|
| 329 |
+
if not show_nsfw and nsfw_flag == '1': continue
|
| 330 |
+
|
| 331 |
+
cat_val = str(row.get('category', '0'))
|
| 332 |
+
cat_text = self.cat_map.get(cat_val, 'Other')
|
| 333 |
+
if cat_text not in target_categories: continue
|
| 334 |
+
|
| 335 |
+
tag_name = row['name']
|
| 336 |
+
count = row['post_count']
|
| 337 |
+
|
| 338 |
+
log_count = np.log1p(count)
|
| 339 |
+
pop_score = log_count / self.max_log_count
|
| 340 |
+
final_score = (score * (1 - popularity_weight)) + (pop_score * popularity_weight)
|
| 341 |
+
|
| 342 |
+
if tag_name not in final_results or final_score > final_results[tag_name]['final_score']:
|
| 343 |
+
final_results[tag_name] = {
|
| 344 |
+
'tag': tag_name,
|
| 345 |
+
'final_score': round(float(final_score), 4),
|
| 346 |
+
'semantic_score': round(float(score), 4),
|
| 347 |
+
'cn_name': row['cn_name'],
|
| 348 |
+
'count': int(count),
|
| 349 |
+
'source': source_word,
|
| 350 |
+
'layer': layer,
|
| 351 |
+
'category': cat_text,
|
| 352 |
+
'nsfw': nsfw_flag,
|
| 353 |
+
'wiki': str(row.get('wiki', ''))
|
| 354 |
+
}
|
| 355 |
+
|
| 356 |
+
sorted_tags = sorted(final_results.items(), key=lambda x: x[1]['final_score'], reverse=True)
|
| 357 |
+
valid_tags = [item[1] for item in sorted_tags if item[1]['final_score'] > 0.45]
|
| 358 |
+
|
| 359 |
+
if len(valid_tags) > limit:
|
| 360 |
+
valid_tags = valid_tags[:limit]
|
| 361 |
+
|
| 362 |
+
tag_string = ", ".join([item['tag'] for item in valid_tags])
|
| 363 |
+
|
| 364 |
+
return tag_string, valid_tags, keywords
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
# NiceGUI 界面
|
| 368 |
+
|
| 369 |
+
# 定义基础列
|
| 370 |
+
base_columns = [
|
| 371 |
+
{'name': 'tag', 'label': '匹配标签', 'field': 'tag', 'align': 'left', 'sortable': True},
|
| 372 |
+
{'name': 'cn_name', 'label': '含义', 'field': 'cn_name', 'align': 'left'},
|
| 373 |
+
{'name': 'category', 'label': '类型', 'field': 'category', 'align': 'left', 'sortable': True},
|
| 374 |
+
{'name': 'nsfw', 'label': '分级', 'field': 'nsfw', 'align': 'center', 'sortable': True},
|
| 375 |
+
{'name': 'final_score', 'label': '综合分', 'field': 'final_score', 'sortable': True},
|
| 376 |
+
{'name': 'count', 'label': '热度', 'field': 'count', 'sortable': True},
|
| 377 |
+
]
|
| 378 |
+
|
| 379 |
+
# 定义可选列
|
| 380 |
+
optional_col_map = {
|
| 381 |
+
'semantic': {'name': 'semantic_score', 'label': '语义分', 'field': 'semantic_score', 'sortable': True},
|
| 382 |
+
'layer': {'name': 'layer', 'label': '匹配层', 'field': 'layer'},
|
| 383 |
+
'source': {'name': 'source', 'label': '匹配来源', 'field': 'source'},
|
| 384 |
+
}
|
| 385 |
+
|
| 386 |
+
|
| 387 |
+
@ui.page('/')
|
| 388 |
+
async def main_page():
|
| 389 |
+
ui.colors(primary='#4A90E2', secondary='#5E6C84', accent='#FF6B6B')
|
| 390 |
+
|
| 391 |
+
full_table_data = []
|
| 392 |
+
current_query_str = ""
|
| 393 |
+
|
| 394 |
+
# 提示区
|
| 395 |
+
with ui.card().classes('w-full max-w-6xl mx-auto bg-orange-50 border-l-4 border-orange-500 mb-2'):
|
| 396 |
+
with ui.column().classes('gap-1'):
|
| 397 |
+
ui.label('⚠️ 注意事项 / Note').classes('text-lg font-bold text-orange-800')
|
| 398 |
+
ui.markdown("""
|
| 399 |
+
- **本网站为AI工具,其结果未必正确无误** (Results may contain errors)
|
| 400 |
+
- **查找结果可能会包括 NSFW 内容** (Results may include NSFW content)
|
| 401 |
+
- **仅支持汉语、英语查找** (Only supports Chinese/English)
|
| 402 |
+
- **仅显示Danbooru频数超过100的标签** (Frequency >= 100)
|
| 403 |
+
- **仅显示特征、角色、作品标签** (General Character and Copyright tags only)
|
| 404 |
+
- **Comfy UI 插件地址** : https://github.com/SuzumiyaAkizuki/ComfyUI-DanbooruSearcher
|
| 405 |
+
""").classes('text-sm text-gray-800 ml-4')
|
| 406 |
+
|
| 407 |
+
# 主体
|
| 408 |
+
with ui.column().classes('w-full max-w-6xl mx-auto p-4 gap-6'):
|
| 409 |
+
with ui.row().classes('items-center gap-2'):
|
| 410 |
+
ui.icon('search', size='2em', color='primary')
|
| 411 |
+
ui.label('Danbooru 标签模糊搜索').classes('text-2xl font-bold text-gray-800')
|
| 412 |
+
|
| 413 |
+
# 基础控制面板
|
| 414 |
+
with ui.card().classes('w-full'):
|
| 415 |
+
with ui.grid(columns=4).classes('w-full gap-8 items-center'):
|
| 416 |
+
input_top_k = ui.number('Top K (语义相关)', value=5, min=1, max=50) \
|
| 417 |
+
.props('outlined dense suffix="个"').classes('w-full')
|
| 418 |
+
|
| 419 |
+
input_limit = ui.number('结果上限', value=80, min=10, max=500) \
|
| 420 |
+
.props('outlined dense suffix="个"').classes('w-full')
|
| 421 |
+
|
| 422 |
+
with ui.column().classes('gap-0'):
|
| 423 |
+
with ui.row().classes('w-full justify-between'):
|
| 424 |
+
ui.label('热度权重').classes('text-xs text-gray-500')
|
| 425 |
+
ui.label().bind_text_from(input_weight := ui.slider(min=0.0, max=1.0, value=0.15, step=0.05),
|
| 426 |
+
'value', lambda v: f"{v:.2f}")
|
| 427 |
+
input_weight.classes('w-full')
|
| 428 |
+
|
| 429 |
+
input_nsfw = ui.switch('显示 NSFW', value=False).props('color=red').classes('w-full')
|
| 430 |
+
|
| 431 |
+
# 高级设置面板
|
| 432 |
+
with ui.expansion('高级设置 (Advanced Settings)', icon='tune').classes('w-full bg-gray-50 border rounded-lg'):
|
| 433 |
+
with ui.column().classes('w-full p-4 gap-4'):
|
| 434 |
+
|
| 435 |
+
# 分词开关
|
| 436 |
+
input_segment = ui.switch('启用智能分词 (Segmentation)', value=True).props('color=primary')
|
| 437 |
+
ui.label('关闭后系统将只匹配完整句子,适用于精准搜索整句。').classes('text-xs text-gray-500 -mt-2 ml-10')
|
| 438 |
+
|
| 439 |
+
ui.separator()
|
| 440 |
+
|
| 441 |
+
# 匹配层筛选
|
| 442 |
+
ui.label('匹配层筛选 (Target Layers):').classes('font-bold text-gray-700')
|
| 443 |
+
with ui.row().classes('gap-4'):
|
| 444 |
+
layer_options = ['英文', '中文扩展词', '释义', '中文核心词']
|
| 445 |
+
selected_layers = {layer: True for layer in layer_options}
|
| 446 |
+
|
| 447 |
+
def toggle_layer(l, value): selected_layers[l] = value
|
| 448 |
+
|
| 449 |
+
for layer in layer_options:
|
| 450 |
+
ui.checkbox(layer, value=True, on_change=lambda e, l=layer: toggle_layer(l, e.value))
|
| 451 |
+
|
| 452 |
+
ui.separator()
|
| 453 |
+
|
| 454 |
+
# 类型筛选
|
| 455 |
+
ui.label('标签类型筛选 (Categories):').classes('font-bold text-gray-700')
|
| 456 |
+
with ui.row().classes('gap-4 flex-wrap'):
|
| 457 |
+
cat_options = ['General', 'Copyright', 'Character']
|
| 458 |
+
selected_cats = {cat: True for cat in cat_options}
|
| 459 |
+
|
| 460 |
+
def toggle_cat(c, value): selected_cats[c] = value
|
| 461 |
+
|
| 462 |
+
for cat in cat_options:
|
| 463 |
+
color_map = {'General': 'blue', 'Copyright': 'pink', 'Character': 'green'}
|
| 464 |
+
ui.checkbox(cat, value=True, on_change=lambda e, c=cat: toggle_cat(c, e.value)) \
|
| 465 |
+
.props(f'color={color_map.get(cat, "primary")}')
|
| 466 |
+
|
| 467 |
+
ui.separator()
|
| 468 |
+
|
| 469 |
+
# 表格显示选项
|
| 470 |
+
ui.label('表格显示选项 (Display Options):').classes('font-bold text-gray-700')
|
| 471 |
+
with ui.row().classes('gap-6'):
|
| 472 |
+
sw_semantic = ui.switch('显示语义分', value=False)
|
| 473 |
+
sw_layer = ui.switch('显示匹配层', value=False)
|
| 474 |
+
sw_source = ui.switch('显示匹配来源', value=False)
|
| 475 |
+
|
| 476 |
+
# 动态更新表格列
|
| 477 |
+
def update_table_columns():
|
| 478 |
+
cols = list(base_columns) # 复制基础列
|
| 479 |
+
if sw_semantic.value: cols.append(optional_col_map['semantic'])
|
| 480 |
+
if sw_layer.value: cols.append(optional_col_map['layer'])
|
| 481 |
+
if sw_source.value: cols.append(optional_col_map['source'])
|
| 482 |
+
result_table.columns = cols
|
| 483 |
+
|
| 484 |
+
sw_semantic.on('update:model-value', update_table_columns)
|
| 485 |
+
sw_layer.on('update:model-value', update_table_columns)
|
| 486 |
+
sw_source.on('update:model-value', update_table_columns)
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
# 搜索输入区
|
| 490 |
+
with ui.card().classes('w-full p-0 overflow-hidden'):
|
| 491 |
+
with ui.column().classes('w-full p-6 gap-4'):
|
| 492 |
+
ui.label('画面描述').classes('text-lg font-bold text-gray-700')
|
| 493 |
+
search_input = ui.textarea(placeholder='例如:一个穿着白色水手服的女孩在雨中奔跑').classes(
|
| 494 |
+
'w-full text-lg').props('outlined rows=3')
|
| 495 |
+
|
| 496 |
+
keywords_container = ui.row().classes('gap-2 items-center')
|
| 497 |
+
spinner = ui.spinner(size='2em').classes('hidden')
|
| 498 |
+
|
| 499 |
+
def filter_table_by_source(keyword):
|
| 500 |
+
if not keyword or keyword == 'ALL':
|
| 501 |
+
result_table.rows = full_table_data
|
| 502 |
+
else:
|
| 503 |
+
result_table.rows = [row for row in full_table_data if row['source'] == keyword]
|
| 504 |
+
|
| 505 |
+
for child in keywords_container.default_slot.children:
|
| 506 |
+
if isinstance(child, ui.chip):
|
| 507 |
+
is_selected = False
|
| 508 |
+
if keyword == 'ALL' and child.text == '全部':
|
| 509 |
+
is_selected = True
|
| 510 |
+
elif keyword == current_query_str and child.text == '整句':
|
| 511 |
+
is_selected = True
|
| 512 |
+
elif child.text == keyword:
|
| 513 |
+
is_selected = True
|
| 514 |
+
|
| 515 |
+
child.props(
|
| 516 |
+
f'color={"primary" if is_selected else "grey-4"} text-color={"white" if is_selected else "black"}')
|
| 517 |
+
|
| 518 |
+
async def perform_search():
|
| 519 |
+
nonlocal full_table_data, current_query_str
|
| 520 |
+
query = search_input.value.strip()
|
| 521 |
+
if not query: return
|
| 522 |
+
|
| 523 |
+
current_query_str = query
|
| 524 |
+
search_btn.disable()
|
| 525 |
+
spinner.classes(remove='hidden')
|
| 526 |
+
ui.notify('正在搜索...', type='info')
|
| 527 |
+
|
| 528 |
+
target_layers_list = [k for k, v in selected_layers.items() if v]
|
| 529 |
+
target_cats_list = [k for k, v in selected_cats.items() if v]
|
| 530 |
+
|
| 531 |
+
if not target_layers_list:
|
| 532 |
+
ui.notify('请至少选择一个匹配层!', type='warning')
|
| 533 |
+
search_btn.enable()
|
| 534 |
+
spinner.classes(add='hidden')
|
| 535 |
+
return
|
| 536 |
+
|
| 537 |
+
try:
|
| 538 |
+
tagger = await DanbooruTagger.get_instance()
|
| 539 |
+
|
| 540 |
+
tags_str, table_data, keywords = await run.io_bound(
|
| 541 |
+
tagger.search,
|
| 542 |
+
query,
|
| 543 |
+
int(input_top_k.value),
|
| 544 |
+
int(input_limit.value),
|
| 545 |
+
float(input_weight.value),
|
| 546 |
+
input_nsfw.value,
|
| 547 |
+
input_segment.value,
|
| 548 |
+
target_layers_list,
|
| 549 |
+
target_cats_list
|
| 550 |
+
)
|
| 551 |
+
|
| 552 |
+
full_table_data = table_data
|
| 553 |
+
|
| 554 |
+
all_result_area.value = tags_str
|
| 555 |
+
result_table.rows = table_data
|
| 556 |
+
result_table.selected = []
|
| 557 |
+
update_selection_display(None)
|
| 558 |
+
|
| 559 |
+
keywords_container.clear()
|
| 560 |
+
with keywords_container:
|
| 561 |
+
ui.label('分词筛选:').classes('text-sm text-gray-500 font-bold mr-2')
|
| 562 |
+
ui.chip('全部', on_click=lambda: filter_table_by_source('ALL')) \
|
| 563 |
+
.props('color=primary text-color=white clickable')
|
| 564 |
+
|
| 565 |
+
if input_segment.value:
|
| 566 |
+
ui.chip('整句', on_click=lambda: filter_table_by_source(current_query_str)) \
|
| 567 |
+
.props('color=grey-4 text-color=black clickable')
|
| 568 |
+
for kw in keywords:
|
| 569 |
+
ui.chip(kw, on_click=lambda k=kw: filter_table_by_source(k)) \
|
| 570 |
+
.props('color=grey-4 text-color=black clickable')
|
| 571 |
+
else:
|
| 572 |
+
ui.label('(分词已关闭)').classes('text-xs text-gray-400')
|
| 573 |
+
|
| 574 |
+
ui.notify(f'找到 {len(table_data)} 个标签', type='positive')
|
| 575 |
+
|
| 576 |
+
except Exception as e:
|
| 577 |
+
ui.notify(f'错误: {str(e)}', type='negative')
|
| 578 |
+
finally:
|
| 579 |
+
search_btn.enable()
|
| 580 |
+
spinner.classes(add='hidden')
|
| 581 |
+
|
| 582 |
+
with ui.row().classes('w-full justify-end items-center gap-4'):
|
| 583 |
+
spinner
|
| 584 |
+
search_btn = ui.button('开始搜索', on_click=perform_search, icon='search')
|
| 585 |
+
search_btn.classes('px-8 py-2 text-lg').props('unelevated color=primary')
|
| 586 |
+
|
| 587 |
+
search_input.on('keydown.ctrl.enter', perform_search)
|
| 588 |
+
|
| 589 |
+
# 结果表格
|
| 590 |
+
with ui.row().classes('w-full gap-6'):
|
| 591 |
+
with ui.card().classes('w-1/3 flex-grow'):
|
| 592 |
+
ui.label('推荐 Prompt (全部)').classes('font-bold text-gray-600')
|
| 593 |
+
all_result_area = ui.textarea().classes('w-full h-full bg-gray-50').props(
|
| 594 |
+
'readonly outlined input-class=text-sm')
|
| 595 |
+
|
| 596 |
+
with ui.column().classes('w-2/3 flex-grow'):
|
| 597 |
+
with ui.card().classes('w-full bg-blue-50 border-blue-200 border'):
|
| 598 |
+
with ui.row().classes('w-full items-center justify-between'):
|
| 599 |
+
with ui.row().classes('items-center gap-2'):
|
| 600 |
+
ui.icon('check_circle', color='primary')
|
| 601 |
+
ui.label('已选标签:').classes('font-bold text-primary')
|
| 602 |
+
selection_count_label = ui.label('0').classes(
|
| 603 |
+
'bg-primary text-white px-2 rounded-full text-sm')
|
| 604 |
+
copy_btn = ui.button('复制选中', icon='content_copy').props('dense unelevated color=primary')
|
| 605 |
+
|
| 606 |
+
selected_display = ui.textarea().classes('w-full mt-2').props(
|
| 607 |
+
'outlined dense rows=2 readonly bg-white')
|
| 608 |
+
|
| 609 |
+
def copy_selection():
|
| 610 |
+
ui.clipboard.write(selected_display.value)
|
| 611 |
+
ui.notify('已复制选中标签!', type='positive')
|
| 612 |
+
|
| 613 |
+
copy_btn.on_click(copy_selection)
|
| 614 |
+
|
| 615 |
+
def update_selection_display(e):
|
| 616 |
+
selected_rows = result_table.selected
|
| 617 |
+
tags = [row['tag'] for row in selected_rows]
|
| 618 |
+
selected_display.value = ", ".join(tags)
|
| 619 |
+
selection_count_label.text = str(len(tags))
|
| 620 |
+
|
| 621 |
+
result_table = ui.table(
|
| 622 |
+
columns=base_columns,
|
| 623 |
+
rows=[],
|
| 624 |
+
pagination=10,
|
| 625 |
+
selection='multiple',
|
| 626 |
+
row_key='tag'
|
| 627 |
+
).classes('w-full')
|
| 628 |
+
|
| 629 |
+
result_table.on('selection', update_selection_display)
|
| 630 |
+
|
| 631 |
+
result_table.add_slot('body-cell-final_score', '''
|
| 632 |
+
<q-td :props="props">
|
| 633 |
+
<q-badge :color="props.value > 0.6 ? 'green' : (props.value > 0.5 ? 'teal' : 'orange')">
|
| 634 |
+
{{ props.value }}
|
| 635 |
+
</q-badge>
|
| 636 |
+
</q-td>
|
| 637 |
+
''')
|
| 638 |
+
|
| 639 |
+
result_table.add_slot('body-cell-category', '''
|
| 640 |
+
<q-td :props="props">
|
| 641 |
+
<q-badge :color="
|
| 642 |
+
props.value === 'General' ? 'blue' :
|
| 643 |
+
(props.value === 'Character' ? 'green' :
|
| 644 |
+
(props.value === 'Copyright' ? 'pink' : 'red'))
|
| 645 |
+
" outline>
|
| 646 |
+
{{ props.value }}
|
| 647 |
+
</q-badge>
|
| 648 |
+
</q-td>
|
| 649 |
+
''')
|
| 650 |
+
|
| 651 |
+
result_table.add_slot('body-cell-nsfw', '''
|
| 652 |
+
<q-td :props="props">
|
| 653 |
+
<div v-if="props.value === '1'" title="NSFW Content" class="text-red-500">🔴</div>
|
| 654 |
+
<div v-else class="text-green-500">🟢</div>
|
| 655 |
+
</q-td>
|
| 656 |
+
''')
|
| 657 |
+
|
| 658 |
+
# 4. 中文含义分词显示 + 悬停显示 Wiki (修复字体大小问题)
|
| 659 |
+
result_table.add_slot('body-cell-cn_name', '''
|
| 660 |
+
<q-td :props="props">
|
| 661 |
+
<template v-if="props.value">
|
| 662 |
+
<q-badge
|
| 663 |
+
v-for="(item, index) in props.value.split(',')"
|
| 664 |
+
:key="index"
|
| 665 |
+
:color="index === 0 ? 'black' : 'grey'"
|
| 666 |
+
outline
|
| 667 |
+
style="font-size: 14px"
|
| 668 |
+
class="q-mr-xs q-mb-xs cursor-help"
|
| 669 |
+
>
|
| 670 |
+
{{ item }}
|
| 671 |
+
</q-badge>
|
| 672 |
+
</template>
|
| 673 |
+
<q-tooltip
|
| 674 |
+
v-if="props.row.wiki"
|
| 675 |
+
content-class="bg-black text-white shadow-4"
|
| 676 |
+
max-width="500px"
|
| 677 |
+
:offset="[10, 10]"
|
| 678 |
+
>
|
| 679 |
+
<div style="font-size: 14px; line-height: 1.5;">
|
| 680 |
+
{{ props.row.wiki }}
|
| 681 |
+
</div>
|
| 682 |
+
</q-tooltip>
|
| 683 |
+
</q-td>
|
| 684 |
+
''')
|
| 685 |
+
|
| 686 |
+
|
| 687 |
+
if __name__ in {"__main__", "__mp_main__"}:
|
| 688 |
+
if is_running_on_huggingface_space():
|
| 689 |
+
host = '0.0.0.0'
|
| 690 |
+
port = 7860
|
| 691 |
+
else:
|
| 692 |
+
host = '127.0.0.1'
|
| 693 |
+
port = 1145
|
| 694 |
+
|
| 695 |
+
ui.run(
|
| 696 |
+
host=host,
|
| 697 |
+
port=port,
|
| 698 |
+
title='Danbooru Tags Searcher',
|
| 699 |
+
reload=True,
|
| 700 |
+
show=True
|
| 701 |
+
)
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
nicegui
|
| 2 |
+
pandas
|
| 3 |
+
sentence-transformers
|
| 4 |
+
torch
|
| 5 |
+
jieba
|
tags_enhanced.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|