Spaces:
Runtime error

Runtime error
GitHub Actions commited on
Commit ·
fda0b63
1
Parent(s): 45235e6
Auto-deploy from GitHub Actions
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- app/__init__.py +1 -3
- hf_space/Dockerfile +3 -2
- hf_space/hf_space/app.py +1 -19
- hf_space/hf_space/app/__init__.py +3 -1
- hf_space/hf_space/app/main.py +11 -1
- hf_space/hf_space/app_entry.py +19 -0
- hf_space/hf_space/hf_space/Dockerfile +1 -1
- hf_space/hf_space/hf_space/README.md +17 -8
- hf_space/hf_space/hf_space/hf_space/.gitattributes +2 -33
- hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy-assets.yml +69 -0
- hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy.yml +4 -0
- hf_space/hf_space/hf_space/hf_space/.gitignore +3 -1
- hf_space/hf_space/hf_space/hf_space/app.py +25 -0
- hf_space/hf_space/hf_space/hf_space/app/main.py +190 -13
- hf_space/hf_space/hf_space/hf_space/gradio_app.py +96 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/README.md +136 -18
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/README.md +13 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/drift_report.html +140 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/logs_storage.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/AMT_ANNUITY.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/AMT_CREDIT.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/AMT_GOODS_PRICE.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/CODE_GENDER.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/DAYS_BIRTH.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/DAYS_EMPLOYED.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/EXT_SOURCE_1.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/EXT_SOURCE_2.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/EXT_SOURCE_3.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/FLAG_OWN_CAR.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/prediction_rate.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/score_distribution.png +0 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/predictions_sample.jsonl +2 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/runbook.md +28 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/performance/benchmark_results.json +20 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/performance/performance_report.md +50 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/docs/performance/profile_summary.txt +38 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy.yml +7 -5
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.gitignore +2 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app/main.py +374 -32
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/README.md +141 -25
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.dockerignore +6 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy.yml +54 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.gitignore +194 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/LICENSE +8 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app/__init__.py +1 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app/main.py +828 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.gitattributes +35 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/Dockerfile +17 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/README.md +192 -0
- hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app.py +0 -0
app/__init__.py
CHANGED
|
@@ -1,3 +1 @@
|
|
| 1 |
-
"""
|
| 2 |
-
|
| 3 |
-
from app_entry import app, demo # re-export for uvicorn app:app
|
|
|
|
| 1 |
+
"""Package marker for the FastAPI app package."""
|
|
|
|
|
|
hf_space/Dockerfile
CHANGED
|
@@ -9,8 +9,9 @@ COPY requirements.txt .
|
|
| 9 |
RUN pip install --no-cache-dir -r requirements.txt
|
| 10 |
|
| 11 |
COPY app/ app/
|
| 12 |
-
COPY
|
| 13 |
-
COPY
|
|
|
|
| 14 |
|
| 15 |
EXPOSE 7860
|
| 16 |
|
|
|
|
| 9 |
RUN pip install --no-cache-dir -r requirements.txt
|
| 10 |
|
| 11 |
COPY app/ app/
|
| 12 |
+
COPY app_entry.py app.py gradio_app.py ./
|
| 13 |
+
COPY data/ data/
|
| 14 |
+
COPY artifacts/ artifacts/
|
| 15 |
|
| 16 |
EXPOSE 7860
|
| 17 |
|
hf_space/hf_space/app.py
CHANGED
|
@@ -1,22 +1,4 @@
|
|
| 1 |
-
from
|
| 2 |
-
import gradio as gr
|
| 3 |
-
|
| 4 |
-
from app.main import app as api_app
|
| 5 |
-
from app.main import startup_event
|
| 6 |
-
from gradio_app import demo
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
root_app = FastAPI()
|
| 10 |
-
root_app.mount("/api", api_app)
|
| 11 |
-
root_app = gr.mount_gradio_app(root_app, demo, path="/")
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
@root_app.on_event("startup")
|
| 15 |
-
def _startup() -> None:
|
| 16 |
-
startup_event()
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
app = root_app
|
| 20 |
|
| 21 |
|
| 22 |
if __name__ == "__main__":
|
|
|
|
| 1 |
+
from app_entry import app, demo # re-export for HF Spaces
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
|
| 4 |
if __name__ == "__main__":
|
hf_space/hf_space/app/__init__.py
CHANGED
|
@@ -1 +1,3 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Expose combined ASGI app for HF Spaces default loader."""
|
| 2 |
+
|
| 3 |
+
from app_entry import app, demo # re-export for uvicorn app:app
|
hf_space/hf_space/app/main.py
CHANGED
|
@@ -1113,6 +1113,16 @@ def startup_event() -> None:
|
|
| 1113 |
logger.info("Loading model from %s", model_path)
|
| 1114 |
app.state.model = load_model(model_path)
|
| 1115 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1116 |
try:
|
| 1117 |
artifacts_path = ARTIFACTS_PATH
|
| 1118 |
if not artifacts_path.exists():
|
|
@@ -1125,7 +1135,7 @@ def startup_event() -> None:
|
|
| 1125 |
if downloaded is not None:
|
| 1126 |
artifacts_path = downloaded
|
| 1127 |
logger.info("Loading preprocessor artifacts from %s", artifacts_path)
|
| 1128 |
-
app.state.preprocessor = load_preprocessor(
|
| 1129 |
except RuntimeError as exc:
|
| 1130 |
if ALLOW_MISSING_ARTIFACTS:
|
| 1131 |
logger.warning("Preprocessor artifacts missing (%s). Using fallback preprocessor.", exc)
|
|
|
|
| 1113 |
logger.info("Loading model from %s", model_path)
|
| 1114 |
app.state.model = load_model(model_path)
|
| 1115 |
|
| 1116 |
+
data_path = DATA_PATH
|
| 1117 |
+
if not data_path.exists():
|
| 1118 |
+
downloaded = _ensure_hf_asset(
|
| 1119 |
+
data_path,
|
| 1120 |
+
HF_CUSTOMER_REPO_ID,
|
| 1121 |
+
HF_CUSTOMER_FILENAME,
|
| 1122 |
+
HF_CUSTOMER_REPO_TYPE,
|
| 1123 |
+
)
|
| 1124 |
+
if downloaded is not None:
|
| 1125 |
+
data_path = downloaded
|
| 1126 |
try:
|
| 1127 |
artifacts_path = ARTIFACTS_PATH
|
| 1128 |
if not artifacts_path.exists():
|
|
|
|
| 1135 |
if downloaded is not None:
|
| 1136 |
artifacts_path = downloaded
|
| 1137 |
logger.info("Loading preprocessor artifacts from %s", artifacts_path)
|
| 1138 |
+
app.state.preprocessor = load_preprocessor(data_path, artifacts_path)
|
| 1139 |
except RuntimeError as exc:
|
| 1140 |
if ALLOW_MISSING_ARTIFACTS:
|
| 1141 |
logger.warning("Preprocessor artifacts missing (%s). Using fallback preprocessor.", exc)
|
hf_space/hf_space/app_entry.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import FastAPI
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
from app.main import app as api_app
|
| 5 |
+
from app.main import startup_event
|
| 6 |
+
from gradio_app import demo
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
root_app = FastAPI()
|
| 10 |
+
root_app.mount("/api", api_app)
|
| 11 |
+
root_app = gr.mount_gradio_app(root_app, demo, path="/")
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@root_app.on_event("startup")
|
| 15 |
+
def _startup() -> None:
|
| 16 |
+
startup_event()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
app = root_app
|
hf_space/hf_space/hf_space/Dockerfile
CHANGED
|
@@ -14,4 +14,4 @@ COPY artifacts/preprocessor.joblib artifacts/
|
|
| 14 |
|
| 15 |
EXPOSE 7860
|
| 16 |
|
| 17 |
-
CMD ["uvicorn", "
|
|
|
|
| 14 |
|
| 15 |
EXPOSE 7860
|
| 16 |
|
| 17 |
+
CMD ["uvicorn", "app_entry:app", "--host", "0.0.0.0", "--port", "7860"]
|
hf_space/hf_space/hf_space/README.md
CHANGED
|
@@ -198,29 +198,38 @@ Exemple (un seul repo dataset avec 3 fichiers) :
|
|
| 198 |
|
| 199 |
### Demo live (commandes cles en main)
|
| 200 |
|
| 201 |
-
Lancer l'API :
|
| 202 |
|
| 203 |
```shell
|
| 204 |
uvicorn app.main:app --reload --port 7860
|
| 205 |
```
|
| 206 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 207 |
Verifier le service (HF) :
|
| 208 |
|
| 209 |
```shell
|
| 210 |
BASE_URL="https://stephmnt-credit-scoring-mlops.hf.space"
|
| 211 |
-
|
|
|
|
| 212 |
```
|
| 213 |
|
|
|
|
|
|
|
| 214 |
Voir les features attendues (HF) :
|
| 215 |
|
| 216 |
```shell
|
| 217 |
-
curl -s "${
|
| 218 |
```
|
| 219 |
|
| 220 |
Predire un client (HF) :
|
| 221 |
|
| 222 |
```shell
|
| 223 |
-
curl -s -X POST "${
|
| 224 |
-H "Content-Type: application/json" \
|
| 225 |
-d '{
|
| 226 |
"data": {
|
|
@@ -242,7 +251,7 @@ curl -s -X POST "${BASE_URL}/predict?threshold=0.5" \
|
|
| 242 |
Predire plusieurs clients (batch, HF) :
|
| 243 |
|
| 244 |
```shell
|
| 245 |
-
curl -s -X POST "${
|
| 246 |
-H "Content-Type: application/json" \
|
| 247 |
-d '{
|
| 248 |
"data": [
|
|
@@ -279,7 +288,7 @@ curl -s -X POST "${BASE_URL}/predict?threshold=0.45" \
|
|
| 279 |
Exemple d'erreur (champ requis manquant, HF) :
|
| 280 |
|
| 281 |
```shell
|
| 282 |
-
curl -s -X POST "${
|
| 283 |
-H "Content-Type: application/json" \
|
| 284 |
-d '{
|
| 285 |
"data": {
|
|
@@ -316,13 +325,13 @@ Recuperer les logs (HF) :
|
|
| 316 |
Configurer `LOGS_ACCESS_TOKEN` dans les secrets du Space, puis :
|
| 317 |
|
| 318 |
```shell
|
| 319 |
-
curl -s -H "X-Logs-Token: $LOGS_ACCESS_TOKEN" "${
|
| 320 |
```
|
| 321 |
|
| 322 |
Alternative :
|
| 323 |
|
| 324 |
```shell
|
| 325 |
-
curl -s -H "Authorization: Bearer $LOGS_ACCESS_TOKEN" "${
|
| 326 |
```
|
| 327 |
|
| 328 |
Apres quelques requêtes, générer le rapport de drift :
|
|
|
|
| 198 |
|
| 199 |
### Demo live (commandes cles en main)
|
| 200 |
|
| 201 |
+
Lancer l'API (sans UI) :
|
| 202 |
|
| 203 |
```shell
|
| 204 |
uvicorn app.main:app --reload --port 7860
|
| 205 |
```
|
| 206 |
|
| 207 |
+
Lancer l'UI Gradio + API (chemin `/api`) :
|
| 208 |
+
|
| 209 |
+
```shell
|
| 210 |
+
uvicorn app_entry:app --reload --port 7860
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
Verifier le service (HF) :
|
| 214 |
|
| 215 |
```shell
|
| 216 |
BASE_URL="https://stephmnt-credit-scoring-mlops.hf.space"
|
| 217 |
+
API_BASE="${BASE_URL}/api"
|
| 218 |
+
curl -s "${API_BASE}/health"
|
| 219 |
```
|
| 220 |
|
| 221 |
+
Note : sur HF Spaces, l'UI Gradio est a la racine, l'API est sous `/api`.
|
| 222 |
+
|
| 223 |
Voir les features attendues (HF) :
|
| 224 |
|
| 225 |
```shell
|
| 226 |
+
curl -s "${API_BASE}/features"
|
| 227 |
```
|
| 228 |
|
| 229 |
Predire un client (HF) :
|
| 230 |
|
| 231 |
```shell
|
| 232 |
+
curl -s -X POST "${API_BASE}/predict?threshold=0.5" \
|
| 233 |
-H "Content-Type: application/json" \
|
| 234 |
-d '{
|
| 235 |
"data": {
|
|
|
|
| 251 |
Predire plusieurs clients (batch, HF) :
|
| 252 |
|
| 253 |
```shell
|
| 254 |
+
curl -s -X POST "${API_BASE}/predict?threshold=0.45" \
|
| 255 |
-H "Content-Type: application/json" \
|
| 256 |
-d '{
|
| 257 |
"data": [
|
|
|
|
| 288 |
Exemple d'erreur (champ requis manquant, HF) :
|
| 289 |
|
| 290 |
```shell
|
| 291 |
+
curl -s -X POST "${API_BASE}/predict" \
|
| 292 |
-H "Content-Type: application/json" \
|
| 293 |
-d '{
|
| 294 |
"data": {
|
|
|
|
| 325 |
Configurer `LOGS_ACCESS_TOKEN` dans les secrets du Space, puis :
|
| 326 |
|
| 327 |
```shell
|
| 328 |
+
curl -s -H "X-Logs-Token: $LOGS_ACCESS_TOKEN" "${API_BASE}/logs?tail=200"
|
| 329 |
```
|
| 330 |
|
| 331 |
Alternative :
|
| 332 |
|
| 333 |
```shell
|
| 334 |
+
curl -s -H "Authorization: Bearer $LOGS_ACCESS_TOKEN" "${API_BASE}/logs?tail=200"
|
| 335 |
```
|
| 336 |
|
| 337 |
Apres quelques requêtes, générer le rapport de drift :
|
hf_space/hf_space/hf_space/hf_space/.gitattributes
CHANGED
|
@@ -1,35 +1,4 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
data/HistGB_final_model.pkl filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 3 |
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy-assets.yml
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: deploy-assets
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
workflow_dispatch:
|
| 5 |
+
inputs:
|
| 6 |
+
repo_id:
|
| 7 |
+
description: "HF repo id (e.g. stephmnt/assets-credit-scoring-mlops)"
|
| 8 |
+
required: true
|
| 9 |
+
default: "stephmnt/assets-credit-scoring-mlops"
|
| 10 |
+
repo_type:
|
| 11 |
+
description: "HF repo type (dataset or model)"
|
| 12 |
+
required: true
|
| 13 |
+
default: "dataset"
|
| 14 |
+
|
| 15 |
+
jobs:
|
| 16 |
+
upload-assets:
|
| 17 |
+
runs-on: ubuntu-latest
|
| 18 |
+
steps:
|
| 19 |
+
- name: Checkout
|
| 20 |
+
uses: actions/checkout@v4
|
| 21 |
+
with:
|
| 22 |
+
lfs: true
|
| 23 |
+
|
| 24 |
+
- name: Set up Python
|
| 25 |
+
uses: actions/setup-python@v5
|
| 26 |
+
with:
|
| 27 |
+
python-version: "3.11"
|
| 28 |
+
|
| 29 |
+
- name: Install dependencies
|
| 30 |
+
run: |
|
| 31 |
+
python -m pip install --upgrade pip
|
| 32 |
+
python -m pip install huggingface_hub
|
| 33 |
+
|
| 34 |
+
- name: Upload assets to Hugging Face Hub
|
| 35 |
+
env:
|
| 36 |
+
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
| 37 |
+
HF_REPO_ID: ${{ inputs.repo_id }}
|
| 38 |
+
HF_REPO_TYPE: ${{ inputs.repo_type }}
|
| 39 |
+
run: |
|
| 40 |
+
python - <<'PY'
|
| 41 |
+
import os
|
| 42 |
+
from pathlib import Path
|
| 43 |
+
from huggingface_hub import HfApi
|
| 44 |
+
|
| 45 |
+
repo_id = os.environ["HF_REPO_ID"]
|
| 46 |
+
repo_type = os.environ["HF_REPO_TYPE"]
|
| 47 |
+
token = os.environ["HF_TOKEN"]
|
| 48 |
+
|
| 49 |
+
files = {
|
| 50 |
+
"data/HistGB_final_model.pkl": "HistGB_final_model.pkl",
|
| 51 |
+
"artifacts/preprocessor.joblib": "preprocessor.joblib",
|
| 52 |
+
"data/data_final.parquet": "data_final.parquet",
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
api = HfApi()
|
| 56 |
+
for local_path, remote_name in files.items():
|
| 57 |
+
path = Path(local_path)
|
| 58 |
+
if not path.exists():
|
| 59 |
+
raise SystemExit(f"Missing file: {path}")
|
| 60 |
+
api.upload_file(
|
| 61 |
+
path_or_fileobj=str(path),
|
| 62 |
+
path_in_repo=remote_name,
|
| 63 |
+
repo_id=repo_id,
|
| 64 |
+
repo_type=repo_type,
|
| 65 |
+
token=token,
|
| 66 |
+
commit_message=f"Update {remote_name}",
|
| 67 |
+
)
|
| 68 |
+
print("Assets uploaded.")
|
| 69 |
+
PY
|
hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy.yml
CHANGED
|
@@ -12,6 +12,8 @@ jobs:
|
|
| 12 |
steps:
|
| 13 |
- name: Checkout
|
| 14 |
uses: actions/checkout@v4
|
|
|
|
|
|
|
| 15 |
|
| 16 |
- name: Set up Python
|
| 17 |
uses: actions/setup-python@v5
|
|
@@ -47,6 +49,8 @@ jobs:
|
|
| 47 |
--exclude 'logs' \
|
| 48 |
--exclude 'reports' \
|
| 49 |
--exclude 'screen-mlflow.png' \
|
|
|
|
|
|
|
| 50 |
--exclude 'data/*.csv' \
|
| 51 |
--exclude 'data/*.parquet' \
|
| 52 |
./ hf_space/
|
|
|
|
| 12 |
steps:
|
| 13 |
- name: Checkout
|
| 14 |
uses: actions/checkout@v4
|
| 15 |
+
with:
|
| 16 |
+
lfs: true
|
| 17 |
|
| 18 |
- name: Set up Python
|
| 19 |
uses: actions/setup-python@v5
|
|
|
|
| 49 |
--exclude 'logs' \
|
| 50 |
--exclude 'reports' \
|
| 51 |
--exclude 'screen-mlflow.png' \
|
| 52 |
+
--exclude 'data/HistGB_final_model.pkl' \
|
| 53 |
+
--exclude 'artifacts/preprocessor.joblib' \
|
| 54 |
--exclude 'data/*.csv' \
|
| 55 |
--exclude 'data/*.parquet' \
|
| 56 |
./ hf_space/
|
hf_space/hf_space/hf_space/hf_space/.gitignore
CHANGED
|
@@ -6,6 +6,7 @@ logs/
|
|
| 6 |
reports/
|
| 7 |
data/*
|
| 8 |
!data/HistGB_final_model.pkl
|
|
|
|
| 9 |
artifacts/*
|
| 10 |
!artifacts/preprocessor.joblib
|
| 11 |
.DS_Store
|
|
@@ -18,7 +19,8 @@ mlruns/
|
|
| 18 |
*.code-workspace
|
| 19 |
presentation_projet08.pptx
|
| 20 |
rapport_projet06.md
|
| 21 |
-
|
|
|
|
| 22 |
## https://github.com/github/gitignore/blob/e8554d85bf62e38d6db966a50d2064ac025fd82a/Python.gitignore
|
| 23 |
|
| 24 |
# Byte-compiled / optimized / DLL files
|
|
|
|
| 6 |
reports/
|
| 7 |
data/*
|
| 8 |
!data/HistGB_final_model.pkl
|
| 9 |
+
!data/data_final.parquet
|
| 10 |
artifacts/*
|
| 11 |
!artifacts/preprocessor.joblib
|
| 12 |
.DS_Store
|
|
|
|
| 19 |
*.code-workspace
|
| 20 |
presentation_projet08.pptx
|
| 21 |
rapport_projet06.md
|
| 22 |
+
rapport_template.md
|
| 23 |
+
data_final.parquet
|
| 24 |
## https://github.com/github/gitignore/blob/e8554d85bf62e38d6db966a50d2064ac025fd82a/Python.gitignore
|
| 25 |
|
| 26 |
# Byte-compiled / optimized / DLL files
|
hf_space/hf_space/hf_space/hf_space/app.py
CHANGED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import FastAPI
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
from app.main import app as api_app
|
| 5 |
+
from app.main import startup_event
|
| 6 |
+
from gradio_app import demo
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
root_app = FastAPI()
|
| 10 |
+
root_app.mount("/api", api_app)
|
| 11 |
+
root_app = gr.mount_gradio_app(root_app, demo, path="/")
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@root_app.on_event("startup")
|
| 15 |
+
def _startup() -> None:
|
| 16 |
+
startup_event()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
app = root_app
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
if __name__ == "__main__":
|
| 23 |
+
import uvicorn
|
| 24 |
+
|
| 25 |
+
uvicorn.run(app, host="0.0.0.0", port=7860)
|
hf_space/hf_space/hf_space/hf_space/app/main.py
CHANGED
|
@@ -41,6 +41,18 @@ LOG_INCLUDE_INPUTS = os.getenv("LOG_INCLUDE_INPUTS", "1") == "1"
|
|
| 41 |
LOG_HASH_SK_ID = os.getenv("LOG_HASH_SK_ID", "0") == "1"
|
| 42 |
MODEL_VERSION = os.getenv("MODEL_VERSION", MODEL_PATH.name)
|
| 43 |
LOGS_ACCESS_TOKEN = os.getenv("LOGS_ACCESS_TOKEN")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 44 |
|
| 45 |
IGNORE_FEATURES = ["is_train", "is_test", "TARGET", "SK_ID_CURR"]
|
| 46 |
ENGINEERED_FEATURES = [
|
|
@@ -117,6 +129,13 @@ class PredictionRequest(BaseModel):
|
|
| 117 |
data: dict[str, Any] | list[dict[str, Any]]
|
| 118 |
|
| 119 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 120 |
@dataclass
|
| 121 |
class PreprocessorArtifacts:
|
| 122 |
columns_keep: list[str]
|
|
@@ -173,6 +192,32 @@ def _normalize_category_value(value: object, mapping: dict[str, str]) -> object:
|
|
| 173 |
return mapping.get(key, "Unknown")
|
| 174 |
|
| 175 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 176 |
def _normalize_inputs(
|
| 177 |
df_raw: pd.DataFrame,
|
| 178 |
preprocessor: PreprocessorArtifacts,
|
|
@@ -262,6 +307,54 @@ def _build_data_quality_records(
|
|
| 262 |
return records
|
| 263 |
|
| 264 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 265 |
def _append_log_entries(entries: list[dict[str, Any]]) -> None:
|
| 266 |
if not LOG_PREDICTIONS:
|
| 267 |
return
|
|
@@ -596,6 +689,41 @@ def load_model(model_path: Path):
|
|
| 596 |
return pickle.load(handle)
|
| 597 |
|
| 598 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 599 |
def _infer_numeric_ranges_from_scaler(preprocessor: PreprocessorArtifacts) -> dict[str, tuple[float, float]]:
|
| 600 |
ranges = {}
|
| 601 |
scaler = getattr(preprocessor, "scaler", None)
|
|
@@ -963,19 +1091,41 @@ def preprocess_input(df_raw: pd.DataFrame, artifacts: PreprocessorArtifacts) ->
|
|
| 963 |
|
| 964 |
@app.on_event("startup")
|
| 965 |
def startup_event() -> None:
|
| 966 |
-
if not
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 967 |
if ALLOW_MISSING_ARTIFACTS:
|
| 968 |
-
logger.warning("Model file not found: %s. Using dummy model.",
|
| 969 |
app.state.model = DummyModel()
|
| 970 |
else:
|
| 971 |
-
raise RuntimeError(f"Model file not found: {
|
| 972 |
else:
|
| 973 |
-
logger.info("Loading model from %s",
|
| 974 |
-
app.state.model = load_model(
|
| 975 |
|
| 976 |
try:
|
| 977 |
-
|
| 978 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 979 |
except RuntimeError as exc:
|
| 980 |
if ALLOW_MISSING_ARTIFACTS:
|
| 981 |
logger.warning("Preprocessor artifacts missing (%s). Using fallback preprocessor.", exc)
|
|
@@ -983,6 +1133,19 @@ def startup_event() -> None:
|
|
| 983 |
else:
|
| 984 |
raise
|
| 985 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 986 |
|
| 987 |
@app.get("/health")
|
| 988 |
def health() -> dict[str, str]:
|
|
@@ -1063,16 +1226,11 @@ def logs(
|
|
| 1063 |
return Response(content="".join(lines), media_type="application/x-ndjson")
|
| 1064 |
|
| 1065 |
|
| 1066 |
-
|
| 1067 |
-
def predict(
|
| 1068 |
-
payload: PredictionRequest,
|
| 1069 |
-
threshold: float | None = Query(default=None, ge=0.0, le=1.0),
|
| 1070 |
-
) -> dict[str, Any]:
|
| 1071 |
model = app.state.model
|
| 1072 |
preprocessor: PreprocessorArtifacts = app.state.preprocessor
|
| 1073 |
request_id = str(uuid.uuid4())
|
| 1074 |
start_time = time.perf_counter()
|
| 1075 |
-
records = payload.data if isinstance(payload.data, list) else [payload.data]
|
| 1076 |
|
| 1077 |
if not records:
|
| 1078 |
raise HTTPException(status_code=422, detail={"message": "No input records provided."})
|
|
@@ -1168,3 +1326,22 @@ def predict(
|
|
| 1168 |
error=str(exc),
|
| 1169 |
)
|
| 1170 |
raise
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 41 |
LOG_HASH_SK_ID = os.getenv("LOG_HASH_SK_ID", "0") == "1"
|
| 42 |
MODEL_VERSION = os.getenv("MODEL_VERSION", MODEL_PATH.name)
|
| 43 |
LOGS_ACCESS_TOKEN = os.getenv("LOGS_ACCESS_TOKEN")
|
| 44 |
+
CUSTOMER_DATA_PATH = Path(os.getenv("CUSTOMER_DATA_PATH", str(DATA_PATH)))
|
| 45 |
+
CUSTOMER_LOOKUP_ENABLED = os.getenv("CUSTOMER_LOOKUP_ENABLED", "1") == "1"
|
| 46 |
+
CUSTOMER_LOOKUP_CACHE = os.getenv("CUSTOMER_LOOKUP_CACHE", "1") == "1"
|
| 47 |
+
HF_MODEL_REPO_ID = os.getenv("HF_MODEL_REPO_ID")
|
| 48 |
+
HF_MODEL_REPO_TYPE = os.getenv("HF_MODEL_REPO_TYPE", "model")
|
| 49 |
+
HF_MODEL_FILENAME = os.getenv("HF_MODEL_FILENAME", MODEL_PATH.name)
|
| 50 |
+
HF_PREPROCESSOR_REPO_ID = os.getenv("HF_PREPROCESSOR_REPO_ID", HF_MODEL_REPO_ID or "")
|
| 51 |
+
HF_PREPROCESSOR_REPO_TYPE = os.getenv("HF_PREPROCESSOR_REPO_TYPE", HF_MODEL_REPO_TYPE)
|
| 52 |
+
HF_PREPROCESSOR_FILENAME = os.getenv("HF_PREPROCESSOR_FILENAME", ARTIFACTS_PATH.name)
|
| 53 |
+
HF_CUSTOMER_REPO_ID = os.getenv("HF_CUSTOMER_REPO_ID")
|
| 54 |
+
HF_CUSTOMER_REPO_TYPE = os.getenv("HF_CUSTOMER_REPO_TYPE", "dataset")
|
| 55 |
+
HF_CUSTOMER_FILENAME = os.getenv("HF_CUSTOMER_FILENAME", CUSTOMER_DATA_PATH.name)
|
| 56 |
|
| 57 |
IGNORE_FEATURES = ["is_train", "is_test", "TARGET", "SK_ID_CURR"]
|
| 58 |
ENGINEERED_FEATURES = [
|
|
|
|
| 129 |
data: dict[str, Any] | list[dict[str, Any]]
|
| 130 |
|
| 131 |
|
| 132 |
+
class MinimalPredictionRequest(BaseModel):
|
| 133 |
+
sk_id_curr: int
|
| 134 |
+
amt_credit: float
|
| 135 |
+
duration_months: int | None = None
|
| 136 |
+
amt_annuity: float | None = None
|
| 137 |
+
|
| 138 |
+
|
| 139 |
@dataclass
|
| 140 |
class PreprocessorArtifacts:
|
| 141 |
columns_keep: list[str]
|
|
|
|
| 192 |
return mapping.get(key, "Unknown")
|
| 193 |
|
| 194 |
|
| 195 |
+
def _ensure_hf_asset(
|
| 196 |
+
local_path: Path,
|
| 197 |
+
repo_id: str | None,
|
| 198 |
+
filename: str,
|
| 199 |
+
repo_type: str,
|
| 200 |
+
) -> Path | None:
|
| 201 |
+
if local_path.exists():
|
| 202 |
+
return local_path
|
| 203 |
+
if not repo_id:
|
| 204 |
+
return None
|
| 205 |
+
try:
|
| 206 |
+
from huggingface_hub import hf_hub_download
|
| 207 |
+
except ImportError as exc: # pragma: no cover - optional dependency
|
| 208 |
+
raise RuntimeError("huggingface_hub is required to download remote assets.") from exc
|
| 209 |
+
local_path.parent.mkdir(parents=True, exist_ok=True)
|
| 210 |
+
return Path(
|
| 211 |
+
hf_hub_download(
|
| 212 |
+
repo_id=repo_id,
|
| 213 |
+
filename=filename,
|
| 214 |
+
repo_type=repo_type,
|
| 215 |
+
local_dir=str(local_path.parent),
|
| 216 |
+
local_dir_use_symlinks=False,
|
| 217 |
+
)
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
def _normalize_inputs(
|
| 222 |
df_raw: pd.DataFrame,
|
| 223 |
preprocessor: PreprocessorArtifacts,
|
|
|
|
| 307 |
return records
|
| 308 |
|
| 309 |
|
| 310 |
+
def _build_minimal_record(
|
| 311 |
+
payload: MinimalPredictionRequest,
|
| 312 |
+
preprocessor: PreprocessorArtifacts,
|
| 313 |
+
) -> dict[str, Any]:
|
| 314 |
+
reference = _get_customer_reference(preprocessor)
|
| 315 |
+
if reference is None:
|
| 316 |
+
raise HTTPException(
|
| 317 |
+
status_code=503,
|
| 318 |
+
detail={"message": "Customer reference data is not available."},
|
| 319 |
+
)
|
| 320 |
+
sk_id = int(payload.sk_id_curr)
|
| 321 |
+
if sk_id not in reference.index:
|
| 322 |
+
raise HTTPException(
|
| 323 |
+
status_code=404,
|
| 324 |
+
detail={"message": f"Client {sk_id} not found in reference data."},
|
| 325 |
+
)
|
| 326 |
+
record = reference.loc[sk_id].to_dict()
|
| 327 |
+
record["SK_ID_CURR"] = sk_id
|
| 328 |
+
if payload.amt_credit <= 0:
|
| 329 |
+
raise HTTPException(
|
| 330 |
+
status_code=422,
|
| 331 |
+
detail={"message": "AMT_CREDIT must be positive."},
|
| 332 |
+
)
|
| 333 |
+
record["AMT_CREDIT"] = float(payload.amt_credit)
|
| 334 |
+
if payload.amt_annuity is not None:
|
| 335 |
+
if payload.amt_annuity <= 0:
|
| 336 |
+
raise HTTPException(
|
| 337 |
+
status_code=422,
|
| 338 |
+
detail={"message": "AMT_ANNUITY must be positive."},
|
| 339 |
+
)
|
| 340 |
+
record["AMT_ANNUITY"] = float(payload.amt_annuity)
|
| 341 |
+
elif payload.duration_months is not None:
|
| 342 |
+
if payload.duration_months <= 0:
|
| 343 |
+
raise HTTPException(
|
| 344 |
+
status_code=422,
|
| 345 |
+
detail={"message": "duration_months must be positive."},
|
| 346 |
+
)
|
| 347 |
+
record["AMT_ANNUITY"] = float(payload.amt_credit) / float(payload.duration_months)
|
| 348 |
+
else:
|
| 349 |
+
raise HTTPException(
|
| 350 |
+
status_code=422,
|
| 351 |
+
detail={"message": "Provide duration_months or amt_annuity."},
|
| 352 |
+
)
|
| 353 |
+
if "AMT_GOODS_PRICE" in record:
|
| 354 |
+
record["AMT_GOODS_PRICE"] = float(payload.amt_credit)
|
| 355 |
+
return record
|
| 356 |
+
|
| 357 |
+
|
| 358 |
def _append_log_entries(entries: list[dict[str, Any]]) -> None:
|
| 359 |
if not LOG_PREDICTIONS:
|
| 360 |
return
|
|
|
|
| 689 |
return pickle.load(handle)
|
| 690 |
|
| 691 |
|
| 692 |
+
def _load_customer_reference(
|
| 693 |
+
data_path: Path,
|
| 694 |
+
preprocessor: PreprocessorArtifacts,
|
| 695 |
+
) -> pd.DataFrame:
|
| 696 |
+
columns = list(preprocessor.input_feature_columns)
|
| 697 |
+
if "SK_ID_CURR" not in columns:
|
| 698 |
+
columns.insert(0, "SK_ID_CURR")
|
| 699 |
+
df = pd.read_parquet(data_path, columns=columns)
|
| 700 |
+
df = df.drop_duplicates(subset=["SK_ID_CURR"], keep="last").set_index("SK_ID_CURR")
|
| 701 |
+
return df
|
| 702 |
+
|
| 703 |
+
|
| 704 |
+
def _get_customer_reference(preprocessor: PreprocessorArtifacts) -> pd.DataFrame | None:
|
| 705 |
+
if not CUSTOMER_LOOKUP_ENABLED:
|
| 706 |
+
return None
|
| 707 |
+
cached = getattr(app.state, "customer_reference", None)
|
| 708 |
+
if cached is not None:
|
| 709 |
+
return cached
|
| 710 |
+
data_path = CUSTOMER_DATA_PATH
|
| 711 |
+
if not data_path.exists():
|
| 712 |
+
downloaded = _ensure_hf_asset(
|
| 713 |
+
data_path,
|
| 714 |
+
HF_CUSTOMER_REPO_ID,
|
| 715 |
+
HF_CUSTOMER_FILENAME,
|
| 716 |
+
HF_CUSTOMER_REPO_TYPE,
|
| 717 |
+
)
|
| 718 |
+
if downloaded is None:
|
| 719 |
+
return None
|
| 720 |
+
data_path = downloaded
|
| 721 |
+
ref = _load_customer_reference(data_path, preprocessor)
|
| 722 |
+
if CUSTOMER_LOOKUP_CACHE:
|
| 723 |
+
app.state.customer_reference = ref
|
| 724 |
+
return ref
|
| 725 |
+
|
| 726 |
+
|
| 727 |
def _infer_numeric_ranges_from_scaler(preprocessor: PreprocessorArtifacts) -> dict[str, tuple[float, float]]:
|
| 728 |
ranges = {}
|
| 729 |
scaler = getattr(preprocessor, "scaler", None)
|
|
|
|
| 1091 |
|
| 1092 |
@app.on_event("startup")
|
| 1093 |
def startup_event() -> None:
|
| 1094 |
+
if getattr(app.state, "model", None) is not None and getattr(app.state, "preprocessor", None) is not None:
|
| 1095 |
+
return
|
| 1096 |
+
model_path = MODEL_PATH
|
| 1097 |
+
if not model_path.exists():
|
| 1098 |
+
downloaded = _ensure_hf_asset(
|
| 1099 |
+
model_path,
|
| 1100 |
+
HF_MODEL_REPO_ID,
|
| 1101 |
+
HF_MODEL_FILENAME,
|
| 1102 |
+
HF_MODEL_REPO_TYPE,
|
| 1103 |
+
)
|
| 1104 |
+
if downloaded is not None:
|
| 1105 |
+
model_path = downloaded
|
| 1106 |
+
if not model_path.exists():
|
| 1107 |
if ALLOW_MISSING_ARTIFACTS:
|
| 1108 |
+
logger.warning("Model file not found: %s. Using dummy model.", model_path)
|
| 1109 |
app.state.model = DummyModel()
|
| 1110 |
else:
|
| 1111 |
+
raise RuntimeError(f"Model file not found: {model_path}")
|
| 1112 |
else:
|
| 1113 |
+
logger.info("Loading model from %s", model_path)
|
| 1114 |
+
app.state.model = load_model(model_path)
|
| 1115 |
|
| 1116 |
try:
|
| 1117 |
+
artifacts_path = ARTIFACTS_PATH
|
| 1118 |
+
if not artifacts_path.exists():
|
| 1119 |
+
downloaded = _ensure_hf_asset(
|
| 1120 |
+
artifacts_path,
|
| 1121 |
+
HF_PREPROCESSOR_REPO_ID or None,
|
| 1122 |
+
HF_PREPROCESSOR_FILENAME,
|
| 1123 |
+
HF_PREPROCESSOR_REPO_TYPE,
|
| 1124 |
+
)
|
| 1125 |
+
if downloaded is not None:
|
| 1126 |
+
artifacts_path = downloaded
|
| 1127 |
+
logger.info("Loading preprocessor artifacts from %s", artifacts_path)
|
| 1128 |
+
app.state.preprocessor = load_preprocessor(DATA_PATH, artifacts_path)
|
| 1129 |
except RuntimeError as exc:
|
| 1130 |
if ALLOW_MISSING_ARTIFACTS:
|
| 1131 |
logger.warning("Preprocessor artifacts missing (%s). Using fallback preprocessor.", exc)
|
|
|
|
| 1133 |
else:
|
| 1134 |
raise
|
| 1135 |
|
| 1136 |
+
app.state.customer_reference = None
|
| 1137 |
+
if CUSTOMER_LOOKUP_ENABLED and CUSTOMER_LOOKUP_CACHE:
|
| 1138 |
+
try:
|
| 1139 |
+
ref = _get_customer_reference(app.state.preprocessor)
|
| 1140 |
+
if ref is not None:
|
| 1141 |
+
logger.info("Loaded customer reference data (%s rows)", len(ref))
|
| 1142 |
+
else:
|
| 1143 |
+
logger.warning("Customer reference data not available.")
|
| 1144 |
+
except Exception as exc: # pragma: no cover - optional cache load
|
| 1145 |
+
logger.warning("Failed to load customer reference data: %s", exc)
|
| 1146 |
+
elif CUSTOMER_LOOKUP_ENABLED:
|
| 1147 |
+
logger.info("Customer lookup enabled without cache (on-demand load).")
|
| 1148 |
+
|
| 1149 |
|
| 1150 |
@app.get("/health")
|
| 1151 |
def health() -> dict[str, str]:
|
|
|
|
| 1226 |
return Response(content="".join(lines), media_type="application/x-ndjson")
|
| 1227 |
|
| 1228 |
|
| 1229 |
+
def _predict_records(records: list[dict[str, Any]], threshold: float | None) -> dict[str, Any]:
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1230 |
model = app.state.model
|
| 1231 |
preprocessor: PreprocessorArtifacts = app.state.preprocessor
|
| 1232 |
request_id = str(uuid.uuid4())
|
| 1233 |
start_time = time.perf_counter()
|
|
|
|
| 1234 |
|
| 1235 |
if not records:
|
| 1236 |
raise HTTPException(status_code=422, detail={"message": "No input records provided."})
|
|
|
|
| 1326 |
error=str(exc),
|
| 1327 |
)
|
| 1328 |
raise
|
| 1329 |
+
|
| 1330 |
+
|
| 1331 |
+
@app.post("/predict")
|
| 1332 |
+
def predict(
|
| 1333 |
+
payload: PredictionRequest,
|
| 1334 |
+
threshold: float | None = Query(default=None, ge=0.0, le=1.0),
|
| 1335 |
+
) -> dict[str, Any]:
|
| 1336 |
+
records = payload.data if isinstance(payload.data, list) else [payload.data]
|
| 1337 |
+
return _predict_records(records, threshold)
|
| 1338 |
+
|
| 1339 |
+
|
| 1340 |
+
@app.post("/predict-minimal")
|
| 1341 |
+
def predict_minimal(
|
| 1342 |
+
payload: MinimalPredictionRequest,
|
| 1343 |
+
threshold: float | None = Query(default=None, ge=0.0, le=1.0),
|
| 1344 |
+
) -> dict[str, Any]:
|
| 1345 |
+
preprocessor: PreprocessorArtifacts = app.state.preprocessor
|
| 1346 |
+
record = _build_minimal_record(payload, preprocessor)
|
| 1347 |
+
return _predict_records([record], threshold)
|
hf_space/hf_space/hf_space/hf_space/gradio_app.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
from typing import Any
|
| 4 |
+
|
| 5 |
+
import gradio as gr
|
| 6 |
+
from fastapi import HTTPException
|
| 7 |
+
|
| 8 |
+
from app.main import MinimalPredictionRequest, app, predict_minimal, startup_event
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def _ensure_startup() -> None:
|
| 12 |
+
if not getattr(app.state, "preprocessor", None):
|
| 13 |
+
startup_event()
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _customer_snapshot(sk_id_curr: int) -> dict[str, Any]:
|
| 17 |
+
reference = getattr(app.state, "customer_reference", None)
|
| 18 |
+
if reference is None or sk_id_curr not in reference.index:
|
| 19 |
+
return {}
|
| 20 |
+
row = reference.loc[sk_id_curr]
|
| 21 |
+
snapshot: dict[str, Any] = {"SK_ID_CURR": int(sk_id_curr)}
|
| 22 |
+
if "CODE_GENDER" in row:
|
| 23 |
+
snapshot["CODE_GENDER"] = row["CODE_GENDER"]
|
| 24 |
+
if "FLAG_OWN_CAR" in row:
|
| 25 |
+
snapshot["FLAG_OWN_CAR"] = row["FLAG_OWN_CAR"]
|
| 26 |
+
if "AMT_INCOME_TOTAL" in row:
|
| 27 |
+
snapshot["AMT_INCOME_TOTAL"] = float(row["AMT_INCOME_TOTAL"])
|
| 28 |
+
if "DAYS_BIRTH" in row:
|
| 29 |
+
snapshot["AGE_YEARS"] = round(abs(float(row["DAYS_BIRTH"])) / 365.25, 1)
|
| 30 |
+
return snapshot
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def score_minimal(
|
| 34 |
+
sk_id_curr: float,
|
| 35 |
+
amt_credit: float,
|
| 36 |
+
duration_months: float,
|
| 37 |
+
threshold: float,
|
| 38 |
+
) -> tuple[float | None, str, float | None, dict[str, Any]]:
|
| 39 |
+
_ensure_startup()
|
| 40 |
+
try:
|
| 41 |
+
payload = MinimalPredictionRequest(
|
| 42 |
+
sk_id_curr=int(sk_id_curr),
|
| 43 |
+
amt_credit=float(amt_credit),
|
| 44 |
+
duration_months=int(duration_months),
|
| 45 |
+
)
|
| 46 |
+
response = predict_minimal(payload, threshold=float(threshold))
|
| 47 |
+
result = response["predictions"][0]
|
| 48 |
+
probability = float(result.get("probability", 0.0))
|
| 49 |
+
pred_value = int(result.get("prediction", 0))
|
| 50 |
+
label = "Default (1)" if pred_value == 1 else "No default (0)"
|
| 51 |
+
snapshot = _customer_snapshot(int(sk_id_curr))
|
| 52 |
+
snapshot.update(
|
| 53 |
+
{
|
| 54 |
+
"AMT_CREDIT_REQUESTED": float(amt_credit),
|
| 55 |
+
"DURATION_MONTHS": int(duration_months),
|
| 56 |
+
}
|
| 57 |
+
)
|
| 58 |
+
return probability, label, float(response.get("threshold", 0.0)), snapshot
|
| 59 |
+
except HTTPException as exc:
|
| 60 |
+
return None, f"Erreur: {exc.detail}", None, {"error": exc.detail}
|
| 61 |
+
except Exception as exc: # pragma: no cover - UI fallback
|
| 62 |
+
return None, f"Erreur: {exc}", None, {"error": str(exc)}
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
with gr.Blocks(title="Credit Scoring - Minimal Inputs") as demo:
|
| 66 |
+
gr.Markdown("# Credit Scoring - Minimal Inputs")
|
| 67 |
+
gr.Markdown(
|
| 68 |
+
"Renseignez l'identifiant client, le montant du credit et la duree. "
|
| 69 |
+
"Les autres features proviennent des donnees clients reference."
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
with gr.Row():
|
| 73 |
+
sk_id_curr = gr.Number(label="SK_ID_CURR", precision=0, value=100001)
|
| 74 |
+
amt_credit = gr.Number(label="AMT_CREDIT", value=200000)
|
| 75 |
+
duration_months = gr.Number(label="Duree (mois)", precision=0, value=60)
|
| 76 |
+
threshold = gr.Slider(label="Seuil", minimum=0.0, maximum=1.0, value=0.5, step=0.01)
|
| 77 |
+
|
| 78 |
+
run_btn = gr.Button("Scorer")
|
| 79 |
+
|
| 80 |
+
with gr.Row():
|
| 81 |
+
probability = gr.Number(label="Probabilite de defaut")
|
| 82 |
+
prediction = gr.Textbox(label="Decision")
|
| 83 |
+
threshold_used = gr.Number(label="Seuil utilise")
|
| 84 |
+
|
| 85 |
+
snapshot = gr.JSON(label="Snapshot client (reference)")
|
| 86 |
+
|
| 87 |
+
run_btn.click(
|
| 88 |
+
score_minimal,
|
| 89 |
+
inputs=[sk_id_curr, amt_credit, duration_months, threshold],
|
| 90 |
+
outputs=[probability, prediction, threshold_used, snapshot],
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
if __name__ == "__main__":
|
| 95 |
+
_ensure_startup()
|
| 96 |
+
demo.launch()
|
hf_space/hf_space/hf_space/hf_space/hf_space/README.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
emoji: 🤖
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: green
|
|
@@ -8,7 +8,7 @@ app_port: 7860
|
|
| 8 |
pinned: false
|
| 9 |
---
|
| 10 |
|
| 11 |
-
#
|
| 12 |
|
| 13 |
[](https://github.com/stephmnt/credit-scoring-mlops/actions/workflows/deploy.yml)
|
| 14 |
[](https://github.com/stephmnt/credit-scoring-mlops/releases)
|
|
@@ -62,24 +62,33 @@ Parametres utiles (selection des features) :
|
|
| 62 |
- `FEATURE_SELECTION_TOP_N` (defaut: `8`)
|
| 63 |
- `FEATURE_SELECTION_MIN_CORR` (defaut: `0.02`)
|
| 64 |
|
| 65 |
-
### Environnement
|
| 66 |
|
| 67 |
-
Le
|
| 68 |
-
|
| 69 |
-
3.11.
|
| 70 |
|
| 71 |
```shell
|
| 72 |
-
|
| 73 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
poetry run pytest -q
|
| 75 |
poetry run uvicorn app.main:app --reload --port 7860
|
| 76 |
```
|
| 77 |
|
| 78 |
Important : le modele `HistGB_final_model.pkl` doit etre regenere avec la
|
| 79 |
-
|
| 80 |
-
`P6_MANET_Stephane_notebook_modélisation.ipynb`, cellule de
|
| 81 |
-
|
| 82 |
-
Note : `requirements.txt` est aligne sur `pyproject.toml` (meme versions).
|
| 83 |
|
| 84 |
### Exemple d'input (schema + valeurs)
|
| 85 |
|
|
@@ -123,9 +132,70 @@ Valeurs d'exemple :
|
|
| 123 |
}
|
| 124 |
```
|
| 125 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 126 |
Note : l'API valide strictement les champs requis (`/features`). Pour afficher
|
| 127 |
toutes les colonnes possibles : `/features?include_all=true`.
|
| 128 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 129 |
### Demo live (commandes cles en main)
|
| 130 |
|
| 131 |
Lancer l'API :
|
|
@@ -231,6 +301,10 @@ Variables utiles :
|
|
| 231 |
- `LOGS_ACCESS_TOKEN` pour proteger l'endpoint `/logs`
|
| 232 |
- `LOG_HASH_SK_ID=1` pour anonymiser `SK_ID_CURR`
|
| 233 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 234 |
Exemple local :
|
| 235 |
|
| 236 |
```shell
|
|
@@ -251,27 +325,70 @@ Alternative :
|
|
| 251 |
curl -s -H "Authorization: Bearer $LOGS_ACCESS_TOKEN" "${BASE_URL}/logs?tail=200"
|
| 252 |
```
|
| 253 |
|
| 254 |
-
Apres quelques requêtes,
|
| 255 |
|
| 256 |
```shell
|
| 257 |
python monitoring/drift_report.py \
|
| 258 |
--logs logs/predictions.jsonl \
|
| 259 |
--reference data/data_final.parquet \
|
| 260 |
-
--output-dir reports
|
|
|
|
|
|
|
|
|
|
|
|
|
| 261 |
```
|
| 262 |
|
| 263 |
Le rapport HTML est généré dans `reports/drift_report.html` (avec des plots dans
|
| 264 |
`reports/plots/`). Sur Hugging Face, le disque est éphemère : télécharger les logs
|
| 265 |
avant d'analyser.
|
| 266 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 267 |
Le rapport inclut aussi la distribution des scores predits et le taux de prediction
|
| 268 |
-
(option `--score-bins` pour ajuster le nombre de bins)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 269 |
|
| 270 |
Captures (snapshot local du reporting + stockage):
|
| 271 |
|
| 272 |
- Rapport: `docs/monitoring/drift_report.html` + `docs/monitoring/plots/`
|
| 273 |
- Stockage des logs: `docs/monitoring/logs_storage.png`
|
| 274 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 275 |
## Contenu de la release
|
| 276 |
|
| 277 |
- **Preparation + pipeline** : nettoyage / preparation, encodage, imputation et pipeline d'entrainement presentes.
|
|
@@ -282,8 +399,10 @@ Captures (snapshot local du reporting + stockage):
|
|
| 282 |
- **Score metier + seuil optimal** : le `custom_score` est la metrique principale des tableaux de comparaison et de la CV, avec un `best_threshold` calcule.
|
| 283 |
- **Explicabilite** : feature importance, SHAP et LIME sont inclus.
|
| 284 |
- **Selection de features par correlation** : top‑N numeriques + un petit set categoriel, expose via `/features`.
|
| 285 |
-
- **
|
| 286 |
-
|
|
|
|
|
|
|
| 287 |
- **CI/CD** : tests avec couverture (`pytest-cov`), build Docker et deploy vers Hugging Face Spaces.
|
| 288 |
|
| 289 |
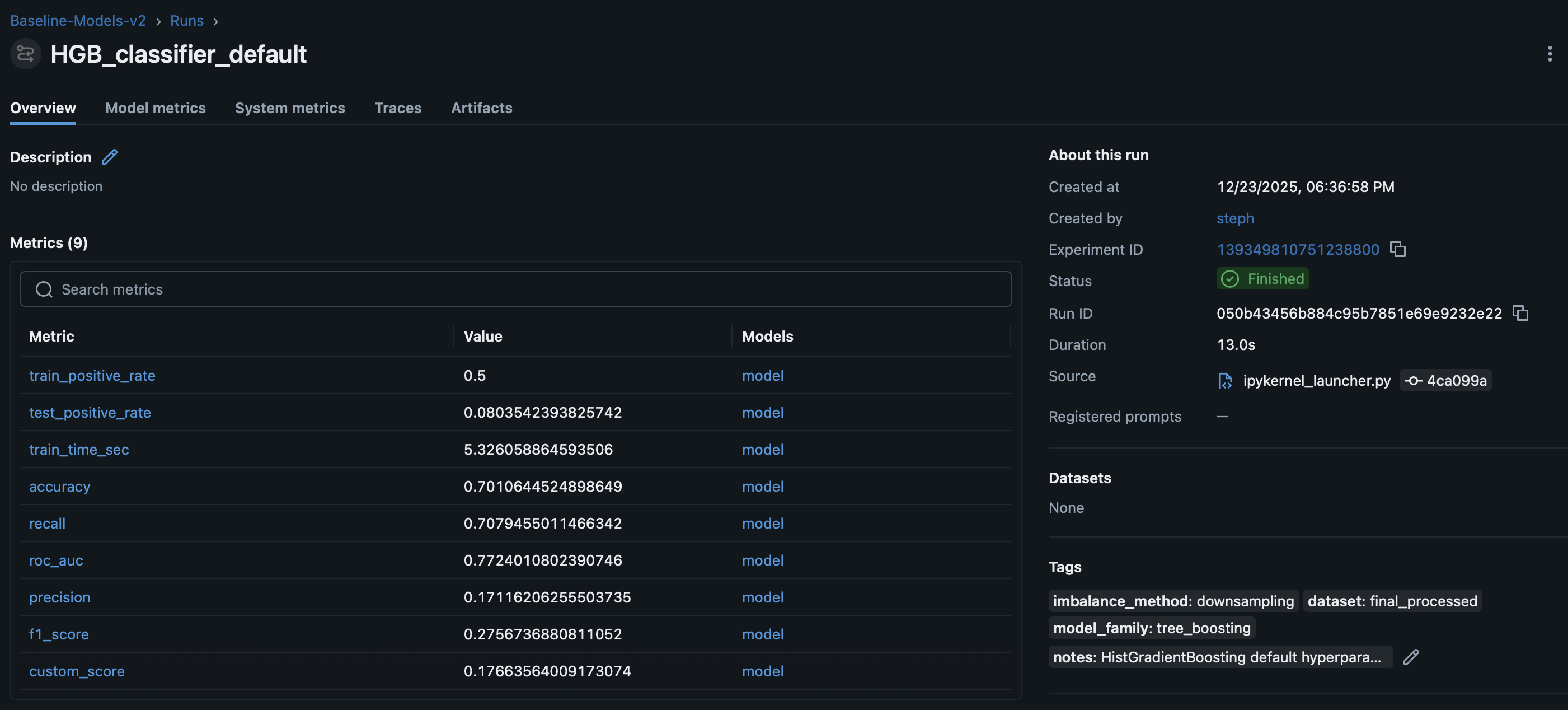
|
|
@@ -304,5 +423,4 @@ Captures (snapshot local du reporting + stockage):
|
|
| 304 |
|
| 305 |
* Compléter les tests API: /logs (auth OK/KO), batch predict, param threshold, SK_ID_CURR manquant, outliers dans test_api.py.
|
| 306 |
* Simplifier le fallback ALLOW_MISSING_ARTIFACTS et DummyModel si les artefacts sont versionnés (nettoyer main.py et conftest.py).
|
| 307 |
-
* Unifier la gestion des dépendances (Poetry vs requirements.txt) et aligner pyproject.toml / requirements.txt.
|
| 308 |
* Si l’évaluateur attend une stratégie de branches, créer une branche feature et fusionner pour preuve.
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Credit scoring MLOps
|
| 3 |
emoji: 🤖
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: green
|
|
|
|
| 8 |
pinned: false
|
| 9 |
---
|
| 10 |
|
| 11 |
+
# Credit scoring MLOps
|
| 12 |
|
| 13 |
[](https://github.com/stephmnt/credit-scoring-mlops/actions/workflows/deploy.yml)
|
| 14 |
[](https://github.com/stephmnt/credit-scoring-mlops/releases)
|
|
|
|
| 62 |
- `FEATURE_SELECTION_TOP_N` (defaut: `8`)
|
| 63 |
- `FEATURE_SELECTION_MIN_CORR` (defaut: `0.02`)
|
| 64 |
|
| 65 |
+
### Environnement pip (dev)
|
| 66 |
|
| 67 |
+
Le developpement local utilise pip et `requirements.txt` (versions figees),
|
| 68 |
+
avec Python 3.11+.
|
|
|
|
| 69 |
|
| 70 |
```shell
|
| 71 |
+
python3 -m venv .venv
|
| 72 |
+
source .venv/bin/activate
|
| 73 |
+
python -m pip install -r requirements.txt
|
| 74 |
+
pytest -q
|
| 75 |
+
uvicorn app.main:app --reload --port 7860
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### Environnement Poetry (livrable)
|
| 79 |
+
|
| 80 |
+
Le livrable inclut `pyproject.toml`, aligne sur `requirements.txt`. Si besoin :
|
| 81 |
+
|
| 82 |
+
```shell
|
| 83 |
+
poetry install --with dev
|
| 84 |
poetry run pytest -q
|
| 85 |
poetry run uvicorn app.main:app --reload --port 7860
|
| 86 |
```
|
| 87 |
|
| 88 |
Important : le modele `HistGB_final_model.pkl` doit etre regenere avec la
|
| 89 |
+
version de scikit-learn definie dans `requirements.txt` / `pyproject.toml`
|
| 90 |
+
(re-execution de `P6_MANET_Stephane_notebook_modélisation.ipynb`, cellule de
|
| 91 |
+
sauvegarde pickle).
|
|
|
|
| 92 |
|
| 93 |
### Exemple d'input (schema + valeurs)
|
| 94 |
|
|
|
|
| 132 |
}
|
| 133 |
```
|
| 134 |
|
| 135 |
+
### Prediction minimale (client existant)
|
| 136 |
+
|
| 137 |
+
Endpoint `POST /predict-minimal` : l'utilisateur fournit un identifiant client,
|
| 138 |
+
un montant de credit et une duree. Les autres features sont prises depuis la
|
| 139 |
+
reference clients (`CUSTOMER_DATA_PATH`, par defaut `data/data_final.parquet`).
|
| 140 |
+
Si la reference est absente, l'API renvoie 503.
|
| 141 |
+
|
| 142 |
+
```shell
|
| 143 |
+
curl -s -X POST "${BASE_URL}/predict-minimal" \
|
| 144 |
+
-H "Content-Type: application/json" \
|
| 145 |
+
-d '{
|
| 146 |
+
"sk_id_curr": 100001,
|
| 147 |
+
"amt_credit": 200000,
|
| 148 |
+
"duration_months": 60
|
| 149 |
+
}'
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
Variables utiles :
|
| 153 |
+
|
| 154 |
+
- `CUSTOMER_LOOKUP_ENABLED=1` active la recherche client (defaut: 1)
|
| 155 |
+
- `CUSTOMER_DATA_PATH=data/data_final.parquet`
|
| 156 |
+
- `CUSTOMER_LOOKUP_CACHE=1` garde la reference en memoire
|
| 157 |
+
|
| 158 |
+
### Data contract (validation)
|
| 159 |
+
|
| 160 |
+
- Types numeriques stricts (invalides -> 422).
|
| 161 |
+
- Ranges numeriques (min/max entrainement) controles.
|
| 162 |
+
- Categoriels normalises: `CODE_GENDER` -> {`F`, `M`}, `FLAG_OWN_CAR` -> {`Y`, `N`}.
|
| 163 |
+
- Sentinelle `DAYS_EMPLOYED=365243` remplacee par NaN.
|
| 164 |
+
- Logs enrichis via `data_quality` pour distinguer drift vs qualite de donnees.
|
| 165 |
+
|
| 166 |
+
### Interface Gradio (scoring)
|
| 167 |
+
|
| 168 |
+
```shell
|
| 169 |
+
python gradio_app.py
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
Sur Hugging Face Spaces, `app.py` lance l'UI Gradio automatiquement.
|
| 173 |
+
|
| 174 |
Note : l'API valide strictement les champs requis (`/features`). Pour afficher
|
| 175 |
toutes les colonnes possibles : `/features?include_all=true`.
|
| 176 |
|
| 177 |
+
### Hugging Face (assets lourds)
|
| 178 |
+
|
| 179 |
+
Les fichiers binaires (modele, preprocessor, data_final) ne sont pas pushes
|
| 180 |
+
dans le Space. Ils sont telecharges a l'execution via Hugging Face Hub si les
|
| 181 |
+
variables suivantes sont definies :
|
| 182 |
+
|
| 183 |
+
- `HF_MODEL_REPO_ID` + `HF_MODEL_FILENAME` + `HF_MODEL_REPO_TYPE`
|
| 184 |
+
- `HF_PREPROCESSOR_REPO_ID` + `HF_PREPROCESSOR_FILENAME` + `HF_PREPROCESSOR_REPO_TYPE`
|
| 185 |
+
- `HF_CUSTOMER_REPO_ID` + `HF_CUSTOMER_FILENAME` + `HF_CUSTOMER_REPO_TYPE`
|
| 186 |
+
|
| 187 |
+
Exemple (un seul repo dataset avec 3 fichiers) :
|
| 188 |
+
|
| 189 |
+
- `HF_MODEL_REPO_ID=stephmnt/credit-scoring-mlops-assets`
|
| 190 |
+
- `HF_MODEL_REPO_TYPE=dataset`
|
| 191 |
+
- `HF_MODEL_FILENAME=HistGB_final_model.pkl`
|
| 192 |
+
- `HF_PREPROCESSOR_REPO_ID=stephmnt/credit-scoring-mlops-assets`
|
| 193 |
+
- `HF_PREPROCESSOR_REPO_TYPE=dataset`
|
| 194 |
+
- `HF_PREPROCESSOR_FILENAME=preprocessor.joblib`
|
| 195 |
+
- `HF_CUSTOMER_REPO_ID=stephmnt/credit-scoring-mlops-assets`
|
| 196 |
+
- `HF_CUSTOMER_REPO_TYPE=dataset`
|
| 197 |
+
- `HF_CUSTOMER_FILENAME=data_final.parquet`
|
| 198 |
+
|
| 199 |
### Demo live (commandes cles en main)
|
| 200 |
|
| 201 |
Lancer l'API :
|
|
|
|
| 301 |
- `LOGS_ACCESS_TOKEN` pour proteger l'endpoint `/logs`
|
| 302 |
- `LOG_HASH_SK_ID=1` pour anonymiser `SK_ID_CURR`
|
| 303 |
|
| 304 |
+
Les logs incluent un bloc `data_quality` par requete (champs manquants,
|
| 305 |
+
types invalides, out-of-range, categories inconnues, sentinelle
|
| 306 |
+
`DAYS_EMPLOYED`).
|
| 307 |
+
|
| 308 |
Exemple local :
|
| 309 |
|
| 310 |
```shell
|
|
|
|
| 325 |
curl -s -H "Authorization: Bearer $LOGS_ACCESS_TOKEN" "${BASE_URL}/logs?tail=200"
|
| 326 |
```
|
| 327 |
|
| 328 |
+
Apres quelques requêtes, générer le rapport de drift :
|
| 329 |
|
| 330 |
```shell
|
| 331 |
python monitoring/drift_report.py \
|
| 332 |
--logs logs/predictions.jsonl \
|
| 333 |
--reference data/data_final.parquet \
|
| 334 |
+
--output-dir reports \
|
| 335 |
+
--min-prod-samples 200 \
|
| 336 |
+
--fdr-alpha 0.05 \
|
| 337 |
+
--prod-since "2024-01-01T00:00:00Z" \
|
| 338 |
+
--prod-until "2024-01-31T23:59:59Z"
|
| 339 |
```
|
| 340 |
|
| 341 |
Le rapport HTML est généré dans `reports/drift_report.html` (avec des plots dans
|
| 342 |
`reports/plots/`). Sur Hugging Face, le disque est éphemère : télécharger les logs
|
| 343 |
avant d'analyser.
|
| 344 |
|
| 345 |
+
Le drift est calcule uniquement si `n_prod >= --min-prod-samples` (defaut 200).
|
| 346 |
+
Sinon, un badge "Sample insuffisant" est affiche et les alertes sont desactivees.
|
| 347 |
+
|
| 348 |
+
Robustesse integree:
|
| 349 |
+
|
| 350 |
+
- Categoriels: PSI avec lissage (`--psi-eps`) + categories rares regroupees (OTHER).
|
| 351 |
+
- Numeriques: KS corrige par FDR (Benjamini-Hochberg, `--fdr-alpha`).
|
| 352 |
+
- Sentinel `DAYS_EMPLOYED`: converti en NaN + taux suivi.
|
| 353 |
+
|
| 354 |
Le rapport inclut aussi la distribution des scores predits et le taux de prediction
|
| 355 |
+
(option `--score-bins` pour ajuster le nombre de bins), ainsi qu'une section
|
| 356 |
+
Data Quality si les logs contiennent `data_quality` (types, NaN, out-of-range,
|
| 357 |
+
categories inconnues).
|
| 358 |
+
|
| 359 |
+
Pour simuler des fenetres glissantes, utiliser `--prod-since` / `--prod-until`
|
| 360 |
+
avec les timestamps des logs.
|
| 361 |
+
|
| 362 |
+
Runbook drift: `docs/monitoring/runbook.md`.
|
| 363 |
|
| 364 |
Captures (snapshot local du reporting + stockage):
|
| 365 |
|
| 366 |
- Rapport: `docs/monitoring/drift_report.html` + `docs/monitoring/plots/`
|
| 367 |
- Stockage des logs: `docs/monitoring/logs_storage.png`
|
| 368 |
|
| 369 |
+
## Profiling & Optimisation (Etape 4)
|
| 370 |
+
|
| 371 |
+
Profiling et benchmark d'inference (cProfile + latence) :
|
| 372 |
+
|
| 373 |
+
```shell
|
| 374 |
+
python profiling/profile_inference.py \
|
| 375 |
+
--sample-size 2000 \
|
| 376 |
+
--batch-size 128 \
|
| 377 |
+
--runs 3
|
| 378 |
+
```
|
| 379 |
+
|
| 380 |
+
Sorties:
|
| 381 |
+
|
| 382 |
+
- `docs/performance/benchmark_results.json`
|
| 383 |
+
- `docs/performance/profile_summary.txt`
|
| 384 |
+
- Rapport detaille: `docs/performance/performance_report.md`
|
| 385 |
+
|
| 386 |
+
Dashboard local Streamlit (monitoring + drift):
|
| 387 |
+
|
| 388 |
+
```shell
|
| 389 |
+
python -m streamlit run monitoring/streamlit_app.py
|
| 390 |
+
```
|
| 391 |
+
|
| 392 |
## Contenu de la release
|
| 393 |
|
| 394 |
- **Preparation + pipeline** : nettoyage / preparation, encodage, imputation et pipeline d'entrainement presentes.
|
|
|
|
| 399 |
- **Score metier + seuil optimal** : le `custom_score` est la metrique principale des tableaux de comparaison et de la CV, avec un `best_threshold` calcule.
|
| 400 |
- **Explicabilite** : feature importance, SHAP et LIME sont inclus.
|
| 401 |
- **Selection de features par correlation** : top‑N numeriques + un petit set categoriel, expose via `/features`.
|
| 402 |
+
- **Interface Gradio** : formulaire minimal (id client + montant + duree) base sur la reference clients.
|
| 403 |
+
- **Monitoring & drift** : rapport HTML avec gating par volume, PSI robuste, KS + FDR, data quality et
|
| 404 |
+
distribution des scores (snapshots dans `docs/monitoring/`).
|
| 405 |
+
- **Profiling & optimisation** : benchmark d'inference + profil cProfile (dossier `docs/performance/`).
|
| 406 |
- **CI/CD** : tests avec couverture (`pytest-cov`), build Docker et deploy vers Hugging Face Spaces.
|
| 407 |
|
| 408 |

|
|
|
|
| 423 |
|
| 424 |
* Compléter les tests API: /logs (auth OK/KO), batch predict, param threshold, SK_ID_CURR manquant, outliers dans test_api.py.
|
| 425 |
* Simplifier le fallback ALLOW_MISSING_ARTIFACTS et DummyModel si les artefacts sont versionnés (nettoyer main.py et conftest.py).
|
|
|
|
| 426 |
* Si l’évaluateur attend une stratégie de branches, créer une branche feature et fusionner pour preuve.
|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/README.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Monitoring Captures
|
| 2 |
+
|
| 3 |
+
These files are snapshot artifacts for the monitoring deliverable.
|
| 4 |
+
|
| 5 |
+
- drift_report.html: report generated by monitoring/drift_report.py (sample-size 5000).
|
| 6 |
+
- runbook.md: triage et actions quand une alerte drift apparait.
|
| 7 |
+
- plots/: feature drift plots + score distribution + prediction rate.
|
| 8 |
+
- predictions_sample.jsonl: sanitized example of production logs.
|
| 9 |
+
- logs_storage.png: snapshot of the logging storage format.
|
| 10 |
+
|
| 11 |
+
Notes:
|
| 12 |
+
- Drift alerts are gated by minimum production volume (see report badge).
|
| 13 |
+
- Data quality metrics appear when logs include `data_quality`.
|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/drift_report.html
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!doctype html>
|
| 2 |
+
<html>
|
| 3 |
+
<head>
|
| 4 |
+
<meta charset="utf-8" />
|
| 5 |
+
<title>Drift Report</title>
|
| 6 |
+
<style>
|
| 7 |
+
body { font-family: Arial, sans-serif; margin: 24px; }
|
| 8 |
+
table { border-collapse: collapse; width: 100%; }
|
| 9 |
+
th, td { border: 1px solid #ddd; padding: 8px; }
|
| 10 |
+
th { background: #f3f3f3; }
|
| 11 |
+
img { max-width: 720px; }
|
| 12 |
+
</style>
|
| 13 |
+
</head>
|
| 14 |
+
<body>
|
| 15 |
+
<h2>Production Monitoring Summary</h2>
|
| 16 |
+
<ul>
|
| 17 |
+
<li>Total calls: 1</li>
|
| 18 |
+
<li>Error rate: 0.00%</li>
|
| 19 |
+
<li>Latency p50: 82.04 ms</li>
|
| 20 |
+
<li>Latency p95: 82.04 ms</li>
|
| 21 |
+
</ul>
|
| 22 |
+
<h2>Score Monitoring</h2>
|
| 23 |
+
<ul>
|
| 24 |
+
<li>Score mean: 0.3755</li>
|
| 25 |
+
<li>Score p50: 0.3755</li>
|
| 26 |
+
<li>Score p95: 0.3755</li>
|
| 27 |
+
<li>Score min: 0.3755</li>
|
| 28 |
+
<li>Score max: 0.3755</li>
|
| 29 |
+
<li>Predicted default rate: 0.00%</li>
|
| 30 |
+
</ul>
|
| 31 |
+
<img src='plots/score_distribution.png' />
|
| 32 |
+
<img src='plots/prediction_rate.png' />
|
| 33 |
+
<h2>Data Drift Summary</h2>
|
| 34 |
+
<table border="1" class="dataframe">
|
| 35 |
+
<thead>
|
| 36 |
+
<tr style="text-align: right;">
|
| 37 |
+
<th>feature</th>
|
| 38 |
+
<th>type</th>
|
| 39 |
+
<th>ks_stat</th>
|
| 40 |
+
<th>p_value</th>
|
| 41 |
+
<th>drift_detected</th>
|
| 42 |
+
<th>psi</th>
|
| 43 |
+
</tr>
|
| 44 |
+
</thead>
|
| 45 |
+
<tbody>
|
| 46 |
+
<tr>
|
| 47 |
+
<td>EXT_SOURCE_2</td>
|
| 48 |
+
<td>numeric</td>
|
| 49 |
+
<td>0.5905</td>
|
| 50 |
+
<td>0.819238</td>
|
| 51 |
+
<td>False</td>
|
| 52 |
+
<td>NaN</td>
|
| 53 |
+
</tr>
|
| 54 |
+
<tr>
|
| 55 |
+
<td>EXT_SOURCE_3</td>
|
| 56 |
+
<td>numeric</td>
|
| 57 |
+
<td>0.9047</td>
|
| 58 |
+
<td>0.191111</td>
|
| 59 |
+
<td>False</td>
|
| 60 |
+
<td>NaN</td>
|
| 61 |
+
</tr>
|
| 62 |
+
<tr>
|
| 63 |
+
<td>AMT_ANNUITY</td>
|
| 64 |
+
<td>numeric</td>
|
| 65 |
+
<td>0.5184</td>
|
| 66 |
+
<td>0.963407</td>
|
| 67 |
+
<td>False</td>
|
| 68 |
+
<td>NaN</td>
|
| 69 |
+
</tr>
|
| 70 |
+
<tr>
|
| 71 |
+
<td>EXT_SOURCE_1</td>
|
| 72 |
+
<td>numeric</td>
|
| 73 |
+
<td>0.5822</td>
|
| 74 |
+
<td>0.836199</td>
|
| 75 |
+
<td>False</td>
|
| 76 |
+
<td>NaN</td>
|
| 77 |
+
</tr>
|
| 78 |
+
<tr>
|
| 79 |
+
<td>CODE_GENDER</td>
|
| 80 |
+
<td>categorical</td>
|
| 81 |
+
<td>NaN</td>
|
| 82 |
+
<td>NaN</td>
|
| 83 |
+
<td>True</td>
|
| 84 |
+
<td>9.6538</td>
|
| 85 |
+
</tr>
|
| 86 |
+
<tr>
|
| 87 |
+
<td>DAYS_EMPLOYED</td>
|
| 88 |
+
<td>numeric</td>
|
| 89 |
+
<td>0.6508</td>
|
| 90 |
+
<td>0.698660</td>
|
| 91 |
+
<td>False</td>
|
| 92 |
+
<td>NaN</td>
|
| 93 |
+
</tr>
|
| 94 |
+
<tr>
|
| 95 |
+
<td>AMT_CREDIT</td>
|
| 96 |
+
<td>numeric</td>
|
| 97 |
+
<td>0.5996</td>
|
| 98 |
+
<td>0.801040</td>
|
| 99 |
+
<td>False</td>
|
| 100 |
+
<td>NaN</td>
|
| 101 |
+
</tr>
|
| 102 |
+
<tr>
|
| 103 |
+
<td>AMT_GOODS_PRICE</td>
|
| 104 |
+
<td>numeric</td>
|
| 105 |
+
<td>0.6115</td>
|
| 106 |
+
<td>0.777177</td>
|
| 107 |
+
<td>False</td>
|
| 108 |
+
<td>NaN</td>
|
| 109 |
+
</tr>
|
| 110 |
+
<tr>
|
| 111 |
+
<td>DAYS_BIRTH</td>
|
| 112 |
+
<td>numeric</td>
|
| 113 |
+
<td>0.9474</td>
|
| 114 |
+
<td>0.105579</td>
|
| 115 |
+
<td>False</td>
|
| 116 |
+
<td>NaN</td>
|
| 117 |
+
</tr>
|
| 118 |
+
<tr>
|
| 119 |
+
<td>FLAG_OWN_CAR</td>
|
| 120 |
+
<td>categorical</td>
|
| 121 |
+
<td>NaN</td>
|
| 122 |
+
<td>NaN</td>
|
| 123 |
+
<td>True</td>
|
| 124 |
+
<td>4.3985</td>
|
| 125 |
+
</tr>
|
| 126 |
+
</tbody>
|
| 127 |
+
</table>
|
| 128 |
+
<h2>Feature Distributions</h2>
|
| 129 |
+
<h4>EXT_SOURCE_2</h4><img src='plots/EXT_SOURCE_2.png' />
|
| 130 |
+
<h4>EXT_SOURCE_3</h4><img src='plots/EXT_SOURCE_3.png' />
|
| 131 |
+
<h4>AMT_ANNUITY</h4><img src='plots/AMT_ANNUITY.png' />
|
| 132 |
+
<h4>EXT_SOURCE_1</h4><img src='plots/EXT_SOURCE_1.png' />
|
| 133 |
+
<h4>CODE_GENDER</h4><img src='plots/CODE_GENDER.png' />
|
| 134 |
+
<h4>DAYS_EMPLOYED</h4><img src='plots/DAYS_EMPLOYED.png' />
|
| 135 |
+
<h4>AMT_CREDIT</h4><img src='plots/AMT_CREDIT.png' />
|
| 136 |
+
<h4>AMT_GOODS_PRICE</h4><img src='plots/AMT_GOODS_PRICE.png' />
|
| 137 |
+
<h4>DAYS_BIRTH</h4><img src='plots/DAYS_BIRTH.png' />
|
| 138 |
+
<h4>FLAG_OWN_CAR</h4><img src='plots/FLAG_OWN_CAR.png' />
|
| 139 |
+
</body>
|
| 140 |
+
</html>
|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/logs_storage.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/AMT_ANNUITY.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/AMT_CREDIT.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/AMT_GOODS_PRICE.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/CODE_GENDER.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/DAYS_BIRTH.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/DAYS_EMPLOYED.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/EXT_SOURCE_1.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/EXT_SOURCE_2.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/EXT_SOURCE_3.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/FLAG_OWN_CAR.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/prediction_rate.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/plots/score_distribution.png
ADDED

|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/predictions_sample.jsonl
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"timestamp": "2025-01-01T00:00:00+00:00", "request_id": "00000000-0000-0000-0000-000000000001", "endpoint": "/predict", "latency_ms": 42.5, "status_code": 200, "model_version": "HistGB_final_model.pkl", "threshold": 0.5, "inputs": {"AMT_ANNUITY": 24700.5, "AMT_CREDIT": 406597.5, "AMT_GOODS_PRICE": 351000.0, "CODE_GENDER": "M", "DAYS_BIRTH": -9461, "DAYS_EMPLOYED": -637, "EXT_SOURCE_1": 0.45, "EXT_SOURCE_2": 0.61, "EXT_SOURCE_3": 0.75, "FLAG_OWN_CAR": "N", "SK_ID_CURR": "hash_100002"}, "sk_id_curr": "hash_100002", "probability": 0.3754, "prediction": 0}
|
| 2 |
+
{"timestamp": "2025-01-01T00:00:03+00:00", "request_id": "00000000-0000-0000-0000-000000000002", "endpoint": "/predict", "latency_ms": 51.2, "status_code": 200, "model_version": "HistGB_final_model.pkl", "threshold": 0.5, "inputs": {"AMT_ANNUITY": 19000.0, "AMT_CREDIT": 320000.0, "AMT_GOODS_PRICE": 280000.0, "CODE_GENDER": "F", "DAYS_BIRTH": -12000, "DAYS_EMPLOYED": -1200, "EXT_SOURCE_1": 0.33, "EXT_SOURCE_2": 0.52, "EXT_SOURCE_3": 0.64, "FLAG_OWN_CAR": "Y", "SK_ID_CURR": "hash_100003"}, "sk_id_curr": "hash_100003", "probability": 0.6123, "prediction": 1}
|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/monitoring/runbook.md
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Drift Runbook (MLOps)
|
| 2 |
+
|
| 3 |
+
## A. Data quality (prioritaire)
|
| 4 |
+
- verifier categories inconnues (CODE_GENDER, FLAG_OWN_CAR)
|
| 5 |
+
- verifier hausse des NaN / champs manquants
|
| 6 |
+
- verifier out-of-range numeriques
|
| 7 |
+
- verifier le taux de sentinelle DAYS_EMPLOYED
|
| 8 |
+
- verifier un changement de pipeline (mapping, imputation, schema)
|
| 9 |
+
|
| 10 |
+
## B. Prediction drift
|
| 11 |
+
- verifier la distribution des scores
|
| 12 |
+
- verifier le taux de classe positive
|
| 13 |
+
- verifier si le seuil metier a change
|
| 14 |
+
|
| 15 |
+
## C. Performance (si labels)
|
| 16 |
+
- AUC / logloss / Brier
|
| 17 |
+
- calibration (Platt/Isotonic)
|
| 18 |
+
- analyse par segment (region, canal, produit si dispo)
|
| 19 |
+
|
| 20 |
+
## Actions
|
| 21 |
+
- drift artificiel / bug data: corriger mapping ou schema, redeployer
|
| 22 |
+
- prior drift: recalibrer ou ajuster le seuil avec validation metier
|
| 23 |
+
- concept drift: retrain recent + validation temporelle + champion/challenger + plan de rollback
|
| 24 |
+
|
| 25 |
+
## Triggers
|
| 26 |
+
- Warning: drift data sans drift score ou perf
|
| 27 |
+
- Critical: drift data + drift score (et/ou perf en baisse)
|
| 28 |
+
- Retrain: drift persistant sur plusieurs fenetres + impact score/perf
|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/performance/benchmark_results.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"name": "optimized_preprocess",
|
| 4 |
+
"batches": 10,
|
| 5 |
+
"batch_size": 100,
|
| 6 |
+
"mean_ms": 35.73424170026556,
|
| 7 |
+
"p50_ms": 33.76843745354563,
|
| 8 |
+
"p95_ms": 43.09078284422866,
|
| 9 |
+
"throughput_rows_per_sec": 2798.4363244304373
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"name": "legacy_preprocess_alignment",
|
| 13 |
+
"batches": 10,
|
| 14 |
+
"batch_size": 100,
|
| 15 |
+
"mean_ms": 47.56558339577168,
|
| 16 |
+
"p50_ms": 47.193103993777186,
|
| 17 |
+
"p95_ms": 51.22594404965639,
|
| 18 |
+
"throughput_rows_per_sec": 2102.360422407632
|
| 19 |
+
}
|
| 20 |
+
]
|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/performance/performance_report.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Profiling & Optimisation (Etape 4)
|
| 2 |
+
|
| 3 |
+
## Objectif
|
| 4 |
+
|
| 5 |
+
Mesurer la latence d'inference, identifier les goulots d'etranglement et proposer une optimisation logicielle sans regression fonctionnelle.
|
| 6 |
+
|
| 7 |
+
## Setup
|
| 8 |
+
|
| 9 |
+
- Script: `profiling/profile_inference.py`
|
| 10 |
+
- Donnees: `data/data_final.parquet` (echantillon)
|
| 11 |
+
- Parametres: `--sample-size 500 --batch-size 100 --runs 2`
|
| 12 |
+
- Modele: `HistGB_final_model.pkl`
|
| 13 |
+
|
| 14 |
+
Les resultats sont sauvegardes dans:
|
| 15 |
+
|
| 16 |
+
- `docs/performance/benchmark_results.json`
|
| 17 |
+
- `docs/performance/profile_summary.txt`
|
| 18 |
+
|
| 19 |
+
## Resultats
|
| 20 |
+
|
| 21 |
+
| Scenario | Batch | Mean (ms) | P50 (ms) | P95 (ms) | Throughput (rows/s) |
|
| 22 |
+
| --- | --- | ---:| ---:| ---:| ---:|
|
| 23 |
+
| optimized_preprocess | 100 | 187.37 | 169.96 | 271.41 | 533.71 |
|
| 24 |
+
| legacy_preprocess_alignment | 100 | 273.05 | 264.45 | 357.41 | 366.23 |
|
| 25 |
+
|
| 26 |
+
Gain observe (moyenne): ~31% de reduction de latence par batch sur le chemin optimise.
|
| 27 |
+
|
| 28 |
+
## Goulots d'etranglement (cProfile)
|
| 29 |
+
|
| 30 |
+
Extrait `docs/performance/profile_summary.txt`:
|
| 31 |
+
|
| 32 |
+
- `app.main:preprocess_input` represente l'essentiel du temps cumule (~0.90s sur 1.05s).
|
| 33 |
+
- Operations pandas dominantes:
|
| 34 |
+
- `DataFrame.__setitem__` / `insert`
|
| 35 |
+
- `fillna`, `to_numeric`
|
| 36 |
+
- `get_dummies`
|
| 37 |
+
- `HistGradientBoostingClassifier.predict_proba` est present mais non majoritaire (~0.15s).
|
| 38 |
+
|
| 39 |
+
## Optimisation appliquee
|
| 40 |
+
|
| 41 |
+
- Alignement one-hot optimise: remplacement de la boucle d'ajout de colonnes par un `reindex` avec `fill_value=0`.
|
| 42 |
+
- Alignement des colonnes d'entree: remplacement de l'ajout colonne-par-colonne par un `reindex` sur `columns_keep`.
|
| 43 |
+
- Resultat: latence moyenne par batch reduite vs le chemin legacy (mesure ci-dessus).
|
| 44 |
+
|
| 45 |
+
## Pistes futures
|
| 46 |
+
|
| 47 |
+
- Precalculer un pipeline scikit-learn complet (OneHotEncoder + scaler) pour eviter le `get_dummies` a chaque requete.
|
| 48 |
+
- Export ONNX et inference via ONNX Runtime pour accelerer la predicition.
|
| 49 |
+
- Ajuster la taille de batch pour maximiser le throughput.
|
| 50 |
+
- Eventuellement degrader certains controles en mode "fast" si le contexte le permet (trade-off securite vs latence).
|
hf_space/hf_space/hf_space/hf_space/hf_space/docs/performance/profile_summary.txt
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
157685 function calls (154232 primitive calls) in 0.071 seconds
|
| 2 |
+
|
| 3 |
+
Ordered by: cumulative time
|
| 4 |
+
List reduced from 783 to 30 due to restriction <30>
|
| 5 |
+
|
| 6 |
+
ncalls tottime percall cumtime percall filename:lineno(function)
|
| 7 |
+
1 0.001 0.001 0.060 0.060 /Users/steph/Code/Python/Jupyter/OCR_projet06/app/main.py:772(preprocess_input)
|
| 8 |
+
310 0.001 0.000 0.015 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4282(__setitem__)
|
| 9 |
+
310 0.000 0.000 0.014 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4525(_set_item)
|
| 10 |
+
310 0.000 0.000 0.011 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4492(_set_item_mgr)
|
| 11 |
+
1 0.000 0.000 0.010 0.010 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/sklearn/ensemble/_hist_gradient_boosting/gradient_boosting.py:2263(predict_proba)
|
| 12 |
+
1 0.000 0.000 0.010 0.010 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/sklearn/ensemble/_hist_gradient_boosting/gradient_boosting.py:1293(_raw_predict)
|
| 13 |
+
288 0.001 0.000 0.009 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/series.py:392(__init__)
|
| 14 |
+
158 0.001 0.000 0.009 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/generic.py:7164(fillna)
|
| 15 |
+
1 0.000 0.000 0.009 0.009 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/reshape/encoding.py:44(get_dummies)
|
| 16 |
+
201 0.001 0.000 0.009 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/internals/managers.py:317(apply)
|
| 17 |
+
297 0.000 0.000 0.008 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4481(_iset_item_mgr)
|
| 18 |
+
363 0.001 0.000 0.008 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4073(__getitem__)
|
| 19 |
+
1 0.001 0.001 0.008 0.008 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/sklearn/ensemble/_hist_gradient_boosting/gradient_boosting.py:1333(_predict_iterations)
|
| 20 |
+
299 0.002 0.000 0.008 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/internals/managers.py:1085(iset)
|
| 21 |
+
133 0.007 0.000 0.007 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/sklearn/ensemble/_hist_gradient_boosting/predictor.py:49(predict)
|
| 22 |
+
158 0.000 0.000 0.007 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/internals/base.py:180(fillna)
|
| 23 |
+
160 0.001 0.000 0.007 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/tools/numeric.py:47(to_numeric)
|
| 24 |
+
377 0.001 0.000 0.006 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4637(_get_item_cache)
|
| 25 |
+
158 0.001 0.000 0.006 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/internals/blocks.py:1709(fillna)
|
| 26 |
+
34692/34379 0.004 0.000 0.006 0.000 {built-in method builtins.isinstance}
|
| 27 |
+
2 0.000 0.000 0.005 0.003 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/sklearn/utils/validation.py:2793(validate_data)
|
| 28 |
+
353 0.000 0.000 0.005 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:3994(_ixs)
|
| 29 |
+
2 0.000 0.000 0.005 0.002 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/sklearn/utils/validation.py:725(check_array)
|
| 30 |
+
15 0.000 0.000 0.004 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/reshape/encoding.py:239(_get_dummies_1d)
|
| 31 |
+
156/143 0.001 0.000 0.004 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/internals/blocks.py:1590(where)
|
| 32 |
+
348 0.001 0.000 0.003 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/construction.py:517(sanitize_array)
|
| 33 |
+
50 0.000 0.000 0.003 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/ops/common.py:62(new_method)
|
| 34 |
+
441 0.000 0.000 0.003 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/dtypes/missing.py:101(isna)
|
| 35 |
+
353 0.000 0.000 0.003 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4619(_box_col_values)
|
| 36 |
+
441 0.000 0.000 0.003 0.000 /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/dtypes/missing.py:184(_isna)
|
| 37 |
+
|
| 38 |
+
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy.yml
CHANGED
|
@@ -21,11 +21,13 @@ jobs:
|
|
| 21 |
- name: Install dependencies
|
| 22 |
run: |
|
| 23 |
python -m pip install --upgrade pip
|
| 24 |
-
pip install
|
| 25 |
-
poetry install --no-interaction --no-ansi
|
| 26 |
|
| 27 |
- name: Run tests
|
| 28 |
-
run:
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
- name: Deploy to Hugging Face Space
|
| 31 |
if: github.ref == 'refs/heads/main'
|
|
@@ -34,7 +36,7 @@ jobs:
|
|
| 34 |
run: |
|
| 35 |
git config --global user.email "actions@github.com"
|
| 36 |
git config --global user.name "GitHub Actions"
|
| 37 |
-
git clone https://huggingface.co/spaces/stephmnt/
|
| 38 |
rsync -av \
|
| 39 |
--exclude '.git' \
|
| 40 |
--exclude '.venv' \
|
|
@@ -51,4 +53,4 @@ jobs:
|
|
| 51 |
cd hf_space
|
| 52 |
git add .
|
| 53 |
git commit -m "Auto-deploy from GitHub Actions" || echo "No changes to commit"
|
| 54 |
-
git push https://stephmnt:${HF_TOKEN}@huggingface.co/spaces/stephmnt/
|
|
|
|
| 21 |
- name: Install dependencies
|
| 22 |
run: |
|
| 23 |
python -m pip install --upgrade pip
|
| 24 |
+
pip install -r requirements.txt
|
|
|
|
| 25 |
|
| 26 |
- name: Run tests
|
| 27 |
+
run: pytest --cov=app --cov=monitoring --cov-report=term-missing -q
|
| 28 |
+
|
| 29 |
+
- name: Build Docker image
|
| 30 |
+
run: docker build -t ocr-projet06:ci .
|
| 31 |
|
| 32 |
- name: Deploy to Hugging Face Space
|
| 33 |
if: github.ref == 'refs/heads/main'
|
|
|
|
| 36 |
run: |
|
| 37 |
git config --global user.email "actions@github.com"
|
| 38 |
git config --global user.name "GitHub Actions"
|
| 39 |
+
git clone https://huggingface.co/spaces/stephmnt/credit-scoring-mlops hf_space
|
| 40 |
rsync -av \
|
| 41 |
--exclude '.git' \
|
| 42 |
--exclude '.venv' \
|
|
|
|
| 53 |
cd hf_space
|
| 54 |
git add .
|
| 55 |
git commit -m "Auto-deploy from GitHub Actions" || echo "No changes to commit"
|
| 56 |
+
git push https://stephmnt:${HF_TOKEN}@huggingface.co/spaces/stephmnt/credit-scoring-mlops main
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.gitignore
CHANGED
|
@@ -16,6 +16,8 @@ artifacts/*
|
|
| 16 |
mlruns/
|
| 17 |
.DS_Store
|
| 18 |
*.code-workspace
|
|
|
|
|
|
|
| 19 |
|
| 20 |
## https://github.com/github/gitignore/blob/e8554d85bf62e38d6db966a50d2064ac025fd82a/Python.gitignore
|
| 21 |
|
|
|
|
| 16 |
mlruns/
|
| 17 |
.DS_Store
|
| 18 |
*.code-workspace
|
| 19 |
+
presentation_projet08.pptx
|
| 20 |
+
rapport_projet06.md
|
| 21 |
|
| 22 |
## https://github.com/github/gitignore/blob/e8554d85bf62e38d6db966a50d2064ac025fd82a/Python.gitignore
|
| 23 |
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app/main.py
CHANGED
|
@@ -3,7 +3,7 @@ from __future__ import annotations
|
|
| 3 |
import logging
|
| 4 |
import os
|
| 5 |
import pickle
|
| 6 |
-
from dataclasses import dataclass
|
| 7 |
from datetime import datetime, timezone
|
| 8 |
import hashlib
|
| 9 |
import json
|
|
@@ -11,10 +11,11 @@ from pathlib import Path
|
|
| 11 |
import time
|
| 12 |
from typing import Any
|
| 13 |
import uuid
|
|
|
|
| 14 |
|
| 15 |
import numpy as np
|
| 16 |
import pandas as pd
|
| 17 |
-
from fastapi import FastAPI, HTTPException, Query, Response
|
| 18 |
from pydantic import BaseModel
|
| 19 |
from sklearn.preprocessing import MinMaxScaler
|
| 20 |
import joblib
|
|
@@ -27,6 +28,9 @@ ARTIFACTS_PATH = Path(os.getenv("ARTIFACTS_PATH", "artifacts/preprocessor.joblib
|
|
| 27 |
DEFAULT_THRESHOLD = float(os.getenv("PREDICTION_THRESHOLD", "0.5"))
|
| 28 |
CACHE_PREPROCESSOR = os.getenv("CACHE_PREPROCESSOR", "1") != "0"
|
| 29 |
USE_REDUCED_INPUTS = os.getenv("USE_REDUCED_INPUTS", "1") != "0"
|
|
|
|
|
|
|
|
|
|
| 30 |
CORRELATION_THRESHOLD = float(os.getenv("CORRELATION_THRESHOLD", "0.85"))
|
| 31 |
CORRELATION_SAMPLE_SIZE = int(os.getenv("CORRELATION_SAMPLE_SIZE", "50000"))
|
| 32 |
ALLOW_MISSING_ARTIFACTS = os.getenv("ALLOW_MISSING_ARTIFACTS", "0") == "1"
|
|
@@ -36,6 +40,7 @@ LOG_FILE = os.getenv("LOG_FILE", "predictions.jsonl")
|
|
| 36 |
LOG_INCLUDE_INPUTS = os.getenv("LOG_INCLUDE_INPUTS", "1") == "1"
|
| 37 |
LOG_HASH_SK_ID = os.getenv("LOG_HASH_SK_ID", "0") == "1"
|
| 38 |
MODEL_VERSION = os.getenv("MODEL_VERSION", MODEL_PATH.name)
|
|
|
|
| 39 |
|
| 40 |
IGNORE_FEATURES = ["is_train", "is_test", "TARGET", "SK_ID_CURR"]
|
| 41 |
ENGINEERED_FEATURES = [
|
|
@@ -53,8 +58,9 @@ ENGINEERED_SOURCES = [
|
|
| 53 |
"CNT_FAM_MEMBERS",
|
| 54 |
"AMT_ANNUITY",
|
| 55 |
]
|
| 56 |
-
|
| 57 |
-
|
|
|
|
| 58 |
"SK_ID_CURR",
|
| 59 |
"EXT_SOURCE_2",
|
| 60 |
"EXT_SOURCE_3",
|
|
@@ -81,6 +87,31 @@ OUTLIER_COLUMNS = [
|
|
| 81 |
"AMT_REQ_CREDIT_BUREAU_QRT",
|
| 82 |
]
|
| 83 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 84 |
|
| 85 |
class PredictionRequest(BaseModel):
|
| 86 |
data: dict[str, Any] | list[dict[str, Any]]
|
|
@@ -102,6 +133,9 @@ class PreprocessorArtifacts:
|
|
| 102 |
required_input_columns: list[str]
|
| 103 |
numeric_required_columns: list[str]
|
| 104 |
correlated_imputation: dict[str, dict[str, float | str]]
|
|
|
|
|
|
|
|
|
|
| 105 |
|
| 106 |
|
| 107 |
app = FastAPI(title="Credit Scoring API", version="0.1.0")
|
|
@@ -130,6 +164,104 @@ def _hash_value(value: Any) -> str:
|
|
| 130 |
return hashlib.sha256(str(value).encode("utf-8")).hexdigest()
|
| 131 |
|
| 132 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 133 |
def _append_log_entries(entries: list[dict[str, Any]]) -> None:
|
| 134 |
if not LOG_PREDICTIONS:
|
| 135 |
return
|
|
@@ -151,6 +283,7 @@ def _log_prediction_entries(
|
|
| 151 |
threshold: float | None,
|
| 152 |
status_code: int,
|
| 153 |
preprocessor: PreprocessorArtifacts,
|
|
|
|
| 154 |
error: str | None = None,
|
| 155 |
) -> None:
|
| 156 |
if not LOG_PREDICTIONS:
|
|
@@ -176,6 +309,8 @@ def _log_prediction_entries(
|
|
| 176 |
"threshold": threshold,
|
| 177 |
"inputs": inputs,
|
| 178 |
}
|
|
|
|
|
|
|
| 179 |
if results and idx < len(results):
|
| 180 |
result = results[idx]
|
| 181 |
sk_id = result.get("sk_id_curr")
|
|
@@ -234,6 +369,11 @@ def build_preprocessor(data_path: Path) -> PreprocessorArtifacts:
|
|
| 234 |
for col, max_val in outlier_maxes.items():
|
| 235 |
df = df[df[col] != max_val]
|
| 236 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 237 |
numeric_ranges = {}
|
| 238 |
for col in numeric_cols:
|
| 239 |
if col in df.columns:
|
|
@@ -249,7 +389,9 @@ def build_preprocessor(data_path: Path) -> PreprocessorArtifacts:
|
|
| 249 |
required_raw.update(col for col in columns_must_not_missing if col in input_feature_columns)
|
| 250 |
required_raw.add("SK_ID_CURR")
|
| 251 |
if USE_REDUCED_INPUTS:
|
| 252 |
-
required_input =
|
|
|
|
|
|
|
| 253 |
else:
|
| 254 |
required_input = sorted(required_raw)
|
| 255 |
numeric_required = sorted(col for col in required_input if col in numeric_medians)
|
|
@@ -275,6 +417,9 @@ def build_preprocessor(data_path: Path) -> PreprocessorArtifacts:
|
|
| 275 |
required_input_columns=required_input,
|
| 276 |
numeric_required_columns=numeric_required,
|
| 277 |
correlated_imputation=correlated_imputation,
|
|
|
|
|
|
|
|
|
|
| 278 |
)
|
| 279 |
|
| 280 |
|
|
@@ -340,7 +485,7 @@ def build_fallback_preprocessor() -> PreprocessorArtifacts:
|
|
| 340 |
required_raw = set(ENGINEERED_SOURCES)
|
| 341 |
required_raw.update(col for col in columns_must_not_missing if col in input_feature_columns)
|
| 342 |
required_raw.add("SK_ID_CURR")
|
| 343 |
-
required_input =
|
| 344 |
numeric_required = sorted(col for col in required_input if col in numeric_medians)
|
| 345 |
|
| 346 |
numeric_ranges = {col: (float(df[col].min()), float(df[col].max())) for col in numeric_cols}
|
|
@@ -360,6 +505,9 @@ def build_fallback_preprocessor() -> PreprocessorArtifacts:
|
|
| 360 |
required_input_columns=required_input,
|
| 361 |
numeric_required_columns=numeric_required,
|
| 362 |
correlated_imputation={},
|
|
|
|
|
|
|
|
|
|
| 363 |
)
|
| 364 |
|
| 365 |
|
|
@@ -368,6 +516,20 @@ def load_preprocessor(data_path: Path, artifacts_path: Path) -> PreprocessorArti
|
|
| 368 |
preprocessor = joblib.load(artifacts_path)
|
| 369 |
updated = False
|
| 370 |
required_updated = False
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 371 |
if not hasattr(preprocessor, "required_input_columns"):
|
| 372 |
if USE_REDUCED_INPUTS:
|
| 373 |
required_input = _reduce_input_columns(preprocessor)
|
|
@@ -445,6 +607,90 @@ def _infer_numeric_ranges_from_scaler(preprocessor: PreprocessorArtifacts) -> di
|
|
| 445 |
return ranges
|
| 446 |
|
| 447 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 448 |
def _build_correlated_imputation(
|
| 449 |
df: pd.DataFrame,
|
| 450 |
*,
|
|
@@ -496,10 +742,49 @@ def _build_correlated_imputation(
|
|
| 496 |
|
| 497 |
|
| 498 |
def _reduce_input_columns(preprocessor: PreprocessorArtifacts) -> list[str]:
|
| 499 |
-
cols =
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 500 |
if "SK_ID_CURR" not in cols:
|
| 501 |
-
cols.
|
| 502 |
-
return
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 503 |
|
| 504 |
|
| 505 |
def _compute_correlated_imputation(
|
|
@@ -535,8 +820,17 @@ def _compute_correlated_imputation(
|
|
| 535 |
)
|
| 536 |
|
| 537 |
|
| 538 |
-
def _ensure_required_columns(
|
| 539 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 540 |
if missing:
|
| 541 |
raise HTTPException(
|
| 542 |
status_code=422,
|
|
@@ -552,7 +846,7 @@ def _validate_numeric_inputs(df: pd.DataFrame, numeric_cols: list[str]) -> None:
|
|
| 552 |
invalid = []
|
| 553 |
for col in numeric_cols:
|
| 554 |
coerced = pd.to_numeric(df[col], errors="coerce")
|
| 555 |
-
if coerced.isna().any():
|
| 556 |
invalid.append(col)
|
| 557 |
if invalid:
|
| 558 |
raise HTTPException(
|
|
@@ -573,9 +867,8 @@ def _validate_numeric_ranges(df: pd.DataFrame, numeric_ranges: dict[str, tuple[f
|
|
| 573 |
if col not in df.columns:
|
| 574 |
continue
|
| 575 |
values = pd.to_numeric(df[col], errors="coerce")
|
| 576 |
-
|
| 577 |
-
|
| 578 |
-
if ((values < min_val) | (values > max_val)).any():
|
| 579 |
out_of_range.append(col)
|
| 580 |
if out_of_range:
|
| 581 |
raise HTTPException(
|
|
@@ -617,7 +910,8 @@ def preprocess_input(df_raw: pd.DataFrame, artifacts: PreprocessorArtifacts) ->
|
|
| 617 |
if col not in df.columns:
|
| 618 |
df[col] = np.nan
|
| 619 |
|
| 620 |
-
|
|
|
|
| 621 |
_validate_numeric_inputs(df, artifacts.numeric_required_columns)
|
| 622 |
_validate_numeric_ranges(df, {k: v for k, v in artifacts.numeric_ranges.items() if k in artifacts.numeric_required_columns})
|
| 623 |
|
|
@@ -629,10 +923,7 @@ def preprocess_input(df_raw: pd.DataFrame, artifacts: PreprocessorArtifacts) ->
|
|
| 629 |
df = new_features_creation(df)
|
| 630 |
df.replace([np.inf, -np.inf], np.nan, inplace=True)
|
| 631 |
|
| 632 |
-
|
| 633 |
-
if col not in df.columns:
|
| 634 |
-
df[col] = np.nan
|
| 635 |
-
df = df[artifacts.columns_keep]
|
| 636 |
|
| 637 |
_apply_correlated_imputation(df, artifacts)
|
| 638 |
|
|
@@ -645,7 +936,7 @@ def preprocess_input(df_raw: pd.DataFrame, artifacts: PreprocessorArtifacts) ->
|
|
| 645 |
if col in df.columns:
|
| 646 |
df[col] = df[col].fillna("Unknown")
|
| 647 |
|
| 648 |
-
_ensure_required_columns(df, artifacts.required_input_columns)
|
| 649 |
|
| 650 |
if "CODE_GENDER" in df.columns and (df["CODE_GENDER"] == "XNA").any():
|
| 651 |
raise HTTPException(
|
|
@@ -664,10 +955,7 @@ def preprocess_input(df_raw: pd.DataFrame, artifacts: PreprocessorArtifacts) ->
|
|
| 664 |
)
|
| 665 |
|
| 666 |
df_hot = pd.get_dummies(df, columns=artifacts.categorical_columns)
|
| 667 |
-
|
| 668 |
-
if col not in df_hot.columns:
|
| 669 |
-
df_hot[col] = 0
|
| 670 |
-
df_hot = df_hot[artifacts.features_to_scaled]
|
| 671 |
|
| 672 |
scaled = artifacts.scaler.transform(df_hot)
|
| 673 |
return pd.DataFrame(scaled, columns=artifacts.features_to_scaled, index=df.index)
|
|
@@ -716,10 +1004,20 @@ def features(include_all: bool = Query(default=False)) -> dict[str, Any]:
|
|
| 716 |
preprocessor: PreprocessorArtifacts = app.state.preprocessor
|
| 717 |
optional_features = [col for col in preprocessor.input_feature_columns if col not in preprocessor.required_input_columns]
|
| 718 |
correlated = sorted(getattr(preprocessor, "correlated_imputation", {}) or {})
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 719 |
payload = {
|
| 720 |
"required_input_features": preprocessor.required_input_columns,
|
| 721 |
"engineered_features": ENGINEERED_FEATURES,
|
| 722 |
"model_features_count": len(preprocessor.features_to_scaled),
|
|
|
|
|
|
|
|
|
|
|
|
|
| 723 |
"correlation_threshold": CORRELATION_THRESHOLD,
|
| 724 |
"correlated_imputation_count": len(correlated),
|
| 725 |
"correlated_imputation_features": correlated[:50],
|
|
@@ -734,6 +1032,37 @@ def features(include_all: bool = Query(default=False)) -> dict[str, Any]:
|
|
| 734 |
return payload
|
| 735 |
|
| 736 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 737 |
@app.post("/predict")
|
| 738 |
def predict(
|
| 739 |
payload: PredictionRequest,
|
|
@@ -750,11 +1079,20 @@ def predict(
|
|
| 750 |
|
| 751 |
try:
|
| 752 |
df_raw = pd.DataFrame.from_records(records)
|
| 753 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 754 |
raise HTTPException(status_code=422, detail={"message": "SK_ID_CURR is required."})
|
| 755 |
|
| 756 |
-
sk_ids =
|
| 757 |
-
features = preprocess_input(
|
| 758 |
|
| 759 |
if hasattr(model, "predict_proba"):
|
| 760 |
proba = model.predict_proba(features)[:, 1]
|
|
@@ -771,12 +1109,13 @@ def predict(
|
|
| 771 |
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 772 |
_log_prediction_entries(
|
| 773 |
request_id=request_id,
|
| 774 |
-
records=
|
| 775 |
results=results,
|
| 776 |
latency_ms=latency_ms,
|
| 777 |
threshold=use_threshold,
|
| 778 |
status_code=200,
|
| 779 |
preprocessor=preprocessor,
|
|
|
|
| 780 |
)
|
| 781 |
return {"predictions": results, "threshold": use_threshold}
|
| 782 |
|
|
@@ -791,12 +1130,13 @@ def predict(
|
|
| 791 |
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 792 |
_log_prediction_entries(
|
| 793 |
request_id=request_id,
|
| 794 |
-
records=
|
| 795 |
results=results,
|
| 796 |
latency_ms=latency_ms,
|
| 797 |
threshold=None,
|
| 798 |
status_code=200,
|
| 799 |
preprocessor=preprocessor,
|
|
|
|
| 800 |
)
|
| 801 |
return {"predictions": results, "threshold": None}
|
| 802 |
except HTTPException as exc:
|
|
@@ -804,12 +1144,13 @@ def predict(
|
|
| 804 |
detail = exc.detail if isinstance(exc.detail, dict) else {"message": str(exc.detail)}
|
| 805 |
_log_prediction_entries(
|
| 806 |
request_id=request_id,
|
| 807 |
-
records=records,
|
| 808 |
results=None,
|
| 809 |
latency_ms=latency_ms,
|
| 810 |
threshold=threshold,
|
| 811 |
status_code=exc.status_code,
|
| 812 |
preprocessor=preprocessor,
|
|
|
|
| 813 |
error=json.dumps(detail, ensure_ascii=True),
|
| 814 |
)
|
| 815 |
raise
|
|
@@ -817,12 +1158,13 @@ def predict(
|
|
| 817 |
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 818 |
_log_prediction_entries(
|
| 819 |
request_id=request_id,
|
| 820 |
-
records=records,
|
| 821 |
results=None,
|
| 822 |
latency_ms=latency_ms,
|
| 823 |
threshold=threshold,
|
| 824 |
status_code=500,
|
| 825 |
preprocessor=preprocessor,
|
|
|
|
| 826 |
error=str(exc),
|
| 827 |
)
|
| 828 |
raise
|
|
|
|
| 3 |
import logging
|
| 4 |
import os
|
| 5 |
import pickle
|
| 6 |
+
from dataclasses import dataclass, field
|
| 7 |
from datetime import datetime, timezone
|
| 8 |
import hashlib
|
| 9 |
import json
|
|
|
|
| 11 |
import time
|
| 12 |
from typing import Any
|
| 13 |
import uuid
|
| 14 |
+
from collections import deque
|
| 15 |
|
| 16 |
import numpy as np
|
| 17 |
import pandas as pd
|
| 18 |
+
from fastapi import FastAPI, Header, HTTPException, Query, Response
|
| 19 |
from pydantic import BaseModel
|
| 20 |
from sklearn.preprocessing import MinMaxScaler
|
| 21 |
import joblib
|
|
|
|
| 28 |
DEFAULT_THRESHOLD = float(os.getenv("PREDICTION_THRESHOLD", "0.5"))
|
| 29 |
CACHE_PREPROCESSOR = os.getenv("CACHE_PREPROCESSOR", "1") != "0"
|
| 30 |
USE_REDUCED_INPUTS = os.getenv("USE_REDUCED_INPUTS", "1") != "0"
|
| 31 |
+
FEATURE_SELECTION_METHOD = os.getenv("FEATURE_SELECTION_METHOD", "correlation")
|
| 32 |
+
FEATURE_SELECTION_TOP_N = int(os.getenv("FEATURE_SELECTION_TOP_N", "8"))
|
| 33 |
+
FEATURE_SELECTION_MIN_CORR = float(os.getenv("FEATURE_SELECTION_MIN_CORR", "0.02"))
|
| 34 |
CORRELATION_THRESHOLD = float(os.getenv("CORRELATION_THRESHOLD", "0.85"))
|
| 35 |
CORRELATION_SAMPLE_SIZE = int(os.getenv("CORRELATION_SAMPLE_SIZE", "50000"))
|
| 36 |
ALLOW_MISSING_ARTIFACTS = os.getenv("ALLOW_MISSING_ARTIFACTS", "0") == "1"
|
|
|
|
| 40 |
LOG_INCLUDE_INPUTS = os.getenv("LOG_INCLUDE_INPUTS", "1") == "1"
|
| 41 |
LOG_HASH_SK_ID = os.getenv("LOG_HASH_SK_ID", "0") == "1"
|
| 42 |
MODEL_VERSION = os.getenv("MODEL_VERSION", MODEL_PATH.name)
|
| 43 |
+
LOGS_ACCESS_TOKEN = os.getenv("LOGS_ACCESS_TOKEN")
|
| 44 |
|
| 45 |
IGNORE_FEATURES = ["is_train", "is_test", "TARGET", "SK_ID_CURR"]
|
| 46 |
ENGINEERED_FEATURES = [
|
|
|
|
| 58 |
"CNT_FAM_MEMBERS",
|
| 59 |
"AMT_ANNUITY",
|
| 60 |
]
|
| 61 |
+
FEATURE_SELECTION_CATEGORICAL_INPUTS = ["CODE_GENDER", "FLAG_OWN_CAR"]
|
| 62 |
+
# Default reduced inputs (fallback when correlation-based selection is unavailable).
|
| 63 |
+
DEFAULT_REDUCED_INPUT_FEATURES = [
|
| 64 |
"SK_ID_CURR",
|
| 65 |
"EXT_SOURCE_2",
|
| 66 |
"EXT_SOURCE_3",
|
|
|
|
| 87 |
"AMT_REQ_CREDIT_BUREAU_QRT",
|
| 88 |
]
|
| 89 |
|
| 90 |
+
CODE_GENDER_MAPPING = {
|
| 91 |
+
"F": "F",
|
| 92 |
+
"FEMALE": "F",
|
| 93 |
+
"0": "F",
|
| 94 |
+
"W": "F",
|
| 95 |
+
"WOMAN": "F",
|
| 96 |
+
"M": "M",
|
| 97 |
+
"MALE": "M",
|
| 98 |
+
"1": "M",
|
| 99 |
+
"MAN": "M",
|
| 100 |
+
}
|
| 101 |
+
FLAG_OWN_CAR_MAPPING = {
|
| 102 |
+
"Y": "Y",
|
| 103 |
+
"YES": "Y",
|
| 104 |
+
"TRUE": "Y",
|
| 105 |
+
"1": "Y",
|
| 106 |
+
"T": "Y",
|
| 107 |
+
"N": "N",
|
| 108 |
+
"NO": "N",
|
| 109 |
+
"FALSE": "N",
|
| 110 |
+
"0": "N",
|
| 111 |
+
"F": "N",
|
| 112 |
+
}
|
| 113 |
+
DAYS_EMPLOYED_SENTINEL = 365243
|
| 114 |
+
|
| 115 |
|
| 116 |
class PredictionRequest(BaseModel):
|
| 117 |
data: dict[str, Any] | list[dict[str, Any]]
|
|
|
|
| 133 |
required_input_columns: list[str]
|
| 134 |
numeric_required_columns: list[str]
|
| 135 |
correlated_imputation: dict[str, dict[str, float | str]]
|
| 136 |
+
reduced_input_columns: list[str] = field(default_factory=list)
|
| 137 |
+
feature_selection_method: str = "default"
|
| 138 |
+
feature_selection_scores: dict[str, float] = field(default_factory=dict)
|
| 139 |
|
| 140 |
|
| 141 |
app = FastAPI(title="Credit Scoring API", version="0.1.0")
|
|
|
|
| 164 |
return hashlib.sha256(str(value).encode("utf-8")).hexdigest()
|
| 165 |
|
| 166 |
|
| 167 |
+
def _normalize_category_value(value: object, mapping: dict[str, str]) -> object:
|
| 168 |
+
if pd.isna(value):
|
| 169 |
+
return np.nan
|
| 170 |
+
key = str(value).strip().upper()
|
| 171 |
+
if not key:
|
| 172 |
+
return np.nan
|
| 173 |
+
return mapping.get(key, "Unknown")
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def _normalize_inputs(
|
| 177 |
+
df_raw: pd.DataFrame,
|
| 178 |
+
preprocessor: PreprocessorArtifacts,
|
| 179 |
+
) -> tuple[pd.DataFrame, dict[str, pd.Series], pd.Series]:
|
| 180 |
+
df = df_raw.copy()
|
| 181 |
+
for col in preprocessor.required_input_columns:
|
| 182 |
+
if col not in df.columns:
|
| 183 |
+
df[col] = np.nan
|
| 184 |
+
|
| 185 |
+
unknown_masks: dict[str, pd.Series] = {}
|
| 186 |
+
if "CODE_GENDER" in df.columns:
|
| 187 |
+
raw = df["CODE_GENDER"]
|
| 188 |
+
normalized = raw.apply(lambda v: _normalize_category_value(v, CODE_GENDER_MAPPING))
|
| 189 |
+
unknown_masks["CODE_GENDER"] = normalized.eq("Unknown") & raw.notna()
|
| 190 |
+
df["CODE_GENDER"] = normalized
|
| 191 |
+
if "FLAG_OWN_CAR" in df.columns:
|
| 192 |
+
raw = df["FLAG_OWN_CAR"]
|
| 193 |
+
normalized = raw.apply(lambda v: _normalize_category_value(v, FLAG_OWN_CAR_MAPPING))
|
| 194 |
+
unknown_masks["FLAG_OWN_CAR"] = normalized.eq("Unknown") & raw.notna()
|
| 195 |
+
df["FLAG_OWN_CAR"] = normalized
|
| 196 |
+
|
| 197 |
+
sentinel_mask = pd.Series(False, index=df.index)
|
| 198 |
+
if "DAYS_EMPLOYED" in df.columns:
|
| 199 |
+
values = pd.to_numeric(df["DAYS_EMPLOYED"], errors="coerce")
|
| 200 |
+
sentinel_mask = values == DAYS_EMPLOYED_SENTINEL
|
| 201 |
+
if sentinel_mask.any():
|
| 202 |
+
df.loc[sentinel_mask, "DAYS_EMPLOYED"] = np.nan
|
| 203 |
+
|
| 204 |
+
return df, unknown_masks, sentinel_mask
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def _build_data_quality_records(
|
| 208 |
+
df_raw: pd.DataFrame,
|
| 209 |
+
df_norm: pd.DataFrame,
|
| 210 |
+
unknown_masks: dict[str, pd.Series],
|
| 211 |
+
sentinel_mask: pd.Series,
|
| 212 |
+
preprocessor: PreprocessorArtifacts,
|
| 213 |
+
) -> list[dict[str, Any]]:
|
| 214 |
+
required_cols = preprocessor.required_input_columns
|
| 215 |
+
numeric_required = preprocessor.numeric_required_columns
|
| 216 |
+
numeric_ranges = {
|
| 217 |
+
col: bounds
|
| 218 |
+
for col, bounds in preprocessor.numeric_ranges.items()
|
| 219 |
+
if col in numeric_required
|
| 220 |
+
}
|
| 221 |
+
|
| 222 |
+
missing_mask = df_norm[required_cols].isna() if required_cols else pd.DataFrame(index=df_norm.index)
|
| 223 |
+
invalid_masks: dict[str, pd.Series] = {}
|
| 224 |
+
out_of_range_masks: dict[str, pd.Series] = {}
|
| 225 |
+
|
| 226 |
+
for col in numeric_required:
|
| 227 |
+
if col not in df_raw.columns:
|
| 228 |
+
invalid_masks[col] = pd.Series(False, index=df_norm.index)
|
| 229 |
+
continue
|
| 230 |
+
raw = df_raw[col]
|
| 231 |
+
coerced = pd.to_numeric(raw, errors="coerce")
|
| 232 |
+
invalid_masks[col] = coerced.isna() & raw.notna()
|
| 233 |
+
|
| 234 |
+
for col, (min_val, max_val) in numeric_ranges.items():
|
| 235 |
+
if col not in df_norm.columns:
|
| 236 |
+
out_of_range_masks[col] = pd.Series(False, index=df_norm.index)
|
| 237 |
+
continue
|
| 238 |
+
values = pd.to_numeric(df_norm[col], errors="coerce")
|
| 239 |
+
out_of_range_masks[col] = (values < min_val) | (values > max_val)
|
| 240 |
+
|
| 241 |
+
records: list[dict[str, Any]] = []
|
| 242 |
+
for idx in df_norm.index:
|
| 243 |
+
missing_cols = (
|
| 244 |
+
[col for col in required_cols if missing_mask.at[idx, col]]
|
| 245 |
+
if required_cols
|
| 246 |
+
else []
|
| 247 |
+
)
|
| 248 |
+
invalid_cols = [col for col, mask in invalid_masks.items() if mask.at[idx]]
|
| 249 |
+
out_of_range_cols = [col for col, mask in out_of_range_masks.items() if mask.at[idx]]
|
| 250 |
+
unknown_cols = [col for col, mask in unknown_masks.items() if mask.at[idx]]
|
| 251 |
+
nan_rate = float(missing_mask.loc[idx].mean()) if not missing_mask.empty else 0.0
|
| 252 |
+
records.append(
|
| 253 |
+
{
|
| 254 |
+
"missing_required_columns": missing_cols,
|
| 255 |
+
"invalid_numeric_columns": invalid_cols,
|
| 256 |
+
"out_of_range_columns": out_of_range_cols,
|
| 257 |
+
"unknown_categories": unknown_cols,
|
| 258 |
+
"days_employed_sentinel": bool(sentinel_mask.at[idx]) if not sentinel_mask.empty else False,
|
| 259 |
+
"nan_rate": nan_rate,
|
| 260 |
+
}
|
| 261 |
+
)
|
| 262 |
+
return records
|
| 263 |
+
|
| 264 |
+
|
| 265 |
def _append_log_entries(entries: list[dict[str, Any]]) -> None:
|
| 266 |
if not LOG_PREDICTIONS:
|
| 267 |
return
|
|
|
|
| 283 |
threshold: float | None,
|
| 284 |
status_code: int,
|
| 285 |
preprocessor: PreprocessorArtifacts,
|
| 286 |
+
data_quality: list[dict[str, Any]] | None = None,
|
| 287 |
error: str | None = None,
|
| 288 |
) -> None:
|
| 289 |
if not LOG_PREDICTIONS:
|
|
|
|
| 309 |
"threshold": threshold,
|
| 310 |
"inputs": inputs,
|
| 311 |
}
|
| 312 |
+
if data_quality and idx < len(data_quality):
|
| 313 |
+
entry["data_quality"] = data_quality[idx]
|
| 314 |
if results and idx < len(results):
|
| 315 |
result = results[idx]
|
| 316 |
sk_id = result.get("sk_id_curr")
|
|
|
|
| 369 |
for col, max_val in outlier_maxes.items():
|
| 370 |
df = df[df[col] != max_val]
|
| 371 |
|
| 372 |
+
reduced_input_columns, selection_scores, selection_method = _compute_reduced_inputs(
|
| 373 |
+
df,
|
| 374 |
+
input_feature_columns=input_feature_columns,
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
numeric_ranges = {}
|
| 378 |
for col in numeric_cols:
|
| 379 |
if col in df.columns:
|
|
|
|
| 389 |
required_raw.update(col for col in columns_must_not_missing if col in input_feature_columns)
|
| 390 |
required_raw.add("SK_ID_CURR")
|
| 391 |
if USE_REDUCED_INPUTS:
|
| 392 |
+
required_input = reduced_input_columns
|
| 393 |
+
if not required_input:
|
| 394 |
+
required_input = _fallback_reduced_inputs(input_feature_columns)
|
| 395 |
else:
|
| 396 |
required_input = sorted(required_raw)
|
| 397 |
numeric_required = sorted(col for col in required_input if col in numeric_medians)
|
|
|
|
| 417 |
required_input_columns=required_input,
|
| 418 |
numeric_required_columns=numeric_required,
|
| 419 |
correlated_imputation=correlated_imputation,
|
| 420 |
+
reduced_input_columns=reduced_input_columns,
|
| 421 |
+
feature_selection_method=selection_method,
|
| 422 |
+
feature_selection_scores=selection_scores,
|
| 423 |
)
|
| 424 |
|
| 425 |
|
|
|
|
| 485 |
required_raw = set(ENGINEERED_SOURCES)
|
| 486 |
required_raw.update(col for col in columns_must_not_missing if col in input_feature_columns)
|
| 487 |
required_raw.add("SK_ID_CURR")
|
| 488 |
+
required_input = _fallback_reduced_inputs(input_feature_columns)
|
| 489 |
numeric_required = sorted(col for col in required_input if col in numeric_medians)
|
| 490 |
|
| 491 |
numeric_ranges = {col: (float(df[col].min()), float(df[col].max())) for col in numeric_cols}
|
|
|
|
| 505 |
required_input_columns=required_input,
|
| 506 |
numeric_required_columns=numeric_required,
|
| 507 |
correlated_imputation={},
|
| 508 |
+
reduced_input_columns=required_input,
|
| 509 |
+
feature_selection_method="fallback",
|
| 510 |
+
feature_selection_scores={},
|
| 511 |
)
|
| 512 |
|
| 513 |
|
|
|
|
| 516 |
preprocessor = joblib.load(artifacts_path)
|
| 517 |
updated = False
|
| 518 |
required_updated = False
|
| 519 |
+
if not hasattr(preprocessor, "reduced_input_columns") or not preprocessor.reduced_input_columns:
|
| 520 |
+
reduced_cols, selection_scores, selection_method = _compute_reduced_inputs_from_data(
|
| 521 |
+
data_path, preprocessor
|
| 522 |
+
)
|
| 523 |
+
preprocessor.reduced_input_columns = reduced_cols
|
| 524 |
+
preprocessor.feature_selection_method = selection_method
|
| 525 |
+
preprocessor.feature_selection_scores = selection_scores
|
| 526 |
+
updated = True
|
| 527 |
+
if not hasattr(preprocessor, "feature_selection_method"):
|
| 528 |
+
preprocessor.feature_selection_method = "default"
|
| 529 |
+
updated = True
|
| 530 |
+
if not hasattr(preprocessor, "feature_selection_scores"):
|
| 531 |
+
preprocessor.feature_selection_scores = {}
|
| 532 |
+
updated = True
|
| 533 |
if not hasattr(preprocessor, "required_input_columns"):
|
| 534 |
if USE_REDUCED_INPUTS:
|
| 535 |
required_input = _reduce_input_columns(preprocessor)
|
|
|
|
| 607 |
return ranges
|
| 608 |
|
| 609 |
|
| 610 |
+
def _dedupe_preserve_order(values: list[str]) -> list[str]:
|
| 611 |
+
seen: set[str] = set()
|
| 612 |
+
output: list[str] = []
|
| 613 |
+
for value in values:
|
| 614 |
+
if value in seen:
|
| 615 |
+
continue
|
| 616 |
+
seen.add(value)
|
| 617 |
+
output.append(value)
|
| 618 |
+
return output
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
def _fallback_reduced_inputs(input_feature_columns: list[str]) -> list[str]:
|
| 622 |
+
cols = [
|
| 623 |
+
col
|
| 624 |
+
for col in DEFAULT_REDUCED_INPUT_FEATURES
|
| 625 |
+
if col in input_feature_columns or col == "SK_ID_CURR"
|
| 626 |
+
]
|
| 627 |
+
if "SK_ID_CURR" not in cols:
|
| 628 |
+
cols.insert(0, "SK_ID_CURR")
|
| 629 |
+
return _dedupe_preserve_order(cols)
|
| 630 |
+
|
| 631 |
+
|
| 632 |
+
def _select_reduced_inputs_by_correlation(
|
| 633 |
+
df: pd.DataFrame,
|
| 634 |
+
*,
|
| 635 |
+
input_feature_columns: list[str],
|
| 636 |
+
top_n: int,
|
| 637 |
+
min_corr: float,
|
| 638 |
+
) -> tuple[list[str], dict[str, float]]:
|
| 639 |
+
if "TARGET" not in df.columns:
|
| 640 |
+
return [], {}
|
| 641 |
+
df_corr = df
|
| 642 |
+
if CORRELATION_SAMPLE_SIZE > 0 and len(df_corr) > CORRELATION_SAMPLE_SIZE:
|
| 643 |
+
df_corr = df_corr.sample(CORRELATION_SAMPLE_SIZE, random_state=42)
|
| 644 |
+
numeric_cols = [
|
| 645 |
+
col
|
| 646 |
+
for col in df_corr.select_dtypes(include=["number"]).columns
|
| 647 |
+
if col in input_feature_columns
|
| 648 |
+
and col not in {"TARGET", "SK_ID_CURR", "is_train", "is_test"}
|
| 649 |
+
]
|
| 650 |
+
if not numeric_cols:
|
| 651 |
+
return [], {}
|
| 652 |
+
corr = df_corr[numeric_cols + ["TARGET"]].corr()["TARGET"].drop("TARGET")
|
| 653 |
+
corr = corr.dropna()
|
| 654 |
+
if corr.empty:
|
| 655 |
+
return [], {}
|
| 656 |
+
corr = corr.reindex(corr.abs().sort_values(ascending=False).index)
|
| 657 |
+
if min_corr > 0:
|
| 658 |
+
corr = corr[corr.abs() >= min_corr]
|
| 659 |
+
selected_numeric = list(corr.index[:top_n])
|
| 660 |
+
scores = {col: float(abs(corr.loc[col])) for col in selected_numeric}
|
| 661 |
+
selected = ["SK_ID_CURR"]
|
| 662 |
+
selected.extend(selected_numeric)
|
| 663 |
+
selected.extend(
|
| 664 |
+
col
|
| 665 |
+
for col in FEATURE_SELECTION_CATEGORICAL_INPUTS
|
| 666 |
+
if col in input_feature_columns
|
| 667 |
+
)
|
| 668 |
+
selected = [
|
| 669 |
+
col for col in selected if col in input_feature_columns or col == "SK_ID_CURR"
|
| 670 |
+
]
|
| 671 |
+
return _dedupe_preserve_order(selected), scores
|
| 672 |
+
|
| 673 |
+
|
| 674 |
+
def _compute_reduced_inputs(
|
| 675 |
+
df: pd.DataFrame | None,
|
| 676 |
+
*,
|
| 677 |
+
input_feature_columns: list[str],
|
| 678 |
+
) -> tuple[list[str], dict[str, float], str]:
|
| 679 |
+
if FEATURE_SELECTION_METHOD != "correlation":
|
| 680 |
+
return _fallback_reduced_inputs(input_feature_columns), {}, "default"
|
| 681 |
+
if df is None or "TARGET" not in df.columns:
|
| 682 |
+
return _fallback_reduced_inputs(input_feature_columns), {}, "default"
|
| 683 |
+
reduced_cols, scores = _select_reduced_inputs_by_correlation(
|
| 684 |
+
df,
|
| 685 |
+
input_feature_columns=input_feature_columns,
|
| 686 |
+
top_n=FEATURE_SELECTION_TOP_N,
|
| 687 |
+
min_corr=FEATURE_SELECTION_MIN_CORR,
|
| 688 |
+
)
|
| 689 |
+
if not reduced_cols:
|
| 690 |
+
return _fallback_reduced_inputs(input_feature_columns), {}, "default"
|
| 691 |
+
return reduced_cols, scores, "correlation"
|
| 692 |
+
|
| 693 |
+
|
| 694 |
def _build_correlated_imputation(
|
| 695 |
df: pd.DataFrame,
|
| 696 |
*,
|
|
|
|
| 742 |
|
| 743 |
|
| 744 |
def _reduce_input_columns(preprocessor: PreprocessorArtifacts) -> list[str]:
|
| 745 |
+
cols = getattr(preprocessor, "reduced_input_columns", None) or []
|
| 746 |
+
if not cols:
|
| 747 |
+
cols = _fallback_reduced_inputs(preprocessor.input_feature_columns)
|
| 748 |
+
cols = [
|
| 749 |
+
col
|
| 750 |
+
for col in cols
|
| 751 |
+
if col in preprocessor.input_feature_columns or col == "SK_ID_CURR"
|
| 752 |
+
]
|
| 753 |
if "SK_ID_CURR" not in cols:
|
| 754 |
+
cols.insert(0, "SK_ID_CURR")
|
| 755 |
+
return _dedupe_preserve_order(cols)
|
| 756 |
+
|
| 757 |
+
|
| 758 |
+
def _compute_reduced_inputs_from_data(
|
| 759 |
+
data_path: Path,
|
| 760 |
+
preprocessor: PreprocessorArtifacts,
|
| 761 |
+
) -> tuple[list[str], dict[str, float], str]:
|
| 762 |
+
if not data_path.exists():
|
| 763 |
+
return _fallback_reduced_inputs(preprocessor.input_feature_columns), {}, "default"
|
| 764 |
+
df = pd.read_parquet(data_path)
|
| 765 |
+
df = new_features_creation(df)
|
| 766 |
+
df.replace([np.inf, -np.inf], np.nan, inplace=True)
|
| 767 |
+
|
| 768 |
+
if preprocessor.columns_keep:
|
| 769 |
+
df = df[preprocessor.columns_keep]
|
| 770 |
+
if preprocessor.columns_must_not_missing:
|
| 771 |
+
df = df.dropna(subset=preprocessor.columns_must_not_missing)
|
| 772 |
+
|
| 773 |
+
numeric_cols = df.select_dtypes(include=["number"]).columns
|
| 774 |
+
df[numeric_cols] = df[numeric_cols].fillna(pd.Series(preprocessor.numeric_medians))
|
| 775 |
+
|
| 776 |
+
for col in preprocessor.categorical_columns:
|
| 777 |
+
if col in df.columns:
|
| 778 |
+
df[col] = df[col].fillna("Unknown")
|
| 779 |
+
|
| 780 |
+
if "CODE_GENDER" in df.columns:
|
| 781 |
+
df = df[df["CODE_GENDER"] != "XNA"]
|
| 782 |
+
|
| 783 |
+
for col, max_val in preprocessor.outlier_maxes.items():
|
| 784 |
+
if col in df.columns:
|
| 785 |
+
df = df[df[col] != max_val]
|
| 786 |
+
|
| 787 |
+
return _compute_reduced_inputs(df, input_feature_columns=preprocessor.input_feature_columns)
|
| 788 |
|
| 789 |
|
| 790 |
def _compute_correlated_imputation(
|
|
|
|
| 820 |
)
|
| 821 |
|
| 822 |
|
| 823 |
+
def _ensure_required_columns(
|
| 824 |
+
df: pd.DataFrame,
|
| 825 |
+
required_cols: list[str],
|
| 826 |
+
allow_missing: set[str] | None = None,
|
| 827 |
+
) -> None:
|
| 828 |
+
allow_missing = allow_missing or set()
|
| 829 |
+
missing = [
|
| 830 |
+
col
|
| 831 |
+
for col in required_cols
|
| 832 |
+
if col not in df.columns or (col not in allow_missing and df[col].isna().any())
|
| 833 |
+
]
|
| 834 |
if missing:
|
| 835 |
raise HTTPException(
|
| 836 |
status_code=422,
|
|
|
|
| 846 |
invalid = []
|
| 847 |
for col in numeric_cols:
|
| 848 |
coerced = pd.to_numeric(df[col], errors="coerce")
|
| 849 |
+
if (coerced.isna() & df[col].notna()).any():
|
| 850 |
invalid.append(col)
|
| 851 |
if invalid:
|
| 852 |
raise HTTPException(
|
|
|
|
| 867 |
if col not in df.columns:
|
| 868 |
continue
|
| 869 |
values = pd.to_numeric(df[col], errors="coerce")
|
| 870 |
+
mask = values.notna()
|
| 871 |
+
if mask.any() and ((values[mask] < min_val) | (values[mask] > max_val)).any():
|
|
|
|
| 872 |
out_of_range.append(col)
|
| 873 |
if out_of_range:
|
| 874 |
raise HTTPException(
|
|
|
|
| 910 |
if col not in df.columns:
|
| 911 |
df[col] = np.nan
|
| 912 |
|
| 913 |
+
allow_missing = {"DAYS_EMPLOYED"}
|
| 914 |
+
_ensure_required_columns(df, artifacts.required_input_columns, allow_missing=allow_missing)
|
| 915 |
_validate_numeric_inputs(df, artifacts.numeric_required_columns)
|
| 916 |
_validate_numeric_ranges(df, {k: v for k, v in artifacts.numeric_ranges.items() if k in artifacts.numeric_required_columns})
|
| 917 |
|
|
|
|
| 923 |
df = new_features_creation(df)
|
| 924 |
df.replace([np.inf, -np.inf], np.nan, inplace=True)
|
| 925 |
|
| 926 |
+
df = df.reindex(columns=artifacts.columns_keep, fill_value=np.nan)
|
|
|
|
|
|
|
|
|
|
| 927 |
|
| 928 |
_apply_correlated_imputation(df, artifacts)
|
| 929 |
|
|
|
|
| 936 |
if col in df.columns:
|
| 937 |
df[col] = df[col].fillna("Unknown")
|
| 938 |
|
| 939 |
+
_ensure_required_columns(df, artifacts.required_input_columns, allow_missing=allow_missing)
|
| 940 |
|
| 941 |
if "CODE_GENDER" in df.columns and (df["CODE_GENDER"] == "XNA").any():
|
| 942 |
raise HTTPException(
|
|
|
|
| 955 |
)
|
| 956 |
|
| 957 |
df_hot = pd.get_dummies(df, columns=artifacts.categorical_columns)
|
| 958 |
+
df_hot = df_hot.reindex(columns=artifacts.features_to_scaled, fill_value=0)
|
|
|
|
|
|
|
|
|
|
| 959 |
|
| 960 |
scaled = artifacts.scaler.transform(df_hot)
|
| 961 |
return pd.DataFrame(scaled, columns=artifacts.features_to_scaled, index=df.index)
|
|
|
|
| 1004 |
preprocessor: PreprocessorArtifacts = app.state.preprocessor
|
| 1005 |
optional_features = [col for col in preprocessor.input_feature_columns if col not in preprocessor.required_input_columns]
|
| 1006 |
correlated = sorted(getattr(preprocessor, "correlated_imputation", {}) or {})
|
| 1007 |
+
scores = getattr(preprocessor, "feature_selection_scores", {}) or {}
|
| 1008 |
+
selection_scores = {
|
| 1009 |
+
col: round(scores[col], 4)
|
| 1010 |
+
for col in preprocessor.required_input_columns
|
| 1011 |
+
if col in scores
|
| 1012 |
+
}
|
| 1013 |
payload = {
|
| 1014 |
"required_input_features": preprocessor.required_input_columns,
|
| 1015 |
"engineered_features": ENGINEERED_FEATURES,
|
| 1016 |
"model_features_count": len(preprocessor.features_to_scaled),
|
| 1017 |
+
"feature_selection_method": preprocessor.feature_selection_method,
|
| 1018 |
+
"feature_selection_top_n": FEATURE_SELECTION_TOP_N,
|
| 1019 |
+
"feature_selection_min_corr": FEATURE_SELECTION_MIN_CORR,
|
| 1020 |
+
"feature_selection_scores": selection_scores,
|
| 1021 |
"correlation_threshold": CORRELATION_THRESHOLD,
|
| 1022 |
"correlated_imputation_count": len(correlated),
|
| 1023 |
"correlated_imputation_features": correlated[:50],
|
|
|
|
| 1032 |
return payload
|
| 1033 |
|
| 1034 |
|
| 1035 |
+
@app.get("/logs")
|
| 1036 |
+
def logs(
|
| 1037 |
+
tail: int = Query(default=200, ge=1, le=2000),
|
| 1038 |
+
x_logs_token: str | None = Header(default=None, alias="X-Logs-Token"),
|
| 1039 |
+
authorization: str | None = Header(default=None),
|
| 1040 |
+
) -> Response:
|
| 1041 |
+
if not LOGS_ACCESS_TOKEN:
|
| 1042 |
+
raise HTTPException(status_code=503, detail={"message": "Logs access token not configured."})
|
| 1043 |
+
|
| 1044 |
+
token = x_logs_token
|
| 1045 |
+
if token is None and authorization:
|
| 1046 |
+
prefix = "bearer "
|
| 1047 |
+
if authorization.lower().startswith(prefix):
|
| 1048 |
+
token = authorization[len(prefix):].strip() or None
|
| 1049 |
+
|
| 1050 |
+
if token != LOGS_ACCESS_TOKEN:
|
| 1051 |
+
raise HTTPException(status_code=403, detail={"message": "Invalid logs access token."})
|
| 1052 |
+
|
| 1053 |
+
if not LOG_PREDICTIONS:
|
| 1054 |
+
raise HTTPException(status_code=404, detail={"message": "Prediction logging is disabled."})
|
| 1055 |
+
|
| 1056 |
+
log_path = LOG_DIR / LOG_FILE
|
| 1057 |
+
if not log_path.exists():
|
| 1058 |
+
raise HTTPException(status_code=404, detail={"message": "Log file not found."})
|
| 1059 |
+
|
| 1060 |
+
with log_path.open("r", encoding="utf-8") as handle:
|
| 1061 |
+
lines = deque(handle, maxlen=tail)
|
| 1062 |
+
|
| 1063 |
+
return Response(content="".join(lines), media_type="application/x-ndjson")
|
| 1064 |
+
|
| 1065 |
+
|
| 1066 |
@app.post("/predict")
|
| 1067 |
def predict(
|
| 1068 |
payload: PredictionRequest,
|
|
|
|
| 1079 |
|
| 1080 |
try:
|
| 1081 |
df_raw = pd.DataFrame.from_records(records)
|
| 1082 |
+
df_norm, unknown_masks, sentinel_mask = _normalize_inputs(df_raw, preprocessor)
|
| 1083 |
+
log_records = df_norm.to_dict(orient="records")
|
| 1084 |
+
dq_records = _build_data_quality_records(
|
| 1085 |
+
df_raw,
|
| 1086 |
+
df_norm,
|
| 1087 |
+
unknown_masks,
|
| 1088 |
+
sentinel_mask,
|
| 1089 |
+
preprocessor,
|
| 1090 |
+
)
|
| 1091 |
+
if "SK_ID_CURR" not in df_norm.columns:
|
| 1092 |
raise HTTPException(status_code=422, detail={"message": "SK_ID_CURR is required."})
|
| 1093 |
|
| 1094 |
+
sk_ids = df_norm["SK_ID_CURR"].tolist()
|
| 1095 |
+
features = preprocess_input(df_norm, preprocessor)
|
| 1096 |
|
| 1097 |
if hasattr(model, "predict_proba"):
|
| 1098 |
proba = model.predict_proba(features)[:, 1]
|
|
|
|
| 1109 |
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 1110 |
_log_prediction_entries(
|
| 1111 |
request_id=request_id,
|
| 1112 |
+
records=log_records,
|
| 1113 |
results=results,
|
| 1114 |
latency_ms=latency_ms,
|
| 1115 |
threshold=use_threshold,
|
| 1116 |
status_code=200,
|
| 1117 |
preprocessor=preprocessor,
|
| 1118 |
+
data_quality=dq_records,
|
| 1119 |
)
|
| 1120 |
return {"predictions": results, "threshold": use_threshold}
|
| 1121 |
|
|
|
|
| 1130 |
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 1131 |
_log_prediction_entries(
|
| 1132 |
request_id=request_id,
|
| 1133 |
+
records=log_records,
|
| 1134 |
results=results,
|
| 1135 |
latency_ms=latency_ms,
|
| 1136 |
threshold=None,
|
| 1137 |
status_code=200,
|
| 1138 |
preprocessor=preprocessor,
|
| 1139 |
+
data_quality=dq_records,
|
| 1140 |
)
|
| 1141 |
return {"predictions": results, "threshold": None}
|
| 1142 |
except HTTPException as exc:
|
|
|
|
| 1144 |
detail = exc.detail if isinstance(exc.detail, dict) else {"message": str(exc.detail)}
|
| 1145 |
_log_prediction_entries(
|
| 1146 |
request_id=request_id,
|
| 1147 |
+
records=log_records if "log_records" in locals() else records,
|
| 1148 |
results=None,
|
| 1149 |
latency_ms=latency_ms,
|
| 1150 |
threshold=threshold,
|
| 1151 |
status_code=exc.status_code,
|
| 1152 |
preprocessor=preprocessor,
|
| 1153 |
+
data_quality=dq_records if "dq_records" in locals() else None,
|
| 1154 |
error=json.dumps(detail, ensure_ascii=True),
|
| 1155 |
)
|
| 1156 |
raise
|
|
|
|
| 1158 |
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 1159 |
_log_prediction_entries(
|
| 1160 |
request_id=request_id,
|
| 1161 |
+
records=log_records if "log_records" in locals() else records,
|
| 1162 |
results=None,
|
| 1163 |
latency_ms=latency_ms,
|
| 1164 |
threshold=threshold,
|
| 1165 |
status_code=500,
|
| 1166 |
preprocessor=preprocessor,
|
| 1167 |
+
data_quality=dq_records if "dq_records" in locals() else None,
|
| 1168 |
error=str(exc),
|
| 1169 |
)
|
| 1170 |
raise
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/README.md
CHANGED
|
@@ -10,9 +10,9 @@ pinned: false
|
|
| 10 |
|
| 11 |
# OCR Projet 06 – Crédit
|
| 12 |
|
| 13 |
-
[ ou une liste d'objets (plusieurs clients). La liste des
|
| 46 |
-
features requises (jeu reduit) est disponible via l'endpoint `/features`. Les
|
| 47 |
-
autres champs sont optionnels et seront completes par des valeurs par defaut.
|
| 48 |
|
| 49 |
-
Inputs minimums (10 + `SK_ID_CURR`) :
|
| 50 |
|
| 51 |
- `EXT_SOURCE_2`
|
| 52 |
- `EXT_SOURCE_3`
|
|
@@ -59,6 +56,12 @@ Inputs minimums (10 + `SK_ID_CURR`) :
|
|
| 59 |
- `DAYS_BIRTH`
|
| 60 |
- `FLAG_OWN_CAR`
|
| 61 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
### Environnement Poetry (recommande)
|
| 63 |
|
| 64 |
Le fichier `pyproject.toml` fixe des versions compatibles pour un stack recent
|
|
@@ -131,22 +134,23 @@ Lancer l'API :
|
|
| 131 |
uvicorn app.main:app --reload --port 7860
|
| 132 |
```
|
| 133 |
|
| 134 |
-
Verifier le service :
|
| 135 |
|
| 136 |
```shell
|
| 137 |
-
|
|
|
|
| 138 |
```
|
| 139 |
|
| 140 |
-
Voir les features attendues :
|
| 141 |
|
| 142 |
```shell
|
| 143 |
-
curl -s
|
| 144 |
```
|
| 145 |
|
| 146 |
-
Predire un client :
|
| 147 |
|
| 148 |
```shell
|
| 149 |
-
curl -s -X POST "
|
| 150 |
-H "Content-Type: application/json" \
|
| 151 |
-d '{
|
| 152 |
"data": {
|
|
@@ -165,6 +169,109 @@ curl -s -X POST "http://127.0.0.1:7860/predict?threshold=0.5" \
|
|
| 165 |
}'
|
| 166 |
```
|
| 167 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 168 |
## Contenu de la release
|
| 169 |
|
| 170 |
- **Preparation + pipeline** : nettoyage / preparation, encodage, imputation et pipeline d'entrainement presentes.
|
|
@@ -174,19 +281,28 @@ curl -s -X POST "http://127.0.0.1:7860/predict?threshold=0.5" \
|
|
| 174 |
- **Validation croisee + tuning** : `StratifiedKFold`, `GridSearchCV` et Hyperopt sont utilises.
|
| 175 |
- **Score metier + seuil optimal** : le `custom_score` est la metrique principale des tableaux de comparaison et de la CV, avec un `best_threshold` calcule.
|
| 176 |
- **Explicabilite** : feature importance, SHAP et LIME sont inclus.
|
| 177 |
-
- **
|
| 178 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 179 |
|
| 180 |
-
|
| 181 |
|
| 182 |
-
##
|
| 183 |
|
| 184 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 185 |
|
| 186 |
-
##
|
| 187 |
|
| 188 |
-
|
| 189 |
-
|
| 190 |
-
|
| 191 |
-
|
| 192 |
-
- **Registry** : espace MLflow pour versionner et promouvoir un modele (ex. "Staging").
|
|
|
|
| 10 |
|
| 11 |
# OCR Projet 06 – Crédit
|
| 12 |
|
| 13 |
+
[](https://github.com/stephmnt/credit-scoring-mlops/actions/workflows/deploy.yml)
|
| 14 |
+
[](https://github.com/stephmnt/credit-scoring-mlops/releases)
|
| 15 |
+
[](https://github.com/stephmnt/credit-scoring-mlops/blob/main/LICENSE)
|
| 16 |
|
| 17 |
## Lancer MLFlow
|
| 18 |
|
|
|
|
| 41 |
|
| 42 |
## API FastAPI
|
| 43 |
|
| 44 |
+
L'API attend un payload JSON avec une cle `data`. La valeur peut etre un objet unique (un client) ou une liste d'objets (plusieurs clients). La liste des features requises (jeu reduit) est disponible via l'endpoint `/features`. Les autres champs sont optionnels et seront completes par des valeurs par defaut.
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |
+
Inputs minimums (10 + `SK_ID_CURR`) derives d'une selection par correlation (voir `/features`) :
|
| 47 |
|
| 48 |
- `EXT_SOURCE_2`
|
| 49 |
- `EXT_SOURCE_3`
|
|
|
|
| 56 |
- `DAYS_BIRTH`
|
| 57 |
- `FLAG_OWN_CAR`
|
| 58 |
|
| 59 |
+
Parametres utiles (selection des features) :
|
| 60 |
+
|
| 61 |
+
- `FEATURE_SELECTION_METHOD` (defaut: `correlation`)
|
| 62 |
+
- `FEATURE_SELECTION_TOP_N` (defaut: `8`)
|
| 63 |
+
- `FEATURE_SELECTION_MIN_CORR` (defaut: `0.02`)
|
| 64 |
+
|
| 65 |
### Environnement Poetry (recommande)
|
| 66 |
|
| 67 |
Le fichier `pyproject.toml` fixe des versions compatibles pour un stack recent
|
|
|
|
| 134 |
uvicorn app.main:app --reload --port 7860
|
| 135 |
```
|
| 136 |
|
| 137 |
+
Verifier le service (HF) :
|
| 138 |
|
| 139 |
```shell
|
| 140 |
+
BASE_URL="https://stephmnt-credit-scoring-mlops.hf.space"
|
| 141 |
+
curl -s "${BASE_URL}/health"
|
| 142 |
```
|
| 143 |
|
| 144 |
+
Voir les features attendues (HF) :
|
| 145 |
|
| 146 |
```shell
|
| 147 |
+
curl -s "${BASE_URL}/features"
|
| 148 |
```
|
| 149 |
|
| 150 |
+
Predire un client (HF) :
|
| 151 |
|
| 152 |
```shell
|
| 153 |
+
curl -s -X POST "${BASE_URL}/predict?threshold=0.5" \
|
| 154 |
-H "Content-Type: application/json" \
|
| 155 |
-d '{
|
| 156 |
"data": {
|
|
|
|
| 169 |
}'
|
| 170 |
```
|
| 171 |
|
| 172 |
+
Predire plusieurs clients (batch, HF) :
|
| 173 |
+
|
| 174 |
+
```shell
|
| 175 |
+
curl -s -X POST "${BASE_URL}/predict?threshold=0.45" \
|
| 176 |
+
-H "Content-Type: application/json" \
|
| 177 |
+
-d '{
|
| 178 |
+
"data": [
|
| 179 |
+
{
|
| 180 |
+
"SK_ID_CURR": 100002,
|
| 181 |
+
"EXT_SOURCE_2": 0.61,
|
| 182 |
+
"EXT_SOURCE_3": 0.75,
|
| 183 |
+
"AMT_ANNUITY": 24700.5,
|
| 184 |
+
"EXT_SOURCE_1": 0.45,
|
| 185 |
+
"CODE_GENDER": "M",
|
| 186 |
+
"DAYS_EMPLOYED": -637,
|
| 187 |
+
"AMT_CREDIT": 406597.5,
|
| 188 |
+
"AMT_GOODS_PRICE": 351000.0,
|
| 189 |
+
"DAYS_BIRTH": -9461,
|
| 190 |
+
"FLAG_OWN_CAR": "N"
|
| 191 |
+
},
|
| 192 |
+
{
|
| 193 |
+
"SK_ID_CURR": 100003,
|
| 194 |
+
"EXT_SOURCE_2": 0.52,
|
| 195 |
+
"EXT_SOURCE_3": 0.64,
|
| 196 |
+
"AMT_ANNUITY": 19000.0,
|
| 197 |
+
"EXT_SOURCE_1": 0.33,
|
| 198 |
+
"CODE_GENDER": "F",
|
| 199 |
+
"DAYS_EMPLOYED": -1200,
|
| 200 |
+
"AMT_CREDIT": 320000.0,
|
| 201 |
+
"AMT_GOODS_PRICE": 280000.0,
|
| 202 |
+
"DAYS_BIRTH": -12000,
|
| 203 |
+
"FLAG_OWN_CAR": "Y"
|
| 204 |
+
}
|
| 205 |
+
]
|
| 206 |
+
}'
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
Exemple d'erreur (champ requis manquant, HF) :
|
| 210 |
+
|
| 211 |
+
```shell
|
| 212 |
+
curl -s -X POST "${BASE_URL}/predict" \
|
| 213 |
+
-H "Content-Type: application/json" \
|
| 214 |
+
-d '{
|
| 215 |
+
"data": {
|
| 216 |
+
"EXT_SOURCE_2": 0.61
|
| 217 |
+
}
|
| 218 |
+
}'
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
## Monitoring & Data Drift (Etape 3)
|
| 222 |
+
|
| 223 |
+
L'API enregistre les appels `/predict` en JSONL (inputs, outputs, latence).
|
| 224 |
+
Par defaut, les logs sont stockes dans `logs/predictions.jsonl`.
|
| 225 |
+
|
| 226 |
+
Variables utiles :
|
| 227 |
+
|
| 228 |
+
- `LOG_PREDICTIONS=1` active l'ecriture des logs (defaut: 1)
|
| 229 |
+
- `LOG_DIR=logs`
|
| 230 |
+
- `LOG_FILE=predictions.jsonl`
|
| 231 |
+
- `LOGS_ACCESS_TOKEN` pour proteger l'endpoint `/logs`
|
| 232 |
+
- `LOG_HASH_SK_ID=1` pour anonymiser `SK_ID_CURR`
|
| 233 |
+
|
| 234 |
+
Exemple local :
|
| 235 |
+
|
| 236 |
+
```shell
|
| 237 |
+
LOG_PREDICTIONS=1 LOG_DIR=logs uvicorn app.main:app --reload --port 7860
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
Recuperer les logs (HF) :
|
| 241 |
+
|
| 242 |
+
Configurer `LOGS_ACCESS_TOKEN` dans les secrets du Space, puis :
|
| 243 |
+
|
| 244 |
+
```shell
|
| 245 |
+
curl -s -H "X-Logs-Token: $LOGS_ACCESS_TOKEN" "${BASE_URL}/logs?tail=200"
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
Alternative :
|
| 249 |
+
|
| 250 |
+
```shell
|
| 251 |
+
curl -s -H "Authorization: Bearer $LOGS_ACCESS_TOKEN" "${BASE_URL}/logs?tail=200"
|
| 252 |
+
```
|
| 253 |
+
|
| 254 |
+
Apres quelques requêtes, gélérer le rapport de drift :
|
| 255 |
+
|
| 256 |
+
```shell
|
| 257 |
+
python monitoring/drift_report.py \
|
| 258 |
+
--logs logs/predictions.jsonl \
|
| 259 |
+
--reference data/data_final.parquet \
|
| 260 |
+
--output-dir reports
|
| 261 |
+
```
|
| 262 |
+
|
| 263 |
+
Le rapport HTML est généré dans `reports/drift_report.html` (avec des plots dans
|
| 264 |
+
`reports/plots/`). Sur Hugging Face, le disque est éphemère : télécharger les logs
|
| 265 |
+
avant d'analyser.
|
| 266 |
+
|
| 267 |
+
Le rapport inclut aussi la distribution des scores predits et le taux de prediction
|
| 268 |
+
(option `--score-bins` pour ajuster le nombre de bins).
|
| 269 |
+
|
| 270 |
+
Captures (snapshot local du reporting + stockage):
|
| 271 |
+
|
| 272 |
+
- Rapport: `docs/monitoring/drift_report.html` + `docs/monitoring/plots/`
|
| 273 |
+
- Stockage des logs: `docs/monitoring/logs_storage.png`
|
| 274 |
+
|
| 275 |
## Contenu de la release
|
| 276 |
|
| 277 |
- **Preparation + pipeline** : nettoyage / preparation, encodage, imputation et pipeline d'entrainement presentes.
|
|
|
|
| 281 |
- **Validation croisee + tuning** : `StratifiedKFold`, `GridSearchCV` et Hyperopt sont utilises.
|
| 282 |
- **Score metier + seuil optimal** : le `custom_score` est la metrique principale des tableaux de comparaison et de la CV, avec un `best_threshold` calcule.
|
| 283 |
- **Explicabilite** : feature importance, SHAP et LIME sont inclus.
|
| 284 |
+
- **Selection de features par correlation** : top‑N numeriques + un petit set categoriel, expose via `/features`.
|
| 285 |
+
- **Monitoring & drift** : rapport HTML avec KS/PSI + distribution des scores predits et taux de prediction
|
| 286 |
+
(snapshots dans `docs/monitoring/`).
|
| 287 |
+
- **CI/CD** : tests avec couverture (`pytest-cov`), build Docker et deploy vers Hugging Face Spaces.
|
| 288 |
+
|
| 289 |
+

|
| 290 |
+
|
| 291 |
+
### Manques prioritaires
|
| 292 |
|
| 293 |
+
* Mission 2 Étape 4 non couverte: pas de profiling/optimisation post‑déploiement ni rapport de gains, à livrer avec une version optimisée.
|
| 294 |
|
| 295 |
+
### Preuves / doc à compléter
|
| 296 |
|
| 297 |
+
* Lien explicite vers le dépôt public + stratégie de versions/branches à ajouter dans README.md.
|
| 298 |
+
* Preuve de model registry/serving MLflow à conserver (capture UI registry ou commande de serving) en plus de screen-mlflow.png.
|
| 299 |
+
* Dataset de référence non versionné (data_final.parquet est ignoré), documenter l’obtention pour exécuter drift_report.py.
|
| 300 |
+
* Badge GitHub Actions pointe vers OCR_Projet05 dans README.md, corriger l’URL.
|
| 301 |
+
* RGPD/PII: LOG_HASH_SK_ID est désactivé par défaut dans main.py, préciser l’activation en prod dans README.md.
|
| 302 |
|
| 303 |
+
### Améliorations recommandées
|
| 304 |
|
| 305 |
+
* Compléter les tests API: /logs (auth OK/KO), batch predict, param threshold, SK_ID_CURR manquant, outliers dans test_api.py.
|
| 306 |
+
* Simplifier le fallback ALLOW_MISSING_ARTIFACTS et DummyModel si les artefacts sont versionnés (nettoyer main.py et conftest.py).
|
| 307 |
+
* Unifier la gestion des dépendances (Poetry vs requirements.txt) et aligner pyproject.toml / requirements.txt.
|
| 308 |
+
* Si l’évaluateur attend une stratégie de branches, créer une branche feature et fusionner pour preuve.
|
|
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.dockerignore
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
mlruns/
|
| 2 |
+
*.ipynb
|
| 3 |
+
data/*.csv
|
| 4 |
+
data/*.parquet
|
| 5 |
+
!data/data_final.parquet
|
| 6 |
+
!data/HistGB_final_model.pkl
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.github/workflows/deploy.yml
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: ci-cd
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
push:
|
| 5 |
+
branches: ["main"]
|
| 6 |
+
pull_request:
|
| 7 |
+
branches: ["main"]
|
| 8 |
+
|
| 9 |
+
jobs:
|
| 10 |
+
test-build:
|
| 11 |
+
runs-on: ubuntu-latest
|
| 12 |
+
steps:
|
| 13 |
+
- name: Checkout
|
| 14 |
+
uses: actions/checkout@v4
|
| 15 |
+
|
| 16 |
+
- name: Set up Python
|
| 17 |
+
uses: actions/setup-python@v5
|
| 18 |
+
with:
|
| 19 |
+
python-version: "3.11"
|
| 20 |
+
|
| 21 |
+
- name: Install dependencies
|
| 22 |
+
run: |
|
| 23 |
+
python -m pip install --upgrade pip
|
| 24 |
+
pip install poetry
|
| 25 |
+
poetry install --no-interaction --no-ansi
|
| 26 |
+
|
| 27 |
+
- name: Run tests
|
| 28 |
+
run: poetry run pytest -q
|
| 29 |
+
|
| 30 |
+
- name: Deploy to Hugging Face Space
|
| 31 |
+
if: github.ref == 'refs/heads/main'
|
| 32 |
+
env:
|
| 33 |
+
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
| 34 |
+
run: |
|
| 35 |
+
git config --global user.email "actions@github.com"
|
| 36 |
+
git config --global user.name "GitHub Actions"
|
| 37 |
+
git clone https://huggingface.co/spaces/stephmnt/ocr_projet06 hf_space
|
| 38 |
+
rsync -av \
|
| 39 |
+
--exclude '.git' \
|
| 40 |
+
--exclude '.venv' \
|
| 41 |
+
--exclude '.pytest_cache' \
|
| 42 |
+
--exclude '__pycache__' \
|
| 43 |
+
--exclude 'mlruns' \
|
| 44 |
+
--exclude '*.ipynb' \
|
| 45 |
+
--exclude 'logs' \
|
| 46 |
+
--exclude 'reports' \
|
| 47 |
+
--exclude 'screen-mlflow.png' \
|
| 48 |
+
--exclude 'data/*.csv' \
|
| 49 |
+
--exclude 'data/*.parquet' \
|
| 50 |
+
./ hf_space/
|
| 51 |
+
cd hf_space
|
| 52 |
+
git add .
|
| 53 |
+
git commit -m "Auto-deploy from GitHub Actions" || echo "No changes to commit"
|
| 54 |
+
git push https://stephmnt:${HF_TOKEN}@huggingface.co/spaces/stephmnt/ocr_projet06 main
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.gitignore
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ressources/
|
| 2 |
+
.venv/
|
| 3 |
+
__pycache__/
|
| 4 |
+
*.pyc
|
| 5 |
+
logs/
|
| 6 |
+
reports/
|
| 7 |
+
data/*
|
| 8 |
+
!data/HistGB_final_model.pkl
|
| 9 |
+
artifacts/*
|
| 10 |
+
!artifacts/preprocessor.joblib
|
| 11 |
+
.DS_Store
|
| 12 |
+
.vscode/
|
| 13 |
+
.idea/
|
| 14 |
+
.env
|
| 15 |
+
.ipynb_checkpoints/
|
| 16 |
+
mlruns/
|
| 17 |
+
.DS_Store
|
| 18 |
+
*.code-workspace
|
| 19 |
+
|
| 20 |
+
## https://github.com/github/gitignore/blob/e8554d85bf62e38d6db966a50d2064ac025fd82a/Python.gitignore
|
| 21 |
+
|
| 22 |
+
# Byte-compiled / optimized / DLL files
|
| 23 |
+
__pycache__/
|
| 24 |
+
*.py[cod]
|
| 25 |
+
*$py.class
|
| 26 |
+
|
| 27 |
+
# C extensions
|
| 28 |
+
*.so
|
| 29 |
+
|
| 30 |
+
# Distribution / packaging
|
| 31 |
+
.Python
|
| 32 |
+
build/
|
| 33 |
+
develop-eggs/
|
| 34 |
+
dist/
|
| 35 |
+
downloads/
|
| 36 |
+
eggs/
|
| 37 |
+
.eggs/
|
| 38 |
+
lib/
|
| 39 |
+
lib64/
|
| 40 |
+
parts/
|
| 41 |
+
sdist/
|
| 42 |
+
var/
|
| 43 |
+
wheels/
|
| 44 |
+
share/python-wheels/
|
| 45 |
+
*.egg-info/
|
| 46 |
+
.installed.cfg
|
| 47 |
+
*.egg
|
| 48 |
+
MANIFEST
|
| 49 |
+
|
| 50 |
+
# PyInstaller
|
| 51 |
+
# Usually these files are written by a python script from a template
|
| 52 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 53 |
+
*.manifest
|
| 54 |
+
*.spec
|
| 55 |
+
|
| 56 |
+
# Installer logs
|
| 57 |
+
pip-log.txt
|
| 58 |
+
pip-delete-this-directory.txt
|
| 59 |
+
|
| 60 |
+
# Unit test / coverage reports
|
| 61 |
+
htmlcov/
|
| 62 |
+
.tox/
|
| 63 |
+
.nox/
|
| 64 |
+
.coverage
|
| 65 |
+
.coverage.*
|
| 66 |
+
.cache
|
| 67 |
+
nosetests.xml
|
| 68 |
+
coverage.xml
|
| 69 |
+
*.cover
|
| 70 |
+
*.py,cover
|
| 71 |
+
.hypothesis/
|
| 72 |
+
.pytest_cache/
|
| 73 |
+
cover/
|
| 74 |
+
|
| 75 |
+
# Translations
|
| 76 |
+
*.mo
|
| 77 |
+
*.pot
|
| 78 |
+
|
| 79 |
+
# Django stuff:
|
| 80 |
+
*.log
|
| 81 |
+
local_settings.py
|
| 82 |
+
db.sqlite3
|
| 83 |
+
db.sqlite3-journal
|
| 84 |
+
|
| 85 |
+
# Flask stuff:
|
| 86 |
+
instance/
|
| 87 |
+
.webassets-cache
|
| 88 |
+
|
| 89 |
+
# Scrapy stuff:
|
| 90 |
+
.scrapy
|
| 91 |
+
|
| 92 |
+
# PyBuilder
|
| 93 |
+
.pybuilder/
|
| 94 |
+
target/
|
| 95 |
+
|
| 96 |
+
# Jupyter Notebook
|
| 97 |
+
.ipynb_checkpoints
|
| 98 |
+
|
| 99 |
+
# IPython
|
| 100 |
+
profile_default/
|
| 101 |
+
ipython_config.py
|
| 102 |
+
|
| 103 |
+
# pyenv
|
| 104 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 105 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 106 |
+
# .python-version
|
| 107 |
+
|
| 108 |
+
# pipenv
|
| 109 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 110 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 111 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 112 |
+
# install all needed dependencies.
|
| 113 |
+
#Pipfile.lock
|
| 114 |
+
|
| 115 |
+
# UV
|
| 116 |
+
# Similar to Pipfile.lock, it is generally recommended to include uv.lock in version control.
|
| 117 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 118 |
+
# commonly ignored for libraries.
|
| 119 |
+
#uv.lock
|
| 120 |
+
|
| 121 |
+
# poetry
|
| 122 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 123 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 124 |
+
# commonly ignored for libraries.
|
| 125 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 126 |
+
#poetry.lock
|
| 127 |
+
|
| 128 |
+
# pdm
|
| 129 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 130 |
+
#pdm.lock
|
| 131 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 132 |
+
# in version control.
|
| 133 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 134 |
+
.pdm.toml
|
| 135 |
+
.pdm-python
|
| 136 |
+
.pdm-build/
|
| 137 |
+
|
| 138 |
+
# pixi
|
| 139 |
+
# pixi.lock should be committed to version control for reproducibility
|
| 140 |
+
# .pixi/ contains the environments and should not be committed
|
| 141 |
+
.pixi/
|
| 142 |
+
|
| 143 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 144 |
+
__pypackages__/
|
| 145 |
+
|
| 146 |
+
# Celery stuff
|
| 147 |
+
celerybeat-schedule
|
| 148 |
+
celerybeat.pid
|
| 149 |
+
|
| 150 |
+
# SageMath parsed files
|
| 151 |
+
*.sage.py
|
| 152 |
+
|
| 153 |
+
# Environments
|
| 154 |
+
.env
|
| 155 |
+
.venv
|
| 156 |
+
env/
|
| 157 |
+
venv/
|
| 158 |
+
ENV/
|
| 159 |
+
env.bak/
|
| 160 |
+
venv.bak/
|
| 161 |
+
|
| 162 |
+
# Spyder project settings
|
| 163 |
+
.spyderproject
|
| 164 |
+
.spyproject
|
| 165 |
+
|
| 166 |
+
# Rope project settings
|
| 167 |
+
.ropeproject
|
| 168 |
+
|
| 169 |
+
# mypy
|
| 170 |
+
.mypy_cache/
|
| 171 |
+
.dmypy.json
|
| 172 |
+
dmypy.json
|
| 173 |
+
|
| 174 |
+
# Pyre type checker
|
| 175 |
+
.pyre/
|
| 176 |
+
|
| 177 |
+
# pytype static type analyzer
|
| 178 |
+
.pytype/
|
| 179 |
+
|
| 180 |
+
# Cython debug symbols
|
| 181 |
+
cython_debug/
|
| 182 |
+
|
| 183 |
+
# PyCharm
|
| 184 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 185 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 186 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 187 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 188 |
+
#.idea/
|
| 189 |
+
|
| 190 |
+
# Ruff stuff:
|
| 191 |
+
.ruff_cache/
|
| 192 |
+
|
| 193 |
+
# PyPI configuration file
|
| 194 |
+
.pypirc
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/LICENSE
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The MIT License (MIT)
|
| 2 |
+
Copyright (c) 2025, Stéphane Manet
|
| 3 |
+
|
| 4 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
| 5 |
+
|
| 6 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 7 |
+
|
| 8 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# Package marker for app module.
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app/main.py
ADDED
|
@@ -0,0 +1,828 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
import pickle
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
from datetime import datetime, timezone
|
| 8 |
+
import hashlib
|
| 9 |
+
import json
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
import time
|
| 12 |
+
from typing import Any
|
| 13 |
+
import uuid
|
| 14 |
+
|
| 15 |
+
import numpy as np
|
| 16 |
+
import pandas as pd
|
| 17 |
+
from fastapi import FastAPI, HTTPException, Query, Response
|
| 18 |
+
from pydantic import BaseModel
|
| 19 |
+
from sklearn.preprocessing import MinMaxScaler
|
| 20 |
+
import joblib
|
| 21 |
+
|
| 22 |
+
logger = logging.getLogger("uvicorn.error")
|
| 23 |
+
|
| 24 |
+
MODEL_PATH = Path(os.getenv("MODEL_PATH", "data/HistGB_final_model.pkl"))
|
| 25 |
+
DATA_PATH = Path(os.getenv("DATA_PATH", "data/data_final.parquet"))
|
| 26 |
+
ARTIFACTS_PATH = Path(os.getenv("ARTIFACTS_PATH", "artifacts/preprocessor.joblib"))
|
| 27 |
+
DEFAULT_THRESHOLD = float(os.getenv("PREDICTION_THRESHOLD", "0.5"))
|
| 28 |
+
CACHE_PREPROCESSOR = os.getenv("CACHE_PREPROCESSOR", "1") != "0"
|
| 29 |
+
USE_REDUCED_INPUTS = os.getenv("USE_REDUCED_INPUTS", "1") != "0"
|
| 30 |
+
CORRELATION_THRESHOLD = float(os.getenv("CORRELATION_THRESHOLD", "0.85"))
|
| 31 |
+
CORRELATION_SAMPLE_SIZE = int(os.getenv("CORRELATION_SAMPLE_SIZE", "50000"))
|
| 32 |
+
ALLOW_MISSING_ARTIFACTS = os.getenv("ALLOW_MISSING_ARTIFACTS", "0") == "1"
|
| 33 |
+
LOG_PREDICTIONS = os.getenv("LOG_PREDICTIONS", "1") == "1"
|
| 34 |
+
LOG_DIR = Path(os.getenv("LOG_DIR", "logs"))
|
| 35 |
+
LOG_FILE = os.getenv("LOG_FILE", "predictions.jsonl")
|
| 36 |
+
LOG_INCLUDE_INPUTS = os.getenv("LOG_INCLUDE_INPUTS", "1") == "1"
|
| 37 |
+
LOG_HASH_SK_ID = os.getenv("LOG_HASH_SK_ID", "0") == "1"
|
| 38 |
+
MODEL_VERSION = os.getenv("MODEL_VERSION", MODEL_PATH.name)
|
| 39 |
+
|
| 40 |
+
IGNORE_FEATURES = ["is_train", "is_test", "TARGET", "SK_ID_CURR"]
|
| 41 |
+
ENGINEERED_FEATURES = [
|
| 42 |
+
"DAYS_EMPLOYED_PERC",
|
| 43 |
+
"INCOME_CREDIT_PERC",
|
| 44 |
+
"INCOME_PER_PERSON",
|
| 45 |
+
"ANNUITY_INCOME_PERC",
|
| 46 |
+
"PAYMENT_RATE",
|
| 47 |
+
]
|
| 48 |
+
ENGINEERED_SOURCES = [
|
| 49 |
+
"DAYS_EMPLOYED",
|
| 50 |
+
"DAYS_BIRTH",
|
| 51 |
+
"AMT_INCOME_TOTAL",
|
| 52 |
+
"AMT_CREDIT",
|
| 53 |
+
"CNT_FAM_MEMBERS",
|
| 54 |
+
"AMT_ANNUITY",
|
| 55 |
+
]
|
| 56 |
+
# Top inputs derived from SHAP importance (modeling notebook), limited to application features.
|
| 57 |
+
REDUCED_INPUT_FEATURES = [
|
| 58 |
+
"SK_ID_CURR",
|
| 59 |
+
"EXT_SOURCE_2",
|
| 60 |
+
"EXT_SOURCE_3",
|
| 61 |
+
"AMT_ANNUITY",
|
| 62 |
+
"EXT_SOURCE_1",
|
| 63 |
+
"CODE_GENDER",
|
| 64 |
+
"DAYS_EMPLOYED",
|
| 65 |
+
"AMT_CREDIT",
|
| 66 |
+
"AMT_GOODS_PRICE",
|
| 67 |
+
"DAYS_BIRTH",
|
| 68 |
+
"FLAG_OWN_CAR",
|
| 69 |
+
]
|
| 70 |
+
OUTLIER_COLUMNS = [
|
| 71 |
+
"CNT_FAM_MEMBERS",
|
| 72 |
+
"AMT_INCOME_TOTAL",
|
| 73 |
+
"AMT_ANNUITY",
|
| 74 |
+
"DAYS_EMPLOYED",
|
| 75 |
+
"OBS_60_CNT_SOCIAL_CIRCLE",
|
| 76 |
+
"OBS_30_CNT_SOCIAL_CIRCLE",
|
| 77 |
+
"DEF_60_CNT_SOCIAL_CIRCLE",
|
| 78 |
+
"DEF_30_CNT_SOCIAL_CIRCLE",
|
| 79 |
+
"REGION_POPULATION_RELATIVE",
|
| 80 |
+
"AMT_REQ_CREDIT_BUREAU_YEAR",
|
| 81 |
+
"AMT_REQ_CREDIT_BUREAU_QRT",
|
| 82 |
+
]
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class PredictionRequest(BaseModel):
|
| 86 |
+
data: dict[str, Any] | list[dict[str, Any]]
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
@dataclass
|
| 90 |
+
class PreprocessorArtifacts:
|
| 91 |
+
columns_keep: list[str]
|
| 92 |
+
columns_must_not_missing: list[str]
|
| 93 |
+
numeric_medians: dict[str, float]
|
| 94 |
+
categorical_columns: list[str]
|
| 95 |
+
outlier_maxes: dict[str, float]
|
| 96 |
+
numeric_ranges: dict[str, tuple[float, float]]
|
| 97 |
+
features_to_scaled: list[str]
|
| 98 |
+
scaler: MinMaxScaler
|
| 99 |
+
raw_feature_columns: list[str]
|
| 100 |
+
input_feature_columns: list[str]
|
| 101 |
+
required_raw_columns: list[str]
|
| 102 |
+
required_input_columns: list[str]
|
| 103 |
+
numeric_required_columns: list[str]
|
| 104 |
+
correlated_imputation: dict[str, dict[str, float | str]]
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
app = FastAPI(title="Credit Scoring API", version="0.1.0")
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class DummyModel:
|
| 111 |
+
def predict_proba(self, X: pd.DataFrame | np.ndarray) -> np.ndarray:
|
| 112 |
+
count = len(X)
|
| 113 |
+
return np.tile([0.5, 0.5], (count, 1))
|
| 114 |
+
|
| 115 |
+
def predict(self, X: pd.DataFrame | np.ndarray) -> np.ndarray:
|
| 116 |
+
return np.zeros(len(X), dtype=int)
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def _json_fallback(obj: Any) -> Any:
|
| 120 |
+
if isinstance(obj, (np.integer, np.floating)):
|
| 121 |
+
return obj.item()
|
| 122 |
+
if isinstance(obj, (np.ndarray,)):
|
| 123 |
+
return obj.tolist()
|
| 124 |
+
if isinstance(obj, (pd.Timestamp,)):
|
| 125 |
+
return obj.isoformat()
|
| 126 |
+
return str(obj)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def _hash_value(value: Any) -> str:
|
| 130 |
+
return hashlib.sha256(str(value).encode("utf-8")).hexdigest()
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def _append_log_entries(entries: list[dict[str, Any]]) -> None:
|
| 134 |
+
if not LOG_PREDICTIONS:
|
| 135 |
+
return
|
| 136 |
+
try:
|
| 137 |
+
LOG_DIR.mkdir(parents=True, exist_ok=True)
|
| 138 |
+
log_path = LOG_DIR / LOG_FILE
|
| 139 |
+
with log_path.open("a", encoding="utf-8") as handle:
|
| 140 |
+
for entry in entries:
|
| 141 |
+
handle.write(json.dumps(entry, ensure_ascii=True, default=_json_fallback) + "\n")
|
| 142 |
+
except OSError as exc:
|
| 143 |
+
logger.warning("Failed to write prediction logs: %s", exc)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def _log_prediction_entries(
|
| 147 |
+
request_id: str,
|
| 148 |
+
records: list[dict[str, Any]],
|
| 149 |
+
results: list[dict[str, Any]] | None,
|
| 150 |
+
latency_ms: float,
|
| 151 |
+
threshold: float | None,
|
| 152 |
+
status_code: int,
|
| 153 |
+
preprocessor: PreprocessorArtifacts,
|
| 154 |
+
error: str | None = None,
|
| 155 |
+
) -> None:
|
| 156 |
+
if not LOG_PREDICTIONS:
|
| 157 |
+
return
|
| 158 |
+
if not records:
|
| 159 |
+
records = [{}]
|
| 160 |
+
timestamp = datetime.now(timezone.utc).isoformat()
|
| 161 |
+
required_cols = preprocessor.required_input_columns
|
| 162 |
+
entries: list[dict[str, Any]] = []
|
| 163 |
+
for idx, record in enumerate(records):
|
| 164 |
+
inputs: dict[str, Any] = {}
|
| 165 |
+
if LOG_INCLUDE_INPUTS:
|
| 166 |
+
inputs = {col: record.get(col) for col in required_cols if col in record}
|
| 167 |
+
if LOG_HASH_SK_ID and "SK_ID_CURR" in inputs:
|
| 168 |
+
inputs["SK_ID_CURR"] = _hash_value(inputs["SK_ID_CURR"])
|
| 169 |
+
entry: dict[str, Any] = {
|
| 170 |
+
"timestamp": timestamp,
|
| 171 |
+
"request_id": request_id,
|
| 172 |
+
"endpoint": "/predict",
|
| 173 |
+
"latency_ms": round(latency_ms, 3),
|
| 174 |
+
"status_code": status_code,
|
| 175 |
+
"model_version": MODEL_VERSION,
|
| 176 |
+
"threshold": threshold,
|
| 177 |
+
"inputs": inputs,
|
| 178 |
+
}
|
| 179 |
+
if results and idx < len(results):
|
| 180 |
+
result = results[idx]
|
| 181 |
+
sk_id = result.get("sk_id_curr")
|
| 182 |
+
entry.update(
|
| 183 |
+
{
|
| 184 |
+
"sk_id_curr": _hash_value(sk_id) if LOG_HASH_SK_ID and sk_id is not None else sk_id,
|
| 185 |
+
"probability": result.get("probability"),
|
| 186 |
+
"prediction": result.get("prediction"),
|
| 187 |
+
}
|
| 188 |
+
)
|
| 189 |
+
if error:
|
| 190 |
+
entry["error"] = error
|
| 191 |
+
entries.append(entry)
|
| 192 |
+
_append_log_entries(entries)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def new_features_creation(df: pd.DataFrame) -> pd.DataFrame:
|
| 196 |
+
df_features = df.copy()
|
| 197 |
+
for col in ENGINEERED_SOURCES:
|
| 198 |
+
if col not in df_features.columns:
|
| 199 |
+
df_features[col] = np.nan
|
| 200 |
+
df_features["DAYS_EMPLOYED_PERC"] = df_features["DAYS_EMPLOYED"] / df_features["DAYS_BIRTH"]
|
| 201 |
+
df_features["INCOME_CREDIT_PERC"] = df_features["AMT_INCOME_TOTAL"] / df_features["AMT_CREDIT"]
|
| 202 |
+
df_features["INCOME_PER_PERSON"] = df_features["AMT_INCOME_TOTAL"] / df_features["CNT_FAM_MEMBERS"]
|
| 203 |
+
df_features["ANNUITY_INCOME_PERC"] = df_features["AMT_ANNUITY"] / df_features["AMT_INCOME_TOTAL"]
|
| 204 |
+
df_features["PAYMENT_RATE"] = df_features["AMT_ANNUITY"] / df_features["AMT_CREDIT"]
|
| 205 |
+
return df_features
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def build_preprocessor(data_path: Path) -> PreprocessorArtifacts:
|
| 209 |
+
df = pd.read_parquet(data_path)
|
| 210 |
+
raw_feature_columns = df.columns.tolist()
|
| 211 |
+
input_feature_columns = [c for c in raw_feature_columns if c not in ["is_train", "is_test", "TARGET"]]
|
| 212 |
+
|
| 213 |
+
df = new_features_creation(df)
|
| 214 |
+
df.replace([np.inf, -np.inf], np.nan, inplace=True)
|
| 215 |
+
|
| 216 |
+
missing_rate = df.isna().mean()
|
| 217 |
+
columns_keep = missing_rate[missing_rate < 0.60].index.tolist()
|
| 218 |
+
columns_must_not_missing = missing_rate[missing_rate < 0.010].index.tolist()
|
| 219 |
+
|
| 220 |
+
df = df[columns_keep]
|
| 221 |
+
df = df.dropna(subset=columns_must_not_missing)
|
| 222 |
+
|
| 223 |
+
numeric_cols = df.select_dtypes(include=["number"]).columns
|
| 224 |
+
numeric_medians = df[numeric_cols].median().to_dict()
|
| 225 |
+
df[numeric_cols] = df[numeric_cols].fillna(numeric_medians)
|
| 226 |
+
|
| 227 |
+
categorical_columns = df.select_dtypes(include=["object"]).columns.tolist()
|
| 228 |
+
df[categorical_columns] = df[categorical_columns].fillna("Unknown")
|
| 229 |
+
|
| 230 |
+
if "CODE_GENDER" in df.columns:
|
| 231 |
+
df = df[df["CODE_GENDER"] != "XNA"]
|
| 232 |
+
|
| 233 |
+
outlier_maxes = {col: df[col].max() for col in OUTLIER_COLUMNS if col in df.columns}
|
| 234 |
+
for col, max_val in outlier_maxes.items():
|
| 235 |
+
df = df[df[col] != max_val]
|
| 236 |
+
|
| 237 |
+
numeric_ranges = {}
|
| 238 |
+
for col in numeric_cols:
|
| 239 |
+
if col in df.columns:
|
| 240 |
+
numeric_ranges[col] = (float(df[col].min()), float(df[col].max()))
|
| 241 |
+
|
| 242 |
+
df_hot = pd.get_dummies(df, columns=categorical_columns)
|
| 243 |
+
features_to_scaled = [col for col in df_hot.columns if col not in IGNORE_FEATURES]
|
| 244 |
+
|
| 245 |
+
scaler = MinMaxScaler()
|
| 246 |
+
scaler.fit(df_hot[features_to_scaled])
|
| 247 |
+
|
| 248 |
+
required_raw = set(ENGINEERED_SOURCES)
|
| 249 |
+
required_raw.update(col for col in columns_must_not_missing if col in input_feature_columns)
|
| 250 |
+
required_raw.add("SK_ID_CURR")
|
| 251 |
+
if USE_REDUCED_INPUTS:
|
| 252 |
+
required_input = sorted({col for col in REDUCED_INPUT_FEATURES if col in input_feature_columns})
|
| 253 |
+
else:
|
| 254 |
+
required_input = sorted(required_raw)
|
| 255 |
+
numeric_required = sorted(col for col in required_input if col in numeric_medians)
|
| 256 |
+
correlated_imputation = _build_correlated_imputation(
|
| 257 |
+
df,
|
| 258 |
+
input_feature_columns=input_feature_columns,
|
| 259 |
+
numeric_required=numeric_required,
|
| 260 |
+
threshold=CORRELATION_THRESHOLD,
|
| 261 |
+
)
|
| 262 |
+
|
| 263 |
+
return PreprocessorArtifacts(
|
| 264 |
+
columns_keep=columns_keep,
|
| 265 |
+
columns_must_not_missing=columns_must_not_missing,
|
| 266 |
+
numeric_medians={k: float(v) for k, v in numeric_medians.items()},
|
| 267 |
+
categorical_columns=categorical_columns,
|
| 268 |
+
outlier_maxes={k: float(v) for k, v in outlier_maxes.items()},
|
| 269 |
+
numeric_ranges=numeric_ranges,
|
| 270 |
+
features_to_scaled=features_to_scaled,
|
| 271 |
+
scaler=scaler,
|
| 272 |
+
raw_feature_columns=raw_feature_columns,
|
| 273 |
+
input_feature_columns=input_feature_columns,
|
| 274 |
+
required_raw_columns=sorted(required_raw),
|
| 275 |
+
required_input_columns=required_input,
|
| 276 |
+
numeric_required_columns=numeric_required,
|
| 277 |
+
correlated_imputation=correlated_imputation,
|
| 278 |
+
)
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
def build_fallback_preprocessor() -> PreprocessorArtifacts:
|
| 282 |
+
base = pd.DataFrame(
|
| 283 |
+
[
|
| 284 |
+
{
|
| 285 |
+
"SK_ID_CURR": 100001,
|
| 286 |
+
"EXT_SOURCE_1": 0.45,
|
| 287 |
+
"EXT_SOURCE_2": 0.61,
|
| 288 |
+
"EXT_SOURCE_3": 0.75,
|
| 289 |
+
"AMT_ANNUITY": 24700.5,
|
| 290 |
+
"AMT_CREDIT": 406597.5,
|
| 291 |
+
"AMT_GOODS_PRICE": 351000.0,
|
| 292 |
+
"DAYS_BIRTH": -9461,
|
| 293 |
+
"DAYS_EMPLOYED": -637,
|
| 294 |
+
"CODE_GENDER": "M",
|
| 295 |
+
"FLAG_OWN_CAR": "N",
|
| 296 |
+
"AMT_INCOME_TOTAL": 202500.0,
|
| 297 |
+
"CNT_FAM_MEMBERS": 1,
|
| 298 |
+
"CNT_CHILDREN": 0,
|
| 299 |
+
},
|
| 300 |
+
{
|
| 301 |
+
"SK_ID_CURR": 100002,
|
| 302 |
+
"EXT_SOURCE_1": 0.35,
|
| 303 |
+
"EXT_SOURCE_2": 0.52,
|
| 304 |
+
"EXT_SOURCE_3": 0.68,
|
| 305 |
+
"AMT_ANNUITY": 22000.0,
|
| 306 |
+
"AMT_CREDIT": 350000.0,
|
| 307 |
+
"AMT_GOODS_PRICE": 300000.0,
|
| 308 |
+
"DAYS_BIRTH": -12000,
|
| 309 |
+
"DAYS_EMPLOYED": -1200,
|
| 310 |
+
"CODE_GENDER": "F",
|
| 311 |
+
"FLAG_OWN_CAR": "Y",
|
| 312 |
+
"AMT_INCOME_TOTAL": 180000.0,
|
| 313 |
+
"CNT_FAM_MEMBERS": 2,
|
| 314 |
+
"CNT_CHILDREN": 1,
|
| 315 |
+
},
|
| 316 |
+
]
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
df = new_features_creation(base)
|
| 320 |
+
df.replace([np.inf, -np.inf], np.nan, inplace=True)
|
| 321 |
+
|
| 322 |
+
columns_keep = df.columns.tolist()
|
| 323 |
+
columns_must_not_missing = [col for col in columns_keep if col not in IGNORE_FEATURES]
|
| 324 |
+
|
| 325 |
+
numeric_cols = df.select_dtypes(include=["number"]).columns
|
| 326 |
+
numeric_medians = df[numeric_cols].median().to_dict()
|
| 327 |
+
df[numeric_cols] = df[numeric_cols].fillna(numeric_medians)
|
| 328 |
+
|
| 329 |
+
categorical_columns = df.select_dtypes(include=["object"]).columns.tolist()
|
| 330 |
+
df[categorical_columns] = df[categorical_columns].fillna("Unknown")
|
| 331 |
+
|
| 332 |
+
df_hot = pd.get_dummies(df, columns=categorical_columns)
|
| 333 |
+
features_to_scaled = [col for col in df_hot.columns if col not in IGNORE_FEATURES]
|
| 334 |
+
scaler = MinMaxScaler()
|
| 335 |
+
scaler.fit(df_hot[features_to_scaled])
|
| 336 |
+
|
| 337 |
+
raw_feature_columns = df.columns.tolist()
|
| 338 |
+
input_feature_columns = [c for c in raw_feature_columns if c not in ["is_train", "is_test", "TARGET"]]
|
| 339 |
+
|
| 340 |
+
required_raw = set(ENGINEERED_SOURCES)
|
| 341 |
+
required_raw.update(col for col in columns_must_not_missing if col in input_feature_columns)
|
| 342 |
+
required_raw.add("SK_ID_CURR")
|
| 343 |
+
required_input = sorted({col for col in REDUCED_INPUT_FEATURES if col in input_feature_columns})
|
| 344 |
+
numeric_required = sorted(col for col in required_input if col in numeric_medians)
|
| 345 |
+
|
| 346 |
+
numeric_ranges = {col: (float(df[col].min()), float(df[col].max())) for col in numeric_cols}
|
| 347 |
+
|
| 348 |
+
return PreprocessorArtifacts(
|
| 349 |
+
columns_keep=columns_keep,
|
| 350 |
+
columns_must_not_missing=columns_must_not_missing,
|
| 351 |
+
numeric_medians={k: float(v) for k, v in numeric_medians.items()},
|
| 352 |
+
categorical_columns=categorical_columns,
|
| 353 |
+
outlier_maxes={},
|
| 354 |
+
numeric_ranges=numeric_ranges,
|
| 355 |
+
features_to_scaled=features_to_scaled,
|
| 356 |
+
scaler=scaler,
|
| 357 |
+
raw_feature_columns=raw_feature_columns,
|
| 358 |
+
input_feature_columns=input_feature_columns,
|
| 359 |
+
required_raw_columns=sorted(required_raw),
|
| 360 |
+
required_input_columns=required_input,
|
| 361 |
+
numeric_required_columns=numeric_required,
|
| 362 |
+
correlated_imputation={},
|
| 363 |
+
)
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
def load_preprocessor(data_path: Path, artifacts_path: Path) -> PreprocessorArtifacts:
|
| 367 |
+
if artifacts_path.exists():
|
| 368 |
+
preprocessor = joblib.load(artifacts_path)
|
| 369 |
+
updated = False
|
| 370 |
+
required_updated = False
|
| 371 |
+
if not hasattr(preprocessor, "required_input_columns"):
|
| 372 |
+
if USE_REDUCED_INPUTS:
|
| 373 |
+
required_input = _reduce_input_columns(preprocessor)
|
| 374 |
+
else:
|
| 375 |
+
required_input = preprocessor.required_raw_columns
|
| 376 |
+
preprocessor.required_input_columns = required_input
|
| 377 |
+
required_updated = True
|
| 378 |
+
updated = True
|
| 379 |
+
if not hasattr(preprocessor, "numeric_required_columns"):
|
| 380 |
+
preprocessor.numeric_required_columns = sorted(
|
| 381 |
+
col for col in preprocessor.required_input_columns if col in preprocessor.numeric_medians
|
| 382 |
+
)
|
| 383 |
+
updated = True
|
| 384 |
+
if not hasattr(preprocessor, "numeric_ranges"):
|
| 385 |
+
numeric_ranges = _infer_numeric_ranges_from_scaler(preprocessor)
|
| 386 |
+
if numeric_ranges:
|
| 387 |
+
preprocessor.numeric_ranges = numeric_ranges
|
| 388 |
+
updated = True
|
| 389 |
+
else:
|
| 390 |
+
if not data_path.exists():
|
| 391 |
+
raise RuntimeError(f"Data file not found to rebuild preprocessor: {data_path}")
|
| 392 |
+
preprocessor = build_preprocessor(data_path)
|
| 393 |
+
updated = True
|
| 394 |
+
if USE_REDUCED_INPUTS:
|
| 395 |
+
reduced = _reduce_input_columns(preprocessor)
|
| 396 |
+
if preprocessor.required_input_columns != reduced:
|
| 397 |
+
preprocessor.required_input_columns = reduced
|
| 398 |
+
required_updated = True
|
| 399 |
+
updated = True
|
| 400 |
+
else:
|
| 401 |
+
if preprocessor.required_input_columns != preprocessor.required_raw_columns:
|
| 402 |
+
preprocessor.required_input_columns = preprocessor.required_raw_columns
|
| 403 |
+
required_updated = True
|
| 404 |
+
updated = True
|
| 405 |
+
desired_numeric_required = sorted(
|
| 406 |
+
col for col in preprocessor.required_input_columns if col in preprocessor.numeric_medians
|
| 407 |
+
)
|
| 408 |
+
if getattr(preprocessor, "numeric_required_columns", None) != desired_numeric_required:
|
| 409 |
+
preprocessor.numeric_required_columns = desired_numeric_required
|
| 410 |
+
updated = True
|
| 411 |
+
if not hasattr(preprocessor, "correlated_imputation") or required_updated:
|
| 412 |
+
if data_path.exists():
|
| 413 |
+
preprocessor.correlated_imputation = _compute_correlated_imputation(data_path, preprocessor)
|
| 414 |
+
else:
|
| 415 |
+
preprocessor.correlated_imputation = {}
|
| 416 |
+
updated = True
|
| 417 |
+
if updated and CACHE_PREPROCESSOR:
|
| 418 |
+
artifacts_path.parent.mkdir(parents=True, exist_ok=True)
|
| 419 |
+
joblib.dump(preprocessor, artifacts_path)
|
| 420 |
+
return preprocessor
|
| 421 |
+
|
| 422 |
+
if not data_path.exists():
|
| 423 |
+
raise RuntimeError(f"Data file not found to build preprocessor: {data_path}")
|
| 424 |
+
|
| 425 |
+
preprocessor = build_preprocessor(data_path)
|
| 426 |
+
if CACHE_PREPROCESSOR:
|
| 427 |
+
artifacts_path.parent.mkdir(parents=True, exist_ok=True)
|
| 428 |
+
joblib.dump(preprocessor, artifacts_path)
|
| 429 |
+
return preprocessor
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
def load_model(model_path: Path):
|
| 433 |
+
with model_path.open("rb") as handle:
|
| 434 |
+
return pickle.load(handle)
|
| 435 |
+
|
| 436 |
+
|
| 437 |
+
def _infer_numeric_ranges_from_scaler(preprocessor: PreprocessorArtifacts) -> dict[str, tuple[float, float]]:
|
| 438 |
+
ranges = {}
|
| 439 |
+
scaler = getattr(preprocessor, "scaler", None)
|
| 440 |
+
if scaler is None or not hasattr(scaler, "data_min_") or not hasattr(scaler, "data_max_"):
|
| 441 |
+
return ranges
|
| 442 |
+
for idx, col in enumerate(preprocessor.features_to_scaled):
|
| 443 |
+
if col in preprocessor.numeric_medians:
|
| 444 |
+
ranges[col] = (float(scaler.data_min_[idx]), float(scaler.data_max_[idx]))
|
| 445 |
+
return ranges
|
| 446 |
+
|
| 447 |
+
|
| 448 |
+
def _build_correlated_imputation(
|
| 449 |
+
df: pd.DataFrame,
|
| 450 |
+
*,
|
| 451 |
+
input_feature_columns: list[str],
|
| 452 |
+
numeric_required: list[str],
|
| 453 |
+
threshold: float,
|
| 454 |
+
) -> dict[str, dict[str, float | str]]:
|
| 455 |
+
if not numeric_required:
|
| 456 |
+
return {}
|
| 457 |
+
numeric_cols = [
|
| 458 |
+
col
|
| 459 |
+
for col in df.select_dtypes(include=["number"]).columns
|
| 460 |
+
if col in input_feature_columns and col not in {"TARGET", "is_train", "is_test", "SK_ID_CURR"}
|
| 461 |
+
]
|
| 462 |
+
if not numeric_cols:
|
| 463 |
+
return {}
|
| 464 |
+
df_corr = df
|
| 465 |
+
if CORRELATION_SAMPLE_SIZE > 0 and len(df_corr) > CORRELATION_SAMPLE_SIZE:
|
| 466 |
+
df_corr = df_corr.sample(CORRELATION_SAMPLE_SIZE, random_state=42)
|
| 467 |
+
corr = df_corr[numeric_cols].corr()
|
| 468 |
+
correlated = {}
|
| 469 |
+
for col in numeric_cols:
|
| 470 |
+
if col in numeric_required:
|
| 471 |
+
continue
|
| 472 |
+
best_feature = None
|
| 473 |
+
best_corr = 0.0
|
| 474 |
+
for req in numeric_required:
|
| 475 |
+
if req not in corr.columns or col not in corr.index:
|
| 476 |
+
continue
|
| 477 |
+
corr_val = corr.at[col, req]
|
| 478 |
+
if pd.isna(corr_val):
|
| 479 |
+
continue
|
| 480 |
+
if abs(corr_val) > abs(best_corr): # type: ignore
|
| 481 |
+
best_corr = float(corr_val) # type: ignore
|
| 482 |
+
best_feature = req
|
| 483 |
+
if best_feature is None or abs(best_corr) < threshold:
|
| 484 |
+
continue
|
| 485 |
+
proxy_values = df_corr[best_feature].to_numpy()
|
| 486 |
+
if np.nanstd(proxy_values) == 0:
|
| 487 |
+
continue
|
| 488 |
+
slope, intercept = np.polyfit(proxy_values, df_corr[col].to_numpy(), 1)
|
| 489 |
+
correlated[col] = {
|
| 490 |
+
"proxy": best_feature,
|
| 491 |
+
"slope": float(slope),
|
| 492 |
+
"intercept": float(intercept),
|
| 493 |
+
"corr": float(best_corr),
|
| 494 |
+
}
|
| 495 |
+
return correlated
|
| 496 |
+
|
| 497 |
+
|
| 498 |
+
def _reduce_input_columns(preprocessor: PreprocessorArtifacts) -> list[str]:
|
| 499 |
+
cols = [col for col in REDUCED_INPUT_FEATURES if col in preprocessor.input_feature_columns or col == "SK_ID_CURR"]
|
| 500 |
+
if "SK_ID_CURR" not in cols:
|
| 501 |
+
cols.append("SK_ID_CURR")
|
| 502 |
+
return sorted(set(cols))
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
def _compute_correlated_imputation(
|
| 506 |
+
data_path: Path,
|
| 507 |
+
preprocessor: PreprocessorArtifacts,
|
| 508 |
+
) -> dict[str, dict[str, float | str]]:
|
| 509 |
+
df = pd.read_parquet(data_path)
|
| 510 |
+
df = new_features_creation(df)
|
| 511 |
+
df.replace([np.inf, -np.inf], np.nan, inplace=True)
|
| 512 |
+
|
| 513 |
+
df = df[preprocessor.columns_keep]
|
| 514 |
+
df = df.dropna(subset=preprocessor.columns_must_not_missing)
|
| 515 |
+
|
| 516 |
+
numeric_cols = df.select_dtypes(include=["number"]).columns
|
| 517 |
+
df[numeric_cols] = df[numeric_cols].fillna(pd.Series(preprocessor.numeric_medians))
|
| 518 |
+
|
| 519 |
+
for col in preprocessor.categorical_columns:
|
| 520 |
+
if col in df.columns:
|
| 521 |
+
df[col] = df[col].fillna("Unknown")
|
| 522 |
+
|
| 523 |
+
if "CODE_GENDER" in df.columns:
|
| 524 |
+
df = df[df["CODE_GENDER"] != "XNA"]
|
| 525 |
+
|
| 526 |
+
for col, max_val in preprocessor.outlier_maxes.items():
|
| 527 |
+
if col in df.columns:
|
| 528 |
+
df = df[df[col] != max_val]
|
| 529 |
+
|
| 530 |
+
return _build_correlated_imputation(
|
| 531 |
+
df,
|
| 532 |
+
input_feature_columns=preprocessor.input_feature_columns,
|
| 533 |
+
numeric_required=preprocessor.numeric_required_columns,
|
| 534 |
+
threshold=CORRELATION_THRESHOLD,
|
| 535 |
+
)
|
| 536 |
+
|
| 537 |
+
|
| 538 |
+
def _ensure_required_columns(df: pd.DataFrame, required_cols: list[str]) -> None:
|
| 539 |
+
missing = [col for col in required_cols if col not in df.columns or df[col].isna().any()]
|
| 540 |
+
if missing:
|
| 541 |
+
raise HTTPException(
|
| 542 |
+
status_code=422,
|
| 543 |
+
detail={
|
| 544 |
+
"message": "Missing required input columns.",
|
| 545 |
+
"missing_columns": missing[:25],
|
| 546 |
+
"missing_count": len(missing),
|
| 547 |
+
},
|
| 548 |
+
)
|
| 549 |
+
|
| 550 |
+
|
| 551 |
+
def _validate_numeric_inputs(df: pd.DataFrame, numeric_cols: list[str]) -> None:
|
| 552 |
+
invalid = []
|
| 553 |
+
for col in numeric_cols:
|
| 554 |
+
coerced = pd.to_numeric(df[col], errors="coerce")
|
| 555 |
+
if coerced.isna().any():
|
| 556 |
+
invalid.append(col)
|
| 557 |
+
if invalid:
|
| 558 |
+
raise HTTPException(
|
| 559 |
+
status_code=422,
|
| 560 |
+
detail={
|
| 561 |
+
"message": "Invalid numeric values provided.",
|
| 562 |
+
"invalid_columns": invalid[:25],
|
| 563 |
+
"invalid_count": len(invalid),
|
| 564 |
+
},
|
| 565 |
+
)
|
| 566 |
+
|
| 567 |
+
|
| 568 |
+
def _validate_numeric_ranges(df: pd.DataFrame, numeric_ranges: dict[str, tuple[float, float]]) -> None:
|
| 569 |
+
if not numeric_ranges:
|
| 570 |
+
return
|
| 571 |
+
out_of_range = []
|
| 572 |
+
for col, (min_val, max_val) in numeric_ranges.items():
|
| 573 |
+
if col not in df.columns:
|
| 574 |
+
continue
|
| 575 |
+
values = pd.to_numeric(df[col], errors="coerce")
|
| 576 |
+
if values.isna().any():
|
| 577 |
+
continue
|
| 578 |
+
if ((values < min_val) | (values > max_val)).any():
|
| 579 |
+
out_of_range.append(col)
|
| 580 |
+
if out_of_range:
|
| 581 |
+
raise HTTPException(
|
| 582 |
+
status_code=422,
|
| 583 |
+
detail={
|
| 584 |
+
"message": "Input contains values outside expected ranges.",
|
| 585 |
+
"out_of_range_columns": out_of_range[:25],
|
| 586 |
+
"out_of_range_count": len(out_of_range),
|
| 587 |
+
},
|
| 588 |
+
)
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
def _apply_correlated_imputation(df: pd.DataFrame, artifacts: PreprocessorArtifacts) -> None:
|
| 592 |
+
correlated = getattr(artifacts, "correlated_imputation", {}) or {}
|
| 593 |
+
if not correlated:
|
| 594 |
+
return
|
| 595 |
+
for col, info in correlated.items():
|
| 596 |
+
if col not in df.columns or col in artifacts.required_input_columns:
|
| 597 |
+
continue
|
| 598 |
+
proxy = info.get("proxy")
|
| 599 |
+
if proxy is None or proxy not in df.columns:
|
| 600 |
+
continue
|
| 601 |
+
missing = df[col].isna()
|
| 602 |
+
if not missing.any():
|
| 603 |
+
continue
|
| 604 |
+
proxy_values = pd.to_numeric(df[proxy], errors="coerce")
|
| 605 |
+
if proxy_values.isna().any():
|
| 606 |
+
continue
|
| 607 |
+
df.loc[missing, col] = info["slope"] * proxy_values[missing] + info["intercept"]
|
| 608 |
+
if col in artifacts.numeric_ranges:
|
| 609 |
+
min_val, max_val = artifacts.numeric_ranges[col]
|
| 610 |
+
df.loc[missing, col] = df.loc[missing, col].clip(min_val, max_val)
|
| 611 |
+
|
| 612 |
+
|
| 613 |
+
def preprocess_input(df_raw: pd.DataFrame, artifacts: PreprocessorArtifacts) -> pd.DataFrame:
|
| 614 |
+
df = df_raw.copy()
|
| 615 |
+
|
| 616 |
+
for col in artifacts.required_input_columns:
|
| 617 |
+
if col not in df.columns:
|
| 618 |
+
df[col] = np.nan
|
| 619 |
+
|
| 620 |
+
_ensure_required_columns(df, artifacts.required_input_columns)
|
| 621 |
+
_validate_numeric_inputs(df, artifacts.numeric_required_columns)
|
| 622 |
+
_validate_numeric_ranges(df, {k: v for k, v in artifacts.numeric_ranges.items() if k in artifacts.numeric_required_columns})
|
| 623 |
+
|
| 624 |
+
df["is_train"] = 0
|
| 625 |
+
df["is_test"] = 1
|
| 626 |
+
if "TARGET" not in df.columns:
|
| 627 |
+
df["TARGET"] = 0
|
| 628 |
+
|
| 629 |
+
df = new_features_creation(df)
|
| 630 |
+
df.replace([np.inf, -np.inf], np.nan, inplace=True)
|
| 631 |
+
|
| 632 |
+
for col in artifacts.columns_keep:
|
| 633 |
+
if col not in df.columns:
|
| 634 |
+
df[col] = np.nan
|
| 635 |
+
df = df[artifacts.columns_keep]
|
| 636 |
+
|
| 637 |
+
_apply_correlated_imputation(df, artifacts)
|
| 638 |
+
|
| 639 |
+
for col, median in artifacts.numeric_medians.items():
|
| 640 |
+
if col in df.columns:
|
| 641 |
+
df[col] = pd.to_numeric(df[col], errors="coerce")
|
| 642 |
+
df[col] = df[col].fillna(median)
|
| 643 |
+
|
| 644 |
+
for col in artifacts.categorical_columns:
|
| 645 |
+
if col in df.columns:
|
| 646 |
+
df[col] = df[col].fillna("Unknown")
|
| 647 |
+
|
| 648 |
+
_ensure_required_columns(df, artifacts.required_input_columns)
|
| 649 |
+
|
| 650 |
+
if "CODE_GENDER" in df.columns and (df["CODE_GENDER"] == "XNA").any():
|
| 651 |
+
raise HTTPException(
|
| 652 |
+
status_code=422,
|
| 653 |
+
detail={"message": "CODE_GENDER cannot be 'XNA' based on training rules."},
|
| 654 |
+
)
|
| 655 |
+
|
| 656 |
+
for col, max_val in artifacts.outlier_maxes.items():
|
| 657 |
+
if col in df.columns and (df[col] >= max_val).any():
|
| 658 |
+
raise HTTPException(
|
| 659 |
+
status_code=422,
|
| 660 |
+
detail={
|
| 661 |
+
"message": "Input contains outlier values removed during training.",
|
| 662 |
+
"outlier_columns": [col],
|
| 663 |
+
},
|
| 664 |
+
)
|
| 665 |
+
|
| 666 |
+
df_hot = pd.get_dummies(df, columns=artifacts.categorical_columns)
|
| 667 |
+
for col in artifacts.features_to_scaled:
|
| 668 |
+
if col not in df_hot.columns:
|
| 669 |
+
df_hot[col] = 0
|
| 670 |
+
df_hot = df_hot[artifacts.features_to_scaled]
|
| 671 |
+
|
| 672 |
+
scaled = artifacts.scaler.transform(df_hot)
|
| 673 |
+
return pd.DataFrame(scaled, columns=artifacts.features_to_scaled, index=df.index)
|
| 674 |
+
|
| 675 |
+
|
| 676 |
+
@app.on_event("startup")
|
| 677 |
+
def startup_event() -> None:
|
| 678 |
+
if not MODEL_PATH.exists():
|
| 679 |
+
if ALLOW_MISSING_ARTIFACTS:
|
| 680 |
+
logger.warning("Model file not found: %s. Using dummy model.", MODEL_PATH)
|
| 681 |
+
app.state.model = DummyModel()
|
| 682 |
+
else:
|
| 683 |
+
raise RuntimeError(f"Model file not found: {MODEL_PATH}")
|
| 684 |
+
else:
|
| 685 |
+
logger.info("Loading model from %s", MODEL_PATH)
|
| 686 |
+
app.state.model = load_model(MODEL_PATH)
|
| 687 |
+
|
| 688 |
+
try:
|
| 689 |
+
logger.info("Loading preprocessor artifacts from %s", ARTIFACTS_PATH)
|
| 690 |
+
app.state.preprocessor = load_preprocessor(DATA_PATH, ARTIFACTS_PATH)
|
| 691 |
+
except RuntimeError as exc:
|
| 692 |
+
if ALLOW_MISSING_ARTIFACTS:
|
| 693 |
+
logger.warning("Preprocessor artifacts missing (%s). Using fallback preprocessor.", exc)
|
| 694 |
+
app.state.preprocessor = build_fallback_preprocessor()
|
| 695 |
+
else:
|
| 696 |
+
raise
|
| 697 |
+
|
| 698 |
+
|
| 699 |
+
@app.get("/health")
|
| 700 |
+
def health() -> dict[str, str]:
|
| 701 |
+
return {"status": "ok"}
|
| 702 |
+
|
| 703 |
+
|
| 704 |
+
@app.get("/")
|
| 705 |
+
def root() -> dict[str, str]:
|
| 706 |
+
return {"message": "Credit Scoring API. See /docs for Swagger UI."}
|
| 707 |
+
|
| 708 |
+
|
| 709 |
+
@app.get("/favicon.ico")
|
| 710 |
+
def favicon() -> Response:
|
| 711 |
+
return Response(status_code=204)
|
| 712 |
+
|
| 713 |
+
|
| 714 |
+
@app.get("/features")
|
| 715 |
+
def features(include_all: bool = Query(default=False)) -> dict[str, Any]:
|
| 716 |
+
preprocessor: PreprocessorArtifacts = app.state.preprocessor
|
| 717 |
+
optional_features = [col for col in preprocessor.input_feature_columns if col not in preprocessor.required_input_columns]
|
| 718 |
+
correlated = sorted(getattr(preprocessor, "correlated_imputation", {}) or {})
|
| 719 |
+
payload = {
|
| 720 |
+
"required_input_features": preprocessor.required_input_columns,
|
| 721 |
+
"engineered_features": ENGINEERED_FEATURES,
|
| 722 |
+
"model_features_count": len(preprocessor.features_to_scaled),
|
| 723 |
+
"correlation_threshold": CORRELATION_THRESHOLD,
|
| 724 |
+
"correlated_imputation_count": len(correlated),
|
| 725 |
+
"correlated_imputation_features": correlated[:50],
|
| 726 |
+
}
|
| 727 |
+
if include_all:
|
| 728 |
+
payload["input_features"] = preprocessor.input_feature_columns
|
| 729 |
+
payload["optional_input_features"] = optional_features
|
| 730 |
+
else:
|
| 731 |
+
payload["input_features"] = preprocessor.required_input_columns
|
| 732 |
+
payload["optional_input_features"] = []
|
| 733 |
+
payload["optional_input_features_count"] = len(optional_features)
|
| 734 |
+
return payload
|
| 735 |
+
|
| 736 |
+
|
| 737 |
+
@app.post("/predict")
|
| 738 |
+
def predict(
|
| 739 |
+
payload: PredictionRequest,
|
| 740 |
+
threshold: float | None = Query(default=None, ge=0.0, le=1.0),
|
| 741 |
+
) -> dict[str, Any]:
|
| 742 |
+
model = app.state.model
|
| 743 |
+
preprocessor: PreprocessorArtifacts = app.state.preprocessor
|
| 744 |
+
request_id = str(uuid.uuid4())
|
| 745 |
+
start_time = time.perf_counter()
|
| 746 |
+
records = payload.data if isinstance(payload.data, list) else [payload.data]
|
| 747 |
+
|
| 748 |
+
if not records:
|
| 749 |
+
raise HTTPException(status_code=422, detail={"message": "No input records provided."})
|
| 750 |
+
|
| 751 |
+
try:
|
| 752 |
+
df_raw = pd.DataFrame.from_records(records)
|
| 753 |
+
if "SK_ID_CURR" not in df_raw.columns:
|
| 754 |
+
raise HTTPException(status_code=422, detail={"message": "SK_ID_CURR is required."})
|
| 755 |
+
|
| 756 |
+
sk_ids = df_raw["SK_ID_CURR"].tolist()
|
| 757 |
+
features = preprocess_input(df_raw, preprocessor)
|
| 758 |
+
|
| 759 |
+
if hasattr(model, "predict_proba"):
|
| 760 |
+
proba = model.predict_proba(features)[:, 1]
|
| 761 |
+
use_threshold = DEFAULT_THRESHOLD if threshold is None else threshold
|
| 762 |
+
preds = (proba >= use_threshold).astype(int)
|
| 763 |
+
results = [
|
| 764 |
+
{
|
| 765 |
+
"sk_id_curr": sk_id,
|
| 766 |
+
"probability": float(prob),
|
| 767 |
+
"prediction": int(pred),
|
| 768 |
+
}
|
| 769 |
+
for sk_id, prob, pred in zip(sk_ids, proba, preds)
|
| 770 |
+
]
|
| 771 |
+
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 772 |
+
_log_prediction_entries(
|
| 773 |
+
request_id=request_id,
|
| 774 |
+
records=records,
|
| 775 |
+
results=results,
|
| 776 |
+
latency_ms=latency_ms,
|
| 777 |
+
threshold=use_threshold,
|
| 778 |
+
status_code=200,
|
| 779 |
+
preprocessor=preprocessor,
|
| 780 |
+
)
|
| 781 |
+
return {"predictions": results, "threshold": use_threshold}
|
| 782 |
+
|
| 783 |
+
preds = model.predict(features)
|
| 784 |
+
results = [
|
| 785 |
+
{
|
| 786 |
+
"sk_id_curr": sk_id,
|
| 787 |
+
"prediction": int(pred),
|
| 788 |
+
}
|
| 789 |
+
for sk_id, pred in zip(sk_ids, preds)
|
| 790 |
+
]
|
| 791 |
+
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 792 |
+
_log_prediction_entries(
|
| 793 |
+
request_id=request_id,
|
| 794 |
+
records=records,
|
| 795 |
+
results=results,
|
| 796 |
+
latency_ms=latency_ms,
|
| 797 |
+
threshold=None,
|
| 798 |
+
status_code=200,
|
| 799 |
+
preprocessor=preprocessor,
|
| 800 |
+
)
|
| 801 |
+
return {"predictions": results, "threshold": None}
|
| 802 |
+
except HTTPException as exc:
|
| 803 |
+
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 804 |
+
detail = exc.detail if isinstance(exc.detail, dict) else {"message": str(exc.detail)}
|
| 805 |
+
_log_prediction_entries(
|
| 806 |
+
request_id=request_id,
|
| 807 |
+
records=records,
|
| 808 |
+
results=None,
|
| 809 |
+
latency_ms=latency_ms,
|
| 810 |
+
threshold=threshold,
|
| 811 |
+
status_code=exc.status_code,
|
| 812 |
+
preprocessor=preprocessor,
|
| 813 |
+
error=json.dumps(detail, ensure_ascii=True),
|
| 814 |
+
)
|
| 815 |
+
raise
|
| 816 |
+
except Exception as exc:
|
| 817 |
+
latency_ms = (time.perf_counter() - start_time) * 1000.0
|
| 818 |
+
_log_prediction_entries(
|
| 819 |
+
request_id=request_id,
|
| 820 |
+
records=records,
|
| 821 |
+
results=None,
|
| 822 |
+
latency_ms=latency_ms,
|
| 823 |
+
threshold=threshold,
|
| 824 |
+
status_code=500,
|
| 825 |
+
preprocessor=preprocessor,
|
| 826 |
+
error=str(exc),
|
| 827 |
+
)
|
| 828 |
+
raise
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/Dockerfile
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.11-slim
|
| 2 |
+
|
| 3 |
+
WORKDIR /app
|
| 4 |
+
|
| 5 |
+
ENV PYTHONDONTWRITEBYTECODE=1
|
| 6 |
+
ENV PYTHONUNBUFFERED=1
|
| 7 |
+
|
| 8 |
+
COPY requirements.txt .
|
| 9 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 10 |
+
|
| 11 |
+
COPY app/ app/
|
| 12 |
+
COPY data/HistGB_final_model.pkl data/
|
| 13 |
+
COPY artifacts/preprocessor.joblib artifacts/
|
| 14 |
+
|
| 15 |
+
EXPOSE 7860
|
| 16 |
+
|
| 17 |
+
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "7860"]
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/README.md
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: OCR Projet 06
|
| 3 |
+
emoji: 🤖
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: green
|
| 6 |
+
sdk: docker
|
| 7 |
+
app_port: 7860
|
| 8 |
+
pinned: false
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# OCR Projet 06 – Crédit
|
| 12 |
+
|
| 13 |
+
[](https://github.com/stephmnt/OCR_Projet05/actions/workflows/deploy.yml)
|
| 14 |
+
[](https://github.com/stephmnt/OCR_Projet06/releases)
|
| 15 |
+
[](https://github.com/stephmnt/OCR_Projet06/blob/main/LICENSE)
|
| 16 |
+
|
| 17 |
+
## Lancer MLFlow
|
| 18 |
+
|
| 19 |
+
Le notebook est configure pour utiliser un serveur MLflow local (`http://127.0.0.1:5000`).
|
| 20 |
+
Pour voir les runs et creer l'experiment, demarrer le serveur avec le meme backend :
|
| 21 |
+
|
| 22 |
+
```shell
|
| 23 |
+
mlflow server \
|
| 24 |
+
--host 127.0.0.1 \
|
| 25 |
+
--port 5000 \
|
| 26 |
+
--backend-store-uri "file:${PWD}/mlruns" \
|
| 27 |
+
--default-artifact-root "file:${PWD}/mlruns"
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
Seulement l'interface (sans API), lancer :
|
| 31 |
+
|
| 32 |
+
```shell
|
| 33 |
+
mlflow ui --backend-store-uri "file:${PWD}/mlruns" --port 5000
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Pour tester le serving du modele en staging :
|
| 37 |
+
|
| 38 |
+
```shell
|
| 39 |
+
mlflow models serve -m "models:/credit_scoring_model/Staging" -p 5001 --no-conda
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
## API FastAPI
|
| 43 |
+
|
| 44 |
+
L'API attend un payload JSON avec une cle `data`. La valeur peut etre un objet
|
| 45 |
+
unique (un client) ou une liste d'objets (plusieurs clients). La liste des
|
| 46 |
+
features requises (jeu reduit) est disponible via l'endpoint `/features`. Les
|
| 47 |
+
autres champs sont optionnels et seront completes par des valeurs par defaut.
|
| 48 |
+
|
| 49 |
+
Inputs minimums (10 + `SK_ID_CURR`) :
|
| 50 |
+
|
| 51 |
+
- `EXT_SOURCE_2`
|
| 52 |
+
- `EXT_SOURCE_3`
|
| 53 |
+
- `AMT_ANNUITY`
|
| 54 |
+
- `EXT_SOURCE_1`
|
| 55 |
+
- `CODE_GENDER`
|
| 56 |
+
- `DAYS_EMPLOYED`
|
| 57 |
+
- `AMT_CREDIT`
|
| 58 |
+
- `AMT_GOODS_PRICE`
|
| 59 |
+
- `DAYS_BIRTH`
|
| 60 |
+
- `FLAG_OWN_CAR`
|
| 61 |
+
|
| 62 |
+
### Environnement Poetry (recommande)
|
| 63 |
+
|
| 64 |
+
Le fichier `pyproject.toml` fixe des versions compatibles pour un stack recent
|
| 65 |
+
(`numpy>=2`, `pyarrow>=15`, `scikit-learn>=1.6`). L'environnement vise Python
|
| 66 |
+
3.11.
|
| 67 |
+
|
| 68 |
+
```shell
|
| 69 |
+
poetry env use 3.11
|
| 70 |
+
poetry install
|
| 71 |
+
poetry run pytest -q
|
| 72 |
+
poetry run uvicorn app.main:app --reload --port 7860
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
Important : le modele `HistGB_final_model.pkl` doit etre regenere avec la
|
| 76 |
+
nouvelle version de scikit-learn (re-execution de
|
| 77 |
+
`P6_MANET_Stephane_notebook_modélisation.ipynb`, cellule de sauvegarde pickle).
|
| 78 |
+
|
| 79 |
+
Note : `requirements.txt` est aligne sur `pyproject.toml` (meme versions).
|
| 80 |
+
|
| 81 |
+
### Exemple d'input (schema + valeurs)
|
| 82 |
+
|
| 83 |
+
Schema :
|
| 84 |
+
|
| 85 |
+
```json
|
| 86 |
+
{
|
| 87 |
+
"data": {
|
| 88 |
+
"SK_ID_CURR": "int",
|
| 89 |
+
"EXT_SOURCE_2": "float",
|
| 90 |
+
"EXT_SOURCE_3": "float",
|
| 91 |
+
"AMT_ANNUITY": "float",
|
| 92 |
+
"EXT_SOURCE_1": "float",
|
| 93 |
+
"CODE_GENDER": "str",
|
| 94 |
+
"DAYS_EMPLOYED": "int",
|
| 95 |
+
"AMT_CREDIT": "float",
|
| 96 |
+
"AMT_GOODS_PRICE": "float",
|
| 97 |
+
"DAYS_BIRTH": "int",
|
| 98 |
+
"FLAG_OWN_CAR": "str"
|
| 99 |
+
}
|
| 100 |
+
}
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
Valeurs d'exemple :
|
| 104 |
+
|
| 105 |
+
```json
|
| 106 |
+
{
|
| 107 |
+
"data": {
|
| 108 |
+
"SK_ID_CURR": 100002,
|
| 109 |
+
"EXT_SOURCE_2": 0.61,
|
| 110 |
+
"EXT_SOURCE_3": 0.75,
|
| 111 |
+
"AMT_ANNUITY": 24700.5,
|
| 112 |
+
"EXT_SOURCE_1": 0.45,
|
| 113 |
+
"CODE_GENDER": "M",
|
| 114 |
+
"DAYS_EMPLOYED": -637,
|
| 115 |
+
"AMT_CREDIT": 406597.5,
|
| 116 |
+
"AMT_GOODS_PRICE": 351000.0,
|
| 117 |
+
"DAYS_BIRTH": -9461,
|
| 118 |
+
"FLAG_OWN_CAR": "N"
|
| 119 |
+
}
|
| 120 |
+
}
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
Note : l'API valide strictement les champs requis (`/features`). Pour afficher
|
| 124 |
+
toutes les colonnes possibles : `/features?include_all=true`.
|
| 125 |
+
|
| 126 |
+
### Demo live (commandes cles en main)
|
| 127 |
+
|
| 128 |
+
Lancer l'API :
|
| 129 |
+
|
| 130 |
+
```shell
|
| 131 |
+
uvicorn app.main:app --reload --port 7860
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
Verifier le service :
|
| 135 |
+
|
| 136 |
+
```shell
|
| 137 |
+
curl -s http://127.0.0.1:7860/health
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
Voir les features attendues :
|
| 141 |
+
|
| 142 |
+
```shell
|
| 143 |
+
curl -s http://127.0.0.1:7860/features
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
Predire un client :
|
| 147 |
+
|
| 148 |
+
```shell
|
| 149 |
+
curl -s -X POST "http://127.0.0.1:7860/predict?threshold=0.5" \
|
| 150 |
+
-H "Content-Type: application/json" \
|
| 151 |
+
-d '{
|
| 152 |
+
"data": {
|
| 153 |
+
"SK_ID_CURR": 100002,
|
| 154 |
+
"EXT_SOURCE_2": 0.61,
|
| 155 |
+
"EXT_SOURCE_3": 0.75,
|
| 156 |
+
"AMT_ANNUITY": 24700.5,
|
| 157 |
+
"EXT_SOURCE_1": 0.45,
|
| 158 |
+
"CODE_GENDER": "M",
|
| 159 |
+
"DAYS_EMPLOYED": -637,
|
| 160 |
+
"AMT_CREDIT": 406597.5,
|
| 161 |
+
"AMT_GOODS_PRICE": 351000.0,
|
| 162 |
+
"DAYS_BIRTH": -9461,
|
| 163 |
+
"FLAG_OWN_CAR": "N"
|
| 164 |
+
}
|
| 165 |
+
}'
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
## Contenu de la release
|
| 169 |
+
|
| 170 |
+
- **Preparation + pipeline** : nettoyage / preparation, encodage, imputation et pipeline d'entrainement presentes.
|
| 171 |
+
- **Gestion du desequilibre** : un sous-echantillonnage est applique sur le jeu d'entrainement final.
|
| 172 |
+
- **Comparaison multi-modeles** : baseline, Naive Bayes, Logistic Regression, Decision Tree, Random Forest,
|
| 173 |
+
HistGradientBoosting, LGBM, XGB sont compares.
|
| 174 |
+
- **Validation croisee + tuning** : `StratifiedKFold`, `GridSearchCV` et Hyperopt sont utilises.
|
| 175 |
+
- **Score metier + seuil optimal** : le `custom_score` est la metrique principale des tableaux de comparaison et de la CV, avec un `best_threshold` calcule.
|
| 176 |
+
- **Explicabilite** : feature importance, SHAP et LIME sont inclus.
|
| 177 |
+
- **MLOps (MLflow)** : tracking des params / metriques (dont `custom_score` et `best_threshold`), tags,
|
| 178 |
+
registry et passage en "Staging".
|
| 179 |
+
|
| 180 |
+
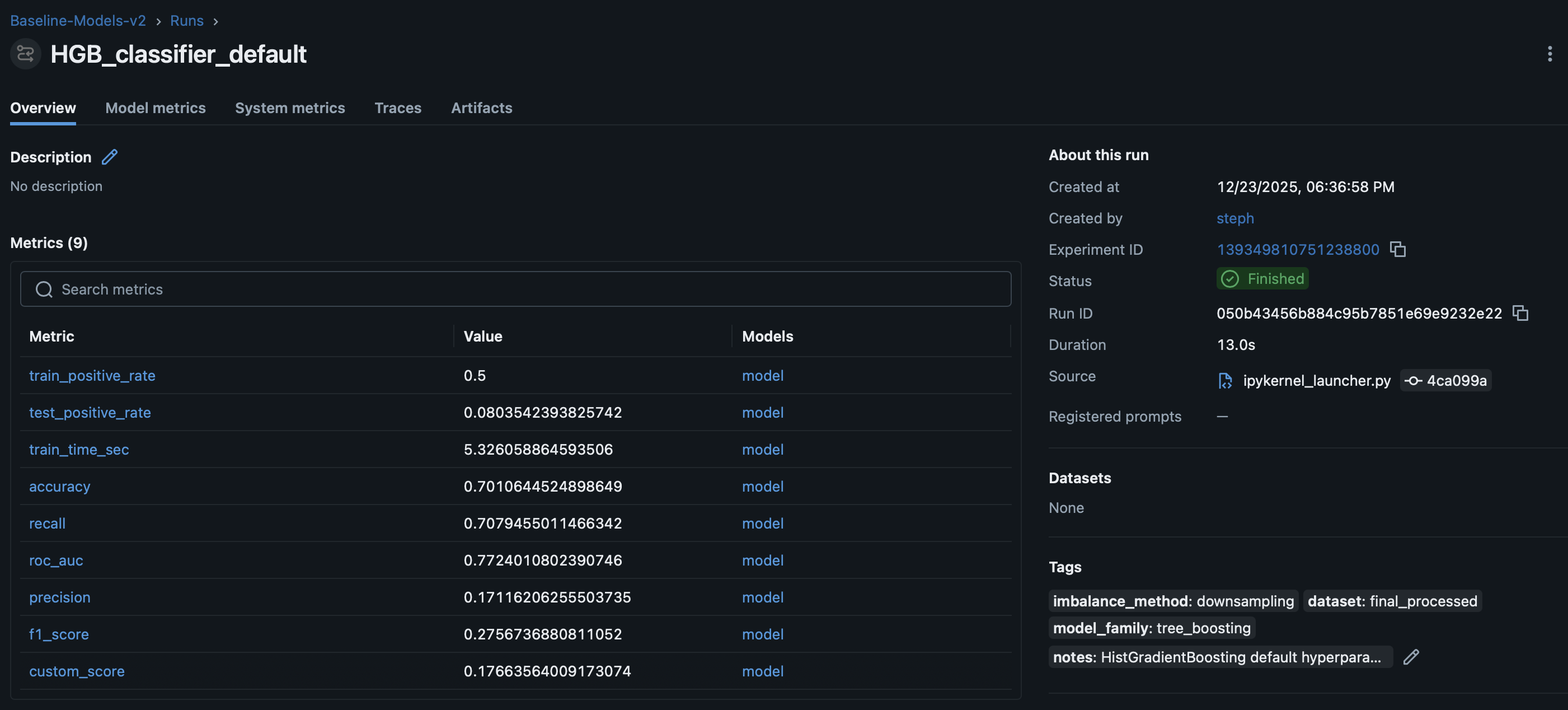
|
| 181 |
+
|
| 182 |
+
## Réduction des features
|
| 183 |
+
|
| 184 |
+
Réduction des features : l’API utilise un top‑10 SHAP, alors que la mission insiste sur une réduction à l’aide d’une matrice de corrélation. La corrélation est bien documentée dans le notebook d’exploration, mais la liste utilisée par l’API n’est pas explicitement issue de cette matrice. À clarifier dans la doc ou aligner la sélection sur la corrélation.
|
| 185 |
+
|
| 186 |
+
## Glossaire rapide
|
| 187 |
+
|
| 188 |
+
- **custom_score** : metrique metier qui penalise plus fortement les faux negatifs que les faux positifs.
|
| 189 |
+
- **Seuil optimal** : probabilite qui sert a transformer un score en classe 0/1.
|
| 190 |
+
- **Validation croisee (CV)** : evaluation sur plusieurs sous-echantillons pour eviter un resultat "chanceux".
|
| 191 |
+
- **MLflow tracking** : historique des runs, parametres et metriques.
|
| 192 |
+
- **Registry** : espace MLflow pour versionner et promouvoir un modele (ex. "Staging").
|
hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/hf_space/app.py
ADDED
|
File without changes
|