diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..b35e164c0a6a72efe2270409ea6e0e78098e33a9
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,141 @@
+log/
+output/
+.vscode/
+workspace/
+tmp_occupy_memory_saves/
+run*.sh
+py-thin-plate-spline
+wandb/
+pretrain/
+Pytorch-Correlation-extension/
+result
+
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+pip-wheel-metadata/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+.python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..cbe5ad1670406e4402217edfb82d2c56af7e8631
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,437 @@
+Attribution-NonCommercial-ShareAlike 4.0 International
+
+=======================================================================
+
+Creative Commons Corporation ("Creative Commons") is not a law firm and
+does not provide legal services or legal advice. Distribution of
+Creative Commons public licenses does not create a lawyer-client or
+other relationship. Creative Commons makes its licenses and related
+information available on an "as-is" basis. Creative Commons gives no
+warranties regarding its licenses, any material licensed under their
+terms and conditions, or any related information. Creative Commons
+disclaims all liability for damages resulting from their use to the
+fullest extent possible.
+
+Using Creative Commons Public Licenses
+
+Creative Commons public licenses provide a standard set of terms and
+conditions that creators and other rights holders may use to share
+original works of authorship and other material subject to copyright
+and certain other rights specified in the public license below. The
+following considerations are for informational purposes only, are not
+exhaustive, and do not form part of our licenses.
+
+ Considerations for licensors: Our public licenses are
+ intended for use by those authorized to give the public
+ permission to use material in ways otherwise restricted by
+ copyright and certain other rights. Our licenses are
+ irrevocable. Licensors should read and understand the terms
+ and conditions of the license they choose before applying it.
+ Licensors should also secure all rights necessary before
+ applying our licenses so that the public can reuse the
+ material as expected. Licensors should clearly mark any
+ material not subject to the license. This includes other CC-
+ licensed material, or material used under an exception or
+ limitation to copyright. More considerations for licensors:
+ wiki.creativecommons.org/Considerations_for_licensors
+
+ Considerations for the public: By using one of our public
+ licenses, a licensor grants the public permission to use the
+ licensed material under specified terms and conditions. If
+ the licensor's permission is not necessary for any reason--for
+ example, because of any applicable exception or limitation to
+ copyright--then that use is not regulated by the license. Our
+ licenses grant only permissions under copyright and certain
+ other rights that a licensor has authority to grant. Use of
+ the licensed material may still be restricted for other
+ reasons, including because others have copyright or other
+ rights in the material. A licensor may make special requests,
+ such as asking that all changes be marked or described.
+ Although not required by our licenses, you are encouraged to
+ respect those requests where reasonable. More considerations
+ for the public:
+ wiki.creativecommons.org/Considerations_for_licensees
+
+=======================================================================
+
+Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
+Public License
+
+By exercising the Licensed Rights (defined below), You accept and agree
+to be bound by the terms and conditions of this Creative Commons
+Attribution-NonCommercial-ShareAlike 4.0 International Public License
+("Public License"). To the extent this Public License may be
+interpreted as a contract, You are granted the Licensed Rights in
+consideration of Your acceptance of these terms and conditions, and the
+Licensor grants You such rights in consideration of benefits the
+Licensor receives from making the Licensed Material available under
+these terms and conditions.
+
+
+Section 1 -- Definitions.
+
+ a. Adapted Material means material subject to Copyright and Similar
+ Rights that is derived from or based upon the Licensed Material
+ and in which the Licensed Material is translated, altered,
+ arranged, transformed, or otherwise modified in a manner requiring
+ permission under the Copyright and Similar Rights held by the
+ Licensor. For purposes of this Public License, where the Licensed
+ Material is a musical work, performance, or sound recording,
+ Adapted Material is always produced where the Licensed Material is
+ synched in timed relation with a moving image.
+
+ b. Adapter's License means the license You apply to Your Copyright
+ and Similar Rights in Your contributions to Adapted Material in
+ accordance with the terms and conditions of this Public License.
+
+ c. BY-NC-SA Compatible License means a license listed at
+ creativecommons.org/compatiblelicenses, approved by Creative
+ Commons as essentially the equivalent of this Public License.
+
+ d. Copyright and Similar Rights means copyright and/or similar rights
+ closely related to copyright including, without limitation,
+ performance, broadcast, sound recording, and Sui Generis Database
+ Rights, without regard to how the rights are labeled or
+ categorized. For purposes of this Public License, the rights
+ specified in Section 2(b)(1)-(2) are not Copyright and Similar
+ Rights.
+
+ e. Effective Technological Measures means those measures that, in the
+ absence of proper authority, may not be circumvented under laws
+ fulfilling obligations under Article 11 of the WIPO Copyright
+ Treaty adopted on December 20, 1996, and/or similar international
+ agreements.
+
+ f. Exceptions and Limitations means fair use, fair dealing, and/or
+ any other exception or limitation to Copyright and Similar Rights
+ that applies to Your use of the Licensed Material.
+
+ g. License Elements means the license attributes listed in the name
+ of a Creative Commons Public License. The License Elements of this
+ Public License are Attribution, NonCommercial, and ShareAlike.
+
+ h. Licensed Material means the artistic or literary work, database,
+ or other material to which the Licensor applied this Public
+ License.
+
+ i. Licensed Rights means the rights granted to You subject to the
+ terms and conditions of this Public License, which are limited to
+ all Copyright and Similar Rights that apply to Your use of the
+ Licensed Material and that the Licensor has authority to license.
+
+ j. Licensor means the individual(s) or entity(ies) granting rights
+ under this Public License.
+
+ k. NonCommercial means not primarily intended for or directed towards
+ commercial advantage or monetary compensation. For purposes of
+ this Public License, the exchange of the Licensed Material for
+ other material subject to Copyright and Similar Rights by digital
+ file-sharing or similar means is NonCommercial provided there is
+ no payment of monetary compensation in connection with the
+ exchange.
+
+ l. Share means to provide material to the public by any means or
+ process that requires permission under the Licensed Rights, such
+ as reproduction, public display, public performance, distribution,
+ dissemination, communication, or importation, and to make material
+ available to the public including in ways that members of the
+ public may access the material from a place and at a time
+ individually chosen by them.
+
+ m. Sui Generis Database Rights means rights other than copyright
+ resulting from Directive 96/9/EC of the European Parliament and of
+ the Council of 11 March 1996 on the legal protection of databases,
+ as amended and/or succeeded, as well as other essentially
+ equivalent rights anywhere in the world.
+
+ n. You means the individual or entity exercising the Licensed Rights
+ under this Public License. Your has a corresponding meaning.
+
+
+Section 2 -- Scope.
+
+ a. License grant.
+
+ 1. Subject to the terms and conditions of this Public License,
+ the Licensor hereby grants You a worldwide, royalty-free,
+ non-sublicensable, non-exclusive, irrevocable license to
+ exercise the Licensed Rights in the Licensed Material to:
+
+ a. reproduce and Share the Licensed Material, in whole or
+ in part, for NonCommercial purposes only; and
+
+ b. produce, reproduce, and Share Adapted Material for
+ NonCommercial purposes only.
+
+ 2. Exceptions and Limitations. For the avoidance of doubt, where
+ Exceptions and Limitations apply to Your use, this Public
+ License does not apply, and You do not need to comply with
+ its terms and conditions.
+
+ 3. Term. The term of this Public License is specified in Section
+ 6(a).
+
+ 4. Media and formats; technical modifications allowed. The
+ Licensor authorizes You to exercise the Licensed Rights in
+ all media and formats whether now known or hereafter created,
+ and to make technical modifications necessary to do so. The
+ Licensor waives and/or agrees not to assert any right or
+ authority to forbid You from making technical modifications
+ necessary to exercise the Licensed Rights, including
+ technical modifications necessary to circumvent Effective
+ Technological Measures. For purposes of this Public License,
+ simply making modifications authorized by this Section 2(a)
+ (4) never produces Adapted Material.
+
+ 5. Downstream recipients.
+
+ a. Offer from the Licensor -- Licensed Material. Every
+ recipient of the Licensed Material automatically
+ receives an offer from the Licensor to exercise the
+ Licensed Rights under the terms and conditions of this
+ Public License.
+
+ b. Additional offer from the Licensor -- Adapted Material.
+ Every recipient of Adapted Material from You
+ automatically receives an offer from the Licensor to
+ exercise the Licensed Rights in the Adapted Material
+ under the conditions of the Adapter's License You apply.
+
+ c. No downstream restrictions. You may not offer or impose
+ any additional or different terms or conditions on, or
+ apply any Effective Technological Measures to, the
+ Licensed Material if doing so restricts exercise of the
+ Licensed Rights by any recipient of the Licensed
+ Material.
+
+ 6. No endorsement. Nothing in this Public License constitutes or
+ may be construed as permission to assert or imply that You
+ are, or that Your use of the Licensed Material is, connected
+ with, or sponsored, endorsed, or granted official status by,
+ the Licensor or others designated to receive attribution as
+ provided in Section 3(a)(1)(A)(i).
+
+ b. Other rights.
+
+ 1. Moral rights, such as the right of integrity, are not
+ licensed under this Public License, nor are publicity,
+ privacy, and/or other similar personality rights; however, to
+ the extent possible, the Licensor waives and/or agrees not to
+ assert any such rights held by the Licensor to the limited
+ extent necessary to allow You to exercise the Licensed
+ Rights, but not otherwise.
+
+ 2. Patent and trademark rights are not licensed under this
+ Public License.
+
+ 3. To the extent possible, the Licensor waives any right to
+ collect royalties from You for the exercise of the Licensed
+ Rights, whether directly or through a collecting society
+ under any voluntary or waivable statutory or compulsory
+ licensing scheme. In all other cases the Licensor expressly
+ reserves any right to collect such royalties, including when
+ the Licensed Material is used other than for NonCommercial
+ purposes.
+
+
+Section 3 -- License Conditions.
+
+Your exercise of the Licensed Rights is expressly made subject to the
+following conditions.
+
+ a. Attribution.
+
+ 1. If You Share the Licensed Material (including in modified
+ form), You must:
+
+ a. retain the following if it is supplied by the Licensor
+ with the Licensed Material:
+
+ i. identification of the creator(s) of the Licensed
+ Material and any others designated to receive
+ attribution, in any reasonable manner requested by
+ the Licensor (including by pseudonym if
+ designated);
+
+ ii. a copyright notice;
+
+ iii. a notice that refers to this Public License;
+
+ iv. a notice that refers to the disclaimer of
+ warranties;
+
+ v. a URI or hyperlink to the Licensed Material to the
+ extent reasonably practicable;
+
+ b. indicate if You modified the Licensed Material and
+ retain an indication of any previous modifications; and
+
+ c. indicate the Licensed Material is licensed under this
+ Public License, and include the text of, or the URI or
+ hyperlink to, this Public License.
+
+ 2. You may satisfy the conditions in Section 3(a)(1) in any
+ reasonable manner based on the medium, means, and context in
+ which You Share the Licensed Material. For example, it may be
+ reasonable to satisfy the conditions by providing a URI or
+ hyperlink to a resource that includes the required
+ information.
+ 3. If requested by the Licensor, You must remove any of the
+ information required by Section 3(a)(1)(A) to the extent
+ reasonably practicable.
+
+ b. ShareAlike.
+
+ In addition to the conditions in Section 3(a), if You Share
+ Adapted Material You produce, the following conditions also apply.
+
+ 1. The Adapter's License You apply must be a Creative Commons
+ license with the same License Elements, this version or
+ later, or a BY-NC-SA Compatible License.
+
+ 2. You must include the text of, or the URI or hyperlink to, the
+ Adapter's License You apply. You may satisfy this condition
+ in any reasonable manner based on the medium, means, and
+ context in which You Share Adapted Material.
+
+ 3. You may not offer or impose any additional or different terms
+ or conditions on, or apply any Effective Technological
+ Measures to, Adapted Material that restrict exercise of the
+ rights granted under the Adapter's License You apply.
+
+
+Section 4 -- Sui Generis Database Rights.
+
+Where the Licensed Rights include Sui Generis Database Rights that
+apply to Your use of the Licensed Material:
+
+ a. for the avoidance of doubt, Section 2(a)(1) grants You the right
+ to extract, reuse, reproduce, and Share all or a substantial
+ portion of the contents of the database for NonCommercial purposes
+ only;
+
+ b. if You include all or a substantial portion of the database
+ contents in a database in which You have Sui Generis Database
+ Rights, then the database in which You have Sui Generis Database
+ Rights (but not its individual contents) is Adapted Material,
+ including for purposes of Section 3(b); and
+
+ c. You must comply with the conditions in Section 3(a) if You Share
+ all or a substantial portion of the contents of the database.
+
+For the avoidance of doubt, this Section 4 supplements and does not
+replace Your obligations under this Public License where the Licensed
+Rights include other Copyright and Similar Rights.
+
+
+Section 5 -- Disclaimer of Warranties and Limitation of Liability.
+
+ a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
+ EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
+ AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
+ ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
+ IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
+ WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
+ PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
+ ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
+ KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
+ ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
+
+ b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
+ TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
+ NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
+ INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
+ COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
+ USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
+ ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
+ DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
+ IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
+
+ c. The disclaimer of warranties and limitation of liability provided
+ above shall be interpreted in a manner that, to the extent
+ possible, most closely approximates an absolute disclaimer and
+ waiver of all liability.
+
+
+Section 6 -- Term and Termination.
+
+ a. This Public License applies for the term of the Copyright and
+ Similar Rights licensed here. However, if You fail to comply with
+ this Public License, then Your rights under this Public License
+ terminate automatically.
+
+ b. Where Your right to use the Licensed Material has terminated under
+ Section 6(a), it reinstates:
+
+ 1. automatically as of the date the violation is cured, provided
+ it is cured within 30 days of Your discovery of the
+ violation; or
+
+ 2. upon express reinstatement by the Licensor.
+
+ For the avoidance of doubt, this Section 6(b) does not affect any
+ right the Licensor may have to seek remedies for Your violations
+ of this Public License.
+
+ c. For the avoidance of doubt, the Licensor may also offer the
+ Licensed Material under separate terms or conditions or stop
+ distributing the Licensed Material at any time; however, doing so
+ will not terminate this Public License.
+
+ d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
+ License.
+
+
+Section 7 -- Other Terms and Conditions.
+
+ a. The Licensor shall not be bound by any additional or different
+ terms or conditions communicated by You unless expressly agreed.
+
+ b. Any arrangements, understandings, or agreements regarding the
+ Licensed Material not stated herein are separate from and
+ independent of the terms and conditions of this Public License.
+
+
+Section 8 -- Interpretation.
+
+ a. For the avoidance of doubt, this Public License does not, and
+ shall not be interpreted to, reduce, limit, restrict, or impose
+ conditions on any use of the Licensed Material that could lawfully
+ be made without permission under this Public License.
+
+ b. To the extent possible, if any provision of this Public License is
+ deemed unenforceable, it shall be automatically reformed to the
+ minimum extent necessary to make it enforceable. If the provision
+ cannot be reformed, it shall be severed from this Public License
+ without affecting the enforceability of the remaining terms and
+ conditions.
+
+ c. No term or condition of this Public License will be waived and no
+ failure to comply consented to unless expressly agreed to by the
+ Licensor.
+
+ d. Nothing in this Public License constitutes or may be interpreted
+ as a limitation upon, or waiver of, any privileges and immunities
+ that apply to the Licensor or You, including from the legal
+ processes of any jurisdiction or authority.
+
+=======================================================================
+
+Creative Commons is not a party to its public
+licenses. Notwithstanding, Creative Commons may elect to apply one of
+its public licenses to material it publishes and in those instances
+will be considered the “Licensor.” The text of the Creative Commons
+public licenses is dedicated to the public domain under the CC0 Public
+Domain Dedication. Except for the limited purpose of indicating that
+material is shared under a Creative Commons public license or as
+otherwise permitted by the Creative Commons policies published at
+creativecommons.org/policies, Creative Commons does not authorize the
+use of the trademark "Creative Commons" or any other trademark or logo
+of Creative Commons without its prior written consent including,
+without limitation, in connection with any unauthorized modifications
+to any of its public licenses or any other arrangements,
+understandings, or agreements concerning use of licensed material. For
+the avoidance of doubt, this paragraph does not form part of the
+public licenses.
+
+Creative Commons may be contacted at creativecommons.org.
diff --git a/dataset/__init__.py b/dataset/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/dataset/range_transform.py b/dataset/range_transform.py
new file mode 100644
index 0000000000000000000000000000000000000000..990bd338f661f443145d10954dc5d2074a01f07f
--- /dev/null
+++ b/dataset/range_transform.py
@@ -0,0 +1,44 @@
+import torchvision.transforms as transforms
+import util.functional as F
+import numpy as np
+from skimage import color
+
+im_mean = (124, 116, 104)
+
+im_normalization = transforms.Normalize(
+ mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225]
+ )
+
+inv_im_trans = transforms.Normalize(
+ mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
+ std=[1/0.229, 1/0.224, 1/0.225])
+
+# tensor l[-1, 1] ab[-1, 1]
+# numpy l[0 100] ab[-127 128]
+# transforms.Normalize: x_new = (x-mean) / std
+inv_lll2rgb_trans = transforms.Normalize(
+ mean=[-1, 0, 0],
+ std=[1/50., 1/110., 1/110.])
+
+im_rgb2lab_normalization = transforms.Normalize(
+ mean=[50, 0, 0],
+ std=[50, 110, 110])
+
+class ToTensor(object):
+ def __init__(self):
+ pass
+
+ def __call__(self, inputs):
+ return F.to_mytensor(inputs)
+
+class RGB2Lab(object):
+ def __init__(self):
+ pass
+
+ def __call__(self, inputs):
+ # default return float64
+ # return color.rgb2lab(inputs)
+
+ # return float32
+ return np.float32(color.rgb2lab(inputs))
\ No newline at end of file
diff --git a/dataset/reseed.py b/dataset/reseed.py
new file mode 100644
index 0000000000000000000000000000000000000000..600c998fa33485c073af7f9e13e885350a5c6940
--- /dev/null
+++ b/dataset/reseed.py
@@ -0,0 +1,6 @@
+import torch
+import random
+
+def reseed(seed):
+ random.seed(seed)
+ torch.manual_seed(seed)
\ No newline at end of file
diff --git a/dataset/static_dataset.py b/dataset/static_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..f487cb2fe6b34d0db799f5fa7ab9a6459fdfbc26
--- /dev/null
+++ b/dataset/static_dataset.py
@@ -0,0 +1,179 @@
+import os
+from os import path
+
+import torch
+from torch.utils.data.dataset import Dataset
+from torchvision import transforms
+from torchvision.transforms import InterpolationMode
+from PIL import Image
+import numpy as np
+
+from dataset.range_transform import im_normalization, im_mean
+from dataset.tps import random_tps_warp
+from dataset.reseed import reseed
+
+
+class StaticTransformDataset(Dataset):
+ """
+ Generate pseudo VOS data by applying random transforms on static images.
+ Single-object only.
+
+ Method 0 - FSS style (class/1.jpg class/1.png)
+ Method 1 - Others style (XXX.jpg XXX.png)
+ """
+ def __init__(self, parameters, num_frames=3, max_num_obj=1):
+ self.num_frames = num_frames
+ self.max_num_obj = max_num_obj
+
+ self.im_list = []
+ for parameter in parameters:
+ root, method, multiplier = parameter
+ if method == 0:
+ # Get images
+ classes = os.listdir(root)
+ for c in classes:
+ imgs = os.listdir(path.join(root, c))
+ jpg_list = [im for im in imgs if 'jpg' in im[-3:].lower()]
+
+ joint_list = [path.join(root, c, im) for im in jpg_list]
+ self.im_list.extend(joint_list * multiplier)
+
+ elif method == 1:
+ self.im_list.extend([path.join(root, im) for im in os.listdir(root) if '.jpg' in im] * multiplier)
+
+ print(f'{len(self.im_list)} images found.')
+
+ # These set of transform is the same for im/gt pairs, but different among the 3 sampled frames
+ self.pair_im_lone_transform = transforms.Compose([
+ transforms.ColorJitter(0.1, 0.05, 0.05, 0), # No hue change here as that's not realistic
+ ])
+
+ self.pair_im_dual_transform = transforms.Compose([
+ transforms.RandomAffine(degrees=20, scale=(0.9,1.1), shear=10, interpolation=InterpolationMode.BICUBIC, fill=im_mean),
+ transforms.Resize(384, InterpolationMode.BICUBIC),
+ transforms.RandomCrop((384, 384), pad_if_needed=True, fill=im_mean),
+ ])
+
+ self.pair_gt_dual_transform = transforms.Compose([
+ transforms.RandomAffine(degrees=20, scale=(0.9,1.1), shear=10, interpolation=InterpolationMode.BICUBIC, fill=0),
+ transforms.Resize(384, InterpolationMode.NEAREST),
+ transforms.RandomCrop((384, 384), pad_if_needed=True, fill=0),
+ ])
+
+
+ # These transform are the same for all pairs in the sampled sequence
+ self.all_im_lone_transform = transforms.Compose([
+ transforms.ColorJitter(0.1, 0.05, 0.05, 0.05),
+ transforms.RandomGrayscale(0.05),
+ ])
+
+ self.all_im_dual_transform = transforms.Compose([
+ transforms.RandomAffine(degrees=0, scale=(0.8, 1.5), fill=im_mean),
+ transforms.RandomHorizontalFlip(),
+ ])
+
+ self.all_gt_dual_transform = transforms.Compose([
+ transforms.RandomAffine(degrees=0, scale=(0.8, 1.5), fill=0),
+ transforms.RandomHorizontalFlip(),
+ ])
+
+ # Final transform without randomness
+ self.final_im_transform = transforms.Compose([
+ transforms.ToTensor(),
+ im_normalization,
+ ])
+
+ self.final_gt_transform = transforms.Compose([
+ transforms.ToTensor(),
+ ])
+
+ def _get_sample(self, idx):
+ im = Image.open(self.im_list[idx]).convert('RGB')
+ gt = Image.open(self.im_list[idx][:-3]+'png').convert('L')
+
+ sequence_seed = np.random.randint(2147483647)
+
+ images = []
+ masks = []
+ for _ in range(self.num_frames):
+ reseed(sequence_seed)
+ this_im = self.all_im_dual_transform(im)
+ this_im = self.all_im_lone_transform(this_im)
+ reseed(sequence_seed)
+ this_gt = self.all_gt_dual_transform(gt)
+
+ pairwise_seed = np.random.randint(2147483647)
+ reseed(pairwise_seed)
+ this_im = self.pair_im_dual_transform(this_im)
+ this_im = self.pair_im_lone_transform(this_im)
+ reseed(pairwise_seed)
+ this_gt = self.pair_gt_dual_transform(this_gt)
+
+ # Use TPS only some of the times
+ # Not because TPS is bad -- just that it is too slow and I need to speed up data loading
+ if np.random.rand() < 0.33:
+ this_im, this_gt = random_tps_warp(this_im, this_gt, scale=0.02)
+
+ this_im = self.final_im_transform(this_im)
+ this_gt = self.final_gt_transform(this_gt)
+
+ images.append(this_im)
+ masks.append(this_gt)
+
+ images = torch.stack(images, 0)
+ masks = torch.stack(masks, 0)
+
+ return images, masks.numpy()
+
+ def __getitem__(self, idx):
+ additional_objects = np.random.randint(self.max_num_obj)
+ indices = [idx, *np.random.randint(self.__len__(), size=additional_objects)]
+
+ merged_images = None
+ merged_masks = np.zeros((self.num_frames, 384, 384), dtype=np.int)
+
+ for i, list_id in enumerate(indices):
+ images, masks = self._get_sample(list_id)
+ if merged_images is None:
+ merged_images = images
+ else:
+ merged_images = merged_images*(1-masks) + images*masks
+ merged_masks[masks[:,0]>0.5] = (i+1)
+
+ masks = merged_masks
+
+ labels = np.unique(masks[0])
+ # Remove background
+ labels = labels[labels!=0]
+ target_objects = labels.tolist()
+
+ # Generate one-hot ground-truth
+ cls_gt = np.zeros((self.num_frames, 384, 384), dtype=np.int)
+ first_frame_gt = np.zeros((1, self.max_num_obj, 384, 384), dtype=np.int)
+ for i, l in enumerate(target_objects):
+ this_mask = (masks==l)
+ cls_gt[this_mask] = i+1
+ first_frame_gt[0,i] = (this_mask[0])
+ cls_gt = np.expand_dims(cls_gt, 1)
+
+ info = {}
+ info['name'] = self.im_list[idx]
+ info['num_objects'] = max(1, len(target_objects))
+
+ # 1 if object exist, 0 otherwise
+ selector = [1 if i < info['num_objects'] else 0 for i in range(self.max_num_obj)]
+ selector = torch.FloatTensor(selector)
+
+ data = {
+ 'rgb': merged_images,
+ 'first_frame_gt': first_frame_gt,
+ 'cls_gt': cls_gt,
+ 'selector': selector,
+ 'info': info
+ }
+
+ return data
+
+
+ def __len__(self):
+ return len(self.im_list)
diff --git a/dataset/tps.py b/dataset/tps.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ee3747c110a8ca03169e3ece5654ba4e8abd7fe
--- /dev/null
+++ b/dataset/tps.py
@@ -0,0 +1,37 @@
+import numpy as np
+from PIL import Image
+import cv2
+import thinplate as tps
+
+cv2.setNumThreads(0)
+
+def pick_random_points(h, w, n_samples):
+ y_idx = np.random.choice(np.arange(h), size=n_samples, replace=False)
+ x_idx = np.random.choice(np.arange(w), size=n_samples, replace=False)
+ return y_idx/h, x_idx/w
+
+
+def warp_dual_cv(img, mask, c_src, c_dst):
+ dshape = img.shape
+ theta = tps.tps_theta_from_points(c_src, c_dst, reduced=True)
+ grid = tps.tps_grid(theta, c_dst, dshape)
+ mapx, mapy = tps.tps_grid_to_remap(grid, img.shape)
+ return cv2.remap(img, mapx, mapy, cv2.INTER_LINEAR), cv2.remap(mask, mapx, mapy, cv2.INTER_NEAREST)
+
+
+def random_tps_warp(img, mask, scale, n_ctrl_pts=12):
+ """
+ Apply a random TPS warp of the input image and mask
+ Uses randomness from numpy
+ """
+ img = np.asarray(img)
+ mask = np.asarray(mask)
+
+ h, w = mask.shape
+ points = pick_random_points(h, w, n_ctrl_pts)
+ c_src = np.stack(points, 1)
+ c_dst = c_src + np.random.normal(scale=scale, size=c_src.shape)
+ warp_im, warp_gt = warp_dual_cv(img, mask, c_src, c_dst)
+
+ return Image.fromarray(warp_im), Image.fromarray(warp_gt)
+
diff --git a/dataset/util.py b/dataset/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f1dc551cb940b095a55d15f3dfef8f77513df22
--- /dev/null
+++ b/dataset/util.py
@@ -0,0 +1,12 @@
+import numpy as np
+
+def all_to_onehot(masks, labels):
+ if len(masks.shape) == 3:
+ Ms = np.zeros((len(labels), masks.shape[0], masks.shape[1], masks.shape[2]), dtype=np.uint8)
+ else:
+ Ms = np.zeros((len(labels), masks.shape[0], masks.shape[1]), dtype=np.uint8)
+
+ for ni, l in enumerate(labels):
+ Ms[ni] = (masks == l).astype(np.uint8)
+
+ return Ms
diff --git a/dataset/vos_dataset.py b/dataset/vos_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..6140d42beff54772ca484271256eb0821233e44a
--- /dev/null
+++ b/dataset/vos_dataset.py
@@ -0,0 +1,210 @@
+import os
+from os import path, replace
+
+import torch
+from torch.utils.data.dataset import Dataset
+from torchvision import transforms
+from torchvision.transforms import InterpolationMode
+from PIL import Image
+import numpy as np
+
+from dataset.range_transform import im_normalization, im_mean, im_rgb2lab_normalization, ToTensor, RGB2Lab
+from dataset.reseed import reseed
+
+import util.functional as F
+
+class VOSDataset_221128_TransColorization_batch(Dataset):
+ """
+ Works for DAVIS/YouTubeVOS/BL30K training
+ For each sequence:
+ - Pick three frames
+ - Pick two objects
+ - Apply some random transforms that are the same for all frames
+ - Apply random transform to each of the frame
+ - The distance between frames is controlled
+ """
+ def __init__(self, im_root, gt_root, max_jump, is_bl, subset=None, num_frames=3, max_num_obj=2, finetune=False):
+ self.im_root = im_root
+ self.gt_root = gt_root
+ self.max_jump = max_jump
+ self.is_bl = is_bl
+ self.num_frames = num_frames
+ self.max_num_obj = max_num_obj
+
+ self.videos = []
+ self.frames = {}
+ vid_list = sorted(os.listdir(self.im_root))
+ # Pre-filtering
+ for vid in vid_list:
+ if subset is not None:
+ if vid not in subset:
+ continue
+ frames = sorted(os.listdir(os.path.join(self.im_root, vid)))
+ if len(frames) < num_frames:
+ continue
+ self.frames[vid] = frames
+ self.videos.append(vid)
+
+ print('%d out of %d videos accepted in %s.' % (len(self.videos), len(vid_list), im_root))
+
+ # These set of transform is the same for im/gt pairs, but different among the 3 sampled frames
+ self.pair_im_lone_transform = transforms.Compose([
+ transforms.ColorJitter(0.01, 0.01, 0.01, 0),
+ ])
+
+ self.pair_im_dual_transform = transforms.Compose([
+ transforms.RandomAffine(degrees=0 if finetune or self.is_bl else 15, shear=0 if finetune or self.is_bl else 10, interpolation=InterpolationMode.BILINEAR, fill=im_mean),
+ ])
+
+ self.pair_gt_dual_transform = transforms.Compose([
+ transforms.RandomAffine(degrees=0 if finetune or self.is_bl else 15, shear=0 if finetune or self.is_bl else 10, interpolation=InterpolationMode.NEAREST, fill=0),
+ ])
+
+ # These transform are the same for all pairs in the sampled sequence
+ self.all_im_lone_transform = transforms.Compose([
+ transforms.ColorJitter(0.1, 0.03, 0.03, 0),
+ # transforms.RandomGrayscale(0.05),
+ ])
+
+ patchsz = 448 # 224
+ self.all_im_dual_transform = transforms.Compose([
+ transforms.RandomHorizontalFlip(),
+ transforms.RandomResizedCrop((patchsz, patchsz), scale=(0.36,1.00), interpolation=InterpolationMode.BILINEAR)
+ ])
+
+ self.all_gt_dual_transform = transforms.Compose([
+ transforms.RandomHorizontalFlip(),
+ transforms.RandomResizedCrop((patchsz, patchsz), scale=(0.36,1.00), interpolation=InterpolationMode.NEAREST)
+ ])
+
+ # Final transform without randomness
+ self.final_im_transform = transforms.Compose([
+ RGB2Lab(),
+ ToTensor(),
+ im_rgb2lab_normalization,
+ ])
+
+ def __getitem__(self, idx):
+ video = self.videos[idx]
+ info = {}
+ info['name'] = video
+
+ vid_im_path = path.join(self.im_root, video)
+ vid_gt_path = path.join(self.gt_root, video)
+ frames = self.frames[video]
+
+ trials = 0
+ while trials < 5:
+ info['frames'] = [] # Appended with actual frames
+
+ num_frames = self.num_frames
+ length = len(frames)
+ this_max_jump = min(len(frames), self.max_jump)
+
+ # iterative sampling
+ frames_idx = [np.random.randint(length)]
+ acceptable_set = set(range(max(0, frames_idx[-1]-this_max_jump), min(length, frames_idx[-1]+this_max_jump+1))).difference(set(frames_idx))
+ while(len(frames_idx) < num_frames):
+ idx = np.random.choice(list(acceptable_set))
+ frames_idx.append(idx)
+ new_set = set(range(max(0, frames_idx[-1]-this_max_jump), min(length, frames_idx[-1]+this_max_jump+1)))
+ acceptable_set = acceptable_set.union(new_set).difference(set(frames_idx))
+
+ frames_idx = sorted(frames_idx)
+ if np.random.rand() < 0.5:
+ # Reverse time
+ frames_idx = frames_idx[::-1]
+
+ sequence_seed = np.random.randint(2147483647)
+ images = []
+ masks = []
+ target_objects = []
+ for f_idx in frames_idx:
+ jpg_name = frames[f_idx]
+ png_name = jpg_name.replace('.jpg', '.png')
+ info['frames'].append(jpg_name)
+
+ reseed(sequence_seed)
+ this_im = Image.open(path.join(vid_im_path, jpg_name)).convert('RGB')
+ this_im = self.all_im_dual_transform(this_im)
+ this_im = self.all_im_lone_transform(this_im)
+
+ reseed(sequence_seed)
+ this_gt = Image.open(path.join(vid_gt_path, png_name)).convert('P')
+ this_gt = self.all_gt_dual_transform(this_gt)
+
+ pairwise_seed = np.random.randint(2147483647)
+ reseed(pairwise_seed)
+ this_im = self.pair_im_dual_transform(this_im)
+ this_im = self.pair_im_lone_transform(this_im)
+
+ reseed(pairwise_seed)
+ this_gt = self.pair_gt_dual_transform(this_gt)
+
+ this_im = self.final_im_transform(this_im)
+ # print('1', torch.max(this_im[:1,:,:]), torch.min(this_im[:1,:,:]))
+ # print('2', torch.max(this_im[1:3,:,:]), torch.min(this_im[1:3,:,:]))
+ # print('3', torch.max(this_im), torch.min(this_im));assert 1==0
+ # print(this_im.size());assert 1==0
+
+ this_gt = np.array(this_gt)
+
+ this_im_l = this_im[:1,:,:]
+ this_im_ab = this_im[1:3,:,:]
+ # print(this_im_l.size(), this_im_ab.size());assert 1==0
+
+ # images.append(this_im_l)
+ # masks.append(this_im_ab)
+
+ this_im_lll = this_im_l.repeat(3,1,1)
+ images.append(this_im_lll)
+ masks.append(this_im_ab)
+
+ images = torch.stack(images, 0)
+ # print(images.size());assert 1==0
+
+ # target_objects = labels.tolist()
+ break
+
+ first_frame_gt = masks[0].unsqueeze(0)
+ # print(first_frame_gt.size());assert 1==0
+
+ info['num_objects'] = 2
+
+ masks = np.stack(masks, 0)
+ # print(np.shape(masks));assert 1==0
+
+
+ cls_gt = masks
+
+ # # Generate one-hot ground-truth
+ # cls_gt = np.zeros((self.num_frames, 384, 384), dtype=np.int)
+ # first_frame_gt = np.zeros((1, self.max_num_obj, 384, 384), dtype=np.int)
+ # for i, l in enumerate(target_objects):
+ # this_mask = (masks==l)
+ # cls_gt[this_mask] = i+1
+ # first_frame_gt[0,i] = (this_mask[0])
+ # cls_gt = np.expand_dims(cls_gt, 1)
+
+ # 1 if object exist, 0 otherwise
+ selector = [1 if i < info['num_objects'] else 0 for i in range(self.max_num_obj)]
+
+ # print(info['num_objects'], self.max_num_obj, selector);assert 1==0
+
+ selector = torch.FloatTensor(selector)
+
+ # print(images.size(), np.shape(first_frame_gt), np.shape(cls_gt));assert 1==0
+ ### torch.Size([8, 3, 384, 384]) torch.Size([1, 2, 384, 384]) (8, 2, 384, 384)
+
+ data = {
+ 'rgb': images,
+ 'first_frame_gt': first_frame_gt,
+ 'cls_gt': cls_gt,
+ 'selector': selector,
+ 'info': info,
+ }
+
+ return data
+
+ def __len__(self):
+ return len(self.videos)
diff --git a/inference/__init__.py b/inference/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/data/__init__.py b/inference/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/data/mask_mapper.py b/inference/data/mask_mapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..686466c59cf21ea319f1ee933d7c67d1b63b7b74
--- /dev/null
+++ b/inference/data/mask_mapper.py
@@ -0,0 +1,67 @@
+import numpy as np
+import torch
+
+from dataset.util import all_to_onehot
+
+
+class MaskMapper:
+ """
+ This class is used to convert a indexed-mask to a one-hot representation.
+ It also takes care of remapping non-continuous indices
+ It has two modes:
+ 1. Default. Only masks with new indices are supposed to go into the remapper.
+ This is also the case for YouTubeVOS.
+ i.e., regions with index 0 are not "background", but "don't care".
+
+ 2. Exhaustive. Regions with index 0 are considered "background".
+ Every single pixel is considered to be "labeled".
+ """
+ def __init__(self):
+ self.labels = []
+ self.remappings = {}
+
+ # if coherent, no mapping is required
+ self.coherent = True
+
+ def convert_mask(self, mask, exhaustive=False):
+ # mask is in index representation, H*W numpy array
+ labels = np.unique(mask).astype(np.uint8)
+ labels = labels[labels!=0].tolist()
+
+ new_labels = list(set(labels) - set(self.labels))
+ # print('new_labels', new_labels) # [255]
+ if not exhaustive:
+ assert len(new_labels) == len(labels), 'Old labels found in non-exhaustive mode'
+
+ # add new remappings
+ for i, l in enumerate(new_labels):
+ self.remappings[l] = i+len(self.labels)+1
+ if self.coherent and i+len(self.labels)+1 != l:
+ self.coherent = False
+
+ if exhaustive:
+ new_mapped_labels = range(1, len(self.labels)+len(new_labels)+1)
+ else:
+ if self.coherent:
+ new_mapped_labels = new_labels
+ else:
+ new_mapped_labels = range(len(self.labels)+1, len(self.labels)+len(new_labels)+1)
+ # print(list(new_mapped_labels));assert 1==0 # [1]
+
+ self.labels.extend(new_labels)
+ # print(self.labels);assert 1==0 # [255]
+ mask = torch.from_numpy(all_to_onehot(mask, self.labels)).float()
+
+ # mask num_objects*H*W; new_mapped_labels: [num_objects]
+ return mask, new_mapped_labels
+
+
+ def remap_index_mask(self, mask):
+ # mask is in index representation, H*W numpy array
+ if self.coherent:
+ return mask
+
+ new_mask = np.zeros_like(mask)
+ for l, i in self.remappings.items():
+ new_mask[mask==i] = l
+ return new_mask
\ No newline at end of file
diff --git a/inference/data/test_datasets.py b/inference/data/test_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..231852a338cabbc2102f44d89e780846ce5dc367
--- /dev/null
+++ b/inference/data/test_datasets.py
@@ -0,0 +1,29 @@
+import os
+from os import path
+import json
+
+from inference.data.video_reader import VideoReader_221128_TransColorization
+
+class DAVISTestDataset_221128_TransColorization_batch:
+ def __init__(self, data_root, imset='2017/val.txt', size=-1):
+ self.image_dir = data_root
+ self.mask_dir = imset
+ self.size_dir = data_root
+ self.size = size
+
+ self.vid_list = [clip_name for clip_name in sorted(os.listdir(data_root)) if clip_name != '.DS_Store']
+
+ # print(lst, len(lst), self.vid_list, self.vid_list_DAVIS2016, path.join(data_root, 'ImageSets', imset));assert 1==0
+
+ def get_datasets(self):
+ for video in self.vid_list:
+ # print(self.image_dir, video, path.join(self.image_dir, video));assert 1==0
+ yield VideoReader_221128_TransColorization(video,
+ path.join(self.image_dir, video),
+ path.join(self.mask_dir, video),
+ size=self.size,
+ size_dir=path.join(self.size_dir, video),
+ )
+
+ def __len__(self):
+ return len(self.vid_list)
diff --git a/inference/data/video_reader.py b/inference/data/video_reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..c6e05950761a9218a530e67ee4546dc2e22f4b60
--- /dev/null
+++ b/inference/data/video_reader.py
@@ -0,0 +1,107 @@
+import os
+from os import path
+
+from torch.utils.data.dataset import Dataset
+from torchvision import transforms
+from torchvision.transforms import InterpolationMode
+import torch.nn.functional as Ff
+from PIL import Image
+import numpy as np
+
+from dataset.range_transform import im_normalization, im_rgb2lab_normalization, ToTensor, RGB2Lab
+
+class VideoReader_221128_TransColorization(Dataset):
+ """
+ This class is used to read a video, one frame at a time
+ """
+ def __init__(self, vid_name, image_dir, mask_dir, size=-1, to_save=None, use_all_mask=False, size_dir=None):
+ """
+ image_dir - points to a directory of jpg images
+ mask_dir - points to a directory of png masks
+ size - resize min. side to size. Does nothing if <0.
+ to_save - optionally contains a list of file names without extensions
+ where the segmentation mask is required
+ use_all_mask - when true, read all available mask in mask_dir.
+ Default false. Set to true for YouTubeVOS validation.
+ """
+ self.vid_name = vid_name
+ self.image_dir = image_dir
+ self.mask_dir = mask_dir
+ self.to_save = to_save
+ self.use_all_mask = use_all_mask
+ # print('use_all_mask', use_all_mask);assert 1==0
+ if size_dir is None:
+ self.size_dir = self.image_dir
+ else:
+ self.size_dir = size_dir
+
+ self.frames = [img for img in sorted(os.listdir(self.image_dir)) if img.endswith('.jpg') or img.endswith('.png')]
+ self.palette = Image.open(path.join(mask_dir, sorted(os.listdir(mask_dir))[0])).getpalette()
+ self.first_gt_path = path.join(self.mask_dir, sorted(os.listdir(self.mask_dir))[0])
+ self.suffix = self.first_gt_path.split('.')[-1]
+
+ if size < 0:
+ self.im_transform = transforms.Compose([
+ RGB2Lab(),
+ ToTensor(),
+ im_rgb2lab_normalization,
+ ])
+ else:
+ self.im_transform = transforms.Compose([
+ transforms.ToTensor(),
+ im_normalization,
+ transforms.Resize(size, interpolation=InterpolationMode.BILINEAR),
+ ])
+ self.size = size
+
+
+ def __getitem__(self, idx):
+ frame = self.frames[idx]
+ info = {}
+ data = {}
+ info['frame'] = frame
+ info['vid_name'] = self.vid_name
+ info['save'] = (self.to_save is None) or (frame[:-4] in self.to_save)
+
+ im_path = path.join(self.image_dir, frame)
+ img = Image.open(im_path).convert('RGB')
+
+ if self.image_dir == self.size_dir:
+ shape = np.array(img).shape[:2]
+ else:
+ size_path = path.join(self.size_dir, frame)
+ size_im = Image.open(size_path).convert('RGB')
+ shape = np.array(size_im).shape[:2]
+
+ gt_path = path.join(self.mask_dir, sorted(os.listdir(self.mask_dir))[idx]) if idx < len(os.listdir(self.mask_dir)) else None
+
+ img = self.im_transform(img)
+ img_l = img[:1,:,:]
+ img_lll = img_l.repeat(3,1,1)
+
+ load_mask = self.use_all_mask or (gt_path == self.first_gt_path)
+ if load_mask and path.exists(gt_path):
+ mask = Image.open(gt_path).convert('RGB')
+ mask = self.im_transform(mask)
+ mask_ab = mask[1:3,:,:]
+ data['mask'] = mask_ab
+
+ info['shape'] = shape
+ info['need_resize'] = not (self.size < 0)
+ data['rgb'] = img_lll
+ data['info'] = info
+
+ return data
+
+ def resize_mask(self, mask):
+ # mask transform is applied AFTER mapper, so we need to post-process it in eval.py
+ h, w = mask.shape[-2:]
+ min_hw = min(h, w)
+ return Ff.interpolate(mask, (int(h/min_hw*self.size), int(w/min_hw*self.size)),
+ mode='nearest')
+
+ def get_palette(self):
+ return self.palette
+
+ def __len__(self):
+ return len(self.frames)
diff --git a/inference/inference_core.py b/inference/inference_core.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0323f90ec28860afc3f67bade617a3691d04f87
--- /dev/null
+++ b/inference/inference_core.py
@@ -0,0 +1,111 @@
+from inference.memory_manager import MemoryManager
+from model.network import ColorMNet
+from model.aggregate import aggregate
+
+from util.tensor_util import pad_divide_by, unpad
+import torch
+
+class InferenceCore:
+ def __init__(self, network:ColorMNet, config):
+ self.config = config
+ self.network = network
+ self.mem_every = config['mem_every']
+ self.deep_update_every = config['deep_update_every']
+ self.enable_long_term = config['enable_long_term']
+
+ # if deep_update_every < 0, synchronize deep update with memory frame
+ self.deep_update_sync = (self.deep_update_every < 0)
+
+ self.clear_memory()
+ self.all_labels = None
+
+ self.last_ti_key = None
+ self.last_ti_value = None
+
+ def clear_memory(self):
+ self.curr_ti = -1
+ self.last_mem_ti = 0
+ if not self.deep_update_sync:
+ self.last_deep_update_ti = -self.deep_update_every
+ self.memory = MemoryManager(config=self.config)
+
+ def update_config(self, config):
+ self.mem_every = config['mem_every']
+ self.deep_update_every = config['deep_update_every']
+ self.enable_long_term = config['enable_long_term']
+
+ # if deep_update_every < 0, synchronize deep update with memory frame
+ self.deep_update_sync = (self.deep_update_every < 0)
+ self.memory.update_config(config)
+
+ def set_all_labels(self, all_labels):
+ # self.all_labels = [l.item() for l in all_labels]
+ self.all_labels = all_labels
+
+ def step(self, image, mask=None, valid_labels=None, end=False):
+ # image: 3*H*W
+ # mask: num_objects*H*W or None
+ self.curr_ti += 1
+ divide_by = 112 # 16
+ image, self.pad = pad_divide_by(image, divide_by)
+ image = image.unsqueeze(0) # add the batch dimension
+
+ is_mem_frame = ((self.curr_ti-self.last_mem_ti >= self.mem_every) or (mask is not None)) and (not end)
+ need_segment = (self.curr_ti > 0) and ((valid_labels is None) or (len(self.all_labels) != len(valid_labels)))
+ is_deep_update = (
+ (self.deep_update_sync and is_mem_frame) or # synchronized
+ (not self.deep_update_sync and self.curr_ti-self.last_deep_update_ti >= self.deep_update_every) # no-sync
+ ) and (not end)
+ is_normal_update = (not self.deep_update_sync or not is_deep_update) and (not end)
+
+ key, shrinkage, selection, f16, f8, f4 = self.network.encode_key(image,
+ need_ek=(self.enable_long_term or need_segment),
+ need_sk=is_mem_frame)
+ multi_scale_features = (f16, f8, f4)
+
+ # segment the current frame is needed
+ if need_segment:
+ memory_readout = self.memory.match_memory(key, selection).unsqueeze(0)
+
+ # short term memory
+ batch, num_objects, value_dim, h, w = self.last_ti_value.shape
+ last_ti_value = self.last_ti_value.flatten(start_dim=1, end_dim=2)
+ memory_value_short, _ = self.network.short_term_attn(key, self.last_ti_key, last_ti_value, None, key.shape[-2:])
+ memory_value_short = memory_value_short.permute(1, 2, 0).view(batch, num_objects, value_dim, h, w)
+ memory_readout += memory_value_short
+
+ hidden, _, pred_prob_with_bg = self.network.segment(multi_scale_features, memory_readout,
+ self.memory.get_hidden(), h_out=is_normal_update, strip_bg=False)
+ # remove batch dim
+ pred_prob_with_bg = pred_prob_with_bg[0]
+ pred_prob_no_bg = pred_prob_with_bg
+ if is_normal_update:
+ self.memory.set_hidden(hidden)
+ else:
+ pred_prob_no_bg = pred_prob_with_bg = None
+
+ # use the input mask if any
+ if mask is not None:
+ mask, _ = pad_divide_by(mask, divide_by)
+
+ pred_prob_with_bg = mask
+
+ self.memory.create_hidden_state(2, key)
+
+ # save as memory if needed
+ if is_mem_frame:
+ value, hidden = self.network.encode_value(image, f16, self.memory.get_hidden(),
+ pred_prob_with_bg.unsqueeze(0), is_deep_update=is_deep_update)
+
+ self.memory.add_memory(key, shrinkage, value, self.all_labels,
+ selection=selection if self.enable_long_term else None)
+ self.last_mem_ti = self.curr_ti
+
+ self.last_ti_key = key
+ self.last_ti_value = value
+
+ if is_deep_update:
+ self.memory.set_hidden(hidden)
+ self.last_deep_update_ti = self.curr_ti
+
+ return unpad(pred_prob_with_bg, self.pad)
diff --git a/inference/interact/__init__.py b/inference/interact/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/LICENSE b/inference/interact/fbrs/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..fa0086a952236971ab37901954d596efae9f4af6
--- /dev/null
+++ b/inference/interact/fbrs/LICENSE
@@ -0,0 +1,373 @@
+Mozilla Public License Version 2.0
+==================================
+
+1. Definitions
+--------------
+
+1.1. "Contributor"
+ means each individual or legal entity that creates, contributes to
+ the creation of, or owns Covered Software.
+
+1.2. "Contributor Version"
+ means the combination of the Contributions of others (if any) used
+ by a Contributor and that particular Contributor's Contribution.
+
+1.3. "Contribution"
+ means Covered Software of a particular Contributor.
+
+1.4. "Covered Software"
+ means Source Code Form to which the initial Contributor has attached
+ the notice in Exhibit A, the Executable Form of such Source Code
+ Form, and Modifications of such Source Code Form, in each case
+ including portions thereof.
+
+1.5. "Incompatible With Secondary Licenses"
+ means
+
+ (a) that the initial Contributor has attached the notice described
+ in Exhibit B to the Covered Software; or
+
+ (b) that the Covered Software was made available under the terms of
+ version 1.1 or earlier of the License, but not also under the
+ terms of a Secondary License.
+
+1.6. "Executable Form"
+ means any form of the work other than Source Code Form.
+
+1.7. "Larger Work"
+ means a work that combines Covered Software with other material, in
+ a separate file or files, that is not Covered Software.
+
+1.8. "License"
+ means this document.
+
+1.9. "Licensable"
+ means having the right to grant, to the maximum extent possible,
+ whether at the time of the initial grant or subsequently, any and
+ all of the rights conveyed by this License.
+
+1.10. "Modifications"
+ means any of the following:
+
+ (a) any file in Source Code Form that results from an addition to,
+ deletion from, or modification of the contents of Covered
+ Software; or
+
+ (b) any new file in Source Code Form that contains any Covered
+ Software.
+
+1.11. "Patent Claims" of a Contributor
+ means any patent claim(s), including without limitation, method,
+ process, and apparatus claims, in any patent Licensable by such
+ Contributor that would be infringed, but for the grant of the
+ License, by the making, using, selling, offering for sale, having
+ made, import, or transfer of either its Contributions or its
+ Contributor Version.
+
+1.12. "Secondary License"
+ means either the GNU General Public License, Version 2.0, the GNU
+ Lesser General Public License, Version 2.1, the GNU Affero General
+ Public License, Version 3.0, or any later versions of those
+ licenses.
+
+1.13. "Source Code Form"
+ means the form of the work preferred for making modifications.
+
+1.14. "You" (or "Your")
+ means an individual or a legal entity exercising rights under this
+ License. For legal entities, "You" includes any entity that
+ controls, is controlled by, or is under common control with You. For
+ purposes of this definition, "control" means (a) the power, direct
+ or indirect, to cause the direction or management of such entity,
+ whether by contract or otherwise, or (b) ownership of more than
+ fifty percent (50%) of the outstanding shares or beneficial
+ ownership of such entity.
+
+2. License Grants and Conditions
+--------------------------------
+
+2.1. Grants
+
+Each Contributor hereby grants You a world-wide, royalty-free,
+non-exclusive license:
+
+(a) under intellectual property rights (other than patent or trademark)
+ Licensable by such Contributor to use, reproduce, make available,
+ modify, display, perform, distribute, and otherwise exploit its
+ Contributions, either on an unmodified basis, with Modifications, or
+ as part of a Larger Work; and
+
+(b) under Patent Claims of such Contributor to make, use, sell, offer
+ for sale, have made, import, and otherwise transfer either its
+ Contributions or its Contributor Version.
+
+2.2. Effective Date
+
+The licenses granted in Section 2.1 with respect to any Contribution
+become effective for each Contribution on the date the Contributor first
+distributes such Contribution.
+
+2.3. Limitations on Grant Scope
+
+The licenses granted in this Section 2 are the only rights granted under
+this License. No additional rights or licenses will be implied from the
+distribution or licensing of Covered Software under this License.
+Notwithstanding Section 2.1(b) above, no patent license is granted by a
+Contributor:
+
+(a) for any code that a Contributor has removed from Covered Software;
+ or
+
+(b) for infringements caused by: (i) Your and any other third party's
+ modifications of Covered Software, or (ii) the combination of its
+ Contributions with other software (except as part of its Contributor
+ Version); or
+
+(c) under Patent Claims infringed by Covered Software in the absence of
+ its Contributions.
+
+This License does not grant any rights in the trademarks, service marks,
+or logos of any Contributor (except as may be necessary to comply with
+the notice requirements in Section 3.4).
+
+2.4. Subsequent Licenses
+
+No Contributor makes additional grants as a result of Your choice to
+distribute the Covered Software under a subsequent version of this
+License (see Section 10.2) or under the terms of a Secondary License (if
+permitted under the terms of Section 3.3).
+
+2.5. Representation
+
+Each Contributor represents that the Contributor believes its
+Contributions are its original creation(s) or it has sufficient rights
+to grant the rights to its Contributions conveyed by this License.
+
+2.6. Fair Use
+
+This License is not intended to limit any rights You have under
+applicable copyright doctrines of fair use, fair dealing, or other
+equivalents.
+
+2.7. Conditions
+
+Sections 3.1, 3.2, 3.3, and 3.4 are conditions of the licenses granted
+in Section 2.1.
+
+3. Responsibilities
+-------------------
+
+3.1. Distribution of Source Form
+
+All distribution of Covered Software in Source Code Form, including any
+Modifications that You create or to which You contribute, must be under
+the terms of this License. You must inform recipients that the Source
+Code Form of the Covered Software is governed by the terms of this
+License, and how they can obtain a copy of this License. You may not
+attempt to alter or restrict the recipients' rights in the Source Code
+Form.
+
+3.2. Distribution of Executable Form
+
+If You distribute Covered Software in Executable Form then:
+
+(a) such Covered Software must also be made available in Source Code
+ Form, as described in Section 3.1, and You must inform recipients of
+ the Executable Form how they can obtain a copy of such Source Code
+ Form by reasonable means in a timely manner, at a charge no more
+ than the cost of distribution to the recipient; and
+
+(b) You may distribute such Executable Form under the terms of this
+ License, or sublicense it under different terms, provided that the
+ license for the Executable Form does not attempt to limit or alter
+ the recipients' rights in the Source Code Form under this License.
+
+3.3. Distribution of a Larger Work
+
+You may create and distribute a Larger Work under terms of Your choice,
+provided that You also comply with the requirements of this License for
+the Covered Software. If the Larger Work is a combination of Covered
+Software with a work governed by one or more Secondary Licenses, and the
+Covered Software is not Incompatible With Secondary Licenses, this
+License permits You to additionally distribute such Covered Software
+under the terms of such Secondary License(s), so that the recipient of
+the Larger Work may, at their option, further distribute the Covered
+Software under the terms of either this License or such Secondary
+License(s).
+
+3.4. Notices
+
+You may not remove or alter the substance of any license notices
+(including copyright notices, patent notices, disclaimers of warranty,
+or limitations of liability) contained within the Source Code Form of
+the Covered Software, except that You may alter any license notices to
+the extent required to remedy known factual inaccuracies.
+
+3.5. Application of Additional Terms
+
+You may choose to offer, and to charge a fee for, warranty, support,
+indemnity or liability obligations to one or more recipients of Covered
+Software. However, You may do so only on Your own behalf, and not on
+behalf of any Contributor. You must make it absolutely clear that any
+such warranty, support, indemnity, or liability obligation is offered by
+You alone, and You hereby agree to indemnify every Contributor for any
+liability incurred by such Contributor as a result of warranty, support,
+indemnity or liability terms You offer. You may include additional
+disclaimers of warranty and limitations of liability specific to any
+jurisdiction.
+
+4. Inability to Comply Due to Statute or Regulation
+---------------------------------------------------
+
+If it is impossible for You to comply with any of the terms of this
+License with respect to some or all of the Covered Software due to
+statute, judicial order, or regulation then You must: (a) comply with
+the terms of this License to the maximum extent possible; and (b)
+describe the limitations and the code they affect. Such description must
+be placed in a text file included with all distributions of the Covered
+Software under this License. Except to the extent prohibited by statute
+or regulation, such description must be sufficiently detailed for a
+recipient of ordinary skill to be able to understand it.
+
+5. Termination
+--------------
+
+5.1. The rights granted under this License will terminate automatically
+if You fail to comply with any of its terms. However, if You become
+compliant, then the rights granted under this License from a particular
+Contributor are reinstated (a) provisionally, unless and until such
+Contributor explicitly and finally terminates Your grants, and (b) on an
+ongoing basis, if such Contributor fails to notify You of the
+non-compliance by some reasonable means prior to 60 days after You have
+come back into compliance. Moreover, Your grants from a particular
+Contributor are reinstated on an ongoing basis if such Contributor
+notifies You of the non-compliance by some reasonable means, this is the
+first time You have received notice of non-compliance with this License
+from such Contributor, and You become compliant prior to 30 days after
+Your receipt of the notice.
+
+5.2. If You initiate litigation against any entity by asserting a patent
+infringement claim (excluding declaratory judgment actions,
+counter-claims, and cross-claims) alleging that a Contributor Version
+directly or indirectly infringes any patent, then the rights granted to
+You by any and all Contributors for the Covered Software under Section
+2.1 of this License shall terminate.
+
+5.3. In the event of termination under Sections 5.1 or 5.2 above, all
+end user license agreements (excluding distributors and resellers) which
+have been validly granted by You or Your distributors under this License
+prior to termination shall survive termination.
+
+************************************************************************
+* *
+* 6. Disclaimer of Warranty *
+* ------------------------- *
+* *
+* Covered Software is provided under this License on an "as is" *
+* basis, without warranty of any kind, either expressed, implied, or *
+* statutory, including, without limitation, warranties that the *
+* Covered Software is free of defects, merchantable, fit for a *
+* particular purpose or non-infringing. The entire risk as to the *
+* quality and performance of the Covered Software is with You. *
+* Should any Covered Software prove defective in any respect, You *
+* (not any Contributor) assume the cost of any necessary servicing, *
+* repair, or correction. This disclaimer of warranty constitutes an *
+* essential part of this License. No use of any Covered Software is *
+* authorized under this License except under this disclaimer. *
+* *
+************************************************************************
+
+************************************************************************
+* *
+* 7. Limitation of Liability *
+* -------------------------- *
+* *
+* Under no circumstances and under no legal theory, whether tort *
+* (including negligence), contract, or otherwise, shall any *
+* Contributor, or anyone who distributes Covered Software as *
+* permitted above, be liable to You for any direct, indirect, *
+* special, incidental, or consequential damages of any character *
+* including, without limitation, damages for lost profits, loss of *
+* goodwill, work stoppage, computer failure or malfunction, or any *
+* and all other commercial damages or losses, even if such party *
+* shall have been informed of the possibility of such damages. This *
+* limitation of liability shall not apply to liability for death or *
+* personal injury resulting from such party's negligence to the *
+* extent applicable law prohibits such limitation. Some *
+* jurisdictions do not allow the exclusion or limitation of *
+* incidental or consequential damages, so this exclusion and *
+* limitation may not apply to You. *
+* *
+************************************************************************
+
+8. Litigation
+-------------
+
+Any litigation relating to this License may be brought only in the
+courts of a jurisdiction where the defendant maintains its principal
+place of business and such litigation shall be governed by laws of that
+jurisdiction, without reference to its conflict-of-law provisions.
+Nothing in this Section shall prevent a party's ability to bring
+cross-claims or counter-claims.
+
+9. Miscellaneous
+----------------
+
+This License represents the complete agreement concerning the subject
+matter hereof. If any provision of this License is held to be
+unenforceable, such provision shall be reformed only to the extent
+necessary to make it enforceable. Any law or regulation which provides
+that the language of a contract shall be construed against the drafter
+shall not be used to construe this License against a Contributor.
+
+10. Versions of the License
+---------------------------
+
+10.1. New Versions
+
+Mozilla Foundation is the license steward. Except as provided in Section
+10.3, no one other than the license steward has the right to modify or
+publish new versions of this License. Each version will be given a
+distinguishing version number.
+
+10.2. Effect of New Versions
+
+You may distribute the Covered Software under the terms of the version
+of the License under which You originally received the Covered Software,
+or under the terms of any subsequent version published by the license
+steward.
+
+10.3. Modified Versions
+
+If you create software not governed by this License, and you want to
+create a new license for such software, you may create and use a
+modified version of this License if you rename the license and remove
+any references to the name of the license steward (except to note that
+such modified license differs from this License).
+
+10.4. Distributing Source Code Form that is Incompatible With Secondary
+Licenses
+
+If You choose to distribute Source Code Form that is Incompatible With
+Secondary Licenses under the terms of this version of the License, the
+notice described in Exhibit B of this License must be attached.
+
+Exhibit A - Source Code Form License Notice
+-------------------------------------------
+
+ This Source Code Form is subject to the terms of the Mozilla Public
+ License, v. 2.0. If a copy of the MPL was not distributed with this
+ file, You can obtain one at http://mozilla.org/MPL/2.0/.
+
+If it is not possible or desirable to put the notice in a particular
+file, then You may include the notice in a location (such as a LICENSE
+file in a relevant directory) where a recipient would be likely to look
+for such a notice.
+
+You may add additional accurate notices of copyright ownership.
+
+Exhibit B - "Incompatible With Secondary Licenses" Notice
+---------------------------------------------------------
+
+ This Source Code Form is "Incompatible With Secondary Licenses", as
+ defined by the Mozilla Public License, v. 2.0.
\ No newline at end of file
diff --git a/inference/interact/fbrs/__init__.py b/inference/interact/fbrs/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/controller.py b/inference/interact/fbrs/controller.py
new file mode 100644
index 0000000000000000000000000000000000000000..57a0a9b7fec9a7bc9d0b6bc605b268b662fef77b
--- /dev/null
+++ b/inference/interact/fbrs/controller.py
@@ -0,0 +1,103 @@
+import torch
+
+from ..fbrs.inference import clicker
+from ..fbrs.inference.predictors import get_predictor
+
+
+class InteractiveController:
+ def __init__(self, net, device, predictor_params, prob_thresh=0.5):
+ self.net = net.to(device)
+ self.prob_thresh = prob_thresh
+ self.clicker = clicker.Clicker()
+ self.states = []
+ self.probs_history = []
+ self.object_count = 0
+ self._result_mask = None
+
+ self.image = None
+ self.predictor = None
+ self.device = device
+ self.predictor_params = predictor_params
+ self.reset_predictor()
+
+ def set_image(self, image):
+ self.image = image
+ self._result_mask = torch.zeros(image.shape[-2:], dtype=torch.uint8)
+ self.object_count = 0
+ self.reset_last_object()
+
+ def add_click(self, x, y, is_positive):
+ self.states.append({
+ 'clicker': self.clicker.get_state(),
+ 'predictor': self.predictor.get_states()
+ })
+
+ click = clicker.Click(is_positive=is_positive, coords=(y, x))
+ self.clicker.add_click(click)
+ pred = self.predictor.get_prediction(self.clicker)
+ torch.cuda.empty_cache()
+
+ if self.probs_history:
+ self.probs_history.append((self.probs_history[-1][0], pred))
+ else:
+ self.probs_history.append((torch.zeros_like(pred), pred))
+
+ def undo_click(self):
+ if not self.states:
+ return
+
+ prev_state = self.states.pop()
+ self.clicker.set_state(prev_state['clicker'])
+ self.predictor.set_states(prev_state['predictor'])
+ self.probs_history.pop()
+
+ def partially_finish_object(self):
+ object_prob = self.current_object_prob
+ if object_prob is None:
+ return
+
+ self.probs_history.append((object_prob, torch.zeros_like(object_prob)))
+ self.states.append(self.states[-1])
+
+ self.clicker.reset_clicks()
+ self.reset_predictor()
+
+ def finish_object(self):
+ object_prob = self.current_object_prob
+ if object_prob is None:
+ return
+
+ self.object_count += 1
+ object_mask = object_prob > self.prob_thresh
+ self._result_mask[object_mask] = self.object_count
+ self.reset_last_object()
+
+ def reset_last_object(self):
+ self.states = []
+ self.probs_history = []
+ self.clicker.reset_clicks()
+ self.reset_predictor()
+
+ def reset_predictor(self, predictor_params=None):
+ if predictor_params is not None:
+ self.predictor_params = predictor_params
+ self.predictor = get_predictor(self.net, device=self.device,
+ **self.predictor_params)
+ if self.image is not None:
+ self.predictor.set_input_image(self.image)
+
+ @property
+ def current_object_prob(self):
+ if self.probs_history:
+ current_prob_total, current_prob_additive = self.probs_history[-1]
+ return torch.maximum(current_prob_total, current_prob_additive)
+ else:
+ return None
+
+ @property
+ def is_incomplete_mask(self):
+ return len(self.probs_history) > 0
+
+ @property
+ def result_mask(self):
+ return self._result_mask.clone()
diff --git a/inference/interact/fbrs/inference/__init__.py b/inference/interact/fbrs/inference/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/inference/clicker.py b/inference/interact/fbrs/inference/clicker.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1ea9cf319f88639fa0af45088cdf79c8954f83a
--- /dev/null
+++ b/inference/interact/fbrs/inference/clicker.py
@@ -0,0 +1,103 @@
+from collections import namedtuple
+
+import numpy as np
+from copy import deepcopy
+from scipy.ndimage import distance_transform_edt
+
+Click = namedtuple('Click', ['is_positive', 'coords'])
+
+
+class Clicker(object):
+ def __init__(self, gt_mask=None, init_clicks=None, ignore_label=-1):
+ if gt_mask is not None:
+ self.gt_mask = gt_mask == 1
+ self.not_ignore_mask = gt_mask != ignore_label
+ else:
+ self.gt_mask = None
+
+ self.reset_clicks()
+
+ if init_clicks is not None:
+ for click in init_clicks:
+ self.add_click(click)
+
+ def make_next_click(self, pred_mask):
+ assert self.gt_mask is not None
+ click = self._get_click(pred_mask)
+ self.add_click(click)
+
+ def get_clicks(self, clicks_limit=None):
+ return self.clicks_list[:clicks_limit]
+
+ def _get_click(self, pred_mask, padding=True):
+ fn_mask = np.logical_and(np.logical_and(self.gt_mask, np.logical_not(pred_mask)), self.not_ignore_mask)
+ fp_mask = np.logical_and(np.logical_and(np.logical_not(self.gt_mask), pred_mask), self.not_ignore_mask)
+
+ if padding:
+ fn_mask = np.pad(fn_mask, ((1, 1), (1, 1)), 'constant')
+ fp_mask = np.pad(fp_mask, ((1, 1), (1, 1)), 'constant')
+
+ fn_mask_dt = distance_transform_edt(fn_mask)
+ fp_mask_dt = distance_transform_edt(fp_mask)
+
+ if padding:
+ fn_mask_dt = fn_mask_dt[1:-1, 1:-1]
+ fp_mask_dt = fp_mask_dt[1:-1, 1:-1]
+
+ fn_mask_dt = fn_mask_dt * self.not_clicked_map
+ fp_mask_dt = fp_mask_dt * self.not_clicked_map
+
+ fn_max_dist = np.max(fn_mask_dt)
+ fp_max_dist = np.max(fp_mask_dt)
+
+ is_positive = fn_max_dist > fp_max_dist
+ if is_positive:
+ coords_y, coords_x = np.where(fn_mask_dt == fn_max_dist) # coords is [y, x]
+ else:
+ coords_y, coords_x = np.where(fp_mask_dt == fp_max_dist) # coords is [y, x]
+
+ return Click(is_positive=is_positive, coords=(coords_y[0], coords_x[0]))
+
+ def add_click(self, click):
+ coords = click.coords
+
+ if click.is_positive:
+ self.num_pos_clicks += 1
+ else:
+ self.num_neg_clicks += 1
+
+ self.clicks_list.append(click)
+ if self.gt_mask is not None:
+ self.not_clicked_map[coords[0], coords[1]] = False
+
+ def _remove_last_click(self):
+ click = self.clicks_list.pop()
+ coords = click.coords
+
+ if click.is_positive:
+ self.num_pos_clicks -= 1
+ else:
+ self.num_neg_clicks -= 1
+
+ if self.gt_mask is not None:
+ self.not_clicked_map[coords[0], coords[1]] = True
+
+ def reset_clicks(self):
+ if self.gt_mask is not None:
+ self.not_clicked_map = np.ones_like(self.gt_mask, dtype=np.bool)
+
+ self.num_pos_clicks = 0
+ self.num_neg_clicks = 0
+
+ self.clicks_list = []
+
+ def get_state(self):
+ return deepcopy(self.clicks_list)
+
+ def set_state(self, state):
+ self.reset_clicks()
+ for click in state:
+ self.add_click(click)
+
+ def __len__(self):
+ return len(self.clicks_list)
diff --git a/inference/interact/fbrs/inference/evaluation.py b/inference/interact/fbrs/inference/evaluation.py
new file mode 100644
index 0000000000000000000000000000000000000000..6be3ed813eb257309f433ece0035e0890a82207e
--- /dev/null
+++ b/inference/interact/fbrs/inference/evaluation.py
@@ -0,0 +1,56 @@
+from time import time
+
+import numpy as np
+import torch
+
+from ..inference import utils
+from ..inference.clicker import Clicker
+
+try:
+ get_ipython()
+ from tqdm import tqdm_notebook as tqdm
+except NameError:
+ from tqdm import tqdm
+
+
+def evaluate_dataset(dataset, predictor, oracle_eval=False, **kwargs):
+ all_ious = []
+
+ start_time = time()
+ for index in tqdm(range(len(dataset)), leave=False):
+ sample = dataset.get_sample(index)
+ item = dataset[index]
+
+ if oracle_eval:
+ gt_mask = torch.tensor(sample['instances_mask'], dtype=torch.float32)
+ gt_mask = gt_mask.unsqueeze(0).unsqueeze(0)
+ predictor.opt_functor.mask_loss.set_gt_mask(gt_mask)
+ _, sample_ious, _ = evaluate_sample(item['images'], sample['instances_mask'], predictor, **kwargs)
+ all_ious.append(sample_ious)
+ end_time = time()
+ elapsed_time = end_time - start_time
+
+ return all_ious, elapsed_time
+
+
+def evaluate_sample(image_nd, instances_mask, predictor, max_iou_thr,
+ pred_thr=0.49, max_clicks=20):
+ clicker = Clicker(gt_mask=instances_mask)
+ pred_mask = np.zeros_like(instances_mask)
+ ious_list = []
+
+ with torch.no_grad():
+ predictor.set_input_image(image_nd)
+
+ for click_number in range(max_clicks):
+ clicker.make_next_click(pred_mask)
+ pred_probs = predictor.get_prediction(clicker)
+ pred_mask = pred_probs > pred_thr
+
+ iou = utils.get_iou(instances_mask, pred_mask)
+ ious_list.append(iou)
+
+ if iou >= max_iou_thr:
+ break
+
+ return clicker.clicks_list, np.array(ious_list, dtype=np.float32), pred_probs
diff --git a/inference/interact/fbrs/inference/predictors/__init__.py b/inference/interact/fbrs/inference/predictors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..04b8b8618cd33efabdaec69328de2f5a8a58d2f9
--- /dev/null
+++ b/inference/interact/fbrs/inference/predictors/__init__.py
@@ -0,0 +1,95 @@
+from .base import BasePredictor
+from .brs import InputBRSPredictor, FeatureBRSPredictor, HRNetFeatureBRSPredictor
+from .brs_functors import InputOptimizer, ScaleBiasOptimizer
+from ..transforms import ZoomIn
+from ...model.is_hrnet_model import DistMapsHRNetModel
+
+
+def get_predictor(net, brs_mode, device,
+ prob_thresh=0.49,
+ with_flip=True,
+ zoom_in_params=dict(),
+ predictor_params=None,
+ brs_opt_func_params=None,
+ lbfgs_params=None):
+ lbfgs_params_ = {
+ 'm': 20,
+ 'factr': 0,
+ 'pgtol': 1e-8,
+ 'maxfun': 20,
+ }
+
+ predictor_params_ = {
+ 'optimize_after_n_clicks': 1
+ }
+
+ if zoom_in_params is not None:
+ zoom_in = ZoomIn(**zoom_in_params)
+ else:
+ zoom_in = None
+
+ if lbfgs_params is not None:
+ lbfgs_params_.update(lbfgs_params)
+ lbfgs_params_['maxiter'] = 2 * lbfgs_params_['maxfun']
+
+ if brs_opt_func_params is None:
+ brs_opt_func_params = dict()
+
+ if brs_mode == 'NoBRS':
+ if predictor_params is not None:
+ predictor_params_.update(predictor_params)
+ predictor = BasePredictor(net, device, zoom_in=zoom_in, with_flip=with_flip, **predictor_params_)
+ elif brs_mode.startswith('f-BRS'):
+ predictor_params_.update({
+ 'net_clicks_limit': 8,
+ })
+ if predictor_params is not None:
+ predictor_params_.update(predictor_params)
+
+ insertion_mode = {
+ 'f-BRS-A': 'after_c4',
+ 'f-BRS-B': 'after_aspp',
+ 'f-BRS-C': 'after_deeplab'
+ }[brs_mode]
+
+ opt_functor = ScaleBiasOptimizer(prob_thresh=prob_thresh,
+ with_flip=with_flip,
+ optimizer_params=lbfgs_params_,
+ **brs_opt_func_params)
+
+ if isinstance(net, DistMapsHRNetModel):
+ FeaturePredictor = HRNetFeatureBRSPredictor
+ insertion_mode = {'after_c4': 'A', 'after_aspp': 'A', 'after_deeplab': 'C'}[insertion_mode]
+ else:
+ FeaturePredictor = FeatureBRSPredictor
+
+ predictor = FeaturePredictor(net, device,
+ opt_functor=opt_functor,
+ with_flip=with_flip,
+ insertion_mode=insertion_mode,
+ zoom_in=zoom_in,
+ **predictor_params_)
+ elif brs_mode == 'RGB-BRS' or brs_mode == 'DistMap-BRS':
+ use_dmaps = brs_mode == 'DistMap-BRS'
+
+ predictor_params_.update({
+ 'net_clicks_limit': 5,
+ })
+ if predictor_params is not None:
+ predictor_params_.update(predictor_params)
+
+ opt_functor = InputOptimizer(prob_thresh=prob_thresh,
+ with_flip=with_flip,
+ optimizer_params=lbfgs_params_,
+ **brs_opt_func_params)
+
+ predictor = InputBRSPredictor(net, device,
+ optimize_target='dmaps' if use_dmaps else 'rgb',
+ opt_functor=opt_functor,
+ with_flip=with_flip,
+ zoom_in=zoom_in,
+ **predictor_params_)
+ else:
+ raise NotImplementedError
+
+ return predictor
diff --git a/inference/interact/fbrs/inference/predictors/base.py b/inference/interact/fbrs/inference/predictors/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..3776506328ef9457afdad047fb4219c5e25c3ab6
--- /dev/null
+++ b/inference/interact/fbrs/inference/predictors/base.py
@@ -0,0 +1,100 @@
+import torch
+import torch.nn.functional as F
+
+from ..transforms import AddHorizontalFlip, SigmoidForPred, LimitLongestSide
+
+
+class BasePredictor(object):
+ def __init__(self, net, device,
+ net_clicks_limit=None,
+ with_flip=False,
+ zoom_in=None,
+ max_size=None,
+ **kwargs):
+ self.net = net
+ self.with_flip = with_flip
+ self.net_clicks_limit = net_clicks_limit
+ self.original_image = None
+ self.device = device
+ self.zoom_in = zoom_in
+
+ self.transforms = [zoom_in] if zoom_in is not None else []
+ if max_size is not None:
+ self.transforms.append(LimitLongestSide(max_size=max_size))
+ self.transforms.append(SigmoidForPred())
+ if with_flip:
+ self.transforms.append(AddHorizontalFlip())
+
+ def set_input_image(self, image_nd):
+ for transform in self.transforms:
+ transform.reset()
+ self.original_image = image_nd.to(self.device)
+ if len(self.original_image.shape) == 3:
+ self.original_image = self.original_image.unsqueeze(0)
+
+ def get_prediction(self, clicker):
+ clicks_list = clicker.get_clicks()
+
+ image_nd, clicks_lists, is_image_changed = self.apply_transforms(
+ self.original_image, [clicks_list]
+ )
+
+ pred_logits = self._get_prediction(image_nd, clicks_lists, is_image_changed)
+ prediction = F.interpolate(pred_logits, mode='bilinear', align_corners=True,
+ size=image_nd.size()[2:])
+
+ for t in reversed(self.transforms):
+ prediction = t.inv_transform(prediction)
+
+ if self.zoom_in is not None and self.zoom_in.check_possible_recalculation():
+ print('zooming')
+ return self.get_prediction(clicker)
+
+ # return prediction.cpu().numpy()[0, 0]
+ return prediction
+
+ def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
+ points_nd = self.get_points_nd(clicks_lists)
+ return self.net(image_nd, points_nd)['instances']
+
+ def _get_transform_states(self):
+ return [x.get_state() for x in self.transforms]
+
+ def _set_transform_states(self, states):
+ assert len(states) == len(self.transforms)
+ for state, transform in zip(states, self.transforms):
+ transform.set_state(state)
+
+ def apply_transforms(self, image_nd, clicks_lists):
+ is_image_changed = False
+ for t in self.transforms:
+ image_nd, clicks_lists = t.transform(image_nd, clicks_lists)
+ is_image_changed |= t.image_changed
+
+ return image_nd, clicks_lists, is_image_changed
+
+ def get_points_nd(self, clicks_lists):
+ total_clicks = []
+ num_pos_clicks = [sum(x.is_positive for x in clicks_list) for clicks_list in clicks_lists]
+ num_neg_clicks = [len(clicks_list) - num_pos for clicks_list, num_pos in zip(clicks_lists, num_pos_clicks)]
+ num_max_points = max(num_pos_clicks + num_neg_clicks)
+ if self.net_clicks_limit is not None:
+ num_max_points = min(self.net_clicks_limit, num_max_points)
+ num_max_points = max(1, num_max_points)
+
+ for clicks_list in clicks_lists:
+ clicks_list = clicks_list[:self.net_clicks_limit]
+ pos_clicks = [click.coords for click in clicks_list if click.is_positive]
+ pos_clicks = pos_clicks + (num_max_points - len(pos_clicks)) * [(-1, -1)]
+
+ neg_clicks = [click.coords for click in clicks_list if not click.is_positive]
+ neg_clicks = neg_clicks + (num_max_points - len(neg_clicks)) * [(-1, -1)]
+ total_clicks.append(pos_clicks + neg_clicks)
+
+ return torch.tensor(total_clicks, device=self.device)
+
+ def get_states(self):
+ return {'transform_states': self._get_transform_states()}
+
+ def set_states(self, states):
+ self._set_transform_states(states['transform_states'])
diff --git a/inference/interact/fbrs/inference/predictors/brs.py b/inference/interact/fbrs/inference/predictors/brs.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfc7296e52d5e575956eec8a614682a35cff9cd7
--- /dev/null
+++ b/inference/interact/fbrs/inference/predictors/brs.py
@@ -0,0 +1,280 @@
+import torch
+import torch.nn.functional as F
+import numpy as np
+from scipy.optimize import fmin_l_bfgs_b
+
+from .base import BasePredictor
+from ...model.is_hrnet_model import DistMapsHRNetModel
+
+
+class BRSBasePredictor(BasePredictor):
+ def __init__(self, model, device, opt_functor, optimize_after_n_clicks=1, **kwargs):
+ super().__init__(model, device, **kwargs)
+ self.optimize_after_n_clicks = optimize_after_n_clicks
+ self.opt_functor = opt_functor
+
+ self.opt_data = None
+ self.input_data = None
+
+ def set_input_image(self, image_nd):
+ super().set_input_image(image_nd)
+ self.opt_data = None
+ self.input_data = None
+
+ def _get_clicks_maps_nd(self, clicks_lists, image_shape, radius=1):
+ pos_clicks_map = np.zeros((len(clicks_lists), 1) + image_shape, dtype=np.float32)
+ neg_clicks_map = np.zeros((len(clicks_lists), 1) + image_shape, dtype=np.float32)
+
+ for list_indx, clicks_list in enumerate(clicks_lists):
+ for click in clicks_list:
+ y, x = click.coords
+ y, x = int(round(y)), int(round(x))
+ y1, x1 = y - radius, x - radius
+ y2, x2 = y + radius + 1, x + radius + 1
+
+ if click.is_positive:
+ pos_clicks_map[list_indx, 0, y1:y2, x1:x2] = True
+ else:
+ neg_clicks_map[list_indx, 0, y1:y2, x1:x2] = True
+
+ with torch.no_grad():
+ pos_clicks_map = torch.from_numpy(pos_clicks_map).to(self.device)
+ neg_clicks_map = torch.from_numpy(neg_clicks_map).to(self.device)
+
+ return pos_clicks_map, neg_clicks_map
+
+ def get_states(self):
+ return {'transform_states': self._get_transform_states(), 'opt_data': self.opt_data}
+
+ def set_states(self, states):
+ self._set_transform_states(states['transform_states'])
+ self.opt_data = states['opt_data']
+
+
+class FeatureBRSPredictor(BRSBasePredictor):
+ def __init__(self, model, device, opt_functor, insertion_mode='after_deeplab', **kwargs):
+ super().__init__(model, device, opt_functor=opt_functor, **kwargs)
+ self.insertion_mode = insertion_mode
+ self._c1_features = None
+
+ if self.insertion_mode == 'after_deeplab':
+ self.num_channels = model.feature_extractor.ch
+ elif self.insertion_mode == 'after_c4':
+ self.num_channels = model.feature_extractor.aspp_in_channels
+ elif self.insertion_mode == 'after_aspp':
+ self.num_channels = model.feature_extractor.ch + 32
+ else:
+ raise NotImplementedError
+
+ def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
+ points_nd = self.get_points_nd(clicks_lists)
+ pos_mask, neg_mask = self._get_clicks_maps_nd(clicks_lists, image_nd.shape[2:])
+
+ num_clicks = len(clicks_lists[0])
+ bs = image_nd.shape[0] // 2 if self.with_flip else image_nd.shape[0]
+
+ if self.opt_data is None or self.opt_data.shape[0] // (2 * self.num_channels) != bs:
+ self.opt_data = np.zeros((bs * 2 * self.num_channels), dtype=np.float32)
+
+ if num_clicks <= self.net_clicks_limit or is_image_changed or self.input_data is None:
+ self.input_data = self._get_head_input(image_nd, points_nd)
+
+ def get_prediction_logits(scale, bias):
+ scale = scale.view(bs, -1, 1, 1)
+ bias = bias.view(bs, -1, 1, 1)
+ if self.with_flip:
+ scale = scale.repeat(2, 1, 1, 1)
+ bias = bias.repeat(2, 1, 1, 1)
+
+ scaled_backbone_features = self.input_data * scale
+ scaled_backbone_features = scaled_backbone_features + bias
+ if self.insertion_mode == 'after_c4':
+ x = self.net.feature_extractor.aspp(scaled_backbone_features)
+ x = F.interpolate(x, mode='bilinear', size=self._c1_features.size()[2:],
+ align_corners=True)
+ x = torch.cat((x, self._c1_features), dim=1)
+ scaled_backbone_features = self.net.feature_extractor.head(x)
+ elif self.insertion_mode == 'after_aspp':
+ scaled_backbone_features = self.net.feature_extractor.head(scaled_backbone_features)
+
+ pred_logits = self.net.head(scaled_backbone_features)
+ pred_logits = F.interpolate(pred_logits, size=image_nd.size()[2:], mode='bilinear',
+ align_corners=True)
+ return pred_logits
+
+ self.opt_functor.init_click(get_prediction_logits, pos_mask, neg_mask, self.device)
+ if num_clicks > self.optimize_after_n_clicks:
+ opt_result = fmin_l_bfgs_b(func=self.opt_functor, x0=self.opt_data,
+ **self.opt_functor.optimizer_params)
+ self.opt_data = opt_result[0]
+
+ with torch.no_grad():
+ if self.opt_functor.best_prediction is not None:
+ opt_pred_logits = self.opt_functor.best_prediction
+ else:
+ opt_data_nd = torch.from_numpy(self.opt_data).to(self.device)
+ opt_vars, _ = self.opt_functor.unpack_opt_params(opt_data_nd)
+ opt_pred_logits = get_prediction_logits(*opt_vars)
+
+ return opt_pred_logits
+
+ def _get_head_input(self, image_nd, points):
+ with torch.no_grad():
+ coord_features = self.net.dist_maps(image_nd, points)
+ x = self.net.rgb_conv(torch.cat((image_nd, coord_features), dim=1))
+ if self.insertion_mode == 'after_c4' or self.insertion_mode == 'after_aspp':
+ c1, _, c3, c4 = self.net.feature_extractor.backbone(x)
+ c1 = self.net.feature_extractor.skip_project(c1)
+
+ if self.insertion_mode == 'after_aspp':
+ x = self.net.feature_extractor.aspp(c4)
+ x = F.interpolate(x, size=c1.size()[2:], mode='bilinear', align_corners=True)
+ x = torch.cat((x, c1), dim=1)
+ backbone_features = x
+ else:
+ backbone_features = c4
+ self._c1_features = c1
+ else:
+ backbone_features = self.net.feature_extractor(x)[0]
+
+ return backbone_features
+
+
+class HRNetFeatureBRSPredictor(BRSBasePredictor):
+ def __init__(self, model, device, opt_functor, insertion_mode='A', **kwargs):
+ super().__init__(model, device, opt_functor=opt_functor, **kwargs)
+ self.insertion_mode = insertion_mode
+ self._c1_features = None
+
+ if self.insertion_mode == 'A':
+ self.num_channels = sum(k * model.feature_extractor.width for k in [1, 2, 4, 8])
+ elif self.insertion_mode == 'C':
+ self.num_channels = 2 * model.feature_extractor.ocr_width
+ else:
+ raise NotImplementedError
+
+ def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
+ points_nd = self.get_points_nd(clicks_lists)
+ pos_mask, neg_mask = self._get_clicks_maps_nd(clicks_lists, image_nd.shape[2:])
+ num_clicks = len(clicks_lists[0])
+ bs = image_nd.shape[0] // 2 if self.with_flip else image_nd.shape[0]
+
+ if self.opt_data is None or self.opt_data.shape[0] // (2 * self.num_channels) != bs:
+ self.opt_data = np.zeros((bs * 2 * self.num_channels), dtype=np.float32)
+
+ if num_clicks <= self.net_clicks_limit or is_image_changed or self.input_data is None:
+ self.input_data = self._get_head_input(image_nd, points_nd)
+
+ def get_prediction_logits(scale, bias):
+ scale = scale.view(bs, -1, 1, 1)
+ bias = bias.view(bs, -1, 1, 1)
+ if self.with_flip:
+ scale = scale.repeat(2, 1, 1, 1)
+ bias = bias.repeat(2, 1, 1, 1)
+
+ scaled_backbone_features = self.input_data * scale
+ scaled_backbone_features = scaled_backbone_features + bias
+ if self.insertion_mode == 'A':
+ out_aux = self.net.feature_extractor.aux_head(scaled_backbone_features)
+ feats = self.net.feature_extractor.conv3x3_ocr(scaled_backbone_features)
+
+ context = self.net.feature_extractor.ocr_gather_head(feats, out_aux)
+ feats = self.net.feature_extractor.ocr_distri_head(feats, context)
+ pred_logits = self.net.feature_extractor.cls_head(feats)
+ elif self.insertion_mode == 'C':
+ pred_logits = self.net.feature_extractor.cls_head(scaled_backbone_features)
+ else:
+ raise NotImplementedError
+
+ pred_logits = F.interpolate(pred_logits, size=image_nd.size()[2:], mode='bilinear',
+ align_corners=True)
+ return pred_logits
+
+ self.opt_functor.init_click(get_prediction_logits, pos_mask, neg_mask, self.device)
+ if num_clicks > self.optimize_after_n_clicks:
+ opt_result = fmin_l_bfgs_b(func=self.opt_functor, x0=self.opt_data,
+ **self.opt_functor.optimizer_params)
+ self.opt_data = opt_result[0]
+
+ with torch.no_grad():
+ if self.opt_functor.best_prediction is not None:
+ opt_pred_logits = self.opt_functor.best_prediction
+ else:
+ opt_data_nd = torch.from_numpy(self.opt_data).to(self.device)
+ opt_vars, _ = self.opt_functor.unpack_opt_params(opt_data_nd)
+ opt_pred_logits = get_prediction_logits(*opt_vars)
+
+ return opt_pred_logits
+
+ def _get_head_input(self, image_nd, points):
+ with torch.no_grad():
+ coord_features = self.net.dist_maps(image_nd, points)
+ x = self.net.rgb_conv(torch.cat((image_nd, coord_features), dim=1))
+ feats = self.net.feature_extractor.compute_hrnet_feats(x)
+ if self.insertion_mode == 'A':
+ backbone_features = feats
+ elif self.insertion_mode == 'C':
+ out_aux = self.net.feature_extractor.aux_head(feats)
+ feats = self.net.feature_extractor.conv3x3_ocr(feats)
+
+ context = self.net.feature_extractor.ocr_gather_head(feats, out_aux)
+ backbone_features = self.net.feature_extractor.ocr_distri_head(feats, context)
+ else:
+ raise NotImplementedError
+
+ return backbone_features
+
+
+class InputBRSPredictor(BRSBasePredictor):
+ def __init__(self, model, device, opt_functor, optimize_target='rgb', **kwargs):
+ super().__init__(model, device, opt_functor=opt_functor, **kwargs)
+ self.optimize_target = optimize_target
+
+ def _get_prediction(self, image_nd, clicks_lists, is_image_changed):
+ points_nd = self.get_points_nd(clicks_lists)
+ pos_mask, neg_mask = self._get_clicks_maps_nd(clicks_lists, image_nd.shape[2:])
+ num_clicks = len(clicks_lists[0])
+
+ if self.opt_data is None or is_image_changed:
+ opt_channels = 2 if self.optimize_target == 'dmaps' else 3
+ bs = image_nd.shape[0] // 2 if self.with_flip else image_nd.shape[0]
+ self.opt_data = torch.zeros((bs, opt_channels, image_nd.shape[2], image_nd.shape[3]),
+ device=self.device, dtype=torch.float32)
+
+ def get_prediction_logits(opt_bias):
+ input_image = image_nd
+ if self.optimize_target == 'rgb':
+ input_image = input_image + opt_bias
+ dmaps = self.net.dist_maps(input_image, points_nd)
+ if self.optimize_target == 'dmaps':
+ dmaps = dmaps + opt_bias
+
+ x = self.net.rgb_conv(torch.cat((input_image, dmaps), dim=1))
+ if self.optimize_target == 'all':
+ x = x + opt_bias
+
+ if isinstance(self.net, DistMapsHRNetModel):
+ pred_logits = self.net.feature_extractor(x)[0]
+ else:
+ backbone_features = self.net.feature_extractor(x)
+ pred_logits = self.net.head(backbone_features[0])
+ pred_logits = F.interpolate(pred_logits, size=image_nd.size()[2:], mode='bilinear', align_corners=True)
+
+ return pred_logits
+
+ self.opt_functor.init_click(get_prediction_logits, pos_mask, neg_mask, self.device,
+ shape=self.opt_data.shape)
+ if num_clicks > self.optimize_after_n_clicks:
+ opt_result = fmin_l_bfgs_b(func=self.opt_functor, x0=self.opt_data.cpu().numpy().ravel(),
+ **self.opt_functor.optimizer_params)
+
+ self.opt_data = torch.from_numpy(opt_result[0]).view(self.opt_data.shape).to(self.device)
+
+ with torch.no_grad():
+ if self.opt_functor.best_prediction is not None:
+ opt_pred_logits = self.opt_functor.best_prediction
+ else:
+ opt_vars, _ = self.opt_functor.unpack_opt_params(self.opt_data)
+ opt_pred_logits = get_prediction_logits(*opt_vars)
+
+ return opt_pred_logits
diff --git a/inference/interact/fbrs/inference/predictors/brs_functors.py b/inference/interact/fbrs/inference/predictors/brs_functors.py
new file mode 100644
index 0000000000000000000000000000000000000000..92a5d9915ac0516144430db4ce06d1477319e694
--- /dev/null
+++ b/inference/interact/fbrs/inference/predictors/brs_functors.py
@@ -0,0 +1,109 @@
+import torch
+import numpy as np
+
+from ...model.metrics import _compute_iou
+from .brs_losses import BRSMaskLoss
+
+
+class BaseOptimizer:
+ def __init__(self, optimizer_params,
+ prob_thresh=0.49,
+ reg_weight=1e-3,
+ min_iou_diff=0.01,
+ brs_loss=BRSMaskLoss(),
+ with_flip=False,
+ flip_average=False,
+ **kwargs):
+ self.brs_loss = brs_loss
+ self.optimizer_params = optimizer_params
+ self.prob_thresh = prob_thresh
+ self.reg_weight = reg_weight
+ self.min_iou_diff = min_iou_diff
+ self.with_flip = with_flip
+ self.flip_average = flip_average
+
+ self.best_prediction = None
+ self._get_prediction_logits = None
+ self._opt_shape = None
+ self._best_loss = None
+ self._click_masks = None
+ self._last_mask = None
+ self.device = None
+
+ def init_click(self, get_prediction_logits, pos_mask, neg_mask, device, shape=None):
+ self.best_prediction = None
+ self._get_prediction_logits = get_prediction_logits
+ self._click_masks = (pos_mask, neg_mask)
+ self._opt_shape = shape
+ self._last_mask = None
+ self.device = device
+
+ def __call__(self, x):
+ opt_params = torch.from_numpy(x).float().to(self.device)
+ opt_params.requires_grad_(True)
+
+ with torch.enable_grad():
+ opt_vars, reg_loss = self.unpack_opt_params(opt_params)
+ result_before_sigmoid = self._get_prediction_logits(*opt_vars)
+ result = torch.sigmoid(result_before_sigmoid)
+
+ pos_mask, neg_mask = self._click_masks
+ if self.with_flip and self.flip_average:
+ result, result_flipped = torch.chunk(result, 2, dim=0)
+ result = 0.5 * (result + torch.flip(result_flipped, dims=[3]))
+ pos_mask, neg_mask = pos_mask[:result.shape[0]], neg_mask[:result.shape[0]]
+
+ loss, f_max_pos, f_max_neg = self.brs_loss(result, pos_mask, neg_mask)
+ loss = loss + reg_loss
+
+ f_val = loss.detach().cpu().numpy()
+ if self.best_prediction is None or f_val < self._best_loss:
+ self.best_prediction = result_before_sigmoid.detach()
+ self._best_loss = f_val
+
+ if f_max_pos < (1 - self.prob_thresh) and f_max_neg < self.prob_thresh:
+ return [f_val, np.zeros_like(x)]
+
+ current_mask = result > self.prob_thresh
+ if self._last_mask is not None and self.min_iou_diff > 0:
+ diff_iou = _compute_iou(current_mask, self._last_mask)
+ if len(diff_iou) > 0 and diff_iou.mean() > 1 - self.min_iou_diff:
+ return [f_val, np.zeros_like(x)]
+ self._last_mask = current_mask
+
+ loss.backward()
+ f_grad = opt_params.grad.cpu().numpy().ravel().astype(np.float)
+
+ return [f_val, f_grad]
+
+ def unpack_opt_params(self, opt_params):
+ raise NotImplementedError
+
+
+class InputOptimizer(BaseOptimizer):
+ def unpack_opt_params(self, opt_params):
+ opt_params = opt_params.view(self._opt_shape)
+ if self.with_flip:
+ opt_params_flipped = torch.flip(opt_params, dims=[3])
+ opt_params = torch.cat([opt_params, opt_params_flipped], dim=0)
+ reg_loss = self.reg_weight * torch.sum(opt_params**2)
+
+ return (opt_params,), reg_loss
+
+
+class ScaleBiasOptimizer(BaseOptimizer):
+ def __init__(self, *args, scale_act=None, reg_bias_weight=10.0, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.scale_act = scale_act
+ self.reg_bias_weight = reg_bias_weight
+
+ def unpack_opt_params(self, opt_params):
+ scale, bias = torch.chunk(opt_params, 2, dim=0)
+ reg_loss = self.reg_weight * (torch.sum(scale**2) + self.reg_bias_weight * torch.sum(bias**2))
+
+ if self.scale_act == 'tanh':
+ scale = torch.tanh(scale)
+ elif self.scale_act == 'sin':
+ scale = torch.sin(scale)
+
+ return (1 + scale, bias), reg_loss
diff --git a/inference/interact/fbrs/inference/predictors/brs_losses.py b/inference/interact/fbrs/inference/predictors/brs_losses.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d9998ab120b9987e79509d0ee594e8b6c431a9f
--- /dev/null
+++ b/inference/interact/fbrs/inference/predictors/brs_losses.py
@@ -0,0 +1,58 @@
+import torch
+
+from ...model.losses import SigmoidBinaryCrossEntropyLoss
+
+
+class BRSMaskLoss(torch.nn.Module):
+ def __init__(self, eps=1e-5):
+ super().__init__()
+ self._eps = eps
+
+ def forward(self, result, pos_mask, neg_mask):
+ pos_diff = (1 - result) * pos_mask
+ pos_target = torch.sum(pos_diff ** 2)
+ pos_target = pos_target / (torch.sum(pos_mask) + self._eps)
+
+ neg_diff = result * neg_mask
+ neg_target = torch.sum(neg_diff ** 2)
+ neg_target = neg_target / (torch.sum(neg_mask) + self._eps)
+
+ loss = pos_target + neg_target
+
+ with torch.no_grad():
+ f_max_pos = torch.max(torch.abs(pos_diff)).item()
+ f_max_neg = torch.max(torch.abs(neg_diff)).item()
+
+ return loss, f_max_pos, f_max_neg
+
+
+class OracleMaskLoss(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.gt_mask = None
+ self.loss = SigmoidBinaryCrossEntropyLoss(from_sigmoid=True)
+ self.predictor = None
+ self.history = []
+
+ def set_gt_mask(self, gt_mask):
+ self.gt_mask = gt_mask
+ self.history = []
+
+ def forward(self, result, pos_mask, neg_mask):
+ gt_mask = self.gt_mask.to(result.device)
+ if self.predictor.object_roi is not None:
+ r1, r2, c1, c2 = self.predictor.object_roi[:4]
+ gt_mask = gt_mask[:, :, r1:r2 + 1, c1:c2 + 1]
+ gt_mask = torch.nn.functional.interpolate(gt_mask, result.size()[2:], mode='bilinear', align_corners=True)
+
+ if result.shape[0] == 2:
+ gt_mask_flipped = torch.flip(gt_mask, dims=[3])
+ gt_mask = torch.cat([gt_mask, gt_mask_flipped], dim=0)
+
+ loss = self.loss(result, gt_mask)
+ self.history.append(loss.detach().cpu().numpy()[0])
+
+ if len(self.history) > 5 and abs(self.history[-5] - self.history[-1]) < 1e-5:
+ return 0, 0, 0
+
+ return loss, 1.0, 1.0
diff --git a/inference/interact/fbrs/inference/transforms/__init__.py b/inference/interact/fbrs/inference/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..cbd54e38a2f84b3fef481672a7ceab070eb01b82
--- /dev/null
+++ b/inference/interact/fbrs/inference/transforms/__init__.py
@@ -0,0 +1,5 @@
+from .base import SigmoidForPred
+from .flip import AddHorizontalFlip
+from .zoom_in import ZoomIn
+from .limit_longest_side import LimitLongestSide
+from .crops import Crops
diff --git a/inference/interact/fbrs/inference/transforms/base.py b/inference/interact/fbrs/inference/transforms/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb5a2deb3c44f5aed7530fd1e299fff1273737b8
--- /dev/null
+++ b/inference/interact/fbrs/inference/transforms/base.py
@@ -0,0 +1,38 @@
+import torch
+
+
+class BaseTransform(object):
+ def __init__(self):
+ self.image_changed = False
+
+ def transform(self, image_nd, clicks_lists):
+ raise NotImplementedError
+
+ def inv_transform(self, prob_map):
+ raise NotImplementedError
+
+ def reset(self):
+ raise NotImplementedError
+
+ def get_state(self):
+ raise NotImplementedError
+
+ def set_state(self, state):
+ raise NotImplementedError
+
+
+class SigmoidForPred(BaseTransform):
+ def transform(self, image_nd, clicks_lists):
+ return image_nd, clicks_lists
+
+ def inv_transform(self, prob_map):
+ return torch.sigmoid(prob_map)
+
+ def reset(self):
+ pass
+
+ def get_state(self):
+ return None
+
+ def set_state(self, state):
+ pass
diff --git a/inference/interact/fbrs/inference/transforms/crops.py b/inference/interact/fbrs/inference/transforms/crops.py
new file mode 100644
index 0000000000000000000000000000000000000000..0910a2825608cf3fa761212d182dc1e8e5c242c4
--- /dev/null
+++ b/inference/interact/fbrs/inference/transforms/crops.py
@@ -0,0 +1,97 @@
+import math
+
+import torch
+import numpy as np
+
+from ...inference.clicker import Click
+from .base import BaseTransform
+
+
+class Crops(BaseTransform):
+ def __init__(self, crop_size=(320, 480), min_overlap=0.2):
+ super().__init__()
+ self.crop_height, self.crop_width = crop_size
+ self.min_overlap = min_overlap
+
+ self.x_offsets = None
+ self.y_offsets = None
+ self._counts = None
+
+ def transform(self, image_nd, clicks_lists):
+ assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
+ image_height, image_width = image_nd.shape[2:4]
+ self._counts = None
+
+ if image_height < self.crop_height or image_width < self.crop_width:
+ return image_nd, clicks_lists
+
+ self.x_offsets = get_offsets(image_width, self.crop_width, self.min_overlap)
+ self.y_offsets = get_offsets(image_height, self.crop_height, self.min_overlap)
+ self._counts = np.zeros((image_height, image_width))
+
+ image_crops = []
+ for dy in self.y_offsets:
+ for dx in self.x_offsets:
+ self._counts[dy:dy + self.crop_height, dx:dx + self.crop_width] += 1
+ image_crop = image_nd[:, :, dy:dy + self.crop_height, dx:dx + self.crop_width]
+ image_crops.append(image_crop)
+ image_crops = torch.cat(image_crops, dim=0)
+ self._counts = torch.tensor(self._counts, device=image_nd.device, dtype=torch.float32)
+
+ clicks_list = clicks_lists[0]
+ clicks_lists = []
+ for dy in self.y_offsets:
+ for dx in self.x_offsets:
+ crop_clicks = [Click(is_positive=x.is_positive, coords=(x.coords[0] - dy, x.coords[1] - dx))
+ for x in clicks_list]
+ clicks_lists.append(crop_clicks)
+
+ return image_crops, clicks_lists
+
+ def inv_transform(self, prob_map):
+ if self._counts is None:
+ return prob_map
+
+ new_prob_map = torch.zeros((1, 1, *self._counts.shape),
+ dtype=prob_map.dtype, device=prob_map.device)
+
+ crop_indx = 0
+ for dy in self.y_offsets:
+ for dx in self.x_offsets:
+ new_prob_map[0, 0, dy:dy + self.crop_height, dx:dx + self.crop_width] += prob_map[crop_indx, 0]
+ crop_indx += 1
+ new_prob_map = torch.div(new_prob_map, self._counts)
+
+ return new_prob_map
+
+ def get_state(self):
+ return self.x_offsets, self.y_offsets, self._counts
+
+ def set_state(self, state):
+ self.x_offsets, self.y_offsets, self._counts = state
+
+ def reset(self):
+ self.x_offsets = None
+ self.y_offsets = None
+ self._counts = None
+
+
+def get_offsets(length, crop_size, min_overlap_ratio=0.2):
+ if length == crop_size:
+ return [0]
+
+ N = (length / crop_size - min_overlap_ratio) / (1 - min_overlap_ratio)
+ N = math.ceil(N)
+
+ overlap_ratio = (N - length / crop_size) / (N - 1)
+ overlap_width = int(crop_size * overlap_ratio)
+
+ offsets = [0]
+ for i in range(1, N):
+ new_offset = offsets[-1] + crop_size - overlap_width
+ if new_offset + crop_size > length:
+ new_offset = length - crop_size
+
+ offsets.append(new_offset)
+
+ return offsets
diff --git a/inference/interact/fbrs/inference/transforms/flip.py b/inference/interact/fbrs/inference/transforms/flip.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1543cb65f8d3892054dc96f39a8196987fb6bfd
--- /dev/null
+++ b/inference/interact/fbrs/inference/transforms/flip.py
@@ -0,0 +1,37 @@
+import torch
+
+from ..clicker import Click
+from .base import BaseTransform
+
+
+class AddHorizontalFlip(BaseTransform):
+ def transform(self, image_nd, clicks_lists):
+ assert len(image_nd.shape) == 4
+ image_nd = torch.cat([image_nd, torch.flip(image_nd, dims=[3])], dim=0)
+
+ image_width = image_nd.shape[3]
+ clicks_lists_flipped = []
+ for clicks_list in clicks_lists:
+ clicks_list_flipped = [Click(is_positive=click.is_positive,
+ coords=(click.coords[0], image_width - click.coords[1] - 1))
+ for click in clicks_list]
+ clicks_lists_flipped.append(clicks_list_flipped)
+ clicks_lists = clicks_lists + clicks_lists_flipped
+
+ return image_nd, clicks_lists
+
+ def inv_transform(self, prob_map):
+ assert len(prob_map.shape) == 4 and prob_map.shape[0] % 2 == 0
+ num_maps = prob_map.shape[0] // 2
+ prob_map, prob_map_flipped = prob_map[:num_maps], prob_map[num_maps:]
+
+ return 0.5 * (prob_map + torch.flip(prob_map_flipped, dims=[3]))
+
+ def get_state(self):
+ return None
+
+ def set_state(self, state):
+ pass
+
+ def reset(self):
+ pass
diff --git a/inference/interact/fbrs/inference/transforms/limit_longest_side.py b/inference/interact/fbrs/inference/transforms/limit_longest_side.py
new file mode 100644
index 0000000000000000000000000000000000000000..50c5a53d2670df52285621dc0d33e86df520d77c
--- /dev/null
+++ b/inference/interact/fbrs/inference/transforms/limit_longest_side.py
@@ -0,0 +1,22 @@
+from .zoom_in import ZoomIn, get_roi_image_nd
+
+
+class LimitLongestSide(ZoomIn):
+ def __init__(self, max_size=800):
+ super().__init__(target_size=max_size, skip_clicks=0)
+
+ def transform(self, image_nd, clicks_lists):
+ assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
+ image_max_size = max(image_nd.shape[2:4])
+ self.image_changed = False
+
+ if image_max_size <= self.target_size:
+ return image_nd, clicks_lists
+ self._input_image = image_nd
+
+ self._object_roi = (0, image_nd.shape[2] - 1, 0, image_nd.shape[3] - 1)
+ self._roi_image = get_roi_image_nd(image_nd, self._object_roi, self.target_size)
+ self.image_changed = True
+
+ tclicks_lists = [self._transform_clicks(clicks_lists[0])]
+ return self._roi_image, tclicks_lists
diff --git a/inference/interact/fbrs/inference/transforms/zoom_in.py b/inference/interact/fbrs/inference/transforms/zoom_in.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c11ecc241570fe2429e85bdccbb713a70d9ffd6
--- /dev/null
+++ b/inference/interact/fbrs/inference/transforms/zoom_in.py
@@ -0,0 +1,171 @@
+import torch
+
+from ..clicker import Click
+from ...utils.misc import get_bbox_iou, get_bbox_from_mask, expand_bbox, clamp_bbox
+from .base import BaseTransform
+
+
+class ZoomIn(BaseTransform):
+ def __init__(self,
+ target_size=400,
+ skip_clicks=1,
+ expansion_ratio=1.4,
+ min_crop_size=200,
+ recompute_thresh_iou=0.5,
+ prob_thresh=0.50):
+ super().__init__()
+ self.target_size = target_size
+ self.min_crop_size = min_crop_size
+ self.skip_clicks = skip_clicks
+ self.expansion_ratio = expansion_ratio
+ self.recompute_thresh_iou = recompute_thresh_iou
+ self.prob_thresh = prob_thresh
+
+ self._input_image_shape = None
+ self._prev_probs = None
+ self._object_roi = None
+ self._roi_image = None
+
+ def transform(self, image_nd, clicks_lists):
+ assert image_nd.shape[0] == 1 and len(clicks_lists) == 1
+ self.image_changed = False
+
+ clicks_list = clicks_lists[0]
+ if len(clicks_list) <= self.skip_clicks:
+ return image_nd, clicks_lists
+
+ self._input_image_shape = image_nd.shape
+
+ current_object_roi = None
+ if self._prev_probs is not None:
+ current_pred_mask = (self._prev_probs > self.prob_thresh)[0, 0]
+ if current_pred_mask.sum() > 0:
+ current_object_roi = get_object_roi(current_pred_mask, clicks_list,
+ self.expansion_ratio, self.min_crop_size)
+
+ if current_object_roi is None:
+ return image_nd, clicks_lists
+
+ update_object_roi = False
+ if self._object_roi is None:
+ update_object_roi = True
+ elif not check_object_roi(self._object_roi, clicks_list):
+ update_object_roi = True
+ elif get_bbox_iou(current_object_roi, self._object_roi) < self.recompute_thresh_iou:
+ update_object_roi = True
+
+ if update_object_roi:
+ self._object_roi = current_object_roi
+ self._roi_image = get_roi_image_nd(image_nd, self._object_roi, self.target_size)
+ self.image_changed = True
+
+ tclicks_lists = [self._transform_clicks(clicks_list)]
+ return self._roi_image.to(image_nd.device), tclicks_lists
+
+ def inv_transform(self, prob_map):
+ if self._object_roi is None:
+ self._prev_probs = prob_map.cpu().numpy()
+ return prob_map
+
+ assert prob_map.shape[0] == 1
+ rmin, rmax, cmin, cmax = self._object_roi
+ prob_map = torch.nn.functional.interpolate(prob_map, size=(rmax - rmin + 1, cmax - cmin + 1),
+ mode='bilinear', align_corners=True)
+
+ if self._prev_probs is not None:
+ new_prob_map = torch.zeros(*self._prev_probs.shape, device=prob_map.device, dtype=prob_map.dtype)
+ new_prob_map[:, :, rmin:rmax + 1, cmin:cmax + 1] = prob_map
+ else:
+ new_prob_map = prob_map
+
+ self._prev_probs = new_prob_map.cpu().numpy()
+
+ return new_prob_map
+
+ def check_possible_recalculation(self):
+ if self._prev_probs is None or self._object_roi is not None or self.skip_clicks > 0:
+ return False
+
+ pred_mask = (self._prev_probs > self.prob_thresh)[0, 0]
+ if pred_mask.sum() > 0:
+ possible_object_roi = get_object_roi(pred_mask, [],
+ self.expansion_ratio, self.min_crop_size)
+ image_roi = (0, self._input_image_shape[2] - 1, 0, self._input_image_shape[3] - 1)
+ if get_bbox_iou(possible_object_roi, image_roi) < 0.50:
+ return True
+ return False
+
+ def get_state(self):
+ roi_image = self._roi_image.cpu() if self._roi_image is not None else None
+ return self._input_image_shape, self._object_roi, self._prev_probs, roi_image, self.image_changed
+
+ def set_state(self, state):
+ self._input_image_shape, self._object_roi, self._prev_probs, self._roi_image, self.image_changed = state
+
+ def reset(self):
+ self._input_image_shape = None
+ self._object_roi = None
+ self._prev_probs = None
+ self._roi_image = None
+ self.image_changed = False
+
+ def _transform_clicks(self, clicks_list):
+ if self._object_roi is None:
+ return clicks_list
+
+ rmin, rmax, cmin, cmax = self._object_roi
+ crop_height, crop_width = self._roi_image.shape[2:]
+
+ transformed_clicks = []
+ for click in clicks_list:
+ new_r = crop_height * (click.coords[0] - rmin) / (rmax - rmin + 1)
+ new_c = crop_width * (click.coords[1] - cmin) / (cmax - cmin + 1)
+ transformed_clicks.append(Click(is_positive=click.is_positive, coords=(new_r, new_c)))
+ return transformed_clicks
+
+
+def get_object_roi(pred_mask, clicks_list, expansion_ratio, min_crop_size):
+ pred_mask = pred_mask.copy()
+
+ for click in clicks_list:
+ if click.is_positive:
+ pred_mask[int(click.coords[0]), int(click.coords[1])] = 1
+
+ bbox = get_bbox_from_mask(pred_mask)
+ bbox = expand_bbox(bbox, expansion_ratio, min_crop_size)
+ h, w = pred_mask.shape[0], pred_mask.shape[1]
+ bbox = clamp_bbox(bbox, 0, h - 1, 0, w - 1)
+
+ return bbox
+
+
+def get_roi_image_nd(image_nd, object_roi, target_size):
+ rmin, rmax, cmin, cmax = object_roi
+
+ height = rmax - rmin + 1
+ width = cmax - cmin + 1
+
+ if isinstance(target_size, tuple):
+ new_height, new_width = target_size
+ else:
+ scale = target_size / max(height, width)
+ new_height = int(round(height * scale))
+ new_width = int(round(width * scale))
+
+ with torch.no_grad():
+ roi_image_nd = image_nd[:, :, rmin:rmax + 1, cmin:cmax + 1]
+ roi_image_nd = torch.nn.functional.interpolate(roi_image_nd, size=(new_height, new_width),
+ mode='bilinear', align_corners=True)
+
+ return roi_image_nd
+
+
+def check_object_roi(object_roi, clicks_list):
+ for click in clicks_list:
+ if click.is_positive:
+ if click.coords[0] < object_roi[0] or click.coords[0] >= object_roi[1]:
+ return False
+ if click.coords[1] < object_roi[2] or click.coords[1] >= object_roi[3]:
+ return False
+
+ return True
diff --git a/inference/interact/fbrs/inference/utils.py b/inference/interact/fbrs/inference/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d29b890294d16a9b780f79a2629505c10ff1cee
--- /dev/null
+++ b/inference/interact/fbrs/inference/utils.py
@@ -0,0 +1,177 @@
+from datetime import timedelta
+from pathlib import Path
+
+import torch
+import numpy as np
+
+from ..model.is_deeplab_model import get_deeplab_model
+from ..model.is_hrnet_model import get_hrnet_model
+
+
+def get_time_metrics(all_ious, elapsed_time):
+ n_images = len(all_ious)
+ n_clicks = sum(map(len, all_ious))
+
+ mean_spc = elapsed_time / n_clicks
+ mean_spi = elapsed_time / n_images
+
+ return mean_spc, mean_spi
+
+
+def load_is_model(checkpoint, device, backbone='auto', **kwargs):
+ if isinstance(checkpoint, (str, Path)):
+ state_dict = torch.load(checkpoint, map_location='cpu')
+ else:
+ state_dict = checkpoint
+
+ if backbone == 'auto':
+ for k in state_dict.keys():
+ if 'feature_extractor.stage2.0.branches' in k:
+ return load_hrnet_is_model(state_dict, device, backbone, **kwargs)
+ return load_deeplab_is_model(state_dict, device, backbone, **kwargs)
+ elif 'resnet' in backbone:
+ return load_deeplab_is_model(state_dict, device, backbone, **kwargs)
+ elif 'hrnet' in backbone:
+ return load_hrnet_is_model(state_dict, device, backbone, **kwargs)
+ else:
+ raise NotImplementedError('Unknown backbone')
+
+
+def load_hrnet_is_model(state_dict, device, backbone='auto', width=48, ocr_width=256,
+ small=False, cpu_dist_maps=False, norm_radius=260):
+ if backbone == 'auto':
+ num_fe_weights = len([x for x in state_dict.keys() if 'feature_extractor.' in x])
+ small = num_fe_weights < 1800
+
+ ocr_f_down = [v for k, v in state_dict.items() if 'object_context_block.f_down.1.0.bias' in k]
+ assert len(ocr_f_down) == 1
+ ocr_width = ocr_f_down[0].shape[0]
+
+ s2_conv1_w = [v for k, v in state_dict.items() if 'stage2.0.branches.0.0.conv1.weight' in k]
+ assert len(s2_conv1_w) == 1
+ width = s2_conv1_w[0].shape[0]
+
+ model = get_hrnet_model(width=width, ocr_width=ocr_width, small=small,
+ with_aux_output=False, cpu_dist_maps=cpu_dist_maps,
+ norm_radius=norm_radius)
+
+ model.load_state_dict(state_dict, strict=False)
+ for param in model.parameters():
+ param.requires_grad = False
+ model.to(device)
+ model.eval()
+
+ return model
+
+
+def load_deeplab_is_model(state_dict, device, backbone='auto', deeplab_ch=128, aspp_dropout=0.2,
+ cpu_dist_maps=False, norm_radius=260):
+ if backbone == 'auto':
+ num_backbone_params = len([x for x in state_dict.keys()
+ if 'feature_extractor.backbone' in x and not('num_batches_tracked' in x)])
+
+ if num_backbone_params <= 181:
+ backbone = 'resnet34'
+ elif num_backbone_params <= 276:
+ backbone = 'resnet50'
+ elif num_backbone_params <= 531:
+ backbone = 'resnet101'
+ else:
+ raise NotImplementedError('Unknown backbone')
+
+ if 'aspp_dropout' in state_dict:
+ aspp_dropout = float(state_dict['aspp_dropout'].cpu().numpy())
+ else:
+ aspp_project_weight = [v for k, v in state_dict.items() if 'aspp.project.0.weight' in k][0]
+ deeplab_ch = aspp_project_weight.size(0)
+ if deeplab_ch == 256:
+ aspp_dropout = 0.5
+
+ model = get_deeplab_model(backbone=backbone, deeplab_ch=deeplab_ch,
+ aspp_dropout=aspp_dropout, cpu_dist_maps=cpu_dist_maps,
+ norm_radius=norm_radius)
+
+ model.load_state_dict(state_dict, strict=False)
+ for param in model.parameters():
+ param.requires_grad = False
+ model.to(device)
+ model.eval()
+
+ return model
+
+
+def get_iou(gt_mask, pred_mask, ignore_label=-1):
+ ignore_gt_mask_inv = gt_mask != ignore_label
+ obj_gt_mask = gt_mask == 1
+
+ intersection = np.logical_and(np.logical_and(pred_mask, obj_gt_mask), ignore_gt_mask_inv).sum()
+ union = np.logical_and(np.logical_or(pred_mask, obj_gt_mask), ignore_gt_mask_inv).sum()
+
+ return intersection / union
+
+
+def compute_noc_metric(all_ious, iou_thrs, max_clicks=20):
+ def _get_noc(iou_arr, iou_thr):
+ vals = iou_arr >= iou_thr
+ return np.argmax(vals) + 1 if np.any(vals) else max_clicks
+
+ noc_list = []
+ over_max_list = []
+ for iou_thr in iou_thrs:
+ scores_arr = np.array([_get_noc(iou_arr, iou_thr)
+ for iou_arr in all_ious], dtype=np.int)
+
+ score = scores_arr.mean()
+ over_max = (scores_arr == max_clicks).sum()
+
+ noc_list.append(score)
+ over_max_list.append(over_max)
+
+ return noc_list, over_max_list
+
+
+def find_checkpoint(weights_folder, checkpoint_name):
+ weights_folder = Path(weights_folder)
+ if ':' in checkpoint_name:
+ model_name, checkpoint_name = checkpoint_name.split(':')
+ models_candidates = [x for x in weights_folder.glob(f'{model_name}*') if x.is_dir()]
+ assert len(models_candidates) == 1
+ model_folder = models_candidates[0]
+ else:
+ model_folder = weights_folder
+
+ if checkpoint_name.endswith('.pth'):
+ if Path(checkpoint_name).exists():
+ checkpoint_path = checkpoint_name
+ else:
+ checkpoint_path = weights_folder / checkpoint_name
+ else:
+ model_checkpoints = list(model_folder.rglob(f'{checkpoint_name}*.pth'))
+ assert len(model_checkpoints) == 1
+ checkpoint_path = model_checkpoints[0]
+
+ return str(checkpoint_path)
+
+
+def get_results_table(noc_list, over_max_list, brs_type, dataset_name, mean_spc, elapsed_time,
+ n_clicks=20, model_name=None):
+ table_header = (f'|{"BRS Type":^13}|{"Dataset":^11}|'
+ f'{"NoC@80%":^9}|{"NoC@85%":^9}|{"NoC@90%":^9}|'
+ f'{">="+str(n_clicks)+"@85%":^9}|{">="+str(n_clicks)+"@90%":^9}|'
+ f'{"SPC,s":^7}|{"Time":^9}|')
+ row_width = len(table_header)
+
+ header = f'Eval results for model: {model_name}\n' if model_name is not None else ''
+ header += '-' * row_width + '\n'
+ header += table_header + '\n' + '-' * row_width
+
+ eval_time = str(timedelta(seconds=int(elapsed_time)))
+ table_row = f'|{brs_type:^13}|{dataset_name:^11}|'
+ table_row += f'{noc_list[0]:^9.2f}|'
+ table_row += f'{noc_list[1]:^9.2f}|' if len(noc_list) > 1 else f'{"?":^9}|'
+ table_row += f'{noc_list[2]:^9.2f}|' if len(noc_list) > 2 else f'{"?":^9}|'
+ table_row += f'{over_max_list[1]:^9}|' if len(noc_list) > 1 else f'{"?":^9}|'
+ table_row += f'{over_max_list[2]:^9}|' if len(noc_list) > 2 else f'{"?":^9}|'
+ table_row += f'{mean_spc:^7.3f}|{eval_time:^9}|'
+
+ return header, table_row
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/__init__.py b/inference/interact/fbrs/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/model/initializer.py b/inference/interact/fbrs/model/initializer.py
new file mode 100644
index 0000000000000000000000000000000000000000..470c7df4659bc1e80ceec80a170b3b2e0302fb84
--- /dev/null
+++ b/inference/interact/fbrs/model/initializer.py
@@ -0,0 +1,105 @@
+import torch
+import torch.nn as nn
+import numpy as np
+
+
+class Initializer(object):
+ def __init__(self, local_init=True, gamma=None):
+ self.local_init = local_init
+ self.gamma = gamma
+
+ def __call__(self, m):
+ if getattr(m, '__initialized', False):
+ return
+
+ if isinstance(m, (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d,
+ nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d,
+ nn.GroupNorm, nn.SyncBatchNorm)) or 'BatchNorm' in m.__class__.__name__:
+ if m.weight is not None:
+ self._init_gamma(m.weight.data)
+ if m.bias is not None:
+ self._init_beta(m.bias.data)
+ else:
+ if getattr(m, 'weight', None) is not None:
+ self._init_weight(m.weight.data)
+ if getattr(m, 'bias', None) is not None:
+ self._init_bias(m.bias.data)
+
+ if self.local_init:
+ object.__setattr__(m, '__initialized', True)
+
+ def _init_weight(self, data):
+ nn.init.uniform_(data, -0.07, 0.07)
+
+ def _init_bias(self, data):
+ nn.init.constant_(data, 0)
+
+ def _init_gamma(self, data):
+ if self.gamma is None:
+ nn.init.constant_(data, 1.0)
+ else:
+ nn.init.normal_(data, 1.0, self.gamma)
+
+ def _init_beta(self, data):
+ nn.init.constant_(data, 0)
+
+
+class Bilinear(Initializer):
+ def __init__(self, scale, groups, in_channels, **kwargs):
+ super().__init__(**kwargs)
+ self.scale = scale
+ self.groups = groups
+ self.in_channels = in_channels
+
+ def _init_weight(self, data):
+ """Reset the weight and bias."""
+ bilinear_kernel = self.get_bilinear_kernel(self.scale)
+ weight = torch.zeros_like(data)
+ for i in range(self.in_channels):
+ if self.groups == 1:
+ j = i
+ else:
+ j = 0
+ weight[i, j] = bilinear_kernel
+ data[:] = weight
+
+ @staticmethod
+ def get_bilinear_kernel(scale):
+ """Generate a bilinear upsampling kernel."""
+ kernel_size = 2 * scale - scale % 2
+ scale = (kernel_size + 1) // 2
+ center = scale - 0.5 * (1 + kernel_size % 2)
+
+ og = np.ogrid[:kernel_size, :kernel_size]
+ kernel = (1 - np.abs(og[0] - center) / scale) * (1 - np.abs(og[1] - center) / scale)
+
+ return torch.tensor(kernel, dtype=torch.float32)
+
+
+class XavierGluon(Initializer):
+ def __init__(self, rnd_type='uniform', factor_type='avg', magnitude=3, **kwargs):
+ super().__init__(**kwargs)
+
+ self.rnd_type = rnd_type
+ self.factor_type = factor_type
+ self.magnitude = float(magnitude)
+
+ def _init_weight(self, arr):
+ fan_in, fan_out = nn.init._calculate_fan_in_and_fan_out(arr)
+
+ if self.factor_type == 'avg':
+ factor = (fan_in + fan_out) / 2.0
+ elif self.factor_type == 'in':
+ factor = fan_in
+ elif self.factor_type == 'out':
+ factor = fan_out
+ else:
+ raise ValueError('Incorrect factor type')
+ scale = np.sqrt(self.magnitude / factor)
+
+ if self.rnd_type == 'uniform':
+ nn.init.uniform_(arr, -scale, scale)
+ elif self.rnd_type == 'gaussian':
+ nn.init.normal_(arr, 0, scale)
+ else:
+ raise ValueError('Unknown random type')
diff --git a/inference/interact/fbrs/model/is_deeplab_model.py b/inference/interact/fbrs/model/is_deeplab_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..c9a75cc0f56c1a068dc742f65a42a6ec85e9ad83
--- /dev/null
+++ b/inference/interact/fbrs/model/is_deeplab_model.py
@@ -0,0 +1,86 @@
+import torch
+import torch.nn as nn
+
+from .ops import DistMaps
+from .modeling.deeplab_v3 import DeepLabV3Plus
+from .modeling.basic_blocks import SepConvHead
+
+
+def get_deeplab_model(backbone='resnet50', deeplab_ch=256, aspp_dropout=0.5,
+ norm_layer=nn.BatchNorm2d, backbone_norm_layer=None,
+ use_rgb_conv=True, cpu_dist_maps=False,
+ norm_radius=260):
+ model = DistMapsModel(
+ feature_extractor=DeepLabV3Plus(backbone=backbone,
+ ch=deeplab_ch,
+ project_dropout=aspp_dropout,
+ norm_layer=norm_layer,
+ backbone_norm_layer=backbone_norm_layer),
+ head=SepConvHead(1, in_channels=deeplab_ch, mid_channels=deeplab_ch // 2,
+ num_layers=2, norm_layer=norm_layer),
+ use_rgb_conv=use_rgb_conv,
+ norm_layer=norm_layer,
+ norm_radius=norm_radius,
+ cpu_dist_maps=cpu_dist_maps
+ )
+
+ return model
+
+
+class DistMapsModel(nn.Module):
+ def __init__(self, feature_extractor, head, norm_layer=nn.BatchNorm2d, use_rgb_conv=True,
+ cpu_dist_maps=False, norm_radius=260):
+ super(DistMapsModel, self).__init__()
+
+ if use_rgb_conv:
+ self.rgb_conv = nn.Sequential(
+ nn.Conv2d(in_channels=5, out_channels=8, kernel_size=1),
+ nn.LeakyReLU(negative_slope=0.2),
+ norm_layer(8),
+ nn.Conv2d(in_channels=8, out_channels=3, kernel_size=1),
+ )
+ else:
+ self.rgb_conv = None
+
+ self.dist_maps = DistMaps(norm_radius=norm_radius, spatial_scale=1.0,
+ cpu_mode=cpu_dist_maps)
+ self.feature_extractor = feature_extractor
+ self.head = head
+
+ def forward(self, image, points):
+ coord_features = self.dist_maps(image, points)
+
+ if self.rgb_conv is not None:
+ x = self.rgb_conv(torch.cat((image, coord_features), dim=1))
+ else:
+ c1, c2 = torch.chunk(coord_features, 2, dim=1)
+ c3 = torch.ones_like(c1)
+ coord_features = torch.cat((c1, c2, c3), dim=1)
+ x = 0.8 * image * coord_features + 0.2 * image
+
+ backbone_features = self.feature_extractor(x)
+ instance_out = self.head(backbone_features[0])
+ instance_out = nn.functional.interpolate(instance_out, size=image.size()[2:],
+ mode='bilinear', align_corners=True)
+
+ return {'instances': instance_out}
+
+ def load_weights(self, path_to_weights):
+ current_state_dict = self.state_dict()
+ new_state_dict = torch.load(path_to_weights, map_location='cpu')
+ current_state_dict.update(new_state_dict)
+ self.load_state_dict(current_state_dict)
+
+ def get_trainable_params(self):
+ backbone_params = nn.ParameterList()
+ other_params = nn.ParameterList()
+
+ for name, param in self.named_parameters():
+ if param.requires_grad:
+ if 'backbone' in name:
+ backbone_params.append(param)
+ else:
+ other_params.append(param)
+ return backbone_params, other_params
+
+
diff --git a/inference/interact/fbrs/model/is_hrnet_model.py b/inference/interact/fbrs/model/is_hrnet_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ced540a782c7b6e5b498d2e345faa95cb4015f4c
--- /dev/null
+++ b/inference/interact/fbrs/model/is_hrnet_model.py
@@ -0,0 +1,87 @@
+import torch
+import torch.nn as nn
+
+from .ops import DistMaps
+from .modeling.hrnet_ocr import HighResolutionNet
+
+
+def get_hrnet_model(width=48, ocr_width=256, small=False, norm_radius=260,
+ use_rgb_conv=True, with_aux_output=False, cpu_dist_maps=False,
+ norm_layer=nn.BatchNorm2d):
+ model = DistMapsHRNetModel(
+ feature_extractor=HighResolutionNet(width=width, ocr_width=ocr_width, small=small,
+ num_classes=1, norm_layer=norm_layer),
+ use_rgb_conv=use_rgb_conv,
+ with_aux_output=with_aux_output,
+ norm_layer=norm_layer,
+ norm_radius=norm_radius,
+ cpu_dist_maps=cpu_dist_maps
+ )
+
+ return model
+
+
+class DistMapsHRNetModel(nn.Module):
+ def __init__(self, feature_extractor, use_rgb_conv=True, with_aux_output=False,
+ norm_layer=nn.BatchNorm2d, norm_radius=260, cpu_dist_maps=False):
+ super(DistMapsHRNetModel, self).__init__()
+ self.with_aux_output = with_aux_output
+
+ if use_rgb_conv:
+ self.rgb_conv = nn.Sequential(
+ nn.Conv2d(in_channels=5, out_channels=8, kernel_size=1),
+ nn.LeakyReLU(negative_slope=0.2),
+ norm_layer(8),
+ nn.Conv2d(in_channels=8, out_channels=3, kernel_size=1),
+ )
+ else:
+ self.rgb_conv = None
+
+ self.dist_maps = DistMaps(norm_radius=norm_radius, spatial_scale=1.0, cpu_mode=cpu_dist_maps)
+ self.feature_extractor = feature_extractor
+
+ def forward(self, image, points):
+ coord_features = self.dist_maps(image, points)
+
+ if self.rgb_conv is not None:
+ x = self.rgb_conv(torch.cat((image, coord_features), dim=1))
+ else:
+ c1, c2 = torch.chunk(coord_features, 2, dim=1)
+ c3 = torch.ones_like(c1)
+ coord_features = torch.cat((c1, c2, c3), dim=1)
+ x = 0.8 * image * coord_features + 0.2 * image
+
+ feature_extractor_out = self.feature_extractor(x)
+ instance_out = feature_extractor_out[0]
+ instance_out = nn.functional.interpolate(instance_out, size=image.size()[2:],
+ mode='bilinear', align_corners=True)
+ outputs = {'instances': instance_out}
+ if self.with_aux_output:
+ instance_aux_out = feature_extractor_out[1]
+ instance_aux_out = nn.functional.interpolate(instance_aux_out, size=image.size()[2:],
+ mode='bilinear', align_corners=True)
+ outputs['instances_aux'] = instance_aux_out
+
+ return outputs
+
+ def load_weights(self, path_to_weights):
+ current_state_dict = self.state_dict()
+ new_state_dict = torch.load(path_to_weights)
+ current_state_dict.update(new_state_dict)
+ self.load_state_dict(current_state_dict)
+
+ def get_trainable_params(self):
+ backbone_params = nn.ParameterList()
+ other_params = nn.ParameterList()
+ other_params_keys = []
+ nonbackbone_keywords = ['rgb_conv', 'aux_head', 'cls_head', 'conv3x3_ocr', 'ocr_distri_head']
+
+ for name, param in self.named_parameters():
+ if param.requires_grad:
+ if any(x in name for x in nonbackbone_keywords):
+ other_params.append(param)
+ other_params_keys.append(name)
+ else:
+ backbone_params.append(param)
+ print('Nonbackbone params:', sorted(other_params_keys))
+ return backbone_params, other_params
diff --git a/inference/interact/fbrs/model/losses.py b/inference/interact/fbrs/model/losses.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd89bf02b108533bc8c5639f233549d7387d3dbc
--- /dev/null
+++ b/inference/interact/fbrs/model/losses.py
@@ -0,0 +1,134 @@
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..utils import misc
+
+
+class NormalizedFocalLossSigmoid(nn.Module):
+ def __init__(self, axis=-1, alpha=0.25, gamma=2,
+ from_logits=False, batch_axis=0,
+ weight=None, size_average=True, detach_delimeter=True,
+ eps=1e-12, scale=1.0,
+ ignore_label=-1):
+ super(NormalizedFocalLossSigmoid, self).__init__()
+ self._axis = axis
+ self._alpha = alpha
+ self._gamma = gamma
+ self._ignore_label = ignore_label
+ self._weight = weight if weight is not None else 1.0
+ self._batch_axis = batch_axis
+
+ self._scale = scale
+ self._from_logits = from_logits
+ self._eps = eps
+ self._size_average = size_average
+ self._detach_delimeter = detach_delimeter
+ self._k_sum = 0
+
+ def forward(self, pred, label, sample_weight=None):
+ one_hot = label > 0
+ sample_weight = label != self._ignore_label
+
+ if not self._from_logits:
+ pred = torch.sigmoid(pred)
+
+ alpha = torch.where(one_hot, self._alpha * sample_weight, (1 - self._alpha) * sample_weight)
+ pt = torch.where(one_hot, pred, 1 - pred)
+ pt = torch.where(sample_weight, pt, torch.ones_like(pt))
+
+ beta = (1 - pt) ** self._gamma
+
+ sw_sum = torch.sum(sample_weight, dim=(-2, -1), keepdim=True)
+ beta_sum = torch.sum(beta, dim=(-2, -1), keepdim=True)
+ mult = sw_sum / (beta_sum + self._eps)
+ if self._detach_delimeter:
+ mult = mult.detach()
+ beta = beta * mult
+
+ ignore_area = torch.sum(label == self._ignore_label, dim=tuple(range(1, label.dim()))).cpu().numpy()
+ sample_mult = torch.mean(mult, dim=tuple(range(1, mult.dim()))).cpu().numpy()
+ if np.any(ignore_area == 0):
+ self._k_sum = 0.9 * self._k_sum + 0.1 * sample_mult[ignore_area == 0].mean()
+
+ loss = -alpha * beta * torch.log(torch.min(pt + self._eps, torch.ones(1, dtype=torch.float).to(pt.device)))
+ loss = self._weight * (loss * sample_weight)
+
+ if self._size_average:
+ bsum = torch.sum(sample_weight, dim=misc.get_dims_with_exclusion(sample_weight.dim(), self._batch_axis))
+ loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis)) / (bsum + self._eps)
+ else:
+ loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
+
+ return self._scale * loss
+
+ def log_states(self, sw, name, global_step):
+ sw.add_scalar(tag=name + '_k', value=self._k_sum, global_step=global_step)
+
+
+class FocalLoss(nn.Module):
+ def __init__(self, axis=-1, alpha=0.25, gamma=2,
+ from_logits=False, batch_axis=0,
+ weight=None, num_class=None,
+ eps=1e-9, size_average=True, scale=1.0):
+ super(FocalLoss, self).__init__()
+ self._axis = axis
+ self._alpha = alpha
+ self._gamma = gamma
+ self._weight = weight if weight is not None else 1.0
+ self._batch_axis = batch_axis
+
+ self._scale = scale
+ self._num_class = num_class
+ self._from_logits = from_logits
+ self._eps = eps
+ self._size_average = size_average
+
+ def forward(self, pred, label, sample_weight=None):
+ if not self._from_logits:
+ pred = F.sigmoid(pred)
+
+ one_hot = label > 0
+ pt = torch.where(one_hot, pred, 1 - pred)
+
+ t = label != -1
+ alpha = torch.where(one_hot, self._alpha * t, (1 - self._alpha) * t)
+ beta = (1 - pt) ** self._gamma
+
+ loss = -alpha * beta * torch.log(torch.min(pt + self._eps, torch.ones(1, dtype=torch.float).to(pt.device)))
+ sample_weight = label != -1
+
+ loss = self._weight * (loss * sample_weight)
+
+ if self._size_average:
+ tsum = torch.sum(label == 1, dim=misc.get_dims_with_exclusion(label.dim(), self._batch_axis))
+ loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis)) / (tsum + self._eps)
+ else:
+ loss = torch.sum(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
+
+ return self._scale * loss
+
+
+class SigmoidBinaryCrossEntropyLoss(nn.Module):
+ def __init__(self, from_sigmoid=False, weight=None, batch_axis=0, ignore_label=-1):
+ super(SigmoidBinaryCrossEntropyLoss, self).__init__()
+ self._from_sigmoid = from_sigmoid
+ self._ignore_label = ignore_label
+ self._weight = weight if weight is not None else 1.0
+ self._batch_axis = batch_axis
+
+ def forward(self, pred, label):
+ label = label.view(pred.size())
+ sample_weight = label != self._ignore_label
+ label = torch.where(sample_weight, label, torch.zeros_like(label))
+
+ if not self._from_sigmoid:
+ loss = torch.relu(pred) - pred * label + F.softplus(-torch.abs(pred))
+ else:
+ eps = 1e-12
+ loss = -(torch.log(pred + eps) * label
+ + torch.log(1. - pred + eps) * (1. - label))
+
+ loss = self._weight * (loss * sample_weight)
+ return torch.mean(loss, dim=misc.get_dims_with_exclusion(loss.dim(), self._batch_axis))
diff --git a/inference/interact/fbrs/model/metrics.py b/inference/interact/fbrs/model/metrics.py
new file mode 100644
index 0000000000000000000000000000000000000000..9944feb1cf76cfb8707122c7a6ea7a830c02070a
--- /dev/null
+++ b/inference/interact/fbrs/model/metrics.py
@@ -0,0 +1,101 @@
+import torch
+import numpy as np
+
+from ..utils import misc
+
+
+class TrainMetric(object):
+ def __init__(self, pred_outputs, gt_outputs):
+ self.pred_outputs = pred_outputs
+ self.gt_outputs = gt_outputs
+
+ def update(self, *args, **kwargs):
+ raise NotImplementedError
+
+ def get_epoch_value(self):
+ raise NotImplementedError
+
+ def reset_epoch_stats(self):
+ raise NotImplementedError
+
+ def log_states(self, sw, tag_prefix, global_step):
+ pass
+
+ @property
+ def name(self):
+ return type(self).__name__
+
+
+class AdaptiveIoU(TrainMetric):
+ def __init__(self, init_thresh=0.4, thresh_step=0.025, thresh_beta=0.99, iou_beta=0.9,
+ ignore_label=-1, from_logits=True,
+ pred_output='instances', gt_output='instances'):
+ super().__init__(pred_outputs=(pred_output,), gt_outputs=(gt_output,))
+ self._ignore_label = ignore_label
+ self._from_logits = from_logits
+ self._iou_thresh = init_thresh
+ self._thresh_step = thresh_step
+ self._thresh_beta = thresh_beta
+ self._iou_beta = iou_beta
+ self._ema_iou = 0.0
+ self._epoch_iou_sum = 0.0
+ self._epoch_batch_count = 0
+
+ def update(self, pred, gt):
+ gt_mask = gt > 0
+ if self._from_logits:
+ pred = torch.sigmoid(pred)
+
+ gt_mask_area = torch.sum(gt_mask, dim=(1, 2)).detach().cpu().numpy()
+ if np.all(gt_mask_area == 0):
+ return
+
+ ignore_mask = gt == self._ignore_label
+ max_iou = _compute_iou(pred > self._iou_thresh, gt_mask, ignore_mask).mean()
+ best_thresh = self._iou_thresh
+ for t in [best_thresh - self._thresh_step, best_thresh + self._thresh_step]:
+ temp_iou = _compute_iou(pred > t, gt_mask, ignore_mask).mean()
+ if temp_iou > max_iou:
+ max_iou = temp_iou
+ best_thresh = t
+
+ self._iou_thresh = self._thresh_beta * self._iou_thresh + (1 - self._thresh_beta) * best_thresh
+ self._ema_iou = self._iou_beta * self._ema_iou + (1 - self._iou_beta) * max_iou
+ self._epoch_iou_sum += max_iou
+ self._epoch_batch_count += 1
+
+ def get_epoch_value(self):
+ if self._epoch_batch_count > 0:
+ return self._epoch_iou_sum / self._epoch_batch_count
+ else:
+ return 0.0
+
+ def reset_epoch_stats(self):
+ self._epoch_iou_sum = 0.0
+ self._epoch_batch_count = 0
+
+ def log_states(self, sw, tag_prefix, global_step):
+ sw.add_scalar(tag=tag_prefix + '_ema_iou', value=self._ema_iou, global_step=global_step)
+ sw.add_scalar(tag=tag_prefix + '_iou_thresh', value=self._iou_thresh, global_step=global_step)
+
+ @property
+ def iou_thresh(self):
+ return self._iou_thresh
+
+
+def _compute_iou(pred_mask, gt_mask, ignore_mask=None, keep_ignore=False):
+ if ignore_mask is not None:
+ pred_mask = torch.where(ignore_mask, torch.zeros_like(pred_mask), pred_mask)
+
+ reduction_dims = misc.get_dims_with_exclusion(gt_mask.dim(), 0)
+ union = torch.mean((pred_mask | gt_mask).float(), dim=reduction_dims).detach().cpu().numpy()
+ intersection = torch.mean((pred_mask & gt_mask).float(), dim=reduction_dims).detach().cpu().numpy()
+ nonzero = union > 0
+
+ iou = intersection[nonzero] / union[nonzero]
+ if not keep_ignore:
+ return iou
+ else:
+ result = np.full_like(intersection, -1)
+ result[nonzero] = iou
+ return result
diff --git a/inference/interact/fbrs/model/modeling/__init__.py b/inference/interact/fbrs/model/modeling/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/model/modeling/basic_blocks.py b/inference/interact/fbrs/model/modeling/basic_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..35946e8b6639460d5822b46a3e82a85bc4f1060e
--- /dev/null
+++ b/inference/interact/fbrs/model/modeling/basic_blocks.py
@@ -0,0 +1,71 @@
+import torch.nn as nn
+
+from ...model import ops
+
+
+class ConvHead(nn.Module):
+ def __init__(self, out_channels, in_channels=32, num_layers=1,
+ kernel_size=3, padding=1,
+ norm_layer=nn.BatchNorm2d):
+ super(ConvHead, self).__init__()
+ convhead = []
+
+ for i in range(num_layers):
+ convhead.extend([
+ nn.Conv2d(in_channels, in_channels, kernel_size, padding=padding),
+ nn.ReLU(),
+ norm_layer(in_channels) if norm_layer is not None else nn.Identity()
+ ])
+ convhead.append(nn.Conv2d(in_channels, out_channels, 1, padding=0))
+
+ self.convhead = nn.Sequential(*convhead)
+
+ def forward(self, *inputs):
+ return self.convhead(inputs[0])
+
+
+class SepConvHead(nn.Module):
+ def __init__(self, num_outputs, in_channels, mid_channels, num_layers=1,
+ kernel_size=3, padding=1, dropout_ratio=0.0, dropout_indx=0,
+ norm_layer=nn.BatchNorm2d):
+ super(SepConvHead, self).__init__()
+
+ sepconvhead = []
+
+ for i in range(num_layers):
+ sepconvhead.append(
+ SeparableConv2d(in_channels=in_channels if i == 0 else mid_channels,
+ out_channels=mid_channels,
+ dw_kernel=kernel_size, dw_padding=padding,
+ norm_layer=norm_layer, activation='relu')
+ )
+ if dropout_ratio > 0 and dropout_indx == i:
+ sepconvhead.append(nn.Dropout(dropout_ratio))
+
+ sepconvhead.append(
+ nn.Conv2d(in_channels=mid_channels, out_channels=num_outputs, kernel_size=1, padding=0)
+ )
+
+ self.layers = nn.Sequential(*sepconvhead)
+
+ def forward(self, *inputs):
+ x = inputs[0]
+
+ return self.layers(x)
+
+
+class SeparableConv2d(nn.Module):
+ def __init__(self, in_channels, out_channels, dw_kernel, dw_padding, dw_stride=1,
+ activation=None, use_bias=False, norm_layer=None):
+ super(SeparableConv2d, self).__init__()
+ _activation = ops.select_activation_function(activation)
+ self.body = nn.Sequential(
+ nn.Conv2d(in_channels, in_channels, kernel_size=dw_kernel, stride=dw_stride,
+ padding=dw_padding, bias=use_bias, groups=in_channels),
+ nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=use_bias),
+ norm_layer(out_channels) if norm_layer is not None else nn.Identity(),
+ _activation()
+ )
+
+ def forward(self, x):
+ return self.body(x)
diff --git a/inference/interact/fbrs/model/modeling/deeplab_v3.py b/inference/interact/fbrs/model/modeling/deeplab_v3.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e863862c48a75a2ba9d9aa8a8025ee4333308d5
--- /dev/null
+++ b/inference/interact/fbrs/model/modeling/deeplab_v3.py
@@ -0,0 +1,176 @@
+from contextlib import ExitStack
+
+import torch
+from torch import nn
+import torch.nn.functional as F
+
+from .basic_blocks import SeparableConv2d
+from .resnet import ResNetBackbone
+from ...model import ops
+
+
+class DeepLabV3Plus(nn.Module):
+ def __init__(self, backbone='resnet50', norm_layer=nn.BatchNorm2d,
+ backbone_norm_layer=None,
+ ch=256,
+ project_dropout=0.5,
+ inference_mode=False,
+ **kwargs):
+ super(DeepLabV3Plus, self).__init__()
+ if backbone_norm_layer is None:
+ backbone_norm_layer = norm_layer
+
+ self.backbone_name = backbone
+ self.norm_layer = norm_layer
+ self.backbone_norm_layer = backbone_norm_layer
+ self.inference_mode = False
+ self.ch = ch
+ self.aspp_in_channels = 2048
+ self.skip_project_in_channels = 256 # layer 1 out_channels
+
+ self._kwargs = kwargs
+ if backbone == 'resnet34':
+ self.aspp_in_channels = 512
+ self.skip_project_in_channels = 64
+
+ self.backbone = ResNetBackbone(backbone=self.backbone_name, pretrained_base=False,
+ norm_layer=self.backbone_norm_layer, **kwargs)
+
+ self.head = _DeepLabHead(in_channels=ch + 32, mid_channels=ch, out_channels=ch,
+ norm_layer=self.norm_layer)
+ self.skip_project = _SkipProject(self.skip_project_in_channels, 32, norm_layer=self.norm_layer)
+ self.aspp = _ASPP(in_channels=self.aspp_in_channels,
+ atrous_rates=[12, 24, 36],
+ out_channels=ch,
+ project_dropout=project_dropout,
+ norm_layer=self.norm_layer)
+
+ if inference_mode:
+ self.set_prediction_mode()
+
+ def load_pretrained_weights(self):
+ pretrained = ResNetBackbone(backbone=self.backbone_name, pretrained_base=True,
+ norm_layer=self.backbone_norm_layer, **self._kwargs)
+ backbone_state_dict = self.backbone.state_dict()
+ pretrained_state_dict = pretrained.state_dict()
+
+ backbone_state_dict.update(pretrained_state_dict)
+ self.backbone.load_state_dict(backbone_state_dict)
+
+ if self.inference_mode:
+ for param in self.backbone.parameters():
+ param.requires_grad = False
+
+ def set_prediction_mode(self):
+ self.inference_mode = True
+ self.eval()
+
+ def forward(self, x):
+ with ExitStack() as stack:
+ if self.inference_mode:
+ stack.enter_context(torch.no_grad())
+
+ c1, _, c3, c4 = self.backbone(x)
+ c1 = self.skip_project(c1)
+
+ x = self.aspp(c4)
+ x = F.interpolate(x, c1.size()[2:], mode='bilinear', align_corners=True)
+ x = torch.cat((x, c1), dim=1)
+ x = self.head(x)
+
+ return x,
+
+
+class _SkipProject(nn.Module):
+ def __init__(self, in_channels, out_channels, norm_layer=nn.BatchNorm2d):
+ super(_SkipProject, self).__init__()
+ _activation = ops.select_activation_function("relu")
+
+ self.skip_project = nn.Sequential(
+ nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
+ norm_layer(out_channels),
+ _activation()
+ )
+
+ def forward(self, x):
+ return self.skip_project(x)
+
+
+class _DeepLabHead(nn.Module):
+ def __init__(self, out_channels, in_channels, mid_channels=256, norm_layer=nn.BatchNorm2d):
+ super(_DeepLabHead, self).__init__()
+
+ self.block = nn.Sequential(
+ SeparableConv2d(in_channels=in_channels, out_channels=mid_channels, dw_kernel=3,
+ dw_padding=1, activation='relu', norm_layer=norm_layer),
+ SeparableConv2d(in_channels=mid_channels, out_channels=mid_channels, dw_kernel=3,
+ dw_padding=1, activation='relu', norm_layer=norm_layer),
+ nn.Conv2d(in_channels=mid_channels, out_channels=out_channels, kernel_size=1)
+ )
+
+ def forward(self, x):
+ return self.block(x)
+
+
+class _ASPP(nn.Module):
+ def __init__(self, in_channels, atrous_rates, out_channels=256,
+ project_dropout=0.5, norm_layer=nn.BatchNorm2d):
+ super(_ASPP, self).__init__()
+
+ b0 = nn.Sequential(
+ nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, bias=False),
+ norm_layer(out_channels),
+ nn.ReLU()
+ )
+
+ rate1, rate2, rate3 = tuple(atrous_rates)
+ b1 = _ASPPConv(in_channels, out_channels, rate1, norm_layer)
+ b2 = _ASPPConv(in_channels, out_channels, rate2, norm_layer)
+ b3 = _ASPPConv(in_channels, out_channels, rate3, norm_layer)
+ b4 = _AsppPooling(in_channels, out_channels, norm_layer=norm_layer)
+
+ self.concurent = nn.ModuleList([b0, b1, b2, b3, b4])
+
+ project = [
+ nn.Conv2d(in_channels=5*out_channels, out_channels=out_channels,
+ kernel_size=1, bias=False),
+ norm_layer(out_channels),
+ nn.ReLU()
+ ]
+ if project_dropout > 0:
+ project.append(nn.Dropout(project_dropout))
+ self.project = nn.Sequential(*project)
+
+ def forward(self, x):
+ x = torch.cat([block(x) for block in self.concurent], dim=1)
+
+ return self.project(x)
+
+
+class _AsppPooling(nn.Module):
+ def __init__(self, in_channels, out_channels, norm_layer):
+ super(_AsppPooling, self).__init__()
+
+ self.gap = nn.Sequential(
+ nn.AdaptiveAvgPool2d((1, 1)),
+ nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
+ kernel_size=1, bias=False),
+ norm_layer(out_channels),
+ nn.ReLU()
+ )
+
+ def forward(self, x):
+ pool = self.gap(x)
+ return F.interpolate(pool, x.size()[2:], mode='bilinear', align_corners=True)
+
+
+def _ASPPConv(in_channels, out_channels, atrous_rate, norm_layer):
+ block = nn.Sequential(
+ nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
+ kernel_size=3, padding=atrous_rate,
+ dilation=atrous_rate, bias=False),
+ norm_layer(out_channels),
+ nn.ReLU()
+ )
+
+ return block
diff --git a/inference/interact/fbrs/model/modeling/hrnet_ocr.py b/inference/interact/fbrs/model/modeling/hrnet_ocr.py
new file mode 100644
index 0000000000000000000000000000000000000000..c24a367dfd2d7b648018cc34366c0376f297b91e
--- /dev/null
+++ b/inference/interact/fbrs/model/modeling/hrnet_ocr.py
@@ -0,0 +1,399 @@
+import os
+import numpy as np
+import torch
+import torch.nn as nn
+import torch._utils
+import torch.nn.functional as F
+from .ocr import SpatialOCR_Module, SpatialGather_Module
+from .resnetv1b import BasicBlockV1b, BottleneckV1b
+
+relu_inplace = True
+
+
+class HighResolutionModule(nn.Module):
+ def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
+ num_channels, fuse_method,multi_scale_output=True,
+ norm_layer=nn.BatchNorm2d, align_corners=True):
+ super(HighResolutionModule, self).__init__()
+ self._check_branches(num_branches, num_blocks, num_inchannels, num_channels)
+
+ self.num_inchannels = num_inchannels
+ self.fuse_method = fuse_method
+ self.num_branches = num_branches
+ self.norm_layer = norm_layer
+ self.align_corners = align_corners
+
+ self.multi_scale_output = multi_scale_output
+
+ self.branches = self._make_branches(
+ num_branches, blocks, num_blocks, num_channels)
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU(inplace=relu_inplace)
+
+ def _check_branches(self, num_branches, num_blocks, num_inchannels, num_channels):
+ if num_branches != len(num_blocks):
+ error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
+ num_branches, len(num_blocks))
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_channels):
+ error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
+ num_branches, len(num_channels))
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_inchannels):
+ error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
+ num_branches, len(num_inchannels))
+ raise ValueError(error_msg)
+
+ def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
+ stride=1):
+ downsample = None
+ if stride != 1 or \
+ self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
+ downsample = nn.Sequential(
+ nn.Conv2d(self.num_inchannels[branch_index],
+ num_channels[branch_index] * block.expansion,
+ kernel_size=1, stride=stride, bias=False),
+ self.norm_layer(num_channels[branch_index] * block.expansion),
+ )
+
+ layers = []
+ layers.append(block(self.num_inchannels[branch_index],
+ num_channels[branch_index], stride,
+ downsample=downsample, norm_layer=self.norm_layer))
+ self.num_inchannels[branch_index] = \
+ num_channels[branch_index] * block.expansion
+ for i in range(1, num_blocks[branch_index]):
+ layers.append(block(self.num_inchannels[branch_index],
+ num_channels[branch_index],
+ norm_layer=self.norm_layer))
+
+ return nn.Sequential(*layers)
+
+ def _make_branches(self, num_branches, block, num_blocks, num_channels):
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(
+ self._make_one_branch(i, block, num_blocks, num_channels))
+
+ return nn.ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ num_inchannels = self.num_inchannels
+ fuse_layers = []
+ for i in range(num_branches if self.multi_scale_output else 1):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(nn.Sequential(
+ nn.Conv2d(in_channels=num_inchannels[j],
+ out_channels=num_inchannels[i],
+ kernel_size=1,
+ bias=False),
+ self.norm_layer(num_inchannels[i])))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv3x3s = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ num_outchannels_conv3x3 = num_inchannels[i]
+ conv3x3s.append(nn.Sequential(
+ nn.Conv2d(num_inchannels[j],
+ num_outchannels_conv3x3,
+ kernel_size=3, stride=2, padding=1, bias=False),
+ self.norm_layer(num_outchannels_conv3x3)))
+ else:
+ num_outchannels_conv3x3 = num_inchannels[j]
+ conv3x3s.append(nn.Sequential(
+ nn.Conv2d(num_inchannels[j],
+ num_outchannels_conv3x3,
+ kernel_size=3, stride=2, padding=1, bias=False),
+ self.norm_layer(num_outchannels_conv3x3),
+ nn.ReLU(inplace=relu_inplace)))
+ fuse_layer.append(nn.Sequential(*conv3x3s))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def get_num_inchannels(self):
+ return self.num_inchannels
+
+ def forward(self, x):
+ if self.num_branches == 1:
+ return [self.branches[0](x[0])]
+
+ for i in range(self.num_branches):
+ x[i] = self.branches[i](x[i])
+
+ x_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
+ for j in range(1, self.num_branches):
+ if i == j:
+ y = y + x[j]
+ elif j > i:
+ width_output = x[i].shape[-1]
+ height_output = x[i].shape[-2]
+ y = y + F.interpolate(
+ self.fuse_layers[i][j](x[j]),
+ size=[height_output, width_output],
+ mode='bilinear', align_corners=self.align_corners)
+ else:
+ y = y + self.fuse_layers[i][j](x[j])
+ x_fuse.append(self.relu(y))
+
+ return x_fuse
+
+
+class HighResolutionNet(nn.Module):
+ def __init__(self, width, num_classes, ocr_width=256, small=False,
+ norm_layer=nn.BatchNorm2d, align_corners=True):
+ super(HighResolutionNet, self).__init__()
+ self.norm_layer = norm_layer
+ self.width = width
+ self.ocr_width = ocr_width
+ self.align_corners = align_corners
+
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)
+ self.bn1 = norm_layer(64)
+ self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False)
+ self.bn2 = norm_layer(64)
+ self.relu = nn.ReLU(inplace=relu_inplace)
+
+ num_blocks = 2 if small else 4
+
+ stage1_num_channels = 64
+ self.layer1 = self._make_layer(BottleneckV1b, 64, stage1_num_channels, blocks=num_blocks)
+ stage1_out_channel = BottleneckV1b.expansion * stage1_num_channels
+
+ self.stage2_num_branches = 2
+ num_channels = [width, 2 * width]
+ num_inchannels = [
+ num_channels[i] * BasicBlockV1b.expansion for i in range(len(num_channels))]
+ self.transition1 = self._make_transition_layer(
+ [stage1_out_channel], num_inchannels)
+ self.stage2, pre_stage_channels = self._make_stage(
+ BasicBlockV1b, num_inchannels=num_inchannels, num_modules=1, num_branches=self.stage2_num_branches,
+ num_blocks=2 * [num_blocks], num_channels=num_channels)
+
+ self.stage3_num_branches = 3
+ num_channels = [width, 2 * width, 4 * width]
+ num_inchannels = [
+ num_channels[i] * BasicBlockV1b.expansion for i in range(len(num_channels))]
+ self.transition2 = self._make_transition_layer(
+ pre_stage_channels, num_inchannels)
+ self.stage3, pre_stage_channels = self._make_stage(
+ BasicBlockV1b, num_inchannels=num_inchannels,
+ num_modules=3 if small else 4, num_branches=self.stage3_num_branches,
+ num_blocks=3 * [num_blocks], num_channels=num_channels)
+
+ self.stage4_num_branches = 4
+ num_channels = [width, 2 * width, 4 * width, 8 * width]
+ num_inchannels = [
+ num_channels[i] * BasicBlockV1b.expansion for i in range(len(num_channels))]
+ self.transition3 = self._make_transition_layer(
+ pre_stage_channels, num_inchannels)
+ self.stage4, pre_stage_channels = self._make_stage(
+ BasicBlockV1b, num_inchannels=num_inchannels, num_modules=2 if small else 3,
+ num_branches=self.stage4_num_branches,
+ num_blocks=4 * [num_blocks], num_channels=num_channels)
+
+ last_inp_channels = np.int(np.sum(pre_stage_channels))
+ ocr_mid_channels = 2 * ocr_width
+ ocr_key_channels = ocr_width
+
+ self.conv3x3_ocr = nn.Sequential(
+ nn.Conv2d(last_inp_channels, ocr_mid_channels,
+ kernel_size=3, stride=1, padding=1),
+ norm_layer(ocr_mid_channels),
+ nn.ReLU(inplace=relu_inplace),
+ )
+ self.ocr_gather_head = SpatialGather_Module(num_classes)
+
+ self.ocr_distri_head = SpatialOCR_Module(in_channels=ocr_mid_channels,
+ key_channels=ocr_key_channels,
+ out_channels=ocr_mid_channels,
+ scale=1,
+ dropout=0.05,
+ norm_layer=norm_layer,
+ align_corners=align_corners)
+ self.cls_head = nn.Conv2d(
+ ocr_mid_channels, num_classes, kernel_size=1, stride=1, padding=0, bias=True)
+
+ self.aux_head = nn.Sequential(
+ nn.Conv2d(last_inp_channels, last_inp_channels,
+ kernel_size=1, stride=1, padding=0),
+ norm_layer(last_inp_channels),
+ nn.ReLU(inplace=relu_inplace),
+ nn.Conv2d(last_inp_channels, num_classes,
+ kernel_size=1, stride=1, padding=0, bias=True)
+ )
+
+ def _make_transition_layer(
+ self, num_channels_pre_layer, num_channels_cur_layer):
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(nn.Sequential(
+ nn.Conv2d(num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ self.norm_layer(num_channels_cur_layer[i]),
+ nn.ReLU(inplace=relu_inplace)))
+ else:
+ transition_layers.append(None)
+ else:
+ conv3x3s = []
+ for j in range(i + 1 - num_branches_pre):
+ inchannels = num_channels_pre_layer[-1]
+ outchannels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else inchannels
+ conv3x3s.append(nn.Sequential(
+ nn.Conv2d(inchannels, outchannels,
+ kernel_size=3, stride=2, padding=1, bias=False),
+ self.norm_layer(outchannels),
+ nn.ReLU(inplace=relu_inplace)))
+ transition_layers.append(nn.Sequential(*conv3x3s))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_layer(self, block, inplanes, planes, blocks, stride=1):
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ nn.Conv2d(inplanes, planes * block.expansion,
+ kernel_size=1, stride=stride, bias=False),
+ self.norm_layer(planes * block.expansion),
+ )
+
+ layers = []
+ layers.append(block(inplanes, planes, stride,
+ downsample=downsample, norm_layer=self.norm_layer))
+ inplanes = planes * block.expansion
+ for i in range(1, blocks):
+ layers.append(block(inplanes, planes, norm_layer=self.norm_layer))
+
+ return nn.Sequential(*layers)
+
+ def _make_stage(self, block, num_inchannels,
+ num_modules, num_branches, num_blocks, num_channels,
+ fuse_method='SUM',
+ multi_scale_output=True):
+ modules = []
+ for i in range(num_modules):
+ # multi_scale_output is only used last module
+ if not multi_scale_output and i == num_modules - 1:
+ reset_multi_scale_output = False
+ else:
+ reset_multi_scale_output = True
+ modules.append(
+ HighResolutionModule(num_branches,
+ block,
+ num_blocks,
+ num_inchannels,
+ num_channels,
+ fuse_method,
+ reset_multi_scale_output,
+ norm_layer=self.norm_layer,
+ align_corners=self.align_corners)
+ )
+ num_inchannels = modules[-1].get_num_inchannels()
+
+ return nn.Sequential(*modules), num_inchannels
+
+ def forward(self, x):
+ feats = self.compute_hrnet_feats(x)
+ out_aux = self.aux_head(feats)
+ feats = self.conv3x3_ocr(feats)
+
+ context = self.ocr_gather_head(feats, out_aux)
+ feats = self.ocr_distri_head(feats, context)
+ out = self.cls_head(feats)
+
+ return [out, out_aux]
+
+ def compute_hrnet_feats(self, x):
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu(x)
+ x = self.conv2(x)
+ x = self.bn2(x)
+ x = self.relu(x)
+ x = self.layer1(x)
+
+ x_list = []
+ for i in range(self.stage2_num_branches):
+ if self.transition1[i] is not None:
+ x_list.append(self.transition1[i](x))
+ else:
+ x_list.append(x)
+ y_list = self.stage2(x_list)
+
+ x_list = []
+ for i in range(self.stage3_num_branches):
+ if self.transition2[i] is not None:
+ if i < self.stage2_num_branches:
+ x_list.append(self.transition2[i](y_list[i]))
+ else:
+ x_list.append(self.transition2[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage3(x_list)
+
+ x_list = []
+ for i in range(self.stage4_num_branches):
+ if self.transition3[i] is not None:
+ if i < self.stage3_num_branches:
+ x_list.append(self.transition3[i](y_list[i]))
+ else:
+ x_list.append(self.transition3[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ x = self.stage4(x_list)
+
+ # Upsampling
+ x0_h, x0_w = x[0].size(2), x[0].size(3)
+ x1 = F.interpolate(x[1], size=(x0_h, x0_w),
+ mode='bilinear', align_corners=self.align_corners)
+ x2 = F.interpolate(x[2], size=(x0_h, x0_w),
+ mode='bilinear', align_corners=self.align_corners)
+ x3 = F.interpolate(x[3], size=(x0_h, x0_w),
+ mode='bilinear', align_corners=self.align_corners)
+
+ return torch.cat([x[0], x1, x2, x3], 1)
+
+ def load_pretrained_weights(self, pretrained_path=''):
+ model_dict = self.state_dict()
+
+ if not os.path.exists(pretrained_path):
+ print(f'\nFile "{pretrained_path}" does not exist.')
+ print('You need to specify the correct path to the pre-trained weights.\n'
+ 'You can download the weights for HRNet from the repository:\n'
+ 'https://github.com/HRNet/HRNet-Image-Classification')
+ exit(1)
+ pretrained_dict = torch.load(pretrained_path, map_location={'cuda:0': 'cpu'})
+ pretrained_dict = {k.replace('last_layer', 'aux_head').replace('model.', ''): v for k, v in
+ pretrained_dict.items()}
+
+ print('model_dict-pretrained_dict:', sorted(list(set(model_dict) - set(pretrained_dict))))
+ print('pretrained_dict-model_dict:', sorted(list(set(pretrained_dict) - set(model_dict))))
+
+ pretrained_dict = {k: v for k, v in pretrained_dict.items()
+ if k in model_dict.keys()}
+
+ model_dict.update(pretrained_dict)
+ self.load_state_dict(model_dict)
diff --git a/inference/interact/fbrs/model/modeling/ocr.py b/inference/interact/fbrs/model/modeling/ocr.py
new file mode 100644
index 0000000000000000000000000000000000000000..df3b4f67959fc6a088b93ee7a34b15c1e07402df
--- /dev/null
+++ b/inference/interact/fbrs/model/modeling/ocr.py
@@ -0,0 +1,141 @@
+import torch
+import torch.nn as nn
+import torch._utils
+import torch.nn.functional as F
+
+
+class SpatialGather_Module(nn.Module):
+ """
+ Aggregate the context features according to the initial
+ predicted probability distribution.
+ Employ the soft-weighted method to aggregate the context.
+ """
+
+ def __init__(self, cls_num=0, scale=1):
+ super(SpatialGather_Module, self).__init__()
+ self.cls_num = cls_num
+ self.scale = scale
+
+ def forward(self, feats, probs):
+ batch_size, c, h, w = probs.size(0), probs.size(1), probs.size(2), probs.size(3)
+ probs = probs.view(batch_size, c, -1)
+ feats = feats.view(batch_size, feats.size(1), -1)
+ feats = feats.permute(0, 2, 1) # batch x hw x c
+ probs = F.softmax(self.scale * probs, dim=2) # batch x k x hw
+ ocr_context = torch.matmul(probs, feats) \
+ .permute(0, 2, 1).unsqueeze(3) # batch x k x c
+ return ocr_context
+
+
+class SpatialOCR_Module(nn.Module):
+ """
+ Implementation of the OCR module:
+ We aggregate the global object representation to update the representation for each pixel.
+ """
+
+ def __init__(self,
+ in_channels,
+ key_channels,
+ out_channels,
+ scale=1,
+ dropout=0.1,
+ norm_layer=nn.BatchNorm2d,
+ align_corners=True):
+ super(SpatialOCR_Module, self).__init__()
+ self.object_context_block = ObjectAttentionBlock2D(in_channels, key_channels, scale,
+ norm_layer, align_corners)
+ _in_channels = 2 * in_channels
+
+ self.conv_bn_dropout = nn.Sequential(
+ nn.Conv2d(_in_channels, out_channels, kernel_size=1, padding=0, bias=False),
+ nn.Sequential(norm_layer(out_channels), nn.ReLU(inplace=True)),
+ nn.Dropout2d(dropout)
+ )
+
+ def forward(self, feats, proxy_feats):
+ context = self.object_context_block(feats, proxy_feats)
+
+ output = self.conv_bn_dropout(torch.cat([context, feats], 1))
+
+ return output
+
+
+class ObjectAttentionBlock2D(nn.Module):
+ '''
+ The basic implementation for object context block
+ Input:
+ N X C X H X W
+ Parameters:
+ in_channels : the dimension of the input feature map
+ key_channels : the dimension after the key/query transform
+ scale : choose the scale to downsample the input feature maps (save memory cost)
+ bn_type : specify the bn type
+ Return:
+ N X C X H X W
+ '''
+
+ def __init__(self,
+ in_channels,
+ key_channels,
+ scale=1,
+ norm_layer=nn.BatchNorm2d,
+ align_corners=True):
+ super(ObjectAttentionBlock2D, self).__init__()
+ self.scale = scale
+ self.in_channels = in_channels
+ self.key_channels = key_channels
+ self.align_corners = align_corners
+
+ self.pool = nn.MaxPool2d(kernel_size=(scale, scale))
+ self.f_pixel = nn.Sequential(
+ nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
+ kernel_size=1, stride=1, padding=0, bias=False),
+ nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True)),
+ nn.Conv2d(in_channels=self.key_channels, out_channels=self.key_channels,
+ kernel_size=1, stride=1, padding=0, bias=False),
+ nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True))
+ )
+ self.f_object = nn.Sequential(
+ nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
+ kernel_size=1, stride=1, padding=0, bias=False),
+ nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True)),
+ nn.Conv2d(in_channels=self.key_channels, out_channels=self.key_channels,
+ kernel_size=1, stride=1, padding=0, bias=False),
+ nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True))
+ )
+ self.f_down = nn.Sequential(
+ nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
+ kernel_size=1, stride=1, padding=0, bias=False),
+ nn.Sequential(norm_layer(self.key_channels), nn.ReLU(inplace=True))
+ )
+ self.f_up = nn.Sequential(
+ nn.Conv2d(in_channels=self.key_channels, out_channels=self.in_channels,
+ kernel_size=1, stride=1, padding=0, bias=False),
+ nn.Sequential(norm_layer(self.in_channels), nn.ReLU(inplace=True))
+ )
+
+ def forward(self, x, proxy):
+ batch_size, h, w = x.size(0), x.size(2), x.size(3)
+ if self.scale > 1:
+ x = self.pool(x)
+
+ query = self.f_pixel(x).view(batch_size, self.key_channels, -1)
+ query = query.permute(0, 2, 1)
+ key = self.f_object(proxy).view(batch_size, self.key_channels, -1)
+ value = self.f_down(proxy).view(batch_size, self.key_channels, -1)
+ value = value.permute(0, 2, 1)
+
+ sim_map = torch.matmul(query, key)
+ sim_map = (self.key_channels ** -.5) * sim_map
+ sim_map = F.softmax(sim_map, dim=-1)
+
+ # add bg context ...
+ context = torch.matmul(sim_map, value)
+ context = context.permute(0, 2, 1).contiguous()
+ context = context.view(batch_size, self.key_channels, *x.size()[2:])
+ context = self.f_up(context)
+ if self.scale > 1:
+ context = F.interpolate(input=context, size=(h, w),
+ mode='bilinear', align_corners=self.align_corners)
+
+ return context
diff --git a/inference/interact/fbrs/model/modeling/resnet.py b/inference/interact/fbrs/model/modeling/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..349ea1cbd882a9b0daa1d6146b634e9baf3726e0
--- /dev/null
+++ b/inference/interact/fbrs/model/modeling/resnet.py
@@ -0,0 +1,39 @@
+import torch
+from .resnetv1b import resnet34_v1b, resnet50_v1s, resnet101_v1s, resnet152_v1s
+
+
+class ResNetBackbone(torch.nn.Module):
+ def __init__(self, backbone='resnet50', pretrained_base=True, dilated=True, **kwargs):
+ super(ResNetBackbone, self).__init__()
+
+ if backbone == 'resnet34':
+ pretrained = resnet34_v1b(pretrained=pretrained_base, dilated=dilated, **kwargs)
+ elif backbone == 'resnet50':
+ pretrained = resnet50_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
+ elif backbone == 'resnet101':
+ pretrained = resnet101_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
+ elif backbone == 'resnet152':
+ pretrained = resnet152_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
+ else:
+ raise RuntimeError(f'unknown backbone: {backbone}')
+
+ self.conv1 = pretrained.conv1
+ self.bn1 = pretrained.bn1
+ self.relu = pretrained.relu
+ self.maxpool = pretrained.maxpool
+ self.layer1 = pretrained.layer1
+ self.layer2 = pretrained.layer2
+ self.layer3 = pretrained.layer3
+ self.layer4 = pretrained.layer4
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+ c1 = self.layer1(x)
+ c2 = self.layer2(c1)
+ c3 = self.layer3(c2)
+ c4 = self.layer4(c3)
+
+ return c1, c2, c3, c4
diff --git a/inference/interact/fbrs/model/modeling/resnetv1b.py b/inference/interact/fbrs/model/modeling/resnetv1b.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ad24cef5bde19f2627cfd3f755636f37cfb39ac
--- /dev/null
+++ b/inference/interact/fbrs/model/modeling/resnetv1b.py
@@ -0,0 +1,276 @@
+import torch
+import torch.nn as nn
+GLUON_RESNET_TORCH_HUB = 'rwightman/pytorch-pretrained-gluonresnet'
+
+
+class BasicBlockV1b(nn.Module):
+ expansion = 1
+
+ def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None,
+ previous_dilation=1, norm_layer=nn.BatchNorm2d):
+ super(BasicBlockV1b, self).__init__()
+ self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
+ padding=dilation, dilation=dilation, bias=False)
+ self.bn1 = norm_layer(planes)
+ self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1,
+ padding=previous_dilation, dilation=previous_dilation, bias=False)
+ self.bn2 = norm_layer(planes)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out = out + residual
+ out = self.relu(out)
+
+ return out
+
+
+class BottleneckV1b(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None,
+ previous_dilation=1, norm_layer=nn.BatchNorm2d):
+ super(BottleneckV1b, self).__init__()
+ self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
+ self.bn1 = norm_layer(planes)
+
+ self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
+ padding=dilation, dilation=dilation, bias=False)
+ self.bn2 = norm_layer(planes)
+
+ self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
+ self.bn3 = norm_layer(planes * self.expansion)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.bn3(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out = out + residual
+ out = self.relu(out)
+
+ return out
+
+
+class ResNetV1b(nn.Module):
+ """ Pre-trained ResNetV1b Model, which produces the strides of 8 featuremaps at conv5.
+
+ Parameters
+ ----------
+ block : Block
+ Class for the residual block. Options are BasicBlockV1, BottleneckV1.
+ layers : list of int
+ Numbers of layers in each block
+ classes : int, default 1000
+ Number of classification classes.
+ dilated : bool, default False
+ Applying dilation strategy to pretrained ResNet yielding a stride-8 model,
+ typically used in Semantic Segmentation.
+ norm_layer : object
+ Normalization layer used (default: :class:`nn.BatchNorm2d`)
+ deep_stem : bool, default False
+ Whether to replace the 7x7 conv1 with 3 3x3 convolution layers.
+ avg_down : bool, default False
+ Whether to use average pooling for projection skip connection between stages/downsample.
+ final_drop : float, default 0.0
+ Dropout ratio before the final classification layer.
+
+ Reference:
+ - He, Kaiming, et al. "Deep residual learning for image recognition."
+ Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
+
+ - Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions."
+ """
+ def __init__(self, block, layers, classes=1000, dilated=True, deep_stem=False, stem_width=32,
+ avg_down=False, final_drop=0.0, norm_layer=nn.BatchNorm2d):
+ self.inplanes = stem_width*2 if deep_stem else 64
+ super(ResNetV1b, self).__init__()
+ if not deep_stem:
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
+ else:
+ self.conv1 = nn.Sequential(
+ nn.Conv2d(3, stem_width, kernel_size=3, stride=2, padding=1, bias=False),
+ norm_layer(stem_width),
+ nn.ReLU(True),
+ nn.Conv2d(stem_width, stem_width, kernel_size=3, stride=1, padding=1, bias=False),
+ norm_layer(stem_width),
+ nn.ReLU(True),
+ nn.Conv2d(stem_width, 2*stem_width, kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ self.bn1 = norm_layer(self.inplanes)
+ self.relu = nn.ReLU(True)
+ self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
+ self.layer1 = self._make_layer(block, 64, layers[0], avg_down=avg_down,
+ norm_layer=norm_layer)
+ self.layer2 = self._make_layer(block, 128, layers[1], stride=2, avg_down=avg_down,
+ norm_layer=norm_layer)
+ if dilated:
+ self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2,
+ avg_down=avg_down, norm_layer=norm_layer)
+ self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4,
+ avg_down=avg_down, norm_layer=norm_layer)
+ else:
+ self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
+ avg_down=avg_down, norm_layer=norm_layer)
+ self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
+ avg_down=avg_down, norm_layer=norm_layer)
+ self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
+ self.drop = None
+ if final_drop > 0.0:
+ self.drop = nn.Dropout(final_drop)
+ self.fc = nn.Linear(512 * block.expansion, classes)
+
+ def _make_layer(self, block, planes, blocks, stride=1, dilation=1,
+ avg_down=False, norm_layer=nn.BatchNorm2d):
+ downsample = None
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = []
+ if avg_down:
+ if dilation == 1:
+ downsample.append(
+ nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True, count_include_pad=False)
+ )
+ else:
+ downsample.append(
+ nn.AvgPool2d(kernel_size=1, stride=1, ceil_mode=True, count_include_pad=False)
+ )
+ downsample.extend([
+ nn.Conv2d(self.inplanes, out_channels=planes * block.expansion,
+ kernel_size=1, stride=1, bias=False),
+ norm_layer(planes * block.expansion)
+ ])
+ downsample = nn.Sequential(*downsample)
+ else:
+ downsample = nn.Sequential(
+ nn.Conv2d(self.inplanes, out_channels=planes * block.expansion,
+ kernel_size=1, stride=stride, bias=False),
+ norm_layer(planes * block.expansion)
+ )
+
+ layers = []
+ if dilation in (1, 2):
+ layers.append(block(self.inplanes, planes, stride, dilation=1, downsample=downsample,
+ previous_dilation=dilation, norm_layer=norm_layer))
+ elif dilation == 4:
+ layers.append(block(self.inplanes, planes, stride, dilation=2, downsample=downsample,
+ previous_dilation=dilation, norm_layer=norm_layer))
+ else:
+ raise RuntimeError("=> unknown dilation size: {}".format(dilation))
+
+ self.inplanes = planes * block.expansion
+ for _ in range(1, blocks):
+ layers.append(block(self.inplanes, planes, dilation=dilation,
+ previous_dilation=dilation, norm_layer=norm_layer))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+
+ x = self.avgpool(x)
+ x = x.view(x.size(0), -1)
+ if self.drop is not None:
+ x = self.drop(x)
+ x = self.fc(x)
+
+ return x
+
+
+def _safe_state_dict_filtering(orig_dict, model_dict_keys):
+ filtered_orig_dict = {}
+ for k, v in orig_dict.items():
+ if k in model_dict_keys:
+ filtered_orig_dict[k] = v
+ else:
+ print(f"[ERROR] Failed to load <{k}> in backbone")
+ return filtered_orig_dict
+
+
+def resnet34_v1b(pretrained=False, **kwargs):
+ model = ResNetV1b(BasicBlockV1b, [3, 4, 6, 3], **kwargs)
+ if pretrained:
+ model_dict = model.state_dict()
+ filtered_orig_dict = _safe_state_dict_filtering(
+ torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet34_v1b', pretrained=True).state_dict(),
+ model_dict.keys()
+ )
+ model_dict.update(filtered_orig_dict)
+ model.load_state_dict(model_dict)
+ return model
+
+
+def resnet50_v1s(pretrained=False, **kwargs):
+ model = ResNetV1b(BottleneckV1b, [3, 4, 6, 3], deep_stem=True, stem_width=64, **kwargs)
+ if pretrained:
+ model_dict = model.state_dict()
+ filtered_orig_dict = _safe_state_dict_filtering(
+ torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet50_v1s', pretrained=True).state_dict(),
+ model_dict.keys()
+ )
+ model_dict.update(filtered_orig_dict)
+ model.load_state_dict(model_dict)
+ return model
+
+
+def resnet101_v1s(pretrained=False, **kwargs):
+ model = ResNetV1b(BottleneckV1b, [3, 4, 23, 3], deep_stem=True, stem_width=64, **kwargs)
+ if pretrained:
+ model_dict = model.state_dict()
+ filtered_orig_dict = _safe_state_dict_filtering(
+ torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet101_v1s', pretrained=True).state_dict(),
+ model_dict.keys()
+ )
+ model_dict.update(filtered_orig_dict)
+ model.load_state_dict(model_dict)
+ return model
+
+
+def resnet152_v1s(pretrained=False, **kwargs):
+ model = ResNetV1b(BottleneckV1b, [3, 8, 36, 3], deep_stem=True, stem_width=64, **kwargs)
+ if pretrained:
+ model_dict = model.state_dict()
+ filtered_orig_dict = _safe_state_dict_filtering(
+ torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet152_v1s', pretrained=True).state_dict(),
+ model_dict.keys()
+ )
+ model_dict.update(filtered_orig_dict)
+ model.load_state_dict(model_dict)
+ return model
diff --git a/inference/interact/fbrs/model/ops.py b/inference/interact/fbrs/model/ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..f46ae39aeb14cdb0ca6d9922b67f4562c40be8df
--- /dev/null
+++ b/inference/interact/fbrs/model/ops.py
@@ -0,0 +1,83 @@
+import torch
+from torch import nn as nn
+import numpy as np
+
+from . import initializer as initializer
+from ..utils.cython import get_dist_maps
+
+
+def select_activation_function(activation):
+ if isinstance(activation, str):
+ if activation.lower() == 'relu':
+ return nn.ReLU
+ elif activation.lower() == 'softplus':
+ return nn.Softplus
+ else:
+ raise ValueError(f"Unknown activation type {activation}")
+ elif isinstance(activation, nn.Module):
+ return activation
+ else:
+ raise ValueError(f"Unknown activation type {activation}")
+
+
+class BilinearConvTranspose2d(nn.ConvTranspose2d):
+ def __init__(self, in_channels, out_channels, scale, groups=1):
+ kernel_size = 2 * scale - scale % 2
+ self.scale = scale
+
+ super().__init__(
+ in_channels, out_channels,
+ kernel_size=kernel_size,
+ stride=scale,
+ padding=1,
+ groups=groups,
+ bias=False)
+
+ self.apply(initializer.Bilinear(scale=scale, in_channels=in_channels, groups=groups))
+
+
+class DistMaps(nn.Module):
+ def __init__(self, norm_radius, spatial_scale=1.0, cpu_mode=False):
+ super(DistMaps, self).__init__()
+ self.spatial_scale = spatial_scale
+ self.norm_radius = norm_radius
+ self.cpu_mode = cpu_mode
+
+ def get_coord_features(self, points, batchsize, rows, cols):
+ if self.cpu_mode:
+ coords = []
+ for i in range(batchsize):
+ norm_delimeter = self.spatial_scale * self.norm_radius
+ coords.append(get_dist_maps(points[i].cpu().float().numpy(), rows, cols,
+ norm_delimeter))
+ coords = torch.from_numpy(np.stack(coords, axis=0)).to(points.device).float()
+ else:
+ num_points = points.shape[1] // 2
+ points = points.view(-1, 2)
+ invalid_points = torch.max(points, dim=1, keepdim=False)[0] < 0
+ row_array = torch.arange(start=0, end=rows, step=1, dtype=torch.float32, device=points.device)
+ col_array = torch.arange(start=0, end=cols, step=1, dtype=torch.float32, device=points.device)
+
+ coord_rows, coord_cols = torch.meshgrid(row_array, col_array)
+ coords = torch.stack((coord_rows, coord_cols), dim=0).unsqueeze(0).repeat(points.size(0), 1, 1, 1)
+
+ add_xy = (points * self.spatial_scale).view(points.size(0), points.size(1), 1, 1)
+ coords.add_(-add_xy)
+ coords.div_(self.norm_radius * self.spatial_scale)
+ coords.mul_(coords)
+
+ coords[:, 0] += coords[:, 1]
+ coords = coords[:, :1]
+
+ coords[invalid_points, :, :, :] = 1e6
+
+ coords = coords.view(-1, num_points, 1, rows, cols)
+ coords = coords.min(dim=1)[0] # -> (bs * num_masks * 2) x 1 x h x w
+ coords = coords.view(-1, 2, rows, cols)
+
+ coords.sqrt_().mul_(2).tanh_()
+
+ return coords
+
+ def forward(self, x, coords):
+ return self.get_coord_features(coords, x.shape[0], x.shape[2], x.shape[3])
diff --git a/inference/interact/fbrs/model/syncbn/LICENSE b/inference/interact/fbrs/model/syncbn/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..fec54698d35926513ca1ddb7b6cee791daca834e
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2018 Tamaki Kojima
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/inference/interact/fbrs/model/syncbn/README.md b/inference/interact/fbrs/model/syncbn/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d9a9ea21ca73d08dbac027aea3a4909d6b67ace3
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/README.md
@@ -0,0 +1,127 @@
+# pytorch-syncbn
+
+Tamaki Kojima(tamakoji@gmail.com)
+
+## Announcement
+
+**Pytorch 1.0 support**
+
+## Overview
+This is alternative implementation of "Synchronized Multi-GPU Batch Normalization" which computes global stats across gpus instead of locally computed. SyncBN are getting important for those input image is large, and must use multi-gpu to increase the minibatch-size for the training.
+
+The code was inspired by [Pytorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding) and [Inplace-ABN](https://github.com/mapillary/inplace_abn)
+
+## Remarks
+- Unlike [Pytorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding), you don't need custom `nn.DataParallel`
+- Unlike [Inplace-ABN](https://github.com/mapillary/inplace_abn), you can just replace your `nn.BatchNorm2d` to this module implementation, since it will not mark for inplace operation
+- You can plug into arbitrary module written in PyTorch to enable Synchronized BatchNorm
+- Backward computation is rewritten and tested against behavior of `nn.BatchNorm2d`
+
+## Requirements
+For PyTorch, please refer to https://pytorch.org/
+
+NOTE : The code is tested only with PyTorch v1.0.0, CUDA10/CuDNN7.4.2 on ubuntu18.04
+
+It utilize Pytorch JIT mechanism to compile seamlessly, using ninja. Please install ninja-build before use.
+
+```
+sudo apt-get install ninja-build
+```
+
+Also install all dependencies for python. For pip, run:
+
+
+```
+pip install -U -r requirements.txt
+```
+
+## Build
+
+There is no need to build. just run and JIT will take care.
+JIT and cpp extensions are supported after PyTorch0.4, however it is highly recommended to use PyTorch > 1.0 due to huge design changes.
+
+## Usage
+
+Please refer to [`test.py`](./test.py) for testing the difference between `nn.BatchNorm2d` and `modules.nn.BatchNorm2d`
+
+```
+import torch
+from modules import nn as NN
+num_gpu = torch.cuda.device_count()
+model = nn.Sequential(
+ nn.Conv2d(3, 3, 1, 1, bias=False),
+ NN.BatchNorm2d(3),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(3, 3, 1, 1, bias=False),
+ NN.BatchNorm2d(3),
+).cuda()
+model = nn.DataParallel(model, device_ids=range(num_gpu))
+x = torch.rand(num_gpu, 3, 2, 2).cuda()
+z = model(x)
+```
+
+## Math
+
+### Forward
+1. compute 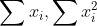 in each gpu
+2. gather all from workers to master and compute
in each gpu
+2. gather all from workers to master and compute 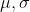 where
+
+
where
+
+ 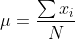 +
+ and
+
+
+
+ and
+
+ 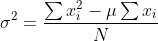 +
+ and then above global stats to be shared to all gpus, update running_mean and running_var by moving average using global stats.
+
+3. forward batchnorm using global stats by
+
+
+
+ and then above global stats to be shared to all gpus, update running_mean and running_var by moving average using global stats.
+
+3. forward batchnorm using global stats by
+
+ 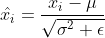 +
+ and then
+
+
+
+ and then
+
+ 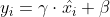 +
+ where
+
+ where 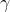 is weight parameter and
is weight parameter and 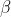 is bias parameter.
+
+4. save
is bias parameter.
+
+4. save 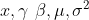 for backward
+
+### Backward
+
+1. Restore saved
+
+2. Compute below sums on each gpu
+
+
for backward
+
+### Backward
+
+1. Restore saved
+
+2. Compute below sums on each gpu
+
+ ) +
+ and
+
+
+
+ and
+
+ ) +
+ where
+
+ where 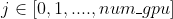 +
+ then gather them at master node to sum up global, and normalize with N where N is total number of elements for each channels. Global sums are then shared among all gpus.
+
+3. compute gradients using global stats
+
+
+
+ then gather them at master node to sum up global, and normalize with N where N is total number of elements for each channels. Global sums are then shared among all gpus.
+
+3. compute gradients using global stats
+
+ 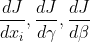 +
+ where
+
+
+
+ where
+
+ ) +
+ and
+
+
+
+ and
+
+ ) +
+ and finally,
+
+
+
+ and finally,
+
+ 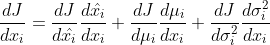 +
+
+
+ }}(N\frac{dJ}{d\hat{x_i}}-\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}})-\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}\hat{x_j}))) +
+
+
+ }}(N\frac{dJ}{dy_i}-\sum_{j=1}^{N}(\frac{dJ}{dy_j})-\hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{dy_j}\hat{x_j}))) +
+ Note that in the implementation, normalization with N is performed at step (2) and above equation and implementation is not exactly the same, but mathematically is same.
+
+ You can go deeper on above explanation at [Kevin Zakka's Blog](https://kevinzakka.github.io/2016/09/14/batch_normalization/)
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/__init__.py b/inference/interact/fbrs/model/syncbn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/model/syncbn/modules/__init__.py b/inference/interact/fbrs/model/syncbn/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py b/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8eb83a9d88b25cb8f1faebc9236da929a7722c7
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py
@@ -0,0 +1 @@
+from .syncbn import batchnorm2d_sync
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py b/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0c14098f0cfa422920f01fe4985dbeb7fedc2d1
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py
@@ -0,0 +1,54 @@
+"""
+/*****************************************************************************/
+
+Extension module loader
+
+code referenced from : https://github.com/facebookresearch/maskrcnn-benchmark
+
+/*****************************************************************************/
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import glob
+import os.path
+
+import torch
+
+try:
+ from torch.utils.cpp_extension import load
+ from torch.utils.cpp_extension import CUDA_HOME
+except ImportError:
+ raise ImportError(
+ "The cpp layer extensions requires PyTorch 0.4 or higher")
+
+
+def _load_C_extensions():
+ this_dir = os.path.dirname(os.path.abspath(__file__))
+ this_dir = os.path.join(this_dir, "csrc")
+
+ main_file = glob.glob(os.path.join(this_dir, "*.cpp"))
+ sources_cpu = glob.glob(os.path.join(this_dir, "cpu", "*.cpp"))
+ sources_cuda = glob.glob(os.path.join(this_dir, "cuda", "*.cu"))
+
+ sources = main_file + sources_cpu
+
+ extra_cflags = []
+ extra_cuda_cflags = []
+ if torch.cuda.is_available() and CUDA_HOME is not None:
+ sources.extend(sources_cuda)
+ extra_cflags = ["-O3", "-DWITH_CUDA"]
+ extra_cuda_cflags = ["--expt-extended-lambda"]
+ sources = [os.path.join(this_dir, s) for s in sources]
+ extra_include_paths = [this_dir]
+ return load(
+ name="ext_lib",
+ sources=sources,
+ extra_cflags=extra_cflags,
+ extra_include_paths=extra_include_paths,
+ extra_cuda_cflags=extra_cuda_cflags,
+ )
+
+
+_backend = _load_C_extensions()
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h
new file mode 100644
index 0000000000000000000000000000000000000000..52567a478633aa043ad86624253763e594121bd1
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h
@@ -0,0 +1,70 @@
+/*****************************************************************************
+
+SyncBN
+
+*****************************************************************************/
+#pragma once
+
+#ifdef WITH_CUDA
+#include "cuda/ext_lib.h"
+#endif
+
+/// SyncBN
+
+std::vector syncbn_sum_sqsum(const at::Tensor& x) {
+ if (x.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_sum_sqsum_cuda(x);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
+
+at::Tensor syncbn_forward(const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean,
+ const at::Tensor& var, bool affine, float eps) {
+ if (x.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_forward_cuda(x, weight, bias, mean, var, affine, eps);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
+
+std::vector syncbn_backward_xhat(const at::Tensor& dz,
+ const at::Tensor& x,
+ const at::Tensor& mean,
+ const at::Tensor& var, float eps) {
+ if (dz.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_backward_xhat_cuda(dz, x, mean, var, eps);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
+
+std::vector syncbn_backward(
+ const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
+ const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
+ float eps) {
+ if (dz.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_backward_cuda(dz, x, weight, bias, mean, var, sum_dz,
+ sum_dz_xhat, affine, eps);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu
new file mode 100644
index 0000000000000000000000000000000000000000..9458eba4f4715673ba480fae2c318f4745e8fe78
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu
@@ -0,0 +1,280 @@
+/*****************************************************************************
+
+CUDA SyncBN code
+
+code referenced from : https://github.com/mapillary/inplace_abn
+
+*****************************************************************************/
+#include
+#include
+#include
+#include
+#include "cuda/common.h"
+
+// Utilities
+void get_dims(at::Tensor x, int64_t &num, int64_t &chn, int64_t &sp) {
+ num = x.size(0);
+ chn = x.size(1);
+ sp = 1;
+ for (int64_t i = 2; i < x.ndimension(); ++i) sp *= x.size(i);
+}
+
+/// SyncBN
+
+template
+struct SqSumOp {
+ __device__ SqSumOp(const T *t, int c, int s) : tensor(t), chn(c), sp(s) {}
+ __device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
+ T x = tensor[(batch * chn + plane) * sp + n];
+ return Pair(x, x * x); // x, x^2
+ }
+ const T *tensor;
+ const int chn;
+ const int sp;
+};
+
+template
+__global__ void syncbn_sum_sqsum_kernel(const T *x, T *sum, T *sqsum,
+ int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ Pair res =
+ reduce, SqSumOp>(SqSumOp(x, chn, sp), plane, num, chn, sp);
+ __syncthreads();
+ if (threadIdx.x == 0) {
+ sum[plane] = res.v1;
+ sqsum[plane] = res.v2;
+ }
+}
+
+std::vector syncbn_sum_sqsum_cuda(const at::Tensor &x) {
+ CHECK_INPUT(x);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Prepare output tensors
+ auto sum = at::empty({chn}, x.options());
+ auto sqsum = at::empty({chn}, x.options());
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_sum_sqsum_cuda", ([&] {
+ syncbn_sum_sqsum_kernel<<>>(
+ x.data(), sum.data(),
+ sqsum.data(), num, chn, sp);
+ }));
+ return {sum, sqsum};
+}
+
+template
+__global__ void syncbn_forward_kernel(T *z, const T *x, const T *weight,
+ const T *bias, const T *mean,
+ const T *var, bool affine, float eps,
+ int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ T _mean = mean[plane];
+ T _var = var[plane];
+ T _weight = affine ? weight[plane] : T(1);
+ T _bias = affine ? bias[plane] : T(0);
+ float _invstd = T(0);
+ if (_var || eps) {
+ _invstd = rsqrt(_var + eps);
+ }
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ T _x = x[(batch * chn + plane) * sp + n];
+ T _xhat = (_x - _mean) * _invstd;
+ T _z = _xhat * _weight + _bias;
+ z[(batch * chn + plane) * sp + n] = _z;
+ }
+ }
+}
+
+at::Tensor syncbn_forward_cuda(const at::Tensor &x, const at::Tensor &weight,
+ const at::Tensor &bias, const at::Tensor &mean,
+ const at::Tensor &var, bool affine, float eps) {
+ CHECK_INPUT(x);
+ CHECK_INPUT(weight);
+ CHECK_INPUT(bias);
+ CHECK_INPUT(mean);
+ CHECK_INPUT(var);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ auto z = at::zeros_like(x);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_forward_cuda", ([&] {
+ syncbn_forward_kernel<<>>(
+ z.data(), x.data(),
+ weight.data(), bias.data(),
+ mean.data(), var.data(),
+ affine, eps, num, chn, sp);
+ }));
+ return z;
+}
+
+template
+struct XHatOp {
+ __device__ XHatOp(T _weight, T _bias, const T *_dz, const T *_x, int c, int s)
+ : weight(_weight), bias(_bias), x(_x), dz(_dz), chn(c), sp(s) {}
+ __device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
+ // xhat = (x - bias) * weight
+ T _xhat = (x[(batch * chn + plane) * sp + n] - bias) * weight;
+ // dxhat * x_hat
+ T _dz = dz[(batch * chn + plane) * sp + n];
+ return Pair(_dz, _dz * _xhat);
+ }
+ const T weight;
+ const T bias;
+ const T *dz;
+ const T *x;
+ const int chn;
+ const int sp;
+};
+
+template
+__global__ void syncbn_backward_xhat_kernel(const T *dz, const T *x,
+ const T *mean, const T *var,
+ T *sum_dz, T *sum_dz_xhat,
+ float eps, int num, int chn,
+ int sp) {
+ int plane = blockIdx.x;
+ T _mean = mean[plane];
+ T _var = var[plane];
+ T _invstd = T(0);
+ if (_var || eps) {
+ _invstd = rsqrt(_var + eps);
+ }
+ Pair res = reduce, XHatOp>(
+ XHatOp(_invstd, _mean, dz, x, chn, sp), plane, num, chn, sp);
+ __syncthreads();
+ if (threadIdx.x == 0) {
+ // \sum(\frac{dJ}{dy_i})
+ sum_dz[plane] = res.v1;
+ // \sum(\frac{dJ}{dy_i}*\hat{x_i})
+ sum_dz_xhat[plane] = res.v2;
+ }
+}
+
+std::vector syncbn_backward_xhat_cuda(const at::Tensor &dz,
+ const at::Tensor &x,
+ const at::Tensor &mean,
+ const at::Tensor &var,
+ float eps) {
+ CHECK_INPUT(dz);
+ CHECK_INPUT(x);
+ CHECK_INPUT(mean);
+ CHECK_INPUT(var);
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+ // Prepare output tensors
+ auto sum_dz = at::empty({chn}, x.options());
+ auto sum_dz_xhat = at::empty({chn}, x.options());
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_backward_xhat_cuda", ([&] {
+ syncbn_backward_xhat_kernel<<>>(
+ dz.data(), x.data(), mean.data(),
+ var.data(), sum_dz.data(),
+ sum_dz_xhat.data(), eps, num, chn, sp);
+ }));
+ return {sum_dz, sum_dz_xhat};
+}
+
+template
+__global__ void syncbn_backward_kernel(const T *dz, const T *x, const T *weight,
+ const T *bias, const T *mean,
+ const T *var, const T *sum_dz,
+ const T *sum_dz_xhat, T *dx, T *dweight,
+ T *dbias, bool affine, float eps,
+ int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ T _mean = mean[plane];
+ T _var = var[plane];
+ T _weight = affine ? weight[plane] : T(1);
+ T _sum_dz = sum_dz[plane];
+ T _sum_dz_xhat = sum_dz_xhat[plane];
+ T _invstd = T(0);
+ if (_var || eps) {
+ _invstd = rsqrt(_var + eps);
+ }
+ /*
+ \frac{dJ}{dx_i} = \frac{1}{N\sqrt{(\sigma^2+\epsilon)}} (
+ N\frac{dJ}{d\hat{x_i}} -
+ \sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}) -
+ \hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}\hat{x_j})
+ )
+ Note : N is omitted here since it will be accumulated and
+ _sum_dz and _sum_dz_xhat expected to be already normalized
+ before the call.
+ */
+ if (dx) {
+ T _mul = _weight * _invstd;
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ T _dz = dz[(batch * chn + plane) * sp + n];
+ T _xhat = (x[(batch * chn + plane) * sp + n] - _mean) * _invstd;
+ T _dx = (_dz - _sum_dz - _xhat * _sum_dz_xhat) * _mul;
+ dx[(batch * chn + plane) * sp + n] = _dx;
+ }
+ }
+ }
+ __syncthreads();
+ if (threadIdx.x == 0) {
+ if (affine) {
+ T _norm = num * sp;
+ dweight[plane] += _sum_dz_xhat * _norm;
+ dbias[plane] += _sum_dz * _norm;
+ }
+ }
+}
+
+std::vector syncbn_backward_cuda(
+ const at::Tensor &dz, const at::Tensor &x, const at::Tensor &weight,
+ const at::Tensor &bias, const at::Tensor &mean, const at::Tensor &var,
+ const at::Tensor &sum_dz, const at::Tensor &sum_dz_xhat, bool affine,
+ float eps) {
+ CHECK_INPUT(dz);
+ CHECK_INPUT(x);
+ CHECK_INPUT(weight);
+ CHECK_INPUT(bias);
+ CHECK_INPUT(mean);
+ CHECK_INPUT(var);
+ CHECK_INPUT(sum_dz);
+ CHECK_INPUT(sum_dz_xhat);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Prepare output tensors
+ auto dx = at::zeros_like(dz);
+ auto dweight = at::zeros_like(weight);
+ auto dbias = at::zeros_like(bias);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_backward_cuda", ([&] {
+ syncbn_backward_kernel<<>>(
+ dz.data(), x.data(), weight.data(),
+ bias.data(), mean.data(), var.data(),
+ sum_dz.data(), sum_dz_xhat.data(),
+ dx.data(), dweight.data(),
+ dbias.data(), affine, eps, num, chn, sp);
+ }));
+ return {dx, dweight, dbias};
+}
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h
new file mode 100644
index 0000000000000000000000000000000000000000..a6cb2debeea3b8caa0f7c640601a94dce4e629cb
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h
@@ -0,0 +1,124 @@
+/*****************************************************************************
+
+CUDA utility funcs
+
+code referenced from : https://github.com/mapillary/inplace_abn
+
+*****************************************************************************/
+#pragma once
+
+#include
+
+// Checks
+#ifndef AT_CHECK
+ #define AT_CHECK AT_ASSERT
+#endif
+#define CHECK_CUDA(x) AT_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) AT_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+/*
+ * General settings
+ */
+const int WARP_SIZE = 32;
+const int MAX_BLOCK_SIZE = 512;
+
+template
+struct Pair {
+ T v1, v2;
+ __device__ Pair() {}
+ __device__ Pair(T _v1, T _v2) : v1(_v1), v2(_v2) {}
+ __device__ Pair(T v) : v1(v), v2(v) {}
+ __device__ Pair(int v) : v1(v), v2(v) {}
+ __device__ Pair &operator+=(const Pair &a) {
+ v1 += a.v1;
+ v2 += a.v2;
+ return *this;
+ }
+};
+
+/*
+ * Utility functions
+ */
+template
+__device__ __forceinline__ T WARP_SHFL_XOR(T value, int laneMask,
+ int width = warpSize,
+ unsigned int mask = 0xffffffff) {
+#if CUDART_VERSION >= 9000
+ return __shfl_xor_sync(mask, value, laneMask, width);
+#else
+ return __shfl_xor(value, laneMask, width);
+#endif
+}
+
+__device__ __forceinline__ int getMSB(int val) { return 31 - __clz(val); }
+
+static int getNumThreads(int nElem) {
+ int threadSizes[5] = {32, 64, 128, 256, MAX_BLOCK_SIZE};
+ for (int i = 0; i != 5; ++i) {
+ if (nElem <= threadSizes[i]) {
+ return threadSizes[i];
+ }
+ }
+ return MAX_BLOCK_SIZE;
+}
+
+template
+static __device__ __forceinline__ T warpSum(T val) {
+#if __CUDA_ARCH__ >= 300
+ for (int i = 0; i < getMSB(WARP_SIZE); ++i) {
+ val += WARP_SHFL_XOR(val, 1 << i, WARP_SIZE);
+ }
+#else
+ __shared__ T values[MAX_BLOCK_SIZE];
+ values[threadIdx.x] = val;
+ __threadfence_block();
+ const int base = (threadIdx.x / WARP_SIZE) * WARP_SIZE;
+ for (int i = 1; i < WARP_SIZE; i++) {
+ val += values[base + ((i + threadIdx.x) % WARP_SIZE)];
+ }
+#endif
+ return val;
+}
+
+template
+static __device__ __forceinline__ Pair warpSum(Pair value) {
+ value.v1 = warpSum(value.v1);
+ value.v2 = warpSum(value.v2);
+ return value;
+}
+
+template
+__device__ T reduce(Op op, int plane, int N, int C, int S) {
+ T sum = (T)0;
+ for (int batch = 0; batch < N; ++batch) {
+ for (int x = threadIdx.x; x < S; x += blockDim.x) {
+ sum += op(batch, plane, x);
+ }
+ }
+
+ // sum over NumThreads within a warp
+ sum = warpSum(sum);
+
+ // 'transpose', and reduce within warp again
+ __shared__ T shared[32];
+ __syncthreads();
+ if (threadIdx.x % WARP_SIZE == 0) {
+ shared[threadIdx.x / WARP_SIZE] = sum;
+ }
+ if (threadIdx.x >= blockDim.x / WARP_SIZE && threadIdx.x < WARP_SIZE) {
+ // zero out the other entries in shared
+ shared[threadIdx.x] = (T)0;
+ }
+ __syncthreads();
+ if (threadIdx.x / WARP_SIZE == 0) {
+ sum = warpSum(shared[threadIdx.x]);
+ if (threadIdx.x == 0) {
+ shared[0] = sum;
+ }
+ }
+ __syncthreads();
+
+ // Everyone picks it up, should be broadcast into the whole gradInput
+ return shared[0];
+}
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h
new file mode 100644
index 0000000000000000000000000000000000000000..1d707615ffcf5ad7dcabc60de8c9a0cfe035bf14
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h
@@ -0,0 +1,24 @@
+/*****************************************************************************
+
+CUDA SyncBN code
+
+*****************************************************************************/
+#pragma once
+#include
+#include
+
+/// Sync-BN
+std::vector syncbn_sum_sqsum_cuda(const at::Tensor& x);
+at::Tensor syncbn_forward_cuda(const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean,
+ const at::Tensor& var, bool affine, float eps);
+std::vector syncbn_backward_xhat_cuda(const at::Tensor& dz,
+ const at::Tensor& x,
+ const at::Tensor& mean,
+ const at::Tensor& var,
+ float eps);
+std::vector syncbn_backward_cuda(
+ const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
+ const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
+ float eps);
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..9c2ecf142dd70de8a3bdaf9b04470c4cacee3086
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp
@@ -0,0 +1,10 @@
+#include "bn.h"
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("syncbn_sum_sqsum", &syncbn_sum_sqsum, "Sum and Sum^2 computation");
+ m.def("syncbn_forward", &syncbn_forward, "SyncBN forward computation");
+ m.def("syncbn_backward_xhat", &syncbn_backward_xhat,
+ "First part of SyncBN backward computation");
+ m.def("syncbn_backward", &syncbn_backward,
+ "Second part of SyncBN backward computation");
+}
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py b/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py
new file mode 100644
index 0000000000000000000000000000000000000000..867a432d14f4f28c25075caa85b22726424293ae
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py
@@ -0,0 +1,137 @@
+"""
+/*****************************************************************************/
+
+BatchNorm2dSync with multi-gpu
+
+code referenced from : https://github.com/mapillary/inplace_abn
+
+/*****************************************************************************/
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import torch.cuda.comm as comm
+from torch.autograd import Function
+from torch.autograd.function import once_differentiable
+from ._csrc import _backend
+
+
+def _count_samples(x):
+ count = 1
+ for i, s in enumerate(x.size()):
+ if i != 1:
+ count *= s
+ return count
+
+
+class BatchNorm2dSyncFunc(Function):
+
+ @staticmethod
+ def forward(ctx, x, weight, bias, running_mean, running_var,
+ extra, compute_stats=True, momentum=0.1, eps=1e-05):
+ def _parse_extra(ctx, extra):
+ ctx.is_master = extra["is_master"]
+ if ctx.is_master:
+ ctx.master_queue = extra["master_queue"]
+ ctx.worker_queues = extra["worker_queues"]
+ ctx.worker_ids = extra["worker_ids"]
+ else:
+ ctx.master_queue = extra["master_queue"]
+ ctx.worker_queue = extra["worker_queue"]
+ # Save context
+ if extra is not None:
+ _parse_extra(ctx, extra)
+ ctx.compute_stats = compute_stats
+ ctx.momentum = momentum
+ ctx.eps = eps
+ ctx.affine = weight is not None and bias is not None
+ if ctx.compute_stats:
+ N = _count_samples(x) * (ctx.master_queue.maxsize + 1)
+ assert N > 1
+ # 1. compute sum(x) and sum(x^2)
+ xsum, xsqsum = _backend.syncbn_sum_sqsum(x.detach())
+ if ctx.is_master:
+ xsums, xsqsums = [xsum], [xsqsum]
+ # master : gatther all sum(x) and sum(x^2) from slaves
+ for _ in range(ctx.master_queue.maxsize):
+ xsum_w, xsqsum_w = ctx.master_queue.get()
+ ctx.master_queue.task_done()
+ xsums.append(xsum_w)
+ xsqsums.append(xsqsum_w)
+ xsum = comm.reduce_add(xsums)
+ xsqsum = comm.reduce_add(xsqsums)
+ mean = xsum / N
+ sumvar = xsqsum - xsum * mean
+ var = sumvar / N
+ uvar = sumvar / (N - 1)
+ # master : broadcast global mean, variance to all slaves
+ tensors = comm.broadcast_coalesced(
+ (mean, uvar, var), [mean.get_device()] + ctx.worker_ids)
+ for ts, queue in zip(tensors[1:], ctx.worker_queues):
+ queue.put(ts)
+ else:
+ # slave : send sum(x) and sum(x^2) to master
+ ctx.master_queue.put((xsum, xsqsum))
+ # slave : get global mean and variance
+ mean, uvar, var = ctx.worker_queue.get()
+ ctx.worker_queue.task_done()
+
+ # Update running stats
+ running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
+ running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * uvar)
+ ctx.N = N
+ ctx.save_for_backward(x, weight, bias, mean, var)
+ else:
+ mean, var = running_mean, running_var
+
+ # do batch norm forward
+ z = _backend.syncbn_forward(x, weight, bias, mean, var,
+ ctx.affine, ctx.eps)
+ return z
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, dz):
+ x, weight, bias, mean, var = ctx.saved_tensors
+ dz = dz.contiguous()
+
+ # 1. compute \sum(\frac{dJ}{dy_i}) and \sum(\frac{dJ}{dy_i}*\hat{x_i})
+ sum_dz, sum_dz_xhat = _backend.syncbn_backward_xhat(
+ dz, x, mean, var, ctx.eps)
+ if ctx.is_master:
+ sum_dzs, sum_dz_xhats = [sum_dz], [sum_dz_xhat]
+ # master : gatther from slaves
+ for _ in range(ctx.master_queue.maxsize):
+ sum_dz_w, sum_dz_xhat_w = ctx.master_queue.get()
+ ctx.master_queue.task_done()
+ sum_dzs.append(sum_dz_w)
+ sum_dz_xhats.append(sum_dz_xhat_w)
+ # master : compute global stats
+ sum_dz = comm.reduce_add(sum_dzs)
+ sum_dz_xhat = comm.reduce_add(sum_dz_xhats)
+ sum_dz /= ctx.N
+ sum_dz_xhat /= ctx.N
+ # master : broadcast global stats
+ tensors = comm.broadcast_coalesced(
+ (sum_dz, sum_dz_xhat), [mean.get_device()] + ctx.worker_ids)
+ for ts, queue in zip(tensors[1:], ctx.worker_queues):
+ queue.put(ts)
+ else:
+ # slave : send to master
+ ctx.master_queue.put((sum_dz, sum_dz_xhat))
+ # slave : get global stats
+ sum_dz, sum_dz_xhat = ctx.worker_queue.get()
+ ctx.worker_queue.task_done()
+
+ # do batch norm backward
+ dx, dweight, dbias = _backend.syncbn_backward(
+ dz, x, weight, bias, mean, var, sum_dz, sum_dz_xhat,
+ ctx.affine, ctx.eps)
+
+ return dx, dweight, dbias, \
+ None, None, None, None, None, None
+
+batchnorm2d_sync = BatchNorm2dSyncFunc.apply
+
+__all__ = ["batchnorm2d_sync"]
diff --git a/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py b/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c5aca9879273811b681baddc5755e20e838a361
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py
@@ -0,0 +1 @@
+from .syncbn import *
diff --git a/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py b/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py
new file mode 100644
index 0000000000000000000000000000000000000000..b118c9d4aac3ee86821797bc9f794cd9aa38b1b2
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py
@@ -0,0 +1,148 @@
+"""
+/*****************************************************************************/
+
+BatchNorm2dSync with multi-gpu
+
+/*****************************************************************************/
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+try:
+ # python 3
+ from queue import Queue
+except ImportError:
+ # python 2
+ from Queue import Queue
+
+import torch
+import torch.nn as nn
+from torch.nn import functional as F
+from torch.nn.parameter import Parameter
+from isegm.model.syncbn.modules.functional import batchnorm2d_sync
+
+
+class _BatchNorm(nn.Module):
+ """
+ Customized BatchNorm from nn.BatchNorm
+ >> added freeze attribute to enable bn freeze.
+ """
+
+ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
+ track_running_stats=True):
+ super(_BatchNorm, self).__init__()
+ self.num_features = num_features
+ self.eps = eps
+ self.momentum = momentum
+ self.affine = affine
+ self.track_running_stats = track_running_stats
+ self.freezed = False
+ if self.affine:
+ self.weight = Parameter(torch.Tensor(num_features))
+ self.bias = Parameter(torch.Tensor(num_features))
+ else:
+ self.register_parameter('weight', None)
+ self.register_parameter('bias', None)
+ if self.track_running_stats:
+ self.register_buffer('running_mean', torch.zeros(num_features))
+ self.register_buffer('running_var', torch.ones(num_features))
+ else:
+ self.register_parameter('running_mean', None)
+ self.register_parameter('running_var', None)
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ if self.track_running_stats:
+ self.running_mean.zero_()
+ self.running_var.fill_(1)
+ if self.affine:
+ self.weight.data.uniform_()
+ self.bias.data.zero_()
+
+ def _check_input_dim(self, input):
+ return NotImplemented
+
+ def forward(self, input):
+ self._check_input_dim(input)
+
+ compute_stats = not self.freezed and \
+ self.training and self.track_running_stats
+
+ ret = F.batch_norm(input, self.running_mean, self.running_var,
+ self.weight, self.bias, compute_stats,
+ self.momentum, self.eps)
+ return ret
+
+ def extra_repr(self):
+ return '{num_features}, eps={eps}, momentum={momentum}, '\
+ 'affine={affine}, ' \
+ 'track_running_stats={track_running_stats}'.format(
+ **self.__dict__)
+
+
+class BatchNorm2dNoSync(_BatchNorm):
+ """
+ Equivalent to nn.BatchNorm2d
+ """
+
+ def _check_input_dim(self, input):
+ if input.dim() != 4:
+ raise ValueError('expected 4D input (got {}D input)'
+ .format(input.dim()))
+
+
+class BatchNorm2dSync(BatchNorm2dNoSync):
+ """
+ BatchNorm2d with automatic multi-GPU Sync
+ """
+
+ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
+ track_running_stats=True):
+ super(BatchNorm2dSync, self).__init__(
+ num_features, eps=eps, momentum=momentum, affine=affine,
+ track_running_stats=track_running_stats)
+ self.sync_enabled = True
+ self.devices = list(range(torch.cuda.device_count()))
+ if len(self.devices) > 1:
+ # Initialize queues
+ self.worker_ids = self.devices[1:]
+ self.master_queue = Queue(len(self.worker_ids))
+ self.worker_queues = [Queue(1) for _ in self.worker_ids]
+
+ def forward(self, x):
+ compute_stats = not self.freezed and \
+ self.training and self.track_running_stats
+ if self.sync_enabled and compute_stats and len(self.devices) > 1:
+ if x.get_device() == self.devices[0]:
+ # Master mode
+ extra = {
+ "is_master": True,
+ "master_queue": self.master_queue,
+ "worker_queues": self.worker_queues,
+ "worker_ids": self.worker_ids
+ }
+ else:
+ # Worker mode
+ extra = {
+ "is_master": False,
+ "master_queue": self.master_queue,
+ "worker_queue": self.worker_queues[
+ self.worker_ids.index(x.get_device())]
+ }
+ return batchnorm2d_sync(x, self.weight, self.bias,
+ self.running_mean, self.running_var,
+ extra, compute_stats, self.momentum,
+ self.eps)
+ return super(BatchNorm2dSync, self).forward(x)
+
+ def __repr__(self):
+ """repr"""
+ rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
+ 'affine={affine}, ' \
+ 'track_running_stats={track_running_stats},' \
+ 'devices={devices})'
+ return rep.format(name=self.__class__.__name__, **self.__dict__)
+
+#BatchNorm2d = BatchNorm2dNoSync
+BatchNorm2d = BatchNorm2dSync
diff --git a/inference/interact/fbrs/utils/__init__.py b/inference/interact/fbrs/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/utils/cython/__init__.py b/inference/interact/fbrs/utils/cython/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb66bdbba883b9477bbc1a52d8355131d32a04cb
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/__init__.py
@@ -0,0 +1,2 @@
+# noinspection PyUnresolvedReferences
+from .dist_maps import get_dist_maps
\ No newline at end of file
diff --git a/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx
new file mode 100644
index 0000000000000000000000000000000000000000..779a7f02ad7c2ba25e68302c6fc6683cd4ab54f7
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx
@@ -0,0 +1,63 @@
+import numpy as np
+cimport cython
+cimport numpy as np
+from libc.stdlib cimport malloc, free
+
+ctypedef struct qnode:
+ int row
+ int col
+ int layer
+ int orig_row
+ int orig_col
+
+@cython.infer_types(True)
+@cython.boundscheck(False)
+@cython.wraparound(False)
+@cython.nonecheck(False)
+def get_dist_maps(np.ndarray[np.float32_t, ndim=2, mode="c"] points,
+ int height, int width, float norm_delimeter):
+ cdef np.ndarray[np.float32_t, ndim=3, mode="c"] dist_maps = \
+ np.full((2, height, width), 1e6, dtype=np.float32, order="C")
+
+ cdef int *dxy = [-1, 0, 0, -1, 0, 1, 1, 0]
+ cdef int i, j, x, y, dx, dy
+ cdef qnode v
+ cdef qnode *q = malloc((4 * height * width + 1) * sizeof(qnode))
+ cdef int qhead = 0, qtail = -1
+ cdef float ndist
+
+ for i in range(points.shape[0]):
+ x, y = round(points[i, 0]), round(points[i, 1])
+ if x >= 0:
+ qtail += 1
+ q[qtail].row = x
+ q[qtail].col = y
+ q[qtail].orig_row = x
+ q[qtail].orig_col = y
+ if i >= points.shape[0] / 2:
+ q[qtail].layer = 1
+ else:
+ q[qtail].layer = 0
+ dist_maps[q[qtail].layer, x, y] = 0
+
+ while qtail - qhead + 1 > 0:
+ v = q[qhead]
+ qhead += 1
+
+ for k in range(4):
+ x = v.row + dxy[2 * k]
+ y = v.col + dxy[2 * k + 1]
+
+ ndist = ((x - v.orig_row)/norm_delimeter) ** 2 + ((y - v.orig_col)/norm_delimeter) ** 2
+ if (x >= 0 and y >= 0 and x < height and y < width and
+ dist_maps[v.layer, x, y] > ndist):
+ qtail += 1
+ q[qtail].orig_col = v.orig_col
+ q[qtail].orig_row = v.orig_row
+ q[qtail].layer = v.layer
+ q[qtail].row = x
+ q[qtail].col = y
+ dist_maps[v.layer, x, y] = ndist
+
+ free(q)
+ return dist_maps
diff --git a/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld
new file mode 100644
index 0000000000000000000000000000000000000000..bd4451729201b5ebc6bbbd8f392389ab6b530636
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld
@@ -0,0 +1,7 @@
+import numpy
+
+def make_ext(modname, pyxfilename):
+ from distutils.extension import Extension
+ return Extension(modname, [pyxfilename],
+ include_dirs=[numpy.get_include()],
+ extra_compile_args=['-O3'], language='c++')
diff --git a/inference/interact/fbrs/utils/cython/dist_maps.py b/inference/interact/fbrs/utils/cython/dist_maps.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ffa1e3f25231cd7c48b66ef8ef5167235c3ea4e
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/dist_maps.py
@@ -0,0 +1,3 @@
+import pyximport; pyximport.install(pyximport=True, language_level=3)
+# noinspection PyUnresolvedReferences
+from ._get_dist_maps import get_dist_maps
\ No newline at end of file
diff --git a/inference/interact/fbrs/utils/misc.py b/inference/interact/fbrs/utils/misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..65ce96dc5667494446110fda75e29243338e2b88
--- /dev/null
+++ b/inference/interact/fbrs/utils/misc.py
@@ -0,0 +1,62 @@
+from functools import partial
+
+import torch
+import numpy as np
+
+
+def get_dims_with_exclusion(dim, exclude=None):
+ dims = list(range(dim))
+ if exclude is not None:
+ dims.remove(exclude)
+
+ return dims
+
+
+def get_unique_labels(mask):
+ return np.nonzero(np.bincount(mask.flatten() + 1))[0] - 1
+
+
+def get_bbox_from_mask(mask):
+ rows = np.any(mask, axis=1)
+ cols = np.any(mask, axis=0)
+ rmin, rmax = np.where(rows)[0][[0, -1]]
+ cmin, cmax = np.where(cols)[0][[0, -1]]
+
+ return rmin, rmax, cmin, cmax
+
+
+def expand_bbox(bbox, expand_ratio, min_crop_size=None):
+ rmin, rmax, cmin, cmax = bbox
+ rcenter = 0.5 * (rmin + rmax)
+ ccenter = 0.5 * (cmin + cmax)
+ height = expand_ratio * (rmax - rmin + 1)
+ width = expand_ratio * (cmax - cmin + 1)
+ if min_crop_size is not None:
+ height = max(height, min_crop_size)
+ width = max(width, min_crop_size)
+
+ rmin = int(round(rcenter - 0.5 * height))
+ rmax = int(round(rcenter + 0.5 * height))
+ cmin = int(round(ccenter - 0.5 * width))
+ cmax = int(round(ccenter + 0.5 * width))
+
+ return rmin, rmax, cmin, cmax
+
+
+def clamp_bbox(bbox, rmin, rmax, cmin, cmax):
+ return (max(rmin, bbox[0]), min(rmax, bbox[1]),
+ max(cmin, bbox[2]), min(cmax, bbox[3]))
+
+
+def get_bbox_iou(b1, b2):
+ h_iou = get_segments_iou(b1[:2], b2[:2])
+ w_iou = get_segments_iou(b1[2:4], b2[2:4])
+ return h_iou * w_iou
+
+
+def get_segments_iou(s1, s2):
+ a, b = s1
+ c, d = s2
+ intersection = max(0, min(b, d) - max(a, c) + 1)
+ union = max(1e-6, max(b, d) - min(a, c) + 1)
+ return intersection / union
diff --git a/inference/interact/fbrs/utils/vis.py b/inference/interact/fbrs/utils/vis.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c1a291306453c15bdfe5117302beb62e0fe7248
--- /dev/null
+++ b/inference/interact/fbrs/utils/vis.py
@@ -0,0 +1,129 @@
+from functools import lru_cache
+
+import cv2
+import numpy as np
+
+
+def visualize_instances(imask, bg_color=255,
+ boundaries_color=None, boundaries_width=1, boundaries_alpha=0.8):
+ num_objects = imask.max() + 1
+ palette = get_palette(num_objects)
+ if bg_color is not None:
+ palette[0] = bg_color
+
+ result = palette[imask].astype(np.uint8)
+ if boundaries_color is not None:
+ boundaries_mask = get_boundaries(imask, boundaries_width=boundaries_width)
+ tresult = result.astype(np.float32)
+ tresult[boundaries_mask] = boundaries_color
+ tresult = tresult * boundaries_alpha + (1 - boundaries_alpha) * result
+ result = tresult.astype(np.uint8)
+
+ return result
+
+
+@lru_cache(maxsize=16)
+def get_palette(num_cls):
+ palette = np.zeros(3 * num_cls, dtype=np.int32)
+
+ for j in range(0, num_cls):
+ lab = j
+ i = 0
+
+ while lab > 0:
+ palette[j*3 + 0] |= (((lab >> 0) & 1) << (7-i))
+ palette[j*3 + 1] |= (((lab >> 1) & 1) << (7-i))
+ palette[j*3 + 2] |= (((lab >> 2) & 1) << (7-i))
+ i = i + 1
+ lab >>= 3
+
+ return palette.reshape((-1, 3))
+
+
+def visualize_mask(mask, num_cls):
+ palette = get_palette(num_cls)
+ mask[mask == -1] = 0
+
+ return palette[mask].astype(np.uint8)
+
+
+def visualize_proposals(proposals_info, point_color=(255, 0, 0), point_radius=1):
+ proposal_map, colors, candidates = proposals_info
+
+ proposal_map = draw_probmap(proposal_map)
+ for x, y in candidates:
+ proposal_map = cv2.circle(proposal_map, (y, x), point_radius, point_color, -1)
+
+ return proposal_map
+
+
+def draw_probmap(x):
+ return cv2.applyColorMap((x * 255).astype(np.uint8), cv2.COLORMAP_HOT)
+
+
+def draw_points(image, points, color, radius=3):
+ image = image.copy()
+ for p in points:
+ image = cv2.circle(image, (int(p[1]), int(p[0])), radius, color, -1)
+
+ return image
+
+
+def draw_instance_map(x, palette=None):
+ num_colors = x.max() + 1
+ if palette is None:
+ palette = get_palette(num_colors)
+
+ return palette[x].astype(np.uint8)
+
+
+def blend_mask(image, mask, alpha=0.6):
+ if mask.min() == -1:
+ mask = mask.copy() + 1
+
+ imap = draw_instance_map(mask)
+ result = (image * (1 - alpha) + alpha * imap).astype(np.uint8)
+ return result
+
+
+def get_boundaries(instances_masks, boundaries_width=1):
+ boundaries = np.zeros((instances_masks.shape[0], instances_masks.shape[1]), dtype=np.bool)
+
+ for obj_id in np.unique(instances_masks.flatten()):
+ if obj_id == 0:
+ continue
+
+ obj_mask = instances_masks == obj_id
+ kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+ inner_mask = cv2.erode(obj_mask.astype(np.uint8), kernel, iterations=boundaries_width).astype(np.bool)
+
+ obj_boundary = np.logical_xor(obj_mask, np.logical_and(inner_mask, obj_mask))
+ boundaries = np.logical_or(boundaries, obj_boundary)
+ return boundaries
+
+
+def draw_with_blend_and_clicks(img, mask=None, alpha=0.6, clicks_list=None, pos_color=(0, 255, 0),
+ neg_color=(255, 0, 0), radius=4):
+ result = img.copy()
+
+ if mask is not None:
+ palette = get_palette(np.max(mask) + 1)
+ rgb_mask = palette[mask.astype(np.uint8)]
+
+ mask_region = (mask > 0).astype(np.uint8)
+ result = result * (1 - mask_region[:, :, np.newaxis]) + \
+ (1 - alpha) * mask_region[:, :, np.newaxis] * result + \
+ alpha * rgb_mask
+ result = result.astype(np.uint8)
+
+ # result = (result * (1 - alpha) + alpha * rgb_mask).astype(np.uint8)
+
+ if clicks_list is not None and len(clicks_list) > 0:
+ pos_points = [click.coords for click in clicks_list if click.is_positive]
+ neg_points = [click.coords for click in clicks_list if not click.is_positive]
+
+ result = draw_points(result, pos_points, pos_color, radius=radius)
+ result = draw_points(result, neg_points, neg_color, radius=radius)
+
+ return result
+
diff --git a/inference/interact/fbrs_controller.py b/inference/interact/fbrs_controller.py
new file mode 100644
index 0000000000000000000000000000000000000000..1fe9ca496193829990b3db7b0f141aabeb61fd35
--- /dev/null
+++ b/inference/interact/fbrs_controller.py
@@ -0,0 +1,53 @@
+import torch
+from .fbrs.controller import InteractiveController
+from .fbrs.inference import utils
+
+
+class FBRSController:
+ def __init__(self, checkpoint_path, device='cuda:0', max_size=800):
+ model = utils.load_is_model(checkpoint_path, device, cpu_dist_maps=True, norm_radius=260)
+
+ # Predictor params
+ zoomin_params = {
+ 'skip_clicks': 1,
+ 'target_size': 480,
+ 'expansion_ratio': 1.4,
+ }
+
+ predictor_params = {
+ 'brs_mode': 'f-BRS-B',
+ 'prob_thresh': 0.5,
+ 'zoom_in_params': zoomin_params,
+ 'predictor_params': {
+ 'net_clicks_limit': 8,
+ 'max_size': 800,
+ },
+ 'brs_opt_func_params': {'min_iou_diff': 1e-3},
+ 'lbfgs_params': {'maxfun': 20}
+ }
+
+ self.controller = InteractiveController(model, device, predictor_params)
+ self.anchored = False
+ self.device = device
+
+ def unanchor(self):
+ self.anchored = False
+
+ def interact(self, image, x, y, is_positive):
+ image = image.to(self.device, non_blocking=True)
+ if not self.anchored:
+ self.controller.set_image(image)
+ self.controller.reset_predictor()
+ self.anchored = True
+
+ self.controller.add_click(x, y, is_positive)
+ # return self.controller.result_mask
+ # return self.controller.probs_history[-1][1]
+ return (self.controller.probs_history[-1][1]>0.5).float()
+
+ def undo(self):
+ self.controller.undo_click()
+ if len(self.controller.probs_history) == 0:
+ return None
+ else:
+ return (self.controller.probs_history[-1][1]>0.5).float()
\ No newline at end of file
diff --git a/inference/interact/gui.py b/inference/interact/gui.py
new file mode 100644
index 0000000000000000000000000000000000000000..039a382bda5b5a892723df894c4dffab356e99c4
--- /dev/null
+++ b/inference/interact/gui.py
@@ -0,0 +1,933 @@
+"""
+Based on https://github.com/hkchengrex/MiVOS/tree/MiVOS-STCN
+(which is based on https://github.com/seoungwugoh/ivs-demo)
+
+This version is much simplified.
+In this repo, we don't have
+- local control
+- fusion module
+- undo
+- timers
+
+but with XMem as the backbone and is more memory (for both CPU and GPU) friendly
+"""
+
+import functools
+
+import os
+import cv2
+# fix conflicts between qt5 and cv2
+os.environ.pop("QT_QPA_PLATFORM_PLUGIN_PATH")
+
+import numpy as np
+import torch
+
+from PyQt5.QtWidgets import (QWidget, QApplication, QComboBox, QCheckBox,
+ QHBoxLayout, QLabel, QPushButton, QTextEdit, QSpinBox, QFileDialog,
+ QPlainTextEdit, QVBoxLayout, QSizePolicy, QButtonGroup, QSlider, QShortcut, QRadioButton)
+
+from PyQt5.QtGui import QPixmap, QKeySequence, QImage, QTextCursor, QIcon
+from PyQt5.QtCore import Qt, QTimer
+
+from model.network import XMem
+
+from inference.inference_core import InferenceCore
+from .s2m_controller import S2MController
+from .fbrs_controller import FBRSController
+
+from .interactive_utils import *
+from .interaction import *
+from .resource_manager import ResourceManager
+from .gui_utils import *
+
+
+class App(QWidget):
+ def __init__(self, net: XMem,
+ resource_manager: ResourceManager,
+ s2m_ctrl:S2MController,
+ fbrs_ctrl:FBRSController, config):
+ super().__init__()
+
+ self.initialized = False
+ self.num_objects = config['num_objects']
+ self.s2m_controller = s2m_ctrl
+ self.fbrs_controller = fbrs_ctrl
+ self.config = config
+ self.processor = InferenceCore(net, config)
+ self.processor.set_all_labels(list(range(1, self.num_objects+1)))
+ self.res_man = resource_manager
+
+ self.num_frames = len(self.res_man)
+ self.height, self.width = self.res_man.h, self.res_man.w
+
+ # set window
+ self.setWindowTitle('XMem Demo')
+ self.setGeometry(100, 100, self.width, self.height+100)
+ self.setWindowIcon(QIcon('docs/icon.png'))
+
+ # some buttons
+ self.play_button = QPushButton('Play Video')
+ self.play_button.clicked.connect(self.on_play_video)
+ self.commit_button = QPushButton('Commit')
+ self.commit_button.clicked.connect(self.on_commit)
+
+ self.forward_run_button = QPushButton('Forward Propagate')
+ self.forward_run_button.clicked.connect(self.on_forward_propagation)
+ self.forward_run_button.setMinimumWidth(200)
+
+ self.backward_run_button = QPushButton('Backward Propagate')
+ self.backward_run_button.clicked.connect(self.on_backward_propagation)
+ self.backward_run_button.setMinimumWidth(200)
+
+ self.reset_button = QPushButton('Reset Frame')
+ self.reset_button.clicked.connect(self.on_reset_mask)
+
+ # LCD
+ self.lcd = QTextEdit()
+ self.lcd.setReadOnly(True)
+ self.lcd.setMaximumHeight(28)
+ self.lcd.setMaximumWidth(120)
+ self.lcd.setText('{: 4d} / {: 4d}'.format(0, self.num_frames-1))
+
+ # timeline slider
+ self.tl_slider = QSlider(Qt.Horizontal)
+ self.tl_slider.valueChanged.connect(self.tl_slide)
+ self.tl_slider.setMinimum(0)
+ self.tl_slider.setMaximum(self.num_frames-1)
+ self.tl_slider.setValue(0)
+ self.tl_slider.setTickPosition(QSlider.TicksBelow)
+ self.tl_slider.setTickInterval(1)
+
+ # brush size slider
+ self.brush_label = QLabel()
+ self.brush_label.setAlignment(Qt.AlignCenter)
+ self.brush_label.setMinimumWidth(100)
+
+ self.brush_slider = QSlider(Qt.Horizontal)
+ self.brush_slider.valueChanged.connect(self.brush_slide)
+ self.brush_slider.setMinimum(1)
+ self.brush_slider.setMaximum(100)
+ self.brush_slider.setValue(3)
+ self.brush_slider.setTickPosition(QSlider.TicksBelow)
+ self.brush_slider.setTickInterval(2)
+ self.brush_slider.setMinimumWidth(300)
+
+ # combobox
+ self.combo = QComboBox(self)
+ self.combo.addItem("davis")
+ self.combo.addItem("fade")
+ self.combo.addItem("light")
+ self.combo.addItem("popup")
+ self.combo.addItem("layered")
+ self.combo.currentTextChanged.connect(self.set_viz_mode)
+
+ self.save_visualization_checkbox = QCheckBox(self)
+ self.save_visualization_checkbox.toggled.connect(self.on_save_visualization_toggle)
+ self.save_visualization_checkbox.setChecked(False)
+ self.save_visualization = False
+
+ # Radio buttons for type of interactions
+ self.curr_interaction = 'Click'
+ self.interaction_group = QButtonGroup()
+ self.radio_fbrs = QRadioButton('Click')
+ self.radio_s2m = QRadioButton('Scribble')
+ self.radio_free = QRadioButton('Free')
+ self.interaction_group.addButton(self.radio_fbrs)
+ self.interaction_group.addButton(self.radio_s2m)
+ self.interaction_group.addButton(self.radio_free)
+ self.radio_fbrs.toggled.connect(self.interaction_radio_clicked)
+ self.radio_s2m.toggled.connect(self.interaction_radio_clicked)
+ self.radio_free.toggled.connect(self.interaction_radio_clicked)
+ self.radio_fbrs.toggle()
+
+ # Main canvas -> QLabel
+ self.main_canvas = QLabel()
+ self.main_canvas.setSizePolicy(QSizePolicy.Expanding,
+ QSizePolicy.Expanding)
+ self.main_canvas.setAlignment(Qt.AlignCenter)
+ self.main_canvas.setMinimumSize(100, 100)
+
+ self.main_canvas.mousePressEvent = self.on_mouse_press
+ self.main_canvas.mouseMoveEvent = self.on_mouse_motion
+ self.main_canvas.setMouseTracking(True) # Required for all-time tracking
+ self.main_canvas.mouseReleaseEvent = self.on_mouse_release
+
+ # Minimap -> Also a QLbal
+ self.minimap = QLabel()
+ self.minimap.setSizePolicy(QSizePolicy.Expanding,
+ QSizePolicy.Expanding)
+ self.minimap.setAlignment(Qt.AlignTop)
+ self.minimap.setMinimumSize(100, 100)
+
+ # Zoom-in buttons
+ self.zoom_p_button = QPushButton('Zoom +')
+ self.zoom_p_button.clicked.connect(self.on_zoom_plus)
+ self.zoom_m_button = QPushButton('Zoom -')
+ self.zoom_m_button.clicked.connect(self.on_zoom_minus)
+
+ # Parameters setting
+ self.clear_mem_button = QPushButton('Clear memory')
+ self.clear_mem_button.clicked.connect(self.on_clear_memory)
+
+ self.work_mem_gauge, self.work_mem_gauge_layout = create_gauge('Working memory size')
+ self.long_mem_gauge, self.long_mem_gauge_layout = create_gauge('Long-term memory size')
+ self.gpu_mem_gauge, self.gpu_mem_gauge_layout = create_gauge('GPU mem. (all processes, w/ caching)')
+ self.torch_mem_gauge, self.torch_mem_gauge_layout = create_gauge('GPU mem. (used by torch, w/o caching)')
+
+ self.update_memory_size()
+ self.update_gpu_usage()
+
+ self.work_mem_min, self.work_mem_min_layout = create_parameter_box(1, 100, 'Min. working memory frames',
+ callback=self.on_work_min_change)
+ self.work_mem_max, self.work_mem_max_layout = create_parameter_box(2, 100, 'Max. working memory frames',
+ callback=self.on_work_max_change)
+ self.long_mem_max, self.long_mem_max_layout = create_parameter_box(1000, 100000,
+ 'Max. long-term memory size', step=1000, callback=self.update_config)
+ self.num_prototypes_box, self.num_prototypes_box_layout = create_parameter_box(32, 1280,
+ 'Number of prototypes', step=32, callback=self.update_config)
+ self.mem_every_box, self.mem_every_box_layout = create_parameter_box(1, 100, 'Memory frame every (r)',
+ callback=self.update_config)
+
+ self.work_mem_min.setValue(self.processor.memory.min_mt_frames)
+ self.work_mem_max.setValue(self.processor.memory.max_mt_frames)
+ self.long_mem_max.setValue(self.processor.memory.max_long_elements)
+ self.num_prototypes_box.setValue(self.processor.memory.num_prototypes)
+ self.mem_every_box.setValue(self.processor.mem_every)
+
+ # import mask/layer
+ self.import_mask_button = QPushButton('Import mask')
+ self.import_mask_button.clicked.connect(self.on_import_mask)
+ self.import_layer_button = QPushButton('Import layer')
+ self.import_layer_button.clicked.connect(self.on_import_layer)
+
+ # Console on the GUI
+ self.console = QPlainTextEdit()
+ self.console.setReadOnly(True)
+ self.console.setMinimumHeight(100)
+ self.console.setMaximumHeight(100)
+
+ # navigator
+ navi = QHBoxLayout()
+ navi.addWidget(self.lcd)
+ navi.addWidget(self.play_button)
+
+ interact_subbox = QVBoxLayout()
+ interact_topbox = QHBoxLayout()
+ interact_botbox = QHBoxLayout()
+ interact_topbox.setAlignment(Qt.AlignCenter)
+ interact_topbox.addWidget(self.radio_s2m)
+ interact_topbox.addWidget(self.radio_fbrs)
+ interact_topbox.addWidget(self.radio_free)
+ interact_topbox.addWidget(self.brush_label)
+ interact_botbox.addWidget(self.brush_slider)
+ interact_subbox.addLayout(interact_topbox)
+ interact_subbox.addLayout(interact_botbox)
+ navi.addLayout(interact_subbox)
+
+ navi.addStretch(1)
+ navi.addWidget(self.reset_button)
+
+ navi.addStretch(1)
+ navi.addWidget(QLabel('Overlay Mode'))
+ navi.addWidget(self.combo)
+ navi.addWidget(QLabel('Save overlay during propagation'))
+ navi.addWidget(self.save_visualization_checkbox)
+ navi.addStretch(1)
+ navi.addWidget(self.commit_button)
+ navi.addWidget(self.forward_run_button)
+ navi.addWidget(self.backward_run_button)
+
+ # Drawing area, main canvas and minimap
+ draw_area = QHBoxLayout()
+ draw_area.addWidget(self.main_canvas, 4)
+
+ # Minimap area
+ minimap_area = QVBoxLayout()
+ minimap_area.setAlignment(Qt.AlignTop)
+ mini_label = QLabel('Minimap')
+ mini_label.setAlignment(Qt.AlignTop)
+ minimap_area.addWidget(mini_label)
+
+ # Minimap zooming
+ minimap_ctrl = QHBoxLayout()
+ minimap_ctrl.setAlignment(Qt.AlignTop)
+ minimap_ctrl.addWidget(self.zoom_p_button)
+ minimap_ctrl.addWidget(self.zoom_m_button)
+ minimap_area.addLayout(minimap_ctrl)
+ minimap_area.addWidget(self.minimap)
+
+ # Parameters
+ minimap_area.addLayout(self.work_mem_gauge_layout)
+ minimap_area.addLayout(self.long_mem_gauge_layout)
+ minimap_area.addLayout(self.gpu_mem_gauge_layout)
+ minimap_area.addLayout(self.torch_mem_gauge_layout)
+ minimap_area.addWidget(self.clear_mem_button)
+ minimap_area.addLayout(self.work_mem_min_layout)
+ minimap_area.addLayout(self.work_mem_max_layout)
+ minimap_area.addLayout(self.long_mem_max_layout)
+ minimap_area.addLayout(self.num_prototypes_box_layout)
+ minimap_area.addLayout(self.mem_every_box_layout)
+
+ # import mask/layer
+ import_area = QHBoxLayout()
+ import_area.setAlignment(Qt.AlignTop)
+ import_area.addWidget(self.import_mask_button)
+ import_area.addWidget(self.import_layer_button)
+ minimap_area.addLayout(import_area)
+
+ # console
+ minimap_area.addWidget(self.console)
+
+ draw_area.addLayout(minimap_area, 1)
+
+ layout = QVBoxLayout()
+ layout.addLayout(draw_area)
+ layout.addWidget(self.tl_slider)
+ layout.addLayout(navi)
+ self.setLayout(layout)
+
+ # timer to play video
+ self.timer = QTimer()
+ self.timer.setSingleShot(False)
+
+ # timer to update GPU usage
+ self.gpu_timer = QTimer()
+ self.gpu_timer.setSingleShot(False)
+ self.gpu_timer.timeout.connect(self.on_gpu_timer)
+ self.gpu_timer.setInterval(2000)
+ self.gpu_timer.start()
+
+ # current frame info
+ self.curr_frame_dirty = False
+ self.current_image = np.zeros((self.height, self.width, 3), dtype=np.uint8)
+ self.current_image_torch = None
+ self.current_mask = np.zeros((self.height, self.width), dtype=np.uint8)
+ self.current_prob = torch.zeros((self.num_objects, self.height, self.width), dtype=torch.float).cuda()
+
+ # initialize visualization
+ self.viz_mode = 'davis'
+ self.vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
+ self.vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
+ self.brush_vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
+ self.brush_vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
+ self.cursur = 0
+ self.on_showing = None
+
+ # Zoom parameters
+ self.zoom_pixels = 150
+
+ # initialize action
+ self.interaction = None
+ self.pressed = False
+ self.right_click = False
+ self.current_object = 1
+ self.last_ex = self.last_ey = 0
+
+ self.propagating = False
+
+ # Objects shortcuts
+ for i in range(1, self.num_objects+1):
+ QShortcut(QKeySequence(str(i)), self).activated.connect(functools.partial(self.hit_number_key, i))
+
+ # <- and -> shortcuts
+ QShortcut(QKeySequence(Qt.Key_Left), self).activated.connect(self.on_prev_frame)
+ QShortcut(QKeySequence(Qt.Key_Right), self).activated.connect(self.on_next_frame)
+
+ self.interacted_prob = None
+ self.overlay_layer = None
+ self.overlay_layer_torch = None
+
+ # the object id used for popup/layered overlay
+ self.vis_target_objects = [1]
+ # try to load the default overlay
+ self._try_load_layer('./docs/ECCV-logo.png')
+
+ self.load_current_image_mask()
+ self.show_current_frame()
+ self.show()
+
+ self.console_push_text('Initialized.')
+ self.initialized = True
+
+ def resizeEvent(self, event):
+ self.show_current_frame()
+
+ def console_push_text(self, text):
+ self.console.moveCursor(QTextCursor.End)
+ self.console.insertPlainText(text+'\n')
+
+ def interaction_radio_clicked(self, event):
+ self.last_interaction = self.curr_interaction
+ if self.radio_s2m.isChecked():
+ self.curr_interaction = 'Scribble'
+ self.brush_size = 3
+ self.brush_slider.setDisabled(True)
+ elif self.radio_fbrs.isChecked():
+ self.curr_interaction = 'Click'
+ self.brush_size = 3
+ self.brush_slider.setDisabled(True)
+ elif self.radio_free.isChecked():
+ self.brush_slider.setDisabled(False)
+ self.brush_slide()
+ self.curr_interaction = 'Free'
+ if self.curr_interaction == 'Scribble':
+ self.commit_button.setEnabled(True)
+ else:
+ self.commit_button.setEnabled(False)
+
+ def load_current_image_mask(self, no_mask=False):
+ self.current_image = self.res_man.get_image(self.cursur)
+ self.current_image_torch = None
+
+ if not no_mask:
+ loaded_mask = self.res_man.get_mask(self.cursur)
+ if loaded_mask is None:
+ self.current_mask.fill(0)
+ else:
+ self.current_mask = loaded_mask.copy()
+ self.current_prob = None
+
+ def load_current_torch_image_mask(self, no_mask=False):
+ if self.current_image_torch is None:
+ self.current_image_torch, self.current_image_torch_no_norm = image_to_torch(self.current_image)
+
+ if self.current_prob is None and not no_mask:
+ self.current_prob = index_numpy_to_one_hot_torch(self.current_mask, self.num_objects+1).cuda()
+
+ def compose_current_im(self):
+ self.viz = get_visualization(self.viz_mode, self.current_image, self.current_mask,
+ self.overlay_layer, self.vis_target_objects)
+
+ def update_interact_vis(self):
+ # Update the interactions without re-computing the overlay
+ height, width, channel = self.viz.shape
+ bytesPerLine = 3 * width
+
+ vis_map = self.vis_map
+ vis_alpha = self.vis_alpha
+ brush_vis_map = self.brush_vis_map
+ brush_vis_alpha = self.brush_vis_alpha
+
+ self.viz_with_stroke = self.viz*(1-vis_alpha) + vis_map*vis_alpha
+ self.viz_with_stroke = self.viz_with_stroke*(1-brush_vis_alpha) + brush_vis_map*brush_vis_alpha
+ self.viz_with_stroke = self.viz_with_stroke.astype(np.uint8)
+
+ qImg = QImage(self.viz_with_stroke.data, width, height, bytesPerLine, QImage.Format_RGB888)
+ self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
+ Qt.KeepAspectRatio, Qt.FastTransformation)))
+
+ self.main_canvas_size = self.main_canvas.size()
+ self.image_size = qImg.size()
+
+ def update_minimap(self):
+ ex, ey = self.last_ex, self.last_ey
+ r = self.zoom_pixels//2
+ ex = int(round(max(r, min(self.width-r, ex))))
+ ey = int(round(max(r, min(self.height-r, ey))))
+
+ patch = self.viz_with_stroke[ey-r:ey+r, ex-r:ex+r, :].astype(np.uint8)
+
+ height, width, channel = patch.shape
+ bytesPerLine = 3 * width
+ qImg = QImage(patch.data, width, height, bytesPerLine, QImage.Format_RGB888)
+ self.minimap.setPixmap(QPixmap(qImg.scaled(self.minimap.size(),
+ Qt.KeepAspectRatio, Qt.FastTransformation)))
+
+ def update_current_image_fast(self):
+ # fast path, uses gpu. Changes the image in-place to avoid copying
+ self.viz = get_visualization_torch(self.viz_mode, self.current_image_torch_no_norm,
+ self.current_prob, self.overlay_layer_torch, self.vis_target_objects)
+ if self.save_visualization:
+ self.res_man.save_visualization(self.cursur, self.viz)
+
+ height, width, channel = self.viz.shape
+ bytesPerLine = 3 * width
+
+ qImg = QImage(self.viz.data, width, height, bytesPerLine, QImage.Format_RGB888)
+ self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
+ Qt.KeepAspectRatio, Qt.FastTransformation)))
+
+ def show_current_frame(self, fast=False):
+ # Re-compute overlay and show the image
+ if fast:
+ self.update_current_image_fast()
+ else:
+ self.compose_current_im()
+ self.update_interact_vis()
+ self.update_minimap()
+
+ self.lcd.setText('{: 3d} / {: 3d}'.format(self.cursur, self.num_frames-1))
+ self.tl_slider.setValue(self.cursur)
+
+ def pixel_pos_to_image_pos(self, x, y):
+ # Un-scale and un-pad the label coordinates into image coordinates
+ oh, ow = self.image_size.height(), self.image_size.width()
+ nh, nw = self.main_canvas_size.height(), self.main_canvas_size.width()
+
+ h_ratio = nh/oh
+ w_ratio = nw/ow
+ dominate_ratio = min(h_ratio, w_ratio)
+
+ # Solve scale
+ x /= dominate_ratio
+ y /= dominate_ratio
+
+ # Solve padding
+ fh, fw = nh/dominate_ratio, nw/dominate_ratio
+ x -= (fw-ow)/2
+ y -= (fh-oh)/2
+
+ return x, y
+
+ def is_pos_out_of_bound(self, x, y):
+ x, y = self.pixel_pos_to_image_pos(x, y)
+
+ out_of_bound = (
+ (x < 0) or
+ (y < 0) or
+ (x > self.width-1) or
+ (y > self.height-1)
+ )
+
+ return out_of_bound
+
+ def get_scaled_pos(self, x, y):
+ x, y = self.pixel_pos_to_image_pos(x, y)
+
+ x = max(0, min(self.width-1, x))
+ y = max(0, min(self.height-1, y))
+
+ return x, y
+
+ def clear_visualization(self):
+ self.vis_map.fill(0)
+ self.vis_alpha.fill(0)
+
+ def reset_this_interaction(self):
+ self.complete_interaction()
+ self.clear_visualization()
+ self.interaction = None
+ if self.fbrs_controller is not None:
+ self.fbrs_controller.unanchor()
+
+ def set_viz_mode(self):
+ self.viz_mode = self.combo.currentText()
+ self.show_current_frame()
+
+ def save_current_mask(self):
+ # save mask to hard disk
+ self.res_man.save_mask(self.cursur, self.current_mask)
+
+ def tl_slide(self):
+ # if we are propagating, the on_run function will take care of everything
+ # don't do duplicate work here
+ if not self.propagating:
+ if self.curr_frame_dirty:
+ self.save_current_mask()
+ self.curr_frame_dirty = False
+
+ self.reset_this_interaction()
+ self.cursur = self.tl_slider.value()
+ self.load_current_image_mask()
+ self.show_current_frame()
+
+ def brush_slide(self):
+ self.brush_size = self.brush_slider.value()
+ self.brush_label.setText('Brush size: %d' % self.brush_size)
+ try:
+ if type(self.interaction) == FreeInteraction:
+ self.interaction.set_size(self.brush_size)
+ except AttributeError:
+ # Initialization, forget about it
+ pass
+
+ def on_forward_propagation(self):
+ if self.propagating:
+ # acts as a pause button
+ self.propagating = False
+ else:
+ self.propagate_fn = self.on_next_frame
+ self.backward_run_button.setEnabled(False)
+ self.forward_run_button.setText('Pause Propagation')
+ self.on_propagation()
+
+ def on_backward_propagation(self):
+ if self.propagating:
+ # acts as a pause button
+ self.propagating = False
+ else:
+ self.propagate_fn = self.on_prev_frame
+ self.forward_run_button.setEnabled(False)
+ self.backward_run_button.setText('Pause Propagation')
+ self.on_propagation()
+
+ def on_pause(self):
+ self.propagating = False
+ self.forward_run_button.setEnabled(True)
+ self.backward_run_button.setEnabled(True)
+ self.clear_mem_button.setEnabled(True)
+ self.forward_run_button.setText('Forward Propagate')
+ self.backward_run_button.setText('Backward Propagate')
+ self.console_push_text('Propagation stopped.')
+
+ def on_propagation(self):
+ # start to propagate
+ self.load_current_torch_image_mask()
+ self.show_current_frame(fast=True)
+
+ self.console_push_text('Propagation started.')
+ self.current_prob = self.processor.step(self.current_image_torch, self.current_prob[1:])
+ self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
+ # clear
+ self.interacted_prob = None
+ self.reset_this_interaction()
+
+ self.propagating = True
+ self.clear_mem_button.setEnabled(False)
+ # propagate till the end
+ while self.propagating:
+ self.propagate_fn()
+
+ self.load_current_image_mask(no_mask=True)
+ self.load_current_torch_image_mask(no_mask=True)
+
+ self.current_prob = self.processor.step(self.current_image_torch)
+ self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
+
+ self.save_current_mask()
+ self.show_current_frame(fast=True)
+
+ self.update_memory_size()
+ QApplication.processEvents()
+
+ if self.cursur == 0 or self.cursur == self.num_frames-1:
+ break
+
+ self.propagating = False
+ self.curr_frame_dirty = False
+ self.on_pause()
+ self.tl_slide()
+ QApplication.processEvents()
+
+ def pause_propagation(self):
+ self.propagating = False
+
+ def on_commit(self):
+ self.complete_interaction()
+ self.update_interacted_mask()
+
+ def on_prev_frame(self):
+ # self.tl_slide will trigger on setValue
+ self.cursur = max(0, self.cursur-1)
+ self.tl_slider.setValue(self.cursur)
+
+ def on_next_frame(self):
+ # self.tl_slide will trigger on setValue
+ self.cursur = min(self.cursur+1, self.num_frames-1)
+ self.tl_slider.setValue(self.cursur)
+
+ def on_play_video_timer(self):
+ self.cursur += 1
+ if self.cursur > self.num_frames-1:
+ self.cursur = 0
+ self.tl_slider.setValue(self.cursur)
+
+ def on_play_video(self):
+ if self.timer.isActive():
+ self.timer.stop()
+ self.play_button.setText('Play Video')
+ else:
+ self.timer.start(1000 / 30)
+ self.play_button.setText('Stop Video')
+
+ def on_reset_mask(self):
+ self.current_mask.fill(0)
+ if self.current_prob is not None:
+ self.current_prob.fill_(0)
+ self.curr_frame_dirty = True
+ self.save_current_mask()
+ self.reset_this_interaction()
+ self.show_current_frame()
+
+ def on_zoom_plus(self):
+ self.zoom_pixels -= 25
+ self.zoom_pixels = max(50, self.zoom_pixels)
+ self.update_minimap()
+
+ def on_zoom_minus(self):
+ self.zoom_pixels += 25
+ self.zoom_pixels = min(self.zoom_pixels, 300)
+ self.update_minimap()
+
+ def set_navi_enable(self, boolean):
+ self.zoom_p_button.setEnabled(boolean)
+ self.zoom_m_button.setEnabled(boolean)
+ self.run_button.setEnabled(boolean)
+ self.tl_slider.setEnabled(boolean)
+ self.play_button.setEnabled(boolean)
+ self.lcd.setEnabled(boolean)
+
+ def hit_number_key(self, number):
+ if number == self.current_object:
+ return
+ self.current_object = number
+ if self.fbrs_controller is not None:
+ self.fbrs_controller.unanchor()
+ self.console_push_text(f'Current object changed to {number}.')
+ self.clear_brush()
+ self.vis_brush(self.last_ex, self.last_ey)
+ self.update_interact_vis()
+ self.show_current_frame()
+
+ def clear_brush(self):
+ self.brush_vis_map.fill(0)
+ self.brush_vis_alpha.fill(0)
+
+ def vis_brush(self, ex, ey):
+ self.brush_vis_map = cv2.circle(self.brush_vis_map,
+ (int(round(ex)), int(round(ey))), self.brush_size//2+1, color_map[self.current_object], thickness=-1)
+ self.brush_vis_alpha = cv2.circle(self.brush_vis_alpha,
+ (int(round(ex)), int(round(ey))), self.brush_size//2+1, 0.5, thickness=-1)
+
+ def on_mouse_press(self, event):
+ if self.is_pos_out_of_bound(event.x(), event.y()):
+ return
+
+ # mid-click
+ if (event.button() == Qt.MidButton):
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ target_object = self.current_mask[int(ey),int(ex)]
+ if target_object in self.vis_target_objects:
+ self.vis_target_objects.remove(target_object)
+ else:
+ self.vis_target_objects.append(target_object)
+ self.console_push_text(f'Target objects for visualization changed to {self.vis_target_objects}')
+ self.show_current_frame()
+ return
+
+ self.right_click = (event.button() == Qt.RightButton)
+ self.pressed = True
+
+ h, w = self.height, self.width
+
+ self.load_current_torch_image_mask()
+ image = self.current_image_torch
+
+ last_interaction = self.interaction
+ new_interaction = None
+ if self.curr_interaction == 'Scribble':
+ if last_interaction is None or type(last_interaction) != ScribbleInteraction:
+ self.complete_interaction()
+ new_interaction = ScribbleInteraction(image, torch.from_numpy(self.current_mask).float().cuda(),
+ (h, w), self.s2m_controller, self.num_objects)
+ elif self.curr_interaction == 'Free':
+ if last_interaction is None or type(last_interaction) != FreeInteraction:
+ self.complete_interaction()
+ new_interaction = FreeInteraction(image, self.current_mask, (h, w),
+ self.num_objects)
+ new_interaction.set_size(self.brush_size)
+ elif self.curr_interaction == 'Click':
+ if (last_interaction is None or type(last_interaction) != ClickInteraction
+ or last_interaction.tar_obj != self.current_object):
+ self.complete_interaction()
+ self.fbrs_controller.unanchor()
+ new_interaction = ClickInteraction(image, self.current_prob, (h, w),
+ self.fbrs_controller, self.current_object)
+
+ if new_interaction is not None:
+ self.interaction = new_interaction
+
+ # Just motion it as the first step
+ self.on_mouse_motion(event)
+
+ def on_mouse_motion(self, event):
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ self.last_ex, self.last_ey = ex, ey
+ self.clear_brush()
+ # Visualize
+ self.vis_brush(ex, ey)
+ if self.pressed:
+ if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
+ obj = 0 if self.right_click else self.current_object
+ self.vis_map, self.vis_alpha = self.interaction.push_point(
+ ex, ey, obj, (self.vis_map, self.vis_alpha)
+ )
+ self.update_interact_vis()
+ self.update_minimap()
+
+ def update_interacted_mask(self):
+ self.current_prob = self.interacted_prob
+ self.current_mask = torch_prob_to_numpy_mask(self.interacted_prob)
+ self.show_current_frame()
+ self.save_current_mask()
+ self.curr_frame_dirty = False
+
+ def complete_interaction(self):
+ if self.interaction is not None:
+ self.clear_visualization()
+ self.interaction = None
+
+ def on_mouse_release(self, event):
+ if not self.pressed:
+ # this can happen when the initial press is out-of-bound
+ return
+
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+
+ self.console_push_text('%s interaction at frame %d.' % (self.curr_interaction, self.cursur))
+ interaction = self.interaction
+
+ if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
+ self.on_mouse_motion(event)
+ interaction.end_path()
+ if self.curr_interaction == 'Free':
+ self.clear_visualization()
+ elif self.curr_interaction == 'Click':
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ self.vis_map, self.vis_alpha = interaction.push_point(ex, ey,
+ self.right_click, (self.vis_map, self.vis_alpha))
+
+ self.interacted_prob = interaction.predict()
+ self.update_interacted_mask()
+ self.update_gpu_usage()
+
+ self.pressed = self.right_click = False
+
+ def wheelEvent(self, event):
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ if self.curr_interaction == 'Free':
+ self.brush_slider.setValue(self.brush_slider.value() + event.angleDelta().y()//30)
+ self.clear_brush()
+ self.vis_brush(ex, ey)
+ self.update_interact_vis()
+ self.update_minimap()
+
+ def update_gpu_usage(self):
+ info = torch.cuda.mem_get_info()
+ global_free, global_total = info
+ global_free /= (2**30)
+ global_total /= (2**30)
+ global_used = global_total - global_free
+
+ self.gpu_mem_gauge.setFormat(f'{global_used:.01f} GB / {global_total:.01f} GB')
+ self.gpu_mem_gauge.setValue(round(global_used/global_total*100))
+
+ used_by_torch = torch.cuda.max_memory_allocated() / (2**20)
+ self.torch_mem_gauge.setFormat(f'{used_by_torch:.0f} MB / {global_total:.01f} GB')
+ self.torch_mem_gauge.setValue(round(used_by_torch/global_total*100/1024))
+
+ def on_gpu_timer(self):
+ self.update_gpu_usage()
+
+ def update_memory_size(self):
+ try:
+ max_work_elements = self.processor.memory.max_work_elements
+ max_long_elements = self.processor.memory.max_long_elements
+
+ curr_work_elements = self.processor.memory.work_mem.size
+ curr_long_elements = self.processor.memory.long_mem.size
+
+ self.work_mem_gauge.setFormat(f'{curr_work_elements} / {max_work_elements}')
+ self.work_mem_gauge.setValue(round(curr_work_elements/max_work_elements*100))
+
+ self.long_mem_gauge.setFormat(f'{curr_long_elements} / {max_long_elements}')
+ self.long_mem_gauge.setValue(round(curr_long_elements/max_long_elements*100))
+
+ except AttributeError:
+ self.work_mem_gauge.setFormat('Unknown')
+ self.long_mem_gauge.setFormat('Unknown')
+ self.work_mem_gauge.setValue(0)
+ self.long_mem_gauge.setValue(0)
+
+ def on_work_min_change(self):
+ if self.initialized:
+ self.work_mem_min.setValue(min(self.work_mem_min.value(), self.work_mem_max.value()-1))
+ self.update_config()
+
+ def on_work_max_change(self):
+ if self.initialized:
+ self.work_mem_max.setValue(max(self.work_mem_max.value(), self.work_mem_min.value()+1))
+ self.update_config()
+
+ def update_config(self):
+ if self.initialized:
+ self.config['min_mid_term_frames'] = self.work_mem_min.value()
+ self.config['max_mid_term_frames'] = self.work_mem_max.value()
+ self.config['max_long_term_elements'] = self.long_mem_max.value()
+ self.config['num_prototypes'] = self.num_prototypes_box.value()
+ self.config['mem_every'] = self.mem_every_box.value()
+
+ self.processor.update_config(self.config)
+
+ def on_clear_memory(self):
+ self.processor.clear_memory()
+ torch.cuda.empty_cache()
+ self.update_gpu_usage()
+ self.update_memory_size()
+
+ def _open_file(self, prompt):
+ options = QFileDialog.Options()
+ file_name, _ = QFileDialog.getOpenFileName(self, prompt, "", "Image files (*)", options=options)
+ return file_name
+
+ def on_import_mask(self):
+ file_name = self._open_file('Mask')
+ if len(file_name) == 0:
+ return
+
+ mask = self.res_man.read_external_image(file_name, size=(self.height, self.width))
+
+ shape_condition = (
+ (len(mask.shape) == 2) and
+ (mask.shape[-1] == self.width) and
+ (mask.shape[-2] == self.height)
+ )
+
+ object_condition = (
+ mask.max() <= self.num_objects
+ )
+
+ if not shape_condition:
+ self.console_push_text(f'Expected ({self.height}, {self.width}). Got {mask.shape} instead.')
+ elif not object_condition:
+ self.console_push_text(f'Expected {self.num_objects} objects. Got {mask.max()} objects instead.')
+ else:
+ self.console_push_text(f'Mask file {file_name} loaded.')
+ self.current_image_torch = self.current_prob = None
+ self.current_mask = mask
+ self.show_current_frame()
+ self.save_current_mask()
+
+ def on_import_layer(self):
+ file_name = self._open_file('Layer')
+ if len(file_name) == 0:
+ return
+
+ self._try_load_layer(file_name)
+
+ def _try_load_layer(self, file_name):
+ try:
+ layer = self.res_man.read_external_image(file_name, size=(self.height, self.width))
+
+ if layer.shape[-1] == 3:
+ layer = np.concatenate([layer, np.ones_like(layer[:,:,0:1])*255], axis=-1)
+
+ condition = (
+ (len(layer.shape) == 3) and
+ (layer.shape[-1] == 4) and
+ (layer.shape[-2] == self.width) and
+ (layer.shape[-3] == self.height)
+ )
+
+ if not condition:
+ self.console_push_text(f'Expected ({self.height}, {self.width}, 4). Got {layer.shape}.')
+ else:
+ self.console_push_text(f'Layer file {file_name} loaded.')
+ self.overlay_layer = layer
+ self.overlay_layer_torch = torch.from_numpy(layer).float().cuda()/255
+ self.show_current_frame()
+ except FileNotFoundError:
+ self.console_push_text(f'{file_name} not found.')
+
+ def on_save_visualization_toggle(self):
+ self.save_visualization = self.save_visualization_checkbox.isChecked()
diff --git a/inference/interact/gui_utils.py b/inference/interact/gui_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..daf852b30a84893c836d7c3350b727aeed5d0a6b
--- /dev/null
+++ b/inference/interact/gui_utils.py
@@ -0,0 +1,40 @@
+from PyQt5.QtCore import Qt
+from PyQt5.QtWidgets import (QHBoxLayout, QLabel, QSpinBox, QVBoxLayout, QProgressBar)
+
+
+def create_parameter_box(min_val, max_val, text, step=1, callback=None):
+ layout = QHBoxLayout()
+
+ dial = QSpinBox()
+ dial.setMaximumHeight(28)
+ dial.setMaximumWidth(150)
+ dial.setMinimum(min_val)
+ dial.setMaximum(max_val)
+ dial.setAlignment(Qt.AlignRight)
+ dial.setSingleStep(step)
+ dial.valueChanged.connect(callback)
+
+ label = QLabel(text)
+ label.setAlignment(Qt.AlignRight)
+
+ layout.addWidget(label)
+ layout.addWidget(dial)
+
+ return dial, layout
+
+
+def create_gauge(text):
+ layout = QHBoxLayout()
+
+ gauge = QProgressBar()
+ gauge.setMaximumHeight(28)
+ gauge.setMaximumWidth(200)
+ gauge.setAlignment(Qt.AlignCenter)
+
+ label = QLabel(text)
+ label.setAlignment(Qt.AlignRight)
+
+ layout.addWidget(label)
+ layout.addWidget(gauge)
+
+ return gauge, layout
diff --git a/inference/interact/interaction.py b/inference/interact/interaction.py
new file mode 100644
index 0000000000000000000000000000000000000000..19f83f9d58a00cac079a7ba5c239196378603b64
--- /dev/null
+++ b/inference/interact/interaction.py
@@ -0,0 +1,252 @@
+"""
+Contains all the types of interaction related to the GUI
+Not related to automatic evaluation in the DAVIS dataset
+
+You can inherit the Interaction class to create new interaction types
+undo is (sometimes partially) supported
+"""
+
+
+import torch
+import torch.nn.functional as F
+import numpy as np
+import cv2
+import time
+from .interactive_utils import color_map, index_numpy_to_one_hot_torch
+
+
+def aggregate_sbg(prob, keep_bg=False, hard=False):
+ device = prob.device
+ k, h, w = prob.shape
+ ex_prob = torch.zeros((k+1, h, w), device=device)
+ ex_prob[0] = 0.5
+ ex_prob[1:] = prob
+ ex_prob = torch.clamp(ex_prob, 1e-7, 1-1e-7)
+ logits = torch.log((ex_prob /(1-ex_prob)))
+
+ if hard:
+ # Very low temperature o((⊙﹏⊙))o 🥶
+ logits *= 1000
+
+ if keep_bg:
+ return F.softmax(logits, dim=0)
+ else:
+ return F.softmax(logits, dim=0)[1:]
+
+def aggregate_wbg(prob, keep_bg=False, hard=False):
+ k, h, w = prob.shape
+ new_prob = torch.cat([
+ torch.prod(1-prob, dim=0, keepdim=True),
+ prob
+ ], 0).clamp(1e-7, 1-1e-7)
+ logits = torch.log((new_prob /(1-new_prob)))
+
+ if hard:
+ # Very low temperature o((⊙﹏⊙))o 🥶
+ logits *= 1000
+
+ if keep_bg:
+ return F.softmax(logits, dim=0)
+ else:
+ return F.softmax(logits, dim=0)[1:]
+
+class Interaction:
+ def __init__(self, image, prev_mask, true_size, controller):
+ self.image = image
+ self.prev_mask = prev_mask
+ self.controller = controller
+ self.start_time = time.time()
+
+ self.h, self.w = true_size
+
+ self.out_prob = None
+ self.out_mask = None
+
+ def predict(self):
+ pass
+
+
+class FreeInteraction(Interaction):
+ def __init__(self, image, prev_mask, true_size, num_objects):
+ """
+ prev_mask should be index format numpy array
+ """
+ super().__init__(image, prev_mask, true_size, None)
+
+ self.K = num_objects
+
+ self.drawn_map = self.prev_mask.copy()
+ self.curr_path = [[] for _ in range(self.K + 1)]
+
+ self.size = None
+
+ def set_size(self, size):
+ self.size = size
+
+ """
+ k - object id
+ vis - a tuple (visualization map, pass through alpha). None if not needed.
+ """
+ def push_point(self, x, y, k, vis=None):
+ if vis is not None:
+ vis_map, vis_alpha = vis
+ selected = self.curr_path[k]
+ selected.append((x, y))
+ if len(selected) >= 2:
+ cv2.line(self.drawn_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ k, thickness=self.size)
+
+ # Plot visualization
+ if vis is not None:
+ # Visualization for drawing
+ if k == 0:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ else:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ # Visualization on/off boolean filter
+ vis_alpha = cv2.line(vis_alpha,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ 0.75, thickness=self.size)
+
+ if vis is not None:
+ return vis_map, vis_alpha
+
+ def end_path(self):
+ # Complete the drawing
+ self.curr_path = [[] for _ in range(self.K + 1)]
+
+ def predict(self):
+ self.out_prob = index_numpy_to_one_hot_torch(self.drawn_map, self.K+1).cuda()
+ # self.out_prob = torch.from_numpy(self.drawn_map).float().cuda()
+ # self.out_prob, _ = pad_divide_by(self.out_prob, 16, self.out_prob.shape[-2:])
+ # self.out_prob = aggregate_sbg(self.out_prob, keep_bg=True)
+ return self.out_prob
+
+class ScribbleInteraction(Interaction):
+ def __init__(self, image, prev_mask, true_size, controller, num_objects):
+ """
+ prev_mask should be in an indexed form
+ """
+ super().__init__(image, prev_mask, true_size, controller)
+
+ self.K = num_objects
+
+ self.drawn_map = np.empty((self.h, self.w), dtype=np.uint8)
+ self.drawn_map.fill(255)
+ # background + k
+ self.curr_path = [[] for _ in range(self.K + 1)]
+ self.size = 3
+
+ """
+ k - object id
+ vis - a tuple (visualization map, pass through alpha). None if not needed.
+ """
+ def push_point(self, x, y, k, vis=None):
+ if vis is not None:
+ vis_map, vis_alpha = vis
+ selected = self.curr_path[k]
+ selected.append((x, y))
+ if len(selected) >= 2:
+ self.drawn_map = cv2.line(self.drawn_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ k, thickness=self.size)
+
+ # Plot visualization
+ if vis is not None:
+ # Visualization for drawing
+ if k == 0:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ else:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ # Visualization on/off boolean filter
+ vis_alpha = cv2.line(vis_alpha,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ 0.75, thickness=self.size)
+
+ # Optional vis return
+ if vis is not None:
+ return vis_map, vis_alpha
+
+ def end_path(self):
+ # Complete the drawing
+ self.curr_path = [[] for _ in range(self.K + 1)]
+
+ def predict(self):
+ self.out_prob = self.controller.interact(self.image.unsqueeze(0), self.prev_mask, self.drawn_map)
+ self.out_prob = aggregate_wbg(self.out_prob, keep_bg=True, hard=True)
+ return self.out_prob
+
+
+class ClickInteraction(Interaction):
+ def __init__(self, image, prev_mask, true_size, controller, tar_obj):
+ """
+ prev_mask in a prob. form
+ """
+ super().__init__(image, prev_mask, true_size, controller)
+ self.tar_obj = tar_obj
+
+ # negative/positive for each object
+ self.pos_clicks = []
+ self.neg_clicks = []
+
+ self.out_prob = self.prev_mask.clone()
+
+ """
+ neg - Negative interaction or not
+ vis - a tuple (visualization map, pass through alpha). None if not needed.
+ """
+ def push_point(self, x, y, neg, vis=None):
+ # Clicks
+ if neg:
+ self.neg_clicks.append((x, y))
+ else:
+ self.pos_clicks.append((x, y))
+
+ # Do the prediction
+ self.obj_mask = self.controller.interact(self.image.unsqueeze(0), x, y, not neg)
+
+ # Plot visualization
+ if vis is not None:
+ vis_map, vis_alpha = vis
+ # Visualization for clicks
+ if neg:
+ vis_map = cv2.circle(vis_map,
+ (int(round(x)), int(round(y))),
+ 2, color_map[0], thickness=-1)
+ else:
+ vis_map = cv2.circle(vis_map,
+ (int(round(x)), int(round(y))),
+ 2, color_map[self.tar_obj], thickness=-1)
+
+ vis_alpha = cv2.circle(vis_alpha,
+ (int(round(x)), int(round(y))),
+ 2, 1, thickness=-1)
+
+ # Optional vis return
+ return vis_map, vis_alpha
+
+ def predict(self):
+ self.out_prob = self.prev_mask.clone()
+ # a small hack to allow the interacting object to overwrite existing masks
+ # without remembering all the object probabilities
+ self.out_prob = torch.clamp(self.out_prob, max=0.9)
+ self.out_prob[self.tar_obj] = self.obj_mask
+ self.out_prob = aggregate_wbg(self.out_prob[1:], keep_bg=True, hard=True)
+ return self.out_prob
diff --git a/inference/interact/interactive_utils.py b/inference/interact/interactive_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..9961f63aab4f59323454f34d76241a743190198f
--- /dev/null
+++ b/inference/interact/interactive_utils.py
@@ -0,0 +1,175 @@
+# Modifed from https://github.com/seoungwugoh/ivs-demo
+
+import numpy as np
+
+import torch
+import torch.nn.functional as F
+from util.palette import davis_palette
+from dataset.range_transform import im_normalization
+
+def image_to_torch(frame: np.ndarray, device='cuda'):
+ # frame: H*W*3 numpy array
+ frame = frame.transpose(2, 0, 1)
+ frame = torch.from_numpy(frame).float().to(device)/255
+ frame_norm = im_normalization(frame)
+ return frame_norm, frame
+
+def torch_prob_to_numpy_mask(prob):
+ mask = torch.argmax(prob, dim=0)
+ mask = mask.cpu().numpy().astype(np.uint8)
+ return mask
+
+def index_numpy_to_one_hot_torch(mask, num_classes):
+ mask = torch.from_numpy(mask).long()
+ return F.one_hot(mask, num_classes=num_classes).permute(2, 0, 1).float()
+
+"""
+Some constants fro visualization
+"""
+color_map_np = np.frombuffer(davis_palette, dtype=np.uint8).reshape(-1, 3).copy()
+# scales for better visualization
+color_map_np = (color_map_np.astype(np.float32)*1.5).clip(0, 255).astype(np.uint8)
+color_map = color_map_np.tolist()
+if torch.cuda.is_available():
+ color_map_torch = torch.from_numpy(color_map_np).cuda() / 255
+
+grayscale_weights = np.array([[0.3,0.59,0.11]]).astype(np.float32)
+if torch.cuda.is_available():
+ grayscale_weights_torch = torch.from_numpy(grayscale_weights).cuda().unsqueeze(0)
+
+def get_visualization(mode, image, mask, layer, target_object):
+ if mode == 'fade':
+ return overlay_davis(image, mask, fade=True)
+ elif mode == 'davis':
+ return overlay_davis(image, mask)
+ elif mode == 'light':
+ return overlay_davis(image, mask, 0.9)
+ elif mode == 'popup':
+ return overlay_popup(image, mask, target_object)
+ elif mode == 'layered':
+ if layer is None:
+ print('Layer file not given. Defaulting to DAVIS.')
+ return overlay_davis(image, mask)
+ else:
+ return overlay_layer(image, mask, layer, target_object)
+ else:
+ raise NotImplementedError
+
+def get_visualization_torch(mode, image, prob, layer, target_object):
+ if mode == 'fade':
+ return overlay_davis_torch(image, prob, fade=True)
+ elif mode == 'davis':
+ return overlay_davis_torch(image, prob)
+ elif mode == 'light':
+ return overlay_davis_torch(image, prob, 0.9)
+ elif mode == 'popup':
+ return overlay_popup_torch(image, prob, target_object)
+ elif mode == 'layered':
+ if layer is None:
+ print('Layer file not given. Defaulting to DAVIS.')
+ return overlay_davis_torch(image, prob)
+ else:
+ return overlay_layer_torch(image, prob, layer, target_object)
+ else:
+ raise NotImplementedError
+
+def overlay_davis(image, mask, alpha=0.5, fade=False):
+ """ Overlay segmentation on top of RGB image. from davis official"""
+ im_overlay = image.copy()
+
+ colored_mask = color_map_np[mask]
+ foreground = image*alpha + (1-alpha)*colored_mask
+ binary_mask = (mask > 0)
+ # Compose image
+ im_overlay[binary_mask] = foreground[binary_mask]
+ if fade:
+ im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
+ return im_overlay.astype(image.dtype)
+
+def overlay_popup(image, mask, target_object):
+ # Keep foreground colored. Convert background to grayscale.
+ im_overlay = image.copy()
+
+ binary_mask = ~(np.isin(mask, target_object))
+ colored_region = (im_overlay[binary_mask]*grayscale_weights).sum(-1, keepdims=-1)
+ im_overlay[binary_mask] = colored_region
+ return im_overlay.astype(image.dtype)
+
+def overlay_layer(image, mask, layer, target_object):
+ # insert a layer between foreground and background
+ # The CPU version is less accurate because we are using the hard mask
+ # The GPU version has softer edges as it uses soft probabilities
+ obj_mask = (np.isin(mask, target_object)).astype(np.float32)
+ layer_alpha = layer[:, :, 3].astype(np.float32) / 255
+ layer_rgb = layer[:, :, :3]
+ background_alpha = np.maximum(obj_mask, layer_alpha)[:,:,np.newaxis]
+ obj_mask = obj_mask[:,:,np.newaxis]
+ im_overlay = (image*(1-background_alpha) + layer_rgb*(1-obj_mask) + image*obj_mask).clip(0, 255)
+ return im_overlay.astype(image.dtype)
+
+def overlay_davis_torch(image, mask, alpha=0.5, fade=False):
+ """ Overlay segmentation on top of RGB image. from davis official"""
+ # Changes the image in-place to avoid copying
+ image = image.permute(1, 2, 0)
+ im_overlay = image
+ mask = torch.argmax(mask, dim=0)
+
+ colored_mask = color_map_torch[mask]
+ foreground = image*alpha + (1-alpha)*colored_mask
+ binary_mask = (mask > 0)
+ # Compose image
+ im_overlay[binary_mask] = foreground[binary_mask]
+ if fade:
+ im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
+
+ im_overlay = (im_overlay*255).cpu().numpy()
+ im_overlay = im_overlay.astype(np.uint8)
+
+ return im_overlay
+
+def overlay_popup_torch(image, mask, target_object):
+ # Keep foreground colored. Convert background to grayscale.
+ image = image.permute(1, 2, 0)
+
+ if len(target_object) == 0:
+ obj_mask = torch.zeros_like(mask[0]).unsqueeze(2)
+ else:
+ # I should not need to convert this to numpy.
+ # uUsing list works most of the time but consistently fails
+ # if I include first object -> exclude it -> include it again.
+ # I check everywhere and it makes absolutely no sense.
+ # I am blaming this on PyTorch and calling it a day
+ obj_mask = mask[np.array(target_object,dtype=np.int32)].sum(0).unsqueeze(2)
+ gray_image = (image*grayscale_weights_torch).sum(-1, keepdim=True)
+ im_overlay = obj_mask*image + (1-obj_mask)*gray_image
+
+ im_overlay = (im_overlay*255).cpu().numpy()
+ im_overlay = im_overlay.astype(np.uint8)
+
+ return im_overlay
+
+def overlay_layer_torch(image, mask, layer, target_object):
+ # insert a layer between foreground and background
+ # The CPU version is less accurate because we are using the hard mask
+ # The GPU version has softer edges as it uses soft probabilities
+ image = image.permute(1, 2, 0)
+
+ if len(target_object) == 0:
+ obj_mask = torch.zeros_like(mask[0])
+ else:
+ # I should not need to convert this to numpy.
+ # uUsing list works most of the time but consistently fails
+ # if I include first object -> exclude it -> include it again.
+ # I check everywhere and it makes absolutely no sense.
+ # I am blaming this on PyTorch and calling it a day
+ obj_mask = mask[np.array(target_object,dtype=np.int32)].sum(0)
+ layer_alpha = layer[:, :, 3]
+ layer_rgb = layer[:, :, :3]
+ background_alpha = torch.maximum(obj_mask, layer_alpha).unsqueeze(2)
+ obj_mask = obj_mask.unsqueeze(2)
+ im_overlay = (image*(1-background_alpha) + layer_rgb*(1-obj_mask) + image*obj_mask).clip(0, 1)
+
+ im_overlay = (im_overlay*255).cpu().numpy()
+ im_overlay = im_overlay.astype(np.uint8)
+
+ return im_overlay
diff --git a/inference/interact/resource_manager.py b/inference/interact/resource_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0f28af2e35a3ea29958e5eee4e19b26f1fa010b
--- /dev/null
+++ b/inference/interact/resource_manager.py
@@ -0,0 +1,206 @@
+import os
+from os import path
+import shutil
+import collections
+
+import cv2
+from PIL import Image
+if not hasattr(Image, 'Resampling'): # Pillow<9.0
+ Image.Resampling = Image
+import numpy as np
+
+from util.palette import davis_palette
+import progressbar
+
+
+# https://bugs.python.org/issue28178
+# ah python ah why
+class LRU:
+ def __init__(self, func, maxsize=128):
+ self.cache = collections.OrderedDict()
+ self.func = func
+ self.maxsize = maxsize
+
+ def __call__(self, *args):
+ cache = self.cache
+ if args in cache:
+ cache.move_to_end(args)
+ return cache[args]
+ result = self.func(*args)
+ cache[args] = result
+ if len(cache) > self.maxsize:
+ cache.popitem(last=False)
+ return result
+
+ def invalidate(self, key):
+ self.cache.pop(key, None)
+
+
+class ResourceManager:
+ def __init__(self, config):
+ # determine inputs
+ images = config['images']
+ video = config['video']
+ self.workspace = config['workspace']
+ self.size = config['size']
+ self.palette = davis_palette
+
+ # create temporary workspace if not specified
+ if self.workspace is None:
+ if images is not None:
+ basename = path.basename(images)
+ elif video is not None:
+ basename = path.basename(video)[:-4]
+ else:
+ raise NotImplementedError(
+ 'Either images, video, or workspace has to be specified')
+
+ self.workspace = path.join('./workspace', basename)
+
+ print(f'Workspace is in: {self.workspace}')
+
+ # determine the location of input images
+ need_decoding = False
+ need_resizing = False
+ if path.exists(path.join(self.workspace, 'images')):
+ pass
+ elif images is not None:
+ need_resizing = True
+ elif video is not None:
+ # will decode video into frames later
+ need_decoding = True
+
+ # create workspace subdirectories
+ self.image_dir = path.join(self.workspace, 'images')
+ self.mask_dir = path.join(self.workspace, 'masks')
+ os.makedirs(self.image_dir, exist_ok=True)
+ os.makedirs(self.mask_dir, exist_ok=True)
+
+ # convert read functions to be buffered
+ self.get_image = LRU(self._get_image_unbuffered, maxsize=config['buffer_size'])
+ self.get_mask = LRU(self._get_mask_unbuffered, maxsize=config['buffer_size'])
+
+ # extract frames from video
+ if need_decoding:
+ self._extract_frames(video)
+
+ # copy/resize existing images to the workspace
+ if need_resizing:
+ self._copy_resize_frames(images)
+
+ # read all frame names
+ self.names = sorted(os.listdir(self.image_dir))
+ self.names = [f[:-4] for f in self.names] # remove extensions
+ self.length = len(self.names)
+
+ assert self.length > 0, f'No images found! Check {self.workspace}/images. Remove folder if necessary.'
+
+ print(f'{self.length} images found.')
+
+ self.height, self.width = self.get_image(0).shape[:2]
+ self.visualization_init = False
+
+ def _extract_frames(self, video):
+ cap = cv2.VideoCapture(video)
+ frame_index = 0
+ print(f'Extracting frames from {video} into {self.image_dir}...')
+ bar = progressbar.ProgressBar(max_value=progressbar.UnknownLength)
+ while(cap.isOpened()):
+ _, frame = cap.read()
+ if frame is None:
+ break
+ if self.size > 0:
+ h, w = frame.shape[:2]
+ new_w = (w*self.size//min(w, h))
+ new_h = (h*self.size//min(w, h))
+ if new_w != w or new_h != h:
+ frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
+ cv2.imwrite(path.join(self.image_dir, f'{frame_index:07d}.jpg'), frame)
+ frame_index += 1
+ bar.update(frame_index)
+ bar.finish()
+ print('Done!')
+
+ def _copy_resize_frames(self, images):
+ image_list = os.listdir(images)
+ print(f'Copying/resizing frames into {self.image_dir}...')
+ for image_name in progressbar.progressbar(image_list):
+ if self.size < 0:
+ # just copy
+ shutil.copy2(path.join(images, image_name), self.image_dir)
+ else:
+ frame = cv2.imread(path.join(images, image_name))
+ h, w = frame.shape[:2]
+ new_w = (w*self.size//min(w, h))
+ new_h = (h*self.size//min(w, h))
+ if new_w != w or new_h != h:
+ frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
+ cv2.imwrite(path.join(self.image_dir, image_name), frame)
+ print('Done!')
+
+ def save_mask(self, ti, mask):
+ # mask should be uint8 H*W without channels
+ assert 0 <= ti < self.length
+ assert isinstance(mask, np.ndarray)
+
+ mask = Image.fromarray(mask)
+ mask.putpalette(self.palette)
+ mask.save(path.join(self.mask_dir, self.names[ti]+'.png'))
+ self.invalidate(ti)
+
+ def save_visualization(self, ti, image):
+ # image should be uint8 3*H*W
+ assert 0 <= ti < self.length
+ assert isinstance(image, np.ndarray)
+ if not self.visualization_init:
+ self.visualization_dir = path.join(self.workspace, 'visualization')
+ os.makedirs(self.visualization_dir, exist_ok=True)
+ self.visualization_init = True
+
+ image = Image.fromarray(image)
+ image.save(path.join(self.visualization_dir, self.names[ti]+'.jpg'))
+
+ def _get_image_unbuffered(self, ti):
+ # returns H*W*3 uint8 array
+ assert 0 <= ti < self.length
+
+ image = Image.open(path.join(self.image_dir, self.names[ti]+'.jpg'))
+ image = np.array(image)
+ return image
+
+ def _get_mask_unbuffered(self, ti):
+ # returns H*W uint8 array
+ assert 0 <= ti < self.length
+
+ mask_path = path.join(self.mask_dir, self.names[ti]+'.png')
+ if path.exists(mask_path):
+ mask = Image.open(mask_path)
+ mask = np.array(mask)
+ return mask
+ else:
+ return None
+
+ def read_external_image(self, file_name, size=None):
+ image = Image.open(file_name)
+ is_mask = image.mode in ['L', 'P']
+ if size is not None:
+ # PIL uses (width, height)
+ image = image.resize((size[1], size[0]),
+ resample=Image.Resampling.NEAREST if is_mask else Image.Resampling.BICUBIC)
+ image = np.array(image)
+ return image
+
+ def invalidate(self, ti):
+ # the image buffer is never invalidated
+ self.get_mask.invalidate((ti,))
+
+ def __len__(self):
+ return self.length
+
+ @property
+ def h(self):
+ return self.height
+
+ @property
+ def w(self):
+ return self.width
diff --git a/inference/interact/s2m/__init__.py b/inference/interact/s2m/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/s2m/_deeplab.py b/inference/interact/s2m/_deeplab.py
new file mode 100644
index 0000000000000000000000000000000000000000..e663007dde9a56add1aa540be76cf2f5d81de82f
--- /dev/null
+++ b/inference/interact/s2m/_deeplab.py
@@ -0,0 +1,180 @@
+# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from .utils import _SimpleSegmentationModel
+
+
+__all__ = ["DeepLabV3"]
+
+
+class DeepLabV3(_SimpleSegmentationModel):
+ """
+ Implements DeepLabV3 model from
+ `"Rethinking Atrous Convolution for Semantic Image Segmentation"
+ `_.
+
+ Arguments:
+ backbone (nn.Module): the network used to compute the features for the model.
+ The backbone should return an OrderedDict[Tensor], with the key being
+ "out" for the last feature map used, and "aux" if an auxiliary classifier
+ is used.
+ classifier (nn.Module): module that takes the "out" element returned from
+ the backbone and returns a dense prediction.
+ aux_classifier (nn.Module, optional): auxiliary classifier used during training
+ """
+ pass
+
+class DeepLabHeadV3Plus(nn.Module):
+ def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):
+ super(DeepLabHeadV3Plus, self).__init__()
+ self.project = nn.Sequential(
+ nn.Conv2d(low_level_channels, 48, 1, bias=False),
+ nn.BatchNorm2d(48),
+ nn.ReLU(inplace=True),
+ )
+
+ self.aspp = ASPP(in_channels, aspp_dilate)
+
+ self.classifier = nn.Sequential(
+ nn.Conv2d(304, 256, 3, padding=1, bias=False),
+ nn.BatchNorm2d(256),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(256, num_classes, 1)
+ )
+ self._init_weight()
+
+ def forward(self, feature):
+ low_level_feature = self.project( feature['low_level'] )
+ output_feature = self.aspp(feature['out'])
+ output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
+ return self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
+
+ def _init_weight(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+class DeepLabHead(nn.Module):
+ def __init__(self, in_channels, num_classes, aspp_dilate=[12, 24, 36]):
+ super(DeepLabHead, self).__init__()
+
+ self.classifier = nn.Sequential(
+ ASPP(in_channels, aspp_dilate),
+ nn.Conv2d(256, 256, 3, padding=1, bias=False),
+ nn.BatchNorm2d(256),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(256, num_classes, 1)
+ )
+ self._init_weight()
+
+ def forward(self, feature):
+ return self.classifier( feature['out'] )
+
+ def _init_weight(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+class AtrousSeparableConvolution(nn.Module):
+ """ Atrous Separable Convolution
+ """
+ def __init__(self, in_channels, out_channels, kernel_size,
+ stride=1, padding=0, dilation=1, bias=True):
+ super(AtrousSeparableConvolution, self).__init__()
+ self.body = nn.Sequential(
+ # Separable Conv
+ nn.Conv2d( in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, bias=bias, groups=in_channels ),
+ # PointWise Conv
+ nn.Conv2d( in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
+ )
+
+ self._init_weight()
+
+ def forward(self, x):
+ return self.body(x)
+
+ def _init_weight(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+class ASPPConv(nn.Sequential):
+ def __init__(self, in_channels, out_channels, dilation):
+ modules = [
+ nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True)
+ ]
+ super(ASPPConv, self).__init__(*modules)
+
+class ASPPPooling(nn.Sequential):
+ def __init__(self, in_channels, out_channels):
+ super(ASPPPooling, self).__init__(
+ nn.AdaptiveAvgPool2d(1),
+ nn.Conv2d(in_channels, out_channels, 1, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True))
+
+ def forward(self, x):
+ size = x.shape[-2:]
+ x = super(ASPPPooling, self).forward(x)
+ return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
+
+class ASPP(nn.Module):
+ def __init__(self, in_channels, atrous_rates):
+ super(ASPP, self).__init__()
+ out_channels = 256
+ modules = []
+ modules.append(nn.Sequential(
+ nn.Conv2d(in_channels, out_channels, 1, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True)))
+
+ rate1, rate2, rate3 = tuple(atrous_rates)
+ modules.append(ASPPConv(in_channels, out_channels, rate1))
+ modules.append(ASPPConv(in_channels, out_channels, rate2))
+ modules.append(ASPPConv(in_channels, out_channels, rate3))
+ modules.append(ASPPPooling(in_channels, out_channels))
+
+ self.convs = nn.ModuleList(modules)
+
+ self.project = nn.Sequential(
+ nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True),
+ nn.Dropout(0.1),)
+
+ def forward(self, x):
+ res = []
+ for conv in self.convs:
+ res.append(conv(x))
+ res = torch.cat(res, dim=1)
+ return self.project(res)
+
+
+
+def convert_to_separable_conv(module):
+ new_module = module
+ if isinstance(module, nn.Conv2d) and module.kernel_size[0]>1:
+ new_module = AtrousSeparableConvolution(module.in_channels,
+ module.out_channels,
+ module.kernel_size,
+ module.stride,
+ module.padding,
+ module.dilation,
+ module.bias)
+ for name, child in module.named_children():
+ new_module.add_module(name, convert_to_separable_conv(child))
+ return new_module
\ No newline at end of file
diff --git a/inference/interact/s2m/s2m_network.py b/inference/interact/s2m/s2m_network.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4f9a3fc4fcc9cc4210485fe24e4d740464d3f8a
--- /dev/null
+++ b/inference/interact/s2m/s2m_network.py
@@ -0,0 +1,65 @@
+# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
+
+from .utils import IntermediateLayerGetter
+from ._deeplab import DeepLabHead, DeepLabHeadV3Plus, DeepLabV3
+from . import s2m_resnet
+
+def _segm_resnet(name, backbone_name, num_classes, output_stride, pretrained_backbone):
+
+ if output_stride==8:
+ replace_stride_with_dilation=[False, True, True]
+ aspp_dilate = [12, 24, 36]
+ else:
+ replace_stride_with_dilation=[False, False, True]
+ aspp_dilate = [6, 12, 18]
+
+ backbone = s2m_resnet.__dict__[backbone_name](
+ pretrained=pretrained_backbone,
+ replace_stride_with_dilation=replace_stride_with_dilation)
+
+ inplanes = 2048
+ low_level_planes = 256
+
+ if name=='deeplabv3plus':
+ return_layers = {'layer4': 'out', 'layer1': 'low_level'}
+ classifier = DeepLabHeadV3Plus(inplanes, low_level_planes, num_classes, aspp_dilate)
+ elif name=='deeplabv3':
+ return_layers = {'layer4': 'out'}
+ classifier = DeepLabHead(inplanes , num_classes, aspp_dilate)
+ backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
+
+ model = DeepLabV3(backbone, classifier)
+ return model
+
+def _load_model(arch_type, backbone, num_classes, output_stride, pretrained_backbone):
+
+ if backbone.startswith('resnet'):
+ model = _segm_resnet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
+ else:
+ raise NotImplementedError
+ return model
+
+
+# Deeplab v3
+def deeplabv3_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
+ """Constructs a DeepLabV3 model with a ResNet-50 backbone.
+
+ Args:
+ num_classes (int): number of classes.
+ output_stride (int): output stride for deeplab.
+ pretrained_backbone (bool): If True, use the pretrained backbone.
+ """
+ return _load_model('deeplabv3', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
+
+
+# Deeplab v3+
+def deeplabv3plus_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
+ """Constructs a DeepLabV3 model with a ResNet-50 backbone.
+
+ Args:
+ num_classes (int): number of classes.
+ output_stride (int): output stride for deeplab.
+ pretrained_backbone (bool): If True, use the pretrained backbone.
+ """
+ return _load_model('deeplabv3plus', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
+
diff --git a/inference/interact/s2m/s2m_resnet.py b/inference/interact/s2m/s2m_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..89f1ce042c69daa9b18172a0aadf9bc1de6f300e
--- /dev/null
+++ b/inference/interact/s2m/s2m_resnet.py
@@ -0,0 +1,182 @@
+import torch
+import torch.nn as nn
+try:
+ from torchvision.models.utils import load_state_dict_from_url
+except ModuleNotFoundError:
+ from torch.utils.model_zoo import load_url as load_state_dict_from_url
+
+
+__all__ = ['ResNet', 'resnet50']
+
+
+model_urls = {
+ 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
+}
+
+
+def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
+ """3x3 convolution with padding"""
+ return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
+ padding=dilation, groups=groups, bias=False, dilation=dilation)
+
+
+def conv1x1(in_planes, out_planes, stride=1):
+ """1x1 convolution"""
+ return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
+
+
+class Bottleneck(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
+ base_width=64, dilation=1, norm_layer=None):
+ super(Bottleneck, self).__init__()
+ if norm_layer is None:
+ norm_layer = nn.BatchNorm2d
+ width = int(planes * (base_width / 64.)) * groups
+ # Both self.conv2 and self.downsample layers downsample the input when stride != 1
+ self.conv1 = conv1x1(inplanes, width)
+ self.bn1 = norm_layer(width)
+ self.conv2 = conv3x3(width, width, stride, groups, dilation)
+ self.bn2 = norm_layer(width)
+ self.conv3 = conv1x1(width, planes * self.expansion)
+ self.bn3 = norm_layer(planes * self.expansion)
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.bn3(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+
+ return out
+
+
+class ResNet(nn.Module):
+
+ def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
+ groups=1, width_per_group=64, replace_stride_with_dilation=None,
+ norm_layer=None):
+ super(ResNet, self).__init__()
+ if norm_layer is None:
+ norm_layer = nn.BatchNorm2d
+ self._norm_layer = norm_layer
+
+ self.inplanes = 64
+ self.dilation = 1
+ if replace_stride_with_dilation is None:
+ # each element in the tuple indicates if we should replace
+ # the 2x2 stride with a dilated convolution instead
+ replace_stride_with_dilation = [False, False, False]
+ if len(replace_stride_with_dilation) != 3:
+ raise ValueError("replace_stride_with_dilation should be None "
+ "or a 3-element tuple, got {}".format(replace_stride_with_dilation))
+ self.groups = groups
+ self.base_width = width_per_group
+ self.conv1 = nn.Conv2d(6, self.inplanes, kernel_size=7, stride=2, padding=3,
+ bias=False)
+ self.bn1 = norm_layer(self.inplanes)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+ self.layer1 = self._make_layer(block, 64, layers[0])
+ self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
+ dilate=replace_stride_with_dilation[0])
+ self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
+ dilate=replace_stride_with_dilation[1])
+ self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
+ dilate=replace_stride_with_dilation[2])
+ self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
+ self.fc = nn.Linear(512 * block.expansion, num_classes)
+
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+ # Zero-initialize the last BN in each residual branch,
+ # so that the residual branch starts with zeros, and each residual block behaves like an identity.
+ # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
+ if zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ nn.init.constant_(m.bn3.weight, 0)
+
+ def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
+ norm_layer = self._norm_layer
+ downsample = None
+ previous_dilation = self.dilation
+ if dilate:
+ self.dilation *= stride
+ stride = 1
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ conv1x1(self.inplanes, planes * block.expansion, stride),
+ norm_layer(planes * block.expansion),
+ )
+
+ layers = []
+ layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
+ self.base_width, previous_dilation, norm_layer))
+ self.inplanes = planes * block.expansion
+ for _ in range(1, blocks):
+ layers.append(block(self.inplanes, planes, groups=self.groups,
+ base_width=self.base_width, dilation=self.dilation,
+ norm_layer=norm_layer))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+
+ x = self.avgpool(x)
+ x = torch.flatten(x, 1)
+ x = self.fc(x)
+
+ return x
+
+
+def _resnet(arch, block, layers, pretrained, progress, **kwargs):
+ model = ResNet(block, layers, **kwargs)
+ if pretrained:
+ state_dict = load_state_dict_from_url(model_urls[arch],
+ progress=progress)
+ model.load_state_dict(state_dict)
+ return model
+
+
+def resnet50(pretrained=False, progress=True, **kwargs):
+ r"""ResNet-50 model from
+ `"Deep Residual Learning for Image Recognition" `_
+
+ Args:
+ pretrained (bool): If True, returns a model pre-trained on ImageNet
+ progress (bool): If True, displays a progress bar of the download to stderr
+ """
+ return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
+ **kwargs)
diff --git a/inference/interact/s2m/utils.py b/inference/interact/s2m/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c2adecf63baa9c2db4cc70b04c25200f6bc0a6a6
--- /dev/null
+++ b/inference/interact/s2m/utils.py
@@ -0,0 +1,78 @@
+# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
+
+import torch
+import torch.nn as nn
+import numpy as np
+import torch.nn.functional as F
+from collections import OrderedDict
+
+class _SimpleSegmentationModel(nn.Module):
+ def __init__(self, backbone, classifier):
+ super(_SimpleSegmentationModel, self).__init__()
+ self.backbone = backbone
+ self.classifier = classifier
+
+ def forward(self, x):
+ input_shape = x.shape[-2:]
+ features = self.backbone(x)
+ x = self.classifier(features)
+ x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
+ return x
+
+
+class IntermediateLayerGetter(nn.ModuleDict):
+ """
+ Module wrapper that returns intermediate layers from a model
+
+ It has a strong assumption that the modules have been registered
+ into the model in the same order as they are used.
+ This means that one should **not** reuse the same nn.Module
+ twice in the forward if you want this to work.
+
+ Additionally, it is only able to query submodules that are directly
+ assigned to the model. So if `model` is passed, `model.feature1` can
+ be returned, but not `model.feature1.layer2`.
+
+ Arguments:
+ model (nn.Module): model on which we will extract the features
+ return_layers (Dict[name, new_name]): a dict containing the names
+ of the modules for which the activations will be returned as
+ the key of the dict, and the value of the dict is the name
+ of the returned activation (which the user can specify).
+
+ Examples::
+
+ >>> m = torchvision.models.resnet18(pretrained=True)
+ >>> # extract layer1 and layer3, giving as names `feat1` and feat2`
+ >>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
+ >>> {'layer1': 'feat1', 'layer3': 'feat2'})
+ >>> out = new_m(torch.rand(1, 3, 224, 224))
+ >>> print([(k, v.shape) for k, v in out.items()])
+ >>> [('feat1', torch.Size([1, 64, 56, 56])),
+ >>> ('feat2', torch.Size([1, 256, 14, 14]))]
+ """
+ def __init__(self, model, return_layers):
+ if not set(return_layers).issubset([name for name, _ in model.named_children()]):
+ raise ValueError("return_layers are not present in model")
+
+ orig_return_layers = return_layers
+ return_layers = {k: v for k, v in return_layers.items()}
+ layers = OrderedDict()
+ for name, module in model.named_children():
+ layers[name] = module
+ if name in return_layers:
+ del return_layers[name]
+ if not return_layers:
+ break
+
+ super(IntermediateLayerGetter, self).__init__(layers)
+ self.return_layers = orig_return_layers
+
+ def forward(self, x):
+ out = OrderedDict()
+ for name, module in self.named_children():
+ x = module(x)
+ if name in self.return_layers:
+ out_name = self.return_layers[name]
+ out[out_name] = x
+ return out
diff --git a/inference/interact/s2m_controller.py b/inference/interact/s2m_controller.py
new file mode 100644
index 0000000000000000000000000000000000000000..e222259eebdf3938290c476f85ba8c8d79fb626d
--- /dev/null
+++ b/inference/interact/s2m_controller.py
@@ -0,0 +1,39 @@
+import torch
+import numpy as np
+from ..interact.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
+
+from util.tensor_util import pad_divide_by, unpad
+
+
+class S2MController:
+ """
+ A controller for Scribble-to-Mask (for user interaction, not for DAVIS)
+ Takes the image, previous mask, and scribbles to produce a new mask
+ ignore_class is usually 255
+ 0 is NOT the ignore class -- it is the label for the background
+ """
+ def __init__(self, s2m_net:S2M, num_objects, ignore_class, device='cuda:0'):
+ self.s2m_net = s2m_net
+ self.num_objects = num_objects
+ self.ignore_class = ignore_class
+ self.device = device
+
+ def interact(self, image, prev_mask, scr_mask):
+ image = image.to(self.device, non_blocking=True)
+ prev_mask = prev_mask.unsqueeze(0)
+
+ h, w = image.shape[-2:]
+ unaggre_mask = torch.zeros((self.num_objects, h, w), dtype=torch.float32, device=image.device)
+
+ for ki in range(1, self.num_objects+1):
+ p_srb = (scr_mask==ki).astype(np.uint8)
+ n_srb = ((scr_mask!=ki) * (scr_mask!=self.ignore_class)).astype(np.uint8)
+
+ Rs = torch.from_numpy(np.stack([p_srb, n_srb], 0)).unsqueeze(0).float().to(image.device)
+
+ inputs = torch.cat([image, (prev_mask==ki).float().unsqueeze(0), Rs], 1)
+ inputs, pads = pad_divide_by(inputs, 16)
+
+ unaggre_mask[ki-1] = unpad(torch.sigmoid(self.s2m_net(inputs)), pads)
+
+ return unaggre_mask
\ No newline at end of file
diff --git a/inference/interact/timer.py b/inference/interact/timer.py
new file mode 100644
index 0000000000000000000000000000000000000000..d134aa180275528c0d485e6d237cd6832f62d77e
--- /dev/null
+++ b/inference/interact/timer.py
@@ -0,0 +1,33 @@
+import time
+
+class Timer:
+ def __init__(self):
+ self._acc_time = 0
+ self._paused = True
+
+ def start(self):
+ if self._paused:
+ self.last_time = time.time()
+ self._paused = False
+ return self
+
+ def pause(self):
+ self.count()
+ self._paused = True
+ return self
+
+ def count(self):
+ if self._paused:
+ return self._acc_time
+ t = time.time()
+ self._acc_time += t - self.last_time
+ self.last_time = t
+ return self._acc_time
+
+ def format(self):
+ # count = int(self.count()*100)
+ # return '%02d:%02d:%02d' % (count//6000, (count//100)%60, count%100)
+ return '%03.2f' % self.count()
+
+ def __str__(self):
+ return self.format()
\ No newline at end of file
diff --git a/inference/kv_memory_store.py b/inference/kv_memory_store.py
new file mode 100644
index 0000000000000000000000000000000000000000..33a332625f03b39f38f4b7162dcaddc8bafa262e
--- /dev/null
+++ b/inference/kv_memory_store.py
@@ -0,0 +1,215 @@
+import torch
+from typing import List
+
+class KeyValueMemoryStore:
+ """
+ Works for key/value pairs type storage
+ e.g., working and long-term memory
+ """
+
+ """
+ An object group is created when new objects enter the video
+ Objects in the same group share the same temporal extent
+ i.e., objects initialized in the same frame are in the same group
+ For DAVIS/interactive, there is only one object group
+ For YouTubeVOS, there can be multiple object groups
+ """
+
+ def __init__(self, count_usage: bool):
+ self.count_usage = count_usage
+
+ # keys are stored in a single tensor and are shared between groups/objects
+ # values are stored as a list indexed by object groups
+ self.k = None
+ self.v = []
+ self.obj_groups = []
+ # for debugging only
+ self.all_objects = []
+
+ # shrinkage and selection are also single tensors
+ self.s = self.e = None
+
+ # usage
+ if self.count_usage:
+ self.use_count = self.life_count = None
+
+ def add(self, key, value, shrinkage, selection, objects: List[int]):
+ new_count = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32)
+ new_life = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32) + 1e-7
+
+ # add the key
+ if self.k is None:
+ self.k = key
+ self.s = shrinkage
+ self.e = selection
+ if self.count_usage:
+ self.use_count = new_count
+ self.life_count = new_life
+ else:
+ self.k = torch.cat([self.k, key], -1)
+ if shrinkage is not None:
+ self.s = torch.cat([self.s, shrinkage], -1)
+ if selection is not None:
+ self.e = torch.cat([self.e, selection], -1)
+ if self.count_usage:
+ self.use_count = torch.cat([self.use_count, new_count], -1)
+ self.life_count = torch.cat([self.life_count, new_life], -1)
+
+ # add the value
+ if objects is not None:
+ # When objects is given, v is a tensor; used in working memory
+ assert isinstance(value, torch.Tensor)
+ # First consume objects that are already in the memory bank
+ # cannot use set here because we need to preserve order
+ # shift by one as background is not part of value
+ remaining_objects = [obj-1 for obj in objects]
+ for gi, group in enumerate(self.obj_groups):
+ for obj in group:
+ # should properly raise an error if there are overlaps in obj_groups
+ remaining_objects.remove(obj)
+ self.v[gi] = torch.cat([self.v[gi], value[group]], -1)
+
+ # If there are remaining objects, add them as a new group
+ if len(remaining_objects) > 0:
+ new_group = list(remaining_objects)
+ self.v.append(value[new_group])
+ self.obj_groups.append(new_group)
+ self.all_objects.extend(new_group)
+
+ assert sorted(self.all_objects) == self.all_objects, 'Objects MUST be inserted in sorted order '
+ else:
+ # When objects is not given, v is a list that already has the object groups sorted
+ # used in long-term memory
+ assert isinstance(value, list)
+ for gi, gv in enumerate(value):
+ if gv is None:
+ continue
+ if gi < self.num_groups:
+ self.v[gi] = torch.cat([self.v[gi], gv], -1)
+ else:
+ self.v.append(gv)
+
+ def update_usage(self, usage):
+ # increase all life count by 1
+ # increase use of indexed elements
+ if not self.count_usage:
+ return
+
+ self.use_count += usage.view_as(self.use_count)
+ self.life_count += 1
+
+ def sieve_by_range(self, start: int, end: int, min_size: int):
+ # keep only the elements *outside* of this range (with some boundary conditions)
+ # i.e., concat (a[:start], a[end:])
+ # min_size is only used for values, we do not sieve values under this size
+ # (because they are not consolidated)
+
+ if end == 0:
+ # negative 0 would not work as the end index!
+ self.k = self.k[:,:,:start]
+ if self.count_usage:
+ self.use_count = self.use_count[:,:,:start]
+ self.life_count = self.life_count[:,:,:start]
+ if self.s is not None:
+ self.s = self.s[:,:,:start]
+ if self.e is not None:
+ self.e = self.e[:,:,:start]
+
+ for gi in range(self.num_groups):
+ if self.v[gi].shape[-1] >= min_size:
+ self.v[gi] = self.v[gi][:,:,:start]
+ else:
+ self.k = torch.cat([self.k[:,:,:start], self.k[:,:,end:]], -1)
+ if self.count_usage:
+ self.use_count = torch.cat([self.use_count[:,:,:start], self.use_count[:,:,end:]], -1)
+ self.life_count = torch.cat([self.life_count[:,:,:start], self.life_count[:,:,end:]], -1)
+ if self.s is not None:
+ self.s = torch.cat([self.s[:,:,:start], self.s[:,:,end:]], -1)
+ if self.e is not None:
+ self.e = torch.cat([self.e[:,:,:start], self.e[:,:,end:]], -1)
+
+ for gi in range(self.num_groups):
+ if self.v[gi].shape[-1] >= min_size:
+ self.v[gi] = torch.cat([self.v[gi][:,:,:start], self.v[gi][:,:,end:]], -1)
+
+ def remove_obsolete_features(self, max_size: int):
+ # normalize with life duration
+ usage = self.get_usage().flatten()
+
+ values, _ = torch.topk(usage, k=(self.size-max_size), largest=False, sorted=True)
+ survived = (usage > values[-1])
+
+ self.k = self.k[:, :, survived]
+ self.s = self.s[:, :, survived] if self.s is not None else None
+ # Long-term memory does not store ek so this should not be needed
+ self.e = self.e[:, :, survived] if self.e is not None else None
+ if self.num_groups > 1:
+ raise NotImplementedError("""The current data structure does not support feature removal with
+ multiple object groups (e.g., some objects start to appear later in the video)
+ The indices for "survived" is based on keys but not all values are present for every key
+ Basically we need to remap the indices for keys to values
+ """)
+ for gi in range(self.num_groups):
+ self.v[gi] = self.v[gi][:, :, survived]
+
+ self.use_count = self.use_count[:, :, survived]
+ self.life_count = self.life_count[:, :, survived]
+
+ def get_usage(self):
+ # return normalized usage
+ if not self.count_usage:
+ raise RuntimeError('I did not count usage!')
+ else:
+ usage = self.use_count / self.life_count
+ return usage
+
+ def get_all_sliced(self, start: int, end: int):
+ # return k, sk, ek, usage in order, sliced by start and end
+
+ if end == 0:
+ # negative 0 would not work as the end index!
+ k = self.k[:,:,start:]
+ sk = self.s[:,:,start:] if self.s is not None else None
+ ek = self.e[:,:,start:] if self.e is not None else None
+ usage = self.get_usage()[:,:,start:]
+ else:
+ k = self.k[:,:,start:end]
+ sk = self.s[:,:,start:end] if self.s is not None else None
+ ek = self.e[:,:,start:end] if self.e is not None else None
+ usage = self.get_usage()[:,:,start:end]
+
+ return k, sk, ek, usage
+
+ def get_v_size(self, ni: int):
+ return self.v[ni].shape[2]
+
+ def engaged(self):
+ return self.k is not None
+
+ @property
+ def size(self):
+ if self.k is None:
+ return 0
+ else:
+ return self.k.shape[-1]
+
+ @property
+ def num_groups(self):
+ return len(self.v)
+
+ @property
+ def key(self):
+ return self.k
+
+ @property
+ def value(self):
+ return self.v
+
+ @property
+ def shrinkage(self):
+ return self.s
+
+ @property
+ def selection(self):
+ return self.e
+
diff --git a/inference/memory_manager.py b/inference/memory_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3ab693497586d84e848ce8261abfdf319c555ad
--- /dev/null
+++ b/inference/memory_manager.py
@@ -0,0 +1,284 @@
+import torch
+import warnings
+
+from inference.kv_memory_store import KeyValueMemoryStore
+from model.memory_util import *
+
+
+class MemoryManager:
+ """
+ Manages all three memory stores and the transition between working/long-term memory
+ """
+ def __init__(self, config):
+ self.hidden_dim = config['hidden_dim']
+ self.top_k = config['top_k']
+
+ self.enable_long_term = config['enable_long_term']
+ self.enable_long_term_usage = config['enable_long_term_count_usage']
+ if self.enable_long_term:
+ self.max_mt_frames = config['max_mid_term_frames']
+ self.min_mt_frames = config['min_mid_term_frames']
+ self.num_prototypes = config['num_prototypes']
+ self.max_long_elements = config['max_long_term_elements']
+
+ # dimensions will be inferred from input later
+ self.CK = self.CV = None
+ self.H = self.W = None
+
+ # The hidden state will be stored in a single tensor for all objects
+ # B x num_objects x CH x H x W
+ self.hidden = None
+
+ self.work_mem = KeyValueMemoryStore(count_usage=self.enable_long_term)
+ if self.enable_long_term:
+ self.long_mem = KeyValueMemoryStore(count_usage=self.enable_long_term_usage)
+
+ self.reset_config = True
+
+ def update_config(self, config):
+ self.reset_config = True
+ self.hidden_dim = config['hidden_dim']
+ self.top_k = config['top_k']
+
+ assert self.enable_long_term == config['enable_long_term'], 'cannot update this'
+ assert self.enable_long_term_usage == config['enable_long_term_count_usage'], 'cannot update this'
+
+ self.enable_long_term_usage = config['enable_long_term_count_usage']
+ if self.enable_long_term:
+ self.max_mt_frames = config['max_mid_term_frames']
+ self.min_mt_frames = config['min_mid_term_frames']
+ self.num_prototypes = config['num_prototypes']
+ self.max_long_elements = config['max_long_term_elements']
+
+ def _readout(self, affinity, v):
+ # this function is for a single object group
+ return v @ affinity
+
+ def match_memory(self, query_key, selection):
+ # query_key: B x C^k x H x W
+ # selection: B x C^k x H x W
+ num_groups = self.work_mem.num_groups
+ h, w = query_key.shape[-2:]
+
+ query_key = query_key.flatten(start_dim=2)
+ selection = selection.flatten(start_dim=2) if selection is not None else None
+
+ """
+ Memory readout using keys
+ """
+
+ if self.enable_long_term and self.long_mem.engaged():
+ # Use long-term memory
+ long_mem_size = self.long_mem.size
+ memory_key = torch.cat([self.long_mem.key, self.work_mem.key], -1)
+ shrinkage = torch.cat([self.long_mem.shrinkage, self.work_mem.shrinkage], -1)
+
+ similarity = get_similarity(memory_key, shrinkage, query_key, selection)
+ work_mem_similarity = similarity[:, long_mem_size:]
+ long_mem_similarity = similarity[:, :long_mem_size]
+
+ # get the usage with the first group
+ # the first group always have all the keys valid
+ affinity, usage = do_softmax(
+ torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(0):], work_mem_similarity], 1),
+ top_k=self.top_k, inplace=True, return_usage=True)
+ affinity = [affinity]
+
+ # compute affinity group by group as later groups only have a subset of keys
+ for gi in range(1, num_groups):
+ if gi < self.long_mem.num_groups:
+ # merge working and lt similarities before softmax
+ affinity_one_group = do_softmax(
+ torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(gi):],
+ work_mem_similarity[:, -self.work_mem.get_v_size(gi):]], 1),
+ top_k=self.top_k, inplace=True)
+ else:
+ # no long-term memory for this group
+ affinity_one_group = do_softmax(work_mem_similarity[:, -self.work_mem.get_v_size(gi):],
+ top_k=self.top_k, inplace=(gi==num_groups-1))
+ affinity.append(affinity_one_group)
+
+ all_memory_value = []
+ for gi, gv in enumerate(self.work_mem.value):
+ # merge the working and lt values before readout
+ if gi < self.long_mem.num_groups:
+ all_memory_value.append(torch.cat([self.long_mem.value[gi], self.work_mem.value[gi]], -1))
+ else:
+ all_memory_value.append(gv)
+
+ """
+ Record memory usage for working and long-term memory
+ """
+ # ignore the index return for long-term memory
+ work_usage = usage[:, long_mem_size:]
+ self.work_mem.update_usage(work_usage.flatten())
+
+ if self.enable_long_term_usage:
+ # ignore the index return for working memory
+ long_usage = usage[:, :long_mem_size]
+ self.long_mem.update_usage(long_usage.flatten())
+ else:
+ # No long-term memory
+ similarity = get_similarity(self.work_mem.key, self.work_mem.shrinkage, query_key, selection)
+
+ if self.enable_long_term:
+ affinity, usage = do_softmax(similarity, inplace=(num_groups==1),
+ top_k=self.top_k, return_usage=True)
+
+ # Record memory usage for working memory
+ self.work_mem.update_usage(usage.flatten())
+ else:
+ affinity = do_softmax(similarity, inplace=(num_groups==1),
+ top_k=self.top_k, return_usage=False)
+
+ affinity = [affinity]
+
+ # compute affinity group by group as later groups only have a subset of keys
+ for gi in range(1, num_groups):
+ affinity_one_group = do_softmax(similarity[:, -self.work_mem.get_v_size(gi):],
+ top_k=self.top_k, inplace=(gi==num_groups-1))
+ affinity.append(affinity_one_group)
+
+ all_memory_value = self.work_mem.value
+
+ # Shared affinity within each group
+ all_readout_mem = torch.cat([
+ self._readout(affinity[gi], gv)
+ for gi, gv in enumerate(all_memory_value)
+ ], 0)
+
+ return all_readout_mem.view(all_readout_mem.shape[0], self.CV, h, w)
+
+ def add_memory(self, key, shrinkage, value, objects, selection=None):
+ # key: 1*C*H*W
+ # value: 1*num_objects*C*H*W
+ # objects contain a list of object indices
+ if self.H is None or self.reset_config:
+ self.reset_config = False
+ self.H, self.W = key.shape[-2:]
+ self.HW = self.H*self.W
+ if self.enable_long_term:
+ # convert from num. frames to num. nodes
+ self.min_work_elements = self.min_mt_frames*self.HW
+ self.max_work_elements = self.max_mt_frames*self.HW
+
+ # key: 1*C*N
+ # value: num_objects*C*N
+ key = key.flatten(start_dim=2)
+ shrinkage = shrinkage.flatten(start_dim=2)
+ value = value[0].flatten(start_dim=2)
+
+ self.CK = key.shape[1]
+ self.CV = value.shape[1]
+
+ if selection is not None:
+ if not self.enable_long_term:
+ warnings.warn('the selection factor is only needed in long-term mode', UserWarning)
+ selection = selection.flatten(start_dim=2)
+
+ self.work_mem.add(key, value, shrinkage, selection, objects)
+
+ # long-term memory cleanup
+ if self.enable_long_term:
+ # Do memory compressed if needed
+ if self.work_mem.size >= self.max_work_elements:
+ # Remove obsolete features if needed
+ if self.long_mem.size >= (self.max_long_elements-self.num_prototypes):
+ self.long_mem.remove_obsolete_features(self.max_long_elements-self.num_prototypes)
+
+ self.compress_features()
+
+
+ def create_hidden_state(self, n, sample_key):
+ # n is the TOTAL number of objects
+ h, w = sample_key.shape[-2:]
+ if self.hidden is None:
+ self.hidden = torch.zeros((1, n, self.hidden_dim, h, w), device=sample_key.device)
+ elif self.hidden.shape[1] != n:
+ self.hidden = torch.cat([
+ self.hidden,
+ torch.zeros((1, n-self.hidden.shape[1], self.hidden_dim, h, w), device=sample_key.device)
+ ], 1)
+
+ assert(self.hidden.shape[1] == n)
+
+ def set_hidden(self, hidden):
+ self.hidden = hidden
+
+ def get_hidden(self):
+ return self.hidden
+
+ def compress_features(self):
+ HW = self.HW
+ candidate_value = []
+ total_work_mem_size = self.work_mem.size
+ for gv in self.work_mem.value:
+ # Some object groups might be added later in the video
+ # So not all keys have values associated with all objects
+ # We need to keep track of the key->value validity
+ mem_size_in_this_group = gv.shape[-1]
+ if mem_size_in_this_group == total_work_mem_size:
+ # full LT
+ candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
+ else:
+ # mem_size is smaller than total_work_mem_size, but at least HW
+ assert HW <= mem_size_in_this_group < total_work_mem_size
+ if mem_size_in_this_group > self.min_work_elements+HW:
+ # part of this object group still goes into LT
+ candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
+ else:
+ # this object group cannot go to the LT at all
+ candidate_value.append(None)
+
+ # perform memory consolidation
+ prototype_key, prototype_value, prototype_shrinkage = self.consolidation(
+ *self.work_mem.get_all_sliced(HW, -self.min_work_elements+HW), candidate_value)
+
+ # remove consolidated working memory
+ self.work_mem.sieve_by_range(HW, -self.min_work_elements+HW, min_size=self.min_work_elements+HW)
+
+ # add to long-term memory
+ self.long_mem.add(prototype_key, prototype_value, prototype_shrinkage, selection=None, objects=None)
+
+ def consolidation(self, candidate_key, candidate_shrinkage, candidate_selection, usage, candidate_value):
+ # keys: 1*C*N
+ # values: num_objects*C*N
+ N = candidate_key.shape[-1]
+
+ # find the indices with max usage
+ _, max_usage_indices = torch.topk(usage, k=self.num_prototypes, dim=-1, sorted=True)
+ prototype_indices = max_usage_indices.flatten()
+
+ # Prototypes are invalid for out-of-bound groups
+ validity = [prototype_indices >= (N-gv.shape[2]) if gv is not None else None for gv in candidate_value]
+
+ prototype_key = candidate_key[:, :, prototype_indices]
+ prototype_selection = candidate_selection[:, :, prototype_indices] if candidate_selection is not None else None
+
+ """
+ Potentiation step
+ """
+ similarity = get_similarity(candidate_key, candidate_shrinkage, prototype_key, prototype_selection)
+
+ # convert similarity to affinity
+ # need to do it group by group since the softmax normalization would be different
+ affinity = [
+ do_softmax(similarity[:, -gv.shape[2]:, validity[gi]]) if gv is not None else None
+ for gi, gv in enumerate(candidate_value)
+ ]
+
+ # some values can be have all False validity. Weed them out.
+ affinity = [
+ aff if aff is None or aff.shape[-1] > 0 else None for aff in affinity
+ ]
+
+ # readout the values
+ prototype_value = [
+ self._readout(affinity[gi], gv) if affinity[gi] is not None else None
+ for gi, gv in enumerate(candidate_value)
+ ]
+
+ # readout the shrinkage term
+ prototype_shrinkage = self._readout(affinity[0], candidate_shrinkage) if candidate_shrinkage is not None else None
+
+ return prototype_key, prototype_value, prototype_shrinkage
diff --git a/input/blackswan/00000.png b/input/blackswan/00000.png
new file mode 100644
index 0000000000000000000000000000000000000000..3daeddee9b13c2d98cae65bcd584e67a7a5aa4ad
Binary files /dev/null and b/input/blackswan/00000.png differ
diff --git a/input/blackswan/00001.png b/input/blackswan/00001.png
new file mode 100644
index 0000000000000000000000000000000000000000..4e3d3dd49677f83d8c0cfb2e44520808cfae9bb1
Binary files /dev/null and b/input/blackswan/00001.png differ
diff --git a/input/blackswan/00002.png b/input/blackswan/00002.png
new file mode 100644
index 0000000000000000000000000000000000000000..8cff513acad481f397dca72a9abab7937396c6a9
Binary files /dev/null and b/input/blackswan/00002.png differ
diff --git a/input/blackswan/00003.png b/input/blackswan/00003.png
new file mode 100644
index 0000000000000000000000000000000000000000..4de4854720fce434d73ca6c3dd08c39207fbec6d
Binary files /dev/null and b/input/blackswan/00003.png differ
diff --git a/input/blackswan/00004.png b/input/blackswan/00004.png
new file mode 100644
index 0000000000000000000000000000000000000000..687b05e9149267a9323e18d8ce3f8a8e5e6414ee
Binary files /dev/null and b/input/blackswan/00004.png differ
diff --git a/input/blackswan/00005.png b/input/blackswan/00005.png
new file mode 100644
index 0000000000000000000000000000000000000000..7627fdff9669c24fa466bf0b5446484e555f3110
Binary files /dev/null and b/input/blackswan/00005.png differ
diff --git a/input/blackswan/00006.png b/input/blackswan/00006.png
new file mode 100644
index 0000000000000000000000000000000000000000..6008c7e885819a783e46be59e7fa1afdfb39440a
Binary files /dev/null and b/input/blackswan/00006.png differ
diff --git a/input/blackswan/00007.png b/input/blackswan/00007.png
new file mode 100644
index 0000000000000000000000000000000000000000..09a0bfb317ede78eec273ed227bd2fefe1d1289b
Binary files /dev/null and b/input/blackswan/00007.png differ
diff --git a/input/blackswan/00008.png b/input/blackswan/00008.png
new file mode 100644
index 0000000000000000000000000000000000000000..8befb43c7e113711b5a604b4a14f1c0280b0d222
Binary files /dev/null and b/input/blackswan/00008.png differ
diff --git a/input/blackswan/00009.png b/input/blackswan/00009.png
new file mode 100644
index 0000000000000000000000000000000000000000..3a7fd79e302e17cf72635e36195518eda9207759
Binary files /dev/null and b/input/blackswan/00009.png differ
diff --git a/input/blackswan/00010.png b/input/blackswan/00010.png
new file mode 100644
index 0000000000000000000000000000000000000000..30e77e82ea7b8994df1cd86b9a78d2ae8d8ca805
Binary files /dev/null and b/input/blackswan/00010.png differ
diff --git a/input/blackswan/00011.png b/input/blackswan/00011.png
new file mode 100644
index 0000000000000000000000000000000000000000..281508d8ef82eb584bcfe605bd362dc5dfc2c9d4
Binary files /dev/null and b/input/blackswan/00011.png differ
diff --git a/input/blackswan/00012.png b/input/blackswan/00012.png
new file mode 100644
index 0000000000000000000000000000000000000000..d8191811bbec2bc0fec65a107d7e7a12dbb7c894
Binary files /dev/null and b/input/blackswan/00012.png differ
diff --git a/input/blackswan/00013.png b/input/blackswan/00013.png
new file mode 100644
index 0000000000000000000000000000000000000000..6d8eb2ea540bc860801751c2de81743f79c6f117
Binary files /dev/null and b/input/blackswan/00013.png differ
diff --git a/input/blackswan/00014.png b/input/blackswan/00014.png
new file mode 100644
index 0000000000000000000000000000000000000000..1a00bee60bddb2b209ada6101a7dabe367fe95b0
Binary files /dev/null and b/input/blackswan/00014.png differ
diff --git a/input/blackswan/00015.png b/input/blackswan/00015.png
new file mode 100644
index 0000000000000000000000000000000000000000..525d8adf20c44d5457897eced67663ee31f2ecc2
Binary files /dev/null and b/input/blackswan/00015.png differ
diff --git a/input/blackswan/00016.png b/input/blackswan/00016.png
new file mode 100644
index 0000000000000000000000000000000000000000..926fbe7154c9ea50da38f8da6b95ce818f6cac5f
Binary files /dev/null and b/input/blackswan/00016.png differ
diff --git a/input/blackswan/00017.png b/input/blackswan/00017.png
new file mode 100644
index 0000000000000000000000000000000000000000..871bad747eafeec29a94d4bd4b9242027050fb12
Binary files /dev/null and b/input/blackswan/00017.png differ
diff --git a/input/blackswan/00018.png b/input/blackswan/00018.png
new file mode 100644
index 0000000000000000000000000000000000000000..8855a4a77ecbdc8236a4e21baa985b0453f7f94a
Binary files /dev/null and b/input/blackswan/00018.png differ
diff --git a/input/blackswan/00019.png b/input/blackswan/00019.png
new file mode 100644
index 0000000000000000000000000000000000000000..54052ca5f3ce592a77375c1c283a515216ad738e
Binary files /dev/null and b/input/blackswan/00019.png differ
diff --git a/input/blackswan/00020.png b/input/blackswan/00020.png
new file mode 100644
index 0000000000000000000000000000000000000000..f73b15e01ec5fd759a08225ead1b57dec0e3625c
Binary files /dev/null and b/input/blackswan/00020.png differ
diff --git a/input/blackswan/00021.png b/input/blackswan/00021.png
new file mode 100644
index 0000000000000000000000000000000000000000..b7a9b440e309692fd076d43bc938025d7e3009ad
Binary files /dev/null and b/input/blackswan/00021.png differ
diff --git a/input/blackswan/00022.png b/input/blackswan/00022.png
new file mode 100644
index 0000000000000000000000000000000000000000..f8828e56e54d45a87338f9f1a9f9b007536dbfc7
Binary files /dev/null and b/input/blackswan/00022.png differ
diff --git a/input/blackswan/00023.png b/input/blackswan/00023.png
new file mode 100644
index 0000000000000000000000000000000000000000..3b0a26ea83f9d7e4bceaef7b59e0474f9438f1ed
Binary files /dev/null and b/input/blackswan/00023.png differ
diff --git a/input/blackswan/00024.png b/input/blackswan/00024.png
new file mode 100644
index 0000000000000000000000000000000000000000..7c3800fecfc1d33d147e7fff9535f9c83782a03b
Binary files /dev/null and b/input/blackswan/00024.png differ
diff --git a/input/blackswan/00025.png b/input/blackswan/00025.png
new file mode 100644
index 0000000000000000000000000000000000000000..805fddc4c09de2465fb5104307174a457a386382
Binary files /dev/null and b/input/blackswan/00025.png differ
diff --git a/input/blackswan/00026.png b/input/blackswan/00026.png
new file mode 100644
index 0000000000000000000000000000000000000000..f3ffa44062a393a8adb2d15db5b104b4b967a119
Binary files /dev/null and b/input/blackswan/00026.png differ
diff --git a/input/blackswan/00027.png b/input/blackswan/00027.png
new file mode 100644
index 0000000000000000000000000000000000000000..b491fe2a6bb7604f7324fed9e7b6cfeabf711f1e
Binary files /dev/null and b/input/blackswan/00027.png differ
diff --git a/input/blackswan/00028.png b/input/blackswan/00028.png
new file mode 100644
index 0000000000000000000000000000000000000000..b6df5eede90ab15197877877f54b63110622b661
Binary files /dev/null and b/input/blackswan/00028.png differ
diff --git a/input/blackswan/00029.png b/input/blackswan/00029.png
new file mode 100644
index 0000000000000000000000000000000000000000..3e134241a7b72a71260574a25305057a75fdf653
Binary files /dev/null and b/input/blackswan/00029.png differ
diff --git a/input/blackswan/00030.png b/input/blackswan/00030.png
new file mode 100644
index 0000000000000000000000000000000000000000..2f7a438871076b04c2e9f8589d7c5decf113af17
Binary files /dev/null and b/input/blackswan/00030.png differ
diff --git a/input/blackswan/00031.png b/input/blackswan/00031.png
new file mode 100644
index 0000000000000000000000000000000000000000..06c9985e1a3017147d6821bb04c1feff330df770
Binary files /dev/null and b/input/blackswan/00031.png differ
diff --git a/input/blackswan/00032.png b/input/blackswan/00032.png
new file mode 100644
index 0000000000000000000000000000000000000000..65181c862bcdf6b046c6c8ff8b7298b17f80cf00
Binary files /dev/null and b/input/blackswan/00032.png differ
diff --git a/input/blackswan/00033.png b/input/blackswan/00033.png
new file mode 100644
index 0000000000000000000000000000000000000000..2b1897362f7936a208cdc53393f6ea4b2a6205f8
Binary files /dev/null and b/input/blackswan/00033.png differ
diff --git a/input/blackswan/00034.png b/input/blackswan/00034.png
new file mode 100644
index 0000000000000000000000000000000000000000..29da4528c83eaa36635a6ef6434d149ca48976a5
Binary files /dev/null and b/input/blackswan/00034.png differ
diff --git a/input/blackswan/00035.png b/input/blackswan/00035.png
new file mode 100644
index 0000000000000000000000000000000000000000..25c7d53a9fcff3c1496e78adc735e0e0b2596814
Binary files /dev/null and b/input/blackswan/00035.png differ
diff --git a/input/blackswan/00036.png b/input/blackswan/00036.png
new file mode 100644
index 0000000000000000000000000000000000000000..49daf9e8feb78c6ff5de5fab40ac44dd8d847b4a
Binary files /dev/null and b/input/blackswan/00036.png differ
diff --git a/input/blackswan/00037.png b/input/blackswan/00037.png
new file mode 100644
index 0000000000000000000000000000000000000000..a584a712cdef876c0ff6e436702d8264c98bf13e
Binary files /dev/null and b/input/blackswan/00037.png differ
diff --git a/input/blackswan/00038.png b/input/blackswan/00038.png
new file mode 100644
index 0000000000000000000000000000000000000000..4e55ec2761f64a751c0dd20b236046de9766c9ad
Binary files /dev/null and b/input/blackswan/00038.png differ
diff --git a/input/blackswan/00039.png b/input/blackswan/00039.png
new file mode 100644
index 0000000000000000000000000000000000000000..15f547c33bfd454dcdb8b6c95bf4fe85f3a0b636
Binary files /dev/null and b/input/blackswan/00039.png differ
diff --git a/input/blackswan/00040.png b/input/blackswan/00040.png
new file mode 100644
index 0000000000000000000000000000000000000000..75b00d03b9e00562adf755afa79bb5f9603910d7
Binary files /dev/null and b/input/blackswan/00040.png differ
diff --git a/input/blackswan/00041.png b/input/blackswan/00041.png
new file mode 100644
index 0000000000000000000000000000000000000000..1d918ba53affeb5ab2ce9829b2dc59e263a61b8b
Binary files /dev/null and b/input/blackswan/00041.png differ
diff --git a/input/blackswan/00042.png b/input/blackswan/00042.png
new file mode 100644
index 0000000000000000000000000000000000000000..70395b42de9dbf440eddd845c16f5c8cb44fce09
Binary files /dev/null and b/input/blackswan/00042.png differ
diff --git a/input/blackswan/00043.png b/input/blackswan/00043.png
new file mode 100644
index 0000000000000000000000000000000000000000..dc90f09eb0997efeec7a056b7706849a6bea5471
Binary files /dev/null and b/input/blackswan/00043.png differ
diff --git a/input/blackswan/00044.png b/input/blackswan/00044.png
new file mode 100644
index 0000000000000000000000000000000000000000..c1ca7a3198d7c8822f444be0725847cacff59482
Binary files /dev/null and b/input/blackswan/00044.png differ
diff --git a/input/blackswan/00045.png b/input/blackswan/00045.png
new file mode 100644
index 0000000000000000000000000000000000000000..089ad8c08b6f377835a43ee225e6cbc9458456ad
Binary files /dev/null and b/input/blackswan/00045.png differ
diff --git a/input/blackswan/00046.png b/input/blackswan/00046.png
new file mode 100644
index 0000000000000000000000000000000000000000..7b8681a108f4b1bcaa434e42b546490e295ef4ca
Binary files /dev/null and b/input/blackswan/00046.png differ
diff --git a/input/blackswan/00047.png b/input/blackswan/00047.png
new file mode 100644
index 0000000000000000000000000000000000000000..f737576977efdab060b2ea861441bf32a7a6181e
Binary files /dev/null and b/input/blackswan/00047.png differ
diff --git a/input/blackswan/00048.png b/input/blackswan/00048.png
new file mode 100644
index 0000000000000000000000000000000000000000..fa06c0db7b1c7956e081b553f03d938377e74f7a
Binary files /dev/null and b/input/blackswan/00048.png differ
diff --git a/input/blackswan/00049.png b/input/blackswan/00049.png
new file mode 100644
index 0000000000000000000000000000000000000000..1505fa35e8731f872ec83cb60c1d1a0b7c3f98da
Binary files /dev/null and b/input/blackswan/00049.png differ
diff --git a/model/__init__.py b/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/model/aggregate.py b/model/aggregate.py
new file mode 100644
index 0000000000000000000000000000000000000000..7622391fb3ac9aa8b515df88cf3ea5297b367538
--- /dev/null
+++ b/model/aggregate.py
@@ -0,0 +1,17 @@
+import torch
+import torch.nn.functional as F
+
+
+# Soft aggregation from STM
+def aggregate(prob, dim, return_logits=False):
+ new_prob = torch.cat([
+ torch.prod(1-prob, dim=dim, keepdim=True),
+ prob
+ ], dim).clamp(1e-7, 1-1e-7)
+ logits = torch.log((new_prob /(1-new_prob)))
+ prob = F.softmax(logits, dim=dim)
+
+ if return_logits:
+ return logits, prob
+ else:
+ return prob
\ No newline at end of file
diff --git a/model/attention.py b/model/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..c593383fbbc9568301bc63b4a89f8af4f92f05f1
--- /dev/null
+++ b/model/attention.py
@@ -0,0 +1,916 @@
+import math
+import pdb
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from model.basic import DropOutLogit, ScaleOffset, DWConv2d
+
+
+def multiply_by_ychunks(x, y, chunks=1):
+ if chunks <= 1:
+ return x @ y
+ else:
+ return torch.cat([x @ _y for _y in y.chunk(chunks, dim=-1)], dim=-1)
+
+
+def multiply_by_xchunks(x, y, chunks=1):
+ if chunks <= 1:
+ return x @ y
+ else:
+ return torch.cat([_x @ y for _x in x.chunk(chunks, dim=-2)], dim=-2)
+
+
+# Long-term attention
+class MultiheadAttention(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head=8,
+ dropout=0.,
+ use_linear=True,
+ d_att=None,
+ use_dis=False,
+ qk_chunks=1,
+ max_mem_len_ratio=-1,
+ top_k=-1):
+ super().__init__()
+ self.d_model = d_model
+ self.num_head = num_head
+ self.use_dis = use_dis
+ self.qk_chunks = qk_chunks
+ self.max_mem_len_ratio = float(max_mem_len_ratio)
+ self.top_k = top_k
+
+ self.hidden_dim = d_model // num_head
+ self.d_att = self.hidden_dim if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_linear = use_linear
+
+ if use_linear:
+ self.linear_Q = nn.Linear(d_model, d_model)
+ self.linear_K = nn.Linear(d_model, d_model)
+ self.linear_V = nn.Linear(d_model, d_model)
+
+ self.dropout = nn.Dropout(dropout)
+ self.drop_prob = dropout
+ self.projection = nn.Linear(d_model, d_model)
+ self._init_weight()
+
+ def forward(self, Q, K, V):
+ """
+ :param Q: A 3d tensor with shape of [T_q, bs, C_q]
+ :param K: A 3d tensor with shape of [T_k, bs, C_k]
+ :param V: A 3d tensor with shape of [T_v, bs, C_v]
+ """
+ num_head = self.num_head
+ hidden_dim = self.hidden_dim
+
+ bs = Q.size()[1]
+
+ # Linear projections
+ if self.use_linear:
+ Q = self.linear_Q(Q)
+ K = self.linear_K(K)
+ V = self.linear_V(V)
+
+ # Scale
+ Q = Q / self.T
+
+ if not self.training and self.max_mem_len_ratio > 0:
+ mem_len_ratio = float(K.size(0)) / Q.size(0)
+ if mem_len_ratio > self.max_mem_len_ratio:
+ scaling_ratio = math.log(mem_len_ratio) / math.log(
+ self.max_mem_len_ratio)
+ Q = Q * scaling_ratio
+
+ # Multi-head
+ Q = Q.view(-1, bs, num_head, self.d_att).permute(1, 2, 0, 3)
+ K = K.view(-1, bs, num_head, self.d_att).permute(1, 2, 3, 0)
+ V = V.view(-1, bs, num_head, hidden_dim).permute(1, 2, 0, 3)
+
+ # Multiplication
+ QK = multiply_by_ychunks(Q, K, self.qk_chunks)
+ if self.use_dis:
+ QK = 2 * QK - K.pow(2).sum(dim=-2, keepdim=True)
+
+ # Activation
+ if not self.training and self.top_k > 0 and self.top_k < QK.size()[-1]:
+ top_QK, indices = torch.topk(QK, k=self.top_k, dim=-1)
+ top_attn = torch.softmax(top_QK, dim=-1)
+ attn = torch.zeros_like(QK).scatter_(-1, indices, top_attn)
+ else:
+ attn = torch.softmax(QK, dim=-1)
+
+ # Dropouts
+ attn = self.dropout(attn)
+
+ # Weighted sum
+ outputs = multiply_by_xchunks(attn, V,
+ self.qk_chunks).permute(2, 0, 1, 3)
+
+ # Restore shape
+ outputs = outputs.reshape(-1, bs, self.d_model)
+
+ outputs = self.projection(outputs)
+
+ return outputs, attn
+
+ def _init_weight(self):
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+
+
+# Short-term attention
+class MultiheadLocalAttentionV1(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True,
+ enable_corr=True):
+ super().__init__()
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.T = ((d_model / num_head)**0.5)
+
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_Q = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_K = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_model, d_model, kernel_size=1)
+
+ self.relative_emb_k = nn.Conv2d(d_model,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+ self.relative_emb_v = nn.Parameter(
+ torch.zeros([
+ self.num_head, d_model // self.num_head,
+ self.window_size * self.window_size
+ ]))
+
+ self.enable_corr = enable_corr
+
+ if enable_corr:
+ from spatial_correlation_sampler import SpatialCorrelationSampler
+ self.correlation_sampler = SpatialCorrelationSampler(
+ kernel_size=1,
+ patch_size=self.window_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ dilation_patch=self.dilation)
+
+ self.projection = nn.Linear(d_model, d_model)
+
+ self.dropout = nn.Dropout(dropout)
+ self.drop_prob = dropout
+
+ def forward(self, q, k, v):
+ n, c, h, w = v.size()
+
+ if self.use_linear:
+ q = self.linear_Q(q)
+ k = self.linear_K(k)
+ v = self.linear_V(v)
+
+ hidden_dim = c // self.num_head
+
+ relative_emb = self.relative_emb_k(q)
+ memory_mask = torch.ones((1, 1, h, w), device=v.device).float()
+
+ # Scale
+ q = q / self.T
+
+ q = q.view(-1, hidden_dim, h, w)
+ k = k.reshape(-1, hidden_dim, h, w).contiguous()
+ unfolded_vu = self.pad_and_unfold(v).view(
+ n, self.num_head, hidden_dim, self.window_size * self.window_size,
+ h * w) + self.relative_emb_v.unsqueeze(0).unsqueeze(-1)
+
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+ unfolded_k_mask = self.pad_and_unfold(memory_mask).bool().view(
+ 1, 1, self.window_size * self.window_size,
+ h * w).expand(n, self.num_head, -1, -1)
+
+ if self.enable_corr:
+ qk = self.correlation_sampler(q, k).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w) + relative_emb
+ else:
+ unfolded_k = self.pad_and_unfold(k).view(
+ n * self.num_head, hidden_dim,
+ self.window_size * self.window_size, h, w)
+ qk = (q.unsqueeze(2) * unfolded_k).sum(dim=1).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w) + relative_emb
+
+ qk_mask = 1 - unfolded_k_mask
+
+ qk -= qk_mask * 1e+8 if qk.dtype == torch.float32 else qk_mask * 1e+4
+
+ local_attn = torch.softmax(qk, dim=2)
+
+ local_attn = self.dropout(local_attn)
+
+ output = (local_attn.unsqueeze(2) * unfolded_vu).sum(dim=3).permute(
+ 3, 0, 1, 2).view(h * w, n, c)
+
+ output = self.projection(output)
+
+ return output, local_attn
+
+ def pad_and_unfold(self, x):
+ pad_pixel = self.max_dis * self.dilation
+ x = F.pad(x, (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0)
+ x = F.unfold(x,
+ kernel_size=(self.window_size, self.window_size),
+ stride=(1, 1),
+ dilation=self.dilation)
+ return x
+
+
+class MultiheadLocalAttentionV2(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True,
+ enable_corr=True,
+ d_att=None,
+ use_dis=False):
+ super().__init__()
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.hidden_dim = d_model // num_head
+ self.d_att = self.hidden_dim if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_dis = use_dis
+
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_Q = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_K = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_model, d_model, kernel_size=1)
+
+ self.relative_emb_k = nn.Conv2d(self.d_att * self.num_head,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+ self.relative_emb_v = nn.Parameter(
+ torch.zeros([
+ self.num_head, d_model // self.num_head,
+ self.window_size * self.window_size
+ ]))
+
+ self.enable_corr = enable_corr
+
+ if enable_corr:
+ from spatial_correlation_sampler import SpatialCorrelationSampler
+ self.correlation_sampler = SpatialCorrelationSampler(
+ kernel_size=1,
+ patch_size=self.window_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ dilation_patch=self.dilation)
+
+ self.projection = nn.Linear(d_model, d_model)
+
+ self.dropout = nn.Dropout(dropout)
+
+ self.drop_prob = dropout
+
+ self.local_mask = None
+ self.last_size_2d = None
+ self.qk_mask = None
+
+ def forward(self, q, k, v):
+ n, c, h, w = v.size()
+
+ if self.use_linear:
+ q = self.linear_Q(q)
+ k = self.linear_K(k)
+ v = self.linear_V(v)
+
+ hidden_dim = self.hidden_dim
+
+ if self.qk_mask is not None and (h, w) == self.last_size_2d:
+ qk_mask = self.qk_mask
+ else:
+ memory_mask = torch.ones((1, 1, h, w), device=v.device).float()
+ unfolded_k_mask = self.pad_and_unfold(memory_mask).view(
+ 1, 1, self.window_size * self.window_size, h * w)
+ qk_mask = 1 - unfolded_k_mask
+ self.qk_mask = qk_mask
+
+ relative_emb = self.relative_emb_k(q)
+
+ # Scale
+ q = q / self.T
+
+ q = q.view(-1, self.d_att, h, w)
+ k = k.view(-1, self.d_att, h, w)
+ v = v.view(-1, self.num_head, hidden_dim, h * w)
+
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+
+ if self.enable_corr:
+ qk = self.correlation_sampler(q, k).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ else:
+ unfolded_k = self.pad_and_unfold(k).view(
+ n * self.num_head, hidden_dim,
+ self.window_size * self.window_size, h, w)
+ qk = (q.unsqueeze(2) * unfolded_k).sum(dim=1).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ if self.use_dis:
+ qk = 2 * qk - self.pad_and_unfold(
+ k.pow(2).sum(dim=1, keepdim=True)).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w)
+
+ qk = qk + relative_emb
+
+ qk -= qk_mask * 1e+8 if qk.dtype == torch.float32 else qk_mask * 1e+4
+
+ local_attn = torch.softmax(qk, dim=2)
+
+ local_attn = self.dropout(local_attn)
+
+ agg_bias = torch.einsum('bhwn,hcw->bhnc', local_attn,
+ self.relative_emb_v)
+
+ global_attn = self.local2global(local_attn, h, w)
+
+ agg_value = (global_attn @ v.transpose(-2, -1))
+
+ output = (agg_value + agg_bias).permute(2, 0, 1,
+ 3).reshape(h * w, n, c)
+
+ output = self.projection(output)
+
+ self.last_size_2d = (h, w)
+ return output, local_attn
+
+ def local2global(self, local_attn, height, width):
+ batch_size = local_attn.size()[0]
+
+ pad_height = height + 2 * self.max_dis
+ pad_width = width + 2 * self.max_dis
+
+ if self.local_mask is not None and (height,
+ width) == self.last_size_2d:
+ local_mask = self.local_mask
+ else:
+ ky, kx = torch.meshgrid([
+ torch.arange(0, pad_height, device=local_attn.device),
+ torch.arange(0, pad_width, device=local_attn.device)
+ ])
+ qy, qx = torch.meshgrid([
+ torch.arange(0, height, device=local_attn.device),
+ torch.arange(0, width, device=local_attn.device)
+ ])
+
+ offset_y = qy.reshape(-1, 1) - ky.reshape(1, -1) + self.max_dis
+ offset_x = qx.reshape(-1, 1) - kx.reshape(1, -1) + self.max_dis
+
+ local_mask = (offset_y.abs() <= self.max_dis) & (offset_x.abs() <=
+ self.max_dis)
+ local_mask = local_mask.view(1, 1, height * width, pad_height,
+ pad_width)
+ self.local_mask = local_mask
+
+ global_attn = torch.zeros(
+ (batch_size, self.num_head, height * width, pad_height, pad_width),
+ device=local_attn.device)
+ global_attn = global_attn.type(torch.HalfTensor).cuda()
+ global_attn[local_mask.expand(batch_size, self.num_head,
+ -1, -1, -1)] = local_attn.transpose(
+ -1, -2).reshape(-1)
+ global_attn = global_attn[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis].reshape(
+ batch_size, self.num_head,
+ height * width, height * width)
+
+ return global_attn
+
+ def pad_and_unfold(self, x):
+ pad_pixel = self.max_dis * self.dilation
+ x = F.pad(x, (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0)
+ x = F.unfold(x,
+ kernel_size=(self.window_size, self.window_size),
+ stride=(1, 1),
+ dilation=self.dilation)
+ return x
+
+
+class MultiheadLocalAttentionV3(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True):
+ super().__init__()
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.T = ((d_model / num_head)**0.5)
+
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_Q = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_K = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_model, d_model, kernel_size=1)
+
+ self.relative_emb_k = nn.Conv2d(d_model,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+ self.relative_emb_v = nn.Parameter(
+ torch.zeros([
+ self.num_head, d_model // self.num_head,
+ self.window_size * self.window_size
+ ]))
+
+ self.projection = nn.Linear(d_model, d_model)
+ self.dropout = DropOutLogit(dropout)
+
+ self.padded_local_mask = None
+ self.local_mask = None
+ self.last_size_2d = None
+ self.qk_mask = None
+
+ def forward(self, q, k, v):
+ n, c, h, w = q.size()
+
+ if self.use_linear:
+ q = self.linear_Q(q)
+ k = self.linear_K(k)
+ v = self.linear_V(v)
+
+ hidden_dim = c // self.num_head
+
+ relative_emb = self.relative_emb_k(q)
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+ padded_local_mask, local_mask = self.compute_mask(h,
+ w,
+ device=q.device)
+ qk_mask = (~padded_local_mask).float()
+
+ # Scale
+ q = q / self.T
+
+ q = q.view(-1, self.num_head, hidden_dim, h * w)
+ k = k.view(-1, self.num_head, hidden_dim, h * w)
+ v = v.view(-1, self.num_head, hidden_dim, h * w)
+
+ qk = q.transpose(-1, -2) @ k # [B, nH, kL, qL]
+
+ pad_pixel = self.max_dis * self.dilation
+
+ padded_qk = F.pad(qk.view(-1, self.num_head, h * w, h, w),
+ (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=-1e+8 if qk.dtype == torch.float32 else -1e+4)
+
+ qk_mask = qk_mask * 1e+8 if (padded_qk.dtype
+ == torch.float32) else qk_mask * 1e+4
+ padded_qk = padded_qk - qk_mask
+
+ padded_qk[padded_local_mask.expand(n, self.num_head, -1, -1,
+ -1)] += relative_emb.transpose(
+ -1, -2).reshape(-1)
+ padded_qk = self.dropout(padded_qk)
+
+ local_qk = padded_qk[padded_local_mask.expand(n, self.num_head, -1, -1,
+ -1)]
+
+ global_qk = padded_qk[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis].reshape(
+ n, self.num_head, h * w, h * w)
+
+ local_attn = torch.softmax(local_qk.reshape(
+ n, self.num_head, h * w, self.window_size * self.window_size),
+ dim=3)
+ global_attn = torch.softmax(global_qk, dim=3)
+
+ agg_bias = torch.einsum('bhnw,hcw->nbhc', local_attn,
+ self.relative_emb_v).reshape(h * w, n, c)
+
+ agg_value = (global_attn @ v.transpose(-2, -1))
+
+ output = agg_value + agg_bias
+
+ output = self.projection(output)
+
+ self.last_size_2d = (h, w)
+ return output, local_attn
+
+ def compute_mask(self, height, width, device=None):
+ pad_height = height + 2 * self.max_dis
+ pad_width = width + 2 * self.max_dis
+
+ if self.padded_local_mask is not None and (height,
+ width) == self.last_size_2d:
+ padded_local_mask = self.padded_local_mask
+ local_mask = self.local_mask
+
+ else:
+ ky, kx = torch.meshgrid([
+ torch.arange(0, pad_height, device=device),
+ torch.arange(0, pad_width, device=device)
+ ])
+ qy, qx = torch.meshgrid([
+ torch.arange(0, height, device=device),
+ torch.arange(0, width, device=device)
+ ])
+
+ qy = qy.reshape(-1, 1)
+ qx = qx.reshape(-1, 1)
+ offset_y = qy - ky.reshape(1, -1) + self.max_dis
+ offset_x = qx - kx.reshape(1, -1) + self.max_dis
+ padded_local_mask = (offset_y.abs() <= self.max_dis) & (
+ offset_x.abs() <= self.max_dis)
+ padded_local_mask = padded_local_mask.view(1, 1, height * width,
+ pad_height, pad_width)
+ local_mask = padded_local_mask[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis]
+ pad_pixel = self.max_dis * self.dilation
+ local_mask = F.pad(local_mask.float(),
+ (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0).view(1, 1, height * width, pad_height,
+ pad_width)
+ self.padded_local_mask = padded_local_mask
+ self.local_mask = local_mask
+
+ return padded_local_mask, local_mask
+
+
+def linear_gate(x, dim=-1):
+ # return F.relu_(x).pow(2.) / x.size()[dim]
+ return torch.softmax(x, dim=dim)
+
+
+def silu(x):
+ return x * torch.sigmoid(x)
+
+
+class GatedPropagation(nn.Module):
+ def __init__(self,
+ d_qk,
+ d_vu,
+ num_head=8,
+ dropout=0.,
+ use_linear=True,
+ d_att=None,
+ use_dis=False,
+ qk_chunks=1,
+ max_mem_len_ratio=-1,
+ top_k=-1,
+ expand_ratio=2.):
+ super().__init__()
+ expand_ratio = expand_ratio
+ self.expand_d_vu = int(d_vu * expand_ratio)
+ self.d_vu = d_vu
+ self.d_qk = d_qk
+ self.num_head = num_head
+ self.use_dis = use_dis
+ self.qk_chunks = qk_chunks
+ self.max_mem_len_ratio = float(max_mem_len_ratio)
+ self.top_k = top_k
+
+ self.hidden_dim = self.expand_d_vu // num_head
+ self.d_att = d_qk // num_head if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_linear = use_linear
+ self.d_middle = self.d_att * self.num_head
+
+ if use_linear:
+ self.linear_QK = nn.Linear(d_qk, self.d_middle)
+ half_d_vu = self.hidden_dim * num_head // 2
+ self.linear_V1 = nn.Linear(d_vu // 2, half_d_vu)
+ self.linear_V2 = nn.Linear(d_vu // 2, half_d_vu)
+ self.linear_U1 = nn.Linear(d_vu // 2, half_d_vu)
+ self.linear_U2 = nn.Linear(d_vu // 2, half_d_vu)
+
+ self.dropout = nn.Dropout(dropout)
+ self.drop_prob = dropout
+
+ self.dw_conv = DWConv2d(self.expand_d_vu)
+ self.projection = nn.Linear(self.expand_d_vu, d_vu)
+
+ self._init_weight()
+
+ def forward(self, Q, K, V, U, size_2d):
+ """
+ :param Q: A 3d tensor with shape of [T_q, bs, C_q]
+ :param K: A 3d tensor with shape of [T_k, bs, C_k]
+ :param V: A 3d tensor with shape of [T_v, bs, C_v]
+ """
+ num_head = self.num_head
+ hidden_dim = self.hidden_dim
+
+ l, bs, _ = Q.size()
+
+ # Linear projections
+ if self.use_linear:
+ Q = K = self.linear_QK(Q)
+
+ def cat(X1, X2):
+ if num_head > 1:
+ X1 = X1.view(-1, bs, num_head, hidden_dim // 2)
+ X2 = X2.view(-1, bs, num_head, hidden_dim // 2)
+ X = torch.cat([X1, X2],
+ dim=-1).view(-1, bs, num_head * hidden_dim)
+ else:
+ X = torch.cat([X1, X2], dim=-1)
+ return X
+
+ V1, V2 = torch.split(V, self.d_vu // 2, dim=-1)
+ V1 = self.linear_V1(V1)
+ V2 = self.linear_V2(V2)
+ V = silu(cat(V1, V2))
+
+ U1, U2 = torch.split(U, self.d_vu // 2, dim=-1)
+ U1 = self.linear_U1(U1)
+ U2 = self.linear_U2(U2)
+ U = silu(cat(U1, U2))
+
+ # Scale
+ Q = Q / self.T
+
+ if not self.training and self.max_mem_len_ratio > 0:
+ mem_len_ratio = float(K.size(0)) / Q.size(0)
+ if mem_len_ratio > self.max_mem_len_ratio:
+ scaling_ratio = math.log(mem_len_ratio) / math.log(
+ self.max_mem_len_ratio)
+ Q = Q * scaling_ratio
+
+ # Multi-head
+ Q = Q.view(-1, bs, num_head, self.d_att).permute(1, 2, 0, 3)
+ K = K.view(-1, bs, num_head, self.d_att).permute(1, 2, 3, 0)
+ V = V.view(-1, bs, num_head, hidden_dim).permute(1, 2, 0, 3)
+
+ # Multiplication
+ QK = multiply_by_ychunks(Q, K, self.qk_chunks)
+ if self.use_dis:
+ QK = 2 * QK - K.pow(2).sum(dim=-2, keepdim=True)
+
+ # Activation
+ if not self.training and self.top_k > 0 and self.top_k < QK.size()[-1]:
+ top_QK, indices = torch.topk(QK, k=self.top_k, dim=-1)
+ top_attn = linear_gate(top_QK, dim=-1)
+ attn = torch.zeros_like(QK).scatter_(-1, indices, top_attn)
+ else:
+ attn = linear_gate(QK, dim=-1)
+
+ # Dropouts
+ attn = self.dropout(attn)
+
+ # Weighted sum
+ outputs = multiply_by_xchunks(attn, V,
+ self.qk_chunks).permute(2, 0, 1, 3)
+
+ # Restore shape
+ outputs = outputs.reshape(l, bs, -1) * U
+
+ outputs = self.dw_conv(outputs, size_2d)
+ outputs = self.projection(outputs)
+
+ return outputs, attn
+
+ def _init_weight(self):
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+
+
+class LocalGatedPropagation(nn.Module):
+ def __init__(self,
+ d_qk,
+ d_vu,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True,
+ enable_corr=True,
+ d_att=None,
+ use_dis=False,
+ expand_ratio=2.):
+ super().__init__()
+ expand_ratio = expand_ratio
+ self.expand_d_vu = int(d_vu * expand_ratio)
+ self.d_qk = d_qk
+ self.d_vu = d_vu
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.hidden_dim = self.expand_d_vu // num_head
+ self.d_att = d_qk // num_head if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_dis = use_dis
+
+ self.d_middle = self.d_att * self.num_head
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_QK = nn.Conv2d(d_qk, self.d_middle, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_vu,
+ self.expand_d_vu,
+ kernel_size=1,
+ groups=2)
+ self.linear_U = nn.Conv2d(d_vu,
+ self.expand_d_vu,
+ kernel_size=1,
+ groups=2)
+
+ self.relative_emb_k = nn.Conv2d(self.d_middle,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+
+ self.enable_corr = enable_corr
+
+ if enable_corr:
+ from spatial_correlation_sampler import SpatialCorrelationSampler
+ self.correlation_sampler = SpatialCorrelationSampler(
+ kernel_size=1,
+ patch_size=self.window_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ dilation_patch=self.dilation)
+
+ self.dw_conv = DWConv2d(self.expand_d_vu)
+ self.projection = nn.Linear(self.expand_d_vu, d_vu)
+
+ self.dropout = nn.Dropout(dropout)
+
+ self.drop_prob = dropout
+
+ self.local_mask = None
+ self.last_size_2d = None
+ self.qk_mask = None
+
+ def forward(self, q, k, v, u, size_2d):
+ n, c, h, w = v.size()
+ hidden_dim = self.hidden_dim
+
+ if self.use_linear:
+ q = k = self.linear_QK(q)
+ v = silu(self.linear_V(v))
+ # u = silu(self.linear_U(u))
+ if self.num_head > 1:
+ v = v.view(-1, 2, self.num_head, hidden_dim // 2,
+ h * w).permute(0, 2, 1, 3, 4).reshape(n, -1, h, w)
+ # u = u.view(-1, 2, self.num_head, hidden_dim // 2,
+ # h * w).permute(4, 0, 2, 1, 3).reshape(h * w, n, -1)
+ # else:
+ # u = u.permute(2, 3, 0, 1).reshape(h * w, n, -1)
+
+ if self.qk_mask is not None and (h, w) == self.last_size_2d:
+ qk_mask = self.qk_mask
+ else:
+ memory_mask = torch.ones((1, 1, h, w), device=v.device).float()
+ unfolded_k_mask = self.pad_and_unfold(memory_mask).view(
+ 1, 1, self.window_size * self.window_size, h * w)
+ qk_mask = 1 - unfolded_k_mask
+ self.qk_mask = qk_mask
+
+ relative_emb = self.relative_emb_k(q)
+
+ # Scale
+ q = q / self.T
+
+ # print(q.shape)
+ # print(self.d_att, h, w)
+ # pdb.set_trace()
+ q = q.view(-1, self.d_att, h, w)
+ k = k.view(-1, self.d_att, h, w).contiguous()
+ v = v.view(-1, self.num_head, hidden_dim, h * w)
+ # print([n,c,h,w], q.shape, k.shape, v.shape);assert 0
+ # [4, 1024, 24, 24] torch.Size([4, 64, 24, 24]) torch.Size([4, 64, 24, 24]) torch.Size([2, 1, 2048, 576])
+
+
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+
+ if self.enable_corr:
+ qk = self.correlation_sampler(q, k).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ else:
+ unfolded_k = self.pad_and_unfold(k).view(
+ n * self.num_head, hidden_dim,
+ self.window_size * self.window_size, h, w)
+ qk = (q.unsqueeze(2) * unfolded_k).sum(dim=1).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ if self.use_dis:
+ qk = 2 * qk - self.pad_and_unfold(
+ k.pow(2).sum(dim=1, keepdim=True)).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w)
+
+ qk = qk + relative_emb
+
+ qk -= qk_mask * 1e+8 if qk.dtype == torch.float32 else qk_mask * 1e+4
+
+ local_attn = linear_gate(qk, dim=2)
+
+ local_attn = self.dropout(local_attn)
+
+ global_attn = self.local2global(local_attn, h, w)
+
+ agg_value = (global_attn @ v.transpose(-2, -1)).permute(
+ 2, 0, 1, 3).reshape(h * w, n, -1)
+
+ # output = agg_value * u
+ output = agg_value
+
+ output = self.dw_conv(output, size_2d)
+ output = self.projection(output)
+
+ self.last_size_2d = (h, w)
+ return output, local_attn
+
+ def local2global(self, local_attn, height, width):
+ batch_size = local_attn.size()[0]
+
+ pad_height = height + 2 * self.max_dis
+ pad_width = width + 2 * self.max_dis
+
+ if self.local_mask is not None and (height,
+ width) == self.last_size_2d:
+ local_mask = self.local_mask
+ else:
+ ky, kx = torch.meshgrid([
+ torch.arange(0, pad_height, device=local_attn.device),
+ torch.arange(0, pad_width, device=local_attn.device)
+ ])
+ qy, qx = torch.meshgrid([
+ torch.arange(0, height, device=local_attn.device),
+ torch.arange(0, width, device=local_attn.device)
+ ])
+
+ offset_y = qy.reshape(-1, 1) - ky.reshape(1, -1) + self.max_dis
+ offset_x = qx.reshape(-1, 1) - kx.reshape(1, -1) + self.max_dis
+
+ local_mask = (offset_y.abs() <= self.max_dis) & (offset_x.abs() <=
+ self.max_dis)
+ local_mask = local_mask.view(1, 1, height * width, pad_height,
+ pad_width)
+ self.local_mask = local_mask
+
+ global_attn = torch.zeros(
+ (batch_size, self.num_head, height * width, pad_height, pad_width),
+ device=local_attn.device)
+ # global_attn = global_attn.type(torch.HalfTensor).cuda()
+ global_attn[local_mask.expand(batch_size, self.num_head,
+ -1, -1, -1)] = local_attn.transpose(
+ -1, -2).reshape(-1)
+ global_attn = global_attn[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis].reshape(
+ batch_size, self.num_head,
+ height * width, height * width)
+
+ return global_attn
+
+ def pad_and_unfold(self, x):
+ pad_pixel = self.max_dis * self.dilation
+ x = F.pad(x, (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0)
+ x = F.unfold(x,
+ kernel_size=(self.window_size, self.window_size),
+ stride=(1, 1),
+ dilation=self.dilation)
+ return x
diff --git a/model/basic.py b/model/basic.py
new file mode 100644
index 0000000000000000000000000000000000000000..d09b2efa0801bd3ead0f7baf9388aa21a7ea79fe
--- /dev/null
+++ b/model/basic.py
@@ -0,0 +1,205 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+
+class ResBlock(nn.Module):
+ def __init__(self, indim, outdim=None, stride=1):
+ super(ResBlock, self).__init__()
+ if outdim == None:
+ outdim = indim
+ if indim == outdim and stride == 1:
+ self.downsample = None
+ else:
+ self.downsample = nn.Conv2d(indim, outdim, kernel_size=3, padding=1, stride=stride)
+ self.gn3 = nn.GroupNorm(8, outdim)
+
+ self.conv1 = nn.Conv2d(indim, outdim, kernel_size=3, padding=1, stride=stride)
+ self.conv2 = nn.Conv2d(outdim, outdim, kernel_size=3, padding=1)
+
+ self.gn1 = nn.GroupNorm(8, outdim)
+ self.gn2 = nn.GroupNorm(8, outdim)
+
+ def forward(self, x):
+ r = self.conv1(F.relu(x))
+ r = self.gn1(r)
+
+ r = self.conv2(F.relu(r))
+ r = self.gn2(r)
+
+ if self.downsample is not None:
+ x = self.gn3(self.downsample(x))
+
+ return x + r
+
+class ResGN(nn.Module):
+ def __init__(self, indim, outdim):
+ super().__init__()
+ self.res1 = ResBlock(indim, outdim)
+ self.res2 = ResBlock(outdim, outdim)
+ def forward(self, x):
+ return self.res2(self.res1(x))
+
+class GroupNorm1D(nn.Module):
+ def __init__(self, indim, groups=8):
+ super().__init__()
+ self.gn = nn.GroupNorm(groups, indim)
+
+ def forward(self, x):
+ return self.gn(x.permute(1, 2, 0)).permute(2, 0, 1)
+
+
+class GNActDWConv2d(nn.Module):
+ def __init__(self, indim, gn_groups=32):
+ super().__init__()
+ self.gn = nn.GroupNorm(gn_groups, indim)
+ self.conv = nn.Conv2d(indim,
+ indim,
+ 5,
+ dilation=1,
+ padding=2,
+ groups=indim,
+ bias=False)
+
+ def forward(self, x, size_2d):
+ h, w = size_2d
+ _, bs, c = x.size()
+ x = x.view(h, w, bs, c).permute(2, 3, 0, 1)
+ x = self.gn(x)
+ x = F.gelu(x)
+ x = self.conv(x)
+ x = x.view(bs, c, h * w).permute(2, 0, 1)
+ return x
+
+
+class DWConv2d(nn.Module):
+ def __init__(self, indim, dropout=0.1):
+ super().__init__()
+ self.conv = nn.Conv2d(indim,
+ indim,
+ 5,
+ dilation=1,
+ padding=2,
+ groups=indim,
+ bias=False)
+ self.dropout = nn.Dropout2d(p=dropout, inplace=True)
+
+ def forward(self, x, size_2d):
+ h, w = size_2d
+ _, bs, c = x.size()
+ x = x.view(h, w, bs, c).permute(2, 3, 0, 1)
+ x = self.conv(x)
+ x = self.dropout(x)
+ x = x.view(bs, c, h * w).permute(2, 0, 1)
+ return x
+
+
+class ScaleOffset(nn.Module):
+ def __init__(self, indim):
+ super().__init__()
+ self.gamma = nn.Parameter(torch.ones(indim))
+ # torch.nn.init.normal_(self.gamma, std=0.02)
+ self.beta = nn.Parameter(torch.zeros(indim))
+
+ def forward(self, x):
+ if len(x.size()) == 3:
+ return x * self.gamma + self.beta
+ else:
+ return x * self.gamma.view(1, -1, 1, 1) + self.beta.view(
+ 1, -1, 1, 1)
+
+
+class ConvGN(nn.Module):
+ def __init__(self, indim, outdim, kernel_size, gn_groups=8):
+ super().__init__()
+ self.conv = nn.Conv2d(indim,
+ outdim,
+ kernel_size,
+ padding=kernel_size // 2)
+ self.gn = nn.GroupNorm(gn_groups, outdim)
+
+ def forward(self, x):
+ return self.gn(self.conv(x))
+
+
+def seq_to_2d(tensor, size_2d):
+ h, w = size_2d
+ _, n, c = tensor.size()
+ tensor = tensor.view(h, w, n, c).permute(2, 3, 0, 1).contiguous()
+ return tensor
+
+
+def drop_path(x, drop_prob: float = 0., training: bool = False):
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (
+ x.shape[0],
+ x.shape[1],
+ ) + (1, ) * (x.ndim - 2
+ ) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(
+ shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+def mask_out(x, y, mask_rate=0.15, training=False):
+ if mask_rate == 0. or not training:
+ return x
+
+ keep_prob = 1 - mask_rate
+ shape = (
+ x.shape[0],
+ x.shape[1],
+ ) + (1, ) * (x.ndim - 2
+ ) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(
+ shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x * random_tensor + y * (1 - random_tensor)
+
+ return output
+
+
+class DropPath(nn.Module):
+ def __init__(self, drop_prob=None, batch_dim=0):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+ self.batch_dim = batch_dim
+
+ def forward(self, x):
+ return self.drop_path(x, self.drop_prob)
+
+ def drop_path(self, x, drop_prob):
+ if drop_prob == 0. or not self.training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = [1 for _ in range(x.ndim)]
+ shape[self.batch_dim] = x.shape[self.batch_dim]
+ random_tensor = keep_prob + torch.rand(
+ shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class DropOutLogit(nn.Module):
+ def __init__(self, drop_prob=None):
+ super(DropOutLogit, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return self.drop_logit(x, self.drop_prob)
+
+ def drop_logit(self, x, drop_prob):
+ if drop_prob == 0. or not self.training:
+ return x
+ random_tensor = drop_prob + torch.rand(
+ x.shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ mask = random_tensor * 1e+8 if (
+ x.dtype == torch.float32) else random_tensor * 1e+4
+ output = x - mask
+ return output
diff --git a/model/cbam.py b/model/cbam.py
new file mode 100644
index 0000000000000000000000000000000000000000..6423358429e2843b1f36ceb2bc1a485ea72b8eb4
--- /dev/null
+++ b/model/cbam.py
@@ -0,0 +1,77 @@
+# Modified from https://github.com/Jongchan/attention-module/blob/master/MODELS/cbam.py
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+class BasicConv(nn.Module):
+ def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
+ super(BasicConv, self).__init__()
+ self.out_channels = out_planes
+ self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
+
+ def forward(self, x):
+ x = self.conv(x)
+ return x
+
+class Flatten(nn.Module):
+ def forward(self, x):
+ return x.view(x.size(0), -1)
+
+class ChannelGate(nn.Module):
+ def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
+ super(ChannelGate, self).__init__()
+ self.gate_channels = gate_channels
+ self.mlp = nn.Sequential(
+ Flatten(),
+ nn.Linear(gate_channels, gate_channels // reduction_ratio),
+ nn.ReLU(),
+ nn.Linear(gate_channels // reduction_ratio, gate_channels)
+ )
+ self.pool_types = pool_types
+ def forward(self, x):
+ channel_att_sum = None
+ for pool_type in self.pool_types:
+ if pool_type=='avg':
+ avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
+ channel_att_raw = self.mlp( avg_pool )
+ elif pool_type=='max':
+ max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
+ channel_att_raw = self.mlp( max_pool )
+
+ if channel_att_sum is None:
+ channel_att_sum = channel_att_raw
+ else:
+ channel_att_sum = channel_att_sum + channel_att_raw
+
+ scale = torch.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)
+ return x * scale
+
+class ChannelPool(nn.Module):
+ def forward(self, x):
+ return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
+
+class SpatialGate(nn.Module):
+ def __init__(self):
+ super(SpatialGate, self).__init__()
+ kernel_size = 7
+ self.compress = ChannelPool()
+ self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2)
+ def forward(self, x):
+ x_compress = self.compress(x)
+ x_out = self.spatial(x_compress)
+ scale = torch.sigmoid(x_out) # broadcasting
+ return x * scale
+
+class CBAM(nn.Module):
+ def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
+ super(CBAM, self).__init__()
+ self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
+ self.no_spatial=no_spatial
+ if not no_spatial:
+ self.SpatialGate = SpatialGate()
+ def forward(self, x):
+ x_out = self.ChannelGate(x)
+ if not self.no_spatial:
+ x_out = self.SpatialGate(x_out)
+ return x_out
diff --git a/model/group_modules.py b/model/group_modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd22bedb429aaed6adf37e5455e0732af7e52dab
--- /dev/null
+++ b/model/group_modules.py
@@ -0,0 +1,93 @@
+"""
+Group-specific modules
+They handle features that also depends on the mask.
+Features are typically of shape
+ batch_size * num_objects * num_channels * H * W
+
+All of them are permutation equivariant w.r.t. to the num_objects dimension
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def interpolate_groups(g, ratio, mode, align_corners):
+ if len(g.shape) == 4:
+ g = F.interpolate(g, scale_factor=ratio, mode=mode, align_corners=align_corners)
+ elif len(g.shape) == 5:
+ batch_size, num_objects = g.shape[:2]
+ g = F.interpolate(g.flatten(start_dim=0, end_dim=1),
+ scale_factor=ratio, mode=mode, align_corners=align_corners)
+ g = g.view(batch_size, num_objects, *g.shape[1:])
+ return g
+
+def upsample_groups(g, ratio=2, mode='bilinear', align_corners=False):
+ return interpolate_groups(g, ratio, mode, align_corners)
+
+def downsample_groups(g, ratio=1/2, mode='area', align_corners=None):
+ return interpolate_groups(g, ratio, mode, align_corners)
+
+
+class GConv2D(nn.Conv2d):
+ def forward(self, g):
+ batch_size, num_objects = g.shape[:2]
+ g = super().forward(g.flatten(start_dim=0, end_dim=1))
+ return g.view(batch_size, num_objects, *g.shape[1:])
+
+
+class GroupResBlock(nn.Module):
+ def __init__(self, in_dim, out_dim):
+ super().__init__()
+
+ if in_dim == out_dim:
+ self.downsample = None
+ else:
+ self.downsample = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
+
+ self.conv1 = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
+ self.conv2 = GConv2D(out_dim, out_dim, kernel_size=3, padding=1)
+
+ def forward(self, g):
+ out_g = self.conv1(F.relu(g))
+ out_g = self.conv2(F.relu(out_g))
+
+ if self.downsample is not None:
+ g = self.downsample(g)
+
+ return out_g + g
+
+
+class MainToGroupDistributor(nn.Module):
+ def __init__(self, x_transform=None, method='cat', reverse_order=False):
+ super().__init__()
+
+ self.x_transform = x_transform
+ self.method = method
+ self.reverse_order = reverse_order
+
+ def forward(self, x, g):
+ num_objects = g.shape[1]
+
+ while 0: print(num_objects, g.size())
+ # 3 torch.Size([8, 3, 2, 384, 384])
+
+ if self.x_transform is not None:
+ x = self.x_transform(x)
+
+ if self.method == 'cat':
+ if self.reverse_order:
+ g = torch.cat([g, x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1)], 2)
+ else:
+ # print('2', g.size(), x.size(), x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1).size())
+ # torch.Size([8, 2, 2, 224, 224]) torch.Size([8, 3, 224, 224]) torch.Size([8, 2, 3, 224, 224])
+ # torch.Size([1, 1, 2, 480, 864]) torch.Size([1, 3, 480, 864]) torch.Size([1, 1, 3, 480, 864])
+ g = torch.cat([x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1), g], 2)
+ elif self.method == 'add':
+ # print(g.size(), x.size(), x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1).size())
+ # torch.Size([8, 2, 512, 16, 16]) torch.Size([8, 512, 16, 16]) torch.Size([8, 2, 512, 16, 16])
+ g = x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1) + g
+ else:
+ raise NotImplementedError
+
+ return g
diff --git a/model/losses.py b/model/losses.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a5d901cb95f12b90699b2a5d7c081e18eab7a1a
--- /dev/null
+++ b/model/losses.py
@@ -0,0 +1,91 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from collections import defaultdict
+
+
+def dice_loss(input_mask, cls_gt):
+ num_objects = input_mask.shape[1]
+ losses = []
+ for i in range(num_objects):
+ mask = input_mask[:,i].flatten(start_dim=1)
+ # background not in mask, so we add one to cls_gt
+ gt = (cls_gt==(i+1)).float().flatten(start_dim=1)
+ numerator = 2 * (mask * gt).sum(-1)
+ denominator = mask.sum(-1) + gt.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ losses.append(loss)
+ return torch.cat(losses).mean()
+
+def l1_loss(input, target):
+ out = torch.abs(input - target)
+ return out.mean()
+
+
+# https://stackoverflow.com/questions/63735255/how-do-i-compute-bootstrapped-cross-entropy-loss-in-pytorch
+class BootstrappedCE(nn.Module):
+ def __init__(self, start_warm, end_warm, top_p=0.15):
+ super().__init__()
+
+ self.start_warm = start_warm
+ self.end_warm = end_warm
+ self.top_p = top_p
+
+ def forward(self, input, target, it):
+ if it < self.start_warm:
+
+ return F.cross_entropy(input, target), 1.0
+
+ raw_loss = F.cross_entropy(input, target, reduction='none').view(-1)
+ num_pixels = raw_loss.numel()
+
+ if it > self.end_warm:
+ this_p = self.top_p
+ else:
+ this_p = self.top_p + (1-self.top_p)*((self.end_warm-it)/(self.end_warm-self.start_warm))
+ loss, _ = torch.topk(raw_loss, int(num_pixels * this_p), sorted=False)
+ return loss.mean(), this_p
+
+
+class LossComputer:
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.bce = BootstrappedCE(config['start_warm'], config['end_warm'])
+
+ def compute(self, data, num_objects, it):
+ losses = defaultdict(int)
+
+ b, t = data['rgb'].shape[:2]
+
+ losses['total_loss'] = 0
+ for ti in range(1, t):
+ for bi in range(b):
+ loss, p = self.bce(data[f'logits_{ti}'][bi:bi+1, :num_objects[bi]+1], data['cls_gt'][bi:bi+1,ti,0], it)
+ losses['p'] += p / b / (t-1)
+ losses[f'ce_loss_{ti}'] += loss / b
+
+ losses['total_loss'] += losses['ce_loss_%d'%ti]
+ losses[f'dice_loss_{ti}'] = dice_loss(data[f'masks_{ti}'], data['cls_gt'][:,ti,0])
+ losses['total_loss'] += losses[f'dice_loss_{ti}']
+
+ return losses
+
+
+ def compute_l1loss(self, data, num_objects, it):
+ losses = defaultdict(int)
+
+ b, t = data['rgb'].shape[:2]
+
+ losses['total_loss'] = 0
+ for ti in range(1, t):
+ for bi in range(b):
+ losses['p'] = 0
+ losses[f'ce_loss_{ti}'] = 0
+
+ losses['total_loss'] += losses['ce_loss_%d'%ti]
+ losses[f'dice_loss_{ti}'] = l1_loss(data[f'masks_{ti}'], data['cls_gt'][:,ti])
+ losses['total_loss'] += losses[f'dice_loss_{ti}']
+
+ return losses
diff --git a/model/memory_util.py b/model/memory_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..faf6197b8c4ea990317476e2e3aeb8952a78aedf
--- /dev/null
+++ b/model/memory_util.py
@@ -0,0 +1,80 @@
+import math
+import numpy as np
+import torch
+from typing import Optional
+
+
+def get_similarity(mk, ms, qk, qe):
+ # used for training/inference and memory reading/memory potentiation
+ # mk: B x CK x [N] - Memory keys
+ # ms: B x 1 x [N] - Memory shrinkage
+ # qk: B x CK x [HW/P] - Query keys
+ # qe: B x CK x [HW/P] - Query selection
+ # Dimensions in [] are flattened
+ CK = mk.shape[1]
+ mk = mk.flatten(start_dim=2)
+ ms = ms.flatten(start_dim=1).unsqueeze(2) if ms is not None else None
+ qk = qk.flatten(start_dim=2)
+ qe = qe.flatten(start_dim=2) if qe is not None else None
+
+ if qe is not None:
+ # See appendix for derivation
+ # or you can just trust me ヽ(ー_ー )ノ
+ mk = mk.transpose(1, 2)
+ a_sq = (mk.pow(2) @ qe)
+ two_ab = 2 * (mk @ (qk * qe))
+ b_sq = (qe * qk.pow(2)).sum(1, keepdim=True)
+ similarity = (-a_sq+two_ab-b_sq)
+ else:
+ # similar to STCN if we don't have the selection term
+ a_sq = mk.pow(2).sum(1).unsqueeze(2)
+ two_ab = 2 * (mk.transpose(1, 2) @ qk)
+ similarity = (-a_sq+two_ab)
+
+ if ms is not None:
+ similarity = similarity * ms / math.sqrt(CK) # B*N*HW
+ else:
+ similarity = similarity / math.sqrt(CK) # B*N*HW
+
+ return similarity
+
+def do_softmax(similarity, top_k: Optional[int]=None, inplace=False, return_usage=False):
+ # normalize similarity with top-k softmax
+ # similarity: B x N x [HW/P]
+ # use inplace with care
+ if top_k is not None:
+ values, indices = torch.topk(similarity, k=top_k, dim=1)
+
+ x_exp = values.exp_()
+ x_exp /= torch.sum(x_exp, dim=1, keepdim=True)
+ if inplace:
+ similarity.zero_().scatter_(1, indices, x_exp) # B*N*HW
+ affinity = similarity
+ else:
+ affinity = torch.zeros_like(similarity).scatter_(1, indices, x_exp) # B*N*HW
+ else:
+ maxes = torch.max(similarity, dim=1, keepdim=True)[0]
+ x_exp = torch.exp(similarity - maxes)
+ x_exp_sum = torch.sum(x_exp, dim=1, keepdim=True)
+ affinity = x_exp / x_exp_sum
+ indices = None
+
+ if return_usage:
+ return affinity, affinity.sum(dim=2)
+
+ return affinity
+
+def get_affinity(mk, ms, qk, qe):
+ # shorthand used in training with no top-k
+ similarity = get_similarity(mk, ms, qk, qe)
+ affinity = do_softmax(similarity)
+ return affinity
+
+def readout(affinity, mv):
+ B, CV, T, H, W = mv.shape
+
+ mo = mv.view(B, CV, T*H*W)
+ mem = torch.bmm(mo, affinity)
+ mem = mem.view(B, CV, H, W)
+
+ return mem
diff --git a/model/modules.py b/model/modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..cea6986e89e05c8e701753800891b79ff327ff73
--- /dev/null
+++ b/model/modules.py
@@ -0,0 +1,271 @@
+"""
+modules.py - This file stores the rather boring network blocks.
+
+x - usually means features that only depends on the image
+g - usually means features that also depends on the mask.
+ They might have an extra "group" or "num_objects" dimension, hence
+ batch_size * num_objects * num_channels * H * W
+
+The trailing number of a variable usually denote the stride
+
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from model.group_modules import *
+from model import resnet
+from model.cbam import CBAM
+
+
+class FeatureFusionBlock(nn.Module):
+ def __init__(self, x_in_dim, g_in_dim, g_mid_dim, g_out_dim):
+ super().__init__()
+
+ self.distributor = MainToGroupDistributor()
+ self.block1 = GroupResBlock(x_in_dim+g_in_dim, g_mid_dim)
+ self.attention = CBAM(g_mid_dim)
+ self.block2 = GroupResBlock(g_mid_dim, g_out_dim)
+
+ def forward(self, x, g):
+ batch_size, num_objects = g.shape[:2]
+
+ g = self.distributor(x, g)
+ g = self.block1(g)
+ r = self.attention(g.flatten(start_dim=0, end_dim=1))
+ r = r.view(batch_size, num_objects, *r.shape[1:])
+
+ g = self.block2(g+r)
+
+ return g
+
+
+class HiddenUpdater(nn.Module):
+ # Used in the decoder, multi-scale feature + GRU
+ def __init__(self, g_dims, mid_dim, hidden_dim, ratio=1/2):
+ super().__init__()
+ self.hidden_dim = hidden_dim
+ self.ratio = ratio
+
+ self.g16_conv = GConv2D(g_dims[0], mid_dim, kernel_size=1)
+ self.g8_conv = GConv2D(g_dims[1], mid_dim, kernel_size=1)
+ self.g4_conv = GConv2D(g_dims[2], mid_dim, kernel_size=1)
+
+ self.transform = GConv2D(mid_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
+
+ nn.init.xavier_normal_(self.transform.weight)
+
+ def forward(self, g, h):
+ g = self.g16_conv(g[0]) + self.g8_conv(downsample_groups(g[1], ratio=1/2)) + \
+ self.g4_conv(downsample_groups(g[2], ratio=1/4))
+ # g = self.g16_conv(g[0]) + self.g8_conv(downsample_groups(g[1], self.ratio)) + \
+ # self.g4_conv(downsample_groups(g[2], ratio=self.ratio))
+
+ g = torch.cat([g, h], 2)
+
+ # defined slightly differently than standard GRU,
+ # namely the new value is generated before the forget gate.
+ # might provide better gradient but frankly it was initially just an
+ # implementation error that I never bothered fixing
+ values = self.transform(g)
+ forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
+ update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
+ new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
+ new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
+
+ return new_h
+
+
+class HiddenReinforcer(nn.Module):
+ # Used in the value encoder, a single GRU
+ def __init__(self, g_dim, hidden_dim):
+ super().__init__()
+ self.hidden_dim = hidden_dim
+ self.transform = GConv2D(g_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
+
+ nn.init.xavier_normal_(self.transform.weight)
+
+ def forward(self, g, h):
+ g = torch.cat([g, h], 2)
+
+ # defined slightly differently than standard GRU,
+ # namely the new value is generated before the forget gate.
+ # might provide better gradient but frankly it was initially just an
+ # implementation error that I never bothered fixing
+ values = self.transform(g)
+ forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
+ update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
+ new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
+ new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
+
+ return new_h
+
+
+class ValueEncoder(nn.Module):
+ def __init__(self, value_dim, hidden_dim, single_object=False):
+ super().__init__()
+
+ self.single_object = single_object
+ network = resnet.resnet18(pretrained=True, extra_dim=1 if single_object else 2)
+ self.conv1 = network.conv1
+ self.bn1 = network.bn1
+ self.relu = network.relu # 1/2, 64
+ self.maxpool = network.maxpool
+
+ self.layer1 = network.layer1 # 1/4, 64
+ self.layer2 = network.layer2 # 1/8, 128
+ self.layer3 = network.layer3 # 1/16, 256
+
+ self.distributor = MainToGroupDistributor()
+ self.fuser = FeatureFusionBlock(1024, 256, value_dim, value_dim) # (1024 256) -> (384 256) -> (384 256)
+ if hidden_dim > 0:
+ self.hidden_reinforce = HiddenReinforcer(value_dim, hidden_dim)
+ else:
+ self.hidden_reinforce = None
+
+ def forward(self, image, image_feat_f16, h, masks, others, is_deep_update=True):
+ # image_feat_f16 is the feature from the key encoder
+ if not self.single_object:
+ g = torch.stack([masks, others], 2)
+ else:
+ g = masks.unsqueeze(2)
+ g = self.distributor(image, g)
+
+ batch_size, num_objects = g.shape[:2]
+ g = g.flatten(start_dim=0, end_dim=1)
+
+ g = self.conv1(g)
+ g = self.bn1(g) # 1/2, 64
+ g = self.maxpool(g) # 1/4, 64
+ g = self.relu(g)
+
+ g = self.layer1(g) # 1/4
+ g = self.layer2(g) # 1/8
+ g = self.layer3(g) # 1/16
+
+ # handle dim problem raised by vit
+ g = F.interpolate(g, image_feat_f16.shape[2:], mode='bilinear', align_corners=False)
+
+ g = g.view(batch_size, num_objects, *g.shape[1:])
+ g = self.fuser(image_feat_f16, g)
+
+ if is_deep_update and self.hidden_reinforce is not None:
+ h = self.hidden_reinforce(g, h)
+
+ return g, h
+
+class KeyEncoder_DINOv2_v6(nn.Module):
+ def __init__(self):
+ super().__init__()
+ network = resnet.resnet50(pretrained=True)
+ self.conv1 = network.conv1
+ self.bn1 = network.bn1
+ self.relu = network.relu # 1/2, 64
+ self.maxpool = network.maxpool
+
+ self.res2 = network.layer1 # 1/4, 256
+ self.layer2 = network.layer2 # 1/8, 512
+ self.layer3 = network.layer3 # 1/16, 1024
+
+ self.network2 = resnet.Segmentor()
+
+ self.fuse1 = resnet.Fuse(384 * 4, 1024) # n = [8, 9, 10, 11]
+ self.fuse2 = resnet.Fuse(384 * 4, 512)
+ self.fuse3 = resnet.Fuse(384 * 4, 256)
+
+ self.upsample2 = nn.Upsample(scale_factor=2, mode='bilinear')
+ self.upsample4 = nn.Upsample(scale_factor=4, mode='bilinear')
+
+ def forward(self, f):
+ x = self.conv1(f)
+ x = self.bn1(x)
+ x = self.relu(x) # 1/2, 64
+ x = self.maxpool(x) # 1/4, 64
+ f4 = self.res2(x) # 1/4, 256
+ f8 = self.layer2(f4) # 1/8, 512
+ f16 = self.layer3(f8) # 1/16, 1024
+
+ f16_dino = self.network2(f) # 1/14, 384 -> interp to 1/16
+
+ g16 = self.fuse1(f16_dino, f16)
+ g8 = self.fuse2(self.upsample2(f16_dino), f8)
+ g4 = self.fuse3(self.upsample4(f16_dino), f4)
+
+ return g16, g8, g4
+
+class UpsampleBlock(nn.Module):
+ def __init__(self, skip_dim, g_up_dim, g_out_dim, scale_factor=2):
+ super().__init__()
+ self.skip_conv = nn.Conv2d(skip_dim, g_up_dim, kernel_size=3, padding=1)
+ self.distributor = MainToGroupDistributor(method='add')
+ self.out_conv = GroupResBlock(g_up_dim, g_out_dim)
+ self.scale_factor = scale_factor
+
+ def forward(self, skip_f, up_g):
+ skip_f = self.skip_conv(skip_f)
+ g = upsample_groups(up_g, ratio=self.scale_factor)
+ g = self.distributor(skip_f, g)
+ g = self.out_conv(g)
+ return g
+
+
+class KeyProjection(nn.Module):
+ def __init__(self, in_dim, keydim):
+ super().__init__()
+
+ self.key_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
+ # shrinkage
+ self.d_proj = nn.Conv2d(in_dim, 1, kernel_size=3, padding=1)
+ # selection
+ self.e_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
+
+ nn.init.orthogonal_(self.key_proj.weight.data)
+ nn.init.zeros_(self.key_proj.bias.data)
+
+ def forward(self, x, need_s, need_e):
+ shrinkage = self.d_proj(x)**2 + 1 if (need_s) else None
+ selection = torch.sigmoid(self.e_proj(x)) if (need_e) else None
+
+ return self.key_proj(x), shrinkage, selection
+
+
+class Decoder(nn.Module):
+ def __init__(self, val_dim, hidden_dim):
+ super().__init__()
+
+ self.fuser = FeatureFusionBlock(1024, val_dim+hidden_dim, 512, 512) # (1024, val_dim+hidden_dim, 512, 512) -> (384, val_dim+hidden_dim, 512, 512) -> (1536, val_dim+hidden_dim, 512, 512)
+ if hidden_dim > 0:
+ self.hidden_update = HiddenUpdater([512, 256, 256+1], 256, hidden_dim, 1)
+ else:
+ self.hidden_update = None
+
+ self.up_16_8 = UpsampleBlock(512, 512, 256) # 1/16 -> 1/8
+ self.up_8_4 = UpsampleBlock(256, 256, 256) # 1/8 -> 1/4
+
+ self.pred = nn.Conv2d(256, 1, kernel_size=3, padding=1, stride=1)
+
+ def forward(self, f16, f8, f4, hidden_state, memory_readout, h_out=True):
+ batch_size, num_objects = memory_readout.shape[:2]
+
+ if self.hidden_update is not None:
+ g16 = self.fuser(f16, torch.cat([memory_readout, hidden_state], 2))
+ else:
+ g16 = self.fuser(f16, memory_readout)
+
+ g8 = self.up_16_8(f8, g16)
+
+ g4 = self.up_8_4(f4, g8)
+
+ logits = self.pred(F.relu(g4.flatten(start_dim=0, end_dim=1)))
+
+ if h_out and self.hidden_update is not None:
+ g4 = torch.cat([g4, logits.view(batch_size, num_objects, 1, *logits.shape[-2:])], 2)
+ hidden_state = self.hidden_update([g16, g8, g4], hidden_state)
+ else:
+ hidden_state = None
+
+ logits = F.interpolate(logits, scale_factor=4, mode='bilinear', align_corners=False)
+ logits = logits.view(batch_size, num_objects, *logits.shape[-2:])
+
+ return hidden_state, logits
diff --git a/model/network.py b/model/network.py
new file mode 100644
index 0000000000000000000000000000000000000000..8994c43681ba624b82a445af8614cbb642adbcae
--- /dev/null
+++ b/model/network.py
@@ -0,0 +1,225 @@
+"""
+This file defines XMem, the highest level nn.Module interface
+During training, it is used by trainer.py
+During evaluation, it is used by inference_core.py
+
+It further depends on modules.py which gives more detailed implementations of sub-modules
+"""
+
+import torch
+import torch.nn as nn
+
+from model.aggregate import aggregate
+from model.modules import *
+from model.memory_util import *
+
+from model.attention import LocalGatedPropagation
+
+class ColorMNet(nn.Module):
+ def __init__(self, config, model_path=None, map_location=None):
+ """
+ model_path/map_location are used in evaluation only
+ map_location is for converting models saved in cuda to cpu
+ """
+ super().__init__()
+ model_weights = self.init_hyperparameters(config, model_path, map_location)
+
+ self.single_object = config.get('single_object', False)
+ print(f'Single object mode: {self.single_object}')
+
+ self.key_encoder = KeyEncoder_DINOv2_v6()
+
+ self.value_encoder = ValueEncoder(self.value_dim, self.hidden_dim, self.single_object)
+
+ # Projection from f16 feature space to key/value space
+ self.key_proj = KeyProjection(1024, self.key_dim) # 1024 -> 384 -> 3072
+
+ self.short_term_attn = LocalGatedPropagation(d_qk=64, # 256
+ d_vu=512 * 2,
+ num_head=1,
+ dilation=1,
+ use_linear=False,
+ dropout=0,
+ d_att=64, # 128
+ max_dis=7,
+ expand_ratio=1)
+
+ self.decoder = Decoder(self.value_dim, self.hidden_dim)
+
+ if model_weights is not None:
+ self.load_weights(model_weights, init_as_zero_if_needed=True)
+
+ def encode_key(self, frame, need_sk=True, need_ek=True):
+ # Determine input shape
+ if len(frame.shape) == 5:
+ # shape is b*t*c*h*w
+ need_reshape = True
+ b, t = frame.shape[:2]
+ # flatten so that we can feed them into a 2D CNN
+ frame = frame.flatten(start_dim=0, end_dim=1)
+ elif len(frame.shape) == 4:
+ # shape is b*c*h*w
+ need_reshape = False
+ else:
+ raise NotImplementedError
+
+ f16, f8, f4 = self.key_encoder(frame)
+ key, shrinkage, selection = self.key_proj(f16, need_sk, need_ek)
+
+ if need_reshape:
+ # B*C*T*H*W
+ key = key.view(b, t, *key.shape[-3:]).transpose(1, 2).contiguous()
+ if shrinkage is not None:
+ shrinkage = shrinkage.view(b, t, *shrinkage.shape[-3:]).transpose(1, 2).contiguous()
+ if selection is not None:
+ selection = selection.view(b, t, *selection.shape[-3:]).transpose(1, 2).contiguous()
+
+ # B*T*C*H*W
+ f16 = f16.view(b, t, *f16.shape[-3:])
+ f8 = f8.view(b, t, *f8.shape[-3:])
+ f4 = f4.view(b, t, *f4.shape[-3:])
+
+ return key, shrinkage, selection, f16, f8, f4
+
+ def encode_value(self, frame, image_feat_f16, h16, masks, is_deep_update=True):
+ num_objects = masks.shape[1]
+ if num_objects != 1:
+ others = torch.cat([
+ torch.sum(
+ masks[:, [j for j in range(num_objects) if i!=j]]
+ , dim=1, keepdim=True)
+ for i in range(num_objects)], 1)
+ else:
+ others = torch.zeros_like(masks)
+
+ g16, h16 = self.value_encoder(frame, image_feat_f16, h16, masks, others, is_deep_update)
+
+ return g16, h16
+
+ # Used in training only.
+ # This step is replaced by MemoryManager in test time
+ def read_memory(self, query_key, query_selection, memory_key,
+ memory_shrinkage, memory_value):
+ """
+ query_key : B * CK * H * W
+ query_selection : B * CK * H * W
+ memory_key : B * CK * T * H * W
+ memory_shrinkage: B * 1 * T * H * W
+ memory_value : B * num_objects * CV * T * H * W
+ """
+ batch_size, num_objects = memory_value.shape[:2]
+ memory_value = memory_value.flatten(start_dim=1, end_dim=2)
+
+ affinity = get_affinity(memory_key, memory_shrinkage, query_key, query_selection)
+ memory = readout(affinity, memory_value)
+ memory = memory.view(batch_size, num_objects, self.value_dim, *memory.shape[-2:])
+
+ return memory
+
+ def read_memory_short(self, query_key, memory_key, memory_value):
+ """
+ query_key : B * CK * H * W
+ query_selection : B * CK * H * W
+ memory_key : B * CK * T * H * W
+ memory_shrinkage: B * 1 * T * H * W
+ memory_value : B * num_objects * CV * T * H * W
+ """
+ batch_size, num_objects = memory_value.shape[:2]
+ memory_value = memory_value.flatten(start_dim=1, end_dim=2)
+
+ size_2d = query_key.shape[-2:]
+ memory_value_short, _ = self.short_term_attn(query_key, memory_key, memory_value, None, size_2d)
+
+ memory_value_short = memory_value_short.permute(1, 2, 0).view(batch_size, num_objects, self.value_dim, *memory_value.shape[-2:])
+
+ return memory_value_short
+
+ def segment(self, multi_scale_features, memory_readout,
+ hidden_state, selector=None, h_out=True, strip_bg=True):
+
+ hidden_state, logits = self.decoder(*multi_scale_features, hidden_state, memory_readout, h_out=h_out)
+
+ prob = torch.tanh(logits)
+ logits = prob
+
+ return hidden_state, logits, prob
+
+ def forward(self, mode, *args, **kwargs):
+ if mode == 'encode_key':
+ return self.encode_key(*args, **kwargs)
+ elif mode == 'encode_value':
+ return self.encode_value(*args, **kwargs)
+ elif mode == 'read_memory':
+ return self.read_memory(*args, **kwargs)
+ elif mode == 'read_memory_short':
+ return self.read_memory_short(*args, **kwargs)
+ elif mode == 'segment':
+ return self.segment(*args, **kwargs)
+ else:
+ raise NotImplementedError
+
+ def init_hyperparameters(self, config, model_path=None, map_location=None):
+ """
+ Init three hyperparameters: key_dim, value_dim, and hidden_dim
+ If model_path is provided, we load these from the model weights
+ The actual parameters are then updated to the config in-place
+
+ Otherwise we load it either from the config or default
+ """
+ if model_path is not None:
+ # load the model and key/value/hidden dimensions with some hacks
+ # config is updated with the loaded parameters
+ model_weights = torch.load(model_path, map_location=map_location)
+ self.key_dim = model_weights['key_proj.key_proj.weight'].shape[0]
+ self.value_dim = model_weights['value_encoder.fuser.block2.conv2.weight'].shape[0]
+ self.disable_hidden = 'decoder.hidden_update.transform.weight' not in model_weights
+ if self.disable_hidden:
+ self.hidden_dim = 0
+ else:
+ self.hidden_dim = model_weights['decoder.hidden_update.transform.weight'].shape[0]//3
+ print(f'Hyperparameters read from the model weights: '
+ f'C^k={self.key_dim}, C^v={self.value_dim}, C^h={self.hidden_dim}')
+ else:
+ model_weights = None
+ # load dimensions from config or default
+ if 'key_dim' not in config:
+ self.key_dim = 64
+ print(f'key_dim not found in config. Set to default {self.key_dim}')
+ else:
+ self.key_dim = config['key_dim']
+
+ if 'value_dim' not in config:
+ self.value_dim = 512
+ print(f'value_dim not found in config. Set to default {self.value_dim}')
+ else:
+ self.value_dim = config['value_dim']
+
+ if 'hidden_dim' not in config:
+ self.hidden_dim = 64
+ print(f'hidden_dim not found in config. Set to default {self.hidden_dim}')
+ else:
+ self.hidden_dim = config['hidden_dim']
+
+ self.disable_hidden = (self.hidden_dim <= 0)
+
+ config['key_dim'] = self.key_dim
+ config['value_dim'] = self.value_dim
+ config['hidden_dim'] = self.hidden_dim
+
+ return model_weights
+
+ def load_weights(self, src_dict, init_as_zero_if_needed=False):
+ # Maps SO weight (without other_mask) to MO weight (with other_mask)
+ for k in list(src_dict.keys()):
+ if k == 'value_encoder.conv1.weight':
+ if src_dict[k].shape[1] == 4:
+ print('Converting weights from single object to multiple objects.')
+ pads = torch.zeros((64,1,7,7), device=src_dict[k].device)
+ if not init_as_zero_if_needed:
+ print('Randomly initialized padding.')
+ nn.init.orthogonal_(pads)
+ else:
+ print('Zero-initialized padding.')
+ src_dict[k] = torch.cat([src_dict[k], pads], 1)
+
+ self.load_state_dict(src_dict)
diff --git a/model/resnet.py b/model/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..c6ea3acb36a9879fffe55c3a78b5ce4d23704c5f
--- /dev/null
+++ b/model/resnet.py
@@ -0,0 +1,399 @@
+"""
+resnet.py - A modified ResNet structure
+We append extra channels to the first conv by some network surgery
+"""
+
+from collections import OrderedDict
+import math
+
+import torch
+import torch.nn as nn
+from torch.utils import model_zoo
+
+from torch.hub import load
+import torchvision.models as models
+import warnings
+warnings.filterwarnings("ignore")
+import torch.nn.functional as F
+
+from einops import rearrange
+
+def load_weights_add_extra_dim(target, source_state, extra_dim=1):
+ new_dict = OrderedDict()
+
+ for k1, v1 in target.state_dict().items():
+ if not 'num_batches_tracked' in k1:
+ if k1 in source_state:
+ tar_v = source_state[k1]
+
+ if v1.shape != tar_v.shape:
+ # Init the new segmentation channel with zeros
+ # print(v1.shape, tar_v.shape)
+ c, _, w, h = v1.shape
+ pads = torch.zeros((c,extra_dim,w,h), device=tar_v.device)
+ nn.init.orthogonal_(pads)
+ tar_v = torch.cat([tar_v, pads], 1)
+
+ new_dict[k1] = tar_v
+
+ target.load_state_dict(new_dict)
+
+
+model_urls = {
+ 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
+ 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
+}
+
+
+def conv3x3(in_planes, out_planes, stride=1, dilation=1):
+ return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
+ padding=dilation, dilation=dilation, bias=False)
+
+
+class BasicBlock(nn.Module):
+ expansion = 1
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
+ super(BasicBlock, self).__init__()
+ self.conv1 = conv3x3(inplanes, planes, stride=stride, dilation=dilation)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.relu = nn.ReLU(inplace=True)
+ self.conv2 = conv3x3(planes, planes, stride=1, dilation=dilation)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out += residual
+ out = self.relu(out)
+
+ return out
+
+
+class Bottleneck(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
+ super(Bottleneck, self).__init__()
+ self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,
+ padding=dilation, bias=False)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
+ self.bn3 = nn.BatchNorm2d(planes * 4)
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.bn3(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out += residual
+ out = self.relu(out)
+
+ return out
+
+
+class ResNet(nn.Module):
+ def __init__(self, block, layers=(3, 4, 23, 3), extra_dim=0):
+ self.inplanes = 64
+ super(ResNet, self).__init__()
+ self.conv1 = nn.Conv2d(3+extra_dim, 64, kernel_size=7, stride=2, padding=3, bias=False)
+ self.bn1 = nn.BatchNorm2d(64)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+ self.layer1 = self._make_layer(block, 64, layers[0])
+ self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
+ self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
+ self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
+
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
+ m.weight.data.normal_(0, math.sqrt(2. / n))
+ elif isinstance(m, nn.BatchNorm2d):
+ m.weight.data.fill_(1)
+ m.bias.data.zero_()
+
+ def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
+ downsample = None
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ nn.Conv2d(self.inplanes, planes * block.expansion,
+ kernel_size=1, stride=stride, bias=False),
+ nn.BatchNorm2d(planes * block.expansion),
+ )
+
+ layers = [block(self.inplanes, planes, stride, downsample)]
+ self.inplanes = planes * block.expansion
+ for i in range(1, blocks):
+ layers.append(block(self.inplanes, planes, dilation=dilation))
+
+ return nn.Sequential(*layers)
+
+def resnet18(pretrained=True, extra_dim=0):
+ model = ResNet(BasicBlock, [2, 2, 2, 2], extra_dim)
+ if pretrained:
+ load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet18']), extra_dim)
+ return model
+
+def resnet50(pretrained=True, extra_dim=0):
+ model = ResNet(Bottleneck, [3, 4, 6, 3], extra_dim)
+ if pretrained:
+ load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet50']), extra_dim)
+ return model
+
+dino_backbones = {
+ 'dinov2_s':{
+ 'name':'dinov2_vits14',
+ 'embedding_size':384,
+ 'patch_size':14
+ },
+ 'dinov2_b':{
+ 'name':'dinov2_vitb14',
+ 'embedding_size':768,
+ 'patch_size':14
+ },
+ 'dinov2_l':{
+ 'name':'dinov2_vitl14',
+ 'embedding_size':1024,
+ 'patch_size':14
+ },
+ 'dinov2_g':{
+ 'name':'dinov2_vitg14',
+ 'embedding_size':1536,
+ 'patch_size':14
+ },
+}
+
+class conv_head(nn.Module):
+ def __init__(self, embedding_size = 384, num_classes = 5):
+ super(conv_head, self).__init__()
+ self.segmentation_conv = nn.Sequential(
+ nn.Upsample(scale_factor=2),
+ nn.Conv2d(embedding_size, 64, (3,3), padding=(1,1)),
+ nn.Upsample(scale_factor=2),
+ nn.Conv2d(64, num_classes, (3,3), padding=(1,1)),
+ )
+
+ def forward(self, x):
+ x = self.segmentation_conv(x)
+ x = torch.sigmoid(x)
+ return x
+
+class Segmentor(nn.Module):
+ def __init__(self, num_classes=5, backbone = 'dinov2_s', head = 'conv', backbones = dino_backbones):
+ super(Segmentor, self).__init__()
+ self.heads = {
+ 'conv':conv_head
+ }
+ # internet
+ self.backbones = dino_backbones
+ self.backbone = load('facebookresearch/dinov2', self.backbones[backbone]['name']) # add trust_repo to
+ self.backbone.eval()
+
+ # # local
+ # self.backbones = dino_backbones
+ # self.backbone = load('/root/.cache/torch/hub/facebookresearch_dinov2_main', self.backbones[backbone]['name'], source='local', pretrained=False) # add trust_repo to
+ # self.backbone.load_state_dict(torch.load('/root/.cache/torch/hub/checkpoints/dinov2_vits14_pretrain.pth'))
+ # self.backbone.eval()
+
+ self.conv3 = nn.Conv2d(1536, 1536, kernel_size=1, bias=False)
+ self.bn3 = nn.BatchNorm2d(1536)
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ with torch.no_grad():
+ tokens = self.backbone.get_intermediate_layers(x, n=[8, 9, 10, 11], reshape=True) # last n=4 [8, 9, 10, 11]
+
+ f16 = torch.cat(tokens, dim=1)
+
+ f16 = self.conv3(f16)
+ f16 = self.bn3(f16)
+ f16 = self.relu(f16)
+
+ old_size = (f16.shape[2], f16.shape[3])
+ new_size = (int(old_size[0]*14/16), int(old_size[1]*14/16))
+ f16 = F.interpolate(f16, size=new_size, mode='bilinear', align_corners=False) # scale_factor=3.5
+
+ return f16
+
+class LayerNormFunction(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x, weight, bias, eps):
+ ctx.eps = eps
+ N, C, H, W = x.size()
+ mu = x.mean(1, keepdim=True)
+ var = (x - mu).pow(2).mean(1, keepdim=True)
+ y = (x - mu) / (var + eps).sqrt()
+ ctx.save_for_backward(y, var, weight)
+ y = weight.view(1, C, 1, 1) * y + bias.view(1, C, 1, 1)
+ return y
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ eps = ctx.eps
+
+ N, C, H, W = grad_output.size()
+ y, var, weight = ctx.saved_variables
+ g = grad_output * weight.view(1, C, 1, 1)
+ mean_g = g.mean(dim=1, keepdim=True)
+
+ mean_gy = (g * y).mean(dim=1, keepdim=True)
+ gx = 1. / torch.sqrt(var + eps) * (g - y * mean_gy - mean_g)
+ return gx, (grad_output * y).sum(dim=3).sum(dim=2).sum(dim=0), grad_output.sum(dim=3).sum(dim=2).sum(
+ dim=0), None
+
+class LayerNorm2d(nn.Module):
+
+ def __init__(self, channels, eps=1e-6):
+ super(LayerNorm2d, self).__init__()
+ self.register_parameter('weight', nn.Parameter(torch.ones(channels)))
+ self.register_parameter('bias', nn.Parameter(torch.zeros(channels)))
+ self.eps = eps
+
+ def forward(self, x):
+ return LayerNormFunction.apply(x, self.weight, self.bias, self.eps)
+
+class CrossChannelAttention(nn.Module):
+ def __init__(self, dim, heads=8):
+ super().__init__()
+
+ self.temperature = nn.Parameter(torch.ones(heads, 1, 1))
+
+ self.heads = heads
+
+ self.to_q = nn.Conv2d(dim, dim * 2, kernel_size=1, bias=True)
+ self.to_q_dw = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim * 2, bias=True)
+
+ self.to_k = nn.Conv2d(dim, dim * 2, kernel_size=1, bias=True)
+ self.to_k_dw = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim * 2, bias=True)
+
+ self.to_v = nn.Conv2d(dim, dim * 2, kernel_size=1, bias=True)
+ self.to_v_dw = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim * 2, bias=True)
+
+ self.to_out = nn.Sequential(
+ nn.Conv2d(dim*2, dim,1,1,0),
+ )
+
+ def forward(self, encoder, decoder):
+ # h = self.heads
+ b, c, h, w = encoder.shape
+
+ q = self.to_q_dw(self.to_q(encoder))
+
+ k = self.to_k_dw(self.to_k(decoder))
+ v = self.to_v_dw(self.to_v(decoder))
+
+ q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.heads)
+ k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.heads)
+ v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.heads)
+
+ q = torch.nn.functional.normalize(q, dim=-1)
+ k = torch.nn.functional.normalize(k, dim=-1)
+
+ attn = (q @ k.transpose(-2, -1)) * self.temperature
+ attn = attn.softmax(dim=-1)
+
+ out = (attn @ v)
+
+ out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.heads, h=h, w=w)
+
+ return self.to_out(out)
+
+def normalize(in_channels):
+ return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
+
+@torch.jit.script
+def swish(x):
+ return x * torch.sigmoid(x)
+
+class ResBlock(nn.Module):
+ def __init__(self, in_channels, out_channels=None):
+ super(ResBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = in_channels if out_channels is None else out_channels
+ self.norm1 = normalize(in_channels)
+ self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.norm2 = normalize(out_channels)
+ self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+ if self.in_channels != self.out_channels:
+ self.conv_out = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x_in):
+ x = x_in
+ x = self.norm1(x)
+
+ x = swish(x)
+ # x = x * torch.sigmoid(x)
+
+ x = self.conv1(x)
+ x = self.norm2(x)
+
+ x = swish(x)
+ # x = x * torch.sigmoid(x)
+
+ x = self.conv2(x)
+ if self.in_channels != self.out_channels:
+ x_in = self.conv_out(x_in)
+
+ return x + x_in
+
+class Fuse(nn.Module):
+ def __init__(self, dine_feat, out_feat):
+ # need to key same channel and HW for enc / dnc
+ super(Fuse, self).__init__()
+
+ self.encode_enc = nn.Conv2d(dine_feat, out_feat, kernel_size=3, stride=1, padding=1)
+
+ self.dim = out_feat
+ self.norm1 = LayerNorm2d(self.dim)
+ self.norm2 = LayerNorm2d(self.dim)
+
+ self.dine_feat = dine_feat
+ self.out_feat = out_feat
+ self.crossattn = CrossChannelAttention(dim=out_feat)
+
+ self.norm3 = LayerNorm2d(self.dim)
+ self.relu3 = nn.ReLU(inplace=True)
+
+ def forward(self, enc, dnc):
+ enc = self.encode_enc(enc)
+
+ res = enc
+ enc = self.norm1(enc)
+ dnc = self.norm2(dnc)
+ output = self.crossattn(enc, dnc) + res
+
+ output = self.norm3(output)
+ output = self.relu3(output)
+
+ return output
\ No newline at end of file
diff --git a/ref/blackswan/00000.png b/ref/blackswan/00000.png
new file mode 100644
index 0000000000000000000000000000000000000000..3daeddee9b13c2d98cae65bcd584e67a7a5aa4ad
Binary files /dev/null and b/ref/blackswan/00000.png differ
diff --git a/saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth b/saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth
new file mode 100644
index 0000000000000000000000000000000000000000..265a8b64426936a298bc12e216aaed3a0393c101
--- /dev/null
+++ b/saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:eaf6301d1a088c0d7133008079a83b5fac1fc0f791061b2cf1b657602013457a
+size 494884817
diff --git a/scripts/__init__.py b/scripts/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/scripts/download_bl30k.py b/scripts/download_bl30k.py
new file mode 100644
index 0000000000000000000000000000000000000000..501a7e2ffa4b7913df7fe8f3c865d17e5b1fa371
--- /dev/null
+++ b/scripts/download_bl30k.py
@@ -0,0 +1,50 @@
+import os
+import gdown
+import tarfile
+
+
+LICENSE = """
+This dataset is a derivative of ShapeNet.
+Please read and respect their licenses and terms before use.
+Textures and skybox image are obtained from Google image search with the "non-commercial reuse" flag.
+Do not use this dataset for commercial purposes.
+You should cite both ShapeNet and our paper if you use this dataset.
+"""
+
+print(LICENSE)
+print('Datasets will be downloaded and extracted to ../BL30K')
+print('The script will download and extract the segment one by one')
+print('You are going to need ~1TB of free disk space')
+reply = input('[y] to confirm, others to exit: ')
+if reply != 'y':
+ exit()
+
+links = [
+ 'https://drive.google.com/uc?id=1z9V5zxLOJLNt1Uj7RFqaP2FZWKzyXvVc',
+ 'https://drive.google.com/uc?id=11-IzgNwEAPxgagb67FSrBdzZR7OKAEdJ',
+ 'https://drive.google.com/uc?id=1ZfIv6GTo-OGpXpoKen1fUvDQ0A_WoQ-Q',
+ 'https://drive.google.com/uc?id=1G4eXgYS2kL7_Cc0x3N1g1x7Zl8D_aU_-',
+ 'https://drive.google.com/uc?id=1Y8q0V_oBwJIY27W_6-8CD1dRqV2gNTdE',
+ 'https://drive.google.com/uc?id=1nawBAazf_unMv46qGBHhWcQ4JXZ5883r',
+]
+
+names = [
+ 'BL30K_a.tar',
+ 'BL30K_b.tar',
+ 'BL30K_c.tar',
+ 'BL30K_d.tar',
+ 'BL30K_e.tar',
+ 'BL30K_f.tar',
+]
+
+for i, link in enumerate(links):
+ print('Downloading segment %d/%d ...' % (i, len(links)))
+ gdown.download(link, output='../%s' % names[i], quiet=False)
+ print('Extracting...')
+ with tarfile.open('../%s' % names[i], 'r') as tar_file:
+ tar_file.extractall('../%s' % names[i])
+ print('Cleaning up...')
+ os.remove('../%s' % names[i])
+
+
+print('Done.')
\ No newline at end of file
diff --git a/scripts/download_datasets.py b/scripts/download_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..7537aead493306d869fc7f0605cfaef994c68673
--- /dev/null
+++ b/scripts/download_datasets.py
@@ -0,0 +1,149 @@
+import os
+import gdown
+import zipfile
+from scripts import resize_youtube
+
+
+LICENSE = """
+These are either re-distribution of the original datasets or derivatives (through simple processing) of the original datasets.
+Please read and respect their licenses and terms before use.
+You should cite the original papers if you use any of the datasets.
+
+For BL30K, see download_bl30k.py
+
+Links:
+DUTS: http://saliencydetection.net/duts
+HRSOD: https://github.com/yi94code/HRSOD
+FSS: https://github.com/HKUSTCV/FSS-1000
+ECSSD: https://www.cse.cuhk.edu.hk/leojia/projects/hsaliency/dataset.html
+BIG: https://github.com/hkchengrex/CascadePSP
+
+YouTubeVOS: https://youtube-vos.org
+DAVIS: https://davischallenge.org/
+BL30K: https://github.com/hkchengrex/MiVOS
+Long-Time Video: https://github.com/xmlyqing00/AFB-URR
+"""
+
+print(LICENSE)
+print('Datasets will be downloaded and extracted to ../YouTube, ../YouTube2018, ../static, ../DAVIS, ../long_video_set')
+reply = input('[y] to confirm, others to exit: ')
+if reply != 'y':
+ exit()
+
+
+"""
+Static image data
+"""
+os.makedirs('../static', exist_ok=True)
+print('Downloading static datasets...')
+gdown.download('https://drive.google.com/uc?id=1wUJq3HcLdN-z1t4CsUhjeZ9BVDb9YKLd', output='../static/static_data.zip', quiet=False)
+print('Extracting static datasets...')
+with zipfile.ZipFile('../static/static_data.zip', 'r') as zip_file:
+ zip_file.extractall('../static/')
+print('Cleaning up static datasets...')
+os.remove('../static/static_data.zip')
+
+
+"""
+DAVIS dataset
+"""
+# Google drive mirror: https://drive.google.com/drive/folders/1hEczGHw7qcMScbCJukZsoOW4Q9byx16A?usp=sharing
+os.makedirs('../DAVIS/2017', exist_ok=True)
+
+print('Downloading DAVIS 2016...')
+gdown.download('https://drive.google.com/uc?id=198aRlh5CpAoFz0hfRgYbiNenn_K8DxWD', output='../DAVIS/DAVIS-data.zip', quiet=False)
+
+print('Downloading DAVIS 2017 trainval...')
+gdown.download('https://drive.google.com/uc?id=1kiaxrX_4GuW6NmiVuKGSGVoKGWjOdp6d', output='../DAVIS/2017/DAVIS-2017-trainval-480p.zip', quiet=False)
+
+print('Downloading DAVIS 2017 testdev...')
+gdown.download('https://drive.google.com/uc?id=1fmkxU2v9cQwyb62Tj1xFDdh2p4kDsUzD', output='../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', quiet=False)
+
+print('Downloading DAVIS 2017 scribbles...')
+gdown.download('https://drive.google.com/uc?id=1JzIQSu36h7dVM8q0VoE4oZJwBXvrZlkl', output='../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', quiet=False)
+
+print('Extracting DAVIS datasets...')
+with zipfile.ZipFile('../DAVIS/DAVIS-data.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/')
+os.rename('../DAVIS/DAVIS', '../DAVIS/2016')
+
+with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-trainval-480p.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/2017/')
+with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/2017/')
+os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/trainval')
+
+with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/2017/')
+os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/test-dev')
+
+print('Cleaning up DAVIS datasets...')
+os.remove('../DAVIS/2017/DAVIS-2017-trainval-480p.zip')
+os.remove('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip')
+os.remove('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip')
+os.remove('../DAVIS/DAVIS-data.zip')
+
+
+"""
+YouTubeVOS dataset
+"""
+os.makedirs('../YouTube', exist_ok=True)
+os.makedirs('../YouTube/all_frames', exist_ok=True)
+
+print('Downloading YouTubeVOS train...')
+gdown.download('https://drive.google.com/uc?id=13Eqw0gVK-AO5B-cqvJ203mZ2vzWck9s4', output='../YouTube/train.zip', quiet=False)
+print('Downloading YouTubeVOS val...')
+gdown.download('https://drive.google.com/uc?id=1o586Wjya-f2ohxYf9C1RlRH-gkrzGS8t', output='../YouTube/valid.zip', quiet=False)
+print('Downloading YouTubeVOS all frames valid...')
+gdown.download('https://drive.google.com/uc?id=1rWQzZcMskgpEQOZdJPJ7eTmLCBEIIpEN', output='../YouTube/all_frames/valid.zip', quiet=False)
+
+print('Extracting YouTube datasets...')
+with zipfile.ZipFile('../YouTube/train.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube/')
+with zipfile.ZipFile('../YouTube/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube/')
+with zipfile.ZipFile('../YouTube/all_frames/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube/all_frames')
+
+print('Cleaning up YouTubeVOS datasets...')
+os.remove('../YouTube/train.zip')
+os.remove('../YouTube/valid.zip')
+os.remove('../YouTube/all_frames/valid.zip')
+
+print('Resizing YouTubeVOS to 480p...')
+resize_youtube.resize_all('../YouTube/train', '../YouTube/train_480p')
+
+# YouTubeVOS 2018
+os.makedirs('../YouTube2018', exist_ok=True)
+os.makedirs('../YouTube2018/all_frames', exist_ok=True)
+
+print('Downloading YouTubeVOS2018 val...')
+gdown.download('https://drive.google.com/uc?id=1-QrceIl5sUNTKz7Iq0UsWC6NLZq7girr', output='../YouTube2018/valid.zip', quiet=False)
+print('Downloading YouTubeVOS2018 all frames valid...')
+gdown.download('https://drive.google.com/uc?id=1yVoHM6zgdcL348cFpolFcEl4IC1gorbV', output='../YouTube2018/all_frames/valid.zip', quiet=False)
+
+print('Extracting YouTube2018 datasets...')
+with zipfile.ZipFile('../YouTube2018/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube2018/')
+with zipfile.ZipFile('../YouTube2018/all_frames/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube2018/all_frames')
+
+print('Cleaning up YouTubeVOS2018 datasets...')
+os.remove('../YouTube2018/valid.zip')
+os.remove('../YouTube2018/all_frames/valid.zip')
+
+
+"""
+Long-Time Video dataset
+"""
+os.makedirs('../long_video_set', exist_ok=True)
+print('Downloading long video dataset...')
+gdown.download('https://drive.google.com/uc?id=100MxAuV0_UL20ca5c-5CNpqQ5QYPDSoz', output='../long_video_set/LongTimeVideo.zip', quiet=False)
+print('Extracting long video dataset...')
+with zipfile.ZipFile('../long_video_set/LongTimeVideo.zip', 'r') as zip_file:
+ zip_file.extractall('../long_video_set/')
+print('Cleaning up long video dataset...')
+os.remove('../long_video_set/LongTimeVideo.zip')
+
+
+print('Done.')
\ No newline at end of file
diff --git a/scripts/download_models.sh b/scripts/download_models.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ba669b54cec4ef7344326fc8b3e340501ca1bc90
--- /dev/null
+++ b/scripts/download_models.sh
@@ -0,0 +1,2 @@
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem-s012.pth
\ No newline at end of file
diff --git a/scripts/download_models_demo.sh b/scripts/download_models_demo.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a63f700c6d3daf5e97dad00dfcacb8e029bbce12
--- /dev/null
+++ b/scripts/download_models_demo.sh
@@ -0,0 +1,3 @@
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/fbrs.pth
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/s2m.pth
\ No newline at end of file
diff --git a/scripts/expand_long_vid.py b/scripts/expand_long_vid.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae237bc39d04f520b706769ac74139631cc88012
--- /dev/null
+++ b/scripts/expand_long_vid.py
@@ -0,0 +1,36 @@
+import sys
+import os
+from os import path
+from shutil import copy2
+
+input_path = sys.argv[1]
+output_path = sys.argv[2]
+multiplier = int(sys.argv[3])
+image_path = path.join(input_path, 'JPEGImages')
+gt_path = path.join(input_path, 'Annotations')
+
+videos = sorted(os.listdir(image_path))
+
+for vid in videos:
+ os.makedirs(path.join(output_path, 'JPEGImages', vid), exist_ok=True)
+ os.makedirs(path.join(output_path, 'Annotations', vid), exist_ok=True)
+ frames = sorted(os.listdir(path.join(image_path, vid)))
+
+ num_frames = len(frames)
+ counter = 0
+ output_counter = 0
+ direction = 1
+ for _ in range(multiplier):
+ for _ in range(num_frames):
+ copy2(path.join(image_path, vid, frames[counter]),
+ path.join(output_path, 'JPEGImages', vid, f'{output_counter:05d}.jpg'))
+
+ mask_path = path.join(gt_path, vid, frames[counter].replace('.jpg', '.png'))
+ if path.exists(mask_path):
+ copy2(mask_path,
+ path.join(output_path, 'Annotations', vid, f'{output_counter:05d}.png'))
+
+ counter += direction
+ output_counter += 1
+ if counter == 0 or counter == len(frames) - 1:
+ direction *= -1
diff --git a/scripts/resize_youtube.py b/scripts/resize_youtube.py
new file mode 100644
index 0000000000000000000000000000000000000000..501e9f54cde1a44ff11f2d7e640dd7f0748ce78e
--- /dev/null
+++ b/scripts/resize_youtube.py
@@ -0,0 +1,77 @@
+import sys
+import os
+from os import path
+
+from PIL import Image
+import numpy as np
+from progressbar import progressbar
+from multiprocessing import Pool
+
+new_min_size = 480
+
+def resize_vid_jpeg(inputs):
+ vid_name, folder_path, out_path = inputs
+
+ vid_path = path.join(folder_path, vid_name)
+ vid_out_path = path.join(out_path, 'JPEGImages', vid_name)
+ os.makedirs(vid_out_path, exist_ok=True)
+
+ for im_name in os.listdir(vid_path):
+ hr_im = Image.open(path.join(vid_path, im_name))
+ w, h = hr_im.size
+
+ ratio = new_min_size / min(w, h)
+
+ lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.BICUBIC)
+ lr_im.save(path.join(vid_out_path, im_name))
+
+def resize_vid_anno(inputs):
+ vid_name, folder_path, out_path = inputs
+
+ vid_path = path.join(folder_path, vid_name)
+ vid_out_path = path.join(out_path, 'Annotations', vid_name)
+ os.makedirs(vid_out_path, exist_ok=True)
+
+ for im_name in os.listdir(vid_path):
+ hr_im = Image.open(path.join(vid_path, im_name)).convert('P')
+ w, h = hr_im.size
+
+ ratio = new_min_size / min(w, h)
+
+ lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.NEAREST)
+ lr_im.save(path.join(vid_out_path, im_name))
+
+
+def resize_all(in_path, out_path):
+ for folder in os.listdir(in_path):
+
+ if folder not in ['JPEGImages', 'Annotations']:
+ continue
+ folder_path = path.join(in_path, folder)
+ videos = os.listdir(folder_path)
+
+ videos = [(v, folder_path, out_path) for v in videos]
+
+ if folder == 'JPEGImages':
+ print('Processing images')
+ os.makedirs(path.join(out_path, 'JPEGImages'), exist_ok=True)
+
+ pool = Pool(processes=8)
+ for _ in progressbar(pool.imap_unordered(resize_vid_jpeg, videos), max_value=len(videos)):
+ pass
+ else:
+ print('Processing annotations')
+ os.makedirs(path.join(out_path, 'Annotations'), exist_ok=True)
+
+ pool = Pool(processes=8)
+ for _ in progressbar(pool.imap_unordered(resize_vid_anno, videos), max_value=len(videos)):
+ pass
+
+
+if __name__ == '__main__':
+ in_path = sys.argv[1]
+ out_path = sys.argv[2]
+
+ resize_all(in_path, out_path)
+
+ print('Done.')
\ No newline at end of file
diff --git a/test.py b/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..adfad1999984c9292daa78fb99bd1e865afff348
--- /dev/null
+++ b/test.py
@@ -0,0 +1,230 @@
+import os
+from os import path
+from argparse import ArgumentParser
+import shutil
+
+import torch
+import torch.nn.functional as F
+from torch.utils.data import DataLoader
+import numpy as np
+from PIL import Image
+
+from inference.data.test_datasets import DAVISTestDataset_221128_TransColorization_batch
+from inference.data.mask_mapper import MaskMapper
+from model.network import ColorMNet
+from inference.inference_core import InferenceCore
+
+from progressbar import progressbar
+
+from dataset.range_transform import inv_im_trans, inv_lll2rgb_trans
+
+from skimage import color, io
+import cv2
+
+try:
+ import hickle as hkl
+except ImportError:
+ print('Failed to import hickle. Fine if not using multi-scale testing.')
+
+
+"""
+Arguments loading
+"""
+parser = ArgumentParser()
+parser.add_argument('--model', default='saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth')
+
+# dataset setting
+parser.add_argument('--d16_batch_path', default='input')
+parser.add_argument('--deoldify_path', default='ref')
+parser.add_argument('--output', default='result')
+
+# For generic (G) evaluation, point to a folder that contains "JPEGImages" and "Annotations"
+parser.add_argument('--generic_path')
+parser.add_argument('--dataset', help='D16/D17/Y18/Y19/LV1/LV3/G', default='D16_batch')
+parser.add_argument('--split', help='val/test', default='val')
+parser.add_argument('--save_all', action='store_true',
+ help='Save all frames. Useful only in YouTubeVOS/long-time video', )
+parser.add_argument('--benchmark', action='store_true', help='enable to disable amp for FPS benchmarking')
+
+# Long-term memory options
+parser.add_argument('--disable_long_term', action='store_true')
+parser.add_argument('--max_mid_term_frames', help='T_max in paper, decrease to save memory', type=int, default=10)
+parser.add_argument('--min_mid_term_frames', help='T_min in paper, decrease to save memory', type=int, default=5)
+parser.add_argument('--max_long_term_elements', help='LT_max in paper, increase if objects disappear for a long time',
+ type=int, default=10000)
+parser.add_argument('--num_prototypes', help='P in paper', type=int, default=128)
+
+parser.add_argument('--top_k', type=int, default=30)
+parser.add_argument('--mem_every', help='r in paper. Increase to improve running speed.', type=int, default=5)
+parser.add_argument('--deep_update_every', help='Leave -1 normally to synchronize with mem_every', type=int, default=-1)
+
+# Multi-scale options
+parser.add_argument('--save_scores', action='store_true')
+parser.add_argument('--flip', action='store_true')
+parser.add_argument('--size', default=-1, type=int,
+ help='Resize the shorter side to this size. -1 to use original resolution. ')
+
+args = parser.parse_args()
+config = vars(args)
+config['enable_long_term'] = not config['disable_long_term']
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def tensor_to_np_float(image):
+ image_np = image.numpy().astype('float32')
+ return image_np
+
+def lab2rgb_transform_PIL(mask):
+ mask_d = detach_to_cpu(mask)
+ mask_d = inv_lll2rgb_trans(mask_d)
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ return im.clip(0, 1)
+
+if args.output is None:
+ args.output = f'.output/{args.dataset}_{args.split}'
+ print(f'Output path not provided. Defaulting to {args.output}')
+
+"""
+Data preparation
+"""
+is_youtube = args.dataset.startswith('Y')
+is_davis = args.dataset.startswith('D')
+is_lv = args.dataset.startswith('LV')
+
+if is_youtube or args.save_scores:
+ out_path = path.join(args.output, 'Annotations')
+else:
+ out_path = args.output
+
+if args.split == 'val':
+ # Set up Dataset, a small hack to use the image set in the 2017 folder because the 2016 one is of a different format
+ meta_dataset = DAVISTestDataset_221128_TransColorization_batch(args.d16_batch_path, imset=args.deoldify_path, size=args.size)
+else:
+ raise NotImplementedError
+palette = None
+
+torch.autograd.set_grad_enabled(False)
+
+# Set up loader
+meta_loader = meta_dataset.get_datasets()
+
+# Load our checkpoint
+network = ColorMNet(config, args.model).cuda().eval()
+if args.model is not None:
+ model_weights = torch.load(args.model)
+ network.load_weights(model_weights, init_as_zero_if_needed=True)
+else:
+ print('No model loaded.')
+
+total_process_time = 0
+total_frames = 0
+
+# Start eval
+for vid_reader in progressbar(meta_loader, max_value=len(meta_dataset), redirect_stdout=True):
+
+ loader = DataLoader(vid_reader, batch_size=1, shuffle=False, num_workers=2)
+ vid_name = vid_reader.vid_name
+ vid_length = len(loader)
+ # no need to count usage for LT if the video is not that long anyway
+ config['enable_long_term_count_usage'] = (
+ config['enable_long_term'] and
+ (vid_length
+ / (config['max_mid_term_frames']-config['min_mid_term_frames'])
+ * config['num_prototypes'])
+ >= config['max_long_term_elements']
+ )
+
+ mapper = MaskMapper()
+ processor = InferenceCore(network, config=config)
+ first_mask_loaded = False
+
+ for ti, data in enumerate(loader):
+ with torch.cuda.amp.autocast(enabled=not args.benchmark):
+ rgb = data['rgb'].cuda()[0]
+ msk = data.get('mask')
+ info = data['info']
+ frame = info['frame'][0]
+ shape = info['shape']
+ need_resize = info['need_resize'][0]
+
+ """
+ For timing see https://discuss.pytorch.org/t/how-to-measure-time-in-pytorch/26964
+ Seems to be very similar in testing as my previous timing method
+ with two cuda sync + time.time() in STCN though
+ """
+ start = torch.cuda.Event(enable_timing=True)
+ end = torch.cuda.Event(enable_timing=True)
+ start.record()
+
+ if not first_mask_loaded:
+ if msk is not None:
+ first_mask_loaded = True
+ else:
+ # no point to do anything without a mask
+ continue
+
+ if args.flip:
+ rgb = torch.flip(rgb, dims=[-1])
+ msk = torch.flip(msk, dims=[-1]) if msk is not None else None
+
+ # Map possibly non-continuous labels to continuous ones
+ if msk is not None:
+ msk = torch.Tensor(msk[0]).cuda()
+ if need_resize:
+ msk = vid_reader.resize_mask(msk.unsqueeze(0))[0]
+ processor.set_all_labels(list(range(1,3)))
+ labels = range(1,3)
+ else:
+ labels = None
+
+ # Run the model on this frame
+ prob = processor.step(rgb, msk, labels, end=(ti==vid_length-1))
+
+ # Upsample to original size if needed
+ if need_resize:
+ prob = F.interpolate(prob.unsqueeze(1), shape, mode='bilinear', align_corners=False)[:,0]
+
+ end.record()
+ torch.cuda.synchronize()
+ total_process_time += (start.elapsed_time(end)/1000)
+ total_frames += 1
+
+ if args.flip:
+ prob = torch.flip(prob, dims=[-1])
+
+ if args.save_scores:
+ prob = (prob.detach().cpu().numpy()*255).astype(np.uint8)
+
+ # Save the mask
+ if args.save_all or info['save'][0]:
+ this_out_path = path.join(out_path, vid_name)
+ os.makedirs(this_out_path, exist_ok=True)
+
+ out_mask_final = lab2rgb_transform_PIL(torch.cat([rgb[:1,:,:], prob], dim=0))
+ out_mask_final = out_mask_final * 255
+ out_mask_final = out_mask_final.astype(np.uint8)
+
+ out_img = Image.fromarray(out_mask_final)
+ out_img.save(os.path.join(this_out_path, frame[:-4]+'.png'))
+
+print(f'Total processing time: {total_process_time}')
+print(f'Total processed frames: {total_frames}')
+print(f'FPS: {total_frames / total_process_time}')
+print(f'Max allocated memory (MB): {torch.cuda.max_memory_allocated() / (2**20)}')
+
+if not args.save_scores:
+ if is_youtube:
+ print('Making zip for YouTubeVOS...')
+ shutil.make_archive(path.join(args.output, path.basename(args.output)), 'zip', args.output, 'Annotations')
+ elif is_davis and args.split == 'test':
+ print('Making zip for DAVIS test-dev...')
+ shutil.make_archive(args.output, 'zip', args.output)
diff --git a/util/__init__.py b/util/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/util/configuration.py b/util/configuration.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7f7c8345d285100a84c9a72f84976454f0e4106
--- /dev/null
+++ b/util/configuration.py
@@ -0,0 +1,143 @@
+from argparse import ArgumentParser
+
+
+def none_or_default(x, default):
+ return x if x is not None else default
+
+class Configuration():
+ def parse(self, unknown_arg_ok=False):
+ parser = ArgumentParser()
+
+ # Enable torch.backends.cudnn.benchmark -- Faster in some cases, test in your own environment
+ parser.add_argument('--benchmark', action='store_true')
+ parser.add_argument('--no_amp', action='store_true')
+
+ # Data parameters
+ parser.add_argument('--static_root', help='Static training data root', default='../static')
+ parser.add_argument('--bl_root', help='Blender training data root', default='../BL30K')
+ parser.add_argument('--yv_root', help='YouTubeVOS data root', default='../YouTube')
+ parser.add_argument('--davis_root', help='DAVIS data root', default='/data2/yangyixin/data/DAVIS')
+ parser.add_argument('--num_workers', help='Total number of dataloader workers across all GPUs processes', type=int, default=16)
+
+ parser.add_argument('--key_dim', default=64, type=int)
+ parser.add_argument('--value_dim', default=512, type=int)
+ parser.add_argument('--hidden_dim', default=64, help='Set to =0 to disable', type=int)
+
+ parser.add_argument('--deep_update_prob', default=0.2, type=float)
+
+ parser.add_argument('--stages', help='Training stage (0-static images, 1-Blender dataset, 2-DAVIS+YouTubeVOS)', default='02')
+
+ parser.add_argument('--server', help='Training stage (0-pjs-04, 1-A6000Local)', default='0')
+ parser.add_argument('--savepath', help='Blender training data root', default='/data1/yangyixin/code/xmem')
+
+ """
+ Stage-specific learning parameters
+ Batch sizes are effective -- you don't have to scale them when you scale the number processes
+ """
+ # Stage 0, static images
+ parser.add_argument('--s0_batch_size', default=16, type=int)
+ parser.add_argument('--s0_iterations', default=150000, type=int)
+ parser.add_argument('--s0_finetune', default=0, type=int)
+ parser.add_argument('--s0_steps', nargs="*", default=[], type=int)
+ parser.add_argument('--s0_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s0_num_ref_frames', default=2, type=int)
+ parser.add_argument('--s0_num_frames', default=3, type=int)
+ parser.add_argument('--s0_start_warm', default=20000, type=int)
+ parser.add_argument('--s0_end_warm', default=70000, type=int)
+
+ # Stage 1, BL30K
+ parser.add_argument('--s1_batch_size', default=8, type=int)
+ parser.add_argument('--s1_iterations', default=250000, type=int)
+ # fine-tune means fewer augmentations to train the sensory memory
+ parser.add_argument('--s1_finetune', default=0, type=int)
+ parser.add_argument('--s1_steps', nargs="*", default=[200000], type=int)
+ parser.add_argument('--s1_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s1_num_ref_frames', default=3, type=int)
+ parser.add_argument('--s1_num_frames', default=8, type=int)
+ parser.add_argument('--s1_start_warm', default=20000, type=int)
+ parser.add_argument('--s1_end_warm', default=70000, type=int)
+
+ # Stage 2, DAVIS+YoutubeVOS, longer
+ parser.add_argument('--s2_batch_size', default=2, type=int)
+ parser.add_argument('--s2_iterations', default=150000, type=int)
+ # fine-tune means fewer augmentations to train the sensory memory
+ parser.add_argument('--s2_finetune', default=10000, type=int)
+ parser.add_argument('--s2_steps', nargs="*", default=[120000], type=int)
+
+ # parser.add_argument('--s2_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s2_lr', help='Initial learning rate', default=2e-5, type=float)
+
+ parser.add_argument('--s2_num_ref_frames', default=3, type=int)
+ parser.add_argument('--s2_num_frames', default=8, type=int)
+ parser.add_argument('--s2_start_warm', default=20000, type=int)
+ parser.add_argument('--s2_end_warm', default=70000, type=int)
+
+ # Stage 3, DAVIS+YoutubeVOS, shorter
+ parser.add_argument('--s3_batch_size', default=8, type=int)
+ parser.add_argument('--s3_iterations', default=100000, type=int)
+ # fine-tune means fewer augmentations to train the sensory memory
+ parser.add_argument('--s3_finetune', default=10000, type=int)
+ parser.add_argument('--s3_steps', nargs="*", default=[80000], type=int)
+ parser.add_argument('--s3_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s3_num_ref_frames', default=3, type=int)
+ parser.add_argument('--s3_num_frames', default=8, type=int)
+ parser.add_argument('--s3_start_warm', default=20000, type=int)
+ parser.add_argument('--s3_end_warm', default=70000, type=int)
+
+ parser.add_argument('--gamma', help='LR := LR*gamma at every decay step', default=0.1, type=float)
+ parser.add_argument('--weight_decay', default=0.05, type=float)
+
+ # Loading
+ parser.add_argument('--load_network', help='Path to pretrained network weight only')
+ parser.add_argument('--load_checkpoint', help='Path to the checkpoint file, including network, optimizer and such')
+
+ # Logging information
+ parser.add_argument('--log_text_interval', default=100, type=int)
+
+ parser.add_argument('--log_image_interval', default=100, type=int)
+
+ parser.add_argument('--save_network_interval', default=2500, type=int)
+ parser.add_argument('--save_checkpoint_interval', default=999999999999999999999, type=int)
+ parser.add_argument('--exp_id', help='Experiment UNIQUE id, use NULL to disable logging to tensorboard', default='NULL')
+ parser.add_argument('--debug', help='Debug mode which logs information more often', action='store_true')
+
+ # # Multiprocessing parameters, not set by users
+ # parser.add_argument('--local_rank', default=0, type=int, help='Local rank of this process')
+
+ if unknown_arg_ok:
+ args, _ = parser.parse_known_args()
+ self.args = vars(args)
+ else:
+ self.args = vars(parser.parse_args())
+
+ self.args['amp'] = not self.args['no_amp']
+
+ # check if the stages are valid
+ stage_to_perform = list(self.args['stages'])
+ for s in stage_to_perform:
+ if s not in ['0', '1', '2', '3']:
+ raise NotImplementedError
+
+ def get_stage_parameters(self, stage):
+ parameters = {
+ 'batch_size': self.args['s%s_batch_size'%stage],
+ 'iterations': self.args['s%s_iterations'%stage],
+ 'finetune': self.args['s%s_finetune'%stage],
+ 'steps': self.args['s%s_steps'%stage],
+ 'lr': self.args['s%s_lr'%stage],
+ 'num_ref_frames': self.args['s%s_num_ref_frames'%stage],
+ 'num_frames': self.args['s%s_num_frames'%stage],
+ 'start_warm': self.args['s%s_start_warm'%stage],
+ 'end_warm': self.args['s%s_end_warm'%stage],
+ }
+
+ return parameters
+
+ def __getitem__(self, key):
+ return self.args[key]
+
+ def __setitem__(self, key, value):
+ self.args[key] = value
+
+ def __str__(self):
+ return str(self.args)
diff --git a/util/davis_subset.txt b/util/davis_subset.txt
new file mode 100644
index 0000000000000000000000000000000000000000..875c2409d2cc4cfc4491ebf7703cb432b26678d8
--- /dev/null
+++ b/util/davis_subset.txt
@@ -0,0 +1,60 @@
+bear
+bmx-bumps
+boat
+boxing-fisheye
+breakdance-flare
+bus
+car-turn
+cat-girl
+classic-car
+color-run
+crossing
+dance-jump
+dancing
+disc-jockey
+dog-agility
+dog-gooses
+dogs-scale
+drift-turn
+drone
+elephant
+flamingo
+hike
+hockey
+horsejump-low
+kid-football
+kite-walk
+koala
+lady-running
+lindy-hop
+longboard
+lucia
+mallard-fly
+mallard-water
+miami-surf
+motocross-bumps
+motorbike
+night-race
+paragliding
+planes-water
+rallye
+rhino
+rollerblade
+schoolgirls
+scooter-board
+scooter-gray
+sheep
+skate-park
+snowboard
+soccerball
+stroller
+stunt
+surf
+swing
+tennis
+tractor-sand
+train
+tuk-tuk
+upside-down
+varanus-cage
+walking
\ No newline at end of file
diff --git a/util/functional.py b/util/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b276eee81513b51baf2d5d9afd0a42366050dc2
--- /dev/null
+++ b/util/functional.py
@@ -0,0 +1,605 @@
+from __future__ import division
+
+import math
+import random
+
+import torch
+from PIL import Image, ImageEnhance, ImageOps
+
+try:
+ import accimage
+except ImportError:
+ accimage = None
+import collections
+import numbers
+import types
+import warnings
+
+import numpy as np
+
+
+def _is_pil_image(img):
+ if accimage is not None:
+ return isinstance(img, (Image.Image, accimage.Image))
+ else:
+ return isinstance(img, Image.Image)
+
+
+def _is_tensor_image(img):
+ return torch.is_tensor(img) and img.ndimension() == 3
+
+
+def _is_numpy_image(img):
+ return isinstance(img, np.ndarray) and (img.ndim in {2, 3})
+
+
+def to_tensor(pic):
+ """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
+
+ See ``ToTensor`` for more details.
+
+ Args:
+ pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
+
+ Returns:
+ Tensor: Converted image.
+ """
+ if not (_is_pil_image(pic) or _is_numpy_image(pic)):
+ raise TypeError("pic should be PIL Image or ndarray. Got {}".format(type(pic)))
+
+ if isinstance(pic, np.ndarray):
+ # handle numpy array
+ img = torch.from_numpy(pic.transpose((2, 0, 1)))
+ # backward compatibility
+ return img.float().div(255)
+
+ if accimage is not None and isinstance(pic, accimage.Image):
+ nppic = np.zeros([pic.channels, pic.height, pic.width], dtype=np.float32)
+ pic.copyto(nppic)
+ return torch.from_numpy(nppic)
+
+ # handle PIL Image
+ if pic.mode == "I":
+ img = torch.from_numpy(np.array(pic, np.int32, copy=False))
+ elif pic.mode == "I;16":
+ img = torch.from_numpy(np.array(pic, np.int16, copy=False))
+ else:
+ img = torch.ByteTensor(torch.ByteStorage.from_buffer(pic.tobytes()))
+ # PIL image mode: 1, L, P, I, F, RGB, YCbCr, RGBA, CMYK
+ if pic.mode == "YCbCr":
+ nchannel = 3
+ elif pic.mode == "I;16":
+ nchannel = 1
+ else:
+ nchannel = len(pic.mode)
+ img = img.view(pic.size[1], pic.size[0], nchannel)
+ # put it from HWC to CHW format
+ # yikes, this transpose takes 80% of the loading time/CPU
+ img = img.transpose(0, 1).transpose(0, 2).contiguous()
+ if isinstance(img, torch.ByteTensor):
+ return img.float().div(255)
+ else:
+ return img
+
+
+def to_mytensor(pic):
+ """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
+
+ See ``ToTensor`` for more details.
+
+ Args:
+ pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
+
+ Returns:
+ Tensor: Converted image.
+ """
+ pic_arr = np.array(pic)
+ if pic_arr.ndim == 2:
+ pic_arr = pic_arr[..., np.newaxis]
+ img = torch.from_numpy(pic_arr.transpose((2, 0, 1)))
+ if not isinstance(img, torch.FloatTensor):
+ return img.float() # no normalize .div(255)
+ else:
+ return img
+
+
+def to_pil_image(pic, mode=None):
+ """Convert a tensor or an ndarray to PIL Image.
+
+ See :class:`~torchvision.transforms.ToPIlImage` for more details.
+
+ Args:
+ pic (Tensor or numpy.ndarray): Image to be converted to PIL Image.
+ mode (`PIL.Image mode`_): color space and pixel depth of input data (optional).
+
+ .. _PIL.Image mode: http://pillow.readthedocs.io/en/3.4.x/handbook/concepts.html#modes
+
+ Returns:
+ PIL Image: Image converted to PIL Image.
+ """
+ if not (_is_numpy_image(pic) or _is_tensor_image(pic)):
+ raise TypeError("pic should be Tensor or ndarray. Got {}.".format(type(pic)))
+
+ npimg = pic
+ if isinstance(pic, torch.FloatTensor):
+ pic = pic.mul(255).byte()
+ if torch.is_tensor(pic):
+ npimg = np.transpose(pic.numpy(), (1, 2, 0))
+
+ if not isinstance(npimg, np.ndarray):
+ raise TypeError("Input pic must be a torch.Tensor or NumPy ndarray, " + "not {}".format(type(npimg)))
+
+ if npimg.shape[2] == 1:
+ expected_mode = None
+ npimg = npimg[:, :, 0]
+ if npimg.dtype == np.uint8:
+ expected_mode = "L"
+ if npimg.dtype == np.int16:
+ expected_mode = "I;16"
+ if npimg.dtype == np.int32:
+ expected_mode = "I"
+ elif npimg.dtype == np.float32:
+ expected_mode = "F"
+ if mode is not None and mode != expected_mode:
+ raise ValueError(
+ "Incorrect mode ({}) supplied for input type {}. Should be {}".format(mode, np.dtype, expected_mode)
+ )
+ mode = expected_mode
+
+ elif npimg.shape[2] == 4:
+ permitted_4_channel_modes = ["RGBA", "CMYK"]
+ if mode is not None and mode not in permitted_4_channel_modes:
+ raise ValueError("Only modes {} are supported for 4D inputs".format(permitted_4_channel_modes))
+
+ if mode is None and npimg.dtype == np.uint8:
+ mode = "RGBA"
+ else:
+ permitted_3_channel_modes = ["RGB", "YCbCr", "HSV"]
+ if mode is not None and mode not in permitted_3_channel_modes:
+ raise ValueError("Only modes {} are supported for 3D inputs".format(permitted_3_channel_modes))
+ if mode is None and npimg.dtype == np.uint8:
+ mode = "RGB"
+
+ if mode is None:
+ raise TypeError("Input type {} is not supported".format(npimg.dtype))
+
+ return Image.fromarray(npimg, mode=mode)
+
+
+def normalize(tensor, mean, std):
+ """Normalize a tensor image with mean and standard deviation.
+
+ See ``Normalize`` for more details.
+
+ Args:
+ tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
+ mean (sequence): Sequence of means for each channel.
+ std (sequence): Sequence of standard deviations for each channely.
+
+ Returns:
+ Tensor: Normalized Tensor image.
+ """
+ if not _is_tensor_image(tensor):
+ raise TypeError("tensor is not a torch image.")
+ # TODO: make efficient
+ if tensor.size(0) == 1:
+ tensor.sub_(mean).div_(std)
+ else:
+ for t, m, s in zip(tensor, mean, std):
+ t.sub_(m).div_(s)
+ return tensor
+
+
+def resize(img, size, interpolation=Image.BILINEAR):
+ """Resize the input PIL Image to the given size.
+
+ Args:
+ img (PIL Image): Image to be resized.
+ size (sequence or int): Desired output size. If size is a sequence like
+ (h, w), the output size will be matched to this. If size is an int,
+ the smaller edge of the image will be matched to this number maintaing
+ the aspect ratio. i.e, if height > width, then image will be rescaled to
+ (size * height / width, size)
+ interpolation (int, optional): Desired interpolation. Default is
+ ``PIL.Image.BILINEAR``
+
+ Returns:
+ PIL Image: Resized image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+ if not isinstance(size, int) and (not isinstance(size, collections.Iterable) or len(size) != 2):
+ raise TypeError("Got inappropriate size arg: {}".format(size))
+
+ if not isinstance(size, int):
+ return img.resize(size[::-1], interpolation)
+
+ w, h = img.size
+ if (w <= h and w == size) or (h <= w and h == size):
+ return img
+ if w < h:
+ ow = size
+ oh = int(round(size * h / w))
+ else:
+ oh = size
+ ow = int(round(size * w / h))
+ return img.resize((ow, oh), interpolation)
+
+
+def scale(*args, **kwargs):
+ warnings.warn("The use of the transforms.Scale transform is deprecated, " + "please use transforms.Resize instead.")
+ return resize(*args, **kwargs)
+
+
+def pad(img, padding, fill=0):
+ """Pad the given PIL Image on all sides with the given "pad" value.
+
+ Args:
+ img (PIL Image): Image to be padded.
+ padding (int or tuple): Padding on each border. If a single int is provided this
+ is used to pad all borders. If tuple of length 2 is provided this is the padding
+ on left/right and top/bottom respectively. If a tuple of length 4 is provided
+ this is the padding for the left, top, right and bottom borders
+ respectively.
+ fill: Pixel fill value. Default is 0. If a tuple of
+ length 3, it is used to fill R, G, B channels respectively.
+
+ Returns:
+ PIL Image: Padded image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ if not isinstance(padding, (numbers.Number, tuple)):
+ raise TypeError("Got inappropriate padding arg")
+ if not isinstance(fill, (numbers.Number, str, tuple)):
+ raise TypeError("Got inappropriate fill arg")
+
+ if isinstance(padding, collections.Sequence) and len(padding) not in [2, 4]:
+ raise ValueError(
+ "Padding must be an int or a 2, or 4 element tuple, not a " + "{} element tuple".format(len(padding))
+ )
+
+ return ImageOps.expand(img, border=padding, fill=fill)
+
+
+def crop(img, i, j, h, w):
+ """Crop the given PIL Image.
+
+ Args:
+ img (PIL Image): Image to be cropped.
+ i: Upper pixel coordinate.
+ j: Left pixel coordinate.
+ h: Height of the cropped image.
+ w: Width of the cropped image.
+
+ Returns:
+ PIL Image: Cropped image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.crop((j, i, j + w, i + h))
+
+
+def center_crop(img, output_size):
+ if isinstance(output_size, numbers.Number):
+ output_size = (int(output_size), int(output_size))
+ w, h = img.size
+ th, tw = output_size
+ i = int(round((h - th) / 2.0))
+ j = int(round((w - tw) / 2.0))
+ return crop(img, i, j, th, tw)
+
+
+def resized_crop(img, i, j, h, w, size, interpolation=Image.BILINEAR):
+ """Crop the given PIL Image and resize it to desired size.
+
+ Notably used in RandomResizedCrop.
+
+ Args:
+ img (PIL Image): Image to be cropped.
+ i: Upper pixel coordinate.
+ j: Left pixel coordinate.
+ h: Height of the cropped image.
+ w: Width of the cropped image.
+ size (sequence or int): Desired output size. Same semantics as ``scale``.
+ interpolation (int, optional): Desired interpolation. Default is
+ ``PIL.Image.BILINEAR``.
+ Returns:
+ PIL Image: Cropped image.
+ """
+ assert _is_pil_image(img), "img should be PIL Image"
+ img = crop(img, i, j, h, w)
+ img = resize(img, size, interpolation)
+ return img
+
+
+def hflip(img):
+ """Horizontally flip the given PIL Image.
+
+ Args:
+ img (PIL Image): Image to be flipped.
+
+ Returns:
+ PIL Image: Horizontall flipped image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.transpose(Image.FLIP_LEFT_RIGHT)
+
+
+def vflip(img):
+ """Vertically flip the given PIL Image.
+
+ Args:
+ img (PIL Image): Image to be flipped.
+
+ Returns:
+ PIL Image: Vertically flipped image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.transpose(Image.FLIP_TOP_BOTTOM)
+
+
+def five_crop(img, size):
+ """Crop the given PIL Image into four corners and the central crop.
+
+ .. Note::
+ This transform returns a tuple of images and there may be a
+ mismatch in the number of inputs and targets your ``Dataset`` returns.
+
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ Returns:
+ tuple: tuple (tl, tr, bl, br, center) corresponding top left,
+ top right, bottom left, bottom right and center crop.
+ """
+ if isinstance(size, numbers.Number):
+ size = (int(size), int(size))
+ else:
+ assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
+
+ w, h = img.size
+ crop_h, crop_w = size
+ if crop_w > w or crop_h > h:
+ raise ValueError("Requested crop size {} is bigger than input size {}".format(size, (h, w)))
+ tl = img.crop((0, 0, crop_w, crop_h))
+ tr = img.crop((w - crop_w, 0, w, crop_h))
+ bl = img.crop((0, h - crop_h, crop_w, h))
+ br = img.crop((w - crop_w, h - crop_h, w, h))
+ center = center_crop(img, (crop_h, crop_w))
+ return (tl, tr, bl, br, center)
+
+
+def ten_crop(img, size, vertical_flip=False):
+ """Crop the given PIL Image into four corners and the central crop plus the
+ flipped version of these (horizontal flipping is used by default).
+
+ .. Note::
+ This transform returns a tuple of images and there may be a
+ mismatch in the number of inputs and targets your ``Dataset`` returns.
+
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ vertical_flip (bool): Use vertical flipping instead of horizontal
+
+ Returns:
+ tuple: tuple (tl, tr, bl, br, center, tl_flip, tr_flip, bl_flip,
+ br_flip, center_flip) corresponding top left, top right,
+ bottom left, bottom right and center crop and same for the
+ flipped image.
+ """
+ if isinstance(size, numbers.Number):
+ size = (int(size), int(size))
+ else:
+ assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
+
+ first_five = five_crop(img, size)
+
+ if vertical_flip:
+ img = vflip(img)
+ else:
+ img = hflip(img)
+
+ second_five = five_crop(img, size)
+ return first_five + second_five
+
+
+def adjust_brightness(img, brightness_factor):
+ """Adjust brightness of an Image.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ brightness_factor (float): How much to adjust the brightness. Can be
+ any non negative number. 0 gives a black image, 1 gives the
+ original image while 2 increases the brightness by a factor of 2.
+
+ Returns:
+ PIL Image: Brightness adjusted image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ enhancer = ImageEnhance.Brightness(img)
+ img = enhancer.enhance(brightness_factor)
+ return img
+
+
+def adjust_contrast(img, contrast_factor):
+ """Adjust contrast of an Image.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ contrast_factor (float): How much to adjust the contrast. Can be any
+ non negative number. 0 gives a solid gray image, 1 gives the
+ original image while 2 increases the contrast by a factor of 2.
+
+ Returns:
+ PIL Image: Contrast adjusted image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ enhancer = ImageEnhance.Contrast(img)
+ img = enhancer.enhance(contrast_factor)
+ return img
+
+
+def adjust_saturation(img, saturation_factor):
+ """Adjust color saturation of an image.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ saturation_factor (float): How much to adjust the saturation. 0 will
+ give a black and white image, 1 will give the original image while
+ 2 will enhance the saturation by a factor of 2.
+
+ Returns:
+ PIL Image: Saturation adjusted image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ enhancer = ImageEnhance.Color(img)
+ img = enhancer.enhance(saturation_factor)
+ return img
+
+
+def adjust_hue(img, hue_factor):
+ """Adjust hue of an image.
+
+ The image hue is adjusted by converting the image to HSV and
+ cyclically shifting the intensities in the hue channel (H).
+ The image is then converted back to original image mode.
+
+ `hue_factor` is the amount of shift in H channel and must be in the
+ interval `[-0.5, 0.5]`.
+
+ See https://en.wikipedia.org/wiki/Hue for more details on Hue.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ hue_factor (float): How much to shift the hue channel. Should be in
+ [-0.5, 0.5]. 0.5 and -0.5 give complete reversal of hue channel in
+ HSV space in positive and negative direction respectively.
+ 0 means no shift. Therefore, both -0.5 and 0.5 will give an image
+ with complementary colors while 0 gives the original image.
+
+ Returns:
+ PIL Image: Hue adjusted image.
+ """
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError("hue_factor is not in [-0.5, 0.5].".format(hue_factor))
+
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ input_mode = img.mode
+ if input_mode in {"L", "1", "I", "F"}:
+ return img
+
+ h, s, v = img.convert("HSV").split()
+
+ np_h = np.array(h, dtype=np.uint8)
+ # uint8 addition take cares of rotation across boundaries
+ with np.errstate(over="ignore"):
+ np_h += np.uint8(hue_factor * 255)
+ h = Image.fromarray(np_h, "L")
+
+ img = Image.merge("HSV", (h, s, v)).convert(input_mode)
+ return img
+
+
+def adjust_gamma(img, gamma, gain=1):
+ """Perform gamma correction on an image.
+
+ Also known as Power Law Transform. Intensities in RGB mode are adjusted
+ based on the following equation:
+
+ I_out = 255 * gain * ((I_in / 255) ** gamma)
+
+ See https://en.wikipedia.org/wiki/Gamma_correction for more details.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ gamma (float): Non negative real number. gamma larger than 1 make the
+ shadows darker, while gamma smaller than 1 make dark regions
+ lighter.
+ gain (float): The constant multiplier.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ if gamma < 0:
+ raise ValueError("Gamma should be a non-negative real number")
+
+ input_mode = img.mode
+ img = img.convert("RGB")
+
+ np_img = np.array(img, dtype=np.float32)
+ np_img = 255 * gain * ((np_img / 255) ** gamma)
+ np_img = np.uint8(np.clip(np_img, 0, 255))
+
+ img = Image.fromarray(np_img, "RGB").convert(input_mode)
+ return img
+
+
+def rotate(img, angle, resample=False, expand=False, center=None):
+ """Rotate the image by angle and then (optionally) translate it by (n_columns, n_rows)
+
+
+ Args:
+ img (PIL Image): PIL Image to be rotated.
+ angle ({float, int}): In degrees degrees counter clockwise order.
+ resample ({PIL.Image.NEAREST, PIL.Image.BILINEAR, PIL.Image.BICUBIC}, optional):
+ An optional resampling filter.
+ See http://pillow.readthedocs.io/en/3.4.x/handbook/concepts.html#filters
+ If omitted, or if the image has mode "1" or "P", it is set to PIL.Image.NEAREST.
+ expand (bool, optional): Optional expansion flag.
+ If true, expands the output image to make it large enough to hold the entire rotated image.
+ If false or omitted, make the output image the same size as the input image.
+ Note that the expand flag assumes rotation around the center and no translation.
+ center (2-tuple, optional): Optional center of rotation.
+ Origin is the upper left corner.
+ Default is the center of the image.
+ """
+
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.rotate(angle, resample, expand, center)
+
+
+def to_grayscale(img, num_output_channels=1):
+ """Convert image to grayscale version of image.
+
+ Args:
+ img (PIL Image): Image to be converted to grayscale.
+
+ Returns:
+ PIL Image: Grayscale version of the image.
+ if num_output_channels == 1 : returned image is single channel
+ if num_output_channels == 3 : returned image is 3 channel with r == g == b
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ if num_output_channels == 1:
+ img = img.convert("L")
+ elif num_output_channels == 3:
+ img = img.convert("L")
+ np_img = np.array(img, dtype=np.uint8)
+ np_img = np.dstack([np_img, np_img, np_img])
+ img = Image.fromarray(np_img, "RGB")
+ else:
+ raise ValueError("num_output_channels should be either 1 or 3")
+
+ return img
diff --git a/util/image_saver.py b/util/image_saver.py
new file mode 100644
index 0000000000000000000000000000000000000000..619471921c328beac88734bed36c507ee4e4290b
--- /dev/null
+++ b/util/image_saver.py
@@ -0,0 +1,302 @@
+import cv2
+import numpy as np
+
+import torch
+from dataset.range_transform import inv_im_trans, inv_lll2rgb_trans
+from collections import defaultdict
+
+from PIL import Image
+from skimage import color, io
+
+import util.functional as F
+class Normalize(object):
+ def __init__(self):
+ pass
+
+ def __call__(self, inputs):
+ inputs[0:1, :, :] = F.normalize(inputs[0:1, :, :], 50, 1)
+ inputs[1:3, :, :] = F.normalize(inputs[1:3, :, :], (0, 0), (1, 1))
+ return inputs
+
+def tensor_to_numpy(image):
+ image_np = (image.numpy() * 255).astype('uint8')
+ return image_np
+
+def tensor_to_np_float(image):
+ image_np = image.numpy().astype('float32')
+ return image_np
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def transpose_np(x):
+ return np.transpose(x, [1,2,0])
+
+def tensor_to_gray_im(x):
+ x = detach_to_cpu(x)
+ x = tensor_to_numpy(x)
+ x = transpose_np(x)
+ return x
+
+def tensor_to_im(x):
+ x = detach_to_cpu(x)
+ x = inv_im_trans(x).clamp(0, 1)
+ x = tensor_to_numpy(x)
+ x = transpose_np(x)
+ return x
+
+# Predefined key <-> caption dict
+key_captions = {
+ 'im': 'Image',
+ 'gt': 'GT',
+}
+
+"""
+Return an image array with captions
+keys in dictionary will be used as caption if not provided
+values should contain lists of cv2 images
+"""
+def get_image_array(images, grid_shape, captions={}):
+ h, w = grid_shape
+ cate_counts = len(images)
+ rows_counts = len(next(iter(images.values())))
+
+ font = cv2.FONT_HERSHEY_SIMPLEX
+
+ output_image = np.zeros([w*cate_counts, h*(rows_counts+1), 3], dtype=np.uint8)
+ col_cnt = 0
+ for k, v in images.items():
+
+ # Default as key value itself
+ caption = captions.get(k, k)
+
+ # Handles new line character
+ dy = 40
+ for i, line in enumerate(caption.split('\n')):
+ cv2.putText(output_image, line, (10, col_cnt*w+100+i*dy),
+ font, 0.8, (255,255,255), 2, cv2.LINE_AA)
+
+ # Put images
+ for row_cnt, img in enumerate(v):
+ im_shape = img.shape
+ if len(im_shape) == 2:
+ img = img[..., np.newaxis]
+
+ img = (img * 255).astype('uint8')
+
+ output_image[(col_cnt+0)*w:(col_cnt+1)*w,
+ (row_cnt+1)*h:(row_cnt+2)*h, :] = img
+
+ col_cnt += 1
+
+ return output_image
+
+def base_transform(im, size):
+ im = tensor_to_np_float(im)
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ # Resize
+ if im.shape[1] != size:
+ im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
+
+ return im.clip(0, 1)
+
+def im_transform(im, size):
+ return base_transform(inv_im_trans(detach_to_cpu(im)), size=size)
+
+def mask_transform(mask, size):
+ return base_transform(detach_to_cpu(mask), size=size)
+
+def out_transform(mask, size):
+ return base_transform(detach_to_cpu(torch.sigmoid(mask)), size=size)
+
+def lll2rgb_transform(mask, size):
+ flag_test = False
+
+ mask_d = detach_to_cpu(mask)
+
+ mask_d[1:3,:,:] = 0
+
+ if flag_test: print('before inv', mask_d.size(), torch.min(mask_d), torch.max(mask_d))
+ mask_d = inv_lll2rgb_trans(mask_d)
+ if flag_test: print('after inv', mask_d.size(), torch.min(mask_d), torch.max(mask_d));assert 1==0
+
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ # Resize
+ if im.shape[1] != size:
+ im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
+
+ return im.clip(0, 1)
+
+def lab2rgb_transform(mask, size):
+ flag_test = False
+
+ mask_d = detach_to_cpu(mask)
+
+ if flag_test: print('before inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d))
+ mask_d = inv_lll2rgb_trans(mask_d)
+ if flag_test: print('after inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d));assert 1==0
+
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ # Resize
+ if im.shape[1] != size:
+ im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
+
+ return im.clip(0, 1)
+
+
+
+def pool_pairs_221128_TransColorization(images, size, num_objects):
+ req_images = defaultdict(list)
+
+ b, t = images['rgb'].shape[:2]
+
+ # limit the number of images saved
+ b = min(2, b)
+
+ # find max num objects
+
+ # max_num_objects = max(num_objects[:b])
+ max_num_objects = 1
+
+ GT_suffix = ''
+ for bi in range(b):
+ GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
+
+ # print(images['rgb'].size(), b, max_num_objects, images['info']['name'], GT_suffix)
+ # print(images['info']['name'][0][-25:-4])
+ # print(images['info']['name'][1][-25:-4])
+ # assert 1==0
+
+ for bi in range(b):
+ for ti in range(t):
+
+ req_images['RGB'].append(lll2rgb_transform(images['rgb'][bi,ti], size))
+
+ for oi in range(max_num_objects):
+ if ti == 0 or oi >= num_objects[bi]:
+
+ # req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # print(images['rgb'][bi,ti][:1,:,:].size(), images['first_frame_gt'][bi][0,:].size());assert 1==0
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['first_frame_gt'][bi][0,:]], dim=0), size))
+
+
+ else:
+ # req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['masks_%d'%ti][bi][:]], dim=0), size))
+
+ # req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
+ # print(images['cls_gt'][bi,ti,:,:].size());assert 1==0
+ req_images['GT_%d_%s'%(oi, GT_suffix)].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['cls_gt'][bi,ti,:,:]], dim=0), size))
+
+ # print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
+ # print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
+
+
+ return get_image_array(req_images, size, key_captions)
+
+
+def pool_pairs_221128_TransColorization_val(images, size, num_objects):
+ req_images = defaultdict(list)
+
+ b, t = images['rgb'].shape[:2]
+
+ # limit the number of images saved
+ b = min(2, b)
+
+ # find max num objects
+
+ # max_num_objects = max(num_objects[:b])
+ max_num_objects = 1
+
+ GT_suffix = ''
+ for bi in range(b):
+ GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
+
+ # print(images['rgb'].size(), b, max_num_objects, images['info']['name'], GT_suffix)
+ # print(images['info']['name'][0][-25:-4])
+ # print(images['info']['name'][1][-25:-4])
+ # assert 1==0
+
+ for bi in range(b):
+ for ti in range(t):
+
+ req_images['RGB'].append(lll2rgb_transform(images['rgb'][bi,ti], size))
+
+ for oi in range(max_num_objects):
+ if ti == 0 or oi >= num_objects[bi]:
+
+ # req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # print(images['rgb'][bi,ti][:1,:,:].size(), images['first_frame_gt'][bi][0,:].size());assert 1==0
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['first_frame_gt'][bi][0,:]], dim=0), size))
+
+
+ else:
+ # req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['masks_%d'%ti][bi][:]], dim=0), size))
+
+ # req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
+ # print(images['cls_gt'][bi,ti,:,:].size());assert 1==0
+ req_images['GT_%d_%s'%(oi, GT_suffix)].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['cls_gt'][bi,ti,:,:]], dim=0), size))
+
+ # print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
+ # print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
+
+
+ return get_image_array(req_images, size, key_captions)
+
+
+
+def pool_pairs(images, size, num_objects):
+ req_images = defaultdict(list)
+
+ b, t = images['rgb'].shape[:2]
+
+ # limit the number of images saved
+ b = min(2, b)
+
+ # find max num objects
+ max_num_objects = max(num_objects[:b])
+
+ GT_suffix = ''
+ for bi in range(b):
+ GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
+
+ for bi in range(b):
+ for ti in range(t):
+ req_images['RGB'].append(im_transform(images['rgb'][bi,ti], size))
+ for oi in range(max_num_objects):
+ if ti == 0 or oi >= num_objects[bi]:
+ req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # req_images['Mask_X8_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # req_images['Mask_X16_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ else:
+ req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
+ # req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][2], size))
+ # req_images['Mask_X8_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][1], size))
+ # req_images['Mask_X16_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][0], size))
+ req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
+ # print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
+ # print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
+
+
+ return get_image_array(req_images, size, key_captions)
\ No newline at end of file
diff --git a/util/load_subset.py b/util/load_subset.py
new file mode 100644
index 0000000000000000000000000000000000000000..3191f4fef05cec04a11eafdfa42b34b98a35549e
--- /dev/null
+++ b/util/load_subset.py
@@ -0,0 +1,16 @@
+"""
+load_subset.py - Presents a subset of data
+DAVIS - only the training set
+YouTubeVOS - I manually filtered some erroneous ones out but I haven't checked all
+"""
+
+
+def load_sub_davis(path='util/davis_subset.txt'):
+ with open(path, mode='r') as f:
+ subset = set(f.read().splitlines())
+ return subset
+
+def load_sub_yv(path='util/yv_subset.txt'):
+ with open(path, mode='r') as f:
+ subset = set(f.read().splitlines())
+ return subset
diff --git a/util/log_integrator.py b/util/log_integrator.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4b26d53de98b16e145090bcddf2041a3f2d1394
--- /dev/null
+++ b/util/log_integrator.py
@@ -0,0 +1,80 @@
+"""
+Integrate numerical values for some iterations
+Typically used for loss computation / logging to tensorboard
+Call finalize and create a new Integrator when you want to display/log
+"""
+
+import torch
+
+
+class Integrator:
+ def __init__(self, logger, distributed=True, local_rank=0, world_size=1):
+ self.values = {}
+ self.counts = {}
+ self.hooks = [] # List is used here to maintain insertion order
+
+ self.logger = logger
+
+ self.distributed = distributed
+ self.local_rank = local_rank
+ self.world_size = world_size
+
+ def add_tensor(self, key, tensor):
+ if key not in self.values:
+ self.counts[key] = 1
+ if type(tensor) == float or type(tensor) == int:
+ self.values[key] = tensor
+ else:
+ self.values[key] = tensor.mean().item()
+ else:
+ self.counts[key] += 1
+ if type(tensor) == float or type(tensor) == int:
+ self.values[key] += tensor
+ else:
+ self.values[key] += tensor.mean().item()
+
+ def add_dict(self, tensor_dict):
+ for k, v in tensor_dict.items():
+ self.add_tensor(k, v)
+
+ def add_hook(self, hook):
+ """
+ Adds a custom hook, i.e. compute new metrics using values in the dict
+ The hook takes the dict as argument, and returns a (k, v) tuple
+ e.g. for computing IoU
+ """
+ if type(hook) == list:
+ self.hooks.extend(hook)
+ else:
+ self.hooks.append(hook)
+
+ def reset_except_hooks(self):
+ self.values = {}
+ self.counts = {}
+
+ # Average and output the metrics
+ def finalize(self, prefix, it, f=None):
+
+ for hook in self.hooks:
+ k, v = hook(self.values)
+ self.add_tensor(k, v)
+
+ for k, v in self.values.items():
+
+ if k[:4] == 'hide':
+ continue
+
+ avg = v / self.counts[k]
+
+ if self.distributed:
+ # Inplace operation
+ avg = torch.tensor(avg).cuda()
+ torch.distributed.reduce(avg, dst=0)
+
+ if self.local_rank == 0:
+ avg = (avg/self.world_size).cpu().item()
+ self.logger.log_metrics(prefix, k, avg, it, f)
+ else:
+ # Simple does it
+ self.logger.log_metrics(prefix, k, avg, it, f)
+
diff --git a/util/logger.py b/util/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..7dd9fb29bb3f5b0e9ba9e2ee425f420e743d10e7
--- /dev/null
+++ b/util/logger.py
@@ -0,0 +1,101 @@
+"""
+Dumps things to tensorboard and console
+"""
+
+import os
+import warnings
+
+import torchvision.transforms as transforms
+from torch.utils.tensorboard import SummaryWriter
+
+
+def tensor_to_numpy(image):
+ image_np = (image.numpy() * 255).astype('uint8')
+ return image_np
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def fix_width_trunc(x):
+ return ('{:.9s}'.format('{:0.9f}'.format(x)))
+
+class TensorboardLogger:
+ def __init__(self, short_id, id, git_info, flag_occupy_memory, savepath='.'):
+ self.short_id = short_id
+ if self.short_id == 'NULL':
+ self.short_id = 'DEBUG'
+
+ if id is None:
+ self.no_log = True
+ warnings.warn('Logging has been disbaled.')
+ else:
+ self.no_log = False
+
+ self.inv_im_trans = transforms.Normalize(
+ mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
+ std=[1/0.229, 1/0.224, 1/0.225])
+
+ self.inv_seg_trans = transforms.Normalize(
+ mean=[-0.5/0.5],
+ std=[1/0.5])
+
+ log_path = os.path.join('.', 'tmp_occupy_memory_saves', '%s' % id) if flag_occupy_memory else os.path.join(savepath, 'saves', '%s' % id)
+ self.logger = SummaryWriter(log_path)
+
+ self.log_string('git', git_info)
+
+ def log_scalar(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ self.logger.add_scalar(tag, x, step)
+
+ def log_metrics(self, l1_tag, l2_tag, val, step, f=None):
+ tag = l1_tag + '/' + l2_tag
+ text = '{:s} - It {:6d} [{:5s}] [{:13}]: {:s}'.format(self.short_id, step, l1_tag.upper(), l2_tag, fix_width_trunc(val))
+ print(text)
+ if f is not None:
+ f.write(text + '\n')
+ f.flush()
+ self.log_scalar(tag, val, step)
+
+ def log_im(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = detach_to_cpu(x)
+ x = self.inv_im_trans(x)
+ x = tensor_to_numpy(x)
+ self.logger.add_image(tag, x, step)
+
+ def log_cv2(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = x.transpose((2, 0, 1))
+ self.logger.add_image(tag, x, step)
+
+ def log_seg(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = detach_to_cpu(x)
+ x = self.inv_seg_trans(x)
+ x = tensor_to_numpy(x)
+ self.logger.add_image(tag, x, step)
+
+ def log_gray(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = detach_to_cpu(x)
+ x = tensor_to_numpy(x)
+ self.logger.add_image(tag, x, step)
+
+ def log_string(self, tag, x):
+ print(tag, x)
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ self.logger.add_text(tag, x)
+
\ No newline at end of file
diff --git a/util/palette.py b/util/palette.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2541659563056b015b3d6e4c2b0accef3b4e831
--- /dev/null
+++ b/util/palette.py
@@ -0,0 +1,3 @@
+davis_palette = b'\x00\x00\x00\x80\x00\x00\x00\x80\x00\x80\x80\x00\x00\x00\x80\x80\x00\x80\x00\x80\x80\x80\x80\x80@\x00\x00\xc0\x00\x00@\x80\x00\xc0\x80\x00@\x00\x80\xc0\x00\x80@\x80\x80\xc0\x80\x80\x00@\x00\x80@\x00\x00\xc0\x00\x80\xc0\x00\x00@\x80\x80@\x80\x00\xc0\x80\x80\xc0\x80@@\x00\xc0@\x00@\xc0\x00\xc0\xc0\x00@@\x80\xc0@\x80@\xc0\x80\xc0\xc0\x80\x00\x00@\x80\x00@\x00\x80@\x80\x80@\x00\x00\xc0\x80\x00\xc0\x00\x80\xc0\x80\x80\xc0@\x00@\xc0\x00@@\x80@\xc0\x80@@\x00\xc0\xc0\x00\xc0@\x80\xc0\xc0\x80\xc0\x00@@\x80@@\x00\xc0@\x80\xc0@\x00@\xc0\x80@\xc0\x00\xc0\xc0\x80\xc0\xc0@@@\xc0@@@\xc0@\xc0\xc0@@@\xc0\xc0@\xc0@\xc0\xc0\xc0\xc0\xc0 \x00\x00\xa0\x00\x00 \x80\x00\xa0\x80\x00 \x00\x80\xa0\x00\x80 \x80\x80\xa0\x80\x80`\x00\x00\xe0\x00\x00`\x80\x00\xe0\x80\x00`\x00\x80\xe0\x00\x80`\x80\x80\xe0\x80\x80 @\x00\xa0@\x00 \xc0\x00\xa0\xc0\x00 @\x80\xa0@\x80 \xc0\x80\xa0\xc0\x80`@\x00\xe0@\x00`\xc0\x00\xe0\xc0\x00`@\x80\xe0@\x80`\xc0\x80\xe0\xc0\x80 \x00@\xa0\x00@ \x80@\xa0\x80@ \x00\xc0\xa0\x00\xc0 \x80\xc0\xa0\x80\xc0`\x00@\xe0\x00@`\x80@\xe0\x80@`\x00\xc0\xe0\x00\xc0`\x80\xc0\xe0\x80\xc0 @@\xa0@@ \xc0@\xa0\xc0@ @\xc0\xa0@\xc0 \xc0\xc0\xa0\xc0\xc0`@@\xe0@@`\xc0@\xe0\xc0@`@\xc0\xe0@\xc0`\xc0\xc0\xe0\xc0\xc0\x00 \x00\x80 \x00\x00\xa0\x00\x80\xa0\x00\x00 \x80\x80 \x80\x00\xa0\x80\x80\xa0\x80@ \x00\xc0 \x00@\xa0\x00\xc0\xa0\x00@ \x80\xc0 \x80@\xa0\x80\xc0\xa0\x80\x00`\x00\x80`\x00\x00\xe0\x00\x80\xe0\x00\x00`\x80\x80`\x80\x00\xe0\x80\x80\xe0\x80@`\x00\xc0`\x00@\xe0\x00\xc0\xe0\x00@`\x80\xc0`\x80@\xe0\x80\xc0\xe0\x80\x00 @\x80 @\x00\xa0@\x80\xa0@\x00 \xc0\x80 \xc0\x00\xa0\xc0\x80\xa0\xc0@ @\xc0 @@\xa0@\xc0\xa0@@ \xc0\xc0 \xc0@\xa0\xc0\xc0\xa0\xc0\x00`@\x80`@\x00\xe0@\x80\xe0@\x00`\xc0\x80`\xc0\x00\xe0\xc0\x80\xe0\xc0@`@\xc0`@@\xe0@\xc0\xe0@@`\xc0\xc0`\xc0@\xe0\xc0\xc0\xe0\xc0 \x00\xa0 \x00 \xa0\x00\xa0\xa0\x00 \x80\xa0 \x80 \xa0\x80\xa0\xa0\x80` \x00\xe0 \x00`\xa0\x00\xe0\xa0\x00` \x80\xe0 \x80`\xa0\x80\xe0\xa0\x80 `\x00\xa0`\x00 \xe0\x00\xa0\xe0\x00 `\x80\xa0`\x80 \xe0\x80\xa0\xe0\x80``\x00\xe0`\x00`\xe0\x00\xe0\xe0\x00``\x80\xe0`\x80`\xe0\x80\xe0\xe0\x80 @\xa0 @ \xa0@\xa0\xa0@ \xc0\xa0 \xc0 \xa0\xc0\xa0\xa0\xc0` @\xe0 @`\xa0@\xe0\xa0@` \xc0\xe0 \xc0`\xa0\xc0\xe0\xa0\xc0 `@\xa0`@ \xe0@\xa0\xe0@ `\xc0\xa0`\xc0 \xe0\xc0\xa0\xe0\xc0``@\xe0`@`\xe0@\xe0\xe0@``\xc0\xe0`\xc0`\xe0\xc0\xe0\xe0\xc0'
+
+youtube_palette = b'\x00\x00\x00\xec_g\xf9\x91W\xfa\xc8c\x99\xc7\x94b\xb3\xb2f\x99\xcc\xc5\x94\xc5\xabyg\xff\xff\xffes~\x0b\x0b\x0b\x0c\x0c\x0c\r\r\r\x0e\x0e\x0e\x0f\x0f\x0f'
diff --git a/util/tensor_util.py b/util/tensor_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..05189d38e2b0b0d1d08bd7804b8e43418d6da637
--- /dev/null
+++ b/util/tensor_util.py
@@ -0,0 +1,47 @@
+import torch.nn.functional as F
+
+
+def compute_tensor_iu(seg, gt):
+ intersection = (seg & gt).float().sum()
+ union = (seg | gt).float().sum()
+
+ return intersection, union
+
+def compute_tensor_iou(seg, gt):
+ intersection, union = compute_tensor_iu(seg, gt)
+ iou = (intersection + 1e-6) / (union + 1e-6)
+
+ return iou
+
+# STM
+def pad_divide_by(in_img, d):
+ h, w = in_img.shape[-2:]
+
+ if h % d > 0:
+ new_h = h + d - h % d
+ else:
+ new_h = h
+ if w % d > 0:
+ new_w = w + d - w % d
+ else:
+ new_w = w
+ lh, uh = int((new_h-h) / 2), int(new_h-h) - int((new_h-h) / 2)
+ lw, uw = int((new_w-w) / 2), int(new_w-w) - int((new_w-w) / 2)
+ pad_array = (int(lw), int(uw), int(lh), int(uh))
+ out = F.pad(in_img, pad_array)
+ return out, pad_array
+
+def unpad(img, pad):
+ if len(img.shape) == 4:
+ if pad[2]+pad[3] > 0:
+ img = img[:,:,pad[2]:-pad[3],:]
+ if pad[0]+pad[1] > 0:
+ img = img[:,:,:,pad[0]:-pad[1]]
+ elif len(img.shape) == 3:
+ if pad[2]+pad[3] > 0:
+ img = img[:,pad[2]:-pad[3],:]
+ if pad[0]+pad[1] > 0:
+ img = img[:,:,pad[0]:-pad[1]]
+ else:
+ raise NotImplementedError
+ return img
\ No newline at end of file
diff --git a/util/transforms.py b/util/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..df7a54559a329a84aec339182d2aa07f3ee4fdb0
--- /dev/null
+++ b/util/transforms.py
@@ -0,0 +1,61 @@
+
+from dataset.range_transform import inv_im_trans, inv_lll2rgb_trans
+from skimage import color, io
+import cv2
+import numpy as np
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def tensor_to_np_float(image):
+ image_np = image.numpy().astype('float32')
+ return image_np
+
+def lab2rgb_transform_PIL(mask):
+ flag_test = False
+
+ mask_d = detach_to_cpu(mask)
+
+ if flag_test: print('before inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d))
+ mask_d = inv_lll2rgb_trans(mask_d)
+ if flag_test: print('after inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d));assert 1==0
+
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ return im.clip(0, 1)
+
+def calculate_psnr(img1, img2):
+ mse_value = ((img1 - img2)**2).mean()
+ if mse_value == 0:
+ result = float('inf')
+ else:
+ result = 20. * np.log10(255. / np.sqrt(mse_value))
+ return result
+
+def calculate_psnr_for_folder(gt_folder, result_folder):
+ result_clips = sorted(os.listdir(result_folder))
+
+ psnr_values = []
+ for clip in result_clips:
+ path_clip = os.path.join(result_folder, clip)
+ test_files = sorted(os.listdir(path_clip))
+
+ for img in test_files:
+ gt_path = os.path.join(gt_folder, clip, img)
+ result_path = os.path.join(path_clip, img)
+
+ gt_img = np.array(Image.open(gt_path))
+ result_img = np.array(Image.open(result_path))
+
+ psnr = calculate_psnr(gt_img, result_img)
+ psnr_values.append(psnr)
+
+ avg_psnr = np.mean(psnr_values)
+ return avg_psnr
\ No newline at end of file
diff --git a/util/yv_subset.txt b/util/yv_subset.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a26e50a7b8e6233bf17c542b540765cd8a1c5716
--- /dev/null
+++ b/util/yv_subset.txt
@@ -0,0 +1,3464 @@
+003234408d
+0043f083b5
+0044fa5fba
+005a527edd
+0065b171f9
+00917dcfc4
+00a23ccf53
+00ad5016a4
+01082ae388
+011ac0a06f
+013099c098
+0155498c85
+01694ad9c8
+017ac35701
+01b80e8e1a
+01baa5a4e1
+01c3111683
+01c4cb5ffe
+01c76f0a82
+01c783268c
+01ed275c6e
+01ff60d1fa
+020cd28cd2
+02264db755
+0248626d9a
+02668dbffa
+0274193026
+02d28375aa
+02f3a5c4df
+031ccc99b1
+0321b18c10
+0348a45bca
+0355e92655
+0358b938c1
+0368107cf1
+0379ddf557
+038b2cc71d
+038c15a5dd
+03a06cc98a
+03a63e187f
+03c95b4dae
+03e2b57b0e
+04194e1248
+0444918a5f
+04460a7a52
+04474174a4
+0450095513
+045f00aed2
+04667fabaa
+04735c5030
+04990d1915
+04d62d9d98
+04f21da964
+04fbad476e
+04fe256562
+0503bf89c9
+0536c9eed0
+054acb238f
+05579ca250
+056c200404
+05774f3a2c
+058a7592c8
+05a0a513df
+05a569d8aa
+05aa652648
+05d7715782
+05e0b0f28f
+05fdbbdd7a
+05ffcfed85
+0630391881
+06840b2bbe
+068f7dce6f
+0693719753
+06ce2b51fb
+06e224798e
+06ee361788
+06fbb3fa2c
+0700264286
+070c918ca7
+07129e14a4
+07177017e9
+07238ffc58
+07353b2a89
+0738493cbf
+075926c651
+075c701292
+0762ea9a30
+07652ee4af
+076f206928
+077d32af19
+079049275c
+07913cdda7
+07a11a35e8
+07ac33b6df
+07b6e8fda8
+07c62c3d11
+07cc1c7d74
+080196ef01
+081207976e
+081ae4fa44
+081d8250cb
+082900c5d4
+0860df21e2
+0866d4c5e3
+0891ac2eb6
+08931bc458
+08aa2705d5
+08c8450db7
+08d50b926c
+08e1e4de15
+08e48c1a48
+08f561c65e
+08feb87790
+09049f6fe3
+092e4ff450
+09338adea8
+093c335ccc
+0970d28339
+0974a213dc
+097b471ed8
+0990941758
+09a348f4fa
+09a6841288
+09c5bad17b
+09c9ce80c7
+09ff54fef4
+0a23765d15
+0a275e7f12
+0a2f2bd294
+0a7a2514aa
+0a7b27fde9
+0a8c467cc3
+0ac8c560ae
+0b1627e896
+0b285c47f6
+0b34ec1d55
+0b5b5e8e5a
+0b68535614
+0b6f9105fc
+0b7dbfa3cb
+0b9cea51ca
+0b9d012be8
+0bcfc4177d
+0bd37b23c1
+0bd864064c
+0c11c6bf7b
+0c26bc77ac
+0c3a04798c
+0c44a9d545
+0c817cc390
+0ca839ee9a
+0cd7ac0ac0
+0ce06e0121
+0cfe974a89
+0d2fcc0dcd
+0d3aad05d2
+0d40b015f4
+0d97fba242
+0d9cc80d7e
+0dab85b6d3
+0db5c427a5
+0dbaf284f1
+0de4923598
+0df28a9101
+0e04f636c4
+0e05f0e232
+0e0930474b
+0e27472bea
+0e30020549
+0e621feb6c
+0e803c7d73
+0e9ebe4e3c
+0e9f2785ec
+0ea68d418b
+0eb403a222
+0ee92053d6
+0eefca067f
+0f17fa6fcb
+0f1ac8e9a3
+0f202e9852
+0f2ab8b1ff
+0f51a78756
+0f5fbe16b0
+0f6072077b
+0f6b69b2f4
+0f6c2163de
+0f74ec5599
+0f9683715b
+0fa7b59356
+0fb173695b
+0fc958cde2
+0fe7b1a621
+0ffcdb491c
+101caff7d4
+1022fe8417
+1032e80b37
+103f501680
+104e64565f
+104f1ab997
+106242403f
+10b31f5431
+10eced835e
+110d26fa3a
+1122c1d16a
+1145b49a5f
+11485838c2
+114e7676ec
+1157472b95
+115ee1072c
+1171141012
+117757b4b8
+1178932d2f
+117cc76bda
+1180cbf814
+1187bbd0e3
+1197e44b26
+119cf20728
+119dd54871
+11a0c3b724
+11a6ba8c94
+11c722a456
+11cbcb0b4d
+11ccf5e99d
+11ce6f452e
+11e53de6f2
+11feabe596
+120cb9514d
+12156b25b3
+122896672d
+1232b2f1d4
+1233ac8596
+1239c87234
+1250423f7c
+1257a1bc67
+125d1b19dd
+126d203967
+1295e19071
+12ad198c54
+12bddb2bcb
+12ec9b93ee
+12eebedc35
+132852e094
+1329409f2a
+13325cfa14
+134d06dbf9
+135625b53d
+13870016f9
+13960b3c84
+13adaad9d9
+13ae097e20
+13e3070469
+13f6a8c20d
+1416925cf2
+142d2621f5
+145d5d7c03
+145fdc3ac5
+1471274fa7
+14a6b5a139
+14c21cea0d
+14dae0dc93
+14f9bd22b5
+14fd28ae99
+15097d5d4e
+150ea711f2
+1514e3563f
+152aaa3a9e
+152b7d3bd7
+15617297cc
+15abbe0c52
+15d1fb3de5
+15f67b0fab
+161eb59aad
+16288ea47f
+164410ce62
+165c3c8cd4
+165c42b41b
+165ec9e22b
+1669502269
+16763cccbb
+16adde065e
+16af445362
+16afd538ad
+16c3fa4d5d
+16d1d65c27
+16e8599e94
+16fe9fb444
+1705796b02
+1724db7671
+17418e81ea
+175169edbb
+17622326fd
+17656bae77
+17b0d94172
+17c220e4f6
+17c7bcd146
+17cb4afe89
+17cd79a434
+17d18604c3
+17d8ca1a37
+17e33f4330
+17f7a6d805
+180abc8378
+183ba3d652
+185bf64702
+18913cc690
+1892651815
+189ac8208a
+189b44e92c
+18ac264b76
+18b245ab49
+18b5cebc34
+18bad52083
+18bb5144d5
+18c6f205c5
+1903f9ea15
+1917b209f2
+191e74c01d
+19367bb94e
+193ffaa217
+19696b67d3
+197f3ab6f3
+1981e763cc
+198afe39ae
+19a6e62b9b
+19b60d5335
+19c00c11f9
+19e061eb88
+19e8bc6178
+19ee80dac6
+1a25a9170a
+1a359a6c1a
+1a3e87c566
+1a5fe06b00
+1a6c0fbd1e
+1a6f3b5a4b
+1a8afbad92
+1a8bdc5842
+1a95752aca
+1a9c131cb7
+1aa3da3ee3
+1ab27ec7ea
+1abf16d21d
+1acd0f993b
+1ad202e499
+1af8d2395d
+1afd39a1fa
+1b2d31306f
+1b3fa67f0e
+1b43fa74b4
+1b73ea9fc2
+1b7e8bb255
+1b8680f8cd
+1b883843c0
+1b8898785b
+1b88ba1aa4
+1b96a498e5
+1bbc4c274f
+1bd87fe9ab
+1c4090c75b
+1c41934f84
+1c72b04b56
+1c87955a3a
+1c9f9eb792
+1ca240fede
+1ca5673803
+1cada35274
+1cb44b920d
+1cd10e62be
+1d3087d5e5
+1d3685150a
+1d6ff083aa
+1d746352a6
+1da256d146
+1da4e956b1
+1daf812218
+1dba687bce
+1dce57d05d
+1de4a9e537
+1dec5446c8
+1dfbe6f586
+1e1a18c45a
+1e1e42529d
+1e4be70796
+1eb60959c8
+1ec8b2566b
+1ecdc2941c
+1ee0ac70ff
+1ef8e17def
+1f1a2a9fc0
+1f1beb8daa
+1f2609ee13
+1f3876f8d0
+1f4ec0563d
+1f64955634
+1f7d31b5b2
+1f8014b7fd
+1f9c7d10f1
+1fa350df76
+1fc9538993
+1fe2f0ec59
+2000c02f9d
+20142b2f05
+201a8d75e5
+2023b3ee4f
+202b767bbc
+203594a418
+2038987336
+2039c3aecb
+204a90d81f
+207bc6cf01
+208833d1d1
+20c6d8b362
+20e3e52e0a
+2117fa0c14
+211bc5d102
+2120d9c3c3
+2125235a49
+21386f5978
+2142af8795
+215dfc0f73
+217bae91e5
+217c0d44e4
+219057c87b
+21d0edbf81
+21df87ad76
+21f1d089f5
+21f4019116
+222597030f
+222904eb5b
+223a0e0657
+223bd973ab
+22472f7395
+224e7c833e
+225aba51d9
+2261d421ea
+2263a8782b
+2268cb1ffd
+2268e93b0a
+2293c99f3f
+22a1141970
+22b13084b2
+22d9f5ab0c
+22f02efe3a
+232c09b75b
+2350d71b4b
+2376440551
+2383d8aafd
+238b84e67f
+238d4b86f6
+238d947c6b
+23993ce90d
+23b0c8a9ab
+23b3beafcc
+23d80299fe
+23f404a9fc
+240118e58a
+2431dec2fd
+24440e0ac7
+2457274dbc
+2465bf515d
+246b142c4d
+247d729e36
+2481ceafeb
+24866b4e6a
+2489d78320
+24ab0b83e8
+24b0868d92
+24b5207cd9
+24ddf05c03
+250116161c
+256ad2e3fc
+256bd83d5e
+256dcc8ab8
+2589956baa
+258b3b33c6
+25ad437e29
+25ae395636
+25c750c6db
+25d2c3fe5d
+25dc80db7c
+25f97e926f
+26011bc28b
+260846ffbe
+260dd9ad33
+267964ee57
+2680861931
+268ac7d3fc
+26b895d91e
+26bc786d4f
+26ddd2ef12
+26de3d18ca
+26f7784762
+2703e52a6a
+270ed80c12
+2719b742ab
+272f4163d0
+27303333e1
+27659fa7d6
+279214115d
+27a5f92a9c
+27cf2af1f3
+27f0d5f8a2
+28075f33c1
+281629cb41
+282b0d51f5
+282fcab00b
+28449fa0dc
+28475208ca
+285580b7c4
+285b69e223
+288c117201
+28a8eb9623
+28bf9c3cf3
+28c6b8f86a
+28c972dacd
+28d9fa6016
+28e392de91
+28f4a45190
+298c844fc9
+29a0356a2b
+29d779f9e3
+29dde5f12b
+29de7b6579
+29e630bdd0
+29f2332d30
+2a18873352
+2a3824ff31
+2a559dd27f
+2a5c09acbd
+2a63eb1524
+2a6a30a4ea
+2a6d9099d1
+2a821394e3
+2a8c5b1342
+2abc8d66d2
+2ac9ef904a
+2b08f37364
+2b351bfd7d
+2b659a49d7
+2b69ee5c26
+2b6c30bbbd
+2b88561cf2
+2b8b14954e
+2ba621c750
+2bab50f9a7
+2bb00c2434
+2bbde474ef
+2bdd82fb86
+2be06fb855
+2bf545c2f5
+2bffe4cf9a
+2c04b887b7
+2c05209105
+2c0ad8cf39
+2c11fedca8
+2c1a94ebfb
+2c1e8c8e2f
+2c29fabcf1
+2c2c076c01
+2c3ea7ee7d
+2c41fa0648
+2c44bb6d1c
+2c54cfbb78
+2c5537eddf
+2c6e63b7de
+2cb10c6a7e
+2cbcd5ccd1
+2cc5d9c5f6
+2cd01cf915
+2cdbf5f0a7
+2ce660f123
+2cf114677e
+2d01eef98e
+2d03593bdc
+2d183ac8c4
+2d33ad3935
+2d3991d83e
+2d4333577b
+2d4d015c64
+2d8f5e5025
+2d900bdb8e
+2d9a1a1d49
+2db0576a5c
+2dc0838721
+2dcc417f82
+2df005b843
+2df356de14
+2e00393d96
+2e03b8127a
+2e0f886168
+2e2bf37e6d
+2e42410932
+2ea78f46e4
+2ebb017a26
+2ee2edba2a
+2efb07554a
+2f17e4fc1e
+2f2c65c2f3
+2f2d9b33be
+2f309c206b
+2f53822e88
+2f53998171
+2f5b0c89b1
+2f680909e6
+2f710f66bd
+2f724132b9
+2f7e3517ae
+2f96f5fc6f
+2f97d9fecb
+2fbfa431ec
+2fc9520b53
+2fcd9f4c62
+2feb30f208
+2ff7f5744f
+30085a2cc6
+30176e3615
+301f72ee11
+3026bb2f61
+30318465dc
+3054ca937d
+306121e726
+3064ad91e8
+307444a47f
+307bbb7409
+30a20194ab
+30c35c64a4
+30dbdb2cd6
+30fc77d72f
+310021b58b
+3113140ee8
+3150b2ee57
+31539918c4
+318dfe2ce2
+3193da4835
+319f725ad9
+31bbd0d793
+322505c47f
+322b237865
+322da43910
+3245e049fb
+324c4c38f6
+324e35111a
+3252398f09
+327dc4cabf
+328d918c7d
+3290c0de97
+3299ae3116
+32a7cd687b
+33098cedb4
+3332334ac4
+334cb835ac
+3355e056eb
+33639a2847
+3373891cdc
+337975816b
+33e29d7e91
+34046fe4f2
+3424f58959
+34370a710f
+343bc6a65a
+3450382ef7
+3454303a08
+346aacf439
+346e92ff37
+34a5ece7dd
+34b109755a
+34d1b37101
+34dd2c70a7
+34efa703df
+34fbee00a6
+3504df2fda
+35195a56a1
+351c822748
+351cfd6bc5
+3543d8334c
+35573455c7
+35637a827f
+357a710863
+358bf16f9e
+35ab34cc34
+35c6235b8d
+35d01a438a
+3605019d3b
+3609bc3f88
+360e25da17
+36299c687c
+362c5bc56e
+3649228783
+365b0501ea
+365f459863
+369893f3ad
+369c9977e1
+369dde050a
+36c7dac02f
+36d5b1493b
+36f5cc68fd
+3735480d18
+374b479880
+375a49d38f
+375a5c0e09
+376bda9651
+377db65f60
+37c19d1087
+37d4ae24fc
+37ddce7f8b
+37e10d33af
+37e45c6247
+37fa0001e8
+3802d458c0
+382caa3cb4
+383bb93111
+388843df90
+38924f4a7f
+38b00f93d7
+38c197c10e
+38c9c3d801
+38eb2bf67f
+38fe9b3ed1
+390352cced
+390c51b987
+390ca6f1d6
+392bc0f8a1
+392ecb43bd
+3935291688
+3935e63b41
+394454fa9c
+394638fc8b
+39545e20b7
+397abeae8f
+3988074b88
+398f5d5f19
+39bc49a28c
+39befd99fb
+39c3c7bf55
+39d584b09f
+39f6f6ffb1
+3a079fb484
+3a0d3a81b7
+3a1d55d22b
+3a20a7583e
+3a2c1f66e5
+3a33f4d225
+3a3bf84b13
+3a4565e5ec
+3a4e32ed5e
+3a7ad86ce0
+3a7bdde9b8
+3a98867cbe
+3aa3f1c9e8
+3aa7fce8b6
+3aa876887d
+3ab807ded6
+3ab9b1a85a
+3adac8d7da
+3ae1a4016f
+3ae2deaec2
+3ae81609d6
+3af847e62f
+3b23792b84
+3b3b0af2ee
+3b512dad74
+3b6c7988f6
+3b6e983b5b
+3b74a0fc20
+3b7a50b80d
+3b96d3492f
+3b9ad0c5a9
+3b9ba0894a
+3bb4e10ed7
+3bd9a9b515
+3beef45388
+3c019c0a24
+3c090704aa
+3c2784fc0d
+3c47ab95f8
+3c4db32d74
+3c5ff93faf
+3c700f073e
+3c713cbf2f
+3c8320669c
+3c90d225ee
+3cadbcc404
+3cb9be84a5
+3cc37fd487
+3cc6f90cb2
+3cd5e035ef
+3cdf03531b
+3cdf828f59
+3d254b0bca
+3d5aeac5ba
+3d690473e1
+3d69fed2fb
+3d8997aeb6
+3db0d6b07e
+3db1ddb8cf
+3db907ac77
+3dcbc0635b
+3dd48ed55f
+3de4ac4ec4
+3decd63d88
+3e04a6be11
+3e108fb65a
+3e1448b01c
+3e16c19634
+3e2845307e
+3e38336da5
+3e3a819865
+3e3e4be915
+3e680622d7
+3e7d2aeb07
+3e7d8f363d
+3e91f10205
+3ea4c49bbe
+3eb39d11ab
+3ec273c8d5
+3ed3f91271
+3ee062a2fd
+3eede9782c
+3ef2fa99cb
+3efc6e9892
+3f0b0dfddd
+3f0c860359
+3f18728586
+3f3b15f083
+3f45a470ad
+3f4f3bc803
+3fd96c5267
+3fea675fab
+3fee8cbc9f
+3fff16d112
+401888b36c
+4019231330
+402316532d
+402680df52
+404d02e0c0
+40709263a8
+4083cfbe15
+40a96c5cb1
+40b8e50f82
+40f4026bf5
+4100b57a3a
+41059fdd0b
+41124e36de
+4122aba5f9
+413bab0f0d
+4164faee0b
+418035eec9
+4182d51532
+418bb97e10
+41a34c20e7
+41dab05200
+41ff6d5e2a
+420caf0859
+42264230ba
+425a0c96e0
+42da96b87c
+42eb5a5b0f
+42f17cd14d
+42f5c61c49
+42ffdcdee9
+432f9884f9
+43326d9940
+4350f3ab60
+4399ffade3
+43a6c21f37
+43b5555faa
+43d63b752a
+4416bdd6ac
+4444753edd
+444aa274e7
+444d4e0596
+446b8b5f7a
+4478f694bb
+44b1da0d87
+44b4dad8c9
+44b5ece1b9
+44d239b24e
+44eaf8f51e
+44f4f57099
+44f7422af2
+450787ac97
+4523656564
+4536c882e5
+453b65daa4
+454f227427
+45636d806a
+456fb9362e
+457e717a14
+45a89f35e1
+45bf0e947d
+45c36a9eab
+45d9fc1357
+45f8128b97
+4607f6c03c
+46146dfd39
+4620e66b1e
+4625f3f2d3
+462b22f263
+4634736113
+463c0f4fdd
+46565a75f8
+46630b55ae
+466839cb37
+466ba4ae0c
+4680236c9d
+46bf4e8709
+46e18e42f1
+46f5093c59
+47269e0499
+472da1c484
+47354fab09
+4743bb84a7
+474a796272
+4783d2ab87
+479cad5da3
+479f5d7ef6
+47a05fbd1d
+4804ee2767
+4810c3fbca
+482fb439c2
+48375af288
+484ab44de4
+485f3944cd
+4867b84887
+486a8ac57e
+486e69c5bd
+48812cf33e
+4894b3b9ea
+48bd66517d
+48d83b48a4
+49058178b8
+4918d10ff0
+4932911f80
+49405b7900
+49972c2d14
+499bf07002
+49b16e9377
+49c104258e
+49c879f82d
+49e7326789
+49ec3e406a
+49fbf0c98a
+4a0255c865
+4a088fe99a
+4a341402d0
+4a3471bdf5
+4a4b50571c
+4a50f3d2e9
+4a6e3faaa1
+4a7191f08a
+4a86fcfc30
+4a885fa3ef
+4a8af115de
+4aa2e0f865
+4aa9d6527f
+4abb74bb52
+4ae13de1cd
+4af8cb323f
+4b02c272b3
+4b19c529fb
+4b2974eff4
+4b3154c159
+4b54d2587f
+4b556740ff
+4b67aa9ef6
+4b97cc7b8d
+4baa1ed4aa
+4bc8c676bb
+4beaea4dbe
+4bf5763d24
+4bffa92b67
+4c25dfa8ec
+4c397b6fd4
+4c51e75d66
+4c7710908f
+4c9b5017be
+4ca2ffc361
+4cad2e93bc
+4cd427b535
+4cd9a4b1ef
+4cdfe3c2b2
+4cef87b649
+4cf208e9b3
+4cf5bc3e60
+4cfdd73249
+4cff5c9e42
+4d26d41091
+4d5c23c554
+4d67c59727
+4d983cad9f
+4da0d00b55
+4daa179861
+4dadd57153
+4db117e6c5
+4de4ce4dea
+4dfaee19e5
+4dfdd7fab0
+4e3f346aa5
+4e49c2a9c7
+4e4e06a749
+4e70279712
+4e72856cc7
+4e752f8075
+4e7a28907f
+4e824b9247
+4e82b1df57
+4e87a639bc
+4ea77bfd15
+4eb6fc23a2
+4ec9da329e
+4efb9a0720
+4f062fbc63
+4f35be0e0b
+4f37e86797
+4f414dd6e7
+4f424abded
+4f470cc3ae
+4f601d255a
+4f7386a1ab
+4f824d3dcd
+4f827b0751
+4f8db33a13
+4fa160f8a3
+4fa9c30a45
+4facd8f0e8
+4fca07ad01
+4fded94004
+4fdfef4dea
+4feb3ac01f
+4fffec8479
+500c835a86
+50168342bf
+50243cffdc
+5031d5a036
+504dd9c0fd
+50568fbcfb
+5069c7c5b3
+508189ac91
+50b6b3d4b7
+50c6f4fe3e
+50cce40173
+50efbe152f
+50f290b95d
+5104aa1fea
+5110dc72c0
+511e8ecd7f
+513aada14e
+5158d6e985
+5161e1fa57
+51794ddd58
+517d276725
+51a597ee04
+51b37b6d97
+51b5dc30a0
+51e85b347b
+51eea1fdac
+51eef778af
+51f384721c
+521cfadcb4
+52355da42f
+5247d4b160
+524b470fd0
+524cee1534
+5252195e8a
+5255c9ca97
+525928f46f
+526df007a7
+529b12de78
+52c7a3d653
+52c8ec0373
+52d225ed52
+52ee406d9e
+52ff1ccd4a
+53143511e8
+5316d11eb7
+53253f2362
+534a560609
+5352c4a70e
+536096501f
+536b17bcea
+5380eaabff
+5390a43a54
+53af427bb2
+53bf5964ce
+53c30110b5
+53cad8e44a
+53d9c45013
+53e274f1b5
+53e32d21ea
+540850e1c7
+540cb31cfe
+541c4da30f
+541d7935d7
+545468262b
+5458647306
+54657855cd
+547b3fb23b
+5497dc3712
+549c56f1d4
+54a4260bb1
+54b98b8d5e
+54e1054b0f
+54e8867b83
+54ebe34f6e
+5519b4ad13
+551acbffd5
+55341f42da
+5566ab97e1
+556c79bbf2
+5589637cc4
+558aa072f0
+559824b6f6
+55c1764e90
+55eda6c77e
+562d173565
+5665c024cb
+566cef4959
+5675d78833
+5678a91bd8
+567a2b4bd0
+569c282890
+56cc449917
+56e71f3e07
+56f09b9d92
+56fc0e8cf9
+571ca79c71
+57243657cf
+57246af7d1
+57427393e9
+574b682c19
+578f211b86
+5790ac295d
+579393912d
+57a344ab1a
+57bd3bcda4
+57bfb7fa4c
+57c010175e
+57c457cc75
+57c7fc2183
+57d5289a01
+58045fde85
+58163c37cd
+582d463e5c
+5851739c15
+585dd0f208
+587250f3c3
+589e4cc1de
+589f65f5d5
+58a07c17d5
+58adc6d8b6
+58b9bcf656
+58c374917e
+58fc75fd42
+5914c30f05
+59323787d5
+5937b08d69
+594065ddd7
+595a0ceea6
+59623ec40b
+597ff7ef78
+598935ef05
+598c2ad3b2
+59a6459751
+59b175e138
+59bf0a149f
+59d53d1649
+59e3e6fae7
+59fe33e560
+5a13a73fe5
+5a25c22770
+5a4a785006
+5a50640995
+5a75f7a1cf
+5a841e59ad
+5a91c5ab6d
+5ab49d9de0
+5aba1057fe
+5abe46ba6d
+5ac7c88d0c
+5aeb95cc7d
+5af15e4fc3
+5afe381ae4
+5b07b4229d
+5b1001cc4f
+5b1df237d2
+5b263013bf
+5b27d19f0b
+5b48ae16c5
+5b5babc719
+5baaebdf00
+5bab55cdbe
+5bafef6e79
+5bd1f84545
+5bddc3ba25
+5bdf7c20d2
+5bf23bc9d3
+5c01f6171a
+5c021681b7
+5c185cff1d
+5c42aba280
+5c44bf8ab6
+5c4c574894
+5c52fa4662
+5c6ea7dac3
+5c74315dc2
+5c7668855e
+5c83e96778
+5ca36173e4
+5cac477371
+5cb0cb1b2f
+5cb0cfb98f
+5cb49a19cf
+5cbf7dc388
+5d0e07d126
+5d1e24b6e3
+5d663000ff
+5da6b2dc5d
+5de9b90f24
+5e08de0ed7
+5e1011df9a
+5e1ce354fd
+5e35512dd7
+5e418b25f9
+5e4849935a
+5e4ee19663
+5e886ef78f
+5e8d00b974
+5e8d59dc31
+5ed838bd5c
+5edda6ee5a
+5ede4d2f7a
+5ede9767da
+5eec4d9fe5
+5eecf07824
+5eef7ed4f4
+5ef5860ac6
+5ef6573a99
+5f1193e72b
+5f29ced797
+5f32cf521e
+5f51876986
+5f6ebe94a9
+5f6f14977c
+5f808d0d2d
+5fb8aded6a
+5fba90767d
+5fd1c7a3df
+5fd3da9f68
+5fee2570ae
+5ff66140d6
+5ff8b85b53
+600803c0f6
+600be7f53e
+6024888af8
+603189a03c
+6057307f6e
+6061ddbb65
+606c86c455
+60c61cc2e5
+60e51ff1ae
+610e38b751
+61344be2f6
+6135e27185
+614afe7975
+614e571886
+614e7078db
+619812a1a7
+61b481a78b
+61c7172650
+61cf7e40d2
+61d08ef5a1
+61da008958
+61ed178ecb
+61f5d1282c
+61fd977e49
+621584cffe
+625817a927
+625892cf0b
+625b89d28a
+629995af95
+62a0840bb5
+62ad6e121c
+62d6ece152
+62ede7b2da
+62f025e1bc
+6316faaebc
+63281534dc
+634058dda0
+6353f09384
+6363c87314
+636e4872e0
+637681cd6b
+6376d49f31
+6377809ec2
+63936d7de5
+639bddef11
+63d37e9fd3
+63d90c2bae
+63e544a5d6
+63ebbcf874
+63fff40b31
+6406c72e4d
+64148128be
+6419386729
+643092bc41
+644081b88d
+64453cf61d
+644bad9729
+6454f548fd
+645913b63a
+64750b825f
+64a43876b7
+64dd6c83e3
+64e05bf46e
+64f55f1478
+650b0165e4
+651066ed39
+652b67d960
+653821d680
+6538d00d73
+65866dce22
+6589565c8c
+659832db64
+65ab7e1d98
+65b7dda462
+65bd5eb4f5
+65dcf115ab
+65e9825801
+65f9afe51c
+65ff12bcb5
+666b660284
+6671643f31
+668364b372
+66852243cb
+6693a52081
+669b572898
+66e98e78f5
+670f12e88f
+674c12c92d
+675c27208a
+675ed3e1ca
+67741db50a
+678a2357eb
+67b0f4d562
+67cfbff9b1
+67e717d6bd
+67ea169a3b
+67ea809e0e
+681249baa3
+683de643d9
+6846ac20df
+6848e012ef
+684bcd8812
+684dc1c40c
+685a1fa9cf
+686dafaac9
+68807d8601
+6893778c77
+6899d2dabe
+68a2fad4ab
+68cb45fda3
+68cc4a1970
+68dcb40675
+68ea4a8c3d
+68f6e7fbf0
+68fa8300b4
+69023db81f
+6908ccf557
+691a111e7c
+6927723ba5
+692ca0e1a2
+692eb57b63
+69340faa52
+693cbf0c9d
+6942f684ad
+6944fc833b
+69491c0ebf
+695b61a2b0
+6979b4d83f
+697d4fdb02
+69910460a4
+6997636670
+69a436750b
+69aebf7669
+69b8c17047
+69c67f109f
+69e0e7b868
+69ea9c09d1
+69f0af42a6
+6a078cdcc7
+6a37a91708
+6a42176f2e
+6a48e4aea8
+6a5977be3a
+6a5de0535f
+6a80d2e2e5
+6a96c8815d
+6a986084e2
+6aa8e50445
+6ab9dce449
+6abf0ba6b2
+6acc6049d9
+6adb31756c
+6ade215eb0
+6afb7d50e4
+6afd692f1a
+6b0b1044fe
+6b17c67633
+6b1b6ef28b
+6b1e04d00d
+6b2261888d
+6b25d6528a
+6b3a24395c
+6b685eb75b
+6b79be238c
+6b928b7ba6
+6b9c43c25a
+6ba99cc41f
+6bdab62bcd
+6bf2e853b1
+6bf584200f
+6bf95df2b9
+6c0949c51c
+6c11a5f11f
+6c23d89189
+6c4387daf5
+6c4ce479a4
+6c5123e4bc
+6c54265f16
+6c56848429
+6c623fac5f
+6c81b014e9
+6c99ea7c31
+6c9d29d509
+6c9e3b7d1a
+6ca006e283
+6caeb928d6
+6cb2ee722a
+6cbfd32c5e
+6cc791250b
+6cccc985e0
+6d12e30c48
+6d4bf200ad
+6d6d2b8843
+6d6eea5682
+6d7a3d0c21
+6d7efa9b9e
+6da21f5c91
+6da6adabc0
+6dd2827fbb
+6dd36705b9
+6df3637557
+6dfe55e9e5
+6e1a21ba55
+6e2f834767
+6e36e4929a
+6e4f460caf
+6e618d26b6
+6ead4670f7
+6eaff19b9f
+6eb2e1cd9e
+6eb30b3b5a
+6eca26c202
+6ecad29e52
+6ef0b44654
+6efcfe9275
+6f4789045c
+6f49f522ef
+6f67d7c4c4
+6f96e91d81
+6fc6fce380
+6fc9b44c00
+6fce7f3226
+6fdf1ca888
+702fd8b729
+70405185d2
+7053e4f41e
+707bf4ce41
+7082544248
+708535b72a
+7094ac0f60
+70a6b875fa
+70c3e97e41
+7106b020ab
+711dce6fe2
+7136a4453f
+7143fb084f
+714d902095
+7151c53b32
+715357be94
+7163b8085f
+716df1aa59
+71caded286
+71d2665f35
+71d67b9e19
+71e06dda39
+720b398b9c
+720e3fa04c
+720e7a5f1e
+721bb6f2cb
+722803f4f2
+72552a07c9
+726243a205
+72690ef572
+728cda9b65
+728e81c319
+72a810a799
+72acb8cdf6
+72b01281f9
+72cac683e4
+72cadebbce
+72cae058a5
+72d8dba870
+72e8d1c1ff
+72edc08285
+72f04f1a38
+731b825695
+7320b49b13
+732626383b
+732df1eb05
+73329902ab
+733798921e
+733824d431
+734ea0d7fb
+735a7cf7b9
+7367a42892
+7368d5c053
+73c6ae7711
+73e1852735
+73e4e5cc74
+73eac9156b
+73f8441a88
+7419e2ab3f
+74267f68b9
+7435690c8c
+747c44785c
+747f1b1f2f
+748b2d5c01
+74d4cee0a4
+74ec2b3073
+74ef677020
+750be4c4d8
+75172d4ac8
+75285a7eb1
+75504539c3
+7550949b1d
+7551cbd537
+75595b453d
+7559b4b0ec
+755bd1fbeb
+756f76f74d
+7570ca7f3c
+757a69746e
+757cac96c6
+7584129dc3
+75a058dbcd
+75b09ce005
+75cae39a8f
+75cee6caf0
+75cf58fb2c
+75d5c2f32a
+75eaf5669d
+75f7937438
+75f99bd3b3
+75fa586876
+7613df1f84
+762e1b3487
+76379a3e69
+764271f0f3
+764503c499
+7660005554
+7666351b84
+76693db153
+767856368b
+768671f652
+768802b80d
+76962c7ed2
+76a75f4eee
+76b90809f7
+770a441457
+772a0fa402
+772f2ffc3e
+774f6c2175
+77610860e0
+777e58ff3d
+77920f1708
+7799df28e7
+779e847a9a
+77ba4edc72
+77c834dc43
+77d8aa8691
+77e7f38f4d
+77eea6845e
+7806308f33
+78254660ea
+7828af8bff
+784398620a
+784d201b12
+78613981ed
+78896c6baf
+78aff3ebc0
+78c7c03716
+78d3676361
+78e29dd4c3
+78f1a1a54f
+79208585cd
+792218456c
+7923bad550
+794e6fc49f
+796e6762ce
+797cd21f71
+79921b21c2
+79a5778027
+79bc006280
+79bf95e624
+79d9e00c55
+79e20fc008
+79e9db913e
+79f014085e
+79fcbb433a
+7a13a5dfaa
+7a14bc9a36
+7a3c535f70
+7a446a51e9
+7a56e759c5
+7a5f46198d
+7a626ec98d
+7a802264c4
+7a8b5456ca
+7abdff3086
+7aecf9f7ac
+7b0fd09c28
+7b18b3db87
+7b39fe7371
+7b49e03d4c
+7b5388c9f1
+7b5cf7837f
+7b733d31d8
+7b74fd7b98
+7b918ccb8a
+7ba3ce3485
+7bb0abc031
+7bb5bb25cd
+7bb7dac673
+7bc7761b8c
+7bf3820566
+7c03a18ec1
+7c078f211b
+7c37d7991a
+7c4ec17eff
+7c649c2aaf
+7c73340ab7
+7c78a2266d
+7c88ce3c5b
+7ca6843a72
+7cc9258dee
+7cec7296ae
+7d0ffa68a4
+7d11b4450f
+7d1333fcbe
+7d18074fef
+7d18c8c716
+7d508fb027
+7d55f791f0
+7d74e3c2f6
+7d783f67a9
+7d83a5d854
+7dd409947e
+7de45f75e5
+7e0cd25696
+7e1922575c
+7e1e3bbcc1
+7e24023274
+7e2f212fd3
+7e6d1cc1f4
+7e7cdcb284
+7e9b6bef69
+7ea5b49283
+7eb2605d96
+7eb26b8485
+7ecd1f0c69
+7f02b3cfe2
+7f1723f0d5
+7f21063c3a
+7f3658460e
+7f54132e48
+7f559f9d4a
+7f5faedf8b
+7f838baf2b
+7fa5f527e3
+7ff84d66dd
+802b45c8c4
+804382b1ad
+804c558adb
+804f6338a4
+8056117b89
+806b6223ab
+8088bda461
+80b790703b
+80c4a94706
+80ce2e351b
+80db581acd
+80e12193df
+80e41b608f
+80f16b016d
+81541b3725
+8175486e6a
+8179095000
+8193671178
+81a58d2c6b
+81aa1286fb
+81dffd30fb
+8200245704
+823e7a86e8
+824973babb
+824ca5538f
+827171a845
+8273a03530
+827cf4f886
+82b865c7dd
+82c1517708
+82d15514d6
+82e117b900
+82fec06574
+832b5ef379
+83424c9fbf
+8345358fb8
+834b50b31b
+835e3b67d7
+836ea92b15
+837c618777
+838eb3bd89
+839381063f
+839bc71489
+83a8151377
+83ae88d217
+83ca8bcad0
+83ce590d7f
+83d3130ba0
+83d40bcba5
+83daba503a
+83de906ec0
+84044f37f3
+84696b5a5e
+84752191a3
+847eeeb2e0
+848e7835a0
+84a4b29286
+84a4bf147d
+84be115c09
+84d95c4350
+84e0922cf7
+84f0cfc665
+8515f6db22
+851f2f32c1
+852a4d6067
+854c48b02a
+857a387c86
+859633d56a
+85a4f4a639
+85ab85510c
+85b1eda0d9
+85dc1041c6
+85e081f3c7
+85f75187ad
+8604bb2b75
+860745b042
+863b4049d7
+8643de22d0
+8647d06439
+864ffce4fe
+8662d9441a
+8666521b13
+868d6a0685
+869fa45998
+86a40b655d
+86a8ae4223
+86b2180703
+86c85d27df
+86d3755680
+86e61829a1
+871015806c
+871e409c5c
+8744b861ce
+8749369ba0
+878a299541
+8792c193a0
+8799ab0118
+87d1f7d741
+882b9e4500
+885673ea17
+8859dedf41
+8873ab2806
+887a93b198
+8883e991a9
+8891aa6dfa
+8899d8cbcd
+88b8274d67
+88d3b80af6
+88ede83da2
+88f345941b
+890976d6da
+8909bde9ab
+8929c7d5d9
+89363acf76
+89379487e0
+8939db6354
+893f658345
+8953138465
+895c96d671
+895cbf96f9
+895e8b29a7
+898fa256c8
+89986c60be
+89b874547b
+89bdb021d5
+89c802ff9c
+89d6336c2b
+89ebb27334
+8a27e2407c
+8a31f7bca5
+8a4a2fc105
+8a5d6c619c
+8a75ad7924
+8aa817e4ed
+8aad0591eb
+8aca214360
+8ae168c71b
+8b0cfbab97
+8b3645d826
+8b3805dbd4
+8b473f0f5d
+8b4f6d1186
+8b4fb018b7
+8b518ee936
+8b523bdfd6
+8b52fb5fba
+8b91036e5c
+8b99a77ac5
+8ba04b1e7b
+8ba782192f
+8bbeaad78b
+8bd1b45776
+8bd7a2dda6
+8bdb091ccf
+8be56f165d
+8be950d00f
+8bf84e7d45
+8bffc4374b
+8bfff50747
+8c09867481
+8c0a3251c3
+8c3015cccb
+8c469815cf
+8c9ccfedc7
+8ca1af9f3c
+8ca3f6e6c1
+8ca6a4f60f
+8cac6900fe
+8cba221a1e
+8cbbe62ccd
+8d064b29e2
+8d167e7c08
+8d4ab94e1c
+8d81f6f899
+8d87897d66
+8dcccd2bd2
+8dcfb878a8
+8dd3ab71b9
+8dda6bf10f
+8ddd51ca94
+8dea22c533
+8def5bd3bf
+8e1848197c
+8e3a83cf2d
+8e478e73f3
+8e98ae3c84
+8ea6687ab0
+8eb0d315c1
+8ec10891f9
+8ec3065ec2
+8ecf51a971
+8eddbab9f7
+8ee198467a
+8ee2368f40
+8ef595ce82
+8f0a653ad7
+8f1204a732
+8f1600f7f6
+8f16366707
+8f1ce0a411
+8f2e05e814
+8f320d0e09
+8f3b4a84ad
+8f3fdad3da
+8f5d3622d8
+8f62a2c633
+8f81c9405a
+8f8c974d53
+8f918598b6
+8ff61619f6
+9002761b41
+90107941f3
+90118a42ee
+902bc16b37
+903e87e0d6
+9041a0f489
+9047bf3222
+9057bfa502
+90617b0954
+9076f4b6db
+9077e69b08
+909655b4a6
+909c2eca88
+909dbd1b76
+90bc4a319a
+90c7a87887
+90cc785ddd
+90d300f09b
+9101ea9b1b
+9108130458
+911ac9979b
+9151cad9b5
+9153762797
+91634ee0c9
+916942666f
+9198cfb4ea
+919ac864d6
+91b67d58d4
+91bb8df281
+91be106477
+91c33b4290
+91ca7dd9f3
+91d095f869
+91f107082e
+920329dd5e
+920c959958
+92128fbf4b
+9223dacb40
+923137bb7f
+9268e1f88a
+927647fe08
+9276f5ba47
+92a28cd233
+92b5c1fc6d
+92c46be756
+92dabbe3a0
+92e3159361
+92ebab216a
+934bdc2893
+9359174efc
+935d97dd2f
+935feaba1b
+93901858ee
+939378f6d6
+939bdf742e
+93a22bee7e
+93da9aeddf
+93e2feacce
+93e6f1fdf9
+93e811e393
+93e85d8fd3
+93f623d716
+93ff35e801
+94031f12f2
+94091a4873
+94125907e3
+9418653742
+941c870569
+94209c86f0
+9437c715eb
+9445c3eca2
+9467c8617c
+946d71fb5d
+948f3ae6fb
+9498baa359
+94a33abeab
+94bf1af5e3
+94cf3a8025
+94db712ac8
+94e4b66cff
+94e76cbaf6
+950be91db1
+952058e2d0
+952633c37f
+952ec313fe
+9533fc037c
+9574b81269
+9579b73761
+957f7bc48b
+958073d2b0
+9582e0eb33
+9584092d0b
+95b58b8004
+95bd88da55
+95f74a9959
+962781c601
+962f045bf5
+964ad23b44
+967b90590e
+967bffe201
+96825c4714
+968492136a
+9684ef9d64
+968c41829e
+96a856ef9a
+96dfc49961
+96e1a5b4f8
+96e6ff0917
+96fb88e9d7
+96fbe5fc23
+96fc924050
+9715cc83dc
+9720eff40f
+972c187c0d
+97476eb38d
+97659ed431
+9773492949
+97756b264f
+977bff0d10
+97ab569ff3
+97ba838008
+97d9d008c7
+97e59f09fa
+97eb642e56
+98043e2d14
+981ff580cf
+983e66cbfc
+984f0f1c36
+98595f2bb4
+985c3be474
+9869a12362
+986b5a5e18
+9877af5063
+98911292da
+9893a3cf77
+9893d9202d
+98a8b06e7f
+98ac6f93d9
+98b6974d12
+98ba3c9417
+98c7c00a19
+98d044f206
+98e909f9d1
+98fe7f0410
+990f2742c7
+992bd0779a
+994b9b47ba
+9955b76bf5
+9966f3adac
+997117a654
+999d53d841
+99c04108d3
+99c4277aee
+99c6b1acf2
+99dc8bb20b
+99fcba71e5
+99fecd4efb
+9a02c70ba2
+9a08e7a6f8
+9a2f2c0f86
+9a3254a76e
+9a3570a020
+9a39112493
+9a4e9fd399
+9a50af4bfb
+9a68631d24
+9a72318dbf
+9a767493b7
+9a7fc1548b
+9a84ccf6a7
+9a9c0e15b7
+9adf06d89b
+9b22b54ee4
+9b473fc8fe
+9b4f081782
+9b997664ba
+9bc454e109
+9bccfd04de
+9bce4583a2
+9bebf1b87f
+9bfc50d261
+9c166c86ff
+9c293ef4d7
+9c29c047b0
+9c3bc2e2a7
+9c3ce23bd1
+9c404cac0c
+9c5180d23a
+9c7feca6e4
+9caa49d3ff
+9cb2f1b646
+9ce6f765c3
+9cfee34031
+9d01f08ec6
+9d04c280b8
+9d12ceaddc
+9d15f8cb3c
+9d2101e9bf
+9d407c3aeb
+9ddefc6165
+9df0b1e298
+9e16f115d8
+9e249b4982
+9e29b1982c
+9e493e4773
+9e4c752cd0
+9e4de40671
+9e6319faeb
+9e6ddbb52d
+9eadcea74f
+9ecec5f8ea
+9efb47b595
+9f30bfe61e
+9f3734c3a4
+9f5b858101
+9f66640cda
+9f913803e9
+9f97bc74c8
+9fbad86e20
+9fc2bad316
+9fc5c3af78
+9fcb310255
+9fcc256871
+9fd2fd4d47
+a0071ae316
+a023141022
+a046399a74
+a066e739c1
+a06722ba82
+a07a15dd64
+a07b47f694
+a09c39472e
+a0b208fe2e
+a0b61c959e
+a0bc6c611d
+a0e6da5ba2
+a1193d6490
+a14ef483ff
+a14f709908
+a15ccc5658
+a16062456f
+a174e8d989
+a177c2733c
+a17c62e764
+a18ad065fc
+a1aaf63216
+a1bb65fb91
+a1bd8e5349
+a1dfdd0cac
+a2052e4f6c
+a20fd34693
+a21ffe4d81
+a22349e647
+a235d01ec1
+a24f63e8a2
+a2554c9f6d
+a263ce8a87
+a29bfc29ec
+a2a80072d4
+a2a800ab63
+a2bcd10a33
+a2bdaff3b0
+a2c146ab0d
+a2c996e429
+a2dc51ebe8
+a2e6608bfa
+a2f2a55f01
+a301869dea
+a31fccd2cc
+a34f440f33
+a35e0206da
+a36bdc4cab
+a36e8c79d8
+a378053b20
+a37db3a2b3
+a38950ebc2
+a39a0eb433
+a39c9bca52
+a3a945dc8c
+a3b40a0c1e
+a3b8588550
+a3c502bec3
+a3f2878017
+a3f4d58010
+a3f51855c3
+a402dc0dfe
+a4065a7eda
+a412bb2fef
+a416b56b53
+a41ec95906
+a43299e362
+a4757bd7af
+a48c53c454
+a49dcf9ad5
+a4a506521f
+a4ba7753d9
+a4bac06849
+a4f05d681c
+a50c10060f
+a50eb5a0ea
+a5122c6ec6
+a522b1aa79
+a590915345
+a5b5b59139
+a5b77abe43
+a5c2b2c3e1
+a5cd17bb11
+a5da03aef1
+a5dd11de0d
+a5ea2b93b6
+a5eaeac80b
+a5ec5b0265
+a5f350a87e
+a5f472caf4
+a6027a53cf
+a61715bb1b
+a61cf4389d
+a61d9bbd9b
+a6470dbbf5
+a64a40f3eb
+a653d5c23b
+a65bd23cb5
+a66e0b7ad4
+a66fc5053c
+a68259572b
+a6a810a92c
+a6bc36937f
+a6c3a374e9
+a6d8a4228d
+a6f4e0817f
+a71e0481f5
+a7203deb2d
+a7392d4438
+a73d3c3902
+a7491f1578
+a74b9ca19c
+a77b7a91df
+a78195a5f5
+a78758d4ce
+a7e6d6c29a
+a800d85e88
+a832fa8790
+a83d06410d
+a8999af004
+a8f78125b9
+a907b18df1
+a919392446
+a965504e88
+a96b84b8d2
+a973f239cd
+a977126596
+a9804f2a08
+a984e56893
+a99738f24c
+a99bdd0079
+a9c9c1517e
+a9cbf9c41b
+a9e42e3c0c
+aa07b7c1c0
+aa175e5ec7
+aa1a338630
+aa27d7b868
+aa45f1caaf
+aa49e46432
+aa51934e1b
+aa6287bb6c
+aa6d999971
+aa85278334
+aab33f0e2a
+aaba004362
+aade4cf385
+aae78feda4
+aaed233bf3
+aaff16c2db
+ab199e8dfb
+ab23b78715
+ab2e1b5577
+ab33a18ded
+ab45078265
+ab56201494
+ab90f0d24b
+abab2e6c20
+abb50c8697
+abbe2d15a0
+abbe73cd21
+abe61a11bb
+abeae8ce21
+ac2b431d5f
+ac2cb1b9eb
+ac31fcd6d0
+ac3d3a126d
+ac46bd8087
+ac783ef388
+acb73e4297
+acbf581760
+accafc3531
+acf2c4b745
+acf44293a2
+acf736a27b
+acff336758
+ad1fe56886
+ad28f9b9d9
+ad2de9f80e
+ad397527b2
+ad3d1cfbcb
+ad3fada9d9
+ad4108ee8e
+ad54468654
+ad573f7d31
+ad6255bc29
+ad65ebaa07
+ad97cc064a
+adabbd1cc4
+adb0b5a270
+adc648f890
+add21ee467
+adfd15ceef
+adfdd52eac
+ae01cdab63
+ae0b50ff4f
+ae13ee3d70
+ae1bcbd423
+ae20d09dea
+ae2cecf5f6
+ae3bc4a0ef
+ae499c7514
+ae628f2cd4
+ae8545d581
+ae93214fe6
+ae9cd16dbf
+aeba9ac967
+aebb242b5c
+aed4e0b4c4
+aedd71f125
+aef3e2cb0e
+af0b54cee3
+af3de54c7a
+af5fd24a36
+af8826d084
+af8ad72057
+afb71e22c5
+afcb331e1f
+afe1a35c1e
+b01080b5d3
+b05ad0d345
+b0623a6232
+b064dbd4b7
+b06ed37831
+b06f5888e6
+b08dcc490e
+b0a68228dc
+b0aece727f
+b0b0731606
+b0c7f11f9f
+b0cca8b830
+b0dd580a89
+b0de66ca08
+b0df7c5c5c
+b0f5295608
+b11099eb09
+b132a53086
+b1399fac64
+b13abc0c69
+b1457e3b5e
+b15bf4453b
+b179c4a82d
+b17ee70e8c
+b190b1aa65
+b19b3e22c0
+b19c561fab
+b1d1cd2e6e
+b1d7c03927
+b1d7fe2753
+b1f540a4bd
+b1fc9c64e1
+b1fcbb3ced
+b220939e93
+b22099b419
+b241e95235
+b2432ae86d
+b2456267df
+b247940d01
+b24af1c35c
+b24f600420
+b24fe36b2a
+b258fb0b7d
+b26b219919
+b26d9904de
+b274456ce1
+b27b28d581
+b2a26bc912
+b2a9c51e1b
+b2b0baf470
+b2b2756fe7
+b2ce7699e3
+b2edc76bd2
+b2f6b52100
+b30bf47bcd
+b34105a4e9
+b372a82edf
+b3779a1962
+b379ab4ff5
+b37a1d69e3
+b37c01396e
+b382b09e25
+b3996e4ba5
+b3d9ca2aee
+b3dde1e1e9
+b3eb7f05eb
+b40b25055c
+b41e0f1f19
+b44e32a42b
+b4805ae9cd
+b4807569a5
+b48efceb3e
+b493c25c7f
+b4b565aba1
+b4b715a15b
+b4d0c90bf4
+b4d84bc371
+b4e5ad97aa
+b4eaea9e6b
+b50f4b90d5
+b53f675641
+b54278cd43
+b554843889
+b573c0677a
+b58d853734
+b5943b18ab
+b5a09a83f3
+b5aae1fe25
+b5b9da5364
+b5eb64d419
+b5ebb1d000
+b5f1c0c96a
+b5f7fece90
+b6070de1bb
+b60a76fe73
+b61f998772
+b62c943664
+b63094ba0c
+b64fca8100
+b673e7dcfb
+b678b7db00
+b68fc1b217
+b69926d9fa
+b6a1df3764
+b6a4859528
+b6b4738b78
+b6b4f847b7
+b6b8d502d4
+b6bb00e366
+b6d65a9eef
+b6d79a0845
+b6e9ec577f
+b6ec609f7b
+b6f92a308d
+b70a2c0ab1
+b70a5a0d50
+b70c052f2f
+b70d231781
+b72ac6e10b
+b7302d8226
+b73867d769
+b751e767f2
+b76df6e059
+b77e5eddef
+b7a2c2c83c
+b7bcbe6466
+b7c2a469c4
+b7d69da8f0
+b7f31b7c36
+b7f675fb98
+b7fb871660
+b82e5ad1c9
+b841cfb932
+b84b8ae665
+b85b78ac2b
+b86c17caa6
+b86e50d82d
+b871db031a
+b87d56925a
+b8aaa59b75
+b8c03d1091
+b8c3210036
+b8e16df00b
+b8f34cf72e
+b8fb75864e
+b9004db86c
+b9166cbae9
+b920b256a6
+b938d79dff
+b93963f214
+b941aef1a0
+b94d34d14e
+b964c57da4
+b96a95bc7a
+b96c57d2c7
+b9b6bdde0c
+b9bcb3e0f2
+b9d3b92169
+b9dd4b306c
+b9f43ef41e
+ba1f03c811
+ba3a775d7b
+ba3c7f2a31
+ba3fcd417d
+ba5e1f4faa
+ba795f3089
+ba8a291e6a
+ba98512f97
+bac9db04f5
+baedae3442
+baff40d29d
+bb04e28695
+bb1b0ee89f
+bb1c770fe7
+bb1fc34f99
+bb2d220506
+bb334e5cdb
+bb337f9830
+bb721eb9aa
+bb87ff58bd
+bb89a6b18a
+bbaa9a036a
+bbb4302dda
+bbd31510cf
+bbe0256a75
+bc141b9ad5
+bc17ab8a99
+bc318160de
+bc3b9ee033
+bc4240b43c
+bc4ce49105
+bc4f71372d
+bc6b8d6371
+bcaad44ad7
+bcc241b081
+bcc5d8095e
+bcd1d39afb
+bd0d849da4
+bd0e9ed437
+bd2c94730f
+bd321d2be6
+bd3ec46511
+bd5b2e2848
+bd7e02b139
+bd96f9943a
+bda224cb25
+bda4a82837
+bdb74e333f
+bdccd69dde
+bddcc15521
+be116aab29
+be15e18f1e
+be1a284edb
+be2a367a7b
+be376082d0
+be3e3cffbd
+be5d1d89a0
+be8b72fe37
+be9b29e08e
+bea1f6e62c
+bea83281b5
+beb921a4c9
+bec5e9edcd
+beeb8a3f92
+bf2232b58d
+bf28751739
+bf443804e8
+bf461df850
+bf5374f122
+bf551a6f60
+bf8d0f5ada
+bf961167a6
+bfab1ad8f9
+bfcb05d88d
+bfd8f6e6c9
+bfd91d0742
+bfe262322f
+c013f42ed7
+c01878083f
+c01faff1ed
+c046fd0edb
+c053e35f97
+c079a6482d
+c0847b521a
+c0a1e06710
+c0e8d4635c
+c0e973ad85
+c0f49c6579
+c0f5b222d7
+c10d07c90d
+c1268d998c
+c130c3fc0c
+c14826ad5e
+c15b922281
+c16f09cb63
+c18e19d922
+c1c830a735
+c1e8aeea45
+c20a5ccc99
+c20fd5e597
+c219d6f8dc
+c2406ae462
+c26f7b5824
+c279e641ee
+c27adaeac5
+c2a35c1cda
+c2a9903b8b
+c2b62567c1
+c2b974ec8c
+c2baaff7bf
+c2be6900f2
+c304dd44d5
+c307f33da2
+c30a7b62c9
+c3128733ee
+c31fa6c598
+c325c8201e
+c32d4aa5d1
+c33f28249a
+c34365e2d7
+c3457af795
+c34d120a88
+c3509e728d
+c35e4fa6c4
+c36240d96f
+c3641dfc5a
+c37b17a4a9
+c39559ddf6
+c3b0c6e180
+c3b3d82e6c
+c3be369fdb
+c3bf1e40c2
+c3c760b015
+c3dd38bf98
+c3e4274614
+c3edc48cbd
+c41e6587f5
+c4272227b0
+c42917fe82
+c438858117
+c44676563f
+c44beb7472
+c45411dacb
+c4571bedc8
+c46deb2956
+c479ee052e
+c47d551843
+c49f07d46d
+c4cc40c1fc
+c4f256f5d5
+c4f5b1ddcc
+c4ff9b4885
+c52bce43db
+c544da6854
+c55784c766
+c557b69fbf
+c593a3f7ab
+c598faa682
+c5ab1f09c8
+c5b6da8602
+c5b9128d94
+c5e845c6b7
+c5fba7b341
+c60897f093
+c61fe6ed7c
+c62188c536
+c64035b2e2
+c69689f177
+c6a12c131f
+c6bb6d2d5c
+c6c18e860f
+c6d9526e0d
+c6e55c33f0
+c7030b28bd
+c70682c7cc
+c70f9be8c5
+c71f30d7b6
+c73c8e747f
+c760eeb8b3
+c7637cab0a
+c7a1a17308
+c7bf937af5
+c7c2860db3
+c7cef4aee2
+c7ebfc5d57
+c813dcf13c
+c82235a49a
+c82a7619a1
+c82ecb90cb
+c844f03dc7
+c8557963f3
+c89147e6e8
+c8a46ff0c8
+c8ab107dd5
+c8b869a04a
+c8c7b306a6
+c8c8b28781
+c8d79e3163
+c8edab0415
+c8f494f416
+c8f6cba9fd
+c909ceea97
+c9188f4980
+c922365dd4
+c92c8c3c75
+c937eb0b83
+c94b31b5e5
+c95cd17749
+c96379c03c
+c96465ee65
+c965afa713
+c9734b451f
+c9862d82dc
+c98b6fe013
+c9999b7c48
+c99e92aaf0
+c9b3a8fbda
+c9bf64e965
+c9c3cb3797
+c9d1c60cd0
+c9de9c22c4
+ca1828fa54
+ca346f17eb
+ca3787d3d3
+ca4b99cbac
+ca91c69e3b
+ca91e99105
+caa8e97f81
+caac5807f8
+cabba242c2
+cad5a656a9
+cad673e375
+cad8a85930
+cae7b0a02b
+cae7ef3184
+caeb6b6cbb
+caecf0a5db
+cb15312003
+cb2e35d610
+cb35a87504
+cb3f22b0cf
+cbb410da64
+cc8728052e
+cc892997b8
+cce03c2a9b
+cd47a23e31
+cd4dc03dc0
+cd5ae611da
+cd603bb9d1
+cd8f49734c
+cdc6b1c032
+cdcfe008ad
+cdd57027c2
+ce1af99b4b
+ce1bc5743a
+ce25872021
+ce2776f78f
+ce49b1f474
+ce4f0a266f
+ce5641b195
+ce6866aa19
+ce712ed3c9
+ce7d1c8117
+ce7dbeaa88
+ce9b015a5e
+cea7697b25
+cebbd826cf
+cec3415361
+cec41ad4f4
+ced49d26df
+ced7705ab2
+cef824a1e1
+cf13f5c95a
+cf4376a52d
+cf85ab28b5
+cfc2e50b9d
+cfcd571fff
+cfd9d4ae47
+cfda2dcce5
+cff035928b
+cff8191891
+d01608c2a5
+d01a8f1f83
+d021d68bca
+d04258ca14
+d0483573dc
+d04a90aaff
+d05279c0bd
+d0696bd5fc
+d072fda75b
+d0a83bcd9f
+d0ab39112e
+d0acde820f
+d0b4442c71
+d0c65e9e95
+d0fb600c73
+d107a1457c
+d123d674c1
+d14d1e9289
+d154e3388e
+d177e9878a
+d1802f69f8
+d182c4483a
+d195d31128
+d200838929
+d205e3cff5
+d247420c4c
+d2484bff33
+d26f6ed9b0
+d280fcd1cb
+d2857f0faa
+d292a50c7f
+d295ea2dc7
+d2a58b4fa6
+d2b026739a
+d2ebe0890f
+d2ede5d862
+d301ca58cc
+d3069da8bb
+d343d4a77d
+d355e634ef
+d367fb5253
+d36d16358e
+d38bc77e2c
+d38d1679e2
+d3932ad4bd
+d3987b2930
+d39934abe3
+d3ae1c3f4c
+d3b088e593
+d3e6e05e16
+d3eefae7c5
+d3f55f5ab8
+d3f5c309cc
+d4034a7fdf
+d4193011f3
+d429c67630
+d42c0ff975
+d44a764409
+d44e6acd1d
+d45158c175
+d454e8444f
+d45f62717e
+d48ebdcf74
+d49ab52a25
+d4a607ad81
+d4b063c7db
+d4da13e9ba
+d4dd1a7d00
+d4f4f7c9c3
+d521aba02e
+d535bb1b97
+d53b955f78
+d55cb7a205
+d55f247a45
+d5695544d8
+d5853d9b8b
+d5b6c6d94a
+d5cae12834
+d5df027f0c
+d5ee40e5d0
+d600046f73
+d632fd3510
+d6476cad55
+d65a7bae86
+d664c89912
+d689658f06
+d6917db4be
+d69967143e
+d699d3d798
+d69f757a3f
+d6ac0e065c
+d6c02bfda5
+d6c1b5749e
+d6e12ef6cc
+d6eed152c4
+d6faaaf726
+d704766646
+d708e1350c
+d7135cf104
+d7157a9f44
+d719cf9316
+d724134cfd
+d73a60a244
+d7411662da
+d74875ea7c
+d756f5a694
+d7572b7d8a
+d763bd6d96
+d7697c8b13
+d7797196b4
+d79c834768
+d7b34e5d73
+d7bb6b37a7
+d7c7e064a6
+d7fbf545b3
+d82a0aa15b
+d847e24abd
+d8596701b7
+d86101499c
+d87069ba86
+d87160957b
+d874654b52
+d88a403092
+d8aee40f3f
+d8e77a222d
+d8eb07c381
+d9010348a1
+d90e3cf281
+d92532c7b2
+d927fae122
+d95707bca8
+d973b31c00
+d991cb471d
+d992c69d37
+d99d770820
+d9b63abc11
+d9db6f1983
+d9e52be2d2
+d9edc82650
+da01070697
+da070ea4b7
+da080507b9
+da0e944cc4
+da28d94ff4
+da5d78b9d1
+da6003fc72
+da690fee9f
+da6c68708f
+da7a816676
+dac361e828
+dac71659b8
+dad980385d
+daebc12b77
+db0968cdd3
+db231a7100
+db59282ace
+db7f267c3f
+dba35b87fd
+dbba735a50
+dbca076acd
+dbd66dc3ac
+dbdc3c292b
+dbf4a5b32b
+dbfc417d28
+dc1745e0a2
+dc32a44804
+dc34b35e30
+dc504a4f79
+dc704dd647
+dc71bc6918
+dc7771b3be
+dcf8c93617
+dd0f4c9fb9
+dd415df125
+dd601f9a3f
+dd61d903df
+dd77583736
+dd8636bd8b
+dd9fe6c6ac
+ddb2da4c14
+ddcd450d47
+dde8e67fb4
+ddfc3f04d3
+de2ab79dfa
+de2f35b2fd
+de30990a51
+de36b216da
+de37403340
+de46e4943b
+de4ddbccb1
+de5e480f05
+de6a9382ca
+de74a601d3
+de827c510d
+ded6069f7b
+defb71c741
+df01f277f1
+df05214b82
+df0638b0a0
+df11931ffe
+df1b0e4620
+df20a8650d
+df2bc56d7c
+df365282c6
+df39a0d9df
+df3c430c24
+df5536cfb9
+df59cfd91d
+df5e2152b3
+df741313c9
+df7626172f
+df8ad5deb9
+df96aa609a
+df9705605c
+df9c91c4da
+dfc0d3d27a
+dfdbf91a99
+e00baaae9b
+e0a938c6e7
+e0b2ceee6f
+e0bdb5dfae
+e0be1f6e17
+e0c478f775
+e0de82caa7
+e0f217dd59
+e0f7208874
+e0fb58395e
+e1194c2e9d
+e11adcd05d
+e128124b9d
+e1495354e4
+e1561d6d4b
+e158805399
+e16945b951
+e19edcd34b
+e1a1544285
+e1ab7957f4
+e1d26d35be
+e1e957085b
+e1f14510fa
+e214b160f4
+e2167379b8
+e21acb20ab
+e221105579
+e22ddf8a1b
+e22de45950
+e22ffc469b
+e23cca5244
+e252f46f0b
+e25fa6cf39
+e26e486026
+e275760245
+e27bbedbfe
+e29e9868a8
+e2b37ff8af
+e2b608d309
+e2bef4da9a
+e2c87a6421
+e2ea25542c
+e2fb1d6497
+e2fcc99117
+e33c18412a
+e348377191
+e352cb59c8
+e36ac982f0
+e391bc981e
+e39e3e0a06
+e3bf38265f
+e3d5b2cd21
+e3d60e82d5
+e3e3245492
+e3e4134877
+e3f4635e03
+e4004ee048
+e402d1afa5
+e415093d27
+e41ceb5d81
+e424653b78
+e42b6d3dbb
+e42d60f0d4
+e436d0ff1e
+e43d7ae2c5
+e4428801bc
+e44e0b4917
+e470345ede
+e48e8b4263
+e4922e3726
+e4936852bb
+e495f32c60
+e499228f26
+e4af66e163
+e4b2095f58
+e4d19c8283
+e4d4872dab
+e4e2983570
+e4eaa63aab
+e4ef0a3a34
+e4f8e5f46e
+e4ffb6d0dd
+e53e21aa02
+e57f4f668b
+e588433c1e
+e597442c99
+e5abc0e96b
+e5be628030
+e5ce96a55d
+e5d6b70a9f
+e5fde1574c
+e625e1d27b
+e6261d2348
+e6267d46bc
+e6295f223f
+e63463d8c6
+e6387bd1e0
+e653883384
+e65f134e0b
+e668ef5664
+e672ccd250
+e674510b20
+e676107765
+e699da0cdf
+e6be243065
+e6deab5e0b
+e6f065f2b9
+e71629e7b5
+e72a7d7b0b
+e72f6104e1
+e75a466eea
+e76c55933f
+e7784ec8ad
+e78922e5e6
+e78d450a9c
+e7c6354e77
+e7c8de1fce
+e7ea10db28
+e803918710
+e8073a140b
+e828dd02db
+e845994987
+e8485a2615
+e85c5118a7
+e88b6736e4
+e8962324e3
+e8b3018d36
+e8cee8bf0b
+e8d97ebece
+e8da49ea6a
+e8ed1a3ccf
+e8f7904326
+e8f8341dec
+e8fa21eb13
+e90c10fc4c
+e914b8cac8
+e92b6bfea4
+e92e1b7623
+e93f83e512
+e9422ad240
+e9460b55f9
+e9502628f6
+e950befd5f
+e9582bdd1b
+e95e5afe0f
+e97cfac475
+e98d57d99c
+e98eda8978
+e99706b555
+e9bc0760ba
+e9d3c78bf3
+e9ec1b7ea8
+ea065cc205
+ea138b6617
+ea16d3fd48
+ea2545d64b
+ea286a581c
+ea320da917
+ea345f3627
+ea3b94a591
+ea444a37eb
+ea4a01216b
+ea5672ffa8
+eaa99191cb
+eaab4d746c
+eac7a59bc1
+ead5d3835a
+eaec65cfa7
+eaed1a87be
+eb2f821c6f
+eb383cb82e
+eb6992fe02
+eb6ac20a01
+eb6d7ab39e
+eb7921facd
+eb8fce51a6
+ebbb90e9f9
+ebbf5c9ee1
+ebc4ec32e6
+ebe56e5ef8
+ec1299aee4
+ec139ff675
+ec193e1a01
+ec28252938
+ec387be051
+ec3d4fac00
+ec4186ce12
+ec579c2f96
+ecae59b782
+ecb33a0448
+ece6bc9e92
+ecfedd4035
+ecfff22fd6
+ed3291c3d6
+ed3cd5308d
+ed3e6fc1a5
+ed72ae8825
+ed7455da68
+ed844e879f
+ed8f814b2b
+ed911a1f63
+ed9ff4f649
+eda8ab984b
+edb8878849
+edbfdfe1b4
+edd22c46a2
+edd663afa3
+ede3552eae
+edeab61ee0
+ee07583fc0
+ee316eaed6
+ee3f509537
+ee40a1e491
+ee4bf100f1
+ee6f9b01f9
+ee947ed771
+ee9706ac7f
+ee9a7840ae
+eeb90cb569
+eebf45e5c5
+eeed0c7d73
+ef0061a309
+ef07f1a655
+ef0a8e8f35
+ef232a2aed
+ef308ad2e9
+ef44945428
+ef45ce3035
+ef5dde449d
+ef5e770988
+ef6359cea3
+ef65268834
+ef6cb5eae0
+ef78972bc2
+ef8cfcfc4f
+ef96501dd0
+ef9a2e976b
+efb24f950f
+efce0c1868
+efe5ac6901
+efe828affa
+efea4e0523
+f0268aa627
+f0483250c8
+f04cf99ee6
+f05b189097
+f08928c6d3
+f09d74856f
+f0a7607d63
+f0ad38da27
+f0c34e1213
+f0c7f86c29
+f0dfa18ba7
+f0eb3179f7
+f119bab27d
+f14409b6a3
+f1489baff4
+f14c18cf6a
+f15c607b92
+f1af214222
+f1b77bd309
+f1ba9e1a3e
+f1d99239eb
+f1dc710cf4
+f1ec5c08fa
+f22648fe12
+f22d21f1f1
+f233257395
+f23e95dbe5
+f2445b1572
+f253b3486d
+f277c7a6a4
+f2ab2b84d6
+f2b7c9b1f3
+f2b83d5ce5
+f2c276018f
+f2cfd94d64
+f2dd6e3add
+f2e7653f16
+f2f333ad06
+f2f55d6713
+f2fdb6abec
+f305a56d9f
+f3085d6570
+f3325c3338
+f3400f1204
+f34497c932
+f34a56525e
+f36483c824
+f3704d5663
+f3734c4913
+f38e5aa5b4
+f3986fba44
+f3a0ffc7d9
+f3b24a7d28
+f3e6c35ec3
+f3fc0ea80b
+f40a683fbe
+f4207ca554
+f4377499c2
+f46184f393
+f46c2d0a6d
+f46c364dca
+f46f7a0b63
+f46fe141b0
+f470b9aeb0
+f47eb7437f
+f48b535719
+f49e4866ac
+f4aa882cfd
+f4daa3dbd5
+f4dd51ac35
+f507a1b9dc
+f51c5ac84b
+f52104164b
+f54c67b9bb
+f5966cadd2
+f5bddf5598
+f5d85cfd17
+f5e2e7d6a0
+f5f051e9b4
+f5f8a93a76
+f6283e8af5
+f635e9568b
+f6474735be
+f659251be2
+f66981af4e
+f6708fa398
+f697fe8e8f
+f6adb12c42
+f6c7906ca4
+f6cd0a8016
+f6d6f15ae7
+f6e501892c
+f6f59d986f
+f6fe8c90a5
+f714160545
+f74c3888d7
+f7782c430e
+f7783ae5f2
+f77ab47923
+f788a98327
+f7961ac1f0
+f7a71e7574
+f7a8521432
+f7afbf4947
+f7b7cd5f44
+f7cf4b4a39
+f7d49799ad
+f7e0c9bb83
+f7e5b84928
+f7e6bd58be
+f7f2a38ac6
+f7f6cb2d6d
+f83f19e796
+f85796a921
+f8603c26b2
+f8819b42ec
+f891f8eaa1
+f89288d10c
+f895ae8cc1
+f8b4ac12f1
+f8c3fb2b01
+f8c8de2764
+f8db369b40
+f8fcb6a78c
+f94aafdeef
+f95d217b70
+f9681d5103
+f9750192a4
+f9823a32c2
+f991ddb4c2
+f99d535567
+f9ae3d98b7
+f9b6217959
+f9bd1fabf5
+f9c68eaa64
+f9d3e04c4f
+f9daf64494
+f9e4cc5a0a
+f9ea6b7f31
+f9f3852526
+fa04c615cf
+fa08e00a56
+fa4370d74d
+fa67744af3
+fa88d48a92
+fa8b904cc9
+fa9526bdf1
+fa9b9d2426
+fad633fbe1
+faf5222dc3
+faff0e15f1
+fb08c64e8c
+fb23455a7f
+fb2e19fa6e
+fb34dfbb77
+fb47fcea1e
+fb49738155
+fb4cbc514b
+fb4e6062f7
+fb5ba7ad6e
+fb63cd1236
+fb81157a07
+fb92abdaeb
+fba22a6848
+fbaca0c9df
+fbc645f602
+fbd77444cd
+fbe53dc8e8
+fbe541dd73
+fbe8488798
+fbfd25174f
+fc28cb305e
+fc33b1ffd6
+fc6186f0bb
+fc918e3a40
+fc96cda9d8
+fc9832eea4
+fcb10d0f81
+fcd20a2509
+fcf637e3ab
+fcfd81727f
+fd31890379
+fd33551c28
+fd542da05e
+fd6789b3fe
+fd77828200
+fd7af75f4d
+fdb28d0fbb
+fdb3d1fb1e
+fdb8b04124
+fdc6e3d581
+fdfce7e6fc
+fe0f76d41b
+fe24b0677d
+fe3c02699d
+fe58b48235
+fe6a5596b8
+fe6c244f63
+fe7afec086
+fe985d510a
+fe9db35d15
+fea8ffcd36
+feb1080388
+fed208bfca
+feda5ad1c2
+feec95b386
+ff15a5eff6
+ff204daf4b
+ff25f55852
+ff2ada194f
+ff2ce142e8
+ff49d36d20
+ff5a1ec4f3
+ff66152b25
+ff692fdc56
+ff773b1a1e
+ff97129478
+ffb904207d
+ffc43fc345
+fffe5f8df6
+
+ Note that in the implementation, normalization with N is performed at step (2) and above equation and implementation is not exactly the same, but mathematically is same.
+
+ You can go deeper on above explanation at [Kevin Zakka's Blog](https://kevinzakka.github.io/2016/09/14/batch_normalization/)
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/__init__.py b/inference/interact/fbrs/model/syncbn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/model/syncbn/modules/__init__.py b/inference/interact/fbrs/model/syncbn/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py b/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8eb83a9d88b25cb8f1faebc9236da929a7722c7
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/__init__.py
@@ -0,0 +1 @@
+from .syncbn import batchnorm2d_sync
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py b/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0c14098f0cfa422920f01fe4985dbeb7fedc2d1
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/_csrc.py
@@ -0,0 +1,54 @@
+"""
+/*****************************************************************************/
+
+Extension module loader
+
+code referenced from : https://github.com/facebookresearch/maskrcnn-benchmark
+
+/*****************************************************************************/
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import glob
+import os.path
+
+import torch
+
+try:
+ from torch.utils.cpp_extension import load
+ from torch.utils.cpp_extension import CUDA_HOME
+except ImportError:
+ raise ImportError(
+ "The cpp layer extensions requires PyTorch 0.4 or higher")
+
+
+def _load_C_extensions():
+ this_dir = os.path.dirname(os.path.abspath(__file__))
+ this_dir = os.path.join(this_dir, "csrc")
+
+ main_file = glob.glob(os.path.join(this_dir, "*.cpp"))
+ sources_cpu = glob.glob(os.path.join(this_dir, "cpu", "*.cpp"))
+ sources_cuda = glob.glob(os.path.join(this_dir, "cuda", "*.cu"))
+
+ sources = main_file + sources_cpu
+
+ extra_cflags = []
+ extra_cuda_cflags = []
+ if torch.cuda.is_available() and CUDA_HOME is not None:
+ sources.extend(sources_cuda)
+ extra_cflags = ["-O3", "-DWITH_CUDA"]
+ extra_cuda_cflags = ["--expt-extended-lambda"]
+ sources = [os.path.join(this_dir, s) for s in sources]
+ extra_include_paths = [this_dir]
+ return load(
+ name="ext_lib",
+ sources=sources,
+ extra_cflags=extra_cflags,
+ extra_include_paths=extra_include_paths,
+ extra_cuda_cflags=extra_cuda_cflags,
+ )
+
+
+_backend = _load_C_extensions()
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h
new file mode 100644
index 0000000000000000000000000000000000000000..52567a478633aa043ad86624253763e594121bd1
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/bn.h
@@ -0,0 +1,70 @@
+/*****************************************************************************
+
+SyncBN
+
+*****************************************************************************/
+#pragma once
+
+#ifdef WITH_CUDA
+#include "cuda/ext_lib.h"
+#endif
+
+/// SyncBN
+
+std::vector syncbn_sum_sqsum(const at::Tensor& x) {
+ if (x.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_sum_sqsum_cuda(x);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
+
+at::Tensor syncbn_forward(const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean,
+ const at::Tensor& var, bool affine, float eps) {
+ if (x.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_forward_cuda(x, weight, bias, mean, var, affine, eps);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
+
+std::vector syncbn_backward_xhat(const at::Tensor& dz,
+ const at::Tensor& x,
+ const at::Tensor& mean,
+ const at::Tensor& var, float eps) {
+ if (dz.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_backward_xhat_cuda(dz, x, mean, var, eps);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
+
+std::vector syncbn_backward(
+ const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
+ const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
+ float eps) {
+ if (dz.is_cuda()) {
+#ifdef WITH_CUDA
+ return syncbn_backward_cuda(dz, x, weight, bias, mean, var, sum_dz,
+ sum_dz_xhat, affine, eps);
+#else
+ AT_ERROR("Not compiled with GPU support");
+#endif
+ } else {
+ AT_ERROR("CPU implementation not supported");
+ }
+}
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu
new file mode 100644
index 0000000000000000000000000000000000000000..9458eba4f4715673ba480fae2c318f4745e8fe78
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/bn_cuda.cu
@@ -0,0 +1,280 @@
+/*****************************************************************************
+
+CUDA SyncBN code
+
+code referenced from : https://github.com/mapillary/inplace_abn
+
+*****************************************************************************/
+#include
+#include
+#include
+#include
+#include "cuda/common.h"
+
+// Utilities
+void get_dims(at::Tensor x, int64_t &num, int64_t &chn, int64_t &sp) {
+ num = x.size(0);
+ chn = x.size(1);
+ sp = 1;
+ for (int64_t i = 2; i < x.ndimension(); ++i) sp *= x.size(i);
+}
+
+/// SyncBN
+
+template
+struct SqSumOp {
+ __device__ SqSumOp(const T *t, int c, int s) : tensor(t), chn(c), sp(s) {}
+ __device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
+ T x = tensor[(batch * chn + plane) * sp + n];
+ return Pair(x, x * x); // x, x^2
+ }
+ const T *tensor;
+ const int chn;
+ const int sp;
+};
+
+template
+__global__ void syncbn_sum_sqsum_kernel(const T *x, T *sum, T *sqsum,
+ int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ Pair res =
+ reduce, SqSumOp>(SqSumOp(x, chn, sp), plane, num, chn, sp);
+ __syncthreads();
+ if (threadIdx.x == 0) {
+ sum[plane] = res.v1;
+ sqsum[plane] = res.v2;
+ }
+}
+
+std::vector syncbn_sum_sqsum_cuda(const at::Tensor &x) {
+ CHECK_INPUT(x);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Prepare output tensors
+ auto sum = at::empty({chn}, x.options());
+ auto sqsum = at::empty({chn}, x.options());
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_sum_sqsum_cuda", ([&] {
+ syncbn_sum_sqsum_kernel<<>>(
+ x.data(), sum.data(),
+ sqsum.data(), num, chn, sp);
+ }));
+ return {sum, sqsum};
+}
+
+template
+__global__ void syncbn_forward_kernel(T *z, const T *x, const T *weight,
+ const T *bias, const T *mean,
+ const T *var, bool affine, float eps,
+ int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ T _mean = mean[plane];
+ T _var = var[plane];
+ T _weight = affine ? weight[plane] : T(1);
+ T _bias = affine ? bias[plane] : T(0);
+ float _invstd = T(0);
+ if (_var || eps) {
+ _invstd = rsqrt(_var + eps);
+ }
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ T _x = x[(batch * chn + plane) * sp + n];
+ T _xhat = (_x - _mean) * _invstd;
+ T _z = _xhat * _weight + _bias;
+ z[(batch * chn + plane) * sp + n] = _z;
+ }
+ }
+}
+
+at::Tensor syncbn_forward_cuda(const at::Tensor &x, const at::Tensor &weight,
+ const at::Tensor &bias, const at::Tensor &mean,
+ const at::Tensor &var, bool affine, float eps) {
+ CHECK_INPUT(x);
+ CHECK_INPUT(weight);
+ CHECK_INPUT(bias);
+ CHECK_INPUT(mean);
+ CHECK_INPUT(var);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ auto z = at::zeros_like(x);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_forward_cuda", ([&] {
+ syncbn_forward_kernel<<>>(
+ z.data(), x.data(),
+ weight.data(), bias.data(),
+ mean.data(), var.data(),
+ affine, eps, num, chn, sp);
+ }));
+ return z;
+}
+
+template
+struct XHatOp {
+ __device__ XHatOp(T _weight, T _bias, const T *_dz, const T *_x, int c, int s)
+ : weight(_weight), bias(_bias), x(_x), dz(_dz), chn(c), sp(s) {}
+ __device__ __forceinline__ Pair operator()(int batch, int plane, int n) {
+ // xhat = (x - bias) * weight
+ T _xhat = (x[(batch * chn + plane) * sp + n] - bias) * weight;
+ // dxhat * x_hat
+ T _dz = dz[(batch * chn + plane) * sp + n];
+ return Pair(_dz, _dz * _xhat);
+ }
+ const T weight;
+ const T bias;
+ const T *dz;
+ const T *x;
+ const int chn;
+ const int sp;
+};
+
+template
+__global__ void syncbn_backward_xhat_kernel(const T *dz, const T *x,
+ const T *mean, const T *var,
+ T *sum_dz, T *sum_dz_xhat,
+ float eps, int num, int chn,
+ int sp) {
+ int plane = blockIdx.x;
+ T _mean = mean[plane];
+ T _var = var[plane];
+ T _invstd = T(0);
+ if (_var || eps) {
+ _invstd = rsqrt(_var + eps);
+ }
+ Pair res = reduce, XHatOp>(
+ XHatOp(_invstd, _mean, dz, x, chn, sp), plane, num, chn, sp);
+ __syncthreads();
+ if (threadIdx.x == 0) {
+ // \sum(\frac{dJ}{dy_i})
+ sum_dz[plane] = res.v1;
+ // \sum(\frac{dJ}{dy_i}*\hat{x_i})
+ sum_dz_xhat[plane] = res.v2;
+ }
+}
+
+std::vector syncbn_backward_xhat_cuda(const at::Tensor &dz,
+ const at::Tensor &x,
+ const at::Tensor &mean,
+ const at::Tensor &var,
+ float eps) {
+ CHECK_INPUT(dz);
+ CHECK_INPUT(x);
+ CHECK_INPUT(mean);
+ CHECK_INPUT(var);
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+ // Prepare output tensors
+ auto sum_dz = at::empty({chn}, x.options());
+ auto sum_dz_xhat = at::empty({chn}, x.options());
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_backward_xhat_cuda", ([&] {
+ syncbn_backward_xhat_kernel<<>>(
+ dz.data(), x.data(), mean.data(),
+ var.data(), sum_dz.data(),
+ sum_dz_xhat.data(), eps, num, chn, sp);
+ }));
+ return {sum_dz, sum_dz_xhat};
+}
+
+template
+__global__ void syncbn_backward_kernel(const T *dz, const T *x, const T *weight,
+ const T *bias, const T *mean,
+ const T *var, const T *sum_dz,
+ const T *sum_dz_xhat, T *dx, T *dweight,
+ T *dbias, bool affine, float eps,
+ int num, int chn, int sp) {
+ int plane = blockIdx.x;
+ T _mean = mean[plane];
+ T _var = var[plane];
+ T _weight = affine ? weight[plane] : T(1);
+ T _sum_dz = sum_dz[plane];
+ T _sum_dz_xhat = sum_dz_xhat[plane];
+ T _invstd = T(0);
+ if (_var || eps) {
+ _invstd = rsqrt(_var + eps);
+ }
+ /*
+ \frac{dJ}{dx_i} = \frac{1}{N\sqrt{(\sigma^2+\epsilon)}} (
+ N\frac{dJ}{d\hat{x_i}} -
+ \sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}) -
+ \hat{x_i}\sum_{j=1}^{N}(\frac{dJ}{d\hat{x_j}}\hat{x_j})
+ )
+ Note : N is omitted here since it will be accumulated and
+ _sum_dz and _sum_dz_xhat expected to be already normalized
+ before the call.
+ */
+ if (dx) {
+ T _mul = _weight * _invstd;
+ for (int batch = 0; batch < num; ++batch) {
+ for (int n = threadIdx.x; n < sp; n += blockDim.x) {
+ T _dz = dz[(batch * chn + plane) * sp + n];
+ T _xhat = (x[(batch * chn + plane) * sp + n] - _mean) * _invstd;
+ T _dx = (_dz - _sum_dz - _xhat * _sum_dz_xhat) * _mul;
+ dx[(batch * chn + plane) * sp + n] = _dx;
+ }
+ }
+ }
+ __syncthreads();
+ if (threadIdx.x == 0) {
+ if (affine) {
+ T _norm = num * sp;
+ dweight[plane] += _sum_dz_xhat * _norm;
+ dbias[plane] += _sum_dz * _norm;
+ }
+ }
+}
+
+std::vector syncbn_backward_cuda(
+ const at::Tensor &dz, const at::Tensor &x, const at::Tensor &weight,
+ const at::Tensor &bias, const at::Tensor &mean, const at::Tensor &var,
+ const at::Tensor &sum_dz, const at::Tensor &sum_dz_xhat, bool affine,
+ float eps) {
+ CHECK_INPUT(dz);
+ CHECK_INPUT(x);
+ CHECK_INPUT(weight);
+ CHECK_INPUT(bias);
+ CHECK_INPUT(mean);
+ CHECK_INPUT(var);
+ CHECK_INPUT(sum_dz);
+ CHECK_INPUT(sum_dz_xhat);
+
+ // Extract dimensions
+ int64_t num, chn, sp;
+ get_dims(x, num, chn, sp);
+
+ // Prepare output tensors
+ auto dx = at::zeros_like(dz);
+ auto dweight = at::zeros_like(weight);
+ auto dbias = at::zeros_like(bias);
+
+ // Run kernel
+ dim3 blocks(chn);
+ dim3 threads(getNumThreads(sp));
+ AT_DISPATCH_FLOATING_TYPES(
+ x.type(), "syncbn_backward_cuda", ([&] {
+ syncbn_backward_kernel<<>>(
+ dz.data(), x.data(), weight.data(),
+ bias.data(), mean.data(), var.data(),
+ sum_dz.data(), sum_dz_xhat.data(),
+ dx.data(), dweight.data(),
+ dbias.data(), affine, eps, num, chn, sp);
+ }));
+ return {dx, dweight, dbias};
+}
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h
new file mode 100644
index 0000000000000000000000000000000000000000..a6cb2debeea3b8caa0f7c640601a94dce4e629cb
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/common.h
@@ -0,0 +1,124 @@
+/*****************************************************************************
+
+CUDA utility funcs
+
+code referenced from : https://github.com/mapillary/inplace_abn
+
+*****************************************************************************/
+#pragma once
+
+#include
+
+// Checks
+#ifndef AT_CHECK
+ #define AT_CHECK AT_ASSERT
+#endif
+#define CHECK_CUDA(x) AT_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) AT_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+/*
+ * General settings
+ */
+const int WARP_SIZE = 32;
+const int MAX_BLOCK_SIZE = 512;
+
+template
+struct Pair {
+ T v1, v2;
+ __device__ Pair() {}
+ __device__ Pair(T _v1, T _v2) : v1(_v1), v2(_v2) {}
+ __device__ Pair(T v) : v1(v), v2(v) {}
+ __device__ Pair(int v) : v1(v), v2(v) {}
+ __device__ Pair &operator+=(const Pair &a) {
+ v1 += a.v1;
+ v2 += a.v2;
+ return *this;
+ }
+};
+
+/*
+ * Utility functions
+ */
+template
+__device__ __forceinline__ T WARP_SHFL_XOR(T value, int laneMask,
+ int width = warpSize,
+ unsigned int mask = 0xffffffff) {
+#if CUDART_VERSION >= 9000
+ return __shfl_xor_sync(mask, value, laneMask, width);
+#else
+ return __shfl_xor(value, laneMask, width);
+#endif
+}
+
+__device__ __forceinline__ int getMSB(int val) { return 31 - __clz(val); }
+
+static int getNumThreads(int nElem) {
+ int threadSizes[5] = {32, 64, 128, 256, MAX_BLOCK_SIZE};
+ for (int i = 0; i != 5; ++i) {
+ if (nElem <= threadSizes[i]) {
+ return threadSizes[i];
+ }
+ }
+ return MAX_BLOCK_SIZE;
+}
+
+template
+static __device__ __forceinline__ T warpSum(T val) {
+#if __CUDA_ARCH__ >= 300
+ for (int i = 0; i < getMSB(WARP_SIZE); ++i) {
+ val += WARP_SHFL_XOR(val, 1 << i, WARP_SIZE);
+ }
+#else
+ __shared__ T values[MAX_BLOCK_SIZE];
+ values[threadIdx.x] = val;
+ __threadfence_block();
+ const int base = (threadIdx.x / WARP_SIZE) * WARP_SIZE;
+ for (int i = 1; i < WARP_SIZE; i++) {
+ val += values[base + ((i + threadIdx.x) % WARP_SIZE)];
+ }
+#endif
+ return val;
+}
+
+template
+static __device__ __forceinline__ Pair warpSum(Pair value) {
+ value.v1 = warpSum(value.v1);
+ value.v2 = warpSum(value.v2);
+ return value;
+}
+
+template
+__device__ T reduce(Op op, int plane, int N, int C, int S) {
+ T sum = (T)0;
+ for (int batch = 0; batch < N; ++batch) {
+ for (int x = threadIdx.x; x < S; x += blockDim.x) {
+ sum += op(batch, plane, x);
+ }
+ }
+
+ // sum over NumThreads within a warp
+ sum = warpSum(sum);
+
+ // 'transpose', and reduce within warp again
+ __shared__ T shared[32];
+ __syncthreads();
+ if (threadIdx.x % WARP_SIZE == 0) {
+ shared[threadIdx.x / WARP_SIZE] = sum;
+ }
+ if (threadIdx.x >= blockDim.x / WARP_SIZE && threadIdx.x < WARP_SIZE) {
+ // zero out the other entries in shared
+ shared[threadIdx.x] = (T)0;
+ }
+ __syncthreads();
+ if (threadIdx.x / WARP_SIZE == 0) {
+ sum = warpSum(shared[threadIdx.x]);
+ if (threadIdx.x == 0) {
+ shared[0] = sum;
+ }
+ }
+ __syncthreads();
+
+ // Everyone picks it up, should be broadcast into the whole gradInput
+ return shared[0];
+}
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h
new file mode 100644
index 0000000000000000000000000000000000000000..1d707615ffcf5ad7dcabc60de8c9a0cfe035bf14
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/cuda/ext_lib.h
@@ -0,0 +1,24 @@
+/*****************************************************************************
+
+CUDA SyncBN code
+
+*****************************************************************************/
+#pragma once
+#include
+#include
+
+/// Sync-BN
+std::vector syncbn_sum_sqsum_cuda(const at::Tensor& x);
+at::Tensor syncbn_forward_cuda(const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean,
+ const at::Tensor& var, bool affine, float eps);
+std::vector syncbn_backward_xhat_cuda(const at::Tensor& dz,
+ const at::Tensor& x,
+ const at::Tensor& mean,
+ const at::Tensor& var,
+ float eps);
+std::vector syncbn_backward_cuda(
+ const at::Tensor& dz, const at::Tensor& x, const at::Tensor& weight,
+ const at::Tensor& bias, const at::Tensor& mean, const at::Tensor& var,
+ const at::Tensor& sum_dz, const at::Tensor& sum_dz_xhat, bool affine,
+ float eps);
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..9c2ecf142dd70de8a3bdaf9b04470c4cacee3086
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/csrc/ext_lib.cpp
@@ -0,0 +1,10 @@
+#include "bn.h"
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("syncbn_sum_sqsum", &syncbn_sum_sqsum, "Sum and Sum^2 computation");
+ m.def("syncbn_forward", &syncbn_forward, "SyncBN forward computation");
+ m.def("syncbn_backward_xhat", &syncbn_backward_xhat,
+ "First part of SyncBN backward computation");
+ m.def("syncbn_backward", &syncbn_backward,
+ "Second part of SyncBN backward computation");
+}
\ No newline at end of file
diff --git a/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py b/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py
new file mode 100644
index 0000000000000000000000000000000000000000..867a432d14f4f28c25075caa85b22726424293ae
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/functional/syncbn.py
@@ -0,0 +1,137 @@
+"""
+/*****************************************************************************/
+
+BatchNorm2dSync with multi-gpu
+
+code referenced from : https://github.com/mapillary/inplace_abn
+
+/*****************************************************************************/
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import torch.cuda.comm as comm
+from torch.autograd import Function
+from torch.autograd.function import once_differentiable
+from ._csrc import _backend
+
+
+def _count_samples(x):
+ count = 1
+ for i, s in enumerate(x.size()):
+ if i != 1:
+ count *= s
+ return count
+
+
+class BatchNorm2dSyncFunc(Function):
+
+ @staticmethod
+ def forward(ctx, x, weight, bias, running_mean, running_var,
+ extra, compute_stats=True, momentum=0.1, eps=1e-05):
+ def _parse_extra(ctx, extra):
+ ctx.is_master = extra["is_master"]
+ if ctx.is_master:
+ ctx.master_queue = extra["master_queue"]
+ ctx.worker_queues = extra["worker_queues"]
+ ctx.worker_ids = extra["worker_ids"]
+ else:
+ ctx.master_queue = extra["master_queue"]
+ ctx.worker_queue = extra["worker_queue"]
+ # Save context
+ if extra is not None:
+ _parse_extra(ctx, extra)
+ ctx.compute_stats = compute_stats
+ ctx.momentum = momentum
+ ctx.eps = eps
+ ctx.affine = weight is not None and bias is not None
+ if ctx.compute_stats:
+ N = _count_samples(x) * (ctx.master_queue.maxsize + 1)
+ assert N > 1
+ # 1. compute sum(x) and sum(x^2)
+ xsum, xsqsum = _backend.syncbn_sum_sqsum(x.detach())
+ if ctx.is_master:
+ xsums, xsqsums = [xsum], [xsqsum]
+ # master : gatther all sum(x) and sum(x^2) from slaves
+ for _ in range(ctx.master_queue.maxsize):
+ xsum_w, xsqsum_w = ctx.master_queue.get()
+ ctx.master_queue.task_done()
+ xsums.append(xsum_w)
+ xsqsums.append(xsqsum_w)
+ xsum = comm.reduce_add(xsums)
+ xsqsum = comm.reduce_add(xsqsums)
+ mean = xsum / N
+ sumvar = xsqsum - xsum * mean
+ var = sumvar / N
+ uvar = sumvar / (N - 1)
+ # master : broadcast global mean, variance to all slaves
+ tensors = comm.broadcast_coalesced(
+ (mean, uvar, var), [mean.get_device()] + ctx.worker_ids)
+ for ts, queue in zip(tensors[1:], ctx.worker_queues):
+ queue.put(ts)
+ else:
+ # slave : send sum(x) and sum(x^2) to master
+ ctx.master_queue.put((xsum, xsqsum))
+ # slave : get global mean and variance
+ mean, uvar, var = ctx.worker_queue.get()
+ ctx.worker_queue.task_done()
+
+ # Update running stats
+ running_mean.mul_((1 - ctx.momentum)).add_(ctx.momentum * mean)
+ running_var.mul_((1 - ctx.momentum)).add_(ctx.momentum * uvar)
+ ctx.N = N
+ ctx.save_for_backward(x, weight, bias, mean, var)
+ else:
+ mean, var = running_mean, running_var
+
+ # do batch norm forward
+ z = _backend.syncbn_forward(x, weight, bias, mean, var,
+ ctx.affine, ctx.eps)
+ return z
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, dz):
+ x, weight, bias, mean, var = ctx.saved_tensors
+ dz = dz.contiguous()
+
+ # 1. compute \sum(\frac{dJ}{dy_i}) and \sum(\frac{dJ}{dy_i}*\hat{x_i})
+ sum_dz, sum_dz_xhat = _backend.syncbn_backward_xhat(
+ dz, x, mean, var, ctx.eps)
+ if ctx.is_master:
+ sum_dzs, sum_dz_xhats = [sum_dz], [sum_dz_xhat]
+ # master : gatther from slaves
+ for _ in range(ctx.master_queue.maxsize):
+ sum_dz_w, sum_dz_xhat_w = ctx.master_queue.get()
+ ctx.master_queue.task_done()
+ sum_dzs.append(sum_dz_w)
+ sum_dz_xhats.append(sum_dz_xhat_w)
+ # master : compute global stats
+ sum_dz = comm.reduce_add(sum_dzs)
+ sum_dz_xhat = comm.reduce_add(sum_dz_xhats)
+ sum_dz /= ctx.N
+ sum_dz_xhat /= ctx.N
+ # master : broadcast global stats
+ tensors = comm.broadcast_coalesced(
+ (sum_dz, sum_dz_xhat), [mean.get_device()] + ctx.worker_ids)
+ for ts, queue in zip(tensors[1:], ctx.worker_queues):
+ queue.put(ts)
+ else:
+ # slave : send to master
+ ctx.master_queue.put((sum_dz, sum_dz_xhat))
+ # slave : get global stats
+ sum_dz, sum_dz_xhat = ctx.worker_queue.get()
+ ctx.worker_queue.task_done()
+
+ # do batch norm backward
+ dx, dweight, dbias = _backend.syncbn_backward(
+ dz, x, weight, bias, mean, var, sum_dz, sum_dz_xhat,
+ ctx.affine, ctx.eps)
+
+ return dx, dweight, dbias, \
+ None, None, None, None, None, None
+
+batchnorm2d_sync = BatchNorm2dSyncFunc.apply
+
+__all__ = ["batchnorm2d_sync"]
diff --git a/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py b/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c5aca9879273811b681baddc5755e20e838a361
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/nn/__init__.py
@@ -0,0 +1 @@
+from .syncbn import *
diff --git a/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py b/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py
new file mode 100644
index 0000000000000000000000000000000000000000..b118c9d4aac3ee86821797bc9f794cd9aa38b1b2
--- /dev/null
+++ b/inference/interact/fbrs/model/syncbn/modules/nn/syncbn.py
@@ -0,0 +1,148 @@
+"""
+/*****************************************************************************/
+
+BatchNorm2dSync with multi-gpu
+
+/*****************************************************************************/
+"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+try:
+ # python 3
+ from queue import Queue
+except ImportError:
+ # python 2
+ from Queue import Queue
+
+import torch
+import torch.nn as nn
+from torch.nn import functional as F
+from torch.nn.parameter import Parameter
+from isegm.model.syncbn.modules.functional import batchnorm2d_sync
+
+
+class _BatchNorm(nn.Module):
+ """
+ Customized BatchNorm from nn.BatchNorm
+ >> added freeze attribute to enable bn freeze.
+ """
+
+ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
+ track_running_stats=True):
+ super(_BatchNorm, self).__init__()
+ self.num_features = num_features
+ self.eps = eps
+ self.momentum = momentum
+ self.affine = affine
+ self.track_running_stats = track_running_stats
+ self.freezed = False
+ if self.affine:
+ self.weight = Parameter(torch.Tensor(num_features))
+ self.bias = Parameter(torch.Tensor(num_features))
+ else:
+ self.register_parameter('weight', None)
+ self.register_parameter('bias', None)
+ if self.track_running_stats:
+ self.register_buffer('running_mean', torch.zeros(num_features))
+ self.register_buffer('running_var', torch.ones(num_features))
+ else:
+ self.register_parameter('running_mean', None)
+ self.register_parameter('running_var', None)
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ if self.track_running_stats:
+ self.running_mean.zero_()
+ self.running_var.fill_(1)
+ if self.affine:
+ self.weight.data.uniform_()
+ self.bias.data.zero_()
+
+ def _check_input_dim(self, input):
+ return NotImplemented
+
+ def forward(self, input):
+ self._check_input_dim(input)
+
+ compute_stats = not self.freezed and \
+ self.training and self.track_running_stats
+
+ ret = F.batch_norm(input, self.running_mean, self.running_var,
+ self.weight, self.bias, compute_stats,
+ self.momentum, self.eps)
+ return ret
+
+ def extra_repr(self):
+ return '{num_features}, eps={eps}, momentum={momentum}, '\
+ 'affine={affine}, ' \
+ 'track_running_stats={track_running_stats}'.format(
+ **self.__dict__)
+
+
+class BatchNorm2dNoSync(_BatchNorm):
+ """
+ Equivalent to nn.BatchNorm2d
+ """
+
+ def _check_input_dim(self, input):
+ if input.dim() != 4:
+ raise ValueError('expected 4D input (got {}D input)'
+ .format(input.dim()))
+
+
+class BatchNorm2dSync(BatchNorm2dNoSync):
+ """
+ BatchNorm2d with automatic multi-GPU Sync
+ """
+
+ def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True,
+ track_running_stats=True):
+ super(BatchNorm2dSync, self).__init__(
+ num_features, eps=eps, momentum=momentum, affine=affine,
+ track_running_stats=track_running_stats)
+ self.sync_enabled = True
+ self.devices = list(range(torch.cuda.device_count()))
+ if len(self.devices) > 1:
+ # Initialize queues
+ self.worker_ids = self.devices[1:]
+ self.master_queue = Queue(len(self.worker_ids))
+ self.worker_queues = [Queue(1) for _ in self.worker_ids]
+
+ def forward(self, x):
+ compute_stats = not self.freezed and \
+ self.training and self.track_running_stats
+ if self.sync_enabled and compute_stats and len(self.devices) > 1:
+ if x.get_device() == self.devices[0]:
+ # Master mode
+ extra = {
+ "is_master": True,
+ "master_queue": self.master_queue,
+ "worker_queues": self.worker_queues,
+ "worker_ids": self.worker_ids
+ }
+ else:
+ # Worker mode
+ extra = {
+ "is_master": False,
+ "master_queue": self.master_queue,
+ "worker_queue": self.worker_queues[
+ self.worker_ids.index(x.get_device())]
+ }
+ return batchnorm2d_sync(x, self.weight, self.bias,
+ self.running_mean, self.running_var,
+ extra, compute_stats, self.momentum,
+ self.eps)
+ return super(BatchNorm2dSync, self).forward(x)
+
+ def __repr__(self):
+ """repr"""
+ rep = '{name}({num_features}, eps={eps}, momentum={momentum},' \
+ 'affine={affine}, ' \
+ 'track_running_stats={track_running_stats},' \
+ 'devices={devices})'
+ return rep.format(name=self.__class__.__name__, **self.__dict__)
+
+#BatchNorm2d = BatchNorm2dNoSync
+BatchNorm2d = BatchNorm2dSync
diff --git a/inference/interact/fbrs/utils/__init__.py b/inference/interact/fbrs/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/fbrs/utils/cython/__init__.py b/inference/interact/fbrs/utils/cython/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb66bdbba883b9477bbc1a52d8355131d32a04cb
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/__init__.py
@@ -0,0 +1,2 @@
+# noinspection PyUnresolvedReferences
+from .dist_maps import get_dist_maps
\ No newline at end of file
diff --git a/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx
new file mode 100644
index 0000000000000000000000000000000000000000..779a7f02ad7c2ba25e68302c6fc6683cd4ab54f7
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyx
@@ -0,0 +1,63 @@
+import numpy as np
+cimport cython
+cimport numpy as np
+from libc.stdlib cimport malloc, free
+
+ctypedef struct qnode:
+ int row
+ int col
+ int layer
+ int orig_row
+ int orig_col
+
+@cython.infer_types(True)
+@cython.boundscheck(False)
+@cython.wraparound(False)
+@cython.nonecheck(False)
+def get_dist_maps(np.ndarray[np.float32_t, ndim=2, mode="c"] points,
+ int height, int width, float norm_delimeter):
+ cdef np.ndarray[np.float32_t, ndim=3, mode="c"] dist_maps = \
+ np.full((2, height, width), 1e6, dtype=np.float32, order="C")
+
+ cdef int *dxy = [-1, 0, 0, -1, 0, 1, 1, 0]
+ cdef int i, j, x, y, dx, dy
+ cdef qnode v
+ cdef qnode *q = malloc((4 * height * width + 1) * sizeof(qnode))
+ cdef int qhead = 0, qtail = -1
+ cdef float ndist
+
+ for i in range(points.shape[0]):
+ x, y = round(points[i, 0]), round(points[i, 1])
+ if x >= 0:
+ qtail += 1
+ q[qtail].row = x
+ q[qtail].col = y
+ q[qtail].orig_row = x
+ q[qtail].orig_col = y
+ if i >= points.shape[0] / 2:
+ q[qtail].layer = 1
+ else:
+ q[qtail].layer = 0
+ dist_maps[q[qtail].layer, x, y] = 0
+
+ while qtail - qhead + 1 > 0:
+ v = q[qhead]
+ qhead += 1
+
+ for k in range(4):
+ x = v.row + dxy[2 * k]
+ y = v.col + dxy[2 * k + 1]
+
+ ndist = ((x - v.orig_row)/norm_delimeter) ** 2 + ((y - v.orig_col)/norm_delimeter) ** 2
+ if (x >= 0 and y >= 0 and x < height and y < width and
+ dist_maps[v.layer, x, y] > ndist):
+ qtail += 1
+ q[qtail].orig_col = v.orig_col
+ q[qtail].orig_row = v.orig_row
+ q[qtail].layer = v.layer
+ q[qtail].row = x
+ q[qtail].col = y
+ dist_maps[v.layer, x, y] = ndist
+
+ free(q)
+ return dist_maps
diff --git a/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld
new file mode 100644
index 0000000000000000000000000000000000000000..bd4451729201b5ebc6bbbd8f392389ab6b530636
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/_get_dist_maps.pyxbld
@@ -0,0 +1,7 @@
+import numpy
+
+def make_ext(modname, pyxfilename):
+ from distutils.extension import Extension
+ return Extension(modname, [pyxfilename],
+ include_dirs=[numpy.get_include()],
+ extra_compile_args=['-O3'], language='c++')
diff --git a/inference/interact/fbrs/utils/cython/dist_maps.py b/inference/interact/fbrs/utils/cython/dist_maps.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ffa1e3f25231cd7c48b66ef8ef5167235c3ea4e
--- /dev/null
+++ b/inference/interact/fbrs/utils/cython/dist_maps.py
@@ -0,0 +1,3 @@
+import pyximport; pyximport.install(pyximport=True, language_level=3)
+# noinspection PyUnresolvedReferences
+from ._get_dist_maps import get_dist_maps
\ No newline at end of file
diff --git a/inference/interact/fbrs/utils/misc.py b/inference/interact/fbrs/utils/misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..65ce96dc5667494446110fda75e29243338e2b88
--- /dev/null
+++ b/inference/interact/fbrs/utils/misc.py
@@ -0,0 +1,62 @@
+from functools import partial
+
+import torch
+import numpy as np
+
+
+def get_dims_with_exclusion(dim, exclude=None):
+ dims = list(range(dim))
+ if exclude is not None:
+ dims.remove(exclude)
+
+ return dims
+
+
+def get_unique_labels(mask):
+ return np.nonzero(np.bincount(mask.flatten() + 1))[0] - 1
+
+
+def get_bbox_from_mask(mask):
+ rows = np.any(mask, axis=1)
+ cols = np.any(mask, axis=0)
+ rmin, rmax = np.where(rows)[0][[0, -1]]
+ cmin, cmax = np.where(cols)[0][[0, -1]]
+
+ return rmin, rmax, cmin, cmax
+
+
+def expand_bbox(bbox, expand_ratio, min_crop_size=None):
+ rmin, rmax, cmin, cmax = bbox
+ rcenter = 0.5 * (rmin + rmax)
+ ccenter = 0.5 * (cmin + cmax)
+ height = expand_ratio * (rmax - rmin + 1)
+ width = expand_ratio * (cmax - cmin + 1)
+ if min_crop_size is not None:
+ height = max(height, min_crop_size)
+ width = max(width, min_crop_size)
+
+ rmin = int(round(rcenter - 0.5 * height))
+ rmax = int(round(rcenter + 0.5 * height))
+ cmin = int(round(ccenter - 0.5 * width))
+ cmax = int(round(ccenter + 0.5 * width))
+
+ return rmin, rmax, cmin, cmax
+
+
+def clamp_bbox(bbox, rmin, rmax, cmin, cmax):
+ return (max(rmin, bbox[0]), min(rmax, bbox[1]),
+ max(cmin, bbox[2]), min(cmax, bbox[3]))
+
+
+def get_bbox_iou(b1, b2):
+ h_iou = get_segments_iou(b1[:2], b2[:2])
+ w_iou = get_segments_iou(b1[2:4], b2[2:4])
+ return h_iou * w_iou
+
+
+def get_segments_iou(s1, s2):
+ a, b = s1
+ c, d = s2
+ intersection = max(0, min(b, d) - max(a, c) + 1)
+ union = max(1e-6, max(b, d) - min(a, c) + 1)
+ return intersection / union
diff --git a/inference/interact/fbrs/utils/vis.py b/inference/interact/fbrs/utils/vis.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c1a291306453c15bdfe5117302beb62e0fe7248
--- /dev/null
+++ b/inference/interact/fbrs/utils/vis.py
@@ -0,0 +1,129 @@
+from functools import lru_cache
+
+import cv2
+import numpy as np
+
+
+def visualize_instances(imask, bg_color=255,
+ boundaries_color=None, boundaries_width=1, boundaries_alpha=0.8):
+ num_objects = imask.max() + 1
+ palette = get_palette(num_objects)
+ if bg_color is not None:
+ palette[0] = bg_color
+
+ result = palette[imask].astype(np.uint8)
+ if boundaries_color is not None:
+ boundaries_mask = get_boundaries(imask, boundaries_width=boundaries_width)
+ tresult = result.astype(np.float32)
+ tresult[boundaries_mask] = boundaries_color
+ tresult = tresult * boundaries_alpha + (1 - boundaries_alpha) * result
+ result = tresult.astype(np.uint8)
+
+ return result
+
+
+@lru_cache(maxsize=16)
+def get_palette(num_cls):
+ palette = np.zeros(3 * num_cls, dtype=np.int32)
+
+ for j in range(0, num_cls):
+ lab = j
+ i = 0
+
+ while lab > 0:
+ palette[j*3 + 0] |= (((lab >> 0) & 1) << (7-i))
+ palette[j*3 + 1] |= (((lab >> 1) & 1) << (7-i))
+ palette[j*3 + 2] |= (((lab >> 2) & 1) << (7-i))
+ i = i + 1
+ lab >>= 3
+
+ return palette.reshape((-1, 3))
+
+
+def visualize_mask(mask, num_cls):
+ palette = get_palette(num_cls)
+ mask[mask == -1] = 0
+
+ return palette[mask].astype(np.uint8)
+
+
+def visualize_proposals(proposals_info, point_color=(255, 0, 0), point_radius=1):
+ proposal_map, colors, candidates = proposals_info
+
+ proposal_map = draw_probmap(proposal_map)
+ for x, y in candidates:
+ proposal_map = cv2.circle(proposal_map, (y, x), point_radius, point_color, -1)
+
+ return proposal_map
+
+
+def draw_probmap(x):
+ return cv2.applyColorMap((x * 255).astype(np.uint8), cv2.COLORMAP_HOT)
+
+
+def draw_points(image, points, color, radius=3):
+ image = image.copy()
+ for p in points:
+ image = cv2.circle(image, (int(p[1]), int(p[0])), radius, color, -1)
+
+ return image
+
+
+def draw_instance_map(x, palette=None):
+ num_colors = x.max() + 1
+ if palette is None:
+ palette = get_palette(num_colors)
+
+ return palette[x].astype(np.uint8)
+
+
+def blend_mask(image, mask, alpha=0.6):
+ if mask.min() == -1:
+ mask = mask.copy() + 1
+
+ imap = draw_instance_map(mask)
+ result = (image * (1 - alpha) + alpha * imap).astype(np.uint8)
+ return result
+
+
+def get_boundaries(instances_masks, boundaries_width=1):
+ boundaries = np.zeros((instances_masks.shape[0], instances_masks.shape[1]), dtype=np.bool)
+
+ for obj_id in np.unique(instances_masks.flatten()):
+ if obj_id == 0:
+ continue
+
+ obj_mask = instances_masks == obj_id
+ kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
+ inner_mask = cv2.erode(obj_mask.astype(np.uint8), kernel, iterations=boundaries_width).astype(np.bool)
+
+ obj_boundary = np.logical_xor(obj_mask, np.logical_and(inner_mask, obj_mask))
+ boundaries = np.logical_or(boundaries, obj_boundary)
+ return boundaries
+
+
+def draw_with_blend_and_clicks(img, mask=None, alpha=0.6, clicks_list=None, pos_color=(0, 255, 0),
+ neg_color=(255, 0, 0), radius=4):
+ result = img.copy()
+
+ if mask is not None:
+ palette = get_palette(np.max(mask) + 1)
+ rgb_mask = palette[mask.astype(np.uint8)]
+
+ mask_region = (mask > 0).astype(np.uint8)
+ result = result * (1 - mask_region[:, :, np.newaxis]) + \
+ (1 - alpha) * mask_region[:, :, np.newaxis] * result + \
+ alpha * rgb_mask
+ result = result.astype(np.uint8)
+
+ # result = (result * (1 - alpha) + alpha * rgb_mask).astype(np.uint8)
+
+ if clicks_list is not None and len(clicks_list) > 0:
+ pos_points = [click.coords for click in clicks_list if click.is_positive]
+ neg_points = [click.coords for click in clicks_list if not click.is_positive]
+
+ result = draw_points(result, pos_points, pos_color, radius=radius)
+ result = draw_points(result, neg_points, neg_color, radius=radius)
+
+ return result
+
diff --git a/inference/interact/fbrs_controller.py b/inference/interact/fbrs_controller.py
new file mode 100644
index 0000000000000000000000000000000000000000..1fe9ca496193829990b3db7b0f141aabeb61fd35
--- /dev/null
+++ b/inference/interact/fbrs_controller.py
@@ -0,0 +1,53 @@
+import torch
+from .fbrs.controller import InteractiveController
+from .fbrs.inference import utils
+
+
+class FBRSController:
+ def __init__(self, checkpoint_path, device='cuda:0', max_size=800):
+ model = utils.load_is_model(checkpoint_path, device, cpu_dist_maps=True, norm_radius=260)
+
+ # Predictor params
+ zoomin_params = {
+ 'skip_clicks': 1,
+ 'target_size': 480,
+ 'expansion_ratio': 1.4,
+ }
+
+ predictor_params = {
+ 'brs_mode': 'f-BRS-B',
+ 'prob_thresh': 0.5,
+ 'zoom_in_params': zoomin_params,
+ 'predictor_params': {
+ 'net_clicks_limit': 8,
+ 'max_size': 800,
+ },
+ 'brs_opt_func_params': {'min_iou_diff': 1e-3},
+ 'lbfgs_params': {'maxfun': 20}
+ }
+
+ self.controller = InteractiveController(model, device, predictor_params)
+ self.anchored = False
+ self.device = device
+
+ def unanchor(self):
+ self.anchored = False
+
+ def interact(self, image, x, y, is_positive):
+ image = image.to(self.device, non_blocking=True)
+ if not self.anchored:
+ self.controller.set_image(image)
+ self.controller.reset_predictor()
+ self.anchored = True
+
+ self.controller.add_click(x, y, is_positive)
+ # return self.controller.result_mask
+ # return self.controller.probs_history[-1][1]
+ return (self.controller.probs_history[-1][1]>0.5).float()
+
+ def undo(self):
+ self.controller.undo_click()
+ if len(self.controller.probs_history) == 0:
+ return None
+ else:
+ return (self.controller.probs_history[-1][1]>0.5).float()
\ No newline at end of file
diff --git a/inference/interact/gui.py b/inference/interact/gui.py
new file mode 100644
index 0000000000000000000000000000000000000000..039a382bda5b5a892723df894c4dffab356e99c4
--- /dev/null
+++ b/inference/interact/gui.py
@@ -0,0 +1,933 @@
+"""
+Based on https://github.com/hkchengrex/MiVOS/tree/MiVOS-STCN
+(which is based on https://github.com/seoungwugoh/ivs-demo)
+
+This version is much simplified.
+In this repo, we don't have
+- local control
+- fusion module
+- undo
+- timers
+
+but with XMem as the backbone and is more memory (for both CPU and GPU) friendly
+"""
+
+import functools
+
+import os
+import cv2
+# fix conflicts between qt5 and cv2
+os.environ.pop("QT_QPA_PLATFORM_PLUGIN_PATH")
+
+import numpy as np
+import torch
+
+from PyQt5.QtWidgets import (QWidget, QApplication, QComboBox, QCheckBox,
+ QHBoxLayout, QLabel, QPushButton, QTextEdit, QSpinBox, QFileDialog,
+ QPlainTextEdit, QVBoxLayout, QSizePolicy, QButtonGroup, QSlider, QShortcut, QRadioButton)
+
+from PyQt5.QtGui import QPixmap, QKeySequence, QImage, QTextCursor, QIcon
+from PyQt5.QtCore import Qt, QTimer
+
+from model.network import XMem
+
+from inference.inference_core import InferenceCore
+from .s2m_controller import S2MController
+from .fbrs_controller import FBRSController
+
+from .interactive_utils import *
+from .interaction import *
+from .resource_manager import ResourceManager
+from .gui_utils import *
+
+
+class App(QWidget):
+ def __init__(self, net: XMem,
+ resource_manager: ResourceManager,
+ s2m_ctrl:S2MController,
+ fbrs_ctrl:FBRSController, config):
+ super().__init__()
+
+ self.initialized = False
+ self.num_objects = config['num_objects']
+ self.s2m_controller = s2m_ctrl
+ self.fbrs_controller = fbrs_ctrl
+ self.config = config
+ self.processor = InferenceCore(net, config)
+ self.processor.set_all_labels(list(range(1, self.num_objects+1)))
+ self.res_man = resource_manager
+
+ self.num_frames = len(self.res_man)
+ self.height, self.width = self.res_man.h, self.res_man.w
+
+ # set window
+ self.setWindowTitle('XMem Demo')
+ self.setGeometry(100, 100, self.width, self.height+100)
+ self.setWindowIcon(QIcon('docs/icon.png'))
+
+ # some buttons
+ self.play_button = QPushButton('Play Video')
+ self.play_button.clicked.connect(self.on_play_video)
+ self.commit_button = QPushButton('Commit')
+ self.commit_button.clicked.connect(self.on_commit)
+
+ self.forward_run_button = QPushButton('Forward Propagate')
+ self.forward_run_button.clicked.connect(self.on_forward_propagation)
+ self.forward_run_button.setMinimumWidth(200)
+
+ self.backward_run_button = QPushButton('Backward Propagate')
+ self.backward_run_button.clicked.connect(self.on_backward_propagation)
+ self.backward_run_button.setMinimumWidth(200)
+
+ self.reset_button = QPushButton('Reset Frame')
+ self.reset_button.clicked.connect(self.on_reset_mask)
+
+ # LCD
+ self.lcd = QTextEdit()
+ self.lcd.setReadOnly(True)
+ self.lcd.setMaximumHeight(28)
+ self.lcd.setMaximumWidth(120)
+ self.lcd.setText('{: 4d} / {: 4d}'.format(0, self.num_frames-1))
+
+ # timeline slider
+ self.tl_slider = QSlider(Qt.Horizontal)
+ self.tl_slider.valueChanged.connect(self.tl_slide)
+ self.tl_slider.setMinimum(0)
+ self.tl_slider.setMaximum(self.num_frames-1)
+ self.tl_slider.setValue(0)
+ self.tl_slider.setTickPosition(QSlider.TicksBelow)
+ self.tl_slider.setTickInterval(1)
+
+ # brush size slider
+ self.brush_label = QLabel()
+ self.brush_label.setAlignment(Qt.AlignCenter)
+ self.brush_label.setMinimumWidth(100)
+
+ self.brush_slider = QSlider(Qt.Horizontal)
+ self.brush_slider.valueChanged.connect(self.brush_slide)
+ self.brush_slider.setMinimum(1)
+ self.brush_slider.setMaximum(100)
+ self.brush_slider.setValue(3)
+ self.brush_slider.setTickPosition(QSlider.TicksBelow)
+ self.brush_slider.setTickInterval(2)
+ self.brush_slider.setMinimumWidth(300)
+
+ # combobox
+ self.combo = QComboBox(self)
+ self.combo.addItem("davis")
+ self.combo.addItem("fade")
+ self.combo.addItem("light")
+ self.combo.addItem("popup")
+ self.combo.addItem("layered")
+ self.combo.currentTextChanged.connect(self.set_viz_mode)
+
+ self.save_visualization_checkbox = QCheckBox(self)
+ self.save_visualization_checkbox.toggled.connect(self.on_save_visualization_toggle)
+ self.save_visualization_checkbox.setChecked(False)
+ self.save_visualization = False
+
+ # Radio buttons for type of interactions
+ self.curr_interaction = 'Click'
+ self.interaction_group = QButtonGroup()
+ self.radio_fbrs = QRadioButton('Click')
+ self.radio_s2m = QRadioButton('Scribble')
+ self.radio_free = QRadioButton('Free')
+ self.interaction_group.addButton(self.radio_fbrs)
+ self.interaction_group.addButton(self.radio_s2m)
+ self.interaction_group.addButton(self.radio_free)
+ self.radio_fbrs.toggled.connect(self.interaction_radio_clicked)
+ self.radio_s2m.toggled.connect(self.interaction_radio_clicked)
+ self.radio_free.toggled.connect(self.interaction_radio_clicked)
+ self.radio_fbrs.toggle()
+
+ # Main canvas -> QLabel
+ self.main_canvas = QLabel()
+ self.main_canvas.setSizePolicy(QSizePolicy.Expanding,
+ QSizePolicy.Expanding)
+ self.main_canvas.setAlignment(Qt.AlignCenter)
+ self.main_canvas.setMinimumSize(100, 100)
+
+ self.main_canvas.mousePressEvent = self.on_mouse_press
+ self.main_canvas.mouseMoveEvent = self.on_mouse_motion
+ self.main_canvas.setMouseTracking(True) # Required for all-time tracking
+ self.main_canvas.mouseReleaseEvent = self.on_mouse_release
+
+ # Minimap -> Also a QLbal
+ self.minimap = QLabel()
+ self.minimap.setSizePolicy(QSizePolicy.Expanding,
+ QSizePolicy.Expanding)
+ self.minimap.setAlignment(Qt.AlignTop)
+ self.minimap.setMinimumSize(100, 100)
+
+ # Zoom-in buttons
+ self.zoom_p_button = QPushButton('Zoom +')
+ self.zoom_p_button.clicked.connect(self.on_zoom_plus)
+ self.zoom_m_button = QPushButton('Zoom -')
+ self.zoom_m_button.clicked.connect(self.on_zoom_minus)
+
+ # Parameters setting
+ self.clear_mem_button = QPushButton('Clear memory')
+ self.clear_mem_button.clicked.connect(self.on_clear_memory)
+
+ self.work_mem_gauge, self.work_mem_gauge_layout = create_gauge('Working memory size')
+ self.long_mem_gauge, self.long_mem_gauge_layout = create_gauge('Long-term memory size')
+ self.gpu_mem_gauge, self.gpu_mem_gauge_layout = create_gauge('GPU mem. (all processes, w/ caching)')
+ self.torch_mem_gauge, self.torch_mem_gauge_layout = create_gauge('GPU mem. (used by torch, w/o caching)')
+
+ self.update_memory_size()
+ self.update_gpu_usage()
+
+ self.work_mem_min, self.work_mem_min_layout = create_parameter_box(1, 100, 'Min. working memory frames',
+ callback=self.on_work_min_change)
+ self.work_mem_max, self.work_mem_max_layout = create_parameter_box(2, 100, 'Max. working memory frames',
+ callback=self.on_work_max_change)
+ self.long_mem_max, self.long_mem_max_layout = create_parameter_box(1000, 100000,
+ 'Max. long-term memory size', step=1000, callback=self.update_config)
+ self.num_prototypes_box, self.num_prototypes_box_layout = create_parameter_box(32, 1280,
+ 'Number of prototypes', step=32, callback=self.update_config)
+ self.mem_every_box, self.mem_every_box_layout = create_parameter_box(1, 100, 'Memory frame every (r)',
+ callback=self.update_config)
+
+ self.work_mem_min.setValue(self.processor.memory.min_mt_frames)
+ self.work_mem_max.setValue(self.processor.memory.max_mt_frames)
+ self.long_mem_max.setValue(self.processor.memory.max_long_elements)
+ self.num_prototypes_box.setValue(self.processor.memory.num_prototypes)
+ self.mem_every_box.setValue(self.processor.mem_every)
+
+ # import mask/layer
+ self.import_mask_button = QPushButton('Import mask')
+ self.import_mask_button.clicked.connect(self.on_import_mask)
+ self.import_layer_button = QPushButton('Import layer')
+ self.import_layer_button.clicked.connect(self.on_import_layer)
+
+ # Console on the GUI
+ self.console = QPlainTextEdit()
+ self.console.setReadOnly(True)
+ self.console.setMinimumHeight(100)
+ self.console.setMaximumHeight(100)
+
+ # navigator
+ navi = QHBoxLayout()
+ navi.addWidget(self.lcd)
+ navi.addWidget(self.play_button)
+
+ interact_subbox = QVBoxLayout()
+ interact_topbox = QHBoxLayout()
+ interact_botbox = QHBoxLayout()
+ interact_topbox.setAlignment(Qt.AlignCenter)
+ interact_topbox.addWidget(self.radio_s2m)
+ interact_topbox.addWidget(self.radio_fbrs)
+ interact_topbox.addWidget(self.radio_free)
+ interact_topbox.addWidget(self.brush_label)
+ interact_botbox.addWidget(self.brush_slider)
+ interact_subbox.addLayout(interact_topbox)
+ interact_subbox.addLayout(interact_botbox)
+ navi.addLayout(interact_subbox)
+
+ navi.addStretch(1)
+ navi.addWidget(self.reset_button)
+
+ navi.addStretch(1)
+ navi.addWidget(QLabel('Overlay Mode'))
+ navi.addWidget(self.combo)
+ navi.addWidget(QLabel('Save overlay during propagation'))
+ navi.addWidget(self.save_visualization_checkbox)
+ navi.addStretch(1)
+ navi.addWidget(self.commit_button)
+ navi.addWidget(self.forward_run_button)
+ navi.addWidget(self.backward_run_button)
+
+ # Drawing area, main canvas and minimap
+ draw_area = QHBoxLayout()
+ draw_area.addWidget(self.main_canvas, 4)
+
+ # Minimap area
+ minimap_area = QVBoxLayout()
+ minimap_area.setAlignment(Qt.AlignTop)
+ mini_label = QLabel('Minimap')
+ mini_label.setAlignment(Qt.AlignTop)
+ minimap_area.addWidget(mini_label)
+
+ # Minimap zooming
+ minimap_ctrl = QHBoxLayout()
+ minimap_ctrl.setAlignment(Qt.AlignTop)
+ minimap_ctrl.addWidget(self.zoom_p_button)
+ minimap_ctrl.addWidget(self.zoom_m_button)
+ minimap_area.addLayout(minimap_ctrl)
+ minimap_area.addWidget(self.minimap)
+
+ # Parameters
+ minimap_area.addLayout(self.work_mem_gauge_layout)
+ minimap_area.addLayout(self.long_mem_gauge_layout)
+ minimap_area.addLayout(self.gpu_mem_gauge_layout)
+ minimap_area.addLayout(self.torch_mem_gauge_layout)
+ minimap_area.addWidget(self.clear_mem_button)
+ minimap_area.addLayout(self.work_mem_min_layout)
+ minimap_area.addLayout(self.work_mem_max_layout)
+ minimap_area.addLayout(self.long_mem_max_layout)
+ minimap_area.addLayout(self.num_prototypes_box_layout)
+ minimap_area.addLayout(self.mem_every_box_layout)
+
+ # import mask/layer
+ import_area = QHBoxLayout()
+ import_area.setAlignment(Qt.AlignTop)
+ import_area.addWidget(self.import_mask_button)
+ import_area.addWidget(self.import_layer_button)
+ minimap_area.addLayout(import_area)
+
+ # console
+ minimap_area.addWidget(self.console)
+
+ draw_area.addLayout(minimap_area, 1)
+
+ layout = QVBoxLayout()
+ layout.addLayout(draw_area)
+ layout.addWidget(self.tl_slider)
+ layout.addLayout(navi)
+ self.setLayout(layout)
+
+ # timer to play video
+ self.timer = QTimer()
+ self.timer.setSingleShot(False)
+
+ # timer to update GPU usage
+ self.gpu_timer = QTimer()
+ self.gpu_timer.setSingleShot(False)
+ self.gpu_timer.timeout.connect(self.on_gpu_timer)
+ self.gpu_timer.setInterval(2000)
+ self.gpu_timer.start()
+
+ # current frame info
+ self.curr_frame_dirty = False
+ self.current_image = np.zeros((self.height, self.width, 3), dtype=np.uint8)
+ self.current_image_torch = None
+ self.current_mask = np.zeros((self.height, self.width), dtype=np.uint8)
+ self.current_prob = torch.zeros((self.num_objects, self.height, self.width), dtype=torch.float).cuda()
+
+ # initialize visualization
+ self.viz_mode = 'davis'
+ self.vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
+ self.vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
+ self.brush_vis_map = np.zeros((self.height, self.width, 3), dtype=np.uint8)
+ self.brush_vis_alpha = np.zeros((self.height, self.width, 1), dtype=np.float32)
+ self.cursur = 0
+ self.on_showing = None
+
+ # Zoom parameters
+ self.zoom_pixels = 150
+
+ # initialize action
+ self.interaction = None
+ self.pressed = False
+ self.right_click = False
+ self.current_object = 1
+ self.last_ex = self.last_ey = 0
+
+ self.propagating = False
+
+ # Objects shortcuts
+ for i in range(1, self.num_objects+1):
+ QShortcut(QKeySequence(str(i)), self).activated.connect(functools.partial(self.hit_number_key, i))
+
+ # <- and -> shortcuts
+ QShortcut(QKeySequence(Qt.Key_Left), self).activated.connect(self.on_prev_frame)
+ QShortcut(QKeySequence(Qt.Key_Right), self).activated.connect(self.on_next_frame)
+
+ self.interacted_prob = None
+ self.overlay_layer = None
+ self.overlay_layer_torch = None
+
+ # the object id used for popup/layered overlay
+ self.vis_target_objects = [1]
+ # try to load the default overlay
+ self._try_load_layer('./docs/ECCV-logo.png')
+
+ self.load_current_image_mask()
+ self.show_current_frame()
+ self.show()
+
+ self.console_push_text('Initialized.')
+ self.initialized = True
+
+ def resizeEvent(self, event):
+ self.show_current_frame()
+
+ def console_push_text(self, text):
+ self.console.moveCursor(QTextCursor.End)
+ self.console.insertPlainText(text+'\n')
+
+ def interaction_radio_clicked(self, event):
+ self.last_interaction = self.curr_interaction
+ if self.radio_s2m.isChecked():
+ self.curr_interaction = 'Scribble'
+ self.brush_size = 3
+ self.brush_slider.setDisabled(True)
+ elif self.radio_fbrs.isChecked():
+ self.curr_interaction = 'Click'
+ self.brush_size = 3
+ self.brush_slider.setDisabled(True)
+ elif self.radio_free.isChecked():
+ self.brush_slider.setDisabled(False)
+ self.brush_slide()
+ self.curr_interaction = 'Free'
+ if self.curr_interaction == 'Scribble':
+ self.commit_button.setEnabled(True)
+ else:
+ self.commit_button.setEnabled(False)
+
+ def load_current_image_mask(self, no_mask=False):
+ self.current_image = self.res_man.get_image(self.cursur)
+ self.current_image_torch = None
+
+ if not no_mask:
+ loaded_mask = self.res_man.get_mask(self.cursur)
+ if loaded_mask is None:
+ self.current_mask.fill(0)
+ else:
+ self.current_mask = loaded_mask.copy()
+ self.current_prob = None
+
+ def load_current_torch_image_mask(self, no_mask=False):
+ if self.current_image_torch is None:
+ self.current_image_torch, self.current_image_torch_no_norm = image_to_torch(self.current_image)
+
+ if self.current_prob is None and not no_mask:
+ self.current_prob = index_numpy_to_one_hot_torch(self.current_mask, self.num_objects+1).cuda()
+
+ def compose_current_im(self):
+ self.viz = get_visualization(self.viz_mode, self.current_image, self.current_mask,
+ self.overlay_layer, self.vis_target_objects)
+
+ def update_interact_vis(self):
+ # Update the interactions without re-computing the overlay
+ height, width, channel = self.viz.shape
+ bytesPerLine = 3 * width
+
+ vis_map = self.vis_map
+ vis_alpha = self.vis_alpha
+ brush_vis_map = self.brush_vis_map
+ brush_vis_alpha = self.brush_vis_alpha
+
+ self.viz_with_stroke = self.viz*(1-vis_alpha) + vis_map*vis_alpha
+ self.viz_with_stroke = self.viz_with_stroke*(1-brush_vis_alpha) + brush_vis_map*brush_vis_alpha
+ self.viz_with_stroke = self.viz_with_stroke.astype(np.uint8)
+
+ qImg = QImage(self.viz_with_stroke.data, width, height, bytesPerLine, QImage.Format_RGB888)
+ self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
+ Qt.KeepAspectRatio, Qt.FastTransformation)))
+
+ self.main_canvas_size = self.main_canvas.size()
+ self.image_size = qImg.size()
+
+ def update_minimap(self):
+ ex, ey = self.last_ex, self.last_ey
+ r = self.zoom_pixels//2
+ ex = int(round(max(r, min(self.width-r, ex))))
+ ey = int(round(max(r, min(self.height-r, ey))))
+
+ patch = self.viz_with_stroke[ey-r:ey+r, ex-r:ex+r, :].astype(np.uint8)
+
+ height, width, channel = patch.shape
+ bytesPerLine = 3 * width
+ qImg = QImage(patch.data, width, height, bytesPerLine, QImage.Format_RGB888)
+ self.minimap.setPixmap(QPixmap(qImg.scaled(self.minimap.size(),
+ Qt.KeepAspectRatio, Qt.FastTransformation)))
+
+ def update_current_image_fast(self):
+ # fast path, uses gpu. Changes the image in-place to avoid copying
+ self.viz = get_visualization_torch(self.viz_mode, self.current_image_torch_no_norm,
+ self.current_prob, self.overlay_layer_torch, self.vis_target_objects)
+ if self.save_visualization:
+ self.res_man.save_visualization(self.cursur, self.viz)
+
+ height, width, channel = self.viz.shape
+ bytesPerLine = 3 * width
+
+ qImg = QImage(self.viz.data, width, height, bytesPerLine, QImage.Format_RGB888)
+ self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
+ Qt.KeepAspectRatio, Qt.FastTransformation)))
+
+ def show_current_frame(self, fast=False):
+ # Re-compute overlay and show the image
+ if fast:
+ self.update_current_image_fast()
+ else:
+ self.compose_current_im()
+ self.update_interact_vis()
+ self.update_minimap()
+
+ self.lcd.setText('{: 3d} / {: 3d}'.format(self.cursur, self.num_frames-1))
+ self.tl_slider.setValue(self.cursur)
+
+ def pixel_pos_to_image_pos(self, x, y):
+ # Un-scale and un-pad the label coordinates into image coordinates
+ oh, ow = self.image_size.height(), self.image_size.width()
+ nh, nw = self.main_canvas_size.height(), self.main_canvas_size.width()
+
+ h_ratio = nh/oh
+ w_ratio = nw/ow
+ dominate_ratio = min(h_ratio, w_ratio)
+
+ # Solve scale
+ x /= dominate_ratio
+ y /= dominate_ratio
+
+ # Solve padding
+ fh, fw = nh/dominate_ratio, nw/dominate_ratio
+ x -= (fw-ow)/2
+ y -= (fh-oh)/2
+
+ return x, y
+
+ def is_pos_out_of_bound(self, x, y):
+ x, y = self.pixel_pos_to_image_pos(x, y)
+
+ out_of_bound = (
+ (x < 0) or
+ (y < 0) or
+ (x > self.width-1) or
+ (y > self.height-1)
+ )
+
+ return out_of_bound
+
+ def get_scaled_pos(self, x, y):
+ x, y = self.pixel_pos_to_image_pos(x, y)
+
+ x = max(0, min(self.width-1, x))
+ y = max(0, min(self.height-1, y))
+
+ return x, y
+
+ def clear_visualization(self):
+ self.vis_map.fill(0)
+ self.vis_alpha.fill(0)
+
+ def reset_this_interaction(self):
+ self.complete_interaction()
+ self.clear_visualization()
+ self.interaction = None
+ if self.fbrs_controller is not None:
+ self.fbrs_controller.unanchor()
+
+ def set_viz_mode(self):
+ self.viz_mode = self.combo.currentText()
+ self.show_current_frame()
+
+ def save_current_mask(self):
+ # save mask to hard disk
+ self.res_man.save_mask(self.cursur, self.current_mask)
+
+ def tl_slide(self):
+ # if we are propagating, the on_run function will take care of everything
+ # don't do duplicate work here
+ if not self.propagating:
+ if self.curr_frame_dirty:
+ self.save_current_mask()
+ self.curr_frame_dirty = False
+
+ self.reset_this_interaction()
+ self.cursur = self.tl_slider.value()
+ self.load_current_image_mask()
+ self.show_current_frame()
+
+ def brush_slide(self):
+ self.brush_size = self.brush_slider.value()
+ self.brush_label.setText('Brush size: %d' % self.brush_size)
+ try:
+ if type(self.interaction) == FreeInteraction:
+ self.interaction.set_size(self.brush_size)
+ except AttributeError:
+ # Initialization, forget about it
+ pass
+
+ def on_forward_propagation(self):
+ if self.propagating:
+ # acts as a pause button
+ self.propagating = False
+ else:
+ self.propagate_fn = self.on_next_frame
+ self.backward_run_button.setEnabled(False)
+ self.forward_run_button.setText('Pause Propagation')
+ self.on_propagation()
+
+ def on_backward_propagation(self):
+ if self.propagating:
+ # acts as a pause button
+ self.propagating = False
+ else:
+ self.propagate_fn = self.on_prev_frame
+ self.forward_run_button.setEnabled(False)
+ self.backward_run_button.setText('Pause Propagation')
+ self.on_propagation()
+
+ def on_pause(self):
+ self.propagating = False
+ self.forward_run_button.setEnabled(True)
+ self.backward_run_button.setEnabled(True)
+ self.clear_mem_button.setEnabled(True)
+ self.forward_run_button.setText('Forward Propagate')
+ self.backward_run_button.setText('Backward Propagate')
+ self.console_push_text('Propagation stopped.')
+
+ def on_propagation(self):
+ # start to propagate
+ self.load_current_torch_image_mask()
+ self.show_current_frame(fast=True)
+
+ self.console_push_text('Propagation started.')
+ self.current_prob = self.processor.step(self.current_image_torch, self.current_prob[1:])
+ self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
+ # clear
+ self.interacted_prob = None
+ self.reset_this_interaction()
+
+ self.propagating = True
+ self.clear_mem_button.setEnabled(False)
+ # propagate till the end
+ while self.propagating:
+ self.propagate_fn()
+
+ self.load_current_image_mask(no_mask=True)
+ self.load_current_torch_image_mask(no_mask=True)
+
+ self.current_prob = self.processor.step(self.current_image_torch)
+ self.current_mask = torch_prob_to_numpy_mask(self.current_prob)
+
+ self.save_current_mask()
+ self.show_current_frame(fast=True)
+
+ self.update_memory_size()
+ QApplication.processEvents()
+
+ if self.cursur == 0 or self.cursur == self.num_frames-1:
+ break
+
+ self.propagating = False
+ self.curr_frame_dirty = False
+ self.on_pause()
+ self.tl_slide()
+ QApplication.processEvents()
+
+ def pause_propagation(self):
+ self.propagating = False
+
+ def on_commit(self):
+ self.complete_interaction()
+ self.update_interacted_mask()
+
+ def on_prev_frame(self):
+ # self.tl_slide will trigger on setValue
+ self.cursur = max(0, self.cursur-1)
+ self.tl_slider.setValue(self.cursur)
+
+ def on_next_frame(self):
+ # self.tl_slide will trigger on setValue
+ self.cursur = min(self.cursur+1, self.num_frames-1)
+ self.tl_slider.setValue(self.cursur)
+
+ def on_play_video_timer(self):
+ self.cursur += 1
+ if self.cursur > self.num_frames-1:
+ self.cursur = 0
+ self.tl_slider.setValue(self.cursur)
+
+ def on_play_video(self):
+ if self.timer.isActive():
+ self.timer.stop()
+ self.play_button.setText('Play Video')
+ else:
+ self.timer.start(1000 / 30)
+ self.play_button.setText('Stop Video')
+
+ def on_reset_mask(self):
+ self.current_mask.fill(0)
+ if self.current_prob is not None:
+ self.current_prob.fill_(0)
+ self.curr_frame_dirty = True
+ self.save_current_mask()
+ self.reset_this_interaction()
+ self.show_current_frame()
+
+ def on_zoom_plus(self):
+ self.zoom_pixels -= 25
+ self.zoom_pixels = max(50, self.zoom_pixels)
+ self.update_minimap()
+
+ def on_zoom_minus(self):
+ self.zoom_pixels += 25
+ self.zoom_pixels = min(self.zoom_pixels, 300)
+ self.update_minimap()
+
+ def set_navi_enable(self, boolean):
+ self.zoom_p_button.setEnabled(boolean)
+ self.zoom_m_button.setEnabled(boolean)
+ self.run_button.setEnabled(boolean)
+ self.tl_slider.setEnabled(boolean)
+ self.play_button.setEnabled(boolean)
+ self.lcd.setEnabled(boolean)
+
+ def hit_number_key(self, number):
+ if number == self.current_object:
+ return
+ self.current_object = number
+ if self.fbrs_controller is not None:
+ self.fbrs_controller.unanchor()
+ self.console_push_text(f'Current object changed to {number}.')
+ self.clear_brush()
+ self.vis_brush(self.last_ex, self.last_ey)
+ self.update_interact_vis()
+ self.show_current_frame()
+
+ def clear_brush(self):
+ self.brush_vis_map.fill(0)
+ self.brush_vis_alpha.fill(0)
+
+ def vis_brush(self, ex, ey):
+ self.brush_vis_map = cv2.circle(self.brush_vis_map,
+ (int(round(ex)), int(round(ey))), self.brush_size//2+1, color_map[self.current_object], thickness=-1)
+ self.brush_vis_alpha = cv2.circle(self.brush_vis_alpha,
+ (int(round(ex)), int(round(ey))), self.brush_size//2+1, 0.5, thickness=-1)
+
+ def on_mouse_press(self, event):
+ if self.is_pos_out_of_bound(event.x(), event.y()):
+ return
+
+ # mid-click
+ if (event.button() == Qt.MidButton):
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ target_object = self.current_mask[int(ey),int(ex)]
+ if target_object in self.vis_target_objects:
+ self.vis_target_objects.remove(target_object)
+ else:
+ self.vis_target_objects.append(target_object)
+ self.console_push_text(f'Target objects for visualization changed to {self.vis_target_objects}')
+ self.show_current_frame()
+ return
+
+ self.right_click = (event.button() == Qt.RightButton)
+ self.pressed = True
+
+ h, w = self.height, self.width
+
+ self.load_current_torch_image_mask()
+ image = self.current_image_torch
+
+ last_interaction = self.interaction
+ new_interaction = None
+ if self.curr_interaction == 'Scribble':
+ if last_interaction is None or type(last_interaction) != ScribbleInteraction:
+ self.complete_interaction()
+ new_interaction = ScribbleInteraction(image, torch.from_numpy(self.current_mask).float().cuda(),
+ (h, w), self.s2m_controller, self.num_objects)
+ elif self.curr_interaction == 'Free':
+ if last_interaction is None or type(last_interaction) != FreeInteraction:
+ self.complete_interaction()
+ new_interaction = FreeInteraction(image, self.current_mask, (h, w),
+ self.num_objects)
+ new_interaction.set_size(self.brush_size)
+ elif self.curr_interaction == 'Click':
+ if (last_interaction is None or type(last_interaction) != ClickInteraction
+ or last_interaction.tar_obj != self.current_object):
+ self.complete_interaction()
+ self.fbrs_controller.unanchor()
+ new_interaction = ClickInteraction(image, self.current_prob, (h, w),
+ self.fbrs_controller, self.current_object)
+
+ if new_interaction is not None:
+ self.interaction = new_interaction
+
+ # Just motion it as the first step
+ self.on_mouse_motion(event)
+
+ def on_mouse_motion(self, event):
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ self.last_ex, self.last_ey = ex, ey
+ self.clear_brush()
+ # Visualize
+ self.vis_brush(ex, ey)
+ if self.pressed:
+ if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
+ obj = 0 if self.right_click else self.current_object
+ self.vis_map, self.vis_alpha = self.interaction.push_point(
+ ex, ey, obj, (self.vis_map, self.vis_alpha)
+ )
+ self.update_interact_vis()
+ self.update_minimap()
+
+ def update_interacted_mask(self):
+ self.current_prob = self.interacted_prob
+ self.current_mask = torch_prob_to_numpy_mask(self.interacted_prob)
+ self.show_current_frame()
+ self.save_current_mask()
+ self.curr_frame_dirty = False
+
+ def complete_interaction(self):
+ if self.interaction is not None:
+ self.clear_visualization()
+ self.interaction = None
+
+ def on_mouse_release(self, event):
+ if not self.pressed:
+ # this can happen when the initial press is out-of-bound
+ return
+
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+
+ self.console_push_text('%s interaction at frame %d.' % (self.curr_interaction, self.cursur))
+ interaction = self.interaction
+
+ if self.curr_interaction == 'Scribble' or self.curr_interaction == 'Free':
+ self.on_mouse_motion(event)
+ interaction.end_path()
+ if self.curr_interaction == 'Free':
+ self.clear_visualization()
+ elif self.curr_interaction == 'Click':
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ self.vis_map, self.vis_alpha = interaction.push_point(ex, ey,
+ self.right_click, (self.vis_map, self.vis_alpha))
+
+ self.interacted_prob = interaction.predict()
+ self.update_interacted_mask()
+ self.update_gpu_usage()
+
+ self.pressed = self.right_click = False
+
+ def wheelEvent(self, event):
+ ex, ey = self.get_scaled_pos(event.x(), event.y())
+ if self.curr_interaction == 'Free':
+ self.brush_slider.setValue(self.brush_slider.value() + event.angleDelta().y()//30)
+ self.clear_brush()
+ self.vis_brush(ex, ey)
+ self.update_interact_vis()
+ self.update_minimap()
+
+ def update_gpu_usage(self):
+ info = torch.cuda.mem_get_info()
+ global_free, global_total = info
+ global_free /= (2**30)
+ global_total /= (2**30)
+ global_used = global_total - global_free
+
+ self.gpu_mem_gauge.setFormat(f'{global_used:.01f} GB / {global_total:.01f} GB')
+ self.gpu_mem_gauge.setValue(round(global_used/global_total*100))
+
+ used_by_torch = torch.cuda.max_memory_allocated() / (2**20)
+ self.torch_mem_gauge.setFormat(f'{used_by_torch:.0f} MB / {global_total:.01f} GB')
+ self.torch_mem_gauge.setValue(round(used_by_torch/global_total*100/1024))
+
+ def on_gpu_timer(self):
+ self.update_gpu_usage()
+
+ def update_memory_size(self):
+ try:
+ max_work_elements = self.processor.memory.max_work_elements
+ max_long_elements = self.processor.memory.max_long_elements
+
+ curr_work_elements = self.processor.memory.work_mem.size
+ curr_long_elements = self.processor.memory.long_mem.size
+
+ self.work_mem_gauge.setFormat(f'{curr_work_elements} / {max_work_elements}')
+ self.work_mem_gauge.setValue(round(curr_work_elements/max_work_elements*100))
+
+ self.long_mem_gauge.setFormat(f'{curr_long_elements} / {max_long_elements}')
+ self.long_mem_gauge.setValue(round(curr_long_elements/max_long_elements*100))
+
+ except AttributeError:
+ self.work_mem_gauge.setFormat('Unknown')
+ self.long_mem_gauge.setFormat('Unknown')
+ self.work_mem_gauge.setValue(0)
+ self.long_mem_gauge.setValue(0)
+
+ def on_work_min_change(self):
+ if self.initialized:
+ self.work_mem_min.setValue(min(self.work_mem_min.value(), self.work_mem_max.value()-1))
+ self.update_config()
+
+ def on_work_max_change(self):
+ if self.initialized:
+ self.work_mem_max.setValue(max(self.work_mem_max.value(), self.work_mem_min.value()+1))
+ self.update_config()
+
+ def update_config(self):
+ if self.initialized:
+ self.config['min_mid_term_frames'] = self.work_mem_min.value()
+ self.config['max_mid_term_frames'] = self.work_mem_max.value()
+ self.config['max_long_term_elements'] = self.long_mem_max.value()
+ self.config['num_prototypes'] = self.num_prototypes_box.value()
+ self.config['mem_every'] = self.mem_every_box.value()
+
+ self.processor.update_config(self.config)
+
+ def on_clear_memory(self):
+ self.processor.clear_memory()
+ torch.cuda.empty_cache()
+ self.update_gpu_usage()
+ self.update_memory_size()
+
+ def _open_file(self, prompt):
+ options = QFileDialog.Options()
+ file_name, _ = QFileDialog.getOpenFileName(self, prompt, "", "Image files (*)", options=options)
+ return file_name
+
+ def on_import_mask(self):
+ file_name = self._open_file('Mask')
+ if len(file_name) == 0:
+ return
+
+ mask = self.res_man.read_external_image(file_name, size=(self.height, self.width))
+
+ shape_condition = (
+ (len(mask.shape) == 2) and
+ (mask.shape[-1] == self.width) and
+ (mask.shape[-2] == self.height)
+ )
+
+ object_condition = (
+ mask.max() <= self.num_objects
+ )
+
+ if not shape_condition:
+ self.console_push_text(f'Expected ({self.height}, {self.width}). Got {mask.shape} instead.')
+ elif not object_condition:
+ self.console_push_text(f'Expected {self.num_objects} objects. Got {mask.max()} objects instead.')
+ else:
+ self.console_push_text(f'Mask file {file_name} loaded.')
+ self.current_image_torch = self.current_prob = None
+ self.current_mask = mask
+ self.show_current_frame()
+ self.save_current_mask()
+
+ def on_import_layer(self):
+ file_name = self._open_file('Layer')
+ if len(file_name) == 0:
+ return
+
+ self._try_load_layer(file_name)
+
+ def _try_load_layer(self, file_name):
+ try:
+ layer = self.res_man.read_external_image(file_name, size=(self.height, self.width))
+
+ if layer.shape[-1] == 3:
+ layer = np.concatenate([layer, np.ones_like(layer[:,:,0:1])*255], axis=-1)
+
+ condition = (
+ (len(layer.shape) == 3) and
+ (layer.shape[-1] == 4) and
+ (layer.shape[-2] == self.width) and
+ (layer.shape[-3] == self.height)
+ )
+
+ if not condition:
+ self.console_push_text(f'Expected ({self.height}, {self.width}, 4). Got {layer.shape}.')
+ else:
+ self.console_push_text(f'Layer file {file_name} loaded.')
+ self.overlay_layer = layer
+ self.overlay_layer_torch = torch.from_numpy(layer).float().cuda()/255
+ self.show_current_frame()
+ except FileNotFoundError:
+ self.console_push_text(f'{file_name} not found.')
+
+ def on_save_visualization_toggle(self):
+ self.save_visualization = self.save_visualization_checkbox.isChecked()
diff --git a/inference/interact/gui_utils.py b/inference/interact/gui_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..daf852b30a84893c836d7c3350b727aeed5d0a6b
--- /dev/null
+++ b/inference/interact/gui_utils.py
@@ -0,0 +1,40 @@
+from PyQt5.QtCore import Qt
+from PyQt5.QtWidgets import (QHBoxLayout, QLabel, QSpinBox, QVBoxLayout, QProgressBar)
+
+
+def create_parameter_box(min_val, max_val, text, step=1, callback=None):
+ layout = QHBoxLayout()
+
+ dial = QSpinBox()
+ dial.setMaximumHeight(28)
+ dial.setMaximumWidth(150)
+ dial.setMinimum(min_val)
+ dial.setMaximum(max_val)
+ dial.setAlignment(Qt.AlignRight)
+ dial.setSingleStep(step)
+ dial.valueChanged.connect(callback)
+
+ label = QLabel(text)
+ label.setAlignment(Qt.AlignRight)
+
+ layout.addWidget(label)
+ layout.addWidget(dial)
+
+ return dial, layout
+
+
+def create_gauge(text):
+ layout = QHBoxLayout()
+
+ gauge = QProgressBar()
+ gauge.setMaximumHeight(28)
+ gauge.setMaximumWidth(200)
+ gauge.setAlignment(Qt.AlignCenter)
+
+ label = QLabel(text)
+ label.setAlignment(Qt.AlignRight)
+
+ layout.addWidget(label)
+ layout.addWidget(gauge)
+
+ return gauge, layout
diff --git a/inference/interact/interaction.py b/inference/interact/interaction.py
new file mode 100644
index 0000000000000000000000000000000000000000..19f83f9d58a00cac079a7ba5c239196378603b64
--- /dev/null
+++ b/inference/interact/interaction.py
@@ -0,0 +1,252 @@
+"""
+Contains all the types of interaction related to the GUI
+Not related to automatic evaluation in the DAVIS dataset
+
+You can inherit the Interaction class to create new interaction types
+undo is (sometimes partially) supported
+"""
+
+
+import torch
+import torch.nn.functional as F
+import numpy as np
+import cv2
+import time
+from .interactive_utils import color_map, index_numpy_to_one_hot_torch
+
+
+def aggregate_sbg(prob, keep_bg=False, hard=False):
+ device = prob.device
+ k, h, w = prob.shape
+ ex_prob = torch.zeros((k+1, h, w), device=device)
+ ex_prob[0] = 0.5
+ ex_prob[1:] = prob
+ ex_prob = torch.clamp(ex_prob, 1e-7, 1-1e-7)
+ logits = torch.log((ex_prob /(1-ex_prob)))
+
+ if hard:
+ # Very low temperature o((⊙﹏⊙))o 🥶
+ logits *= 1000
+
+ if keep_bg:
+ return F.softmax(logits, dim=0)
+ else:
+ return F.softmax(logits, dim=0)[1:]
+
+def aggregate_wbg(prob, keep_bg=False, hard=False):
+ k, h, w = prob.shape
+ new_prob = torch.cat([
+ torch.prod(1-prob, dim=0, keepdim=True),
+ prob
+ ], 0).clamp(1e-7, 1-1e-7)
+ logits = torch.log((new_prob /(1-new_prob)))
+
+ if hard:
+ # Very low temperature o((⊙﹏⊙))o 🥶
+ logits *= 1000
+
+ if keep_bg:
+ return F.softmax(logits, dim=0)
+ else:
+ return F.softmax(logits, dim=0)[1:]
+
+class Interaction:
+ def __init__(self, image, prev_mask, true_size, controller):
+ self.image = image
+ self.prev_mask = prev_mask
+ self.controller = controller
+ self.start_time = time.time()
+
+ self.h, self.w = true_size
+
+ self.out_prob = None
+ self.out_mask = None
+
+ def predict(self):
+ pass
+
+
+class FreeInteraction(Interaction):
+ def __init__(self, image, prev_mask, true_size, num_objects):
+ """
+ prev_mask should be index format numpy array
+ """
+ super().__init__(image, prev_mask, true_size, None)
+
+ self.K = num_objects
+
+ self.drawn_map = self.prev_mask.copy()
+ self.curr_path = [[] for _ in range(self.K + 1)]
+
+ self.size = None
+
+ def set_size(self, size):
+ self.size = size
+
+ """
+ k - object id
+ vis - a tuple (visualization map, pass through alpha). None if not needed.
+ """
+ def push_point(self, x, y, k, vis=None):
+ if vis is not None:
+ vis_map, vis_alpha = vis
+ selected = self.curr_path[k]
+ selected.append((x, y))
+ if len(selected) >= 2:
+ cv2.line(self.drawn_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ k, thickness=self.size)
+
+ # Plot visualization
+ if vis is not None:
+ # Visualization for drawing
+ if k == 0:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ else:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ # Visualization on/off boolean filter
+ vis_alpha = cv2.line(vis_alpha,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ 0.75, thickness=self.size)
+
+ if vis is not None:
+ return vis_map, vis_alpha
+
+ def end_path(self):
+ # Complete the drawing
+ self.curr_path = [[] for _ in range(self.K + 1)]
+
+ def predict(self):
+ self.out_prob = index_numpy_to_one_hot_torch(self.drawn_map, self.K+1).cuda()
+ # self.out_prob = torch.from_numpy(self.drawn_map).float().cuda()
+ # self.out_prob, _ = pad_divide_by(self.out_prob, 16, self.out_prob.shape[-2:])
+ # self.out_prob = aggregate_sbg(self.out_prob, keep_bg=True)
+ return self.out_prob
+
+class ScribbleInteraction(Interaction):
+ def __init__(self, image, prev_mask, true_size, controller, num_objects):
+ """
+ prev_mask should be in an indexed form
+ """
+ super().__init__(image, prev_mask, true_size, controller)
+
+ self.K = num_objects
+
+ self.drawn_map = np.empty((self.h, self.w), dtype=np.uint8)
+ self.drawn_map.fill(255)
+ # background + k
+ self.curr_path = [[] for _ in range(self.K + 1)]
+ self.size = 3
+
+ """
+ k - object id
+ vis - a tuple (visualization map, pass through alpha). None if not needed.
+ """
+ def push_point(self, x, y, k, vis=None):
+ if vis is not None:
+ vis_map, vis_alpha = vis
+ selected = self.curr_path[k]
+ selected.append((x, y))
+ if len(selected) >= 2:
+ self.drawn_map = cv2.line(self.drawn_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ k, thickness=self.size)
+
+ # Plot visualization
+ if vis is not None:
+ # Visualization for drawing
+ if k == 0:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ else:
+ vis_map = cv2.line(vis_map,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ color_map[k], thickness=self.size)
+ # Visualization on/off boolean filter
+ vis_alpha = cv2.line(vis_alpha,
+ (int(round(selected[-2][0])), int(round(selected[-2][1]))),
+ (int(round(selected[-1][0])), int(round(selected[-1][1]))),
+ 0.75, thickness=self.size)
+
+ # Optional vis return
+ if vis is not None:
+ return vis_map, vis_alpha
+
+ def end_path(self):
+ # Complete the drawing
+ self.curr_path = [[] for _ in range(self.K + 1)]
+
+ def predict(self):
+ self.out_prob = self.controller.interact(self.image.unsqueeze(0), self.prev_mask, self.drawn_map)
+ self.out_prob = aggregate_wbg(self.out_prob, keep_bg=True, hard=True)
+ return self.out_prob
+
+
+class ClickInteraction(Interaction):
+ def __init__(self, image, prev_mask, true_size, controller, tar_obj):
+ """
+ prev_mask in a prob. form
+ """
+ super().__init__(image, prev_mask, true_size, controller)
+ self.tar_obj = tar_obj
+
+ # negative/positive for each object
+ self.pos_clicks = []
+ self.neg_clicks = []
+
+ self.out_prob = self.prev_mask.clone()
+
+ """
+ neg - Negative interaction or not
+ vis - a tuple (visualization map, pass through alpha). None if not needed.
+ """
+ def push_point(self, x, y, neg, vis=None):
+ # Clicks
+ if neg:
+ self.neg_clicks.append((x, y))
+ else:
+ self.pos_clicks.append((x, y))
+
+ # Do the prediction
+ self.obj_mask = self.controller.interact(self.image.unsqueeze(0), x, y, not neg)
+
+ # Plot visualization
+ if vis is not None:
+ vis_map, vis_alpha = vis
+ # Visualization for clicks
+ if neg:
+ vis_map = cv2.circle(vis_map,
+ (int(round(x)), int(round(y))),
+ 2, color_map[0], thickness=-1)
+ else:
+ vis_map = cv2.circle(vis_map,
+ (int(round(x)), int(round(y))),
+ 2, color_map[self.tar_obj], thickness=-1)
+
+ vis_alpha = cv2.circle(vis_alpha,
+ (int(round(x)), int(round(y))),
+ 2, 1, thickness=-1)
+
+ # Optional vis return
+ return vis_map, vis_alpha
+
+ def predict(self):
+ self.out_prob = self.prev_mask.clone()
+ # a small hack to allow the interacting object to overwrite existing masks
+ # without remembering all the object probabilities
+ self.out_prob = torch.clamp(self.out_prob, max=0.9)
+ self.out_prob[self.tar_obj] = self.obj_mask
+ self.out_prob = aggregate_wbg(self.out_prob[1:], keep_bg=True, hard=True)
+ return self.out_prob
diff --git a/inference/interact/interactive_utils.py b/inference/interact/interactive_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..9961f63aab4f59323454f34d76241a743190198f
--- /dev/null
+++ b/inference/interact/interactive_utils.py
@@ -0,0 +1,175 @@
+# Modifed from https://github.com/seoungwugoh/ivs-demo
+
+import numpy as np
+
+import torch
+import torch.nn.functional as F
+from util.palette import davis_palette
+from dataset.range_transform import im_normalization
+
+def image_to_torch(frame: np.ndarray, device='cuda'):
+ # frame: H*W*3 numpy array
+ frame = frame.transpose(2, 0, 1)
+ frame = torch.from_numpy(frame).float().to(device)/255
+ frame_norm = im_normalization(frame)
+ return frame_norm, frame
+
+def torch_prob_to_numpy_mask(prob):
+ mask = torch.argmax(prob, dim=0)
+ mask = mask.cpu().numpy().astype(np.uint8)
+ return mask
+
+def index_numpy_to_one_hot_torch(mask, num_classes):
+ mask = torch.from_numpy(mask).long()
+ return F.one_hot(mask, num_classes=num_classes).permute(2, 0, 1).float()
+
+"""
+Some constants fro visualization
+"""
+color_map_np = np.frombuffer(davis_palette, dtype=np.uint8).reshape(-1, 3).copy()
+# scales for better visualization
+color_map_np = (color_map_np.astype(np.float32)*1.5).clip(0, 255).astype(np.uint8)
+color_map = color_map_np.tolist()
+if torch.cuda.is_available():
+ color_map_torch = torch.from_numpy(color_map_np).cuda() / 255
+
+grayscale_weights = np.array([[0.3,0.59,0.11]]).astype(np.float32)
+if torch.cuda.is_available():
+ grayscale_weights_torch = torch.from_numpy(grayscale_weights).cuda().unsqueeze(0)
+
+def get_visualization(mode, image, mask, layer, target_object):
+ if mode == 'fade':
+ return overlay_davis(image, mask, fade=True)
+ elif mode == 'davis':
+ return overlay_davis(image, mask)
+ elif mode == 'light':
+ return overlay_davis(image, mask, 0.9)
+ elif mode == 'popup':
+ return overlay_popup(image, mask, target_object)
+ elif mode == 'layered':
+ if layer is None:
+ print('Layer file not given. Defaulting to DAVIS.')
+ return overlay_davis(image, mask)
+ else:
+ return overlay_layer(image, mask, layer, target_object)
+ else:
+ raise NotImplementedError
+
+def get_visualization_torch(mode, image, prob, layer, target_object):
+ if mode == 'fade':
+ return overlay_davis_torch(image, prob, fade=True)
+ elif mode == 'davis':
+ return overlay_davis_torch(image, prob)
+ elif mode == 'light':
+ return overlay_davis_torch(image, prob, 0.9)
+ elif mode == 'popup':
+ return overlay_popup_torch(image, prob, target_object)
+ elif mode == 'layered':
+ if layer is None:
+ print('Layer file not given. Defaulting to DAVIS.')
+ return overlay_davis_torch(image, prob)
+ else:
+ return overlay_layer_torch(image, prob, layer, target_object)
+ else:
+ raise NotImplementedError
+
+def overlay_davis(image, mask, alpha=0.5, fade=False):
+ """ Overlay segmentation on top of RGB image. from davis official"""
+ im_overlay = image.copy()
+
+ colored_mask = color_map_np[mask]
+ foreground = image*alpha + (1-alpha)*colored_mask
+ binary_mask = (mask > 0)
+ # Compose image
+ im_overlay[binary_mask] = foreground[binary_mask]
+ if fade:
+ im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
+ return im_overlay.astype(image.dtype)
+
+def overlay_popup(image, mask, target_object):
+ # Keep foreground colored. Convert background to grayscale.
+ im_overlay = image.copy()
+
+ binary_mask = ~(np.isin(mask, target_object))
+ colored_region = (im_overlay[binary_mask]*grayscale_weights).sum(-1, keepdims=-1)
+ im_overlay[binary_mask] = colored_region
+ return im_overlay.astype(image.dtype)
+
+def overlay_layer(image, mask, layer, target_object):
+ # insert a layer between foreground and background
+ # The CPU version is less accurate because we are using the hard mask
+ # The GPU version has softer edges as it uses soft probabilities
+ obj_mask = (np.isin(mask, target_object)).astype(np.float32)
+ layer_alpha = layer[:, :, 3].astype(np.float32) / 255
+ layer_rgb = layer[:, :, :3]
+ background_alpha = np.maximum(obj_mask, layer_alpha)[:,:,np.newaxis]
+ obj_mask = obj_mask[:,:,np.newaxis]
+ im_overlay = (image*(1-background_alpha) + layer_rgb*(1-obj_mask) + image*obj_mask).clip(0, 255)
+ return im_overlay.astype(image.dtype)
+
+def overlay_davis_torch(image, mask, alpha=0.5, fade=False):
+ """ Overlay segmentation on top of RGB image. from davis official"""
+ # Changes the image in-place to avoid copying
+ image = image.permute(1, 2, 0)
+ im_overlay = image
+ mask = torch.argmax(mask, dim=0)
+
+ colored_mask = color_map_torch[mask]
+ foreground = image*alpha + (1-alpha)*colored_mask
+ binary_mask = (mask > 0)
+ # Compose image
+ im_overlay[binary_mask] = foreground[binary_mask]
+ if fade:
+ im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
+
+ im_overlay = (im_overlay*255).cpu().numpy()
+ im_overlay = im_overlay.astype(np.uint8)
+
+ return im_overlay
+
+def overlay_popup_torch(image, mask, target_object):
+ # Keep foreground colored. Convert background to grayscale.
+ image = image.permute(1, 2, 0)
+
+ if len(target_object) == 0:
+ obj_mask = torch.zeros_like(mask[0]).unsqueeze(2)
+ else:
+ # I should not need to convert this to numpy.
+ # uUsing list works most of the time but consistently fails
+ # if I include first object -> exclude it -> include it again.
+ # I check everywhere and it makes absolutely no sense.
+ # I am blaming this on PyTorch and calling it a day
+ obj_mask = mask[np.array(target_object,dtype=np.int32)].sum(0).unsqueeze(2)
+ gray_image = (image*grayscale_weights_torch).sum(-1, keepdim=True)
+ im_overlay = obj_mask*image + (1-obj_mask)*gray_image
+
+ im_overlay = (im_overlay*255).cpu().numpy()
+ im_overlay = im_overlay.astype(np.uint8)
+
+ return im_overlay
+
+def overlay_layer_torch(image, mask, layer, target_object):
+ # insert a layer between foreground and background
+ # The CPU version is less accurate because we are using the hard mask
+ # The GPU version has softer edges as it uses soft probabilities
+ image = image.permute(1, 2, 0)
+
+ if len(target_object) == 0:
+ obj_mask = torch.zeros_like(mask[0])
+ else:
+ # I should not need to convert this to numpy.
+ # uUsing list works most of the time but consistently fails
+ # if I include first object -> exclude it -> include it again.
+ # I check everywhere and it makes absolutely no sense.
+ # I am blaming this on PyTorch and calling it a day
+ obj_mask = mask[np.array(target_object,dtype=np.int32)].sum(0)
+ layer_alpha = layer[:, :, 3]
+ layer_rgb = layer[:, :, :3]
+ background_alpha = torch.maximum(obj_mask, layer_alpha).unsqueeze(2)
+ obj_mask = obj_mask.unsqueeze(2)
+ im_overlay = (image*(1-background_alpha) + layer_rgb*(1-obj_mask) + image*obj_mask).clip(0, 1)
+
+ im_overlay = (im_overlay*255).cpu().numpy()
+ im_overlay = im_overlay.astype(np.uint8)
+
+ return im_overlay
diff --git a/inference/interact/resource_manager.py b/inference/interact/resource_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0f28af2e35a3ea29958e5eee4e19b26f1fa010b
--- /dev/null
+++ b/inference/interact/resource_manager.py
@@ -0,0 +1,206 @@
+import os
+from os import path
+import shutil
+import collections
+
+import cv2
+from PIL import Image
+if not hasattr(Image, 'Resampling'): # Pillow<9.0
+ Image.Resampling = Image
+import numpy as np
+
+from util.palette import davis_palette
+import progressbar
+
+
+# https://bugs.python.org/issue28178
+# ah python ah why
+class LRU:
+ def __init__(self, func, maxsize=128):
+ self.cache = collections.OrderedDict()
+ self.func = func
+ self.maxsize = maxsize
+
+ def __call__(self, *args):
+ cache = self.cache
+ if args in cache:
+ cache.move_to_end(args)
+ return cache[args]
+ result = self.func(*args)
+ cache[args] = result
+ if len(cache) > self.maxsize:
+ cache.popitem(last=False)
+ return result
+
+ def invalidate(self, key):
+ self.cache.pop(key, None)
+
+
+class ResourceManager:
+ def __init__(self, config):
+ # determine inputs
+ images = config['images']
+ video = config['video']
+ self.workspace = config['workspace']
+ self.size = config['size']
+ self.palette = davis_palette
+
+ # create temporary workspace if not specified
+ if self.workspace is None:
+ if images is not None:
+ basename = path.basename(images)
+ elif video is not None:
+ basename = path.basename(video)[:-4]
+ else:
+ raise NotImplementedError(
+ 'Either images, video, or workspace has to be specified')
+
+ self.workspace = path.join('./workspace', basename)
+
+ print(f'Workspace is in: {self.workspace}')
+
+ # determine the location of input images
+ need_decoding = False
+ need_resizing = False
+ if path.exists(path.join(self.workspace, 'images')):
+ pass
+ elif images is not None:
+ need_resizing = True
+ elif video is not None:
+ # will decode video into frames later
+ need_decoding = True
+
+ # create workspace subdirectories
+ self.image_dir = path.join(self.workspace, 'images')
+ self.mask_dir = path.join(self.workspace, 'masks')
+ os.makedirs(self.image_dir, exist_ok=True)
+ os.makedirs(self.mask_dir, exist_ok=True)
+
+ # convert read functions to be buffered
+ self.get_image = LRU(self._get_image_unbuffered, maxsize=config['buffer_size'])
+ self.get_mask = LRU(self._get_mask_unbuffered, maxsize=config['buffer_size'])
+
+ # extract frames from video
+ if need_decoding:
+ self._extract_frames(video)
+
+ # copy/resize existing images to the workspace
+ if need_resizing:
+ self._copy_resize_frames(images)
+
+ # read all frame names
+ self.names = sorted(os.listdir(self.image_dir))
+ self.names = [f[:-4] for f in self.names] # remove extensions
+ self.length = len(self.names)
+
+ assert self.length > 0, f'No images found! Check {self.workspace}/images. Remove folder if necessary.'
+
+ print(f'{self.length} images found.')
+
+ self.height, self.width = self.get_image(0).shape[:2]
+ self.visualization_init = False
+
+ def _extract_frames(self, video):
+ cap = cv2.VideoCapture(video)
+ frame_index = 0
+ print(f'Extracting frames from {video} into {self.image_dir}...')
+ bar = progressbar.ProgressBar(max_value=progressbar.UnknownLength)
+ while(cap.isOpened()):
+ _, frame = cap.read()
+ if frame is None:
+ break
+ if self.size > 0:
+ h, w = frame.shape[:2]
+ new_w = (w*self.size//min(w, h))
+ new_h = (h*self.size//min(w, h))
+ if new_w != w or new_h != h:
+ frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
+ cv2.imwrite(path.join(self.image_dir, f'{frame_index:07d}.jpg'), frame)
+ frame_index += 1
+ bar.update(frame_index)
+ bar.finish()
+ print('Done!')
+
+ def _copy_resize_frames(self, images):
+ image_list = os.listdir(images)
+ print(f'Copying/resizing frames into {self.image_dir}...')
+ for image_name in progressbar.progressbar(image_list):
+ if self.size < 0:
+ # just copy
+ shutil.copy2(path.join(images, image_name), self.image_dir)
+ else:
+ frame = cv2.imread(path.join(images, image_name))
+ h, w = frame.shape[:2]
+ new_w = (w*self.size//min(w, h))
+ new_h = (h*self.size//min(w, h))
+ if new_w != w or new_h != h:
+ frame = cv2.resize(frame,dsize=(new_w,new_h),interpolation=cv2.INTER_AREA)
+ cv2.imwrite(path.join(self.image_dir, image_name), frame)
+ print('Done!')
+
+ def save_mask(self, ti, mask):
+ # mask should be uint8 H*W without channels
+ assert 0 <= ti < self.length
+ assert isinstance(mask, np.ndarray)
+
+ mask = Image.fromarray(mask)
+ mask.putpalette(self.palette)
+ mask.save(path.join(self.mask_dir, self.names[ti]+'.png'))
+ self.invalidate(ti)
+
+ def save_visualization(self, ti, image):
+ # image should be uint8 3*H*W
+ assert 0 <= ti < self.length
+ assert isinstance(image, np.ndarray)
+ if not self.visualization_init:
+ self.visualization_dir = path.join(self.workspace, 'visualization')
+ os.makedirs(self.visualization_dir, exist_ok=True)
+ self.visualization_init = True
+
+ image = Image.fromarray(image)
+ image.save(path.join(self.visualization_dir, self.names[ti]+'.jpg'))
+
+ def _get_image_unbuffered(self, ti):
+ # returns H*W*3 uint8 array
+ assert 0 <= ti < self.length
+
+ image = Image.open(path.join(self.image_dir, self.names[ti]+'.jpg'))
+ image = np.array(image)
+ return image
+
+ def _get_mask_unbuffered(self, ti):
+ # returns H*W uint8 array
+ assert 0 <= ti < self.length
+
+ mask_path = path.join(self.mask_dir, self.names[ti]+'.png')
+ if path.exists(mask_path):
+ mask = Image.open(mask_path)
+ mask = np.array(mask)
+ return mask
+ else:
+ return None
+
+ def read_external_image(self, file_name, size=None):
+ image = Image.open(file_name)
+ is_mask = image.mode in ['L', 'P']
+ if size is not None:
+ # PIL uses (width, height)
+ image = image.resize((size[1], size[0]),
+ resample=Image.Resampling.NEAREST if is_mask else Image.Resampling.BICUBIC)
+ image = np.array(image)
+ return image
+
+ def invalidate(self, ti):
+ # the image buffer is never invalidated
+ self.get_mask.invalidate((ti,))
+
+ def __len__(self):
+ return self.length
+
+ @property
+ def h(self):
+ return self.height
+
+ @property
+ def w(self):
+ return self.width
diff --git a/inference/interact/s2m/__init__.py b/inference/interact/s2m/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/inference/interact/s2m/_deeplab.py b/inference/interact/s2m/_deeplab.py
new file mode 100644
index 0000000000000000000000000000000000000000..e663007dde9a56add1aa540be76cf2f5d81de82f
--- /dev/null
+++ b/inference/interact/s2m/_deeplab.py
@@ -0,0 +1,180 @@
+# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from .utils import _SimpleSegmentationModel
+
+
+__all__ = ["DeepLabV3"]
+
+
+class DeepLabV3(_SimpleSegmentationModel):
+ """
+ Implements DeepLabV3 model from
+ `"Rethinking Atrous Convolution for Semantic Image Segmentation"
+ `_.
+
+ Arguments:
+ backbone (nn.Module): the network used to compute the features for the model.
+ The backbone should return an OrderedDict[Tensor], with the key being
+ "out" for the last feature map used, and "aux" if an auxiliary classifier
+ is used.
+ classifier (nn.Module): module that takes the "out" element returned from
+ the backbone and returns a dense prediction.
+ aux_classifier (nn.Module, optional): auxiliary classifier used during training
+ """
+ pass
+
+class DeepLabHeadV3Plus(nn.Module):
+ def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):
+ super(DeepLabHeadV3Plus, self).__init__()
+ self.project = nn.Sequential(
+ nn.Conv2d(low_level_channels, 48, 1, bias=False),
+ nn.BatchNorm2d(48),
+ nn.ReLU(inplace=True),
+ )
+
+ self.aspp = ASPP(in_channels, aspp_dilate)
+
+ self.classifier = nn.Sequential(
+ nn.Conv2d(304, 256, 3, padding=1, bias=False),
+ nn.BatchNorm2d(256),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(256, num_classes, 1)
+ )
+ self._init_weight()
+
+ def forward(self, feature):
+ low_level_feature = self.project( feature['low_level'] )
+ output_feature = self.aspp(feature['out'])
+ output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
+ return self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
+
+ def _init_weight(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+class DeepLabHead(nn.Module):
+ def __init__(self, in_channels, num_classes, aspp_dilate=[12, 24, 36]):
+ super(DeepLabHead, self).__init__()
+
+ self.classifier = nn.Sequential(
+ ASPP(in_channels, aspp_dilate),
+ nn.Conv2d(256, 256, 3, padding=1, bias=False),
+ nn.BatchNorm2d(256),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(256, num_classes, 1)
+ )
+ self._init_weight()
+
+ def forward(self, feature):
+ return self.classifier( feature['out'] )
+
+ def _init_weight(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+class AtrousSeparableConvolution(nn.Module):
+ """ Atrous Separable Convolution
+ """
+ def __init__(self, in_channels, out_channels, kernel_size,
+ stride=1, padding=0, dilation=1, bias=True):
+ super(AtrousSeparableConvolution, self).__init__()
+ self.body = nn.Sequential(
+ # Separable Conv
+ nn.Conv2d( in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, bias=bias, groups=in_channels ),
+ # PointWise Conv
+ nn.Conv2d( in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
+ )
+
+ self._init_weight()
+
+ def forward(self, x):
+ return self.body(x)
+
+ def _init_weight(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight)
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+class ASPPConv(nn.Sequential):
+ def __init__(self, in_channels, out_channels, dilation):
+ modules = [
+ nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True)
+ ]
+ super(ASPPConv, self).__init__(*modules)
+
+class ASPPPooling(nn.Sequential):
+ def __init__(self, in_channels, out_channels):
+ super(ASPPPooling, self).__init__(
+ nn.AdaptiveAvgPool2d(1),
+ nn.Conv2d(in_channels, out_channels, 1, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True))
+
+ def forward(self, x):
+ size = x.shape[-2:]
+ x = super(ASPPPooling, self).forward(x)
+ return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
+
+class ASPP(nn.Module):
+ def __init__(self, in_channels, atrous_rates):
+ super(ASPP, self).__init__()
+ out_channels = 256
+ modules = []
+ modules.append(nn.Sequential(
+ nn.Conv2d(in_channels, out_channels, 1, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True)))
+
+ rate1, rate2, rate3 = tuple(atrous_rates)
+ modules.append(ASPPConv(in_channels, out_channels, rate1))
+ modules.append(ASPPConv(in_channels, out_channels, rate2))
+ modules.append(ASPPConv(in_channels, out_channels, rate3))
+ modules.append(ASPPPooling(in_channels, out_channels))
+
+ self.convs = nn.ModuleList(modules)
+
+ self.project = nn.Sequential(
+ nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
+ nn.BatchNorm2d(out_channels),
+ nn.ReLU(inplace=True),
+ nn.Dropout(0.1),)
+
+ def forward(self, x):
+ res = []
+ for conv in self.convs:
+ res.append(conv(x))
+ res = torch.cat(res, dim=1)
+ return self.project(res)
+
+
+
+def convert_to_separable_conv(module):
+ new_module = module
+ if isinstance(module, nn.Conv2d) and module.kernel_size[0]>1:
+ new_module = AtrousSeparableConvolution(module.in_channels,
+ module.out_channels,
+ module.kernel_size,
+ module.stride,
+ module.padding,
+ module.dilation,
+ module.bias)
+ for name, child in module.named_children():
+ new_module.add_module(name, convert_to_separable_conv(child))
+ return new_module
\ No newline at end of file
diff --git a/inference/interact/s2m/s2m_network.py b/inference/interact/s2m/s2m_network.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4f9a3fc4fcc9cc4210485fe24e4d740464d3f8a
--- /dev/null
+++ b/inference/interact/s2m/s2m_network.py
@@ -0,0 +1,65 @@
+# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
+
+from .utils import IntermediateLayerGetter
+from ._deeplab import DeepLabHead, DeepLabHeadV3Plus, DeepLabV3
+from . import s2m_resnet
+
+def _segm_resnet(name, backbone_name, num_classes, output_stride, pretrained_backbone):
+
+ if output_stride==8:
+ replace_stride_with_dilation=[False, True, True]
+ aspp_dilate = [12, 24, 36]
+ else:
+ replace_stride_with_dilation=[False, False, True]
+ aspp_dilate = [6, 12, 18]
+
+ backbone = s2m_resnet.__dict__[backbone_name](
+ pretrained=pretrained_backbone,
+ replace_stride_with_dilation=replace_stride_with_dilation)
+
+ inplanes = 2048
+ low_level_planes = 256
+
+ if name=='deeplabv3plus':
+ return_layers = {'layer4': 'out', 'layer1': 'low_level'}
+ classifier = DeepLabHeadV3Plus(inplanes, low_level_planes, num_classes, aspp_dilate)
+ elif name=='deeplabv3':
+ return_layers = {'layer4': 'out'}
+ classifier = DeepLabHead(inplanes , num_classes, aspp_dilate)
+ backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
+
+ model = DeepLabV3(backbone, classifier)
+ return model
+
+def _load_model(arch_type, backbone, num_classes, output_stride, pretrained_backbone):
+
+ if backbone.startswith('resnet'):
+ model = _segm_resnet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
+ else:
+ raise NotImplementedError
+ return model
+
+
+# Deeplab v3
+def deeplabv3_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
+ """Constructs a DeepLabV3 model with a ResNet-50 backbone.
+
+ Args:
+ num_classes (int): number of classes.
+ output_stride (int): output stride for deeplab.
+ pretrained_backbone (bool): If True, use the pretrained backbone.
+ """
+ return _load_model('deeplabv3', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
+
+
+# Deeplab v3+
+def deeplabv3plus_resnet50(num_classes=1, output_stride=16, pretrained_backbone=False):
+ """Constructs a DeepLabV3 model with a ResNet-50 backbone.
+
+ Args:
+ num_classes (int): number of classes.
+ output_stride (int): output stride for deeplab.
+ pretrained_backbone (bool): If True, use the pretrained backbone.
+ """
+ return _load_model('deeplabv3plus', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
+
diff --git a/inference/interact/s2m/s2m_resnet.py b/inference/interact/s2m/s2m_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..89f1ce042c69daa9b18172a0aadf9bc1de6f300e
--- /dev/null
+++ b/inference/interact/s2m/s2m_resnet.py
@@ -0,0 +1,182 @@
+import torch
+import torch.nn as nn
+try:
+ from torchvision.models.utils import load_state_dict_from_url
+except ModuleNotFoundError:
+ from torch.utils.model_zoo import load_url as load_state_dict_from_url
+
+
+__all__ = ['ResNet', 'resnet50']
+
+
+model_urls = {
+ 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
+}
+
+
+def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
+ """3x3 convolution with padding"""
+ return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
+ padding=dilation, groups=groups, bias=False, dilation=dilation)
+
+
+def conv1x1(in_planes, out_planes, stride=1):
+ """1x1 convolution"""
+ return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
+
+
+class Bottleneck(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
+ base_width=64, dilation=1, norm_layer=None):
+ super(Bottleneck, self).__init__()
+ if norm_layer is None:
+ norm_layer = nn.BatchNorm2d
+ width = int(planes * (base_width / 64.)) * groups
+ # Both self.conv2 and self.downsample layers downsample the input when stride != 1
+ self.conv1 = conv1x1(inplanes, width)
+ self.bn1 = norm_layer(width)
+ self.conv2 = conv3x3(width, width, stride, groups, dilation)
+ self.bn2 = norm_layer(width)
+ self.conv3 = conv1x1(width, planes * self.expansion)
+ self.bn3 = norm_layer(planes * self.expansion)
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.bn3(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.relu(out)
+
+ return out
+
+
+class ResNet(nn.Module):
+
+ def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
+ groups=1, width_per_group=64, replace_stride_with_dilation=None,
+ norm_layer=None):
+ super(ResNet, self).__init__()
+ if norm_layer is None:
+ norm_layer = nn.BatchNorm2d
+ self._norm_layer = norm_layer
+
+ self.inplanes = 64
+ self.dilation = 1
+ if replace_stride_with_dilation is None:
+ # each element in the tuple indicates if we should replace
+ # the 2x2 stride with a dilated convolution instead
+ replace_stride_with_dilation = [False, False, False]
+ if len(replace_stride_with_dilation) != 3:
+ raise ValueError("replace_stride_with_dilation should be None "
+ "or a 3-element tuple, got {}".format(replace_stride_with_dilation))
+ self.groups = groups
+ self.base_width = width_per_group
+ self.conv1 = nn.Conv2d(6, self.inplanes, kernel_size=7, stride=2, padding=3,
+ bias=False)
+ self.bn1 = norm_layer(self.inplanes)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+ self.layer1 = self._make_layer(block, 64, layers[0])
+ self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
+ dilate=replace_stride_with_dilation[0])
+ self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
+ dilate=replace_stride_with_dilation[1])
+ self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
+ dilate=replace_stride_with_dilation[2])
+ self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
+ self.fc = nn.Linear(512 * block.expansion, num_classes)
+
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+ # Zero-initialize the last BN in each residual branch,
+ # so that the residual branch starts with zeros, and each residual block behaves like an identity.
+ # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
+ if zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ nn.init.constant_(m.bn3.weight, 0)
+
+ def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
+ norm_layer = self._norm_layer
+ downsample = None
+ previous_dilation = self.dilation
+ if dilate:
+ self.dilation *= stride
+ stride = 1
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ conv1x1(self.inplanes, planes * block.expansion, stride),
+ norm_layer(planes * block.expansion),
+ )
+
+ layers = []
+ layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
+ self.base_width, previous_dilation, norm_layer))
+ self.inplanes = planes * block.expansion
+ for _ in range(1, blocks):
+ layers.append(block(self.inplanes, planes, groups=self.groups,
+ base_width=self.base_width, dilation=self.dilation,
+ norm_layer=norm_layer))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+
+ x = self.avgpool(x)
+ x = torch.flatten(x, 1)
+ x = self.fc(x)
+
+ return x
+
+
+def _resnet(arch, block, layers, pretrained, progress, **kwargs):
+ model = ResNet(block, layers, **kwargs)
+ if pretrained:
+ state_dict = load_state_dict_from_url(model_urls[arch],
+ progress=progress)
+ model.load_state_dict(state_dict)
+ return model
+
+
+def resnet50(pretrained=False, progress=True, **kwargs):
+ r"""ResNet-50 model from
+ `"Deep Residual Learning for Image Recognition" `_
+
+ Args:
+ pretrained (bool): If True, returns a model pre-trained on ImageNet
+ progress (bool): If True, displays a progress bar of the download to stderr
+ """
+ return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
+ **kwargs)
diff --git a/inference/interact/s2m/utils.py b/inference/interact/s2m/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c2adecf63baa9c2db4cc70b04c25200f6bc0a6a6
--- /dev/null
+++ b/inference/interact/s2m/utils.py
@@ -0,0 +1,78 @@
+# Credit: https://github.com/VainF/DeepLabV3Plus-Pytorch
+
+import torch
+import torch.nn as nn
+import numpy as np
+import torch.nn.functional as F
+from collections import OrderedDict
+
+class _SimpleSegmentationModel(nn.Module):
+ def __init__(self, backbone, classifier):
+ super(_SimpleSegmentationModel, self).__init__()
+ self.backbone = backbone
+ self.classifier = classifier
+
+ def forward(self, x):
+ input_shape = x.shape[-2:]
+ features = self.backbone(x)
+ x = self.classifier(features)
+ x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
+ return x
+
+
+class IntermediateLayerGetter(nn.ModuleDict):
+ """
+ Module wrapper that returns intermediate layers from a model
+
+ It has a strong assumption that the modules have been registered
+ into the model in the same order as they are used.
+ This means that one should **not** reuse the same nn.Module
+ twice in the forward if you want this to work.
+
+ Additionally, it is only able to query submodules that are directly
+ assigned to the model. So if `model` is passed, `model.feature1` can
+ be returned, but not `model.feature1.layer2`.
+
+ Arguments:
+ model (nn.Module): model on which we will extract the features
+ return_layers (Dict[name, new_name]): a dict containing the names
+ of the modules for which the activations will be returned as
+ the key of the dict, and the value of the dict is the name
+ of the returned activation (which the user can specify).
+
+ Examples::
+
+ >>> m = torchvision.models.resnet18(pretrained=True)
+ >>> # extract layer1 and layer3, giving as names `feat1` and feat2`
+ >>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
+ >>> {'layer1': 'feat1', 'layer3': 'feat2'})
+ >>> out = new_m(torch.rand(1, 3, 224, 224))
+ >>> print([(k, v.shape) for k, v in out.items()])
+ >>> [('feat1', torch.Size([1, 64, 56, 56])),
+ >>> ('feat2', torch.Size([1, 256, 14, 14]))]
+ """
+ def __init__(self, model, return_layers):
+ if not set(return_layers).issubset([name for name, _ in model.named_children()]):
+ raise ValueError("return_layers are not present in model")
+
+ orig_return_layers = return_layers
+ return_layers = {k: v for k, v in return_layers.items()}
+ layers = OrderedDict()
+ for name, module in model.named_children():
+ layers[name] = module
+ if name in return_layers:
+ del return_layers[name]
+ if not return_layers:
+ break
+
+ super(IntermediateLayerGetter, self).__init__(layers)
+ self.return_layers = orig_return_layers
+
+ def forward(self, x):
+ out = OrderedDict()
+ for name, module in self.named_children():
+ x = module(x)
+ if name in self.return_layers:
+ out_name = self.return_layers[name]
+ out[out_name] = x
+ return out
diff --git a/inference/interact/s2m_controller.py b/inference/interact/s2m_controller.py
new file mode 100644
index 0000000000000000000000000000000000000000..e222259eebdf3938290c476f85ba8c8d79fb626d
--- /dev/null
+++ b/inference/interact/s2m_controller.py
@@ -0,0 +1,39 @@
+import torch
+import numpy as np
+from ..interact.s2m.s2m_network import deeplabv3plus_resnet50 as S2M
+
+from util.tensor_util import pad_divide_by, unpad
+
+
+class S2MController:
+ """
+ A controller for Scribble-to-Mask (for user interaction, not for DAVIS)
+ Takes the image, previous mask, and scribbles to produce a new mask
+ ignore_class is usually 255
+ 0 is NOT the ignore class -- it is the label for the background
+ """
+ def __init__(self, s2m_net:S2M, num_objects, ignore_class, device='cuda:0'):
+ self.s2m_net = s2m_net
+ self.num_objects = num_objects
+ self.ignore_class = ignore_class
+ self.device = device
+
+ def interact(self, image, prev_mask, scr_mask):
+ image = image.to(self.device, non_blocking=True)
+ prev_mask = prev_mask.unsqueeze(0)
+
+ h, w = image.shape[-2:]
+ unaggre_mask = torch.zeros((self.num_objects, h, w), dtype=torch.float32, device=image.device)
+
+ for ki in range(1, self.num_objects+1):
+ p_srb = (scr_mask==ki).astype(np.uint8)
+ n_srb = ((scr_mask!=ki) * (scr_mask!=self.ignore_class)).astype(np.uint8)
+
+ Rs = torch.from_numpy(np.stack([p_srb, n_srb], 0)).unsqueeze(0).float().to(image.device)
+
+ inputs = torch.cat([image, (prev_mask==ki).float().unsqueeze(0), Rs], 1)
+ inputs, pads = pad_divide_by(inputs, 16)
+
+ unaggre_mask[ki-1] = unpad(torch.sigmoid(self.s2m_net(inputs)), pads)
+
+ return unaggre_mask
\ No newline at end of file
diff --git a/inference/interact/timer.py b/inference/interact/timer.py
new file mode 100644
index 0000000000000000000000000000000000000000..d134aa180275528c0d485e6d237cd6832f62d77e
--- /dev/null
+++ b/inference/interact/timer.py
@@ -0,0 +1,33 @@
+import time
+
+class Timer:
+ def __init__(self):
+ self._acc_time = 0
+ self._paused = True
+
+ def start(self):
+ if self._paused:
+ self.last_time = time.time()
+ self._paused = False
+ return self
+
+ def pause(self):
+ self.count()
+ self._paused = True
+ return self
+
+ def count(self):
+ if self._paused:
+ return self._acc_time
+ t = time.time()
+ self._acc_time += t - self.last_time
+ self.last_time = t
+ return self._acc_time
+
+ def format(self):
+ # count = int(self.count()*100)
+ # return '%02d:%02d:%02d' % (count//6000, (count//100)%60, count%100)
+ return '%03.2f' % self.count()
+
+ def __str__(self):
+ return self.format()
\ No newline at end of file
diff --git a/inference/kv_memory_store.py b/inference/kv_memory_store.py
new file mode 100644
index 0000000000000000000000000000000000000000..33a332625f03b39f38f4b7162dcaddc8bafa262e
--- /dev/null
+++ b/inference/kv_memory_store.py
@@ -0,0 +1,215 @@
+import torch
+from typing import List
+
+class KeyValueMemoryStore:
+ """
+ Works for key/value pairs type storage
+ e.g., working and long-term memory
+ """
+
+ """
+ An object group is created when new objects enter the video
+ Objects in the same group share the same temporal extent
+ i.e., objects initialized in the same frame are in the same group
+ For DAVIS/interactive, there is only one object group
+ For YouTubeVOS, there can be multiple object groups
+ """
+
+ def __init__(self, count_usage: bool):
+ self.count_usage = count_usage
+
+ # keys are stored in a single tensor and are shared between groups/objects
+ # values are stored as a list indexed by object groups
+ self.k = None
+ self.v = []
+ self.obj_groups = []
+ # for debugging only
+ self.all_objects = []
+
+ # shrinkage and selection are also single tensors
+ self.s = self.e = None
+
+ # usage
+ if self.count_usage:
+ self.use_count = self.life_count = None
+
+ def add(self, key, value, shrinkage, selection, objects: List[int]):
+ new_count = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32)
+ new_life = torch.zeros((key.shape[0], 1, key.shape[2]), device=key.device, dtype=torch.float32) + 1e-7
+
+ # add the key
+ if self.k is None:
+ self.k = key
+ self.s = shrinkage
+ self.e = selection
+ if self.count_usage:
+ self.use_count = new_count
+ self.life_count = new_life
+ else:
+ self.k = torch.cat([self.k, key], -1)
+ if shrinkage is not None:
+ self.s = torch.cat([self.s, shrinkage], -1)
+ if selection is not None:
+ self.e = torch.cat([self.e, selection], -1)
+ if self.count_usage:
+ self.use_count = torch.cat([self.use_count, new_count], -1)
+ self.life_count = torch.cat([self.life_count, new_life], -1)
+
+ # add the value
+ if objects is not None:
+ # When objects is given, v is a tensor; used in working memory
+ assert isinstance(value, torch.Tensor)
+ # First consume objects that are already in the memory bank
+ # cannot use set here because we need to preserve order
+ # shift by one as background is not part of value
+ remaining_objects = [obj-1 for obj in objects]
+ for gi, group in enumerate(self.obj_groups):
+ for obj in group:
+ # should properly raise an error if there are overlaps in obj_groups
+ remaining_objects.remove(obj)
+ self.v[gi] = torch.cat([self.v[gi], value[group]], -1)
+
+ # If there are remaining objects, add them as a new group
+ if len(remaining_objects) > 0:
+ new_group = list(remaining_objects)
+ self.v.append(value[new_group])
+ self.obj_groups.append(new_group)
+ self.all_objects.extend(new_group)
+
+ assert sorted(self.all_objects) == self.all_objects, 'Objects MUST be inserted in sorted order '
+ else:
+ # When objects is not given, v is a list that already has the object groups sorted
+ # used in long-term memory
+ assert isinstance(value, list)
+ for gi, gv in enumerate(value):
+ if gv is None:
+ continue
+ if gi < self.num_groups:
+ self.v[gi] = torch.cat([self.v[gi], gv], -1)
+ else:
+ self.v.append(gv)
+
+ def update_usage(self, usage):
+ # increase all life count by 1
+ # increase use of indexed elements
+ if not self.count_usage:
+ return
+
+ self.use_count += usage.view_as(self.use_count)
+ self.life_count += 1
+
+ def sieve_by_range(self, start: int, end: int, min_size: int):
+ # keep only the elements *outside* of this range (with some boundary conditions)
+ # i.e., concat (a[:start], a[end:])
+ # min_size is only used for values, we do not sieve values under this size
+ # (because they are not consolidated)
+
+ if end == 0:
+ # negative 0 would not work as the end index!
+ self.k = self.k[:,:,:start]
+ if self.count_usage:
+ self.use_count = self.use_count[:,:,:start]
+ self.life_count = self.life_count[:,:,:start]
+ if self.s is not None:
+ self.s = self.s[:,:,:start]
+ if self.e is not None:
+ self.e = self.e[:,:,:start]
+
+ for gi in range(self.num_groups):
+ if self.v[gi].shape[-1] >= min_size:
+ self.v[gi] = self.v[gi][:,:,:start]
+ else:
+ self.k = torch.cat([self.k[:,:,:start], self.k[:,:,end:]], -1)
+ if self.count_usage:
+ self.use_count = torch.cat([self.use_count[:,:,:start], self.use_count[:,:,end:]], -1)
+ self.life_count = torch.cat([self.life_count[:,:,:start], self.life_count[:,:,end:]], -1)
+ if self.s is not None:
+ self.s = torch.cat([self.s[:,:,:start], self.s[:,:,end:]], -1)
+ if self.e is not None:
+ self.e = torch.cat([self.e[:,:,:start], self.e[:,:,end:]], -1)
+
+ for gi in range(self.num_groups):
+ if self.v[gi].shape[-1] >= min_size:
+ self.v[gi] = torch.cat([self.v[gi][:,:,:start], self.v[gi][:,:,end:]], -1)
+
+ def remove_obsolete_features(self, max_size: int):
+ # normalize with life duration
+ usage = self.get_usage().flatten()
+
+ values, _ = torch.topk(usage, k=(self.size-max_size), largest=False, sorted=True)
+ survived = (usage > values[-1])
+
+ self.k = self.k[:, :, survived]
+ self.s = self.s[:, :, survived] if self.s is not None else None
+ # Long-term memory does not store ek so this should not be needed
+ self.e = self.e[:, :, survived] if self.e is not None else None
+ if self.num_groups > 1:
+ raise NotImplementedError("""The current data structure does not support feature removal with
+ multiple object groups (e.g., some objects start to appear later in the video)
+ The indices for "survived" is based on keys but not all values are present for every key
+ Basically we need to remap the indices for keys to values
+ """)
+ for gi in range(self.num_groups):
+ self.v[gi] = self.v[gi][:, :, survived]
+
+ self.use_count = self.use_count[:, :, survived]
+ self.life_count = self.life_count[:, :, survived]
+
+ def get_usage(self):
+ # return normalized usage
+ if not self.count_usage:
+ raise RuntimeError('I did not count usage!')
+ else:
+ usage = self.use_count / self.life_count
+ return usage
+
+ def get_all_sliced(self, start: int, end: int):
+ # return k, sk, ek, usage in order, sliced by start and end
+
+ if end == 0:
+ # negative 0 would not work as the end index!
+ k = self.k[:,:,start:]
+ sk = self.s[:,:,start:] if self.s is not None else None
+ ek = self.e[:,:,start:] if self.e is not None else None
+ usage = self.get_usage()[:,:,start:]
+ else:
+ k = self.k[:,:,start:end]
+ sk = self.s[:,:,start:end] if self.s is not None else None
+ ek = self.e[:,:,start:end] if self.e is not None else None
+ usage = self.get_usage()[:,:,start:end]
+
+ return k, sk, ek, usage
+
+ def get_v_size(self, ni: int):
+ return self.v[ni].shape[2]
+
+ def engaged(self):
+ return self.k is not None
+
+ @property
+ def size(self):
+ if self.k is None:
+ return 0
+ else:
+ return self.k.shape[-1]
+
+ @property
+ def num_groups(self):
+ return len(self.v)
+
+ @property
+ def key(self):
+ return self.k
+
+ @property
+ def value(self):
+ return self.v
+
+ @property
+ def shrinkage(self):
+ return self.s
+
+ @property
+ def selection(self):
+ return self.e
+
diff --git a/inference/memory_manager.py b/inference/memory_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3ab693497586d84e848ce8261abfdf319c555ad
--- /dev/null
+++ b/inference/memory_manager.py
@@ -0,0 +1,284 @@
+import torch
+import warnings
+
+from inference.kv_memory_store import KeyValueMemoryStore
+from model.memory_util import *
+
+
+class MemoryManager:
+ """
+ Manages all three memory stores and the transition between working/long-term memory
+ """
+ def __init__(self, config):
+ self.hidden_dim = config['hidden_dim']
+ self.top_k = config['top_k']
+
+ self.enable_long_term = config['enable_long_term']
+ self.enable_long_term_usage = config['enable_long_term_count_usage']
+ if self.enable_long_term:
+ self.max_mt_frames = config['max_mid_term_frames']
+ self.min_mt_frames = config['min_mid_term_frames']
+ self.num_prototypes = config['num_prototypes']
+ self.max_long_elements = config['max_long_term_elements']
+
+ # dimensions will be inferred from input later
+ self.CK = self.CV = None
+ self.H = self.W = None
+
+ # The hidden state will be stored in a single tensor for all objects
+ # B x num_objects x CH x H x W
+ self.hidden = None
+
+ self.work_mem = KeyValueMemoryStore(count_usage=self.enable_long_term)
+ if self.enable_long_term:
+ self.long_mem = KeyValueMemoryStore(count_usage=self.enable_long_term_usage)
+
+ self.reset_config = True
+
+ def update_config(self, config):
+ self.reset_config = True
+ self.hidden_dim = config['hidden_dim']
+ self.top_k = config['top_k']
+
+ assert self.enable_long_term == config['enable_long_term'], 'cannot update this'
+ assert self.enable_long_term_usage == config['enable_long_term_count_usage'], 'cannot update this'
+
+ self.enable_long_term_usage = config['enable_long_term_count_usage']
+ if self.enable_long_term:
+ self.max_mt_frames = config['max_mid_term_frames']
+ self.min_mt_frames = config['min_mid_term_frames']
+ self.num_prototypes = config['num_prototypes']
+ self.max_long_elements = config['max_long_term_elements']
+
+ def _readout(self, affinity, v):
+ # this function is for a single object group
+ return v @ affinity
+
+ def match_memory(self, query_key, selection):
+ # query_key: B x C^k x H x W
+ # selection: B x C^k x H x W
+ num_groups = self.work_mem.num_groups
+ h, w = query_key.shape[-2:]
+
+ query_key = query_key.flatten(start_dim=2)
+ selection = selection.flatten(start_dim=2) if selection is not None else None
+
+ """
+ Memory readout using keys
+ """
+
+ if self.enable_long_term and self.long_mem.engaged():
+ # Use long-term memory
+ long_mem_size = self.long_mem.size
+ memory_key = torch.cat([self.long_mem.key, self.work_mem.key], -1)
+ shrinkage = torch.cat([self.long_mem.shrinkage, self.work_mem.shrinkage], -1)
+
+ similarity = get_similarity(memory_key, shrinkage, query_key, selection)
+ work_mem_similarity = similarity[:, long_mem_size:]
+ long_mem_similarity = similarity[:, :long_mem_size]
+
+ # get the usage with the first group
+ # the first group always have all the keys valid
+ affinity, usage = do_softmax(
+ torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(0):], work_mem_similarity], 1),
+ top_k=self.top_k, inplace=True, return_usage=True)
+ affinity = [affinity]
+
+ # compute affinity group by group as later groups only have a subset of keys
+ for gi in range(1, num_groups):
+ if gi < self.long_mem.num_groups:
+ # merge working and lt similarities before softmax
+ affinity_one_group = do_softmax(
+ torch.cat([long_mem_similarity[:, -self.long_mem.get_v_size(gi):],
+ work_mem_similarity[:, -self.work_mem.get_v_size(gi):]], 1),
+ top_k=self.top_k, inplace=True)
+ else:
+ # no long-term memory for this group
+ affinity_one_group = do_softmax(work_mem_similarity[:, -self.work_mem.get_v_size(gi):],
+ top_k=self.top_k, inplace=(gi==num_groups-1))
+ affinity.append(affinity_one_group)
+
+ all_memory_value = []
+ for gi, gv in enumerate(self.work_mem.value):
+ # merge the working and lt values before readout
+ if gi < self.long_mem.num_groups:
+ all_memory_value.append(torch.cat([self.long_mem.value[gi], self.work_mem.value[gi]], -1))
+ else:
+ all_memory_value.append(gv)
+
+ """
+ Record memory usage for working and long-term memory
+ """
+ # ignore the index return for long-term memory
+ work_usage = usage[:, long_mem_size:]
+ self.work_mem.update_usage(work_usage.flatten())
+
+ if self.enable_long_term_usage:
+ # ignore the index return for working memory
+ long_usage = usage[:, :long_mem_size]
+ self.long_mem.update_usage(long_usage.flatten())
+ else:
+ # No long-term memory
+ similarity = get_similarity(self.work_mem.key, self.work_mem.shrinkage, query_key, selection)
+
+ if self.enable_long_term:
+ affinity, usage = do_softmax(similarity, inplace=(num_groups==1),
+ top_k=self.top_k, return_usage=True)
+
+ # Record memory usage for working memory
+ self.work_mem.update_usage(usage.flatten())
+ else:
+ affinity = do_softmax(similarity, inplace=(num_groups==1),
+ top_k=self.top_k, return_usage=False)
+
+ affinity = [affinity]
+
+ # compute affinity group by group as later groups only have a subset of keys
+ for gi in range(1, num_groups):
+ affinity_one_group = do_softmax(similarity[:, -self.work_mem.get_v_size(gi):],
+ top_k=self.top_k, inplace=(gi==num_groups-1))
+ affinity.append(affinity_one_group)
+
+ all_memory_value = self.work_mem.value
+
+ # Shared affinity within each group
+ all_readout_mem = torch.cat([
+ self._readout(affinity[gi], gv)
+ for gi, gv in enumerate(all_memory_value)
+ ], 0)
+
+ return all_readout_mem.view(all_readout_mem.shape[0], self.CV, h, w)
+
+ def add_memory(self, key, shrinkage, value, objects, selection=None):
+ # key: 1*C*H*W
+ # value: 1*num_objects*C*H*W
+ # objects contain a list of object indices
+ if self.H is None or self.reset_config:
+ self.reset_config = False
+ self.H, self.W = key.shape[-2:]
+ self.HW = self.H*self.W
+ if self.enable_long_term:
+ # convert from num. frames to num. nodes
+ self.min_work_elements = self.min_mt_frames*self.HW
+ self.max_work_elements = self.max_mt_frames*self.HW
+
+ # key: 1*C*N
+ # value: num_objects*C*N
+ key = key.flatten(start_dim=2)
+ shrinkage = shrinkage.flatten(start_dim=2)
+ value = value[0].flatten(start_dim=2)
+
+ self.CK = key.shape[1]
+ self.CV = value.shape[1]
+
+ if selection is not None:
+ if not self.enable_long_term:
+ warnings.warn('the selection factor is only needed in long-term mode', UserWarning)
+ selection = selection.flatten(start_dim=2)
+
+ self.work_mem.add(key, value, shrinkage, selection, objects)
+
+ # long-term memory cleanup
+ if self.enable_long_term:
+ # Do memory compressed if needed
+ if self.work_mem.size >= self.max_work_elements:
+ # Remove obsolete features if needed
+ if self.long_mem.size >= (self.max_long_elements-self.num_prototypes):
+ self.long_mem.remove_obsolete_features(self.max_long_elements-self.num_prototypes)
+
+ self.compress_features()
+
+
+ def create_hidden_state(self, n, sample_key):
+ # n is the TOTAL number of objects
+ h, w = sample_key.shape[-2:]
+ if self.hidden is None:
+ self.hidden = torch.zeros((1, n, self.hidden_dim, h, w), device=sample_key.device)
+ elif self.hidden.shape[1] != n:
+ self.hidden = torch.cat([
+ self.hidden,
+ torch.zeros((1, n-self.hidden.shape[1], self.hidden_dim, h, w), device=sample_key.device)
+ ], 1)
+
+ assert(self.hidden.shape[1] == n)
+
+ def set_hidden(self, hidden):
+ self.hidden = hidden
+
+ def get_hidden(self):
+ return self.hidden
+
+ def compress_features(self):
+ HW = self.HW
+ candidate_value = []
+ total_work_mem_size = self.work_mem.size
+ for gv in self.work_mem.value:
+ # Some object groups might be added later in the video
+ # So not all keys have values associated with all objects
+ # We need to keep track of the key->value validity
+ mem_size_in_this_group = gv.shape[-1]
+ if mem_size_in_this_group == total_work_mem_size:
+ # full LT
+ candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
+ else:
+ # mem_size is smaller than total_work_mem_size, but at least HW
+ assert HW <= mem_size_in_this_group < total_work_mem_size
+ if mem_size_in_this_group > self.min_work_elements+HW:
+ # part of this object group still goes into LT
+ candidate_value.append(gv[:,:,HW:-self.min_work_elements+HW])
+ else:
+ # this object group cannot go to the LT at all
+ candidate_value.append(None)
+
+ # perform memory consolidation
+ prototype_key, prototype_value, prototype_shrinkage = self.consolidation(
+ *self.work_mem.get_all_sliced(HW, -self.min_work_elements+HW), candidate_value)
+
+ # remove consolidated working memory
+ self.work_mem.sieve_by_range(HW, -self.min_work_elements+HW, min_size=self.min_work_elements+HW)
+
+ # add to long-term memory
+ self.long_mem.add(prototype_key, prototype_value, prototype_shrinkage, selection=None, objects=None)
+
+ def consolidation(self, candidate_key, candidate_shrinkage, candidate_selection, usage, candidate_value):
+ # keys: 1*C*N
+ # values: num_objects*C*N
+ N = candidate_key.shape[-1]
+
+ # find the indices with max usage
+ _, max_usage_indices = torch.topk(usage, k=self.num_prototypes, dim=-1, sorted=True)
+ prototype_indices = max_usage_indices.flatten()
+
+ # Prototypes are invalid for out-of-bound groups
+ validity = [prototype_indices >= (N-gv.shape[2]) if gv is not None else None for gv in candidate_value]
+
+ prototype_key = candidate_key[:, :, prototype_indices]
+ prototype_selection = candidate_selection[:, :, prototype_indices] if candidate_selection is not None else None
+
+ """
+ Potentiation step
+ """
+ similarity = get_similarity(candidate_key, candidate_shrinkage, prototype_key, prototype_selection)
+
+ # convert similarity to affinity
+ # need to do it group by group since the softmax normalization would be different
+ affinity = [
+ do_softmax(similarity[:, -gv.shape[2]:, validity[gi]]) if gv is not None else None
+ for gi, gv in enumerate(candidate_value)
+ ]
+
+ # some values can be have all False validity. Weed them out.
+ affinity = [
+ aff if aff is None or aff.shape[-1] > 0 else None for aff in affinity
+ ]
+
+ # readout the values
+ prototype_value = [
+ self._readout(affinity[gi], gv) if affinity[gi] is not None else None
+ for gi, gv in enumerate(candidate_value)
+ ]
+
+ # readout the shrinkage term
+ prototype_shrinkage = self._readout(affinity[0], candidate_shrinkage) if candidate_shrinkage is not None else None
+
+ return prototype_key, prototype_value, prototype_shrinkage
diff --git a/input/blackswan/00000.png b/input/blackswan/00000.png
new file mode 100644
index 0000000000000000000000000000000000000000..3daeddee9b13c2d98cae65bcd584e67a7a5aa4ad
Binary files /dev/null and b/input/blackswan/00000.png differ
diff --git a/input/blackswan/00001.png b/input/blackswan/00001.png
new file mode 100644
index 0000000000000000000000000000000000000000..4e3d3dd49677f83d8c0cfb2e44520808cfae9bb1
Binary files /dev/null and b/input/blackswan/00001.png differ
diff --git a/input/blackswan/00002.png b/input/blackswan/00002.png
new file mode 100644
index 0000000000000000000000000000000000000000..8cff513acad481f397dca72a9abab7937396c6a9
Binary files /dev/null and b/input/blackswan/00002.png differ
diff --git a/input/blackswan/00003.png b/input/blackswan/00003.png
new file mode 100644
index 0000000000000000000000000000000000000000..4de4854720fce434d73ca6c3dd08c39207fbec6d
Binary files /dev/null and b/input/blackswan/00003.png differ
diff --git a/input/blackswan/00004.png b/input/blackswan/00004.png
new file mode 100644
index 0000000000000000000000000000000000000000..687b05e9149267a9323e18d8ce3f8a8e5e6414ee
Binary files /dev/null and b/input/blackswan/00004.png differ
diff --git a/input/blackswan/00005.png b/input/blackswan/00005.png
new file mode 100644
index 0000000000000000000000000000000000000000..7627fdff9669c24fa466bf0b5446484e555f3110
Binary files /dev/null and b/input/blackswan/00005.png differ
diff --git a/input/blackswan/00006.png b/input/blackswan/00006.png
new file mode 100644
index 0000000000000000000000000000000000000000..6008c7e885819a783e46be59e7fa1afdfb39440a
Binary files /dev/null and b/input/blackswan/00006.png differ
diff --git a/input/blackswan/00007.png b/input/blackswan/00007.png
new file mode 100644
index 0000000000000000000000000000000000000000..09a0bfb317ede78eec273ed227bd2fefe1d1289b
Binary files /dev/null and b/input/blackswan/00007.png differ
diff --git a/input/blackswan/00008.png b/input/blackswan/00008.png
new file mode 100644
index 0000000000000000000000000000000000000000..8befb43c7e113711b5a604b4a14f1c0280b0d222
Binary files /dev/null and b/input/blackswan/00008.png differ
diff --git a/input/blackswan/00009.png b/input/blackswan/00009.png
new file mode 100644
index 0000000000000000000000000000000000000000..3a7fd79e302e17cf72635e36195518eda9207759
Binary files /dev/null and b/input/blackswan/00009.png differ
diff --git a/input/blackswan/00010.png b/input/blackswan/00010.png
new file mode 100644
index 0000000000000000000000000000000000000000..30e77e82ea7b8994df1cd86b9a78d2ae8d8ca805
Binary files /dev/null and b/input/blackswan/00010.png differ
diff --git a/input/blackswan/00011.png b/input/blackswan/00011.png
new file mode 100644
index 0000000000000000000000000000000000000000..281508d8ef82eb584bcfe605bd362dc5dfc2c9d4
Binary files /dev/null and b/input/blackswan/00011.png differ
diff --git a/input/blackswan/00012.png b/input/blackswan/00012.png
new file mode 100644
index 0000000000000000000000000000000000000000..d8191811bbec2bc0fec65a107d7e7a12dbb7c894
Binary files /dev/null and b/input/blackswan/00012.png differ
diff --git a/input/blackswan/00013.png b/input/blackswan/00013.png
new file mode 100644
index 0000000000000000000000000000000000000000..6d8eb2ea540bc860801751c2de81743f79c6f117
Binary files /dev/null and b/input/blackswan/00013.png differ
diff --git a/input/blackswan/00014.png b/input/blackswan/00014.png
new file mode 100644
index 0000000000000000000000000000000000000000..1a00bee60bddb2b209ada6101a7dabe367fe95b0
Binary files /dev/null and b/input/blackswan/00014.png differ
diff --git a/input/blackswan/00015.png b/input/blackswan/00015.png
new file mode 100644
index 0000000000000000000000000000000000000000..525d8adf20c44d5457897eced67663ee31f2ecc2
Binary files /dev/null and b/input/blackswan/00015.png differ
diff --git a/input/blackswan/00016.png b/input/blackswan/00016.png
new file mode 100644
index 0000000000000000000000000000000000000000..926fbe7154c9ea50da38f8da6b95ce818f6cac5f
Binary files /dev/null and b/input/blackswan/00016.png differ
diff --git a/input/blackswan/00017.png b/input/blackswan/00017.png
new file mode 100644
index 0000000000000000000000000000000000000000..871bad747eafeec29a94d4bd4b9242027050fb12
Binary files /dev/null and b/input/blackswan/00017.png differ
diff --git a/input/blackswan/00018.png b/input/blackswan/00018.png
new file mode 100644
index 0000000000000000000000000000000000000000..8855a4a77ecbdc8236a4e21baa985b0453f7f94a
Binary files /dev/null and b/input/blackswan/00018.png differ
diff --git a/input/blackswan/00019.png b/input/blackswan/00019.png
new file mode 100644
index 0000000000000000000000000000000000000000..54052ca5f3ce592a77375c1c283a515216ad738e
Binary files /dev/null and b/input/blackswan/00019.png differ
diff --git a/input/blackswan/00020.png b/input/blackswan/00020.png
new file mode 100644
index 0000000000000000000000000000000000000000..f73b15e01ec5fd759a08225ead1b57dec0e3625c
Binary files /dev/null and b/input/blackswan/00020.png differ
diff --git a/input/blackswan/00021.png b/input/blackswan/00021.png
new file mode 100644
index 0000000000000000000000000000000000000000..b7a9b440e309692fd076d43bc938025d7e3009ad
Binary files /dev/null and b/input/blackswan/00021.png differ
diff --git a/input/blackswan/00022.png b/input/blackswan/00022.png
new file mode 100644
index 0000000000000000000000000000000000000000..f8828e56e54d45a87338f9f1a9f9b007536dbfc7
Binary files /dev/null and b/input/blackswan/00022.png differ
diff --git a/input/blackswan/00023.png b/input/blackswan/00023.png
new file mode 100644
index 0000000000000000000000000000000000000000..3b0a26ea83f9d7e4bceaef7b59e0474f9438f1ed
Binary files /dev/null and b/input/blackswan/00023.png differ
diff --git a/input/blackswan/00024.png b/input/blackswan/00024.png
new file mode 100644
index 0000000000000000000000000000000000000000..7c3800fecfc1d33d147e7fff9535f9c83782a03b
Binary files /dev/null and b/input/blackswan/00024.png differ
diff --git a/input/blackswan/00025.png b/input/blackswan/00025.png
new file mode 100644
index 0000000000000000000000000000000000000000..805fddc4c09de2465fb5104307174a457a386382
Binary files /dev/null and b/input/blackswan/00025.png differ
diff --git a/input/blackswan/00026.png b/input/blackswan/00026.png
new file mode 100644
index 0000000000000000000000000000000000000000..f3ffa44062a393a8adb2d15db5b104b4b967a119
Binary files /dev/null and b/input/blackswan/00026.png differ
diff --git a/input/blackswan/00027.png b/input/blackswan/00027.png
new file mode 100644
index 0000000000000000000000000000000000000000..b491fe2a6bb7604f7324fed9e7b6cfeabf711f1e
Binary files /dev/null and b/input/blackswan/00027.png differ
diff --git a/input/blackswan/00028.png b/input/blackswan/00028.png
new file mode 100644
index 0000000000000000000000000000000000000000..b6df5eede90ab15197877877f54b63110622b661
Binary files /dev/null and b/input/blackswan/00028.png differ
diff --git a/input/blackswan/00029.png b/input/blackswan/00029.png
new file mode 100644
index 0000000000000000000000000000000000000000..3e134241a7b72a71260574a25305057a75fdf653
Binary files /dev/null and b/input/blackswan/00029.png differ
diff --git a/input/blackswan/00030.png b/input/blackswan/00030.png
new file mode 100644
index 0000000000000000000000000000000000000000..2f7a438871076b04c2e9f8589d7c5decf113af17
Binary files /dev/null and b/input/blackswan/00030.png differ
diff --git a/input/blackswan/00031.png b/input/blackswan/00031.png
new file mode 100644
index 0000000000000000000000000000000000000000..06c9985e1a3017147d6821bb04c1feff330df770
Binary files /dev/null and b/input/blackswan/00031.png differ
diff --git a/input/blackswan/00032.png b/input/blackswan/00032.png
new file mode 100644
index 0000000000000000000000000000000000000000..65181c862bcdf6b046c6c8ff8b7298b17f80cf00
Binary files /dev/null and b/input/blackswan/00032.png differ
diff --git a/input/blackswan/00033.png b/input/blackswan/00033.png
new file mode 100644
index 0000000000000000000000000000000000000000..2b1897362f7936a208cdc53393f6ea4b2a6205f8
Binary files /dev/null and b/input/blackswan/00033.png differ
diff --git a/input/blackswan/00034.png b/input/blackswan/00034.png
new file mode 100644
index 0000000000000000000000000000000000000000..29da4528c83eaa36635a6ef6434d149ca48976a5
Binary files /dev/null and b/input/blackswan/00034.png differ
diff --git a/input/blackswan/00035.png b/input/blackswan/00035.png
new file mode 100644
index 0000000000000000000000000000000000000000..25c7d53a9fcff3c1496e78adc735e0e0b2596814
Binary files /dev/null and b/input/blackswan/00035.png differ
diff --git a/input/blackswan/00036.png b/input/blackswan/00036.png
new file mode 100644
index 0000000000000000000000000000000000000000..49daf9e8feb78c6ff5de5fab40ac44dd8d847b4a
Binary files /dev/null and b/input/blackswan/00036.png differ
diff --git a/input/blackswan/00037.png b/input/blackswan/00037.png
new file mode 100644
index 0000000000000000000000000000000000000000..a584a712cdef876c0ff6e436702d8264c98bf13e
Binary files /dev/null and b/input/blackswan/00037.png differ
diff --git a/input/blackswan/00038.png b/input/blackswan/00038.png
new file mode 100644
index 0000000000000000000000000000000000000000..4e55ec2761f64a751c0dd20b236046de9766c9ad
Binary files /dev/null and b/input/blackswan/00038.png differ
diff --git a/input/blackswan/00039.png b/input/blackswan/00039.png
new file mode 100644
index 0000000000000000000000000000000000000000..15f547c33bfd454dcdb8b6c95bf4fe85f3a0b636
Binary files /dev/null and b/input/blackswan/00039.png differ
diff --git a/input/blackswan/00040.png b/input/blackswan/00040.png
new file mode 100644
index 0000000000000000000000000000000000000000..75b00d03b9e00562adf755afa79bb5f9603910d7
Binary files /dev/null and b/input/blackswan/00040.png differ
diff --git a/input/blackswan/00041.png b/input/blackswan/00041.png
new file mode 100644
index 0000000000000000000000000000000000000000..1d918ba53affeb5ab2ce9829b2dc59e263a61b8b
Binary files /dev/null and b/input/blackswan/00041.png differ
diff --git a/input/blackswan/00042.png b/input/blackswan/00042.png
new file mode 100644
index 0000000000000000000000000000000000000000..70395b42de9dbf440eddd845c16f5c8cb44fce09
Binary files /dev/null and b/input/blackswan/00042.png differ
diff --git a/input/blackswan/00043.png b/input/blackswan/00043.png
new file mode 100644
index 0000000000000000000000000000000000000000..dc90f09eb0997efeec7a056b7706849a6bea5471
Binary files /dev/null and b/input/blackswan/00043.png differ
diff --git a/input/blackswan/00044.png b/input/blackswan/00044.png
new file mode 100644
index 0000000000000000000000000000000000000000..c1ca7a3198d7c8822f444be0725847cacff59482
Binary files /dev/null and b/input/blackswan/00044.png differ
diff --git a/input/blackswan/00045.png b/input/blackswan/00045.png
new file mode 100644
index 0000000000000000000000000000000000000000..089ad8c08b6f377835a43ee225e6cbc9458456ad
Binary files /dev/null and b/input/blackswan/00045.png differ
diff --git a/input/blackswan/00046.png b/input/blackswan/00046.png
new file mode 100644
index 0000000000000000000000000000000000000000..7b8681a108f4b1bcaa434e42b546490e295ef4ca
Binary files /dev/null and b/input/blackswan/00046.png differ
diff --git a/input/blackswan/00047.png b/input/blackswan/00047.png
new file mode 100644
index 0000000000000000000000000000000000000000..f737576977efdab060b2ea861441bf32a7a6181e
Binary files /dev/null and b/input/blackswan/00047.png differ
diff --git a/input/blackswan/00048.png b/input/blackswan/00048.png
new file mode 100644
index 0000000000000000000000000000000000000000..fa06c0db7b1c7956e081b553f03d938377e74f7a
Binary files /dev/null and b/input/blackswan/00048.png differ
diff --git a/input/blackswan/00049.png b/input/blackswan/00049.png
new file mode 100644
index 0000000000000000000000000000000000000000..1505fa35e8731f872ec83cb60c1d1a0b7c3f98da
Binary files /dev/null and b/input/blackswan/00049.png differ
diff --git a/model/__init__.py b/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/model/aggregate.py b/model/aggregate.py
new file mode 100644
index 0000000000000000000000000000000000000000..7622391fb3ac9aa8b515df88cf3ea5297b367538
--- /dev/null
+++ b/model/aggregate.py
@@ -0,0 +1,17 @@
+import torch
+import torch.nn.functional as F
+
+
+# Soft aggregation from STM
+def aggregate(prob, dim, return_logits=False):
+ new_prob = torch.cat([
+ torch.prod(1-prob, dim=dim, keepdim=True),
+ prob
+ ], dim).clamp(1e-7, 1-1e-7)
+ logits = torch.log((new_prob /(1-new_prob)))
+ prob = F.softmax(logits, dim=dim)
+
+ if return_logits:
+ return logits, prob
+ else:
+ return prob
\ No newline at end of file
diff --git a/model/attention.py b/model/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..c593383fbbc9568301bc63b4a89f8af4f92f05f1
--- /dev/null
+++ b/model/attention.py
@@ -0,0 +1,916 @@
+import math
+import pdb
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from model.basic import DropOutLogit, ScaleOffset, DWConv2d
+
+
+def multiply_by_ychunks(x, y, chunks=1):
+ if chunks <= 1:
+ return x @ y
+ else:
+ return torch.cat([x @ _y for _y in y.chunk(chunks, dim=-1)], dim=-1)
+
+
+def multiply_by_xchunks(x, y, chunks=1):
+ if chunks <= 1:
+ return x @ y
+ else:
+ return torch.cat([_x @ y for _x in x.chunk(chunks, dim=-2)], dim=-2)
+
+
+# Long-term attention
+class MultiheadAttention(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head=8,
+ dropout=0.,
+ use_linear=True,
+ d_att=None,
+ use_dis=False,
+ qk_chunks=1,
+ max_mem_len_ratio=-1,
+ top_k=-1):
+ super().__init__()
+ self.d_model = d_model
+ self.num_head = num_head
+ self.use_dis = use_dis
+ self.qk_chunks = qk_chunks
+ self.max_mem_len_ratio = float(max_mem_len_ratio)
+ self.top_k = top_k
+
+ self.hidden_dim = d_model // num_head
+ self.d_att = self.hidden_dim if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_linear = use_linear
+
+ if use_linear:
+ self.linear_Q = nn.Linear(d_model, d_model)
+ self.linear_K = nn.Linear(d_model, d_model)
+ self.linear_V = nn.Linear(d_model, d_model)
+
+ self.dropout = nn.Dropout(dropout)
+ self.drop_prob = dropout
+ self.projection = nn.Linear(d_model, d_model)
+ self._init_weight()
+
+ def forward(self, Q, K, V):
+ """
+ :param Q: A 3d tensor with shape of [T_q, bs, C_q]
+ :param K: A 3d tensor with shape of [T_k, bs, C_k]
+ :param V: A 3d tensor with shape of [T_v, bs, C_v]
+ """
+ num_head = self.num_head
+ hidden_dim = self.hidden_dim
+
+ bs = Q.size()[1]
+
+ # Linear projections
+ if self.use_linear:
+ Q = self.linear_Q(Q)
+ K = self.linear_K(K)
+ V = self.linear_V(V)
+
+ # Scale
+ Q = Q / self.T
+
+ if not self.training and self.max_mem_len_ratio > 0:
+ mem_len_ratio = float(K.size(0)) / Q.size(0)
+ if mem_len_ratio > self.max_mem_len_ratio:
+ scaling_ratio = math.log(mem_len_ratio) / math.log(
+ self.max_mem_len_ratio)
+ Q = Q * scaling_ratio
+
+ # Multi-head
+ Q = Q.view(-1, bs, num_head, self.d_att).permute(1, 2, 0, 3)
+ K = K.view(-1, bs, num_head, self.d_att).permute(1, 2, 3, 0)
+ V = V.view(-1, bs, num_head, hidden_dim).permute(1, 2, 0, 3)
+
+ # Multiplication
+ QK = multiply_by_ychunks(Q, K, self.qk_chunks)
+ if self.use_dis:
+ QK = 2 * QK - K.pow(2).sum(dim=-2, keepdim=True)
+
+ # Activation
+ if not self.training and self.top_k > 0 and self.top_k < QK.size()[-1]:
+ top_QK, indices = torch.topk(QK, k=self.top_k, dim=-1)
+ top_attn = torch.softmax(top_QK, dim=-1)
+ attn = torch.zeros_like(QK).scatter_(-1, indices, top_attn)
+ else:
+ attn = torch.softmax(QK, dim=-1)
+
+ # Dropouts
+ attn = self.dropout(attn)
+
+ # Weighted sum
+ outputs = multiply_by_xchunks(attn, V,
+ self.qk_chunks).permute(2, 0, 1, 3)
+
+ # Restore shape
+ outputs = outputs.reshape(-1, bs, self.d_model)
+
+ outputs = self.projection(outputs)
+
+ return outputs, attn
+
+ def _init_weight(self):
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+
+
+# Short-term attention
+class MultiheadLocalAttentionV1(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True,
+ enable_corr=True):
+ super().__init__()
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.T = ((d_model / num_head)**0.5)
+
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_Q = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_K = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_model, d_model, kernel_size=1)
+
+ self.relative_emb_k = nn.Conv2d(d_model,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+ self.relative_emb_v = nn.Parameter(
+ torch.zeros([
+ self.num_head, d_model // self.num_head,
+ self.window_size * self.window_size
+ ]))
+
+ self.enable_corr = enable_corr
+
+ if enable_corr:
+ from spatial_correlation_sampler import SpatialCorrelationSampler
+ self.correlation_sampler = SpatialCorrelationSampler(
+ kernel_size=1,
+ patch_size=self.window_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ dilation_patch=self.dilation)
+
+ self.projection = nn.Linear(d_model, d_model)
+
+ self.dropout = nn.Dropout(dropout)
+ self.drop_prob = dropout
+
+ def forward(self, q, k, v):
+ n, c, h, w = v.size()
+
+ if self.use_linear:
+ q = self.linear_Q(q)
+ k = self.linear_K(k)
+ v = self.linear_V(v)
+
+ hidden_dim = c // self.num_head
+
+ relative_emb = self.relative_emb_k(q)
+ memory_mask = torch.ones((1, 1, h, w), device=v.device).float()
+
+ # Scale
+ q = q / self.T
+
+ q = q.view(-1, hidden_dim, h, w)
+ k = k.reshape(-1, hidden_dim, h, w).contiguous()
+ unfolded_vu = self.pad_and_unfold(v).view(
+ n, self.num_head, hidden_dim, self.window_size * self.window_size,
+ h * w) + self.relative_emb_v.unsqueeze(0).unsqueeze(-1)
+
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+ unfolded_k_mask = self.pad_and_unfold(memory_mask).bool().view(
+ 1, 1, self.window_size * self.window_size,
+ h * w).expand(n, self.num_head, -1, -1)
+
+ if self.enable_corr:
+ qk = self.correlation_sampler(q, k).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w) + relative_emb
+ else:
+ unfolded_k = self.pad_and_unfold(k).view(
+ n * self.num_head, hidden_dim,
+ self.window_size * self.window_size, h, w)
+ qk = (q.unsqueeze(2) * unfolded_k).sum(dim=1).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w) + relative_emb
+
+ qk_mask = 1 - unfolded_k_mask
+
+ qk -= qk_mask * 1e+8 if qk.dtype == torch.float32 else qk_mask * 1e+4
+
+ local_attn = torch.softmax(qk, dim=2)
+
+ local_attn = self.dropout(local_attn)
+
+ output = (local_attn.unsqueeze(2) * unfolded_vu).sum(dim=3).permute(
+ 3, 0, 1, 2).view(h * w, n, c)
+
+ output = self.projection(output)
+
+ return output, local_attn
+
+ def pad_and_unfold(self, x):
+ pad_pixel = self.max_dis * self.dilation
+ x = F.pad(x, (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0)
+ x = F.unfold(x,
+ kernel_size=(self.window_size, self.window_size),
+ stride=(1, 1),
+ dilation=self.dilation)
+ return x
+
+
+class MultiheadLocalAttentionV2(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True,
+ enable_corr=True,
+ d_att=None,
+ use_dis=False):
+ super().__init__()
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.hidden_dim = d_model // num_head
+ self.d_att = self.hidden_dim if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_dis = use_dis
+
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_Q = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_K = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_model, d_model, kernel_size=1)
+
+ self.relative_emb_k = nn.Conv2d(self.d_att * self.num_head,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+ self.relative_emb_v = nn.Parameter(
+ torch.zeros([
+ self.num_head, d_model // self.num_head,
+ self.window_size * self.window_size
+ ]))
+
+ self.enable_corr = enable_corr
+
+ if enable_corr:
+ from spatial_correlation_sampler import SpatialCorrelationSampler
+ self.correlation_sampler = SpatialCorrelationSampler(
+ kernel_size=1,
+ patch_size=self.window_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ dilation_patch=self.dilation)
+
+ self.projection = nn.Linear(d_model, d_model)
+
+ self.dropout = nn.Dropout(dropout)
+
+ self.drop_prob = dropout
+
+ self.local_mask = None
+ self.last_size_2d = None
+ self.qk_mask = None
+
+ def forward(self, q, k, v):
+ n, c, h, w = v.size()
+
+ if self.use_linear:
+ q = self.linear_Q(q)
+ k = self.linear_K(k)
+ v = self.linear_V(v)
+
+ hidden_dim = self.hidden_dim
+
+ if self.qk_mask is not None and (h, w) == self.last_size_2d:
+ qk_mask = self.qk_mask
+ else:
+ memory_mask = torch.ones((1, 1, h, w), device=v.device).float()
+ unfolded_k_mask = self.pad_and_unfold(memory_mask).view(
+ 1, 1, self.window_size * self.window_size, h * w)
+ qk_mask = 1 - unfolded_k_mask
+ self.qk_mask = qk_mask
+
+ relative_emb = self.relative_emb_k(q)
+
+ # Scale
+ q = q / self.T
+
+ q = q.view(-1, self.d_att, h, w)
+ k = k.view(-1, self.d_att, h, w)
+ v = v.view(-1, self.num_head, hidden_dim, h * w)
+
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+
+ if self.enable_corr:
+ qk = self.correlation_sampler(q, k).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ else:
+ unfolded_k = self.pad_and_unfold(k).view(
+ n * self.num_head, hidden_dim,
+ self.window_size * self.window_size, h, w)
+ qk = (q.unsqueeze(2) * unfolded_k).sum(dim=1).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ if self.use_dis:
+ qk = 2 * qk - self.pad_and_unfold(
+ k.pow(2).sum(dim=1, keepdim=True)).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w)
+
+ qk = qk + relative_emb
+
+ qk -= qk_mask * 1e+8 if qk.dtype == torch.float32 else qk_mask * 1e+4
+
+ local_attn = torch.softmax(qk, dim=2)
+
+ local_attn = self.dropout(local_attn)
+
+ agg_bias = torch.einsum('bhwn,hcw->bhnc', local_attn,
+ self.relative_emb_v)
+
+ global_attn = self.local2global(local_attn, h, w)
+
+ agg_value = (global_attn @ v.transpose(-2, -1))
+
+ output = (agg_value + agg_bias).permute(2, 0, 1,
+ 3).reshape(h * w, n, c)
+
+ output = self.projection(output)
+
+ self.last_size_2d = (h, w)
+ return output, local_attn
+
+ def local2global(self, local_attn, height, width):
+ batch_size = local_attn.size()[0]
+
+ pad_height = height + 2 * self.max_dis
+ pad_width = width + 2 * self.max_dis
+
+ if self.local_mask is not None and (height,
+ width) == self.last_size_2d:
+ local_mask = self.local_mask
+ else:
+ ky, kx = torch.meshgrid([
+ torch.arange(0, pad_height, device=local_attn.device),
+ torch.arange(0, pad_width, device=local_attn.device)
+ ])
+ qy, qx = torch.meshgrid([
+ torch.arange(0, height, device=local_attn.device),
+ torch.arange(0, width, device=local_attn.device)
+ ])
+
+ offset_y = qy.reshape(-1, 1) - ky.reshape(1, -1) + self.max_dis
+ offset_x = qx.reshape(-1, 1) - kx.reshape(1, -1) + self.max_dis
+
+ local_mask = (offset_y.abs() <= self.max_dis) & (offset_x.abs() <=
+ self.max_dis)
+ local_mask = local_mask.view(1, 1, height * width, pad_height,
+ pad_width)
+ self.local_mask = local_mask
+
+ global_attn = torch.zeros(
+ (batch_size, self.num_head, height * width, pad_height, pad_width),
+ device=local_attn.device)
+ global_attn = global_attn.type(torch.HalfTensor).cuda()
+ global_attn[local_mask.expand(batch_size, self.num_head,
+ -1, -1, -1)] = local_attn.transpose(
+ -1, -2).reshape(-1)
+ global_attn = global_attn[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis].reshape(
+ batch_size, self.num_head,
+ height * width, height * width)
+
+ return global_attn
+
+ def pad_and_unfold(self, x):
+ pad_pixel = self.max_dis * self.dilation
+ x = F.pad(x, (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0)
+ x = F.unfold(x,
+ kernel_size=(self.window_size, self.window_size),
+ stride=(1, 1),
+ dilation=self.dilation)
+ return x
+
+
+class MultiheadLocalAttentionV3(nn.Module):
+ def __init__(self,
+ d_model,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True):
+ super().__init__()
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.T = ((d_model / num_head)**0.5)
+
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_Q = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_K = nn.Conv2d(d_model, d_model, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_model, d_model, kernel_size=1)
+
+ self.relative_emb_k = nn.Conv2d(d_model,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+ self.relative_emb_v = nn.Parameter(
+ torch.zeros([
+ self.num_head, d_model // self.num_head,
+ self.window_size * self.window_size
+ ]))
+
+ self.projection = nn.Linear(d_model, d_model)
+ self.dropout = DropOutLogit(dropout)
+
+ self.padded_local_mask = None
+ self.local_mask = None
+ self.last_size_2d = None
+ self.qk_mask = None
+
+ def forward(self, q, k, v):
+ n, c, h, w = q.size()
+
+ if self.use_linear:
+ q = self.linear_Q(q)
+ k = self.linear_K(k)
+ v = self.linear_V(v)
+
+ hidden_dim = c // self.num_head
+
+ relative_emb = self.relative_emb_k(q)
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+ padded_local_mask, local_mask = self.compute_mask(h,
+ w,
+ device=q.device)
+ qk_mask = (~padded_local_mask).float()
+
+ # Scale
+ q = q / self.T
+
+ q = q.view(-1, self.num_head, hidden_dim, h * w)
+ k = k.view(-1, self.num_head, hidden_dim, h * w)
+ v = v.view(-1, self.num_head, hidden_dim, h * w)
+
+ qk = q.transpose(-1, -2) @ k # [B, nH, kL, qL]
+
+ pad_pixel = self.max_dis * self.dilation
+
+ padded_qk = F.pad(qk.view(-1, self.num_head, h * w, h, w),
+ (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=-1e+8 if qk.dtype == torch.float32 else -1e+4)
+
+ qk_mask = qk_mask * 1e+8 if (padded_qk.dtype
+ == torch.float32) else qk_mask * 1e+4
+ padded_qk = padded_qk - qk_mask
+
+ padded_qk[padded_local_mask.expand(n, self.num_head, -1, -1,
+ -1)] += relative_emb.transpose(
+ -1, -2).reshape(-1)
+ padded_qk = self.dropout(padded_qk)
+
+ local_qk = padded_qk[padded_local_mask.expand(n, self.num_head, -1, -1,
+ -1)]
+
+ global_qk = padded_qk[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis].reshape(
+ n, self.num_head, h * w, h * w)
+
+ local_attn = torch.softmax(local_qk.reshape(
+ n, self.num_head, h * w, self.window_size * self.window_size),
+ dim=3)
+ global_attn = torch.softmax(global_qk, dim=3)
+
+ agg_bias = torch.einsum('bhnw,hcw->nbhc', local_attn,
+ self.relative_emb_v).reshape(h * w, n, c)
+
+ agg_value = (global_attn @ v.transpose(-2, -1))
+
+ output = agg_value + agg_bias
+
+ output = self.projection(output)
+
+ self.last_size_2d = (h, w)
+ return output, local_attn
+
+ def compute_mask(self, height, width, device=None):
+ pad_height = height + 2 * self.max_dis
+ pad_width = width + 2 * self.max_dis
+
+ if self.padded_local_mask is not None and (height,
+ width) == self.last_size_2d:
+ padded_local_mask = self.padded_local_mask
+ local_mask = self.local_mask
+
+ else:
+ ky, kx = torch.meshgrid([
+ torch.arange(0, pad_height, device=device),
+ torch.arange(0, pad_width, device=device)
+ ])
+ qy, qx = torch.meshgrid([
+ torch.arange(0, height, device=device),
+ torch.arange(0, width, device=device)
+ ])
+
+ qy = qy.reshape(-1, 1)
+ qx = qx.reshape(-1, 1)
+ offset_y = qy - ky.reshape(1, -1) + self.max_dis
+ offset_x = qx - kx.reshape(1, -1) + self.max_dis
+ padded_local_mask = (offset_y.abs() <= self.max_dis) & (
+ offset_x.abs() <= self.max_dis)
+ padded_local_mask = padded_local_mask.view(1, 1, height * width,
+ pad_height, pad_width)
+ local_mask = padded_local_mask[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis]
+ pad_pixel = self.max_dis * self.dilation
+ local_mask = F.pad(local_mask.float(),
+ (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0).view(1, 1, height * width, pad_height,
+ pad_width)
+ self.padded_local_mask = padded_local_mask
+ self.local_mask = local_mask
+
+ return padded_local_mask, local_mask
+
+
+def linear_gate(x, dim=-1):
+ # return F.relu_(x).pow(2.) / x.size()[dim]
+ return torch.softmax(x, dim=dim)
+
+
+def silu(x):
+ return x * torch.sigmoid(x)
+
+
+class GatedPropagation(nn.Module):
+ def __init__(self,
+ d_qk,
+ d_vu,
+ num_head=8,
+ dropout=0.,
+ use_linear=True,
+ d_att=None,
+ use_dis=False,
+ qk_chunks=1,
+ max_mem_len_ratio=-1,
+ top_k=-1,
+ expand_ratio=2.):
+ super().__init__()
+ expand_ratio = expand_ratio
+ self.expand_d_vu = int(d_vu * expand_ratio)
+ self.d_vu = d_vu
+ self.d_qk = d_qk
+ self.num_head = num_head
+ self.use_dis = use_dis
+ self.qk_chunks = qk_chunks
+ self.max_mem_len_ratio = float(max_mem_len_ratio)
+ self.top_k = top_k
+
+ self.hidden_dim = self.expand_d_vu // num_head
+ self.d_att = d_qk // num_head if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_linear = use_linear
+ self.d_middle = self.d_att * self.num_head
+
+ if use_linear:
+ self.linear_QK = nn.Linear(d_qk, self.d_middle)
+ half_d_vu = self.hidden_dim * num_head // 2
+ self.linear_V1 = nn.Linear(d_vu // 2, half_d_vu)
+ self.linear_V2 = nn.Linear(d_vu // 2, half_d_vu)
+ self.linear_U1 = nn.Linear(d_vu // 2, half_d_vu)
+ self.linear_U2 = nn.Linear(d_vu // 2, half_d_vu)
+
+ self.dropout = nn.Dropout(dropout)
+ self.drop_prob = dropout
+
+ self.dw_conv = DWConv2d(self.expand_d_vu)
+ self.projection = nn.Linear(self.expand_d_vu, d_vu)
+
+ self._init_weight()
+
+ def forward(self, Q, K, V, U, size_2d):
+ """
+ :param Q: A 3d tensor with shape of [T_q, bs, C_q]
+ :param K: A 3d tensor with shape of [T_k, bs, C_k]
+ :param V: A 3d tensor with shape of [T_v, bs, C_v]
+ """
+ num_head = self.num_head
+ hidden_dim = self.hidden_dim
+
+ l, bs, _ = Q.size()
+
+ # Linear projections
+ if self.use_linear:
+ Q = K = self.linear_QK(Q)
+
+ def cat(X1, X2):
+ if num_head > 1:
+ X1 = X1.view(-1, bs, num_head, hidden_dim // 2)
+ X2 = X2.view(-1, bs, num_head, hidden_dim // 2)
+ X = torch.cat([X1, X2],
+ dim=-1).view(-1, bs, num_head * hidden_dim)
+ else:
+ X = torch.cat([X1, X2], dim=-1)
+ return X
+
+ V1, V2 = torch.split(V, self.d_vu // 2, dim=-1)
+ V1 = self.linear_V1(V1)
+ V2 = self.linear_V2(V2)
+ V = silu(cat(V1, V2))
+
+ U1, U2 = torch.split(U, self.d_vu // 2, dim=-1)
+ U1 = self.linear_U1(U1)
+ U2 = self.linear_U2(U2)
+ U = silu(cat(U1, U2))
+
+ # Scale
+ Q = Q / self.T
+
+ if not self.training and self.max_mem_len_ratio > 0:
+ mem_len_ratio = float(K.size(0)) / Q.size(0)
+ if mem_len_ratio > self.max_mem_len_ratio:
+ scaling_ratio = math.log(mem_len_ratio) / math.log(
+ self.max_mem_len_ratio)
+ Q = Q * scaling_ratio
+
+ # Multi-head
+ Q = Q.view(-1, bs, num_head, self.d_att).permute(1, 2, 0, 3)
+ K = K.view(-1, bs, num_head, self.d_att).permute(1, 2, 3, 0)
+ V = V.view(-1, bs, num_head, hidden_dim).permute(1, 2, 0, 3)
+
+ # Multiplication
+ QK = multiply_by_ychunks(Q, K, self.qk_chunks)
+ if self.use_dis:
+ QK = 2 * QK - K.pow(2).sum(dim=-2, keepdim=True)
+
+ # Activation
+ if not self.training and self.top_k > 0 and self.top_k < QK.size()[-1]:
+ top_QK, indices = torch.topk(QK, k=self.top_k, dim=-1)
+ top_attn = linear_gate(top_QK, dim=-1)
+ attn = torch.zeros_like(QK).scatter_(-1, indices, top_attn)
+ else:
+ attn = linear_gate(QK, dim=-1)
+
+ # Dropouts
+ attn = self.dropout(attn)
+
+ # Weighted sum
+ outputs = multiply_by_xchunks(attn, V,
+ self.qk_chunks).permute(2, 0, 1, 3)
+
+ # Restore shape
+ outputs = outputs.reshape(l, bs, -1) * U
+
+ outputs = self.dw_conv(outputs, size_2d)
+ outputs = self.projection(outputs)
+
+ return outputs, attn
+
+ def _init_weight(self):
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+
+
+class LocalGatedPropagation(nn.Module):
+ def __init__(self,
+ d_qk,
+ d_vu,
+ num_head,
+ dropout=0.,
+ max_dis=7,
+ dilation=1,
+ use_linear=True,
+ enable_corr=True,
+ d_att=None,
+ use_dis=False,
+ expand_ratio=2.):
+ super().__init__()
+ expand_ratio = expand_ratio
+ self.expand_d_vu = int(d_vu * expand_ratio)
+ self.d_qk = d_qk
+ self.d_vu = d_vu
+ self.dilation = dilation
+ self.window_size = 2 * max_dis + 1
+ self.max_dis = max_dis
+ self.num_head = num_head
+ self.hidden_dim = self.expand_d_vu // num_head
+ self.d_att = d_qk // num_head if d_att is None else d_att
+ self.T = self.d_att**0.5
+ self.use_dis = use_dis
+
+ self.d_middle = self.d_att * self.num_head
+ self.use_linear = use_linear
+ if use_linear:
+ self.linear_QK = nn.Conv2d(d_qk, self.d_middle, kernel_size=1)
+ self.linear_V = nn.Conv2d(d_vu,
+ self.expand_d_vu,
+ kernel_size=1,
+ groups=2)
+ self.linear_U = nn.Conv2d(d_vu,
+ self.expand_d_vu,
+ kernel_size=1,
+ groups=2)
+
+ self.relative_emb_k = nn.Conv2d(self.d_middle,
+ num_head * self.window_size *
+ self.window_size,
+ kernel_size=1,
+ groups=num_head)
+
+ self.enable_corr = enable_corr
+
+ if enable_corr:
+ from spatial_correlation_sampler import SpatialCorrelationSampler
+ self.correlation_sampler = SpatialCorrelationSampler(
+ kernel_size=1,
+ patch_size=self.window_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ dilation_patch=self.dilation)
+
+ self.dw_conv = DWConv2d(self.expand_d_vu)
+ self.projection = nn.Linear(self.expand_d_vu, d_vu)
+
+ self.dropout = nn.Dropout(dropout)
+
+ self.drop_prob = dropout
+
+ self.local_mask = None
+ self.last_size_2d = None
+ self.qk_mask = None
+
+ def forward(self, q, k, v, u, size_2d):
+ n, c, h, w = v.size()
+ hidden_dim = self.hidden_dim
+
+ if self.use_linear:
+ q = k = self.linear_QK(q)
+ v = silu(self.linear_V(v))
+ # u = silu(self.linear_U(u))
+ if self.num_head > 1:
+ v = v.view(-1, 2, self.num_head, hidden_dim // 2,
+ h * w).permute(0, 2, 1, 3, 4).reshape(n, -1, h, w)
+ # u = u.view(-1, 2, self.num_head, hidden_dim // 2,
+ # h * w).permute(4, 0, 2, 1, 3).reshape(h * w, n, -1)
+ # else:
+ # u = u.permute(2, 3, 0, 1).reshape(h * w, n, -1)
+
+ if self.qk_mask is not None and (h, w) == self.last_size_2d:
+ qk_mask = self.qk_mask
+ else:
+ memory_mask = torch.ones((1, 1, h, w), device=v.device).float()
+ unfolded_k_mask = self.pad_and_unfold(memory_mask).view(
+ 1, 1, self.window_size * self.window_size, h * w)
+ qk_mask = 1 - unfolded_k_mask
+ self.qk_mask = qk_mask
+
+ relative_emb = self.relative_emb_k(q)
+
+ # Scale
+ q = q / self.T
+
+ # print(q.shape)
+ # print(self.d_att, h, w)
+ # pdb.set_trace()
+ q = q.view(-1, self.d_att, h, w)
+ k = k.view(-1, self.d_att, h, w).contiguous()
+ v = v.view(-1, self.num_head, hidden_dim, h * w)
+ # print([n,c,h,w], q.shape, k.shape, v.shape);assert 0
+ # [4, 1024, 24, 24] torch.Size([4, 64, 24, 24]) torch.Size([4, 64, 24, 24]) torch.Size([2, 1, 2048, 576])
+
+
+ relative_emb = relative_emb.view(n, self.num_head,
+ self.window_size * self.window_size,
+ h * w)
+
+ if self.enable_corr:
+ qk = self.correlation_sampler(q, k).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ else:
+ unfolded_k = self.pad_and_unfold(k).view(
+ n * self.num_head, hidden_dim,
+ self.window_size * self.window_size, h, w)
+ qk = (q.unsqueeze(2) * unfolded_k).sum(dim=1).view(
+ n, self.num_head, self.window_size * self.window_size, h * w)
+ if self.use_dis:
+ qk = 2 * qk - self.pad_and_unfold(
+ k.pow(2).sum(dim=1, keepdim=True)).view(
+ n, self.num_head, self.window_size * self.window_size,
+ h * w)
+
+ qk = qk + relative_emb
+
+ qk -= qk_mask * 1e+8 if qk.dtype == torch.float32 else qk_mask * 1e+4
+
+ local_attn = linear_gate(qk, dim=2)
+
+ local_attn = self.dropout(local_attn)
+
+ global_attn = self.local2global(local_attn, h, w)
+
+ agg_value = (global_attn @ v.transpose(-2, -1)).permute(
+ 2, 0, 1, 3).reshape(h * w, n, -1)
+
+ # output = agg_value * u
+ output = agg_value
+
+ output = self.dw_conv(output, size_2d)
+ output = self.projection(output)
+
+ self.last_size_2d = (h, w)
+ return output, local_attn
+
+ def local2global(self, local_attn, height, width):
+ batch_size = local_attn.size()[0]
+
+ pad_height = height + 2 * self.max_dis
+ pad_width = width + 2 * self.max_dis
+
+ if self.local_mask is not None and (height,
+ width) == self.last_size_2d:
+ local_mask = self.local_mask
+ else:
+ ky, kx = torch.meshgrid([
+ torch.arange(0, pad_height, device=local_attn.device),
+ torch.arange(0, pad_width, device=local_attn.device)
+ ])
+ qy, qx = torch.meshgrid([
+ torch.arange(0, height, device=local_attn.device),
+ torch.arange(0, width, device=local_attn.device)
+ ])
+
+ offset_y = qy.reshape(-1, 1) - ky.reshape(1, -1) + self.max_dis
+ offset_x = qx.reshape(-1, 1) - kx.reshape(1, -1) + self.max_dis
+
+ local_mask = (offset_y.abs() <= self.max_dis) & (offset_x.abs() <=
+ self.max_dis)
+ local_mask = local_mask.view(1, 1, height * width, pad_height,
+ pad_width)
+ self.local_mask = local_mask
+
+ global_attn = torch.zeros(
+ (batch_size, self.num_head, height * width, pad_height, pad_width),
+ device=local_attn.device)
+ # global_attn = global_attn.type(torch.HalfTensor).cuda()
+ global_attn[local_mask.expand(batch_size, self.num_head,
+ -1, -1, -1)] = local_attn.transpose(
+ -1, -2).reshape(-1)
+ global_attn = global_attn[:, :, :, self.max_dis:-self.max_dis,
+ self.max_dis:-self.max_dis].reshape(
+ batch_size, self.num_head,
+ height * width, height * width)
+
+ return global_attn
+
+ def pad_and_unfold(self, x):
+ pad_pixel = self.max_dis * self.dilation
+ x = F.pad(x, (pad_pixel, pad_pixel, pad_pixel, pad_pixel),
+ mode='constant',
+ value=0)
+ x = F.unfold(x,
+ kernel_size=(self.window_size, self.window_size),
+ stride=(1, 1),
+ dilation=self.dilation)
+ return x
diff --git a/model/basic.py b/model/basic.py
new file mode 100644
index 0000000000000000000000000000000000000000..d09b2efa0801bd3ead0f7baf9388aa21a7ea79fe
--- /dev/null
+++ b/model/basic.py
@@ -0,0 +1,205 @@
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+
+class ResBlock(nn.Module):
+ def __init__(self, indim, outdim=None, stride=1):
+ super(ResBlock, self).__init__()
+ if outdim == None:
+ outdim = indim
+ if indim == outdim and stride == 1:
+ self.downsample = None
+ else:
+ self.downsample = nn.Conv2d(indim, outdim, kernel_size=3, padding=1, stride=stride)
+ self.gn3 = nn.GroupNorm(8, outdim)
+
+ self.conv1 = nn.Conv2d(indim, outdim, kernel_size=3, padding=1, stride=stride)
+ self.conv2 = nn.Conv2d(outdim, outdim, kernel_size=3, padding=1)
+
+ self.gn1 = nn.GroupNorm(8, outdim)
+ self.gn2 = nn.GroupNorm(8, outdim)
+
+ def forward(self, x):
+ r = self.conv1(F.relu(x))
+ r = self.gn1(r)
+
+ r = self.conv2(F.relu(r))
+ r = self.gn2(r)
+
+ if self.downsample is not None:
+ x = self.gn3(self.downsample(x))
+
+ return x + r
+
+class ResGN(nn.Module):
+ def __init__(self, indim, outdim):
+ super().__init__()
+ self.res1 = ResBlock(indim, outdim)
+ self.res2 = ResBlock(outdim, outdim)
+ def forward(self, x):
+ return self.res2(self.res1(x))
+
+class GroupNorm1D(nn.Module):
+ def __init__(self, indim, groups=8):
+ super().__init__()
+ self.gn = nn.GroupNorm(groups, indim)
+
+ def forward(self, x):
+ return self.gn(x.permute(1, 2, 0)).permute(2, 0, 1)
+
+
+class GNActDWConv2d(nn.Module):
+ def __init__(self, indim, gn_groups=32):
+ super().__init__()
+ self.gn = nn.GroupNorm(gn_groups, indim)
+ self.conv = nn.Conv2d(indim,
+ indim,
+ 5,
+ dilation=1,
+ padding=2,
+ groups=indim,
+ bias=False)
+
+ def forward(self, x, size_2d):
+ h, w = size_2d
+ _, bs, c = x.size()
+ x = x.view(h, w, bs, c).permute(2, 3, 0, 1)
+ x = self.gn(x)
+ x = F.gelu(x)
+ x = self.conv(x)
+ x = x.view(bs, c, h * w).permute(2, 0, 1)
+ return x
+
+
+class DWConv2d(nn.Module):
+ def __init__(self, indim, dropout=0.1):
+ super().__init__()
+ self.conv = nn.Conv2d(indim,
+ indim,
+ 5,
+ dilation=1,
+ padding=2,
+ groups=indim,
+ bias=False)
+ self.dropout = nn.Dropout2d(p=dropout, inplace=True)
+
+ def forward(self, x, size_2d):
+ h, w = size_2d
+ _, bs, c = x.size()
+ x = x.view(h, w, bs, c).permute(2, 3, 0, 1)
+ x = self.conv(x)
+ x = self.dropout(x)
+ x = x.view(bs, c, h * w).permute(2, 0, 1)
+ return x
+
+
+class ScaleOffset(nn.Module):
+ def __init__(self, indim):
+ super().__init__()
+ self.gamma = nn.Parameter(torch.ones(indim))
+ # torch.nn.init.normal_(self.gamma, std=0.02)
+ self.beta = nn.Parameter(torch.zeros(indim))
+
+ def forward(self, x):
+ if len(x.size()) == 3:
+ return x * self.gamma + self.beta
+ else:
+ return x * self.gamma.view(1, -1, 1, 1) + self.beta.view(
+ 1, -1, 1, 1)
+
+
+class ConvGN(nn.Module):
+ def __init__(self, indim, outdim, kernel_size, gn_groups=8):
+ super().__init__()
+ self.conv = nn.Conv2d(indim,
+ outdim,
+ kernel_size,
+ padding=kernel_size // 2)
+ self.gn = nn.GroupNorm(gn_groups, outdim)
+
+ def forward(self, x):
+ return self.gn(self.conv(x))
+
+
+def seq_to_2d(tensor, size_2d):
+ h, w = size_2d
+ _, n, c = tensor.size()
+ tensor = tensor.view(h, w, n, c).permute(2, 3, 0, 1).contiguous()
+ return tensor
+
+
+def drop_path(x, drop_prob: float = 0., training: bool = False):
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (
+ x.shape[0],
+ x.shape[1],
+ ) + (1, ) * (x.ndim - 2
+ ) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(
+ shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+def mask_out(x, y, mask_rate=0.15, training=False):
+ if mask_rate == 0. or not training:
+ return x
+
+ keep_prob = 1 - mask_rate
+ shape = (
+ x.shape[0],
+ x.shape[1],
+ ) + (1, ) * (x.ndim - 2
+ ) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(
+ shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x * random_tensor + y * (1 - random_tensor)
+
+ return output
+
+
+class DropPath(nn.Module):
+ def __init__(self, drop_prob=None, batch_dim=0):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+ self.batch_dim = batch_dim
+
+ def forward(self, x):
+ return self.drop_path(x, self.drop_prob)
+
+ def drop_path(self, x, drop_prob):
+ if drop_prob == 0. or not self.training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = [1 for _ in range(x.ndim)]
+ shape[self.batch_dim] = x.shape[self.batch_dim]
+ random_tensor = keep_prob + torch.rand(
+ shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class DropOutLogit(nn.Module):
+ def __init__(self, drop_prob=None):
+ super(DropOutLogit, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return self.drop_logit(x, self.drop_prob)
+
+ def drop_logit(self, x, drop_prob):
+ if drop_prob == 0. or not self.training:
+ return x
+ random_tensor = drop_prob + torch.rand(
+ x.shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ mask = random_tensor * 1e+8 if (
+ x.dtype == torch.float32) else random_tensor * 1e+4
+ output = x - mask
+ return output
diff --git a/model/cbam.py b/model/cbam.py
new file mode 100644
index 0000000000000000000000000000000000000000..6423358429e2843b1f36ceb2bc1a485ea72b8eb4
--- /dev/null
+++ b/model/cbam.py
@@ -0,0 +1,77 @@
+# Modified from https://github.com/Jongchan/attention-module/blob/master/MODELS/cbam.py
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+class BasicConv(nn.Module):
+ def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
+ super(BasicConv, self).__init__()
+ self.out_channels = out_planes
+ self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
+
+ def forward(self, x):
+ x = self.conv(x)
+ return x
+
+class Flatten(nn.Module):
+ def forward(self, x):
+ return x.view(x.size(0), -1)
+
+class ChannelGate(nn.Module):
+ def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
+ super(ChannelGate, self).__init__()
+ self.gate_channels = gate_channels
+ self.mlp = nn.Sequential(
+ Flatten(),
+ nn.Linear(gate_channels, gate_channels // reduction_ratio),
+ nn.ReLU(),
+ nn.Linear(gate_channels // reduction_ratio, gate_channels)
+ )
+ self.pool_types = pool_types
+ def forward(self, x):
+ channel_att_sum = None
+ for pool_type in self.pool_types:
+ if pool_type=='avg':
+ avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
+ channel_att_raw = self.mlp( avg_pool )
+ elif pool_type=='max':
+ max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
+ channel_att_raw = self.mlp( max_pool )
+
+ if channel_att_sum is None:
+ channel_att_sum = channel_att_raw
+ else:
+ channel_att_sum = channel_att_sum + channel_att_raw
+
+ scale = torch.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)
+ return x * scale
+
+class ChannelPool(nn.Module):
+ def forward(self, x):
+ return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
+
+class SpatialGate(nn.Module):
+ def __init__(self):
+ super(SpatialGate, self).__init__()
+ kernel_size = 7
+ self.compress = ChannelPool()
+ self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2)
+ def forward(self, x):
+ x_compress = self.compress(x)
+ x_out = self.spatial(x_compress)
+ scale = torch.sigmoid(x_out) # broadcasting
+ return x * scale
+
+class CBAM(nn.Module):
+ def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
+ super(CBAM, self).__init__()
+ self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
+ self.no_spatial=no_spatial
+ if not no_spatial:
+ self.SpatialGate = SpatialGate()
+ def forward(self, x):
+ x_out = self.ChannelGate(x)
+ if not self.no_spatial:
+ x_out = self.SpatialGate(x_out)
+ return x_out
diff --git a/model/group_modules.py b/model/group_modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd22bedb429aaed6adf37e5455e0732af7e52dab
--- /dev/null
+++ b/model/group_modules.py
@@ -0,0 +1,93 @@
+"""
+Group-specific modules
+They handle features that also depends on the mask.
+Features are typically of shape
+ batch_size * num_objects * num_channels * H * W
+
+All of them are permutation equivariant w.r.t. to the num_objects dimension
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+def interpolate_groups(g, ratio, mode, align_corners):
+ if len(g.shape) == 4:
+ g = F.interpolate(g, scale_factor=ratio, mode=mode, align_corners=align_corners)
+ elif len(g.shape) == 5:
+ batch_size, num_objects = g.shape[:2]
+ g = F.interpolate(g.flatten(start_dim=0, end_dim=1),
+ scale_factor=ratio, mode=mode, align_corners=align_corners)
+ g = g.view(batch_size, num_objects, *g.shape[1:])
+ return g
+
+def upsample_groups(g, ratio=2, mode='bilinear', align_corners=False):
+ return interpolate_groups(g, ratio, mode, align_corners)
+
+def downsample_groups(g, ratio=1/2, mode='area', align_corners=None):
+ return interpolate_groups(g, ratio, mode, align_corners)
+
+
+class GConv2D(nn.Conv2d):
+ def forward(self, g):
+ batch_size, num_objects = g.shape[:2]
+ g = super().forward(g.flatten(start_dim=0, end_dim=1))
+ return g.view(batch_size, num_objects, *g.shape[1:])
+
+
+class GroupResBlock(nn.Module):
+ def __init__(self, in_dim, out_dim):
+ super().__init__()
+
+ if in_dim == out_dim:
+ self.downsample = None
+ else:
+ self.downsample = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
+
+ self.conv1 = GConv2D(in_dim, out_dim, kernel_size=3, padding=1)
+ self.conv2 = GConv2D(out_dim, out_dim, kernel_size=3, padding=1)
+
+ def forward(self, g):
+ out_g = self.conv1(F.relu(g))
+ out_g = self.conv2(F.relu(out_g))
+
+ if self.downsample is not None:
+ g = self.downsample(g)
+
+ return out_g + g
+
+
+class MainToGroupDistributor(nn.Module):
+ def __init__(self, x_transform=None, method='cat', reverse_order=False):
+ super().__init__()
+
+ self.x_transform = x_transform
+ self.method = method
+ self.reverse_order = reverse_order
+
+ def forward(self, x, g):
+ num_objects = g.shape[1]
+
+ while 0: print(num_objects, g.size())
+ # 3 torch.Size([8, 3, 2, 384, 384])
+
+ if self.x_transform is not None:
+ x = self.x_transform(x)
+
+ if self.method == 'cat':
+ if self.reverse_order:
+ g = torch.cat([g, x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1)], 2)
+ else:
+ # print('2', g.size(), x.size(), x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1).size())
+ # torch.Size([8, 2, 2, 224, 224]) torch.Size([8, 3, 224, 224]) torch.Size([8, 2, 3, 224, 224])
+ # torch.Size([1, 1, 2, 480, 864]) torch.Size([1, 3, 480, 864]) torch.Size([1, 1, 3, 480, 864])
+ g = torch.cat([x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1), g], 2)
+ elif self.method == 'add':
+ # print(g.size(), x.size(), x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1).size())
+ # torch.Size([8, 2, 512, 16, 16]) torch.Size([8, 512, 16, 16]) torch.Size([8, 2, 512, 16, 16])
+ g = x.unsqueeze(1).expand(-1,num_objects,-1,-1,-1) + g
+ else:
+ raise NotImplementedError
+
+ return g
diff --git a/model/losses.py b/model/losses.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a5d901cb95f12b90699b2a5d7c081e18eab7a1a
--- /dev/null
+++ b/model/losses.py
@@ -0,0 +1,91 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from collections import defaultdict
+
+
+def dice_loss(input_mask, cls_gt):
+ num_objects = input_mask.shape[1]
+ losses = []
+ for i in range(num_objects):
+ mask = input_mask[:,i].flatten(start_dim=1)
+ # background not in mask, so we add one to cls_gt
+ gt = (cls_gt==(i+1)).float().flatten(start_dim=1)
+ numerator = 2 * (mask * gt).sum(-1)
+ denominator = mask.sum(-1) + gt.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ losses.append(loss)
+ return torch.cat(losses).mean()
+
+def l1_loss(input, target):
+ out = torch.abs(input - target)
+ return out.mean()
+
+
+# https://stackoverflow.com/questions/63735255/how-do-i-compute-bootstrapped-cross-entropy-loss-in-pytorch
+class BootstrappedCE(nn.Module):
+ def __init__(self, start_warm, end_warm, top_p=0.15):
+ super().__init__()
+
+ self.start_warm = start_warm
+ self.end_warm = end_warm
+ self.top_p = top_p
+
+ def forward(self, input, target, it):
+ if it < self.start_warm:
+
+ return F.cross_entropy(input, target), 1.0
+
+ raw_loss = F.cross_entropy(input, target, reduction='none').view(-1)
+ num_pixels = raw_loss.numel()
+
+ if it > self.end_warm:
+ this_p = self.top_p
+ else:
+ this_p = self.top_p + (1-self.top_p)*((self.end_warm-it)/(self.end_warm-self.start_warm))
+ loss, _ = torch.topk(raw_loss, int(num_pixels * this_p), sorted=False)
+ return loss.mean(), this_p
+
+
+class LossComputer:
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.bce = BootstrappedCE(config['start_warm'], config['end_warm'])
+
+ def compute(self, data, num_objects, it):
+ losses = defaultdict(int)
+
+ b, t = data['rgb'].shape[:2]
+
+ losses['total_loss'] = 0
+ for ti in range(1, t):
+ for bi in range(b):
+ loss, p = self.bce(data[f'logits_{ti}'][bi:bi+1, :num_objects[bi]+1], data['cls_gt'][bi:bi+1,ti,0], it)
+ losses['p'] += p / b / (t-1)
+ losses[f'ce_loss_{ti}'] += loss / b
+
+ losses['total_loss'] += losses['ce_loss_%d'%ti]
+ losses[f'dice_loss_{ti}'] = dice_loss(data[f'masks_{ti}'], data['cls_gt'][:,ti,0])
+ losses['total_loss'] += losses[f'dice_loss_{ti}']
+
+ return losses
+
+
+ def compute_l1loss(self, data, num_objects, it):
+ losses = defaultdict(int)
+
+ b, t = data['rgb'].shape[:2]
+
+ losses['total_loss'] = 0
+ for ti in range(1, t):
+ for bi in range(b):
+ losses['p'] = 0
+ losses[f'ce_loss_{ti}'] = 0
+
+ losses['total_loss'] += losses['ce_loss_%d'%ti]
+ losses[f'dice_loss_{ti}'] = l1_loss(data[f'masks_{ti}'], data['cls_gt'][:,ti])
+ losses['total_loss'] += losses[f'dice_loss_{ti}']
+
+ return losses
diff --git a/model/memory_util.py b/model/memory_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..faf6197b8c4ea990317476e2e3aeb8952a78aedf
--- /dev/null
+++ b/model/memory_util.py
@@ -0,0 +1,80 @@
+import math
+import numpy as np
+import torch
+from typing import Optional
+
+
+def get_similarity(mk, ms, qk, qe):
+ # used for training/inference and memory reading/memory potentiation
+ # mk: B x CK x [N] - Memory keys
+ # ms: B x 1 x [N] - Memory shrinkage
+ # qk: B x CK x [HW/P] - Query keys
+ # qe: B x CK x [HW/P] - Query selection
+ # Dimensions in [] are flattened
+ CK = mk.shape[1]
+ mk = mk.flatten(start_dim=2)
+ ms = ms.flatten(start_dim=1).unsqueeze(2) if ms is not None else None
+ qk = qk.flatten(start_dim=2)
+ qe = qe.flatten(start_dim=2) if qe is not None else None
+
+ if qe is not None:
+ # See appendix for derivation
+ # or you can just trust me ヽ(ー_ー )ノ
+ mk = mk.transpose(1, 2)
+ a_sq = (mk.pow(2) @ qe)
+ two_ab = 2 * (mk @ (qk * qe))
+ b_sq = (qe * qk.pow(2)).sum(1, keepdim=True)
+ similarity = (-a_sq+two_ab-b_sq)
+ else:
+ # similar to STCN if we don't have the selection term
+ a_sq = mk.pow(2).sum(1).unsqueeze(2)
+ two_ab = 2 * (mk.transpose(1, 2) @ qk)
+ similarity = (-a_sq+two_ab)
+
+ if ms is not None:
+ similarity = similarity * ms / math.sqrt(CK) # B*N*HW
+ else:
+ similarity = similarity / math.sqrt(CK) # B*N*HW
+
+ return similarity
+
+def do_softmax(similarity, top_k: Optional[int]=None, inplace=False, return_usage=False):
+ # normalize similarity with top-k softmax
+ # similarity: B x N x [HW/P]
+ # use inplace with care
+ if top_k is not None:
+ values, indices = torch.topk(similarity, k=top_k, dim=1)
+
+ x_exp = values.exp_()
+ x_exp /= torch.sum(x_exp, dim=1, keepdim=True)
+ if inplace:
+ similarity.zero_().scatter_(1, indices, x_exp) # B*N*HW
+ affinity = similarity
+ else:
+ affinity = torch.zeros_like(similarity).scatter_(1, indices, x_exp) # B*N*HW
+ else:
+ maxes = torch.max(similarity, dim=1, keepdim=True)[0]
+ x_exp = torch.exp(similarity - maxes)
+ x_exp_sum = torch.sum(x_exp, dim=1, keepdim=True)
+ affinity = x_exp / x_exp_sum
+ indices = None
+
+ if return_usage:
+ return affinity, affinity.sum(dim=2)
+
+ return affinity
+
+def get_affinity(mk, ms, qk, qe):
+ # shorthand used in training with no top-k
+ similarity = get_similarity(mk, ms, qk, qe)
+ affinity = do_softmax(similarity)
+ return affinity
+
+def readout(affinity, mv):
+ B, CV, T, H, W = mv.shape
+
+ mo = mv.view(B, CV, T*H*W)
+ mem = torch.bmm(mo, affinity)
+ mem = mem.view(B, CV, H, W)
+
+ return mem
diff --git a/model/modules.py b/model/modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..cea6986e89e05c8e701753800891b79ff327ff73
--- /dev/null
+++ b/model/modules.py
@@ -0,0 +1,271 @@
+"""
+modules.py - This file stores the rather boring network blocks.
+
+x - usually means features that only depends on the image
+g - usually means features that also depends on the mask.
+ They might have an extra "group" or "num_objects" dimension, hence
+ batch_size * num_objects * num_channels * H * W
+
+The trailing number of a variable usually denote the stride
+
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from model.group_modules import *
+from model import resnet
+from model.cbam import CBAM
+
+
+class FeatureFusionBlock(nn.Module):
+ def __init__(self, x_in_dim, g_in_dim, g_mid_dim, g_out_dim):
+ super().__init__()
+
+ self.distributor = MainToGroupDistributor()
+ self.block1 = GroupResBlock(x_in_dim+g_in_dim, g_mid_dim)
+ self.attention = CBAM(g_mid_dim)
+ self.block2 = GroupResBlock(g_mid_dim, g_out_dim)
+
+ def forward(self, x, g):
+ batch_size, num_objects = g.shape[:2]
+
+ g = self.distributor(x, g)
+ g = self.block1(g)
+ r = self.attention(g.flatten(start_dim=0, end_dim=1))
+ r = r.view(batch_size, num_objects, *r.shape[1:])
+
+ g = self.block2(g+r)
+
+ return g
+
+
+class HiddenUpdater(nn.Module):
+ # Used in the decoder, multi-scale feature + GRU
+ def __init__(self, g_dims, mid_dim, hidden_dim, ratio=1/2):
+ super().__init__()
+ self.hidden_dim = hidden_dim
+ self.ratio = ratio
+
+ self.g16_conv = GConv2D(g_dims[0], mid_dim, kernel_size=1)
+ self.g8_conv = GConv2D(g_dims[1], mid_dim, kernel_size=1)
+ self.g4_conv = GConv2D(g_dims[2], mid_dim, kernel_size=1)
+
+ self.transform = GConv2D(mid_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
+
+ nn.init.xavier_normal_(self.transform.weight)
+
+ def forward(self, g, h):
+ g = self.g16_conv(g[0]) + self.g8_conv(downsample_groups(g[1], ratio=1/2)) + \
+ self.g4_conv(downsample_groups(g[2], ratio=1/4))
+ # g = self.g16_conv(g[0]) + self.g8_conv(downsample_groups(g[1], self.ratio)) + \
+ # self.g4_conv(downsample_groups(g[2], ratio=self.ratio))
+
+ g = torch.cat([g, h], 2)
+
+ # defined slightly differently than standard GRU,
+ # namely the new value is generated before the forget gate.
+ # might provide better gradient but frankly it was initially just an
+ # implementation error that I never bothered fixing
+ values = self.transform(g)
+ forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
+ update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
+ new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
+ new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
+
+ return new_h
+
+
+class HiddenReinforcer(nn.Module):
+ # Used in the value encoder, a single GRU
+ def __init__(self, g_dim, hidden_dim):
+ super().__init__()
+ self.hidden_dim = hidden_dim
+ self.transform = GConv2D(g_dim+hidden_dim, hidden_dim*3, kernel_size=3, padding=1)
+
+ nn.init.xavier_normal_(self.transform.weight)
+
+ def forward(self, g, h):
+ g = torch.cat([g, h], 2)
+
+ # defined slightly differently than standard GRU,
+ # namely the new value is generated before the forget gate.
+ # might provide better gradient but frankly it was initially just an
+ # implementation error that I never bothered fixing
+ values = self.transform(g)
+ forget_gate = torch.sigmoid(values[:,:,:self.hidden_dim])
+ update_gate = torch.sigmoid(values[:,:,self.hidden_dim:self.hidden_dim*2])
+ new_value = torch.tanh(values[:,:,self.hidden_dim*2:])
+ new_h = forget_gate*h*(1-update_gate) + update_gate*new_value
+
+ return new_h
+
+
+class ValueEncoder(nn.Module):
+ def __init__(self, value_dim, hidden_dim, single_object=False):
+ super().__init__()
+
+ self.single_object = single_object
+ network = resnet.resnet18(pretrained=True, extra_dim=1 if single_object else 2)
+ self.conv1 = network.conv1
+ self.bn1 = network.bn1
+ self.relu = network.relu # 1/2, 64
+ self.maxpool = network.maxpool
+
+ self.layer1 = network.layer1 # 1/4, 64
+ self.layer2 = network.layer2 # 1/8, 128
+ self.layer3 = network.layer3 # 1/16, 256
+
+ self.distributor = MainToGroupDistributor()
+ self.fuser = FeatureFusionBlock(1024, 256, value_dim, value_dim) # (1024 256) -> (384 256) -> (384 256)
+ if hidden_dim > 0:
+ self.hidden_reinforce = HiddenReinforcer(value_dim, hidden_dim)
+ else:
+ self.hidden_reinforce = None
+
+ def forward(self, image, image_feat_f16, h, masks, others, is_deep_update=True):
+ # image_feat_f16 is the feature from the key encoder
+ if not self.single_object:
+ g = torch.stack([masks, others], 2)
+ else:
+ g = masks.unsqueeze(2)
+ g = self.distributor(image, g)
+
+ batch_size, num_objects = g.shape[:2]
+ g = g.flatten(start_dim=0, end_dim=1)
+
+ g = self.conv1(g)
+ g = self.bn1(g) # 1/2, 64
+ g = self.maxpool(g) # 1/4, 64
+ g = self.relu(g)
+
+ g = self.layer1(g) # 1/4
+ g = self.layer2(g) # 1/8
+ g = self.layer3(g) # 1/16
+
+ # handle dim problem raised by vit
+ g = F.interpolate(g, image_feat_f16.shape[2:], mode='bilinear', align_corners=False)
+
+ g = g.view(batch_size, num_objects, *g.shape[1:])
+ g = self.fuser(image_feat_f16, g)
+
+ if is_deep_update and self.hidden_reinforce is not None:
+ h = self.hidden_reinforce(g, h)
+
+ return g, h
+
+class KeyEncoder_DINOv2_v6(nn.Module):
+ def __init__(self):
+ super().__init__()
+ network = resnet.resnet50(pretrained=True)
+ self.conv1 = network.conv1
+ self.bn1 = network.bn1
+ self.relu = network.relu # 1/2, 64
+ self.maxpool = network.maxpool
+
+ self.res2 = network.layer1 # 1/4, 256
+ self.layer2 = network.layer2 # 1/8, 512
+ self.layer3 = network.layer3 # 1/16, 1024
+
+ self.network2 = resnet.Segmentor()
+
+ self.fuse1 = resnet.Fuse(384 * 4, 1024) # n = [8, 9, 10, 11]
+ self.fuse2 = resnet.Fuse(384 * 4, 512)
+ self.fuse3 = resnet.Fuse(384 * 4, 256)
+
+ self.upsample2 = nn.Upsample(scale_factor=2, mode='bilinear')
+ self.upsample4 = nn.Upsample(scale_factor=4, mode='bilinear')
+
+ def forward(self, f):
+ x = self.conv1(f)
+ x = self.bn1(x)
+ x = self.relu(x) # 1/2, 64
+ x = self.maxpool(x) # 1/4, 64
+ f4 = self.res2(x) # 1/4, 256
+ f8 = self.layer2(f4) # 1/8, 512
+ f16 = self.layer3(f8) # 1/16, 1024
+
+ f16_dino = self.network2(f) # 1/14, 384 -> interp to 1/16
+
+ g16 = self.fuse1(f16_dino, f16)
+ g8 = self.fuse2(self.upsample2(f16_dino), f8)
+ g4 = self.fuse3(self.upsample4(f16_dino), f4)
+
+ return g16, g8, g4
+
+class UpsampleBlock(nn.Module):
+ def __init__(self, skip_dim, g_up_dim, g_out_dim, scale_factor=2):
+ super().__init__()
+ self.skip_conv = nn.Conv2d(skip_dim, g_up_dim, kernel_size=3, padding=1)
+ self.distributor = MainToGroupDistributor(method='add')
+ self.out_conv = GroupResBlock(g_up_dim, g_out_dim)
+ self.scale_factor = scale_factor
+
+ def forward(self, skip_f, up_g):
+ skip_f = self.skip_conv(skip_f)
+ g = upsample_groups(up_g, ratio=self.scale_factor)
+ g = self.distributor(skip_f, g)
+ g = self.out_conv(g)
+ return g
+
+
+class KeyProjection(nn.Module):
+ def __init__(self, in_dim, keydim):
+ super().__init__()
+
+ self.key_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
+ # shrinkage
+ self.d_proj = nn.Conv2d(in_dim, 1, kernel_size=3, padding=1)
+ # selection
+ self.e_proj = nn.Conv2d(in_dim, keydim, kernel_size=3, padding=1)
+
+ nn.init.orthogonal_(self.key_proj.weight.data)
+ nn.init.zeros_(self.key_proj.bias.data)
+
+ def forward(self, x, need_s, need_e):
+ shrinkage = self.d_proj(x)**2 + 1 if (need_s) else None
+ selection = torch.sigmoid(self.e_proj(x)) if (need_e) else None
+
+ return self.key_proj(x), shrinkage, selection
+
+
+class Decoder(nn.Module):
+ def __init__(self, val_dim, hidden_dim):
+ super().__init__()
+
+ self.fuser = FeatureFusionBlock(1024, val_dim+hidden_dim, 512, 512) # (1024, val_dim+hidden_dim, 512, 512) -> (384, val_dim+hidden_dim, 512, 512) -> (1536, val_dim+hidden_dim, 512, 512)
+ if hidden_dim > 0:
+ self.hidden_update = HiddenUpdater([512, 256, 256+1], 256, hidden_dim, 1)
+ else:
+ self.hidden_update = None
+
+ self.up_16_8 = UpsampleBlock(512, 512, 256) # 1/16 -> 1/8
+ self.up_8_4 = UpsampleBlock(256, 256, 256) # 1/8 -> 1/4
+
+ self.pred = nn.Conv2d(256, 1, kernel_size=3, padding=1, stride=1)
+
+ def forward(self, f16, f8, f4, hidden_state, memory_readout, h_out=True):
+ batch_size, num_objects = memory_readout.shape[:2]
+
+ if self.hidden_update is not None:
+ g16 = self.fuser(f16, torch.cat([memory_readout, hidden_state], 2))
+ else:
+ g16 = self.fuser(f16, memory_readout)
+
+ g8 = self.up_16_8(f8, g16)
+
+ g4 = self.up_8_4(f4, g8)
+
+ logits = self.pred(F.relu(g4.flatten(start_dim=0, end_dim=1)))
+
+ if h_out and self.hidden_update is not None:
+ g4 = torch.cat([g4, logits.view(batch_size, num_objects, 1, *logits.shape[-2:])], 2)
+ hidden_state = self.hidden_update([g16, g8, g4], hidden_state)
+ else:
+ hidden_state = None
+
+ logits = F.interpolate(logits, scale_factor=4, mode='bilinear', align_corners=False)
+ logits = logits.view(batch_size, num_objects, *logits.shape[-2:])
+
+ return hidden_state, logits
diff --git a/model/network.py b/model/network.py
new file mode 100644
index 0000000000000000000000000000000000000000..8994c43681ba624b82a445af8614cbb642adbcae
--- /dev/null
+++ b/model/network.py
@@ -0,0 +1,225 @@
+"""
+This file defines XMem, the highest level nn.Module interface
+During training, it is used by trainer.py
+During evaluation, it is used by inference_core.py
+
+It further depends on modules.py which gives more detailed implementations of sub-modules
+"""
+
+import torch
+import torch.nn as nn
+
+from model.aggregate import aggregate
+from model.modules import *
+from model.memory_util import *
+
+from model.attention import LocalGatedPropagation
+
+class ColorMNet(nn.Module):
+ def __init__(self, config, model_path=None, map_location=None):
+ """
+ model_path/map_location are used in evaluation only
+ map_location is for converting models saved in cuda to cpu
+ """
+ super().__init__()
+ model_weights = self.init_hyperparameters(config, model_path, map_location)
+
+ self.single_object = config.get('single_object', False)
+ print(f'Single object mode: {self.single_object}')
+
+ self.key_encoder = KeyEncoder_DINOv2_v6()
+
+ self.value_encoder = ValueEncoder(self.value_dim, self.hidden_dim, self.single_object)
+
+ # Projection from f16 feature space to key/value space
+ self.key_proj = KeyProjection(1024, self.key_dim) # 1024 -> 384 -> 3072
+
+ self.short_term_attn = LocalGatedPropagation(d_qk=64, # 256
+ d_vu=512 * 2,
+ num_head=1,
+ dilation=1,
+ use_linear=False,
+ dropout=0,
+ d_att=64, # 128
+ max_dis=7,
+ expand_ratio=1)
+
+ self.decoder = Decoder(self.value_dim, self.hidden_dim)
+
+ if model_weights is not None:
+ self.load_weights(model_weights, init_as_zero_if_needed=True)
+
+ def encode_key(self, frame, need_sk=True, need_ek=True):
+ # Determine input shape
+ if len(frame.shape) == 5:
+ # shape is b*t*c*h*w
+ need_reshape = True
+ b, t = frame.shape[:2]
+ # flatten so that we can feed them into a 2D CNN
+ frame = frame.flatten(start_dim=0, end_dim=1)
+ elif len(frame.shape) == 4:
+ # shape is b*c*h*w
+ need_reshape = False
+ else:
+ raise NotImplementedError
+
+ f16, f8, f4 = self.key_encoder(frame)
+ key, shrinkage, selection = self.key_proj(f16, need_sk, need_ek)
+
+ if need_reshape:
+ # B*C*T*H*W
+ key = key.view(b, t, *key.shape[-3:]).transpose(1, 2).contiguous()
+ if shrinkage is not None:
+ shrinkage = shrinkage.view(b, t, *shrinkage.shape[-3:]).transpose(1, 2).contiguous()
+ if selection is not None:
+ selection = selection.view(b, t, *selection.shape[-3:]).transpose(1, 2).contiguous()
+
+ # B*T*C*H*W
+ f16 = f16.view(b, t, *f16.shape[-3:])
+ f8 = f8.view(b, t, *f8.shape[-3:])
+ f4 = f4.view(b, t, *f4.shape[-3:])
+
+ return key, shrinkage, selection, f16, f8, f4
+
+ def encode_value(self, frame, image_feat_f16, h16, masks, is_deep_update=True):
+ num_objects = masks.shape[1]
+ if num_objects != 1:
+ others = torch.cat([
+ torch.sum(
+ masks[:, [j for j in range(num_objects) if i!=j]]
+ , dim=1, keepdim=True)
+ for i in range(num_objects)], 1)
+ else:
+ others = torch.zeros_like(masks)
+
+ g16, h16 = self.value_encoder(frame, image_feat_f16, h16, masks, others, is_deep_update)
+
+ return g16, h16
+
+ # Used in training only.
+ # This step is replaced by MemoryManager in test time
+ def read_memory(self, query_key, query_selection, memory_key,
+ memory_shrinkage, memory_value):
+ """
+ query_key : B * CK * H * W
+ query_selection : B * CK * H * W
+ memory_key : B * CK * T * H * W
+ memory_shrinkage: B * 1 * T * H * W
+ memory_value : B * num_objects * CV * T * H * W
+ """
+ batch_size, num_objects = memory_value.shape[:2]
+ memory_value = memory_value.flatten(start_dim=1, end_dim=2)
+
+ affinity = get_affinity(memory_key, memory_shrinkage, query_key, query_selection)
+ memory = readout(affinity, memory_value)
+ memory = memory.view(batch_size, num_objects, self.value_dim, *memory.shape[-2:])
+
+ return memory
+
+ def read_memory_short(self, query_key, memory_key, memory_value):
+ """
+ query_key : B * CK * H * W
+ query_selection : B * CK * H * W
+ memory_key : B * CK * T * H * W
+ memory_shrinkage: B * 1 * T * H * W
+ memory_value : B * num_objects * CV * T * H * W
+ """
+ batch_size, num_objects = memory_value.shape[:2]
+ memory_value = memory_value.flatten(start_dim=1, end_dim=2)
+
+ size_2d = query_key.shape[-2:]
+ memory_value_short, _ = self.short_term_attn(query_key, memory_key, memory_value, None, size_2d)
+
+ memory_value_short = memory_value_short.permute(1, 2, 0).view(batch_size, num_objects, self.value_dim, *memory_value.shape[-2:])
+
+ return memory_value_short
+
+ def segment(self, multi_scale_features, memory_readout,
+ hidden_state, selector=None, h_out=True, strip_bg=True):
+
+ hidden_state, logits = self.decoder(*multi_scale_features, hidden_state, memory_readout, h_out=h_out)
+
+ prob = torch.tanh(logits)
+ logits = prob
+
+ return hidden_state, logits, prob
+
+ def forward(self, mode, *args, **kwargs):
+ if mode == 'encode_key':
+ return self.encode_key(*args, **kwargs)
+ elif mode == 'encode_value':
+ return self.encode_value(*args, **kwargs)
+ elif mode == 'read_memory':
+ return self.read_memory(*args, **kwargs)
+ elif mode == 'read_memory_short':
+ return self.read_memory_short(*args, **kwargs)
+ elif mode == 'segment':
+ return self.segment(*args, **kwargs)
+ else:
+ raise NotImplementedError
+
+ def init_hyperparameters(self, config, model_path=None, map_location=None):
+ """
+ Init three hyperparameters: key_dim, value_dim, and hidden_dim
+ If model_path is provided, we load these from the model weights
+ The actual parameters are then updated to the config in-place
+
+ Otherwise we load it either from the config or default
+ """
+ if model_path is not None:
+ # load the model and key/value/hidden dimensions with some hacks
+ # config is updated with the loaded parameters
+ model_weights = torch.load(model_path, map_location=map_location)
+ self.key_dim = model_weights['key_proj.key_proj.weight'].shape[0]
+ self.value_dim = model_weights['value_encoder.fuser.block2.conv2.weight'].shape[0]
+ self.disable_hidden = 'decoder.hidden_update.transform.weight' not in model_weights
+ if self.disable_hidden:
+ self.hidden_dim = 0
+ else:
+ self.hidden_dim = model_weights['decoder.hidden_update.transform.weight'].shape[0]//3
+ print(f'Hyperparameters read from the model weights: '
+ f'C^k={self.key_dim}, C^v={self.value_dim}, C^h={self.hidden_dim}')
+ else:
+ model_weights = None
+ # load dimensions from config or default
+ if 'key_dim' not in config:
+ self.key_dim = 64
+ print(f'key_dim not found in config. Set to default {self.key_dim}')
+ else:
+ self.key_dim = config['key_dim']
+
+ if 'value_dim' not in config:
+ self.value_dim = 512
+ print(f'value_dim not found in config. Set to default {self.value_dim}')
+ else:
+ self.value_dim = config['value_dim']
+
+ if 'hidden_dim' not in config:
+ self.hidden_dim = 64
+ print(f'hidden_dim not found in config. Set to default {self.hidden_dim}')
+ else:
+ self.hidden_dim = config['hidden_dim']
+
+ self.disable_hidden = (self.hidden_dim <= 0)
+
+ config['key_dim'] = self.key_dim
+ config['value_dim'] = self.value_dim
+ config['hidden_dim'] = self.hidden_dim
+
+ return model_weights
+
+ def load_weights(self, src_dict, init_as_zero_if_needed=False):
+ # Maps SO weight (without other_mask) to MO weight (with other_mask)
+ for k in list(src_dict.keys()):
+ if k == 'value_encoder.conv1.weight':
+ if src_dict[k].shape[1] == 4:
+ print('Converting weights from single object to multiple objects.')
+ pads = torch.zeros((64,1,7,7), device=src_dict[k].device)
+ if not init_as_zero_if_needed:
+ print('Randomly initialized padding.')
+ nn.init.orthogonal_(pads)
+ else:
+ print('Zero-initialized padding.')
+ src_dict[k] = torch.cat([src_dict[k], pads], 1)
+
+ self.load_state_dict(src_dict)
diff --git a/model/resnet.py b/model/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..c6ea3acb36a9879fffe55c3a78b5ce4d23704c5f
--- /dev/null
+++ b/model/resnet.py
@@ -0,0 +1,399 @@
+"""
+resnet.py - A modified ResNet structure
+We append extra channels to the first conv by some network surgery
+"""
+
+from collections import OrderedDict
+import math
+
+import torch
+import torch.nn as nn
+from torch.utils import model_zoo
+
+from torch.hub import load
+import torchvision.models as models
+import warnings
+warnings.filterwarnings("ignore")
+import torch.nn.functional as F
+
+from einops import rearrange
+
+def load_weights_add_extra_dim(target, source_state, extra_dim=1):
+ new_dict = OrderedDict()
+
+ for k1, v1 in target.state_dict().items():
+ if not 'num_batches_tracked' in k1:
+ if k1 in source_state:
+ tar_v = source_state[k1]
+
+ if v1.shape != tar_v.shape:
+ # Init the new segmentation channel with zeros
+ # print(v1.shape, tar_v.shape)
+ c, _, w, h = v1.shape
+ pads = torch.zeros((c,extra_dim,w,h), device=tar_v.device)
+ nn.init.orthogonal_(pads)
+ tar_v = torch.cat([tar_v, pads], 1)
+
+ new_dict[k1] = tar_v
+
+ target.load_state_dict(new_dict)
+
+
+model_urls = {
+ 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
+ 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
+}
+
+
+def conv3x3(in_planes, out_planes, stride=1, dilation=1):
+ return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
+ padding=dilation, dilation=dilation, bias=False)
+
+
+class BasicBlock(nn.Module):
+ expansion = 1
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
+ super(BasicBlock, self).__init__()
+ self.conv1 = conv3x3(inplanes, planes, stride=stride, dilation=dilation)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.relu = nn.ReLU(inplace=True)
+ self.conv2 = conv3x3(planes, planes, stride=1, dilation=dilation)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out += residual
+ out = self.relu(out)
+
+ return out
+
+
+class Bottleneck(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
+ super(Bottleneck, self).__init__()
+ self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,
+ padding=dilation, bias=False)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
+ self.bn3 = nn.BatchNorm2d(planes * 4)
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.bn3(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out += residual
+ out = self.relu(out)
+
+ return out
+
+
+class ResNet(nn.Module):
+ def __init__(self, block, layers=(3, 4, 23, 3), extra_dim=0):
+ self.inplanes = 64
+ super(ResNet, self).__init__()
+ self.conv1 = nn.Conv2d(3+extra_dim, 64, kernel_size=7, stride=2, padding=3, bias=False)
+ self.bn1 = nn.BatchNorm2d(64)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+ self.layer1 = self._make_layer(block, 64, layers[0])
+ self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
+ self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
+ self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
+
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
+ m.weight.data.normal_(0, math.sqrt(2. / n))
+ elif isinstance(m, nn.BatchNorm2d):
+ m.weight.data.fill_(1)
+ m.bias.data.zero_()
+
+ def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
+ downsample = None
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ nn.Conv2d(self.inplanes, planes * block.expansion,
+ kernel_size=1, stride=stride, bias=False),
+ nn.BatchNorm2d(planes * block.expansion),
+ )
+
+ layers = [block(self.inplanes, planes, stride, downsample)]
+ self.inplanes = planes * block.expansion
+ for i in range(1, blocks):
+ layers.append(block(self.inplanes, planes, dilation=dilation))
+
+ return nn.Sequential(*layers)
+
+def resnet18(pretrained=True, extra_dim=0):
+ model = ResNet(BasicBlock, [2, 2, 2, 2], extra_dim)
+ if pretrained:
+ load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet18']), extra_dim)
+ return model
+
+def resnet50(pretrained=True, extra_dim=0):
+ model = ResNet(Bottleneck, [3, 4, 6, 3], extra_dim)
+ if pretrained:
+ load_weights_add_extra_dim(model, model_zoo.load_url(model_urls['resnet50']), extra_dim)
+ return model
+
+dino_backbones = {
+ 'dinov2_s':{
+ 'name':'dinov2_vits14',
+ 'embedding_size':384,
+ 'patch_size':14
+ },
+ 'dinov2_b':{
+ 'name':'dinov2_vitb14',
+ 'embedding_size':768,
+ 'patch_size':14
+ },
+ 'dinov2_l':{
+ 'name':'dinov2_vitl14',
+ 'embedding_size':1024,
+ 'patch_size':14
+ },
+ 'dinov2_g':{
+ 'name':'dinov2_vitg14',
+ 'embedding_size':1536,
+ 'patch_size':14
+ },
+}
+
+class conv_head(nn.Module):
+ def __init__(self, embedding_size = 384, num_classes = 5):
+ super(conv_head, self).__init__()
+ self.segmentation_conv = nn.Sequential(
+ nn.Upsample(scale_factor=2),
+ nn.Conv2d(embedding_size, 64, (3,3), padding=(1,1)),
+ nn.Upsample(scale_factor=2),
+ nn.Conv2d(64, num_classes, (3,3), padding=(1,1)),
+ )
+
+ def forward(self, x):
+ x = self.segmentation_conv(x)
+ x = torch.sigmoid(x)
+ return x
+
+class Segmentor(nn.Module):
+ def __init__(self, num_classes=5, backbone = 'dinov2_s', head = 'conv', backbones = dino_backbones):
+ super(Segmentor, self).__init__()
+ self.heads = {
+ 'conv':conv_head
+ }
+ # internet
+ self.backbones = dino_backbones
+ self.backbone = load('facebookresearch/dinov2', self.backbones[backbone]['name']) # add trust_repo to
+ self.backbone.eval()
+
+ # # local
+ # self.backbones = dino_backbones
+ # self.backbone = load('/root/.cache/torch/hub/facebookresearch_dinov2_main', self.backbones[backbone]['name'], source='local', pretrained=False) # add trust_repo to
+ # self.backbone.load_state_dict(torch.load('/root/.cache/torch/hub/checkpoints/dinov2_vits14_pretrain.pth'))
+ # self.backbone.eval()
+
+ self.conv3 = nn.Conv2d(1536, 1536, kernel_size=1, bias=False)
+ self.bn3 = nn.BatchNorm2d(1536)
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ with torch.no_grad():
+ tokens = self.backbone.get_intermediate_layers(x, n=[8, 9, 10, 11], reshape=True) # last n=4 [8, 9, 10, 11]
+
+ f16 = torch.cat(tokens, dim=1)
+
+ f16 = self.conv3(f16)
+ f16 = self.bn3(f16)
+ f16 = self.relu(f16)
+
+ old_size = (f16.shape[2], f16.shape[3])
+ new_size = (int(old_size[0]*14/16), int(old_size[1]*14/16))
+ f16 = F.interpolate(f16, size=new_size, mode='bilinear', align_corners=False) # scale_factor=3.5
+
+ return f16
+
+class LayerNormFunction(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x, weight, bias, eps):
+ ctx.eps = eps
+ N, C, H, W = x.size()
+ mu = x.mean(1, keepdim=True)
+ var = (x - mu).pow(2).mean(1, keepdim=True)
+ y = (x - mu) / (var + eps).sqrt()
+ ctx.save_for_backward(y, var, weight)
+ y = weight.view(1, C, 1, 1) * y + bias.view(1, C, 1, 1)
+ return y
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ eps = ctx.eps
+
+ N, C, H, W = grad_output.size()
+ y, var, weight = ctx.saved_variables
+ g = grad_output * weight.view(1, C, 1, 1)
+ mean_g = g.mean(dim=1, keepdim=True)
+
+ mean_gy = (g * y).mean(dim=1, keepdim=True)
+ gx = 1. / torch.sqrt(var + eps) * (g - y * mean_gy - mean_g)
+ return gx, (grad_output * y).sum(dim=3).sum(dim=2).sum(dim=0), grad_output.sum(dim=3).sum(dim=2).sum(
+ dim=0), None
+
+class LayerNorm2d(nn.Module):
+
+ def __init__(self, channels, eps=1e-6):
+ super(LayerNorm2d, self).__init__()
+ self.register_parameter('weight', nn.Parameter(torch.ones(channels)))
+ self.register_parameter('bias', nn.Parameter(torch.zeros(channels)))
+ self.eps = eps
+
+ def forward(self, x):
+ return LayerNormFunction.apply(x, self.weight, self.bias, self.eps)
+
+class CrossChannelAttention(nn.Module):
+ def __init__(self, dim, heads=8):
+ super().__init__()
+
+ self.temperature = nn.Parameter(torch.ones(heads, 1, 1))
+
+ self.heads = heads
+
+ self.to_q = nn.Conv2d(dim, dim * 2, kernel_size=1, bias=True)
+ self.to_q_dw = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim * 2, bias=True)
+
+ self.to_k = nn.Conv2d(dim, dim * 2, kernel_size=1, bias=True)
+ self.to_k_dw = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim * 2, bias=True)
+
+ self.to_v = nn.Conv2d(dim, dim * 2, kernel_size=1, bias=True)
+ self.to_v_dw = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim * 2, bias=True)
+
+ self.to_out = nn.Sequential(
+ nn.Conv2d(dim*2, dim,1,1,0),
+ )
+
+ def forward(self, encoder, decoder):
+ # h = self.heads
+ b, c, h, w = encoder.shape
+
+ q = self.to_q_dw(self.to_q(encoder))
+
+ k = self.to_k_dw(self.to_k(decoder))
+ v = self.to_v_dw(self.to_v(decoder))
+
+ q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.heads)
+ k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.heads)
+ v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.heads)
+
+ q = torch.nn.functional.normalize(q, dim=-1)
+ k = torch.nn.functional.normalize(k, dim=-1)
+
+ attn = (q @ k.transpose(-2, -1)) * self.temperature
+ attn = attn.softmax(dim=-1)
+
+ out = (attn @ v)
+
+ out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.heads, h=h, w=w)
+
+ return self.to_out(out)
+
+def normalize(in_channels):
+ return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
+
+@torch.jit.script
+def swish(x):
+ return x * torch.sigmoid(x)
+
+class ResBlock(nn.Module):
+ def __init__(self, in_channels, out_channels=None):
+ super(ResBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = in_channels if out_channels is None else out_channels
+ self.norm1 = normalize(in_channels)
+ self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.norm2 = normalize(out_channels)
+ self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
+ if self.in_channels != self.out_channels:
+ self.conv_out = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, x_in):
+ x = x_in
+ x = self.norm1(x)
+
+ x = swish(x)
+ # x = x * torch.sigmoid(x)
+
+ x = self.conv1(x)
+ x = self.norm2(x)
+
+ x = swish(x)
+ # x = x * torch.sigmoid(x)
+
+ x = self.conv2(x)
+ if self.in_channels != self.out_channels:
+ x_in = self.conv_out(x_in)
+
+ return x + x_in
+
+class Fuse(nn.Module):
+ def __init__(self, dine_feat, out_feat):
+ # need to key same channel and HW for enc / dnc
+ super(Fuse, self).__init__()
+
+ self.encode_enc = nn.Conv2d(dine_feat, out_feat, kernel_size=3, stride=1, padding=1)
+
+ self.dim = out_feat
+ self.norm1 = LayerNorm2d(self.dim)
+ self.norm2 = LayerNorm2d(self.dim)
+
+ self.dine_feat = dine_feat
+ self.out_feat = out_feat
+ self.crossattn = CrossChannelAttention(dim=out_feat)
+
+ self.norm3 = LayerNorm2d(self.dim)
+ self.relu3 = nn.ReLU(inplace=True)
+
+ def forward(self, enc, dnc):
+ enc = self.encode_enc(enc)
+
+ res = enc
+ enc = self.norm1(enc)
+ dnc = self.norm2(dnc)
+ output = self.crossattn(enc, dnc) + res
+
+ output = self.norm3(output)
+ output = self.relu3(output)
+
+ return output
\ No newline at end of file
diff --git a/ref/blackswan/00000.png b/ref/blackswan/00000.png
new file mode 100644
index 0000000000000000000000000000000000000000..3daeddee9b13c2d98cae65bcd584e67a7a5aa4ad
Binary files /dev/null and b/ref/blackswan/00000.png differ
diff --git a/saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth b/saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth
new file mode 100644
index 0000000000000000000000000000000000000000..265a8b64426936a298bc12e216aaed3a0393c101
--- /dev/null
+++ b/saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:eaf6301d1a088c0d7133008079a83b5fac1fc0f791061b2cf1b657602013457a
+size 494884817
diff --git a/scripts/__init__.py b/scripts/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/scripts/download_bl30k.py b/scripts/download_bl30k.py
new file mode 100644
index 0000000000000000000000000000000000000000..501a7e2ffa4b7913df7fe8f3c865d17e5b1fa371
--- /dev/null
+++ b/scripts/download_bl30k.py
@@ -0,0 +1,50 @@
+import os
+import gdown
+import tarfile
+
+
+LICENSE = """
+This dataset is a derivative of ShapeNet.
+Please read and respect their licenses and terms before use.
+Textures and skybox image are obtained from Google image search with the "non-commercial reuse" flag.
+Do not use this dataset for commercial purposes.
+You should cite both ShapeNet and our paper if you use this dataset.
+"""
+
+print(LICENSE)
+print('Datasets will be downloaded and extracted to ../BL30K')
+print('The script will download and extract the segment one by one')
+print('You are going to need ~1TB of free disk space')
+reply = input('[y] to confirm, others to exit: ')
+if reply != 'y':
+ exit()
+
+links = [
+ 'https://drive.google.com/uc?id=1z9V5zxLOJLNt1Uj7RFqaP2FZWKzyXvVc',
+ 'https://drive.google.com/uc?id=11-IzgNwEAPxgagb67FSrBdzZR7OKAEdJ',
+ 'https://drive.google.com/uc?id=1ZfIv6GTo-OGpXpoKen1fUvDQ0A_WoQ-Q',
+ 'https://drive.google.com/uc?id=1G4eXgYS2kL7_Cc0x3N1g1x7Zl8D_aU_-',
+ 'https://drive.google.com/uc?id=1Y8q0V_oBwJIY27W_6-8CD1dRqV2gNTdE',
+ 'https://drive.google.com/uc?id=1nawBAazf_unMv46qGBHhWcQ4JXZ5883r',
+]
+
+names = [
+ 'BL30K_a.tar',
+ 'BL30K_b.tar',
+ 'BL30K_c.tar',
+ 'BL30K_d.tar',
+ 'BL30K_e.tar',
+ 'BL30K_f.tar',
+]
+
+for i, link in enumerate(links):
+ print('Downloading segment %d/%d ...' % (i, len(links)))
+ gdown.download(link, output='../%s' % names[i], quiet=False)
+ print('Extracting...')
+ with tarfile.open('../%s' % names[i], 'r') as tar_file:
+ tar_file.extractall('../%s' % names[i])
+ print('Cleaning up...')
+ os.remove('../%s' % names[i])
+
+
+print('Done.')
\ No newline at end of file
diff --git a/scripts/download_datasets.py b/scripts/download_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..7537aead493306d869fc7f0605cfaef994c68673
--- /dev/null
+++ b/scripts/download_datasets.py
@@ -0,0 +1,149 @@
+import os
+import gdown
+import zipfile
+from scripts import resize_youtube
+
+
+LICENSE = """
+These are either re-distribution of the original datasets or derivatives (through simple processing) of the original datasets.
+Please read and respect their licenses and terms before use.
+You should cite the original papers if you use any of the datasets.
+
+For BL30K, see download_bl30k.py
+
+Links:
+DUTS: http://saliencydetection.net/duts
+HRSOD: https://github.com/yi94code/HRSOD
+FSS: https://github.com/HKUSTCV/FSS-1000
+ECSSD: https://www.cse.cuhk.edu.hk/leojia/projects/hsaliency/dataset.html
+BIG: https://github.com/hkchengrex/CascadePSP
+
+YouTubeVOS: https://youtube-vos.org
+DAVIS: https://davischallenge.org/
+BL30K: https://github.com/hkchengrex/MiVOS
+Long-Time Video: https://github.com/xmlyqing00/AFB-URR
+"""
+
+print(LICENSE)
+print('Datasets will be downloaded and extracted to ../YouTube, ../YouTube2018, ../static, ../DAVIS, ../long_video_set')
+reply = input('[y] to confirm, others to exit: ')
+if reply != 'y':
+ exit()
+
+
+"""
+Static image data
+"""
+os.makedirs('../static', exist_ok=True)
+print('Downloading static datasets...')
+gdown.download('https://drive.google.com/uc?id=1wUJq3HcLdN-z1t4CsUhjeZ9BVDb9YKLd', output='../static/static_data.zip', quiet=False)
+print('Extracting static datasets...')
+with zipfile.ZipFile('../static/static_data.zip', 'r') as zip_file:
+ zip_file.extractall('../static/')
+print('Cleaning up static datasets...')
+os.remove('../static/static_data.zip')
+
+
+"""
+DAVIS dataset
+"""
+# Google drive mirror: https://drive.google.com/drive/folders/1hEczGHw7qcMScbCJukZsoOW4Q9byx16A?usp=sharing
+os.makedirs('../DAVIS/2017', exist_ok=True)
+
+print('Downloading DAVIS 2016...')
+gdown.download('https://drive.google.com/uc?id=198aRlh5CpAoFz0hfRgYbiNenn_K8DxWD', output='../DAVIS/DAVIS-data.zip', quiet=False)
+
+print('Downloading DAVIS 2017 trainval...')
+gdown.download('https://drive.google.com/uc?id=1kiaxrX_4GuW6NmiVuKGSGVoKGWjOdp6d', output='../DAVIS/2017/DAVIS-2017-trainval-480p.zip', quiet=False)
+
+print('Downloading DAVIS 2017 testdev...')
+gdown.download('https://drive.google.com/uc?id=1fmkxU2v9cQwyb62Tj1xFDdh2p4kDsUzD', output='../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', quiet=False)
+
+print('Downloading DAVIS 2017 scribbles...')
+gdown.download('https://drive.google.com/uc?id=1JzIQSu36h7dVM8q0VoE4oZJwBXvrZlkl', output='../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', quiet=False)
+
+print('Extracting DAVIS datasets...')
+with zipfile.ZipFile('../DAVIS/DAVIS-data.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/')
+os.rename('../DAVIS/DAVIS', '../DAVIS/2016')
+
+with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-trainval-480p.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/2017/')
+with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/2017/')
+os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/trainval')
+
+with zipfile.ZipFile('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip', 'r') as zip_file:
+ zip_file.extractall('../DAVIS/2017/')
+os.rename('../DAVIS/2017/DAVIS', '../DAVIS/2017/test-dev')
+
+print('Cleaning up DAVIS datasets...')
+os.remove('../DAVIS/2017/DAVIS-2017-trainval-480p.zip')
+os.remove('../DAVIS/2017/DAVIS-2017-test-dev-480p.zip')
+os.remove('../DAVIS/2017/DAVIS-2017-scribbles-trainval.zip')
+os.remove('../DAVIS/DAVIS-data.zip')
+
+
+"""
+YouTubeVOS dataset
+"""
+os.makedirs('../YouTube', exist_ok=True)
+os.makedirs('../YouTube/all_frames', exist_ok=True)
+
+print('Downloading YouTubeVOS train...')
+gdown.download('https://drive.google.com/uc?id=13Eqw0gVK-AO5B-cqvJ203mZ2vzWck9s4', output='../YouTube/train.zip', quiet=False)
+print('Downloading YouTubeVOS val...')
+gdown.download('https://drive.google.com/uc?id=1o586Wjya-f2ohxYf9C1RlRH-gkrzGS8t', output='../YouTube/valid.zip', quiet=False)
+print('Downloading YouTubeVOS all frames valid...')
+gdown.download('https://drive.google.com/uc?id=1rWQzZcMskgpEQOZdJPJ7eTmLCBEIIpEN', output='../YouTube/all_frames/valid.zip', quiet=False)
+
+print('Extracting YouTube datasets...')
+with zipfile.ZipFile('../YouTube/train.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube/')
+with zipfile.ZipFile('../YouTube/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube/')
+with zipfile.ZipFile('../YouTube/all_frames/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube/all_frames')
+
+print('Cleaning up YouTubeVOS datasets...')
+os.remove('../YouTube/train.zip')
+os.remove('../YouTube/valid.zip')
+os.remove('../YouTube/all_frames/valid.zip')
+
+print('Resizing YouTubeVOS to 480p...')
+resize_youtube.resize_all('../YouTube/train', '../YouTube/train_480p')
+
+# YouTubeVOS 2018
+os.makedirs('../YouTube2018', exist_ok=True)
+os.makedirs('../YouTube2018/all_frames', exist_ok=True)
+
+print('Downloading YouTubeVOS2018 val...')
+gdown.download('https://drive.google.com/uc?id=1-QrceIl5sUNTKz7Iq0UsWC6NLZq7girr', output='../YouTube2018/valid.zip', quiet=False)
+print('Downloading YouTubeVOS2018 all frames valid...')
+gdown.download('https://drive.google.com/uc?id=1yVoHM6zgdcL348cFpolFcEl4IC1gorbV', output='../YouTube2018/all_frames/valid.zip', quiet=False)
+
+print('Extracting YouTube2018 datasets...')
+with zipfile.ZipFile('../YouTube2018/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube2018/')
+with zipfile.ZipFile('../YouTube2018/all_frames/valid.zip', 'r') as zip_file:
+ zip_file.extractall('../YouTube2018/all_frames')
+
+print('Cleaning up YouTubeVOS2018 datasets...')
+os.remove('../YouTube2018/valid.zip')
+os.remove('../YouTube2018/all_frames/valid.zip')
+
+
+"""
+Long-Time Video dataset
+"""
+os.makedirs('../long_video_set', exist_ok=True)
+print('Downloading long video dataset...')
+gdown.download('https://drive.google.com/uc?id=100MxAuV0_UL20ca5c-5CNpqQ5QYPDSoz', output='../long_video_set/LongTimeVideo.zip', quiet=False)
+print('Extracting long video dataset...')
+with zipfile.ZipFile('../long_video_set/LongTimeVideo.zip', 'r') as zip_file:
+ zip_file.extractall('../long_video_set/')
+print('Cleaning up long video dataset...')
+os.remove('../long_video_set/LongTimeVideo.zip')
+
+
+print('Done.')
\ No newline at end of file
diff --git a/scripts/download_models.sh b/scripts/download_models.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ba669b54cec4ef7344326fc8b3e340501ca1bc90
--- /dev/null
+++ b/scripts/download_models.sh
@@ -0,0 +1,2 @@
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem-s012.pth
\ No newline at end of file
diff --git a/scripts/download_models_demo.sh b/scripts/download_models_demo.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a63f700c6d3daf5e97dad00dfcacb8e029bbce12
--- /dev/null
+++ b/scripts/download_models_demo.sh
@@ -0,0 +1,3 @@
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/fbrs.pth
+wget -P ./saves/ https://github.com/hkchengrex/XMem/releases/download/v1.0/s2m.pth
\ No newline at end of file
diff --git a/scripts/expand_long_vid.py b/scripts/expand_long_vid.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae237bc39d04f520b706769ac74139631cc88012
--- /dev/null
+++ b/scripts/expand_long_vid.py
@@ -0,0 +1,36 @@
+import sys
+import os
+from os import path
+from shutil import copy2
+
+input_path = sys.argv[1]
+output_path = sys.argv[2]
+multiplier = int(sys.argv[3])
+image_path = path.join(input_path, 'JPEGImages')
+gt_path = path.join(input_path, 'Annotations')
+
+videos = sorted(os.listdir(image_path))
+
+for vid in videos:
+ os.makedirs(path.join(output_path, 'JPEGImages', vid), exist_ok=True)
+ os.makedirs(path.join(output_path, 'Annotations', vid), exist_ok=True)
+ frames = sorted(os.listdir(path.join(image_path, vid)))
+
+ num_frames = len(frames)
+ counter = 0
+ output_counter = 0
+ direction = 1
+ for _ in range(multiplier):
+ for _ in range(num_frames):
+ copy2(path.join(image_path, vid, frames[counter]),
+ path.join(output_path, 'JPEGImages', vid, f'{output_counter:05d}.jpg'))
+
+ mask_path = path.join(gt_path, vid, frames[counter].replace('.jpg', '.png'))
+ if path.exists(mask_path):
+ copy2(mask_path,
+ path.join(output_path, 'Annotations', vid, f'{output_counter:05d}.png'))
+
+ counter += direction
+ output_counter += 1
+ if counter == 0 or counter == len(frames) - 1:
+ direction *= -1
diff --git a/scripts/resize_youtube.py b/scripts/resize_youtube.py
new file mode 100644
index 0000000000000000000000000000000000000000..501e9f54cde1a44ff11f2d7e640dd7f0748ce78e
--- /dev/null
+++ b/scripts/resize_youtube.py
@@ -0,0 +1,77 @@
+import sys
+import os
+from os import path
+
+from PIL import Image
+import numpy as np
+from progressbar import progressbar
+from multiprocessing import Pool
+
+new_min_size = 480
+
+def resize_vid_jpeg(inputs):
+ vid_name, folder_path, out_path = inputs
+
+ vid_path = path.join(folder_path, vid_name)
+ vid_out_path = path.join(out_path, 'JPEGImages', vid_name)
+ os.makedirs(vid_out_path, exist_ok=True)
+
+ for im_name in os.listdir(vid_path):
+ hr_im = Image.open(path.join(vid_path, im_name))
+ w, h = hr_im.size
+
+ ratio = new_min_size / min(w, h)
+
+ lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.BICUBIC)
+ lr_im.save(path.join(vid_out_path, im_name))
+
+def resize_vid_anno(inputs):
+ vid_name, folder_path, out_path = inputs
+
+ vid_path = path.join(folder_path, vid_name)
+ vid_out_path = path.join(out_path, 'Annotations', vid_name)
+ os.makedirs(vid_out_path, exist_ok=True)
+
+ for im_name in os.listdir(vid_path):
+ hr_im = Image.open(path.join(vid_path, im_name)).convert('P')
+ w, h = hr_im.size
+
+ ratio = new_min_size / min(w, h)
+
+ lr_im = hr_im.resize((int(w*ratio), int(h*ratio)), Image.NEAREST)
+ lr_im.save(path.join(vid_out_path, im_name))
+
+
+def resize_all(in_path, out_path):
+ for folder in os.listdir(in_path):
+
+ if folder not in ['JPEGImages', 'Annotations']:
+ continue
+ folder_path = path.join(in_path, folder)
+ videos = os.listdir(folder_path)
+
+ videos = [(v, folder_path, out_path) for v in videos]
+
+ if folder == 'JPEGImages':
+ print('Processing images')
+ os.makedirs(path.join(out_path, 'JPEGImages'), exist_ok=True)
+
+ pool = Pool(processes=8)
+ for _ in progressbar(pool.imap_unordered(resize_vid_jpeg, videos), max_value=len(videos)):
+ pass
+ else:
+ print('Processing annotations')
+ os.makedirs(path.join(out_path, 'Annotations'), exist_ok=True)
+
+ pool = Pool(processes=8)
+ for _ in progressbar(pool.imap_unordered(resize_vid_anno, videos), max_value=len(videos)):
+ pass
+
+
+if __name__ == '__main__':
+ in_path = sys.argv[1]
+ out_path = sys.argv[2]
+
+ resize_all(in_path, out_path)
+
+ print('Done.')
\ No newline at end of file
diff --git a/test.py b/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..adfad1999984c9292daa78fb99bd1e865afff348
--- /dev/null
+++ b/test.py
@@ -0,0 +1,230 @@
+import os
+from os import path
+from argparse import ArgumentParser
+import shutil
+
+import torch
+import torch.nn.functional as F
+from torch.utils.data import DataLoader
+import numpy as np
+from PIL import Image
+
+from inference.data.test_datasets import DAVISTestDataset_221128_TransColorization_batch
+from inference.data.mask_mapper import MaskMapper
+from model.network import ColorMNet
+from inference.inference_core import InferenceCore
+
+from progressbar import progressbar
+
+from dataset.range_transform import inv_im_trans, inv_lll2rgb_trans
+
+from skimage import color, io
+import cv2
+
+try:
+ import hickle as hkl
+except ImportError:
+ print('Failed to import hickle. Fine if not using multi-scale testing.')
+
+
+"""
+Arguments loading
+"""
+parser = ArgumentParser()
+parser.add_argument('--model', default='saves/DINOv2FeatureV6_LocalAtten_s2_154000.pth')
+
+# dataset setting
+parser.add_argument('--d16_batch_path', default='input')
+parser.add_argument('--deoldify_path', default='ref')
+parser.add_argument('--output', default='result')
+
+# For generic (G) evaluation, point to a folder that contains "JPEGImages" and "Annotations"
+parser.add_argument('--generic_path')
+parser.add_argument('--dataset', help='D16/D17/Y18/Y19/LV1/LV3/G', default='D16_batch')
+parser.add_argument('--split', help='val/test', default='val')
+parser.add_argument('--save_all', action='store_true',
+ help='Save all frames. Useful only in YouTubeVOS/long-time video', )
+parser.add_argument('--benchmark', action='store_true', help='enable to disable amp for FPS benchmarking')
+
+# Long-term memory options
+parser.add_argument('--disable_long_term', action='store_true')
+parser.add_argument('--max_mid_term_frames', help='T_max in paper, decrease to save memory', type=int, default=10)
+parser.add_argument('--min_mid_term_frames', help='T_min in paper, decrease to save memory', type=int, default=5)
+parser.add_argument('--max_long_term_elements', help='LT_max in paper, increase if objects disappear for a long time',
+ type=int, default=10000)
+parser.add_argument('--num_prototypes', help='P in paper', type=int, default=128)
+
+parser.add_argument('--top_k', type=int, default=30)
+parser.add_argument('--mem_every', help='r in paper. Increase to improve running speed.', type=int, default=5)
+parser.add_argument('--deep_update_every', help='Leave -1 normally to synchronize with mem_every', type=int, default=-1)
+
+# Multi-scale options
+parser.add_argument('--save_scores', action='store_true')
+parser.add_argument('--flip', action='store_true')
+parser.add_argument('--size', default=-1, type=int,
+ help='Resize the shorter side to this size. -1 to use original resolution. ')
+
+args = parser.parse_args()
+config = vars(args)
+config['enable_long_term'] = not config['disable_long_term']
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def tensor_to_np_float(image):
+ image_np = image.numpy().astype('float32')
+ return image_np
+
+def lab2rgb_transform_PIL(mask):
+ mask_d = detach_to_cpu(mask)
+ mask_d = inv_lll2rgb_trans(mask_d)
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ return im.clip(0, 1)
+
+if args.output is None:
+ args.output = f'.output/{args.dataset}_{args.split}'
+ print(f'Output path not provided. Defaulting to {args.output}')
+
+"""
+Data preparation
+"""
+is_youtube = args.dataset.startswith('Y')
+is_davis = args.dataset.startswith('D')
+is_lv = args.dataset.startswith('LV')
+
+if is_youtube or args.save_scores:
+ out_path = path.join(args.output, 'Annotations')
+else:
+ out_path = args.output
+
+if args.split == 'val':
+ # Set up Dataset, a small hack to use the image set in the 2017 folder because the 2016 one is of a different format
+ meta_dataset = DAVISTestDataset_221128_TransColorization_batch(args.d16_batch_path, imset=args.deoldify_path, size=args.size)
+else:
+ raise NotImplementedError
+palette = None
+
+torch.autograd.set_grad_enabled(False)
+
+# Set up loader
+meta_loader = meta_dataset.get_datasets()
+
+# Load our checkpoint
+network = ColorMNet(config, args.model).cuda().eval()
+if args.model is not None:
+ model_weights = torch.load(args.model)
+ network.load_weights(model_weights, init_as_zero_if_needed=True)
+else:
+ print('No model loaded.')
+
+total_process_time = 0
+total_frames = 0
+
+# Start eval
+for vid_reader in progressbar(meta_loader, max_value=len(meta_dataset), redirect_stdout=True):
+
+ loader = DataLoader(vid_reader, batch_size=1, shuffle=False, num_workers=2)
+ vid_name = vid_reader.vid_name
+ vid_length = len(loader)
+ # no need to count usage for LT if the video is not that long anyway
+ config['enable_long_term_count_usage'] = (
+ config['enable_long_term'] and
+ (vid_length
+ / (config['max_mid_term_frames']-config['min_mid_term_frames'])
+ * config['num_prototypes'])
+ >= config['max_long_term_elements']
+ )
+
+ mapper = MaskMapper()
+ processor = InferenceCore(network, config=config)
+ first_mask_loaded = False
+
+ for ti, data in enumerate(loader):
+ with torch.cuda.amp.autocast(enabled=not args.benchmark):
+ rgb = data['rgb'].cuda()[0]
+ msk = data.get('mask')
+ info = data['info']
+ frame = info['frame'][0]
+ shape = info['shape']
+ need_resize = info['need_resize'][0]
+
+ """
+ For timing see https://discuss.pytorch.org/t/how-to-measure-time-in-pytorch/26964
+ Seems to be very similar in testing as my previous timing method
+ with two cuda sync + time.time() in STCN though
+ """
+ start = torch.cuda.Event(enable_timing=True)
+ end = torch.cuda.Event(enable_timing=True)
+ start.record()
+
+ if not first_mask_loaded:
+ if msk is not None:
+ first_mask_loaded = True
+ else:
+ # no point to do anything without a mask
+ continue
+
+ if args.flip:
+ rgb = torch.flip(rgb, dims=[-1])
+ msk = torch.flip(msk, dims=[-1]) if msk is not None else None
+
+ # Map possibly non-continuous labels to continuous ones
+ if msk is not None:
+ msk = torch.Tensor(msk[0]).cuda()
+ if need_resize:
+ msk = vid_reader.resize_mask(msk.unsqueeze(0))[0]
+ processor.set_all_labels(list(range(1,3)))
+ labels = range(1,3)
+ else:
+ labels = None
+
+ # Run the model on this frame
+ prob = processor.step(rgb, msk, labels, end=(ti==vid_length-1))
+
+ # Upsample to original size if needed
+ if need_resize:
+ prob = F.interpolate(prob.unsqueeze(1), shape, mode='bilinear', align_corners=False)[:,0]
+
+ end.record()
+ torch.cuda.synchronize()
+ total_process_time += (start.elapsed_time(end)/1000)
+ total_frames += 1
+
+ if args.flip:
+ prob = torch.flip(prob, dims=[-1])
+
+ if args.save_scores:
+ prob = (prob.detach().cpu().numpy()*255).astype(np.uint8)
+
+ # Save the mask
+ if args.save_all or info['save'][0]:
+ this_out_path = path.join(out_path, vid_name)
+ os.makedirs(this_out_path, exist_ok=True)
+
+ out_mask_final = lab2rgb_transform_PIL(torch.cat([rgb[:1,:,:], prob], dim=0))
+ out_mask_final = out_mask_final * 255
+ out_mask_final = out_mask_final.astype(np.uint8)
+
+ out_img = Image.fromarray(out_mask_final)
+ out_img.save(os.path.join(this_out_path, frame[:-4]+'.png'))
+
+print(f'Total processing time: {total_process_time}')
+print(f'Total processed frames: {total_frames}')
+print(f'FPS: {total_frames / total_process_time}')
+print(f'Max allocated memory (MB): {torch.cuda.max_memory_allocated() / (2**20)}')
+
+if not args.save_scores:
+ if is_youtube:
+ print('Making zip for YouTubeVOS...')
+ shutil.make_archive(path.join(args.output, path.basename(args.output)), 'zip', args.output, 'Annotations')
+ elif is_davis and args.split == 'test':
+ print('Making zip for DAVIS test-dev...')
+ shutil.make_archive(args.output, 'zip', args.output)
diff --git a/util/__init__.py b/util/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/util/configuration.py b/util/configuration.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7f7c8345d285100a84c9a72f84976454f0e4106
--- /dev/null
+++ b/util/configuration.py
@@ -0,0 +1,143 @@
+from argparse import ArgumentParser
+
+
+def none_or_default(x, default):
+ return x if x is not None else default
+
+class Configuration():
+ def parse(self, unknown_arg_ok=False):
+ parser = ArgumentParser()
+
+ # Enable torch.backends.cudnn.benchmark -- Faster in some cases, test in your own environment
+ parser.add_argument('--benchmark', action='store_true')
+ parser.add_argument('--no_amp', action='store_true')
+
+ # Data parameters
+ parser.add_argument('--static_root', help='Static training data root', default='../static')
+ parser.add_argument('--bl_root', help='Blender training data root', default='../BL30K')
+ parser.add_argument('--yv_root', help='YouTubeVOS data root', default='../YouTube')
+ parser.add_argument('--davis_root', help='DAVIS data root', default='/data2/yangyixin/data/DAVIS')
+ parser.add_argument('--num_workers', help='Total number of dataloader workers across all GPUs processes', type=int, default=16)
+
+ parser.add_argument('--key_dim', default=64, type=int)
+ parser.add_argument('--value_dim', default=512, type=int)
+ parser.add_argument('--hidden_dim', default=64, help='Set to =0 to disable', type=int)
+
+ parser.add_argument('--deep_update_prob', default=0.2, type=float)
+
+ parser.add_argument('--stages', help='Training stage (0-static images, 1-Blender dataset, 2-DAVIS+YouTubeVOS)', default='02')
+
+ parser.add_argument('--server', help='Training stage (0-pjs-04, 1-A6000Local)', default='0')
+ parser.add_argument('--savepath', help='Blender training data root', default='/data1/yangyixin/code/xmem')
+
+ """
+ Stage-specific learning parameters
+ Batch sizes are effective -- you don't have to scale them when you scale the number processes
+ """
+ # Stage 0, static images
+ parser.add_argument('--s0_batch_size', default=16, type=int)
+ parser.add_argument('--s0_iterations', default=150000, type=int)
+ parser.add_argument('--s0_finetune', default=0, type=int)
+ parser.add_argument('--s0_steps', nargs="*", default=[], type=int)
+ parser.add_argument('--s0_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s0_num_ref_frames', default=2, type=int)
+ parser.add_argument('--s0_num_frames', default=3, type=int)
+ parser.add_argument('--s0_start_warm', default=20000, type=int)
+ parser.add_argument('--s0_end_warm', default=70000, type=int)
+
+ # Stage 1, BL30K
+ parser.add_argument('--s1_batch_size', default=8, type=int)
+ parser.add_argument('--s1_iterations', default=250000, type=int)
+ # fine-tune means fewer augmentations to train the sensory memory
+ parser.add_argument('--s1_finetune', default=0, type=int)
+ parser.add_argument('--s1_steps', nargs="*", default=[200000], type=int)
+ parser.add_argument('--s1_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s1_num_ref_frames', default=3, type=int)
+ parser.add_argument('--s1_num_frames', default=8, type=int)
+ parser.add_argument('--s1_start_warm', default=20000, type=int)
+ parser.add_argument('--s1_end_warm', default=70000, type=int)
+
+ # Stage 2, DAVIS+YoutubeVOS, longer
+ parser.add_argument('--s2_batch_size', default=2, type=int)
+ parser.add_argument('--s2_iterations', default=150000, type=int)
+ # fine-tune means fewer augmentations to train the sensory memory
+ parser.add_argument('--s2_finetune', default=10000, type=int)
+ parser.add_argument('--s2_steps', nargs="*", default=[120000], type=int)
+
+ # parser.add_argument('--s2_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s2_lr', help='Initial learning rate', default=2e-5, type=float)
+
+ parser.add_argument('--s2_num_ref_frames', default=3, type=int)
+ parser.add_argument('--s2_num_frames', default=8, type=int)
+ parser.add_argument('--s2_start_warm', default=20000, type=int)
+ parser.add_argument('--s2_end_warm', default=70000, type=int)
+
+ # Stage 3, DAVIS+YoutubeVOS, shorter
+ parser.add_argument('--s3_batch_size', default=8, type=int)
+ parser.add_argument('--s3_iterations', default=100000, type=int)
+ # fine-tune means fewer augmentations to train the sensory memory
+ parser.add_argument('--s3_finetune', default=10000, type=int)
+ parser.add_argument('--s3_steps', nargs="*", default=[80000], type=int)
+ parser.add_argument('--s3_lr', help='Initial learning rate', default=1e-5, type=float)
+ parser.add_argument('--s3_num_ref_frames', default=3, type=int)
+ parser.add_argument('--s3_num_frames', default=8, type=int)
+ parser.add_argument('--s3_start_warm', default=20000, type=int)
+ parser.add_argument('--s3_end_warm', default=70000, type=int)
+
+ parser.add_argument('--gamma', help='LR := LR*gamma at every decay step', default=0.1, type=float)
+ parser.add_argument('--weight_decay', default=0.05, type=float)
+
+ # Loading
+ parser.add_argument('--load_network', help='Path to pretrained network weight only')
+ parser.add_argument('--load_checkpoint', help='Path to the checkpoint file, including network, optimizer and such')
+
+ # Logging information
+ parser.add_argument('--log_text_interval', default=100, type=int)
+
+ parser.add_argument('--log_image_interval', default=100, type=int)
+
+ parser.add_argument('--save_network_interval', default=2500, type=int)
+ parser.add_argument('--save_checkpoint_interval', default=999999999999999999999, type=int)
+ parser.add_argument('--exp_id', help='Experiment UNIQUE id, use NULL to disable logging to tensorboard', default='NULL')
+ parser.add_argument('--debug', help='Debug mode which logs information more often', action='store_true')
+
+ # # Multiprocessing parameters, not set by users
+ # parser.add_argument('--local_rank', default=0, type=int, help='Local rank of this process')
+
+ if unknown_arg_ok:
+ args, _ = parser.parse_known_args()
+ self.args = vars(args)
+ else:
+ self.args = vars(parser.parse_args())
+
+ self.args['amp'] = not self.args['no_amp']
+
+ # check if the stages are valid
+ stage_to_perform = list(self.args['stages'])
+ for s in stage_to_perform:
+ if s not in ['0', '1', '2', '3']:
+ raise NotImplementedError
+
+ def get_stage_parameters(self, stage):
+ parameters = {
+ 'batch_size': self.args['s%s_batch_size'%stage],
+ 'iterations': self.args['s%s_iterations'%stage],
+ 'finetune': self.args['s%s_finetune'%stage],
+ 'steps': self.args['s%s_steps'%stage],
+ 'lr': self.args['s%s_lr'%stage],
+ 'num_ref_frames': self.args['s%s_num_ref_frames'%stage],
+ 'num_frames': self.args['s%s_num_frames'%stage],
+ 'start_warm': self.args['s%s_start_warm'%stage],
+ 'end_warm': self.args['s%s_end_warm'%stage],
+ }
+
+ return parameters
+
+ def __getitem__(self, key):
+ return self.args[key]
+
+ def __setitem__(self, key, value):
+ self.args[key] = value
+
+ def __str__(self):
+ return str(self.args)
diff --git a/util/davis_subset.txt b/util/davis_subset.txt
new file mode 100644
index 0000000000000000000000000000000000000000..875c2409d2cc4cfc4491ebf7703cb432b26678d8
--- /dev/null
+++ b/util/davis_subset.txt
@@ -0,0 +1,60 @@
+bear
+bmx-bumps
+boat
+boxing-fisheye
+breakdance-flare
+bus
+car-turn
+cat-girl
+classic-car
+color-run
+crossing
+dance-jump
+dancing
+disc-jockey
+dog-agility
+dog-gooses
+dogs-scale
+drift-turn
+drone
+elephant
+flamingo
+hike
+hockey
+horsejump-low
+kid-football
+kite-walk
+koala
+lady-running
+lindy-hop
+longboard
+lucia
+mallard-fly
+mallard-water
+miami-surf
+motocross-bumps
+motorbike
+night-race
+paragliding
+planes-water
+rallye
+rhino
+rollerblade
+schoolgirls
+scooter-board
+scooter-gray
+sheep
+skate-park
+snowboard
+soccerball
+stroller
+stunt
+surf
+swing
+tennis
+tractor-sand
+train
+tuk-tuk
+upside-down
+varanus-cage
+walking
\ No newline at end of file
diff --git a/util/functional.py b/util/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b276eee81513b51baf2d5d9afd0a42366050dc2
--- /dev/null
+++ b/util/functional.py
@@ -0,0 +1,605 @@
+from __future__ import division
+
+import math
+import random
+
+import torch
+from PIL import Image, ImageEnhance, ImageOps
+
+try:
+ import accimage
+except ImportError:
+ accimage = None
+import collections
+import numbers
+import types
+import warnings
+
+import numpy as np
+
+
+def _is_pil_image(img):
+ if accimage is not None:
+ return isinstance(img, (Image.Image, accimage.Image))
+ else:
+ return isinstance(img, Image.Image)
+
+
+def _is_tensor_image(img):
+ return torch.is_tensor(img) and img.ndimension() == 3
+
+
+def _is_numpy_image(img):
+ return isinstance(img, np.ndarray) and (img.ndim in {2, 3})
+
+
+def to_tensor(pic):
+ """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
+
+ See ``ToTensor`` for more details.
+
+ Args:
+ pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
+
+ Returns:
+ Tensor: Converted image.
+ """
+ if not (_is_pil_image(pic) or _is_numpy_image(pic)):
+ raise TypeError("pic should be PIL Image or ndarray. Got {}".format(type(pic)))
+
+ if isinstance(pic, np.ndarray):
+ # handle numpy array
+ img = torch.from_numpy(pic.transpose((2, 0, 1)))
+ # backward compatibility
+ return img.float().div(255)
+
+ if accimage is not None and isinstance(pic, accimage.Image):
+ nppic = np.zeros([pic.channels, pic.height, pic.width], dtype=np.float32)
+ pic.copyto(nppic)
+ return torch.from_numpy(nppic)
+
+ # handle PIL Image
+ if pic.mode == "I":
+ img = torch.from_numpy(np.array(pic, np.int32, copy=False))
+ elif pic.mode == "I;16":
+ img = torch.from_numpy(np.array(pic, np.int16, copy=False))
+ else:
+ img = torch.ByteTensor(torch.ByteStorage.from_buffer(pic.tobytes()))
+ # PIL image mode: 1, L, P, I, F, RGB, YCbCr, RGBA, CMYK
+ if pic.mode == "YCbCr":
+ nchannel = 3
+ elif pic.mode == "I;16":
+ nchannel = 1
+ else:
+ nchannel = len(pic.mode)
+ img = img.view(pic.size[1], pic.size[0], nchannel)
+ # put it from HWC to CHW format
+ # yikes, this transpose takes 80% of the loading time/CPU
+ img = img.transpose(0, 1).transpose(0, 2).contiguous()
+ if isinstance(img, torch.ByteTensor):
+ return img.float().div(255)
+ else:
+ return img
+
+
+def to_mytensor(pic):
+ """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
+
+ See ``ToTensor`` for more details.
+
+ Args:
+ pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
+
+ Returns:
+ Tensor: Converted image.
+ """
+ pic_arr = np.array(pic)
+ if pic_arr.ndim == 2:
+ pic_arr = pic_arr[..., np.newaxis]
+ img = torch.from_numpy(pic_arr.transpose((2, 0, 1)))
+ if not isinstance(img, torch.FloatTensor):
+ return img.float() # no normalize .div(255)
+ else:
+ return img
+
+
+def to_pil_image(pic, mode=None):
+ """Convert a tensor or an ndarray to PIL Image.
+
+ See :class:`~torchvision.transforms.ToPIlImage` for more details.
+
+ Args:
+ pic (Tensor or numpy.ndarray): Image to be converted to PIL Image.
+ mode (`PIL.Image mode`_): color space and pixel depth of input data (optional).
+
+ .. _PIL.Image mode: http://pillow.readthedocs.io/en/3.4.x/handbook/concepts.html#modes
+
+ Returns:
+ PIL Image: Image converted to PIL Image.
+ """
+ if not (_is_numpy_image(pic) or _is_tensor_image(pic)):
+ raise TypeError("pic should be Tensor or ndarray. Got {}.".format(type(pic)))
+
+ npimg = pic
+ if isinstance(pic, torch.FloatTensor):
+ pic = pic.mul(255).byte()
+ if torch.is_tensor(pic):
+ npimg = np.transpose(pic.numpy(), (1, 2, 0))
+
+ if not isinstance(npimg, np.ndarray):
+ raise TypeError("Input pic must be a torch.Tensor or NumPy ndarray, " + "not {}".format(type(npimg)))
+
+ if npimg.shape[2] == 1:
+ expected_mode = None
+ npimg = npimg[:, :, 0]
+ if npimg.dtype == np.uint8:
+ expected_mode = "L"
+ if npimg.dtype == np.int16:
+ expected_mode = "I;16"
+ if npimg.dtype == np.int32:
+ expected_mode = "I"
+ elif npimg.dtype == np.float32:
+ expected_mode = "F"
+ if mode is not None and mode != expected_mode:
+ raise ValueError(
+ "Incorrect mode ({}) supplied for input type {}. Should be {}".format(mode, np.dtype, expected_mode)
+ )
+ mode = expected_mode
+
+ elif npimg.shape[2] == 4:
+ permitted_4_channel_modes = ["RGBA", "CMYK"]
+ if mode is not None and mode not in permitted_4_channel_modes:
+ raise ValueError("Only modes {} are supported for 4D inputs".format(permitted_4_channel_modes))
+
+ if mode is None and npimg.dtype == np.uint8:
+ mode = "RGBA"
+ else:
+ permitted_3_channel_modes = ["RGB", "YCbCr", "HSV"]
+ if mode is not None and mode not in permitted_3_channel_modes:
+ raise ValueError("Only modes {} are supported for 3D inputs".format(permitted_3_channel_modes))
+ if mode is None and npimg.dtype == np.uint8:
+ mode = "RGB"
+
+ if mode is None:
+ raise TypeError("Input type {} is not supported".format(npimg.dtype))
+
+ return Image.fromarray(npimg, mode=mode)
+
+
+def normalize(tensor, mean, std):
+ """Normalize a tensor image with mean and standard deviation.
+
+ See ``Normalize`` for more details.
+
+ Args:
+ tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
+ mean (sequence): Sequence of means for each channel.
+ std (sequence): Sequence of standard deviations for each channely.
+
+ Returns:
+ Tensor: Normalized Tensor image.
+ """
+ if not _is_tensor_image(tensor):
+ raise TypeError("tensor is not a torch image.")
+ # TODO: make efficient
+ if tensor.size(0) == 1:
+ tensor.sub_(mean).div_(std)
+ else:
+ for t, m, s in zip(tensor, mean, std):
+ t.sub_(m).div_(s)
+ return tensor
+
+
+def resize(img, size, interpolation=Image.BILINEAR):
+ """Resize the input PIL Image to the given size.
+
+ Args:
+ img (PIL Image): Image to be resized.
+ size (sequence or int): Desired output size. If size is a sequence like
+ (h, w), the output size will be matched to this. If size is an int,
+ the smaller edge of the image will be matched to this number maintaing
+ the aspect ratio. i.e, if height > width, then image will be rescaled to
+ (size * height / width, size)
+ interpolation (int, optional): Desired interpolation. Default is
+ ``PIL.Image.BILINEAR``
+
+ Returns:
+ PIL Image: Resized image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+ if not isinstance(size, int) and (not isinstance(size, collections.Iterable) or len(size) != 2):
+ raise TypeError("Got inappropriate size arg: {}".format(size))
+
+ if not isinstance(size, int):
+ return img.resize(size[::-1], interpolation)
+
+ w, h = img.size
+ if (w <= h and w == size) or (h <= w and h == size):
+ return img
+ if w < h:
+ ow = size
+ oh = int(round(size * h / w))
+ else:
+ oh = size
+ ow = int(round(size * w / h))
+ return img.resize((ow, oh), interpolation)
+
+
+def scale(*args, **kwargs):
+ warnings.warn("The use of the transforms.Scale transform is deprecated, " + "please use transforms.Resize instead.")
+ return resize(*args, **kwargs)
+
+
+def pad(img, padding, fill=0):
+ """Pad the given PIL Image on all sides with the given "pad" value.
+
+ Args:
+ img (PIL Image): Image to be padded.
+ padding (int or tuple): Padding on each border. If a single int is provided this
+ is used to pad all borders. If tuple of length 2 is provided this is the padding
+ on left/right and top/bottom respectively. If a tuple of length 4 is provided
+ this is the padding for the left, top, right and bottom borders
+ respectively.
+ fill: Pixel fill value. Default is 0. If a tuple of
+ length 3, it is used to fill R, G, B channels respectively.
+
+ Returns:
+ PIL Image: Padded image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ if not isinstance(padding, (numbers.Number, tuple)):
+ raise TypeError("Got inappropriate padding arg")
+ if not isinstance(fill, (numbers.Number, str, tuple)):
+ raise TypeError("Got inappropriate fill arg")
+
+ if isinstance(padding, collections.Sequence) and len(padding) not in [2, 4]:
+ raise ValueError(
+ "Padding must be an int or a 2, or 4 element tuple, not a " + "{} element tuple".format(len(padding))
+ )
+
+ return ImageOps.expand(img, border=padding, fill=fill)
+
+
+def crop(img, i, j, h, w):
+ """Crop the given PIL Image.
+
+ Args:
+ img (PIL Image): Image to be cropped.
+ i: Upper pixel coordinate.
+ j: Left pixel coordinate.
+ h: Height of the cropped image.
+ w: Width of the cropped image.
+
+ Returns:
+ PIL Image: Cropped image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.crop((j, i, j + w, i + h))
+
+
+def center_crop(img, output_size):
+ if isinstance(output_size, numbers.Number):
+ output_size = (int(output_size), int(output_size))
+ w, h = img.size
+ th, tw = output_size
+ i = int(round((h - th) / 2.0))
+ j = int(round((w - tw) / 2.0))
+ return crop(img, i, j, th, tw)
+
+
+def resized_crop(img, i, j, h, w, size, interpolation=Image.BILINEAR):
+ """Crop the given PIL Image and resize it to desired size.
+
+ Notably used in RandomResizedCrop.
+
+ Args:
+ img (PIL Image): Image to be cropped.
+ i: Upper pixel coordinate.
+ j: Left pixel coordinate.
+ h: Height of the cropped image.
+ w: Width of the cropped image.
+ size (sequence or int): Desired output size. Same semantics as ``scale``.
+ interpolation (int, optional): Desired interpolation. Default is
+ ``PIL.Image.BILINEAR``.
+ Returns:
+ PIL Image: Cropped image.
+ """
+ assert _is_pil_image(img), "img should be PIL Image"
+ img = crop(img, i, j, h, w)
+ img = resize(img, size, interpolation)
+ return img
+
+
+def hflip(img):
+ """Horizontally flip the given PIL Image.
+
+ Args:
+ img (PIL Image): Image to be flipped.
+
+ Returns:
+ PIL Image: Horizontall flipped image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.transpose(Image.FLIP_LEFT_RIGHT)
+
+
+def vflip(img):
+ """Vertically flip the given PIL Image.
+
+ Args:
+ img (PIL Image): Image to be flipped.
+
+ Returns:
+ PIL Image: Vertically flipped image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.transpose(Image.FLIP_TOP_BOTTOM)
+
+
+def five_crop(img, size):
+ """Crop the given PIL Image into four corners and the central crop.
+
+ .. Note::
+ This transform returns a tuple of images and there may be a
+ mismatch in the number of inputs and targets your ``Dataset`` returns.
+
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ Returns:
+ tuple: tuple (tl, tr, bl, br, center) corresponding top left,
+ top right, bottom left, bottom right and center crop.
+ """
+ if isinstance(size, numbers.Number):
+ size = (int(size), int(size))
+ else:
+ assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
+
+ w, h = img.size
+ crop_h, crop_w = size
+ if crop_w > w or crop_h > h:
+ raise ValueError("Requested crop size {} is bigger than input size {}".format(size, (h, w)))
+ tl = img.crop((0, 0, crop_w, crop_h))
+ tr = img.crop((w - crop_w, 0, w, crop_h))
+ bl = img.crop((0, h - crop_h, crop_w, h))
+ br = img.crop((w - crop_w, h - crop_h, w, h))
+ center = center_crop(img, (crop_h, crop_w))
+ return (tl, tr, bl, br, center)
+
+
+def ten_crop(img, size, vertical_flip=False):
+ """Crop the given PIL Image into four corners and the central crop plus the
+ flipped version of these (horizontal flipping is used by default).
+
+ .. Note::
+ This transform returns a tuple of images and there may be a
+ mismatch in the number of inputs and targets your ``Dataset`` returns.
+
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ vertical_flip (bool): Use vertical flipping instead of horizontal
+
+ Returns:
+ tuple: tuple (tl, tr, bl, br, center, tl_flip, tr_flip, bl_flip,
+ br_flip, center_flip) corresponding top left, top right,
+ bottom left, bottom right and center crop and same for the
+ flipped image.
+ """
+ if isinstance(size, numbers.Number):
+ size = (int(size), int(size))
+ else:
+ assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
+
+ first_five = five_crop(img, size)
+
+ if vertical_flip:
+ img = vflip(img)
+ else:
+ img = hflip(img)
+
+ second_five = five_crop(img, size)
+ return first_five + second_five
+
+
+def adjust_brightness(img, brightness_factor):
+ """Adjust brightness of an Image.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ brightness_factor (float): How much to adjust the brightness. Can be
+ any non negative number. 0 gives a black image, 1 gives the
+ original image while 2 increases the brightness by a factor of 2.
+
+ Returns:
+ PIL Image: Brightness adjusted image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ enhancer = ImageEnhance.Brightness(img)
+ img = enhancer.enhance(brightness_factor)
+ return img
+
+
+def adjust_contrast(img, contrast_factor):
+ """Adjust contrast of an Image.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ contrast_factor (float): How much to adjust the contrast. Can be any
+ non negative number. 0 gives a solid gray image, 1 gives the
+ original image while 2 increases the contrast by a factor of 2.
+
+ Returns:
+ PIL Image: Contrast adjusted image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ enhancer = ImageEnhance.Contrast(img)
+ img = enhancer.enhance(contrast_factor)
+ return img
+
+
+def adjust_saturation(img, saturation_factor):
+ """Adjust color saturation of an image.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ saturation_factor (float): How much to adjust the saturation. 0 will
+ give a black and white image, 1 will give the original image while
+ 2 will enhance the saturation by a factor of 2.
+
+ Returns:
+ PIL Image: Saturation adjusted image.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ enhancer = ImageEnhance.Color(img)
+ img = enhancer.enhance(saturation_factor)
+ return img
+
+
+def adjust_hue(img, hue_factor):
+ """Adjust hue of an image.
+
+ The image hue is adjusted by converting the image to HSV and
+ cyclically shifting the intensities in the hue channel (H).
+ The image is then converted back to original image mode.
+
+ `hue_factor` is the amount of shift in H channel and must be in the
+ interval `[-0.5, 0.5]`.
+
+ See https://en.wikipedia.org/wiki/Hue for more details on Hue.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ hue_factor (float): How much to shift the hue channel. Should be in
+ [-0.5, 0.5]. 0.5 and -0.5 give complete reversal of hue channel in
+ HSV space in positive and negative direction respectively.
+ 0 means no shift. Therefore, both -0.5 and 0.5 will give an image
+ with complementary colors while 0 gives the original image.
+
+ Returns:
+ PIL Image: Hue adjusted image.
+ """
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError("hue_factor is not in [-0.5, 0.5].".format(hue_factor))
+
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ input_mode = img.mode
+ if input_mode in {"L", "1", "I", "F"}:
+ return img
+
+ h, s, v = img.convert("HSV").split()
+
+ np_h = np.array(h, dtype=np.uint8)
+ # uint8 addition take cares of rotation across boundaries
+ with np.errstate(over="ignore"):
+ np_h += np.uint8(hue_factor * 255)
+ h = Image.fromarray(np_h, "L")
+
+ img = Image.merge("HSV", (h, s, v)).convert(input_mode)
+ return img
+
+
+def adjust_gamma(img, gamma, gain=1):
+ """Perform gamma correction on an image.
+
+ Also known as Power Law Transform. Intensities in RGB mode are adjusted
+ based on the following equation:
+
+ I_out = 255 * gain * ((I_in / 255) ** gamma)
+
+ See https://en.wikipedia.org/wiki/Gamma_correction for more details.
+
+ Args:
+ img (PIL Image): PIL Image to be adjusted.
+ gamma (float): Non negative real number. gamma larger than 1 make the
+ shadows darker, while gamma smaller than 1 make dark regions
+ lighter.
+ gain (float): The constant multiplier.
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ if gamma < 0:
+ raise ValueError("Gamma should be a non-negative real number")
+
+ input_mode = img.mode
+ img = img.convert("RGB")
+
+ np_img = np.array(img, dtype=np.float32)
+ np_img = 255 * gain * ((np_img / 255) ** gamma)
+ np_img = np.uint8(np.clip(np_img, 0, 255))
+
+ img = Image.fromarray(np_img, "RGB").convert(input_mode)
+ return img
+
+
+def rotate(img, angle, resample=False, expand=False, center=None):
+ """Rotate the image by angle and then (optionally) translate it by (n_columns, n_rows)
+
+
+ Args:
+ img (PIL Image): PIL Image to be rotated.
+ angle ({float, int}): In degrees degrees counter clockwise order.
+ resample ({PIL.Image.NEAREST, PIL.Image.BILINEAR, PIL.Image.BICUBIC}, optional):
+ An optional resampling filter.
+ See http://pillow.readthedocs.io/en/3.4.x/handbook/concepts.html#filters
+ If omitted, or if the image has mode "1" or "P", it is set to PIL.Image.NEAREST.
+ expand (bool, optional): Optional expansion flag.
+ If true, expands the output image to make it large enough to hold the entire rotated image.
+ If false or omitted, make the output image the same size as the input image.
+ Note that the expand flag assumes rotation around the center and no translation.
+ center (2-tuple, optional): Optional center of rotation.
+ Origin is the upper left corner.
+ Default is the center of the image.
+ """
+
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ return img.rotate(angle, resample, expand, center)
+
+
+def to_grayscale(img, num_output_channels=1):
+ """Convert image to grayscale version of image.
+
+ Args:
+ img (PIL Image): Image to be converted to grayscale.
+
+ Returns:
+ PIL Image: Grayscale version of the image.
+ if num_output_channels == 1 : returned image is single channel
+ if num_output_channels == 3 : returned image is 3 channel with r == g == b
+ """
+ if not _is_pil_image(img):
+ raise TypeError("img should be PIL Image. Got {}".format(type(img)))
+
+ if num_output_channels == 1:
+ img = img.convert("L")
+ elif num_output_channels == 3:
+ img = img.convert("L")
+ np_img = np.array(img, dtype=np.uint8)
+ np_img = np.dstack([np_img, np_img, np_img])
+ img = Image.fromarray(np_img, "RGB")
+ else:
+ raise ValueError("num_output_channels should be either 1 or 3")
+
+ return img
diff --git a/util/image_saver.py b/util/image_saver.py
new file mode 100644
index 0000000000000000000000000000000000000000..619471921c328beac88734bed36c507ee4e4290b
--- /dev/null
+++ b/util/image_saver.py
@@ -0,0 +1,302 @@
+import cv2
+import numpy as np
+
+import torch
+from dataset.range_transform import inv_im_trans, inv_lll2rgb_trans
+from collections import defaultdict
+
+from PIL import Image
+from skimage import color, io
+
+import util.functional as F
+class Normalize(object):
+ def __init__(self):
+ pass
+
+ def __call__(self, inputs):
+ inputs[0:1, :, :] = F.normalize(inputs[0:1, :, :], 50, 1)
+ inputs[1:3, :, :] = F.normalize(inputs[1:3, :, :], (0, 0), (1, 1))
+ return inputs
+
+def tensor_to_numpy(image):
+ image_np = (image.numpy() * 255).astype('uint8')
+ return image_np
+
+def tensor_to_np_float(image):
+ image_np = image.numpy().astype('float32')
+ return image_np
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def transpose_np(x):
+ return np.transpose(x, [1,2,0])
+
+def tensor_to_gray_im(x):
+ x = detach_to_cpu(x)
+ x = tensor_to_numpy(x)
+ x = transpose_np(x)
+ return x
+
+def tensor_to_im(x):
+ x = detach_to_cpu(x)
+ x = inv_im_trans(x).clamp(0, 1)
+ x = tensor_to_numpy(x)
+ x = transpose_np(x)
+ return x
+
+# Predefined key <-> caption dict
+key_captions = {
+ 'im': 'Image',
+ 'gt': 'GT',
+}
+
+"""
+Return an image array with captions
+keys in dictionary will be used as caption if not provided
+values should contain lists of cv2 images
+"""
+def get_image_array(images, grid_shape, captions={}):
+ h, w = grid_shape
+ cate_counts = len(images)
+ rows_counts = len(next(iter(images.values())))
+
+ font = cv2.FONT_HERSHEY_SIMPLEX
+
+ output_image = np.zeros([w*cate_counts, h*(rows_counts+1), 3], dtype=np.uint8)
+ col_cnt = 0
+ for k, v in images.items():
+
+ # Default as key value itself
+ caption = captions.get(k, k)
+
+ # Handles new line character
+ dy = 40
+ for i, line in enumerate(caption.split('\n')):
+ cv2.putText(output_image, line, (10, col_cnt*w+100+i*dy),
+ font, 0.8, (255,255,255), 2, cv2.LINE_AA)
+
+ # Put images
+ for row_cnt, img in enumerate(v):
+ im_shape = img.shape
+ if len(im_shape) == 2:
+ img = img[..., np.newaxis]
+
+ img = (img * 255).astype('uint8')
+
+ output_image[(col_cnt+0)*w:(col_cnt+1)*w,
+ (row_cnt+1)*h:(row_cnt+2)*h, :] = img
+
+ col_cnt += 1
+
+ return output_image
+
+def base_transform(im, size):
+ im = tensor_to_np_float(im)
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ # Resize
+ if im.shape[1] != size:
+ im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
+
+ return im.clip(0, 1)
+
+def im_transform(im, size):
+ return base_transform(inv_im_trans(detach_to_cpu(im)), size=size)
+
+def mask_transform(mask, size):
+ return base_transform(detach_to_cpu(mask), size=size)
+
+def out_transform(mask, size):
+ return base_transform(detach_to_cpu(torch.sigmoid(mask)), size=size)
+
+def lll2rgb_transform(mask, size):
+ flag_test = False
+
+ mask_d = detach_to_cpu(mask)
+
+ mask_d[1:3,:,:] = 0
+
+ if flag_test: print('before inv', mask_d.size(), torch.min(mask_d), torch.max(mask_d))
+ mask_d = inv_lll2rgb_trans(mask_d)
+ if flag_test: print('after inv', mask_d.size(), torch.min(mask_d), torch.max(mask_d));assert 1==0
+
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ # Resize
+ if im.shape[1] != size:
+ im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
+
+ return im.clip(0, 1)
+
+def lab2rgb_transform(mask, size):
+ flag_test = False
+
+ mask_d = detach_to_cpu(mask)
+
+ if flag_test: print('before inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d))
+ mask_d = inv_lll2rgb_trans(mask_d)
+ if flag_test: print('after inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d));assert 1==0
+
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ # Resize
+ if im.shape[1] != size:
+ im = cv2.resize(im, size, interpolation=cv2.INTER_NEAREST)
+
+ return im.clip(0, 1)
+
+
+
+def pool_pairs_221128_TransColorization(images, size, num_objects):
+ req_images = defaultdict(list)
+
+ b, t = images['rgb'].shape[:2]
+
+ # limit the number of images saved
+ b = min(2, b)
+
+ # find max num objects
+
+ # max_num_objects = max(num_objects[:b])
+ max_num_objects = 1
+
+ GT_suffix = ''
+ for bi in range(b):
+ GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
+
+ # print(images['rgb'].size(), b, max_num_objects, images['info']['name'], GT_suffix)
+ # print(images['info']['name'][0][-25:-4])
+ # print(images['info']['name'][1][-25:-4])
+ # assert 1==0
+
+ for bi in range(b):
+ for ti in range(t):
+
+ req_images['RGB'].append(lll2rgb_transform(images['rgb'][bi,ti], size))
+
+ for oi in range(max_num_objects):
+ if ti == 0 or oi >= num_objects[bi]:
+
+ # req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # print(images['rgb'][bi,ti][:1,:,:].size(), images['first_frame_gt'][bi][0,:].size());assert 1==0
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['first_frame_gt'][bi][0,:]], dim=0), size))
+
+
+ else:
+ # req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['masks_%d'%ti][bi][:]], dim=0), size))
+
+ # req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
+ # print(images['cls_gt'][bi,ti,:,:].size());assert 1==0
+ req_images['GT_%d_%s'%(oi, GT_suffix)].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['cls_gt'][bi,ti,:,:]], dim=0), size))
+
+ # print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
+ # print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
+
+
+ return get_image_array(req_images, size, key_captions)
+
+
+def pool_pairs_221128_TransColorization_val(images, size, num_objects):
+ req_images = defaultdict(list)
+
+ b, t = images['rgb'].shape[:2]
+
+ # limit the number of images saved
+ b = min(2, b)
+
+ # find max num objects
+
+ # max_num_objects = max(num_objects[:b])
+ max_num_objects = 1
+
+ GT_suffix = ''
+ for bi in range(b):
+ GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
+
+ # print(images['rgb'].size(), b, max_num_objects, images['info']['name'], GT_suffix)
+ # print(images['info']['name'][0][-25:-4])
+ # print(images['info']['name'][1][-25:-4])
+ # assert 1==0
+
+ for bi in range(b):
+ for ti in range(t):
+
+ req_images['RGB'].append(lll2rgb_transform(images['rgb'][bi,ti], size))
+
+ for oi in range(max_num_objects):
+ if ti == 0 or oi >= num_objects[bi]:
+
+ # req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # print(images['rgb'][bi,ti][:1,:,:].size(), images['first_frame_gt'][bi][0,:].size());assert 1==0
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['first_frame_gt'][bi][0,:]], dim=0), size))
+
+
+ else:
+ # req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
+ req_images['Mask_%d'%oi].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['masks_%d'%ti][bi][:]], dim=0), size))
+
+ # req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
+ # print(images['cls_gt'][bi,ti,:,:].size());assert 1==0
+ req_images['GT_%d_%s'%(oi, GT_suffix)].append(lab2rgb_transform(torch.cat([images['rgb'][bi,ti][:1,:,:], images['cls_gt'][bi,ti,:,:]], dim=0), size))
+
+ # print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
+ # print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
+
+
+ return get_image_array(req_images, size, key_captions)
+
+
+
+def pool_pairs(images, size, num_objects):
+ req_images = defaultdict(list)
+
+ b, t = images['rgb'].shape[:2]
+
+ # limit the number of images saved
+ b = min(2, b)
+
+ # find max num objects
+ max_num_objects = max(num_objects[:b])
+
+ GT_suffix = ''
+ for bi in range(b):
+ GT_suffix += ' \n%s' % images['info']['name'][bi][-25:-4]
+
+ for bi in range(b):
+ for ti in range(t):
+ req_images['RGB'].append(im_transform(images['rgb'][bi,ti], size))
+ for oi in range(max_num_objects):
+ if ti == 0 or oi >= num_objects[bi]:
+ req_images['Mask_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # req_images['Mask_X8_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ # req_images['Mask_X16_%d'%oi].append(mask_transform(images['first_frame_gt'][bi][0,oi], size))
+ else:
+ req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi], size))
+ # req_images['Mask_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][2], size))
+ # req_images['Mask_X8_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][1], size))
+ # req_images['Mask_X16_%d'%oi].append(mask_transform(images['masks_%d'%ti][bi][oi][0], size))
+ req_images['GT_%d_%s'%(oi, GT_suffix)].append(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size))
+ # print((images['cls_gt'][bi,ti,0]==(oi+1)).shape)
+ # print(mask_transform(images['cls_gt'][bi,ti,0]==(oi+1), size).shape)
+
+
+ return get_image_array(req_images, size, key_captions)
\ No newline at end of file
diff --git a/util/load_subset.py b/util/load_subset.py
new file mode 100644
index 0000000000000000000000000000000000000000..3191f4fef05cec04a11eafdfa42b34b98a35549e
--- /dev/null
+++ b/util/load_subset.py
@@ -0,0 +1,16 @@
+"""
+load_subset.py - Presents a subset of data
+DAVIS - only the training set
+YouTubeVOS - I manually filtered some erroneous ones out but I haven't checked all
+"""
+
+
+def load_sub_davis(path='util/davis_subset.txt'):
+ with open(path, mode='r') as f:
+ subset = set(f.read().splitlines())
+ return subset
+
+def load_sub_yv(path='util/yv_subset.txt'):
+ with open(path, mode='r') as f:
+ subset = set(f.read().splitlines())
+ return subset
diff --git a/util/log_integrator.py b/util/log_integrator.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4b26d53de98b16e145090bcddf2041a3f2d1394
--- /dev/null
+++ b/util/log_integrator.py
@@ -0,0 +1,80 @@
+"""
+Integrate numerical values for some iterations
+Typically used for loss computation / logging to tensorboard
+Call finalize and create a new Integrator when you want to display/log
+"""
+
+import torch
+
+
+class Integrator:
+ def __init__(self, logger, distributed=True, local_rank=0, world_size=1):
+ self.values = {}
+ self.counts = {}
+ self.hooks = [] # List is used here to maintain insertion order
+
+ self.logger = logger
+
+ self.distributed = distributed
+ self.local_rank = local_rank
+ self.world_size = world_size
+
+ def add_tensor(self, key, tensor):
+ if key not in self.values:
+ self.counts[key] = 1
+ if type(tensor) == float or type(tensor) == int:
+ self.values[key] = tensor
+ else:
+ self.values[key] = tensor.mean().item()
+ else:
+ self.counts[key] += 1
+ if type(tensor) == float or type(tensor) == int:
+ self.values[key] += tensor
+ else:
+ self.values[key] += tensor.mean().item()
+
+ def add_dict(self, tensor_dict):
+ for k, v in tensor_dict.items():
+ self.add_tensor(k, v)
+
+ def add_hook(self, hook):
+ """
+ Adds a custom hook, i.e. compute new metrics using values in the dict
+ The hook takes the dict as argument, and returns a (k, v) tuple
+ e.g. for computing IoU
+ """
+ if type(hook) == list:
+ self.hooks.extend(hook)
+ else:
+ self.hooks.append(hook)
+
+ def reset_except_hooks(self):
+ self.values = {}
+ self.counts = {}
+
+ # Average and output the metrics
+ def finalize(self, prefix, it, f=None):
+
+ for hook in self.hooks:
+ k, v = hook(self.values)
+ self.add_tensor(k, v)
+
+ for k, v in self.values.items():
+
+ if k[:4] == 'hide':
+ continue
+
+ avg = v / self.counts[k]
+
+ if self.distributed:
+ # Inplace operation
+ avg = torch.tensor(avg).cuda()
+ torch.distributed.reduce(avg, dst=0)
+
+ if self.local_rank == 0:
+ avg = (avg/self.world_size).cpu().item()
+ self.logger.log_metrics(prefix, k, avg, it, f)
+ else:
+ # Simple does it
+ self.logger.log_metrics(prefix, k, avg, it, f)
+
diff --git a/util/logger.py b/util/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..7dd9fb29bb3f5b0e9ba9e2ee425f420e743d10e7
--- /dev/null
+++ b/util/logger.py
@@ -0,0 +1,101 @@
+"""
+Dumps things to tensorboard and console
+"""
+
+import os
+import warnings
+
+import torchvision.transforms as transforms
+from torch.utils.tensorboard import SummaryWriter
+
+
+def tensor_to_numpy(image):
+ image_np = (image.numpy() * 255).astype('uint8')
+ return image_np
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def fix_width_trunc(x):
+ return ('{:.9s}'.format('{:0.9f}'.format(x)))
+
+class TensorboardLogger:
+ def __init__(self, short_id, id, git_info, flag_occupy_memory, savepath='.'):
+ self.short_id = short_id
+ if self.short_id == 'NULL':
+ self.short_id = 'DEBUG'
+
+ if id is None:
+ self.no_log = True
+ warnings.warn('Logging has been disbaled.')
+ else:
+ self.no_log = False
+
+ self.inv_im_trans = transforms.Normalize(
+ mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
+ std=[1/0.229, 1/0.224, 1/0.225])
+
+ self.inv_seg_trans = transforms.Normalize(
+ mean=[-0.5/0.5],
+ std=[1/0.5])
+
+ log_path = os.path.join('.', 'tmp_occupy_memory_saves', '%s' % id) if flag_occupy_memory else os.path.join(savepath, 'saves', '%s' % id)
+ self.logger = SummaryWriter(log_path)
+
+ self.log_string('git', git_info)
+
+ def log_scalar(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ self.logger.add_scalar(tag, x, step)
+
+ def log_metrics(self, l1_tag, l2_tag, val, step, f=None):
+ tag = l1_tag + '/' + l2_tag
+ text = '{:s} - It {:6d} [{:5s}] [{:13}]: {:s}'.format(self.short_id, step, l1_tag.upper(), l2_tag, fix_width_trunc(val))
+ print(text)
+ if f is not None:
+ f.write(text + '\n')
+ f.flush()
+ self.log_scalar(tag, val, step)
+
+ def log_im(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = detach_to_cpu(x)
+ x = self.inv_im_trans(x)
+ x = tensor_to_numpy(x)
+ self.logger.add_image(tag, x, step)
+
+ def log_cv2(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = x.transpose((2, 0, 1))
+ self.logger.add_image(tag, x, step)
+
+ def log_seg(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = detach_to_cpu(x)
+ x = self.inv_seg_trans(x)
+ x = tensor_to_numpy(x)
+ self.logger.add_image(tag, x, step)
+
+ def log_gray(self, tag, x, step):
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ x = detach_to_cpu(x)
+ x = tensor_to_numpy(x)
+ self.logger.add_image(tag, x, step)
+
+ def log_string(self, tag, x):
+ print(tag, x)
+ if self.no_log:
+ warnings.warn('Logging has been disabled.')
+ return
+ self.logger.add_text(tag, x)
+
\ No newline at end of file
diff --git a/util/palette.py b/util/palette.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2541659563056b015b3d6e4c2b0accef3b4e831
--- /dev/null
+++ b/util/palette.py
@@ -0,0 +1,3 @@
+davis_palette = b'\x00\x00\x00\x80\x00\x00\x00\x80\x00\x80\x80\x00\x00\x00\x80\x80\x00\x80\x00\x80\x80\x80\x80\x80@\x00\x00\xc0\x00\x00@\x80\x00\xc0\x80\x00@\x00\x80\xc0\x00\x80@\x80\x80\xc0\x80\x80\x00@\x00\x80@\x00\x00\xc0\x00\x80\xc0\x00\x00@\x80\x80@\x80\x00\xc0\x80\x80\xc0\x80@@\x00\xc0@\x00@\xc0\x00\xc0\xc0\x00@@\x80\xc0@\x80@\xc0\x80\xc0\xc0\x80\x00\x00@\x80\x00@\x00\x80@\x80\x80@\x00\x00\xc0\x80\x00\xc0\x00\x80\xc0\x80\x80\xc0@\x00@\xc0\x00@@\x80@\xc0\x80@@\x00\xc0\xc0\x00\xc0@\x80\xc0\xc0\x80\xc0\x00@@\x80@@\x00\xc0@\x80\xc0@\x00@\xc0\x80@\xc0\x00\xc0\xc0\x80\xc0\xc0@@@\xc0@@@\xc0@\xc0\xc0@@@\xc0\xc0@\xc0@\xc0\xc0\xc0\xc0\xc0 \x00\x00\xa0\x00\x00 \x80\x00\xa0\x80\x00 \x00\x80\xa0\x00\x80 \x80\x80\xa0\x80\x80`\x00\x00\xe0\x00\x00`\x80\x00\xe0\x80\x00`\x00\x80\xe0\x00\x80`\x80\x80\xe0\x80\x80 @\x00\xa0@\x00 \xc0\x00\xa0\xc0\x00 @\x80\xa0@\x80 \xc0\x80\xa0\xc0\x80`@\x00\xe0@\x00`\xc0\x00\xe0\xc0\x00`@\x80\xe0@\x80`\xc0\x80\xe0\xc0\x80 \x00@\xa0\x00@ \x80@\xa0\x80@ \x00\xc0\xa0\x00\xc0 \x80\xc0\xa0\x80\xc0`\x00@\xe0\x00@`\x80@\xe0\x80@`\x00\xc0\xe0\x00\xc0`\x80\xc0\xe0\x80\xc0 @@\xa0@@ \xc0@\xa0\xc0@ @\xc0\xa0@\xc0 \xc0\xc0\xa0\xc0\xc0`@@\xe0@@`\xc0@\xe0\xc0@`@\xc0\xe0@\xc0`\xc0\xc0\xe0\xc0\xc0\x00 \x00\x80 \x00\x00\xa0\x00\x80\xa0\x00\x00 \x80\x80 \x80\x00\xa0\x80\x80\xa0\x80@ \x00\xc0 \x00@\xa0\x00\xc0\xa0\x00@ \x80\xc0 \x80@\xa0\x80\xc0\xa0\x80\x00`\x00\x80`\x00\x00\xe0\x00\x80\xe0\x00\x00`\x80\x80`\x80\x00\xe0\x80\x80\xe0\x80@`\x00\xc0`\x00@\xe0\x00\xc0\xe0\x00@`\x80\xc0`\x80@\xe0\x80\xc0\xe0\x80\x00 @\x80 @\x00\xa0@\x80\xa0@\x00 \xc0\x80 \xc0\x00\xa0\xc0\x80\xa0\xc0@ @\xc0 @@\xa0@\xc0\xa0@@ \xc0\xc0 \xc0@\xa0\xc0\xc0\xa0\xc0\x00`@\x80`@\x00\xe0@\x80\xe0@\x00`\xc0\x80`\xc0\x00\xe0\xc0\x80\xe0\xc0@`@\xc0`@@\xe0@\xc0\xe0@@`\xc0\xc0`\xc0@\xe0\xc0\xc0\xe0\xc0 \x00\xa0 \x00 \xa0\x00\xa0\xa0\x00 \x80\xa0 \x80 \xa0\x80\xa0\xa0\x80` \x00\xe0 \x00`\xa0\x00\xe0\xa0\x00` \x80\xe0 \x80`\xa0\x80\xe0\xa0\x80 `\x00\xa0`\x00 \xe0\x00\xa0\xe0\x00 `\x80\xa0`\x80 \xe0\x80\xa0\xe0\x80``\x00\xe0`\x00`\xe0\x00\xe0\xe0\x00``\x80\xe0`\x80`\xe0\x80\xe0\xe0\x80 @\xa0 @ \xa0@\xa0\xa0@ \xc0\xa0 \xc0 \xa0\xc0\xa0\xa0\xc0` @\xe0 @`\xa0@\xe0\xa0@` \xc0\xe0 \xc0`\xa0\xc0\xe0\xa0\xc0 `@\xa0`@ \xe0@\xa0\xe0@ `\xc0\xa0`\xc0 \xe0\xc0\xa0\xe0\xc0``@\xe0`@`\xe0@\xe0\xe0@``\xc0\xe0`\xc0`\xe0\xc0\xe0\xe0\xc0'
+
+youtube_palette = b'\x00\x00\x00\xec_g\xf9\x91W\xfa\xc8c\x99\xc7\x94b\xb3\xb2f\x99\xcc\xc5\x94\xc5\xabyg\xff\xff\xffes~\x0b\x0b\x0b\x0c\x0c\x0c\r\r\r\x0e\x0e\x0e\x0f\x0f\x0f'
diff --git a/util/tensor_util.py b/util/tensor_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..05189d38e2b0b0d1d08bd7804b8e43418d6da637
--- /dev/null
+++ b/util/tensor_util.py
@@ -0,0 +1,47 @@
+import torch.nn.functional as F
+
+
+def compute_tensor_iu(seg, gt):
+ intersection = (seg & gt).float().sum()
+ union = (seg | gt).float().sum()
+
+ return intersection, union
+
+def compute_tensor_iou(seg, gt):
+ intersection, union = compute_tensor_iu(seg, gt)
+ iou = (intersection + 1e-6) / (union + 1e-6)
+
+ return iou
+
+# STM
+def pad_divide_by(in_img, d):
+ h, w = in_img.shape[-2:]
+
+ if h % d > 0:
+ new_h = h + d - h % d
+ else:
+ new_h = h
+ if w % d > 0:
+ new_w = w + d - w % d
+ else:
+ new_w = w
+ lh, uh = int((new_h-h) / 2), int(new_h-h) - int((new_h-h) / 2)
+ lw, uw = int((new_w-w) / 2), int(new_w-w) - int((new_w-w) / 2)
+ pad_array = (int(lw), int(uw), int(lh), int(uh))
+ out = F.pad(in_img, pad_array)
+ return out, pad_array
+
+def unpad(img, pad):
+ if len(img.shape) == 4:
+ if pad[2]+pad[3] > 0:
+ img = img[:,:,pad[2]:-pad[3],:]
+ if pad[0]+pad[1] > 0:
+ img = img[:,:,:,pad[0]:-pad[1]]
+ elif len(img.shape) == 3:
+ if pad[2]+pad[3] > 0:
+ img = img[:,pad[2]:-pad[3],:]
+ if pad[0]+pad[1] > 0:
+ img = img[:,:,pad[0]:-pad[1]]
+ else:
+ raise NotImplementedError
+ return img
\ No newline at end of file
diff --git a/util/transforms.py b/util/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..df7a54559a329a84aec339182d2aa07f3ee4fdb0
--- /dev/null
+++ b/util/transforms.py
@@ -0,0 +1,61 @@
+
+from dataset.range_transform import inv_im_trans, inv_lll2rgb_trans
+from skimage import color, io
+import cv2
+import numpy as np
+
+def detach_to_cpu(x):
+ return x.detach().cpu()
+
+def tensor_to_np_float(image):
+ image_np = image.numpy().astype('float32')
+ return image_np
+
+def lab2rgb_transform_PIL(mask):
+ flag_test = False
+
+ mask_d = detach_to_cpu(mask)
+
+ if flag_test: print('before inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d))
+ mask_d = inv_lll2rgb_trans(mask_d)
+ if flag_test: print('after inv', mask_d.size(), torch.max(mask_d), torch.min(mask_d));assert 1==0
+
+ im = tensor_to_np_float(mask_d)
+
+ if len(im.shape) == 3:
+ im = im.transpose((1, 2, 0))
+ else:
+ im = im[:, :, None]
+
+ im = color.lab2rgb(im)
+
+ return im.clip(0, 1)
+
+def calculate_psnr(img1, img2):
+ mse_value = ((img1 - img2)**2).mean()
+ if mse_value == 0:
+ result = float('inf')
+ else:
+ result = 20. * np.log10(255. / np.sqrt(mse_value))
+ return result
+
+def calculate_psnr_for_folder(gt_folder, result_folder):
+ result_clips = sorted(os.listdir(result_folder))
+
+ psnr_values = []
+ for clip in result_clips:
+ path_clip = os.path.join(result_folder, clip)
+ test_files = sorted(os.listdir(path_clip))
+
+ for img in test_files:
+ gt_path = os.path.join(gt_folder, clip, img)
+ result_path = os.path.join(path_clip, img)
+
+ gt_img = np.array(Image.open(gt_path))
+ result_img = np.array(Image.open(result_path))
+
+ psnr = calculate_psnr(gt_img, result_img)
+ psnr_values.append(psnr)
+
+ avg_psnr = np.mean(psnr_values)
+ return avg_psnr
\ No newline at end of file
diff --git a/util/yv_subset.txt b/util/yv_subset.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a26e50a7b8e6233bf17c542b540765cd8a1c5716
--- /dev/null
+++ b/util/yv_subset.txt
@@ -0,0 +1,3464 @@
+003234408d
+0043f083b5
+0044fa5fba
+005a527edd
+0065b171f9
+00917dcfc4
+00a23ccf53
+00ad5016a4
+01082ae388
+011ac0a06f
+013099c098
+0155498c85
+01694ad9c8
+017ac35701
+01b80e8e1a
+01baa5a4e1
+01c3111683
+01c4cb5ffe
+01c76f0a82
+01c783268c
+01ed275c6e
+01ff60d1fa
+020cd28cd2
+02264db755
+0248626d9a
+02668dbffa
+0274193026
+02d28375aa
+02f3a5c4df
+031ccc99b1
+0321b18c10
+0348a45bca
+0355e92655
+0358b938c1
+0368107cf1
+0379ddf557
+038b2cc71d
+038c15a5dd
+03a06cc98a
+03a63e187f
+03c95b4dae
+03e2b57b0e
+04194e1248
+0444918a5f
+04460a7a52
+04474174a4
+0450095513
+045f00aed2
+04667fabaa
+04735c5030
+04990d1915
+04d62d9d98
+04f21da964
+04fbad476e
+04fe256562
+0503bf89c9
+0536c9eed0
+054acb238f
+05579ca250
+056c200404
+05774f3a2c
+058a7592c8
+05a0a513df
+05a569d8aa
+05aa652648
+05d7715782
+05e0b0f28f
+05fdbbdd7a
+05ffcfed85
+0630391881
+06840b2bbe
+068f7dce6f
+0693719753
+06ce2b51fb
+06e224798e
+06ee361788
+06fbb3fa2c
+0700264286
+070c918ca7
+07129e14a4
+07177017e9
+07238ffc58
+07353b2a89
+0738493cbf
+075926c651
+075c701292
+0762ea9a30
+07652ee4af
+076f206928
+077d32af19
+079049275c
+07913cdda7
+07a11a35e8
+07ac33b6df
+07b6e8fda8
+07c62c3d11
+07cc1c7d74
+080196ef01
+081207976e
+081ae4fa44
+081d8250cb
+082900c5d4
+0860df21e2
+0866d4c5e3
+0891ac2eb6
+08931bc458
+08aa2705d5
+08c8450db7
+08d50b926c
+08e1e4de15
+08e48c1a48
+08f561c65e
+08feb87790
+09049f6fe3
+092e4ff450
+09338adea8
+093c335ccc
+0970d28339
+0974a213dc
+097b471ed8
+0990941758
+09a348f4fa
+09a6841288
+09c5bad17b
+09c9ce80c7
+09ff54fef4
+0a23765d15
+0a275e7f12
+0a2f2bd294
+0a7a2514aa
+0a7b27fde9
+0a8c467cc3
+0ac8c560ae
+0b1627e896
+0b285c47f6
+0b34ec1d55
+0b5b5e8e5a
+0b68535614
+0b6f9105fc
+0b7dbfa3cb
+0b9cea51ca
+0b9d012be8
+0bcfc4177d
+0bd37b23c1
+0bd864064c
+0c11c6bf7b
+0c26bc77ac
+0c3a04798c
+0c44a9d545
+0c817cc390
+0ca839ee9a
+0cd7ac0ac0
+0ce06e0121
+0cfe974a89
+0d2fcc0dcd
+0d3aad05d2
+0d40b015f4
+0d97fba242
+0d9cc80d7e
+0dab85b6d3
+0db5c427a5
+0dbaf284f1
+0de4923598
+0df28a9101
+0e04f636c4
+0e05f0e232
+0e0930474b
+0e27472bea
+0e30020549
+0e621feb6c
+0e803c7d73
+0e9ebe4e3c
+0e9f2785ec
+0ea68d418b
+0eb403a222
+0ee92053d6
+0eefca067f
+0f17fa6fcb
+0f1ac8e9a3
+0f202e9852
+0f2ab8b1ff
+0f51a78756
+0f5fbe16b0
+0f6072077b
+0f6b69b2f4
+0f6c2163de
+0f74ec5599
+0f9683715b
+0fa7b59356
+0fb173695b
+0fc958cde2
+0fe7b1a621
+0ffcdb491c
+101caff7d4
+1022fe8417
+1032e80b37
+103f501680
+104e64565f
+104f1ab997
+106242403f
+10b31f5431
+10eced835e
+110d26fa3a
+1122c1d16a
+1145b49a5f
+11485838c2
+114e7676ec
+1157472b95
+115ee1072c
+1171141012
+117757b4b8
+1178932d2f
+117cc76bda
+1180cbf814
+1187bbd0e3
+1197e44b26
+119cf20728
+119dd54871
+11a0c3b724
+11a6ba8c94
+11c722a456
+11cbcb0b4d
+11ccf5e99d
+11ce6f452e
+11e53de6f2
+11feabe596
+120cb9514d
+12156b25b3
+122896672d
+1232b2f1d4
+1233ac8596
+1239c87234
+1250423f7c
+1257a1bc67
+125d1b19dd
+126d203967
+1295e19071
+12ad198c54
+12bddb2bcb
+12ec9b93ee
+12eebedc35
+132852e094
+1329409f2a
+13325cfa14
+134d06dbf9
+135625b53d
+13870016f9
+13960b3c84
+13adaad9d9
+13ae097e20
+13e3070469
+13f6a8c20d
+1416925cf2
+142d2621f5
+145d5d7c03
+145fdc3ac5
+1471274fa7
+14a6b5a139
+14c21cea0d
+14dae0dc93
+14f9bd22b5
+14fd28ae99
+15097d5d4e
+150ea711f2
+1514e3563f
+152aaa3a9e
+152b7d3bd7
+15617297cc
+15abbe0c52
+15d1fb3de5
+15f67b0fab
+161eb59aad
+16288ea47f
+164410ce62
+165c3c8cd4
+165c42b41b
+165ec9e22b
+1669502269
+16763cccbb
+16adde065e
+16af445362
+16afd538ad
+16c3fa4d5d
+16d1d65c27
+16e8599e94
+16fe9fb444
+1705796b02
+1724db7671
+17418e81ea
+175169edbb
+17622326fd
+17656bae77
+17b0d94172
+17c220e4f6
+17c7bcd146
+17cb4afe89
+17cd79a434
+17d18604c3
+17d8ca1a37
+17e33f4330
+17f7a6d805
+180abc8378
+183ba3d652
+185bf64702
+18913cc690
+1892651815
+189ac8208a
+189b44e92c
+18ac264b76
+18b245ab49
+18b5cebc34
+18bad52083
+18bb5144d5
+18c6f205c5
+1903f9ea15
+1917b209f2
+191e74c01d
+19367bb94e
+193ffaa217
+19696b67d3
+197f3ab6f3
+1981e763cc
+198afe39ae
+19a6e62b9b
+19b60d5335
+19c00c11f9
+19e061eb88
+19e8bc6178
+19ee80dac6
+1a25a9170a
+1a359a6c1a
+1a3e87c566
+1a5fe06b00
+1a6c0fbd1e
+1a6f3b5a4b
+1a8afbad92
+1a8bdc5842
+1a95752aca
+1a9c131cb7
+1aa3da3ee3
+1ab27ec7ea
+1abf16d21d
+1acd0f993b
+1ad202e499
+1af8d2395d
+1afd39a1fa
+1b2d31306f
+1b3fa67f0e
+1b43fa74b4
+1b73ea9fc2
+1b7e8bb255
+1b8680f8cd
+1b883843c0
+1b8898785b
+1b88ba1aa4
+1b96a498e5
+1bbc4c274f
+1bd87fe9ab
+1c4090c75b
+1c41934f84
+1c72b04b56
+1c87955a3a
+1c9f9eb792
+1ca240fede
+1ca5673803
+1cada35274
+1cb44b920d
+1cd10e62be
+1d3087d5e5
+1d3685150a
+1d6ff083aa
+1d746352a6
+1da256d146
+1da4e956b1
+1daf812218
+1dba687bce
+1dce57d05d
+1de4a9e537
+1dec5446c8
+1dfbe6f586
+1e1a18c45a
+1e1e42529d
+1e4be70796
+1eb60959c8
+1ec8b2566b
+1ecdc2941c
+1ee0ac70ff
+1ef8e17def
+1f1a2a9fc0
+1f1beb8daa
+1f2609ee13
+1f3876f8d0
+1f4ec0563d
+1f64955634
+1f7d31b5b2
+1f8014b7fd
+1f9c7d10f1
+1fa350df76
+1fc9538993
+1fe2f0ec59
+2000c02f9d
+20142b2f05
+201a8d75e5
+2023b3ee4f
+202b767bbc
+203594a418
+2038987336
+2039c3aecb
+204a90d81f
+207bc6cf01
+208833d1d1
+20c6d8b362
+20e3e52e0a
+2117fa0c14
+211bc5d102
+2120d9c3c3
+2125235a49
+21386f5978
+2142af8795
+215dfc0f73
+217bae91e5
+217c0d44e4
+219057c87b
+21d0edbf81
+21df87ad76
+21f1d089f5
+21f4019116
+222597030f
+222904eb5b
+223a0e0657
+223bd973ab
+22472f7395
+224e7c833e
+225aba51d9
+2261d421ea
+2263a8782b
+2268cb1ffd
+2268e93b0a
+2293c99f3f
+22a1141970
+22b13084b2
+22d9f5ab0c
+22f02efe3a
+232c09b75b
+2350d71b4b
+2376440551
+2383d8aafd
+238b84e67f
+238d4b86f6
+238d947c6b
+23993ce90d
+23b0c8a9ab
+23b3beafcc
+23d80299fe
+23f404a9fc
+240118e58a
+2431dec2fd
+24440e0ac7
+2457274dbc
+2465bf515d
+246b142c4d
+247d729e36
+2481ceafeb
+24866b4e6a
+2489d78320
+24ab0b83e8
+24b0868d92
+24b5207cd9
+24ddf05c03
+250116161c
+256ad2e3fc
+256bd83d5e
+256dcc8ab8
+2589956baa
+258b3b33c6
+25ad437e29
+25ae395636
+25c750c6db
+25d2c3fe5d
+25dc80db7c
+25f97e926f
+26011bc28b
+260846ffbe
+260dd9ad33
+267964ee57
+2680861931
+268ac7d3fc
+26b895d91e
+26bc786d4f
+26ddd2ef12
+26de3d18ca
+26f7784762
+2703e52a6a
+270ed80c12
+2719b742ab
+272f4163d0
+27303333e1
+27659fa7d6
+279214115d
+27a5f92a9c
+27cf2af1f3
+27f0d5f8a2
+28075f33c1
+281629cb41
+282b0d51f5
+282fcab00b
+28449fa0dc
+28475208ca
+285580b7c4
+285b69e223
+288c117201
+28a8eb9623
+28bf9c3cf3
+28c6b8f86a
+28c972dacd
+28d9fa6016
+28e392de91
+28f4a45190
+298c844fc9
+29a0356a2b
+29d779f9e3
+29dde5f12b
+29de7b6579
+29e630bdd0
+29f2332d30
+2a18873352
+2a3824ff31
+2a559dd27f
+2a5c09acbd
+2a63eb1524
+2a6a30a4ea
+2a6d9099d1
+2a821394e3
+2a8c5b1342
+2abc8d66d2
+2ac9ef904a
+2b08f37364
+2b351bfd7d
+2b659a49d7
+2b69ee5c26
+2b6c30bbbd
+2b88561cf2
+2b8b14954e
+2ba621c750
+2bab50f9a7
+2bb00c2434
+2bbde474ef
+2bdd82fb86
+2be06fb855
+2bf545c2f5
+2bffe4cf9a
+2c04b887b7
+2c05209105
+2c0ad8cf39
+2c11fedca8
+2c1a94ebfb
+2c1e8c8e2f
+2c29fabcf1
+2c2c076c01
+2c3ea7ee7d
+2c41fa0648
+2c44bb6d1c
+2c54cfbb78
+2c5537eddf
+2c6e63b7de
+2cb10c6a7e
+2cbcd5ccd1
+2cc5d9c5f6
+2cd01cf915
+2cdbf5f0a7
+2ce660f123
+2cf114677e
+2d01eef98e
+2d03593bdc
+2d183ac8c4
+2d33ad3935
+2d3991d83e
+2d4333577b
+2d4d015c64
+2d8f5e5025
+2d900bdb8e
+2d9a1a1d49
+2db0576a5c
+2dc0838721
+2dcc417f82
+2df005b843
+2df356de14
+2e00393d96
+2e03b8127a
+2e0f886168
+2e2bf37e6d
+2e42410932
+2ea78f46e4
+2ebb017a26
+2ee2edba2a
+2efb07554a
+2f17e4fc1e
+2f2c65c2f3
+2f2d9b33be
+2f309c206b
+2f53822e88
+2f53998171
+2f5b0c89b1
+2f680909e6
+2f710f66bd
+2f724132b9
+2f7e3517ae
+2f96f5fc6f
+2f97d9fecb
+2fbfa431ec
+2fc9520b53
+2fcd9f4c62
+2feb30f208
+2ff7f5744f
+30085a2cc6
+30176e3615
+301f72ee11
+3026bb2f61
+30318465dc
+3054ca937d
+306121e726
+3064ad91e8
+307444a47f
+307bbb7409
+30a20194ab
+30c35c64a4
+30dbdb2cd6
+30fc77d72f
+310021b58b
+3113140ee8
+3150b2ee57
+31539918c4
+318dfe2ce2
+3193da4835
+319f725ad9
+31bbd0d793
+322505c47f
+322b237865
+322da43910
+3245e049fb
+324c4c38f6
+324e35111a
+3252398f09
+327dc4cabf
+328d918c7d
+3290c0de97
+3299ae3116
+32a7cd687b
+33098cedb4
+3332334ac4
+334cb835ac
+3355e056eb
+33639a2847
+3373891cdc
+337975816b
+33e29d7e91
+34046fe4f2
+3424f58959
+34370a710f
+343bc6a65a
+3450382ef7
+3454303a08
+346aacf439
+346e92ff37
+34a5ece7dd
+34b109755a
+34d1b37101
+34dd2c70a7
+34efa703df
+34fbee00a6
+3504df2fda
+35195a56a1
+351c822748
+351cfd6bc5
+3543d8334c
+35573455c7
+35637a827f
+357a710863
+358bf16f9e
+35ab34cc34
+35c6235b8d
+35d01a438a
+3605019d3b
+3609bc3f88
+360e25da17
+36299c687c
+362c5bc56e
+3649228783
+365b0501ea
+365f459863
+369893f3ad
+369c9977e1
+369dde050a
+36c7dac02f
+36d5b1493b
+36f5cc68fd
+3735480d18
+374b479880
+375a49d38f
+375a5c0e09
+376bda9651
+377db65f60
+37c19d1087
+37d4ae24fc
+37ddce7f8b
+37e10d33af
+37e45c6247
+37fa0001e8
+3802d458c0
+382caa3cb4
+383bb93111
+388843df90
+38924f4a7f
+38b00f93d7
+38c197c10e
+38c9c3d801
+38eb2bf67f
+38fe9b3ed1
+390352cced
+390c51b987
+390ca6f1d6
+392bc0f8a1
+392ecb43bd
+3935291688
+3935e63b41
+394454fa9c
+394638fc8b
+39545e20b7
+397abeae8f
+3988074b88
+398f5d5f19
+39bc49a28c
+39befd99fb
+39c3c7bf55
+39d584b09f
+39f6f6ffb1
+3a079fb484
+3a0d3a81b7
+3a1d55d22b
+3a20a7583e
+3a2c1f66e5
+3a33f4d225
+3a3bf84b13
+3a4565e5ec
+3a4e32ed5e
+3a7ad86ce0
+3a7bdde9b8
+3a98867cbe
+3aa3f1c9e8
+3aa7fce8b6
+3aa876887d
+3ab807ded6
+3ab9b1a85a
+3adac8d7da
+3ae1a4016f
+3ae2deaec2
+3ae81609d6
+3af847e62f
+3b23792b84
+3b3b0af2ee
+3b512dad74
+3b6c7988f6
+3b6e983b5b
+3b74a0fc20
+3b7a50b80d
+3b96d3492f
+3b9ad0c5a9
+3b9ba0894a
+3bb4e10ed7
+3bd9a9b515
+3beef45388
+3c019c0a24
+3c090704aa
+3c2784fc0d
+3c47ab95f8
+3c4db32d74
+3c5ff93faf
+3c700f073e
+3c713cbf2f
+3c8320669c
+3c90d225ee
+3cadbcc404
+3cb9be84a5
+3cc37fd487
+3cc6f90cb2
+3cd5e035ef
+3cdf03531b
+3cdf828f59
+3d254b0bca
+3d5aeac5ba
+3d690473e1
+3d69fed2fb
+3d8997aeb6
+3db0d6b07e
+3db1ddb8cf
+3db907ac77
+3dcbc0635b
+3dd48ed55f
+3de4ac4ec4
+3decd63d88
+3e04a6be11
+3e108fb65a
+3e1448b01c
+3e16c19634
+3e2845307e
+3e38336da5
+3e3a819865
+3e3e4be915
+3e680622d7
+3e7d2aeb07
+3e7d8f363d
+3e91f10205
+3ea4c49bbe
+3eb39d11ab
+3ec273c8d5
+3ed3f91271
+3ee062a2fd
+3eede9782c
+3ef2fa99cb
+3efc6e9892
+3f0b0dfddd
+3f0c860359
+3f18728586
+3f3b15f083
+3f45a470ad
+3f4f3bc803
+3fd96c5267
+3fea675fab
+3fee8cbc9f
+3fff16d112
+401888b36c
+4019231330
+402316532d
+402680df52
+404d02e0c0
+40709263a8
+4083cfbe15
+40a96c5cb1
+40b8e50f82
+40f4026bf5
+4100b57a3a
+41059fdd0b
+41124e36de
+4122aba5f9
+413bab0f0d
+4164faee0b
+418035eec9
+4182d51532
+418bb97e10
+41a34c20e7
+41dab05200
+41ff6d5e2a
+420caf0859
+42264230ba
+425a0c96e0
+42da96b87c
+42eb5a5b0f
+42f17cd14d
+42f5c61c49
+42ffdcdee9
+432f9884f9
+43326d9940
+4350f3ab60
+4399ffade3
+43a6c21f37
+43b5555faa
+43d63b752a
+4416bdd6ac
+4444753edd
+444aa274e7
+444d4e0596
+446b8b5f7a
+4478f694bb
+44b1da0d87
+44b4dad8c9
+44b5ece1b9
+44d239b24e
+44eaf8f51e
+44f4f57099
+44f7422af2
+450787ac97
+4523656564
+4536c882e5
+453b65daa4
+454f227427
+45636d806a
+456fb9362e
+457e717a14
+45a89f35e1
+45bf0e947d
+45c36a9eab
+45d9fc1357
+45f8128b97
+4607f6c03c
+46146dfd39
+4620e66b1e
+4625f3f2d3
+462b22f263
+4634736113
+463c0f4fdd
+46565a75f8
+46630b55ae
+466839cb37
+466ba4ae0c
+4680236c9d
+46bf4e8709
+46e18e42f1
+46f5093c59
+47269e0499
+472da1c484
+47354fab09
+4743bb84a7
+474a796272
+4783d2ab87
+479cad5da3
+479f5d7ef6
+47a05fbd1d
+4804ee2767
+4810c3fbca
+482fb439c2
+48375af288
+484ab44de4
+485f3944cd
+4867b84887
+486a8ac57e
+486e69c5bd
+48812cf33e
+4894b3b9ea
+48bd66517d
+48d83b48a4
+49058178b8
+4918d10ff0
+4932911f80
+49405b7900
+49972c2d14
+499bf07002
+49b16e9377
+49c104258e
+49c879f82d
+49e7326789
+49ec3e406a
+49fbf0c98a
+4a0255c865
+4a088fe99a
+4a341402d0
+4a3471bdf5
+4a4b50571c
+4a50f3d2e9
+4a6e3faaa1
+4a7191f08a
+4a86fcfc30
+4a885fa3ef
+4a8af115de
+4aa2e0f865
+4aa9d6527f
+4abb74bb52
+4ae13de1cd
+4af8cb323f
+4b02c272b3
+4b19c529fb
+4b2974eff4
+4b3154c159
+4b54d2587f
+4b556740ff
+4b67aa9ef6
+4b97cc7b8d
+4baa1ed4aa
+4bc8c676bb
+4beaea4dbe
+4bf5763d24
+4bffa92b67
+4c25dfa8ec
+4c397b6fd4
+4c51e75d66
+4c7710908f
+4c9b5017be
+4ca2ffc361
+4cad2e93bc
+4cd427b535
+4cd9a4b1ef
+4cdfe3c2b2
+4cef87b649
+4cf208e9b3
+4cf5bc3e60
+4cfdd73249
+4cff5c9e42
+4d26d41091
+4d5c23c554
+4d67c59727
+4d983cad9f
+4da0d00b55
+4daa179861
+4dadd57153
+4db117e6c5
+4de4ce4dea
+4dfaee19e5
+4dfdd7fab0
+4e3f346aa5
+4e49c2a9c7
+4e4e06a749
+4e70279712
+4e72856cc7
+4e752f8075
+4e7a28907f
+4e824b9247
+4e82b1df57
+4e87a639bc
+4ea77bfd15
+4eb6fc23a2
+4ec9da329e
+4efb9a0720
+4f062fbc63
+4f35be0e0b
+4f37e86797
+4f414dd6e7
+4f424abded
+4f470cc3ae
+4f601d255a
+4f7386a1ab
+4f824d3dcd
+4f827b0751
+4f8db33a13
+4fa160f8a3
+4fa9c30a45
+4facd8f0e8
+4fca07ad01
+4fded94004
+4fdfef4dea
+4feb3ac01f
+4fffec8479
+500c835a86
+50168342bf
+50243cffdc
+5031d5a036
+504dd9c0fd
+50568fbcfb
+5069c7c5b3
+508189ac91
+50b6b3d4b7
+50c6f4fe3e
+50cce40173
+50efbe152f
+50f290b95d
+5104aa1fea
+5110dc72c0
+511e8ecd7f
+513aada14e
+5158d6e985
+5161e1fa57
+51794ddd58
+517d276725
+51a597ee04
+51b37b6d97
+51b5dc30a0
+51e85b347b
+51eea1fdac
+51eef778af
+51f384721c
+521cfadcb4
+52355da42f
+5247d4b160
+524b470fd0
+524cee1534
+5252195e8a
+5255c9ca97
+525928f46f
+526df007a7
+529b12de78
+52c7a3d653
+52c8ec0373
+52d225ed52
+52ee406d9e
+52ff1ccd4a
+53143511e8
+5316d11eb7
+53253f2362
+534a560609
+5352c4a70e
+536096501f
+536b17bcea
+5380eaabff
+5390a43a54
+53af427bb2
+53bf5964ce
+53c30110b5
+53cad8e44a
+53d9c45013
+53e274f1b5
+53e32d21ea
+540850e1c7
+540cb31cfe
+541c4da30f
+541d7935d7
+545468262b
+5458647306
+54657855cd
+547b3fb23b
+5497dc3712
+549c56f1d4
+54a4260bb1
+54b98b8d5e
+54e1054b0f
+54e8867b83
+54ebe34f6e
+5519b4ad13
+551acbffd5
+55341f42da
+5566ab97e1
+556c79bbf2
+5589637cc4
+558aa072f0
+559824b6f6
+55c1764e90
+55eda6c77e
+562d173565
+5665c024cb
+566cef4959
+5675d78833
+5678a91bd8
+567a2b4bd0
+569c282890
+56cc449917
+56e71f3e07
+56f09b9d92
+56fc0e8cf9
+571ca79c71
+57243657cf
+57246af7d1
+57427393e9
+574b682c19
+578f211b86
+5790ac295d
+579393912d
+57a344ab1a
+57bd3bcda4
+57bfb7fa4c
+57c010175e
+57c457cc75
+57c7fc2183
+57d5289a01
+58045fde85
+58163c37cd
+582d463e5c
+5851739c15
+585dd0f208
+587250f3c3
+589e4cc1de
+589f65f5d5
+58a07c17d5
+58adc6d8b6
+58b9bcf656
+58c374917e
+58fc75fd42
+5914c30f05
+59323787d5
+5937b08d69
+594065ddd7
+595a0ceea6
+59623ec40b
+597ff7ef78
+598935ef05
+598c2ad3b2
+59a6459751
+59b175e138
+59bf0a149f
+59d53d1649
+59e3e6fae7
+59fe33e560
+5a13a73fe5
+5a25c22770
+5a4a785006
+5a50640995
+5a75f7a1cf
+5a841e59ad
+5a91c5ab6d
+5ab49d9de0
+5aba1057fe
+5abe46ba6d
+5ac7c88d0c
+5aeb95cc7d
+5af15e4fc3
+5afe381ae4
+5b07b4229d
+5b1001cc4f
+5b1df237d2
+5b263013bf
+5b27d19f0b
+5b48ae16c5
+5b5babc719
+5baaebdf00
+5bab55cdbe
+5bafef6e79
+5bd1f84545
+5bddc3ba25
+5bdf7c20d2
+5bf23bc9d3
+5c01f6171a
+5c021681b7
+5c185cff1d
+5c42aba280
+5c44bf8ab6
+5c4c574894
+5c52fa4662
+5c6ea7dac3
+5c74315dc2
+5c7668855e
+5c83e96778
+5ca36173e4
+5cac477371
+5cb0cb1b2f
+5cb0cfb98f
+5cb49a19cf
+5cbf7dc388
+5d0e07d126
+5d1e24b6e3
+5d663000ff
+5da6b2dc5d
+5de9b90f24
+5e08de0ed7
+5e1011df9a
+5e1ce354fd
+5e35512dd7
+5e418b25f9
+5e4849935a
+5e4ee19663
+5e886ef78f
+5e8d00b974
+5e8d59dc31
+5ed838bd5c
+5edda6ee5a
+5ede4d2f7a
+5ede9767da
+5eec4d9fe5
+5eecf07824
+5eef7ed4f4
+5ef5860ac6
+5ef6573a99
+5f1193e72b
+5f29ced797
+5f32cf521e
+5f51876986
+5f6ebe94a9
+5f6f14977c
+5f808d0d2d
+5fb8aded6a
+5fba90767d
+5fd1c7a3df
+5fd3da9f68
+5fee2570ae
+5ff66140d6
+5ff8b85b53
+600803c0f6
+600be7f53e
+6024888af8
+603189a03c
+6057307f6e
+6061ddbb65
+606c86c455
+60c61cc2e5
+60e51ff1ae
+610e38b751
+61344be2f6
+6135e27185
+614afe7975
+614e571886
+614e7078db
+619812a1a7
+61b481a78b
+61c7172650
+61cf7e40d2
+61d08ef5a1
+61da008958
+61ed178ecb
+61f5d1282c
+61fd977e49
+621584cffe
+625817a927
+625892cf0b
+625b89d28a
+629995af95
+62a0840bb5
+62ad6e121c
+62d6ece152
+62ede7b2da
+62f025e1bc
+6316faaebc
+63281534dc
+634058dda0
+6353f09384
+6363c87314
+636e4872e0
+637681cd6b
+6376d49f31
+6377809ec2
+63936d7de5
+639bddef11
+63d37e9fd3
+63d90c2bae
+63e544a5d6
+63ebbcf874
+63fff40b31
+6406c72e4d
+64148128be
+6419386729
+643092bc41
+644081b88d
+64453cf61d
+644bad9729
+6454f548fd
+645913b63a
+64750b825f
+64a43876b7
+64dd6c83e3
+64e05bf46e
+64f55f1478
+650b0165e4
+651066ed39
+652b67d960
+653821d680
+6538d00d73
+65866dce22
+6589565c8c
+659832db64
+65ab7e1d98
+65b7dda462
+65bd5eb4f5
+65dcf115ab
+65e9825801
+65f9afe51c
+65ff12bcb5
+666b660284
+6671643f31
+668364b372
+66852243cb
+6693a52081
+669b572898
+66e98e78f5
+670f12e88f
+674c12c92d
+675c27208a
+675ed3e1ca
+67741db50a
+678a2357eb
+67b0f4d562
+67cfbff9b1
+67e717d6bd
+67ea169a3b
+67ea809e0e
+681249baa3
+683de643d9
+6846ac20df
+6848e012ef
+684bcd8812
+684dc1c40c
+685a1fa9cf
+686dafaac9
+68807d8601
+6893778c77
+6899d2dabe
+68a2fad4ab
+68cb45fda3
+68cc4a1970
+68dcb40675
+68ea4a8c3d
+68f6e7fbf0
+68fa8300b4
+69023db81f
+6908ccf557
+691a111e7c
+6927723ba5
+692ca0e1a2
+692eb57b63
+69340faa52
+693cbf0c9d
+6942f684ad
+6944fc833b
+69491c0ebf
+695b61a2b0
+6979b4d83f
+697d4fdb02
+69910460a4
+6997636670
+69a436750b
+69aebf7669
+69b8c17047
+69c67f109f
+69e0e7b868
+69ea9c09d1
+69f0af42a6
+6a078cdcc7
+6a37a91708
+6a42176f2e
+6a48e4aea8
+6a5977be3a
+6a5de0535f
+6a80d2e2e5
+6a96c8815d
+6a986084e2
+6aa8e50445
+6ab9dce449
+6abf0ba6b2
+6acc6049d9
+6adb31756c
+6ade215eb0
+6afb7d50e4
+6afd692f1a
+6b0b1044fe
+6b17c67633
+6b1b6ef28b
+6b1e04d00d
+6b2261888d
+6b25d6528a
+6b3a24395c
+6b685eb75b
+6b79be238c
+6b928b7ba6
+6b9c43c25a
+6ba99cc41f
+6bdab62bcd
+6bf2e853b1
+6bf584200f
+6bf95df2b9
+6c0949c51c
+6c11a5f11f
+6c23d89189
+6c4387daf5
+6c4ce479a4
+6c5123e4bc
+6c54265f16
+6c56848429
+6c623fac5f
+6c81b014e9
+6c99ea7c31
+6c9d29d509
+6c9e3b7d1a
+6ca006e283
+6caeb928d6
+6cb2ee722a
+6cbfd32c5e
+6cc791250b
+6cccc985e0
+6d12e30c48
+6d4bf200ad
+6d6d2b8843
+6d6eea5682
+6d7a3d0c21
+6d7efa9b9e
+6da21f5c91
+6da6adabc0
+6dd2827fbb
+6dd36705b9
+6df3637557
+6dfe55e9e5
+6e1a21ba55
+6e2f834767
+6e36e4929a
+6e4f460caf
+6e618d26b6
+6ead4670f7
+6eaff19b9f
+6eb2e1cd9e
+6eb30b3b5a
+6eca26c202
+6ecad29e52
+6ef0b44654
+6efcfe9275
+6f4789045c
+6f49f522ef
+6f67d7c4c4
+6f96e91d81
+6fc6fce380
+6fc9b44c00
+6fce7f3226
+6fdf1ca888
+702fd8b729
+70405185d2
+7053e4f41e
+707bf4ce41
+7082544248
+708535b72a
+7094ac0f60
+70a6b875fa
+70c3e97e41
+7106b020ab
+711dce6fe2
+7136a4453f
+7143fb084f
+714d902095
+7151c53b32
+715357be94
+7163b8085f
+716df1aa59
+71caded286
+71d2665f35
+71d67b9e19
+71e06dda39
+720b398b9c
+720e3fa04c
+720e7a5f1e
+721bb6f2cb
+722803f4f2
+72552a07c9
+726243a205
+72690ef572
+728cda9b65
+728e81c319
+72a810a799
+72acb8cdf6
+72b01281f9
+72cac683e4
+72cadebbce
+72cae058a5
+72d8dba870
+72e8d1c1ff
+72edc08285
+72f04f1a38
+731b825695
+7320b49b13
+732626383b
+732df1eb05
+73329902ab
+733798921e
+733824d431
+734ea0d7fb
+735a7cf7b9
+7367a42892
+7368d5c053
+73c6ae7711
+73e1852735
+73e4e5cc74
+73eac9156b
+73f8441a88
+7419e2ab3f
+74267f68b9
+7435690c8c
+747c44785c
+747f1b1f2f
+748b2d5c01
+74d4cee0a4
+74ec2b3073
+74ef677020
+750be4c4d8
+75172d4ac8
+75285a7eb1
+75504539c3
+7550949b1d
+7551cbd537
+75595b453d
+7559b4b0ec
+755bd1fbeb
+756f76f74d
+7570ca7f3c
+757a69746e
+757cac96c6
+7584129dc3
+75a058dbcd
+75b09ce005
+75cae39a8f
+75cee6caf0
+75cf58fb2c
+75d5c2f32a
+75eaf5669d
+75f7937438
+75f99bd3b3
+75fa586876
+7613df1f84
+762e1b3487
+76379a3e69
+764271f0f3
+764503c499
+7660005554
+7666351b84
+76693db153
+767856368b
+768671f652
+768802b80d
+76962c7ed2
+76a75f4eee
+76b90809f7
+770a441457
+772a0fa402
+772f2ffc3e
+774f6c2175
+77610860e0
+777e58ff3d
+77920f1708
+7799df28e7
+779e847a9a
+77ba4edc72
+77c834dc43
+77d8aa8691
+77e7f38f4d
+77eea6845e
+7806308f33
+78254660ea
+7828af8bff
+784398620a
+784d201b12
+78613981ed
+78896c6baf
+78aff3ebc0
+78c7c03716
+78d3676361
+78e29dd4c3
+78f1a1a54f
+79208585cd
+792218456c
+7923bad550
+794e6fc49f
+796e6762ce
+797cd21f71
+79921b21c2
+79a5778027
+79bc006280
+79bf95e624
+79d9e00c55
+79e20fc008
+79e9db913e
+79f014085e
+79fcbb433a
+7a13a5dfaa
+7a14bc9a36
+7a3c535f70
+7a446a51e9
+7a56e759c5
+7a5f46198d
+7a626ec98d
+7a802264c4
+7a8b5456ca
+7abdff3086
+7aecf9f7ac
+7b0fd09c28
+7b18b3db87
+7b39fe7371
+7b49e03d4c
+7b5388c9f1
+7b5cf7837f
+7b733d31d8
+7b74fd7b98
+7b918ccb8a
+7ba3ce3485
+7bb0abc031
+7bb5bb25cd
+7bb7dac673
+7bc7761b8c
+7bf3820566
+7c03a18ec1
+7c078f211b
+7c37d7991a
+7c4ec17eff
+7c649c2aaf
+7c73340ab7
+7c78a2266d
+7c88ce3c5b
+7ca6843a72
+7cc9258dee
+7cec7296ae
+7d0ffa68a4
+7d11b4450f
+7d1333fcbe
+7d18074fef
+7d18c8c716
+7d508fb027
+7d55f791f0
+7d74e3c2f6
+7d783f67a9
+7d83a5d854
+7dd409947e
+7de45f75e5
+7e0cd25696
+7e1922575c
+7e1e3bbcc1
+7e24023274
+7e2f212fd3
+7e6d1cc1f4
+7e7cdcb284
+7e9b6bef69
+7ea5b49283
+7eb2605d96
+7eb26b8485
+7ecd1f0c69
+7f02b3cfe2
+7f1723f0d5
+7f21063c3a
+7f3658460e
+7f54132e48
+7f559f9d4a
+7f5faedf8b
+7f838baf2b
+7fa5f527e3
+7ff84d66dd
+802b45c8c4
+804382b1ad
+804c558adb
+804f6338a4
+8056117b89
+806b6223ab
+8088bda461
+80b790703b
+80c4a94706
+80ce2e351b
+80db581acd
+80e12193df
+80e41b608f
+80f16b016d
+81541b3725
+8175486e6a
+8179095000
+8193671178
+81a58d2c6b
+81aa1286fb
+81dffd30fb
+8200245704
+823e7a86e8
+824973babb
+824ca5538f
+827171a845
+8273a03530
+827cf4f886
+82b865c7dd
+82c1517708
+82d15514d6
+82e117b900
+82fec06574
+832b5ef379
+83424c9fbf
+8345358fb8
+834b50b31b
+835e3b67d7
+836ea92b15
+837c618777
+838eb3bd89
+839381063f
+839bc71489
+83a8151377
+83ae88d217
+83ca8bcad0
+83ce590d7f
+83d3130ba0
+83d40bcba5
+83daba503a
+83de906ec0
+84044f37f3
+84696b5a5e
+84752191a3
+847eeeb2e0
+848e7835a0
+84a4b29286
+84a4bf147d
+84be115c09
+84d95c4350
+84e0922cf7
+84f0cfc665
+8515f6db22
+851f2f32c1
+852a4d6067
+854c48b02a
+857a387c86
+859633d56a
+85a4f4a639
+85ab85510c
+85b1eda0d9
+85dc1041c6
+85e081f3c7
+85f75187ad
+8604bb2b75
+860745b042
+863b4049d7
+8643de22d0
+8647d06439
+864ffce4fe
+8662d9441a
+8666521b13
+868d6a0685
+869fa45998
+86a40b655d
+86a8ae4223
+86b2180703
+86c85d27df
+86d3755680
+86e61829a1
+871015806c
+871e409c5c
+8744b861ce
+8749369ba0
+878a299541
+8792c193a0
+8799ab0118
+87d1f7d741
+882b9e4500
+885673ea17
+8859dedf41
+8873ab2806
+887a93b198
+8883e991a9
+8891aa6dfa
+8899d8cbcd
+88b8274d67
+88d3b80af6
+88ede83da2
+88f345941b
+890976d6da
+8909bde9ab
+8929c7d5d9
+89363acf76
+89379487e0
+8939db6354
+893f658345
+8953138465
+895c96d671
+895cbf96f9
+895e8b29a7
+898fa256c8
+89986c60be
+89b874547b
+89bdb021d5
+89c802ff9c
+89d6336c2b
+89ebb27334
+8a27e2407c
+8a31f7bca5
+8a4a2fc105
+8a5d6c619c
+8a75ad7924
+8aa817e4ed
+8aad0591eb
+8aca214360
+8ae168c71b
+8b0cfbab97
+8b3645d826
+8b3805dbd4
+8b473f0f5d
+8b4f6d1186
+8b4fb018b7
+8b518ee936
+8b523bdfd6
+8b52fb5fba
+8b91036e5c
+8b99a77ac5
+8ba04b1e7b
+8ba782192f
+8bbeaad78b
+8bd1b45776
+8bd7a2dda6
+8bdb091ccf
+8be56f165d
+8be950d00f
+8bf84e7d45
+8bffc4374b
+8bfff50747
+8c09867481
+8c0a3251c3
+8c3015cccb
+8c469815cf
+8c9ccfedc7
+8ca1af9f3c
+8ca3f6e6c1
+8ca6a4f60f
+8cac6900fe
+8cba221a1e
+8cbbe62ccd
+8d064b29e2
+8d167e7c08
+8d4ab94e1c
+8d81f6f899
+8d87897d66
+8dcccd2bd2
+8dcfb878a8
+8dd3ab71b9
+8dda6bf10f
+8ddd51ca94
+8dea22c533
+8def5bd3bf
+8e1848197c
+8e3a83cf2d
+8e478e73f3
+8e98ae3c84
+8ea6687ab0
+8eb0d315c1
+8ec10891f9
+8ec3065ec2
+8ecf51a971
+8eddbab9f7
+8ee198467a
+8ee2368f40
+8ef595ce82
+8f0a653ad7
+8f1204a732
+8f1600f7f6
+8f16366707
+8f1ce0a411
+8f2e05e814
+8f320d0e09
+8f3b4a84ad
+8f3fdad3da
+8f5d3622d8
+8f62a2c633
+8f81c9405a
+8f8c974d53
+8f918598b6
+8ff61619f6
+9002761b41
+90107941f3
+90118a42ee
+902bc16b37
+903e87e0d6
+9041a0f489
+9047bf3222
+9057bfa502
+90617b0954
+9076f4b6db
+9077e69b08
+909655b4a6
+909c2eca88
+909dbd1b76
+90bc4a319a
+90c7a87887
+90cc785ddd
+90d300f09b
+9101ea9b1b
+9108130458
+911ac9979b
+9151cad9b5
+9153762797
+91634ee0c9
+916942666f
+9198cfb4ea
+919ac864d6
+91b67d58d4
+91bb8df281
+91be106477
+91c33b4290
+91ca7dd9f3
+91d095f869
+91f107082e
+920329dd5e
+920c959958
+92128fbf4b
+9223dacb40
+923137bb7f
+9268e1f88a
+927647fe08
+9276f5ba47
+92a28cd233
+92b5c1fc6d
+92c46be756
+92dabbe3a0
+92e3159361
+92ebab216a
+934bdc2893
+9359174efc
+935d97dd2f
+935feaba1b
+93901858ee
+939378f6d6
+939bdf742e
+93a22bee7e
+93da9aeddf
+93e2feacce
+93e6f1fdf9
+93e811e393
+93e85d8fd3
+93f623d716
+93ff35e801
+94031f12f2
+94091a4873
+94125907e3
+9418653742
+941c870569
+94209c86f0
+9437c715eb
+9445c3eca2
+9467c8617c
+946d71fb5d
+948f3ae6fb
+9498baa359
+94a33abeab
+94bf1af5e3
+94cf3a8025
+94db712ac8
+94e4b66cff
+94e76cbaf6
+950be91db1
+952058e2d0
+952633c37f
+952ec313fe
+9533fc037c
+9574b81269
+9579b73761
+957f7bc48b
+958073d2b0
+9582e0eb33
+9584092d0b
+95b58b8004
+95bd88da55
+95f74a9959
+962781c601
+962f045bf5
+964ad23b44
+967b90590e
+967bffe201
+96825c4714
+968492136a
+9684ef9d64
+968c41829e
+96a856ef9a
+96dfc49961
+96e1a5b4f8
+96e6ff0917
+96fb88e9d7
+96fbe5fc23
+96fc924050
+9715cc83dc
+9720eff40f
+972c187c0d
+97476eb38d
+97659ed431
+9773492949
+97756b264f
+977bff0d10
+97ab569ff3
+97ba838008
+97d9d008c7
+97e59f09fa
+97eb642e56
+98043e2d14
+981ff580cf
+983e66cbfc
+984f0f1c36
+98595f2bb4
+985c3be474
+9869a12362
+986b5a5e18
+9877af5063
+98911292da
+9893a3cf77
+9893d9202d
+98a8b06e7f
+98ac6f93d9
+98b6974d12
+98ba3c9417
+98c7c00a19
+98d044f206
+98e909f9d1
+98fe7f0410
+990f2742c7
+992bd0779a
+994b9b47ba
+9955b76bf5
+9966f3adac
+997117a654
+999d53d841
+99c04108d3
+99c4277aee
+99c6b1acf2
+99dc8bb20b
+99fcba71e5
+99fecd4efb
+9a02c70ba2
+9a08e7a6f8
+9a2f2c0f86
+9a3254a76e
+9a3570a020
+9a39112493
+9a4e9fd399
+9a50af4bfb
+9a68631d24
+9a72318dbf
+9a767493b7
+9a7fc1548b
+9a84ccf6a7
+9a9c0e15b7
+9adf06d89b
+9b22b54ee4
+9b473fc8fe
+9b4f081782
+9b997664ba
+9bc454e109
+9bccfd04de
+9bce4583a2
+9bebf1b87f
+9bfc50d261
+9c166c86ff
+9c293ef4d7
+9c29c047b0
+9c3bc2e2a7
+9c3ce23bd1
+9c404cac0c
+9c5180d23a
+9c7feca6e4
+9caa49d3ff
+9cb2f1b646
+9ce6f765c3
+9cfee34031
+9d01f08ec6
+9d04c280b8
+9d12ceaddc
+9d15f8cb3c
+9d2101e9bf
+9d407c3aeb
+9ddefc6165
+9df0b1e298
+9e16f115d8
+9e249b4982
+9e29b1982c
+9e493e4773
+9e4c752cd0
+9e4de40671
+9e6319faeb
+9e6ddbb52d
+9eadcea74f
+9ecec5f8ea
+9efb47b595
+9f30bfe61e
+9f3734c3a4
+9f5b858101
+9f66640cda
+9f913803e9
+9f97bc74c8
+9fbad86e20
+9fc2bad316
+9fc5c3af78
+9fcb310255
+9fcc256871
+9fd2fd4d47
+a0071ae316
+a023141022
+a046399a74
+a066e739c1
+a06722ba82
+a07a15dd64
+a07b47f694
+a09c39472e
+a0b208fe2e
+a0b61c959e
+a0bc6c611d
+a0e6da5ba2
+a1193d6490
+a14ef483ff
+a14f709908
+a15ccc5658
+a16062456f
+a174e8d989
+a177c2733c
+a17c62e764
+a18ad065fc
+a1aaf63216
+a1bb65fb91
+a1bd8e5349
+a1dfdd0cac
+a2052e4f6c
+a20fd34693
+a21ffe4d81
+a22349e647
+a235d01ec1
+a24f63e8a2
+a2554c9f6d
+a263ce8a87
+a29bfc29ec
+a2a80072d4
+a2a800ab63
+a2bcd10a33
+a2bdaff3b0
+a2c146ab0d
+a2c996e429
+a2dc51ebe8
+a2e6608bfa
+a2f2a55f01
+a301869dea
+a31fccd2cc
+a34f440f33
+a35e0206da
+a36bdc4cab
+a36e8c79d8
+a378053b20
+a37db3a2b3
+a38950ebc2
+a39a0eb433
+a39c9bca52
+a3a945dc8c
+a3b40a0c1e
+a3b8588550
+a3c502bec3
+a3f2878017
+a3f4d58010
+a3f51855c3
+a402dc0dfe
+a4065a7eda
+a412bb2fef
+a416b56b53
+a41ec95906
+a43299e362
+a4757bd7af
+a48c53c454
+a49dcf9ad5
+a4a506521f
+a4ba7753d9
+a4bac06849
+a4f05d681c
+a50c10060f
+a50eb5a0ea
+a5122c6ec6
+a522b1aa79
+a590915345
+a5b5b59139
+a5b77abe43
+a5c2b2c3e1
+a5cd17bb11
+a5da03aef1
+a5dd11de0d
+a5ea2b93b6
+a5eaeac80b
+a5ec5b0265
+a5f350a87e
+a5f472caf4
+a6027a53cf
+a61715bb1b
+a61cf4389d
+a61d9bbd9b
+a6470dbbf5
+a64a40f3eb
+a653d5c23b
+a65bd23cb5
+a66e0b7ad4
+a66fc5053c
+a68259572b
+a6a810a92c
+a6bc36937f
+a6c3a374e9
+a6d8a4228d
+a6f4e0817f
+a71e0481f5
+a7203deb2d
+a7392d4438
+a73d3c3902
+a7491f1578
+a74b9ca19c
+a77b7a91df
+a78195a5f5
+a78758d4ce
+a7e6d6c29a
+a800d85e88
+a832fa8790
+a83d06410d
+a8999af004
+a8f78125b9
+a907b18df1
+a919392446
+a965504e88
+a96b84b8d2
+a973f239cd
+a977126596
+a9804f2a08
+a984e56893
+a99738f24c
+a99bdd0079
+a9c9c1517e
+a9cbf9c41b
+a9e42e3c0c
+aa07b7c1c0
+aa175e5ec7
+aa1a338630
+aa27d7b868
+aa45f1caaf
+aa49e46432
+aa51934e1b
+aa6287bb6c
+aa6d999971
+aa85278334
+aab33f0e2a
+aaba004362
+aade4cf385
+aae78feda4
+aaed233bf3
+aaff16c2db
+ab199e8dfb
+ab23b78715
+ab2e1b5577
+ab33a18ded
+ab45078265
+ab56201494
+ab90f0d24b
+abab2e6c20
+abb50c8697
+abbe2d15a0
+abbe73cd21
+abe61a11bb
+abeae8ce21
+ac2b431d5f
+ac2cb1b9eb
+ac31fcd6d0
+ac3d3a126d
+ac46bd8087
+ac783ef388
+acb73e4297
+acbf581760
+accafc3531
+acf2c4b745
+acf44293a2
+acf736a27b
+acff336758
+ad1fe56886
+ad28f9b9d9
+ad2de9f80e
+ad397527b2
+ad3d1cfbcb
+ad3fada9d9
+ad4108ee8e
+ad54468654
+ad573f7d31
+ad6255bc29
+ad65ebaa07
+ad97cc064a
+adabbd1cc4
+adb0b5a270
+adc648f890
+add21ee467
+adfd15ceef
+adfdd52eac
+ae01cdab63
+ae0b50ff4f
+ae13ee3d70
+ae1bcbd423
+ae20d09dea
+ae2cecf5f6
+ae3bc4a0ef
+ae499c7514
+ae628f2cd4
+ae8545d581
+ae93214fe6
+ae9cd16dbf
+aeba9ac967
+aebb242b5c
+aed4e0b4c4
+aedd71f125
+aef3e2cb0e
+af0b54cee3
+af3de54c7a
+af5fd24a36
+af8826d084
+af8ad72057
+afb71e22c5
+afcb331e1f
+afe1a35c1e
+b01080b5d3
+b05ad0d345
+b0623a6232
+b064dbd4b7
+b06ed37831
+b06f5888e6
+b08dcc490e
+b0a68228dc
+b0aece727f
+b0b0731606
+b0c7f11f9f
+b0cca8b830
+b0dd580a89
+b0de66ca08
+b0df7c5c5c
+b0f5295608
+b11099eb09
+b132a53086
+b1399fac64
+b13abc0c69
+b1457e3b5e
+b15bf4453b
+b179c4a82d
+b17ee70e8c
+b190b1aa65
+b19b3e22c0
+b19c561fab
+b1d1cd2e6e
+b1d7c03927
+b1d7fe2753
+b1f540a4bd
+b1fc9c64e1
+b1fcbb3ced
+b220939e93
+b22099b419
+b241e95235
+b2432ae86d
+b2456267df
+b247940d01
+b24af1c35c
+b24f600420
+b24fe36b2a
+b258fb0b7d
+b26b219919
+b26d9904de
+b274456ce1
+b27b28d581
+b2a26bc912
+b2a9c51e1b
+b2b0baf470
+b2b2756fe7
+b2ce7699e3
+b2edc76bd2
+b2f6b52100
+b30bf47bcd
+b34105a4e9
+b372a82edf
+b3779a1962
+b379ab4ff5
+b37a1d69e3
+b37c01396e
+b382b09e25
+b3996e4ba5
+b3d9ca2aee
+b3dde1e1e9
+b3eb7f05eb
+b40b25055c
+b41e0f1f19
+b44e32a42b
+b4805ae9cd
+b4807569a5
+b48efceb3e
+b493c25c7f
+b4b565aba1
+b4b715a15b
+b4d0c90bf4
+b4d84bc371
+b4e5ad97aa
+b4eaea9e6b
+b50f4b90d5
+b53f675641
+b54278cd43
+b554843889
+b573c0677a
+b58d853734
+b5943b18ab
+b5a09a83f3
+b5aae1fe25
+b5b9da5364
+b5eb64d419
+b5ebb1d000
+b5f1c0c96a
+b5f7fece90
+b6070de1bb
+b60a76fe73
+b61f998772
+b62c943664
+b63094ba0c
+b64fca8100
+b673e7dcfb
+b678b7db00
+b68fc1b217
+b69926d9fa
+b6a1df3764
+b6a4859528
+b6b4738b78
+b6b4f847b7
+b6b8d502d4
+b6bb00e366
+b6d65a9eef
+b6d79a0845
+b6e9ec577f
+b6ec609f7b
+b6f92a308d
+b70a2c0ab1
+b70a5a0d50
+b70c052f2f
+b70d231781
+b72ac6e10b
+b7302d8226
+b73867d769
+b751e767f2
+b76df6e059
+b77e5eddef
+b7a2c2c83c
+b7bcbe6466
+b7c2a469c4
+b7d69da8f0
+b7f31b7c36
+b7f675fb98
+b7fb871660
+b82e5ad1c9
+b841cfb932
+b84b8ae665
+b85b78ac2b
+b86c17caa6
+b86e50d82d
+b871db031a
+b87d56925a
+b8aaa59b75
+b8c03d1091
+b8c3210036
+b8e16df00b
+b8f34cf72e
+b8fb75864e
+b9004db86c
+b9166cbae9
+b920b256a6
+b938d79dff
+b93963f214
+b941aef1a0
+b94d34d14e
+b964c57da4
+b96a95bc7a
+b96c57d2c7
+b9b6bdde0c
+b9bcb3e0f2
+b9d3b92169
+b9dd4b306c
+b9f43ef41e
+ba1f03c811
+ba3a775d7b
+ba3c7f2a31
+ba3fcd417d
+ba5e1f4faa
+ba795f3089
+ba8a291e6a
+ba98512f97
+bac9db04f5
+baedae3442
+baff40d29d
+bb04e28695
+bb1b0ee89f
+bb1c770fe7
+bb1fc34f99
+bb2d220506
+bb334e5cdb
+bb337f9830
+bb721eb9aa
+bb87ff58bd
+bb89a6b18a
+bbaa9a036a
+bbb4302dda
+bbd31510cf
+bbe0256a75
+bc141b9ad5
+bc17ab8a99
+bc318160de
+bc3b9ee033
+bc4240b43c
+bc4ce49105
+bc4f71372d
+bc6b8d6371
+bcaad44ad7
+bcc241b081
+bcc5d8095e
+bcd1d39afb
+bd0d849da4
+bd0e9ed437
+bd2c94730f
+bd321d2be6
+bd3ec46511
+bd5b2e2848
+bd7e02b139
+bd96f9943a
+bda224cb25
+bda4a82837
+bdb74e333f
+bdccd69dde
+bddcc15521
+be116aab29
+be15e18f1e
+be1a284edb
+be2a367a7b
+be376082d0
+be3e3cffbd
+be5d1d89a0
+be8b72fe37
+be9b29e08e
+bea1f6e62c
+bea83281b5
+beb921a4c9
+bec5e9edcd
+beeb8a3f92
+bf2232b58d
+bf28751739
+bf443804e8
+bf461df850
+bf5374f122
+bf551a6f60
+bf8d0f5ada
+bf961167a6
+bfab1ad8f9
+bfcb05d88d
+bfd8f6e6c9
+bfd91d0742
+bfe262322f
+c013f42ed7
+c01878083f
+c01faff1ed
+c046fd0edb
+c053e35f97
+c079a6482d
+c0847b521a
+c0a1e06710
+c0e8d4635c
+c0e973ad85
+c0f49c6579
+c0f5b222d7
+c10d07c90d
+c1268d998c
+c130c3fc0c
+c14826ad5e
+c15b922281
+c16f09cb63
+c18e19d922
+c1c830a735
+c1e8aeea45
+c20a5ccc99
+c20fd5e597
+c219d6f8dc
+c2406ae462
+c26f7b5824
+c279e641ee
+c27adaeac5
+c2a35c1cda
+c2a9903b8b
+c2b62567c1
+c2b974ec8c
+c2baaff7bf
+c2be6900f2
+c304dd44d5
+c307f33da2
+c30a7b62c9
+c3128733ee
+c31fa6c598
+c325c8201e
+c32d4aa5d1
+c33f28249a
+c34365e2d7
+c3457af795
+c34d120a88
+c3509e728d
+c35e4fa6c4
+c36240d96f
+c3641dfc5a
+c37b17a4a9
+c39559ddf6
+c3b0c6e180
+c3b3d82e6c
+c3be369fdb
+c3bf1e40c2
+c3c760b015
+c3dd38bf98
+c3e4274614
+c3edc48cbd
+c41e6587f5
+c4272227b0
+c42917fe82
+c438858117
+c44676563f
+c44beb7472
+c45411dacb
+c4571bedc8
+c46deb2956
+c479ee052e
+c47d551843
+c49f07d46d
+c4cc40c1fc
+c4f256f5d5
+c4f5b1ddcc
+c4ff9b4885
+c52bce43db
+c544da6854
+c55784c766
+c557b69fbf
+c593a3f7ab
+c598faa682
+c5ab1f09c8
+c5b6da8602
+c5b9128d94
+c5e845c6b7
+c5fba7b341
+c60897f093
+c61fe6ed7c
+c62188c536
+c64035b2e2
+c69689f177
+c6a12c131f
+c6bb6d2d5c
+c6c18e860f
+c6d9526e0d
+c6e55c33f0
+c7030b28bd
+c70682c7cc
+c70f9be8c5
+c71f30d7b6
+c73c8e747f
+c760eeb8b3
+c7637cab0a
+c7a1a17308
+c7bf937af5
+c7c2860db3
+c7cef4aee2
+c7ebfc5d57
+c813dcf13c
+c82235a49a
+c82a7619a1
+c82ecb90cb
+c844f03dc7
+c8557963f3
+c89147e6e8
+c8a46ff0c8
+c8ab107dd5
+c8b869a04a
+c8c7b306a6
+c8c8b28781
+c8d79e3163
+c8edab0415
+c8f494f416
+c8f6cba9fd
+c909ceea97
+c9188f4980
+c922365dd4
+c92c8c3c75
+c937eb0b83
+c94b31b5e5
+c95cd17749
+c96379c03c
+c96465ee65
+c965afa713
+c9734b451f
+c9862d82dc
+c98b6fe013
+c9999b7c48
+c99e92aaf0
+c9b3a8fbda
+c9bf64e965
+c9c3cb3797
+c9d1c60cd0
+c9de9c22c4
+ca1828fa54
+ca346f17eb
+ca3787d3d3
+ca4b99cbac
+ca91c69e3b
+ca91e99105
+caa8e97f81
+caac5807f8
+cabba242c2
+cad5a656a9
+cad673e375
+cad8a85930
+cae7b0a02b
+cae7ef3184
+caeb6b6cbb
+caecf0a5db
+cb15312003
+cb2e35d610
+cb35a87504
+cb3f22b0cf
+cbb410da64
+cc8728052e
+cc892997b8
+cce03c2a9b
+cd47a23e31
+cd4dc03dc0
+cd5ae611da
+cd603bb9d1
+cd8f49734c
+cdc6b1c032
+cdcfe008ad
+cdd57027c2
+ce1af99b4b
+ce1bc5743a
+ce25872021
+ce2776f78f
+ce49b1f474
+ce4f0a266f
+ce5641b195
+ce6866aa19
+ce712ed3c9
+ce7d1c8117
+ce7dbeaa88
+ce9b015a5e
+cea7697b25
+cebbd826cf
+cec3415361
+cec41ad4f4
+ced49d26df
+ced7705ab2
+cef824a1e1
+cf13f5c95a
+cf4376a52d
+cf85ab28b5
+cfc2e50b9d
+cfcd571fff
+cfd9d4ae47
+cfda2dcce5
+cff035928b
+cff8191891
+d01608c2a5
+d01a8f1f83
+d021d68bca
+d04258ca14
+d0483573dc
+d04a90aaff
+d05279c0bd
+d0696bd5fc
+d072fda75b
+d0a83bcd9f
+d0ab39112e
+d0acde820f
+d0b4442c71
+d0c65e9e95
+d0fb600c73
+d107a1457c
+d123d674c1
+d14d1e9289
+d154e3388e
+d177e9878a
+d1802f69f8
+d182c4483a
+d195d31128
+d200838929
+d205e3cff5
+d247420c4c
+d2484bff33
+d26f6ed9b0
+d280fcd1cb
+d2857f0faa
+d292a50c7f
+d295ea2dc7
+d2a58b4fa6
+d2b026739a
+d2ebe0890f
+d2ede5d862
+d301ca58cc
+d3069da8bb
+d343d4a77d
+d355e634ef
+d367fb5253
+d36d16358e
+d38bc77e2c
+d38d1679e2
+d3932ad4bd
+d3987b2930
+d39934abe3
+d3ae1c3f4c
+d3b088e593
+d3e6e05e16
+d3eefae7c5
+d3f55f5ab8
+d3f5c309cc
+d4034a7fdf
+d4193011f3
+d429c67630
+d42c0ff975
+d44a764409
+d44e6acd1d
+d45158c175
+d454e8444f
+d45f62717e
+d48ebdcf74
+d49ab52a25
+d4a607ad81
+d4b063c7db
+d4da13e9ba
+d4dd1a7d00
+d4f4f7c9c3
+d521aba02e
+d535bb1b97
+d53b955f78
+d55cb7a205
+d55f247a45
+d5695544d8
+d5853d9b8b
+d5b6c6d94a
+d5cae12834
+d5df027f0c
+d5ee40e5d0
+d600046f73
+d632fd3510
+d6476cad55
+d65a7bae86
+d664c89912
+d689658f06
+d6917db4be
+d69967143e
+d699d3d798
+d69f757a3f
+d6ac0e065c
+d6c02bfda5
+d6c1b5749e
+d6e12ef6cc
+d6eed152c4
+d6faaaf726
+d704766646
+d708e1350c
+d7135cf104
+d7157a9f44
+d719cf9316
+d724134cfd
+d73a60a244
+d7411662da
+d74875ea7c
+d756f5a694
+d7572b7d8a
+d763bd6d96
+d7697c8b13
+d7797196b4
+d79c834768
+d7b34e5d73
+d7bb6b37a7
+d7c7e064a6
+d7fbf545b3
+d82a0aa15b
+d847e24abd
+d8596701b7
+d86101499c
+d87069ba86
+d87160957b
+d874654b52
+d88a403092
+d8aee40f3f
+d8e77a222d
+d8eb07c381
+d9010348a1
+d90e3cf281
+d92532c7b2
+d927fae122
+d95707bca8
+d973b31c00
+d991cb471d
+d992c69d37
+d99d770820
+d9b63abc11
+d9db6f1983
+d9e52be2d2
+d9edc82650
+da01070697
+da070ea4b7
+da080507b9
+da0e944cc4
+da28d94ff4
+da5d78b9d1
+da6003fc72
+da690fee9f
+da6c68708f
+da7a816676
+dac361e828
+dac71659b8
+dad980385d
+daebc12b77
+db0968cdd3
+db231a7100
+db59282ace
+db7f267c3f
+dba35b87fd
+dbba735a50
+dbca076acd
+dbd66dc3ac
+dbdc3c292b
+dbf4a5b32b
+dbfc417d28
+dc1745e0a2
+dc32a44804
+dc34b35e30
+dc504a4f79
+dc704dd647
+dc71bc6918
+dc7771b3be
+dcf8c93617
+dd0f4c9fb9
+dd415df125
+dd601f9a3f
+dd61d903df
+dd77583736
+dd8636bd8b
+dd9fe6c6ac
+ddb2da4c14
+ddcd450d47
+dde8e67fb4
+ddfc3f04d3
+de2ab79dfa
+de2f35b2fd
+de30990a51
+de36b216da
+de37403340
+de46e4943b
+de4ddbccb1
+de5e480f05
+de6a9382ca
+de74a601d3
+de827c510d
+ded6069f7b
+defb71c741
+df01f277f1
+df05214b82
+df0638b0a0
+df11931ffe
+df1b0e4620
+df20a8650d
+df2bc56d7c
+df365282c6
+df39a0d9df
+df3c430c24
+df5536cfb9
+df59cfd91d
+df5e2152b3
+df741313c9
+df7626172f
+df8ad5deb9
+df96aa609a
+df9705605c
+df9c91c4da
+dfc0d3d27a
+dfdbf91a99
+e00baaae9b
+e0a938c6e7
+e0b2ceee6f
+e0bdb5dfae
+e0be1f6e17
+e0c478f775
+e0de82caa7
+e0f217dd59
+e0f7208874
+e0fb58395e
+e1194c2e9d
+e11adcd05d
+e128124b9d
+e1495354e4
+e1561d6d4b
+e158805399
+e16945b951
+e19edcd34b
+e1a1544285
+e1ab7957f4
+e1d26d35be
+e1e957085b
+e1f14510fa
+e214b160f4
+e2167379b8
+e21acb20ab
+e221105579
+e22ddf8a1b
+e22de45950
+e22ffc469b
+e23cca5244
+e252f46f0b
+e25fa6cf39
+e26e486026
+e275760245
+e27bbedbfe
+e29e9868a8
+e2b37ff8af
+e2b608d309
+e2bef4da9a
+e2c87a6421
+e2ea25542c
+e2fb1d6497
+e2fcc99117
+e33c18412a
+e348377191
+e352cb59c8
+e36ac982f0
+e391bc981e
+e39e3e0a06
+e3bf38265f
+e3d5b2cd21
+e3d60e82d5
+e3e3245492
+e3e4134877
+e3f4635e03
+e4004ee048
+e402d1afa5
+e415093d27
+e41ceb5d81
+e424653b78
+e42b6d3dbb
+e42d60f0d4
+e436d0ff1e
+e43d7ae2c5
+e4428801bc
+e44e0b4917
+e470345ede
+e48e8b4263
+e4922e3726
+e4936852bb
+e495f32c60
+e499228f26
+e4af66e163
+e4b2095f58
+e4d19c8283
+e4d4872dab
+e4e2983570
+e4eaa63aab
+e4ef0a3a34
+e4f8e5f46e
+e4ffb6d0dd
+e53e21aa02
+e57f4f668b
+e588433c1e
+e597442c99
+e5abc0e96b
+e5be628030
+e5ce96a55d
+e5d6b70a9f
+e5fde1574c
+e625e1d27b
+e6261d2348
+e6267d46bc
+e6295f223f
+e63463d8c6
+e6387bd1e0
+e653883384
+e65f134e0b
+e668ef5664
+e672ccd250
+e674510b20
+e676107765
+e699da0cdf
+e6be243065
+e6deab5e0b
+e6f065f2b9
+e71629e7b5
+e72a7d7b0b
+e72f6104e1
+e75a466eea
+e76c55933f
+e7784ec8ad
+e78922e5e6
+e78d450a9c
+e7c6354e77
+e7c8de1fce
+e7ea10db28
+e803918710
+e8073a140b
+e828dd02db
+e845994987
+e8485a2615
+e85c5118a7
+e88b6736e4
+e8962324e3
+e8b3018d36
+e8cee8bf0b
+e8d97ebece
+e8da49ea6a
+e8ed1a3ccf
+e8f7904326
+e8f8341dec
+e8fa21eb13
+e90c10fc4c
+e914b8cac8
+e92b6bfea4
+e92e1b7623
+e93f83e512
+e9422ad240
+e9460b55f9
+e9502628f6
+e950befd5f
+e9582bdd1b
+e95e5afe0f
+e97cfac475
+e98d57d99c
+e98eda8978
+e99706b555
+e9bc0760ba
+e9d3c78bf3
+e9ec1b7ea8
+ea065cc205
+ea138b6617
+ea16d3fd48
+ea2545d64b
+ea286a581c
+ea320da917
+ea345f3627
+ea3b94a591
+ea444a37eb
+ea4a01216b
+ea5672ffa8
+eaa99191cb
+eaab4d746c
+eac7a59bc1
+ead5d3835a
+eaec65cfa7
+eaed1a87be
+eb2f821c6f
+eb383cb82e
+eb6992fe02
+eb6ac20a01
+eb6d7ab39e
+eb7921facd
+eb8fce51a6
+ebbb90e9f9
+ebbf5c9ee1
+ebc4ec32e6
+ebe56e5ef8
+ec1299aee4
+ec139ff675
+ec193e1a01
+ec28252938
+ec387be051
+ec3d4fac00
+ec4186ce12
+ec579c2f96
+ecae59b782
+ecb33a0448
+ece6bc9e92
+ecfedd4035
+ecfff22fd6
+ed3291c3d6
+ed3cd5308d
+ed3e6fc1a5
+ed72ae8825
+ed7455da68
+ed844e879f
+ed8f814b2b
+ed911a1f63
+ed9ff4f649
+eda8ab984b
+edb8878849
+edbfdfe1b4
+edd22c46a2
+edd663afa3
+ede3552eae
+edeab61ee0
+ee07583fc0
+ee316eaed6
+ee3f509537
+ee40a1e491
+ee4bf100f1
+ee6f9b01f9
+ee947ed771
+ee9706ac7f
+ee9a7840ae
+eeb90cb569
+eebf45e5c5
+eeed0c7d73
+ef0061a309
+ef07f1a655
+ef0a8e8f35
+ef232a2aed
+ef308ad2e9
+ef44945428
+ef45ce3035
+ef5dde449d
+ef5e770988
+ef6359cea3
+ef65268834
+ef6cb5eae0
+ef78972bc2
+ef8cfcfc4f
+ef96501dd0
+ef9a2e976b
+efb24f950f
+efce0c1868
+efe5ac6901
+efe828affa
+efea4e0523
+f0268aa627
+f0483250c8
+f04cf99ee6
+f05b189097
+f08928c6d3
+f09d74856f
+f0a7607d63
+f0ad38da27
+f0c34e1213
+f0c7f86c29
+f0dfa18ba7
+f0eb3179f7
+f119bab27d
+f14409b6a3
+f1489baff4
+f14c18cf6a
+f15c607b92
+f1af214222
+f1b77bd309
+f1ba9e1a3e
+f1d99239eb
+f1dc710cf4
+f1ec5c08fa
+f22648fe12
+f22d21f1f1
+f233257395
+f23e95dbe5
+f2445b1572
+f253b3486d
+f277c7a6a4
+f2ab2b84d6
+f2b7c9b1f3
+f2b83d5ce5
+f2c276018f
+f2cfd94d64
+f2dd6e3add
+f2e7653f16
+f2f333ad06
+f2f55d6713
+f2fdb6abec
+f305a56d9f
+f3085d6570
+f3325c3338
+f3400f1204
+f34497c932
+f34a56525e
+f36483c824
+f3704d5663
+f3734c4913
+f38e5aa5b4
+f3986fba44
+f3a0ffc7d9
+f3b24a7d28
+f3e6c35ec3
+f3fc0ea80b
+f40a683fbe
+f4207ca554
+f4377499c2
+f46184f393
+f46c2d0a6d
+f46c364dca
+f46f7a0b63
+f46fe141b0
+f470b9aeb0
+f47eb7437f
+f48b535719
+f49e4866ac
+f4aa882cfd
+f4daa3dbd5
+f4dd51ac35
+f507a1b9dc
+f51c5ac84b
+f52104164b
+f54c67b9bb
+f5966cadd2
+f5bddf5598
+f5d85cfd17
+f5e2e7d6a0
+f5f051e9b4
+f5f8a93a76
+f6283e8af5
+f635e9568b
+f6474735be
+f659251be2
+f66981af4e
+f6708fa398
+f697fe8e8f
+f6adb12c42
+f6c7906ca4
+f6cd0a8016
+f6d6f15ae7
+f6e501892c
+f6f59d986f
+f6fe8c90a5
+f714160545
+f74c3888d7
+f7782c430e
+f7783ae5f2
+f77ab47923
+f788a98327
+f7961ac1f0
+f7a71e7574
+f7a8521432
+f7afbf4947
+f7b7cd5f44
+f7cf4b4a39
+f7d49799ad
+f7e0c9bb83
+f7e5b84928
+f7e6bd58be
+f7f2a38ac6
+f7f6cb2d6d
+f83f19e796
+f85796a921
+f8603c26b2
+f8819b42ec
+f891f8eaa1
+f89288d10c
+f895ae8cc1
+f8b4ac12f1
+f8c3fb2b01
+f8c8de2764
+f8db369b40
+f8fcb6a78c
+f94aafdeef
+f95d217b70
+f9681d5103
+f9750192a4
+f9823a32c2
+f991ddb4c2
+f99d535567
+f9ae3d98b7
+f9b6217959
+f9bd1fabf5
+f9c68eaa64
+f9d3e04c4f
+f9daf64494
+f9e4cc5a0a
+f9ea6b7f31
+f9f3852526
+fa04c615cf
+fa08e00a56
+fa4370d74d
+fa67744af3
+fa88d48a92
+fa8b904cc9
+fa9526bdf1
+fa9b9d2426
+fad633fbe1
+faf5222dc3
+faff0e15f1
+fb08c64e8c
+fb23455a7f
+fb2e19fa6e
+fb34dfbb77
+fb47fcea1e
+fb49738155
+fb4cbc514b
+fb4e6062f7
+fb5ba7ad6e
+fb63cd1236
+fb81157a07
+fb92abdaeb
+fba22a6848
+fbaca0c9df
+fbc645f602
+fbd77444cd
+fbe53dc8e8
+fbe541dd73
+fbe8488798
+fbfd25174f
+fc28cb305e
+fc33b1ffd6
+fc6186f0bb
+fc918e3a40
+fc96cda9d8
+fc9832eea4
+fcb10d0f81
+fcd20a2509
+fcf637e3ab
+fcfd81727f
+fd31890379
+fd33551c28
+fd542da05e
+fd6789b3fe
+fd77828200
+fd7af75f4d
+fdb28d0fbb
+fdb3d1fb1e
+fdb8b04124
+fdc6e3d581
+fdfce7e6fc
+fe0f76d41b
+fe24b0677d
+fe3c02699d
+fe58b48235
+fe6a5596b8
+fe6c244f63
+fe7afec086
+fe985d510a
+fe9db35d15
+fea8ffcd36
+feb1080388
+fed208bfca
+feda5ad1c2
+feec95b386
+ff15a5eff6
+ff204daf4b
+ff25f55852
+ff2ada194f
+ff2ce142e8
+ff49d36d20
+ff5a1ec4f3
+ff66152b25
+ff692fdc56
+ff773b1a1e
+ff97129478
+ffb904207d
+ffc43fc345
+fffe5f8df6