diff --git a/InternVL/.github/CONTRIBUTING.md b/InternVL/.github/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..19668fe9e40ae1b8d91f14375ba7428c39c19edb
--- /dev/null
+++ b/InternVL/.github/CONTRIBUTING.md
@@ -0,0 +1,234 @@
+## Contributing to InternLM
+
+Welcome to the InternLM community, all kinds of contributions are welcomed, including but not limited to
+
+**Fix bug**
+
+You can directly post a Pull Request to fix typo in code or documents
+
+The steps to fix the bug of code implementation are as follows.
+
+1. If the modification involve significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss with you and propose an proper solution.
+
+2. Posting a pull request after fixing the bug and adding corresponding unit test.
+
+**New Feature or Enhancement**
+
+1. If the modification involve significant changes, you should create an issue to discuss with our developers to propose an proper design.
+2. Post a Pull Request after implementing the new feature or enhancement and add corresponding unit test.
+
+**Document**
+
+You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
+
+### Pull Request Workflow
+
+If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the develop mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. Fork and clone
+
+If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
+
+ +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/lmdeploy.git
+```
+
+After that, you should add official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:InternLM/lmdeploy.git
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/lmdeploy.git (fetch)
+origin git@github.com:{username}/lmdeploy.git (push)
+upstream git@github.com:InternLM/lmdeploy.git (fetch)
+upstream git@github.com:InternLM/lmdeploy.git (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of InternLM. **Note**: The following code should be executed under the lmdeploy directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
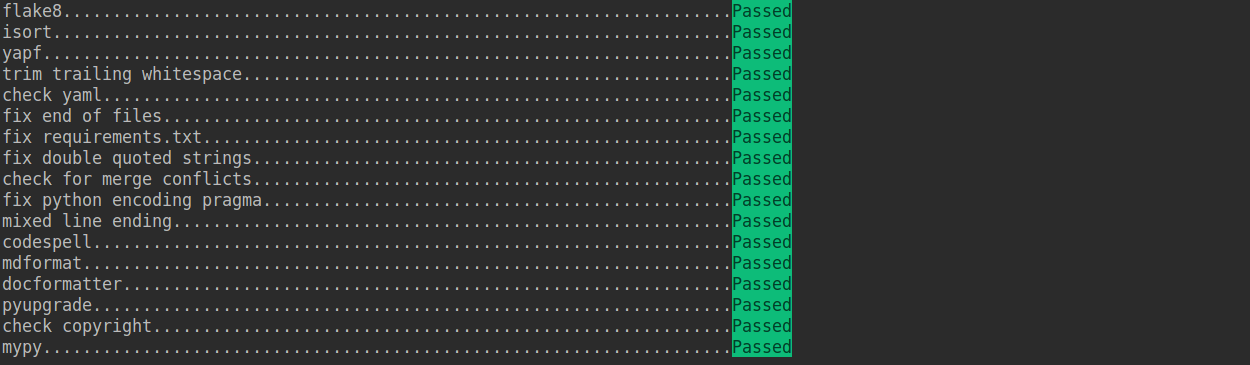
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/lmdeploy.git
+```
+
+After that, you should add official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:InternLM/lmdeploy.git
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/lmdeploy.git (fetch)
+origin git@github.com:{username}/lmdeploy.git (push)
+upstream git@github.com:InternLM/lmdeploy.git (fetch)
+upstream git@github.com:InternLM/lmdeploy.git (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of InternLM. **Note**: The following code should be executed under the lmdeploy directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+ +
+
+
+ +
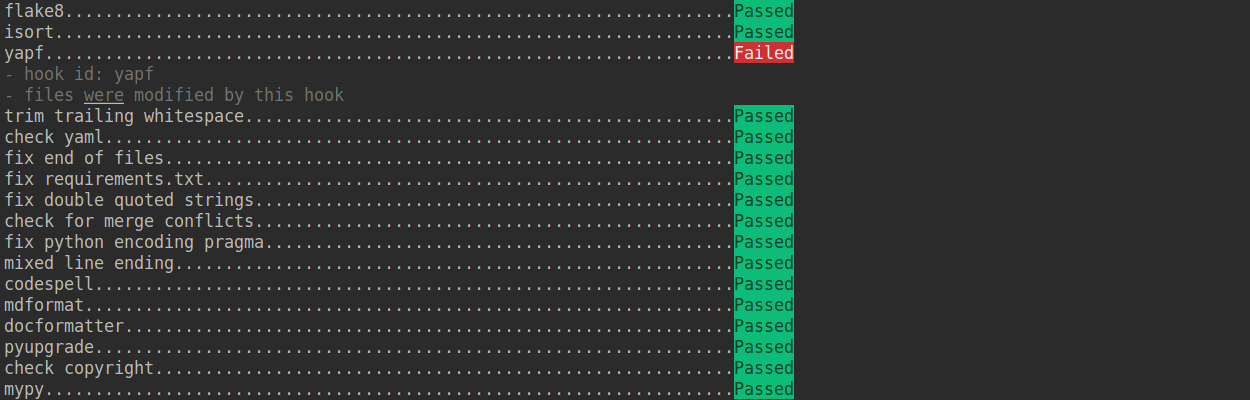
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+ +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- lmdeploy introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- lmdeploy introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+ +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) If it is your first contribution, please sign the CLA
+
+ +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+ +
+IternLM will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+IternLM will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+The clang-format config is stored in [.clang-format](../.clang-format). And it's recommended to use clang-format version **11**. Please do not use older or newer versions as they will result in differences after formatting, which can cause the [lint](https://github.com/InternLM/lmdeploy/blob/main/.github/workflows/lint.yml#L25) to fail.
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/InternVL/internvl_chat_llava/LICENSE b/InternVL/internvl_chat_llava/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/InternVL/internvl_chat_llava/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/InternVL/internvl_chat_llava/README.md b/InternVL/internvl_chat_llava/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c162ea562ae96c627500d867c06c003e8ea8bd9
--- /dev/null
+++ b/InternVL/internvl_chat_llava/README.md
@@ -0,0 +1,506 @@
+# InternVL for Multimodal Dialogue using LLaVA Codebase
+
+This folder contains the implementation of the InternVL-Chat V1.0, which corresponds to Section 4.4 of our [InternVL 1.0 paper](https://arxiv.org/pdf/2312.14238).
+
+In this part, we mainly use the [LLaVA codebase](https://github.com/haotian-liu/LLaVA) to evaluate InternVL in creating multimodal dialogue systems. Thanks for this great work.
+We have retained the original documentation of LLaVA-1.5 as a more detailed manual. In most cases, you will only need to refer to the new documentation that we have added.
+
+> Note: To unify the environment across different tasks, we have made some compatibility modifications to the LLaVA-1.5 code, allowing it to support `transformers==4.37.2` (originally locked at 4.31.0). Please note that `transformers==4.37.2` should be installed.
+
+## 🛠️ Installation
+
+First, follow the [installation guide](../INSTALLATION.md) to perform some basic installations.
+
+In addition, using this codebase requires executing the following steps:
+
+- Install other requirements:
+
+ ```bash
+ pip install --upgrade pip # enable PEP 660 support
+ pip install -e .
+ ```
+
+## 📦 Model Preparation
+
+| model name | type | download | size |
+| ----------------------- | ----------- | ---------------------------------------------------------------------- | :-----: |
+| InternViT-6B-224px | huggingface | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-224px) | 12 GB |
+| InternViT-6B-448px-V1-0 | huggingface | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-0) | 12 GB |
+| vicuna-13b-v1.5 | huggingface | 🤗 [HF link](https://huggingface.co/lmsys/vicuna-7b-v1.5) | 13.5 GB |
+| vicuna-7b-v1.5 | huggingface | 🤗 [HF link](https://huggingface.co/lmsys/vicuna-13b-v1.5) | 26.1 GB |
+
+Please download the above model weights and place them in the `pretrained/` folder.
+
+```sh
+cd pretrained/
+# pip install -U huggingface_hub
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternViT-6B-224px --local-dir InternViT-6B-224px
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternViT-6B-448px-V1-0 --local-dir InternViT-6B-448px
+huggingface-cli download --resume-download --local-dir-use-symlinks False lmsys/vicuna-13b-v1.5 --local-dir vicuna-13b-v1.5
+huggingface-cli download --resume-download --local-dir-use-symlinks False lmsys/vicuna-7b-v1.5 --local-dir vicuna-7b-v1.5
+```
+
+The directory structure is:
+
+```sh
+pretrained
+│── InternViT-6B-224px/
+│── InternViT-6B-448px/
+│── vicuna-13b-v1.5/
+└── vicuna-7b-v1.5/
+```
+
+## 🔥 Training
+
+- InternViT-6B-224px + Vicuna-7B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_224to336_vicuna7b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_224to336_vicuna7b.sh
+```
+
+- InternViT-6B-224px + Vicuna-13B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_224to336_vicuna13b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_224to336_vicuna13b.sh
+```
+
+- InternViT-6B-448px + Vicuna-7B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_448_vicuna7b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_448_vicuna7b.sh
+```
+
+- InternViT-6B-448px + Vicuna-13B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_448_vicuna13b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_448_vicuna13b.sh
+```
+
+## 🤗 Model Zoo
+
+| method | vision encoder | LLM | res. | VQAv2 | GQA | VizWiz | SQA | TextVQA | POPE | MME | MMB | MMBCN | MMVet | Download |
+| ----------------- | :------------: | :---: | :--: | :---: | :--: | :----: | :--: | :-----: | :--: | :----: | :--: | :--------------: | :---: | :----------------------------------------------------------------------------------: |
+| LLaVA-1.5 | CLIP-L-336px | V-7B | 336 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 | 58.3 | 30.5 | 🤗 [HF link](https://huggingface.co/liuhaotian/llava-v1.5-7b) |
+| LLaVA-1.5 | CLIP-L-336px | V-13B | 336 | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 1531.3 | 67.7 | 63.6 | 35.4 | 🤗 [HF link](https://huggingface.co/liuhaotian/llava-v1.5-13b) |
+| InternVL-Chat-1.0 | IViT-6B-224px | V-7B | 336 | 79.3 | 62.9 | 52.5 | 66.2 | 57.0 | 86.4 | 1525.1 | 64.6 | 57.6 | 31.2 | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B) |
+| InternVL-Chat-1.0 | IViT-6B-224px | V-13B | 336 | 80.2 | 63.9 | 54.6 | 70.1 | 58.7 | 87.1 | 1546.9 | 66.5 | 61.9 | 33.7 | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B) |
+| InternVL-Chat-1.0 | IViT-6B-448px | V-13B | 448 | 82.0 | 64.1 | 60.1 | 71.6 | 64.8 | 87.2 | 1579.0 | 68.2 | 64.0 | 36.7 | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B-448px) |
+
+Please download the above model weights and place them in the `pretrained/` folder.
+
+```shell
+cd pretrained/
+# pip install -U huggingface_hub
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B --local-dir InternVL-Chat-ViT-6B-Vicuna-7B
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B --local-dir InternVL-Chat-ViT-6B-Vicuna-13B
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B-448px --local-dir InternVL-Chat-ViT-6B-Vicuna-13B-448px
+
+```
+
+The directory structure is:
+
+```
+pretrained
+│── InternViT-6B-224px/
+│── InternViT-6B-448px/
+│── vicuna-13b-v1.5/
+│── vicuna-7b-v1.5/
+│── InternVL-Chat-ViT-6B-Vicuna-7B/
+│── InternVL-Chat-ViT-6B-Vicuna-13B/
+└── InternVL-Chat-ViT-6B-Vicuna-13B-448px/
+```
+
+## 🖥️ Demo
+
+The method for deploying the demo is consistent with LLaVA-1.5. You only need to change the model path. The specific steps are as follows:
+
+**Launch a controller**
+
+```shell
+python -m llava.serve.controller --host 0.0.0.0 --port 10000
+```
+
+**Launch a gradio web server**
+
+```shell
+python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload --port 10038
+```
+
+**Launch a model worker**
+
+```shell
+# OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path ./pretrained/InternVL-Chat-ViT-6B-Vicuna-7B
+# OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40001 --worker http://localhost:40001 --model-path ./pretrained/InternVL-Chat-ViT-6B-Vicuna-13B
+```
+
+After completing the above steps, you can access the web demo at `http://localhost:10038` and see the following page. Note that the models deployed here are `InternVL-Chat-ViT-6B-Vicuna-7B` and `InternVL-Chat-ViT-6B-Vicuna-13B`, which are the two models of our InternVL 1.0. The only difference from LLaVA-1.5 is that the CLIP-ViT-300M has been replaced with our InternViT-6B.
+
+If you need a more effective MLLM, please check out our InternVL2 series models.
+For more details on deploying the demo, please refer to [here](#gradio-web-ui).
+
+
+
+## 💡 Testing
+
+The method for testing the model remains the same as LLaVA-1.5; you just need to change the path of the script. Our scripts are located in `scripts_internvl/`.
+
+For example, testing `MME` using a single GPU:
+
+```shell
+sh scripts_internvl/eval/mme.sh pretrained/InternVL-Chat-ViT-6B-Vicuna-7B/
+```
+
+______________________________________________________________________
+
+## 🌋 LLaVA: Large Language and Vision Assistant
+
+*Visual instruction tuning towards large language and vision models with GPT-4 level capabilities.*
+
+\[[Project Page](https://llava-vl.github.io/)\] \[[Demo](https://llava.hliu.cc/)\] \[[Data](https://github.com/haotian-liu/LLaVA/blob/main/docs/Data.md)\] \[[Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md)\]
+
+🤝Community Contributions: \[[llama.cpp](https://github.com/ggerganov/llama.cpp/pull/3436)\] \[[Colab](https://github.com/camenduru/LLaVA-colab)\] \[[🤗Space](https://huggingface.co/spaces/badayvedat/LLaVA)\]
+
+**Improved Baselines with Visual Instruction Tuning** \[[Paper](https://arxiv.org/abs/2310.03744)\]
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+The clang-format config is stored in [.clang-format](../.clang-format). And it's recommended to use clang-format version **11**. Please do not use older or newer versions as they will result in differences after formatting, which can cause the [lint](https://github.com/InternLM/lmdeploy/blob/main/.github/workflows/lint.yml#L25) to fail.
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/InternVL/internvl_chat_llava/LICENSE b/InternVL/internvl_chat_llava/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/InternVL/internvl_chat_llava/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/InternVL/internvl_chat_llava/README.md b/InternVL/internvl_chat_llava/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c162ea562ae96c627500d867c06c003e8ea8bd9
--- /dev/null
+++ b/InternVL/internvl_chat_llava/README.md
@@ -0,0 +1,506 @@
+# InternVL for Multimodal Dialogue using LLaVA Codebase
+
+This folder contains the implementation of the InternVL-Chat V1.0, which corresponds to Section 4.4 of our [InternVL 1.0 paper](https://arxiv.org/pdf/2312.14238).
+
+In this part, we mainly use the [LLaVA codebase](https://github.com/haotian-liu/LLaVA) to evaluate InternVL in creating multimodal dialogue systems. Thanks for this great work.
+We have retained the original documentation of LLaVA-1.5 as a more detailed manual. In most cases, you will only need to refer to the new documentation that we have added.
+
+> Note: To unify the environment across different tasks, we have made some compatibility modifications to the LLaVA-1.5 code, allowing it to support `transformers==4.37.2` (originally locked at 4.31.0). Please note that `transformers==4.37.2` should be installed.
+
+## 🛠️ Installation
+
+First, follow the [installation guide](../INSTALLATION.md) to perform some basic installations.
+
+In addition, using this codebase requires executing the following steps:
+
+- Install other requirements:
+
+ ```bash
+ pip install --upgrade pip # enable PEP 660 support
+ pip install -e .
+ ```
+
+## 📦 Model Preparation
+
+| model name | type | download | size |
+| ----------------------- | ----------- | ---------------------------------------------------------------------- | :-----: |
+| InternViT-6B-224px | huggingface | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-224px) | 12 GB |
+| InternViT-6B-448px-V1-0 | huggingface | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-0) | 12 GB |
+| vicuna-13b-v1.5 | huggingface | 🤗 [HF link](https://huggingface.co/lmsys/vicuna-7b-v1.5) | 13.5 GB |
+| vicuna-7b-v1.5 | huggingface | 🤗 [HF link](https://huggingface.co/lmsys/vicuna-13b-v1.5) | 26.1 GB |
+
+Please download the above model weights and place them in the `pretrained/` folder.
+
+```sh
+cd pretrained/
+# pip install -U huggingface_hub
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternViT-6B-224px --local-dir InternViT-6B-224px
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternViT-6B-448px-V1-0 --local-dir InternViT-6B-448px
+huggingface-cli download --resume-download --local-dir-use-symlinks False lmsys/vicuna-13b-v1.5 --local-dir vicuna-13b-v1.5
+huggingface-cli download --resume-download --local-dir-use-symlinks False lmsys/vicuna-7b-v1.5 --local-dir vicuna-7b-v1.5
+```
+
+The directory structure is:
+
+```sh
+pretrained
+│── InternViT-6B-224px/
+│── InternViT-6B-448px/
+│── vicuna-13b-v1.5/
+└── vicuna-7b-v1.5/
+```
+
+## 🔥 Training
+
+- InternViT-6B-224px + Vicuna-7B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_224to336_vicuna7b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_224to336_vicuna7b.sh
+```
+
+- InternViT-6B-224px + Vicuna-13B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_224to336_vicuna13b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_224to336_vicuna13b.sh
+```
+
+- InternViT-6B-448px + Vicuna-7B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_448_vicuna7b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_448_vicuna7b.sh
+```
+
+- InternViT-6B-448px + Vicuna-13B:
+
+```shell
+# pretrain
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/pretrain_internvit6b_448_vicuna13b.sh
+# finetune
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 sh scripts_internvl/finetune_internvit6b_448_vicuna13b.sh
+```
+
+## 🤗 Model Zoo
+
+| method | vision encoder | LLM | res. | VQAv2 | GQA | VizWiz | SQA | TextVQA | POPE | MME | MMB | MMBCN | MMVet | Download |
+| ----------------- | :------------: | :---: | :--: | :---: | :--: | :----: | :--: | :-----: | :--: | :----: | :--: | :--------------: | :---: | :----------------------------------------------------------------------------------: |
+| LLaVA-1.5 | CLIP-L-336px | V-7B | 336 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 | 58.3 | 30.5 | 🤗 [HF link](https://huggingface.co/liuhaotian/llava-v1.5-7b) |
+| LLaVA-1.5 | CLIP-L-336px | V-13B | 336 | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 1531.3 | 67.7 | 63.6 | 35.4 | 🤗 [HF link](https://huggingface.co/liuhaotian/llava-v1.5-13b) |
+| InternVL-Chat-1.0 | IViT-6B-224px | V-7B | 336 | 79.3 | 62.9 | 52.5 | 66.2 | 57.0 | 86.4 | 1525.1 | 64.6 | 57.6 | 31.2 | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B) |
+| InternVL-Chat-1.0 | IViT-6B-224px | V-13B | 336 | 80.2 | 63.9 | 54.6 | 70.1 | 58.7 | 87.1 | 1546.9 | 66.5 | 61.9 | 33.7 | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B) |
+| InternVL-Chat-1.0 | IViT-6B-448px | V-13B | 448 | 82.0 | 64.1 | 60.1 | 71.6 | 64.8 | 87.2 | 1579.0 | 68.2 | 64.0 | 36.7 | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B-448px) |
+
+Please download the above model weights and place them in the `pretrained/` folder.
+
+```shell
+cd pretrained/
+# pip install -U huggingface_hub
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B --local-dir InternVL-Chat-ViT-6B-Vicuna-7B
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B --local-dir InternVL-Chat-ViT-6B-Vicuna-13B
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B-448px --local-dir InternVL-Chat-ViT-6B-Vicuna-13B-448px
+
+```
+
+The directory structure is:
+
+```
+pretrained
+│── InternViT-6B-224px/
+│── InternViT-6B-448px/
+│── vicuna-13b-v1.5/
+│── vicuna-7b-v1.5/
+│── InternVL-Chat-ViT-6B-Vicuna-7B/
+│── InternVL-Chat-ViT-6B-Vicuna-13B/
+└── InternVL-Chat-ViT-6B-Vicuna-13B-448px/
+```
+
+## 🖥️ Demo
+
+The method for deploying the demo is consistent with LLaVA-1.5. You only need to change the model path. The specific steps are as follows:
+
+**Launch a controller**
+
+```shell
+python -m llava.serve.controller --host 0.0.0.0 --port 10000
+```
+
+**Launch a gradio web server**
+
+```shell
+python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload --port 10038
+```
+
+**Launch a model worker**
+
+```shell
+# OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path ./pretrained/InternVL-Chat-ViT-6B-Vicuna-7B
+# OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-13B
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40001 --worker http://localhost:40001 --model-path ./pretrained/InternVL-Chat-ViT-6B-Vicuna-13B
+```
+
+After completing the above steps, you can access the web demo at `http://localhost:10038` and see the following page. Note that the models deployed here are `InternVL-Chat-ViT-6B-Vicuna-7B` and `InternVL-Chat-ViT-6B-Vicuna-13B`, which are the two models of our InternVL 1.0. The only difference from LLaVA-1.5 is that the CLIP-ViT-300M has been replaced with our InternViT-6B.
+
+If you need a more effective MLLM, please check out our InternVL2 series models.
+For more details on deploying the demo, please refer to [here](#gradio-web-ui).
+
+
+
+## 💡 Testing
+
+The method for testing the model remains the same as LLaVA-1.5; you just need to change the path of the script. Our scripts are located in `scripts_internvl/`.
+
+For example, testing `MME` using a single GPU:
+
+```shell
+sh scripts_internvl/eval/mme.sh pretrained/InternVL-Chat-ViT-6B-Vicuna-7B/
+```
+
+______________________________________________________________________
+
+## 🌋 LLaVA: Large Language and Vision Assistant
+
+*Visual instruction tuning towards large language and vision models with GPT-4 level capabilities.*
+
+\[[Project Page](https://llava-vl.github.io/)\] \[[Demo](https://llava.hliu.cc/)\] \[[Data](https://github.com/haotian-liu/LLaVA/blob/main/docs/Data.md)\] \[[Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md)\]
+
+🤝Community Contributions: \[[llama.cpp](https://github.com/ggerganov/llama.cpp/pull/3436)\] \[[Colab](https://github.com/camenduru/LLaVA-colab)\] \[[🤗Space](https://huggingface.co/spaces/badayvedat/LLaVA)\]
+
+**Improved Baselines with Visual Instruction Tuning** \[[Paper](https://arxiv.org/abs/2310.03744)\]
+[Haotian Liu](https://hliu.cc), [Chunyuan Li](https://chunyuan.li/), [Yuheng Li](https://yuheng-li.github.io/), [Yong Jae Lee](https://pages.cs.wisc.edu/~yongjaelee/)
+
+**Visual Instruction Tuning** (NeurIPS 2023, **Oral**) \[[Paper](https://arxiv.org/abs/2304.08485)\]
+[Haotian Liu\*](https://hliu.cc), [Chunyuan Li\*](https://chunyuan.li/), [Qingyang Wu](https://scholar.google.ca/citations?user=HDiw-TsAAAAJ&hl=en/), [Yong Jae Lee](https://pages.cs.wisc.edu/~yongjaelee/) (\*Equal Contribution)
+
+### Release
+
+- \[10/12\] 🔥 Check out the Korean LLaVA (Ko-LLaVA), created by ETRI, who has generously supported our research! \[[🤗 Demo](https://huggingface.co/spaces/etri-vilab/Ko-LLaVA)\]
+
+- \[10/12\] LLaVA is now supported in [llama.cpp](https://github.com/ggerganov/llama.cpp/pull/3436) with 4-bit / 5-bit quantization support!
+
+- \[10/11\] The training data and scripts of LLaVA-1.5 are released [here](https://github.com/haotian-liu/LLaVA#train), and evaluation scripts are released [here](https://github.com/haotian-liu/LLaVA/blob/main/docs/Evaluation.md)!
+
+- \[10/5\] 🔥 LLaVA-1.5 is out! Achieving SoTA on 11 benchmarks, with just simple modifications to the original LLaVA, utilizes all public data, completes training in ~1 day on a single 8-A100 node, and surpasses methods like Qwen-VL-Chat that use billion-scale data. Check out the [technical report](https://arxiv.org/abs/2310.03744), and explore the [demo](https://llava.hliu.cc/)! Models are available in [Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md).
+
+- \[9/26\] LLaVA is improved with reinforcement learning from human feedback (RLHF) to improve fact grounding and reduce hallucination. Check out the new SFT and RLHF checkpoints at project [\[LLavA-RLHF\]](https://llava-rlhf.github.io/)
+
+- \[9/22\] [LLaVA](https://arxiv.org/abs/2304.08485) is accepted by NeurIPS 2023 as **oral presentation**, and [LLaVA-Med](https://arxiv.org/abs/2306.00890) is accepted by NeurIPS 2023 Datasets and Benchmarks Track as **spotlight presentation**.
+
+- \[9/20\] We summarize our empirical study of training 33B and 65B LLaVA models in a [note](https://arxiv.org/abs/2309.09958). Further, if you are interested in the comprehensive review, evolution and trend of multimodal foundation models, please check out our recent survey paper [\`\`Multimodal Foundation Models: From Specialists to General-Purpose Assistants''.](https://arxiv.org/abs/2309.10020)
+
+
+  +
+
+
+- \[7/19\] 🔥 We release a major upgrade, including support for LLaMA-2, LoRA training, 4-/8-bit inference, higher resolution (336x336), and a lot more. We release [LLaVA Bench](https://github.com/haotian-liu/LLaVA/blob/main/docs/LLaVA_Bench.md) for benchmarking open-ended visual chat with results from Bard and Bing-Chat. We also support and verify training with RTX 3090 and RTX A6000. Check out [LLaVA-from-LLaMA-2](https://github.com/haotian-liu/LLaVA/blob/main/docs/LLaVA_from_LLaMA2.md), and our [model zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md)!
+
+- \[6/26\] [CVPR 2023 Tutorial](https://vlp-tutorial.github.io/) on **Large Multimodal Models: Towards Building and Surpassing Multimodal GPT-4**! Please check out \[[Slides](https://datarelease.blob.core.windows.net/tutorial/vision_foundation_models_2023/slides/Chunyuan_cvpr2023_tutorial_lmm.pdf)\] \[[Notes](https://arxiv.org/abs/2306.14895)\] \[[YouTube](https://youtu.be/mkI7EPD1vp8)\] \[[Bilibli](https://www.bilibili.com/video/BV1Ng4y1T7v3/)\].
+
+- \[6/11\] We released the preview for the most requested feature: DeepSpeed and LoRA support! Please see documentations [here](./docs/LoRA.md).
+
+- \[6/1\] We released **LLaVA-Med: Large Language and Vision Assistant for Biomedicine**, a step towards building biomedical domain large language and vision models with GPT-4 level capabilities. Checkout the [paper](https://arxiv.org/abs/2306.00890) and [page](https://github.com/microsoft/LLaVA-Med).
+
+- \[5/6\] We are releasing [LLaVA-Lighting-MPT-7B-preview](https://huggingface.co/liuhaotian/LLaVA-Lightning-MPT-7B-preview), based on MPT-7B-Chat! See [here](#LLaVA-MPT-7b) for more details.
+
+- \[5/2\] 🔥 We are releasing LLaVA-Lighting! Train a lite, multimodal GPT-4 with just $40 in 3 hours! See [here](#train-llava-lightning) for more details.
+
+- \[4/27\] Thanks to the community effort, LLaVA-13B with 4-bit quantization allows you to run on a GPU with as few as 12GB VRAM! Try it out [here](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/llava).
+
+- \[4/17\] 🔥 We released **LLaVA: Large Language and Vision Assistant**. We propose visual instruction tuning, towards building large language and vision models with GPT-4 level capabilities. Checkout the [paper](https://arxiv.org/abs/2304.08485) and [demo](https://llava.hliu.cc/).
+
+
+
+[](https://github.com/tatsu-lab/stanford_alpaca/blob/main/LICENSE)
+[](https://github.com/tatsu-lab/stanford_alpaca/blob/main/DATA_LICENSE)
+**Usage and License Notices**: The data and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
+
+### Contents
+
+- [Install](#install)
+- [LLaVA Weights](#llava-weights)
+- [Demo](#Demo)
+- [Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md)
+- [Dataset](https://github.com/haotian-liu/LLaVA/blob/main/docs/Data.md)
+- [Train](#train)
+- [Evaluation](#evaluation)
+
+### Install
+
+1. Clone this repository and navigate to LLaVA folder
+
+ ```bash
+ git clone https://github.com/haotian-liu/LLaVA.git
+ cd LLaVA
+ ```
+
+2. Install Package
+
+ ```Shell
+ conda create -n llava python=3.10 -y
+ conda activate llava
+ pip install --upgrade pip # enable PEP 660 support
+ pip install -e .
+ ```
+
+3. Install additional packages for training cases
+
+ ```
+ pip install ninja
+ pip install flash-attn --no-build-isolation
+ ```
+
+#### Upgrade to latest code base
+
+```Shell
+git pull
+pip uninstall transformers
+pip install -e .
+```
+
+### LLaVA Weights
+
+Please check out our [Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md) for all public LLaVA checkpoints, and the instructions of how to use the weights.
+
+### Demo
+
+To run our demo, you need to prepare LLaVA checkpoints locally. Please follow the instructions [here](#llava-weights) to download the checkpoints.
+
+#### Gradio Web UI
+
+To launch a Gradio demo locally, please run the following commands one by one. If you plan to launch multiple model workers to compare between different checkpoints, you only need to launch the controller and the web server *ONCE*.
+
+##### Launch a controller
+
+```Shell
+python -m llava.serve.controller --host 0.0.0.0 --port 10000
+```
+
+##### Launch a gradio web server.
+
+```Shell
+python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
+```
+
+You just launched the Gradio web interface. Now, you can open the web interface with the URL printed on the screen. You may notice that there is no model in the model list. Do not worry, as we have not launched any model worker yet. It will be automatically updated when you launch a model worker.
+
+##### Launch a model worker
+
+This is the actual *worker* that performs the inference on the GPU. Each worker is responsible for a single model specified in `--model-path`.
+
+```Shell
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b
+```
+
+Wait until the process finishes loading the model and you see "Uvicorn running on ...". Now, refresh your Gradio web UI, and you will see the model you just launched in the model list.
+
+You can launch as many workers as you want, and compare between different model checkpoints in the same Gradio interface. Please keep the `--controller` the same, and modify the `--port` and `--worker` to a different port number for each worker.
+
+```Shell
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port --worker http://localhost: --model-path
+```
+
+If you are using an Apple device with an M1 or M2 chip, you can specify the mps device by using the `--device` flag: `--device mps`.
+
+##### Launch a model worker (Multiple GPUs, when GPU VRAM \<= 24GB)
+
+If the VRAM of your GPU is less than 24GB (e.g., RTX 3090, RTX 4090, etc.), you may try running it with multiple GPUs. Our latest code base will automatically try to use multiple GPUs if you have more than one GPU. You can specify which GPUs to use with `CUDA_VISIBLE_DEVICES`. Below is an example of running with the first two GPUs.
+
+```Shell
+CUDA_VISIBLE_DEVICES=0,1 python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b
+```
+
+##### Launch a model worker (4-bit, 8-bit inference, quantized)
+
+You can launch the model worker with quantized bits (4-bit, 8-bit), which allows you to run the inference with reduced GPU memory footprint, potentially allowing you to run on a GPU with as few as 12GB VRAM. Note that inference with quantized bits may not be as accurate as the full-precision model. Simply append `--load-4bit` or `--load-8bit` to the **model worker** command that you are executing. Below is an example of running with 4-bit quantization.
+
+```Shell
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b --load-4bit
+```
+
+##### Launch a model worker (LoRA weights, unmerged)
+
+You can launch the model worker with LoRA weights, without merging them with the base checkpoint, to save disk space. There will be additional loading time, while the inference speed is the same as the merged checkpoints. Unmerged LoRA checkpoints do not have `lora-merge` in the model name, and are usually much smaller (less than 1GB) than the merged checkpoints (13G for 7B, and 25G for 13B).
+
+To load unmerged LoRA weights, you simply need to pass an additional argument `--model-base`, which is the base LLM that is used to train the LoRA weights. You can check the base LLM of each LoRA weights in the [model zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md).
+
+```Shell
+python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1-0719-336px-lora-vicuna-13b-v1.3 --model-base lmsys/vicuna-13b-v1.3
+```
+
+#### CLI Inference
+
+Chat about images using LLaVA without the need of Gradio interface. It also supports multiple GPUs, 4-bit and 8-bit quantized inference. With 4-bit quantization, for our LLaVA-1.5-7B, it uses less than 8GB VRAM on a single GPU.
+
+```Shell
+python -m llava.serve.cli \
+ --model-path liuhaotian/llava-v1.5-7b \
+ --image-file "https://llava-vl.github.io/static/images/view.jpg" \
+ --load-4bit
+```
+
+### Train
+
+*Below is the latest training configuration for LLaVA v1.5. For legacy models, please refer to README of [this](https://github.com/haotian-liu/LLaVA/tree/v1.0.1) version for now. We'll add them in a separate doc later.*
+
+LLaVA training consists of two stages: (1) feature alignment stage: use our 558K subset of the LAION-CC-SBU dataset to connect a *frozen pretrained* vision encoder to a *frozen LLM*; (2) visual instruction tuning stage: use 150K GPT-generated multimodal instruction-following data, plus around 515K VQA data from academic-oriented tasks, to teach the model to follow multimodal instructions.
+
+LLaVA is trained on 8 A100 GPUs with 80GB memory. To train on fewer GPUs, you can reduce the `per_device_train_batch_size` and increase the `gradient_accumulation_steps` accordingly. Always keep the global batch size the same: `per_device_train_batch_size` x `gradient_accumulation_steps` x `num_gpus`.
+
+#### Hyperparameters
+
+We use a similar set of hyperparameters as Vicuna in finetuning. Both hyperparameters used in pretraining and finetuning are provided below.
+
+1. Pretraining
+
+| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
+| -------------- | ----------------: | ------------: | -----: | ---------: | -----------: |
+| LLaVA-v1.5-13B | 256 | 1e-3 | 1 | 2048 | 0 |
+
+2. Finetuning
+
+| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
+| -------------- | ----------------: | ------------: | -----: | ---------: | -----------: |
+| LLaVA-v1.5-13B | 128 | 2e-5 | 1 | 2048 | 0 |
+
+#### Download Vicuna checkpoints (automatically)
+
+Our base model Vicuna v1.5, which is an instruction-tuned chatbot, will be downloaded automatically when you run our provided training scripts. No action is needed.
+
+#### Pretrain (feature alignment)
+
+Please download the 558K subset of the LAION-CC-SBU dataset with BLIP captions we use in the paper [here](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain).
+
+Pretrain takes around 5.5 hours for LLaVA-v1.5-13B on 8x A100 (80G), due to the increased resolution to 336px. It takes around 3.5 hours for LLaVA-v1.5-7B.
+
+Training script with DeepSpeed ZeRO-2: [`pretrain.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/v1_5/pretrain.sh).
+
+- `--mm_projector_type mlp2x_gelu`: the two-layer MLP vision-language connector.
+- `--vision_tower openai/clip-vit-large-patch14-336`: CLIP ViT-L/14 336px.
+
+#### Visual Instruction Tuning
+
+1. Prepare data
+
+Please download the annotation of the final mixture our instruction tuning data [llava_v1_5_mix665k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/llava_v1_5_mix665k.json), and download the images from constituting datasets:
+
+- COCO: [train2017](http://images.cocodataset.org/zips/train2017.zip)
+- GQA: [images](https://downloads.cs.stanford.edu/nlp/data/gqa/images.zip)
+- OCR-VQA: [download script](https://drive.google.com/drive/folders/1_GYPY5UkUy7HIcR0zq3ZCFgeZN7BAfm_?usp=sharing)
+- TextVQA: [train_val_images](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip)
+- VisualGenome: [part1](https://cs.stanford.edu/people/rak248/VG_100K_2/images.zip), [part2](https://cs.stanford.edu/people/rak248/VG_100K_2/images2.zip)
+
+After downloading all of them, organize the data as follows in `./playground/data`,
+
+```
+├── coco
+│ └── train2017
+├── gqa
+│ └── images
+├── ocr_vqa
+│ └── images
+├── textvqa
+│ └── train_images
+└── vg
+ ├── VG_100K
+ └── VG_100K_2
+```
+
+2. Start training!
+
+You may download our pretrained projectors in [Model Zoo](https://github.com/haotian-liu/LLaVA/blob/main/docs/MODEL_ZOO.md). It is not recommended to use legacy projectors, as they may be trained with a different version of the codebase, and if any option is off, the model will not function/train as we expected.
+
+Visual instruction tuning takes around 20 hours for LLaVA-v1.5-13B on 8x A100 (80G), due to the increased resolution to 336px. It takes around 10 hours for LLaVA-v1.5-7B on 8x A100 (40G).
+
+Training script with DeepSpeed ZeRO-3: [`finetune.sh`](https://github.com/haotian-liu/LLaVA/blob/main/scripts/v1_5/finetune.sh).
+
+New options to note:
+
+- `--mm_projector_type mlp2x_gelu`: the two-layer MLP vision-language connector.
+- `--vision_tower openai/clip-vit-large-patch14-336`: CLIP ViT-L/14 336px.
+- `--image_aspect_ratio pad`: this pads the non-square images to square, instead of cropping them; it slightly reduces hallucination.
+- `--group_by_modality_length True`: this should only be used when your instruction tuning dataset contains both language (e.g. ShareGPT) and multimodal (e.g. LLaVA-Instruct). It makes the training sampler only sample a single modality (either image or language) during training, which we observe to speed up training by ~25%, and does not affect the final outcome.
+
+### Evaluation
+
+In LLaVA-1.5, we evaluate models on a diverse set of 12 benchmarks. To ensure the reproducibility, we evaluate the models with greedy decoding. We do not evaluate using beam search to make the inference process consistent with the chat demo of real-time outputs.
+
+See [Evaluation.md](https://github.com/haotian-liu/LLaVA/blob/main/docs/Evaluation.md).
+
+#### GPT-assisted Evaluation
+
+Our GPT-assisted evaluation pipeline for multimodal modeling is provided for a comprehensive understanding of the capabilities of vision-language models. Please see our paper for more details.
+
+1. Generate LLaVA responses
+
+```Shell
+python model_vqa.py \
+ --model-path ./checkpoints/LLaVA-13B-v0 \
+ --question-file \
+ playground/data/coco2014_val_qa_eval/qa90_questions.jsonl \
+ --image-folder \
+ /path/to/coco2014_val \
+ --answers-file \
+ /path/to/answer-file-our.jsonl
+```
+
+2. Evaluate the generated responses. In our case, [`answer-file-ref.jsonl`](./playground/data/coco2014_val_qa_eval/qa90_gpt4_answer.jsonl) is the response generated by text-only GPT-4 (0314), with the context captions/boxes provided.
+
+```Shell
+OPENAI_API_KEY="sk-***********************************" python llava/eval/eval_gpt_review_visual.py \
+ --question playground/data/coco2014_val_qa_eval/qa90_questions.jsonl \
+ --context llava/eval/table/caps_boxes_coco2014_val_80.jsonl \
+ --answer-list \
+ /path/to/answer-file-ref.jsonl \
+ /path/to/answer-file-our.jsonl \
+ --rule llava/eval/table/rule.json \
+ --output /path/to/review.json
+```
+
+3. Summarize the evaluation results
+
+```Shell
+python summarize_gpt_review.py
+```
+
+### Citation
+
+If you find LLaVA useful for your research and applications, please cite using this BibTeX:
+
+```bibtex
+@misc{liu2023improvedllava,
+ title={Improved Baselines with Visual Instruction Tuning},
+ author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae},
+ publisher={arXiv:2310.03744},
+ year={2023},
+}
+
+@misc{liu2023llava,
+ title={Visual Instruction Tuning},
+ author={Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
+ publisher={arXiv:2304.08485},
+ year={2023},
+}
+```
+
+### Acknowledgement
+
+- [Vicuna](https://github.com/lm-sys/FastChat): the codebase we built upon, and our base model Vicuna-13B that has the amazing language capabilities!
+
+### Related Projects
+
+- [Instruction Tuning with GPT-4](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM)
+- [LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day](https://github.com/microsoft/LLaVA-Med)
+- [Otter: In-Context Multi-Modal Instruction Tuning](https://github.com/Luodian/Otter)
+
+For future project ideas, please check out:
+
+- [SEEM: Segment Everything Everywhere All at Once](https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once)
+- [Grounded-Segment-Anything](https://github.com/IDEA-Research/Grounded-Segment-Anything) to detect, segment, and generate anything by marrying [Grounding DINO](https://github.com/IDEA-Research/GroundingDINO) and [Segment-Anything](https://github.com/facebookresearch/segment-anything).
diff --git a/InternVL/internvl_chat_llava/pyproject.toml b/InternVL/internvl_chat_llava/pyproject.toml
new file mode 100644
index 0000000000000000000000000000000000000000..e0261353e94b6b0074120deefcec1958ddf7ac25
--- /dev/null
+++ b/InternVL/internvl_chat_llava/pyproject.toml
@@ -0,0 +1,33 @@
+[build-system]
+requires = ["setuptools>=61.0"]
+build-backend = "setuptools.build_meta"
+
+[project]
+name = "llava"
+version = "1.1.1"
+description = "Towards GPT-4 like large language and visual assistant."
+readme = "README.md"
+requires-python = ">=3.8"
+classifiers = [
+ "Programming Language :: Python :: 3",
+ "License :: OSI Approved :: Apache Software License",
+]
+dependencies = [
+ "torch>=2", "torchvision>=0.15",
+ "transformers>=4.37.2", "tokenizers==0.15.1", "sentencepiece==0.1.99", "shortuuid",
+ "accelerate", "peft>=0.4.0", "bitsandbytes==0.41.0",
+ "pydantic", "markdown2[all]", "numpy", "scikit-learn>=1.2.2",
+ "gradio==3.35.2", "gradio_client==0.2.9",
+ "requests", "httpx==0.24.0", "uvicorn", "fastapi",
+ "deepspeed==0.13.5", "einops", "einops-exts", "timm==0.9.12",
+]
+
+[project.urls]
+"Homepage" = "https://github.com/OpenGVLab/InternVL"
+"Bug Tracker" = "https://github.com/OpenGVLab/InternVL/issues"
+
+[tool.setuptools.packages.find]
+exclude = ["assets*", "benchmark*", "docs", "dist*", "playground*", "scripts*", "tests*"]
+
+[tool.wheel]
+exclude = ["assets*", "benchmark*", "docs", "dist*", "playground*", "scripts*", "tests*"]
diff --git a/InternVL/internvl_g/README.md b/InternVL/internvl_g/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e902e37db97fa64cc1d54178c769c2c5728a55bb
--- /dev/null
+++ b/InternVL/internvl_g/README.md
@@ -0,0 +1,497 @@
+# InternVL Stage-2 Pre-training & Retrieval Fine-tuning
+
+This folder contains the implementation of the InternVL 1.0 for stage2 pre-training and retrieval fine-tuning, which corresponds to Section 4.3 of our [InternVL 1.0 paper](https://arxiv.org/pdf/2312.14238).
+
+
+
+## 🛠️ Installation
+
+Follow the [installation guide](../INSTALLATION.md) to perform installations.
+
+## 📦 Data Preparation
+
+Three datasets need to be prepared: COCO Caption, Flickr30K, and NoCaps.
+
+
+COCO Caption
+
+```bash
+mkdir -p data/coco && cd data/coco
+
+# download coco images
+wget http://images.cocodataset.org/zips/train2014.zip && unzip train2014.zip
+wget http://images.cocodataset.org/zips/val2014.zip && unzip val2014.zip
+wget http://images.cocodataset.org/zips/test2015.zip && unzip test2015.zip
+
+mkdir -p annotations && cd annotations/
+# download converted annotation files
+wget https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_train.json
+wget https://github.com/OpenGVLab/InternVL/releases/download/data/coco_karpathy_test.json
+wget https://github.com/OpenGVLab/InternVL/releases/download/data/coco_karpathy_test_gt.json
+cd ../../../
+```
+
+
+
+
+Flickr30K
+
+```bash
+mkdir -p data/flickr30k && cd data/flickr30k
+
+# download images from https://bryanplummer.com/Flickr30kEntities/
+# karpathy split annotations can be downloaded from the following link:
+# https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_test_karpathy.txt
+# this file is provided by the clip-benchmark repository.
+# We convert this txt file to json format, download the converted file:
+wget https://github.com/OpenGVLab/InternVL/releases/download/data/flickr30k_cn_test.txt
+wget https://github.com/OpenGVLab/InternVL/releases/download/data/flickr30k_cn_train.txt
+wget https://github.com/OpenGVLab/InternVL/releases/download/data/flickr30k_test_karpathy.json
+wget https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_test_karpathy.txt
+wget https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_train_karpathy.txt
+wget https://github.com/mehdidc/retrieval_annotations/releases/download/1.0.0/flickr30k_val_karpathy.txt
+
+cd ../..
+```
+
+
+
+
+NoCaps
+
+```bash
+mkdir -p data/nocaps && cd data/nocaps
+
+# download images from https://nocaps.org/download
+# original annotations can be downloaded from https://nocaps.s3.amazonaws.com/nocaps_val_4500_captions.json
+wget https://nocaps.s3.amazonaws.com/nocaps_val_4500_captions.json
+
+cd ../..
+```
+
+
+
+After the download is complete, the directory structure is:
+
+```shell
+data
+├── coco
+│ ├── annotations
+│ │ ├── coco_karpathy_train.json
+│ ├── test2017
+│ ├── train2014
+│ ├── train2017
+│ ├── val2014
+│ └── val2017
+├── flickr30k
+│ ├── flickr30k_cn_test.txt
+│ ├── flickr30k_cn_train.txt
+│ ├── flickr30k_test_karpathy.json
+│ ├── flickr30k_test_karpathy.txt
+│ ├── flickr30k_train_karpathy.txt
+│ ├── flickr30k_val_karpathy.txt
+│ └── Images
+└── nocaps
+ ├── images
+ └── nocaps_val_4500_captions.json
+```
+
+## 📦 Model Preparation
+
+| model name | type | download | size |
+| ------------------ | ----------- | ----------------------------------------------------------------- | :-----: |
+| InternVL-14B-224px | huggingface | 🤗 [HF link](https://huggingface.co/OpenGVLab/InternVL-14B-224px) | 27.7 GB |
+
+Please download the above model weights and place them in the `pretrained/` folder.
+
+```sh
+cd pretrained/
+# pip install -U huggingface_hub
+huggingface-cli download --resume-download --local-dir-use-symlinks False OpenGVLab/InternVL-14B-224px --local-dir InternVL-14B-224px
+```
+
+The directory structure is:
+
+```sh
+pretrained
+└── InternVL-14B-224px/
+```
+
+## 🔥 Generative Pre-training
+
+There are currently no plans to release this part of the code.
+
+## 📊 Evaluation
+
+### Zero-Shot Image Captioning
+
+| model | dataset | BLEU4 | METEOR | CIDEr |
+| ---------- | ----------------------- | ----- | ------ | ----- |
+| InternVL-G | COCO Karpathy test | 37.1 | 30.1 | 128.2 |
+| InternVL-G | Flickr30K Karpathy test | 27.0 | 25.3 | 79.2 |
+| InternVL-G | NoCaps val | 44.3 | 30.1 | 113.7 |
+
+
+ [InternVL-G] COCO Karpathy test
+
+```bash
+sh evaluate.sh pretrained/InternVL-14B-224px caption-coco
+```
+
+Expected results:
+
+```
+['coco', 'English caption:', 10.5974, dict_items([('Bleu_1', 0.7876323287981284), ('Bleu_2', 0.6353512494727918), ('Bleu_3', 0.49108984183589743), ('Bleu_4', 0.37062736733849205), ('METEOR', 0.30106315496945923), ('ROUGE_L', 0.5898249189475652), ('CIDEr', 1.281844384075423)])]
+```
+
+
+
+
+ [InternVL-G] Flickr30K Karpathy test
+
+```
+sh evaluate.sh pretrained/InternVL-14B-224px caption-flickr30k
+```
+
+Expected results:
+
+```bash
+['flickr30k', 'English caption:', 10.666, dict_items([('Bleu_1', 0.7182900534357628), ('Bleu_2', 0.5353390037921949), ('Bleu_3', 0.3834462132295285), ('Bleu_4', 0.2702131471765472), ('METEOR', 0.25263515267930103), ('ROUGE_L', 0.5305876871149064), ('CIDEr', 0.7919734768328237)])]
+```
+
+
+
+
+ [InternVL-G] NoCaps val
+
+```bash
+sh evaluate.sh pretrained/InternVL-14B-224px caption-nocaps
+```
+
+Expected results:
+
+```
+['nocaps', 'English caption:', 10.463111111111111, dict_items([('Bleu_1', 0.8518290482155187), ('Bleu_2', 0.7165227921485106), ('Bleu_3', 0.5733723839888316), ('Bleu_4', 0.44268902150723105), ('METEOR', 0.30078174807736896), ('ROUGE_L', 0.6070208063052156), ('CIDEr', 1.1371742045267772)])]
+```
+
+
+
+### Fine-tuned Image-Text Retrieval
+
+#### Flickr30K fine-tuned model: [InternVL-14B-Flickr30K-FT-364px](https://huggingface.co/OpenGVLab/InternVL-14B-Flickr30K-FT-364px)
+
+
+
+ | model |
+ Flickr30K |
+ avg |
+
+
+
+ | image-to-text |
+ text-to-image |
+
+
+ | R@1 |
+ R@5 |
+ R@10 |
+ R@1 |
+ R@5 |
+ R@10 |
+
+
+
+ | InternVL-C-FT |
+ 97.2 |
+ 100.0 |
+ 100.0 |
+ 88.5 |
+ 98.4 |
+ 99.2 |
+ 97.2 |
+
+
+ | InternVL-G-FT |
+ 97.9 |
+ 100.0 |
+ 100.0 |
+ 89.6 |
+ 98.6 |
+ 99.2 |
+ 97.6 |
+
+
+
+
+
+ [InternVL-C-FT] Flickr30K
+
+```bash
+cd ../clip_benchmark/
+CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "en" --task "zeroshot_retrieval" \
+ --dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_c_retrieval_hf \
+ --pretrained ./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10/ --output result_ft.json
+```
+
+Expected results:
+
+```
+{"dataset": "flickr30k", "model": "internvl_c_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10", "task": "zeroshot_retrieval",
+"metrics": {"image_retrieval_recall@1": 0.8853999972343445, "text_retrieval_recall@1": 0.972000002861023,
+"image_retrieval_recall@5": 0.9836000204086304, "text_retrieval_recall@5": 1.0,
+"image_retrieval_recall@10": 0.9923999905586243, "text_retrieval_recall@10": 1.0}, "language": "en"}
+```
+
+
+
+
+ [InternVL-G-FT] Flickr30K
+
+```bash
+cd ../clip_benchmark/
+CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "en" --task "zeroshot_retrieval" \
+ --dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_g_retrieval_hf \
+ --pretrained ./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10/ --output result_ft.json
+```
+
+Expected results:
+
+```
+{"dataset": "flickr30k", "model": "internvl_g_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickr_364_bs1024_ep10", "task": "zeroshot_retrieval",
+"metrics": {"image_retrieval_recall@1": 0.895799994468689, "text_retrieval_recall@1": 0.9789999723434448,
+"image_retrieval_recall@5": 0.9861999750137329, "text_retrieval_recall@5": 1.0,
+"image_retrieval_recall@10": 0.9922000169754028, "text_retrieval_recall@10": 1.0}, "language": "en"}
+```
+
+
+
+#### Flickr30K-CN fine-tuned model: [InternVL-14B-FlickrCN-FT-364px](https://huggingface.co/OpenGVLab/InternVL-14B-FlickrCN-FT-364px)
+
+
+
+ | model |
+ Flickr30K-CN |
+ avg |
+
+
+
+ | image-to-text |
+ text-to-image |
+
+
+ | R@1 |
+ R@5 |
+ R@10 |
+ R@1 |
+ R@5 |
+ R@10 |
+
+
+
+ | InternVL-C-FT |
+ 96.5 |
+ 99.9 |
+ 100.0 |
+ 85.2 |
+ 97.0 |
+ 98.5 |
+ 96.2 |
+
+
+ | InternVL-G-FT |
+ 96.9 |
+ 99.9 |
+ 100.0 |
+ 85.9 |
+ 97.1 |
+ 98.7 |
+ 96.4 |
+
+
+
+
+
+ [InternVL-C-FT] Flickr30K-CN
+
+```bash
+cd ../clip_benchmark/
+CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "cn" --task "zeroshot_retrieval" \
+ --dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_c_retrieval_hf \
+ --pretrained ./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10/ --output result_ft.json
+```
+
+Expected results:
+
+```
+{"dataset": "flickr30k", "model": "internvl_c_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10", "task": "zeroshot_retrieval",
+"metrics": {"image_retrieval_recall@1": 0.8521999716758728, "text_retrieval_recall@1": 0.9649999737739563,
+"image_retrieval_recall@5": 0.9697999954223633, "text_retrieval_recall@5": 0.9990000128746033,
+"image_retrieval_recall@10": 0.9854000210762024, "text_retrieval_recall@10": 1.0}, "language": "cn"}
+```
+
+
+
+
+ [InternVL-G-FT] Flickr30K-CN
+
+```bash
+cd ../clip_benchmark/
+CUDA_VISIBLE_DEVICES=0 python3 clip_benchmark/cli.py eval --model_type internvl --language "cn" --task "zeroshot_retrieval" \
+ --dataset "flickr30k" --dataset_root ./data/flickr30k --model internvl_g_retrieval_hf \
+ --pretrained ./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10/ --output result_ft.json
+```
+
+Expected results:
+
+```
+{"dataset": "flickr30k", "model": "internvl_g_retrieval_hf", "pretrained": "./work_dirs/internvl_stage2_finetune_flickrcn_364_bs1024_ep10", "task": "zeroshot_retrieval",
+"metrics": {"image_retrieval_recall@1": 0.8587999939918518, "text_retrieval_recall@1": 0.968999981880188,
+"image_retrieval_recall@5": 0.9714000225067139, "text_retrieval_recall@5": 0.9990000128746033,
+"image_retrieval_recall@10": 0.9865999817848206, "text_retrieval_recall@10": 1.0}, "language": "cn"}
+```
+
+
+
+## 🔥 Retrieval Fine-tuning (Fully)
+
+> Note: In our experiments, full parameter fine-tuning achieves the best results on image-text retrieval tasks in Flickr30K and COCO. By following the experimental hyperparameters in this section, you can reproduce the model performance reported in the [Evaluation section](#evaluation).
+
+To fine-tune InternVL on Flickr30K with 32 GPUs and slurm system, run:
+
+```bash
+PARTITION='your partition' GPUS=32 sh shell/finetune/internvl_stage2_finetune_flickr_364_bs1024_ep10.sh
+```
+
+To fine-tune InternVL on Flickr30K-CN with 32 GPUs and slurm system, run:
+
+```shell
+PARTITION='your partition' GPUS=32 sh shell/finetune/internvl_stage2_finetune_flickrcn_364_bs1024_ep10.sh
+```
+
+To fine-tune InternVL on COCO with 32 GPUs and slurm system, run:
+
+```shell
+PARTITION='your partition' GPUS=32 sh shell/finetune/internvl_stage2_finetune_coco_364_bs1024_ep5.sh
+```
+
+The hyperparameters used here are:
+
+| config | Flickr30K | Flickr30K-CN | COCO |
+| --------------------------- | ----------------------------------- | ----------------------------------- | ----------------------------------- |
+| learning rate | 1e-6 | 1e-6 | 1e-6 |
+| layer-wise lr
decay rate | InternViT-6B (0.9),
QLLaMA (0.9) | InternViT-6B (0.9),
QLLaMA (0.9) | InternViT-6B (0.9),
QLLaMA (0.9) |
+| optimizer | AdamW | AdamW | AdamW |
+| weight decay | 0.05 | 0.05 | 0.05 |
+| input resolution | 364x364 | 364x364 | 364x364 |
+| total batch size | 1024 | 1024 | 1024 |
+| warm-up iterations | 100 | 100 | 100 |
+| training epochs | 10 | 10 | 5 |
+| drop path rate | 0.3 | 0.3 | 0.3 |
+| numerical precision | zero1 + bf16 | zero1 + bf16 | zero1 + bf16 |
+| trainable / total params | 14B / 14B | 14B / 14B | 14B / 14B |
+| GPUs for training | 32×A100 (80G) | 32×A100 (80G) | 32×A100 (80G) |
+| Required GPU memory | 80G | 80G | 80G |
+
+## 🔥 Retrieval Fine-tuning (Head)
+
+> Note: This section demonstrates how to perform a cost-effective fine-tuning of our model. The hyperparameters shown here are not optimized for any specific task. For practical applications, further adjustments to the hyperparameters may be necessary to achieve optimal performance.
+
+To fine-tune the head of InternVL on Flickr30K with 4 GPUs, run:
+
+```bash
+GPUS=4 BATCH_SIZE=32 sh shell/head_finetune/internvl_stage2_finetune_flickr_224_bs1024_ep10_head_4gpu.sh
+```
+
+To fine-tune the head of InternVL on Flickr30K-CN with 4 GPUs, run:
+
+```shell
+GPUS=4 BATCH_SIZE=32 sh shell/head_finetune/internvl_stage2_finetune_flickrcn_224_bs1024_ep10_head_4gpu.sh
+```
+
+To fine-tune the head of InternVL on COCO with 4 GPUs, run:
+
+```shell
+GPUS=4 BATCH_SIZE=32 shell/head_finetune/internvl_stage2_finetune_coco_224_bs1024_ep5_head_4gpu.sh
+```
+
+The hyperparameters used here are:
+
+| config | Flickr30K | Flickr30K-CN | COCO |
+| ------------------------ | ------------- | ------------- | ------------- |
+| learning rate | 1e-6 | 1e-6 | 1e-6 |
+| optimizer | AdamW | AdamW | AdamW |
+| weight decay | 0.05 | 0.05 | 0.05 |
+| input resolution | 224x224 | 224x224 | 224x224 |
+| total batch size | 4x32 | 4x32 | 4x32 |
+| warm-up iterations | 100 | 100 | 100 |
+| training epochs | 10 | 10 | 5 |
+| drop path rate | 0.0 | 0.0 | 0.3 |
+| numerical precision | zero3 + bf16 | zero3 + bf16 | zero1 + bf16 |
+| trainable / total params | 0.2B / 14B | 0.2B / 14B | 0.2B / 14B |
+| GPUs for training | 4×GPU (>=32G) | 4×GPU (>=32G) | 4×GPU (>=32G) |
+| Required GPU memory | 24G | 24G | 24G |
+
+## 🔥 Retrieval Fine-tuning (LoRA)
+
+> Note: This section demonstrates how to perform a cost-effective fine-tuning of our model. The hyperparameters shown here are not optimized for any specific task. For practical applications, further adjustments to the hyperparameters may be necessary to achieve optimal performance.
+
+To fine-tune InternVL using LoRA on Flickr30K with 4 GPUs, run:
+
+```bash
+GPUS=4 BATCH_SIZE=32 sh shell/lora_finetune/internvl_stage2_finetune_flickr_224_bs1024_ep10_lora16_4gpu.sh
+```
+
+To fine-tune InternVL using LoRA on Flickr30K-CN with 4 GPUs, run:
+
+```shell
+GPUS=4 BATCH_SIZE=32 sh shell/lora_finetune/internvl_stage2_finetune_flickrcn_224_bs1024_ep10_lora16_4gpu.sh
+```
+
+To fine-tune InternVL using LoRA on COCO with 4 GPUs, run:
+
+```shell
+GPUS=4 BATCH_SIZE=32 shell/lora_finetune/internvl_stage2_finetune_coco_224_bs1024_ep5_lora16_4gpu.sh
+```
+
+The hyperparameters used here are:
+
+| config | Flickr30K | Flickr30K-CN | COCO |
+| ------------------------ | ------------- | ------------- | ------------- |
+| learning rate | 1e-6 | 1e-6 | 1e-6 |
+| optimizer | AdamW | AdamW | AdamW |
+| lora rank | 16 | 16 | 16 |
+| weight decay | 0.05 | 0.05 | 0.05 |
+| input resolution | 224x224 | 224x224 | 224x224 |
+| total batch size | 4x32 | 4x32 | 4x32 |
+| warm-up iterations | 100 | 100 | 100 |
+| training epochs | 10 | 10 | 5 |
+| drop path rate | 0.0 | 0.0 | 0.3 |
+| numerical precision | zero3 + bf16 | zero3 + bf16 | zero1 + bf16 |
+| trainable / total params | 0.3B / 14B | 0.3B / 14B | 0.3B / 14B |
+| GPUs for training | 4×GPU (>=40G) | 4×GPU (>=40G) | 4×GPU (>=40G) |
+| Required GPU memory | 37G | 37G | 37G |
+
+## Fine-Tuning a Custom Dataset
+
+1. **Organize Your Data**: Format your dataset similar to COCO or Flickr30K.
+
+2. **Update Meta Information**: Add your dataset's meta information to the `ds_collections` dictionary in `internvl_g/internvl/train/internvl_stage2_finetune.py`. For example:
+
+ ```python
+ ds_collections = {
+ 'my_dataset_flickr_format': {
+ 'root': './data/my_dataset/images/',
+ 'annotation': './data/my_dataset/annotations.txt',
+ },
+ 'my_dataset_coco_format': {
+ 'root': './data/my_dataset/',
+ 'annotation': './data/my_dataset/annotations.json',
+ },
+ }
+ ```
+
+3. **Name Your Dataset**:
+
+ - Include `flickr_format` or `coco_format` in your dataset's `dataset_name`. This will allow the script to reuse the Flickr30K or COCO dataloader accordingly.
+
+By following these steps, you can easily fine-tune the InternVL model on your custom dataset using the existing COCO or Flickr30K data loading mechanisms.
diff --git a/InternVL/segmentation/dist_test.sh b/InternVL/segmentation/dist_test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e66ffec6f7e112670df86c33721e8fa7d337e6b0
--- /dev/null
+++ b/InternVL/segmentation/dist_test.sh
@@ -0,0 +1,9 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+CHECKPOINT=$2
+GPUS=$3
+PORT=${PORT:-29510}
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+torchrun --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/test.py $CONFIG $CHECKPOINT --launcher pytorch ${@:4}
diff --git a/InternVL/segmentation/dist_train.sh b/InternVL/segmentation/dist_train.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ccf2159759c0901b478629a66d2a63f44fe6ba48
--- /dev/null
+++ b/InternVL/segmentation/dist_train.sh
@@ -0,0 +1,9 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+GPUS=$2
+PORT=${PORT:-29300}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+torchrun --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/train.py $CONFIG --launcher pytorch --deterministic ${@:3}
diff --git a/InternVL/segmentation/train.py b/InternVL/segmentation/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..b538e45e15f2a29a149436f7634282de56c3a670
--- /dev/null
+++ b/InternVL/segmentation/train.py
@@ -0,0 +1,220 @@
+# --------------------------------------------------------
+# InternVL
+# Copyright (c) 2023 OpenGVLab
+# Licensed under The MIT License [see LICENSE for details]
+# --------------------------------------------------------
+import argparse
+import copy
+import os
+import os.path as osp
+import time
+import warnings
+
+import mmcv
+import mmcv_custom # noqa: F401,F403
+import mmseg_custom # noqa: F401,F403
+import torch
+from mmcv.cnn.utils import revert_sync_batchnorm
+from mmcv.runner import get_dist_info, init_dist
+from mmcv.utils import Config, DictAction, get_git_hash
+from mmseg import __version__
+from mmseg.apis import init_random_seed, set_random_seed, train_segmentor
+from mmseg.datasets import build_dataset
+from mmseg.models import build_segmentor
+from mmseg.utils import collect_env, get_root_logger
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a segmentor')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument('--work-dir', help='the dir to save logs and models')
+ parser.add_argument(
+ '--load-from', help='the checkpoint file to load weights from')
+ parser.add_argument(
+ '--resume-from', help='the checkpoint file to resume from')
+ parser.add_argument(
+ '--no-validate',
+ action='store_true',
+ help='whether not to evaluate the checkpoint during training')
+ group_gpus = parser.add_mutually_exclusive_group()
+ group_gpus.add_argument(
+ '--gpus',
+ type=int,
+ help='number of gpus to use '
+ '(only applicable to non-distributed training)')
+ group_gpus.add_argument(
+ '--gpu-ids',
+ type=int,
+ nargs='+',
+ help='ids of gpus to use '
+ '(only applicable to non-distributed training)')
+ parser.add_argument('--seed', type=int, default=None, help='random seed')
+ parser.add_argument(
+ '--deterministic',
+ action='store_true',
+ help='whether to set deterministic options for CUDNN backend.')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help="--options is deprecated in favor of --cfg_options' and it will "
+ 'not be supported in version v0.22.0. Override some settings in the '
+ 'used config, the key-value pair in xxx=yyy format will be merged '
+ 'into config file. If the value to be overwritten is a list, it '
+ 'should be like key="[a,b]" or key=a,b It also allows nested '
+ 'list/tuple values, e.g. key="[(a,b),(c,d)]" Note that the quotation '
+ 'marks are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ parser.add_argument(
+ '--auto-resume',
+ action='store_true',
+ help='resume from the latest checkpoint automatically.')
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options. '
+ '--options will not be supported in version v0.22.0.')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ if args.load_from is not None:
+ cfg.load_from = args.load_from
+ if args.resume_from is not None:
+ cfg.resume_from = args.resume_from
+ if args.gpu_ids is not None:
+ cfg.gpu_ids = args.gpu_ids
+ else:
+ cfg.gpu_ids = range(1) if args.gpus is None else range(args.gpus)
+ cfg.auto_resume = args.auto_resume
+
+ # init distributed env first, since logger depends on the dist info.
+ if args.launcher == 'none':
+ distributed = False
+ else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+ # gpu_ids is used to calculate iter when resuming checkpoint
+ _, world_size = get_dist_info()
+ cfg.gpu_ids = range(world_size)
+
+ cfg.device = 'cuda' # fix 'ConfigDict' object has no attribute 'device'
+ # create work_dir
+ mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
+ # dump config
+ cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
+ # init the logger before other steps
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
+ logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
+
+ # init the meta dict to record some important information such as
+ # environment info and seed, which will be logged
+ meta = dict()
+ # log env info
+ env_info_dict = collect_env()
+ env_info = '\n'.join([f'{k}: {v}' for k, v in env_info_dict.items()])
+ dash_line = '-' * 60 + '\n'
+ logger.info('Environment info:\n' + dash_line + env_info + '\n' +
+ dash_line)
+ meta['env_info'] = env_info
+
+ # log some basic info
+ logger.info(f'Distributed training: {distributed}')
+ logger.info(f'Config:\n{cfg.pretty_text}')
+
+ # set random seeds
+ seed = init_random_seed(args.seed)
+ logger.info(f'Set random seed to {seed}, '
+ f'deterministic: {args.deterministic}')
+ set_random_seed(seed, deterministic=args.deterministic)
+ cfg.seed = seed
+ meta['seed'] = seed
+ meta['exp_name'] = osp.basename(args.config)
+
+ model = build_segmentor(
+ cfg.model,
+ train_cfg=cfg.get('train_cfg'),
+ test_cfg=cfg.get('test_cfg'))
+ model.init_weights()
+
+ # SyncBN is not support for DP
+ if not distributed:
+ warnings.warn(
+ 'SyncBN is only supported with DDP. To be compatible with DP, '
+ 'we convert SyncBN to BN. Please use dist_train.sh which can '
+ 'avoid this error.')
+ model = revert_sync_batchnorm(model)
+
+ logger.info(model)
+
+ datasets = [build_dataset(cfg.data.train)]
+ if len(cfg.workflow) == 2:
+ val_dataset = copy.deepcopy(cfg.data.val)
+ val_dataset.pipeline = cfg.data.train.pipeline
+ datasets.append(build_dataset(val_dataset))
+ if cfg.checkpoint_config is not None:
+ # save mmseg version, config file content and class names in
+ # checkpoints as meta data
+ cfg.checkpoint_config.meta = dict(
+ mmseg_version=f'{__version__}+{get_git_hash()[:7]}',
+ config=cfg.pretty_text,
+ CLASSES=datasets[0].CLASSES,
+ PALETTE=datasets[0].PALETTE)
+ # add an attribute for visualization convenience
+ model.CLASSES = datasets[0].CLASSES
+ # passing checkpoint meta for saving best checkpoint
+ meta.update(cfg.checkpoint_config.meta)
+ train_segmentor(
+ model,
+ datasets,
+ cfg,
+ distributed=distributed,
+ validate=(not args.no_validate),
+ timestamp=timestamp,
+ meta=meta)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/InternVL/streamlit_demo/constants.py b/InternVL/streamlit_demo/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c37af1aeef36d56987e8373514e0e5e5b5a5ccd
--- /dev/null
+++ b/InternVL/streamlit_demo/constants.py
@@ -0,0 +1,23 @@
+# --------------------------------------------------------
+# InternVL
+# Copyright (c) 2024 OpenGVLab
+# Licensed under The MIT License [see LICENSE for details]
+# --------------------------------------------------------
+
+CONTROLLER_HEART_BEAT_EXPIRATION = 30
+WORKER_HEART_BEAT_INTERVAL = 15
+
+LOGDIR = 'logs/'
+
+# Model Constants
+IGNORE_INDEX = -100
+IMAGE_TOKEN_INDEX = -200
+DEFAULT_IMAGE_TOKEN = ''
+DEFAULT_IMAGE_PATCH_TOKEN = ''
+DEFAULT_IM_START_TOKEN = '![]() '
+DEFAULT_IM_END_TOKEN = ''
+IMAGE_PLACEHOLDER = ''
+IMAGENET_MEAN = (0.485, 0.456, 0.406)
+IMAGENET_STD = (0.229, 0.224, 0.225)
+
+server_error_msg = '**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**'
diff --git a/InternVL/streamlit_demo/controller.py b/InternVL/streamlit_demo/controller.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a8e090e8f250a11cd6064ed80d8a649258e1e42
--- /dev/null
+++ b/InternVL/streamlit_demo/controller.py
@@ -0,0 +1,291 @@
+"""
+A controller manages distributed workers.
+It sends worker addresses to clients.
+"""
+import argparse
+import dataclasses
+import json
+import re
+import threading
+import time
+from enum import Enum, auto
+from typing import List
+
+import numpy as np
+import requests
+import uvicorn
+from fastapi import FastAPI, Request
+from fastapi.responses import StreamingResponse
+from utils import build_logger, server_error_msg
+
+CONTROLLER_HEART_BEAT_EXPIRATION = 30
+logger = build_logger('controller', 'controller.log')
+
+
+class DispatchMethod(Enum):
+ LOTTERY = auto()
+ SHORTEST_QUEUE = auto()
+
+ @classmethod
+ def from_str(cls, name):
+ if name == 'lottery':
+ return cls.LOTTERY
+ elif name == 'shortest_queue':
+ return cls.SHORTEST_QUEUE
+ else:
+ raise ValueError(f'Invalid dispatch method')
+
+
+@dataclasses.dataclass
+class WorkerInfo:
+ model_names: List[str]
+ speed: int
+ queue_length: int
+ check_heart_beat: bool
+ last_heart_beat: str
+
+
+def heart_beat_controller(controller):
+ while True:
+ time.sleep(CONTROLLER_HEART_BEAT_EXPIRATION)
+ controller.remove_stable_workers_by_expiration()
+
+
+class Controller:
+ def __init__(self, dispatch_method: str):
+ # Dict[str -> WorkerInfo]
+ self.worker_info = {}
+ self.dispatch_method = DispatchMethod.from_str(dispatch_method)
+
+ self.heart_beat_thread = threading.Thread(
+ target=heart_beat_controller, args=(self,))
+ self.heart_beat_thread.start()
+
+ logger.info('Init controller')
+
+ def register_worker(self, worker_name: str, check_heart_beat: bool,
+ worker_status: dict):
+ if worker_name not in self.worker_info:
+ logger.info(f'Register a new worker: {worker_name}')
+ else:
+ logger.info(f'Register an existing worker: {worker_name}')
+
+ if not worker_status:
+ worker_status = self.get_worker_status(worker_name)
+ if not worker_status:
+ return False
+
+ self.worker_info[worker_name] = WorkerInfo(
+ worker_status['model_names'], worker_status['speed'], worker_status['queue_length'],
+ check_heart_beat, time.time())
+
+ logger.info(f'Register done: {worker_name}, {worker_status}')
+ return True
+
+ def get_worker_status(self, worker_name: str):
+ try:
+ r = requests.post(worker_name + '/worker_get_status', timeout=5)
+ except requests.exceptions.RequestException as e:
+ logger.error(f'Get status fails: {worker_name}, {e}')
+ return None
+
+ if r.status_code != 200:
+ logger.error(f'Get status fails: {worker_name}, {r}')
+ return None
+
+ return r.json()
+
+ def remove_worker(self, worker_name: str):
+ del self.worker_info[worker_name]
+
+ def refresh_all_workers(self):
+ old_info = dict(self.worker_info)
+ self.worker_info = {}
+
+ for w_name, w_info in old_info.items():
+ if not self.register_worker(w_name, w_info.check_heart_beat, None):
+ logger.info(f'Remove stale worker: {w_name}')
+
+ def list_models(self):
+ model_names = set()
+
+ for w_name, w_info in self.worker_info.items():
+ model_names.update(w_info.model_names)
+
+ def extract_key(s):
+ if 'Pro' in s:
+ return 999
+ match = re.match(r'InternVL2-(\d+)B', s)
+ if match:
+ return int(match.group(1))
+ return -1
+
+ def custom_sort_key(s):
+ key = extract_key(s)
+ # Return a tuple where -1 will ensure that non-matching items come last
+ return (0 if key != -1 else 1, -key if key != -1 else s)
+
+ sorted_list = sorted(list(model_names), key=custom_sort_key)
+ return sorted_list
+
+ def get_worker_address(self, model_name: str):
+ if self.dispatch_method == DispatchMethod.LOTTERY:
+ worker_names = []
+ worker_speeds = []
+ for w_name, w_info in self.worker_info.items():
+ if model_name in w_info.model_names:
+ worker_names.append(w_name)
+ worker_speeds.append(w_info.speed)
+ worker_speeds = np.array(worker_speeds, dtype=np.float32)
+ norm = np.sum(worker_speeds)
+ if norm < 1e-4:
+ return ''
+ worker_speeds = worker_speeds / norm
+ if True: # Directly return address
+ pt = np.random.choice(np.arange(len(worker_names)),
+ p=worker_speeds)
+ worker_name = worker_names[pt]
+ return worker_name
+
+ elif self.dispatch_method == DispatchMethod.SHORTEST_QUEUE:
+ worker_names = []
+ worker_qlen = []
+ for w_name, w_info in self.worker_info.items():
+ if model_name in w_info.model_names:
+ worker_names.append(w_name)
+ worker_qlen.append(w_info.queue_length / w_info.speed)
+ if len(worker_names) == 0:
+ return ''
+ min_index = np.argmin(worker_qlen)
+ w_name = worker_names[min_index]
+ self.worker_info[w_name].queue_length += 1
+ logger.info(f'names: {worker_names}, queue_lens: {worker_qlen}, ret: {w_name}')
+ return w_name
+ else:
+ raise ValueError(f'Invalid dispatch method: {self.dispatch_method}')
+
+ def receive_heart_beat(self, worker_name: str, queue_length: int):
+ if worker_name not in self.worker_info:
+ logger.info(f'Receive unknown heart beat. {worker_name}')
+ return False
+
+ self.worker_info[worker_name].queue_length = queue_length
+ self.worker_info[worker_name].last_heart_beat = time.time()
+ logger.info(f'Receive heart beat. {worker_name}')
+ return True
+
+ def remove_stable_workers_by_expiration(self):
+ expire = time.time() - CONTROLLER_HEART_BEAT_EXPIRATION
+ to_delete = []
+ for worker_name, w_info in self.worker_info.items():
+ if w_info.check_heart_beat and w_info.last_heart_beat < expire:
+ to_delete.append(worker_name)
+
+ for worker_name in to_delete:
+ self.remove_worker(worker_name)
+
+ def worker_api_generate_stream(self, params):
+ worker_addr = self.get_worker_address(params['model'])
+ if not worker_addr:
+ logger.info(f"no worker: {params['model']}")
+ ret = {
+ 'text': server_error_msg,
+ 'error_code': 2,
+ }
+ yield json.dumps(ret).encode() + b'\0'
+
+ try:
+ response = requests.post(worker_addr + '/worker_generate_stream',
+ json=params, stream=True, timeout=5)
+ for chunk in response.iter_lines(decode_unicode=False, delimiter=b'\0'):
+ if chunk:
+ yield chunk + b'\0'
+ except requests.exceptions.RequestException as e:
+ logger.info(f'worker timeout: {worker_addr}')
+ ret = {
+ 'text': server_error_msg,
+ 'error_code': 3,
+ }
+ yield json.dumps(ret).encode() + b'\0'
+
+ # Let the controller act as a worker to achieve hierarchical
+ # management. This can be used to connect isolated sub networks.
+ def worker_api_get_status(self):
+ model_names = set()
+ speed = 0
+ queue_length = 0
+
+ for w_name in self.worker_info:
+ worker_status = self.get_worker_status(w_name)
+ if worker_status is not None:
+ model_names.update(worker_status['model_names'])
+ speed += worker_status['speed']
+ queue_length += worker_status['queue_length']
+
+ return {
+ 'model_names': list(model_names),
+ 'speed': speed,
+ 'queue_length': queue_length,
+ }
+
+
+app = FastAPI()
+
+
+@app.post('/register_worker')
+async def register_worker(request: Request):
+ data = await request.json()
+ controller.register_worker(
+ data['worker_name'], data['check_heart_beat'],
+ data.get('worker_status', None))
+
+
+@app.post('/refresh_all_workers')
+async def refresh_all_workers():
+ models = controller.refresh_all_workers()
+
+
+@app.post('/list_models')
+async def list_models():
+ models = controller.list_models()
+ return {'models': models}
+
+
+@app.post('/get_worker_address')
+async def get_worker_address(request: Request):
+ data = await request.json()
+ addr = controller.get_worker_address(data['model'])
+ return {'address': addr}
+
+
+@app.post('/receive_heart_beat')
+async def receive_heart_beat(request: Request):
+ data = await request.json()
+ exist = controller.receive_heart_beat(
+ data['worker_name'], data['queue_length'])
+ return {'exist': exist}
+
+
+@app.post('/worker_generate_stream')
+async def worker_api_generate_stream(request: Request):
+ params = await request.json()
+ generator = controller.worker_api_generate_stream(params)
+ return StreamingResponse(generator)
+
+
+@app.post('/worker_get_status')
+async def worker_api_get_status(request: Request):
+ return controller.worker_api_get_status()
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--host', type=str, default='0.0.0.0')
+ parser.add_argument('--port', type=int, default=10075)
+ parser.add_argument('--dispatch-method', type=str, choices=[
+ 'lottery', 'shortest_queue'], default='shortest_queue')
+ args = parser.parse_args()
+ logger.info(f'args: {args}')
+
+ controller = Controller(args.dispatch_method)
+ uvicorn.run(app, host=args.host, port=args.port, log_level='info')
diff --git a/InternVL/streamlit_demo/model_worker.py b/InternVL/streamlit_demo/model_worker.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6fc90b7e3e742cb0fe61b9a5cd81b813068e3b7
--- /dev/null
+++ b/InternVL/streamlit_demo/model_worker.py
@@ -0,0 +1,442 @@
+# --------------------------------------------------------
+# InternVL
+# Copyright (c) 2024 OpenGVLab
+# Licensed under The MIT License [see LICENSE for details]
+# --------------------------------------------------------
+
+"""
+A model worker executes the model.
+"""
+import argparse
+import asyncio
+import base64
+import json
+import math
+import threading
+import time
+import uuid
+from functools import partial
+from io import BytesIO
+from threading import Thread
+
+import requests
+import torch
+import torchvision.transforms as T
+import uvicorn
+from constants import IMAGENET_MEAN, IMAGENET_STD, WORKER_HEART_BEAT_INTERVAL
+from fastapi import BackgroundTasks, FastAPI, Request
+from fastapi.responses import StreamingResponse
+from PIL import Image
+from torchvision.transforms.functional import InterpolationMode
+from transformers import AutoModel, AutoTokenizer, TextIteratorStreamer
+from utils import build_logger, pretty_print_semaphore, server_error_msg
+
+worker_id = str(uuid.uuid4())[:6]
+logger = build_logger('model_worker', f'model_worker_{worker_id}.log')
+global_counter = 0
+model_semaphore = None
+
+
+def load_image_from_base64(image):
+ return Image.open(BytesIO(base64.b64decode(image)))
+
+
+def build_transform(input_size):
+ MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
+ transform = T.Compose([
+ T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
+ T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
+ T.ToTensor(),
+ T.Normalize(mean=MEAN, std=STD)
+ ])
+ return transform
+
+
+def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
+ best_ratio_diff = float('inf')
+ best_ratio = (1, 1)
+ area = width * height
+ for ratio in target_ratios:
+ target_aspect_ratio = ratio[0] / ratio[1]
+ ratio_diff = abs(aspect_ratio - target_aspect_ratio)
+ if ratio_diff < best_ratio_diff:
+ best_ratio_diff = ratio_diff
+ best_ratio = ratio
+ elif ratio_diff == best_ratio_diff:
+ if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
+ best_ratio = ratio
+ return best_ratio
+
+
+def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):
+ orig_width, orig_height = image.size
+ aspect_ratio = orig_width / orig_height
+
+ # calculate the existing image aspect ratio
+ target_ratios = set(
+ (i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
+ i * j <= max_num and i * j >= min_num)
+ target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
+
+ # find the closest aspect ratio to the target
+ target_aspect_ratio = find_closest_aspect_ratio(
+ aspect_ratio, target_ratios, orig_width, orig_height, image_size)
+
+ # calculate the target width and height
+ target_width = image_size * target_aspect_ratio[0]
+ target_height = image_size * target_aspect_ratio[1]
+ blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
+
+ # resize the image
+ resized_img = image.resize((target_width, target_height))
+ processed_images = []
+ for i in range(blocks):
+ box = (
+ (i % (target_width // image_size)) * image_size,
+ (i // (target_width // image_size)) * image_size,
+ ((i % (target_width // image_size)) + 1) * image_size,
+ ((i // (target_width // image_size)) + 1) * image_size
+ )
+ # split the image
+ split_img = resized_img.crop(box)
+ processed_images.append(split_img)
+ assert len(processed_images) == blocks
+ if use_thumbnail and len(processed_images) != 1:
+ thumbnail_img = image.resize((image_size, image_size))
+ processed_images.append(thumbnail_img)
+ return processed_images
+
+
+def heart_beat_worker(controller):
+ while True:
+ time.sleep(WORKER_HEART_BEAT_INTERVAL)
+ controller.send_heart_beat()
+
+
+def split_model(model_name, vit_alpha=0.5):
+ device_map = {}
+ world_size = torch.cuda.device_count()
+ num_layers = {
+ 'InternVL-Chat-V1-1': 40, 'InternVL-Chat-V1-2': 60, 'InternVL-Chat-V1-2-Plus': 60,
+ 'Mini-InternVL-2B-V1-5': 24, 'Mini-InternVL-4B-V1-5': 32, 'InternVL-Chat-V1-5': 48,
+ 'InternVL2-8B': 32, 'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80,
+ 'InternVL2-78B': 80, 'InternVL2-Pro': 80}[model_name]
+ # Since the first GPU will be used for ViT, treat it as half a GPU.
+ num_layers_per_gpu = math.ceil(num_layers / (world_size - vit_alpha))
+ num_layers_per_gpu = [num_layers_per_gpu] * world_size
+ num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * (1 - vit_alpha))
+ layer_cnt = 0
+ for i, num_layer in enumerate(num_layers_per_gpu):
+ for j in range(num_layer):
+ device_map[f'language_model.model.layers.{layer_cnt}'] = i
+ layer_cnt += 1
+ device_map['vision_model'] = 0
+ device_map['mlp1'] = 0
+ device_map['language_model.model.tok_embeddings'] = 0
+ device_map['language_model.model.embed_tokens'] = 0
+ device_map['language_model.output'] = 0
+ device_map['language_model.model.norm'] = 0
+ device_map['language_model.lm_head'] = 0
+ device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
+
+ return device_map
+
+
+class ModelWorker:
+ def __init__(self, controller_addr, worker_addr, worker_id, model_path, model_name,
+ load_8bit, device, context_len=8192):
+ self.controller_addr = controller_addr
+ self.worker_addr = worker_addr
+ self.worker_id = worker_id
+ if model_path.endswith('/'):
+ model_path = model_path[:-1]
+ if model_name is None:
+ model_paths = model_path.split('/')
+ if model_paths[-1].startswith('checkpoint-'):
+ self.model_name = model_paths[-2] + '_' + model_paths[-1]
+ else:
+ self.model_name = model_paths[-1]
+ else:
+ self.model_name = model_name
+
+ logger.info(f'Loading the model {self.model_name} on worker {worker_id} ...')
+
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
+ tokens_to_keep = ['', '', '
'
+DEFAULT_IM_END_TOKEN = ''
+IMAGE_PLACEHOLDER = ''
+IMAGENET_MEAN = (0.485, 0.456, 0.406)
+IMAGENET_STD = (0.229, 0.224, 0.225)
+
+server_error_msg = '**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**'
diff --git a/InternVL/streamlit_demo/controller.py b/InternVL/streamlit_demo/controller.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a8e090e8f250a11cd6064ed80d8a649258e1e42
--- /dev/null
+++ b/InternVL/streamlit_demo/controller.py
@@ -0,0 +1,291 @@
+"""
+A controller manages distributed workers.
+It sends worker addresses to clients.
+"""
+import argparse
+import dataclasses
+import json
+import re
+import threading
+import time
+from enum import Enum, auto
+from typing import List
+
+import numpy as np
+import requests
+import uvicorn
+from fastapi import FastAPI, Request
+from fastapi.responses import StreamingResponse
+from utils import build_logger, server_error_msg
+
+CONTROLLER_HEART_BEAT_EXPIRATION = 30
+logger = build_logger('controller', 'controller.log')
+
+
+class DispatchMethod(Enum):
+ LOTTERY = auto()
+ SHORTEST_QUEUE = auto()
+
+ @classmethod
+ def from_str(cls, name):
+ if name == 'lottery':
+ return cls.LOTTERY
+ elif name == 'shortest_queue':
+ return cls.SHORTEST_QUEUE
+ else:
+ raise ValueError(f'Invalid dispatch method')
+
+
+@dataclasses.dataclass
+class WorkerInfo:
+ model_names: List[str]
+ speed: int
+ queue_length: int
+ check_heart_beat: bool
+ last_heart_beat: str
+
+
+def heart_beat_controller(controller):
+ while True:
+ time.sleep(CONTROLLER_HEART_BEAT_EXPIRATION)
+ controller.remove_stable_workers_by_expiration()
+
+
+class Controller:
+ def __init__(self, dispatch_method: str):
+ # Dict[str -> WorkerInfo]
+ self.worker_info = {}
+ self.dispatch_method = DispatchMethod.from_str(dispatch_method)
+
+ self.heart_beat_thread = threading.Thread(
+ target=heart_beat_controller, args=(self,))
+ self.heart_beat_thread.start()
+
+ logger.info('Init controller')
+
+ def register_worker(self, worker_name: str, check_heart_beat: bool,
+ worker_status: dict):
+ if worker_name not in self.worker_info:
+ logger.info(f'Register a new worker: {worker_name}')
+ else:
+ logger.info(f'Register an existing worker: {worker_name}')
+
+ if not worker_status:
+ worker_status = self.get_worker_status(worker_name)
+ if not worker_status:
+ return False
+
+ self.worker_info[worker_name] = WorkerInfo(
+ worker_status['model_names'], worker_status['speed'], worker_status['queue_length'],
+ check_heart_beat, time.time())
+
+ logger.info(f'Register done: {worker_name}, {worker_status}')
+ return True
+
+ def get_worker_status(self, worker_name: str):
+ try:
+ r = requests.post(worker_name + '/worker_get_status', timeout=5)
+ except requests.exceptions.RequestException as e:
+ logger.error(f'Get status fails: {worker_name}, {e}')
+ return None
+
+ if r.status_code != 200:
+ logger.error(f'Get status fails: {worker_name}, {r}')
+ return None
+
+ return r.json()
+
+ def remove_worker(self, worker_name: str):
+ del self.worker_info[worker_name]
+
+ def refresh_all_workers(self):
+ old_info = dict(self.worker_info)
+ self.worker_info = {}
+
+ for w_name, w_info in old_info.items():
+ if not self.register_worker(w_name, w_info.check_heart_beat, None):
+ logger.info(f'Remove stale worker: {w_name}')
+
+ def list_models(self):
+ model_names = set()
+
+ for w_name, w_info in self.worker_info.items():
+ model_names.update(w_info.model_names)
+
+ def extract_key(s):
+ if 'Pro' in s:
+ return 999
+ match = re.match(r'InternVL2-(\d+)B', s)
+ if match:
+ return int(match.group(1))
+ return -1
+
+ def custom_sort_key(s):
+ key = extract_key(s)
+ # Return a tuple where -1 will ensure that non-matching items come last
+ return (0 if key != -1 else 1, -key if key != -1 else s)
+
+ sorted_list = sorted(list(model_names), key=custom_sort_key)
+ return sorted_list
+
+ def get_worker_address(self, model_name: str):
+ if self.dispatch_method == DispatchMethod.LOTTERY:
+ worker_names = []
+ worker_speeds = []
+ for w_name, w_info in self.worker_info.items():
+ if model_name in w_info.model_names:
+ worker_names.append(w_name)
+ worker_speeds.append(w_info.speed)
+ worker_speeds = np.array(worker_speeds, dtype=np.float32)
+ norm = np.sum(worker_speeds)
+ if norm < 1e-4:
+ return ''
+ worker_speeds = worker_speeds / norm
+ if True: # Directly return address
+ pt = np.random.choice(np.arange(len(worker_names)),
+ p=worker_speeds)
+ worker_name = worker_names[pt]
+ return worker_name
+
+ elif self.dispatch_method == DispatchMethod.SHORTEST_QUEUE:
+ worker_names = []
+ worker_qlen = []
+ for w_name, w_info in self.worker_info.items():
+ if model_name in w_info.model_names:
+ worker_names.append(w_name)
+ worker_qlen.append(w_info.queue_length / w_info.speed)
+ if len(worker_names) == 0:
+ return ''
+ min_index = np.argmin(worker_qlen)
+ w_name = worker_names[min_index]
+ self.worker_info[w_name].queue_length += 1
+ logger.info(f'names: {worker_names}, queue_lens: {worker_qlen}, ret: {w_name}')
+ return w_name
+ else:
+ raise ValueError(f'Invalid dispatch method: {self.dispatch_method}')
+
+ def receive_heart_beat(self, worker_name: str, queue_length: int):
+ if worker_name not in self.worker_info:
+ logger.info(f'Receive unknown heart beat. {worker_name}')
+ return False
+
+ self.worker_info[worker_name].queue_length = queue_length
+ self.worker_info[worker_name].last_heart_beat = time.time()
+ logger.info(f'Receive heart beat. {worker_name}')
+ return True
+
+ def remove_stable_workers_by_expiration(self):
+ expire = time.time() - CONTROLLER_HEART_BEAT_EXPIRATION
+ to_delete = []
+ for worker_name, w_info in self.worker_info.items():
+ if w_info.check_heart_beat and w_info.last_heart_beat < expire:
+ to_delete.append(worker_name)
+
+ for worker_name in to_delete:
+ self.remove_worker(worker_name)
+
+ def worker_api_generate_stream(self, params):
+ worker_addr = self.get_worker_address(params['model'])
+ if not worker_addr:
+ logger.info(f"no worker: {params['model']}")
+ ret = {
+ 'text': server_error_msg,
+ 'error_code': 2,
+ }
+ yield json.dumps(ret).encode() + b'\0'
+
+ try:
+ response = requests.post(worker_addr + '/worker_generate_stream',
+ json=params, stream=True, timeout=5)
+ for chunk in response.iter_lines(decode_unicode=False, delimiter=b'\0'):
+ if chunk:
+ yield chunk + b'\0'
+ except requests.exceptions.RequestException as e:
+ logger.info(f'worker timeout: {worker_addr}')
+ ret = {
+ 'text': server_error_msg,
+ 'error_code': 3,
+ }
+ yield json.dumps(ret).encode() + b'\0'
+
+ # Let the controller act as a worker to achieve hierarchical
+ # management. This can be used to connect isolated sub networks.
+ def worker_api_get_status(self):
+ model_names = set()
+ speed = 0
+ queue_length = 0
+
+ for w_name in self.worker_info:
+ worker_status = self.get_worker_status(w_name)
+ if worker_status is not None:
+ model_names.update(worker_status['model_names'])
+ speed += worker_status['speed']
+ queue_length += worker_status['queue_length']
+
+ return {
+ 'model_names': list(model_names),
+ 'speed': speed,
+ 'queue_length': queue_length,
+ }
+
+
+app = FastAPI()
+
+
+@app.post('/register_worker')
+async def register_worker(request: Request):
+ data = await request.json()
+ controller.register_worker(
+ data['worker_name'], data['check_heart_beat'],
+ data.get('worker_status', None))
+
+
+@app.post('/refresh_all_workers')
+async def refresh_all_workers():
+ models = controller.refresh_all_workers()
+
+
+@app.post('/list_models')
+async def list_models():
+ models = controller.list_models()
+ return {'models': models}
+
+
+@app.post('/get_worker_address')
+async def get_worker_address(request: Request):
+ data = await request.json()
+ addr = controller.get_worker_address(data['model'])
+ return {'address': addr}
+
+
+@app.post('/receive_heart_beat')
+async def receive_heart_beat(request: Request):
+ data = await request.json()
+ exist = controller.receive_heart_beat(
+ data['worker_name'], data['queue_length'])
+ return {'exist': exist}
+
+
+@app.post('/worker_generate_stream')
+async def worker_api_generate_stream(request: Request):
+ params = await request.json()
+ generator = controller.worker_api_generate_stream(params)
+ return StreamingResponse(generator)
+
+
+@app.post('/worker_get_status')
+async def worker_api_get_status(request: Request):
+ return controller.worker_api_get_status()
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--host', type=str, default='0.0.0.0')
+ parser.add_argument('--port', type=int, default=10075)
+ parser.add_argument('--dispatch-method', type=str, choices=[
+ 'lottery', 'shortest_queue'], default='shortest_queue')
+ args = parser.parse_args()
+ logger.info(f'args: {args}')
+
+ controller = Controller(args.dispatch_method)
+ uvicorn.run(app, host=args.host, port=args.port, log_level='info')
diff --git a/InternVL/streamlit_demo/model_worker.py b/InternVL/streamlit_demo/model_worker.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6fc90b7e3e742cb0fe61b9a5cd81b813068e3b7
--- /dev/null
+++ b/InternVL/streamlit_demo/model_worker.py
@@ -0,0 +1,442 @@
+# --------------------------------------------------------
+# InternVL
+# Copyright (c) 2024 OpenGVLab
+# Licensed under The MIT License [see LICENSE for details]
+# --------------------------------------------------------
+
+"""
+A model worker executes the model.
+"""
+import argparse
+import asyncio
+import base64
+import json
+import math
+import threading
+import time
+import uuid
+from functools import partial
+from io import BytesIO
+from threading import Thread
+
+import requests
+import torch
+import torchvision.transforms as T
+import uvicorn
+from constants import IMAGENET_MEAN, IMAGENET_STD, WORKER_HEART_BEAT_INTERVAL
+from fastapi import BackgroundTasks, FastAPI, Request
+from fastapi.responses import StreamingResponse
+from PIL import Image
+from torchvision.transforms.functional import InterpolationMode
+from transformers import AutoModel, AutoTokenizer, TextIteratorStreamer
+from utils import build_logger, pretty_print_semaphore, server_error_msg
+
+worker_id = str(uuid.uuid4())[:6]
+logger = build_logger('model_worker', f'model_worker_{worker_id}.log')
+global_counter = 0
+model_semaphore = None
+
+
+def load_image_from_base64(image):
+ return Image.open(BytesIO(base64.b64decode(image)))
+
+
+def build_transform(input_size):
+ MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
+ transform = T.Compose([
+ T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
+ T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
+ T.ToTensor(),
+ T.Normalize(mean=MEAN, std=STD)
+ ])
+ return transform
+
+
+def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
+ best_ratio_diff = float('inf')
+ best_ratio = (1, 1)
+ area = width * height
+ for ratio in target_ratios:
+ target_aspect_ratio = ratio[0] / ratio[1]
+ ratio_diff = abs(aspect_ratio - target_aspect_ratio)
+ if ratio_diff < best_ratio_diff:
+ best_ratio_diff = ratio_diff
+ best_ratio = ratio
+ elif ratio_diff == best_ratio_diff:
+ if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
+ best_ratio = ratio
+ return best_ratio
+
+
+def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):
+ orig_width, orig_height = image.size
+ aspect_ratio = orig_width / orig_height
+
+ # calculate the existing image aspect ratio
+ target_ratios = set(
+ (i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
+ i * j <= max_num and i * j >= min_num)
+ target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
+
+ # find the closest aspect ratio to the target
+ target_aspect_ratio = find_closest_aspect_ratio(
+ aspect_ratio, target_ratios, orig_width, orig_height, image_size)
+
+ # calculate the target width and height
+ target_width = image_size * target_aspect_ratio[0]
+ target_height = image_size * target_aspect_ratio[1]
+ blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
+
+ # resize the image
+ resized_img = image.resize((target_width, target_height))
+ processed_images = []
+ for i in range(blocks):
+ box = (
+ (i % (target_width // image_size)) * image_size,
+ (i // (target_width // image_size)) * image_size,
+ ((i % (target_width // image_size)) + 1) * image_size,
+ ((i // (target_width // image_size)) + 1) * image_size
+ )
+ # split the image
+ split_img = resized_img.crop(box)
+ processed_images.append(split_img)
+ assert len(processed_images) == blocks
+ if use_thumbnail and len(processed_images) != 1:
+ thumbnail_img = image.resize((image_size, image_size))
+ processed_images.append(thumbnail_img)
+ return processed_images
+
+
+def heart_beat_worker(controller):
+ while True:
+ time.sleep(WORKER_HEART_BEAT_INTERVAL)
+ controller.send_heart_beat()
+
+
+def split_model(model_name, vit_alpha=0.5):
+ device_map = {}
+ world_size = torch.cuda.device_count()
+ num_layers = {
+ 'InternVL-Chat-V1-1': 40, 'InternVL-Chat-V1-2': 60, 'InternVL-Chat-V1-2-Plus': 60,
+ 'Mini-InternVL-2B-V1-5': 24, 'Mini-InternVL-4B-V1-5': 32, 'InternVL-Chat-V1-5': 48,
+ 'InternVL2-8B': 32, 'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80,
+ 'InternVL2-78B': 80, 'InternVL2-Pro': 80}[model_name]
+ # Since the first GPU will be used for ViT, treat it as half a GPU.
+ num_layers_per_gpu = math.ceil(num_layers / (world_size - vit_alpha))
+ num_layers_per_gpu = [num_layers_per_gpu] * world_size
+ num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * (1 - vit_alpha))
+ layer_cnt = 0
+ for i, num_layer in enumerate(num_layers_per_gpu):
+ for j in range(num_layer):
+ device_map[f'language_model.model.layers.{layer_cnt}'] = i
+ layer_cnt += 1
+ device_map['vision_model'] = 0
+ device_map['mlp1'] = 0
+ device_map['language_model.model.tok_embeddings'] = 0
+ device_map['language_model.model.embed_tokens'] = 0
+ device_map['language_model.output'] = 0
+ device_map['language_model.model.norm'] = 0
+ device_map['language_model.lm_head'] = 0
+ device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
+
+ return device_map
+
+
+class ModelWorker:
+ def __init__(self, controller_addr, worker_addr, worker_id, model_path, model_name,
+ load_8bit, device, context_len=8192):
+ self.controller_addr = controller_addr
+ self.worker_addr = worker_addr
+ self.worker_id = worker_id
+ if model_path.endswith('/'):
+ model_path = model_path[:-1]
+ if model_name is None:
+ model_paths = model_path.split('/')
+ if model_paths[-1].startswith('checkpoint-'):
+ self.model_name = model_paths[-2] + '_' + model_paths[-1]
+ else:
+ self.model_name = model_paths[-1]
+ else:
+ self.model_name = model_name
+
+ logger.info(f'Loading the model {self.model_name} on worker {worker_id} ...')
+
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
+ tokens_to_keep = ['', '', '[', ']']
+ tokenizer.additional_special_tokens = [item for item in tokenizer.additional_special_tokens if item not in tokens_to_keep]
+ self.tokenizer = tokenizer
+
+ if device == 'auto':
+ device_map = split_model(self.model_name)
+ self.model = AutoModel.from_pretrained(
+ model_path,
+ load_in_8bit=load_8bit,
+ torch_dtype=torch.bfloat16,
+ device_map=device_map,
+ trust_remote_code=True).eval()
+ else:
+ self.model = AutoModel.from_pretrained(
+ model_path,
+ load_in_8bit=load_8bit,
+ torch_dtype=torch.bfloat16,
+ trust_remote_code=True).eval()
+ if not load_8bit and not device == 'auto':
+ self.model = self.model.cuda()
+ self.load_8bit = load_8bit
+ self.device = device
+ self.model_path = model_path
+ self.image_size = self.model.config.force_image_size
+ self.context_len = context_len
+ self.register_to_controller()
+ self.heart_beat_thread = threading.Thread(
+ target=heart_beat_worker, args=(self,))
+ self.heart_beat_thread.start()
+
+ def reload_model(self):
+ del self.model
+ torch.cuda.empty_cache()
+ if self.device == 'auto':
+ device_map = split_model(self.model_name)
+ self.model = AutoModel.from_pretrained(
+ self.model_path,
+ load_in_8bit=self.load_8bit,
+ torch_dtype=torch.bfloat16,
+ device_map=device_map,
+ trust_remote_code=True).eval()
+ else:
+ self.model = AutoModel.from_pretrained(
+ self.model_path,
+ load_in_8bit=self.load_8bit,
+ torch_dtype=torch.bfloat16,
+ trust_remote_code=True).eval()
+ if not self.load_8bit and not self.device == 'auto':
+ self.model = self.model.cuda()
+
+ def register_to_controller(self):
+ logger.info('Register to controller')
+
+ url = self.controller_addr + '/register_worker'
+ data = {
+ 'worker_name': self.worker_addr,
+ 'check_heart_beat': True,
+ 'worker_status': self.get_status()
+ }
+ r = requests.post(url, json=data)
+ assert r.status_code == 200
+
+ def send_heart_beat(self):
+ logger.info(f'Send heart beat. Models: {[self.model_name]}. '
+ f'Semaphore: {pretty_print_semaphore(model_semaphore)}. '
+ f'global_counter: {global_counter}')
+
+ url = self.controller_addr + '/receive_heart_beat'
+
+ while True:
+ try:
+ ret = requests.post(url, json={
+ 'worker_name': self.worker_addr,
+ 'queue_length': self.get_queue_length()}, timeout=5)
+ exist = ret.json()['exist']
+ break
+ except requests.exceptions.RequestException as e:
+ logger.error(f'heart beat error: {e}')
+ time.sleep(5)
+
+ if not exist:
+ self.register_to_controller()
+
+ def get_queue_length(self):
+ if model_semaphore is None:
+ return 0
+ else:
+ return args.limit_model_concurrency - model_semaphore._value + (len(
+ model_semaphore._waiters) if model_semaphore._waiters is not None else 0)
+
+ def get_status(self):
+ return {
+ 'model_names': [self.model_name],
+ 'speed': 1,
+ 'queue_length': self.get_queue_length(),
+ }
+
+ @torch.inference_mode()
+ def generate_stream(self, params):
+ system_message = params['prompt'][0]['content']
+ send_messages = params['prompt'][1:]
+ max_input_tiles = params['max_input_tiles']
+ temperature = params['temperature']
+ top_p = params['top_p']
+ max_new_tokens = params['max_new_tokens']
+ repetition_penalty = params['repetition_penalty']
+ do_sample = True if temperature > 0.0 else False
+
+ global_image_cnt = 0
+ history, pil_images, max_input_tile_list = [], [], []
+ for message in send_messages:
+ if message['role'] == 'user':
+ prefix = ''
+ if 'image' in message:
+ max_input_tile_temp = []
+ for image_str in message['image']:
+ pil_images.append(load_image_from_base64(image_str))
+ prefix += f'Image-{global_image_cnt + 1}: \n'
+ global_image_cnt += 1
+ max_input_tile_temp.append(max(1, max_input_tiles // len(message['image'])))
+ if len(max_input_tile_temp) > 0:
+ max_input_tile_list.append(max_input_tile_temp)
+ content = prefix + message['content']
+ history.append([content, ])
+ else:
+ history[-1].append(message['content'])
+ question, history = history[-1][0], history[:-1]
+
+ if global_image_cnt == 1:
+ question = question.replace('Image-1: \n', '\n')
+ history = [[item[0].replace('Image-1: \n', '\n'), item[1]] for item in history]
+
+ # Create a new list to store processed sublists
+ flattened_list = []
+ # Iterate through all but the last sublist in max_input_tile_list and process them
+ for sublist in max_input_tile_list[:-1]:
+ processed_sublist = [1] * len(sublist) # Change each element in the sublist to 1
+ flattened_list.extend(processed_sublist) # Flatten the processed sublist and add to the new list
+ # If max_input_tile_list is not empty, add the last sublist to the new list
+ if max_input_tile_list:
+ flattened_list.extend(max_input_tile_list[-1])
+ max_input_tile_list = flattened_list
+ assert len(max_input_tile_list) == len(pil_images), 'The number of max_input_tile_list and pil_images should be the same.'
+
+ old_system_message = self.model.system_message
+ self.model.system_message = system_message
+ image_tiles, num_patches_list = [], []
+ transform = build_transform(input_size=self.image_size)
+ if len(pil_images) > 0:
+ for current_max_input_tiles, pil_image in zip(max_input_tile_list, pil_images):
+ if self.model.config.dynamic_image_size:
+ tiles = dynamic_preprocess(
+ pil_image, image_size=self.image_size, max_num=current_max_input_tiles,
+ use_thumbnail=self.model.config.use_thumbnail)
+ else:
+ tiles = [pil_image]
+ num_patches_list.append(len(tiles))
+ image_tiles += tiles
+ pixel_values = [transform(item) for item in image_tiles]
+ pixel_values = torch.stack(pixel_values).to(self.model.device, dtype=torch.bfloat16)
+ logger.info(f'Split images to {pixel_values.shape}')
+ else:
+ pixel_values = None
+
+ streamer = TextIteratorStreamer(self.tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
+ generation_config = dict(
+ num_beams=1,
+ max_new_tokens=max_new_tokens,
+ do_sample=do_sample,
+ temperature=temperature,
+ repetition_penalty=repetition_penalty,
+ max_length=self.context_len,
+ top_p=top_p,
+ streamer=streamer,
+ )
+ logger.info(f'Generation config: {generation_config}')
+
+ thread = Thread(target=self.model.chat, kwargs=dict(
+ tokenizer=self.tokenizer,
+ pixel_values=pixel_values,
+ num_patches_list=num_patches_list,
+ question=question,
+ history=history,
+ return_history=False,
+ generation_config=generation_config,
+ ))
+ thread.start()
+
+ generated_text = ''
+ for new_text in streamer:
+ generated_text += new_text
+ if generated_text.endswith(self.model.conv_template.sep):
+ generated_text = generated_text[:-len(self.model.conv_template.sep)]
+ yield json.dumps({'text': generated_text, 'error_code': 0}).encode() + b'\0'
+ logger.info(f'max_input_tile_list: {max_input_tile_list}, history: {history}, '
+ f'question: {question}, answer: {generated_text}')
+ self.model.system_message = old_system_message
+
+ def generate_stream_gate(self, params):
+ try:
+ for x in self.generate_stream(params):
+ yield x
+ except ValueError as e:
+ print('Caught ValueError:', e)
+ ret = {
+ 'text': server_error_msg,
+ 'error_code': 1,
+ }
+ yield json.dumps(ret).encode() + b'\0'
+ except torch.cuda.CudaError as e:
+ print('Caught torch.cuda.CudaError:', e)
+ ret = {
+ 'text': server_error_msg,
+ 'error_code': 1,
+ }
+ yield json.dumps(ret).encode() + b'\0'
+ except Exception as e:
+ print('Caught Unknown Error', e)
+ ret = {
+ 'text': server_error_msg,
+ 'error_code': 1,
+ }
+ yield json.dumps(ret).encode() + b'\0'
+
+
+app = FastAPI()
+
+
+def release_model_semaphore(fn=None):
+ model_semaphore.release()
+ if fn is not None:
+ fn()
+
+
+@app.post('/worker_generate_stream')
+async def generate_stream(request: Request):
+ global model_semaphore, global_counter
+ global_counter += 1
+ params = await request.json()
+
+ if model_semaphore is None:
+ model_semaphore = asyncio.Semaphore(args.limit_model_concurrency)
+ await model_semaphore.acquire()
+ worker.send_heart_beat()
+ generator = worker.generate_stream_gate(params)
+ background_tasks = BackgroundTasks()
+ background_tasks.add_task(partial(release_model_semaphore, fn=worker.send_heart_beat))
+ return StreamingResponse(generator, background=background_tasks)
+
+
+@app.post('/worker_get_status')
+async def get_status(request: Request):
+ return worker.get_status()
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--host', type=str, default='0.0.0.0')
+ parser.add_argument('--port', type=int, default=21002)
+ parser.add_argument('--worker-address', type=str, default='http://localhost:21002')
+ parser.add_argument('--controller-address', type=str, default='http://localhost:21001')
+ parser.add_argument('--model-path', type=str, default='facebook/opt-350m')
+ parser.add_argument('--model-name', type=str)
+ parser.add_argument('--device', type=str, default='cuda')
+ parser.add_argument('--limit-model-concurrency', type=int, default=5)
+ parser.add_argument('--stream-interval', type=int, default=1)
+ parser.add_argument('--load-8bit', action='store_true')
+ args = parser.parse_args()
+ logger.info(f'args: {args}')
+
+ worker = ModelWorker(args.controller_address,
+ args.worker_address,
+ worker_id,
+ args.model_path,
+ args.model_name,
+ args.load_8bit,
+ args.device)
+ uvicorn.run(app, host=args.host, port=args.port, log_level='info')
diff --git a/InternVL/video_retrieval/test_msrvtt.py b/InternVL/video_retrieval/test_msrvtt.py
new file mode 100644
index 0000000000000000000000000000000000000000..c52ac7a70d0ac68a0343023c1952a8feffe90b18
--- /dev/null
+++ b/InternVL/video_retrieval/test_msrvtt.py
@@ -0,0 +1,156 @@
+import argparse
+import io
+import json
+import math
+import os
+
+import decord
+import mmengine
+import numpy as np
+import torch
+import tqdm
+from transformers import AutoModel, AutoTokenizer, CLIPImageProcessor
+
+
+def recall_at_k(scores, positive_pairs, k):
+ """
+ Compute the recall at k for each sample
+ :param scores: compability score between text and image embeddings (nb texts, nb images)
+ :param k: number of images to consider per text, for retrieval
+ :param positive_pairs: boolean matrix of positive pairs (nb texts, nb images)
+ :return: recall at k averaged over all texts
+ """
+ nb_texts, nb_images = scores.shape
+ # for each text, sort according to image scores in decreasing order
+ topk_indices = torch.topk(scores, k, dim=1)[1]
+ # compute number of positives for each text
+ nb_positive = positive_pairs.sum(dim=1)
+ # nb_texts, k, nb_images
+ topk_indices_onehot = torch.nn.functional.one_hot(topk_indices, num_classes=nb_images)
+ # compute number of true positives
+ positive_pairs_reshaped = positive_pairs.view(nb_texts, 1, nb_images)
+ # a true positive means a positive among the topk
+ nb_true_positive = (topk_indices_onehot * positive_pairs_reshaped).sum(dim=(1, 2))
+ # compute recall at k
+ recall_at_k = (nb_true_positive / nb_positive)
+ return recall_at_k
+
+
+def batchify(func, X, Y, batch_size, device, *args, **kwargs):
+ results = []
+ for start in range(0, len(X), batch_size):
+ end = start + batch_size
+ x = X[start:end].to(device)
+ y = Y[start:end].to(device)
+ result = func(x, y, *args, **kwargs).cpu()
+ results.append(result)
+ return torch.cat(results)
+
+
+def validate_msrvtt(model, tokenizer, image_processor, root, metadata,
+ num_frames=1, prefix='summarize:', mode='InternVL-G', recall_k_list=[1, 5, 10],
+ use_dsl=True, eval_batch_size=32):
+ metadata = json.load(open(metadata))
+
+ video_features = []
+ text_features = []
+
+ # compute text features
+ print('Computing text features', flush=True)
+ for data in tqdm.tqdm(metadata):
+ caption = prefix + data['caption']
+ input_ids = tokenizer(caption, return_tensors='pt', max_length=80,
+ truncation=True, padding='max_length').input_ids.cuda()
+ with torch.no_grad():
+ feat = model.encode_text(input_ids)
+ text_features.append(feat.cpu())
+ text_features = torch.cat(text_features)
+
+ # compute video features
+ print('Computing video features', flush=True)
+ for data in tqdm.tqdm(metadata):
+ video_id = data['video']
+ video_path = os.path.join(root, video_id)
+ video_data = mmengine.get(video_path)
+ video_data = io.BytesIO(video_data)
+ video_reader = decord.VideoReader(video_data)
+
+ # uniformly sample frames
+ interval = math.ceil(len(video_reader) / num_frames)
+ frames_id = np.arange(0, len(video_reader), interval) + interval // 2
+ assert len(frames_id) == num_frames and frames_id[-1] < len(video_reader)
+
+ frames = video_reader.get_batch(frames_id).asnumpy()
+
+ pixel_values = image_processor(images=frames, return_tensors='pt').pixel_values
+ with torch.no_grad():
+ pixel_values = pixel_values.to(torch.bfloat16).cuda()
+ feat = model.encode_image(pixel_values, mode=mode)
+ feat = feat.mean(dim=0, keepdim=True)
+ video_features.append(feat.cpu())
+ video_features = torch.cat(video_features)
+
+ print('Computing metrics', flush=True)
+ texts_emb = text_features / text_features.norm(dim=-1, keepdim=True)
+ images_emb = video_features / video_features.norm(dim=-1, keepdim=True)
+
+ # get the score for each text and image pair
+ scores = texts_emb @ images_emb.t()
+
+ # construct a the positive pair matrix, which tells whether each text-image pair is a positive or not
+ positive_pairs = torch.zeros_like(scores, dtype=bool)
+ positive_pairs[torch.arange(len(scores)), torch.arange(len(scores))] = True
+
+ scores_T = scores.T
+ positive_pairs_T = positive_pairs.T
+
+ if use_dsl:
+ scores = scores * scores.softmax(dim=0)
+ scores_T = scores_T * scores_T.softmax(dim=0)
+
+ metrics = {}
+ for recall_k in recall_k_list:
+ # Note that recall_at_k computes **actual** recall i.e. nb_true_positive/nb_positives, where the number
+ # of true positives, e.g. for text retrieval, is, for each image, the number of retrieved texts matching that image among the top-k.
+ # Also, the number of positives are the total number of texts matching the image in the dataset, as we have a set of captions
+ # for each image, that number will be greater than 1 for text retrieval.
+ # However, image/text retrieval recall@k, the way it is done in CLIP-like papers, is a bit different.
+ # recall@k, in CLIP-like papers, is, for each image, either 1 or 0. It is 1 if atleast one text matches the image among the top-k.
+ # so we can easily compute that using the actual recall, by checking whether there is at least one true positive,
+ # which would be the case if the recall is greater than 0. One we compute the recal for each image (or text), we average
+ # it over the dataset.
+ metrics[f't2v_retrieval_recall@{recall_k}'] = (
+ batchify(recall_at_k, scores, positive_pairs, eval_batch_size, scores.device,
+ k=recall_k) > 0).float().mean().item()
+ metrics[f'v2t_retrieval_recall@{recall_k}'] = (
+ batchify(recall_at_k, scores_T, positive_pairs_T, eval_batch_size, scores.device,
+ k=recall_k) > 0).float().mean().item()
+
+ print(metrics)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='validate MSR-VTT', add_help=False)
+ parser.add_argument('--video-root', type=str)
+ parser.add_argument('--metadata', type=str)
+ parser.add_argument('--mode', type=str, default='InternVL-C',choices=['InternVL-C', 'InternVL-G'])
+ parser.add_argument('--num-frames', type=int, default=1)
+ args = parser.parse_args()
+
+ model = AutoModel.from_pretrained(
+ 'OpenGVLab/InternVL-14B-224px',
+ torch_dtype=torch.bfloat16,
+ low_cpu_mem_usage=True,
+ trust_remote_code=True).cuda().eval()
+
+ image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternVL-14B-224px')
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ 'OpenGVLab/InternVL-14B-224px', use_fast=False, add_eos_token=True)
+ tokenizer.pad_token_id = 0 # set pad_token_id to 0
+
+ metrics = validate_msrvtt(model, tokenizer, image_processor,
+ root=args.video_root,
+ metadata=args.metadata,
+ mode=args.mode,
+ num_frames=args.num_frames,)
diff --git a/sglang/examples/frontend_language/quick_start/gemini_example_chat.py b/sglang/examples/frontend_language/quick_start/gemini_example_chat.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ae6231095f432b2dedb13ddb22aa6a272cd182f
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/gemini_example_chat.py
@@ -0,0 +1,73 @@
+"""
+Usage:
+export GCP_PROJECT_ID=******
+python3 gemini_example_chat.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def multi_turn_question(s, question_1, question_2):
+ s += sgl.user(question_1)
+ s += sgl.assistant(sgl.gen("answer_1", max_tokens=256))
+ s += sgl.user(question_2)
+ s += sgl.assistant(sgl.gen("answer_2", max_tokens=256))
+
+
+def single():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ )
+
+ for m in state.messages():
+ print(m["role"], ":", m["content"])
+
+ print("\n-- answer_1 --\n", state["answer_1"])
+
+
+def stream():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ stream=True,
+ )
+
+ for out in state.text_iter():
+ print(out, end="", flush=True)
+ print()
+
+
+def batch():
+ states = multi_turn_question.run_batch(
+ [
+ {
+ "question_1": "What is the capital of the United States?",
+ "question_2": "List two local attractions.",
+ },
+ {
+ "question_1": "What is the capital of France?",
+ "question_2": "What is the population of this city?",
+ },
+ ]
+ )
+
+ for s in states:
+ print(s.messages())
+
+
+if __name__ == "__main__":
+ sgl.set_default_backend(sgl.VertexAI("gemini-pro"))
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ single()
+
+ # Stream output
+ print("\n========== stream ==========\n")
+ stream()
+
+ # Run a batch of requests
+ print("\n========== batch ==========\n")
+ batch()
diff --git a/sglang/examples/frontend_language/quick_start/gemini_example_multimodal_chat.py b/sglang/examples/frontend_language/quick_start/gemini_example_multimodal_chat.py
new file mode 100644
index 0000000000000000000000000000000000000000..afe0c723ff1cb23bd7c5eb157e78850ecc2501c2
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/gemini_example_multimodal_chat.py
@@ -0,0 +1,30 @@
+"""
+Usage:
+export GCP_PROJECT_ID=******
+python3 gemini_example_multimodal_chat.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def image_qa(s, image_file1, image_file2, question):
+ s += sgl.user(sgl.image(image_file1) + sgl.image(image_file2) + question)
+ s += sgl.assistant(sgl.gen("answer", max_tokens=256))
+
+
+if __name__ == "__main__":
+ sgl.set_default_backend(sgl.VertexAI("gemini-pro-vision"))
+
+ state = image_qa.run(
+ image_file1="./images/cat.jpeg",
+ image_file2="./images/dog.jpeg",
+ question="Describe difference of the two images in one sentence.",
+ stream=True,
+ )
+
+ for out in state.text_iter("answer"):
+ print(out, end="", flush=True)
+ print()
+
+ print(state["answer"])
diff --git a/sglang/examples/frontend_language/quick_start/local_example_complete.py b/sglang/examples/frontend_language/quick_start/local_example_complete.py
new file mode 100644
index 0000000000000000000000000000000000000000..00a451cf642e54b01795d5c3d353e10517983f86
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/local_example_complete.py
@@ -0,0 +1,70 @@
+"""
+Usage:
+python3 local_example_complete.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def few_shot_qa(s, question):
+ s += """The following are questions with answers.
+Q: What is the capital of France?
+A: Paris
+Q: What is the capital of Germany?
+A: Berlin
+Q: What is the capital of Italy?
+A: Rome
+"""
+ s += "Q: " + question + "\n"
+ s += "A:" + sgl.gen("answer", stop="\n", temperature=0)
+
+
+def single():
+ state = few_shot_qa.run(question="What is the capital of the United States?")
+ answer = state["answer"].strip().lower()
+
+ assert "washington" in answer, f"answer: {state['answer']}"
+
+ print(state.text())
+
+
+def stream():
+ state = few_shot_qa.run(
+ question="What is the capital of the United States?", stream=True
+ )
+
+ for out in state.text_iter("answer"):
+ print(out, end="", flush=True)
+ print()
+
+
+def batch():
+ states = few_shot_qa.run_batch(
+ [
+ {"question": "What is the capital of the United States?"},
+ {"question": "What is the capital of China?"},
+ ]
+ )
+
+ for s in states:
+ print(s["answer"])
+
+
+if __name__ == "__main__":
+ runtime = sgl.Runtime(model_path="meta-llama/Llama-2-7b-chat-hf")
+ sgl.set_default_backend(runtime)
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ single()
+
+ # Stream output
+ print("\n========== stream ==========\n")
+ stream()
+
+ # Run a batch of requests
+ print("\n========== batch ==========\n")
+ batch()
+
+ runtime.shutdown()
diff --git a/sglang/examples/frontend_language/quick_start/local_example_llava_next.py b/sglang/examples/frontend_language/quick_start/local_example_llava_next.py
new file mode 100644
index 0000000000000000000000000000000000000000..c941a549ec4746e1a90c93fbf2503e37f6a0ec0d
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/local_example_llava_next.py
@@ -0,0 +1,78 @@
+"""
+Usage: python3 local_example_llava_next.py
+"""
+
+import sglang as sgl
+from sglang.lang.chat_template import get_chat_template
+
+
+@sgl.function
+def image_qa(s, image_path, question):
+ s += sgl.user(sgl.image(image_path) + question)
+ s += sgl.assistant(sgl.gen("answer"))
+
+
+def single():
+ state = image_qa.run(
+ image_path="images/cat.jpeg", question="What is this?", max_new_tokens=128
+ )
+ print(state["answer"], "\n")
+
+
+def stream():
+ state = image_qa.run(
+ image_path="images/cat.jpeg",
+ question="What is this?",
+ max_new_tokens=64,
+ stream=True,
+ )
+
+ for out in state.text_iter("answer"):
+ print(out, end="", flush=True)
+ print()
+
+
+def batch():
+ states = image_qa.run_batch(
+ [
+ {"image_path": "images/cat.jpeg", "question": "What is this?"},
+ {"image_path": "images/dog.jpeg", "question": "What is this?"},
+ ],
+ max_new_tokens=128,
+ )
+ for s in states:
+ print(s["answer"], "\n")
+
+
+if __name__ == "__main__":
+ import multiprocessing as mp
+
+ mp.set_start_method("spawn", force=True)
+
+ runtime = sgl.Runtime(model_path="lmms-lab/llama3-llava-next-8b")
+ runtime.endpoint.chat_template = get_chat_template("llama-3-instruct-llava")
+
+ # Or you can use the 72B model
+ # runtime = sgl.Runtime(model_path="lmms-lab/llava-next-72b", tp_size=8)
+ # runtime.endpoint.chat_template = get_chat_template("chatml-llava")
+
+ sgl.set_default_backend(runtime)
+ print(f"chat template: {runtime.endpoint.chat_template.name}")
+
+ # Or you can use API models
+ # sgl.set_default_backend(sgl.OpenAI("gpt-4-vision-preview"))
+ # sgl.set_default_backend(sgl.VertexAI("gemini-pro-vision"))
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ single()
+
+ # Stream output
+ print("\n========== stream ==========\n")
+ stream()
+
+ # Run a batch of requests
+ print("\n========== batch ==========\n")
+ batch()
+
+ runtime.shutdown()
diff --git a/sglang/examples/frontend_language/quick_start/openai_example_chat.py b/sglang/examples/frontend_language/quick_start/openai_example_chat.py
new file mode 100644
index 0000000000000000000000000000000000000000..9511e21cf431169acfd732dab41ec002f38b2c9f
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/openai_example_chat.py
@@ -0,0 +1,74 @@
+"""
+Usage:
+export OPENAI_API_KEY=sk-******
+python3 openai_example_chat.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def multi_turn_question(s, question_1, question_2):
+ s += sgl.system("You are a helpful assistant.")
+ s += sgl.user(question_1)
+ s += sgl.assistant(sgl.gen("answer_1", max_tokens=256))
+ s += sgl.user(question_2)
+ s += sgl.assistant(sgl.gen("answer_2", max_tokens=256))
+
+
+def single():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ )
+
+ for m in state.messages():
+ print(m["role"], ":", m["content"])
+
+ print("\n-- answer_1 --\n", state["answer_1"])
+
+
+def stream():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ stream=True,
+ )
+
+ for out in state.text_iter():
+ print(out, end="", flush=True)
+ print()
+
+
+def batch():
+ states = multi_turn_question.run_batch(
+ [
+ {
+ "question_1": "What is the capital of the United States?",
+ "question_2": "List two local attractions.",
+ },
+ {
+ "question_1": "What is the capital of France?",
+ "question_2": "What is the population of this city?",
+ },
+ ]
+ )
+
+ for s in states:
+ print(s.messages())
+
+
+if __name__ == "__main__":
+ sgl.set_default_backend(sgl.OpenAI("gpt-3.5-turbo"))
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ single()
+
+ # Stream output
+ print("\n========== stream ==========\n")
+ stream()
+
+ # Run a batch of requests
+ print("\n========== batch ==========\n")
+ batch()
diff --git a/sglang/examples/frontend_language/quick_start/openai_example_complete.py b/sglang/examples/frontend_language/quick_start/openai_example_complete.py
new file mode 100644
index 0000000000000000000000000000000000000000..d64bcaf1c301c6083184767630e26c662fc18446
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/openai_example_complete.py
@@ -0,0 +1,68 @@
+"""
+Usage:
+export OPENAI_API_KEY=sk-******
+python3 openai_example_complete.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def few_shot_qa(s, question):
+ s += """The following are questions with answers.
+Q: What is the capital of France?
+A: Paris
+Q: What is the capital of Germany?
+A: Berlin
+Q: What is the capital of Italy?
+A: Rome
+"""
+ s += "Q: " + question + "\n"
+ s += "A:" + sgl.gen("answer", stop="\n", temperature=0)
+
+
+def single():
+ state = few_shot_qa.run(question="What is the capital of the United States?")
+ answer = state["answer"].strip().lower()
+
+ assert "washington" in answer, f"answer: {state['answer']}"
+
+ print(state.text())
+
+
+def stream():
+ state = few_shot_qa.run(
+ question="What is the capital of the United States?", stream=True
+ )
+
+ for out in state.text_iter("answer"):
+ print(out, end="", flush=True)
+ print()
+
+
+def batch():
+ states = few_shot_qa.run_batch(
+ [
+ {"question": "What is the capital of the United States?"},
+ {"question": "What is the capital of China?"},
+ ]
+ )
+
+ for s in states:
+ print(s["answer"])
+
+
+if __name__ == "__main__":
+ sgl.set_default_backend(sgl.OpenAI("gpt-3.5-turbo-instruct"))
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ single()
+
+ # Stream output
+ print("\n========== stream ==========\n")
+ stream()
+
+ # Run a batch of requests
+ print("\n========== batch ==========\n")
+ batch()
diff --git a/sglang/examples/frontend_language/quick_start/openrouter_example_chat.py b/sglang/examples/frontend_language/quick_start/openrouter_example_chat.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0b6f15bcbc77b725956b00fda7b08393e990b00
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/openrouter_example_chat.py
@@ -0,0 +1,81 @@
+"""
+Usage:
+export OPENROUTER_API_KEY=sk-******
+python3 together_example_chat.py
+"""
+
+import os
+
+import sglang as sgl
+
+
+@sgl.function
+def multi_turn_question(s, question_1, question_2):
+ s += sgl.system("You are a helpful assistant.")
+ s += sgl.user(question_1)
+ s += sgl.assistant(sgl.gen("answer_1", max_tokens=256))
+ s += sgl.user(question_2)
+ s += sgl.assistant(sgl.gen("answer_2", max_tokens=256))
+
+
+def single():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ )
+
+ for m in state.messages():
+ print(m["role"], ":", m["content"])
+
+ print("\n-- answer_1 --\n", state["answer_1"])
+
+
+def stream():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ stream=True,
+ )
+
+ for out in state.text_iter():
+ print(out, end="", flush=True)
+ print()
+
+
+def batch():
+ states = multi_turn_question.run_batch(
+ [
+ {
+ "question_1": "What is the capital of the United States?",
+ "question_2": "List two local attractions.",
+ },
+ {
+ "question_1": "What is the capital of France?",
+ "question_2": "What is the population of this city?",
+ },
+ ]
+ )
+
+ for s in states:
+ print(s.messages())
+
+
+if __name__ == "__main__":
+ backend = sgl.OpenAI(
+ model_name="google/gemma-7b-it:free",
+ base_url="https://openrouter.ai/api/v1",
+ api_key=os.environ.get("OPENROUTER_API_KEY"),
+ )
+ sgl.set_default_backend(backend)
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ single()
+
+ # Stream output
+ print("\n========== stream ==========\n")
+ stream()
+
+ # Run a batch of requests
+ print("\n========== batch ==========\n")
+ batch()
diff --git a/sglang/examples/frontend_language/quick_start/together_example_complete.py b/sglang/examples/frontend_language/quick_start/together_example_complete.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9119ed6cbaa6964153aff41c70da8eab5b234ad
--- /dev/null
+++ b/sglang/examples/frontend_language/quick_start/together_example_complete.py
@@ -0,0 +1,76 @@
+"""
+Usage:
+export TOGETHER_API_KEY=sk-******
+python3 together_example_complete.py
+"""
+
+import os
+
+import sglang as sgl
+
+
+@sgl.function
+def few_shot_qa(s, question):
+ s += """The following are questions with answers.
+Q: What is the capital of France?
+A: Paris
+Q: What is the capital of Germany?
+A: Berlin
+Q: What is the capital of Italy?
+A: Rome
+"""
+ s += "Q: " + question + "\n"
+ s += "A:" + sgl.gen("answer", stop="\n", temperature=0)
+
+
+def single():
+ state = few_shot_qa.run(question="What is the capital of the United States?")
+ answer = state["answer"].strip().lower()
+
+ assert "washington" in answer, f"answer: {state['answer']}"
+
+ print(state.text())
+
+
+def stream():
+ state = few_shot_qa.run(
+ question="What is the capital of the United States?", stream=True
+ )
+
+ for out in state.text_iter("answer"):
+ print(out, end="", flush=True)
+ print()
+
+
+def batch():
+ states = few_shot_qa.run_batch(
+ [
+ {"question": "What is the capital of the United States?"},
+ {"question": "What is the capital of China?"},
+ ]
+ )
+
+ for s in states:
+ print(s["answer"])
+
+
+if __name__ == "__main__":
+ backend = sgl.OpenAI(
+ model_name="mistralai/Mixtral-8x7B-Instruct-v0.1",
+ is_chat_model=False,
+ base_url="https://api.together.xyz/v1",
+ api_key=os.environ.get("TOGETHER_API_KEY"),
+ )
+ sgl.set_default_backend(backend)
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ single()
+
+ # Stream output
+ print("\n========== stream ==========\n")
+ stream()
+
+ # Run a batch of requests
+ print("\n========== batch ==========\n")
+ batch()
diff --git a/sglang/examples/frontend_language/usage/chinese_regex.py b/sglang/examples/frontend_language/usage/chinese_regex.py
new file mode 100644
index 0000000000000000000000000000000000000000..78e9c7e160dcffcb5a5e111602eaea0cab24e00c
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/chinese_regex.py
@@ -0,0 +1,53 @@
+import sglang as sgl
+
+character_regex = (
+ r"""\{\n"""
+ + r""" "姓名": "[^"]{1,32}",\n"""
+ + r""" "学院": "(格兰芬多|赫奇帕奇|拉文克劳|斯莱特林)",\n"""
+ + r""" "血型": "(纯血|混血|麻瓜)",\n"""
+ + r""" "职业": "(学生|教师|傲罗|魔法部|食死徒|凤凰社成员)",\n"""
+ + r""" "魔杖": \{\n"""
+ + r""" "材质": "[^"]{1,32}",\n"""
+ + r""" "杖芯": "[^"]{1,32}",\n"""
+ + r""" "长度": [0-9]{1,2}\.[0-9]{0,2}\n"""
+ + r""" \},\n"""
+ + r""" "存活": "(存活|死亡)",\n"""
+ + r""" "守护神": "[^"]{1,32}",\n"""
+ + r""" "博格特": "[^"]{1,32}"\n"""
+ + r"""\}"""
+)
+
+
+@sgl.function
+def character_gen(s, name):
+ s += name + " 是一名哈利波特系列小说中的角色。请填写以下关于这个角色的信息。"
+ s += """\
+这是一个例子
+{
+ "姓名": "哈利波特",
+ "学院": "格兰芬多",
+ "血型": "混血",
+ "职业": "学生",
+ "魔杖": {
+ "材质": "冬青木",
+ "杖芯": "凤凰尾羽",
+ "长度": 11.0
+ },
+ "存活": "存活",
+ "守护神": "麋鹿",
+ "博格特": "摄魂怪"
+}
+"""
+ s += f"现在请你填写{name}的信息:\n"
+ s += sgl.gen("json_output", max_tokens=256, regex=character_regex)
+
+
+def main():
+ backend = sgl.RuntimeEndpoint("http://localhost:30000")
+ sgl.set_default_backend(backend)
+ ret = character_gen.run(name="赫敏格兰杰", temperature=0)
+ print(ret.text())
+
+
+if __name__ == "__main__":
+ main()
diff --git a/sglang/examples/frontend_language/usage/choices_logprob.py b/sglang/examples/frontend_language/usage/choices_logprob.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cd733fe90acc9abfd2d45ccf4c47d2c49f60e06
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/choices_logprob.py
@@ -0,0 +1,44 @@
+"""
+Usage:
+python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
+python choices_logprob.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def tool_use(s, question):
+ s += "To answer this question: " + question + ", "
+ s += "I need to use a " + sgl.gen("tool", choices=["calculator", "search engine"])
+
+
+def main():
+ # Run one case
+ question = "What is 5 + 5?"
+ state = tool_use.run(question)
+ print("questions:", question)
+ print("choice:", state["tool"])
+ meta_info = state.get_meta_info("tool")
+ print("logprobs of choice 1", meta_info["input_token_logprobs"][0])
+ print("logprobs of choice 2", meta_info["input_token_logprobs"][1])
+ print("-" * 50)
+
+ # Run a batch
+ questions = [
+ "What is 5 + 6?",
+ "Who is Michael Jordan?",
+ ]
+ states = tool_use.run_batch([{"question": q} for q in questions])
+ for question, state in zip(questions, states):
+ print("questions:", question)
+ print("choice:", state["tool"])
+ meta_info = state.get_meta_info("tool")
+ print("logprobs of choice 1", meta_info["input_token_logprobs"][0])
+ print("logprobs of choice 2", meta_info["input_token_logprobs"][1])
+ print("-" * 50)
+
+
+if __name__ == "__main__":
+ sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:30000"))
+ main()
diff --git a/sglang/examples/frontend_language/usage/cot_decoding.py b/sglang/examples/frontend_language/usage/cot_decoding.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a7a04bce23ff19a7f33aa308cd717bf109b32bf
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/cot_decoding.py
@@ -0,0 +1,115 @@
+from math import exp
+from pprint import pformat
+
+import sglang as sgl
+
+YELLOW = "\033[1;33m"
+GREEN = "\033[1;32m"
+BLUE = "\033[1;34m"
+CLEAR = "\033[1;0m"
+
+
+@sgl.function
+def cot_decoding(s, question, get_top_k, is_chat_model, verbose):
+ """CoT Decoding: http://arxiv.org/abs/2402.10200"""
+
+ if is_chat_model:
+ s += sgl.user("Question: " + question + "\nAnswer:")
+ s += sgl.assistant_begin()
+ else:
+ s += "Question: " + question + "\nAnswer:"
+
+ step_0 = s.fork(1)[0]
+ forks = s.fork(get_top_k)
+ answer_forks = s.fork(get_top_k)
+
+ # decoding step 0
+ step_0 += sgl.gen(
+ "get_top_k",
+ max_tokens=0,
+ return_logprob=True,
+ top_logprobs_num=get_top_k,
+ return_text_in_logprobs=True,
+ )
+ logprobs = step_0.get_meta_info("get_top_k")["output_top_logprobs"][0]
+
+ print("Decoding step 0:", ", ".join(pformat(token[2]) for token in logprobs))
+ for idx, (f, token) in enumerate(zip(forks, logprobs)):
+ logprob, token_id, text = token
+ f += text
+
+ if text == "<|end_of_text|>":
+ print(
+ f"{YELLOW}Path #{idx} {pformat(text)}[{exp(logprob):.3f}] (score=nan, answer=nan){CLEAR}"
+ )
+ continue
+
+ # continue greedy decoding
+ f += sgl.gen(
+ "answer",
+ temperature=0,
+ max_tokens=1024,
+ return_logprob=True,
+ top_logprobs_num=2,
+ return_text_in_logprobs=True,
+ )
+
+ # calculate probability disparity between the top and secondary tokens
+ x1s = [exp(xt[0][0]) for xt in f.get_meta_info("answer")["output_top_logprobs"]]
+ x2s = [exp(xt[1][0]) for xt in f.get_meta_info("answer")["output_top_logprobs"]]
+ tokens = [xt[0][2] for xt in f.get_meta_info("answer")["output_top_logprobs"]]
+ delta = (sum(x1s) - sum(x2s)) / len(x1s)
+
+ # extract the answer span (without the '<|end_of_text|>' token)
+ answer_forks[idx] += text + f["answer"] + "\nSo the answer is"
+ answer_forks[idx] += sgl.gen(
+ "answer_span",
+ temperature=0,
+ max_tokens=64,
+ return_logprob=True,
+ top_logprobs_num=2,
+ return_text_in_logprobs=True,
+ )
+ answer = answer_forks[idx]["answer_span"].replace("\n", " ").strip(":")
+ print(
+ f"{YELLOW}Path #{idx} {pformat(text)}[{exp(logprob):.3f}] (score={delta}, answer={answer}){CLEAR}"
+ )
+ generated_text = str(answer_forks[idx])[len("ProgramState(") : -1]
+ print(f"{BLUE}{pformat(generated_text)}{CLEAR}")
+
+ if verbose:
+ answer_tokens = [
+ xt[0][2]
+ for xt in answer_forks[idx].get_meta_info("answer_span")[
+ "output_top_logprobs"
+ ]
+ ]
+ answer_x1s = [
+ exp(xt[0][0])
+ for xt in answer_forks[idx].get_meta_info("answer_span")[
+ "output_top_logprobs"
+ ]
+ ]
+ answer_x2s = [
+ exp(xt[1][0])
+ for xt in answer_forks[idx].get_meta_info("answer_span")[
+ "output_top_logprobs"
+ ]
+ ]
+
+ for token, x1, x2 in zip(tokens, x1s, x2s):
+ print(f" {GREEN}{pformat(token)}{CLEAR}({x1:.3f}-{x2:.3f})", end="")
+ print("\n===========")
+ for token, x1, x2 in zip(answer_tokens, answer_x1s, answer_x2s):
+ print(f" {GREEN}{pformat(token)}{CLEAR}({x1:.3f}-{x2:.3f})", end="")
+ print()
+
+
+sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:30000"))
+
+state = cot_decoding.run(
+ question=r"Claire makes a 3 egg omelet every morning for breakfast. How many dozens of eggs will she eat in 4 weeks?",
+ get_top_k=10,
+ is_chat_model=True,
+ verbose=False,
+)
diff --git a/sglang/examples/frontend_language/usage/json_decode.py b/sglang/examples/frontend_language/usage/json_decode.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce8f5ba70627210811514f441e9322c18994db38
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/json_decode.py
@@ -0,0 +1,83 @@
+"""
+Usage:
+python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
+python json_decode.py
+"""
+
+from enum import Enum
+
+from pydantic import BaseModel
+
+import sglang as sgl
+from sglang.srt.constrained import build_regex_from_object
+
+character_regex = (
+ r"""\{\n"""
+ + r""" "name": "[\w\d\s]{1,16}",\n"""
+ + r""" "house": "(Gryffindor|Slytherin|Ravenclaw|Hufflepuff)",\n"""
+ + r""" "blood status": "(Pure-blood|Half-blood|Muggle-born)",\n"""
+ + r""" "occupation": "(student|teacher|auror|ministry of magic|death eater|order of the phoenix)",\n"""
+ + r""" "wand": \{\n"""
+ + r""" "wood": "[\w\d\s]{1,16}",\n"""
+ + r""" "core": "[\w\d\s]{1,16}",\n"""
+ + r""" "length": [0-9]{1,2}\.[0-9]{0,2}\n"""
+ + r""" \},\n"""
+ + r""" "alive": "(Alive|Deceased)",\n"""
+ + r""" "patronus": "[\w\d\s]{1,16}",\n"""
+ + r""" "bogart": "[\w\d\s]{1,16}"\n"""
+ + r"""\}"""
+)
+
+
+@sgl.function
+def character_gen(s, name):
+ s += (
+ name
+ + " is a character in Harry Potter. Please fill in the following information about this character.\n"
+ )
+ s += "The constrained regex is:\n"
+ s += character_regex + "\n"
+ s += "The JSON output is:\n"
+ s += sgl.gen("json_output", max_tokens=256, regex=character_regex)
+
+
+def driver_character_gen():
+ state = character_gen.run(name="Hermione Granger")
+ print(state.text())
+
+
+class Weapon(str, Enum):
+ sword = "sword"
+ axe = "axe"
+ mace = "mace"
+ spear = "spear"
+ bow = "bow"
+ crossbow = "crossbow"
+
+
+class Wizard(BaseModel):
+ name: str
+ age: int
+ weapon: Weapon
+
+
+@sgl.function
+def pydantic_wizard_gen(s):
+ s += "Give me a description about a wizard in the JSON format.\n"
+ s += sgl.gen(
+ "character",
+ max_tokens=128,
+ temperature=0,
+ regex=build_regex_from_object(Wizard), # Requires pydantic >= 2.0
+ )
+
+
+def driver_pydantic_wizard_gen():
+ state = pydantic_wizard_gen.run()
+ print(state.text())
+
+
+if __name__ == "__main__":
+ sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:30000"))
+ driver_character_gen()
+ # driver_pydantic_wizard_gen()
diff --git a/sglang/examples/frontend_language/usage/json_logprobs.py b/sglang/examples/frontend_language/usage/json_logprobs.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa0e1b81f3361bfdedf862742396712ec93e742a
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/json_logprobs.py
@@ -0,0 +1,104 @@
+# NOTE: Currently this can only be run through HTTP requests.
+import json
+from concurrent.futures import ThreadPoolExecutor
+
+from json_decode import character_regex
+
+from sglang.utils import http_request
+
+character_names = ["Hermione Granger", "Ron Weasley", "Harry Potter"]
+
+base_url = "http://localhost:30000"
+
+prompt = "is a character in Harry Potter. Please fill in the following information about this character.\n"
+
+
+def openai_api_request(name):
+ data = {
+ "model": "",
+ "prompt": name + prompt,
+ "temperature": 0,
+ "max_tokens": 128,
+ "regex": character_regex,
+ "logprobs": 3,
+ }
+ res = http_request(base_url + "/v1/completions", json=data).json()
+
+ # with open(f"json_logprobs_{name.replace(' ', '_')}_tmp.json", "w") as fout:
+ # fout.write(json.dumps(res, indent=4))
+
+ logprobs = res["choices"][0]["logprobs"]
+ usage = res["usage"]
+ assert len(logprobs["token_logprobs"]) == len(logprobs["tokens"])
+ assert len(logprobs["token_logprobs"]) == len(logprobs["top_logprobs"])
+ assert len(logprobs["token_logprobs"]) == usage["completion_tokens"] - 1
+
+ return res
+
+
+def srt_api_request(name):
+ data = {
+ "text": name + prompt,
+ "sampling_params": {
+ "temperature": 0,
+ "max_new_tokens": 128,
+ "regex": character_regex,
+ },
+ "return_logprob": True,
+ "logprob_start_len": 0,
+ "top_logprobs_num": 3,
+ "return_text_in_logprobs": True,
+ }
+
+ res = http_request(base_url + "/generate", json=data).json()
+
+ # with open(f"json_logprobs_{name.replace(' ', '_')}_tmp.json", "w") as fout:
+ # fout.write(json.dumps(res, indent=4))
+
+ meta_info = res["meta_info"]
+ assert len(meta_info["input_token_logprobs"]) == len(
+ meta_info["input_top_logprobs"]
+ )
+ assert len(meta_info["output_token_logprobs"]) == len(
+ meta_info["output_top_logprobs"]
+ )
+ assert len(meta_info["input_token_logprobs"]) == meta_info["prompt_tokens"]
+ assert len(meta_info["output_token_logprobs"]) == meta_info["completion_tokens"] - 1
+
+ return res
+
+
+def pretty_print(res):
+ meta_info = res["meta_info"]
+
+ print("\n\n", "=" * 30, "Prefill", "=" * 30)
+ for i in range(len(meta_info["input_token_logprobs"])):
+ print(f"{str(meta_info['input_token_logprobs'][i][2].encode()): <20}", end="")
+ top_ks = (
+ [str(t[2].encode()) for t in meta_info["input_top_logprobs"][i]]
+ if meta_info["input_top_logprobs"][i]
+ else []
+ )
+ for top_k in top_ks:
+ print(f"{top_k: <15}", end="")
+ print()
+
+ print("\n\n", "=" * 30, "Decode", "=" * 30)
+ for i in range(len(meta_info["output_token_logprobs"])):
+ print(f"{str(meta_info['output_token_logprobs'][i][2].encode()): <20}", end="")
+ top_ks = [str(t[2].encode()) for t in meta_info["output_top_logprobs"][i]]
+ for top_k in top_ks:
+ print(f"{top_k: <15}", end="")
+ print()
+
+ print(res["text"])
+
+
+if __name__ == "__main__":
+ with ThreadPoolExecutor() as executor:
+ ress = executor.map(srt_api_request, character_names)
+
+ for res in ress:
+ pretty_print(res)
+
+ openai_api_request("Hermione Granger")
diff --git a/sglang/examples/frontend_language/usage/llava_video/srt_example_llava_v.py b/sglang/examples/frontend_language/usage/llava_video/srt_example_llava_v.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc56d421038029280abac4ccd8204623f0291b39
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/llava_video/srt_example_llava_v.py
@@ -0,0 +1,260 @@
+"""
+Usage:
+pip install opencv-python-headless
+
+python3 srt_example_llava_v.py
+"""
+
+import argparse
+import csv
+import json
+import os
+import time
+
+import requests
+
+import sglang as sgl
+
+
+@sgl.function
+def video_qa(s, num_frames, video_path, question):
+ s += sgl.user(sgl.video(video_path, num_frames) + question)
+ s += sgl.assistant(sgl.gen("answer"))
+
+
+def single(path, num_frames=16):
+ state = video_qa.run(
+ num_frames=num_frames,
+ video_path=path,
+ question="Please provide a detailed description of the video, focusing on the main subjects, their actions, the background scenes",
+ temperature=0.0,
+ max_new_tokens=1024,
+ )
+ print(state["answer"], "\n")
+
+
+def split_into_chunks(lst, num_chunks):
+ """Split a list into a specified number of chunks."""
+ # Calculate the chunk size using integer division. Note that this may drop some items if not evenly divisible.
+ chunk_size = len(lst) // num_chunks
+
+ if chunk_size == 0:
+ chunk_size = len(lst)
+ # Use list comprehension to generate chunks. The last chunk will take any remainder if the list size isn't evenly divisible.
+ chunks = [lst[i : i + chunk_size] for i in range(0, len(lst), chunk_size)]
+ # Ensure we have exactly num_chunks chunks, even if some are empty
+ chunks.extend([[] for _ in range(num_chunks - len(chunks))])
+ return chunks
+
+
+def save_batch_results(batch_video_files, states, cur_chunk, batch_idx, save_dir):
+ csv_filename = f"{save_dir}/chunk_{cur_chunk}_batch_{batch_idx}.csv"
+ with open(csv_filename, "w", newline="") as csvfile:
+ writer = csv.writer(csvfile)
+ writer.writerow(["video_name", "answer"])
+ for video_path, state in zip(batch_video_files, states):
+ video_name = os.path.basename(video_path)
+ writer.writerow([video_name, state["answer"]])
+
+
+def compile_and_cleanup_final_results(cur_chunk, num_batches, save_dir):
+ final_csv_filename = f"{save_dir}/final_results_chunk_{cur_chunk}.csv"
+ with open(final_csv_filename, "w", newline="") as final_csvfile:
+ writer = csv.writer(final_csvfile)
+ writer.writerow(["video_name", "answer"])
+ for batch_idx in range(num_batches):
+ batch_csv_filename = f"{save_dir}/chunk_{cur_chunk}_batch_{batch_idx}.csv"
+ with open(batch_csv_filename, "r") as batch_csvfile:
+ reader = csv.reader(batch_csvfile)
+ next(reader) # Skip header row
+ for row in reader:
+ writer.writerow(row)
+ os.remove(batch_csv_filename)
+
+
+def find_video_files(video_dir):
+ # Check if the video_dir is actually a file
+ if os.path.isfile(video_dir):
+ # If it's a file, return it as a single-element list
+ return [video_dir]
+
+ # Original logic to find video files in a directory
+ video_files = []
+ for root, dirs, files in os.walk(video_dir):
+ for file in files:
+ if file.endswith((".mp4", ".avi", ".mov")):
+ video_files.append(os.path.join(root, file))
+ return video_files
+
+
+def batch(video_dir, save_dir, cur_chunk, num_chunks, num_frames=16, batch_size=64):
+ video_files = find_video_files(video_dir)
+ chunked_video_files = split_into_chunks(video_files, num_chunks)[cur_chunk]
+ num_batches = 0
+
+ for i in range(0, len(chunked_video_files), batch_size):
+ batch_video_files = chunked_video_files[i : i + batch_size]
+ print(f"Processing batch of {len(batch_video_files)} video(s)...")
+
+ if not batch_video_files:
+ print("No video files found in the specified directory.")
+ return
+
+ batch_input = [
+ {
+ "num_frames": num_frames,
+ "video_path": video_path,
+ "question": "Please provide a detailed description of the video, focusing on the main subjects, their actions, the background scenes.",
+ }
+ for video_path in batch_video_files
+ ]
+
+ start_time = time.time()
+ states = video_qa.run_batch(batch_input, max_new_tokens=512, temperature=0.2)
+ total_time = time.time() - start_time
+ average_time = total_time / len(batch_video_files)
+ print(
+ f"Number of videos in batch: {len(batch_video_files)}. Average processing time per video: {average_time:.2f} seconds. Total time for this batch: {total_time:.2f} seconds"
+ )
+
+ save_batch_results(batch_video_files, states, cur_chunk, num_batches, save_dir)
+ num_batches += 1
+
+ compile_and_cleanup_final_results(cur_chunk, num_batches, save_dir)
+
+
+if __name__ == "__main__":
+
+ url = "https://raw.githubusercontent.com/EvolvingLMMs-Lab/sglang/dev/onevision_local/assets/jobs.mp4"
+
+ cache_dir = os.path.expanduser("~/.cache")
+ file_path = os.path.join(cache_dir, "jobs.mp4")
+
+ os.makedirs(cache_dir, exist_ok=True)
+
+ response = requests.get(url)
+ response.raise_for_status() # Raise an exception for bad responses
+
+ with open(file_path, "wb") as f:
+ f.write(response.content)
+
+ print(f"File downloaded and saved to: {file_path}")
+ # Create the parser
+ parser = argparse.ArgumentParser(
+ description="Run video processing with specified port."
+ )
+
+ # Add an argument for the port
+ parser.add_argument(
+ "--port",
+ type=int,
+ default=30000,
+ help="The master port for distributed serving.",
+ )
+ parser.add_argument(
+ "--chunk-idx", type=int, default=0, help="The index of the chunk to process."
+ )
+ parser.add_argument(
+ "--num-chunks", type=int, default=8, help="The number of chunks to process."
+ )
+ parser.add_argument(
+ "--save-dir",
+ type=str,
+ default="./work_dirs/llava_video",
+ help="The directory to save the processed video files.",
+ )
+ parser.add_argument(
+ "--video-dir",
+ type=str,
+ default=os.path.expanduser("~/.cache/jobs.mp4"),
+ help="The directory or path for the processed video files.",
+ )
+ parser.add_argument(
+ "--model-path",
+ type=str,
+ default="lmms-lab/LLaVA-NeXT-Video-7B",
+ help="The model path for the video processing.",
+ )
+ parser.add_argument(
+ "--num-frames",
+ type=int,
+ default=16,
+ help="The number of frames to process in each video.",
+ )
+ parser.add_argument("--mm_spatial_pool_stride", type=int, default=2)
+
+ # Parse the arguments
+ args = parser.parse_args()
+ cur_port = args.port
+ cur_chunk = args.chunk_idx
+ num_chunks = args.num_chunks
+ num_frames = args.num_frames
+
+ if "34b" in args.model_path.lower():
+ tokenizer_path = "liuhaotian/llava-v1.6-34b-tokenizer"
+ elif "7b" in args.model_path.lower():
+ tokenizer_path = "llava-hf/llava-1.5-7b-hf"
+ else:
+ print("Invalid model path. Please specify a valid model path.")
+ exit()
+
+ model_override_args = {}
+ model_override_args["mm_spatial_pool_stride"] = args.mm_spatial_pool_stride
+ model_override_args["architectures"] = ["LlavaVidForCausalLM"]
+ model_override_args["num_frames"] = args.num_frames
+ model_override_args["model_type"] = "llava"
+
+ if "34b" in args.model_path.lower():
+ model_override_args["image_token_index"] = 64002
+
+ if args.num_frames == 32:
+ model_override_args["rope_scaling"] = {"factor": 2.0, "rope_type": "linear"}
+ model_override_args["max_sequence_length"] = 4096 * 2
+ model_override_args["tokenizer_model_max_length"] = 4096 * 2
+ elif args.num_frames < 32:
+ pass
+ else:
+ print(
+ "The maximum number of frames to process is 32. Please specify a valid number of frames."
+ )
+ exit()
+
+ runtime = sgl.Runtime(
+ model_path=args.model_path, # "liuhaotian/llava-v1.6-vicuna-7b",
+ tokenizer_path=tokenizer_path,
+ port=cur_port,
+ json_model_override_args=json.dumps(model_override_args),
+ tp_size=1,
+ )
+ sgl.set_default_backend(runtime)
+ print(f"chat template: {runtime.endpoint.chat_template.name}")
+
+ # Run a single request
+ print("\n========== single ==========\n")
+ root = args.video_dir
+ if os.path.isfile(root):
+ video_files = [root]
+ else:
+ video_files = [
+ os.path.join(root, f)
+ for f in os.listdir(root)
+ if f.endswith((".mp4", ".avi", ".mov"))
+ ] # Add more extensions if needed
+ start_time = time.time() # Start time for processing a single video
+ for cur_video in video_files[:1]:
+ print(cur_video)
+ single(cur_video, num_frames)
+ end_time = time.time() # End time for processing a single video
+ total_time = end_time - start_time
+ average_time = total_time / len(
+ video_files
+ ) # Calculate the average processing time
+ print(f"Average processing time per video: {average_time:.2f} seconds")
+ runtime.shutdown()
+
+ # # Run a batch of requests
+ # print("\n========== batch ==========\n")
+ # if not os.path.exists(args.save_dir):
+ # os.makedirs(args.save_dir)
+ # batch(args.video_dir, args.save_dir, cur_chunk, num_chunks, num_frames, num_chunks)
+ # runtime.shutdown()
diff --git a/sglang/examples/frontend_language/usage/llava_video/srt_example_llava_v.sh b/sglang/examples/frontend_language/usage/llava_video/srt_example_llava_v.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ffb1af96dfdc91a745830d1bf57db2f798845374
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/llava_video/srt_example_llava_v.sh
@@ -0,0 +1,131 @@
+#!/bin/bash
+
+##### USAGE #####
+# - First node:
+# ```sh
+# bash examples/usage/llava_video/srt_example_llava_v.sh K 0 YOUR_VIDEO_PATH YOUR_MODEL_PATH FRAMES_PER_VIDEO
+# ```
+# - Second node:
+# ```sh
+# bash examples/usage/llava_video/srt_example_llava_v.sh K 1 YOUR_VIDEO_PATH YOUR_MODEL_PATH FRAMES_PER_VIDEO
+# ```
+# - The K node:
+# ```sh
+# bash examples/usage/llava_video/srt_example_llava_v.sh K K-1 YOUR_VIDEO_PATH YOUR_MODEL_PATH FRAMES_PER_VIDEO
+# ```
+
+
+# Replace `K`, `YOUR_VIDEO_PATH`, `YOUR_MODEL_PATH`, and `FRAMES_PER_VIDEO` with your specific details.
+# CURRENT_ROOT="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
+CURRENT_ROOT=$(dirname "$0")
+
+echo ${CURRENT_ROOT}
+
+cd ${CURRENT_ROOT}
+
+export PYTHONWARNINGS=ignore
+
+START_TIME=$(date +%s) # Capture start time
+
+NUM_NODES=$1
+
+CUR_NODES_IDX=$2
+
+VIDEO_DIR=$3
+
+MODEL_PATH=$4
+
+NUM_FRAMES=$5
+
+
+# FRAME_FORMAT=$6
+
+# FRAME_FORMAT=$(echo $FRAME_FORMAT | tr '[:lower:]' '[:upper:]')
+
+# # Check if FRAME_FORMAT is either JPEG or PNG
+# if [[ "$FRAME_FORMAT" != "JPEG" && "$FRAME_FORMAT" != "PNG" ]]; then
+# echo "Error: FRAME_FORMAT must be either JPEG or PNG."
+# exit 1
+# fi
+
+# export TARGET_FRAMES=$TARGET_FRAMES
+
+echo "Each video you will sample $NUM_FRAMES frames"
+
+# export FRAME_FORMAT=$FRAME_FORMAT
+
+# echo "The frame format is $FRAME_FORMAT"
+
+# Assuming GPULIST is a bash array containing your GPUs
+GPULIST=(0 1 2 3 4 5 6 7)
+LOCAL_CHUNKS=${#GPULIST[@]}
+
+echo "Number of GPUs in GPULIST: $LOCAL_CHUNKS"
+
+ALL_CHUNKS=$((NUM_NODES * LOCAL_CHUNKS))
+
+# Calculate GPUs per chunk
+GPUS_PER_CHUNK=1
+
+echo $GPUS_PER_CHUNK
+
+for IDX in $(seq 1 $LOCAL_CHUNKS); do
+ (
+ START=$(((IDX-1) * GPUS_PER_CHUNK))
+ LENGTH=$GPUS_PER_CHUNK # Length for slicing, not the end index
+
+ CHUNK_GPUS=(${GPULIST[@]:$START:$LENGTH})
+
+ # Convert the chunk GPUs array to a comma-separated string
+ CHUNK_GPUS_STR=$(IFS=,; echo "${CHUNK_GPUS[*]}")
+
+ LOCAL_IDX=$((CUR_NODES_IDX * LOCAL_CHUNKS + IDX))
+
+ echo "Chunk $(($LOCAL_IDX - 1)) will run on GPUs $CHUNK_GPUS_STR"
+
+ # Calculate the port for this chunk. Ensure it's incremented by 5 for each chunk.
+ PORT=$((10000 + RANDOM % 55536))
+
+ MAX_RETRIES=10
+ RETRY_COUNT=0
+ COMMAND_STATUS=1 # Initialize as failed
+
+ while [ $RETRY_COUNT -lt $MAX_RETRIES ] && [ $COMMAND_STATUS -ne 0 ]; do
+ echo "Running chunk $(($LOCAL_IDX - 1)) on GPUs $CHUNK_GPUS_STR with port $PORT. Attempt $(($RETRY_COUNT + 1))"
+
+#!/bin/bash
+ CUDA_VISIBLE_DEVICES=$CHUNK_GPUS_STR python3 srt_example_llava_v.py \
+ --port $PORT \
+ --num-chunks $ALL_CHUNKS \
+ --chunk-idx $(($LOCAL_IDX - 1)) \
+ --save-dir work_dirs/llava_next_video_inference_results \
+ --video-dir $VIDEO_DIR \
+ --model-path $MODEL_PATH \
+ --num-frames $NUM_FRAMES #&
+
+ wait $! # Wait for the process to finish and capture its exit status
+ COMMAND_STATUS=$?
+
+ if [ $COMMAND_STATUS -ne 0 ]; then
+ echo "Execution failed for chunk $(($LOCAL_IDX - 1)), attempt $(($RETRY_COUNT + 1)). Retrying..."
+ RETRY_COUNT=$(($RETRY_COUNT + 1))
+ sleep 180 # Wait a bit before retrying
+ else
+ echo "Execution succeeded for chunk $(($LOCAL_IDX - 1))."
+ fi
+ done
+
+ if [ $COMMAND_STATUS -ne 0 ]; then
+ echo "Execution failed for chunk $(($LOCAL_IDX - 1)) after $MAX_RETRIES attempts."
+ fi
+ ) #&
+ sleep 2 # Slight delay to stagger the start times
+done
+
+wait
+
+cat work_dirs/llava_next_video_inference_results/final_results_chunk_*.csv > work_dirs/llava_next_video_inference_results/final_results_node_${CUR_NODES_IDX}.csv
+
+END_TIME=$(date +%s) # Capture end time
+ELAPSED_TIME=$(($END_TIME - $START_TIME))
+echo "Total execution time: $ELAPSED_TIME seconds."
diff --git a/sglang/examples/frontend_language/usage/openai_chat_speculative.py b/sglang/examples/frontend_language/usage/openai_chat_speculative.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3fd74ed896196b51ef21392e87aa6f480649410
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/openai_chat_speculative.py
@@ -0,0 +1,155 @@
+"""
+Usage:
+***Note: for speculative execution to work, user must put all "gen" in "assistant".
+Show in "assistant" the desired answer format. Each "gen" term should have a stop token.
+The stream mode is not supported in speculative execution.
+
+E.g.
+correct:
+ sgl.assistant("\nName:" + sgl.gen("name", stop="\n") + "\nBirthday:" + sgl.gen("birthday", stop="\n") + "\nJob:" + sgl.gen("job", stop="\n"))
+incorrect:
+ s += sgl.assistant("\nName:" + sgl.gen("name", stop="\n"))
+ s += sgl.assistant("\nBirthday:" + sgl.gen("birthday", stop="\n"))
+ s += sgl.assistant("\nJob:" + sgl.gen("job", stop="\n"))
+
+export OPENAI_API_KEY=sk-******
+python3 openai_chat_speculative.py
+"""
+
+import sglang as sgl
+from sglang import OpenAI, function, set_default_backend
+
+
+@function(num_api_spec_tokens=256)
+def gen_character_spec(s):
+ s += sgl.system("You are a helpful assistant.")
+ s += sgl.user("Construct a character within the following format:")
+ s += sgl.assistant(
+ "Name: Steve Jobs.\nBirthday: February 24, 1955.\nJob: Apple CEO.\n"
+ )
+ s += sgl.user("Please generate new Name, Birthday and Job.\n")
+ s += sgl.assistant(
+ "Name:"
+ + sgl.gen("name", stop="\n")
+ + "\nBirthday:"
+ + sgl.gen("birthday", stop="\n")
+ + "\nJob:"
+ + sgl.gen("job", stop="\n")
+ )
+
+
+@function(num_api_spec_tokens=256)
+def gen_character_spec_no_few_shot(s):
+ s += sgl.user("Construct a character. For each field stop with a newline\n")
+ s += sgl.assistant(
+ "Name:"
+ + sgl.gen("name", stop="\n")
+ + "\nAge:"
+ + sgl.gen("age", stop="\n")
+ + "\nJob:"
+ + sgl.gen("job", stop="\n")
+ )
+
+
+@function
+def gen_character_normal(s):
+ s += sgl.system("You are a helpful assistant.")
+ s += sgl.user("What's the answer of 23 + 8?")
+ s += sgl.assistant(sgl.gen("answer", max_tokens=64))
+
+
+@function(num_api_spec_tokens=1024)
+def multi_turn_question(s, question_1, question_2):
+ s += sgl.system("You are a helpful assistant.")
+ s += sgl.user("Answer questions in the following format:")
+ s += sgl.user(
+ "Question 1: What is the capital of France?\nQuestion 2: What is the population of this city?\n"
+ )
+ s += sgl.assistant(
+ "Answer 1: The capital of France is Paris.\nAnswer 2: The population of Paris in 2024 is estimated to be around 2.1 million for the city proper.\n"
+ )
+ s += sgl.user("Question 1: " + question_1 + "\nQuestion 2: " + question_2)
+ s += sgl.assistant(
+ "Answer 1: "
+ + sgl.gen("answer_1", stop="\n")
+ + "\nAnswer 2: "
+ + sgl.gen("answer_2", stop="\n")
+ )
+
+
+def test_spec_single_turn():
+ backend.token_usage.reset()
+
+ state = gen_character_spec.run()
+ for m in state.messages():
+ print(m["role"], ":", m["content"])
+
+ print("\n-- name:", state["name"])
+ print("-- birthday:", state["birthday"])
+ print("-- job:", state["job"])
+ print(backend.token_usage)
+
+
+def test_inaccurate_spec_single_turn():
+ state = gen_character_spec_no_few_shot.run()
+ for m in state.messages():
+ print(m["role"], ":", m["content"])
+
+ print("\n-- name:", state["name"])
+ print("\n-- age:", state["age"])
+ print("\n-- job:", state["job"])
+
+
+def test_normal_single_turn():
+ state = gen_character_normal.run()
+ for m in state.messages():
+ print(m["role"], ":", m["content"])
+
+
+def test_spec_multi_turn():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions in the capital of the United States.",
+ )
+
+ for m in state.messages():
+ print(m["role"], ":", m["content"])
+
+ print("\n-- answer_1 --\n", state["answer_1"])
+ print("\n-- answer_2 --\n", state["answer_2"])
+
+
+def test_spec_multi_turn_stream():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ stream=True,
+ )
+
+ for out in state.text_iter():
+ print(out, end="", flush=True)
+
+
+if __name__ == "__main__":
+ backend = OpenAI("gpt-4-turbo")
+ set_default_backend(backend)
+
+ print("\n========== test spec single turn ==========\n")
+ # expect reasonable answer for each field
+ test_spec_single_turn()
+
+ print("\n========== test inaccurate spec single turn ==========\n")
+ # expect incomplete or unreasonable answers
+ test_inaccurate_spec_single_turn()
+
+ print("\n========== test normal single turn ==========\n")
+ # expect reasonable answer
+ test_normal_single_turn()
+
+ print("\n========== test spec multi turn ==========\n")
+ # expect answer with same format as in the few shot
+ test_spec_multi_turn()
+
+ print("\n========== test spec multi turn stream ==========\n")
+ # expect error in stream_executor: stream is not supported...
+ test_spec_multi_turn_stream()
diff --git a/sglang/examples/frontend_language/usage/openai_speculative.py b/sglang/examples/frontend_language/usage/openai_speculative.py
new file mode 100644
index 0000000000000000000000000000000000000000..4389cb059595c8704e28f77b16abafef0e31fed8
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/openai_speculative.py
@@ -0,0 +1,54 @@
+"""
+Usage:
+python3 openai_speculative.py
+"""
+
+from sglang import OpenAI, function, gen, set_default_backend
+
+
+@function(num_api_spec_tokens=64)
+def gen_character_spec(s):
+ s += "Construct a character within the following format:\n"
+ s += "Name: Steve Jobs.\nBirthday: February 24, 1955.\nJob: Apple CEO.\n"
+ s += "\nPlease generate new Name, Birthday and Job.\n"
+ s += "Name:" + gen("name", stop="\n") + "\nBirthday:" + gen("birthday", stop="\n")
+ s += "\nJob:" + gen("job", stop="\n") + "\n"
+
+
+@function
+def gen_character_no_spec(s):
+ s += "Construct a character within the following format:\n"
+ s += "Name: Steve Jobs.\nBirthday: February 24, 1955.\nJob: Apple CEO.\n"
+ s += "\nPlease generate new Name, Birthday and Job.\n"
+ s += "Name:" + gen("name", stop="\n") + "\nBirthday:" + gen("birthday", stop="\n")
+ s += "\nJob:" + gen("job", stop="\n") + "\n"
+
+
+@function(num_api_spec_tokens=64)
+def gen_character_spec_no_few_shot(s):
+ # s += "Construct a character with name, birthday, and job:\n"
+ s += "Construct a character:\n"
+ s += "Name:" + gen("name", stop="\n") + "\nBirthday:" + gen("birthday", stop="\n")
+ s += "\nJob:" + gen("job", stop="\n") + "\n"
+
+
+if __name__ == "__main__":
+ backend = OpenAI("gpt-3.5-turbo-instruct")
+ set_default_backend(backend)
+
+ for function in [
+ gen_character_spec,
+ gen_character_no_spec,
+ gen_character_spec_no_few_shot,
+ ]:
+ backend.token_usage.reset()
+
+ print(f"function: {function.func.__name__}")
+
+ state = function.run()
+
+ print("...name:", state["name"])
+ print("...birthday:", state["birthday"])
+ print("...job:", state["job"])
+ print(backend.token_usage)
+ print()
diff --git a/sglang/examples/frontend_language/usage/parallel_sample.py b/sglang/examples/frontend_language/usage/parallel_sample.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f3cf170000ea55a0e709db7f6c34e7d72b229cd
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/parallel_sample.py
@@ -0,0 +1,40 @@
+"""
+Usage:
+python3 parallel_sample.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def parallel_sample(s, question, n):
+ s += (
+ "Question: Compute 1 + 2 + 3\n"
+ "Reasoning: I need to use a calculator.\n"
+ "Tool: calculator\n"
+ "Answer: 6\n"
+ "Question: Compute 3 + 2 + 2\n"
+ "Reasoning: I will try a calculator.\n"
+ "Tool: calculator\n"
+ "Answer: 7\n"
+ )
+ s += "Question: " + question + "\n"
+ forks = s.fork(n)
+ forks += "Reasoning:" + sgl.gen("reasoning", stop="\n") + "\n"
+ forks += "Tool:" + sgl.gen("tool", choices=["calculator", "browser"]) + "\n"
+ forks += "Answer:" + sgl.gen("answer", stop="\n") + "\n"
+ forks.join()
+
+
+sgl.set_default_backend(sgl.OpenAI("gpt-3.5-turbo-instruct"))
+# sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:30000"))
+
+state = parallel_sample.run(question="Compute 5 + 2 + 4.", n=5, temperature=1.0)
+
+for i in range(5):
+ obj = {
+ "reasoning": state["reasoning"][i],
+ "tool": state["tool"][i],
+ "answer": state["answer"][i],
+ }
+ print(f"[{i}], {obj}")
diff --git a/sglang/examples/frontend_language/usage/rag_using_parea/trace_and_evaluate_rag_using_parea.ipynb b/sglang/examples/frontend_language/usage/rag_using_parea/trace_and_evaluate_rag_using_parea.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..3c1b2a6c400bf46ef8932bf220becb655c9df203
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/rag_using_parea/trace_and_evaluate_rag_using_parea.ipynb
@@ -0,0 +1,408 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# RAG Powered by SGLang & Chroma Evaluated using Parea\n",
+ "\n",
+ "In this notebook, we will build a simple RAG pipeline using SGLang to execute our LLM calls, Chroma as vector database for retrieval and [Parea](https://www.parea.ai) for tracing and evaluation. We will then evaluate the performance of our RAG pipeline. The dataset we will use was created by [Virat](https://twitter.com/virattt) and contains 100 questions, contexts and answers from the Airbnb 2023 10k filing.\n",
+ "\n",
+ "The RAG pipeline consists of two steps:\n",
+ "1. Retrieval: Given a question, we retrieve the relevant context from all provided contexts.\n",
+ "2. Generation: Given the question and the retrieved context, we generate an answer.\n",
+ "\n",
+ "ℹ️ This notebook requires an OpenAI API key.\n",
+ "\n",
+ "ℹ️ This notebook requires a Parea API key, which can be created [here](https://docs.parea.ai/api-reference/authentication#parea-api-key)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setting up the environment\n",
+ "\n",
+ "We will first install the necessary packages: `sglang`, `parea-ai` and `chromadb`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# note, if you use a Mac M1 chip, you might need to install grpcio 1.59.0 first such that installing chromadb works\n",
+ "# !pip install grpcio==1.59.0\n",
+ "\n",
+ "!pip install sglang[openai] parea-ai chromadb"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Create a Parea API key as outlined [here](https://docs.parea.ai/api-reference/authentication#parea-api-key) and save it in a `.env` file as `PAREA_API_KEY=your-api-key`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Indexing the data\n",
+ "\n",
+ "Now it's time to download the data & index it! For that, we create a collection called `contexts` in Chroma and add the contexts as documents."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "import os\n",
+ "from typing import List\n",
+ "\n",
+ "import chromadb\n",
+ "\n",
+ "path_qca = \"airbnb-2023-10k-qca.json\"\n",
+ "\n",
+ "if not os.path.exists(path_qca):\n",
+ " !wget https://virattt.github.io/datasets/abnb-2023-10k.json -O airbnb-2023-10k-qca.json\n",
+ "\n",
+ "with open(path_qca, \"r\") as f:\n",
+ " question_context_answers = json.load(f)\n",
+ "\n",
+ "chroma_client = chromadb.PersistentClient()\n",
+ "collection = chroma_client.get_or_create_collection(name=\"contexts\")\n",
+ "if collection.count() == 0:\n",
+ " collection.add(\n",
+ " documents=[qca[\"context\"] for qca in question_context_answers],\n",
+ " ids=[str(i) for i in range(len(question_context_answers))],\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Defining the RAG pipeline\n",
+ "\n",
+ "We will start with importing the necessary packages, setting up tracing of OpenAI calls via Parea and setting OpenAI as the default backend for SGLang."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import time\n",
+ "\n",
+ "from dotenv import load_dotenv\n",
+ "\n",
+ "from sglang import function, user, assistant, gen, set_default_backend, OpenAI\n",
+ "from sglang.lang.interpreter import ProgramState\n",
+ "from parea import Parea, trace\n",
+ "\n",
+ "\n",
+ "load_dotenv()\n",
+ "\n",
+ "os.environ[\"TOKENIZERS_PARALLELISM\"] = \"false\"\n",
+ "\n",
+ "p = Parea(api_key=os.getenv(\"PAREA_API_KEY\"), project_name=\"rag_sglang\")\n",
+ "p.integrate_with_sglang()\n",
+ "\n",
+ "set_default_backend(OpenAI(\"gpt-3.5-turbo\"))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we can define our retrieval step shown below. Notice, the `trace` decorator which will automatically trace inputs, output, latency, etc. of that call."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@trace\n",
+ "def retrieval(question: str) -> List[str]:\n",
+ " return collection.query(query_texts=[question], n_results=1)[\"documents\"][0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Next we will define the generation step which uses SGLang to execute the LLM call."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@function\n",
+ "def generation_sglang(s, question: str, *context: str):\n",
+ " context = \"\\n\".join(context)\n",
+ " s += user(\n",
+ " f\"Given this question:\\n{question}\\n\\nAnd this context:\\n{context}\\n\\nAnswer the question.\"\n",
+ " )\n",
+ " s += assistant(gen(\"answer\"))\n",
+ "\n",
+ "\n",
+ "@trace\n",
+ "def generation(question: str, *context):\n",
+ " state: ProgramState = generation_sglang.run(question, *context)\n",
+ " while not state.stream_executor.is_finished:\n",
+ " time.sleep(1)\n",
+ " return state.stream_executor.variables[\"answer\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, we can tie it together and execute a sample query."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@trace\n",
+ "def rag_pipeline(question: str) -> str:\n",
+ " contexts = retrieval(question)\n",
+ " return generation(question, *contexts)\n",
+ "\n",
+ "\n",
+ "rag_pipeline(\n",
+ " \"When did the World Health Organization formally declare an end to the COVID-19 global health emergency?\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Debug Trace\n",
+ "\n",
+ "The output is unfortunately wrong! Using the traced pipeline, we can see that\n",
+ "\n",
+ "- the context is relevant to the question and contains the correct information\n",
+ "- but, the generation step is cut off as max tokens is set to 16\n",
+ "\n",
+ "When opening the generation step in the playground and rerunning the prompt with max. tokens set to 1000, the correct answer is produced.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Evaluating RAG Pipelines\n",
+ "\n",
+ "Before we apply above's fix, let's dive into evaluating RAG pipelines.\n",
+ "\n",
+ "RAG pipelines consist of a retrieval step to fetch relevant information and a generation step to generate a response to a users question. A RAG pipeline can fail at either step. E.g. the retrieval step can fail to find relevant information which makes generating the correct impossible. Another failure mode is that the generation step doesn't leverage the retrieved information correctly. We will apply the following evaluation metrics to understand different failure modes:\n",
+ "\n",
+ "- `context_relevancy`: measures how relevant the context is given the question\n",
+ "- `percent_target_supported_by_context`: measures how much of the target answer is supported by the context; this will give an upper ceiling of how well the generation step can perform\n",
+ "- `answer_context_faithfulness`: measures how much the generated answer utilizes the context\n",
+ "- `answer_matches_target`: measures how well the generated answer matches the target answer judged by a LLM and gives a sense of accuracy of our entire pipeline\n",
+ "\n",
+ "To use these evaluation metrics, we can import them from `parea.evals.rag` and `parea.evals.general` and apply them to a function by specifying in the `trace` decorator which evaluation metrics to use. The `@trace` decorator will automatically log the results of the evaluation metrics to the Parea dashboard.\n",
+ "\n",
+ "Applying them to the retrieval step:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from parea.evals.rag import (\n",
+ " context_query_relevancy_factory,\n",
+ " percent_target_supported_by_context_factory,\n",
+ ")\n",
+ "\n",
+ "\n",
+ "context_relevancy_eval = context_query_relevancy_factory()\n",
+ "percent_target_supported_by_context = percent_target_supported_by_context_factory()\n",
+ "\n",
+ "\n",
+ "@trace(eval_funcs=[context_relevancy_eval, percent_target_supported_by_context])\n",
+ "def retrieval(question: str) -> List[str]:\n",
+ " return collection.query(query_texts=[question], n_results=1)[\"documents\"][0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we can apply `answer_context_faithfulness` and `answer_matches_target` to the generation step."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from parea.evals.general import answer_matches_target_llm_grader_factory\n",
+ "from parea.evals.rag import answer_context_faithfulness_statement_level_factory\n",
+ "\n",
+ "\n",
+ "answer_context_faithfulness = answer_context_faithfulness_statement_level_factory()\n",
+ "answer_matches_target_llm_grader = answer_matches_target_llm_grader_factory()\n",
+ "\n",
+ "\n",
+ "@function\n",
+ "def generation_sglang(s, question: str, *context: str):\n",
+ " context = \"\\n\".join(context)\n",
+ " s += user(\n",
+ " f\"Given this question:\\n{question}\\n\\nAnd this context:\\n{context}\\n\\nAnswer the question.\"\n",
+ " )\n",
+ " s += assistant(gen(\"answer\", max_tokens=1_000))\n",
+ "\n",
+ "\n",
+ "@trace(eval_funcs=[answer_context_faithfulness, answer_matches_target_llm_grader])\n",
+ "def generation(question: str, *context):\n",
+ " state: ProgramState = generation_sglang.run(question, *context)\n",
+ " while not state.stream_executor.is_finished:\n",
+ " time.sleep(1)\n",
+ " return state.stream_executor.variables[\"answer\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, we tie them together & execute the original sample query."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@trace\n",
+ "def rag_pipeline(question: str) -> str:\n",
+ " contexts = retrieval(question)\n",
+ " return generation(question, *contexts)\n",
+ "\n",
+ "\n",
+ "rag_pipeline(\n",
+ " \"When did the World Health Organization formally declare an end to the COVID-19 global health emergency?\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Great, the answer is correct! Can you spot the line where we fixed the output truncation issue?\n",
+ "\n",
+ "The evaluation scores appear in the bottom right of the logs (screenshot below). Note, that there is no score for `answer_matches_target_llm_grader` and `percent_target_supported_by_context` as these evals are automatically skipped if the target answer is not provided.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Running an experiment\n",
+ "\n",
+ "Now we are (almost) ready to evaluate the performance of our RAG pipeline on the entire dataset. First, we will need to apply the `nest_asyncio` package to avoid issues with the Jupyter notebook event loop."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install nest-asyncio\n",
+ "import nest_asyncio\n",
+ "\n",
+ "nest_asyncio.apply()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Running the actual experiment is straight-forward. For that we use `p.experiment` to initialize the experiment with a name, the data (list of key-value pairs fed into our entry function) and the entry function. We then call `run` on the experiment to execute it. Note, that `target` is a reserved key in the data dictionary and will be used as the target answer for evaluation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "e = p.experiment(\n",
+ " \"RAG\",\n",
+ " data=[\n",
+ " {\n",
+ " \"question\": qca[\"question\"],\n",
+ " \"target\": qca[\"answer\"],\n",
+ " }\n",
+ " for qca in question_context_answers\n",
+ " ],\n",
+ " func=rag_pipeline,\n",
+ ").run()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Analyzing the results\n",
+ "\n",
+ "When opening above experiment, we will see an overview of the experiment as shown below. The upper half shows a summary of the statistics on the left and charts to investigate the distribution and relationships of scores on the right. The lower half is a table with the individual traces which we can use to debug individual samples.\n",
+ "\n",
+ "When looking at the statistics, we can see that the accuracy of our RAG pipeline is 22% as measured by `answer_matches_target_llm_grader`. Though when checking the quality of our retrieval step (`context_query_relevancy`), we can see that our retrival step is fetching relevant information in only 27% of all samples. As shown in the GIF, we investigate the relationship between the two and see the two scores have 95% agreement. This confirms that the retrieval step is a major bottleneck for our RAG pipeline. So, now it's your turn to improve the retrieval step!\n",
+ "\n",
+ "Note, above link isn't publicly accessible but the experiment can be accessed through [here](https://app.parea.ai/public-experiments/parea/rag_sglang/30f0244a-d56c-44ff-bdfb-8f47626304b6).\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 2
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython2"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/sglang/examples/frontend_language/usage/readme_examples.py b/sglang/examples/frontend_language/usage/readme_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..7269ef1485dd20828d38f74403e5a45a4933fdc9
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/readme_examples.py
@@ -0,0 +1,109 @@
+"""
+Usage:
+python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
+python readme_examples.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def tool_use(s, question):
+ s += "To answer this question: " + question + ". "
+ s += (
+ "I need to use a "
+ + sgl.gen("tool", choices=["calculator", "search engine"])
+ + ". "
+ )
+
+ if s["tool"] == "calculator":
+ s += "The math expression is" + sgl.gen("expression")
+ elif s["tool"] == "search engine":
+ s += "The key word to search is" + sgl.gen("word")
+
+
+@sgl.function
+def tip_suggestion(s):
+ s += (
+ "Here are two tips for staying healthy: "
+ "1. Balanced Diet. 2. Regular Exercise.\n\n"
+ )
+
+ forks = s.fork(2)
+ for i, f in enumerate(forks):
+ f += f"Now, expand tip {i+1} into a paragraph:\n"
+ f += sgl.gen(f"detailed_tip", max_tokens=256, stop="\n\n")
+
+ s += "Tip 1:" + forks[0]["detailed_tip"] + "\n"
+ s += "Tip 2:" + forks[1]["detailed_tip"] + "\n"
+ s += "In summary" + sgl.gen("summary")
+
+
+@sgl.function
+def regular_expression_gen(s):
+ s += "Q: What is the IP address of the Google DNS servers?\n"
+ s += "A: " + sgl.gen(
+ "answer",
+ temperature=0,
+ regex=r"((25[0-5]|2[0-4]\d|[01]?\d\d?).){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)",
+ )
+
+
+@sgl.function
+def text_qa(s, question):
+ s += "Q: " + question + "\n"
+ s += "A:" + sgl.gen("answer", stop="\n")
+
+
+def driver_tool_use():
+ state = tool_use.run(question="What is the capital of the United States?")
+ print(state.text())
+ print("\n")
+
+
+def driver_tip_suggestion():
+ state = tip_suggestion.run()
+ print(state.text())
+ print("\n")
+
+
+def driver_regex():
+ state = regular_expression_gen.run()
+ print(state.text())
+ print("\n")
+
+
+def driver_batching():
+ states = text_qa.run_batch(
+ [
+ {"question": "What is the capital of the United Kingdom?"},
+ {"question": "What is the capital of France?"},
+ {"question": "What is the capital of Japan?"},
+ ],
+ progress_bar=True,
+ )
+
+ for s in states:
+ print(s.text())
+ print("\n")
+
+
+def driver_stream():
+ state = text_qa.run(
+ question="What is the capital of France?", temperature=0.1, stream=True
+ )
+
+ for out in state.text_iter():
+ print(out, end="", flush=True)
+ print("\n")
+
+
+if __name__ == "__main__":
+ # sgl.set_default_backend(sgl.OpenAI("gpt-3.5-turbo-instruct"))
+ sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:30000"))
+
+ driver_tool_use()
+ driver_tip_suggestion()
+ driver_regex()
+ driver_batching()
+ driver_stream()
diff --git a/sglang/examples/frontend_language/usage/sgl_gen_min_tokens.py b/sglang/examples/frontend_language/usage/sgl_gen_min_tokens.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5088199b92af94b0a5f02efccb0e8fe80772ad5
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/sgl_gen_min_tokens.py
@@ -0,0 +1,35 @@
+"""
+This example demonstrates how to use `min_tokens` to enforce sgl.gen to generate a longer sequence
+
+Usage:
+python3 sgl_gen_min_tokens.py
+"""
+
+import sglang as sgl
+
+
+@sgl.function
+def long_answer(s):
+ s += sgl.user("What is the capital of the United States?")
+ s += sgl.assistant(sgl.gen("answer", min_tokens=64, max_tokens=128))
+
+
+@sgl.function
+def short_answer(s):
+ s += sgl.user("What is the capital of the United States?")
+ s += sgl.assistant(sgl.gen("answer"))
+
+
+if __name__ == "__main__":
+ runtime = sgl.Runtime(model_path="meta-llama/Meta-Llama-3.1-8B-Instruct")
+ sgl.set_default_backend(runtime)
+
+ state = long_answer.run()
+ print("=" * 20)
+ print("Longer Answer", state["answer"])
+
+ state = short_answer.run()
+ print("=" * 20)
+ print("Short Answer", state["answer"])
+
+ runtime.shutdown()
diff --git a/sglang/examples/frontend_language/usage/streaming.py b/sglang/examples/frontend_language/usage/streaming.py
new file mode 100644
index 0000000000000000000000000000000000000000..506ee35c6f07f61937b975d0b1ace1c527bf832d
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/streaming.py
@@ -0,0 +1,49 @@
+"""
+Usage:
+python3 streaming.py
+"""
+
+import asyncio
+
+import sglang as sgl
+
+
+@sgl.function
+def multi_turn_question(s, question_1, question_2):
+ s += sgl.system("You are a helpful assistant.")
+ s += sgl.user(question_1)
+ s += sgl.assistant(sgl.gen("answer_1", max_tokens=256))
+ s += sgl.user(question_2)
+ s += sgl.assistant(sgl.gen("answer_2", max_tokens=256))
+
+
+sgl.set_default_backend(sgl.OpenAI("gpt-3.5-turbo"))
+
+
+def stream_a_variable():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ stream=True,
+ )
+
+ for out in state.text_iter(var_name="answer_2"):
+ print(out, end="", flush=True)
+ print("\n")
+
+
+async def async_stream():
+ state = multi_turn_question.run(
+ question_1="What is the capital of the United States?",
+ question_2="List two local attractions.",
+ stream=True,
+ )
+
+ async for out in state.text_async_iter(var_name="answer_2"):
+ print(out, end="", flush=True)
+ print("\n")
+
+
+if __name__ == "__main__":
+ stream_a_variable()
+ asyncio.run(async_stream())
diff --git a/sglang/examples/frontend_language/usage/triton/Dockerfile b/sglang/examples/frontend_language/usage/triton/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..e4741a1dbf7e84704089288bbab6423f15ccd92e
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/triton/Dockerfile
@@ -0,0 +1,10 @@
+FROM nvcr.io/nvidia/tritonserver:24.01-py3
+
+WORKDIR /opt
+
+RUN git clone https://github.com/sgl-project/sglang.git
+
+WORKDIR /opt/sglang
+RUN pip install --upgrade pip && \
+ pip install -e "python[all]" && \
+ pip install datasets
diff --git a/sglang/examples/frontend_language/usage/triton/README.md b/sglang/examples/frontend_language/usage/triton/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b2e55961f41acad4459c9e537a2e9d7c67f81e21
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/triton/README.md
@@ -0,0 +1,35 @@
+# sglang_triton
+
+Build the docker image:
+```
+docker build -t sglang-triton .
+```
+
+Then do:
+```
+docker run -ti --gpus=all --network=host --name sglang-triton -v ./models:/mnt/models sglang-triton
+```
+
+inside the docker container:
+```
+cd sglang
+python3 -m sglang.launch_server --model-path mistralai/Mistral-7B-Instruct-v0.2 --port 30000 --mem-fraction-static 0.9
+```
+
+with another shell, inside the docker container:
+```
+docker exec -ti sglang-triton /bin/bash
+cd /mnt
+tritonserver --model-repository=/mnt/models
+```
+
+
+Send request to the server:
+```
+curl -X POST http://localhost:8000/v2/models/character_generation/generate \
+-H "Content-Type: application/json" \
+-d '{
+ "INPUT_TEXT": ["harry"]
+}'
+
+```
diff --git a/sglang/examples/frontend_language/usage/triton/models/character_generation/1/model.py b/sglang/examples/frontend_language/usage/triton/models/character_generation/1/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..5550e93984b75d8a354ce6dbee66705ddecd76d9
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/triton/models/character_generation/1/model.py
@@ -0,0 +1,55 @@
+import numpy
+import triton_python_backend_utils as pb_utils
+from pydantic import BaseModel
+
+import sglang as sgl
+from sglang import function, set_default_backend
+from sglang.srt.constrained import build_regex_from_object
+
+sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:30000"))
+
+
+class Character(BaseModel):
+ name: str
+ eye_color: str
+ house: str
+
+
+@function
+def character_gen(s, name):
+ s += (
+ name
+ + " is a character in Harry Potter. Please fill in the following information about this character.\n"
+ )
+ s += sgl.gen(
+ "json_output", max_tokens=256, regex=build_regex_from_object(Character)
+ )
+
+
+class TritonPythonModel:
+ def initialize(self, args):
+ print("Initialized.")
+
+ def execute(self, requests):
+ responses = []
+ for request in requests:
+ tensor_in = pb_utils.get_input_tensor_by_name(request, "INPUT_TEXT")
+ if tensor_in is None:
+ return pb_utils.InferenceResponse(output_tensors=[])
+
+ input_list_names = [
+ i.decode("utf-8") if isinstance(i, bytes) else i
+ for i in tensor_in.as_numpy().tolist()
+ ]
+
+ input_list_dicts = [{"name": i} for i in input_list_names]
+
+ states = character_gen.run_batch(input_list_dicts)
+ character_strs = [state.text() for state in states]
+
+ tensor_out = pb_utils.Tensor(
+ "OUTPUT_TEXT", numpy.array(character_strs, dtype=object)
+ )
+
+ responses.append(pb_utils.InferenceResponse(output_tensors=[tensor_out]))
+ return responses
diff --git a/sglang/examples/frontend_language/usage/triton/models/character_generation/config.pbtxt b/sglang/examples/frontend_language/usage/triton/models/character_generation/config.pbtxt
new file mode 100644
index 0000000000000000000000000000000000000000..7546f993acfb28aae4b012e5d11627ed588bcb0f
--- /dev/null
+++ b/sglang/examples/frontend_language/usage/triton/models/character_generation/config.pbtxt
@@ -0,0 +1,23 @@
+name: "character_generation"
+backend: "python"
+input [
+ {
+ name: "INPUT_TEXT"
+ data_type: TYPE_STRING
+ dims: [ -1 ]
+ }
+]
+output [
+ {
+ name: "OUTPUT_TEXT"
+ data_type: TYPE_STRING
+ dims: [ -1 ]
+ }
+]
+instance_group [
+ {
+ count: 1
+ kind: KIND_GPU
+ gpus: [ 0 ]
+ }
+]
diff --git a/sglang/examples/monitoring/grafana.json b/sglang/examples/monitoring/grafana.json
new file mode 100644
index 0000000000000000000000000000000000000000..e7d436de23cd72bbf3d170401b97b49813225a26
--- /dev/null
+++ b/sglang/examples/monitoring/grafana.json
@@ -0,0 +1,1720 @@
+{
+ "annotations": {
+ "list": [
+ {
+ "builtIn": 1,
+ "datasource": {
+ "type": "grafana",
+ "uid": "-- Grafana --"
+ },
+ "enable": true,
+ "hide": true,
+ "iconColor": "rgba(0, 211, 255, 1)",
+ "name": "Annotations & Alerts",
+ "type": "dashboard"
+ }
+ ]
+ },
+ "editable": true,
+ "fiscalYearStartMonth": 0,
+ "graphTooltip": 0,
+ "id": 1,
+ "links": [],
+ "panels": [
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "description": "max-running-requests from server argument",
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "thresholds"
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 3,
+ "x": 0,
+ "y": 0
+ },
+ "id": 2,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "percentChangeColorMode": "standard",
+ "reduceOptions": {
+ "calcs": [
+ "last"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "showPercentChange": false,
+ "textMode": "auto",
+ "wideLayout": true
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "builder",
+ "expr": "sglang:max_running_requests{name=\"$name\", instance=\"$instance\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "__auto",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Max Running Requests",
+ "type": "stat"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "description": "Supported context length with loaded model",
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "thresholds"
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 3,
+ "x": 3,
+ "y": 0
+ },
+ "id": 1,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "percentChangeColorMode": "standard",
+ "reduceOptions": {
+ "calcs": [
+ "last"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "showPercentChange": false,
+ "textMode": "auto",
+ "wideLayout": true
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "builder",
+ "expr": "sglang:context_len{instance=\"$instance\", name=\"$name\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "__auto",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Max Context Length",
+ "type": "stat"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "description": "max_total_tokens",
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "thresholds"
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 3,
+ "x": 6,
+ "y": 0
+ },
+ "id": 4,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "percentChangeColorMode": "standard",
+ "reduceOptions": {
+ "calcs": [
+ "last"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "showPercentChange": false,
+ "textMode": "auto",
+ "wideLayout": true
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "builder",
+ "expr": "sglang:max_total_num_tokens{instance=\"$instance\", name=\"$name\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "__auto",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Max Total Num Tokens",
+ "type": "stat"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "description": "max_prefill_tokens from server args",
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "thresholds"
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 3,
+ "x": 9,
+ "y": 0
+ },
+ "id": 3,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "none",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "percentChangeColorMode": "standard",
+ "reduceOptions": {
+ "calcs": [
+ "last"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "showPercentChange": false,
+ "textMode": "auto",
+ "wideLayout": true
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sglang:max_prefill_tokens{instance=\"$instance\", name=\"$name\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "__auto",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Max Prefill Tokens",
+ "type": "stat"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "thresholds"
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 6,
+ "x": 12,
+ "y": 0
+ },
+ "id": 6,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "area",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "percentChangeColorMode": "standard",
+ "reduceOptions": {
+ "calcs": [
+ "lastNotNull"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "showPercentChange": false,
+ "textMode": "auto",
+ "wideLayout": true
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sglang:cached_token{instance=\"$instance\", name=\"$name\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Cached Tokens",
+ "type": "stat"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "description": "",
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "thresholds"
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 3,
+ "w": 6,
+ "x": 18,
+ "y": 0
+ },
+ "id": 5,
+ "options": {
+ "colorMode": "value",
+ "graphMode": "area",
+ "justifyMode": "auto",
+ "orientation": "auto",
+ "percentChangeColorMode": "standard",
+ "reduceOptions": {
+ "calcs": [
+ "lastNotNull"
+ ],
+ "fields": "",
+ "values": false
+ },
+ "showPercentChange": false,
+ "textMode": "auto",
+ "wideLayout": true
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sglang:cache_hit_rate{instance=\"$instance\", name=\"$name\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Cache Hit Rate (%)",
+ "type": "stat"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 0,
+ "y": 3
+ },
+ "id": 14,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.99, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{instance=\"$instance\", name=\"$name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P99",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.9, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{instance=\"$instance\", name=\"$name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P90",
+ "range": true,
+ "refId": "B",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "builder",
+ "expr": "histogram_quantile(0.95, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{instance=\"$instance\", name=\"$model_name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P95",
+ "range": true,
+ "refId": "C",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "builder",
+ "expr": "histogram_quantile(0.5, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{instance=\"$instance\", name=\"$model_name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P50",
+ "range": true,
+ "refId": "D",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "builder",
+ "expr": "rate(sglang:e2e_request_latency_seconds_sum{instance=\"$instance\", name=\"$model_name\"}[$__rate_interval]) / rate(sglang:e2e_request_latency_seconds_count[$__rate_interval])",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "Average",
+ "range": true,
+ "refId": "E",
+ "useBackend": false
+ }
+ ],
+ "title": "E2E Request Latency (S)",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 12,
+ "y": 3
+ },
+ "id": 18,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "editorMode": "code",
+ "expr": "sglang:gen_throughput{instance=\"$instance\", name=\"$name\"}",
+ "instant": false,
+ "legendFormat": "__auto",
+ "range": true,
+ "refId": "A"
+ }
+ ],
+ "title": "Generation Throughput (Token / S)",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 0,
+ "y": 11
+ },
+ "id": 7,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sglang:num_requests_running{instance=\"$instance\", name=\"$name\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Num Requests Running",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 12,
+ "y": 11
+ },
+ "id": 8,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sglang:num_requests_waiting{instance=\"$instance\", name=\"$name\"}",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Number of Requests Waiting",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 0,
+ "y": 19
+ },
+ "id": 16,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.99, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P99",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.9, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P90",
+ "range": true,
+ "refId": "B",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.95, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P95",
+ "range": true,
+ "refId": "C",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.5, sum by(le) (rate(sglang:e2e_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "P50",
+ "range": true,
+ "refId": "D",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "rate(sglang:e2e_request_latency_seconds_sum{name=\"$name\"}[$__rate_interval]) / rate(sglang:e2e_request_latency_seconds_count{name=\"$name\"}[$__rate_interval])",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "Average",
+ "range": true,
+ "refId": "E",
+ "useBackend": false
+ }
+ ],
+ "title": "Time Request Decoding (S)",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "description": "Time requests waiting before added to batch",
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 12,
+ "y": 19
+ },
+ "id": 15,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.99, sum by (le) (rate(sglang:waiting_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "instant": false,
+ "legendFormat": "P99",
+ "range": true,
+ "refId": "A"
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.95, sum by (le) (rate(sglang:waiting_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "hide": false,
+ "instant": false,
+ "legendFormat": "P95",
+ "range": true,
+ "refId": "B"
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.9, sum by (le) (rate(sglang:waiting_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "hide": false,
+ "instant": false,
+ "legendFormat": "P90",
+ "range": true,
+ "refId": "C"
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "editorMode": "code",
+ "expr": "histogram_quantile(0.5, sum by (le) (rate(sglang:waiting_request_latency_seconds_bucket{name=\"$name\"}[$__rate_interval])))",
+ "hide": false,
+ "instant": false,
+ "legendFormat": "P50",
+ "range": true,
+ "refId": "D"
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "editorMode": "code",
+ "expr": "rate(sglang:waiting_request_latency_seconds_sum{name=\"$name\"}[$__rate_interval])\r\n/\r\nrate(sglang:waiting_request_latency_seconds_count{name=\"$name\"}[$__rate_interval])",
+ "hide": false,
+ "instant": false,
+ "legendFormat": "Average",
+ "range": true,
+ "refId": "E"
+ }
+ ],
+ "title": "Time Request Waiting (S)",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 0,
+ "y": 27
+ },
+ "id": 11,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sum(rate(sglang:request_prompt_tokens_sum{instance=\"$instance\", name=\"$name\"}[$__rate_interval])) by (instance, name)",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ },
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "",
+ "fullMetaSearch": false,
+ "hide": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "__auto",
+ "range": true,
+ "refId": "B",
+ "useBackend": false
+ }
+ ],
+ "title": "Prompt Tokens",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "color": {
+ "mode": "palette-classic"
+ },
+ "custom": {
+ "axisBorderShow": false,
+ "axisCenteredZero": false,
+ "axisColorMode": "text",
+ "axisLabel": "",
+ "axisPlacement": "auto",
+ "barAlignment": 0,
+ "barWidthFactor": 0.6,
+ "drawStyle": "line",
+ "fillOpacity": 0,
+ "gradientMode": "none",
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "insertNulls": false,
+ "lineInterpolation": "linear",
+ "lineWidth": 1,
+ "pointSize": 5,
+ "scaleDistribution": {
+ "type": "linear"
+ },
+ "showPoints": "auto",
+ "spanNulls": false,
+ "stacking": {
+ "group": "A",
+ "mode": "none"
+ },
+ "thresholdsStyle": {
+ "mode": "off"
+ }
+ },
+ "mappings": [],
+ "thresholds": {
+ "mode": "absolute",
+ "steps": [
+ {
+ "color": "green",
+ "value": null
+ },
+ {
+ "color": "red",
+ "value": 80
+ }
+ ]
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 12,
+ "y": 27
+ },
+ "id": 17,
+ "options": {
+ "legend": {
+ "calcs": [],
+ "displayMode": "list",
+ "placement": "bottom",
+ "showLegend": true
+ },
+ "tooltip": {
+ "mode": "single",
+ "sort": "none"
+ }
+ },
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sum(rate(sglang:request_generation_tokens_sum{instance=\"$instance\", name=\"$name\"}[$__rate_interval])) by (instance, name)",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Generated Tokens",
+ "type": "timeseries"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "fieldConfig": {
+ "defaults": {
+ "custom": {
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "scaleDistribution": {
+ "type": "linear"
+ }
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 0,
+ "y": 35
+ },
+ "id": 13,
+ "options": {
+ "calculate": false,
+ "calculation": {
+ "yBuckets": {
+ "scale": {
+ "log": 2,
+ "type": "log"
+ }
+ }
+ },
+ "cellGap": 1,
+ "color": {
+ "exponent": 0.5,
+ "fill": "dark-orange",
+ "mode": "scheme",
+ "reverse": false,
+ "scale": "exponential",
+ "scheme": "Oranges",
+ "steps": 64
+ },
+ "exemplars": {
+ "color": "rgba(255,0,255,0.7)"
+ },
+ "filterValues": {
+ "le": 1e-9
+ },
+ "legend": {
+ "show": true
+ },
+ "rowsFrame": {
+ "layout": "auto"
+ },
+ "tooltip": {
+ "mode": "single",
+ "showColorScale": false,
+ "yHistogram": false
+ },
+ "yAxis": {
+ "axisPlacement": "left",
+ "reverse": false
+ }
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sum by(le) (increase(sglang:request_prompt_tokens_bucket{name=\"$name\", instance=\"$instance\"}[$__rate_interval]))",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Request Prompt Tokens",
+ "type": "heatmap"
+ },
+ {
+ "datasource": {
+ "default": true,
+ "type": "prometheus",
+ "uid": "ee2vha8w6f5kwf"
+ },
+ "description": "",
+ "fieldConfig": {
+ "defaults": {
+ "custom": {
+ "hideFrom": {
+ "legend": false,
+ "tooltip": false,
+ "viz": false
+ },
+ "scaleDistribution": {
+ "type": "linear"
+ }
+ }
+ },
+ "overrides": []
+ },
+ "gridPos": {
+ "h": 8,
+ "w": 12,
+ "x": 12,
+ "y": 35
+ },
+ "id": 12,
+ "options": {
+ "calculate": false,
+ "calculation": {
+ "xBuckets": {
+ "mode": "size",
+ "value": ""
+ },
+ "yBuckets": {
+ "mode": "size",
+ "scale": {
+ "log": 2,
+ "type": "log"
+ },
+ "value": ""
+ }
+ },
+ "cellGap": 1,
+ "color": {
+ "exponent": 0.5,
+ "fill": "dark-orange",
+ "min": 0,
+ "mode": "scheme",
+ "reverse": false,
+ "scale": "exponential",
+ "scheme": "Spectral",
+ "steps": 64
+ },
+ "exemplars": {
+ "color": "rgba(255,0,255,0.7)"
+ },
+ "filterValues": {
+ "le": 1e-9
+ },
+ "legend": {
+ "show": true
+ },
+ "rowsFrame": {
+ "layout": "auto",
+ "value": "Request count"
+ },
+ "tooltip": {
+ "mode": "single",
+ "showColorScale": false,
+ "yHistogram": true
+ },
+ "yAxis": {
+ "axisLabel": "Generation Length",
+ "axisPlacement": "left",
+ "reverse": false,
+ "unit": "none"
+ }
+ },
+ "pluginVersion": "11.2.0",
+ "targets": [
+ {
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "disableTextWrap": false,
+ "editorMode": "code",
+ "expr": "sum by(le) (increase(sglang:request_generation_tokens_bucket{name=\"$name\", instance=\"$instance\"}[$__rate_interval]))",
+ "fullMetaSearch": false,
+ "includeNullMetadata": true,
+ "instant": false,
+ "legendFormat": "{{__name__}}",
+ "range": true,
+ "refId": "A",
+ "useBackend": false
+ }
+ ],
+ "title": "Request Generation Tokens",
+ "type": "heatmap"
+ }
+ ],
+ "refresh": "5s",
+ "schemaVersion": 39,
+ "tags": [],
+ "templating": {
+ "list": [
+ {
+ "current": {
+ "selected": false,
+ "text": "127.0.0.1:30000",
+ "value": "127.0.0.1:30000"
+ },
+ "datasource": {
+ "type": "prometheus",
+ "uid": "ddyfngn31dg5cf"
+ },
+ "definition": "label_values(instance)",
+ "hide": 0,
+ "includeAll": false,
+ "label": "instance",
+ "multi": false,
+ "name": "instance",
+ "options": [],
+ "query": {
+ "qryType": 1,
+ "query": "label_values(instance)",
+ "refId": "PrometheusVariableQueryEditor-VariableQuery"
+ },
+ "refresh": 1,
+ "regex": "",
+ "skipUrlSync": false,
+ "sort": 0,
+ "type": "query"
+ },
+ {
+ "current": {
+ "selected": true,
+ "text": "google/gemma-2-9b-it",
+ "value": "google/gemma-2-9b-it"
+ },
+ "definition": "label_values(name)",
+ "hide": 1,
+ "includeAll": false,
+ "label": "name",
+ "multi": false,
+ "name": "name",
+ "options": [],
+ "query": {
+ "qryType": 1,
+ "query": "label_values(name)",
+ "refId": "PrometheusVariableQueryEditor-VariableQuery"
+ },
+ "refresh": 1,
+ "regex": "",
+ "skipUrlSync": false,
+ "sort": 0,
+ "type": "query"
+ }
+ ]
+ },
+ "time": {
+ "from": "now-30m",
+ "to": "now"
+ },
+ "timepicker": {},
+ "timezone": "browser",
+ "title": "SGLang Dashboard",
+ "uid": "ddyp55uq7brpcc",
+ "version": 3,
+ "weekStart": ""
+}
diff --git a/sglang/examples/monitoring/prometheus.yaml b/sglang/examples/monitoring/prometheus.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ba16ac3bd307c1711c00b866b204827bace796b6
--- /dev/null
+++ b/sglang/examples/monitoring/prometheus.yaml
@@ -0,0 +1,10 @@
+# prometheus.yaml
+global:
+ scrape_interval: 5s
+ evaluation_interval: 30s
+
+scrape_configs:
+ - job_name: sglang
+ static_configs:
+ - targets:
+ - '127.0.0.1:30000'
diff --git a/sglang/examples/runtime/lora.py b/sglang/examples/runtime/lora.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf3fc2d9ec783e44f809f9f20f8c2ec9ea5edbbe
--- /dev/null
+++ b/sglang/examples/runtime/lora.py
@@ -0,0 +1,37 @@
+# launch server
+# python -m sglang.launch_server --model mistralai/Mistral-7B-Instruct-v0.3 --lora-paths /home/ying/test_lora lora1=/home/ying/test_lora_1 lora2=/home/ying/test_lora_2 --disable-radix --disable-cuda-graph --max-loras-per-batch 4
+
+# send requests
+# lora_path[i] specifies the LoRA used for text[i], so make sure they have the same length
+# use None to specify base-only prompt, e.x. "lora_path": [None, "/home/ying/test_lora"]
+import json
+
+import requests
+
+url = "http://127.0.0.1:30000"
+json_data = {
+ "text": [
+ "prompt 1",
+ "prompt 2",
+ "prompt 3",
+ "prompt 4",
+ "prompt 5",
+ "prompt 6",
+ "prompt 7",
+ ],
+ "sampling_params": {"max_new_tokens": 32},
+ "lora_path": [
+ "/home/ying/test_lora",
+ "lora1",
+ "lora2",
+ "lora1",
+ "lora2",
+ None,
+ None,
+ ],
+}
+response = requests.post(
+ url + "/generate",
+ json=json_data,
+)
+print(json.dumps(response.json()))
diff --git a/sglang/examples/runtime/openai_batch_complete.py b/sglang/examples/runtime/openai_batch_complete.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f5be3d306a9a93b5b013a8a872d40b2b469333e
--- /dev/null
+++ b/sglang/examples/runtime/openai_batch_complete.py
@@ -0,0 +1,93 @@
+"""
+Usage:
+python -m sglang.launch_server --model-path meta-llama/Llama-2-7b-chat-hf --port 30000
+python openai_batch_complete.py
+Note: Before running this script,
+you should create the input.jsonl file with the following content:
+{"custom_id": "request-1", "method": "POST", "url": "/v1/completions", "body": {"model": "gpt-3.5-turbo-instruct", "prompt": "List 3 names of famous soccer player: ", "max_tokens": 200}}
+{"custom_id": "request-2", "method": "POST", "url": "/v1/completions", "body": {"model": "gpt-3.5-turbo-instruct", "prompt": "List 6 names of famous basketball player: ", "max_tokens": 400}}
+{"custom_id": "request-3", "method": "POST", "url": "/v1/completions", "body": {"model": "gpt-3.5-turbo-instruct", "prompt": "List 6 names of famous basketball player: ", "max_tokens": 400}}
+"""
+
+import json
+import time
+
+import openai
+
+
+class OpenAIBatchProcessor:
+ def __init__(self):
+ client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
+
+ self.client = client
+
+ def process_batch(self, input_file_path, endpoint, completion_window):
+
+ # Upload the input file
+ with open(input_file_path, "rb") as file:
+ uploaded_file = self.client.files.create(file=file, purpose="batch")
+
+ # Create the batch job
+ batch_job = self.client.batches.create(
+ input_file_id=uploaded_file.id,
+ endpoint=endpoint,
+ completion_window=completion_window,
+ )
+
+ # Monitor the batch job status
+ while batch_job.status not in ["completed", "failed", "cancelled"]:
+ time.sleep(3) # Wait for 3 seconds before checking the status again
+ print(
+ f"Batch job status: {batch_job.status}...trying again in 3 seconds..."
+ )
+ batch_job = self.client.batches.retrieve(batch_job.id)
+
+ # Check the batch job status and errors
+ if batch_job.status == "failed":
+ print(f"Batch job failed with status: {batch_job.status}")
+ print(f"Batch job errors: {batch_job.errors}")
+ return None
+
+ # If the batch job is completed, process the results
+ if batch_job.status == "completed":
+
+ # print result of batch job
+ print("batch", batch_job.request_counts)
+
+ result_file_id = batch_job.output_file_id
+ # Retrieve the file content from the server
+ file_response = self.client.files.content(result_file_id)
+ result_content = file_response.read() # Read the content of the file
+
+ # Save the content to a local file
+ result_file_name = "batch_job_complete_results.jsonl"
+ with open(result_file_name, "wb") as file:
+ file.write(result_content) # Write the binary content to the file
+ # Load data from the saved JSONL file
+ results = []
+ with open(result_file_name, "r", encoding="utf-8") as file:
+ for line in file:
+ json_object = json.loads(
+ line.strip()
+ ) # Parse each line as a JSON object
+ results.append(json_object)
+
+ return results
+ else:
+ print(f"Batch job failed with status: {batch_job.status}")
+ return None
+
+
+# Initialize the OpenAIBatchProcessor
+processor = OpenAIBatchProcessor()
+
+# Process the batch job
+input_file_path = "input.jsonl"
+endpoint = "/v1/completions"
+completion_window = "24h"
+
+# Process the batch job
+results = processor.process_batch(input_file_path, endpoint, completion_window)
+
+# Print the results
+print(results)
diff --git a/sglang/examples/runtime/openai_chat_with_response_prefill.py b/sglang/examples/runtime/openai_chat_with_response_prefill.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b1604b3023e84ac1af40a1ef037a8087b0b7b7b
--- /dev/null
+++ b/sglang/examples/runtime/openai_chat_with_response_prefill.py
@@ -0,0 +1,34 @@
+"""
+Usage:
+python -m sglang.launch_server --model-path meta-llama/Llama-3.1-8B-Instruct --port 30000
+python openai_chat.py
+"""
+
+import openai
+from openai import OpenAI
+
+client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
+
+response = client.chat.completions.create(
+ model="meta-llama/Llama-3.1-8B-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful AI assistant"},
+ {
+ "role": "user",
+ "content": """
+Extract the name, size, price, and color from this product description as a JSON object:
+
+
+The SmartHome Mini is a compact smart home assistant available in black or white for only $49.99. At just 5 inches wide, it lets you control lights, thermostats, and other connected devices via voice or app—no matter where you place it in your home. This affordable little hub brings convenient hands-free control to your smart devices.
+
+""",
+ },
+ {
+ "role": "assistant",
+ "content": "{\n",
+ },
+ ],
+ temperature=0,
+)
+
+print(response.choices[0].message.content)
diff --git a/sglang/scripts/deprecated/convert_yi_vl.py b/sglang/scripts/deprecated/convert_yi_vl.py
new file mode 100644
index 0000000000000000000000000000000000000000..bdf37ff92bb177242420235168311463411187c0
--- /dev/null
+++ b/sglang/scripts/deprecated/convert_yi_vl.py
@@ -0,0 +1,38 @@
+"""
+Convert Yi-VL config into a format useable with SGLang
+
+Usage: python3 scripts/convert_yi_vl.py --model-path
+"""
+
+import argparse
+import json
+import os
+
+from transformers import AutoConfig, AutoTokenizer
+
+
+def add_image_token(model_path: str):
+ tokenizer = AutoTokenizer.from_pretrained(model_path)
+ tokenizer.add_tokens([""], special_tokens=True)
+
+ print(tokenizer)
+ tokenizer.save_pretrained(model_path)
+
+
+def edit_model_config(model_path):
+ config = AutoConfig.from_pretrained(model_path)
+
+ setattr(config, "architectures", ["YiVLForCausalLM"])
+ setattr(config, "image_token_index", 64002)
+
+ print(config)
+ config.save_pretrained(model_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model-path", type=str)
+ args = parser.parse_args()
+
+ add_image_token(args.model_path)
+ edit_model_config(args.model_path)
diff --git a/sglang/scripts/deprecated/test_httpserver_classify.py b/sglang/scripts/deprecated/test_httpserver_classify.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb88802999a7251d319f5ce2ffced86359c72ffc
--- /dev/null
+++ b/sglang/scripts/deprecated/test_httpserver_classify.py
@@ -0,0 +1,85 @@
+"""
+Usage:
+python3 -m sglang.launch_server --model-path /model/llama-classification --is-embedding --disable-radix-cache
+
+python3 test_httpserver_classify.py
+"""
+
+import argparse
+
+import numpy as np
+import requests
+
+
+def get_logits_deprecated(url: str, prompt: str):
+ response = requests.post(
+ url + "/generate",
+ json={
+ "text": prompt,
+ "sampling_params": {
+ "max_new_tokens": 0,
+ },
+ "return_logprob": True,
+ },
+ )
+ return response.json()["meta_info"]["normalized_prompt_logprob"]
+
+
+def get_logits_batch_deprecated(url: str, prompts: list[str]):
+ response = requests.post(
+ url + "/generate",
+ json={
+ "text": prompts,
+ "sampling_params": {
+ "max_new_tokens": 0,
+ },
+ "return_logprob": True,
+ },
+ )
+ ret = response.json()
+ logits = np.array(
+ list(
+ ret[i]["meta_info"]["normalized_prompt_logprob"]
+ for i in range(len(prompts))
+ )
+ )
+ return logits
+
+
+def get_logits(url: str, prompt: str):
+ response = requests.post(
+ url + "/classify",
+ json={"text": prompt},
+ )
+ return response.json()["embedding"]
+
+
+def get_logits_batch(url: str, prompts: list[str]):
+ response = requests.post(
+ url + "/classify",
+ json={"text": prompts},
+ )
+ return np.array([x["embedding"] for x in response.json()])
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--host", type=str, default="http://127.0.0.1")
+ parser.add_argument("--port", type=int, default=30000)
+ args = parser.parse_args()
+
+ url = f"{args.host}:{args.port}"
+
+ # A single request
+ prompt = "This is a test prompt.<|eot_id|>"
+ logits = get_logits(url, prompt)
+ print(f"{logits=}")
+
+ # A batch of requests
+ prompts = [
+ "This is a test prompt.<|eot_id|>",
+ "This is another test prompt.<|eot_id|>",
+ "This is a long long long long test prompt.<|eot_id|>",
+ ]
+ logits = get_logits_batch(url, prompts)
+ print(f"{logits=}")
diff --git a/sglang/scripts/deprecated/test_httpserver_decode_stream.py b/sglang/scripts/deprecated/test_httpserver_decode_stream.py
new file mode 100644
index 0000000000000000000000000000000000000000..955c368d15490f12db7f60b86a88aa9aafec01e4
--- /dev/null
+++ b/sglang/scripts/deprecated/test_httpserver_decode_stream.py
@@ -0,0 +1,69 @@
+"""
+Usage:
+python3 -m sglang.launch_server --model-path TinyLlama/TinyLlama-1.1B-Chat-v0.4 --port 30000
+python3 test_httpserver_decode_stream.py
+
+Output:
+The capital of France is Paris.\nThe capital of the United States is Washington, D.C.\nThe capital of Canada is Ottawa.\nThe capital of Japan is Tokyo
+"""
+
+import argparse
+import json
+
+import requests
+
+
+def test_decode_stream(url, return_logprob, top_logprobs_num):
+ response = requests.post(
+ url + "/generate",
+ json={
+ "text": "The capital of France is",
+ "sampling_params": {
+ "temperature": 0,
+ "max_new_tokens": 128,
+ },
+ "stream": True,
+ "return_logprob": return_logprob,
+ "top_logprobs_num": top_logprobs_num,
+ "return_text_in_logprobs": True,
+ "logprob_start_len": 0,
+ },
+ stream=True,
+ )
+
+ prev = 0
+ for chunk in response.iter_lines(decode_unicode=False):
+ chunk = chunk.decode("utf-8")
+ if chunk and chunk.startswith("data:"):
+ if chunk == "data: [DONE]":
+ break
+ data = json.loads(chunk[5:].strip("\n"))
+
+ if return_logprob:
+ assert data["meta_info"]["input_token_logprobs"] is not None
+ assert data["meta_info"]["output_token_logprobs"] is not None
+ assert data["meta_info"]["normalized_prompt_logprob"] is not None
+ for logprob, token_id, token_text in data["meta_info"][
+ "output_token_logprobs"
+ ][prev:]:
+ print(f"{token_text:12s}\t{logprob}\t{token_id}", flush=True)
+ prev = len(data["meta_info"]["output_token_logprobs"])
+ else:
+ output = data["text"].strip()
+ print(output[prev:], end="", flush=True)
+ prev = len(output)
+
+ print("=" * 100)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--host", type=str, default="http://127.0.0.1")
+ parser.add_argument("--port", type=int, default=30000)
+ args = parser.parse_args()
+
+ url = f"{args.host}:{args.port}"
+
+ test_decode_stream(url, False, 0)
+ test_decode_stream(url, True, 0)
+ test_decode_stream(url, True, 3)
diff --git a/sglang/scripts/deprecated/test_httpserver_llava.py b/sglang/scripts/deprecated/test_httpserver_llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..791fc6deb1faa081f717d81576467d889f00109d
--- /dev/null
+++ b/sglang/scripts/deprecated/test_httpserver_llava.py
@@ -0,0 +1,88 @@
+"""
+Usage:
+python3 -m sglang.launch_server --model-path liuhaotian/llava-v1.5-7b --tokenizer-path llava-hf/llava-1.5-7b-hf --port 30000
+python3 test_httpserver_llava.py
+
+Output:
+The image features a man standing on the back of a yellow taxi cab, holding
+"""
+
+import argparse
+import asyncio
+import json
+
+import aiohttp
+import requests
+
+
+async def send_request(url, data, delay=0):
+ await asyncio.sleep(delay)
+ async with aiohttp.ClientSession() as session:
+ async with session.post(url, json=data) as resp:
+ output = await resp.json()
+ return output
+
+
+async def test_concurrent(args):
+ url = f"{args.host}:{args.port}"
+
+ response = []
+ for i in range(8):
+ response.append(
+ send_request(
+ url + "/generate",
+ {
+ "text": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: \nDescribe this picture ASSISTANT:",
+ "image_data": "example_image.png",
+ "sampling_params": {
+ "temperature": 0,
+ "max_new_tokens": 64,
+ },
+ },
+ )
+ )
+
+ rets = await asyncio.gather(*response)
+ for ret in rets:
+ print(ret["text"])
+
+
+def test_streaming(args):
+ url = f"{args.host}:{args.port}"
+
+ response = requests.post(
+ url + "/generate",
+ json={
+ "text": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: \nDescribe this picture ASSISTANT:",
+ "image_data": "example_image.png",
+ "sampling_params": {
+ "temperature": 0,
+ "max_new_tokens": 128,
+ },
+ "stream": True,
+ },
+ stream=True,
+ )
+
+ prev = 0
+ for chunk in response.iter_lines(decode_unicode=False):
+ chunk = chunk.decode("utf-8")
+ if chunk and chunk.startswith("data:"):
+ if chunk == "data: [DONE]":
+ break
+ data = json.loads(chunk[5:].strip("\n"))
+ output = data["text"].strip()
+ print(output[prev:], end="", flush=True)
+ prev = len(output)
+ print("")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--host", type=str, default="http://127.0.0.1")
+ parser.add_argument("--port", type=int, default=30000)
+ args = parser.parse_args()
+
+ asyncio.run(test_concurrent(args))
+
+ test_streaming(args)
diff --git a/sglang/scripts/deprecated/test_httpserver_reuse.py b/sglang/scripts/deprecated/test_httpserver_reuse.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef866afc6bd8ce3ced8373b3f69f02f9ac5914e5
--- /dev/null
+++ b/sglang/scripts/deprecated/test_httpserver_reuse.py
@@ -0,0 +1,42 @@
+"""
+python3 -m sglang.launch_server --model-path TinyLlama/TinyLlama-1.1B-Chat-v0.4 --port 30000
+
+Output:
+The capital of France is Paris.\nThe capital of the United States is Washington, D.C.\nThe capital of Canada is Ottawa.\nThe capital of Japan is Tokyo
+"""
+
+import argparse
+
+import requests
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--host", type=str, default="http://127.0.0.1")
+ parser.add_argument("--port", type=int, default=30000)
+ args = parser.parse_args()
+
+ url = f"{args.host}:{args.port}"
+
+ response = requests.post(
+ url + "/generate",
+ json={
+ "text": "The capital of France is",
+ "sampling_params": {
+ "temperature": 0,
+ "max_new_tokens": 32,
+ },
+ },
+ )
+ print(response.json())
+
+ response = requests.post(
+ url + "/generate",
+ json={
+ "text": "The capital of France is Paris.\nThe capital of the United States is",
+ "sampling_params": {
+ "temperature": 0,
+ "max_new_tokens": 32,
+ },
+ },
+ )
+ print(response.json())
diff --git a/sglang/scripts/deprecated/test_jump_forward.py b/sglang/scripts/deprecated/test_jump_forward.py
new file mode 100644
index 0000000000000000000000000000000000000000..60074a040054d92623cc004ac58ba3c4a530c9d5
--- /dev/null
+++ b/sglang/scripts/deprecated/test_jump_forward.py
@@ -0,0 +1,138 @@
+import argparse
+from enum import Enum
+
+from pydantic import BaseModel, constr
+
+import sglang as sgl
+from sglang.srt.constrained import build_regex_from_object
+from sglang.test.test_utils import (
+ add_common_sglang_args_and_parse,
+ select_sglang_backend,
+)
+
+IP_REGEX = r"((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)"
+
+ip_jump_forward = (
+ r"The google's DNS sever address is "
+ + IP_REGEX
+ + r" and "
+ + IP_REGEX
+ + r". "
+ + r"The google's website domain name is "
+ + r"www\.(\w)+\.(\w)+"
+ + r"."
+)
+
+
+# fmt: off
+@sgl.function
+def regex_gen(s):
+ s += "Q: What is the IP address of the Google DNS servers?\n"
+ s += "A: " + sgl.gen(
+ "answer",
+ max_tokens=128,
+ temperature=0,
+ regex=ip_jump_forward,
+ )
+# fmt: on
+
+json_jump_forward = (
+ r"""The information about Hogwarts is in the following JSON format\.\n"""
+ + r"""\n\{\n"""
+ + r""" "name": "[\w\d\s]*",\n"""
+ + r""" "country": "[\w\d\s]*",\n"""
+ + r""" "latitude": [-+]?[0-9]*\.?[0-9]+,\n"""
+ + r""" "population": [-+]?[0-9]+,\n"""
+ + r""" "top 3 landmarks": \["[\w\d\s]*", "[\w\d\s]*", "[\w\d\s]*"\],\n"""
+ + r"""\}\n"""
+)
+
+# fmt: off
+@sgl.function
+def json_gen(s):
+ s += sgl.gen(
+ "json",
+ max_tokens=128,
+ temperature=0,
+ regex=json_jump_forward,
+ )
+# fmt: on
+
+
+class Weapon(str, Enum):
+ sword = "sword"
+ axe = "axe"
+ mace = "mace"
+ spear = "spear"
+ bow = "bow"
+ crossbow = "crossbow"
+
+
+class Armor(str, Enum):
+ leather = "leather"
+ chainmail = "chainmail"
+ plate = "plate"
+
+
+class Character(BaseModel):
+ name: constr(max_length=10)
+ age: int
+ armor: Armor
+ weapon: Weapon
+ strength: int
+
+
+@sgl.function
+def character_gen(s):
+ s += "Give me a character description who is a wizard.\n"
+ s += sgl.gen(
+ "character",
+ max_tokens=128,
+ temperature=0,
+ regex=build_regex_from_object(Character),
+ )
+
+
+def main(args):
+ # Select backend
+ backend = select_sglang_backend(args)
+ sgl.set_default_backend(backend)
+
+ state = regex_gen.run(temperature=0)
+
+ print("=" * 20, "IP TEST", "=" * 20)
+ print(state.text())
+
+ state = json_gen.run(temperature=0)
+
+ print("=" * 20, "JSON TEST", "=" * 20)
+ print(state.text())
+
+ state = character_gen.run(temperature=0)
+
+ print("=" * 20, "CHARACTER TEST", "=" * 20)
+ print(state.text())
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ args = add_common_sglang_args_and_parse(parser)
+ main(args)
+
+# ==================== IP TEST ====================
+# Q: What is the IP address of the Google DNS servers?
+# A: The google's DNS sever address is 8.8.8.8 and 8.8.4.4. The google's website domain name is www.google.com.
+# ==================== JSON TEST ====================
+# The information about Hogwarts is in the following JSON format.
+
+# {
+# "name": "Hogwarts School of Witchcraft and Wizardry",
+# "country": "Scotland",
+# "latitude": 55.566667,
+# "population": 1000,
+# "top 3 landmarks": ["Hogwarts Castle", "The Great Hall", "The Forbidden Forest"],
+# }
+
+# ==================== CHARACTER TEST ====================
+# Give me a character description who is a wizard.
+# { "name" : "Merlin", "age" : 500, "armor" : "chainmail" , "weapon" : "sword" , "strength" : 10 }
diff --git a/sglang/scripts/deprecated/test_robust.py b/sglang/scripts/deprecated/test_robust.py
new file mode 100644
index 0000000000000000000000000000000000000000..633e2e649c1abadf7718c3d72b59b41174bfebef
--- /dev/null
+++ b/sglang/scripts/deprecated/test_robust.py
@@ -0,0 +1,132 @@
+import argparse
+import random
+import string
+
+from vllm.transformers_utils.tokenizer import get_tokenizer
+
+import sglang as sgl
+from sglang.test.test_utils import (
+ add_common_sglang_args_and_parse,
+ select_sglang_backend,
+)
+
+TOKENIZER = None
+RANDOM_PREFILL_LEN = None
+RANDOM_DECODE_LEN = None
+
+
+def gen_prompt(token_num):
+ if RANDOM_PREFILL_LEN:
+ token_num = random.randint(1, token_num)
+
+ cha_set = string.ascii_letters + string.digits
+ ret = "".join(random.choices(cha_set, k=token_num))
+ while len(TOKENIZER(ret).input_ids) < token_num:
+ ret += random.choice(cha_set)
+
+ return ret
+
+
+def robust_test_dfs(s, d, args, leaf_states):
+ if d == 0:
+ s += "END"
+ leaf_states.append(s)
+ return
+
+ s += gen_prompt(args.len_prefill)
+ forks = s.fork(args.num_fork)
+ for fork_s in forks:
+ fork_s += gen_prompt(args.len_prefill)
+ new_tokens = (
+ args.len_decode
+ if not RANDOM_DECODE_LEN
+ else random.randint(1, args.len_decode)
+ )
+ fork_s += sgl.gen(
+ max_tokens=new_tokens,
+ ignore_eos=True,
+ )
+
+ for fork_s in forks:
+ robust_test_dfs(fork_s, d - 1, args, leaf_states)
+
+
+def robust_test_bfs(s, args, leaf_states):
+ old_forks = [s]
+ new_forks = []
+ for _ in range(args.depth):
+ for old_fork in old_forks:
+ old_fork += gen_prompt(args.len_prefill)
+ forks = old_fork.fork(args.num_fork)
+ for fork_s in forks:
+ fork_s += gen_prompt(args.len_prefill)
+ new_tokens = (
+ args.len_decode
+ if not RANDOM_DECODE_LEN
+ else random.randint(1, args.len_decode)
+ )
+ fork_s += sgl.gen(
+ max_tokens=new_tokens,
+ ignore_eos=True,
+ )
+ new_forks.extend(forks)
+
+ old_forks = new_forks
+ new_forks = []
+
+ for old_fork in old_forks:
+ old_fork += "END"
+ leaf_states.append(old_fork)
+
+
+@sgl.function
+def robust_test(s, args):
+ leaf_states = []
+ if args.mode == "bfs":
+ robust_test_bfs(s, args, leaf_states)
+ else:
+ robust_test_dfs(s, args.depth, args, leaf_states)
+ return leaf_states
+
+
+def main(args):
+ backend = select_sglang_backend(args)
+
+ arguments = [{"args": args} for _ in range(args.num_req)]
+
+ states = robust_test.run_batch(
+ arguments, temperature=0, backend=backend, num_threads=args.parallel
+ )
+
+ with open(f"tmp_robust_{args.mode}.txt", "w") as f:
+ for state in states:
+ leaf_states = state.ret_value
+ for leaf_state in leaf_states:
+ assert leaf_state.text()[-3:] == "END"
+ f.write(leaf_state.text()[:-3] + "\n")
+
+
+if __name__ == "__main__":
+ # fmt: off
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--num-req", type=int, default=2)
+ parser.add_argument("--depth", type=int, default=3)
+ parser.add_argument("--num-fork", type=int, default=2)
+ parser.add_argument("--len-prefill", type=int, default=128)
+ parser.add_argument("--len-decode", type=int, default=128)
+ parser.add_argument("--random-prefill-len", action="store_true")
+ parser.add_argument("--random-decode-len", action="store_true")
+ parser.add_argument("--mode", type=str, default="bfs", choices=["dfs", "bfs"])
+ parser.add_argument("--tokenizer", type=str, default = "meta-llama/Llama-2-7b-chat-hf")
+ parser.add_argument("--trust-remote-code", action="store_true")
+ parser.add_argument("--seed", type=int, default=42)
+ args = add_common_sglang_args_and_parse(parser)
+ # fmt: on
+
+ RANDOM_PREFILL_LEN = args.random_prefill_len
+ RANDOM_DECODE_LEN = args.random_decode_len
+ TOKENIZER = get_tokenizer(args.tokenizer, trust_remote_code=args.trust_remote_code)
+
+ random.seed(args.seed)
+
+ main(args)
diff --git a/sglang/scripts/playground/launch_tgi.sh b/sglang/scripts/playground/launch_tgi.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a32405cdd3f3061093929a95ecb8c16d71643415
--- /dev/null
+++ b/sglang/scripts/playground/launch_tgi.sh
@@ -0,0 +1,7 @@
+# Assuming the model is downdloaded at /home/ubuntu/model_weights/Llama-2-7b-chat-hf
+docker run --name tgi --rm -ti --gpus all --network host \
+ -v /home/ubuntu/model_weights/Llama-2-7b-chat-hf:/Llama-2-7b-chat-hf \
+ ghcr.io/huggingface/text-generation-inference:1.1.0 \
+ --model-id /Llama-2-7b-chat-hf --num-shard 1 --trust-remote-code \
+ --max-input-length 2048 --max-total-tokens 4096 \
+ --port 24000
diff --git a/sglang/scripts/playground/load_tokenizer.py b/sglang/scripts/playground/load_tokenizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..94cf34bc71f52c7035d93b0f9508ae30da892e91
--- /dev/null
+++ b/sglang/scripts/playground/load_tokenizer.py
@@ -0,0 +1,14 @@
+import argparse
+import code
+
+from sglang.srt.hf_transformers_utils import get_tokenizer
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--name", type=str, default="meta-llama/Meta-Llama-3-8B-Instruct"
+ )
+ args = parser.parse_args()
+
+ t = get_tokenizer(args.name)
+ code.interact(local=locals())
diff --git a/sglang/scripts/playground/lora/analyzer.py b/sglang/scripts/playground/lora/analyzer.py
new file mode 100644
index 0000000000000000000000000000000000000000..15568fc189b8fbe96355a55c76af19aa05b08c1c
--- /dev/null
+++ b/sglang/scripts/playground/lora/analyzer.py
@@ -0,0 +1,77 @@
+import glob
+import json
+import os
+import re
+import sys
+
+from tqdm import tqdm
+
+sys.path.append("../../")
+from fix_corrupted_json import clean_json_file
+
+dirpath = "/Users/ying"
+output_file_prefix = "analyzed_log"
+
+time = {}
+tot_time = {}
+size = {}
+
+os.system(f"rm {output_file_prefix}*")
+
+for dirname in glob.glob(os.path.join(dirpath, "trace*")):
+ print(dirname)
+ trace_name = dirname.split("/")[-1]
+ time[trace_name] = {}
+ size[trace_name] = {}
+ total_time = 0
+ for filename in tqdm(glob.glob(os.path.join(dirname, "*.json"))):
+ step_name = filename.split("/")[-1].split(".")[0]
+ step_name = "_".join(step_name.split("_")[1:])
+ if "prefill" not in filename and "decode" not in filename:
+ continue
+
+ match = re.search(r"(prefill|decode)_step_(\d+)\.json", filename)
+ if match:
+ phase = match.group(1)
+ step = match.group(2)
+ else:
+ raise Exception(f"Cannot parse {filename}")
+
+ try:
+ with open(filename, "r") as f:
+ trace = json.load(f)
+ except:
+ clean_json_file(filename, filename)
+ with open(filename, "r") as f:
+ trace = json.load(f)
+
+ for event in trace["traceEvents"]:
+ name = event["name"]
+ if name in ["profile_prefill_step", "profile_decode_step"]:
+ dur = event["dur"] / 1e3
+ time[trace_name][step_name] = dur
+ break
+ total_time += dur
+
+ step = int(step_name.split("_")[-1])
+ with open(os.path.join(dirname, f"size_{step}.json"), "r") as f:
+ size_info = json.load(f)
+ size[trace_name][step_name] = size_info["size"]
+
+ tot_time[trace_name] = total_time
+ time[trace_name] = dict(
+ sorted(time[trace_name].items(), key=lambda x: int(x[0].split("_")[-1]))
+ )
+ size[trace_name] = dict(
+ sorted(size[trace_name].items(), key=lambda x: int(x[0].split("_")[-1]))
+ )
+
+ with open(f"{output_file_prefix}_{trace_name}", "a") as f:
+ for k, v in time[trace_name].items():
+ size_v = size[trace_name][k]
+ print(f"{k:>15}{v:10.2f}\t{size_v}")
+ f.write(f"{k:>15}{v:10.2f}\t{size_v}\n")
+
+with open(f"{output_file_prefix}_total_time", "w") as f:
+ print(tot_time)
+ json.dump(tot_time, f)
diff --git a/sglang/scripts/playground/lora/lora_hf_play.py b/sglang/scripts/playground/lora/lora_hf_play.py
new file mode 100644
index 0000000000000000000000000000000000000000..0abddd2c13971a80a5f62043fc4b31fba304928f
--- /dev/null
+++ b/sglang/scripts/playground/lora/lora_hf_play.py
@@ -0,0 +1,62 @@
+import torch
+from peft import PeftModel
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+MODEL = "mistralai/Mistral-7B-Instruct-v0.3"
+# ADAPTER = "winddude/wizardLM-LlaMA-LoRA-7B"
+ADAPTER = "/home/ying/test_lora"
+HF_TOKEN = "..."
+
+
+prompt = """
+### Instruction:
+Write a poem about the transformers Python library.
+Mention the word "large language models" in that poem.
+### Response:
+The Transformers are large language models,
+They're used to make predictions on text.
+"""
+
+
+tokenizer = LlamaTokenizer.from_pretrained(MODEL)
+
+base_model = LlamaForCausalLM.from_pretrained(
+ MODEL,
+ device_map="auto",
+ # load_in_8bit=True,
+ torch_dtype=torch.float16,
+ # use_auth_token=HF_TOKEN,
+).cuda()
+
+
+# base model generate
+with torch.no_grad():
+ output_tensors = base_model.generate(
+ input_ids=tokenizer(prompt, return_tensors="pt").input_ids.cuda(),
+ max_new_tokens=32,
+ do_sample=False,
+ )[0]
+
+output = tokenizer.decode(output_tensors, skip_special_tokens=True)
+print("======= base output ========")
+print(output)
+
+
+# peft model generate
+model = PeftModel.from_pretrained(
+ base_model,
+ ADAPTER,
+ torch_dtype=torch.float16,
+ is_trainable=False,
+)
+
+with torch.no_grad():
+ output_tensors = model.generate(
+ input_ids=tokenizer(prompt, return_tensors="pt").input_ids.cuda(),
+ max_new_tokens=32,
+ do_sample=False,
+ )[0]
+
+output = tokenizer.decode(output_tensors, skip_special_tokens=True)
+print("======= peft output ========")
+print(output)
diff --git a/sglang/scripts/playground/lora/lora_vllm_play.py b/sglang/scripts/playground/lora/lora_vllm_play.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f77d8beab2737e25eea010fe748e15935a6953a
--- /dev/null
+++ b/sglang/scripts/playground/lora/lora_vllm_play.py
@@ -0,0 +1,30 @@
+from vllm import LLM, SamplingParams
+from vllm.lora.request import LoRARequest
+
+MODEL = "mistralai/Mistral-7B-Instruct-v0.3"
+ADAPTER = "/home/ying/test_lora"
+prompt = """
+### Instruction:
+Write a poem about the transformers Python library.
+Mention the word "large language models" in that poem.
+### Response:
+The Transformers are large language models,
+They're used to make predictions on text.
+"""
+
+
+llm = LLM(model=MODEL, enable_lora=True)
+
+sampling_params = SamplingParams(
+ temperature=0,
+ max_tokens=32,
+)
+
+prompts = [prompt]
+
+outputs = llm.generate(
+ prompts, sampling_params, lora_request=LoRARequest("test_lora", 1, ADAPTER)
+)
+
+print(outputs[0].prompt)
+print(outputs[0].outputs[0].text)
diff --git a/sglang/scripts/playground/reference_hf.py b/sglang/scripts/playground/reference_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ece3d648a98705468162d3b301625da809e087d
--- /dev/null
+++ b/sglang/scripts/playground/reference_hf.py
@@ -0,0 +1,194 @@
+"""
+Usage:
+python3 reference_hf.py --model TinyLlama/TinyLlama-1.1B-Chat-v0.4
+
+Reference output:
+========== Prompt 0 ==========
+prefill logits (final) tensor([-8.3125, -7.1172, 3.3398, ..., -4.9531, -4.1328, -3.4141],
+ device='cuda:0')
+ The capital of France is Paris.
+The capital of the United States is Washington, D.C.
+
+========== Prompt 1 ==========
+prefill logits (final) tensor([-8.9062, -9.0156, 4.1484, ..., -4.9922, -4.4961, -4.0742],
+ device='cuda:0')
+ The capital of the United Kindom is London.
+The capital of the United Kingdom is London.
+The capital of
+
+========== Prompt 2 ==========
+prefill logits (final) tensor([-9.6328, -9.0547, 4.0234, ..., -5.3047, -4.7148, -4.4609],
+ device='cuda:0')
+ Today is a sunny day and I like to go for a walk in the park.
+I'm going to the
+"""
+
+import argparse
+
+import requests
+import torch
+from PIL import Image
+from transformers import (
+ AutoModelForCausalLM,
+ AutoModelForImageTextToText,
+ AutoProcessor,
+)
+
+from sglang.srt.hf_transformers_utils import get_tokenizer
+
+
+@torch.no_grad()
+def vlm_text_with_image(args):
+ # Load the processor and model for ImageTextToText tasks
+ processor = AutoProcessor.from_pretrained(args.model_path, trust_remote_code=True)
+ model = AutoModelForImageTextToText.from_pretrained(
+ args.model_path,
+ torch_dtype=args.dtype,
+ low_cpu_mem_usage=True,
+ device_map="auto",
+ trust_remote_code=True,
+ )
+
+ torch.cuda.set_device(0)
+
+ # List of image URLs to process
+ image_urls = [
+ "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
+ ]
+
+ # Conversation template for the processor
+ conversation = [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ },
+ {"type": "text", "text": "Describe this image."},
+ ],
+ }
+ ]
+
+ max_new_tokens = args.max_new_tokens
+
+ for i, url in enumerate(image_urls):
+ # Load the image from the URL
+ image = Image.open(requests.get(url, stream=True).raw)
+
+ # Apply the chat template to the text prompt
+ # Notice that not all processors support chat templates.
+ # LLaVA and QWen are two processors that support chat templates.
+ if not hasattr(processor, "apply_chat_template"):
+ raise ValueError("The processor does not support chat templates.")
+ text_prompt = processor.apply_chat_template(
+ conversation, add_generation_prompt=True
+ )
+
+ # Prepare inputs for the model
+ inputs = processor(text=[text_prompt], images=[image], return_tensors="pt").to(
+ "cuda:0"
+ )
+
+ # Generate output from the model
+ output_ids = model.generate(
+ **inputs, do_sample=False, max_new_tokens=max_new_tokens
+ )
+ output_str = processor.decode(output_ids[0])
+
+ # Get the logits from the model's forward pass
+ outputs = model.forward(**inputs)
+ logits = outputs.logits[0, -1, :]
+
+ print(f"\n========== Image {i} ==========")
+ print("prefill logits (final)", logits)
+ # TODO(gaocegege): The output contains numerous <|image_pad|> tokens,
+ # making it cluttered and difficult to read.
+ # These tokens should be removed or cleaned up for better readability.
+ print(output_str)
+
+
+@torch.no_grad()
+def normal_text(args):
+ t = get_tokenizer(args.model_path, trust_remote_code=True)
+ m = AutoModelForCausalLM.from_pretrained(
+ args.model_path,
+ torch_dtype=args.dtype,
+ low_cpu_mem_usage=True,
+ device_map="auto",
+ trust_remote_code=True,
+ )
+
+ prompts = [
+ "The capital of France is",
+ "The capital of the United Kindom is",
+ "Today is a sunny day and I like",
+ ]
+ max_new_tokens = args.max_new_tokens
+
+ torch.cuda.set_device(0)
+
+ for i, p in enumerate(prompts):
+ if isinstance(p, str):
+ input_ids = t.encode(p, return_tensors="pt").to("cuda:0")
+ else:
+ input_ids = torch.tensor([p], device="cuda:0")
+
+ output_ids = m.generate(
+ input_ids, do_sample=False, max_new_tokens=max_new_tokens
+ )
+ output_str = t.decode(output_ids[0])
+
+ prefill_logits = m.forward(input_ids).logits[0][-1]
+
+ print(f"\n========== Prompt {i} ==========")
+ print("prefill logits (final)", prefill_logits)
+ print(output_str)
+
+
+@torch.no_grad()
+def synthetic_tokens(args):
+ m = AutoModelForCausalLM.from_pretrained(
+ args.model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True
+ )
+ m.cuda()
+ print(m)
+
+ input_len = 256
+ output_len = 8
+ prompts = [list(range(5, 5 + input_len))]
+
+ for p in prompts:
+ input_ids = p
+ for i in range(output_len + 1):
+ prefill_logits = m.forward(torch.tensor([input_ids], device="cuda")).logits[
+ 0
+ ][-1]
+
+ if i == 0:
+ print("prefill logits", prefill_logits)
+ else:
+ print("decode", i - 1, prefill_logits)
+
+ input_ids.append(torch.argmax(prefill_logits).item())
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--model-path",
+ type=str,
+ default="TinyLlama/TinyLlama-1.1B-Chat-v0.4",
+ # default="meta-llama/Llama-2-7b-chat-hf",
+ )
+ parser.add_argument("--max-new-tokens", type=int, default=16)
+
+ parser.add_argument("--dtype", type=str, default="float16")
+
+ parser.add_argument("--model-type", type=str, default="text")
+
+ args = parser.parse_args()
+
+ if args.model_type == "vlm":
+ vlm_text_with_image(args)
+ else:
+ normal_text(args)
diff --git a/sglang/scripts/playground/router/test_tree.py b/sglang/scripts/playground/router/test_tree.py
new file mode 100644
index 0000000000000000000000000000000000000000..af41c738e02140b2b1f9f9ee4019cac7b97fac28
--- /dev/null
+++ b/sglang/scripts/playground/router/test_tree.py
@@ -0,0 +1,207 @@
+import random
+import string
+import time
+import unittest
+from typing import Dict, List, Tuple
+
+from tree import MultiTenantRadixTree
+
+
+class TestMultiTenantRadixTree(unittest.TestCase):
+ def setUp(self):
+ self.tree = MultiTenantRadixTree()
+
+ def test_insert_exact_match(self):
+ """Test 1: Basic insert and exact match operations"""
+ # Insert a single string for one tenant
+ self.tree.insert("hello", "tenant1")
+ matched, tenant = self.tree.prefix_match("hello")
+ self.assertEqual(matched, "hello")
+ self.assertEqual(tenant, "tenant1")
+
+ # Insert same string for different tenant
+ self.tree.insert("hello", "tenant2")
+ matched, tenant = self.tree.prefix_match("hello")
+ self.assertIn(tenant, ["tenant1", "tenant2"])
+
+ # Insert different string for same tenant
+ self.tree.insert("world", "tenant1")
+ matched, tenant = self.tree.prefix_match("world")
+ self.assertEqual(matched, "world")
+ self.assertEqual(tenant, "tenant1")
+
+ print(self.tree.pretty_print())
+
+ def test_insert_partial_match(self):
+ """Test 2: Insert with partial matching scenarios"""
+ # Test partial matches with common prefixes
+ self.tree.insert("hello", "tenant1")
+ print(self.tree.pretty_print())
+ self.tree.insert("help", "tenant2")
+ print(self.tree.pretty_print())
+
+ # Match exact strings
+ matched, tenant = self.tree.prefix_match("hello")
+ self.assertEqual(matched, "hello")
+ self.assertEqual(tenant, "tenant1")
+
+ matched, tenant = self.tree.prefix_match("help")
+ self.assertEqual(matched, "help")
+ self.assertEqual(tenant, "tenant2")
+
+ # Match partial string
+ matched, tenant = self.tree.prefix_match("hel")
+ self.assertEqual(matched, "hel")
+ self.assertIn(tenant, ["tenant1", "tenant2"])
+
+ # Match longer string
+ matched, tenant = self.tree.prefix_match("hello_world")
+ self.assertEqual(matched, "hello")
+ self.assertEqual(tenant, "tenant1")
+
+ def test_insert_edge_cases(self):
+ """Test 3: Edge cases for insert and match operations"""
+ # Empty string
+ self.tree.insert("", "tenant1")
+ matched, tenant = self.tree.prefix_match("")
+ self.assertEqual(matched, "")
+ self.assertEqual(tenant, "tenant1")
+
+ # Single character
+ self.tree.insert("a", "tenant1")
+ matched, tenant = self.tree.prefix_match("a")
+ self.assertEqual(matched, "a")
+ self.assertEqual(tenant, "tenant1")
+
+ # Very long string
+ long_str = "a" * 1000
+ self.tree.insert(long_str, "tenant1")
+ matched, tenant = self.tree.prefix_match(long_str)
+ self.assertEqual(matched, long_str)
+ self.assertEqual(tenant, "tenant1")
+
+ # Unicode characters
+ self.tree.insert("你好", "tenant1")
+ matched, tenant = self.tree.prefix_match("你好")
+ self.assertEqual(matched, "你好")
+ self.assertEqual(tenant, "tenant1")
+
+ def test_simple_eviction(self):
+ """Test 4: Simple eviction scenarios
+ Tenant1: limit 10 chars
+ Tenant2: limit 5 chars
+
+ Should demonstrate:
+ 1. Basic eviction when size limit exceeded
+ 2. Proper eviction based on last access time
+ 3. Verification that shared nodes remain intact for other tenants
+ """
+ # Set up size limits
+ max_size = {"tenant1": 10, "tenant2": 5}
+
+ # Insert strings for both tenants
+ self.tree.insert("hello", "tenant1") # size 5
+ self.tree.insert("hello", "tenant2") # size 5
+ self.tree.insert("world", "tenant2") # size 5, total for tenant2 = 10
+
+ # Verify initial sizes
+ sizes_before = self.tree.get_used_size_per_tenant()
+ self.assertEqual(sizes_before["tenant1"], 5) # "hello" = 5
+ self.assertEqual(sizes_before["tenant2"], 10) # "hello" + "world" = 10
+
+ # Evict - should remove "hello" from tenant2 as it's the oldest
+ self.tree.evict_tenant_data(max_size)
+
+ # Verify sizes after eviction
+ sizes_after = self.tree.get_used_size_per_tenant()
+ self.assertEqual(sizes_after["tenant1"], 5) # Should be unchanged
+ self.assertEqual(sizes_after["tenant2"], 5) # Only "world" remains
+
+ # Verify "world" remains for tenant2 (was accessed more recently)
+ matched, tenant = self.tree.prefix_match("world")
+ self.assertEqual(matched, "world")
+ self.assertEqual(tenant, "tenant2")
+
+ def test_medium_eviction(self):
+ """Test 5: Medium complexity eviction scenarios with shared prefixes
+ Tenant1: limit 10 chars
+ Tenant2: limit 7 chars (forces one string to be evicted)
+
+ Tree structure after inserts:
+ └── 'h' [t1, t2]
+ ├── 'i' [t1, t2] # Oldest for t2
+ └── 'e' [t1, t2]
+ ├── 'llo' [t1, t2]
+ └── 'y' [t2] # Newest for t2
+
+ Size calculations:
+ tenant1: "h"(1) + "i"(1) + "e"(1) + "llo"(3) = 6 chars
+ tenant2: "h"(1) + "i"(1) + "e"(1) + "llo"(3) + "y"(1) = 7 chars
+
+ After eviction (tenant2 exceeds limit by 1 char):
+ "hi" should be removed from tenant2 as it's the oldest access
+ """
+ max_size = {
+ "tenant1": 10,
+ "tenant2": 6,
+ } # tenant2 will need to evict one string
+
+ # Create a tree with overlapping prefixes
+ self.tree.insert("hi", "tenant1")
+ self.tree.insert("hi", "tenant2") # OLDEST for t2
+
+ self.tree.insert("hello", "tenant1")
+ self.tree.insert("hello", "tenant2")
+
+ self.tree.insert("hey", "tenant2") # NEWEST for t2
+
+ # Verify initial sizes
+ sizes_before = self.tree.get_used_size_per_tenant()
+ self.assertEqual(sizes_before["tenant1"], 6) # h(1) + i(1) + e(1) + llo(3) = 6
+ self.assertEqual(
+ sizes_before["tenant2"], 7
+ ) # h(1) + i(1) + e(1) + llo(3) + y(1) = 7
+
+ print("\nTree before eviction:")
+ print(self.tree.pretty_print())
+
+ # Evict - should remove "hi" from tenant2 as it's the oldest
+ self.tree.evict_tenant_data(max_size)
+
+ print("\nTree after eviction:")
+ print(self.tree.pretty_print())
+
+ # Verify sizes after eviction
+ sizes_after = self.tree.get_used_size_per_tenant()
+ self.assertEqual(sizes_after["tenant1"], 6) # Should be unchanged
+ self.assertEqual(sizes_after["tenant2"], 6) # h(1) + e(1) + llo(3) + y(1) = 6
+
+ def test_advanced_eviction(self):
+ ...
+ # Create 4 tenants
+ # Each tenants keeps adding strings with shared prefixes to thousands usage
+ # Set a strict limit for each tenant to only 100
+ # At the end, check whether all of the tenant is under 100 after eviction
+
+ max_size = {"tenant1": 100, "tenant2": 100, "tenant3": 100, "tenant4": 100}
+
+ prefixes = ["aqwefcisdf", "iajsdfkmade", "kjnzxcvewqe", "iejksduqasd"]
+ for i in range(100):
+ for j, prefix in enumerate(prefixes):
+ random_suffix = "".join(random.choices(string.ascii_letters, k=10))
+ self.tree.insert(prefix + random_suffix, f"tenant{j+1}")
+
+ sizes_before = self.tree.get_used_size_per_tenant()
+ print(sizes_before)
+
+ self.tree.evict_tenant_data(max_size)
+
+ sizes_after = self.tree.get_used_size_per_tenant()
+ print(sizes_after)
+ # ensure size_after is below max_size
+ for tenant, size in sizes_after.items():
+ self.assertLessEqual(size, max_size[tenant])
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/sglang/scripts/playground/router/tree.py b/sglang/scripts/playground/router/tree.py
new file mode 100644
index 0000000000000000000000000000000000000000..9cbfa7cfe9337a2178329fbfd722ee4d6c5d2626
--- /dev/null
+++ b/sglang/scripts/playground/router/tree.py
@@ -0,0 +1,292 @@
+import time
+from collections import defaultdict
+from typing import Dict, List
+
+
+class Node:
+ def __init__(self):
+ self.children: Dict[str, Node] = dict()
+ # We choose to use text because most of the use cases are text-to-text,
+ # so we can save the tokenizing overhead.
+ self.text: str = ""
+ # Maps tenant_id to their last access timestamp
+ self.tenant_last_access_time: Dict[str, float] = dict()
+ self.parent = None
+
+
+def shared_prefix_length(s1, s2):
+ min_length = min(len(s1), len(s2))
+ for i in range(min_length):
+ if s1[i] != s2[i]:
+ return i
+ return min_length
+
+
+class MultiTenantRadixTree:
+ """
+ Python Reference of Rust implementation of MultiTenantRadixTree
+
+ MultiTenantRadixTree is the overlap of multiple radix trees by different tenant
+ Each node in the tree can be owned by multiple tenants, allowing for efficient storage of common prefixes
+ while maintaining tenant isolation.
+
+ Key concepts:
+ - Tenant: An entity that owns a subset of the stored strings
+ - Each node tracks which tenants have access to it via tenant_last_access_time
+ - The tree structure is shared, but queries can be filtered by tenant_id
+ """
+
+ def __init__(self):
+ self.root = Node()
+
+ def insert(self, s: str, tenant_id: str) -> None:
+ """
+ Insert string 's' and associate it with the given tenant_id.
+
+ Args:
+ s: The string to insert
+ tenant_id: The identifier of the tenant who owns this string
+ """
+ curr = self.root
+ curr_idx = 0
+ curr.tenant_last_access_time[tenant_id] = time.time()
+
+ while curr_idx < len(s):
+ matched_node = None
+ if s[curr_idx] in curr.children:
+ matched_node = curr.children[s[curr_idx]]
+
+ if matched_node is None:
+ # No match => create a new node
+ new_node = Node()
+ new_node.text = s[curr_idx:]
+ new_node.parent = curr
+
+ curr.children[s[curr_idx]] = new_node
+ curr_idx = len(s)
+ curr = new_node
+ curr.tenant_last_access_time[tenant_id] = time.time()
+ else:
+ shared_len = shared_prefix_length(s[curr_idx:], matched_node.text)
+
+ # 1. If the matched text is shorter than the node text => split the node
+ if shared_len < len(matched_node.text):
+ # Split structure: [matched_node] => [new_node] -> [contracted_matched_node]
+
+ matched_text = matched_node.text[:shared_len]
+ unmatched_text = matched_node.text[shared_len:]
+
+ new_node = Node()
+ new_node.text = matched_text
+ new_node.children = {unmatched_text[0]: matched_node}
+ new_node.parent = curr
+ new_node.parent.children[matched_text[0]] = new_node
+ new_node.tenant_last_access_time = (
+ matched_node.tenant_last_access_time.copy()
+ )
+
+ # Contract matched node
+ matched_node.text = unmatched_text
+ matched_node.parent = new_node
+
+ curr_idx += shared_len
+ curr = new_node
+ curr.tenant_last_access_time[tenant_id] = time.time()
+ # 2. If the matched text is longer or equal to the node text => walk down the node
+ else:
+ curr_idx += shared_len
+ curr = matched_node
+ curr.tenant_last_access_time[tenant_id] = time.time()
+
+ def prefix_match(self, s: str) -> tuple[str, int]:
+ """
+ Match string 's' with multiple tenants' trees in one operation.
+
+ Args:
+ s: The string to match
+
+ Returns:
+ Tuple(str, int): The longest prefix of 's' that matches the tree and the first tenant_id that own the matched prefix
+ """
+ curr = self.root
+ curr_idx = 0
+
+ ret_text = ""
+ ret_tenant = None
+
+ while curr_idx < len(s):
+ matched_node = None
+ if s[curr_idx] in curr.children:
+ matched_node = curr.children[s[curr_idx]]
+
+ if matched_node is None:
+ break
+
+ shared_len = shared_prefix_length(s[curr_idx:], matched_node.text)
+ if shared_len == len(matched_node.text):
+ curr_idx += shared_len
+ curr = matched_node
+ else:
+ curr_idx += shared_len
+ curr = matched_node
+ break
+
+ selected_tenant = list(curr.tenant_last_access_time.keys())[0]
+
+ # traverse back to the root to update last access time for the selected tenant
+ while curr != self.root:
+ curr.tenant_last_access_time[selected_tenant] = time.time()
+ curr = curr.parent
+
+ return s[:curr_idx], selected_tenant
+
+ def evict_tenant_data(self, max_size_per_tenant: Dict[str, int]) -> None:
+ """
+ Evict data for tenants that have exceeded their storage limits.
+
+ Args:
+ max_size_per_tenant: Dictionary mapping tenant_id to their maximum allowed storage size
+ """
+
+ def leaf_of(node):
+ """
+ If the node is a leaf for a tenant, add tenant_id to the return list
+ This will return list of tenant ids
+ If not a leaf for all tenants, return []
+ """
+ candidates = dict([(k, True) for k in node.tenant_last_access_time.keys()])
+
+ for n in node.children.values():
+ for c in n.tenant_last_access_time.keys():
+ candidates[c] = False
+
+ return [k for k, v in candidates.items() if v]
+
+ # maintain a heap with (time, tenant, node) as the value
+ import heapq
+
+ # 1. traverse the tree to
+ # a. add all the leaves into a heap (a node with N tenants will be added N times into the heap)
+ # b. calculate the used size for each tenant
+ # do a dfs with stack
+ stack = [self.root]
+ pq = []
+ used_size_per_tenant = defaultdict(int)
+
+ while stack:
+ curr = stack.pop()
+ for t in curr.tenant_last_access_time.keys():
+ used_size_per_tenant[t] += len(curr.text)
+
+ for c in curr.children.values():
+ stack.append(c)
+
+ # if the node is a leaf for a tenant, add the tenant to the heap
+ tenants = leaf_of(curr)
+ for t in tenants:
+ heapq.heappush(pq, (curr.tenant_last_access_time[t], t, curr))
+
+ # 2. pop the heap
+ # a. if the tenant's used size is less than the limit, continue
+ # b. if the tenant's used size is greater than the limit, remove the leaf and update the used size, and add its parent to the heap
+ while len(pq) > 0:
+ time, tenant, node = heapq.heappop(pq)
+ if used_size_per_tenant[tenant] <= max_size_per_tenant[tenant]:
+ continue
+
+ # remove the leaf
+ used_size_per_tenant[tenant] -= len(node.text)
+ del node.tenant_last_access_time[tenant]
+ # if no children and no tenants, remove the node
+ if len(node.children) == 0 and len(node.tenant_last_access_time) == 0:
+ del node.parent.children[node.text[0]]
+
+ # add its parent to the heap
+ if tenant in leaf_of(node.parent):
+ heapq.heappush(
+ pq,
+ (node.parent.tenant_last_access_time[tenant], tenant, node.parent),
+ )
+
+ def get_used_size_per_tenant(self) -> Dict[str, int]:
+ """
+ Calculate the used storage size for each tenant.
+
+ Returns:
+ Dict[str, int]: A dictionary mapping tenant_id to their used storage size
+ """
+ used_size_per_tenant = defaultdict(int)
+
+ stack = [self.root]
+ while stack:
+ curr = stack.pop()
+ for t in curr.tenant_last_access_time.keys():
+ used_size_per_tenant[t] += len(curr.text)
+
+ for c in curr.children.values():
+ stack.append(c)
+
+ return used_size_per_tenant
+
+ def remove_tenant(self, tenant_id: str) -> None:
+ """
+ Remove all data associated with a specific tenant from the tree.
+ This operation maintains the integrity of the shared tree structure while
+ removing only the specified tenant's access information.
+
+ Args:
+ tenant_id: The identifier of the tenant whose data should be removed
+ """
+ # TODO: Implementation needed
+ pass
+
+ def pretty_print(self) -> str:
+ """
+ Returns a string representation of the tree showing the structure, tenant ownership,
+ and leaf status for each node.
+
+ Returns:
+ str: A formatted string showing the tree hierarchy with tenant information
+ """
+
+ def _node_to_str(node: Node, prefix: str = "", is_last: bool = True) -> str:
+ # Current node representation
+ node_str = prefix
+ node_str += "└── " if is_last else "├── "
+
+ # Add node text
+ node_str += f"'{node.text}' ["
+
+ # Add tenant information including both timestamp and leaf status
+ tenant_info = []
+ for tid, ts in node.tenant_last_access_time.items():
+ time_str = (
+ time.strftime("%H:%M:%S.", time.localtime(ts))
+ + f"{(ts % 1):0.3f}"[2:]
+ )
+ tenant_info.append(f"{tid} | {time_str}")
+
+ node_str += ", ".join(tenant_info)
+ node_str += "]\n"
+
+ # Handle children
+ children = list(node.children.items())
+ for i, (char, child) in enumerate(children):
+ is_last_child = i == len(children) - 1
+ # Adjust prefix for children based on whether this is the last child
+ new_prefix = prefix + (" " if is_last else "│ ")
+ node_str += _node_to_str(child, new_prefix, is_last_child)
+
+ return node_str
+
+ if not self.root.children:
+ return "Empty tree"
+
+ # Start with root's children since root itself is just an empty node
+ result = ""
+ children = list(self.root.children.items())
+ for i, (char, child) in enumerate(children):
+ is_last = i == len(children) - 1
+ result += _node_to_str(child, "", is_last)
+
+ return result
diff --git a/sglang/sgl-kernel/src/sgl-kernel/__init__.py b/sglang/sgl-kernel/src/sgl-kernel/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0705b6efa71a7a99a9e499a60af716dbbef01a27
--- /dev/null
+++ b/sglang/sgl-kernel/src/sgl-kernel/__init__.py
@@ -0,0 +1,13 @@
+from sgl_kernel.ops import (
+ custom_dispose,
+ custom_reduce,
+ init_custom_reduce,
+ moe_align_block_size,
+)
+
+__all__ = [
+ "moe_align_block_size",
+ "init_custom_reduce",
+ "custom_dispose",
+ "custom_reduce",
+]
diff --git a/sglang/sgl-kernel/src/sgl-kernel/csrc/moe_align_kernel.cu b/sglang/sgl-kernel/src/sgl-kernel/csrc/moe_align_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..31bb97fc4114282f2c6967f08d7240a26e105a78
--- /dev/null
+++ b/sglang/sgl-kernel/src/sgl-kernel/csrc/moe_align_kernel.cu
@@ -0,0 +1,117 @@
+// Adapted from https://github.com/vllm-project/vllm/blob/v0.6.5/csrc/moe/moe_align_sum_kernels.cu
+
+#include
+#include
+#include
+
+#include
+
+#include "utils.hpp"
+
+#ifdef USE_ROCM
+#include
+#endif
+
+#ifndef USE_ROCM
+#define WARP_SIZE 32
+#else
+#define WARP_SIZE warpSize
+#endif
+
+#ifndef USE_ROCM
+#define DevFuncAttribute_SET_MaxDynamicSharedMemorySize(FUNC, VAL) \
+ cudaFuncSetAttribute(FUNC, cudaFuncAttributeMaxDynamicSharedMemorySize, VAL)
+#else
+#define DevFuncAttribute_SET_MaxDynamicSharedMemorySize(FUNC, VAL) \
+ hipFuncSetAttribute(FUNC, hipFuncAttributeMaxDynamicSharedMemorySize, VAL)
+#endif
+
+#define CEILDIV(x, y) (((x) + (y)-1) / (y))
+
+#define DISPATCH_CASE_INTEGRAL_TYPES(...) \
+ AT_DISPATCH_CASE(at::ScalarType::Byte, __VA_ARGS__) \
+ AT_DISPATCH_CASE(at::ScalarType::Char, __VA_ARGS__) \
+ AT_DISPATCH_CASE(at::ScalarType::Short, __VA_ARGS__) \
+ AT_DISPATCH_CASE(at::ScalarType::Int, __VA_ARGS__) \
+ AT_DISPATCH_CASE(at::ScalarType::Long, __VA_ARGS__)
+
+#define DISPATCH_INTEGRAL_TYPES(TYPE, NAME, ...) \
+ AT_DISPATCH_SWITCH(TYPE, NAME, DISPATCH_CASE_INTEGRAL_TYPES(__VA_ARGS__))
+
+__device__ __forceinline__ int32_t index(int32_t total_col, int32_t row, int32_t col) {
+ // don't worry about overflow because num_experts is relatively small
+ return row * total_col + col;
+}
+
+template
+__global__ void moe_align_block_size_kernel(scalar_t* __restrict__ topk_ids, int32_t* sorted_token_ids,
+ int32_t* expert_ids, int32_t* total_tokens_post_pad, int32_t num_experts,
+ int32_t block_size, size_t numel, int32_t* cumsum) {
+ __shared__ int32_t shared_counts[32][8];
+ __shared__ int32_t local_offsets[256];
+
+ const int warp_id = threadIdx.x / WARP_SIZE;
+ const int lane_id = threadIdx.x % WARP_SIZE;
+ const int experts_per_warp = 8;
+ const int my_expert_start = warp_id * experts_per_warp;
+
+ for (int i = 0; i < experts_per_warp; ++i) {
+ if (my_expert_start + i < num_experts) {
+ shared_counts[warp_id][i] = 0;
+ }
+ }
+
+ const size_t tokens_per_thread = CEILDIV(numel, blockDim.x);
+ const size_t start_idx = threadIdx.x * tokens_per_thread;
+
+ for (int i = start_idx; i < numel && i < start_idx + tokens_per_thread; ++i) {
+ int expert_id = topk_ids[i];
+ int warp_idx = expert_id / experts_per_warp;
+ int expert_offset = expert_id % experts_per_warp;
+ atomicAdd(&shared_counts[warp_idx][expert_offset], 1);
+ }
+
+ __syncthreads();
+
+ if (threadIdx.x == 0) {
+ cumsum[0] = 0;
+ for (int i = 1; i <= num_experts; ++i) {
+ int expert_count = 0;
+ int warp_idx = (i - 1) / experts_per_warp;
+ int expert_offset = (i - 1) % experts_per_warp;
+ expert_count = shared_counts[warp_idx][expert_offset];
+
+ cumsum[i] = cumsum[i - 1] + CEILDIV(expert_count, block_size) * block_size;
+ }
+ *total_tokens_post_pad = cumsum[num_experts];
+ }
+
+ __syncthreads();
+
+ if (threadIdx.x < num_experts) {
+ for (int i = cumsum[threadIdx.x]; i < cumsum[threadIdx.x + 1]; i += block_size) {
+ expert_ids[i / block_size] = threadIdx.x;
+ }
+ local_offsets[threadIdx.x] = cumsum[threadIdx.x];
+ }
+
+ __syncthreads();
+
+ for (int i = start_idx; i < numel && i < start_idx + tokens_per_thread; ++i) {
+ int32_t expert_id = topk_ids[i];
+ int32_t rank_post_pad = atomicAdd(&local_offsets[expert_id], 1);
+ sorted_token_ids[rank_post_pad] = i;
+ }
+}
+
+void moe_align_block_size(torch::Tensor topk_ids, int64_t num_experts, int64_t block_size,
+ torch::Tensor sorted_token_ids, torch::Tensor experts_ids, torch::Tensor num_tokens_post_pad,
+ torch::Tensor token_cnts_buffer, torch::Tensor cumsum_buffer) {
+ const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
+ DISPATCH_INTEGRAL_TYPES(topk_ids.scalar_type(), "moe_align_block_size_kernel", [&] {
+ auto kernel = moe_align_block_size_kernel;
+ kernel<<<1, 1024, 0, stream>>>(topk_ids.data_ptr(), sorted_token_ids.data_ptr(),
+ experts_ids.data_ptr(), num_tokens_post_pad.data_ptr(),
+ num_experts, block_size, topk_ids.numel(), cumsum_buffer.data_ptr());
+ });
+}
diff --git a/sglang/sgl-kernel/src/sgl-kernel/csrc/sgl_kernel_ops.cu b/sglang/sgl-kernel/src/sgl-kernel/csrc/sgl_kernel_ops.cu
new file mode 100644
index 0000000000000000000000000000000000000000..69b8f8eebc5342b507bbaff7881422f7a069de70
--- /dev/null
+++ b/sglang/sgl-kernel/src/sgl-kernel/csrc/sgl_kernel_ops.cu
@@ -0,0 +1,22 @@
+#include "utils.hpp"
+
+// trt_reduce
+using fptr_t = int64_t;
+fptr_t init_custom_ar(int64_t rank_id, int64_t world_size, const std::vector& buffers,
+ const std::vector& barrier_in, const std::vector& barrier_out);
+void dispose(fptr_t _fa);
+void all_reduce(fptr_t _fa, torch::Tensor& inp, torch::Tensor& out);
+
+// moe_align_block_size
+void moe_align_block_size(torch::Tensor topk_ids, int64_t num_experts, int64_t block_size,
+ torch::Tensor sorted_token_ids, torch::Tensor experts_ids, torch::Tensor num_tokens_post_pad,
+ torch::Tensor token_cnts_buffer, torch::Tensor cumsum_buffer);
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ // trt_reduce
+ m.def("init_custom_ar", &init_custom_ar, "init custom allreduce meta (CUDA)");
+ m.def("dispose", &dispose, "dispose custom allreduce meta");
+ m.def("all_reduce", &all_reduce, "custom all reduce (CUDA)");
+ // moe_align_block_size
+ m.def("moe_align_block_size", &moe_align_block_size, "MOE Align Block Size (CUDA)");
+}
diff --git a/sglang/sgl-kernel/src/sgl-kernel/csrc/trt_reduce_internal.cuh b/sglang/sgl-kernel/src/sgl-kernel/csrc/trt_reduce_internal.cuh
new file mode 100644
index 0000000000000000000000000000000000000000..1c7c714dc4a817e244961a2e552b02c0ad9c6bfe
--- /dev/null
+++ b/sglang/sgl-kernel/src/sgl-kernel/csrc/trt_reduce_internal.cuh
@@ -0,0 +1,89 @@
+// reference:
+// https://github.com/NVIDIA/TensorRT-LLM/blob/release/0.14/cpp/tensorrt_llm/plugins/ncclPlugin/allreducePlugin.cpp
+/*
+ * Copyright (c) 2022-2024, NVIDIA CORPORATION. All rights reserved.
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+#pragma once
+#include
+#include
+#include
+
+#include "utils.hpp"
+
+namespace trt_llm {
+constexpr size_t WARP_SIZE = 32;
+constexpr size_t MAX_ALL_REDUCE_BLOCKS = 36;
+constexpr size_t MAX_RANKS_PER_NODE = 8;
+constexpr size_t DEFAULT_BLOCK_SIZE = 512;
+
+enum class AllReduceStrategyType : int8_t {
+ RING = 0,
+ ONESHOT = 1,
+ TWOSHOT = 2,
+ AUTO = 3,
+};
+
+struct AllReduceParams {
+ size_t elts_size;
+ size_t elts_total;
+ size_t elts_per_rank;
+ size_t elts_per_block;
+ size_t rank_offset;
+ size_t ranks_per_node, rank, local_rank;
+ uint32_t barrier_flag;
+ uint32_t* peer_barrier_ptrs_in[MAX_RANKS_PER_NODE];
+ uint32_t* peer_barrier_ptrs_out[MAX_RANKS_PER_NODE];
+ void* peer_comm_buffer_ptrs[MAX_RANKS_PER_NODE];
+ void* local_input_buffer_ptr;
+ void* local_output_buffer_ptr;
+};
+
+inline size_t GetMaxRequiredWorkspaceSize(int world_size) {
+ if (world_size <= 2) {
+ return 16 * 1024 * 1024;
+ }
+ return 8 * 1024 * 1024;
+}
+
+inline AllReduceStrategyType SelectImplementation(size_t message_size, int world_size) {
+ const size_t maxWorkspaceSize = GetMaxRequiredWorkspaceSize(world_size);
+
+ if (message_size > maxWorkspaceSize) {
+ assert(false && "Custom allreduce do not ring currently");
+ return AllReduceStrategyType::RING;
+ }
+
+ if (world_size <= 2) {
+ return AllReduceStrategyType::ONESHOT;
+ }
+
+ if (world_size <= 4) {
+ if (message_size < 1 * 1024 * 1024) {
+ return AllReduceStrategyType::ONESHOT;
+ }
+ return AllReduceStrategyType::TWOSHOT;
+ }
+
+ if (message_size < 512 * 1024) {
+ return AllReduceStrategyType::ONESHOT;
+ }
+ return AllReduceStrategyType::TWOSHOT;
+}
+
+void trtCustomAllReduce(AllReduceParams& params, at::ScalarType data_type, AllReduceStrategyType strat,
+ cudaStream_t stream);
+
+} // namespace trt_llm
diff --git a/sglang/sgl-kernel/src/sgl-kernel/csrc/trt_reduce_kernel.cu b/sglang/sgl-kernel/src/sgl-kernel/csrc/trt_reduce_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..59b548c77e9e6f78bc3e77f9ca340ec43becb5a5
--- /dev/null
+++ b/sglang/sgl-kernel/src/sgl-kernel/csrc/trt_reduce_kernel.cu
@@ -0,0 +1,102 @@
+// reference: https://github.com/NVIDIA/TensorRT-LLM/blob/release/0.14/cpp/tensorrt_llm/kernels/customAllReduceKernels.h
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include "trt_reduce_internal.cuh"
+
+using namespace trt_llm;
+
+using fptr_t = int64_t;
+
+class AllReduceMeta {
+ public:
+ AllReduceMeta(int64_t rank_id, int64_t world_size, const std::vector& buffers,
+ const std::vector& barrier_in, const std::vector& barrier_out) {
+ this->rank_id = (int)rank_id;
+ this->world_size = (int)world_size;
+ this->buffers = buffers;
+ this->barrier_in = barrier_in;
+ this->barrier_out = barrier_out;
+ }
+
+ public:
+ int world_size;
+ int rank_id;
+ std::vector buffers;
+ std::vector barrier_in;
+ std::vector barrier_out;
+ int barrier_flag = 1;
+};
+
+// Get the number of bits for a given data type.
+inline int get_bits(at::ScalarType dtype) {
+ switch (dtype) {
+ case at::ScalarType::Float:
+ return 32;
+ case at::ScalarType::Half:
+ case at::ScalarType::BFloat16:
+ return 16;
+ default:
+ assert(false && "Unsupported data type");
+ }
+}
+
+// Check if customized all-reduce kernels can be applied.
+inline bool CanApplyCustomAllReduce(int64_t num_elements, at::ScalarType dtype) {
+ // The customized all-reduce kernel has the following requirement(s).
+ return num_elements % (16 / ((get_bits(dtype) + 7) / 8)) == 0;
+}
+
+fptr_t init_custom_ar(int64_t rank_id, int64_t world_size, const std::vector& buffers,
+ const std::vector& barrier_in, const std::vector& barrier_out) {
+ auto m = new AllReduceMeta(rank_id, world_size, buffers, barrier_in, barrier_out);
+ return (fptr_t)m;
+}
+
+void dispose(fptr_t _fa) {
+ auto fa = reinterpret_cast(_fa);
+ delete fa;
+}
+
+void all_reduce(fptr_t _fa, torch::Tensor& inp, torch::Tensor& out) {
+ AllReduceMeta* m = reinterpret_cast(_fa);
+ auto stream = c10::cuda::getCurrentCUDAStream().stream();
+ auto num_elements = inp.numel();
+ auto dtype = inp.scalar_type();
+ AllReduceStrategyType strategy = SelectImplementation(num_elements * ((get_bits(dtype) + 7) / 8), m->world_size);
+
+ // should be gurantee in python code
+ assert(strategy == AllReduceStrategyType::ONESHOT || strategy == AllReduceStrategyType::TWOSHOT);
+ assert(CanApplyCustomAllReduce(num_elements, dtype));
+
+ // Initialize the all-reduce kernel arguments.
+ int world_size = m->world_size;
+
+ AllReduceParams params;
+ params.ranks_per_node = world_size;
+ params.rank = m->rank_id;
+ params.local_rank = m->rank_id;
+ params.local_input_buffer_ptr = inp.data_ptr();
+ params.local_output_buffer_ptr = out.data_ptr();
+ params.elts_total = inp.numel();
+ params.elts_size = inp.element_size();
+ params.barrier_flag = ++(m->barrier_flag);
+
+ for (int i = 0; i < world_size; ++i) {
+ params.peer_comm_buffer_ptrs[i] = reinterpret_cast(m->buffers[i]);
+ }
+ for (int i = 0; i < world_size; ++i) {
+ params.peer_barrier_ptrs_in[i] = reinterpret_cast(m->barrier_in[i]);
+ }
+ for (int i = 0; i < world_size; ++i) {
+ params.peer_barrier_ptrs_out[i] = reinterpret_cast(m->barrier_out[i]);
+ }
+
+ auto data_type = out.scalar_type();
+ trtCustomAllReduce(params, data_type, strategy, stream);
+}
diff --git a/sglang/sgl-kernel/src/sgl-kernel/csrc/utils.hpp b/sglang/sgl-kernel/src/sgl-kernel/csrc/utils.hpp
new file mode 100644
index 0000000000000000000000000000000000000000..bbdc6311be9ce97b831c5cab4d8473f71495cc3b
--- /dev/null
+++ b/sglang/sgl-kernel/src/sgl-kernel/csrc/utils.hpp
@@ -0,0 +1,36 @@
+#pragma once
+#include
+
+#include
+
+struct cuda_error : public std::runtime_error {
+ /**
+ * @brief Constructs a `cuda_error` object with the given `message`.
+ *
+ * @param message The error char array used to construct `cuda_error`
+ */
+ cuda_error(const char* message) : std::runtime_error(message) {}
+ /**
+ * @brief Constructs a `cuda_error` object with the given `message` string.
+ *
+ * @param message The `std::string` used to construct `cuda_error`
+ */
+ cuda_error(std::string const& message) : cuda_error{message.c_str()} {}
+};
+
+#define CHECK_CUDA_SUCCESS(cmd) \
+ do { \
+ cudaError_t e = cmd; \
+ if (e != cudaSuccess) { \
+ std::stringstream _message; \
+ auto s = cudaGetErrorString(e); \
+ _message << std::string(s) + "\n" << __FILE__ << ':' << __LINE__; \
+ throw cuda_error(_message.str()); \
+ } \
+ } while (0)
+
+#define CHECK_IS_CUDA(x) TORCH_CHECK(x.device().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_IS_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_CUDA_INPUT(x) \
+ CHECK_IS_CUDA(x); \
+ CHECK_IS_CONTIGUOUS(x)
diff --git a/sglang/sgl-kernel/src/sgl-kernel/ops/__init__.py b/sglang/sgl-kernel/src/sgl-kernel/ops/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..aee968ae67b428017bc40ce8856da3918dbb4801
--- /dev/null
+++ b/sglang/sgl-kernel/src/sgl-kernel/ops/__init__.py
@@ -0,0 +1,38 @@
+from sgl_kernel.ops._kernels import all_reduce as _all_reduce
+from sgl_kernel.ops._kernels import dispose as _dispose
+from sgl_kernel.ops._kernels import init_custom_ar as _init_custom_ar
+from sgl_kernel.ops._kernels import moe_align_block_size as _moe_align_block_size
+
+
+def init_custom_reduce(rank_id, num_devices, buffers, barrier_in, barrier_out):
+ return _init_custom_ar(rank_id, num_devices, buffers, barrier_in, barrier_out)
+
+
+def custom_dispose(fa):
+ _dispose(fa)
+
+
+def custom_reduce(fa, inp, out):
+ _all_reduce(fa, inp, out)
+
+
+def moe_align_block_size(
+ topk_ids,
+ num_experts,
+ block_size,
+ sorted_token_ids,
+ experts_ids,
+ num_tokens_post_pad,
+ token_cnts_buffer,
+ cumsum_buffer,
+):
+ _moe_align_block_size(
+ topk_ids,
+ num_experts,
+ block_size,
+ sorted_token_ids,
+ experts_ids,
+ num_tokens_post_pad,
+ token_cnts_buffer,
+ cumsum_buffer,
+ )
diff --git a/sglang/sgl-kernel/tests/test_trt_reduce.py b/sglang/sgl-kernel/tests/test_trt_reduce.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5ce1b41db1430ede54e40e5a466b8d536902eb0
--- /dev/null
+++ b/sglang/sgl-kernel/tests/test_trt_reduce.py
@@ -0,0 +1,242 @@
+import ctypes
+import logging
+import os
+import random
+import socket
+import time
+import unittest
+from typing import Any, List, Optional, Union
+
+import ray
+import torch
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
+from vllm import _custom_ops as vllm_ops
+
+from sglang.srt.distributed.device_communicators.cuda_wrapper import CudaRTLibrary
+
+logger = logging.getLogger(__name__)
+
+
+def get_open_port() -> int:
+ # try ipv4
+ try:
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.bind(("127.0.0.1", 0))
+ return s.getsockname()[1]
+ except OSError:
+ # try ipv6
+ with socket.socket(socket.AF_INET6, socket.SOCK_STREAM) as s:
+ s.bind(("127.0.0.1", 0))
+ return s.getsockname()[1]
+
+
+def multi_process_parallel(
+ world_size: int,
+ cls: Any,
+ test_target: Any,
+) -> None:
+ # Using ray helps debugging the error when it failed
+ # as compared to multiprocessing.
+ # NOTE: We need to set working_dir for distributed tests,
+ # otherwise we may get import errors on ray workers
+ ray.init(log_to_driver=True)
+
+ distributed_init_port = get_open_port()
+ refs = []
+ for rank in range(world_size):
+ refs.append(test_target.remote(cls, world_size, rank, distributed_init_port))
+ ray.get(refs)
+
+ ray.shutdown()
+
+
+class TestCustomAllReduce(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls):
+ random.seed(42)
+ cls.test_sizes = [512, 4096, 32768, 262144, 524288, 1048576, 2097152]
+ cls.world_sizes = [2, 4, 8]
+
+ @staticmethod
+ def create_shared_buffer(
+ size_in_bytes: int, group: Optional[ProcessGroup] = None
+ ) -> List[int]:
+ """
+ Creates a shared buffer and returns a list of pointers
+ representing the buffer on all processes in the group.
+ """
+ lib = CudaRTLibrary()
+ pointer = lib.cudaMalloc(size_in_bytes)
+ handle = lib.cudaIpcGetMemHandle(pointer)
+ world_size = dist.get_world_size(group=group)
+ rank = dist.get_rank(group=group)
+ handles = [None] * world_size
+ dist.all_gather_object(handles, handle, group=group)
+
+ pointers: List[int] = []
+ for i, h in enumerate(handles):
+ if i == rank:
+ pointers.append(pointer.value) # type: ignore
+ else:
+ pointers.append(lib.cudaIpcOpenMemHandle(h).value) # type: ignore
+
+ return pointers
+
+ @staticmethod
+ def free_shared_buffer(
+ pointers: List[int], group: Optional[ProcessGroup] = None
+ ) -> None:
+ rank = dist.get_rank(group=group)
+ lib = CudaRTLibrary()
+ lib.cudaFree(ctypes.c_void_p(pointers[rank]))
+
+ def test_correctness(self):
+ for world_size in self.world_sizes:
+ if world_size > torch.cuda.device_count():
+ continue
+ multi_process_parallel(world_size, self, self.correctness)
+
+ def test_performance(self):
+ for world_size in self.world_sizes:
+ if world_size > torch.cuda.device_count():
+ continue
+ multi_process_parallel(world_size, self, self.performance)
+
+ def init_custom_allreduce(self, rank, world_size, group):
+ import sgl_kernel
+
+ buffer_max_size = 8 * 1024 * 1024
+ barrier_max_size = 8 * (24 + 2) * 8
+
+ self.buffer_ptrs = self.create_shared_buffer(buffer_max_size, group=group)
+ self.barrier_in_ptrs = self.create_shared_buffer(barrier_max_size, group=group)
+ self.barrier_out_ptrs = self.create_shared_buffer(barrier_max_size, group=group)
+
+ self.custom_ptr = sgl_kernel.ops.init_custom_reduce(
+ rank,
+ world_size,
+ self.buffer_ptrs,
+ self.barrier_in_ptrs,
+ self.barrier_out_ptrs,
+ )
+
+ def custom_allreduce(self, inp, out):
+ import sgl_kernel
+
+ sgl_kernel.ops.custom_reduce(self.custom_ptr, inp, out)
+
+ def free_custom_allreduce(self, group):
+ import sgl_kernel
+
+ self.free_shared_buffer(self.buffer_ptrs, group)
+ self.free_shared_buffer(self.barrier_in_ptrs, group)
+ self.free_shared_buffer(self.barrier_out_ptrs, group)
+ sgl_kernel.ops.custom_dispose(self.custom_ptr)
+
+ def init_vllm_allreduce(self, rank, group):
+ self.vllm_rank = rank
+ self.vllm_max_size = 8 * 1024 * 1024
+ self.vllm_meta_ptrs = self.create_shared_buffer(
+ vllm_ops.meta_size() + self.vllm_max_size, group=group
+ )
+ self.vllm_buffer_ptrs = self.create_shared_buffer(
+ self.vllm_max_size, group=group
+ )
+ self.vllm_rank_data = torch.empty(
+ 8 * 1024 * 1024, dtype=torch.uint8, device=torch.device(f"cuda:{rank}")
+ )
+ self.vllm_ptr = vllm_ops.init_custom_ar(
+ self.vllm_meta_ptrs, self.vllm_rank_data, rank, True
+ )
+ vllm_ops.register_buffer(self.vllm_ptr, self.vllm_buffer_ptrs)
+
+ def vllm_allreduce(self, inp, out):
+ vllm_ops.all_reduce(
+ self.vllm_ptr,
+ inp,
+ out,
+ self.vllm_buffer_ptrs[self.vllm_rank],
+ self.vllm_max_size,
+ )
+
+ def free_vllm_allreduce(self, group):
+ vllm_ops.dispose(self.vllm_ptr)
+ self.free_shared_buffer(self.vllm_meta_ptrs, group)
+ self.free_shared_buffer(self.vllm_buffer_ptrs, group)
+
+ @staticmethod
+ def init_distributed_env(world_size, rank, distributed_init_port):
+ del os.environ["CUDA_VISIBLE_DEVICES"]
+ device = torch.device(f"cuda:{rank}")
+ torch.cuda.set_device(device)
+ ranks = [i for i in range(world_size)]
+ distributed_init_method = f"tcp://localhost:{distributed_init_port}"
+ dist.init_process_group(
+ backend="nccl",
+ init_method=distributed_init_method,
+ rank=rank,
+ world_size=world_size,
+ )
+ group = torch.distributed.new_group(ranks, backend="gloo")
+ return group
+
+ # compare result with torch.distributed
+ @ray.remote(num_gpus=1, max_calls=1)
+ def correctness(self, world_size, rank, distributed_init_port):
+ group = self.init_distributed_env(world_size, rank, distributed_init_port)
+
+ self.init_custom_allreduce(rank=rank, world_size=world_size, group=group)
+
+ test_loop = 10
+ for sz in self.test_sizes:
+ for dtype in [torch.float32, torch.float16, torch.bfloat16]:
+ for _ in range(test_loop):
+ inp1 = torch.randint(
+ 1, 16, (sz,), dtype=dtype, device=torch.cuda.current_device()
+ )
+ out1 = torch.empty_like(inp1)
+ self.custom_allreduce(inp1, out1)
+
+ dist.all_reduce(inp1, group=group)
+ torch.testing.assert_close(out1, inp1)
+
+ self.free_custom_allreduce(group)
+
+ # compare performance with vllm
+ @ray.remote(num_gpus=1, max_calls=1)
+ def performance(self, world_size, rank, distributed_init_port):
+ group = self.init_distributed_env(world_size, rank, distributed_init_port)
+
+ self.init_vllm_allreduce(rank, group)
+ self.init_custom_allreduce(rank=rank, world_size=world_size, group=group)
+
+ for sz in self.test_sizes:
+ inp1 = torch.randint(
+ 1, 16, (sz,), dtype=torch.float32, device=torch.cuda.current_device()
+ )
+ out1 = torch.empty_like(inp1)
+ test_loop = 5000
+ start = time.time()
+ for _ in range(test_loop):
+ self.custom_allreduce(inp1, out1)
+ elapse_custom = time.time() - start
+
+ start = time.time()
+ for _ in range(test_loop):
+ self.vllm_allreduce(inp1, out1)
+ elapse_vllm = time.time() - start
+
+ if rank == 0:
+ logger.warning(
+ f"test_size = {sz}, world_size = {world_size}, "
+ f"vllm time = {elapse_vllm * 1000 / test_loop:.4f}ms,"
+ f"custom time = {elapse_custom * 1000 / test_loop:.4f}ms"
+ )
+
+ self.free_custom_allreduce(group)
+ self.free_vllm_allreduce(group)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/sglang/sgl-router/py_src/sglang_router/__init__.py b/sglang/sgl-router/py_src/sglang_router/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..285ee173ba92ce5f9c532d9c7ea7c77c5e2578ea
--- /dev/null
+++ b/sglang/sgl-router/py_src/sglang_router/__init__.py
@@ -0,0 +1,11 @@
+# a lightweihgt wrapper on router with argument type and comments
+from sglang_router_rs import PolicyType
+
+# no wrapper on policy type => direct export
+from .router import Router
+
+__all__ = ["Router", "PolicyType"]
+
+from sglang_router.version import __version__
+
+__all__ += ["__version__"]
diff --git a/sglang/sgl-router/py_src/sglang_router/launch_router.py b/sglang/sgl-router/py_src/sglang_router/launch_router.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4f26a8d4bcea55210684fcfe687dfdb66c183c2
--- /dev/null
+++ b/sglang/sgl-router/py_src/sglang_router/launch_router.py
@@ -0,0 +1,249 @@
+import argparse
+import dataclasses
+import logging
+import sys
+from typing import List, Optional
+
+from sglang_router import Router
+from sglang_router_rs import PolicyType
+
+
+def setup_logger():
+ logger = logging.getLogger("router")
+ logger.setLevel(logging.INFO)
+
+ formatter = logging.Formatter(
+ "[Router (Python)] %(asctime)s - %(levelname)s - %(message)s",
+ datefmt="%Y-%m-%d %H:%M:%S",
+ )
+
+ handler = logging.StreamHandler()
+ handler.setFormatter(formatter)
+ logger.addHandler(handler)
+
+ return logger
+
+
+@dataclasses.dataclass
+class RouterArgs:
+ # Worker configuration
+ worker_urls: List[str]
+ host: str = "127.0.0.1"
+ port: int = 30000
+
+ # Routing policy
+ policy: str = "cache_aware"
+ cache_threshold: float = 0.5
+ balance_abs_threshold: int = 32
+ balance_rel_threshold: float = 1.0001
+ eviction_interval: int = 60
+ max_tree_size: int = 2**24
+ max_payload_size: int = 4 * 1024 * 1024 # 4MB
+ verbose: bool = False
+
+ @staticmethod
+ def add_cli_args(
+ parser: argparse.ArgumentParser,
+ use_router_prefix: bool = False,
+ exclude_host_port: bool = False,
+ ):
+ """
+ Add router-specific arguments to an argument parser.
+
+ Args:
+ parser: The argument parser to add arguments to
+ use_router_prefix: If True, prefix all arguments with 'router-' to avoid conflicts
+ exclude_host_port: If True, don't add host and port arguments (used when inheriting from server)
+ """
+ prefix = "router-" if use_router_prefix else ""
+
+ # Worker configuration
+ if not exclude_host_port:
+ parser.add_argument(
+ "--host",
+ type=str,
+ default=RouterArgs.host,
+ help="Host address to bind the router server",
+ )
+ parser.add_argument(
+ "--port",
+ type=int,
+ default=RouterArgs.port,
+ help="Port number to bind the router server",
+ )
+
+ parser.add_argument(
+ "--worker-urls",
+ type=str,
+ nargs="+",
+ help="List of worker URLs (e.g., http://worker1:8000 http://worker2:8000)",
+ )
+
+ # Routing policy configuration
+ parser.add_argument(
+ f"--{prefix}policy",
+ type=str,
+ default=RouterArgs.policy,
+ choices=["random", "round_robin", "cache_aware"],
+ help="Load balancing policy to use",
+ )
+ parser.add_argument(
+ f"--{prefix}cache-threshold",
+ type=float,
+ default=RouterArgs.cache_threshold,
+ help="Cache threshold (0.0-1.0) for cache-aware routing",
+ )
+ parser.add_argument(
+ f"--{prefix}balance-abs-threshold",
+ type=int,
+ default=RouterArgs.balance_abs_threshold,
+ help="Load balancing is triggered when (max_load - min_load) > abs_threshold AND max_load > min_load * rel_threshold. Otherwise, use cache aware",
+ )
+ parser.add_argument(
+ f"--{prefix}balance-rel-threshold",
+ type=float,
+ default=RouterArgs.balance_rel_threshold,
+ help="Load balancing is triggered when (max_load - min_load) > abs_threshold AND max_load > min_load * rel_threshold. Otherwise, use cache aware",
+ )
+ parser.add_argument(
+ f"--{prefix}eviction-interval",
+ type=int,
+ default=RouterArgs.eviction_interval,
+ help="Interval in seconds between cache eviction operations",
+ )
+ parser.add_argument(
+ f"--{prefix}max-tree-size",
+ type=int,
+ default=RouterArgs.max_tree_size,
+ help="Maximum size of the approximation tree for cache-aware routing",
+ )
+ parser.add_argument(
+ f"--{prefix}max-payload-size",
+ type=int,
+ default=RouterArgs.max_payload_size,
+ help="Maximum payload size in bytes",
+ )
+ parser.add_argument(
+ f"--{prefix}verbose",
+ action="store_true",
+ help="Enable verbose logging",
+ )
+
+ @classmethod
+ def from_cli_args(
+ cls, args: argparse.Namespace, use_router_prefix: bool = False
+ ) -> "RouterArgs":
+ """
+ Create RouterArgs instance from parsed command line arguments.
+
+ Args:
+ args: Parsed command line arguments
+ use_router_prefix: If True, look for arguments with 'router-' prefix
+ """
+ prefix = "router_" if use_router_prefix else ""
+ return cls(
+ worker_urls=args.worker_urls,
+ host=args.host,
+ port=args.port,
+ policy=getattr(args, f"{prefix}policy"),
+ cache_threshold=getattr(args, f"{prefix}cache_threshold"),
+ balance_abs_threshold=getattr(args, f"{prefix}balance_abs_threshold"),
+ balance_rel_threshold=getattr(args, f"{prefix}balance_rel_threshold"),
+ eviction_interval=getattr(args, f"{prefix}eviction_interval"),
+ max_tree_size=getattr(args, f"{prefix}max_tree_size"),
+ max_payload_size=getattr(args, f"{prefix}max_payload_size"),
+ verbose=getattr(args, f"{prefix}verbose", False),
+ )
+
+
+def policy_from_str(policy_str: str) -> PolicyType:
+ """Convert policy string to PolicyType enum."""
+ policy_map = {
+ "random": PolicyType.Random,
+ "round_robin": PolicyType.RoundRobin,
+ "cache_aware": PolicyType.CacheAware,
+ }
+ return policy_map[policy_str]
+
+
+def launch_router(args: argparse.Namespace) -> Optional[Router]:
+ """
+ Launch the SGLang router with the configuration from parsed arguments.
+
+ Args:
+ args: Namespace object containing router configuration
+ Can be either raw argparse.Namespace or converted RouterArgs
+
+ Returns:
+ Router instance if successful, None if failed
+ """
+ logger = logging.getLogger("router")
+ try:
+ # Convert to RouterArgs if needed
+ if not isinstance(args, RouterArgs):
+ router_args = RouterArgs.from_cli_args(args)
+ else:
+ router_args = args
+
+ router = Router(
+ worker_urls=router_args.worker_urls,
+ policy=policy_from_str(router_args.policy),
+ host=router_args.host,
+ port=router_args.port,
+ cache_threshold=router_args.cache_threshold,
+ balance_abs_threshold=router_args.balance_abs_threshold,
+ balance_rel_threshold=router_args.balance_rel_threshold,
+ eviction_interval_secs=router_args.eviction_interval,
+ max_tree_size=router_args.max_tree_size,
+ max_payload_size=router_args.max_payload_size,
+ verbose=router_args.verbose,
+ )
+
+ router.start()
+ return router
+
+ except Exception as e:
+ logger.error(f"Error starting router: {e}")
+ return None
+
+
+class CustomHelpFormatter(
+ argparse.RawDescriptionHelpFormatter, argparse.ArgumentDefaultsHelpFormatter
+):
+ """Custom formatter that preserves both description formatting and shows defaults"""
+
+ pass
+
+
+def parse_router_args(args: List[str]) -> RouterArgs:
+ """Parse command line arguments and return RouterArgs instance."""
+ parser = argparse.ArgumentParser(
+ description="""SGLang Router - High-performance request distribution across worker nodes
+
+Usage:
+This launcher enables starting a router with individual worker instances. It is useful for
+multi-node setups or when you want to start workers and router separately.
+
+Examples:
+ python -m sglang_router.launch_router --worker-urls http://worker1:8000 http://worker2:8000
+ python -m sglang_router.launch_router --worker-urls http://worker1:8000 http://worker2:8000 --cache-threshold 0.7 --balance-abs-threshold 64 --balance-rel-threshold 1.2
+
+ """,
+ formatter_class=CustomHelpFormatter,
+ )
+
+ RouterArgs.add_cli_args(parser, use_router_prefix=False)
+ return RouterArgs.from_cli_args(parser.parse_args(args), use_router_prefix=False)
+
+
+def main() -> None:
+ logger = setup_logger()
+ router_args = parse_router_args(sys.argv[1:])
+ router = launch_router(router_args)
+
+ if router is None:
+ sys.exit(1)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/sglang/sgl-router/py_src/sglang_router/router.py b/sglang/sgl-router/py_src/sglang_router/router.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ce21c3d78ea6f0518465b9b3b260722abb93022
--- /dev/null
+++ b/sglang/sgl-router/py_src/sglang_router/router.py
@@ -0,0 +1,67 @@
+from typing import List, Optional
+
+from sglang_router_rs import PolicyType
+from sglang_router_rs import Router as _Router
+
+
+class Router:
+ """
+ A high-performance router for distributing requests across worker nodes.
+
+ Args:
+ worker_urls: List of URLs for worker nodes that will handle requests. Each URL should include
+ the protocol, host, and port (e.g., ['http://worker1:8000', 'http://worker2:8000'])
+ policy: Load balancing policy to use. Options:
+ - PolicyType.Random: Randomly select workers
+ - PolicyType.RoundRobin: Distribute requests in round-robin fashion
+ - PolicyType.CacheAware: Distribute requests based on cache state and load balance
+ host: Host address to bind the router server. Default: '127.0.0.1'
+ port: Port number to bind the router server. Default: 3001
+ cache_threshold: Cache threshold (0.0-1.0) for cache-aware routing. Routes to cached worker
+ if the match rate exceeds threshold, otherwise routes to the worker with the smallest
+ tree. Default: 0.5
+ balance_abs_threshold: Load balancing is triggered when (max_load - min_load) > abs_threshold
+ AND max_load > min_load * rel_threshold. Otherwise, use cache aware. Default: 32
+ balance_rel_threshold: Load balancing is triggered when (max_load - min_load) > abs_threshold
+ AND max_load > min_load * rel_threshold. Otherwise, use cache aware. Default: 1.0001
+ eviction_interval_secs: Interval in seconds between cache eviction operations in cache-aware
+ routing. Default: 60
+ max_payload_size: Maximum payload size in bytes. Default: 4MB
+ max_tree_size: Maximum size of the approximation tree for cache-aware routing. Default: 2^24
+ verbose: Enable verbose logging. Default: False
+ """
+
+ def __init__(
+ self,
+ worker_urls: List[str],
+ policy: PolicyType = PolicyType.RoundRobin,
+ host: str = "127.0.0.1",
+ port: int = 3001,
+ cache_threshold: float = 0.50,
+ balance_abs_threshold: int = 32,
+ balance_rel_threshold: float = 1.0001,
+ eviction_interval_secs: int = 60,
+ max_tree_size: int = 2**24,
+ max_payload_size: int = 4 * 1024 * 1024, # 4MB
+ verbose: bool = False,
+ ):
+ self._router = _Router(
+ worker_urls=worker_urls,
+ policy=policy,
+ host=host,
+ port=port,
+ cache_threshold=cache_threshold,
+ balance_abs_threshold=balance_abs_threshold,
+ balance_rel_threshold=balance_rel_threshold,
+ eviction_interval_secs=eviction_interval_secs,
+ max_tree_size=max_tree_size,
+ max_payload_size=max_payload_size,
+ verbose=verbose,
+ )
+
+ def start(self) -> None:
+ """Start the router server.
+
+ This method blocks until the server is shut down.
+ """
+ self._router.start()
diff --git a/sglang/sgl-router/py_test/run_suite.py b/sglang/sgl-router/py_test/run_suite.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f012b75162472fc09cb96ed4bf15adaf7ccc259
--- /dev/null
+++ b/sglang/sgl-router/py_test/run_suite.py
@@ -0,0 +1,19 @@
+import argparse
+import glob
+
+from sglang.test.test_utils import run_unittest_files
+
+if __name__ == "__main__":
+ arg_parser = argparse.ArgumentParser()
+ arg_parser.add_argument(
+ "--timeout-per-file",
+ type=int,
+ default=1000,
+ help="The time limit for running one file in seconds.",
+ )
+ args = arg_parser.parse_args()
+
+ files = glob.glob("**/test_*.py", recursive=True)
+
+ exit_code = run_unittest_files(files, args.timeout_per_file)
+ exit(exit_code)
diff --git a/sglang/sgl-router/py_test/test_launch_router.py b/sglang/sgl-router/py_test/test_launch_router.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c3700d423ba53a9ee93e582a626722865726613
--- /dev/null
+++ b/sglang/sgl-router/py_test/test_launch_router.py
@@ -0,0 +1,67 @@
+import multiprocessing
+import time
+import unittest
+from types import SimpleNamespace
+
+
+def terminate_process(process: multiprocessing.Process, timeout: float = 1.0) -> None:
+ """Terminate a process gracefully, with forced kill as fallback.
+
+ Args:
+ process: The process to terminate
+ timeout: Seconds to wait for graceful termination before forcing kill
+ """
+ if not process.is_alive():
+ return
+
+ process.terminate()
+ process.join(timeout=timeout)
+ if process.is_alive():
+ process.kill() # Force kill if terminate didn't work
+ process.join()
+
+
+class TestLaunchRouter(unittest.TestCase):
+ def test_launch_router_no_exception(self):
+
+ # Create SimpleNamespace with default arguments
+ args = SimpleNamespace(
+ worker_urls=["http://localhost:8000"],
+ host="127.0.0.1",
+ port=30000,
+ policy="cache_aware",
+ cache_threshold=0.5,
+ balance_abs_threshold=32,
+ balance_rel_threshold=1.0001,
+ eviction_interval=60,
+ max_tree_size=2**24,
+ max_payload_size=4 * 1024 * 1024, # 4MB
+ verbose=False,
+ )
+
+ def run_router():
+ try:
+ from sglang_router.launch_router import launch_router
+
+ router = launch_router(args)
+ if router is None:
+ return 1
+ return 0
+ except Exception as e:
+ print(e)
+ return 1
+
+ # Start router in separate process
+ process = multiprocessing.Process(target=run_router)
+ try:
+ process.start()
+ # Wait 3 seconds
+ time.sleep(3)
+ # Process is still running means router started successfully
+ self.assertTrue(process.is_alive())
+ finally:
+ terminate_process(process)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/sglang/sgl-router/py_test/test_launch_server.py b/sglang/sgl-router/py_test/test_launch_server.py
new file mode 100644
index 0000000000000000000000000000000000000000..e11602933a63f1b5d1b7b735b29a0a222fa48131
--- /dev/null
+++ b/sglang/sgl-router/py_test/test_launch_server.py
@@ -0,0 +1,338 @@
+import socket
+import subprocess
+import time
+import unittest
+from types import SimpleNamespace
+
+import requests
+
+from sglang.srt.utils import kill_process_tree
+from sglang.test.run_eval import run_eval
+from sglang.test.test_utils import (
+ DEFAULT_MODEL_NAME_FOR_TEST,
+ DEFAULT_TIMEOUT_FOR_SERVER_LAUNCH,
+ DEFAULT_URL_FOR_TEST,
+)
+
+
+def popen_launch_router(
+ model: str,
+ base_url: str,
+ dp_size: int,
+ timeout: float,
+ policy: str = "cache_aware",
+ max_payload_size: int = None,
+):
+ """
+ Launch the router server process.
+
+ Args:
+ model: Model path/name
+ base_url: Server base URL
+ dp_size: Data parallel size
+ timeout: Server launch timeout
+ policy: Router policy, one of "cache_aware", "round_robin", "random"
+ max_payload_size: Maximum payload size in bytes
+ """
+ _, host, port = base_url.split(":")
+ host = host[2:]
+
+ command = [
+ "python3",
+ "-m",
+ "sglang_router.launch_server",
+ "--model-path",
+ model,
+ "--host",
+ host,
+ "--port",
+ port,
+ "--dp",
+ str(dp_size),
+ "--router-eviction-interval",
+ "5",
+ "--router-policy",
+ policy,
+ ]
+
+ if max_payload_size is not None:
+ command.extend(["--router-max-payload-size", str(max_payload_size)])
+
+ process = subprocess.Popen(command, stdout=None, stderr=None)
+
+ start_time = time.time()
+ with requests.Session() as session:
+ while time.time() - start_time < timeout:
+ try:
+ response = session.get(f"{base_url}/health")
+ if response.status_code == 200:
+ print(f"Router {base_url} is healthy")
+ return process
+ except requests.RequestException:
+ pass
+ time.sleep(10)
+
+ raise TimeoutError("Router failed to start within the timeout period.")
+
+
+def find_available_port():
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.bind(("127.0.0.1", 0))
+ return s.getsockname()[1]
+
+
+def popen_launch_server(
+ model: str,
+ base_url: str,
+ timeout: float,
+):
+ _, host, port = base_url.split(":")
+ host = host[2:]
+
+ command = [
+ "python3",
+ "-m",
+ "sglang.launch_server",
+ "--model-path",
+ model,
+ "--host",
+ host,
+ "--port",
+ port,
+ "--base-gpu-id",
+ "1",
+ ]
+
+ process = subprocess.Popen(command, stdout=None, stderr=None)
+
+ # intentionally don't wait and defer the job to the router health check
+ return process
+
+
+def terminate_and_wait(process, timeout=300):
+ """Terminate a process and wait until it is terminated.
+
+ Args:
+ process: subprocess.Popen object
+ timeout: maximum time to wait in seconds
+
+ Raises:
+ TimeoutError: if process does not terminate within timeout
+ """
+ if process is None:
+ return
+
+ process.terminate()
+ start_time = time.time()
+
+ while process.poll() is None:
+ print(f"Terminating process {process.pid}")
+ if time.time() - start_time > timeout:
+ raise TimeoutError(
+ f"Process {process.pid} failed to terminate within {timeout}s"
+ )
+ time.sleep(1)
+
+ print(f"Process {process.pid} is successfully terminated")
+
+
+class TestLaunchServer(unittest.TestCase):
+ def setUp(self):
+ self.model = DEFAULT_MODEL_NAME_FOR_TEST
+ self.base_url = DEFAULT_URL_FOR_TEST
+ self.process = None
+ self.other_process = []
+
+ def tearDown(self):
+ print("Running tearDown...")
+ if self.process:
+ terminate_and_wait(self.process)
+ for process in self.other_process:
+ terminate_and_wait(process)
+ print("tearDown done")
+
+ def test_1_mmlu(self):
+ print("Running test_1_mmlu...")
+ # DP size = 2
+ self.process = popen_launch_router(
+ self.model,
+ self.base_url,
+ dp_size=2,
+ timeout=DEFAULT_TIMEOUT_FOR_SERVER_LAUNCH,
+ policy="cache_aware",
+ )
+
+ args = SimpleNamespace(
+ base_url=self.base_url,
+ model=self.model,
+ eval_name="mmlu",
+ num_examples=64,
+ num_threads=32,
+ temperature=0.1,
+ )
+
+ metrics = run_eval(args)
+ score = metrics["score"]
+ THRESHOLD = 0.65
+ passed = score >= THRESHOLD
+ msg = f"MMLU test {'passed' if passed else 'failed'} with score {score:.3f} (threshold: {THRESHOLD})"
+ self.assertGreaterEqual(score, THRESHOLD, msg)
+
+ def test_2_add_and_remove_worker(self):
+ print("Running test_2_add_and_remove_worker...")
+ # DP size = 1
+ self.process = popen_launch_router(
+ self.model,
+ self.base_url,
+ dp_size=1,
+ timeout=DEFAULT_TIMEOUT_FOR_SERVER_LAUNCH,
+ policy="round_robin", # use round robin to make sure every worker processes requests
+ )
+ # 1. start a worker
+ port = find_available_port()
+ worker_url = f"http://127.0.0.1:{port}"
+ worker_process = popen_launch_server(
+ self.model, worker_url, DEFAULT_TIMEOUT_FOR_SERVER_LAUNCH
+ )
+ self.other_process.append(worker_process)
+
+ # 2. use /add_worker api to add it the the router. It will be used by router after it is healthy
+ with requests.Session() as session:
+ response = session.post(f"{self.base_url}/add_worker?url={worker_url}")
+ print(f"status code: {response.status_code}, response: {response.text}")
+ self.assertEqual(response.status_code, 200)
+
+ # 3. run mmlu
+ args = SimpleNamespace(
+ base_url=self.base_url,
+ model=self.model,
+ eval_name="mmlu",
+ num_examples=64,
+ num_threads=32,
+ temperature=0.1,
+ )
+ metrics = run_eval(args)
+ score = metrics["score"]
+ THRESHOLD = 0.65
+ passed = score >= THRESHOLD
+ msg = f"MMLU test {'passed' if passed else 'failed'} with score {score:.3f} (threshold: {THRESHOLD})"
+ self.assertGreaterEqual(score, THRESHOLD, msg)
+
+ # 4. use /remove_worker api to remove it from the router
+ with requests.Session() as session:
+ response = session.post(f"{self.base_url}/remove_worker?url={worker_url}")
+ print(f"status code: {response.status_code}, response: {response.text}")
+ self.assertEqual(response.status_code, 200)
+
+ # 5. run mmlu again
+ metrics = run_eval(args)
+ score = metrics["score"]
+ THRESHOLD = 0.65
+ passed = score >= THRESHOLD
+ msg = f"MMLU test {'passed' if passed else 'failed'} with score {score:.3f} (threshold: {THRESHOLD})"
+ self.assertGreaterEqual(score, THRESHOLD, msg)
+
+ def test_3_lazy_fault_tolerance(self):
+ print("Running test_3_lazy_fault_tolerance...")
+ # DP size = 1
+ self.process = popen_launch_router(
+ self.model,
+ self.base_url,
+ dp_size=1,
+ timeout=DEFAULT_TIMEOUT_FOR_SERVER_LAUNCH,
+ policy="round_robin",
+ )
+
+ # 1. start a worker
+ port = find_available_port()
+ worker_url = f"http://127.0.0.1:{port}"
+ worker_process = popen_launch_server(
+ self.model, worker_url, DEFAULT_TIMEOUT_FOR_SERVER_LAUNCH
+ )
+ self.other_process.append(worker_process)
+
+ # 2. use /add_worker api to add it the the router. It will be used by router after it is healthy
+ with requests.Session() as session:
+ response = session.post(f"{self.base_url}/add_worker?url={worker_url}")
+ print(f"status code: {response.status_code}, response: {response.text}")
+ self.assertEqual(response.status_code, 200)
+
+ # Start a thread to kill the worker after 10 seconds to mimic abrupt worker failure
+ def kill_worker():
+ time.sleep(10)
+ kill_process_tree(worker_process.pid)
+ print("Worker process killed")
+
+ import threading
+
+ kill_thread = threading.Thread(target=kill_worker)
+ kill_thread.daemon = True
+ kill_thread.start()
+
+ # 3. run mmlu
+ args = SimpleNamespace(
+ base_url=self.base_url,
+ model=self.model,
+ eval_name="mmlu",
+ num_examples=256,
+ num_threads=32,
+ temperature=0.1,
+ )
+ metrics = run_eval(args)
+ score = metrics["score"]
+ THRESHOLD = 0.65
+ passed = score >= THRESHOLD
+ msg = f"MMLU test {'passed' if passed else 'failed'} with score {score:.3f} (threshold: {THRESHOLD})"
+ self.assertGreaterEqual(score, THRESHOLD, msg)
+
+ def test_4_payload_size(self):
+ print("Running test_4_payload_size...")
+ # Start router with 3MB limit
+ self.process = popen_launch_router(
+ self.model,
+ self.base_url,
+ dp_size=1,
+ timeout=DEFAULT_TIMEOUT_FOR_SERVER_LAUNCH,
+ policy="round_robin",
+ max_payload_size=1 * 1024 * 1024, # 1MB limit
+ )
+
+ # Test case 1: Payload just under 1MB should succeed
+ payload_0_5_mb = {
+ "text": "x" * int(0.5 * 1024 * 1024), # 0.5MB of text
+ "temperature": 0.0,
+ }
+
+ with requests.Session() as session:
+ response = session.post(
+ f"{self.base_url}/generate",
+ json=payload_0_5_mb,
+ headers={"Content-Type": "application/json"},
+ )
+ self.assertEqual(
+ response.status_code,
+ 200,
+ f"0.5MB payload should succeed but got status {response.status_code}",
+ )
+
+ # Test case 2: Payload over 1MB should fail
+ payload_1_plus_mb = {
+ "text": "x" * int((1.2 * 1024 * 1024)), # 1.2MB of text
+ "temperature": 0.0,
+ }
+
+ with requests.Session() as session:
+ response = session.post(
+ f"{self.base_url}/generate",
+ json=payload_1_plus_mb,
+ headers={"Content-Type": "application/json"},
+ )
+ self.assertEqual(
+ response.status_code,
+ 413, # Payload Too Large
+ f"1.2MB payload should fail with 413 but got status {response.status_code}",
+ )
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/sglang/sgl-router/src/lib.rs b/sglang/sgl-router/src/lib.rs
new file mode 100644
index 0000000000000000000000000000000000000000..2d8cf4c0c8d63d91e5347890fd3082cf604750a9
--- /dev/null
+++ b/sglang/sgl-router/src/lib.rs
@@ -0,0 +1,108 @@
+use pyo3::prelude::*;
+pub mod router;
+pub mod server;
+pub mod tree;
+
+#[pyclass(eq)]
+#[derive(Clone, PartialEq)]
+pub enum PolicyType {
+ Random,
+ RoundRobin,
+ CacheAware,
+}
+
+#[pyclass]
+struct Router {
+ host: String,
+ port: u16,
+ worker_urls: Vec,
+ policy: PolicyType,
+ cache_threshold: f32,
+ balance_abs_threshold: usize,
+ balance_rel_threshold: f32,
+ eviction_interval_secs: u64,
+ max_tree_size: usize,
+ max_payload_size: usize,
+ verbose: bool,
+}
+
+#[pymethods]
+impl Router {
+ #[new]
+ #[pyo3(signature = (
+ worker_urls,
+ policy = PolicyType::RoundRobin,
+ host = String::from("127.0.0.1"),
+ port = 3001,
+ cache_threshold = 0.50,
+ balance_abs_threshold = 32,
+ balance_rel_threshold = 1.0001,
+ eviction_interval_secs = 60,
+ max_tree_size = 2usize.pow(24),
+ max_payload_size = 4 * 1024 * 1024,
+ verbose = false
+ ))]
+ fn new(
+ worker_urls: Vec,
+ policy: PolicyType,
+ host: String,
+ port: u16,
+ cache_threshold: f32,
+ balance_abs_threshold: usize,
+ balance_rel_threshold: f32,
+ eviction_interval_secs: u64,
+ max_tree_size: usize,
+ max_payload_size: usize,
+ verbose: bool,
+ ) -> PyResult {
+ Ok(Router {
+ host,
+ port,
+ worker_urls,
+ policy,
+ cache_threshold,
+ balance_abs_threshold,
+ balance_rel_threshold,
+ eviction_interval_secs,
+ max_tree_size,
+ max_payload_size,
+ verbose,
+ })
+ }
+
+ fn start(&self) -> PyResult<()> {
+ let policy_config = match &self.policy {
+ PolicyType::Random => router::PolicyConfig::RandomConfig,
+ PolicyType::RoundRobin => router::PolicyConfig::RoundRobinConfig,
+ PolicyType::CacheAware => router::PolicyConfig::CacheAwareConfig {
+ cache_threshold: self.cache_threshold,
+ balance_abs_threshold: self.balance_abs_threshold,
+ balance_rel_threshold: self.balance_rel_threshold,
+ eviction_interval_secs: self.eviction_interval_secs,
+ max_tree_size: self.max_tree_size,
+ },
+ };
+
+ actix_web::rt::System::new().block_on(async move {
+ server::startup(server::ServerConfig {
+ host: self.host.clone(),
+ port: self.port,
+ worker_urls: self.worker_urls.clone(),
+ policy_config,
+ verbose: self.verbose,
+ max_payload_size: self.max_payload_size,
+ })
+ .await
+ .unwrap();
+ });
+
+ Ok(())
+ }
+}
+
+#[pymodule]
+fn sglang_router_rs(m: &Bound<'_, PyModule>) -> PyResult<()> {
+ m.add_class::()?;
+ m.add_class::()?;
+ Ok(())
+}
diff --git a/sglang/sgl-router/src/server.rs b/sglang/sgl-router/src/server.rs
new file mode 100644
index 0000000000000000000000000000000000000000..09878f07f8ec414831f63a0b4a687198842e36f0
--- /dev/null
+++ b/sglang/sgl-router/src/server.rs
@@ -0,0 +1,192 @@
+use crate::router::PolicyConfig;
+use crate::router::Router;
+use actix_web::{get, post, web, App, HttpRequest, HttpResponse, HttpServer, Responder};
+use bytes::Bytes;
+use env_logger::Builder;
+use log::{info, LevelFilter};
+use std::collections::HashMap;
+use std::io::Write;
+
+#[derive(Debug)]
+pub struct AppState {
+ router: Router,
+ client: reqwest::Client,
+}
+
+impl AppState {
+ pub fn new(
+ worker_urls: Vec,
+ client: reqwest::Client,
+ policy_config: PolicyConfig,
+ ) -> Self {
+ // Create router based on policy
+ let router = match Router::new(worker_urls, policy_config) {
+ Ok(router) => router,
+ Err(error) => panic!("Failed to create router: {}", error),
+ };
+
+ Self { router, client }
+ }
+}
+
+#[get("/health")]
+async fn health(data: web::Data) -> impl Responder {
+ data.router.route_to_first(&data.client, "/health").await
+}
+
+#[get("/health_generate")]
+async fn health_generate(data: web::Data) -> impl Responder {
+ data.router
+ .route_to_first(&data.client, "/health_generate")
+ .await
+}
+
+#[get("/get_server_info")]
+async fn get_server_info(data: web::Data) -> impl Responder {
+ data.router
+ .route_to_first(&data.client, "/get_server_info")
+ .await
+}
+
+#[get("/v1/models")]
+async fn v1_models(data: web::Data) -> impl Responder {
+ data.router.route_to_first(&data.client, "/v1/models").await
+}
+
+#[get("/get_model_info")]
+async fn get_model_info(data: web::Data) -> impl Responder {
+ data.router
+ .route_to_first(&data.client, "/get_model_info")
+ .await
+}
+
+#[post("/generate")]
+async fn generate(req: HttpRequest, body: Bytes, data: web::Data) -> impl Responder {
+ data.router
+ .route_generate_request(&data.client, &req, &body, "/generate")
+ .await
+}
+
+#[post("/v1/chat/completions")]
+async fn v1_chat_completions(
+ req: HttpRequest,
+ body: Bytes,
+ data: web::Data,
+) -> impl Responder {
+ data.router
+ .route_generate_request(&data.client, &req, &body, "/v1/chat/completions")
+ .await
+}
+
+#[post("/v1/completions")]
+async fn v1_completions(
+ req: HttpRequest,
+ body: Bytes,
+ data: web::Data,
+) -> impl Responder {
+ data.router
+ .route_generate_request(&data.client, &req, &body, "/v1/completions")
+ .await
+}
+
+#[post("/add_worker")]
+async fn add_worker(
+ query: web::Query>,
+ data: web::Data,
+) -> impl Responder {
+ let worker_url = match query.get("url") {
+ Some(url) => url.to_string(),
+ None => {
+ return HttpResponse::BadRequest()
+ .body("Worker URL required. Provide 'url' query parameter")
+ }
+ };
+
+ match data.router.add_worker(&worker_url).await {
+ Ok(message) => HttpResponse::Ok().body(message),
+ Err(error) => HttpResponse::BadRequest().body(error),
+ }
+}
+
+#[post("/remove_worker")]
+async fn remove_worker(
+ query: web::Query>,
+ data: web::Data,
+) -> impl Responder {
+ let worker_url = match query.get("url") {
+ Some(url) => url.to_string(),
+ None => return HttpResponse::BadRequest().finish(),
+ };
+ data.router.remove_worker(&worker_url);
+ HttpResponse::Ok().body(format!("Successfully removed worker: {}", worker_url))
+}
+
+pub struct ServerConfig {
+ pub host: String,
+ pub port: u16,
+ pub worker_urls: Vec,
+ pub policy_config: PolicyConfig,
+ pub verbose: bool,
+ pub max_payload_size: usize,
+}
+
+pub async fn startup(config: ServerConfig) -> std::io::Result<()> {
+ Builder::new()
+ .format(|buf, record| {
+ use chrono::Local;
+ writeln!(
+ buf,
+ "[Router (Rust)] {} - {} - {}",
+ Local::now().format("%Y-%m-%d %H:%M:%S"),
+ record.level(),
+ record.args()
+ )
+ })
+ .filter(
+ None,
+ if config.verbose {
+ LevelFilter::Debug
+ } else {
+ LevelFilter::Info
+ },
+ )
+ .init();
+
+ let client = reqwest::Client::builder()
+ .build()
+ .expect("Failed to create HTTP client");
+
+ let app_state = web::Data::new(AppState::new(
+ config.worker_urls.clone(),
+ client,
+ config.policy_config.clone(),
+ ));
+
+ info!("✅ Starting router on {}:{}", config.host, config.port);
+ info!("✅ Serving Worker URLs: {:?}", config.worker_urls);
+ info!("✅ Policy Config: {:?}", config.policy_config);
+ info!(
+ "✅ Max payload size: {} MB",
+ config.max_payload_size / (1024 * 1024)
+ );
+
+ HttpServer::new(move || {
+ App::new()
+ .app_data(app_state.clone())
+ .app_data(web::JsonConfig::default().limit(config.max_payload_size))
+ .app_data(web::PayloadConfig::default().limit(config.max_payload_size))
+ .service(generate)
+ .service(v1_chat_completions)
+ .service(v1_completions)
+ .service(v1_models)
+ .service(get_model_info)
+ .service(health)
+ .service(health_generate)
+ .service(get_server_info)
+ .service(add_worker)
+ .service(remove_worker)
+ })
+ .bind((config.host, config.port))?
+ .run()
+ .await
+}
diff --git a/sglang/sgl-router/src/tree.rs b/sglang/sgl-router/src/tree.rs
new file mode 100644
index 0000000000000000000000000000000000000000..e8dc8b7a0dae59672c46c91795734dddd79139a9
--- /dev/null
+++ b/sglang/sgl-router/src/tree.rs
@@ -0,0 +1,1483 @@
+use dashmap::mapref::entry::Entry;
+use dashmap::DashMap;
+use log::info;
+
+use std::cmp::Reverse;
+use std::collections::BinaryHeap;
+use std::collections::HashMap;
+use std::collections::VecDeque;
+use std::sync::Arc;
+use std::sync::RwLock;
+
+use std::time::Duration;
+use std::time::{SystemTime, UNIX_EPOCH};
+
+type NodeRef = Arc;
+
+#[derive(Debug)]
+struct Node {
+ children: DashMap,
+ text: RwLock,
+ tenant_last_access_time: DashMap,
+ parent: RwLock>,
+}
+
+#[derive(Debug)]
+pub struct Tree {
+ root: NodeRef,
+ pub tenant_char_count: DashMap,
+}
+
+// For the heap
+
+struct EvictionEntry {
+ timestamp: u128,
+ tenant: String,
+ node: NodeRef,
+}
+
+impl Eq for EvictionEntry {}
+
+impl PartialOrd for EvictionEntry {
+ fn partial_cmp(&self, other: &Self) -> Option {
+ Some(self.timestamp.cmp(&other.timestamp))
+ }
+}
+
+impl Ord for EvictionEntry {
+ fn cmp(&self, other: &Self) -> std::cmp::Ordering {
+ self.timestamp.cmp(&other.timestamp)
+ }
+}
+
+impl PartialEq for EvictionEntry {
+ fn eq(&self, other: &Self) -> bool {
+ self.timestamp == other.timestamp
+ }
+}
+
+// For char operations
+// Note that in rust, `.len()` or slice is operated on the "byte" level. It causes issues for UTF-8 characters because one character might use multiple bytes.
+// https://en.wikipedia.org/wiki/UTF-8
+
+fn shared_prefix_count(a: &str, b: &str) -> usize {
+ let mut i = 0;
+ let mut a_iter = a.chars();
+ let mut b_iter = b.chars();
+
+ loop {
+ match (a_iter.next(), b_iter.next()) {
+ (Some(a_char), Some(b_char)) if a_char == b_char => {
+ i += 1;
+ }
+ _ => break,
+ }
+ }
+
+ return i;
+}
+
+fn slice_by_chars(s: &str, start: usize, end: usize) -> String {
+ s.chars().skip(start).take(end - start).collect()
+}
+
+impl Tree {
+ /*
+ Thread-safe multi tenant radix tree
+
+ 1. Storing data for multiple tenants (the overlap of multiple radix tree)
+ 2. Node-level lock to enable concurrent acesss on nodes
+ 3. Leaf LRU eviction based on tenant access time
+ */
+
+ pub fn new() -> Self {
+ Tree {
+ root: Arc::new(Node {
+ children: DashMap::new(),
+ text: RwLock::new("".to_string()),
+ tenant_last_access_time: DashMap::new(),
+ parent: RwLock::new(None),
+ }),
+ tenant_char_count: DashMap::new(),
+ }
+ }
+
+ pub fn insert(&self, text: &str, tenant: &str) {
+ // Insert text into tree with given tenant
+
+ let mut curr = Arc::clone(&self.root);
+ let mut curr_idx = 0;
+
+ let timestamp_ms = SystemTime::now()
+ .duration_since(UNIX_EPOCH)
+ .unwrap()
+ .as_millis();
+
+ curr.tenant_last_access_time
+ .insert(tenant.to_string(), timestamp_ms);
+
+ self.tenant_char_count
+ .entry(tenant.to_string())
+ .or_insert(0);
+
+ let mut prev = Arc::clone(&self.root);
+
+ let text_count = text.chars().count();
+
+ while curr_idx < text_count {
+ let first_char = text.chars().nth(curr_idx).unwrap();
+
+ curr = prev;
+
+ // dashmap.entry locks the entry until the op is done
+ // if using contains_key + insert, there will be an issue that
+ // 1. "apple" and "app" entered at the same time
+ // 2. and get inserted to the dashmap concurrently, so only one is inserted
+
+ match curr.children.entry(first_char) {
+ Entry::Vacant(entry) => {
+ /*
+ no matched
+ [curr]
+ becomes
+ [curr] => [new node]
+ */
+
+ let curr_text = slice_by_chars(text, curr_idx, text_count);
+ let curr_text_count = curr_text.chars().count();
+ let new_node = Arc::new(Node {
+ children: DashMap::new(),
+ text: RwLock::new(curr_text),
+ tenant_last_access_time: DashMap::new(),
+ parent: RwLock::new(Some(Arc::clone(&curr))),
+ });
+
+ // Increment char count when creating new node with tenant
+ self.tenant_char_count
+ .entry(tenant.to_string())
+ .and_modify(|count| *count += curr_text_count)
+ .or_insert(curr_text_count);
+
+ new_node
+ .tenant_last_access_time
+ .insert(tenant.to_string(), timestamp_ms);
+
+ entry.insert(Arc::clone(&new_node));
+
+ prev = Arc::clone(&new_node);
+ curr_idx = text_count;
+ }
+
+ Entry::Occupied(mut entry) => {
+ // matched
+ let matched_node = entry.get().clone();
+
+ let matched_node_text = matched_node.text.read().unwrap().to_owned();
+ let matched_node_text_count = matched_node_text.chars().count();
+
+ let curr_text = slice_by_chars(text, curr_idx, text_count);
+ let shared_count = shared_prefix_count(&matched_node_text, &curr_text);
+
+ if shared_count < matched_node_text_count {
+ /*
+ split the matched node
+ [curr] -> [matched_node] =>
+ becomes
+ [curr] -> [new_node] -> [contracted_matched_node]
+ */
+
+ let matched_text = slice_by_chars(&matched_node_text, 0, shared_count);
+ let contracted_text = slice_by_chars(
+ &matched_node_text,
+ shared_count,
+ matched_node_text_count,
+ );
+ let matched_text_count = matched_text.chars().count();
+
+ let new_node = Arc::new(Node {
+ text: RwLock::new(matched_text),
+ children: DashMap::new(),
+ parent: RwLock::new(Some(Arc::clone(&curr))),
+ tenant_last_access_time: matched_node.tenant_last_access_time.clone(),
+ });
+
+ let first_new_char = contracted_text.chars().nth(0).unwrap();
+ new_node
+ .children
+ .insert(first_new_char, Arc::clone(&matched_node));
+
+ entry.insert(Arc::clone(&new_node));
+
+ *matched_node.text.write().unwrap() = contracted_text;
+ *matched_node.parent.write().unwrap() = Some(Arc::clone(&new_node));
+
+ prev = Arc::clone(&new_node);
+
+ // Increment char count for the tenant in the new split node
+ if !prev.tenant_last_access_time.contains_key(tenant) {
+ self.tenant_char_count
+ .entry(tenant.to_string())
+ .and_modify(|count| *count += matched_text_count)
+ .or_insert(matched_text_count);
+ }
+
+ prev.tenant_last_access_time
+ .insert(tenant.to_string(), timestamp_ms);
+
+ curr_idx += shared_count;
+ } else {
+ // move to next node
+ prev = Arc::clone(&matched_node);
+
+ // Increment char count when adding tenant to existing node
+ if !prev.tenant_last_access_time.contains_key(tenant) {
+ self.tenant_char_count
+ .entry(tenant.to_string())
+ .and_modify(|count| *count += matched_node_text_count)
+ .or_insert(matched_node_text_count);
+ }
+
+ prev.tenant_last_access_time
+ .insert(tenant.to_string(), timestamp_ms);
+ curr_idx += shared_count;
+ }
+ }
+ }
+ }
+ }
+
+ #[allow(unused_assignments)]
+ pub fn prefix_match(&self, text: &str) -> (String, String) {
+ let mut curr = Arc::clone(&self.root);
+ let mut curr_idx = 0;
+
+ let mut prev = Arc::clone(&self.root);
+ let text_count = text.chars().count();
+
+ while curr_idx < text_count {
+ let first_char = text.chars().nth(curr_idx).unwrap();
+ let curr_text = slice_by_chars(text, curr_idx, text_count);
+
+ curr = prev.clone();
+
+ match curr.children.entry(first_char) {
+ Entry::Occupied(entry) => {
+ let matched_node = entry.get().clone();
+ let shared_count =
+ shared_prefix_count(&matched_node.text.read().unwrap(), &curr_text);
+
+ let matched_node_text_count = matched_node.text.read().unwrap().chars().count();
+
+ if shared_count == matched_node_text_count {
+ // Full match with current node's text, continue to next node
+ curr_idx += shared_count;
+ prev = Arc::clone(&matched_node);
+ } else {
+ // Partial match, stop here
+ curr_idx += shared_count;
+ prev = Arc::clone(&matched_node);
+ break;
+ }
+ }
+ Entry::Vacant(_) => {
+ // No match found, stop here
+ break;
+ }
+ }
+ }
+
+ curr = prev.clone();
+
+ // Select the first tenant (key in the map)
+ let tenant = curr
+ .tenant_last_access_time
+ .iter()
+ .next()
+ .map(|kv| kv.key().to_owned())
+ .unwrap_or("empty".to_string());
+
+ // Traverse from the curr node to the root and update the timestamp
+
+ let timestamp_ms = SystemTime::now()
+ .duration_since(UNIX_EPOCH)
+ .unwrap()
+ .as_millis();
+
+ if !tenant.eq("empty") {
+ let mut current_node = Some(curr);
+ while let Some(node) = current_node {
+ node.tenant_last_access_time
+ .insert(tenant.clone(), timestamp_ms);
+ current_node = node.parent.read().unwrap().clone();
+ }
+ }
+
+ let ret_text = slice_by_chars(text, 0, curr_idx);
+ (ret_text, tenant)
+ }
+
+ #[allow(unused_assignments)]
+ pub fn prefix_match_tenant(&self, text: &str, tenant: &str) -> String {
+ let mut curr = Arc::clone(&self.root);
+ let mut curr_idx = 0;
+
+ let mut prev = Arc::clone(&self.root);
+ let text_count = text.chars().count();
+
+ while curr_idx < text_count {
+ let first_char = text.chars().nth(curr_idx).unwrap();
+ let curr_text = slice_by_chars(text, curr_idx, text_count);
+
+ curr = prev.clone();
+
+ match curr.children.entry(first_char) {
+ Entry::Occupied(entry) => {
+ let matched_node = entry.get().clone();
+
+ // Only continue matching if this node belongs to the specified tenant
+ if !matched_node.tenant_last_access_time.contains_key(tenant) {
+ break;
+ }
+
+ let shared_count =
+ shared_prefix_count(&matched_node.text.read().unwrap(), &curr_text);
+
+ let matched_node_text_count = matched_node.text.read().unwrap().chars().count();
+
+ if shared_count == matched_node_text_count {
+ // Full match with current node's text, continue to next node
+ curr_idx += shared_count;
+ prev = Arc::clone(&matched_node);
+ } else {
+ // Partial match, stop here
+ curr_idx += shared_count;
+ prev = Arc::clone(&matched_node);
+ break;
+ }
+ }
+ Entry::Vacant(_) => {
+ // No match found, stop here
+ break;
+ }
+ }
+ }
+
+ curr = prev.clone();
+
+ // Only update timestamp if we found a match for the specified tenant
+ if curr.tenant_last_access_time.contains_key(tenant) {
+ let timestamp_ms = SystemTime::now()
+ .duration_since(UNIX_EPOCH)
+ .unwrap()
+ .as_millis();
+
+ let mut current_node = Some(curr);
+ while let Some(node) = current_node {
+ node.tenant_last_access_time
+ .insert(tenant.to_string(), timestamp_ms);
+ current_node = node.parent.read().unwrap().clone();
+ }
+ }
+
+ slice_by_chars(text, 0, curr_idx)
+ }
+
+ fn leaf_of(node: &NodeRef) -> Vec {
+ /*
+ Return the list of tenants if it's a leaf for the tenant
+ */
+ let mut candidates: HashMap = node
+ .tenant_last_access_time
+ .iter()
+ .map(|entry| (entry.key().clone(), true))
+ .collect();
+
+ for child in node.children.iter() {
+ for tenant in child.value().tenant_last_access_time.iter() {
+ candidates.insert(tenant.key().clone(), false);
+ }
+ }
+
+ candidates
+ .into_iter()
+ .filter(|(_, is_leaf)| *is_leaf)
+ .map(|(tenant, _)| tenant)
+ .collect()
+ }
+
+ pub fn evict_tenant_by_size(&self, max_size: usize) {
+ // Calculate used size and collect leaves
+ let mut stack = vec![Arc::clone(&self.root)];
+ let mut pq = BinaryHeap::new();
+
+ while let Some(curr) = stack.pop() {
+ for child in curr.children.iter() {
+ stack.push(Arc::clone(child.value()));
+ }
+
+ // Add leaves to priority queue
+ for tenant in Tree::leaf_of(&curr) {
+ if let Some(timestamp) = curr.tenant_last_access_time.get(&tenant) {
+ pq.push(Reverse(EvictionEntry {
+ timestamp: *timestamp,
+ tenant: tenant.clone(),
+ node: Arc::clone(&curr),
+ }));
+ }
+ }
+ }
+
+ info!("Before eviction - Used size per tenant:");
+ for entry in self.tenant_char_count.iter() {
+ info!("Tenant: {}, Size: {}", entry.key(), entry.value());
+ }
+
+ // Process eviction
+ while let Some(Reverse(entry)) = pq.pop() {
+ let EvictionEntry { tenant, node, .. } = entry;
+
+ if let Some(used_size) = self.tenant_char_count.get(&tenant) {
+ if *used_size <= max_size {
+ continue;
+ }
+ }
+
+ // Decrement when removing tenant from node
+ if node.tenant_last_access_time.contains_key(&tenant) {
+ self.tenant_char_count
+ .entry(tenant.clone())
+ .and_modify(|count| {
+ if *count > 0 {
+ *count -= node.text.read().unwrap().chars().count();
+ }
+ });
+ }
+
+ // Remove tenant from node
+ node.tenant_last_access_time.remove(&tenant);
+
+ // Remove empty nodes
+ if node.children.is_empty() && node.tenant_last_access_time.is_empty() {
+ if let Some(parent) = node.parent.write().unwrap().as_ref() {
+ let first_char = node.text.read().unwrap().chars().next().unwrap();
+ parent.children.remove(&first_char);
+ }
+ }
+
+ // Add parent to queue if it becomes a leaf
+ if let Some(parent) = node.parent.read().unwrap().as_ref() {
+ if Tree::leaf_of(parent).contains(&tenant) {
+ if let Some(timestamp) = parent.tenant_last_access_time.get(&tenant) {
+ pq.push(Reverse(EvictionEntry {
+ timestamp: *timestamp,
+ tenant: tenant.clone(),
+ node: Arc::clone(parent),
+ }));
+ }
+ }
+ };
+ }
+
+ info!("After eviction - Used size per tenant:");
+ for entry in self.tenant_char_count.iter() {
+ info!("Tenant: {}, Size: {}", entry.key(), entry.value());
+ }
+ }
+
+ pub fn remove_tenant(&self, tenant: &str) {
+ // 1. Find all the leaves for the tenant
+ let mut stack = vec![Arc::clone(&self.root)];
+ let mut queue = VecDeque::new();
+
+ while let Some(curr) = stack.pop() {
+ for child in curr.children.iter() {
+ stack.push(Arc::clone(child.value()));
+ }
+
+ if Tree::leaf_of(&curr).contains(&tenant.to_string()) {
+ queue.push_back(Arc::clone(&curr));
+ }
+ }
+
+ // 2. Start from the leaves and traverse up to the root, removing the tenant from each node
+ while let Some(curr) = queue.pop_front() {
+ // remove tenant from node
+ curr.tenant_last_access_time.remove(&tenant.to_string());
+
+ // remove empty nodes
+ if curr.children.is_empty() && curr.tenant_last_access_time.is_empty() {
+ if let Some(parent) = curr.parent.read().unwrap().as_ref() {
+ let first_char = curr.text.read().unwrap().chars().next().unwrap();
+ parent.children.remove(&first_char);
+ }
+ }
+
+ // add parent to queue if it becomes a leaf
+ if let Some(parent) = curr.parent.read().unwrap().as_ref() {
+ if Tree::leaf_of(parent).contains(&tenant.to_string()) {
+ queue.push_back(Arc::clone(&parent));
+ }
+ }
+ }
+
+ // 3. Remove the tenant from the tenant_char_count map
+ self.tenant_char_count.remove(&tenant.to_string());
+ }
+
+ pub fn get_tenant_char_count(&self) -> HashMap {
+ self.tenant_char_count
+ .iter()
+ .map(|entry| (entry.key().clone(), *entry.value()))
+ .collect()
+ }
+
+ pub fn get_smallest_tenant(&self) -> String {
+ // Return a placeholder if there are no tenants
+ if self.tenant_char_count.is_empty() {
+ return "empty".to_string();
+ }
+
+ // Find the tenant with minimum char count
+ let mut min_tenant = None;
+ let mut min_count = usize::MAX;
+
+ for entry in self.tenant_char_count.iter() {
+ let tenant = entry.key();
+ let count = *entry.value();
+
+ if count < min_count {
+ min_count = count;
+ min_tenant = Some(tenant.clone());
+ }
+ }
+
+ // Return the found tenant or "empty" if somehow none was found
+ min_tenant.unwrap_or_else(|| "empty".to_string())
+ }
+
+ pub fn get_used_size_per_tenant(&self) -> HashMap {
+ // perform a DFS to traverse all nodes and calculate the total size used by each tenant
+
+ let mut used_size_per_tenant: HashMap = HashMap::new();
+ let mut stack = vec![Arc::clone(&self.root)];
+
+ while let Some(curr) = stack.pop() {
+ let text_count = curr.text.read().unwrap().chars().count();
+
+ for tenant in curr.tenant_last_access_time.iter() {
+ let size = used_size_per_tenant
+ .entry(tenant.key().clone())
+ .or_insert(0);
+ *size += text_count;
+ }
+
+ for child in curr.children.iter() {
+ stack.push(Arc::clone(child.value()));
+ }
+ }
+
+ used_size_per_tenant
+ }
+
+ fn node_to_string(node: &NodeRef, prefix: &str, is_last: bool) -> String {
+ let mut result = String::new();
+
+ // Add prefix and branch character
+ result.push_str(prefix);
+ result.push_str(if is_last { "└── " } else { "├── " });
+
+ // Add node text
+ let node_text = node.text.read().unwrap();
+ result.push_str(&format!("'{}' [", node_text));
+
+ // Add tenant information with timestamps
+ let mut tenant_info = Vec::new();
+ for entry in node.tenant_last_access_time.iter() {
+ let tenant_id = entry.key();
+ let timestamp_ms = entry.value();
+
+ // Convert milliseconds to seconds and remaining milliseconds
+ let seconds = (timestamp_ms / 1000) as u64;
+ let millis = (timestamp_ms % 1000) as u32;
+
+ // Create SystemTime from Unix timestamp
+ let system_time = UNIX_EPOCH + Duration::from_secs(seconds);
+
+ // Format time as HH:MM:SS.mmm
+ let datetime = system_time.duration_since(UNIX_EPOCH).unwrap();
+ let hours = (datetime.as_secs() % 86400) / 3600;
+ let minutes = (datetime.as_secs() % 3600) / 60;
+ let seconds = datetime.as_secs() % 60;
+
+ tenant_info.push(format!(
+ "{} | {:02}:{:02}:{:02}.{:03}",
+ tenant_id, hours, minutes, seconds, millis
+ ));
+ }
+
+ result.push_str(&tenant_info.join(", "));
+ result.push_str("]\n");
+
+ // Process children
+ let children: Vec<_> = node.children.iter().collect();
+ let child_count = children.len();
+
+ for (i, entry) in children.iter().enumerate() {
+ let is_last_child = i == child_count - 1;
+ let new_prefix = format!("{}{}", prefix, if is_last { " " } else { "│ " });
+
+ result.push_str(&Tree::node_to_string(
+ entry.value(),
+ &new_prefix,
+ is_last_child,
+ ));
+ }
+
+ result
+ }
+
+ pub fn pretty_print(&self) {
+ if self.root.children.is_empty() {
+ return;
+ }
+
+ let mut result = String::new();
+ let children: Vec<_> = self.root.children.iter().collect();
+ let child_count = children.len();
+
+ for (i, entry) in children.iter().enumerate() {
+ let is_last = i == child_count - 1;
+ result.push_str(&Tree::node_to_string(entry.value(), "", is_last));
+ }
+
+ println!("{result}");
+
+ return;
+ }
+}
+
+// Unit tests
+#[cfg(test)]
+mod tests {
+ use rand::distributions::Alphanumeric;
+ use rand::distributions::DistString;
+ use rand::thread_rng;
+ use rand::Rng;
+ use std::thread;
+ use std::time::Instant;
+
+ use super::*;
+
+ #[test]
+ fn test_get_smallest_tenant() {
+ let tree = Tree::new();
+
+ // Test empty tree
+ assert_eq!(tree.get_smallest_tenant(), "empty");
+
+ // Insert data for tenant1 - "ap" + "icot" = 6 chars
+ tree.insert("ap", "tenant1");
+ tree.insert("icot", "tenant1");
+
+ // Insert data for tenant2 - "cat" = 3 chars
+ tree.insert("cat", "tenant2");
+
+ // Test - tenant2 should be smallest with 3 chars vs 6 chars
+ assert_eq!(
+ tree.get_smallest_tenant(),
+ "tenant2",
+ "Expected tenant2 to be smallest with 3 characters."
+ );
+
+ // Insert overlapping data for tenant3 and tenant4 to test equal counts
+ // tenant3: "do" = 2 chars
+ // tenant4: "hi" = 2 chars
+ tree.insert("do", "tenant3");
+ tree.insert("hi", "tenant4");
+
+ // Test - should return either tenant3 or tenant4 (both have 2 chars)
+ let smallest = tree.get_smallest_tenant();
+ assert!(
+ smallest == "tenant3" || smallest == "tenant4",
+ "Expected either tenant3 or tenant4 (both have 2 characters), got {}",
+ smallest
+ );
+
+ // Add more text to tenant4 to make it larger
+ tree.insert("hello", "tenant4"); // Now tenant4 has "hi" + "hello" = 6 chars
+
+ // Now tenant3 should be smallest (2 chars vs 6 chars for tenant4)
+ assert_eq!(
+ tree.get_smallest_tenant(),
+ "tenant3",
+ "Expected tenant3 to be smallest with 2 characters"
+ );
+
+ // Test eviction
+ tree.evict_tenant_by_size(3); // This should evict tenants with more than 3 chars
+
+ let post_eviction_smallest = tree.get_smallest_tenant();
+ println!("Smallest tenant after eviction: {}", post_eviction_smallest);
+ }
+
+ #[test]
+ fn test_tenant_char_count() {
+ let tree = Tree::new();
+
+ // Phase 1: Initial insertions
+ tree.insert("apple", "tenant1");
+ tree.insert("apricot", "tenant1");
+ tree.insert("banana", "tenant1");
+ tree.insert("amplify", "tenant2");
+ tree.insert("application", "tenant2");
+
+ let computed_sizes = tree.get_used_size_per_tenant();
+ let maintained_counts: HashMap = tree
+ .tenant_char_count
+ .iter()
+ .map(|entry| (entry.key().clone(), *entry.value()))
+ .collect();
+
+ println!("Phase 1 - Maintained vs Computed counts:");
+ println!(
+ "Maintained: {:?}\nComputed: {:?}",
+ maintained_counts, computed_sizes
+ );
+ assert_eq!(
+ maintained_counts, computed_sizes,
+ "Phase 1: Initial insertions"
+ );
+
+ // Phase 2: Additional insertions
+ tree.insert("apartment", "tenant1");
+ tree.insert("appetite", "tenant2");
+ tree.insert("ball", "tenant1");
+ tree.insert("box", "tenant2");
+
+ let computed_sizes = tree.get_used_size_per_tenant();
+ let maintained_counts: HashMap = tree
+ .tenant_char_count
+ .iter()
+ .map(|entry| (entry.key().clone(), *entry.value()))
+ .collect();
+
+ println!("Phase 2 - Maintained vs Computed counts:");
+ println!(
+ "Maintained: {:?}\nComputed: {:?}",
+ maintained_counts, computed_sizes
+ );
+ assert_eq!(
+ maintained_counts, computed_sizes,
+ "Phase 2: Additional insertions"
+ );
+
+ // Phase 3: Overlapping insertions
+ tree.insert("zebra", "tenant1");
+ tree.insert("zebra", "tenant2");
+ tree.insert("zero", "tenant1");
+ tree.insert("zero", "tenant2");
+
+ let computed_sizes = tree.get_used_size_per_tenant();
+ let maintained_counts: HashMap = tree
+ .tenant_char_count
+ .iter()
+ .map(|entry| (entry.key().clone(), *entry.value()))
+ .collect();
+
+ println!("Phase 3 - Maintained vs Computed counts:");
+ println!(
+ "Maintained: {:?}\nComputed: {:?}",
+ maintained_counts, computed_sizes
+ );
+ assert_eq!(
+ maintained_counts, computed_sizes,
+ "Phase 3: Overlapping insertions"
+ );
+
+ // Phase 4: Eviction test
+ tree.evict_tenant_by_size(10);
+
+ let computed_sizes = tree.get_used_size_per_tenant();
+ let maintained_counts: HashMap = tree
+ .tenant_char_count
+ .iter()
+ .map(|entry| (entry.key().clone(), *entry.value()))
+ .collect();
+
+ println!("Phase 4 - Maintained vs Computed counts:");
+ println!(
+ "Maintained: {:?}\nComputed: {:?}",
+ maintained_counts, computed_sizes
+ );
+ assert_eq!(maintained_counts, computed_sizes, "Phase 4: After eviction");
+ }
+
+ fn random_string(len: usize) -> String {
+ Alphanumeric.sample_string(&mut thread_rng(), len)
+ }
+
+ #[test]
+ fn test_cold_start() {
+ let tree = Tree::new();
+
+ let (matched_text, tenant) = tree.prefix_match("hello");
+
+ assert_eq!(matched_text, "");
+ assert_eq!(tenant, "empty");
+ }
+
+ #[test]
+ fn test_exact_match_seq() {
+ let tree = Tree::new();
+ tree.insert("hello", "tenant1");
+ tree.pretty_print();
+ tree.insert("apple", "tenant2");
+ tree.pretty_print();
+ tree.insert("banana", "tenant3");
+ tree.pretty_print();
+
+ let (matched_text, tenant) = tree.prefix_match("hello");
+ assert_eq!(matched_text, "hello");
+ assert_eq!(tenant, "tenant1");
+
+ let (matched_text, tenant) = tree.prefix_match("apple");
+ assert_eq!(matched_text, "apple");
+ assert_eq!(tenant, "tenant2");
+
+ let (matched_text, tenant) = tree.prefix_match("banana");
+ assert_eq!(matched_text, "banana");
+ assert_eq!(tenant, "tenant3");
+ }
+
+ #[test]
+ fn test_exact_match_concurrent() {
+ let tree = Arc::new(Tree::new());
+
+ // spawn 3 threads for insert
+ let tree_clone = Arc::clone(&tree);
+
+ let texts = vec!["hello", "apple", "banana"];
+ let tenants = vec!["tenant1", "tenant2", "tenant3"];
+
+ let mut handles = vec![];
+
+ for i in 0..3 {
+ let tree_clone = Arc::clone(&tree_clone);
+ let text = texts[i];
+ let tenant = tenants[i];
+
+ let handle = thread::spawn(move || {
+ tree_clone.insert(text, tenant);
+ });
+
+ handles.push(handle);
+ }
+
+ // wait
+ for handle in handles {
+ handle.join().unwrap();
+ }
+
+ // spawn 3 threads for match
+ let mut handles = vec![];
+
+ let tree_clone = Arc::clone(&tree);
+
+ for i in 0..3 {
+ let tree_clone = Arc::clone(&tree_clone);
+ let text = texts[i];
+ let tenant = tenants[i];
+
+ let handle = thread::spawn(move || {
+ let (matched_text, matched_tenant) = tree_clone.prefix_match(text);
+ assert_eq!(matched_text, text);
+ assert_eq!(matched_tenant, tenant);
+ });
+
+ handles.push(handle);
+ }
+
+ // wait
+ for handle in handles {
+ handle.join().unwrap();
+ }
+ }
+
+ #[test]
+ fn test_partial_match_concurrent() {
+ let tree = Arc::new(Tree::new());
+
+ // spawn 3 threads for insert
+ let tree_clone = Arc::clone(&tree);
+
+ let texts = vec!["apple", "apabc", "acbdeds"];
+
+ let mut handles = vec![];
+
+ for i in 0..3 {
+ let tree_clone = Arc::clone(&tree_clone);
+ let text = texts[i];
+ let tenant = "tenant0";
+
+ let handle = thread::spawn(move || {
+ tree_clone.insert(text, tenant);
+ });
+
+ handles.push(handle);
+ }
+
+ // wait
+ for handle in handles {
+ handle.join().unwrap();
+ }
+
+ // spawn 3 threads for match
+ let mut handles = vec![];
+
+ let tree_clone = Arc::clone(&tree);
+
+ for i in 0..3 {
+ let tree_clone = Arc::clone(&tree_clone);
+ let text = texts[i];
+ let tenant = "tenant0";
+
+ let handle = thread::spawn(move || {
+ let (matched_text, matched_tenant) = tree_clone.prefix_match(text);
+ assert_eq!(matched_text, text);
+ assert_eq!(matched_tenant, tenant);
+ });
+
+ handles.push(handle);
+ }
+
+ // wait
+ for handle in handles {
+ handle.join().unwrap();
+ }
+ }
+
+ #[test]
+ fn test_group_prefix_insert_match_concurrent() {
+ let prefix = vec![
+ "Clock strikes midnight, I'm still wide awake",
+ "Got dreams bigger than these city lights",
+ "Time waits for no one, gotta make my move",
+ "Started from the bottom, that's no metaphor",
+ ];
+ let suffix = vec![
+ "Got too much to prove, ain't got time to lose",
+ "History in the making, yeah, you can't erase this",
+ ];
+ let tree = Arc::new(Tree::new());
+
+ let mut handles = vec![];
+
+ for i in 0..prefix.len() {
+ for j in 0..suffix.len() {
+ let tree_clone = Arc::clone(&tree);
+ let text = format!("{} {}", prefix[i], suffix[j]);
+ let tenant = format!("tenant{}", i);
+
+ let handle = thread::spawn(move || {
+ tree_clone.insert(&text, &tenant);
+ });
+
+ handles.push(handle);
+ }
+ }
+
+ // wait
+ for handle in handles {
+ handle.join().unwrap();
+ }
+
+ tree.pretty_print();
+
+ // check matching using multi threads
+
+ let mut handles = vec![];
+
+ for i in 0..prefix.len() {
+ let tree_clone = Arc::clone(&tree);
+ let text = prefix[i];
+
+ let handle = thread::spawn(move || {
+ let (matched_text, matched_tenant) = tree_clone.prefix_match(text);
+ let tenant = format!("tenant{}", i);
+ assert_eq!(matched_text, text);
+ assert_eq!(matched_tenant, tenant);
+ });
+
+ handles.push(handle);
+ }
+
+ // wait
+ for handle in handles {
+ handle.join().unwrap();
+ }
+ }
+
+ #[test]
+ fn test_mixed_concurrent_insert_match() {
+ // ensure it does not deadlock instead of doing correctness check
+
+ let prefix = vec![
+ "Clock strikes midnight, I'm still wide awake",
+ "Got dreams bigger than these city lights",
+ "Time waits for no one, gotta make my move",
+ "Started from the bottom, that's no metaphor",
+ ];
+ let suffix = vec![
+ "Got too much to prove, ain't got time to lose",
+ "History in the making, yeah, you can't erase this",
+ ];
+ let tree = Arc::new(Tree::new());
+
+ let mut handles = vec![];
+
+ for i in 0..prefix.len() {
+ for j in 0..suffix.len() {
+ let tree_clone = Arc::clone(&tree);
+ let text = format!("{} {}", prefix[i], suffix[j]);
+ let tenant = format!("tenant{}", i);
+
+ let handle = thread::spawn(move || {
+ tree_clone.insert(&text, &tenant);
+ });
+
+ handles.push(handle);
+ }
+ }
+
+ // check matching using multi threads
+
+ for i in 0..prefix.len() {
+ let tree_clone = Arc::clone(&tree);
+ let text = prefix[i];
+
+ let handle = thread::spawn(move || {
+ let (_matched_text, _matched_tenant) = tree_clone.prefix_match(text);
+ });
+
+ handles.push(handle);
+ }
+
+ // wait
+ for handle in handles {
+ handle.join().unwrap();
+ }
+ }
+
+ #[test]
+ fn test_utf8_split_seq() {
+ // The string should be indexed and splitted by a utf-8 value basis instead of byte basis
+ // use .chars() to get the iterator of the utf-8 value
+ let tree = Arc::new(Tree::new());
+
+ let test_pairs = vec![
+ ("你好嗎", "tenant1"),
+ ("你好喔", "tenant2"),
+ ("你心情好嗎", "tenant3"),
+ ];
+
+ // Insert sequentially
+ for i in 0..test_pairs.len() {
+ let text = test_pairs[i].0;
+ let tenant = test_pairs[i].1;
+ tree.insert(text, tenant);
+ }
+
+ tree.pretty_print();
+
+ // Test sequentially
+
+ for i in 0..test_pairs.len() {
+ let (matched_text, matched_tenant) = tree.prefix_match(test_pairs[i].0);
+ assert_eq!(matched_text, test_pairs[i].0);
+ assert_eq!(matched_tenant, test_pairs[i].1);
+ }
+ }
+
+ #[test]
+ fn test_utf8_split_concurrent() {
+ let tree = Arc::new(Tree::new());
+
+ let test_pairs = vec![
+ ("你好嗎", "tenant1"),
+ ("你好喔", "tenant2"),
+ ("你心情好嗎", "tenant3"),
+ ];
+
+ // Create multiple threads for insertion
+ let mut handles = vec![];
+
+ for i in 0..test_pairs.len() {
+ let tree_clone = Arc::clone(&tree);
+ let text = test_pairs[i].0.to_string();
+ let tenant = test_pairs[i].1.to_string();
+
+ let handle = thread::spawn(move || {
+ tree_clone.insert(&text, &tenant);
+ });
+
+ handles.push(handle);
+ }
+
+ // Wait for all insertions to complete
+ for handle in handles {
+ handle.join().unwrap();
+ }
+
+ tree.pretty_print();
+
+ // Create multiple threads for matching
+ let mut handles = vec![];
+
+ for i in 0..test_pairs.len() {
+ let tree_clone = Arc::clone(&tree);
+ let text = test_pairs[i].0.to_string();
+ let tenant = test_pairs[i].1.to_string();
+
+ let handle = thread::spawn(move || {
+ let (matched_text, matched_tenant) = tree_clone.prefix_match(&text);
+ assert_eq!(matched_text, text);
+ assert_eq!(matched_tenant, tenant);
+ });
+
+ handles.push(handle);
+ }
+
+ // Wait for all matches to complete
+ for handle in handles {
+ handle.join().unwrap();
+ }
+ }
+
+ #[test]
+ fn test_simple_eviction() {
+ let tree = Tree::new();
+ let max_size = 5;
+
+ // Insert strings for both tenants
+ tree.insert("hello", "tenant1"); // size 5
+
+ tree.insert("hello", "tenant2"); // size 5
+ thread::sleep(Duration::from_millis(10));
+ tree.insert("world", "tenant2"); // size 5, total for tenant2 = 10
+
+ tree.pretty_print();
+
+ // Verify initial sizes
+ let sizes_before = tree.get_used_size_per_tenant();
+ assert_eq!(sizes_before.get("tenant1").unwrap(), &5); // "hello" = 5
+ assert_eq!(sizes_before.get("tenant2").unwrap(), &10); // "hello" + "world" = 10
+
+ // Evict - should remove "hello" from tenant2 as it's the oldest
+ tree.evict_tenant_by_size(max_size);
+
+ tree.pretty_print();
+
+ // Verify sizes after eviction
+ let sizes_after = tree.get_used_size_per_tenant();
+ assert_eq!(sizes_after.get("tenant1").unwrap(), &5); // Should be unchanged
+ assert_eq!(sizes_after.get("tenant2").unwrap(), &5); // Only "world" remains
+
+ // Verify "world" remains for tenant2
+ let (matched, tenant) = tree.prefix_match("world");
+ assert_eq!(matched, "world");
+ assert_eq!(tenant, "tenant2");
+ }
+
+ #[test]
+ fn test_advanced_eviction() {
+ let tree = Tree::new();
+
+ // Set limits for each tenant
+ let max_size: usize = 100;
+
+ // Define prefixes
+ let prefixes = vec!["aqwefcisdf", "iajsdfkmade", "kjnzxcvewqe", "iejksduqasd"];
+
+ // Insert strings with shared prefixes
+ for _i in 0..100 {
+ for (j, prefix) in prefixes.iter().enumerate() {
+ let random_suffix = random_string(10);
+ let text = format!("{}{}", prefix, random_suffix);
+ let tenant = format!("tenant{}", j + 1);
+ tree.insert(&text, &tenant);
+ }
+ }
+
+ // Perform eviction
+ tree.evict_tenant_by_size(max_size);
+
+ // Check sizes after eviction
+ let sizes_after = tree.get_used_size_per_tenant();
+ // Verify all tenants are under their size limits
+ for (tenant, &size) in sizes_after.iter() {
+ assert!(
+ size <= max_size,
+ "Tenant {} exceeds size limit. Current size: {}, Limit: {}",
+ tenant,
+ size,
+ max_size
+ );
+ }
+ }
+
+ #[test]
+ fn test_concurrent_operations_with_eviction() {
+ // Ensure eviction works fine with concurrent insert and match operations for a given period
+
+ let tree = Arc::new(Tree::new());
+ let mut handles = vec![];
+ let test_duration = Duration::from_secs(10);
+ let start_time = Instant::now();
+ let max_size = 100; // Single max size for all tenants
+
+ // Spawn eviction thread
+ {
+ let tree = Arc::clone(&tree);
+ let handle = thread::spawn(move || {
+ while start_time.elapsed() < test_duration {
+ // Run eviction
+ tree.evict_tenant_by_size(max_size);
+
+ // Sleep for 5 seconds
+ thread::sleep(Duration::from_secs(5));
+ }
+ });
+ handles.push(handle);
+ }
+
+ // Spawn 4 worker threads
+ for thread_id in 0..4 {
+ let tree = Arc::clone(&tree);
+ let handle = thread::spawn(move || {
+ let mut rng = rand::thread_rng();
+ let tenant = format!("tenant{}", thread_id + 1);
+ let prefix = format!("prefix{}", thread_id);
+
+ while start_time.elapsed() < test_duration {
+ // Random decision: match or insert (70% match, 30% insert)
+ if rng.gen_bool(0.7) {
+ // Perform match operation
+ let random_len = rng.gen_range(3..10);
+ let search_str = format!("{}{}", prefix, random_string(random_len));
+ let (_matched, _) = tree.prefix_match(&search_str);
+ } else {
+ // Perform insert operation
+ let random_len = rng.gen_range(5..15);
+ let insert_str = format!("{}{}", prefix, random_string(random_len));
+ tree.insert(&insert_str, &tenant);
+ // println!("Thread {} inserted: {}", thread_id, insert_str);
+ }
+
+ // Small random sleep to vary timing
+ thread::sleep(Duration::from_millis(rng.gen_range(10..100)));
+ }
+ });
+ handles.push(handle);
+ }
+
+ // Wait for all threads to complete
+ for handle in handles {
+ handle.join().unwrap();
+ }
+
+ // final eviction
+ tree.evict_tenant_by_size(max_size);
+
+ // Final size check
+ let final_sizes = tree.get_used_size_per_tenant();
+ println!("Final sizes after test completion: {:?}", final_sizes);
+
+ // Verify all tenants are under limit
+ for (_, &size) in final_sizes.iter() {
+ assert!(
+ size <= max_size,
+ "Tenant exceeds size limit. Final size: {}, Limit: {}",
+ size,
+ max_size
+ );
+ }
+ }
+
+ #[test]
+ fn test_leaf_of() {
+ let tree = Tree::new();
+
+ // Single node
+ tree.insert("hello", "tenant1");
+ let leaves = Tree::leaf_of(&tree.root.children.get(&'h').unwrap());
+ assert_eq!(leaves, vec!["tenant1"]);
+
+ // Node with multiple tenants
+ tree.insert("hello", "tenant2");
+ let leaves = Tree::leaf_of(&tree.root.children.get(&'h').unwrap());
+ assert_eq!(leaves.len(), 2);
+ assert!(leaves.contains(&"tenant1".to_string()));
+ assert!(leaves.contains(&"tenant2".to_string()));
+
+ // Non-leaf node
+ tree.insert("hi", "tenant1");
+ let leaves = Tree::leaf_of(&tree.root.children.get(&'h').unwrap());
+ assert!(leaves.is_empty());
+ }
+
+ #[test]
+ fn test_get_used_size_per_tenant() {
+ let tree = Tree::new();
+
+ // Single tenant
+ tree.insert("hello", "tenant1");
+ tree.insert("world", "tenant1");
+ let sizes = tree.get_used_size_per_tenant();
+
+ tree.pretty_print();
+ println!("{:?}", sizes);
+ assert_eq!(sizes.get("tenant1").unwrap(), &10); // "hello" + "world"
+
+ // Multiple tenants sharing nodes
+ tree.insert("hello", "tenant2");
+ tree.insert("help", "tenant2");
+ let sizes = tree.get_used_size_per_tenant();
+
+ tree.pretty_print();
+ println!("{:?}", sizes);
+ assert_eq!(sizes.get("tenant1").unwrap(), &10);
+ assert_eq!(sizes.get("tenant2").unwrap(), &6); // "hello" + "p"
+
+ // UTF-8 characters
+ tree.insert("你好", "tenant3");
+ let sizes = tree.get_used_size_per_tenant();
+ tree.pretty_print();
+ println!("{:?}", sizes);
+ assert_eq!(sizes.get("tenant3").unwrap(), &2); // 2 Chinese characters
+
+ tree.pretty_print();
+ }
+
+ #[test]
+ fn test_prefix_match_tenant() {
+ let tree = Tree::new();
+
+ // Insert overlapping prefixes for different tenants
+ tree.insert("hello", "tenant1"); // tenant1: hello
+ tree.insert("hello", "tenant2"); // tenant2: hello
+ tree.insert("hello world", "tenant2"); // tenant2: hello -> world
+ tree.insert("help", "tenant1"); // tenant1: hel -> p
+ tree.insert("helicopter", "tenant2"); // tenant2: hel -> icopter
+
+ // Test tenant1's data
+ assert_eq!(tree.prefix_match_tenant("hello", "tenant1"), "hello"); // Full match for tenant1
+ assert_eq!(tree.prefix_match_tenant("help", "tenant1"), "help"); // Exclusive to tenant1
+ assert_eq!(tree.prefix_match_tenant("hel", "tenant1"), "hel"); // Shared prefix
+ assert_eq!(tree.prefix_match_tenant("hello world", "tenant1"), "hello"); // Should stop at tenant1's boundary
+ assert_eq!(tree.prefix_match_tenant("helicopter", "tenant1"), "hel"); // Should stop at tenant1's boundary
+
+ // Test tenant2's data
+ assert_eq!(tree.prefix_match_tenant("hello", "tenant2"), "hello"); // Full match for tenant2
+ assert_eq!(
+ tree.prefix_match_tenant("hello world", "tenant2"),
+ "hello world"
+ ); // Exclusive to tenant2
+ assert_eq!(
+ tree.prefix_match_tenant("helicopter", "tenant2"),
+ "helicopter"
+ ); // Exclusive to tenant2
+ assert_eq!(tree.prefix_match_tenant("hel", "tenant2"), "hel"); // Shared prefix
+ assert_eq!(tree.prefix_match_tenant("help", "tenant2"), "hel"); // Should stop at tenant2's boundary
+
+ // Test non-existent tenant
+ assert_eq!(tree.prefix_match_tenant("hello", "tenant3"), ""); // Non-existent tenant
+ assert_eq!(tree.prefix_match_tenant("help", "tenant3"), ""); // Non-existent tenant
+ }
+
+ #[test]
+ fn test_simple_tenant_eviction() {
+ let tree = Tree::new();
+
+ // Insert data for multiple tenants
+ tree.insert("hello", "tenant1");
+ tree.insert("world", "tenant1");
+ tree.insert("hello", "tenant2");
+ tree.insert("help", "tenant2");
+
+ // Verify initial state
+ let initial_sizes = tree.get_used_size_per_tenant();
+ assert_eq!(initial_sizes.get("tenant1").unwrap(), &10); // "hello" + "world"
+ assert_eq!(initial_sizes.get("tenant2").unwrap(), &6); // "hello" + "p"
+
+ // Evict tenant1
+ tree.remove_tenant("tenant1");
+
+ // Verify after eviction
+ let final_sizes = tree.get_used_size_per_tenant();
+ assert!(
+ !final_sizes.contains_key("tenant1"),
+ "tenant1 should be completely removed"
+ );
+ assert_eq!(
+ final_sizes.get("tenant2").unwrap(),
+ &6,
+ "tenant2 should be unaffected"
+ );
+
+ // Verify tenant1's data is inaccessible
+ assert_eq!(tree.prefix_match_tenant("hello", "tenant1"), "");
+ assert_eq!(tree.prefix_match_tenant("world", "tenant1"), "");
+
+ // Verify tenant2's data is still accessible
+ assert_eq!(tree.prefix_match_tenant("hello", "tenant2"), "hello");
+ assert_eq!(tree.prefix_match_tenant("help", "tenant2"), "help");
+ }
+
+ #[test]
+ fn test_complex_tenant_eviction() {
+ let tree = Tree::new();
+
+ // Create a more complex tree structure with shared prefixes
+ tree.insert("apple", "tenant1");
+ tree.insert("application", "tenant1");
+ tree.insert("apple", "tenant2");
+ tree.insert("appetite", "tenant2");
+ tree.insert("banana", "tenant1");
+ tree.insert("banana", "tenant2");
+ tree.insert("ball", "tenant2");
+
+ // Verify initial state
+ let initial_sizes = tree.get_used_size_per_tenant();
+ println!("Initial sizes: {:?}", initial_sizes);
+ tree.pretty_print();
+
+ // Evict tenant1
+ tree.remove_tenant("tenant1");
+
+ // Verify final state
+ let final_sizes = tree.get_used_size_per_tenant();
+ println!("Final sizes: {:?}", final_sizes);
+ tree.pretty_print();
+
+ // Verify tenant1 is completely removed
+ assert!(
+ !final_sizes.contains_key("tenant1"),
+ "tenant1 should be completely removed"
+ );
+
+ // Verify all tenant1's data is inaccessible
+ assert_eq!(tree.prefix_match_tenant("apple", "tenant1"), "");
+ assert_eq!(tree.prefix_match_tenant("application", "tenant1"), "");
+ assert_eq!(tree.prefix_match_tenant("banana", "tenant1"), "");
+
+ // Verify tenant2's data is intact
+ assert_eq!(tree.prefix_match_tenant("apple", "tenant2"), "apple");
+ assert_eq!(tree.prefix_match_tenant("appetite", "tenant2"), "appetite");
+ assert_eq!(tree.prefix_match_tenant("banana", "tenant2"), "banana");
+ assert_eq!(tree.prefix_match_tenant("ball", "tenant2"), "ball");
+
+ // Verify the tree structure is still valid for tenant2
+ let tenant2_size = final_sizes.get("tenant2").unwrap();
+ assert_eq!(tenant2_size, &(5 + 5 + 6 + 2)); // "apple" + "etite" + "banana" + "ll"
+ }
+}