

Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- BIAS.md +4 -0
- EXPLAINABILITY.md +13 -0
- PRIVACY.md +10 -0
- README.md +277 -0
- SAFETY.md +7 -0
- added_tokens.json +24 -0
- chat_template.jinja +20 -0
- config.json +95 -0
- generation_config.json +6 -0
- merges.txt +0 -0
- model-00001-of-00007.safetensors +3 -0
- model-00002-of-00007.safetensors +3 -0
- model-00003-of-00007.safetensors +3 -0
- model-00004-of-00007.safetensors +3 -0
- model-00005-of-00007.safetensors +3 -0
- model-00006-of-00007.safetensors +3 -0
- model-00007-of-00007.safetensors +3 -0
- model.safetensors.index.json +778 -0
- special_tokens_map.json +31 -0
- tokenizer.json +3 -0
- tokenizer_config.json +209 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
BIAS.md
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:---------------------------------------------------------------------------------------------------|:---------------
|
| 3 |
+
Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing: | None
|
| 4 |
+
Measures taken to mitigate against unwanted bias: | None
|
EXPLAINABILITY.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------
|
| 3 |
+
Intended Task/Domain: | Reasoning for Math, Code Science Solution Generation
|
| 4 |
+
Model Type: | Transformer
|
| 5 |
+
Intended Users: | Solving competitive programming questions and evaluation for benchmark comparison.
|
| 6 |
+
Output: | Text
|
| 7 |
+
Describe how the model works: | The model generates a reasoning trace and responds with a final solution in response to a user prompting a programming question.
|
| 8 |
+
Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable
|
| 9 |
+
Technical Limitations & Mitigation: | This model is not applicable for Software Engineering tasks. It primarily should be used for competitive coding challenges that require optimized code solutions that can operate in appropriate space and time complexity.
|
| 10 |
+
Verified to have met prescribed NVIDIA quality standards: | Yes
|
| 11 |
+
Performance Metrics: | Pass@1 score
|
| 12 |
+
Potential Known Risks: | The model may provide incorrect code solutions that fail to solve the problem. The model may enter a feedback loop and constantly generate reasoning tokens without generating the final solution.
|
| 13 |
+
Licensing: | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/deed.en/)
|
PRIVACY.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:----------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------
|
| 3 |
+
Generatable or reverse engineerable personal data? | No
|
| 4 |
+
Personal data used to create this model? | No
|
| 5 |
+
How often is the dataset reviewed? | Before Release
|
| 6 |
+
Is there provenance for all datasets used in training? | Yes
|
| 7 |
+
Does data labeling (annotation, metadata) comply with privacy laws? | Yes
|
| 8 |
+
Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data.
|
| 9 |
+
Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/
|
| 10 |
+
|
README.md
ADDED
|
@@ -0,0 +1,277 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: cc-by-4.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
base_model:
|
| 6 |
+
- nvidia/OpenReasoning-Nemotron-32B
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
library_name: transformers
|
| 9 |
+
tags:
|
| 10 |
+
- nvidia
|
| 11 |
+
- unsloth
|
| 12 |
+
- code
|
| 13 |
+
---
|
| 14 |
+
> [!NOTE]
|
| 15 |
+
> Includes Unsloth **chat template fixes**! <br> For `llama.cpp`, use `--jinja`
|
| 16 |
+
>
|
| 17 |
+
|
| 18 |
+
<div>
|
| 19 |
+
<p style="margin-top: 0;margin-bottom: 0;">
|
| 20 |
+
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
|
| 21 |
+
</p>
|
| 22 |
+
<div style="display: flex; gap: 5px; align-items: center; ">
|
| 23 |
+
<a href="https://github.com/unslothai/unsloth/">
|
| 24 |
+
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
|
| 25 |
+
</a>
|
| 26 |
+
<a href="https://discord.gg/unsloth">
|
| 27 |
+
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
|
| 28 |
+
</a>
|
| 29 |
+
<a href="https://docs.unsloth.ai/">
|
| 30 |
+
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
|
| 31 |
+
</a>
|
| 32 |
+
</div>
|
| 33 |
+
</div>
|
| 34 |
+
|
| 35 |
+
# OpenReasoning-Nemotron-32B Overview
|
| 36 |
+
|
| 37 |
+
## Description: <br>
|
| 38 |
+
OpenReasoning-Nemotron-32B is a large language model (LLM) which is a derivative of Qwen2.5-32B-Instruct (AKA the reference model). It is a reasoning model that is post-trained for reasoning about math, code and science solution generation. We evaluated this model with up to 64K output tokens. The OpenReasoning model is available in the following sizes: 1.5B, 7B and 14B and 32B. <br>
|
| 39 |
+
|
| 40 |
+
This model is ready for commercial/non-commercial research use. <br>
|
| 41 |
+
|
| 42 |
+
### License/Terms of Use: <br>
|
| 43 |
+
GOVERNING TERMS: Use of the models listed above are governed by the [Creative Commons Attribution 4.0 International License (CC-BY-4.0)](https://creativecommons.org/licenses/by/4.0/legalcode.en). ADDITIONAL INFORMATION: [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct/blob/main/LICENSE)
|
| 44 |
+
|
| 45 |
+
## Scores on Reasoning Benchmarks
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
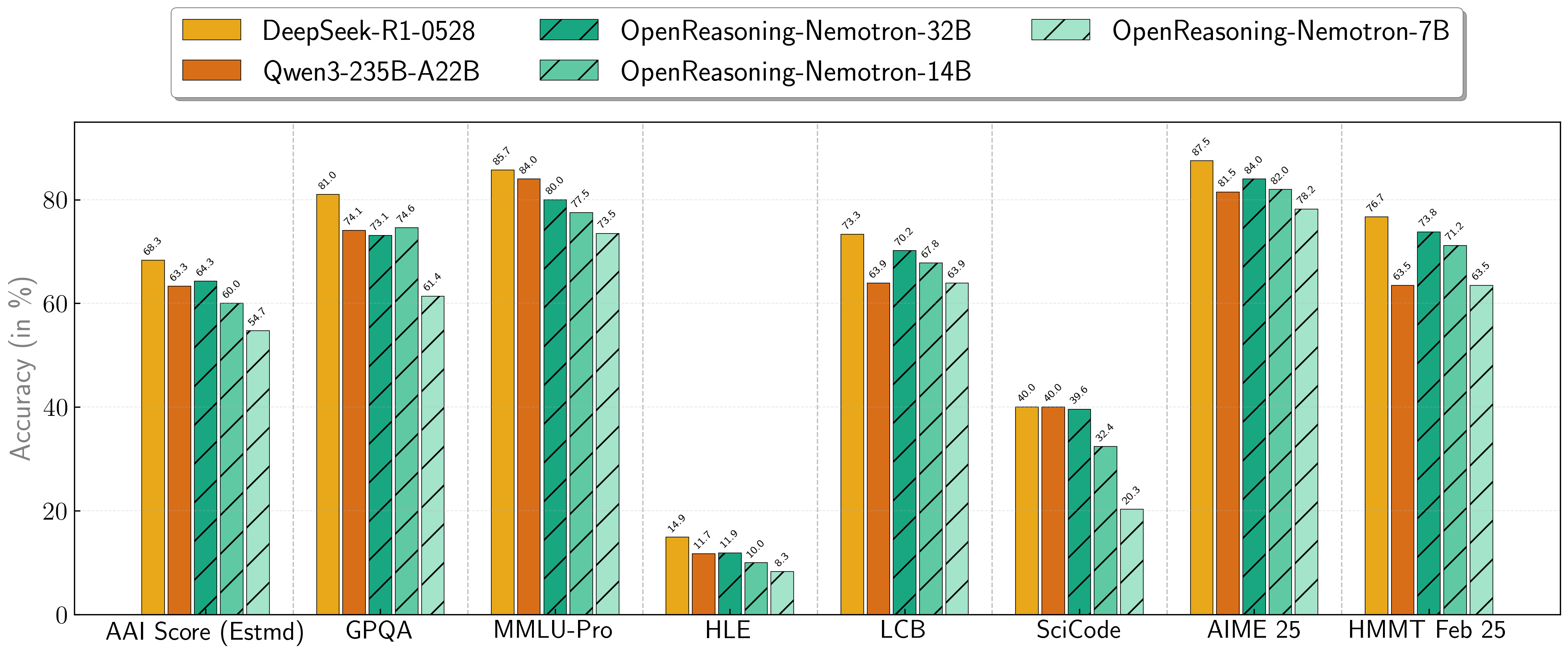
Our models demonstrate exceptional performance across a suite of challenging reasoning benchmarks. The 7B, 14B, and 32B models consistently set new state-of-the-art records for their size classes.
|
| 50 |
+
|
| 51 |
+
| **Model** | **AritificalAnalysisIndex*** | **GPQA** | **MMLU-PRO** | **HLE** | **LiveCodeBench*** | **SciCode** | **AIME24** | **AIME25** | **HMMT FEB 25** |
|
| 52 |
+
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
|
| 53 |
+
| **1.5B**| 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
|
| 54 |
+
| **7B** | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
|
| 55 |
+
| **14B** | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
|
| 56 |
+
| **32B** | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
|
| 57 |
+
|
| 58 |
+
\* This is our estimation of the Artificial Analysis Intelligence Index, not an official score.
|
| 59 |
+
|
| 60 |
+
\* LiveCodeBench version 6, date range 2408-2505.
|
| 61 |
+
|
| 62 |
+
## Combining the work of multiple agents
|
| 63 |
+
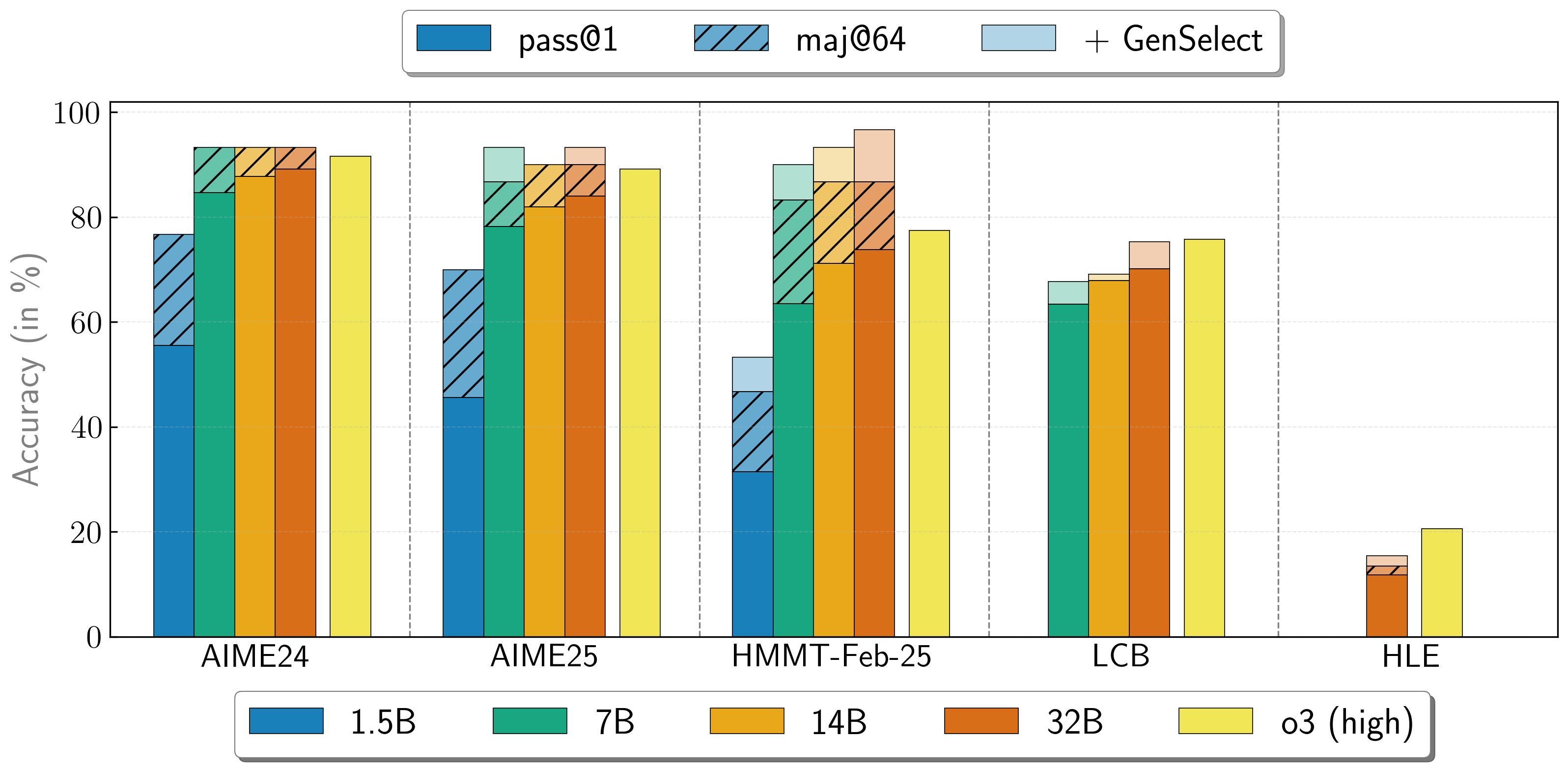
OpenReasoning-Nemotron models can be used in a "heavy" mode by starting multiple parallel generations and combining them together via [generative solution selection (GenSelect)](https://arxiv.org/abs/2504.16891). To add this "skill" we follow the original GenSelect training pipeline except we do not train on the selection summary but use the full reasoning trace of DeepSeek R1 0528 671B instead. We only train models to select the best solution for math problems but surprisingly find that this capability directly generalizes to code and science questions! With this "heavy" GenSelect inference mode, OpenReasoning-Nemotron-32B model surpasses O3 (High) on math and coding benchmarks.
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
| **Model** | **Pass@1 (Avg@64)** | **Majority@64** | **GenSelect** |
|
| 68 |
+
| :--- | :--- | :--- | :--- |
|
| 69 |
+
| **1.5B** | | | |
|
| 70 |
+
| **AIME24** | 55.5 | 76.7 | 76.7 |
|
| 71 |
+
| **AIME25** | 45.6 | 70.0 | 70.0 |
|
| 72 |
+
| **HMMT Feb 25** | 31.5 | 46.7 | 53.3 |
|
| 73 |
+
| **7B** | | | |
|
| 74 |
+
| **AIME24** | 84.7 | 93.3 | 93.3 |
|
| 75 |
+
| **AIME25** | 78.2 | 86.7 | 93.3 |
|
| 76 |
+
| **HMMT Feb 25** | 63.5 | 83.3 | 90.0 |
|
| 77 |
+
| **LCB v6 2408-2505** | 63.4 | n/a | 67.7 |
|
| 78 |
+
| **14B** | | | |
|
| 79 |
+
| **AIME24** | 87.8 | 93.3 | 93.3 |
|
| 80 |
+
| **AIME25** | 82.0 | 90.0 | 90.0 |
|
| 81 |
+
| **HMMT Feb 25** | 71.2 | 86.7 | 93.3 |
|
| 82 |
+
| **LCB v6 2408-2505** | 67.9 | n/a | 69.1 |
|
| 83 |
+
| **32B** | | | |
|
| 84 |
+
| **AIME24** | 89.2 | 93.3 | 93.3 |
|
| 85 |
+
| **AIME25** | 84.0 | 90.0 | 93.3 |
|
| 86 |
+
| **HMMT Feb 25** | 73.8 | 86.7 | 96.7 |
|
| 87 |
+
| **LCB v6 2408-2505** | 70.2 | n/a | 75.3 |
|
| 88 |
+
| **HLE** | 11.8 | 13.4 | 15.5 |
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
## How to use the models?
|
| 92 |
+
|
| 93 |
+
To run inference on coding problems:
|
| 94 |
+
|
| 95 |
+
````python
|
| 96 |
+
import transformers
|
| 97 |
+
import torch
|
| 98 |
+
model_id = "nvidia/OpenReasoning-Nemotron-32B"
|
| 99 |
+
pipeline = transformers.pipeline(
|
| 100 |
+
"text-generation",
|
| 101 |
+
model=model_id,
|
| 102 |
+
model_kwargs={"torch_dtype": torch.bfloat16},
|
| 103 |
+
device_map="auto",
|
| 104 |
+
)
|
| 105 |
+
# Code generation prompt
|
| 106 |
+
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
|
| 107 |
+
Please use python programming language only.
|
| 108 |
+
You must use ```python for just the final solution code block with the following format:
|
| 109 |
+
```python
|
| 110 |
+
# Your code here
|
| 111 |
+
```
|
| 112 |
+
{user}
|
| 113 |
+
"""
|
| 114 |
+
|
| 115 |
+
# Math generation prompt
|
| 116 |
+
# prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.
|
| 117 |
+
#
|
| 118 |
+
# {user}
|
| 119 |
+
# """
|
| 120 |
+
|
| 121 |
+
# Science generation prompt
|
| 122 |
+
# You can refer to prompts here -
|
| 123 |
+
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
|
| 124 |
+
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (for GPQA)
|
| 125 |
+
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
|
| 126 |
+
|
| 127 |
+
messages = [
|
| 128 |
+
{
|
| 129 |
+
"role": "user",
|
| 130 |
+
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
|
| 131 |
+
]
|
| 132 |
+
outputs = pipeline(
|
| 133 |
+
messages,
|
| 134 |
+
max_new_tokens=64000,
|
| 135 |
+
)
|
| 136 |
+
print(outputs[0]["generated_text"][-1]['content'])
|
| 137 |
+
````
|
| 138 |
+
|
| 139 |
+
## Citation
|
| 140 |
+
|
| 141 |
+
If you find the data useful, please cite:
|
| 142 |
+
```
|
| 143 |
+
@article{ahmad2025opencodereasoning,
|
| 144 |
+
title={OpenCodeReasoning: Advancing Data Distillation for Competitive Coding},
|
| 145 |
+
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
|
| 146 |
+
year={2025},
|
| 147 |
+
eprint={2504.01943},
|
| 148 |
+
archivePrefix={arXiv},
|
| 149 |
+
primaryClass={cs.CL},
|
| 150 |
+
url={https://arxiv.org/abs/2504.01943},
|
| 151 |
+
}
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
```
|
| 155 |
+
@misc{ahmad2025opencodereasoningiisimpletesttime,
|
| 156 |
+
title={OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique},
|
| 157 |
+
author={Wasi Uddin Ahmad and Somshubra Majumdar and Aleksander Ficek and Sean Narenthiran and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Vahid Noroozi and Boris Ginsburg},
|
| 158 |
+
year={2025},
|
| 159 |
+
eprint={2507.09075},
|
| 160 |
+
archivePrefix={arXiv},
|
| 161 |
+
primaryClass={cs.CL},
|
| 162 |
+
url={https://arxiv.org/abs/2507.09075},
|
| 163 |
+
}
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
```
|
| 167 |
+
@misc{moshkov2025aimo2winningsolutionbuilding,
|
| 168 |
+
title={AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset},
|
| 169 |
+
author={Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
|
| 170 |
+
year={2025},
|
| 171 |
+
eprint={2504.16891},
|
| 172 |
+
archivePrefix={arXiv},
|
| 173 |
+
primaryClass={cs.AI},
|
| 174 |
+
url={https://arxiv.org/abs/2504.16891},
|
| 175 |
+
}
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
## Additional Information:
|
| 179 |
+
|
| 180 |
+
### Deployment Geography:
|
| 181 |
+
Global<br>
|
| 182 |
+
|
| 183 |
+
### Use Case: <br>
|
| 184 |
+
This model is intended for developers and researchers who work on competitive math, code and science problems. It has been trained via only supervised fine-tuning to achieve strong scores on benchmarks. <br>
|
| 185 |
+
|
| 186 |
+
### Release Date: <br>
|
| 187 |
+
Huggingface [07/16/2025] via https://huggingface.co/nvidia/OpenReasoning-Nemotron-32B/ <br>
|
| 188 |
+
|
| 189 |
+
## Reference(s):
|
| 190 |
+
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
|
| 191 |
+
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
|
| 192 |
+
* [2504.16891] AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
|
| 193 |
+
<br>
|
| 194 |
+
|
| 195 |
+
## Model Architecture: <br>
|
| 196 |
+
Architecture Type: Dense decoder-only Transformer model
|
| 197 |
+
Network Architecture: Qwen-32B-Instruct
|
| 198 |
+
<br>
|
| 199 |
+
**This model was developed based on Qwen2.5-32B-Instruct and has 32B model parameters. <br>**
|
| 200 |
+
|
| 201 |
+
**OpenReasoning-Nemotron-1.5B was developed based on Qwen2.5-1.5B-Instruct and has 1.5B model parameters. <br>**
|
| 202 |
+
|
| 203 |
+
**OpenReasoning-Nemotron-7B was developed based on Qwen2.5-7B-Instruct and has 7B model parameters. <br>**
|
| 204 |
+
|
| 205 |
+
**OpenReasoning-Nemotron-14B was developed based on Qwen2.5-14B-Instruct and has 14B model parameters. <br>**
|
| 206 |
+
|
| 207 |
+
**OpenReasoning-Nemotron-32B was developed based on Qwen2.5-32B-Instruct and has 32B model parameters. <br>**
|
| 208 |
+
|
| 209 |
+
## Input: <br>
|
| 210 |
+
**Input Type(s):** Text <br>
|
| 211 |
+
**Input Format(s):** String <br>
|
| 212 |
+
**Input Parameters:** One-Dimensional (1D) <br>
|
| 213 |
+
**Other Properties Related to Input:** Trained for up to 64,000 output tokens <br>
|
| 214 |
+
|
| 215 |
+
## Output: <br>
|
| 216 |
+
**Output Type(s):** Text <br>
|
| 217 |
+
**Output Format:** String <br>
|
| 218 |
+
**Output Parameters:** One-Dimensional (1D) <br>
|
| 219 |
+
**Other Properties Related to Output:** Trained for up to 64,000 output tokens <br>
|
| 220 |
+
|
| 221 |
+
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
|
| 222 |
+
|
| 223 |
+
## Software Integration : <br>
|
| 224 |
+
* Runtime Engine: NeMo 2.3.0 <br>
|
| 225 |
+
* Recommended Hardware Microarchitecture Compatibility: <br>
|
| 226 |
+
NVIDIA Ampere <br>
|
| 227 |
+
NVIDIA Hopper <br>
|
| 228 |
+
* Preferred/Supported Operating System(s): Linux <br>
|
| 229 |
+
|
| 230 |
+
## Model Version(s):
|
| 231 |
+
1.0 (7/16/2025) <br>
|
| 232 |
+
OpenReasoning-Nemotron-32B<br>
|
| 233 |
+
OpenReasoning-Nemotron-14B<br>
|
| 234 |
+
OpenReasoning-Nemotron-7B<br>
|
| 235 |
+
OpenReasoning-Nemotron-1.5B<br>
|
| 236 |
+
|
| 237 |
+
# Training and Evaluation Datasets: <br>
|
| 238 |
+
|
| 239 |
+
## Training Dataset:
|
| 240 |
+
|
| 241 |
+
The training corpus for OpenReasoning-Nemotron-32B is comprised of questions from [OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning) dataset, [OpenCodeReasoning-II](https://arxiv.org/abs/2507.09075), [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning), and the Synthetic Science questions from the [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset). All responses are generated using DeepSeek-R1-0528. We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
|
| 242 |
+
|
| 243 |
+
Data Collection Method: Hybrid: Automated, Human, Synthetic <br>
|
| 244 |
+
Labeling Method: Hybrid: Automated, Human, Synthetic <br>
|
| 245 |
+
Properties: 5M DeepSeek-R1-0528 generated responses from OpenCodeReasoning questions (https://huggingface.co/datasets/nvidia/OpenCodeReasoning), [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning), and the Synthetic Science questions from the [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset). We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
|
| 246 |
+
|
| 247 |
+
## Evaluation Dataset:
|
| 248 |
+
We used the following benchmarks to evaluate the model holistically.
|
| 249 |
+
|
| 250 |
+
### Math
|
| 251 |
+
- AIME 2024/2025 <br>
|
| 252 |
+
- HMMT <br>
|
| 253 |
+
- BRUNO 2025 <br>
|
| 254 |
+
|
| 255 |
+
### Code
|
| 256 |
+
- LiveCodeBench <br>
|
| 257 |
+
- SciCode <br>
|
| 258 |
+
|
| 259 |
+
### Science
|
| 260 |
+
- GPQA <br>
|
| 261 |
+
- MMLU-PRO <br>
|
| 262 |
+
- HLE <br>
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
Data Collection Method: Hybrid: Automated, Human, Synthetic <br>
|
| 266 |
+
Labeling Method: Hybrid: Automated, Human, Synthetic <br>
|
| 267 |
+
|
| 268 |
+
## Inference:
|
| 269 |
+
**Acceleration Engine:** vLLM, Tensor(RT)-LLM <br>
|
| 270 |
+
**Test Hardware** NVIDIA H100-80GB <br>
|
| 271 |
+
|
| 272 |
+
## Ethical Considerations:
|
| 273 |
+
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
|
| 274 |
+
|
| 275 |
+
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards.
|
| 276 |
+
|
| 277 |
+
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
SAFETY.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:---------------------------------------------------|:----------------------------------
|
| 3 |
+
Model Application Field(s): | Reasoning for Code Generation<br>
|
| 4 |
+
Describe the life critical impact (if present). | Not Applicable <br>
|
| 5 |
+
Use Case Restrictions: | Abide by CC BY 4.0 <br>
|
| 6 |
+
Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to.
|
| 7 |
+
|
added_tokens.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</tool_call>": 151658,
|
| 3 |
+
"<tool_call>": 151657,
|
| 4 |
+
"<|box_end|>": 151649,
|
| 5 |
+
"<|box_start|>": 151648,
|
| 6 |
+
"<|endoftext|>": 151643,
|
| 7 |
+
"<|file_sep|>": 151664,
|
| 8 |
+
"<|fim_middle|>": 151660,
|
| 9 |
+
"<|fim_pad|>": 151662,
|
| 10 |
+
"<|fim_prefix|>": 151659,
|
| 11 |
+
"<|fim_suffix|>": 151661,
|
| 12 |
+
"<|im_end|>": 151645,
|
| 13 |
+
"<|im_start|>": 151644,
|
| 14 |
+
"<|image_pad|>": 151655,
|
| 15 |
+
"<|object_ref_end|>": 151647,
|
| 16 |
+
"<|object_ref_start|>": 151646,
|
| 17 |
+
"<|quad_end|>": 151651,
|
| 18 |
+
"<|quad_start|>": 151650,
|
| 19 |
+
"<|repo_name|>": 151663,
|
| 20 |
+
"<|video_pad|>": 151656,
|
| 21 |
+
"<|vision_end|>": 151653,
|
| 22 |
+
"<|vision_pad|>": 151654,
|
| 23 |
+
"<|vision_start|>": 151652
|
| 24 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{%- if messages[0]['role'] == 'system' %}
|
| 2 |
+
{{- '<|im_start|>system
|
| 3 |
+
' + messages[0]['content'] + '<|im_end|>
|
| 4 |
+
' }}
|
| 5 |
+
{%- else %}
|
| 6 |
+
{{- '<|im_start|>system
|
| 7 |
+
<|im_end|>
|
| 8 |
+
' }}
|
| 9 |
+
{%- endif %}
|
| 10 |
+
{%- for message in messages %}
|
| 11 |
+
{%- if (message.role == 'user') or (message.role == 'system' and not loop.first) or (message.role == 'assistant') %}
|
| 12 |
+
{{- '<|im_start|>' + message.role + '
|
| 13 |
+
' + message.content + '<|im_end|>' + '
|
| 14 |
+
' }}
|
| 15 |
+
{%- endif %}
|
| 16 |
+
{%- endfor %}
|
| 17 |
+
{%- if add_generation_prompt %}
|
| 18 |
+
{{- '<|im_start|>assistant
|
| 19 |
+
' }}
|
| 20 |
+
{%- endif %}
|
config.json
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen2ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"eos_token_id": 151643,
|
| 7 |
+
"hidden_act": "silu",
|
| 8 |
+
"hidden_size": 5120,
|
| 9 |
+
"initializer_range": 0.02,
|
| 10 |
+
"intermediate_size": 27648,
|
| 11 |
+
"layer_types": [
|
| 12 |
+
"full_attention",
|
| 13 |
+
"full_attention",
|
| 14 |
+
"full_attention",
|
| 15 |
+
"full_attention",
|
| 16 |
+
"full_attention",
|
| 17 |
+
"full_attention",
|
| 18 |
+
"full_attention",
|
| 19 |
+
"full_attention",
|
| 20 |
+
"full_attention",
|
| 21 |
+
"full_attention",
|
| 22 |
+
"full_attention",
|
| 23 |
+
"full_attention",
|
| 24 |
+
"full_attention",
|
| 25 |
+
"full_attention",
|
| 26 |
+
"full_attention",
|
| 27 |
+
"full_attention",
|
| 28 |
+
"full_attention",
|
| 29 |
+
"full_attention",
|
| 30 |
+
"full_attention",
|
| 31 |
+
"full_attention",
|
| 32 |
+
"full_attention",
|
| 33 |
+
"full_attention",
|
| 34 |
+
"full_attention",
|
| 35 |
+
"full_attention",
|
| 36 |
+
"full_attention",
|
| 37 |
+
"full_attention",
|
| 38 |
+
"full_attention",
|
| 39 |
+
"full_attention",
|
| 40 |
+
"full_attention",
|
| 41 |
+
"full_attention",
|
| 42 |
+
"full_attention",
|
| 43 |
+
"full_attention",
|
| 44 |
+
"full_attention",
|
| 45 |
+
"full_attention",
|
| 46 |
+
"full_attention",
|
| 47 |
+
"full_attention",
|
| 48 |
+
"full_attention",
|
| 49 |
+
"full_attention",
|
| 50 |
+
"full_attention",
|
| 51 |
+
"full_attention",
|
| 52 |
+
"full_attention",
|
| 53 |
+
"full_attention",
|
| 54 |
+
"full_attention",
|
| 55 |
+
"full_attention",
|
| 56 |
+
"full_attention",
|
| 57 |
+
"full_attention",
|
| 58 |
+
"full_attention",
|
| 59 |
+
"full_attention",
|
| 60 |
+
"full_attention",
|
| 61 |
+
"full_attention",
|
| 62 |
+
"full_attention",
|
| 63 |
+
"full_attention",
|
| 64 |
+
"full_attention",
|
| 65 |
+
"full_attention",
|
| 66 |
+
"full_attention",
|
| 67 |
+
"full_attention",
|
| 68 |
+
"full_attention",
|
| 69 |
+
"full_attention",
|
| 70 |
+
"full_attention",
|
| 71 |
+
"full_attention",
|
| 72 |
+
"full_attention",
|
| 73 |
+
"full_attention",
|
| 74 |
+
"full_attention",
|
| 75 |
+
"full_attention"
|
| 76 |
+
],
|
| 77 |
+
"max_position_embeddings": 131072,
|
| 78 |
+
"max_window_layers": 64,
|
| 79 |
+
"model_type": "qwen2",
|
| 80 |
+
"num_attention_heads": 40,
|
| 81 |
+
"num_hidden_layers": 64,
|
| 82 |
+
"num_key_value_heads": 8,
|
| 83 |
+
"pad_token_id": 151654,
|
| 84 |
+
"rms_norm_eps": 1e-05,
|
| 85 |
+
"rope_scaling": null,
|
| 86 |
+
"rope_theta": 1000000.0,
|
| 87 |
+
"sliding_window": null,
|
| 88 |
+
"tie_word_embeddings": false,
|
| 89 |
+
"torch_dtype": "bfloat16",
|
| 90 |
+
"transformers_version": "4.53.2",
|
| 91 |
+
"unsloth_fixed": true,
|
| 92 |
+
"use_cache": true,
|
| 93 |
+
"use_sliding_window": false,
|
| 94 |
+
"vocab_size": 152064
|
| 95 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 151643,
|
| 4 |
+
"eos_token_id": 151643,
|
| 5 |
+
"transformers_version": "4.47.1"
|
| 6 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a33b4071d66ce4b7619d6c6afc58a94c4c502e0bbabad04d88e54b481798cc59
|
| 3 |
+
size 9767790336
|
model-00002-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:01d1f06666b14c42151739d69a76fc9054236e6192d99d595f1f19920a92319d
|
| 3 |
+
size 9752118784
|
model-00003-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:18bf2cd1f1dd2c559272627ad8460b8ad7f83c7ae60a6a268315f0b96dd92491
|
| 3 |
+
size 9752118816
|
model-00004-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c56e81bc54f1cff3ce84d244a65c1126bafb8a1e4b80a19b44618fba9ce479d
|
| 3 |
+
size 9752118816
|
model-00005-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:82997b9f1ba9457dc9b863b817b6952c6a750c188f37e842c1d862ede02febba
|
| 3 |
+
size 9752118816
|
model-00006-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f3baa296d7d556ee239179714f4f1dfb0b693e8a7b0fd68d5e0725c915acfa6a
|
| 3 |
+
size 9752118816
|
model-00007-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:354a694ed0b7e0d5961cfe2f36cc970066ec39414abfb8170cc2f3c4c0c5ad59
|
| 3 |
+
size 6999457200
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,778 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 65527752704
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00007-of-00007.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00007.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 20 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 21 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 22 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 23 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 24 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 27 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 28 |
+
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 29 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 30 |
+
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 31 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 32 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 33 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 34 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 35 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 36 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 37 |
+
"model.layers.10.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 38 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 39 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 40 |
+
"model.layers.10.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 41 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 42 |
+
"model.layers.10.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 43 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 44 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 45 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 46 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 47 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 48 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 49 |
+
"model.layers.11.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 50 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 51 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 52 |
+
"model.layers.11.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 53 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 54 |
+
"model.layers.11.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 55 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 56 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 57 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 58 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 59 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 60 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 61 |
+
"model.layers.12.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 62 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 63 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 64 |
+
"model.layers.12.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 65 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 66 |
+
"model.layers.12.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 67 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 68 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 69 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 70 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 71 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 72 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 73 |
+
"model.layers.13.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 74 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 75 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 76 |
+
"model.layers.13.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 77 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 78 |
+
"model.layers.13.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 79 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 80 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 81 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 82 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 83 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 84 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 85 |
+
"model.layers.14.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 86 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 87 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 88 |
+
"model.layers.14.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 89 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 90 |
+
"model.layers.14.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 91 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 92 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 93 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 94 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 95 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 96 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 97 |
+
"model.layers.15.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 98 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 99 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 100 |
+
"model.layers.15.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 101 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 102 |
+
"model.layers.15.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 103 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 104 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 105 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 106 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 107 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 108 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 109 |
+
"model.layers.16.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 110 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 111 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 112 |
+
"model.layers.16.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 113 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 114 |
+
"model.layers.16.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 115 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 116 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 117 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 118 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 119 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 120 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 121 |
+
"model.layers.17.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 122 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 123 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 124 |
+
"model.layers.17.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 125 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 126 |
+
"model.layers.17.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 127 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 128 |
+
"model.layers.18.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 129 |
+
"model.layers.18.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 130 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 131 |
+
"model.layers.18.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 132 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 133 |
+
"model.layers.18.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 134 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 135 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 136 |
+
"model.layers.18.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 137 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 138 |
+
"model.layers.18.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 139 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 140 |
+
"model.layers.19.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 141 |
+
"model.layers.19.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 142 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 143 |
+
"model.layers.19.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 144 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 145 |
+
"model.layers.19.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 146 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 147 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 148 |
+
"model.layers.19.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 149 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 150 |
+
"model.layers.19.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 151 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 152 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 153 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 154 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 155 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 156 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 157 |
+
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 158 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 159 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 160 |
+
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 161 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 162 |
+
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 163 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 164 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 165 |
+
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 166 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 167 |
+
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 168 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 169 |
+
"model.layers.20.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 170 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 171 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 172 |
+
"model.layers.20.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 173 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 174 |
+
"model.layers.20.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 175 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 176 |
+
"model.layers.21.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 177 |
+
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 178 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 179 |
+
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 180 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 181 |
+
"model.layers.21.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 182 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 183 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 184 |
+
"model.layers.21.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 185 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 186 |
+
"model.layers.21.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 187 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 188 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 189 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 190 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 191 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 192 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 193 |
+
"model.layers.22.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 194 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 195 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 196 |
+
"model.layers.22.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 197 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 198 |
+
"model.layers.22.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 199 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 200 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 201 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 202 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 203 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 204 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 205 |
+
"model.layers.23.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 206 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 207 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 208 |
+
"model.layers.23.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 209 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 210 |
+
"model.layers.23.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 211 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 212 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 213 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 214 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 215 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 216 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 217 |
+
"model.layers.24.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 218 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 219 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 220 |
+
"model.layers.24.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 221 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 222 |
+
"model.layers.24.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 223 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 224 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 225 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 226 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 227 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 228 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 229 |
+
"model.layers.25.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 230 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 231 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 232 |
+
"model.layers.25.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 233 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 234 |
+
"model.layers.25.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 235 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 236 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 237 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 238 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 239 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 240 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 241 |
+
"model.layers.26.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 242 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 243 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 244 |
+
"model.layers.26.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 245 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 246 |
+
"model.layers.26.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 247 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 248 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 249 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
| 250 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 251 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
| 252 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
| 253 |
+
"model.layers.27.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 254 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 255 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 256 |
+
"model.layers.27.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 257 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 258 |
+
"model.layers.27.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 259 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 260 |
+
"model.layers.28.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 261 |
+
"model.layers.28.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 262 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
| 263 |
+
"model.layers.28.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 264 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 265 |
+
"model.layers.28.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
| 266 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
| 267 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
| 268 |
+
"model.layers.28.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
| 269 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
| 270 |
+
"model.layers.28.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
| 271 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
| 272 |
+
"model.layers.29.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 273 |
+
"model.layers.29.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 274 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 275 |
+
"model.layers.29.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 276 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 277 |
+
"model.layers.29.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 278 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 279 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 280 |
+
"model.layers.29.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 281 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 282 |
+
"model.layers.29.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 283 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 284 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 285 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 286 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 287 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 288 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 289 |
+
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 290 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 291 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 292 |
+
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 293 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 294 |
+
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 295 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 296 |
+
"model.layers.30.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 297 |
+
"model.layers.30.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 298 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 299 |
+
"model.layers.30.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 300 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 301 |
+
"model.layers.30.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 302 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 303 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 304 |
+
"model.layers.30.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 305 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 306 |
+
"model.layers.30.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 307 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 308 |
+
"model.layers.31.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 309 |
+
"model.layers.31.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 310 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 311 |
+
"model.layers.31.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 312 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 313 |
+
"model.layers.31.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 314 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 315 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 316 |
+
"model.layers.31.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 317 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 318 |
+
"model.layers.31.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 319 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 320 |
+
"model.layers.32.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 321 |
+
"model.layers.32.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 322 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 323 |
+
"model.layers.32.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 324 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 325 |
+
"model.layers.32.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 326 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 327 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 328 |
+
"model.layers.32.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 329 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 330 |
+
"model.layers.32.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 331 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 332 |
+
"model.layers.33.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 333 |
+
"model.layers.33.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 334 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 335 |
+
"model.layers.33.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 336 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 337 |
+
"model.layers.33.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 338 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 339 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 340 |
+
"model.layers.33.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 341 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 342 |
+
"model.layers.33.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 343 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 344 |
+
"model.layers.34.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 345 |
+
"model.layers.34.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 346 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 347 |
+
"model.layers.34.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 348 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 349 |
+
"model.layers.34.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 350 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 351 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 352 |
+
"model.layers.34.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 353 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 354 |
+
"model.layers.34.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 355 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 356 |
+
"model.layers.35.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 357 |
+
"model.layers.35.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 358 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 359 |
+
"model.layers.35.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 360 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 361 |
+
"model.layers.35.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 362 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 363 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 364 |
+
"model.layers.35.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 365 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 366 |
+
"model.layers.35.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 367 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 368 |
+
"model.layers.36.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 369 |
+
"model.layers.36.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 370 |
+
"model.layers.36.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 371 |
+
"model.layers.36.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 372 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 373 |
+
"model.layers.36.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 374 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 375 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 376 |
+
"model.layers.36.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 377 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 378 |
+
"model.layers.36.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 379 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 380 |
+
"model.layers.37.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 381 |
+
"model.layers.37.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
| 382 |
+
"model.layers.37.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 383 |
+
"model.layers.37.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
| 384 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
| 385 |
+
"model.layers.37.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 386 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 387 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 388 |
+
"model.layers.37.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 389 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 390 |
+
"model.layers.37.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 391 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 392 |
+
"model.layers.38.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 393 |
+
"model.layers.38.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 394 |
+
"model.layers.38.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
| 395 |
+
"model.layers.38.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 396 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 397 |
+
"model.layers.38.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
| 398 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
| 399 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
| 400 |
+
"model.layers.38.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
| 401 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
| 402 |
+
"model.layers.38.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
| 403 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
| 404 |
+
"model.layers.39.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 405 |
+
"model.layers.39.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 406 |
+
"model.layers.39.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 407 |
+
"model.layers.39.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 408 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 409 |
+
"model.layers.39.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 410 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 411 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 412 |
+
"model.layers.39.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 413 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 414 |
+
"model.layers.39.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 415 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 416 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 417 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 418 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 419 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 420 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 421 |
+
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 422 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 423 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 424 |
+
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 425 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 426 |
+
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 427 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 428 |
+
"model.layers.40.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 429 |
+
"model.layers.40.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 430 |
+
"model.layers.40.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 431 |
+
"model.layers.40.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 432 |
+
"model.layers.40.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 433 |
+
"model.layers.40.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 434 |
+
"model.layers.40.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 435 |
+
"model.layers.40.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 436 |
+
"model.layers.40.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 437 |
+
"model.layers.40.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 438 |
+
"model.layers.40.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 439 |
+
"model.layers.40.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 440 |
+
"model.layers.41.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 441 |
+
"model.layers.41.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 442 |
+
"model.layers.41.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 443 |
+
"model.layers.41.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 444 |
+
"model.layers.41.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 445 |
+
"model.layers.41.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 446 |
+
"model.layers.41.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 447 |
+
"model.layers.41.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 448 |
+
"model.layers.41.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 449 |
+
"model.layers.41.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 450 |
+
"model.layers.41.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 451 |
+
"model.layers.41.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 452 |
+
"model.layers.42.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 453 |
+
"model.layers.42.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 454 |
+
"model.layers.42.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 455 |
+
"model.layers.42.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 456 |
+
"model.layers.42.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 457 |
+
"model.layers.42.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 458 |
+
"model.layers.42.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 459 |
+
"model.layers.42.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 460 |
+
"model.layers.42.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 461 |
+
"model.layers.42.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 462 |
+
"model.layers.42.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 463 |
+
"model.layers.42.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 464 |
+
"model.layers.43.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 465 |
+
"model.layers.43.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 466 |
+
"model.layers.43.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 467 |
+
"model.layers.43.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 468 |
+
"model.layers.43.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 469 |
+
"model.layers.43.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 470 |
+
"model.layers.43.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 471 |
+
"model.layers.43.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 472 |
+
"model.layers.43.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 473 |
+
"model.layers.43.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 474 |
+
"model.layers.43.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 475 |
+
"model.layers.43.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 476 |
+
"model.layers.44.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 477 |
+
"model.layers.44.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 478 |
+
"model.layers.44.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 479 |
+
"model.layers.44.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 480 |
+
"model.layers.44.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 481 |
+
"model.layers.44.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 482 |
+
"model.layers.44.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 483 |
+
"model.layers.44.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 484 |
+
"model.layers.44.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 485 |
+
"model.layers.44.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 486 |
+
"model.layers.44.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 487 |
+
"model.layers.44.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 488 |
+
"model.layers.45.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 489 |
+
"model.layers.45.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 490 |
+
"model.layers.45.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 491 |
+
"model.layers.45.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 492 |
+
"model.layers.45.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 493 |
+
"model.layers.45.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 494 |
+
"model.layers.45.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 495 |
+
"model.layers.45.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 496 |
+
"model.layers.45.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 497 |
+
"model.layers.45.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 498 |
+
"model.layers.45.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 499 |
+
"model.layers.45.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 500 |
+
"model.layers.46.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 501 |
+
"model.layers.46.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 502 |
+
"model.layers.46.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 503 |
+
"model.layers.46.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 504 |
+
"model.layers.46.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 505 |
+
"model.layers.46.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 506 |
+
"model.layers.46.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 507 |
+
"model.layers.46.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 508 |
+
"model.layers.46.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 509 |
+
"model.layers.46.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 510 |
+
"model.layers.46.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 511 |
+
"model.layers.46.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 512 |
+
"model.layers.47.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 513 |
+
"model.layers.47.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
| 514 |
+
"model.layers.47.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 515 |
+
"model.layers.47.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
| 516 |
+
"model.layers.47.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
| 517 |
+
"model.layers.47.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 518 |
+
"model.layers.47.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 519 |
+
"model.layers.47.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 520 |
+
"model.layers.47.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 521 |
+
"model.layers.47.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 522 |
+
"model.layers.47.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 523 |
+
"model.layers.47.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 524 |
+
"model.layers.48.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 525 |
+
"model.layers.48.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 526 |
+
"model.layers.48.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
| 527 |
+
"model.layers.48.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 528 |
+
"model.layers.48.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 529 |
+
"model.layers.48.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
| 530 |
+
"model.layers.48.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
| 531 |
+
"model.layers.48.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
| 532 |
+
"model.layers.48.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
| 533 |
+
"model.layers.48.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
| 534 |
+
"model.layers.48.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
| 535 |
+
"model.layers.48.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
| 536 |
+
"model.layers.49.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 537 |
+
"model.layers.49.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 538 |
+
"model.layers.49.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 539 |
+
"model.layers.49.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 540 |
+
"model.layers.49.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 541 |
+
"model.layers.49.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 542 |
+
"model.layers.49.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 543 |
+
"model.layers.49.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 544 |
+
"model.layers.49.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 545 |
+
"model.layers.49.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 546 |
+
"model.layers.49.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 547 |
+
"model.layers.49.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 548 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 549 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 550 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 551 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 552 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 553 |
+
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 554 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 555 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 556 |
+
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 557 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 558 |
+
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 559 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 560 |
+
"model.layers.50.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 561 |
+
"model.layers.50.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 562 |
+
"model.layers.50.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 563 |
+
"model.layers.50.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 564 |
+
"model.layers.50.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 565 |
+
"model.layers.50.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 566 |
+
"model.layers.50.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 567 |
+
"model.layers.50.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 568 |
+
"model.layers.50.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 569 |
+
"model.layers.50.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 570 |
+
"model.layers.50.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 571 |
+
"model.layers.50.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 572 |
+
"model.layers.51.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 573 |
+
"model.layers.51.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 574 |
+
"model.layers.51.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 575 |
+
"model.layers.51.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 576 |
+
"model.layers.51.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 577 |
+
"model.layers.51.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 578 |
+
"model.layers.51.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 579 |
+
"model.layers.51.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 580 |
+
"model.layers.51.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 581 |
+
"model.layers.51.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 582 |
+
"model.layers.51.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 583 |
+
"model.layers.51.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 584 |
+
"model.layers.52.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 585 |
+
"model.layers.52.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 586 |
+
"model.layers.52.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 587 |
+
"model.layers.52.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 588 |
+
"model.layers.52.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 589 |
+
"model.layers.52.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 590 |
+
"model.layers.52.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 591 |
+
"model.layers.52.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 592 |
+
"model.layers.52.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 593 |
+
"model.layers.52.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 594 |
+
"model.layers.52.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 595 |
+
"model.layers.52.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 596 |
+
"model.layers.53.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 597 |
+
"model.layers.53.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 598 |
+
"model.layers.53.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 599 |
+
"model.layers.53.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 600 |
+
"model.layers.53.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 601 |
+
"model.layers.53.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 602 |
+
"model.layers.53.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 603 |
+
"model.layers.53.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 604 |
+
"model.layers.53.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 605 |
+
"model.layers.53.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 606 |
+
"model.layers.53.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 607 |
+
"model.layers.53.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 608 |
+
"model.layers.54.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 609 |
+
"model.layers.54.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 610 |
+
"model.layers.54.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 611 |
+
"model.layers.54.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 612 |
+
"model.layers.54.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 613 |
+
"model.layers.54.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 614 |
+
"model.layers.54.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 615 |
+
"model.layers.54.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 616 |
+
"model.layers.54.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 617 |
+
"model.layers.54.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 618 |
+
"model.layers.54.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 619 |
+
"model.layers.54.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 620 |
+
"model.layers.55.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 621 |
+
"model.layers.55.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 622 |
+
"model.layers.55.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 623 |
+
"model.layers.55.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 624 |
+
"model.layers.55.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 625 |
+
"model.layers.55.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 626 |
+
"model.layers.55.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 627 |
+
"model.layers.55.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 628 |
+
"model.layers.55.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 629 |
+
"model.layers.55.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 630 |
+
"model.layers.55.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 631 |
+
"model.layers.55.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 632 |
+
"model.layers.56.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 633 |
+
"model.layers.56.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 634 |
+
"model.layers.56.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 635 |
+
"model.layers.56.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 636 |
+
"model.layers.56.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 637 |
+
"model.layers.56.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 638 |
+
"model.layers.56.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 639 |
+
"model.layers.56.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 640 |
+
"model.layers.56.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 641 |
+
"model.layers.56.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 642 |
+
"model.layers.56.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 643 |
+
"model.layers.56.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 644 |
+
"model.layers.57.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 645 |
+
"model.layers.57.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
| 646 |
+
"model.layers.57.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 647 |
+
"model.layers.57.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
| 648 |
+
"model.layers.57.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
| 649 |
+
"model.layers.57.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 650 |
+
"model.layers.57.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 651 |
+
"model.layers.57.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 652 |
+
"model.layers.57.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 653 |
+
"model.layers.57.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 654 |
+
"model.layers.57.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 655 |
+
"model.layers.57.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 656 |
+
"model.layers.58.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 657 |
+
"model.layers.58.mlp.down_proj.weight": "model-00007-of-00007.safetensors",
|
| 658 |
+
"model.layers.58.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
| 659 |
+
"model.layers.58.mlp.up_proj.weight": "model-00007-of-00007.safetensors",
|
| 660 |
+
"model.layers.58.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 661 |
+
"model.layers.58.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
| 662 |
+
"model.layers.58.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
| 663 |
+
"model.layers.58.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
| 664 |
+
"model.layers.58.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
| 665 |
+
"model.layers.58.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
| 666 |
+
"model.layers.58.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
| 667 |
+
"model.layers.58.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
| 668 |
+
"model.layers.59.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 669 |
+
"model.layers.59.mlp.down_proj.weight": "model-00007-of-00007.safetensors",
|
| 670 |
+
"model.layers.59.mlp.gate_proj.weight": "model-00007-of-00007.safetensors",
|
| 671 |
+
"model.layers.59.mlp.up_proj.weight": "model-00007-of-00007.safetensors",
|
| 672 |
+
"model.layers.59.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 673 |
+
"model.layers.59.self_attn.k_proj.bias": "model-00007-of-00007.safetensors",
|
| 674 |
+
"model.layers.59.self_attn.k_proj.weight": "model-00007-of-00007.safetensors",
|
| 675 |
+
"model.layers.59.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
| 676 |
+
"model.layers.59.self_attn.q_proj.bias": "model-00007-of-00007.safetensors",
|
| 677 |
+
"model.layers.59.self_attn.q_proj.weight": "model-00007-of-00007.safetensors",
|
| 678 |
+
"model.layers.59.self_attn.v_proj.bias": "model-00007-of-00007.safetensors",
|
| 679 |
+
"model.layers.59.self_attn.v_proj.weight": "model-00007-of-00007.safetensors",
|
| 680 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 681 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 682 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 683 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 684 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 685 |
+
"model.layers.6.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 686 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 687 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 688 |
+
"model.layers.6.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 689 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 690 |
+
"model.layers.6.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 691 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 692 |
+
"model.layers.60.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 693 |
+
"model.layers.60.mlp.down_proj.weight": "model-00007-of-00007.safetensors",
|
| 694 |
+
"model.layers.60.mlp.gate_proj.weight": "model-00007-of-00007.safetensors",
|
| 695 |
+
"model.layers.60.mlp.up_proj.weight": "model-00007-of-00007.safetensors",
|
| 696 |
+
"model.layers.60.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 697 |
+
"model.layers.60.self_attn.k_proj.bias": "model-00007-of-00007.safetensors",
|
| 698 |
+
"model.layers.60.self_attn.k_proj.weight": "model-00007-of-00007.safetensors",
|
| 699 |
+
"model.layers.60.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
| 700 |
+
"model.layers.60.self_attn.q_proj.bias": "model-00007-of-00007.safetensors",
|
| 701 |
+
"model.layers.60.self_attn.q_proj.weight": "model-00007-of-00007.safetensors",
|
| 702 |
+
"model.layers.60.self_attn.v_proj.bias": "model-00007-of-00007.safetensors",
|
| 703 |
+
"model.layers.60.self_attn.v_proj.weight": "model-00007-of-00007.safetensors",
|
| 704 |
+
"model.layers.61.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 705 |
+
"model.layers.61.mlp.down_proj.weight": "model-00007-of-00007.safetensors",
|
| 706 |
+
"model.layers.61.mlp.gate_proj.weight": "model-00007-of-00007.safetensors",
|
| 707 |
+
"model.layers.61.mlp.up_proj.weight": "model-00007-of-00007.safetensors",
|
| 708 |
+
"model.layers.61.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 709 |
+
"model.layers.61.self_attn.k_proj.bias": "model-00007-of-00007.safetensors",
|
| 710 |
+
"model.layers.61.self_attn.k_proj.weight": "model-00007-of-00007.safetensors",
|
| 711 |
+
"model.layers.61.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
| 712 |
+
"model.layers.61.self_attn.q_proj.bias": "model-00007-of-00007.safetensors",
|
| 713 |
+
"model.layers.61.self_attn.q_proj.weight": "model-00007-of-00007.safetensors",
|
| 714 |
+
"model.layers.61.self_attn.v_proj.bias": "model-00007-of-00007.safetensors",
|
| 715 |
+
"model.layers.61.self_attn.v_proj.weight": "model-00007-of-00007.safetensors",
|
| 716 |
+
"model.layers.62.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 717 |
+
"model.layers.62.mlp.down_proj.weight": "model-00007-of-00007.safetensors",
|
| 718 |
+
"model.layers.62.mlp.gate_proj.weight": "model-00007-of-00007.safetensors",
|
| 719 |
+
"model.layers.62.mlp.up_proj.weight": "model-00007-of-00007.safetensors",
|
| 720 |
+
"model.layers.62.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 721 |
+
"model.layers.62.self_attn.k_proj.bias": "model-00007-of-00007.safetensors",
|
| 722 |
+
"model.layers.62.self_attn.k_proj.weight": "model-00007-of-00007.safetensors",
|
| 723 |
+
"model.layers.62.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
| 724 |
+
"model.layers.62.self_attn.q_proj.bias": "model-00007-of-00007.safetensors",
|
| 725 |
+
"model.layers.62.self_attn.q_proj.weight": "model-00007-of-00007.safetensors",
|
| 726 |
+
"model.layers.62.self_attn.v_proj.bias": "model-00007-of-00007.safetensors",
|
| 727 |
+
"model.layers.62.self_attn.v_proj.weight": "model-00007-of-00007.safetensors",
|
| 728 |
+
"model.layers.63.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 729 |
+
"model.layers.63.mlp.down_proj.weight": "model-00007-of-00007.safetensors",
|
| 730 |
+
"model.layers.63.mlp.gate_proj.weight": "model-00007-of-00007.safetensors",
|
| 731 |
+
"model.layers.63.mlp.up_proj.weight": "model-00007-of-00007.safetensors",
|
| 732 |
+
"model.layers.63.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
| 733 |
+
"model.layers.63.self_attn.k_proj.bias": "model-00007-of-00007.safetensors",
|
| 734 |
+
"model.layers.63.self_attn.k_proj.weight": "model-00007-of-00007.safetensors",
|
| 735 |
+
"model.layers.63.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
| 736 |
+
"model.layers.63.self_attn.q_proj.bias": "model-00007-of-00007.safetensors",
|
| 737 |
+
"model.layers.63.self_attn.q_proj.weight": "model-00007-of-00007.safetensors",
|
| 738 |
+
"model.layers.63.self_attn.v_proj.bias": "model-00007-of-00007.safetensors",
|
| 739 |
+
"model.layers.63.self_attn.v_proj.weight": "model-00007-of-00007.safetensors",
|
| 740 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 741 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
| 742 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 743 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
| 744 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
| 745 |
+
"model.layers.7.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 746 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 747 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 748 |
+
"model.layers.7.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 749 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 750 |
+
"model.layers.7.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 751 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 752 |
+
"model.layers.8.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 753 |
+
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 754 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
| 755 |
+
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 756 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 757 |
+
"model.layers.8.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
| 758 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
| 759 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
| 760 |
+
"model.layers.8.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
| 761 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
| 762 |
+
"model.layers.8.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
| 763 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
| 764 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 765 |
+
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
| 766 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
| 767 |
+
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
| 768 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
| 769 |
+
"model.layers.9.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
| 770 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
| 771 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
| 772 |
+
"model.layers.9.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
| 773 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
| 774 |
+
"model.layers.9.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
| 775 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
| 776 |
+
"model.norm.weight": "model-00007-of-00007.safetensors"
|
| 777 |
+
}
|
| 778 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|vision_pad|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c5ae00e602b8860cbd784ba82a8aa14e8feecec692e7076590d014d7b7fdafa
|
| 3 |
+
size 11421896
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
}
|
| 181 |
+
},
|
| 182 |
+
"additional_special_tokens": [
|
| 183 |
+
"<|im_start|>",
|
| 184 |
+
"<|im_end|>",
|
| 185 |
+
"<|object_ref_start|>",
|
| 186 |
+
"<|object_ref_end|>",
|
| 187 |
+
"<|box_start|>",
|
| 188 |
+
"<|box_end|>",
|
| 189 |
+
"<|quad_start|>",
|
| 190 |
+
"<|quad_end|>",
|
| 191 |
+
"<|vision_start|>",
|
| 192 |
+
"<|vision_end|>",
|
| 193 |
+
"<|vision_pad|>",
|
| 194 |
+
"<|image_pad|>",
|
| 195 |
+
"<|video_pad|>"
|
| 196 |
+
],
|
| 197 |
+
"bos_token": null,
|
| 198 |
+
"clean_up_tokenization_spaces": false,
|
| 199 |
+
"eos_token": "<|im_end|>",
|
| 200 |
+
"errors": "replace",
|
| 201 |
+
"extra_special_tokens": {},
|
| 202 |
+
"model_max_length": 131072,
|
| 203 |
+
"pad_token": "<|vision_pad|>",
|
| 204 |
+
"padding_side": "left",
|
| 205 |
+
"split_special_tokens": false,
|
| 206 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 207 |
+
"unk_token": null,
|
| 208 |
+
"chat_template": "{%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}\n{%- else %}\n {{- '<|im_start|>system\n<|im_end|>\n' }}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == 'user') or (message.role == 'system' and not loop.first) or (message.role == 'assistant') %}\n {{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\n' }}\n{%- endif %}"
|
| 209 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|