

Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +2 -0
- README.md +240 -3
- added_tokens.json +28 -0
- chat_template.jinja +117 -0
- config.json +277 -0
- generation_config.json +13 -0
- merges.txt +0 -0
- model-00001-of-00040.safetensors +3 -0
- model-00002-of-00040.safetensors +3 -0
- model-00003-of-00040.safetensors +3 -0
- model-00004-of-00040.safetensors +3 -0
- model-00005-of-00040.safetensors +3 -0
- model-00006-of-00040.safetensors +3 -0
- model-00007-of-00040.safetensors +3 -0
- model-00008-of-00040.safetensors +3 -0
- model-00009-of-00040.safetensors +3 -0
- model-00010-of-00040.safetensors +3 -0
- model-00011-of-00040.safetensors +3 -0
- model-00012-of-00040.safetensors +3 -0
- model-00013-of-00040.safetensors +3 -0
- model-00014-of-00040.safetensors +3 -0
- model-00015-of-00040.safetensors +3 -0
- model-00016-of-00040.safetensors +3 -0
- model-00017-of-00040.safetensors +3 -0
- model-00018-of-00040.safetensors +3 -0
- model-00019-of-00040.safetensors +3 -0
- model-00020-of-00040.safetensors +3 -0
- model-00021-of-00040.safetensors +3 -0
- model-00022-of-00040.safetensors +3 -0
- model-00023-of-00040.safetensors +3 -0
- model-00024-of-00040.safetensors +3 -0
- model-00025-of-00040.safetensors +3 -0
- model-00026-of-00040.safetensors +3 -0
- model-00027-of-00040.safetensors +3 -0
- model-00028-of-00040.safetensors +3 -0
- model-00029-of-00040.safetensors +3 -0
- model-00030-of-00040.safetensors +3 -0
- model-00031-of-00040.safetensors +3 -0
- model-00032-of-00040.safetensors +3 -0
- model-00033-of-00040.safetensors +3 -0
- model-00034-of-00040.safetensors +3 -0
- model-00035-of-00040.safetensors +3 -0
- model-00036-of-00040.safetensors +3 -0
- model-00037-of-00040.safetensors +3 -0
- model-00038-of-00040.safetensors +3 -0
- model-00039-of-00040.safetensors +3 -0
- model-00040-of-00040.safetensors +3 -0
- model.safetensors.index.json +3 -0
- qwen3_coder_detector_sgl.py +474 -0
- qwen3coder_tool_parser_vllm.py +690 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
model.safetensors.index.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,240 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- unsloth
|
| 4 |
+
base_model:
|
| 5 |
+
- Qwen/Qwen3-Coder-Next-FP8
|
| 6 |
+
library_name: transformers
|
| 7 |
+
license: apache-2.0
|
| 8 |
+
license_link: https://huggingface.co/Qwen/Qwen3-Coder-Next/blob/main/LICENSE
|
| 9 |
+
pipeline_tag: text-generation
|
| 10 |
+
---
|
| 11 |
+
> [!NOTE]
|
| 12 |
+
> Includes Unsloth **chat template fixes**! <br> For `llama.cpp`, use `--jinja`
|
| 13 |
+
>
|
| 14 |
+
|
| 15 |
+
<div>
|
| 16 |
+
<p style="margin-top: 0;margin-bottom: 0;">
|
| 17 |
+
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
|
| 18 |
+
</p>
|
| 19 |
+
<div style="display: flex; gap: 5px; align-items: center; ">
|
| 20 |
+
<a href="https://github.com/unslothai/unsloth/">
|
| 21 |
+
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
|
| 22 |
+
</a>
|
| 23 |
+
<a href="https://discord.gg/unsloth">
|
| 24 |
+
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
|
| 25 |
+
</a>
|
| 26 |
+
<a href="https://docs.unsloth.ai/">
|
| 27 |
+
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
|
| 28 |
+
</a>
|
| 29 |
+
</div>
|
| 30 |
+
</div>
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# Qwen3-Coder-Next-FP8
|
| 34 |
+
|
| 35 |
+
## Highlights
|
| 36 |
+
|
| 37 |
+
Today, we're announcing **Qwen3-Coder-Next-FP8**, an open-weight language model designed specifically for coding agents and local development. It features the following key enhancements:
|
| 38 |
+
|
| 39 |
+
- **Super Efficient with Significant Performance**: With only 3B activated parameters (80B total parameters), it achieves performance comparable to models with 10–20x more active parameters, making it highly cost-effective for agent deployment.
|
| 40 |
+
- **Advanced Agentic Capabilities**: Through an elaborate training recipe, it excels at long-horizon reasoning, complex tool usage, and recovery from execution failures, ensuring robust performance in dynamic coding tasks.
|
| 41 |
+
- **Versatile Integration with Real-World IDE**: Its 256k context length, combined with adaptability to various scaffold templates, enables seamless integration with different CLI/IDE platforms (e.g., Claude Code, Qwen Code, Qoder, Kilo, Trae, Cline, etc.), supporting diverse development environments.
|
| 42 |
+
|
| 43 |
+
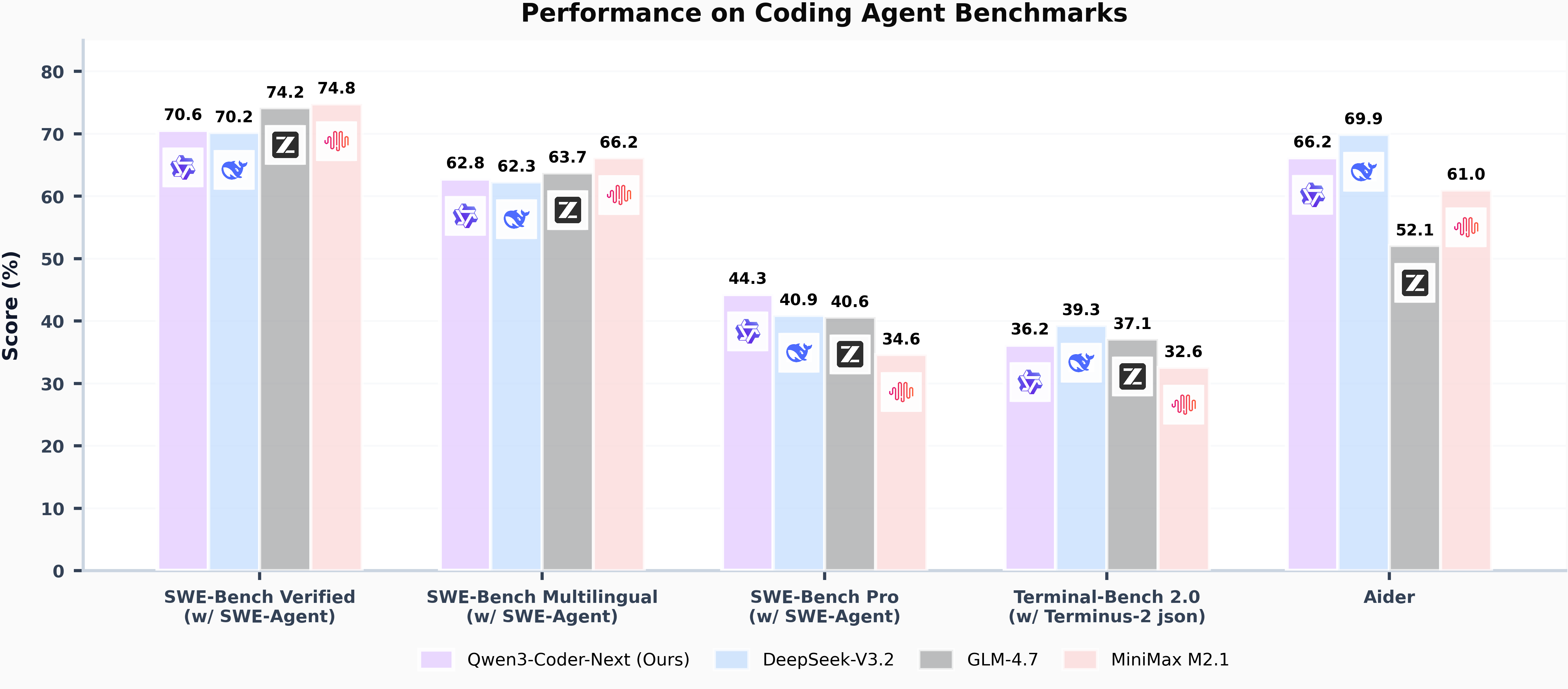
|
| 44 |
+
|
| 45 |
+
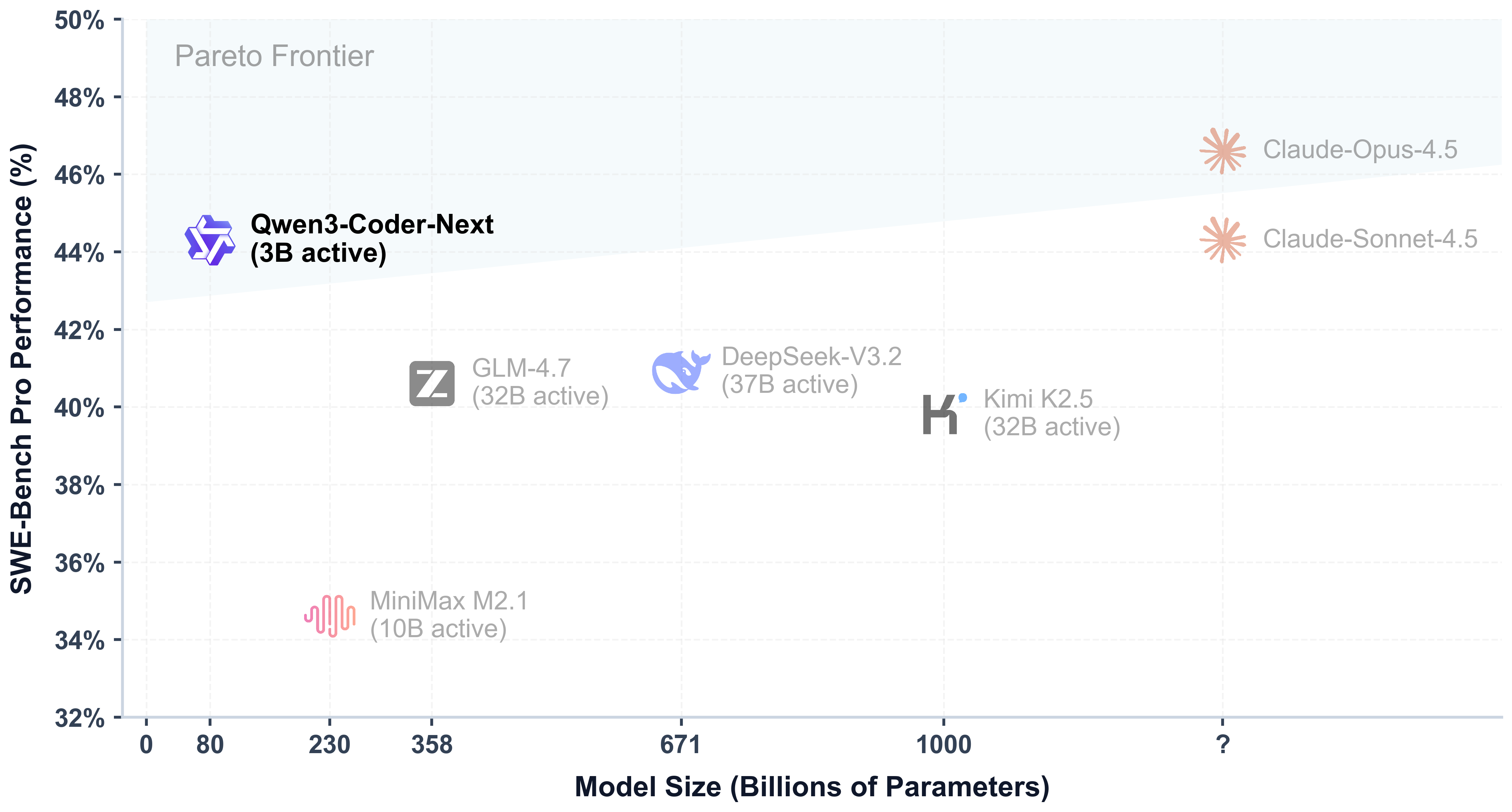
|
| 46 |
+
|
| 47 |
+
> [!Note]
|
| 48 |
+
> This repository contains the **FP8-quantized Qwen3-Coder-Next** model checkpoint for convenience and performance.
|
| 49 |
+
> The quantization method is "fine-grained fp8" quantization with block size of 128.
|
| 50 |
+
> You can find more details in the `quantization_config` field in `config.json`.
|
| 51 |
+
>
|
| 52 |
+
> In addition, the experimental results presented in this model card are obtained from the original bfloat16 model prior to FP8 quantization.
|
| 53 |
+
|
| 54 |
+
## Model Overview
|
| 55 |
+
|
| 56 |
+
**Qwen3-Coder-Next-FP8** has the following features:
|
| 57 |
+
- Type: Causal Language Models
|
| 58 |
+
- Training Stage: Pretraining & Post-training
|
| 59 |
+
- Number of Parameters: 80B in total and 3B activated
|
| 60 |
+
- Number of Parameters (Non-Embedding): 79B
|
| 61 |
+
- Hidden Dimension: 2048
|
| 62 |
+
- Number of Layers: 48
|
| 63 |
+
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> 1 \* (Gated Attention -> MoE))
|
| 64 |
+
- Gated Attention:
|
| 65 |
+
- Number of Attention Heads: 16 for Q and 2 for KV
|
| 66 |
+
- Head Dimension: 256
|
| 67 |
+
- Rotary Position Embedding Dimension: 64
|
| 68 |
+
- Gated DeltaNet:
|
| 69 |
+
- Number of Linear Attention Heads: 32 for V and 16 for QK
|
| 70 |
+
- Head Dimension: 128
|
| 71 |
+
- Mixture of Experts:
|
| 72 |
+
- Number of Experts: 512
|
| 73 |
+
- Number of Activated Experts: 10
|
| 74 |
+
- Number of Shared Experts: 1
|
| 75 |
+
- Expert Intermediate Dimension: 512
|
| 76 |
+
- Context Length: 262,144 natively
|
| 77 |
+
|
| 78 |
+
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
|
| 79 |
+
|
| 80 |
+
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwen.ai/blog?id=qwen3-coder-next), [GitHub](https://github.com/QwenLM/Qwen3-Coder), and [Documentation](https://qwen.readthedocs.io/en/latest/).
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## Quickstart
|
| 84 |
+
|
| 85 |
+
We advise you to use the latest version of `transformers`.
|
| 86 |
+
|
| 87 |
+
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
|
| 88 |
+
```python
|
| 89 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 90 |
+
|
| 91 |
+
model_name = "Qwen/Qwen3-Coder-Next-FP8"
|
| 92 |
+
|
| 93 |
+
# load the tokenizer and the model
|
| 94 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 95 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 96 |
+
model_name,
|
| 97 |
+
torch_dtype="auto",
|
| 98 |
+
device_map="auto"
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
# prepare the model input
|
| 102 |
+
prompt = "Write a quick sort algorithm."
|
| 103 |
+
messages = [
|
| 104 |
+
{"role": "user", "content": prompt}
|
| 105 |
+
]
|
| 106 |
+
text = tokenizer.apply_chat_template(
|
| 107 |
+
messages,
|
| 108 |
+
tokenize=False,
|
| 109 |
+
add_generation_prompt=True,
|
| 110 |
+
)
|
| 111 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 112 |
+
|
| 113 |
+
# conduct text completion
|
| 114 |
+
generated_ids = model.generate(
|
| 115 |
+
**model_inputs,
|
| 116 |
+
max_new_tokens=65536
|
| 117 |
+
)
|
| 118 |
+
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
|
| 119 |
+
|
| 120 |
+
content = tokenizer.decode(output_ids, skip_special_tokens=True)
|
| 121 |
+
|
| 122 |
+
print("content:", content)
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
|
| 126 |
+
|
| 127 |
+
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
|
| 128 |
+
|
| 129 |
+
## Deployment
|
| 130 |
+
|
| 131 |
+
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
|
| 132 |
+
|
| 133 |
+
### SGLang
|
| 134 |
+
|
| 135 |
+
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
|
| 136 |
+
SGLang could be used to launch a server with OpenAI-compatible API service.
|
| 137 |
+
|
| 138 |
+
`sglang>=v0.5.8` is required for Qwen3-Coder-Next-FP8, which can be installed using:
|
| 139 |
+
```shell
|
| 140 |
+
pip install 'sglang[all]>=v0.5.8'
|
| 141 |
+
```
|
| 142 |
+
See [its documentation](https://docs.sglang.ai/get_started/install.html) for more details.
|
| 143 |
+
|
| 144 |
+
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 145 |
+
```shell
|
| 146 |
+
python -m sglang.launch_server --model Qwen/Qwen3-Coder-Next-FP8 --port 30000 --tp-size 2 --tool-call-parser qwen3_coder```
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
> [!Note]
|
| 150 |
+
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fails to start.
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
### vLLM
|
| 154 |
+
|
| 155 |
+
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
|
| 156 |
+
vLLM could be used to launch a server with OpenAI-compatible API service.
|
| 157 |
+
|
| 158 |
+
`vllm>=0.15.0` is required for Qwen3-Coder-Next-FP8, which can be installed using:
|
| 159 |
+
```shell
|
| 160 |
+
pip install 'vllm>=0.15.0'
|
| 161 |
+
```
|
| 162 |
+
See [its documentation](https://docs.vllm.ai/en/stable/getting_started/installation/index.html) for more details.
|
| 163 |
+
|
| 164 |
+
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 165 |
+
```shell
|
| 166 |
+
vllm serve Qwen/Qwen3-Coder-Next-FP8 --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coder
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
> [!Note]
|
| 170 |
+
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fails to start.
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
## Agentic Coding
|
| 174 |
+
|
| 175 |
+
Qwen3-Coder-Next-FP8 excels in tool calling capabilities.
|
| 176 |
+
|
| 177 |
+
You can simply define or use any tools as following example.
|
| 178 |
+
```python
|
| 179 |
+
# Your tool implementation
|
| 180 |
+
def square_the_number(num: float) -> dict:
|
| 181 |
+
return num ** 2
|
| 182 |
+
|
| 183 |
+
# Define Tools
|
| 184 |
+
tools=[
|
| 185 |
+
{
|
| 186 |
+
"type":"function",
|
| 187 |
+
"function":{
|
| 188 |
+
"name": "square_the_number",
|
| 189 |
+
"description": "output the square of the number.",
|
| 190 |
+
"parameters": {
|
| 191 |
+
"type": "object",
|
| 192 |
+
"required": ["input_num"],
|
| 193 |
+
"properties": {
|
| 194 |
+
'input_num': {
|
| 195 |
+
'type': 'number',
|
| 196 |
+
'description': 'input_num is a number that will be squared'
|
| 197 |
+
}
|
| 198 |
+
},
|
| 199 |
+
}
|
| 200 |
+
}
|
| 201 |
+
}
|
| 202 |
+
]
|
| 203 |
+
|
| 204 |
+
from openai import OpenAI
|
| 205 |
+
# Define LLM
|
| 206 |
+
client = OpenAI(
|
| 207 |
+
# Use a custom endpoint compatible with OpenAI API
|
| 208 |
+
base_url='http://localhost:8000/v1', # api_base
|
| 209 |
+
api_key="EMPTY"
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
messages = [{'role': 'user', 'content': 'square the number 1024'}]
|
| 213 |
+
|
| 214 |
+
completion = client.chat.completions.create(
|
| 215 |
+
messages=messages,
|
| 216 |
+
model="Qwen3-Coder-Next-FP8",
|
| 217 |
+
max_tokens=65536,
|
| 218 |
+
tools=tools,
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
print(completion.choices[0])
|
| 222 |
+
```
|
| 223 |
+
|
| 224 |
+
## Best Practices
|
| 225 |
+
|
| 226 |
+
To achieve optimal performance, we recommend the following sampling parameters: `temperature=1.0`, `top_p=0.95`, `top_k=40`.
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
## Citation
|
| 230 |
+
|
| 231 |
+
If you find our work helpful, feel free to give us a cite.
|
| 232 |
+
|
| 233 |
+
```
|
| 234 |
+
@techreport{qwen_qwen3_coder_next_tech_report,
|
| 235 |
+
title = {Qwen3-Coder-Next Technical Report},
|
| 236 |
+
author = {{Qwen Team}},
|
| 237 |
+
url = {https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf},
|
| 238 |
+
note = {Accessed: 2026-02-03}
|
| 239 |
+
}
|
| 240 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</think>": 151668,
|
| 3 |
+
"</tool_call>": 151658,
|
| 4 |
+
"</tool_response>": 151666,
|
| 5 |
+
"<think>": 151667,
|
| 6 |
+
"<tool_call>": 151657,
|
| 7 |
+
"<tool_response>": 151665,
|
| 8 |
+
"<|box_end|>": 151649,
|
| 9 |
+
"<|box_start|>": 151648,
|
| 10 |
+
"<|endoftext|>": 151643,
|
| 11 |
+
"<|file_sep|>": 151664,
|
| 12 |
+
"<|fim_middle|>": 151660,
|
| 13 |
+
"<|fim_pad|>": 151662,
|
| 14 |
+
"<|fim_prefix|>": 151659,
|
| 15 |
+
"<|fim_suffix|>": 151661,
|
| 16 |
+
"<|im_end|>": 151645,
|
| 17 |
+
"<|im_start|>": 151644,
|
| 18 |
+
"<|image_pad|>": 151655,
|
| 19 |
+
"<|object_ref_end|>": 151647,
|
| 20 |
+
"<|object_ref_start|>": 151646,
|
| 21 |
+
"<|quad_end|>": 151651,
|
| 22 |
+
"<|quad_start|>": 151650,
|
| 23 |
+
"<|repo_name|>": 151663,
|
| 24 |
+
"<|video_pad|>": 151656,
|
| 25 |
+
"<|vision_end|>": 151653,
|
| 26 |
+
"<|vision_pad|>": 151654,
|
| 27 |
+
"<|vision_start|>": 151652
|
| 28 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{% macro render_extra_keys(json_dict, handled_keys) %}
|
| 2 |
+
{%- if json_dict is mapping %}
|
| 3 |
+
{%- for json_key in json_dict if json_key not in handled_keys %}
|
| 4 |
+
{%- if json_dict[json_key] is string %}
|
| 5 |
+
{{-'\n<' ~ json_key ~ '>' ~ (json_dict[json_key] | string) ~ '</' ~ json_key ~ '>' }}
|
| 6 |
+
{%- else %}
|
| 7 |
+
{{- '\n<' ~ json_key ~ '>' ~ (json_dict[json_key] | tojson | safe) ~ '</' ~ json_key ~ '>' }}
|
| 8 |
+
{%- endif %}
|
| 9 |
+
{%- endfor %}
|
| 10 |
+
{%- endif %}
|
| 11 |
+
{%- endmacro %}
|
| 12 |
+
|
| 13 |
+
{%- if messages[0]["role"] == "system" %}
|
| 14 |
+
{%- set system_message = messages[0]["content"] %}
|
| 15 |
+
{%- set loop_messages = messages[1:] %}
|
| 16 |
+
{%- else %}
|
| 17 |
+
{%- set loop_messages = messages %}
|
| 18 |
+
{%- endif %}
|
| 19 |
+
|
| 20 |
+
{%- if not tools is defined %}
|
| 21 |
+
{%- set tools = [] %}
|
| 22 |
+
{%- endif %}
|
| 23 |
+
|
| 24 |
+
{%- if system_message is defined %}
|
| 25 |
+
{{- "<|im_start|>system\n" + system_message }}
|
| 26 |
+
{%- else %}
|
| 27 |
+
{%- if tools is iterable and tools | length > 0 %}
|
| 28 |
+
{{- "<|im_start|>system\nYou are Qwen, a helpful AI assistant that can interact with a computer to solve tasks." }}
|
| 29 |
+
{%- endif %}
|
| 30 |
+
{%- endif %}
|
| 31 |
+
{%- if tools is iterable and tools | length > 0 %}
|
| 32 |
+
{{- "\n\n# Tools\n\nYou have access to the following functions:\n\n" }}
|
| 33 |
+
{{- "<tools>" }}
|
| 34 |
+
{%- for tool in tools %}
|
| 35 |
+
{%- if tool.function is defined %}
|
| 36 |
+
{%- set tool = tool.function %}
|
| 37 |
+
{%- endif %}
|
| 38 |
+
{{- "\n<function>\n<name>" ~ tool.name ~ "</name>" }}
|
| 39 |
+
{%- if tool.description is defined %}
|
| 40 |
+
{{- '\n<description>' ~ (tool.description | trim) ~ '</description>' }}
|
| 41 |
+
{%- endif %}
|
| 42 |
+
{{- '\n<parameters>' }}
|
| 43 |
+
{%- if tool.parameters is defined and tool.parameters is mapping and tool.parameters.properties is defined and tool.parameters.properties is mapping %}
|
| 44 |
+
{%- for param_name, param_fields in tool.parameters.properties|items %}
|
| 45 |
+
{{- '\n<parameter>' }}
|
| 46 |
+
{{- '\n<name>' ~ param_name ~ '</name>' }}
|
| 47 |
+
{%- if param_fields.type is defined %}
|
| 48 |
+
{{- '\n<type>' ~ (param_fields.type | string) ~ '</type>' }}
|
| 49 |
+
{%- endif %}
|
| 50 |
+
{%- if param_fields.description is defined %}
|
| 51 |
+
{{- '\n<description>' ~ (param_fields.description | trim) ~ '</description>' }}
|
| 52 |
+
{%- endif %}
|
| 53 |
+
{%- set handled_keys = ['name', 'type', 'description'] %}
|
| 54 |
+
{{- render_extra_keys(param_fields, handled_keys) }}
|
| 55 |
+
{{- '\n</parameter>' }}
|
| 56 |
+
{%- endfor %}
|
| 57 |
+
{%- endif %}
|
| 58 |
+
{%- set handled_keys = ['type', 'properties'] %}
|
| 59 |
+
{{- render_extra_keys(tool.parameters, handled_keys) }}
|
| 60 |
+
{{- '\n</parameters>' }}
|
| 61 |
+
{%- set handled_keys = ['type', 'name', 'description', 'parameters'] %}
|
| 62 |
+
{{- render_extra_keys(tool, handled_keys) }}
|
| 63 |
+
{{- '\n</function>' }}
|
| 64 |
+
{%- endfor %}
|
| 65 |
+
{{- "\n</tools>" }}
|
| 66 |
+
{{- '\n\nIf you choose to call a function ONLY reply in the following format with NO suffix:\n\n<tool_call>\n<function=example_function_name>\n<parameter=example_parameter_1>\nvalue_1\n</parameter>\n<parameter=example_parameter_2>\nThis is the value for the second parameter\nthat can span\nmultiple lines\n</parameter>\n</function>\n</tool_call>\n\n<IMPORTANT>\nReminder:\n- Function calls MUST follow the specified format: an inner <function=...></function> block must be nested within <tool_call></tool_call> XML tags\n- Required parameters MUST be specified\n- You may provide optional reasoning for your function call in natural language BEFORE the function call, but NOT after\n- If there is no function call available, answer the question like normal with your current knowledge and do not tell the user about function calls\n</IMPORTANT>' }}
|
| 67 |
+
{%- endif %}
|
| 68 |
+
{%- if system_message is defined %}
|
| 69 |
+
{{- '<|im_end|>\n' }}
|
| 70 |
+
{%- else %}
|
| 71 |
+
{%- if tools is iterable and tools | length > 0 %}
|
| 72 |
+
{{- '<|im_end|>\n' }}
|
| 73 |
+
{%- endif %}
|
| 74 |
+
{%- endif %}
|
| 75 |
+
{%- for message in loop_messages %}
|
| 76 |
+
{%- if message.role == "assistant" and message.tool_calls is defined and message.tool_calls is iterable and message.tool_calls | length > 0 %}
|
| 77 |
+
{{- '<|im_start|>' + message.role }}
|
| 78 |
+
{%- if message.content is defined and message.content is string and message.content | trim | length > 0 %}
|
| 79 |
+
{{- '\n' + message.content | trim + '\n' }}
|
| 80 |
+
{%- endif %}
|
| 81 |
+
{%- for tool_call in message.tool_calls %}
|
| 82 |
+
{%- if tool_call.function is defined %}
|
| 83 |
+
{%- set tool_call = tool_call.function %}
|
| 84 |
+
{%- endif %}
|
| 85 |
+
{{- '\n<tool_call>\n<function=' + tool_call.name + '>\n' }}
|
| 86 |
+
{%- if tool_call.arguments is defined %}
|
| 87 |
+
{%- for args_name, args_value in tool_call.arguments|items %}
|
| 88 |
+
{{- '<parameter=' + args_name + '>\n' }}
|
| 89 |
+
{%- set args_value = args_value if args_value is string else args_value | tojson | safe %}
|
| 90 |
+
{{- args_value }}
|
| 91 |
+
{{- '\n</parameter>\n' }}
|
| 92 |
+
{%- endfor %}
|
| 93 |
+
{%- endif %}
|
| 94 |
+
{{- '</function>\n</tool_call>' }}
|
| 95 |
+
{%- endfor %}
|
| 96 |
+
{{- '<|im_end|>\n' }}
|
| 97 |
+
{%- elif message.role == "user" or message.role == "system" or message.role == "assistant" %}
|
| 98 |
+
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
|
| 99 |
+
{%- elif message.role == "tool" %}
|
| 100 |
+
{%- if loop.previtem and loop.previtem.role != "tool" %}
|
| 101 |
+
{{- '<|im_start|>user' }}
|
| 102 |
+
{%- endif %}
|
| 103 |
+
{{- '\n<tool_response>\n' }}
|
| 104 |
+
{{- message.content }}
|
| 105 |
+
{{- '\n</tool_response>' }}
|
| 106 |
+
{%- if not loop.last and loop.nextitem.role != "tool" %}
|
| 107 |
+
{{- '<|im_end|>\n' }}
|
| 108 |
+
{%- elif loop.last %}
|
| 109 |
+
{{- '<|im_end|>\n' }}
|
| 110 |
+
{%- endif %}
|
| 111 |
+
{%- else %}
|
| 112 |
+
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>\n' }}
|
| 113 |
+
{%- endif %}
|
| 114 |
+
{%- endfor %}
|
| 115 |
+
{%- if add_generation_prompt %}
|
| 116 |
+
{{- '<|im_start|>assistant\n' }}
|
| 117 |
+
{%- endif %}
|
config.json
ADDED
|
@@ -0,0 +1,277 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen3NextForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0,
|
| 7 |
+
"decoder_sparse_step": 1,
|
| 8 |
+
"torch_dtype": "bfloat16",
|
| 9 |
+
"eos_token_id": 151645,
|
| 10 |
+
"full_attention_interval": 4,
|
| 11 |
+
"head_dim": 256,
|
| 12 |
+
"hidden_act": "silu",
|
| 13 |
+
"hidden_size": 2048,
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"intermediate_size": 5120,
|
| 16 |
+
"layer_types": [
|
| 17 |
+
"linear_attention",
|
| 18 |
+
"linear_attention",
|
| 19 |
+
"linear_attention",
|
| 20 |
+
"full_attention",
|
| 21 |
+
"linear_attention",
|
| 22 |
+
"linear_attention",
|
| 23 |
+
"linear_attention",
|
| 24 |
+
"full_attention",
|
| 25 |
+
"linear_attention",
|
| 26 |
+
"linear_attention",
|
| 27 |
+
"linear_attention",
|
| 28 |
+
"full_attention",
|
| 29 |
+
"linear_attention",
|
| 30 |
+
"linear_attention",
|
| 31 |
+
"linear_attention",
|
| 32 |
+
"full_attention",
|
| 33 |
+
"linear_attention",
|
| 34 |
+
"linear_attention",
|
| 35 |
+
"linear_attention",
|
| 36 |
+
"full_attention",
|
| 37 |
+
"linear_attention",
|
| 38 |
+
"linear_attention",
|
| 39 |
+
"linear_attention",
|
| 40 |
+
"full_attention",
|
| 41 |
+
"linear_attention",
|
| 42 |
+
"linear_attention",
|
| 43 |
+
"linear_attention",
|
| 44 |
+
"full_attention",
|
| 45 |
+
"linear_attention",
|
| 46 |
+
"linear_attention",
|
| 47 |
+
"linear_attention",
|
| 48 |
+
"full_attention",
|
| 49 |
+
"linear_attention",
|
| 50 |
+
"linear_attention",
|
| 51 |
+
"linear_attention",
|
| 52 |
+
"full_attention",
|
| 53 |
+
"linear_attention",
|
| 54 |
+
"linear_attention",
|
| 55 |
+
"linear_attention",
|
| 56 |
+
"full_attention",
|
| 57 |
+
"linear_attention",
|
| 58 |
+
"linear_attention",
|
| 59 |
+
"linear_attention",
|
| 60 |
+
"full_attention",
|
| 61 |
+
"linear_attention",
|
| 62 |
+
"linear_attention",
|
| 63 |
+
"linear_attention",
|
| 64 |
+
"full_attention"
|
| 65 |
+
],
|
| 66 |
+
"linear_conv_kernel_dim": 4,
|
| 67 |
+
"linear_key_head_dim": 128,
|
| 68 |
+
"linear_num_key_heads": 16,
|
| 69 |
+
"linear_num_value_heads": 32,
|
| 70 |
+
"linear_value_head_dim": 128,
|
| 71 |
+
"max_position_embeddings": 262144,
|
| 72 |
+
"mlp_only_layers": [],
|
| 73 |
+
"model_type": "qwen3_next",
|
| 74 |
+
"moe_intermediate_size": 512,
|
| 75 |
+
"norm_topk_prob": true,
|
| 76 |
+
"num_attention_heads": 16,
|
| 77 |
+
"num_experts": 512,
|
| 78 |
+
"num_experts_per_tok": 10,
|
| 79 |
+
"num_hidden_layers": 48,
|
| 80 |
+
"num_key_value_heads": 2,
|
| 81 |
+
"output_router_logits": false,
|
| 82 |
+
"pad_token_id": 151654,
|
| 83 |
+
"partial_rotary_factor": 0.25,
|
| 84 |
+
"quantization_config": {
|
| 85 |
+
"act_per_tensor": false,
|
| 86 |
+
"activation_scheme": "dynamic",
|
| 87 |
+
"modules_to_not_convert": [
|
| 88 |
+
"lm_head",
|
| 89 |
+
"model.embed_tokens",
|
| 90 |
+
"model.layers.0.linear_attn.conv1d",
|
| 91 |
+
"model.layers.0.linear_attn.in_proj_ba",
|
| 92 |
+
"model.layers.0.mlp.gate",
|
| 93 |
+
"model.layers.0.mlp.shared_expert_gate",
|
| 94 |
+
"model.layers.1.linear_attn.conv1d",
|
| 95 |
+
"model.layers.1.linear_attn.in_proj_ba",
|
| 96 |
+
"model.layers.1.mlp.gate",
|
| 97 |
+
"model.layers.1.mlp.shared_expert_gate",
|
| 98 |
+
"model.layers.10.linear_attn.conv1d",
|
| 99 |
+
"model.layers.10.linear_attn.in_proj_ba",
|
| 100 |
+
"model.layers.10.mlp.gate",
|
| 101 |
+
"model.layers.10.mlp.shared_expert_gate",
|
| 102 |
+
"model.layers.11.mlp.gate",
|
| 103 |
+
"model.layers.11.mlp.shared_expert_gate",
|
| 104 |
+
"model.layers.12.linear_attn.conv1d",
|
| 105 |
+
"model.layers.12.linear_attn.in_proj_ba",
|
| 106 |
+
"model.layers.12.mlp.gate",
|
| 107 |
+
"model.layers.12.mlp.shared_expert_gate",
|
| 108 |
+
"model.layers.13.linear_attn.conv1d",
|
| 109 |
+
"model.layers.13.linear_attn.in_proj_ba",
|
| 110 |
+
"model.layers.13.mlp.gate",
|
| 111 |
+
"model.layers.13.mlp.shared_expert_gate",
|
| 112 |
+
"model.layers.14.linear_attn.conv1d",
|
| 113 |
+
"model.layers.14.linear_attn.in_proj_ba",
|
| 114 |
+
"model.layers.14.mlp.gate",
|
| 115 |
+
"model.layers.14.mlp.shared_expert_gate",
|
| 116 |
+
"model.layers.15.mlp.gate",
|
| 117 |
+
"model.layers.15.mlp.shared_expert_gate",
|
| 118 |
+
"model.layers.16.linear_attn.conv1d",
|
| 119 |
+
"model.layers.16.linear_attn.in_proj_ba",
|
| 120 |
+
"model.layers.16.mlp.gate",
|
| 121 |
+
"model.layers.16.mlp.shared_expert_gate",
|
| 122 |
+
"model.layers.17.linear_attn.conv1d",
|
| 123 |
+
"model.layers.17.linear_attn.in_proj_ba",
|
| 124 |
+
"model.layers.17.mlp.gate",
|
| 125 |
+
"model.layers.17.mlp.shared_expert_gate",
|
| 126 |
+
"model.layers.18.linear_attn.conv1d",
|
| 127 |
+
"model.layers.18.linear_attn.in_proj_ba",
|
| 128 |
+
"model.layers.18.mlp.gate",
|
| 129 |
+
"model.layers.18.mlp.shared_expert_gate",
|
| 130 |
+
"model.layers.19.mlp.gate",
|
| 131 |
+
"model.layers.19.mlp.shared_expert_gate",
|
| 132 |
+
"model.layers.2.linear_attn.conv1d",
|
| 133 |
+
"model.layers.2.linear_attn.in_proj_ba",
|
| 134 |
+
"model.layers.2.mlp.gate",
|
| 135 |
+
"model.layers.2.mlp.shared_expert_gate",
|
| 136 |
+
"model.layers.20.linear_attn.conv1d",
|
| 137 |
+
"model.layers.20.linear_attn.in_proj_ba",
|
| 138 |
+
"model.layers.20.mlp.gate",
|
| 139 |
+
"model.layers.20.mlp.shared_expert_gate",
|
| 140 |
+
"model.layers.21.linear_attn.conv1d",
|
| 141 |
+
"model.layers.21.linear_attn.in_proj_ba",
|
| 142 |
+
"model.layers.21.mlp.gate",
|
| 143 |
+
"model.layers.21.mlp.shared_expert_gate",
|
| 144 |
+
"model.layers.22.linear_attn.conv1d",
|
| 145 |
+
"model.layers.22.linear_attn.in_proj_ba",
|
| 146 |
+
"model.layers.22.mlp.gate",
|
| 147 |
+
"model.layers.22.mlp.shared_expert_gate",
|
| 148 |
+
"model.layers.23.mlp.gate",
|
| 149 |
+
"model.layers.23.mlp.shared_expert_gate",
|
| 150 |
+
"model.layers.24.linear_attn.conv1d",
|
| 151 |
+
"model.layers.24.linear_attn.in_proj_ba",
|
| 152 |
+
"model.layers.24.mlp.gate",
|
| 153 |
+
"model.layers.24.mlp.shared_expert_gate",
|
| 154 |
+
"model.layers.25.linear_attn.conv1d",
|
| 155 |
+
"model.layers.25.linear_attn.in_proj_ba",
|
| 156 |
+
"model.layers.25.mlp.gate",
|
| 157 |
+
"model.layers.25.mlp.shared_expert_gate",
|
| 158 |
+
"model.layers.26.linear_attn.conv1d",
|
| 159 |
+
"model.layers.26.linear_attn.in_proj_ba",
|
| 160 |
+
"model.layers.26.mlp.gate",
|
| 161 |
+
"model.layers.26.mlp.shared_expert_gate",
|
| 162 |
+
"model.layers.27.mlp.gate",
|
| 163 |
+
"model.layers.27.mlp.shared_expert_gate",
|
| 164 |
+
"model.layers.28.linear_attn.conv1d",
|
| 165 |
+
"model.layers.28.linear_attn.in_proj_ba",
|
| 166 |
+
"model.layers.28.mlp.gate",
|
| 167 |
+
"model.layers.28.mlp.shared_expert_gate",
|
| 168 |
+
"model.layers.29.linear_attn.conv1d",
|
| 169 |
+
"model.layers.29.linear_attn.in_proj_ba",
|
| 170 |
+
"model.layers.29.mlp.gate",
|
| 171 |
+
"model.layers.29.mlp.shared_expert_gate",
|
| 172 |
+
"model.layers.3.mlp.gate",
|
| 173 |
+
"model.layers.3.mlp.shared_expert_gate",
|
| 174 |
+
"model.layers.30.linear_attn.conv1d",
|
| 175 |
+
"model.layers.30.linear_attn.in_proj_ba",
|
| 176 |
+
"model.layers.30.mlp.gate",
|
| 177 |
+
"model.layers.30.mlp.shared_expert_gate",
|
| 178 |
+
"model.layers.31.mlp.gate",
|
| 179 |
+
"model.layers.31.mlp.shared_expert_gate",
|
| 180 |
+
"model.layers.32.linear_attn.conv1d",
|
| 181 |
+
"model.layers.32.linear_attn.in_proj_ba",
|
| 182 |
+
"model.layers.32.mlp.gate",
|
| 183 |
+
"model.layers.32.mlp.shared_expert_gate",
|
| 184 |
+
"model.layers.33.linear_attn.conv1d",
|
| 185 |
+
"model.layers.33.linear_attn.in_proj_ba",
|
| 186 |
+
"model.layers.33.mlp.gate",
|
| 187 |
+
"model.layers.33.mlp.shared_expert_gate",
|
| 188 |
+
"model.layers.34.linear_attn.conv1d",
|
| 189 |
+
"model.layers.34.linear_attn.in_proj_ba",
|
| 190 |
+
"model.layers.34.mlp.gate",
|
| 191 |
+
"model.layers.34.mlp.shared_expert_gate",
|
| 192 |
+
"model.layers.35.mlp.gate",
|
| 193 |
+
"model.layers.35.mlp.shared_expert_gate",
|
| 194 |
+
"model.layers.36.linear_attn.conv1d",
|
| 195 |
+
"model.layers.36.linear_attn.in_proj_ba",
|
| 196 |
+
"model.layers.36.mlp.gate",
|
| 197 |
+
"model.layers.36.mlp.shared_expert_gate",
|
| 198 |
+
"model.layers.37.linear_attn.conv1d",
|
| 199 |
+
"model.layers.37.linear_attn.in_proj_ba",
|
| 200 |
+
"model.layers.37.mlp.gate",
|
| 201 |
+
"model.layers.37.mlp.shared_expert_gate",
|
| 202 |
+
"model.layers.38.linear_attn.conv1d",
|
| 203 |
+
"model.layers.38.linear_attn.in_proj_ba",
|
| 204 |
+
"model.layers.38.mlp.gate",
|
| 205 |
+
"model.layers.38.mlp.shared_expert_gate",
|
| 206 |
+
"model.layers.39.mlp.gate",
|
| 207 |
+
"model.layers.39.mlp.shared_expert_gate",
|
| 208 |
+
"model.layers.4.linear_attn.conv1d",
|
| 209 |
+
"model.layers.4.linear_attn.in_proj_ba",
|
| 210 |
+
"model.layers.4.mlp.gate",
|
| 211 |
+
"model.layers.4.mlp.shared_expert_gate",
|
| 212 |
+
"model.layers.40.linear_attn.conv1d",
|
| 213 |
+
"model.layers.40.linear_attn.in_proj_ba",
|
| 214 |
+
"model.layers.40.mlp.gate",
|
| 215 |
+
"model.layers.40.mlp.shared_expert_gate",
|
| 216 |
+
"model.layers.41.linear_attn.conv1d",
|
| 217 |
+
"model.layers.41.linear_attn.in_proj_ba",
|
| 218 |
+
"model.layers.41.mlp.gate",
|
| 219 |
+
"model.layers.41.mlp.shared_expert_gate",
|
| 220 |
+
"model.layers.42.linear_attn.conv1d",
|
| 221 |
+
"model.layers.42.linear_attn.in_proj_ba",
|
| 222 |
+
"model.layers.42.mlp.gate",
|
| 223 |
+
"model.layers.42.mlp.shared_expert_gate",
|
| 224 |
+
"model.layers.43.mlp.gate",
|
| 225 |
+
"model.layers.43.mlp.shared_expert_gate",
|
| 226 |
+
"model.layers.44.linear_attn.conv1d",
|
| 227 |
+
"model.layers.44.linear_attn.in_proj_ba",
|
| 228 |
+
"model.layers.44.mlp.gate",
|
| 229 |
+
"model.layers.44.mlp.shared_expert_gate",
|
| 230 |
+
"model.layers.45.linear_attn.conv1d",
|
| 231 |
+
"model.layers.45.linear_attn.in_proj_ba",
|
| 232 |
+
"model.layers.45.mlp.gate",
|
| 233 |
+
"model.layers.45.mlp.shared_expert_gate",
|
| 234 |
+
"model.layers.46.linear_attn.conv1d",
|
| 235 |
+
"model.layers.46.linear_attn.in_proj_ba",
|
| 236 |
+
"model.layers.46.mlp.gate",
|
| 237 |
+
"model.layers.46.mlp.shared_expert_gate",
|
| 238 |
+
"model.layers.47.mlp.gate",
|
| 239 |
+
"model.layers.47.mlp.shared_expert_gate",
|
| 240 |
+
"model.layers.5.linear_attn.conv1d",
|
| 241 |
+
"model.layers.5.linear_attn.in_proj_ba",
|
| 242 |
+
"model.layers.5.mlp.gate",
|
| 243 |
+
"model.layers.5.mlp.shared_expert_gate",
|
| 244 |
+
"model.layers.6.linear_attn.conv1d",
|
| 245 |
+
"model.layers.6.linear_attn.in_proj_ba",
|
| 246 |
+
"model.layers.6.mlp.gate",
|
| 247 |
+
"model.layers.6.mlp.shared_expert_gate",
|
| 248 |
+
"model.layers.7.mlp.gate",
|
| 249 |
+
"model.layers.7.mlp.shared_expert_gate",
|
| 250 |
+
"model.layers.8.linear_attn.conv1d",
|
| 251 |
+
"model.layers.8.linear_attn.in_proj_ba",
|
| 252 |
+
"model.layers.8.mlp.gate",
|
| 253 |
+
"model.layers.8.mlp.shared_expert_gate",
|
| 254 |
+
"model.layers.9.linear_attn.conv1d",
|
| 255 |
+
"model.layers.9.linear_attn.in_proj_ba",
|
| 256 |
+
"model.layers.9.mlp.gate",
|
| 257 |
+
"model.layers.9.mlp.shared_expert_gate"
|
| 258 |
+
],
|
| 259 |
+
"quant_method": "fp8",
|
| 260 |
+
"weight_block_size": [
|
| 261 |
+
128,
|
| 262 |
+
128
|
| 263 |
+
],
|
| 264 |
+
"weight_per_tensor": false
|
| 265 |
+
},
|
| 266 |
+
"rms_norm_eps": 1e-06,
|
| 267 |
+
"rope_scaling": null,
|
| 268 |
+
"rope_theta": 5000000,
|
| 269 |
+
"router_aux_loss_coef": 0.001,
|
| 270 |
+
"shared_expert_intermediate_size": 512,
|
| 271 |
+
"tie_word_embeddings": false,
|
| 272 |
+
"transformers_version": "4.57.6",
|
| 273 |
+
"unsloth_fixed": true,
|
| 274 |
+
"use_cache": true,
|
| 275 |
+
"use_sliding_window": false,
|
| 276 |
+
"vocab_size": 151936
|
| 277 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 151643,
|
| 9 |
+
"temperature": 1.0,
|
| 10 |
+
"top_k": 40,
|
| 11 |
+
"top_p": 0.95,
|
| 12 |
+
"transformers_version": "4.57.3"
|
| 13 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:81fc8306344bb5d37b3a1d6c267fb7b0f2cf05ecb05cd065016aab87e6a55a33
|
| 3 |
+
size 2313917472
|
model-00002-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7c1eb3b175b9122bf28e64dca9dac63696c229bd6e0ced2351a4e2c414aa33af
|
| 3 |
+
size 2001731528
|
model-00003-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62c034d5f7b21b25cc2497a9cebfbebbda500d0d3a9b08381d476c481dc2df5b
|
| 3 |
+
size 2001406544
|
model-00004-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:879eaa1ce8ba3b7c3e48c24deb039a9972bcb724f790945a916003efd4312616
|
| 3 |
+
size 2001732024
|
model-00005-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:785259af0e3e7959d48360927f9556f1b636a5d800dcbc8d2a11c295b9caab4f
|
| 3 |
+
size 2001732960
|
model-00006-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:79c183f8388e35516509d9488c2e6a6f0aaafc1ff5a3c8b1c872d5d23622c385
|
| 3 |
+
size 2002790192
|
model-00007-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5b33fd40d09ef4ddd75ac342c6661a3658e26d1b3ca7e38d0774a0b9d235c73a
|
| 3 |
+
size 2001731792
|
model-00008-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3993df6622752249b565409a8c339f933e2bc326d432c75385ade37f74c18257
|
| 3 |
+
size 2001731960
|
model-00009-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:074c68c97085550d3746cc6fb0e0ec74ee634c09c9bd59a9d1abb099e251ae89
|
| 3 |
+
size 2001737552
|
model-00010-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9ff4156992002e43012eabf9f0c7dcc7c9e7060d124af9ac188461aa4f93ef0d
|
| 3 |
+
size 2001411064
|
model-00011-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7a94ef41eabb382b138e781ac0f6054e649ee6e9583298e0b84a0dd75f4d4f97
|
| 3 |
+
size 2003119416
|
model-00012-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:185b7d1bfc64adfa9076918c56b77391d589e99d254c84b281fd79c8a2b8b98d
|
| 3 |
+
size 2001735720
|
model-00013-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f2a2457629e7b1c5264aa0a3b9304aab17e5fc9781d7267677ec7aa19273dc9d
|
| 3 |
+
size 2001410320
|
model-00014-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:88fd3310606c521c8553ee83ad84c0b82eec892818029e1db6d99ba45a300478
|
| 3 |
+
size 2001736280
|
model-00015-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c98a491d0e3295f39a0bca7bdf9833255c544e9302b4d3d15d1146d90c024aad
|
| 3 |
+
size 2003119368
|
model-00016-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ddfb0d48974186fd19a54c4ae5cc354151d8346528adb5184b8fa2b26bade09b
|
| 3 |
+
size 2001409888
|
model-00017-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:87963822288f82be220324a4bf3a0f93b60ae5b0ffec858bf443589fae11118e
|
| 3 |
+
size 2001735720
|
model-00018-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f81bca32c73a477483552e472fb05ebff3f47a32c23f6ffbb46f8b5a9d40074d
|
| 3 |
+
size 2001735784
|
model-00019-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f9a7b626201b4a3f3a6273d1355b6af0b01039c185302421f3be2ceac3011a7
|
| 3 |
+
size 2001736712
|
model-00020-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:20b837e2920bd389b1f4da9a147691bd87daea509e6b19514000b43fe9543bfc
|
| 3 |
+
size 2002792760
|
model-00021-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e5ae0ae4f8a7d4df1b091d0042bfe3eb30cf6fbdbdf214597e830d8791031b4e
|
| 3 |
+
size 2001735552
|
model-00022-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b141f2a16a1216c332cb2efdf842a9512fd190b4dccf7223c93bc1a2c44bcb87
|
| 3 |
+
size 2001735720
|
model-00023-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a27074531ffc6f64232a473a523f65d8de1a6172b4de09c0578a9ad08717171c
|
| 3 |
+
size 2001410368
|
model-00024-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:24a04b08e9c736a14b13a2929d49ec48d13b1946ea997101cde853764a94eb21
|
| 3 |
+
size 2001737192
|
model-00025-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:50ed4184a0f85b89ce4b4f7ec0f5062c1ef281c0eda3f00f1f48e4707d567b98
|
| 3 |
+
size 2003119408
|
model-00026-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:95f5114fe6e7e3bc997c13d913c67b45adec715fc6ae6e4fe6fcabca743686f5
|
| 3 |
+
size 2001410328
|
model-00027-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1d403f9008dfec3c99d45e3bc5a75630b68c50a5b701d3e7016cd678b7f16e11
|
| 3 |
+
size 2001735720
|
model-00028-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:35a968fef6f36d50cab8a43ee4d824023466a992a025a4d6ab1d48ce17dd22de
|
| 3 |
+
size 2001736272
|
model-00029-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:82f9a8ae7e2936360a0b114bdfb01469fd466287749c8ea404aede06384f459f
|
| 3 |
+
size 2002793952
|
model-00030-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ce9c6ca2e0c57f86b4ec98a2725f6f38d5886af94d4951fce282ce0b3b3c1dec
|
| 3 |
+
size 2001735296
|
model-00031-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:69e0054fffd16d7f7ef743d6db5a50efcdb3981092229c81ad0f44bd16183704
|
| 3 |
+
size 2001735720
|
model-00032-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b59cc011d44011b7814ad764470ea7dc54846ec4404751ed3421f3155503154c
|
| 3 |
+
size 2001735784
|
model-00033-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dfdac2e0770457ed5b49b7e9cf498c91a784c61ba13646f92e7dade7a6a3c636
|
| 3 |
+
size 2001410816
|
model-00034-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3dc60cb85567bf1d1f1e7e6f5e5a34e42d5e4e5e4983ac12d1aee1b899b84e69
|
| 3 |
+
size 2003119328
|
model-00035-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6a302b467f63f704626f7ca5cb528e395002fc64718d8d77c65a1d197f9b2275
|
| 3 |
+
size 2001735544
|
model-00036-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:093fb4c1cc509039c693d60f0c73ef32756f15769dad7d5f9b0a94796b64263b
|
| 3 |
+
size 2001410328
|
model-00037-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:859ba58bd90503512f9d4c9bbc7765b6de69774d8337daf70edf43ebba69dbc5
|
| 3 |
+
size 2001735824
|
model-00038-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8ab001453b89e4312ea0ee5191e0da4012f9e770946fb7884788cec5b98428a9
|
| 3 |
+
size 2001737184
|
model-00039-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4beb85e677e9e2982b7e5b1371151a31ef679ecc715257897c88982441692cad
|
| 3 |
+
size 2002794000
|
model-00040-of-00040.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9db4ee4a0f2aa63f3fdb981bdccd7f933ae5ce4305257e4755fd4a097a12afb8
|
| 3 |
+
size 1994375208
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ac9834aa1e30eb60d921d25e1755f97e92dfd47cf74ac2613e474243adcc4cf
|
| 3 |
+
size 14819483
|
qwen3_coder_detector_sgl.py
ADDED
|
@@ -0,0 +1,474 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
import re
|
| 5 |
+
from typing import Any, List, Optional
|
| 6 |
+
|
| 7 |
+
from sglang.srt.entrypoints.openai.protocol import Tool
|
| 8 |
+
from sglang.srt.function_call.base_format_detector import BaseFormatDetector
|
| 9 |
+
from sglang.srt.function_call.core_types import (
|
| 10 |
+
StreamingParseResult,
|
| 11 |
+
ToolCallItem,
|
| 12 |
+
_GetInfoFunc,
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class Qwen3CoderDetector(BaseFormatDetector):
|
| 19 |
+
def __init__(self):
|
| 20 |
+
super().__init__()
|
| 21 |
+
|
| 22 |
+
# Sentinel tokens
|
| 23 |
+
self.tool_call_start_token: str = "<tool_call>"
|
| 24 |
+
self.tool_call_end_token: str = "</tool_call>"
|
| 25 |
+
self.tool_call_prefix: str = "<function="
|
| 26 |
+
self.function_end_token: str = "</function>"
|
| 27 |
+
self.parameter_prefix: str = "<parameter="
|
| 28 |
+
self.parameter_end_token: str = "</parameter>"
|
| 29 |
+
|
| 30 |
+
# Regex for non-streaming fallback
|
| 31 |
+
self.tool_call_regex = re.compile(r"<tool_call>(.*?)</tool_call>", re.DOTALL)
|
| 32 |
+
self.tool_call_function_regex = re.compile(
|
| 33 |
+
r"<function=(.*?)</function>|<function=(.*)$", re.DOTALL
|
| 34 |
+
)
|
| 35 |
+
self.tool_call_parameter_regex = re.compile(
|
| 36 |
+
r"<parameter=(.*?)(?:</parameter>|(?=<parameter=)|(?=</function>)|$)",
|
| 37 |
+
re.DOTALL,
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
# Streaming State
|
| 41 |
+
# Base class already initializes _buffer, we just use it directly
|
| 42 |
+
# No need to check with hasattr - we control the lifecycle through inheritance
|
| 43 |
+
|
| 44 |
+
# Index pointing to the next character to be processed in buffer
|
| 45 |
+
self.parsed_pos: int = 0
|
| 46 |
+
# Parameter count inside the current tool being processed, used to determine whether to add comma
|
| 47 |
+
self.current_tool_param_count: int = 0
|
| 48 |
+
# Flag indicating whether current tool has already sent '{'
|
| 49 |
+
self.json_started: bool = False
|
| 50 |
+
|
| 51 |
+
# [FIX] New state flag: mark whether inside tool_call structure block
|
| 52 |
+
self.is_inside_tool_call: bool = False
|
| 53 |
+
|
| 54 |
+
# Initialize attributes that were missing in the original PR
|
| 55 |
+
self.current_func_name: Optional[str] = None
|
| 56 |
+
|
| 57 |
+
def has_tool_call(self, text: str) -> bool:
|
| 58 |
+
return self.tool_call_start_token in text
|
| 59 |
+
|
| 60 |
+
def _get_arguments_config(
|
| 61 |
+
self, func_name: str, tools: Optional[list[Tool]]
|
| 62 |
+
) -> dict:
|
| 63 |
+
"""Extract argument configuration for a function."""
|
| 64 |
+
if tools is None:
|
| 65 |
+
return {}
|
| 66 |
+
for config in tools:
|
| 67 |
+
try:
|
| 68 |
+
config_type = config.type
|
| 69 |
+
config_function = config.function
|
| 70 |
+
config_function_name = config_function.name
|
| 71 |
+
except AttributeError:
|
| 72 |
+
continue
|
| 73 |
+
|
| 74 |
+
if config_type == "function" and config_function_name == func_name:
|
| 75 |
+
try:
|
| 76 |
+
params = config_function.parameters
|
| 77 |
+
except AttributeError:
|
| 78 |
+
return {}
|
| 79 |
+
|
| 80 |
+
if isinstance(params, dict) and "properties" in params:
|
| 81 |
+
return params["properties"]
|
| 82 |
+
elif isinstance(params, dict):
|
| 83 |
+
return params
|
| 84 |
+
else:
|
| 85 |
+
return {}
|
| 86 |
+
logger.warning(f"Tool '{func_name}' is not defined in the tools list.")
|
| 87 |
+
return {}
|
| 88 |
+
|
| 89 |
+
def _convert_param_value(
|
| 90 |
+
self, param_value: str, param_name: str, param_config: dict, func_name: str
|
| 91 |
+
) -> Any:
|
| 92 |
+
"""Convert parameter value based on its type in the schema."""
|
| 93 |
+
# Handle null value for any type
|
| 94 |
+
if param_value.lower() == "null":
|
| 95 |
+
return None
|
| 96 |
+
|
| 97 |
+
if param_name not in param_config:
|
| 98 |
+
if param_config != {}:
|
| 99 |
+
logger.warning(
|
| 100 |
+
f"Parsed parameter '{param_name}' is not defined in the tool "
|
| 101 |
+
f"parameters for tool '{func_name}', directly returning the string value."
|
| 102 |
+
)
|
| 103 |
+
return param_value
|
| 104 |
+
|
| 105 |
+
if (
|
| 106 |
+
isinstance(param_config[param_name], dict)
|
| 107 |
+
and "type" in param_config[param_name]
|
| 108 |
+
):
|
| 109 |
+
param_type = str(param_config[param_name]["type"]).strip().lower()
|
| 110 |
+
else:
|
| 111 |
+
param_type = "string"
|
| 112 |
+
if param_type in ["string", "str", "text", "varchar", "char", "enum"]:
|
| 113 |
+
return param_value
|
| 114 |
+
elif (
|
| 115 |
+
param_type.startswith("int")
|
| 116 |
+
or param_type.startswith("uint")
|
| 117 |
+
or param_type.startswith("long")
|
| 118 |
+
or param_type.startswith("short")
|
| 119 |
+
or param_type.startswith("unsigned")
|
| 120 |
+
):
|
| 121 |
+
try:
|
| 122 |
+
param_value = int(param_value)
|
| 123 |
+
except Exception:
|
| 124 |
+
logger.warning(
|
| 125 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' is not an integer in tool "
|
| 126 |
+
f"'{func_name}', degenerating to string."
|
| 127 |
+
)
|
| 128 |
+
return param_value
|
| 129 |
+
elif param_type.startswith("num") or param_type.startswith("float"):
|
| 130 |
+
try:
|
| 131 |
+
maybe_convert = (
|
| 132 |
+
False if "." in param_value or "e" in param_value.lower() else True
|
| 133 |
+
)
|
| 134 |
+
param_value: float = float(param_value)
|
| 135 |
+
if maybe_convert and param_value.is_integer():
|
| 136 |
+
param_value = int(param_value)
|
| 137 |
+
except Exception:
|
| 138 |
+
logger.warning(
|
| 139 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' is not a float in tool "
|
| 140 |
+
f"'{func_name}', degenerating to string."
|
| 141 |
+
)
|
| 142 |
+
return param_value
|
| 143 |
+
elif param_type in ["boolean", "bool", "binary"]:
|
| 144 |
+
param_value = param_value.lower()
|
| 145 |
+
if param_value not in ["true", "false"]:
|
| 146 |
+
logger.warning(
|
| 147 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' is not a boolean (`true` of `false`) in tool '{func_name}', degenerating to false."
|
| 148 |
+
)
|
| 149 |
+
return param_value == "true"
|
| 150 |
+
else:
|
| 151 |
+
if (
|
| 152 |
+
param_type in ["object", "array", "arr"]
|
| 153 |
+
or param_type.startswith("dict")
|
| 154 |
+
or param_type.startswith("list")
|
| 155 |
+
):
|
| 156 |
+
try:
|
| 157 |
+
param_value = json.loads(param_value)
|
| 158 |
+
return param_value
|
| 159 |
+
except Exception:
|
| 160 |
+
logger.warning(
|
| 161 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' cannot be parsed with json.loads in tool "
|
| 162 |
+
f"'{func_name}', will try other methods to parse it."
|
| 163 |
+
)
|
| 164 |
+
try:
|
| 165 |
+
param_value = ast.literal_eval(param_value) # safer
|
| 166 |
+
except Exception:
|
| 167 |
+
logger.warning(
|
| 168 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' cannot be converted via Python `ast.literal_eval()` in tool '{func_name}', degenerating to string."
|
| 169 |
+
)
|
| 170 |
+
return param_value
|
| 171 |
+
|
| 172 |
+
def detect_and_parse(self, text: str, tools: List[Tool]) -> StreamingParseResult:
|
| 173 |
+
"""One-shot parsing for non-streaming scenarios."""
|
| 174 |
+
if self.tool_call_start_token not in text:
|
| 175 |
+
return StreamingParseResult(normal_text=text)
|
| 176 |
+
|
| 177 |
+
calls = []
|
| 178 |
+
try:
|
| 179 |
+
# Simple cleanup of the text to find tool calls
|
| 180 |
+
# Note: This is a simplified regex approach consistent with vLLM
|
| 181 |
+
raw_tool_calls = self.tool_call_regex.findall(text)
|
| 182 |
+
if not raw_tool_calls:
|
| 183 |
+
# Fallback: maybe the whole text is inside the tag or tags are stripped
|
| 184 |
+
if self.tool_call_prefix in text:
|
| 185 |
+
raw_tool_calls = [text]
|
| 186 |
+
|
| 187 |
+
tool_idx = 0
|
| 188 |
+
for tool_content in raw_tool_calls:
|
| 189 |
+
# Find function calls
|
| 190 |
+
funcs = self.tool_call_function_regex.findall(tool_content)
|
| 191 |
+
for func_match in funcs:
|
| 192 |
+
func_body = func_match[0] or func_match[1]
|
| 193 |
+
if ">" not in func_body:
|
| 194 |
+
continue
|
| 195 |
+
|
| 196 |
+
name_end = func_body.index(">")
|
| 197 |
+
func_name = func_body[:name_end]
|
| 198 |
+
params_str = func_body[name_end + 1 :]
|
| 199 |
+
|
| 200 |
+
param_config = self._get_arguments_config(func_name, tools)
|
| 201 |
+
parsed_params = {}
|
| 202 |
+
|
| 203 |
+
for p_match in self.tool_call_parameter_regex.findall(params_str):
|
| 204 |
+
if ">" not in p_match:
|
| 205 |
+
continue
|
| 206 |
+
p_idx = p_match.index(">")
|
| 207 |
+
p_name = p_match[:p_idx]
|
| 208 |
+
p_val = p_match[p_idx + 1 :]
|
| 209 |
+
# Remove prefixing and trailing \n
|
| 210 |
+
if p_val.startswith("\n"):
|
| 211 |
+
p_val = p_val[1:]
|
| 212 |
+
if p_val.endswith("\n"):
|
| 213 |
+
p_val = p_val[:-1]
|
| 214 |
+
|
| 215 |
+
parsed_params[p_name] = self._convert_param_value(
|
| 216 |
+
p_val, p_name, param_config, func_name
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
calls.append(
|
| 220 |
+
ToolCallItem(
|
| 221 |
+
tool_index=tool_idx,
|
| 222 |
+
name=func_name,
|
| 223 |
+
parameters=json.dumps(parsed_params, ensure_ascii=False),
|
| 224 |
+
)
|
| 225 |
+
)
|
| 226 |
+
tool_idx += 1
|
| 227 |
+
|
| 228 |
+
# Determine normal text (text before the first tool call)
|
| 229 |
+
start_idx = text.find(self.tool_call_start_token)
|
| 230 |
+
if start_idx == -1:
|
| 231 |
+
start_idx = text.find(self.tool_call_prefix)
|
| 232 |
+
normal_text = text[:start_idx] if start_idx > 0 else ""
|
| 233 |
+
|
| 234 |
+
return StreamingParseResult(normal_text=normal_text, calls=calls)
|
| 235 |
+
|
| 236 |
+
except Exception as e:
|
| 237 |
+
logger.error(f"Error in detect_and_parse: {e}")
|
| 238 |
+
return StreamingParseResult(normal_text=text)
|
| 239 |
+
|
| 240 |
+
def parse_streaming_increment(
|
| 241 |
+
self, new_text: str, tools: List[Tool]
|
| 242 |
+
) -> StreamingParseResult:
|
| 243 |
+
"""
|
| 244 |
+
Robust cursor-based streaming parser.
|
| 245 |
+
"""
|
| 246 |
+
self._buffer += new_text
|
| 247 |
+
|
| 248 |
+
# Guard against empty buffer
|
| 249 |
+
if not self._buffer:
|
| 250 |
+
return StreamingParseResult()
|
| 251 |
+
|
| 252 |
+
calls = []
|
| 253 |
+
normal_text_chunks = []
|
| 254 |
+
|
| 255 |
+
while True:
|
| 256 |
+
# Working text slice
|
| 257 |
+
current_slice = self._buffer[self.parsed_pos :]
|
| 258 |
+
|
| 259 |
+
# Optimization: If almost empty, wait for more
|
| 260 |
+
if not current_slice:
|
| 261 |
+
break
|
| 262 |
+
|
| 263 |
+
# -------------------------------------------------------
|
| 264 |
+
# 1. Priority detection: check if it's the start of Tool Call
|
| 265 |
+
# -------------------------------------------------------
|
| 266 |
+
if current_slice.startswith(self.tool_call_start_token):
|
| 267 |
+
self.parsed_pos += len(self.tool_call_start_token)
|
| 268 |
+
self.is_inside_tool_call = True
|
| 269 |
+
continue
|
| 270 |
+
|
| 271 |
+
# -------------------------------------------------------
|
| 272 |
+
# 2. Function Name: <function=name>
|
| 273 |
+
# -------------------------------------------------------
|
| 274 |
+
if current_slice.startswith(self.tool_call_prefix):
|
| 275 |
+
end_angle = current_slice.find(">")
|
| 276 |
+
if end_angle != -1:
|
| 277 |
+
func_name = current_slice[len(self.tool_call_prefix) : end_angle]
|
| 278 |
+
|
| 279 |
+
self.current_tool_id += 1
|
| 280 |
+
self.current_tool_name_sent = True
|
| 281 |
+
self.current_tool_param_count = 0
|
| 282 |
+
self.json_started = False
|
| 283 |
+
self.current_func_name = func_name
|
| 284 |
+
|
| 285 |
+
calls.append(
|
| 286 |
+
ToolCallItem(
|
| 287 |
+
tool_index=self.current_tool_id,
|
| 288 |
+
name=func_name,
|
| 289 |
+
parameters="",
|
| 290 |
+
)
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
self.parsed_pos += end_angle + 1
|
| 294 |
+
continue
|
| 295 |
+
else:
|
| 296 |
+
# Incomplete tag
|
| 297 |
+
break
|
| 298 |
+
|
| 299 |
+
# -------------------------------------------------------
|
| 300 |
+
# 3. Parameter: <parameter=name>value...
|
| 301 |
+
# -------------------------------------------------------
|
| 302 |
+
if current_slice.startswith(self.parameter_prefix):
|
| 303 |
+
name_end = current_slice.find(">")
|
| 304 |
+
if name_end != -1:
|
| 305 |
+
value_start_idx = name_end + 1
|
| 306 |
+
rest_of_slice = current_slice[value_start_idx:]
|
| 307 |
+
|
| 308 |
+
# A parameter can end in multiple ways:
|
| 309 |
+
# 1. [Normal] Encounter </parameter>
|
| 310 |
+
# 2. [Abnormal] Encounter next <parameter=
|
| 311 |
+
# 3. [Abnormal] Encounter </function>
|
| 312 |
+
# So we need to find the smallest one as the parameter end position.
|
| 313 |
+
cand_end_param = rest_of_slice.find(self.parameter_end_token)
|
| 314 |
+
cand_next_param = rest_of_slice.find(self.parameter_prefix)
|
| 315 |
+
cand_end_func = rest_of_slice.find(self.function_end_token)
|
| 316 |
+
|
| 317 |
+
candidates = []
|
| 318 |
+
if cand_end_param != -1:
|
| 319 |
+
candidates.append(
|
| 320 |
+
(cand_end_param, len(self.parameter_end_token))
|
| 321 |
+
)
|
| 322 |
+
if cand_next_param != -1:
|
| 323 |
+
candidates.append((cand_next_param, 0))
|
| 324 |
+
if cand_end_func != -1:
|
| 325 |
+
candidates.append((cand_end_func, 0))
|
| 326 |
+
|
| 327 |
+
if candidates:
|
| 328 |
+
best_cand = min(candidates, key=lambda x: x[0])
|
| 329 |
+
end_pos = best_cand[0]
|
| 330 |
+
end_token_len = best_cand[1]
|
| 331 |
+
|
| 332 |
+
param_name = current_slice[
|
| 333 |
+
len(self.parameter_prefix) : name_end
|
| 334 |
+
]
|
| 335 |
+
raw_value = rest_of_slice[:end_pos]
|
| 336 |
+
|
| 337 |
+
# Cleanup value
|
| 338 |
+
if raw_value.startswith("\n"):
|
| 339 |
+
raw_value = raw_value[1:]
|
| 340 |
+
if raw_value.endswith("\n"):
|
| 341 |
+
raw_value = raw_value[:-1]
|
| 342 |
+
|
| 343 |
+
# JSON Construction
|
| 344 |
+
if not self.json_started:
|
| 345 |
+
calls.append(
|
| 346 |
+
ToolCallItem(
|
| 347 |
+
tool_index=self.current_tool_id, parameters="{"
|
| 348 |
+
)
|
| 349 |
+
)
|
| 350 |
+
self.json_started = True
|
| 351 |
+
|
| 352 |
+
param_config = self._get_arguments_config(
|
| 353 |
+
self.current_func_name, tools
|
| 354 |
+
)
|
| 355 |
+
converted_val = self._convert_param_value(
|
| 356 |
+
raw_value, param_name, param_config, self.current_func_name
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
# Construct JSON fragment: "key": value
|
| 360 |
+
# Note: We must be careful with json.dumps to ensure valid JSON streaming
|
| 361 |
+
json_key_val = f"{json.dumps(param_name)}: {json.dumps(converted_val, ensure_ascii=False)}"
|
| 362 |
+
|
| 363 |
+
if self.current_tool_param_count > 0:
|
| 364 |
+
fragment = f", {json_key_val}"
|
| 365 |
+
else:
|
| 366 |
+
fragment = json_key_val
|
| 367 |
+
|
| 368 |
+
calls.append(
|
| 369 |
+
ToolCallItem(
|
| 370 |
+
tool_index=self.current_tool_id, parameters=fragment
|
| 371 |
+
)
|
| 372 |
+
)
|
| 373 |
+
self.current_tool_param_count += 1
|
| 374 |
+
|
| 375 |
+
# Advance cursor
|
| 376 |
+
total_len = (name_end + 1) + end_pos + end_token_len
|
| 377 |
+
self.parsed_pos += total_len
|
| 378 |
+
continue
|
| 379 |
+
|
| 380 |
+
# Incomplete parameter tag or value
|
| 381 |
+
break
|
| 382 |
+
|
| 383 |
+
# -------------------------------------------------------
|
| 384 |
+
# 4. Function End: </function>
|
| 385 |
+
# -------------------------------------------------------
|
| 386 |
+
if current_slice.startswith(self.function_end_token):
|
| 387 |
+
if not self.json_started:
|
| 388 |
+
calls.append(
|
| 389 |
+
ToolCallItem(tool_index=self.current_tool_id, parameters="{")
|
| 390 |
+
)
|
| 391 |
+
self.json_started = True
|
| 392 |
+
|
| 393 |
+
calls.append(
|
| 394 |
+
ToolCallItem(tool_index=self.current_tool_id, parameters="}")
|
| 395 |
+
)
|
| 396 |
+
self.parsed_pos += len(self.function_end_token)
|
| 397 |
+
self.current_func_name = None
|
| 398 |
+
continue
|
| 399 |
+
|
| 400 |
+
# -------------------------------------------------------
|
| 401 |
+
# 5. Tool Call End: </tool_call>
|
| 402 |
+
# -------------------------------------------------------
|
| 403 |
+
if current_slice.startswith(self.tool_call_end_token):
|
| 404 |
+
self.parsed_pos += len(self.tool_call_end_token)
|
| 405 |
+
self.is_inside_tool_call = False # [FIX] Exit tool call region
|
| 406 |
+
continue
|
| 407 |
+
|
| 408 |
+
# -------------------------------------------------------
|
| 409 |
+
# 6. Handling content / whitespace / normal text
|
| 410 |
+
# -------------------------------------------------------
|
| 411 |
+
# If current position is not the start of a tag (i.e., doesn't start with <), it might be plain text,
|
| 412 |
+
# or a newline between two tags.
|
| 413 |
+
# But we need to be careful not to output truncated tags like "<fun" as text.
|
| 414 |
+
|
| 415 |
+
next_open_angle = current_slice.find("<")
|
| 416 |
+
|
| 417 |
+
if next_open_angle == -1:
|
| 418 |
+
# This entire segment is plain text
|
| 419 |
+
if not self.is_inside_tool_call:
|
| 420 |
+
normal_text_chunks.append(current_slice)
|
| 421 |
+
# [FIX] If inside tool call, discard this text (usually \n), don't append
|
| 422 |
+
self.parsed_pos += len(current_slice)
|
| 423 |
+
continue
|
| 424 |
+
|
| 425 |
+
elif next_open_angle == 0:
|
| 426 |
+
# Looks like a Tag, but doesn't match any known Tag above
|
| 427 |
+
|
| 428 |
+
possible_tags = [
|
| 429 |
+
self.tool_call_start_token,
|
| 430 |
+
self.tool_call_end_token,
|
| 431 |
+
self.tool_call_prefix,
|
| 432 |
+
self.function_end_token,
|
| 433 |
+
self.parameter_prefix,
|
| 434 |
+
self.parameter_end_token,
|
| 435 |
+
]
|
| 436 |
+
|
| 437 |
+
is_potential_tag = False
|
| 438 |
+
for tag in possible_tags:
|
| 439 |
+
if tag.startswith(current_slice):
|
| 440 |
+
is_potential_tag = True
|
| 441 |
+
break
|
| 442 |
+
|
| 443 |
+
if is_potential_tag:
|
| 444 |
+
break # Wait for more
|
| 445 |
+
else:
|
| 446 |
+
# Just a plain '<' symbol
|
| 447 |
+
if not self.is_inside_tool_call:
|
| 448 |
+
normal_text_chunks.append("<")
|
| 449 |
+
self.parsed_pos += 1
|
| 450 |
+
continue
|
| 451 |
+
|
| 452 |
+
else:
|
| 453 |
+
# '<' is in the middle
|
| 454 |
+
text_segment = current_slice[:next_open_angle]
|
| 455 |
+
if not self.is_inside_tool_call:
|
| 456 |
+
normal_text_chunks.append(text_segment)
|
| 457 |
+
# [FIX] If inside tool call, discard whitespace/text before Tag
|
| 458 |
+
self.parsed_pos += next_open_angle
|
| 459 |
+
continue
|
| 460 |
+
|
| 461 |
+
# Memory Cleanup: Slice the buffer
|
| 462 |
+
# Keep unparsed part, discard parsed part
|
| 463 |
+
if self.parsed_pos > 0:
|
| 464 |
+
self._buffer = self._buffer[self.parsed_pos :]
|
| 465 |
+
self.parsed_pos = 0
|
| 466 |
+
|
| 467 |
+
normal_text = "".join(normal_text_chunks) if normal_text_chunks else ""
|
| 468 |
+
return StreamingParseResult(calls=calls, normal_text=normal_text)
|
| 469 |
+
|
| 470 |
+
def supports_structural_tag(self) -> bool:
|
| 471 |
+
return False
|
| 472 |
+
|
| 473 |
+
def structure_info(self) -> _GetInfoFunc:
|
| 474 |
+
raise NotImplementedError
|
qwen3coder_tool_parser_vllm.py
ADDED
|
@@ -0,0 +1,690 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 2 |
+
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
|
| 3 |
+
import ast
|
| 4 |
+
import json
|
| 5 |
+
import uuid
|
| 6 |
+
from collections.abc import Sequence
|
| 7 |
+
from typing import Any, List, Optional, Union
|
| 8 |
+
|
| 9 |
+
import regex as re
|
| 10 |
+
|
| 11 |
+
from vllm.entrypoints.openai.protocol import (ChatCompletionRequest,
|
| 12 |
+
ChatCompletionToolsParam,
|
| 13 |
+
DeltaFunctionCall, DeltaMessage,
|
| 14 |
+
DeltaToolCall,
|
| 15 |
+
ExtractedToolCallInformation,
|
| 16 |
+
FunctionCall, ToolCall)
|
| 17 |
+
from vllm.entrypoints.openai.tool_parsers.abstract_tool_parser import (
|
| 18 |
+
ToolParser, ToolParserManager)
|
| 19 |
+
from vllm.logger import init_logger
|
| 20 |
+
from vllm.transformers_utils.tokenizer import AnyTokenizer
|
| 21 |
+
|
| 22 |
+
logger = init_logger(__name__)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
@ToolParserManager.register_module("qwen3_coder")
|
| 26 |
+
class Qwen3CoderToolParser(ToolParser):
|
| 27 |
+
|
| 28 |
+
def __init__(self, tokenizer: AnyTokenizer):
|
| 29 |
+
super().__init__(tokenizer)
|
| 30 |
+
|
| 31 |
+
self.current_tool_name_sent: bool = False
|
| 32 |
+
self.prev_tool_call_arr: list[dict] = []
|
| 33 |
+
self.current_tool_id: int = -1
|
| 34 |
+
self.streamed_args_for_tool: list[str] = []
|
| 35 |
+
|
| 36 |
+
# Sentinel tokens for streaming mode
|
| 37 |
+
self.tool_call_start_token: str = "<tool_call>"
|
| 38 |
+
self.tool_call_end_token: str = "</tool_call>"
|
| 39 |
+
self.tool_call_prefix: str = "<function="
|
| 40 |
+
self.function_end_token: str = "</function>"
|
| 41 |
+
self.parameter_prefix: str = "<parameter="
|
| 42 |
+
self.parameter_end_token: str = "</parameter>"
|
| 43 |
+
self.is_tool_call_started: bool = False
|
| 44 |
+
self.failed_count: int = 0
|
| 45 |
+
|
| 46 |
+
# Enhanced streaming state - reset for each new message
|
| 47 |
+
self._reset_streaming_state()
|
| 48 |
+
|
| 49 |
+
# Regex patterns
|
| 50 |
+
self.tool_call_complete_regex = re.compile(
|
| 51 |
+
r"<tool_call>(.*?)</tool_call>", re.DOTALL)
|
| 52 |
+
self.tool_call_regex = re.compile(
|
| 53 |
+
r"<tool_call>(.*?)</tool_call>|<tool_call>(.*?)$", re.DOTALL)
|
| 54 |
+
self.tool_call_function_regex = re.compile(
|
| 55 |
+
r"<function=(.*?)</function>|<function=(.*)$", re.DOTALL)
|
| 56 |
+
self.tool_call_parameter_regex = re.compile(
|
| 57 |
+
r"<parameter=(.*?)(?:</parameter>|(?=<parameter=)|(?=</function>)|$)",
|
| 58 |
+
re.DOTALL)
|
| 59 |
+
|
| 60 |
+
if not self.model_tokenizer:
|
| 61 |
+
raise ValueError(
|
| 62 |
+
"The model tokenizer must be passed to the ToolParser "
|
| 63 |
+
"constructor during construction.")
|
| 64 |
+
|
| 65 |
+
self.tool_call_start_token_id = self.vocab.get(
|
| 66 |
+
self.tool_call_start_token)
|
| 67 |
+
self.tool_call_end_token_id = self.vocab.get(self.tool_call_end_token)
|
| 68 |
+
|
| 69 |
+
if self.tool_call_start_token_id is None or self.tool_call_end_token_id is None:
|
| 70 |
+
raise RuntimeError(
|
| 71 |
+
"Qwen3 XML Tool parser could not locate tool call start/end "
|
| 72 |
+
"tokens in the tokenizer!")
|
| 73 |
+
|
| 74 |
+
logger.info(
|
| 75 |
+
f"vLLM Successfully import tool parser {self.__class__.__name__} !"
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
def _generate_tool_call_id(self) -> str:
|
| 79 |
+
"""Generate a unique tool call ID."""
|
| 80 |
+
return f"call_{uuid.uuid4().hex[:24]}"
|
| 81 |
+
|
| 82 |
+
def _reset_streaming_state(self):
|
| 83 |
+
"""Reset all streaming state."""
|
| 84 |
+
self.current_tool_index = 0
|
| 85 |
+
self.is_tool_call_started = False
|
| 86 |
+
self.header_sent = False
|
| 87 |
+
self.current_tool_id = None
|
| 88 |
+
self.current_function_name = None
|
| 89 |
+
self.current_param_name = None
|
| 90 |
+
self.current_param_value = ""
|
| 91 |
+
self.param_count = 0
|
| 92 |
+
self.in_param = False
|
| 93 |
+
self.in_function = False
|
| 94 |
+
self.accumulated_text = ""
|
| 95 |
+
self.json_started = False
|
| 96 |
+
self.json_closed = False
|
| 97 |
+
# Store accumulated parameters for type conversion
|
| 98 |
+
self.accumulated_params = {}
|
| 99 |
+
self.streaming_request = None
|
| 100 |
+
|
| 101 |
+
def _get_arguments_config(
|
| 102 |
+
self, func_name: str,
|
| 103 |
+
tools: Optional[list[ChatCompletionToolsParam]]) -> dict:
|
| 104 |
+
"""Extract argument configuration for a function."""
|
| 105 |
+
if tools is None:
|
| 106 |
+
return {}
|
| 107 |
+
for config in tools:
|
| 108 |
+
if not hasattr(config, "type") or not (hasattr(
|
| 109 |
+
config, "function") and hasattr(config.function, "name")):
|
| 110 |
+
continue
|
| 111 |
+
if config.type == "function" and config.function.name == func_name:
|
| 112 |
+
if not hasattr(config.function, "parameters"):
|
| 113 |
+
return {}
|
| 114 |
+
params = config.function.parameters
|
| 115 |
+
if isinstance(params, dict) and "properties" in params:
|
| 116 |
+
return params["properties"]
|
| 117 |
+
elif isinstance(params, dict):
|
| 118 |
+
return params
|
| 119 |
+
else:
|
| 120 |
+
return {}
|
| 121 |
+
logger.warning(f"Tool '{func_name}' is not defined in the tools list.")
|
| 122 |
+
return {}
|
| 123 |
+
|
| 124 |
+
def _convert_param_value(self, param_value: str, param_name: str,
|
| 125 |
+
param_config: dict, func_name: str) -> Any:
|
| 126 |
+
"""Convert parameter value based on its type in the schema."""
|
| 127 |
+
# Handle null value for any type
|
| 128 |
+
if param_value.lower() == "null":
|
| 129 |
+
return None
|
| 130 |
+
|
| 131 |
+
if param_name not in param_config:
|
| 132 |
+
if param_config != {}:
|
| 133 |
+
logger.warning(
|
| 134 |
+
f"Parsed parameter '{param_name}' is not defined in the tool "
|
| 135 |
+
f"parameters for tool '{func_name}', directly returning the string value."
|
| 136 |
+
)
|
| 137 |
+
return param_value
|
| 138 |
+
|
| 139 |
+
if isinstance(param_config[param_name],
|
| 140 |
+
dict) and "type" in param_config[param_name]:
|
| 141 |
+
param_type = str(param_config[param_name]["type"]).strip().lower()
|
| 142 |
+
else:
|
| 143 |
+
param_type = "string"
|
| 144 |
+
if param_type in ["string", "str", "text", "varchar", "char", "enum"]:
|
| 145 |
+
return param_value
|
| 146 |
+
elif param_type.startswith("int") or param_type.startswith(
|
| 147 |
+
"uint") or param_type.startswith(
|
| 148 |
+
"long") or param_type.startswith(
|
| 149 |
+
"short") or param_type.startswith("unsigned"):
|
| 150 |
+
try:
|
| 151 |
+
param_value = int(param_value)
|
| 152 |
+
except:
|
| 153 |
+
logger.warning(
|
| 154 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' is not an integer in tool "
|
| 155 |
+
f"'{func_name}', degenerating to string.")
|
| 156 |
+
return param_value
|
| 157 |
+
elif param_type.startswith("num") or param_type.startswith("float"):
|
| 158 |
+
try:
|
| 159 |
+
maybe_convert = False if "." in param_value or "e" in param_value.lower() else True
|
| 160 |
+
param_value: float = float(param_value)
|
| 161 |
+
if maybe_convert and param_value.is_integer():
|
| 162 |
+
param_value = int(param_value)
|
| 163 |
+
except:
|
| 164 |
+
logger.warning(
|
| 165 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' is not a float in tool "
|
| 166 |
+
f"'{func_name}', degenerating to string.")
|
| 167 |
+
return param_value
|
| 168 |
+
elif param_type in ["boolean", "bool", "binary"]:
|
| 169 |
+
param_value = param_value.lower()
|
| 170 |
+
if param_value not in ["true", "false"]:
|
| 171 |
+
logger.warning(
|
| 172 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' is not a boolean (`true` of `false`) in tool '{func_name}', degenerating to false."
|
| 173 |
+
)
|
| 174 |
+
return param_value == "true"
|
| 175 |
+
else:
|
| 176 |
+
if param_type in ["object", "array", "arr"
|
| 177 |
+
] or param_type.startswith(
|
| 178 |
+
"dict") or param_type.startswith("list"):
|
| 179 |
+
try:
|
| 180 |
+
param_value = json.loads(param_value)
|
| 181 |
+
return param_value
|
| 182 |
+
except:
|
| 183 |
+
logger.warning(
|
| 184 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' cannot be parsed with json.loads in tool "
|
| 185 |
+
f"'{func_name}', will try other methods to parse it.")
|
| 186 |
+
try:
|
| 187 |
+
param_value = ast.literal_eval(param_value) # safer
|
| 188 |
+
except:
|
| 189 |
+
logger.warning(
|
| 190 |
+
f"Parsed value '{param_value}' of parameter '{param_name}' cannot be converted via Python `ast.literal_eval()` in tool '{func_name}', degenerating to string."
|
| 191 |
+
)
|
| 192 |
+
return param_value
|
| 193 |
+
|
| 194 |
+
def _parse_xml_function_call(
|
| 195 |
+
self, function_call_str: str,
|
| 196 |
+
tools: Optional[list[ChatCompletionToolsParam]]
|
| 197 |
+
) -> Optional[ToolCall]:
|
| 198 |
+
|
| 199 |
+
# Extract function name
|
| 200 |
+
end_index = function_call_str.index(">")
|
| 201 |
+
function_name = function_call_str[:end_index]
|
| 202 |
+
param_config = self._get_arguments_config(function_name, tools)
|
| 203 |
+
parameters = function_call_str[end_index + 1:]
|
| 204 |
+
param_dict = {}
|
| 205 |
+
for match_text in self.tool_call_parameter_regex.findall(parameters):
|
| 206 |
+
idx = match_text.index(">")
|
| 207 |
+
param_name = match_text[:idx]
|
| 208 |
+
param_value = str(match_text[idx + 1:])
|
| 209 |
+
# Remove prefix and trailing \n
|
| 210 |
+
if param_value.startswith("\n"):
|
| 211 |
+
param_value = param_value[1:]
|
| 212 |
+
if param_value.endswith("\n"):
|
| 213 |
+
param_value = param_value[:-1]
|
| 214 |
+
|
| 215 |
+
param_dict[param_name] = self._convert_param_value(
|
| 216 |
+
param_value, param_name, param_config, function_name)
|
| 217 |
+
return ToolCall(
|
| 218 |
+
type="function",
|
| 219 |
+
function=FunctionCall(name=function_name,
|
| 220 |
+
arguments=json.dumps(param_dict,
|
| 221 |
+
ensure_ascii=False)),
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
def _get_function_calls(self, model_output: str) -> List[str]:
|
| 225 |
+
# Find all tool calls
|
| 226 |
+
matched_ranges = self.tool_call_regex.findall(model_output)
|
| 227 |
+
raw_tool_calls = [
|
| 228 |
+
match[0] if match[0] else match[1] for match in matched_ranges
|
| 229 |
+
]
|
| 230 |
+
|
| 231 |
+
# Back-off strategy if no tool_call tags found
|
| 232 |
+
if len(raw_tool_calls) == 0:
|
| 233 |
+
raw_tool_calls = [model_output]
|
| 234 |
+
|
| 235 |
+
raw_function_calls = []
|
| 236 |
+
for tool_call in raw_tool_calls:
|
| 237 |
+
raw_function_calls.extend(
|
| 238 |
+
self.tool_call_function_regex.findall(tool_call))
|
| 239 |
+
|
| 240 |
+
function_calls = [
|
| 241 |
+
match[0] if match[0] else match[1] for match in raw_function_calls
|
| 242 |
+
]
|
| 243 |
+
return function_calls
|
| 244 |
+
|
| 245 |
+
def extract_tool_calls(
|
| 246 |
+
self,
|
| 247 |
+
model_output: str,
|
| 248 |
+
request: ChatCompletionRequest,
|
| 249 |
+
) -> ExtractedToolCallInformation:
|
| 250 |
+
# Quick check to avoid unnecessary processing
|
| 251 |
+
if self.tool_call_prefix not in model_output:
|
| 252 |
+
return ExtractedToolCallInformation(tools_called=False,
|
| 253 |
+
tool_calls=[],
|
| 254 |
+
content=model_output)
|
| 255 |
+
|
| 256 |
+
try:
|
| 257 |
+
function_calls = self._get_function_calls(model_output)
|
| 258 |
+
if len(function_calls) == 0:
|
| 259 |
+
return ExtractedToolCallInformation(tools_called=False,
|
| 260 |
+
tool_calls=[],
|
| 261 |
+
content=model_output)
|
| 262 |
+
|
| 263 |
+
tool_calls = [
|
| 264 |
+
self._parse_xml_function_call(function_call_str, request.tools)
|
| 265 |
+
for function_call_str in function_calls
|
| 266 |
+
]
|
| 267 |
+
|
| 268 |
+
# Populate prev_tool_call_arr for serving layer to set finish_reason
|
| 269 |
+
self.prev_tool_call_arr.clear() # Clear previous calls
|
| 270 |
+
for tool_call in tool_calls:
|
| 271 |
+
if tool_call:
|
| 272 |
+
self.prev_tool_call_arr.append({
|
| 273 |
+
"name":
|
| 274 |
+
tool_call.function.name,
|
| 275 |
+
"arguments":
|
| 276 |
+
tool_call.function.arguments,
|
| 277 |
+
})
|
| 278 |
+
|
| 279 |
+
# Extract content before tool calls
|
| 280 |
+
content_index = model_output.find(self.tool_call_start_token)
|
| 281 |
+
content_index = content_index if content_index >= 0 else model_output.find(
|
| 282 |
+
self.tool_call_prefix)
|
| 283 |
+
content = model_output[:content_index] # .rstrip()
|
| 284 |
+
|
| 285 |
+
return ExtractedToolCallInformation(
|
| 286 |
+
tools_called=(len(tool_calls) > 0),
|
| 287 |
+
tool_calls=tool_calls,
|
| 288 |
+
content=content if content else None,
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
except Exception:
|
| 292 |
+
logger.exception("Error in extracting tool call from response.")
|
| 293 |
+
return ExtractedToolCallInformation(tools_called=False,
|
| 294 |
+
tool_calls=[],
|
| 295 |
+
content=model_output)
|
| 296 |
+
|
| 297 |
+
def extract_tool_calls_streaming(
|
| 298 |
+
self,
|
| 299 |
+
previous_text: str,
|
| 300 |
+
current_text: str,
|
| 301 |
+
delta_text: str,
|
| 302 |
+
previous_token_ids: Sequence[int],
|
| 303 |
+
current_token_ids: Sequence[int],
|
| 304 |
+
delta_token_ids: Sequence[int],
|
| 305 |
+
request: ChatCompletionRequest,
|
| 306 |
+
) -> Union[DeltaMessage, None]:
|
| 307 |
+
# Store request for type conversion
|
| 308 |
+
if not previous_text:
|
| 309 |
+
self._reset_streaming_state()
|
| 310 |
+
self.streaming_request = request
|
| 311 |
+
|
| 312 |
+
# If no delta text, return None unless it's an EOS token after tool calls
|
| 313 |
+
if not delta_text:
|
| 314 |
+
# Check if this is an EOS token after all tool calls are complete
|
| 315 |
+
# We check for tool calls in the text even if is_tool_call_started is False
|
| 316 |
+
# because it might have been reset after processing all tools
|
| 317 |
+
if delta_token_ids and self.tool_call_end_token_id not in delta_token_ids:
|
| 318 |
+
# Count complete tool calls
|
| 319 |
+
complete_calls = len(
|
| 320 |
+
self.tool_call_complete_regex.findall(current_text))
|
| 321 |
+
|
| 322 |
+
# If we have completed tool calls and populated prev_tool_call_arr
|
| 323 |
+
if complete_calls > 0 and len(self.prev_tool_call_arr) > 0:
|
| 324 |
+
# Check if all tool calls are closed
|
| 325 |
+
open_calls = current_text.count(
|
| 326 |
+
self.tool_call_start_token) - current_text.count(
|
| 327 |
+
self.tool_call_end_token)
|
| 328 |
+
if open_calls == 0:
|
| 329 |
+
# Return empty delta message to allow finish_reason processing
|
| 330 |
+
return DeltaMessage(content="")
|
| 331 |
+
elif not self.is_tool_call_started and current_text:
|
| 332 |
+
# This is a regular content response that's now complete
|
| 333 |
+
return DeltaMessage(content="")
|
| 334 |
+
return None
|
| 335 |
+
|
| 336 |
+
# Update accumulated text
|
| 337 |
+
self.accumulated_text = current_text
|
| 338 |
+
|
| 339 |
+
# Check if we need to advance to next tool
|
| 340 |
+
if self.json_closed and not self.in_function:
|
| 341 |
+
# Check if this tool call has ended
|
| 342 |
+
tool_ends = current_text.count(self.tool_call_end_token)
|
| 343 |
+
if tool_ends > self.current_tool_index:
|
| 344 |
+
# This tool has ended, advance to next
|
| 345 |
+
self.current_tool_index += 1
|
| 346 |
+
self.header_sent = False
|
| 347 |
+
self.param_count = 0
|
| 348 |
+
self.json_started = False
|
| 349 |
+
self.json_closed = False
|
| 350 |
+
self.accumulated_params = {}
|
| 351 |
+
|
| 352 |
+
# Check if there are more tool calls
|
| 353 |
+
tool_starts = current_text.count(self.tool_call_start_token)
|
| 354 |
+
if self.current_tool_index >= tool_starts:
|
| 355 |
+
# No more tool calls
|
| 356 |
+
self.is_tool_call_started = False
|
| 357 |
+
# Continue processing next tool
|
| 358 |
+
return None
|
| 359 |
+
|
| 360 |
+
# Handle normal content before tool calls
|
| 361 |
+
if not self.is_tool_call_started:
|
| 362 |
+
# Check if tool call is starting
|
| 363 |
+
if self.tool_call_start_token_id in delta_token_ids or self.tool_call_start_token in delta_text:
|
| 364 |
+
self.is_tool_call_started = True
|
| 365 |
+
# Return any content before the tool call
|
| 366 |
+
if self.tool_call_start_token in delta_text:
|
| 367 |
+
content_before = delta_text[:delta_text.index(
|
| 368 |
+
self.tool_call_start_token)]
|
| 369 |
+
if content_before:
|
| 370 |
+
return DeltaMessage(content=content_before)
|
| 371 |
+
return None
|
| 372 |
+
else:
|
| 373 |
+
# Check if we're between tool calls - skip whitespace
|
| 374 |
+
if current_text.rstrip().endswith(self.tool_call_end_token):
|
| 375 |
+
# We just ended a tool call, skip whitespace
|
| 376 |
+
if delta_text.strip() == "":
|
| 377 |
+
return None
|
| 378 |
+
# Normal content, no tool call
|
| 379 |
+
return DeltaMessage(content=delta_text)
|
| 380 |
+
|
| 381 |
+
# Check if we're between tool calls (waiting for next one)
|
| 382 |
+
# Count tool calls we've seen vs processed
|
| 383 |
+
tool_starts_count = current_text.count(self.tool_call_start_token)
|
| 384 |
+
if self.current_tool_index >= tool_starts_count:
|
| 385 |
+
# We're past all tool calls, shouldn't be here
|
| 386 |
+
return None
|
| 387 |
+
|
| 388 |
+
# We're in a tool call, find the current tool call portion
|
| 389 |
+
# Need to find the correct tool call based on current_tool_index
|
| 390 |
+
tool_starts = []
|
| 391 |
+
idx = 0
|
| 392 |
+
while True:
|
| 393 |
+
idx = current_text.find(self.tool_call_start_token, idx)
|
| 394 |
+
if idx == -1:
|
| 395 |
+
break
|
| 396 |
+
tool_starts.append(idx)
|
| 397 |
+
idx += len(self.tool_call_start_token)
|
| 398 |
+
|
| 399 |
+
if self.current_tool_index >= len(tool_starts):
|
| 400 |
+
# No more tool calls to process yet
|
| 401 |
+
return None
|
| 402 |
+
|
| 403 |
+
tool_start_idx = tool_starts[self.current_tool_index]
|
| 404 |
+
# Find where this tool call ends (or current position if not ended yet)
|
| 405 |
+
tool_end_idx = current_text.find(self.tool_call_end_token,
|
| 406 |
+
tool_start_idx)
|
| 407 |
+
if tool_end_idx == -1:
|
| 408 |
+
tool_text = current_text[tool_start_idx:]
|
| 409 |
+
else:
|
| 410 |
+
tool_text = current_text[tool_start_idx:tool_end_idx +
|
| 411 |
+
len(self.tool_call_end_token)]
|
| 412 |
+
|
| 413 |
+
# Looking for function header
|
| 414 |
+
if not self.header_sent:
|
| 415 |
+
if self.tool_call_prefix in tool_text:
|
| 416 |
+
func_start = tool_text.find(self.tool_call_prefix) + len(
|
| 417 |
+
self.tool_call_prefix)
|
| 418 |
+
func_end = tool_text.find(">", func_start)
|
| 419 |
+
|
| 420 |
+
if func_end != -1:
|
| 421 |
+
# Found complete function name
|
| 422 |
+
self.current_function_name = tool_text[func_start:func_end]
|
| 423 |
+
self.current_tool_id = self._generate_tool_call_id()
|
| 424 |
+
self.header_sent = True
|
| 425 |
+
self.in_function = True
|
| 426 |
+
|
| 427 |
+
# IMPORTANT: Add to prev_tool_call_arr immediately when we detect a tool call
|
| 428 |
+
# This ensures finish_reason="tool_calls" even if parsing isn't complete
|
| 429 |
+
already_added = any(
|
| 430 |
+
tool.get("name") == self.current_function_name
|
| 431 |
+
for tool in self.prev_tool_call_arr)
|
| 432 |
+
if not already_added:
|
| 433 |
+
self.prev_tool_call_arr.append({
|
| 434 |
+
"name": self.current_function_name,
|
| 435 |
+
"arguments":
|
| 436 |
+
"{}", # Placeholder, will be updated later
|
| 437 |
+
})
|
| 438 |
+
|
| 439 |
+
# Send header with function info
|
| 440 |
+
return DeltaMessage(tool_calls=[
|
| 441 |
+
DeltaToolCall(
|
| 442 |
+
index=self.current_tool_index,
|
| 443 |
+
id=self.current_tool_id,
|
| 444 |
+
function=DeltaFunctionCall(
|
| 445 |
+
name=self.current_function_name, arguments=""),
|
| 446 |
+
type="function",
|
| 447 |
+
)
|
| 448 |
+
])
|
| 449 |
+
return None
|
| 450 |
+
|
| 451 |
+
# We've sent header, now handle function body
|
| 452 |
+
if self.in_function:
|
| 453 |
+
# Send opening brace if not sent yet
|
| 454 |
+
if not self.json_started and self.parameter_prefix not in delta_text:
|
| 455 |
+
self.json_started = True
|
| 456 |
+
return DeltaMessage(tool_calls=[
|
| 457 |
+
DeltaToolCall(
|
| 458 |
+
index=self.current_tool_index,
|
| 459 |
+
function=DeltaFunctionCall(arguments="{"),
|
| 460 |
+
)
|
| 461 |
+
])
|
| 462 |
+
|
| 463 |
+
# Make sure json_started is set if we're processing parameters
|
| 464 |
+
if not self.json_started:
|
| 465 |
+
self.json_started = True
|
| 466 |
+
|
| 467 |
+
# Check for function end in accumulated text
|
| 468 |
+
if not self.json_closed and self.function_end_token in tool_text:
|
| 469 |
+
# Close JSON
|
| 470 |
+
self.json_closed = True
|
| 471 |
+
|
| 472 |
+
# Extract the complete tool call to update prev_tool_call_arr with final arguments
|
| 473 |
+
# Find the function content
|
| 474 |
+
func_start = tool_text.find(self.tool_call_prefix) + len(
|
| 475 |
+
self.tool_call_prefix)
|
| 476 |
+
func_content_end = tool_text.find(self.function_end_token,
|
| 477 |
+
func_start)
|
| 478 |
+
if func_content_end != -1:
|
| 479 |
+
func_content = tool_text[func_start:func_content_end]
|
| 480 |
+
# Parse to get the complete arguments
|
| 481 |
+
try:
|
| 482 |
+
parsed_tool = self._parse_xml_function_call(
|
| 483 |
+
func_content, self.streaming_request.tools
|
| 484 |
+
if self.streaming_request else None)
|
| 485 |
+
if parsed_tool:
|
| 486 |
+
# Update existing entry in prev_tool_call_arr with complete arguments
|
| 487 |
+
for i, tool in enumerate(self.prev_tool_call_arr):
|
| 488 |
+
if tool.get(
|
| 489 |
+
"name") == parsed_tool.function.name:
|
| 490 |
+
self.prev_tool_call_arr[i][
|
| 491 |
+
"arguments"] = parsed_tool.function.arguments
|
| 492 |
+
break
|
| 493 |
+
except Exception:
|
| 494 |
+
pass # Ignore parsing errors during streaming
|
| 495 |
+
|
| 496 |
+
result = DeltaMessage(tool_calls=[
|
| 497 |
+
DeltaToolCall(
|
| 498 |
+
index=self.current_tool_index,
|
| 499 |
+
function=DeltaFunctionCall(arguments="}"),
|
| 500 |
+
)
|
| 501 |
+
])
|
| 502 |
+
|
| 503 |
+
# Reset state for next tool
|
| 504 |
+
self.in_function = False
|
| 505 |
+
self.json_closed = True
|
| 506 |
+
self.accumulated_params = {}
|
| 507 |
+
|
| 508 |
+
return result
|
| 509 |
+
|
| 510 |
+
# Look for parameters
|
| 511 |
+
# Find all parameter starts
|
| 512 |
+
param_starts = []
|
| 513 |
+
idx = 0
|
| 514 |
+
while True:
|
| 515 |
+
idx = tool_text.find(self.parameter_prefix, idx)
|
| 516 |
+
if idx == -1:
|
| 517 |
+
break
|
| 518 |
+
param_starts.append(idx)
|
| 519 |
+
idx += len(self.parameter_prefix)
|
| 520 |
+
|
| 521 |
+
# Check if we should start a new parameter
|
| 522 |
+
if not self.in_param and self.param_count < len(param_starts):
|
| 523 |
+
|
| 524 |
+
if len(param_starts) > self.param_count:
|
| 525 |
+
# Process the next parameter
|
| 526 |
+
param_idx = param_starts[self.param_count]
|
| 527 |
+
param_start = param_idx + len(self.parameter_prefix)
|
| 528 |
+
remaining = tool_text[param_start:]
|
| 529 |
+
|
| 530 |
+
if ">" in remaining:
|
| 531 |
+
# We have the complete parameter name
|
| 532 |
+
name_end = remaining.find(">")
|
| 533 |
+
self.current_param_name = remaining[:name_end]
|
| 534 |
+
|
| 535 |
+
# Find the parameter value
|
| 536 |
+
value_start = param_start + name_end + 1
|
| 537 |
+
value_text = tool_text[value_start:]
|
| 538 |
+
if value_text.startswith("\n"):
|
| 539 |
+
value_text = value_text[1:]
|
| 540 |
+
|
| 541 |
+
# Find where this parameter ends
|
| 542 |
+
param_end_idx = value_text.find(
|
| 543 |
+
self.parameter_end_token)
|
| 544 |
+
if param_end_idx == -1:
|
| 545 |
+
# No closing tag, look for next parameter or function end
|
| 546 |
+
next_param_idx = value_text.find(
|
| 547 |
+
self.parameter_prefix)
|
| 548 |
+
func_end_idx = value_text.find(
|
| 549 |
+
self.function_end_token)
|
| 550 |
+
|
| 551 |
+
if next_param_idx != -1 and (func_end_idx == -1
|
| 552 |
+
or next_param_idx
|
| 553 |
+
< func_end_idx):
|
| 554 |
+
param_end_idx = next_param_idx
|
| 555 |
+
elif func_end_idx != -1:
|
| 556 |
+
param_end_idx = func_end_idx
|
| 557 |
+
else:
|
| 558 |
+
# Neither found, check if tool call is complete
|
| 559 |
+
if self.tool_call_end_token in tool_text:
|
| 560 |
+
# Tool call is complete, so parameter must be complete too
|
| 561 |
+
# Use all remaining text before function end as value
|
| 562 |
+
param_end_idx = len(value_text)
|
| 563 |
+
else:
|
| 564 |
+
# Still streaming, wait for more content
|
| 565 |
+
return None
|
| 566 |
+
|
| 567 |
+
if param_end_idx != -1:
|
| 568 |
+
# Complete parameter found
|
| 569 |
+
param_value = value_text[:param_end_idx]
|
| 570 |
+
if param_value.endswith("\n"):
|
| 571 |
+
param_value = param_value[:-1]
|
| 572 |
+
|
| 573 |
+
# Store raw value for later processing
|
| 574 |
+
self.accumulated_params[
|
| 575 |
+
self.current_param_name] = param_value
|
| 576 |
+
|
| 577 |
+
# Get parameter configuration for type conversion
|
| 578 |
+
param_config = self._get_arguments_config(
|
| 579 |
+
self.current_function_name,
|
| 580 |
+
self.streaming_request.tools
|
| 581 |
+
if self.streaming_request else None)
|
| 582 |
+
|
| 583 |
+
# Convert the parameter value to the appropriate type
|
| 584 |
+
converted_value = self._convert_param_value(
|
| 585 |
+
param_value, self.current_param_name,
|
| 586 |
+
param_config, self.current_function_name)
|
| 587 |
+
|
| 588 |
+
# Build JSON fragment based on the converted type
|
| 589 |
+
# Use json.dumps to properly serialize the value
|
| 590 |
+
serialized_value = json.dumps(converted_value,
|
| 591 |
+
ensure_ascii=False)
|
| 592 |
+
|
| 593 |
+
if self.param_count == 0:
|
| 594 |
+
json_fragment = f'"{self.current_param_name}": {serialized_value}'
|
| 595 |
+
else:
|
| 596 |
+
json_fragment = f', "{self.current_param_name}": {serialized_value}'
|
| 597 |
+
|
| 598 |
+
self.param_count += 1
|
| 599 |
+
|
| 600 |
+
return DeltaMessage(tool_calls=[
|
| 601 |
+
DeltaToolCall(
|
| 602 |
+
index=self.current_tool_index,
|
| 603 |
+
function=DeltaFunctionCall(
|
| 604 |
+
arguments=json_fragment),
|
| 605 |
+
)
|
| 606 |
+
])
|
| 607 |
+
|
| 608 |
+
# Continue parameter value - Not used in the current implementation
|
| 609 |
+
# since we process complete parameters above
|
| 610 |
+
if self.in_param:
|
| 611 |
+
if self.parameter_end_token in delta_text:
|
| 612 |
+
# End of parameter
|
| 613 |
+
end_idx = delta_text.find(self.parameter_end_token)
|
| 614 |
+
value_chunk = delta_text[:end_idx]
|
| 615 |
+
|
| 616 |
+
# Skip past > if at start
|
| 617 |
+
if not self.current_param_value and ">" in value_chunk:
|
| 618 |
+
gt_idx = value_chunk.find(">")
|
| 619 |
+
value_chunk = value_chunk[gt_idx + 1:]
|
| 620 |
+
|
| 621 |
+
if not self.current_param_value and value_chunk.startswith(
|
| 622 |
+
"\n"):
|
| 623 |
+
value_chunk = value_chunk[1:]
|
| 624 |
+
|
| 625 |
+
# Store complete value
|
| 626 |
+
full_value = self.current_param_value + value_chunk
|
| 627 |
+
self.accumulated_params[
|
| 628 |
+
self.current_param_name] = full_value
|
| 629 |
+
|
| 630 |
+
# Get parameter configuration for type conversion
|
| 631 |
+
param_config = self._get_arguments_config(
|
| 632 |
+
self.current_function_name,
|
| 633 |
+
self.streaming_request.tools
|
| 634 |
+
if self.streaming_request else None)
|
| 635 |
+
|
| 636 |
+
# Convert the parameter value to the appropriate type
|
| 637 |
+
converted_value = self._convert_param_value(
|
| 638 |
+
full_value, self.current_param_name, param_config,
|
| 639 |
+
self.current_function_name)
|
| 640 |
+
|
| 641 |
+
# Serialize the converted value
|
| 642 |
+
serialized_value = json.dumps(converted_value,
|
| 643 |
+
ensure_ascii=False)
|
| 644 |
+
|
| 645 |
+
# Since we've been streaming the quoted version, we need to close it properly
|
| 646 |
+
# This is complex - for now just complete the value
|
| 647 |
+
self.in_param = False
|
| 648 |
+
self.current_param_value = ""
|
| 649 |
+
|
| 650 |
+
# Just close the current parameter string
|
| 651 |
+
return DeltaMessage(tool_calls=[
|
| 652 |
+
DeltaToolCall(
|
| 653 |
+
index=self.current_tool_index,
|
| 654 |
+
function=DeltaFunctionCall(
|
| 655 |
+
arguments='"'), # Close the string quote
|
| 656 |
+
)
|
| 657 |
+
])
|
| 658 |
+
else:
|
| 659 |
+
# Continue accumulating value
|
| 660 |
+
value_chunk = delta_text
|
| 661 |
+
|
| 662 |
+
# Handle first chunk after param name
|
| 663 |
+
if not self.current_param_value and ">" in value_chunk:
|
| 664 |
+
gt_idx = value_chunk.find(">")
|
| 665 |
+
value_chunk = value_chunk[gt_idx + 1:]
|
| 666 |
+
|
| 667 |
+
if not self.current_param_value and value_chunk.startswith(
|
| 668 |
+
"\n"):
|
| 669 |
+
value_chunk = value_chunk[1:]
|
| 670 |
+
|
| 671 |
+
if value_chunk:
|
| 672 |
+
# Stream the escaped delta
|
| 673 |
+
prev_escaped = json.dumps(
|
| 674 |
+
self.current_param_value, ensure_ascii=False
|
| 675 |
+
)[1:-1] if self.current_param_value else ""
|
| 676 |
+
self.current_param_value += value_chunk
|
| 677 |
+
full_escaped = json.dumps(self.current_param_value,
|
| 678 |
+
ensure_ascii=False)[1:-1]
|
| 679 |
+
delta_escaped = full_escaped[len(prev_escaped):]
|
| 680 |
+
|
| 681 |
+
if delta_escaped:
|
| 682 |
+
return DeltaMessage(tool_calls=[
|
| 683 |
+
DeltaToolCall(
|
| 684 |
+
index=self.current_tool_index,
|
| 685 |
+
function=DeltaFunctionCall(
|
| 686 |
+
arguments=delta_escaped),
|
| 687 |
+
)
|
| 688 |
+
])
|
| 689 |
+
|
| 690 |
+
return None
|