
File size: 4,503 Bytes
cb50f6a 5d8f693 335fb00 cb50f6a 5d8f693 cb50f6a c947ee2 5d8f693 11b8fda ea8cc34 cb50f6a 8664840 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 18ed6e4 ea8cc34 18ed6e4 ea8cc34 18ed6e4 ea8cc34 18ed6e4 ea8cc34 18ed6e4 ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 cb50f6a ea8cc34 ad858d2 6547e30 ad858d2 ea8cc34 2f9f8f1 cb50f6a 2f9f8f1 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 | ---
license: mit
language:
- en
inference: true
base_model:
- microsoft/codebert-base-mlm
- web3se/SmartBERT-v2
pipeline_tag: fill-mask
tags:
- fill-mask
- smart-contract
- web3
- software-engineering
- embedding
- codebert
library_name: transformers
datasets:
- web3se/smart-contract-intent-vul-dataset
---
# SmartBERT V3 CodeBERT
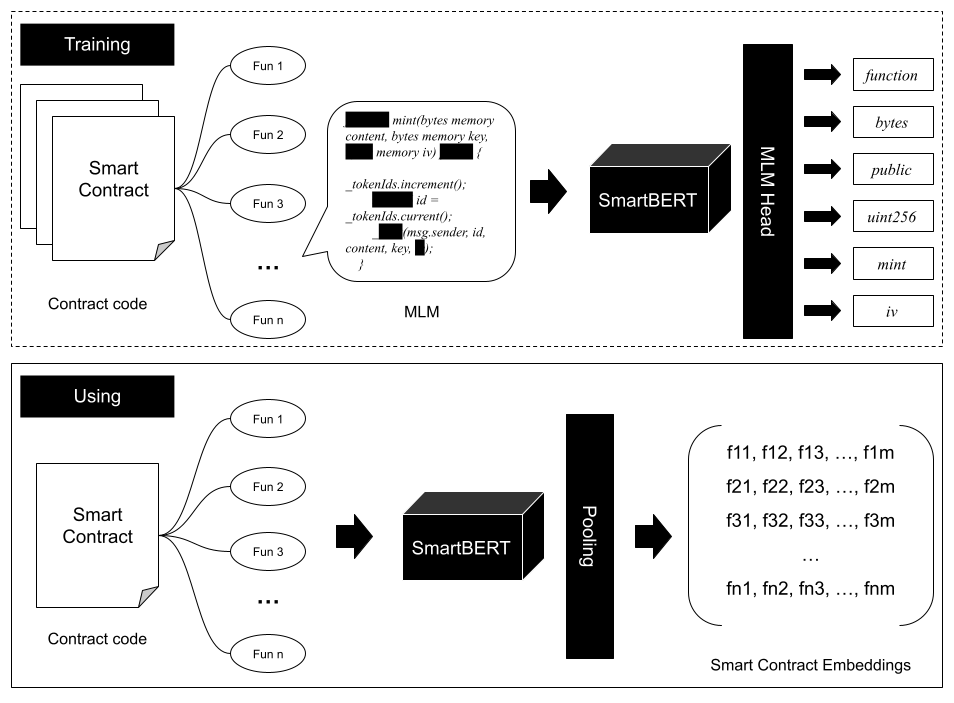
## Overview
**SmartBERT V3** is a domain-adapted pre-trained programming language model for **smart contract code understanding**, built upon **[CodeBERT-base-mlm](https://huggingface.co/microsoft/codebert-base-mlm)**.
The model is further trained on **[SmartBERT V2](https://huggingface.co/web3se/SmartBERT-v2)** with a substantially larger corpus of smart contracts, enabling improved robustness and richer semantic representations of **function-level smart contract code**.
SmartBERT V3 is particularly suitable for tasks such as:
- Smart contract intent detection
- Code representation learning
- Code similarity analysis
- Vulnerability detection
- Smart contract classification
Compared with **SmartBERT V2**, this version significantly expands the training corpus and improves the model’s ability to capture semantic patterns in smart contract functions.
---
## Training Data
SmartBERT V3 was trained on a total of **80,000 smart contracts**, including:
- **16,000 contracts** used in **[SmartBERT V2](https://huggingface.co/web3se/SmartBERT-v2)**
- **64,000 additional smart contracts** collected from public blockchain repositories
All contracts are primarily written in **Solidity** and processed at the **function level** to better capture fine-grained semantic structures of smart contract code.
---
## Training Objective
The model is trained using the **Masked Language Modeling (MLM)** objective, following the same training paradigm as **CodeBERT**.
During training:
- A subset of tokens in the input code is randomly masked
- The model learns to predict these masked tokens from surrounding context
This process enables the model to learn deeper **syntactic and semantic representations** of smart contract programs.
---
## Training Setup
Training was conducted using the **HuggingFace Transformers** framework.
- **Hardware:** 2 × Nvidia A100 (80GB)
- **Training Duration:** Over **30 hours**
- **Training Dataset:** 80,000 smart contracts
- **Evaluation Dataset:** 1,500 smart contracts
Example training configuration:
```python
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
overwrite_output_dir=True,
num_train_epochs=20,
per_device_train_batch_size=64,
save_steps=10000,
save_total_limit=2,
evaluation_strategy="steps",
eval_steps=10000,
resume_from_checkpoint=checkpoint
)
````
---
## Preprocessing
During preprocessing, all newline (`\n`) and tab (`\t`) characters in the *function* code were replaced with a single space to ensure a consistent input format for tokenization.
---
## Base Model
SmartBERT V3 builds upon the following models:
* **Original Model**: [CodeBERT-base-mlm](https://huggingface.co/microsoft/codebert-base-mlm)
* **Intermediate Model**: [SmartBERT V2](https://huggingface.co/web3se/SmartBERT-v2)
---
## Usage
Example usage with HuggingFace Transformers:
```python
from transformers import RobertaTokenizer, RobertaForMaskedLM, pipeline
model = RobertaForMaskedLM.from_pretrained('web3se/SmartBERT-v3')
tokenizer = RobertaTokenizer.from_pretrained('web3se/SmartBERT-v3')
code_example = "function totalSupply() external view <mask> (uint256);"
fill_mask = pipeline('fill-mask', model=model, tokenizer=tokenizer)
outputs = fill_mask(code_example)
print(outputs)
```
---
## How to Use
To train and deploy the SmartBERT V3 model for Web API services, please refer to our GitHub repository: [web3se-lab/SmartBERT](https://github.com/web3se-lab/SmartBERT).
---
## Contributor
* [Youwei Huang](https://www.devil.ren)
* [Sen Fang](https://github.com/TomasAndersonFang)
---
## Citation
```tex
@article{huang2025smart,
title={Smart Contract Intent Detection with Pre-trained Programming Language Model},
author={Huang, Youwei and Li, Jianwen and Fang, Sen and Li, Yao and Yang, Peng and Hu, Bin},
journal={arXiv preprint arXiv:2508.20086},
year={2025}
}
```
---
## Acknowledgement
- [Institute of Intelligent Computing Technology, Suzhou, CAS](http://iict.ac.cn/)
- [Macau University of Science and Technology](http://www.must.edu.mo)
- CAS Mino (中科劢诺) |