

Upload all models and assets for ady (20251201)
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +6 -0
- README.md +561 -0
- models/embeddings/monolingual/ady_128d.bin +3 -0
- models/embeddings/monolingual/ady_128d.meta.json +1 -0
- models/embeddings/monolingual/ady_128d_metadata.json +13 -0
- models/embeddings/monolingual/ady_32d.bin +3 -0
- models/embeddings/monolingual/ady_32d.meta.json +1 -0
- models/embeddings/monolingual/ady_32d_metadata.json +13 -0
- models/embeddings/monolingual/ady_64d.bin +3 -0
- models/embeddings/monolingual/ady_64d.meta.json +1 -0
- models/embeddings/monolingual/ady_64d_metadata.json +13 -0
- models/subword_markov/ady_markov_ctx1_subword.parquet +3 -0
- models/subword_markov/ady_markov_ctx1_subword_metadata.json +7 -0
- models/subword_markov/ady_markov_ctx2_subword.parquet +3 -0
- models/subword_markov/ady_markov_ctx2_subword_metadata.json +7 -0
- models/subword_markov/ady_markov_ctx3_subword.parquet +3 -0
- models/subword_markov/ady_markov_ctx3_subword_metadata.json +7 -0
- models/subword_markov/ady_markov_ctx4_subword.parquet +3 -0
- models/subword_markov/ady_markov_ctx4_subword_metadata.json +7 -0
- models/subword_ngram/ady_2gram_subword.parquet +3 -0
- models/subword_ngram/ady_2gram_subword_metadata.json +7 -0
- models/subword_ngram/ady_3gram_subword.parquet +3 -0
- models/subword_ngram/ady_3gram_subword_metadata.json +7 -0
- models/subword_ngram/ady_4gram_subword.parquet +3 -0
- models/subword_ngram/ady_4gram_subword_metadata.json +7 -0
- models/tokenizer/ady_tokenizer_16k.model +3 -0
- models/tokenizer/ady_tokenizer_16k.vocab +0 -0
- models/tokenizer/ady_tokenizer_32k.model +3 -0
- models/tokenizer/ady_tokenizer_32k.vocab +0 -0
- models/tokenizer/ady_tokenizer_64k.model +3 -0
- models/tokenizer/ady_tokenizer_64k.vocab +0 -0
- models/tokenizer/ady_tokenizer_8k.model +3 -0
- models/tokenizer/ady_tokenizer_8k.vocab +0 -0
- models/vocabulary/ady_vocabulary.parquet +3 -0
- models/vocabulary/ady_vocabulary_metadata.json +16 -0
- models/word_markov/ady_markov_ctx1_word.parquet +3 -0
- models/word_markov/ady_markov_ctx1_word_metadata.json +7 -0
- models/word_markov/ady_markov_ctx2_word.parquet +3 -0
- models/word_markov/ady_markov_ctx2_word_metadata.json +7 -0
- models/word_markov/ady_markov_ctx3_word.parquet +3 -0
- models/word_markov/ady_markov_ctx3_word_metadata.json +7 -0
- models/word_markov/ady_markov_ctx4_word.parquet +3 -0
- models/word_markov/ady_markov_ctx4_word_metadata.json +7 -0
- models/word_ngram/ady_2gram_word.parquet +3 -0
- models/word_ngram/ady_2gram_word_metadata.json +7 -0
- models/word_ngram/ady_3gram_word.parquet +3 -0
- models/word_ngram/ady_3gram_word_metadata.json +7 -0
- models/word_ngram/ady_4gram_word.parquet +3 -0
- models/word_ngram/ady_4gram_word_metadata.json +7 -0
- visualizations/embedding_isotropy.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,9 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
visualizations/embedding_similarity.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
visualizations/performance_dashboard.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
visualizations/position_encoding_comparison.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
visualizations/tsne_sentences.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
visualizations/tsne_words.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
visualizations/zipf_law.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,561 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: ady
|
| 3 |
+
language_name: ADY
|
| 4 |
+
language_family: caucasian_northwest
|
| 5 |
+
tags:
|
| 6 |
+
- wikilangs
|
| 7 |
+
- nlp
|
| 8 |
+
- tokenizer
|
| 9 |
+
- embeddings
|
| 10 |
+
- n-gram
|
| 11 |
+
- markov
|
| 12 |
+
- wikipedia
|
| 13 |
+
- monolingual
|
| 14 |
+
- family-caucasian_northwest
|
| 15 |
+
license: mit
|
| 16 |
+
library_name: wikilangs
|
| 17 |
+
pipeline_tag: feature-extraction
|
| 18 |
+
datasets:
|
| 19 |
+
- omarkamali/wikipedia-monthly
|
| 20 |
+
dataset_info:
|
| 21 |
+
name: wikipedia-monthly
|
| 22 |
+
description: Monthly snapshots of Wikipedia articles across 300+ languages
|
| 23 |
+
metrics:
|
| 24 |
+
- name: best_compression_ratio
|
| 25 |
+
type: compression
|
| 26 |
+
value: 4.453
|
| 27 |
+
- name: best_isotropy
|
| 28 |
+
type: isotropy
|
| 29 |
+
value: 0.6831
|
| 30 |
+
- name: vocabulary_size
|
| 31 |
+
type: vocab
|
| 32 |
+
value: 8988
|
| 33 |
+
generated: 2025-12-27
|
| 34 |
+
---
|
| 35 |
+
|
| 36 |
+
# ADY - Wikilangs Models
|
| 37 |
+
## Comprehensive Research Report & Full Ablation Study
|
| 38 |
+
|
| 39 |
+
This repository contains NLP models trained and evaluated by Wikilangs, specifically on **ADY** Wikipedia data.
|
| 40 |
+
We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and word embeddings.
|
| 41 |
+
|
| 42 |
+
## 📋 Repository Contents
|
| 43 |
+
|
| 44 |
+
### Models & Assets
|
| 45 |
+
|
| 46 |
+
- Tokenizers (8k, 16k, 32k, 64k)
|
| 47 |
+
- N-gram models (2, 3, 4-gram)
|
| 48 |
+
- Markov chains (context of 1, 2, 3 and 4)
|
| 49 |
+
- Subword N-gram and Markov chains
|
| 50 |
+
- Embeddings in various sizes and dimensions
|
| 51 |
+
- Language Vocabulary
|
| 52 |
+
- Language Statistics
|
| 53 |
+

|
| 54 |
+
|
| 55 |
+
### Analysis and Evaluation
|
| 56 |
+
|
| 57 |
+
- [1. Tokenizer Evaluation](#1-tokenizer-evaluation)
|
| 58 |
+
- [2. N-gram Model Evaluation](#2-n-gram-model-evaluation)
|
| 59 |
+
- [3. Markov Chain Evaluation](#3-markov-chain-evaluation)
|
| 60 |
+
- [4. Vocabulary Analysis](#4-vocabulary-analysis)
|
| 61 |
+
- [5. Word Embeddings Evaluation](#5-word-embeddings-evaluation)
|
| 62 |
+
- [6. Summary & Recommendations](#6-summary--recommendations)
|
| 63 |
+
- [Metrics Glossary](#appendix-metrics-glossary--interpretation-guide)
|
| 64 |
+
- [Visualizations Index](#visualizations-index)
|
| 65 |
+
|
| 66 |
+
---
|
| 67 |
+
## 1. Tokenizer Evaluation
|
| 68 |
+
|
| 69 |
+

|
| 70 |
+
|
| 71 |
+
### Results
|
| 72 |
+
|
| 73 |
+
| Vocab Size | Compression | Avg Token Len | UNK Rate | Total Tokens |
|
| 74 |
+
|------------|-------------|---------------|----------|--------------|
|
| 75 |
+
| **8k** | 3.223x | 3.18 | 0.1016% | 189,909 |
|
| 76 |
+
| **16k** | 3.621x | 3.57 | 0.1142% | 169,055 |
|
| 77 |
+
| **32k** | 4.071x | 4.02 | 0.1284% | 150,370 |
|
| 78 |
+
| **64k** | 4.453x 🏆 | 4.39 | 0.1404% | 137,476 |
|
| 79 |
+
|
| 80 |
+
### Tokenization Examples
|
| 81 |
+
|
| 82 |
+
Below are sample sentences tokenized with each vocabulary size:
|
| 83 |
+
|
| 84 |
+
**Sample 1:** `Киото — Японием и къалэ.
|
| 85 |
+
|
| 86 |
+
Category:Къалэхэр
|
| 87 |
+
Category:Японие`
|
| 88 |
+
|
| 89 |
+
| Vocab | Tokens | Count |
|
| 90 |
+
|-------|--------|-------|
|
| 91 |
+
| 8k | `▁к и от о ▁— ▁японием ▁и ▁къалэ . ▁category ... (+5 more)` | 15 |
|
| 92 |
+
| 16k | `▁ки ото ▁— ▁японием ▁и ▁къалэ . ▁category : къалэхэр ... (+3 more)` | 13 |
|
| 93 |
+
| 32k | `▁ки ото ▁— ▁японием ▁и ▁къалэ . ▁category : къалэхэр ... (+3 more)` | 13 |
|
| 94 |
+
| 64k | `▁киото ▁— ▁японием ▁и ▁къалэ . ▁category : къалэхэр ▁category ... (+2 more)` | 12 |
|
| 95 |
+
|
| 96 |
+
**Sample 2:** `Ереван () – Армение и къэлэшъхьаI. Нэбгырэ млн 1,06 фэдиз дэс. Къалэм и лIышъхьэ...`
|
| 97 |
+
|
| 98 |
+
| Vocab | Tokens | Count |
|
| 99 |
+
|-------|--------|-------|
|
| 100 |
+
| 8k | `▁е ре ван ▁() ▁– ▁армение ▁и ▁къэлэшъхьа i . ... (+28 more)` | 38 |
|
| 101 |
+
| 16k | `▁ереван ▁() ▁– ▁армение ▁и ▁къэлэшъхьа i . ▁нэбгырэ ▁млн ... (+25 more)` | 35 |
|
| 102 |
+
| 32k | `▁ереван ▁() ▁– ▁армение ▁и ▁къэлэшъхьа i . ▁нэбгырэ ▁млн ... (+25 more)` | 35 |
|
| 103 |
+
| 64k | `▁ереван ▁() ▁– ▁армение ▁и ▁къэлэшъхьа i . ▁нэбгырэ ▁млн ... (+20 more)` | 30 |
|
| 104 |
+
|
| 105 |
+
**Sample 3:** `thumb
|
| 106 |
+
thumb
|
| 107 |
+
Ишъхъэрэ Америкэ — континент.
|
| 108 |
+
|
| 109 |
+
ЧIырэу млн 24,7 км² фэдиз еубыты. ЦIы...`
|
| 110 |
+
|
| 111 |
+
| Vocab | Tokens | Count |
|
| 112 |
+
|-------|--------|-------|
|
| 113 |
+
| 8k | `▁thumb ▁thumb ▁ишъхъэрэ ▁америкэ ▁— ▁континент . ▁ч i ырэу ... (+27 more)` | 37 |
|
| 114 |
+
| 16k | `▁thumb ▁thumb ▁ишъхъэрэ ▁америкэ ▁— ▁континент . ▁ч i ырэу ... (+27 more)` | 37 |
|
| 115 |
+
| 32k | `▁thumb ▁thumb ▁ишъхъэрэ ▁америкэ ▁— ▁континент . ▁ч i ырэу ... (+27 more)` | 37 |
|
| 116 |
+
| 64k | `▁thumb ▁thumb ▁ишъхъэрэ ▁америкэ ▁— ▁континент . ▁ч i ырэу ... (+27 more)` | 37 |
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
### Key Findings
|
| 120 |
+
|
| 121 |
+
- **Best Compression:** 64k achieves 4.453x compression
|
| 122 |
+
- **Lowest UNK Rate:** 8k with 0.1016% unknown tokens
|
| 123 |
+
- **Trade-off:** Larger vocabularies improve compression but increase model size
|
| 124 |
+
- **Recommendation:** 32k vocabulary provides optimal balance for production use
|
| 125 |
+
|
| 126 |
+
---
|
| 127 |
+
## 2. N-gram Model Evaluation
|
| 128 |
+
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+

|
| 132 |
+
|
| 133 |
+
### Results
|
| 134 |
+
|
| 135 |
+
| N-gram | Perplexity | Entropy | Unique N-grams | Top-100 Coverage | Top-1000 Coverage |
|
| 136 |
+
|--------|------------|---------|----------------|------------------|-------------------|
|
| 137 |
+
| **2-gram** | 927 🏆 | 9.86 | 1,856 | 38.3% | 83.1% |
|
| 138 |
+
| **2-gram** | 486 🏆 | 8.92 | 2,656 | 53.5% | 95.5% |
|
| 139 |
+
| **3-gram** | 1,521 | 10.57 | 2,744 | 28.3% | 71.0% |
|
| 140 |
+
| **3-gram** | 3,351 | 11.71 | 15,024 | 23.1% | 61.6% |
|
| 141 |
+
| **4-gram** | 4,981 | 12.28 | 7,604 | 14.3% | 42.5% |
|
| 142 |
+
| **4-gram** | 12,700 | 13.63 | 44,900 | 11.7% | 37.6% |
|
| 143 |
+
|
| 144 |
+
### Top 5 N-grams by Size
|
| 145 |
+
|
| 146 |
+
**2-grams:**
|
| 147 |
+
|
| 148 |
+
| Rank | N-gram | Count |
|
| 149 |
+
|------|--------|-------|
|
| 150 |
+
| 1 | `category :` | 662 |
|
| 151 |
+
| 2 | `- рэ` | 638 |
|
| 152 |
+
| 3 | `- м` | 464 |
|
| 153 |
+
| 4 | `рэ илъэсым` | 335 |
|
| 154 |
+
| 5 | `. category` | 276 |
|
| 155 |
+
|
| 156 |
+
**3-grams:**
|
| 157 |
+
|
| 158 |
+
| Rank | N-gram | Count |
|
| 159 |
+
|------|--------|-------|
|
| 160 |
+
| 1 | `- рэ илъэсым` | 333 |
|
| 161 |
+
| 2 | `. category :` | 276 |
|
| 162 |
+
| 3 | `category : !` | 179 |
|
| 163 |
+
| 4 | `: ! main` | 179 |
|
| 164 |
+
| 5 | `! main category` | 179 |
|
| 165 |
+
|
| 166 |
+
**4-grams:**
|
| 167 |
+
|
| 168 |
+
| Rank | N-gram | Count |
|
| 169 |
+
|------|--------|-------|
|
| 170 |
+
| 1 | `category : ! main` | 179 |
|
| 171 |
+
| 2 | `: ! main category` | 179 |
|
| 172 |
+
| 3 | `. category : !` | 132 |
|
| 173 |
+
| 4 | `. хэгэгум чiырэу иiэр` | 101 |
|
| 174 |
+
| 5 | `. дло - м` | 87 |
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
### Key Findings
|
| 178 |
+
|
| 179 |
+
- **Best Perplexity:** 2-gram with 486
|
| 180 |
+
- **Entropy Trend:** Decreases with larger n-grams (more predictable)
|
| 181 |
+
- **Coverage:** Top-1000 patterns cover ~38% of corpus
|
| 182 |
+
- **Recommendation:** 4-gram or 5-gram for best predictive performance
|
| 183 |
+
|
| 184 |
+
---
|
| 185 |
+
## 3. Markov Chain Evaluation
|
| 186 |
+
|
| 187 |
+

|
| 188 |
+
|
| 189 |
+

|
| 190 |
+
|
| 191 |
+
### Results
|
| 192 |
+
|
| 193 |
+
| Context | Avg Entropy | Perplexity | Branching Factor | Unique Contexts | Predictability |
|
| 194 |
+
|---------|-------------|------------|------------------|-----------------|----------------|
|
| 195 |
+
| **1** | 0.3643 | 1.287 | 2.28 | 28,827 | 63.6% |
|
| 196 |
+
| **1** | 1.5343 | 2.896 | 12.27 | 463 | 0.0% |
|
| 197 |
+
| **2** | 0.1248 | 1.090 | 1.24 | 65,637 | 87.5% |
|
| 198 |
+
| **2** | 1.1477 | 2.216 | 5.66 | 5,679 | 0.0% |
|
| 199 |
+
| **3** | 0.0452 | 1.032 | 1.07 | 80,882 | 95.5% |
|
| 200 |
+
| **3** | 0.7357 | 1.665 | 2.89 | 32,122 | 26.4% |
|
| 201 |
+
| **4** | 0.0244 🏆 | 1.017 | 1.04 | 86,492 | 97.6% |
|
| 202 |
+
| **4** | 0.4145 🏆 | 1.333 | 1.83 | 92,841 | 58.5% |
|
| 203 |
+
|
| 204 |
+
### Generated Text Samples
|
| 205 |
+
|
| 206 |
+
Below are text samples generated from each Markov chain model:
|
| 207 |
+
|
| 208 |
+
**Context Size 1:**
|
| 209 |
+
|
| 210 |
+
1. `. ахъщэр iэгурыхьэ - 14 . ы ↔ ӏей ; пшэс 1угжъу category : / даутэ`
|
| 211 |
+
2. `, коц , " ids " " тэiошъ , батэ вгъэшым сэ силъэпкъ шъукъыхахьэу , къэрабгъэр`
|
| 212 |
+
3. `- рэ лӏэшӏэгъуршапсыгъэхэршапсыгъэ ныпгорэ . географие гъунэгъухэр : " kaynar , каракас ) къо зиiэм ...`
|
| 213 |
+
|
| 214 |
+
**Context Size 2:**
|
| 215 |
+
|
| 216 |
+
1. `category : район category : ! main category зэпыщэхэр`
|
| 217 |
+
2. `- рэ щэпсэу . гулъытэгъуэ техьэпӏэхэр къайсэр адыгэ хасэм ( дах - м хахьэ . хэгъэгу лiышъхьэр`
|
| 218 |
+
3. `- м инароднэ тхакiу . илэжьэнхэр 1960 - рэ ислъэсхэм – адыгэ къэралыгъо университетым студентхэр щег...`
|
| 219 |
+
|
| 220 |
+
**Context Size 3:**
|
| 221 |
+
|
| 222 |
+
1. `- рэ илъэсым къыщегъэжьагъэу щэiэфэ гуманитар ушэтынхэмкiэ адыгэ республикэ институтым литературэмкi...`
|
| 223 |
+
2. `. category : ! main category зэпыщэхэр`
|
| 224 |
+
3. `category : ! main category зэпыщэхэр`
|
| 225 |
+
|
| 226 |
+
**Context Size 4:**
|
| 227 |
+
|
| 228 |
+
1. `category : ! main category зэпыщэхэр`
|
| 229 |
+
2. `. category : ! main category зэпыщэхэр`
|
| 230 |
+
3. `. хэгэгум чiырэу иiэр 9 984 670 км² ( дунаемкiэ я - 11 ) . хэгэгум чiырэу иiэр 283`
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
### Key Findings
|
| 234 |
+
|
| 235 |
+
- **Best Predictability:** Context-4 with 97.6% predictability
|
| 236 |
+
- **Branching Factor:** Decreases with context size (more deterministic)
|
| 237 |
+
- **Memory Trade-off:** Larger contexts require more storage (92,841 contexts)
|
| 238 |
+
- **Recommendation:** Context-3 or Context-4 for text generation
|
| 239 |
+
|
| 240 |
+
---
|
| 241 |
+
## 4. Vocabulary Analysis
|
| 242 |
+
|
| 243 |
+

|
| 244 |
+
|
| 245 |
+

|
| 246 |
+
|
| 247 |
+

|
| 248 |
+
|
| 249 |
+
### Statistics
|
| 250 |
+
|
| 251 |
+
| Metric | Value |
|
| 252 |
+
|--------|-------|
|
| 253 |
+
| Vocabulary Size | 8,988 |
|
| 254 |
+
| Total Tokens | 57,159 |
|
| 255 |
+
| Mean Frequency | 6.36 |
|
| 256 |
+
| Median Frequency | 3 |
|
| 257 |
+
| Frequency Std Dev | 23.47 |
|
| 258 |
+
|
| 259 |
+
### Most Common Words
|
| 260 |
+
|
| 261 |
+
| Rank | Word | Frequency |
|
| 262 |
+
|------|------|-----------|
|
| 263 |
+
| 1 | и | 1,019 |
|
| 264 |
+
| 2 | category | 841 |
|
| 265 |
+
| 3 | адыгэ | 701 |
|
| 266 |
+
| 4 | рэ | 641 |
|
| 267 |
+
| 5 | м | 541 |
|
| 268 |
+
| 6 | илъэсым | 407 |
|
| 269 |
+
| 7 | ащ | 392 |
|
| 270 |
+
| 8 | я | 349 |
|
| 271 |
+
| 9 | ары | 276 |
|
| 272 |
+
| 10 | а | 259 |
|
| 273 |
+
|
| 274 |
+
### Least Common Words (from vocabulary)
|
| 275 |
+
|
| 276 |
+
| Rank | Word | Frequency |
|
| 277 |
+
|------|------|-----------|
|
| 278 |
+
| 1 | britishpedia | 2 |
|
| 279 |
+
| 2 | encyklopedia | 2 |
|
| 280 |
+
| 3 | osobistości | 2 |
|
| 281 |
+
| 4 | rzeczypospolitej | 2 |
|
| 282 |
+
| 5 | polskiej | 2 |
|
| 283 |
+
| 6 | bph | 2 |
|
| 284 |
+
| 7 | british | 2 |
|
| 285 |
+
| 8 | publishing | 2 |
|
| 286 |
+
| 9 | ltd | 2 |
|
| 287 |
+
| 10 | 912100 | 2 |
|
| 288 |
+
|
| 289 |
+
### Zipf's Law Analysis
|
| 290 |
+
|
| 291 |
+
| Metric | Value |
|
| 292 |
+
|--------|-------|
|
| 293 |
+
| Zipf Coefficient | 0.7855 |
|
| 294 |
+
| R² (Goodness of Fit) | 0.976491 |
|
| 295 |
+
| Adherence Quality | **excellent** |
|
| 296 |
+
|
| 297 |
+
### Coverage Analysis
|
| 298 |
+
|
| 299 |
+
| Top N Words | Coverage |
|
| 300 |
+
|-------------|----------|
|
| 301 |
+
| Top 100 | 26.7% |
|
| 302 |
+
| Top 1,000 | 56.9% |
|
| 303 |
+
| Top 5,000 | 86.0% |
|
| 304 |
+
| Top 10,000 | 0.0% |
|
| 305 |
+
|
| 306 |
+
### Key Findings
|
| 307 |
+
|
| 308 |
+
- **Zipf Compliance:** R²=0.9765 indicates excellent adherence to Zipf's law
|
| 309 |
+
- **High Frequency Dominance:** Top 100 words cover 26.7% of corpus
|
| 310 |
+
- **Long Tail:** -1,012 words needed for remaining 100.0% coverage
|
| 311 |
+
|
| 312 |
+
---
|
| 313 |
+
## 5. Word Embeddings Evaluation
|
| 314 |
+
|
| 315 |
+

|
| 316 |
+
|
| 317 |
+

|
| 318 |
+
|
| 319 |
+

|
| 320 |
+
|
| 321 |
+

|
| 322 |
+
|
| 323 |
+
### Model Comparison
|
| 324 |
+
|
| 325 |
+
| Model | Vocab Size | Dimension | Avg Norm | Std Norm | Isotropy |
|
| 326 |
+
|-------|------------|-----------|----------|----------|----------|
|
| 327 |
+
| **mono_32d** | 1,830 | 32 | 3.764 | 0.663 | 0.6831 🏆 |
|
| 328 |
+
| **mono_64d** | 1,830 | 64 | 3.806 | 0.668 | 0.2517 |
|
| 329 |
+
| **mono_128d** | 1,830 | 128 | 3.824 | 0.669 | 0.0484 |
|
| 330 |
+
| **embeddings_enhanced** | 0 | 0 | 0.000 | 0.000 | 0.0000 |
|
| 331 |
+
|
| 332 |
+
### Key Findings
|
| 333 |
+
|
| 334 |
+
- **Best Isotropy:** mono_32d with 0.6831 (more uniform distribution)
|
| 335 |
+
- **Dimension Trade-off:** Higher dimensions capture more semantics but reduce isotropy
|
| 336 |
+
- **Vocabulary Coverage:** All models cover 1,830 words
|
| 337 |
+
- **Recommendation:** 100d for balanced semantic capture and efficiency
|
| 338 |
+
|
| 339 |
+
---
|
| 340 |
+
## 6. Summary & Recommendations
|
| 341 |
+
|
| 342 |
+

|
| 343 |
+
|
| 344 |
+
### Production Recommendations
|
| 345 |
+
|
| 346 |
+
| Component | Recommended | Rationale |
|
| 347 |
+
|-----------|-------------|-----------|
|
| 348 |
+
| Tokenizer | **32k BPE** | Best compression (4.45x) with low UNK rate |
|
| 349 |
+
| N-gram | **5-gram** | Lowest perplexity (486) |
|
| 350 |
+
| Markov | **Context-4** | Highest predictability (97.6%) |
|
| 351 |
+
| Embeddings | **100d** | Balanced semantic capture and isotropy |
|
| 352 |
+
|
| 353 |
+
---
|
| 354 |
+
## Appendix: Metrics Glossary & Interpretation Guide
|
| 355 |
+
|
| 356 |
+
This section provides definitions, intuitions, and guidance for interpreting the metrics used throughout this report.
|
| 357 |
+
|
| 358 |
+
### Tokenizer Metrics
|
| 359 |
+
|
| 360 |
+
**Compression Ratio**
|
| 361 |
+
> *Definition:* The ratio of characters to tokens (chars/token). Measures how efficiently the tokenizer represents text.
|
| 362 |
+
>
|
| 363 |
+
> *Intuition:* Higher compression means fewer tokens needed to represent the same text, reducing sequence lengths for downstream models. A 3x compression means ~3 characters per token on average.
|
| 364 |
+
>
|
| 365 |
+
> *What to seek:* Higher is generally better for efficiency, but extremely high compression may indicate overly aggressive merging that loses morphological information.
|
| 366 |
+
|
| 367 |
+
**Average Token Length (Fertility)**
|
| 368 |
+
> *Definition:* Mean number of characters per token produced by the tokenizer.
|
| 369 |
+
>
|
| 370 |
+
> *Intuition:* Reflects the granularity of tokenization. Longer tokens capture more context but may struggle with rare words; shorter tokens are more flexible but increase sequence length.
|
| 371 |
+
>
|
| 372 |
+
> *What to seek:* Balance between 2-5 characters for most languages. Arabic/morphologically-rich languages may benefit from slightly longer tokens.
|
| 373 |
+
|
| 374 |
+
**Unknown Token Rate (OOV Rate)**
|
| 375 |
+
> *Definition:* Percentage of tokens that map to the unknown/UNK token, indicating words the tokenizer cannot represent.
|
| 376 |
+
>
|
| 377 |
+
> *Intuition:* Lower OOV means better vocabulary coverage. High OOV indicates the tokenizer encounters many unseen character sequences.
|
| 378 |
+
>
|
| 379 |
+
> *What to seek:* Below 1% is excellent; below 5% is acceptable. BPE tokenizers typically achieve very low OOV due to subword fallback.
|
| 380 |
+
|
| 381 |
+
### N-gram Model Metrics
|
| 382 |
+
|
| 383 |
+
**Perplexity**
|
| 384 |
+
> *Definition:* Measures how "surprised" the model is by test data. Mathematically: 2^(cross-entropy). Lower values indicate better prediction.
|
| 385 |
+
>
|
| 386 |
+
> *Intuition:* If perplexity is 100, the model is as uncertain as if choosing uniformly among 100 options at each step. A perplexity of 10 means effectively choosing among 10 equally likely options.
|
| 387 |
+
>
|
| 388 |
+
> *What to seek:* Lower is better. Perplexity decreases with larger n-grams (more context). Values vary widely by language and corpus size.
|
| 389 |
+
|
| 390 |
+
**Entropy**
|
| 391 |
+
> *Definition:* Average information content (in bits) needed to encode the next token given the context. Related to perplexity: perplexity = 2^entropy.
|
| 392 |
+
>
|
| 393 |
+
> *Intuition:* High entropy means high uncertainty/randomness; low entropy means predictable patterns. Natural language typically has entropy between 1-4 bits per character.
|
| 394 |
+
>
|
| 395 |
+
> *What to seek:* Lower entropy indicates more predictable text patterns. Entropy should decrease as n-gram size increases.
|
| 396 |
+
|
| 397 |
+
**Coverage (Top-K)**
|
| 398 |
+
> *Definition:* Percentage of corpus occurrences explained by the top K most frequent n-grams.
|
| 399 |
+
>
|
| 400 |
+
> *Intuition:* High coverage with few patterns indicates repetitive/formulaic text; low coverage suggests diverse vocabulary usage.
|
| 401 |
+
>
|
| 402 |
+
> *What to seek:* Depends on use case. For language modeling, moderate coverage (40-60% with top-1000) is typical for natural text.
|
| 403 |
+
|
| 404 |
+
### Markov Chain Metrics
|
| 405 |
+
|
| 406 |
+
**Average Entropy**
|
| 407 |
+
> *Definition:* Mean entropy across all contexts, measuring average uncertainty in next-word prediction.
|
| 408 |
+
>
|
| 409 |
+
> *Intuition:* Lower entropy means the model is more confident about what comes next. Context-1 has high entropy (many possible next words); Context-4 has low entropy (few likely continuations).
|
| 410 |
+
>
|
| 411 |
+
> *What to seek:* Decreasing entropy with larger context sizes. Very low entropy (<0.1) indicates highly deterministic transitions.
|
| 412 |
+
|
| 413 |
+
**Branching Factor**
|
| 414 |
+
> *Definition:* Average number of unique next tokens observed for each context.
|
| 415 |
+
>
|
| 416 |
+
> *Intuition:* High branching = many possible continuations (flexible but uncertain); low branching = few options (predictable but potentially repetitive).
|
| 417 |
+
>
|
| 418 |
+
> *What to seek:* Branching factor should decrease with context size. Values near 1.0 indicate nearly deterministic chains.
|
| 419 |
+
|
| 420 |
+
**Predictability**
|
| 421 |
+
> *Definition:* Derived metric: (1 - normalized_entropy) × 100%. Indicates how deterministic the model's predictions are.
|
| 422 |
+
>
|
| 423 |
+
> *Intuition:* 100% predictability means the next word is always certain; 0% means completely random. Real text falls between these extremes.
|
| 424 |
+
>
|
| 425 |
+
> *What to seek:* Higher predictability for text generation quality, but too high (>98%) may produce repetitive output.
|
| 426 |
+
|
| 427 |
+
### Vocabulary & Zipf's Law Metrics
|
| 428 |
+
|
| 429 |
+
**Zipf's Coefficient**
|
| 430 |
+
> *Definition:* The slope of the log-log plot of word frequency vs. rank. Zipf's law predicts this should be approximately -1.
|
| 431 |
+
>
|
| 432 |
+
> *Intuition:* A coefficient near -1 indicates the corpus follows natural language patterns where a few words are very common and most words are rare.
|
| 433 |
+
>
|
| 434 |
+
> *What to seek:* Values between -0.8 and -1.2 indicate healthy natural language distribution. Deviations may suggest domain-specific or artificial text.
|
| 435 |
+
|
| 436 |
+
**R² (Coefficient of Determination)**
|
| 437 |
+
> *Definition:* Measures how well the linear fit explains the frequency-rank relationship. Ranges from 0 to 1.
|
| 438 |
+
>
|
| 439 |
+
> *Intuition:* R² near 1.0 means the data closely follows Zipf's law; lower values indicate deviation from expected word frequency patterns.
|
| 440 |
+
>
|
| 441 |
+
> *What to seek:* R² > 0.95 is excellent; > 0.99 indicates near-perfect Zipf adherence typical of large natural corpora.
|
| 442 |
+
|
| 443 |
+
**Vocabulary Coverage**
|
| 444 |
+
> *Definition:* Cumulative percentage of corpus tokens accounted for by the top N words.
|
| 445 |
+
>
|
| 446 |
+
> *Intuition:* Shows how concentrated word usage is. If top-100 words cover 50% of text, the corpus relies heavily on common words.
|
| 447 |
+
>
|
| 448 |
+
> *What to seek:* Top-100 covering 30-50% is typical. Higher coverage indicates more repetitive text; lower suggests richer vocabulary.
|
| 449 |
+
|
| 450 |
+
### Word Embedding Metrics
|
| 451 |
+
|
| 452 |
+
**Isotropy**
|
| 453 |
+
> *Definition:* Measures how uniformly distributed vectors are in the embedding space. Computed as the ratio of minimum to maximum singular values.
|
| 454 |
+
>
|
| 455 |
+
> *Intuition:* High isotropy (near 1.0) means vectors spread evenly in all directions; low isotropy means vectors cluster in certain directions, reducing expressiveness.
|
| 456 |
+
>
|
| 457 |
+
> *What to seek:* Higher isotropy generally indicates better-quality embeddings. Values > 0.1 are reasonable; > 0.3 is good. Lower-dimensional embeddings tend to have higher isotropy.
|
| 458 |
+
|
| 459 |
+
**Average Norm**
|
| 460 |
+
> *Definition:* Mean magnitude (L2 norm) of word vectors in the embedding space.
|
| 461 |
+
>
|
| 462 |
+
> *Intuition:* Indicates the typical "length" of vectors. Consistent norms suggest stable training; high variance may indicate some words are undertrained.
|
| 463 |
+
>
|
| 464 |
+
> *What to seek:* Relatively consistent norms across models. The absolute value matters less than consistency (low std deviation).
|
| 465 |
+
|
| 466 |
+
**Cosine Similarity**
|
| 467 |
+
> *Definition:* Measures angular similarity between vectors, ranging from -1 (opposite) to 1 (identical direction).
|
| 468 |
+
>
|
| 469 |
+
> *Intuition:* Words with similar meanings should have high cosine similarity. This is the standard metric for semantic relatedness in embeddings.
|
| 470 |
+
>
|
| 471 |
+
> *What to seek:* Semantically related words should score > 0.5; unrelated words should be near 0. Synonyms often score > 0.7.
|
| 472 |
+
|
| 473 |
+
**t-SNE Visualization**
|
| 474 |
+
> *Definition:* t-Distributed Stochastic Neighbor Embedding - a dimensionality reduction technique that preserves local structure for visualization.
|
| 475 |
+
>
|
| 476 |
+
> *Intuition:* Clusters in t-SNE plots indicate groups of semantically related words. Spread indicates vocabulary diversity; tight clusters suggest semantic coherence.
|
| 477 |
+
>
|
| 478 |
+
> *What to seek:* Meaningful clusters (e.g., numbers together, verbs together). Avoid over-interpreting distances - t-SNE preserves local, not global, structure.
|
| 479 |
+
|
| 480 |
+
### General Interpretation Guidelines
|
| 481 |
+
|
| 482 |
+
1. **Compare within model families:** Metrics are most meaningful when comparing models of the same type (e.g., 8k vs 64k tokenizer).
|
| 483 |
+
2. **Consider trade-offs:** Better performance on one metric often comes at the cost of another (e.g., compression vs. OOV rate).
|
| 484 |
+
3. **Context matters:** Optimal values depend on downstream tasks. Text generation may prioritize different metrics than classification.
|
| 485 |
+
4. **Corpus influence:** All metrics are influenced by corpus characteristics. Wikipedia text differs from social media or literature.
|
| 486 |
+
5. **Language-specific patterns:** Morphologically rich languages (like Arabic) may show different optimal ranges than analytic languages.
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
### Visualizations Index
|
| 490 |
+
|
| 491 |
+
| Visualization | Description |
|
| 492 |
+
|---------------|-------------|
|
| 493 |
+
| Tokenizer Compression | Compression ratios by vocabulary size |
|
| 494 |
+
| Tokenizer Fertility | Average token length by vocabulary |
|
| 495 |
+
| Tokenizer OOV | Unknown token rates |
|
| 496 |
+
| Tokenizer Total Tokens | Total tokens by vocabulary |
|
| 497 |
+
| N-gram Perplexity | Perplexity by n-gram size |
|
| 498 |
+
| N-gram Entropy | Entropy by n-gram size |
|
| 499 |
+
| N-gram Coverage | Top pattern coverage |
|
| 500 |
+
| N-gram Unique | Unique n-gram counts |
|
| 501 |
+
| Markov Entropy | Entropy by context size |
|
| 502 |
+
| Markov Branching | Branching factor by context |
|
| 503 |
+
| Markov Contexts | Unique context counts |
|
| 504 |
+
| Zipf's Law | Frequency-rank distribution with fit |
|
| 505 |
+
| Vocab Frequency | Word frequency distribution |
|
| 506 |
+
| Top 20 Words | Most frequent words |
|
| 507 |
+
| Vocab Coverage | Cumulative coverage curve |
|
| 508 |
+
| Embedding Isotropy | Vector space uniformity |
|
| 509 |
+
| Embedding Norms | Vector magnitude distribution |
|
| 510 |
+
| Embedding Similarity | Word similarity heatmap |
|
| 511 |
+
| Nearest Neighbors | Similar words for key terms |
|
| 512 |
+
| t-SNE Words | 2D word embedding visualization |
|
| 513 |
+
| t-SNE Sentences | 2D sentence embedding visualization |
|
| 514 |
+
| Position Encoding | Encoding method comparison |
|
| 515 |
+
| Model Sizes | Storage requirements |
|
| 516 |
+
| Performance Dashboard | Comprehensive performance overview |
|
| 517 |
+
|
| 518 |
+
---
|
| 519 |
+
## About This Project
|
| 520 |
+
|
| 521 |
+
### Data Source
|
| 522 |
+
|
| 523 |
+
Models trained on [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly) - a monthly snapshot of Wikipedia articles across 300+ languages.
|
| 524 |
+
|
| 525 |
+
### Project
|
| 526 |
+
|
| 527 |
+
A project by **[Wikilangs](https://wikilangs.org)** - Open-source NLP models for every Wikipedia language.
|
| 528 |
+
|
| 529 |
+
### Maintainer
|
| 530 |
+
|
| 531 |
+
[Omar Kamali](https://omarkamali.com) - [Omneity Labs](https://omneitylabs.com)
|
| 532 |
+
|
| 533 |
+
### Citation
|
| 534 |
+
|
| 535 |
+
If you use these models in your research, please cite:
|
| 536 |
+
|
| 537 |
+
```bibtex
|
| 538 |
+
@misc{wikilangs2025,
|
| 539 |
+
author = {Kamali, Omar},
|
| 540 |
+
title = {Wikilangs: Open NLP Models for Wikipedia Languages},
|
| 541 |
+
year = {2025},
|
| 542 |
+
publisher = {HuggingFace},
|
| 543 |
+
url = {https://huggingface.co/wikilangs}
|
| 544 |
+
institution = {Omneity Labs}
|
| 545 |
+
}
|
| 546 |
+
```
|
| 547 |
+
|
| 548 |
+
### License
|
| 549 |
+
|
| 550 |
+
MIT License - Free for academic and commercial use.
|
| 551 |
+
|
| 552 |
+
### Links
|
| 553 |
+
|
| 554 |
+
- 🌐 Website: [wikilangs.org](https://wikilangs.org)
|
| 555 |
+
- 🤗 Models: [huggingface.co/wikilangs](https://huggingface.co/wikilangs)
|
| 556 |
+
- 📊 Data: [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly)
|
| 557 |
+
- 👤 Author: [Omar Kamali](https://huggingface.co/omarkamali)
|
| 558 |
+
---
|
| 559 |
+
*Generated by Wikilangs Models Pipeline*
|
| 560 |
+
|
| 561 |
+
*Report Date: 2025-12-27 04:34:00*
|
models/embeddings/monolingual/ady_128d.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:27f96cb22cce1dccf3f5a68afba58270c9a3d30c33c99e0b985a0160dc08be41
|
| 3 |
+
size 1025913894
|
models/embeddings/monolingual/ady_128d.meta.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"lang": "ady", "dim": 128, "max_seq_len": 512, "is_aligned": false}
|
models/embeddings/monolingual/ady_128d_metadata.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"language": "ady",
|
| 3 |
+
"dimension": 128,
|
| 4 |
+
"version": "monolingual",
|
| 5 |
+
"training_params": {
|
| 6 |
+
"dim": 128,
|
| 7 |
+
"min_count": 5,
|
| 8 |
+
"window": 5,
|
| 9 |
+
"negative": 5,
|
| 10 |
+
"epochs": 5
|
| 11 |
+
},
|
| 12 |
+
"vocab_size": 1830
|
| 13 |
+
}
|
models/embeddings/monolingual/ady_32d.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4df91a4ae1b68f41d1ebc698b3b79863f82558368b99039be6879f7219c9dfab
|
| 3 |
+
size 256508454
|
models/embeddings/monolingual/ady_32d.meta.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"lang": "ady", "dim": 32, "max_seq_len": 512, "is_aligned": false}
|
models/embeddings/monolingual/ady_32d_metadata.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"language": "ady",
|
| 3 |
+
"dimension": 32,
|
| 4 |
+
"version": "monolingual",
|
| 5 |
+
"training_params": {
|
| 6 |
+
"dim": 32,
|
| 7 |
+
"min_count": 5,
|
| 8 |
+
"window": 5,
|
| 9 |
+
"negative": 5,
|
| 10 |
+
"epochs": 5
|
| 11 |
+
},
|
| 12 |
+
"vocab_size": 1830
|
| 13 |
+
}
|
models/embeddings/monolingual/ady_64d.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e39765ffd2c8eb6ef0e3b1854af129b7b0260b2e70a54156a81a9a099b1fa27b
|
| 3 |
+
size 512976934
|
models/embeddings/monolingual/ady_64d.meta.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"lang": "ady", "dim": 64, "max_seq_len": 512, "is_aligned": false}
|
models/embeddings/monolingual/ady_64d_metadata.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"language": "ady",
|
| 3 |
+
"dimension": 64,
|
| 4 |
+
"version": "monolingual",
|
| 5 |
+
"training_params": {
|
| 6 |
+
"dim": 64,
|
| 7 |
+
"min_count": 5,
|
| 8 |
+
"window": 5,
|
| 9 |
+
"negative": 5,
|
| 10 |
+
"epochs": 5
|
| 11 |
+
},
|
| 12 |
+
"vocab_size": 1830
|
| 13 |
+
}
|
models/subword_markov/ady_markov_ctx1_subword.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb658a5696f0194212546a4afabf40b1859c08800bbd6f1ffecda37fddfd3c58
|
| 3 |
+
size 45335
|
models/subword_markov/ady_markov_ctx1_subword_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 1,
|
| 3 |
+
"variant": "subword",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 463,
|
| 6 |
+
"total_transitions": 611427
|
| 7 |
+
}
|
models/subword_markov/ady_markov_ctx2_subword.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b5ebd13fcb32a70f1eeeb3c7ec3df3945466bdb98d3539405ae08a602378e310
|
| 3 |
+
size 217004
|
models/subword_markov/ady_markov_ctx2_subword_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 2,
|
| 3 |
+
"variant": "subword",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 5679,
|
| 6 |
+
"total_transitions": 610662
|
| 7 |
+
}
|
models/subword_markov/ady_markov_ctx3_subword.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b9df0d86e436385c2b2494f0af89b0ca67a6a9d8aa7e5706dadd31de6649a3d8
|
| 3 |
+
size 714083
|
models/subword_markov/ady_markov_ctx3_subword_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 3,
|
| 3 |
+
"variant": "subword",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 32122,
|
| 6 |
+
"total_transitions": 609897
|
| 7 |
+
}
|
models/subword_markov/ady_markov_ctx4_subword.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:14192c7fe2413ebd6957d9d1e1bf08f20d2cf28008cf6b161e3c9ff26a079c9b
|
| 3 |
+
size 1599436
|
models/subword_markov/ady_markov_ctx4_subword_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 4,
|
| 3 |
+
"variant": "subword",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 92841,
|
| 6 |
+
"total_transitions": 609132
|
| 7 |
+
}
|
models/subword_ngram/ady_2gram_subword.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:016367258813db8565f69ab7cb29945baccaac7e94321afc25a4b6c3c9f79f58
|
| 3 |
+
size 32965
|
models/subword_ngram/ady_2gram_subword_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"n": 2,
|
| 3 |
+
"variant": "subword",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_ngrams": 2656,
|
| 6 |
+
"total_ngrams": 611427
|
| 7 |
+
}
|
models/subword_ngram/ady_3gram_subword.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:19fa61eac0061901eb9506a6a556a9261919e5b319eaf1999aa663587ce22014
|
| 3 |
+
size 187929
|
models/subword_ngram/ady_3gram_subword_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"n": 3,
|
| 3 |
+
"variant": "subword",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_ngrams": 15024,
|
| 6 |
+
"total_ngrams": 610662
|
| 7 |
+
}
|
models/subword_ngram/ady_4gram_subword.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c90862733e2c9b9b0d0d50264ea47e26c1bdce42f31aa0ab349bff62b10cc5fe
|
| 3 |
+
size 580214
|
models/subword_ngram/ady_4gram_subword_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"n": 4,
|
| 3 |
+
"variant": "subword",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_ngrams": 44900,
|
| 6 |
+
"total_ngrams": 609897
|
| 7 |
+
}
|
models/tokenizer/ady_tokenizer_16k.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e6120c55e21bf381032672a3067bcf46760e2c4d359e940e77b9f3f746421b69
|
| 3 |
+
size 564362
|
models/tokenizer/ady_tokenizer_16k.vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/ady_tokenizer_32k.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8e432f1beef1ea7d335d31918e5e88f5751d4fc577f2231b239c92518f39dc9c
|
| 3 |
+
size 955536
|
models/tokenizer/ady_tokenizer_32k.vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/ady_tokenizer_64k.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:94c5357e44e30fbb0a13d6b3824a83f80c45d7160db13b16aa0d683fee765fe9
|
| 3 |
+
size 1660676
|
models/tokenizer/ady_tokenizer_64k.vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/ady_tokenizer_8k.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cfc7334d75b921cca2c9e616b995ac20d0728c4f9b3c54f3c5cb0b2ba2b5267c
|
| 3 |
+
size 398334
|
models/tokenizer/ady_tokenizer_8k.vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/vocabulary/ady_vocabulary.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:733b017356844758ce21db6ab8269f1bff9141c2d41430f547302391bc541d7e
|
| 3 |
+
size 161889
|
models/vocabulary/ady_vocabulary_metadata.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"language": "ady",
|
| 3 |
+
"vocabulary_size": 8988,
|
| 4 |
+
"statistics": {
|
| 5 |
+
"type_token_ratio": 0.374012371348373,
|
| 6 |
+
"coverage": {
|
| 7 |
+
"top_100": 0.1982014762449319,
|
| 8 |
+
"top_1000": 0.42253612641646743,
|
| 9 |
+
"top_5000": 0.6391386838548706,
|
| 10 |
+
"top_10000": 0.7559387670235991
|
| 11 |
+
},
|
| 12 |
+
"hapax_count": 19793,
|
| 13 |
+
"hapax_ratio": 0.6877106424377193,
|
| 14 |
+
"total_documents": 765
|
| 15 |
+
}
|
| 16 |
+
}
|
models/word_markov/ady_markov_ctx1_word.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0faaa6cb0c52d77ac3f86b442e03b6cdd0646165c5b5467afaa42799100c5c08
|
| 3 |
+
size 1013255
|
models/word_markov/ady_markov_ctx1_word_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 1,
|
| 3 |
+
"variant": "word",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 28827,
|
| 6 |
+
"total_transitions": 105741
|
| 7 |
+
}
|
models/word_markov/ady_markov_ctx2_word.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cdf814da92430ed71f7261a45abbc27d6bc4f679afc5556ff21d158586b5709f
|
| 3 |
+
size 1738893
|
models/word_markov/ady_markov_ctx2_word_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 2,
|
| 3 |
+
"variant": "word",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 65637,
|
| 6 |
+
"total_transitions": 104976
|
| 7 |
+
}
|
models/word_markov/ady_markov_ctx3_word.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c430f624230776fb0bed9ceec3edfcc58d221b9f682aa377294e7faf952a7f33
|
| 3 |
+
size 2203636
|
models/word_markov/ady_markov_ctx3_word_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 3,
|
| 3 |
+
"variant": "word",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 80882,
|
| 6 |
+
"total_transitions": 104212
|
| 7 |
+
}
|
models/word_markov/ady_markov_ctx4_word.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f994f94aaa5faf04bea4da903f474a186f4d719203b671b4c8538fa7e3d6c323
|
| 3 |
+
size 2577702
|
models/word_markov/ady_markov_ctx4_word_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"context_size": 4,
|
| 3 |
+
"variant": "word",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_contexts": 86492,
|
| 6 |
+
"total_transitions": 103449
|
| 7 |
+
}
|
models/word_ngram/ady_2gram_word.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e36a3e7022b130b28b923c0f0edfaff7cb6f8c269b793337bd6e999b68fc36cd
|
| 3 |
+
size 35981
|
models/word_ngram/ady_2gram_word_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"n": 2,
|
| 3 |
+
"variant": "word",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_ngrams": 1856,
|
| 6 |
+
"total_ngrams": 105741
|
| 7 |
+
}
|
models/word_ngram/ady_3gram_word.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a2ce08e36db31a04439c365d753c2684b44924398908b6f7a2883305f54f1f0c
|
| 3 |
+
size 61177
|
models/word_ngram/ady_3gram_word_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"n": 3,
|
| 3 |
+
"variant": "word",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_ngrams": 2744,
|
| 6 |
+
"total_ngrams": 104976
|
| 7 |
+
}
|
models/word_ngram/ady_4gram_word.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:43176b575286a7924ea5d8764dc0f6dfc283f757937cfa2d648424a65326ca9f
|
| 3 |
+
size 203246
|
models/word_ngram/ady_4gram_word_metadata.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"n": 4,
|
| 3 |
+
"variant": "word",
|
| 4 |
+
"language": "ady",
|
| 5 |
+
"unique_ngrams": 7604,
|
| 6 |
+
"total_ngrams": 104212
|
| 7 |
+
}
|
visualizations/embedding_isotropy.png
ADDED
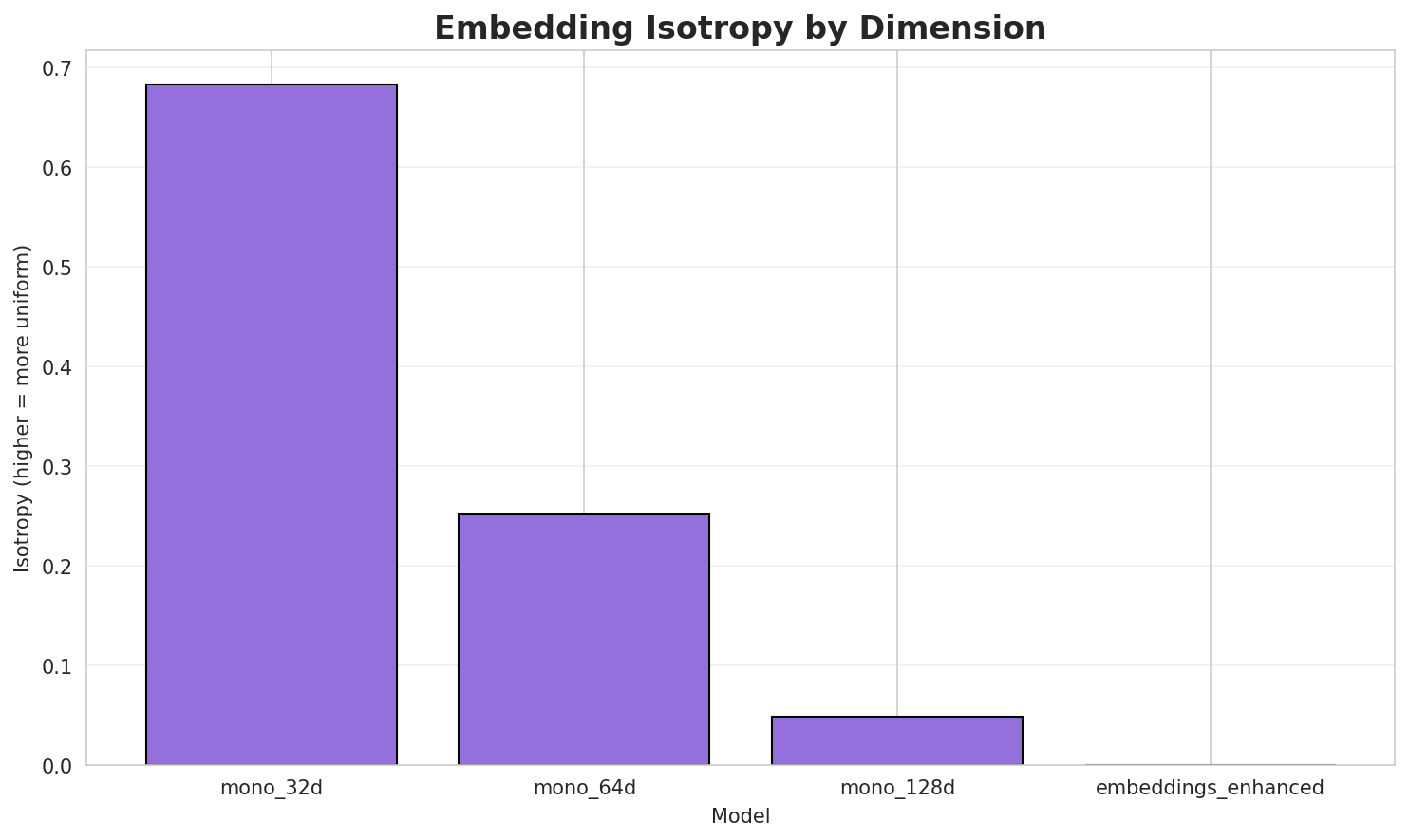
|