

Upload all models and assets for ary (latest)
Browse files- README.md +97 -98
- models/embeddings/aligned/ary_128d.bin +1 -1
- models/embeddings/aligned/ary_128d.projection.npy +1 -1
- models/embeddings/aligned/ary_32d.bin +1 -1
- models/embeddings/aligned/ary_32d.projection.npy +1 -1
- models/embeddings/aligned/ary_64d.bin +1 -1
- models/embeddings/aligned/ary_64d.projection.npy +1 -1
- models/embeddings/monolingual/ary_128d.bin +1 -1
- models/embeddings/monolingual/ary_32d.bin +1 -1
- models/embeddings/monolingual/ary_64d.bin +1 -1
- models/subword_markov/ary_markov_ctx1_subword.parquet +2 -2
- models/subword_markov/ary_markov_ctx2_subword.parquet +2 -2
- models/subword_markov/ary_markov_ctx3_subword.parquet +2 -2
- models/subword_markov/ary_markov_ctx4_subword.parquet +2 -2
- models/subword_ngram/ary_2gram_subword.parquet +2 -2
- models/subword_ngram/ary_3gram_subword.parquet +2 -2
- models/subword_ngram/ary_4gram_subword.parquet +2 -2
- models/subword_ngram/ary_5gram_subword.parquet +2 -2
- models/tokenizer/ary_tokenizer_16k.model +1 -1
- models/tokenizer/ary_tokenizer_32k.model +1 -1
- models/tokenizer/ary_tokenizer_64k.model +1 -1
- models/tokenizer/ary_tokenizer_8k.model +1 -1
- models/word_markov/ary_markov_ctx1_word.parquet +2 -2
- models/word_markov/ary_markov_ctx2_word.parquet +2 -2
- models/word_markov/ary_markov_ctx3_word.parquet +2 -2
- models/word_markov/ary_markov_ctx4_word.parquet +2 -2
- models/word_ngram/ary_2gram_word.parquet +2 -2
- models/word_ngram/ary_3gram_word.parquet +2 -2
- models/word_ngram/ary_4gram_word.parquet +2 -2
- models/word_ngram/ary_5gram_word.parquet +2 -2
- visualizations/embedding_alignment_quality.png +0 -0
- visualizations/embedding_isotropy.png +0 -0
- visualizations/embedding_norms.png +0 -0
- visualizations/embedding_similarity.png +2 -2
- visualizations/embedding_tsne_multilingual.png +2 -2
- visualizations/performance_dashboard.png +2 -2
- visualizations/position_encoding_comparison.png +2 -2
- visualizations/tsne_sentences.png +2 -2
- visualizations/tsne_words.png +2 -2
README.md
CHANGED
|
@@ -36,7 +36,7 @@ metrics:
|
|
| 36 |
value: 4.171
|
| 37 |
- name: best_isotropy
|
| 38 |
type: isotropy
|
| 39 |
-
value: 0.
|
| 40 |
- name: vocabulary_size
|
| 41 |
type: vocab
|
| 42 |
value: 0
|
|
@@ -99,32 +99,32 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 99 |
|
| 100 |
Below are sample sentences tokenized with each vocabulary size:
|
| 101 |
|
| 102 |
-
**Sample 1:** `
|
| 103 |
|
| 104 |
| Vocab | Tokens | Count |
|
| 105 |
|-------|--------|-------|
|
| 106 |
-
| 8k | `▁
|
| 107 |
-
| 16k | `▁
|
| 108 |
-
| 32k | `▁
|
| 109 |
-
| 64k | `▁
|
| 110 |
|
| 111 |
-
**Sample 2:** `
|
| 112 |
|
| 113 |
| Vocab | Tokens | Count |
|
| 114 |
|-------|--------|-------|
|
| 115 |
-
| 8k | `▁
|
| 116 |
-
| 16k | `▁
|
| 117 |
-
| 32k | `▁
|
| 118 |
-
| 64k | `▁
|
| 119 |
|
| 120 |
-
**Sample 3:** `ها
|
| 121 |
|
| 122 |
| Vocab | Tokens | Count |
|
| 123 |
|-------|--------|-------|
|
| 124 |
-
| 8k | `▁
|
| 125 |
-
| 16k | `▁
|
| 126 |
-
| 32k | `▁
|
| 127 |
-
| 64k | `▁
|
| 128 |
|
| 129 |
|
| 130 |
### Key Findings
|
|
@@ -186,17 +186,17 @@ Below are sample sentences tokenized with each vocabulary size:
|
|
| 186 |
| 2 | `نسبة نّاس اللي خدامين` | 2,705 |
|
| 187 |
| 3 | `نّاس اللي خدامين ف` | 2,594 |
|
| 188 |
| 4 | `على حساب لإحصاء الرسمي` | 2,501 |
|
| 189 |
-
| 5 | `لإحصاء الرسمي د
|
| 190 |
|
| 191 |
**5-grams (Word):**
|
| 192 |
|
| 193 |
| Rank | N-gram | Count |
|
| 194 |
|------|--------|-------|
|
| 195 |
| 1 | `نسبة نّاس اللي خدامين ف` | 2,593 |
|
| 196 |
-
| 2 | `هاد دّوار كينتامي
|
| 197 |
-
| 3 | `
|
| 198 |
| 4 | `لمغريب هاد دّوار كينتامي ل` | 2,500 |
|
| 199 |
-
| 5 | `
|
| 200 |
|
| 201 |
**2-grams (Subword):**
|
| 202 |
|
|
@@ -274,27 +274,27 @@ Below are text samples generated from each word-based Markov chain model:
|
|
| 274 |
|
| 275 |
**Context Size 1:**
|
| 276 |
|
| 277 |
-
1. `ف
|
| 278 |
-
2. `و
|
| 279 |
-
3. `د
|
| 280 |
|
| 281 |
**Context Size 2:**
|
| 282 |
|
| 283 |
-
1. `واصلة ل
|
| 284 |
-
2. `نسبة د ال
|
| 285 |
-
3. `ف لمغريب هاد دّوار كينتامي ل مشيخة
|
| 286 |
|
| 287 |
**Context Size 3:**
|
| 288 |
|
| 289 |
-
1. `ف نسبة د ال
|
| 290 |
-
2. `فيها مصدر و بايت زادهوم داريجابوت
|
| 291 |
-
3. `و نسبة د
|
| 292 |
|
| 293 |
**Context Size 4:**
|
| 294 |
|
| 295 |
-
1. `نسبة نّاس اللي خدامين ف
|
| 296 |
-
2. `نّاس اللي خدامين ف لپريڤي
|
| 297 |
-
3. `على حساب لإحصاء الرسمي د عام
|
| 298 |
|
| 299 |
|
| 300 |
### Generated Text Samples (Subword-based)
|
|
@@ -303,27 +303,27 @@ Below are text samples generated from each subword-based Markov chain model:
|
|
| 303 |
|
| 304 |
**Context Size 1:**
|
| 305 |
|
| 306 |
-
1. `_
|
| 307 |
-
2. `ان
|
| 308 |
-
3. `ل
|
| 309 |
|
| 310 |
**Context Size 2:**
|
| 311 |
|
| 312 |
-
1. `ال
|
| 313 |
-
2. `_ل
|
| 314 |
-
3. `ة
|
| 315 |
|
| 316 |
**Context Size 3:**
|
| 317 |
|
| 318 |
-
1. `_الرو
|
| 319 |
-
2. `_ف_
|
| 320 |
-
3. `ات_
|
| 321 |
|
| 322 |
**Context Size 4:**
|
| 323 |
|
| 324 |
-
1. `_ديال_
|
| 325 |
-
2. `ديال_ا
|
| 326 |
-
3. `يال_
|
| 327 |
|
| 328 |
|
| 329 |
### Key Findings
|
|
@@ -428,18 +428,18 @@ Below are text samples generated from each subword-based Markov chain model:
|
|
| 428 |
|
| 429 |
| Model | Dimension | Isotropy | Semantic Density | Alignment R@1 | Alignment R@10 |
|
| 430 |
|-------|-----------|----------|------------------|---------------|----------------|
|
| 431 |
-
| **mono_32d** | 32 | 0.
|
| 432 |
-
| **mono_64d** | 64 | 0.
|
| 433 |
-
| **mono_128d** | 128 | 0.
|
| 434 |
-
| **aligned_32d** | 32 | 0.
|
| 435 |
-
| **aligned_64d** | 64 | 0.
|
| 436 |
-
| **aligned_128d** | 128 | 0.
|
| 437 |
|
| 438 |
### Key Findings
|
| 439 |
|
| 440 |
-
- **Best Isotropy:** mono_32d with 0.
|
| 441 |
-
- **Semantic Density:** Average pairwise similarity of 0.
|
| 442 |
-
- **Alignment Quality:** Aligned models achieve up to
|
| 443 |
- **Recommendation:** 128d aligned for best cross-lingual performance
|
| 444 |
|
| 445 |
---
|
|
@@ -461,17 +461,17 @@ These are the most productive prefixes and suffixes identified by sampling the v
|
|
| 461 |
#### Productive Prefixes
|
| 462 |
| Prefix | Examples |
|
| 463 |
|--------|----------|
|
| 464 |
-
| `-ال` | ال
|
| 465 |
-
| `-لم` | لم
|
| 466 |
-
| `-كا` | كا
|
| 467 |
|
| 468 |
#### Productive Suffixes
|
| 469 |
| Suffix | Examples |
|
| 470 |
|--------|----------|
|
| 471 |
-
| `-ة` |
|
| 472 |
-
| `-ات` |
|
| 473 |
-
| `-ية` | ال
|
| 474 |
-
| `-ين` |
|
| 475 |
|
| 476 |
### 6.3 Bound Stems (Lexical Roots)
|
| 477 |
|
|
@@ -479,18 +479,18 @@ Bound stems are high-frequency subword units that are semantically cohesive but
|
|
| 479 |
|
| 480 |
| Stem | Cohesion | Substitutability | Examples |
|
| 481 |
|------|----------|------------------|----------|
|
| 482 |
-
| `ا
|
| 483 |
-
| `ا
|
| 484 |
-
| `الات` | 1.71x | 65 contexts |
|
| 485 |
-
| `جماع` | 1.
|
| 486 |
-
| `ل
|
| 487 |
-
| `
|
| 488 |
-
| `حصا
|
| 489 |
-
| `مغري` | 2.
|
| 490 |
-
| `
|
| 491 |
-
| `
|
| 492 |
-
| `ل
|
| 493 |
-
| `
|
| 494 |
|
| 495 |
### 6.4 Affix Compatibility (Co-occurrence)
|
| 496 |
|
|
@@ -498,16 +498,15 @@ This table shows which prefixes and suffixes most frequently co-occur on the sam
|
|
| 498 |
|
| 499 |
| Prefix | Suffix | Frequency | Examples |
|
| 500 |
|--------|--------|-----------|----------|
|
| 501 |
-
| `-ال` | `-ة` |
|
| 502 |
-
| `-ال` | `-ات` |
|
| 503 |
-
| `-ال` | `-ية` |
|
| 504 |
-
| `-ال` | `-ين` |
|
| 505 |
-
| `-لم` | `-ة` |
|
| 506 |
-
| `-لم` | `-
|
| 507 |
-
| `-لم` | `-
|
| 508 |
-
| `-لم` | `-ية` |
|
| 509 |
-
| `-كا` | `-
|
| 510 |
-
| `-كا` | `-ين` | 1 words | كاترين, كالكيريين |
|
| 511 |
|
| 512 |
### 6.5 Recursive Morpheme Segmentation
|
| 513 |
|
|
@@ -515,21 +514,21 @@ Using **Recursive Hierarchical Substitutability**, we decompose complex words in
|
|
| 515 |
|
| 516 |
| Word | Suggested Split | Confidence | Stem |
|
| 517 |
|------|-----------------|------------|------|
|
| 518 |
-
| ال
|
| 519 |
-
| ال
|
| 520 |
-
| ل
|
| 521 |
-
| ال
|
| 522 |
-
| ال
|
| 523 |
-
| ال
|
| 524 |
-
| ال
|
| 525 |
-
|
|
| 526 |
-
| ال
|
| 527 |
-
|
|
| 528 |
-
| الم
|
| 529 |
-
| ال
|
| 530 |
-
| ال
|
| 531 |
-
| ال
|
| 532 |
-
| ال
|
| 533 |
|
| 534 |
### 6.6 Linguistic Interpretation
|
| 535 |
|
|
@@ -763,4 +762,4 @@ MIT License - Free for academic and commercial use.
|
|
| 763 |
---
|
| 764 |
*Generated by Wikilangs Models Pipeline*
|
| 765 |
|
| 766 |
-
*Report Date: 2026-01-03
|
|
|
|
| 36 |
value: 4.171
|
| 37 |
- name: best_isotropy
|
| 38 |
type: isotropy
|
| 39 |
+
value: 0.8284
|
| 40 |
- name: vocabulary_size
|
| 41 |
type: vocab
|
| 42 |
value: 0
|
|
|
|
| 99 |
|
| 100 |
Below are sample sentences tokenized with each vocabulary size:
|
| 101 |
|
| 102 |
+
**Sample 1:** `هادي صفحة د التوضيح، كلمة بركان يمكن يكونو عندها هاد لمعاني: بْرْكان: مدينة مغري...`
|
| 103 |
|
| 104 |
| Vocab | Tokens | Count |
|
| 105 |
|-------|--------|-------|
|
| 106 |
+
| 8k | `▁هادي ▁صفحة ▁د ▁التوضيح ، ▁كلمة ▁بركان ▁يمكن ▁يكونو ▁عندها ... (+23 more)` | 33 |
|
| 107 |
+
| 16k | `▁هادي ▁صفحة ▁د ▁التوضيح ، ▁كلمة ▁بركان ▁يمكن ▁يكونو ▁عندها ... (+21 more)` | 31 |
|
| 108 |
+
| 32k | `▁هادي ▁صفحة ▁د ▁التوضيح ، ▁كلمة ▁بركان ▁يمكن ▁يكونو ▁عندها ... (+19 more)` | 29 |
|
| 109 |
+
| 64k | `▁هادي ▁صفحة ▁د ▁التوضيح ، ▁كلمة ▁بركان ▁يمكن ▁يكونو ▁عندها ... (+18 more)` | 28 |
|
| 110 |
|
| 111 |
+
**Sample 2:** `لْفزضاض ؤلا أفزضاض (سمية لعلمية Microcosmus sabatieri) حيوان لاسنسولي كيعيش ف لب...`
|
| 112 |
|
| 113 |
| Vocab | Tokens | Count |
|
| 114 |
|-------|--------|-------|
|
| 115 |
+
| 8k | `▁لْ ف ز ضاض ▁ؤلا ▁أف ز ضاض ▁( سمية ... (+31 more)` | 41 |
|
| 116 |
+
| 16k | `▁لْ ف ز ضاض ▁ؤلا ▁أف ز ضاض ▁( سمية ... (+28 more)` | 38 |
|
| 117 |
+
| 32k | `▁لْف ز ضاض ▁ؤلا ▁أف ز ضاض ▁( سمية ▁لعلمية ... (+25 more)` | 35 |
|
| 118 |
+
| 64k | `▁لْف زضاض ▁ؤلا ▁أف زضاض ▁( سمية ▁لعلمية ▁microcos mus ... (+17 more)` | 27 |
|
| 119 |
|
| 120 |
+
**Sample 3:** `نيلز أبراهام لانݣليت (مزيود ف 9 يوليوز - مات ف 30 مارس هوّا عالم د شّيمي سويدي. ...`
|
| 121 |
|
| 122 |
| Vocab | Tokens | Count |
|
| 123 |
|-------|--------|-------|
|
| 124 |
+
| 8k | `▁نيل ز ▁أب راهام ▁ل انݣ ليت ▁( مزيود ▁ف ... (+19 more)` | 29 |
|
| 125 |
+
| 16k | `▁نيل ز ▁أبراهام ▁ل انݣ ليت ▁( مزيود ▁ف ▁ ... (+16 more)` | 26 |
|
| 126 |
+
| 32k | `▁نيلز ▁أبراهام ▁لانݣ ليت ▁( مزيود ▁ف ▁ 9 ▁يوليوز ... (+14 more)` | 24 |
|
| 127 |
+
| 64k | `▁نيلز ▁أبراهام ▁لانݣليت ▁( مزيود ▁ف ▁ 9 ▁يوليوز ▁- ... (+13 more)` | 23 |
|
| 128 |
|
| 129 |
|
| 130 |
### Key Findings
|
|
|
|
| 186 |
| 2 | `نسبة نّاس اللي خدامين` | 2,705 |
|
| 187 |
| 3 | `نّاس اللي خدامين ف` | 2,594 |
|
| 188 |
| 4 | `على حساب لإحصاء الرسمي` | 2,501 |
|
| 189 |
+
| 5 | `حساب لإحصاء الرسمي د` | 2,500 |
|
| 190 |
|
| 191 |
**5-grams (Word):**
|
| 192 |
|
| 193 |
| Rank | N-gram | Count |
|
| 194 |
|------|--------|-------|
|
| 195 |
| 1 | `نسبة نّاس اللي خدامين ف` | 2,593 |
|
| 196 |
+
| 2 | `ف لمغريب هاد دّوار كينتامي` | 2,500 |
|
| 197 |
+
| 3 | `هاد دّوار كينتامي ل مشيخة` | 2,500 |
|
| 198 |
| 4 | `لمغريب هاد دّوار كينتامي ل` | 2,500 |
|
| 199 |
+
| 5 | `حساب لإحصاء الرسمي د عام` | 2,500 |
|
| 200 |
|
| 201 |
**2-grams (Subword):**
|
| 202 |
|
|
|
|
| 274 |
|
| 275 |
**Context Size 1:**
|
| 276 |
|
| 277 |
+
1. `ف لمغريب فيها 5 463 462 461 كم من غير ب شبه منقّر مكررعبد المسيح في`
|
| 278 |
+
2. `و أداب روسيا ف لمغريب ف وقت مابين اللغات الرسمية ديال حيزب لإستقلال تا سينيما ليها`
|
| 279 |
+
3. `د الناس فليبيا اكتشفو أنه يتقتل ولكن بقات كتلعب فالتيران ديال هاد الريحلة معا لمونتاخاب و`
|
| 280 |
|
| 281 |
**Context Size 2:**
|
| 282 |
|
| 283 |
+
1. `واصلة ل 98 6 و عدد لفاميلات تزاد ب 81 6 و نسبة د الناس و لمحيط`
|
| 284 |
+
2. `نسبة د الشوماج واصلة ل 21 12 نوطات مصادر ف لمغريب جّبل معروف عند الصامويين حتال ليوم`
|
| 285 |
+
3. `ف لمغريب هاد دّوار كينتامي ل مشيخة سدي حمد الدغوغي لي كتضم 14 د دّواور لعاداد د`
|
| 286 |
|
| 287 |
**Context Size 3:**
|
| 288 |
|
| 289 |
+
1. `ف نسبة د التسكويل واصلة ل 91 89 و نسبة د الشوماج واصلة ل 7 6 و لخصوبة`
|
| 290 |
+
2. `فيها مصدر و بايت زادهوم داريجابوت حيين مغاربا د لقرن 21 مغاربا مغاربا فيها مصدر و بايت زادهوم`
|
| 291 |
+
3. `و نسبة د لأمية واصلة ل 53 4 و نسبة د لأمية واصلة ل 92 5 و نسبة`
|
| 292 |
|
| 293 |
**Context Size 4:**
|
| 294 |
|
| 295 |
+
1. `نسبة نّاس اللي خدامين ف دّولة ولا لبيطاليين اللي سبق ليهوم خدمو 44 3 نسبة نّاس اللي خدامين ف`
|
| 296 |
+
2. `نّاس اللي خدامين ف لپريڤي ولا لبيطاليين اللي سبق ليهوم مصادر الدار البيضاء سطات قروية ف إقليم سطات ق...`
|
| 297 |
+
3. `على حساب لإحصاء الرسمي د عام إحصائيات إحصائيات عامة عدد السكان ديال أورسفان نقص ب 30 7 و عدد`
|
| 298 |
|
| 299 |
|
| 300 |
### Generated Text Samples (Subword-based)
|
|
|
|
| 303 |
|
| 304 |
**Context Size 1:**
|
| 305 |
|
| 306 |
+
1. `_دّرى_لجالب_لتالع`
|
| 307 |
+
2. `اكترن_لعاميلة_ن_`
|
| 308 |
+
3. `لت_پرومدي_و_ماتم`
|
| 309 |
|
| 310 |
**Context Size 2:**
|
| 311 |
|
| 312 |
+
1. `الرجل_بين_ماعة_لخ`
|
| 313 |
+
2. `_لكينو_العرفوقعوه`
|
| 314 |
+
3. `ة_27_نت،_خري_د_لج`
|
| 315 |
|
| 316 |
**Context Size 3:**
|
| 317 |
|
| 318 |
+
1. `_الروس_و_هي_ماية_ك`
|
| 319 |
+
2. `_ف_موقريب._الدفايي`
|
| 320 |
+
3. `ات_ف_البالشخصياتول`
|
| 321 |
|
| 322 |
**Context Size 4:**
|
| 323 |
|
| 324 |
+
1. `_ديالو._ميامينش_و_ت`
|
| 325 |
+
2. `ديال_أسباب_الغرب_6_`
|
| 326 |
+
3. `يال_تعرّض_للحزب_الوه`
|
| 327 |
|
| 328 |
|
| 329 |
### Key Findings
|
|
|
|
| 428 |
|
| 429 |
| Model | Dimension | Isotropy | Semantic Density | Alignment R@1 | Alignment R@10 |
|
| 430 |
|-------|-----------|----------|------------------|---------------|----------------|
|
| 431 |
+
| **mono_32d** | 32 | 0.8284 🏆 | 0.3330 | N/A | N/A |
|
| 432 |
+
| **mono_64d** | 64 | 0.8181 | 0.2588 | N/A | N/A |
|
| 433 |
+
| **mono_128d** | 128 | 0.7036 | 0.2093 | N/A | N/A |
|
| 434 |
+
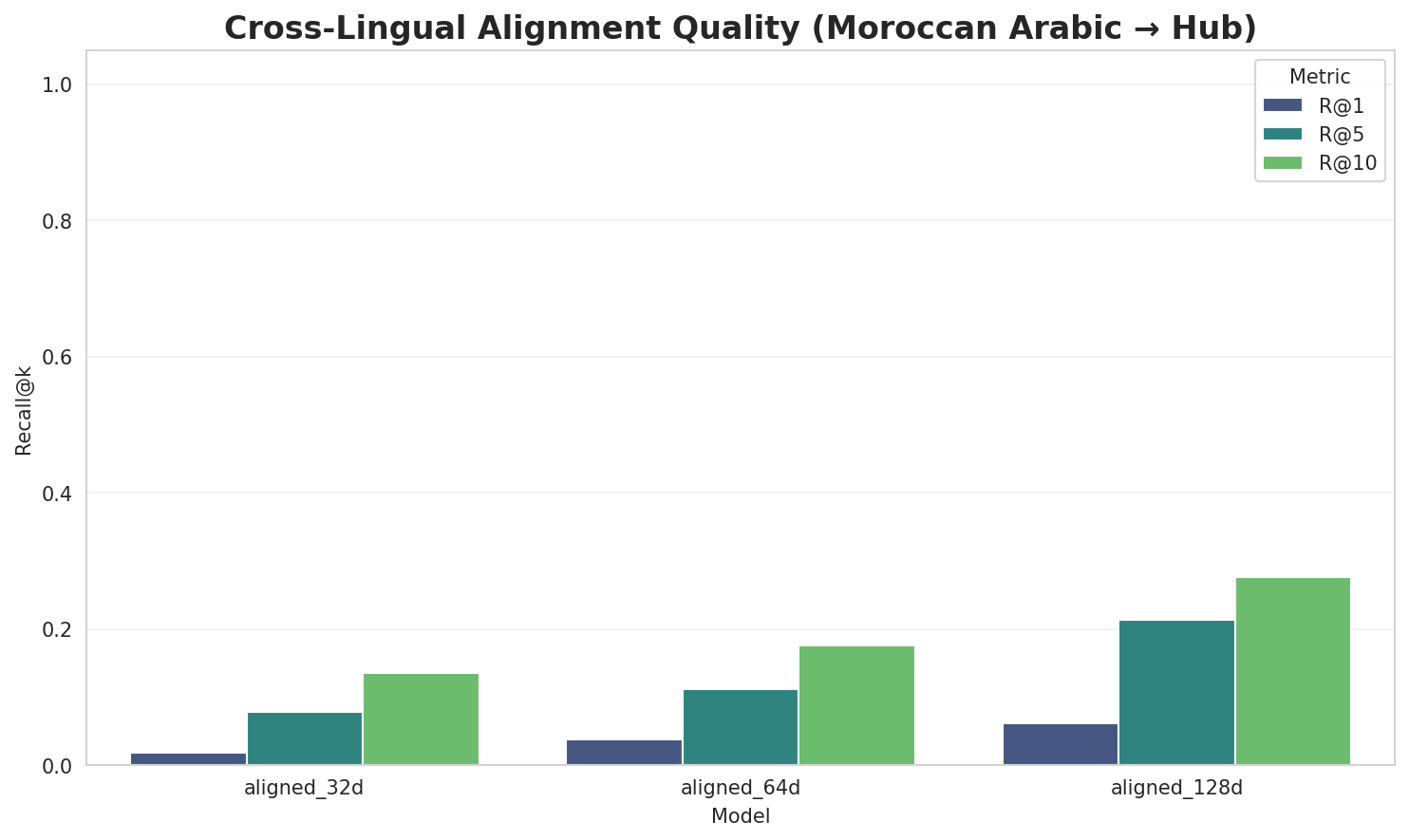
| **aligned_32d** | 32 | 0.8284 | 0.3345 | 0.0180 | 0.1360 |
|
| 435 |
+
| **aligned_64d** | 64 | 0.8181 | 0.2550 | 0.0380 | 0.1760 |
|
| 436 |
+
| **aligned_128d** | 128 | 0.7036 | 0.2072 | 0.0620 | 0.2760 |
|
| 437 |
|
| 438 |
### Key Findings
|
| 439 |
|
| 440 |
+
- **Best Isotropy:** mono_32d with 0.8284 (more uniform distribution)
|
| 441 |
+
- **Semantic Density:** Average pairwise similarity of 0.2663. Lower values indicate better semantic separation.
|
| 442 |
+
- **Alignment Quality:** Aligned models achieve up to 6.2% R@1 in cross-lingual retrieval.
|
| 443 |
- **Recommendation:** 128d aligned for best cross-lingual performance
|
| 444 |
|
| 445 |
---
|
|
|
|
| 461 |
#### Productive Prefixes
|
| 462 |
| Prefix | Examples |
|
| 463 |
|--------|----------|
|
| 464 |
+
| `-ال` | الأمني, اللحظة, الفيرمات |
|
| 465 |
+
| `-لم` | لمتعصبين, لمحافض, لمونضامة |
|
| 466 |
+
| `-كا` | كاتدير, كايتحلو, كايقممو |
|
| 467 |
|
| 468 |
#### Productive Suffixes
|
| 469 |
| Suffix | Examples |
|
| 470 |
|--------|----------|
|
| 471 |
+
| `-ة` | سميّة, رقصة, اللحظة |
|
| 472 |
+
| `-ات` | سطراتيجيات, الفيرمات, لحتيفالات |
|
| 473 |
+
| `-ية` | الشرقية, اللاجنسية, ولوسطانية |
|
| 474 |
+
| `-ين` | لمتعصبين, ثنين, لمالحين |
|
| 475 |
|
| 476 |
### 6.3 Bound Stems (Lexical Roots)
|
| 477 |
|
|
|
|
| 479 |
|
| 480 |
| Stem | Cohesion | Substitutability | Examples |
|
| 481 |
|------|----------|------------------|----------|
|
| 482 |
+
| `انية` | 1.80x | 68 contexts | غانية, ثانية, سانية |
|
| 483 |
+
| `اللو` | 1.74x | 61 contexts | اللوه, اللور, اللول |
|
| 484 |
+
| `الات` | 1.71x | 65 contexts | تالات, حالات, صالات |
|
| 485 |
+
| `جماع` | 1.90x | 38 contexts | جماعي, تجماع, إجماع |
|
| 486 |
+
| `النا` | 1.63x | 63 contexts | الناي, النار, الناس |
|
| 487 |
+
| `لمغر` | 1.92x | 30 contexts | لمغرب, لمغربب, للمغرب |
|
| 488 |
+
| `إحصا` | 2.13x | 17 contexts | إحصاء, لإحصا, إحصائي |
|
| 489 |
+
| `مغري` | 2.08x | 18 contexts | مغريب, مغرية, مغريبي |
|
| 490 |
+
| `حصاء` | 2.24x | 14 contexts | إحصاء, لإحصاء, ليحصاء |
|
| 491 |
+
| `دهوم` | 2.14x | 16 contexts | ضدهوم, يردهوم, زادهوم |
|
| 492 |
+
| `قليم` | 2.06x | 17 contexts | فقليم, اقليم, إقليم |
|
| 493 |
+
| `لجوا` | 1.77x | 26 contexts | لجواب, لجواد, الجوا |
|
| 494 |
|
| 495 |
### 6.4 Affix Compatibility (Co-occurrence)
|
| 496 |
|
|
|
|
| 498 |
|
| 499 |
| Prefix | Suffix | Frequency | Examples |
|
| 500 |
|--------|--------|-----------|----------|
|
| 501 |
+
| `-ال` | `-ة` | 280 words | الراكوبة, العمدة |
|
| 502 |
+
| `-ال` | `-ات` | 163 words | الشلالات, العبرات |
|
| 503 |
+
| `-ال` | `-ية` | 152 words | الزراعية, الطباشيرية |
|
| 504 |
+
| `-ال` | `-ين` | 76 words | الموحدين, الاثنين |
|
| 505 |
+
| `-لم` | `-ة` | 66 words | لمملكة, لمُحمدية |
|
| 506 |
+
| `-لم` | `-ين` | 45 words | لموناضيلين, لمعتقلين |
|
| 507 |
+
| `-لم` | `-ات` | 25 words | لمونضّامات, لممرات |
|
| 508 |
+
| `-لم` | `-ية` | 21 words | لمُحمدية, لمراكشية |
|
| 509 |
+
| `-كا` | `-ين` | 2 words | كايسين, كاتبين |
|
|
|
|
| 510 |
|
| 511 |
### 6.5 Recursive Morpheme Segmentation
|
| 512 |
|
|
|
|
| 514 |
|
| 515 |
| Word | Suggested Split | Confidence | Stem |
|
| 516 |
|------|-----------------|------------|------|
|
| 517 |
+
| التوجيهات | **`ال-توجيه-ات`** | 6.0 | `توجيه` |
|
| 518 |
+
| الصومالية | **`ال-صومال-ية`** | 6.0 | `صومال` |
|
| 519 |
+
| الپاكستانية | **`ال-پاكستان-ية`** | 6.0 | `پاكستان` |
|
| 520 |
+
| الدوّازات | **`ال-دوّاز-ات`** | 6.0 | `دوّاز` |
|
| 521 |
+
| الصالونات | **`ال-صالون-ات`** | 6.0 | `صالون` |
|
| 522 |
+
| التعبيرية | **`ال-تعبير-ية`** | 6.0 | `تعبير` |
|
| 523 |
+
| الانقلابية | **`ال-انقلاب-ية`** | 6.0 | `انقلاب` |
|
| 524 |
+
| لمنقارضين | **`لم-نقارض-ين`** | 6.0 | `نقارض` |
|
| 525 |
+
| التقليديين | **`ال-تقليدي-ين`** | 6.0 | `تقليدي` |
|
| 526 |
+
| لمنتاشرين | **`لم-نتاشر-ين`** | 6.0 | `نتاشر` |
|
| 527 |
+
| الماكينات | **`ال-ماكين-ات`** | 6.0 | `ماكين` |
|
| 528 |
+
| البرونزية | **`ال-برونز-ية`** | 6.0 | `برونز` |
|
| 529 |
+
| التكوينية | **`ال-تكوين-ية`** | 6.0 | `تكوين` |
|
| 530 |
+
| التعليمية | **`ال-تعليم-ية`** | 6.0 | `تعليم` |
|
| 531 |
+
| التلفزيونية | **`ال-تلفزيون-ية`** | 6.0 | `تلفزيون` |
|
| 532 |
|
| 533 |
### 6.6 Linguistic Interpretation
|
| 534 |
|
|
|
|
| 762 |
---
|
| 763 |
*Generated by Wikilangs Models Pipeline*
|
| 764 |
|
| 765 |
+
*Report Date: 2026-01-03 16:42:17*
|
models/embeddings/aligned/ary_128d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1060912662
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec09f2d29ccb3090249f3738f6068e825d70e537decf94ac5428ed8f1bc41e8f
|
| 3 |
size 1060912662
|
models/embeddings/aligned/ary_128d.projection.npy
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 65664
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d5d793e55a655ac0900c665a7dd2b25bfb2c721388f369f0c888b532aab2b2d
|
| 3 |
size 65664
|
models/embeddings/aligned/ary_32d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 265780758
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8540a7a08f8241b60423dc69caaee169822f093e1cf6353b8295063122a7e4bf
|
| 3 |
size 265780758
|
models/embeddings/aligned/ary_32d.projection.npy
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4224
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ce8e1e863fb9c4375db9cffb22d2a2c951ffc80e15e09b06bf6aebee82431cd7
|
| 3 |
size 4224
|
models/embeddings/aligned/ary_64d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 530824726
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:22c1abedc8bbe33e113c64455d6fd411194e4a7ddb5e0a3c659df8c08962758d
|
| 3 |
size 530824726
|
models/embeddings/aligned/ary_64d.projection.npy
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 16512
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:468aba2325cf26abc86b89cccca9a63ff95115fe381081eceafadf68a2846d6b
|
| 3 |
size 16512
|
models/embeddings/monolingual/ary_128d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1060912662
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec09f2d29ccb3090249f3738f6068e825d70e537decf94ac5428ed8f1bc41e8f
|
| 3 |
size 1060912662
|
models/embeddings/monolingual/ary_32d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 265780758
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8540a7a08f8241b60423dc69caaee169822f093e1cf6353b8295063122a7e4bf
|
| 3 |
size 265780758
|
models/embeddings/monolingual/ary_64d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 530824726
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:22c1abedc8bbe33e113c64455d6fd411194e4a7ddb5e0a3c659df8c08962758d
|
| 3 |
size 530824726
|
models/subword_markov/ary_markov_ctx1_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6aa85613e52f70b5400e89d68121d9f314136f411cc3b9ddb727f1a18275c75b
|
| 3 |
+
size 139539
|
models/subword_markov/ary_markov_ctx2_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b46ebfbdafda98e2adad1319ead7fedc44d9204d2776cf2e3205c3bd5f5afebe
|
| 3 |
+
size 797041
|
models/subword_markov/ary_markov_ctx3_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6b4192f99a87bb45ced2563948e266621a565af8ac63ce8f4bde28a93144d756
|
| 3 |
+
size 2874859
|
models/subword_markov/ary_markov_ctx4_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aadd6890898708013a847b49d511a4f98c3b4ee57283f361bdeaeedfa6653f41
|
| 3 |
+
size 9246973
|
models/subword_ngram/ary_2gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:85362146166777b9bcdb0f05aa64508022ee248e5e3f69964e1de614c03e7699
|
| 3 |
+
size 83835
|
models/subword_ngram/ary_3gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:40969977a99672eecdb27448421f16a3f187d65f3c0dc151cea853e070cbadb7
|
| 3 |
+
size 604436
|
models/subword_ngram/ary_4gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2378e1e2d64b3df9e93427a1a78bcd5faaf6ed666409f9219472f778c7c03606
|
| 3 |
+
size 2807017
|
models/subword_ngram/ary_5gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:faf8ee4ec12ef42cd5e3558d66ad4aeff0631f166fba66070e4e84f08a774416
|
| 3 |
+
size 7211281
|
models/tokenizer/ary_tokenizer_16k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 559287
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1180ec148decdb3ef68cab243d4b164e40e6f3a9cd004c5a4a6675974d1751d6
|
| 3 |
size 559287
|
models/tokenizer/ary_tokenizer_32k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 891778
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62ead2fffa727c9fa33838adbab2d6cfe8e11b224486009a2df8900f2a79d842
|
| 3 |
size 891778
|
models/tokenizer/ary_tokenizer_64k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1592960
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1cc3477018e21f222e7e79316e39de3e66d54eaa975a1b19e66cb19ef807cd23
|
| 3 |
size 1592960
|
models/tokenizer/ary_tokenizer_8k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 396519
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6c9d36c71b1333556ef6580bcbbd43671c35b88296320664be74ffda2b47642c
|
| 3 |
size 396519
|
models/word_markov/ary_markov_ctx1_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7a010a2fee1638b81b95efa703c67ec669457295da9be4b0fd98080b9fa5269b
|
| 3 |
+
size 10613710
|
models/word_markov/ary_markov_ctx2_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:712f90109dc88d6441f66e51cbe823ae8692297f944de4a533056a1db4fd292f
|
| 3 |
+
size 26628986
|
models/word_markov/ary_markov_ctx3_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f27df8a6b3c1b3e0c9195f59edb4203d0589a76026e8e82991c554cda82d38f
|
| 3 |
+
size 36690145
|
models/word_markov/ary_markov_ctx4_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3ef1279d7ad2a47057f8d0bf6e4f5d77d61c37b5959fd2a7d151825361e35b07
|
| 3 |
+
size 43890388
|
models/word_ngram/ary_2gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b98d7209f16b65cc7fc1451b153c7385335b01f64114429d12ae9fc216d45517
|
| 3 |
+
size 762878
|
models/word_ngram/ary_3gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e72d04a4c7e230b99474a0984526661b31850682960d936fbac94206078e207
|
| 3 |
+
size 933708
|
models/word_ngram/ary_4gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2c6480b4d3d6aa998d37591d185d676d50cd65bddddabb425217bbafef0318f8
|
| 3 |
+
size 1672666
|
models/word_ngram/ary_5gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7014f4d6e3e91c09d0e7da7fdb93a2871a957cde46d04f371ea8c99ca99f42a0
|
| 3 |
+
size 1491554
|
visualizations/embedding_alignment_quality.png
CHANGED

|
|
visualizations/embedding_isotropy.png
CHANGED

|

|
visualizations/embedding_norms.png
CHANGED

|

|
visualizations/embedding_similarity.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/embedding_tsne_multilingual.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/performance_dashboard.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/position_encoding_comparison.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/tsne_sentences.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/tsne_words.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|