

Upload all models and assets for az (20251001)
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- README.md +299 -146
- models/embeddings/monolingual/az_128d.bin +2 -2
- models/embeddings/monolingual/az_128d_metadata.json +5 -3
- models/embeddings/monolingual/az_32d.bin +2 -2
- models/embeddings/monolingual/az_32d_metadata.json +5 -3
- models/embeddings/monolingual/az_64d.bin +2 -2
- models/embeddings/monolingual/az_64d_metadata.json +5 -3
- models/subword_markov/az_markov_ctx1_subword.parquet +2 -2
- models/subword_markov/az_markov_ctx1_subword_metadata.json +2 -2
- models/subword_markov/az_markov_ctx2_subword.parquet +2 -2
- models/subword_markov/az_markov_ctx2_subword_metadata.json +2 -2
- models/subword_markov/az_markov_ctx3_subword.parquet +2 -2
- models/subword_markov/az_markov_ctx3_subword_metadata.json +2 -2
- models/subword_markov/az_markov_ctx4_subword.parquet +2 -2
- models/subword_markov/az_markov_ctx4_subword_metadata.json +2 -2
- models/subword_ngram/az_2gram_subword.parquet +2 -2
- models/subword_ngram/az_2gram_subword_metadata.json +2 -2
- models/subword_ngram/az_3gram_subword.parquet +2 -2
- models/subword_ngram/az_3gram_subword_metadata.json +2 -2
- models/subword_ngram/az_4gram_subword.parquet +2 -2
- models/subword_ngram/az_4gram_subword_metadata.json +2 -2
- models/tokenizer/az_tokenizer_16k.model +2 -2
- models/tokenizer/az_tokenizer_16k.vocab +0 -0
- models/tokenizer/az_tokenizer_32k.model +2 -2
- models/tokenizer/az_tokenizer_32k.vocab +0 -0
- models/tokenizer/az_tokenizer_64k.model +2 -2
- models/tokenizer/az_tokenizer_64k.vocab +0 -0
- models/tokenizer/az_tokenizer_8k.model +2 -2
- models/tokenizer/az_tokenizer_8k.vocab +0 -0
- models/vocabulary/az_vocabulary.parquet +2 -2
- models/vocabulary/az_vocabulary_metadata.json +10 -9
- models/word_markov/az_markov_ctx1_word.parquet +2 -2
- models/word_markov/az_markov_ctx1_word_metadata.json +2 -2
- models/word_markov/az_markov_ctx2_word.parquet +2 -2
- models/word_markov/az_markov_ctx2_word_metadata.json +2 -2
- models/word_markov/az_markov_ctx3_word.parquet +2 -2
- models/word_markov/az_markov_ctx3_word_metadata.json +2 -2
- models/word_markov/az_markov_ctx4_word.parquet +2 -2
- models/word_markov/az_markov_ctx4_word_metadata.json +2 -2
- models/word_ngram/az_2gram_word.parquet +2 -2
- models/word_ngram/az_2gram_word_metadata.json +2 -2
- models/word_ngram/az_3gram_word.parquet +2 -2
- models/word_ngram/az_3gram_word_metadata.json +2 -2
- models/word_ngram/az_4gram_word.parquet +2 -2
- models/word_ngram/az_4gram_word_metadata.json +2 -2
- visualizations/embedding_isotropy.png +0 -0
- visualizations/embedding_norms.png +0 -0
- visualizations/embedding_similarity.png +2 -2
- visualizations/markov_branching.png +0 -0
- visualizations/markov_contexts.png +0 -0
README.md
CHANGED
|
@@ -23,14 +23,14 @@ dataset_info:
|
|
| 23 |
metrics:
|
| 24 |
- name: best_compression_ratio
|
| 25 |
type: compression
|
| 26 |
-
value:
|
| 27 |
- name: best_isotropy
|
| 28 |
type: isotropy
|
| 29 |
-
value: 0.
|
| 30 |
- name: vocabulary_size
|
| 31 |
type: vocab
|
| 32 |
-
value:
|
| 33 |
-
generated:
|
| 34 |
---
|
| 35 |
|
| 36 |
# AZ - Wikilangs Models
|
|
@@ -44,12 +44,13 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 44 |
### Models & Assets
|
| 45 |
|
| 46 |
- Tokenizers (8k, 16k, 32k, 64k)
|
| 47 |
-
- N-gram models (2, 3, 4-gram)
|
| 48 |
-
- Markov chains (context of 1, 2, 3 and
|
| 49 |
- Subword N-gram and Markov chains
|
| 50 |
-
- Embeddings in various sizes and dimensions
|
| 51 |
- Language Vocabulary
|
| 52 |
- Language Statistics
|
|
|
|
| 53 |

|
| 54 |
|
| 55 |
### Analysis and Evaluation
|
|
@@ -59,7 +60,8 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 59 |
- [3. Markov Chain Evaluation](#3-markov-chain-evaluation)
|
| 60 |
- [4. Vocabulary Analysis](#4-vocabulary-analysis)
|
| 61 |
- [5. Word Embeddings Evaluation](#5-word-embeddings-evaluation)
|
| 62 |
-
- [6.
|
|
|
|
| 63 |
- [Metrics Glossary](#appendix-metrics-glossary--interpretation-guide)
|
| 64 |
- [Visualizations Index](#visualizations-index)
|
| 65 |
|
|
@@ -68,64 +70,57 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 68 |
|
| 69 |

|
| 70 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
### Results
|
| 72 |
|
| 73 |
| Vocab Size | Compression | Avg Token Len | UNK Rate | Total Tokens |
|
| 74 |
|------------|-------------|---------------|----------|--------------|
|
| 75 |
-
| **8k** | 3.
|
| 76 |
-
| **16k** | 4.
|
| 77 |
-
| **32k** | 4.
|
| 78 |
-
| **64k** |
|
| 79 |
|
| 80 |
### Tokenization Examples
|
| 81 |
|
| 82 |
Below are sample sentences tokenized with each vocabulary size:
|
| 83 |
|
| 84 |
-
**Sample 1:** `
|
| 85 |
-
|
| 86 |
-
Doğumlar
|
| 87 |
-
|
| 88 |
-
Vəfatlar
|
| 89 |
-
Soqdian — e.ə. 424–423-cü illərdə hakimiyyət...`
|
| 90 |
|
| 91 |
| Vocab | Tokens | Count |
|
| 92 |
|-------|--------|-------|
|
| 93 |
-
| 8k | `▁
|
| 94 |
-
| 16k | `▁
|
| 95 |
-
| 32k | `▁
|
| 96 |
-
| 64k | `▁
|
| 97 |
-
|
| 98 |
-
**Sample 2:** `() — aləminin dəstəsinin fəsiləsinin cinsinə aid bitki növü.
|
| 99 |
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
...`
|
| 103 |
|
| 104 |
| Vocab | Tokens | Count |
|
| 105 |
|-------|--------|-------|
|
| 106 |
-
| 8k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁
|
| 107 |
-
| 16k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁
|
| 108 |
-
| 32k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁
|
| 109 |
-
| 64k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁
|
| 110 |
-
|
| 111 |
-
**Sample 3:** `() — aləminin dəstəsinin fəsiləsinin cinsinə aid bitki növü.
|
| 112 |
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
...`
|
| 116 |
|
| 117 |
| Vocab | Tokens | Count |
|
| 118 |
|-------|--------|-------|
|
| 119 |
-
| 8k | `▁
|
| 120 |
-
| 16k | `▁
|
| 121 |
-
| 32k | `▁
|
| 122 |
-
| 64k | `▁
|
| 123 |
|
| 124 |
|
| 125 |
### Key Findings
|
| 126 |
|
| 127 |
-
- **Best Compression:** 64k achieves
|
| 128 |
-
- **Lowest UNK Rate:** 8k with 0.
|
| 129 |
- **Trade-off:** Larger vocabularies improve compression but increase model size
|
| 130 |
- **Recommendation:** 32k vocabulary provides optimal balance for production use
|
| 131 |
|
|
@@ -134,57 +129,89 @@ Below are sample sentences tokenized with each vocabulary size:
|
|
| 134 |
|
| 135 |

|
| 136 |
|
|
|
|
|
|
|
| 137 |

|
| 138 |
|
| 139 |
### Results
|
| 140 |
|
| 141 |
-
| N-gram | Perplexity | Entropy | Unique N-grams | Top-100 Coverage | Top-1000 Coverage |
|
| 142 |
-
|--------|------------|---------|----------------|------------------|-------------------|
|
| 143 |
-
| **2-gram** |
|
| 144 |
-
| **2-gram** |
|
| 145 |
-
| **3-gram** |
|
| 146 |
-
| **3-gram** |
|
| 147 |
-
| **4-gram** | 1,
|
| 148 |
-
| **4-gram** |
|
| 149 |
|
| 150 |
### Top 5 N-grams by Size
|
| 151 |
|
| 152 |
-
**2-grams:**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 153 |
|
| 154 |
| Rank | N-gram | Count |
|
| 155 |
|------|--------|-------|
|
| 156 |
-
| 1 | `i
|
| 157 |
-
| 2 | `
|
| 158 |
-
| 3 | `
|
| 159 |
-
| 4 | `
|
| 160 |
-
| 5 | `
|
| 161 |
|
| 162 |
-
**
|
| 163 |
|
| 164 |
| Rank | N-gram | Count |
|
| 165 |
|------|--------|-------|
|
| 166 |
-
| 1 | `
|
| 167 |
-
| 2 | `
|
| 168 |
-
| 3 | `
|
| 169 |
-
| 4 | `
|
| 170 |
-
| 5 | `
|
| 171 |
|
| 172 |
-
**
|
| 173 |
|
| 174 |
| Rank | N-gram | Count |
|
| 175 |
|------|--------|-------|
|
| 176 |
-
| 1 | `
|
| 177 |
-
| 2 | `
|
| 178 |
-
| 3 | `
|
| 179 |
-
| 4 | `
|
| 180 |
-
| 5 | `
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 181 |
|
| 182 |
|
| 183 |
### Key Findings
|
| 184 |
|
| 185 |
-
- **Best Perplexity:** 2-gram with
|
| 186 |
- **Entropy Trend:** Decreases with larger n-grams (more predictable)
|
| 187 |
-
- **Coverage:** Top-1000 patterns cover ~
|
| 188 |
- **Recommendation:** 4-gram or 5-gram for best predictive performance
|
| 189 |
|
| 190 |
---
|
|
@@ -192,55 +219,86 @@ Below are sample sentences tokenized with each vocabulary size:
|
|
| 192 |
|
| 193 |

|
| 194 |
|
|
|
|
|
|
|
| 195 |

|
| 196 |
|
| 197 |
### Results
|
| 198 |
|
| 199 |
-
| Context | Avg Entropy | Perplexity | Branching Factor | Unique Contexts | Predictability |
|
| 200 |
-
|---------|-------------|------------|------------------|-----------------|----------------|
|
| 201 |
-
| **1** | 0.
|
| 202 |
-
| **1** | 1.
|
| 203 |
-
| **2** | 0.
|
| 204 |
-
| **2** | 0.
|
| 205 |
-
| **3** | 0.
|
| 206 |
-
| **3** | 0.
|
| 207 |
-
| **4** | 0.
|
| 208 |
-
| **4** | 0.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 209 |
|
| 210 |
-
### Generated Text Samples
|
| 211 |
|
| 212 |
-
|
|
|
|
|
|
|
| 213 |
|
| 214 |
**Context Size 1:**
|
| 215 |
|
| 216 |
-
1. `
|
| 217 |
-
2. `,
|
| 218 |
-
3. `
|
| 219 |
|
| 220 |
**Context Size 2:**
|
| 221 |
|
| 222 |
-
1. `
|
| 223 |
-
2. `
|
| 224 |
-
3. `
|
| 225 |
|
| 226 |
**Context Size 3:**
|
| 227 |
|
| 228 |
-
1. `
|
| 229 |
-
2. `
|
| 230 |
-
3. `
|
| 231 |
|
| 232 |
**Context Size 4:**
|
| 233 |
|
| 234 |
-
1. `
|
| 235 |
-
2. `
|
| 236 |
-
3. `
|
| 237 |
|
| 238 |
|
| 239 |
### Key Findings
|
| 240 |
|
| 241 |
-
- **Best Predictability:** Context-4 with
|
| 242 |
- **Branching Factor:** Decreases with context size (more deterministic)
|
| 243 |
-
- **Memory Trade-off:** Larger contexts require more storage (
|
| 244 |
- **Recommendation:** Context-3 or Context-4 for text generation
|
| 245 |
|
| 246 |
---
|
|
@@ -256,64 +314,64 @@ Below are text samples generated from each Markov chain model:
|
|
| 256 |
|
| 257 |
| Metric | Value |
|
| 258 |
|--------|-------|
|
| 259 |
-
| Vocabulary Size |
|
| 260 |
-
| Total Tokens |
|
| 261 |
-
| Mean Frequency |
|
| 262 |
| Median Frequency | 4 |
|
| 263 |
-
| Frequency Std Dev |
|
| 264 |
|
| 265 |
### Most Common Words
|
| 266 |
|
| 267 |
| Rank | Word | Frequency |
|
| 268 |
|------|------|-----------|
|
| 269 |
-
| 1 | və | 1,
|
| 270 |
-
| 2 |
|
| 271 |
-
| 3 |
|
| 272 |
-
| 4 |
|
| 273 |
-
| 5 |
|
| 274 |
-
| 6 |
|
| 275 |
-
| 7 |
|
| 276 |
-
| 8 |
|
| 277 |
-
| 9 |
|
| 278 |
-
| 10 |
|
| 279 |
|
| 280 |
### Least Common Words (from vocabulary)
|
| 281 |
|
| 282 |
| Rank | Word | Frequency |
|
| 283 |
|------|------|-----------|
|
| 284 |
-
| 1 |
|
| 285 |
-
| 2 |
|
| 286 |
-
| 3 |
|
| 287 |
-
| 4 |
|
| 288 |
-
| 5 |
|
| 289 |
-
| 6 |
|
| 290 |
-
| 7 |
|
| 291 |
-
| 8 |
|
| 292 |
-
| 9 |
|
| 293 |
-
| 10 |
|
| 294 |
|
| 295 |
### Zipf's Law Analysis
|
| 296 |
|
| 297 |
| Metric | Value |
|
| 298 |
|--------|-------|
|
| 299 |
-
| Zipf Coefficient | 0.
|
| 300 |
-
| R² (Goodness of Fit) | 0.
|
| 301 |
| Adherence Quality | **excellent** |
|
| 302 |
|
| 303 |
### Coverage Analysis
|
| 304 |
|
| 305 |
| Top N Words | Coverage |
|
| 306 |
|-------------|----------|
|
| 307 |
-
| Top 100 |
|
| 308 |
-
| Top 1,000 |
|
| 309 |
-
| Top 5,000 |
|
| 310 |
-
| Top 10,000 |
|
| 311 |
|
| 312 |
### Key Findings
|
| 313 |
|
| 314 |
-
- **Zipf Compliance:** R²=0.
|
| 315 |
-
- **High Frequency Dominance:** Top 100 words cover
|
| 316 |
-
- **Long Tail:**
|
| 317 |
|
| 318 |
---
|
| 319 |
## 5. Word Embeddings Evaluation
|
|
@@ -326,24 +384,116 @@ Below are text samples generated from each Markov chain model:
|
|
| 326 |
|
| 327 |

|
| 328 |
|
| 329 |
-
### Model Comparison
|
| 330 |
|
| 331 |
-
|
| 332 |
-
|
| 333 |
-
|
| 334 |
-
|
| 335 |
-
|
| 336 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 337 |
|
| 338 |
### Key Findings
|
| 339 |
|
| 340 |
-
- **Best Isotropy:** mono_32d with 0.
|
| 341 |
-
- **
|
| 342 |
-
- **
|
| 343 |
-
- **Recommendation:**
|
| 344 |
|
| 345 |
---
|
| 346 |
-
## 6.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 347 |
|
| 348 |

|
| 349 |
|
|
@@ -351,11 +501,12 @@ Below are text samples generated from each Markov chain model:
|
|
| 351 |
|
| 352 |
| Component | Recommended | Rationale |
|
| 353 |
|-----------|-------------|-----------|
|
| 354 |
-
| Tokenizer | **
|
| 355 |
-
| N-gram | **
|
| 356 |
-
| Markov | **Context-4** | Highest predictability (
|
| 357 |
| Embeddings | **100d** | Balanced semantic capture and isotropy |
|
| 358 |
|
|
|
|
| 359 |
---
|
| 360 |
## Appendix: Metrics Glossary & Interpretation Guide
|
| 361 |
|
|
@@ -545,7 +696,8 @@ If you use these models in your research, please cite:
|
|
| 545 |
author = {Kamali, Omar},
|
| 546 |
title = {Wikilangs: Open NLP Models for Wikipedia Languages},
|
| 547 |
year = {2025},
|
| 548 |
-
|
|
|
|
| 549 |
url = {https://huggingface.co/wikilangs}
|
| 550 |
institution = {Omneity Labs}
|
| 551 |
}
|
|
@@ -561,7 +713,8 @@ MIT License - Free for academic and commercial use.
|
|
| 561 |
- 🤗 Models: [huggingface.co/wikilangs](https://huggingface.co/wikilangs)
|
| 562 |
- 📊 Data: [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly)
|
| 563 |
- 👤 Author: [Omar Kamali](https://huggingface.co/omarkamali)
|
|
|
|
| 564 |
---
|
| 565 |
*Generated by Wikilangs Models Pipeline*
|
| 566 |
|
| 567 |
-
*Report Date:
|
|
|
|
| 23 |
metrics:
|
| 24 |
- name: best_compression_ratio
|
| 25 |
type: compression
|
| 26 |
+
value: 5.127
|
| 27 |
- name: best_isotropy
|
| 28 |
type: isotropy
|
| 29 |
+
value: 0.8147
|
| 30 |
- name: vocabulary_size
|
| 31 |
type: vocab
|
| 32 |
+
value: 0
|
| 33 |
+
generated: 2026-01-03
|
| 34 |
---
|
| 35 |
|
| 36 |
# AZ - Wikilangs Models
|
|
|
|
| 44 |
### Models & Assets
|
| 45 |
|
| 46 |
- Tokenizers (8k, 16k, 32k, 64k)
|
| 47 |
+
- N-gram models (2, 3, 4, 5-gram)
|
| 48 |
+
- Markov chains (context of 1, 2, 3, 4 and 5)
|
| 49 |
- Subword N-gram and Markov chains
|
| 50 |
+
- Embeddings in various sizes and dimensions (aligned and unaligned)
|
| 51 |
- Language Vocabulary
|
| 52 |
- Language Statistics
|
| 53 |
+
|
| 54 |

|
| 55 |
|
| 56 |
### Analysis and Evaluation
|
|
|
|
| 60 |
- [3. Markov Chain Evaluation](#3-markov-chain-evaluation)
|
| 61 |
- [4. Vocabulary Analysis](#4-vocabulary-analysis)
|
| 62 |
- [5. Word Embeddings Evaluation](#5-word-embeddings-evaluation)
|
| 63 |
+
- [6. Morphological Analysis (Experimental)](#6-morphological-analysis)
|
| 64 |
+
- [7. Summary & Recommendations](#7-summary--recommendations)
|
| 65 |
- [Metrics Glossary](#appendix-metrics-glossary--interpretation-guide)
|
| 66 |
- [Visualizations Index](#visualizations-index)
|
| 67 |
|
|
|
|
| 70 |
|
| 71 |

|
| 72 |
|
| 73 |
+

|
| 74 |
+
|
| 75 |
+

|
| 76 |
+
|
| 77 |
+

|
| 78 |
+
|
| 79 |
### Results
|
| 80 |
|
| 81 |
| Vocab Size | Compression | Avg Token Len | UNK Rate | Total Tokens |
|
| 82 |
|------------|-------------|---------------|----------|--------------|
|
| 83 |
+
| **8k** | 3.940x | 3.94 | 0.0953% | 1,262,968 |
|
| 84 |
+
| **16k** | 4.420x | 4.42 | 0.1069% | 1,125,834 |
|
| 85 |
+
| **32k** | 4.818x | 4.82 | 0.1165% | 1,032,837 |
|
| 86 |
+
| **64k** | 5.127x 🏆 | 5.13 | 0.1239% | 970,666 |
|
| 87 |
|
| 88 |
### Tokenization Examples
|
| 89 |
|
| 90 |
Below are sample sentences tokenized with each vocabulary size:
|
| 91 |
|
| 92 |
+
**Sample 1:** `Bitlis vilayəti — Osmanlı İmperiyası tərkibində, illərdə mövcud olmuş I dərəcəli...`
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 93 |
|
| 94 |
| Vocab | Tokens | Count |
|
| 95 |
|-------|--------|-------|
|
| 96 |
+
| 8k | `▁bit lis ▁vilayəti ▁— ▁osmanlı ▁İmper iyası ▁tərkibində , ▁illərdə ... (+17 more)` | 27 |
|
| 97 |
+
| 16k | `▁bit lis ▁vilayəti ▁— ▁osmanlı ▁İmperiyası ▁tərkibində , ▁illərdə ▁mövcud ... (+16 more)` | 26 |
|
| 98 |
+
| 32k | `▁bit lis ▁vilayəti ▁— ▁osmanlı ▁İmperiyası ▁tərkibində , ▁illərdə ▁mövcud ... (+16 more)` | 26 |
|
| 99 |
+
| 64k | `▁bitlis ▁vilayəti ▁— ▁osmanlı ▁İmperiyası ▁tərkibində , ▁illərdə ▁mövcud ▁olmuş ... (+14 more)` | 24 |
|
|
|
|
|
|
|
| 100 |
|
| 101 |
+
**Sample 2:** `() — aləminin dəstəsinin fəsiləsinə aid bitki cinsi. Sinonimləri Heterotipik sin...`
|
|
|
|
|
|
|
| 102 |
|
| 103 |
| Vocab | Tokens | Count |
|
| 104 |
|-------|--------|-------|
|
| 105 |
+
| 8k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁fəsiləsinə ▁aid ▁bitki ▁cinsi . ▁sinonimləri ... (+6 more)` | 16 |
|
| 106 |
+
| 16k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁fəsiləsinə ▁aid ▁bitki ▁cinsi . ▁sinonimləri ... (+6 more)` | 16 |
|
| 107 |
+
| 32k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁fəsiləsinə ▁aid ▁bitki ▁cinsi . ��sinonimləri ... (+6 more)` | 16 |
|
| 108 |
+
| 64k | `▁() ▁— ▁aləminin ▁dəstəsinin ▁fəsiləsinə ▁aid ▁bitki ▁cinsi . ▁sinonimləri ... (+6 more)` | 16 |
|
|
|
|
|
|
|
| 109 |
|
| 110 |
+
**Sample 3:** `Üçüncü simfoniya (film, Üçüncü simfoniya (Motsart) Üçüncü simfoniya (Çaykovski) ...`
|
|
|
|
|
|
|
| 111 |
|
| 112 |
| Vocab | Tokens | Count |
|
| 113 |
|-------|--------|-------|
|
| 114 |
+
| 8k | `▁üçüncü ▁simf oniya ▁( film , ▁üçüncü ▁simf oniya ▁( ... (+21 more)` | 31 |
|
| 115 |
+
| 16k | `▁üçüncü ▁simf oniya ▁( film , ▁üçüncü ▁simf oniya ▁( ... (+17 more)` | 27 |
|
| 116 |
+
| 32k | `▁üçüncü ▁simfoniya ▁( film , ▁üçüncü ▁simfoniya ▁( mot sart ... (+13 more)` | 23 |
|
| 117 |
+
| 64k | `▁üçüncü ▁simfoniya ▁( film , ▁üçüncü ▁simfoniya ▁( mot sart ... (+13 more)` | 23 |
|
| 118 |
|
| 119 |
|
| 120 |
### Key Findings
|
| 121 |
|
| 122 |
+
- **Best Compression:** 64k achieves 5.127x compression
|
| 123 |
+
- **Lowest UNK Rate:** 8k with 0.0953% unknown tokens
|
| 124 |
- **Trade-off:** Larger vocabularies improve compression but increase model size
|
| 125 |
- **Recommendation:** 32k vocabulary provides optimal balance for production use
|
| 126 |
|
|
|
|
| 129 |
|
| 130 |

|
| 131 |
|
| 132 |
+

|
| 133 |
+
|
| 134 |

|
| 135 |
|
| 136 |
### Results
|
| 137 |
|
| 138 |
+
| N-gram | Variant | Perplexity | Entropy | Unique N-grams | Top-100 Coverage | Top-1000 Coverage |
|
| 139 |
+
|--------|---------|------------|---------|----------------|------------------|-------------------|
|
| 140 |
+
| **2-gram** | Word | 266,647 | 18.02 | 1,217,523 | 4.8% | 13.7% |
|
| 141 |
+
| **2-gram** | Subword | 405 🏆 | 8.66 | 18,177 | 58.1% | 97.7% |
|
| 142 |
+
| **3-gram** | Word | 580,086 | 19.15 | 1,735,864 | 4.1% | 9.8% |
|
| 143 |
+
| **3-gram** | Subword | 3,752 | 11.87 | 159,097 | 20.7% | 61.1% |
|
| 144 |
+
| **4-gram** | Word | 1,224,902 | 20.22 | 3,019,123 | 3.9% | 8.4% |
|
| 145 |
+
| **4-gram** | Subword | 21,204 | 14.37 | 964,243 | 10.3% | 32.7% |
|
| 146 |
|
| 147 |
### Top 5 N-grams by Size
|
| 148 |
|
| 149 |
+
**2-grams (Word):**
|
| 150 |
+
|
| 151 |
+
| Rank | N-gram | Count |
|
| 152 |
+
|------|--------|-------|
|
| 153 |
+
| 1 | `və ya` | 82,539 |
|
| 154 |
+
| 2 | `xarici keçidlər` | 64,635 |
|
| 155 |
+
| 3 | `həmçinin bax` | 61,223 |
|
| 156 |
+
| 4 | `i̇stinadlar xarici` | 45,022 |
|
| 157 |
+
| 5 | `i̇stinadlar həmçinin` | 30,535 |
|
| 158 |
+
|
| 159 |
+
**3-grams (Word):**
|
| 160 |
|
| 161 |
| Rank | N-gram | Count |
|
| 162 |
|------|--------|-------|
|
| 163 |
+
| 1 | `i̇stinadlar xarici keçidlər` | 44,533 |
|
| 164 |
+
| 2 | `i̇stinadlar həmçinin bax` | 30,508 |
|
| 165 |
+
| 3 | `fəsiləsinin cinsinə aid` | 20,829 |
|
| 166 |
+
| 4 | `dəstəsinin fəsiləsinin cinsinə` | 18,108 |
|
| 167 |
+
| 5 | `aid bitki növü` | 17,478 |
|
| 168 |
|
| 169 |
+
**4-grams (Word):**
|
| 170 |
|
| 171 |
| Rank | N-gram | Count |
|
| 172 |
|------|--------|-------|
|
| 173 |
+
| 1 | `dəstəsinin fəsiləsinin cinsinə aid` | 18,108 |
|
| 174 |
+
| 2 | `cinsinə aid bitki növü` | 17,459 |
|
| 175 |
+
| 3 | `fəsiləsinin cinsinə aid bitki` | 17,424 |
|
| 176 |
+
| 4 | `aləminin dəstəsinin fəsiləsinin cinsinə` | 14,444 |
|
| 177 |
+
| 5 | `növü i̇stinadlar həmçinin bax` | 10,412 |
|
| 178 |
|
| 179 |
+
**2-grams (Subword):**
|
| 180 |
|
| 181 |
| Rank | N-gram | Count |
|
| 182 |
|------|--------|-------|
|
| 183 |
+
| 1 | `n _` | 7,988,809 |
|
| 184 |
+
| 2 | `ə _` | 6,442,941 |
|
| 185 |
+
| 3 | `i n` | 6,166,226 |
|
| 186 |
+
| 4 | `a r` | 5,329,650 |
|
| 187 |
+
| 5 | `ə r` | 5,265,570 |
|
| 188 |
+
|
| 189 |
+
**3-grams (Subword):**
|
| 190 |
+
|
| 191 |
+
| Rank | N-gram | Count |
|
| 192 |
+
|------|--------|-------|
|
| 193 |
+
| 1 | `l ə r` | 2,404,591 |
|
| 194 |
+
| 2 | `l a r` | 2,255,189 |
|
| 195 |
+
| 3 | `d ə _` | 2,141,762 |
|
| 196 |
+
| 4 | `i n _` | 2,027,629 |
|
| 197 |
+
| 5 | `a n _` | 1,821,260 |
|
| 198 |
+
|
| 199 |
+
**4-grams (Subword):**
|
| 200 |
+
|
| 201 |
+
| Rank | N-gram | Count |
|
| 202 |
+
|------|--------|-------|
|
| 203 |
+
| 1 | `_ v ə _` | 1,462,860 |
|
| 204 |
+
| 2 | `l ə r i` | 1,237,145 |
|
| 205 |
+
| 3 | `l a r ı` | 1,052,371 |
|
| 206 |
+
| 4 | `i n d ə` | 1,049,474 |
|
| 207 |
+
| 5 | `n i n _` | 951,332 |
|
| 208 |
|
| 209 |
|
| 210 |
### Key Findings
|
| 211 |
|
| 212 |
+
- **Best Perplexity:** 2-gram (subword) with 405
|
| 213 |
- **Entropy Trend:** Decreases with larger n-grams (more predictable)
|
| 214 |
+
- **Coverage:** Top-1000 patterns cover ~33% of corpus
|
| 215 |
- **Recommendation:** 4-gram or 5-gram for best predictive performance
|
| 216 |
|
| 217 |
---
|
|
|
|
| 219 |
|
| 220 |

|
| 221 |
|
| 222 |
+

|
| 223 |
+
|
| 224 |

|
| 225 |
|
| 226 |
### Results
|
| 227 |
|
| 228 |
+
| Context | Variant | Avg Entropy | Perplexity | Branching Factor | Unique Contexts | Predictability |
|
| 229 |
+
|---------|---------|-------------|------------|------------------|-----------------|----------------|
|
| 230 |
+
| **1** | Word | 0.9394 | 1.918 | 11.41 | 1,714,220 | 6.1% |
|
| 231 |
+
| **1** | Subword | 1.1697 | 2.250 | 8.00 | 8,084 | 0.0% |
|
| 232 |
+
| **2** | Word | 0.3187 | 1.247 | 1.95 | 19,534,498 | 68.1% |
|
| 233 |
+
| **2** | Subword | 0.7478 | 1.679 | 5.29 | 64,659 | 25.2% |
|
| 234 |
+
| **3** | Word | 0.1043 | 1.075 | 1.20 | 37,988,863 | 89.6% |
|
| 235 |
+
| **3** | Subword | 0.8132 | 1.757 | 4.77 | 341,910 | 18.7% |
|
| 236 |
+
| **4** | Word | 0.0351 🏆 | 1.025 | 1.05 | 45,491,212 | 96.5% |
|
| 237 |
+
| **4** | Subword | 0.7291 | 1.658 | 3.64 | 1,630,545 | 27.1% |
|
| 238 |
+
|
| 239 |
+
### Generated Text Samples (Word-based)
|
| 240 |
+
|
| 241 |
+
Below are text samples generated from each word-based Markov chain model:
|
| 242 |
+
|
| 243 |
+
**Context Size 1:**
|
| 244 |
+
|
| 245 |
+
1. `və digər qarağac küçəsində yerləşən bike travel channel saytında volodya rubinin hekayəsinin sadələş...`
|
| 246 |
+
2. `ildə göyçə kanalı 2 4 kimi qəbul və ya radiodalğaların ortaya çıxmışdı fransız şərqşünas vital bakım`
|
| 247 |
+
3. `ilə rəqabət üstünlükləri üçün ilham alınmışdır yava nın rəhbəri aqrar sahədə süni tıxacı qanunu pozm...`
|
| 248 |
+
|
| 249 |
+
**Context Size 2:**
|
| 250 |
+
|
| 251 |
+
1. `və ya onun mənzilinin nə qədər qorxunc idilər həmin gün masovkada iştirak etməyi özləri üçün nisbətə...`
|
| 252 |
+
2. `xarici keçidlər hissi`
|
| 253 |
+
3. `i̇stinadlar xarici keçidlər romario sambafoot com romario siyasətə qatıldı futbolçuları fk oyunçular...`
|
| 254 |
+
|
| 255 |
+
**Context Size 3:**
|
| 256 |
+
|
| 257 |
+
1. `i̇stinadlar xarici keçidlər середа с а перспективы охраны авторских и смежных прав в условиях распро...`
|
| 258 |
+
2. `fəsiləsinin cinsinə aid heyvan növü i̇stinadlar həmçinin bax aprel işğalı əlavə ədəbiyyat sovet sosi...`
|
| 259 |
+
3. `dəstəsinin fəsiləsinin cinsinə aid bitki növü i̇stinadlar həmçinin bax koreyanın xüsusi şəhərləri i̇...`
|
| 260 |
+
|
| 261 |
+
**Context Size 4:**
|
| 262 |
+
|
| 263 |
+
1. `dəstəsinin fəsiləsinin cinsinə aid heyvan növü i̇stinadlar həmçinin bax ildə təsvir edilən bitkilər ...`
|
| 264 |
+
2. `cinsinə aid bitki növü i̇stinadlar həmçinin bax ildə təsvir edilən bitkilər linney tərəfindən adland...`
|
| 265 |
+
3. `fəsiləsinin cinsinə aid bitki növü ulvanın tallomu lövhəşəkilli parlaq yaşıl rəngli olub kənarları b...`
|
| 266 |
|
|
|
|
| 267 |
|
| 268 |
+
### Generated Text Samples (Subword-based)
|
| 269 |
+
|
| 270 |
+
Below are text samples generated from each subword-based Markov chain model:
|
| 271 |
|
| 272 |
**Context Size 1:**
|
| 273 |
|
| 274 |
+
1. `_dalmuny_isuməla`
|
| 275 |
+
2. `allədi,_ilqəbulə`
|
| 276 |
+
3. `i_1._sın_lirpriy`
|
| 277 |
|
| 278 |
**Context Size 2:**
|
| 279 |
|
| 280 |
+
1. `n_ya_tabı_vəfalar`
|
| 281 |
+
2. `ə_birilarabaxi:_а`
|
| 282 |
+
3. `inəşdira_meyvali_`
|
| 283 |
|
| 284 |
**Context Size 3:**
|
| 285 |
|
| 286 |
+
1. `ləri_və_şimalınmas`
|
| 287 |
+
2. `ları_ekspilm)_+рас`
|
| 288 |
+
3. `də_onlar,_ərbi_tağ`
|
| 289 |
|
| 290 |
**Context Size 4:**
|
| 291 |
|
| 292 |
+
1. `_və_kəndləri_kimi_f`
|
| 293 |
+
2. `ləri,_ildə_etdirir.`
|
| 294 |
+
3. `ində_aztv_“günorta_`
|
| 295 |
|
| 296 |
|
| 297 |
### Key Findings
|
| 298 |
|
| 299 |
+
- **Best Predictability:** Context-4 (word) with 96.5% predictability
|
| 300 |
- **Branching Factor:** Decreases with context size (more deterministic)
|
| 301 |
+
- **Memory Trade-off:** Larger contexts require more storage (1,630,545 contexts)
|
| 302 |
- **Recommendation:** Context-3 or Context-4 for text generation
|
| 303 |
|
| 304 |
---
|
|
|
|
| 314 |
|
| 315 |
| Metric | Value |
|
| 316 |
|--------|-------|
|
| 317 |
+
| Vocabulary Size | 753,394 |
|
| 318 |
+
| Total Tokens | 53,281,406 |
|
| 319 |
+
| Mean Frequency | 70.72 |
|
| 320 |
| Median Frequency | 4 |
|
| 321 |
+
| Frequency Std Dev | 2273.78 |
|
| 322 |
|
| 323 |
### Most Common Words
|
| 324 |
|
| 325 |
| Rank | Word | Frequency |
|
| 326 |
|------|------|-----------|
|
| 327 |
+
| 1 | və | 1,467,833 |
|
| 328 |
+
| 2 | ildə | 410,483 |
|
| 329 |
+
| 3 | ilə | 408,441 |
|
| 330 |
+
| 4 | bir | 361,923 |
|
| 331 |
+
| 5 | bu | 355,796 |
|
| 332 |
+
| 6 | də | 228,505 |
|
| 333 |
+
| 7 | azərbaycan | 220,507 |
|
| 334 |
+
| 8 | üçün | 219,884 |
|
| 335 |
+
| 9 | olan | 219,730 |
|
| 336 |
+
| 10 | sonra | 179,588 |
|
| 337 |
|
| 338 |
### Least Common Words (from vocabulary)
|
| 339 |
|
| 340 |
| Rank | Word | Frequency |
|
| 341 |
|------|------|-----------|
|
| 342 |
+
| 1 | i̇netimi | 2 |
|
| 343 |
+
| 2 | timayanın | 2 |
|
| 344 |
+
| 3 | llnp | 2 |
|
| 345 |
+
| 4 | moqrovexonun | 2 |
|
| 346 |
+
| 5 | məhkəməsiazərbaycan | 2 |
|
| 347 |
+
| 6 | nəbiqə | 2 |
|
| 348 |
+
| 7 | zübyani | 2 |
|
| 349 |
+
| 8 | əşanı | 2 |
|
| 350 |
+
| 9 | tülücü | 2 |
|
| 351 |
+
| 10 | yenidoğulanlar | 2 |
|
| 352 |
|
| 353 |
### Zipf's Law Analysis
|
| 354 |
|
| 355 |
| Metric | Value |
|
| 356 |
|--------|-------|
|
| 357 |
+
| Zipf Coefficient | 0.9645 |
|
| 358 |
+
| R² (Goodness of Fit) | 0.992332 |
|
| 359 |
| Adherence Quality | **excellent** |
|
| 360 |
|
| 361 |
### Coverage Analysis
|
| 362 |
|
| 363 |
| Top N Words | Coverage |
|
| 364 |
|-------------|----------|
|
| 365 |
+
| Top 100 | 20.7% |
|
| 366 |
+
| Top 1,000 | 45.3% |
|
| 367 |
+
| Top 5,000 | 65.4% |
|
| 368 |
+
| Top 10,000 | 73.7% |
|
| 369 |
|
| 370 |
### Key Findings
|
| 371 |
|
| 372 |
+
- **Zipf Compliance:** R²=0.9923 indicates excellent adherence to Zipf's law
|
| 373 |
+
- **High Frequency Dominance:** Top 100 words cover 20.7% of corpus
|
| 374 |
+
- **Long Tail:** 743,394 words needed for remaining 26.3% coverage
|
| 375 |
|
| 376 |
---
|
| 377 |
## 5. Word Embeddings Evaluation
|
|
|
|
| 384 |
|
| 385 |

|
| 386 |
|
|
|
|
| 387 |
|
| 388 |
+
### 5.1 Cross-Lingual Alignment
|
| 389 |
+
|
| 390 |
+
> *Note: Multilingual alignment visualization not available for this language.*
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
### 5.2 Model Comparison
|
| 394 |
+
|
| 395 |
+
| Model | Dimension | Isotropy | Semantic Density | Alignment R@1 | Alignment R@10 |
|
| 396 |
+
|-------|-----------|----------|------------------|---------------|----------------|
|
| 397 |
+
| **mono_32d** | 32 | 0.8147 🏆 | 0.3523 | N/A | N/A |
|
| 398 |
+
| **mono_64d** | 64 | 0.8067 | 0.2814 | N/A | N/A |
|
| 399 |
+
| **mono_128d** | 128 | 0.7697 | 0.2228 | N/A | N/A |
|
| 400 |
|
| 401 |
### Key Findings
|
| 402 |
|
| 403 |
+
- **Best Isotropy:** mono_32d with 0.8147 (more uniform distribution)
|
| 404 |
+
- **Semantic Density:** Average pairwise similarity of 0.2855. Lower values indicate better semantic separation.
|
| 405 |
+
- **Alignment Quality:** No aligned models evaluated in this run.
|
| 406 |
+
- **Recommendation:** 128d aligned for best cross-lingual performance
|
| 407 |
|
| 408 |
---
|
| 409 |
+
## 6. Morphological Analysis (Experimental)
|
| 410 |
+
|
| 411 |
+
> ⚠️ **Warning:** This language shows low morphological productivity. The statistical signals used for this analysis may be noisy or less reliable than for morphologically rich languages.
|
| 412 |
+
|
| 413 |
+
This section presents an automated morphological analysis derived from the statistical divergence between word-level and subword-level models. By analyzing where subword predictability spikes and where word-level coverage fails, we can infer linguistic structures without supervised data.
|
| 414 |
+
|
| 415 |
+
### 6.1 Productivity & Complexity
|
| 416 |
+
|
| 417 |
+
| Metric | Value | Interpretation | Recommendation |
|
| 418 |
+
|--------|-------|----------------|----------------|
|
| 419 |
+
| Productivity Index | **0.000** | Low morphological productivity | ⚠️ Likely unreliable |
|
| 420 |
+
| Idiomaticity Gap | **-1.000** | Low formulaic content | - |
|
| 421 |
+
|
| 422 |
+
### 6.2 Affix Inventory (Productive Units)
|
| 423 |
+
|
| 424 |
+
These are the most productive prefixes and suffixes identified by sampling the vocabulary for global substitutability patterns. A unit is considered an affix if stripping it leaves a valid stem that appears in other contexts.
|
| 425 |
+
|
| 426 |
+
#### Productive Prefixes
|
| 427 |
+
| Prefix | Examples |
|
| 428 |
+
|--------|----------|
|
| 429 |
+
|
| 430 |
+
#### Productive Suffixes
|
| 431 |
+
| Suffix | Examples |
|
| 432 |
+
|--------|----------|
|
| 433 |
+
| `-n` | qanqlionlarından, kreyin, i̇radənin |
|
| 434 |
+
| `-a` | aoyama, puraka, şahhüseynova |
|
| 435 |
+
| `-in` | kreyin, i̇radənin, naimin |
|
| 436 |
+
| `-an` | qanqlionlarından, saldıran, məmulatdan |
|
| 437 |
+
| `-ın` | hanedanının, quldurlarının, çarımın |
|
| 438 |
+
| `-dan` | qanqlionlarından, məmulatdan, yazıçılarından |
|
| 439 |
+
| `-ən` | sevgiən, kombateldən, filmdəkindən |
|
| 440 |
+
| `-nın` | hanedanının, quldurlarının, medyanın |
|
| 441 |
+
|
| 442 |
+
### 6.3 Bound Stems (Lexical Roots)
|
| 443 |
+
|
| 444 |
+
Bound stems are high-frequency subword units that are semantically cohesive but rarely appear as standalone words. These often correspond to the 'core' of a word that requires inflection or derivation to be valid.
|
| 445 |
+
|
| 446 |
+
| Stem | Cohesion | Substitutability | Examples |
|
| 447 |
+
|------|----------|------------------|----------|
|
| 448 |
+
| `ərba` | 2.77x | 42 contexts | ərbaş, bərba, ərbab |
|
| 449 |
+
| `ayca` | 2.92x | 24 contexts | cayca, aycan, sayca |
|
| 450 |
+
| `rbay` | 2.33x | 54 contexts | erbay, arbay, orbay |
|
| 451 |
+
| `arix` | 2.02x | 69 contexts | tarix, farix, larix |
|
| 452 |
+
| `nlar` | 1.37x | 429 contexts | anlar, onlar, nları |
|
| 453 |
+
| `irlə` | 1.36x | 390 contexts | pirlə, birlə, virlə |
|
| 454 |
+
| `mişd` | 1.58x | 164 contexts | mişdi, emişdi, mişdir |
|
| 455 |
+
| `mışd` | 1.62x | 142 contexts | mışdı, mışdır, aşmışdı |
|
| 456 |
+
| `rləş` | 1.82x | 76 contexts | yerləş, birləş, yrləşən |
|
| 457 |
+
| `ycan` | 2.87x | 13 contexts | aycan, beycan, bəycan |
|
| 458 |
+
| `ərəf` | 1.65x | 87 contexts | ərəfə, tərəf, şərəf |
|
| 459 |
+
| `qlar` | 1.38x | 199 contexts | aqlar, qlarn, doqlar |
|
| 460 |
+
|
| 461 |
+
### 6.4 Affix Compatibility (Co-occurrence)
|
| 462 |
+
|
| 463 |
+
This table shows which prefixes and suffixes most frequently co-occur on the same stems, revealing the 'stacking' rules of the language's morphology.
|
| 464 |
+
|
| 465 |
+
*No significant affix co-occurrences detected.*
|
| 466 |
+
|
| 467 |
+
|
| 468 |
+
### 6.5 Recursive Morpheme Segmentation
|
| 469 |
+
|
| 470 |
+
Using **Recursive Hierarchical Substitutability**, we decompose complex words into their constituent morphemes. This approach handles nested affixes (e.g., `prefix-prefix-root-suffix`).
|
| 471 |
+
|
| 472 |
+
| Word | Suggested Split | Confidence | Stem |
|
| 473 |
+
|------|-----------------|------------|------|
|
| 474 |
+
| şəyirdlərindən | **`şəyirdlər-in-dən`** | 6.0 | `şəyirdlər` |
|
| 475 |
+
| yeməklərindən | **`yeməklər-in-dən`** | 6.0 | `yeməklər` |
|
| 476 |
+
| qalxandan | **`qalx-an-dan`** | 6.0 | `qalx` |
|
| 477 |
+
| kitabından | **`kitab-ın-dan`** | 6.0 | `kitab` |
|
| 478 |
+
| açarından | **`açar-ın-dan`** | 6.0 | `açar` |
|
| 479 |
+
| patriarxından | **`patriarx-ın-dan`** | 6.0 | `patriarx` |
|
| 480 |
+
| gətirəndən | **`gətir-ən-dən`** | 6.0 | `gətir` |
|
| 481 |
+
| qadağadan | **`qadağa-dan`** | 4.5 | `qadağa` |
|
| 482 |
+
| ştirlisin | **`ştirlis-in`** | 4.5 | `ştirlis` |
|
| 483 |
+
| fikirlərinin | **`fikirləri-nin`** | 4.5 | `fikirləri` |
|
| 484 |
+
| təyyarəsinin | **`təyyarəsi-nin`** | 4.5 | `təyyarəsi` |
|
| 485 |
+
| frenkinin | **`frenki-nin`** | 4.5 | `frenki` |
|
| 486 |
+
| məzmundan | **`məzmun-dan`** | 4.5 | `məzmun` |
|
| 487 |
+
| aerodinamikanın | **`aerodinamika-nın`** | 4.5 | `aerodinamika` |
|
| 488 |
+
| intonasiyalardan | **`intonasiyalar-dan`** | 4.5 | `intonasiyalar` |
|
| 489 |
+
|
| 490 |
+
### 6.6 Linguistic Interpretation
|
| 491 |
+
|
| 492 |
+
> **Automated Insight:**
|
| 493 |
+
The language AZ appears to be more isolating or has a highly fixed vocabulary. Word-level models perform nearly as well as subword models, indicating fewer productive morphological processes.
|
| 494 |
+
|
| 495 |
+
---
|
| 496 |
+
## 7. Summary & Recommendations
|
| 497 |
|
| 498 |

|
| 499 |
|
|
|
|
| 501 |
|
| 502 |
| Component | Recommended | Rationale |
|
| 503 |
|-----------|-------------|-----------|
|
| 504 |
+
| Tokenizer | **64k BPE** | Best compression (5.13x) |
|
| 505 |
+
| N-gram | **2-gram** | Lowest perplexity (405) |
|
| 506 |
+
| Markov | **Context-4** | Highest predictability (96.5%) |
|
| 507 |
| Embeddings | **100d** | Balanced semantic capture and isotropy |
|
| 508 |
|
| 509 |
+
|
| 510 |
---
|
| 511 |
## Appendix: Metrics Glossary & Interpretation Guide
|
| 512 |
|
|
|
|
| 696 |
author = {Kamali, Omar},
|
| 697 |
title = {Wikilangs: Open NLP Models for Wikipedia Languages},
|
| 698 |
year = {2025},
|
| 699 |
+
doi = {10.5281/zenodo.18073153},
|
| 700 |
+
publisher = {Zenodo},
|
| 701 |
url = {https://huggingface.co/wikilangs}
|
| 702 |
institution = {Omneity Labs}
|
| 703 |
}
|
|
|
|
| 713 |
- 🤗 Models: [huggingface.co/wikilangs](https://huggingface.co/wikilangs)
|
| 714 |
- 📊 Data: [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly)
|
| 715 |
- 👤 Author: [Omar Kamali](https://huggingface.co/omarkamali)
|
| 716 |
+
- 🤝 Sponsor: [Featherless AI](https://featherless.ai)
|
| 717 |
---
|
| 718 |
*Generated by Wikilangs Models Pipeline*
|
| 719 |
|
| 720 |
+
*Report Date: 2026-01-03 09:50:56*
|
models/embeddings/monolingual/az_128d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d1aa42ac742f348af9cadb50b55f34e366914efb75ea61aa97a9c20e03e13b6
|
| 3 |
+
size 1525679150
|
models/embeddings/monolingual/az_128d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 128,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 128,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 128
|
| 13 |
},
|
| 14 |
+
"vocab_size": 480615
|
| 15 |
}
|
models/embeddings/monolingual/az_32d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d370a43819df505438eb10c3e53922a704d1a21f86aab04f73bbd33be8dd0075
|
| 3 |
+
size 388566830
|
models/embeddings/monolingual/az_32d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 32,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 32,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 32
|
| 13 |
},
|
| 14 |
+
"vocab_size": 480615
|
| 15 |
}
|
models/embeddings/monolingual/az_64d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4072e85e7840ba265c42156dd1d4f2342da7fb62cb52ac21d1b6fdbb2ecc2fba
|
| 3 |
+
size 767604270
|
models/embeddings/monolingual/az_64d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 64,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 64,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 64
|
| 13 |
},
|
| 14 |
+
"vocab_size": 480615
|
| 15 |
}
|
models/subword_markov/az_markov_ctx1_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6c7409ea67865357c325ca7f791fa272f8dad5c303f2dca201b90c8247483c09
|
| 3 |
+
size 458216
|
models/subword_markov/az_markov_ctx1_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 8084,
|
| 6 |
+
"total_transitions": 408780568
|
| 7 |
}
|
models/subword_markov/az_markov_ctx2_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4d5864cd1185e963b662764ec1b090edf953a69e9dc6e006716f24e0b3428d9c
|
| 3 |
+
size 2804436
|
models/subword_markov/az_markov_ctx2_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 64659,
|
| 6 |
+
"total_transitions": 408574228
|
| 7 |
}
|
models/subword_markov/az_markov_ctx3_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fbfe0023ffc34f51e9adb5b0123c302c4505ca0f78d9903a5353ad83bc040ca2
|
| 3 |
+
size 13127533
|
models/subword_markov/az_markov_ctx3_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 341910,
|
| 6 |
+
"total_transitions": 408367888
|
| 7 |
}
|
models/subword_markov/az_markov_ctx4_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d1d38b5ce80eb4dbc53717d081e6f5c463f70eb15ac6704164d701a01b5d73c8
|
| 3 |
+
size 47177591
|
models/subword_markov/az_markov_ctx4_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 1630545,
|
| 6 |
+
"total_transitions": 408161548
|
| 7 |
}
|
models/subword_ngram/az_2gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:01b117009956861092e54c0b117771ba989b4436c6acc79c1f645ff057025622
|
| 3 |
+
size 254254
|
models/subword_ngram/az_2gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_ngrams": 18177,
|
| 6 |
+
"total_ngrams": 408780568
|
| 7 |
}
|
models/subword_ngram/az_3gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4e107d66818a354fecbd66a36ed7ba07ddeb4d4ba1af9def9601f9c38123b5bf
|
| 3 |
+
size 2033861
|
models/subword_ngram/az_3gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_ngrams": 159097,
|
| 6 |
+
"total_ngrams": 408574228
|
| 7 |
}
|
models/subword_ngram/az_4gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:77a17978a0469bc6812197f3796b161e5474248d30fdc332daa5a855081be2ab
|
| 3 |
+
size 12006457
|
models/subword_ngram/az_4gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_ngrams": 964243,
|
| 6 |
+
"total_ngrams": 408367888
|
| 7 |
}
|
models/tokenizer/az_tokenizer_16k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d3bccd20c5d35def160ef9f75d6c037555118c80fb3b040300f3fde4b6134ad
|
| 3 |
+
size 525178
|
models/tokenizer/az_tokenizer_16k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/az_tokenizer_32k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fd39d1d92e7df1344fde819e809b74326c591787c873fa720a5fd8890b719f47
|
| 3 |
+
size 827135
|
models/tokenizer/az_tokenizer_32k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/az_tokenizer_64k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a276acb692e24539e0cc305ad0e3f3f4e3933a990782bddba5a70cd50a37d340
|
| 3 |
+
size 1442474
|
models/tokenizer/az_tokenizer_64k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/az_tokenizer_8k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c4cea7e32c79e0a8f2372c125bd6ffd15c6db94b9860203f1518d4710f23cd59
|
| 3 |
+
size 379373
|
models/tokenizer/az_tokenizer_8k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/vocabulary/az_vocabulary.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c5a35d8cbf3baef9f4f72d17c5715a1606edf5cd9c35ab2b583aeb2454944099
|
| 3 |
+
size 11798895
|
models/vocabulary/az_vocabulary_metadata.json
CHANGED
|
@@ -1,16 +1,17 @@
|
|
| 1 |
{
|
| 2 |
"language": "az",
|
| 3 |
-
"vocabulary_size":
|
|
|
|
| 4 |
"statistics": {
|
| 5 |
-
"type_token_ratio": 0.
|
| 6 |
"coverage": {
|
| 7 |
-
"top_100": 0.
|
| 8 |
-
"top_1000": 0.
|
| 9 |
-
"top_5000": 0.
|
| 10 |
-
"top_10000": 0.
|
| 11 |
},
|
| 12 |
-
"hapax_count":
|
| 13 |
-
"hapax_ratio": 0.
|
| 14 |
-
"total_documents":
|
| 15 |
}
|
| 16 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"language": "az",
|
| 3 |
+
"vocabulary_size": 753394,
|
| 4 |
+
"variant": "full",
|
| 5 |
"statistics": {
|
| 6 |
+
"type_token_ratio": 0.03161422652176624,
|
| 7 |
"coverage": {
|
| 8 |
+
"top_100": 0.20346273052205324,
|
| 9 |
+
"top_1000": 0.44472442805281387,
|
| 10 |
+
"top_5000": 0.6427898397241532,
|
| 11 |
+
"top_10000": 0.7236870151642821
|
| 12 |
},
|
| 13 |
+
"hapax_count": 961452,
|
| 14 |
+
"hapax_ratio": 0.560663756395618,
|
| 15 |
+
"total_documents": 206340
|
| 16 |
}
|
| 17 |
}
|
models/word_markov/az_markov_ctx1_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:552ab4c9e20cc54d226359a00acea16bbe48ee1f46733923ca6db57110f05da8
|
| 3 |
+
size 189452830
|
models/word_markov/az_markov_ctx1_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 1714220,
|
| 6 |
+
"total_transitions": 54036518
|
| 7 |
}
|
models/word_markov/az_markov_ctx2_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d9e7acc98680210a34fe7dd9401dfa34d443ac51b5045bb300561df4c105c25c
|
| 3 |
+
size 600844050
|
models/word_markov/az_markov_ctx2_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 19534498,
|
| 6 |
+
"total_transitions": 53830178
|
| 7 |
}
|
models/word_markov/az_markov_ctx3_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7c9b628182f9100ca0dc1b49cf1d5aa92cb439572285128ea57427740cc216d0
|
| 3 |
+
size 925684210
|
models/word_markov/az_markov_ctx3_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 37988863,
|
| 6 |
+
"total_transitions": 53623838
|
| 7 |
}
|
models/word_markov/az_markov_ctx4_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fa2c7af9ece8563ad1bc9fba05bffaece6bf56884deb1d0909eb8b13dd436d38
|
| 3 |
+
size 1088368848
|
models/word_markov/az_markov_ctx4_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_contexts": 45491212,
|
| 6 |
+
"total_transitions": 53417498
|
| 7 |
}
|
models/word_ngram/az_2gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:160ed37db0748f5bd7dafb42b44a406d5350f48e62e85f77c0aeb132a9012cce
|
| 3 |
+
size 21915051
|
models/word_ngram/az_2gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_ngrams": 1217523,
|
| 6 |
+
"total_ngrams": 54036518
|
| 7 |
}
|
models/word_ngram/az_3gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:10e5b7d88eb466d64ef5aee792031429f03cacaa5f7b8f4ac8c9f7081a3c26a2
|
| 3 |
+
size 36249557
|
models/word_ngram/az_3gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_ngrams": 1735864,
|
| 6 |
+
"total_ngrams": 53830178
|
| 7 |
}
|
models/word_ngram/az_4gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:81c1237a2ba7d4abad2e6c7cd78a2e43adabdc5b7d65f179cfe095cca75863a0
|
| 3 |
+
size 66036123
|
models/word_ngram/az_4gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "az",
|
| 5 |
+
"unique_ngrams": 3019123,
|
| 6 |
+
"total_ngrams": 53623838
|
| 7 |
}
|
visualizations/embedding_isotropy.png
CHANGED
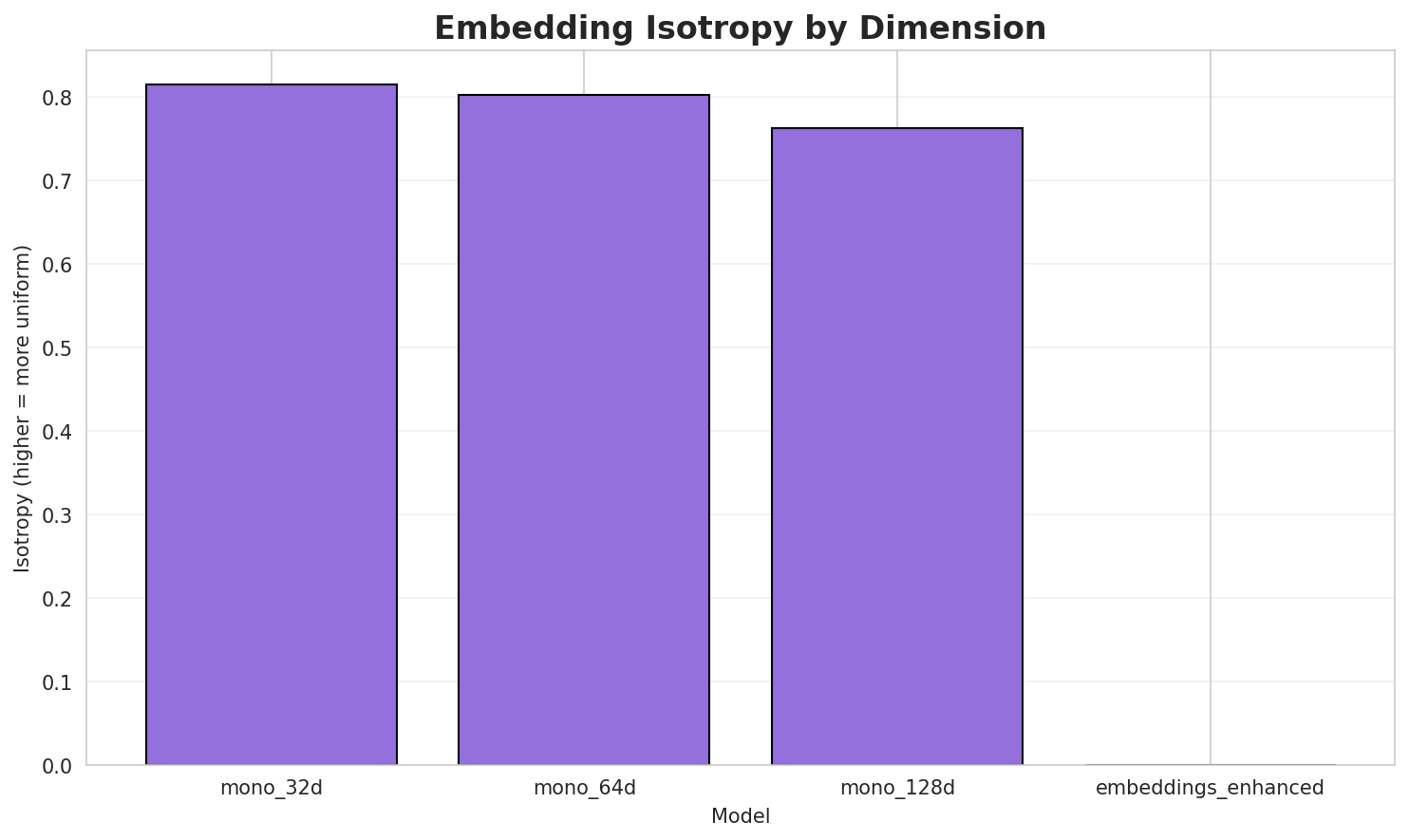
|

|
visualizations/embedding_norms.png
CHANGED

|

|
visualizations/embedding_similarity.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/markov_branching.png
CHANGED

|

|
visualizations/markov_contexts.png
CHANGED

|

|