---
license: apache-2.0
---
# TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos
🔗 Project Page · 📖 Paper · ⭐ GitHub · 📊 Dataset · 🤗 Checkpoints
## Introduction
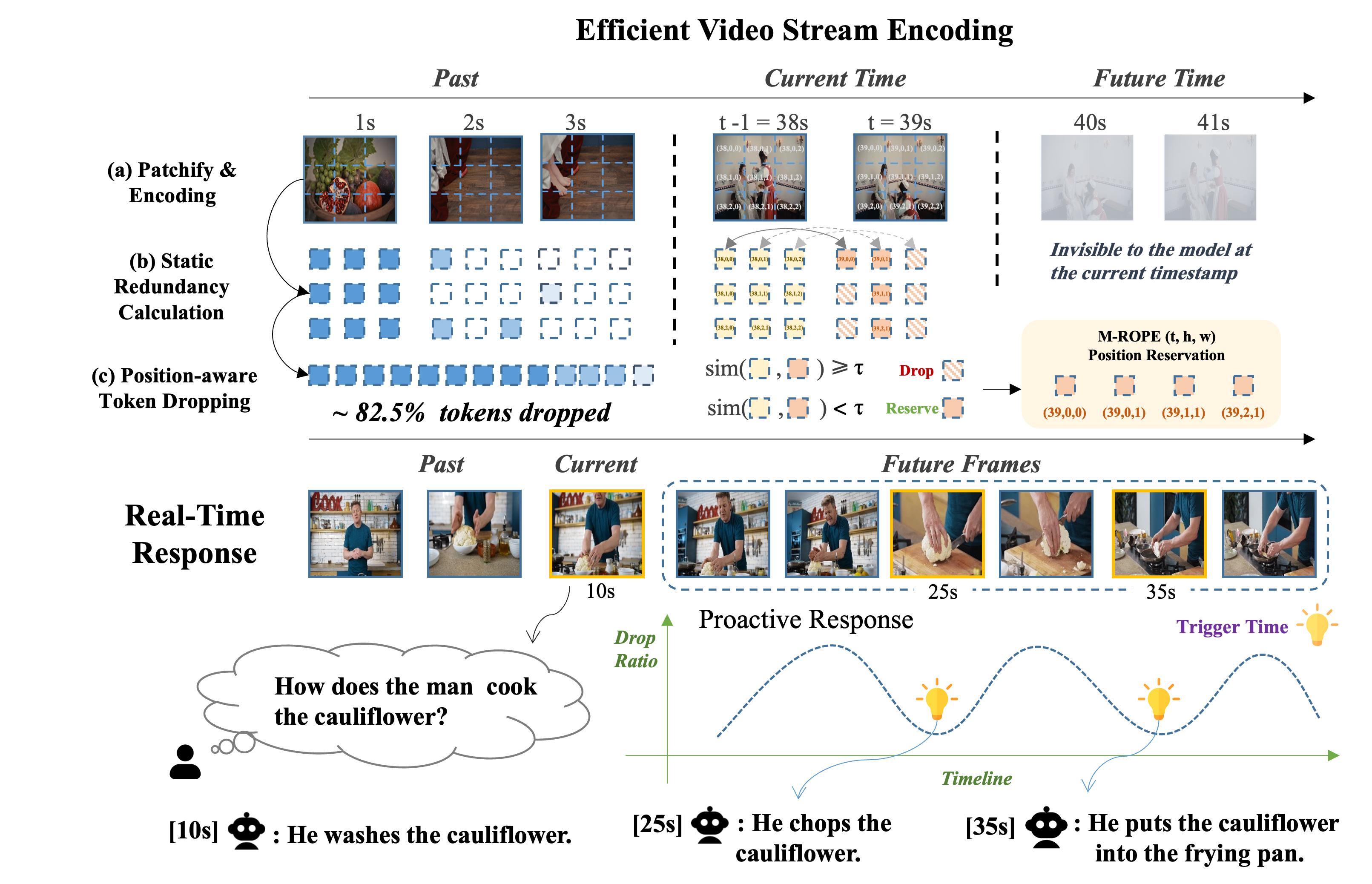
**TimeChat-Online** is a novel online VideoLLM designed for efficient streaming video understanding. Its core innovation, the **Differential Token Drop (DTD)** module, tackles visual redundancy by selectively preserving only meaningful temporal changes while eliminating static content between frames. Our experiments show that over 80% of streaming video content is naturally redundant without requiring user-query guidance.
 ## Key Features of TimeChat-Online
✨ **Video-aware Dynamic Pruning:**
DTD adaptively reduces video tokens from a holistic video perspective, well-suited for both high-speed and slow-motion videos.
📝 **Positional Reservation:**
DTD maintains the fine-grained spatial-temporal positions of retained tokens via M-ROPE, ensuring precise spatial localization and temporal understanding capabilities.
⚡ **Streaming-friendly Design:**
DTD efficiently processes video streams by calculating redundancy only for newly-arriving frames, without re-processing historical video content.
🎉 **Proactive Response Capability:**
TimeChat-Online naturally monitors video scene transitions through the DTD module, enabling autonomous identification of critical moments that require responses without explicit queries.
## Key Features of TimeChat-Online
✨ **Video-aware Dynamic Pruning:**
DTD adaptively reduces video tokens from a holistic video perspective, well-suited for both high-speed and slow-motion videos.
📝 **Positional Reservation:**
DTD maintains the fine-grained spatial-temporal positions of retained tokens via M-ROPE, ensuring precise spatial localization and temporal understanding capabilities.
⚡ **Streaming-friendly Design:**
DTD efficiently processes video streams by calculating redundancy only for newly-arriving frames, without re-processing historical video content.
🎉 **Proactive Response Capability:**
TimeChat-Online naturally monitors video scene transitions through the DTD module, enabling autonomous identification of critical moments that require responses without explicit queries.
 ## Model Architecture
## Model Architecture
## Performance Highlights
- 🏆 **StreamingBench**: Achieves **56.6** accuracy with **82.6%** token reduction (new SOTA)
- 🏆 **OVO-Bench**: achieves 45.6 accuracy with 84.8% token dropped (new SOTA)
- 🏆 **Long Video Benchmarks (MLVU, LongVideoBench, VideoMME)**: Up to **85.0%** reduction in video tokens while maintaining or improving performance
- 🏆 **Zero-shot Integration**: When integrated with Qwen2.5-VL-7B without training, DTD improves VideoMME (long subset) accuracy by **5.7** points while reducing **84.6%** of video tokens
## Quick Start
### requirements
```
pip install transformers==4.49.0
pip install accelerate==1.5.2
pip install qwen-vl-utils[decord]==0.0.8
```
### using transformers and Qwen2_5_VLForConditionalGeneration to chat:
```python
from transformers import AutoProcessor
from qwen_vl_utils import process_vision_info
import time
#pay attention to this line, not import from transformers, import from our GitHub repo's eval folder qwen2_5_vl
from eval.qwen2_5_vl import Qwen2_5_VLForConditionalGeneration
curr_time = datetime.now().strftime("%Y%m%d_%H%M%S")
DROP_METHOD = 'feature'
DROP_THRESHOLD = 0.5
DROP_ABSOLUTE = True
DR_SAVE_PATH = "drop_{curr_time}.jsonl"
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"wyccccc/TimeChatOnline-7B", torch_dtype="torch.bfloat16", attn_implementation="flash_attention_2",
device_map="auto",
)
processor = AutoProcessor.from_pretrained("wyccccc/TimeChatOnline-7B")
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
# "min_pixels": 336*336,
# "max_pixels": 336*336,
# "max_frames": 1016,
# "min_frames": 4,
# "fps": 1.0
},
{
"type": "text",
"text": "Describe this video."
},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(
**inputs,
max_new_tokens=128,
drop_method=DROP_METHOD,
drop_threshold=DROP_THRESHOLD,
drop_absolute=DROP_ABSOLUTE,
dr_save_path=DR_SAVE_PATH,
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
## Citation
If you find our work helpful, please consider citing:
```
@misc{timechatonline,
title={TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos},
author={Linli Yao and Yicheng Li and Yuancheng Wei and Lei Li and Shuhuai Ren and Yuanxin Liu and Kun Ouyang and Lean Wang and Shicheng Li and Sida Li and Lingpeng Kong and Qi Liu and Yuanxing Zhang and Xu Sun},
year={2025},
eprint={2504.17343},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.17343},
}
```
## License and Acknowledgments
- The data, code, and checkpoints are intended and licensed for research use only
- They are restricted to uses that follow the license agreements of the respective datasets and models used in this work
**We thank the following projects for their contributions:** [TimeChat](https://github.com/RenShuhuai-Andy/TimeChat), [Qwen2.5VL](https://github.com/QwenLM/Qwen2.5-VL), [RLT](https://github.com/rccchoudhury/rlt), [VideoLLM-online](https://showlab.github.io/videollm-online/), [OVOBench](https://github.com/joeleelyf/ovo-bench), [StreamingBench](https://github.com/THUNLP-MT/StreamingBench)