
Yuechen Yang
commited on
Commit
·
3e3195e
1
Parent(s):
4e3ae34
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Garbage Classification
|
| 2 |
+
|
| 3 |
+
## Overview
|
| 4 |
+
|
| 5 |
+
### Backgroud
|
| 6 |
+
Garbage classification refers to the separation of several types of different categories in accordance with the environmental impact of the use of the value of the composition of garbage components and the requirements of existing treatment methods.
|
| 7 |
+
|
| 8 |
+
The significance of garbage classification:
|
| 9 |
+
1. Garbage classification reduces the mutual pollution between different garbage, which is beneficial to the recycling of materials.
|
| 10 |
+
2. Garbage classification is conducive to reducing the final waste disposal volume.
|
| 11 |
+
3. Garbage classification is conducive to enhancing the degree of social civilization.
|
| 12 |
+
|
| 13 |
+
### Dataset
|
| 14 |
+
The garbage classification dataset is from Kaggle. There are totally 2467 pictures in this dataset. And this model is an image classification model for this dataset. There are 6 classes for this dataset, which are cardboard (393), glass (491), metal (400), paper(584), plastic (472), and trash(127).
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
|
| 27 |
+
|
| 28 |
+
### Model
|
| 29 |
+
To gain the trianing data, I scraped from the trending topics from Twitter, filtered out the tweets in different languages and left with only tweets in English. There are more than 30k tweets in our training dataset.
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
Then, a BERT model is trained to do the fill-mask task to solve this problem.
|
| 33 |
+
Some special modifications I made to the model are as follows:
|
| 34 |
+
|
| 35 |
+
1. Hashtags are usually consists of multiple words without space. When tokenizing these hashtags, they will be splitted into different words and therefore cannot form up an hashtag when we decode these tokens. For example, "#TheFirstLady" passed in regular tokenizer will be splitted into "#", "The", "First", "#Lady". Therefore, I added the top 1000 trending hashtags to the token dictioanry and provide special token_ids for each hastag.
|
| 36 |
+
|
| 37 |
+
2. When masking the tweets during training, I intentionally mask the tokens that is a hastag, so that the model will learn to predict the place of hashtags specifically.
|
| 38 |
+
|
| 39 |
+
3. After training the model, we limit the potential candidates of [MASK] with the topics existed on Twitter, to get the relavent hashtags the user can add on.
|
| 40 |
+
|
| 41 |
+
### Result
|
| 42 |
+
**Twitter current approach:**
|
| 43 |
+
|
| 44 |
+
<!-- 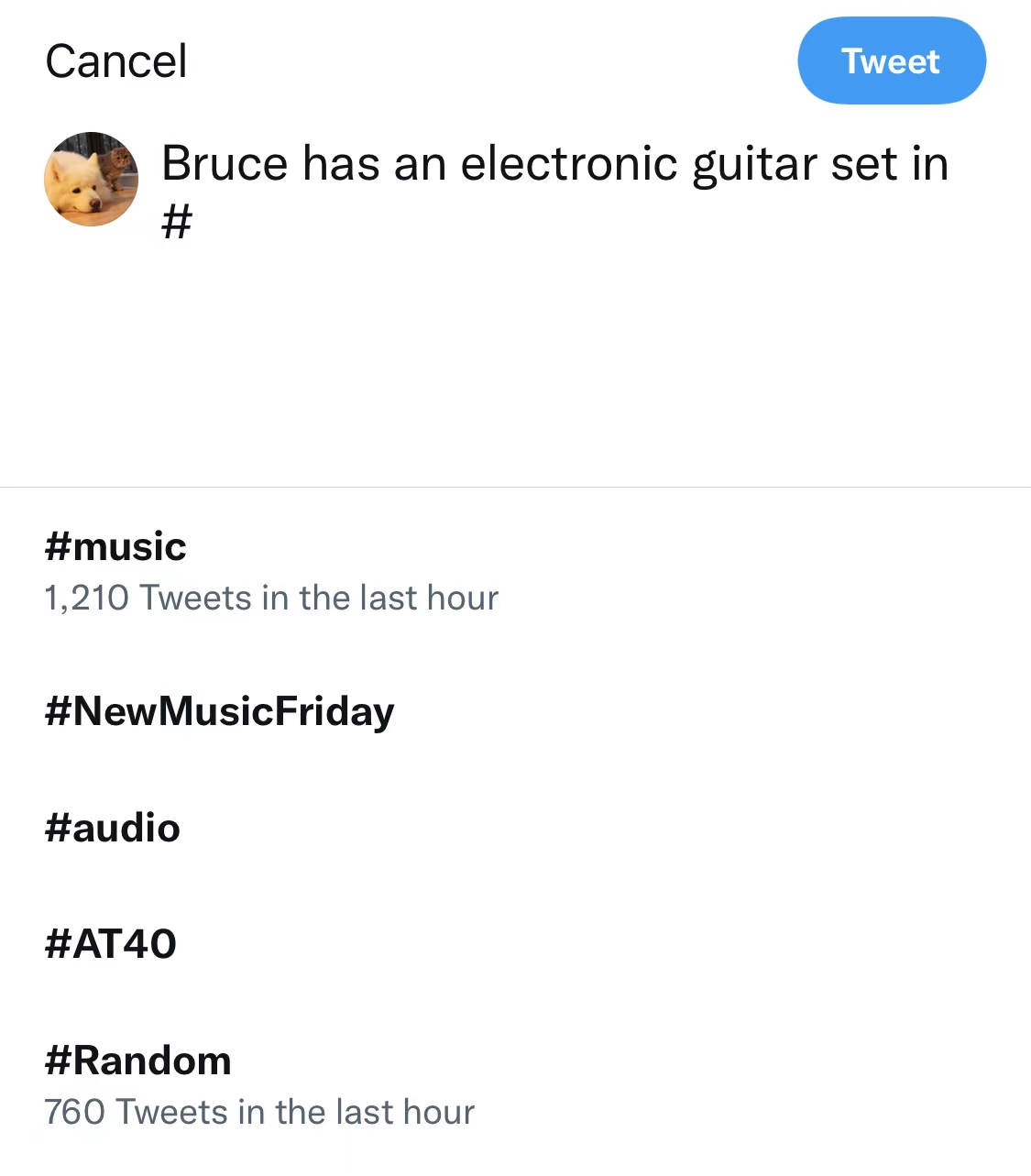 -->
|
| 45 |
+
<img src="https://user-images.githubusercontent.com/56851668/163923465-a0ac8c4b-a6f1-4553-bc70-aff6c8365ef5.jpg" width="500">
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
**Our approach:**
|
| 49 |
+
|
| 50 |
+
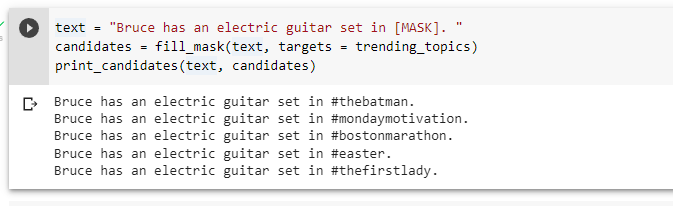
|
| 51 |
+
|
| 52 |
+
**Original tweet:**
|
| 53 |
+
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
## Huggingface Space
|
| 58 |
+
Huggingface space is [here](https://huggingface.co/spaces/vivianhuang88/hashtag_rec).
|
| 59 |
+
|
| 60 |
+
## Huggingface Model Card
|
| 61 |
+
Huggingface model card is [here](https://huggingface.co/vivianhuang88/bert_twitter_hashtag/tree/main).
|
| 62 |
+
|
| 63 |
+
## Critical Analysis
|
| 64 |
+
1. For efficiency consideration, we only added the top 1000 hashtag topics to our vocab dictionary. However, the actual number of potential hashtags should be millions. If adding all the hashtags to the dictionary, the efficiency of this approach will drop expoenentially. But not including these hashtags might also decrease the candidate hashtags for users to choose. In addition to this, topics might be unavailable to be predicted if it is not trained in our model.
|
| 65 |
+
2. Training data is small as well. The size of training data is about 30k.
|
| 66 |
+
3. Predicting tags only depend on context of tweet might not be enough, as people usually provide some information as well in the attached images. Getting information from images could also be an idea.
|
| 67 |
+
4. Future modifications on this model might be add weights on different topics. For example, more recent topics will be weighted higher than older topics.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
## Resource Links
|
| 71 |
+
|
| 72 |
+
[Huggingface tutorial](https://huggingface.co/course/chapter7/3?fw=pt#using-our-finetuned-model)
|
| 73 |
+
|
| 74 |
+
[Huggingface twitter-roberta-base](https://huggingface.co/cardiffnlp/twitter-roberta-base)
|
| 75 |
+
|
| 76 |
+
[Huggingface bert-base-uncased](https://huggingface.co/bert-base-uncased)
|
| 77 |
+
|
| 78 |
+
## Code Demo
|
| 79 |
+
|
| 80 |
+
[Code Demo](https://github.com/zbszd04160408/twitter_hashtag_recommendor/blob/main/30-ModelWalkthrough.ipynb) is inside this repo
|
| 81 |
+
|
| 82 |
+
## Repo
|
| 83 |
+
In this repo
|
| 84 |
+
|
| 85 |
+
## Video Recording
|
| 86 |
+
https://youtu.be/EC18mZBy1Jo
|