---
language:
- en
license: cc-by-nc-nd-4.0
library_name: transformers
pipeline_tag: text-classification
tags:
- emotion-recognition
- bayesian-deep-learning
- mc-dropout
- uncertainty-quantification
- multi-label-classification
datasets:
- Skylion007/openwebtext
- google-research-datasets/go_emotions
metrics:
- precision
- recall
- f1
model-index:
- name: EmCoder
results:
- task:
type: text-classification
name: Multi-label Emotion Classification
dataset:
name: GoEmotions
type: go_emotions
split: test
metrics:
- name: Macro F1
type: f1
value: 0.447
- name: Macro Precision
type: precision
value: 0.464
- name: Macro Recall
type: recall
value: 0.478
---
# EmCoder
Probabilistic Emotion Recognition & Uncertainty Quantification
28 Emotion multi-label Transformer-based classifier trained with MC Dropout methodology
Unlike standard classifiers, EmCoder quantifies what it doesn't know using Monte Carlo Dropout, making it suitable for high-stakes AI pipelines.
EmCoder is optimized for **MC Dropout inference**.
## SOTA benchmark
### Evaluation on the GoEmotions test split (macro avg metrics)
EmCoder achieves competitive F1-score with its compact size (~35% smaller than RoBERTa-base and ~45% smaller than ModernBERT), while providing per-class epistemic uncertainty quantification.
| Model | Precision | Recall | F1-Score | Params |
| :--- | :--- | :--- | :--- | :--- |
| **EmCoder** | **0.464** | **0.478** | **0.447** | **82.1M** |
| Google BERT (Original) | 0.400 | 0.630 | 0.460 | 110M |
| RoBERTa-base | 0.575 | 0.396 | 0.450 | 125M |
| ModernBERT-base | 0.583 | 0.535 | 0.550 | 149M |
## How to use
### 1. Setup & Tokenization
EmCoder uses the `roberta-base` tokenizer for correct token-to-embedding mapping.
```python
import torch
from transformers import AutoModel, AutoTokenizer
repo_id = "yezdata/EmCoder"
# Load the same tokenizer used during training
tokenizer = AutoTokenizer.from_pretrained(repo_id)
# Initialize with same config as training
model = AutoModel.from_pretrained(repo_id, trust_remote_code=True)
```
### 2. Bayesian inference
To obtain probabilistic outputs and uncertainty metrics, use the `mc_forward` method:
```python
# Perform 50 stochastic passes
N_SAMPLES = 50
inputs = tokenizer("I am so happy you are here!", return_tensors="pt")
model.eval()
with torch.inference_mode():
mc_logits = model.mc_forward(inputs['input_ids'], inputs['attention_mask'], n_samples=N_SAMPLES) # Automatically keeps Dropout active, even when in model.eval
# Bayesian Post-processing
all_probs = torch.sigmoid(mc_logits) # (n_samples, B, 28)
mean_probs = all_probs.mean(dim=0) # Mean Predicted Probability
uncertainty = all_probs.std(dim=0) # Epistemic Uncertainty
# Formatted Output
m_probs = mean_probs.squeeze(0)
u_vals = uncertainty.squeeze(0)
print(f"{'Emotion':<15} | {'Prob':<10} | {'Uncertainty':<10}")
print("-" * 40)
sorted_indices = torch.argsort(m_probs, descending=True)
for idx in sorted_indices:
prob, unc = m_probs[idx].item(), u_vals[idx].item()
label = model.config.id2label[idx.item()]
if prob > 0.05: # Print only emotions with prob > 5%
print(f"{label:<15} | {prob:>8.2%} | ±{unc:>8.4f}")
```
## Model Architecture

### Optimization
The model is trained using a Weighted Bayesian Binary Cross Entropy loss:
$$
\mathcal{L}_{Bayesian} = \frac{1}{T} \sum_{t=1}^{T} \text{BCEWithLogits}(z^{(t)}, y; w)
$$
Where weights $w$ are calculated using a logarithmic class-balancing scale to handle extreme label imbalance:
$$
w_{c} = \max\left( 0.1, \min\left( 20, 1 + \ln \left( \frac{N_{neg,c} + \epsilon}{N_{pos,c} + \epsilon} \right) \right) \right)
$$
## Performance on test set
**Using `thresholds.json` optimization from val set (both probability and uncertainty thresholds) for binarizing predictions**
| | precision | recall | f1-score | support |
|:---------------|------------:|---------:|-----------:|----------:|
| micro avg | 0.476 | 0.611 | 0.535 | 6329 |
| macro avg | 0.464 | 0.478 | 0.447 | 6329 |
| weighted avg | 0.511 | 0.611 | 0.542 | 6329 |
| samples avg | 0.524 | 0.637 | 0.55 | 6329 |
|----------------|-------------|----------|------------|-----------|
| admiration | 0.635 | 0.565 | 0.598 | 504 |
| amusement | 0.713 | 0.894 | 0.793 | 264 |
| anger | 0.367 | 0.525 | 0.432 | 198 |
| annoyance | 0.215 | 0.406 | 0.281 | 320 |
| approval | 0.226 | 0.396 | 0.288 | 351 |
| caring | 0.199 | 0.304 | 0.24 | 135 |
| confusion | 0.268 | 0.412 | 0.325 | 153 |
| curiosity | 0.423 | 0.704 | 0.528 | 284 |
| desire | 0.585 | 0.373 | 0.456 | 83 |
| disappointment | 0.176 | 0.146 | 0.159 | 151 |
| disapproval | 0.222 | 0.506 | 0.309 | 267 |
| disgust | 0.56 | 0.382 | 0.454 | 123 |
| embarrassment | 0.423 | 0.297 | 0.349 | 37 |
| excitement | 0.423 | 0.398 | 0.41 | 103 |
| fear | 0.538 | 0.641 | 0.585 | 78 |
| gratitude | 0.943 | 0.886 | 0.914 | 352 |
| grief | 0.111 | 0.333 | 0.167 | 6 |
| joy | 0.503 | 0.602 | 0.548 | 161 |
| love | 0.75 | 0.832 | 0.789 | 238 |
| nervousness | 0.429 | 0.13 | 0.2 | 23 |
| optimism | 0.681 | 0.505 | 0.58 | 186 |
| pride | 0.75 | 0.375 | 0.5 | 16 |
| realization | 0.4 | 0.097 | 0.156 | 145 |
| relief | 0.2 | 0.182 | 0.19 | 11 |
| remorse | 0.527 | 0.857 | 0.653 | 56 |
| sadness | 0.624 | 0.372 | 0.466 | 156 |
| surprise | 0.534 | 0.447 | 0.486 | 141 |
| neutral | 0.567 | 0.804 | 0.665 | 1787 |
**Using default threshold of 0.5 for binarizing predictions**
| | precision | recall | f1-score | support |
|:---------------|------------:|---------:|-----------:|----------:|
| micro avg | 0.494 | 0.596 | 0.54 | 6329 |
| macro avg | 0.408 | 0.495 | 0.44 | 6329 |
| weighted avg | 0.492 | 0.596 | 0.535 | 6329 |
| samples avg | 0.525 | 0.616 | 0.544 | 6329 |
|----------------|-------------|----------|------------|-----------|
| admiration | 0.541 | 0.673 | 0.599 | 504 |
| amusement | 0.688 | 0.909 | 0.783 | 264 |
| anger | 0.419 | 0.47 | 0.443 | 198 |
| annoyance | 0.31 | 0.25 | 0.277 | 320 |
| approval | 0.304 | 0.271 | 0.287 | 351 |
| caring | 0.229 | 0.281 | 0.252 | 135 |
| confusion | 0.26 | 0.497 | 0.342 | 153 |
| curiosity | 0.432 | 0.764 | 0.552 | 284 |
| desire | 0.453 | 0.518 | 0.483 | 83 |
| disappointment | 0.176 | 0.152 | 0.163 | 151 |
| disapproval | 0.279 | 0.404 | 0.33 | 267 |
| disgust | 0.447 | 0.545 | 0.491 | 123 |
| embarrassment | 0.325 | 0.351 | 0.338 | 37 |
| excitement | 0.288 | 0.427 | 0.344 | 103 |
| fear | 0.47 | 0.692 | 0.56 | 78 |
| gratitude | 0.834 | 0.943 | 0.885 | 352 |
| grief | 0 | 0 | 0 | 6 |
| joy | 0.445 | 0.652 | 0.529 | 161 |
| love | 0.724 | 0.895 | 0.801 | 238 |
| nervousness | 0.24 | 0.261 | 0.25 | 23 |
| optimism | 0.483 | 0.543 | 0.511 | 186 |
| pride | 0.667 | 0.375 | 0.48 | 16 |
| realization | 0.226 | 0.166 | 0.191 | 145 |
| relief | 0.222 | 0.182 | 0.2 | 11 |
| remorse | 0.516 | 0.857 | 0.644 | 56 |
| sadness | 0.405 | 0.545 | 0.464 | 156 |
| surprise | 0.429 | 0.539 | 0.478 | 141 |
| neutral | 0.602 | 0.695 | 0.645 | 1787 |
**Model uncertainty quantification on GoEmotions test set**
The distribution demonstrates strong calibration, as the highest error density correlates with increased epistemic uncertainty. While most high-probability predictions are correct, a small fragment of overconfident incorrects remains likely due to dataset bias or linguistic nuances like sarcasm. These outliers identify a clear opportunity for further refinement using **temperature scaling**.

**Confusion matrix**
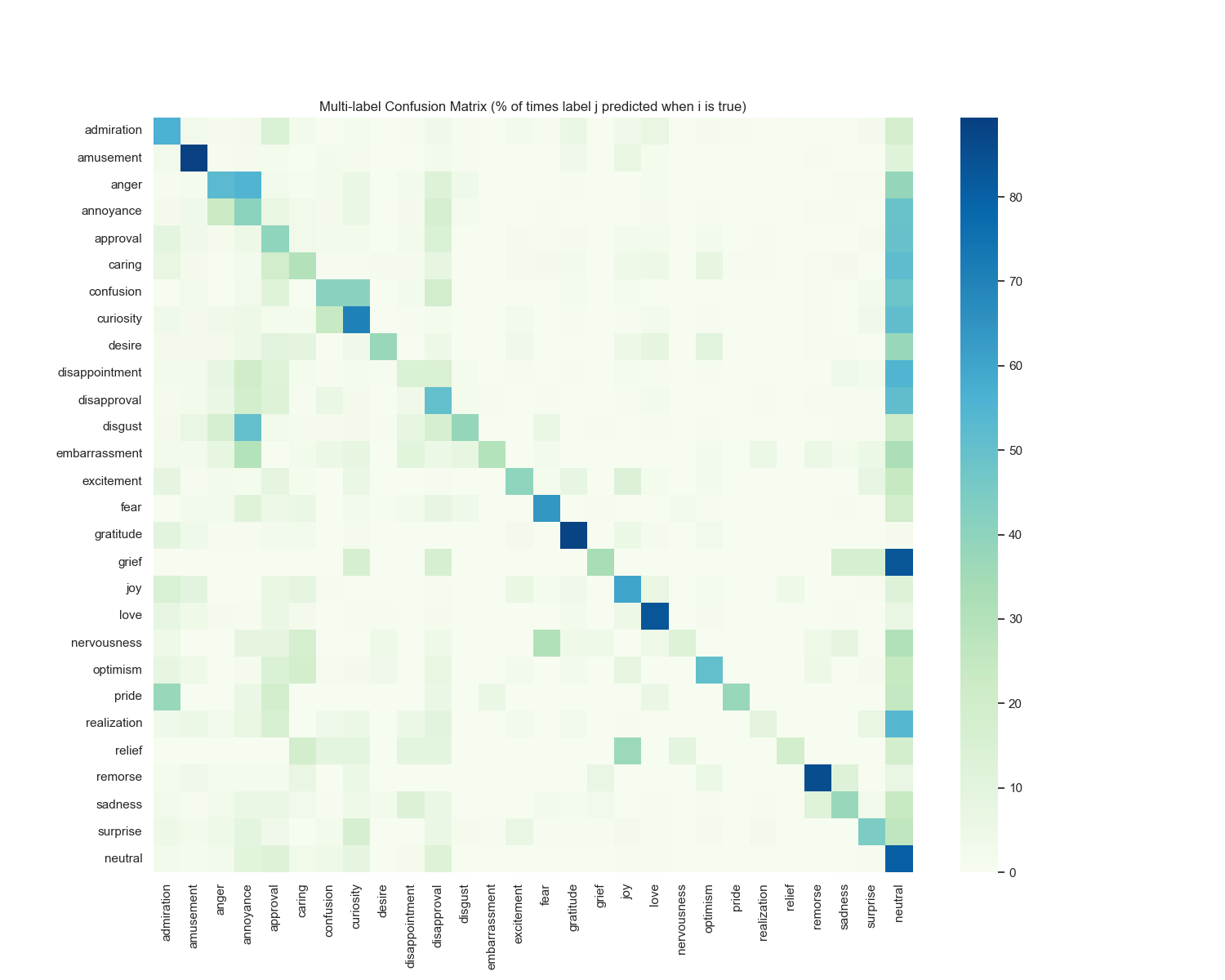
## Workflow

### Note
Note that this model was trained on GoEmotions dataset (social networks domain) and it may not generalize well to other domains.
## Citation
If you use this model, please cite it as follows:
```bibtex
@software{jez2026emcoder,
author = {Václav Jež},
title = {EmCoder: Probabilistic Emotion Recognition & Uncertainty Quantification},
year = {2026},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/yezdata/emcoder}},
version = {1.0.0}
}
```