---
language:
- en
- zh
library_name: transformers
license: mit
pipeline_tag: text-generation
model-index:
- name: GLM-4.6
results:
- task:
type: evaluation
dataset:
name: Artificial Analysis Benchmarks
type: artificial_analysis
metrics:
- name: Artificial Analysis Intelligence Index
type: artificial_analysis_intelligence_index
value: 44.7
- name: Artificial Analysis Coding Index
type: artificial_analysis_coding_index
value: 38.7
- name: Artificial Analysis Math Index
type: artificial_analysis_math_index
value: 44.3
- name: Mmlu Pro
type: mmlu_pro
value: 0.784
- name: Gpqa
type: gpqa
value: 0.632
- name: Hle
type: hle
value: 0.052
- name: Livecodebench
type: livecodebench
value: 0.561
- name: Scicode
type: scicode
value: 0.331
- name: Aime 25
type: aime_25
value: 0.443
- name: Ifbench
type: ifbench
value: 0.367
- name: Lcr
type: lcr
value: 0.263
- name: Terminalbench Hard
type: terminalbench_hard
value: 0.27
- name: Tau2
type: tau2
value: 0.769
source:
name: Artificial Analysis API
url: https://artificialanalysis.ai
---
# GLM-4.6
👋 Join our Discord community.
📖 Check out the GLM-4.6 technical blog, technical report(GLM-4.5), and Zhipu AI technical documentation.
📍 Use GLM-4.6 API services on Z.ai API Platform.
👉 One click to GLM-4.6.
## Model Introduction
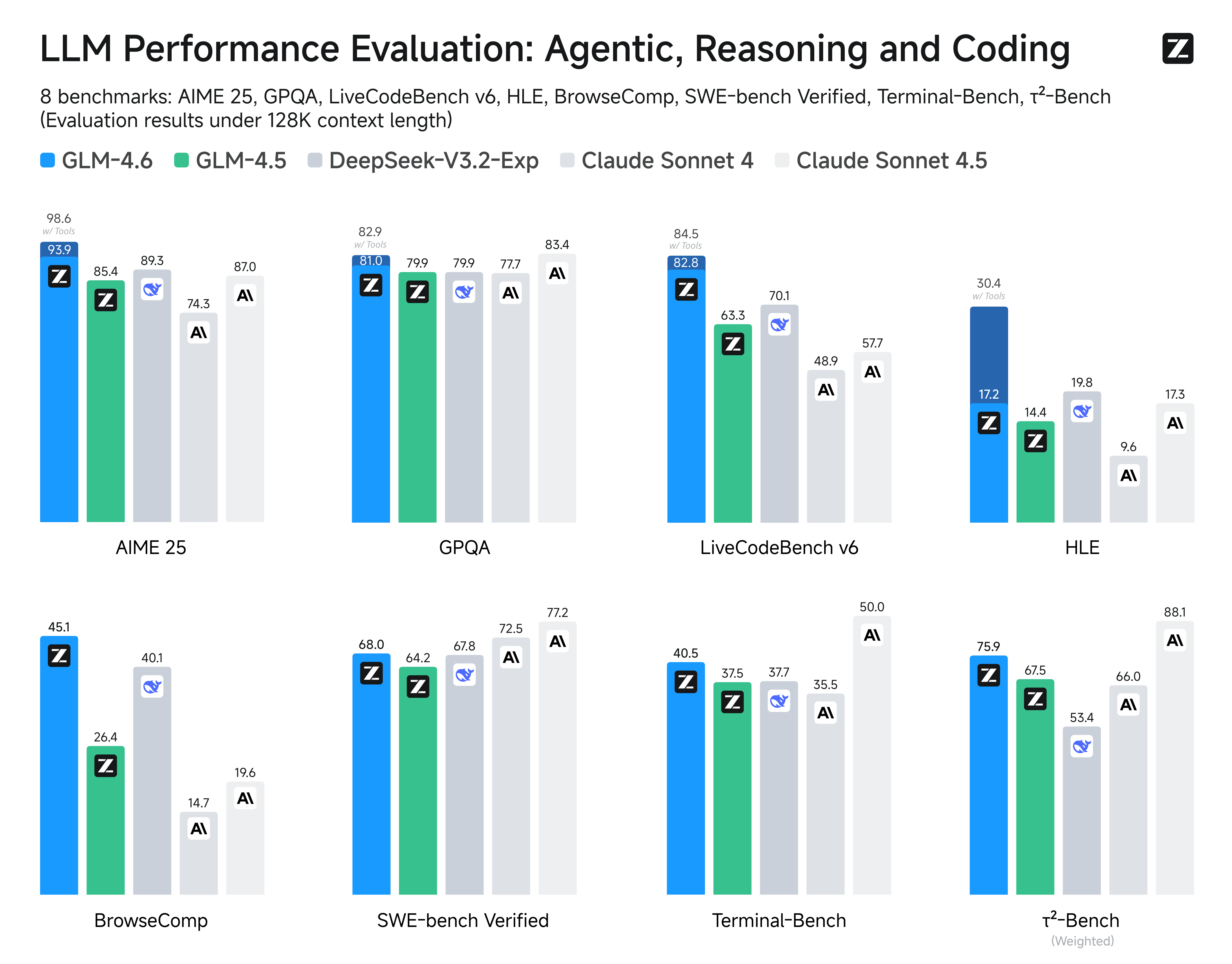
Compared with GLM-4.5, **GLM-4.6** brings several key improvements:
* **Longer context window:** The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
* **Superior coding performance:** The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
* **Advanced reasoning:** GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
* **More capable agents:** GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
* **Refined writing:** Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as **DeepSeek-V3.1-Terminus** and **Claude Sonnet 4**.
## Inference
**Both GLM-4.5 and GLM-4.6 use the same inference method.**
you can check our [github](https://github.com/zai-org/GLM-4.5) for more detail.
## Recommended Evaluation Parameters
For general evaluations, we recommend using a **sampling temperature of 1.0**.
For **code-related evaluation tasks** (such as LCB), it is further recommended to set:
- `top_p = 0.95`
- `top_k = 40`
## Evaluation
- For tool-integrated reasoning, please refer to [this doc](https://github.com/zai-org/GLM-4.5/blob/main/resources/glm_4.6_tir_guide.md).
- For search benchmark, we design a specific format for searching toolcall in thinking mode to support search agent, please refer to [this](https://github.com/zai-org/GLM-4.5/blob/main/resources/trajectory_search.json). for the detailed template.