

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
---
|
| 2 |
language:
|
| 3 |
-
- en
|
| 4 |
-
- zh
|
| 5 |
library_name: transformers
|
| 6 |
license: mit
|
| 7 |
pipeline_tag: text-generation
|
|
@@ -15,29 +15,81 @@ pipeline_tag: text-generation
|
|
| 15 |
<p align="center">
|
| 16 |
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
|
| 17 |
<br>
|
| 18 |
-
📖 Check out the GLM-4.7 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report(GLM-4.5)</a
|
| 19 |
<br>
|
| 20 |
📍 Use GLM-4.7 API services on <a href="https://docs.z.ai/guides/llm/glm-4.7">Z.ai API Platform. </a>
|
| 21 |
<br>
|
| 22 |
👉 One click to <a href="https://chat.z.ai">GLM-4.7</a>.
|
| 23 |
</p>
|
| 24 |
|
|
|
|
| 25 |
|
| 26 |
-
|
| 27 |
|
| 28 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
-
|
|
|
|
| 31 |
|
| 32 |
-
|
| 33 |
|
| 34 |
-
|
| 35 |
|
| 36 |
-
-
|
| 37 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
|
|
|
| 39 |
|
| 40 |
-
|
| 41 |
|
| 42 |
-
|
| 43 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
language:
|
| 3 |
+
- en
|
| 4 |
+
- zh
|
| 5 |
library_name: transformers
|
| 6 |
license: mit
|
| 7 |
pipeline_tag: text-generation
|
|
|
|
| 15 |
<p align="center">
|
| 16 |
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
|
| 17 |
<br>
|
| 18 |
+
📖 Check out the GLM-4.7 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report(GLM-4.5)</a>.
|
| 19 |
<br>
|
| 20 |
📍 Use GLM-4.7 API services on <a href="https://docs.z.ai/guides/llm/glm-4.7">Z.ai API Platform. </a>
|
| 21 |
<br>
|
| 22 |
👉 One click to <a href="https://chat.z.ai">GLM-4.7</a>.
|
| 23 |
</p>
|
| 24 |
|
| 25 |
+
## Introduction
|
| 26 |
|
| 27 |
+
GLM-4.7, your new coding partner, is coming with the following features:
|
| 28 |
|
| 29 |
+
- Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and
|
| 30 |
+
terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%,
|
| 31 |
+
+10.0%) on Terminal Bench. GLM-4.7 also supports thinking before acting, with significant improvements on complex
|
| 32 |
+
tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
|
| 33 |
+
- Vibe Coding: GLM-4.7 takes a major step forward in UI quality. It produces cleaner, more modern webpages and generates
|
| 34 |
+
better-looking slides with more accurate layout and sizing.
|
| 35 |
+
- Tool Using: Tool using is significantly improved. GLM-4.7 achieves open-source SOTA results on multi-step tool using
|
| 36 |
+
benchmarks such as τ^2-Bench and on web browsing via BrowserComp.
|
| 37 |
+
- Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%,
|
| 38 |
+
+12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
|
| 39 |
|
| 40 |
+
More general, one would also witness significant improvements in many other scenarios such as chat, creative writing,
|
| 41 |
+
and role-play scenario.
|
| 42 |
|
| 43 |
+
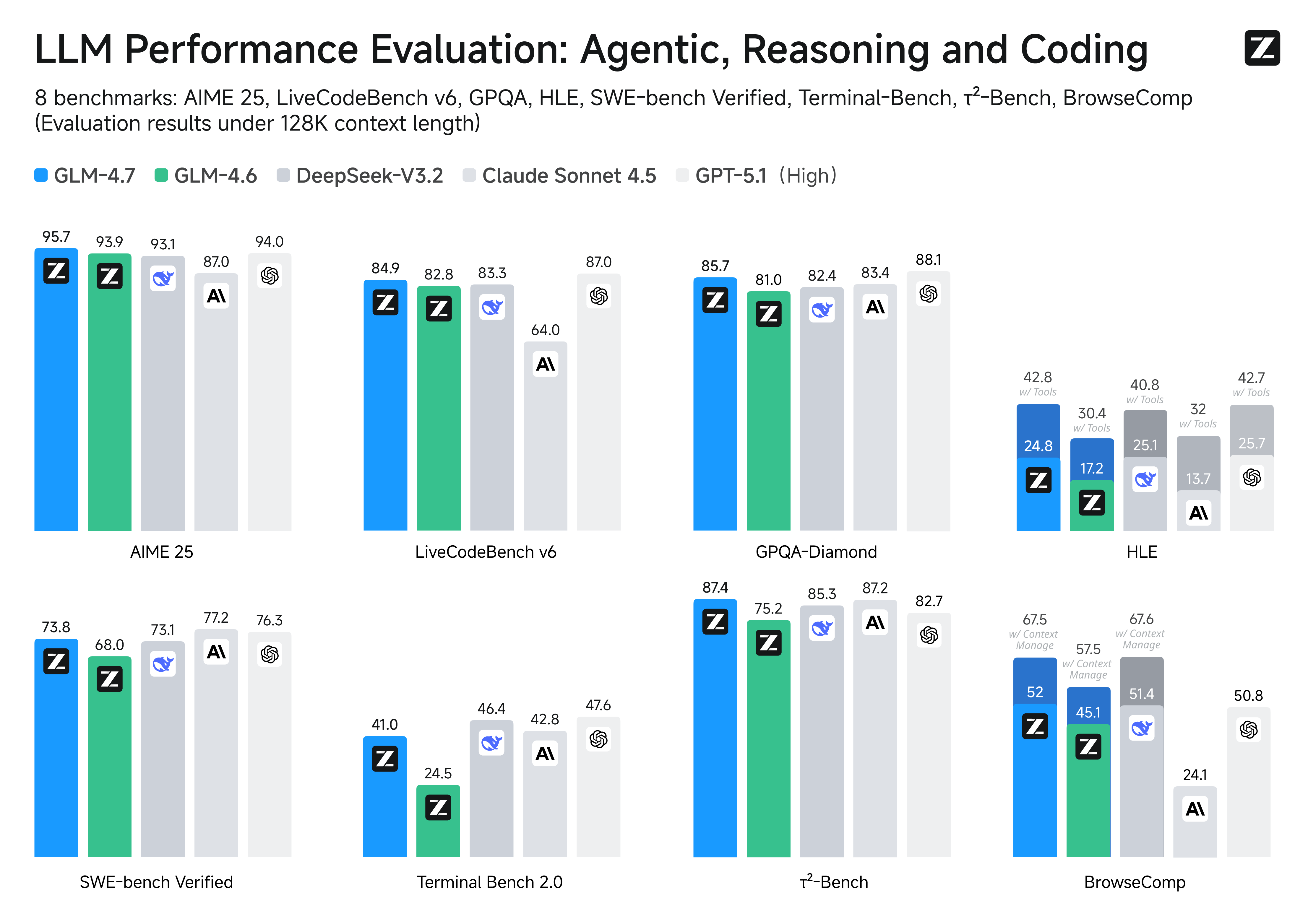
|
| 44 |
|
| 45 |
+
## Benchmark
|
| 46 |
|
| 47 |
+
| Benchmark | GLM-4.7 | GLM-4.6 | MiMo-V2-Flash | Kimi-K2-Thinking | DeepSeek-V3.2 | Gemini-3.0-Pro | Claude-Sonnet-4.5 | GPT-5-High | GPT-5.1-High | GPT-5.2-High |
|
| 48 |
+
|:-------------------------------|:-------:|:-------:|:-------------:|:----------------:|:-------------:|:--------------:|:-----------------:|:----------:|:------------:|:------------:|
|
| 49 |
+
| MMLU-Pro | 84.3 | 83.2 | 84.9 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 | 87.0 | 87.0 |
|
| 50 |
+
| GPQA-Diamond | 85.7 | 81.0 | 83.7 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 | 88.1 | 92.4 |
|
| 51 |
+
| HLE | 24.8 | 17.2 | 22.1 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 | 25.7 | 34.5 |
|
| 52 |
+
| HLE (w/ Tools) | 42.8 | 30.4 | - | 44.9 | 40.8 | 45.8 | 32.0 | 35.2 | 42.7 | 45.5 |
|
| 53 |
+
| AIME 2025 | 95.7 | 93.9 | 94.1 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 | 94.0 | 100.0 |
|
| 54 |
+
| HMMT Feb. 2025 | 97.1 | 89.2 | 84.4 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 | 96.3 | 99.4 |
|
| 55 |
+
| HMMT Nov. 2025 | 93.5 | 87.7 | - | 89.2 | 90.2 | 93.3 | 81.7 | 89.2 | - | - |
|
| 56 |
+
| IMOAnswerBench | 82.0 | 73.5 | - | 78.6 | 78.3 | 83.3 | 65.8 | 76.0 | - | - |
|
| 57 |
+
| LiveCodeBench-v6 | 84.9 | 82.8 | 80.6 | 83.1 | 83.3 | 90.7 | 64.0 | 87.0 | 87.0 | - |
|
| 58 |
+
| SWE-Bench Verified | 73.8 | 68.0 | 73.4 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 | 76.3 | 80.0 |
|
| 59 |
+
| SWE-Bench Multilingual | 66.7 | 53.8 | 71.7 | 61.1 | 70.2 | - | 68.0 | 55.3 | - | - |
|
| 60 |
+
| Terminal Bench Hard | 33.3 | 23.6 | 30.5 | 30.6 | 35.4 / 33 | 39.0 | 33.3 | 30.5 | 43.0 | - |
|
| 61 |
+
| Terminal Bench 2.0 | 41.0 | 24.5 | 38.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 | 47.6 | 54.0 |
|
| 62 |
+
| BrowseComp | 52.0 | 45.1 | 45.4 | - | 51.4 | - | 24.1 | 54.9 | 50.8 | 65.8 |
|
| 63 |
+
| BrowseComp (w/ Context Manage) | 67.5 | 57.5 | 58.3 | 60.2 | 67.6 | 59.2 | - | - | - | - |
|
| 64 |
+
| BrowseComp-Zh | 66.6 | 49.5 | - | 62.3 | 65.0 | - | 42.4 | 63.0 | - | - |
|
| 65 |
+
| τ²-Bench | 87.4 | 75.2 | 80.3 | 74.3 | 85.3 | 90.7 | 87.2 | 82.4 | 82.7 | - |
|
| 66 |
|
| 67 |
+
## Evaluation Parameters
|
| 68 |
|
| 69 |
+
**Default Settings (Most Tasks)**
|
| 70 |
|
| 71 |
+
* temperature: `1.0`
|
| 72 |
+
* top-p: `0.95`
|
| 73 |
+
* max new tokens: `131072`
|
| 74 |
+
|
| 75 |
+
For agentic tasks, please turn on [Preserved Thinking mode](https://docs.z.ai/guides/capabilities/thinking-mode).
|
| 76 |
+
|
| 77 |
+
**Terminal Bench, SWE Bench Verified**
|
| 78 |
+
|
| 79 |
+
* temperature: `0.7`
|
| 80 |
+
* top-p: `1.0`
|
| 81 |
+
* max new tokens: `16384`
|
| 82 |
+
|
| 83 |
+
**τ^2-Bench**
|
| 84 |
+
|
| 85 |
+
* Temperature: `0`
|
| 86 |
+
* Max new tokens: `16384`
|
| 87 |
+
|
| 88 |
+
> For τ^2-Bench evaluation, we added an additional prompt to the Retail and Telecom user interaction to avoid failure
|
| 89 |
+
> modes caused by users ending the interaction incorrectly. For the Airline domain, we applied the domain fixes as
|
| 90 |
+
> proposed in the [Claude Opus 4.5](https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf)
|
| 91 |
+
> release report.
|
| 92 |
+
|
| 93 |
+
## Inference
|
| 94 |
+
|
| 95 |
+
Check our [Github](https://github.com/zai-org/GLM-4.5) For More Detail.
|