
zRzRzRzRzRzRzR
commited on
Commit
·
baee9b2
1
Parent(s):
773a94e
init
Browse files
README.md
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
- zh
|
| 5 |
+
library_name: transformers
|
| 6 |
+
license: mit
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# GLM-5
|
| 11 |
+
|
| 12 |
+
<div align="center">
|
| 13 |
+
<img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/>
|
| 14 |
+
</div>
|
| 15 |
+
<p align="center">
|
| 16 |
+
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
|
| 17 |
+
<br>
|
| 18 |
+
📖 Check out the GLM-5 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>.
|
| 19 |
+
<br>
|
| 20 |
+
📍 Use GLM-5 API services on <a href="https://docs.z.ai/guides/llm/glm-5">Z.ai API Platform. </a>
|
| 21 |
+
<br>
|
| 22 |
+
👉 One click to <a href="https://chat.z.ai">GLM-5</a>.
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
## Introduction
|
| 26 |
+
|
| 27 |
+
We are launching GLM-5, targeting complex systems engineering and long-horizon agentic tasks. Scaling is still one of the most important ways to improve the intelligence efficiency of Artificial General Intelligence (AGI). Compared to GLM-4.5, GLM-5 scales from 355B parameters (32B active) to 744B parameters (40B active), and increases pre-training data from 23T to 28.5T tokens. GLM-5 also integrates DeepSeek Sparse Attention (DSA), largely reducing deployment cost while preserving long-context capacity.
|
| 28 |
+
|
| 29 |
+
Reinforcement learning aims to bridge the gap between competence and excellence in pre-trained models. However, deploying it at scale for LLMs is a challenge due to the RL training inefficiency. To this end, we developed [slime](https://github.com/THUDM/slime), a novel **asynchronous RL infrastructure** that substantially improves training throughput and efficiency, enabling more fine-grained post-training iterations. With advances in both pre-training and post-training, GLM-5 delivers significant improvement compared to GLM-4.7 across a wide range of academic benchmarks and achieves best-in-class performance among all open-source models in the world on reasoning, coding, and agentic tasks, closing the gap with frontier models.
|
| 30 |
+
|
| 31 |
+
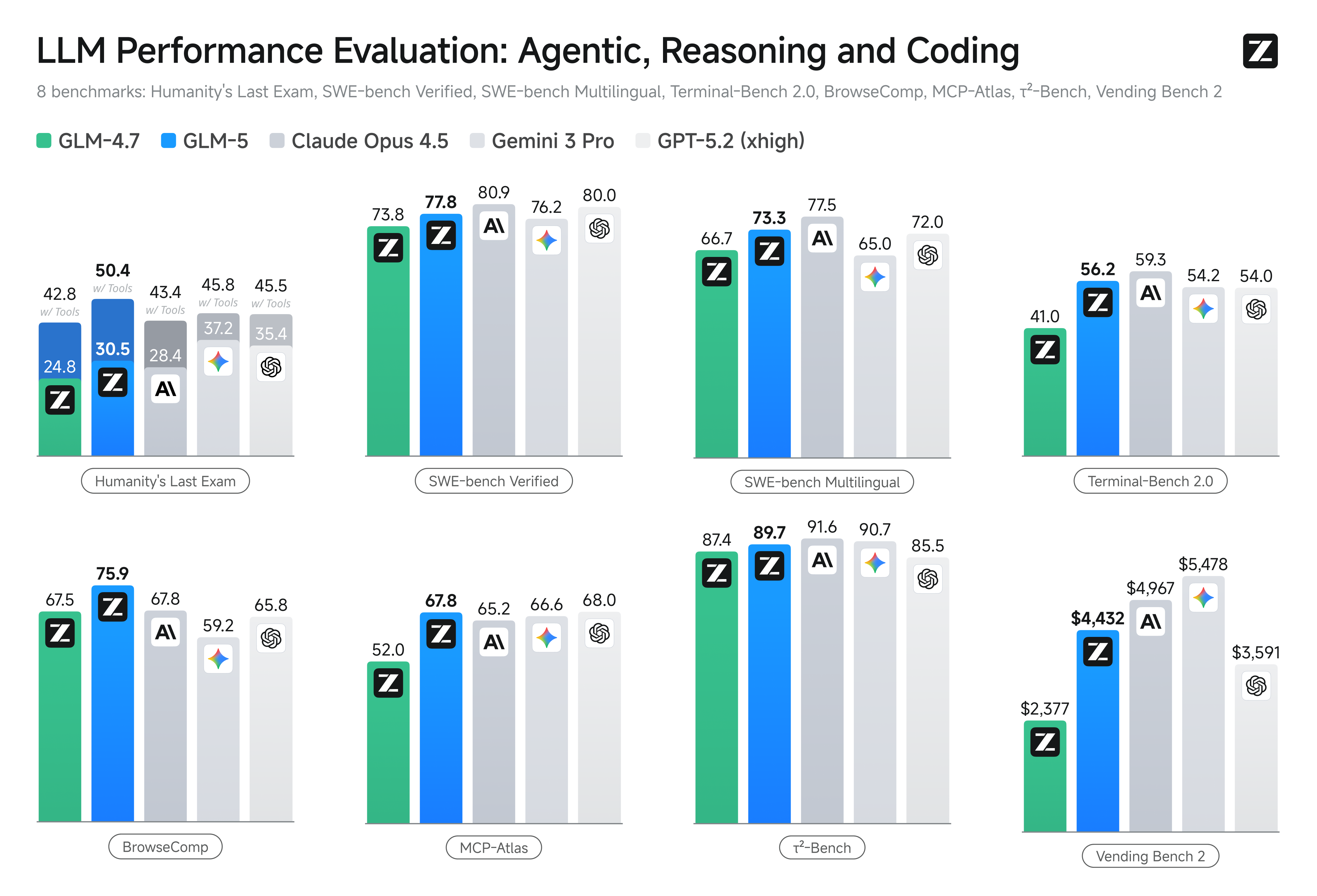
|
| 32 |
+
|
| 33 |
+
GLM-5 is purpose-built for complex systems engineering and long-horizon agentic tasks. On our internal evaluation suite CC-Bench-V2, GLM-5 significantly outperforms GLM-4.7 across frontend, backend, and long-horizon tasks, narrowing the gap to Claude Opus 4.5.
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
On [Vending Bench 2](https://andonlabs.com/evals/vending-bench-2), a benchmark that measures long-term operational capability, GLM-5 ranks \#1 among open-source models. Vending Bench 2 requires the model to run a simulated vending machine business over a one-year horizon; GLM-5 finishes with a final account balance of $4,432, approaching Claude Opus 4.5 and demonstrating strong long-term planning and resource management.
|
| 38 |
+
|
| 39 |
+
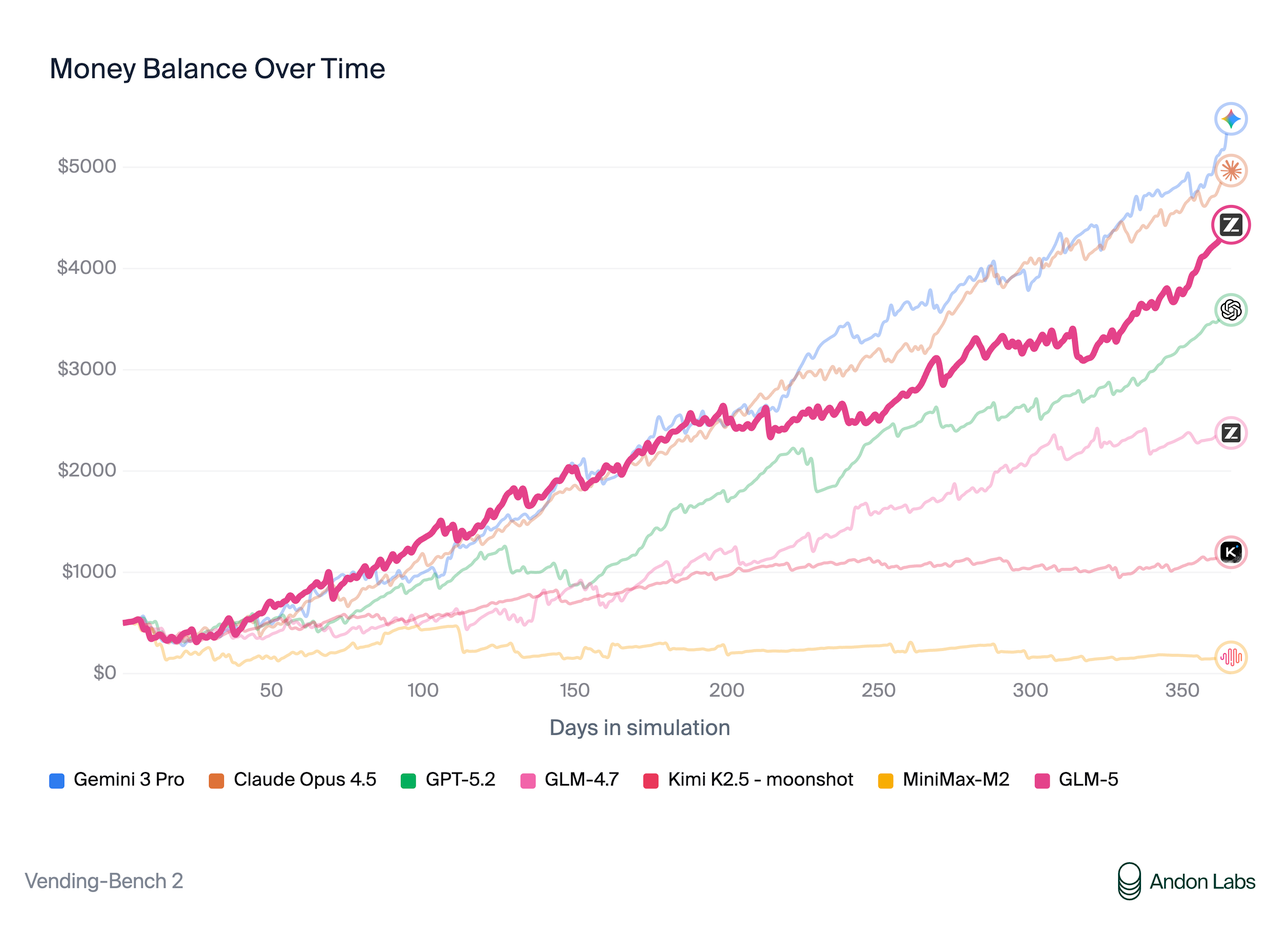
|
| 40 |
+
|
| 41 |
+
## Benchmark
|
| 42 |
+
|
| 43 |
+
| | GLM-5 | GLM-4.7 | DeepSeek-V3.2 | Kimi K2.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (xhigh) |
|
| 44 |
+
| -------------------------------- | ---------------------- | --------- | ------------- | --------- | --------------- | ------------ | --------------- |
|
| 45 |
+
| Reasoning | | | | | | | |
|
| 46 |
+
| HLE | 30.5 | 24.8 | 25.1 | 31.5 | 28.4 | 37.2 | 35.4 |
|
| 47 |
+
| HLE (w/ Tools) | 50.4 | 42.8 | 40.8 | 51.8 | 43.4* | 45.8* | 45.5* |
|
| 48 |
+
| AIME 2026 I | 92.7 | 92.9 | 92.7 | 92.5 | 93.3 | 90.6 | - |
|
| 49 |
+
| HMMT Nov. 2025 | 96.9 | 93.5 | 90.2 | 91.1 | 91.7 | 93.0 | 97.1 |
|
| 50 |
+
| IMOAnswerBench | 82.5 | 82.0 | 78.3 | 81.8 | 78.5 | 83.3 | 86.3 |
|
| 51 |
+
| GPQA-Diamond | 86.0 | 85.7 | 82.4 | 87.6 | 87.0 | 91.9 | 92.4 |
|
| 52 |
+
| Coding | | | | | | | |
|
| 53 |
+
| SWE-bench Verified | 77.8 | 73.8 | 73.1 | 76.8 | 80.9 | 76.2 | 80.0 |
|
| 54 |
+
| SWE-bench Multilingual | 73.3 | 66.7 | 70.2 | 73.0 | 77.5 | 65.0 | 72.0 |
|
| 55 |
+
| Terminal-Bench 2.0 (Terminus 2) | 56.2 / 60.7 (verified) | 41.0 | 39.3 | 50.8 | 59.3 | 54.2 | 54.0 |
|
| 56 |
+
| Terminal-Bench 2.0 (Claude Code) | 56.2 / 61.1 (verified) | 32.8 | 46.4 | - | 57.9 | - | - |
|
| 57 |
+
| CyberGym | 48.3 | 23.5 | 17.3 | 41.3 | 50.6 | 39.9 | - |
|
| 58 |
+
| Agentic | | | | | | | |
|
| 59 |
+
| BrowseComp | 62.0 | 52.0 | 51.4 | 52 / 60.6 | 37.0 | 37.8 | - |
|
| 60 |
+
| BrowseComp (w/ Context Manage) | 75.9 | 67.5 | 67.6 | 74.9 | 57.8 | 59.2 | 65.8 |
|
| 61 |
+
| BrowseComp-Zh | 72.7 | 66.6 | 65.0 | 62.3 | 62.4 | 66.8 | 76.1 |
|
| 62 |
+
| τ²-Bench | 89.7 | 87.4 | 85.3 | 80.2 | 91.6 | 90.7 | 85.5 |
|
| 63 |
+
| MCP-Atlas (Public Set) | 67.8 | 52.0 | 62.2 | 63.8 | 65.2 | 66.6 | 68.0 |
|
| 64 |
+
| Tool-Decathlon | 38.0 | 23.8 | 35.2 | 27.8 | 43.5 | 36.4 | 46.3 |
|
| 65 |
+
| Vending Bench 2 | $4,432.12 | $2,376.82 | $1,034.00 | $1,198.46 | $4,967.06 | $5,478.16 | $3,591.33 |
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
### Footnote
|
| 69 |
+
* **Humanity’s Last Exam (HLE) & other reasoning tasks**: We evaluate with a maximum generation length of 131,072 tokens (`temperature=1.0, top_p=0.95, max_new_tokens=131072`). By default, we report the text-only subset; results marked with * are from the full set. We use GPT-5.2 (medium) as the judge model. For HLE-with-tools, we use a maximum context length of 202,752 tokens.
|
| 70 |
+
* **SWE-bench & SWE-bench Multilingual**: We run the SWE-bench suite with OpenHands using a tailored instruction prompt. Settings: `temperature=0.7, top_p=0.95, max_new_tokens=16384`, with a 200K context window.
|
| 71 |
+
* **BrowserComp**: Without context management, we retain details from the most recent 5 turns. With context management, we use the same discard-all strategy as DeepSeek-v3.2 and Kimi K2.5.
|
| 72 |
+
* **Terminal-Bench 2.0 (Terminus 2)**: We evaluate with the Terminus framework using `timeout=2h, temperature=0.7, top_p=1.0, max_new_tokens=8192`, with a 128K context window. Resource limits are capped at 16 CPUs and 32 GB RAM.
|
| 73 |
+
* **Terminal-Bench 2.0 (Claude Code)**: We evaluate in Claude Code 2.1.14 (think mode, default effort) with `temperature=1.0, top_p=0.95, max_new_tokens=65536`. We remove wall-clock time limits due to generation speed, while preserving per-task CPU and memory constraints. Scores are averaged over 5 runs. We fix environment issues introduced by Claude Code and also report results on a verified Terminal-Bench 2.0 dataset that resolves ambiguous instructions (see: [https://huggingface.co/datasets/zai-org/terminal-bench-2-verified](https://huggingface.co/datasets/zai-org/terminal-bench-2-verified)).
|
| 74 |
+
* **CyberGym**: We evaluate in Claude Code 2.1.18 (think mode, no web tools) with (`temperature=1.0, top_p=1.0, max_new_tokens=32000`) and a 250-minute timeout per task. Results are single-run Pass@1 over 1,507 tasks.
|
| 75 |
+
* **MCP-Atlas**: All models are evaluated in think mode on the 500-task public subset with a 10-minute timeout per task. We use Gemini 3 Pro as the judge model.
|
| 76 |
+
* **τ²-bench**: We add a small prompt adjustment in Retail and Telecom to avoid failures caused by premature user termination. For Airline, we apply the domain fixes proposed in the Claude Opus 4.5 system card.
|
| 77 |
+
* **Vending Bench 2**: Runs are conducted independently by [Andon Labs](https://andonlabs.com/evals/vending-bench-2).
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## Serve GLM-5 Locally
|
| 81 |
+
|
| 82 |
+
### Prepare environment
|
| 83 |
+
|
| 84 |
+
vLLM, SGLang, and xLLM all support local deployment of GLM-5. A simple deployment guide is provided here.
|
| 85 |
+
|
| 86 |
+
+ vLLM
|
| 87 |
+
|
| 88 |
+
Using Docker as:
|
| 89 |
+
|
| 90 |
+
```shell
|
| 91 |
+
docker pull vllm/vllm-openai:nightly
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
or using pip:
|
| 95 |
+
|
| 96 |
+
```shell
|
| 97 |
+
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
then upgrade transformers:
|
| 101 |
+
|
| 102 |
+
```
|
| 103 |
+
pip install git+https://github.com/huggingface/transformers.git
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
+ SGLang
|
| 107 |
+
|
| 108 |
+
Using Docker as:
|
| 109 |
+
```bash
|
| 110 |
+
docker pull lmsysorg/sglang:glm5-hopper # For Hopper GPU
|
| 111 |
+
docker pull lmsysorg/sglang:glm5-blackwell # For Blackwell GPU
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
### Deploy
|
| 115 |
+
|
| 116 |
+
+ vLLM
|
| 117 |
+
|
| 118 |
+
```shell
|
| 119 |
+
vllm serve zai-org/GLM-5-FP8 \
|
| 120 |
+
--tensor-parallel-size 8 \
|
| 121 |
+
--gpu-memory-utilization 0.85 \
|
| 122 |
+
--speculative-config.method mtp \
|
| 123 |
+
--speculative-config.num_speculative_tokens 1 \
|
| 124 |
+
--tool-call-parser glm47 \
|
| 125 |
+
--reasoning-parser glm45 \
|
| 126 |
+
--enable-auto-tool-choice \
|
| 127 |
+
--served-model-name glm-5-fp8
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
Check the [recipes](https://github.com/vllm-project/recipes/blob/main/GLM/GLM5.md) for more details.
|
| 131 |
+
|
| 132 |
+
+ SGLang
|
| 133 |
+
|
| 134 |
+
```shell
|
| 135 |
+
python3 -m sglang.launch_server \
|
| 136 |
+
--model-path zai-org/GLM-5-FP8 \
|
| 137 |
+
--tp-size 8 \
|
| 138 |
+
--tool-call-parser glm47 \
|
| 139 |
+
--reasoning-parser glm45 \
|
| 140 |
+
--speculative-algorithm EAGLE \
|
| 141 |
+
--speculative-num-steps 3 \
|
| 142 |
+
--speculative-eagle-topk 1 \
|
| 143 |
+
--speculative-num-draft-tokens 4 \
|
| 144 |
+
--mem-fraction-static 0.85 \
|
| 145 |
+
--served-model-name glm-5-fp8
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
+ xLLM and other Ascend NPU
|
| 149 |
+
|
| 150 |
+
Please check the deployment guide [here](https://github.com/zai-org/GLM-5/blob/main/example/ascend.md).
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
## Citation
|
| 154 |
+
|
| 155 |
+
Our technical report is coming soon.
|