

Add files using upload-large-folder tool
Browse files- README.md +50 -3
- config.json +119 -0
- configuration_glmasr.py +43 -0
- inference.py +182 -0
- model.safetensors +3 -0
- modeling_audio.py +415 -0
- modeling_glmasr.py +149 -0
- tokenizer.json +0 -0
- tokenizer_config.json +172 -0
README.md
CHANGED
|
@@ -1,3 +1,50 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GLM-ASR-Nano-2512
|
| 2 |
+
|
| 3 |
+
<div align="center">
|
| 4 |
+
<img src="https://raw.githubusercontent.com/zai-org/GLM-ASR/refs/heads/main/resources/logo.svg" width="20%"/>
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
<p align="center">
|
| 8 |
+
👋 Join our <a href="#" target="_blank">Discord</a> community.
|
| 9 |
+
<br>
|
| 10 |
+
🚀 Experience the demo on <a href="#" target="_blank">Hugging Face Spaces</a>.
|
| 11 |
+
<br>
|
| 12 |
+
📦 Download model weights on <a href="#" target="_blank">Hugging Face</a> or <a href="#" target="_blank">ModelScope</a>.
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
## Model Introduction
|
| 16 |
+
|
| 17 |
+
**GLM-ASR-Nano-2512** is a robust, open-source speech recognition model with **1.5B parameters**. Designed for
|
| 18 |
+
real-world complexity, it outperforms OpenAI Whisper V3 on multiple benchmarks while maintaining a compact size.
|
| 19 |
+
|
| 20 |
+
Key capabilities include:
|
| 21 |
+
|
| 22 |
+
* **Exceptional Dialect Support:**
|
| 23 |
+
Beyond standard Mandarin and English, the model is highly optimized for **Cantonese (粤语)** and other dialects,
|
| 24 |
+
effectively bridging the gap in dialectal speech recognition.
|
| 25 |
+
|
| 26 |
+
* **Low-Volume Speech Robustness:**
|
| 27 |
+
Specifically trained for **"Whisper/Quiet Speech"** scenarios. It captures and accurately transcribes extremely
|
| 28 |
+
low-volume audio that traditional models often miss.
|
| 29 |
+
|
| 30 |
+
* **SOTA Performance:**
|
| 31 |
+
Achieves the **lowest average error rate (4.10)** among comparable open-source models, showing significant advantages
|
| 32 |
+
in Chinese benchmarks (Wenet Meeting, Aishell-1, etc..).
|
| 33 |
+
|
| 34 |
+
## Benchmark
|
| 35 |
+
|
| 36 |
+
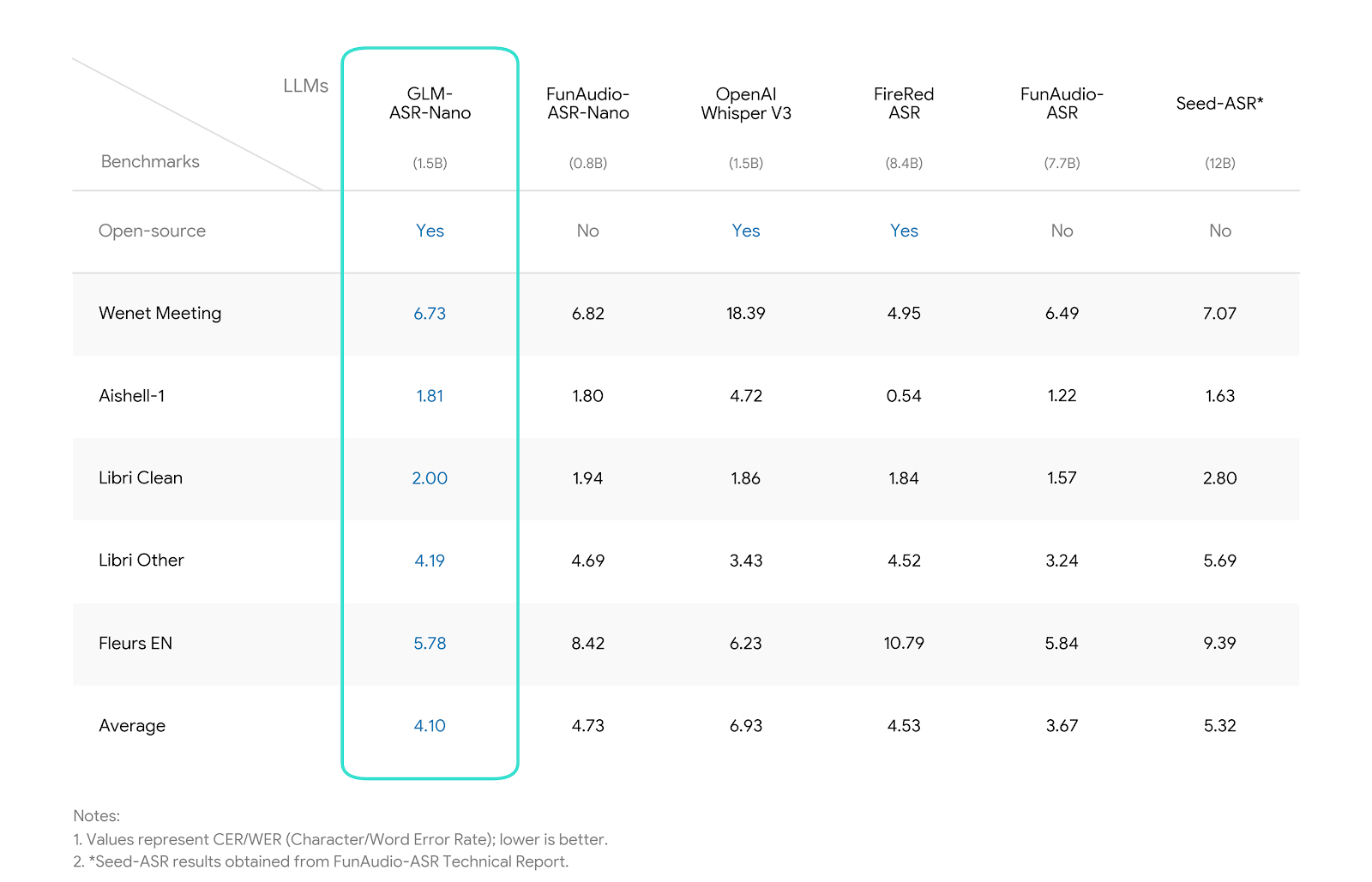
We evaluated GLM-ASR-Nano against leading open-source and closed-source models. The results demonstrate that *
|
| 37 |
+
*GLM-ASR-Nano (1.5B)** achieves superior performance, particularly in challenging acoustic environments.
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
Notes:
|
| 42 |
+
|
| 43 |
+
- Wenet Meeting reflects real-world meeting scenarios with noise and overlapping speech.
|
| 44 |
+
- Aishell-1 is a standard Mandarin benchmark.
|
| 45 |
+
|
| 46 |
+
## Inference
|
| 47 |
+
|
| 48 |
+
`GLM-ASR-Nano-2512` can be easily integrated using the `transformers` library.
|
| 49 |
+
We will support `transformers 5.x` as well as inference frameworks such as `vLLM` and `SGLang`.
|
| 50 |
+
you can check more code in [Github](https://github.com/zai-org/GLM-ASR).
|
config.json
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "zai-org/GLM-ASR-Nano-2512",
|
| 3 |
+
"model_type": "glmasr",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"GlmasrModel"
|
| 6 |
+
],
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_glmasr.GlmasrConfig",
|
| 9 |
+
"AutoModelForCausalLM": "modeling_glmasr.GlmasrModel"
|
| 10 |
+
},
|
| 11 |
+
"torch_dtype": "bfloat16",
|
| 12 |
+
"attn_implementation": "flash_attention_2",
|
| 13 |
+
"lm_config": {
|
| 14 |
+
"architectures": [
|
| 15 |
+
"LlamaForCausalLM"
|
| 16 |
+
],
|
| 17 |
+
"do_sample": false,
|
| 18 |
+
"eos_token_id": [
|
| 19 |
+
59246,
|
| 20 |
+
59253,
|
| 21 |
+
59255
|
| 22 |
+
],
|
| 23 |
+
"hidden_act": "silu",
|
| 24 |
+
"hidden_size": 2048,
|
| 25 |
+
"initializer_range": 0.02,
|
| 26 |
+
"intermediate_size": 6144,
|
| 27 |
+
"length_penalty": 1.0,
|
| 28 |
+
"max_length": 20,
|
| 29 |
+
"max_position_embeddings": 8192,
|
| 30 |
+
"min_length": 0,
|
| 31 |
+
"model_type": "llama",
|
| 32 |
+
"no_repeat_ngram_size": 0,
|
| 33 |
+
"num_attention_heads": 16,
|
| 34 |
+
"num_beam_groups": 1,
|
| 35 |
+
"num_beams": 1,
|
| 36 |
+
"num_hidden_layers": 28,
|
| 37 |
+
"num_key_value_heads": 4,
|
| 38 |
+
"num_return_sequences": 1,
|
| 39 |
+
"pad_token_id": 59260,
|
| 40 |
+
"return_dict": true,
|
| 41 |
+
"rms_norm_eps": 1e-05,
|
| 42 |
+
"rope_dim": 128,
|
| 43 |
+
"rope_theta": 10000.0,
|
| 44 |
+
"torch_dtype": "float16",
|
| 45 |
+
"typical_p": 1.0,
|
| 46 |
+
"vocab_size": 59264
|
| 47 |
+
},
|
| 48 |
+
"whisper_config": {
|
| 49 |
+
"activation_function": "gelu",
|
| 50 |
+
"architectures": [
|
| 51 |
+
"WhisperForConditionalGeneration"
|
| 52 |
+
],
|
| 53 |
+
"begin_suppress_tokens": [
|
| 54 |
+
220,
|
| 55 |
+
50257
|
| 56 |
+
],
|
| 57 |
+
"bos_token_id": 50257,
|
| 58 |
+
"chunk_size_feed_forward": 0,
|
| 59 |
+
"classifier_proj_size": 256,
|
| 60 |
+
"d_model": 1280,
|
| 61 |
+
"decoder_attention_heads": 20,
|
| 62 |
+
"decoder_ffn_dim": 5120,
|
| 63 |
+
"decoder_layerdrop": 0.0,
|
| 64 |
+
"decoder_layers": 32,
|
| 65 |
+
"decoder_start_token_id": 50258,
|
| 66 |
+
"diversity_penalty": 0.0,
|
| 67 |
+
"do_sample": false,
|
| 68 |
+
"dropout": 0.0,
|
| 69 |
+
"early_stopping": false,
|
| 70 |
+
"encoder_attention_heads": 20,
|
| 71 |
+
"encoder_ffn_dim": 5120,
|
| 72 |
+
"encoder_layerdrop": 0.0,
|
| 73 |
+
"encoder_layers": 32,
|
| 74 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 75 |
+
"eos_token_id": 50257,
|
| 76 |
+
"init_std": 0.02,
|
| 77 |
+
"is_decoder": false,
|
| 78 |
+
"is_encoder_decoder": true,
|
| 79 |
+
"length_penalty": 1.0,
|
| 80 |
+
"mask_feature_length": 10,
|
| 81 |
+
"mask_feature_min_masks": 0,
|
| 82 |
+
"mask_feature_prob": 0.0,
|
| 83 |
+
"mask_time_length": 10,
|
| 84 |
+
"mask_time_min_masks": 2,
|
| 85 |
+
"mask_time_prob": 0.05,
|
| 86 |
+
"max_length": 448,
|
| 87 |
+
"max_source_positions": 1500,
|
| 88 |
+
"max_target_positions": 448,
|
| 89 |
+
"median_filter_width": 7,
|
| 90 |
+
"min_length": 0,
|
| 91 |
+
"model_type": "whisper",
|
| 92 |
+
"no_repeat_ngram_size": 0,
|
| 93 |
+
"num_beam_groups": 1,
|
| 94 |
+
"num_beams": 1,
|
| 95 |
+
"num_hidden_layers": 32,
|
| 96 |
+
"num_mel_bins": 128,
|
| 97 |
+
"num_return_sequences": 1,
|
| 98 |
+
"output_attentions": false,
|
| 99 |
+
"output_hidden_states": false,
|
| 100 |
+
"output_scores": false,
|
| 101 |
+
"pad_token_id": 50256,
|
| 102 |
+
"remove_invalid_values": false,
|
| 103 |
+
"repetition_penalty": 1.0,
|
| 104 |
+
"return_dict": true,
|
| 105 |
+
"torch_dtype": "bfloat16",
|
| 106 |
+
"torchscript": false,
|
| 107 |
+
"typical_p": 1.0,
|
| 108 |
+
"use_cache": true,
|
| 109 |
+
"use_weighted_layer_sum": false,
|
| 110 |
+
"vocab_size": 51866
|
| 111 |
+
},
|
| 112 |
+
"adapter_type": "mlp",
|
| 113 |
+
"merge_factor": 4,
|
| 114 |
+
"use_rope": true,
|
| 115 |
+
"max_whisper_length": 1500,
|
| 116 |
+
"max_length": 65536,
|
| 117 |
+
"mlp_adapter_act": "gelu",
|
| 118 |
+
"transformers_version": "4.51.3"
|
| 119 |
+
}
|
configuration_glmasr.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, List, Optional
|
| 2 |
+
|
| 3 |
+
from transformers import LlamaConfig, PretrainedConfig, WhisperConfig
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class GlmasrConfig(PretrainedConfig):
|
| 7 |
+
model_type = "Glmasr"
|
| 8 |
+
is_composition = True
|
| 9 |
+
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
lm_config: Optional[Dict[str, Any] | LlamaConfig] = None,
|
| 13 |
+
whisper_config: Optional[Dict[str, Any] | WhisperConfig] = None,
|
| 14 |
+
adapter_type: str = "mlp",
|
| 15 |
+
merge_factor: int = 2,
|
| 16 |
+
spec_aug: bool = False,
|
| 17 |
+
use_rope: bool = False,
|
| 18 |
+
max_whisper_length: int = 1500,
|
| 19 |
+
max_length: int = 1024,
|
| 20 |
+
mlp_adapter_act: str = "gelu",
|
| 21 |
+
**kwargs,
|
| 22 |
+
):
|
| 23 |
+
super().__init__(**kwargs)
|
| 24 |
+
|
| 25 |
+
if isinstance(lm_config, LlamaConfig):
|
| 26 |
+
self.lm_config = lm_config
|
| 27 |
+
else:
|
| 28 |
+
self.lm_config = LlamaConfig.from_dict(lm_config or {})
|
| 29 |
+
if isinstance(whisper_config, WhisperConfig):
|
| 30 |
+
self.whisper_config = whisper_config
|
| 31 |
+
else:
|
| 32 |
+
self.whisper_config = WhisperConfig.from_dict(whisper_config or {})
|
| 33 |
+
|
| 34 |
+
self.adapter_type = adapter_type
|
| 35 |
+
self.merge_factor = merge_factor
|
| 36 |
+
self.spec_aug = spec_aug
|
| 37 |
+
self.use_rope = use_rope
|
| 38 |
+
self.max_whisper_length = max_whisper_length
|
| 39 |
+
self.max_length = max_length
|
| 40 |
+
self.mlp_adapter_act = mlp_adapter_act
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
__all__ = ["GlmasrConfig"]
|
inference.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torchaudio
|
| 6 |
+
from transformers import (
|
| 7 |
+
AutoConfig,
|
| 8 |
+
AutoModelForCausalLM,
|
| 9 |
+
AutoTokenizer,
|
| 10 |
+
WhisperFeatureExtractor,
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
WHISPER_FEAT_CFG = {
|
| 15 |
+
"chunk_length": 30,
|
| 16 |
+
"feature_extractor_type": "WhisperFeatureExtractor",
|
| 17 |
+
"feature_size": 128,
|
| 18 |
+
"hop_length": 160,
|
| 19 |
+
"n_fft": 400,
|
| 20 |
+
"n_samples": 480000,
|
| 21 |
+
"nb_max_frames": 3000,
|
| 22 |
+
"padding_side": "right",
|
| 23 |
+
"padding_value": 0.0,
|
| 24 |
+
"processor_class": "WhisperProcessor",
|
| 25 |
+
"return_attention_mask": False,
|
| 26 |
+
"sampling_rate": 16000,
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
def get_audio_token_length(seconds, merge_factor=2):
|
| 30 |
+
def get_T_after_cnn(L_in, dilation=1):
|
| 31 |
+
for padding, kernel_size, stride in eval("[(1,3,1)] + [(1,3,2)] "):
|
| 32 |
+
L_out = L_in + 2 * padding - dilation * (kernel_size - 1) - 1
|
| 33 |
+
L_out = 1 + L_out // stride
|
| 34 |
+
L_in = L_out
|
| 35 |
+
return L_out
|
| 36 |
+
|
| 37 |
+
mel_len = int(seconds * 100)
|
| 38 |
+
audio_len_after_cnn = get_T_after_cnn(mel_len)
|
| 39 |
+
audio_token_num = (audio_len_after_cnn - merge_factor) // merge_factor + 1
|
| 40 |
+
|
| 41 |
+
# TODO: current whisper model can't process longer sequence, maybe cut chunk in the future
|
| 42 |
+
audio_token_num = min(audio_token_num, 1500 // merge_factor)
|
| 43 |
+
|
| 44 |
+
return audio_token_num
|
| 45 |
+
|
| 46 |
+
def build_prompt(
|
| 47 |
+
audio_path: Path,
|
| 48 |
+
tokenizer,
|
| 49 |
+
feature_extractor: WhisperFeatureExtractor,
|
| 50 |
+
merge_factor: int,
|
| 51 |
+
chunk_seconds: int = 30,
|
| 52 |
+
) -> dict:
|
| 53 |
+
audio_path = Path(audio_path)
|
| 54 |
+
wav, sr = torchaudio.load(str(audio_path))
|
| 55 |
+
wav = wav[:1, :]
|
| 56 |
+
if sr != feature_extractor.sampling_rate:
|
| 57 |
+
wav = torchaudio.transforms.Resample(sr, feature_extractor.sampling_rate)(wav)
|
| 58 |
+
|
| 59 |
+
tokens = []
|
| 60 |
+
tokens += tokenizer.encode("<|user|>")
|
| 61 |
+
tokens += tokenizer.encode("\n")
|
| 62 |
+
|
| 63 |
+
audios = []
|
| 64 |
+
audio_offsets = []
|
| 65 |
+
audio_length = []
|
| 66 |
+
chunk_size = chunk_seconds * feature_extractor.sampling_rate
|
| 67 |
+
for start in range(0, wav.shape[1], chunk_size):
|
| 68 |
+
chunk = wav[:, start : start + chunk_size]
|
| 69 |
+
mel = feature_extractor(
|
| 70 |
+
chunk.numpy(),
|
| 71 |
+
sampling_rate=feature_extractor.sampling_rate,
|
| 72 |
+
return_tensors="pt",
|
| 73 |
+
padding="max_length",
|
| 74 |
+
)["input_features"]
|
| 75 |
+
audios.append(mel)
|
| 76 |
+
seconds = chunk.shape[1] / feature_extractor.sampling_rate
|
| 77 |
+
num_tokens = get_audio_token_length(seconds, merge_factor)
|
| 78 |
+
tokens += tokenizer.encode("<|begin_of_audio|>")
|
| 79 |
+
audio_offsets.append(len(tokens))
|
| 80 |
+
tokens += [0] * num_tokens
|
| 81 |
+
tokens += tokenizer.encode("<|end_of_audio|>")
|
| 82 |
+
audio_length.append(num_tokens)
|
| 83 |
+
|
| 84 |
+
if not audios:
|
| 85 |
+
raise ValueError("音频内容为空或加载失败。")
|
| 86 |
+
|
| 87 |
+
tokens += tokenizer.encode("<|user|>")
|
| 88 |
+
tokens += tokenizer.encode("\nPlease transcribe this audio into text")
|
| 89 |
+
|
| 90 |
+
tokens += tokenizer.encode("<|assistant|>")
|
| 91 |
+
tokens += tokenizer.encode("\n")
|
| 92 |
+
|
| 93 |
+
batch = {
|
| 94 |
+
"input_ids": torch.tensor([tokens], dtype=torch.long),
|
| 95 |
+
"audios": torch.cat(audios, dim=0),
|
| 96 |
+
"audio_offsets": [audio_offsets],
|
| 97 |
+
"audio_length": [audio_length],
|
| 98 |
+
"attention_mask": torch.ones(1, len(tokens), dtype=torch.long),
|
| 99 |
+
}
|
| 100 |
+
return batch
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def prepare_inputs(batch: dict, device: torch.device) -> tuple[dict, int]:
|
| 104 |
+
tokens = batch["input_ids"].to(device)
|
| 105 |
+
attention_mask = batch["attention_mask"].to(device)
|
| 106 |
+
audios = batch["audios"].to(device)
|
| 107 |
+
model_inputs = {
|
| 108 |
+
"inputs": tokens,
|
| 109 |
+
"attention_mask": attention_mask,
|
| 110 |
+
"audios": audios.to(torch.bfloat16),
|
| 111 |
+
"audio_offsets": batch["audio_offsets"],
|
| 112 |
+
"audio_length": batch["audio_length"],
|
| 113 |
+
}
|
| 114 |
+
return model_inputs, tokens.size(1)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def transcribe(
|
| 118 |
+
checkpoint_dir: Path,
|
| 119 |
+
audio_path: Path,
|
| 120 |
+
tokenizer_path: str | None,
|
| 121 |
+
max_new_tokens: int,
|
| 122 |
+
device: str,
|
| 123 |
+
):
|
| 124 |
+
tokenizer_source = tokenizer_path if tokenizer_path else checkpoint_dir
|
| 125 |
+
tokenizer = AutoTokenizer.from_pretrained(tokenizer_source)
|
| 126 |
+
feature_extractor = WhisperFeatureExtractor(**WHISPER_FEAT_CFG)
|
| 127 |
+
|
| 128 |
+
config = AutoConfig.from_pretrained(checkpoint_dir, trust_remote_code=True)
|
| 129 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 130 |
+
checkpoint_dir,
|
| 131 |
+
config=config,
|
| 132 |
+
torch_dtype=torch.bfloat16,
|
| 133 |
+
trust_remote_code=True,
|
| 134 |
+
).to(device)
|
| 135 |
+
model.eval()
|
| 136 |
+
|
| 137 |
+
batch = build_prompt(
|
| 138 |
+
audio_path,
|
| 139 |
+
tokenizer,
|
| 140 |
+
feature_extractor,
|
| 141 |
+
merge_factor=config.merge_factor,
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
model_inputs, prompt_len = prepare_inputs(batch, device)
|
| 145 |
+
|
| 146 |
+
with torch.inference_mode():
|
| 147 |
+
generated = model.generate(
|
| 148 |
+
**model_inputs,
|
| 149 |
+
max_new_tokens=max_new_tokens,
|
| 150 |
+
do_sample=False,
|
| 151 |
+
)
|
| 152 |
+
transcript_ids = generated[0, prompt_len:].cpu().tolist()
|
| 153 |
+
transcript = tokenizer.decode(transcript_ids, skip_special_tokens=True).strip()
|
| 154 |
+
print("----------")
|
| 155 |
+
print(transcript or "[Empty transcription]")
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def main():
|
| 159 |
+
parser = argparse.ArgumentParser(description="Minimal ASR transcription demo.")
|
| 160 |
+
parser.add_argument("--checkpoint_dir", type=str, default=str(Path(__file__).parent))
|
| 161 |
+
parser.add_argument("--audio", type=str, required=True, help="Path to audio file.")
|
| 162 |
+
parser.add_argument(
|
| 163 |
+
"--tokenizer_path",
|
| 164 |
+
type=str,
|
| 165 |
+
default=None,
|
| 166 |
+
help="Tokenizer directory (defaults to checkpoint dir when omitted).",
|
| 167 |
+
)
|
| 168 |
+
parser.add_argument("--max_new_tokens", type=int, default=128)
|
| 169 |
+
parser.add_argument("--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu")
|
| 170 |
+
args = parser.parse_args()
|
| 171 |
+
|
| 172 |
+
transcribe(
|
| 173 |
+
checkpoint_dir=Path(args.checkpoint_dir),
|
| 174 |
+
audio_path=Path(args.audio),
|
| 175 |
+
tokenizer_path=args.tokenizer_path,
|
| 176 |
+
max_new_tokens=args.max_new_tokens,
|
| 177 |
+
device=args.device,
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
if __name__ == "__main__":
|
| 182 |
+
main()
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f1a7e953150d134cce1a1199d6f18060cb99ee8a9d8e13673ff3bd840da0c096
|
| 3 |
+
size 4524872840
|
modeling_audio.py
ADDED
|
@@ -0,0 +1,415 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Optional, Tuple
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor, nn
|
| 5 |
+
from transformers import WhisperConfig
|
| 6 |
+
from transformers.modeling_flash_attention_utils import _flash_attention_forward
|
| 7 |
+
from transformers.modeling_outputs import BaseModelOutputWithPastAndCrossAttentions
|
| 8 |
+
from transformers.models.whisper.modeling_whisper import WhisperEncoder, WhisperEncoderLayer, WhisperFlashAttention2
|
| 9 |
+
from transformers.utils import logging
|
| 10 |
+
|
| 11 |
+
logger = logging.get_logger(__name__)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class RotaryEmbedding:
|
| 15 |
+
def __init__(self, dim, rope_ratio=1, original_impl=False):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.dim = dim
|
| 18 |
+
self.original_impl = original_impl
|
| 19 |
+
self.rope_ratio = rope_ratio
|
| 20 |
+
|
| 21 |
+
def forward_impl(
|
| 22 |
+
self, seq_len: int, n_elem: int, dtype: torch.dtype, device: torch.device, base: int = 10000
|
| 23 |
+
):
|
| 24 |
+
"""Enhanced Transformer with Rotary Position Embedding.
|
| 25 |
+
|
| 26 |
+
Derived from: https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/
|
| 27 |
+
transformers/rope/__init__.py. MIT License:
|
| 28 |
+
https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/license.
|
| 29 |
+
"""
|
| 30 |
+
# $\Theta = {\theta_i = 10000^{\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$
|
| 31 |
+
base = base * self.rope_ratio
|
| 32 |
+
theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, dtype=torch.float, device=device) / n_elem))
|
| 33 |
+
|
| 34 |
+
# Create position indexes `[0, 1, ..., seq_len - 1]`
|
| 35 |
+
seq_idx = torch.arange(seq_len, dtype=torch.float, device=device)
|
| 36 |
+
|
| 37 |
+
# Calculate the product of position index and $\theta_i$
|
| 38 |
+
idx_theta = torch.outer(seq_idx, theta).float()
|
| 39 |
+
|
| 40 |
+
cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1)
|
| 41 |
+
|
| 42 |
+
# this is to mimic the behaviour of complex32, else we will get different results
|
| 43 |
+
if dtype in (torch.float16, torch.bfloat16, torch.int8):
|
| 44 |
+
cache = cache.bfloat16() if dtype == torch.bfloat16 else cache.half()
|
| 45 |
+
return cache
|
| 46 |
+
|
| 47 |
+
@torch.no_grad()
|
| 48 |
+
def get_emb(self, max_seq_len, dtype, device):
|
| 49 |
+
return self.forward_impl(
|
| 50 |
+
max_seq_len, self.dim, dtype=dtype, device=device,
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> torch.Tensor:
|
| 55 |
+
# x: [b, np, sq, hn]
|
| 56 |
+
b, np, sq, hn = x.size(0), x.size(1), x.size(2), x.size(3)
|
| 57 |
+
rot_dim = rope_cache.shape[-2] * 2
|
| 58 |
+
x, x_pass = x[..., :rot_dim], x[..., rot_dim:]
|
| 59 |
+
# truncate to support variable sizes
|
| 60 |
+
rope_cache = rope_cache[:, :sq]
|
| 61 |
+
xshaped = x.reshape(b, np, sq, rot_dim // 2, 2)
|
| 62 |
+
rope_cache = rope_cache.view(-1, 1, sq, xshaped.size(3), 2)
|
| 63 |
+
x_out2 = torch.stack(
|
| 64 |
+
[
|
| 65 |
+
xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
|
| 66 |
+
xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
|
| 67 |
+
],
|
| 68 |
+
-1,
|
| 69 |
+
)
|
| 70 |
+
x_out2 = x_out2.flatten(3)
|
| 71 |
+
return torch.cat((x_out2, x_pass), dim=-1)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class WhisperRoPEFlashAttn(WhisperFlashAttention2):
|
| 75 |
+
def __init__(self, *args, **kwargs):
|
| 76 |
+
super().__init__(*args, **kwargs)
|
| 77 |
+
|
| 78 |
+
def _reshape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 79 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim)
|
| 80 |
+
|
| 81 |
+
def forward(
|
| 82 |
+
self,
|
| 83 |
+
hidden_states: torch.Tensor,
|
| 84 |
+
key_value_states: Optional[torch.Tensor] = None,
|
| 85 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 86 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 87 |
+
layer_head_mask: Optional[torch.Tensor] = None,
|
| 88 |
+
output_attentions: bool = False,
|
| 89 |
+
rotary_pos_emb: Optional[torch.Tensor] = None,
|
| 90 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 91 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 92 |
+
# WhisperFlashAttention2 attention does not support output_attentions
|
| 93 |
+
if output_attentions:
|
| 94 |
+
# raise ValueError("WhisperFlashAttention2 attention does not support output_attentions")
|
| 95 |
+
logger.warning_once("WhisperFlashAttention2 attention does not support output_attentions, "
|
| 96 |
+
"manually calculating attention weights.")
|
| 97 |
+
|
| 98 |
+
# if key_value_states are provided this layer is used as a cross-attention layer
|
| 99 |
+
# for the decoder
|
| 100 |
+
is_cross_attention = key_value_states is not None
|
| 101 |
+
bsz, q_len, _ = hidden_states.size()
|
| 102 |
+
|
| 103 |
+
# get query proj
|
| 104 |
+
assert not is_cross_attention, "Cross-attention not supported"
|
| 105 |
+
key_states = self._reshape(self.k_proj(hidden_states), -1, bsz)
|
| 106 |
+
query_states = self._reshape(self.q_proj(hidden_states), -1, bsz)
|
| 107 |
+
if rotary_pos_emb is not None:
|
| 108 |
+
logger.warning_once("Using Rotary Position Embedding in WhisperRoPEFlashAttn. ")
|
| 109 |
+
query_states, key_states = [apply_rotary_pos_emb(
|
| 110 |
+
i.transpose(1, 2),
|
| 111 |
+
rotary_pos_emb,
|
| 112 |
+
).transpose(1, 2) for i in (query_states, key_states)]
|
| 113 |
+
# get key, value proj
|
| 114 |
+
# `past_key_value[0].shape[2] == key_value_states.shape[1]`
|
| 115 |
+
# is checking that the `sequence_length` of the `past_key_value` is the same as
|
| 116 |
+
# the provided `key_value_states` to support prefix tuning
|
| 117 |
+
value_states = self._reshape(self.v_proj(hidden_states), -1, bsz)
|
| 118 |
+
if past_key_value is not None:
|
| 119 |
+
# reuse k, v, self_attention
|
| 120 |
+
key_states = torch.cat([past_key_value[0].transpose(1, 2), key_states], dim=1)
|
| 121 |
+
value_states = torch.cat([past_key_value[1].transpose(1, 2), value_states], dim=1)
|
| 122 |
+
|
| 123 |
+
if self.is_decoder:
|
| 124 |
+
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
|
| 125 |
+
# Further calls to cross_attention layer can then reuse all cross-attention
|
| 126 |
+
# key/value_states (first "if" case)
|
| 127 |
+
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
|
| 128 |
+
# all previous decoder key/value_states. Further calls to uni-directional self-attention
|
| 129 |
+
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
|
| 130 |
+
# if encoder bi-directional self-attention `past_key_value` is always `None`
|
| 131 |
+
past_key_value = (key_states.transpose(1, 2), value_states.transpose(1, 2))
|
| 132 |
+
|
| 133 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 134 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 135 |
+
# cast them back in the correct dtype just to be sure everything works as expected.
|
| 136 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 137 |
+
# in fp32. (LlamaRMSNorm handles it correctly)
|
| 138 |
+
|
| 139 |
+
input_dtype = query_states.dtype
|
| 140 |
+
if input_dtype == torch.float32:
|
| 141 |
+
if torch.is_autocast_enabled():
|
| 142 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 143 |
+
# Handle the case where the model is quantized
|
| 144 |
+
elif hasattr(self.config, "_pre_quantization_dtype"):
|
| 145 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 146 |
+
else:
|
| 147 |
+
target_dtype = self.q_proj.weight.dtype
|
| 148 |
+
|
| 149 |
+
query_states = query_states.to(target_dtype)
|
| 150 |
+
key_states = key_states.to(target_dtype)
|
| 151 |
+
value_states = value_states.to(target_dtype)
|
| 152 |
+
|
| 153 |
+
attn_output = _flash_attention_forward(
|
| 154 |
+
query_states,
|
| 155 |
+
key_states,
|
| 156 |
+
value_states,
|
| 157 |
+
attention_mask,
|
| 158 |
+
query_length=q_len,
|
| 159 |
+
is_causal=self.is_causal,
|
| 160 |
+
dropout=self.dropout,
|
| 161 |
+
position_ids=position_ids,
|
| 162 |
+
use_top_left_mask=self._flash_attn_uses_top_left_mask,
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
attn_output = attn_output.reshape(bsz, q_len, -1)
|
| 166 |
+
attn_output = self.out_proj(attn_output)
|
| 167 |
+
|
| 168 |
+
if not output_attentions:
|
| 169 |
+
attn_weights = None
|
| 170 |
+
else:
|
| 171 |
+
attn_weights = (query_states.transpose(1, 2) * self.scaling) @ key_states.permute(0, 2, 3, 1)
|
| 172 |
+
if self.is_causal:
|
| 173 |
+
causal_mask = torch.triu(
|
| 174 |
+
torch.ones(q_len, q_len, device=attn_weights.device), diagonal=1,
|
| 175 |
+
).unsqueeze(0).unsqueeze(0) * -1e9
|
| 176 |
+
attn_weights = attn_weights + causal_mask
|
| 177 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 178 |
+
|
| 179 |
+
return attn_output, attn_weights, past_key_value
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
class WhisperSpecialEncoderLayer(WhisperEncoderLayer):
|
| 183 |
+
def __init__(self, config: WhisperConfig):
|
| 184 |
+
super().__init__(config)
|
| 185 |
+
self.self_attn = WhisperRoPEFlashAttn(
|
| 186 |
+
embed_dim=self.embed_dim,
|
| 187 |
+
num_heads=config.encoder_attention_heads,
|
| 188 |
+
dropout=config.attention_dropout,
|
| 189 |
+
config=config,
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
def forward(
|
| 193 |
+
self,
|
| 194 |
+
hidden_states: torch.Tensor,
|
| 195 |
+
attention_mask: torch.Tensor,
|
| 196 |
+
layer_head_mask: torch.Tensor,
|
| 197 |
+
output_attentions: bool = False,
|
| 198 |
+
rotary_pos_emb: Optional[torch.Tensor] = None,
|
| 199 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 200 |
+
) -> tuple[Tensor, Any]:
|
| 201 |
+
"""
|
| 202 |
+
Args:
|
| 203 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 204 |
+
attention_mask (`torch.FloatTensor`): attention mask of size
|
| 205 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 206 |
+
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
|
| 207 |
+
`(encoder_attention_heads,)`.
|
| 208 |
+
output_attentions (`bool`, *optional*):
|
| 209 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 210 |
+
returned tensors for more detail.
|
| 211 |
+
"""
|
| 212 |
+
residual = hidden_states
|
| 213 |
+
hidden_states = self.self_attn_layer_norm(hidden_states)
|
| 214 |
+
hidden_states, attn_weights, kv_cache = self.self_attn(
|
| 215 |
+
hidden_states=hidden_states,
|
| 216 |
+
attention_mask=attention_mask,
|
| 217 |
+
layer_head_mask=layer_head_mask,
|
| 218 |
+
output_attentions=output_attentions,
|
| 219 |
+
rotary_pos_emb=rotary_pos_emb,
|
| 220 |
+
position_ids=position_ids,
|
| 221 |
+
)
|
| 222 |
+
hidden_states = nn.functional.dropout(
|
| 223 |
+
hidden_states, p=self.dropout, training=self.training
|
| 224 |
+
)
|
| 225 |
+
hidden_states = residual + hidden_states
|
| 226 |
+
|
| 227 |
+
residual = hidden_states
|
| 228 |
+
hidden_states = self.final_layer_norm(hidden_states)
|
| 229 |
+
hidden_states = self.activation_fn(self.fc1(hidden_states))
|
| 230 |
+
hidden_states = nn.functional.dropout(
|
| 231 |
+
hidden_states, p=self.activation_dropout, training=self.training
|
| 232 |
+
)
|
| 233 |
+
hidden_states = self.fc2(hidden_states)
|
| 234 |
+
hidden_states = nn.functional.dropout(
|
| 235 |
+
hidden_states, p=self.dropout, training=self.training
|
| 236 |
+
)
|
| 237 |
+
hidden_states = residual + hidden_states
|
| 238 |
+
|
| 239 |
+
if hidden_states.dtype == torch.float16 and (
|
| 240 |
+
torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
|
| 241 |
+
):
|
| 242 |
+
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
|
| 243 |
+
hidden_states = torch.clamp(
|
| 244 |
+
hidden_states, min=-clamp_value, max=clamp_value
|
| 245 |
+
)
|
| 246 |
+
|
| 247 |
+
outputs = (hidden_states, kv_cache)
|
| 248 |
+
|
| 249 |
+
if output_attentions:
|
| 250 |
+
outputs += (attn_weights,)
|
| 251 |
+
|
| 252 |
+
return outputs
|
| 253 |
+
|
| 254 |
+
class WhisperSpecialEncoder(WhisperEncoder):
|
| 255 |
+
def __init__(
|
| 256 |
+
self,
|
| 257 |
+
config: WhisperConfig,
|
| 258 |
+
use_rope=False,
|
| 259 |
+
rope_ratio=1,
|
| 260 |
+
):
|
| 261 |
+
super().__init__(config)
|
| 262 |
+
self.use_rope = use_rope
|
| 263 |
+
self.layers = nn.ModuleList(
|
| 264 |
+
[WhisperSpecialEncoderLayer(config) for _ in range(config.encoder_layers)]
|
| 265 |
+
)
|
| 266 |
+
if use_rope:
|
| 267 |
+
self.rotary_embedding = RotaryEmbedding(
|
| 268 |
+
config.hidden_size // config.encoder_attention_heads // 2,
|
| 269 |
+
rope_ratio,
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
def forward(
|
| 273 |
+
self,
|
| 274 |
+
input_features,
|
| 275 |
+
attention_mask=None,
|
| 276 |
+
head_mask=None,
|
| 277 |
+
output_attentions=None,
|
| 278 |
+
output_hidden_states=None,
|
| 279 |
+
return_dict=None,
|
| 280 |
+
position_ids=None,
|
| 281 |
+
):
|
| 282 |
+
r"""
|
| 283 |
+
Args:
|
| 284 |
+
input_features (`torch.LongTensor` of shape `(batch_size, feature_size, sequence_length)`):
|
| 285 |
+
Float values of mel features extracted from the raw speech waveform. Raw speech waveform can be
|
| 286 |
+
obtained by loading a `.flac` or `.wav` audio file into an array of type `List[float]` or a
|
| 287 |
+
`numpy.ndarray`, *e.g.* via the soundfile library (`pip install soundfile`). To prepare the array into
|
| 288 |
+
`input_features`, the [`AutoFeatureExtractor`] should be used for extracting the mel features, padding
|
| 289 |
+
and conversion into a tensor of type `torch.FloatTensor`. See [`~WhisperFeatureExtractor.__call__`]
|
| 290 |
+
attention_mask (`torch.Tensor`)`, *optional*):
|
| 291 |
+
Whisper does not support masking of the `input_features`, this argument is preserved for compatibility,
|
| 292 |
+
but it is not used. By default the silence in the input log mel spectrogram are ignored.
|
| 293 |
+
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
|
| 294 |
+
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
|
| 295 |
+
|
| 296 |
+
- 1 indicates the head is **not masked**,
|
| 297 |
+
- 0 indicates the head is **masked**.
|
| 298 |
+
output_attentions (`bool`, *optional*):
|
| 299 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 300 |
+
returned tensors for more detail.
|
| 301 |
+
output_hidden_states (`bool`, *optional*):
|
| 302 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 303 |
+
for more detail.
|
| 304 |
+
return_dict (`bool`, *optional*):
|
| 305 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 306 |
+
"""
|
| 307 |
+
output_attentions = (
|
| 308 |
+
output_attentions
|
| 309 |
+
if output_attentions is not None
|
| 310 |
+
else self.config.output_attentions
|
| 311 |
+
)
|
| 312 |
+
output_hidden_states = (
|
| 313 |
+
output_hidden_states
|
| 314 |
+
if output_hidden_states is not None
|
| 315 |
+
else self.config.output_hidden_states
|
| 316 |
+
)
|
| 317 |
+
return_dict = (
|
| 318 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 319 |
+
)
|
| 320 |
+
# use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 321 |
+
|
| 322 |
+
inputs_embeds = nn.functional.gelu(self.conv1(input_features))
|
| 323 |
+
inputs_embeds = nn.functional.gelu(self.conv2(inputs_embeds))
|
| 324 |
+
|
| 325 |
+
inputs_embeds = inputs_embeds.permute(0, 2, 1)
|
| 326 |
+
if self.use_rope:
|
| 327 |
+
rotary_embs = self.rotary_embedding.get_emb(
|
| 328 |
+
inputs_embeds.shape[1],
|
| 329 |
+
inputs_embeds.dtype,
|
| 330 |
+
inputs_embeds.device,
|
| 331 |
+
)
|
| 332 |
+
if position_ids is not None:
|
| 333 |
+
rotary_embs = rotary_embs[position_ids]
|
| 334 |
+
else:
|
| 335 |
+
rotary_embs = rotary_embs[None]
|
| 336 |
+
hidden_states = inputs_embeds
|
| 337 |
+
else:
|
| 338 |
+
rotary_embs = None
|
| 339 |
+
if position_ids is not None:
|
| 340 |
+
# wrap tail, those are usually paddings to avoid inter-sample conv interfering
|
| 341 |
+
max_l = self.embed_positions.weight.shape[0]
|
| 342 |
+
if position_ids.max() >= max_l:
|
| 343 |
+
print("Pos id max", position_ids.max(), "wrapping")
|
| 344 |
+
embed_pos = self.embed_positions.weight[position_ids % max_l]
|
| 345 |
+
else:
|
| 346 |
+
embed_pos = self.embed_positions.weight[:inputs_embeds.shape[1]]
|
| 347 |
+
hidden_states = inputs_embeds + embed_pos
|
| 348 |
+
hidden_states = nn.functional.dropout(
|
| 349 |
+
hidden_states, p=self.dropout, training=self.training
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
encoder_states = () if output_hidden_states else None
|
| 353 |
+
all_attentions = () if output_attentions else None
|
| 354 |
+
|
| 355 |
+
# check if head_mask has a correct number of layers specified if desired
|
| 356 |
+
if head_mask is not None:
|
| 357 |
+
assert head_mask.size()[0] == (
|
| 358 |
+
len(self.layers)
|
| 359 |
+
), f"The head_mask should be specified for {len(self.layers)} layers, but it is for {head_mask.size()[0]}."
|
| 360 |
+
|
| 361 |
+
for idx, encoder_layer in enumerate(self.layers):
|
| 362 |
+
if output_hidden_states:
|
| 363 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 364 |
+
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
|
| 365 |
+
to_drop = False
|
| 366 |
+
if self.training:
|
| 367 |
+
dropout_probability = torch.rand([])
|
| 368 |
+
if dropout_probability < self.layerdrop: # skip the layer
|
| 369 |
+
to_drop = True
|
| 370 |
+
|
| 371 |
+
if to_drop:
|
| 372 |
+
layer_outputs = (None, None)
|
| 373 |
+
else:
|
| 374 |
+
if self.gradient_checkpointing and self.training:
|
| 375 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 376 |
+
encoder_layer.__call__,
|
| 377 |
+
hidden_states,
|
| 378 |
+
None,
|
| 379 |
+
(head_mask[idx] if head_mask is not None else None),
|
| 380 |
+
output_attentions,
|
| 381 |
+
rotary_embs,
|
| 382 |
+
position_ids,
|
| 383 |
+
)
|
| 384 |
+
else:
|
| 385 |
+
layer_outputs = encoder_layer(
|
| 386 |
+
hidden_states,
|
| 387 |
+
None,
|
| 388 |
+
layer_head_mask=(
|
| 389 |
+
head_mask[idx] if head_mask is not None else None
|
| 390 |
+
),
|
| 391 |
+
output_attentions=output_attentions,
|
| 392 |
+
rotary_pos_emb=rotary_embs,
|
| 393 |
+
position_ids=position_ids,
|
| 394 |
+
)
|
| 395 |
+
|
| 396 |
+
hidden_states = layer_outputs[0]
|
| 397 |
+
|
| 398 |
+
if output_attentions:
|
| 399 |
+
all_attentions = all_attentions + (layer_outputs[2],)
|
| 400 |
+
|
| 401 |
+
hidden_states = self.layer_norm(hidden_states)
|
| 402 |
+
if output_hidden_states:
|
| 403 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 404 |
+
|
| 405 |
+
if not return_dict:
|
| 406 |
+
return tuple(
|
| 407 |
+
v
|
| 408 |
+
for v in [hidden_states, encoder_states, all_attentions]
|
| 409 |
+
if v is not None
|
| 410 |
+
)
|
| 411 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 412 |
+
last_hidden_state=hidden_states,
|
| 413 |
+
hidden_states=encoder_states,
|
| 414 |
+
attentions=all_attentions,
|
| 415 |
+
)
|
modeling_glmasr.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor, nn
|
| 5 |
+
from transformers import LlamaForCausalLM
|
| 6 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 7 |
+
|
| 8 |
+
from .configuration_glmasr import GlmasrConfig
|
| 9 |
+
from .modeling_audio import WhisperSpecialEncoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class AudioMLPAdapter(nn.Module):
|
| 13 |
+
def __init__(self, config: GlmasrConfig):
|
| 14 |
+
super().__init__()
|
| 15 |
+
whisper_config = config.whisper_config
|
| 16 |
+
self.merge_factor = config.merge_factor
|
| 17 |
+
self.whisper = WhisperSpecialEncoder(
|
| 18 |
+
whisper_config,
|
| 19 |
+
use_rope=config.use_rope,
|
| 20 |
+
)
|
| 21 |
+
self.whisper.layer_norm = nn.Identity()
|
| 22 |
+
self.layer_norm = nn.LayerNorm(whisper_config.hidden_size)
|
| 23 |
+
act = {
|
| 24 |
+
"gelu": nn.GELU(),
|
| 25 |
+
"relu": nn.ReLU(),
|
| 26 |
+
"selu": nn.SELU(),
|
| 27 |
+
}[config.mlp_adapter_act]
|
| 28 |
+
hidden = whisper_config.hidden_size * self.merge_factor
|
| 29 |
+
output_dim = config.lm_config.hidden_size
|
| 30 |
+
self.adapting = nn.Sequential(
|
| 31 |
+
nn.Linear(hidden, output_dim * 2),
|
| 32 |
+
act,
|
| 33 |
+
nn.Linear(output_dim * 2, output_dim),
|
| 34 |
+
)
|
| 35 |
+
self.audio_bos_eos_token = nn.Embedding(2, output_dim)
|
| 36 |
+
|
| 37 |
+
def forward(self, audios: Tensor) -> tuple[Tensor, Tensor, Tensor]:
|
| 38 |
+
bsz = audios.size(0)
|
| 39 |
+
encoded = self.whisper(audios)[0]
|
| 40 |
+
encoded = self.layer_norm(encoded)
|
| 41 |
+
encoded = encoded.reshape(bsz, -1, encoded.size(-1) * self.merge_factor)
|
| 42 |
+
adapted = self.adapting(encoded)
|
| 43 |
+
boa = self.audio_bos_eos_token.weight[0][None, :]
|
| 44 |
+
eoa = self.audio_bos_eos_token.weight[1][None, :]
|
| 45 |
+
return adapted, boa, eoa
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class GlmasrModel(LlamaForCausalLM):
|
| 49 |
+
config_class = GlmasrConfig
|
| 50 |
+
|
| 51 |
+
def __init__(self, config: GlmasrConfig):
|
| 52 |
+
super().__init__(config.lm_config)
|
| 53 |
+
self.audio_encoder = AudioMLPAdapter(config)
|
| 54 |
+
self.all_config = config
|
| 55 |
+
|
| 56 |
+
def forward(
|
| 57 |
+
self,
|
| 58 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 59 |
+
audios: Optional[Tensor] = None,
|
| 60 |
+
audio_offsets: Optional[list[list[int]]] = None,
|
| 61 |
+
audio_length: Optional[list[list[int]]] = None,
|
| 62 |
+
attention_mask: Optional[Tensor] = None,
|
| 63 |
+
position_ids: Optional[Tensor] = None,
|
| 64 |
+
past_key_values: Optional[tuple] = None,
|
| 65 |
+
use_cache: Optional[bool] = None,
|
| 66 |
+
**kwargs,
|
| 67 |
+
) -> CausalLMOutputWithPast:
|
| 68 |
+
tokens = input_ids
|
| 69 |
+
vocab_size = self.config.vocab_size
|
| 70 |
+
tokens = torch.clamp(tokens, 0, vocab_size - 1)
|
| 71 |
+
language_embs = self.model.embed_tokens(tokens)
|
| 72 |
+
|
| 73 |
+
have_audio = audios is not None and (
|
| 74 |
+
kwargs.get("past_key_values") is None or len(kwargs["past_key_values"]) == 0
|
| 75 |
+
)
|
| 76 |
+
if have_audio:
|
| 77 |
+
if audio_length is None:
|
| 78 |
+
raise ValueError("audio_length is required when audio_offsets are provided")
|
| 79 |
+
audio_embs, boa, eoa = self.audio_encoder(audios)
|
| 80 |
+
index = 0
|
| 81 |
+
for batch, (offsets, lengths) in enumerate(zip(audio_offsets, audio_length)):
|
| 82 |
+
for offset, length in zip(offsets, lengths):
|
| 83 |
+
language_embs[batch, offset : offset + length] = audio_embs[index, :length]
|
| 84 |
+
language_embs[batch, offset - 1] = boa
|
| 85 |
+
language_embs[batch, offset + length] = eoa
|
| 86 |
+
index += 1
|
| 87 |
+
|
| 88 |
+
kwargs.pop("inputs_embeds", None)
|
| 89 |
+
kwargs.pop("is_first_forward", None)
|
| 90 |
+
|
| 91 |
+
outputs = self.model(
|
| 92 |
+
inputs_embeds=language_embs,
|
| 93 |
+
attention_mask=attention_mask,
|
| 94 |
+
position_ids=position_ids,
|
| 95 |
+
past_key_values=past_key_values,
|
| 96 |
+
use_cache=use_cache,
|
| 97 |
+
**kwargs,
|
| 98 |
+
)
|
| 99 |
+
logits = self.lm_head(outputs[0])
|
| 100 |
+
return CausalLMOutputWithPast(
|
| 101 |
+
loss=None,
|
| 102 |
+
logits=logits,
|
| 103 |
+
past_key_values=outputs.past_key_values,
|
| 104 |
+
hidden_states=outputs.hidden_states,
|
| 105 |
+
attentions=outputs.attentions,
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
def _update_model_kwargs_for_generation(self, *args, **kwargs):
|
| 109 |
+
model_kwargs = super()._update_model_kwargs_for_generation(*args, **kwargs)
|
| 110 |
+
model_kwargs["is_first_forward"] = False
|
| 111 |
+
position_ids = model_kwargs.get("position_ids")
|
| 112 |
+
if position_ids is not None:
|
| 113 |
+
next_pos = position_ids[..., -1:].clone() + 1
|
| 114 |
+
model_kwargs["position_ids"] = torch.cat([position_ids, next_pos], dim=-1)
|
| 115 |
+
return model_kwargs
|
| 116 |
+
|
| 117 |
+
def prepare_inputs_for_generation(
|
| 118 |
+
self,
|
| 119 |
+
*args,
|
| 120 |
+
past_key_values: Optional[tuple] = None,
|
| 121 |
+
attention_mask: Optional[Tensor] = None,
|
| 122 |
+
position_ids: Optional[Tensor] = None,
|
| 123 |
+
use_cache: Optional[bool] = None,
|
| 124 |
+
is_first_forward: bool = True,
|
| 125 |
+
**kwargs,
|
| 126 |
+
):
|
| 127 |
+
prepared = super().prepare_inputs_for_generation(
|
| 128 |
+
*args,
|
| 129 |
+
past_key_values=past_key_values,
|
| 130 |
+
attention_mask=attention_mask,
|
| 131 |
+
position_ids=position_ids,
|
| 132 |
+
use_cache=use_cache,
|
| 133 |
+
is_first_forward=is_first_forward,
|
| 134 |
+
**kwargs,
|
| 135 |
+
)
|
| 136 |
+
for key, value in kwargs.items():
|
| 137 |
+
if key not in prepared and key.startswith("audio"):
|
| 138 |
+
prepared[key] = value
|
| 139 |
+
if is_first_forward and past_key_values is not None and len(past_key_values) > 0:
|
| 140 |
+
cached_len = past_key_values[0][0].shape[2]
|
| 141 |
+
prepared["input_ids"] = prepared["input_ids"][:, cached_len:]
|
| 142 |
+
if "position_ids" in prepared:
|
| 143 |
+
prepared["position_ids"] = prepared["position_ids"][:, cached_len:]
|
| 144 |
+
if not is_first_forward:
|
| 145 |
+
prepared["audios"] = None
|
| 146 |
+
return prepared
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
__all__ = ["GlmasrModel"]
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"59246": {
|
| 4 |
+
"content": "<|endoftext|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"59247": {
|
| 12 |
+
"content": "[MASK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"59248": {
|
| 20 |
+
"content": "[gMASK]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"59249": {
|
| 28 |
+
"content": "[sMASK]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"59250": {
|
| 36 |
+
"content": "<sop>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"59251": {
|
| 44 |
+
"content": "<eop>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"59252": {
|
| 52 |
+
"content": "<|system|>",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
},
|
| 59 |
+
"59253": {
|
| 60 |
+
"content": "<|user|>",
|
| 61 |
+
"lstrip": false,
|
| 62 |
+
"normalized": false,
|
| 63 |
+
"rstrip": false,
|
| 64 |
+
"single_word": false,
|
| 65 |
+
"special": true
|
| 66 |
+
},
|
| 67 |
+
"59254": {
|
| 68 |
+
"content": "<|assistant|>",
|
| 69 |
+
"lstrip": false,
|
| 70 |
+
"normalized": false,
|
| 71 |
+
"rstrip": false,
|
| 72 |
+
"single_word": false,
|
| 73 |
+
"special": true
|
| 74 |
+
},
|
| 75 |
+
"59255": {
|
| 76 |
+
"content": "<|observation|>",
|
| 77 |
+
"lstrip": false,
|
| 78 |
+
"normalized": false,
|
| 79 |
+
"rstrip": false,
|
| 80 |
+
"single_word": false,
|
| 81 |
+
"special": true
|
| 82 |
+
},
|
| 83 |
+
"59256": {
|
| 84 |
+
"content": "<|begin_of_image|>",
|
| 85 |
+
"lstrip": false,
|
| 86 |
+
"normalized": false,
|
| 87 |
+
"rstrip": false,
|
| 88 |
+
"single_word": false,
|
| 89 |
+
"special": true
|
| 90 |
+
},
|
| 91 |
+
"59257": {
|
| 92 |
+
"content": "<|end_of_image|>",
|
| 93 |
+
"lstrip": false,
|
| 94 |
+
"normalized": false,
|
| 95 |
+
"rstrip": false,
|
| 96 |
+
"single_word": false,
|
| 97 |
+
"special": true
|
| 98 |
+
},
|
| 99 |
+
"59258": {
|
| 100 |
+
"content": "<|begin_of_video|>",
|
| 101 |
+
"lstrip": false,
|
| 102 |
+
"normalized": false,
|
| 103 |
+
"rstrip": false,
|
| 104 |
+
"single_word": false,
|
| 105 |
+
"special": true
|
| 106 |
+
},
|
| 107 |
+
"59259": {
|
| 108 |
+
"content": "<|end_of_video|>",
|
| 109 |
+
"lstrip": false,
|
| 110 |
+
"normalized": false,
|
| 111 |
+
"rstrip": false,
|
| 112 |
+
"single_word": false,
|
| 113 |
+
"special": true
|
| 114 |
+
},
|
| 115 |
+
"59260": {
|
| 116 |
+
"content": "<|pad|>",
|
| 117 |
+
"lstrip": false,
|
| 118 |
+
"normalized": false,
|
| 119 |
+
"rstrip": false,
|
| 120 |
+
"single_word": false,
|
| 121 |
+
"special": true
|
| 122 |
+
},
|
| 123 |
+
"59261": {
|
| 124 |
+
"content": "<|begin_of_audio|>",
|
| 125 |
+
"lstrip": false,
|
| 126 |
+
"normalized": false,
|
| 127 |
+
"rstrip": false,
|
| 128 |
+
"single_word": false,
|
| 129 |
+
"special": true
|
| 130 |
+
},
|
| 131 |
+
"59262": {
|
| 132 |
+
"content": "<|end_of_audio|>",
|
| 133 |
+
"lstrip": false,
|
| 134 |
+
"normalized": false,
|
| 135 |
+
"rstrip": false,
|
| 136 |
+
"single_word": false,
|
| 137 |
+
"special": true
|
| 138 |
+
}
|
| 139 |
+
},
|
| 140 |
+
"additional_special_tokens": [
|
| 141 |
+
"<|endoftext|>",
|
| 142 |
+
"[MASK]",
|
| 143 |
+
"[gMASK]",
|
| 144 |
+
"[sMASK]",
|
| 145 |
+
"<sop>",
|
| 146 |
+
"<eop>",
|
| 147 |
+
"<|system|>",
|
| 148 |
+
"<|user|>",
|
| 149 |
+
"<|assistant|>",
|
| 150 |
+
"<|observation|>",
|
| 151 |
+
"<|begin_of_image|>",
|
| 152 |
+
"<|end_of_image|>",
|
| 153 |
+
"<|begin_of_video|>",
|
| 154 |
+
"<|end_of_video|>",
|
| 155 |
+
"<|pad|>",
|
| 156 |
+
"<|begin_of_audio|>",
|
| 157 |
+
"<|end_of_audio|>"
|
| 158 |
+
],
|
| 159 |
+
"clean_up_tokenization_spaces": false,
|
| 160 |
+
"do_lower_case": false,
|
| 161 |
+
"eos_token": "<|endoftext|>",
|
| 162 |
+
"extra_special_tokens": {},
|
| 163 |
+
"model_input_names": [
|
| 164 |
+
"input_ids",
|
| 165 |
+
"attention_mask"
|
| 166 |
+
],
|
| 167 |
+
"model_max_length": 65536,
|
| 168 |
+
"pad_token": "<|endoftext|>",
|
| 169 |
+
"padding_side": "left",
|
| 170 |
+
"remove_space": false,
|
| 171 |
+
"tokenizer_class": "PreTrainedTokenizer"
|
| 172 |
+
}
|