
File size: 6,960 Bytes
47b6bf4 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 |
---
license: mit
language:
- zh
- en
- fr
- es
- ru
- de
- ja
- ko
pipeline_tag: image-to-text
library_name: transformers
---
# GLM-OCR
<div align="center">
<img src=https://raw.githubusercontent.com/zai-org/GLM-OCR/refs/heads/main/resources/logo.svg width="40%"/>
</div>
<p align="center">
👋 Join our <a href="https://raw.githubusercontent.com/zai-org/GLM-OCR/refs/heads/main/resources/wechat.jpg" target="_blank">WeChat</a> and <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community
<br>
📍 Use GLM-OCR's <a href="https://docs.z.ai/guides/vlm/glm-ocr" target="_blank">API</a>
</p>
## Introduction
GLM-OCR is a multimodal OCR model for complex document understanding, built on the GLM-V encoder–decoder architecture. It introduces Multi-Token Prediction (MTP) loss and stable full-task reinforcement learning to improve training efficiency, recognition accuracy, and generalization. The model integrates the CogViT visual encoder pre-trained on large-scale image–text data, a lightweight cross-modal connector with efficient token downsampling, and a GLM-0.5B language decoder. Combined with a two-stage pipeline of layout analysis and parallel recognition based on PP-DocLayout-V3, GLM-OCR delivers robust and high-quality OCR performance across diverse document layouts.
**Key Features**
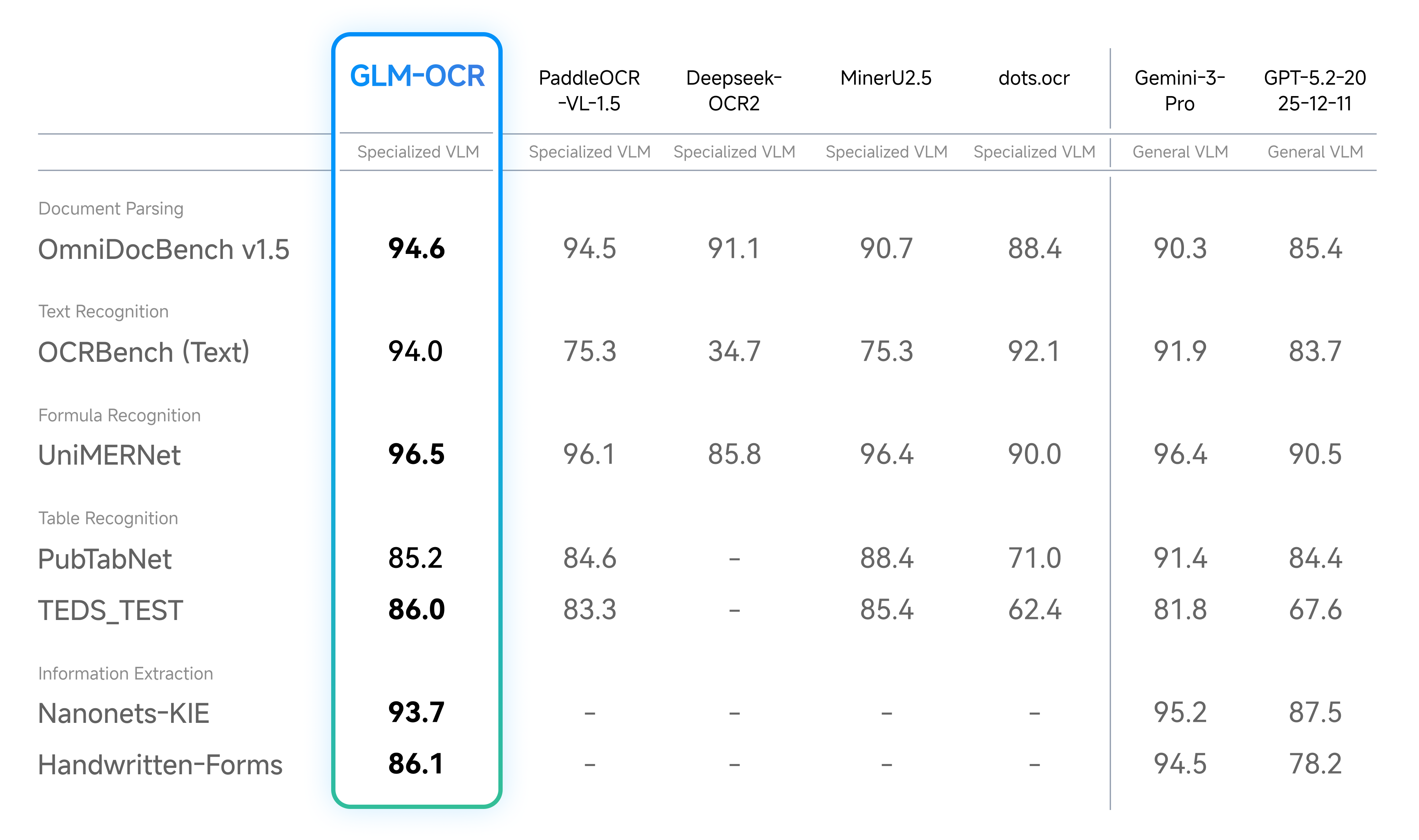
- **State-of-the-Art Performance**: Achieves a score of 94.62 on OmniDocBench V1.5, ranking #1 overall, and delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction.
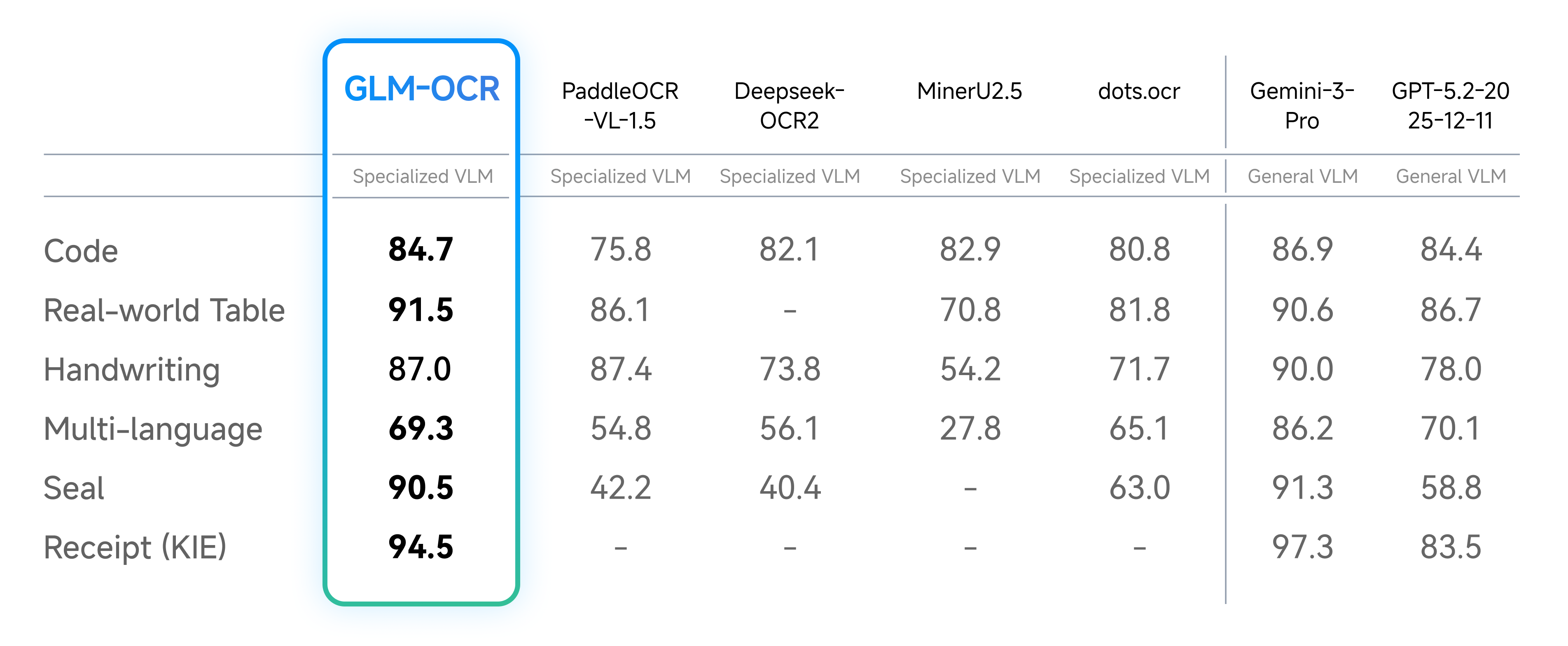
- **Optimized for Real-World Scenarios**: Designed and optimized for practical business use cases, maintaining robust performance on complex tables, code-heavy documents, seals, and other challenging real-world layouts.
- **Efficient Inference**: With only 0.9B parameters, GLM-OCR supports deployment via vLLM, SGLang, and Ollama, significantly reducing inference latency and compute cost, making it ideal for high-concurrency services and edge deployments.
- **Easy to Use**: Fully open-sourced and equipped with a comprehensive [SDK](https://github.com/zai-org/GLM-OCR) and inference toolchain, offering simple installation, one-line invocation, and smooth integration into existing production pipelines.
## Performance
- Document Parsing & Information Extraction
- Real-World Scenarios Performance
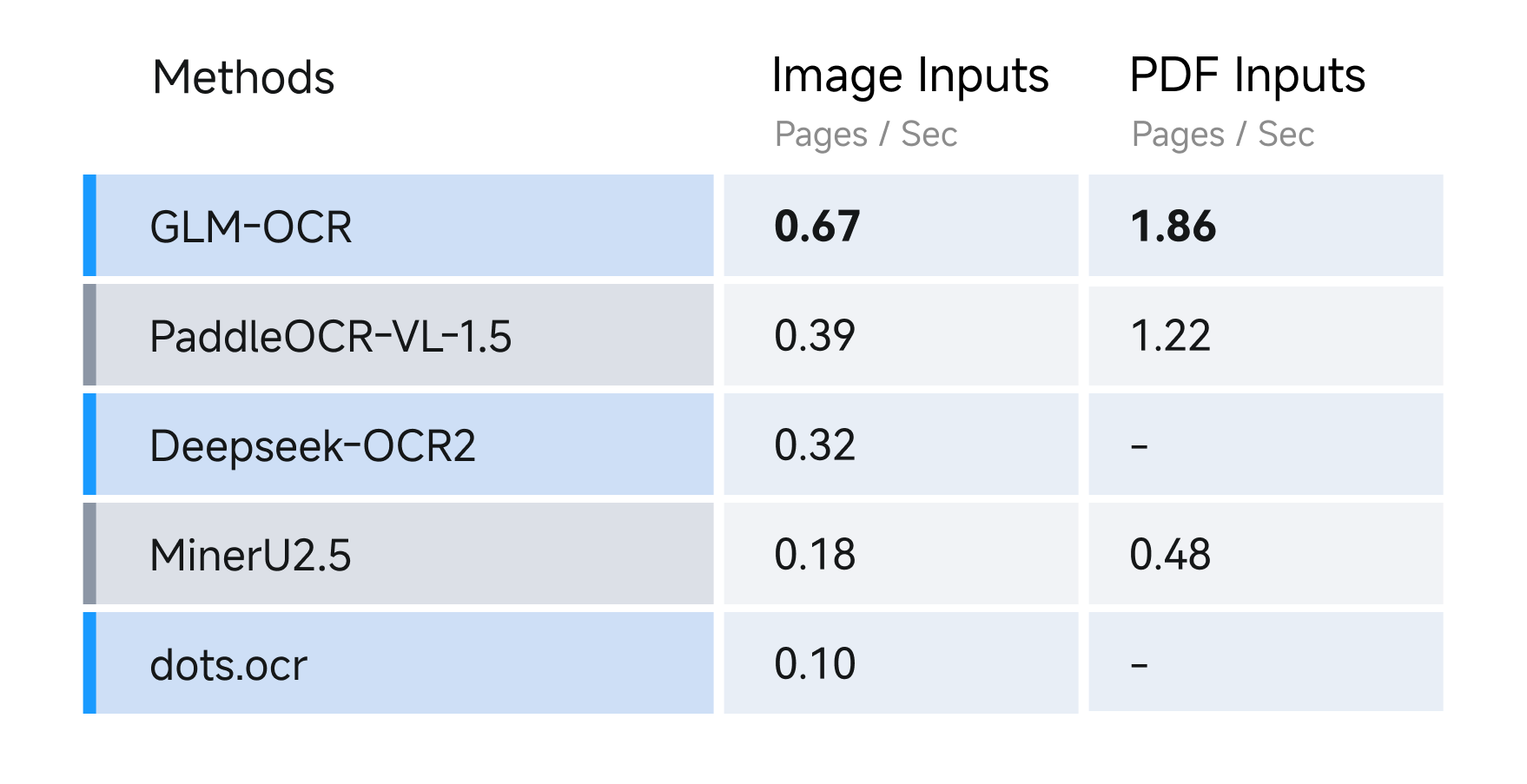
- Speed Test
For speed, we compared different OCR methods under identical hardware and testing conditions (single replica, single concurrency), evaluating their performance in parsing and exporting Markdown files from both image and PDF inputs. Results show GLM-OCR achieves a throughput of 1.86 pages/second for PDF documents and 0.67 images/second for images, significantly outperforming comparable models.
## Usage
### vLLM
1. run
```bash
pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly
```
or using docker with:
```
docker pull vllm/vllm-openai:nightly
```
2. run with:
```bash
pip install git+https://github.com/huggingface/transformers.git
vllm serve zai-org/GLM-OCR --allowed-local-media-path / --port 8080
```
### SGLang
1. using docker with:
```bash
docker pull lmsysorg/sglang:dev
```
or build it from source with:
```bash
pip install git+https://github.com/sgl-project/sglang.git#subdirectory=python
```
2. run with:
```bash
pip install git+https://github.com/huggingface/transformers.git
python -m sglang.launch_server --model zai-org/GLM-OCR --port 8080
```
### Ollama
1. Download [Ollama](https://ollama.com/download).
2. run with:
```bash
ollama run glm-ocr
```
Ollama will automatically use image file path when an image is dragged into the terminal:
```bash
ollama run glm-ocr Text Recognition: ./image.png
```
### Transformers
```
pip install git+https://github.com/huggingface/transformers.git
```
```python
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
MODEL_PATH = "zai-org/GLM-OCR"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "test_image.png"
},
{
"type": "text",
"text": "Text Recognition:"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = AutoModelForImageTextToText.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto",
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
inputs.pop("token_type_ids", None)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
```
### Prompt Limited
GLM-OCR currently supports two types of prompt scenarios:
1. **Document Parsing** – extract raw content from documents. Supported tasks include:
```python
{
"text": "Text Recognition:",
"formula": "Formula Recognition:",
"table": "Table Recognition:"
}
```
2. **Information Extraction** – extract structured information from documents. Prompts must follow a strict JSON schema. For example, to extract personal ID information:
```python
请按下列JSON格式输出图中信息:
{
"id_number": "",
"last_name": "",
"first_name": "",
"date_of_birth": "",
"address": {
"street": "",
"city": "",
"state": "",
"zip_code": ""
},
"dates": {
"issue_date": "",
"expiration_date": ""
},
"sex": ""
}
```
⚠️ Note: When using information extraction, the output must strictly adhere to the defined JSON schema to ensure downstream processing compatibility.
## GLM-OCR SDK
We provide an easy-to-use SDK for using GLM-OCR more efficiently and conveniently. please check our [github](https://github.com/zai-org/GLM-OCR) to get more detail.
## Acknowledgement
This project is inspired by the excellent work of the following projects and communities:
- [PP-DocLayout-V3](https://huggingface.co/PaddlePaddle/PP-DocLayoutV3)
- [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)
- [MinerU](https://github.com/opendatalab/MinerU)
## License
The GLM-OCR model is released under the MIT License.
The complete OCR pipeline integrates [PP-DocLayoutV3](https://huggingface.co/PaddlePaddle/PP-DocLayoutV3) for document layout analysis, which is licensed under the Apache License 2.0. Users should comply with both licenses when using this project.
|