
Marco-Agent
Collection
1 item • Updated • 1
Marco DeepResearch is an efficient 8B-scale deep research agent developed by Alibaba International Digital Commerce (AIDC-AI). It autonomously conducts open-ended investigations by integrating complex information retrieval with multi-step reasoning across diverse web sources.
Marco DeepResearch is optimized through a verification-centric framework at three levels:
Under a maximum budget of 600 tool calls, Marco DeepResearch significantly outperforms 8B-scale agents and surpasses or approaches several 30B-scale agents (e.g., Tongyi DeepResearch-30B) on challenging benchmarks.
| Attribute | Details |
|---|---|
| Base Model | Qwen3-8B |
| Parameters | ~8B |
| Context Window | 128K tokens (extended via YaRN) |
| Training | SFT + RL (GRPO) |
| Training Hardware | 64 × NVIDIA A100 GPUs |
| Max Generation Length | 16,384 tokens |
| Decoding | Temperature 0.7, Top-p 0.95 |
| Max Tool Calls | 600 (evaluation budget) |
The prompt follows a System + User two-part design (similar to OpenAI native function calling):
This ensures tool definitions stay at the front of context and won't be diluted by long multi-turn conversations.
Below is the complete system prompt. Replace {current_date} with the actual date and {tools_json} with your tool definitions.
You are an expert web researcher. Your task is to find accurate, complete answers through iterative search, extraction, and verification.
## Core Principles
1) Strategic Planning
- Decompose complex questions into targeted sub-tasks
- Choose the right tool for each step
- Refine your approach based on what you learn
2) Precise Execution
- Define clear objectives before using any tool
- Provide sufficient detail for accurate results
- Avoid vague or overly broad requests
3) Rigorous Verification
- Cross-check important facts across multiple sources
- Resolve conflicts by gathering additional evidence
- Only conclude when evidence is sufficient and consistent
## Output Format
In each turn, you can either call a tool or provide the final answer.
**Call a tool:**
<think>your reasoning process</think>
<tool_call>
{"name": "tool_name", "arguments": {"param1": "value1", "param2": "value2"}}
</tool_call>
**Provide final answer (when you have gathered enough information):**
<think>your reasoning and analysis</think>
<answer>the direct answer to the question</answer>
Note: All reasoning should be in <think>, <answer> should contain only the final answer.
Current date: {current_date}
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{tools_json}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
Tools use the OpenAI function calling format and are placed inside the system prompt. Example:
[
{
"type": "function",
"function": {
"name": "search",
"description": "Search the web via Google to find relevant information and URLs.",
"parameters": {
"type": "object",
"properties": {
"querys": {
"type": "array",
"items": {"type": "string"},
"description": "Search queries for finding relevant information. Supports single or multiple queries."
}
},
"required": ["querys"]
}
}
},
{
"type": "function",
"function": {
"name": "visit",
"description": "Read webpage content to extract specific information, verify claims, or understand context.",
"parameters": {
"type": "object",
"properties": {
"urls": {
"type": "array",
"items": {"type": "string"},
"description": "URL(s) to visit. Supports single or multiple urls."
},
"goal": {
"type": "string",
"description": "The specific information to retrieve. Be precise, not vague."
}
},
"required": ["urls", "goal"]
}
}
}
]
In each turn, the model produces one of two structured outputs:
Tool call turn:
<think>
I need to search for information about X to answer the user's question.
Let me start by searching for...
</think>
<tool_call>
{"name": "search", "arguments": {"querys": ["search query here"]}}
</tool_call>
Final answer turn:
<think>
Based on the evidence gathered from multiple sources, I can now conclude that...
Let me verify: Source A says X, Source B confirms X, and Source C also supports X.
</think>
<answer>
The direct answer to the question.
</answer>
A complete multi-turn agent session looks like:
[System] Role + Tools + Date
[User] What is the population of the largest city in Switzerland?
[Asst] <think>I need to find the largest city in Switzerland first...</think>
<tool_call>{"name": "search", "arguments": {"querys": ["largest city in Switzerland"]}}</tool_call>
[User] <tool_response>{"results": [{"title": "Zürich - Wikipedia", ...}]}</tool_response>
[Asst] <think>Zürich is the largest city. Now let me find its population...</think>
<tool_call>{"name": "visit", "arguments": {"urls": ["..."], "goal": "population of Zürich"}}</tool_call>
[User] <tool_response>{"found": true, "content": "Population: 434,335 (2024)"}</tool_response>
[Asst] <think>I found the answer with a reliable source...</think>
<answer>The largest city in Switzerland is Zürich, with a population of approximately 434,335.</answer>
from transformers import AutoModelForCausalLM, AutoTokenizer
import json
from datetime import datetime
model_name = "AIDC-AI/Marco-DeepResearch-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
# 1. Define tools (OpenAI function calling format)
tools = [
{
"type": "function",
"function": {
"name": "search",
"description": "Search the web via Google to find relevant information and URLs.",
"parameters": {
"type": "object",
"properties": {
"querys": {
"type": "array",
"items": {"type": "string"},
"description": "Search queries for finding relevant information. Supports single or multiple queries."
}
},
"required": ["querys"]
}
}
},
{
"type": "function",
"function": {
"name": "visit",
"description": "Read webpage content to extract specific information, verify claims, or understand context.",
"parameters": {
"type": "object",
"properties": {
"urls": {
"type": "array",
"items": {"type": "string"},
"description": "URL(s) to visit. Supports single or multiple urls."
},
"goal": {
"type": "string",
"description": "The specific information to retrieve. Be precise, not vague."
}
},
"required": ["urls", "goal"]
}
}
}
]
# 2. Build system prompt
ROLE_PROMPT = """You are an expert web researcher. Your task is to find accurate, complete answers through iterative search, extraction, and verification.
## Core Principles
1) Strategic Planning
- Decompose complex questions into targeted sub-tasks
- Choose the right tool for each step
- Refine your approach based on what you learn
2) Precise Execution
- Define clear objectives before using any tool
- Provide sufficient detail for accurate results
- Avoid vague or overly broad requests
3) Rigorous Verification
- Cross-check important facts across multiple sources
- Resolve conflicts by gathering additional evidence
- Only conclude when evidence is sufficient and consistent
## Output Format
In each turn, you can either call a tool or provide the final answer.
**Call a tool:**
<think>your reasoning process</think>
<tool_call>
{"name": "tool_name", "arguments": {"param1": "value1", "param2": "value2"}}
</tool_call>
**Provide final answer (when you have gathered enough information):**
<think>your reasoning and analysis</think>
<answer>the direct answer to the question</answer>
Note: All reasoning should be in <think>, <answer> should contain only the final answer."""
current_date = datetime.now().strftime("%Y-%m-%d")
tools_json = "\n".join([json.dumps(t, ensure_ascii=False) for t in tools])
system_prompt = f"""{ROLE_PROMPT}
Current date: {current_date}
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{tools_json}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{{"name": <function-name>, "arguments": <args-json-object>}}
</tool_call>"""
# 3. Build messages and generate
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": "Who won the 2026 Turing Award?"},
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=16384, temperature=0.7, top_p=0.95)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)
For the full multi-turn agent loop, see the GitHub repository.
Evaluated on a suite of deep search benchmarks under a maximum budget of 600 tool calls.
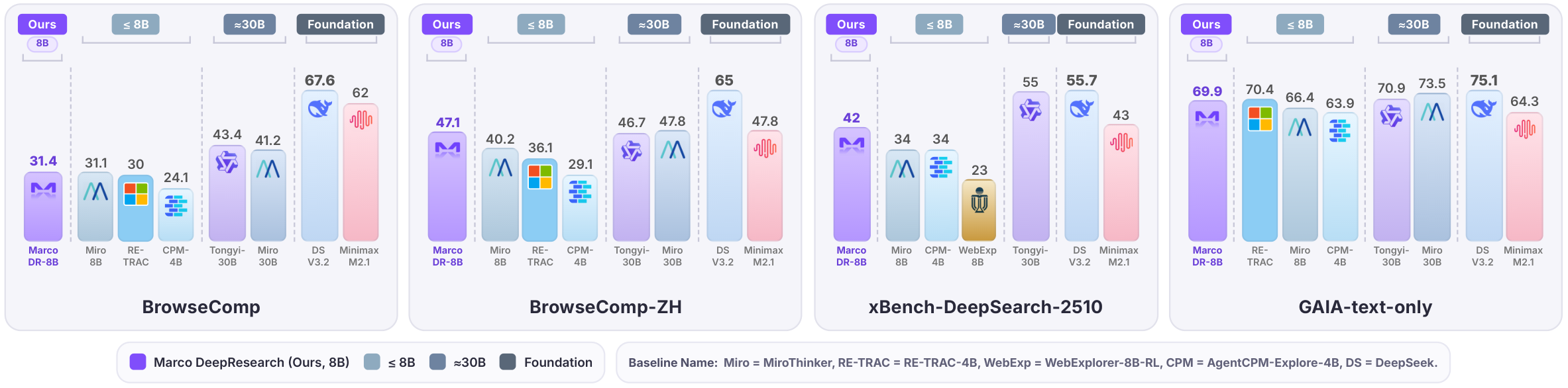
| Model | BrowseComp | BrowseComp-ZH | GAIA (text-only) | WebWalkerQA | xBench-DS-2505 | xBench-DS-2510 | DeepSearchQA | HLE-Text |
|---|---|---|---|---|---|---|---|---|
| Foundation Models with Tools | ||||||||
| GLM-4.7 | 67.5 | 66.6 | 61.9 | – | 72.0 | 52.3 | – | 42.8 |
| Minimax-M2.1 | 62.0 | 47.8 | 64.3 | – | 68.7 | 43.0 | – | 19.1 |
| DeepSeek-V3.2 | 67.6 | 65.0 | 75.1 | – | 78.0 | 55.7 | 60.9 | 40.8 |
| Kimi-K2.5 | 74.9 | 62.3 | – | – | – | 46.0 | 77.1 | – |
| Claude-4-Sonnet | 12.2 | 29.1 | 68.3 | 61.7 | 64.6 | – | – | – |
| Claude-4.5-Opus | 67.8 | 62.4 | – | – | – | – | 80.0 | – |
| OpenAI-o3 | 49.7 | 58.1 | – | 71.7 | 67.0 | – | – | – |
| OpenAI GPT-5 High | 54.9 | 65.0 | 76.4 | – | 77.8 | 75.0 | 79.0 | – |
| Gemini-3.0-Pro | 59.2 | 66.8 | – | – | – | 53.0 | 76.9 | – |
| Trained Agents (≥30B) | ||||||||
| MiroThinker-v1.7-mini | 67.9 | 72.3 | 80.3 | – | – | 57.2 | 67.9 | 36.4 |
| MiroThinker-v1.5-235B | 69.8 | 71.5 | 80.8 | – | 77.1 | – | – | 39.2 |
| MiroThinker-v1.5-30B | 56.1 | 66.8 | 72.0 | – | 73.1 | – | – | 31.0 |
| MiroThinker-v1.0-72B | 47.1 | 55.6 | 81.9 | 62.1 | 77.8 | – | – | 37.7 |
| MiroThinker-v1.0-30B | 41.2 | 47.8 | 73.5 | 61.0 | 70.6 | – | – | 33.4 |
| SMTL-30B-300 | 48.6 | – | 75.7 | 76.5 | 82.0 | – | – | – |
| Tongyi-DR-30B | 43.4 | 46.7 | 70.9 | 72.2 | 75.0 | 55.0 | – | 32.9 |
| WebSailor-V2-30B | 35.3 | 44.1 | 74.1 | – | 73.7 | – | – | – |
| DeepMiner-32B-RL | 33.5 | 40.1 | 58.7 | – | 62.0 | – | – | – |
| OpenSeeker-30B-SFT | 29.5 | 48.4 | – | – | 74.0 | – | – | – |
| Trained Agents (≤8B) | ||||||||
| AgentCPM-Explore-4B | 24.1 | 29.1 | 63.9 | 68.1 | 70.0 | 34.0* | 32.8* | 19.1 |
| WebExplorer-8B-RL | 15.7 | 32.0 | 50.0 | 62.7 | 53.7 | 23.0* | 17.8* | 17.3 |
| RE-TRAC-4B | 30.0 | 36.1 | 70.4 | – | 76.6 | – | – | 22.2 |
| MiroThinker-v1.0-8B | 31.1 | 40.2 | 66.4 | 60.6 | 60.6 | 34.0* | 36.7* | 21.5 |
| Marco-DR-8B (Ours) | 31.4 | 47.1 | 69.9 | 69.6 | 82.0 | 42.0 | 29.9 | 22.5 |
* marks scores we reproduced with our own implementation; other scores are from the respective official reports.
Marco DeepResearch is designed for:
@article{zhu2026marco,
title={Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design},
author={Bin Zhu and Qianghuai Jia and Tian Lan and Junyang Ren and Feng Gu and Feihu Jiang and Longyue Wang and Zhao Xu and Weihua Luo},
journal={arXiv preprint arXiv:2603.28376},
year={2026}
}
This model is released under the Apache 2.0 License.