
File size: 8,706 Bytes
868cbe9 94b3ead f0e0963 94b3ead 6a70fed |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 |
---
language: en
license: mit
tags:
- audio-classification
- tensorflow
- mel-spectrogram-images
- audio-processing
inference: true
datasets:
- AIOmarRehan/Mel_Spectrogram_Images_for_Audio_Classification
---
[If you would like a detailed explanation of this project, please refer to the Medium article below.](https://medium.com/@ai.omar.rehan/building-a-complete-audio-classification-pipeline-using-deep-learning-from-raw-audio-to-mel-9894bd438d85)
---
[The project is also available for testing on Hugging Face.](https://huggingface.co/spaces/AIOmarRehan/Deep_Audio_Classifier_using_CNN)
---
# Audio-Classification-Raw-Audio-to-Mel-Spectrogram-CNNs
Complete end-to-end audio classification pipeline using deep learning. From raw recordings to Mel spectrogram CNNs, includes preprocessing, augmentation, dataset validation, model training, and evaluation — a reproducible blueprint for speech, environmental, or general sound classification tasks.
---
# Audio Classification Pipeline — From Raw Audio to Mel-Spectrogram CNNs
> *“In machine learning, the model is rarely the problem — the data almost always is.”*
> — A reminder I kept repeating to myself while building this project.
This repository contains a complete, professional, end-to-end pipeline for **audio classification using deep learning**, starting from **raw, messy audio recordings** and ending with a fully trained **CNN model** using **Mel spectrograms**.
The workflow includes:
* Raw audio loading
* Cleaning & normalization
* Silence trimming
* Noise reduction
* Chunking
* Data augmentation
* Mel spectrogram generation
* Dataset validation
* CNN training
* Evaluation & metrics
It is a fully reproducible blueprint for real-world audio classification tasks.
---
# Project Structure
Here is a quick table summarizing the core stages of the pipeline:
| Stage | Description | Output |
| ----------------------- | -------------------------------------- | ---------------- |
| **1. Raw Audio** | Unprocessed WAV/MP3 files | Audio dataset |
| **2. Preprocessing** | Trimming, cleaning, resampling | Cleaned signals |
| **3. Augmentation** | Pitch shift, time stretch, noise | Expanded dataset |
| **4. Mel Spectrograms** | Converts audio → images | PNG/IMG files |
| **5. CNN Training** | Deep model learns spectrogram patterns | `.h5` model |
| **6. Evaluation** | Accuracy, F1, Confusion Matrix | Metrics + plots |
---
# 1. Loading & Inspecting Raw Audio
The dataset is loaded from directory structure:
```python
paths = [(path.parts[-2], path.name, str(path))
for path in Path(extract_to).rglob('*.*')
if path.suffix.lower() in audio_extensions]
df = pd.DataFrame(paths, columns=['class', 'filename', 'full_path'])
df = df.sort_values('class').reset_index(drop=True)
```
During EDA, I computed:
* Duration
* Sample rate
* Peak amplitude
And visualized duration distribution:
```python
plt.hist(df['duration'], bins=30, edgecolor='black')
plt.xlabel("Duration (seconds)")
plt.ylabel("Number of recordings")
plt.title("Audio Duration Distribution")
plt.show()
```
---
# 2. Audio Cleaning & Normalization
Bad samples were removed, silent files filtered, and amplitudes normalized:
```python
peak = np.abs(y).max()
if peak > 0:
y = y / peak * 0.99
```
This ensures consistency and prevents the model from learning from corrupted audio.
---
# 3. Advanced Preprocessing
Preprocessing included:
* Silence trimming
* Noise reduction
* Resampling → **16 kHz**
* Mono conversion
* 5-second chunking
```python
TARGET_DURATION = 5.0
TARGET_SR = 16000
TARGET_LENGTH = int(TARGET_DURATION * TARGET_SR)
```
Every audio file becomes a clean, consistent chunk ready for feature extraction.
---
# 4. Audio Augmentation
To improve generalization, I applied augmentations:
```python
augment = Compose([
Shift(min_shift=-0.3, max_shift=0.3, p=0.5),
PitchShift(min_semitones=-2, max_semitones=2, p=0.5),
TimeStretch(min_rate=0.8, max_rate=1.25, p=0.5),
AddGaussianNoise(min_amplitude=0.001, max_amplitude=0.015, p=0.5)
])
```
Every augmented file receives a unique name to avoid collisions.
---
# 5. Mel Spectrogram Generation
Each cleaned audio chunk is transformed into a **Mel spectrogram**:
```python
S = librosa.feature.melspectrogram(
y=y, sr=SR,
n_fft=N_FFT,
hop_length=HOP_LENGTH,
n_mels=N_MELS
)
S_dB = librosa.power_to_db(S, ref=np.max)
```
* Output: **128×128 PNG images**
* Separate directories per class
* Supports both original & augmented samples
These images become the CNN input.
### ***Example of Mel Spectrogram Images***
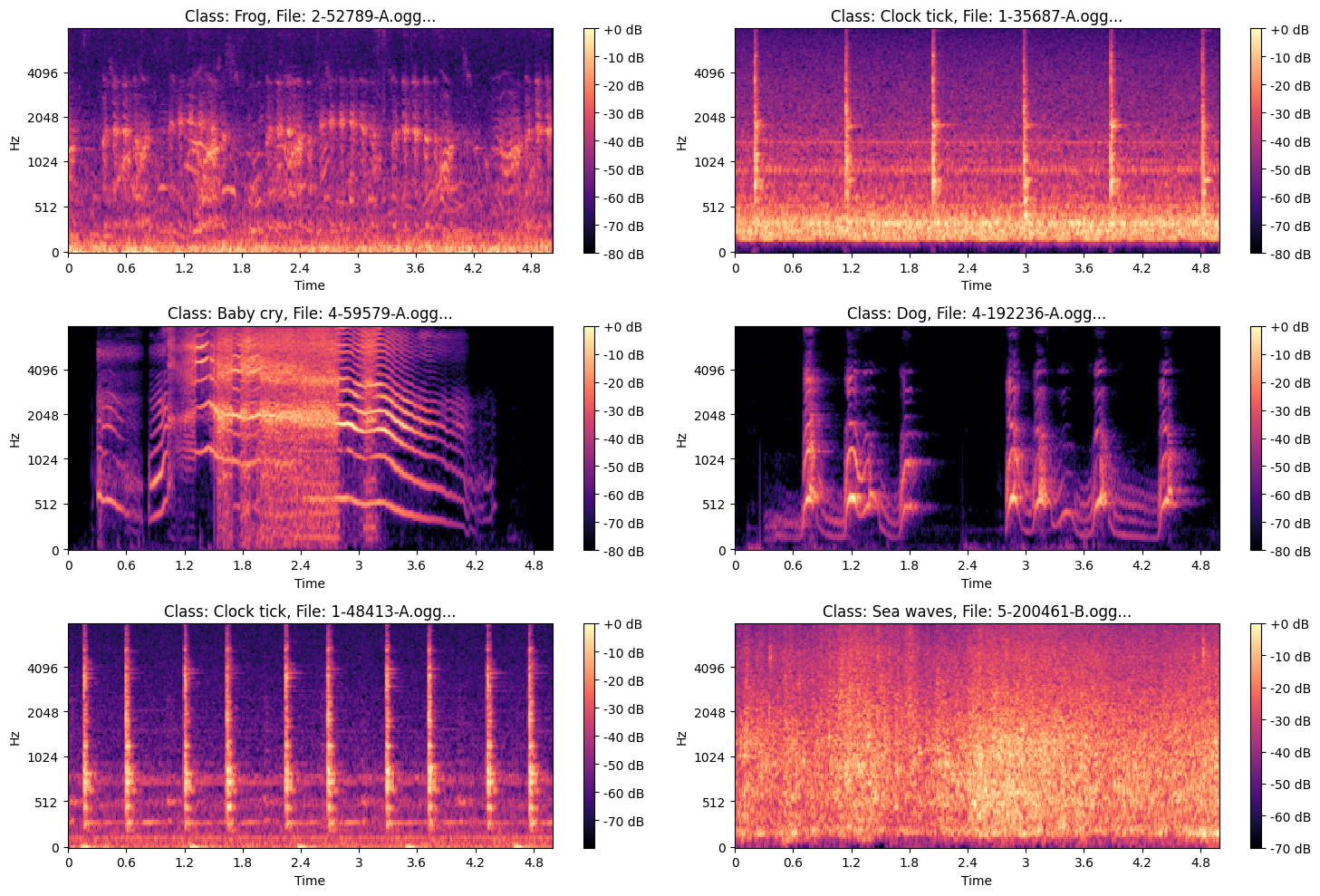
.png?generation=1763570855911665&alt=media)
---
# 6. Dataset Validation
After spectrogram creation:
* Corrupted images removed
* Duplicate hashes filtered
* Filename integrity checked
* Class folders validated
```python
df['file_hash'] = df['full_path'].apply(get_hash)
duplicate_hashes = df[df.duplicated(subset=['file_hash'], keep=False)]
```
This step ensures **clean, reliable** training data.
---
# 7. Building TensorFlow Datasets
The dataset is built with batching, caching, prefetching:
```python
train_ds = tf.data.Dataset.from_tensor_slices((train_paths, train_labels))
train_ds = train_ds.map(load_and_preprocess, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.shuffle(1024).batch(batch_size).prefetch(AUTOTUNE)
```
I used a simple image-level augmentation pipeline:
```python
data_augmentation = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(231, 232, 4)),
tf.keras.layers.RandomFlip("horizontal"),
tf.keras.layers.RandomRotation(0.1),
tf.keras.layers.RandomZoom(0.1),
])
```
---
# 8. CNN Architecture
The CNN captures deep frequency-time patterns across Mel images.
Key features:
* Multiple Conv2D + BatchNorm blocks
* Dropout
* L2 regularization
* Softmax output
```python
model = Sequential([
data_augmentation,
Conv2D(32, (3,3), padding='same', activation='relu', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
MaxPooling2D((2,2)),
Dropout(0.2),
# ... more layers ...
Flatten(),
Dense(num_classes, activation='softmax')
])
```
---
# 9. Training Strategy
```python
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=10)
early_stopping = EarlyStopping(monitor='val_loss', patience=40, restore_best_weights=True)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=50,
callbacks=[reduce_lr, early_stopping]
)
```
The model converges smoothly while avoiding overfitting.
---
# 10. Evaluation
Performance is evaluated using:
* Accuracy
* Precision, recall, F1-score
* Confusion matrix
* ROC/AUC curves
```python
y_pred = np.argmax(model.predict(test_ds), axis=1)
print(classification_report(y_true, y_pred, target_names=le.classes_))
```
Confusion matrix:
```python
sns.heatmap(confusion_matrix(y_true, y_pred), annot=True, cmap='Blues')
plt.title("Confusion Matrix")
plt.show()
```
---
# 11. Saving the Model & Dataset
```python
model.save("Audio_Model_Classification.h5")
shutil.make_archive("/content/spectrograms", 'zip', "/content/spectrograms")
```
The entire spectrogram dataset is also zipped for sharing or deployment.
---
# Final Notes
This project demonstrates:
* How to clean & prepare raw audio at a professional level
* Audio augmentation best practices
* How Mel spectrograms unlock CNN performance
* A full TensorFlow training pipeline
* Proper evaluation, reporting, and dataset integrity
If you're working on sound recognition, speech tasks, or environmental audio detection, this pipeline gives you a **complete production-grade foundation**.
---
# **Results**
> **Note:** Click the image below to view the video showcasing the project’s results.
<a href="https://files.catbox.moe/suzziy.mp4">
<img src="https://images.unsplash.com/photo-1611162616475-46b635cb6868?q=80&w=1974&auto=format&fit=crop&ixlib=rb-4.1.0&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D" width="400">
</a>
<hr style="border-bottom: 5px solid gray; margin-top: 10px;">
> **Note:** If the video above is not working, you can access it directly via the link below.
[Watch Demo Video](Results/Spectrogram_CNN_Audio_Classification.mp4)
|