
CLIPSeg[[clipseg]]
개요[[overview]]
CLIPSeg 모델은 Timo Lüddecke와 Alexander Ecker가 Image Segmentation Using Text and Image Prompts 논문에서 제안했습니다. CLIPSeg는 가중치가 고정된 CLIP 모델에 최소한의 디코더를 결합하여 제로샷 및 원샷 이미지 분할을 수행합니다.
논문 초록은 다음과 같습니다.
이미지 분할은 일반적으로 사전에 정의된 객체 클래스 집합에 대해 모델을 훈련시키는 방식으로 접근합니다. 하지만 새로운 클래스를 추가하거나 보다 복잡한 질의를 처리하려면, 해당 내용을 포함한 데이터 세트로 모델을 다시 훈련해야 하므로 비용이 많이 듭니다. 이에 본 논문에서는 테스트 시점에 텍스트나 이미지로 구성된 임의의 프롬프트만으로 이미지 분할을 수행할 수 있는 시스템을 제안합니다. 이 접근 방식을 통해 서로 다른 과제를 갖는 세 가지 주요 이미지 분할 태스크—지시 표현 분할(referring expression segmentation), 제로샷 분할(zero-shot segmentation), 원샷 분할(one-shot segmentation)—을 단일 통합 모델로 처리할 수 있습니다. 이를 위해 우리는 CLIP 모델을 백본으로 삼고, 고해상도 예측을 가능하게 하는 트랜스포머 기반 디코더를 추가해 이를 확장했습니다. 확장된 PhraseCut 데이터 세트를 활용해 훈련한 본 시스템은 자유 형식의 텍스트 프롬프트나 특정 목적을 표현하는 이미지를 입력으로 받아, 입력 이미지에 대한 이진 분할 맵을 생성합니다. 특히 이미지 기반 프롬프트의 다양한 구성 방식과 그 효과를 자세히 분석하였습니다. 이 새로운 하이브리드 입력 방식은 앞서 언급한 세 가지 태스크뿐만 아니라, 텍스트 또는 이미지로 질의할 수 있는 모든 이진 분할 문제에 유연하게 대응할 수 있습니다. 마지막으로, 본 시스템이 어포던스(affordance)나 객체 속성과 같은 일반화된 질의에도 높은 적응력을 보임을 확인하였습니다.
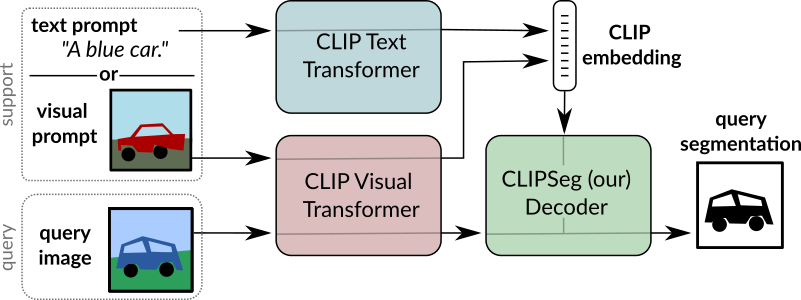
CLIPSeg 개요. 원본 논문에서 발췌.
이 모델은 nielsr님이 기여했습니다. 원본 코드는 여기에서 찾을 수 있습니다.
사용 팁[[usage-tips]]
- [
CLIPSegForImageSegmentation]은 [CLIPSegModel]과 동일한, [CLIPSegModel] 위에 디코더를 추가한 모델입니다. - [
CLIPSegForImageSegmentation]은 테스트 시점에 임의의 프롬프트를 기반으로 이미지 분할을 생성합니다. 이때 프롬프트는 텍스트(input_ids), 이미지(conditional_pixel_values), 사용자 정의 조건부 임베딩(conditional_embeddings)을 사용할 수 있습니다.
리소스[[resources]]
CLIPSeg를 시작하는 데 도움이 될 Hugging Face 공식 자료와 커뮤니티(🌎 아이콘으로 표시)의 유용한 리소스 목록을 아래에 정리했습니다. 혹시 목록에 없는 새로운 자료나 튜토리얼을 공유하고 싶으시다면, 언제든지 Pull Request를 통해 제안해 주세요. 저희가 검토 후 소중히 반영하겠습니다! 기존 자료와 중복되지 않는 새로운 내용이라면 더욱 좋습니다.
- zero-shot image segmentation with CLIPSeg을 시연하는 노트북.
CLIPSegConfig[[transformers.CLIPSegConfig]]
[[autodoc]] CLIPSegConfig
CLIPSegTextConfig[[transformers.CLIPSegTextConfig]]
[[autodoc]] CLIPSegTextConfig
CLIPSegVisionConfig[[transformers.CLIPSegVisionConfig]]
[[autodoc]] CLIPSegVisionConfig
CLIPSegProcessor[[transformers.CLIPSegProcessor]]
[[autodoc]] CLIPSegProcessor
CLIPSegModel[[transformers.CLIPSegModel]]
[[autodoc]] CLIPSegModel - forward - get_text_features - get_image_features
CLIPSegTextModel[[transformers.CLIPSegTextModel]]
[[autodoc]] CLIPSegTextModel - forward
CLIPSegVisionModel[[transformers.CLIPSegVisionModel]]
[[autodoc]] CLIPSegVisionModel - forward
CLIPSegForImageSegmentation[[transformers.CLIPSegForImageSegmentation]]
[[autodoc]] CLIPSegForImageSegmentation - forward