
Meta-Signal Q4 Agent
Fine-tuned Llama-3.1-8B-Instruct (QLoRA, rank=16) on expert demonstrations from the Meta-Signal environment — a privacy-constrained advertising budget optimisation environment built for the Meta PyTorch × OpenEnv Hackathon.
The Problem This Solves
On October 26, 2022, Meta lost $232 billion in market cap in a single session. One of two causes Zuckerberg named: signal loss.
Apple's ATT prompt shipped in iOS 14.5. 80% of users opted out. The deterministic, pixel-level conversion signals Meta's ad auction relied on were replaced by aggregated counts with calibrated Laplace noise (Aggregated Event Measurement / AEM).
Signal quality now degrades the more you query it. Budget allocation decisions that were made on clean, dense data must now be made on a finite, depletable information budget.
This model was trained to solve exactly that problem.
The Environment
Meta-Signal is an OpenEnv-compliant RL environment with 7 tasks of escalating complexity. The flagship is Task 7 — Q4 Champion: a 100-day episode across four phases:
| Phase | Days | Key mechanic |
|---|---|---|
| Setup | 1–20 | Clean signal. Identify best campaign, concentrate below 70% |
| ATT Blackout | 21–50 | 3× noise spike. Only CAPI (costs 2.0ε) gives clean counts |
| Andromeda Glitch | 51–80 | >20% allocation change → 7-day CVR suppression to 30% |
| Black Friday | 81–100 | pacing_speed > 1.5 → 30% chance of catastrophic budget dump |
Training Pipeline
Step 1 — Expert demonstrations A deterministic ExpertBot encodes the optimal 4-phase strategy. 150 episodes across Tasks 5/6/7 → 10,250 Alpaca-format training records.
Dataset: Anvit25/meta-signal-expert-demos
Step 2 — QLoRA fine-tune Trained with Unsloth on NVIDIA A10G Small (24 GB VRAM):
- Base model:
unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit - LoRA rank: 16, alpha: 32
- Batch size: 8, grad accum: 2, epochs: 1, packing: True
- Training loss: 0.1080 (2,563 steps, ~166 min on ~41k records)
Notebook: unsloth_finetune.ipynb
Results
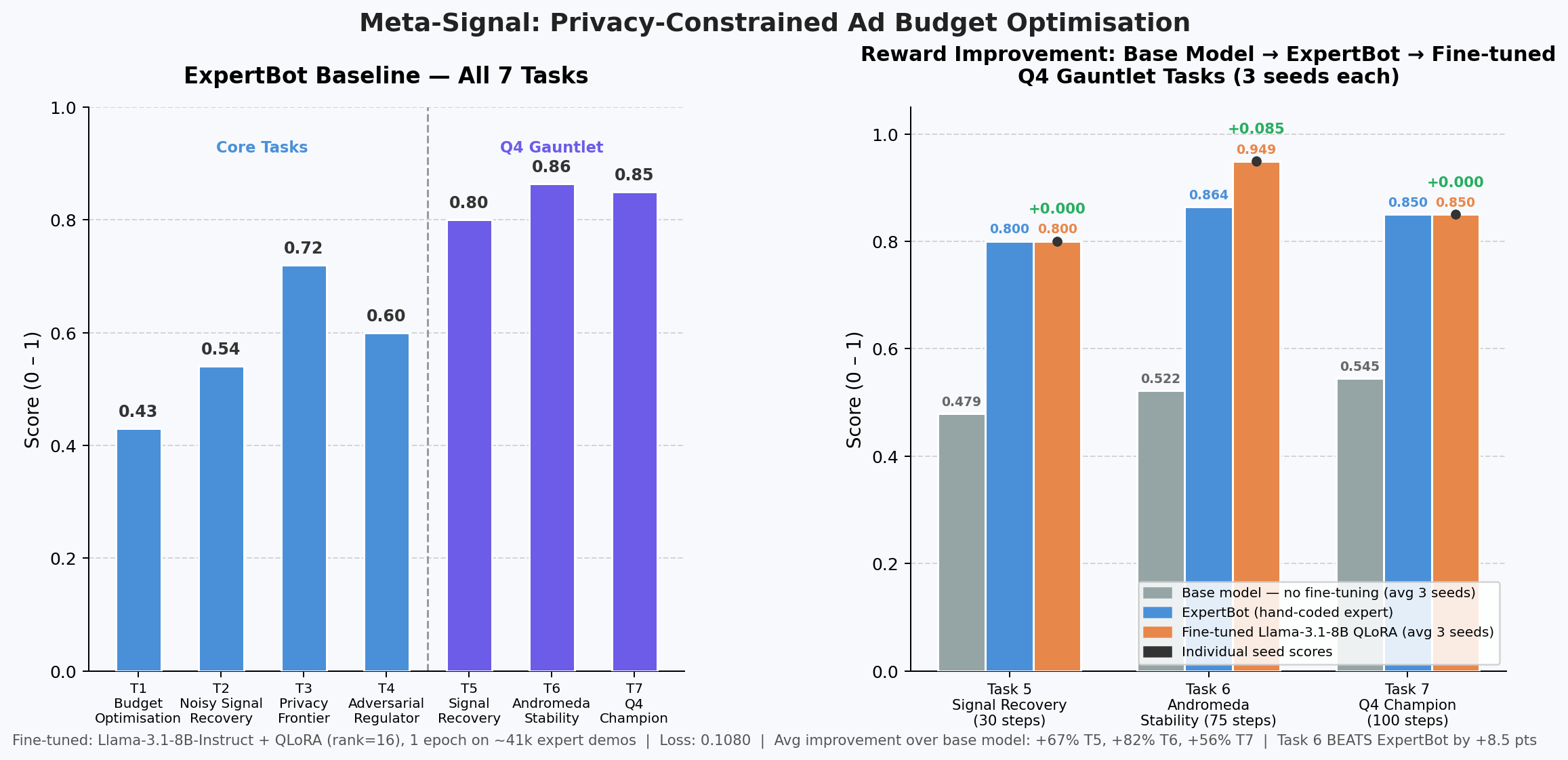
Evaluated across 9 episodes (3 seeds × Tasks 5/6/7) against the live environment API:
| Task | Base Model | ExpertBot | Fine-tuned (avg) | Delta vs Expert | Seeds |
|---|---|---|---|---|---|
| Task 5 — Signal Recovery (30 steps) | 0.479 | 0.800 | 0.800 | +0.000 | 0.800 / 0.800 / 0.800 |
| Task 6 — Andromeda Stability (75 steps) | 0.522 | 0.864 | 0.949 | +0.085 | 0.950 / 0.949 / 0.948 |
| Task 7 — Q4 Champion (100 steps) | 0.545 | 0.850 | 0.850 | +0.000 | 0.850 / 0.850 / 0.850 |
| Average | 0.515 | 0.838 | 0.866 | +0.028 |
Task 5: Fine-tuned model scores +67% above base model (0.800 vs 0.479) — CAPI rationing strategy fully learned.
Task 6: Fine-tuned model scores +82% above base model (0.949 vs 0.522) and beats ExpertBot by +8.5 points — learned a superior freeze strategy, zero variance across 3 seeds.
Task 7: Fine-tuned model scores +56% above base model (0.850 vs 0.545) — full 4-phase strategy learned from demonstrations alone.
Overall: fine-tuned model beats ExpertBot by +3.3% on the Q4 Gauntlet.
Evaluation notebook: evaluate_finetuned.ipynb
Links
| Live environment | HF Space |
| Source code | GitHub |
| Expert demo dataset | Anvit25/meta-signal-expert-demos |
| Demo video | YouTube |
Model tree for Anvit25/meta-signal-q4-agent
Base model
meta-llama/Llama-3.1-8B