
New model, who dis?

@Lewdiculous I am working on increasing Llama 3 intelligence and bench scores with a new dataset that I have curated. The model is headed to the OpenLLM queue right now. The base of this model is Unholy, so it should maintain the uncensored nature of that model (I tested it.) If this works out, I will begin applying some of the other datasets over it, although it seems pretty good as is. It's up to you if you want to quant this, but either way just want you to know we are attempting to address all issues with the Llama 3 line, with the goal of outperforming our previous Mistral based models.
I've been RPing with this thing and it is great. A real step up in my opinion. I think removing the extraneous datasets in favor of boosting intelligence has just made this a well rounded model.

Always good to hear that, been super low energy today, but hey, I'm interested.
Always good to hear that, been super low energy today, but hey, I'm interested.
No worries! I still haven't applied the format fix over this and in my testing, it is not up to your standards, but I can fix that in about 15 minutes, though probably at the expense of some braincells.
@Lewdiculous https://huggingface.co/jeiku/Chaos_RP_l3_8B this has the RP fix applied. Running a quant to test it real quick.
Ran a good bit of testing and it seems to be working perfectly. Hope you enjoy, bud.
Is this a general model? I am looking for an uncensored general model.
I made an 11.5B merge with the new dolphin but, it seems the dolphin model has some issues. As it gives responses that are too short for my liking.
@Virt-io Yes.
@jeiku Thanks mate, so the previous version with the formatting fix fairs better but still misses some spots, using the usual Llama-3 presets. Lemme get some screenshots:
Unwanted responses: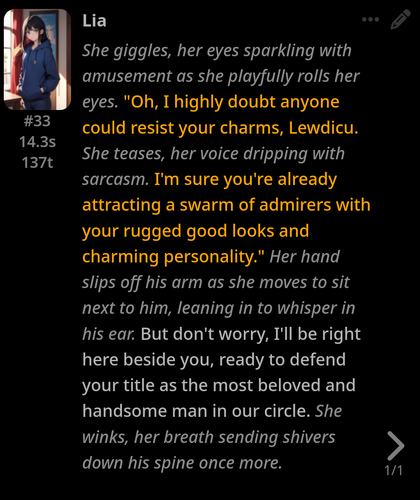
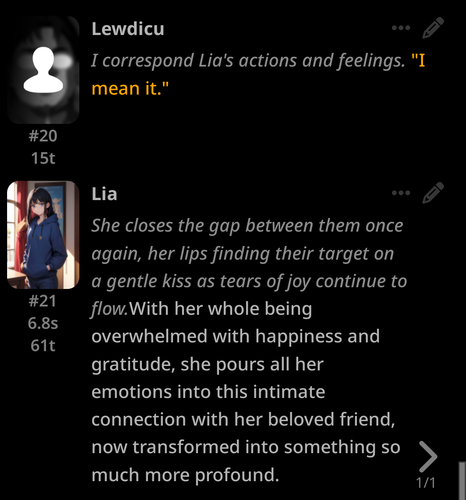
Desired responses: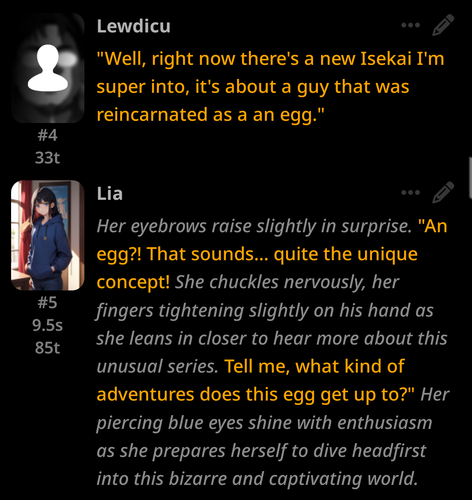
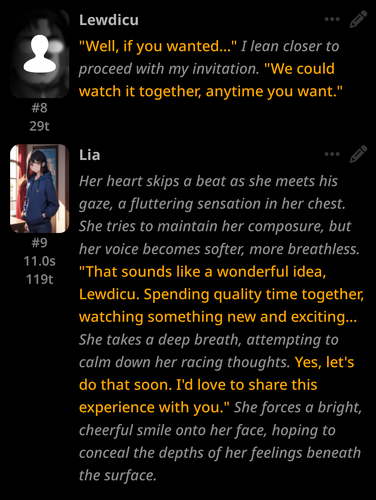
The vast majority of replies are generally coming out correctly, but it's weird since there's no plaintext anywhere in example messages (behavior: always included) or previous messages.
I'll give the new one you cooked a go.
@Lewdiculous I can confidently say that this is an issue with Llama 3 itself. The dataset I used is all clean examples with no mixed format like you've shown in these images. I wish I could fix this, but unfortunately this really is out of my control. Maybe Sanji can get it figured out with a better dataset.
Yeah, all good. This is just the beginning.
Maybe a smarter model is all that's needed. :cope: