
CLIPSeg
Overview
CLIPSeg モデルは、Timo Lüddecke, Alexander Ecker によって Image Segmentation using Text and Image Prompts で提案されました。 そしてアレクサンダー・エッカー。 CLIPSeg は、ゼロショットおよびワンショット画像セグメンテーションのために、凍結された CLIP モデルの上に最小限のデコーダを追加します。
論文の要約は次のとおりです。
画像のセグメンテーションは通常、トレーニングによって解決されます。 オブジェクト クラスの固定セットのモデル。後で追加のクラスやより複雑なクエリを組み込むとコストがかかります これらの式を含むデータセットでモデルを再トレーニングする必要があるためです。ここでシステムを提案します 任意の情報に基づいて画像セグメンテーションを生成できます。 テスト時にプロンプトが表示されます。プロンプトはテキストまたは 画像。このアプローチにより、統一されたモデルを作成できます。 3 つの一般的なセグメンテーション タスクについて (1 回トレーニング済み) 参照式のセグメンテーション、ゼロショット セグメンテーション、ワンショット セグメンテーションという明確な課題が伴います。 CLIP モデルをバックボーンとして構築し、これをトランスベースのデコーダで拡張して、高密度なデータ通信を可能にします。 予測。の拡張バージョンでトレーニングした後、 PhraseCut データセット、私たちのシステムは、フリーテキスト プロンプトまたは クエリを表す追加の画像。後者の画像ベースのプロンプトのさまざまなバリエーションを詳細に分析します。 この新しいハイブリッド入力により、動的適応が可能になります。 前述の 3 つのセグメンテーション タスクのみですが、 テキストまたは画像をクエリするバイナリ セグメンテーション タスクに 定式化することができる。最後に、システムがうまく適応していることがわかりました アフォーダンスまたはプロパティを含む一般化されたクエリ
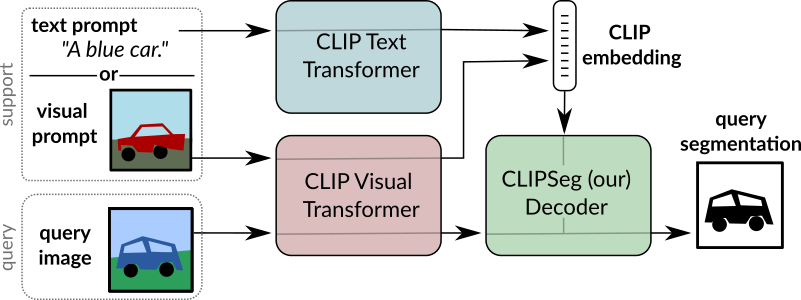
CLIPSeg の概要。 元の論文から抜粋。
このモデルは、nielsr によって提供されました。 元のコードは ここ にあります。
Usage tips
- [
CLIPSegForImageSegmentation] は、[CLIPSegModel] の上にデコーダを追加します。後者は [CLIPModel] と同じです。 - [
CLIPSegForImageSegmentation] は、テスト時に任意のプロンプトに基づいて画像セグメンテーションを生成できます。プロンプトはテキストのいずれかです (input_idsとしてモデルに提供される) または画像 (conditional_pixel_valuesとしてモデルに提供される)。カスタムを提供することもできます 条件付き埋め込み (conditional_embeddingsとしてモデルに提供されます)。
Resources
CLIPSeg の使用を開始するのに役立つ、公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
- CLIPSeg を使用したゼロショット画像セグメンテーション を説明するノートブック。
CLIPSegConfig
[[autodoc]] CLIPSegConfig - from_text_vision_configs
CLIPSegTextConfig
[[autodoc]] CLIPSegTextConfig
CLIPSegVisionConfig
[[autodoc]] CLIPSegVisionConfig
CLIPSegProcessor
[[autodoc]] CLIPSegProcessor
CLIPSegModel
[[autodoc]] CLIPSegModel - forward - get_text_features - get_image_features
CLIPSegTextModel
[[autodoc]] CLIPSegTextModel - forward
CLIPSegVisionModel
[[autodoc]] CLIPSegVisionModel - forward
CLIPSegForImageSegmentation
[[autodoc]] CLIPSegForImageSegmentation - forward