
MeditronFO
Collection
The first fully open medical specialist LLM, outperforms Medgemma on open-ended clinical evaluation • 9 items • Updated • 1
👋 Join our LiGHT community.
📖 Check out the MeditronFO blog and MeditronFO preprint.
🔜 If you are a clinician join the MOOVE initiative here.
[Hugging Face]
[Preprint]
[GitHub]
[Dataset]
License: Apache 2.0 | Authors: LiGHT
We're introducing EuroLLM-9B-MeditronFO, our latest small medical specialist LLM, medical specialization of EuroLLM-9B-Instruct on the Fully Open Meditron Corpus. This model is part of the Fully Open Meditron family — the first end-to-end auditable pipeline for clinical LLMs, with open weights, open data, open training recipe, and clinician-vetted corpus construction.
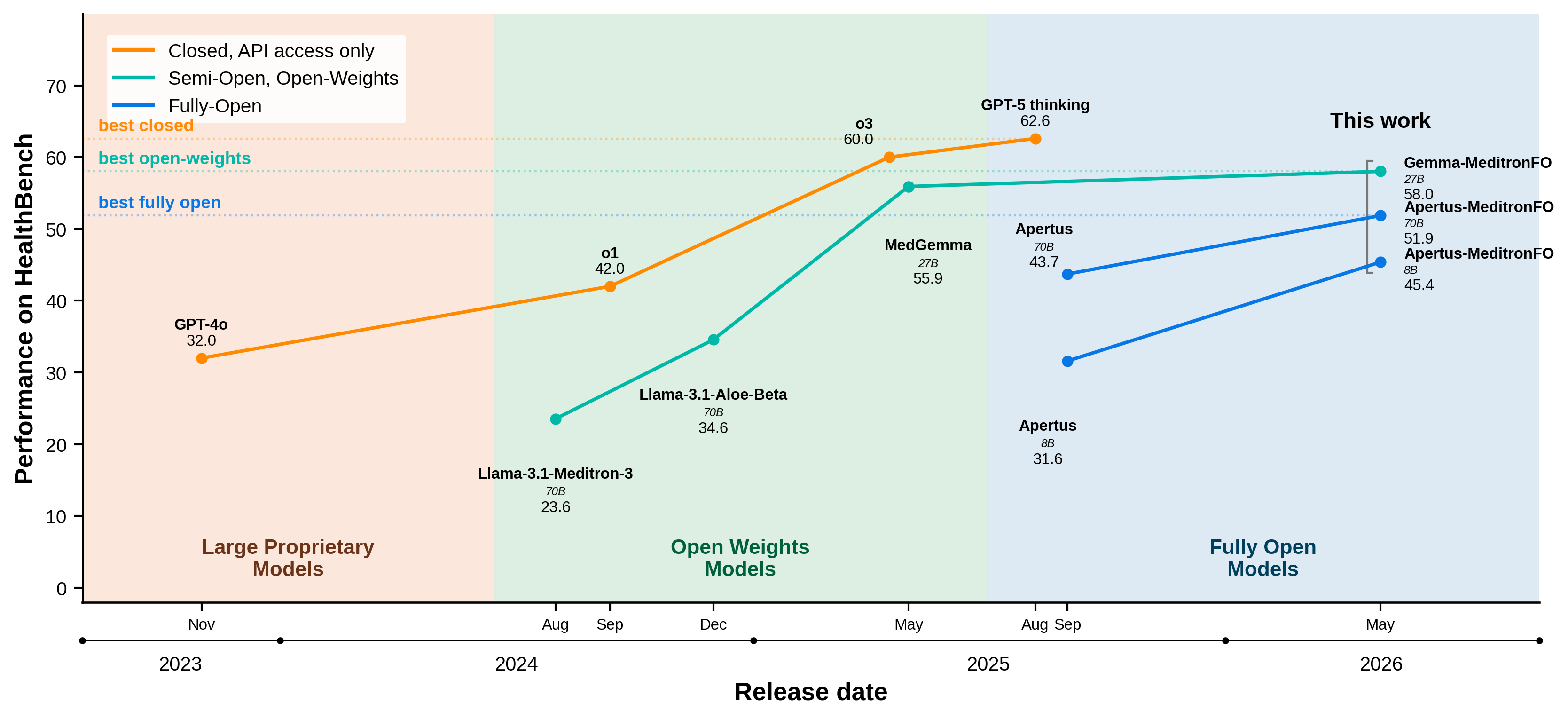
Accuracy (%) on standard medical benchmarks. See the paper for full evaluation details, confidence intervals, and open-ended Auto-MOOVE results.
| Benchmark | EuroLLM-9B-Instruct | EuroLLM-9B-MeditronFO | Δ |
|---|---|---|---|
| MedMCQA | 37.84 | 46.98 | +9.14 |
| MedQA | 48.55 | 49.73 | +1.18 |
| PubMedQA | 40.00 | 67.40 | +27.40 |
| MedXpertQA | 10.33 | 11.63 | +1.30 |
| HealthBench Hard | 13.47 | 31.62 | +18.15 |
| Average | 30.04 | 41.47 | +11.43 |
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "EPFLiGHT/EuroLLM-9B-MeditronFO"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "user", "content": "A 62-year-old woman presents with a three-day history of dyspnea on exertion and a productive cough. What is the differential diagnosis?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=False)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True))
Full hyperparameters are in Appendix I of the paper.
The training was done on 8 nodes of 4 NVIDIA GH200 GPUs for approximately 6 hours on the CSCS Swiss National Supercomputing Centre. Our trainings have a carbon neutral footprint as the CSCS data center is carbon neutral (CSCS energy efficiency).
MeditronFO can produce text on a variety of topics, but the generated content may not always be factually accurate, logically consistent, or free from biases present in the training data. MeditronFO has been trained to be specialised for Medicine and is intended to be used for Medicine related tasks evaluation. These models should be used as assistive tools rather than definitive sources of information. Users should always verify important information and critically evaluate any generated content.
If you find MeditronFO useful in your research, please cite our preprint:
@misc{theimerlienhard2026fullyopenmeditronauditable,
title = {Fully Open Meditron: An Auditable Pipeline for Clinical LLMs},
author = {Xavier Theimer-Lienhard and Mushtaha El-Amin and Fay Elhassan and Sahaj Vaidya and Victor Cartier-Negadi and David Sasu and Lars Klein and Mary-Anne Hartley},
year = {2026},
eprint = {2605.16215},
archivePrefix = {arXiv},
primaryClass = {cs.AI},
url = {https://arxiv.org/abs/2605.16215}
}
Please use the community tab for any discussions or issue related to this model. Questions related to the project can be sent to xavier.theimer-lienhard@epfl.ch or mary-anne.hartley@epfl.ch.