
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,4 +1,161 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
---
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
license: other
|
| 6 |
+
pipeline_tag: image-text-to-text
|
| 7 |
+
tags:
|
| 8 |
+
- robotics
|
| 9 |
+
- vision-language-model
|
| 10 |
+
- embodied-ai
|
| 11 |
+
- manipulation
|
| 12 |
+
- qwen2-vl
|
| 13 |
+
library_name: transformers
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# Embodied-R1-3B-v1
|
| 17 |
+
|
| 18 |
+
**Embodied-R1: Reinforced Embodied Reasoning for General Robotic Manipulation (ICLR 2026)**
|
| 19 |
+
|
| 20 |
+
[[🌐 Project Website](https://embodied-r1.github.io)] [[📄 Paper](http://arxiv.org/abs/2508.13998)] [[🏆 ICLR2026
|
| 21 |
+
Version](https://openreview.net/forum?id=i5wlozMFsQ)] [[🎯 Dataset](https://huggingface.co/datasets/IffYuan/Embodied-R1-Dataset)] [[📦
|
| 22 |
+
Code](https://github.com/pickxiguapi/Embodied-R1)]
|
| 23 |
+
|
| 24 |
+
---
|
| 25 |
+
|
| 26 |
+
## Model Details
|
| 27 |
+
|
| 28 |
+
### Model Description
|
| 29 |
+
|
| 30 |
+
**Embodied-R1** is a 3B vision-language model (VLM) for general robotic manipulation.
|
| 31 |
+
It introduces a **Pointing** mechanism and uses **Reinforced Fine-tuning (RFT)** to bridge perception and action, with strong zero-shot
|
| 32 |
+
generalization in embodied tasks.
|
| 33 |
+
|
| 34 |
+
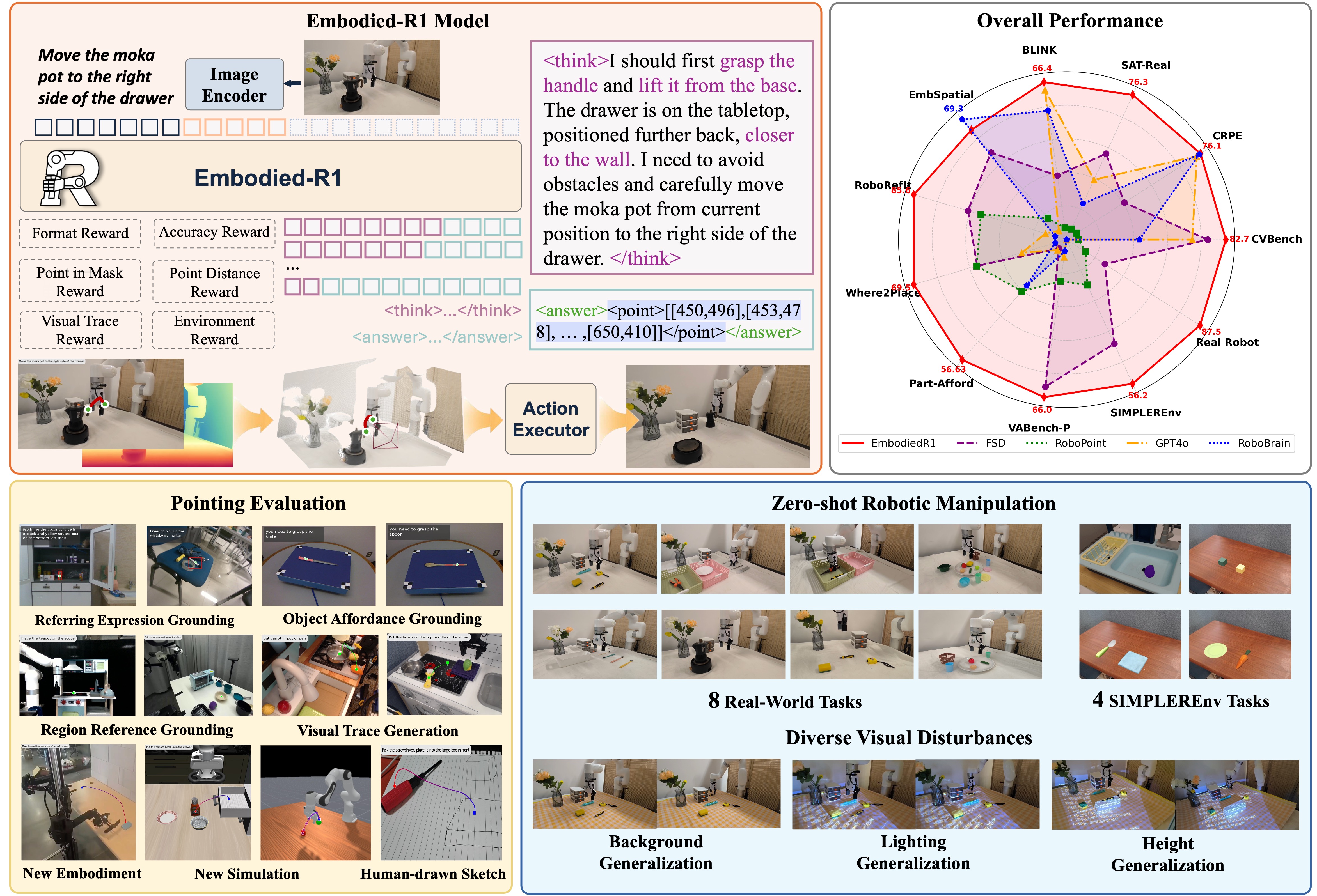
|
| 35 |
+
*Figure: Embodied-R1 framework, performance overview, and zero-shot manipulation demos.*
|
| 36 |
+
|
| 37 |
+
### Model Sources
|
| 38 |
+
|
| 39 |
+
- **Repository:** https://github.com/pickxiguapi/Embodied-R1
|
| 40 |
+
- **Paper:** http://arxiv.org/abs/2508.13998
|
| 41 |
+
- **OpenReview:** https://openreview.net/forum?id=i5wlozMFsQ
|
| 42 |
+
|
| 43 |
+
### Updates
|
| 44 |
+
|
| 45 |
+
- **[2026-03]** VABench-P / VABench-V released:
|
| 46 |
+
[VABench-P](https://huggingface.co/datasets/IffYuan/VABench-P), [VABench-V](https://huggingface.co/datasets/IffYuan/vabench-v)
|
| 47 |
+
- **[2026-03-03]** Embodied-R1 dataset released:
|
| 48 |
+
https://huggingface.co/datasets/IffYuan/Embodied-R1-Dataset
|
| 49 |
+
- **[2026-01-27]** Accepted by ICLR 2026
|
| 50 |
+
- **[2025-08-22]** Embodied-R1-3B-v1 checkpoint released
|
| 51 |
+
|
| 52 |
+
---
|
| 53 |
+
|
| 54 |
+
## Intended Uses
|
| 55 |
+
|
| 56 |
+
### Direct Use
|
| 57 |
+
|
| 58 |
+
This model is intended for **research and benchmarking** in embodied reasoning and robotic manipulation tasks, including:
|
| 59 |
+
- Visual target grounding (VTG)
|
| 60 |
+
- Referring region grounding (RRG/REG-style tasks)
|
| 61 |
+
- Open-form grounding (OFG)
|
| 62 |
+
|
| 63 |
+
### Out-of-Scope Use
|
| 64 |
+
|
| 65 |
+
- Safety-critical real-world deployment without additional safeguards and validation
|
| 66 |
+
- Decision-making in high-risk domains
|
| 67 |
+
- Any use requiring guaranteed robustness under distribution shift
|
| 68 |
+
|
| 69 |
+
---
|
| 70 |
+
|
| 71 |
+
## How to Use
|
| 72 |
+
|
| 73 |
+
### Setup
|
| 74 |
+
|
| 75 |
+
```bash
|
| 76 |
+
git clone https://github.com/pickxiguapi/Embodied-R1.git
|
| 77 |
+
cd Embodied-R1
|
| 78 |
+
|
| 79 |
+
conda create -n embodied_r1 python=3.11 -y
|
| 80 |
+
conda activate embodied_r1
|
| 81 |
+
|
| 82 |
+
pip install transformers==4.51.3 accelerate
|
| 83 |
+
pip install qwen-vl-utils[decord]
|
| 84 |
+
|
| 85 |
+
Inference
|
| 86 |
+
|
| 87 |
+
python inference_example.py
|
| 88 |
+
|
| 89 |
+
Example Tasks
|
| 90 |
+
|
| 91 |
+
- VTG: put the red block on top of the yellow block
|
| 92 |
+
- RRG: put pepper in pan
|
| 93 |
+
- REG: bring me the camel model
|
| 94 |
+
- OFG: loosening stuck bolts
|
| 95 |
+
|
| 96 |
+
(Visualization examples are available in the project repo: assets/)
|
| 97 |
+
|
| 98 |
+
---
|
| 99 |
+
Evaluation
|
| 100 |
+
|
| 101 |
+
cd eval
|
| 102 |
+
python hf_inference_where2place.py
|
| 103 |
+
python hf_inference_vabench_point.py
|
| 104 |
+
...
|
| 105 |
+
|
| 106 |
+
Related benchmarks:
|
| 107 |
+
- Embodied-R1-Dataset
|
| 108 |
+
- VABench-P
|
| 109 |
+
- VABench-V
|
| 110 |
+
|
| 111 |
+
---
|
| 112 |
+
Training
|
| 113 |
+
|
| 114 |
+
Training scripts are available at:
|
| 115 |
+
https://github.com/pickxiguapi/Embodied-R1/tree/main/scripts
|
| 116 |
+
|
| 117 |
+
# Stage 1 training
|
| 118 |
+
bash scripts/stage_1_embodied_r1.sh
|
| 119 |
+
|
| 120 |
+
# Stage 2 training
|
| 121 |
+
bash scripts/stage_2_embodied_r1.sh
|
| 122 |
+
|
| 123 |
+
Key files:
|
| 124 |
+
- scripts/config_stage1.yaml
|
| 125 |
+
- scripts/config_stage2.yaml
|
| 126 |
+
- scripts/stage_1_embodied_r1.sh
|
| 127 |
+
- scripts/stage_2_embodied_r1.sh
|
| 128 |
+
- scripts/model_merger.py (checkpoint merging + HF export)
|
| 129 |
+
|
| 130 |
+
---
|
| 131 |
+
Limitations
|
| 132 |
+
|
| 133 |
+
- Performance may vary across environments, camera viewpoints, and unseen object domains.
|
| 134 |
+
- Outputs are generated from visual-language reasoning and may include localization/action errors.
|
| 135 |
+
- Additional system-level constraints (calibration, motion planning, safety checks) are required for real robot deployment.
|
| 136 |
+
|
| 137 |
+
---
|
| 138 |
+
Citation
|
| 139 |
+
|
| 140 |
+
@article{yuan2026embodied,
|
| 141 |
+
title={Embodied-r1: Reinforced embodied reasoning for general robotic manipulation},
|
| 142 |
+
author={Yuan, Yifu and Cui, Haiqin and Huang, Yaoting and Chen, Yibin and Ni, Fei and Dong, Zibin and Li, Pengyi and Zheng, Yan and
|
| 143 |
+
Tang, Hongyao and Hao, Jianye},
|
| 144 |
+
journal={The Fourteenth International Conference on Learning Representations},
|
| 145 |
+
year={2026}
|
| 146 |
+
}
|
| 147 |
+
|
| 148 |
+
@article{yuan2026seeing,
|
| 149 |
+
title={From seeing to doing: Bridging reasoning and decision for robotic manipulation},
|
| 150 |
+
author={Yuan, Yifu and Cui, Haiqin and Chen, Yibin and Dong, Zibin and Ni, Fei and Kou, Longxin and Liu, Jinyi and Li, Pengyi and
|
| 151 |
+
Zheng, Yan and Hao, Jianye},
|
| 152 |
+
journal={The Fourteenth International Conference on Learning Representations},
|
| 153 |
+
year={2026}
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
---
|
| 157 |
+
Acknowledgements
|
| 158 |
+
|
| 159 |
+
If this model or resources are useful for your research, please consider citing our work and starring the repository.
|
| 160 |
+
|
| 161 |
+
---
|