
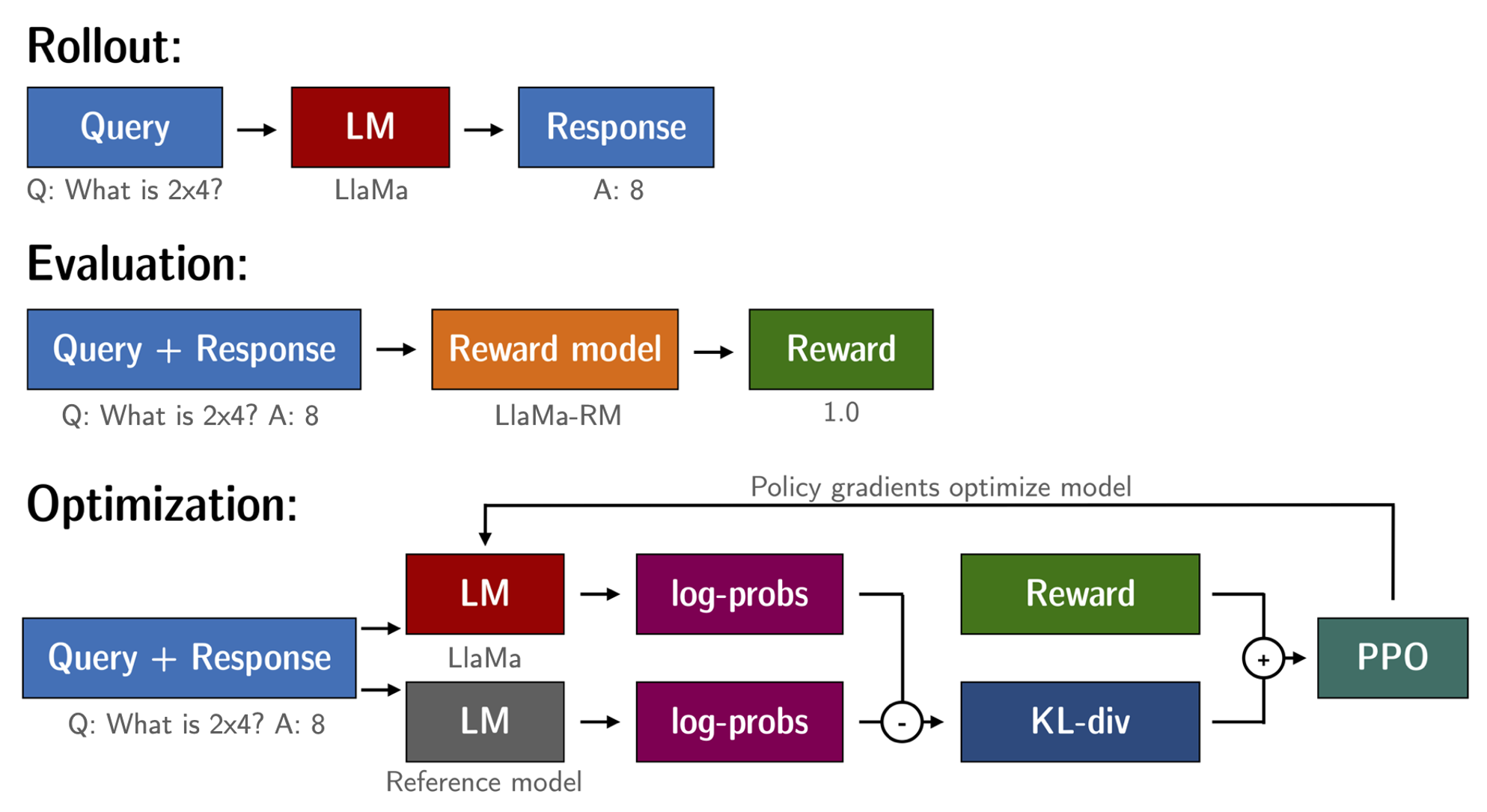
| # RLHF (Reinforcement Learning from Human Feedback)流程 | |
| 1. 首先采用监督学习的方式,使用人工标注的数据在预训练语言模型的基础上进行微调,得到一个初步的语言模型。 | |
| 2. 然后收集人工反馈的数据,这些数据包含人工生成的文本及人工给出的评分。利用这些带评分的数据训练一个reward模型。 | |
| 3. 最后,利用reward模型产生的奖励信号,采用强化学习的方式对第1步得到的语言模型进行优化。在这个步骤中,会生成大量文本,并采用reward模型给出的奖励进行更新。 | |
| 所以整体流程分为监督微调、训练reward模型和强化学习三个阶段。首先利用有限的人工标注数据得到一个初步模型,然后利用更多的人工反馈文本训练reward模型,最后利用强化学习和reward模型的反馈不断优化和提高语言模型。 | |
|  | |
| **Usage** | |
| # 环境配置 | |
| git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git | |
| conda create -n chatglm_etuning python=3.10 | |
| conda activate chatglm_etuning | |
| cd ChatGLM-Efficient-Tuning | |
| pip install -r requirements.txt | |
| # 终端输入 | |
| CUDA_VISIBLE_DEVICES=0 python src/infer.py \ | |
| --checkpoint_dir path_to_checkpoint # repo files | |
| # PPO训练,创建文件夹path_to_rm_checkpoint,将此repo的文件存入其中,运行下列命令,3090预估50小时 | |
| CUDA_VISIBLE_DEVICES=0 python src/train_ppo.py \ | |
| --do_train \ | |
| --dataset alpaca_gpt4_en \ | |
| --finetuning_type lora \ | |
| --reward_model path_to_rm_checkpoint \ | |
| --output_dir path_to_ppo_checkpoint \ | |
| --per_device_train_batch_size 4 \ | |
| --gradient_accumulation_steps 4 \ | |
| --lr_scheduler_type cosine \ | |
| --logging_steps 10 \ | |
| --save_steps 1000 \ | |
| --learning_rate 5e-5 \ | |
| --num_train_epochs 1.0 \ | |
| --fp16 | |
| # https://chatglm.cn/login_v2?md5=Y2t6Vk81QXFCV09FeE1xQTVSVVM4dz09 |