| <p align="center"> |
| <h1 align="center">FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning</h1> |
|
|
| <p align="center"> |
| <a href="https://fapo-rl.github.io/"><img alt="Project Page" src="https://img.shields.io/badge/📒-Project Page-blue"></a> |
| <a href="https://verl.readthedocs.io/en/latest/advance/reward_loop.html"><img alt="Infra Design" src="https://img.shields.io/badge/🏗️-Infra Design-teal"> |
| <a href="https://huggingface.co/collections/dyyyyyyyy/fapo"><img alt="Resources" src="https://img.shields.io/badge/🤗 HuggingFace-Data & Models-green"></a> |
| <a href="https://arxiv.org/abs/2510.22543"><img alt="Paper" src="https://img.shields.io/badge/📄-Arxiv Paper-orange"></a> |
| <a href="https://github.com/yyDing1/FAPO"><img alt="Code" src="https://img.shields.io/badge/💻-Code-blueviolet"></a> |
| </p> |
| |
| This example include a runnable and fully reproducible example that demonstrates how to use reward model to optimize a policy. |
|
|
| ## Quick start |
|
|
| First construct the training and evaluation datasets by: |
|
|
| ```bash |
| python examples/fapo_trainer/prepare_data.py --local_dir ${RAY_DATA_HOME}/data/ |
| ``` |
|
|
| Or you can directly use the data available [here](https://huggingface.co/datasets/dyyyyyyyy/FAPO-Reasoning-Dataset). |
|
|
| To integrate the GRM into the final training, we provide two options: |
|
|
| 1. **Colocate Mode:** The reward model is colocated with the trainer and runs synchronously. |
| 2. **Standalone Mode:** A separate resource pool is allocated to deploy the GenRM, which runs asynchronously. |
|
|
| The following list the most-relevant parameters in the config file: |
|
|
| ```yaml |
| reward: |
| reward_model: |
| model_path: "/path/to/your/reward_model" # your reward model path |
| # whether to enable resource pool for the reward model |
| # True -> Standalone Mode, False -> Colocate Mode |
| enable_resource_pool: True |
| # the number of nodes to deploy the reward model |
| # only effective when enable_resource_pool is True |
| nnodes: 1 |
| # the number of GPUs to deploy the reward model on each node |
| # only effective when enable_resource_pool is True |
| n_gpus_per_node: 8 |
| # inference engine configs, similar to those in rollout configs |
| rollout: |
| # set to True in colocate mode, False in standalone mode |
| free_cache_engine: True |
| # ... (ommitted) |
| |
| # customized reward function, where user should implement the invocation logic |
| # of the specified reward model (both generative and discriminative) |
| custom_reward_function: |
| path: null |
| name: compute_score |
| |
| ``` |
|
|
|  |
|
|
| ## Choice 1: Colocate Reward Model |
|
|
| ```bash |
| cd verl # Repo root |
| export RAY_ADDRESS="..." # The Ray cluster address to connect to |
| export WORKING_DIR="${PWD}" # The local directory to package to the Ray cluster |
| export NNODES=xxx |
| |
| bash examples/fapo_trainer/run_qwen_7b_rm_colocate.sh # 7b fapo model |
| bash examples/fapo_trainer/run_qwen_32b_rm_colocate.sh # 32b fapo model |
| ``` |
|
|
| ## Choice 2: Standalone Reward Model |
|
|
| ```bash |
| cd verl # Repo root |
| export RAY_ADDRESS="..." # The Ray cluster address to connect to |
| export WORKING_DIR="${PWD}" # The local directory to package to the Ray cluster |
| export NNODES=xxx # for actor/rollout/trainer |
| export RM_NODES=xxx # for standalone reward model |
| |
| bash examples/fapo_trainer/run_qwen_7b_rm_standalone.sh # 7b fapo model |
| bash examples/fapo_trainer/run_qwen_32b_rm_standalone.sh # 32b fapo model |
| ``` |
|
|
| ## Results |
|
|
| Compared with baseline (no reward model), FAPO significantly improves the reasoning ability of the model. |
|
|
| 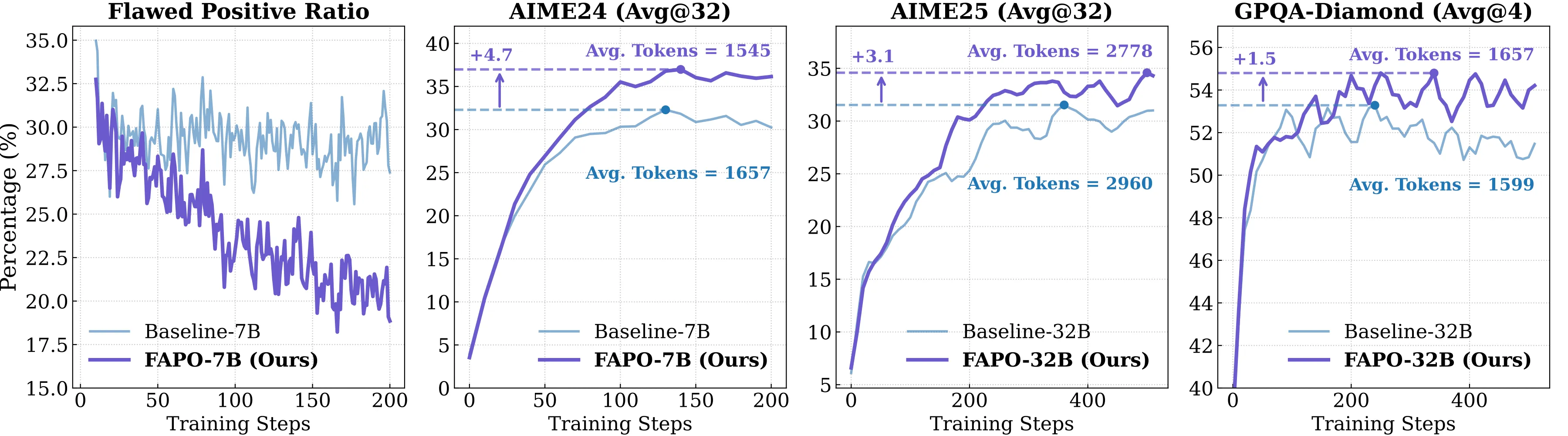 |
|
|
| ## Use discriminative reward model |
|
|
| If you would like to use discriminative reward models, the usage is essentially similar to GenRM. You only need to replace the "/v1/chat/completions" endpoint in the custom reward function with the reward model's endpoint. |
|
|
| We provide a standard way to compute the DisRM reward score, with the implementation in `RewardLoopWorker::compute_score_disrm`. |
|
|
| You can enable this computation method by not specifying a custom reward function. |
|
|
| ## More complex reward model scenarios |
|
|
| Both GenRM and DisRM can obtain reward scores via HTTP requests in the custom reward function. |
| This allows users to flexibly combine rule-based rewards with reward models to construct more sophisticated reward logic. |
|
|
| For more detailed usage instructions and infrastructure design, please refer to the [Reward Loop](https://verl.readthedocs.io/en/latest/advance/reward_loop.html) document. |
|
|
| ## Citation |
|
|
| If you find our works useful for your research, please consider citing: |
|
|
| ```bibtex |
| @article{ding2025fapo, |
| title={FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning}, |
| author={Ding, Yuyang and Zhang, Chi and Li, Juntao and Lin, Haibin and Zhang, Min}, |
| journal={arXiv preprint arXiv:2510.22543}, |
| year={2025} |
| } |
| ``` |
