
Med-Asagi
Collection
2 items • Updated
Med-Asagi は、日本語の医療画像理解を目的として構築した大規模視覚言語モデル(VLM)です。
医療画像と日本語テキストを統合して扱うことができ、画像に対する質問応答や読影支援のようなタスクに利用できます。
本モデルは、医療分野で利用しやすいオープンな日本語医療 VLMの実現を目的として開発されました。ベースアーキテクチャには LLaVA 系の構成を採用し、画像エンコーダに SigLIP、日本語医療 LLM をテキストデコーダとして組み合わせています。総パラメータ数は約 14B です。
本モデルは開発途中のプロトタイプ(ベータ版)です。現時点では性能が十分でない可能性がある点にご注意ください。
言語処理学会の投稿後にモデルの改変(公開可能モデルに変更・学習方法変更)を行ったため、発表した内容とは異なります。そのため、発表内容が再現しないことがありますことをご了解ください。 変更点は以下の3つです。
本研究では、通常の応答のみを生成するモデルに加えて、<description> と <thinking> を含む推論過程を出力するモデルを構築しています。ここで公開しているのは 推論ありモデル です。
日本語の医療画像テキスト対データは公開規模が限られているため、本モデルでは既存の英語医療データをもとに、日本語の大規模学習データを構築しました。 全学習データはMIL-UT/Japanese-Medical-VQA-12mにて公開しています。
最終的に、Stage1, 2 用のキャプションデータとして 12,125,556 件、Stage3 用の VQA データとして 12,125,203 件を用いています。
本モデルは LLaVA ベースのエンコーダ・デコーダ型 VLM です。
| Model components | Model | Parameters |
|---|---|---|
| Image encoder | google/siglip2-so400m-patch16-512 | 428,772,800 |
| Projectpr | 2層 MLP | 64,240,640 |
| LLM | SIP-med-LLM/SIP-jmed-llm-3-13b-OP-4k-base | 13,707,924,480 |
| 合計 | 14,200,937,920 |
学習は 3段階で行っています。
| Stage | 学習対象 | 訓練データ |
|---|---|---|
| Stage1 | プロジェクター層 | Image + Caption |
| Stage2 | プロジェクター層, テキストデコーダ | Image + Enriched caption |
| Stage3 | プロジェクター層, テキストデコーダ | Image + VQA |
学習には Megatron-LM を用いました。
本モデルは、以下の 2 種類の評価で有効性を確認しています。
LLM as a Judgeの評価については医療専門家のフィードバックを受けて、言語処理学会で発表したプロンプトを改変しております。
| Model | Size | ROUGE-L |
|---|---|---|
| Gemma | 27B | 15.99 |
| Phi4 | 6B | 36.31 |
| InternVL | 38B | 24.88 |
| vila_jp | 14B | 40.48 |
| Sarashina | 14B | 17.28 |
| Asagi | 14B | 29.13 |
| Llava med | 8B | 0.90 |
| 推論あり | 14B | 46.47 |
| 推論なし | 14B | 27.36 |
| Model | ROUGE-L | LLM as a Judge |
|---|---|---|
| GPT 5 | 16.11 | 4.05 |
| GPT 4.1 | 13.95 | 3.18 |
| Gemma | 15.50 | 2.12 |
| Phi4 | 16.10 | 2.76 |
| InternVL | 16.77 | 2.80 |
| vila_jp | 16.57 | 2.82 |
| Sarashina | 10.49 | 2.17 |
| Asagi | 16.18 | 2.04 |
| Llava med | 0.05 | 1.00 |
| 推論あり | 15.89 | 3.40 |
| 推論なし | 11.31 | 1.72 |
| 推論あり(SFT) | 30.04 | 3.50 |
| 推論なし(SFT) | 30.16 | 3.14 |
transformers==4.45.1
accelerate==0.34.2
torch==2.4.0
torchvision==0.19.0
import requests
import torch
from PIL import Image
from transformers import AutoModel, AutoProcessor, GenerationConfig
model_path = "MIL-UT/Med-Asagi-14B-reasoning"
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModel.from_pretrained(
model_path, trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
generation_config = GenerationConfig(
do_sample=True,
num_beams=5,
max_new_tokens=512
)
prompt = ("以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。\n\n"
"### 指示:\n<image>\nこの画像を見て、異常所見を述べてください。\n\n### 応答:\n")
# sample image
sample_image_url = "https://www.ringe.jp/files/civic/20190906/img/02-1.jpg"
image = Image.open(requests.get(sample_image_url, stream=True).raw)
inputs = processor(
text=prompt, images=image, return_tensors="pt"
)
inputs_text = processor.tokenizer(prompt, return_tensors="pt")
inputs['input_ids'] = inputs_text['input_ids']
inputs['attention_mask'] = inputs_text['attention_mask']
for k, v in inputs.items():
if v.dtype == torch.float32:
inputs[k] = v.to(model.dtype)
inputs = {k: inputs[k].to(model.device) for k in inputs if k != "token_type_ids"}
generate_ids = model.generate(
**inputs,
generation_config=generation_config
)
generated_text = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
# do not print the prompt
if "<image>" in prompt:
prompt = prompt.replace("<image>", " ")
generated_text = generated_text.replace(prompt, "")
print(f"Generated text: {generated_text}")
出力例:
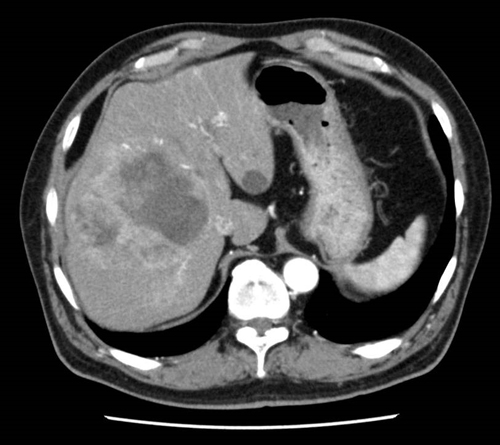
<description>
- 画像は腹部の横断CTスキャンです。
- 肝臓は画像の左側に位置し、右葉に大きく不規則な形状の腫瘤が見られます。
- その腫瘤は密度が不均一で、低密度領域と高密度領域が混在しています。
- 腫瘤の周囲の肝実質は比較的均一な密度を示しています。
- 胃は画像の右側にあり、部分的に内容物が入っています。
- 脾臓は胃の隣に位置し、均一な密度を示しています。
- 脊柱は画像の下部中央にあり、椎体と脊髄管が確認できます。
- 大動脈と下大静脈は脊柱の前方に円形の構造として見えます。
- 肋骨は画像の周辺部に曲線状の高密度構造として描かれています。
- 腹腔内に自由液やガスは認められません。
</description>
<thinking>
まず、画像全体を確認すると、肝臓の右葉に大きく不規則な形状の腫瘤が存在することが分かります。この腫瘤は密度が均一でなく、低密度領域と高密度領域が混在しているため、組織構成が不均一であることが示唆されます。腫瘤の周囲の肝実質は比較的均一な密度を保っており、腫瘤自体が肝臓内部に局在していることが確認できます。
他の臓器(胃、脾臓、脊柱、大動脈・下大静脈、肋骨)はそれぞれ正常な形態と密度で描写されており、特に異常所見は見られません。また、腹腔内に自由液やガスがないことから、急性の腹膜炎や穿孔などの合併症は起きていないと考えられます。
以上の観察結果から、画像上で最も顕著な異常は肝臓右葉に位置する大きく不規則で密度が不均一な腫瘤であると結論付けられます。
</thinking>
答え: 肝臓右葉にある大きく不規則で密度が不均一な腫瘤が画像上の異常所見です。
cc-by-sa-4.0
本モデルを利用した場合は、以下の論文を引用ください。
@inproceedings{ando2026japanese_medical_vlm,
title={医療用大規模日本語視覚言語モデルの構築},
author={安道 健一郎 and 黒瀬 優介 and 菊地 智博 and 牧元 久樹 and 小寺 聡 and 小林 和馬 and 合田 和生 and 村尾 晃平 and 吉田 浩 and 田村 孝之 and 合田 憲人 and 喜連川 優 and 原田 達也},
booktitle={言語処理学会第32回年次大会},
year={2026}
}
問い合わせ先: ando [at] mi.t.u-tokyo.ac.jp までご連絡ください。