
OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique
Paper • 2507.09075 • Published • 19
This model was generated using llama.cpp at commit 3f4fc97f.
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the --tensor-type option in llama.cpp to manually "bump" important layers to higher precision. You can see the implementation here:
👉 Layer bumping with llama.cpp
While this does increase model file size, it significantly improves precision for a given quantization level.
OpenReasoning-Nemotron-7B is a large language model (LLM) which is a derivative of Qwen2.5-7B-Instruct (AKA the reference model). It is a reasoning model that is post-trained for reasoning about math, code and science solution generation. We evaluated this model with up to 64K output tokens. The OpenReasoning model is available in the following sizes: 1.5B, 7B and 14B and 32B.
This model is ready for commercial/non-commercial research use.
GOVERNING TERMS: Use of the models listed above are governed by the Creative Commons Attribution 4.0 International License (CC-BY-4.0). ADDITIONAL INFORMATION: Apache 2.0 License
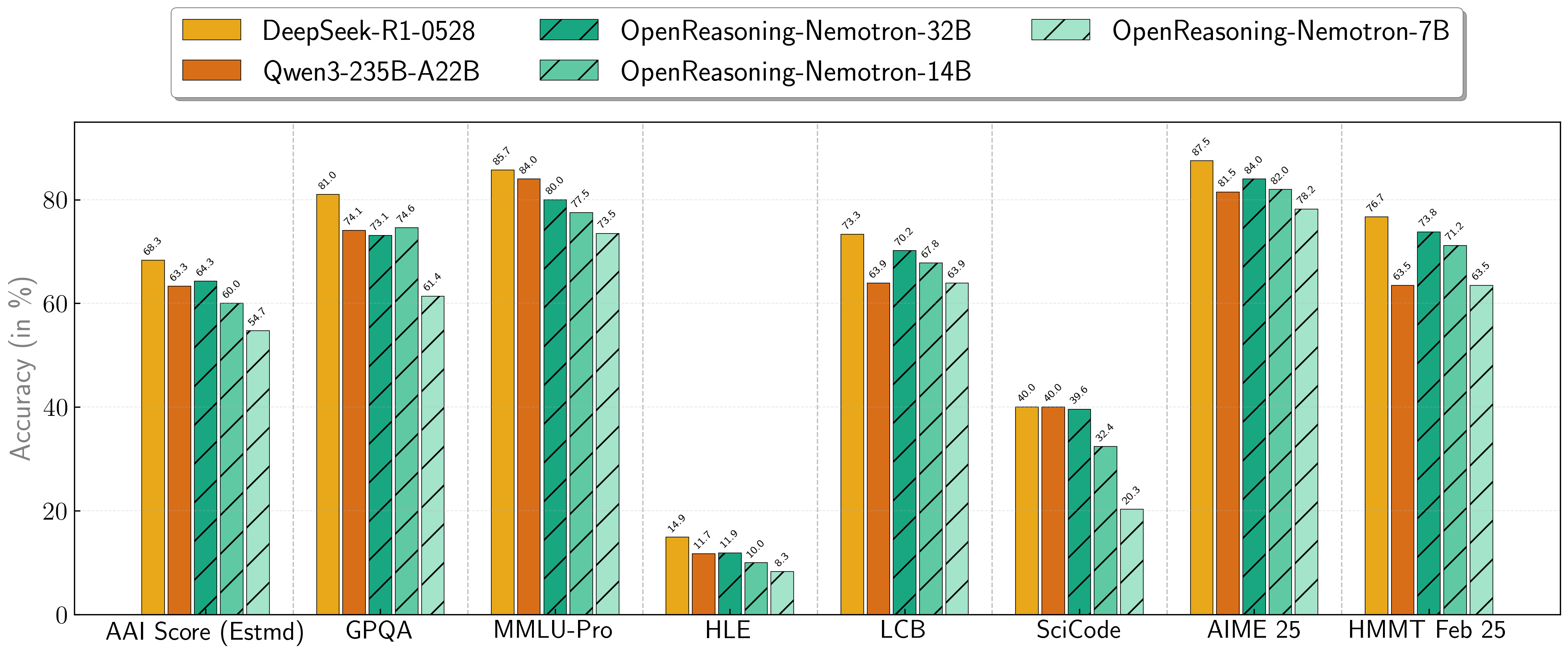
Our models demonstrate exceptional performance across a suite of challenging reasoning benchmarks. The 7B, 14B, and 32B models consistently set new state-of-the-art records for their size classes.
| Model | AritificalAnalysisIndex* | GPQA | MMLU-PRO | HLE | LiveCodeBench* | SciCode | AIME24 | AIME25 | HMMT FEB 25 |
|---|---|---|---|---|---|---|---|---|---|
| 1.5B | 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| 7B | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| 14B | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| 32B | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
* This is our estimation of the Artificial Analysis Intelligence Index, not an official score.
* LiveCodeBench version 6, date range 2408-2505.
OpenReasoning-Nemotron models can be used in a "heavy" mode by starting multiple parallel generations and combining them together via generative solution selection (GenSelect). To add this "skill" we follow the original GenSelect training pipeline except we do not train on the selection summary but use the full reasoning trace of DeepSeek R1 0528 671B instead. We only train models to select the best solution for math problems but surprisingly find that this capability directly generalizes to code and science questions! With this "heavy" GenSelect inference mode, OpenReasoning-Nemotron-32B model surpasses O3 (High) on math and coding benchmarks.
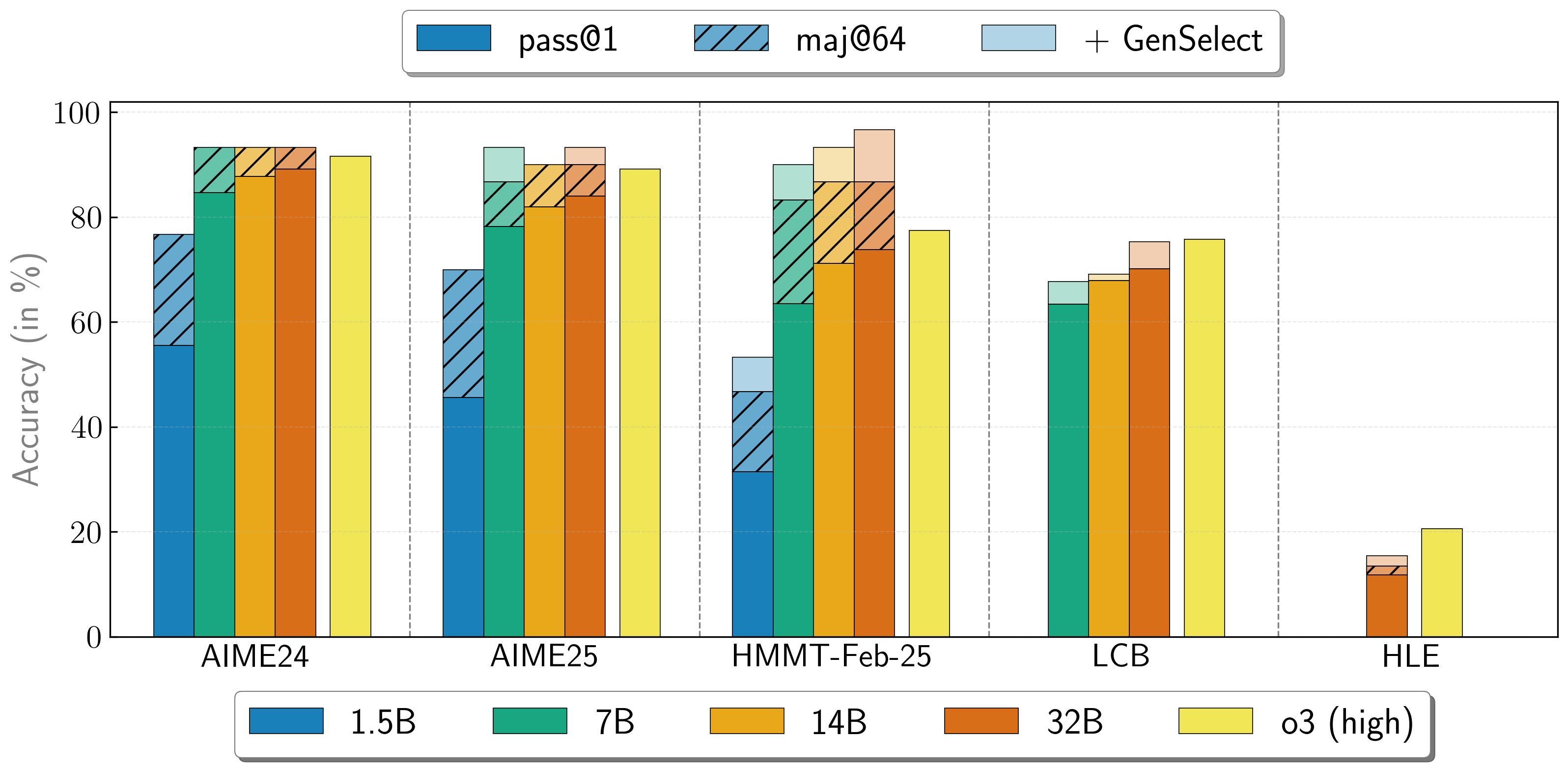
| Model | Pass@1 (Avg@64) | Majority@64 | GenSelect |
|---|---|---|---|
| 1.5B | |||
| AIME24 | 55.5 | 76.7 | 76.7 |
| AIME25 | 45.6 | 70.0 | 70.0 |
| HMMT Feb 25 | 31.5 | 46.7 | 53.3 |
| 7B | |||
| AIME24 | 84.7 | 93.3 | 93.3 |
| AIME25 | 78.2 | 86.7 | 93.3 |
| HMMT Feb 25 | 63.5 | 83.3 | 90.0 |
| LCB v6 2408-2505 | 63.4 | n/a | 67.7 |
| 14B | |||
| AIME24 | 87.8 | 93.3 | 93.3 |
| AIME25 | 82.0 | 90.0 | 90.0 |
| HMMT Feb 25 | 71.2 | 86.7 | 93.3 |
| LCB v6 2408-2505 | 67.9 | n/a | 69.1 |
| 32B | |||
| AIME24 | 89.2 | 93.3 | 93.3 |
| AIME25 | 84.0 | 90.0 | 93.3 |
| HMMT Feb 25 | 73.8 | 86.7 | 96.7 |
| LCB v6 2408-2505 | 70.2 | n/a | 75.3 |
| HLE | 11.8 | 13.4 | 15.5 |
To run inference on coding problems:
import transformers
import torch
model_id = "nvidia/OpenReasoning-Nemotron-7B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
# Code generation prompt
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use python programming language only.
You must use ```python for just the final solution code block with the following format:
```python
# Your code here
```
{user}
"""
# Math generation prompt
# prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.
#
# {user}
# """
# Science generation prompt
# You can refer to prompts here -
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (for GPQA)
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
messages = [
{
"role": "user",
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
]
outputs = pipeline(
messages,
max_new_tokens=64000,
)
print(outputs[0]["generated_text"][-1]['content'])
We have added a simple transformer-based script in this repo to illustrate GenSelect.
To learn how to use the models in GenSelect mode with NeMo-Skills, see our documentation.
To use the model with GenSelect inference, we recommend following our reference implementation in NeMo-Skills. Alternatively, you can manually extract the summary from all solutions and use this prompt for the math problems. We will add the prompt we used for the coding problems and a reference implementation soon!
You can learn more about GenSelect in these papers:
If you find the data useful, please cite:
@article{ahmad2025opencodereasoning,
title={{OpenCodeReasoning: Advancing Data Distillation for Competitive Coding}},
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
year={2025},
eprint={2504.01943},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.01943},
}
@misc{ahmad2025opencodereasoningiisimpletesttime,
title={{OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique}},
author={Wasi Uddin Ahmad and Somshubra Majumdar and Aleksander Ficek and Sean Narenthiran and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Vahid Noroozi and Boris Ginsburg},
year={2025},
eprint={2507.09075},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.09075},
}
@misc{moshkov2025aimo2winningsolutionbuilding,
title={{AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset}},
author={Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
year={2025},
eprint={2504.16891},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.16891},
}
@inproceedings{toshniwal2025genselect,
title={{GenSelect: A Generative Approach to Best-of-N}},
author={Shubham Toshniwal and Ivan Sorokin and Aleksander Ficek and Ivan Moshkov and Igor Gitman},
booktitle={2nd AI for Math Workshop @ ICML 2025},
year={2025},
url={https://openreview.net/forum?id=8LhnmNmUDb}
}
Global
This model is intended for developers and researchers who work on competitive math, code and science problems. It has been trained via only supervised fine-tuning to achieve strong scores on benchmarks.
Huggingface [07/16/2025] via https://huggingface.co/nvidia/OpenReasoning-Nemotron-7B/
Architecture Type: Dense decoder-only Transformer model
Network Architecture: Qwen-7B-Instruct
This model was developed based on Qwen2.5-7B-Instruct and has 7B model parameters.
OpenReasoning-Nemotron-1.5B was developed based on Qwen2.5-1.5B-Instruct and has 1.5B model parameters.
OpenReasoning-Nemotron-7B was developed based on Qwen2.5-7B-Instruct and has 7B model parameters.
OpenReasoning-Nemotron-14B was developed based on Qwen2.5-14B-Instruct and has 14B model parameters.
OpenReasoning-Nemotron-32B was developed based on Qwen2.5-32B-Instruct and has 32B model parameters.
Input Type(s): Text
Input Format(s): String
Input Parameters: One-Dimensional (1D)
Other Properties Related to Input: Trained for up to 64,000 output tokens
Output Type(s): Text
Output Format: String
Output Parameters: One-Dimensional (1D)
Other Properties Related to Output: Trained for up to 64,000 output tokens
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
1.0 (7/16/2025)
OpenReasoning-Nemotron-32B
OpenReasoning-Nemotron-14B
OpenReasoning-Nemotron-7B
OpenReasoning-Nemotron-1.5B
The training corpus for OpenReasoning-Nemotron-7B is comprised of questions from OpenCodeReasoning dataset, OpenCodeReasoning-II, OpenMathReasoning, and the Synthetic Science questions from the Llama-Nemotron-Post-Training-Dataset. All responses are generated using DeepSeek-R1-0528. We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
Data Collection Method: Hybrid: Automated, Human, Synthetic
Labeling Method: Hybrid: Automated, Human, Synthetic
Properties: 5M DeepSeek-R1-0528 generated responses from OpenCodeReasoning questions (https://huggingface.co/datasets/nvidia/OpenCodeReasoning), OpenMathReasoning, and the Synthetic Science questions from the Llama-Nemotron-Post-Training-Dataset. We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
We used the following benchmarks to evaluate the model holistically.
Data Collection Method: Hybrid: Automated, Human, Synthetic
Labeling Method: Hybrid: Automated, Human, Synthetic
Acceleration Engine: vLLM, Tensor(RT)-LLM
Test Hardware NVIDIA H100-80GB
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards.
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns here.
Help me test my AI-Powered Quantum Network Monitor Assistant with quantum-ready security checks:
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : Source Code Quantum Network Monitor. You will also find the code I use to quantize the models if you want to do it yourself GGUFModelBuilder
💬 How to test:
Choose an AI assistant type:
TurboLLM (GPT-4.1-mini) HugLLM (Hugginface Open-source models) TestLLM (Experimental CPU-only)I’m pushing the limits of small open-source models for AI network monitoring, specifically:
🟡 TestLLM – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
🟢 TurboLLM – Uses gpt-4.1-mini :
🔵 HugLLM – Latest Open-source models:
"Give me info on my websites SSL certificate" "Check if my server is using quantum safe encyption for communication" "Run a comprehensive security audit on my server"I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is open source. Feel free to use whatever you find helpful.
If you appreciate the work, please consider buying me a coffee ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
2-bit
3-bit
4-bit
5-bit
6-bit
8-bit
16-bit