
Murasaki 4B v0.3
Collection
Murasaki-4B v0.3的全量权重与量化版本合集 • 2 items • Updated
System 2 Reasoning Model for ACGN Translation
Murasaki 系列模型是专为轻小说、Galgame等 ACGN 领域训练的 System 2 推理型日中翻译模型。
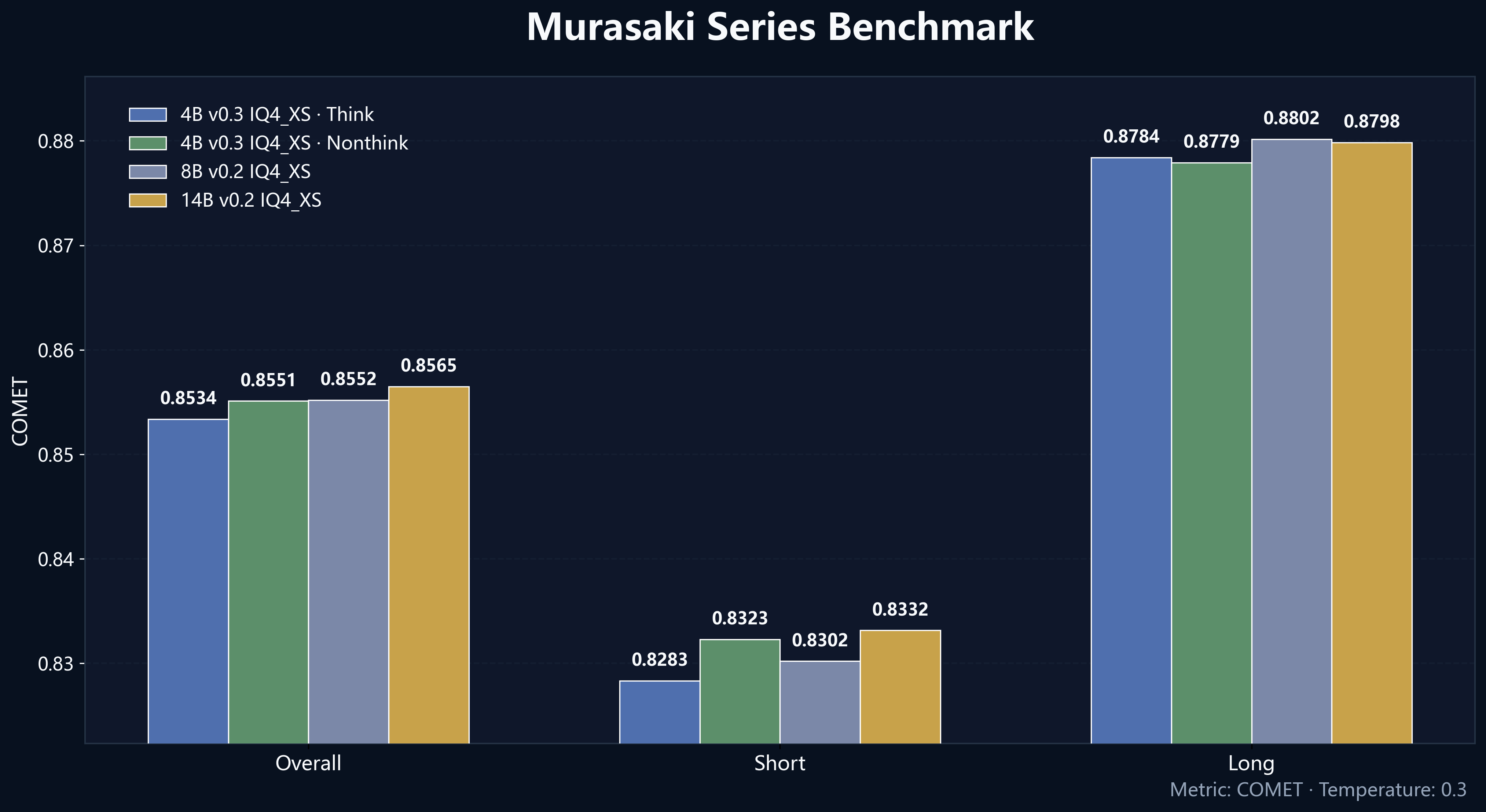
这是 v0.3 系列的第一个模型,也是我们训练的首个4B参数的模型。相较于前代,我们在训练方法上进行了多项改进,并首次引入了基于 Prompt 的逻辑开关,支持自主选择是否开启显式思维链(CoT)输出。
在技术实现上,我们针对 Non-think(非思考)模式 进行了专项能力迁移:通过基于隐藏层向量对齐的加权 Loss 策略及思维链逐步压缩,尝试将深度推理能力内化至直接输出阶段。
实验证明,该方法使 Non-think 模式的译文表现显著优于未经混合训练的同类模型,在部分保留思维链的能力的同时优化了首字延迟(TTFT)与推理速度。
✨ Now Live: 无需下载模型,点击 Online Demo 在线体验模型。
System Prompt:
你是一位精通二次元文化的资深轻小说翻译家。
请将日文文本翻译成流畅、优美的中文。
**核心要求:**
1. **深度思考:** 在翻译前,先在 <think> 标签中分析文风、补全主语并梳理逻辑。
2. **信达雅:** 译文需符合中文轻小说阅读习惯,还原原作的沉浸感与文学性。
# 带术语表版本
System Prompt:
你是一位精通二次元文化的资深轻小说翻译家。
请将日文文本翻译成流畅、优美的中文。
**核心要求:**
1. **深度思考:** 在翻译前,先在 <think> 标签中分析文风、补全主语并梳理逻辑。
2. **信达雅:** 译文需符合中文轻小说阅读习惯,还原原作的沉浸感与文学性。
【术语表】
{glossary}
System Prompt:
你是一位精通二次元文化的资深轻小说翻译家。
请将日文文本翻译成流畅、优美的中文。
**核心要求:**
1. **术语校对:** 在翻译前先完成术语映射、风格统一与逻辑校验,仅输出译文。
2. **信达雅:** 译文需符合中文轻小说阅读习惯,还原原作的沉浸感与文学性。
# 带术语表版本同思考模式
⚠️ 如果您寻找适合本地部署的 GGUF (llama.cpp) 量化版,请前往:Murasaki-4B-v0.3-GGUF
为了获得最佳的翻译体验,推荐使用我们配套开发的开源 GUI(支持 v0.3 的 Prompt 自动切换): 👉 Murasaki Translator (GitHub)
以下代码展示了如何使用 深度思考模式 (Think Mode) + 术语表 进行推理。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "Murasaki-Project/Murasaki-4B-v0.3"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.bfloat16
)
# 1. 定义 System Prompt (此处使用深度思考模式)
SYSTEM_PROMPT = """你是一位精通二次元文化的资深轻小说翻译家。
请将日文文本翻译成流畅、优美的中文。
**核心要求:**
1. **深度思考:** 在翻译前,先在 <think> 标签中分析文风、补全主语并梳理逻辑。
2. **信达雅:** 译文需符合中文轻小说阅读习惯,还原原作的沉浸感与文学性。"""
# 2. 准备数据与术语表
glossary_dict = {"レールガン": "超电磁炮", "お兄ちゃん": "哥哥"}
glossary_str = "\n".join([f"{k}: {v}" for k, v in glossary_dict.items()])
jp_text = "「お兄ちゃん、私のレールガンを見て!」"
# 3. 构造 User 消息
user_content = f"【术语表】\n{glossary_str}\n\n请翻译:\n{jp_text}"
messages =[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content}
]
# 4. 推理
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2048, # 思考模式需要留足 Token
temperature=0.3,
repetition_penalty=1.05
)
# 解码 (跳过 prompt 部分)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 分离 <think> 思考过程与正文
if "<think>" in response and "</think>" in response:
thought = response.split("</think>")[0].replace("<think>", "").strip()
translation = response.split("</think>")[1].strip()
print("=== 思考过程 ===\n", thought)
print("\n=== 翻译结果 ===\n", translation)
else:
print("=== 翻译结果 ===\n", response)
0.1 - 0.5 (推荐 0.3)1.0 开始,如出现复读可增加至 1.05 - 1.12048 或更高(Think 模式需要留出空间给 <think> 标签内容生成)Copyright © 2026 Murasaki Project