
Ostrakon-VL
Collection
Towards Domain-Expert MLLM for FoodService and Retail Stores • 2 items • Updated • 1
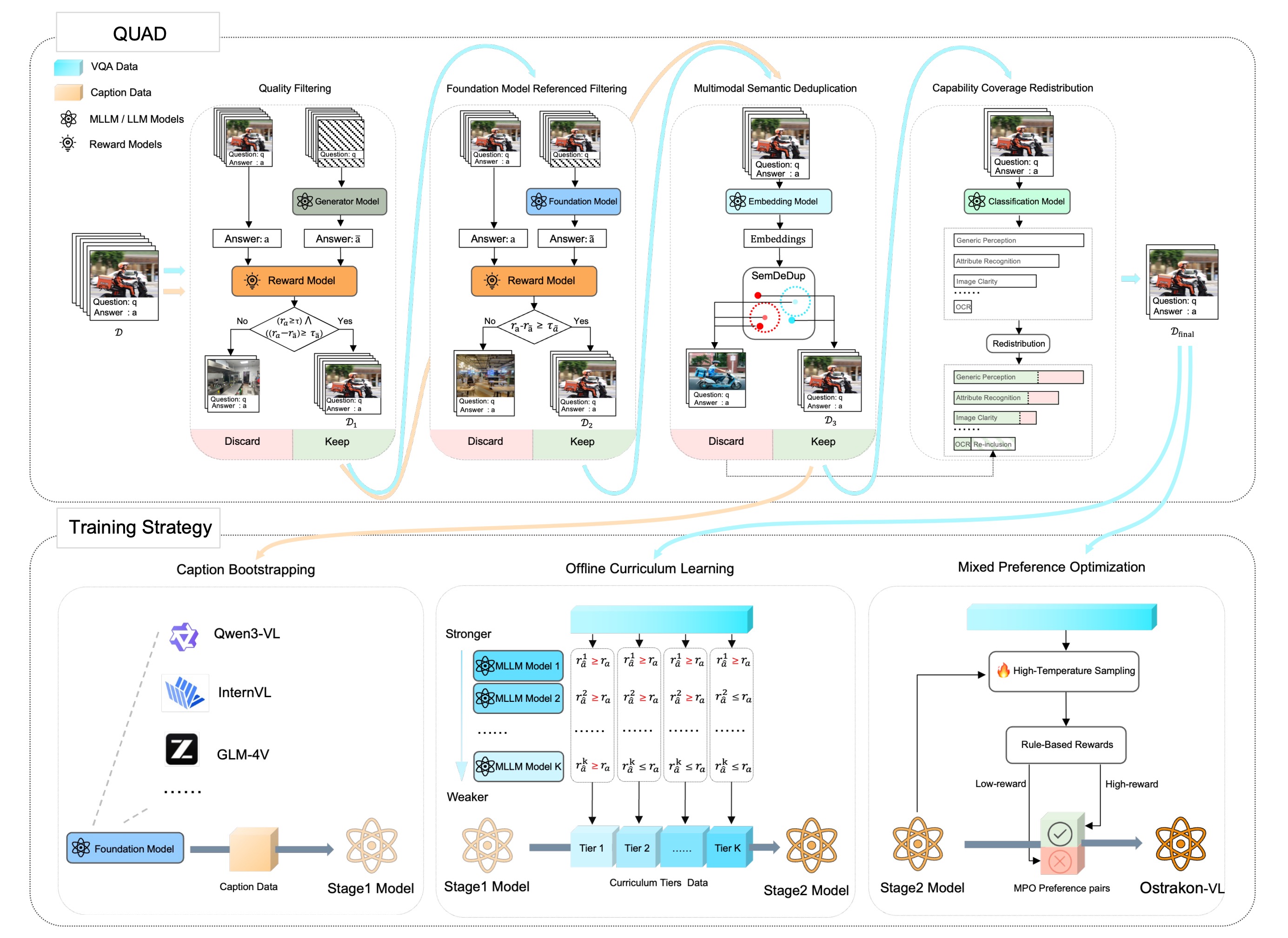
Ostrakon-VL is the first open-source Multimodal Large Language Model (MLLM) specifically designed for Food-Service and Retail Store (FSRS) scenarios. It delivers state-of-the-art performance in real-world retail perception, compliance, and decision-making tasks — outperforming even much larger general-purpose models like Qwen3-VL-235B.
🔥 Key Highlights
- 60.5 average score on ShopBench (Ostrakon-VL-30B-A3B) — outperforming Qwen3-VL-235B by +1.1
- ShopBench: First public benchmark for FSRS, with multi-format inputs and diagnostic metrics
- Model weights are open-sourced
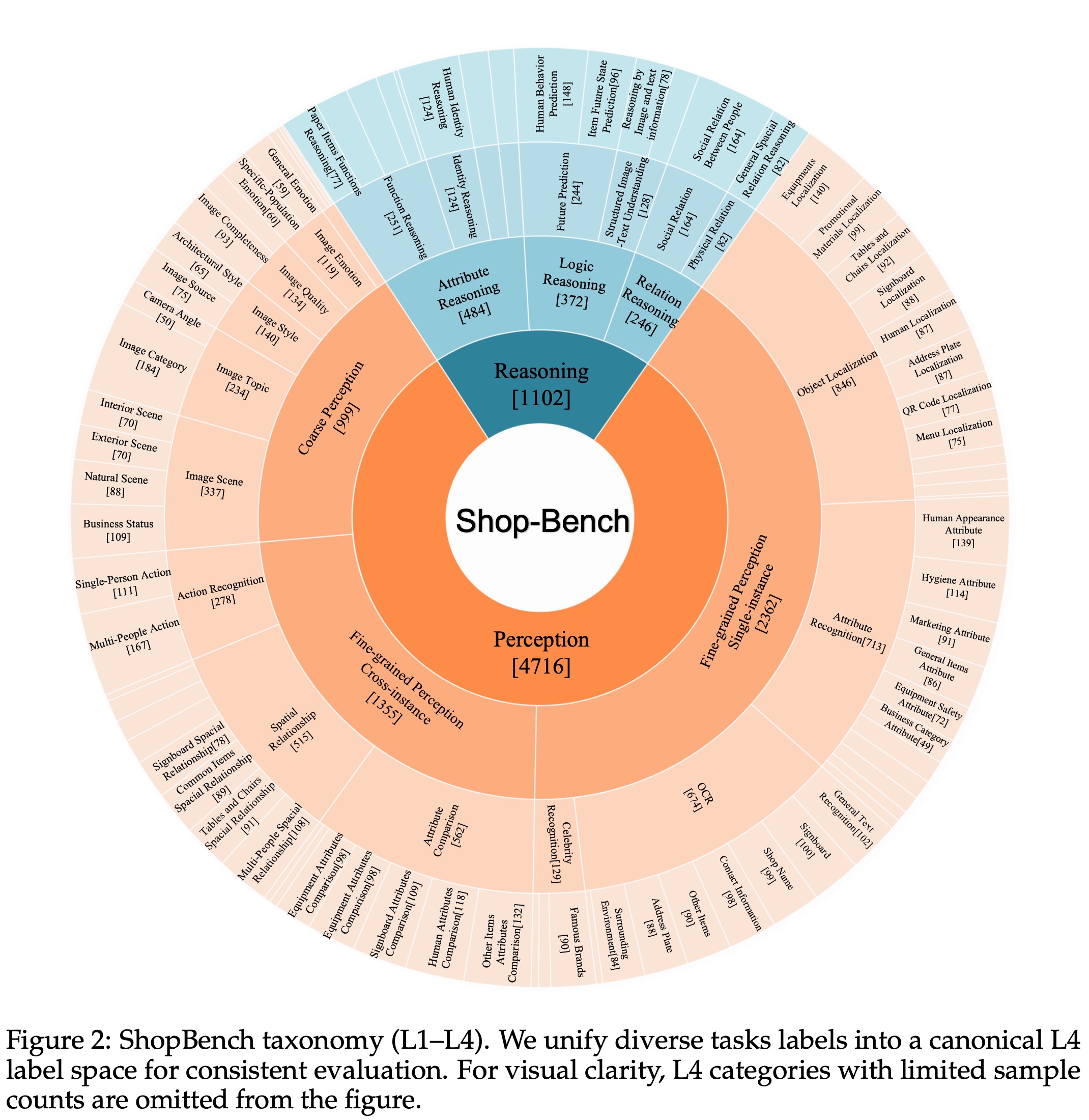
ShopBench is the first standardized evaluation suite specifically designed for the Food-Service and Retail Store (FSRS) domain. Unlike general-purpose multimodal benchmarks, ShopBench addresses the unique challenges of real-world retail environments:
ShopBench enables fair, interpretable, and actionable comparison of MLLMs in realistic FSRS workflows — from storefront compliance checks to kitchen hygiene audits.
Due to legal reasons, the open-sourcing of ShopBench has been postponed.
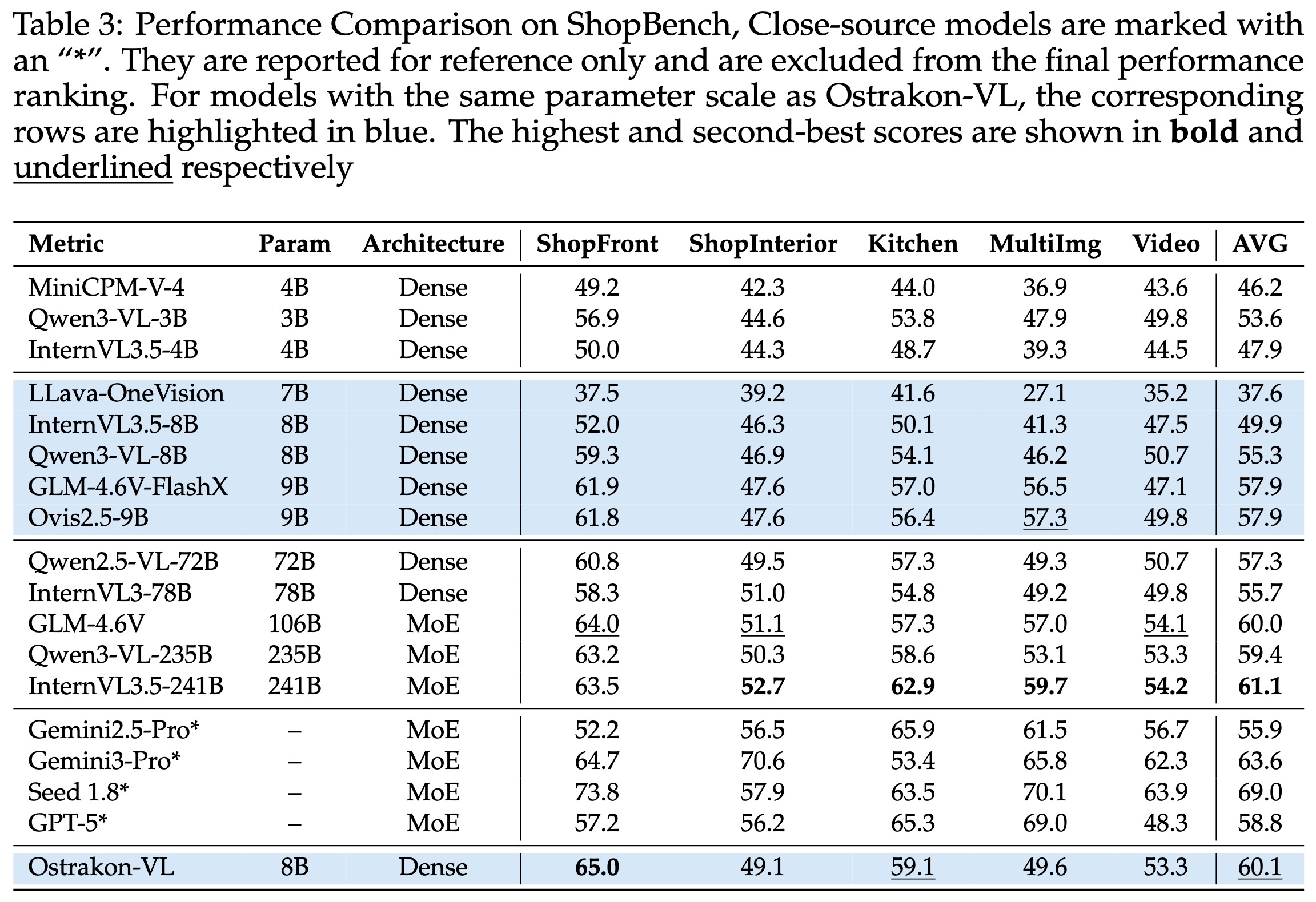
Our Ostrakon-VL models achieve strong performance on ShopBench. Ostrakon-VL-8B reaches an average score of 60.1, showing competitive results among open-source models of similar scale, while Ostrakon-VL-30B-A3B further improves to 60.5 and performs particularly well on ShopFront (65.3) and Video (57.3), demonstrating strong understanding of e-commerce scenarios.
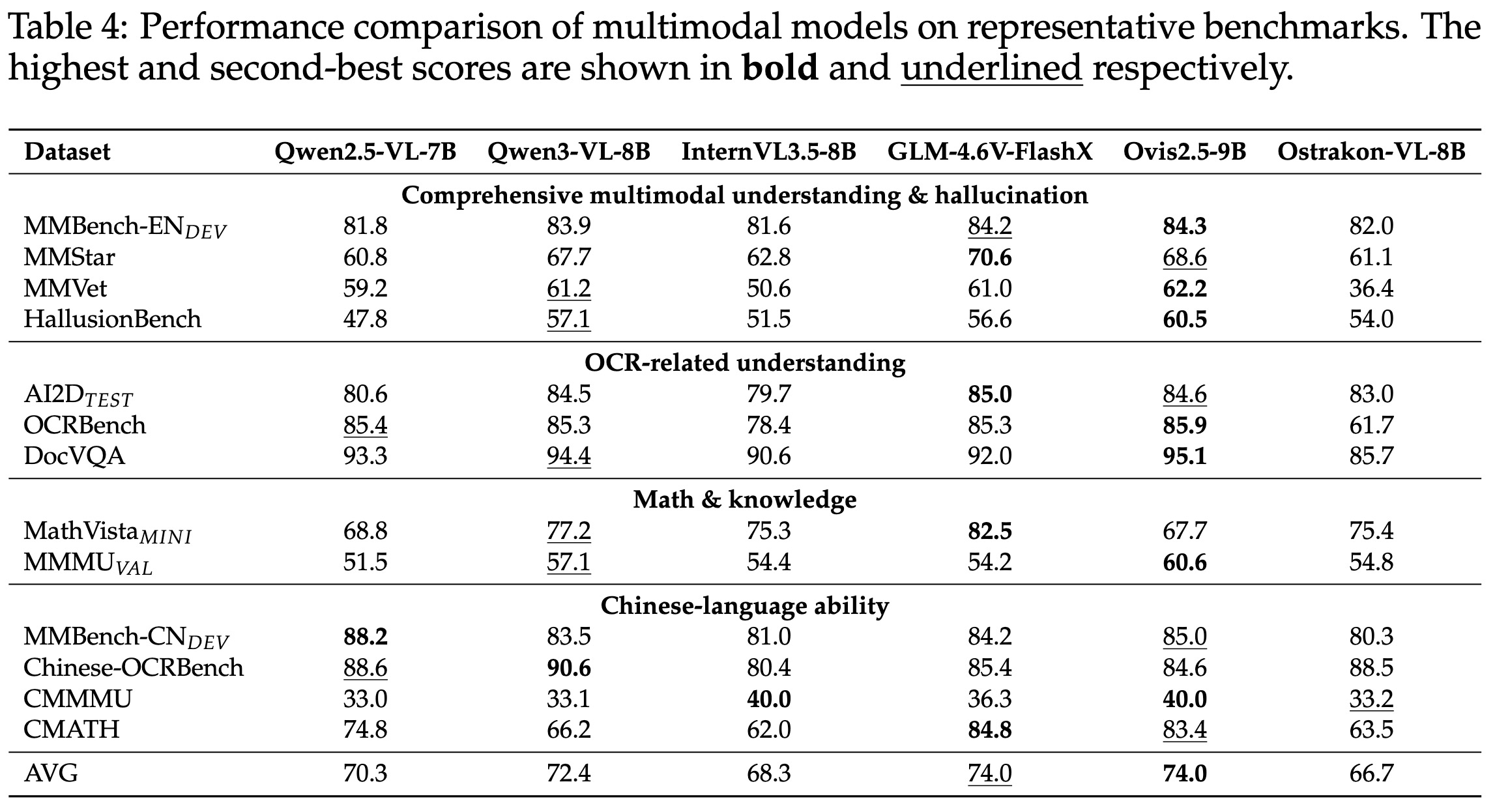
While specialized for FSRS, On representative multimodal benchmarks, Ostrakon-VL shows competitive overall performance across a wide range of tasks. In particular, Ostrakon-VL-30B-A3B achieves strong results on MMBench-EN_DEV (86.7) and AI2D_TEST (86.9), while maintaining solid performance across OCR, math, and Chinese-language benchmarks, demonstrating its broad multimodal capabilities.
Ostrakon-VL is trained via a multi-stage training strategy:
This strategy enables robust, auditable, and rule-compliant reasoning in complex retail environments.
Install dependencies and run inference with just a few lines of code:
pip install torch transformers accelerate
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
from PIL import Image
# Load Ostrakon-VL
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Ostrakon/Ostrakon-VL-30B-A3B",
dtype="bfloat16",
device_map="auto",
)
processor = AutoProcessor.from_pretrained("Ostrakon/Ostrakon-VL-30B-A3B")
def process_local_image(image_path):
image = Image.open(image_path)
image = image.resize((512,512))
return image
image_path = "path/to/img.jpg"
image = process_local_image(image_path)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image
},
{
"type": "text",
"text": "图片中的店铺名是什么?"
}
]
}
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(output_text)
If you find Ostrakon-VL or ShopBench useful in your research, please cite our paper:
@article{shen2026ostrakon,
title={Ostrakon-VL: Towards Domain-Expert MLLM for Food-Service and Retail Stores},
author={Shen, Zhiyong and Zhao, Gongpeng and Zhou, Jun and Yu, Li and Kou, Guandong and Li, Jichen and Dong, Chuanlei and Li, Zuncheng and Li, Kaimao and Wei, Bingkun and others},
journal={arXiv preprint arXiv:2601.21342},
year={2026}
}
We welcome contributions! Please open an issue or submit a PR.